Embed Size (px)
Citation preview

Developer Day
G-3
石川 覚, ソリューションアーキテクト クラスメソッド株式会社
Ⓒ Classmethod, Inc.
2015年03月29日
Amazon Redshift による データ分析基盤の設計・チューニング

石川 覚(いしかわ さとる)
2Ⓒ Classmethod, Inc.
メーカー系SE、VoIP関連ベンチャー企業を経て
CMに2014/06 join
札幌出身、東京に8年
Linux, Java, MySQL マイブームはR
当然 AWS好き
クラスメソッド株式会社 ソリューションアーキテクト
3Ⓒ Classmethod, Inc.
ブログ

4Ⓒ Classmethod, Inc.
カスタマーストーリー / データ
4
カスタマーストーリーで 「データ分析の民主化」をお手伝い
販売データ(POS)やモバイルログなど、企業に存在する様々なデータを集約し、様々な角度から顧客理解を深める、ビックデータ分析基盤を提供します。

5Ⓒ Classmethod, Inc.
アジェンダはじめに
Redshiftのアーキテクチャ
RDS/RDBとの相違点
データ解析基盤の設計 パフォーマンスチューニング トラブルシューティング まとめ

Ⓒ Classmethod, Inc.
はじめに

PostgreSQLと「ざっくり」互換
- PostgreSQL8.3がベース
- 既存のPostgreSQL用ツールが使える
- PostgreSQLのODBC/JDBCによる接続
ParAccelの技術がベース
- 2012年7月にParAccelの技術ラインセンスを獲得
- DBエンジンはParAccel技術がベースとなっている
7Ⓒ Classmethod, Inc.
Redshiftの技術的バックグラウンド

8Ⓒ Classmethod, Inc.
Redshiftに関する誤解難しい・複雑 シンプル
- 徹底したシェアード・ナッシングアーキテクチャー ベンダロックイン ベンダロックオン
- ODBC/JDBCによるオープンなデータベースアクセス
- COPY、UNLOADコマンドによる高速な入出力
- お客様が使いたくて使ってる
高価 高速・低価格
- ノードタイプの変更やノード数の伸縮可能 - 初期投資が不要で低価格

