Embed Size (px)
DESCRIPTION
Оценка систем текстового поиска. Игорь Кураленок Яндекс, СПбГУ. Чему верить?. Верить Методы оценки Известные исследования Факты, подтвержденные статистикой Принять к сведенью ( по желанию ) Выводы о качестве того или иного эксперимента - PowerPoint PPT Presentation
Citation preview

Оценка систем текстового поиска
Игорь Кураленок
Яндекс, СПбГУ

Чему верить?
Верить Методы оценки Известные исследования Факты, подтвержденные статистикой
Принять к сведенью (по желанию) Выводы о качестве того или иного эксперимента Модель того как все на самом деле и как все
взаимосвязано

План
Как люди это делают Как уменьшить количество работы Анализ и обоснование оценки Как (возможно ли?) сделать оценку
статистически корректной Работа в условиях неполных и/или неточных
данных Как еще можно оценить систему текстового
поиска?

План
Как люди это делают Как уменьшить количество работы Анализ и обоснование оценки Как (возможно ли?) сделать оценку
статистически корректной Работа в условиях неполных и/или неточных
данных Как еще можно оценить систему текстового
поиска?

Немного истории
Кренфилдские эксперименты (1966) появление пулинга (1975) Text REtrieval Conference (TREC) (1992) Исследования основ оценки на базе (TREC) (1998-
2001-…) NII Test Collection for IR Systems (NTCIR) (1999) Cross Language Evaluations Forum (CLEF) (2000) Российский семинар по оценке Методов
Информационного Поиска (РОМИП) (2003)

Классическая (Cranfield) процедура оценки Составим список запросов и ограничим коллекцию
документов Для каждой пары запрос/документ выставим
экспертную оценку «релевантности» Будем рассматривать ответ системы не как
последовательность документов, а как множество/последовательность оценок релевантности
На полученной последовательности/множестве оценок релевантности построим метрики

Множественные оценкиРелевантен Не
релевантен
В ответе
Не в ответе

Отсечение на уровне
Уровень меняется в зависимости от запроса
Информация
Оценки на последовательностях

Усреднение
МикроусреднениеСоставляем общую таблицу релевантности
и по ней считаем метрики на множестве
МакроусреднениеУсредняем значения метрик на отдельных
запросах
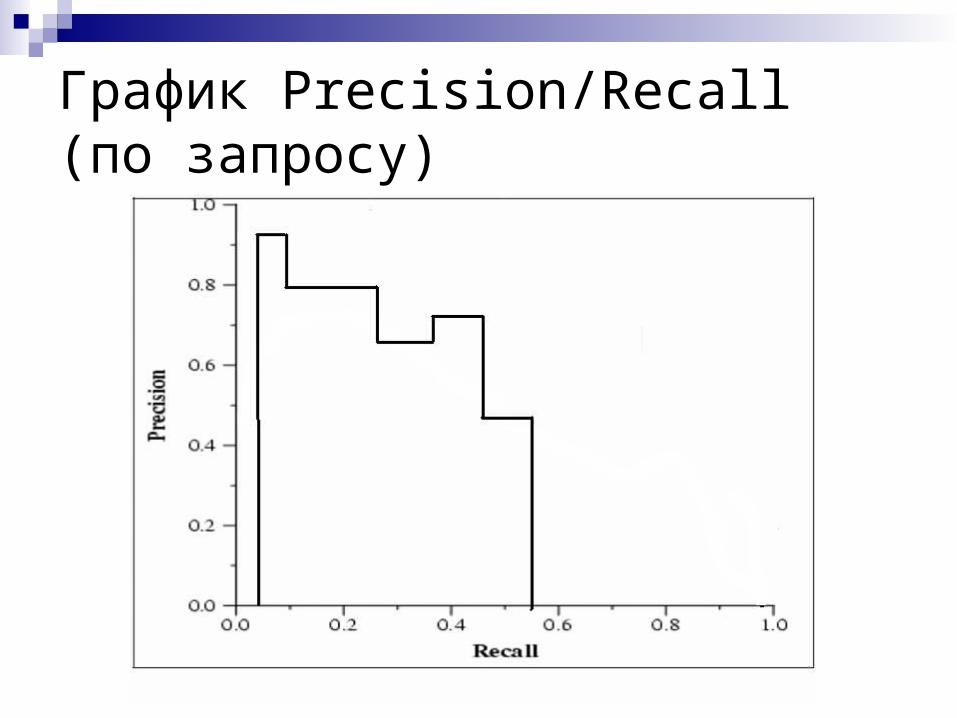
График Precision/Recall (по запросу)

Интегральные метрики
Средняя точность (AP & MAP)
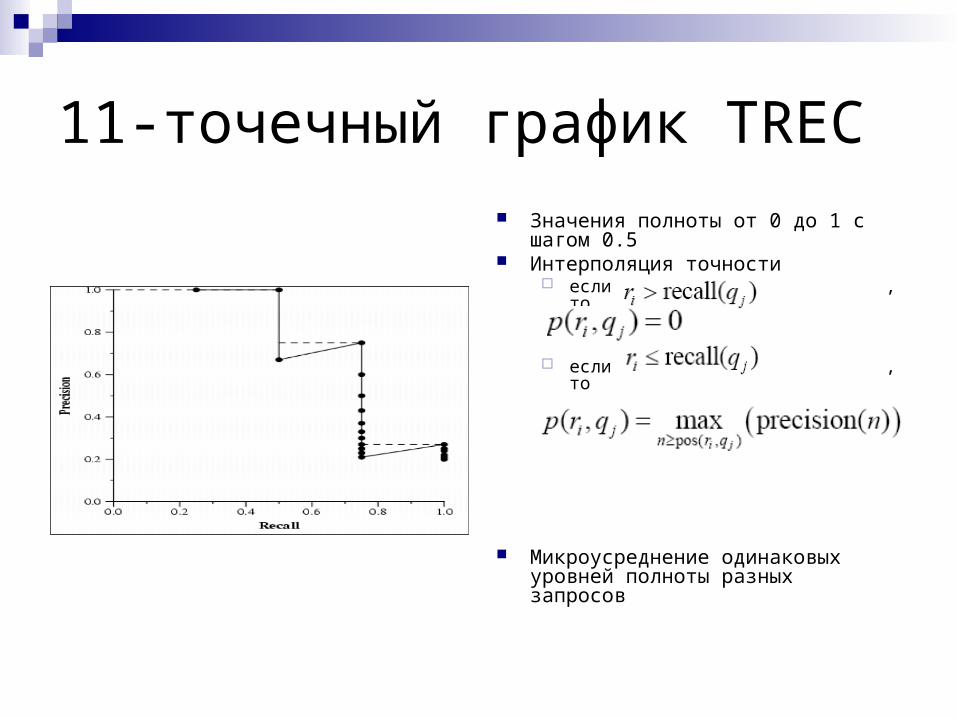
11-точечный график TREC Значения полноты от 0 до 1 с шагом
0.5 Интерполяция точности
если , то
если , то
Микроусреднение одинаковых уровней полноты разных запросов

Многомерная модель релевантности(S. Mizzaro)Информационная потребность: Неосознанная ИП (RIN) Осознанная ИП (PIN) Сформулированная ИП (EIN) Запрос (Q)
Документ Множество нужных документов
(DS) Документ (D) Представление (MD) Профайл (P)
Контекст: тематика, задача, атрибуты пользователя (языки, терпение)
Время

Виды релевантности
Системная релевантность = Запрос + Профайл + * Когнитивная релевантность (пертенентность) =
Неосозная ИП + Документ + * Тематическая релевантность = * + Тема + (Задача?)
+ *

Шкалы релевантности
Позволяет получить больше информации о мнении пользователя
Иногда улучшает согласованность оценок
Позволяет провести оценку на разных уровнях «требовательности пользователя»
Усложняет процедуру построения оценки
Не позволяет использовать классические метрики (делая результаты непонятными слушателям)
Порождает проблему взаимоотношения оценок

