Embed Size (px)
Citation preview

JupyterNotebookHold SparkMachineLearning
- Wayne
優像數位媒體科技股份有限公司
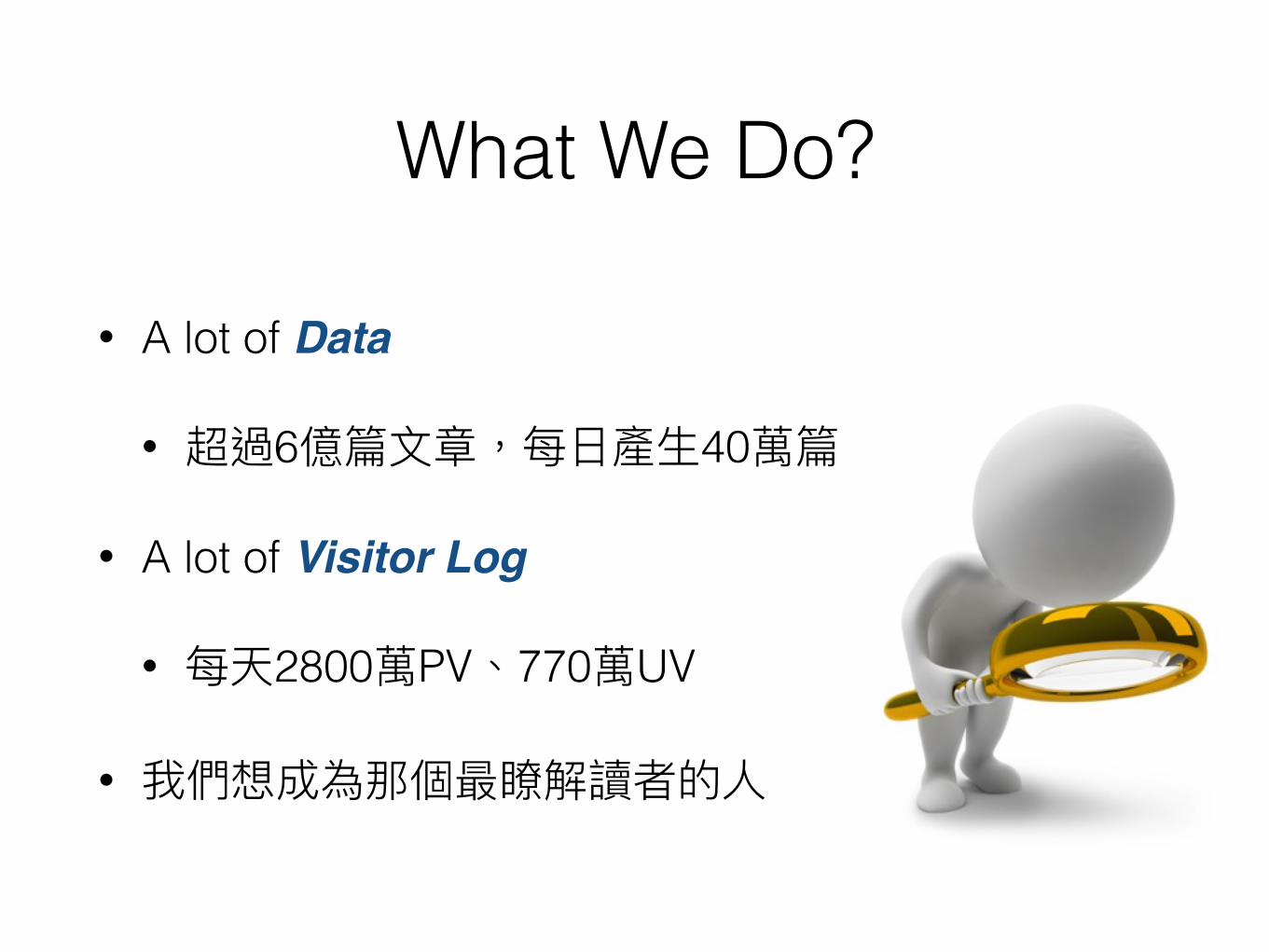
What We Do?
• A lot of Data
• 6 40
• A lot of Visitor Log
• 2800 PV 770 UV
•
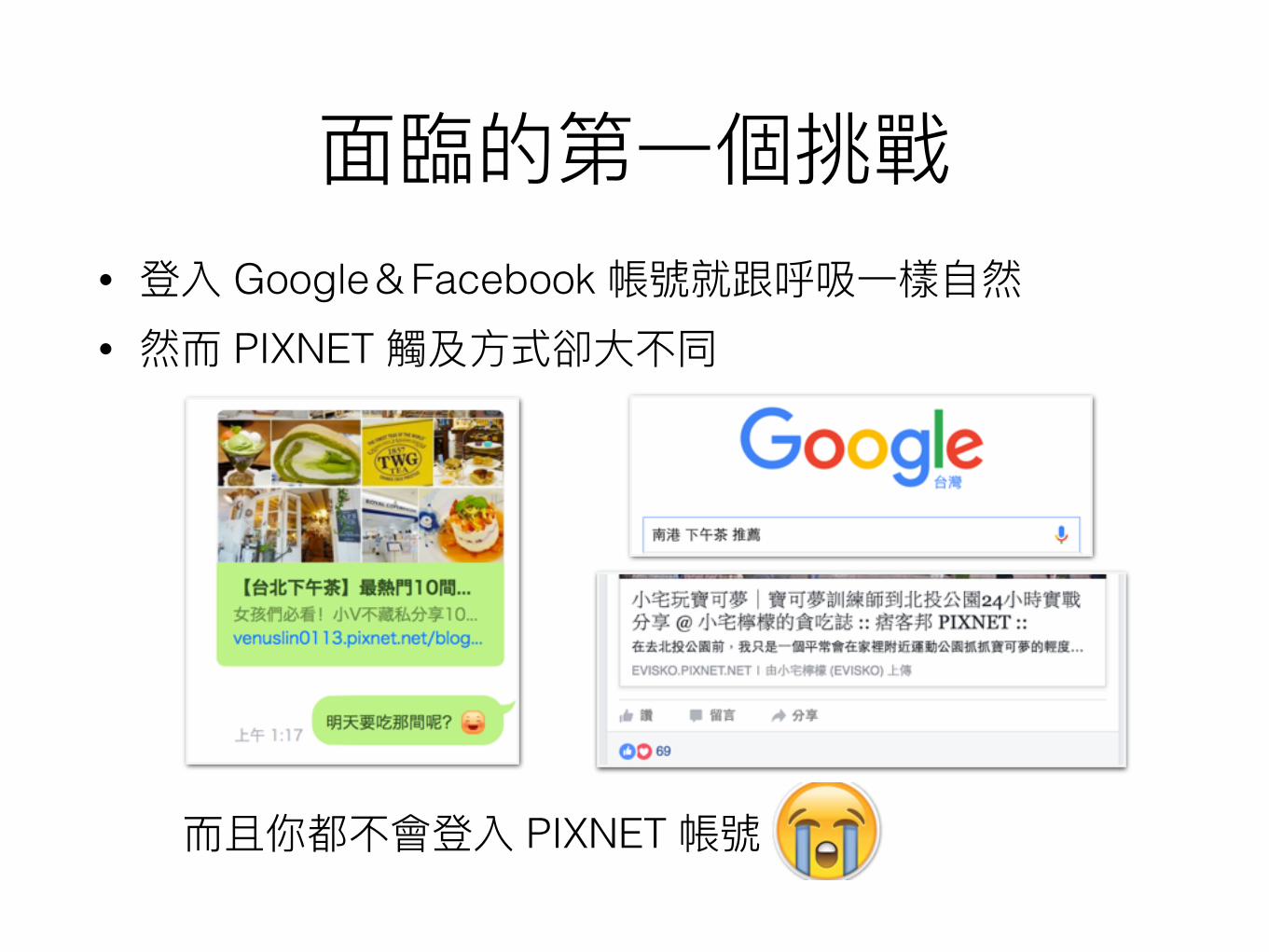
• Google Facebook • PIXNET
PIXNET

