Embed Size (px)
DESCRIPTION
第七章 个体遗传评定 —BLUP 法. 第一节 有关基础知识. 第二节 BLUP 育种值估计. 第三节 遗传参数估计的 REML 方法. 第一节 有关基础知识. 矩阵代数基础. 纯量、矩阵和向量 纯量 ( scalar ) 只有大小的一个数值,也称为标量、数量或元向量。 用数字或经定义的拉丁字母斜体、小写表示。 如 a 、 r 和 k 。. 矩阵 (matrix) 由一定行数和一定列数的纯量,按一定顺序排列的表。 一般用 大写粗体字母 表示。 - PowerPoint PPT Presentation
Citation preview

第七章 个体遗传评定—BLUP 法
第一节 有关基础知识第二节 BLUP 育种值估计
第三节 遗传参数估计的 REML 方法

矩阵代数基础 纯量、矩阵和向量
纯量( scalar )• 只有大小的一个数值,也称为标量、数量或元向量。• 用数字或经定义的拉丁字母斜体、小写表示。• 如 a 、 r 和 k 。
第一节 有关基础知识

矩阵 (matrix)• 由一定行数和一定列数的纯量,按一定顺序排列的表。• 一般用大写粗体字母表示。• 矩阵的阶数 (order) 或维数( dimension )是指矩阵的行数 (m) 和列数 (n) ,表示为 m n 。• 例如:

向量 (Vector)
• 仅有一列或一行的矩阵,前者称为列向量(column vector) , 后 者 称 为 行 向 量 (row
vector) 。• 通常用小写粗体字母表示。• 为区别行向量和列向量,通常在字母的右上角加一撇表示行向量,不加撇表示列向量。• 行向量的阶数为 1j ,列向量的阶数为 j1 。• 例如: 1
23
a 1 2 3a

一些特殊矩阵 方阵 (square matrix) :行数与列数相等的矩阵 , 如 An×n 。 其 他 矩 阵 称 为 直 角 阵(rectangular matrices) 。
对称阵 (symmetric matrix) :元素间满足 aij = aji 的方阵。
a b cc a bb c a
A
a b cb a bc b a
A
1 0.5 0.80.5 1 0.20.8 0.2 1
B

三角阵 (triangular matrix) :• 上三角阵:主对角线以下元素全部为 0 ,即当 j
< i 时, aij = 0 ( j <
i )
11 12 1
22 20
0 0
n
n
nn
a a aa a
a
11
21 22
1 2
0 00
n n nn
aa a
a a a
• 下三角阵:主对角线以上元素全部为 0 ,即当 j > i 时, aij = 0 ( i < j )

对角阵 (diagonal matrix) :除 i=j 时的元素(主对角线元素)外,其它元素均为零的方阵,即 aij = 0 ( j i 时)。通常可以用 Diag {aj } 表示,其中 aj 为该阵的第 i 个对角线元素。
1 0 00 1 0
0 0 1
单位矩阵 (identity matrix) :所有对角线元素为1 ,其他元素均为 0 的矩阵。
11
22
0 00 0
0 0 nn
aa
a

分块矩阵 (block matrix) :用水平和垂直虚线将矩阵分为若干小块,此时的矩阵称为分块矩阵。其中的小块称为子阵 (sub-matrix) 。
1 2
0 0 1 0 02 1 1 0 1
, , 0 0 , 0 1 01 2 2 2 0
0 0 0 0 1
A A O I
2 1 1 0 1
1 2 2 3 0
0 0 1 0 0
0 0 0 1 0
0 0 0 0 1
A1 2
1
A A
O I

分块对角阵 (block diagonal matrix) :主对角线上的子阵都为方阵,其余子阵都是零阵的分块阵。如:
11
22
kk
Α 0 00 Α 0Α
0 0 Α
稀疏矩阵 (sparse matrix) :设矩阵 Amn 中有 s 个非零元素,若 s 远远小于矩阵元素的总数 ( 即 s<<m×n) ,则称 A 为稀疏矩阵。

