Embed Size (px)
DESCRIPTION
【 小暮研究会2 】. 「ベイズのアルゴリズム」:序章 【 1,2:計量経済分析と統計分析 】 【 3:ベイズ定理 】 【 4 (1,1) :構成要素(尤度、例:回帰関数) 】 総合政策学部3年 高阪亮平. 計量経済分析とは. 目的: 経済モデルが実際の経済動向と一致しているか? 一致していると仮定したとき、モデルと異なる構造になる確率がいくらか? 例: 消費= Y 、収入= C 、とした 「 C=α + βY 」という経済モデルの場合 C や Y :観測可能な量、「データ」 α や β :観測不可能な量、「パラメータ」. - PowerPoint PPT Presentation
Citation preview

【小暮研究会2】 「ベイズのアルゴリズム」:序章
【1,2:計量経済分析と統計分析】【 3:ベイズ定理】【 4 (1,1) :構成要素(尤度、例:回
帰関数)】
総合政策学部3年 高阪亮平
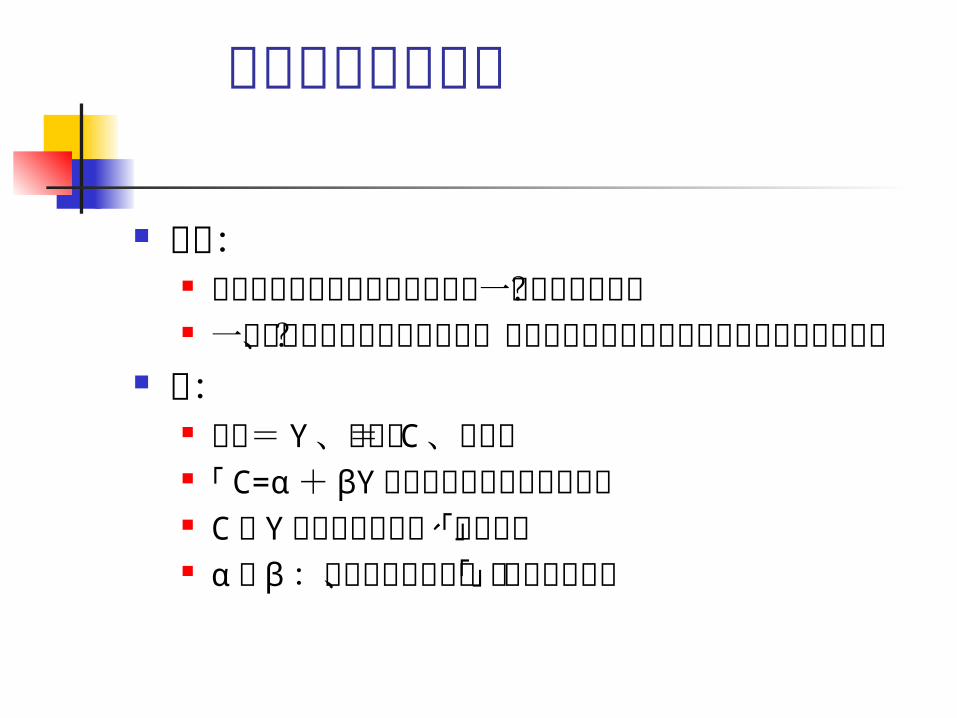
計量経済分析とは
目的: 経済モデルが実際の経済動向と一致しているか? 一致していると仮定したとき、モデルと異なる構
造になる確率がいくらか? 例:
消費= Y 、収入= C 、とした 「 C=α + βY 」という経済モデルの場合 C や Y :観測可能な量、「データ」 α や β :観測不可能な量、「パラメータ」

