Embed Size (px)
Citation preview

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Big DataModelos Predictivos
Retos y generación de nuevas soluciones

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
360 CustomerView
Connectionswithout boundaries
Incredible Speedand Reliability
The promise…

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
3Cambie sus creencias!
+ preguntas, + modelos,
+ Citizen Data Scientists
Menos Servidores, Mas Distributed Poweful Laptops
- Hadoop, - Spark+,
- CODIGO!

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Part 1: Who are we?

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Dr. Ir. Frank Vanden Berghen
Phd. In Applied-Sciences with specialization in applied-mathematics (mathematical optimization)
Building predictive models for more than 15 years, all around the world.
Top winners at various world-level datamining competitions:
5

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
6
Automation
Moore’s Law
Life
of
a
Modelos Predictivos

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
7Objectives & Motivations

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
8At University
IRIDIA=Research in Artificial Intelligence
Neural Networks
One Tree
Forest of Trees

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
9In consulting… Far from AI…
VS
Now: Manual & Archaic(1 to 3 months to get 1 Model)
Self-Learning & Auto-AdaptativeArtificial Intelligence

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
10Market Reality: all is Scoring
Quien? Que?
X SELL
UP SELL
CHURN

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Typical difficulties:
• High Bayes-Error Levels
• Small Target Size (<1%)
• Scalability Issues
• Before all: TIME!
•AUTOMATED?
11Churn, cross-sell, and up-sell models aren’t easy
TIME! THERE IS NO TIME!

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Inventsomething

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Usual time to create one model for a datamining competition: 1 to 3 months
13Ultimate Accuracy & No Free Lunch
Competition Metric WinnerTIMi
(or similarautomated tool)
Difference
Heritage Health Price Some kind of R² 46.12% 46.24% 0.12%
AUSDM2009 (following Netflix) AUC 69.41% 69.24% 0.17%
Kaggle Axa Telematics 2015 AUC 96.35% 95.97% 0.38%PAKDD2007 AUC 70.01% 69.28% 0.73%PAKDD2010* AUC 64.10% 63.30% 0.80%KDD2009-upselling AUC 90.92% 89.94% 0.98%
Datascience.net Axa cross-selling 2015 Lift at 10% 26.09% 24.74% 1.35%KDD2009-churn AUC 76.51% 74.74% 1.77%KDD2009-appetency AUC 88.19% 86.31% 1.88%
“No free lunch”: There will always exists a specific modeling algorithm that surpasses a “generic, general-purpose & automated tool”
*: winning entry removed because it used additional external data and that’s cheating
Look here

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Sales
A typical time-line for a SAS,IBM,R project:
14Back in 2010
A typical time-line for a TIMi project:
idea
Data Preparation Model
Total: 1 – 3 meses. Modelo: 2-6 weeks
Total: 2 – 6 WEEKS. Modelo: 1-5 DAYSidea
ETL
MODEL
CREATIVITY
RUNTIME
Sales
ETL
MODEL
CREATIVITY
RUNTIME
Sales
FUN

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Part 2:Moore’s Law…
…In real life