Ⓒ Classmethod, Inc.
RedshiftのArchitecture

Leader Node - SQL Endpoint - メタデータの管理 - クエリ実行の連携
Compute Nodes - カラムナ・ストレージをローカルに保持 - クエリーを並列実行 - S3, DynamoDB, EMR, SSHを経由して、データのロード・アンロード、バックアップ・リストア
2つのHWプラットフォーム
- データ処理に最適化した - DW1 HDD 2TB~2PBまでスケール
- DW2 SSD 0.16TB~326TBまでスケール
10Ⓒ Classmethod, Inc.
クラスタの構成
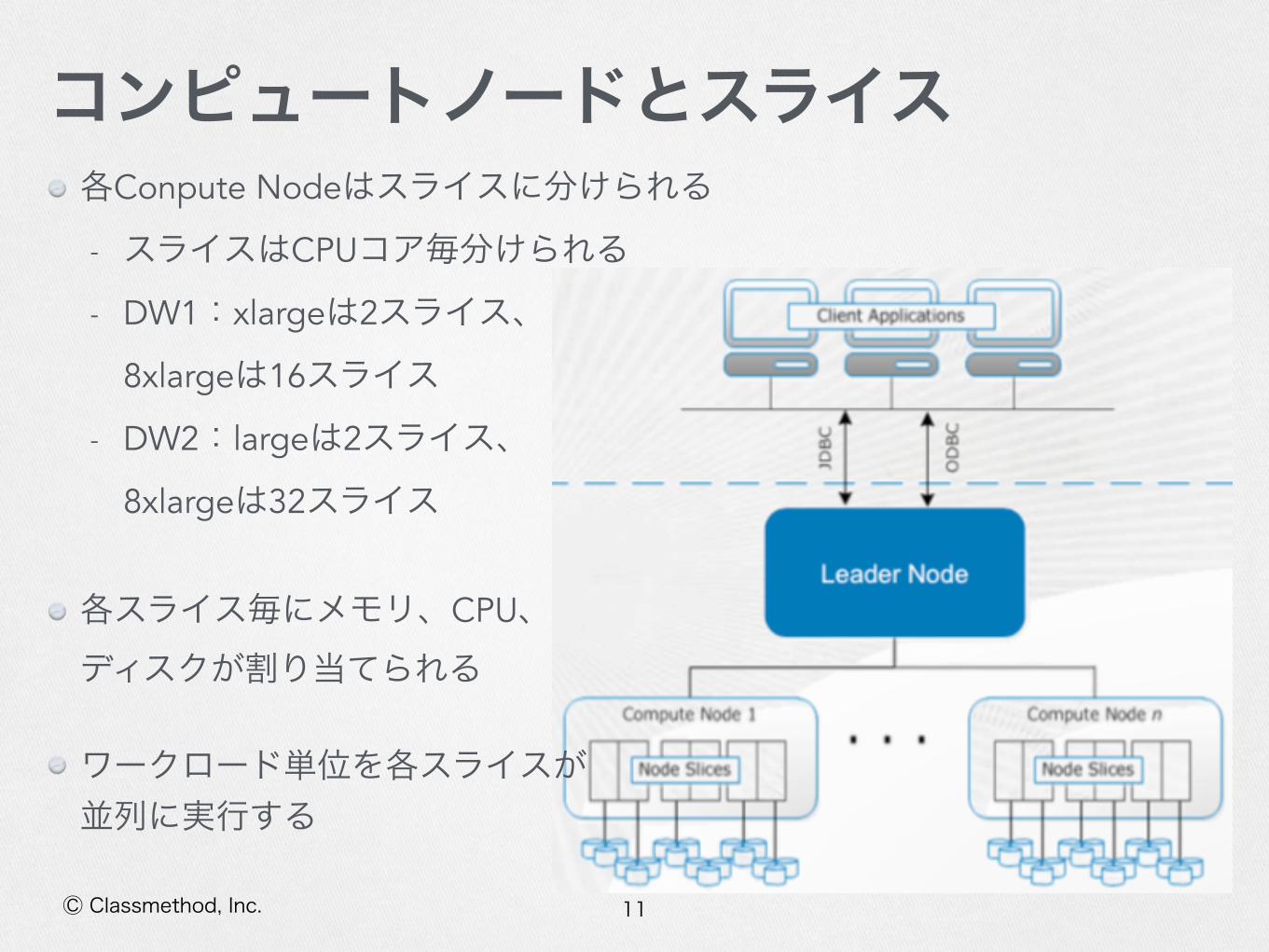
各Conpute Nodeはスライスに分けられる
- スライスはCPUコア毎分けられる
- DW1:xlargeは2スライス、 8xlargeは16スライス
- DW2:largeは2スライス、 8xlargeは32スライス
各スライス毎にメモリ、CPU、 ディスクが割り当てられる
ワークロード単位を各スライスが 並列に実行する
11Ⓒ Classmethod, Inc.
コンピュートノードとスライス

Ⓒ Classmethod, Inc.
RDS/RDBとの相違点

13Ⓒ Classmethod, Inc.
RDSとの違いソートキー、分散キー、列圧縮タイプといったキーや項目がある
- シェアード・ナッシング方式のDWHでは一般的
- ソートキーはあるがインデックスはない
シングルAZのみ
- ノード間通信を高速にするためマルチAZはない

14Ⓒ Classmethod, Inc.
一般的なRDBとの違い(1)主キー制約、一意制約、外部キー制約は違反してもエラーにならない - 重複したキーのデータが投入される
CSVでアップロードする場合
- テキストデータにNULLが含まれると失敗
サポートしているデータ型が11種類のみ
- TEXT型など内部的にVARCHARに勝手に置き換えられる

15Ⓒ Classmethod, Inc.
一般的なRDBとの違い(2)文字コードはUTF-8のみ
- 4バイト以内のUTF-8
日本語の扱いに注意
- NVARCHARやNCHARがない
- CHARにはシングルバイトのみ
- 日本語を入れる場合はNVARCHARやNCHARの4倍サイズを指定したVARCHARを指定する

