Embed Size (px)
DESCRIPTION
Часть I. Структурная геномика: выравнивание последовательностей. Ссылки. Учебники: D.W. Mount. Bioinformatics. Sequence and Genome Analysis. NY, Cold Spring Harbor, 2001. - PowerPoint PPT Presentation
Citation preview

Часть Часть I.I.Структурная геномика:Структурная геномика:
выравнивание выравнивание последовательностейпоследовательностей
СсылкиСсылки♦ Учебники:Учебники:
– D.W. Mount. Bioinformatics. Sequence and Genome D.W. Mount. Bioinformatics. Sequence and Genome Analysis. NY, Cold Spring Harbor, 2001.Analysis. NY, Cold Spring Harbor, 2001.
– A.D. Baxevanis, B.F.F. Ouellette (eds.). Bioinformatics. A Practical A.D. Baxevanis, B.F.F. Ouellette (eds.). Bioinformatics. A Practical Guide to the Analysis of Genes and Proteins. NJ, Wiley, 2005.Guide to the Analysis of Genes and Proteins. NJ, Wiley, 2005.
♦ Обзоры Обзоры и статьии статьи
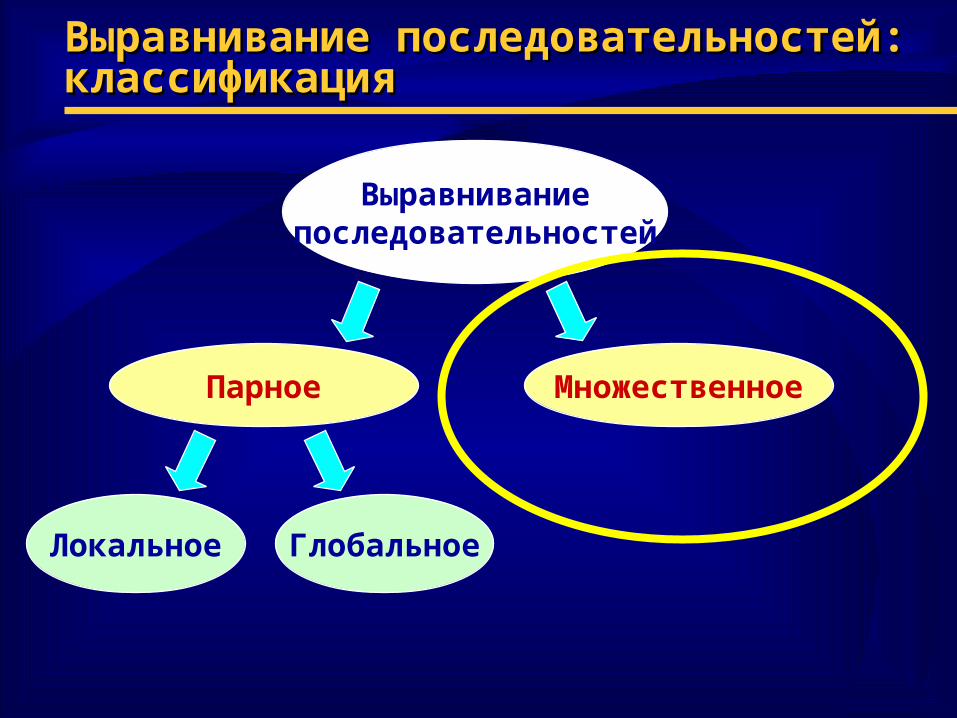
Выравнивание последовательностей: Выравнивание последовательностей: классификацияклассификация
Выравниваниепоследовательностей
Парное Множественное
Локальное Глобальное

Множественное Множественное выравниваниевыравнивание
((multiple alignment)multiple alignment)

Множественное выравнивание: Множественное выравнивание: содержаниесодержание
♦ Определение, разновидности, решаемые Определение, разновидности, решаемые задачи, общие проблемызадачи, общие проблемы
♦ Глобальное выравниваниеГлобальное выравнивание
♦ Оценка качества выравниванияОценка качества выравнивания
♦ Структурное выравниваниеСтруктурное выравнивание
♦ Прогрессивное выравниваниеПрогрессивное выравнивание
♦ Итерационные методыИтерационные методы
♦ Локальные множественные выравниванияЛокальные множественные выравнивания
♦ Вероятностно-статистические методы Вероятностно-статистические методы множественного выравниваниямножественного выравнивания

Множественное Множественное выравнивание: выравнивание:
введениевведение

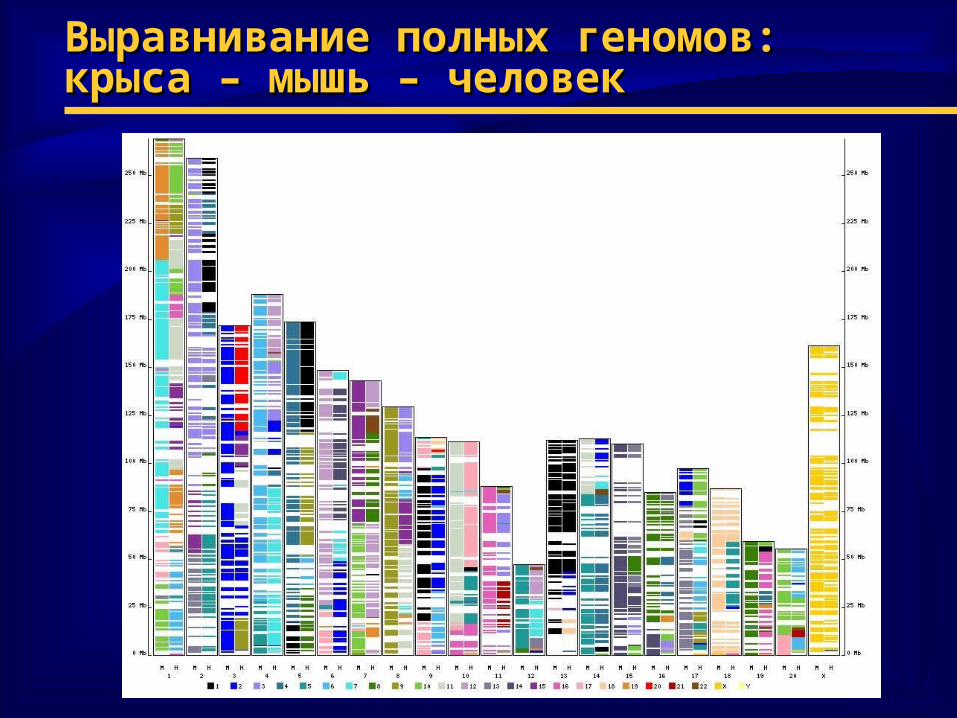
Выравнивание полных геномов:Выравнивание полных геномов:крыса – мышь – человеккрыса – мышь – человек

Множественное выравнивание: Множественное выравнивание: иллюстрациииллюстрации

Множественное выравнивание:Множественное выравнивание:определение и проблемыопределение и проблемы
♦ Определение:Определение: найти оптимальное найти оптимальное соответствие между несколькими соответствие между несколькими последовательностями, если заданыпоследовательностями, если заданы– Матрица соответствияМатрица соответствия– Штраф за делециюШтраф за делецию– Функция веса выравниванияФункция веса выравнивания
♦ Проблемы:Проблемы:– Множество делеций, замен,…– Ограниченное обобщение метода динамического
программирования– Подсчет суммарного веса замен в колонке– Размещение делеций в разных пос-стях и штрафы
за них

Множественное выравнивание:Множественное выравнивание:проблемыпроблемы ( (прод.)прод.)
♦ Проблемы:Проблемы:– Локальные минимумы
• накопление первоначальных ошибок в иерархических алгоритмах
• лучшее дерево соответствует лучшему выравниванию
– Выбор параметров• один набор параметров не может быть
пригодным на все случаи жизни
♦ Сложности выравнивания нарастают с ростом Сложности выравнивания нарастают с ростом различий между последовательностямиразличий между последовательностями

Множественное выравнивание:Множественное выравнивание:три решаемые задачитри решаемые задачи
♦ Поиск Поиск мотивов (блоков)мотивов (блоков) – коротких сигнатур, – коротких сигнатур, идентифицируемых в консервативных участках идентифицируемых в консервативных участках множественного выравниваниямножественного выравнивания– отсутствие вставок и делецийотсутствие вставок и делеций
♦ Построение Построение профилей (матриц весов)профилей (матриц весов): : оценка частоты встречаемости каждой АК в оценка частоты встречаемости каждой АК в каждой позициикаждой позиции
♦ Построение Построение скрытых марковских моделейскрытых марковских моделей ((HMMHMM)) – – обобщенных профилей, описываемых обобщенных профилей, описываемых строго математическистрого математически

Множественное выравнивание:Множественное выравнивание:области применения (1/2)области применения (1/2)♦ Один из ключевых методов в современной Один из ключевых методов в современной
молекулярной биологиимолекулярной биологии♦ Сферы примененияСферы применения
– Филогенетический анализ, Филогенетический анализ, «эволюция» пос-сти«эволюция» пос-сти– Предсказание Предсказание вторичной/третичной структурывторичной/третичной структуры белков белков– Выявление АК-остатков (Выявление АК-остатков (консервативных участковконсервативных участков))
• экспонированных на поверхности белкаэкспонированных на поверхности белка• формирующих активный центрформирующих активный центр• обеспечивающих субстратную специфичностьобеспечивающих субстратную специфичность• критичных для стабилизации втор./трет. структурыкритичных для стабилизации втор./трет. структуры
– Выявление характерных Выявление характерных фрагментовфрагментов для описания для описания белковых семействбелковых семейств
– Выявление неизвестных ранее Выявление неизвестных ранее гомологийгомологий между между генами и последовательностямигенами и последовательностями
– Длинные пос-сти из случайных Длинные пос-сти из случайных коротких фрагментовкоротких фрагментов
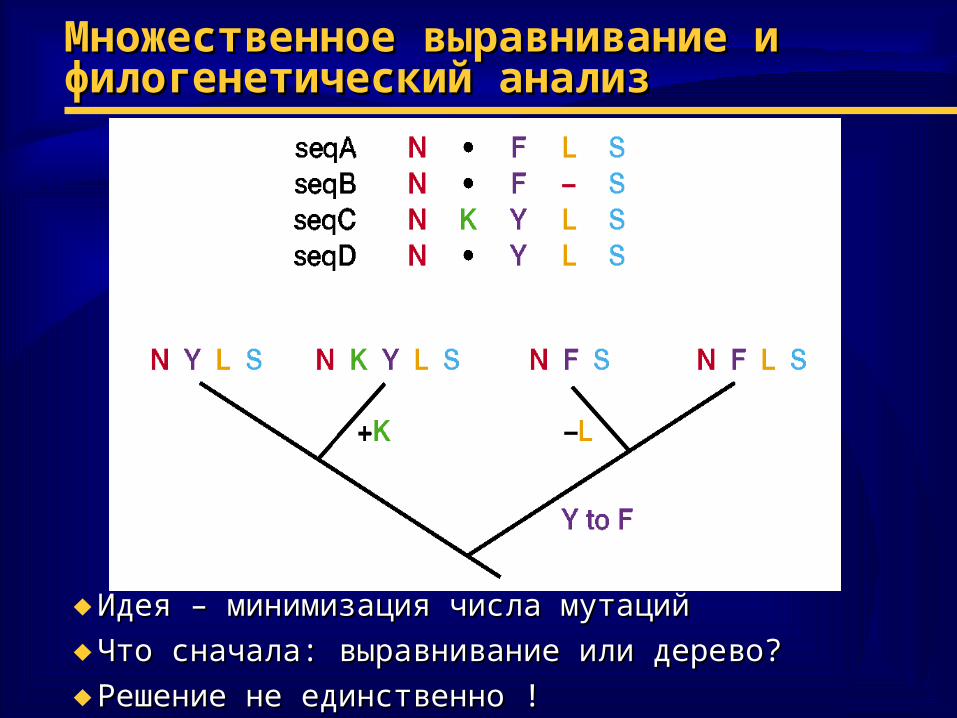
Множественное выравнивание и Множественное выравнивание и филогенетический анализфилогенетический анализ
♦ Идея – минимизация числа мутацийИдея – минимизация числа мутаций
♦ Что сначала: выравнивание или дерево?Что сначала: выравнивание или дерево?
♦ Решение не единственноРешение не единственно ! !

Множественное выравнивание:Множественное выравнивание:консервативные участки во многих пос-стяхконсервативные участки во многих пос-стях
Консервативный – не значит «совпадающий» !

Множественное выравнивание:Множественное выравнивание:белки белки vs.vs. ДНК ДНК♦ Выравнивание Выравнивание белковых семействбелковых семейств
– В алфавите много «букв»В алфавите много «букв»– Эволюционная близость белковых молекул, основа Эволюционная близость белковых молекул, основа
для филогенетических деревьевдля филогенетических деревьев• какие события привели к возникновению данного какие события привели к возникновению данного
семейства?семейства?– Идентификация функционально важных областейИдентификация функционально важных областей– Данные для предсказания структуры– Очевидный «золотой стандарт»
♦ Выравнивание Выравнивание некодирующих участков ДНКнекодирующих участков ДНК– Консервативные участки, отвечающие за регуляцию Консервативные участки, отвечающие за регуляцию
экспрессииэкспрессии– Установление эволюционной близости– Идентификация функционально важных областейИдентификация функционально важных областей– Трудно определяемый «золотой стандарт»

Множественное выравнивание ДНКМножественное выравнивание ДНК
♦ Сайты связывания Сайты связывания TFs = TFs = мотивы ДНК-мотивы ДНК-последовательностейпоследовательностей
♦ Консерватизм– внутривидовой (синергичная регуляция транскрипции
нескольких генов)– межвидовой (близкие механизмы регуляции транскрипции)
♦ Дивергенция– внутривидовая («специальные» цели, завязанные на
метаболизм)– межвидовая (эволюционный дрейф)

Множественное выравнивание ДНК: Множественное выравнивание ДНК: проблемы и варианты решенияпроблемы и варианты решения♦ Гораздо сложнее выравнивания белковГораздо сложнее выравнивания белков
– всего 4 «буквы»всего 4 «буквы»
♦ Отсутствие «золотого стандарта»Отсутствие «золотого стандарта»♦ Необходимость оценитьНеобходимость оценить
– способность связывать белкиспособность связывать белки– влияние на функциювлияние на функцию
♦ Смысл – тестирование гипотезСмысл – тестирование гипотез– об общем предкеоб общем предке– об общих механизмах связывания белковоб общих механизмах связывания белков– о близости функцийо близости функций
♦ Эффективны вероятностно-статистические Эффективны вероятностно-статистические методыметоды– выборки Гиббса– максимизация энтропии

Множественное выравнивание:Множественное выравнивание:четыре группы методовчетыре группы методов
♦ ПрогрессивноеПрогрессивное глобальное выравнивание глобальное выравнивание– начать с наиболее близких пос-стейначать с наиболее близких пос-стей
♦ ИтерационныеИтерационные процедуры процедуры– выравнивание групп пос-стей с последующей выравнивание групп пос-стей с последующей
оптимизациейоптимизацией
♦ Выравнивание Выравнивание по локальным консервативпо локальным консерватив--ным участкамным участкам– построение профилей (разновидности матрицы построение профилей (разновидности матрицы
весов)весов)– поиск блоков в пос-стях (выравниваний без делеций)поиск блоков в пос-стях (выравниваний без делеций)
♦ СтатистическиеСтатистические методы и вероятностные методы и вероятностные моделимодели– поиск шаблонов (поиск шаблонов (patterns)patterns)– скрытые марковские моделискрытые марковские модели

Множественное выравнивание: историяМножественное выравнивание: история
♦ До 1987 г. множественные выравнивания строились До 1987 г. множественные выравнивания строились вручнуювручную
♦ Sankoff (Sankoff (1975 и 19871975 и 1987)) – первый программно – первый программно реализованный алгоритмреализованный алгоритм– основа – филогенетический анализоснова – филогенетический анализ
♦ Barton (1990) – Barton (1990) – оценка качества выравнивания оценка качества выравнивания методом рандомизации, методом рандомизации, AMPSAMPS
♦ Russel & Barton (Russel & Barton (1991992) 2) – структурное выравнивание– структурное выравнивание, , STAMPSTAMP
♦ Thomson et al. (1994) – Thomson et al. (1994) – ClustalWClustalW
♦ Altshul et al. (1997) – Altshul et al. (1997) – PSI-BLASTPSI-BLAST
♦ Notredame et al. (2000) – Notredame et al. (2000) – неиерархическое неиерархическое выравнивание, выравнивание, T-CoffeeT-Coffee
♦ Clamp (2004) - Clamp (2004) - JalViewJalView

