Embed Size (px)
Citation preview

Paradigma Tecnológico
Servicios de formaciónApache Solr


Temario1. Introducción
▪ Apache Solr
▪ Índice invertido
▪ Sorl vs SolrCloud
▪ Apache Zookeeper
2. Arquitectura
▪ Plugins Apache Solr/Lucene
▪ Clustering (Replicación y Sharding)
▪ Monitorización y mantenimiento
3. Indexación
▪ Ingestion
▪ Esquema de Datos
▪ Indexación distribuida
4. Búsqueda
▪ Parámetros y ejemplos de Búsqueda
5. Búsqueda avanzada
▪ Facets
▪ Ordenaciones
▪ Agrupaciones
▪ Multilenguaje (detección de idioma)
▪ Highlighting
▪ Corrección ortográfica
▪ More like this

Paradigma Tecnológico
Servicios de formaciónIntroducción

➢ Apache Solr
▪ Apache Solr es una plataforma de búsqueda empresarial open source
muy popular y con un grado de madurez muy avanzado. Diseñado para
desarrollar una buena experiencia de búsqueda para el usuario.
▪ Cuando una aplicación, página o portal web requiere capacidades de
búsqueda es probable que se necesite un servidor de búsquedas e
indexación y con este fin es para lo que Apache Solr fue creado.
▪ Con ese fin, el de mejorar la experiencia de búsqueda, Apache Solr
incluye muchas propiedades como por ejemplo, búsqueda por full-text
basado en palabras clave, corrección ortográfica, las sugerencias y
recomendaciones en las búsquedas y el resaltado (highlighting).
1. Introducción (I): Apache Solr

➢ Apache Solr
▪ Está escrito usando el lenguaje Java y se utiliza como servidor de búsqueda
independiente dentro de un contenedor de Servlets como Tomcat, Jetty y otros.
▪ Solr está construido sobre la librería Apache Lucene. Podríamos decir que Lucene es
el motor de búsqueda e indexación y que Solr le proporciona una capa de
funcionalidades tales como:
▪ Acceso HTTP a Lucene.
▪ Cachés para lograr mayor velocidad en las búsquedas.
▪ Interfaz de administración web.
▪ Configuración del esquema de datos y del servidor mediante archivos XML.
▪ Facetado de resultados (Agrupación de resultados con contadores).
▪ Distribución de servidores.
1. Introducción (II): Apache Solr

➢ Apache Solr
▪ Apache Lucene, proporciona casi todo lo referente a búsquedas de texto de alto
rendimiento:
▪ Mayor velocidad en la búsqueda de cadenas de texto.
▪ Menor dependencia del tamaño del índice.
▪ Mayor flexibilidad en las búsquedas de texto: Búsquedas por término,
mediante N-Gramas, búsquedas fonéticas…
▪ Mayor facilidad para ordenaciones por score y ponderaciones.
1. Introducción (III): Apache Solr

➢ Apache Solr
▪ En la actualidad Apache Solr se utiliza en infinidad de sitios web para optimizar el rendimiento
de las búsquedas, mejorando de esta manera, la velocidad de navegación global de las páginas
permitiendo acercarnos a la navegación en tiempo real (near real time).
▪ Entre las muchas características sobresalientes de Solr se incluye su robusto motor de
búsqueda de texto completo y facetada, la indexación en tiempo real, clustering, el manejo de
documentos (Word, PDF, etc.) y la búsqueda geoespacial.
▪ La confiabilidad, escalabilidad y tolerancia a fallos son las capacidades que hacen de Solr una
herramienta muy demandada para los desarrolladores, especialmente a los profesionales de
SEO y Desarrolladores.
▪ Cómo sucede con todos los componentes de una arquitectura de software, Solr necesita ser
implementado y configurado de la manera apropiada para que aporte el mejor rendimiento
posible y el finalmente el éxito de la web. Existen muchos parámetros a tener en cuenta en la
implementación de una arquitectura de búsqueda Solr cómo la elección de los campos y
documentos a indexar, el tipo de indexación a usar, las facetas o categorización de los
términos en las búsquedas, condicionales a tener en cuenta, entre otros.
1. Introducción (IV): Apache Solr

➢ Apache Solr
▪ Solr es capaz de conseguir velocidades de respuestas muy altas porque en lugar de buscar el
texto directamente de la fuente en la que se encuentra lo hace sobre un índice. El ejemplo
más claro para representar esto es el de la búsqueda de un concepto o una palabra clave en un
libro (sí, creo que todos recordamos lo que eran :-) aunque hayan quedado en desuso). Si
buscamos ese término nos resultará mucho más fácil buscarlo en su índice de términos o
glosario que se encuentra al final del libro, que ir página por página para localizarlo.
▪ Este tipo de índice es llamado índice invertido (inverted index) porque invierte la estructura de
datos “centrada en páginas” o búsqueda de página a término (page-centric) en una estructura
“centrada en palabras clave” o búsqueda de palabra a página (keyword-centric).
1. Introducción (V): Índice invertido

➢ Apache Solr
▪ Un ejemplo de cómo funciona un sistema de índice invertido:
▪ Tenemos dos documentos ejemplo con un campo llamado “cuerpo” que contiene el
siguiente texto:
El rápido lobo marrón saltó sobre el perezoso perro.
Rápido lobo color marrón brincó sobre los perros perezosos en verano.
▪ Solr crearía el índice invertido partiendo el contenido del campo “cuerpo” de cada documento
en palabras separadas, que en el argot de los índices los llamaríamos términos (terms) o
tokens, que podríamos traducir como muestras o ficha. Tras separar los términos Solr, crea
una lista ordenada de términos únicos, sin repetir las palabras repetidas en ambos
documentos. Él resultado sería una lista de términos similar a:
1. Introducción (VI): Índice invertido
➢ Apache Solr
1. Introducción (VII): Índice invertido
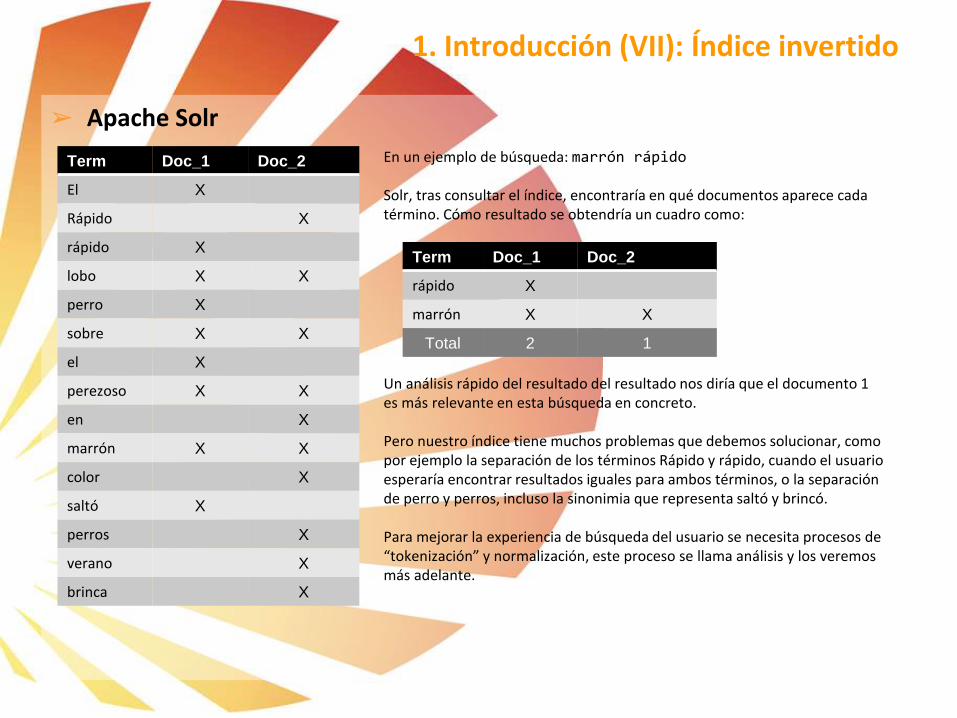
Term Doc_1 Doc_2
El X
Rápido X
rápido X
lobo X X
perro X
sobre X X
el X
perezoso X X
en X
marrón X X
color X
saltó X
perros X
verano X
brinca X
En un ejemplo de búsqueda: marrón rápido
Solr, tras consultar el índice, encontraría en qué documentos aparece cada término. Cómo resultado se obtendría un cuadro como:
Un análisis rápido del resultado del resultado nos diría que el documento 1 es más relevante en esta búsqueda en concreto.
Pero nuestro índice tiene muchos problemas que debemos solucionar, como por ejemplo la separación de los términos Rápido y rápido, cuando el usuario esperaría encontrar resultados iguales para ambos términos, o la separación de perro y perros, incluso la sinonimia que representa saltó y brincó.
Para mejorar la experiencia de búsqueda del usuario se necesita procesos de “tokenización” y normalización, este proceso se llama análisis y los veremos más adelante.
Term Doc_1 Doc_2
rápido X
marrón X X
Total 2 1

➢ Solr vs SolrCloud
▪ A partir de la versión 4, Solr pasó a llamarse SolrCloud. En esta versión Solr incorpora múltiples funcionalidades de
clusterización, alta escalabilidad, tolerancia a fallos, indexación y búsquedas distribuida, búsqueda “near real-time” y
centralización de la configuración y la administración del clúster.
▪ El parámetro zkHost en el arranque determina si se usa SolrCloud o Solr Clasico.
▪ Zookeeper, almacena y sincroniza la información de los nodos del cluster.
▪ Los archivos de configuración de Solr como schema.xml y solrconfig.xml se almacenan en ZooKeeper, el lugar de en el Sistema
de Archivos local.
▪ SolrCloud elimina la especificación clásica master-slave, y automatiza actualizaciones(indexación) y búsqueda de manera de
forma continua entre nodos.
▪ Configuración de solr reducida, solo solr.xml es requerido en los cores de solr. El resto de la configuración de Solr se lee desde
Zookeeper.
▪ Se incorporan API’s para administrar y crear las entidades Collection y CoreAdmin.
▪ Almacena un log de duración y recuperación, el campo especial _version_ ayuda en estos aspectos así como en la
coordinación (elección del nodo overseer y del shard líder).
▪ Se introduce el factor de replicación (Replication factor), que representa el número mínimo de copias de un documento
mantenidas por el cluster.
▪ Soporte Near Real-time para la búsqueda y la indexación mediante los “soft-commits” (openSearch=false) y del handler “/get”
para devolver los últimos valores almacenados. Estas propiedades se basan en la característica de updateLog.
1. Introducción (VIII): Solr vs SolrCloud

➢ Solr vs SolrCloud
▪ Búsqueda distribuida entre Collections (siempre que sean compatibles). http://[solr_host]:[solr_port]/solr/select?collection=collection1,collection2
▪ Las queries enviadas a cualquier nodo realizan automáticamente una búsqueda distribuida completa a través del clúster con
load-balancing y fail-over (tolerancia a errores). Es posible, también, configurar SolrCloud con la características
shards.tolerant=true para devolver sólo los documentos que están disponibles en los shards “vivos”, es decir que si un
servidor no respondiera, la consulta continúa al siguiente shard/servidor levantado. http://[solr_host]:[solr_port]/solr/select?shards=[solr_host]:[solr_port]/solr,[solr_host]:[solr_port]/solr&indent=true&q=t
raining+solr
▪ Los updates que sean enviadas a cualquier nodo del cluste son automáticamente remitidas al shard correcto y replicadas a los
multiples nodos redundantemente.
▪ Nuevo campo _version_ (updateLog depende de este campo) para la actualización get/partial de documentos en modo Near
Real-time.
▪ Una nueva implementación del spellchecker introducida con solr.DirectSolrSpellchecker. Permite usar el índice principal para
proporcionar sugerencias para la correcció ortográfica y se realiza “on the fly” sin necesidad de ser reconstruido tras cada
commit.
1. Introducción (IX): Solr vs SolrCloud

➢ Apache Zookeeper
▪ ZooKeeper proporciona un servicio centralizado para el mantenimiento de información de configuración de los sistemas en los
que se encuentra integrado así como sincronización de manera distribuida que alimenta soluciones de alta disponibilidad.
▪ Cada Zookeeper en una arquitectura SolrCloud debería correr en una máquina dedicada, ya que es un Servicio que requiere
“puntualidad” (Timely Service) y la máquina dedicada ayuda a asegurar respuestas puntuales.
▪ Es conveniente separar en diferentes unidades de disco los logs transaccionales.
▪ Un punto importante es ajustar el tamaño del Java heap. Es importante para evitar el swapping, lo que disminurá
drásticamente el rendimiento de ZooKeeper. Para determinar el valor correcto, se debe realizar pruebas de carga y asegurarse
de que siempre está MUY por debajo del límite de uso del Java heap antes del swapping. Según las propias recomendaciones
de Apache, es mejor no ser “rácano” y configurar un heap máximo de 3GB en una máquina de 4GB (60% de la memoria total
de la máquina.
▪ Se introducen los conceptos: Ensemble y Quorum:
▪ Ensemble, cluster de Servidores Zookeeper vinculados que mantienen la Alta disponibilidad del sistema. Cada servidor
ZooKeeper que forma parte del conjunto tiene conocimiento de quienes son los otros servidores que forman parte.
▪ Quorum: El Zookeeper ensemble se mantiene siempre activo mientras el 50% + 1 de los servidores ZK se mantienen
vivos.
1. Introducción (X): Apache Zookeeper

