Embed Size (px)
Citation preview

Copyright@2014 NTT DATA Mathematical Systems Inc.
Skip-gram について
1
2014/11/21
白川 達也 [email protected]

Copyright@2014 NTT DATA Mathematical Systems Inc. 2
king – man + woman = ?

Copyright@2014 NTT DATA Mathematical Systems Inc. 3
king – man + woman = queen …ですよね?

Copyright@2014 NTT DATA Mathematical Systems Inc. 4
walked – walk + run = ?

Copyright@2014 NTT DATA Mathematical Systems Inc. 5
walked – walk + run = ran …ですよね?

Copyright@2014 NTT DATA Mathematical Systems Inc. 6
france – paris + japan = ?

Copyright@2014 NTT DATA Mathematical Systems Inc. 7
france – paris + japan = tokyo …ですよね?

Copyright@2014 NTT DATA Mathematical Systems Inc. 8
人間はアナロジー関係を適切にとらえることができます。
Skip-gramに代表される言語モデルの進化により、このようなアナロジー関係をある程度機械的に計算できるようになりました。

Copyright@2014 NTT DATA Mathematical Systems Inc. 9
Skip-gram モデル(+ Noise Sampling)
• T. Mikolov+, “Distributed Representations of Words and Phrases and their Compositionality”, NIPS2013
• Skip-gram モデルは、単語に同じ次元のベクタを割り当てます(語 𝑢 に割り当てられたベクタが 𝜃𝑢 )。
• コーパスで共起する単語ペア( 𝑢, 𝑣 ∼ 𝑃𝐷)は、ベクタの内積が大きくなるようにします。
• コーパスの𝑘倍の個数の単語ペア( 𝑢, 𝑣 ∼ 𝑃𝑁)を別途作成しますが、それらの単語ペアのベクタの内積は小さくなるようにします。
Skip-gram (+NS)
maximize𝜃
𝐿(𝜃) = 𝔼 𝑢,𝑣 ∼𝑃𝐷[log𝑃(𝑢, 𝑣; 𝜃)] + 𝑘𝔼 𝑢,𝑣 ∼𝑃𝑁 log(1 − 𝑃(𝑢, 𝑣; 𝜃) ,
𝑤ℎ𝑒𝑟𝑒 𝑃 𝑢, 𝑣; 𝜃 = 𝜎 𝜃𝑢 ⋅ 𝜃𝑣 𝑠𝑖𝑔𝑚𝑜𝑖𝑑
=1
1 + exp (−𝜃𝑢 ⋅ 𝜃𝑣)
Copyright@2014 NTT DATA Mathematical Systems Inc. 10
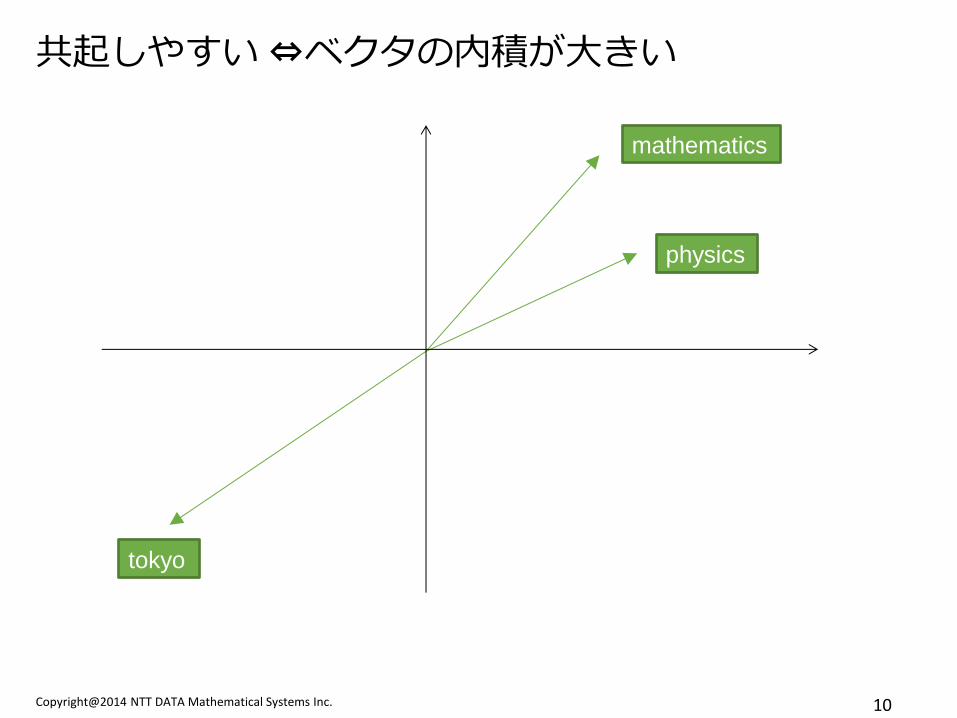
共起しやすい ⇔ベクタの内積が大きい
