Embed Size (px)
Citation preview

Data Crawler using Python (I)2017/08/06 (Wed.)
WeiYuan
site: v123582.github.ioline: weiwei63
§ 全端⼯程師 + 資料科學家略懂⼀點網站前後端開發技術,學過資料探勘與機器學習的⽪⽑。平時熱愛參與技術社群聚會及貢獻開源程式的樂趣。

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁篇§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
3

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁篇§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
4
HTTP (HyperText Transfer Protocol)
5
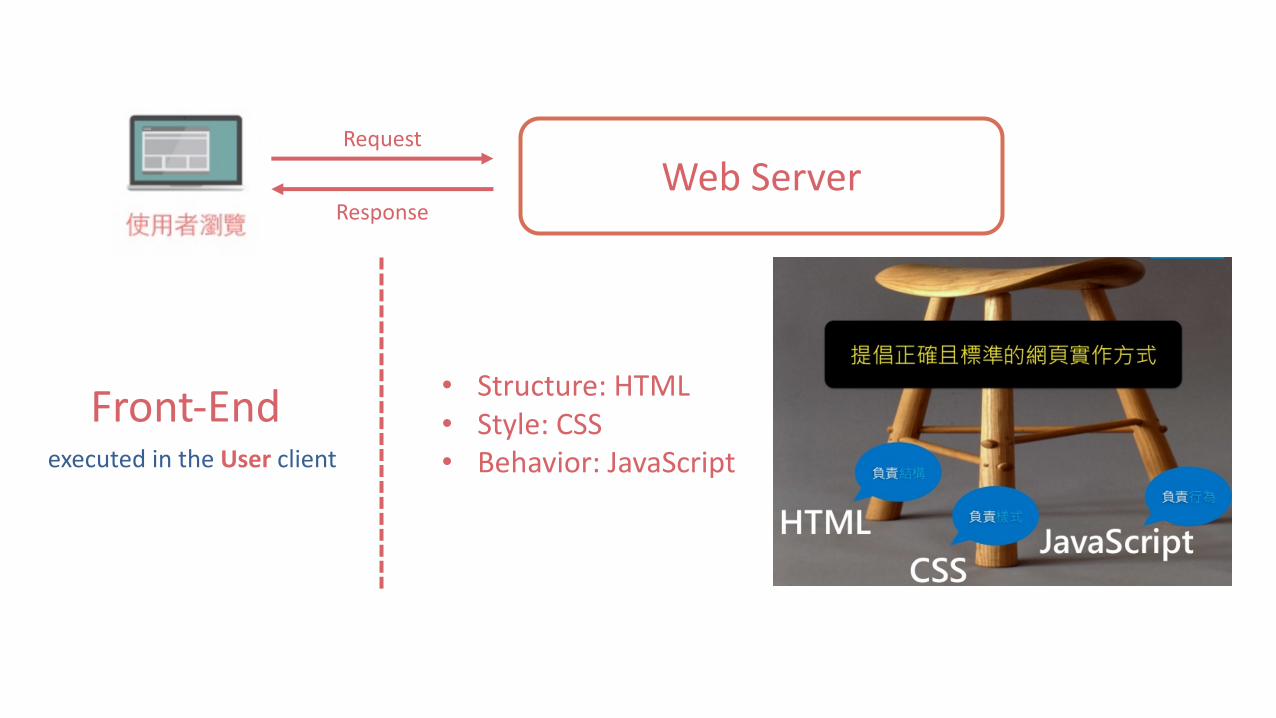
WebServerRequest
Response
Front-End • Structure:HTML• Style:CSS• Behavior:JavaScriptexecutedintheUser client
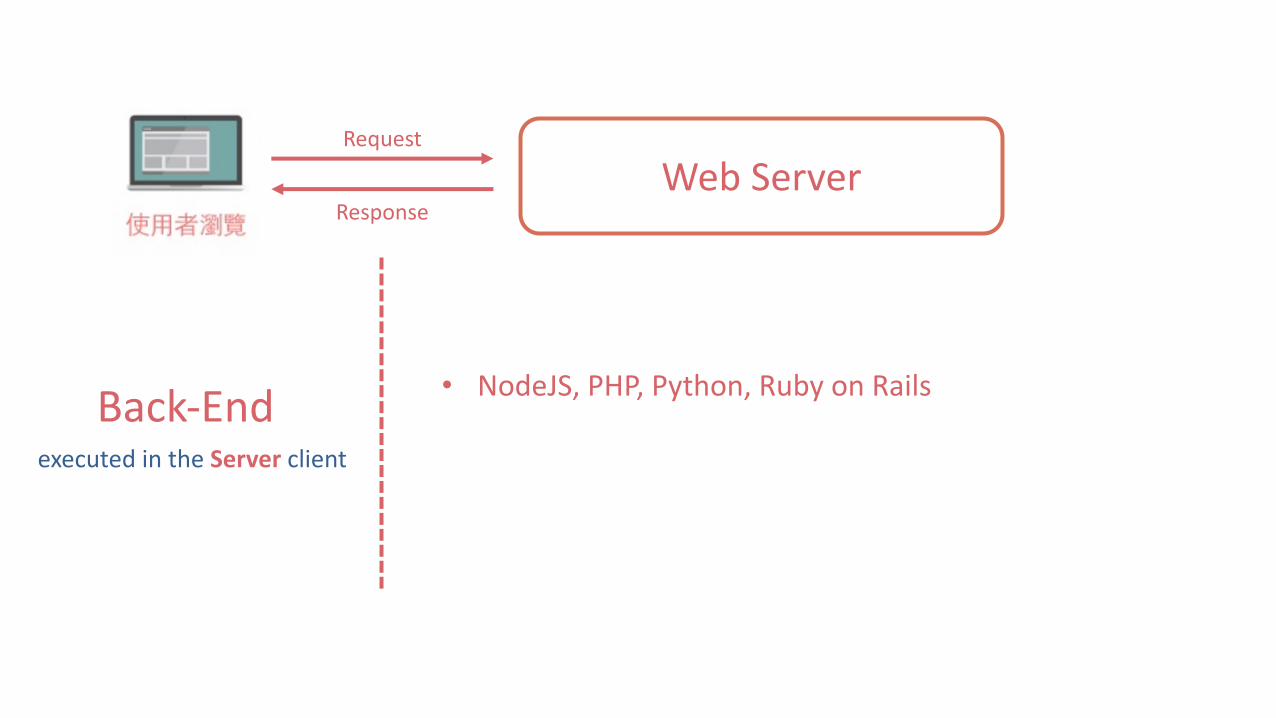
WebServerRequest
Response
Back-End • NodeJS,PHP,Python,RubyonRails
executedintheServer client

