Embed Size (px)
DESCRIPTION
Εισαγωγή στα Conditional Random Fields. Κατερίνα Φραγκιαδάκη Εθνικό Μετσόβιο Πολυτεχνείο. Οργάνωση Ομιλίας. Θεωρία γραφικών μοντέλων ΗΜΜ - generative # discriminative ΜΕΜΜ - Label bias problem Θεωρία CRF Feature Induction Πειραματικά αποτελέσματα. - PowerPoint PPT Presentation
Citation preview

Εισαγωγή στα Conditional Random Fields
Κατερίνα Φραγκιαδάκη
Εθνικό Μετσόβιο Πολυτεχνείο

Οργάνωση Ομιλίας
Θεωρία γραφικών μοντέλων
ΗΜΜ - generative # discriminative
ΜΕΜΜ - Label bias problem
Θεωρία CRF
Feature Induction
Πειραματικά αποτελέσματα

Συστήματα Εξαγωγής Πληροφορίας
•Ραγδαία εξάπλωση του παγκόσμιου Ιστού
•Προσπάθεια αντιμετώπισης της πληροφοριακής έκρηξης

Εξαγωγή ΠληροφορίαςΠεριγραφή ΠροβλήματοςΠεριγραφή Προβλήματος
• InputInput
Ένα κείμενο προς αναγνώριση
• Output
Η πιο πιθανή ακολουθία από ετικέτες για τις λέξεις του κειμένου (το πιο πιθανό labeling)

Βασικά χαρακτηριστικά• Πλούσια αλληλεξαρτώμενα features της
ακολουθίας παρατηρήσεωνΠ.χ. ορθογραφική πληροφορία,part-of-speech, συμμετοχή σε λίστες…
• Εξαρτήσεις μεταξύ των labels των λέξεων
Γραφικά Στατιστικά Μοντέλα

Γραφικά μοντέλα (1)• Χ : σύνολο τυχαίων μεταβλητών εισόδου (λέξεις)-
παρατηρήσιμες
Π.χ. το Χ παίρνει τιμές από διάφορα κείμενα προς αναγνώριση
• Υ : σύνολο τυχαίων μεταβλητών εξόδου (αντίστοιχες labels) -θέλουμε να τις προβλέψουμε
Π.χ. το Υ παίρνει τιμές από τα αντίστοιχα labelings(Με τα μικρά x , y υποδηλώνουμε συγκεκριμένη ανάθεση τιμών
στα παραπάνω σύνολα)
• Α συλλογή υποσυνόλων του ΧUY

Γραφικά μοντέλα (3)
Ζ παράγοντας κανονικοποίησης
Η κατανομή αθροίζει σε 1

Γραφικά Μοντέλα(2)
Μία κατανομή πάνω σε ένα μεγάλο πλήθος τυχαίων μεταβλητών αναπαρίσταται ως ένα γινόμενο τοπικών συναρτήσεων που η καθεμία εξαρτάται από ένα μικρό πλήθος μεταβλητών.

Γραφικά Μοντέλα(2)
ΟρισμόςΈνα γραφικό μοντέλο είναι μια οικογένεια από κατανομές πιθανότητας οι οποίες παραγοντοποιούνται σύμφωνα με κάποιον δεδομένο factor graph
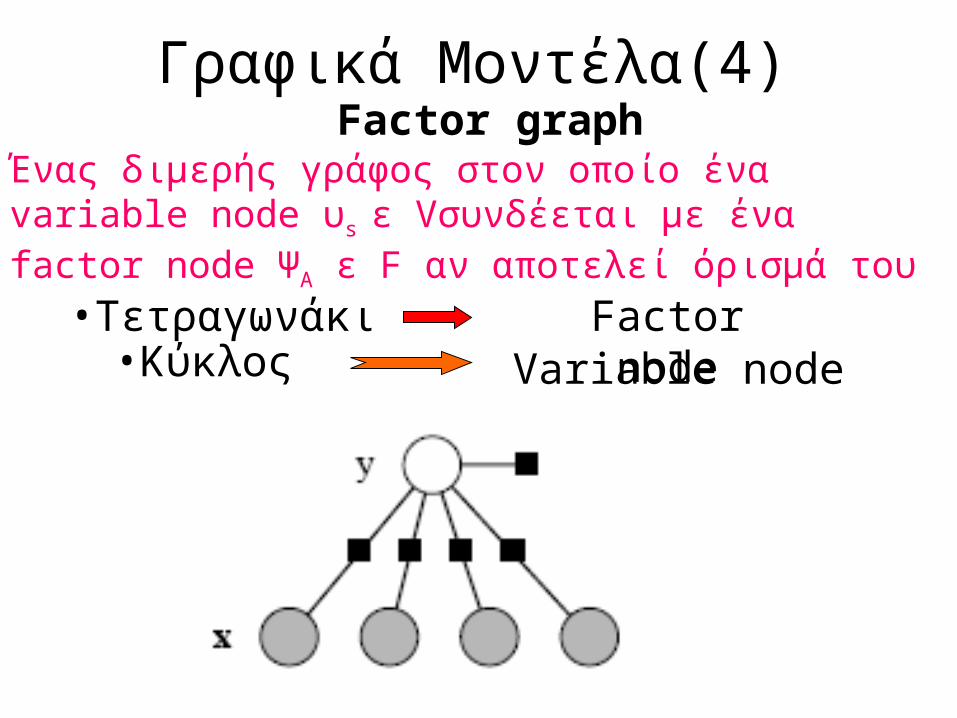
Γραφικά Μοντέλα(4)
•Τετραγωνάκι•Κύκλος
Factor nodeVariable node
Factor graphΈνας διμερής γράφος στον οποίο ένα variable node υs ε Vσυνδέεται με ένα factor node ΨΑ ε F αν αποτελεί όρισμά του

