Embed Size (px)
Citation preview

Recommender Systems
Web Data Mining
1

Phương pháp lọc cộng tác
(Collaborative Filtering)
Phương pháp tư vấn dựa vào lọc cộng tác: Người dùng sẽ được tư vấn một số sản phẩm của những người có sở thích giống họ đã từng ưa thích trong quá khứ
2
Ma trận đánh giá của lọc cộng tác
Các thành phần của hệ thống lọc cộng tác

Lọc cộng tác dựa trên mô hình
(Model-Based Collaborative Filtering)
Tập đánh giá người dùng – sản phẩm được sử dụng để xây dựng mô
hình huấn luyện.
Mô hình huấn luyện này sẽ được sử dụng để đưa ra các đự đoán
quan điểm của người dùng về sản phẩm chưa được họ đánh giá
Ưu điểm:
Mô hình huấn luyện có kích thước nhỏ hơn rất nhiều so với ma trận đánh giá
ban đầu
Cho phép thực hiện dự đoán nhanh, do quá trình dự đoán thực hiện trên mô
hình đã học trước đó.
Mô hình chỉ cần cập nhật lại khi có thay đổi lớn và chỉ thực hiện lại pha xây
dựng mô hình
3

Lọc cộng tác dựa trên mô hình
Các kỹ thuật thông dụng
Mô hình mạng Bayes (Bayesian Belief Net)
Phương pháp phân lớp Navie Bayes
Mô hình ngữ nghĩa ẩn (Laten Semantic Model)
Phương pháp phân rã giá trị riêng (Singular Value Decomposition)
Mô hình đồ thị hai phía (Biparties Graph Model)
Phương pháp truy vấn liên tưởng (Association Retrieval)
4

Mô hình mạng Bayes
(Bayesian Belief Net CF)
Ý tưởng:
Là một đồ thị có hướng, không chu trình với
các bộ (N, A, 𝛩), trong đó:
• Mỗi đỉnh n 𝜖 N biểu diễn cho một biến ngẫu nhiên
• Mỗi cạnh a 𝜖 A nối giữa 2 đỉnh là xác suất liên kết
giữa các biến
• 𝛩 là bảng lưu các giá trị xác suất điều kiện
(CPtable) chỉ ra mức độ phụ thuộc giữa 1 đỉnh và
các đỉnh cha (parent) của nó
Thường được áp dụng trong các phép xử lý
phân lớp dữ liệu 5
C
𝑎1 𝑎2 𝑎𝑛

Phương pháp Naïve Bayes Ý tưởng:
Định lý Bayes:
𝑃 𝐻 𝑋 =𝑃(𝑋|𝐻)𝑃(𝐻)
𝑃(𝑋)=
𝑙𝑖𝑘𝑒ℎ𝑜𝑜𝑑 ∗ 𝑝𝑟𝑖𝑜𝑟
𝑛𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑖𝑛𝑔_𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡
Trong đó: • X = 𝑥1, 𝑥2, … , 𝑥𝑛 là mẫu cần xem xét, 𝑥𝑖 là thuộc tính thứ i c
• H: là một giả thuyết giả định X thuộc vào vào một lớp C đã biết
• P(H): xác suất tiên nghiệm của H, không phụ thuộc vào X
• P(X): xác suất tiên nghiệm của X, không phụ thuộc vào H
• P(X|Y): xác suất hậu nghiệm của X phụ thuộc điều kiện vào H
Cần xác định P(H|X): là xác suất hậu nghiệm của H phụ thuộc điều kiện vào
X, hay nói cách khác là tính xác suất mẫu X thuộc lớp C khi đã biết các
thuộc tính của X.