WebServerRequest
Response
Back-End • NodeJS,PHP,Python,RubyonRails• MVCFramework
executedintheServer client

WebServerRequest
Response
Back-EndexecutedintheServer client
Database
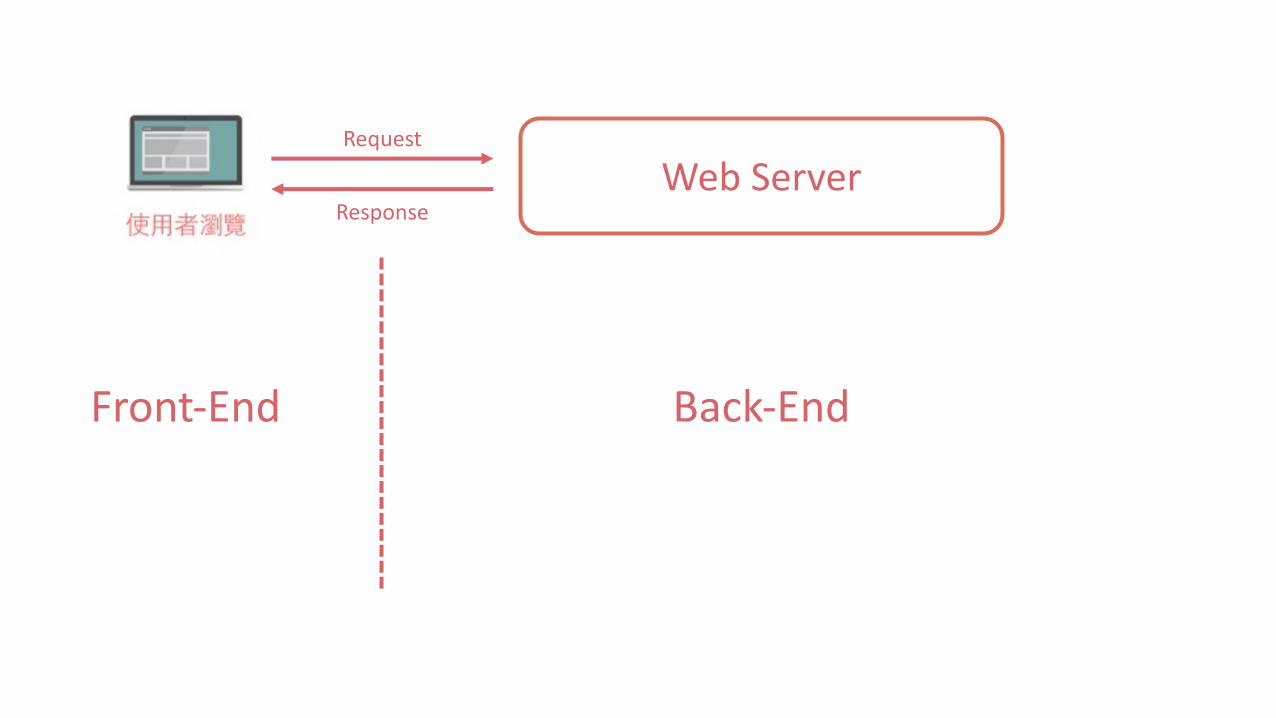
WebServerRequest
Response
Front-End Back-End
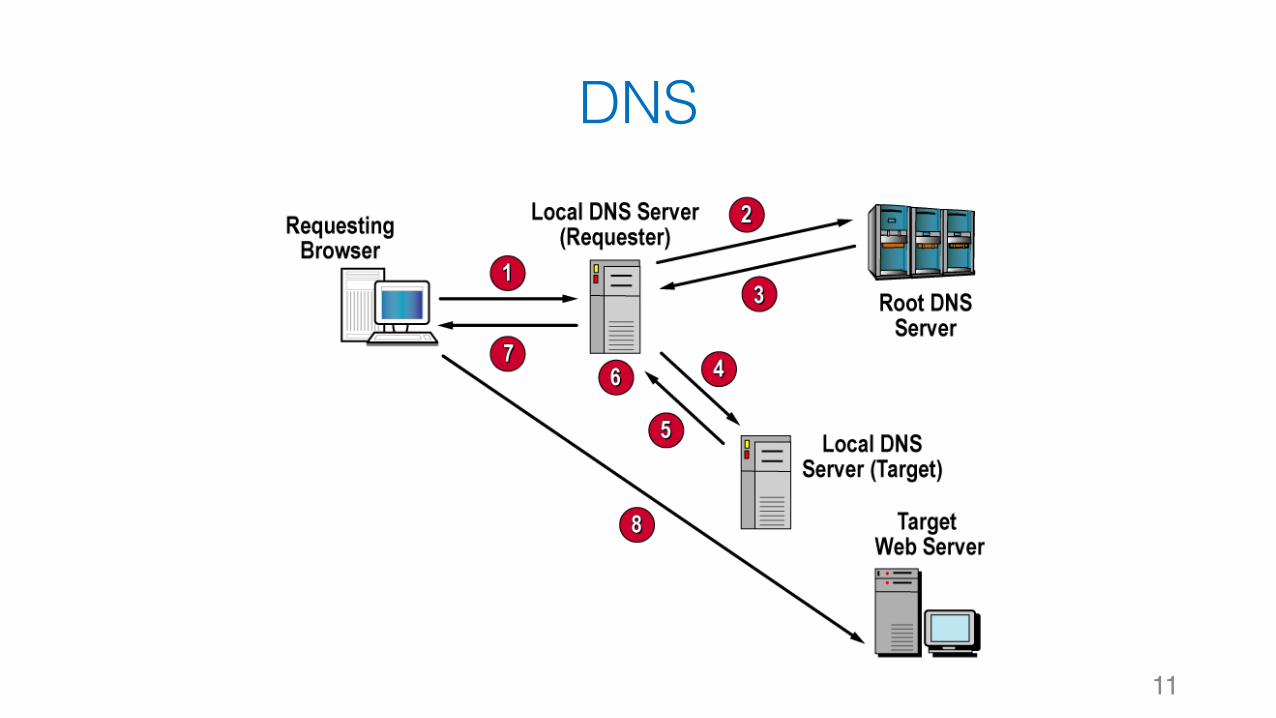
DNS
11
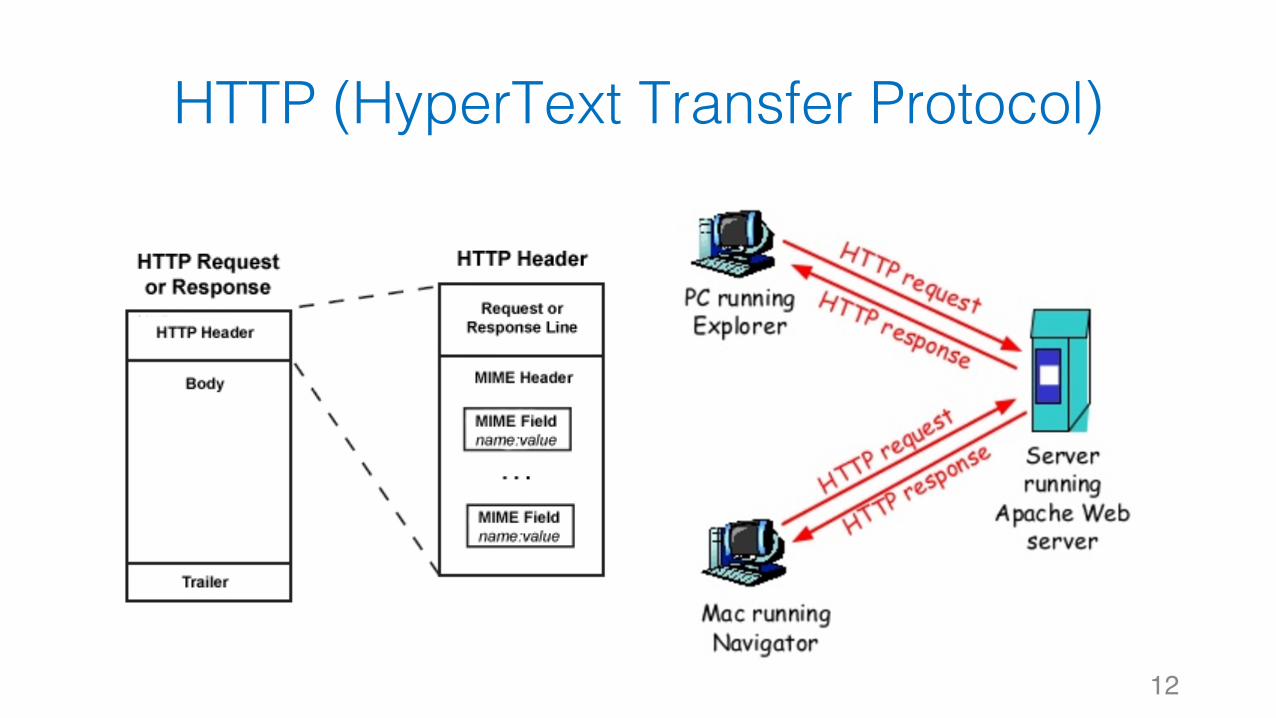