Шкала оценки РОМИП
Соответствует Скорее соответствует Возможно соответствует Не соответствует Не может быть оценен
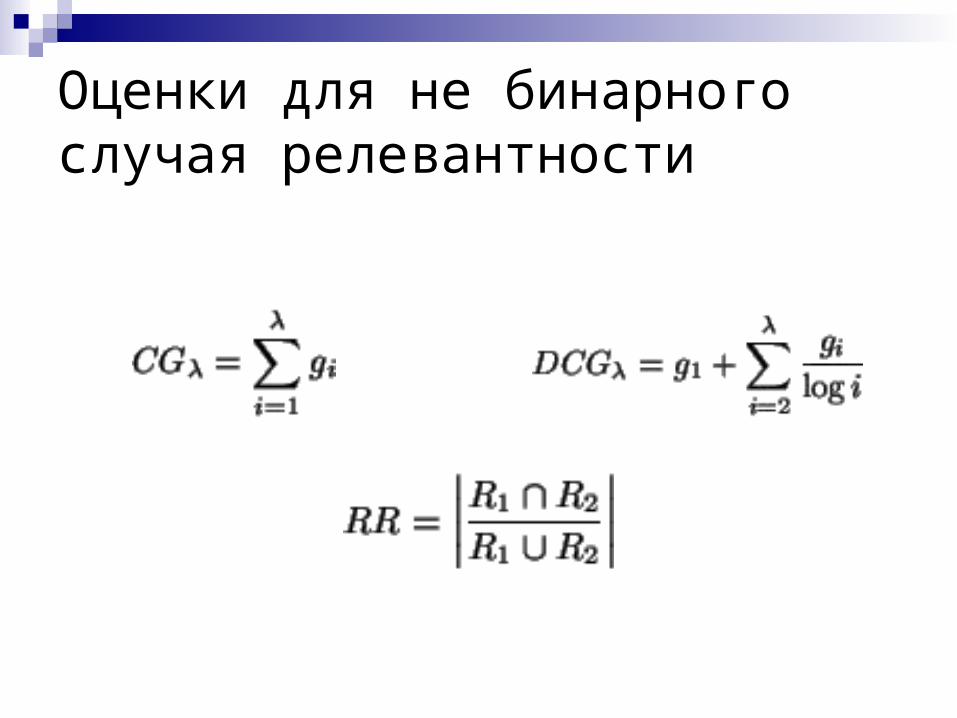
Оценки для не бинарного случая релевантности
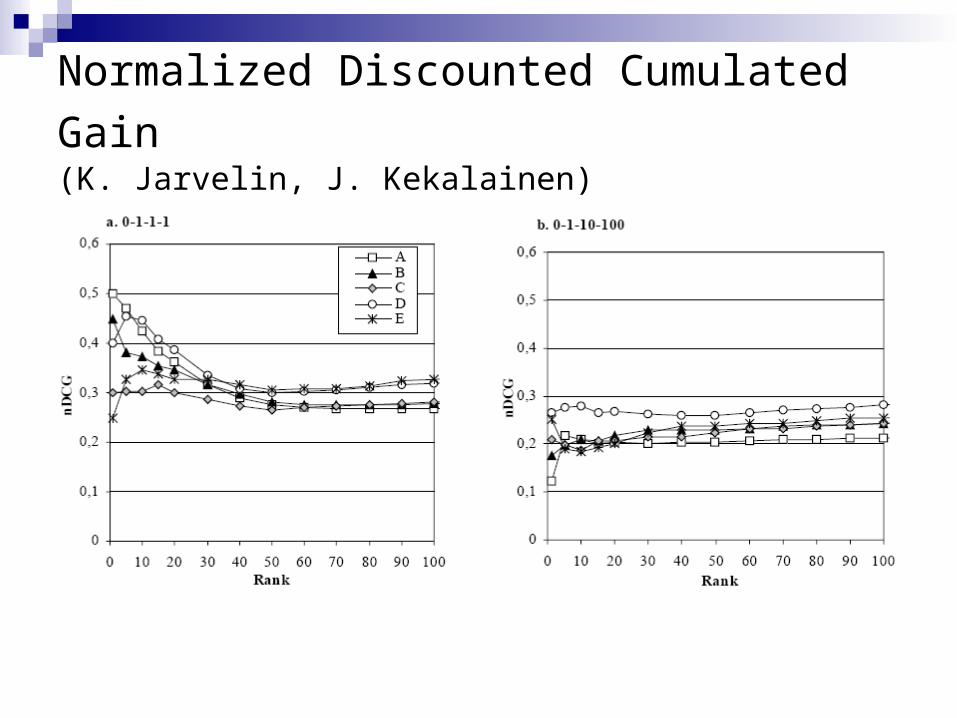
Normalized Discounted Cumulated Gain (K. Jarvelin, J. Kekalainen)

План
Как люди это делают Как уменьшить количество работы Анализ и обоснование оценки Как (возможно ли?) сделать оценку
статистически корректной Работа в условиях неполных и/или неточных
данных Как еще можно оценить систему текстового
поиска?

Пулинг
Для каждого запроса: Собрать результаты систем участников глубины A Выбрать из полученных результатов B первых Удалить дубликаты Проставить оценки релевантности Не оцененные документы считать нерелевантными Оценить весь ответ системы (с глубиной А)
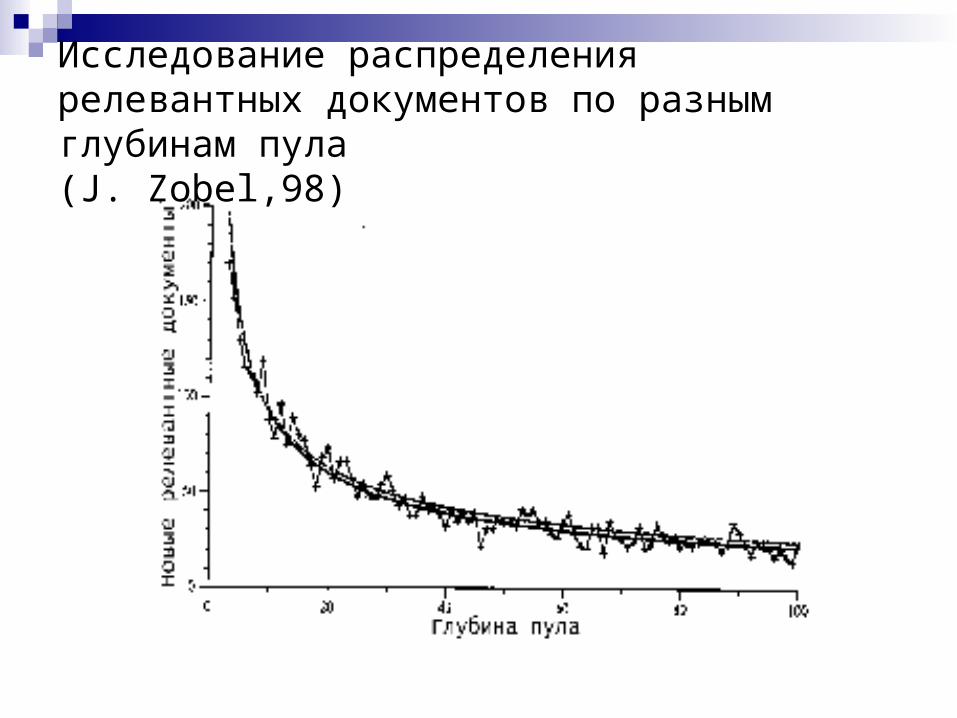
Исследование распределения релевантных документов по разным глубинам пула (J. Zobel,98)

Исследование распределения релевантных документов при изменении числа участников (J. Zobel,98)

Сложности, связанные с пулингом Взаимное усиление систем Недооценка систем, не участвовавших
в оценке Получаемая оценка – оценка снизу

Альтернативы пулингу(G. Cormack, C. Palmer, C. Clarke)
Попросить асессоров любыми способами искать релевантные документы (ISJ)
Случайный выбор документов для оценки (Random)
Move-to-front пулинг
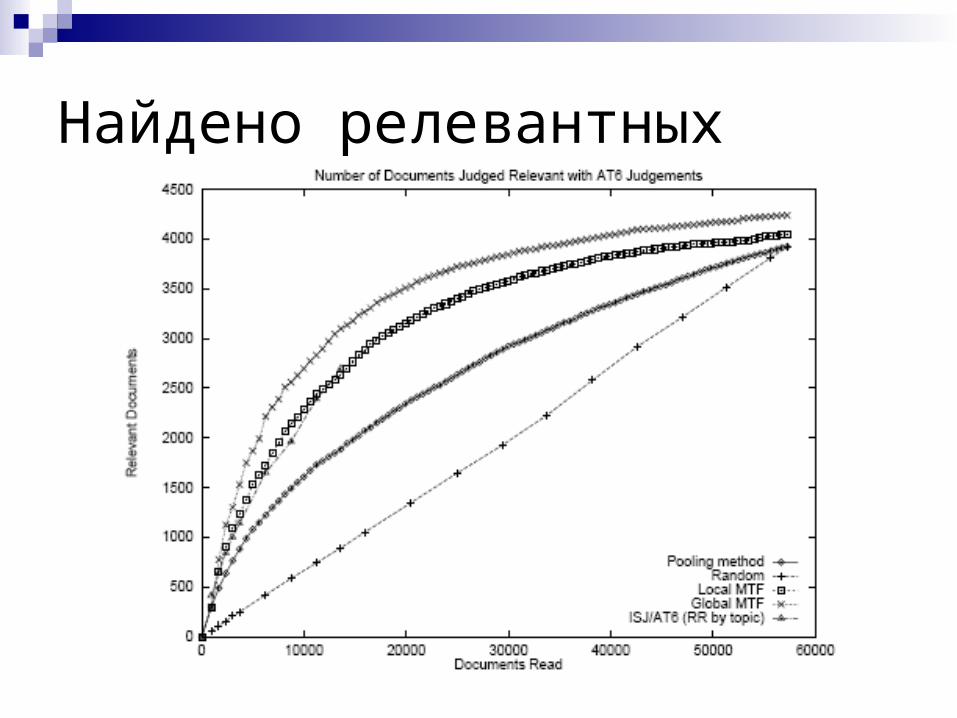
Найдено релевантных
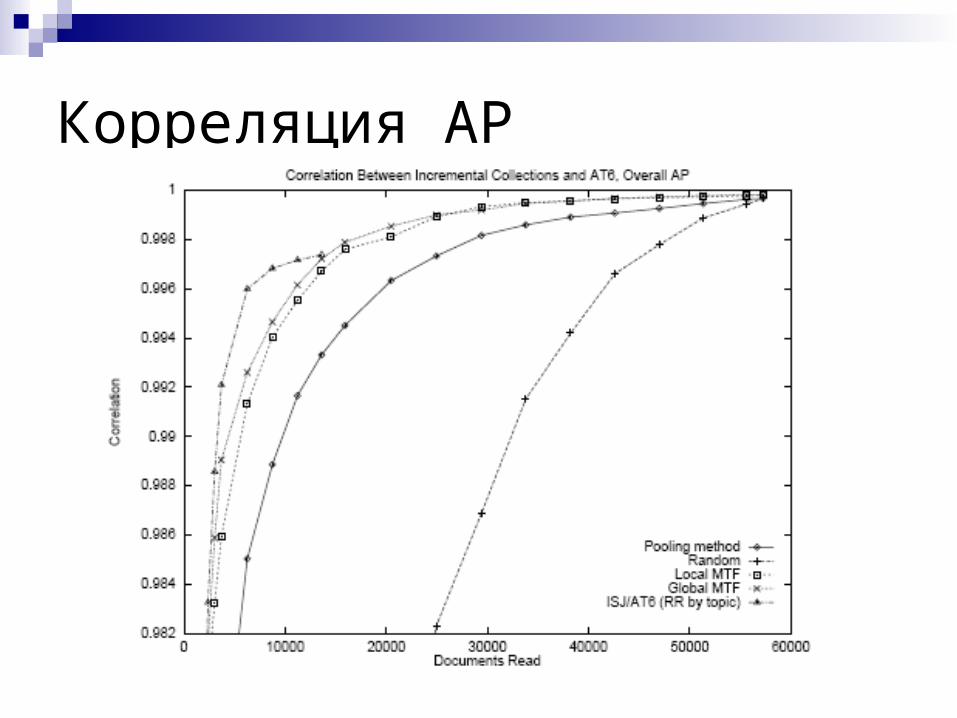
Корреляция AP