矩阵的运算 加法 (addition) :当矩阵 A 和 B 同阶时,有:
ijij ba BA
4 1 5 0 3 2 5 5 56 3 0 4 2 1 9 4 3
A B B A
对于 m n 阶矩阵 A 、 B 和 C ,具有如下性质:• 闭 合 性: A + B 仍然是一个 m n 阶矩阵;• 结 合 性: (A + B) + C = A + (B + C) ;• 交 换 性: A + B = B + A ;• 加性等同: A + 0 = A ;• 加 性 逆: A + (−A) = 0 。
4 5 36 0 2
A 1 0 2
3 4 1
B例如:

对于 m n 阶矩阵 A 和 B 以及纯量 和 , 具有如下性质:• 闭 合 性: A 仍然是一个 m n 阶矩阵;• 结 合 性: () A = (A) ;• 分 配 性: (A+B) =A+B ; (+) A=A+A ;• 等 同 性: 1A = A 。
乘法 (multiplication)
纯量与矩阵相乘:一个纯量 与一个矩阵 A 的乘积是用 去乘 A 的每个元素,表示为 A 。 ijA A

矩阵乘法具有如下性质:• AB BA
• (AB)C = A(BC)
• (A + B)C = AC + BC ; C(A + B) = CA + CB
矩阵相乘:当矩阵 A 的列数与矩阵 B 的行数相等时, A 与 B 可乘,即
r c c l r l ijc A B Cc
ij ik kjk
c a b其中,
例如:

转置 (transposition) :矩阵的行与列对调,用A´ 或 AT 表示,即:
m n ij n m jia a Α Α
矩阵的转置有如下性质:• 当 A 为对称方阵时, A´ = A ;• (A´) ´ = A
• (AB) ´ = B ´A ´
• (AB ´ C) ´ = C ´BA ´
• (A + B + C) ´= A ´ + B ´ + C ´

矩阵的迹 (trace) :一个方阵的迹为其对角线元素之和,表示为:
iii
tr aΑ
迹的运算性质: tr trΑΒ ΒΑ
0.51 0.46 0.33 1.30tr Α
0.51 0.32 0.190.28 0.46 0.140.21 0.16 0.33
A设: 则
tr tr aq q a q a tr tr tr ABC BCA CAB

范数 (norm) :矩阵与其转置矩阵乘积的迹的平方根,即:
5.0
25.0
i jijatr ΑΑΑ
范数的性质:• ||A|| > 0 ,除非 A = 0 ; ||A|| = 0 A=0⇐⇒
• ||kA|| = |k| ||A|| ( k 为一纯量);• ||A+B||≤||A||+||B||
• ||AB||≤||A|| ||B||

逆矩阵 (inverse matrix) :对于一方阵 A ,若存在另一矩阵 B ,使得 AB=BA=I ,则称 B 为A 的逆矩阵,并表示为 A–1,即 A–1 A=I 。
A–1 存在的先决条件:• A 必须是一方阵;• A 的行列式 |A|0 ,即 A 为非奇异阵。
1 1*
| | A A
A
其中, A* 是 A 的伴随矩阵。
对任意 n 阶矩阵 A , 称
为 A 的 伴 随 矩 阵 。 其中, Aij 是 A 中元素 aij 的代数余子式。
11 1
1
*n
n nn
A AA
A a

A–1 具有如下性质:• A–1A=AA–1=I ;• A–1 是唯一的;• ;• (A–1) –1 =A ,因而也是非奇异阵;• (A–1) ´ =(A´) –1 ;• 如 A 为对称阵,则 A–1 也是对称阵;• 若 A 、 B 均可逆,则 (AB)–1 =B–1 A–1 。
ΑΑ
11
如果 n 阶矩阵A 的 行 列 式│ A│≠0 , 则称 A 是非奇异阵;否则,称A 为奇异阵。
非奇异阵也就是满秩矩阵 :对于方阵 A ,如果存在一个同阶的方阵 B ,两方阵的积为单位阵,则称方阵 A 为满秩方阵或非奇异阵。

广义逆 (generalized inverse) :对于任一矩阵 A ,若有矩阵 G ,满足:
AGA = A
则称 G 为 A 的广义逆,记为 A¯ ,即
AA –A = A
广义逆的性质:• 若 A 为方阵且满秩,则 A¯ = A –1 ;• 对于任意矩阵 A , A¯ 必存在。