Local Functions
Θεωρούμε local functions εκθετικής
μορφήςΚυρτότητα!!
•θΑ : πραγματικές παράμετροι
• fΑ : feature functions

Εφαρμογές γραφικών μοντέλων
Είσοδος: διάνυσμα χαρακτηριστικών x=(x1,x2,…xΚ)
Classification
Ζητούμενο: Πρόβλεψη της αντίστοιχης label-κατηγορίας (μία μεταβλητή εξόδου)

Naïve Bayes Classifier
Θεωρεί όλα τα χαρακτηριστικά ανεξάρτητα μεταξύ τους
Παράδειγμα: Τα x1,x2,..xK είναι οι ταυτότητες λέξεων ενός κειμένου και το ζητούμενο είναι να κατηγοριοποιηθεί το κείμενο βάσει περιεχομένου

Logistic regression
Classifier που υπολογίζει δεσμευμένη πιθανότητα!

Ακολουθιακά μοντέλα
• Δε θέλουμε να ταξινομούμε κάθε διάνυσμα παρατήρησης ξεχωριστά
• Στις εφαρμογές κειμένου θέλουμε να εκμεταλλευτούμε τις εξαρτήσεις μεταξύ των labels γειτονικών λέξεων -διανυσμάτων παρατηρήσεων!!
• Εκεί συνίσταται και η δύναμη των γραφικών μοντέλων!!!

Hidden Markov Models
• Χαλαρώνουν την υπόθεση ανεξαρτησίας μεταξύ των μεταβλητών εξόδου οργανώνοντάς τες σε σειρά
• Εδώ το κάθε διάνυσμα παρατήρησης xt αποτελείται μόνο από την ταυτότητα της λέξης

Hidden Markov Models (2)2 υποθέσεις ανεξαρτησίας:
• Κάθε κατάσταση εξαρτάται μόνο από την αμέσως προηγούμενή της
• Κάθε μεταβλητή παρατήρησης xt εξαρτάται μόνο από την παρούσα κατάσταση yt

Hidden Markov Models (3)Συνεπώς μπορούμε να ορίσουμε ένα ΗΜΜ καθορίζοντας τις εξής κατανομές πιθανότητας:
• Την κατανομή πιθανότητας p0(y) πάνω στις αρχικές καταστάσεις
• Την κατανομή πιθανότητας μεταβάσεων p(yt /yt-1).
• Την κατανομή πιθανότητας των παρατηρήσεων p(x t / yt)

Hidden Markov Models (4)
Είναι ένα αυτόματο πεπερασμένων καταστάσεων που μοντελοποιεί μία πιθανοτική παραγωγική διαδικασία για το πώς μία ακολουθία παρατηρήσεων παράγεται ξεκινώντας από κάποια αρχική state, βγάζοντας μια παρατήρηση, πηγαίνοντας σε μία επόμενη state, δίδοντας τη 2η παρατήρηση κοκ.

Discriminative-generative • Κατά παράδοση τα γραφικά μοντέλα
μοντελοποιούν την από κοινού κατανομή p(x,y)
• Εμπεριέχει τον υπολογισμό της p(x)
• Πολύ δύσκολο να χρησιμοποιήσουμε πλούσια αλληλοεξαρτώμενα χαρακτηριστικά της ακολουθίας εισόδου
• Καταλήγουμε σε χρήση λίγων χαρακτηριστικών (στα ΗΜΜ μόνο ταυτότητα λέξης) και υιοθέτηση υποθέσεων ανεξαρτησίας μεταξύ τους!
Βλάπτεται η απόδοση του μοντέλου μας!!!
Discriminative-generative(2)
• Ωστόσο στο πρόβλημα του classification οι ακολουθίες προς αναγνώριση είναι δεδομένες και συνεπώς δε μας απασχολεί η πιθανότητα εμφάνισής τους!
• Συνεπώς αρκεί να ενδιαφερθούμε για την αναπαράσταση της δεσμευμένης πιθανότητας p(y/x) !!

