Embed Size (px)
DESCRIPTION
第三章 栈和队列. 栈 栈的应用 队列 队列的应用. 3.1 栈 3.1.1 栈的定义及基本运算 栈 (Stack) 是限制在表的一端进行插入和删除运算的线性表,通常称插入、删除的这一端为栈顶 (Top) ,另一端为栈底 (Bottom) 。当表中没有元素时称为空栈。 - PowerPoint PPT Presentation
Citation preview
1
栈栈栈的应用栈的应用队列队列队列的应用

2
3.1 栈3.1.1 栈的定义及基本运算 栈 (Stack) 是限制在表的一端进行插入和删
除运算的线性表,通常称插入、删除的这一端为栈顶 (Top) ,另一端为栈底 (Bottom) 。当表中没有元素时称为空栈。
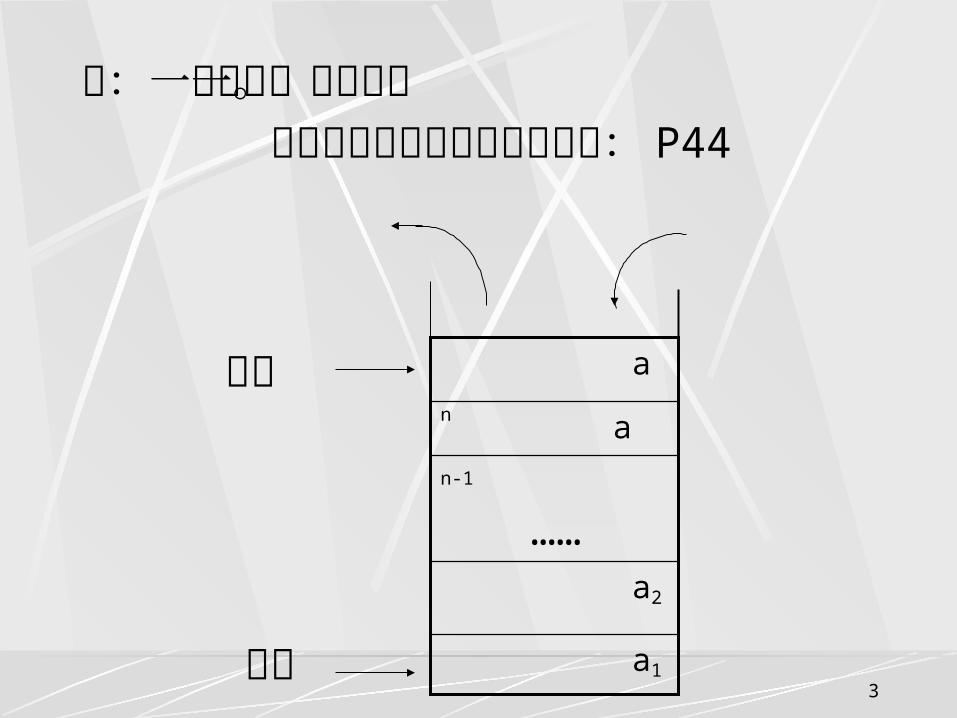
假设栈 S=(a1 , a2 , a3 ,… an) ,则 a1 称为栈底元素, an 为栈顶元素。栈中元素按 a1 ,a2 , a3 ,… an 的次序进栈,退栈的第一个元素应为栈顶元素。换句话说,栈的修改是按后进先出的原则进行的。因此,栈称为后进先出表( LIFO )。
3
例:一叠书或一叠盘子。 栈的抽象数据类型的定义如下: P44
a1
a2
a n-1
a n
……
栈顶
栈底

4
3.1.2 顺序栈 由于栈是运算受限的线性表,因此线性表
的存储结构对栈也适应。 栈的顺序存储结构简称为顺序栈,它是运
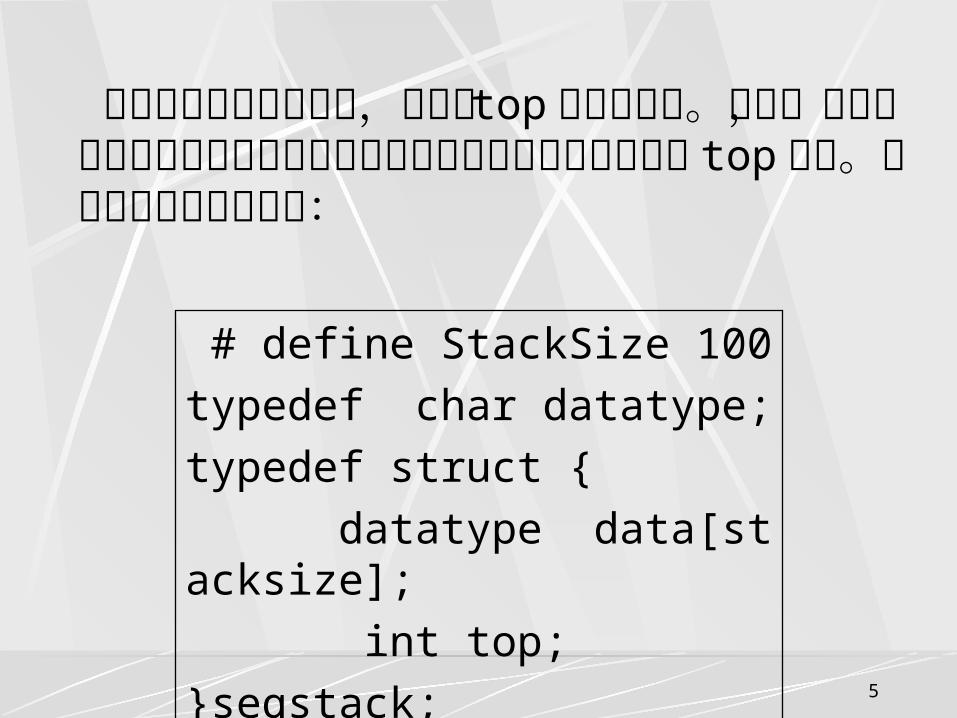
算受限的线性表。因此,可用数组来实现顺序栈。因为栈底位置是固定不变的,所以可以将栈底位置设置在数组的两端的任何一个端点;栈顶位置是随着进栈和退栈操作而变化的,故需用一个整型变量 top
5
来指示当前栈顶的位置,通常称 top 为栈顶指针。因此,顺序栈的类型定义只需将顺序表的类型定义中的长度属性改为 top 即可。顺序栈的类型定义如下:
# define StackSize 100
typedef char datatype;
typedef struct {
datatype data[stacksize];
int top;
}seqstack;
6
top6 5 4 3 2 1 0
-1
7
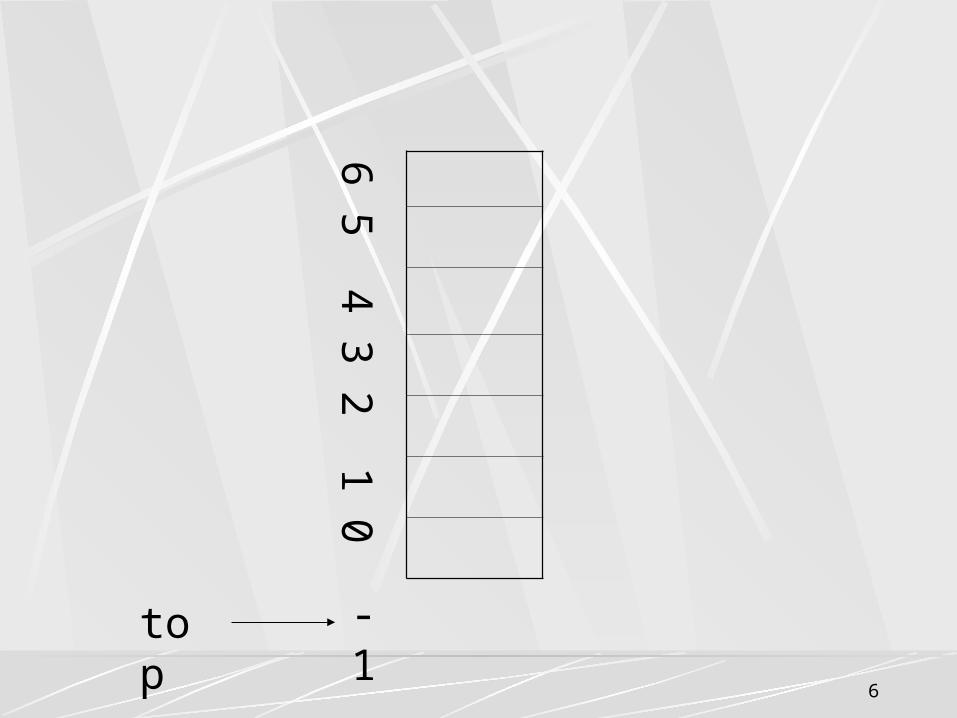
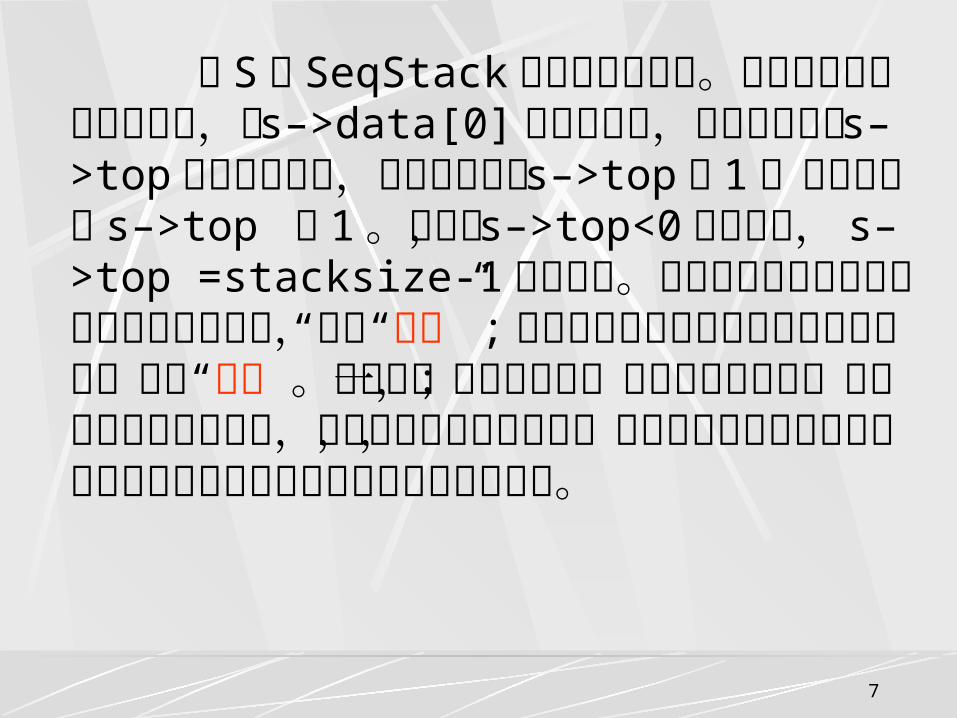
设 S 是 SeqStack 类型的指针变量。若栈底位置在向量的低端,即 s–>data[0] 是栈底元素,那么栈顶指针 s–>top 是正向增加的,即进栈时需将 s–>top 加 1 ,退栈时需将 s–>top 减 1 。因此, s–>top<0 表示空栈, s–>top =stacksize-1 表示栈满。当栈满时再做进栈运算必定产生空间溢出,简称“上溢” ; 当栈空时再做退栈运算也将产生溢出,简称“下溢”。上溢是一种出错状态,应该设法避免之;下溢则可能是正常现象,因为栈在程序中使用时,其初态或终态都是空栈,所以下溢常常用来作为程序控制转移的条件。