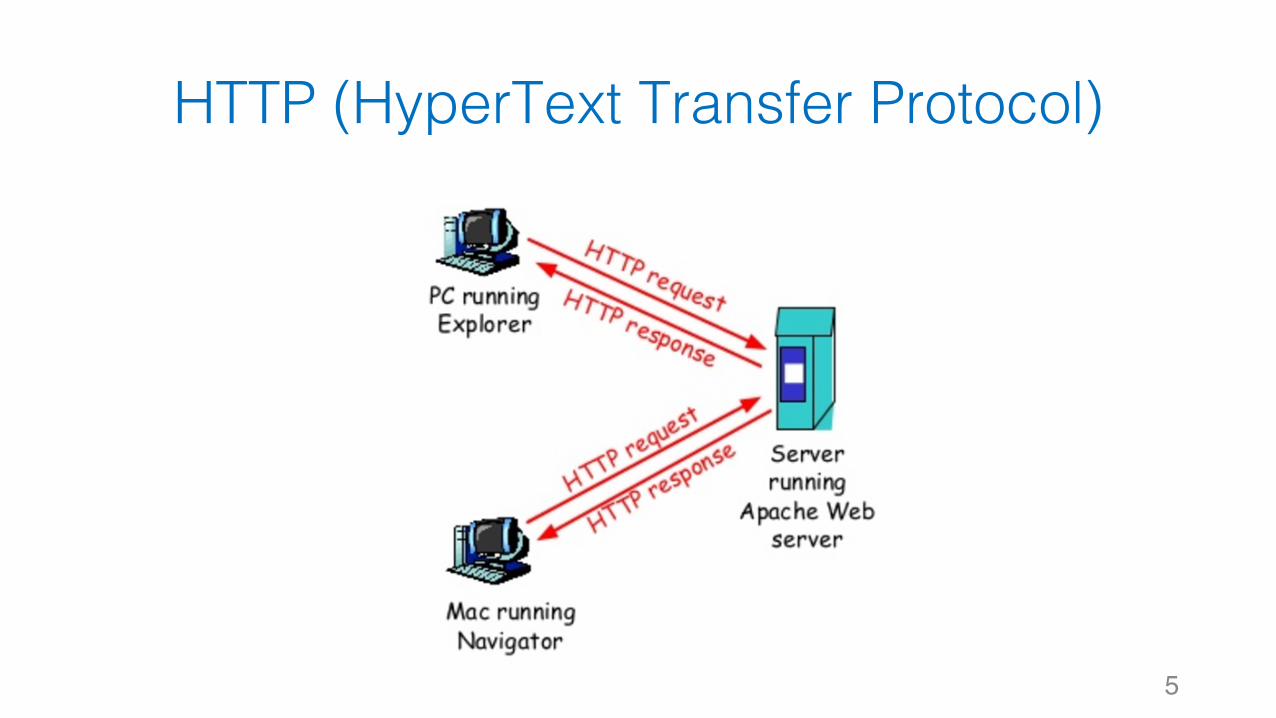
HTTP (HyperText Transfer Protocol)
12
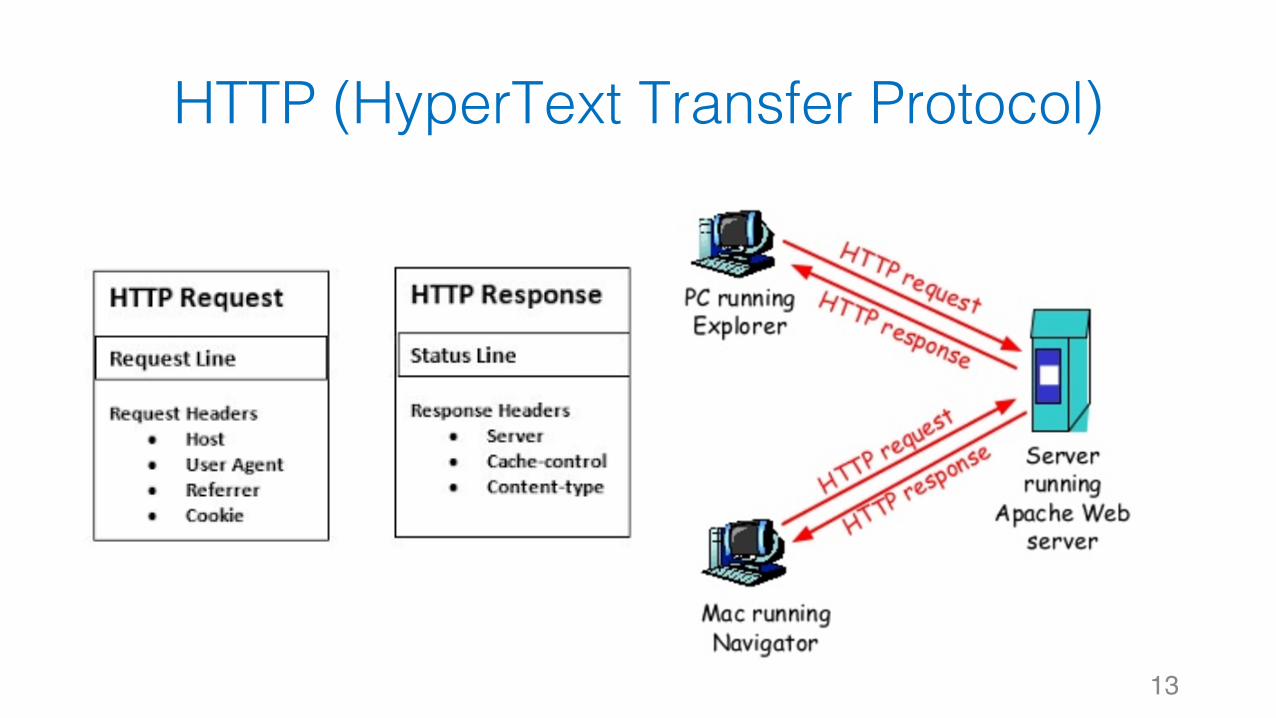
HTTP (HyperText Transfer Protocol)
13