Discriminative-generative(3)
• Conditional models!
• Δυνατότητα χρήσης πλούσιων χαρακτηριστικών για τη βοήθεια της αναγνώρισης της ακολουθίας εισόδου
• Δε γίνεται προσπάθεια το μοντέλο να γεννήσει την ακολουθία εισόδου! Απλά τη λαμβάνει ως συνθήκη στη δεσμευμένη πιθανότητα!

Maximum Entropy Markov Models• Τα ΜΜΕΜs μοντελοποιούν Conditional πιθανότητα.
Ενσωματώνουν πλήθος χαρακτηριστικών της ακολουθίας παρατηρήσεων
• Αντικαθιστούν τα transition και observation functions των HMM με τη συνάρτηση P( s |s’ ,o) που δίνει την πιθανότητα της επόμενης κατάστασης s δεδομένης της παρούσας κατάστασης s’ και του τρέχοντος διανύσματος παρατήρησης
• Με Viterbi παίρνω την πιο πιθανή ακολουθία καταστάσεων δεδομένης μιας ακολουθίας παρατηρήσεων εισόδου

Maximum Entropy Markov Models(2)
Ένα εκθετικό μοντέλο ανά κατάσταση!!

Label-Bias problem
Έχω classifier σε κάθε βήμα για να πάρω την επόμενη κατάσταση
Όσο μικρότερη η εντροπία των επόμενων μεταβάσεων τόσο περισσότερο αγνοούνται οι παρατηρήσεις. Όταν μία state έχει μόνο μία output μετάβαση, θα αγνοήσει παντελώς την παρατήρηση!
Ανά κατάσταση κανονικοποίηση των scores των μεταβάσεων
Οι μεταβάσεις από μία κατάσταση ανταγωνίζονται μεταξύ τους παρά με άλλες μεταβάσεις στο μοντέλο
Το μοντέλο είναι biased προς καταστάσεις με λιγότερες output μεταβάσεις
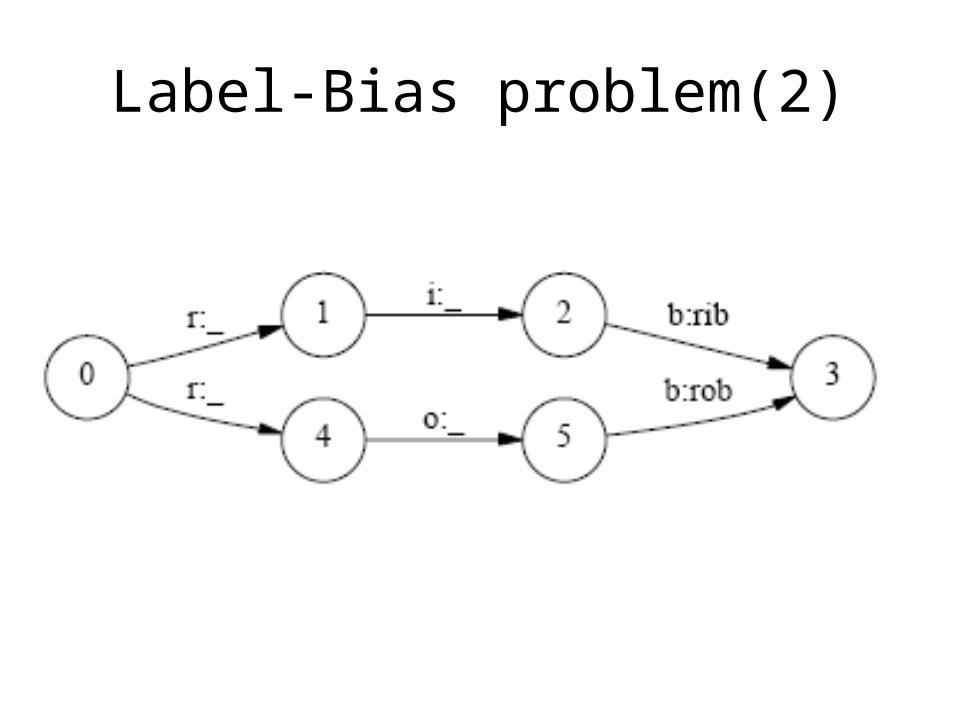
Label-Bias problem(2)

Label-Bias problem(3)
• Τα CRF ξεπερνούν το label-bias πρόβλημα!
• Ενώ τα ΜΕΜΜs έχουν ένα εκθετικό μοντέλο ανά κατάσταση τα CRF χρησιμοποιούν ένα μόνο εκθετικό για τον υπολογισμό της από κοινού πιθανότητας ολόκληρης της ακολουθίας από label δεδομένης της ακολουθίας παρατηρήσεων
• H κανονικοποίηση δε γίνεται ανά κατάσταση αλλά ανά labeling

General form CRFΟρισμός:Χ : τ. μ. πάνω σε ακολουθίες από τ.μ. εισόδου
(παρατηρήσεων) Υ : τ. μ. πάνω σε αντίστοιχες ακολουθίες από
τ.μ. εξόδου (labels)
Έστω G ένας factor graph πάνω στην τυχαία μεταβλητή Υ. Τότε η p(y/x) είναι CRF αν για κάθε δεδομένο x η κατανομή παραγοντοποιείται σύμφωνα με το G.

