Embed Size (px)
Citation preview

Classificazione in efMRI:
Ciaparrone Gioele
Vitale Luca
Anno 2015/2016
1
un caso di studio sulla coniugazione dei verbi

Esperimento
• L’esperimento consiste nel coniugare al participio passato un verbo all’infinito
• I verbi sono raggruppati secondo due criteri:
• Regolari e irregolari
• Numero di coniugazione
• I soggetti sono sottoposti a una scansione fMRI che permette di rilevare cambiamenti nella risposta emodinamica BOLD (Blood Oxygen Level Dependent) all’attività neurale
• L’esperimento è di tipo Rapid Event-Related fMRI
2
Obbiettivo
• Addestrare un classificatore che riesca a distinguere quando il soggetto ha coniugato un verbo regolare da quando ne ha coniugato uno irregolare
3

Dati a disposizione
• Per lo svolgimento del progetto abbiamo utilizzato i dati del soggetto FECO
• VMR – Volume Magnetic Resonance
• VTC – Volume Time Course
• PRT - Protocol
4

Creazione della maschera
• Un volume del VTC contiene 58x40x46 = 106720 voxel
• Utile ridurre il numero di voxel tenuti in considerazione ignorando quelli fuori dal cervello
• Per questo motivo abbiamo creato una maschera che ha ridotto il numero di voxel a 50096
5
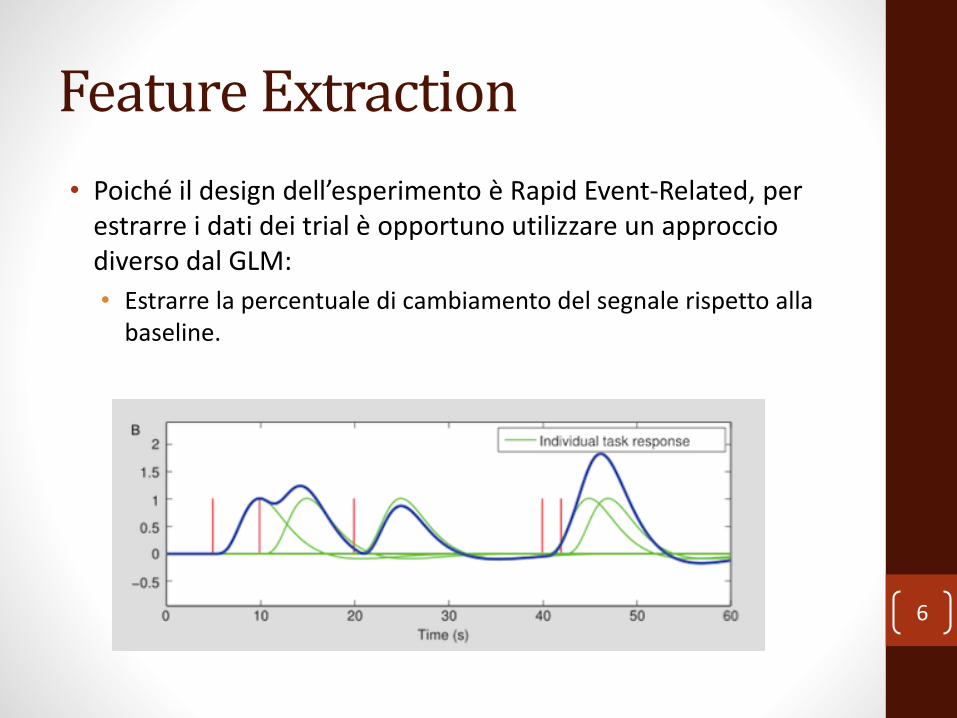
Feature Extraction
• Poiché il design dell’esperimento è Rapid Event-Related, per estrarre i dati dei trial è opportuno utilizzare un approccio diverso dal GLM:
• Estrarre la percentuale di cambiamento del segnale rispetto alla baseline.
6

Feature Selection
• Il numero di trial di training (147) è estremamente inferiore al numero di feature (50096)
• Per effettuare una prima fase di feature selection abbiamo utilizzato due strategie:
• ICA (Indipendent Component Analysis)
• Searchlight
7
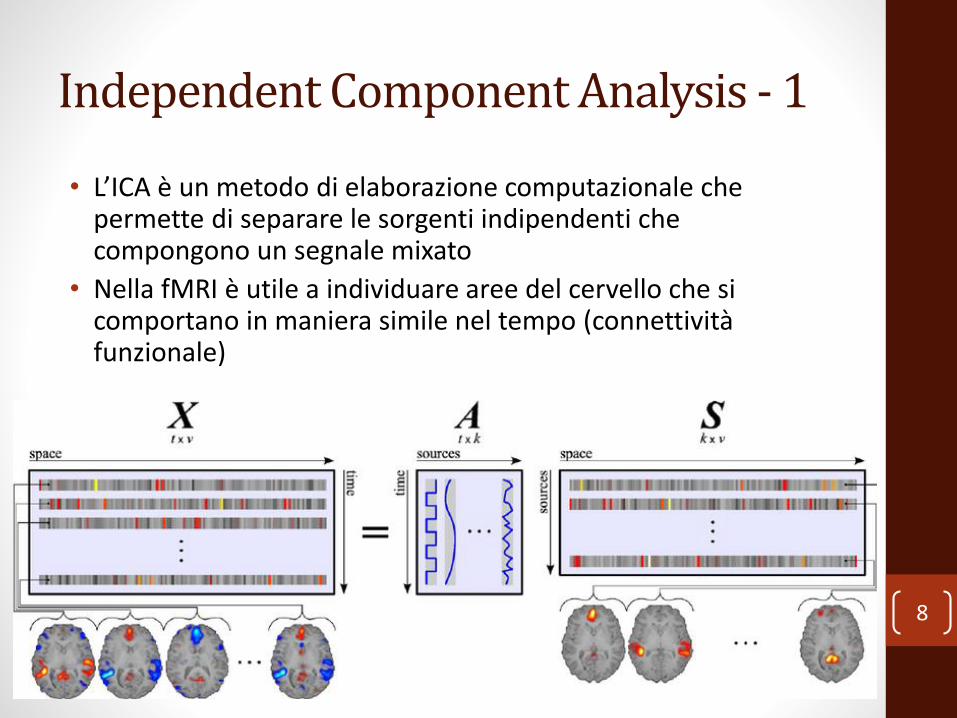
Independent Component Analysis - 1
• L’ICA è un metodo di elaborazione computazionale che permette di separare le sorgenti indipendenti che compongono un segnale mixato
• Nella fMRI è utile a individuare aree del cervello che si comportano in maniera simile nel tempo (connettività funzionale)
8
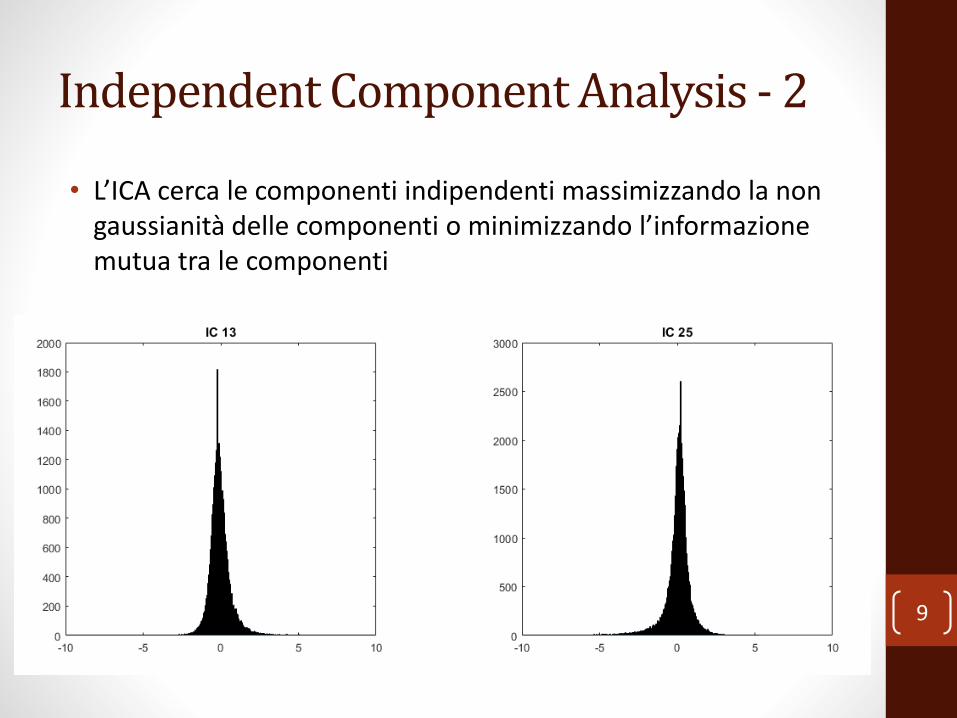
Independent Component Analysis - 2
• L’ICA cerca le componenti indipendenti massimizzando la non gaussianità delle componenti o minimizzando l’informazione mutua tra le componenti
9

