Embed Size (px)
Citation preview

1© 2014 The MathWorks, Inc.
Анализ данных и машинное
обучение в MATLAB
Машинное обучение в MATLAB
Иван Мелёшин
инженер департамента MathWorks

2
Что мы узнаем
Обзор машинного обучения
Доступные алгоритмы в MATLAB
MATLAB как интерактивная среда разработки,
оценки и выбора лучшего алгоритма
3
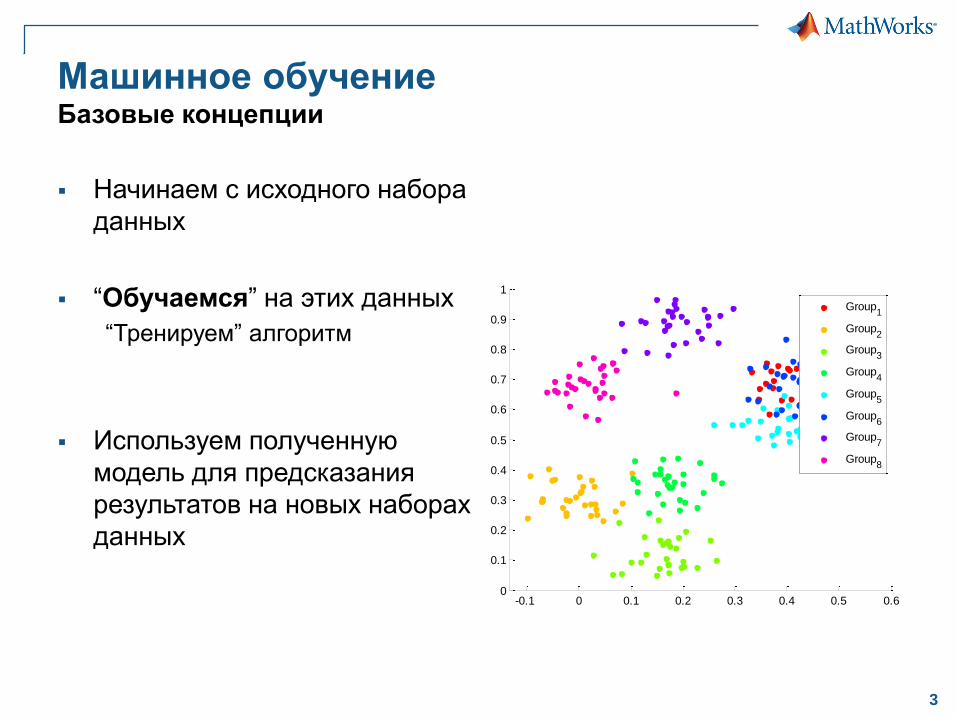
Машинное обучениеБазовые концепции
Начинаем с исходного набора
данных
“Обучаемся” на этих данных
“Тренируем” алгоритм
Используем полученную
модель для предсказания
результатов на новых наборах
данных
-0.1 0 0.1 0.2 0.3 0.4 0.5 0.60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Group1
Group2
Group3
Group4
Group5
Group6
Group7
Group8

4
Используется во многих областях
применения
Биология Финансовые сервисы Обработка аудио, фото и видео Энергия
Определение
опухоли
Исследование
лекарств
Кредитный
скоринг,
трейдинг,
Классификация
облигаций
Распознавание
изображений
Распознавание
речи
Нагрузка,
прогноз цен,
энерготрейдинг

5
Проблемы при работе с алгоритмами
