Embed Size (px)
Citation preview

технологии хранения и обработкибольших объёмов данныхNoSQL СУБД. Google Bigtable
Дмитрий Барашев22 апреля 2016
Computer Science Center

Этот материал распространяется под лицензией
Creative Commons”Attribution - Share Alike” 3.0
http://creativecommons.org/licenses/by-sa/3.0/us/deed.ru
сверстано в онлайн LATEX редакторе
P
a
peeriapapeeria.com

анекдот для затравки
A DBA walks into a NoSQL bar, but turns and leavesbecause he couldn’t find a table
then he walks into Google bar and finds a big table there
3/50

анекдот для затравки
A DBA walks into a NoSQL bar, but turns and leavesbecause he couldn’t find a table
then he walks into Google bar and finds a big table there
3/50

сегодня в программе
Шаблоны доступа к данным
Реляционные СУБД и модные приложения
Таксономия NoSQL
Колоночные СУБД
Bigtable
4/50

последовательный доступ
• Map-Reduce, Pregel: последовательный доступ ипакетная обработка
• Читается много, записывается много• Результат используется напрямую или подаетсяследующим звеньям, но не меняется
• Прекрасно для индексирования всего интернета
5/50

другие приложения
• Твиты, шаринги, лайки, котики, ботнеты• Много данных, постоянно добавляются именяются
• Случайный доступ к данным• Зато данные достаточно локальны
6/50

варианты хранения
• Классическая реляционная СУБД• Oracle, SQL Server, MySQL, etc.
• Модная NoSQL СУБД• MongoDB, Cassandra, HBase, etc.
7/50

классическая реляционная субд
• Заранее известная структура• Данные хранятся построчно• Отношения нормализованы и связаны друг сдругом
• ACID транзакции• SQL, позволяющий выразить очень сложныезапросы
• Архитектура, выжимающая на high-end машиневсё из сравнительно медленных дисков
Это прекрасно и часто ненужно
8/50

классическая реляционная субд
• Заранее известная структура• Данные хранятся построчно• Отношения нормализованы и связаны друг сдругом
• ACID транзакции• SQL, позволяющий выразить очень сложныезапросы
• Архитектура, выжимающая на high-end машиневсё из сравнительно медленных дисков
Это прекрасно и часто ненужно8/50

wat? это ненужно?
• Если у вас банк или ERP система то ваши данные –это ваши деньги
• Конечно же вам нужны ACID транзакции инормализация
• Но никому не интересно, появится фоточка скотиком секундой раньше или позже, и получитлайком больше или меньше
• Зато хочется чтобы сервис был доступен ифренд-лента не тупила
9/50

wat? это ненужно?
• Если у вас банк или ERP система то ваши данные –это ваши деньги
• Конечно же вам нужны ACID транзакции инормализация
• Но никому не интересно, появится фоточка скотиком секундой раньше или позже, и получитлайком больше или меньше
• Зато хочется чтобы сервис был доступен ифренд-лента не тупила
9/50

сегодня в программе
Шаблоны доступа к данным
Реляционные СУБД и модные приложения
Таксономия NoSQL
Колоночные СУБД
Bigtable
10/50

строгая схема и нормализация
• Не дублируй факты! Не допускай аномалий!НФБК! Ключи!
• Это все так – там где данные стоят денег• Но сдружить нормализованные таблицы в СУБД иобъекты в приложении непросто
• Модные приложения не хотят нормализацию ижесткую схему, они хотят ключ-значение
11/50
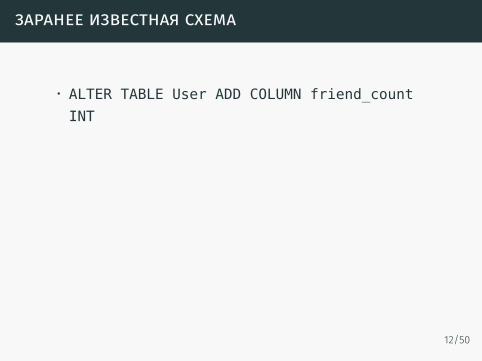
заранее известная схема
• ALTER TABLE User ADD COLUMN friend_countINT
• ALTER command denied to user ’***’ fortable ’User’
• Модные приложения не знают заранее, что импонадобится в будущем• или знают, что поле «номер паспорта» всоцсети заполнит не так много пользователейкак хотелось бы
12/50

заранее известная схема
• ALTER TABLE User ADD COLUMN friend_countINT
• ALTER command denied to user ’***’ fortable ’User’
• Модные приложения не знают заранее, что импонадобится в будущем• или знают, что поле «номер паспорта» всоцсети заполнит не так много пользователейкак хотелось бы
12/50

заранее известная схема
• ALTER TABLE User ADD COLUMN friend_countINT
• ALTER command denied to user ’***’ fortable ’User’
• Модные приложения не знают заранее, что импонадобится в будущем• или знают, что поле «номер паспорта» всоцсети заполнит не так много пользователейкак хотелось бы
12/50