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Moore’s Law:
“The number of transistors that can be fit on a computer chip will double every two years, resulting in periodic increases in computing power.”
16I despise Moore’s law!
FAST implementation, slow runtime No attention to code quality “Algorithmic complexity” ? Efficient code = LOSING TIME
Direct consequence of Moore’s Law:
© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
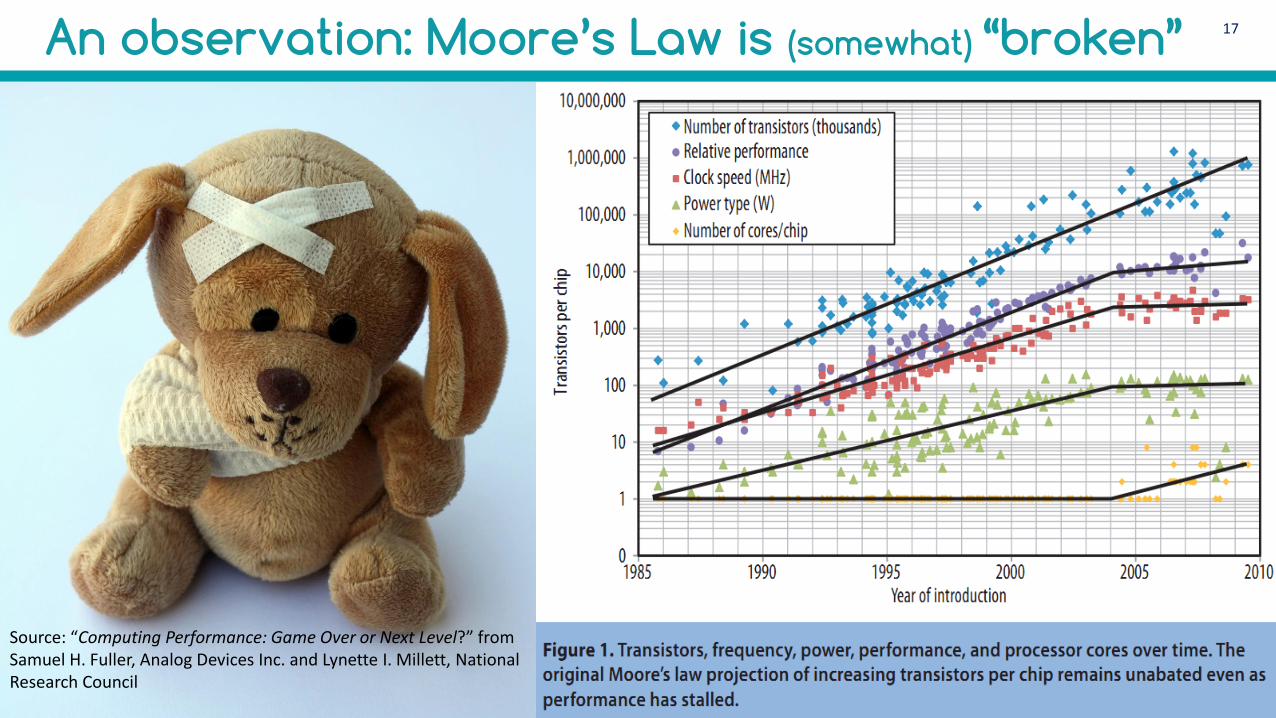
17An observation: Moore’s Law is (somewhat) “broken”
Source: “Computing Performance: Game Over or Next Level?” from Samuel H. Fuller, Analog Devices Inc. and Lynette I. Millett, National Research Council

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
18Moore’s Law is broken: …and it’s terrible!
Exponential Growth of Data Volumes
Technologies such as RFID and smartphones as well as the increasing use of social media application are resulting in a rapid rise in data volumes
(Practically) No Growth in CPU speed
Expectation Gap: factor of 10
Expectation Gap: factor of 1000
Expectation Gap: factor of 100

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
19Moore’s Law is broken: 2 Solutions
• Low-Level Assembler & C code
• Mathematical “tricks”• Algorithmic
It’s the “seventies solution”
• High-Level (i.e. slow) Language (i.e. Java & Spark)
• Computing farm
Supported by:• “Legacy”
• Cloud services (Warning: Linear price-grid!)• Consulting Companies• Coders without any Assembler/C or algorithmic knowledge
This is a possible solution if your wallet can grow exponentially with the size of your data. This will ultimately lead to high cost linked to legacy software.

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
20
OPEN

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Infrastructure
Complexity
Implementation (Time)
Hadoop, Exadata and others cost hundreds of thousands of dollars
Data mining requires PhD’s with years of experience in the field
Implementing predictive models or complex KPI can take months or more to be integrated in the business processes
StorageData can be stored in a highly compressed file format that allows to store (and process) all the data from a 10 millions telecom for 3 years on one simple laptop
Barriers to entry for “Big Data”

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Complexity
Do you need Phd in stats to answer analytical questions?
(See also the concept of “Citizen Developer here: http://www.gartner.com/it-glossary/citizen-developer/ )
© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Complexity

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
Deal with Big Data on a laptop: Live demo!
24Scale of Solution

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
On my laptop:
• Compute a aggregate on a table with 17 columns and 1.3 billion rows: 70 seconds(finest granularity for 2 years of ticket data from a larger retailer with 1 million customer)
• Sort a (CDR) table with 8 columns and 1 billion rows: 120 seconds.(finest granularity for 2 month of CDR data from a telecom with 5 millions subscribers)
• Create 3 KDD-Grade-Predictive models (for churn, cross-sell, up-sell) on a learning dataset (from the KDD2009) with 50K rows and 15K columns (and than apply this model on the same scoring dataset): 20 minutes (about 7 minutes per model)
The laptop has: Core i7 CPU at 2.4 GHz and a simple SSD drive.
25Storage and computational Speed Live Demo!
Conclusion: A simple laptop is enough to store & process all your data, whatever the size, the origin, the granularity, the type or the format of the data.

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
26

© 2016 Timi Americas S.A.S. – TIMi: Faster predictions, better decisions.
27
… to boldly go where no dataminer has bone before!





























