Embed Size (px)
Citation preview

ОПТИМИЗАЦИИ СКОРОСТИ
ВЫПОЛНЕНИЯ ЗАПРОСОВ В РСУБД

КОМУ И КОГДА НУЖНА ОПТИМИЗАЦИЯ?

КАК МОЖНО ОПТИМИЗИРОВАТЬ СКОРОСТЬ
ВЫПОЛНЕНИЯ
На уровне запросов
На уровне схемы
На уровне системы

УРОВЕНЬ ЗАПРОСОВ
Выполнение запроса
Чтение планов выполнения
Управления планами выполнения
Типичные ошибки
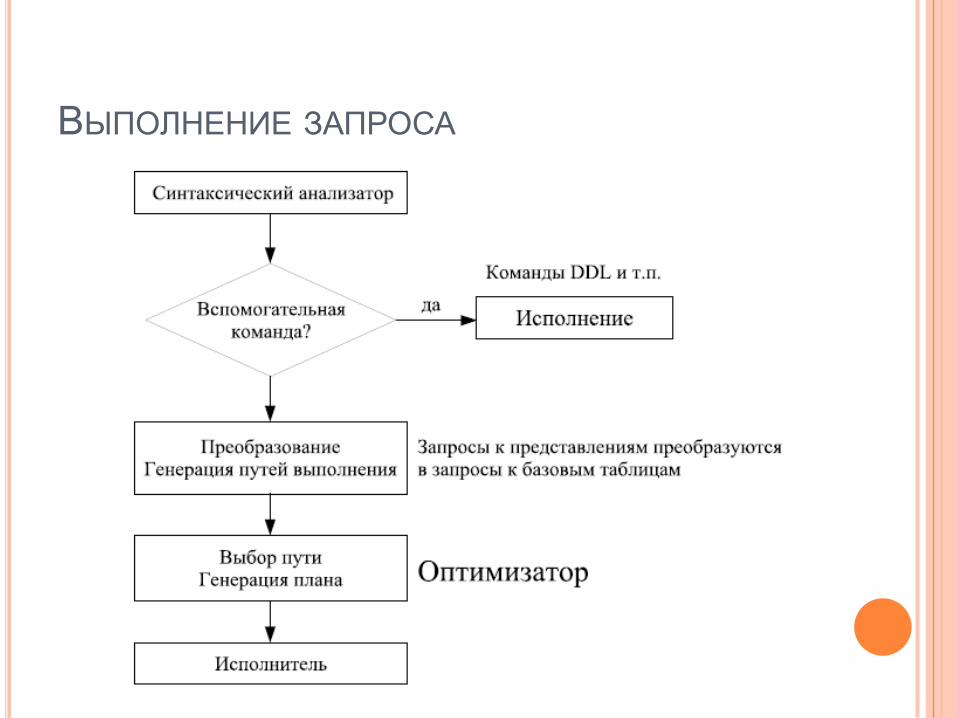
ВЫПОЛНЕНИЕ ЗАПРОСА

ЧТЕНИЕ ПЛАНОВ ВЫПОЛНЕНИЯ (MYSQL)
EXPLAIN - ориентировочный план выполнения
SHOW STATUS - показывает непосредственно что произошло после выполнения запроса, т.е. количество записей, к которым MySQLфизически обратился (притом посредством данной команды можно узнать сколько из них было получено из памяти, а сколько посредством обращения к диску
PROFILING - возможность профайлингазапросов
PROCEDURE ANALYSE() – подсказки по оптимизации

SHOW STATUS
FLUSH STATUS
…
SHOW STATUS LIKE 'Key_read%';
Key_read_requests — Количество запросов на чтение индексных блоков из кеша.
Key_reads — Количество физического чтения индексных блоков с диска. Если число Key_reads большое, тогда, вероятно, ваше key_buffer_size достаточно мало и требует увеличения. Отношение непопаданий в кэш можно посчитать как Key_reads/Key_read_requests.

PROFILING
set profiling=1;
…
show profiles;
select sum(duration) from
information_schema.profiling where
query_id=1;
show profile for query 1;

ЧТЕНИЕ ПЛАНОВ MYSQL
EXPLAIN
Id - Идентификатор (ID) таблицы в запросе. EXPLAIN создает по одной записи для каждой таблицы в запросе.
Select_type - Возможные значения: SIMPLE, PRIMARY, UNION, DEPENDENT UNION, SUBSELECT, иDERIVED.
Table - Имя таблицы, из которой MySQL читает данные
Type - Тип объединения, которое использует MySQL. Возможные значения: eq_ref, ref, range, index, или all.
Possible_keys – Список индексов (или NULL, если индексов нет), которые MySQL может использовать для выборки рядов в таблице.
Key - Название индекса, который использует MySQL (после проверки всех возможных индексов).
Key_len - Размер ключа в байтах.
Ref - Колонки или значения, которые используются для сравнения с ключем.
Rows - Количество рядов, которые MySQL необходимо проверить, для обработки запроса.
Extra - Дополнительная информация о запросе.