Ⓒ Classmethod, Inc.
データ解析基盤の設計
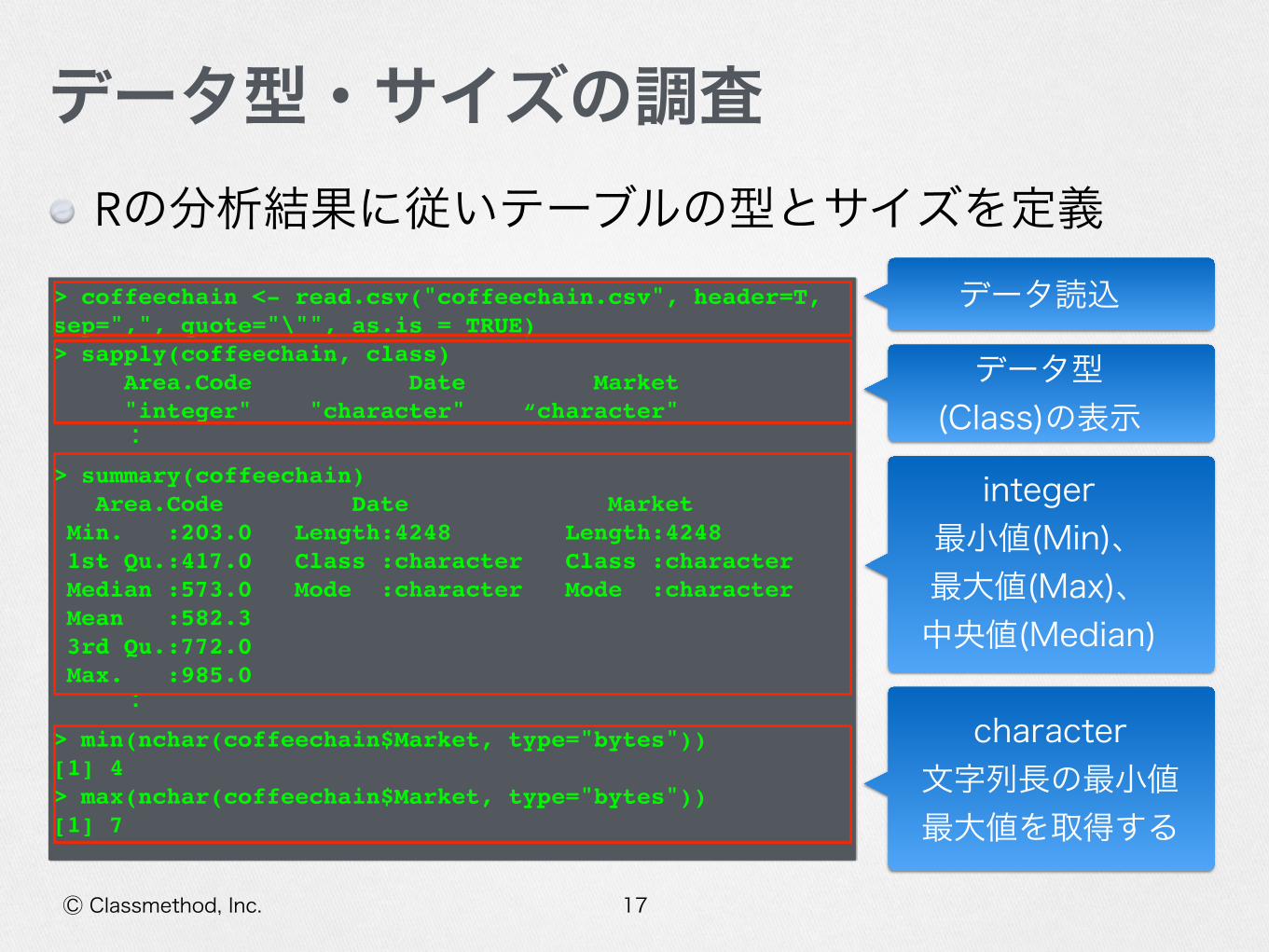
Rの分析結果に従いテーブルの型とサイズを定義
17Ⓒ Classmethod, Inc.
データ型・サイズの調査
> coffeechain <- read.csv("coffeechain.csv", header=T, sep=",", quote="\"", as.is = TRUE)> sapply(coffeechain, class) Area.Code Date Market "integer" "character" “character" :> summary(coffeechain) Area.Code Date Market Min. :203.0 Length:4248 Length:4248 1st Qu.:417.0 Class :character Class :character Median :573.0 Mode :character Mode :character Mean :582.3 3rd Qu.:772.0 Max. :985.0 :> min(nchar(coffeechain$Market, type="bytes"))[1] 4> max(nchar(coffeechain$Market, type="bytes"))[1] 7
データ読込
データ型 (Class)の表示
integer 最小値(Min)、 最大値(Max)、 中央値(Median)
character 文字列長の最小値 最大値を取得する

