Embed Size (px)
Citation preview

@mszymani#Devoxx #TantusData #spark
Apache Spark - if only it worked
Marcin Szymaniuk TantusData
@mszymani#Devoxx #TantusData #spark
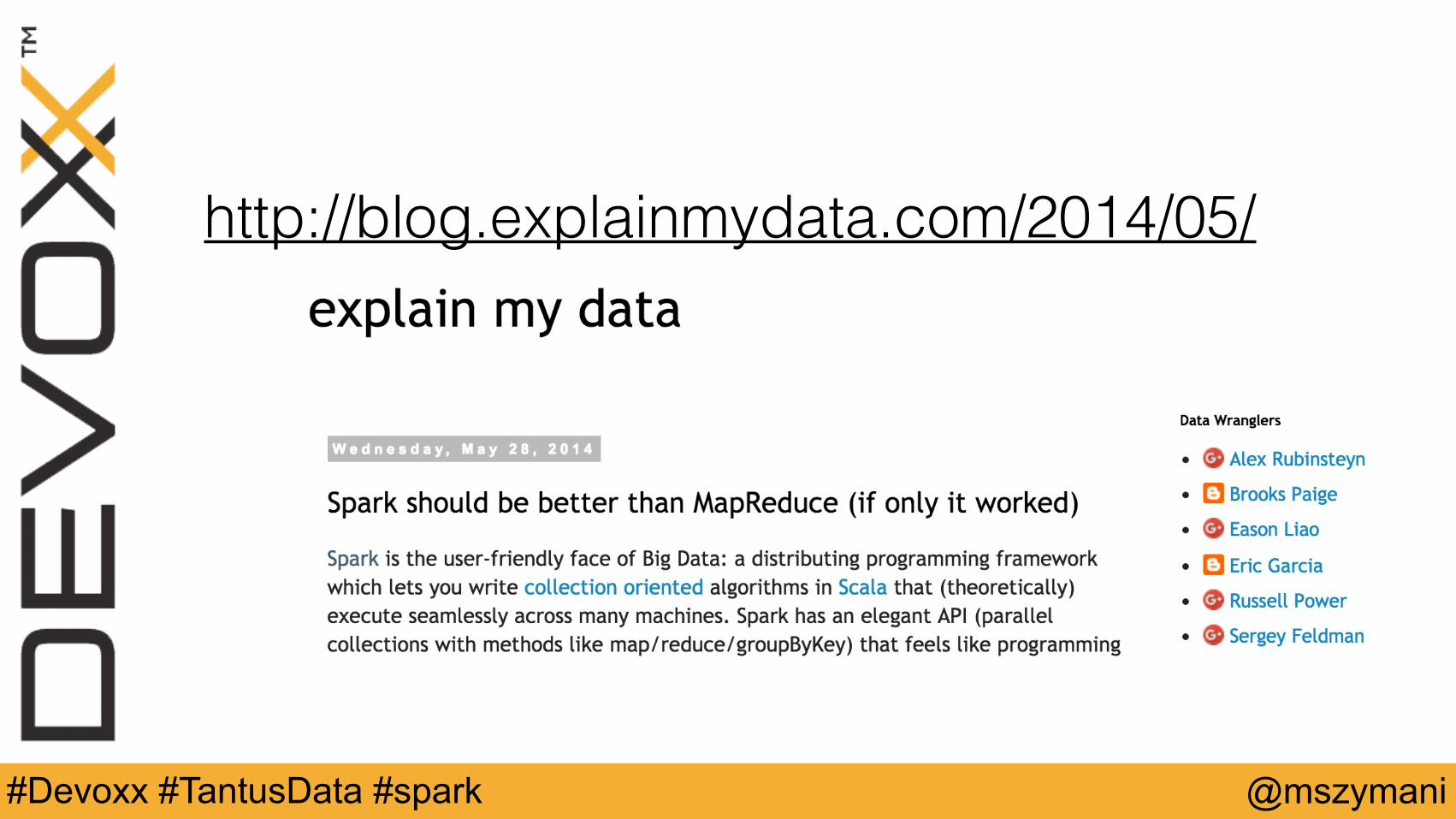
http://blog.explainmydata.com/2014/05/

@mszymani#Devoxx #TantusData #spark
Agenda
• Execution model
• Sizing executors
• Skewed data
• Locality
• Caching
• Debugging tools
• Local run/tests
• Challenge and a draw!

@mszymani#Devoxx #TantusData #spark
What is Spark?
• Engine for distributed data processing
• Java, Scala, R, Python API
• SQL, Streaming, Machine Learning