Machine Learning • label data
•
Gender
Age
Slackbot
Rank

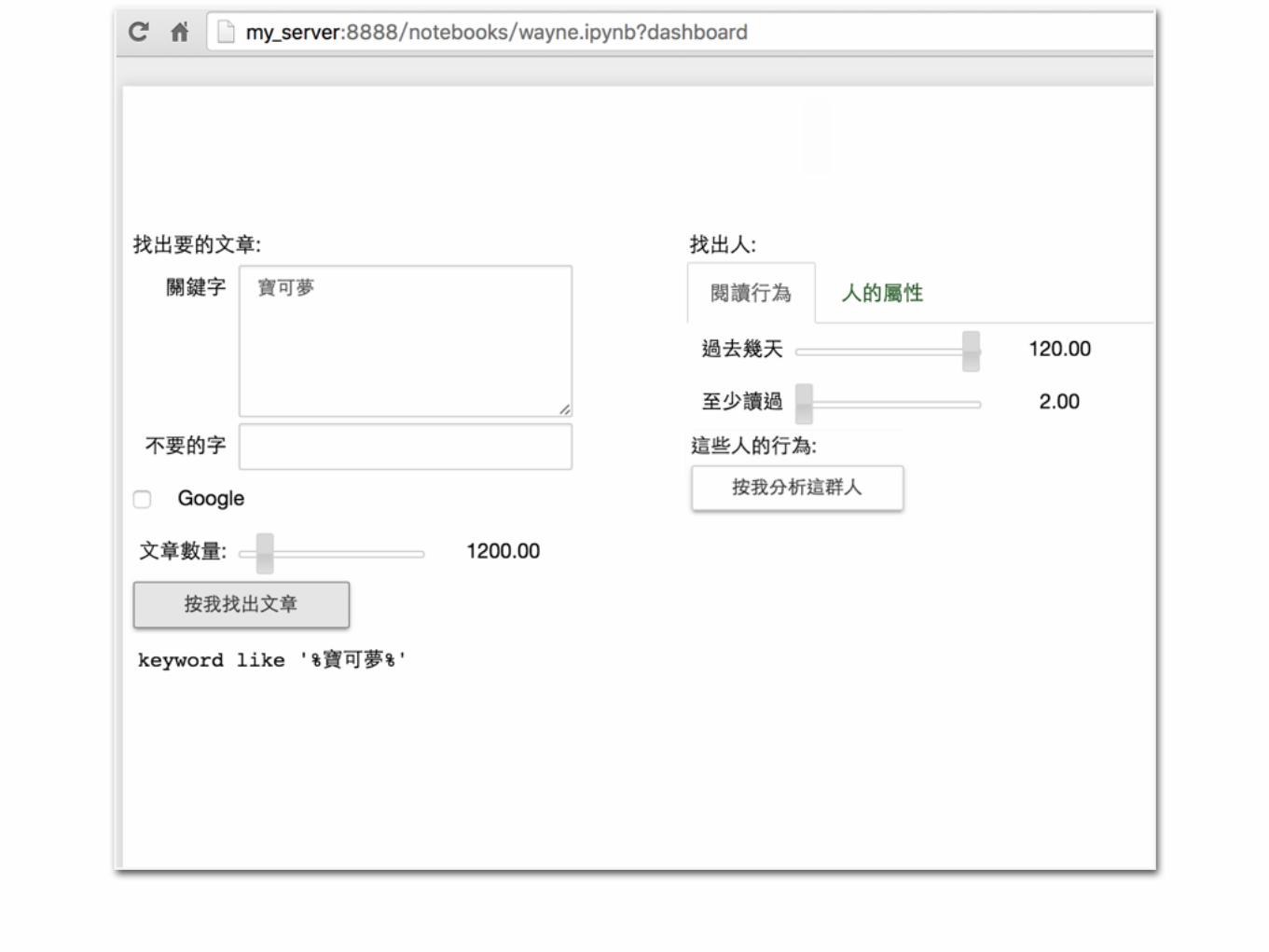
We Almost Build Everything on Notebook
• Python • Dashboard • Spark • script daemon