Phương pháp Naïve Bayes Công thức:
Xác suất một mẫu X với tập thuộc tính đã biết phụ
thuộc vào một phân lớp Ci:
𝑃 𝐶𝑖 𝑋 = 𝑃 𝑋 𝐶𝑖 𝑃(𝐶𝑖)
𝑃(𝑋)
Công thức xác định xác suất Navie Bayes:
Áp dụng công thức làm mượt xác suất Laplace
(Laplace Estimator):
𝑃 𝑋𝑖=𝑥𝑖 𝑌=𝑦 = #(𝑋𝑖=𝑥𝑖,𝑌=𝑦)+1#(𝑌=𝑦)+|𝑋𝑖|
|𝑋𝑖|: kích thước của tập {𝑥𝑖}
p(5)P(U2 =2| 5)P(U4 =4| 5)P(U5=1|4)
=(2/3)*(1/7)*(1/7)*(1/7)=0.0019
p(4)P(U2 =2| 4)P(U4 =4| 4)P(U5=1|4)
=(1/3)*(1/6)*(2/6)*(1/6)=0.0031

Thuật toán Naïve Bayes
Thuật toán chia làm 2 giai đoạn:
Huấn luyện
Input:
Ma trận đánh giá R[m x n], m là số user trong tập huấn luyện, n là số
item trong tập huấn luyện
Tập nhãn/lớp cho từng vector đặc trưng cho đối tượng cần phân lớp
của tập huấn luyện
Output: xác suất P(Ci) và P(Xk|Ci)
Bước 1: Tính P(Ci)
Bước 2: Tính P(Xk|Ci)

Thuật toán Naïve Bayes
Phân lớp:
Input:
Vector đặc trưng của đối tượng cần phần lớp
Các giá trị xác suất P(Ci) và P(Xk|Ci)
Output: Nhãn/lớp của đối tượng cần phân loại
Bước 1: Tính 𝑃 𝐶𝑖 𝑋 = 𝑃(𝐶𝑖) 𝑃 𝑥𝑘 𝐶𝑖𝑛𝑘=1
Bước 2: Tìm và sắp xếp các giá trị P(Ci|X) theo thứ tự giảm dần
Bước 3: Chọn nhãn/lớp Ci có giá trị xác suất lớn nhất để phân lớp cho
đối tượng cần phân loại.

Mô hình ngữ nghĩa ẩn
(Latent Factor Model)
• Ý tưởng:
– Các tham biến ẩn thường ảnh hưởng nhiều đến việc xác định giá
trị ước lượng của người dùng đối với sản phẩm, tuy nhiên thông
thường các yếu tố ẩn này không rõ ràng để phát hiện trong dữ liệu
đánh giá ban đầu
– Dựa vào kỹ thuật lọc thống kê, trong đó các tham biến ẩn được
thiết lập trong một mô hình hỗn hợp để khám phá ra cộng đồng
người dùng phù hợp với mẫu hồ sơ thích hợp.

Phát hiện ngữ nghĩa ẩn dựa trên kỹ thuật phân
rã giá trị riêng (SVD)
A = 𝑈 𝑉𝑇 , ℎ𝑎𝑦 𝐴 = 𝜎𝑖𝑢𝑖𝑟𝑖=1 𝑣𝑖
𝑇
– A: ma trận đánh giá user-item, kích thước mxn
– U: là các vector đặc trưng (eigenvector) của ma trậng 𝐴𝐴𝑇
– V: là các vector đặc trưng (eigenvector) của ma trân 𝐴𝑇𝐴
– : ma trận đường chéo kích thước rxr với các giá trị trên
đường chéo là các trị đặc trưng (𝜎𝑖>0) của ma trận 𝐴𝐴𝑇 tương ứng với các vector đặc trưng trong U và V. Các giá
trị này được sắp xếp theo thứ tự giảm dần.
A mxn
U n x r
:
r x r
𝑉𝑇 r x m
=