@mszymani#Devoxx #TantusData #spark
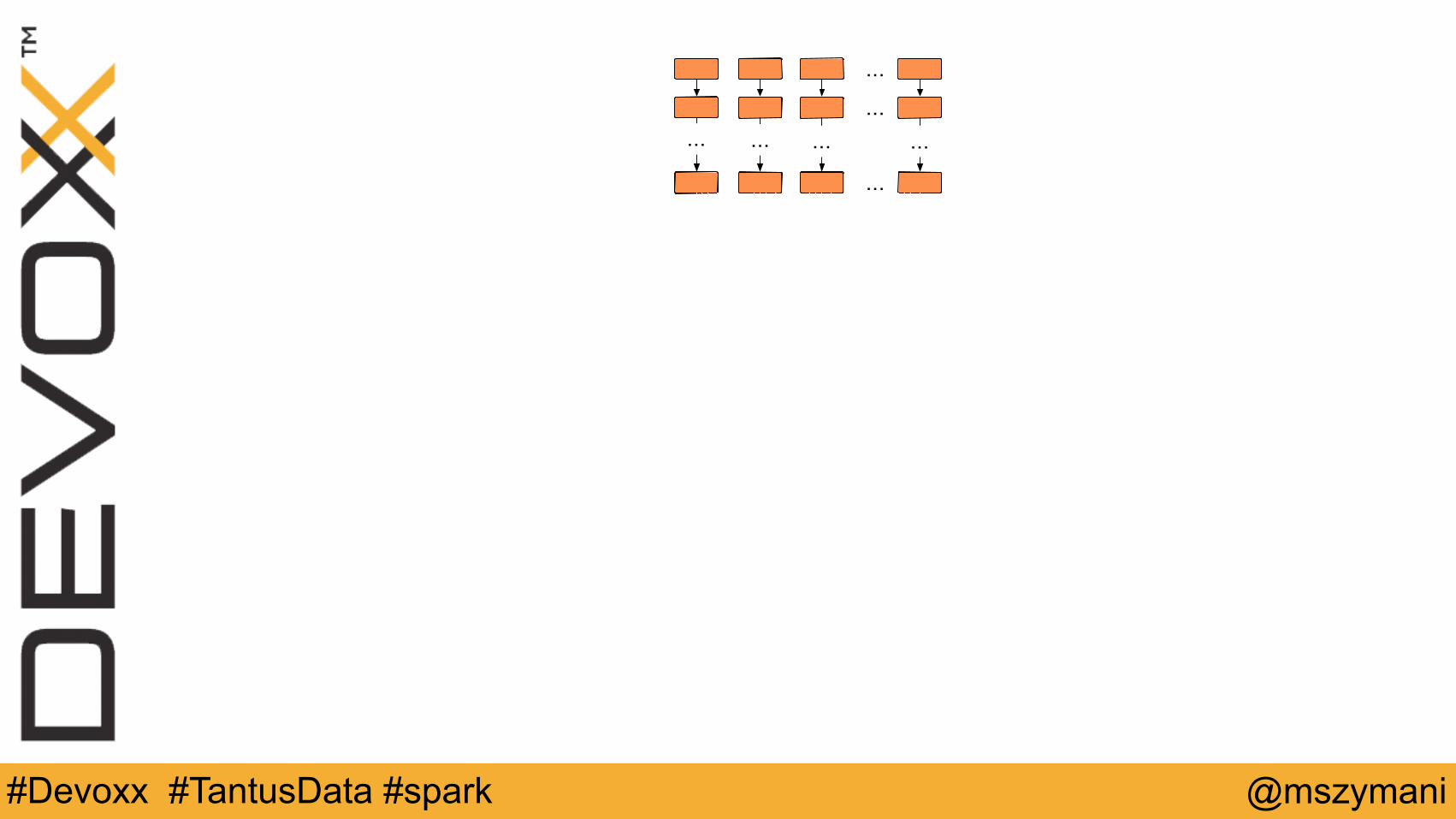
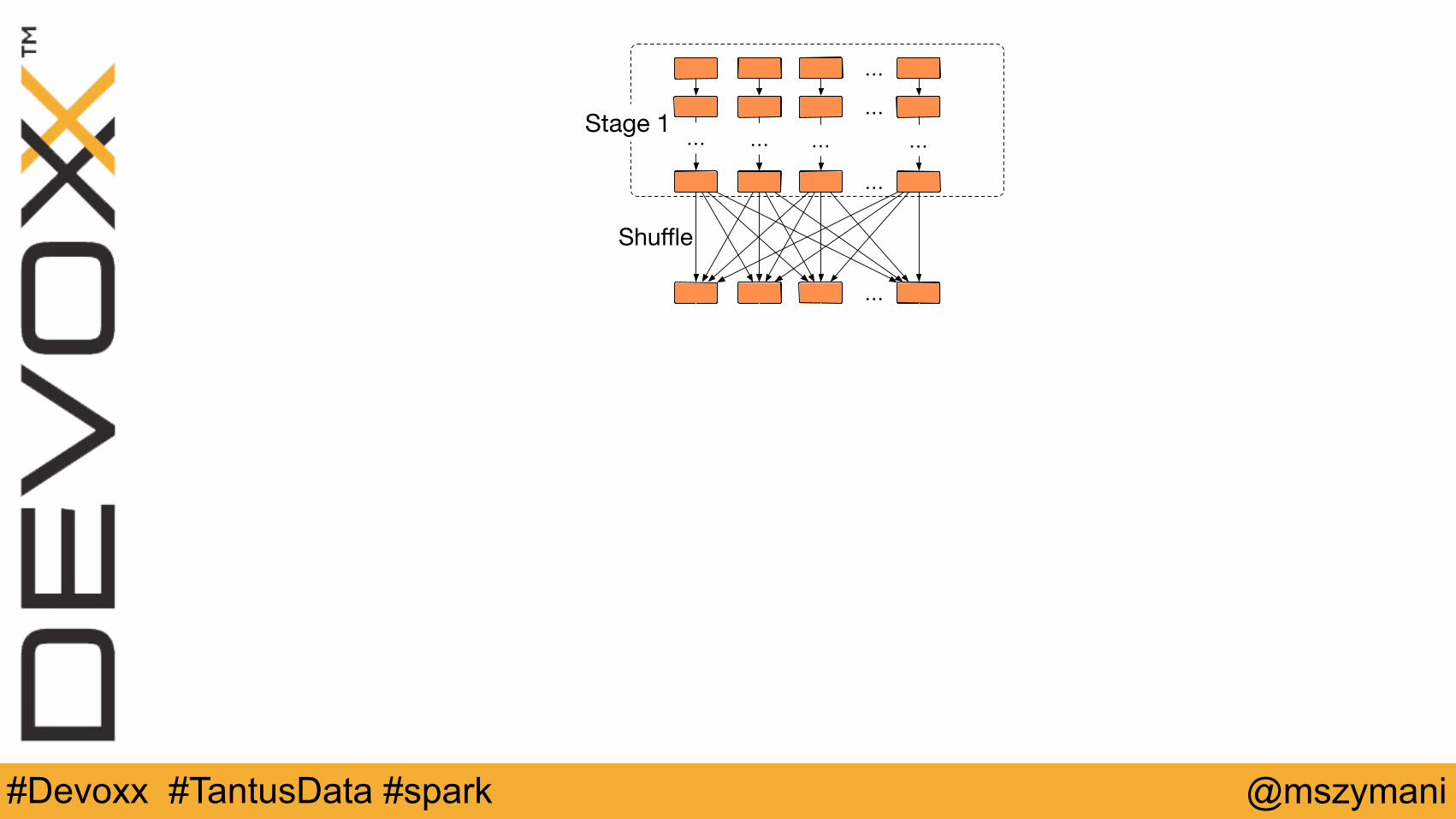
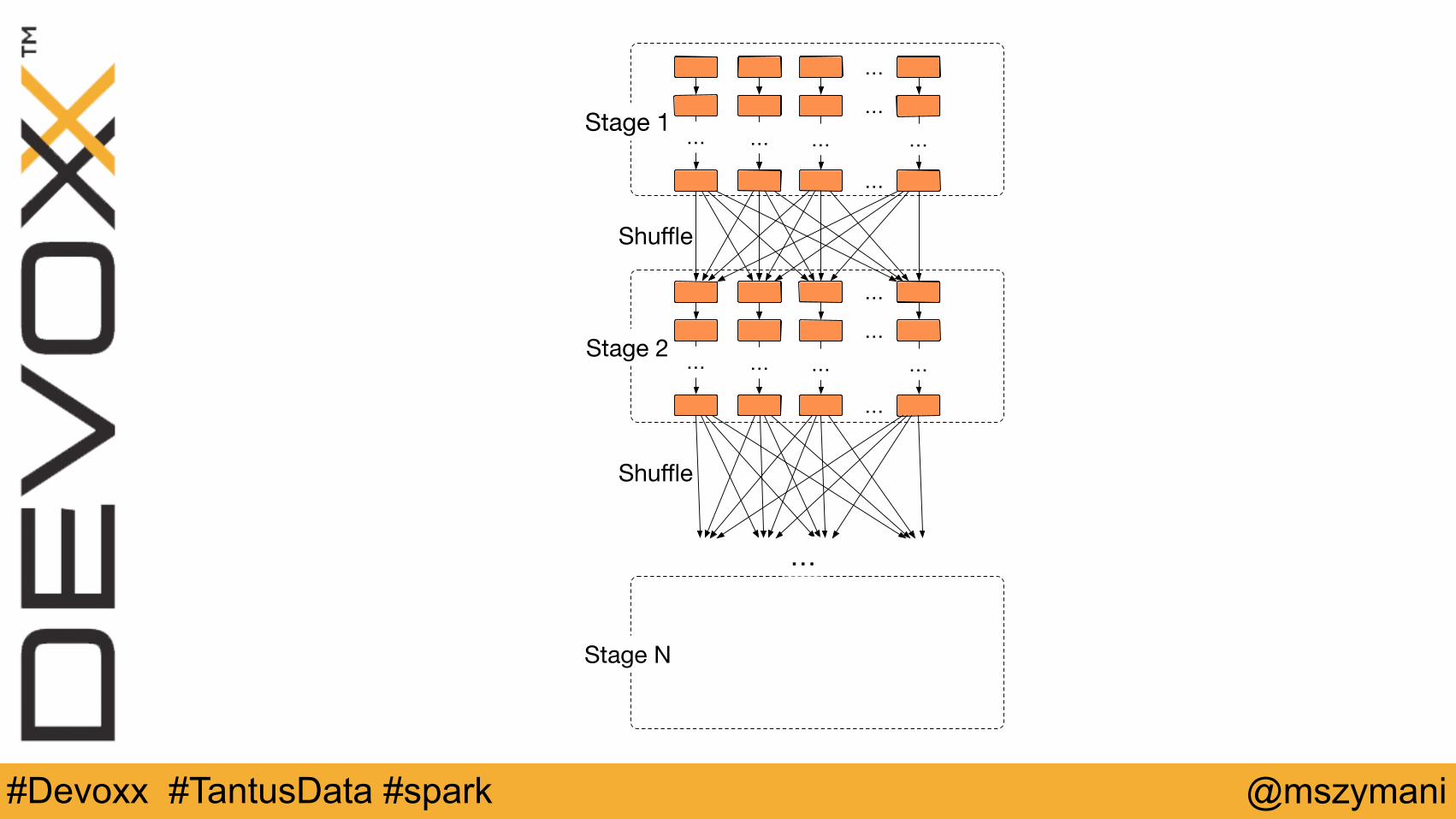
…
…
…
… … … …Stage 1
Stage N
…
…
…
… … … …Stage 2
…
Shuffle
Shuffle
RDD
@mszymani#Devoxx #TantusData #spark
…
…
…
… … … …Stage 1
Stage N
…
…
…
… … … …Stage 2
…
Shuffle
Shuffle
@mszymani#Devoxx #TantusData #spark
…
…
…
… … … …Stage 1
Stage N
…
…
…
… … … …Stage 2
…
Shuffle
Shuffle
@mszymani#Devoxx #TantusData #spark
…
…
…
… … … …Stage 1
Stage N
…
…
…
… … … …Stage 2
…
Shuffle
Shuffle
@mszymani#Devoxx #TantusData #spark
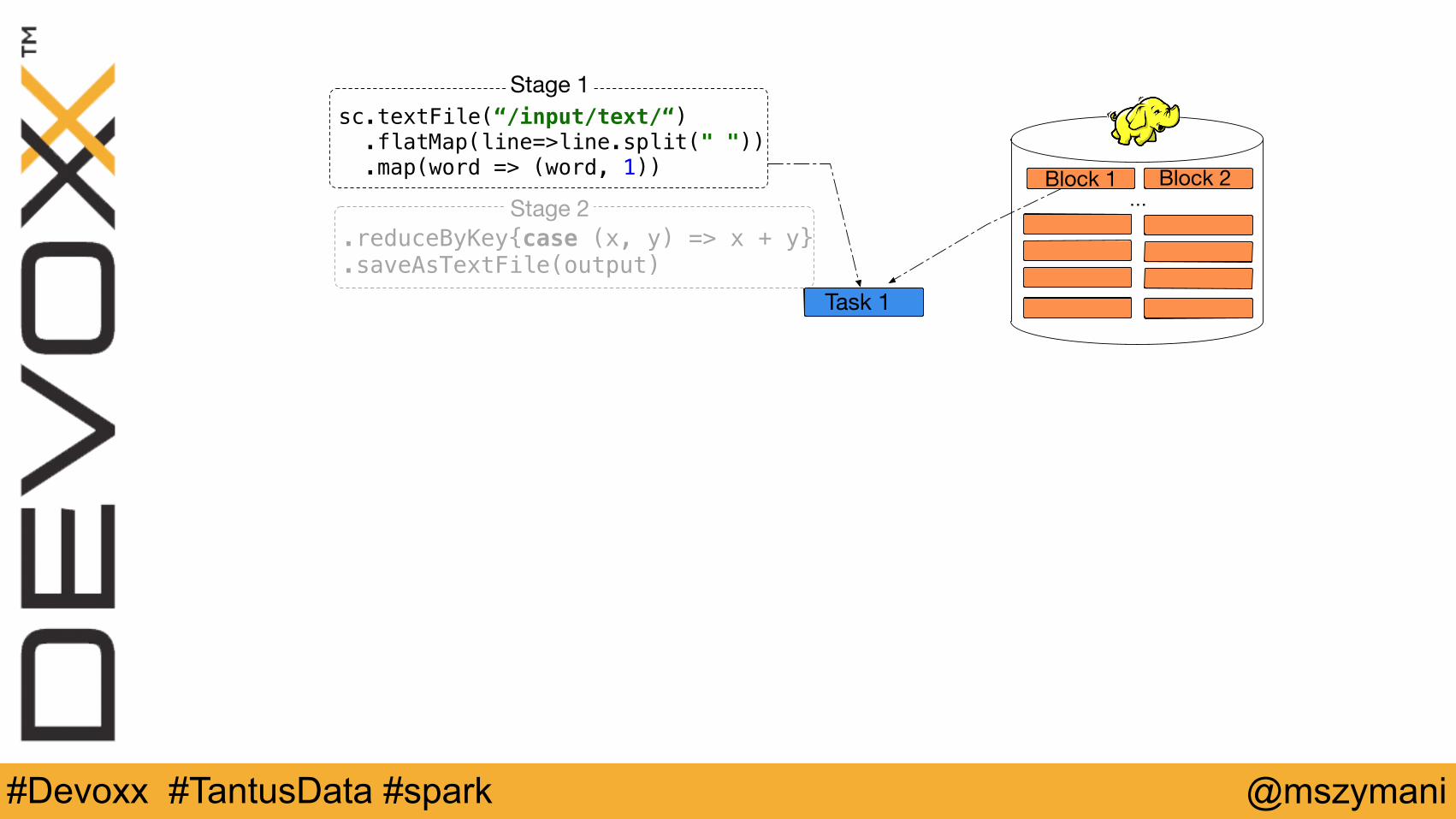
.reduceByKey{case (x, y) => x + y} .saveAsTextFile(output)
Block 1 Block 2…
Task 1
sc.textFile(“/input/text/“) .flatMap(line=>line.split(" ")) .map(word => (word, 1))
Stage 1
Stage 2
… … … …
…
…
…
… … … …
Stage 2…
…
Stage 1
………
@mszymani#Devoxx #TantusData #spark
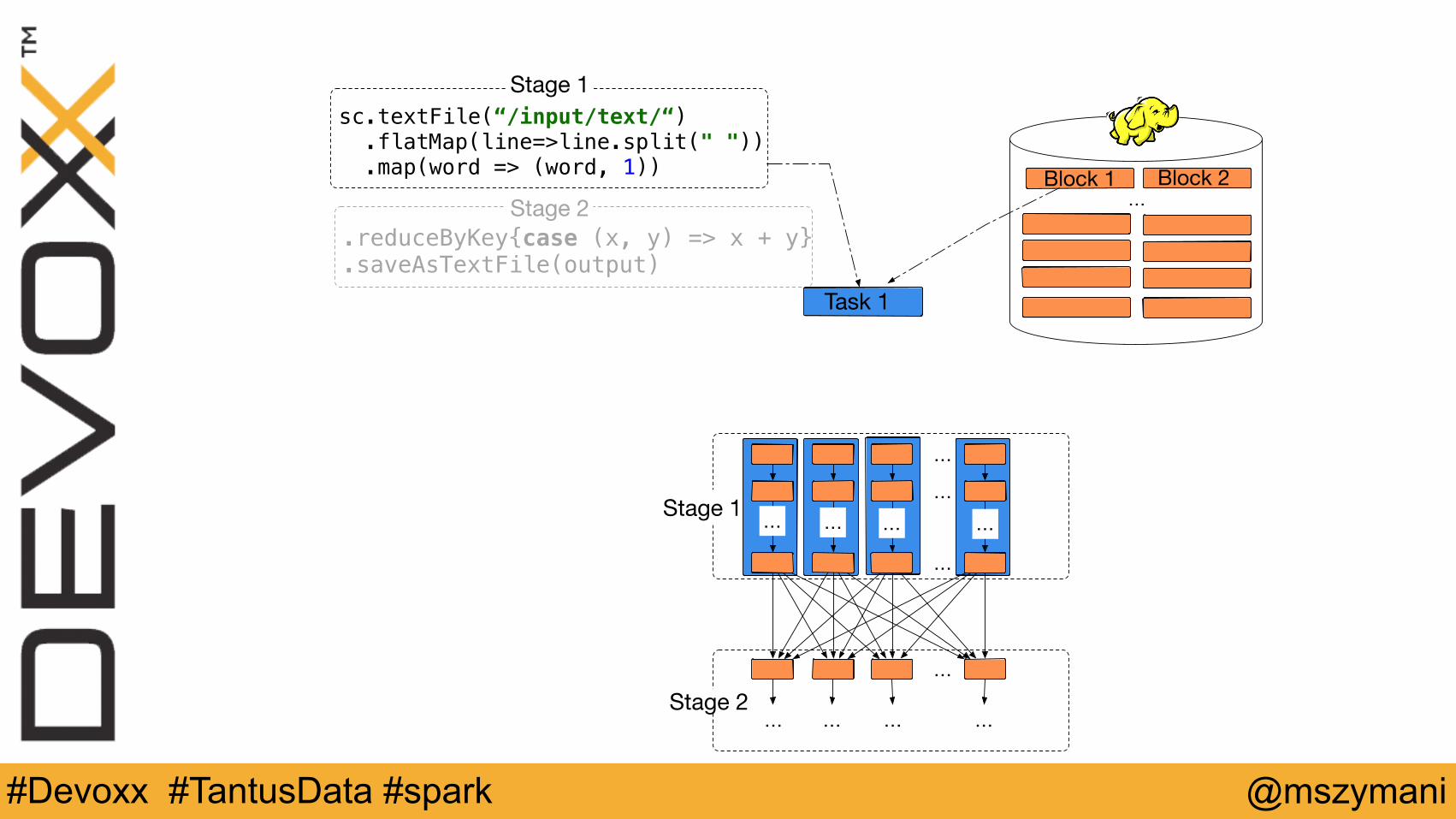
.reduceByKey{case (x, y) => x + y} .saveAsTextFile(output)
Block 1 Block 2…
Task 1
sc.textFile(“/input/text/“) .flatMap(line=>line.split(" ")) .map(word => (word, 1))
Stage 1
Stage 2
… … … …
…
…
…
… … … …
Stage 2…
…
Stage 1
………

