Embed Size (px)
Citation preview

第3章変分近似法第 4回「トピックモデルによる統計的潜在意味解析」
読書会
@ksmzn
会場:株式会社ALBERT西新宿
July 30, 2015
@ksmzn 第 3 章変分近似法 July 30, 2015 1 / 43

自己紹介
Koshi @ksmzn某大学 M2→社会人一年目リサンプリング法を研究してました
@ksmzn 第 3 章変分近似法 July 30, 2015 2 / 43

はじめに
ツッコミをください
@ksmzn 第 3 章変分近似法 July 30, 2015 3 / 43

目次
1 3.3.4 LDAの変分ベイズ法 (準備)
2 3.3.5 LDAの変分ベイズ法 (1)
3 3.3.6 LDAの変分ベイズ法 (2)
4 3.3.7 LDAの変分ベイズ法 (3)
5 3.3.8 LDAの周辺化変分ベイズ法
6 References
@ksmzn 第 3 章変分近似法 July 30, 2015 4 / 43

目次
1 3.3.4 LDAの変分ベイズ法 (準備)
2 3.3.5 LDAの変分ベイズ法 (1)
3 3.3.6 LDAの変分ベイズ法 (2)
4 3.3.7 LDAの変分ベイズ法 (3)
5 3.3.8 LDAの周辺化変分ベイズ法
6 References
@ksmzn 第 3 章変分近似法 July 30, 2015 5 / 43

Dirichlet分布の期待値導出
log θの期待値θ ∼ Dir (θ | α)のとき,プサイ関数Ψ (x) = d log Γ(x)
dx を用いて,
Ep(θ|α)[log θk] = Ψ (αk) − Ψ
K∑k=1
αk
LDAの変分ベイズにおいて、q (z)の導出で用いる
@ksmzn 第 3 章変分近似法 July 30, 2015 6 / 43

目次
1 3.3.4 LDAの変分ベイズ法 (準備)
2 3.3.5 LDAの変分ベイズ法 (1)
3 3.3.6 LDAの変分ベイズ法 (2)
4 3.3.7 LDAの変分ベイズ法 (3)
5 3.3.8 LDAの周辺化変分ベイズ法
6 References
@ksmzn 第 3 章変分近似法 July 30, 2015 7 / 43
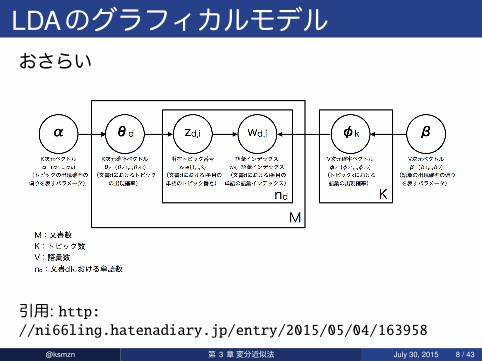
LDAのグラフィカルモデルおさらい
引用: http://ni66ling.hatenadiary.jp/entry/2015/05/04/163958
@ksmzn 第 3 章変分近似法 July 30, 2015 8 / 43

変分ベイズ法の要点
おさらい目的
▶ KL[q (z, θ,ϕ) || p (z, θ,ϕ | w,α,β)]を最小にするq (z, θ,ϕ)を求める.
手法▶ 対数周辺尤度 log p (w | α,β)の変分下限
F[q (z, θ,ϕ)]を求め、それを最大にする q (z, θ,ϕ)を変分法により求める.
▶ q (z, θ,ϕ)に対して因子分解仮定をおき, q (z), q (θ),q (ϕ)を順に繰り返し更新する.
@ksmzn 第 3 章変分近似法 July 30, 2015 9 / 43

変分下限の導出
変分下限の導出プロセス1. 周辺化された確率変数 z, θ,ϕを結合分布として積分形で表示する
2. 変分事後分布を分子分母でキャンセルする形で導入する
3. イエンセンの不等式により下限を求める
@ksmzn 第 3 章変分近似法 July 30, 2015 10 / 43