18Ⓒ Classmethod, Inc.
主キー・ソートキーの指定主キー
- RDBと同様に一意に識別できるキーを指定する
ソートキー - 主キーに加えて、集計したい列を順に追加 - ファクトテーブルは日付など増加する値が一般的 外部キー、一意キー - 必要に応じて設定する制約は有効にならないが、クエリプランナーによって利用されるので設定したほうが良い 圧縮分析(ANALYZE COMPRESSION)の判定に利用される

19Ⓒ Classmethod, Inc.
分散キーの選定EVEN - 各レコードをラウンドロビンでスライスに蓄積する
DISTKEY - 各レコードの明示的に指定したカラム(一つのみ)のハッシュ値に基づきスライスにデータを蓄積する
ALL - 全てのスライスにデータを蓄積するクラスタ内のスライスに対し、均等にデータを配置する ジョイン対象となるテーブルとのコロケーション考慮する データサイズが小さなマスタテーブルやディメンションはALL ファクトテーブルはDISTKEYを指定、不可能な場合はEVEN

20Ⓒ Classmethod, Inc.
データの投入(COPY)COPY from S3 - S3に置いてそのファイルをRedshiftに取込む
- ETL済みのデータ
COPY from EC2 - EC2上のファイルをRedshiftに取込む
- マニフェストファイルはS3に事前に置く必要がある
- VPC内でデータを渡せる