@mszymani#Devoxx #TantusData #spark
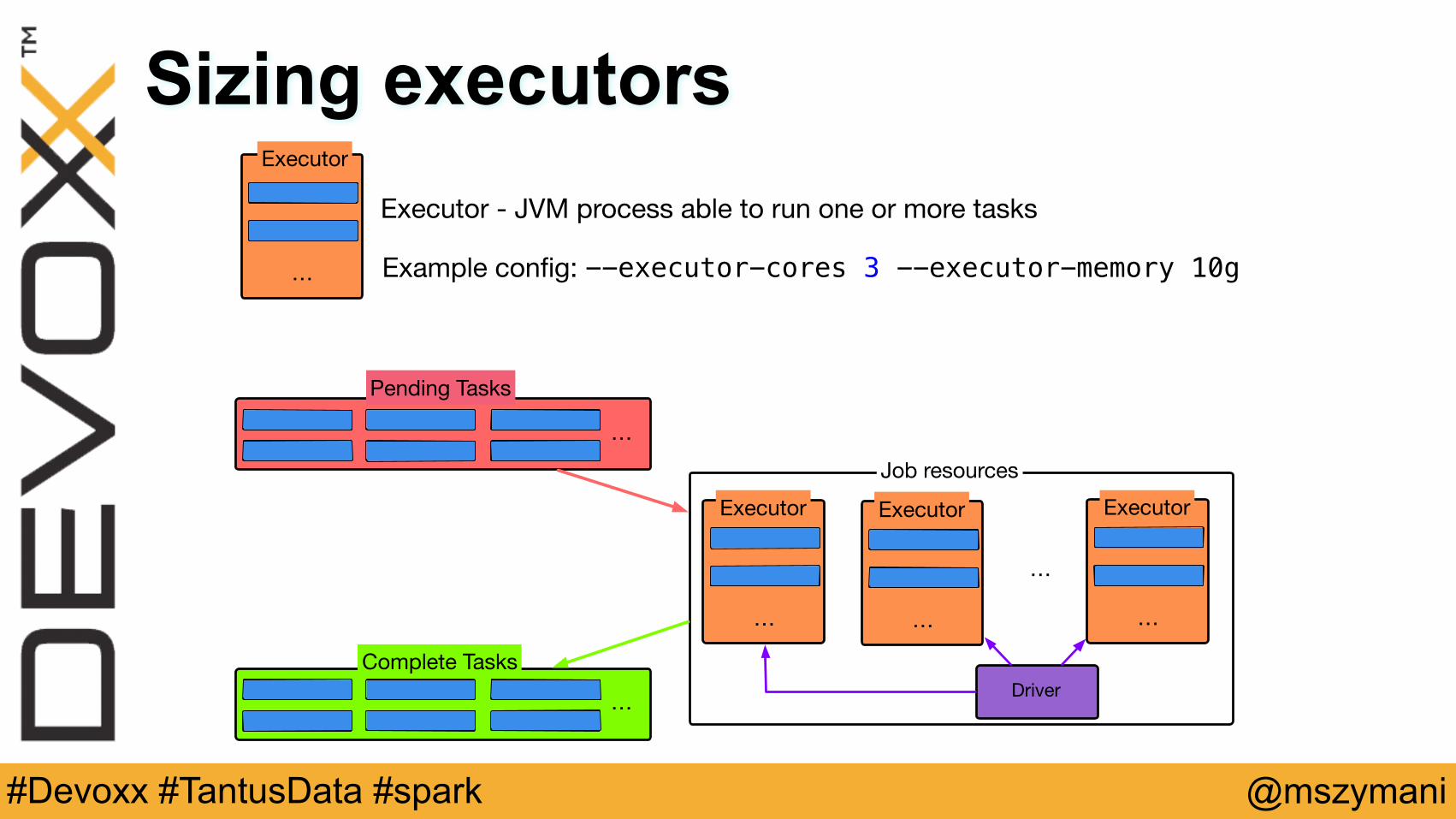
Sizing executorsExecutor - JVM process able to run one or more tasks
…
Executor
Example config: --executor-cores 3 --executor-memory 10g
…
Executor
…
…
Executor
…
Pending Tasks
Complete Tasks
…
…
ExecutorJob resources
@mszymani#Devoxx #TantusData #spark
Executor - JVM process able to run one or more tasks
…
Executor
Example config: --executor-cores 3 --executor-memory 10g
…
Executor
…
…
Executor
…
Pending Tasks
Complete Tasks
…
…
ExecutorJob resources
Driver
Sizing executors
@mszymani#Devoxx #TantusData #spark
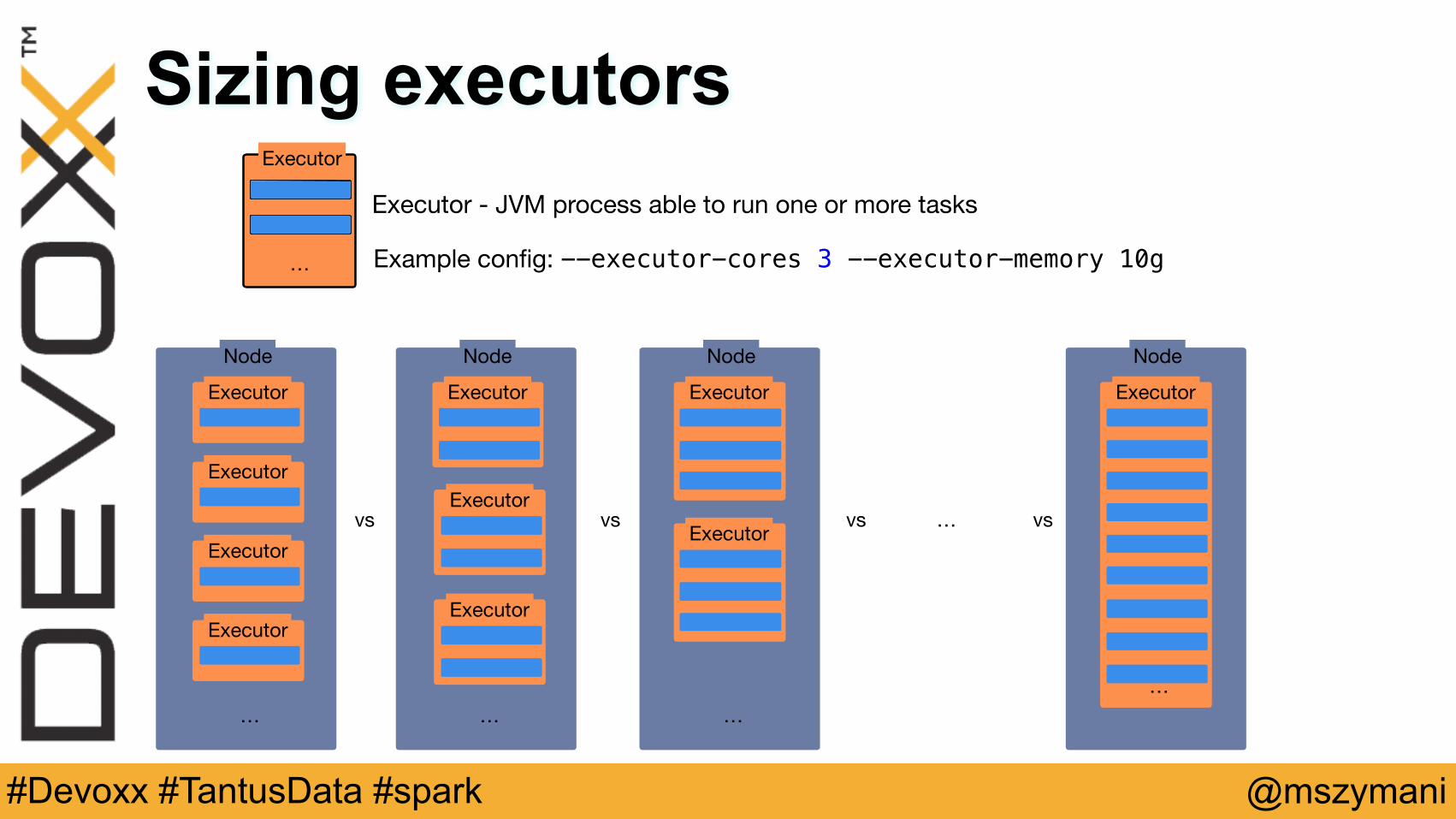
Sizing executorsExecutor - JVM process able to run one or more tasks
…
Executor
Example config: --executor-cores 3 --executor-memory 10g
Executor
Executor
Executor
Executor
Node
…
Executor
Executor
Node
…
Node
…
Executor
Executor
Executor
Executor
Node
Executor
…
vs vs vs vs…