mathematics
physics
tokyo
Copyright@2014 NTT DATA Mathematical Systems Inc. 11
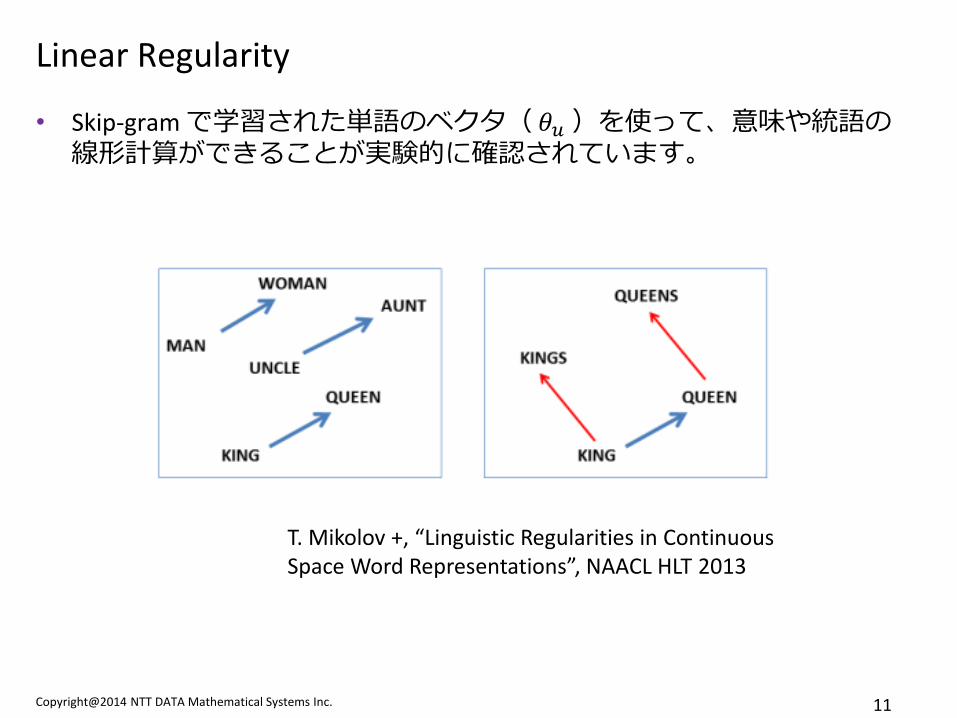
Linear Regularity
• Skip-gram で学習された単語のベクタ( 𝜃𝑢 )を使って、意味や統語の 線形計算ができることが実験的に確認されています。
T. Mikolov +, “Linguistic Regularities in Continuous Space Word Representations”, NAACL HLT 2013
Copyright@2014 NTT DATA Mathematical Systems Inc. 12
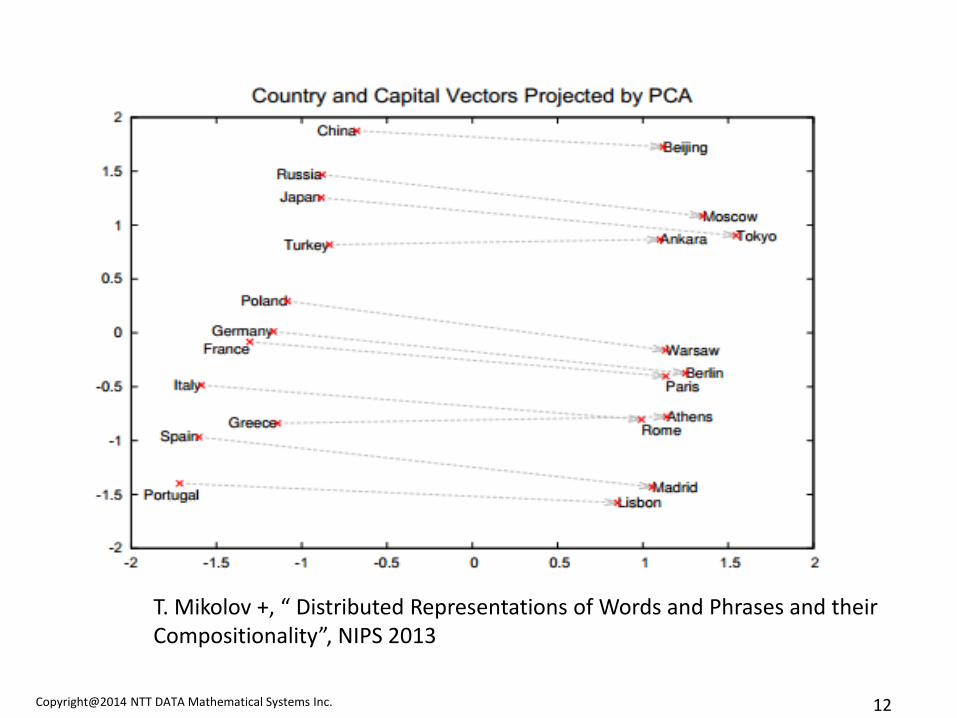
T. Mikolov +, “ Distributed Representations of Words and Phrases and their Compositionality”, NIPS 2013
Copyright@2014 NTT DATA Mathematical Systems Inc. 13
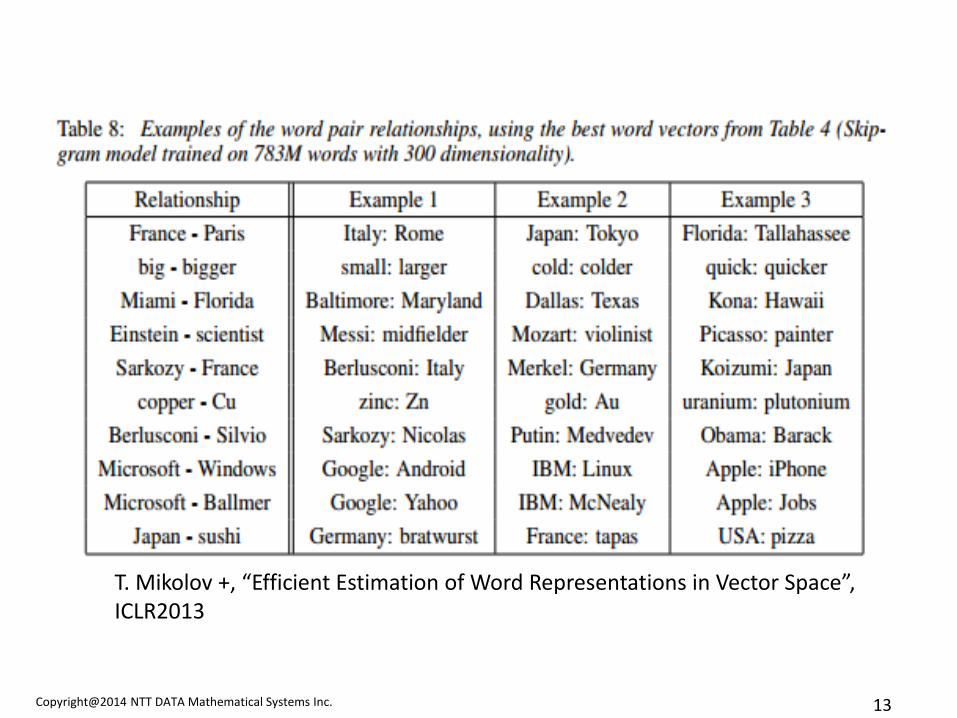
T. Mikolov +, “Efficient Estimation of Word Representations in Vector Space”, ICLR2013