Independent Component Analysis - 3
• Per le componenti indipendenti di una fMRI è possibile utilizzare una “fingerprint” che permette di distinguere la tipologia della componente estratta
10
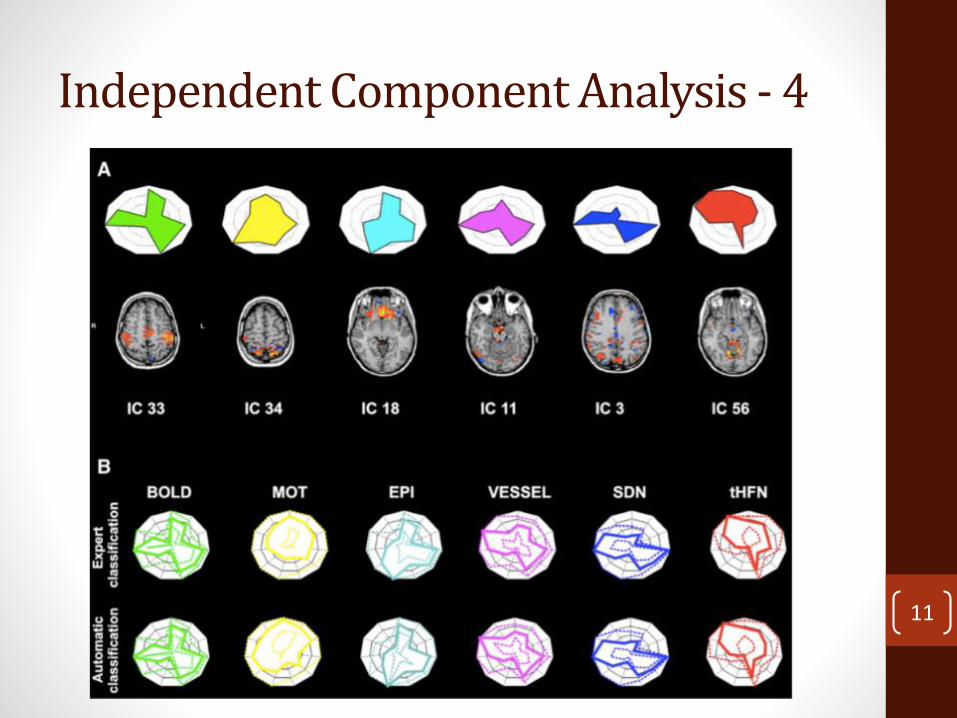
Independent Component Analysis - 4
11
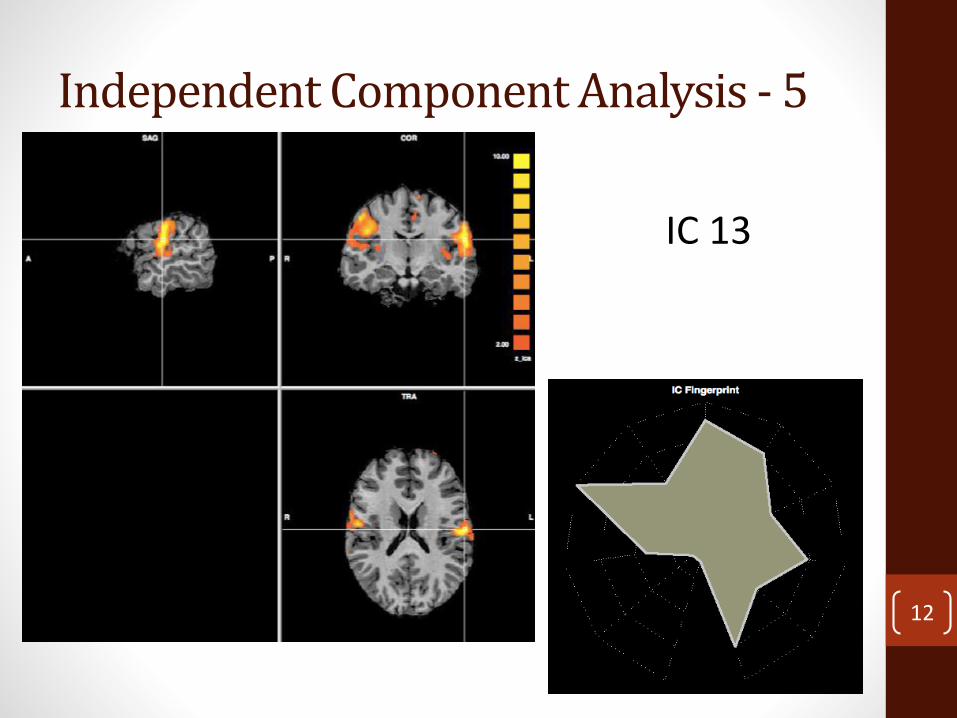
Independent Component Analysis - 5
12
IC 13
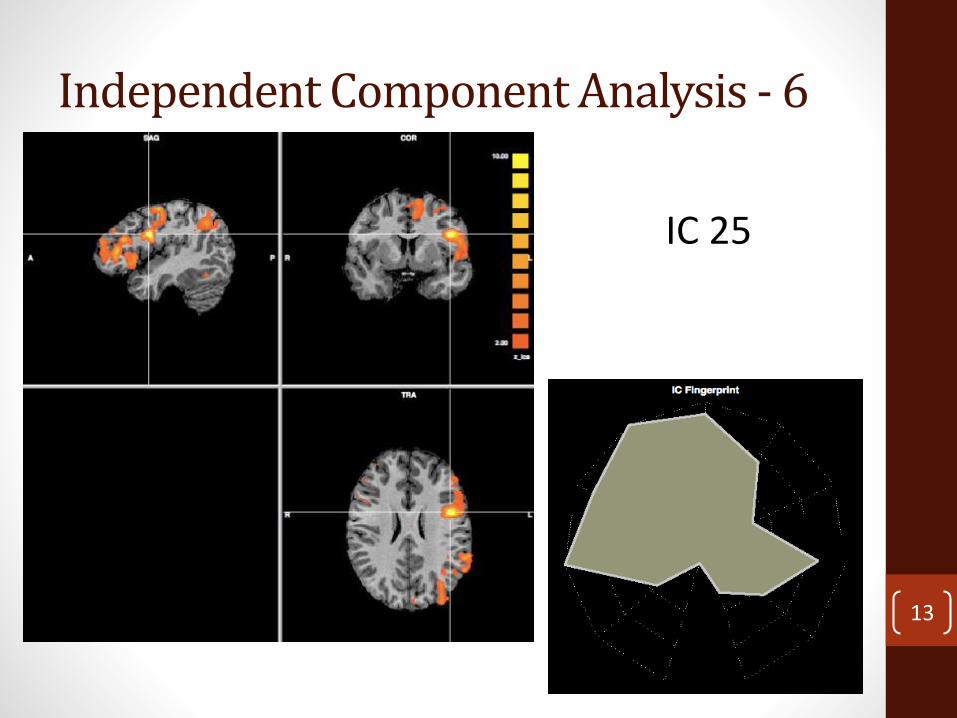
Independent Component Analysis - 6
13
IC 25