@mszymani#Devoxx #TantusData #spark
Sizing executors
• Spark can benefit from running multiple tasks in the same JVM
• Many cores leads to problems: HDFS I/O, GC
• 1-4 CPUs should be good for start
@mszymani#Devoxx #TantusData #spark
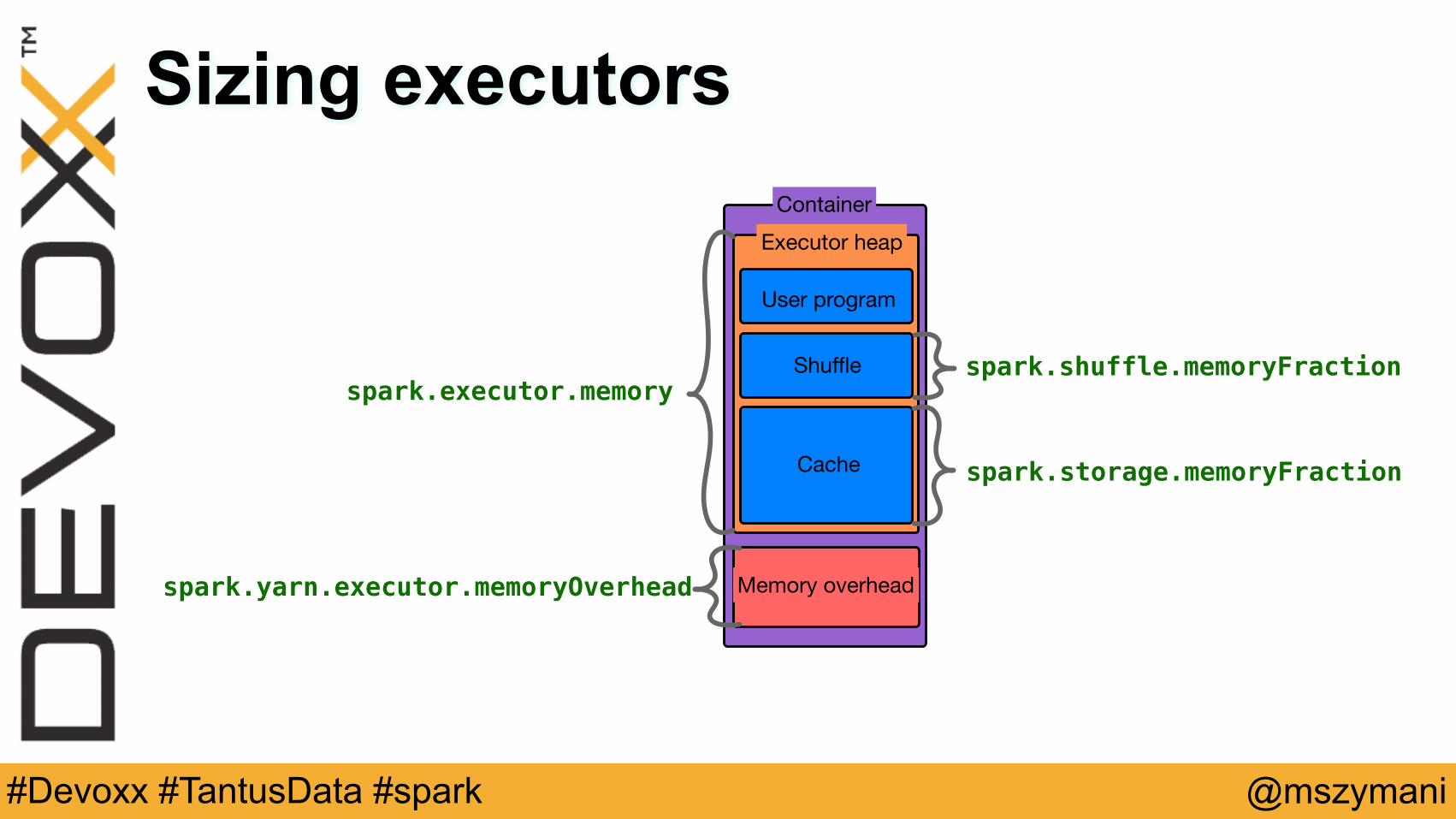
Sizing executors
Executor heap
Container
Memory overhead
spark.executor.memory
spark.yarn.executor.memoryOverhead
spark.shuffle.memoryFraction
spark.storage.memoryFraction
Executor heap
Cache
Shuffle
User program

@mszymani#Devoxx #TantusData #spark
Sizing executors
• Keep in mind memory overhead
• Keep some resources for OS
• Determining memory consumption - cache an RDD
• Consider dynamic resource allocation
@mszymani#Devoxx #TantusData #spark
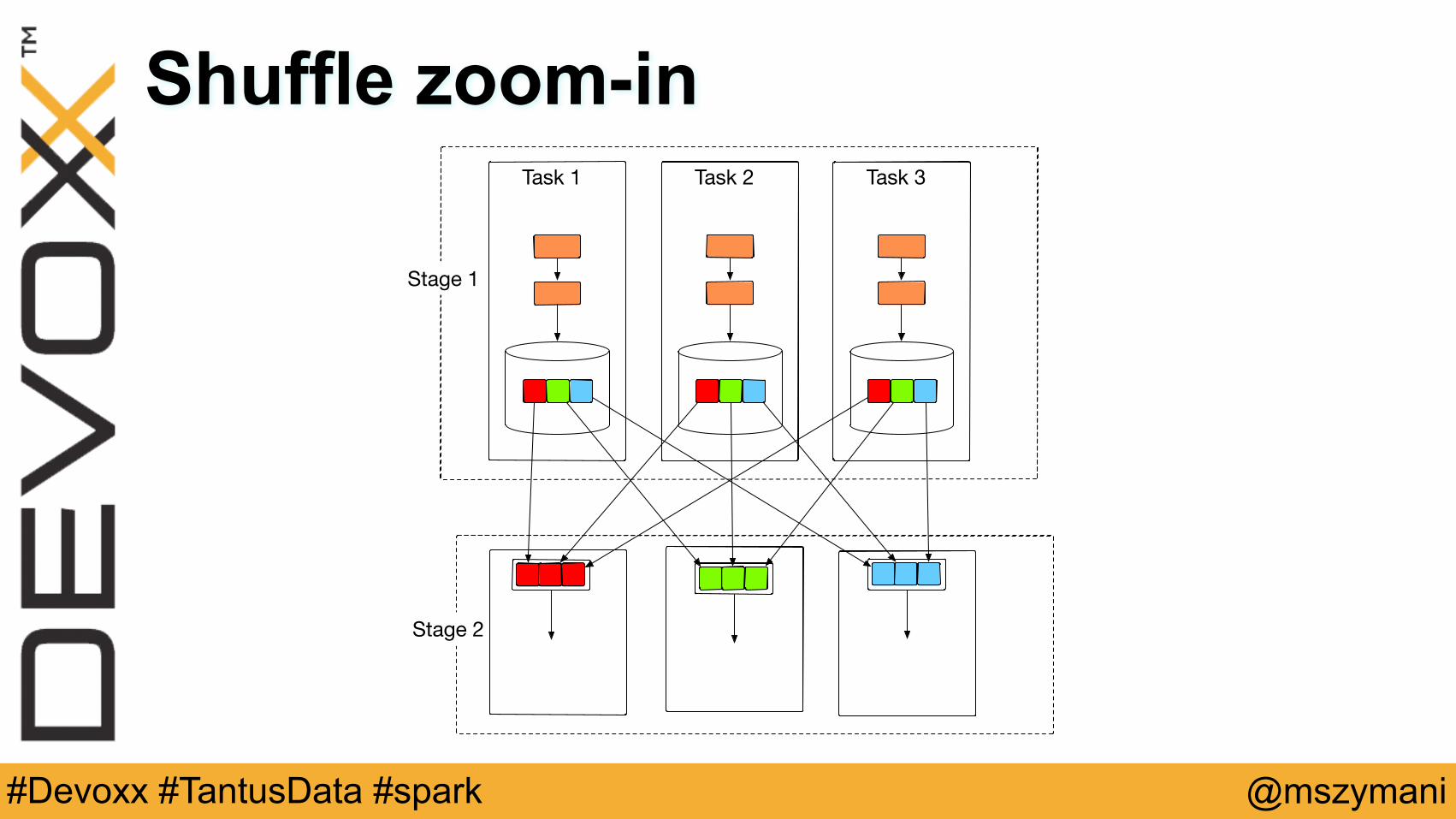
Shuffle zoom-inTask 1 Task 2 Task 3
Stage 1
Stage 2
@mszymani#Devoxx #TantusData #spark
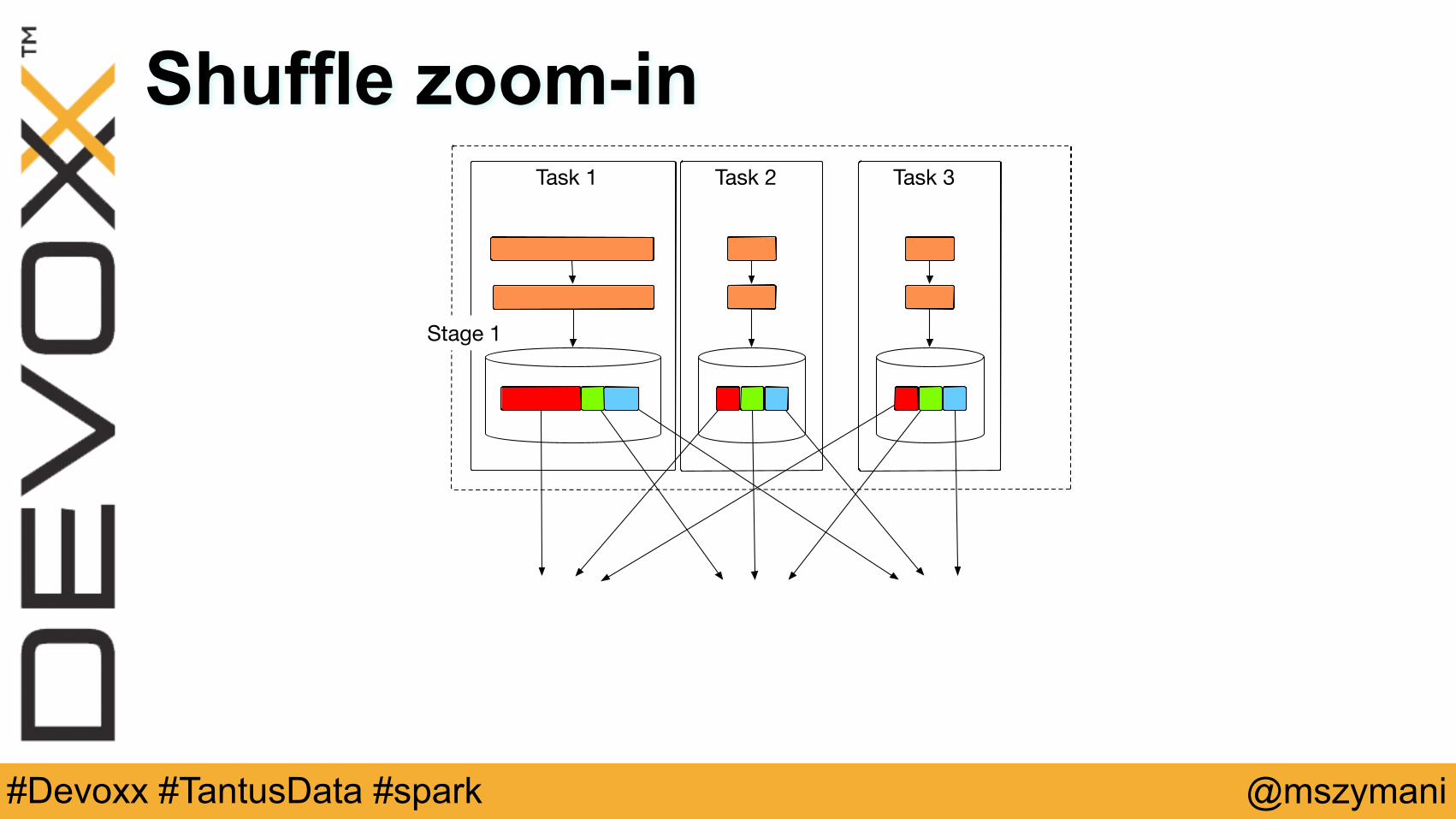
Task 1 Task 2 Task 3
Stage 1
Stage 2
Shuffle zoom-in
@mszymani#Devoxx #TantusData #spark
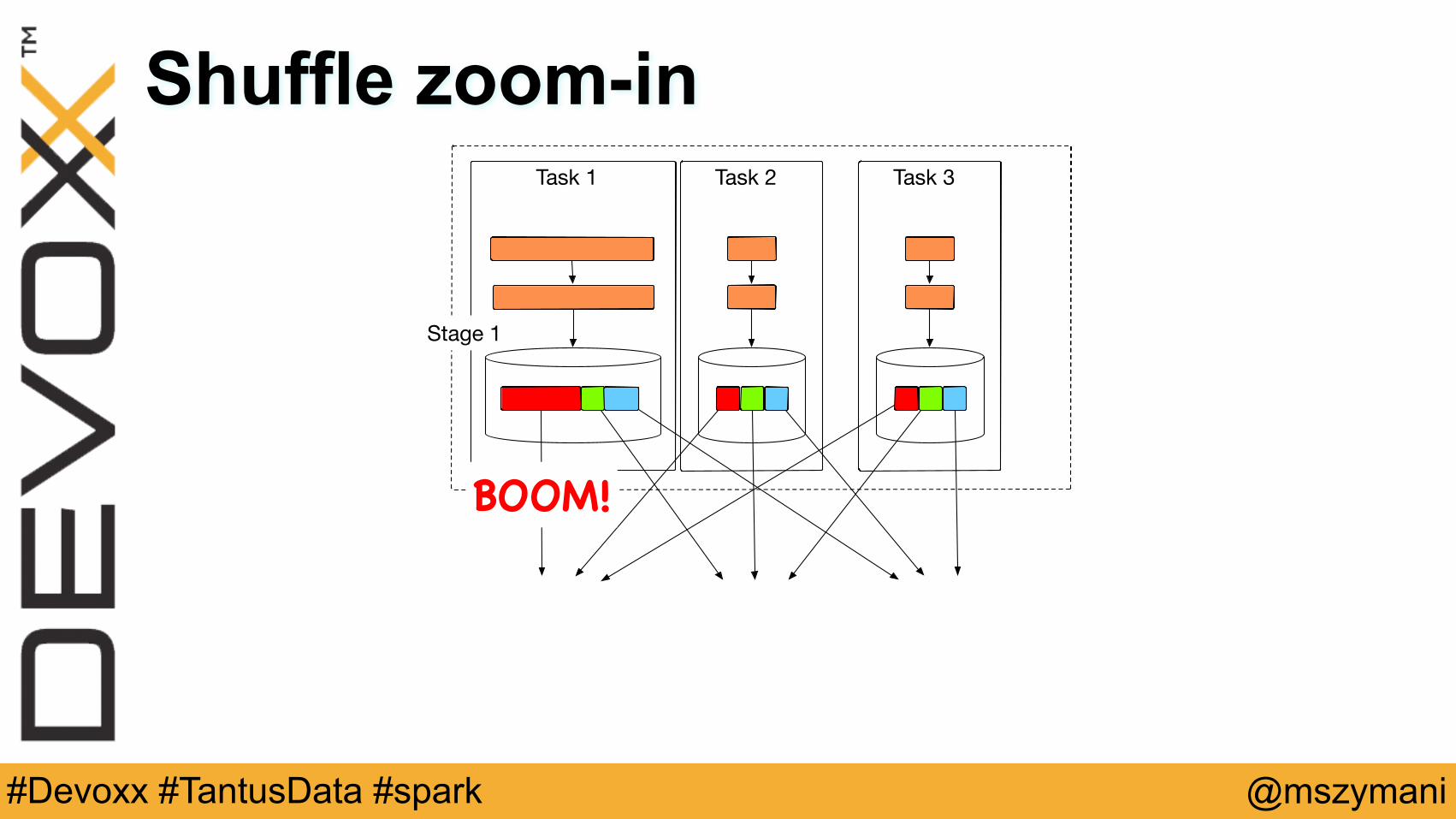
Task 1 Task 2 Task 3
Stage 1
Stage 2
BOOM!BOOM!
Shuffle zoom-in

