Embed Size (px)
Citation preview

Machine learning с использованием нейронных сетей
Дмитрий Лапин
Data science meetup #1
CVisionLab © март 2017
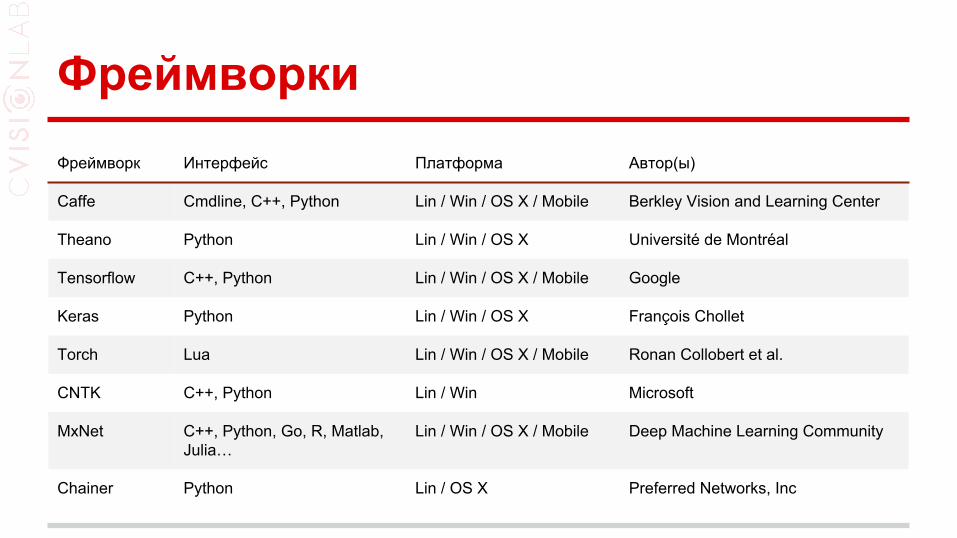
ФреймворкиФреймворк Интерфейс Платформа Автор(ы)
Caffe Cmdline, C++, Python Lin / Win / OS X / Mobile Berkley Vision and Learning Center
Theano Python Lin / Win / OS X Université de Montréal
Tensorflow C++, Python Lin / Win / OS X / Mobile Google
Keras Python Lin / Win / OS X François Chollet
Torch Lua Lin / Win / OS X / Mobile Ronan Collobert et al.
CNTK C++, Python Lin / Win Microsoft
MxNet C++, Python, Go, R, Matlab, Julia…
Lin / Win / OS X / Mobile Deep Machine Learning Community
Chainer Python Lin / OS X Preferred Networks, Inc

Caffe● Один из первых фреймворков● Очень популярный, значительная часть исследователей использует
Caffe● Основной интерфейс — интерфейс командной строки, но есть Python
и C++ интерфейсы.● “Высокоуровневый” фреймворк — оперирует отдельными слоями● Плохо документирован, многие слои есть в отдельных форках, часть
слоев не документирована● Большой репозиторий обученных моделей:
https://github.com/BVLC/caffe/wiki/Model-Zoo

Caffe● Сложно добавлять новый функционал:
○ Нужно написать код для расчета градиентов
○ Нужно пересобирать всю библиотеку
● С++ библиотека упрощает использование в проектах, но:
○ Проблемы при сборке под мобильные платформы
○ Проблемы при несовпадении версий Protobuf
○ Вызывает abort() при ошибках (например, если не найден файл)