計量経済分析(従来の手法とベイズの違
い) 従来の手法
α や β についてデータを用いて「一つの最も正しい値」を求
める。
ベイズの手法 α や β についてデータを用いて「その確率分布」を求める。
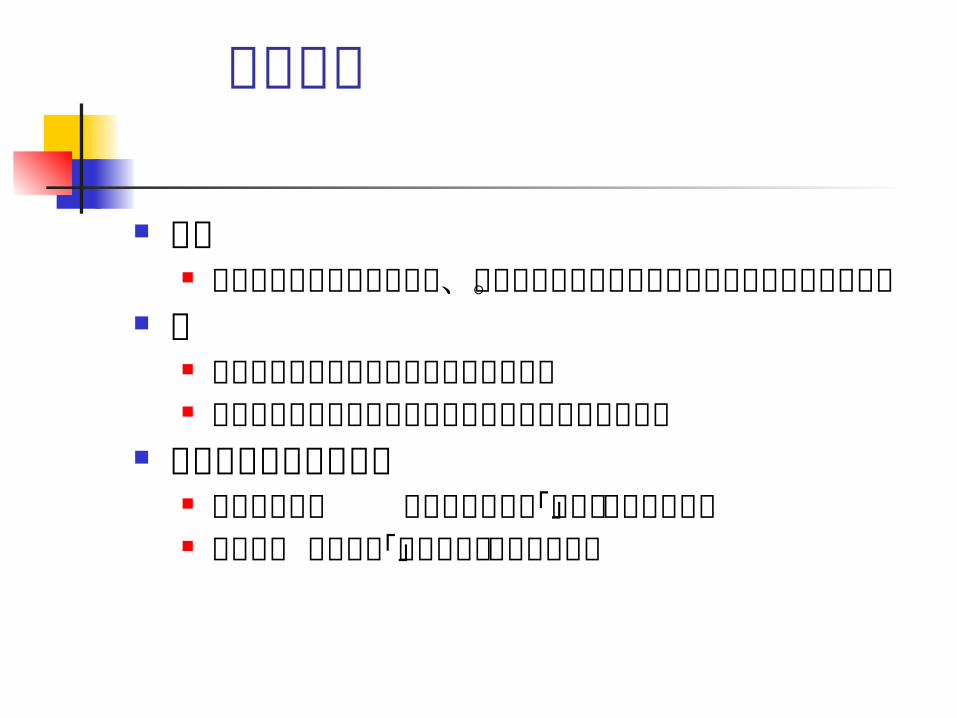
統計分析
目的 膨大で複雑な数値データを、要約してわかりやすく
理解できる形にすること。 例
平均や標準偏差や傾きや回帰直線の計算 散布図やヒストグラムやカーネル平滑化などの視覚
化 計量経済分析との違い
計量経済分析 :データ同士の「関連」の分析を重視
統計分析 :データ「そのもの」の分析を重視
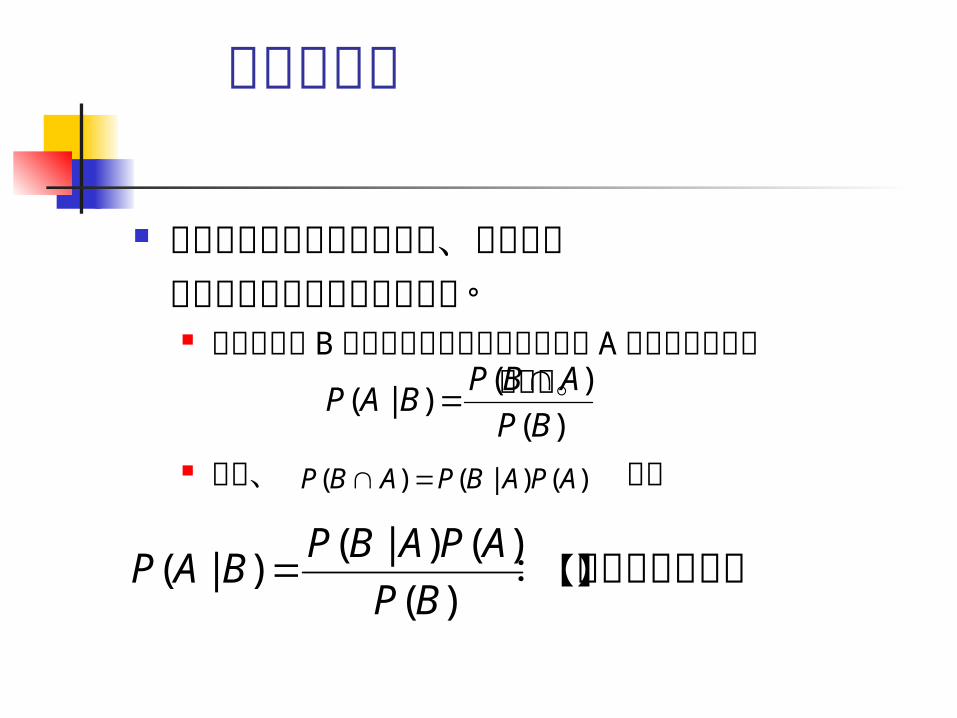
ベイズ定理
ベイジアン計量経済学では、例外なく以下の定理を基本としている。 条件付確率 B が起こったという条件の下で A が起
きる確率は である。