Paradigma Tecnológico
Servicios de formaciónArquitectura
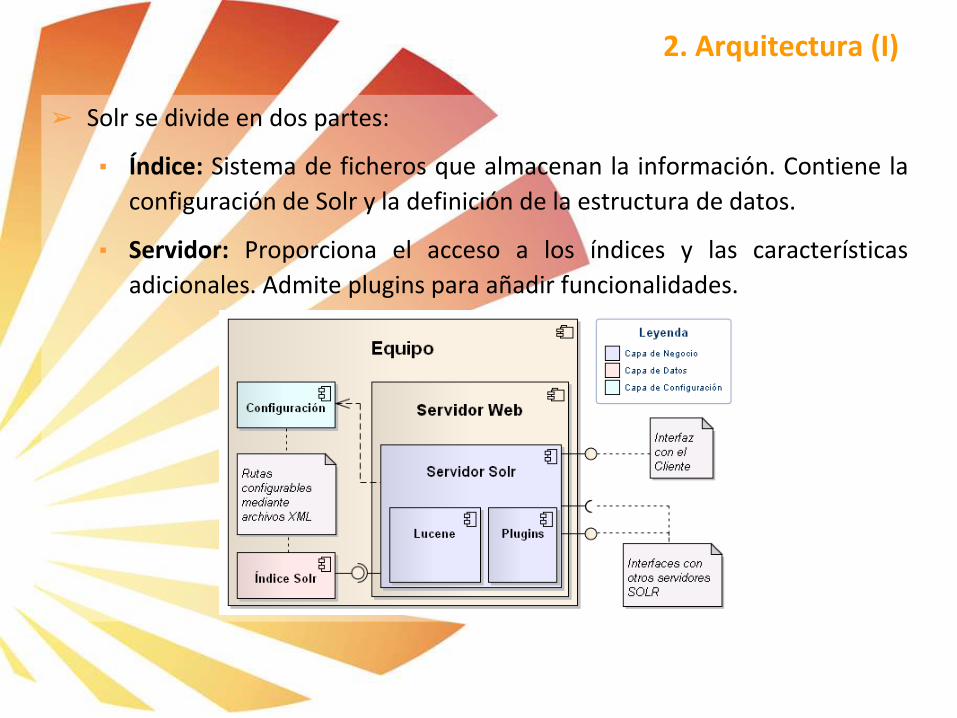
➢ Solr se divide en dos partes:
▪ Índice: Sistema de ficheros que almacenan la información. Contiene la
configuración de Solr y la definición de la estructura de datos.
▪ Servidor: Proporciona el acceso a los índices y las características
adicionales. Admite plugins para añadir funcionalidades.
2. Arquitectura (I)
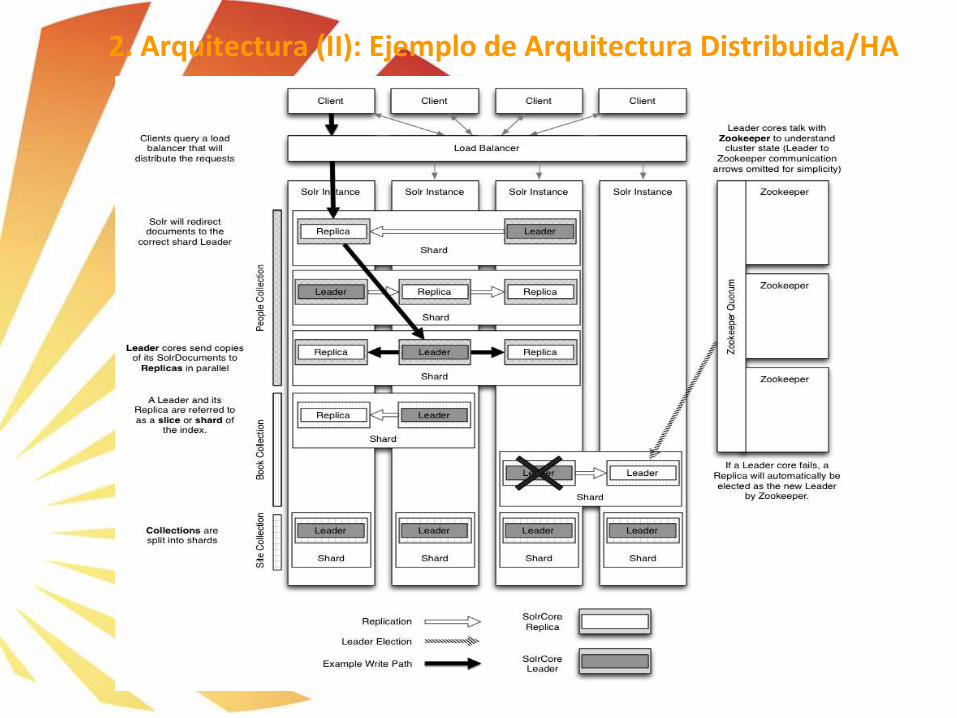
2. Arquitectura (II): Ejemplo de Arquitectura Distribuida/HA
Solr Core
Lucene
Admin
InterfaceStandard
Request
Handler
“Out of the
box”
Request
Handlers
Custom
Request
Handler
Update
Handler
Caching
XML,
JSON, CSV
Update
Interface
Config
Analysis
HTTP Request Servlet
Concurr
ency
Update
Servlet
Replication
Schema
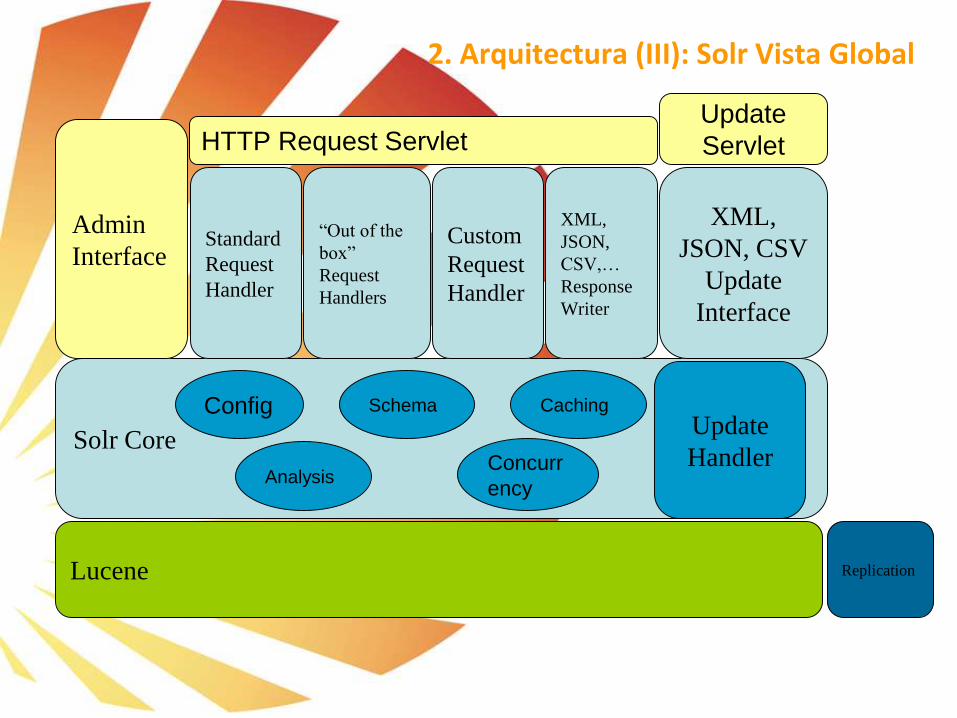
2. Arquitectura (III): Solr Vista Global
XML,
JSON,
CSV,…
Response
Writer
19
Apache Lucene
/select /spell XML CSVXML Binary JSON
Data Import Handler
(SQL/RSS)
Extracting RequestHandler
(PDF/WORD)
CachingFaceting
Query Parsing
Apache Tika
Binary/admin
Highlighting
Schema
Index Replication
Request Handlers Update HandlersResponse Writers
Query
Search Components
Spelling
Faceting
Highlighting Signature
Logging
Update Processors
Indexing
Config
Debug
Statistics
More like this
Distributed Search
Clustering
Filtering Search
Core SearchIndexReader/Searcher
IndexingIndexWriterText Analysis
Analysis
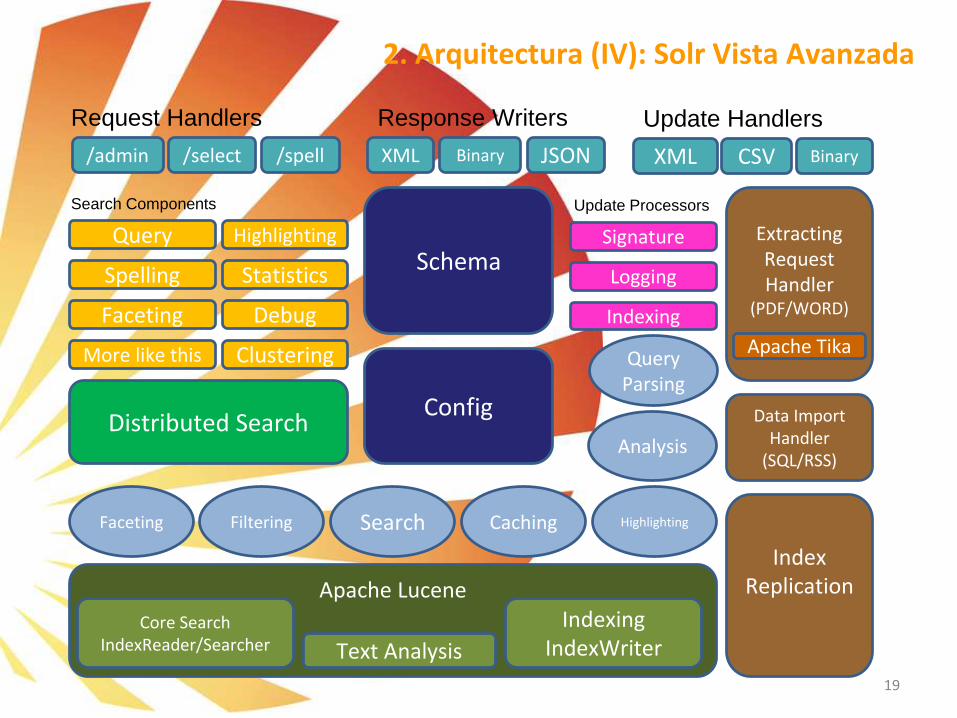
2. Arquitectura (IV): Solr Vista Avanzada