Play Jupyter with PySpark
Config PySpark driver
Execute PySpark on standalone mode

Run as Script or Daemon

Pandas Dataframe on Notebook is Wonderful
From File
From Redshift
From Google Spreadsheet
concat, drop_duplicates, dropna, groupby, …
pandas.read_csv(DICT, header=None, sep=" ", names=[‘word’,'weight','type']) pandas.read_json(TOP_ARTICLE)
sql = “select keyword, sum(clicks) AS cc from search_console WHERE … GROUP BY …” df = read_sql(sql, con=con)
sheet = gc.open_by_url(link) spreadata = pandas.DataFrame(sheet.get_all_records())

ipywidgets• sliders, progress bars, checkboxes, buttons, …
qgrid• Uses SlickGrid to render pandas DataFrames within a Jupyter
notebook. IPython.Display• SVG, Math, Javascript, IFrame, HTML
nbviewer• A simple way to share Jupyter Notebooks
plotly • Make charts and dashboards online

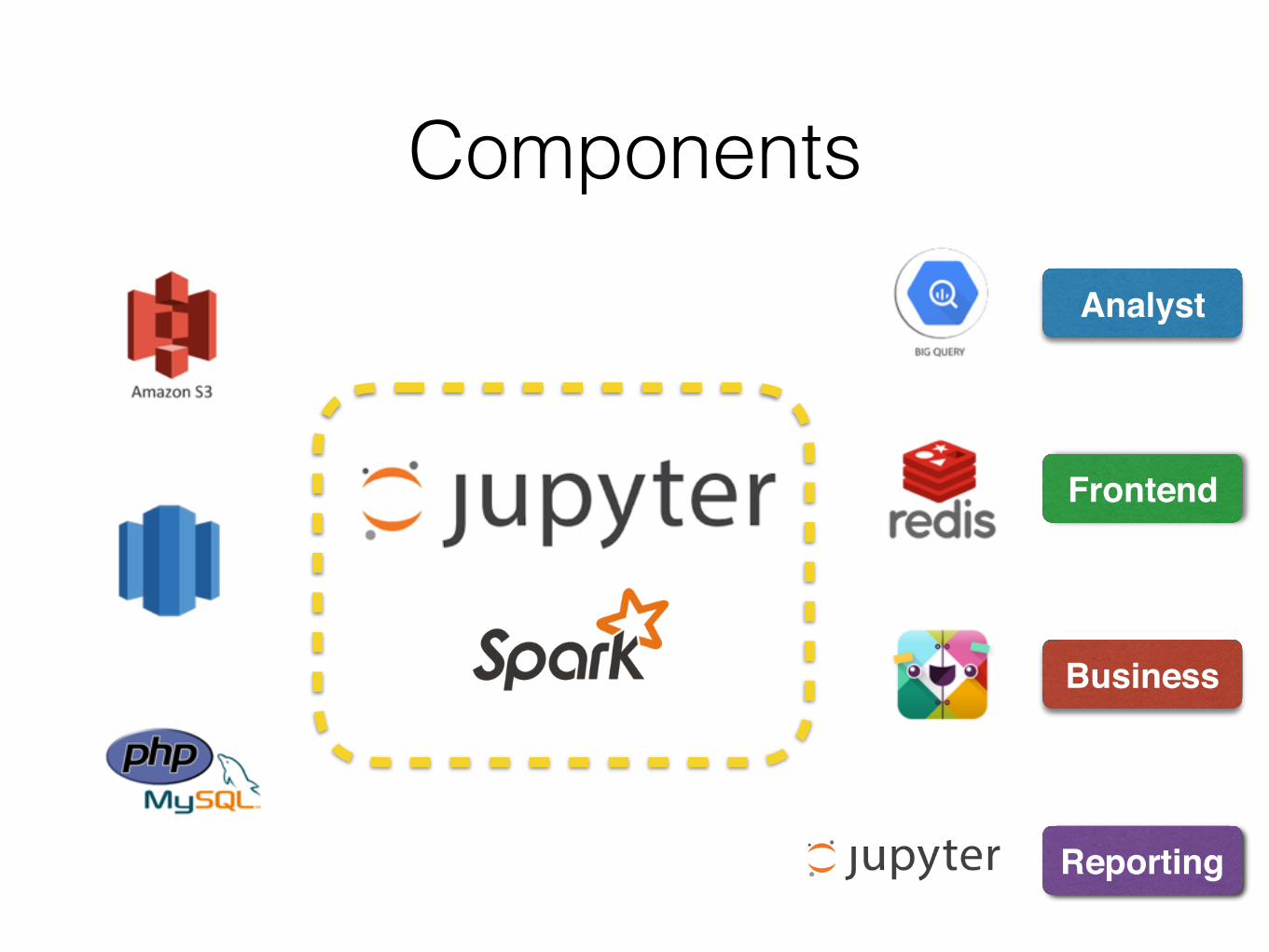
ComponentsAnalyst
Frontend
Business
Reporting
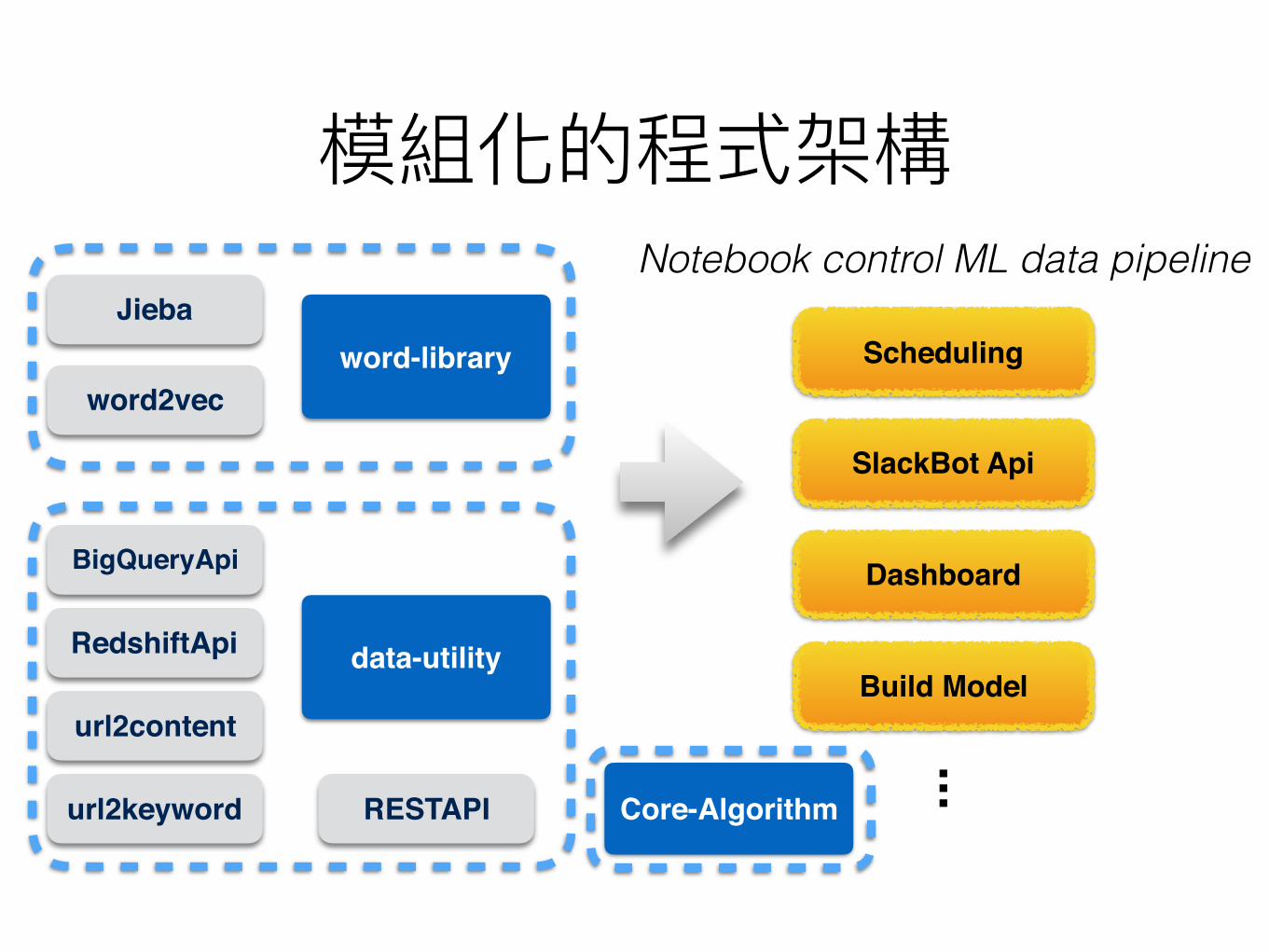
word-libraryJieba
word2vec
data-utility
BigQueryApi
RedshiftApi
url2content
url2keyword RESTAPI
Scheduling
SlackBot Api
Dashboard
Build Model
...
Notebook control ML data pipeline
Core-Algorithm
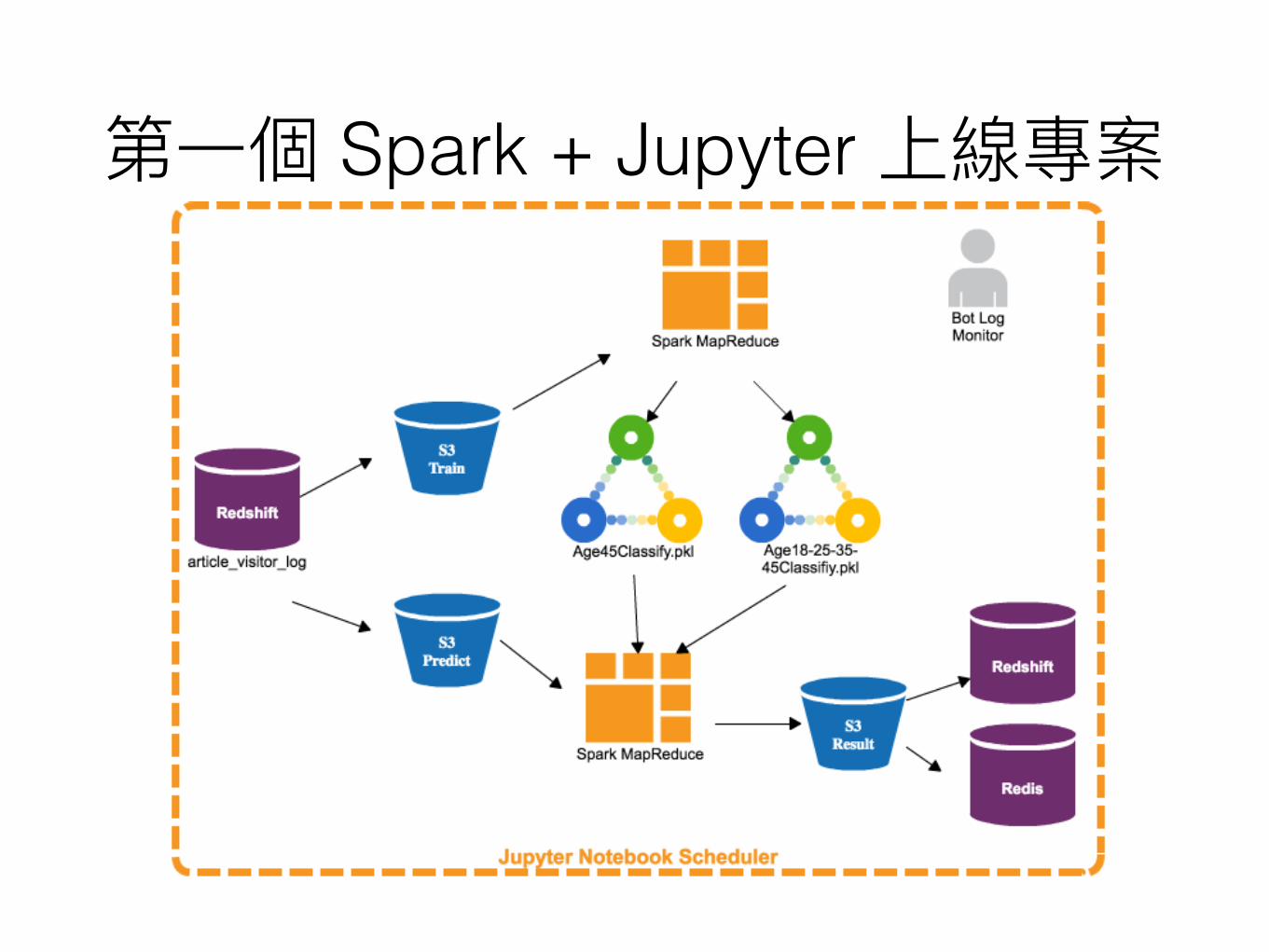
Spark + Jupyter