План
Как люди это делают Как уменьшить количество работы Анализ и обоснование оценки Как (возможно ли?) сделать оценку
статистически корректной Работа в условиях неполных и/или неточных
данных Как еще можно оценить систему текстового
поиска?

Анализ и обоснование классической модели Стабильность метрик Зависимость результатов от набора
экспертов Информация (по Шеннону),
содержащаяся в метриках

Стабильность оценок(C. Buckley, E. Voorhees)
Цели: Как изменяется стабильность ранжирования при
изменении данных на известных метриках Какие минимальные требования к данным для того,
чтобы метрики оставались стабильными
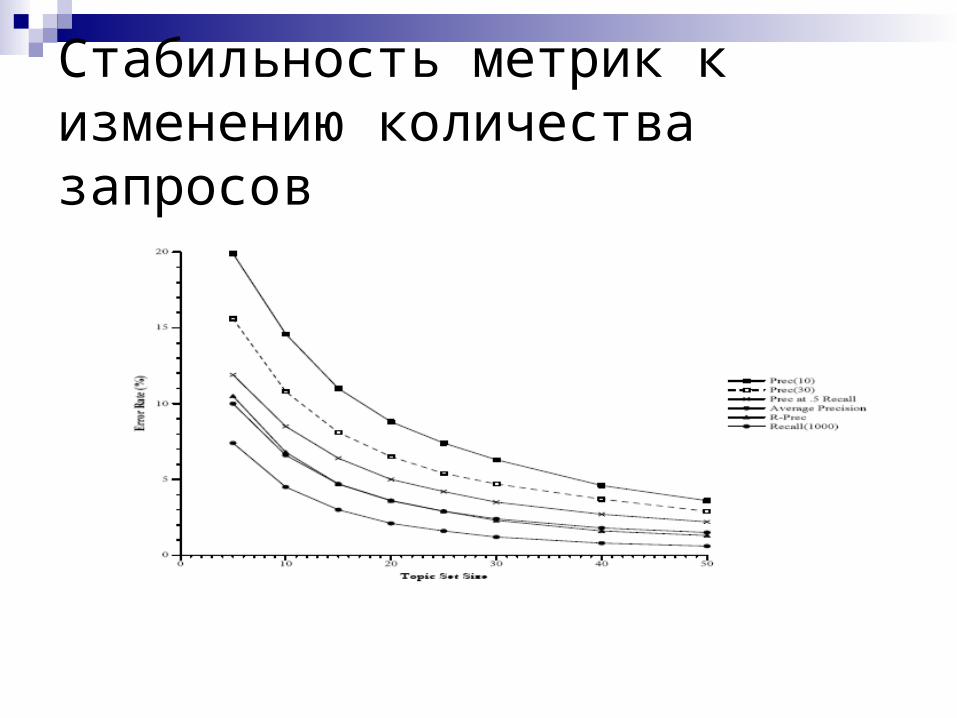
Стабильность метрик к изменению количества запросов
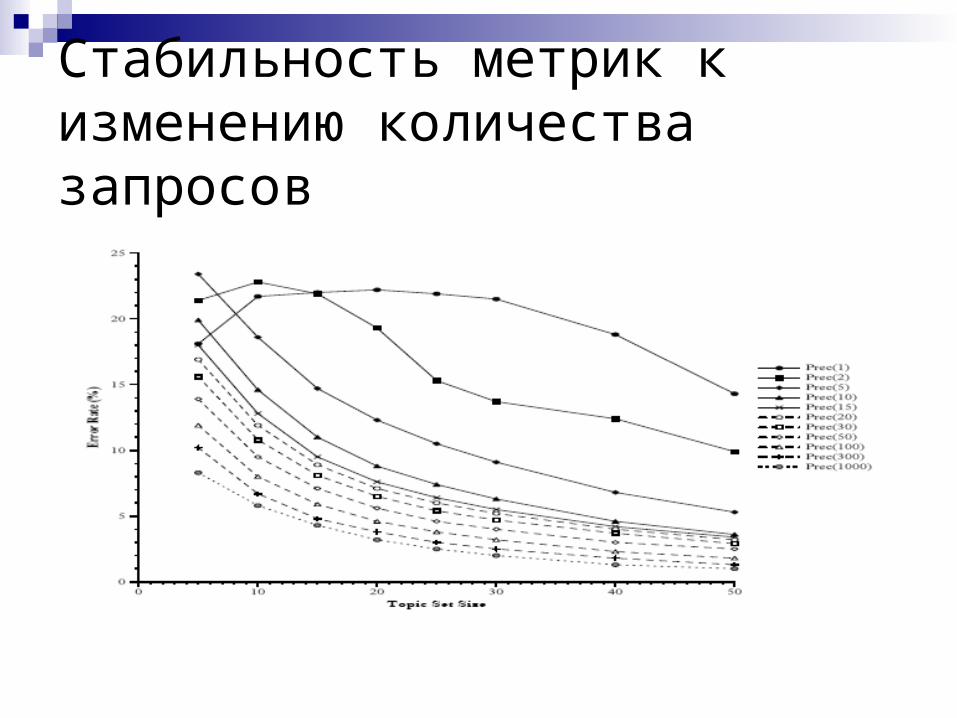
Стабильность метрик к изменению количества запросов
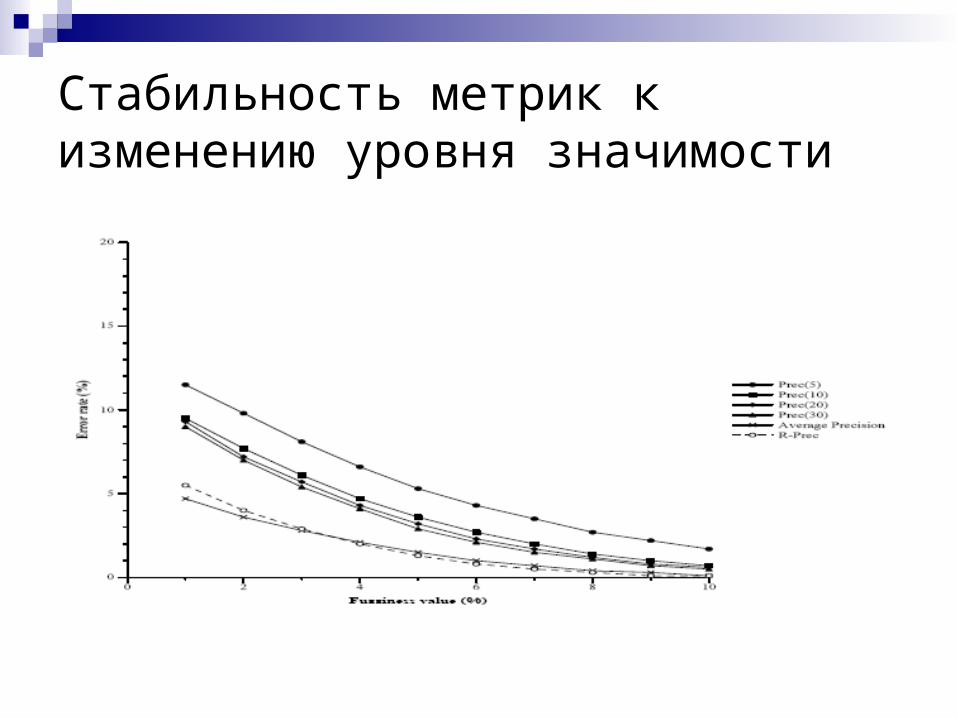
Стабильность метрик к изменению уровня значимости
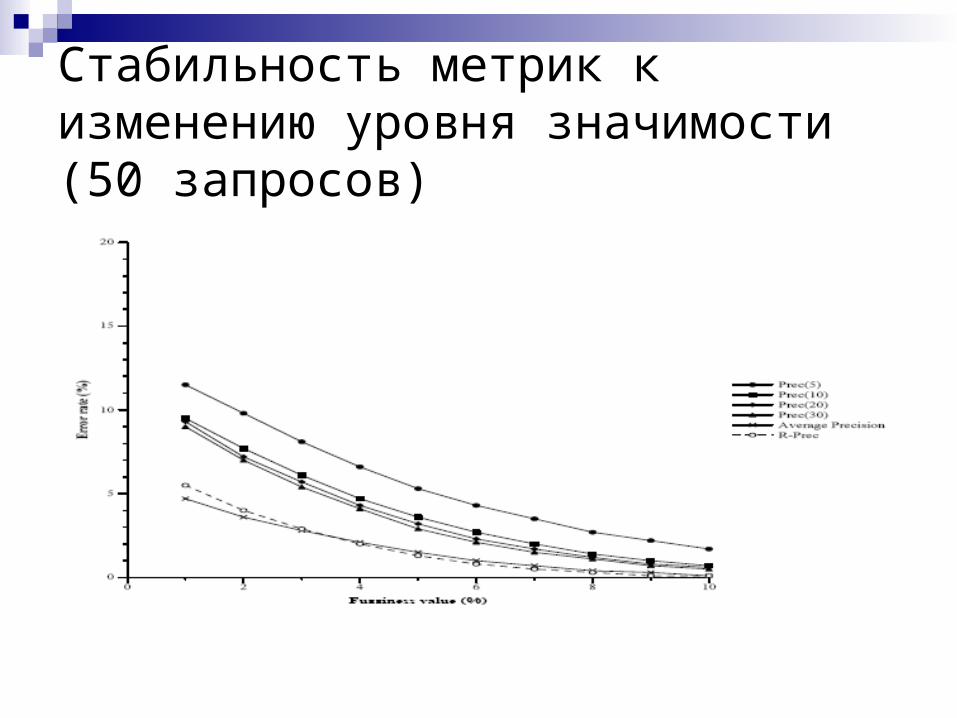
Стабильность метрик к изменению уровня значимости (50 запросов)
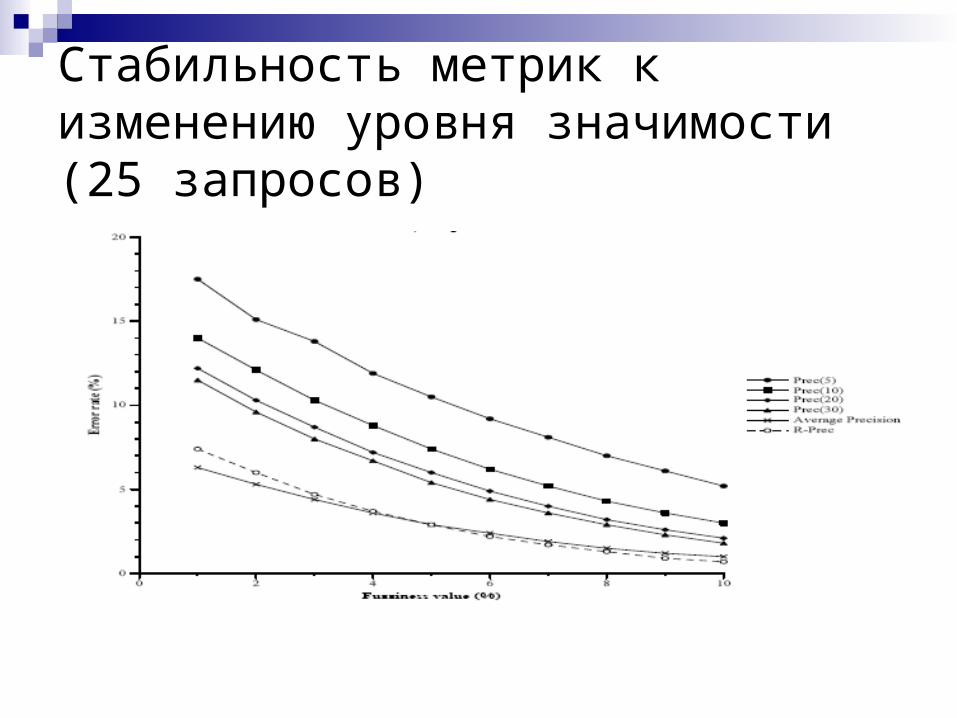
Стабильность метрик к изменению уровня значимости (25 запросов)