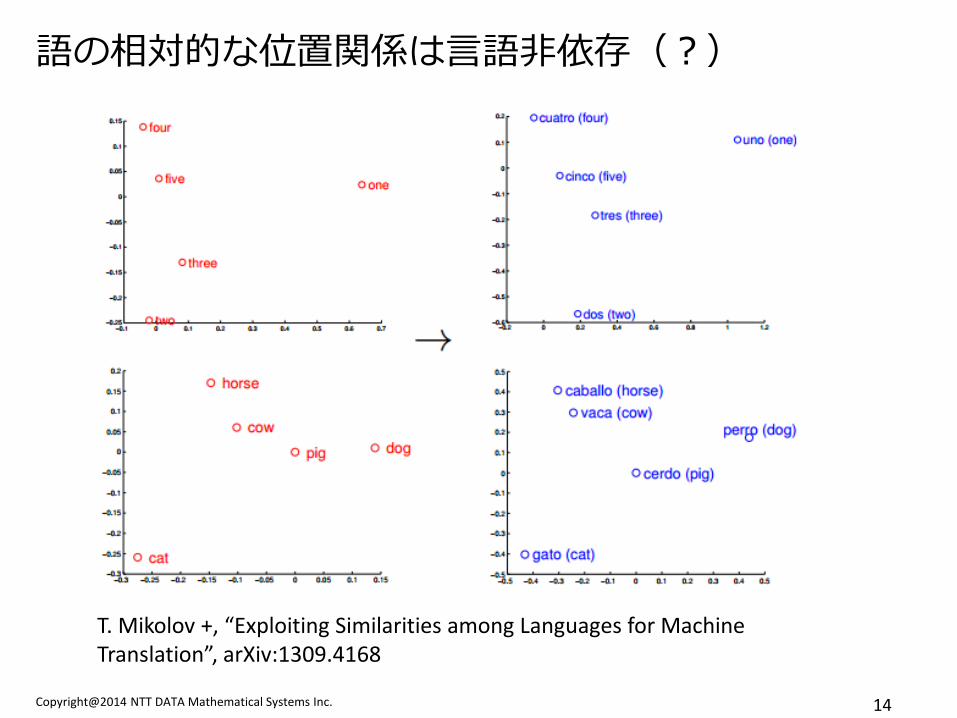
Copyright@2014 NTT DATA Mathematical Systems Inc. 14
語の相対的な位置関係は言語非依存(?)
T. Mikolov +, “Exploiting Similarities among Languages for Machine Translation”, arXiv:1309.4168
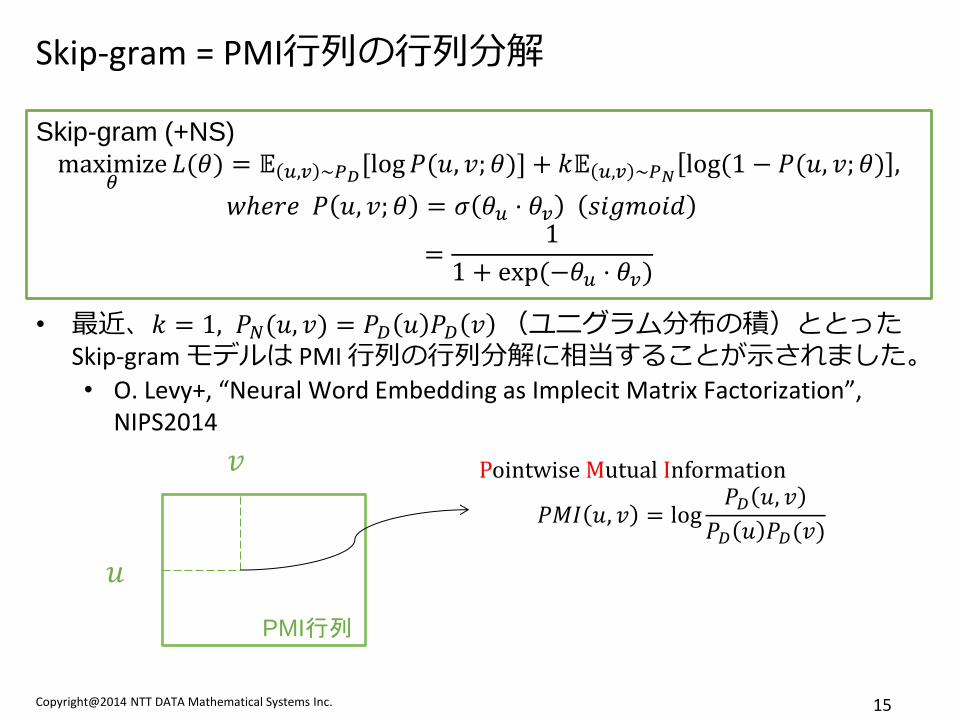
Copyright@2014 NTT DATA Mathematical Systems Inc. 15
Skip-gram = PMI行列の行列分解
• 最近、𝑘 = 1, 𝑃𝑁(𝑢, 𝑣) = 𝑃𝐷 𝑢 𝑃𝐷 𝑣 (ユニグラム分布の積)ととった
Skip-gram モデルは PMI 行列の行列分解に相当することが示されました。
• O. Levy+, “Neural Word Embedding as Implecit Matrix Factorization”, NIPS2014
Skip-gram (+NS)
maximize𝜃
𝐿(𝜃) = 𝔼 𝑢,𝑣 ∼𝑃𝐷[log𝑃(𝑢, 𝑣; 𝜃)] + 𝑘𝔼 𝑢,𝑣 ∼𝑃𝑁 log(1 − 𝑃(𝑢, 𝑣; 𝜃) ,
𝑤ℎ𝑒𝑟𝑒 𝑃 𝑢, 𝑣; 𝜃 = 𝜎 𝜃𝑢 ⋅ 𝜃𝑣 𝑠𝑖𝑔𝑚𝑜𝑖𝑑
=1
1 + exp (−𝜃𝑢 ⋅ 𝜃𝑣)
𝑢
𝑣 Pointwise Mutual Information
𝑃𝑀𝐼 𝑢, 𝑣 = log𝑃𝐷 𝑢, 𝑣
𝑃𝐷 𝑢 𝑃𝐷(𝑣)
PMI行列