8
1 、置空栈 void initstack(seqstack *s)
{ s–>top=-1; }
2 、判断栈空 int stackempty(seqstack *s)
{ return(s–>top==-1); }

9
3 、判断栈满 int stackfull(seqstack *s)
{ return(s–>top==stacksize-1); }
4 、进栈 void push(seqstack *s , datatype x)
{
if (stackfull(s)) error(“stack overflow”);
s–>data[++s–>top]=x;
}

10
5 、退栈 datatype pop(seqstack *s)
{
if(stackempty(s))
error(“stack underflow”);
x=s–>data[top];
s–>top--;
return(x);
//return(s–>data[s–>top--]);
}

11
6 、取栈顶元素 Datatype stacktop(seqstack *s)
{
if(stackempty(s)
error(“stack is empty”);
return (s–>data[s–>top]);
}

12
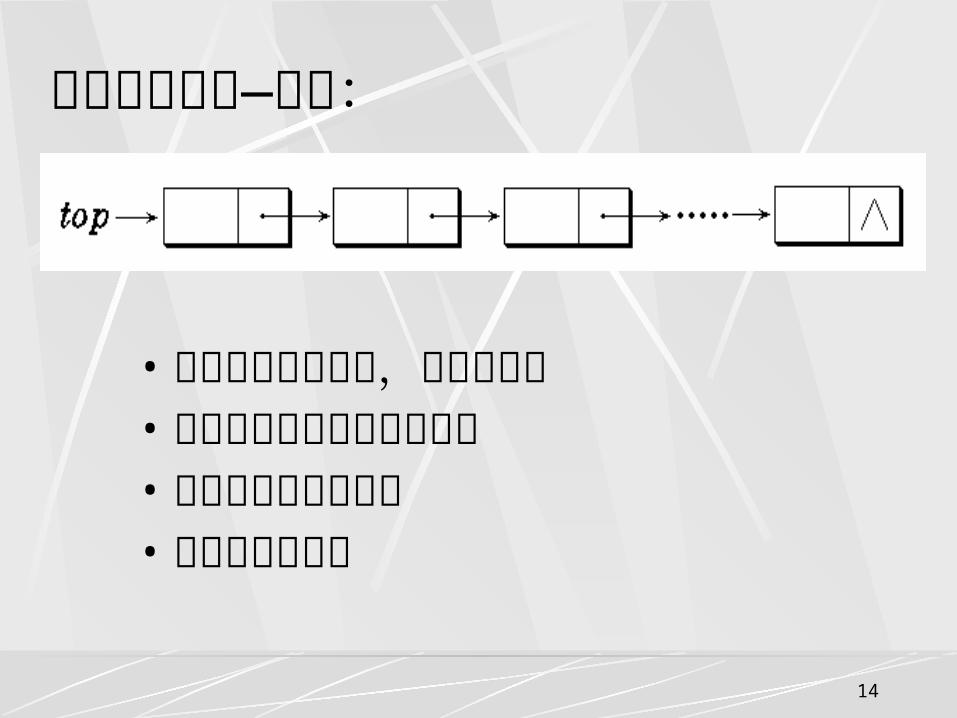
3.1.3 链栈 栈的链式存储结构称为链栈,它的运算是
受限的单链表,插入和删除操作仅限制在表头位置上进行。由于只能在链表头部进行操作,故链表没有必要像单链表那样附加头结点。栈顶指针就是链表的头指针。
链栈的类型说明如下:

13
栈的链接存储结构:
typedef int datatype;
typedef struct node
{ datatype data;
struct node *next;
} linkstack;
14
栈的链接表示—链栈:
• 链式栈无栈满问题,空间可扩充• 插入与删除仅在栈顶处执行• 链式栈的栈顶在链头• 适合于多栈操作
15
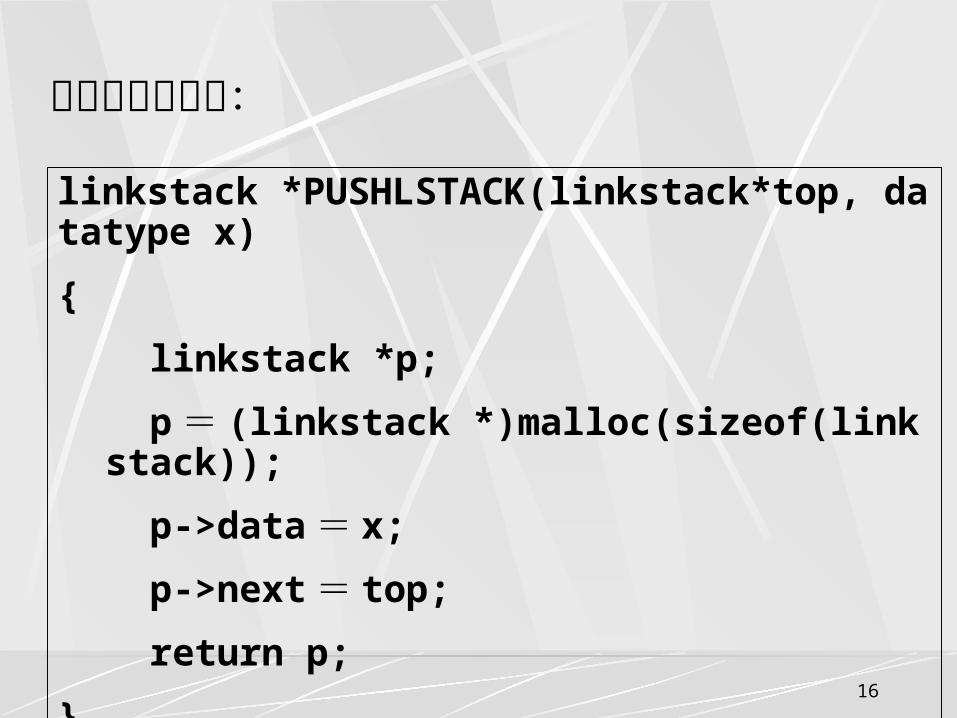
两个堆栈共享空间:
0 maxsize-1
lefttop righttop
16
链栈的进栈算法:
linkstack *PUSHLSTACK(linkstack*top, datatype x)
{
linkstack *p;
p = (linkstack *)malloc(sizeof(linkstack));
p->data = x;
p->next = top;
return p;
}
17
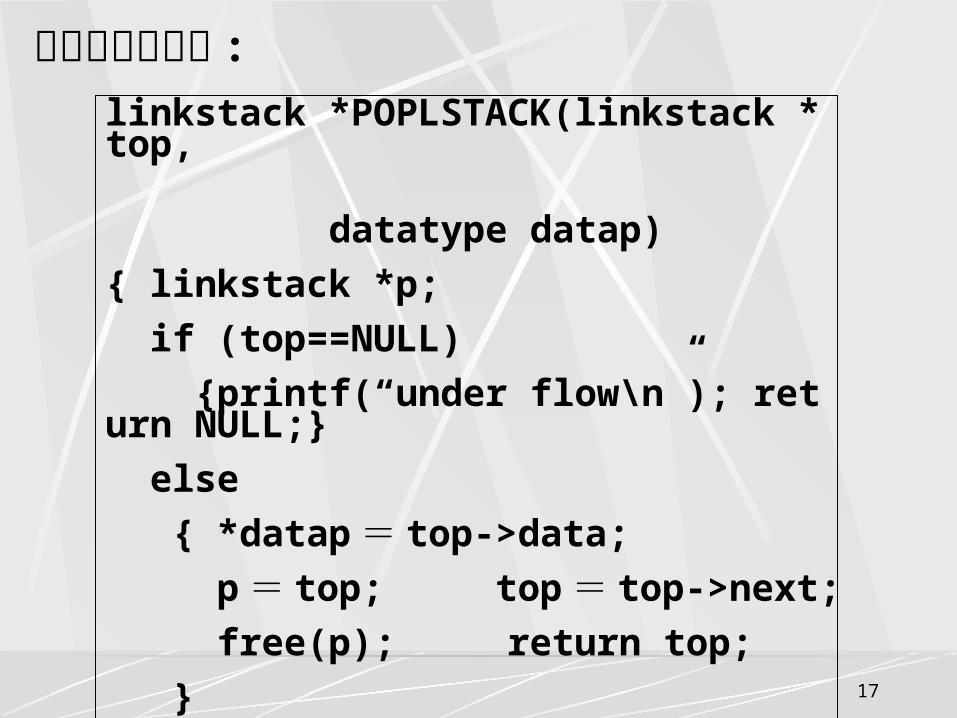
链栈的出栈算法 :
linkstack *POPLSTACK(linkstack *top,
datatype datap)
{ linkstack *p;
if (top==NULL)
{printf(“under flow\n”); return NULL;}
else
{ *datap = top->data;
p = top; top = top->next;
free(p); return top;
}
}