Глобальное Глобальное выравниваниевыравнивание
(обобщение ДП)(обобщение ДП)
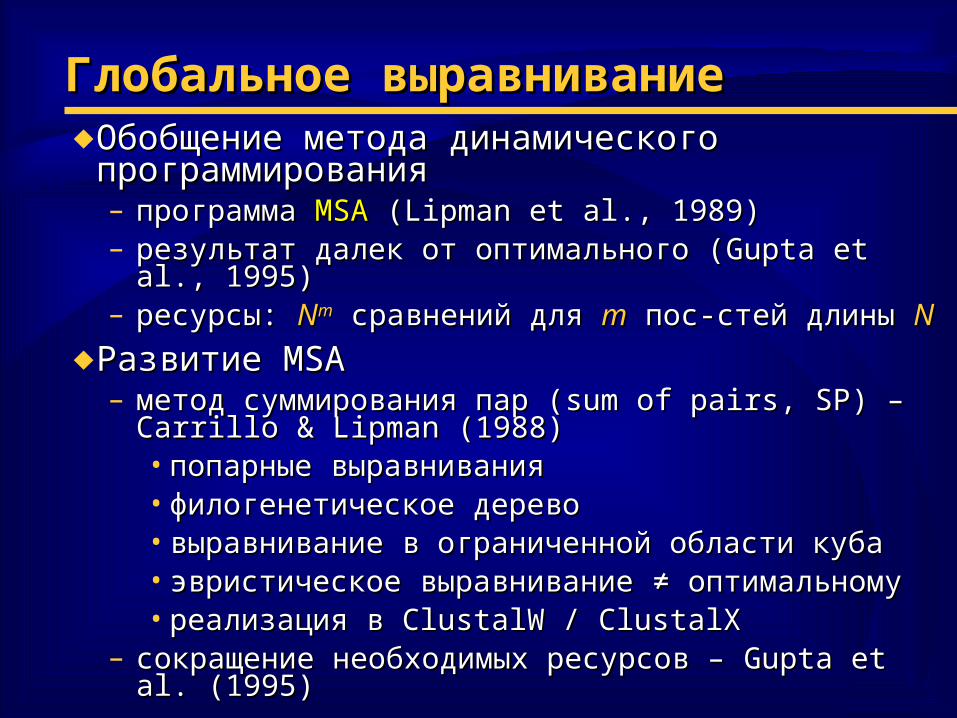
Глобальное выравниваниеГлобальное выравнивание♦ Обобщение метода динамического Обобщение метода динамического
программированияпрограммирования– программа программа MSAMSA (Lipman et al., 1989) (Lipman et al., 1989)– результат далек от оптимального (результат далек от оптимального (Gupta et al., 1995)Gupta et al., 1995)– ресурсы: ресурсы: NNmm сравнений для сравнений для mm пос-стей длины пос-стей длины NN
♦ Развитие Развитие MSAMSA– метод суммирования пар (метод суммирования пар (sum of pairs, SPsum of pairs, SP) – ) – Carrillo Carrillo
& Lipman (1988)& Lipman (1988)• попарные выравниванияпопарные выравнивания• филогенетическое деревофилогенетическое дерево• выравнивание в ограниченной области кубавыравнивание в ограниченной области куба• эвристическое выравнивание эвристическое выравнивание ≠ оптимальному≠ оптимальному• реализация в реализация в ClustalW / ClustalXClustalW / ClustalX
– сокращение необходимых ресурсов – сокращение необходимых ресурсов – Gupta et al.Gupta et al. ((19951995))
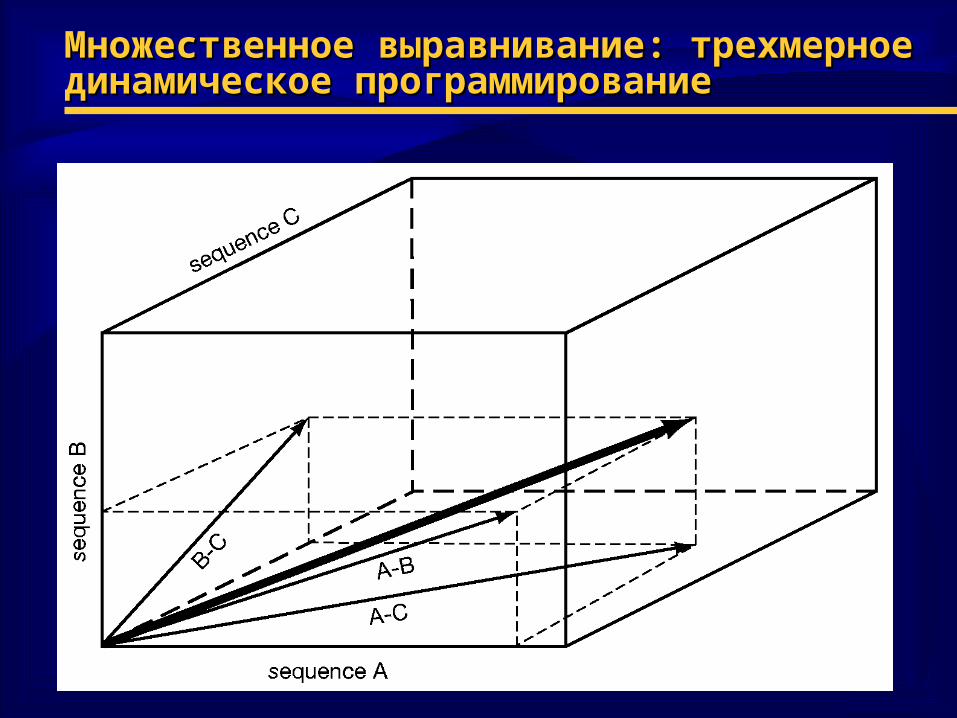
Множественное выравнивание: трехмерное Множественное выравнивание: трехмерное динамическое программированиединамическое программирование
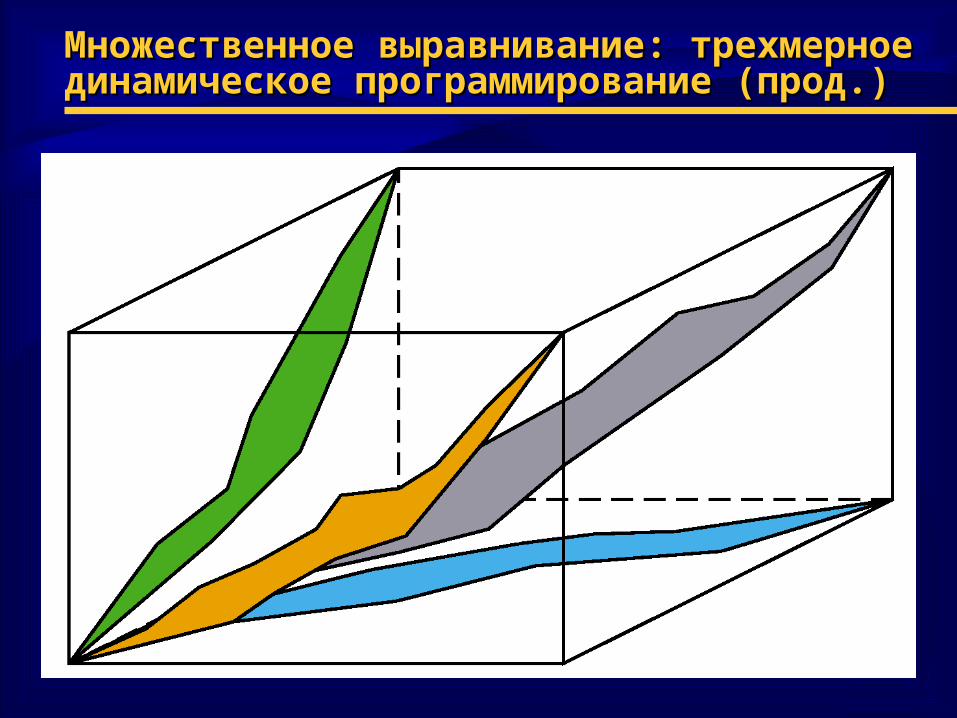
Множественное выравнивание: трехмерное Множественное выравнивание: трехмерное динамическое программирование (прод.)динамическое программирование (прод.)

Глобальное выравнивание (прод.)Глобальное выравнивание (прод.)♦ Оценка качестваОценка качества
– веса множественных выравниваний (веса множественных выравниваний (SP scoreSP score) = ) = сумме весов попарных выравниванийсумме весов попарных выравниваний
– поиск набольшего суммарного весапоиск набольшего суммарного веса– взвешивание весов (опционально)взвешивание весов (опционально)
• по филогенетическому деревупо филогенетическому дереву• учет эволюционно близких пос-стейучет эволюционно близких пос-стей• «дифференц«дифференц..» вес » вес εε для каждой пары = для каждой пары = ((вес пары вес пары
в в MSA) – (MSA) – (вес при оптимальнвес при оптимальн. . парном вырав-нии)парном вырав-нии)• степень дивергенции пос-стей в выравниваниистепень дивергенции пос-стей в выравнивании
δδ = = ΣΣ εεii (чем больше (чем больше δδ, тем сильнее дивергенция), тем сильнее дивергенция)– MSAMSA: матрица замен : матрица замен PAM250, PAM250, постоянный штраф за постоянный штраф за
любую делециюлюбую делецию
♦ Возможность применения к большему числу (6-Возможность применения к большему числу (6-8) 8) короткихкоротких последовательностей последовательностей

Оценка качестваОценка качества
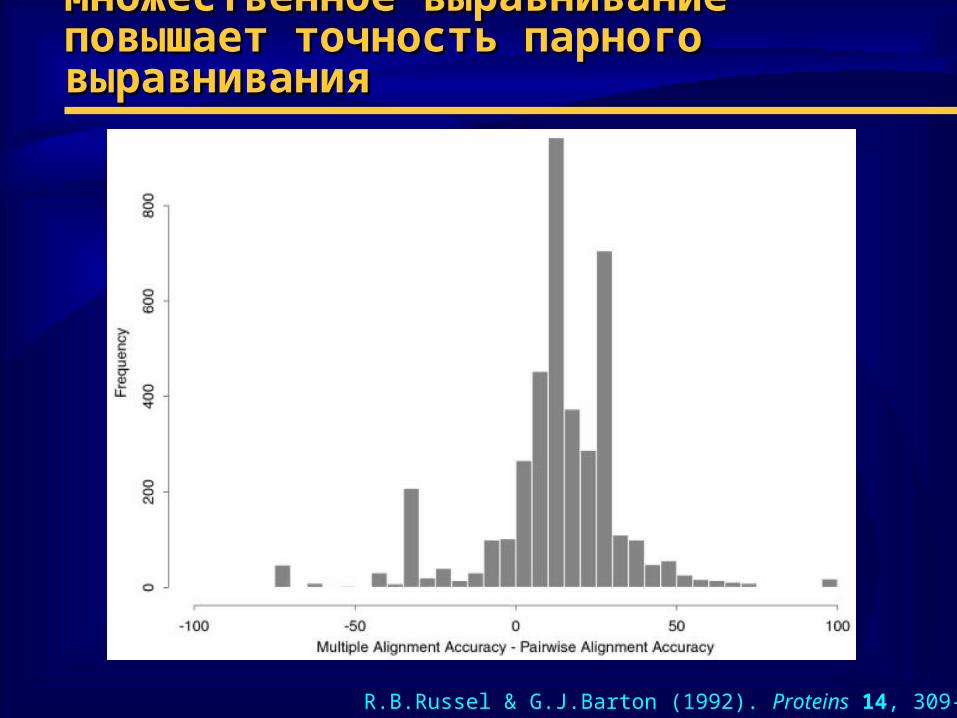
Множественное выравнивание повышает Множественное выравнивание повышает точность парного выравниванияточность парного выравнивания
R.B.Russel & G.J.Barton (1992). Proteins 14, 309-323.

Метод Метод SP SP не свободен от недостатковне свободен от недостатков
♦ SP: SP: сумма весов сумма весов любых парных любых парных комбинаций АК в комбинаций АК в данном столбцеданном столбце
C – C – цистеинцистеин
N - N - аспарагинаспарагин
Расчет весов по BLOSUM62
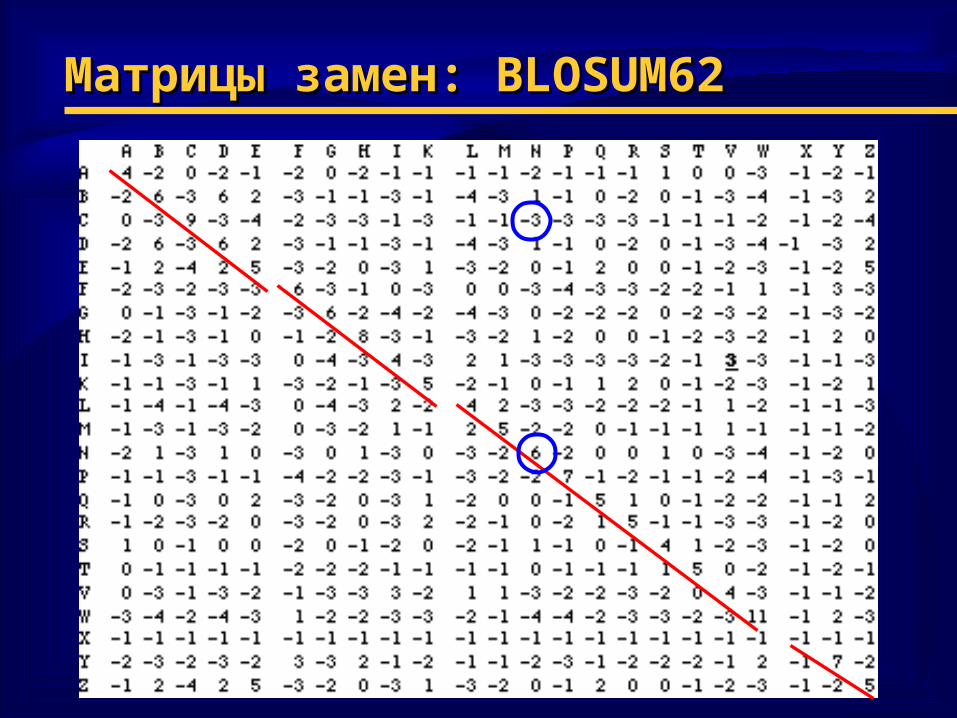
Матрицы замен: Матрицы замен: BLOSUM62BLOSUM62

Метод Метод SP SP не свободен от недостатковне свободен от недостатков
♦ SP: SP: сумма весов сумма весов любых парных любых парных комбинаций АК в комбинаций АК в данном столбцеданном столбце
♦ Быстрое убывание Быстрое убывание веса с ростом числа веса с ростом числа замензамен
♦ Отношение весов Отношение весов при фиксированном при фиксированном числе замен числе замен убывает с ростом убывает с ростом числа пос-стейчисла пос-стей– для одной замены для одной замены
((BLOSUM62)BLOSUM62)
9(n-1)/[6n(n-1)/2] = 9(n-1)/[6n(n-1)/2] = = = 3/n3/n
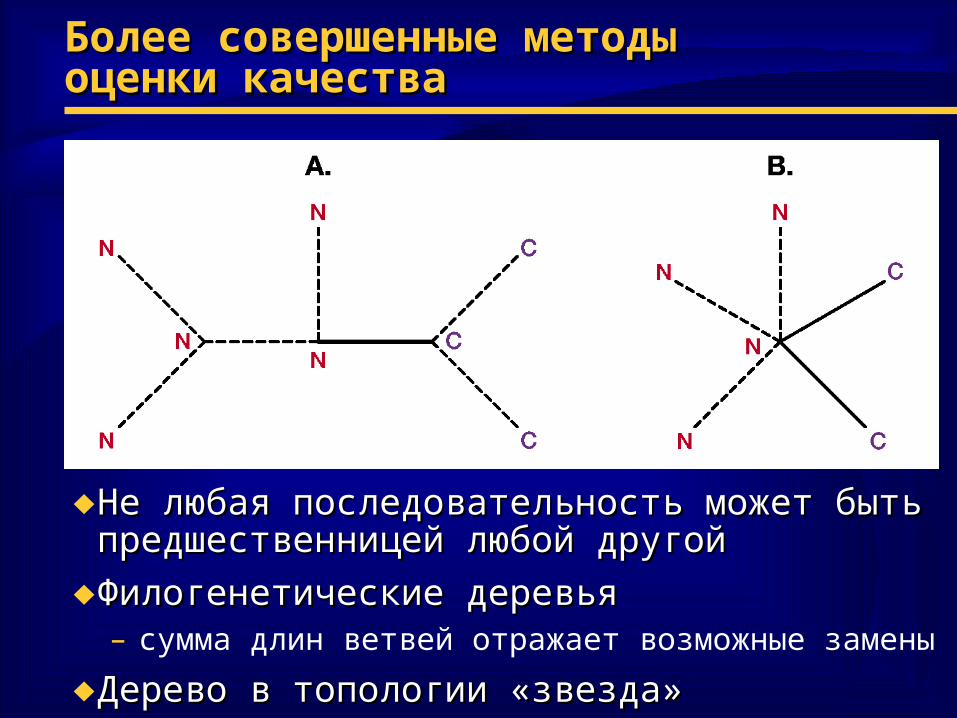
Более совершенные методыБолее совершенные методыоценки качестваоценки качества
♦ Не любая последовательность может быть Не любая последовательность может быть предшественницей любой другойпредшественницей любой другой
♦ Филогенетические деревьяФилогенетические деревья– сумма длин ветвей отражает возможные замены
♦ Дерево в топологии «звезда»Дерево в топологии «звезда»

Статистическая значимость Статистическая значимость выравниваниявыравнивания♦ Оценка качестваОценка качества
– выравнивание с высоким весом не эквивалентно выравнивание с высоким весом не эквивалентно биологической близостибиологической близости
– оценка методом рандомизацииоценка методом рандомизации– случайное перемешивание «букв» в случайное перемешивание «букв» в
последовательности при сохранении состава и последовательности при сохранении состава и длиныдлины
– выборочная функция распределения весоввыборочная функция распределения весов– оценка оценка Z-Z-веса: веса: ZZ = ( = (SS - < - <ss>)/>)/σσ ии Z > 6Z > 6– квантильные оценкиквантильные оценки
♦ НедостаткиНедостатки– ZZ < 6 < 6 может также отвечать осмысленному может также отвечать осмысленному
выравниваниювыравниванию– стандартные таблицы для стандартные таблицы для ZZ дают завышенные дают завышенные
уровни значимостиуровни значимости
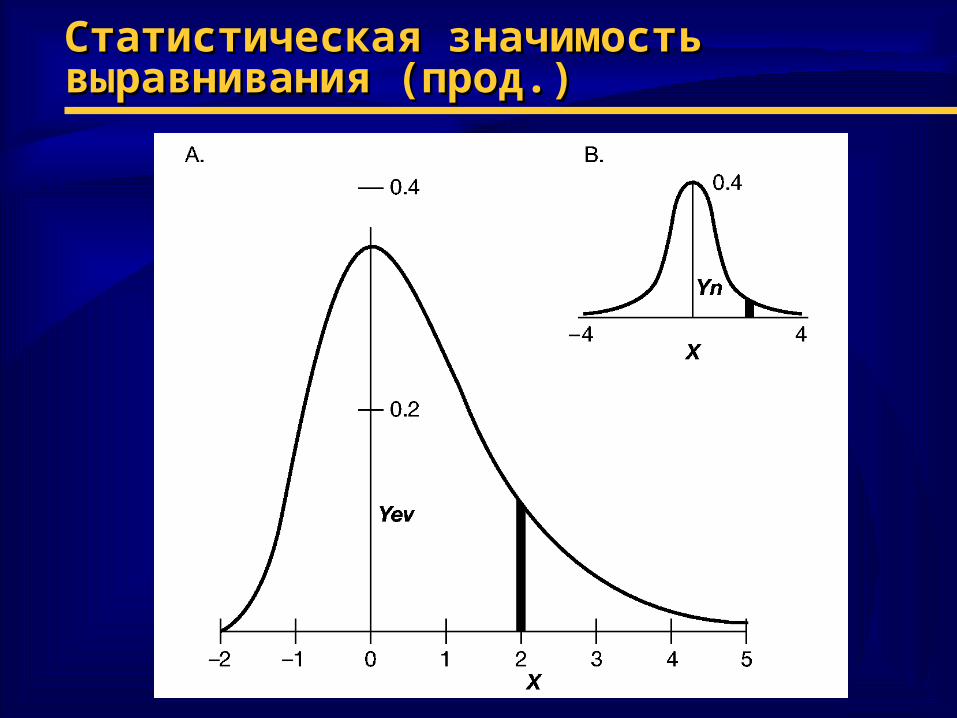
Статистическая значимость Статистическая значимость выравнивания (прод.)выравнивания (прод.)