また、 より)(
)()|(
BP
ABPBAP
)()|()( APABPABP
:【ベイズの定理】)(
)()|()|(
BP
APABPBAP
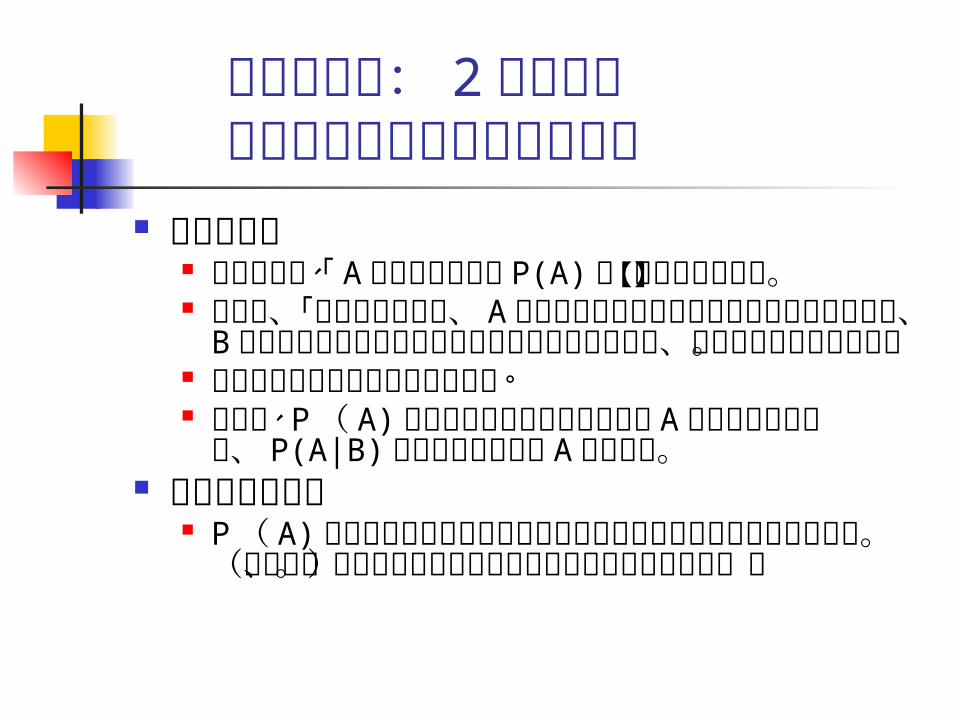
ベイズ定理: 2 つの疑問解釈の問題と適用範囲の問題
確率の解釈 ベイズでは、「 A が起きる確率」 P(A) を【主観的
に】扱う。 つまり、「このデータより、 A という事象はめったに
起きることではないが、 B という事象はよく起きます」ということによって、計量経済分析が行える。
ベイズ定理はその考えを操作する。 つまり、 P ( A) によって主観的に与えられた A につ
いての考えを、 P(A|B) によって別の考え A に変わる。 定理の適用範囲
P ( A) は多くの人が直感的に理解している可能性のあるもののみ扱う。(つまり、月が生チーズでできている確率はないとする。)