Searchlight
• La searchlight è un tipo di analisi multivariata
• L’algoritmo visita tutti i voxel disponibili
• Per ogni voxel vengono selezionati i voxel “vicini” all’interno di una “sfera” di raggio scelto
• Il voxel viene selezionato in base ai risultati di una delle 3 seguenti tecniche:
• Support Vector Machine
• MANOVA
• Integrate t value
14

Searchlight –Risultati
• È stato utilizzato SVM come criterio di valutazione di rilevanza dei voxel
• Voxel risultanti:
• IC 13 + IC 25: 1 voxel
• Zone Anatomiche: 7 voxel
• Ogni esecuzione ha restituito pochi voxel
• I voxel restituiti non hanno permesso di addestrare un classificatore efficace
15

Clustering - 1
• Il clustering è il raggruppamento di elementi omogenei in un insieme di dati
• Il clustering gerarchico è un tipo clustering che mira a costruire una gerarchia. Esistono due tipi di strategie:
• Agglomerativo e divisivo
• Per la creazione dei cluster è possibile utilizzare diverse metriche di dissimilarità
• Distanza euclidea o correlazione
• e diversi metodi di collegamento
• Complete linkage, single linkage e Ward’s method
16
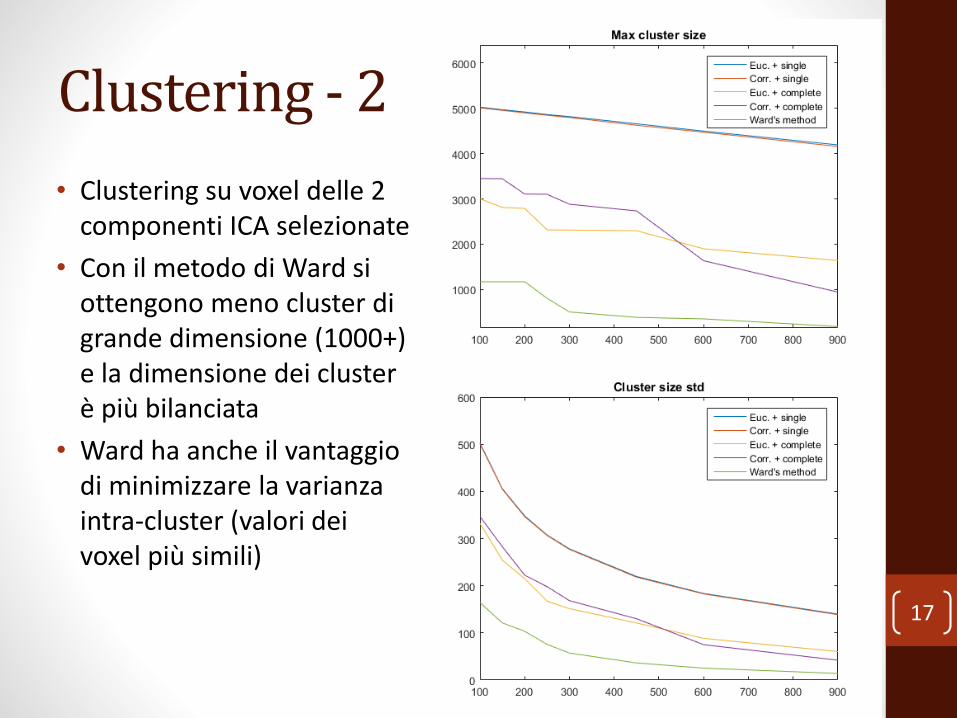
Clustering - 2
17
• Clustering su voxel delle 2 componenti ICA selezionate
• Con il metodo di Ward si ottengono meno cluster di grande dimensione (1000+) e la dimensione dei cluster è più bilanciata
• Ward ha anche il vantaggio di minimizzare la varianza intra-cluster (valori dei voxel più simili)
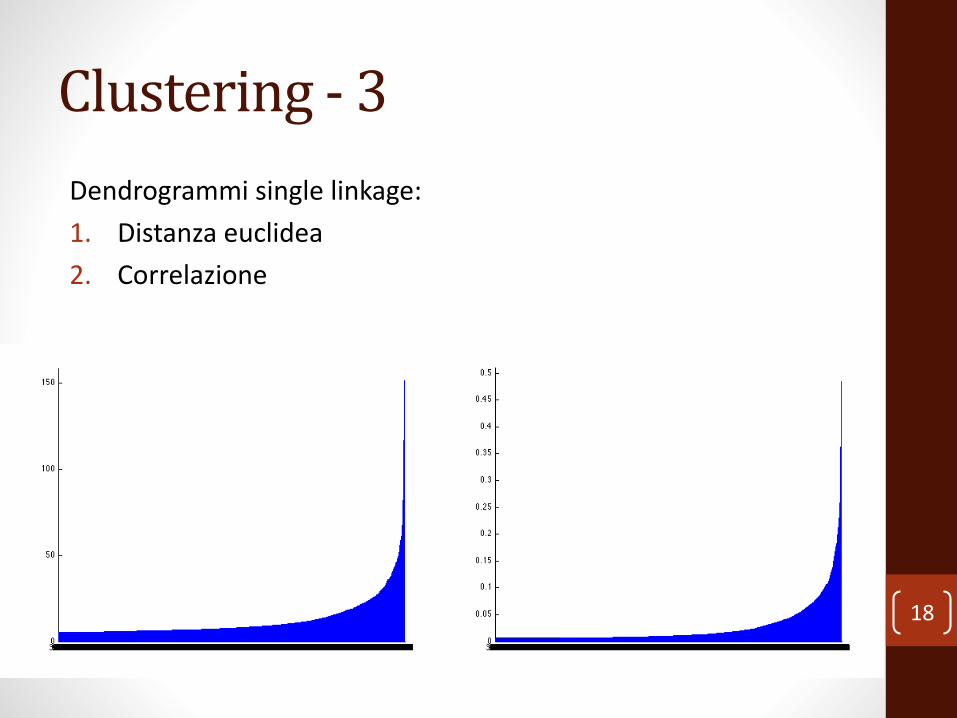
Clustering - 3
Dendrogrammi single linkage:
1. Distanza euclidea
2. Correlazione
18
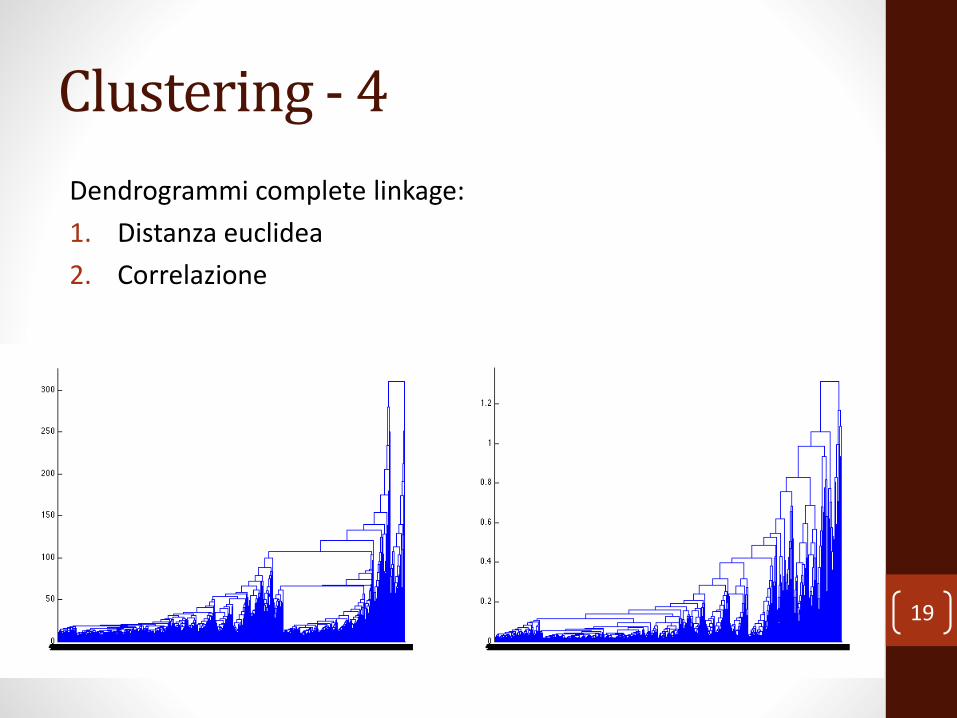
Clustering - 4
Dendrogrammi complete linkage:
1. Distanza euclidea
2. Correlazione
19
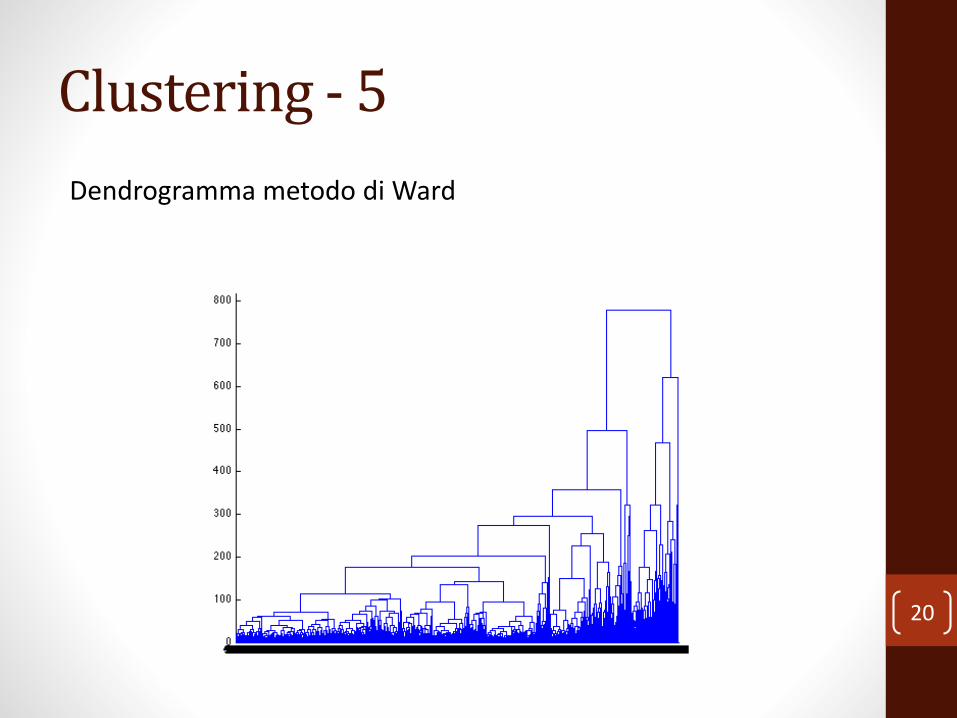
Clustering - 5
Dendrogramma metodo di Ward
20
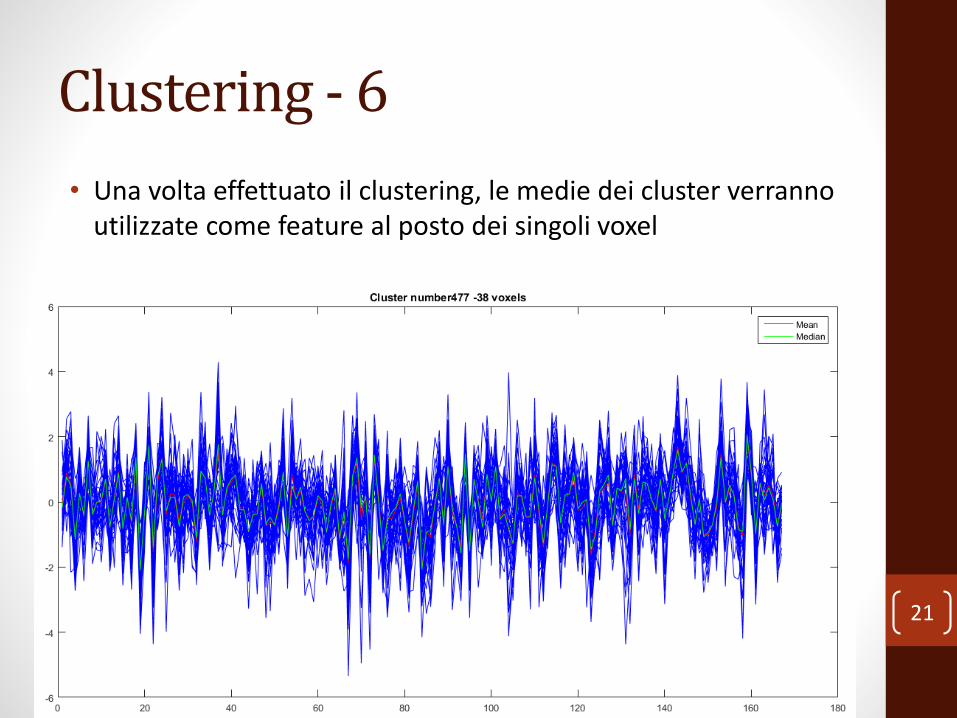
Clustering - 6
• Una volta effettuato il clustering, le medie dei cluster verranno utilizzate come feature al posto dei singoli voxel
21