Phát hiện ngữ nghĩa ẩn dựa trên kỹ thuật phân
rã giá trị riêng (SVD)
• Lựa chọn k giá trị đặc trưng lớn nhất,
khi đó xác định được ma trận 𝐴𝑘 gần
đúng nhất so với A :
• A và 𝐴𝑘 thõa mãn chuẩn Frobenius như
sau:
𝐴𝑘 = 𝑈𝑘 𝑉𝑘𝑇
𝑘 , hay 𝐴𝑘 = 𝜎𝑖𝑢𝑖𝑘𝑖=1 𝑣𝑖
𝑇
𝐴 − 𝐴𝑘 𝐹 = 𝜎2𝑖
min {𝑚,𝑛}𝑖=1 = 𝑎𝑖𝑗
2𝑛𝑗=1
𝑚𝑖=1

Phát hiện ngữ nghĩa ẩn dựa trên kỹ thuật phân
rã giá trị riêng (SVD)
13

Thuật toán phân rã giá trị riêng (SVD)

Phát hiện ngữ nghĩa ẩn dựa trên kỹ thuật phân
rã giá trị riêng (SVD)
Dự đoán đánh giá của người dùng i-th trên sản phẩm j-th là 𝑃𝑖𝑗:
Folding-in SVD theo Sarwar (5): 𝑃 = 𝑈𝑘 × 𝑈𝑇𝑘 × 𝑁𝑢
𝑃𝑖𝑗 = 𝑟𝑖 + 𝑈𝑘. 𝑆𝑘𝑇𝑖 . 𝑆𝑘 . 𝑉𝑘
𝑇 𝑗

Lọc cộng tác dựa trên mô hình đồ thị
hai phía (Biparties Graph)
• Ý tưởng: – Lọc cộng tác có thể xem xét như bài toán tìm kiếm đường đi trên
đồ thị hai phía dựa trên biểu diễn mối quan hệ đánh giá của người
dùng đối với các sản phẩm
• Phương pháp biểu diễn đồ thị: – R=(𝑟𝑖𝑗): ma trận đánh giá đầu vào
– X=(𝑥𝑖𝑗): ma trận cấp NxM với 𝑥𝑖𝑗 xác định bởi:
𝑥𝑖𝑗= 1, 𝑛ế𝑢 𝑟𝑖𝑗 ≠ ∅
0, 𝑛ế𝑢 𝑛𝑔ượ𝑐 𝑙ạ𝑖