推論のためのベイズ定理の利用法
例:( θ =( α,β )) 構造 A では、 C=10+0.9Y ( θ1 =( 10,0.9 )): A 構造 B では、 C=Y ( θ2 =( 0,1 )): B
あなたは、双方の構造は等確率で発生と「とりあえず」仮定( P(A)=P(B)=0.5 )
そのうえで、どちらか片方が正しいと仮定した上での、そのモデルが正しい確率を測定する。 構造 A のとき、その構造がデータどおりの確率 0.1 構造 B のとき、その構造がデータどおりの確率 0.6

推論のためのベイズ定理の利用法
このとき、 P ( E|A )= 0.1 、 P ( E|B )= 0.6 より P(E) = P(E|A)P(A)+P(E|B)P(B)=0.35
またベイズ定理より P(A|E)=1/7 P(B|E)=6/7
となり、 B のほうが A より 6 倍起こりやすいということが、数学的に帰結できる。
(主観による)事前確率 P(A) ↓←(実験や調査による証
拠) (修正された)事後確率 P(A|E)
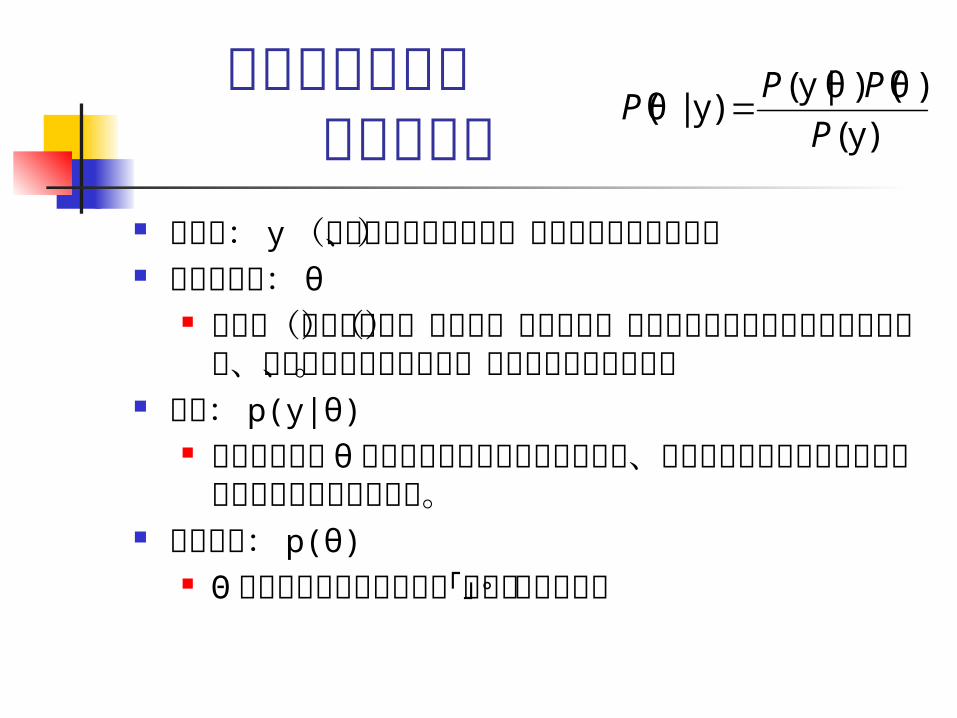
データ: y (観測される前は未知、された後は既知の値)
パラメータ: θ 後述の(証拠による)尤度や(主観的な)事前分布に
よって値が変わるものの、データが観測される前、後において未知の値。
尤度: p(y|θ) パラメータが θ によって特定の値をとったとき、
データがどのように見えるかについての予測を与える。
事前分布: p(θ) Θ のとりうる値についての「考え」を与える。
計量経済モデルの構成要素 )y(
)()|y()y|(
P
PPP
θθθ

ベイズ定理の構成要素
右辺の分母 P(y) は、 θ を含んでいないと見ることができるため、 θ の推定のために無視すると
P(θ|y)∝P(y|θ)P(θ) (∝ :比例するという意味 )
つまり、尤度(関数): P(y|θ) と、事前確率(密度関数) P(θ) をかけ合わせて、事後分布 P(θ|y) を得ると理解してよい。
)y(
)()|y()y|(
P
PPP
θθθ

ベイズのアルゴリズム1. モデルを確率分布の集まりとして
定式化。2. θ についての「あなたの考え」から、
事前確率を構築する。3. データを収集し、ステップ 1 で設
定した分布の集まりに加える。4. ベイズの定理から、 θ についての
「新たな考え」を計算する。 5. モデルを評価する。
: p ( θ )
: p ( y|θ )
: p ( θ|y ) )y(
)()|y()y|(
P
PPP
θθθ

尤度: p(y|θ)の性質
例えば(回帰モデル) 消費= Y 、収入= C 、とした 「 C=α + βY 」という経済モデルの場合
Y と C に実際の観測値をあてはめ、 β の関数としたものが、【尤度】である。
)( /
))(2/(exp{),;(
2
11
22
定値回帰直線の最小二乗推ΣΣ
βτΣβ
i
n
iii
n
iyycbfor
byycl i

尤度: p(y|θ) に関する例:回帰
回帰関数:2つの確率変数の同時分布 変数が X と Y ならば、 y の関数として E(X|Y
=y) 、x の関数として E(Y|X=x) と表現。 例:両親の身長と子供の身長 両親たちの特定の身長 X=x における子供たちの
平均身長 E(Y|X=x) を計算してプロット
その関係を1次の式、線形のグラフにしたものが、従来の線形回帰分析

