Embed Size (px)
DESCRIPTION
知能情報システム特論 正データからの極限同定 (1). 山本 章博 京都大学 情報学研究科 知能情報学専攻 http://www.iip.ist.i.kyoto-u.ac.jp/member/akihiro/ [email protected]. 計算論的な学習モデル. 教師. 概念 M = M( P ) に関する例示. M ( H i ). M = M( P ). 仮説 ( など ) H 1 , H 2 , H 3 ,…. 例 ( データ ) E 1 , E 2 , E 3 ,…. 学習機械 例からを仮説を 導出する アルゴリズム. - PowerPoint PPT Presentation
Citation preview

知能情報システム特論正データからの極限同定 (1)
山本 章博京都大学 情報学研究科 知能情報学専攻http://www.iip.ist.i.kyoto-u.ac.jp/member/akihiro/

例 ( データ )E1, E2, E3,…
仮説 ( など ) H1, H2, H3,…
M(Hi ) M = M(P)
教師
学習機械例からを仮説
を導出するアルゴリズム
概念 M = M(P) に関する例示
計算論的な学習モデル

概念と仮説 U : 訓練例 ( 観測事実 ) の表現からなる空間
論理プログラミングの場合は HB 概念 : U の部分集合
論理プログラミングの場合は M HB 仮説 : 個々の概念を表現する方法
論理プログラミングの場合は M = M(P) 許容性:個々の概念は一つ以上の仮説で表
現されている 概念は,仮説をパラメータとした集合
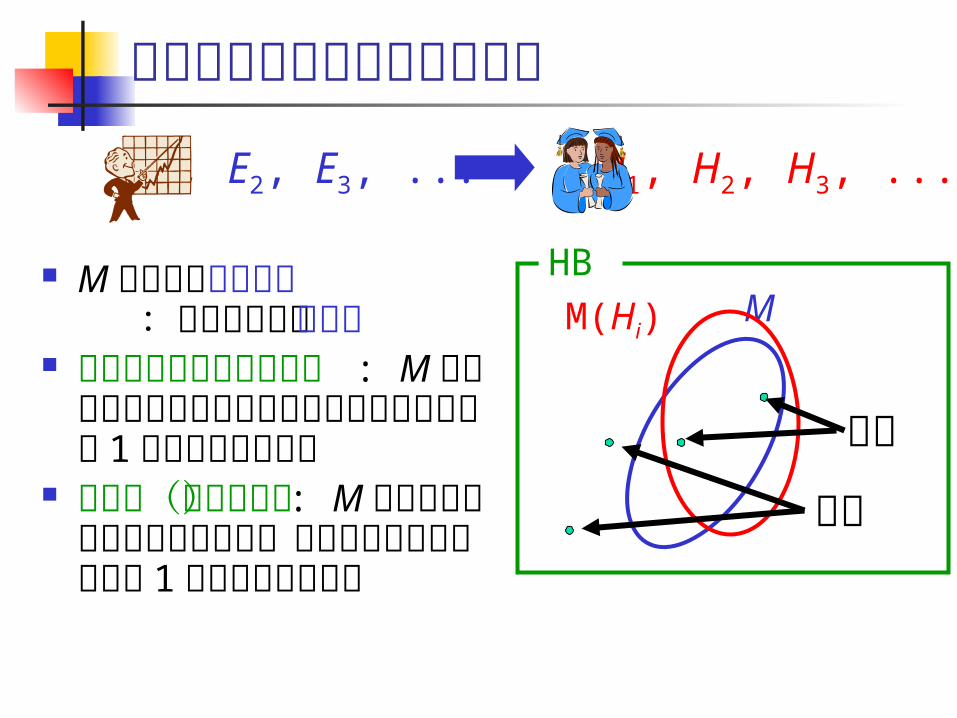
極限同定モデルでの例の提示
M に関する例の提示 :正例と負例の無限列 完全提示(完全データ) :
M に関する全ての正例と全ての負例が少なくとも1 回出現する無限列
正提示(正データ) : Mに関する正例からなる提示で,全ての正例が少なくとも 1 回出現する無限列
H1, H2, H3, ... E1, E2, E3, ...
MM(Hi)
HB
負例
正例

