Embed Size (px)
DESCRIPTION
Автоматизация разработки приложений для графических ускорителей с использованием переписывающих правил. Анатолий Дорошенко, Константин Жереб Институт программных систем НАН Украины Киевское отделение МФТИ. Почему графические ускорители. - PowerPoint PPT Presentation
Citation preview

Автоматизация разработки приложений для графических
ускорителей с использованием переписывающих правил
Анатолий Дорошенко, Константин ЖеребИнститут программных систем НАН Украины
Киевское отделение МФТИ

Почему графические ускорители
• Специализированные устройства, доступные на большинстве компьютеров
• Изначально разработаны для решения графических задач
• Рыночные требования привели к значительному повышению производительности
• Можно использовать для общецелевых вычислений (General Purpose computation on Graphical Processing Units, GPGPU)

Производительность и стоимость
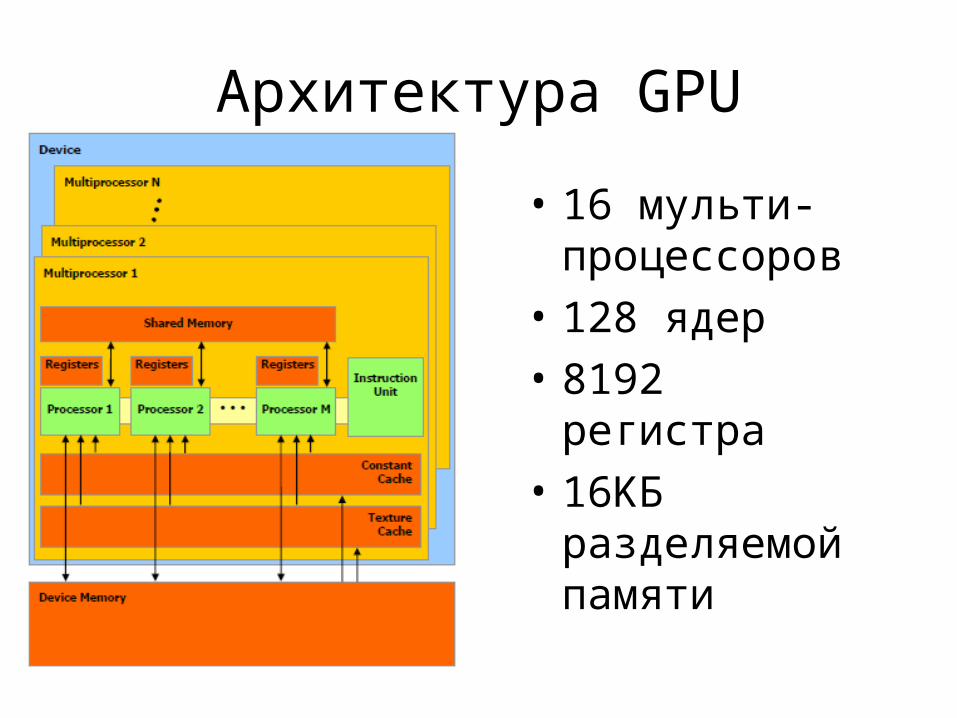
Архитектура GPU
• 16 мульти-процессоров
• 128 ядер• 8192 регистра• 16KБ
разделяемой памяти

Программирование GPU
• Использование графических средств (шейдеры)
• Специализированные средства GPGPU– NVidia CUDA– AMD Stream– OpenCL
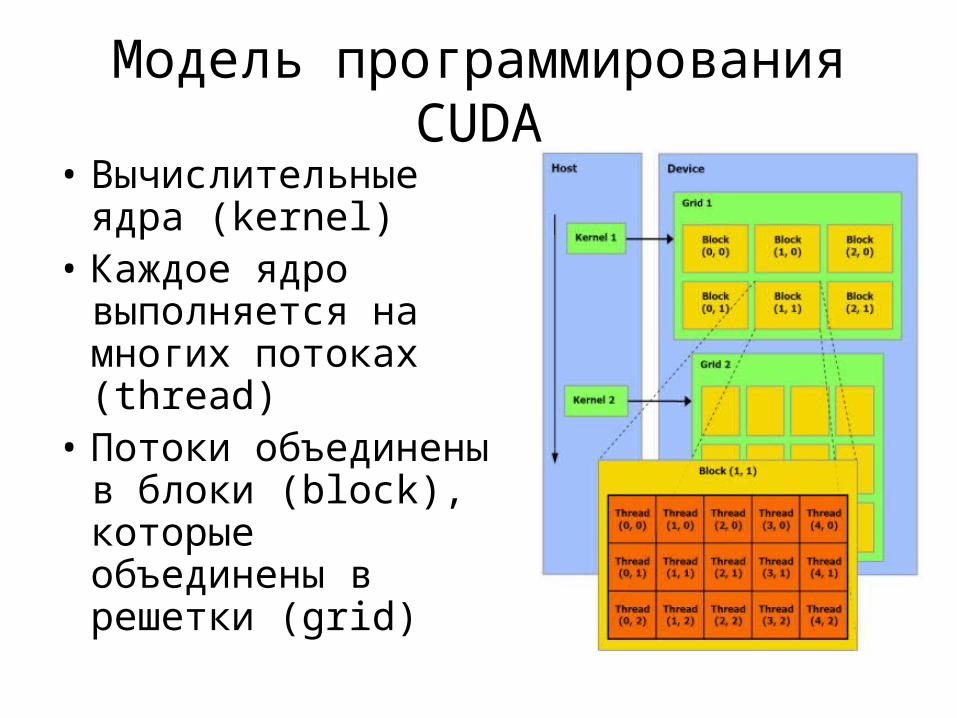
Модель программирования CUDA• Вычислительные
ядра (kernel)• Каждое ядро
выполняется на многих потоках (thread)
• Потоки объединены в блоки (block), которые объединены в решетки (grid)