сложные запросы
• 30 лет назад перед терминалом сидел оператор иписал запросы на SQL или другом языке• он мог написать любой запрос
• Сейчас пользователи смотрят френдленту, жмутлайки и посылают друг другу сообщения• запросы модного приложения не отличаютсяразнообразием
• Значит и движок общего назначения не оченьнужен
13/50

одна high-end машина
• К сожалению на IBM System Z¹ у модногоприложения нет денег
• Даже если бы они и были, модные приложения нехотят• зависеть от одного сервера• от одного датацентра• от одного континента
¹сотни процессоров, терабайты RAM, 250 000транзакций/секунду, цена от $ 1млн.
14/50

одна high-end машина
• К сожалению на IBM System Z¹ у модногоприложения нет денег
• Даже если бы они и были, модные приложения нехотят• зависеть от одного сервера• от одного датацентра• от одного континента
¹сотни процессоров, терабайты RAM, 250 000транзакций/секунду, цена от $ 1млн.
14/50

масштабируемость
• Вторую high-end машину так быстро не включишькак минимум нужен банкет
• И вообще выгодней арендовать (виртуальные)машины в ДЦ чем держать свои
• Значит СУБД должна работать на low-end железе исчитать отказ нормальным явлением• а значит реплицироваться и шардироваться
15/50

транзакционная семантика
• Как только СУБД становится распределенной,сразу возникают проблемы с ACID транзакциями идоступностью системы
• Но модному приложению неважно, когда суммалайков увеличится на 1: в тот момент когда лайкдобавлен, или через 5 минут.
• На смену ACID спешит BASE: Basic Availability, Softstate, Eventually consistent
16/50

железо вообще
• 30 лет назад оперативная память стоила дорого;процессоры были слабые
• Сейчас оперативная память измеряетсятерабайтами и у каждого в кармане по 4процессорных ядра
17/50

железо вообще
• Время позиционирования диска и время доступак RAM изменилось не сильно (20ms→ 4ms длядиска и 200ns→ 100ns для RAM)²
• Зато появилось три уровня кеша которыесущественно быстрее (≈ 1ns)
²http://www.eecs.berkeley.edu/~rcs/research/interactive_latency.html
18/50

Это было и в прошлом: OLTP vs OLAP
19/50

online transaction processing
• данные обновляются, часто параллельно• часто затрагивают одну таблицу и почти всеатрибуты
• запросы высокоселективны• ожидается низкое время отклика
20/50

online analytical processing
• read-only запросы• у сущностей много атрибутов но запросинтересуется небольшим подмножеством
• низкая селективность• всякого рода агрегирование• время выполнения запроса ожидаемо велико
21/50

В середине 90-х появились специальныеOLAP системы
22/50

сегодня в программе
Шаблоны доступа к данным
Реляционные СУБД и модные приложения
Таксономия NoSQL
Колоночные СУБД
Bigtable
23/50

модель данных
«Ключ-значение»мало чем отличается от хештаблицы, значениемобычно является строка• тыщи их. Redis из самых популярных
24/50
модель данных
«Ключ-документ»значением является документ, который можетбыть как BLOB’ом так и сложной структурой. СУБДможет поддерживать поиск по структуредокумента• яркий представитель MongoDB
24/50

физическое хранение данных
Классическое построковое хранение
• все атрибуты кортежа плотно сидят рядом водном дисковом блоке
• атомарное чтение/запись одного кортежа
25/50

физическое хранение данных
Колоночное хранение
• в один блок упаковываются значения одногои того же атрибута разных кортежей
• кортеж разнесен по нескольким блокам• доступ к одному столбцу существенноэффективнее
25/50

сегодня в программе
Шаблоны доступа к данным
Реляционные СУБД и модные приложения
Таксономия NoSQL
Колоночные СУБД
Bigtable
26/50

быстрое получение всех значений атрибута
• Пусть в кортеже в таблице Webtable 1000атрибутов.
• Атрибут site – адрес сайта страницы, атрибутvisits – число посещений сегодня Какая схемахранения выиграет при выполнении запроса?
1 −− это комментарий2 SELECT site, SUM(visits) FROM Url GROUP BY site
27/50

построчное хранение
site …+ 500 … visits …+ 500 …a.example.com … 5 …a.example.com … 15 …a.example.com … 45 …b.example.com … 3 …b.example.com … 0 …b.example.com … 4 …b.example.com … 8 …
28/50

колоночное хранение
site …+ 500 … visits …+ 500 …a.example.com … 5 …a.example.com … 15 …a.example.com … 45 …b.example.com … 3 …b.example.com … 0 …b.example.com … 4 …b.example.com … 8 …
29/50