18
3.2 栈的应用举例 由于栈结构具有的后进先出的固有特性,致
使栈成为程序设计中常用的工具。以下是几个栈应用的例子。
栈的应用举例 -----数制转换 十进制 N 和其它进制数的转换是计算机实现
计算的基本问题 , 其解决方法很多 , 其中一个简单算法基于下列原理 :
N=(n div d)*d+n mod d ( 其中 :div为整除运算 ,mod 为求余运算 ) 例如 (1348)10=(2504)8,其运算过程如下:
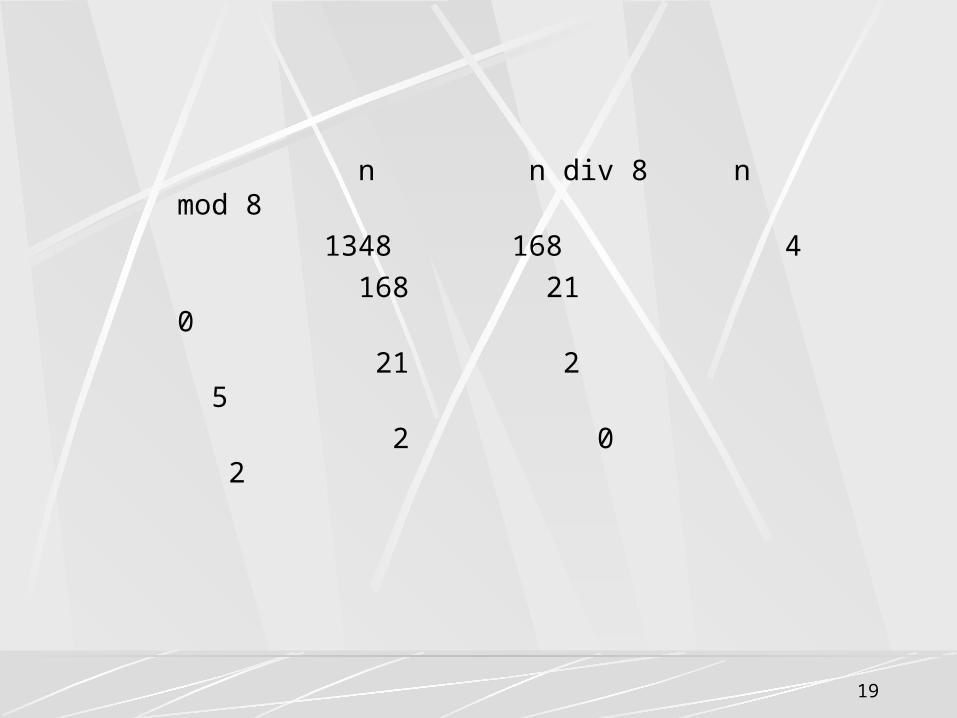
19
n n div 8 n mod 8
1348 168 4
168 21 0
21 2 5
2 0 2

20
void conversion( ){ initstack(s); scanf (“%d”,&n); while(n){ push(s,n%8); n=n/8; } while(! Stackempty(s)){ pop(s,e); printf(“%d”,e); } }

21
seqstack s;
EDIT( )
{ char c;
initstack(&s);
c = getchar();
while (c!=‘*’)
{ if (c==‘#’) POP(&s);
else if (c==‘@’) initstack(&s);
else PUSH(&s,c);
c = getchar();
}
}
输入缓冲区为一堆栈
# 为退格符, @ 为退行符 P49
输入 # ,执行退栈操作
输入 @ ,执行清栈空
输入其他,进栈
栈的应用举例--文字编辑器

22
栈的应用举例--表达式计算
中缀表达式: A + ( B – C / D) × E后缀表达式: ABCD/ - E×+
后缀表达式特点1 、与相应的中缀表达式中的操作数次序相同2 、没有括号
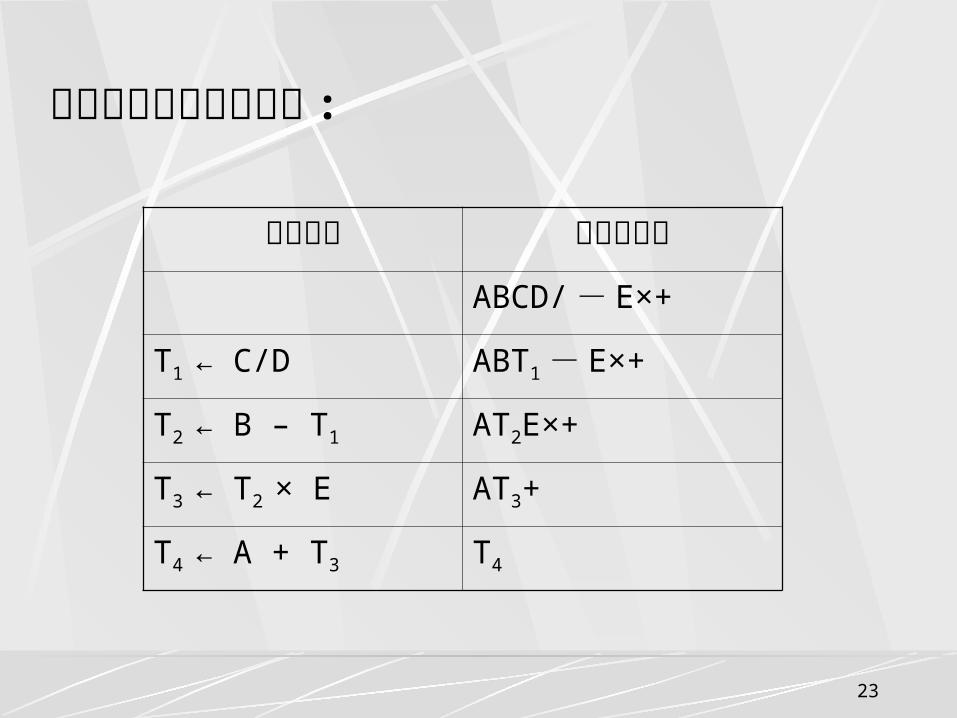
23
后缀表达式的处理过程 :
操作顺序 后缀表达式
ABCD/- E×+
T1 ← C/D ABT1- E×+
T2 ← B – T1 AT2E×+
T3 ← T2 × E AT3+
T4 ← A + T3 T4
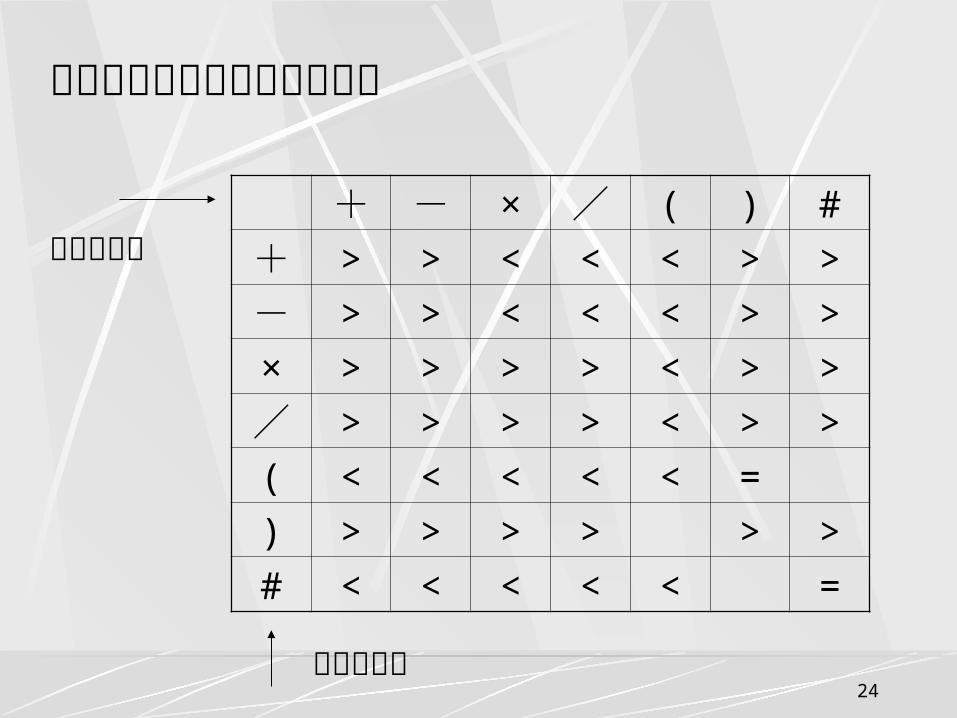
24
中缀表达式转换为后缀表达式
+ - × / ( ) #
+ > > < < < > >
- > > < < < > >
× > > > > < > >
/ > > > > < > >
( < < < < < =
) > > > > > >
# < < < < < =
当前运算符
栈顶运算符

25
步骤 中缀表达式 STACK 输出1 A+ (B- C/
D)×E##
2 + (B- C/ D)×E# # A
3 (B- C/ D)×E# # + A
4 B- C/ D)×E# # + ( A
5 - C/ D)×E# # + ( AB
6 C/ D)×E# # +(- AB
7 / D)×E# # + (- ABC
8 D)×E# # + (- / ABC
9 )×E# # + (- / ABCD

26
中缀表达式转换为后缀表达式的处理规则 :
1 、如为操作数,直接输出到队列;2 、如当前运算符高于栈顶运算符,入栈;3 、如当前运算符低于栈顶运算符,栈顶运算符退栈, 并输出到队列,当前运算符再与栈顶运算符比较;4 、如当前运算符等于栈顶运算符,且栈顶运算符为 “ (”,当前运算符为“)”,则栈顶运算符退栈, 继续读下一符号;5、如当前运算符等于栈顶运算符,且栈顶运算符为 “#” ,当前运算符也为“ #” ,则栈顶运算符退栈, 继续读下一符号;

27
步骤 中缀表达式 STACK 输出10 ×E# # + (- ABCD/
11 ×E# # + ( ABCD/ -12 ×E# # + ABCD/ -13 E# # + × ABCD/ -14 # # + × ABCD/ - E
15 # # + ABCD/ - E ×
16 # # ABCD/ - E × +