Структурное Структурное выравниваниевыравнивание

Структурное выравнивание: зачем?Структурное выравнивание: зачем?♦ ПримененияПрименения
– «золотой стандарт» для выравнивания высоко гомологичных белков – выявление общего предка
– идентификация общих значимых элементов структуры для негомологичных белков
– кластеризация белков (разбиение на белковые семейства) на основе структурной близости
♦ Выравнивание должно отражать сходство Выравнивание должно отражать сходство структурструктур– совпадение общих структурных и функциональных совпадение общих структурных и функциональных
элементовэлементов
♦ Проблема: Проблема: оптимум в вычисленияхоптимум в вычислениях ≠≠
оптимуму в биологииоптимуму в биологии
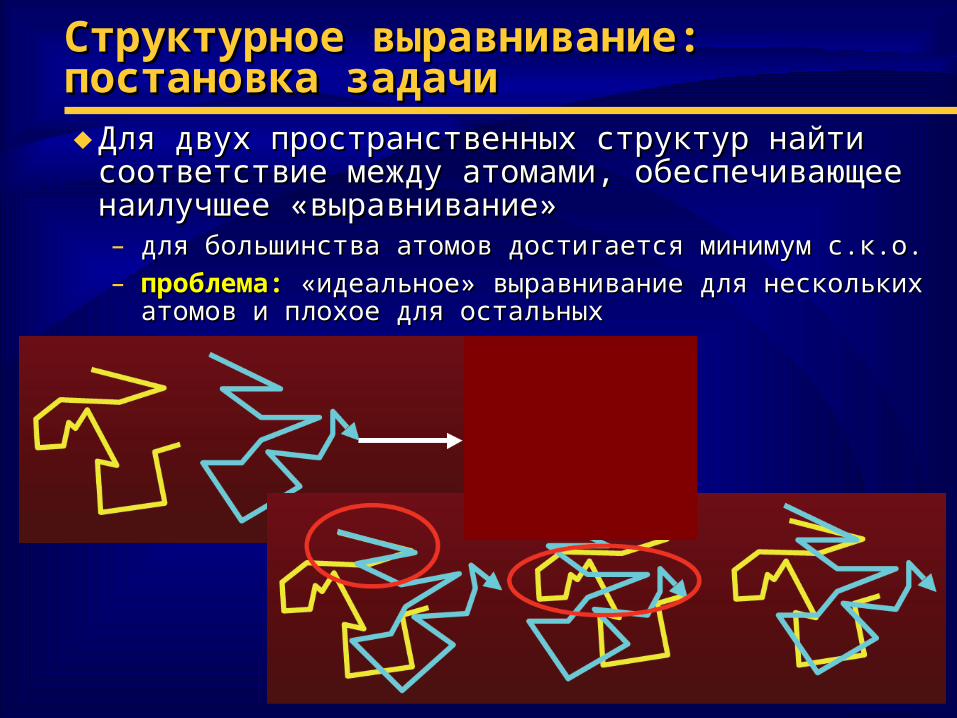
Структурное выравнивание:Структурное выравнивание:постановка задачипостановка задачи♦ Для двух пространственных структур найти Для двух пространственных структур найти
соответствие между атомами, обеспечивающее соответствие между атомами, обеспечивающее наилучшее «выравнивание»наилучшее «выравнивание»– для большинства атомов достигается минимум с.к.о.для большинства атомов достигается минимум с.к.о.– проблема:проблема: «идеальное» выравнивание для нескольких «идеальное» выравнивание для нескольких
атомов и плохоеатомов и плохое для остальныхдля остальных

Структурное выравнивание:Структурное выравнивание:оценка результатаоценка результата♦ КритерииКритерии
– число соответствий между АК– суммарное евклидово расстояние между
выровненными АК– доля идентичных АК среди выровненных– число введенных делеций– размер сравниваемых белков– консерватизм окружения известных активных
центров
♦ Универсальных критериев не существуетУниверсальных критериев не существует♦ ЗамечаниеЗамечание
– отличие от поиска минимума евклидова расстояния отличие от поиска минимума евклидова расстояния при известном соответствии атомовпри известном соответствии атомов
– с.к.о. используется только в качестве метрикис.к.о. используется только в качестве метрики– комбинаторный подходкомбинаторный подход
!!
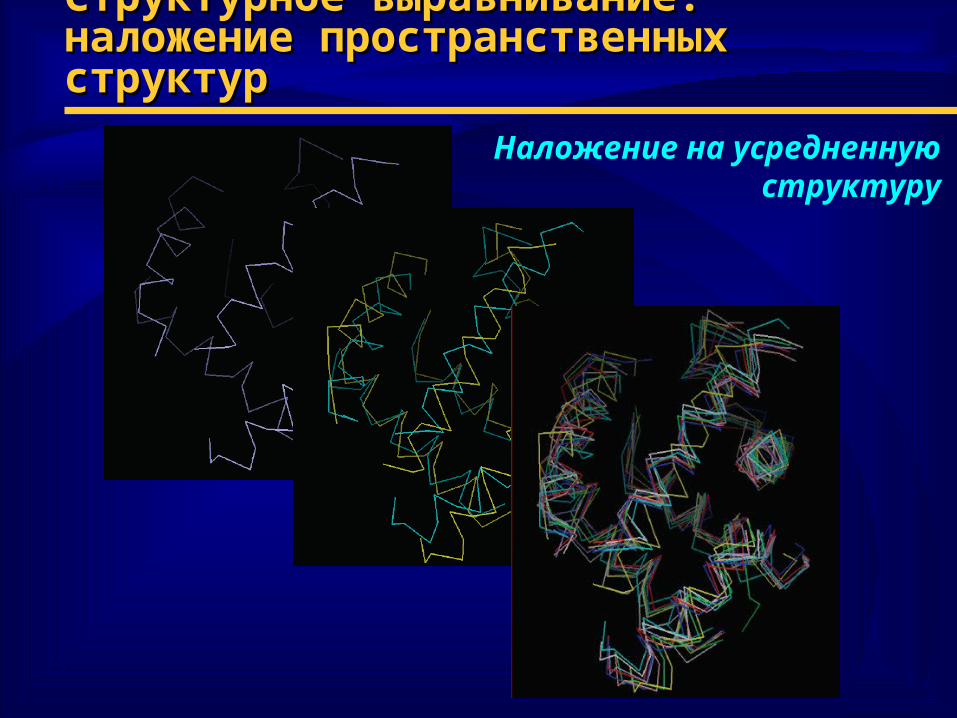
Структурное выравнивание:Структурное выравнивание:наложение пространственных структурналожение пространственных структур
Наложение на усредненнуюструктуру
Структурное выравнивание:Структурное выравнивание:наложение пространственных структурналожение пространственных структур

Структурное выравнивание: различные Структурное выравнивание: различные классы белковых структур (1)классы белковых структур (1)
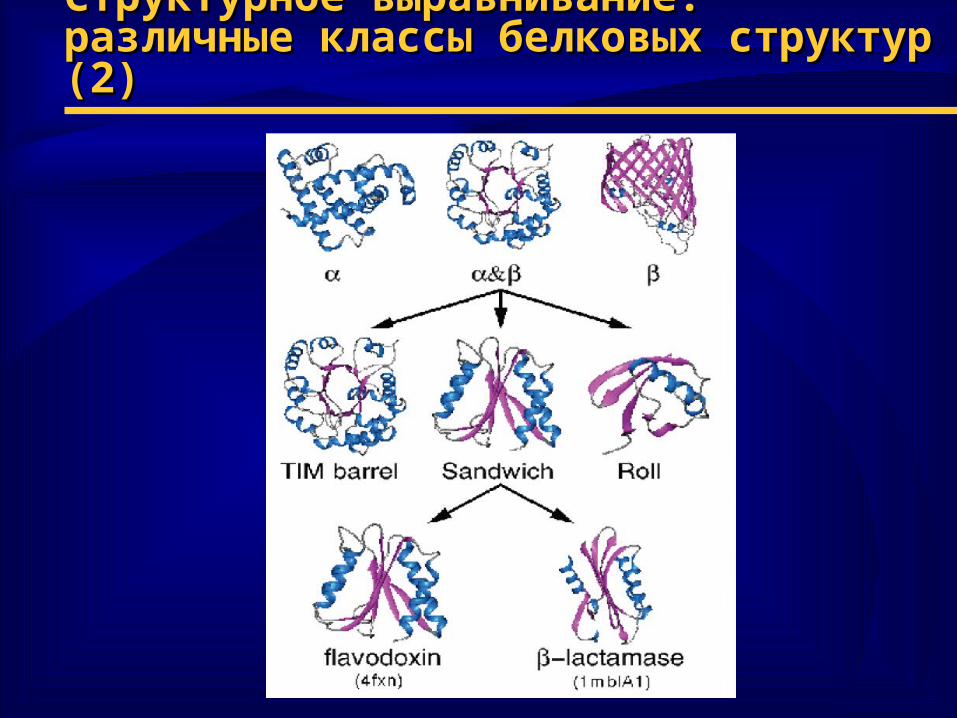
Структурное выравнивание: различные Структурное выравнивание: различные классы белковых структур (2)классы белковых структур (2)

Структурное выравнивание: различные Структурное выравнивание: различные классы белковых структур (3)классы белковых структур (3)
Разные суперсемейства «бочонков»
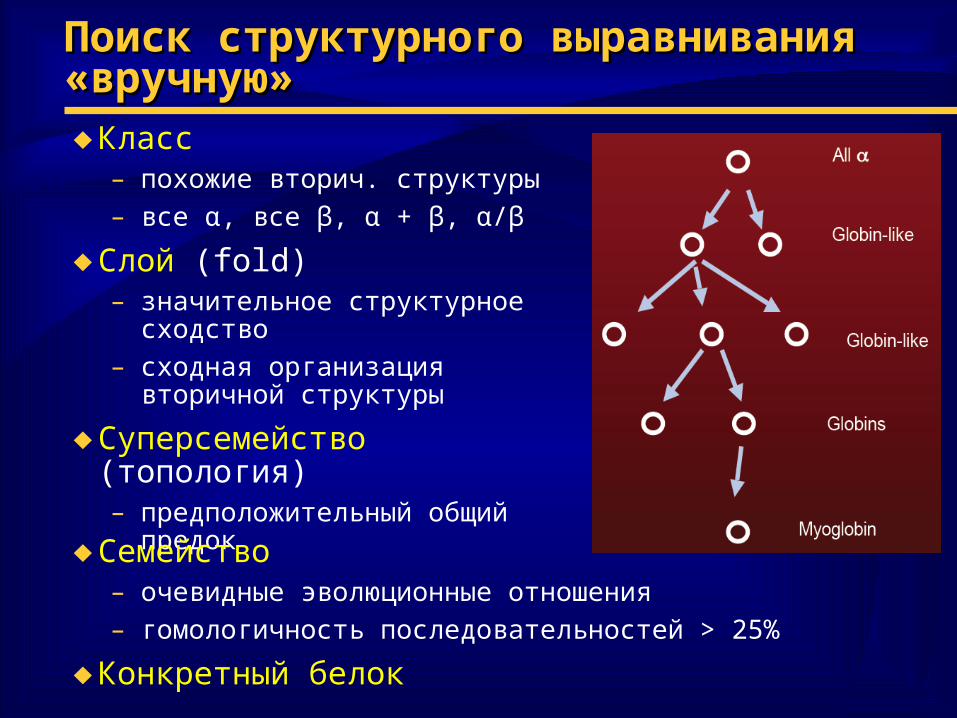
Поиск структурного выравнивания Поиск структурного выравнивания «вручную»«вручную»♦ Класс
– похожие вторич. структуры– все α, все β, α + β, α/β
♦ Слой (fold)– значительное структурное
сходство– сходная организация вторичной
структуры
♦ Суперсемейство (топология)– предположительный общий
предок
♦ Семейство– очевидные эволюционные отношения– гомологичность последовательностей > 25%
♦ Конкретный белок
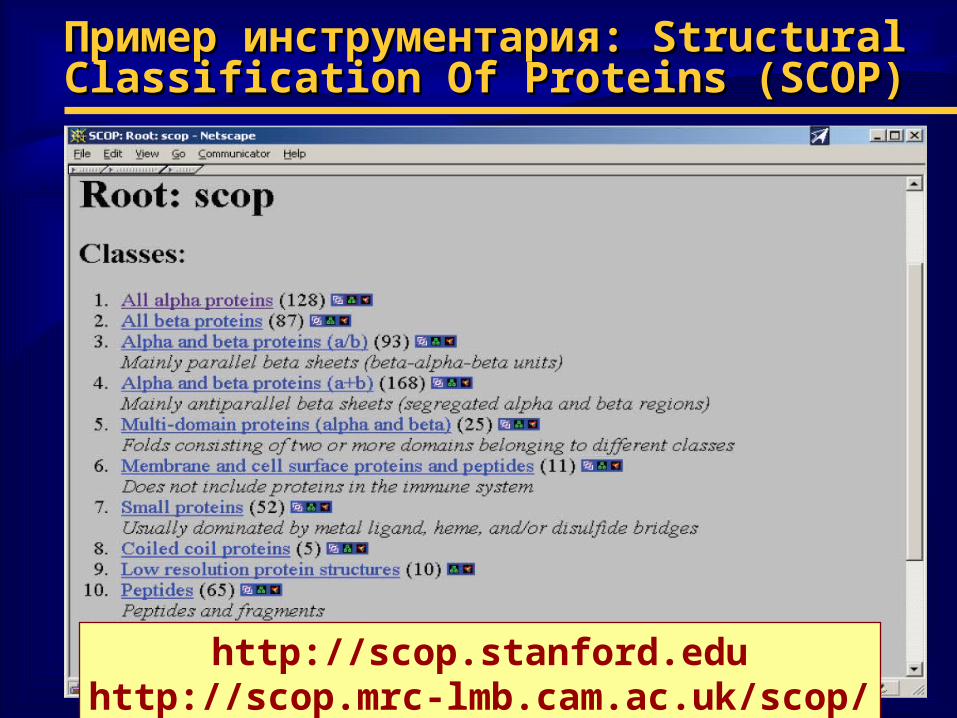
Пример инструментария: Пример инструментария: Structural Structural Classification Of Proteins (SCOP)Classification Of Proteins (SCOP)
http://scop.stanford.eduhttp://scop.mrc-lmb.cam.ac.uk/scop/
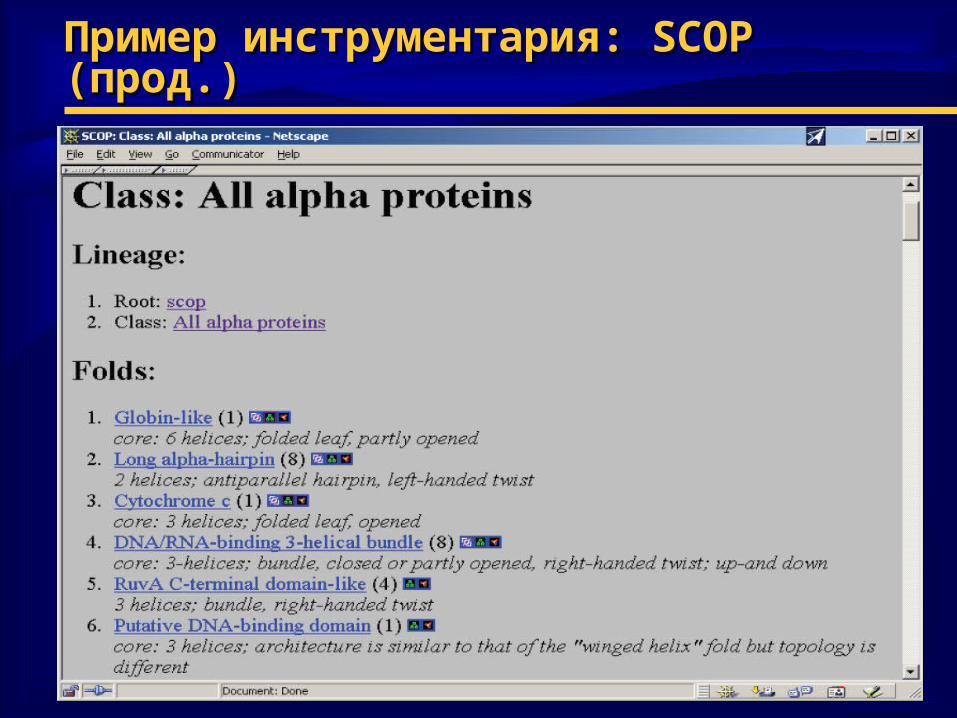
Пример инструментария: Пример инструментария: SCOPSCOP (прод. (прод.))
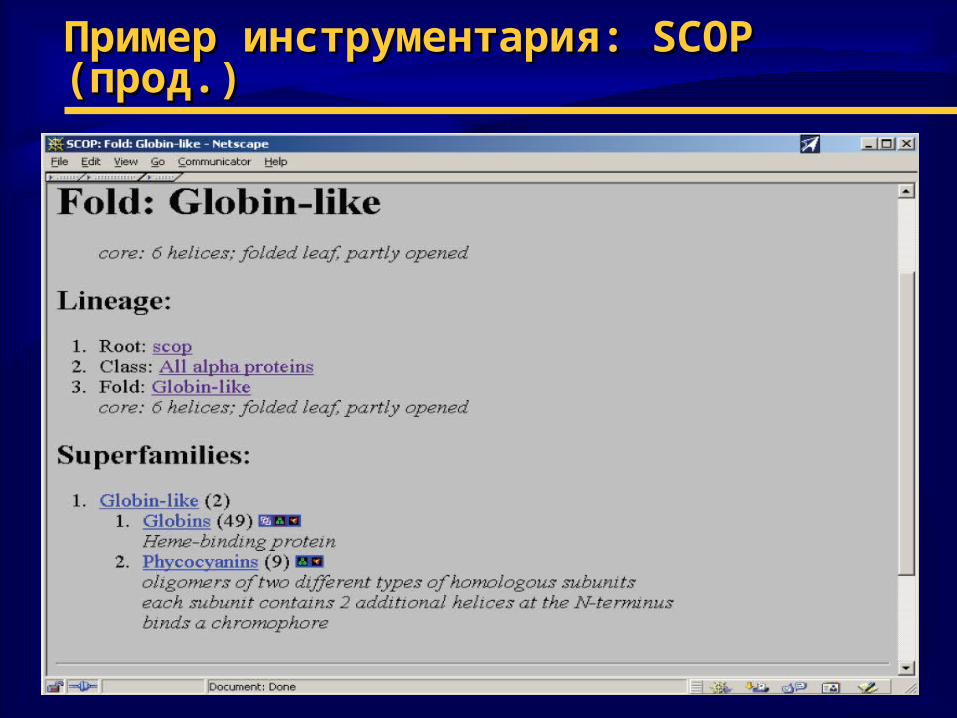
Пример инструментария: Пример инструментария: SCOPSCOP (прод. (прод.))
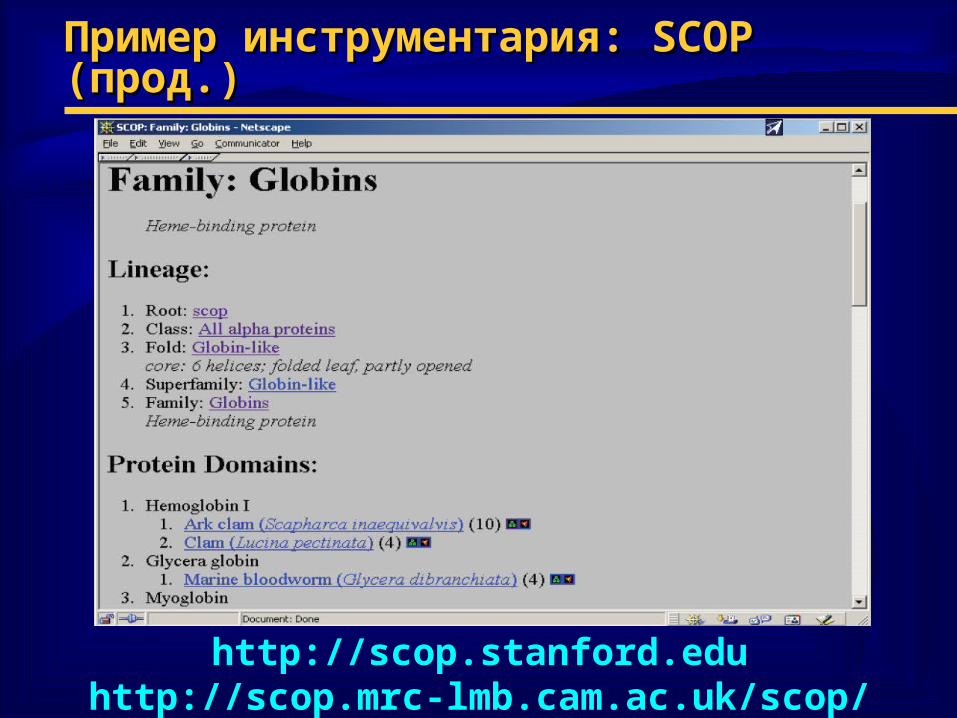
Пример инструментария: Пример инструментария: SCOPSCOP (прод. (прод.))
http://scop.stanford.eduhttp://scop.mrc-lmb.cam.ac.uk/scop/

Как распознать близость структур?Как распознать близость структур?
♦ На глазНа глаз
♦ АлгоритмическиАлгоритмически– точечные методы: установление соответствий по точечные методы: установление соответствий по
точечным свойствам (расстояниям)точечным свойствам (расстояниям)– анализ вторичной структуры: установление установление
соответствий по векторам, изображающим элементы соответствий по векторам, изображающим элементы вторичной структурывторичной структуры
♦ Четыре метода, оперирующих прототипамиЧетыре метода, оперирующих прототипами– STRUCTAL (Levitt, Subbiah, Gerstein)– DALI (Holm, Sander)– LOCK (Singh, Brutlag)– геометрическое хэширование (Nussinov et al)

Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: STRUCTALSTRUCTAL
♦ Итерационное динамическое программирование для Итерационное динамическое программирование для улучшения случайно выбранного начального улучшения случайно выбранного начального выравниваниявыравнивания
♦ Шаги алгоритма1) начать с произвольного набора соответствий между двумя
структурами (выравнивание пос-стей, вторичных структур, на глаз, случайное)
2) выровнять две структуры, исходя из текущего набора соответствий
3) построить матрицу весов (Нидлмана-Вунша), исходя из расстояний между всевозможными парами точек
4) ДП: обратное движение по матрице весов для нахождения выравнивания с наибольшим суммарным весом
5) повторение шагов 2-4, пока суммарный вес не перестанет меняться
♦ Метод эвристический, не гарантирует результата, зависит от выбора начального выравнивания

Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: STRUCTALSTRUCTAL (прод.) (прод.)
♦ Оценка выравнивания: чем лучше Оценка выравнивания: чем лучше выравнивание, тем выше суммарный весвыравнивание, тем выше суммарный вес– возможность учесть дополнительные факторывозможность учесть дополнительные факторы
♦ ВесВес
SS((dd) = ) = MM { 2 / [1 + ( { 2 / [1 + (dd//dd00))22]] – 1}– 1}
где где MM – – максимальный ожидаемый вес, максимальный ожидаемый вес, dd – – измеряемая величина (измеряемая величина (e.g. e.g. расстояние между расстояние между точками), точками), dd00 – – значение значение dd, , соответствующее соответствующее MM = 0 = 0
При При 0 0 ≤ ≤ dd ≤ ≤ dd00 увеличение веса, при увеличение веса, при dd > > dd00 - - штрафштраф
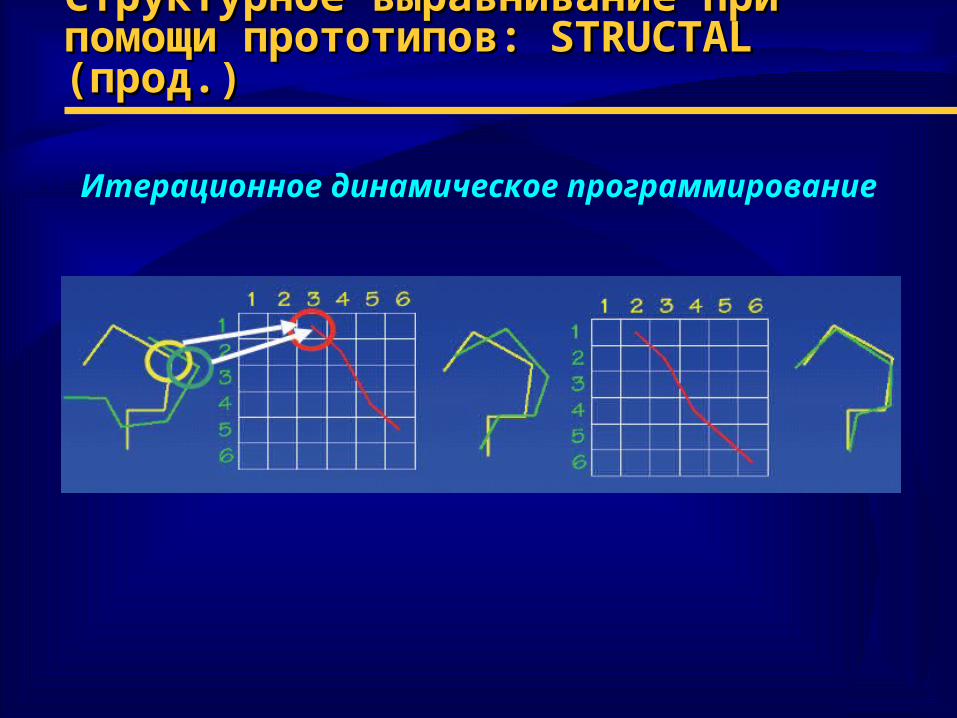
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: STRUCTALSTRUCTAL (прод.) (прод.)
Итерационное динамическое программирование
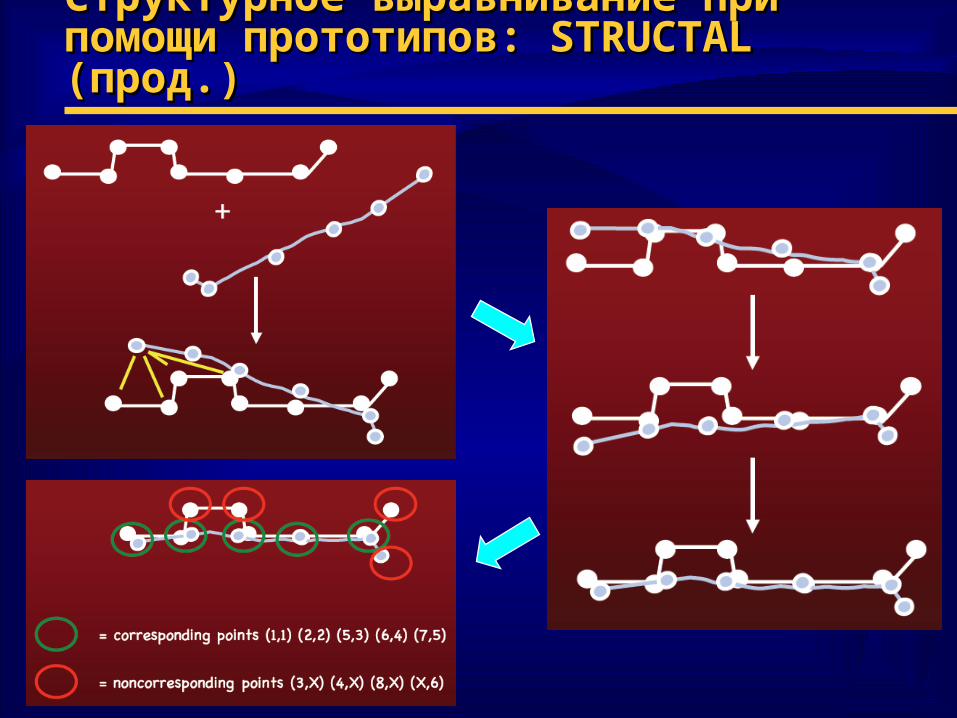
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: STRUCTALSTRUCTAL (прод.) (прод.)

Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: LOCKLOCK
♦ Основная идея:Основная идея:– элементы вторичной структуры представляются при элементы вторичной структуры представляются при
помощи векторовпомощи векторов– быстрый поиск похожих структурбыстрый поиск похожих структур
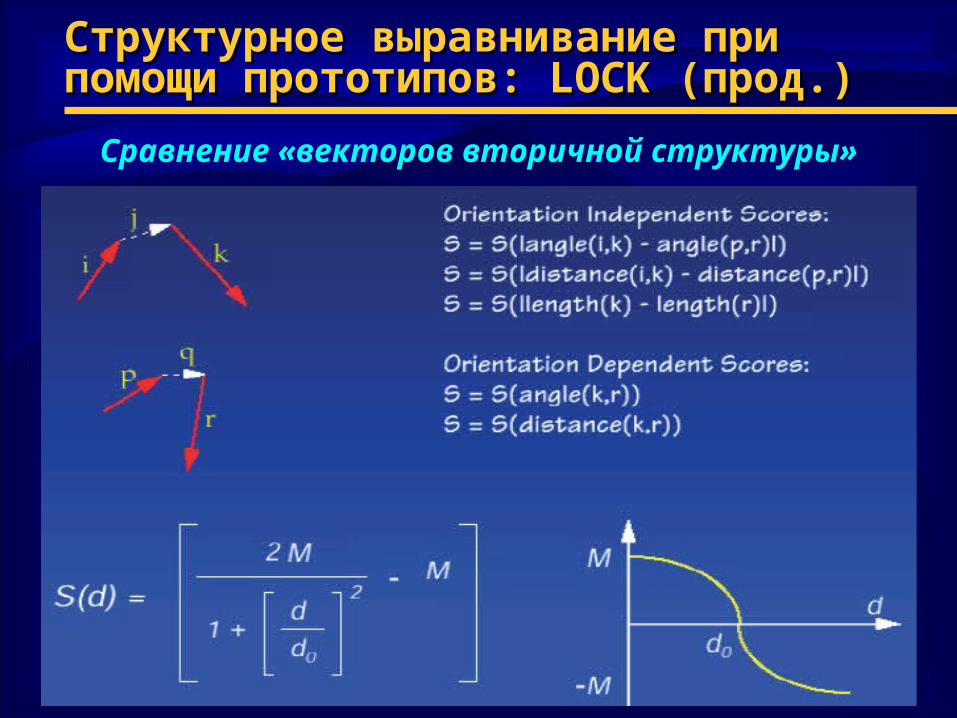
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: LOCK (LOCK (прод.)прод.)
Сравнение «векторов вторичной структуры»
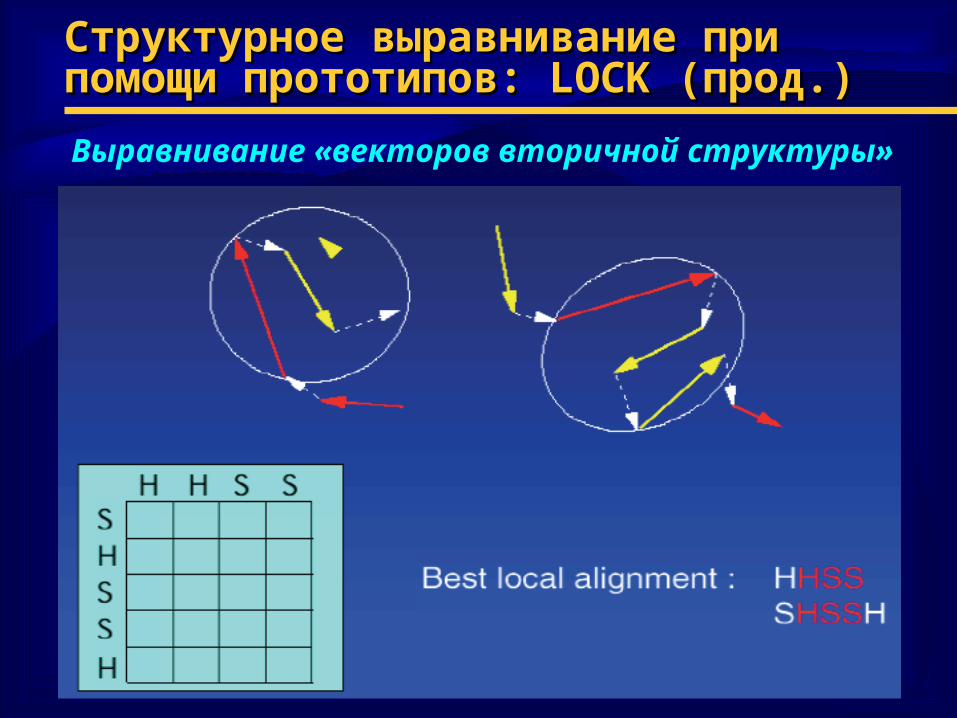
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: LOCK (LOCK (прод.)прод.)
Выравнивание «векторов вторичной структуры»

Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: прототипов: LOCKLOCK (прод.) (прод.)
♦ Шаги алгоритма1) определить локальные элементы вторичной
структуры
2) построить начальное наложение структур методом ДП, используя• выбранную функцию веса• векторное представление элементов вторичной
структуры
3) определить ближайших соседей, минимизируя евклидовы расстояния
4) удалить лишние атомы, чтобы получить минимальное с.к.о.
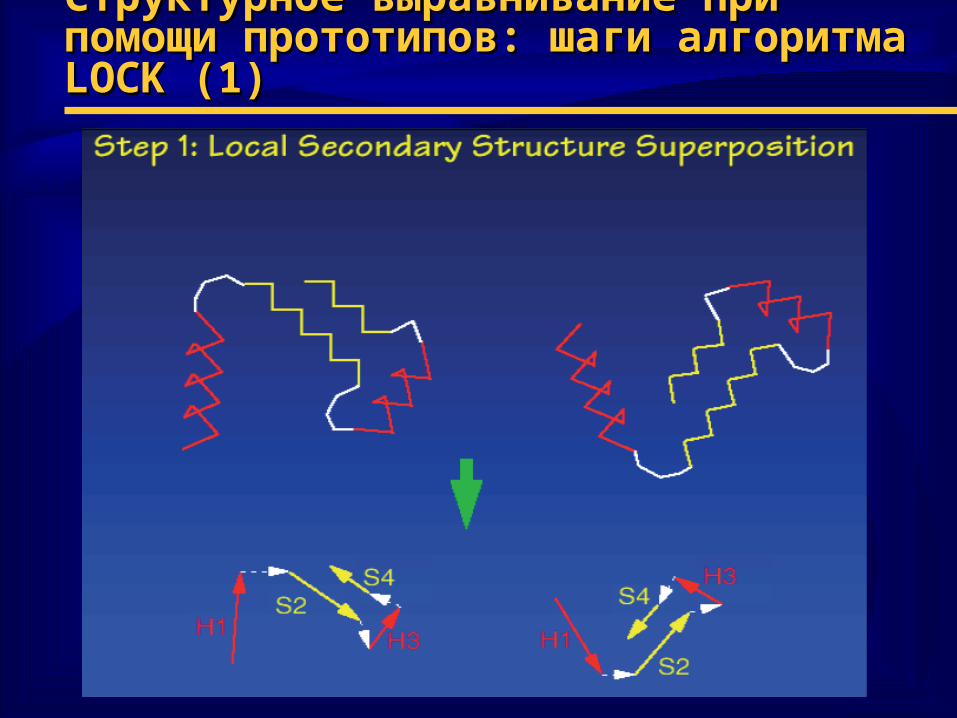
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: шаги алгоритма прототипов: шаги алгоритма LOCKLOCK (1) (1)

Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: шаги алгоритма прототипов: шаги алгоритма LOCKLOCK (1 (1aa))
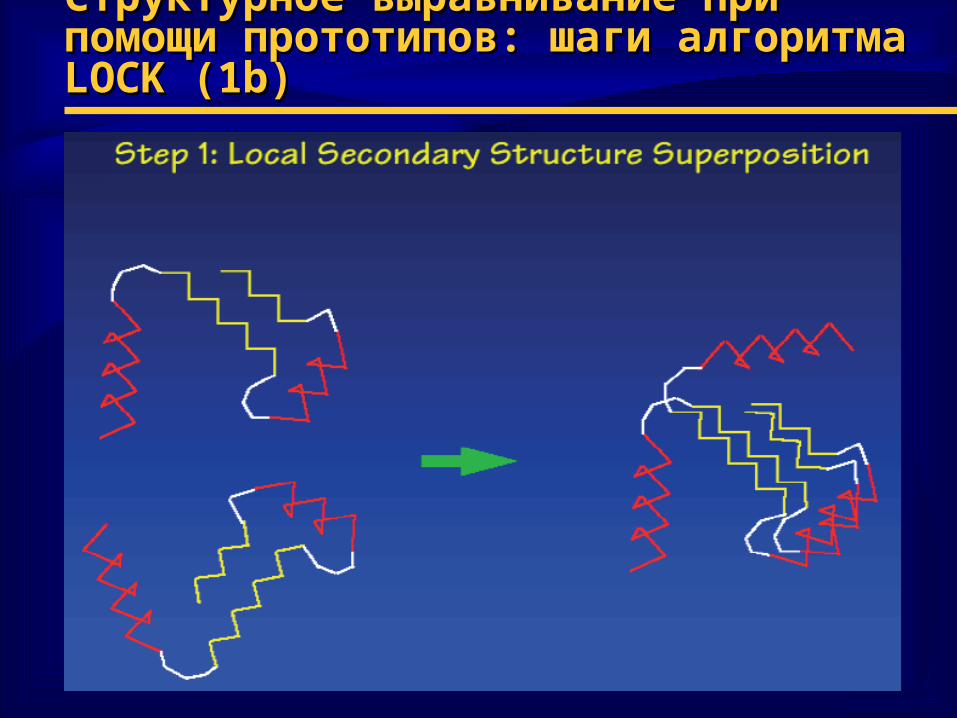
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: шаги алгоритма прототипов: шаги алгоритма LOCKLOCK (1 (1bb))

Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: шаги алгоритма прототипов: шаги алгоритма LOCKLOCK ( (22))
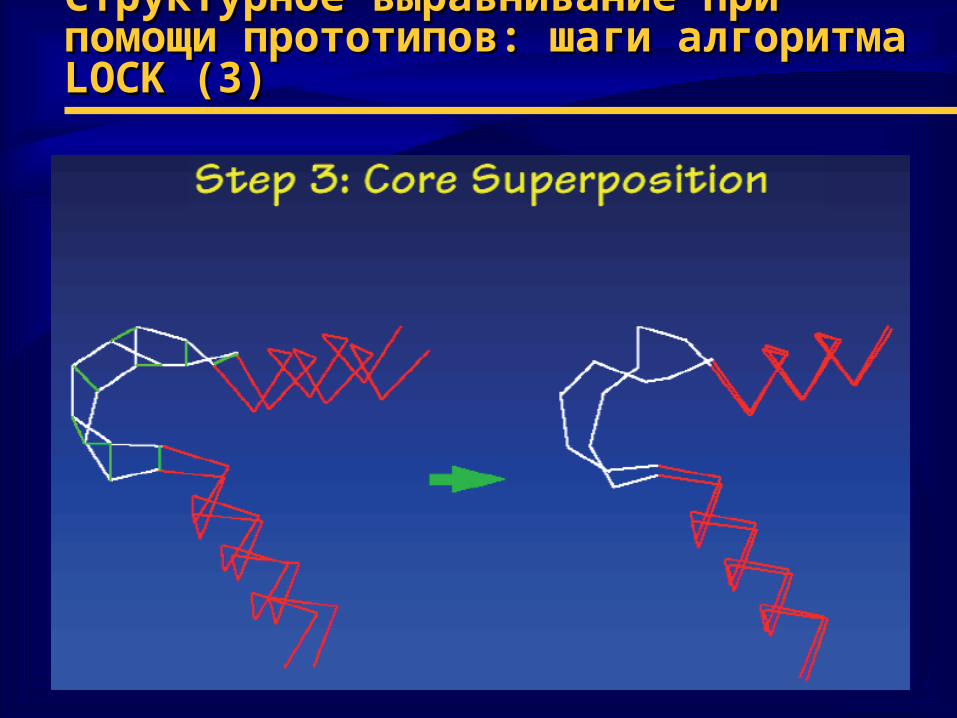
Структурное выравнивание при помощи Структурное выравнивание при помощи прототипов: шаги алгоритма прототипов: шаги алгоритма LOCKLOCK ( (33))

Структурное выравнивание:Структурное выравнивание:«за» и «против»«за» и «против»
♦ «Золотой» стандарт «Золотой» стандарт для выравнивания для выравнивания пос-стейпос-стей
♦ Трехмерная структура Трехмерная структура часто неизвестначасто неизвестна
♦ Структурное Структурное выравнивание выравнивание не не всегдавсегда отражает ход отражает ход эволюцииэволюции– точная точная
последовательность последовательность вставок/замен/делеций вставок/замен/делеций неизвестнанеизвестна