ЧТЕНИЕ ПЛАНОВ ВЫПОЛНЕНИЯ
(POSTGRESQL)
EXPLAIN – предположительный план
выполнения
EXPLAIN ANALYZE – реальный план
выполнения, выводиться после выполнения
запроса
ANALYZE – собрать статистику
VACUUM - дефрагментация
REINDEX

EXPLAIN (POSTGRESQL)
explain select attnamefrom pg_attribute, pg_class
where pg_attribute.attrelid = pg_class.oid
and pg_class.relname = ’pg_proc’
order by pg_attribute.attnum;
Sort (cost=27.66..27.68 rows=7 width=66)
Sort Key: pg_attribute.attnum
-> Nested Loop (cost=0.00..27.56 rows=7 width=66)
-> Index Scan using pg_class_relname_nsp_index on pg_class (cost=0.00..8.27 rows=1 width=4)
Index Cond: (relname = ’pg_proc’::name)
-> Index Scan using pg_attribute_relid_attnum_index onpg_attribute (cost=0.00..19.21 rows=7 width=70)
Index Cond: (pg_attribute.attrelid = pg_class.oid)

УПРАВЛЕНИЯ ПЛАНАМИ ВЫПОЛНЕНИЯ
Использование правильного индекса
Запретить использование неподходящего
индекса
Подсказки для оптимизатора
Запрет Соединения в неправильном порядке
Подсказки

ИСПОЛЬЗОВАНИЕ ПРАВИЛЬНОГО ИНДЕКСА
Таблица.ВедущийСтолбецИндекса = Выражение
Селективное условие по ведущему столбцу
индекса. Условие должно быть таким чтобы БД
могла выделить достаточно узкий диапазон.
Преобразование типов (условие в запросе и
поле должны использовать один тип данных)
Условия соединены оператором OR
В условии присутствуют функции от ведущего
столбца индекса.

ЗАПРЕТИТЬ ИСПОЛЬЗОВАНИЕ
НЕПОДХОДЯЩЕГО ИНДЕКСА
Создать простейшее выражение при
упоминании индексируемого столбца:
O.Regino_ID + 0 = 137
Подсказки:
table_name [[AS] alias] [index_hint]
USE INDEX (index_list)
GNORE INDEX (index_list)
FORCE INDEX (index_list)

ЗАПРЕТ СОЕДИНЕНИЯ В НЕПРАВИЛЬНОМ
ПОРЯДКЕ
Запрещение использования индекса
Использование внешних соединенийSELECT … FROM employees E
LEFT OUTER JOIN location L ON E.location_id = L.id
Отсутствие избыточных условий соединения
SELECT …
FROM employees E, locations L, addresses A
WERE E.location_id = L.id
AND E.location_id = A.id
AND A.zip_code = 95628

ЗАПРЕТ СОЕДИНЕНИЯ В НЕПРАВИЛЬНОМ
ПОРЯДКЕ
Зависимости соединений.
… AND T1.Key2 = T2.Key2
AND T1.Key3 + 0*T2.Key2 = T3.Key3 …
STRAIGHT_JOIN – тоже что и JOIN, только
левая таблица всегда читается до правой.

С ЧЕГО НАЧАТЬ?
--log-slow-queries
логирование медленных запросов,
минимальное значение параметра long_query_time 1,
значение по умолчанию 10
--log-queries-not-using-indexes
логирование запросов, которые не используют индексы

ОШИБКИ (DESIGN )
Сначала нормализуем, потом денормализуем
где необходимо.
Старайтесь всегда создать поле ID.
Индексируйте поля, по которым ищите.
Индексируйте поля для объединения и
используйте для них одинаковые типы столбцов.
Не индексируйте все что попало!
Не включайте в индекс большие колонки.
Не дублируйте индексы
Используйте NOT NULL, если это возможно

ОШИБКИ (SQL)
Используйте Prepared Statements
Не используйте DISTINCT если вы используете
GROUP BY
LIMIT m,n не так быстр как кажется
По возможности заменяйте OR на UNION
GROUP BY … ORDER BY NULL
UNION и UNION ALL две разные операции и
чаще всего вам нужно второе
Минимизируйте коррелируемымые подзапросы