машинного обучения
Много данных, много переменных
Сложные зависимости, что бы описать уравнениями
Требуется значительная техническая экспертиза
Решения типа «черный ящик»
Нет однозначного решения -> требуется
итеративный подход
– Пробовать множество алгоритмов, выбрать лучший
– Требуется много времени

6
Решения на базе MATLAB
Среда работы с данными для интерактивного
исследования
Алгоритмы и приложения для быстрого начала
работы:
– Кластеризация, классификация, регрессия
– Нейросети, аппроксимация кривыми
Легко оценить, повторить расчеты и выбрать
лучший алгоритм
Распараллеливание
7
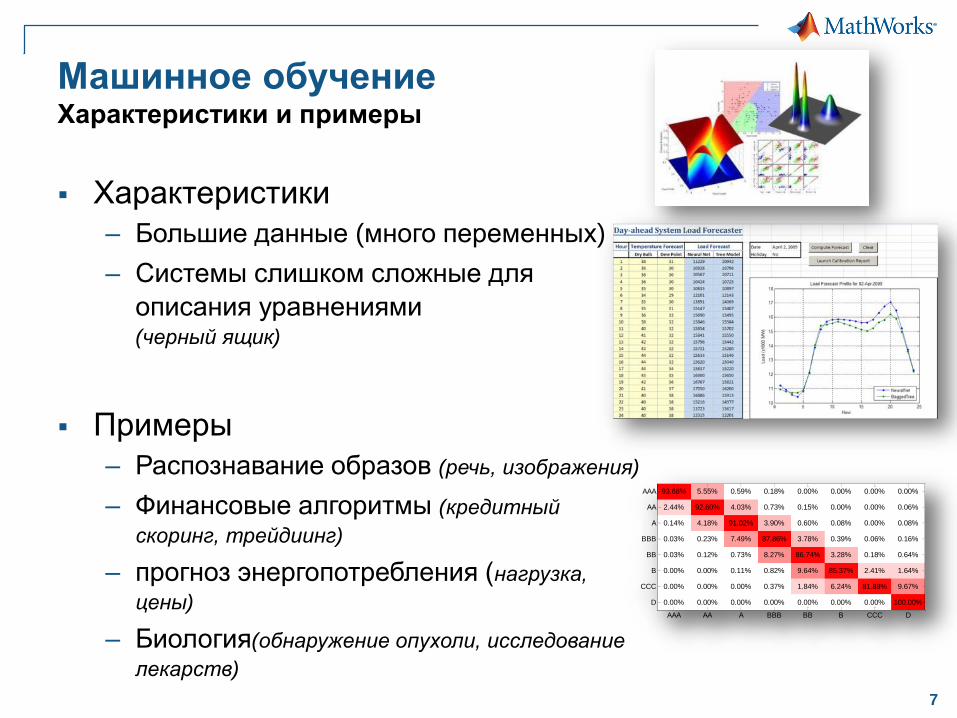
Машинное обучениеХарактеристики и примеры
Характеристики
– Большие данные (много переменных)
– Системы слишком сложные для
описания уравнениями(черный ящик)
Примеры
– Распознавание образов (речь, изображения)
– Финансовые алгоритмы (кредитный
скоринг, трейдиинг)
– прогноз энергопотребления (нагрузка,
цены)
– Биология(обнаружение опухоли, исследование
лекарств)
93.68%
2.44%
0.14%
0.03%
0.03%
0.00%
0.00%
0.00%