General form CRF(2)
• Aν κάθε παράγοντας παίρνει την εκθετική μορφή:
Το σύνολο των παραγόντων του G

General form CRF (3)
• Z παράγοντας κανονικοποίησης

General form CRF (4)Ο υπολογισμός των παραμέτρων θ, θ=(λ1,λ2,…;μ1,μ2…)) του μοντέλου συνίσταται στη μεγιστοποίηση της δεσμευμένης log likelihood των ακολουθιών εξόδου δεδομένου των ακολουθιών εισόδου στo training set

Μαρκοβιανή ιδιότηταΟρισμός:Χ : τ. μ. πάνω σε ακολουθίες από τ.μ. εισόδου (παρατηρήσεων)
Υ : τ. μ. πάνω σε αντίστοιχες ακολουθίες από τ.μ. εξόδου (labels)
Έστω γράφος G(V,E) τέτοιος ώστε Υ= (Υυ) υ ε V, έτσι ώστε η Υ να δεικτοδοτείται από τις κορυφές του G.Τότε το (Χ, Υ) είναι ένα conditional random field στην περίπτωση που δεδομένου του Χ οι τυχαίες μεταβλητές Υυ υπακούουν τη μαρκοβιανή ιδιότητα σε σχέση με το γράφο G, δηλαδή:

Μαρκοβιανή ιδιότητα(2)
• Τα CRF απαλείφουν τις υποθέσεις ανεξαρτησίας μεταξύ των παρατηρήσεων στην ακολουθία εισόδου αλλά κρατάνε τις υποθέσεις ανεξαρτησίας μεταξύ των labels με τον τρόπο που υπαγορεύει ο factor graph
• Dependencies μεταξύ των μεταβλητών εξόδου μπορούμε να αναπαραστήσουμε μόνο αν αυτές αντιστοιχούν σε κορυφές που συμμετέχουν σε κλίκα στο γράφημα.

Μαρκοβιανή ιδιότητα(3)
• Ανάλογα με τις υποθέσεις ανεξαρτησίας που θέτουμε μεταξύ των τ.μ. εξόδου έχουμε και το αντίστοιχο γράφο G
• Ο G δείχνει πως γκρουπάρονται οι μεταβλητές εξόδου στους παράγοντες
• Στον ίδιο παράγοντα μπορούν να μπουν μεταβλητές εξόδου που αντιστοιχίζονται στην ίδια κλίκα στον G-αλληλοεξαρτώμενες

HMM like CRF• Θεωρούμε το γράφο G με μορφή αλυσίδας
Ειδική περίπτωση των linear chain CRF
Ορίζουμε τις παρακάτω feature functions:
Οι αντίστοιχες παράμετροι λy’,y και μy,x παίζουν παρόμοιο ρόλο με τους λογαρίθμους των παραμέτρων των ΗΜΜ p(y’/y) και p(x/y)

Linear chain CRF
• Σε αντίθεση με τα ΗΜΜ like CRF μπορώ να χρησιμοποιήσω πολλαπλά observational features της ακολουθίας παρατηρήσεων
Όχι περιορισμός στην ταυτότητα της λέξης!