28
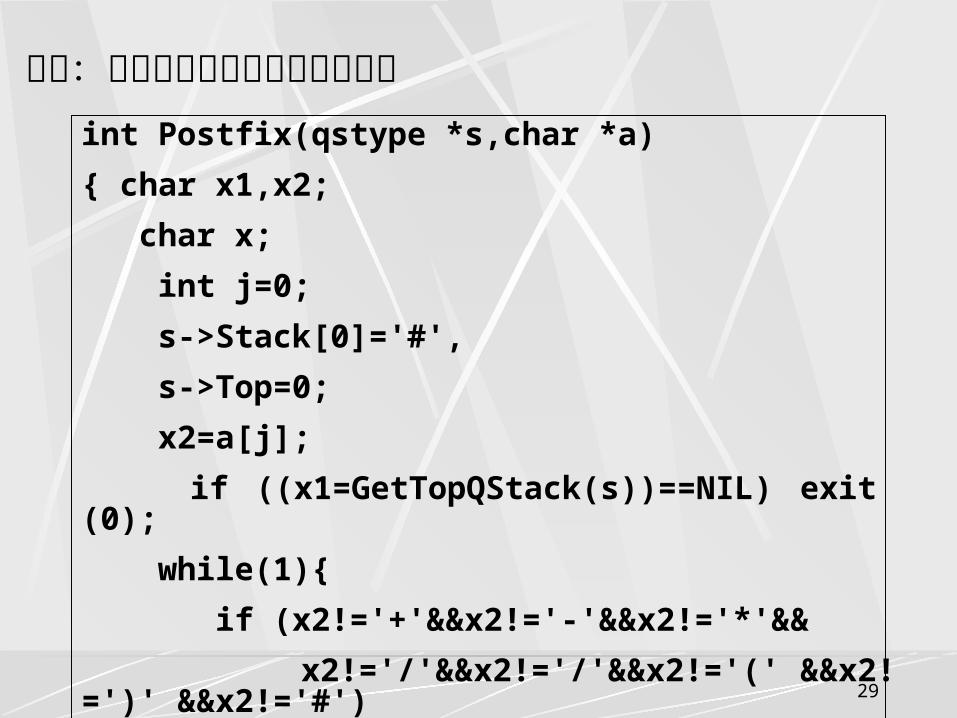
算法步骤:
设置一堆栈,将栈顶预置为 #。顺序读入中缀表达式,当读到的单词为操作数就将其输出,并等着读下一个单词;
当读到的单词为运算符就赋予 x2 ,比较 x2 与栈顶运算符 xl的优先级,若 x2 的优先级高于 xl的,将 x2 进栈,继续读下一个单词;
若 x2 的优先级低于 xl的, xl退栈并作为后缀表达式的一个单词输出,然后继续比较 x2 与新的栈顶运算符 x1 ;
若 x2 的优先级等于 xl的,且 xl为“ (” , X2 为“ )” ,则 xl退栈,然后继续读下一个单词;若 x2 的优先级等于 xl的,且 xl为 #, x2 也为 #,则算法结束
29
算法:中缀表达式变换为后缀表达式int Postfix(qstype *s,char *a)
{ char x1,x2;
char x;
int j=0;
s->Stack[0]='#',
s->Top=0;
x2=a[j];
if ((x1=GetTopQStack(s))==NIL) exit(0);
while(1){
if (x2!='+'&&x2!='-'&&x2!='*'&&
x2!='/'&&x2!='/'&&x2!='(' &&x2!=')' &&x2!='#')

30
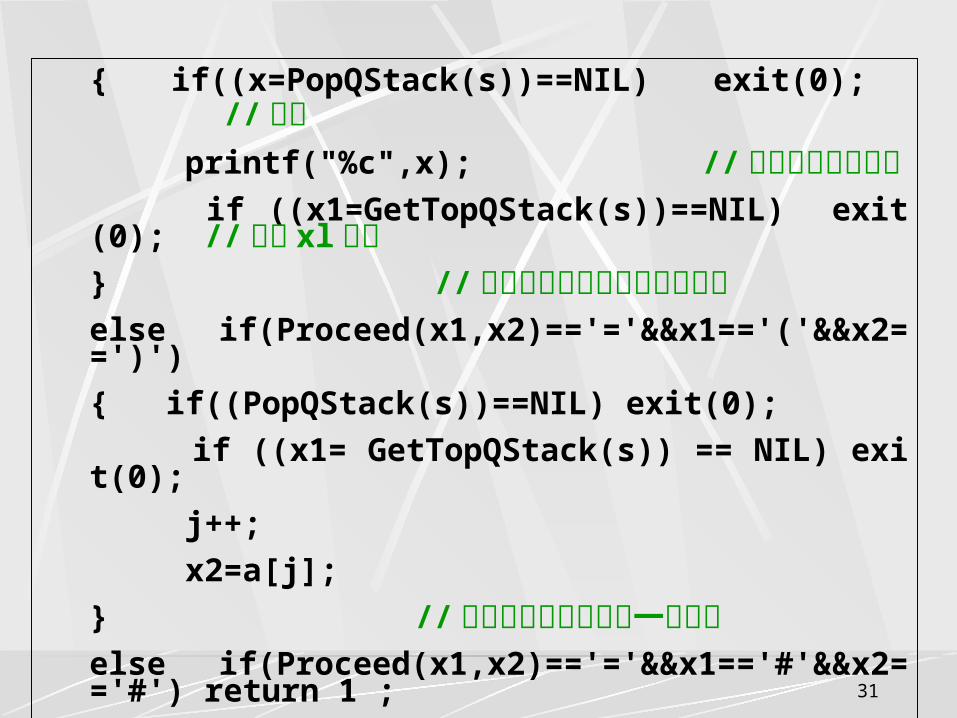
{ printf("%c",x2); // 操作数输出 j++;
x2=a[j]; // 取下一个单词} // 此种情况下 x2 读到的是操作数 else if(Proceed(x1,x2)=='<')
{ if(!PushQStack(s,x2)) exit(0); // 读到的操作符入栈 if((x1=GetTopQStack(s))==NIL) exit(0);
// 更新 xl 的值为新入栈的操作符 j++;
x2=a[j]; // 取下一个单词 } // 栈顶操作符 X1 小于读到的操作符 X2else if(Proceed(x1,x2)=='>')
31
{ if((x=PopQStack(s))==NIL) exit(0); // 退栈 printf("%c",x); // 输出原栈顶操作符 if ((x1=GetTopQStack(s))==NIL) exit(0); // 更新 xl 的值} // 栈顶操作符大于读到的操作符 else if(Proceed(x1,x2)=='='&&x1=='('&&x2==')')
{ if((PopQStack(s))==NIL) exit(0);
if ((x1= GetTopQStack(s)) == NIL) exit(0);
j++;
x2=a[j];
} // 去掉后缀表达式中的一对括号 else if(Proceed(x1,x2)=='='&&x1=='#'&&x2=='#') return 1 ;
}
}

32
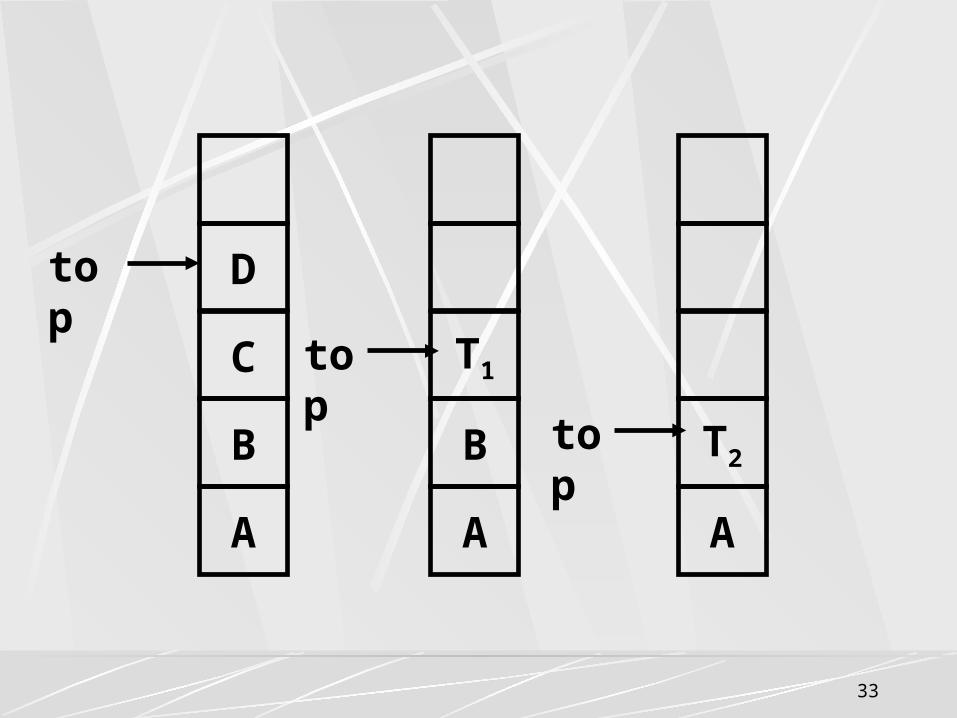
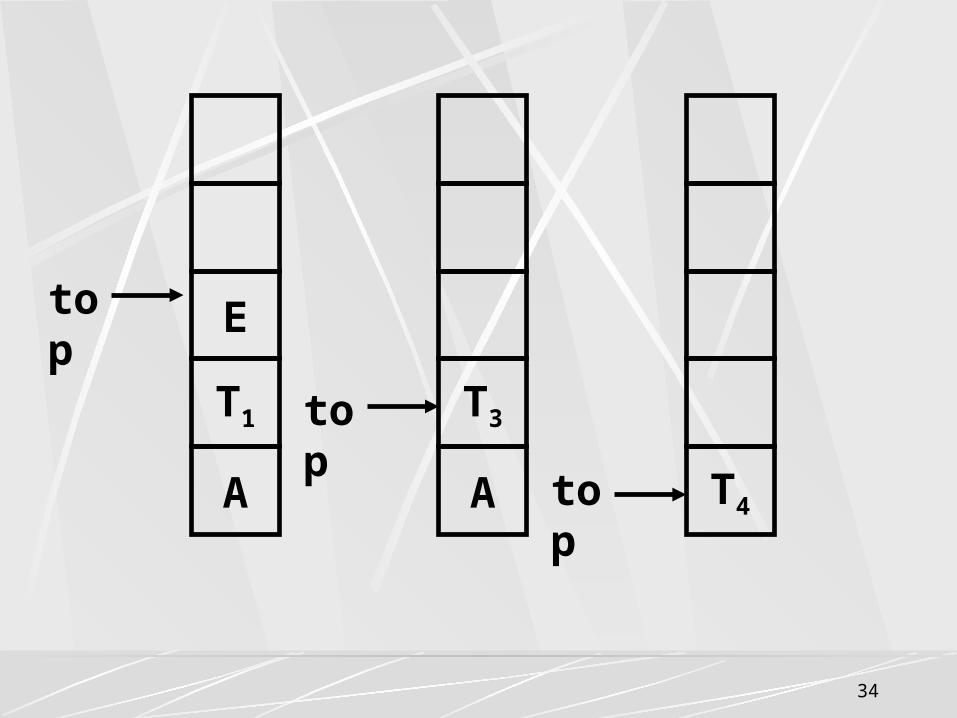
中缀表达式转换成后缀表达式的过程:A+(B-C/D)*E步骤
中缀表达式 STACK
输出 步骤
中缀表达式
STACK
输出
1 A+(B-C/D)*E#
# 9 )*E#
#+(-/
ABCD
2 +(B-C/D)*E#
# A 10 *E#
#+(-
ABCD/
3 (B-C/D)*E#
#+ A 11 *E#
#+( ABCD/-
4 B-C/D)*E#
#+( A 12 *E#
#+ ABCD-
5 -C/D)*E#
#+( AB 13 E#
#+* ABCD-
6 C/D)*E#
#+(- AB 14 #
#+* ABCD-E
7 /D)*E#
#+(- ABC 15 #
#+ ABCD-E*
8 D)*E#
#+(-/
ABC 16 #
# ABCD-E*+
33
D
C
B
A
T1
B
A
top
top
T2
A
top
34
T3
A
top E
T1
A
top
T4top
35
3.4 队列
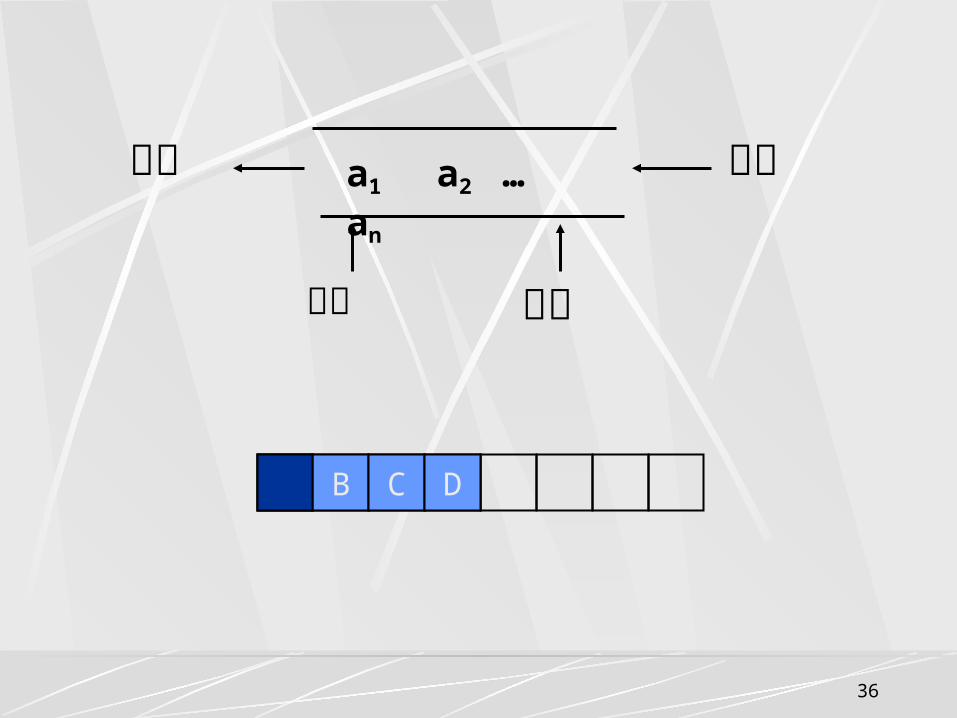
3.4.1 抽象数据类型队列的定义队列 (Queue) 是一种运算受限的线性表。
表的一端进行插入,而在另一端进行删除
队头 (front) 允许删除的一端
队尾 (rear) 允许插入的一端
先进先出 (First In First Out) 的线性表,简称 FIFO表
空队列 当队列中没有元素
36
a1 a2 … an
出队 入队
队头 队尾
A B C D