Copyright@2014 NTT DATA Mathematical Systems Inc. 16
証明
下記の証明は、本質的には次の論文によるものです。
I. J. Goodfellow+, “Generative Adversarial Networks”, NIPS2014 (証明)
𝐿(𝜃) = 𝔼 𝑢,𝑣 ∼𝑃𝐷[log𝑃(𝑢, 𝑣; 𝜃)] + 𝑘𝔼 𝑢,𝑣 ∼𝑃𝑁 log(1 − 𝑃(𝑢, 𝑣; 𝜃)
= 𝑃𝐷 𝑢, 𝑣 log𝑃 𝑢, 𝑣; 𝜃 + 𝑘𝑃𝑁 𝑢, 𝑣 log 1 − 𝑃 𝑢, 𝑣; 𝜃 𝑑(𝑢, 𝑣)
ですが、𝑎 log 𝑥 + 𝑏 log 1 − 𝑥 は𝑥 = 𝑎/(𝑎 + 𝑏)で唯一の最大値をとるので、𝐿(𝜃) を最大化すると、下記へ収束します。
𝑃 𝑢, 𝑣; 𝜃 =𝑃𝐷 𝑢, 𝑣
𝑃𝐷 𝑢, 𝑣 + 𝑘𝑃𝑁(𝑢, 𝑣)= 𝜎 − log
𝑃𝐷 𝑢, 𝑣
𝑘𝑃𝑁 𝑢, 𝑣
𝑃 𝑢, 𝑣; 𝜃 = 𝜎 𝜃𝑢 ⋅ 𝜃𝑣 と比べると
𝜃𝑢 ⋅ 𝜃𝑣 = log𝑃𝐷 𝑢, 𝑣
𝑘𝑃𝑁 𝑢, 𝑣
を得ます。よって、𝑘 = 1, 𝑃𝑁 = 𝑃𝐷 𝑢 𝑃𝐷 𝑣 の場合には、PMI行列の分解になります。