5.55%
92.60%
4.18%
0.23%
0.12%
0.00%
0.00%
0.00%
0.59%
4.03%
91.02%
7.49%
0.73%
0.11%
0.00%
0.00%
0.18%
0.73%
3.90%
87.86%
8.27%
0.82%
0.37%
0.00%
0.00%
0.15%
0.60%
3.78%
86.74%
9.64%
1.84%
0.00%
0.00%
0.00%
0.08%
0.39%
3.28%
85.37%
6.24%
0.00%
0.00%
0.00%
0.00%
0.06%
0.18%
2.41%
81.88%
0.00%
0.00%
0.06%
0.08%
0.16%
0.64%
1.64%
9.67%
100.00%
AAA AA A BBB BB B CCC D
AAA
AA
A
BBB
BB
B
CCC
D
8
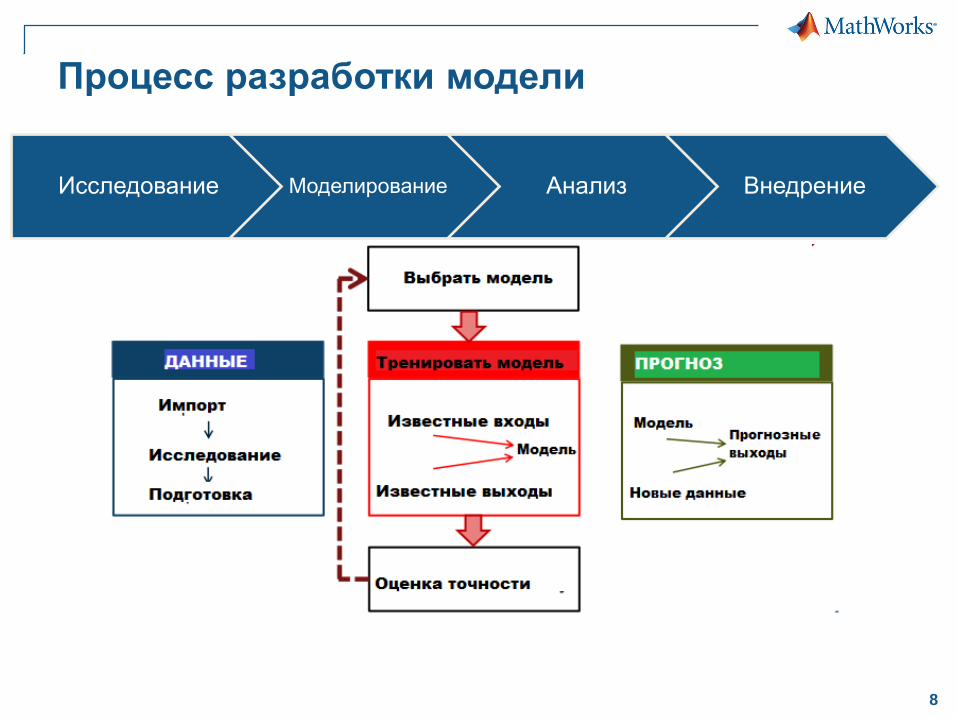
Процесс разработки модели
Исследование Моделирование Анализ Внедрение
9
Процесс разработки модели
ИсследованиеМоделирова
ниеАнализ Внедрение
10
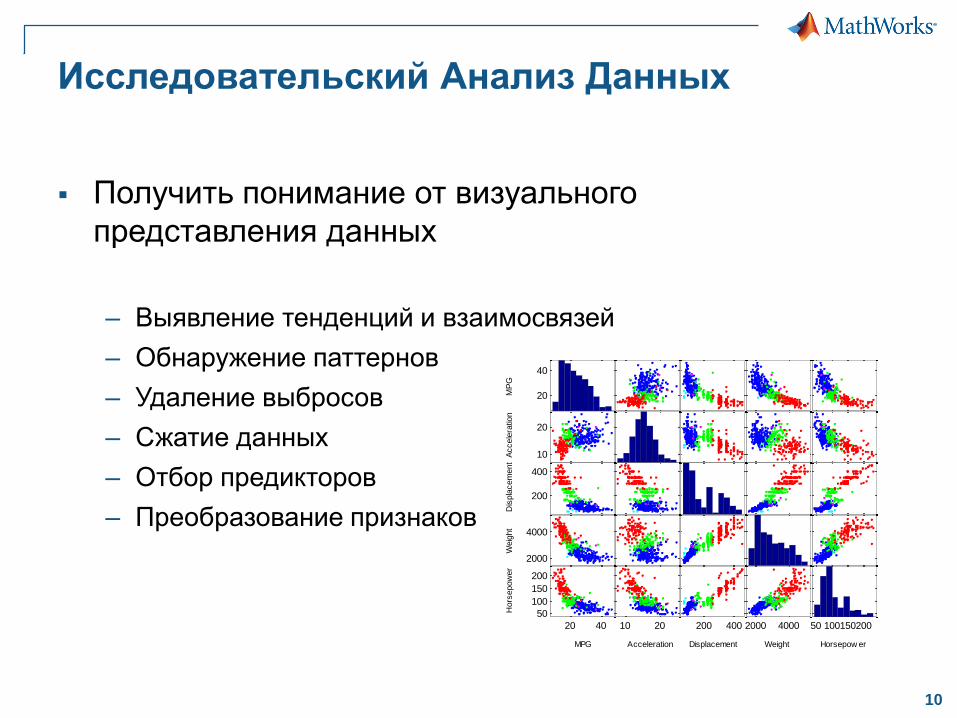
Исследовательский Анализ Данных
Получить понимание от визуального
представления данных
– Выявление тенденций и взаимосвязей
– Обнаружение паттернов
– Удаление выбросов
– Сжатие данных
– Отбор предикторов
– Преобразование признаков
MPG Acceleration Displacement Weight Horsepow er
MP
GA
ccele
ratio
nD
ispla
cem
ent
Weig
ht
Hors
epow
er
50 1001502002000 4000200 40010 2020 40
50
100
150
200
2000
4000
200
400
10
20
20