11 12 1
21 22 2
1 2
n
n
m m mn
a B a B a Ba B a B a B
a B a B a B
A B
Kronecker 乘积 ( 或直积 , direct product)
设 和 分别为 mn 和 pq
阶矩阵,定义 ,称为 A 和 B
的 Kronecker 乘积或直积,记为 。即:
ijaΑ
nqmpija
ΒC
BAC
ijbΒ

直积的有关性质 :
• 0A=A0=0
• (A1+A2)B=(A1B)+(A2B)
• A(B1+B2)=(AB1)+(AB2)
• ( A)( B)= (AB) (、 均为纯量)• (A1B1)(A2B2)=(A1A2) (B1B2) ( 如 A1 与 A2 、B1 与 B2 可乘 )
• (AB)′=A′B′
• (AB)-1=A-1B-1 ( 如 A 、 B 均可逆 )
• (x′ y)′=y x′=yx′

Hadamard 乘积:两个矩阵 A 和 B 的元素间相乘,要求 A 和 B 同阶。用 * 表示:
ijijij abba **ΒΑ

随机变量的期望值和方差设 X 为一随机变量,则: 其数学期望: ,且具有如下性质:( )E X
( k 为一常数)( ) ( )E kX kE X k (X 、 Y 相互独立时 )
( ) ( ) ( ) X YE X Y E X E Y
( ) ( ) ( ) X YE XY E X E Y
其方差: , 且具有如下性质 :2( ) ( )Var X E X 2 2 2( ) ( ) ( )Var kX k Var X k E X
(X 、 Y 相互独立时 )( ) ( ) ( )Var X Y Var X Var Y ( 称为 X 和 Y 的协方差 )
( , ) ( ) ( )X YCov X Y E X E Y

将上述内容推广至多个变量。设 x1,
x2, xn 为 n 个随机变量,则:1
2
n
xx
x
x
1
2( )
n
E
x
21 12 1
221 2 2
21 2
( )n
n
n n n
Var
x V
随机向量
x 的期望向 量
x 的方差 -协方差矩阵
V 的对角线元素为n 个变量的方差;非对角线元素为变量间的协方差。

动物育种中常用的是表型方差 - 协方差矩阵 V 、遗传方差 - 协方差矩阵 G 和残差方差 - 协方差矩阵 R 。
1 12 1
21 2 2
1 2
2
2
2
n
n
n n n
p p p
p p p
p p p
V
1 12 1
21 2 2
1 2
2
2
2
n
n
n n n
a a a
a a a
a a a
G
1 12 1
21 2 2
1 2
2
2
2
n
n
n n n
e e e
e e e
e e e
R

G 阵的构建需要一个由个体间亲缘相关系数组成的矩阵 A ,该矩阵称为加性遗传相关矩阵。由于它是由 Wright 计算近交系数公式中的分子计算而得,故又称为分子血缘相关矩阵。
11 12 1
21 22 2
1 2
n
n
n n nn
a a aa a a
a a a
A
个体 i 和 j
间的加性遗传相关。计算公式:
1 21( ) (1 )2
n n
ij Aa f
个体 i 的近交系数加 1 。即 : 1ii ia f

A 阵元素计算机计算的递推公式:
1 0.5i iii s da a
0.5( )j jij is ida a a
jd
式中: 和 分别为个体 i 的父亲和母亲; 和 分别为个体 j 的父亲和母亲; 为 和 间的加性遗传或亲缘相关系数。若个体 i 的一个亲本或双亲未知, 。 和 分别为个体 i 与 和 间的加性遗传相关。 未知时, ; 未知时, 。
i is da0
i is da
isid
jsjd
isid
ji sajida js
jd
js 0ji sa 0
jida

线性模型基础 模型 (model)
模型:指描述观察值与影响观察值变异性的各个因子间关系的方程式。 因子:影响观察值的因子也称为变量
• 变量可分为离散型变量(变异不连续)和连续型变量;• 离散型因子分为固定因子和随机因子两类;• 连续性变量通常作为协变量看待。

固定因子与随机因子:与抽样和目的有关• 固定因子( fixed factors ):抽取因子的若干特定水平、水平数相对较少、研究目的是要对这些水平的效应进行估计或比较。• 随机因子( random factors ):因子的各水平是其所有水平的一个随机样本、水平数相对较多、研究目的是要对该样本去推断总体。
固定效应与随机效应• 固定效应 ( fixed effects ):固定因子各水平对观察值的效应。• 随机效应 ( random effects ):随机因子各水平对观察值的效应。