変分下限の導出
log p (w | α,β) = log∫ ∑
zp (w, z, θ,ϕ | α,β) dϕdθ
= log∫ ∑
zq (z, θ,ϕ)
p (w, z, θ,ϕ | α,β)q (z, θ,ϕ)
dϕdθ
≥∫ ∑
zq (z, θ,ϕ) log
p (w, z, θ,ϕ | α,β)q (z, θ,ϕ)
dϕdθ
≡ F[q (z, θ,ϕ)
]
@ksmzn 第 3 章変分近似法 July 30, 2015 11 / 43

因子分解仮定q (z, θ,ϕ)に対して因子分解仮定をおく.
q (z, θ,ϕ) =
M∏d=1
nd∏i=1
q(zd,i) M∏
d=1
q (θd)
K∏k=1
q(ϕk)
また、結合分布を展開する.
p (w, z, θ,ϕ | α,β) = p (w | z,ϕ) p (z | θ) p (ϕ | β) p (θ | α)
=
M∏d=1
nd∏i=1
p(wd,i | ϕzd,i
)p(zd,i | θd
) K∏k=1
p(ϕk | β
) M∏d=1
p (θd | α)
@ksmzn 第 3 章変分近似法 July 30, 2015 12 / 43

変分下限の導出
よって、変分下限は,
F[q (z, θ,ϕ)
]=
∫ ∑z
q (z) q (θ) q (ϕ) log p (w | z, θ) p (z | θ) dϕdθ
−∑
zq (z) log q (z)
+
∫q (θ) log
p (θ | α)q (θ)
dθ
+
∫q (ϕ) log
p (ϕ | β)q (ϕ)
dϕ
@ksmzn 第 3 章変分近似法 July 30, 2015 13 / 43

変分下限の導出(続き)
=
∫ M∑d=1
nd∑i=1
q(zd,i)
q (θd) q (ϕ) log p(wd,i | zd,i,ϕ
)p(zd,i | θd
)dϕdθ
−M∑
d=1
nd∑i=1
K∑k=1
q(zd,i = k
)log q
(zd,i = k
)+
M∑d=1
−∫
q (θd) logp (θd | α)
q (θd)dθd
+
K∑k=1
−∫
q(ϕk)
logp(ϕk | β
)q(ϕk) dϕk
@ksmzn 第 3 章変分近似法 July 30, 2015 14 / 43

変分下限を最大にする
変分下限 F[q (z, θ,ϕ)
]を最大にしたい.
→ q (z, θ,ϕ)について因子分解仮定を置いたので,Fの z, θ,ϕに関する部分を抜き出し,それを最大にする q
(zd,i), q (θd) , q
(ϕk)をそれぞれ求
める.
@ksmzn 第 3 章変分近似法 July 30, 2015 15 / 43

q (θd)を求める
変分下限 Fから, q (θd)に関係する項だけを抜き出したF̃[q (θd)
]は,
F̃[q (θd)
]=
∫q (θd)
∑z
q (z)nd∑i=1
log p(zd,i | θd
)dθd
−∫
q (θd) logq (θd)
p (θd | α)dθd
@ksmzn 第 3 章変分近似法 July 30, 2015 16 / 43

q (θd)を求める
これを最大化するには,変分法により,∂ f(θd,q(θd
))∂q(θd
) = 0となる q (θd)を求めればよい
∂ f (θd, q (θd))∂q (θd)
=∑
zq (z)
nd∑i=1
log p(zd,i | θd
) − logq (θd)
p (θd | α)− 1
= 0
これを q (θd)について解く.
@ksmzn 第 3 章変分近似法 July 30, 2015 17 / 43

q (θd)を求める
q (θd) ∝ p (θd | α) exp
∑z
q (z)nd∑i=1
log p(zd,i | θd
)∝
K∏k=1
θαk−1d,k exp
∑z
q (z)nd∑i=1
K∑k=1
δ(zd,i = k
)log θd,k
= exp
K∑k=1
(αk − 1) log θd,k
exp
K∑k=1
nd∑i=1
q(zd,i = k
)log θd,k
= exp
K∑k=1
(αk − 1) log θd,k
exp
K∑k=1
Eq(zd)[nd,k]log θd,k
= exp
K∑k=1
(Eq(zd)
[nd,k]+ αk − 1
)log θd,k
=
K∏k=1
θEq(zd)[nd,k]+αk−1
d,k
@ksmzn 第 3 章変分近似法 July 30, 2015 18 / 43