Lọc cộng tác dựa trên mô hình đồ thị hai phía
(Biparties Graph)
• Phương pháp biểu diễn:
– G=(V,E): đồ thị đánh giá của người dùng đối với sản phẩm theo ma trận X
• Tập đỉnh V = U ∪ P: U tập người dùng; P tập sản phẩm
• Tập cạnh E: tập các cạnh biễu diễn đánh giá người dùng đối với sản phẩm
• Cạnh nối giữa đỉnh 𝑢𝑖 𝜖 𝑈 và đỉnh 𝑝𝑗 𝜖 𝑃 được thiết lập nếu người dùng 𝑢𝑖 đã
đánh giá sản phẩm 𝑝𝑗 (𝑥𝑖𝑗=1)
• Trọng số mỗi cạnh được lấy tương ứng là 𝑟𝑖𝑗
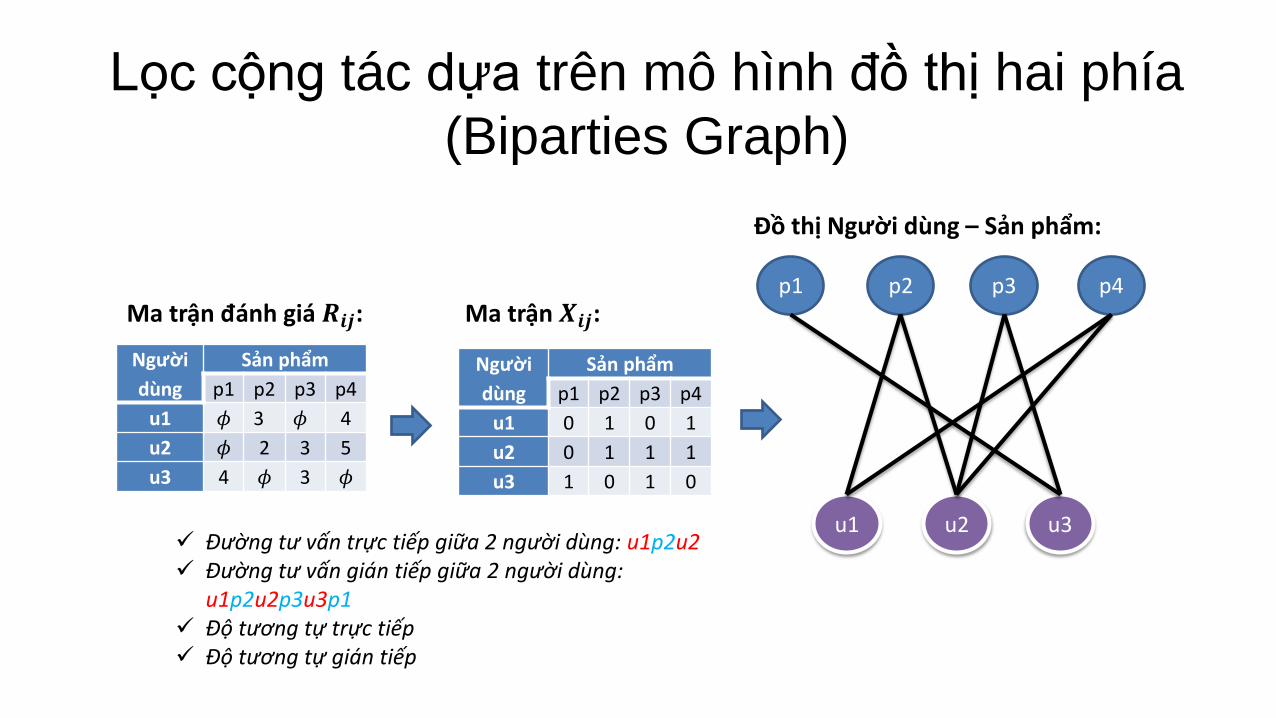
Lọc cộng tác dựa trên mô hình đồ thị hai phía
(Biparties Graph)
Ma trận 𝑿𝒊𝒋: Ma trận đánh giá 𝑹𝒊𝒋:
Đồ thị Người dùng – Sản phẩm:
p3 p1 p2 p4
u3 u1 u2
Người
dùng
Sản phẩm
p1 p2 p3 p4
u1 0 1 0 1
u2 0 1 1 1
u3 1 0 1 0
Người
dùng
Sản phẩm
p1 p2 p3 p4
u1 𝜙 3 𝜙 4
u2 𝜙 2 3 5
u3 4 𝜙 3 𝜙
Đường tư vấn trực tiếp giữa 2 người dùng: u1p2u2 Đường tư vấn gián tiếp giữa 2 người dùng:
u1p2u2p3u3p1 Độ tương tự trực tiếp Độ tương tự gián tiếp