Зависимость результатов от состава экспертной группы (E. Voorhees, 98) Асессоры часто не соглашаются в своих
оценках
Влияет ли это несогласие на финальное ранжирование?
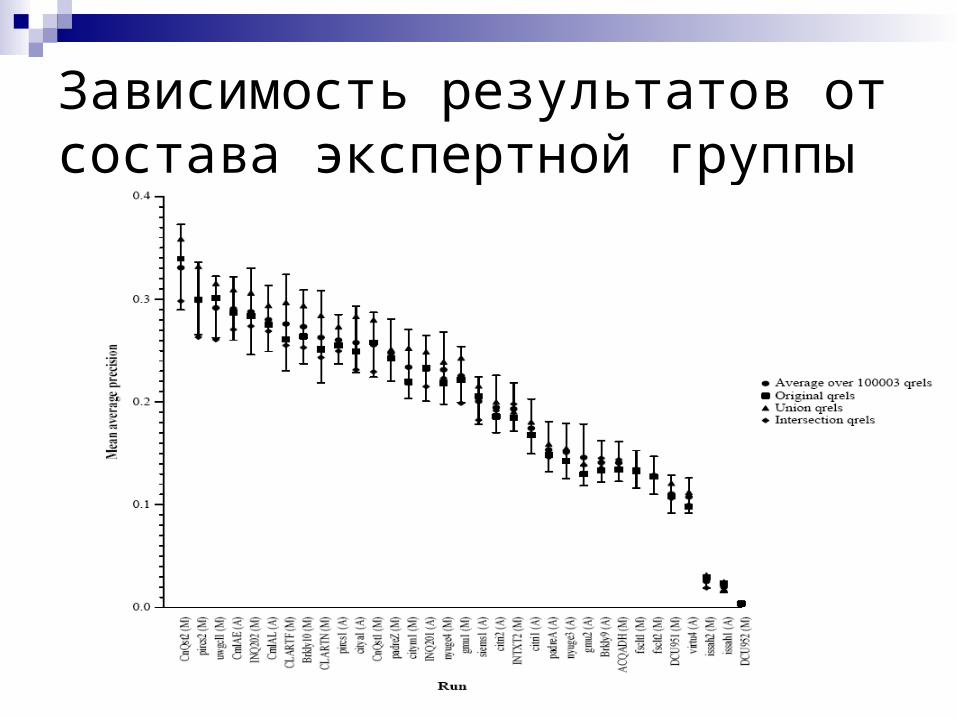
Зависимость результатов от состава экспертной группы

Зависимость результатов от состава экспертной группы

Информация, содержащаяся в известных метриках (J.Aslam, E. Yilmaz, V. Pavlu)
Используя Метод Максимальной Энтропии вычисляем распределение вероятностей релевантности по ответу поисковой системы, исходя из информации о количестве релевантных документов и значения метрики
Восстанавливаем распределение точности по разным уровням полноты
Сравниваем полученный график с наблюдаемым