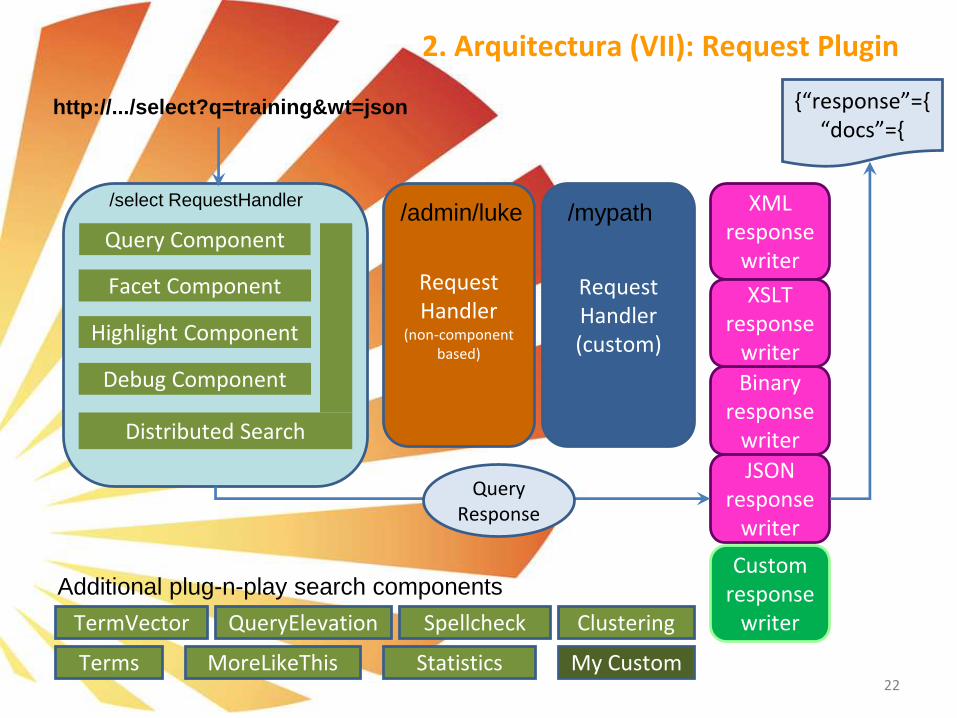
➢ Components, Handlers, Parsers y Analyzers▪ RequestHandlers: Maneja las peticiones (request) con URL’s REST-style. Por ejemplo: “/select”
▪ SearchComponents (parte de SearchHandler) Componentes que controlan las peticiones:
▪ Incluye: Query, Facet, Highlight, Debug, Stats
▪ Capacidad de Búsqueda distribuida.
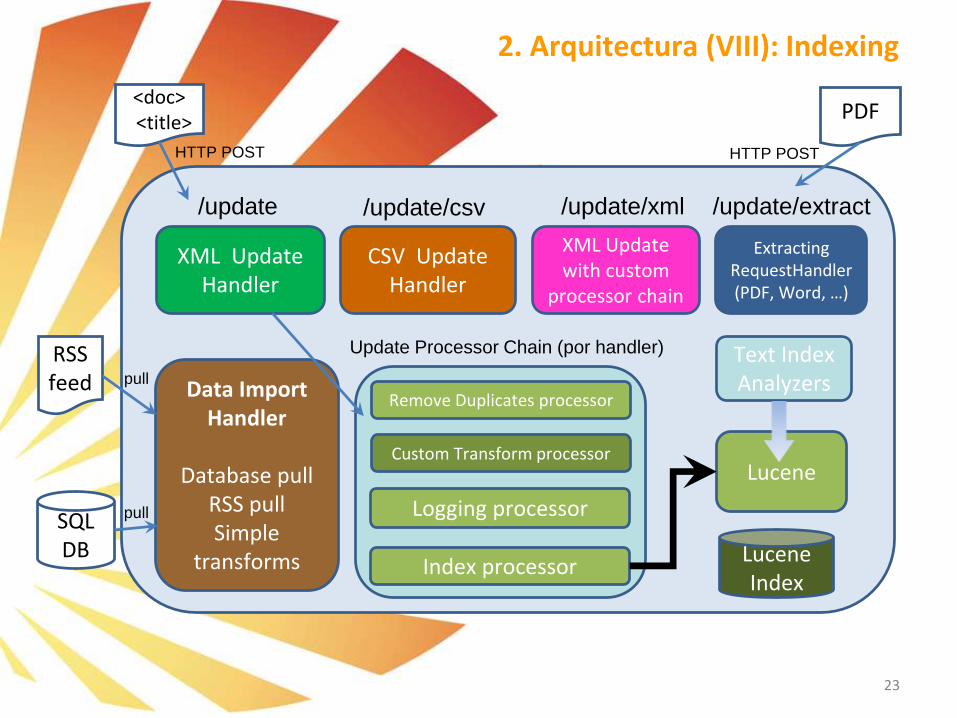
▪ UpdateHandlers: Permite indicar de qué menara se producen las peticiones de actualización / indexación.
▪ Update Processors: Se configuran cadenas de componentes “per-handler” para manejar las actualizaciones.
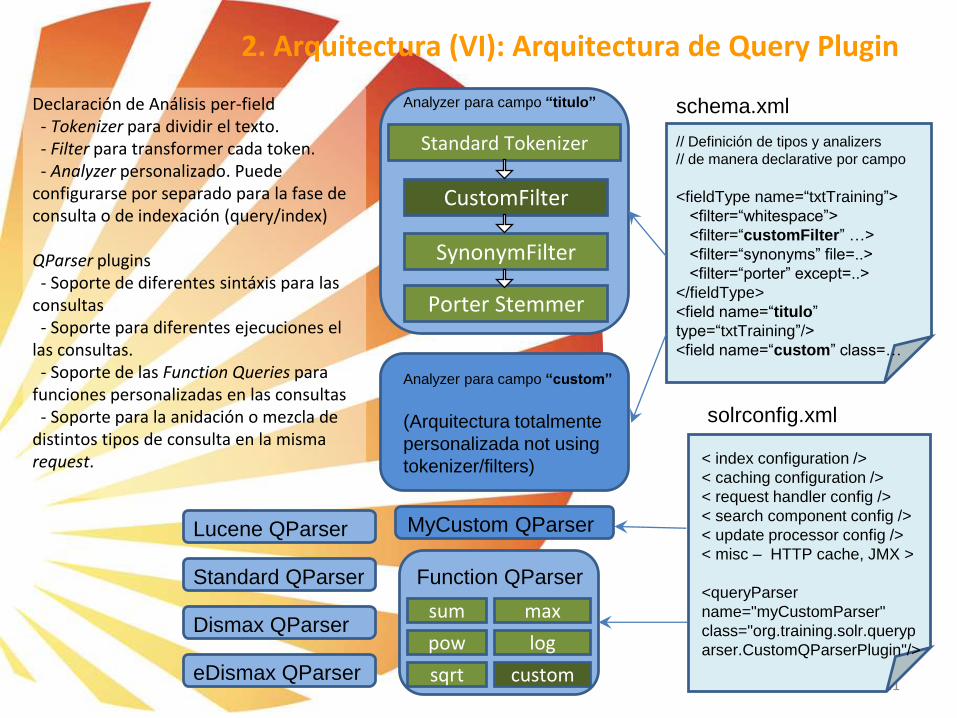
▪ Query Parser plugins (QParser): Solr permite una gran variedad de métodos de consulta, los más habituales son:
▪ Standard Query Parser: Es el más habitual, proviene Lucene Query Parser, pero añade Range Queries ([a TO z]),
negative queries (-abierto:false, que encontraría todos los campos con valores donde abierto es NO falso)
▪ Dismax Query Parser: Método de consulta que permite al usuario influir en los resultados con un Sistema basado en
coeficientes de prioridad “weighting (boosts)”
▪ eDismax Query Parser: Extiende las funcionalidades del Qparser Dismax, añadiendo condiciones AND, OR, NOT, -, and
+. Mejora el Sistema de coeficientes.
▪ Text Analysis plugins: Analyzers, Tokenizers, TokenFilters
▪ Field analyzers: se usan durante el tiempo de indexación (update) y en tiempo de consulta (query). El analizador
examina los campos y genera una cadenas de tokens. Los “Analyzers” pueden ser una única clase o puede estar
compuesta de Tokenizers y Filters.
▪ Tokenizers: dividen los datos en unidades con sentido léxico, el más habitual StandardTokenizer (espacios, puntuación)
▪ Filters: revisan las cadenas de tokens y los manipulan, transforman, ignoran o crean nuevos (stemming/raíz semántica)
Tokenizers and Filters pueden ser combinados para formar cadenas, que resultan en un proceso de transformación dónde la
salida de uno es la entrada del siguiente para mejorar la búsqueda o la idexación.
▪ ResponseWriters: Componentes que serializan y transmiten la respuesta al cliente.
2. Arquitectura (V): Lucene/Solr Plugins
21
schema.xml
solrconfig.xml
Function QParser
sqrt
sum
pow
custom
max
log
MyCustom QParser
Dismax QParser
eDismax QParser
Standard QParser
Lucene QParser
< index configuration />
< caching configuration />
< request handler config />
< search component config />
< update processor config />
< misc – HTTP cache, JMX >
<queryParser
name="myCustomParser"
class="org.training.solr.queryp
arser.CustomQParserPlugin"/>
Standard Tokenizer
Analyzer para campo “titulo”
CustomFilter
SynonymFilter
Porter Stemmer
// Definición de tipos y analizers
// de manera declarative por campo
<fieldType name=“txtTraining”>
<filter=“whitespace”>
<filter=“customFilter” …>
<filter=“synonyms” file=..>
<filter=“porter” except=..>
</fieldType>
<field name=“titulo”
type=“txtTraining”/>
<field name=“custom” class=…
Analyzer para campo “custom”
(Arquitectura totalmente
personalizada not using
tokenizer/filters)
Declaración de Análisis per-field- Tokenizer para dividir el texto.- Filter para transformer cada token.- Analyzer personalizado. Puede
configurarse por separado para la fase de consulta o de indexación (query/index)
QParser plugins- Soporte de diferentes sintáxis para las
consultas- Soporte para diferentes ejecuciones el
las consultas.- Soporte de las Function Queries para
funciones personalizadas en las consultas- Soporte para la anidación o mezcla de
distintos tipos de consulta en la mismarequest.
2. Arquitectura (VI): Arquitectura de Query Plugin
22
/select RequestHandler
Query Component
Facet Component
Highlight Component
Debug Component
Distributed Search
MoreLikeThis StatisticsTerms
SpellcheckTermVector QueryElevation
My Custom
Binary response
writer
JSON response
writer
Custom response
writer
Request Handler
(non-component based)
/admin/luke
Request Handler (custom)
/mypath XML response
writer
XSLT response
writer
http://.../select?q=training&wt=json
Query Response
{“response”={“docs”={
Additional plug-n-play search components
Clustering
2. Arquitectura (VII): Request Plugin
23
XML Update Handler
CSV Update Handler
/update /update/csv
XML Update with custom
processor chain
/update/xml
Extracting RequestHandler(PDF, Word, …)
/update/extract
LuceneIndex
Data ImportHandler
Database pullRSS pullSimple
transforms
SQL DB
RSS feed
<doc><title>
Remove Duplicates processor
Logging processor
Index processor
Custom Transform processor
HTTP POSTHTTP POST
pull
pull
Update Processor Chain (por handler)
Lucene
Text Index Analyzers
2. Arquitectura (VIII): Indexing
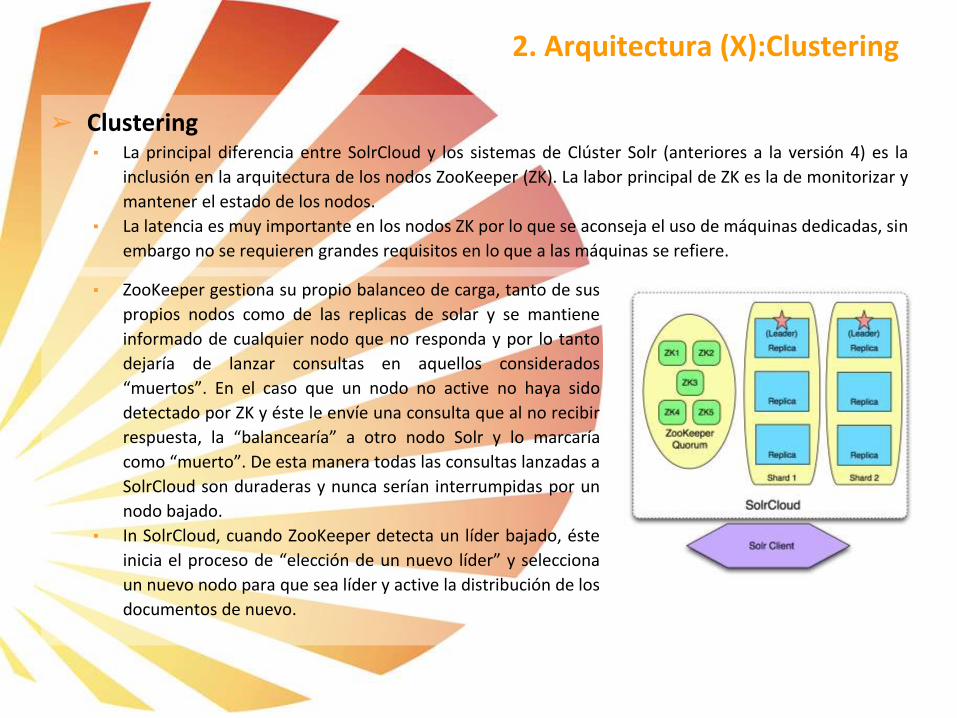
➢ Clustering▪ La principal diferencia entre SolrCloud y los sistemas de Clúster Solr (anteriores a la versión 4) es la
inclusión en la arquitectura de los nodos ZooKeeper (ZK). La labor principal de ZK es la de monitorizar y
mantener el estado de los nodos.
▪ La latencia es muy importante en los nodos ZK por lo que se aconseja el uso de máquinas dedicadas, sin
embargo no se requieren grandes requisitos en lo que a las máquinas se refiere.
2. Arquitectura (X):Clustering
▪ ZooKeeper gestiona su propio balanceo de carga, tanto de sus
propios nodos como de las replicas de solar y se mantiene
informado de cualquier nodo que no responda y por lo tanto
dejaría de lanzar consultas en aquellos considerados
“muertos”. En el caso que un nodo no active no haya sido
detectado por ZK y éste le envíe una consulta que al no recibir
respuesta, la “balancearía” a otro nodo Solr y lo marcaría
como “muerto”. De esta manera todas las consultas lanzadas a
SolrCloud son duraderas y nunca serían interrumpidas por un
nodo bajado.
▪ In SolrCloud, cuando ZooKeeper detecta un líder bajado, éste
inicia el proceso de “elección de un nuevo líder” y selecciona
un nuevo nodo para que sea líder y active la distribución de los
documentos de nuevo.

➢ Clustering▪ El Log de Transacciones (transaction log) asegura que todos los nodos de un mismo shard
están sincronizados, todas las actualizaciones son duraderas y nunca se pierden cuando un
líder se cae. De la misma manera cuando un nodo replica vuelve a levantarse en seguida es
detectado por ZK y se vuelve a unir al clúster, inmediatamente lee el transaction log para
“auto-actualizarse” con relación a las otras máquinas del shard.
▪ Si en el proceso de actualización del nodo caído ocurriera algún problema, o si el tiempo
de inactividad hubiera acumulado demasiadas pérdidas de actualizaciones, se activaría
una replicación estándar y por ultimo se volvería a lanzar el log de transacción antes de
comenzar a server las consultas.
2. Arquitectura (XI):Clustering

➢ Clustering – HA/DR - High Availability/Disaster Recovery▪ En SolrCloud SolrCloud se sustituye el concepto de "masters" y "slaves" por el de
"replicas". Cuando una replica tiene ciertas responsabilidades adicionales se le llama
“leader”, pero un leader y una replica pueden cambiar sus roles sin intervención manual,
de tal manera que cuando el leader no se encuentra disponible otra replica adquiere ese
rol automáticamente.
▪ El proceso por el que los datos son indexados y disponibles en SolrCloud es:1. Las actualizaciones se envían a cada máquina del cluster.
2. Si es necesario las actualizaciones se envían al líder.
3. El líder envía las actualizaciones a todas las replicas (una de las “responsabilidades” del leader.
4. Una vez el leader recibe el “acuse de recibo” de la actualización por parte de todas las replicas la
petición original es respondida.
• El “acuse de recibo” de las replicas no se recibe hasta que la actualización no haya sido
escrita en el log de transacción (tlogs). En este punto incluso si el proceso se interrumpe,
cuando la máquina replica se vuelva a levantar se actualize automáticamente, de tal
manera es prácticamente imposible la perdida de información.
5. Si el “Near Real Time (NRT)” está configurado, las actualizaciones son casi inmediatamente
disponibles para la búsqueda.
2. Arquitectura (XII): Clustering – Características SolrCloud

➢ Clustering – HA/DR - High Availability/Disaster Recovery▪ Cuando una réplica deja de estar disponible: Con levantar un nuevo nodo Solr en el
clúster éste se une a SolrCloud automáticamente (la instancia debe tener el parámetro -
DzkHost especificado). A partir de este punto:
o El nuevo nodo pregunta al Zookeeper ensemble cual es el rol que debe adoptar. Ya
que esta máquina ha sido recién “presentada” en el clúster, es casi seguro que será
una réplica.
o La nueva máquina automáticamente recibe una nueva version de el índice.
o Cualquier actualización en el log de transacción del leader es enviada a la nueva
máquina para que ésta lo indexe.
o Casi todo se realiza de forma directa y automática. Los archivos de configuración
(incluídos schema.xml, solrconfig.xml, etc) son instalados en la nueva máquina y el
índice.
o Todas las peticiones de búsqueda son automáticamente enrutadas a la nueva
máquina después de que ése se haya puesto al día.
2. Arquitectura (XIII): Clustering – Características SolrCloud

➢ Clustering – HA/DR - High Availability/Disaster Recovery▪ Cuando un líder deja de estar disponible:
o Los nodos de SolrCloud activos detectan que el líder no está disponible gracias a
Zookeeper.
o Una de las replicas restantes es elegida como leader y el cluster continua
comportándose como antes.
o Si se necesita seguir con la capacidad de replicación de antes de la caída del leader se
añadiría una nueva máquina como hemos comentado en el punto anterior.
o Se debe tener en cuenta que las actualizaciones de los índices son atómicas de
manera horizontal entre todas las replicas por lo que el Nuevo el log de transacción
del nuevo leader se encontrará actualizado, y las actualizaciones realizadas antes de
que el leader se cayera estarán almacenadas en la replica.
2. Arquitectura (XIV): Clustering – Características SolrCloud