@mszymani#Devoxx #TantusData #spark
We are up & running
• 2G block limit
• Timeouts
• GC overhead limit exceeded
• OOM
• ExecutorLostFailure

@mszymani#Devoxx #TantusData #spark
We are up & runningWhat to watch out for:
• Failing tasks
• GC heavy tasks
• Shuffle read/write sizes
• Long running tasks

@mszymani#Devoxx #TantusData #spark
We are up & running
• Too much data per task?
• Is parallelism level large enough?
• More memory for executor?
def groupByKey(numPartitions: Int)def repartition(numPartitions: Int)
@mszymani#Devoxx #TantusData #spark
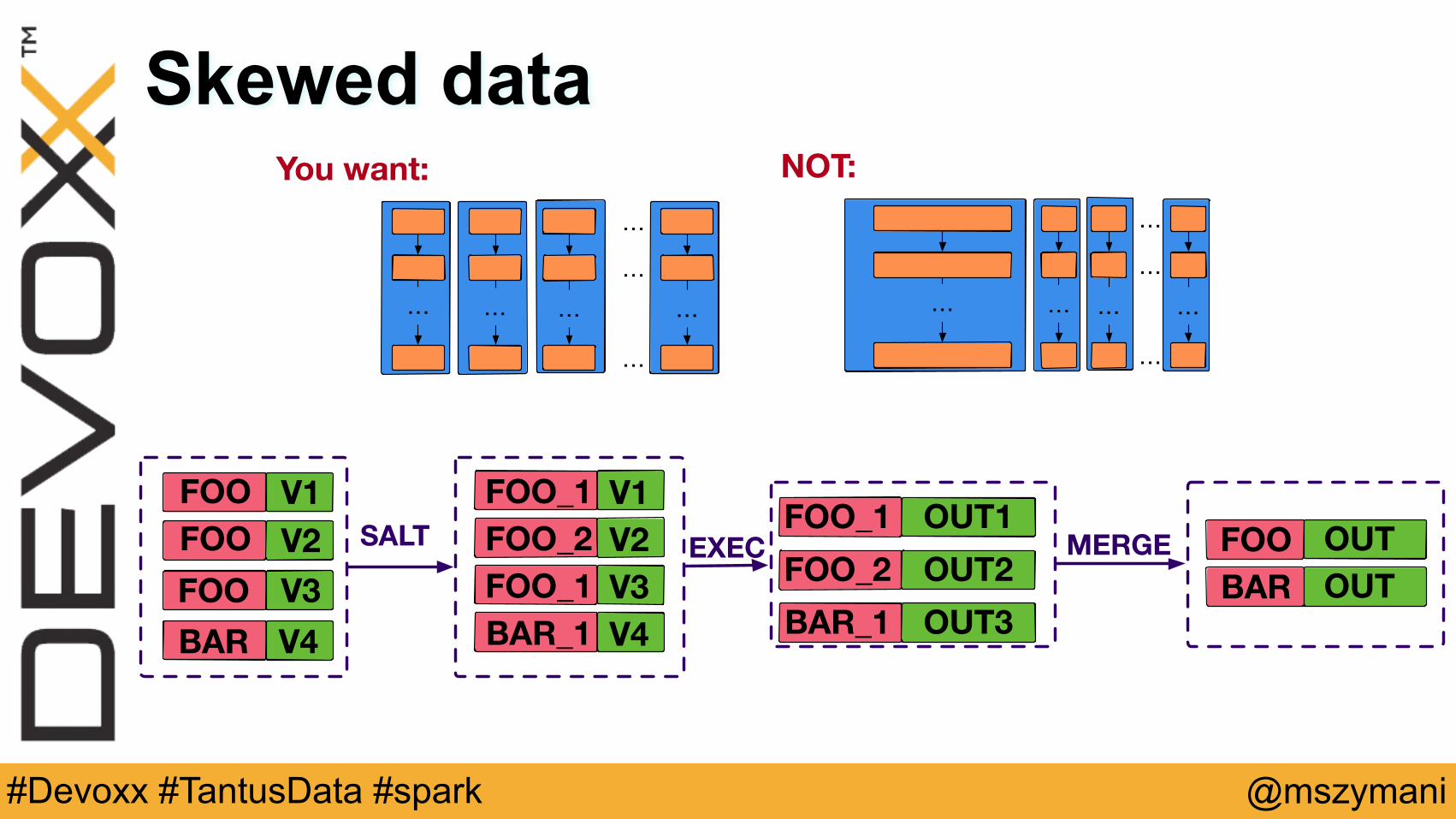
Skewed data
… … … …
…
…
…
… … … … … … … …
…
…
…
… … … …
You want: NOT:
FOO V1FOO V2FOO V3
FOO_1 V1FOO_1 OUT1SALT EXEC FOO OUTMERGE
V4BAR
FOO_2 V2FOO_1 V3BAR_1 V4
FOO_2 OUT2BAR_1 OUT3
BAR OUT
@mszymani#Devoxx #TantusData #spark
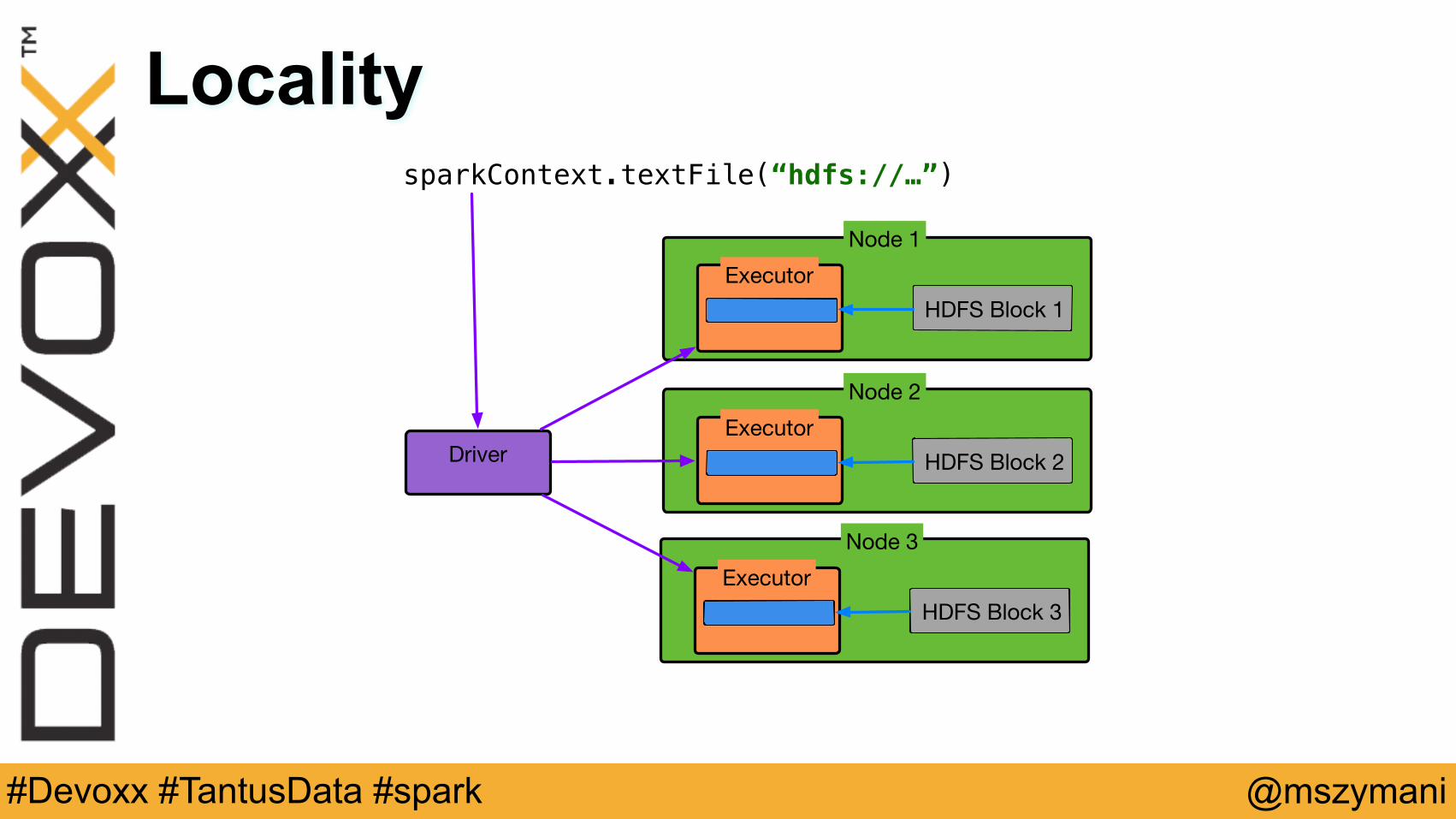
Locality
ExecutorNode 1
HDFS Block 1
ExecutorNode 2
HDFS Block 2
ExecutorNode 3
HDFS Block 3
Driver
sparkContext.textFile(“hdfs://…”)