or • training & prediction
• training • cookie
• • • bottleneck •

• • 4 (about 4 billions record)
• 3
• Run 1 worker with 4 executor instances (per 2 cores, 4 GB RAM)
• Bottleneck • Query ordered data with doing mapPartitions
• Merge 20 millions cookies from 4 billions rows
• ReduceByKey will do lots of shuffle
• Feature selection (sklearn.feature_selection.chi2)

spark-defaults.conf
spark-env.sh
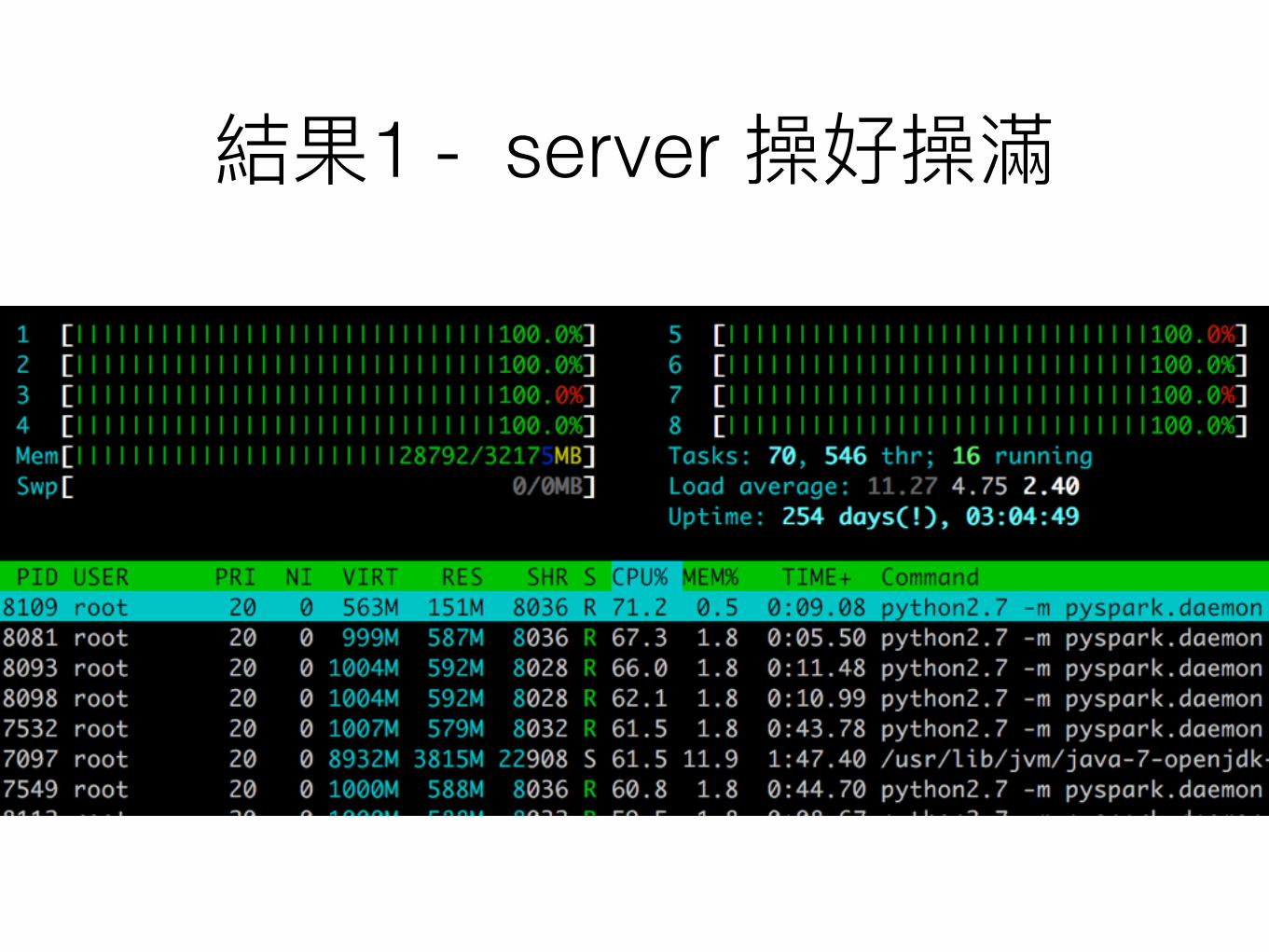
1 - server
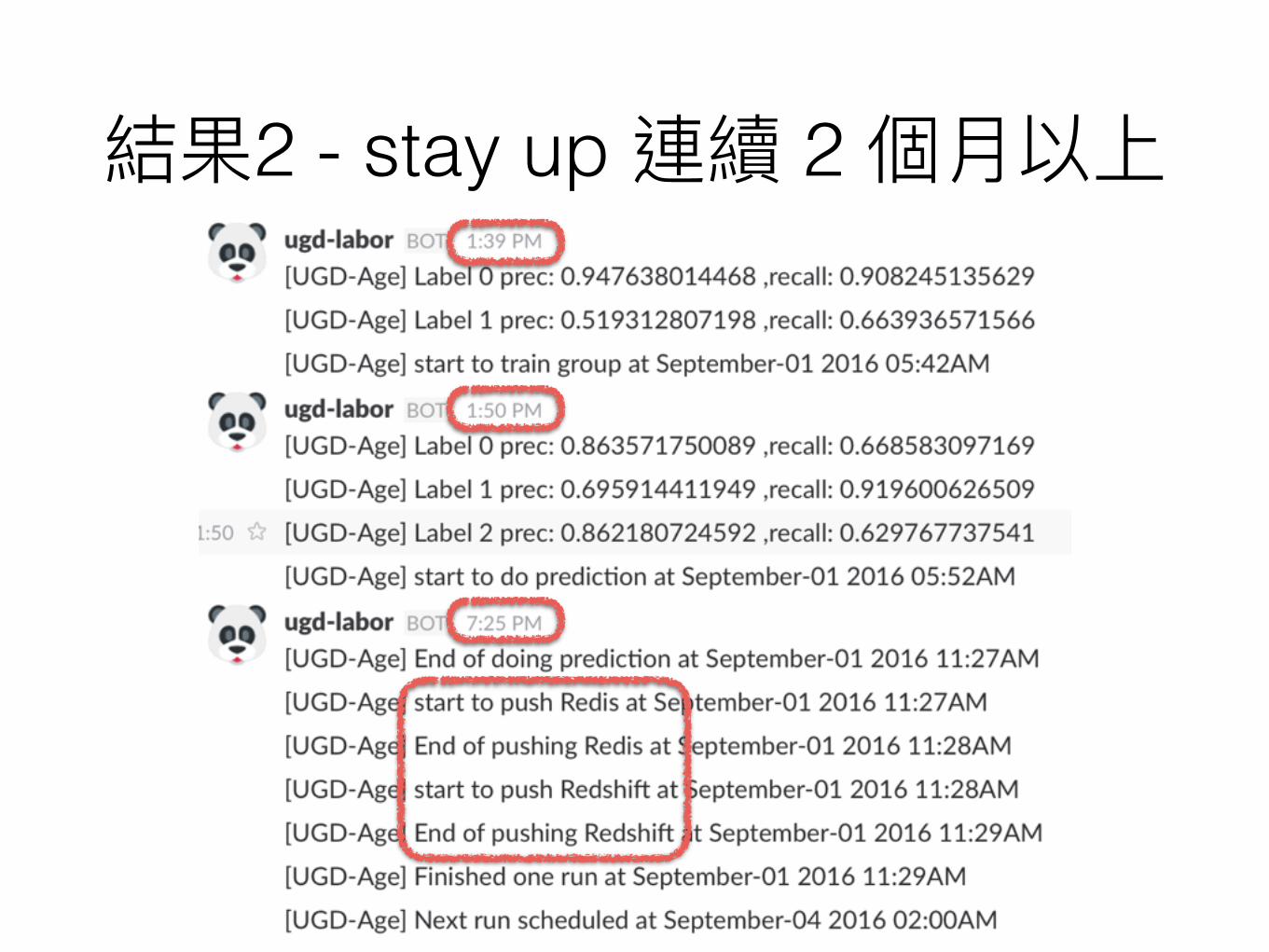
2 - stay up 2