21Ⓒ Classmethod, Inc.
列圧縮タイプデータ投入済みテーブルの分析して推奨列エンコーディングをレポート出力
- ANALYZE COMPRESSIONの例
エンコードタイプ キーワードraw(非圧縮) RAWバイトディクショナリ BYTEDICTデルタ DELTA
DELTA32KLZO LZOmostlyn MOSTLY8
MOSTLY16MOSTLY32
ランレングス RUNLENGTHテキスト TEXT255
TEXT32K
labdb=> ANALYZE COMPRESSION users COMPROWS 1000000; Table | Column | Encoding-------+---------+---------- users | id | delta32 users | name | lzo users | age | bytedict(3 行)
最も圧縮率の高いエンコードタイプで速いものではない エンコードタイプを設定してテーブルの再作成して、データをCOPYコマンドで再投入する必要があり COPYコマンドでCOMPUPDATE ON COMPROWS n を指定すると推奨列エンコードで再作成される
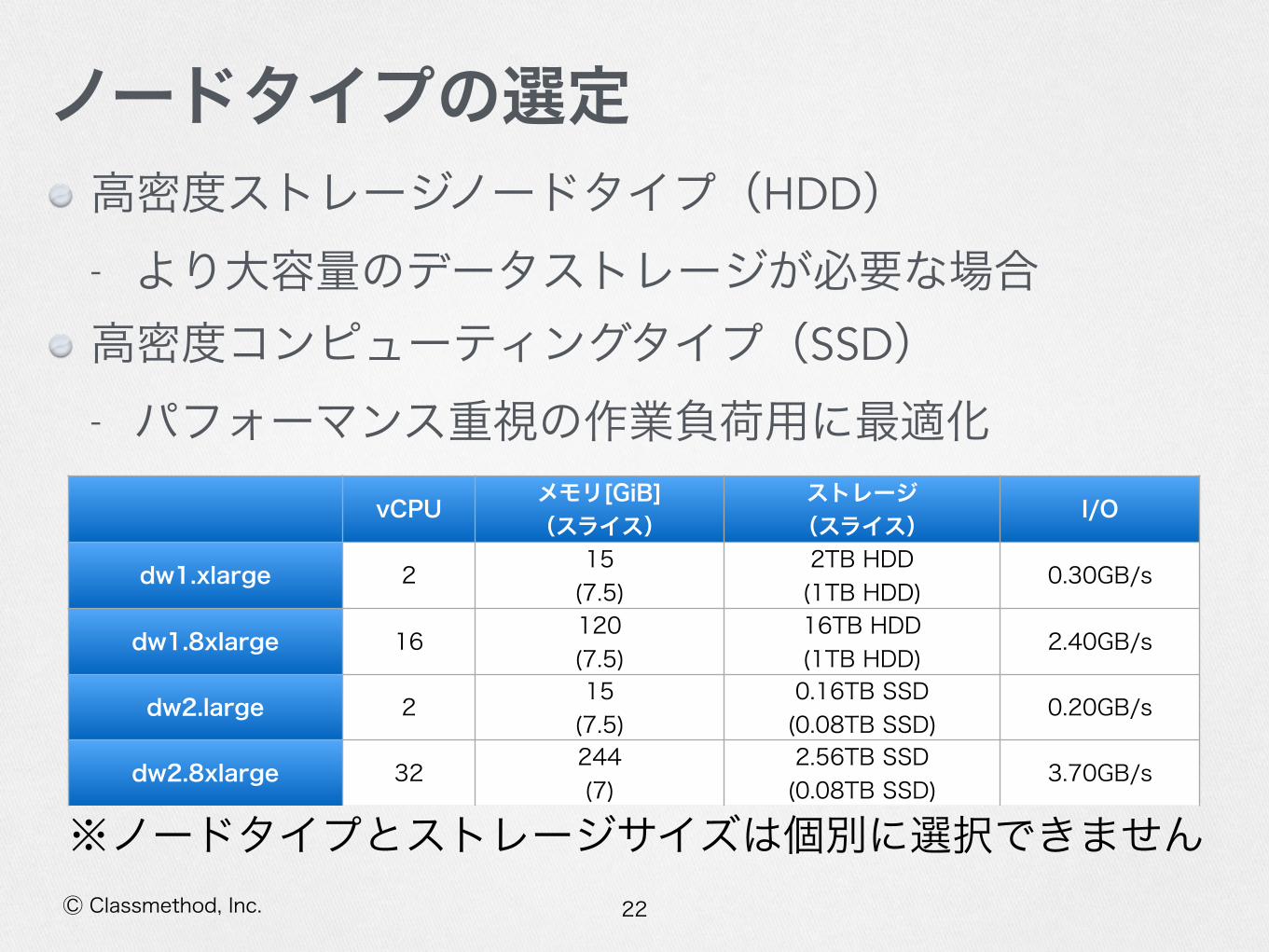
22Ⓒ Classmethod, Inc.
ノードタイプの選定高密度ストレージノードタイプ(HDD)
- より大容量のデータストレージが必要な場合
高密度コンピューティングタイプ(SSD)
- パフォーマンス重視の作業負荷用に最適化vCPU メモリ[GiB]
(スライス)ストレージ (スライス) I/O
dw1.xlarge 2 15 (7.5)
2TB HDD (1TB HDD)
0.30GB/s
dw1.8xlarge 16 120 (7.5)
16TB HDD (1TB HDD)
2.40GB/s
dw2.large 2 15 (7.5)
0.16TB SSD (0.08TB SSD)
0.20GB/s
dw2.8xlarge 32 244 (7)
2.56TB SSD (0.08TB SSD)
3.70GB/s
※ノードタイプとストレージサイズは個別に選択できません