ОШИБКИ
По возможности не используйте SELECT *
SQL_NO_CACHE когда вы делаете SELECT для
часто обновляемого набора данных
Не используйте ORDER BY RAND()
LIMIT 1, когда нужна единственная строка
SELECT * FROM user WHERE state =
'Alabama' LIMIT 1
Используйте ENUM вместо VARCHAR

КОНКРЕТНЫЕ ЗАПРОСЫ
SELECT max(...)/min(...) FROM <big table>
SELECT field FROM foo ORDER BY field DESC LIMIT
1;
Pagination
WHERE … AND NODE_ID > id_from_previous_page
ORDER BY NODE_ID LIMIT 25
SELECT count(*) FROM <big table>
лучше так и использовать

НА УРОВНЕ СХЕМЫ
Нормализация\Денормализация
Блокировки\Транзакции
Типы таблиц
Views
Temporary Tables
Indexes
Тригеры

ТИПЫ ТАБЛИЦ
ISAM - Оригинальный обработчик таблиц.
MyISAM - Новый обработчик, обеспечивающий
переносимость таблиц в бинарном
виде, который заменяет ISAM
BDB – (Berkley DB) Таблицы с поддержкой
транзакций и блокировкой страниц.
InnoDB - Таблицы с поддержкой транзакций и
блокировкой строк
MERGE - Набор таблиц MyISAM, используемый
как одна таблица.
HEAP - Данные для этой таблицы хранятся
только в памяти

VIEWS
CREATE [ALGORITHM = {UNDEFINED | MERGE |
TEMPTABLE}] VIEW
MERGE – при обращении к представлению
добавляет в использующийся оператор
соответствующие части из определения
представления и выполняет получившийся
оператор
TEMPTABLE - заносит содержимое
представления во временную таблицу, над
которой затем выполняется оператор
обращенный к представлению

INDEXES
B-/B+ tree
R-/R+ tree
Hash
Expression
Partial
Reverse
Bitmap
GiST
GIN
Кластерные - строки таблицы
физически хранятся в заданном
порядке и непосредственно
связаны с элементами индекса,
благодаря чему значительно
ускоряется доступ к данным при
использовании запросов,
использующих данный индекс
Некластерные
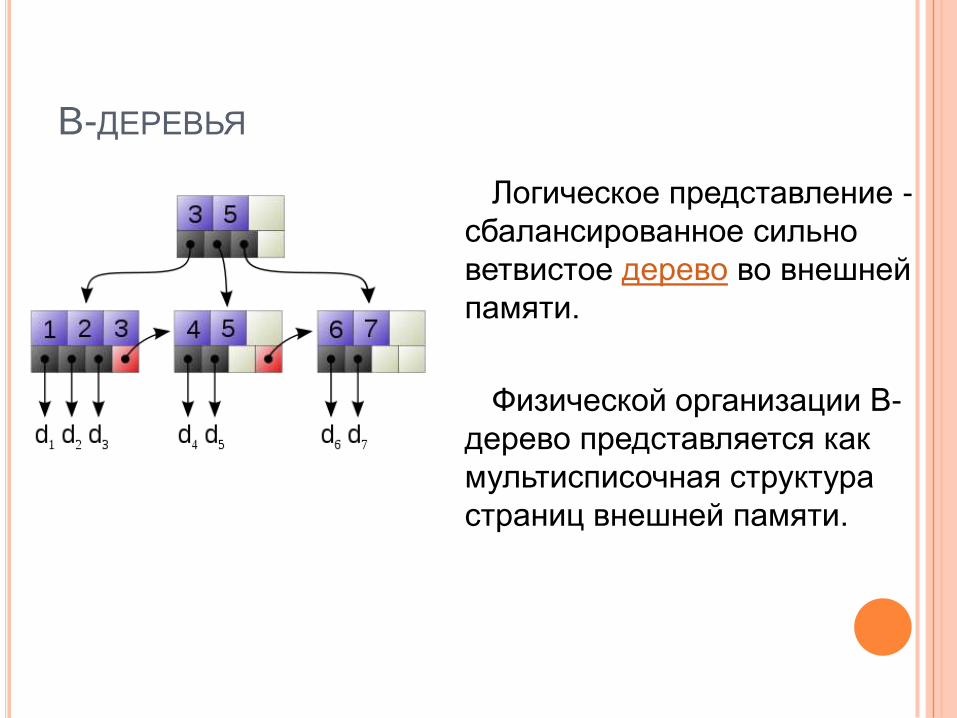
B-ДЕРЕВЬЯ
Логическое представление -
сбалансированное сильно
ветвистое дерево во внешней
памяти.
Физической организации B-
дерево представляется как
мультисписочная структура
страниц внешней памяти.
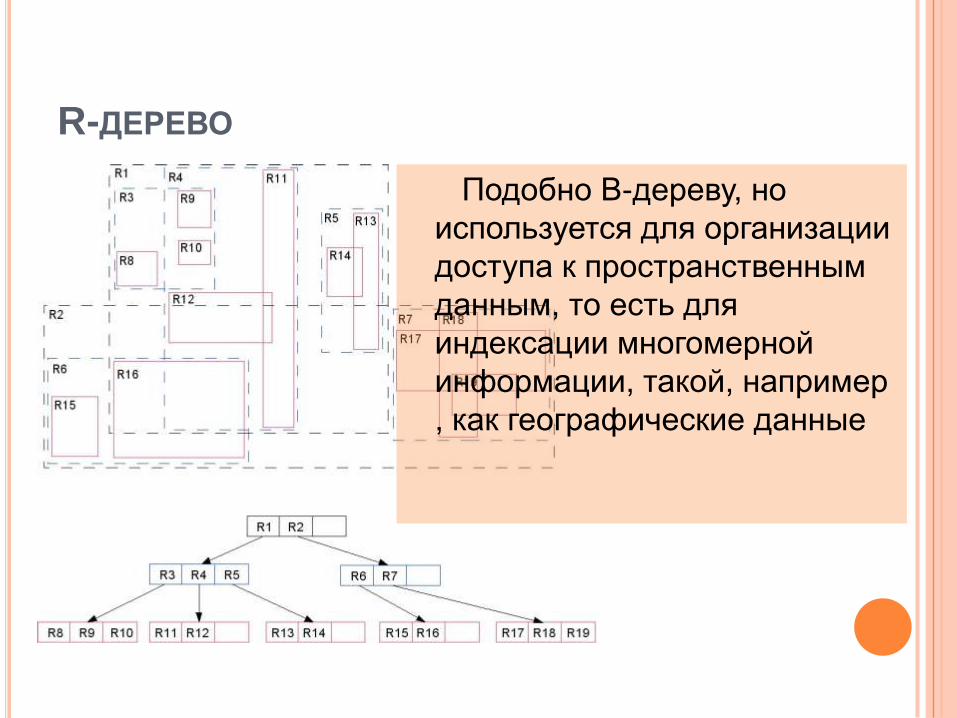
R-ДЕРЕВО
Подобно B-дереву, но
используется для организации
доступа к пространственным
данным, то есть для
индексации многомерной
информации, такой, например
, как географические данные