Copyright@2014 NTT DATA Mathematical Systems Inc. 17
Linear Regularity 再考
• PMI行列の分解であることを想定すると、
のような関係は、任意の語 𝑣 にたいして、
という関係を与えることがわかります。実際、
𝑘𝑖𝑛𝑔 −𝑚𝑎𝑛 = 𝑞𝑢𝑒𝑒𝑛 − 𝑤𝑜𝑚𝑎𝑛
⇒ 𝑣 ⋅ 𝑘𝑖𝑛𝑔 − 𝑚𝑎𝑛 − 𝑞𝑢𝑒𝑒𝑛 + 𝑤𝑜𝑚𝑎𝑛 = 0
⇒ 𝑃𝑀𝐼 𝑣, 𝑘𝑖𝑛𝑔 − 𝑃𝑀𝐼 𝑣,𝑚𝑎𝑛 − 𝑃𝑀𝐼 𝑣, 𝑞𝑢𝑒𝑒𝑛 + 𝑃𝑀𝐼 𝑣,𝑤𝑜𝑚𝑎𝑛 = 0 ここで最後の式の左辺を計算すると
log𝑄 𝑘𝑖𝑛𝑔 𝑣
𝑄 𝑚𝑎𝑛 𝑣∕𝑄 𝑞𝑢𝑒𝑒𝑛 𝑣
𝑄 𝑤𝑜𝑚𝑎𝑛 𝑣= 0
なので、上記関係を得ます。
𝑘𝑖𝑛𝑔 −𝑚𝑎𝑛 = 𝑞𝑢𝑒𝑒𝑛 − 𝑤𝑜𝑚𝑎𝑛 (𝜃𝑘𝑖𝑛𝑔を𝑘𝑖𝑛𝑔などと略記)
𝑄 𝑘𝑖𝑛𝑔 𝑣
𝑄 𝑚𝑎𝑛 𝑣=𝑄 𝑞𝑢𝑒𝑒𝑛 𝑣
𝑄 𝑤𝑜𝑚𝑎𝑛 𝑣 𝑤ℎ𝑒𝑟𝑒 𝑄 𝑢 𝑣 =
𝑃 𝑢 𝑣
𝑃 𝑢
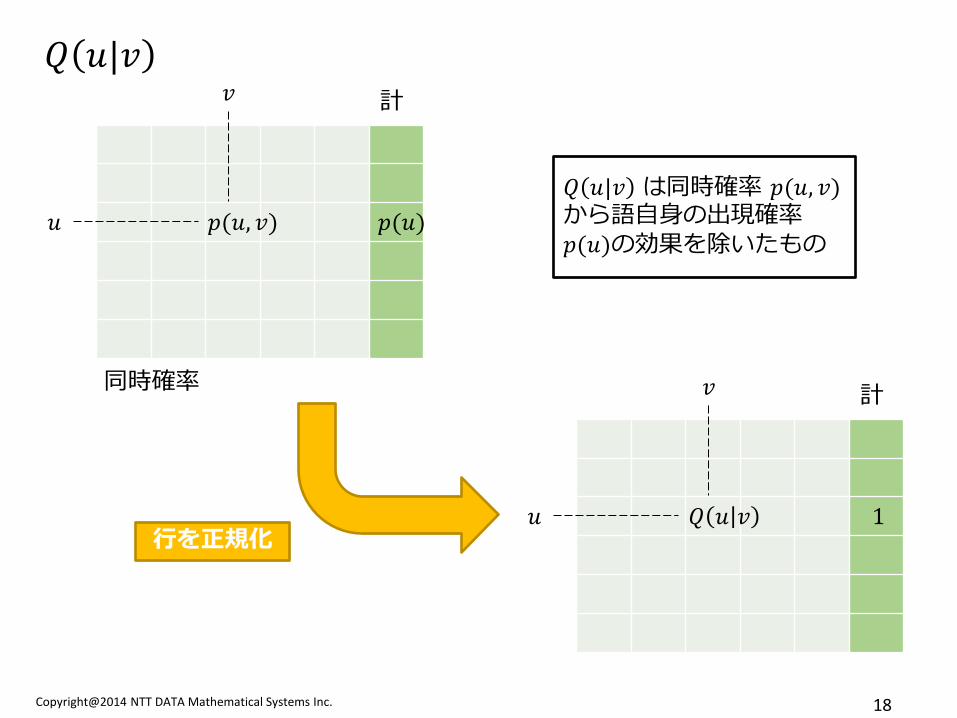
Copyright@2014 NTT DATA Mathematical Systems Inc. 18
𝑄 𝑢|𝑣
𝑢
𝑣
𝑝(𝑢, 𝑣) 𝑝(𝑢)
計
𝑢
𝑣
𝑄 𝑢 𝑣 1
計
行を正規化
同時確率
𝑄 𝑢|𝑣 は同時確率 𝑝(𝑢, 𝑣) から語自身の出現確率𝑝(𝑢)の効果を除いたもの