極限同定 (identification in the limit)[Gold]
学習アルゴリズム IIM が概念 C を極限において (EX) 同定する L の任意の完全提示に対して
N n > N Hn = P かつ M(P) = M .
H1, H2, H3, ... E1, E2, E3, ... 学習アルゴリズム IIM が概念クラス C を
極限において (EX) 同定するC 中の各概念を極限において同定する
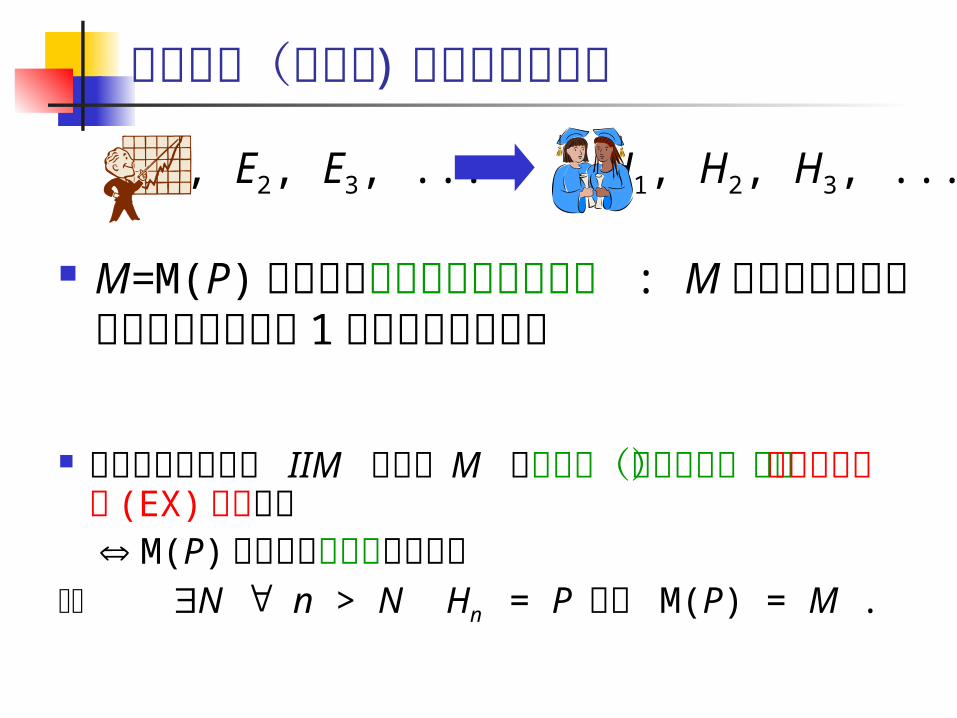
正データ(正提示 ) からの極限同定
M=M(P) に関する正提示(正データ) : Mに関する全ての正例が少なくとも 1 回出現する無限列
H1, H2, H3, ...E1, E2, E3, ... 学習アルゴリズム IIM が概念 M を正提示
(正データ)から極限において (EX) 同定する M(P) の任意の正提示に対して
N n > N Hn = P かつ M(P) = M .

正提示(正データ)E1, E2, E3, …, En,…
仮説 H1, H2, H3,…,Hn,…
M(Hn)
M=M(P)
教師
正提示からの学習の困難さ (1)
対象とする言語全体
・・・
M(P)
E1, E2, …, En
から論理式 Hn
を構成するアルゴリズム
Over generalization

正提示(正データ)E1, E2, E3, …, En,…
仮説 H1, H2, H3,…,Hn,…
M(Hn)
M= M(P)
教師
正提示からの学習の困難さ (2)
対象とする言語全体
・・・
M(P)
E1, E2, …, En
から論理式 Hn
を構成するアルゴリズム
Over fitting

否定的結果Th. [Gold] 概念空間 C(H) は , 全ての有限集合
と無限集合を一つ以上含めば正データから極限同定可能でない.
論理プログラムの最小モデル全体は正データから極限同定可能でない. たとえ停止する論理プログラムだけを扱ったとし
ても
正則言語全体は正データから極限同定可能でない.