线性模型 (linear model)
定义:模型中所包含的各个因子是以相加的形式影响观察值,即它们与观察值的关系为线性关系。 组成:一个完整的模型应包括 3 部分内容:
• 数学方程式(或数学模型式)及其解释;• 模型中随机变量的数学期望、方差协方差;• 建立模型时的所有假设和约束条件。

例 7.1 :
模型中每个参数的解释• yij :第 i 个日龄组的第 j 头肉牛的体重 , 为观察值 ;
• :总体均值,是一常量;• ai :第 i 个日龄组的效应,为固定效应;• eij :随机误差或残差效应。
随机变量的期望、方差及协方差
ij i ijy a e
( ) 0 ( )ij ij iE e E y a 2( ) ( )ij ijVar y Var e
( , ) ( , ) ( , )ij ij ij i j ij ijCov e e Cov e e Cov e e

约束与假设• 所有犊牛都来自同一个品种;• 母亲年龄对犊牛体重无影响;• 犊牛的性别相同或性别对体重无影响;• 除日龄组外的其他环境条件相同。
对每一观察值建立方程式

y11=198= + a1 +e11
y12=204= + a1 +e12
y13=201= + a1 +e13
y21=203= + a2 +e21
y22=206= + a2 +e22
y23=210= + a2 +e23
y31=205= + a3 +e31
y32=212= + a3 +e32
y33=216= + a3 +e33
y41=225= + a4 +e41
y42=220= + a4 +e42
日龄组1 2 3 4观察值 残 差
个
体
1 2 3 4
日
龄
组

y11 =198= + a1 + e11
y12 =204= + a1 + e12
y13 =201= + a1 + e13
y21 =203= + a2 + e21
y22 =206= + a2 + e22
y23 =210= + a2 + e23
y31 =205= + a3 + e31
y32 =212= + a3 + e32
y33 =216= + a3 + e33
y41 =225= + a4 + e41
y41 =220= + a4 + e42
a1
a2
a3
a4
y a e
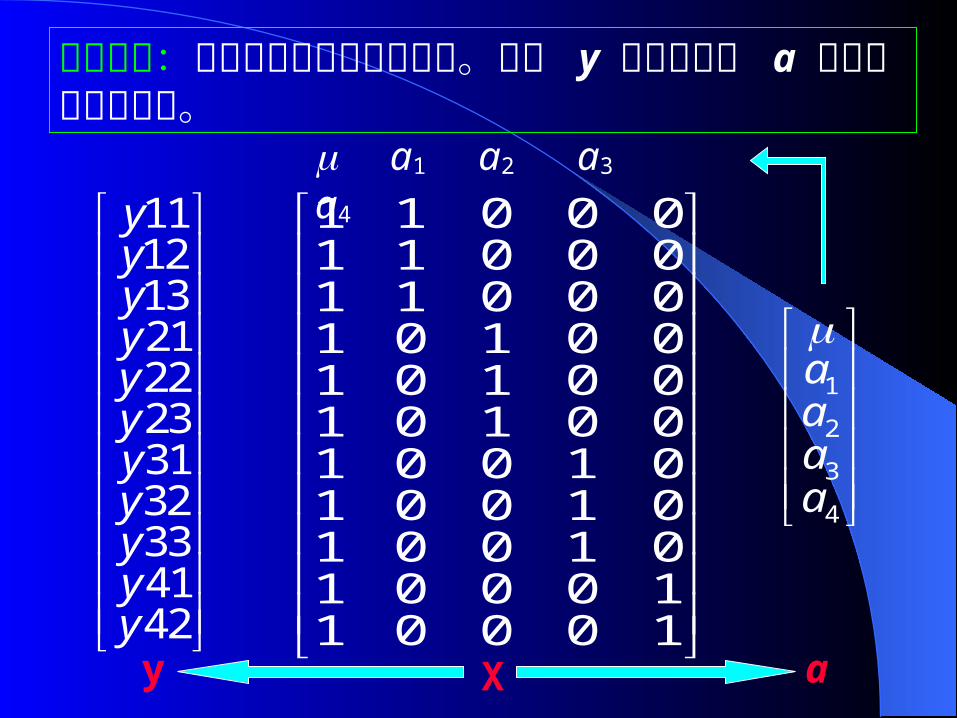
关联矩阵:又称设计矩阵或发生矩阵。指示 y 中的元素与 a 中元素的关联情况。
1 1 0 0 01 1 0 0 01 1 0 0 01 0 1 0 01 0 1 0 01 0 1 0 01 0 0 1 01 0 0 1 01 0 0 1 01 0 0 0 11 0 0 0 1
1112132122233132334142
yyyyyyyyyyy
1
2
3
4
aaaa
a1 a2 a3 a4
y aX