@mszymani#Devoxx #TantusData #spark
Locality
• Increase number of executors
• For small jobs better to leave as is
• spark.locality.wait parameter
@mszymani#Devoxx #TantusData #spark
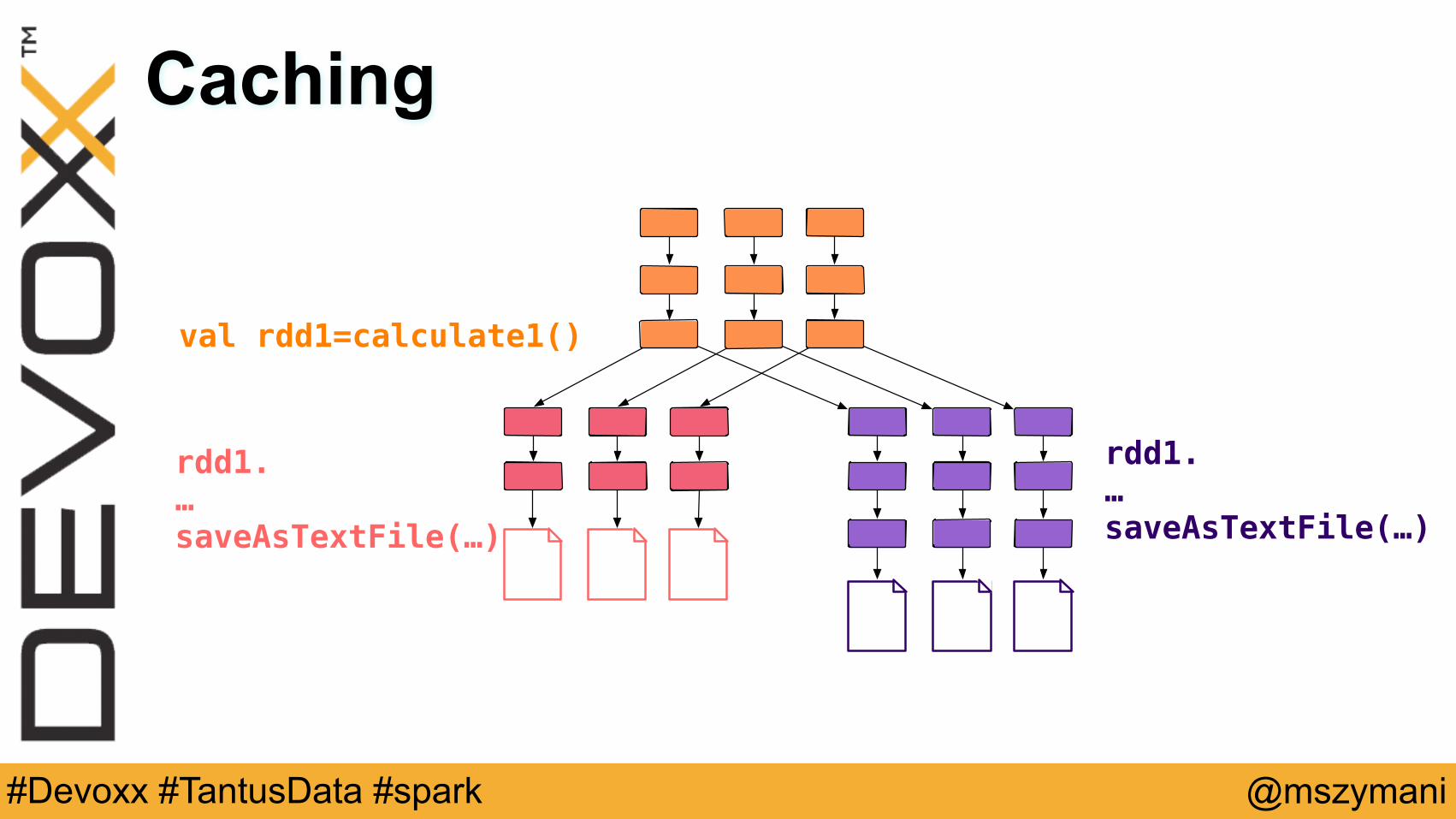
Caching
val rdd1=calculate1()
rdd1.…saveAsTextFile(…)
rdd1.…saveAsTextFile(…)
Executed twice!
@mszymani#Devoxx #TantusData #spark
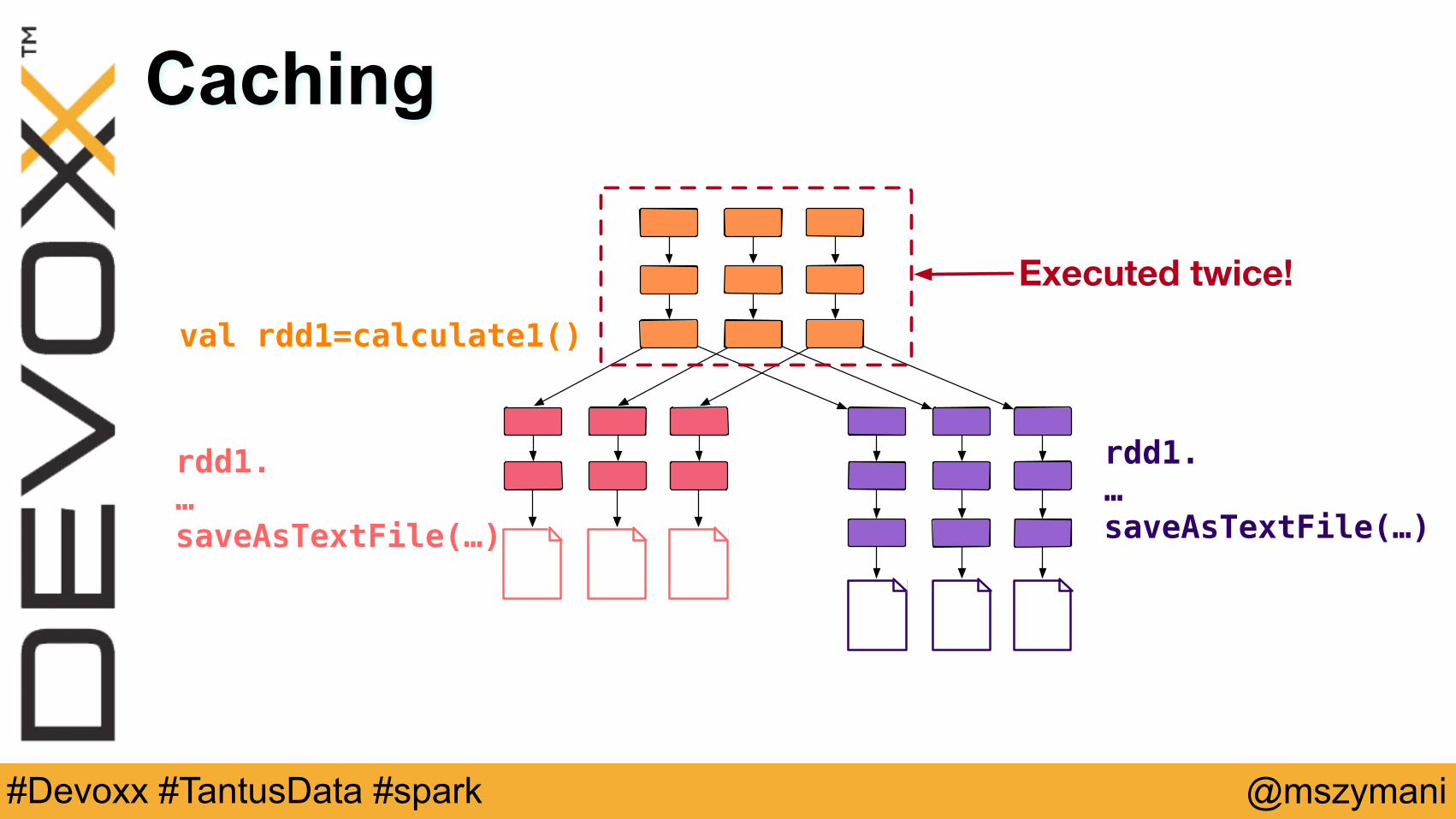
val rdd1=calculate1()
rdd1.…saveAsTextFile(…)
rdd1.…saveAsTextFile(…)
Executed twice!
Caching