Lọc cộng tác dựa trên mô hình đồ thị hai phía
(Biparties Graph)
• Phương pháp truy vấn liên tưởng (Association Retrieval):
– Phương pháp dự đoán 𝑟𝑖𝑗:
𝑟𝑖𝑗 = 𝑎𝑖𝑗𝑐𝑖,𝑐𝑗∈𝑐 𝑛𝑐 𝑛∈𝐶
– Phương pháp tính ma trận tương tự trực tiếp:
• Tính độ tương tự giữa 2 người dùng:
𝑠𝑖𝑚_𝐾(𝑖𝑗) =
max 𝑅 −|𝑟𝑖𝑘 − 𝑟𝑗𝑘 |
max (𝑅), nếu 𝑟𝑖𝑘 và 𝑟𝑗𝑘 𝑘ℎá𝑐 0
0, 𝑛ế𝑢 𝑛𝑔ượ𝑐 𝑙ạ𝑖,
• Tính các phần tử 𝑎𝑖𝑗 của ma trận tương tự trực tiếp 𝐴𝑠𝑖𝑚:
𝑎𝑖𝑗 = 𝑠𝑖𝑚𝑚𝑘=1 _𝐾(𝑖𝑗)
m,nếu i ≠ 𝑗
1, 𝑛ế𝑢 𝑖 = 𝑗
R={0,1,2,3,4,5}
m=4: số lượng sản phẩm
Sim_2(12) = 0.8
Sim_4(12)=0.8
aij = (0.8 + 0.8)/4 = 0.4
𝐴𝑠𝑖𝑚 = 1 0.4 00.4 1 0.250 0.25 1

Lọc cộng tác dựa trên mô hình đồ thị hai phía
(Biparties Graph)
• Phương pháp truy vấn liên tưởng:
– Phương pháp dự đoán 𝑟𝑖𝑗:
𝑟𝑖𝑗 = 𝑎𝑖𝑗𝑐𝑖,𝑐𝑗∈𝑐 𝑛𝑐 𝑛∈𝐶
– Phương pháp tính ma trận tư vấn:
𝑀𝑎𝑡𝑟𝑖𝑥_𝑅𝑀= 𝑅, 𝑛ế𝑢 𝑀 = 1
𝑋. 𝑋𝑇. 𝐴𝑠𝑖𝑚. 𝑀𝑎𝑡𝑟𝑖𝑥_𝑅𝑀−2, 𝑛ế𝑢 𝑀 = 3,5,7, …
𝑀𝑎𝑡𝑟𝑖𝑥_𝑅3 = 0.0000 7.6000 2.4000 12.00001.0000 8.4000 9.7500 18.20008.0000 0.5000 6.7500 1.2500
𝑀𝑎𝑡𝑟𝑖𝑥_𝑅5 = 0.8000 21.9200 12.6000 38.56005.0000 31.4050 32.8575 64.512516.2500 3.1000 15.9375 7.0500
Matrix_R3 (u1,p3) = 2.4
Matrix_R5 (u1,p1) = 0.8
𝐴𝑠𝑖𝑚 = 1 0.4 00.4 1 0.250 0.25 1
X