Degree of Clustering
• Il numero di cluster ottenuto è ancora alto per poter effettuare una classificazione efficace: possiamo usare il DoCper eliminare voxel isolati
• Il DoC calcola per ogni cluster la frazione di voxel contenuta in un gruppo compatto di voxel sul numero totale di voxel
• Un gruppo compatto è un insieme di voxel contigui di dimensione maggiore o uguale a quello di una certa soglia
• Per ogni clustering ottenuto con Ward, utilizzando il DoC il numero di cluster è stato ridotto di circa il 90%
• Tuttavia anche con i cluster ottenuti, le performance di classificazione sono state scarse
22

t-test
• Il t-test è un test statistico di verifica di ipotesi
• Il t-test permette di accettare o rifiutare l’ipotesi nulla che i due campioni da esaminare provengano da distribuzioni con la stessa media
• Il test calcola un parametro statistico t che viene usato per calcolare la probabilità p che l’ipotesi nulla sia vera utilizzando la distribuzione t di Student
• Effettuando il t-test sui vari clustering ottenuti con il DoC, abbiamo selezionato i migliori K cluster secondo p
23

Sequential Feature Selection
• In alternativa al t-test abbiamo ridotto il numero di cluster utilizzando la Sequential Feature Selection
• La selezione delle feature si basa sulla minimizzazione di un criterio di errore
• Esistono varie strategie di selezione
• Sequential Forward Selection
• Sequential Backward Selection
• Sequential Floating Selection
24

Sequential Forward Selection
• La SFS inizia con un insieme vuoto di feature e aggiunge ad ogni passo la feature che minimizza il criterio di errore
• Il criterio da noi utilizzato è l’errore di classificazione calcolato usando SVM con 10-fold cross-validation
25
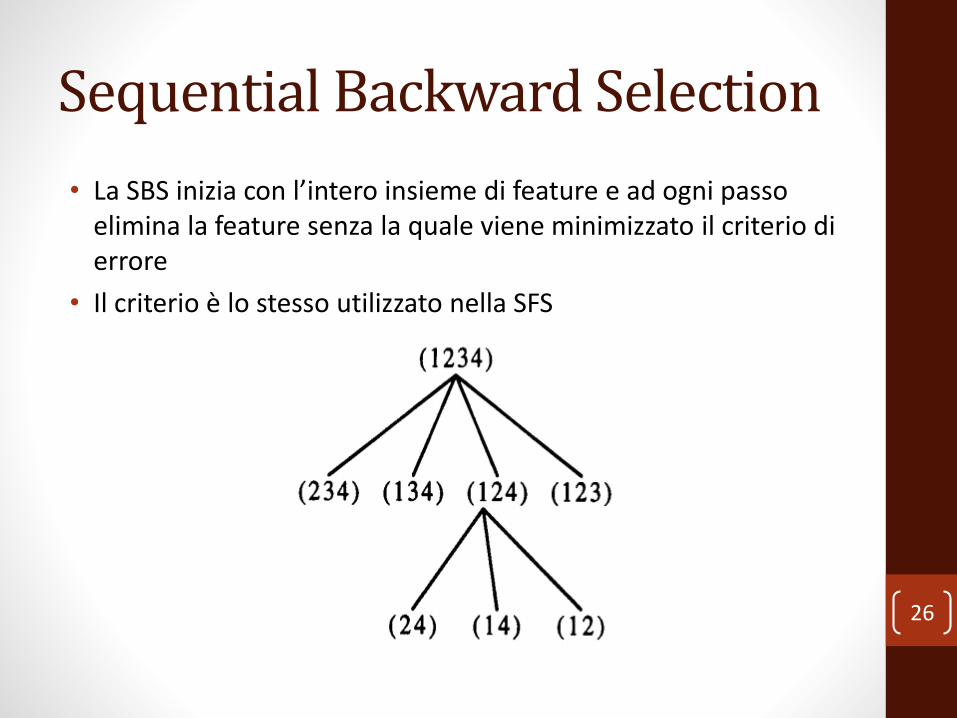
Sequential Backward Selection
• La SBS inizia con l’intero insieme di feature e ad ogni passo elimina la feature senza la quale viene minimizzato il criterio di errore
• Il criterio è lo stesso utilizzato nella SFS
26