37
ADT Queue {数据对象: D= {ai | ai ElemSet, i=1,2,...,n, n≥0}∈数据关系: R1= { <ai-1,ai > | ai-1, ai D, i=2,...,n}∈约定其中 a1 端为队列头, an-1 端为队列尾
} ADT Queue
基本操作 :
Initiate(q) 初始化 Enter (q , x) 入队列 Delete(q) 出队列 Gethead(q) 取队头元素 Empty(q) 判队空否
38
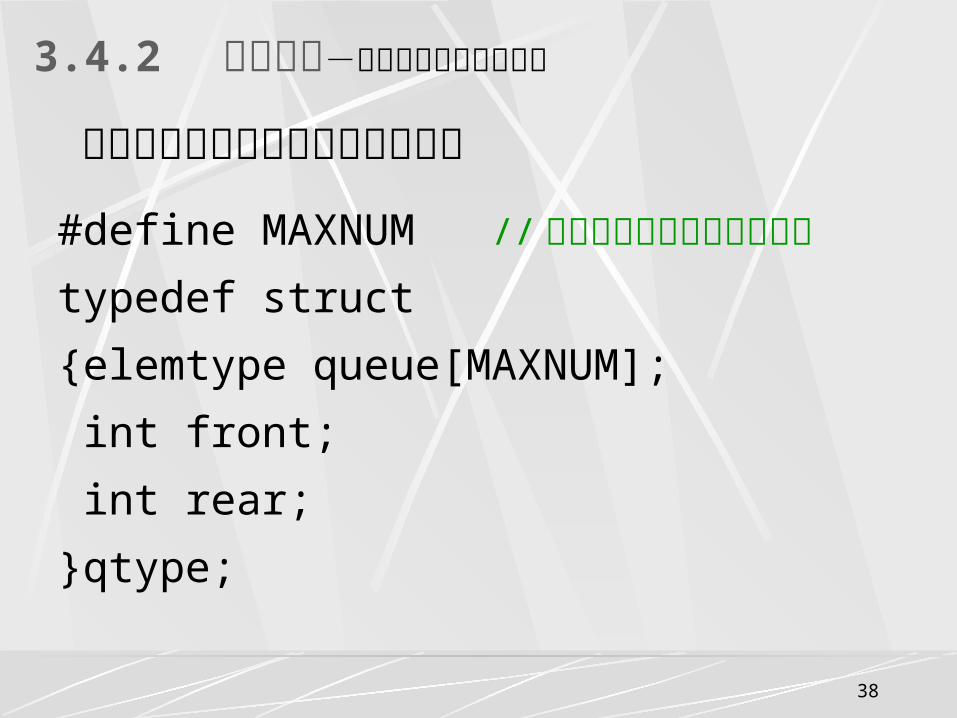
3.4.2 循环队列-队列的顺序表示和实现
队列的顺序存储结构简称顺序队列
#define MAXNUM // 队列允许存放的最大元素数
typedef struct
{elemtype queue[MAXNUM];
int front;
int rear;
}qtype;
39
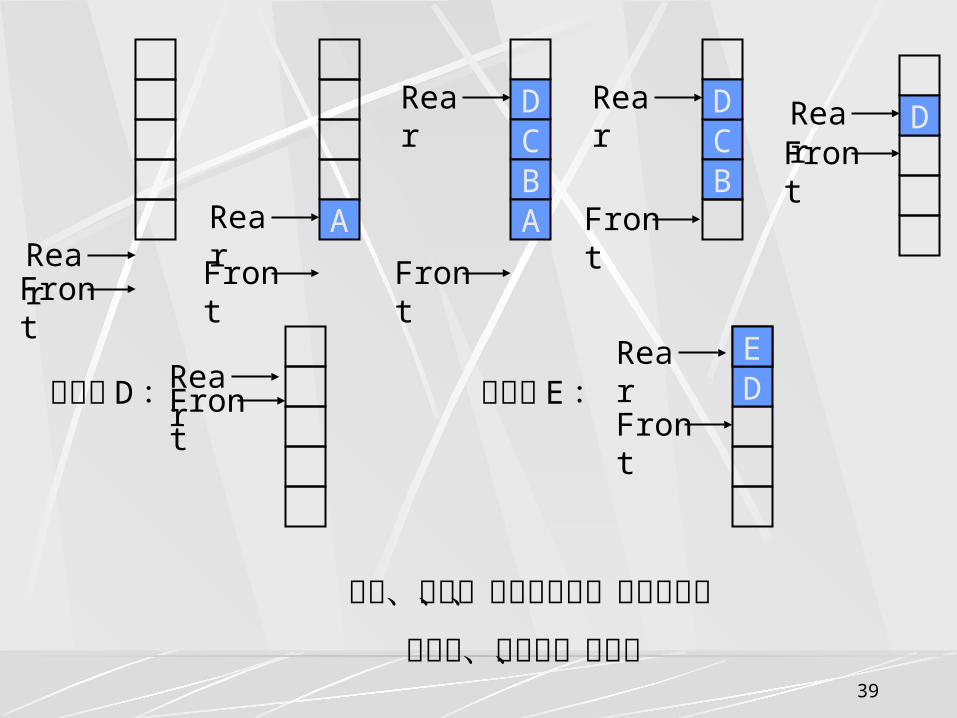
RearFront
ARear
Front
DCBA
Rear
Front
CB
DRear
Front
RearFront
队尾、队头、队尾指示器、队头指示器
空队列、进队列、出队列
DRearFront
DRear
Front
E若删除 D :
若插入 E :