Linear chain CRF (2)• Σε αντίθεση με τα ΗΜΜ like CRF στα
linear chain CRF μπορεί γενικά μία μετάβαση (i,j) να εξαρτάται από το τρέχον διάνυσμα παρατήρησης !
Χρησιμοποιώ feature functions της μορφής: δ{yt=j} δ{yt-1=i} δ{xt=o}
Π.χ. η μετάβαση μεταξύ των καταστάσεων i και j που αντιστοιχούν και οι δύο στην label speaker name εξαρτάται από το αν η παρούσα λέξη αρχίζει με κεφαλαίο
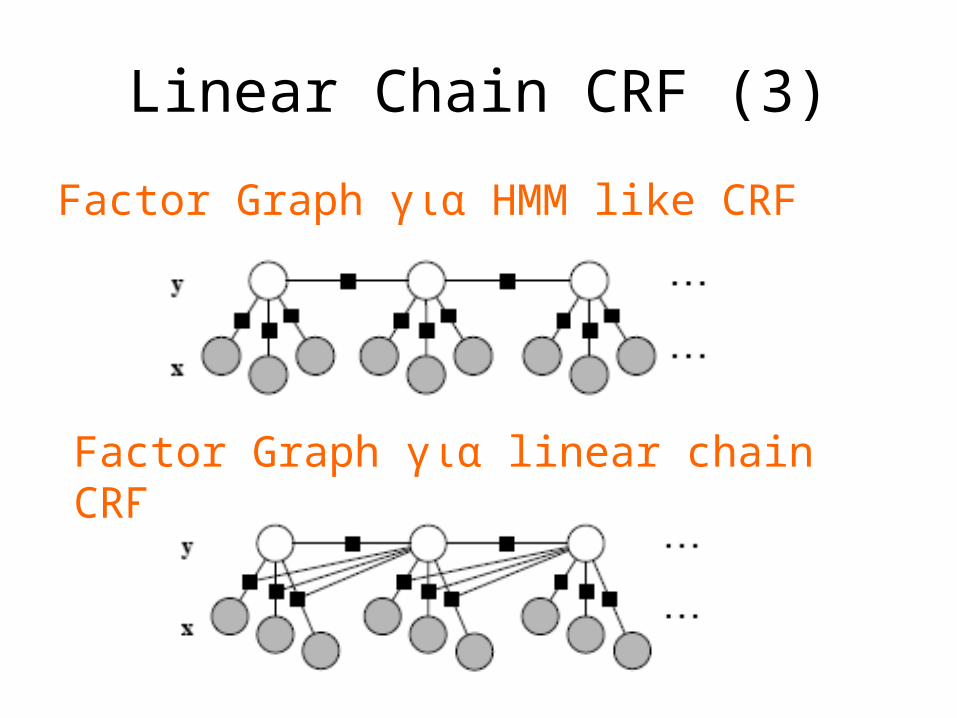
Linear Chain CRF (3)
Factor Graph για HMM like CRF
Factor Graph για linear chain CRF

Linear Chain CRF (4)
Θεωρούμε ότι οι εξαρτήσεις μεταξύ των μεταβλητών εξόδου σχηματίζουν αλυσίδα
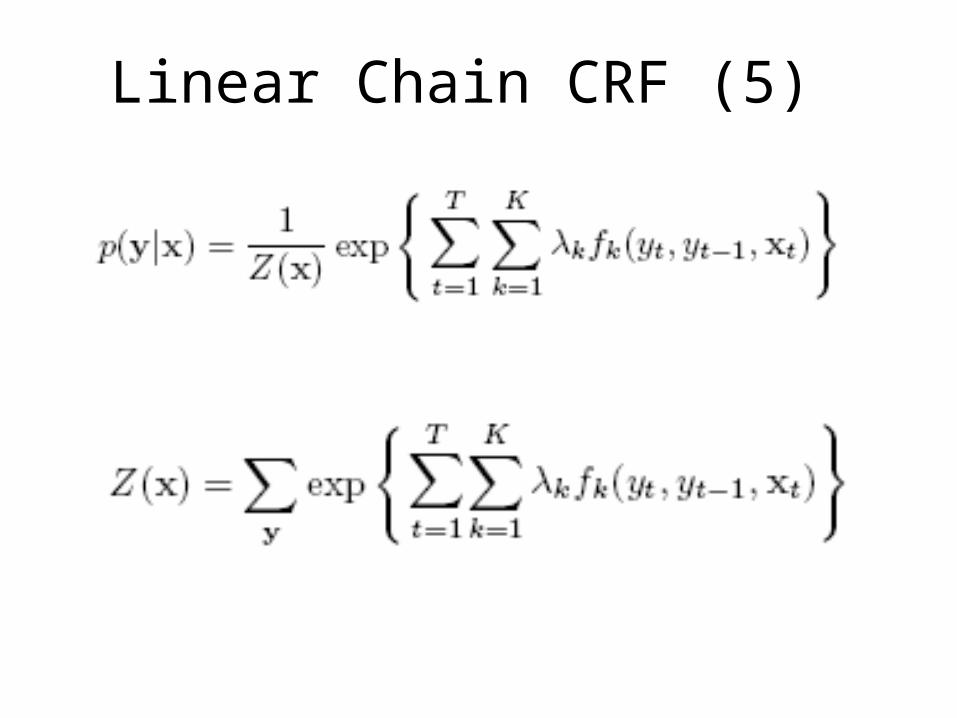
Linear Chain CRF (5)

Feature Functions
• Όσο πιο συχνά επαληθεύεται μία feature function στο training set τόσο πιο μεγάλο βάρος ανατίθεται σε αυτή, τόσο πιο σημαντική είναι.
• Διαισθητικά, αν έχω θετικά βάρη στις ff μπορώ να σκεφτώ ότι όσες περισσότερες ff ικανοποιεί μία ακολουθία τόσο υψηλότερο score p(y/x) ανατίθεται σε αυτή

Feature Functions (2)• Binary ff
• Parameter tying: Το σύνολο παραγόντων:
μοιράζονται τα ίδια βάρη!