Прогрессивное Прогрессивное выравниваниевыравнивание

Прогрессивное выравнивание:Прогрессивное выравнивание: идеяидея♦ Сначала – эволюционно наиболее близкие пос-Сначала – эволюционно наиболее близкие пос-
стисти
♦ Постепенное добавление новых пос-стей / групп Постепенное добавление новых пос-стей / групп пос-стейпос-стей– Waterman & Perlwitz (1984)Waterman & Perlwitz (1984)– Feng & Doolittle (1987, 1996)Feng & Doolittle (1987, 1996)– Higgins Higgins et al.et al. (1996) (1996)– ……
♦ Отображение близости на филогенетическом Отображение близости на филогенетическом дереведереве– методы попарного сравнения пос-стейметоды попарного сравнения пос-стей
♦ Проблема: Проблема: неопределенность отдельных неопределенность отдельных замензамен
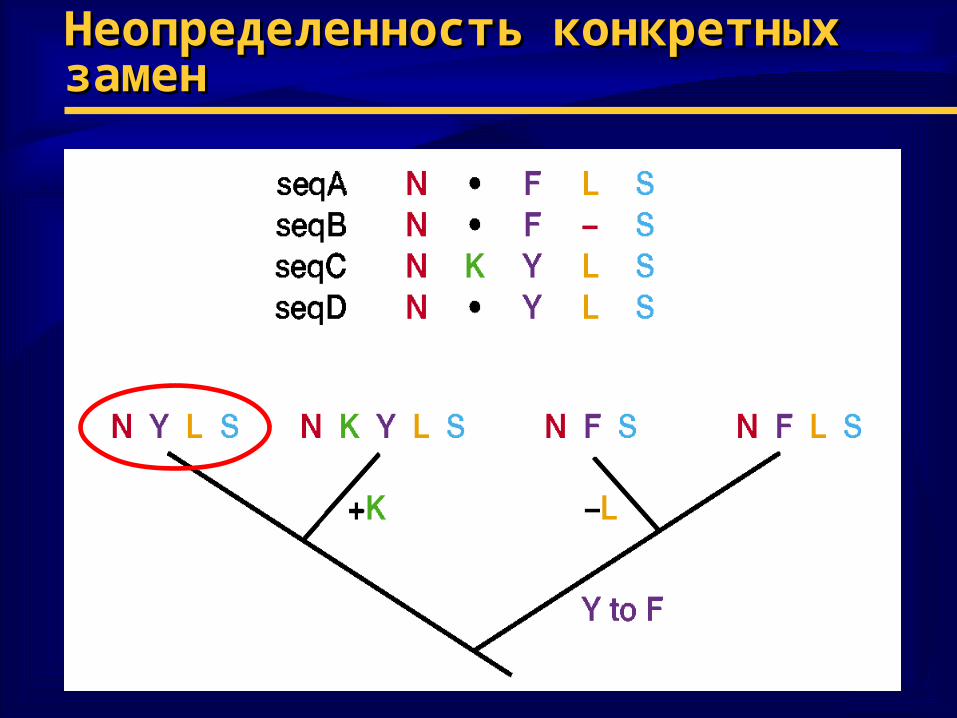
Неопределенность конкретных Неопределенность конкретных замензамен
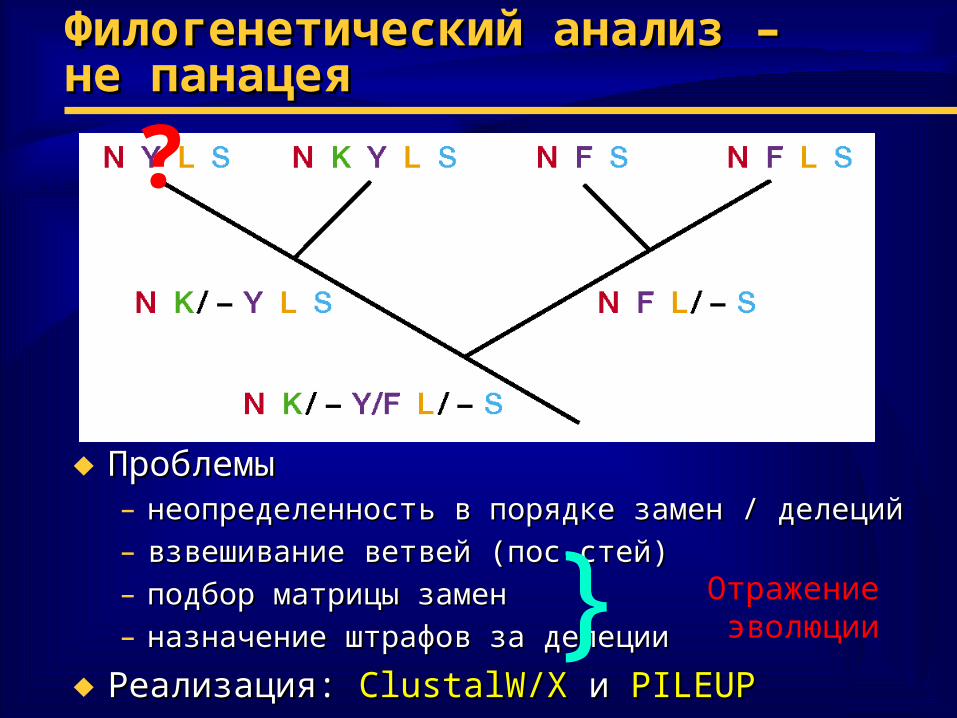
Филогенетический анализ –Филогенетический анализ –не панацеяне панацея
♦ ПроблемыПроблемы– неопределенность в порядке замен / делецийнеопределенность в порядке замен / делеций– взвешивание ветвей (пос-стей)взвешивание ветвей (пос-стей)– подбор матрицы заменподбор матрицы замен– назначение штрафов за делецииназначение штрафов за делеции
♦ Реализация: Реализация: ClustalW/XClustalW/X и и PILEUPPILEUP
?
} ?Отражение эволюции
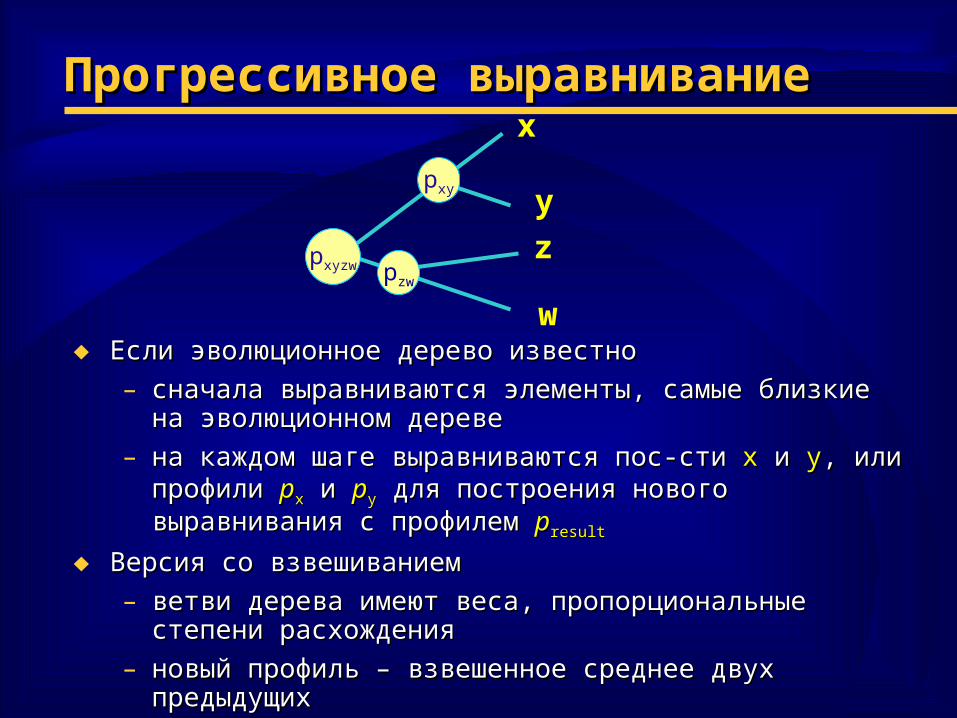
Прогрессивное выравниваниеПрогрессивное выравнивание
♦ Если эволюционное дерево известноЕсли эволюционное дерево известно
– сначала выравниваются элементы, самые близкие на сначала выравниваются элементы, самые близкие на эволюционном деревеэволюционном дереве
– на каждом шаге выравниваются пос-стина каждом шаге выравниваются пос-сти xx и и yy, , или профилиили профили ppxx и и ppyy для построения нового выравнивания с профилемдля построения нового выравнивания с профилем ppresultresult
♦ Версия со взвешиваниемВерсия со взвешиванием
– ветви дерева имеют веса, пропорциональные степени ветви дерева имеют веса, пропорциональные степени расхождениярасхождения
– новый профиль – взвешенное среднее двух предыдущихновый профиль – взвешенное среднее двух предыдущих
x
w
y
z
pxy
pzw
pxyzw

Прогрессивное выравнивание (прод.)Прогрессивное выравнивание (прод.)
♦ Если эволюционное дерево неизвестноЕсли эволюционное дерево неизвестно::
– построить всевозможные парные выравниванияпостроить всевозможные парные выравнивания
– определить матрицу расстоянийопределить матрицу расстояний DD, , элементы которой элементы которой DD(x, y)(x, y) соответствуют эволюционному расстоянию, определенному соответствуют эволюционному расстоянию, определенному по парным выравниваниямпо парным выравниваниям
– реконструировать эволюционное деревореконструировать эволюционное дерево (UPGMA / (UPGMA / объединение соседей объединение соседей / / другие методыдругие методы))
– построить выравнивание на основе реконструированного построить выравнивание на основе реконструированного деревадерева
x
w
y
z?

Прогрессивное выравнивание:Прогрессивное выравнивание:детали алгоритмадетали алгоритма♦ Три этапаТри этапа
– попарные выравнивания «каждая с каждой»попарные выравнивания «каждая с каждой»– филогенетическое дерево по весам парных филогенетическое дерево по весам парных
выравниваний (по генетическим расстояниям)выравниваний (по генетическим расстояниям)– последовательное построение множественного последовательное построение множественного
выравниваниявыравнивания• от похожих – к непохожимот похожих – к непохожим
♦ Первичные выравниванияПервичные выравнивания– kk--кортежикортежи– поиск «мотивов» (поиск «мотивов» (a la FASTAa la FASTA))– обычное или усовершенствованное (обычное или усовершенствованное (Myers & Miller, Myers & Miller,
19881988)) динамическое программированиединамическое программирование
♦ Генетическое расстояниеГенетическое расстояние = (число замен) / = (число замен) / (полное число соответствий)(полное число соответствий)– делеции не учитываютсяделеции не учитываются Дерево

Прогрессивное выравнивание:Прогрессивное выравнивание:детали алгоритма (прод.)детали алгоритма (прод.)♦ Взвешивание пос-стей (ветвей дерева)Взвешивание пос-стей (ветвей дерева)
– мультипликативная модельмультипликативная модель
♦ Штрафы за делецииШтрафы за делеции– предыдущие делеции влияют на последующие предыдущие делеции влияют на последующие
выравниваниявыравнивания– местоположение делеций (учет вторичной структуры)местоположение делеций (учет вторичной структуры)– таблица встречаемости делеций (таблица встречаемости делеций (Pascarella & Argos, Pascarella & Argos,
1992)1992)– штраф за открытие делеции и ее продолжение на штраф за открытие делеции и ее продолжение на
каждую позициюкаждую позицию– штрафы во множественном выравнивании штрафы во множественном выравнивании
модифицируются с учетом матрицы замен, степени модифицируются с учетом матрицы замен, степени сходства и длины пос-стейсходства и длины пос-стей
♦ Схема назначения штрафов в Схема назначения штрафов в ClustalClustal (1988) (1988) противоположна таковой в противоположна таковой в MSAMSA– чем уникальнее пос-сть, тем больше весчем уникальнее пос-сть, тем больше вес

Прогрессивное выравнивание:Прогрессивное выравнивание:взвешивание ветвей деревавзвешивание ветвей дерева
Множественное выравнивание: Множественное выравнивание: популярный инструментарийпопулярный инструментарий
ClustalX
DCSE

Прогрессивное выравнивание:Прогрессивное выравнивание:штрафы за делецииштрафы за делеции
♦ Существующие делеции влияют на Существующие делеции влияют на выравнивание следующих пос-стейвыравнивание следующих пос-стей– их позиции фиксируютсяих позиции фиксируются
♦ ClustalWClustalW: : размещение делеций между размещение делеций между консервативными доменамиконсервативными доменами– Pascarella & Argos (1992): Pascarella & Argos (1992): частоты встречаемости частоты встречаемости
делеций после каждой АК в неконсервативных делеций после каждой АК в неконсервативных участках участках структурно близких белковструктурно близких белков
♦ ШтрафыШтрафы– за открытие делецииза открытие делеции– за продолжение делецииза продолжение делеции– та же схема за делеции внутри существующих та же схема за делеции внутри существующих
делецийделеций

Прогрессивное выравнивание:Прогрессивное выравнивание:штрафы за делеции (прод.)штрафы за делеции (прод.)
♦ Компенсационная модификация штрафовКомпенсационная модификация штрафов– средний вес соответствий по матрице заменсредний вес соответствий по матрице замен– уровень гомологии между пос-стямиуровень гомологии между пос-стями– длины пос-стейдлины пос-стей
♦ Таблица делеций для каждой группы Таблица делеций для каждой группы выравниваемых пос-стейвыравниваемых пос-стей
♦ Другие варианты модификацийДругие варианты модификаций– ↓↓ штрафов для областей с существующими штрафов для областей с существующими
делециямиделециями– ↑↑ штрафов для областей, соседствующих с штрафов для областей, соседствующих с
делециямиделециями– ↑↑ штрафов для областей с гидрофильными АКштрафов для областей с гидрофильными АК

ClustalW: ClustalW: пример выравнивания пример выравнивания семейства глобиновсемейства глобинов

Прогрессивное выравнивание:Прогрессивное выравнивание:проблемыпроблемы
♦ Результат зависит от начальных парных Результат зависит от начальных парных выравниванийвыравниваний– ошибки первых выравниваний накапливаютсяошибки первых выравниваний накапливаются– выравнивание непохожих пос-стей выравнивание непохожих пос-стей Байесовские Байесовские
методы (методы (e.g. HMMe.g. HMM))
♦ Матрица замен и штрафы за делеции должны Матрица замен и штрафы за делеции должны отражать специфику всего набора пос-стейотражать специфику всего набора пос-стей
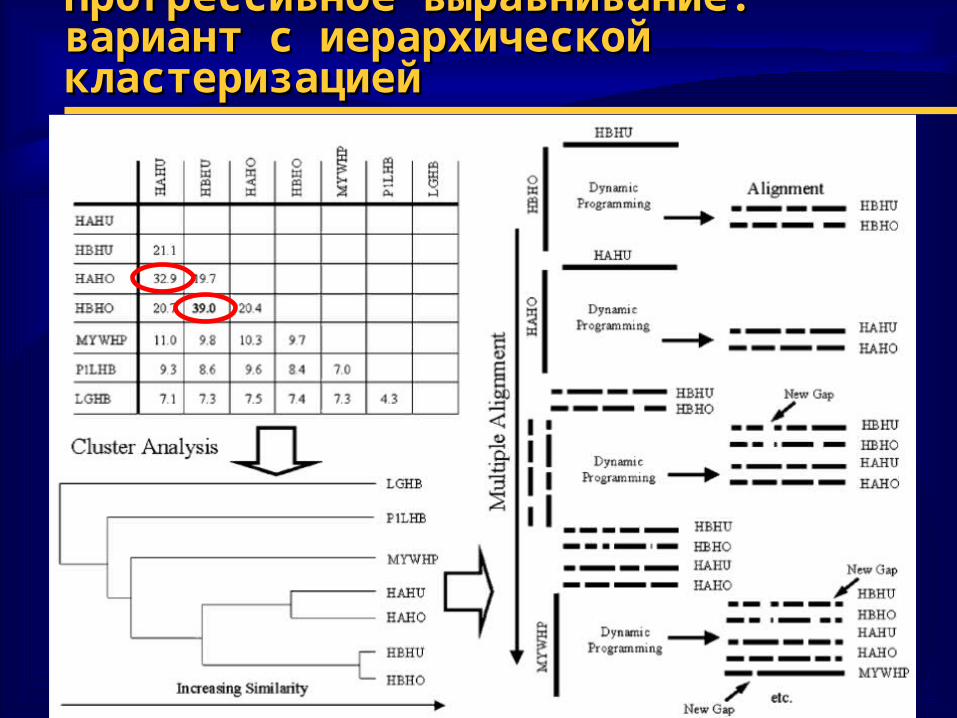
Прогрессивное выравнивание:Прогрессивное выравнивание:вариант с иерархической кластеризациейвариант с иерархической кластеризацией

Инструментарий: Инструментарий: ALSCRIPT (1993)ALSCRIPT (1993)
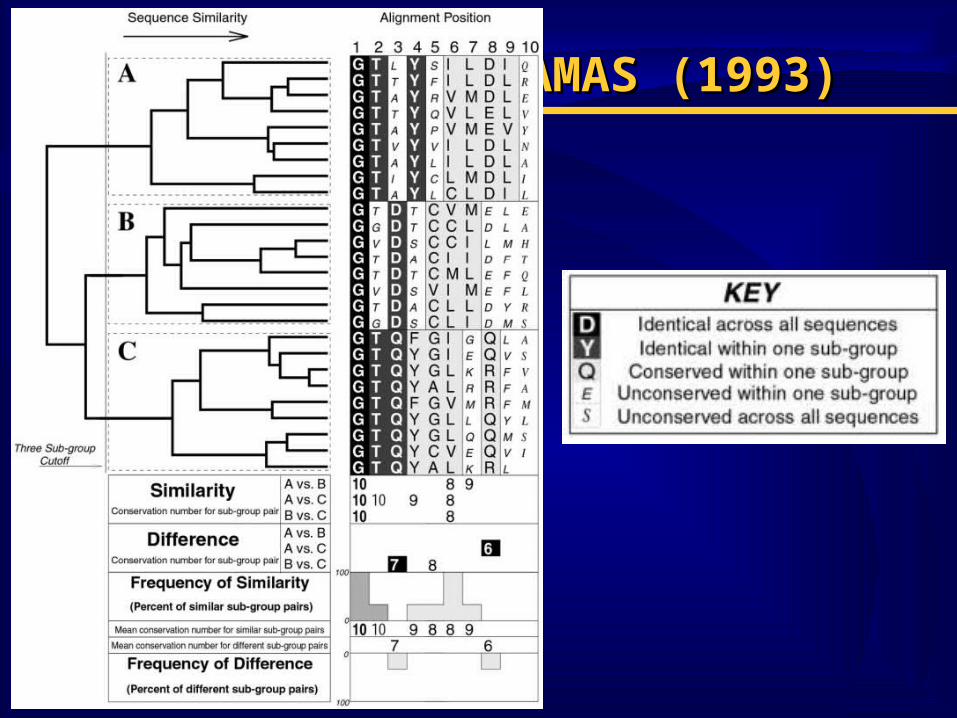
Инструментарий: Инструментарий: AMAS (1993)AMAS (1993)

Итерационное Итерационное выравниваниевыравнивание

Итерационное выравнивание:Итерационное выравнивание:идея методаидея метода♦ ЗадачаЗадача
– избежать накопления ошибок начальных выравниваизбежать накопления ошибок начальных выравнива--ний, свойственных прогрессивным методамний, свойственных прогрессивным методам
♦ Вариант решенияВариант решения– многократные итерационные выравнивания многократные итерационные выравнивания подгрупп подгрупп
последовательностейпоследовательностей– построение общего глобального выравниванияпостроение общего глобального выравнивания– оптимизация общего веса выравнивания (суммы оптимизация общего веса выравнивания (суммы
парных весовпарных весов))
♦ Как выделить эти Как выделить эти подгруппыподгруппы??– известное / предсказанное филогенетическое деревоизвестное / предсказанное филогенетическое дерево– K-out cross validation (KOCV)K-out cross validation (KOCV)– рандомизациярандомизация

Итерационное выравнивание:Итерационное выравнивание:варианты реализацииварианты реализации♦ MultAlinMultAlin (Corpet, (Corpet, 1998)1998)
– пересчет весов парных выравниваний в прогрессивном пересчет весов парных выравниваний в прогрессивном алгоритмеалгоритме
– использование весов для пересчета дереваиспользование весов для пересчета дерева– улучшение множественного выравниванияулучшение множественного выравнивания
♦ PRRPPRRP (1994) (1994)– построение дерева по начальным парным выравниваниямпостроение дерева по начальным парным выравниваниям– вычисление весов по дереву и построение выравниваний вычисление весов по дереву и построение выравниваний
по аналогии с по аналогии с MSAMSA ( (но: локальные участки вместо но: локальные участки вместо глобального выравнивания + возможны делеции)глобального выравнивания + возможны делеции)
– итерационный пересчет локально выровненных участков итерационный пересчет локально выровненных участков для повышения веса выравниваниядля повышения веса выравнивания
– выравнивание с наибольшим весом выравнивание с наибольшим весом новое дерево, новое дерево, новые веса и новые выравниванияновые веса и новые выравнивания
– повторение, пока суммарный вес не перестанет менятьсяповторение, пока суммарный вес не перестанет меняться
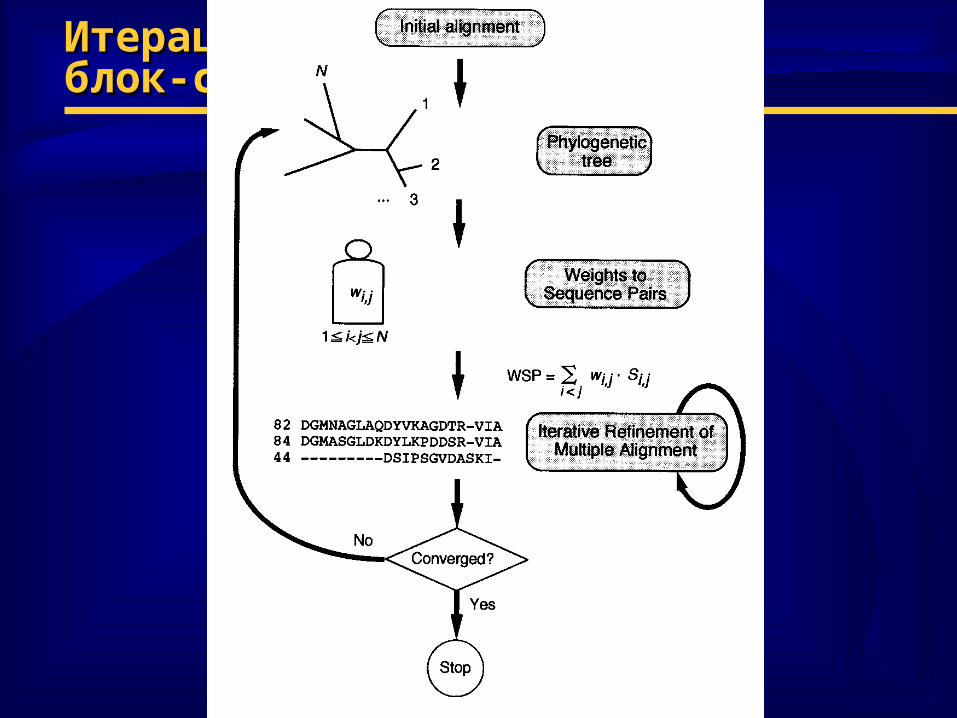
Итерационное выравнивание:Итерационное выравнивание:блок-схема алгоритма блок-схема алгоритма PRRPPRRP