40
11
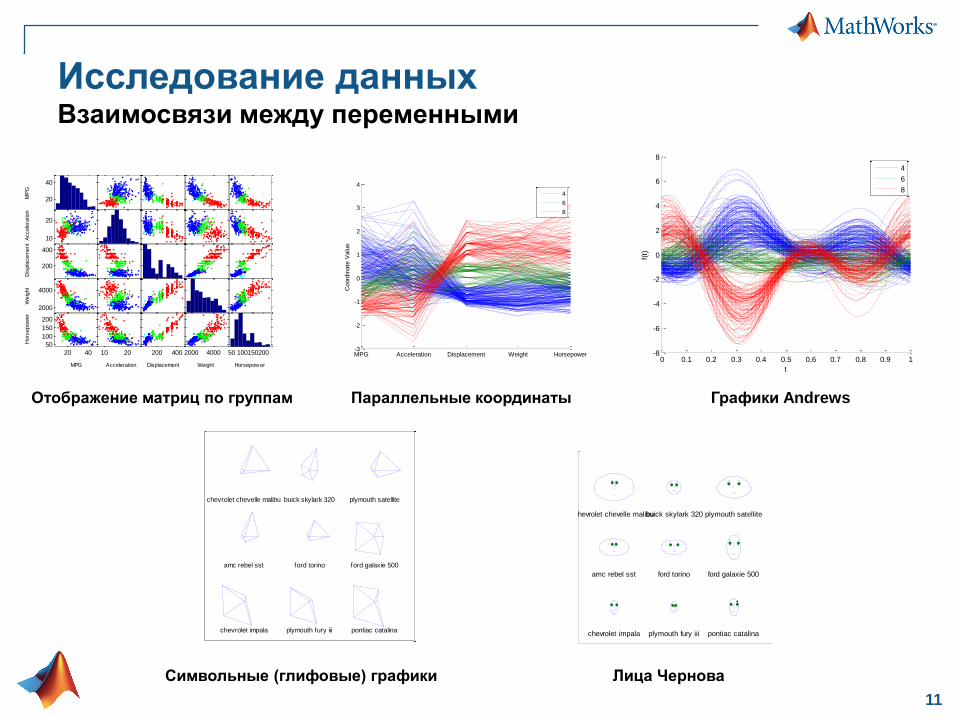
Исследование данныхВзаимосвязи между переменными
Отображение матриц по группам Параллельные координаты Графики Andrews
Символьные (глифовые) графики Лица Чернова
MPG Acceleration Displacement Weight Horsepow er
MP
GA
ccele
ratio
nD
ispla
cem
ent
Weig
ht
Hors
epow
er
50 1001502002000 4000200 40010 2020 40
50
100
150
200
2000
4000
200
400
10
20
20
40
MPG Acceleration Displacement Weight Horsepower-3
-2
-1
0
1
2
3
4
Coord
inate
Valu
e
4
6
8
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1-8
-6
-4
-2
0
2
4
6
8
t
f(t)
4
6
8
chevrolet chevelle malibu buick skylark 320 plymouth satellite
amc rebel sst ford torino ford galaxie 500
chevrolet impala plymouth fury iii pontiac catalina
chevrolet chevelle malibubuick skylark 320 plymouth satellite
amc rebel sst ford torino ford galaxie 500
chevrolet impala plymouth fury iii pontiac catalina

12
Лица Чернова
Для отображение многомерных данных в
виде человеческого лица
Лица легко распознаются и без затруднения
воспринимаются небольшие изменения в нём