Theano● Низкоуровневый фреймворк — оперирует отдельными операциями,
понятие слоя как таковое не существует
● При использовании создается символьный граф:○ Есть отдельный этап оптимизации и компиляции графа
(создается код на C / C++ / Cuda)○ Компиляция занимает заметное количество времени и требует
наличия компиляторов во время работы○ Более точный расчет градиентов за счет дифференцирования
аналитических выражений (большинство использует правило дифференцирования сложной функции — chain rule и считает градиенты численно)
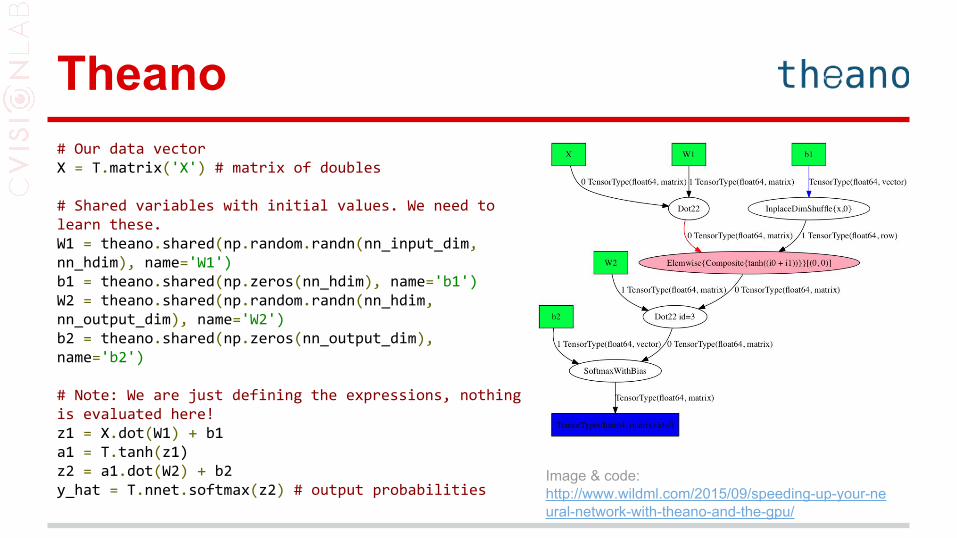
Theano# Our data vectorX = T.matrix('X') # matrix of doubles
# Shared variables with initial values. We need to learn these.W1 = theano.shared(np.random.randn(nn_input_dim, nn_hdim), name='W1')b1 = theano.shared(np.zeros(nn_hdim), name='b1')W2 = theano.shared(np.random.randn(nn_hdim, nn_output_dim), name='W2')b2 = theano.shared(np.zeros(nn_output_dim), name='b2')
# Note: We are just defining the expressions, nothing is evaluated here!z1 = X.dot(W1) + b1a1 = T.tanh(z1)z2 = a1.dot(W2) + b2y_hat = T.nnet.softmax(z2) # output probabilities
Image & code: http://www.wildml.com/2015/09/speeding-up-your-neural-network-with-theano-and-the-gpu/

Theano● Редко используется “напрямую”, обычно используется некоторая
более высокоуровневая обертка, например Lasagne или Keras, а отдельные операции (недоступные в обертках) реализуются самостоятельно
● В большинстве случаев не требуется явно определять расчет градиентов для собственных операций (слоев)
● Нет собственного репозитория с моделями, но можно использовать модели созданные фреймворками на основе Theano

Tensorflow● Стал публичным сравнительно недавно, до этого несколько лет
развивался как закрытый проект Google Brain● Активно развивается и обретает популярность● Содержит как низкоуровневые операции, так и высокоуровненые
операции (и / или обертки)● Как и theano создает вычислительный граф и в этом смысле довольно
похож — если есть опыт работы с theano то использование tensorflow не доставляет особых проблем
● В отличие от theano, не выполняет компиляцию графа перед выполнением, все операции компилируются при сборке tensorflow. В итоге время на загрузку графа (модели) заметно меньше.

Tensorflow● Как и в theano, понятие “слоя” фактически не существует● Хорошо документирован, есть туториалы по использованию, в т.ч. для
тех кто раньше не сталкивался с нейронными сетями, например:https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#0
● Использует собственную систему сборки (Bazel), что не всегда удобно. Как workaround предлагается использовать альтернативные системы сборки (CMake, Makefile)
● Основной API — Python, есть C++ API позволяющий выполнять сохраненный граф (модель)
● Простые средства визуализации и отладки (tensorboard)● Много пред-обученных моделей, в т.ч. официальный репозиторий:
https://github.com/tensorflow/models