Метод Максимальной Энтропии в вычислении вероятности релевантности
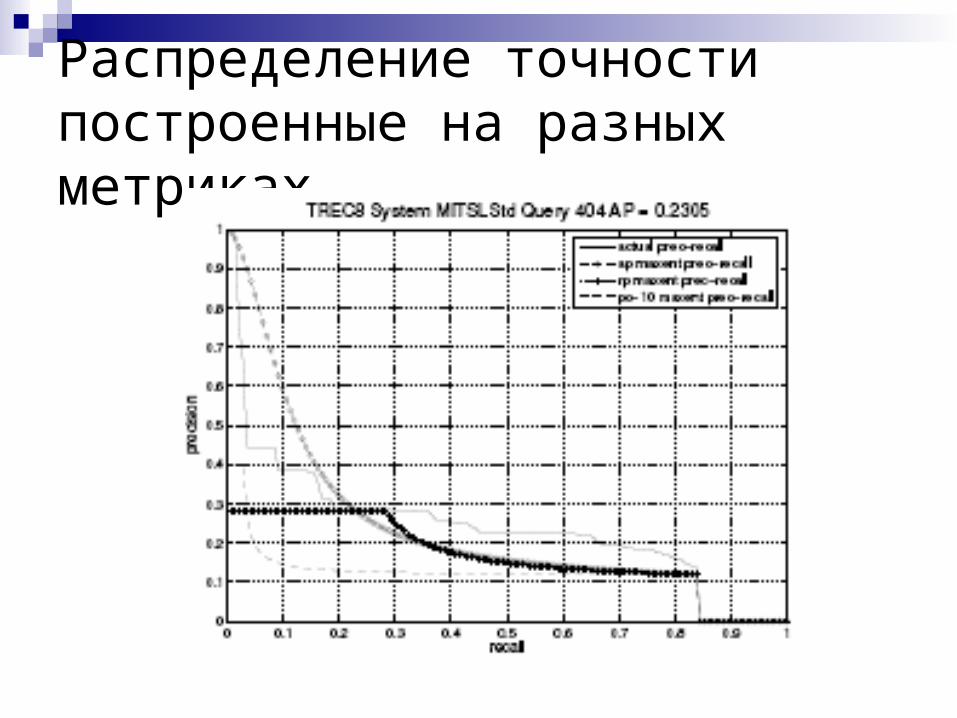
Распределение точности построенные на разных метриках
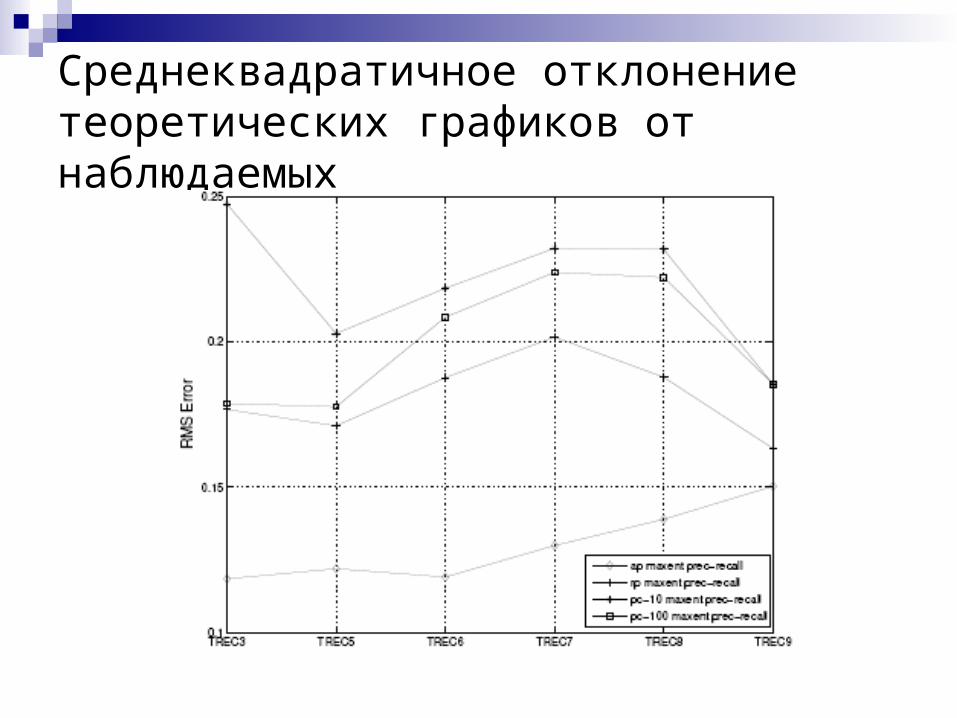
Среднеквадратичное отклонение теоретических графиков от наблюдаемых

План
Как люди это делают Как уменьшить количество работы Анализ и обоснование оценки Как (возможно ли?) сделать оценку
статистически корректной Работа в условиях неполных и/или неточных
данных Как еще можно оценить систему текстового
поиска?

Известные подходы к оценке
Органолептический Аналитический Косвенная оценка
Интерактивная оценкаРешение более общей задачи
Кренфилдская оценка

Требования к оценке
Повторяемость Интерпретируемость Переносимость Низкая стоимость
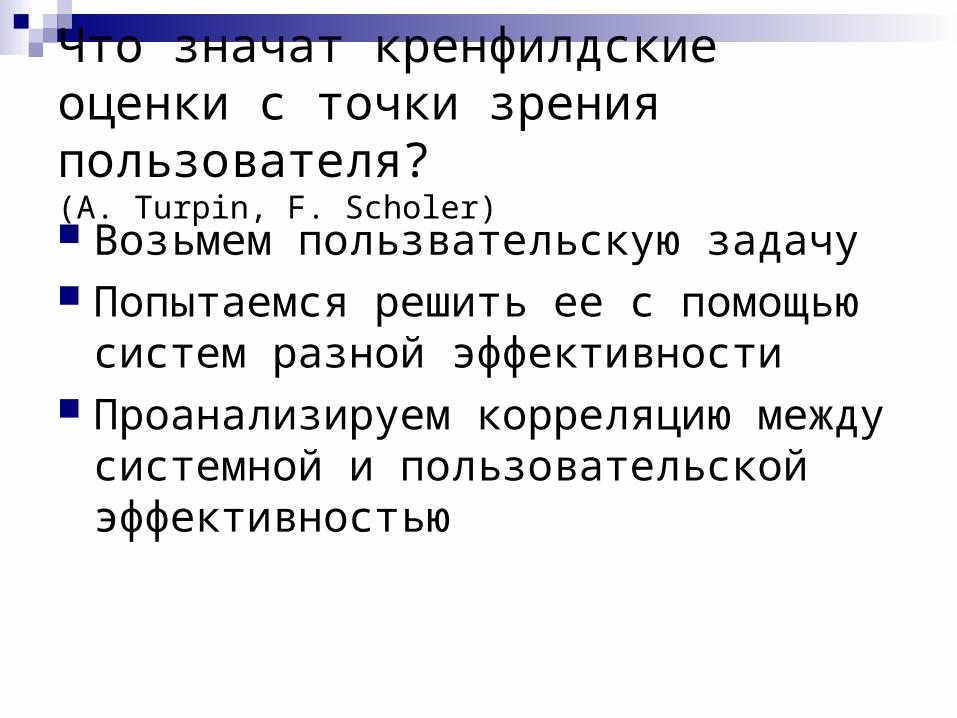
Что значат кренфилдские оценки с точки зрения пользователя?(A. Turpin, F. Scholer)
Возьмем пользвательскую задачу Попытаемся решить ее с помощью
систем разной эффективности Проанализируем корреляцию между
системной и пользовательской эффективностью

Постановка эксперимента
Сформируем ответы с заданными значениями MAP Попросим пользователя найти первый релевантный
документ по каждому из представленных запросов

Корреляция пользовательской и системной эффективности
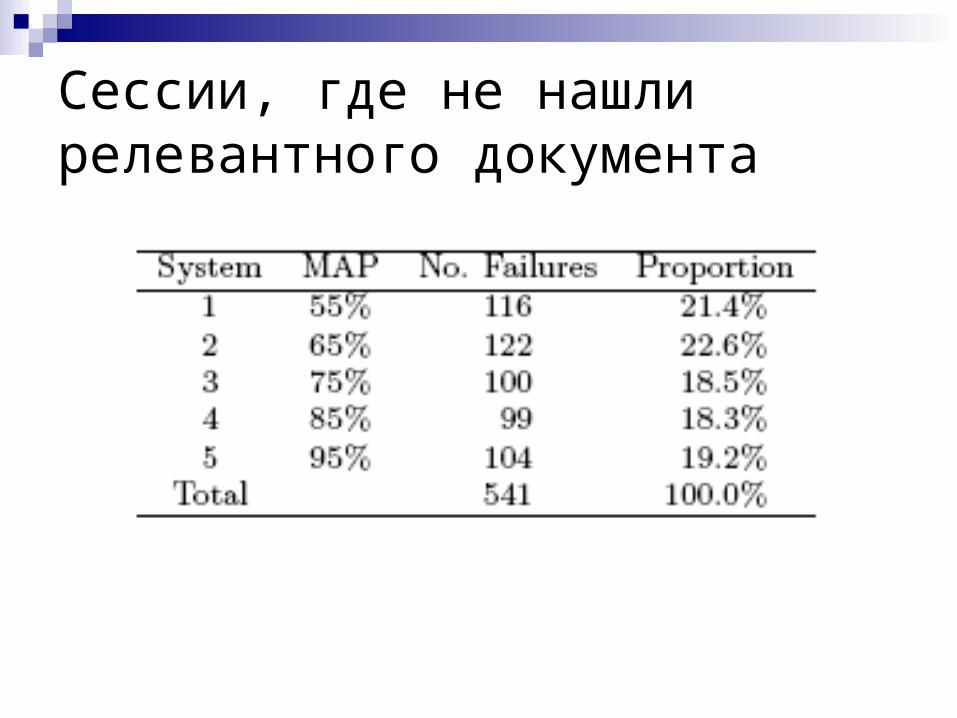
Сессии, где не нашли релевантного документа

Почему так получилось?
Система состоит не только из алгоритма ранжирования
При высоких уровнях точности на первый план выходит «быстродействие» пользователя
Релевантность с точки зрения пользователя отличала от эталонной, по которой мы проводили «настройку»

«Правильная» оценка с точки зрения статистики Определение границ задачи (определение
границ совокупности) Разработка способа создания
репрезентативной выборки Построение оценки по выборке Несмещенные оценки распределены
нормально (позволяет вычислить доверительные интервалы)

Создание коллекции документов
В большинстве случаев невозможно создать репрезентативную выборку:
Проблемы с копирайтом Большие объемы данных Связность Изменчивость
Доступная коллекция хоть как-то относящаяся к реальным данным

Выборка ИП
Мы должны сформировать выборку информационных потребностей а не запросов
ИП должно быть достаточно для того, чтобы доверительные интервалы были достаточно малы, для разделения систем, участвующих в оценке
Набор ИП должен быть минимально смещен относительно случайной выборки из множества ИП пользователей вашей системы

Создание коллекции запросов
Ресурсы оценки ограничены Запрос должен оценивать только тот, кто его создал В коллекция должна содержать ответ на запрос Хочется проводить оценку для n систем сразу (обобщение
аудитории)
Запросы создаются часто от балды