q (θd)を求める
ξθd,k = Eq(zd)[nd,k]+ αk,
ξθd=(ξθd,1, ξ
θd,2, · · · , ξθd,K
)とおくと, q (θd)は ξθ
dをパラメータとする Dirichlet分布 q
(θd | ξθd
)であるから,正規化項を計算して,
q(θd | ξθd
)=Γ(∑K
k=1 ξθd,k
)∏K
k=1 Γ(ξθd,k
) K∏k=1
θξθd,k−1d,k
となる.
@ksmzn 第 3 章変分近似法 July 30, 2015 19 / 43

q(ϕk)を求める
同様に,
ξϕk,v = Eq(z)
[nk,v]+ βv,
ξϕk=(ξϕk,1, ξ
ϕk,2, · · · , ξ
ϕk,v
)とおくと, q
(ϕk)は ξϕ
kをパラメータとする Dirichlet分布 q
(ϕk | ξ
ϕ
k
)であるから,正規化項を計算して,
q(ϕk | ξ
ϕ
k
)=Γ(∑V
v=1 ξϕk,v
)∏V
v=1 Γ(ξϕk,v
) V∏v=1
ϕξϕk,v−1
k,v
となる.
@ksmzn 第 3 章変分近似法 July 30, 2015 20 / 43

q(zd,i)を求める
最後に, q(zd,i)は,
q(zd,i = k
) ∝ exp[Ψ(ξϕk,wd,i
)]exp[Ψ(∑V
v′=1 ξϕk,v′
)] exp[Ψ(ξθd,k
)]exp[Ψ(∑K
k′=1 ξθd,k′
)]となる.
@ksmzn 第 3 章変分近似法 July 30, 2015 21 / 43
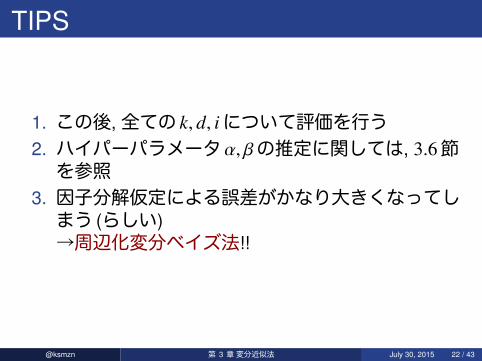
TIPS
1. この後,全ての k, d, iについて評価を行う2. ハイパーパラメータα, βの推定に関しては, 3.6節を参照
3. 因子分解仮定による誤差がかなり大きくなってしまう (らしい)→周辺化変分ベイズ法!!
@ksmzn 第 3 章変分近似法 July 30, 2015 22 / 43

目次
1 3.3.4 LDAの変分ベイズ法 (準備)
2 3.3.5 LDAの変分ベイズ法 (1)
3 3.3.6 LDAの変分ベイズ法 (2)
4 3.3.7 LDAの変分ベイズ法 (3)
5 3.3.8 LDAの周辺化変分ベイズ法
6 References
@ksmzn 第 3 章変分近似法 July 30, 2015 23 / 43

共役性を利用できない場合
▶ 近似事後分布に対して何も分布の条件を置かなかった→多項分布と Dirichlet分布の共役性によるもの
▶ 近似事後分布の形を仮定し,そのパラメータを推定する方法もある
▶ LDAでは共役性を用いることができるので,その必要がない
@ksmzn 第 3 章変分近似法 July 30, 2015 24 / 43

目次
1 3.3.4 LDAの変分ベイズ法 (準備)
2 3.3.5 LDAの変分ベイズ法 (1)
3 3.3.6 LDAの変分ベイズ法 (2)
4 3.3.7 LDAの変分ベイズ法 (3)
5 3.3.8 LDAの周辺化変分ベイズ法
6 References
@ksmzn 第 3 章変分近似法 July 30, 2015 25 / 43

ϕを点推定する
▶ 原論文では, ϕについては点推定を行っている▶ 変分下限からϕに関する部分を抜き出し,
q(ϕk,v)ではなく ϕk,vで微分して求める.
@ksmzn 第 3 章変分近似法 July 30, 2015 26 / 43