E1, E1, …, E2,...
N1+1 回
C(H) に次のような(意地の悪い)提示をLM に与える
N1 n > N2 > N1 Hn = P2 かつ M(P2) = {E1, E2}
C(H) には {E1, E2} が含まれるので,LM は {E1, E2} を極限同定する.
H1,H2,H3,...,P1, P1, …
E1, E1, …, E2, ...
H1,H2,H3,...,P1, P1, …
H1,H2,...,P1,…,P2 ,…

E1,E1,... E2,...,E3,...
N1+1 回
C(H) には {E1, E2 , E3 } が含まれるので,LM は {E1, E2 , E3} を極限同定する.
N3n >N3 > N2> N1 Hn = P3 かつ M(P3)={E1, E2 , E3}
N2+1 回
M(P0)={E1, E2 , E3 , E4,…} は無限集合であったLM は M を極限同定できない!
H1, H2,..., P1,..., P2 ,..., P3 ,...

原子論理式と正データ学習 HATOM = { A A は原子論理式 }
Th. [Lassez et al.] C(HATOM) は反単一化を繰り返し用いることにより , 正データから極限同定可能である .
例 p(x, y, s(z)) HATOM
M(p(x, y, s(z)) p(0,0,s(0)), p(s(0),0,s(0)), p(s(s(0)),0,s(0)), ...
p(0,s(0),s(0)),..., p(0,0,s(s(0))),...}

反単一化 (Anti-Unification)
A の汎化 (generalization) : A = L となる L 異なる部分項には,異なる変数 一つの部分項には,複数の変数も可
p(x, s(0), s(s(0))) p(x, s(y), s(s(0)))
p(x, s(y), s(s(y)))
p(x, y, s(z)) 反単一化 : A と B の共通の汎化を求める 最小共通汎化 L (lca) :
1. A と B の共通の汎化であって , 2. A と B の任意の共通汎化 M に対して ML

反単一化アルゴリズムAlgorithm Anti-Unify(E)
E は基礎原子論理式の有限集合Refine(E, p(x1, x2, …, xn)) を返す ;
Algorithm Refine(E, A)if E M({B}) なる B が (A) に存在 then
そのような B を一つ選び , Refine(E, B) を返す ;
else A を返す ;

反単一化アルゴリズム ( 例 )
p(0, s(0), s(s(0))), p(s(0), 0, s(0)) p(0, s(0), s(s(0))), p(s(0), 0, s(0)) p(X0,s(0), s(0), s(s(0))), p(X0,s(0), 0, s(0))
p(X0,s(0), Xs(0),0, s(s(0))), p(X0,s(0), Xs(0),0, s(0))
p(X0,s(0), Xs(0),0, s(s(0))), p(X0,s(0), Xs(0),0, s(0))
p(X0,s(0), Xs(0),0, s(Xs(0),0)), p(X0,s(0), Xs(0),0, s(Xs(0),0))
p(X, Y, s(Y))

有限の厚さ (finite thickness)
一つの基礎原子論理式に対して,それを含むような概念 L(A) は有限個しかない
一般的
具体的
p(X, Y, Z)
p(s (X), Y, Z) p(X, Y, s(Z)) p(X, Y, Y) …
p(X, Y, s(Y))
p(X, s(Z), s(s(Z))) p(s(0), Y, s(Y))
p(s(0), 0, s(0))p(0, s(0), s(s(0)))

C4: 有限の厚さTh. [Angluin] 概念空間 U が有限の厚さを持て
ば, U は正データから極限同定可能である .
有限の厚さ: 任意の語 w に対して, wL を満たす U 中の L は有限個である .
注 : 概念空間 U が有限の厚さを持ったとしても U が有限の弾力性を持つとは限らない