HTTP (HyperText Transfer Protocol)
14

HTTP (HyperText Transfer Protocol)
15
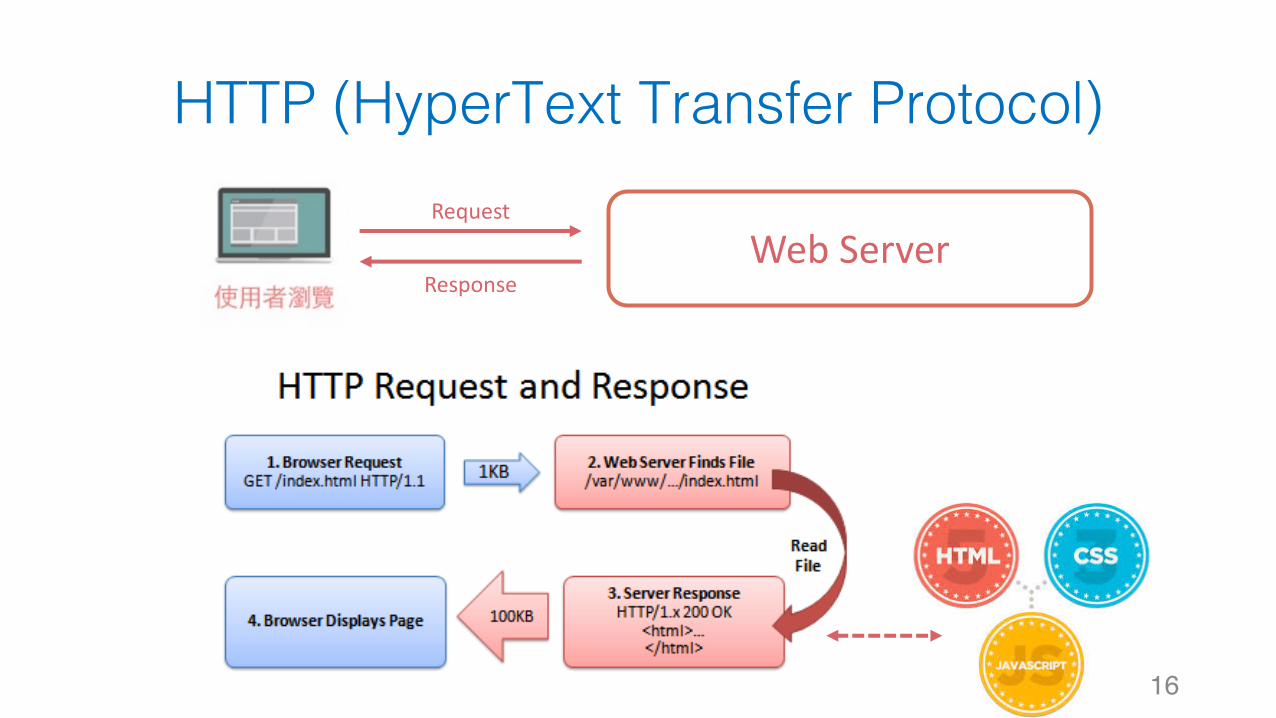
HTTP (HyperText Transfer Protocol)
16
WebServerRequest
Response

17Reference:http://dailuu.ga/wp-content/uploads/2016/10/html-css-javascript.png
12345678910111213141516
<html><head><title>Page Title</title><style># ===== CSS code 放在這邊 =====
</style></head><body><h1>Page Title</h1><p>This is a really interesting
paragraph.</p><script># ===== JavaScript code 放在這邊 =====
</script></body></html>