Keras● Достаточно популярный фреймворк
● Изначально был высокоуровневой оберткой вокруг theano
● Оперирует слоями, но и гораздо менее гибкий чем theano — есть ряд ограничений выйти за которые довольно сложно
● Поддерживает tensorflow или theano в качестве backend-а
○ Модель созданная с одним backend-ом может быть загружена с другим
○ Переключение между backend-ами может быть неэффективным из-за различного внутреннего представления данных в разных backend-ах

Keras● Технически позволяет добраться до внутренних объектов
используемого backend-а, чтобы реализовать свой функционал, но при этом нужно учитывать что backend-ы могут быть разными
● Использует не все возможности tensorflow, поэтому модель может быть менее эффективной чем модель реализованная на tensorflow
● Хорошая документация
● Нет репозитория с пред-обученными моделями, но есть примеры с исходным кодом (необходимо обучать):https://github.com/fchollet/keras/tree/master/examples

Torch● Основной язык — Lua
● Заявлена поддержка мобильных и встраиваемых платформ (с использованием LuaJIT)
● Высокоуровневый фреймворк, оперирует слоями
● Довольно развитое сообщество, с большой вероятностью можно найти решение своей проблемы

CNTK● Многообещающий фреймворк от Microsoft● С++ и Python API● Заявлена высокая производительность,
особенно при распределенных вычислениях (специальный алгоритм градиентного спуска)*
● Активно развивается● Ограниченная поддержка других
платформ● Относительно недавно лицензия не
позволяла использование в коммерческих целях*

MxNet● С++ backend (как в TF), биндинги для нескольких языков: Python, R,
Scala, Julia, Matlab and Javascript
● Заявлена поддержка мобильных и встраиваемых платформ
● Заявлена оптимизация для x86-64, ARMv7, ARM64
● Менее популярный, но встречаются проекты выполненные с его использованием
● Смешанные символьные / императивные вычисления
● Хорошая масштабируемость*:http://en.community.dell.com/techcenter/high-performance-computing/b/general_hpc/archive/2016/11/11/deep-learning-performance-with-p100-gpus

Chainer● Основное отличие — динамические
графы. Граф может меняться в процессе и при этом фреймворк поддерживает расчет градиентов
● Язык — Python● Довольно гибкий, в то же время довольно
сложные архитектуры могут быть описаны небольшим кодом, например ResNet-50:○ 2320 строк в Caffe (prototxt)○ 100 строк кода Chainer
Сравнение от авторов Chainer
Альтернативное сравнение:https://github.com/soumith/convnet-benchmarks
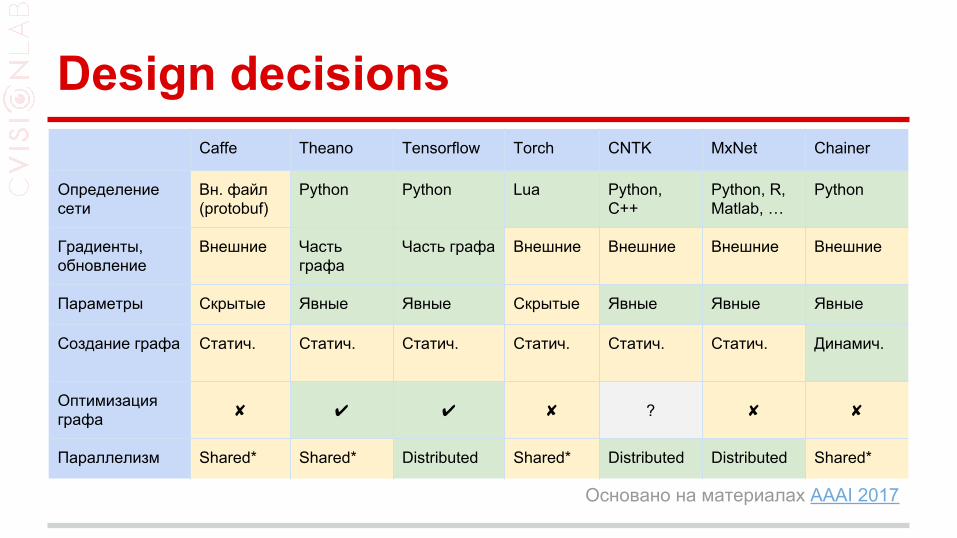
Design decisionsCaffe Theano Tensorflow Torch CNTK MxNet Chainer
Определение сети
Вн. файл (protobuf)
Python Python Lua Python, C++
Python, R, Matlab, …
Python
Градиенты, обновление
Внешние Часть графа
Часть графа Внешние Внешние Внешние Внешние
Параметры Скрытые Явные Явные Скрытые Явные Явные Явные
Создание графа Статич. Статич. Статич. Статич. Статич. Статич. Динамич.
Оптимизация графа ✘ ✔ ✔ ✘ ? ✘ ✘
Параллелизм Shared* Shared* Distributed Shared* Distributed Distributed Shared*
Основано на материалах AAAI 2017