Взаимодействие с CPU
• Язык С – два способа вызова– C for CUDA – расширение языка С– Driver API – набор функций (сложнее, но
предоставляет больший контроль)• C#, Java
– Библиотеки от сторонних разработчиков (CUDA.NET, jCUDA)
– Основаны на driver API (сложность вызова)– Ядра нужно все равно писать на C for CUDA

Почему автоматизация
• Сложная модель программирования• Сложная иерархия памяти• Эффективные программы требуют
низкоуровневой оптимизации• Сложное взаимодействие с языками
высокого уровня

Переписывающие правила
• Программа представляется в виде термов t=f(t1, ..., tn)
• Использование переписывающих правил source [condition] destination [action]
– source – исходный терм (образец)– condition – условие применения (необязательно)
– destination – преобразованный терм– action – дополнительное действие (необязательно)

Платформа Termware
• Платформа переписывающих правил• Декларативное описание• Варианты использования
– Самостоятельно (командная строка, графический интерфейс)
– Интегрируется в приложения
• Изначально на Java, портирована на C#

Почему переписывающие правила
• Способ описания преобразований программ
• Декларативное описание• В сложных случаях можно использовать
процедурный код

Что автоматизируем
• Переход к использованию CUDA– Входные данные – программа на C#
• Оптимизация для CUDA– Структура циклов– Доступ к памяти
• Пример – игра «Жизнь»
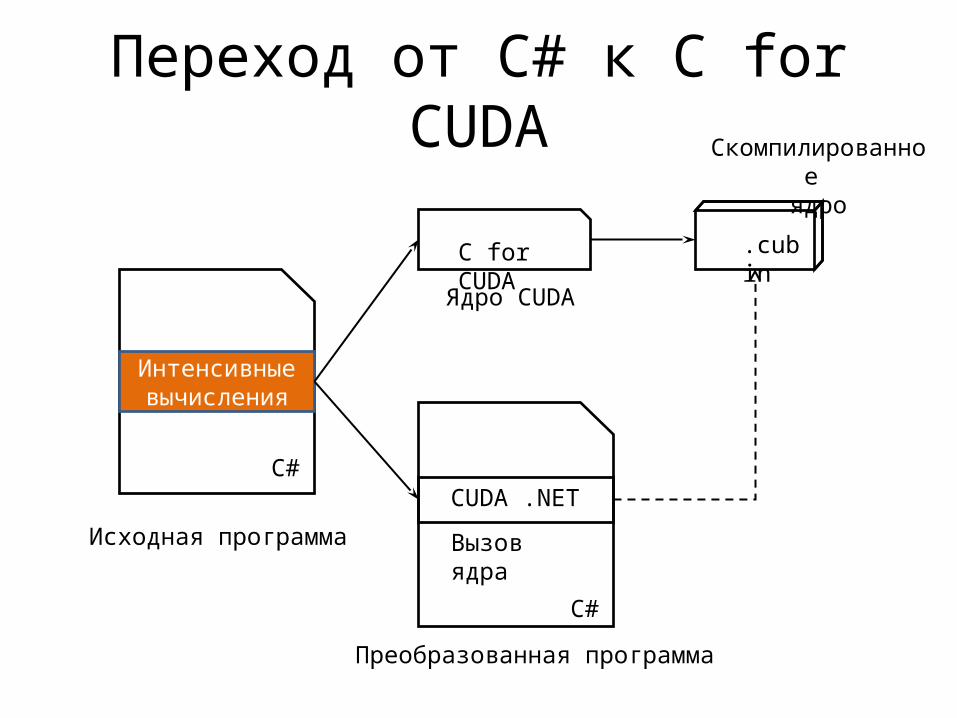
Переход от C# к С for CUDA
C#
Интенсивные вычисления
C for CUDA .cubin
C#
CUDA .NET
Исходная программа
Преобразованная программа
Ядро CUDA
Вызов ядра
Скомпилированное ядро