尤度: p(y|θ) に関する例:回帰 経済モデルを単純に c=βy と表現されるとき。 これを c と y について、平均 βy であるランダムな正
規分布を与えたときの c の値がわかるようにする。 条件付き分布の精度を τ と定義し、 c と y が独立で n
個の c の値の同時確率分布は、それらに対応する y の値が与えられた上で
1行目右辺は、確率変数の正規密度関数、その値がc、平均が βy 、分散が 1/τ 。確率の積という形で表現。
2行目は掛け算の項を省く。「分布のカーネル」と呼ぶ。
n
iii
n
iii
yc
ycycp
1
2
1
22/1
})()2/(exp{
}))(2/(exp{)2/(),|(
βτ
βτπτβ

尤度: p(y|θ) とシミュレーション(1)回帰モデルのための乱数生成
「 C=βY 」という経済モデルの場合 1 : データ数 n 、傾き β 、モデルの条件付分布の精
度 τ の値を選択。 2 : n 個の個数分 10~20 までの一様分布を発生さ
せ y に代入。 3 :正規変量(平均 βyi, 分散 1/τ )の n 個の独立し
た実現値を発生。
> n<-50;beta<-0.9;tau<-1> y<-runif(n,10,20)> consump<-rnorm(n,beta*y,1/sqrt(tau))

尤度: p(y|θ) とシミュレーション(2)尤度関数のプロット
1:最小二乗推定値 bの計算 2: β の値の範囲(点がプロットされる範囲)の
選択(手動で試行錯誤)
> b<-sum(consump*y)/sum(y*y)> betavalues<-seq(0.86,0.94,length=100)
22 ))(2/(exp{),;( byycl i βτΣβ

R でのプロット プロットするためのコマンド> par(mfrow=c(1,2)) #2箇所ウインドウ> plot(y,consump,xlab="Y",ylab="C") # 横軸 y 、縦軸 c としたデータのプロット> curve(b*x,add=T) #回帰直線 c=by を上書き> plot(betavalues,dnorm(betavalues,b,
1/sqrt(tau*sum(y*y))),type="l",xlab="beta",ylab="likelihood")#尤度関数の分布のプロット
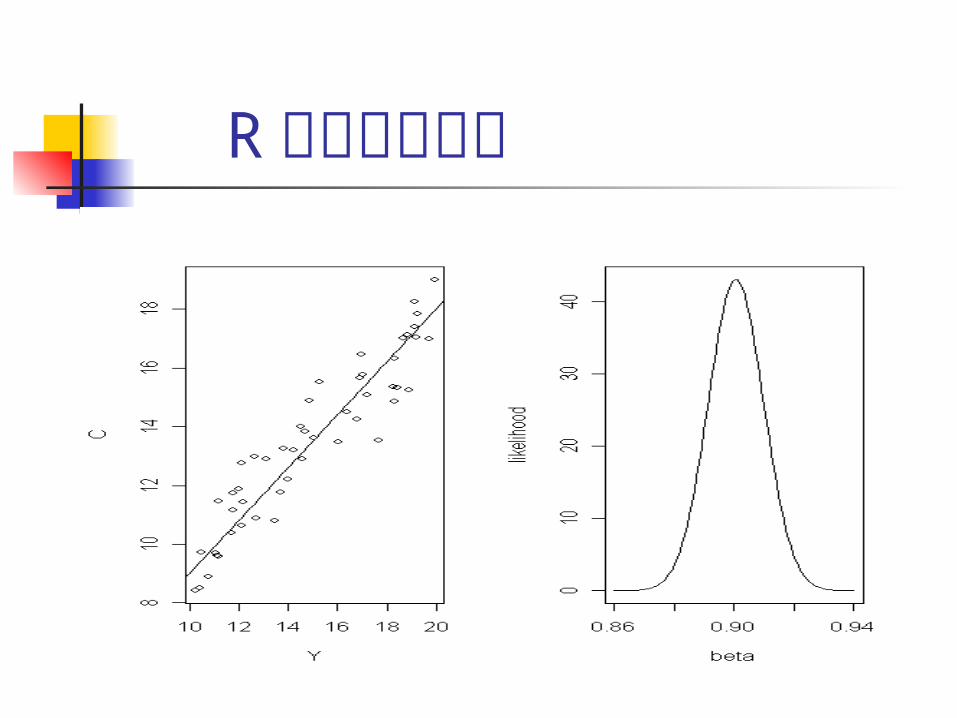
R でのプロット

