Embed Size (px)
Citation preview

Esercitazioni di Statistica con riassunti teorici ed esercizi
Irene Martelli
1/18
1

Esercitazioni di Statistica con riassunti teorici ed esercizi
Irene Martelli
1/18
• Queste slide sono il risultato delle esercitazioni tenute durante il corso di Statistica
presso la facoltà di Scienze Politiche dell’Università di Bologna, nell’A.A. 2012/2013.
• Per gli esercizi si consiglia il libro:
«Statistica e laboratorio» di L. Stracqualursi e M. Matteucci.
Molti esercizi suggeriti in queste slide sono stati presi
dal suddetto libro.
• Le slide coprono tendenzialmente tutti gli argomenti
standard coperti da un corso universitario di primo livello in Statistica.
2

3
Esercitazioni di Statistica con riassunti teorici ed esercizi
1/18
• Distribuzioni di frequenza e rappresentazioni grafiche - Slide 4
• I valori medi - Slide 23
• Variabilità, eterogeneità e concentrazione - Slide 38
• Rapporti e numeri indici - Slide 56
• Distribuzioni di frequenza doppie e connessione - Slide 62
• Correlazione e regressione - Slide 78
• Elementi di probabilità - Slide 93
• Variabili casuali - Slide 106
• Distribuzioni campionarie e stima - Slide 128
Indice degli argomenti

Popolazione, unità statistiche, caratteri e modalità
• Popolazione: insieme delle unità statistiche portatrici di una o più caratteristiche
connesse al fenomeno oggetto di interesse.
• Caratteri: sono le caratteristiche scelte per definire il fenomeno collettivo oggetto di
interesse. Possono essere quantitativi (discreti/continui) o qualitativi
(sconnessi/ordinabili rettilineari/ordinabili ciclici).
• Modalità: rappresentano il diverso modo in cui si presentano i caratteri nelle unità
statistiche.
Carattere oggetto di
studio
Mutabile statistica
Variabile statistica
NO
SI
Interi
Reali
Attributi qualitativi
Attributi quantitativi
Gli attributi ammettono ordine di successione?
I valori assunti possono appartenere all’insieme dei numeri:
Mutabile statistica sconnessa
Mutabile statistica ordinata
Variabile statistica continua
Variabile statistica discreta
5

Esercizio 1
Per ciascun punto rispondere alle seguenti domande:
1. Quali sono le unità statistiche di rilevazione?
2. Quali caratteri vengono rilevati? Che tipo di caratteri sono?
• Al termine dell’Esame di Stato, in una classe terza di una scuola secondaria di primo grado,
ad ogni alunno viene chiesto dove vorrebbe andare in vacanza tra le seguenti possibilità:
città italiana, città straniera, lago, mare, montagna e parco divertimenti.
• Al fine di migliorare il servizio offerto, il
direttore dell'albergo Ariston ha attivato un
sistema di raccolta e registrazione dei dati
dei propri clienti. Nella tabella a lato sono
riportati i dati relativi ai primi 7 clienti che
hanno soggiornato nella struttura nel mese
di settembre.
ID Sesso Età N. notti Giudizio
1 M 27 1 Discreto
2 M 19 3 Ottimo
3 F 18 3 Buono
4 M 38 2 Sufficiente
5 F 34 2 Buono
6 F 26 1 Insufficiente
7 M 21 3 Discreto 6

Distribuzioni di frequenze assolute
• La distribuzione di frequenza è la prima forma di sintesi statistica dei dati, poiché riassume
le informazioni contenute nell’insieme dei valori individuali. È una classificazione delle n
unità statistiche in k classi formate sulla base delle modalità del carattere osservato nel
collettivo.
A ni
a1 n1
a2 n2
… …
ai ni
… …
ak nk
n
X ni
x1 n1
x2 n2
… …
xi ni
… …
xk nk
n
Mutabile statistica Variabile statistica
• Proprietà di esaustività
• Proprietà di disgiuntività
𝑛𝑖 = 𝑛1 + 𝑛2 +⋯+ 𝑛𝑘 = 𝑛
𝑘
𝑖=1
Frequenze Assolute
Totale delle unità statistiche
7

Esercizio 2
• A partire dal seguente protocollo elementare, ovvero
l’insieme dei valori assunti dal carattere oggetto di indagine
nelle unità statistiche del collettivo in esame, costruire la
distribuzione di frequenze assolute.
• Collettivo in esame: 27 giocatori del Milan (portieri esclusi)
• Carattere osservato: Numero di goal segnati nella stagione
2012-13 fino alla giornata 24
• Di che tipo è il carattere osservato?
Fonte: www.legaseriea.it
El Shaarawy Stephan 15 Montolivo Riccardo 2 Pazzini Giampaolo 10
Boateng Kevin-Prince 1 Nocerino Antonio 2
Constant Kevin 0 De Sciglio Mattia 0
Bojan 3 Robinho 2
Abate Ignazio 0 Mexès Philippe 0
Ambrosini Massimo 0 De Jong Nigel 1
Emanuelson Urby 1 Zapata Cristian 0 Bonera Daniele 0
Yepes Mario Alberto 0 Flamini Mathieu 0
Niang M'Baye 0 Antonini Luca 0
Acerbi Francesco 0 Traoré Bakaye 0
Pato 0 Muntari Sulley Ali 0
Balotelli Mario 3 Mesbah Djamel 0
Niang 0 8

Distribuzioni di frequenze relative
• Le frequenze relative descrivono il peso delle classi sul complesso delle osservazioni.
• Generica frequenza relativa della classe i-esima: 𝑓𝑖 = 𝑛𝑖
𝑛 inoltre: 0 ≤ 𝑓𝑖 ≤ 1
𝑓𝑖𝑘𝑖=1 = 1
A ni fi
a1 n1 n1/n
a2 n2 n2/n
… … …
ai ni ni/n
… … …
ak nk nk/n
Totale n 1
X ni fi
x1 n1 n1/n
x2 n2 n2/n
… … …
xi ni ni/n
… … …
xk nk nk/n
Totale n 1
Mutabile statistica Variabile statistica
Frequenze Relative
9

Esercizio 3
Ricorda: è sempre possibile costruire una distribuzione di frequenze relative a partire
dalla distribuzione di frequenze assolute, qualunque sia la natura del carattere.
È invece possibile ricostruire la distribuzione di frequenze assolute a partire dalla
distribuzione di frequenze relative soltanto se conosciamo la numerosità del collettivo n.
• Costruire la distribuzione di frequenze relative a partire dalla distribuzione di
frequenze assolute dell’esercizio 2.
• A partire dalla distribuzione di frequenze relative ottenuta, ricordando che la
numerosità del collettivo è n = 27, ricostruire la distribuzione di frequenze assolute.
10

Distribuzioni di frequenze cumulate
• Nella distribuzione cumulata di un carattere le classi sono formate raggruppando le unità
che presentano un livello del carattere minore o uguale (distribuzione crescente/cumulata)
o maggiore o uguale (distribuzione decrescente/retrocumulata) ad una soglia.
• Generica frequenza cumulata assoluta: 𝑁𝑘= 𝑛𝑖𝑘𝑖=1 e relativa: 𝐹𝑘= 𝑓𝑖
𝑘𝑖=1
X ni Ni fi Fi
(<=) x1 n1 N1 = n1 f1= n1/n F1 = f1
(<=) x2 n2 N2 = n1+n2 f2= n2/n F2 = f1+f2
… … … … …
(<=) xi ni Ni = n1+n2+…+ni fi= ni/n Fi = f1+f2+…+fi
… … … … …
(<=) xk nk Nk = n1+..+ni+..+nk= n fk= nk/n Fk = f1+..+fi+..+fk= 1
Totale n 1
Variabile statistica
11

Esercizio 4
Ricorda: è possibile costruire la distribuzione di frequenze cumulate (assolute e relative)
soltanto per caratteri di natura quantitativa e qualitativa ordinale rettilineare.
Se il carattere è qualitativo sconnesso o qualitativo ordinale ciclico non si possono
costruire distribuzioni di frequenze cumulate.
• Costruire la distribuzione di frequenze cumulate assolute a partire dalla distribuzione di
frequenze assolute dell’esercizio 2.
• Costruire la distribuzione di frequenze cumulate relative a partire dalla distribuzione di
frequenze relative dell’esercizio 3.
12

Esercizio riassuntivo sulle distribuzioni di frequenza
La tabella che segue riporta il genere (maschio/femmina) e l’esito dell’esame di Statistica
(promosso/non promosso) per gli studenti che hanno sostenuto l’esame negli appelli della
sessione estiva.
Genere M F M M M M F M F M M M M F M M M M F F F F F F F
Esito N P P P P N P N N P P N N N P P N P P P N P N N N
• Identificare: le unità statistiche, i caratteri osservati e le modalità.
• Costruire la distribuzione di frequenza assoluta e relativa degli studenti secondo il genere.
• Costruire la distribuzione di frequenza assoluta e relativa degli studenti secondo l’esito
dell’esame.
• È possibile costruire anche le corrispondenti distribuzioni di frequenza cumulata?
Motivare la risposta.
• Costruire la distribuzione di frequenza doppia (sia di frequenze assolute che relative).
Individuare, nella distribuzione di frequenza doppia, le singole distribuzioni di frequenza
dei due caratteri. 13

Esercizio – Trarre informazioni dalle distribuzioni di frequenza
Di un gruppo di persone di età compresa tra i 16 e i 30 è nota la distribuzione per età,
distintamente per maschi e femmine.
16-20 anni 21-25 anni 26-30 anni
Maschi 49 52 63
Femmine 36 26 21
• Qual è la percentuale di maschi con non più di 20 anni?
• Qual è la percentuale di femmine con più di 25 anni?
• Qual è la percentuale di femmine con meno di 26 anni?
• Qual è la percentuale di persone di età compresa tra 21 e 25 anni?
• Nella fascia d’età più bassa, quali sono le percentuali dei maschi e delle femmine?
14

Rappresentazioni grafiche – Grafici a nastro e a torta (1)
Su un collettivo di 35 auto è stato osservato il carattere qualitativo "Paese di produzione"
Produttore Freq. assoluta Freq. Relativa Freq. Relativa %
Italia 15 0,43 42,86
USA 8 0,23 22,86
Giappone 7 0,20 20,00 Europa 5 0,14 14,29
35 1 100
15
8
7
5
0 2 4 6 8 10 12 14 16
Italia
USA
Giappone
Europa
Numero auto prodotte (freq. assolute)
Grafico a nastro
42.86
22.86 20.00
14.29
Grafico a torta (freq. relative %)
Italia
USA
Giappone
Europa15

20.83
29.17 29.17
20.83
Frequenze Relative % - Titolo di studio
Scuola secondariainferiore
Scuola secondariasuperiore
Laurea
Titoli post-laurea
50
70 70
50
0
10
20
30
40
50
60
70
80
Scuola secondariainferiore
Scuola secondariasuperiore
Laurea Titoli post-laurea
Grafico a barre Distribuzione per titolo di studio
Rappresentazioni grafiche – Grafici a nastro e a torta (2)
Distribuzione univariata di un campione della popolazione italiana
per titolo di studio (carattere qualitativo ordinato)
Titolo di studio Freq. Assolute Freq. Relative Freq. Relative %
Scuola secondaria inferiore 50 0,21 20,83
Scuola secondaria superiore 70 0,29 29,17
Laurea 70 0,29 29,17
Titoli post-laurea 50 0,21 20,83
240 1 100
16

Rappresentazioni grafiche – Istogramma
Distribuzione per età' di un collettivo di 32 persone. Carattere quantitativo continuo,
suddiviso in classi definite mediante intervalli chiusi a destra e di uguale ampiezza.
Ampiezza classe età
Classe d'età
Freq. Assolute
Freq. relative
Freq. relative %
Freq. relative cumulate
Freq. relative % cumulate
20 10 |-- 30 9 0,28 28,13 0,28 28,13 20 30 |-- 50 12 0,38 37,50 0,66 65,63 20 50 |-- 70 7 0,22 21,88 0,88 87,50 20 70 |-- 4 0,13 12,50 1,00 100,00
32 1,00 100,00
9
12
7
4
0
2
4
6
8
10
12
14
Fre
qu
en
ze A
sso
lute
Classi di età
10 |-- 30
30 |-- 50
50 |-- 70
70 |--
17

Rappresentazioni grafiche – Linee di tendenza (1)
Il seguente dataset è stato preso dalla relazione economica del
Presidente degli Stati Uniti (Gennaio 2001).
Anno Prodotto interno lordo
(bilioni $)
Popolazione (migliaia)
Tasso % di disoccupazione
1990 5803,20 249973 5,6
1991 5986,20 252665 6,8
1992 6318,90 255410 7,5
1993 6642,30 258119 6,9
1994 7054,30 260637 6,1
1995 7400,50 263082 5,6
1996 7813,20 265502 5,4
1997 8318,40 268048 4,9
1998 8790,20 270509 4,5
1999 9299,20 272945 4,2
18

Rappresentazioni grafiche – Linee di tendenza (2)
Rappresentazione «sbagliata» tramite linee di tendenza:
attenzione ai valori assunti dalle variabili osservate!
0.00
50000.00
100000.00
150000.00
200000.00
250000.00
300000.00
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
PIL
Popolazione
Tasso disocc.
19

Rappresentazioni grafiche – Linee di tendenza (3)
0.00
1000.00
2000.00
3000.00
4000.00
5000.00
6000.00
7000.00
8000.00
9000.00
10000.00
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
Pro
do
tto
Inte
rno
Lo
rdo
Anni
Serie Storica - PIL
20

Rappresentazioni grafiche – Linee di tendenza (4)
235000
240000
245000
250000
255000
260000
265000
270000
275000
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
Po
po
lazi
on
e
Anni
Serie Storica - Popolazione
21

Rappresentazioni grafiche – Linee di tendenza (5)
0
1
2
3
4
5
6
7
8
1990 1991 1992 1993 1994 1995 1996 1997 1998 1999
Tass
o d
i dis
occ
up
azio
ne
Anni
Serie Storica - Tasso di disoccupazione
22

Breve introduzione teorica
• Il nostro obiettivo è riuscire ad avere una percezione immediata degli aspetti specifici
che caratterizzano il fenomeno oggetto di studio nella popolazione prescelta:
determinare una misura o un attributo che possa essere ritenuto «tipico» o
rappresentativo per l’intero collettivo.
MEDIE LASCHE (DI POSIZIONE)
Singole modalità assunte dal carattere (qualitativo o quantitativo) che hanno un ruolo importante nella distribuzione per la posizione che occupano.
MEDIE ALGEBRICHE (ANALITICHE)
Risultato dell’elaborazione algebrica di tutte le modalità osservate;
Per caratteri necessariamente quantitativi.
Media ARITMETICA SEMPLICE
Media ARITMETICA PONDERATA
Media GEOMETRICA
MINIMO e MASSIMO
MODA
MEDIANA
QUANTILI
24
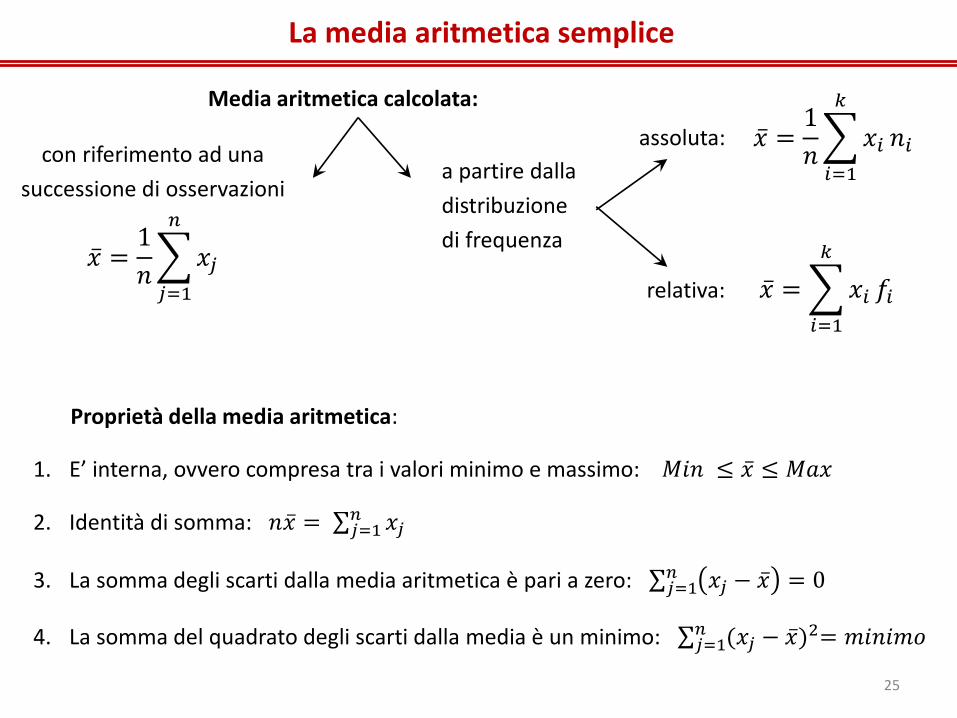
La media aritmetica semplice
Media aritmetica calcolata:
𝑥 =1
𝑛 𝑥𝑗
𝑛
𝑗=1
𝑥 =1
𝑛 𝑥𝑖
𝑘
𝑖=1
𝑛𝑖 con riferimento ad una
successione di osservazioni a partire dalla
distribuzione
di frequenza
𝑥 = 𝑥𝑖
𝑘
𝑖=1
𝑓𝑖
assoluta:
relativa:
Proprietà della media aritmetica:
1. E’ interna, ovvero compresa tra i valori minimo e massimo: 𝑀𝑖𝑛 ≤ 𝑥 ≤ 𝑀𝑎𝑥
2. Identità di somma: 𝑛𝑥 = 𝑥𝑗𝑛𝑗=1
3. La somma degli scarti dalla media aritmetica è pari a zero: 𝑥𝑗 − 𝑥 = 0𝑛𝑗=1
4. La somma del quadrato degli scarti dalla media è un minimo: (𝑥𝑗 − 𝑥 )2= 𝑚𝑖𝑛𝑖𝑚𝑜𝑛𝑗=1
25
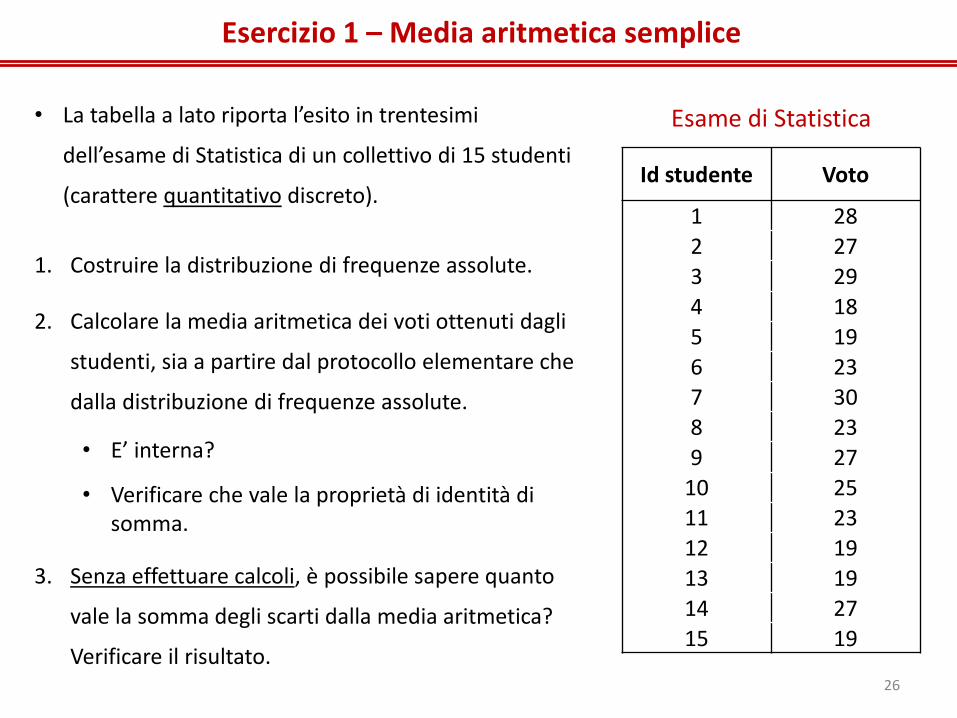
Esercizio 1 – Media aritmetica semplice
1. Costruire la distribuzione di frequenze assolute.
2. Calcolare la media aritmetica dei voti ottenuti dagli
studenti, sia a partire dal protocollo elementare che
dalla distribuzione di frequenze assolute.
• E’ interna?
• Verificare che vale la proprietà di identità di somma.
3. Senza effettuare calcoli, è possibile sapere quanto
vale la somma degli scarti dalla media aritmetica?
Verificare il risultato.
• La tabella a lato riporta l’esito in trentesimi
dell’esame di Statistica di un collettivo di 15 studenti
(carattere quantitativo discreto).
Esame di Statistica
Id studente Voto
1 28
2 27
3 29
4 18
5 19
6 23
7 30
8 23
9 27
10 25
11 23
12 19
13 19
14 27
15 19
26