Feature Functions (3)
• Τα κάθε διάνυσμα παρατήρησης xt περιλαμβάνει παρατηρήσεις από οποιοδήποτε χρονικό βήμα της ακολουθίας εισόδου που συνιστούν τα χρήσιμα χαρακτηριστικά για την απόφαση τη χρονική στιγμή t, όχι περιορισμός στην ταυτότητα της λέξης wt

Feature Functions (4)• Οι feature functions fpk σε γλωσσικές
εφαρμογές επιλέγονται να έχουν την παρακάτω μορφή:
Οι ff σαν να εξαρτώνται μόνο από το διάνυσμα με χαρακτηριστικά της ακολουθίας παρατήρησης, αλλά έχουμε ξεχωριστό σύνολο βαρών για κάθε διαφορετική διαμόρφωση της εξόδου!
Π.χ. αν βρίσκομαι στην κατάσταση με label location και η παρούσα λέξη ανήκει σε λίστα με ονόματα χωρών

Parameter Estimationανεξάρτητα και ομοίως κατανεμημένα δεδομένα εκπαίδευσης
ακολουθία από αντίστοιχες labels
μία ακολουθία εισόδων
Μεγιστοποίηση ως προς θ της:

Parameter Estimation(2)
l(θ) κυρτή

Inference3 σημαντικά προβλήματα• Στη διάρκεια της εκπαίδευσης η εύρεση των
περιθωριακών κατανομών P(yt,yt-1|x) για κάθε ακμή που απαιτούνται για τον υπολογισμό του gradient
• η εύρεση του Ζ(x) που απαιτείται για τον υπολογισμό της πιθανότητας.
• Κατά την πρόβλεψη για να label ένα καινούριο στιγμιότυπο θα πρέπει να υπολογίσουμε το πιο πιθανό Viterbi labeling:

Inference(2)Για τα linear chain CRF όλα τα προβλήματα inference μπορούν να γίνουν αποδοτικά και επακριβώς από παραλλαγές του βασικού αλγορίθμου δυναμικού προγραμματισμού που χρησιμοποιείται στα ΗΜΜ
Z(x)!

Inference(3)αt(j) :η πιθανότητα της μερικής ακολουθίας παρατηρήσεων
x1..xt και της κατάληξης στην κατάσταση i στο χρόνο t
Αναδρομή:
Αρχικοποίηση:

Inference(4)βi(t) : πιθανότητα της μερικής ακολουθίας παρατηρήσεων από
το t+1 μέχρι το τέλος δεδομένης της κατάστασης i στο χρόνο t
Αναδρομή:
Αρχικοποίηση:

Inference(5)• Συνδυάζοντας τα αποτελέσματα από τις
μπροστά και πίσω αναδρομές μπορούμε να υπολογίσουμε τις περιθωριακές κατανομές:
Για την πιο πιθανή ανάθεση label αντικαθιστούμε το άθροισμα με maximization
Αναδρομή Viterbi:
δt(j): η μέγιστη πιθανότητα της μερικής ακολουθίας παρατηρήσεων μέχρι τη στιγμή t και κατάληξης στην κατάσταση j κατά μήκος ενός μονοπατιού

Inference(6)Η γενίκευση των αλγορίθμων forward backward και Viterbi για την περίπτωση των linear chain CRF προκύπτει άμεσα.
Η προς τα εμπρός ,προς τα πίσω και η αναδρομή Viterbi μπορούν να χρησιμοποιηθούν ως έχουν στα linear chain CRF.Αντί του p(x) υπολογίζεται το Ζ(x)!

Feature Induction
• Σημαντική η ενσωμάτωση conjunctions από ατομικά features, αύξηση της τάξης του μοντέλου, πολύπλοκες επιφάνειες απόφασης
• Ανάγκη επιλογής των σημαντικών και σχετικών με την εφαρμογή ατομικών χαρακτηριστικών -αποφυγή overfitting

Feature Induction(2)
Πλεονεκτήματα• Επίτευξη υψηλότερης απόδοσης με πολύ
μικρότερο πλήθος παραμέτρων- οικονομία σε μνήμη, υπολογιστική ισχύ
• Δυνατότητα στο χρήστη να μαντεύει ελεύθερα χαρακτηριστικά σχετικά με την εφαρμογή, χρήση μεγάλων time shifts
• Χρήση πολύπλοκων μοντέλων,second order

Feature Induction(3)- Βήματα του αλγορίθμου
1. Το σύνολο των χαρακτηριστικών κατατάσσονται με βάση το κέρδος τους
2. Επιλέγεται συγκεκριμένος αριθμός από τα πιο κερδοφόρα υποψήφια χαρακτηριστικά, δημιουργούνται όλες οι conjunctions αυτών και προστίθενται στη λίστα των υποψήφιων χαρακτηριστικών.