HASH
They are used only for equality comparisons that
use the = or <=> operators (but are very fast)
The optimizer cannot use a hash index to speed up
ORDER BY operations
This may affect some queries if you change a
MyISAM table to a hash-indexed MEMORY table.
Only whole keys can be used to search for a row.

EXPRESSION & PARTIAL & REVERSE
Expression SELECT * FROM people WHERE
(first_name || ' ' || last_name) = 'John Smith';
CREATE INDEX people_names ON people
((first_name || ' ' || last_name));
Partial SELECT * FROM scheta
WHERE NOT uplocheno AND ...;
CREATE INDEX scheta_neuplocheno ON scheta (id)
WHERE NOT uplocheno;
Reverse
обращает поле переменной — первый символ
считается последним
24538 -> 83542

BITMAP
для данных с малой мощностью множества
(cardinality)

GIST (GENERALIZED SEARCH TREE)
представляет собой систему, объединяющую
большой набор различных алгоритмов сортировки и
поиска, включая B-деревья, B+-деревья, R-
деревья, деревья частичных сумм, ранжированные
B+-деревья, и другие. Она также обеспечивает
интерфейс, обеспечивающий как создание
пользовательских типов данных, так и расширенные
методы запросов, позволяющие выполнять поиск по
ним. Т.е. GiST дает возможность определить, что вы
храните, как вы это храните, и каким образом вы
будете выполнять поиск. Эти возможности
существенно превышают средства, даваемые
стандартными алгоритмами типа B-дерева или R-
дерева.