La media aritmetica ponderata
• Se vogliamo attribuire un’importanza differenziata alle diverse modalità osservate
nel collettivo in esame, è più appropriato usare la media aritmetica ponderata:
𝑥 𝑤 = 𝑥𝑗𝑤𝑗𝑛𝑗=1
𝑤𝑗𝑛𝑗=1
Formula per il calcolo della media aritmetica ponderata:
• Nella formula precedente, con la lettera w sono indicati i pesi: attraverso i pesi
possiamo dare maggiore o minore importanza alle modalità osservate.
• Un esempio tipico è il calcolo della media universitaria: i voti ottenuti agli esami
devono essere pesati con i relativi CFU.
27

Esercizio 2 – Media aritmetica su un collettivo suddiviso in gruppi
1. Interpretare i valori della tabella
2. Calcolare la media del n. di componenti del nucleo familiare per le famiglie con
capofamiglia maschio
3. Calcolare la media del n. di componenti del nucleo familiare per le famiglie con
capofamiglia femmina
4. Calcolare la media del campione suddiviso in due gruppi (caso particolare di media
ponderata: media di due medie con pesi diversi)
5. Ottenere lo stesso risultato del punto 4 a partire dall’intero campione osservato
N° Componenti familiari Capofamiglia
Maschio Femmina 1 5 4 2 7 8 3 4 3 4 10 3 5 3 2 6 3 0
28

La media geometrica
• Media di tipo algebrico che si calcola solo quando tutti i valori sono positivi.
• Data la sequenza delle osservazioni individuali, la media geometrica è data dalla
radice n-esima del prodotto tra gli n valori:
𝑚𝑔 = 𝑥𝑗
𝑛
𝑗=1
𝑛
= 𝑥1 ∙ 𝑥2 ∙ ⋯ ∙ 𝑥𝑛𝑛
Proprietà delle potenze utile per il calcolo «pratico»
… quando usiamo la calcolatrice, per intendersi!! 𝑥𝑗
𝑛
𝑗=1
𝑛
= 𝑥𝑗
𝑛
𝑗=1
1𝑛
𝑚𝑔 = 𝑥𝑖𝑛𝑖
𝑘
𝑖=1
𝑛
= 𝑥1𝑛1 ∙ 𝑥2
𝑛2 ∙ ⋯ ∙ 𝑥𝑘𝑛𝑘𝑛
• La media geometrica gode della proprietà di identità di prodotto:
𝑚𝑔 ×𝑚𝑔 ×⋯×𝑚𝑔 = 𝑥1 × 𝑥2 ×⋯× 𝑥𝑛
29

Esercizio 3 – Media geometrica
Un investitore nel 1994 ha differenziato il suo portafoglio fondi, investendo un capitale C in
fondi obbligazionari e un capitale C’ in fondi azionari.
Quale tipologia di fondo è risultata, nel decennio considerato, più remunerativa, ovvero ha
presentato un rendimento medio annuo più elevato?
Anni Tassi di rendimento fondi obbligazionari
Anni Tassi di rendimento
fondi azionari
1994 -0.013 1994 -0.036 1995 0.104 1995 0.013 1996 0.094 1996 0.084 1997 0.066 1997 0.303 1998 0.052 1998 0.222 1999 0.003 1999 0.357 2000 0.043 2000 -0.088 2001 0.028 2001 -0.170 2002 0.022 2002 -0.263 2003 0.016 2003 0.101
30

Esercizio 4 – Il minimo e il massimo
• Minimo e massimo appartengono alle medie lasche (o di posizione). In generale,
prima di andare a determinare le medie lasche, dobbiamo operare un ordinamento
(crescente o decrescente) delle modalità osservate.
• Se il carattere osservato è quantitativo, possiamo attribuire un valore informativo ai
valori più piccolo e più grande, nella successione ordinata o nella distribuzione di
frequenza: 𝑀𝑖𝑛 = min 𝑥𝑗 𝑀𝑎𝑥 = ma𝑥 𝑥𝑗 𝑗 = 1,… , 𝑛
𝑀𝑖𝑛 = min 𝑥𝑖 𝑀𝑎𝑥 = ma𝑥 𝑥𝑖 𝑖 = 1,… , 𝑘
Esempio tratto dal libro «Statistica per l’analisi operativa dei dati»: Famiglie italiane per numero di stanze dell’abitazione occupata nell’anno 2003 (dati per 10000, fonte: ISTAT)
𝑥𝑖 𝑛𝑖
1 12
2 148
3 489
4 760
5 505
6 310
2224 31

La moda
• Idea intuitiva: modalità più ricorrente nella popolazione statistica di riferimento.
• Definita per tutti i tipi di carattere.
• E’ la modalità a cui corrisponde la massima frequenza (per la sua determinazione
facciamo quindi riferimento alla distribuzione di frequenza)
Esempio tratto dal libro «Statistica per l’analisi operativa dei dati»: Famiglie italiane per numero di stanze dell’abitazione occupata nell’anno 2003 (dati per 10000, fonte: ISTAT)
𝑥𝑖 𝑛𝑖
1 12
2 148
3 489
4 760
5 505
6 310
2224
32
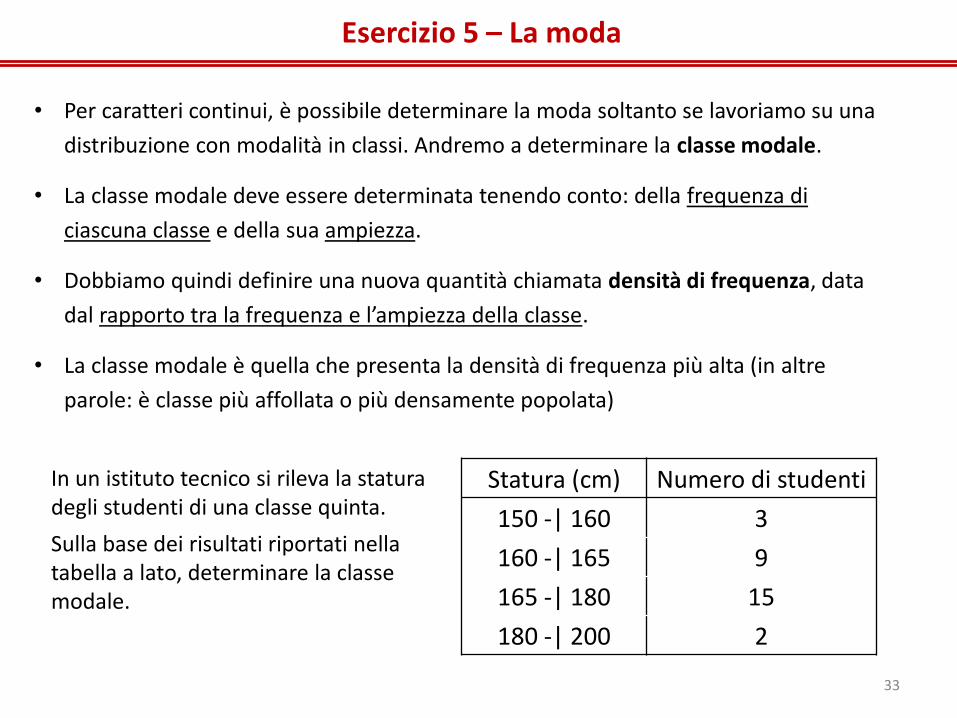
Esercizio 5 – La moda
Statura (cm) Numero di studenti
150 -| 160 3
160 -| 165 9
165 -| 180 15
180 -| 200 2
In un istituto tecnico si rileva la statura degli studenti di una classe quinta.
Sulla base dei risultati riportati nella tabella a lato, determinare la classe modale.
• Per caratteri continui, è possibile determinare la moda soltanto se lavoriamo su una
distribuzione con modalità in classi. Andremo a determinare la classe modale.
• La classe modale deve essere determinata tenendo conto: della frequenza di
ciascuna classe e della sua ampiezza.
• Dobbiamo quindi definire una nuova quantità chiamata densità di frequenza, data
dal rapporto tra la frequenza e l’ampiezza della classe.
• La classe modale è quella che presenta la densità di frequenza più alta (in altre
parole: è classe più affollata o più densamente popolata)
33

La mediana
• La mediana è quella modalità del carattere che consente di suddividere la successione
ordinata di osservazioni in due gruppi aventi la stessa numerosità.
• Poiché dobbiamo ordinare le modalità del carattere osservato, non è possibile
determinare la mediana per caratteri qualitativi sconnessi.
1. Ordiniamo (in modo crescente o decrescente) la nostra serie.
2. Determiniamo la mediana nel seguente modo:
A livello operativo:
𝑀𝑒 =
𝑥(𝑛+1)/2 𝑠𝑒 𝑛 è 𝑑𝑖𝑠𝑝𝑎𝑟𝑖
𝑥𝑛/2, 𝑥𝑛 2 +1 𝑠𝑒 𝑛 è 𝑝𝑎𝑟𝑖
Nel secondo caso (n pari), se le due modalità sono diverse tra loro possono essere sintetizzate con la semisomma se il carattere è quantitativo, altrimenti devono essere tenute in considerazione entrambe (per caratteri qualitativi)
34
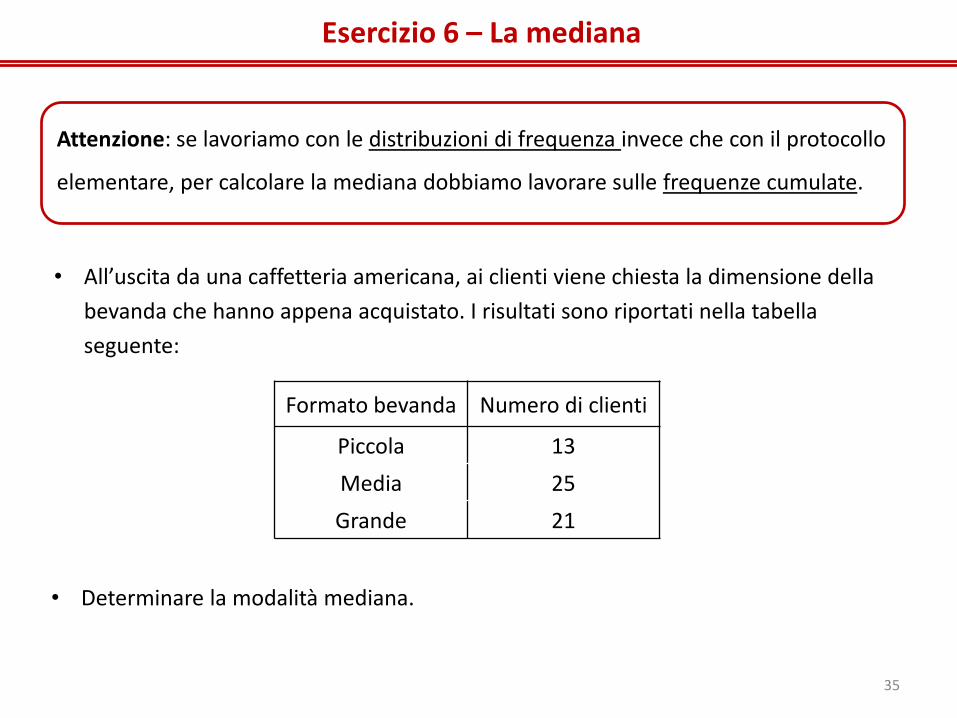
Esercizio 6 – La mediana
Attenzione: se lavoriamo con le distribuzioni di frequenza invece che con il protocollo
elementare, per calcolare la mediana dobbiamo lavorare sulle frequenze cumulate.
• All’uscita da una caffetteria americana, ai clienti viene chiesta la dimensione della
bevanda che hanno appena acquistato. I risultati sono riportati nella tabella
seguente:
Formato bevanda Numero di clienti
Piccola 13
Media 25
Grande 21
• Determinare la modalità mediana.
35

I quantili
• I quantili possono essere considerati come una generalizzazione del concetto di
mediana. Lavoriamo quindi anche in questo caso sulla successione ordinata.
• Andremo a cercare quella modalità al di sotto (o al di sopra) della quale si trova una
prefissata proporzione (o percentuale) q di osservazioni.
• I quartili sono 3 e suddividono la successione ordinata in 4 parti, i decili sono 9 e la
suddividono in 10 parti, e così via…
• I percentili sono 99 e suddividono la successione ordinata in 100 parti.
mediana q=1/2
primo quartile q=1/4
terzo quartile q=3/4 secondo quartile
q=2/4=1/2
• Come nel caso della mediana, se lavoriamo con distribuzioni di frequenza, dobbiamo
fare riferimento alle frequenze cumulate. 36

Esercizio 7 – I quantili
• Nella tabella seguente è riportato il numero medio giornaliero di ore trascorse davanti
al computer osservato in un gruppo di bambini di età compresa tra i 10 e i 14 anni.
𝑥𝑖 𝑛𝑖
0 23
1 45
2 47
3 52
4 21
5 12
• Determinare i quartili e il 90° percentile della distribuzione.
37

Breve introduzione teorica
« Non mi fido molto delle statistiche, perché un uomo con la testa nel forno acceso e
i piedi nel congelatore statisticamente ha una temperatura media. »
Charles Bukowski
• Intervallo di variazione e differenza interquartile
• Devianza, varianza e scarto quadratico medio
• Coefficiente di variazione
• Scostamento semplice medio dalla mediana
• Standardizzazione (utile per confronti)
Variabilità
(per caratteri quantitativi)
• Indice di eterogeneità di Gini Eterogeneità
(anche per caratteri qualitativi)
• Rapporto di concentrazione di Gini Concentrazione
(per caratteri cumulabili e trasferibili) 39

L’intervallo di variazione e la differenza interquartile
Intervallo di variazione (o range):
• Se le classi sono costituite da intervalli:
• E’ sensibile a valori anomali, in quanto risente della presenza di valori estremi
• E’ espresso nella stessa unità di misura della variabile X
Differenza interquartile:
• Non è sensibile a valori anomali
• Attenzione: anche se i quartili possono essere calcolati per variabili qualitative
ordinabili, la differenza interquartile può essere calcolata solo per caratteri
quantitativi (si tratta di un’operazione algebrica!)
𝐼𝑣 = 𝑥𝑚𝑎𝑥 − 𝑥𝑚𝑖𝑛
𝐼𝑞 = 𝑄3/4 − 𝑄1/4
Sono di misure di variabilità che non sfruttano tutte le informazioni disponibili,
ma misurano la diversità tra due particolari termini.
𝑥𝑚𝑖𝑛 = estremo inferiore del primo intervallo
𝑥𝑚𝑎𝑥 = estremo superiore dell’ultimo intervallo
40

Esercizio 1 – Intervallo di variazione e differenza interquartile
• Il Rettore di un’università vuole studiare la produttività della ricerca nel suo ateneo.
Come primo passo, decide di rilevare il numero di articoli pubblicati su una rivista dai
ricercatori confermati nel corso dell’ultimo anno.
• La tabella seguente mostra i risultati per la facoltà di Agraria:
N. Articoli N. Ricercatori
0 -| 2 4
2 -| 5 3
5 -| 10 13
10 -| 12 2
Quali sono il carattere osservato e l’unità statistica di riferimento?
Di che tipo è il carattere osservato?
Calcolare l’intervallo di variazione e la differenza interquartile 41

La devianza
1. E’ sempre positiva (somma di quadrati) ed è pari a zero solo se non c’è variabilità
2. E’ espressa nel quadrato dell’unità di misura della variabile X
3. E’ influenzata dal numero delle unità
Devianza, varianza e scarto quadratico medio sono indicatori di variabilità che
misurano la dispersione dei valori osservati attorno ad un valore medio, in
particolare si basano sui quadrati degli scarti dalla media aritmetica.
𝐷𝑒𝑣 𝑋 = 𝑥𝑗 − 𝑥 2=
𝑛
𝑗=1
𝑥𝑗2 − 𝑛𝑥 2
𝑛
𝑗=1
𝐷𝑒𝑣 𝑋 = 𝑥𝑖 − 𝑥 2𝑛𝑖 =
𝑘
𝑖=1
𝑥𝑖2𝑛𝑖 − 𝑛𝑥 2
𝑘
𝑖=1
• Se lavoriamo con il
protocollo elementare:
• Se lavoriamo con la
distribuzione di frequenza:
Formule definitorie e per il calcolo della devianza
42

La varianza
1. E’ sempre positiva ed è pari a zero solo se non c’è variabilità
2. E’ espressa nel quadrato dell’unità di misura della variabile X
3. Non è influenzata dal numero delle unità
𝑉 𝑋 =1
𝑛 𝑥𝑗 − 𝑥
2=
𝑛
𝑗=1
1
𝑛 𝑥𝑗
2 − 𝑥 2𝑛
𝑗=1
𝑉 𝑋 =1
𝑛 𝑥𝑖 − 𝑥 2𝑛𝑖 =
𝑘
𝑖=1
1
𝑛 𝑥𝑖
2𝑛𝑖 − 𝑥 2𝑘
𝑖=1
• Se lavoriamo con il
protocollo elementare:
• Se lavoriamo con la
distribuzione di frequenza:
Formule definitorie e per il calcolo della varianza
La varianza si calcola dividendo la devianza per il numero di unità osservate:
𝑉 𝑋 = 𝑉𝑎𝑟 𝑋 =𝐷𝑒𝑣(𝑋)
𝑛
43