Feature Induction(4)- Βήματα του αλγορίθμου
3. Τα υποψήφια χαρακτηριστικά κατατάσσονται με βάση το κέρδος τους και προστίθενται στο μοντέλο ένας συγκεκριμένος αριθμός με τα πιο κερδοφόρα χαρακτηριστικά.
4. Χρησιμοποιείται μία quasi-Newton μέθοδο για να υπολογιστούν οι παράμετροι του νέου μοντέλου.
5. Πηγαίνουμε πίσω στο βήμα 1 μέχρι να ικανοποιηθεί κάποια συνθήκη σύγκλισης.

Feature Induction (5)
• Το feature gain ορίζεται σαν τη βελτίωση της δεσμευμένης log πιθανότητας.
Τα βάρη των προϋπάρχοντων features παραμένουν σταθερά.

Feature Induction (6)
• Συμπεριλαμβάνονται στον υπολογισμό του κέρδους μόνο εκείνοι οι μη σωστά αναγνωρισμένοι κόμβοι
• Κάθε κατάσταση ένα ξεχωριστό πρόβλημα. Για τον υπολογισμό της κατανομής πιθανότητας πάνω στις διάφορες labels θεωρούμε τις labels των άλλων κόμβων εξόδου σταθερές
Για τον αποδοτικό υπολογισμό του gain κάποιου χαρακτηριστικού:

Πειραματικά αποτελέσματαFeatures που χρησιμοποιήθηκαν:
•Ταυτότητα λέξης•Έναρξη λέξης με κεφαλαίο γράμμα•Όλα κεφαλαία•Μόνο αριθμητικοί χαρακτήρες•Μόνο μικρά γράμματα•Μόνος χαρακτήρας•Σημείο στίξης•Μέρος του λόγου•Συμμετοχή σε gazeteers λίστες
Χρησιμοποιήθηκε χρονικό παράθυρο μεγέθους 2

Πειραματικά αποτελέσματα (2)Για ΗTML επιπλέον χαρακτηριστικά:• Εμφάνιση με πλάγια γράμματα(italics)• Εμφάνιση με έντονα γράμματα (bold)• Εμφάνιση σε τίτλο• Τίτλοι κάτω από τους οποίους βρίσκεται η
παρούσα λέξη.• Ταυτότητες επόμενων και προηγούμενων
λέξεων μη συμπεριλαμβανομένου των HTML tags.