@mszymani#Devoxx #TantusData #spark
Caching
• Branch in execution plan is a candidate for caching
• Spark UI shows to see how much memory an RDD is taking
• You cannot control priority - it's LRU
• Don't cache to disk if computation is cheap
• Caching with RF - only when recreation is extremely costly
• Checkpointing vs caching
• Shuffle data is automatically persisted
@mszymani#Devoxx #TantusData #spark
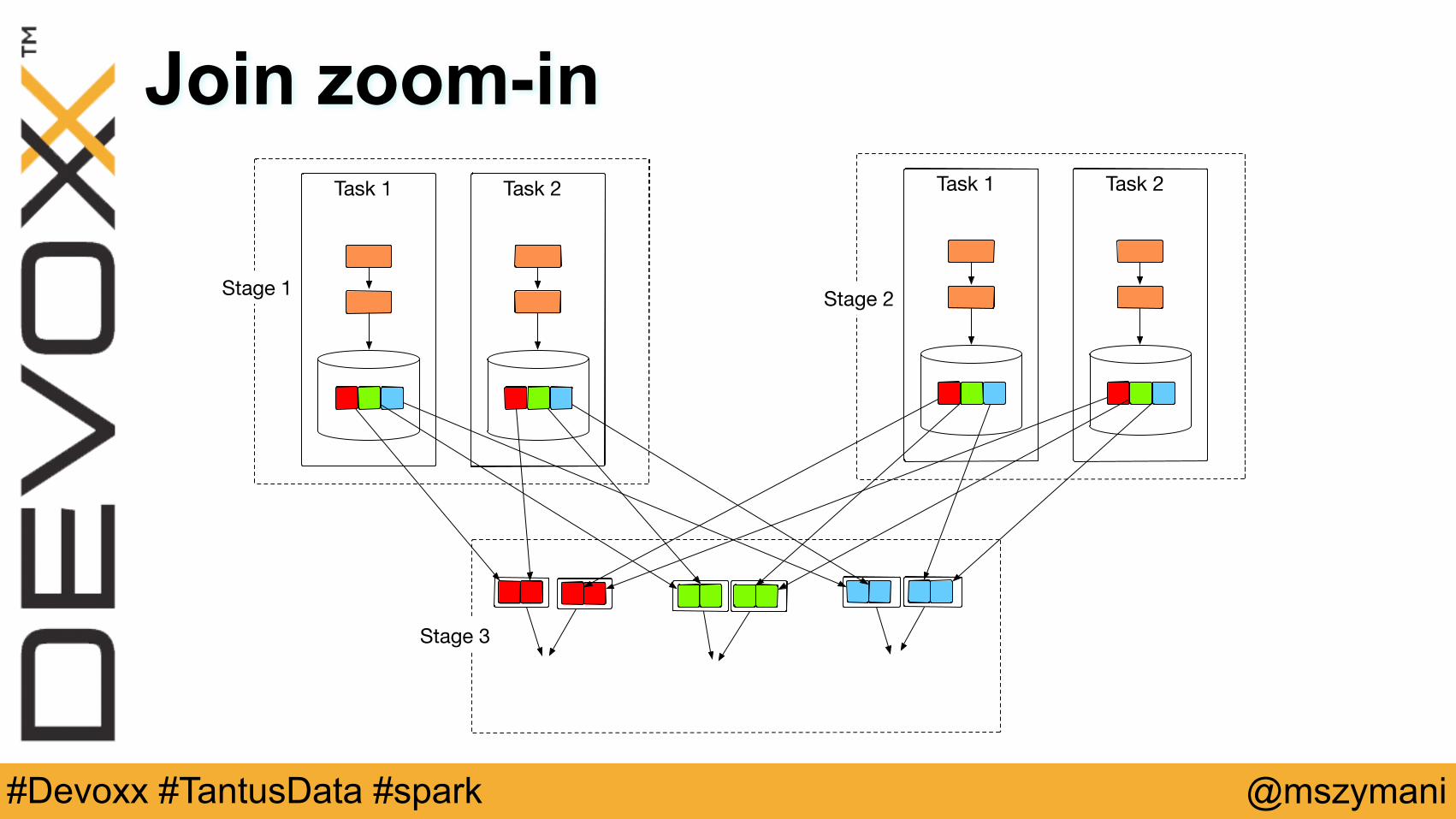
Join zoom-inTask 1 Task 2
Stage 1
Task 1 Task 2
Stage 2
Stage 3
@mszymani#Devoxx #TantusData #spark
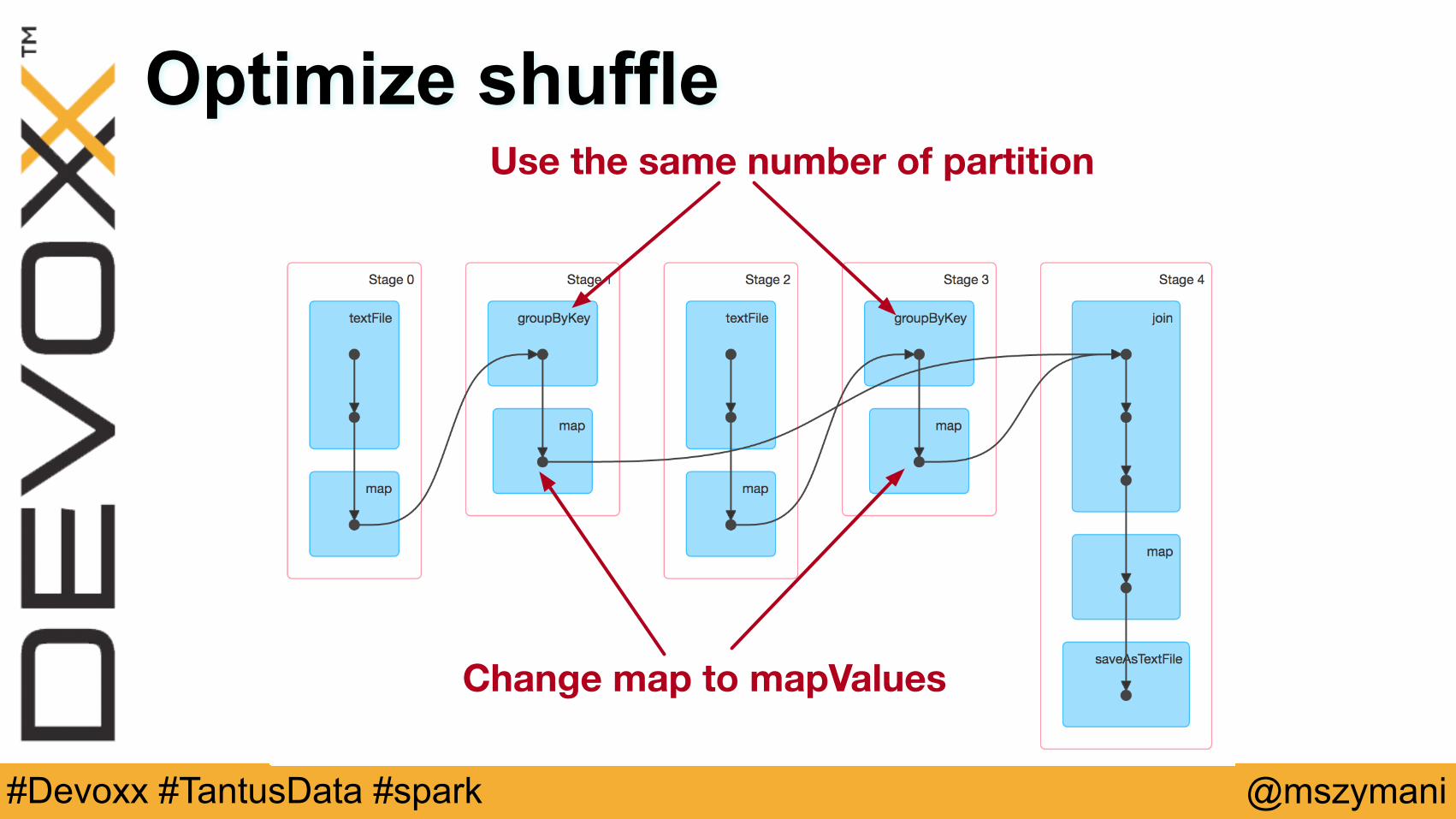
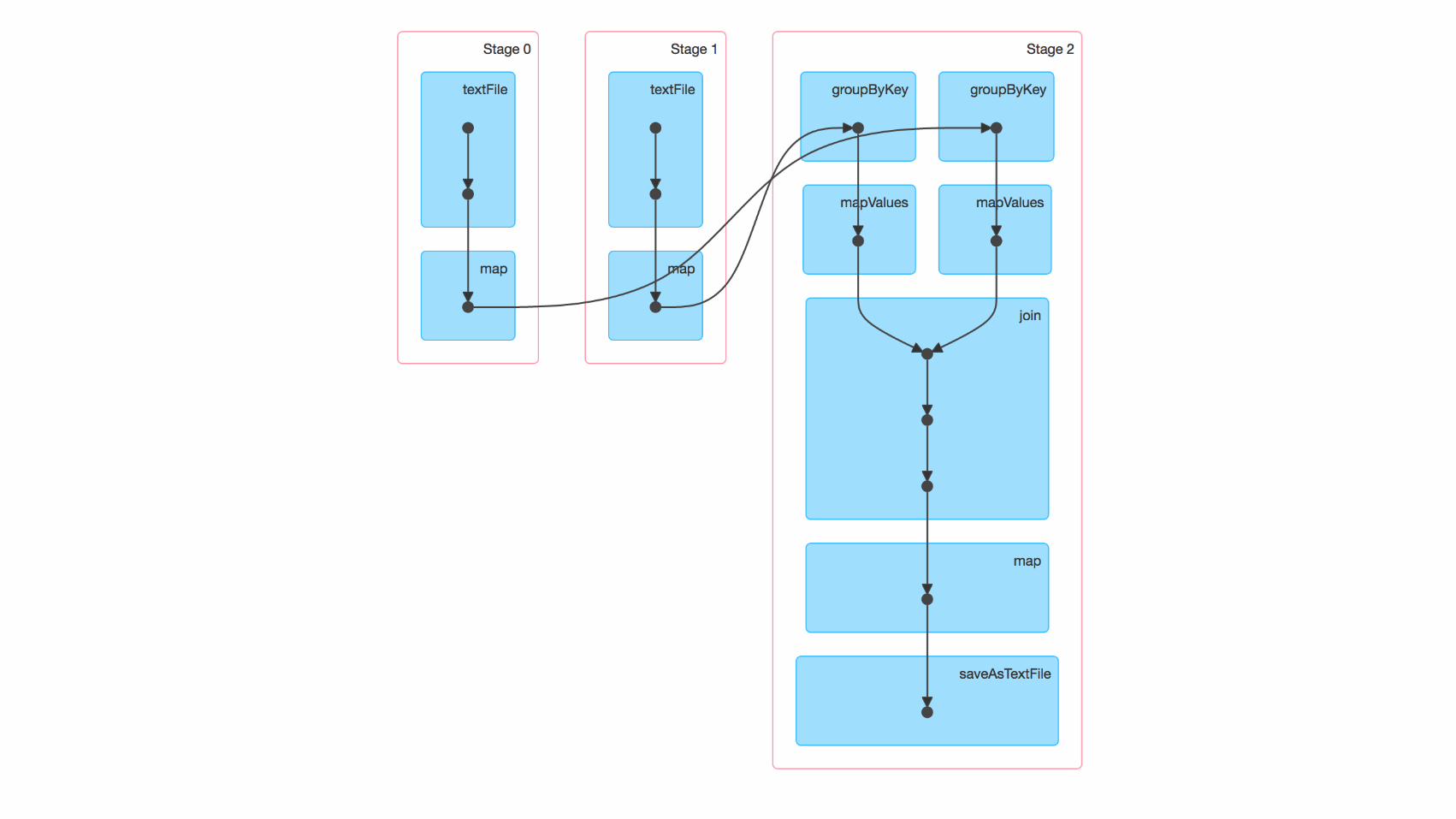
Optimize shuffleUse the same number of partition
Change map to mapValues
@mszymani#Devoxx #TantusData #spark
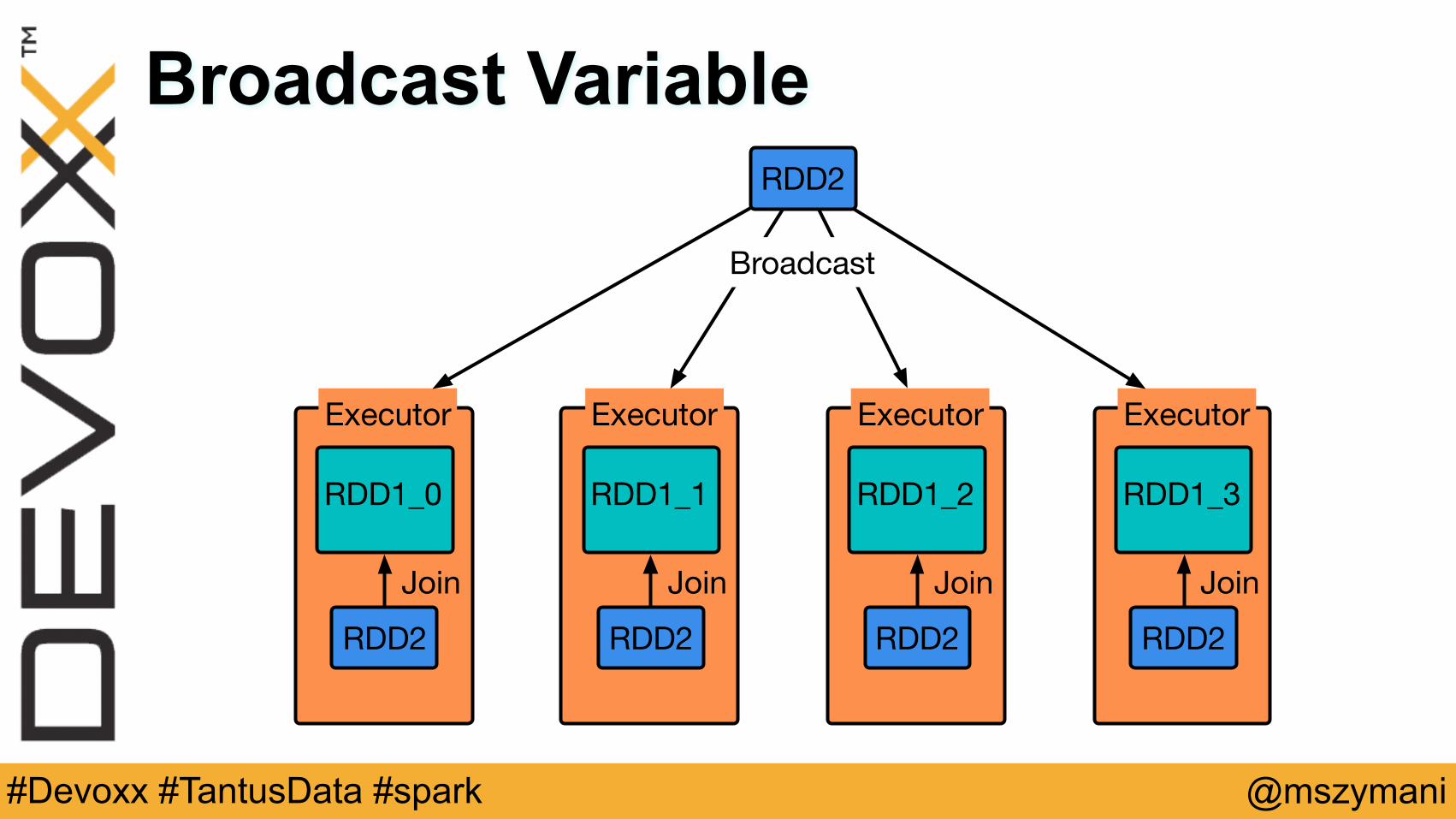
Broadcast Variable
Executor
RDD1_0
RDD2
RDD2Join
Executor
RDD1_1
RDD2Join
Executor
RDD1_2
RDD2Join
Executor
RDD1_3
RDD2Join
Broadcast