Чем отличается академическая оценка от индустриальной (Андреас Раубер)
Академическая: Работает когда нет окончательного
понимания о пользовательских задачах
Оценивает «разумность» поведения хотя бы для какого-то пользователя
Позволяет исследовать различные варианты методологии и их объективные свойства
Минимизирует затраты на проведение эксперимента
Не представляет практического интереса с точки зрения применения в качестве объективных данных (обратная связь,сравнение эффективности в коммерческих целях, …)
Индустриальная: Пользовательские задачи
строго определены рамками интерфейса
Необходима оценка того, как система работает для множества пользователей (зависит от целей системы)
Бюджет и доступные для исследования данные значительно богаче
Должна отражать объективную реальность

Как проводить оценку своей системыС помощью коллекции Оценки смещены, но
смещение случайно Ограничен набор
метрик Доступны
результаты конкурентных подходов
Самостоятельно Только
статистически правильно
Необходима переоценка конкурентных подходов

Кто оценивает релевантность?
Автор информационной потребности:
Разбирается в области поиска ровно настолько сколько может знать человек породивший такой запрос
Имеет четко выраженное представление о том, что хочет найти
Может построить несколько вариантов запроса с одной и той же информационной потребностью
Обученный асессор: Имеет более четкое
представление о качестве документа
Формирует согласованные оценки
Может обрабатывать любой запрос

Как создать «правильную» выборку ИП? Набрать случайных запросов от
пользователей Восстановить по ним наиболее
частотные ИП Обобщить ИП и «объяснить» асессору
что подходит к запросу, а что нет

Многомерная модель релевантности(S. Mizzaro)Информационная потребность: Неосознанная ИП (RIN) Осознанная ИП (PIN) Сформулированная ИП (EIN) Запрос (Q)
Документ Множество нужных документов
(DS) Документ (D) Представление (MD) Профайл (P)
Контекст: тематика, задача, атрибуты пользователя (языки, терпение)
Время

Преобразование запроса
Запрос –> Поле информационных потребностей
Поле ИП преобразуем вПолное описаниеВыбор представителя (случайный?)Выбор подмножества

Как создать «правильную» выборку документов в сети Ограничиться сильно связным
сегментом сети Работать со всем интернетом

Что еще нам мешает применять кренфилдскую модель оценки Оценки на маленьких коллекция становятся
все менее интересны На больших коллекциях (например сеть)
«хвост» пулинга слишком велик Документы/запросы изменяются и коллекция
быстро устаревает Мы вынуждены сравнивать абсолютные
значения метрик, наблюдаемые на разных коллекциях

Что можно с этим поделать
Разработать более стабильные к изменению оценок метрики
Обеспечить малые границы изменения абсолютных значений метрикБольшая согласованность оценок
релевантностиНаучиться оценивать репрезентативную
выборку запросов

Уменьшить разногласия асессоров Создать эталонного пользователя
(коллективный разум), который скажет что такое ошибки
Построить четкие правила оценки для известных эталонному пользователю случаев
Обучить асессора этим правилам до оценки
Смещены ли полученные оценки?
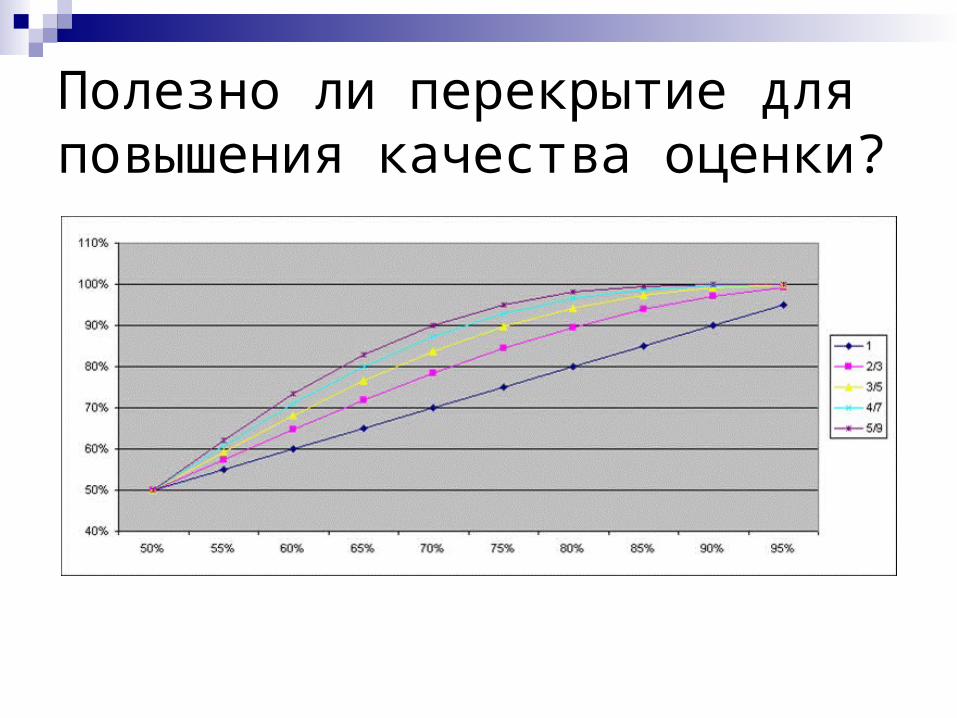
Полезно ли перекрытие для повышения качества оценки?

Оценка в уловиях неполных или неточных данных Оценки быстро устаревают Релевантные документы исчезают Все классические метрики при этом
стремятся к нулю по абсолютному значению и не сохраняют порядок ранжирования систем