目次
1 3.3.4 LDAの変分ベイズ法 (準備)
2 3.3.5 LDAの変分ベイズ法 (1)
3 3.3.6 LDAの変分ベイズ法 (2)
4 3.3.7 LDAの変分ベイズ法 (3)
5 3.3.8 LDAの周辺化変分ベイズ法
6 References
@ksmzn 第 3 章変分近似法 July 30, 2015 27 / 43

周辺化変分ベイズ法 (CVB)
周辺化変分ベイズ法とはCollapsed Variational Bayes (CVB)周辺化ギブスサンプリングと同様に, θdと ϕkを周辺化(積分消去)し,近似事後分布 q (z)を求める.q (z)にのみ因子分解仮定をおけばよい.
q (z) =M∏
d=1
nd∏i=1
q(zd,i)
θ,ϕと zとの依存関係を保持したまま学習できる
@ksmzn 第 3 章変分近似法 July 30, 2015 28 / 43

CVBの変分下限の導出基本的には変分ベイズ法と同様
1. 周辺化された確率変数 zを結合分布として積分形で表示する
2. 変分事後分布を分子分母でキャンセルする形で導入する
3. イエンセンの不等式により下限を求める
log p (w | α,β) = log∑
zp (w, z | α,β) = log
∑z
q (z)p (w, z | α,β)
q (z)
≥∑
zq (z) log
p (w, z | α,β)q (z)
≡ FCVB[q (z)]
@ksmzn 第 3 章変分近似法 July 30, 2015 29 / 43

VBの変分下限と CVBの変分下限
変分ベイズ法 (VB)の変分下限と CVBの変分下限は次の関係が成り立つ.
F[q (z, θ, θ)
] ≤ FCVB[q (z)]
CVBでは, VBより既に大きい変分下限と最大化するので,効率的である.→学習に必要な反復回数が少なく済む!
@ksmzn 第 3 章変分近似法 July 30, 2015 30 / 43

変分下限の最大化
周辺化変分ベイズ法は,以下の最適化問題を解けばよい
q∗ (z) = argmaxq(z)
FCVB[q (z)]
@ksmzn 第 3 章変分近似法 July 30, 2015 31 / 43

変分下限の最大化
VBと同様に,
FCVB[q (z)]=∑
zq (z) log
p (w, z | α,β)q (z)
=∑
zq(zd,i)
q(z\d,i)
logp(wd,i, zd,i | w\d,i, z\d,i,α,β
)p(w\d,i, z\d,i | α,β
)q(zd,i)
q(z\d,i)
から, q(zd,i)に関係のある項を抜き出す
F̃CVB[q(zd,i)]=∑
zq(zd,i)
q(z\d,i)
logp(wd,i, zd,i | w\d,i, z\d,i,α,β
)q(zd,i)
@ksmzn 第 3 章変分近似法 July 30, 2015 32 / 43

CVBで用いる統計量
おさらい (P55)nd,k
nd,k =∑nd
i=1 δ(zd,i = k
)文書 dでトピック kが現れた回数
nk,vnk,v =
∑Md=1∑nd
i=1 δ(wd,i = v, zd,i = k
)全文書で,トピック kが単語 vに対して推定された回数
@ksmzn 第 3 章変分近似法 July 30, 2015 33 / 43

CVBで用いる統計量
これにより
p(wd,i = v, zd,i = k | w\d,i, z\d,i,α,β
)= p(wd,i = v | zd,i = k,w\d,i, z\d,i,β
)p(zd,i = k | z\d,i,α
)=
n\d,ik,v + βv
n\d,ik,. + β.×
n\d,id,k + αk
n\d,id,. + α.
(Dirichlet分布の期待値計算については,式 (2.10)を参照)
@ksmzn 第 3 章変分近似法 July 30, 2015 34 / 43

q(zd,i = k
)を求める変分下限 F̃CVB
[q(zd,i)]を, q
(zd,i = k
)で微分して 0とおき, q
(zd,i = k
)について解くと,
q(zd,i = k
) ∝ exp
∑z
q(z\d,i)
log p(wd,i, zd,i | w\d,i, z\d,i,α,β
)= exp Eq(z\d,i)
[log p
(wd,i, zd,i | w\d,i, z\d,i,α,β
)]∝ exp Eq(z\d,i)
logn\d,ik,v + βv
n\d,ik,. + β.
(n\d,id,k + αk
)=
exp Eq(z\d,i)[log n\d,ik,v + βv
]exp Eq(z\d,i)
[∑Vv′=1 log n\d,ik,v′ + β
′v
]exp Eq(z\d,i)[log(n\d,id,k + αk
)]
@ksmzn 第 3 章変分近似法 July 30, 2015 35 / 43