Sequential Floating Selection
• La Sequential Floating Selection permette, a differenza degli altri due metodi, di eliminare feature precedentemente selezionate o di riaggiungere feature in precedenza scartate
• Abbiamo utilizzato la Sequential Floating Forward Selection, che si basa sulla SFS
• Il criterio utilizzato è la distanza J3, definita come
Trace(Sw-1(Sm))
• Sw: within-class scatter matrix – somma pesata della covarianza delle feature per ogni classe
• Sm: mixture scatter matrix – matrice di covarianza globale (non tiene conto delle classi)
• J3 assume valori alti se i dati di ogni classe sono compatti e distanti tra di loro
27

Dati ottenuti e classificazione
Dopo aver applicato le varie strategie di feature selection, abbiamo ottenuto vari dataset di training con feature diverse:
• Clustering con metodo di Ward con numero di cluster variabile (300-900)
• Cluster selezionati con DoC con threshold variabile (5-15)
• Cluster selezionati dai precedenti con t-test e SequentialFeature Selection
• Voxel singoli dei cluster ottenuti (t-test positivo)
Per la classificazione abbiamo utilizzato Support Vector Machine
28

Support Vector Machine - 1
• SVM è un algoritmo di classificazione lineare che ha come obbiettivo raggiungere il massimo margine di separazione fra le classi
29

Support Vector Machine - 2
• È importante la scelta del parametro di regolarizzazione C• C infinito hard margin
• C grande narrow margin
• C piccolo large margin
30

Support Vector Machine - 3
• Per il nostro problema abbiamo utilizzato SVM con kernellineare, poiché si comporta meglio con dati ad alta dimensionalità
• Per ogni dataset abbiamo determinato il valore di C ottimale eseguendo cross-validation 5 fold (circa 30 pattern per fold)
• Inoltre abbiamo tenuto da parte 20 pattern (10 per classe) per effettuare un test sul modello ottenuto addestrando SVM con il C ottimo
31
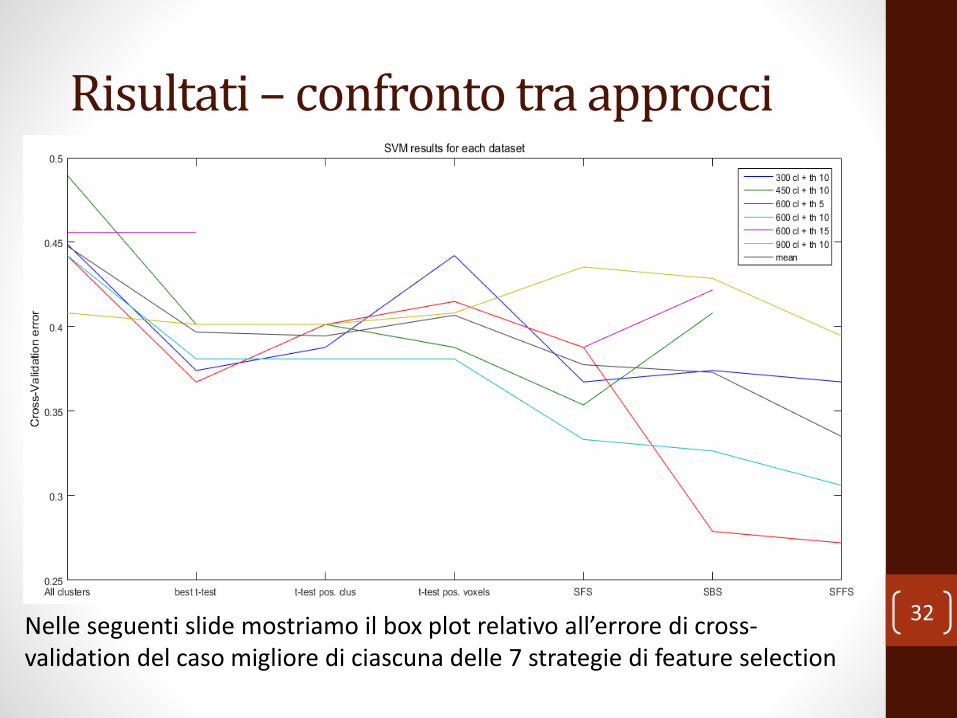
32Nelle seguenti slide mostriamo il box plot relativo all’errore di cross-validation del caso migliore di ciascuna delle 7 strategie di feature selection
Risultati – confronto tra approcci
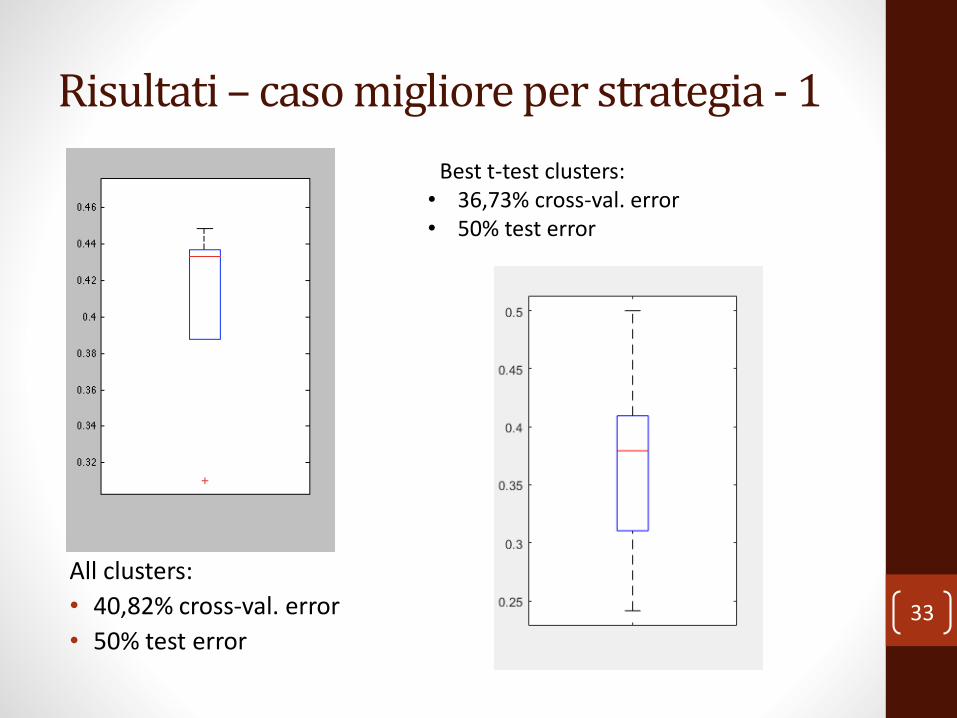
Risultati – caso migliore per strategia - 1
All clusters:
• 40,82% cross-val. error
• 50% test error33
Best t-test clusters:• 36,73% cross-val. error• 50% test error
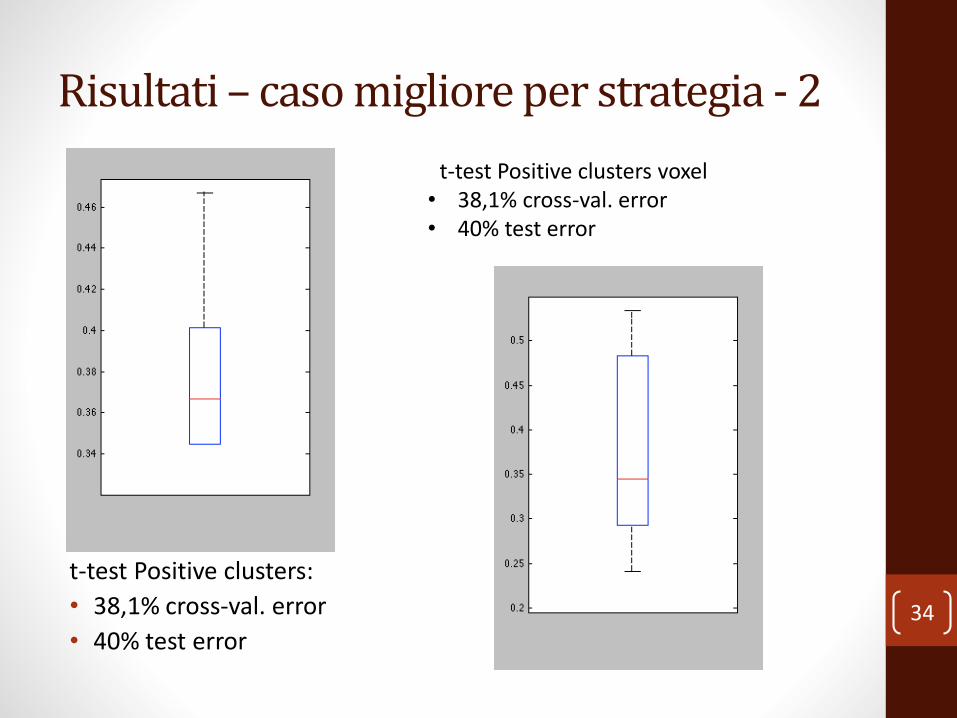
Risultati – caso migliore per strategia - 2
t-test Positive clusters:
• 38,1% cross-val. error
• 40% test error34
t-test Positive clusters voxel• 38,1% cross-val. error• 40% test error