Другие фреймворкиРассмотрены далеко не все фреймворки, есть много других. Вот еще несколько:● Intel Nervana Neon — оптимизированный фреймворк, показывает
очень хорошую производительность● Apple BNNS (Basic Neural Network Subroutins) — не совсем
фреймворк, скорее набор функций, оптимизированных для платформ Apple
● nVidia DIGITS — фреймворк, позволяющий решать довольно ограниченный круг задач, зато очень простой в использовании. Всё, от определения архитектуры до использование обученной сети выполняется из браузера.

Внедрение

Внедрение Не всегда фреймворк который использовался для обучения и фреймворк который будет использоваться в production это один и тот же фреймворк.В большинстве случаев модель можно сконвертировать в формат целевого фреймворка, при этом могут возникнуть следующие проблемы*:
● Различный формат хранения обрабатываемых данных, например: (h×w×c) vs (c×h×w)
● Различный формат хранения параметров (например, часто свертки реализованы как кросс-корреляции)
● Различный набор параметров у одинаковых операций (например, различные параметры padding у сверток)
● Различный набор операций: может возникнуть необходимость заменить одну операцию на несколько

Внедрение Часто при внедрении нужна максимальная производительность, особенно, если внедрение на мобильную или встраиваемую платформу
● Оптимизация графа○ После завершения обучения коэффициенты становятся
константами и некоторые операции можно объединить○ Для уменьшения времени загрузки из графа можно удалить узлы,
которые не нужны для предсказания○ Для некоторых задач (и целевых платформ) есть смысл
выполнить квантизацию — заменить коэффициенты на их 8-и битное представление (и выполнять операции в целых числах)

С чего начать?

Используйте обученные модели● Для многих задач есть готовые модели обученные на огромных
коллекциях данных в течение длительного времени на многих GPU.● Если задача полностью совпадает с уже решенной или является ее
подмножеством, например, задача классификации изображений:
○ Есть множество архитектур, выбирать нужно исходя из соотношения качества классификации и требования к ресурсам
○ Даже если сеть обучена классифицировать на большее количество классов чем нужно для решения задачи нет смысла обучать заново — накладные расходы, обычно, несущественны
● Другие задачи для которых с большой вероятностью можно найти готовые сети: детекция, сегментация

До-обучение (fine-tuning)Если нужно почти то же самое, но другое.Например, если нужно классифицировать различные виды цветов*:
● В сверточных сетях первые (сверточные) слои выделяют признаки. Сети обученные на больших коллекциях выделяют хорошие универсальные признаки
● В таком случае достаточно заново обучить последний — классификационный слой. Это значительно проще и быстрей. Хороший (и простой) пример как это делают: https://codelabs.developers.google.com/codelabs/tensorflow-for-poets
● Это не работает если изображения имеют другой характер (другие признаки), например, если сеть обучена на фотографиях а должна работать на карандашных рисунках

Обучение “с нуля”Типичная причина — не нашлось готовых сетей решающих такую же или похожую задачу.
Перед тем как продолжить сто́ит попытаться найти еще раз.
Если найти всё-таки не удается, то скорее всего придется погрузиться в детали того, как работают нейронные сети и как их обучают. Хороший вводный курс можно найти здесь: http://cs231n.github.io
Неплохой обзор архитектур: http://www.asimovinstitute.org/neural-network-zoo/
Курс на Coursera: https://www.coursera.org/learn/neural-networks






