Copyright@2014 NTT DATA Mathematical Systems Inc. 19
Linear Regularity
𝑘𝑖𝑛𝑔 − 𝑚𝑎𝑛 = 𝑞𝑢𝑒𝑒𝑛 − 𝑤𝑜𝑚𝑎𝑛 ⇒ 𝑄 𝑘𝑖𝑛𝑔 𝑣
𝑄 𝑚𝑎𝑛 𝑣=𝑄 𝑞𝑢𝑒𝑒𝑛 𝑣
𝑄 𝑤𝑜𝑚𝑎𝑛 𝑣
1
1
1
1
𝐴
𝑎
𝐵
𝑏
𝑣 ここの比が常に等しい
𝒌𝒊𝒏𝒈 ∶ 𝒎𝒂𝒏 = 𝒒𝒖𝒆𝒆𝒏 ∶ 𝒘𝒐𝒎𝒂𝒏
king, man, queen, woman 固有の出現確率を無視すると、どんな語に対しても、その語の周辺に「 man に比べて king がどれくらい出やすいか」は、「woman に比べて queen がどれくらい出やすいか」と等しい。

Copyright@2014 NTT DATA Mathematical Systems Inc. 20
逆向きは成り立つか
• 左側の等式が成り立っていれば、すべての語 𝑣 にたいして
𝑃𝑀𝐼 𝑣, 𝐴 − 𝑃𝑀𝐼 𝑣, 𝑎 − 𝑃𝑀𝐼 𝑣, 𝐵 + 𝑃𝑀𝐼 𝑣, 𝑏 = 0 が成り立つので、
𝑣 ⋅ 𝐴 − 𝑎 − 𝐵 + 𝑏 = 0 𝑓𝑜𝑟 𝑎𝑙𝑙 𝑣 となります。このことから、 𝑣 全体が張る空間が豊かな場合(詳しくは、この空間の次元が分散表現の次元と一致する場合)、
𝐴 − 𝑎 = 𝐵 − 𝑏 となることも導かれます。
Q A v
Q a v=𝑄 𝐵 𝑣
𝑄 𝑏 𝑣 ⇒ 𝐴 − 𝑎 = 𝐵 − 𝑏 ?





