локальность данных в кеше
• Кеш процессора не такой уж большой• При построчном хранении будет использоватьсямалая часть
• При колоночном все нужные значения идут другза другом – кеш используется эффективнее
30/50

сжатие значений
• Пусть на каждом сайте от 10 до 1000 страниц, всреднем 500.
• Пусть всего миллион сайтов• Пусть средняя длина адреса 20 байт• Сколько понадобится места для хранения адресовв построчном хранении и сколько в колоночном?
31/50

сжатие значений
• Строковое хранениеsite …+ 500 … visits …+ 500 …
a.example.com … 5 …и еще 400 страниц
a.example.com … 45 …b.example.com … 3 …
и еще 400 страницb.example.com … 8 …
• колоночное хранениеsitea.example.com+400a.example.comb.example.com+400b.example.com
32/50

сегодня в программе
Шаблоны доступа к данным
Реляционные СУБД и модные приложения
Таксономия NoSQL
Колоночные СУБД
Bigtable
33/50

bigtable
• Google, первая половина 2000-х годов• Разреженный распределенный многомерныйсортированный хранимый словарь• или, ммм... большая таблица со строчками иколонками
• Значение – неинтерпретируемый BLOB• Есть третье измерение: номер версии
row : string
column : string
time : int64
→ byte[]
34/50

кортежи таблицы
• Ключ – произвольная последовательностьсимволов
• Кортежи отсортированы в порядкелексикографического возрастания ключей
• Все множество кортежей разбито на таблеты –непересекающиеся непрерывные диапазоны
• Таблет – единица распределения работы инагрузки
• Чтение и запись значений одного кортежаатомарны
35/50

столбцы таблицы
• Семейство: группа однотипных столбцов• В таблице обычно не очень много семейств новнутри семейства может быть много столбцов
• Группы хранения (locality groups) - наборсемейств, которые обычно используются вместе
36/50

sstable
• Сортированное отображение строк в значения• Сортированный массив с разреженным индексомповерх
• SSTable создается для каждой группы хранения• SSTable доступна только на чтение• SSTable живет на GFS
37/50

жизнь системы
• Таблеты обслуживаются таблет-серверами N:1• В специальной таблице METADATA записанораспределение диапазонов ключей по таблетам итаблетов по серверам
• Расположение таблетов METADATA записано вкорневом таблете
• Расположение корневого таблета системеизвестно
• Мастер следит за состоянием таблет-серверов изанимается назначением таблетов
38/50

жизнь клиента
• Клиент читает информацию о том где искатькорневой таблет
• Обращается к корневому таблету заинформацией о METADATA
• Обращается к METADATA за информацией о томгде прописаны таблеты нужной ему строки
• Звонит соответствующему таблет-серверу• Клиенты кешируют метаинформацию
39/50

жизнь записи в таблете
• Запись производится в redo-журнал,подтверждается и записывается в изменяемыйсловарь в памяти (memtable)
• Если кортеж удаляется то записывается«могильный камень»
• Minor compaction: когда memtable становитсядостаточно большим, его замораживают исоздают набор новых SSTable
40/50

жизнь чтения в таблете
• Запрос на чтение должен объединить данные изmemtable и соответствующих SSTable
• Так как все отсортировано по ключу то этонедорогой процесс
41/50

важные события в жизни таблета
• Разделение (split)• Большое уплотнение (major compaction)
42/50

разделение таблета
43/50

равномерно распределенные ключи
44/50
неравномерно распределенные ключи
45/50

большое уплотнение
• В процессе записи постоянно создаются новыенебольшие SSTable
• Время от времени новые и старые SSTable надообъединять
• После уплотнения данные из одного диапазоналежат в одном SSTable и удалены все могильныекамни
46/50

реализации bigtable
• Закрытая в Google (торчит наружу в App Enginedatastore)
• Apache HBase• Cassandra (родом из Facebook)
47/50

spanner
• Пользователи Bigtable хотят большего: свойствреляционной СУБД одновременно с глобальнойрепликацией и доступностью
• Сейчас в Google начинает использоватьсяSpanner:• глобальная репликация• распределённые ACID транзакции• настройка размещения и репликации данныхв зависимости от нужд приложения
48/50
тем временем в реляционных субд. . .
• В PostgreSQL появляется поддержка словарей: типHSTORE
• В PostgreSQL появляется поддержка JSON• и по тестам-пузомеркам она работает лучше,чем MongoDB
• Oracle, MS SQL Server и прочие тоже не спят
49/50

занавес
• Не все большие данные обрабатываютсяконвейерно
• Не всем приложениям нужны возможности игарантии реляционных СУБД
• NoSQL СУБД осблуживают приложения с другимитребованиями
• Google Bigtable – одна из самых ранних NoSQLСУБД
• Реализаций NoSQL СУБД очень много• Традиционные СУБД тоже начинают поддерживатьNoSQL фичи
• А NoSQL СУБД начинают поддерживать ACIDтранзакции
50/50





