➢ Replication. Replication: asegura que la misma parte del índice se divide entre distintos servidores. En
lugar de disponer de un índice se pueden tener todos los deseados. Todos ellos son iguales
y contiene el mismo conjunto de documentos. Con ello se consigue la redundancia y
distribuye las consultas y actualizaciones entre todos los servidores que forman parte de la
replicación.
Replication permite la redundancia de la información, enviando una petición de
actualización para cada nodo del shard.
Si el nodo es una replica, se dirigirá la petición al leader y éste hará lo propio con todas la
replicas, usando el Sistema de versionado para asegurar que cada replica dispone de la
version actualizada.
Esta arquitectura habilita que la información sea recuperada incluso tras un “desastre”
incluso con usando las capacidades Near Real Time de la búsqueda.
Sharding divide un índice entre varios servidores. Es decir los índices no son iguales los
documentos A y B pueden estar en el servidor 1, mientras que los documentos C y D en el
servidor 2. No se aplica la redundancia pero el índice puede crecer más que si estuviera en
un único servidor e puede implicar una mejora de rendimiento en las búsquedas.
2. Arquitectura (XV): Replication & Sharding

➢ Replication & Backup. SolrCloud no dispone de un Sistema de backup integrado avanzado, que permita crear Planes de copias
de seguridad de la información, con el fin de programar cuándo y de qué manera se realizarán las
copias de seguridad. Se encuentra en el “roadmap” del producto la introducción “out of the box” de un
sistema de backup(ver. https://issues.apache.org/jira/browse/SOLR-5750)
Actualmente lo que se habilita es una manera de realizar copias de seguridad usando la API
(ReplicationHandler) de manera similar a:http://host:port/solr/replication?command=backup&location=/path/to/backup/dir/date
Como “buena práctica” en este sentido, es altamente recomendable la creación de un script que podría
ser lanzado de forma temporizada, modo daemon. El script podría incluir la creación del directorio con
la fecha correspondiente en el momento de la realización del backup, la compresión del resultado ya
que éste no viene comprimido y el número total de backups que se guardaran de tal manera que
elimine los backups antiguos.
El resultado de la acción “backup”, es crear un directorio con los ficheros que contienen la información
del índice. Si tuviéramos más de un “shard” de índice, aparecerían tantos directorios como “shards”,
en la arquitectura propuesta no se ha fraccionado el índice en distintos “shards” por lo que no debería
aparecer más de un “snapshot” del índice.
El método de restauración es muy sencillo, entramos en la carpeta creada tras el backup en el
directorio indicado en el parámetro “location” (la carpeta tiene como prefijo “snapshot”) y únicamente
se debe substituir el contenido del directorio en la carpeta:
2. Arquitectura (XVI): Replication & Sharding

➢ Sharding. Sharding: divide un índice entre varios servidores. Es decir los índices no son iguales los
documentos A y B pueden estar en el servidor 1, mientras que los documentos C y D en el
servidor 2. No se aplica la redundancia pero el índice puede crecer más que si estuviera en
un único servidor e puede implicar una mejora de rendimiento en las búsquedas.
Pese a que es posible dividir una collection (shard), no es aconsejable. La funcionalidad
para dividir shards se encuentra en la API de Collections. Esto realmente permite dividir el
shard actual en dos piezas (otros 2 shards). El shard “original” no se modifica, por lo que
esta acción lo que hace efectivamente es copiar los datos en los nuevos shards,
posteriormente se puede borrar el shard original en cualquier momento más adelante
cuando haya pasado un periodo de test. En las últimas versiones el shard “original” se
coloca en estado inactivo.
Gracias al Sharding se distribuye el coste de rendimiento entre múltiples nodos.
Se Paraleliza el coste de las operaciones complejas como ordenaciones y categorización
(sort & facet) entre los distintos sistemas.
Un índice más pequeño = menor JVM heap == menor problemas de GC .
Un índice más pequeño = menor problemas con la caché del OS (MMapDirectory)
La sintaxis rest-style es:http://ip:port/solr/admin/collections?action=SPLITSHARD&shard=shard1&name=collection1
2. Arquitectura (XVII): Replication & Sharding

➢ Monitorización Aunque existen muchas herramientas en el Mercado para monitorizar SolrCloud (Nagios,
OpsView (Nagios fork), Traceview, SPM (Semantext), Zabbix y Ganglia). En general, todas
ellas resultan útiles. Solo a modo de referencia por experiencia propia:
SPM, Traceview como Opsview, no son 100% open Source. OpsView demuestra
problemas de compatibilidad con algunas de las distribuciones Debian actuales y más
comunes (Ubuntu 14.04), por lo que no es aconsejable al al 100%.
Nagios es una de las herramientas más habituales y difundidas, existen una gran cantidad
de conectores (script plugins) que permiten capturar los eventos de Solr y monitorizar
recursos de cada nodo del clúster.
Ganglia es la herramienta que más he usado y configurado en los proyecto en los que he
trabajado. Totalmente OpenSource.
Funciona interceptando los mensajes JMX que SolrCloud realiza por evento. Es
necesario activa JMX para SolrCloud, de tal manera que exponga cada evento.
Ganglia funciona con un servidor aglutinador de la información y en el que se
encuentra el entorno gráfico y un “agente” que se instala en cada host que se desea
monitorizar y que se responsabiliza de interactuar con el S.O. para adquirir las
métricas que nos interesan recoger.
2. Arquitectura (XVIII): Monitorización y mantenimiento

➢ Mantenimiento Las acciones de mantenimiento más habituales son las basadas en la mejora de
rendimiento en indexación y búsquedas. Los tiempos de respuesta en entornos críticos y
de alta carga requieren estructurar planes de mantenimiento a varios niveles.
Hay muchos aspectos a tener en cuenta para mantener el índice de nuestro clúster
SolrCloud entre los más importantes.
Debe existir coherencia entre el sharding y la replicación del índice, cuanto más se
replica el índice más copias de la información se mantienen en el cluster y por lo
tanto en general la Replicación y en general la Alta disponibilidad va en contra del
Alto Rendimiento.
Un índice que aumenta en exceso, implica mayor duración en la reindexación y en las
búsqueda para ello se aconseja el sharding.
En determinadas ocasiones, son los clientes (SolrJ) los que pueden influir en un
mejor rendimiento. Las actualizaciones de campos parciales, el softcommit,
indexación por bloques o entre fechas, pueden ser estrategias apropiadas para llevar
a cabo en muchas ocasiones.
Por supuesto una buena personalización de Solr (SolrConfig.xml y Schema.xml) son
fundamentales para obtener el mejor resultado en las búsquedas, no todo los
campos deben ser indexados o almacenados
2. Arquitectura (XIX): Monitorización y mantenimiento

➢ Mantenimiento Algunas acciones previas puede ser la elección de la Directory Factory, según lo deseado.
solr.SimpleFSDirectoryFactory: basado directorios del filesystem, puede tener
problemas de escalado en sistemas con un alto número de threads.
solr.NIOFSDirectoryFactory: Funciona muy bien con un alto número de threads, no
es recomendado en plataformas Windows, por varios bugs de JVM detectados.
solr.MMapDirectoryFactory: Es muy habitual en entornos Linux, usa memoria virtual
y las propiedades mmap del kernel para acceder a los ficheros del índice
almacenados en disco.
solr.NRTCachingDirectoryFactory: Almacena algunas partes del índice en memoria,
funciona muy bien para operaciones NRT (near real-time).
solr.RAMDirectoryFactory: Almacena toda los datos en RAM. Es muy rápida (en
entornos controlados) pero no persiste en disco en ningún momento.
La realización de pruebas de stress para encontrar la mejor opción para el sistema de
directorios es obligatorio.
2. Arquitectura (XX): Monitorización y mantenimiento
Paradigma Tecnológico
Servicios de formaciónIndexación
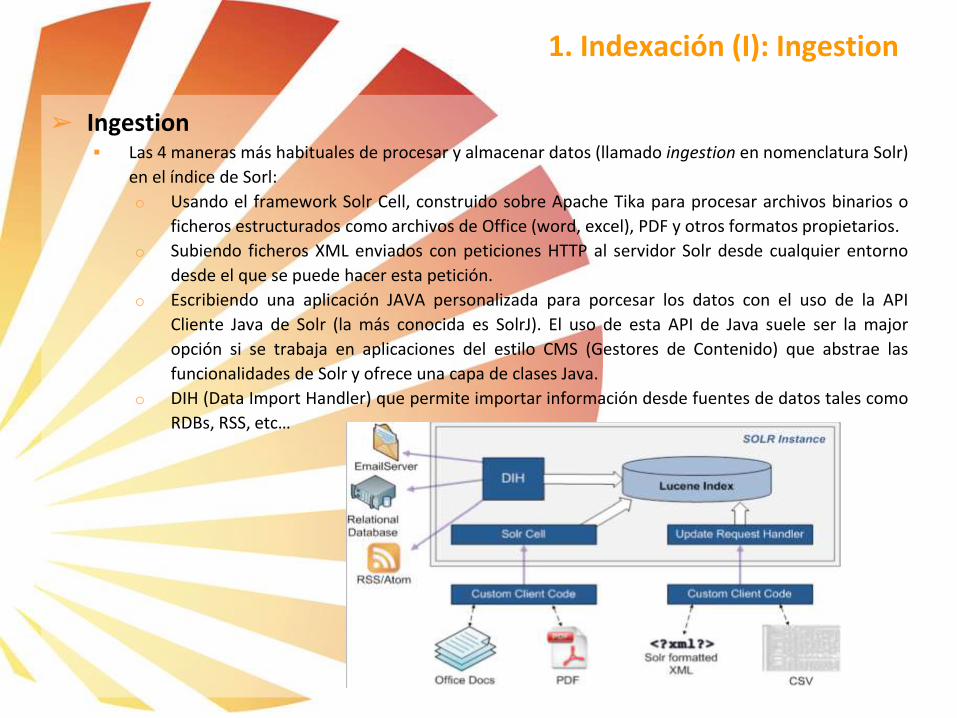
1. Indexación (I): Ingestion
➢ Ingestion Las 4 maneras más habituales de procesar y almacenar datos (llamado ingestion en nomenclatura Solr)
en el índice de Sorl:
o Usando el framework Solr Cell, construido sobre Apache Tika para procesar archivos binarios o
ficheros estructurados como archivos de Office (word, excel), PDF y otros formatos propietarios.
o Subiendo ficheros XML enviados con peticiones HTTP al servidor Solr desde cualquier entorno
desde el que se puede hacer esta petición.
o Escribiendo una aplicación JAVA personalizada para porcesar los datos con el uso de la API
Cliente Java de Solr (la más conocida es SolrJ). El uso de esta API de Java suele ser la major
opción si se trabaja en aplicaciones del estilo CMS (Gestores de Contenido) que abstrae las
funcionalidades de Solr y ofrece una capa de clases Java.
o DIH (Data Import Handler) que permite importar información desde fuentes de datos tales como
RDBs, RSS, etc…

1. Indexación (II): Ingestion
➢ Ingestion Sea cual sea el método de procesamiento de los datos, hay una estructura básica común para que los
datos alimenten el índice de Solr: Un documento que contiene múltiples campos, cada uno con un
nombre y un contenido que puede estar vacío. Uno de los campos es habitualmente designado como
clave primaria o ID único aunque este campo tampoco es estrictamente requerido en Solr.
El funcionamiento de Solr por defecto es el de intentar optimizar en todo momento el índice, por lo
que si en un documento que se precisa indexar el nombre del campo se encuentra en el archivo
schema.xml este fichero se asociará con el índice y todos los pasos del proceso de análisis (tokenizer,
filters, etc…) se le aplicarán a su contenido.
Los campos que no están definidos explícitamente en el esquema de datos de Solr puede ser
ignorados o mapeados en un campo dinámico (Dynamic Field) si existe “matching con el nombre del
campo procesado.

1. Indexación (III): Ingestion
➢ Ingestion via Solr XML HTTP HTTP POST a /update.
El formato del fichero xml a consta de las siguientes etiquetas:
o El elemento <add> indica que el documento o los documentos deben ser procesados para
añadirse al índice según sea preciso (según schema.xml)
o El elemento <doc> refleja que a continuación se listarán los campos de un documento.
o El elemento <field> presenta el contenido de un campo específico.<add>
<doc>
<field name="id">0001A</field>
<field name="tipo">text/xml</field>
<field name="categoria">accesorios_de_interior_de_armario</field>
<field name="titulo">Cesta rejilla lateral Spaceo</field>
<field name="fichero_caracteristicas">centa_rejilla_lateral.xml</field>
<field name="contenido">Cesta de rejilla indicada para colocar tu ropa y
complementos dentro del armario. De 80 x 50 cm. Es extraíble para acceder a su
contenido con una mayor comodidad.</field>
</doc>
<doc boost=“1.5">
...
</doc>
</add>

➢ Ingestion via Solr XML HTTP Existen algunos parámetros que pueden modificar determinados aspectos de como Solr tratará la
información del documento
En la mayoría de los casos no es aconsejable utilizar el boost en tiempo de indexación ya que ese valor
se queda fijado en el índice. Para mayor flexibilidad se aconseja el uso de boost en tiempo de consulta
con los Qparser Dismax o eDismax
Si el schema.xml define claves únicas, por defecto la operación /update para añadir un documento
sobrescribirá, es decir, sustituirá el documento que se encuentre en el índice con la misma clave única.
Si no se define una clave única en tiempo de “actualización” el rendimiento de la indexación será algo
más rápido, ya que no se debe validar la existencia previa del documento a reemplazar.
Si existe una clave única, pero se puede obviar la revisión de clave única, (por ejemplo por que se
construye el índice con un proceso batch y el código de indexación garantiza que nunca se añade el
mismo documento más de una vez) se podría especificar la opción overwrite="false" para añdir tus
documentos.
1. Indexación (IV): Ingestion
<add> commitWithin=number El documento se añadirá al índice tras el número especificado en milisegundos.
<add> overwrite=boolean Por defecto es true. Indica si la clave primaria debe ser revisada para sobre escribir una versión previa del documento.
<doc> boost=float Por defecto es 1.0. Da un valor de boost al documento.
<field> boost=float Por defecto es 1.0. Da un valor de boost para el campo