Lọc cộng tác dựa trên mô hình đồ thị hai phía
(Biparties Graph)
Thuật toán phương pháp truy vấn liên tưởng:
Input: ma trận đánh giá R, chiều dài của đường đi trên đồ thị hai phía M (M
luôn lẻ)
Output: Ma trận tư vấn
Bước 1: Xây dựng ma trận X từ ma trận R, nếu rij khác 0 thì Xij = 1
Bước 2: Thiết lặp bước lặp N = 1
Bước 3: Khởi tạo ma trận tư vấn Matrix_Rn = R
Bước 4: Tính ma trận tương tự trực tiếp Asim
Bước 5: Tính ma trận hoán vị XT của X
Bước 6: Tính ma trận Matrix_RM
Bước 7: Nếu N+2<M thì N=N+2, quay lại Bước 3. Thực hiện cho đến khi N
> M.
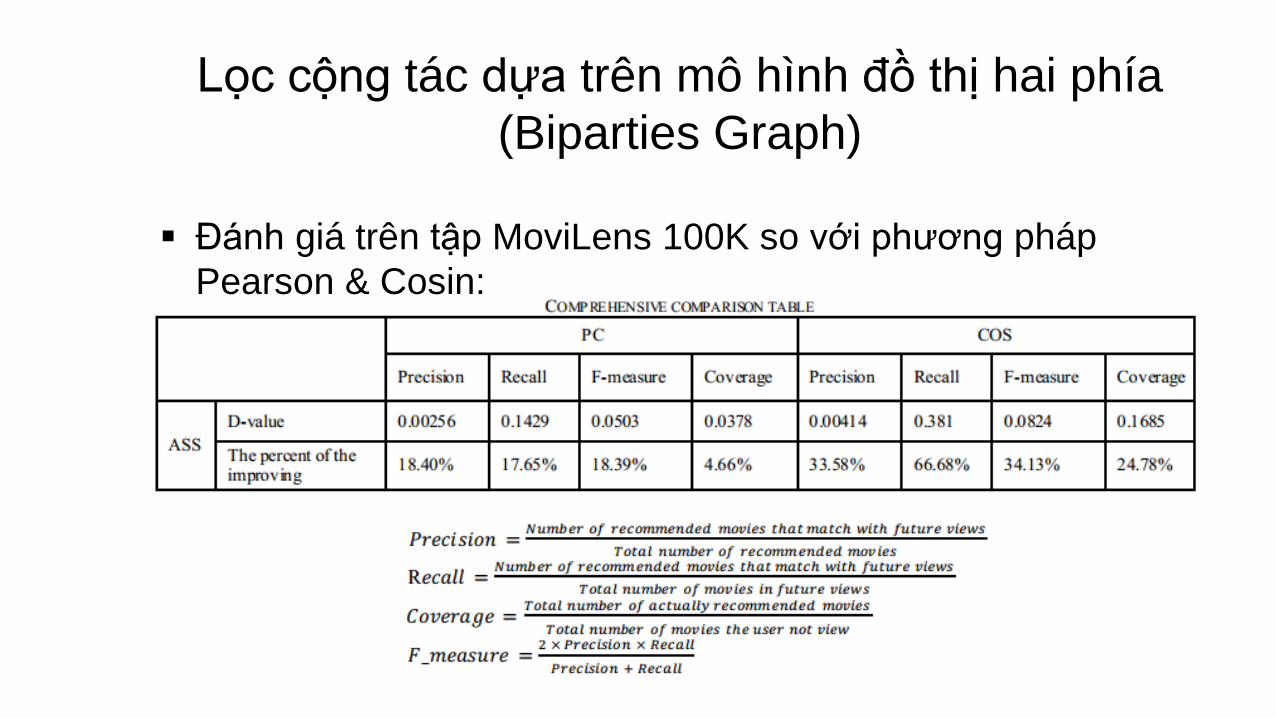
Lọc cộng tác dựa trên mô hình đồ thị hai phía
(Biparties Graph)
Đánh giá trên tập MoviLens 100K so với phương pháp
Pearson & Cosin:
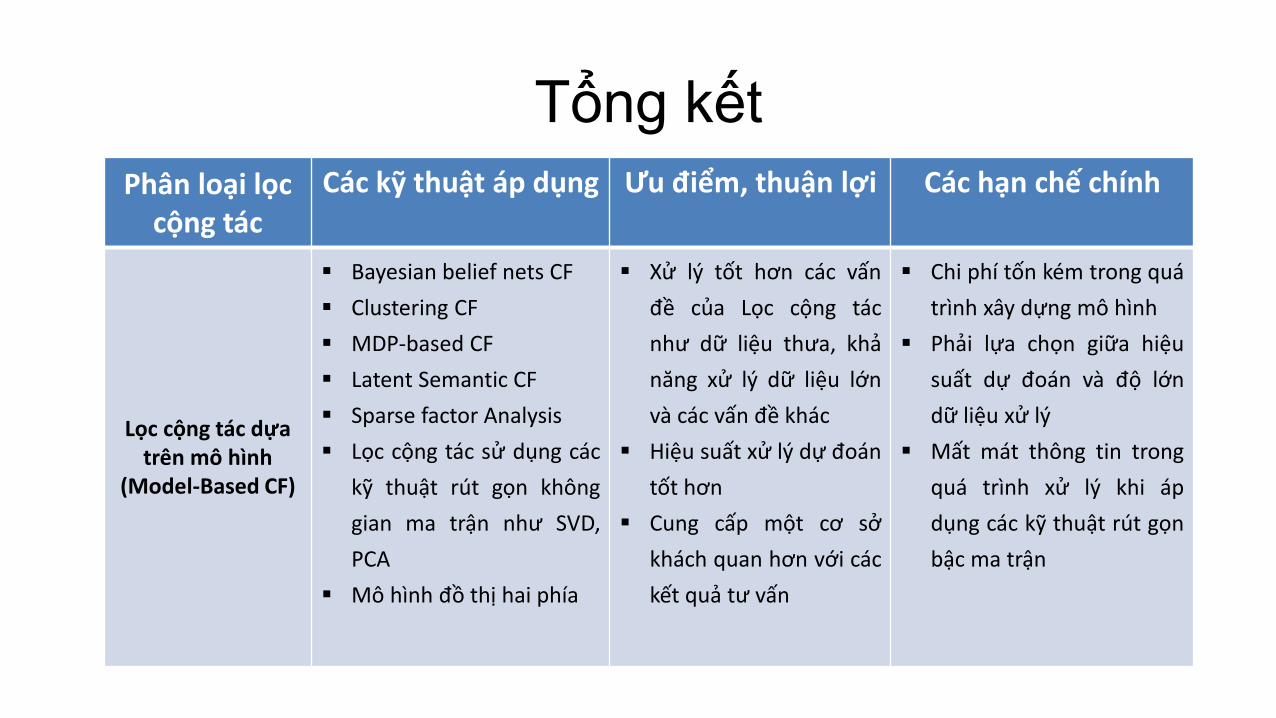
Tổng kết
Phân loại lọc cộng tác
Các kỹ thuật áp dụng Ưu điểm, thuận lợi Các hạn chế chính
Lọc cộng tác dựa trên mô hình
(Model-Based CF)
Bayesian belief nets CF
Clustering CF
MDP-based CF
Latent Semantic CF
Sparse factor Analysis
Lọc cộng tác sử dụng các
kỹ thuật rút gọn không
gian ma trận như SVD,
PCA
Mô hình đồ thị hai phía
Xử lý tốt hơn các vấn
đề của Lọc cộng tác
như dữ liệu thưa, khả
năng xử lý dữ liệu lớn
và các vấn đề khác