23Ⓒ Classmethod, Inc.
パフォーマンスチューニング

24Ⓒ Classmethod, Inc.
最大接続・実行・カーソル数の最適化最大接続・実行・カーソル数の相関
実行時間 vs クエリー並列度
クラスタ WLMのキュー最大同時接続数 500以下 ー最大クエリ同時実行数 50以下(15以下が推奨値) 50以下(15以下が推奨値)最大同時実行カーソル数 クラスタの最大クエリ同時実行数以下 ー
ベストプラクティスは15以下の同時実行レベルを使用すること
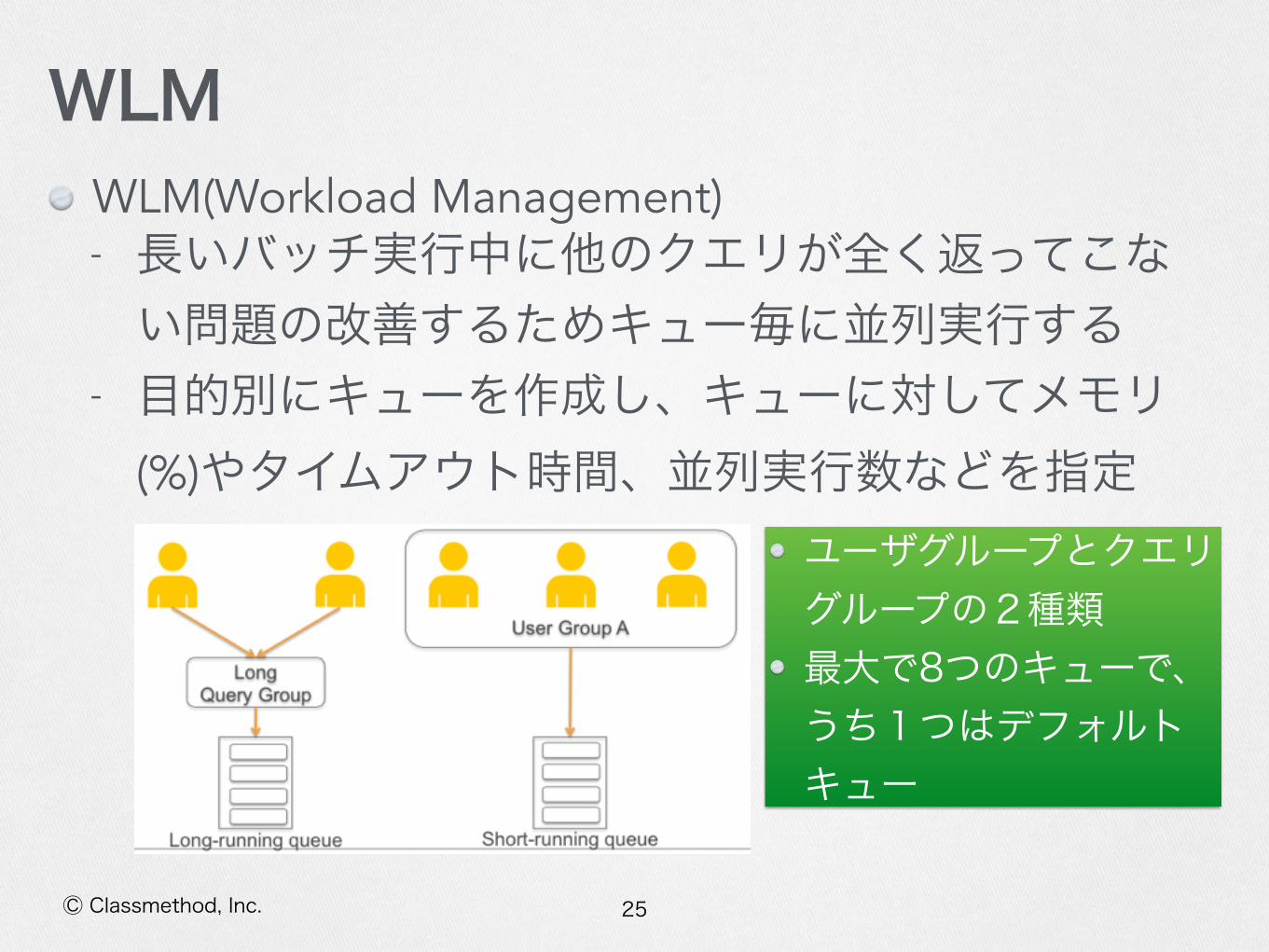
25Ⓒ Classmethod, Inc.
WLMWLM(Workload Management) - 長いバッチ実行中に他のクエリが全く返ってこない問題の改善するためキュー毎に並列実行する
- 目的別にキューを作成し、キューに対してメモリ(%)やタイムアウト時間、並列実行数などを指定
ユーザグループとクエリグループの2種類 最大で8つのキューで、うち1つはデフォルトキュー

26Ⓒ Classmethod, Inc.
1件ずつINSERTは遅い代替案
- INSERT INTO SELECT…のように一括したデータ追加は高速
- 全データ投入ならCOPYの利用も検討
- 上記はテーブルが空の場合、ANALYZEやVACCUM
は不要
- INSERTに限らずクエリーの実行にはオーバヘッドが生じるので、一回のクエリでより多くのデータ処理するように処理方式を見直す

27Ⓒ Classmethod, Inc.
既存の行を置き換えるコマンドがない代替案 - 一部のレコードの入れ替えをするには、ステージングテーブルを使用したマージ(Upsert)する
- 更新したいデータをステージングテーブルにコピー - ステージングテーブルの更新する行と内部結合を使って削除した後、既存の行に置き換える
大量のデータをUpsetする場合は、更新対象テーブルとステージングテーブルのコロケーションを注意する CREATE TABLE LIKE ステートメントを使用してステージングテーブルを作成する