➢ Ingestion via Solr XML HTTP Ejemplos de usos de la indexación vía Solr XML (HTTP requests), para ello usamos curl para realizar las
peticiones HTTP y realizar las actualizaciones mediante el Update Request Handler.
1. Se puede usar la opción curl --data-binary para anexar el mensaje XML al commando curl y generar la
request HTTP POST:curl http://[solr_host]:[solr_port]/solr/mi_collection/update -H "Content-Type: text/xml" --data-binary '
<add>
<doc>
<field name="id">0001A</field>
<field name="tipo">text/xml</field>
<field name="categoria">accesorios_de_interior_de_armario</field>
<field name="titulo">Cesta rejilla lateral Spaceo</field>
<field name="fichero_caracteristicas">centa_rejilla_lateral.xml</field>
<field name="contenido">Cesta de rejilla indicada para colocar tu ropa y complementos dentro del armario. De
80 x 50 cm. Es extraíble para acceder a su contenido con una mayor comodidad.</field>
</doc>
</add>‘
2. También se puede hacer POST de los mensajes XML contenidos en un fichero con la siguiente sintaxis:curl http://[solr_host]:[solr_port]/solr/mi_collection/update -H "Content-Type: text/xml" --data-binary
@midoc.xml
1. Indexación (V): Ingestion

➢ Ingestion via CSV Es posible realizar indexaciones de contenidos almacenados en ficheros CSV.
1. Se puede usar la opción curl --data-binary para anexar el fichero CSV y posteriormente se le indica el
tipo de contenido añadiendolo en el Head con la opción -H:
curl “http://[solr_host]:[solr_port]/solr/update?rowid=id" --data-binary @myfile.csv -H 'Content-
type:application/csv; charset=utf-8‘
2. El CSV Update Handler permite también recoger el fichero almacenado en el File System de la
siguiente forma:
curl ‘http://[solr_host]:[solr_port]/solr/update/csv?stream.file=exampledocs/
data.csv&stream.contentType=text/plain;charset=utf-8’
Entre los muchos parámetros que permite este handler está el de especificar el separador, skip
fieldnames, borrar espacios en blanco (trimming), el encapsulador de cadenas de texto, etc…
curl http://[solr_host]:[solr_port]/
solr/update/csv?commit=true&separator=%09&escape=\&stream.file=/tmp/myfile.text'
1. Indexación (VI): Ingestion

➢ Ingestion de Rich Documents – Apache Tika Apache Tika is una herramienta para detector y extraer metadata y contenido textual estructurado de
varios formatos de document con el uso de librerías de análisis (parsers).
Tika es capaz de identificar el tipo MIME y usar el “parser” apropiado para extraer su contenido para
posteriormente indexarlo. Para ello usa el manejador: ExtractingRequestHandler (Solr Cell – Content
Extraction Library) para las tareas de extracción del texto e indexación. which stands for Content
Extraction
Entre los tipos de formatos que puede analizar están: MS Office, Adobe PDF, XML, HTML, MPEG y
muchos otros.
La configuración de Solr debe activar este Handler, de manera parecida a:
1. Indexación (VII): Ingestion

➢ Ingestion de Rich Documents – Apache Tika Particularidades de ExtractingRequestHandler :
Es possible para añadir otros campos no indexados usando Tika en los documentos enriquecidos,
para ello usamos el parámetro literal
- &literal.id=12345
- &literal.category=sports
Un ejemplo de orden para indexer un fichero html:
curl 'http://[solr_host]:[solr_port]/solr/update/extract?literal.id=doc1&commit=true' -F
Como ocurre con los ficheros CSV se puede hacer “Streaming” del fichero que se encuentre en el
sistema de archivos :
Curl 'http://[solr_host]:[solr_port]/
solr/update/extract?stream.file=/path/news.doc&stream.contentType=application/msword&literal.id=12345’
Incluso permitiría hacer con ficheros remotos siempre que se encuentren accesibles:curl 'http://[solr_host]:[solr_port]/
solr/update/extract?literal.id=123&stream.url=http://www.solr.com/content/articulo.pdf -H
'Content-type:application/pdf’
1. Indexación (VIII): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Existen diferentes técnicas para llevar a cabo la indexación con información procedentes de fuentes de
datos como bases de datos, rss, servidores de email:
o Uso de DIH (Data Import Handler)
o Custom script.
El obstáculo más común en estas operaciones de ingestion es el rendimiento de la operación y el
“flattening” es decir el “aplanamiento” de la información que se encuentra almacenada en ficheros
estructurados con mucha información innecesaria para su almacenamiento.
El DataImportHandler (DIH):
o Permite una configuration driven.
o Puede agregar datos que provengan de multiples tablas de una misma base de datos e incluso de
distintas fuentes de información, agrupando todo en un único documento Solr a indexar.
o Proporciona una muy personalizable herramienta de transformación de datos.
o Puede hacer “full imports” y “delta imports”.
Es “Connectable” (Pluggable) para permitir la indexación desde cualquier tipo de fuente de datos,
incluso realizando conectores personalizados.
1. Indexación (IX): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Pueden ser configuradas una o más instancias de DIH mediante su propio fichero de configuración
Cada instancia de DIH debe ser declarada en el fichero solrconfig.xml y se le debe proporcionar un
nombre único:<requestHandler class="org.apache.solr.handler.dataimport.DataImportHandler“ name="/dataimport">
<lst name="defaults">
<str name="config">db-config.xml</str>
</lst>
</requestHandler>
Permite la conexión a fuentes de datos tales como: Bases de datos relacionales, ficheros planos, XML,
RSS, servidores de email.
Las partes de DIH son:
o Procesadores de entidades (Entity processors): Elementos de configuración que trabajan con las
fuentes de datos. Existe la posibilidad de extender EntityProcessor para crear el apropiado para
nuestra fuente de datos.
o Transformadores (Transformers): Modifican los datos de muchas maneras diferentes, puedes ser
encadenados para que realicen varias transformaciones secuencialmente. Es posible escribir un
transformador personalizado que permita el parsing específico que nuestro proyecto necesita.
1. Indexación (XII): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Las Fuentes de datos de las que permite importar información DIH son:
o Bases de datos. (SQL entity processor, Jdbc datasource)
o RSS o Atom feeds. (XPath entity processor, URL datasource)
o Ficheros XML. (Xpath entity processor, File datasource)
o Ficheros de texto plano. (Plaintext entity processor, File datasource)
o Desde un servidor de email. (Mail entity processor)
Configuraciones de ejemplo posibles:
o SQL entity processor:
1. Indexación (XIII): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Configuraciones de ejemplo posibles:
o Xpath Entity Processor:
1. Indexación (XIV): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Configuraciones de ejemplo posibles:
o Mail Entity Processor:
1. Indexación (XV): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Entrando en detalles sobre los Data Sources más habituales disponibles:
JdbcDataSource: Es el que se especifica por defecto, permite iterar por los registros de una base
de datos uno a uno..
URLDataSource: Se usa para extraer contenido usando localizaciones file:// o http://
FileDataSource: Similar al URLDataSource, pero las localizaciones son especificadas en el
parámetro "basePath".
La clase org.apache.solr.handler.dataimport.DataSource puede ser extendida para manejar
fuentes datos personalizadas.
Entrando en detalles sobre los Entity Processors más habituales disponibles:
SqlEntityProcessor: Es el procesar por defecto si no se especifica ninguno, funciona con un
JdbcDataSource para indexer las tablas de base de datos.
XPathEntityProcessor: Implementa streaming parser (flujos de informaciones) las cuales
soportan sub conjuntos de órdenes con sintaxis xpath, aunque no da soporte complete para
sintaxis xpath aún.
FileListEntityProcessor: No usa un DataSource. Enumera una lista de ficheros y es usado
habitualmente com una entidad “externa” (“outer” entity), para ser aprovechada por cualquier
otra entidad.
CachedSqlEntityProcessor: Extensión de SqlEntityProcessor reduce el número de queries
ejecutadas “cacheando” las filas (Funciona únicamente para entidades anidadas)
PlainTextEntityProcessor: Lee texto de un fichero “plain text".
1. Indexación (XVI): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Los Transformers:
o Los campos procesados puede ser indexados directamente o transformados y modificados.
o Pueden crearse nuevos campos a indexar.
o Pueden ser anidados.
Transformadores que incorpora DIH
RegexTransformer: Manipula un fichero usando regular expressions.
DateFormatTransformer: Analiza y transforma objetos string con formatos date/time con el uso
de la clase java.util.Date
NumberFormatTransformer: “Parsea” numeros desde cadenas de texto.
TemplateTransformer: Especifica un valor de texto a un campo recuperado.
HTMLStringTransformer: Elimina etiquetas HTML.
ClobTransformer: Crea una cadena de texto dese un tipo de dato CLOB.
ScriptTransformer: Escribe transformadores personalizados en JavaScript.
1. Indexación (XVII): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler Los Transformers:
o Los campos procesados puede ser indexados directamente o transformados y modificados.
o Pueden crearse nuevos campos a indexar.
o Pueden ser anidados.
Transformadores que incorpora DIH
RegexTransformer: Manipula un fichero usando regular expressions.
DateFormatTransformer: Analiza y transforma objetos string con formatos date/time con el uso
de la clase java.util.Date
NumberFormatTransformer: “Parsea” numeros desde cadenas de texto.
TemplateTransformer: Especifica un valor de texto a un campo recuperado.
HTMLStringTransformer: Elimina etiquetas HTML.
ClobTransformer: Crea una cadena de texto dese un tipo de dato CLOB.
ScriptTransformer: Escribe transformadores personalizados en JavaScript.
1. Indexación (XVIII): Ingestion

➢ Ingestion desde fuentes de datos – Data Import Handler DIH Full y Delta Imports:
El Elemento deltaQuery se rellena con la clave primaria de la entidad que haya tenido cambos desde la
última indexación (el resultado de un consulta sql), Esa clave primaria será usada para
deltaImportQuery.
El Elemento deltaImportQuery recoge los datos necesarios para rellenar los campos cuando se realiza
el delta-import
➢ Ingestion uso de librerías – SolrJ Librería Java que permite llamar los servicios de Solr mediante clases Java de esta manera
conseguimos abstraernos del método de Ingestion y realizar una aplicación totalmente personalizada.
1. Indexación (XIX): Ingestion

➢ schema.xml: Archivo XML que define las estructura de datos a indexar.
➢ Estructura de un campo campo:
<field name=“nombre de campo" type=“tipo de dato" />
➢ Tipos de Datos: Definidos por clases java. Existen tipos predefinidos y es posible definir tipos custom para
tipos de datos complejos. Se pueden definir tokenizers (separadores de términos) y filters (adaptadores y
modificadores de los términos) en este nivel para que Solr indexe de manera apropiada cada uno de los
términos.
➢ Parámetros opcionales:
▪ default: Valor a usar si no se recibe ninguno
▪ required: Define si un campo es obligatorio.
▪ indexed: Determina si un campo es buscable u ordenable.
▪ stored: Determina si un campo se puede recuperar en una consulta.
▪ multiValued: El campo contiene más de un valor.
▪ Se pueden crear dynamicFields y copyFields, el primero permite tratar campos sin nombre previo
establecido, únicamente indicando un prefijo o sufijo. Los copyFields que permite copiar los contenidos de
un campo (o todos los campos) en otro de destino.
1. Indexación (XX): Esquema de datos

➢ Otras inicializaciones que se pueden parametrizar en el archivo schema.xml son:
<uniqueKey>id</uniqueKey> //Unique Key para los documentos del índice
<defaultSearchField>field</defaultSearchField> //Campo de búsquedas por defecto
<solrQueryParser defaultOperator="OR" /> //Operador por defecto
➢ Canales para el envío de documentos:
▪ Petición HTTP: Envío de instrucción y datos asociados vía HTTP POST.
▪ Cliente Solrj: Cliente java. Permite realizar las diferentes operaciones sobre el índice y enviar la
información en diferentes formatos.
➢ Fuentes de datos para la indexación:
▪ XML: Coherente con la estructura de datos definida.
▪ Objetos Java: Representación binaria del documento XML.
▪ CSV: Documento de texto con valores separados.
▪ Documentos enriquecidos: PDF, XLS, DOC, PPT, …
▪ Base de Datos: Adaptador intermedio (DataImportHandler).
Indexación (XXI): Esquema de datos

Manos a la obra

➢ SolrCloud permite la búsqueda en uno o más shards del índice, así como en una o varias colecciones en la misma consulta.
➢ La arquitectura distribuida de SolrCloud nos permite imaginar una situación en la que tenemos un cluster donde se han
realizado varios shards del índice con sus respectivas replicas. En ese tipo de escenarios, los datos son distribuidos
automáticamente entre todos los shards y posteriormente replicados en sus respectivas réplicas.
➢ El sharding es automático y controlador por SolrCloud (con la ayuda de los ZK).
➢ Podemos realizar pruebas de funcionamiento del Sharding con comandos HTTP.1. http://[solr_host]:[port_host]/solr/collection1_shard1_0_replica1/select?q=*%3A*&rows=0&distrib=false
Obtendríamos un resultado:<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response" numFound="2" start="0"/>
</response>
2. http://[solr_host]:[port_host]/solr/collection1_shard1_1_replica1/select?q=*%3A*&rows=0&distrib=false
Obtendríamos un resultado:<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">0</int>
</lst>
<result name="response" numFound=“1" start="0"/>
</response>
3. http://[solr_host]:[port_host]/solr/collection1_shard1_1_replica1/select?q=*%3A*&rows=0&distrib=true<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">12</int>
</lst>
<result name="response" numFound="3" start="0" maxScore="1.0"/>
</response>
Indexación (XXII): Indexación Distribuida

➢ Es posible detener la distribución automática de documentos aunque exista una configuración distribuida
configurada con varios Sharding. Por requisitos del proyecto es posible querer tener controlada esta
distribución para poder posteriormente realizar la búsqueda sobre la parte del índice que quisiéramos, de
esta manera disminuiríamos los tiempos tanto de indexación como de búsqueda.
➢ Para ello únicamente lo tenemos que especificar en la configuración de Solr (archivo solrconfig.xml) de la
siguiente forma:
<updateRequestProcessorChain>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
<processor class="solr.NoOpDistributingUpdateProcessorFactory" />
</updateRequestProcessorChain>
➢ Posteriormente podríamos realizar las actualizaciones en el shard elegido simplemente indicándoselo al
comando /update (del UpdateHandler)
http://[solr_host]:[port_host]/solr/shard1/update -H "Content-Type: text/xml" --data-binary @midoc.xml
Indexación (XXIII): Indexación Distribuida