BPref(C. Buckley, E. Voorhees)
Возьмем полное множество оценки Начнем последовательно выкидывать оценки
релевантных документов Посчитаем что будет происходить с
ранжированием систем и абсолютными значениями метрик
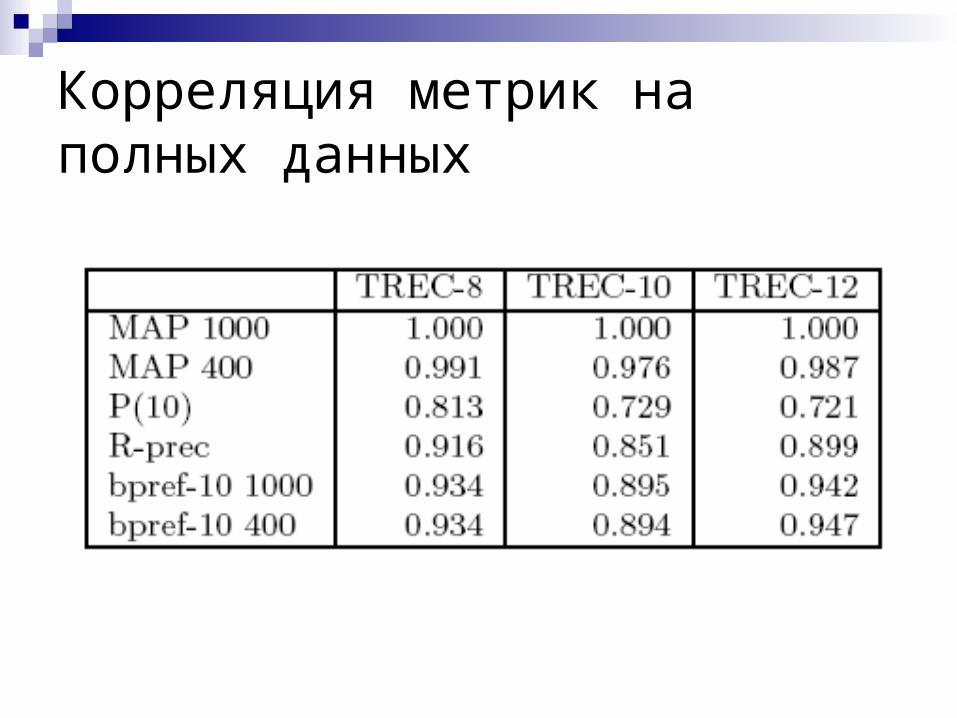
Корреляция метрик на полных данных
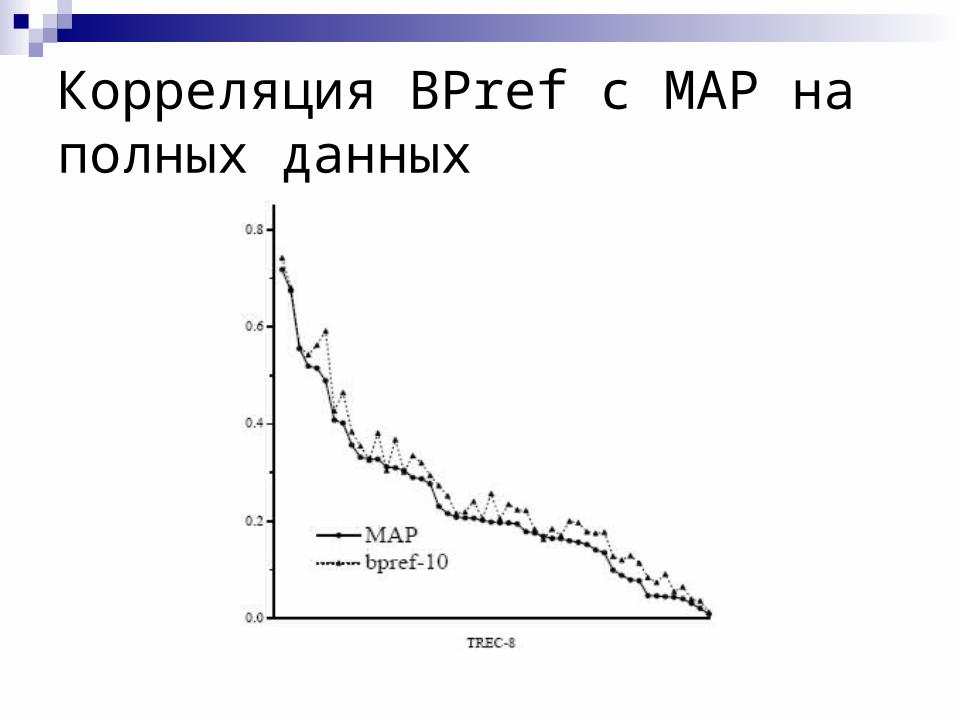
Корреляция BPref c MAP на полных данных
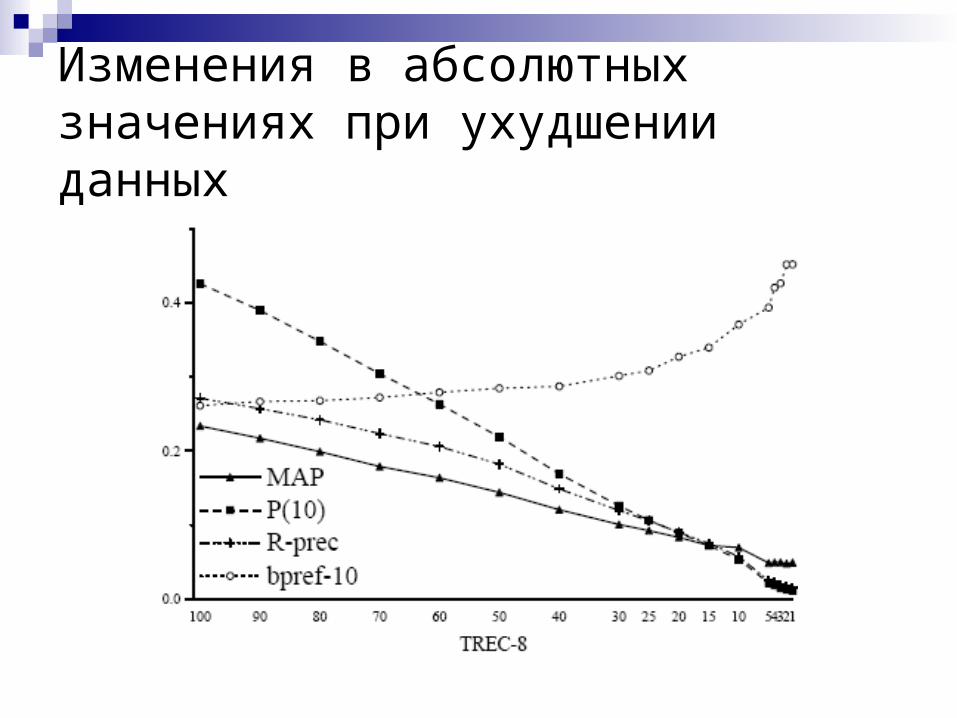
Изменения в абсолютных значениях при ухудшении данных
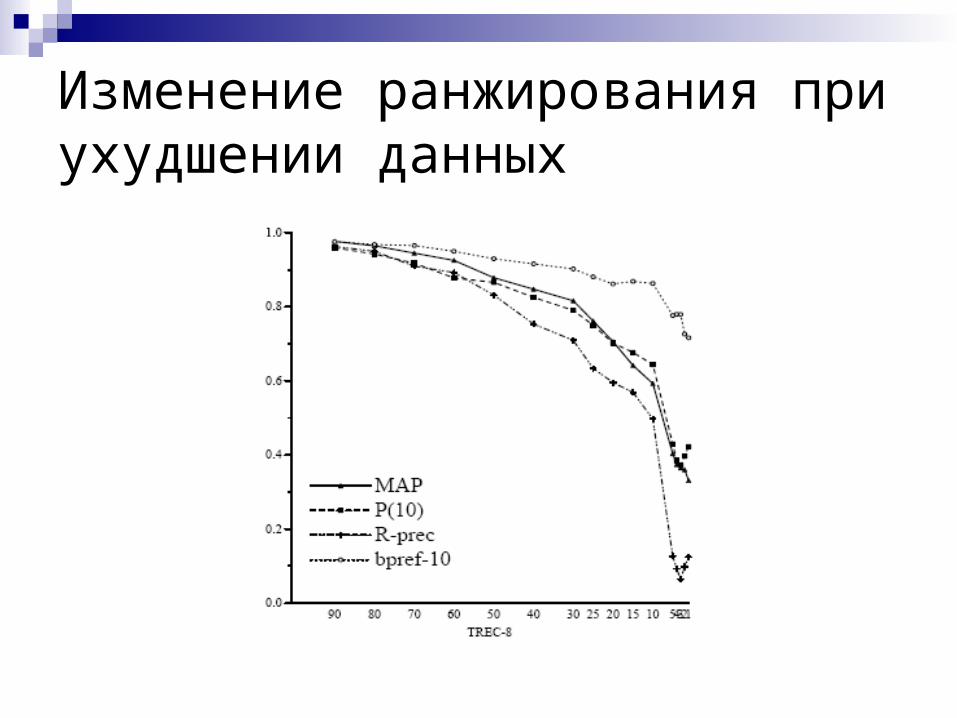
Изменение ранжирования при ухудшении данных
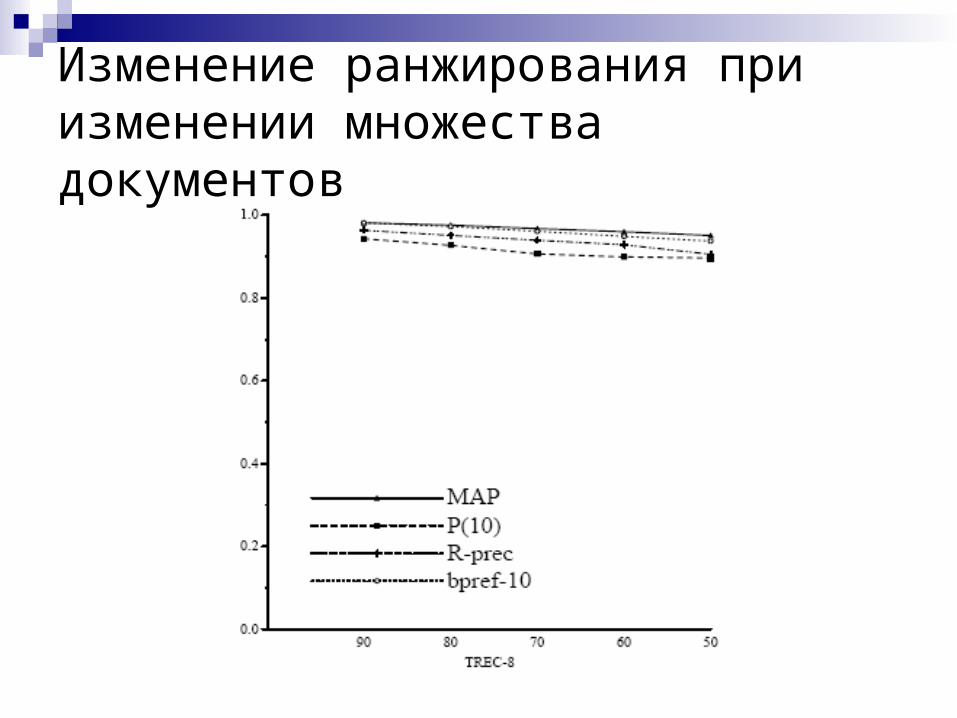
Изменение ранжирования при изменении множества документов

Induced Average Precision
Выкинем все неизвестные документы из выдачи по каждому запросу
Посчитаем MAP на основе полученных данных

Inferred Average Precision
Любой документ выдачи принадлежит одному из трех множеств: Оцененных Неоцененных, но содержащихся в пуле Не вошедших в пул
Попробуем предсказать вероятность релевантности документа на основе его положения в выдаче и данных о принадлежности к одному из множеств