18Reference:http://dailuu.ga/wp-content/uploads/2016/10/html-css-javascript.png
12345678910111213141516
<html><head><title>Page Title</title><style># ===== CSS code 放在這邊 =====
</style></head><body><h1>Page Title</h1><p>This is a really interesting
paragraph.</p><script># ===== JavaScript code 放在這邊 =====
</script></body></html>

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁篇§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
19

20

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁與動態網頁§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
21

靜態網頁
22
WebServerRequest
Response

動態網頁
23
WebServerRequest
Response

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁篇§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
24

網頁資料取得
§先講結論:
1. urllib2 是 Python2 的http訪問庫,是標準庫。2. requests是第三方http訪問庫,需要安裝。 requests 的友好度高一些,推薦使用請求。
25

urllib (Python2)
urllib urllib2
26

urllib (Python3)
urllib
27

request
requests
28

靜態網頁
29
WebServerRequest
Response
#Note:資料爬蟲的本質就是模擬 Request & 攔截 Response
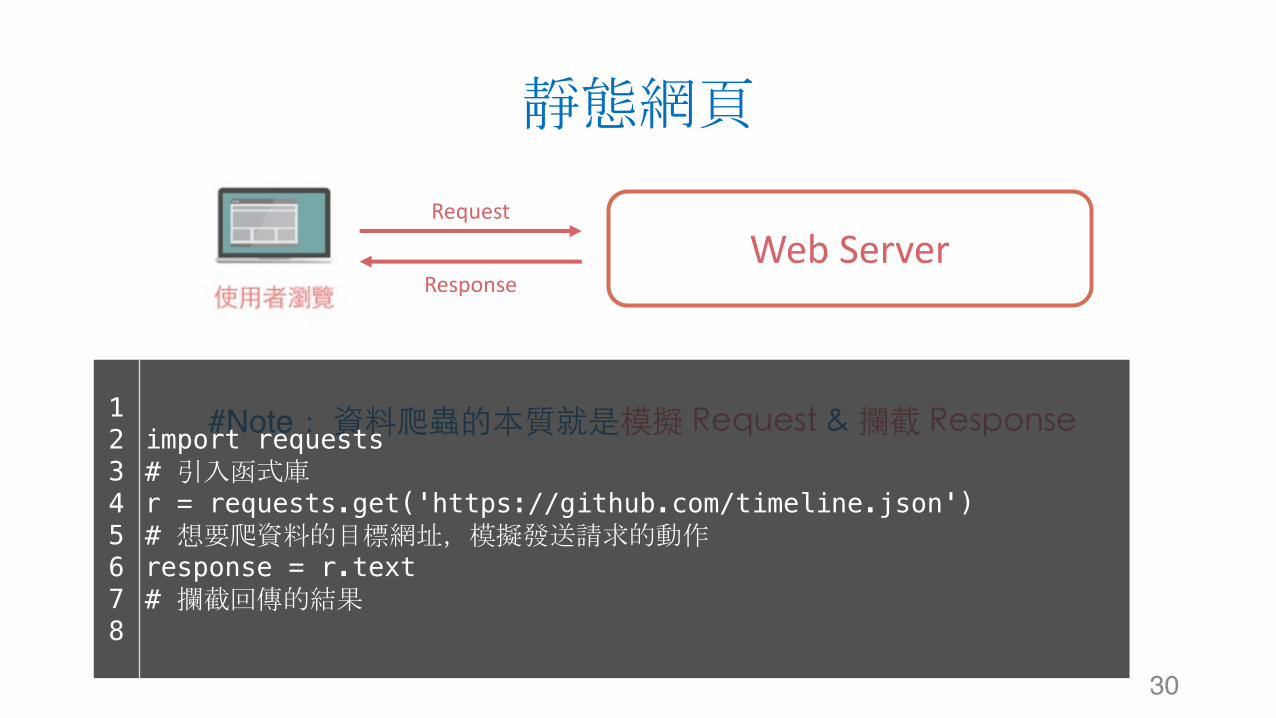
靜態網頁
30
WebServerRequest
Response
#Note:資料爬蟲的本質就是模擬 Request & 攔截 Response12345678
import requests# 引入函式庫r = requests.get('https://github.com/timeline.json')# 想要爬資料的目標網址,模擬發送請求的動作response = r.text# 攔截回傳的結果

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁篇§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
31

靜態網頁
32
WebServerRequest
Response
#Note:攔截到的 Response 其實就是 HTTP 的 Body,網⾴的原始碼

靜態網頁
33
WebServerRequest
Response
#Note:攔截到的 Response 其實就是 HTTP 的 Body,網⾴的原始碼12345678
from bs4 import BeautifulSoupsoup = BeautifulSoup(r.text, 'html.parser')print(soup.prettify())

靜態網頁
34
WebServerRequest
Response
#Note:攔截到的 Response 其實就是 HTTP 的 Body,網⾴的原始碼12345678
soup.titlesoup.title.namesoup.title.stringsoup.title.parent.name
soup.psoup.p['class']