Lo scarto quadratico medio o deviazione standard
1. Per la proprietà di minimo della media aritmetica, è il minimo degli scostamenti
quadratici medi da un qualunque altro valore medio.
2. E’ Sempre maggiore o uguale a zero ed è espresso nell’unità di misura della variabile X
3. Non è influenzato dal numero delle unità
𝑆𝐷 𝑋 =1
𝑛 𝑥𝑗 − 𝑥
2=
𝑛
𝑗=1
1
𝑛 𝑥𝑗
2 − 𝑥 2𝑛
𝑗=1
𝑆𝐷 𝑋 =1
𝑛 𝑥𝑖 − 𝑥 2𝑛𝑖
𝑘
𝑖=1
=1
𝑛 𝑥𝑖
2𝑛𝑖 − 𝑥 2𝑘
𝑖=1
• Se lavoriamo con il
protocollo elementare:
• Se lavoriamo con la
distr. di frequenza:
Formule definitorie e per il calcolo dello scarto quadratico medio
Lo scarto quadratico medio è dato dalla radice quadrata della varianza:
SD 𝑋 = 𝐷𝑆 𝑋 = 𝑆𝑥 2 = 𝑉𝑎𝑟(𝑋)
44
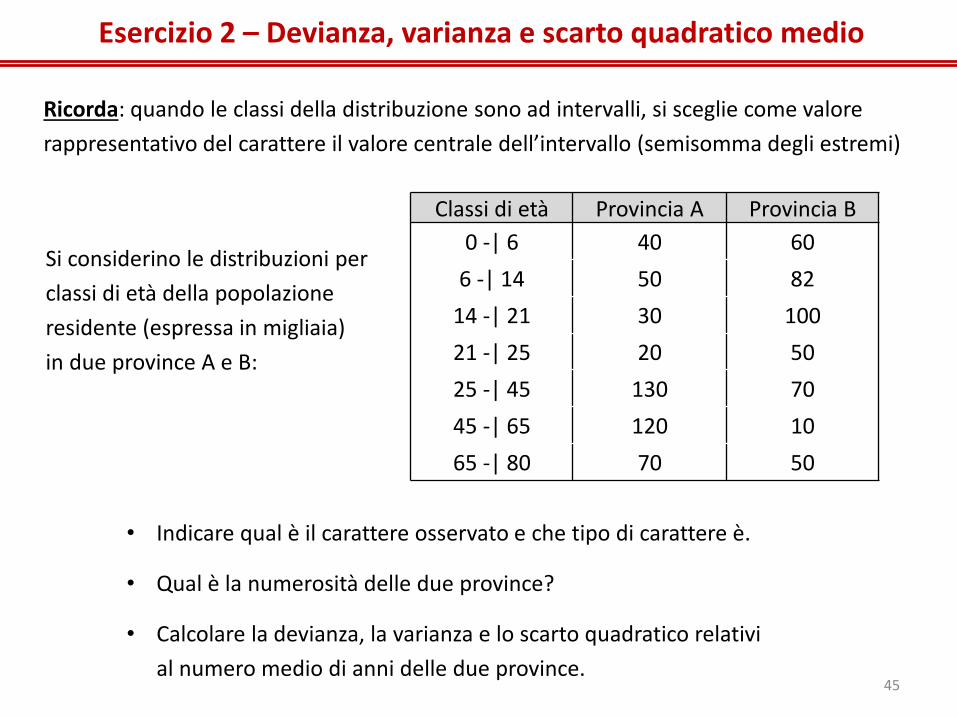
Esercizio 2 – Devianza, varianza e scarto quadratico medio
Ricorda: quando le classi della distribuzione sono ad intervalli, si sceglie come valore
rappresentativo del carattere il valore centrale dell’intervallo (semisomma degli estremi)
Classi di età Provincia A Provincia B
0 -| 6 40 60
6 -| 14 50 82
14 -| 21 30 100
21 -| 25 20 50
25 -| 45 130 70
45 -| 65 120 10
65 -| 80 70 50
Si considerino le distribuzioni per
classi di età della popolazione
residente (espressa in migliaia)
in due province A e B:
• Indicare qual è il carattere osservato e che tipo di carattere è.
• Qual è la numerosità delle due province?
• Calcolare la devianza, la varianza e lo scarto quadratico relativi
al numero medio di anni delle due province. 45

Il coefficiente di variazione
• Devianza
• Varianza
• Scarto quadratico medio
Sono misure di variabilità assolute, ovvero che dipendono
dall’unità di misura del carattere e dal suo ordine di grandezza.
Non sono quindi adatte a effettuare confronti in termini di
variabilità tra distribuzioni.
𝐶𝑉(𝑋) =𝑆𝐷(𝑋)
𝑥
Coefficiente di variazione (o coefficiente di variabilità)
1. E’ un numero puro, che non ha unità di misura (indicatore relativo di variabilità)
2. Può essere utilizzato per confrontare la variabilità:
• Dello stesso carattere in due o più collettivi aventi medie diverse
• Dello stesso carattere espresso in diverse unità di misura
• Di due caratteri diversi per unità di misura e per livello medio 46

Esercizio 3 – Coefficiente di variazione
• Con riferimento all’esercizio 2, quale indicatore è possibile utilizzare per confrontare la
variabilità delle due province?
• Calcolarlo e indicare quale delle due province ha maggior variabilità.
Classi di età Provincia A Provincia B
0 -| 6 40 60
6 -| 14 50 82
14 -| 21 30 100
21 -| 25 20 50
25 -| 45 130 70
45 -| 65 120 10
65 -| 80 70 50
47

Lo scostamento semplice medio dalla mediana
𝑥𝑗 −𝑀𝑒
𝑛
𝑗=1
= 𝑚𝑖𝑛𝑖𝑚𝑜 𝑥𝑖 −𝑀𝑒 𝑛𝑖
𝑘
𝑖=1
= 𝑚𝑖𝑛𝑖𝑚𝑜
• In relazione al
protocollo elementare:
• In relazione alla
distribuzione di frequenza:
• 𝑥𝑗 −𝑀𝑒 sono gli scarti dalla mediana in valore assoluto
• Lo scostamento semplice medio dalla mediana è un minimo
tra tutti gli scostamenti semplici medi (proprietà della mediana)
𝑆𝑀𝐸 =1
𝑛 𝑥𝑗 −𝑀𝑒
𝑛
𝑗=1
𝑆𝑀𝐸 =1
𝑛 𝑥𝑖 −𝑀𝑒
𝑘
𝑖=1
𝑛𝑖
48

Esercizio 4 – Scostamento semplice medio dalla mediana
Individuo Tempo (giorni) per il consumo
di un pacco di biscotti
1 3
2 6
3 15
4 1
5 5
6 35
7 12
8 7
9 5
10 9
• La seguente tabella riporta il tempo (in giorni) impiegato da dieci individui per il
consumo di una confezione di biscotti da 400 grammi:
• Calcolare la mediana
• Calcolare lo scostamento
semplice medio
dalla mediana
• Interpretare il risultato
49

Esercizio 5 – La standardizzazione di variabili
Con 𝑍𝑖 si indica la variabile standardizzata, così definita:
𝑍𝑖 =𝑋𝑗 − 𝑋
𝐷𝑆(𝑋)=
𝑜𝑠𝑠𝑒𝑟𝑣𝑎𝑧𝑖𝑜𝑛𝑒 𝑜𝑟𝑖𝑔𝑖𝑛𝑎𝑟𝑖𝑎 − 𝑚𝑒𝑑𝑖𝑎
𝑑𝑒𝑣𝑖𝑎𝑧𝑖𝑜𝑛𝑒 𝑠𝑡𝑎𝑛𝑑𝑎𝑟𝑑
• La standardizzazione è molto utile quando dobbiamo confrontare variabili non omogenee,
quindi con differenti valori medi e differenti variabilità.
• In valore assoluto Paperino
e Pippo hanno segnato 11
punti, ma quale dei due
giocatori, nel contesto della
rispettiva squadra, è il più
bravo?
Squadra A Punti
Gastone 21
Paperina 13
Paperino 11
Qui 7
Quo 6
Qua 5
Nonna Papera 3
Zio Paperone 2
Squadra B Punti
Topolino 12
Pippo 11
Minni 3
Tip 2
Tap 2
Eta Beta 1
50

Le misure di eterogeneità – L’indice di Gini
• L’eterogeneità di un collettivo rispetto ad un carattere si definisce con riferimento al
comportamento delle frequenze (assolute o relative) osservate per le diverse modalità
assunte dal carattere.
• Situazioni estreme
𝐸𝐺 = 1 − 𝑓𝑖2
𝑘
𝑖=1 Indice di eterogeneità di Gini:
• Valore minimo: 𝐸𝐺 = 0 in situazione di omogeneità, ovvero tutte frequenze relative
nulle, tranne una che è pari ad 1
• Valore massimo: 𝐸𝐺 =𝑘−1
𝑘 in situazione di massima eterogeneità, ovvero tutte le
frequenze relative pari a 1 𝑘
Omogeneità: tutte le unità statistiche presentano la stessa modalità,
ovvero una sola modalità ha frequenza assoluta pari ad n, o frequenza
relativa pari ad 1.
Massima eterogeneità: le unità statistiche sono equiripartite tra le
diverse modalità, ovvero tutte le modalità hanno la stessa frequenza
assoluta n/k o relativa pari a 1/k.
51

Esercizio 6 – Misure di eterogeneità
• Un sabato sera una pizzeria ha contato 240 clienti. Di tali clienti sono state registrate le
ordinazioni effettuate per quanto riguarda le pizze scelte.
• Nella seguente tabella sono riportati i risultati:
Pizza 𝒏𝒊
Margherita 62
Marinara 18
Capricciosa 12
Crudo 21
Cotto e funghi 10
Quattro formaggi 9
Bufala e pomodorini 56
Bresaola, rucola e grana 18
Vegetariana 27
Gorgonzola e salsiccia 7
• Costruire sia la distribuzione di
omogeneità, che quella di
massima eterogeneità
• Calcolare l’indice
di eterogeneità di Gini
52
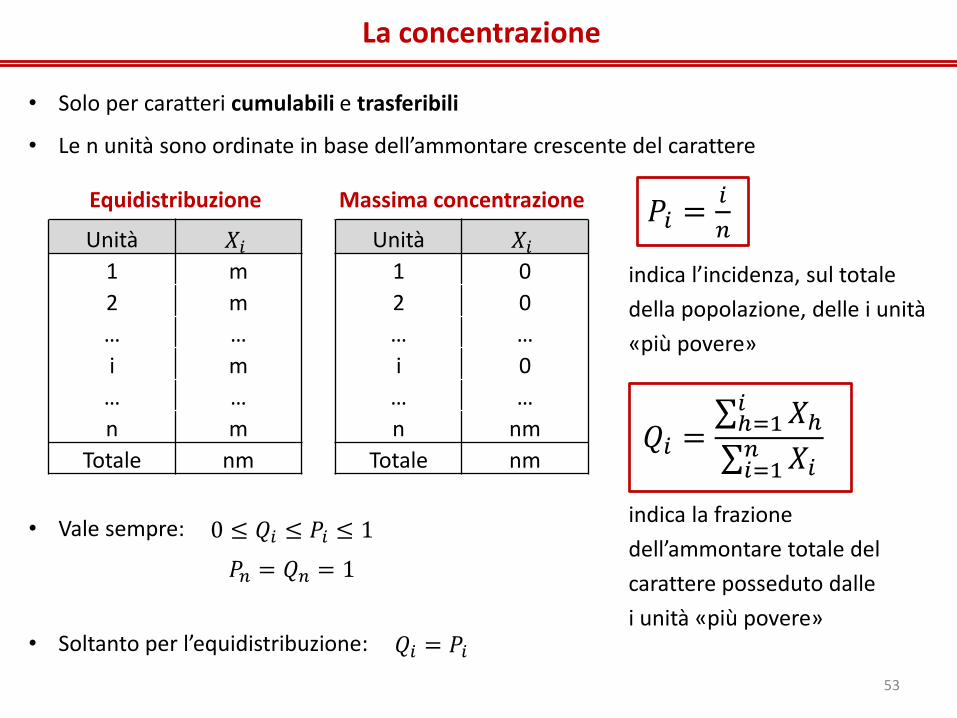
La concentrazione
• Solo per caratteri cumulabili e trasferibili
• Le n unità sono ordinate in base dell’ammontare crescente del carattere
Equidistribuzione
Unità 𝑋𝑖
1 m
2 m
… …
i m
… …
n m
Totale nm
𝑃𝑖 =𝑖
𝑛
indica l’incidenza, sul totale
della popolazione, delle i unità
«più povere»
Massima concentrazione
Unità 𝑋𝑖
1 0
2 0
… …
i 0
… …
n nm
Totale nm 𝑄𝑖 =
𝑋ℎ𝑖ℎ=1
𝑋𝑖𝑛𝑖=1
indica la frazione
dell’ammontare totale del
carattere posseduto dalle
i unità «più povere»
• Vale sempre:
• Soltanto per l’equidistribuzione:
0 ≤ 𝑄𝑖 ≤ 𝑃𝑖 ≤ 1
𝑃𝑛 = 𝑄𝑛 = 1
𝑄𝑖 = 𝑃𝑖
53

Il rapporto di concentrazione di Gini
• Per misurare la concentrazione dobbiamo tenere conto di tutte le
differenze 𝑃𝑖 − 𝑄𝑖 tranne l’ultima che è sempre nulla:
𝑄𝑖 = 𝑋ℎ𝑖ℎ=1
𝑋𝑖𝑛𝑖=1
𝑃𝑖 =𝑖
𝑛
𝐺 = 𝑃𝑖 − 𝑄𝑖
𝑛−1
𝑖=1
dove
• In caso di equidistribuzione si ha: 𝐺 =0
• In caso di massima concentrazione si ha: 𝑄1 = 𝑄2 = ⋯ = 𝑄𝑛−1 = 0
quindi il valore massimo di 𝐺 è pari a 𝐺 = 𝑃𝑖𝑛−1𝑖=1
Rapporto di concentrazione di Gini 𝑔 =
𝑃𝑖 − 𝑄𝑖𝑛−1𝑖=1
𝑃𝑖𝑛−1𝑖=1
= 1 − 𝑄𝑖𝑛−1𝑖=1
𝑃𝑖𝑛−1𝑖=1
0 ≤ 𝑔 ≤ 1 Equidistribuzione Massima concentrazione
54

Esercizio 7 – Rapporto di concentrazione di Gini
Numero di grappoli (in migliaia di unità)
116
82
110
97
80
• Per 5 aziende vinicole presenti su un dato territorio è stato rilevato il numero di grappoli
(in migliaia di unità) presenti sulle viti nei primi giorni di luglio.
• Nella seguente tabella sono riportati i risultati:
Misurare la concentrazione attraverso il rapporto di concentrazione di Gini
e interpretare il risultato 55

I rapporti statistici
• E’ un numero puro che permette confronti nel tempo e nello spazio indipendentemente
dalla dimensione e dalla natura del fenomeno indagato.
• Diversi tipi di rapporti statistici in base al tipo di legame logico esistente tra i due termini:
• Rapporto di composizione o di parte al tutto: mette in relazione l’intensità o la
frequenza di due fenomeni, uno dei quali (numeratore) può considerarsi una parte
dell’altro.
• Rapporto di coesistenza: mette in relazione le frequenze (o le quantità)
corrispondenti di due modalità di un carattere che coesistono in uno stesso
fenomeno.
• Rapporto di derivazione: mette in relazione una frequenza o una quantità di un
carattere con quella di un altro che può essere considerato un presupposto
necessario del primo.
• Rapporto di durata: mette in relazione la consistenza di un fenomeno con
l’ammontare del suo rinnovamento periodico. Il risultato indica la durata del
fenomeno. 57

Esercizio 1 – Rapporti statistici
La tabella che segue riporta la distribuzione di frequenza doppia del genere
(maschio/femmina) e dell’esito dell’esame di Statistica (promosso/non promosso)
per gli studenti che hanno sostenuto l’esame negli appelli della sessione estiva.
Genere Esito
Totale Promosso Non promosso
M 8 6 14
F 5 6 11
Totale 13 12 25
• Quali rapporti di composizione si possono definire? Commentare i risultati.
58

I numeri indici elementari
• In generale i numeri indici (elementari e complessi) sono particolari rapporti statistici
che misurano sinteticamente le variazioni di fenomeni economici in diverse situazioni
di tempo o di luogo (o comunque diverse da una situazione base)
• Sempre positivi e indipendenti dall’unità di misura (numeri puri)
Numero indice elementare
• 𝑋𝑡 (t= 0,1,…,T) serie storica di un fenomeno economico
• b = base del numero indice = tempo base
• t = tempo corrente
• Variazione % del fenomeno:
• Indice a base fissa, mantiene fisso b:
• Indice a base mobile (a catena), se b = t – 1:
𝑖𝑡𝑏 =𝑥𝑡𝑥𝑏
𝑖𝑡𝑏 − 1 100 =𝑥𝑡𝑥𝑏
− 1 100 =𝑥𝑡 − 𝑥𝑏𝑥𝑏
100
𝑖00 =𝑥0𝑥0
= 1, 𝑖10 =𝑥1𝑥0, 𝑖20 =
𝑥2𝑥0
𝑖10 =𝑥1𝑥0, 𝑖21 =
𝑥2𝑥1, 𝑖32 =
𝑥3𝑥2
59

I numeri indici complessi
• Sintetizzano le variazioni di n grandezze (quindi di n numeri indici elementari)
• Problemi nella costruzione di un indice complesso: • Scelta dei beni: indici rappresentativi o completi • Scelta della base: indici a base fissa o mobile • Scelta del criterio di aggregazione • Scelta del sistema di ponderazione: Laspeyres, Paasche e Fisher
Indice di Laspeyres (a ponderazione fissa)
𝑃𝑡𝐿 =
𝑝𝑚𝑡𝑞𝑚𝑏𝑀𝑚=1
𝑝𝑚𝑏𝑞𝑚𝑏𝑀𝑚=1
𝑏 𝑄𝑡𝐿 =
𝑝𝑚𝑏𝑞𝑚𝑡𝑀𝑚=1
𝑝𝑚𝑏𝑞𝑚𝑏𝑀𝑚=1
𝑏
𝑃𝑡𝑃 =
𝑝𝑚𝑡𝑞𝑚𝑡𝑀𝑚=1
𝑝𝑚𝑏𝑞𝑚𝑡𝑀𝑚=1
𝑏 𝑄𝑡𝐿 =
𝑝𝑚𝑡𝑞𝑚𝑡𝑀𝑚=1
𝑝𝑚𝑡𝑞𝑚𝑏𝑀𝑚=1
𝑏
𝑃𝑡𝐹 = 𝑃𝑡
𝐿 ∙ 𝑃𝑡𝑃
𝑏𝑏𝑏 𝑄𝑡𝐹 = 𝑄𝑡
𝐿 ∙ 𝑄𝑡𝑃
𝑏𝑏𝑏
Indice di Paasche (a ponderazione variabile)
Indice ideale di Fisher (a ponderazione incrociata)
60

Esercizio 2 – Numeri indici
Anno Prezzo unitario
2008 40
2009 42
2010 50
2011 70
2012 82
• Calcolare la serie dei numeri indici % a base fissa 2008 e a base fissa 2010.
• Quali sono le variazioni % dei prezzi nei diversi anni dall’anno base 2008?
• Passare dalla serie dei numeri indici a base fissa 2008 a quella a base fissa 2010.
• Calcolare la serie dei numeri indici % a base mobile.
• Passare dalla serie dei numeri indici a base fissa 2008 a quella a base mobile.
• Passare dalla serie dei numeri indici a base mobile a quella a base fissa 2010.
• Qual è stata la variazione media del prezzo del bene considerato tra il 2009 e il 2011? 61