Doing Spark with PHP?
Model Idea 500
training data ( )
3 PHP script
.....
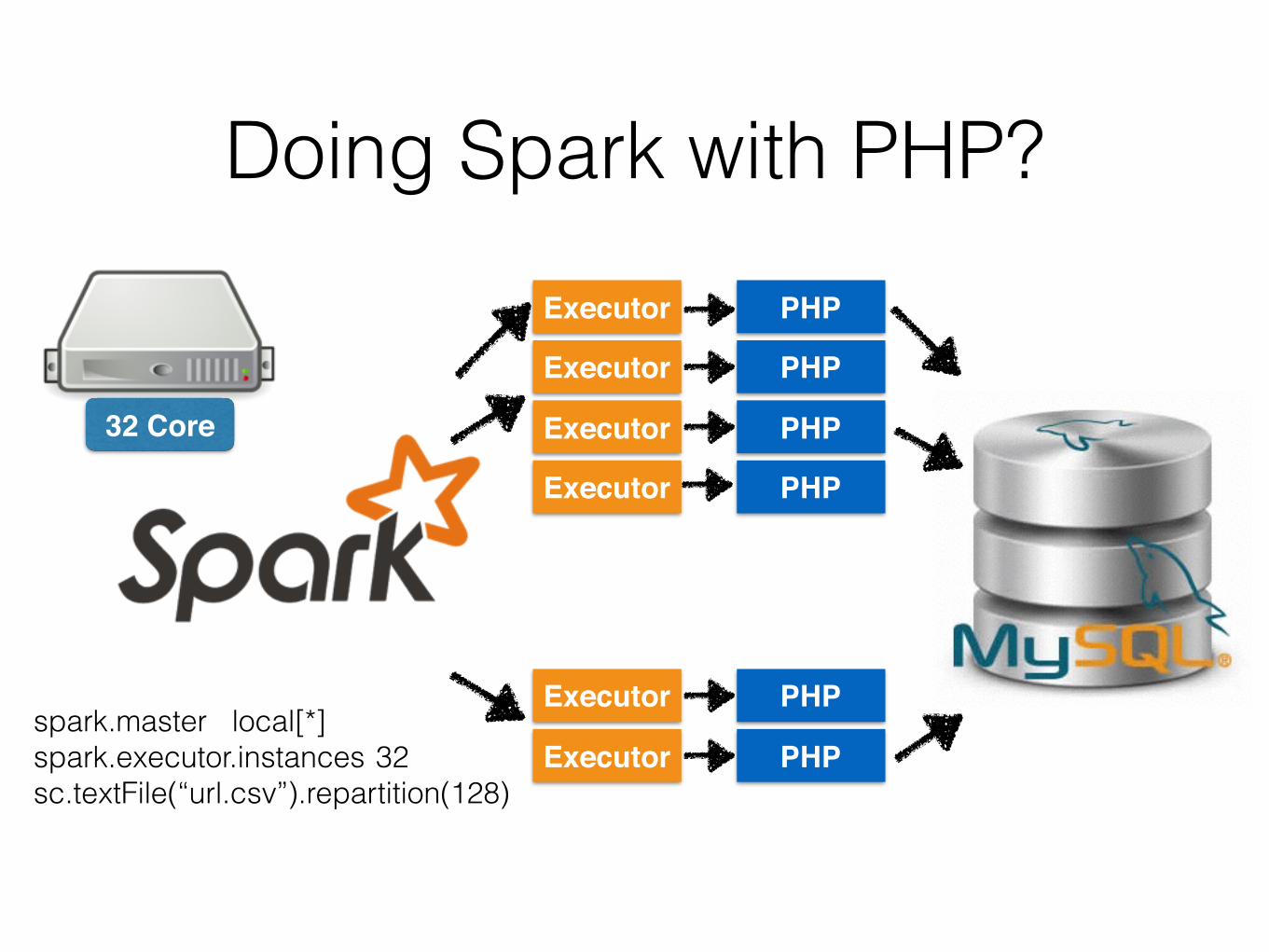
Doing Spark with PHP?
32 Core
Executor
spark.master local[*] spark.executor.instances 32 sc.textFile(“url.csv”).repartition(128)
Executor
Executor
Executor
Executor
Executor
PHP
PHP
PHP
PHP
PHP
PHP
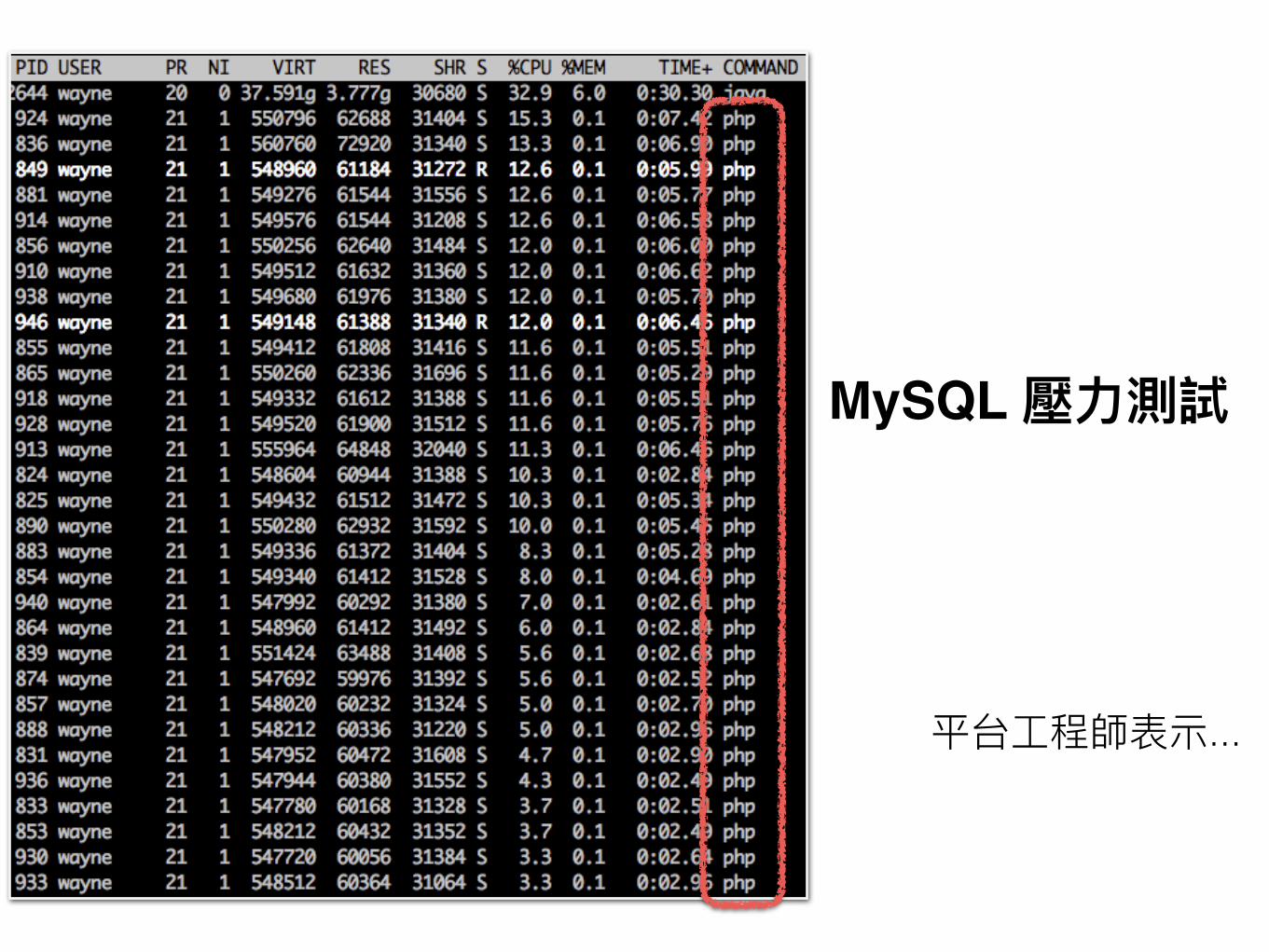
MySQL
...