テイラー展開による近似
前の式の期待値部分は解析的に計算できないので,テイラー展開による近似を行う.
テイラー展開対数関数を aの周りで 2次までテイラー展開すると,
log x ≈ log a +1a
(x − a) − 12a2 (x − a)2
@ksmzn 第 3 章変分近似法 July 30, 2015 36 / 43

テイラー展開による近似a = E [x]とすると,
E[log x] ≈ logE [x] +
V [x]2E [x]2
であるから, n\d,id,k + αkの周りでテイラー展開して近似すると,
E[log(n\d,id,k + αk
)]≈ log
(E[n\d,id,k
]+ αk
)−
V[n\d,id,k
]2(E[n\d,id,k
]+ αk
)2@ksmzn 第 3 章変分近似法 July 30, 2015 37 / 43

テイラー展開による近似また,
E[n\d,id,k
]=∑i′,i
q(zd,i′ = k
)V[n\d,id,k
]=∑i′,i
q(zd,i′ = k
) (1 − q
(zd,i′ = k
))E[n\d,ik,v
]=
M∑d=1
∑i′,
q(zd,i′ = k
)I(wd,i′ = k
)E[n\d,ik,.
]=
V∑v=1
E[n\d,ik,v
]V[n\d,ik,v
]=
M∑d=1
∑i′,
q(zd,i′ = k
) (1 − q
(zd,i′ = k
))I(wd,i′ = k
)2V[n\d,ik,.
]=
V∑v=1
V[n\d,ik,v
]を用いて,
@ksmzn 第 3 章変分近似法 July 30, 2015 38 / 43

テイラー展開による近似近似アルゴリズムは,
q(zd,i = k
) ∝ E[n\d,ik,v
]+ βv∑V
v′=1 E[n\d,ik,v′
]+ β′vE[n\d,id,k
]+ αk
× exp
− V[n\d,ik,v
]2(E[n\d,ik,v
]+ βv
)2 − V[n\d,id,k
]2(E[n\d,id,k
]+ αk
)2
× exp
V[n\d,ik,.
]2(∑V
v=1 E[n\d,ik,v′
]+ βv′)2
@ksmzn 第 3 章変分近似法 July 30, 2015 39 / 43

CVB0
▶ LDAにおいては, 2次近似よりも,0次近似の方が予測性能が良いことが知られている (CVB0).
q(zd,i = k
) ∝ E[n\d,ik,v
]+ βv∑V
v′=1 E[n\d,ik,v′
]+ β′vE[n\d,id,k
]+ αk
▶ それ以外 (計算コスト等)は同等なので, LDAで 2次近似を使う理由はない (のか?)
▶ 詳細は,著者の佐藤先生の論文を.
@ksmzn 第 3 章変分近似法 July 30, 2015 40 / 43

まとめ
1. LDAに変分ベイズ法を適用した2. LDAに周辺化変分ベイズ法を適用した3. 0次近似 (CVB0)の方が 2次近似よりも汎化能力が高い
@ksmzn 第 3 章変分近似法 July 30, 2015 41 / 43

References
[1] 佐藤一誠 (2015)『トピックモデルによる統計的潜在意味解析』 (自然言語処理シリーズ)コロナ社
[2] 岩田具治 (2015)『トピックモデル』(機械学習プロフェッショナルシリーズ),
[3] CVB0へようこそ! - Bag of ML Wordshttp://dr-kayai.hatenablog.com/entry/
2013/12/22/003011
@ksmzn 第 3 章変分近似法 July 30, 2015 42 / 43

ご清聴ありがとうございました.
@ksmzn 第 3 章変分近似法 July 30, 2015 43 / 43





