Итерационное выравнивание:Итерационное выравнивание:варианты реализации (прод.)варианты реализации (прод.)♦ DIALIGNDIALIGN
– участки без делеций в попарных выравниваниях участки без делеций в попарных выравниваниях (аналогично точечной матрице)(аналогично точечной матрице)
– взвешенная сумма диагоналейвзвешенная сумма диагоналей
♦ Генетические алгоритмыГенетические алгоритмы– SAGASAGA (Notredame, Higgins, 1996) (Notredame, Higgins, 1996)– Zhang, Wang (1997)Zhang, Wang (1997)

Генетичекие алгоритмы:Генетичекие алгоритмы:идея и реализацияидея и реализация♦ Идея – имитация событий реальной эволюцииИдея – имитация событий реальной эволюции
♦ Реализация (Реализация (SAGASAGA))– делеции и рекомбинация в процессе репликацииделеции и рекомбинация в процессе репликации– много множественных выравниваний много множественных выравниваний увеличение увеличение
суммарного весасуммарного веса
♦ Проблемы (Проблемы (SAGASAGA))– окончательное выравнивание не всегда оптимально окончательное выравнивание не всегда оптимально
или имеет максимально возможный весили имеет максимально возможный вес– значительные времена счета при значительные времена счета при > 20 > 20 пос-стяхпос-стях

Генетические алгоритмы:Генетические алгоритмы:этапыэтапы♦ Около 100 случайных начальных выравниванийОколо 100 случайных начальных выравниваний
– перекрывание 20-25% от длины пос-стейперекрывание 20-25% от длины пос-стей– делеции на концахделеции на концах
♦ Веса начальных выравниваний (Веса начальных выравниваний (SPSP))– матрицы АК-заменматрицы АК-замен– штрафы за открытие / продолжение делецииштрафы за открытие / продолжение делеции– наилучшее выравнивание – минимальный вес, наилучшее выравнивание – минимальный вес,
ближайший к сумме весов парных выравниванийближайший к сумме весов парных выравниваний
♦ Репликация начальных выравниваний для Репликация начальных выравниваний для генерации следующего поколениягенерации следующего поколения– 50 % выравнивания (наименьшие веса) – неизменны50 % выравнивания (наименьшие веса) – неизменны– оставшиеся 50%: вероятность выбора оставшиеся 50%: вероятность выбора ~ ~ весвес-1-1
– мутации в оставшихся 50% выравниваниймутации в оставшихся 50% выравниваний

Генетичекие алгоритмы:Генетичекие алгоритмы:этапы (прод.)этапы (прод.)♦ Мутации с учетом филогенетического дереваМутации с учетом филогенетического дерева
♦ Мутации сдвигом блоковМутации сдвигом блоков

Генетичекие алгоритмы:Генетичекие алгоритмы:этапы (прод.)этапы (прод.)
♦ Рекомбинации с учетом гомологииРекомбинации с учетом гомологии

Генетичекие алгоритмы:Генетичекие алгоритмы:этапы (прод.)этапы (прод.)♦ МутацииМутации
– прежний порядок АКпрежний порядок АК– добавление и перестановка делеций добавление и перестановка делеций увеличение весаувеличение веса
• ориентация на дерево ориентация на дерево => => группы белков, случайные длины и группы белков, случайные длины и расположение делеций, фиксированные для данной группырасположение делеций, фиксированные для данной группы
• делеции максимизируют вес делеции максимизируют вес – делеции, разделяющие выровненные блокиделеции, разделяющие выровненные блоки
♦ РекомбинацияРекомбинация– без учета гомологий – поиск максимального весабез учета гомологий – поиск максимального веса– учет гомологий – сохранение консервативных позицийучет гомологий – сохранение консервативных позиций
♦ Оценка 50% родительских и 50% дочерних Оценка 50% родительских и 50% дочерних выравниванийвыравниваний– повторение шагов репликацияповторение шагов репликация//мутациимутации//рекомбинации 100-100 рекомбинации 100-100
раз до достижения наилучшего весараз до достижения наилучшего веса
♦ Многократное повторение всего алгоритма до Многократное повторение всего алгоритма до достижения наилучшего веса выравниваниядостижения наилучшего веса выравнивания

Локальные Локальные множественные множественные выравниваниявыравнивания

Локальные множественные Локальные множественные выравнивания: виды алгоритмоввыравнивания: виды алгоритмов
♦ Анализ профилейАнализ профилей
♦ Блочное выравниваниеБлочное выравнивание
♦ Поиск мотивовПоиск мотивов
♦ Статистические методыСтатистические методы

Анализ профилей: введениеАнализ профилей: введение♦ Идея:Идея:
– MSA MSA для группы пос-стейдля группы пос-стей– Выделение высоко консервативных участков в миниВыделение высоко консервативных участков в мини--
MSAMSA– Профиль - матрица весов для миниПрофиль - матрица весов для мини-MSA-MSA– Профиль допускает соответствия, замены, делеции и Профиль допускает соответствия, замены, делеции и
вставкивставки
♦ ПримененияПрименения– поиск соответствий профилю в последовательности-поиск соответствий профилю в последовательности-
мишени (программа мишени (программа ProfilesearchProfilesearch))– в качестве матрицы замен для построения в качестве матрицы замен для построения
выравниваний (программа выравниваний (программа ProfilegapProfilegap))
♦ Две группы алгоритмов построения профилейДве группы алгоритмов построения профилей– метод среднихметод средних– эволюционный методэволюционный метод

Анализ профилей: идентификация в семействе Анализ профилей: идентификация в семействе белков теплового шока (белков теплового шока (hsp70)hsp70)
Матрица весов (профиль) содержит вероятности Матрица весов (профиль) содержит вероятности встречаемости АК в разных позицияхвстречаемости АК в разных позициях

Построение профилей: метод среднихПостроение профилей: метод средних
♦ Элемент матрицы – взвешенная частота Элемент матрицы – взвешенная частота встречаемостивстречаемости– частоты по частоты по MSAMSA– взвешиваниевзвешивание
• все 20 потенциальных предшественниц данной АК все 20 потенциальных предшественниц данной АК равновероятныравновероятны
ИЛИИЛИ
• вероятности предшественников вычисляются из вероятности предшественников вычисляются из матриц замен (матриц замен (PAM, BLOSUMPAM, BLOSUM))
– штрафы за делецииштрафы за делеции

Построение профилей:Построение профилей:эволюционный методэволюционный метод♦ Определение эволюционного расстояния в Определение эволюционного расстояния в
единицах единицах PAM PAM для получения частот АК, для получения частот АК, наблюдаемых в выравниваниинаблюдаемых в выравнивании– разные темпы эволюции в разных колонках разные темпы эволюции в разных колонках MSAMSA– любая АК может быть предшественницей даннойлюбая АК может быть предшественницей данной
♦ Информационная вероятностьИнформационная вероятностьHH = - = - ΣΣaa ffaalog(log(ppaa))
где где ff и и pp – наблюдаемая и ожидаемая частоты – наблюдаемая и ожидаемая частоты встречаемости АК в данной колонке встречаемости АК в данной колонке MSAMSA для для фиксированного предшественникафиксированного предшественника
♦ Информация Информация HH вычисляется для 20 АК и для вычисляется для 20 АК и для разных эволюционных расстояний (разных эволюционных расстояний (PAMPAMnn))– Поиск Поиск nn = = argmin (argmin (HH))
♦ Байесовский анализБайесовский анализP(P(MMaa|F) = P(|F) = P(MMaa) x P(F|) x P(F|MMaa) / ) / ΣΣaa P(P(MMaa) x P(F|) x P(F|MMaa))

Блочное выравнивание: семейство из 34 Блочное выравнивание: семейство из 34 тубулиновых белковтубулиновых белков

Анализ профилей: ограниченияАнализ профилей: ограничения♦ Профиль отражает вариабельность в данном Профиль отражает вариабельность в данном
MSAMSA– смещение в сторону похожих пос-стейсмещение в сторону похожих пос-стей
• вариант коррекции: вариант коррекции: Gribskov & Veternik, 1996Gribskov & Veternik, 1996• взвешивание пос-стей по удаленности на филогенетическом взвешивание пос-стей по удаленности на филогенетическом
дереве: чем меньше расстояние, тем меньше весдереве: чем меньше расстояние, тем меньше вес
♦ Недостаточное число пос-стей в Недостаточное число пос-стей в MSAMSA– некоторые АК на некоторых позициях не некоторые АК на некоторых позициях не
представленыпредставлены
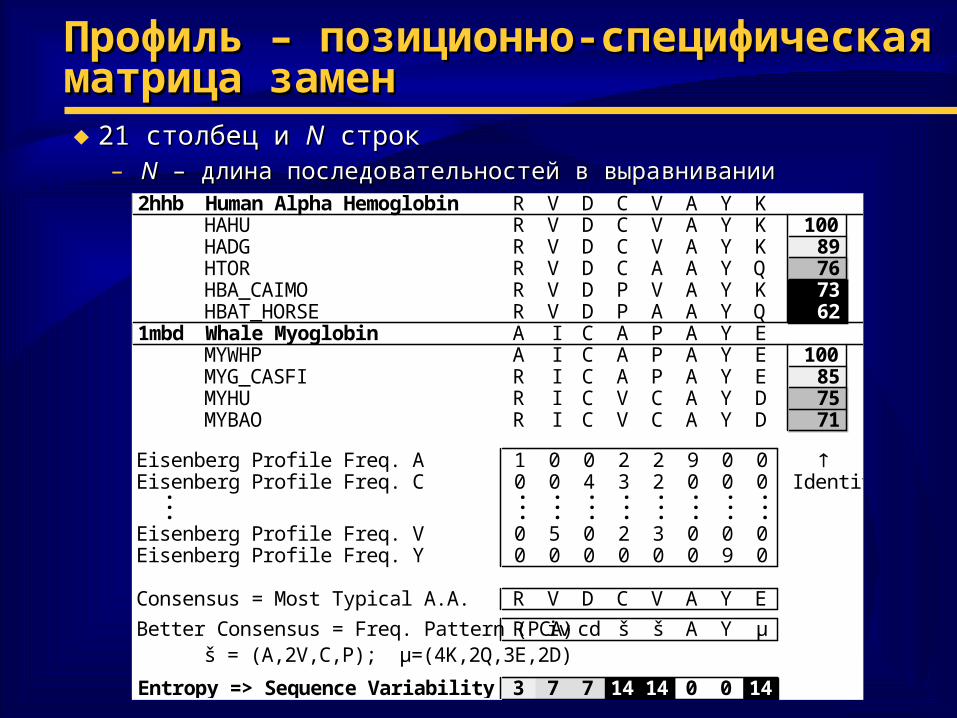
Профиль – позиционно-специфическая Профиль – позиционно-специфическая матрица заменматрица замен♦ 21 столбец и 21 столбец и NN строкстрок
– NN – – длина последовательностей в выравниваниидлина последовательностей в выравнивании2hhb Human Alpha Hemoglobin R V D C V A Y K
HAHU R V D C V A Y K 100HADG R V D C V A Y K 89HTOR R V D C A A Y Q 76HBA_CAIMO R V D P V A Y K 73HBAT_HORSE R V D P A A Y Q 62
1mbd Whale Myoglobin A I C A P A Y EMYWHP A I C A P A Y E 100MYG_CASFI R I C A P A Y E 85MYHU R I C V C A Y D 75MYBAO R I C V C A Y D 71
Eisenberg Profile Freq. A 1 0 0 2 2 9 0 0 Eisenberg Profile Freq. C 0 0 4 3 2 0 0 0 Identity. . . . . . . . .. . . . . . . . .. . . . . . . . .Eisenberg Profile Freq. V 0 5 0 2 3 0 0 0Eisenberg Profile Freq. Y 0 0 0 0 0 0 9 0
Consensus = Most Typical A.A. R V D C V A Y E
Better Consensus = Freq. Pattern (PCA) R iv cd š š A Y µš = (A,2V,C,P); µ=(4K,2Q,3E,2D)
Entropy => Sequence Variability 3 7 7 14 14 0 0 14

Статистические методы Статистические методы множественного множественного выравниваниявыравнивания
Множественное выравнивание на базе Множественное выравнивание на базе вероятностно-статистических методоввероятностно-статистических методов
♦ Максимизация математического ожиданияМаксимизация математического ожидания
♦ Сэмплирование ГиббсаСэмплирование Гиббса
♦ Скрытые марковские моделиСкрытые марковские модели– see Russ Altman, Lecture 4-27-06, pp. 8-20see Russ Altman, Lecture 4-27-06, pp. 8-20

Максимизация Максимизация математического математического
ожиданияожидания

Максимизация математического Максимизация математического ожидания (ожидания (Expectation Maximization, EM)Expectation Maximization, EM)
♦ ПрименениеПрименение– консервативные домены в невыровненных белкахконсервативные домены в невыровненных белках– сайты связывания белков в невыровненных ДНК-сайты связывания белков в невыровненных ДНК-
последовательностяхпоследовательностях
♦ Предварительные шаги алгоритмаПредварительные шаги алгоритма– произвольный выбор начального положения и длины произвольный выбор начального положения и длины
искомого сайта в каждой пос-стиискомого сайта в каждой пос-сти– выравнивание пос-стей по выбранным «искомым» выравнивание пос-стей по выбранным «искомым»
сайтам и вычисление частот встречаемости по сайтам и вычисление частот встречаемости по столбцамстолбцам
♦ Два основных этапа алгоритмаДва основных этапа алгоритма– Ожидание: оценка вероятности обнаружения сайта в Ожидание: оценка вероятности обнаружения сайта в
каждой из позиций каждой из пос-стей по частотамкаждой из позиций каждой из пос-стей по частотам– Максимизация: использование новых частотМаксимизация: использование новых частот
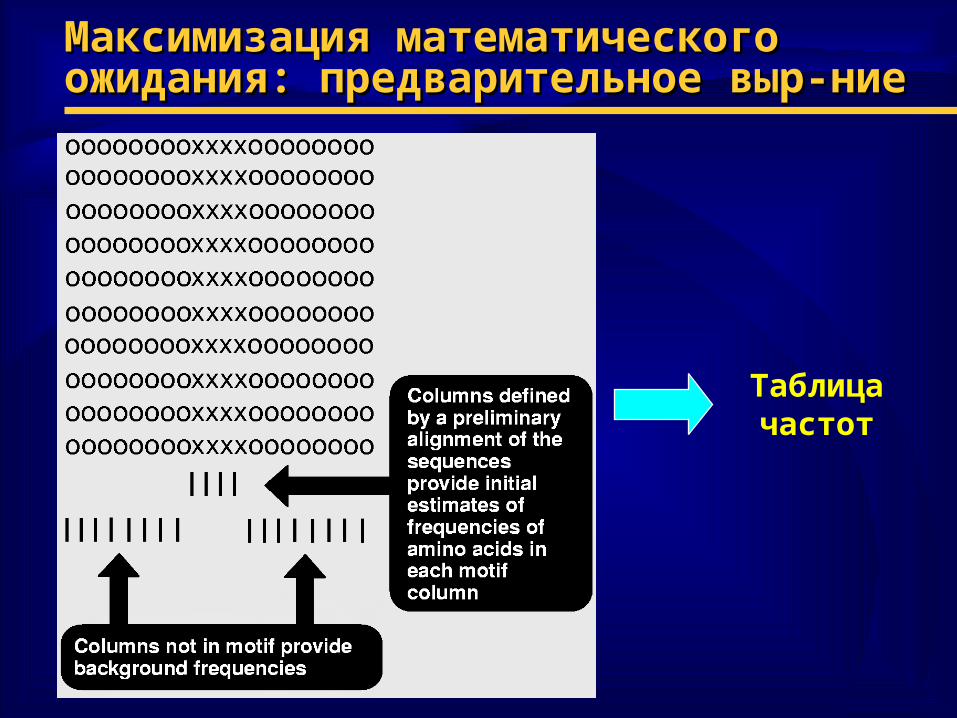
Максимизация математического Максимизация математического ожидания: предварительное выр-ниеожидания: предварительное выр-ние
Таблицачастот
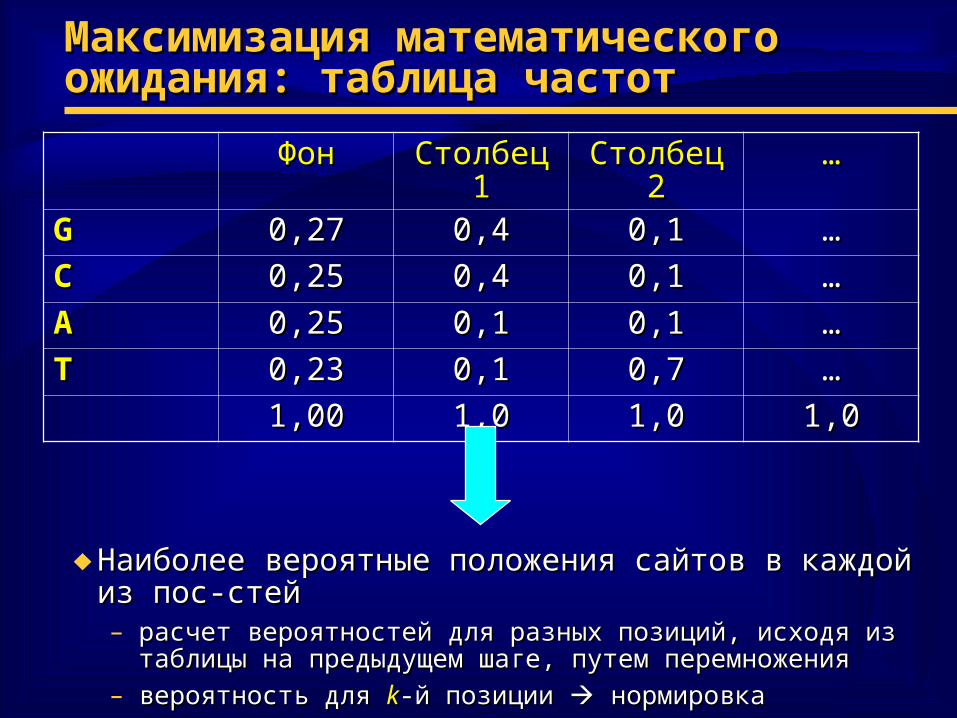
Максимизация математического Максимизация математического ожидания: таблица частотожидания: таблица частот
ФонФон Столбец 1Столбец 1 Столбец 2Столбец 2 ……
GG 0,270,27 0,40,4 0,10,1 ……
CC 0,250,25 0,40,4 0,10,1 ……
AA 0,250,25 0,10,1 0,10,1 ……
TT 0,230,23 0,10,1 0,70,7 ……
1,001,00 1,01,0 1,01,0 1,01,0
♦ Наиболее вероятные положения сайтов в каждой из Наиболее вероятные положения сайтов в каждой из пос-стейпос-стей– расчет вероятностей для разных позиций, исходя из таблицы на расчет вероятностей для разных позиций, исходя из таблицы на
предыдущем шаге, путем перемноженияпредыдущем шаге, путем перемножения– вероятность для вероятность для kk--й позиции й позиции нормировканормировка
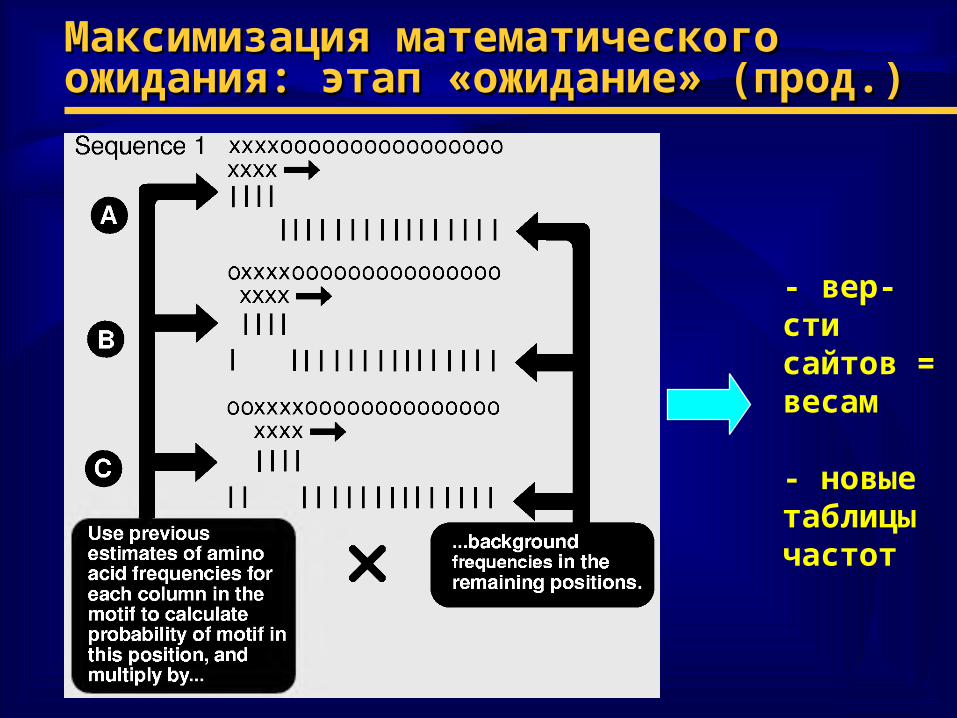
Максимизация математического Максимизация математического ожидания: этап «ожидание» (прод.)ожидания: этап «ожидание» (прод.)
- вер-сти сайтов = весам
- новыетаблицычастот