40
(l) 初始化
void initiateq(qtype *q){
//用指针类型传引用调用
q->front=-1;
q->rear=-1;
}
41
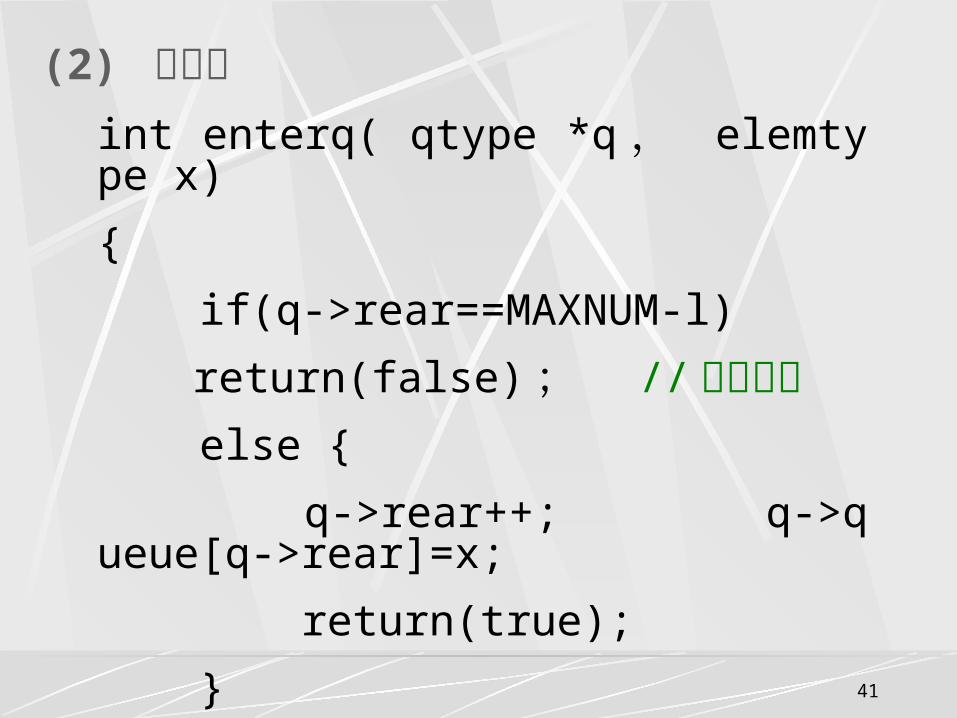
(2) 进队列 int enterq( qtype *q , elemtype x)
{
if(q->rear==MAXNUM-l)
return(false) ; // 队列已满 else {
q->rear++; q->queue[q->rear]=x;
return(true);
}
}

42
(3) 出队列 elemtype deleteq(qtype *q)
{
if(q->front==q->rear) //队列已空 return(ERR); //ERR 为 elemtype 类型常量 else{
q->front++;
return(q->queue[q->front]);
}
}

43
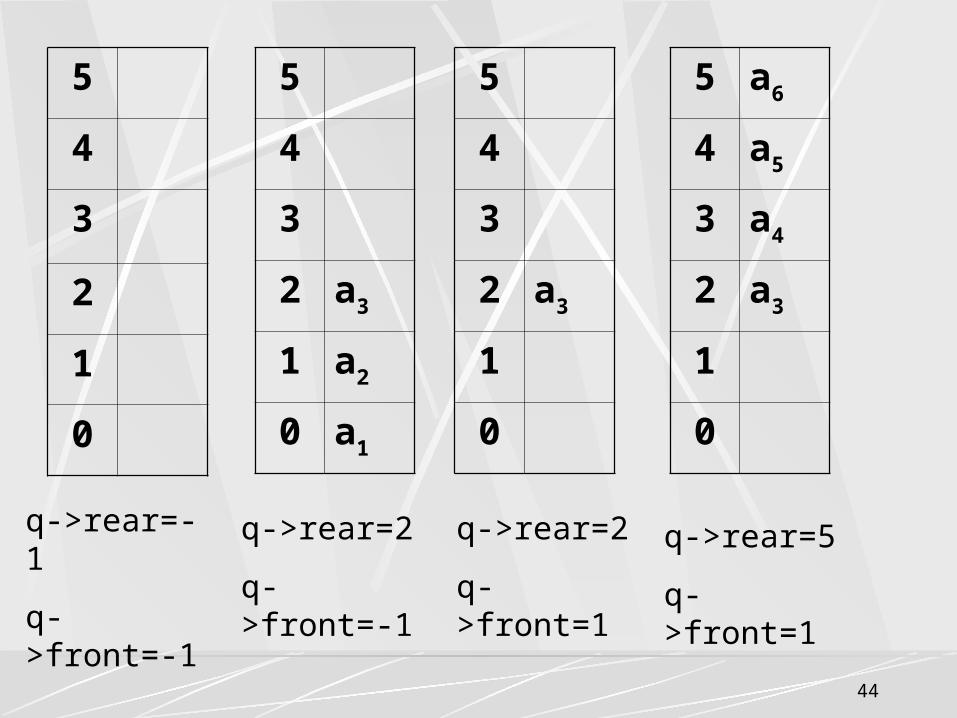
队列中亦有上溢和下溢现象。
此外,顺序队列中还存在“假上溢”现象。
因为在入队和出队的操作中,头尾指针只增加不减小,致使被删除元素的空间永远无法重新利用。
因此,尽管队列中实际的元素个数远远小于向量空间的规模,但也可能由于尾指针巳超出向量空间的上界而不能做入队操作。该现象称为假上溢。
44
5
4
3
2
1
0
q->rear=-1
q->front=-1
5
4
3
2 a3
1 a2
0 a1
5
4
3
2 a3
1
0
5 a6
4 a5
3 a4
2 a3
1
0
q->rear=2
q->front=-1
q->rear=2
q->front=1
q->rear=5
q->front=1
45
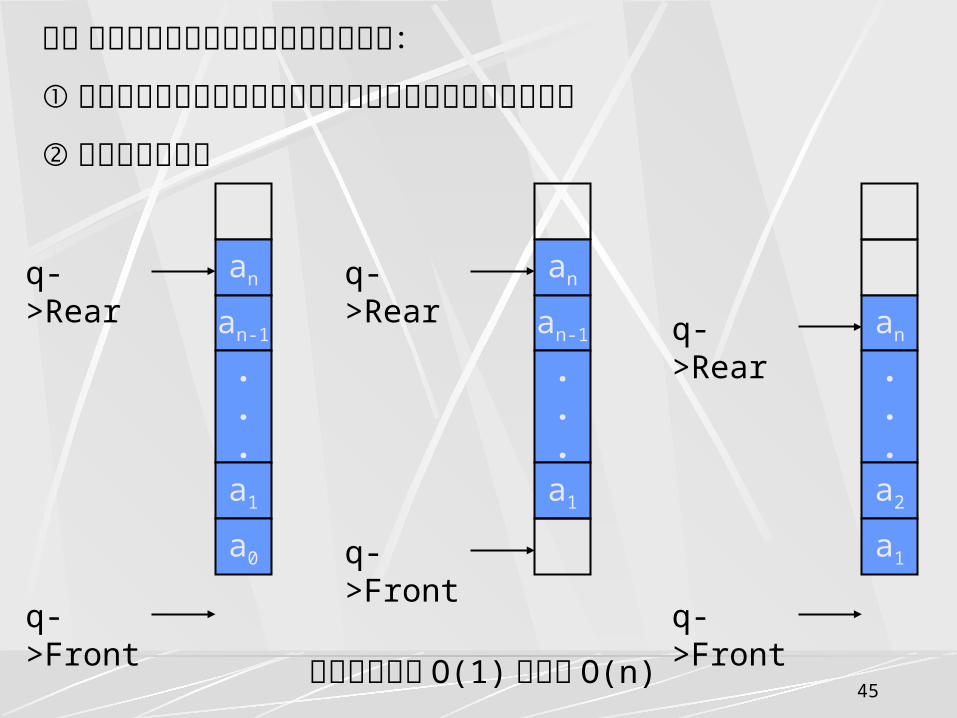
解决顺序队列假溢出问题的四种方法:
①按最大可能的进队列操作次数设置顺序队列的最大元素个数
②修改出队列算法
an
an-1
.
.
.a1
a0
q->Front
q->Rear an
an-1
.
.
.a1
q->Front
q->Rear
an
.
.
.a2
a1
q->Front
q->Rear
时间复杂度由 O(1) 增大为 O(n)
46
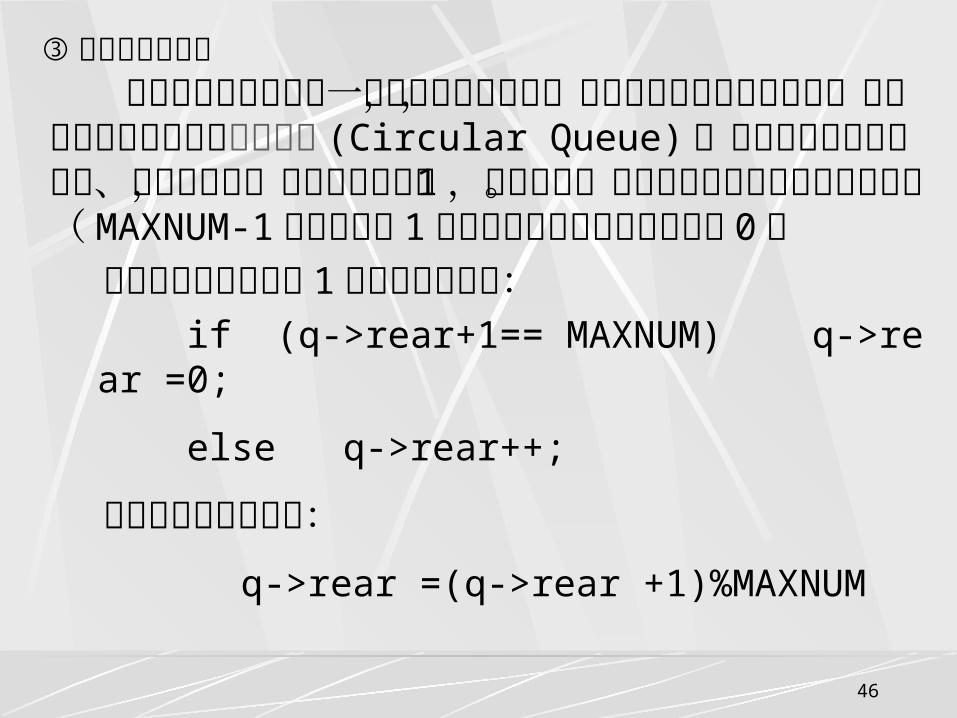
即把向量空间想象为一个首尾相接的圆环,并称这种向量为循环向量,存储在其中的队列称为循环队列(Circular Queue) 。在循环队列中进行出队、入队操作时,头尾指针仍要加 1 ,朝前移动。只不过当头尾指针指向向量上界(MAXNUM-1 )时,其加 1 操作的结果是指向向量的下界 0 。 这种循环意义下的加 1 操作可以描述为:
if (q->rear+1== MAXNUM) q->rear =0;
else q->rear++;
利用模运算可简化为:
q->rear =(q->rear +1)%MAXNUM
③修改进队列算法
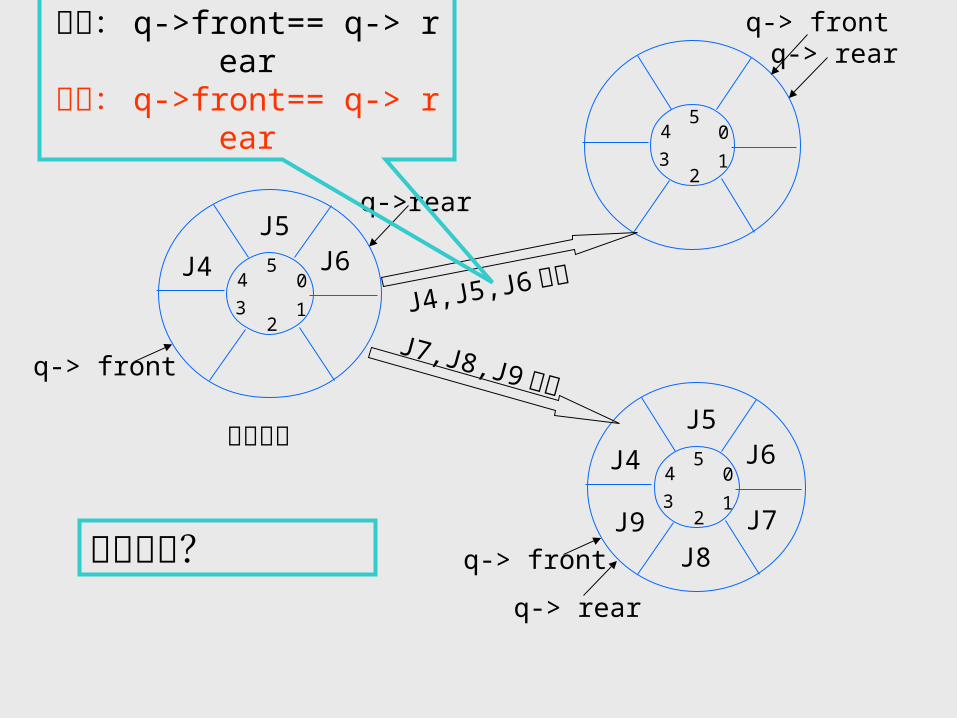
0
12
3
45
q-> rearq-> front
J4
J5J6
0
12
3
45
q-> rear
q-> front
J9J8
J7
J4
J5J6
0
12
3
45
q->rear
q-> front
初始状态
J4,J5,J6 出队
J7,J8,J9 入队
队空: q->front== q-> rear队满: q->front== q-> rear
如何解决?