13
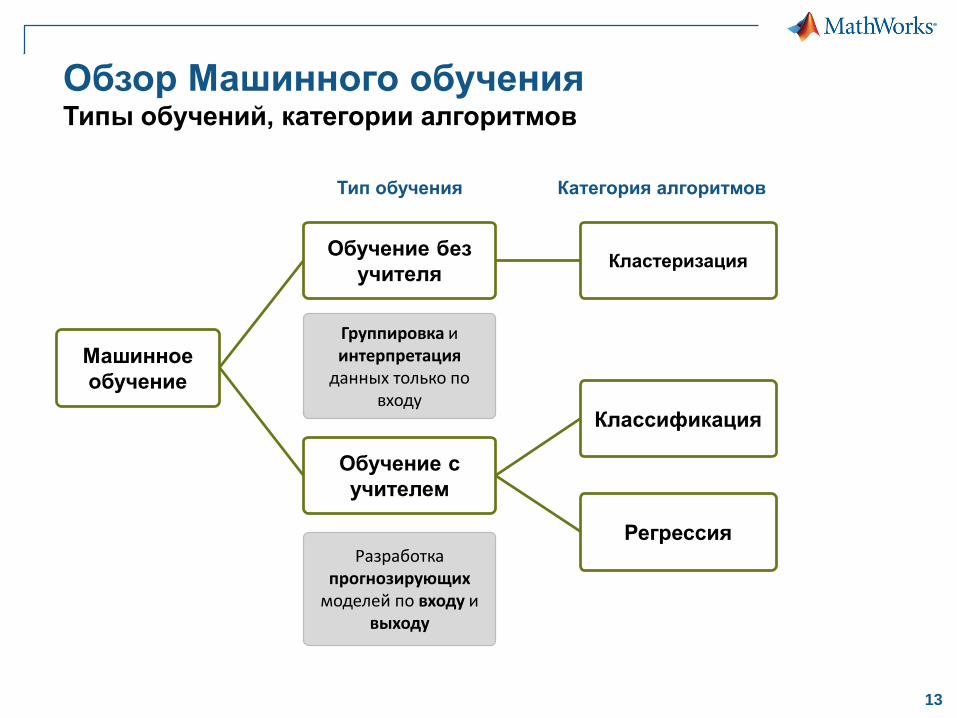
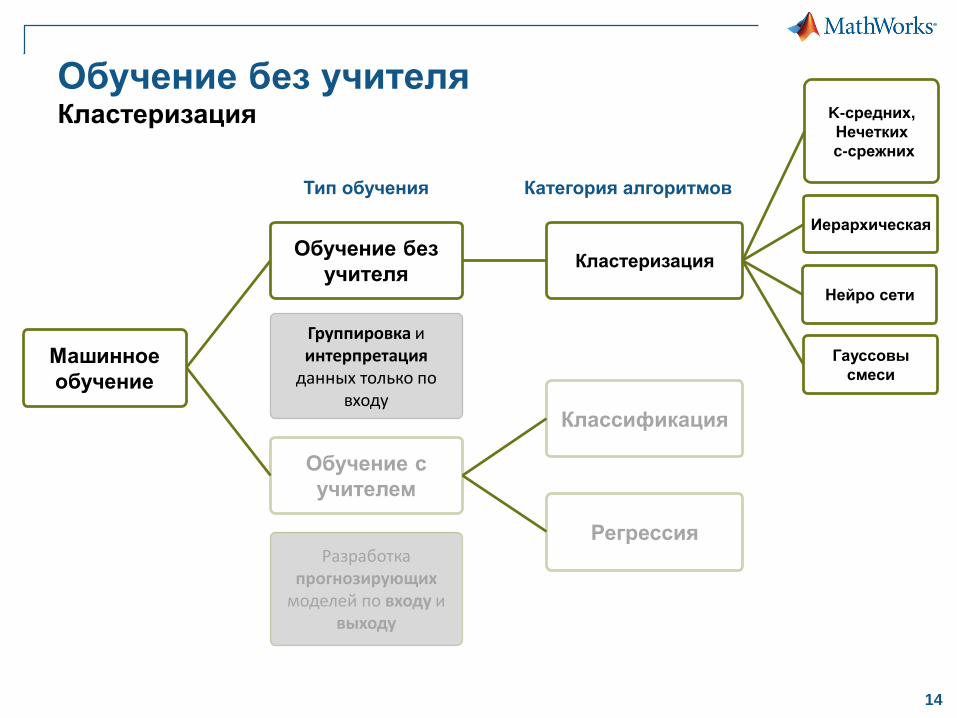
Обзор Машинного обучения Типы обучений, категории алгоритмов
Машинное
обучение
Обучение с
учителем
Классификация
Регрессия
Обучение без
учителяКластеризация
Группировка иинтерпретация
данных только по входу
Разработка прогнозирующих
моделей по входу и выходу
Тип обучения Категория алгоритмов
14
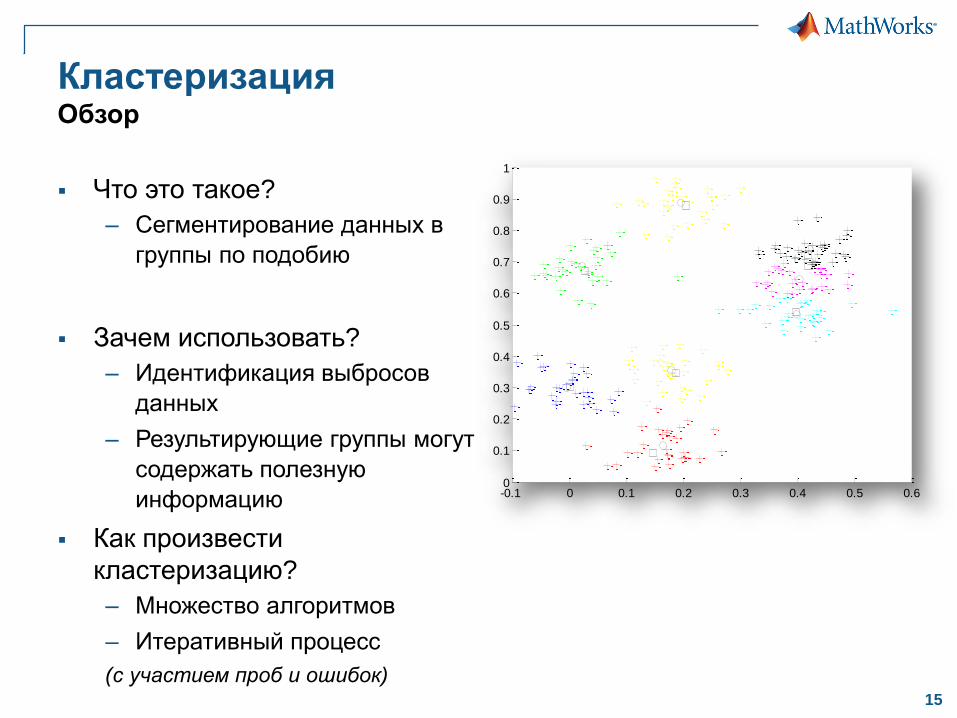
Обучение без учителяКластеризация K-средних,
Нечетких
c-срежних
Иерархическая
Нейро сети
Гауссовы
смесиМашинное
обучение
Обучение с
учителем
Классификация
Регрессия
Обучение без
учителяКластеризация
Группировка иинтерпретация
данных только по входу
Разработка прогнозирующих
моделей по входу и выходу
Тип обучения Категория алгоритмов
15
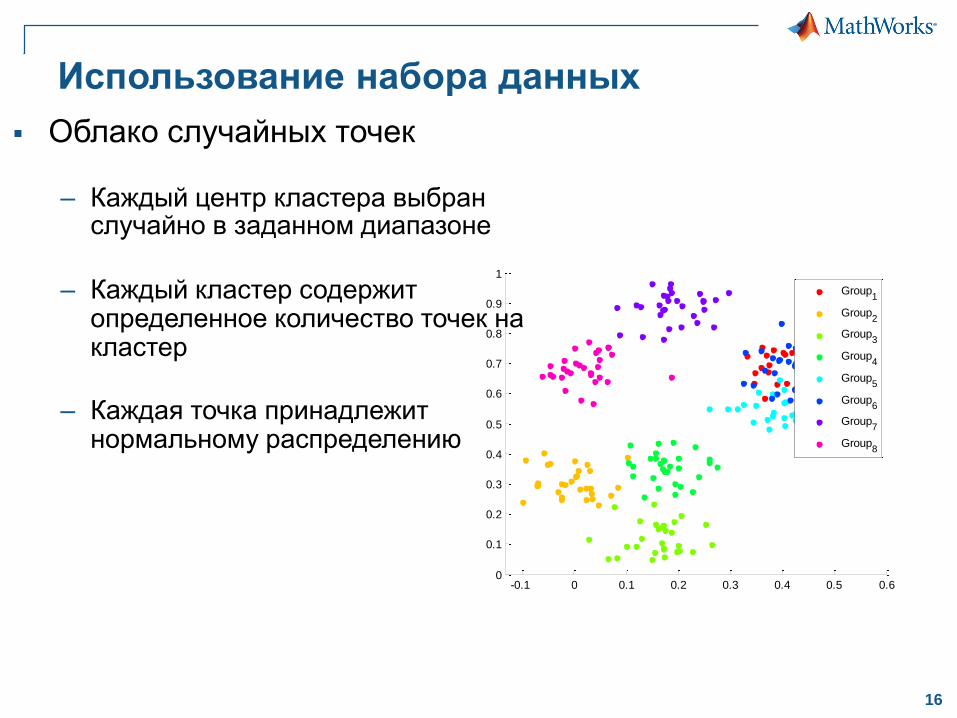
КластеризацияОбзор
Что это такое?
– Сегментирование данных в
группы по подобию
Зачем использовать?
– Идентификация выбросов
данных
– Результирующие группы могут
содержать полезную
информацию
Как произвести
кластеризацию?