Le distribuzioni doppie di frequenza o bivariate
• Definizione: dati due caratteri X e Y, si definisce distribuzione doppia di frequenza
l’insieme delle frequenze congiunte 𝑛𝑖ℎ dove:
• Con 𝑛𝑖ℎ indichiamo le frequenze assolute delle unità che presentano la modalità i-esima
della X e la modalità h-esima della Y.
Riprendiamo l’esempio dell’esame di Statistica che abbiamo visto nella prima esercitazione:
Genere (X)
Esito (Y) Totale
Promosso Non promosso
M 8 6 14
F 5 6 11
Totale 13 12 25
• Il carattere X è il genere e può assumere le modalità M ed F
• Il carattere Y è l’esito e può assumere le modalità P e NP
• Per esempio, la cella evidenziata rappresenta 𝑛𝑀𝑃 ovvero il numero di studenti che presentano la modalità M del carattere X e la modalità P del carattere Y
63

Distribuzioni doppie: schema generale e distribuzioni marginali
𝑦1 … 𝑦ℎ … 𝑦𝑣 Totale
𝑥1 𝑛11 … 𝑛1ℎ … 𝑛1𝑣 𝑛10
⋮ ⋮ ⋮ ⋮ ⋮
𝑥𝑖 𝑛𝑖1 … 𝑛𝑖ℎ … 𝑛𝑖𝑣 𝑛𝑖0
⋮ ⋮ ⋮ ⋮ ⋮
𝑥𝑢 𝑛𝑢1 … 𝑛𝑢ℎ … 𝑛𝑢𝑣 𝑛𝑢0
Totale 𝑛01 … 𝑛0ℎ … 𝑛0𝑣 𝑛
X Y
• In rosso abbiamo la distribuzione doppia dei caratteri X ed Y (frequenze congiunte)
• In blu è evidenziata la distribuzione marginale della X: mi indica quante unità
presentano le diverse modalità del carattere X indipendentemente dalle modalità che le
unità assumono in relazione alla variabile Y.
• In verde è evidenziata la distribuzione marginale della Y. 64

Esercizio 1 – Distribuzioni marginali
• Proprietà che valgono sempre, per costruzione:
• Frequenze marginali del carattere X: 𝑛𝑖0 = 𝑛𝑖ℎ𝑣ℎ=1 per 𝑖 = 1, 2, … , 𝑢
• Frequenze marginali del carattere Y: 𝑛0ℎ = 𝑛𝑖ℎ𝑢𝑖=1 per ℎ = 1, 2, … , 𝑣
• Numerosità totale del collettivo: 𝑛 = 𝑛𝑖ℎ𝑣ℎ=1 =𝑢
𝑖=1 𝑛𝑖0 =𝑢𝑖=1 𝑛0ℎ
𝑣ℎ=1
• Nota bene: le distribuzioni marginali sono distribuzioni univariate.
• Esercizio 2 pag. 157 (Statistica e laboratorio)
La tabella a lato riporta la classificazione
delle atlete di una polisportiva in base
alla statura (cm) e al tipo di sport praticato.
• Qual è l’unità statistica di riferimento?
• Costruire le distribuzioni marginali.
• Quante sono le unità statistiche complessivamente?
Sport
Statura di squadra individuale
160 -| 170 2 12
170 -| 180 8 25
180 -| 190 23 4
65

Le distribuzioni condizionate (1)
• A partire dalla distribuzione doppia posso ottenere le distribuzioni condizionate.
• Distribuzione di X condizionata ad Y: vado a studiare com’è distribuito il carattere X, ma mi
vincolo (condiziono) ad una particolare modalità del carattere Y. Posso avere un numero di
distribuzioni di X condizionate ad Y pari al numero delle modalità del carattere Y (v).
• Per esempio se mi concentro sulla prima modalità di Y:
𝑦1 … 𝑦ℎ … 𝑦𝑣 Totale
𝑥1 𝑛11 … 𝑛1ℎ … 𝑛1𝑣 𝑛10
⋮ ⋮ ⋮ ⋮ ⋮
𝑥𝑖 𝑛𝑖1 … 𝑛𝑖ℎ … 𝑛𝑖𝑣 𝑛𝑖0
⋮ ⋮ ⋮ ⋮ ⋮
𝑥𝑢 𝑛𝑢1 … 𝑛𝑢ℎ … 𝑛𝑢𝑣 𝑛𝑢0
Totale 𝑛01 … 𝑛0ℎ … 𝑛0𝑣 𝑛
X Y Frequenze
𝑥1 𝑛11
⋮ ⋮
𝑥𝑖 𝑛𝑖1
⋮ ⋮
𝑥𝑢 𝑛𝑢1
Totale 𝑛01
X (𝑌 = 𝑦1)
66

Le distribuzioni condizionate (2)
• Distribuzione di Y condizionata ad X: vado a studiare com’è distribuito il carattere y, ma mi
vincolo (condiziono) ad una particolare modalità del carattere X. Posso avere un numero di
distribuzioni di Y condizionate ad X pari al numero delle modalità del carattere X (u).
• Per esempio se mi concentro sull’ultima modalità di X:
• Nota bene: le distribuzioni condizionate sono distribuzioni univariate.
𝑦1 … 𝑦ℎ … 𝑦𝑣 Totale
𝑥1 𝑛11 … 𝑛1ℎ … 𝑛1𝑣 𝑛10
⋮ ⋮ ⋮ ⋮ ⋮
𝑥𝑖 𝑛𝑖1 … 𝑛𝑖ℎ … 𝑛𝑖𝑣 𝑛𝑖0
⋮ ⋮ ⋮ ⋮ ⋮
𝑥𝑢 𝑛𝑢1 … 𝑛𝑢ℎ … 𝑛𝑢𝑣 𝑛𝑢0
Totale 𝑛01 … 𝑛0ℎ … 𝑛0𝑣 𝑛
X Y Frequenze
𝑦1 𝑛𝑢1
⋮ ⋮
𝑦ℎ 𝑛𝑢ℎ
⋮ ⋮
𝑦𝑣 𝑛𝑢𝑣
Totale 𝑛𝑢0
Y (𝑋 = 𝑥𝑢)
67
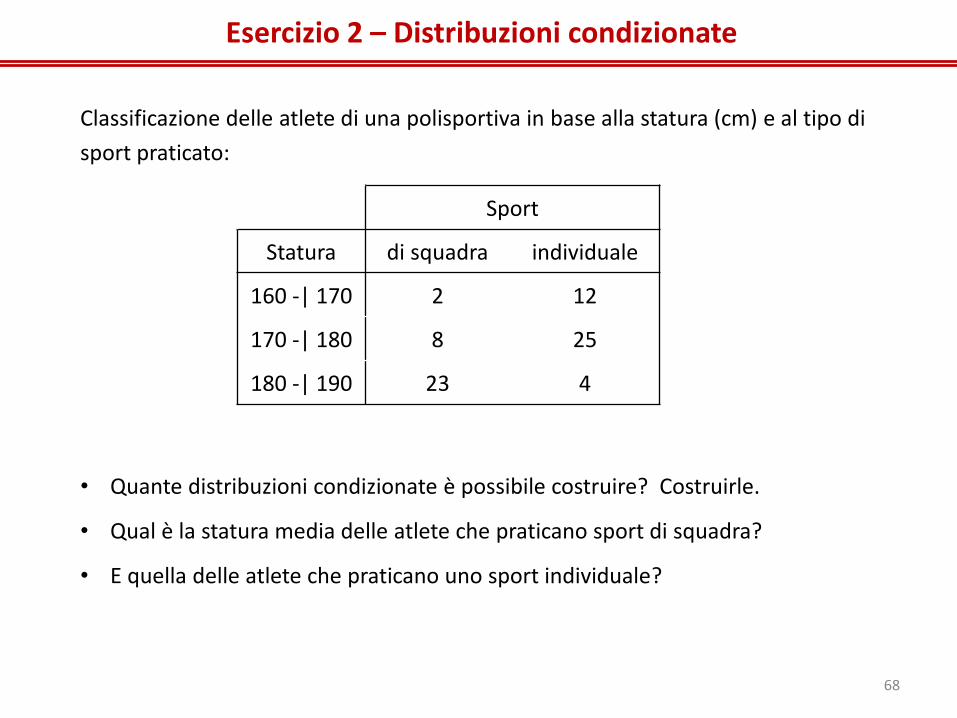
Esercizio 2 – Distribuzioni condizionate
Classificazione delle atlete di una polisportiva in base alla statura (cm) e al tipo di
sport praticato:
• Quante distribuzioni condizionate è possibile costruire? Costruirle.
• Qual è la statura media delle atlete che praticano sport di squadra?
• E quella delle atlete che praticano uno sport individuale?
Sport
Statura di squadra individuale
160 -| 170 2 12
170 -| 180 8 25
180 -| 190 23 4
68

Esercizio 3 – Distribuzioni di frequenze relative
• Come già sappiamo, in generale a partire dalle distribuzioni di frequenze assolute è
possibile passare alle corrispondenti distribuzioni di frequenze relative (o percentuali).
• Si applica lo stesso procedimento anche per le distribuzioni doppie, per quelle
marginali e per quelle condizionate.
• Nota bene: dobbiamo fare attenzione a cosa rapportiamo le singole frequenze assolute
per ottenere le corrispondenti frequenze relative (percentuali).
Con riferimento alla tabella che riporta la classificazione delle atlete in base alla
statura e al tipo di sport praticato, a partire dai risultati ottenuti negli esercizi 1 e 3,
costruire:
• La distribuzione doppia di frequenze relative.
• Le distribuzioni di frequenze relative marginali.
• Le distribuzioni di frequenze relative condizionate.
69

Breve riassunto teorico – Diversi tipi di associazione
• Associazione o connessione statistica: per valutare se due variabili sono legate.
• Connessione: viene analizzata la tabella doppia. Andiamo a studiare se i due caratteri sono indipendenti oppure no.
• Si usa per tutti i tipi di caratteri (unica analisi se entrambi sono qualitativi)
• Dipendenza in media: presenza di un legame tra le medie delle distribuzioni condizionate e la media marginale.
• Carattere dipendente quantitativo.
• Concordanza: presenza di un legame (assoluto)
• Solo per variabili entrambe quantitative.
• Indipendenza statistica o in distribuzione: il carattere X si dice indipendente in
distribuzione da Y se qualsiasi sia la modalità con cui si manifesta Y, la distribuzione
relativa condizionata di X non cambia. Nota bene: è una relazione simmetrica.
Correlazione: valutazione dell’intensità reciproca del legame tra le due variabili
Dipendenza: esistenza di un legame (lineare) di causalità tra le due variabili
70

Connessione e indipendenza in distribuzione tra due caratteri (1)
• La connessione tra due caratteri di una distribuzione doppia va intesa come
l’allontanamento dall’indipendenza distributiva:
• Quindi per prima cosa dobbiamo capire bene cosa si intende per indipendenza in
distribuzione tra due caratteri. Possiamo avere diversi casi, per esempio (vedi slide Prof.):
Indipendenza distributiva → Connessione nulla
Perfetta dipendenza distr. → Connessione massima
𝑦1 𝑦2 𝑦3 Tot.
𝑥1 𝑛11 0 0 𝑛10
𝑥2 0 𝑛22 0 𝑛20
𝑥3 0 0 𝑛33 𝑛30
𝑥4 𝑛41 0 0 𝑛40
𝑥5 0 𝑛52 0 𝑛50
Tot. 𝑛01 𝑛02 𝑛03 𝑛
𝑦1 𝑦2 𝑦3 Tot.
𝑥1 𝑛11 𝑛12 𝑛13 𝑛10
𝑥2 0 𝑛22 0 𝑛20
𝑥3 0 0 𝑛33 𝑛30
𝑥4 𝑛41 𝑛42 0 𝑛40
𝑥5 𝑛51 𝑛52 0 𝑛50
Tot. 𝑛01 𝑛02 𝑛03 𝑛
Perfetta dipendenza Dipendenza non perfetta
71

𝑦1 𝑦2 𝑦3 Tot.
𝑥1 2 2 2 6
𝑥2 1 1 1 3
𝑥3 5 5 5 15
Tot. 8 8 8 24
Perfetta indipendenza
Connessione e indipendenza in distribuzione tra due caratteri (2)
• Quando le frequenze relative condizionate sono uguali
tra loro indipendentemente dalla modalità considerata,
si dice che le variabili sono statisticamente indipendenti.
• Conoscere la modalità 𝑥𝑖 di un’unità non rende più o
meno probabile la sua appartenenza a una specifica
modalità 𝑦ℎ.
• Se Y è indipendente da X allora anche X è indipendente
da Y (è un concetto simmetrico).
• Si può dimostrare (vedi slide Prof.) che, in caso di
perfetta indipendenza in distribuzione,
la generica frequenza congiunta assume il valore:
• Quindi, data una qualsiasi tabella doppia, poiché si dispone dei totali di riga e di
colonna, posso sempre costruire la tabella di indipendenza che contiene le frequenze
congiunte teoriche (per questo sono indicate con l’asterisco) che si avrebbero in caso
di indipendenza.
𝑛𝑖ℎ∗ =
𝑛𝑖0 ∙ 𝑛0ℎ𝑛
2 =6 ∙ 8
24 1 =
3 ∙ 8
24
72

Esercizio 4 – Costruzione della tabella di indipendenza teorica
La tabella a lato riporta la classificazione
delle atlete di una polisportiva in base
alla statura (cm) e al tipo di sport praticato.
• Quali sarebbero le frequenze congiunte
se i due caratteri osservati fossero
indipendenti in distribuzione?
Sport
Statura di squadra individuale
160 -| 170 2 12
170 -| 180 8 25
180 -| 190 23 4
73
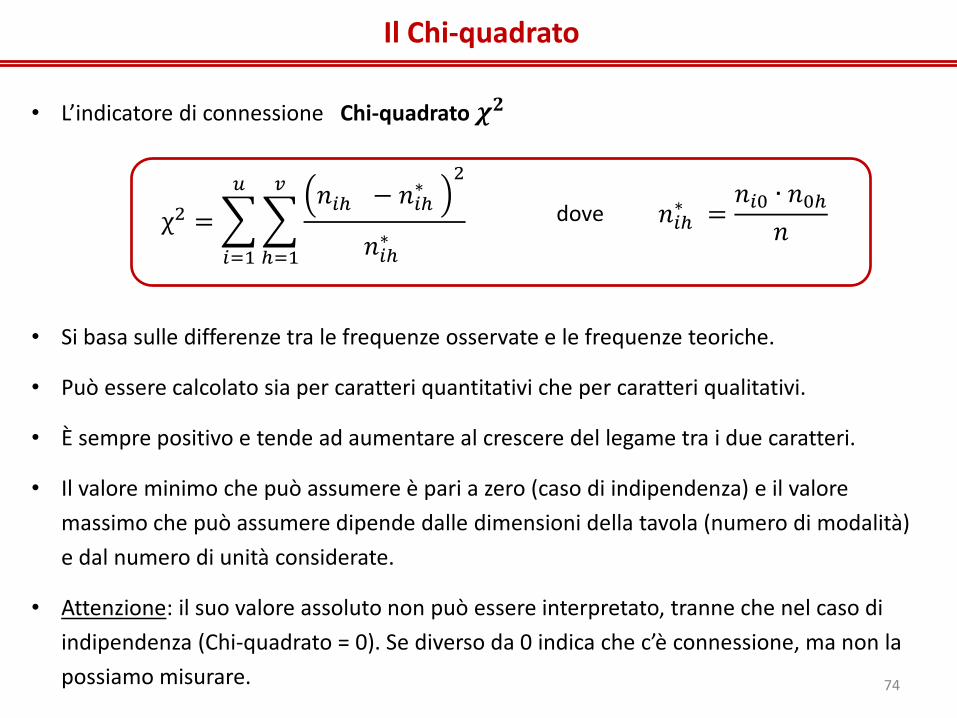
Il Chi-quadrato
• Si basa sulle differenze tra le frequenze osservate e le frequenze teoriche.
• Può essere calcolato sia per caratteri quantitativi che per caratteri qualitativi.
• È sempre positivo e tende ad aumentare al crescere del legame tra i due caratteri.
• Il valore minimo che può assumere è pari a zero (caso di indipendenza) e il valore
massimo che può assumere dipende dalle dimensioni della tavola (numero di modalità)
e dal numero di unità considerate.
• Attenzione: il suo valore assoluto non può essere interpretato, tranne che nel caso di
indipendenza (Chi-quadrato = 0). Se diverso da 0 indica che c’è connessione, ma non la
possiamo misurare.
• L’indicatore di connessione Chi-quadrato 𝝌𝟐
χ2 = 𝑛𝑖ℎ − 𝑛𝑖ℎ
∗2
𝑛𝑖ℎ∗
𝑣
ℎ=1
𝑢
𝑖=1
dove 𝑛𝑖ℎ∗ =
𝑛𝑖0 ∙ 𝑛0ℎ𝑛
74

L’indice di connessione normalizzato
• Si può ricavare un indice di connessione normalizzato (che varia tra 0 ed 1) rapportando il
Chi-quadrato al valore massimo che può assumere.
• Si può dimostrare che: χ2 =max 𝑛 ∙ 𝑚𝑖𝑛 𝑢, 𝑣 − 1
• Indice di connessione normalizzato:
• L’indice di connessione normalizzato varia tra 0 ed 1:
0 ≤χ2
𝑛 ∙ 𝑚𝑖𝑛 𝑢, 𝑣 − 1≤ 1
χ2
𝑛 ∙ 𝑚𝑖𝑛 𝑢, 𝑣 − 1
Numero di modalità della X (righe)
Numero di modalità della Y (colonne)
Connessione nulla (indipendenza distributiva)
Connessione massina (perfetta dipendenza
distributiva)
75
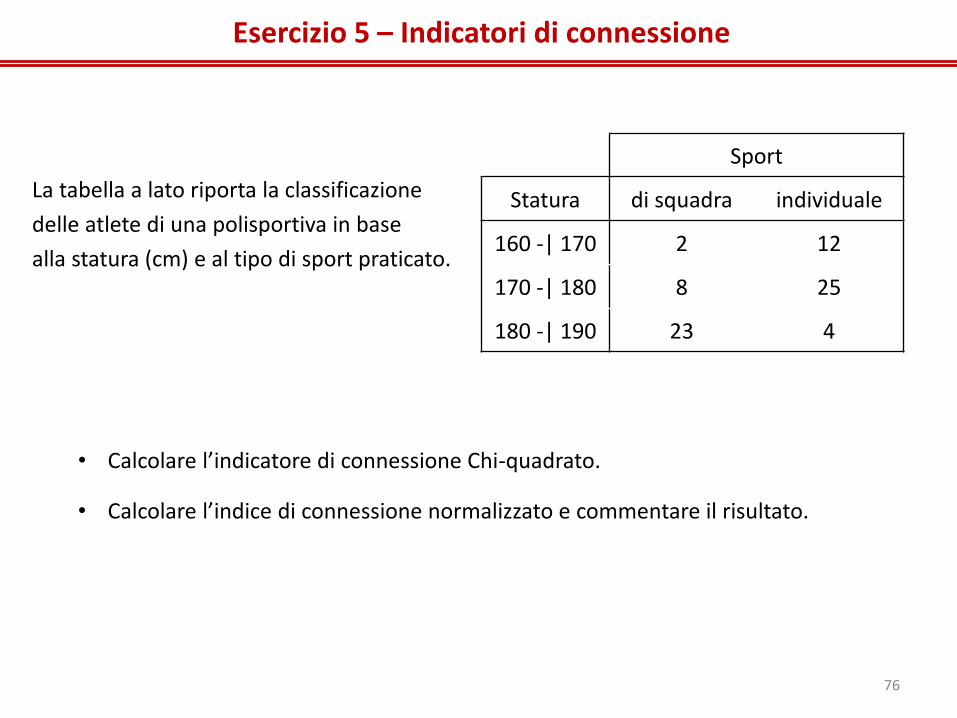
Esercizio 5 – Indicatori di connessione
La tabella a lato riporta la classificazione
delle atlete di una polisportiva in base
alla statura (cm) e al tipo di sport praticato.
• Calcolare l’indicatore di connessione Chi-quadrato.
• Calcolare l’indice di connessione normalizzato e commentare il risultato.
Sport
Statura di squadra individuale
160 -| 170 2 12
170 -| 180 8 25
180 -| 190 23 4
76