Πειραματικά αποτελέσματα (3)
3 Datasets
• Seminar announcements
• CS_courses
• Projects
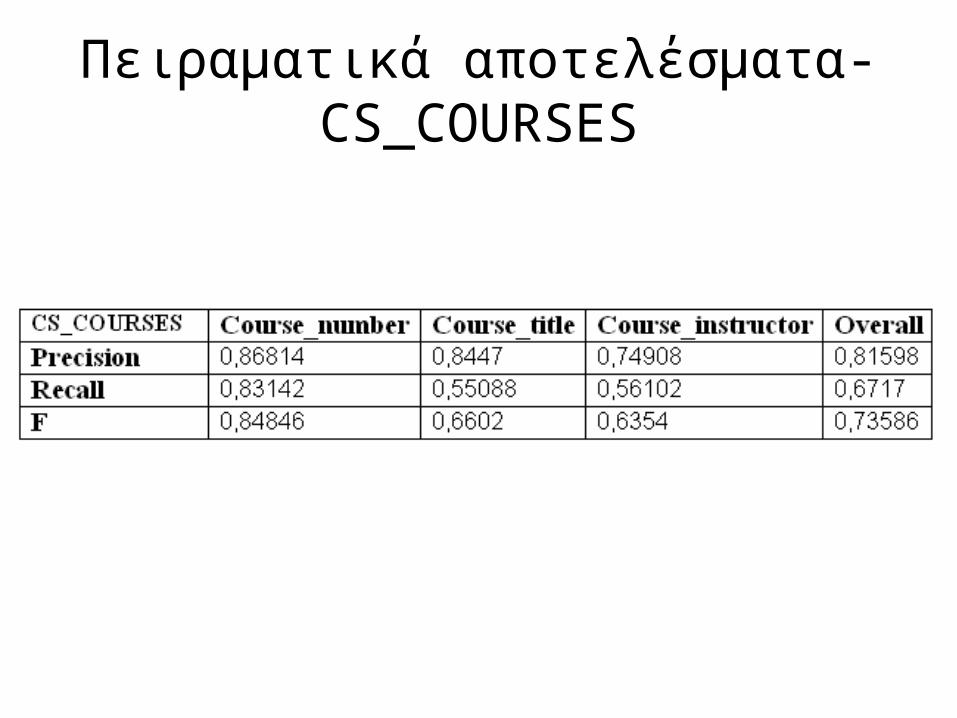
Πειραματικά αποτελέσματα-CS_COURSES
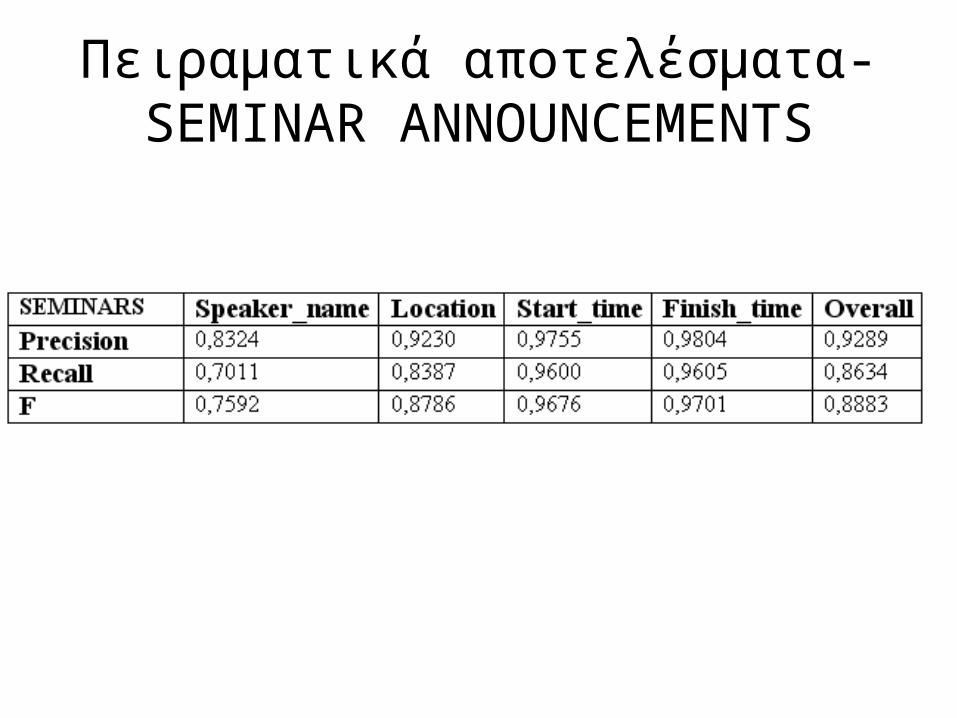
Πειραματικά αποτελέσματα-SEMINAR ANNOUNCEMENTS
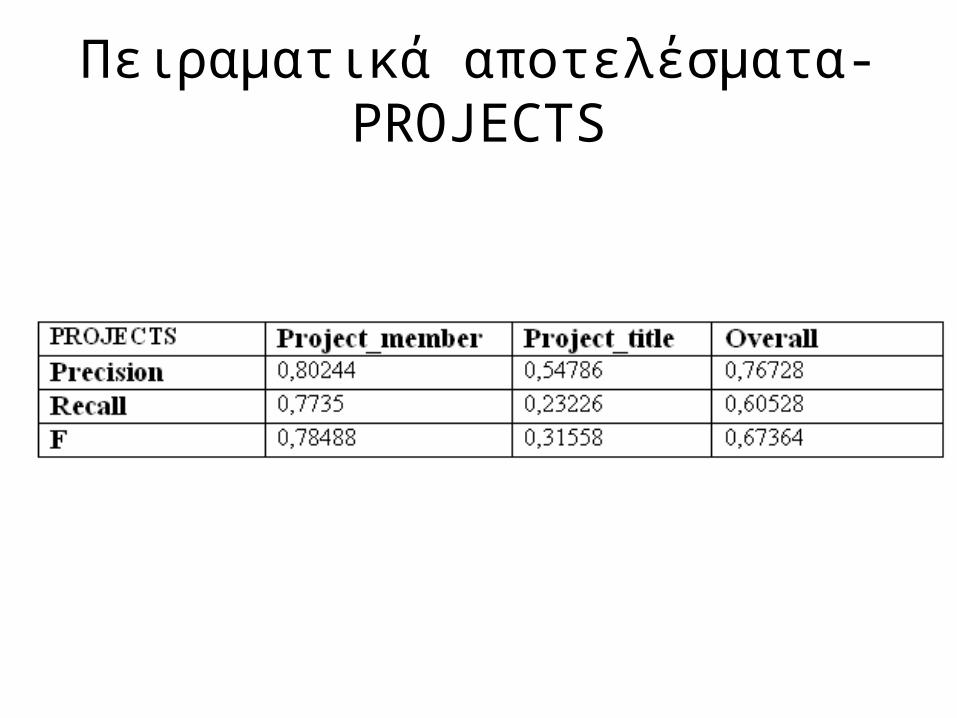
Πειραματικά αποτελέσματα-PROJECTS

Σας ευχαριστώ…

Μαρκοβιανή ιδιότητα (4)Στην περίπτωση που ο γράφος G του Υ είναι δέντρο οι κλίκες του είναι οι ακμές με τις προσκείμενες αντίστοιχες κορυφές. Θεμελιώδες θεώρημα για τα τυχαία πεδία (Hammersley & Clifford, 1971):
• fk feature functions ακμών
• gk feature function κορυφών





