Risultati – caso migliore per strategia - 3
SFS clusters:
• 33,3% cross-val. error
• 25% test error35
SBS• 27,89% cross-val. error• 35% test error

Risultati – caso migliore per strategia - 4
36
SFFS• 27,21% cross-val. error• 25% test error
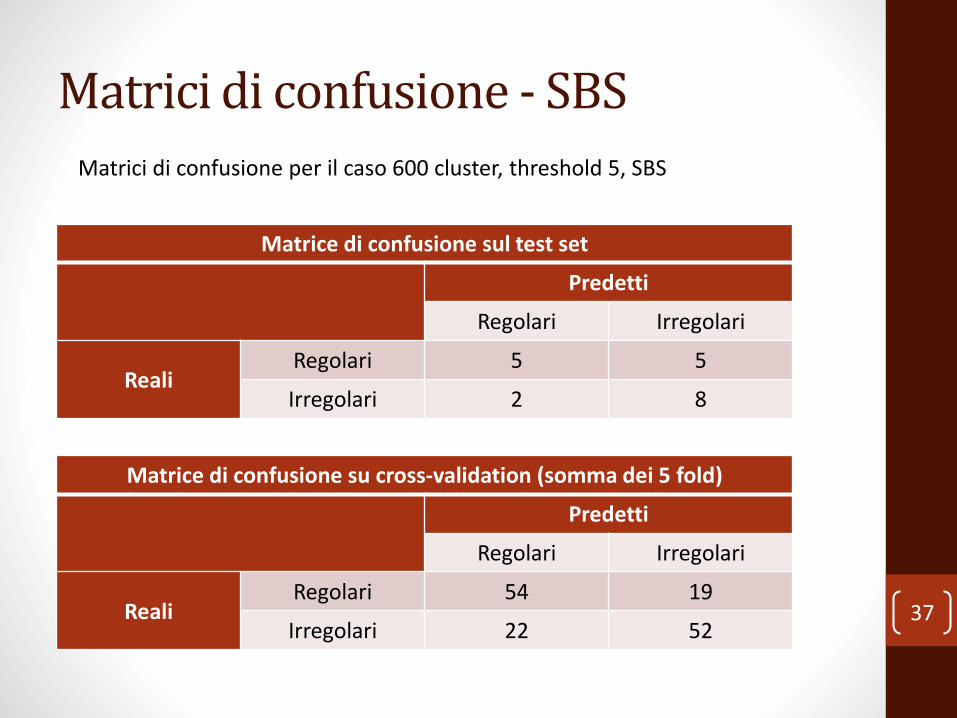
Matrici di confusione - SBS
Matrice di confusione sul test set
Predetti
Regolari Irregolari
RealiRegolari 5 5
Irregolari 2 8
37
Matrice di confusione su cross-validation (somma dei 5 fold)
Predetti
Regolari Irregolari
RealiRegolari 54 19
Irregolari 22 52
Matrici di confusione per il caso 600 cluster, threshold 5, SBS