– Множество алгоритмов
– Итеративный процесс
(с участием проб и ошибок)
-0.1 0 0.1 0.2 0.3 0.4 0.5 0.60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
16
-0.1 0 0.1 0.2 0.3 0.4 0.5 0.60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Group1
Group2
Group3
Group4
Group5
Group6
Group7
Group8
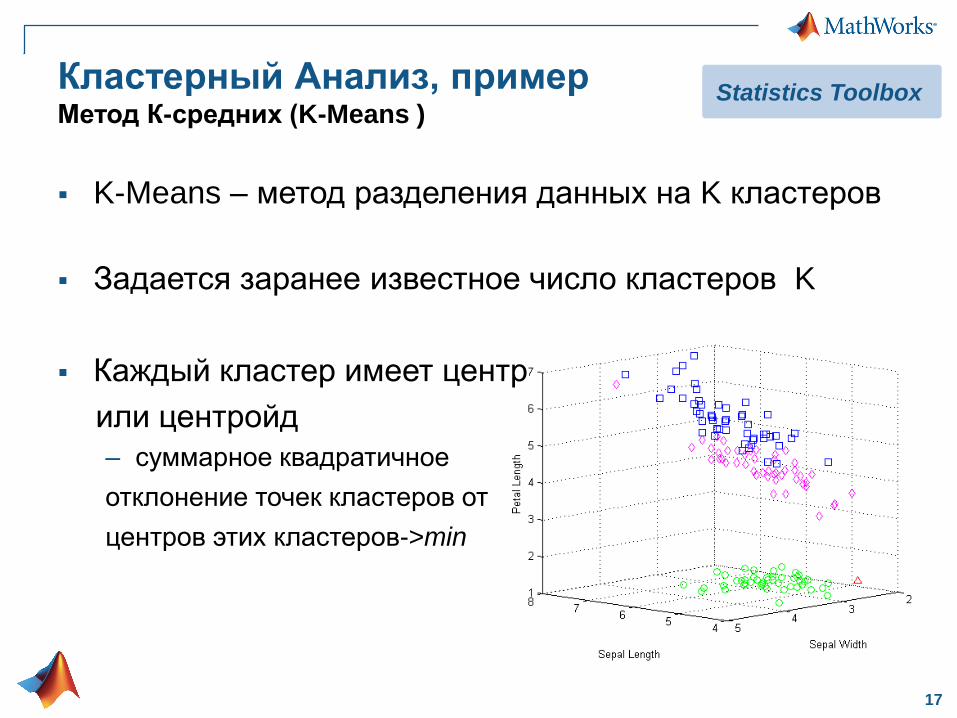
Использование набора данных
Облако случайных точек
– Каждый центр кластера выбран случайно в заданном диапазоне
– Каждый кластер содержит определенное количество точек на кластер
– Каждая точка принадлежит нормальному распределению
17
Кластерный Анализ, примерМетод К-средних (K-Means )
K-Means – метод разделения данных на K кластеров
Задается заранее известное число кластеров K
Каждый кластер имеет центр
или центройд
– суммарное квадратичное
отклонение точек кластеров от
центров этих кластеров->min