Paradigma Tecnológico
Servicios de formaciónBúsqueda

➢ Los parámetros de búsqueda más comunes, es decir los que hacen referencia al SimpleQueryParser
(LuceneQueryParse extendido) son:
q: Petición con formato “campo:valor”
start: Documento inicial a partir del cual se van a mostrar los resultados. (se indica un número entero)
rows: Indica el número máximo de resultados a mostrar.
facets: Indica si se desean mostrar facetas. Este parámetro tiene otros adicionales que permiten
limitar y detallar más las búsquedas
facet_queries:
facet_fields: campos por los que evaluar las facetas.
facet_dates: intervalo de fechas
facet_ranges: límite de resultados (rangos)
Cualquier campo indexado, multivalue y con field type String se convierte automáticamente en un
facet al realizar la query. Lo habitual es crear un campo “categoría” para almacenar esta información,
si la categorización es muy amplia (imaginemos versiones de sistema operativo, o modelos de móvil)
se pueden usar DynamicFields para que sean usados como facets.
sort: Define la ordenación de los resultados. Ordenaciones combinadas. Formato de ordenaciones:
“precio desc, nombre asc”
fl: Campos que se devuelven en la respuesta
fq: Mismo formato que “q”. Limita la query (actúa como filtro). Los resultados se cachean.
Búsqueda (I): Parámetros y ejemplos de búsquedas

➢ Wildcards: Solr no permite wildcards iniciales
word*: * sustituye a cualquier número de caracteres.
w?rd: ? sustituye a un único carácter.
w?*d: Pueden componerse ambos comodines.
➢ Operadores Lógicos
AND: word1 AND word2 = word1 && word2 = +word1 +word2
OR: word1 OR word2 = word1 || word2 = word1 word2
NOT: word1 NOT word2 = word1 -word2
➢ Rangos: Se expresan como “campo:[A TO B]”
➢ Boosting: Se pueden ordenar resultados dando más importancia a ciertos campos
nombre:jose^2 AND alias:pepe^0.7
➢ Fuzzy: Busca términos similares basándose en número de inserciones, borrados o intercambios de
caracteres. Puede definirse el grado de proximidad.
nombre: sony~0.9 -> Devuelve resultados con nombre “sony”
nombre: sony~0.4 -> Devuelve resultados con nombre “coby”
Búsqueda (II): Parámetros y ejemplos de búsquedas

Paradigma Tecnológico
Servicios de formaciónBúsqueda Avanzada

➢ Una de las ventajas de Solr es la habilidad de agrupar los resultados basándose en los contenidos de algunos
campos.
➢ El mecanismo de clasificación de Solr, llamado Faceting, proviene muchas funcionalidades que son casi
indispensables en los buscadores de la mayoría de portales actuales. Entre otras muchas cosas nos permite
conocer el número de documentos con el mismo valor en un campo, y complementarlo con la posibilidad de
filtrar por fechas y rangos (date and rage faceting)
➢ Una descripción más genérica de “Faceting” (facetado) en Solr es la manipulación y el cambio de
organización de los resultados de una búsqueda según la categoría deseada basada en términos indexados.
➢ El resultado de la búsqueda facetada, es la presentación de los términos indexados siguiendo la
categorización estipulada, junto con recuentos numéricos de las coincidencias de cada uno de los términos.
➢ Faceting hace que sea fácil para los usuarios explorar los resultados de búsqueda, filtrando exactamente los
resultados que está buscando.
➢ Algunos consejos de rendimiento a tener en cuenta:
El método de facetado facet.method=fc consume menos memoria cuando un campo tiene un número
de términos únicos (distinct terms, es decir sin ser un campo abierto) asociados a él en el índice.
Siempre es recomendable obtener un resultado acotado en los resultados de las consultas y no
permitir cálculos de facetado demasiado complejos.
Búsqueda Avanzada (I): Facets

➢ Recuperar el número de documentos con el mismo valor en un campo: Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“ciudad" type="string" indexed="true" stored="true" />
Dado el caso en el que tuviéramos indexados tres documentos, dos documentos con valor “Barcelona” en el campo
ciudad, y un tercero con valor “Madrid” en ese mismo campo.
Si realizamos la siguiente búsqueda facetada:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.field=ciudad
A la respuesta de resultados xml habitual, se le añade al final lo relacionado a la búsqueda facetada:
…
<lst name="facet_counts“>
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name=“ciudad"><int name=“Barcelona">2</int><int name=“Madrid">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>
…
Búsqueda Avanzada (II): Facets. Ejemplos

➢ Recuperar el número de documentos que se encuentra entre el mismo rango de valores.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“precio" type="float" indexed="true" stored="true" />
o Dado el caso en el que tuviéramos indexados cuatro documentos, con el campo precio de cada uno los valores: 99.90,
290, 210, 50
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&rows=0&facet=true&facet.range=precio&facet.range.start=0&facet
.range.end=400&facet.range.gap=100
o A la respuesta de resultados xml habitual, se le añade al final lo relacionado a la búsqueda facetada:
…
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
<lst name="facet_ranges">
<lst name="price">
<lst name="counts"><int name="0.0">2</int><int name="100.0">0</int><int name="200.0">2</int><int name="300.0">0</int>
</lst><float name="gap">100.0</float><float name="start">0.0</float><float name="end">400.0</float>
</lst></lst>
</lst>
…
Búsqueda Avanzada (III): Facets. Ejemplos

➢ Recuperar el número de documentos que coinciden con una query y una subquery.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“precio" type="float" indexed="true" stored="true" />
o Dado el caso en el que tuviéramos indexados cuatro documentos, con el campo precio de cada uno los valores: 70, 101,
201, 99.90
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.query=precio:[10 TO
80]&facet.query=precio:[90 TO 300]
o A la respuesta de resultados xml habitual, se le añade al final lo relacionado a la búsqueda facetada:
…
<lst name="facet_counts">
<lst name="facet_queries">
<int name="precio:[10 TO 80]">1</int>
<int name="precio:[90 TO 300]">3</int>
</lst>
<lst name="facet_fields"/>
<lst name="facet_dates"/>
</lst>
…
Búsqueda Avanzada (IV): Facets. Ejemplos

➢ Eliminando filtros de los resultados de la búsqueda facetada.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“ciudad" type="string" indexed="true" stored="true" />
<field name=“provincia" type="string" indexed="true" stored="true />
o Dado el caso en el que tuviéramos indexados cuatro documentos, con la dupla de ciudad-provincia:
[Barcelona,Barcelona], [Oviedo,Asturias], [Barcelona,Barcelona], [Barcelona,Barcelona]
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&fq={!tag=provinciaTag}ciudad:Barcelona&facet.field=
{!ex=provinciaTag}ciudad&facet.field={!ex=provinciaTag}provincia
o En este caso la respuesta solo mostrará los
resultados de todas aquellas que cumplan el filtro
aplicado en fq, además almacenamos ese
filtro {!tag=provinciaTag} para que el resultado de los
contadores de facet no tengan en cuenta el
filtro {!ex=provinciaTag} de los resultados y muestren
el contador de registros que coinciden con el
facet.field sin aplicar el filtro, es decir que tenga en
cuenta TODOS los documentos.
Búsqueda Avanzada (V): Facets. Ejemplos
<result name="response" numFound="3" start="0"><doc><str name="id">1</str><str name="name">Nombre 1</str><str name=“ciudad">Barcelona</str><str name=“provincia">Barcelona</str></doc><doc><str name="id">3</str><str name="name">Nombre 3</str><str name="ciudad">Barcelona</str><str name="provincia">Barcelona</str></doc><doc><str name="id">4</str><str name="name">Nombre 4</str><str name="ciudad">Barcelona</str><str name="provincia">Barcelona</str></doc></result>
<lst name="facet_counts"><lst name="facet_queries"/><lst name="facet_fields"><lst name=“ciudad"><int name=“Barcelona">3</int><int name=“Oviedo">1</int></lst><lst name=“provincia"><int name="Barcelona">3</int><int name=“Asturias">1</int></lst></lst><lst name="facet_dates"/><lst name="facet_ranges"/></lst>

➢ Recuperar los resultados de la búsqueda facetada en orden alfabético.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name=“ciudad" type="string" indexed="true" stored="true" />
o Digamos que tenemos indexados 4 documentos, el campo que nos interesa para la ordenación alfabética es el de
ciudad, los valores de ese campo para cada documento son: New York, Washington, Washington y San Francisco.
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.field=ciudad&facet.sort=index
o En este caso la respuesta muestra los datos sin
ordenar en cambio en relación a los datos de la
búsqueda facetada, los resultados están ordenados
alfabéticamente por el campo ciudad según lo
definido en la consulta para la búsqueda facetada.
Búsqueda Avanzada (VI): Facets. Ejemplos
<result name="response" numFound="4" start="0"><doc><str name="city">New York</str><str name="id">1</str><str name="name">House 1</str></doc><doc><str name="city">Washington</str><str name="id">2</str><str name="name">House 2</str></doc><doc><str name="city">Washington</str><str name="id">3</str><str name="name">House 3</str></doc><doc><str name="city">San Francisco</str><str name="id">4</str><str name="name">House 4</str></doc></result>
<lst name="facet_counts"><lst name="facet_queries"/><lst name="facet_fields"><lst name="city"><int name="New York">1</int><int name="San Francisco">1</int><int name="Washington">2</int>
</lst></lst><lst name="facet_dates"/><lst name="facet_ranges"/></lst>

➢ Implementado “autosuggest” usando facetas
o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true"required="true" />
<field name="titulo" type="text" indexed="true" stored="true" />
<field name="titulo_autocomplete" type="lowercase" indexed="true“ stored="true">
<copyField source=" titulo " dest="titulo_autocomplete" />
<fieldType name="lowercase" class="solr.TextField">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
o Tenemos en este caso indexados 4 documentos, con valores del campo título: “Lucene la base de Solr”, “Yo, yo mismo
y Solr”, “Solr me gusta”, “Solr es el Messi de los buscadores”.
o La búsqueda facetada siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&rows=0&facet=true&facet.field=title_autocomplete&facet.prefix=
so
o En este ejemplo no queremos que nos devuelva nada de la búsqueda y es por eso que indicamos “rows=0”, pero sin
embargo deseamos los datos que nos ofrece el “Faceting” el resultado sería:
<result name="response" numFound="4" start="0"/>
<lst name="facet_counts">
<lst name="facet_queries"/>
<lst name="facet_fields">
<lst name="title_autocomplete">
<int name="solr me gusta">1</int>
<int name=“solr es el Messi de los buscadores">1</int>
</lst>
</lst>
<lst name="facet_dates"/>
<lst name="facet_ranges"/>
</lst>
Búsqueda Avanzada (VII): Facets. Ejemplos

➢ Solr permite realizar ordenaciones de los resultados de las búsqueda, es posible realizarlas con referencia a
cualquier campo siempre que este sea: mutiValued=“false” e indexed=“true”, incluso si el campo en
cuestión no ha sido tokenizado (Sin Analyzer) o usara algún Analyzer que produjera un término único, es
decir, no divide en distintos términos y toma todo lo almacenado en ese campo como un término (por
ejemplo KeywordTokenizer).
➢ También permite ordenar por el “score” (nivel de matching) de un documento sin hacer referencia a ningún
campo en concreto.
Búsqueda Avanzada (VIII): Ordenaciones

➢ Ordenar los resultados por el valor de una función.o Dado este schema.xml (El mismo que en el ejemplo anterior)
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="geo" type="location" indexed="true" stored="true" />
<dynamicField name="*_coordinate" type="tdouble" indexed="true“ stored="false" />
<fieldType name="location" class="solr.LatLonType“ subFieldSuffix="_coordinate"/>
o Disponemos de 3 documentos indexados cuyo campo geo (almacenas coordenadas de geo localización), tiene un
campo de tipo location que está definido con la clase del tipo solr.LatLonType que representa una Latitud/Longitud
como un punto bi-dimensional. El campo geo de los tres documentos tienen los valores (12.2,12.2), (11.1,11.1),
(10.1,10.1)
o La búsqueda avanzada que usaremos será la siguiente
http://[solr_host]:[solr_port]/solr/select?q=*:*&pt=13,13&sort=geodist(geo,13,13)+asc
Es decir el usuario quiere realizer una búsqueda y ordernar los resultados de manera ascendente ren relación a su posición
(13,13)
o La campo dinámico “*_coordinate” es necesario para que el
tipo de campo “location” funcione y pueda ser asignado al campo
geo. Usamos una función que ya se encuentra disponible en Solr
como es “geodist” que calcula la distancia desde un punto,
finalmente como en cualquier ordenación elegimos cómo queremos
hacerla, en nuestro caso “asc” para que devuelva los resultados
ordenados del más cercano al más lejano.
Búsqueda Avanzada (IX): Ordenaciones. Ejemplos
<result name="response" numFound="3" start="0"><doc><str name="id">3</str><str name="name">Company three</str><str name="geo">12.2,12.2</str>
</doc><doc><str name="id">2</str><str name="name">Company two</str><str name="geo">11.1,11.1</str>
</doc><doc><str name="id">1</str><str name="name">Company one</str><str name="geo">10.1,10.1</str>
</doc></result>

➢ Solr incorpora la posibilidad de agrupar resultados usando dos técnicas: el Result Grouping y el field
Collapsing.
Field Collapsing: agrupa los resultados con el mismo valor de campo en una única entrada o a un
número de entradas. Por ejemplo, muchos motores de búsqueda como Google agrupan los resultados
por “site” y por lo tanto una o dos entradas de ese site se acaban mostrando, juntamente con un
enlace para ver más resultados de ese site. Field collapsing puede ser usado también para suprimir los
documentos duplicados. Es decir, se muestra toda la información de una o dos entradas, aunque
existan muchos más resultados que coinciden con la búsqueda.
Result Grouping: esta técnica permite agrupar documentos con valores de campos comunes,
devolviendo los primeros documentos por grupo y los grupos basados en los documentos que haya en
los grupos. Un ejemplo de resultado agrupado es una búsqueda en amazon por un término como
“DVD”, el resultado serían los tres primeros resultados, de cada categoría que contengan documentos
indexados con ese término, por ejemplo ("TVs y Video",“Películas",“Ordenadores", etc)
➢ Es posible usar las agrupaciones con el facetado, aunque el comportamiento predeterminado del facetado
es basarse en documentos y no en grupos es posible hacerlo con órdenes de búsqueda avanzada que
veremos a continuación. Por lo tanto podremos ver resultados facetados a partir de la agrupación de
campos (Field Collapsing).
Búsqueda Avanzada (X): Agrupaciones