Matrici di confusione - SFFS
Matrice di confusione sul test set
Predetti
Regolari Irregolari
RealiRegolari 7 3
Irregolari 2 8
38
Matrice di confusione su cross-validation (somma dei 5 fold)
Predetti
Regolari Irregolari
RealiRegolari 53 20
Irregolari 20 54
Matrici di confusione per il caso 600 cluster, threshold 5, SFFS
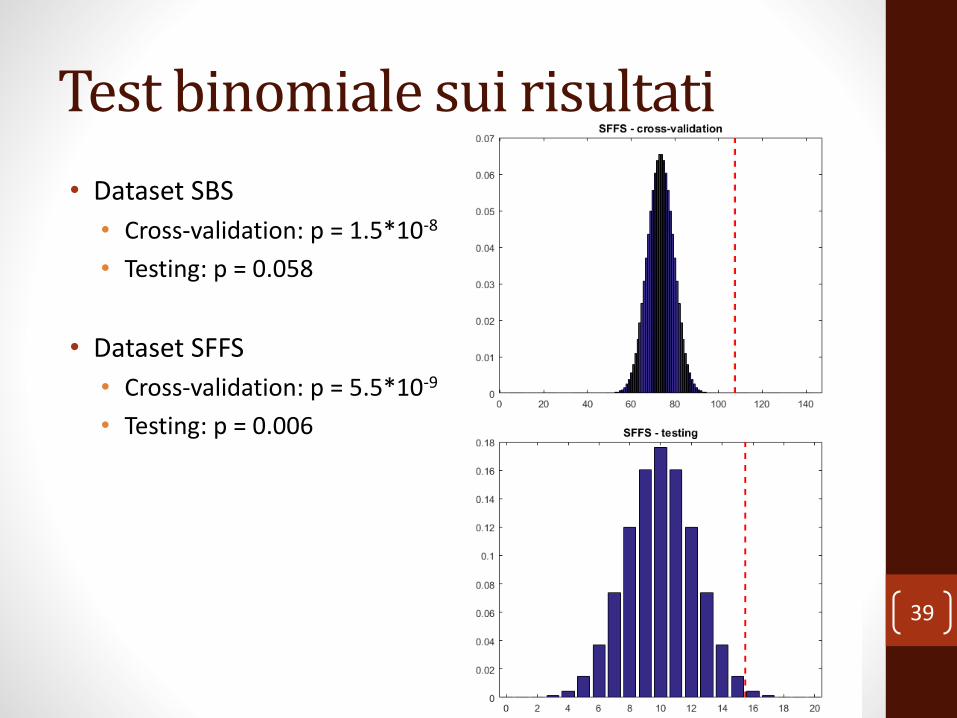
Test binomiale sui risultati
• Dataset SBS
• Cross-validation: p = 1.5*10-8
• Testing: p = 0.058
• Dataset SFFS
• Cross-validation: p = 5.5*10-9
• Testing: p = 0.006
39
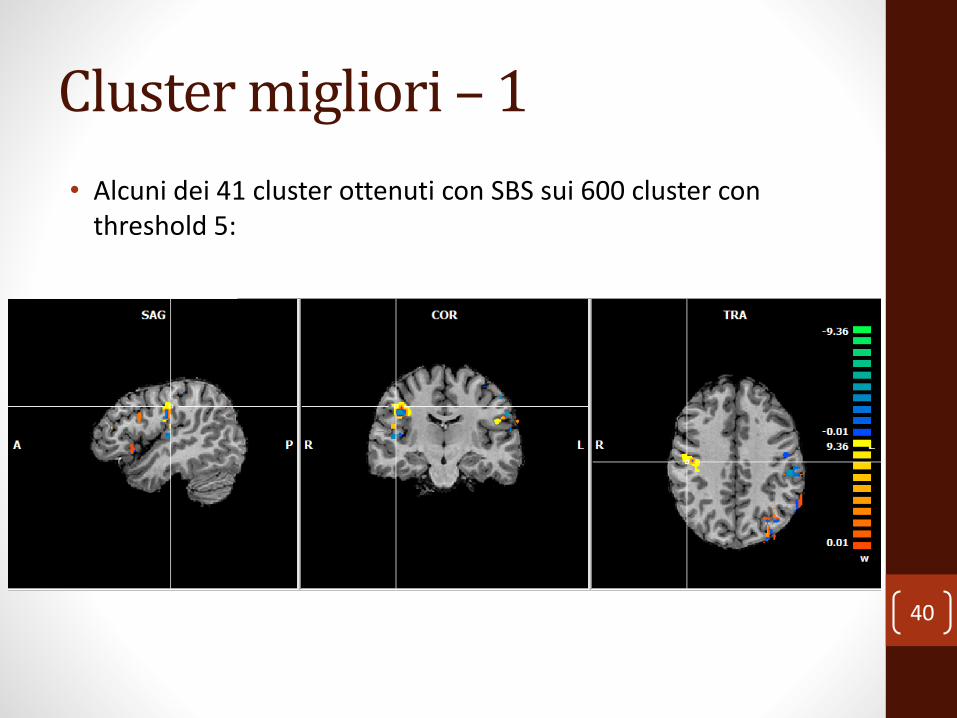
Cluster migliori – 1
• Alcuni dei 41 cluster ottenuti con SBS sui 600 cluster con threshold 5:
40
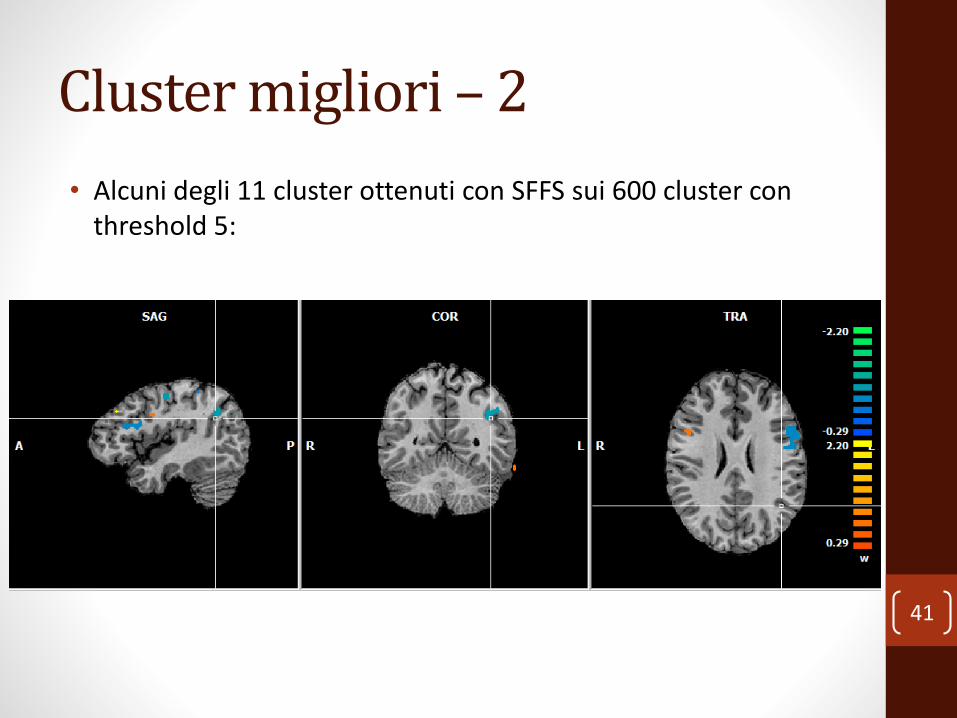
Cluster migliori – 2
• Alcuni degli 11 cluster ottenuti con SFFS sui 600 cluster con threshold 5:
41

Fine
Grazie per l’attenzione!
42





