Esercizio 6 – Esercizio riepilogativo sulla connessione
• Esercizio 4 pag. 159 (Statistica e laboratorio)
Un insieme di 68 individui è stato classificato sulla base delle variabili seguenti:
presenza di affezioni respiratorie croniche X (con modalità sano e malato) e livello di
inquinamento della città di residenza Y (con modalità basso, medio e alto).
• Qual è il numero totale delle unità statistiche?
Qual è il numero di coloro che non sono affetti da patologie respiratorie croniche?
• I due caratteri sono indipendenti in distribuzione?
Calcolare un indicatore che misuri l’eventuale dipendenza.
X
Y Sano Malato
Basso 12 6
Medio 20 13
Alto 4 13
77

Breve riassunto teorico – Diversi tipi di associazione
• Associazione o connessione statistica: per valutare se due variabili sono legate.
• Connessione: viene analizzata la tabella doppia. Andiamo a studiare se i due caratteri sono indipendenti oppure no.
• Si usa per tutti i tipi di caratteri (unica analisi se entrambi sono qualitativi)
• Dipendenza in media: presenza di un legame tra le medie delle distribuzioni condizionate e la media marginale.
• Carattere dipendente quantitativo.
• Concordanza: presenza di un legame (assoluto)
• Solo per variabili entrambe quantitative.
• Indipendenza statistica o in distribuzione: il carattere X si dice indipendente in
distribuzione da Y se qualsiasi sia la modalità con cui si manifesta Y, la distribuzione
relativa condizionata di X non cambia. Nota bene: è una relazione simmetrica.
Correlazione: valutazione dell’intensità reciproca del legame tra le due variabili
Dipendenza: esistenza di un legame (lineare) di causalità tra le due variabili
79

La concordanza
• Solo per caratteri quantitativi: X e Y, variabili quantitative.
• Legame di tipo lineare tra le due variabili: si cerca la direzione prevalente di tale legame.
• Grafico di dispersione → nuvola di punti:
• Se sono disposti lungo una retta,
relazione lineare perfetta:
• Se sono attorno a una retta,
esiste relazione ma non perfetta:
Inoltre:
• Se la nuvola è allungata dal basso verso l’alto: relazione positiva.
• Se la nuvola è allungata dall’alto verso il basso: relazione negativa.
80

Esercizio 1 – Concordanza: grafico di dispersione
• Es. 9 pag. 161 «Statistica e laboratorio»
I seguenti dati si riferiscono alla lunghezza media (Y) e alla larghezza media (X),
entrambe in cm, delle foglie di sei esemplari di una pianta:
X 9 4 10 9 10 6
Y 8 4 18 22 30 8
• Costruire il grafico di dispersione
• Osservare la nuvola di punti e individuare quale tipo di relazione
sussiste tra le due variabili osservate
81

Misura sintetica di concordanza: la covarianza
Ci si chiede, in pratica, se le deviazioni da un termine di
riferimento (media aritmetica) per i due caratteri vadano
nella stessa direzione.
Si considerano quindi gli scostamenti 𝑥 − 𝑥 e 𝑦 − 𝑦 :
1. Scostamenti concordi (entrambi + o -) = I e III quadrante
2. Scostamenti discordi (uno +, l’altro -) = II e IV quadrante
I
III
II
IV
𝑋
𝑌
𝑥
𝑦
Covarianza
• È una misura sintetica di concordanza
• È la media aritmetica dei prodotti degli scarti delle due variabili dalle rispettive medie:
𝜎𝑥𝑦 = 𝑐𝑜𝑣𝑎𝑟 𝑋, 𝑌 =1
𝑛 𝑥𝑗 − 𝑥 𝑦𝑗 − 𝑦 =
1
𝑛 𝑥𝑗𝑦𝑗 − 𝑥 𝑦 =
𝑐𝑜𝑑𝑒𝑣(𝑋, 𝑌)
𝑛
𝑛
𝑗=1
𝑛
𝑗=1
Formula definitoria Formula per il calcolo 82

Indice relativo di concordanza: il coefficiente di correlazione lineare
• Attenzione: la codevianza (e quindi anche la covarianza) è influenzata dall’unità di
misura delle variabili osservate, non è perciò confrontabile. Per effettuare confronti è
necessario un indice relativo.
• Si dimostra che:
• Quindi un indice relativo è:
• Formula alternativa:
𝜎𝑥 e 𝜎𝑦 sono le deviazioni
standard di 𝑋 e 𝑌
𝜎𝑥𝑦 è la covarianza
−𝜎𝑥𝜎𝑦 ≤ 𝜎𝑥𝑦 ≤ 𝜎𝑥𝜎𝑦
𝜌𝑥𝑦 =𝜎𝑥𝑦
𝜎𝑥𝜎𝑦
Coefficiente di correlazione lineare
(di Bravais e Pearson)
• 𝜌𝑥𝑦 = −1
se tra 𝑋 e 𝑌 vi è perfetto legame lineare con caratteri discordi
• 𝜌𝑥𝑦 = 0
se 𝑋 e 𝑌 sono indipendenti o tra loro vi è una relazione non lineare
• 𝜌𝑥𝑦 = 1
se tra 𝑋 e 𝑌 vi è perfetto legame lineare con caratteri concordi
𝜌𝑥𝑦 =𝑐𝑜𝑑𝑒𝑣(𝑋, 𝑌)
𝑑𝑒𝑣 𝑋 𝑑𝑒𝑣(𝑌)=
(𝑥𝑗 − 𝑥 )(𝑦𝑗 − 𝑦 )𝑛𝑗=1
(𝑥𝑗 − 𝑥 )2𝑛𝑗=1 (𝑦𝑗 − 𝑦 )2𝑛
𝑗=1
dove:
83

Esercizio 2 – Covarianza e indice di correlazione lineare
• Es. 9 pag. 161 «Statistica e laboratorio»
I seguenti dati si riferiscono alla lunghezza media (Y) e alla larghezza media (X),
entrambe in cm, delle foglie di sei esemplari di una pianta:
X 9 4 10 9 10 6
Y 8 4 18 22 30 8
• Dopo aver calcolato le medie aritmetiche delle due variabili, osservare i segni
degli scostamenti. Prevalgono quelli concordi o discordi?
Potevo aspettarmi questo risultato?
• Calcolare la covarianza.
• Calcolare l’indice di correlazione lineare.
• Commentare i risultati.
84

Dipendenza e regressione: il modello di regressione lineare (1)
• Consideriamo la direzione dell’associazione tra le due variabili.
• Abbiamo una variabile indipendente o esplicativa (generalmente la X) ed una variabile
dipendente (generalmente la Y).
• Si assume una relazione di tipo lineare → modello statistico di regressione lineare:
• Per ogni unità statistica avremo:
Ordinata all’origine (punto in cui la retta
incontra l’asse Y)
𝑦 = 𝑎 + 𝑏𝑥 + 𝑒
Coefficiente di regressione riassume l’intensità della
dipendenza lineare della Y da X
Termine d’errore
dove 𝑦∗è il valore teorico nel caso di
perfetta dipendenza lineare
𝑒 = 𝑦 − 𝑦∗ Valore osservato di Y
Valore osservato
di X
𝑦𝑗 → valore osservato
𝑦𝑗∗ → valore teorico
𝑦𝑗 = 𝑎 + 𝑏𝑥𝑗 + 𝑒𝑗
𝑦𝑗∗ = 𝑎 + 𝑏𝑥𝑗
𝑒𝑗 = 𝑦𝑗 − 𝑦𝑗∗
𝑥
𝑦
𝑥𝑗
𝑦𝑗
𝐲∗ = 𝐚 + 𝐛𝐱
𝑦𝑗∗
𝑒𝑗
Nota bene: gli errori possono essere negativi (vedi figura)
85

Dipendenza e regressione: il modello di regressione lineare (2)
• Obiettivo: individuare la retta (ovvero stimare i parametri 𝑎 e 𝑏) che più si avvicina ai
punti → criterio di accostamento.
• Metodo dei minimi quadrati: trovare i valori di 𝑎 e 𝑏 che rendono minima la somma dei
quadrati delle differenze tra valore osservato e valore teorico.
𝑦𝑗 − 𝑦𝑗∗
2𝑛
𝑗=1
= 𝑦𝑗 − (𝑎 + 𝑏𝑥𝑗)2= 𝑦𝑗 − 𝑎 − 𝑏𝑥𝑗
2𝑛
𝑗=1
𝑛
𝑗=1
= 𝜑 𝑎, 𝑏 = min
𝐶𝑜𝑑𝑒𝑣 𝑋, 𝑌 = 𝑥𝑗 − 𝑥 𝑦𝑗 − 𝑦 = 𝑥𝑗𝑦𝑗 − 𝑥 𝑦
𝑛
𝑗=1
𝑛
𝑗=1
𝑛 → può essere negativa
𝐷𝑒𝑣 𝑋 = 𝑥𝑗 − 𝑥 2= 𝑥𝑗
2 −
𝑛
𝑗=1
𝑛
𝑗=1
𝑛𝑥 2 → è sempre positiva
𝑏 =𝐶𝑜𝑑𝑒𝑣(𝑋, 𝑌)
𝐷𝑒𝑣(𝑋)=𝐶𝑜𝑑𝑒𝑣(𝑋, 𝑌)/𝑛
𝐷𝑒𝑣(𝑋)/𝑛=𝐶𝑜𝑣𝑎𝑟(𝑋, 𝑌)
𝑉𝑎𝑟(𝑋)=𝜎𝑥𝑦
𝜎𝑥2
𝑎 = 𝑦 − 𝑏𝑥
86

Esercizio 3 – Retta di regressione lineare
• Es. 9 pag. 161 «Statistica e laboratorio»
I seguenti dati si riferiscono alla lunghezza media (Y) e alla larghezza media (X),
entrambe in cm, delle foglie di sei esemplari di una pianta:
X 9 4 10 9 10 6
Y 8 4 18 22 30 8
• Stimare la retta di regressione lineare di Y su X.
• La retta è ascendente o discendente?
• In che punto incontra l’asse delle ordinate?
87

Esercizio 4 – Interpretare il coefficiente di regressione
Il coefficiente di regressione b:
• Indica quanto varia in media Y per ogni variazione unitaria di X →
• Ha il segno della codevianza (o della covarianza):
• 𝑏 > 0 𝐶𝑜𝑑𝑒𝑣 𝑋, 𝑌 > 0 ; retta ascendente; concordanza
• 𝑏 < 0 𝐶𝑜𝑑𝑒𝑣 𝑋, 𝑌 < 0; retta discendente; discordanza
• 𝑏 = 0 𝐶𝑜𝑑𝑒𝑣 𝑋, 𝑌 = 0; retta parallela all’asse delle ascisse (y = 𝑦 ); Y linearmente indipendente da X; indipendenza lineare
variazioni espresse nell’unità di misura della Y
• Es. 9 pag. 161 «Statistica e laboratorio»
• Interpretare il coefficiente di regressione della retta stimata.
88

Esercizio 5 – Correlazione e regressione
Esistono importanti relazioni tra la regressione e la correlazione, infatti:
• se la correlazione è positiva il coefficiente angolare b della regressione è positivo
• se la correlazione è negativa il coefficiente angolare b della regressione è negativo
• se la correlazione è nulla il coefficiente angolare b della regressione è uguale a 0
𝜌𝑥𝑦 =𝜎𝑥𝑦
𝜎𝑥𝜎𝑦 𝑏 =
𝜎𝑥𝑦
𝜎𝑥2
possiamo osservare che:
• Es. 9 pag. 161 «Statistica e laboratorio»
• Verificare che nel nostro esercizio vale la relazione tra coefficiente di
correlazione lineare e coefficiente di regressione.
89

L’indice di determinazione lineare R2
• Scomposizione della devianza di Y: 𝐷𝑒𝑣(𝑌)𝑡𝑜𝑡 = 𝐷𝑒𝑣(𝑌)𝑟𝑒𝑔𝑟 + 𝐷𝑒𝑣(𝑌)𝑑𝑖𝑠𝑝
𝑦𝑗 − 𝑦 2=
𝑛
𝑗=1
𝑦𝑗∗ − 𝑦
2+ 𝑦𝑗 − 𝑦𝑗
∗2
𝑛
𝑗=1
𝑛
𝑗=1
Devianza di regressione indica la parte di variabilità della Y
dovuta alla dipendenza lineare dalla X
Devianza di dispersione misura l’allontanamento tra i valori
osservati 𝑦𝑗 e i valori teorici 𝑦𝑗∗
𝑅2 =𝐷𝑒𝑣(𝑌)𝑟𝑒𝑔𝑟
𝐷𝑒𝑣(𝑌)𝑡𝑜𝑡 = 1 −
𝐷𝑒𝑣(𝑌)𝑑𝑖𝑠𝑝𝐷𝑒𝑣(𝑌)𝑡𝑜𝑡
= 𝑦𝑗
∗ − 𝑦 2
𝑛𝑗=1
𝑦𝑗 − 𝑦 2𝑛
𝑗=1
Devianza totale
• Indica la frazione di variabilità di Y da attribuire alla dipendenza lineare da X
Indice di determinazione lineare
• 𝑅2 = 0 per 𝐷𝑒𝑣(𝑌)𝑟𝑒𝑔𝑟 = 0 → Retta non inclinata e devianza di regressione nulla
• 𝑅2 = 1 per 𝐷𝑒𝑣(𝑌)𝑑𝑖𝑠𝑝 = 0 → Tutta la variabilità di Y è dovuta alla dipendenza lineare tra X e Y e la devianza di dispersione è nulla
0 ≤ 𝑅2 ≤ 1
90

Esercizio 6 - Indice di determinazione lineare R2
• Es. 9 pag. 161 «Statistica e laboratorio»
I seguenti dati si riferiscono alla lunghezza media (Y) e alla larghezza media (X),
entrambe in cm, delle foglie di sei esemplari di una pianta:
X 9 4 10 9 10 6
Y 8 4 18 22 30 8
• Scomporre la devianza di Y in devianza di regressione e
devianza di dispersione.
• Qual è la frazione di variabilità di Y da attribuire alla
dipendenza lineare da X?
91

Esercizio 7 – Esercizio riepilogativo su correlazione e regressione
• Es. 13 pag. 162 «Statistica e laboratorio»
Su 10 banche del territorio forlivese, sono stati osservati il numero di clienti (X) e il
numero di dipendenti (Y), ottenendo le seguenti quantità:
𝑥𝑗 = 2.345
𝑛
𝑗=1
𝑦𝑗 = 180
𝑛
𝑗=1
𝑥𝑗2 = 622.025
𝑛
𝑗=1
𝑦𝑗2 = 3.908
𝑛
𝑗=1
𝑥𝑗𝑦𝑗 = 48.395
𝑛
𝑗=1
• Stimare i parametri della retta di regressione lineare e commentare il valore di 𝑏𝑦𝑥
• In base alla retta stimata, quanti dipendenti dovrebbe avere una banca con 200 clienti?
• Quanta correlazione lineare si realizza tra X e Y, rispetto alla massima ipotizzabile?
• Che percentuale di variabilità del numero di dipendenti è spiegata dalla sua dipendenza
lineare dal numero di clienti?
92

Definizioni di base
Prova aleatoria o esperimento aleatorio:
operazione dove posso avere 2 o più
risultati, ma il risultato che effettivamente
si verifica è incerto.
Spazio fondamentale S: insieme dei
possibili singoli esiti dell’esperimento
aleatorio.
È un insieme esaustivo e disgiuntivo.
Evento elementare: sottoinsieme di S
che contiene un solo elemento
(ciascun singolo esito possibile).
Evento aleatorio E: sottoinsieme di S
(non necessariamente di un solo elemento).
Lancio di un dado
𝑆 = 1, 2, 3, 4, 5, 6
𝑒𝑙𝐸1 = 1 𝑒𝑙𝐸2 = 2 𝑒𝑙𝐸3 = 3
𝑒𝑙𝐸4 = 4 𝑒𝑙𝐸5 = 5 𝑒𝑙𝐸6 = 6
𝐸1 = uscita num. dispari = 1, 3, 5
𝐸2 = uscita num. ≥ a 5 = 5, 6
𝐸3 = uscita num. ≥ a 2 = 2, 3, 4, 5, 6
𝐸6 = uscita num. 6 = 6
Esempio classico
Nota: gli eventi elementari sono eventi aleatori E a tutti gli effetti!
94

Esercizi 1 – Definizioni di base
• Domenica prossima si giocherà la partita di campionato Torino – Juventus, di cui
ovviamente non è ancora noto il risultato (vittoria di una delle due squadre o pareggio)
• Individuare gli eventi elementari e costruire lo spazio fondamentale.
• Quali eventi non elementari si possono costruire a partire dal nostro spazio
fondamentale?
• Si consideri la prova aleatoria «lancio di due monete contemporaneamente»
• Individuare gli eventi elementari e costruire lo spazio fondamentale.
• Individuare almeno due eventi non elementari che si possono costruire a partire
dallo spazio fondamentale.
95
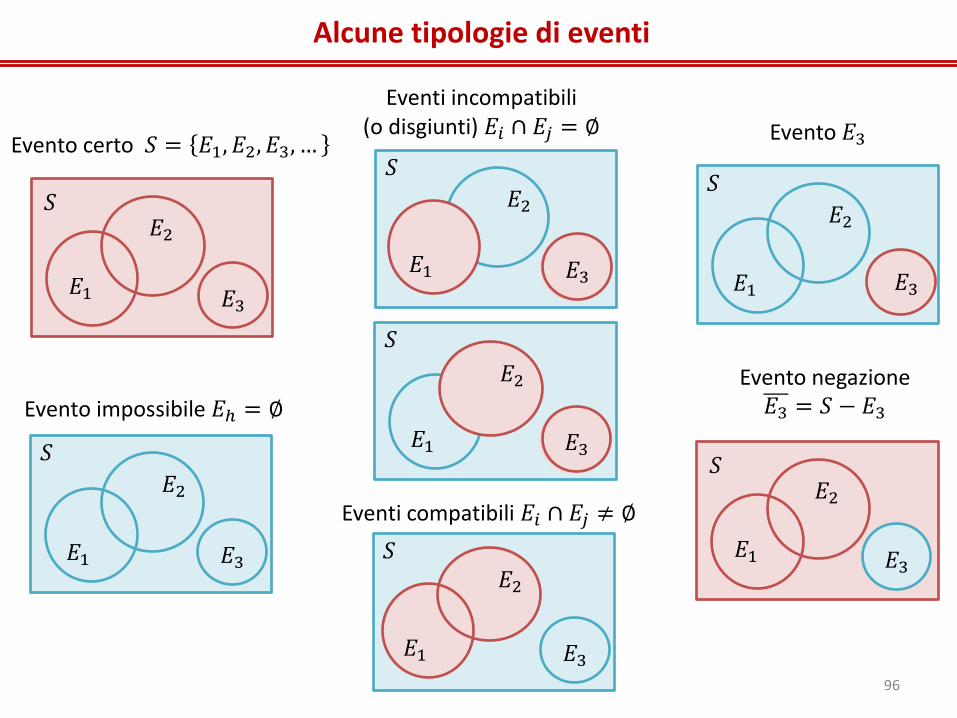
Alcune tipologie di eventi
𝐸1
𝐸2
𝐸3
𝑆
Evento certo 𝑆 = 𝐸1, 𝐸2, 𝐸3, …
Eventi compatibili 𝐸𝑖 ∩ 𝐸𝑗 ≠ ∅
Eventi incompatibili (o disgiunti) 𝐸𝑖 ∩ 𝐸𝑗 = ∅
𝐸2
𝐸3
𝑆
𝐸1
𝑆
𝐸3
𝑆
𝐸1
𝐸2
𝐸3
𝐸1
𝐸2
Evento impossibile 𝐸ℎ = ∅
𝐸1
𝐸2
𝐸3
𝑆
𝐸1
𝐸2
𝑆
Evento 𝐸3
Evento negazione 𝐸3 = 𝑆 − 𝐸3
𝐸3
𝐸3 𝐸1
𝐸2 𝑆
96