@mszymani#Devoxx #TantusData #spark
Optimize shuffle - recap
• Control number of partitions
• Use mapValues instead of map if you can
• Broadcast variables
• Filter before shuffle
• Avoid groupByKey, use reduceByKey

@mszymani#Devoxx #TantusData #spark
Debugging tools
• Spark UI
• HDFS monitoring
• Aggregate your logs
• Extra Java options - observe your GC
• Run and test locally

@mszymani#Devoxx #TantusData #spark
Challenge time!
goo.gl/7eTtvH
@mszymani#Devoxx #TantusData #spark
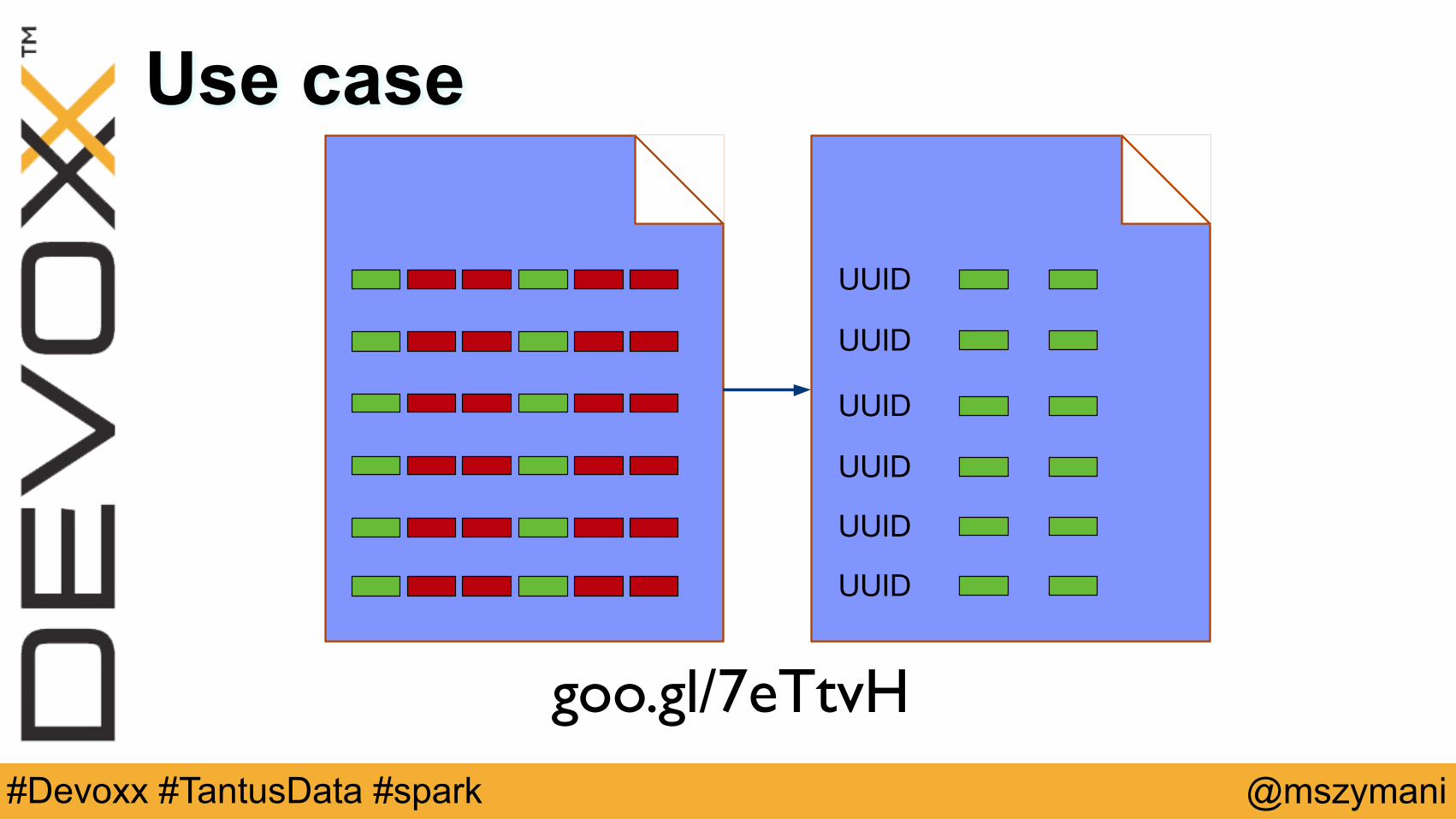
Use case
UUID
UUID
UUID
UUID
UUID
UUID
goo.gl/7eTtvH

@mszymani#Devoxx #TantusData #spark
General notes
• Tests vs no tests? - Test your code!
• You are probably not the only user of the cluster
• What are you optimizing for?
• Share the knowledge
• Spark actually works :)
goo.gl/7eTtvH

@mszymani#Devoxx #TantusData #spark
Q&A






