GIST (GENERALIZED SEARCH TREE)
Стандарные методы навигации по дереву
Обновление дерева
Конкурентность и восстановление после сбоя
GiST позволяет реализовать новый АМ эксперту в области данных
Поддерживает расширяемый набор запросов ( в отличие от Btree)
Новые типы данных обладают производительностью (индексный доступ, конкурентность) и надежностью (протокол логирования), как и встроенные типы

GIN (GENERALIZED INVERTED INDEX)
Поддерживает разные типы данных
Очень быстрый поиск по ключам — Btree
Поддержка partial match
Многоатрибутный индекс
Хорошая масштабируемость (кол-во
ключей, кол-во документов)
Быстрое создание индекса
Медленное обновление индекса :(
Надежность и хороший параллелизм

ПРИЛОЖЕНИЯ (GIST, GIN)
Целочисленные массивы (GiST, GIN)
Полнотекстовый поиск (GiST, GIN)
Данные с древовидной структурой (GiST)
Поиск похожих слов (GiST, GIN)
Rtree (GiST)
PostGIS (postgis.org) (GiST) — spatial index
BLASTgres (GiST) — биоинформатика
Многомерный куб (GiST)
........
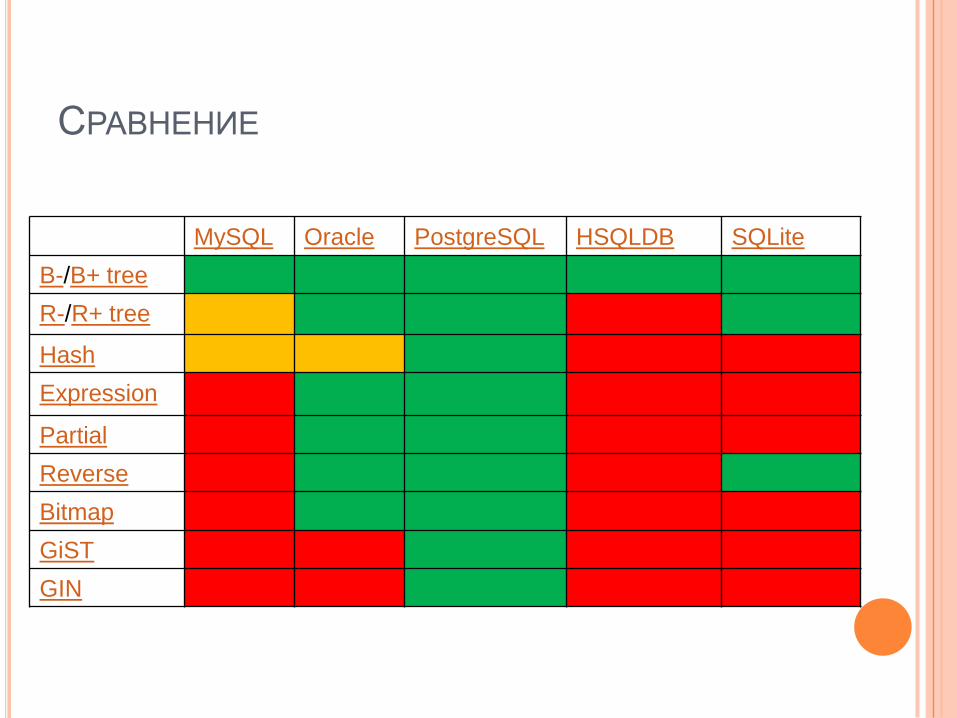
СРАВНЕНИЕ
MySQL Oracle PostgreSQL HSQLDB SQLite
B-/B+ tree
R-/R+ tree
Hash
Expression
Partial
Reverse
Bitmap
GiST
GIN
RDBMS

ТРИГЕРЫ
CREATE TRIGGER trigger_name trigger_time
trigger_event ON tbl_name FOR EACH ROW
trigger_stmt
trigger_time
BEFORE
AFTER
trigger_event
Insert (insert, data load, replace)
Update (update)
Delete (delete, replace)

ДРУГИЕ
Нормализация\Денормализация
Большое количество соединений таблиц
Расчетные значения
Длинные поля
Temporary table
CREATE [TEMPORARY] TABLE …
Блокировки\Транзакции

НА УРОВНЕ СИСТЕМЫ
Наиболее важно настроить потребление
памяти
Нельзя забывать, что РСУБД такое же
приложение как и все остальные на сервере. И
чаще всего оно использует файловую систему
операционной системы, у которой есть свои
КЭШи.
OPTIMIZE TABLE имя_таблицы;
Почистить "дырки" (дефрагментация),
обновить статистику и отсортировать индексы.
ANALYZE TABLE имя_таблицы;
Апдейт статистики оптимизатора.

ЛИТЕРАТУРА
SQL Tuning. Dan Tow
High Performance MySQL. Baron Schwartz, Peter
Zaitsev, Vadim Tkachenko, Jeremy D.
Zawodny, Arjen Lentz,and Derek J. Balling
www.mysql.ru
www.phpclub.ru
http://dev.mysql.com/doc/refman
http://www.mysqlperformanceblog.com
http://highload.ru





