La probabilità: riassunto dei concetti fondamentali
• Probabilità di un evento E: si indica con P(E) ed è un numero compreso tra 0 ed 1 che
misura il grado di incertezza del verificarsi dell’evento E.
0 ≤ 𝑃(𝐸) ≤ 1
Evento impossibile ha probabilità 0.
Esempio: che esca la faccia 8 nel lancio di un dado standard
𝐸 = ∅ e P(∅) = 0
Evento certo ha probabilità 1.
Esempio: che esca un numero compreso tra 1 e 6 nel lancio del dado
𝐸 = 𝑆 e 𝑃 𝑆 = 1
• Probabilità dell’evento negazione 𝑬 (non 𝑬):
𝑃 𝐸 = 1 − 𝑃(𝐸)
𝐸1, 𝐸2 ∈ 𝑆
𝑃 𝐸1 ∪ 𝐸2 = 𝑃 𝐸1 + 𝑃 𝐸2 − 𝑃 𝐸1 ∩ 𝐸2
• Diverse definizioni: classica, frequentista, su scommessa e assiomatica.
• Regola dell’addizione o principio delle probabilità totali:
𝑃 𝐸 = n. casi favorevoli
n. casi possibili
Utile per il calcolo «pratico»
(qualsiasi, anche compatibili)
Uti
le p
er le
pro
pri
età
• 𝑃 𝑆 = 1 • 𝑃 𝐸 ≥ 0 ∀ 𝐸 ∈ 𝑆
• 𝑃 𝐸1 ∪⋯∪ 𝐸ℎ = 𝑃 𝐸1 +⋯+ 𝑃 𝐸ℎ
𝐸𝑖 ∩ 𝐸𝑗 = ∅ ∀ 𝑖, 𝑗 (a due a due incompatibili)
Funzione che associa a un evento E un valore numerico P(E) che soddisfa gli assiomi:
97

Esercizio 2 – Probabilità di eventi
Un’urna contiene venti palline numerate da 1 a 20. La prova aleatoria è l’estrazione di una
pallina da tale urna. Dopo aver definito lo spazio fondamentale, si calcoli:
• La probabilità di ciascun evento elementare
• La probabilità degli eventi:
A = «la pallina estratta ha un numero inferiore a 4 oppure ha un numero multiplo di 6»
B = «la pallina estratta ha un numero multiplo di 2 oppure ha un numero multiplo di 5»
C = «la pallina estratta non è un multiplo di 3»
D = «la pallina estratta ha un numero multiplo di 2 e minore di 8»
E = «la pallina estratta ha un numero maggiore di 35»
F = «la pallina estratta ha un numero compreso tra 1 e 20»
98
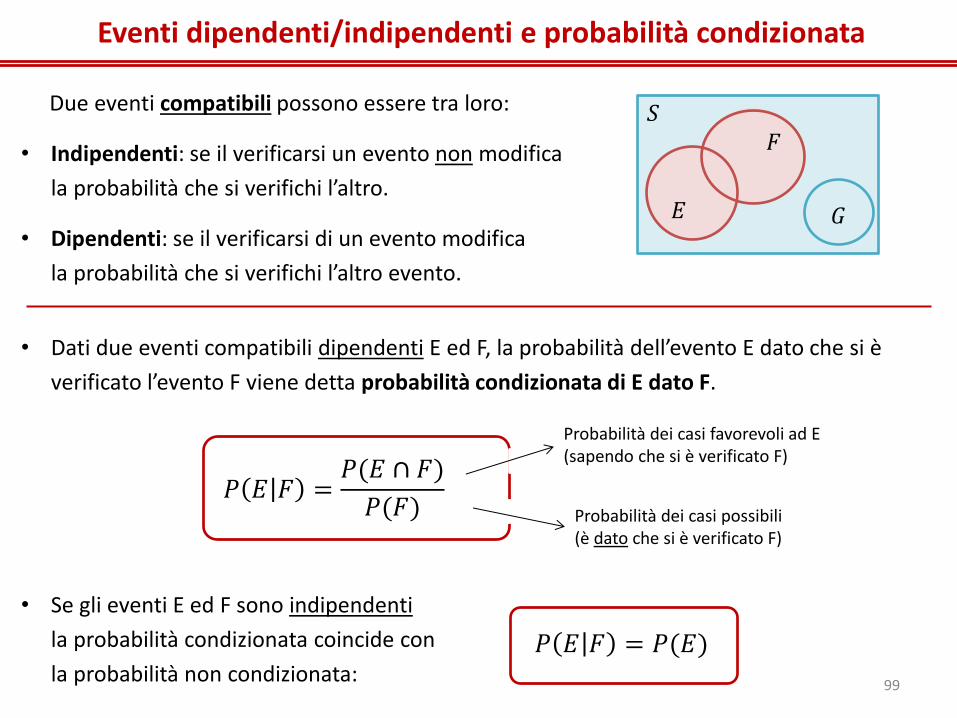
Eventi dipendenti/indipendenti e probabilità condizionata
Due eventi compatibili possono essere tra loro:
• Indipendenti: se il verificarsi un evento non modifica
la probabilità che si verifichi l’altro.
• Dipendenti: se il verificarsi di un evento modifica
la probabilità che si verifichi l’altro evento.
𝐺
𝑆
𝐸
𝐹
• Dati due eventi compatibili dipendenti E ed F, la probabilità dell’evento E dato che si è
verificato l’evento F viene detta probabilità condizionata di E dato F.
• Se gli eventi E ed F sono indipendenti
la probabilità condizionata coincide con
la probabilità non condizionata:
𝑃 𝐸 𝐹 =𝑃(𝐸 ∩ 𝐹)
𝑃(𝐹)
Probabilità dei casi possibili (è dato che si è verificato F)
Probabilità dei casi favorevoli ad E (sapendo che si è verificato F)
𝑃 𝐸 𝐹 = 𝑃(𝐸)
99

Probabilità dell’intersezione
• La probabilità che si verifichino entrambi
gli eventi (intersezione) è positiva solo per
eventi compatibili.
Se invece gli eventi sono incompatibili:
𝐸 ∩ 𝐹 = ∅ e 𝑃 𝐸 ∩ 𝐹 = 𝑃 ∅ = 0.
• E’ data dal prodotto tra la probabilità condizionata di E dato F e la probabilità di F
oppure dal prodotto tra la probabilità condizionata di F dato E e la probabilità di E:
𝑃 𝐸 ∩ 𝐹 = 𝑃 𝐸 𝐹 ∙ 𝑃 𝐹 = 𝑃 𝐹 𝐸 ∙ 𝑃(𝐸)
• Se gli eventi E ed F sono indipendenti, abbiamo visto che la probabilità condizionata
coincide con quella non condizionata 𝑃 𝐸 𝐹 = 𝑃(𝐸) e 𝑃 𝐹 𝐸 = 𝑃(𝐹), quindi:
𝑃 𝐸 ∩ 𝐹 = 𝑃(𝐸) ∙ 𝑃 𝐹 = 𝑃(𝐹) ∙ 𝑃(𝐸)
Eventi dipendenti
Eventi indipendenti
100

Esercizi 3 - Probabilità condizionate e dell’intersezione (1)
Riprendiamo l’esempio classico del lancio di un dado.
Consideriamo i due eventi: E = «uscita di un numero pari» ed F = «uscita di un numero ≤ 4»
• Calcolare la probabilità dell’evento E
• Calcolare la probabilità dell’evento F
• Qual è la probabilità che sia uscito un numero pari, sapendo che il numero uscito è ≤ 4?
• Es. 17 pag. 213 «Statistica e laboratorio»
Sia dato un contenitore con 200 biglie ricoperte da un involucro che le rende indistinguibili
alla vista. Si sa però che 40 biglie gialle, 100 bianche e 60 nere. Calcolare:
• La probabilità, pescando a caso, di estrarre una biglia gialla.
• La probabilità, pescando a caso, di estrarre una biglia gialla o una biglia di un qualsiasi
altro colore.
• La probabilità di ottenere 3 biglie gialle, effettuando 3 estrazioni con reintroduzione
delle biglie nel contenitore. 101

Esercizio 4 – Probabilità condizionate e dell’intersezione (2)
• Viene estratta una pallina. Si calcoli la probabilità degli eventi :
I = «la pallina estratta ha un numero pari, dato che è inferiore ad 11»
J = «la pallina estratta ha un numero non multiplo di 3, dato che è maggiore di 16»
• Vengono effettuate due estrazioni con reintroduzione. Si calcoli la probabilità degli eventi:
K = «le palline estratte nei due turni hanno entrambe un numero multiplo di 5»
L = «la pallina estratta nel primo turno ha un numero pari e quella estratta nel
secondo turno ha un numero minore di 11»
Riprendiamo l’esercizio dell’urna con 20 palline numerate da 1 a 20.
• Vengono effettuate due estrazioni senza reintroduzione. Si calcoli la probabilità degli
eventi:
G = «nel primo turno si estrae la pallina col numero 7 e la pallina estratta nel
secondo turno ha un numero pari»
102
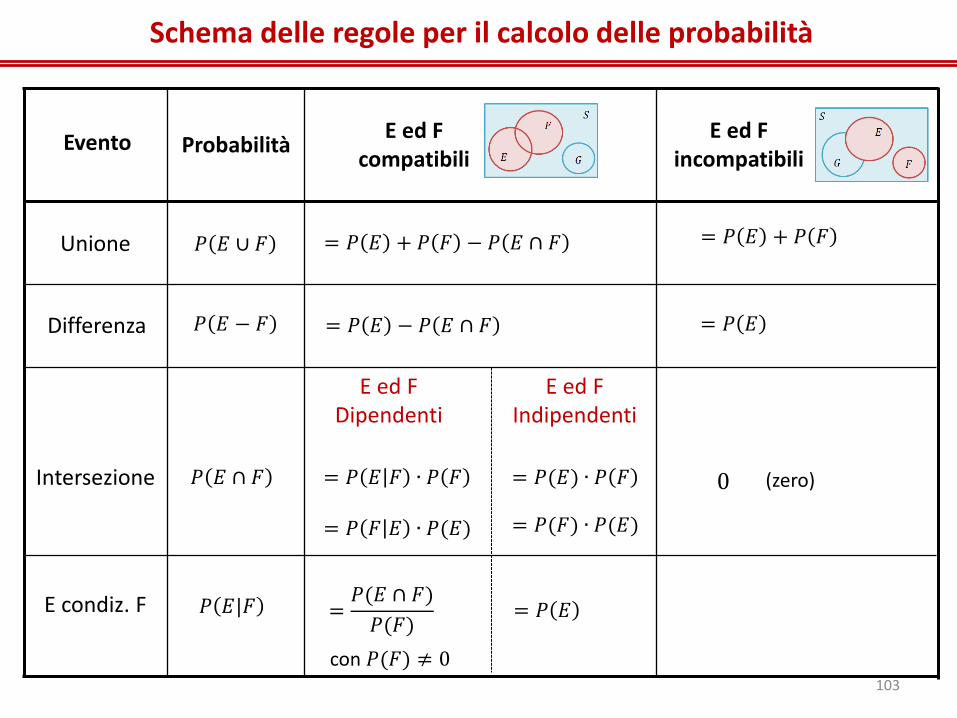
Schema delle regole per il calcolo delle probabilità
Unione
Differenza
Intersezione
E condiz. F
Evento Probabilità E ed F
compatibili E ed F
incompatibili
𝑃 𝐸 ∩ 𝐹
𝑃 𝐸 ∪ 𝐹
𝑃 𝐸 − 𝐹
𝑃 𝐸|𝐹
= 𝑃 𝐸 + 𝑃 𝐹 − 𝑃 𝐸 ∩ 𝐹 = 𝑃 𝐸 + 𝑃 𝐹
= 𝑃 𝐸 − 𝑃 𝐸 ∩ 𝐹 = 𝑃 𝐸
= 𝑃 𝐸 𝐹 ∙ 𝑃 𝐹
= 𝑃 𝐹 𝐸 ∙ 𝑃(𝐸)
E ed F Dipendenti
E ed F Indipendenti
= 𝑃(𝐸) ∙ 𝑃 𝐹
= 𝑃(𝐹) ∙ 𝑃(𝐸)
0 (zero)
=𝑃(𝐸 ∩ 𝐹)
𝑃(𝐹)
con 𝑃(𝐹) ≠ 0
= 𝑃 𝐸
103

Distribuzioni doppie, frequenze relative e probabilità
• Data una distribuzione doppia, possiamo
calcolare le frequenze relative e interpretare
tali frequenze come probabilità:
𝑛𝑖0𝑛
= 𝑓𝑖0 = 𝑃(𝑋 = 𝑥𝑖)
𝑛0ℎ𝑛
= 𝑓0ℎ = 𝑃(𝑌 = 𝑦ℎ)
𝑛𝑖ℎ𝑛0ℎ
= 𝑓𝑖|ℎ = 𝑃(𝑋 = 𝑥𝑖|𝑌 = 𝑦ℎ)
𝑛𝑖ℎ𝑛𝑖0
= 𝑓ℎ|𝑖 = 𝑃(𝑌 = 𝑦ℎ|𝑋 = 𝑥𝑖)
𝑛𝑖ℎ𝑛
= 𝑓𝑖ℎ = 𝑃(𝑋 = 𝑥𝑖 ∩ 𝑌 = 𝑦ℎ)
Probabilità congiunte
Probabilità marginali Probabilità condizionate
104

Esercizio 5 – Frequenze relative e probabilità
• Es. 8 pag. 211 «Statistica e laboratorio»
Un gruppo di persone in età compresa tra 30 e 35 anni è stata classificata secondo
lo stato occupazionale e il possesso di automobile:
Auto nuova
Auto usata
Non possiede auto
Totale
Disoccupato 13 22 16 51
Lavoratore 30 21 7 58
Totale 43 43 23 109
Estraendo una persona a caso, determinare la probabilità:
• Che sia disoccupata
• Che non possieda un auto propria
• Che sia disoccupata e non possieda un auto propria
• Che, dato che la persona estratta lavora, possieda un’auto nuova
Che tipo di probabilità sono (congiunte/marginali/condizionate)? 105
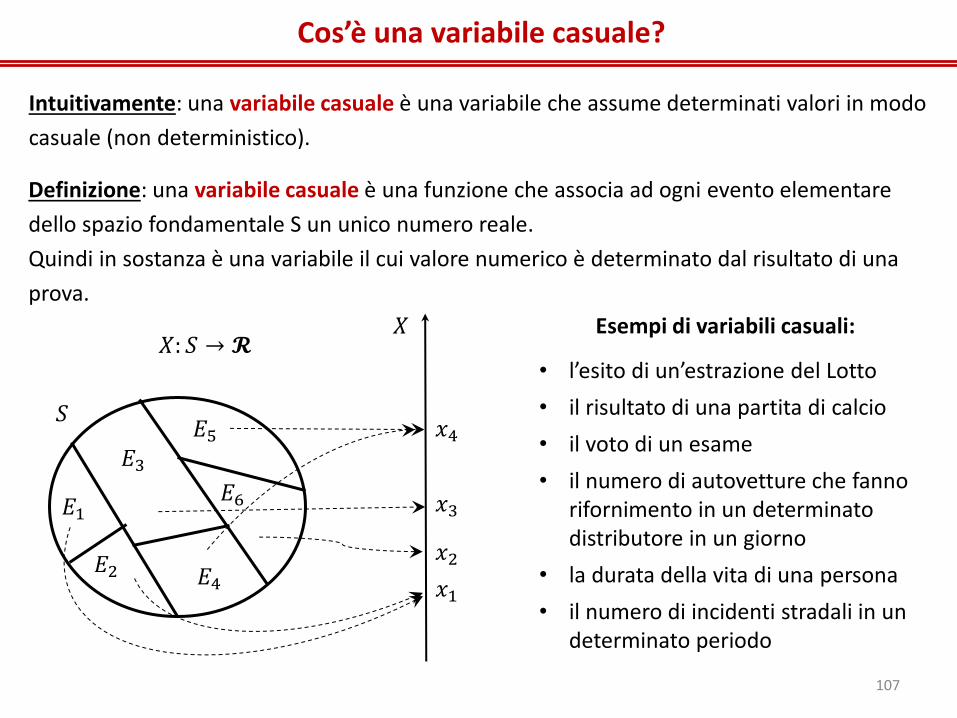
Cos’è una variabile casuale?
Intuitivamente: una variabile casuale è una variabile che assume determinati valori in modo
casuale (non deterministico).
Definizione: una variabile casuale è una funzione che associa ad ogni evento elementare
dello spazio fondamentale S un unico numero reale.
Quindi in sostanza è una variabile il cui valore numerico è determinato dal risultato di una
prova.
Esempi di variabili casuali:
• l’esito di un’estrazione del Lotto
• il risultato di una partita di calcio
• il voto di un esame
• il numero di autovetture che fanno rifornimento in un determinato distributore in un giorno
• la durata della vita di una persona
• il numero di incidenti stradali in un determinato periodo
𝑋: 𝑆 → 𝓡
𝐸1
𝐸2
𝐸3
𝐸4
𝐸5
𝐸6
𝑆
𝑋
𝑥1
𝑥2
𝑥3
𝑥4
107
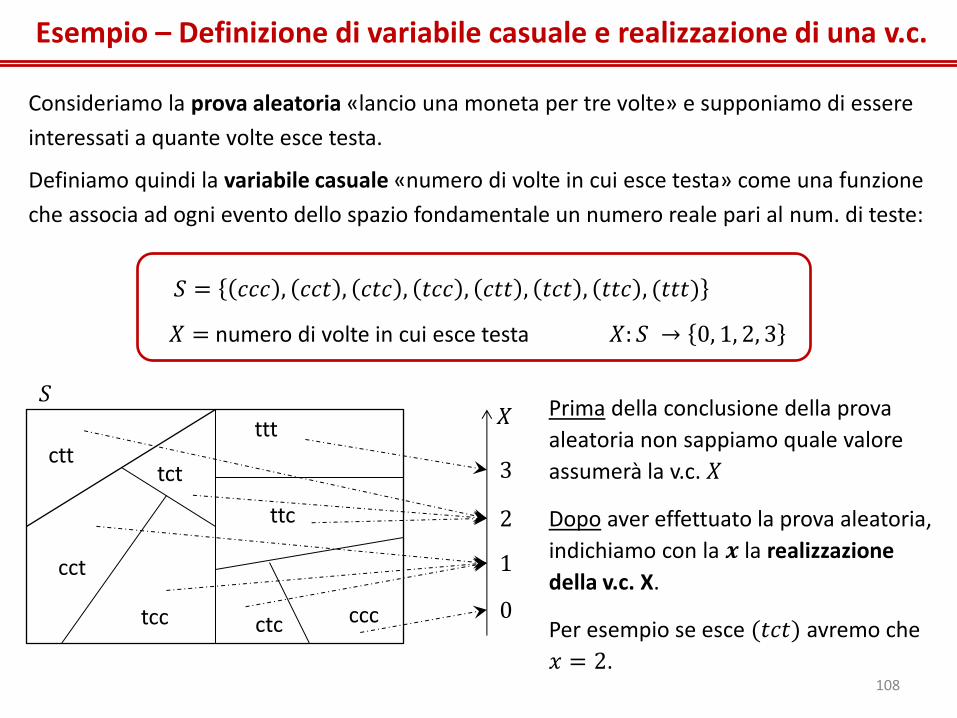
Esempio – Definizione di variabile casuale e realizzazione di una v.c.
Consideriamo la prova aleatoria «lancio una moneta per tre volte» e supponiamo di essere
interessati a quante volte esce testa.
Definiamo quindi la variabile casuale «numero di volte in cui esce testa» come una funzione
che associa ad ogni evento dello spazio fondamentale un numero reale pari al num. di teste:
ccc
cct
ctc tcc 0
1
2
3 ctt
tct
ttc
ttt
𝑆 𝑋
𝑋 = numero di volte in cui esce testa
𝑆 = 𝑐𝑐𝑐 , 𝑐𝑐𝑡 , 𝑐𝑡𝑐 , 𝑡𝑐𝑐 , 𝑐𝑡𝑡 , 𝑡𝑐𝑡 , 𝑡𝑡𝑐 , (𝑡𝑡𝑡)
Prima della conclusione della prova
aleatoria non sappiamo quale valore
assumerà la v.c. 𝑋
Dopo aver effettuato la prova aleatoria,
indichiamo con la 𝒙 la realizzazione
della v.c. X.
Per esempio se esce (𝑡𝑐𝑡) avremo che
𝑥 = 2.
𝑋: 𝑆 → 0, 1, 2, 3
108