模型的矩阵表示:
式中, y 为观察值向量, a 为固定的日龄组向量,e 为随机残差效应向量, X 为 a 的关联矩阵。且有:
y = Xa + e
( ) ( )E E e 0 y Xa
2( ) ( )Var Var y e I
其中, I 为单位矩阵, σ2 为观察值的方差。

线性模型的分类
按模型中各因子的性质分类如下: 固定效应模型 (fixed effect model) :模型中除随机残差外,其余所有效应均为固定效应。
y Xb e
随机效应模型 (random effect model) :模型中除外,其余的所有效应均为随机效应。
y 1μ Zu e

式中: y— 观察值向量; b— 固定效应(包括)向量; u— 随机效应向量; e — 随机残差效应向量 ; X— 固定效应的关联矩阵(设计矩阵或发
生矩阵); Z— 随机效应的关联矩阵(设计矩阵或发
生矩阵)
y Xb Zu e
混合效应模型 (mixed effect model) :模型中除和 e 外,既含有固定效应,也含有随机效应。

第二节 BLUP 育种值估计背 景
• BLUP 法是基于克服传统选择指数法的缺点的。• 选择指数实质上就是育种值的估计值。• 选择指数法假定不存在影响观察值的系统环境效应,或者这些效应已知,可以对观察值进行事先校正,则选择指数是育种值的最佳无偏估值。但是这一假定几乎不能成立。• BLUP 的基本思路是在估计育种值的同时对系统环境效应进行估计和校正。• 根据这一思路, BLUP 法必须基于混合模型。

•最佳 (Best) :估计误差方差 最小; ˆVar A A
•无偏 (Unbiased) :估计值无偏,即估计值的期望值就是真值, ; ˆ 0E A A
基本原理 BLUP 的 涵 义 : BLUP 是 Best Linear
Unbiased prediction 的首字母缩略词,既最佳线性无偏预测。其中:
• 线性 (Linear) :估计值是观察值的线性函数;
•预测 (prediction) :是可以对随机效应进行预测。
通常,对固定效应称估计,对随机效应称预测。

y Xb Zu e
;,, Xbyeu EEE 00
Var Var Cov u G e R u,e 0, ,
Co , (( ), ) ( , ) ( , )v Cov Cov Cov y u Zu e u Zu u e u ZG
混合模型( Mixed model )
式中, y— 观察值向量; b 和 u 分别为固定效应和随机效应向量; e 为随机残差向量; X 和 Z 分别为 b 和 u 的关联矩阵。且有:
( )Var Var y Zu e( ) ( ) 2 ( , )Var Var Cov Zu e u e ZGZ R
V
这里是假定固定效应与随机效应间无互作。育种中是假定遗传与环境间无互作。