➢ Usar un valores de un campo para agrupar los resultados.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="category" type="string" indexed="true" stored="true“ />
<field name="price" type=“tfloat" indexed="true" stored="true" />
o En esta ocasión tenemos 3 documentos 2 con valor “mechanics” en el campo category, y uno más con el valor “it” en
ese mismo campo.
o La búsqueda avanzada para agrupar documentos por los valores de un campo es la siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&group=true&group.field=category
o El resultado de respuesta que recibimos está agrupada, y recoge el
total de documentos que hacen “matching” con la búsqueda, pero
recuperamos un documento por grupo. Se podrían especificar en la
búsqueda múltiples parámetros group.field con diferentes campos para
conseguir agrupaciones más complejas.
Si quisiéramos recuperar los primeros diez documentos de cada grupo en
lugar de solo el primero, usaríamos el parámetro group.limit para indicar cuántos documentos queremos devolver de cada
grupo. Para devolver 10 resultados la query nos quedaría así
http://[solr_host]:[solr_port]/solr/select?q=*:*&group=true
&group.field=category&group.limit=10
Búsqueda Avanzada (XI): Agrupaciones. Ejemplos
<arr name="groups"><lst><str name="groupValue">it</str><result name="doclist" numFound="2" start="0"><doc><str name="id">1</str><str name="name">Solr book</str><str name="category">it</str><float name="price">39.99</float>
</doc></result>
</lst><lst><str name="groupValue">mechanics</str><result name="doclist" numFound="1" start="0"><doc><str name="id">2</str><str name="name">Mechanics book</str><str name="category">mechanics</str><float name="price">19.99</float>
</doc></result>
</lst></arr>

➢ Usar queries para agrupar los resultados.o Dado este schema.xml (El mismo que en el ejemplo anterior)
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="category" type="string" indexed="true" stored="true“ />
<field name="price" type=“tfloat" indexed="true" stored="true" />
o Ahora nos fijamos en el campo “price”, los tres documentos indexados tienen un valor en ese campo de: 39.99, 19.99 y
49.99 respectivamente.
o La búsqueda avanzada que usaremos será:
http://[solr_host]:[solr_port]/solr/select?q=*:*&group=true&group.query=price:[20.0+TO+50.0]
&group.query=price:[1.0+TO+19.99]
o La respuesta es muy parecida a la que obtuvimos en el
ejemplo anterior. Ahora la agrupación se ha realizado basándose
en un rango de valores almacenados en uno de los campos, en
este caso el campo “Price”. Si nos fijamos bien en el resultado
el nombre de los grupos es diferente y refleja la query realizada
es decir “Price:[X TO Y]”. También come el ejemplo anterior
devolvemos el primer valor de cada grupo.
Búsqueda Avanzada (XII): Agrupaciones. Ejemplos
<lst name="grouped"><lst name="price:[20.0 TO 50.0]"><int name="matches">3</int><result name="doclist" numFound="2" start="0"><doc><str name="id">1</str><str name="name">Solr book</str><str name="category">it</str><float name="price">39.99</float>
</doc></result>
</lst><lst name="price:[1.0 TO 19.99]"><int name="matches">3</int><result name="doclist" numFound="1" start="0"><doc><str name="id">2</str><str name="name">Mechanics book</str><str name="category">mechanics</str><float name="price">19.99</float>
</doc></result>
</lst></lst>

➢ Usar funciones de queries para agrupar los resultados. (ver ejemplo Búsqueda Avanzada. Ordenaciones)o Dado este schema.xml (El mismo que en el ejemplo anterior)
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="geo" type="location" indexed="true" stored="true" />
<dynamicField name="*_coordinate" type="tdouble" indexed="true“ stored="false" />
<fieldType name="location" class="solr.LatLonType“ subFieldSuffix="_coordinate"/>
o Disponemos de 3 documentos indexados cuyo campo geo
(almacenas coordenadas de geo localización), tiene un campo
de tipo location que está definido con la clase del tipo
solr.LatLonType que representa una Latitud/Longitud como un
punto bi-dimensional. El campo geo de los tres documentos
tienen los valores (12.2,12.2), (11.1,11.1), (10.1,10.1)
o La búsqueda avanzada que usaremos será la siguiente
http://localhost:8983/solr/select?q=*:*&group=true
&group.func=geodist(geo,0.0,0.0)
o El resultado es una agrupación según el resultado de la
función geodist, que tal y como vimos en el ejemplo de las
ordenaciones hace referencia a la distancia a partir de un punto
concreto.
Búsqueda Avanzada (XIII): Agrupaciones. Ejemplos
<arr name="groups"><lst><double name="groupValue">1584.126028923632</double><result name="doclist" numFound="1" start="0"><doc><str name="id">1</str><str name="name">Company one</str><str name="geo">10.1,10.1</str>
</doc></result>
</lst><lst><double name="groupValue">1740.0195023531824</double><result name="doclist" numFound="1" start="0"><doc><str name="id">2</str><str name="name">Company two</str><str name="geo">11.1,11.1</str>
</doc></result>
</lst><lst><double name="groupValue">1911.187477467305</double><result name="doclist" numFound="1" start="0"><doc><str name="id">3</str><str name="name">Company three</str><str name="geo">12.2,12.2</str>
</doc></result>
</lst></arr>

➢ Cálculos facetados de los documentos relevantes agrupadoso Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“nombre" type="text" indexed="true" stored="true" />
<field name="categoria" type="string" indexed="true" stored="true“ />
<field name="stock" type="boolean" indexed="true" stored="true" />
o Volvemos a tener 4 documentos indexados, con los valores en los campos categoría y stock siguientes: [books, true],
[books, true], [workbooks, false], [workbooks, true]
o La búsqueda avanzada con facetado de documentos agrupados que sugerimos es la siguiente:
http://[solr_host]:[solr_port]/solr/select?q=*:*&facet=true&facet.field=stock&group=true&group.field=categoria
&group.truncate=true
o La respuesta a esta búsqueda, agrupará
por categoría los resultados y nos dará cifras de
facetado por stock, el parámetro de la búsqueda
group.truncate=true cambia el comportamiento
del facetado para que solo devuelva el resultado
más relevante de cada grupo.
Búsqueda Avanzada (XIV): Agrupaciones. Ejemplos
<str name="groupValue">books</str><result name="doclist" numFound="2" start="0"><doc><str name="id">1</str><str name="name">Book 1</str><str name="categoria">books</str><bool name="stock">true</bool></doc>
</result></lst><lst><str name="groupValue">workbooks</str><result name="doclist" numFound="2“ start="0"><doc><str name="id">3</str><str name="name">Workbook 1</str><str name="categoria">workbooks</str><bool name="stock">false</bool>
</doc></result>
<lst name="facet_counts"><lst name="facet_queries"/><lst name="facet_fields"><lst name="stock"><int name="false">1</int><int name="true">1</int>
</lst></lst>
<lst name="facet_dates"/><lst name="facet_ranges"/></lst>

➢ Es habitual la situación dónde tus usuarios esperan recuperar información en su idioma propio, actualmente los
portales globales ofrecen soporte multiidioma y por lo tanto la información que se buscaría debe estar en
consonancia al idioma al que se accede. Es decir el usuario encontraría el contenido que tengamos indexado en su
idioma nativo de manera preferente.
➢ Se debe indicar el idioma del document durante la indexación y almacenar estos documentos con el resto de los
documentos del índice para su posterior uso.
➢ Para la identificación del idioma usaremos uno de los módulos contrib. Para activar la detección del language
debemos crear un directorio langid en nuestro filesystem, convenientemente en el mismo directorio en el que Solr
está instalado y copiaremos las siguientes librerías en ese directorio:
➢ apache-solr-langid-4.0.0.jar (from the dist directory of Apache Solr distribution)
➢ jsonic-1.2.7.jar (from the contrib/langid/lib directory of Apache Solr distribution)
➢ langdetect-1.1.jar (from the contrib/langid/lib directory of Apache Solr distribution)
➢ Tras la creación de ese directorio y el copiado de las librerías tenemos que añadir la configuración necesario en Solr,
todas esas configuraciones se realizan en solrconfig.xml. Lo que haremos es informar a Solr que queremos cargar
unas librerías adicionales. Eso lo haremos añadiendo la siguiente propiedad en la sección “config” de ese fichero:
➢ <lib dir="../../langid/" regex=".*\.jar" />
➢ Terminaremos la configuración añadiendo el Update Request Processor apropiado para la indexación de contenidos
multilenguage:
<updateRequestProcessorChain name="langid">
<processor class="org.apache.solr.update.processor.LangDetectLanguageIdentifierUpdateProcessorFactory">
<str name="langid.fl">name,description</str>
<str name="langid.langField">langId</str>
<str name="langid.fallback">en</str>
</processor>
<processor class="solr.LogUpdateProcessorFactory" />
<processor class="solr.RunUpdateProcessorFactory" />
</updateRequestProcessorChain>
Búsqueda Avanzada (XV): Multilenguaje (detección de idioma)

➢ Es LangDetectLanguageIdentifierUpdateProcessorFactory, se configura con algunos parámetros, todos ellos
muy importantes. La propiedad langid.fl dice al Processor qué campos deben ser usados para detector el
idioma, en nuestro caso, los campos name y description, serán analizados en tiempo de indexación para
posteriormente ser almacenados en el idioma apropiado. El campo langid.langField especifica el campo en
el cual se escribirá el idioma detectado tras el procesado de los campos anteriores, y por ultimo la
propiedad langid.fallback, le sirve a la librería de detección de idima qué language debe ser usado por
defecto si la detección del language falla, en nuestro caso el idioma en el que se almacenarían los
contenidos, de no ser encontrados sería el inglés. Los Processors solr.LogUpdateProcessorFactory y
solr.RunUpdateProcessorFactory, sirven para escribir en el log las actualizaciones de los documentos y para
lanzar la indexación, por lo que, por regla general, ambos son obligatorios.
➢ Por ultimo nos falta decir a Solr que queremos usar el Update Request Processor configurado en el
momento de la indexación. Para ello se añade el parámetro update.chain con el nombre de nuestro “update
chain” que hemos definido anteriomente y que en este caso es: langid. Esta llamada sería algo parecido a:
curl 'http://localhost:8983/solr/update?update.chain=langid' --data-binary @datos.xml -H 'Content-type:application/xml'
curl 'http://localhost:8983/solr/update?update.chain=langid' --data-binary '<commit/>' -H 'Content-type:application/xml'
Búsqueda Avanzada (XVI): Multilenguaje (detección de idioma)

➢ Esta característica de Solr nos permite destacar los términos encontrados que encajan total o parcialmente
con la búsqueda que el usuario haya realizado.
➢ Es muy importante destacar que esta funcionalidad puede afectar el rendimiento en nuestro índice de
varias maneras ya que además de aumentar el tiempo de indexado y búsqueda, incrementar el tamaño de
nuestro índice con campos que dan soporte a esta funcionalidad.
➢ Para habilitar el highlighting, tenemos que añadir los siguientes atributos en los campos sobre los que
queramos aplicar el “resaltado”: termVectors=“true", termPositions=“true", and termOffsets=“true“, y
todos ellos ponerlos a “false” para deshabilitar esta funcionalidad, en todos o en los campos donde no
queramos o vayamos a usar el resaltado. Cómo se ha comentado anteriormente hay que estudiar en
profundidad sobre qué campos se va a poder usar el resaltado ya que la habilitación de estos campos hace
crecer el índice (guardando posiciones vectorizadas para cada campo habilitado de cada documento que lo
incorpora), y sería posible penalizar el rendimiento global de las búsquedas ya que se deberían realizar
sobre un índice más grande.
Búsqueda Avanzada (XVII): Highlighting

Búsqueda Avanzada (XVIII): Highlighting. Ejemplos
➢ Resaltando palabras coindicentes, Highlight Simple.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name=“contenido" type="text" indexed="true" stored="true" />
o Tenemos 4 documentos indexados y con los valores en el campo contenido: “training de solr avanzado”, training de solr
básico”, “Solr el rey de los buscadores”, “Tv3 ha avanzado a Tele5 en número de espectadores”
o La búsqueda avanzada con el highlight activado:
http://localhost:8983/solr/select?q=contenido:avanzado&hl=true&hl.fl=*
o El análisis del resultado nos permite ver que por un lado
se realiza la consulta (contenido:avanzado) que devuelve un
resultado y por otro nos devuelve la lista de resultados con los
contenidos que incorporan las etiquetas que permitirán el
resaltado del contenido una vez se muestre en el Front End.
Este
<result name="response" numFound="1" start="0"><doc><str name="id">4</str><str name="name">Tv3 ha avanzado a Tele5 en número de espectadores</str></doc></result><lst name="highlighting"><lst name="4"><arr name="name"><str><em>Tv3</em> ha avanzado a Tele5 ennúmero de espectadores</str></arr></lst></lst></response>