Esercizio 1 – Definizione di variabile casuale
• La prova aleatoria consiste nel «lancio di un dado standard due volte».
Definiamo le seguenti variabili casuali:
𝑋 = «numero di volte in cui esce un numero pari»
𝑌 = «somma dei numeri ottenuti nei due lanci»
Individuare gli spazi fondamentali più consoni. Quali valori possono assumere le due
variabili casuali definite come funzioni da S ad 𝓡?
• Effettuiamo i due lanci del dado ed otteniamo 6 nel primo e 2 nel secondo .
Quali sono le realizzazioni delle due variabili casuali definite al punto precedente?
109

Esercizio 2 – Variabili casuali discrete e continue
• Una variabile casuale discreta può assumere valori in
un insieme finito (o numerabile) di numeri reali.
• Una variabile casuale continua può assumere tutti i
valori compresi in un intervallo reale.
𝑆 discreto 𝑋 v. c. discreta
𝑆 continuo 𝑋 v. c. continua
• Stabilire la natura (discreta o continua) delle seguenti variabili casuali:
𝑋 = «numero di volte in cui esce testa»
𝑌 = «durata di uno pneumatico»
𝑍 = «numero di pezzi difettosi in 20 prove» (controllo della qualità di un macchinario)
𝑊 = «durata della visita di un utente in una pagina web»
𝑇 = «tempo di attesa prima di poter essere serviti alle poste»
𝑈 = «numero di studenti che passeranno l’esame di Statistica in un corso di 100 studenti» 110

Variabile casuale discreta: distribuzione di probabilità
• Abbiamo visto che una v.c. discreta 𝑋 può assumere valori in un insieme numerabile. Però
(prima di effettuare la prova aleatoria) non è certo quale valore essa assumerà.
• Attraverso la funzione di probabilità possiamo far corrispondere a ciascun valore che la 𝑋
può assumere il rispettivo livello di probabilità.
Proprietà: 𝑃(𝑋 = 𝑥𝑖) ≥ 0 𝑃 𝑋 = 𝑥𝑖 = 1𝑖
𝑃 ∶ 𝑋 → (0,1)
𝑋 = «numero di volte in cui esce testa»
𝑆 = 𝑐𝑐𝑐 , 𝑐𝑐𝑡 , 𝑐𝑡𝑐 , 𝑡𝑐𝑐 , 𝑐𝑡𝑡 , 𝑡𝑐𝑡 , 𝑡𝑡𝑐 , (𝑡𝑡𝑡)
𝑋 ∶ 𝑆 → 0, 1, 2, 3
Livello di probabilità
0 1/8 = 0,125
1 3/8 = 0,375
2 3/8 = 0,375
3 1/8 = 0,125
Tot. 8/8 = 1
𝑃 𝑋 = 0 = 𝑃 𝑐𝑐𝑐 =1
8
𝑃 𝑋 = 1 = 𝑃 𝑐𝑐𝑡 ∪ 𝑐𝑡𝑐 ∪ 𝑡𝑐𝑐 =3
8
𝑃 𝑋 = 2 = 𝑃 𝑐𝑡𝑡 ∪ 𝑡𝑐𝑡 ∪ 𝑡𝑡𝑐 =3
8
𝑃 𝑋 = 3 = 𝑃 𝑡𝑡𝑡 =1
8
• Riprendiamo l’esempio del lancio di una moneta per tre volte:
𝑋 = 𝑥𝑖 𝑃(𝑋 = 𝑥𝑖)
Distribuzione di probabilità
di una v.c. discreta
111

Esercizio 3 – Distribuzione di probabilità di una v.c. discreta
Consideriamo la prova aleatoria «lancio di un dado standard (e regolare) per due
volte» e le variabili casuali definite nell’esercizio 1:
𝑋 = «numero di volte in cui esce un numero pari»
𝑌 = «somma dei numeri ottenuti nei due lanci»
• Determinare le distribuzioni di probabilità delle due variabili casuali.
𝑆 = (11) 2 (21) 3 (31) 4 (41) 5 (51) 6 (61) 7
(12) 3 (22) 4 (32) 5 (42) 6 (52) 7 (62) 8
(13) 4 (23) 5 (33) 6 (43) 7 (53) 8 (63) 9
(14) 5 (24) 6 (34) 7 (44) 8 (54) 9 (64) 10
(15) 6 (25) 7 (35) 8 (45) 9 (55) 10 (65) 11
(16) 7 (26) 8 (36) 9 (46) 10 (56) 11 (66) 12
𝑌 ∶ 𝑆 → 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 Abbiamo visto che:
112
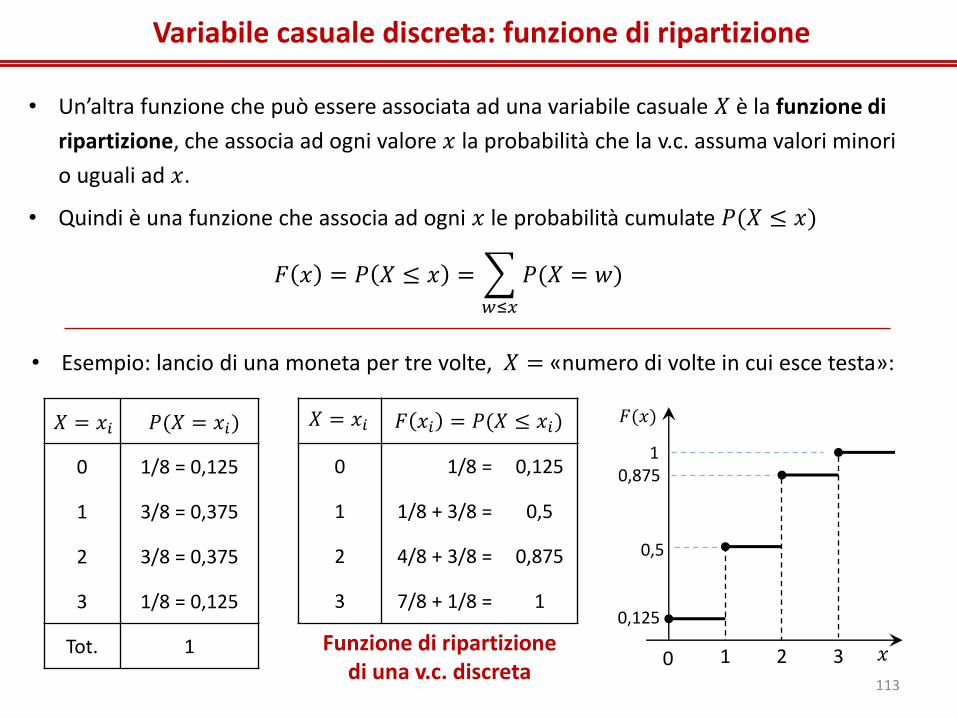
Variabile casuale discreta: funzione di ripartizione
• Un’altra funzione che può essere associata ad una variabile casuale 𝑋 è la funzione di
ripartizione, che associa ad ogni valore 𝑥 la probabilità che la v.c. assuma valori minori
o uguali ad 𝑥.
• Quindi è una funzione che associa ad ogni 𝑥 le probabilità cumulate 𝑃(𝑋 ≤ 𝑥)
𝐹 𝑥 = 𝑃 𝑋 ≤ 𝑥 = 𝑃(𝑋 = 𝑤)
𝑤≤𝑥
• Esempio: lancio di una moneta per tre volte, 𝑋 = «numero di volte in cui esce testa»:
0 1/8 = 0,125
1 3/8 = 0,375
2 3/8 = 0,375
3 1/8 = 0,125
Tot. 1
𝑋 = 𝑥𝑖 𝑃(𝑋 = 𝑥𝑖)
0 1/8 = 0,125
1 1/8 + 3/8 = 0,5
2 4/8 + 3/8 = 0,875
3 7/8 + 1/8 = 1
𝑋 = 𝑥𝑖 𝐹 𝑥𝑖 = 𝑃(𝑋 ≤ 𝑥𝑖)
Funzione di ripartizione di una v.c. discreta
0 3 2 1 𝑥
𝐹(𝑥)
1 0,875
0,5
0,125
113

Esercizio 4 – Variabile casuale discreta: funzione di ripartizione
Consideriamo la prova aleatoria «lancio di un dado standard (e regolare) per due
volte» e le variabili casuali definite nell’esercizio 1:
𝑋 = «numero di volte in cui esce un numero pari»
𝑌 = «somma dei numeri ottenuti nei due lanci»
• Determinare le funzioni di ripartizione delle due variabili casuali.
114

Valore atteso e varianza di una variabile casuale discreta
• Il valore medio o valore atteso di una variabile casuale discreta 𝑋 è definito come:
• La varianza di una variabile casuale discreta 𝑋 è definita come:
• Importanti proprietà:
𝐸 𝑋 = 𝑥𝑗 ∙ 𝑃(𝑥𝑗)
𝑗
= 𝜇
𝑉 𝑋 = 𝐸 𝑋 − 𝜇 2 = (𝑥𝑗 − 𝜇)2∙ 𝑃(𝑥𝑗)
𝑗
= 𝜎2
𝐸 𝑎 + 𝑏𝑋 = 𝑎 + 𝑏𝐸(𝑋)
𝑉 𝑎 + 𝑏𝑋 = 𝑏2𝑉(𝑋)
115

Esercizio 5 – Valore atteso e varianza di una v. c. discreta
Consideriamo la prova aleatoria «lancio di un dado standard (e regolare) per due
volte» e le variabili casuali definite nell’esercizio 1:
𝑋 = «numero di volte in cui esce un numero pari»
𝑌 = «somma dei numeri ottenuti nei due lanci»
• Calcolare valore atteso e varianza delle due variabili casuali.
116

La distribuzione di Bernoulli
• Prova aleatoria con due possibili esiti, indicati di solito con 1 (successo) e 0 (insuccesso),
disgiuntivi (o uno o l’altro) ed esaustivi (uno dei due si verifica necessariamente)
• Tutte le prove che producono solo due possibili risultati generano le cosiddette variabili
casuali di Bernoulli: lancio di una moneta, sesso di un nascituro, superamento o meno di
un certo livello di inflazione, …
• La sua funzione di probabilità può essere espressa come:
• Valore atteso e varianza sono:
v.c. di Bernoulli
il valore 1 con probabilità p
il valore 0 con probabilità 1 – p
può assumere
1 p
0 1 – p
Tot. 1
𝑋 = 𝑥𝑖 𝑃(𝑋 = 𝑥𝑖)
𝑃 𝑋 = 𝑥 = 𝑝𝑥(1 − 𝑝)1−𝑥 per 𝑥 = 0, 1
𝐸 𝑋 = 𝑝 𝑉 𝑋 = 𝑝(1 − 𝑝)
117

Esercizi 6 - Distribuzione di Bernoulli
• Consideriamo la prova aleatoria «lancio di un dado standard (e regolare) per due
volte» e le variabili casuali 𝑍 e 𝑊 definite come:
𝑍 = «esce almeno una volta nei due lanci un numero pari»
𝑊 = «la somma dei numeri ottenuti nei due lanci è maggiore di 8»
• Quali sono le distribuzioni delle due variabili casuali?
• Quali sono le loro distribuzioni di probabilità?
• Calcolare il valore atteso e la varianza delle due variabili casuali (sia applicando
le definizioni di valore atteso e varianza, che utilizzando le formule per la v.c. di
Bernoulli).
118

La distribuzione Binomiale
𝑋 è definita come il «numero di successi ottenuti in una serie di
n prove aleatorie indipendenti», con:
• 𝑃𝑟𝑜𝑏(successo in ogni singola prova) = 𝑝
• 𝑃𝑟𝑜𝑏(insuccesso in ogni singola prova) = 1 − 𝑝
v.c. Binomiale
𝑿~𝑩(𝒏, 𝒑)
𝐸 𝑋 = 𝑛𝑝 𝑉 𝑋 = 𝑛𝑝(1 − 𝑝)
• La sua funzione di probabilità può essere espressa come:
𝑃 𝑋 = 𝑥 = 𝑛𝑥 𝑝𝑥(1 − 𝑝)𝑛−𝑥 per 𝑥 = 0, 1, 2,… , 𝑛
• Valore atteso e varianza sono:
dove: 𝑛𝑥 =
𝑛!
𝑥! 𝑛 − 𝑥 ! 𝑛! = 𝑛 ∙ 𝑛 − 1 ∙ 𝑛 − 2 ∙ ⋯ ∙ 2 ∙ 1 e
119

Esercizio 7 - Distribuzione Binomiale
Consideriamo la prova aleatoria «lancio di un dado standard (e regolare) per 8 volte» e
la variabile casuale definita come:
𝑋 = «numero di volte in cui esce un numero pari in 8 lanci»
• Qual è la distribuzione della variabile casuale?
• Calcolare il valore atteso e la varianza della variabile casuale utilizzando le
formule per la v.c. Binomiale.
• Qual è la probabilità che esca 3 volte un numero pari in 8 lanci?
Es. 19 pag. 214 «Statistica e laboratorio»
Un’azienda che produce televisori spedisce 150 pezzi ad un rivenditore.
Successivamente, l’azienda si accorge di aver spedito al rivenditore 30 televisori
senza telecomando. Scegliendo a caso 8 televisori tra quelli ricevuti dal rivenditore,
qual è la probabilità che non siano estratti televisori senza telecomando? E la
probabilità che sia estratto un solo televisore senza telecomando?
120

Variabile casuale continua: densità di probabilità
• Abbiamo visto che una v.c. continua 𝑋 può assumere tutti i valori compresi in un
intervallo reale.
• A partire dall’insieme dei valori che 𝑋 può assumere, chiameremo funzione di
densità di probabilità la funzione 𝑓(𝑥) per cui l’area sottesa, corrispondente ad un
certo intervallo, è uguale alla probabilità che 𝑋 assuma un valore in quell’intervallo.
• Proprietà delle funzioni di densità:
• 𝑓(𝑥) ≥ 0 sempre
•
• La probabilità che la v.c.
assuma un particolare valore
dell’intervallo è zero.
𝑓 𝑥 𝑑𝑥 = 1
+∞
−∞
𝑃 𝑥𝑎 ≤ 𝑋 ≤ 𝑥𝑏 = 𝑓 𝑥 𝑑𝑥 =𝑥𝑏
𝑥𝑎
0,25
𝑓 𝑥 𝑑𝑥 = 1+∞
−∞
𝑥
𝑓(𝑥)
𝑥𝑎 𝑥𝑏
𝑃 𝑋 = 𝑥𝑎 = 𝑃 𝑋 = 𝑥𝑏 = 0 Attenzione:
(tutta l’area sotto la curva deve essere pari ad 1)
121

V.c. continua: funzione di ripartizione, valore atteso e varianza
• Data una v.c. continua 𝑋, la funzione che fa corrispondere ai valori 𝑥 le probabilità
cumulate 𝑃(𝑋 ≤ 𝑥) viene detta funzione di ripartizione 𝑭(𝒙):
• Il valore atteso di una v.c. continua 𝑋 è definito come:
• La varianza è definita come:
𝐹 𝑥 = 𝑃 𝑋 ≤ 𝑥 = 𝑓(𝑤)
𝑥
−∞
𝑑𝑤
𝐸 𝑋 = 𝑥 ∙ 𝑓 𝑥
+∞
−∞
𝑑𝑥 = 𝜇
𝑉 𝑋 = 𝐸 𝑋 − 𝜇 2 = (𝑥 − 𝜇)2∙ 𝑓 𝑥
+∞
−∞
𝑑𝑥 = 𝜎2
122
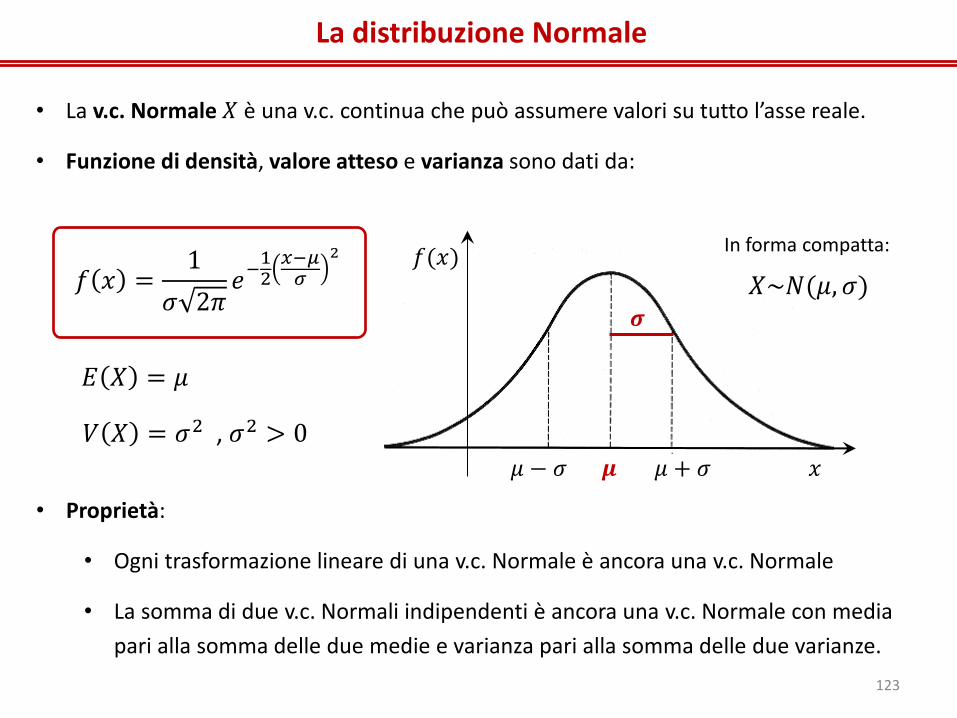
La distribuzione Normale
• La v.c. Normale 𝑋 è una v.c. continua che può assumere valori su tutto l’asse reale.
• Funzione di densità, valore atteso e varianza sono dati da:
𝐸 𝑋 = 𝜇
𝑓 𝑥 =1
𝜎 2𝜋𝑒−12𝑥−𝜇𝜎
2
𝑉 𝑋 = 𝜎2 , 𝜎2 > 0
𝜇 − 𝜎 𝜇 + 𝜎 𝝁
𝝈
𝑥
𝑓(𝑥) 𝑋~𝑁(𝜇, 𝜎)
In forma compatta:
• Proprietà:
• Ogni trasformazione lineare di una v.c. Normale è ancora una v.c. Normale
• La somma di due v.c. Normali indipendenti è ancora una v.c. Normale con media
pari alla somma delle due medie e varianza pari alla somma delle due varianze.
123