;ˆˆ 值是一个广义最小二乘估,即byVXXVXb 11 bXyVZGu 1 ˆˆ
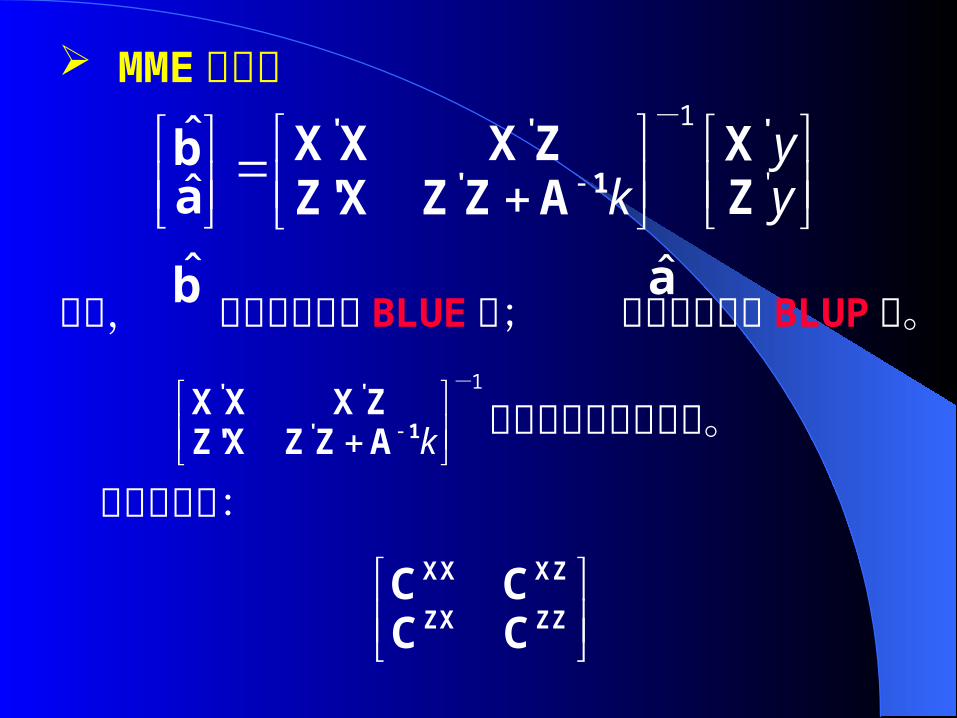
混合模型方程组( MME )
MME 的解:解向量 s 右手项 r系数矩阵 C
注意:尽管 MME 的解中有 V-1 ,但 MME 中没有,直接求解 MME 便可,即 。ˆ 1s C r
C-1 可用分块矩阵表示为: 1
XX XZ
ZX ZZC CCC C
yRZ
yRX
u
b
GZRZXRZ
ZRXXRX1
1
111
11
ˆ
ˆ(1)

式中, y= 表型观测值向量 b= 为固定环境效应向量 X= 固定环境效应 b 的关联矩阵 a= s 个个体的随机加性遗传效应向量 Z= 随机遗传效应 a 的关联矩阵,当 a 中的所有个体都有观测值时,即 s = n 时, Z = I
e= 随机残差效应向量
单性状无重复观察值的动物模型 BLUP
模型表达式 一个个体时:
1
r
jj
y b a e
y Xb Za e n 个个体时:
y 为个体的观察值; bj 为第 j 个固定效应; a 为个体的随机加性遗传效应;e 为随机残差效应。

( ) ( ) 0 E E a e
2 ( ) aVar a G A=2 ( ) eVar e R I
随机效应 a 和 e 的数学期望为:
随机效应 a 和 e 的方差 -协方差矩阵分别为:
其中: 为加性遗传方差; 为随机残差方差;A 为待估个体间的加性遗传相关矩阵( additive
genetic relationship matrix ),即分子亲缘相关系数矩阵( numerator relationship matrix )。
2a 2
e

混合模型方差组( MME )
式中, A-1 = A 的逆矩阵 X′= X 的转置矩阵 Z′= Z 的转置矩阵
2 2 2 22 2
2 2 2 2 2
1 / 1
/y a a ye
a a a y
hk
h
与( 1 )式相比,( 2 ) 式 是 在( 1 )式两边同除了一个 R-1 变换而来。
'
ˆ
ˆyyk
' ' '
' 1X X X Z Xb
a ZZ'X Z Z A(2)
1
'
ˆ
ˆyyk
' ' '
' 1X X X Z Xb
a ZZ'X Z Z A
-
1
k
' '
' 1X X X ZZ'X Z Z A
-
为系数矩阵的逆矩阵。
MME 的求解
XX XZ
ZX ZZC CC C
也可表示为:
其中, 为固定效应的 BLUE 值; 为随机效应的 BLUP 值。
ˆ b ˆ a

个体育种值估计的准确度 (Accuracy, ACC)
用估计育种值与真实育种值之间的相关系数来度量,其计算公式为:
ˆi ia ar
2 2 2ˆ ˆ
ˆ 2ˆ
ˆ( , )1i i i
i i i
i i i
a a a a ei ii a a a
a a a a a a
dCov a aACC r d k
=
式中, 为 中与个体 i 对应的对角线元素。iad ZZC
当个体 i 为非近交个体时:
当个体 i 为近交个体时: 2 2
ˆ 1 ( (1 ) )1
i
i i i
ai a a a i a
i
d kACC r f
f
式中, fi 为个体 i 的近交系数。