48
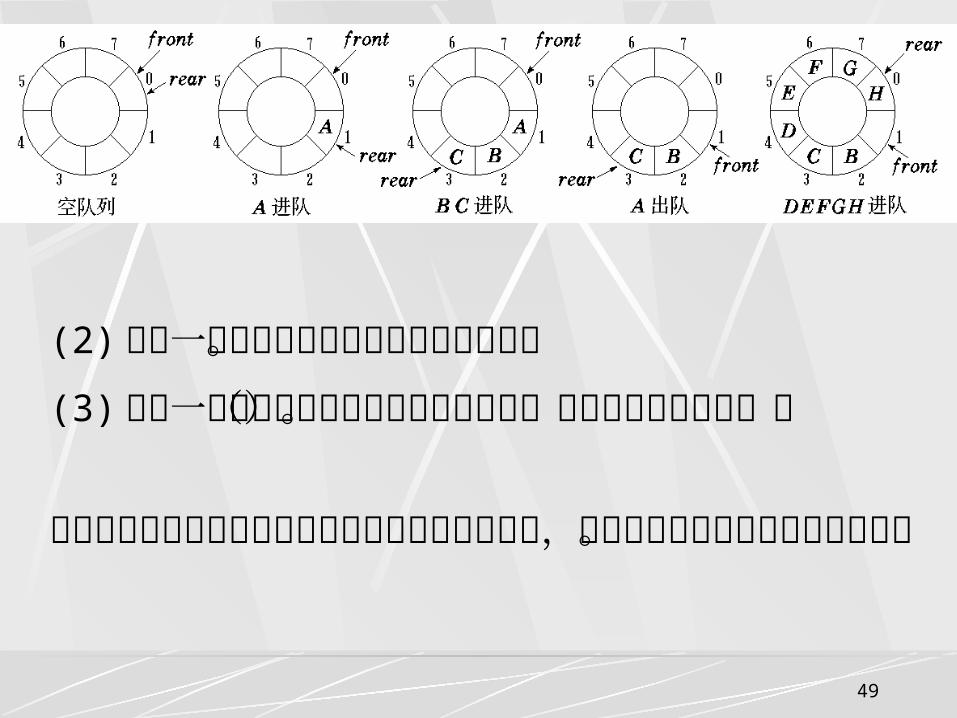
解决方案:(1)少用一个数据元素空间,以队尾指示器加 l 等于队头指示器判断队满,即队满条件为 : (q-> rear+l)%MAXNUM=q->front队空条件仍为 q->rear=q->front 。队空: q->front =q-> rear队满: q->front =(q->rear + 1) % MAXNUM入队 : q->rear = (q->rear + 1) % MAXNUM出队 : q->front = (q->front + 1) % MAXNUM求队长 :(q->rear - q->front+MAXNUM)%MAXNUM
49
(2) 另设一个标志位以区别队列是满还是空。
(3) 使用一个计数器记录队列中元素的总数(实际上是队列长度)。
我们用第三种方法实现循环队列上的六种基本操作,为此先给出循环队列的类型定义。

50
#define MAXNUM 100
typedef char elemtype;
typedef struct{
int front;
int rear;
int count;
elemtype data[MAXNUM] ; }cirqueue;
循环队列的进队列和出队列算法如下:

51
( 1 )置空队 void initqueue(cirqueue *q){
q–>front=q–>rear=-1;
q–>count=0;
}( 2 )判断队空 int queueempty(cirqueue *q) {
return q–>count==0;
}
( 3 )判断队满 int queuefull(cirqueue *q){
return q–>count== MAXNUM -1;
}

52
( 4 )入队 void enqueue(cirqueue *q, elemtype x) {
if(queuefull(q))
{printf(“queue overflow”);
return;}
q–>count++;
q–>rear=(q–>rear+1)%MAXNUM;
q–>data[q–>rear]=x;
}

53
( 5 )出队 elemtype dequeue(cirqueue *q) {
if(queueempty(q)){
printf(“queue underflow”);
return(ERR);
}
q–>count--;
q–>front=(q–>front+1)%MAXNUM;
return q–>data[q–>front];
}

54
( 6 )取头元素 elemtype queuefront(cirqueue *q)
{
if (queueempty(q)){
printf(“queue is empty.”);
return(ERR);
}
return q–>data[q–>front+1];
}

55
3.4.3 链队列
队列的链式存储结构简称为链队列,它是限制仅在表头删除和表尾插入的单链表。显然仅有单链表的头指针不便于在表尾做插入操作,为此再增加一个尾指针,指向链表的最后一个结点。于是,一个链队列由头指针和尾指针唯一确定。
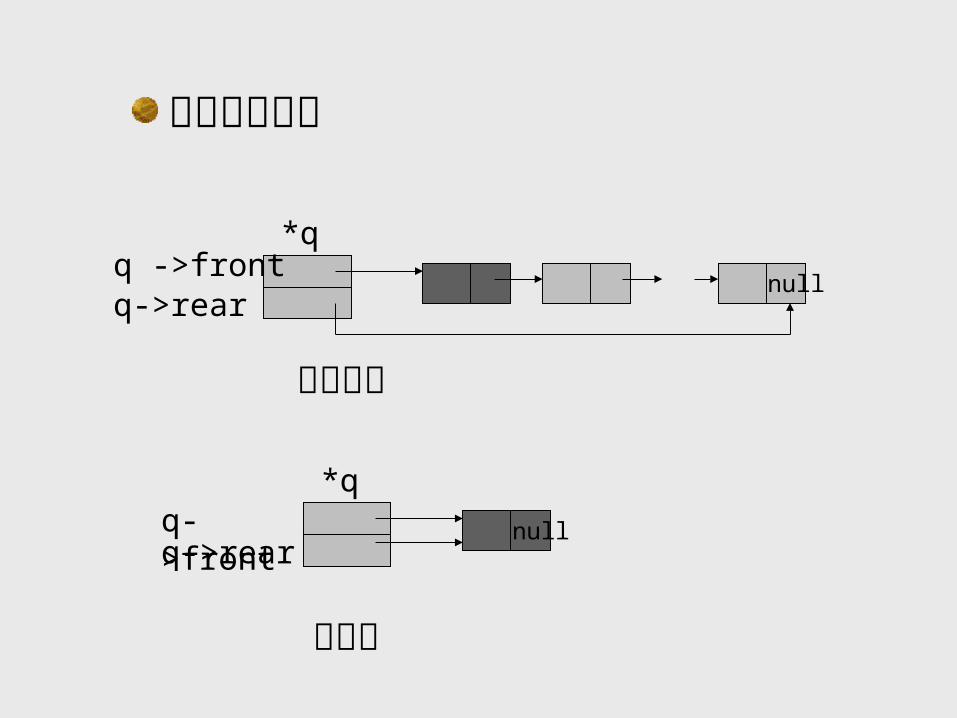
null
*qq ->frontq->rear
非空队列
q->frontq->rear
null
空队列
*q
链队列示意图