靜態網頁
35
WebServerRequest
Response
#Note:攔截到的 Response 其實就是 HTTP 的 Body,網⾴的原始碼12345678
soup.asoup.find_all('a')for link in soup.find_all('a'):
print(link.get('href'))

靜態網頁
36
WebServerRequest
Response
#Note:攔截到的 Response 其實就是 HTTP 的 Body,網⾴的原始碼12345678
soup.find(id="link3")soup.get_text()

Outline§網站運作架構
§資料爬蟲與搜尋引擎
§資料爬蟲 -靜態網頁篇§網頁資料取得: urllib, request§網頁解析器: BeatifulSoup§正規表示式: Regular Expression
37
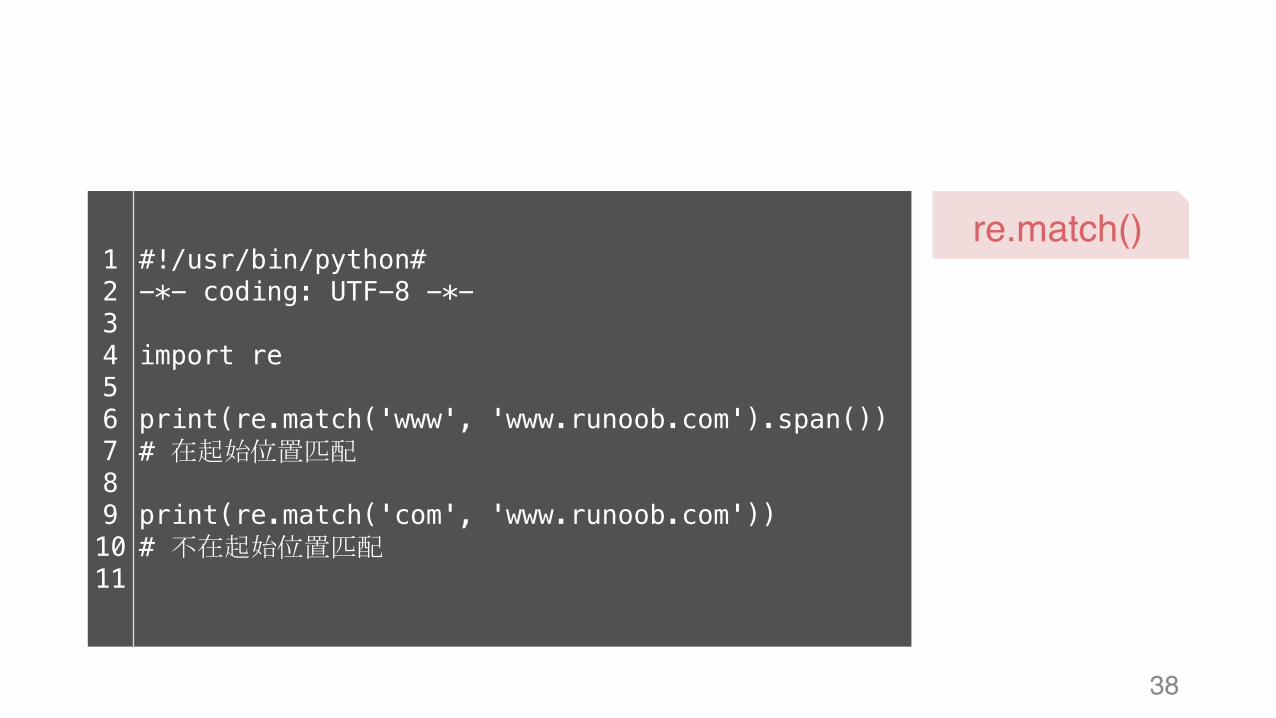
38
re.match()1234567891011
#!/usr/bin/python# -*- coding: UTF-8 -*-