Максимизация математического Максимизация математического ожидания: этап максимизацииожидания: этап максимизации
♦ Таблица частот, полученная на этапе Таблица частот, полученная на этапе «ожидания»«ожидания»
♦ Итерационное повторение двух этапов до тех Итерационное повторение двух этапов до тех пор, пока таблица не перестанет менятьсяпор, пока таблица не перестанет меняться
♦ Альтернативный метод подсчета частот Альтернативный метод подсчета частот встречаемостивстречаемости– матрица весов – нормировка частот «внутри сайта» матрица весов – нормировка частот «внутри сайта»
на фоновые величинына фоновые величины
♦ Реализация – программа Реализация – программа MEME (Multiple EM for MEME (Multiple EM for Motif Elicitation)Motif Elicitation), UCSD Supercomputing Center, UCSD Supercomputing Center– вариация длины мотива вариация длины мотива максимизация вер-стимаксимизация вер-сти– ParaMEMEParaMEME ( (поиск блоков)поиск блоков)– MetaMEMEMetaMEME (HMM) (HMM)

Выборки ГиббсаВыборки Гиббса

Выборки Гиббса (Выборки Гиббса (Gibbs samplerGibbs sampler))♦Lawrence, CE et al. (1993). Detecting subtle
sequence signals: a Gibbs sampling strategy for multiple alignment. Science, 262, 208-14.
♦ ПрименениеПрименение– множественное выравнивание пос-стеймножественное выравнивание пос-стей– поиск мотивов (локальное множественное выр-ние)поиск мотивов (локальное множественное выр-ние)
♦ Та же идея, что в Та же идея, что в EM…EM…– поиск наиболее вероятных мотивовпоиск наиболее вероятных мотивов– оценка их длины и положения в каждой из пос-стейоценка их длины и положения в каждой из пос-стей
♦ … … но другой алгоритмно другой алгоритм– веса мотивов в пос-стях вместо вероятностейвеса мотивов в пос-стях вместо вероятностей

Выборки Гиббса: алгоритм (прод.)Выборки Гиббса: алгоритм (прод.)

Выборки Гиббса: идеяВыборки Гиббса: идея
♦Вероятностный профиль мотива длины wBase\Position 1 2 3 4 … w
A 0.7 0.05 0.2 ...
T 0.1 0.05 0.2 ...
G 0.1 0.1 0.59
C 0.1 0.8 0.01 0.8
♦Фоновые вероятности: A – 0.3, T – 0.3, G – 0.2, C – 0.2
♦Задача: максимизировать разницу между частотным составом мотива и фоновым распределением вероятностей встречаемости

Выборки Гиббса: алгоритмВыборки Гиббса: алгоритм♦ Шаг 1 (предсказание)Шаг 1 (предсказание)::
• произвольное расположение мотива во всех поспроизвольное расположение мотива во всех пос--стях, стях, кроме кроме однойодной
• вероятность встречаемости мотива = произведению частот вероятность встречаемости мотива = произведению частот встречаемости в мотивевстречаемости в мотиве
• фоновая вероятность для мотива = произведению фоновых фоновая вероятность для мотива = произведению фоновых частот встречаемостичастот встречаемости
• движение с единичным «окном»:движение с единичным «окном»: W = PW = Pmotifmotif//PPbgrdbgrd max max• веса веса WW для каждой позиции нормируются на сумму всех для каждой позиции нормируются на сумму всех
весоввесов
♦ Шаг 2 (проверка и коррекция)Шаг 2 (проверка и коррекция)::• случайный выбор расположения мотива в отброшенной пос-случайный выбор расположения мотива в отброшенной пос-
сти в соответствии с нормированными весамисти в соответствии с нормированными весами
♦ Повторение шагов 1 и 2Повторение шагов 1 и 2 сотни или тысячи раз с учетом сотни или тысячи раз с учетом выбранного расположения мотива в ранее отброшенной выбранного расположения мотива в ранее отброшенной пос-стипос-сти
• частоты встречаемости в столбцах мотива должны частоты встречаемости в столбцах мотива должны перестать менятьсяперестать меняться
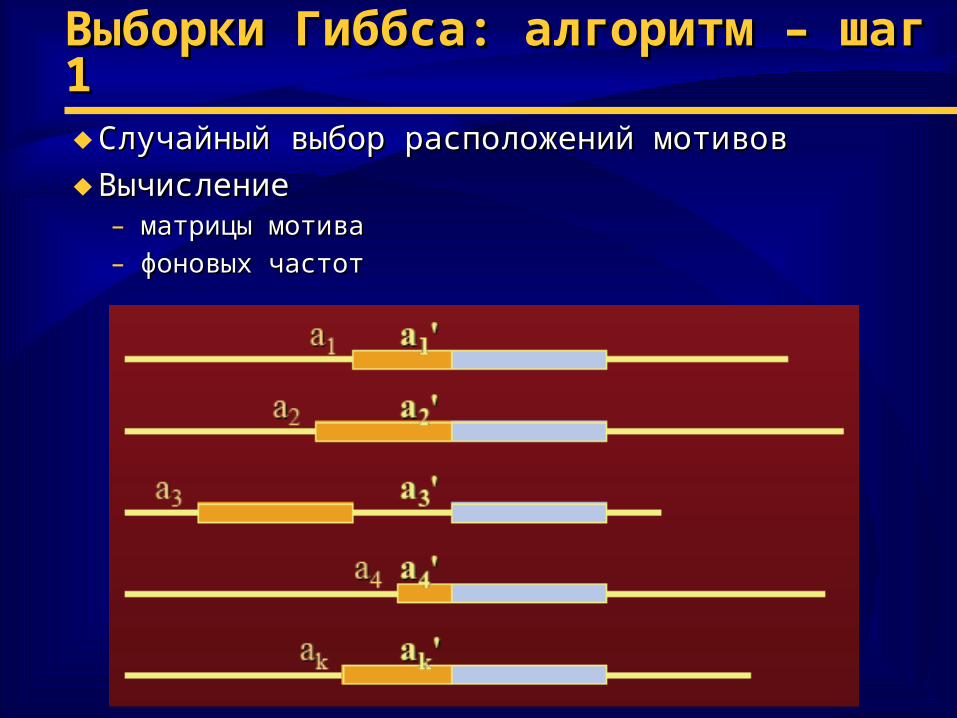
Выборки Гиббса: алгоритм – шаг 1Выборки Гиббса: алгоритм – шаг 1♦ Случайный выбор расположений мотивовСлучайный выбор расположений мотивов
♦ ВычислениеВычисление– матрицы мотиваматрицы мотива– фоновых частотфоновых частот

Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2aa♦ Исключение одной последовательностиИсключение одной последовательности
♦ Обновление матрицы мотиваОбновление матрицы мотива

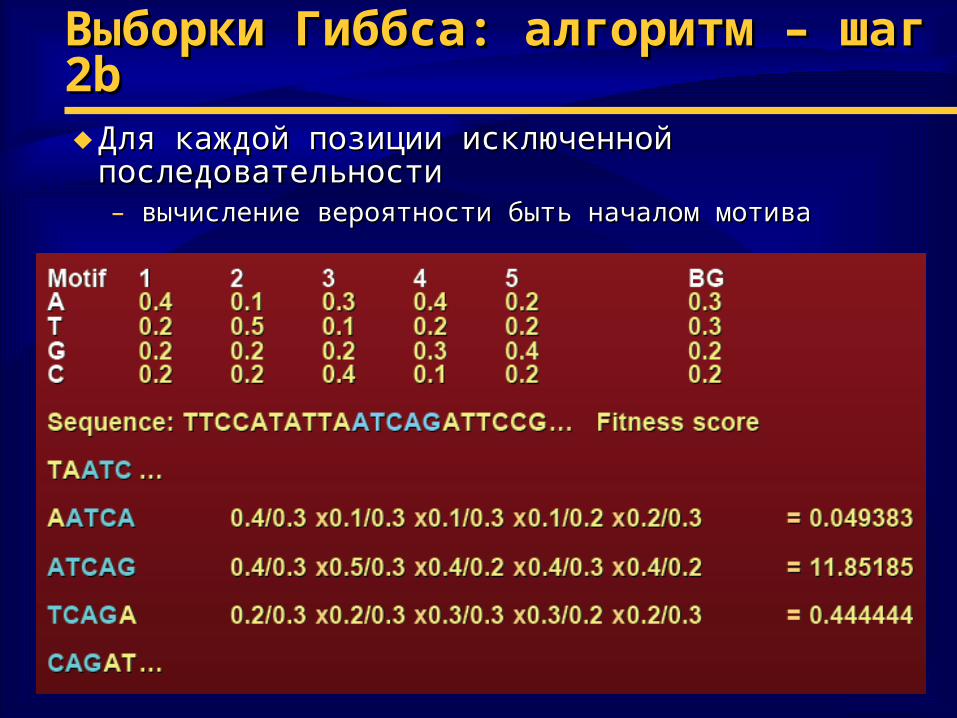
Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2bb♦ Для каждой позиции исключенной Для каждой позиции исключенной
последовательностипоследовательности– вычисление вероятности быть началом мотивавычисление вероятности быть началом мотива

Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2bb♦ Допустим, мотив начинается в позиции p пос-сти и мы
рассматриваем j-ю букву после p (s[p+j] = i)
♦ В какой мере она соответствует j–й позиции мотива?
θj = { nj (s[p + j]) + αi } / (n* + α*)
где s[p + j] -- буква i в позиции p последовательности s
nj(i) – число букв i в позиции j текущей матрицы мотивов
n* -- все буквы, встретившиеся в позиции j мотива = выровненным сегментам
αi – псевдоколичество для буквы i
♦ Вес соответствия мотива, начинающегося в пос-сти с позиции p
Fit (p) = Π θi / θbackground
Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2bb♦ Для каждой позиции исключенной Для каждой позиции исключенной
последовательностипоследовательности– вычисление вероятности быть началом мотивавычисление вероятности быть началом мотива
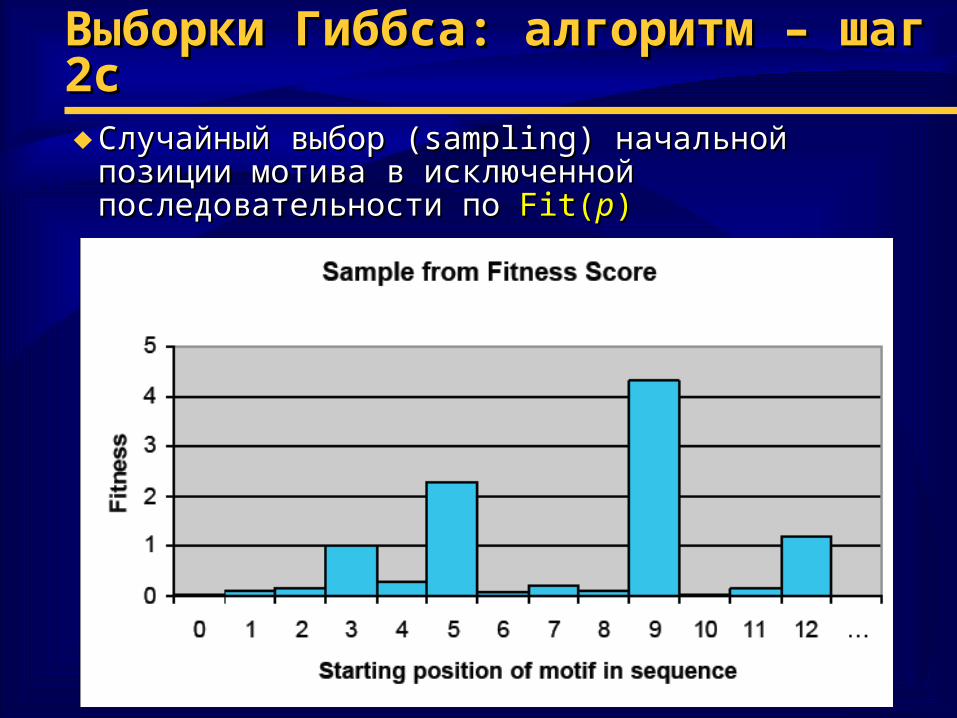
Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2cc♦ Случайный выбор (Случайный выбор (sampling) sampling) начальной позиции начальной позиции
мотива в исключенной последовательности по мотива в исключенной последовательности по Fit(Fit(pp))

Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2cc♦ Случайный выбор (Случайный выбор (sampling) sampling) начальной позиции начальной позиции
мотива в исключенной последовательности по мотива в исключенной последовательности по Fit(Fit(pp))

Выборки Гиббса: алгоритм – шаг 2Выборки Гиббса: алгоритм – шаг 2dd♦ Исключение другой последовательности – до Исключение другой последовательности – до
схождения алгоритмасхождения алгоритма
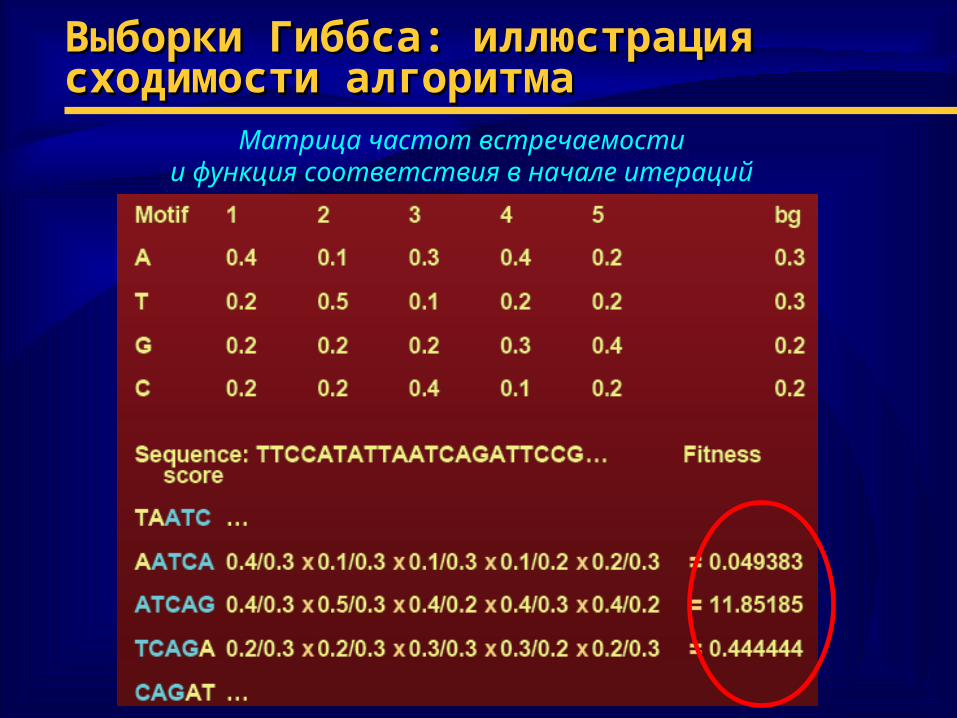
Выборки Гиббса: иллюстрация Выборки Гиббса: иллюстрация сходимости алгоритмасходимости алгоритма
Матрица частот встречаемостии функция соответствия в начале итераций

Выборки Гиббса: иллюстрация Выборки Гиббса: иллюстрация сходимости алгоритма (прод.)сходимости алгоритма (прод.)
Матрица частот встречаемостии функция соответствия вблизи точки сходимости алгоритма

Выборки Гиббса: алгоритм – шаг 3Выборки Гиббса: алгоритм – шаг 3♦ Повторная инициализация алгоритма после Повторная инициализация алгоритма после nn
итераций во избежание локальных максимумовитераций во избежание локальных максимумов– начальные позиции мотивовначальные позиции мотивов– распределение начальных позиций по пос-стямраспределение начальных позиций по пос-стям
♦ По окончании работы алгоритма:По окончании работы алгоритма:– начальные позиции мотивов в каждой пос-сти, начальные позиции мотивов в каждой пос-сти,
которые встречались чаще другихкоторые встречались чаще других

Выборки Гиббса:Выборки Гиббса:куда двигаться дальше?куда двигаться дальше?
♦ Алгоритм стоило бы развить для анализаАлгоритм стоило бы развить для анализа– множественных консервативных мотивов,
разделенных делециями– мотивов неизвестной длины– включения в выравнивания последовательностей, не
содержащих мотива