28Ⓒ Classmethod, Inc.
スライス単位でマルチアップロードデータをスライスの倍数ファイルに分割
split -l `wc -l bigfile.txt | awk '{print $1/32}'` -v bigfile.txt “part-“ 複数のファイルのロード - プレフィックスキーを指定するか、マニフェストファイルにファイルのリストを明示的に指定する リモートホストからデータをロードする場合
- 各エントリは、SSH接続をするので単一ホストの場合はパフォーマンスを考慮する{ "entries": [ {“endpoint":"<ssh_endpoint_or_IP>", "command": "<remote_command>", “mandatory":true, “publickey”: “<public_key>”, "username": “<host_user_name>”} ] }

29Ⓒ Classmethod, Inc.
ノード間転送「再分散」の発生「再分散」の発生要因 - ジョイン対象となるテーブル間でノード間転送が発生する可能性がある クエリプランの表示方法方法1 クエリの先頭に”EXPLAIN”を付けて実行する方法2 Management ConsoleからQueryタブ-Queryの番号をクリックするとQuery Execution Detailsに表示される
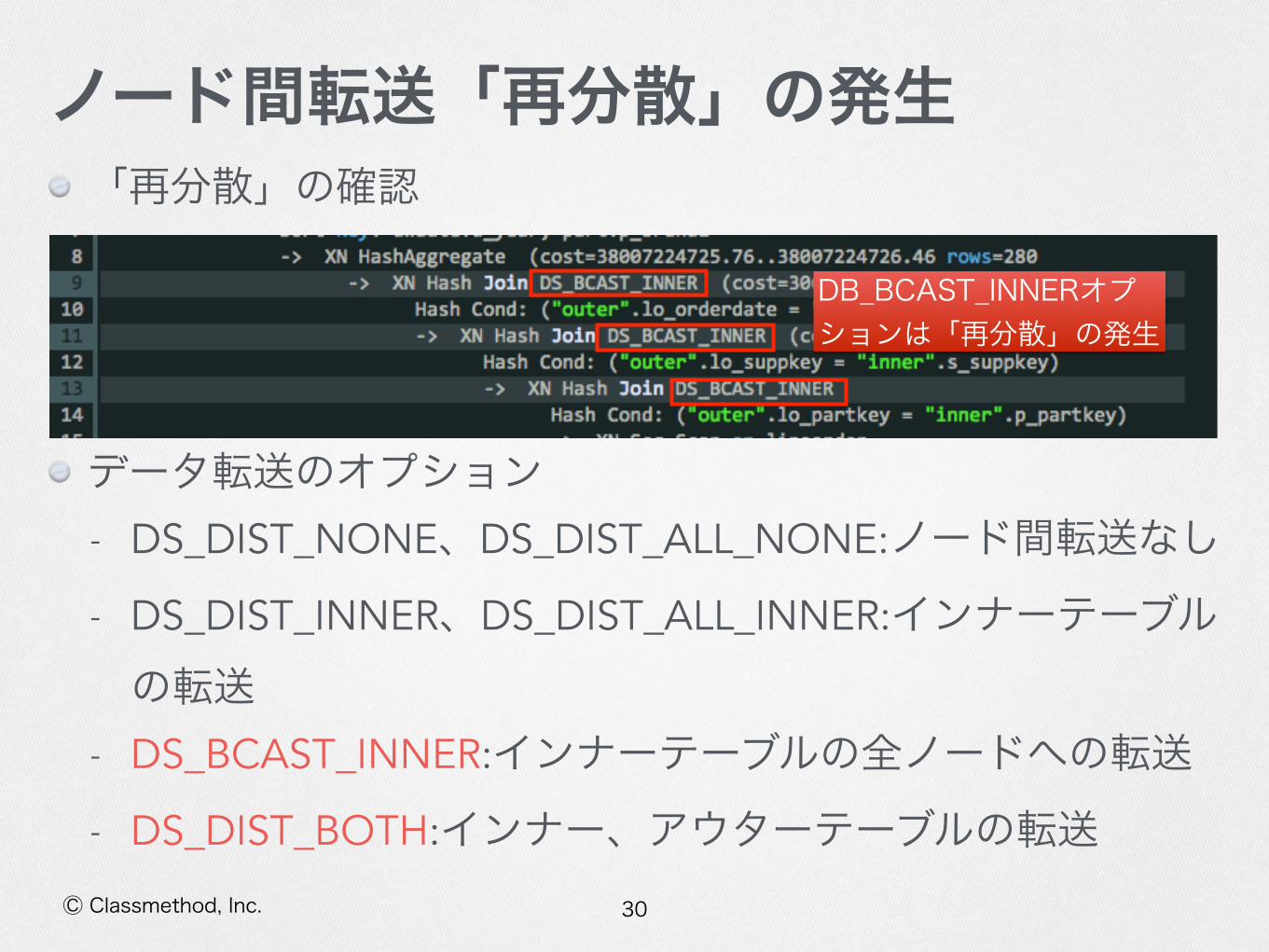
30Ⓒ Classmethod, Inc.
ノード間転送「再分散」の発生「再分散」の確認
データ転送のオプション - DS_DIST_NONE、DS_DIST_ALL_NONE:ノード間転送なし
- DS_DIST_INNER、DS_DIST_ALL_INNER:インナーテーブルの転送
- DS_BCAST_INNER:インナーテーブルの全ノードへの転送
- DS_DIST_BOTH:インナー、アウターテーブルの転送
DB_BCAST_INNERオプションは「再分散」の発生