Búsqueda Avanzada (XIX): Highlighting. Más info
➢ Más cosas sobre el Highlight.➢ Se pueden elegir los campos a resaltar con el parámetro hl.fl seguido de la lista de campos de nuestro esquema
separados en los cuales queremos aplicar el resaltado.
http://localhost:8983/solr/select?q=name:juanjo&hl=true&hl.fl=name,description
➢ En ocasiones es necesario tener unos campos por defecto a los cuales afectará el resaltado, por lo que es posible
añadirlos en la configuración del Handler de Búsqueda (sorl.SearchHandler) con algo parecido como:
<requestHandler name="/browse" class="solr.SearchHandler">
<lst name="defaults">
................
<!-- Highlighting defaults -->
<str name="hl">on</str>
<str name="hl.fl">contenido titulo cabecera nombre</str>
................
</lst>
</requestHandler>
➢ Hay situaciones dónde queremos cambiar los tags html de resaltado por defecto “<em”>. Para hacer esto en tiempo de
búsqueda solo debemos añadir a nuestra query string los parámetros hl.simple.pre y hl.simple.post Por lo que si
queremos resaltar nuestros resultados con el tag “<b></b>” sería tan simple como hacer:
http://localhost:8983/solr/select?q=name:juanjo&hl=true&hl.simple.pre=<b>&hl.simple.post=</b>
➢ De igual manera que con la lista de campos se podría añadir en la configuración del solr.SearchHandler
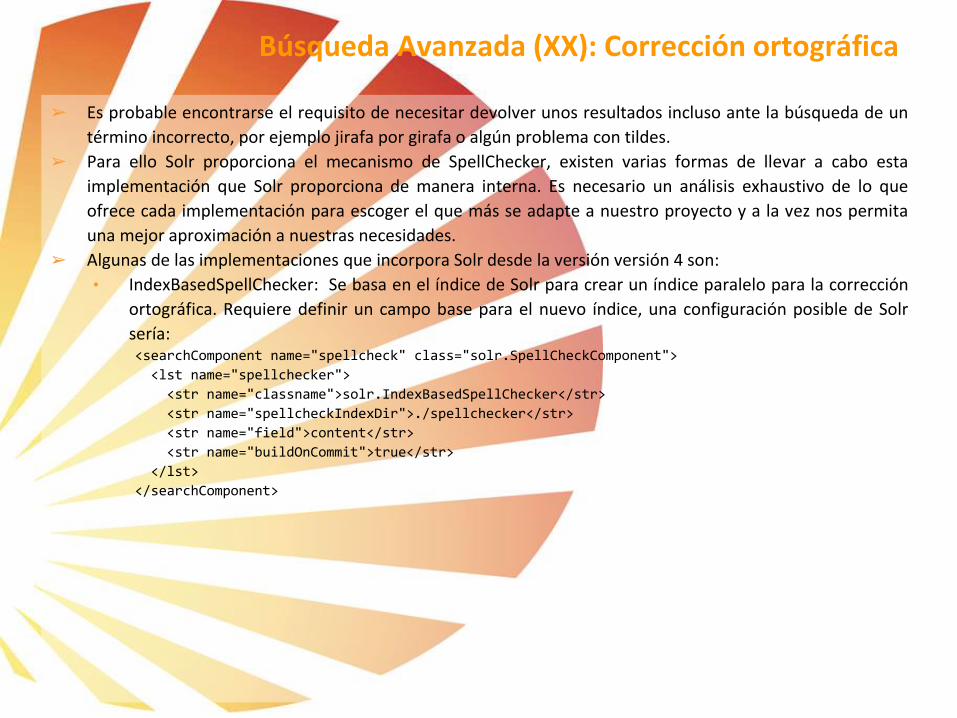
➢ Es probable encontrarse el requisito de necesitar devolver unos resultados incluso ante la búsqueda de un
término incorrecto, por ejemplo jirafa por girafa o algún problema con tildes.
➢ Para ello Solr proporciona el mecanismo de SpellChecker, existen varias formas de llevar a cabo esta
implementación que Solr proporciona de manera interna. Es necesario un análisis exhaustivo de lo que
ofrece cada implementación para escoger el que más se adapte a nuestro proyecto y a la vez nos permita
una mejor aproximación a nuestras necesidades.
➢ Algunas de las implementaciones que incorpora Solr desde la versión versión 4 son:
• IndexBasedSpellChecker: Se basa en el índice de Solr para crear un índice paralelo para la corrección
ortográfica. Requiere definir un campo base para el nuevo índice, una configuración posible de Solr
sería:<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="classname">solr.IndexBasedSpellChecker</str>
<str name="spellcheckIndexDir">./spellchecker</str>
<str name="field">content</str>
<str name="buildOnCommit">true</str>
</lst>
</searchComponent>
Búsqueda Avanzada (XX): Corrección ortográfica

• DirectSolrSpellChecker: Al igual que el anterior usa el índice de Solr como corrector ortográfico pero
en esta implementación no se crea un nuevo índice como con IndexBasedSpellChecker. Ofrece muchas
ventajas en relación con el anterior, ya que no require prácticamente mantenimiento ya que se
conforma con la información regular añadida al índice. Su configuración en solrconfig.xml podría ser:
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="name">default</str>
<str name="field">name</str>
<str name="classname">solr.DirectSolrSpellChecker</str>
<str name="distanceMeasure">internal</str>
<float name="accuracy">0.5</float>
<int name="maxEdits">2</int>
<int name="minPrefix">1</int>
<int name="maxInspections">5</int>
<int name="minQueryLength">4</int>
<float name="maxQueryFrequency">0.01</float>
<float name="thresholdTokenFrequency">.01</float>
</lst>
</searchComponent>
• FileBasedSpellChecker: El FileBasedSpellChecker una un diccionario ortográfico externo mantenido en
un archive txt. Según los requisites esta implementación puede ser útil si se quiere controlar las
correcciones como si de un diccionario se tratara, ya que los anteriores se basan en documentos
indexados que no han pasado filtros “humanos”. En solrconfig.xml, definiríamos el searchComponent
con algo similar a:
<searchComponent name="spellcheck" class="solr.SpellCheckComponent">
<lst name="spellchecker">
<str name="classname">solr.FileBasedSpellChecker</str>
<str name="name">file</str>
<str name="sourceLocation">spellings.txt</str>
<str name="characterEncoding">UTF-8</str>
<str name="spellcheckIndexDir">./spellcheckerFile</str>
</lst>
</searchComponent>
Búsqueda Avanzada (XXI): Corrección ortográfica

Una vez configurado el Search Component para la Corrección ortográfica, como hemos visto en el punto
anterior es necesario añadirlo al request handler que se vaya a usar, de esta manera activamos la corrección
ortográfica en tiempo de búsqueda, añadiendo a la configuración algo parecido a:
<requestHandler name="/spell" class="solr.SearchHandler“ startup="lazy">
<lst name="defaults">
<str name="df">title</str>
<str name="spellcheck.dictionary">direct</str> <!--Podría ser más de uno
<str name="spellcheck">on</str>
<str name="spellcheck.extendedResults">true</str>
<str name="spellcheck.count">5</str>
<str name="spellcheck.collate">true</str>
<str name="spellcheck.collateExtendedResults">true</str>
</lst>
<arr name="last-components">
<str>spellcheck</str>
</arr>
</requestHandler>
▪ La propiedad spellcheck.dictionary especifica el nombre del componente spellchecking que se quiere
usar, esta propiedad debe coincidir con el valor de la propiead “name” de la configuración del
component Search que hemos visto anteriormente.
▪ Activamos los resultados con corrección ortográfica con el valor on en la propiedad “spellcheck”
▪ spellcheck.extendedResults nos permite proporcionar información extendida acerca de cómo se ha
realizado la corrección, por ejemplo si se usa un Search component que usa el índice de Solr para
ofrecer correciones, te da información de cuantas veces aparece ese término en el índice (motive por el
cual ha sido escogido para corregiar el error ortográfico.
▪ La propiedad spellcheck.count property, representa el número máximo de sugerencias de corrección
▪ spellcheck.collate y spellcheck.collateExtendedResults. A true, fuerza a Solr a que realice otra búsqueda
esta vez con los términos “corregidos” según las sugerencias que ha proporcionado el diccionario.
Búsqueda Avanzada (XXII): Corrección ortográfica
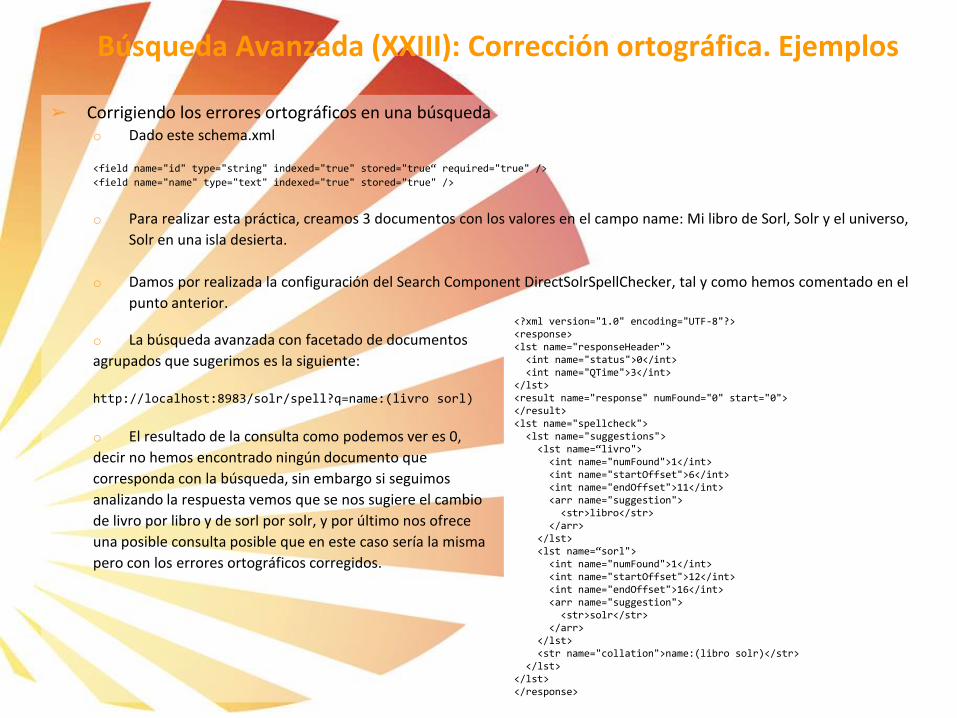
Búsqueda Avanzada (XXIII): Corrección ortográfica. Ejemplos
➢ Corrigiendo los errores ortográficos en una búsquedao Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true" />
o Para realizar esta práctica, creamos 3 documentos con los valores en el campo name: Mi libro de Sorl, Solr y el universo,
Solr en una isla desierta.
o Damos por realizada la configuración del Search Component DirectSolrSpellChecker, tal y como hemos comentado en el
punto anterior.
o La búsqueda avanzada con facetado de documentos
agrupados que sugerimos es la siguiente:
http://localhost:8983/solr/spell?q=name:(livro sorl)
o El resultado de la consulta como podemos ver es 0,
decir no hemos encontrado ningún documento que
corresponda con la búsqueda, sin embargo si seguimos
analizando la respuesta vemos que se nos sugiere el cambio
de livro por libro y de sorl por solr, y por último nos ofrece
una posible consulta posible que en este caso sería la misma
pero con los errores ortográficos corregidos.
<?xml version="1.0" encoding="UTF-8"?><response><lst name="responseHeader"><int name="status">0</int><int name="QTime">3</int>
</lst><result name="response" numFound="0" start="0"></result><lst name="spellcheck"><lst name="suggestions"><lst name=“livro"><int name="numFound">1</int><int name="startOffset">6</int><int name="endOffset">11</int><arr name="suggestion"><str>libro</str>
</arr></lst><lst name=“sorl"><int name="numFound">1</int><int name="startOffset">12</int><int name="endOffset">16</int><arr name="suggestion"><str>solr</str>
</arr></lst><str name="collation">name:(libro solr)</str>
</lst></lst></response>

Existen varias aproximaciones para la configuración de la funcionalidad More Like This:
La más común es usarlo como una configuración en Request Handler para ello se debe habilitar esta característica en el Handler deseado (el que se usa para las queries en general, que suele ser el que tiene el contexto /select, o con uno propio, es decir crear otro Request Handler con un contexto personalizado y que por lo tanto se llame de manera separada. Es la forma más óptima y permite hacer la llamada cuando se desea, ya que se habilitan parámetros para activar esta funcionalidad.
La segunda es similar a la configuración realizada con el Corrector Ortográfico, en este caso crearíamos un Search Component separado, es menos aconsejable ya que realizaría el análisis de los documentos en todos los documentos devueltos.
La última aproximación sería la que corresponde a realizar esta funcionalidad basándonos en un documento de texto externo, en este caso seguiría referenciado en el handler MoreLikeThisHandlerpero la información para realizar la relación entre documentos sería basada en el texto del documento seleccionado.
Al igual que pasaba en la funcionalidad Highlighting, es necesario la introducción de la propiedad
termVectors=“true” en el campo que se quiere habilitar para la recuperación de información MLT.
Búsqueda Avanzada (XXIV): More Like This

Recuperar más documentos similares a los que se han devuelto como resultado.o Dado este schema.xml
<field name="id" type="string" indexed="true" stored="true“ required="true" />
<field name="name" type="text" indexed="true" stored="true“ termVectors="true" />
o Ahora creamos 4 documentos con los valores en el campo name: Solr Training primera sesión, Solr Training segunda
sesión, Solr con ejemplos primera clase, Formación buscadores segunda sesión.
o Damos por realizada la configuración del componente MLT en la configuración de Solr.
o La búsqueda avanzada:
http://localhost:8983/solr/select?q=solr+training+segunda
+sesión&mm=2&qf=name&defType=edismax&mlt=true&mlt.fl=name
&mlt.mintf=1&mlt.mindf=1
Búsqueda Avanzada (XXV): More Like This. Ejemplos
<result name="response" numFound="1" start="0"><doc><str name="id">2</str><str name="name">Solr Training segunda sesión</str><long name="_version_">1415606105364496384</long></doc></result><lst name="moreLikeThis"><result name="2" numFound="3" start="0"><doc><str name="id">1</str><str name="name">Solr Training primera sesión</str><long name="_version_">1415606105279561728</long></doc><doc><str name="id">4</str><str name="name">Formación buscadores segunda sesión</str><long name="_version_">1415606105366593536</long></doc><doc><str name="id">3</str><str name="name">Solr con ejemplos primera clase</str><long name="_version_">1415606105365544960</long></doc></result></lst></response>

Como se puede ver en la configuración de la estructura se añade el parámetro termVectors que prepara al
campo para que su contenido sea indexado con metainformación que permite mejorar el rendimiento en
este tipo de búsqueda, es Bueno poder prever que campos necesitarán esto habilitado siempre que sea
posible.
Si echamos un vistazo a la query, hemos añadido algunos parámetros adicionales al parámetro q estándar,
el parámetro mlt=true nos dice que queremos añadir resultados procesado por el MLT al resultado.
El parámetro mlt.fl nos especificas qué campos queremos usar para que sean analizados por MLT usamos el
campo con nombre “name” field.
mlt.mintf indica a Solr que ignore en los resultados MLT el documento o documentos originales que han
coincidido con la búsqueda, indicando la frecuencia en la que aparece la cadena buscada en el resultado, en
nuestro caso 1 marca el número de veces que debe coincidir para eliminarlo de los resultados MLT.
Para terminar mlt.mindf, le dice a Solr que las palabras que aparezcan menos que el valor de esta propiedad
deben ser ignoradas, es decir, en nuestro caso consideramos palabras que aparezcan al menos en un
documento.
Búsqueda Avanzada (XXVI): More Like This. Ejemplos

¡Muchas gracias!





