Пример правилГенерация ядра CUDA
• _CudaKernel2D($name, $params, $body, $idx1, $idx2) -> _CudaFunctionKernel($name, $params, [_PrepareIdx($idx1,x), _PrepareIdx($idx2,y), _CsToCuda($body)])
• _CudaFunctionKernel($name, $params, $body) -> Function([ExternC,__global__], void,$name,$params,$body)
• _PrepareIdx($idx,$coor) -> DeclarationAssignment( $idx,int, _CudaIdx($coor))
• _CudaIdx($coor) -> Dot(blockIdx,$coor) * Dot(blockDim,$coor) + Dot(threadIdx,$coor)

Вызов ядра
• Проверка наличия CUDA• Инициализация CUDA• Инициализация ядра• Копирование входных данных в графическую
память• Передача параметров ядра• Вызов ядра• Копирование результатов• Освобождение графической памяти

Сгенерированный код
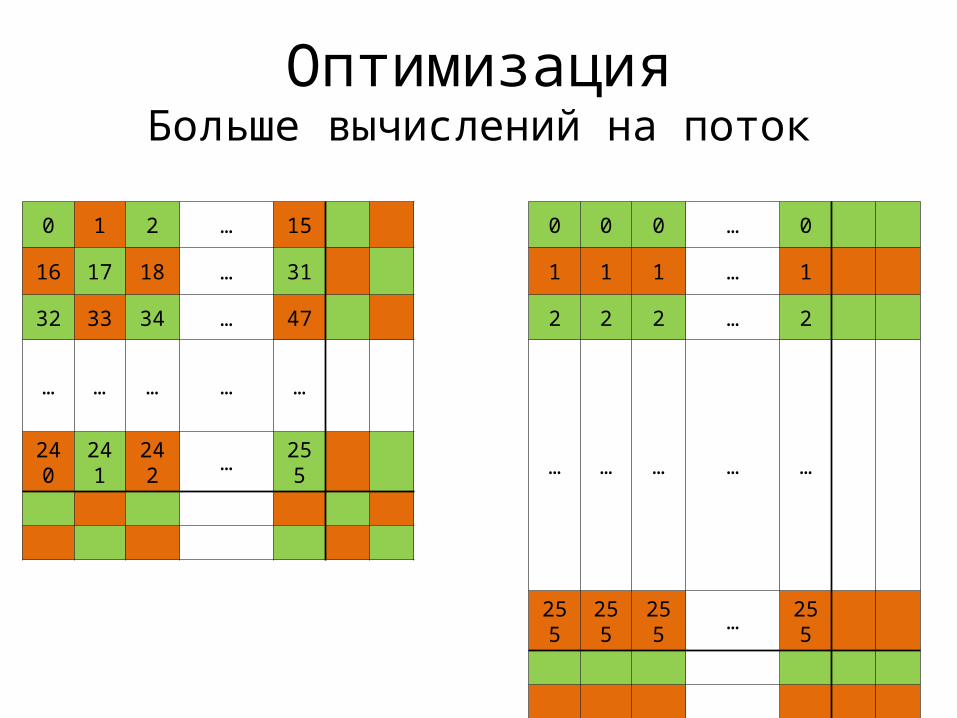
ОптимизацияБольше вычислений на поток
0 1 2 … 15
16 17 18 … 31
32 33 34 … 47
… … … … …
240 241 242 … 255
0 0 0 … 0
1 1 1 … 1
2 2 2 … 2
… … … … …
255 255 255 … 255

ОптимизацияРазделяемая (shared) память
• Добавляем буферы (свой для каждого блока)
• Каждый поток копирует свою часть данных в буфер
• Все вычисления – в буферах, без доступа в глобальную память
• Результаты копируются в глобальную память

Повышение производительности
Вариант Время, с УскорениеCPU 15,66 1GPU, без оптимизаций 1,89 8,3GPU, оптимизация 0,614 25,5
• Поле 512x512, 1000 итераций• Без оптимизаций ускорение в 8 раз
• Практически не требовало вмешательства разработчика
• Оптимизации позволили достичь 25-кратного ускорения

Выводы• GPU – новая перспективная платформа• Программирование для GPU сейчас сложно и
требует автоматизации• Автоматизация преобразований –
переписывающие правила• Распараллеливание и оптимизация программ для
GPU– Достигнуто ускорение в 25 раз
• Дальнейшие исследования– Новые преобразования– Новые задачи– Поддержка других технологий






























