Embed Size (px)
Citation preview

Методы обучения линейных моделей
по материалам лекций К.В. Воронцова
A. AkimenkoMoscow’16

Оглавление
Основные алгоритмы машинного обучения
Постановка задачи обучения
Основные методы обучения
Пример градиентного метода
Что дальше?

Основные алгоритмы машинного обучения
Логические - деревья решений
Метрические - knn, k-means
Линейные - SVM, логистическая/линейная регрессия, PCA
Нейронные сети

Основные алгоритмы машинного обучения
Логические - деревья решений
Метрические - knn, k-means
Линейные - SVM, логистическая/линейная регрессия, PCA
Нейронные сети

Постановка задачи обучения

ОбозначенияX - пространство объектов
F - нормализованное пространство в матричном виде
Y - вектор ответов
w - вектор коэффициентов
x (x1,.., xd) - вектор признаков i-го объекта
R - множество действительных чисел
a(x) - алгоритм, модель
Q(a,X) - функционал ошибки алгоритма а на объектах X
a(x)=argmin(Q(a,X)) - обучение
LM - linear model - линейная модель
GLM - generalized linear model - обобщенная линейная модель (лог регрессия, например)
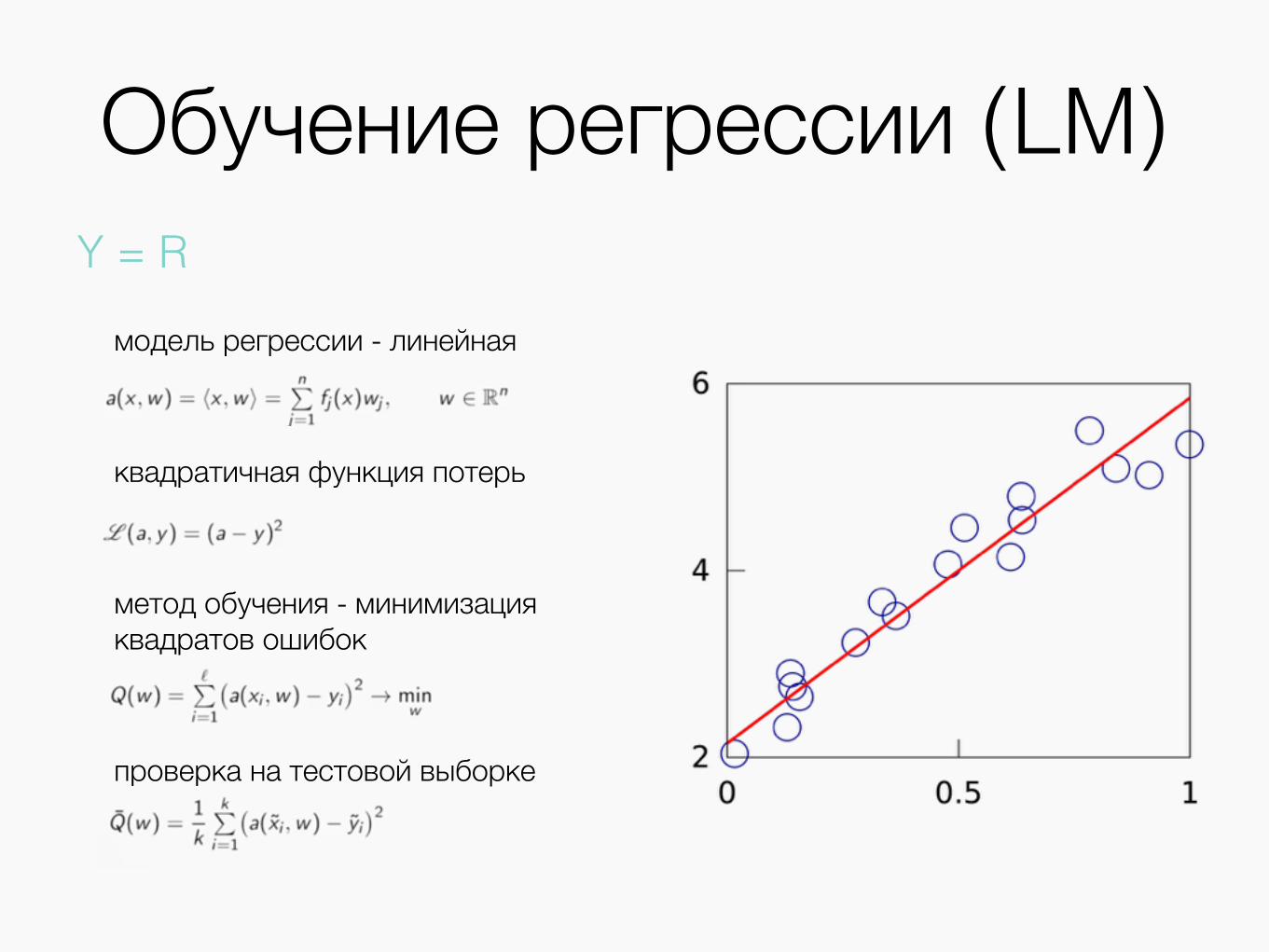
Обучение регрессии (LM)
модель регрессии - линейная
квадратичная функция потерь
метод обучения - минимизация квадратов ошибок
проверка на тестовой выборке
Y = R