Build word2vec Model•
• 120 •
• We choose cppjieba [github] • thread_number=16 • spark.executor.instances 32
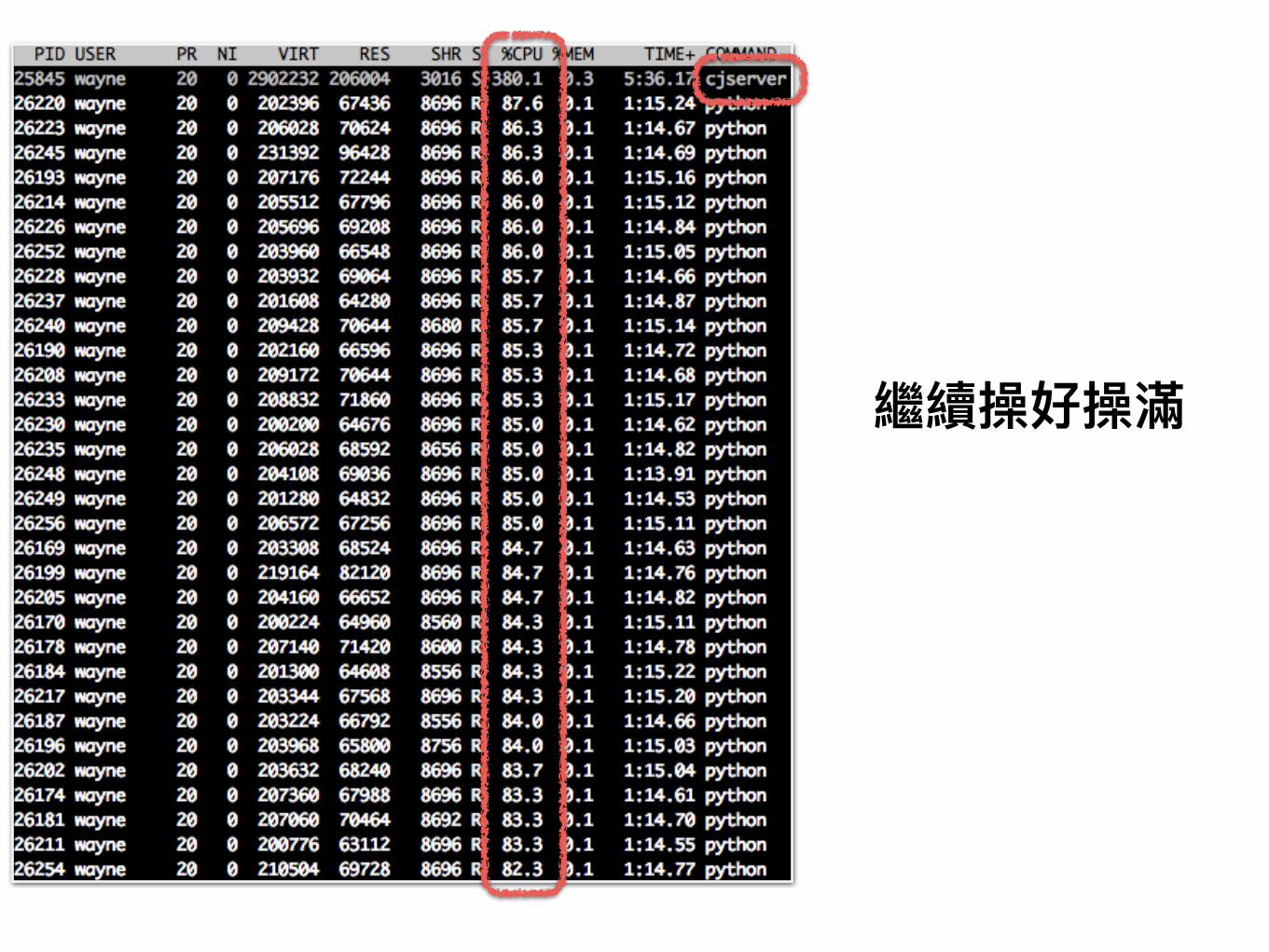

• Jupyter Notebook (data pipeline)
• Jupyter Notebook reopen hard to track status • Slack Channel
• Jupyter Notebook

• Spark
• Jupyter Notebook production


Data Scientist Tool Set
-> ->

Use Notebook to define machine learning workflow
Jupyter Lab• The next generation of the Jupyter Notebook • Jupyter team + Bloomberg + Continuum Analytics
Google Datalab• Cloud Datalab is built on Jupyter, enables analysis of data on BigQuery,
GCE, and Cloud Storage using Python, SQL, and JavaScript. Domino
• A Platform to Accelerate Data Science, makes data scientists more productive and facilitates collaborative, reproducible, reusable analysis.
Zeppelin• Inspired by iPython notebook focusing on providing analytical environment
on top of Hadoop eco-system. Databricks Cloud Notebook
• Notebook Workflows as APIs that allow users to chain notebooks together using the standard control structures of the source programming language.


感謝您的聆聽
優像數位媒體科技股份有限公司