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
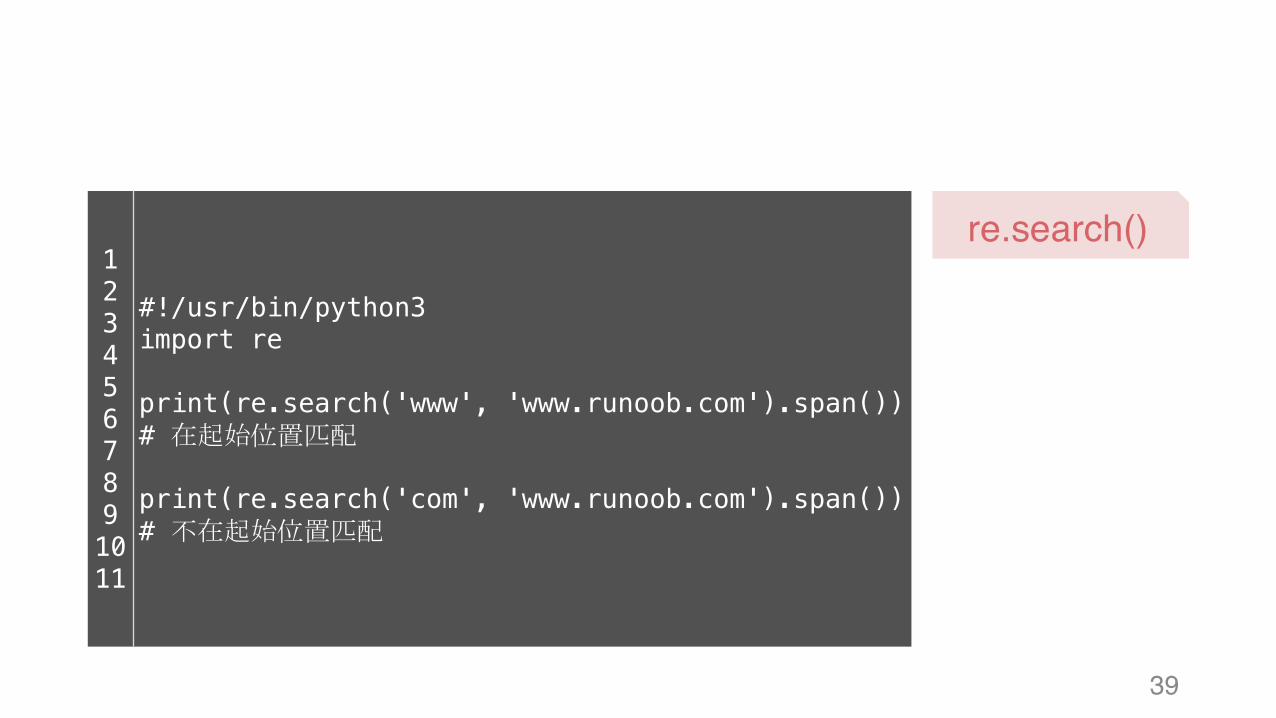
39
re.search()1234567891011
#!/usr/bin/python3import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
40
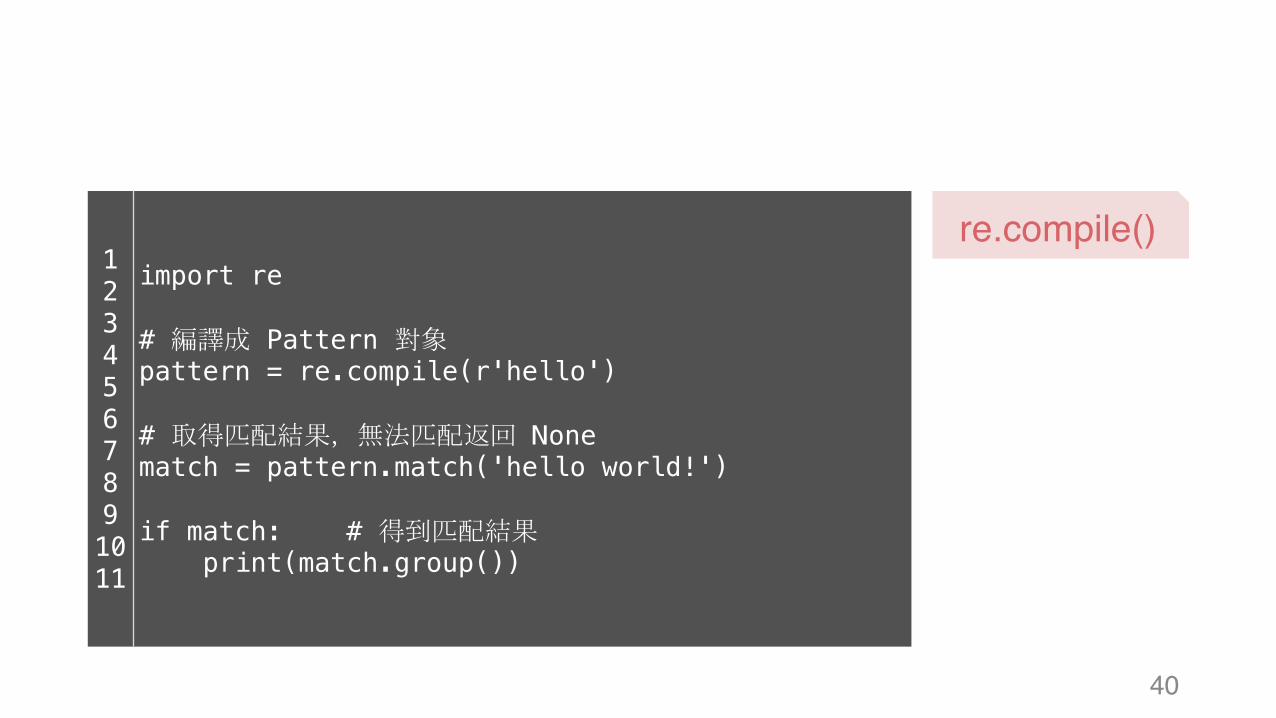
re.compile() 1234567891011
import re
# 編譯成 Pattern 對象pattern = re.compile(r'hello')
# 取得匹配結果,無法匹配返回 Nonematch = pattern.match('hello world!')
if match: # 得到匹配結果print(match.group())

Thanks for listening.2017/08/06 (Wed.) Data Crawler using Python (I)Wei-Yuan [email protected]





