Обучение классификации (GLM)
модель классификации - линейная
бинарная функция потерь
минимизация эмпирического риска
проверка на тестовой выборке
Y = {-1;1}

Обучение классификации (GLM) - функции потерь

Основные методы обучения

Методы обучения
Аналитические
Метод наименьших квадратов (МНК)
Оптимизационные
Градиентные методы (G, SG, SAG, SVRG, …)

Метод наименьших квадратов (МНК)
Функционал ошибки в матричном виде
Необходимое условие минимума в матричном виде
Откуда следует нормальная система задачи МНК:
Решение:
- псевдообратная матрица

Решение МНК через сингулярное разложение (SVD)
Матрица F представляется в виде сингулярного разложения (singular value decomposition, SVD):

Градиентные методыМинимизация эмпирического риска
Численная минимизация методом градиентного спуска
где h - гранитный шаг, называемый также темпом обучения
Идея ускорения сходимости - брать объекты по одному и обновлять веса (процедура Робинса-Монро)
Вариации:
SG - Stochastic Gradient - объект выбирается случайным образом, веса пересчитывается
SAG - Stochastic Average Gradient - объект выбирается случайным образом, веса пересчитываются и усредняются с прошлыми итерациями

Пример градиентного метода

Пример - градиент с L1 нормализацией для GLM на Python (1/2)
k = 0.1 #шаг градиента C = 10 #нормализующий коэффициент epsilon = 1e-5 #триггер сходимости max_iterations = 10000 iteration = 0 # инициализация счётчика итераций l=len(y)
# инициализация коэффициентов w1 = 0.0 w2 = 0.0
задача
решение
xi1 и xi2 — значение первого и второго признаков соответственно на объекте xi
алгоритм (1/2)
k — размер шага

Пример - градиент с L1 нормализацией для GLM на Python (2/2)
# основной цикл while iteration <= max_iterations: sum1=0 sum2=0 for i in range(len(y)): t1 = y[i]*X1[i]*(1 - 1/(1 + math.exp(-y[i]*(w1*X1[i]+w2*X2[i])))) t2 = y[i]*X2[i]*(1 - 1/(1 + math.exp(-y[i]*(w1*X1[i]+w2*X2[i])))) sum1= sum1 +t1 sum2= sum2 +t2 w1_new = w1 + k * 1/l * sum1 - k*C*w1 w2_new = w2 + k * 1/l * sum2 - k*C*w2 # проверка на то, что веса почти сошлись if abs(w1 - w1_new) < epsilon and abs(w2 - w2_new) < epsilon: break w1 = w1_new # сохранение весов w2 = w2_new print iteration, w1, w2 iteration = iteration + 1 # увеличение счётчика итераций
алгоритм (2/2)

Спасибо за внимание!

Что дальше?• Разобрать задачу из Kaggle или банковского скоринга
• Нейросети и глубинное обучение
• Метрические методы и обучение без учителя
• Современные алгоритмы анализа данных - CNN, RNN, BM, xgBoost





