Relationship between true BV and EBV for three accuracy values, r= 0.8, 0.5 and 0.3

对育种值估计准确度的进一步理解
• 个体某一性状的真实育种值只有一个,而且永远不变。• 个体的估计育种值则与信息来源和信息的多少密切相关,并随之变化。• 一般而言,利用的信息越多,准确度越大。• 准确度还是育种值估计中利用信息多少的一个度量。它表明了当拥有更多信息时, EBV 变化的可能性。• 随着准确度的提高, EBV 的变化减小。

估计育种值的可靠性 (Reliability)
预测误差方差 (Prediction error variance, PEV)
估计育种值与真实育种值之间的相关系数 的平方 称为估计育种值的可靠性。可靠性是一个决定系数,是对真实育种值变异中由估计育种值说明的变异部分 ( )的一个度量。
ˆi ia ar2
ˆi ia ar
2 2ˆi ia a ar
PEV 是育种值预测时对误差大小的一个度量。PEV 是对真实育种值变异中未由估计育种值说明的变异部分 ( ) 的一个度量。2 2
ˆ(1 )aa ar

当个体 i 为非近交个体时: 2 2 2 2
ˆˆ( ) (1 )i i ia i i a e aa a a aPEV Var a a d r d k = =
当个体 i 为近交个体时: 2 2 2 2
ˆ(1- )(1 ) (1 )i i i i ia a e a a i a a i aPEV d r f d k f =
育种值估计的准确度可由预测误差方差计算
21
(1 ) a
PEVACC
f
预测误差标准差 (Standard error of prediction, SEP)
2(1 )i ia a i aSEP d k f =


单性状有重复观察值的动物模型 BLUP
模型表达式—重复力模型 (Repeatability model)
1 2y = Xb + Z a + Z p + e
式中, y 为观察值向量; b 为固定效应向量; a为随机加性遗传效应向量; p 为随机永久环境效应向量; e 为随机残差效应向量。 Z1 为加性遗传效应的关联矩阵; Z2 为永久环境效应的关联矩阵。且有:
( ) ( ) ( ) ( )E E E E a 0 p 0 e 0 y Xb2 ( ) aVar a A 2 ( ) eVar e I2 ( ) pVar p I

混合模型方程组
yZ
yZ
yX
p
a
b
IZZZZXZ
ZZAZZXZ
ZXZXXX
2
1
22122
211
111
21
ˆ
ˆ
ˆ
2
1
k
k
其中:2 2
1 2 2
1e
a
hk
h
2
2 2 2
1e
p
rek
re h
其中: h2 为性状的遗传力, re 为性状的重复力。

动物模型 BLUP 的理想性质• 能最有效地充分利用所有亲属的信息;• 能校正由于选配所造成的偏差;• 当利用个体的重复记录时,可将由于淘汰造成的偏差降到最低;• 能考虑不同群体及不同世代的遗传差异;• 能提供个体育种值的最精确的无偏估值。达到如上理想性质的前提是:
数据特别是系谱正确完整; 所用模型是真实模型; 随机效应方差组分已知,而且是正确的。

多性状动物模型 BLUP 育种值估计 模型表达式
以两个性状为例。
性状 1 的模型为: 1 1 1 1 1 1 y X b Z a e
性状 2 的模型为: 2 2 2 2 2 2 y X b Z a e
1 1 1
2 2 2
y a ey a ey a e
1 1
2 2
X 0 Z 0X Z0 X 0 Z
令:
则有:
y Xb Za e

随机效应的期望和方差 - 协方差( ) ( ) E E a e 0 ( )E y Xb
1 12
12 2
2
2 ( ) a a
a a
Var
A Aa G
A A=
1 12
12 2
2
2 ( ) e e
e e
Var
I Ie R
I I=
其中, 和 分别为性状 1 和 2 的加性遗传方差; 为性状 1 和 2 间的加性遗传协方差。 和 分别为性状 1 和 2 的残差方差; 为性状1 和 2 间的残差协方差。 A 为分子血缘相关矩阵;I 为单位矩阵。
1
2a
2
2a
12a1
2e
2
2e
12e