СкрытыеСкрытыемарковские модели марковские модели
((HMMHMM))
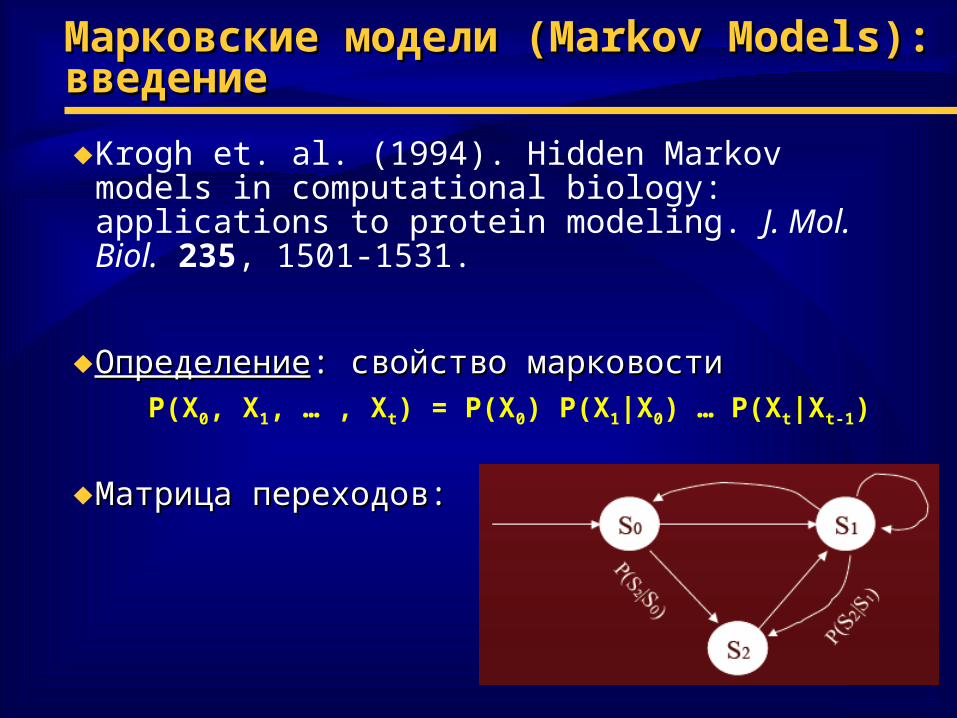
Марковские модели (Марковские модели (Markov Models)Markov Models): : введениевведение
♦Krogh et. al. (1994). Hidden Markov models in computational biology: applications to protein modeling. J. Mol. Biol. 235, 1501-1531.
♦ ОпределениеОпределение: свойство марковости: свойство марковостиP(X0, X1, … , Xt) = P(X0) P(X1|X0) … P(Xt|Xt-1)
♦ Матрица переходов:Матрица переходов:

Марковские модели: введение (прод.)Марковские модели: введение (прод.)
♦Марковская цепь– пос-сть состояний, через которые проходит
система
♦Пример– S0 , S1, S1, S1, S0 , S1, …– вероятность такой пос-сти:
P(Sequence) = P(S0 , S1, S1, S1, S0 , S1,…)
= π (S0) P(S1 | S0 ) P(S1 | S1) P(S1 | S1)…

Марковские модели:Марковские модели:представление последовательности ДНКпредставление последовательности ДНК
P(AGATCG) = π(A) P(G|A) P(A|G) P(T|A)…

Скрытые марковские модели (Скрытые марковские модели (Hidden Hidden Markov Models)Markov Models)
♦Наблюдаемая пос-сть – вероятностная функция некоторой марковской цепи
♦Исходная пос-сть состояний неизвестна (скрыта), но ее можно попробовать восстановить по наблюдаемой пос-сти – «зашумленная пос-сть» «зашумленная пос-сть» возможны ошибкивозможны ошибки

Скрытые марковские модели:Скрытые марковские модели: применениеприменениедля множественного выравниваниядля множественного выравнивания
♦Характеристики семейства выровненных последовательностей– какие АК с какой вероятностью могут появиться в
данном положении?– где наиболее вероятны вставки и делеции?– генерация гипотетических (но вполне вероятных)
новых последовательностей семейства
♦Оценка вероятности принадлежать семейству для новой последовательности– позволяет ли модель создать высоковероятную
последовательность?
♦Построение самого выравнивания– как объяснить «организацию» всех выровненных пос-
стей, считая, что они принадлежат одному семейству?

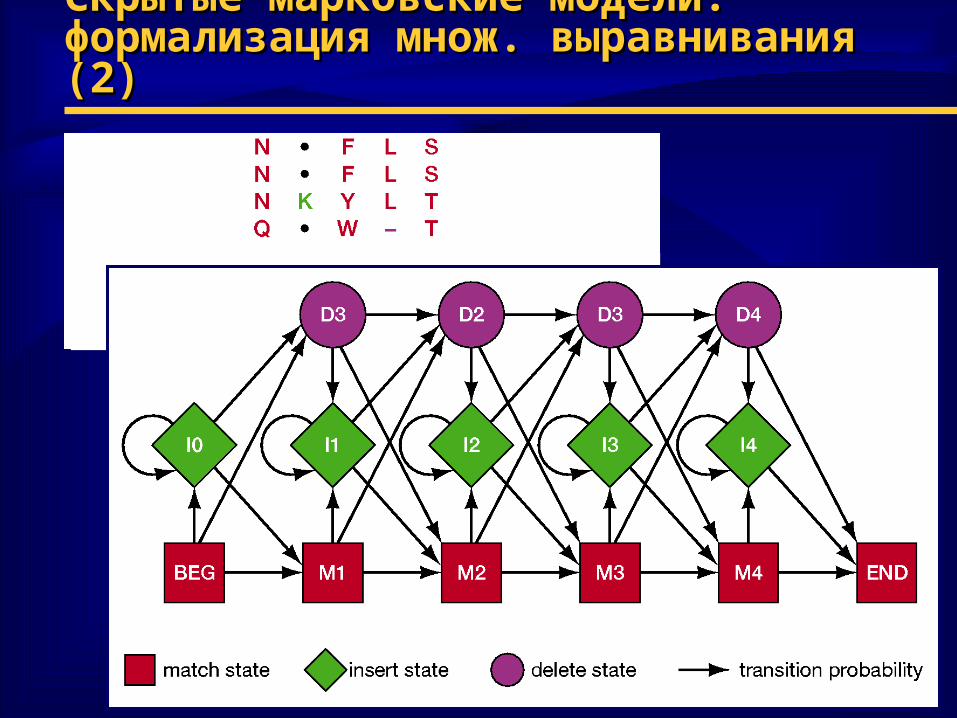
Скрытые марковские модели:Скрытые марковские модели:формализация множ. выравнивания (2)формализация множ. выравнивания (2)
♦ Красный цвет – выравнивание в столбце
♦ Зеленый цвет – вставка символа в столбце
♦ Пурпурный цвет – делеция в столбце

Скрытые марковские модели:Скрытые марковские модели:формализация множ. выравнивания (1)формализация множ. выравнивания (1)
♦ m = состояние выравнивания появление одной АК– выравнивание по соответствию или аналогичной замене в
различных пос-стях
♦ i = состояние вставки появление (N-1) аминокислот, которые не могут быть выровнены
♦ d = состояние делеции новые АК не появляются
Скрытые марковские модели:Скрытые марковские модели:формализация множ. выравнивания (2)формализация множ. выравнивания (2)
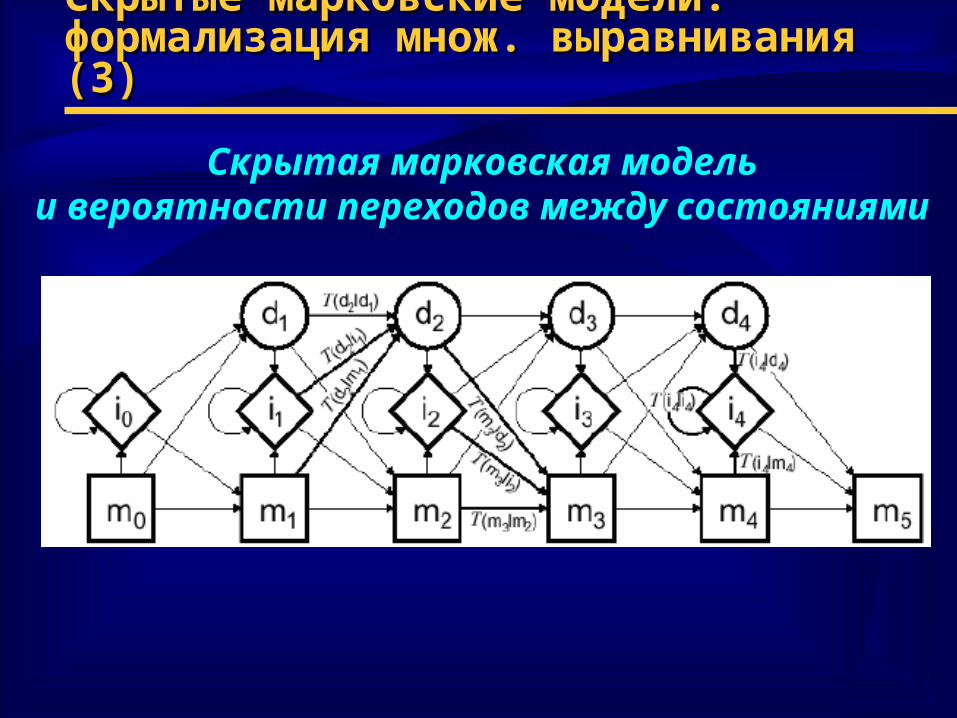
Скрытые марковские модели:Скрытые марковские модели:формализация множ. выравнивания (3)формализация множ. выравнивания (3)
Скрытая марковская модельи вероятности переходов между состояниями
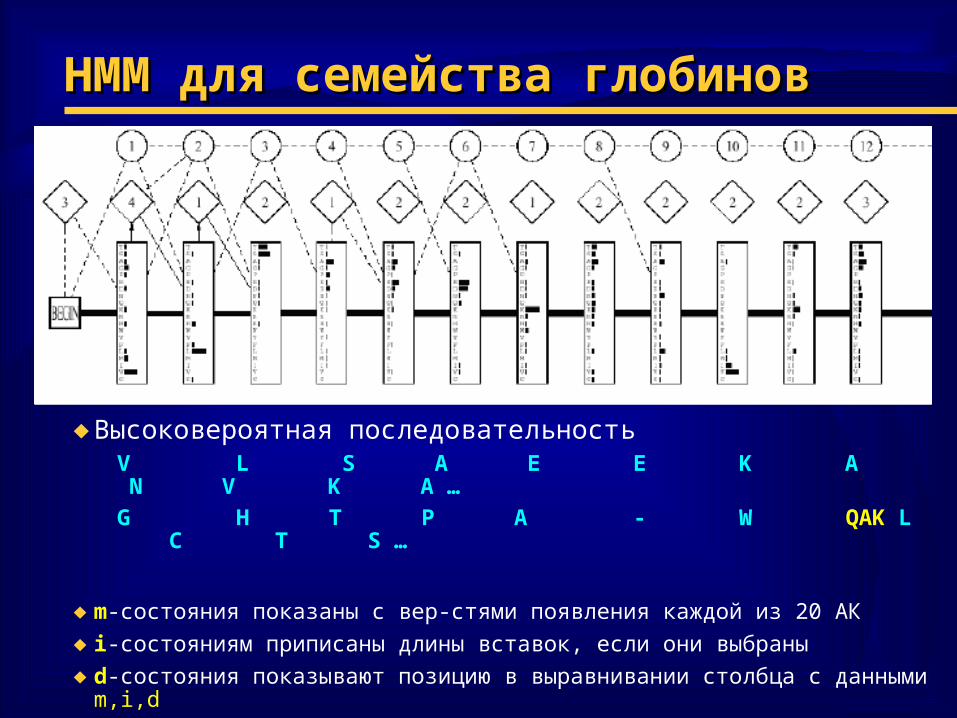
HMM HMM для семейства глобиновдля семейства глобинов
♦ Высоковероятная последовательность V L S A E E K A N V K A …
G H T P A - W QAK L C T S …
♦ m-состояния показаны с вер-стями появления каждой из 20 АК
♦ i-состояниям приписаны длины вставок, если они выбраны
♦ d-состояния показывают позицию в выравнивании столбца с данными m,i,d
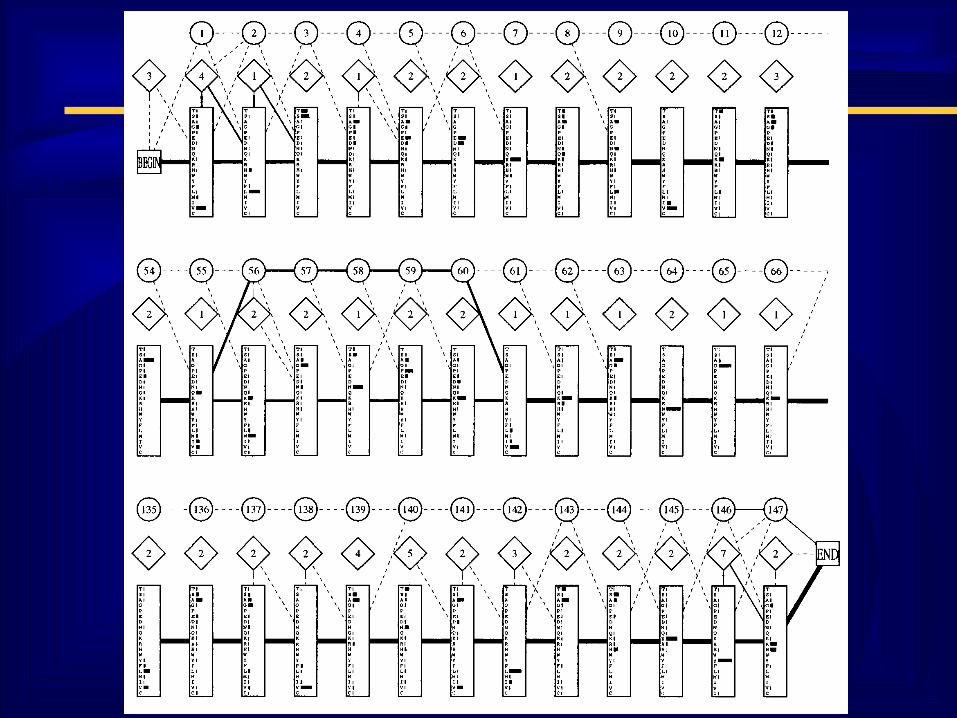

Выравнивание семейства глобиновВыравнивание семейства глобинов
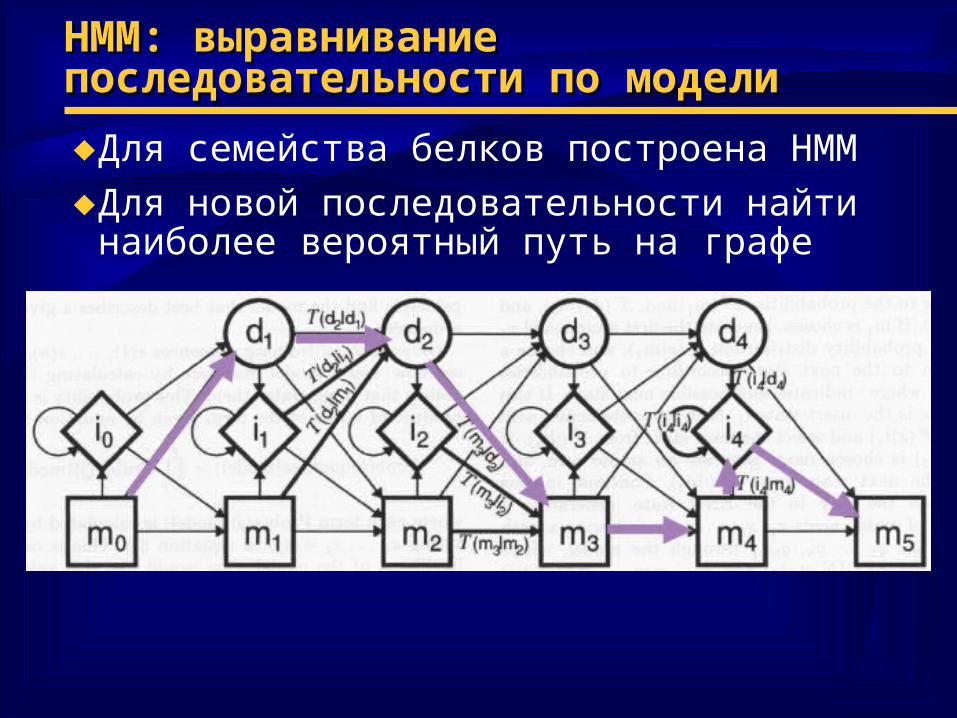
HMMHMM:: выравнивание выравнивание последовательности по моделипоследовательности по модели
♦Для семейства белков построена HMM
♦Для новой последовательности найти наиболее вероятный путь на графе

Скрытые марковские модели: Скрытые марковские модели: программы для множ. выравниванияпрограммы для множ. выравнивания
♦ Sequence Alignment and Modeling (SAM)– Krogh et al. (1994), Hughey & Krogh (1996)
♦ HMMER– Eddy (1998)
♦ Pfam – база данных белковых семейств– Sonhammer et al. (1997)

Скрытые марковские модели:Скрытые марковские модели:три вычислительные задачитри вычислительные задачи
♦ Вероятность наблюдаемой пос-стиВероятность наблюдаемой пос-сти– для даннойдля данной O1, O2, …, Ot найти P(O1, O2, …, Ot)
♦Наиболее вероятная скрытая пос-сть состояний– для даннойдля данной O1, O2, …, Ot найти max P(Q1, Q2, …, Qt|
O1, O2, …, Ot)
– O – наблюдаемые, Q – скрытые состояния
♦Оценка параметров модели– для набора наблюдаемых пос-стей {S1, S2, …, SN} и
заданной топологии модели найти вероятности переходов и вставок max Σ P(Si)

НММ: от обучения к применениюНММ: от обучения к применению♦ Инициализация модели для данного набора пос-стейИнициализация модели для данного набора пос-стей
– своя своя HMM HMM для каждого наборадля каждого набора
♦ Итерационное обучение модели на 20-100 пос-стяхИтерационное обучение модели на 20-100 пос-стях– представление вариабельности пос-стей из одного семействапредставление вариабельности пос-стей из одного семейства– построение наилучшей построение наилучшей HMM HMM для данного семейства пос-стей для данного семейства пос-стей
путем оптимизации вер-стей переходов и АК-состава в каждой путем оптимизации вер-стей переходов и АК-состава в каждой выровненной позициивыровненной позиции
– алгоритм алгоритм forward-backwardforward-backward– алгоритм алгоритм Baum-WelchBaum-Welch
♦ ПримененияПрименения– множественные выравнивания (алгоритм множественные выравнивания (алгоритм ViterbiViterbi, , аналог ДП)аналог ДП)– анализ пос-стей и представление профилей (анализ пос-стей и представление профилей (HMM HMM профиля профиля
пос-сти)пос-сти)– анализ состава пос-стейанализ состава пос-стей– предсказание структуры белковпредсказание структуры белков– локализация генов путем предсказания локализация генов путем предсказания ORFORF

НММ: проблемыНММ: проблемы♦ Значительное числоЗначительное число пос-стей для обучения пос-стей для обучения♦ ЧувствительностьЧувствительность к параметрам инициализации к параметрам инициализации
– чем меньше начальное число пос-стей, тем выше чем меньше начальное число пос-стей, тем выше чувствительность к начальным параметрам моделичувствительность к начальным параметрам модели
– > > 50 пос-стей 50 пос-стей чувствительность минимальначувствительность минимальна– неравномерное распределение частот встречаемости АКнеравномерное распределение частот встречаемости АК
• PAMPAM• BLOSUMBLOSUM• смеси Дирихле (смеси Дирихле (SjSjöölander, 1996lander, 1996))
♦ Слишком строгая Слишком строгая «привязка» к обучающему семейству«привязка» к обучающему семейству– сглаживание частот встречаемости АКсглаживание частот встречаемости АК– сохранение сведений о наиболее консервативных фрагментасохранение сведений о наиболее консервативных фрагмента– метод регуляризацииметод регуляризации
♦ Чем больше различийЧем больше различий в пос-стях, в пос-стях, тем труднее тем труднее построить выравниваниепостроить выравнивание при помощи при помощи HMMHMM
♦ Локальные оптимумыЛокальные оптимумы вместо глобальных вместо глобальных– подмешивание шума при обученииподмешивание шума при обучении– имитационный отжиг (имитационный отжиг (simulated annealingsimulated annealing))






![Геномика Лекция №22intbio.org/bioinf2019-2020/2018-19_lecture22_genomics.pdf · 2020-04-25 · регистрации в Российской Федерации»[19]](https://img.pdfslide.tips/doc/110x75/5fb6f9c32842fc12164ab5e8/-a-2020-04-25-.jpg)






