31Ⓒ Classmethod, Inc.
ノード間転送「再分散」の発生「再分散」の解消
対策はテーブルのコロケーション
- 特にDS_BCAST_INNERとDS_DIST_BOTHは排除
- ジョインに使用するカラムをDISTKEYとして作成、または分散方式ALLでテーブルを再作成する
DS_DIST_ALL_NONE または DS_DIST_NONEになり「再分散」は解消

32Ⓒ Classmethod, Inc.
との連携分析目的ごとのデータマート作成 - 膨大なデータを直接アクセスするには時間を要する - 事前に分析テーマ毎に必要なデータを集計したデータマートを作成する
- Tableauから最新のデータマートを通じてデータ連携する
データマートからTableau用データファイル作成
- 作成したデータファイルはTableau Serverにパブリシュしてセキュアでより多くの方に分析内容を展開

33Ⓒ Classmethod, Inc.
トラブルシューティング

34Ⓒ Classmethod, Inc.
時間がUTC現象 - 「7日前を対象外にする」クエリーを実行すると時間が9時間ずれる 原因
- UTCのため(当たり前ですね)
対策なし
- 現在、RedshiftではタイムゾーンがUTC固定となっており、仕様的にこのタイムゾーンを変更する事は出来ない

35Ⓒ Classmethod, Inc.
EC2のインスタンスタイプ変更後に接続できない現象
- SELECT count(*) FROM xxx は実行できる
- SELECT * FROM xxx limit 10 は数分経過後に落ちる
原因
- EC2インスタンスタイプ毎にMTUが異なる
対策
- MTUを1500に変更する
CC2、C3、C4、R3、CG1、CR1、G2、HS1、HI1、I2、T2、M3 の各インスタンスタイプは、9001 MTU(ジャンボフレーム)を提供します。他のインスタンスタイプは、1500 MTU(Ethernet v2 フレーム)を提供します。(2015/3 現在)
36Ⓒ Classmethod, Inc.
アプリがタイムアウトしても接続が残る現象 - なんか遅い、とにかく遅い 原因 - アプリが切断してもクエリが走り続けている 対策 - リクエストをキャンセルする
- 可能であればWLMでキューにタイムアウトを指定
-- PIDを特定するselect pid, trim(user_name), starttime, substring(query,1,20) from stv_recentswhere status='Running'; -- 特定したプロセスをキャンセルcancel [PID];
ManagementConsoleできるようになりました

37Ⓒ Classmethod, Inc.
まとめ

38Ⓒ Classmethod, Inc.
まとめまずはRDB/RDSとの違いを知ることが近道
- アーキテクチャをご理解ください - 設定項目は少ないですが、同時に必須項目です 適切な分散キーの選定は最優先 - コロケーションとデータの平準化を徹底 - 設定が正しければスライスの増加に比例して線形スケールする
同時実行や粒度の小さいクエリーは向きません - これまで不可能であった大規模なデータの一括集計や分析に注力できるように活用し、チューニングしてください

Developer Day
ご静聴ありがとうございました。 スライドは後日ブログで公開します。
39
G-3
Ⓒ Classmethod, Inc.
#cmdevio2015