尤度: p(y|θ) に関する例:時系列
T
tt
n
t
u
T
t
ttt
u
eyup
yyyyy
u
uyy
t
2
2
2
)2/(2/11
,3,21
1
})2/(exp{
)2/(),|(
:
),(
)(0
:2
2
τ
πτρ
その分布は
の同時密度関数度をρと を与えた下での尤ρータを と設定。既知、モデルのパラメτ簡略化のために、 を
ンダムウォーク)正規分布に従う。(ラτの分散の逆数、精度}は平均数列{
ρ 経済モデルその
τ

尤度: p(y|θ) に関する例:時系列
)(
/for
}))(2/(exp{),,;(
})()2/(exp{),|(
2
21
2 2
211
2
2211
2
211
T
tt
T
t
T
tttt
T
tt
T
ttt
yr
yyyr
ryyyl
yyyup
τ量、精度:中心値:最小二乗推定 尤度:
ρττρ
にρ与えた下での の関数を式全体を尤度カーネル平方和を再整理して、
ρτρ
タの同時密度はた下で観察されるデーパラメータが与えられ

尤度: p(y|θ) とシミュレーション(2)自己回帰データの生成とプロット 1: T,ρ,τ の値を設定。 2: y の値を入れるための空ベクトル生成。 3:時系列の初期値 y1 を選択。 4: y2…y Tの時系列の値を生成。
> T<-51; rho<-0.9;tau<-1> y<-rep(0,T)> y[1]<-0> for(i in 2:n){y[i]<-rho*y[i-1]+rnorm(1,0,1/sqrt(tau))}

R でのプロット プロットするためのコマンド> r<-sum(y[-1]*y[1:n-1])/sum(y[1:n-1]*y[1:n-1])#最小二乗値の計算> rhovalues <- seq(0.4,1.2,length=100)> par(mfrow=c(1,2))> plot(y, xlab="Time",ylab="Y",type="l",lwd=2)> plot(rhovalues,dnorm(rhovalues,r,1/sqrt(tau*sum(y[-
1]*y[-1]))),type="l",xlab="rho",ylab="likelihood")
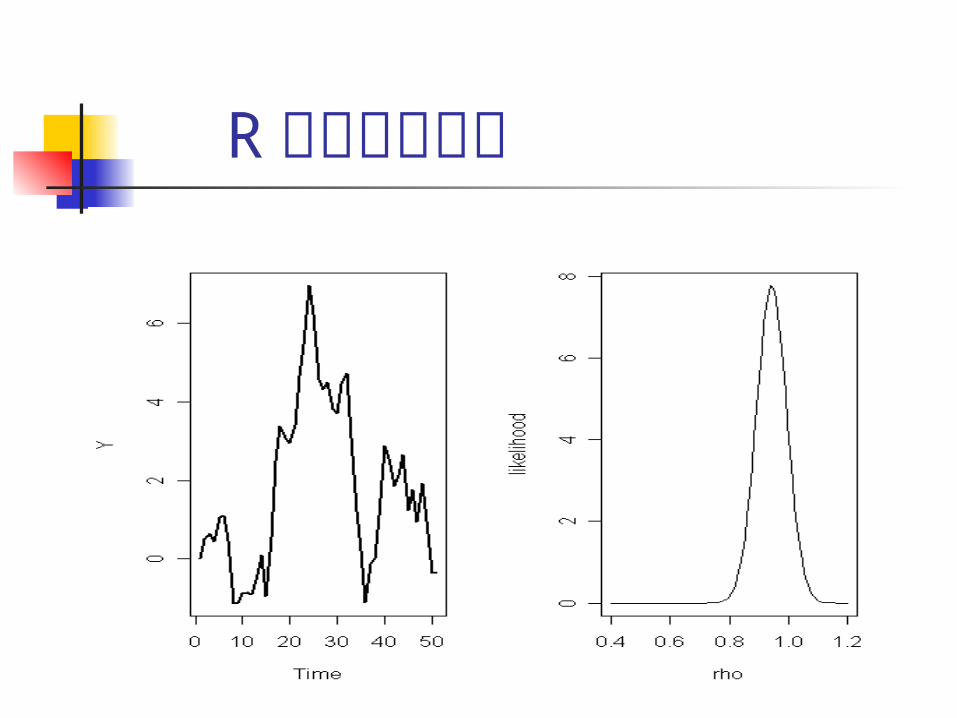
R でのプロット





