MME 及其求解
ˆˆ
1 1 1
11 1 1X R X X R Z X R yb
a Z R yZ R X Z R Z G
计算 G-1 和 R-1 后,代入混合模型方程组求解,便可得到:
1
2
ˆ bb b
1
2
ˆ aa a
固定效应的 BLUE值
加性遗传效应的 BLUP值

第三节 遗传参数估计的 REML 方法
最大似然 (Maximum likelihood, ML) 法 是统计学参数估计的一个重要方法 , 由 Fisher提出。
最大似然法的一般原理
概率函数与密度函数设 f (x, ) 为随机变量 X 的概率函数( X 为离散型变量)或密度函数( X 为连续型变量), 为有关的已知参数,且 X 为 的函数。则 f (x, ) 为已知时, X=x 的发生概率( X 为离散型变量)或X=x 的概率密度( X 为连续型变量)。

似然函数( likelihood function )假定 为待估计的未知参数,但 X=x 已知,为观察值。将 f (, x) 看作是 x 一定时 的一个函数,称之为似然函数,记为 L(, x) ,表示 取不同值时, X=x 发生的可能性或似然性。 最大似然原理寻找一个使得 X=x 发生可能性最大的 值 ,即当X=x 时,寻找 ,满足 其中为参数空间。如果 存在,则称它为 的最大似然估值。
ˆ( , ) max{ ( , ) : }L x L x

注意事项 : 的估计值必须落在参数空间内。我们不考虑参数空间外的 ML 估值。似然函数通常用对数形式,即 ln L 或 log L 。因为在求最大值过程中需要求对数后求导。
混合模型下参数的 ML 估计ML法要求说明数据的分布。对于混合模型,通常假定呈多元正态分布。似然函数的对数为:
其中 C 为常数。根据定义, b 和 σ 的 ML 估值是参数空间 中的一个使上式最大化的一个值。
11 1log ( , ) log ( ) ( )
2 2L C b σ y V y Xb V y Xb

ML 法的缺点
ML 估值被严格地限定在参数空间中,不考虑参数空间之外的具有较大似然值的解;
ML 估值不考虑因估计固定效应而造成的自由度的损失。
对于有限样本, ML 估值有偏。有偏来源主要有两个:

约束最大似然法的一般原理 基本思路
用 个线型独立的误差对照 的约束似然函数 Lr代替全似然函数 L 。其中, n 为有记录的个体数, 为固定效应关联矩阵的秩。
( )n r X K y
( )r X
设混合模型为: y Xb Za e 且有:2 2~ (0, ) ~ (0, )a eN N a A e I
2 2~ ( , )a eN y Xb ZAZ I

对于 y ,总可以找到一个线性函数 ,它满足 ,使得:
K y
K X 0
( )E K y K Xb 0
亦即 不受固定效应影响。K y
若 y服从正态分布,则 也服从正态分布,即:
K y
~ ( , )N K y 0 K VK
的对数似然函数,也即约束似然函数的对数为:
K y
1 1log ( ) log ( )
2 2Lr C -1σ y K VK y K K VK K y

其中, C 为一常数,且有:
0.5( ( )) log 2C n r X
n 为有记录的个体数, 为固定效应关联矩阵的秩。
( )r X
求解上述对数约束似然函数关于 和 的最大值,便可得到 和 的 REML 估值。
2a 2
e2a 2
e
于是:2
22 2
a
a e
h

REML 和 ML 的区别 思路上: ML 是求观察值的似然函数的最大值;而 REML 是求观察值的某一特定线性函数的似然函数的最大值。 结果上:由于 不考虑估计固定效应,因此, REML 法克服了 ML法中产生有偏估值的一个来源,即克服了 ML法中因估计固定效应而造成的自由度的损失。
K y
REML 和 ML 的相同点都具有大样本特性,即小样本数据估值有偏。

非求导的 REML—DFREML
DFREML 、 MTDFREML 、 DMU
求一阶偏导数的 REML—EMREML
VCE 、 REMLF90
利用一阶和二阶偏导数的 REML—AIREML
DFREML 、 AIREMLF90 、 VCE 、 DMU
REML 的有关算法与相关软件





