La distribuzione Normale standardizzata
• La v.c. Normale standardizzata 𝒁 è una v.c. Normale, che può assumere valori su tutto
l’asse reale, ma che ha media μ = 0 e varianza 𝜎2 = 1 .
• Funzione di densità, valore atteso e varianza sono dati da:
• Importante: per la v.c. normale standardizzata si
dispone di tavole che permettono di calcolare le
aree in corrispondenza degli intervalli assunti dalla z.
Quindi se ho una v.c. Normale 𝑋, posso trasformarla in v.c. Normale Standardizzata 𝑍 e poi
andare a cercare sulle tavole i valori delle probabilità degli intervalli che mi interessano.
• Trasformazione da Normale a Normale Standardizzata:
𝐸 𝑍 = 𝜇 = 0
𝑓 𝑧 =1
2𝜋𝑒−
12 𝑧
2
𝑉 𝑍 = 𝜎2 = 1
𝑍 =𝑋 − 𝜇
𝜎 𝑋~𝑁 𝜇, 𝜎 𝑍~𝑁 0, 1
124
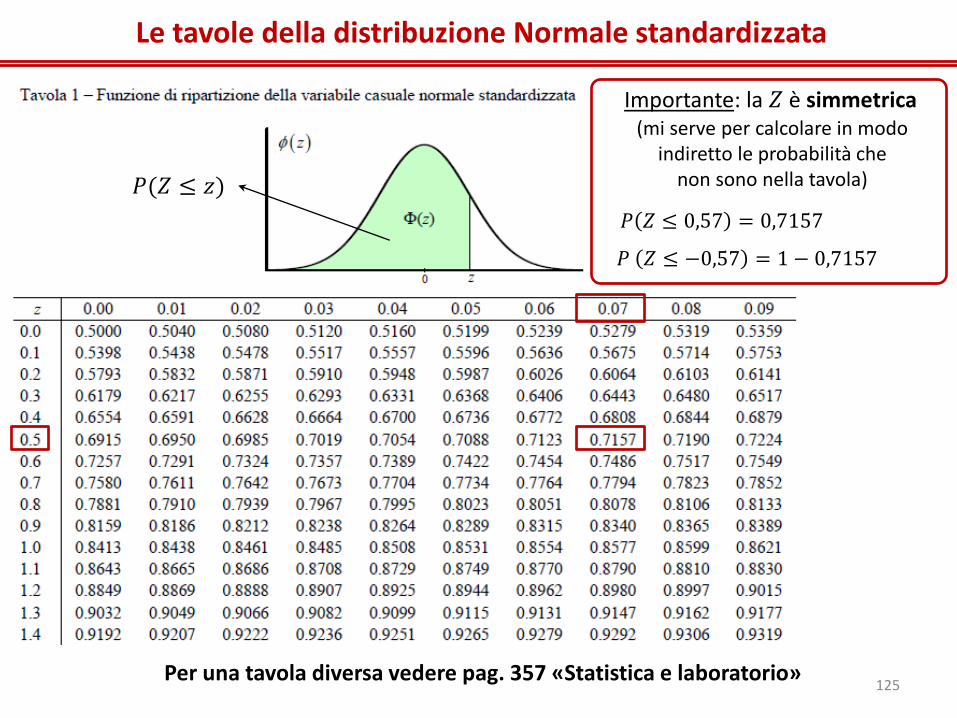
Le tavole della distribuzione Normale standardizzata
𝑃(𝑍 ≤ 𝑧)
𝑃 𝑍 ≤ 0,57 = 0,7157
(mi serve per calcolare in modo indiretto le probabilità che
non sono nella tavola)
𝑃 𝑍 ≤ −0,57 = 1 − 0,7157
Importante: la 𝑍 è simmetrica
Per una tavola diversa vedere pag. 357 «Statistica e laboratorio» 125

Esercizio 7 – Distribuzione Normale (1)
Es. 26 pag. 215 «Statistica e laboratorio»
Un’azienda alimentare confeziona pacchi di pasta il cui peso è distribuito come una
normale con media uguale a 500 gr e deviazione standard pari a 8 gr. Calcolare:
• La probabilità che ci sia un pacco dal peso compreso tra 480 e 490 gr
• La probabilità che ci sia un pacco con peso compreso tra i 490 e 510 gr
• La probabilità che ci sia un pacco con peso inferiore ai 490 gr
• La probabilità che ci sia un pacco con peso superiore ai 480 gr
Es. 28 pag. 215 «Statistica e laboratorio»
Le altezze dei giocatori delle squadre di calcio di un campionato sono distribuite
normalmente con media 178 cm e scarto quadratico medio 8 cm. Calcolare:
• La probabilità che un giocatore abbia altezza superiore a 190 cm
• La probabilità che un giocatore abbia al massimo altezza pari a 170 cm
126

Esercizio 7 – Distribuzione Normale (2)
Esempio a pag. 203 «Statistica e laboratorio»
Determinare le seguenti probabilità per una v.c. Normale standardizzata 𝑍~𝑁(0, 1)
a. 𝑃(𝑍 < 1,62)
b. 𝑃(𝑍 ≥ 1,62)
c. 𝑃(−1,62 ≤ 𝑍 ≤ 0)
d. 𝑃(−1 ≤ 𝑍 ≤ 1,62)
e. 𝑃 0,5 ≤ 𝑍 ≤ 1,62
f. 𝑃(−1,62 ≤ 𝑍 ≤ −0,5)
127

Introduzione: definizioni di base e scopo dell’inferenza
POPOLAZIONE
CAMPIONE
E’ un insieme di unità su cui si può osservare un certo carattere. E’ l’insieme dal quale viene estratto il campione.
• Finita: sappiamo che è composta da 𝑁 unità ed è descritta dai parametri di popolazione:
𝜇 =1
𝑁 𝑥𝑖𝑁𝑖=1 e 𝜎2 =
1
𝑁 (𝑥𝑖 − 𝑥 )2𝑁𝑖=1
• Infinita: composta da unità non tutte determinabili. Indichiamo con Popolazione 𝑋 la variabile casuale 𝑋, caratterizzata da determinati parametri, per esempio valore atteso e varianza di popolazione:
𝜇 = 𝐸(𝑋) e 𝜎2 = 𝐸(𝑋 − 𝜇)2
E’ l’insieme delle unità osservate. Indichiamo con 𝑛 la dimensione del campione. La frazione di campionamento è 𝑛/𝑁.
• Con universo dei campioni (o spazio campionario) 𝜴 indichiamo l’insieme virtuale di
tutti i possibili campioni della stessa numerosità estraibili dalla popolazione.
• Scopo dell’inferenza statistica è ottenere delle informazioni sulla popolazione a partire
dall’osservazione di un campione cercando di commettere il minimo errore (ovviamente
più unità osserviamo, minore è la possibilità di sbagliare). A tale fine è fondamentale che
il campione sia rappresentativo della popolazione. 129

Esercizi – Universo dei campioni
• Es. 1 pag. 245 «Statistica e laboratorio»
Si vuole estrarre un campione di numerosità 𝑛 = 3 da una popolazione che
consiste di 10 unità statistiche. Quanto vale la frazione di campionamento? Qual è
invece il numero complessivo dei campioni casuali estraibili dalla popolazione, se
adoperiamo il campionamento bernoulliano?
• Es. 2 pag 245 «Statistica e laboratorio»
Data una popolazione formata da 5 unità, determinare l’universo bernoulliano dei
campioni di numerosità pari a 2. Qual è la probabilità che un campione venga
estratto?
Determinare inoltre l’universo bernoulliano dei campioni di numerosità pari a 3.
Quanto vale adesso la probabilità che un campione venga estratto?
130

Campionamento da popolazioni finite e infinite, diversi schemi teorici:
Regola di selezione del campione di tipo
probabilistico.
Per una selezione probabilistica dobbiamo
individuare:
• Lo spazio campionario Ω, formato da
tutti i possibili campioni estraibili con una
medesima tecnica dalla popolazione.
• La probabilità di ogni campione 𝑐 ∈ Ω di
essere estratto
La coppia {Ω, probabilità dei campioni in Ω}
è detta piano di campionamento.
In una popolazione infinita, la n-pla di v.c.
𝑋1, 𝑋2, … , 𝑋𝑛
che compongono il campione casuale di
dimensione 𝑛 presenta le seguenti
proprietà:
• 𝑋1, 𝑋2, … , 𝑋𝑛 sono v.c. indipendenti
• ogni v.c. 𝑋𝑖 possiede la stessa
distribuzione di probabilità della
popolazione 𝑋
… da popolazioni finite
… da popolazioni infinite
Campionamento:
Nota: nelle popolazioni finite in cui la dimensione campionaria è molto più piccola rispetto alla
numerosità della popolazione, si può applicare la teoria del campion. da popolazioni infinite. 131
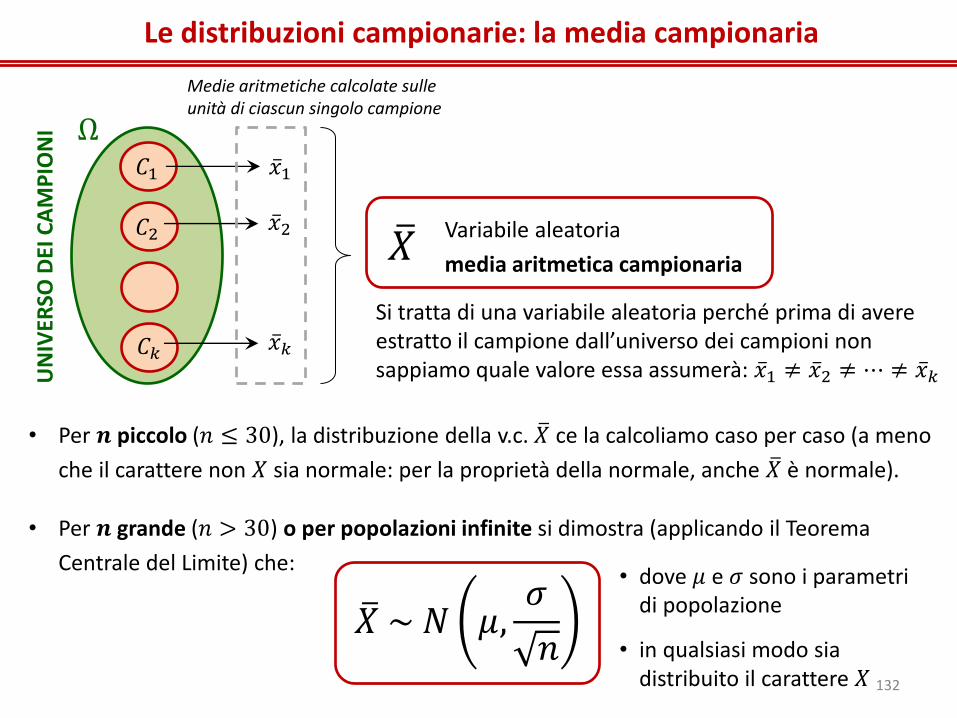
Le distribuzioni campionarie: la media campionaria
Si tratta di una variabile aleatoria perché prima di avere estratto il campione dall’universo dei campioni non sappiamo quale valore essa assumerà: 𝑥 1 ≠ 𝑥 2 ≠ ⋯ ≠ 𝑥 𝑘
𝐶1
𝐶2
𝐶𝑘
UN
IVER
SO D
EI C
AM
PIO
NI
𝑥 1
𝑥 2
𝑥 𝑘
𝑋 Variabile aleatoria
media aritmetica campionaria
Medie aritmetiche calcolate sulle unità di ciascun singolo campione
• Per 𝒏 piccolo (𝑛 ≤ 30), la distribuzione della v.c. 𝑋 ce la calcoliamo caso per caso (a meno
che il carattere non 𝑋 sia normale: per la proprietà della normale, anche 𝑋 è normale).
• Per 𝒏 grande (𝑛 > 30) o per popolazioni infinite si dimostra (applicando il Teorema
Centrale del Limite) che:
𝑋 ~ 𝑁 𝜇,𝜎
𝑛
• dove 𝜇 e 𝜎 sono i parametri di popolazione
• in qualsiasi modo sia distribuito il carattere 𝑋
Ω
132

Esercizio – Distribuzione della media campionaria
• Esercizio:
Una piccola azienda ha 7 dipendenti e siamo interessati al numero di ore di straordinario
effettuate in una settimana. Questi i risultati nella popolazione di riferimento (𝑁 = 7):
• Campionando con reimmissione (campionamento bernoulliano) quanti campioni con
𝑛 = 2 si possono estrarre?
• Elencare gli elementi da cui è composto l’universo bernoulliano dei campioni.
• Qual è la media di popolazione?
• Determinare la distribuzione della v.c. media aritmetica campionaria.
• Supponiamo di estrarre i dipendenti (5, 7). Qual è la realizzazione della v.c. media
aritmetica campionaria?
Dipendente 1 2 3 4 5 6 7
N. ore di straordinario 3 8 4 7 6 6 4
133

La stima puntuale
Popolazione Campione C di numerosità 𝒏
• 𝑋 variabile casuale con distribuzione nota
• 𝑓(𝑥, 𝜃) funzione di densità della v.c. 𝑋
• 𝜃 parametro di popolazione incognito
• (𝑥1, 𝑥2, …, 𝑥𝑛) campione casuale bernoulliano
• (𝑋1, 𝑋2, …, 𝑋𝑛) v.c. indipendenti e
identicamente distribuite
𝜃 = 𝑡ℎ = 𝑔(𝑥1, 𝑥2, …, 𝑥𝑛) è stima puntuale di 𝜃
Attenzione: la stima è un singolo valore! E’ la realizzazione nel campione della v.c. stimatore nell’universo dei campioni Ω:
𝑇ℎ = 𝑔(𝑋1, 𝑋2, …, 𝑋𝑛)
Popolazione Campione C di numerosità 𝒏
• 𝑋 variabile casuale normale
• 𝑓(𝑥, 𝜃) f.d.d. della v.c. normale
• 𝜃 = 𝜇 = ? parametro incognito
• (𝑥1, 𝑥2, …, 𝑥𝑛) campione casuale semplice
• (𝑋1, 𝑋2, …, 𝑋𝑛) v.c. i.i.d.
• Stima puntuale di 𝜇 :
• Stimatore nell’universo dei campioni:
𝜃 = 𝜇 = 𝑡ℎ = 𝑥
Esempio – stima puntuale della media di una popolazione normale
𝑇ℎ = 𝑋 134

• Abbiamo visto che se X~ 𝑁 𝜇, 𝜎 in popolazione, allora Th = 𝑋 ~ 𝑁 𝜇,𝜎
𝑛
• Il nostro obiettivo è trovare un intervallo di valori all’interno del quale sia compreso il
parametro incognito di interesse 𝝁 con un certo livello di confidenza (grado di fiducia).
• Intervallo di confidenza per la media con varianza nota (vedi slide Prof. per la procedura):
• Tuttuavia, poiché io estraggo un singolo campione, sostituisco ad 𝑋 la media del campione
𝑥 = 𝜇 e ottengo così l’intervallo 𝑥 ± 𝑧𝛼 2 ∙ 𝜎 𝑛 che potrebbe contenere la media
incognita con un grado di fiducia pari a 1 − 𝛼.
La stima per intervalli
1 − 𝛼
𝛼/2 𝛼/2
𝑧𝛼/2 −𝑧𝛼/2
𝛼 = 0,05 = 5%
0,95 = 95%
𝑧𝛼/2 = 1,96 −𝑧𝛼 2 = − 1,96
Esempio:
Nel 2,5% dei campioni possibili, lo stimatore assume valore in questo intervallo (che non contiene il valore del parametro incognito)
La probabilità che l’intervallo contenga il valore del
parametro incognito 𝜇 è 0,95. Livello di confidenza del 95%.
INTERVALLO DI CONFIDENZA
𝑍 =𝑋 − 𝜇
𝜎 𝑛
𝑃 𝑋 − 𝑧𝛼 2 ∙ 𝜎 𝑛 < 𝜇 < 𝑋 + 𝑧𝛼 2 ∙ 𝜎 𝑛 = 1 − 𝛼
135

Esercizi – Stima puntuale e per intervalli della media di popolazione
• Es. 4 pag. 245 «Statistica e laboratorio»
Un promotore finanziario, per avere un’idea dei prezzi di alcune merci, esamina i prezzi
riportati in diversi mercati, di seguito riportati: (70, 90, 85, 80, 95, 100, 98, 102, 90, 80)
Nella popolazione di riferimento, il prezzo si distribuisce come una v.a. normale con
varianza pari a 225.
• Calcolare una stima corretta per il prezzo medio di popolazione
• Determinare l’intervallo di confidenza al 95%
• Es. 7 pag 246 «Statistica e laboratorio»
In una popolazione di studenti, il punteggio conseguito all’esame di Statistica (X) si
distribuisce secondo una normale con varianza 13,91. In un campione di 40 studenti si
osserva 𝑥𝑗 = 1.00040𝑗=1 .
• Si determini una stima corretta per la media 𝜇 di popolazione
• Si costruiscano gli intervalli di confidenza al 95% e al 99% per la media 𝜇 di
popolazione e si commentino i risultati 136

Esercizi – Stima puntuale e per intervalli della media di popolazione
• Es. 9 pag. 247 «Statistica e laboratorio»
Durante una prova di selezione per un posto di lavoro viene effettuato un test
scritto. La variabile casuale 𝑋 = «tempo di risposta al test» si distribuisce
normalmente nella popolazione di riferimento, con media incognita e scarto
quadratico medio pari a 4 minuti. In un campione casuale di 20 candidati, si rileva
𝑥𝑗 = 72020𝑗=1 minuti.
• Qual è una stima corretta per il tempo medio di risposta 𝜇 nella
popolazione dei candidati?
• Costruire l’intervallo di confidenza al 99% per 𝜇, commentando il risultato.
137






