Ожидание точности на уровне к:
Если документ не попал в пул –> нерелевантен
Inferred Average Precision
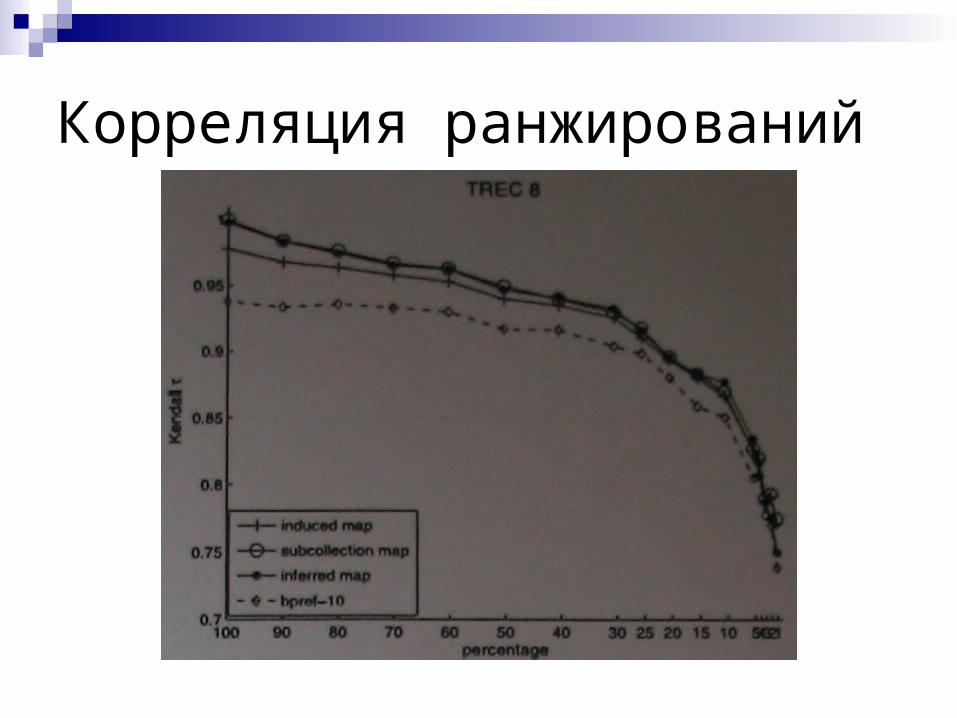
Корреляция ранжирований
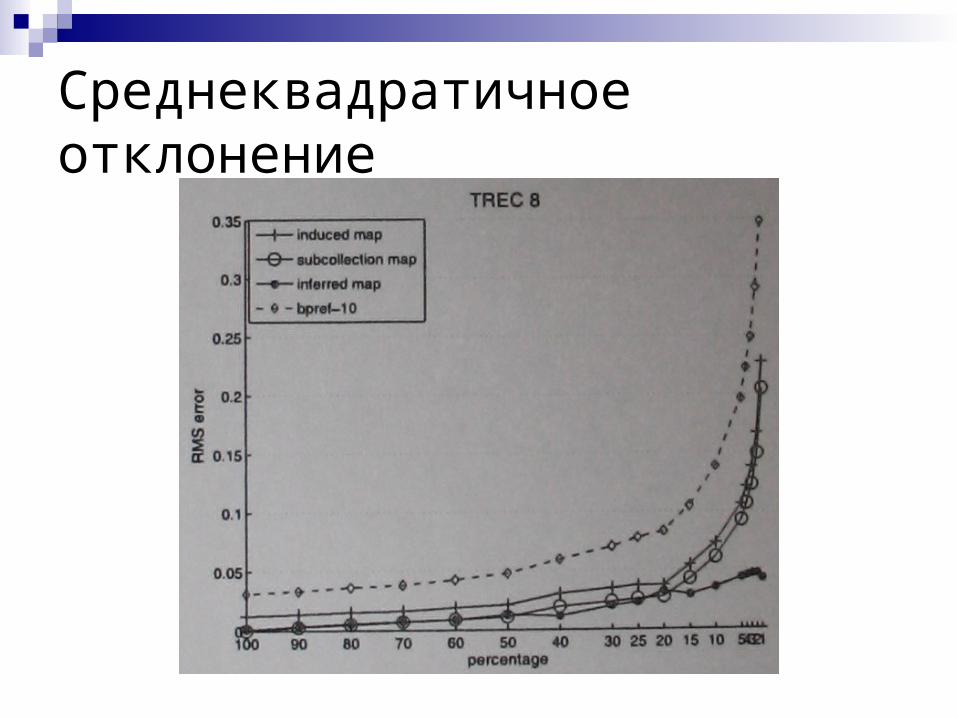
Среднеквадратичное отклонение
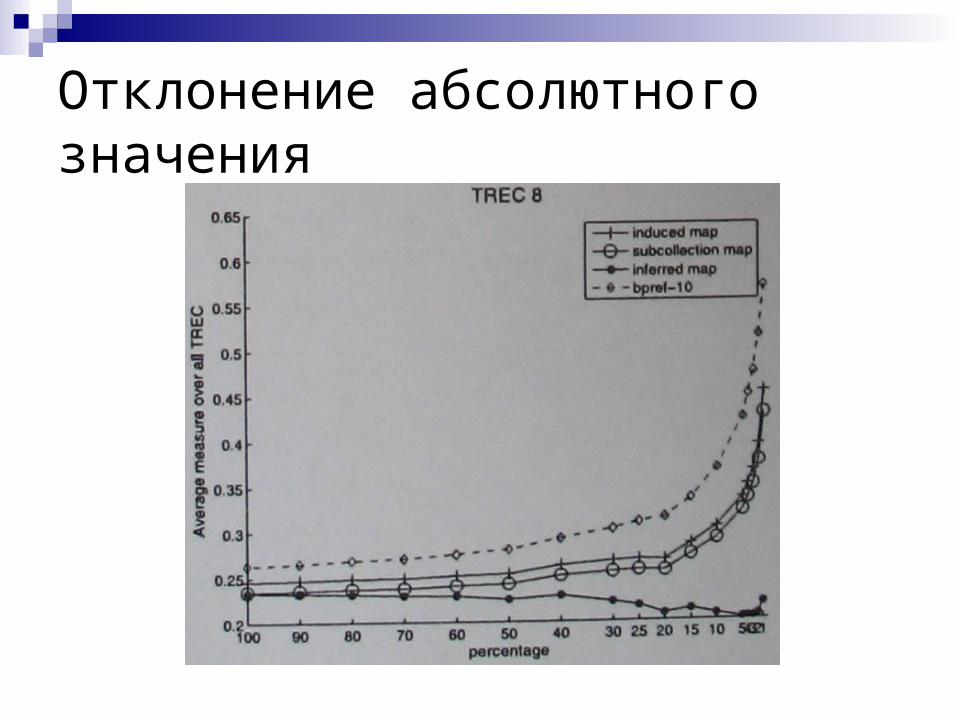
Отклонение абсолютного значения

Можно ли обойтись без оценки релевантности(I. Soboroff, C. Nicholas, P. Cahan)
Асессоры не всегда согласны друг с другом Набор экспертов не влияет (>0.938 T) на
порядок ранжирования систем
Можно попытаться смоделировать
оценку релевантности

Модель случайной оценки
Известен процент релевантных документов в пуле по запросу и его сигма
Смоделируем нормальным распределением число релевантных на запрос
Случайно выберем полученное количество документов из пула
Будем считать что выбранные документы релевантны

Результаты
Полные пулы С дублями
Мелкие пулы По реальным количествам релевантных документов

Можно ли оценить системы с помощью данных о кликах?(T. Joachims)
Клики говорят о сравнительной релевантности документов: Будем представлять пользователю систему с
рандомными ответами и считать клики Получились одинаковые результаты для разных
систем из чего сделано предположение о «смещенности» данных в зависимости от качества
Сольем результаты в один серп, тогда зависимости от качества удастся избежать
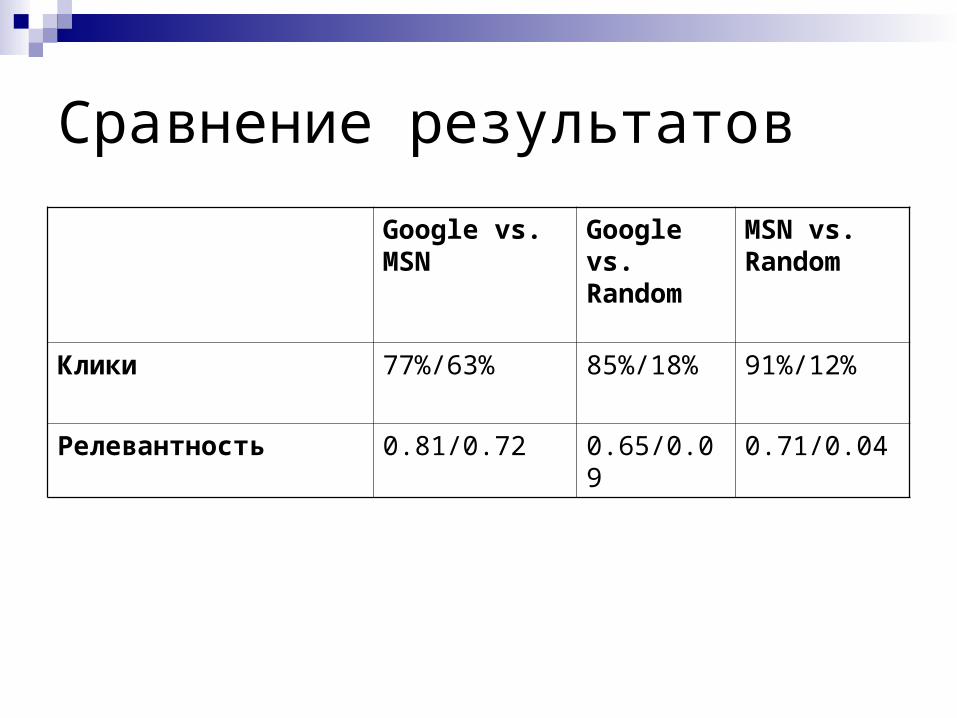
Сравнение результатов
Google vs. MSN
Google vs. Random
MSN vs. Random
Клики 77%/63% 85%/18% 91%/12%
Релевантность 0.81/0.72 0.65/0.09 0.71/0.04

Куда двигать оценку?
Неполные данные с уровнями релевантности Взаимоотношение поведения пользователя и
оценок релевантности Предварительная оценка Переносимость абсолютных результатов Связи между разными видами оценки Создание статистически «правильных
коллекций»





