Statistics Toolbox
18
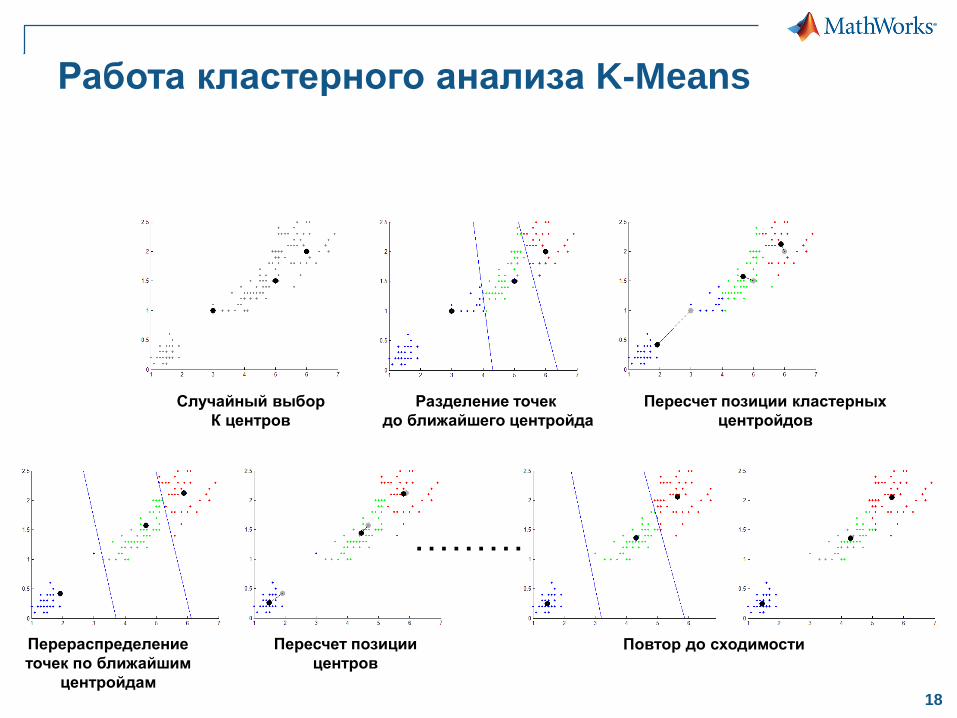
Работа кластерного анализа K-Means
Случайный выбор
К центров
Разделение точек
до ближайшего центройда
Пересчет позиции кластерных
центройдов
Перераспределение
точек по ближайшим
центройдам
Пересчет позиции
центров
Повтор до сходимости
………
19
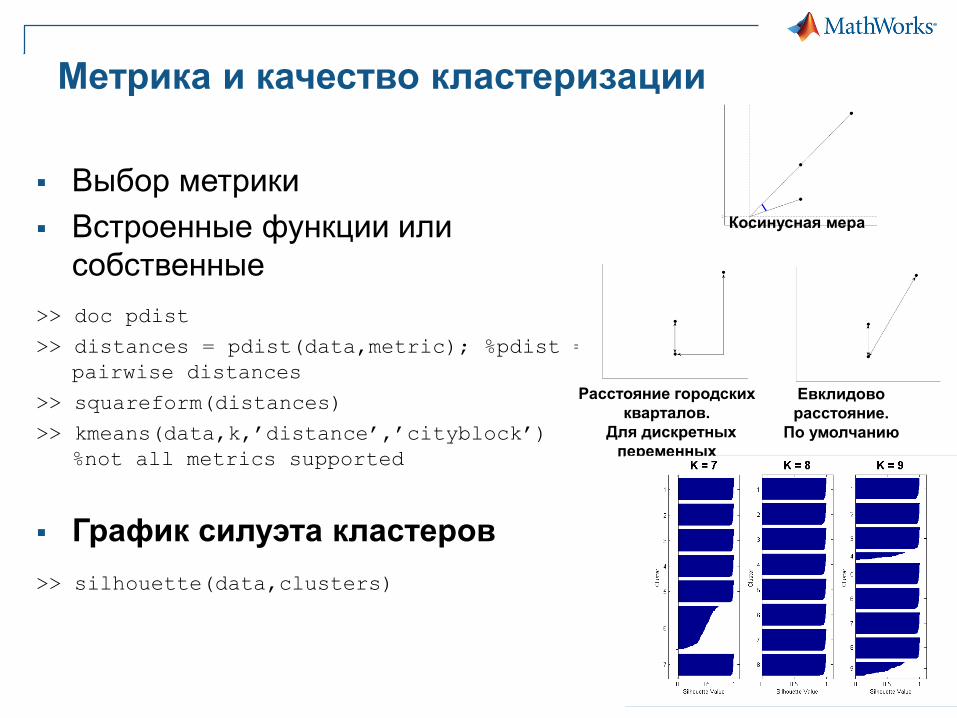
Метрика и качество кластеризации
Выбор метрики
Встроенные функции или
собственные
>> doc pdist
>> distances = pdist(data,metric); %pdist =
pairwise distances
>> squareform(distances)
>> kmeans(data,k,’distance’,’cityblock’)
%not all metrics supported
График силуэта кластеров
>> silhouette(data,clusters)
Евклидово
расстояние.
По умолчанию
Расстояние городских
кварталов.
Для дискретных
переменных
Косинусная мера
20
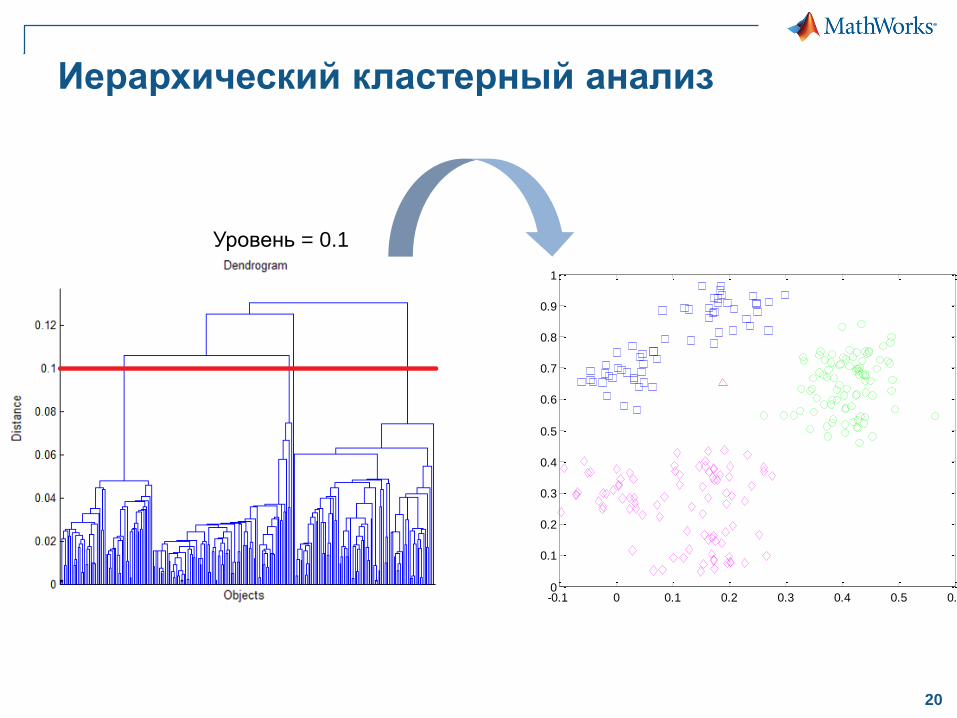
Иерархический кластерный анализ