57
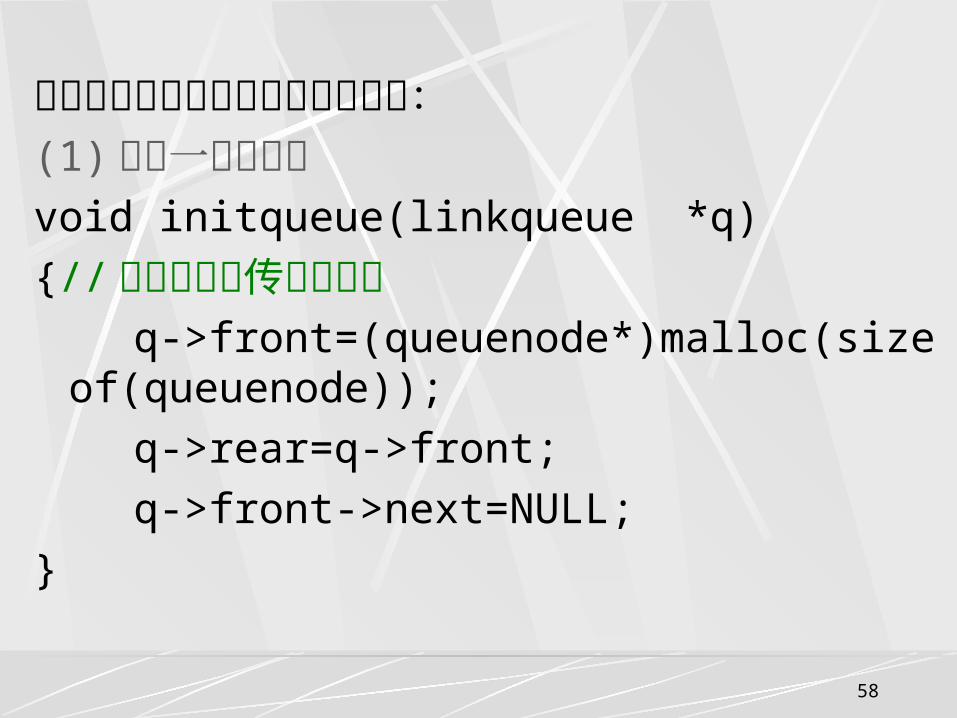
和顺序队列类似,我们也是将这两个指针封装在一起,将链和顺序队列类似,我们也是将这两个指针封装在一起,将链队列的类型队列的类型 LinkQueue 定义为一个结构类型:定义为一个结构类型:
typedef struct queuenode{
elemtype data;
struct queuenode *next;
}queuenode;
typedef struct{
queuenode *front;
queuenode *rear;
}linkqueue;
58
下面给出链队列上实现的基本运算:(1) 构造一个空队列void initqueue(linkqueue *q)
{// 用指针类型传引用调用 q->front=(queuenode*)malloc(sizeof(queuenode));
q->rear=q->front;
q->front->next=NULL;
}

q->frontq ->rear
null
置队空*q

60
(2)队列的判空:
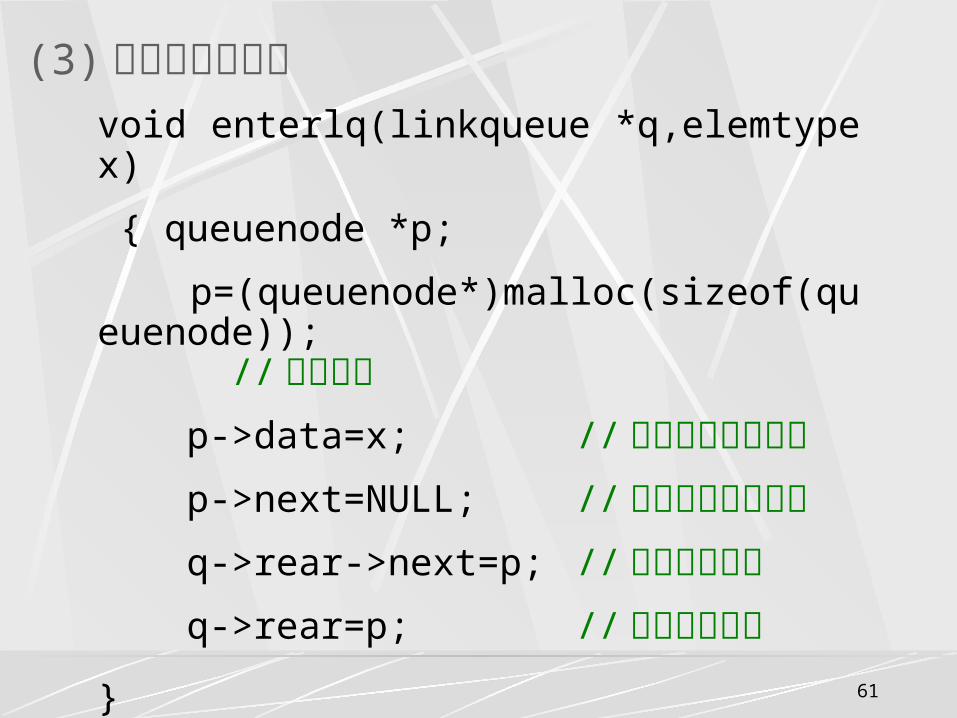
int queueempty(linkqueue *q)
{
return (q->front->next= =NULL &&
q->rear->next= =NULL);
}
61
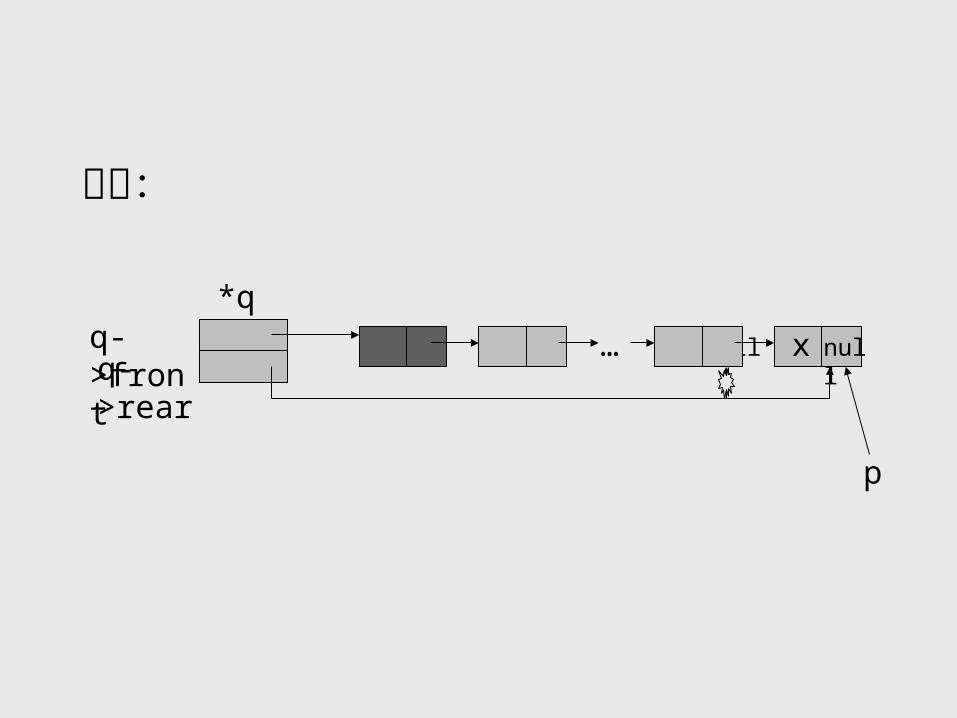
(3) 进队列操作算法 void enterlq(linkqueue *q,elemtype x)
{ queuenode *p;
p=(queuenode*)malloc(sizeof(queuenode)); // 申请结点 p->data=x; // 新结点数据域赋值 p->next=NULL; // 新结点指针域赋值 q->rear->next=p; //链在尾结点后 q->rear=p; //修改队尾指针
}
… null
*qq->frontq->rear
入队:
x null
p
63
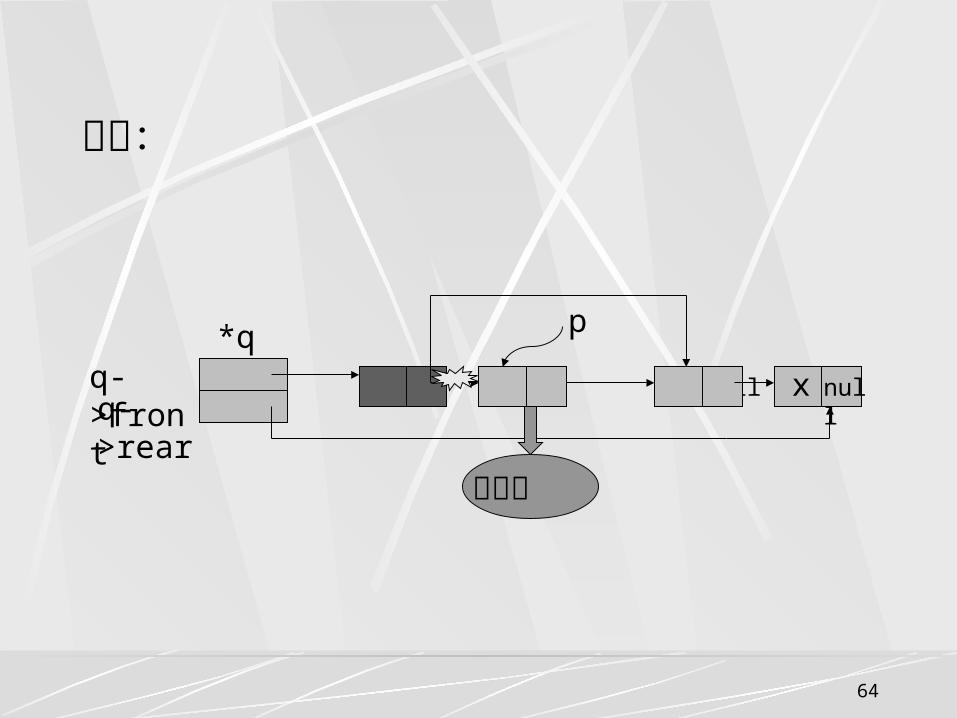
(4) 出队列操作算法elemtype deletelq(linkqueue *q)
{
queuenode *p;
elemtype x ; if (q->front->next==NULL) return(NUIL); //队列空 else {p=q->front->next; //暂存原队头指针 q->front->next=p->next; // 删除队头元素 x=p->data; //暂存原队头元素 free(p); //释放原队头结点空间 return(x); //返回原队头元素 }
}
64
null
*q
q->rearx nullq->front
p
存储池
出队:

65
队列应用举例 划分子集问题问题描述:已知集合 A={a1,a2,……an} ,及集合上的关系 R={ (ai,aj) | ai,ajA, ij} ,其中 (ai,aj) 表示 ai 与 aj
间存在冲突关系。要求将 A划分成互不相交的子集 A1,A2,……Ak,(kn) ,使任何子集中的元素均无冲突关系,同时要求分子集个数尽可能少
例: A={1,2,3,4,5,6,7,8,9} R={ (2,8), (9,4), (2,9), (2,1), (2,5), (6,2), (5,9), (5,6), (5,4), (7,5), (7,6), (3,7), (6,3) } 可行的子集划分为: A1={ 1,3,4,8 } A2={ 2,7 } A3={ 5 } A4={ 6,9 }

66
课外学习看书 p44——70习题 3.3 、 3.4 、 3.12 、 3.13设计 1 、建立一链式栈,并设计 push 、 pop 算法2 、建立一循环队列,并设计入队、出队算
法





