Hiệu suất xử lý dự đoán
tốt hơn
Cung cấp một cơ sở
khách quan hơn với các
kết quả tư vấn
Chi phí tốn kém trong quá
trình xây dựng mô hình
Phải lựa chọn giữa hiệu
suất dự đoán và độ lớn
dữ liệu xử lý
Mất mát thông tin trong
quá trình xử lý khi áp
dụng các kỹ thuật rút gọn
bậc ma trận

Tài liệu tham khảo
1. K. Ming Leung, “Navie Byesian Classifier”, November 28, 2007
2. Xiaoyuan Su, Taghi M. Khoshgoftaar, “Collaborative Filtering for Multi-class Data Using Belief Nets
Algorithms”
3. Kirk Baker, “Singular Value Decomposition Tutorial”, March 29, 2005 (Revised January 14, 2013)
4. Alan Kaylor Cline, Indefjit S.Dhillon, “Computation of the Singular Value Decomposition”
5. Badrul Sarwal, George Karypis, Joseph Konstan, and John Riedl, “Incremental Singular Value
Decomposition Algorithms for Highly Scalable Recommender System”
6. Michael Percy, “Collaborative Filtering for Netflix”, Dec 10, 2009
7. YiBo Chen, ChanLe Wu, Ming Xie and Xiaojun Guo, “Solving the Sparsity Problem in Recommender
Systems Using Association Retrieval”, © 2011 ACADEMY PUBLISHER
8. Xiaoyuan Su and Taghi M.Khoshgoftaar, “A survey of Collaborative Filtering Techniques”, August 3, 2009





