正データからの極限同定可能性
EC1 (必要十分): L の各言語の有限証拠集合を枚挙する手続きが存在する [Angluin]
C2: L の全ての言語が特徴例集合を持つ [Kobayashi]
C3: L が有限の弾力性を持つ [Wright]
C4: L が有限の厚さを持つ [Angluin]
⇒
⇒
⇒
⇒
⇒
⇒
L : 形式言語族

応用例 半構造化文書群からの共通パターン抽出
[Yamamoto et al. 01]

<TABLE><TR>
<TD>a</TD> <TD>b</TD>
</TR>
<TR> <TD>c </TD>
<TD>d</TD> </TR>
</TABLE>
a b
c d
TABLE(TR(TD(a)TD(b))TR(TD(c)TD(d)))
半構造化データ

DOM
TABLE(TR(TD(a)TD(b))TR(TD(c)TD(d)))
<TABLE>
<TR> <TR>
<TD> <TD> <TD> <TD>
a b c d

反単一化への帰着 タグの子の数は,タグによって定まっている.
対象とする表の行数,列数は一定 兄弟タグはコンマで分離
TABLE(TR(TD(a), TD(b)), TR(TD(c),TD(d))) 文字列部分 (PCDATA に相当 ) は記号 1 個と
仮定する. 文字列の構造までは考慮しない
共通パターンを表すために変数を用いる.

変数による共通パターン表現
TABLE(TR(TD(a), TD(b)), TR(TD(a), TD(d)))
TABLE(TR(TD(e), TD(b)), TR(TD(e), TD(h)))
TABLE(TR(TD(X), TD(b)), TR(TD(X), TD(W)))
Xa,e Xa,e Xd,h
a b
a d
e b
e h
X b
X W

正データからの極限同定 (1) 単位節プログラム : 有限個の原子論理式から
なる論理プログラムP : A1 A2
… An
HUNIT : 単位節プログラム全体 ⇒ C(HUNIT ) は正データから極限同定可能でな
い.

応用例 ( 購買履歴からの学習 )
目標 ( 解きたい問題 ): 利用者 ( 消費者 ) の購買履歴 (transaction) か
ら利用者の購買傾向を発見する頻繁に出現するパターン
例 あるインターネット書店 見つけたい購買傾向の例 : 「蹴りたい背中」と「インストール」は同時
に購入される可能性が高い

購買傾向の利用例

頻出パターン発見の定式化(1)
プログラムに与えられるデータ (入力 )
1. トランザクション・データベース D
:購買履歴 ( トランザクション ) の記録
高校数学用語を用いるとトランザクションは
「蹴りたい背中」を買う,「インストール」を買う ,…
などを根元事象とする事象 2. 支持度 (support)

トランザクション・データベース
ID 蹴りたい
インストール
蛇に リトルバイ
限りなく …
… … … … … … …
3256 1 1 1 0 0 …
3257 1 0 0 1 1 …
3258 0 1 0 0 1 …
3259 1 0 1 0 0 …
… … … … … … …
購入した本の種類
トランザクション ( 一回分 )

頻出パターン発見の定式化(2)
求めたい購買傾向 ( 出力 )
相対頻度が支持度 を越える全てのパターン
パターン : 属性の集合 {A1, A2, …, An}
相対頻度 P({ A1, A2, …, An })
D 中のトランザクションで 同時に 1 であるものの個数
D 中のトランザクションの総数

簡単な例
ID A B C D E F
1 1 0 1 0 0 0
2 1 1 1 0 0 0
3 1 0 0 1 1 0
4 0 1 0 0 1 1
P({A})=0.75, P({B})=P({C})= P({E})= 0.5
P({D})=P({F})= 0.25
P({A , B} )=0.25, P({A , C} )=0.5,…

相対頻度の性質
一般に 属性の集合 (連言 ) S , T に対して S T P(S) P(T) : P の単調性
P({A})=0.75 P({A , B} )=0.25
P({B})=0.5 P({A , B} )=0.25
P({A})= 0.75 P({A , C} )=0.5
…

Apriori アルゴリズム [Agrawal et al 93]
P の単調性を用いた頻出結合規則発見1. L1 = {{A} | P({A}) } とする2. k =1 とする3. Ck+1 = { ST | S Lk , T Lk , | ST | = k+1}
とする.4. Lk+1 = {S Ck+1 | P(S) } とする5. Lk+1 = k =1 の値を 1増やして 2 へ戻る

Apriori アルゴリズム (2)
Ck+1 ={S1, S2, …, Sn} のパターン ( 事象 ) Si に対してP(Si)
1. 各 Si に対して , 変数 ni を用意して ,
最初は ni = 0 にしておく .
2. トランザクション・データベース D 中の 各トランザクション t について順に Ck+1 の中の各パターン Si に対して順に
t が満たしていれば ni の値を1増やす .

反単一化としての定式化 トランザクション 1 回分 を p(a1, a2,…, an) で表
す ai = 1 または 0
属性集合 {Ai} を , p(x1, x2,…,1,…, xn) で表す 同様に , 属性集合 S は p(x1,..,1,..,1,..1,.., xn)
トランザクション・データベース R においてP(S) を R |= p(x1,..,1,..,1,..1,.., xn)
と表す

正データからの学習の基本 :EC1
Th. [Angluin] Herbrand モデルの集合 U が正データから極限同定可能であるための必要十分条件は, U 中の各 M(P) の有限証拠集合 (finite tell-tale) が存在し,論理プログラム P を与えると M(P) の有限証拠集合 T(P) の要素を枚挙するアルゴリズムが存在することである .
M(P) の有限証拠集合 (finite tell-tale) T(P) :
T(P) M(P) かつ 他のどのような U 中の (P’) に対しても T(P) M(P’) M(P) とはならない.

枚挙と生成テストによる極限同定
仮説空間 H 内の論理プログラムの枚挙を固定 P1, P2,…, Pn,…
for n = 1 forever
En = An , + k = 1, H = P1
while ( k n )
if ( 0 j n Aj M(H) または T(H) {A1 , A2,…, An })
k ++; H = Pk
output Hn = H

有限証拠集合と特徴例集合
言語 L の有限証拠集合 T : T ⊆L (T は有限集合 ) 全ての L’∈L に対して
T⊆L’⊂L は成り立たないT L
L の特徴例集合 F : F ⊆L (F は有限集合 ) 全ての L’∈L に対して F ⊆L’⇒L⊆L’
F L
×

C2: 特徴例集合の存在Th. [S.Kobayashi] 概念空間 U 中の各概念
L(h) に特徴例集合 (characteristic set) が存在すれば,概念空間 U が正データだけから極限同定可能である .
概念 L(h) の特徴例集合 (characteristic set) C :
C は有限集合, C L(h) かつ どのような U 中の概念 L(h’) に対しても C L(h’) ならば, L(h) L(h’) .
注 EC1 C2 C3 C4

原子論理式に対する推論規則 原子論理式に対する推論規則
A A
A[X := f (X1,…,Xn)] A[X:=Y] n 0 X,Y は A に出現する変数 X1,…,Xn は A には出現しない相異なる変数
述語記号 p の任意の原子論理式 ( の変種 , variant) は上の二つの規則によって , p(X1,…,Xn ) から導出可能

C3: 有限の弾力性Th. [Wright] 概念空間 U が有限の弾力性を持
てば, U は正データから極限同定可能である .
無限の弾力性:語の無限列 w0, w1, w2, …, とU に属する言語の無限列 L(h0), L(h1), L(h2) …,
が存在して, n 1 以上のすべての n について{w0, w1, ..., wn-1 } L(hn) かつ wn L(hn)
有限の弾力性:無限の弾力性が成立たない .
cf. Noether環の ascending chain condition





