-0.1 0 0.1 0.2 0.3 0.4 0.5 0.60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Уровень = 0.1

21
Кластерный анализ Нечеткий c-means
Похож на K-means
Данные не относятся к какому-либо кластеру, а
определяются к каждому с некоторой степенью
принадлежности
Необходим Fuzzy Logic Toolbox™
Для запуска необходимо определить
K>> [centroids, memberships]=fcm(x,K);
22
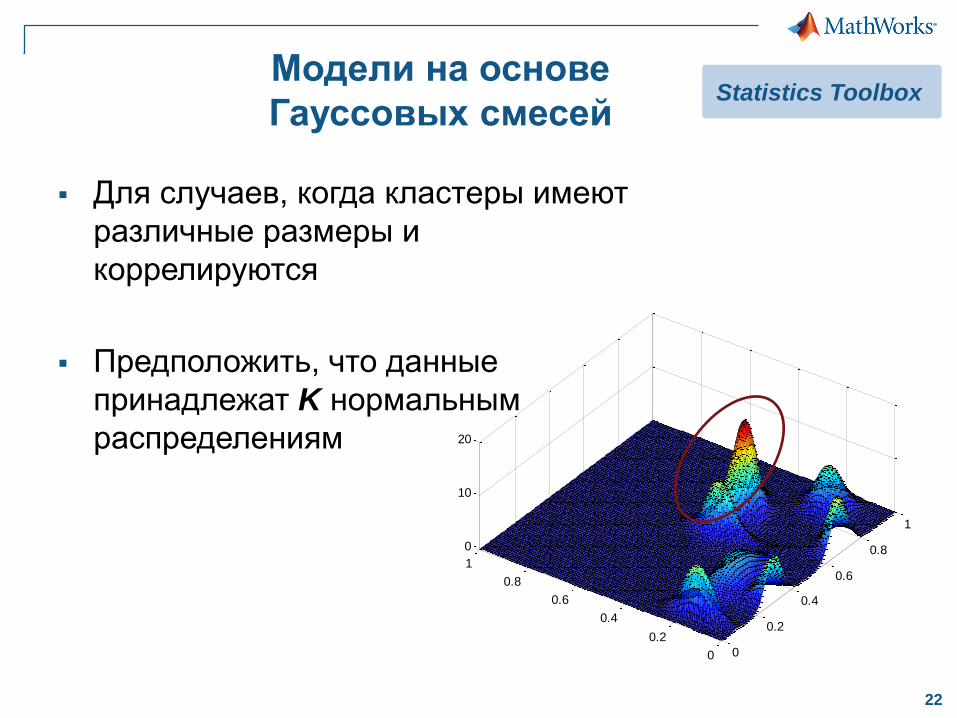
Модели на основе
Гауссовых смесей
Для случаев, когда кластеры имеют
различные размеры и
коррелируются
Предположить, что данные
принадлежат K нормальным
распределениям
0
0.2
0.4
0.6
0.8
1
0
0.2
0.4
0.6
0.8
1
0
10
20
Statistics Toolbox
23
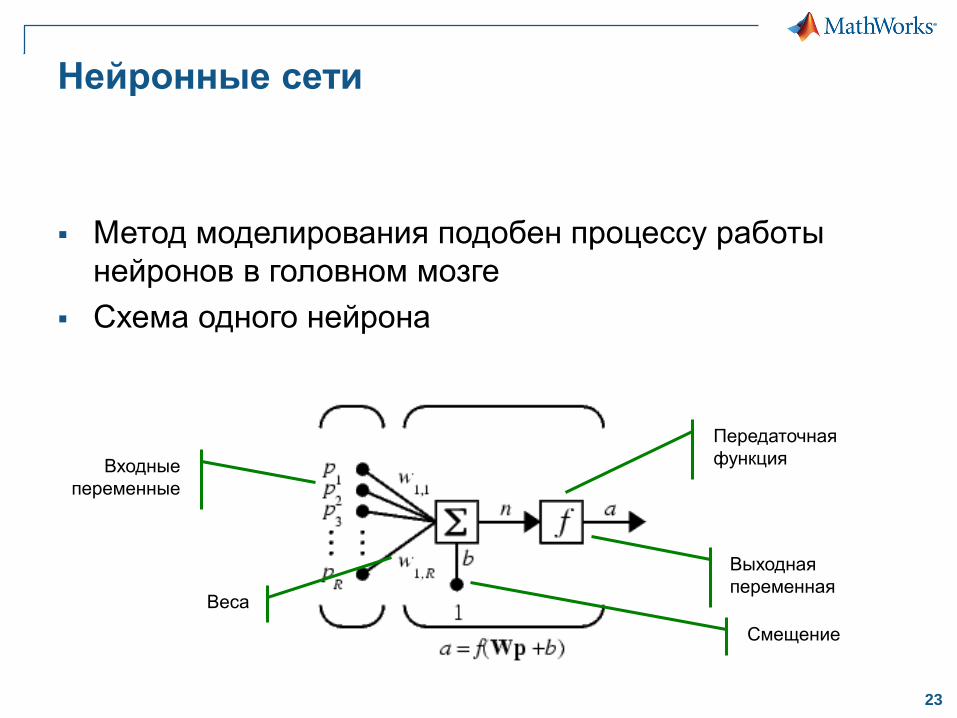
Нейронные сети
Метод моделирования подобен процессу работы
нейронов в головном мозге
Схема одного нейрона
Входные
переменные
Веса
Смещение
Выходная
переменная
Передаточная
функция
24
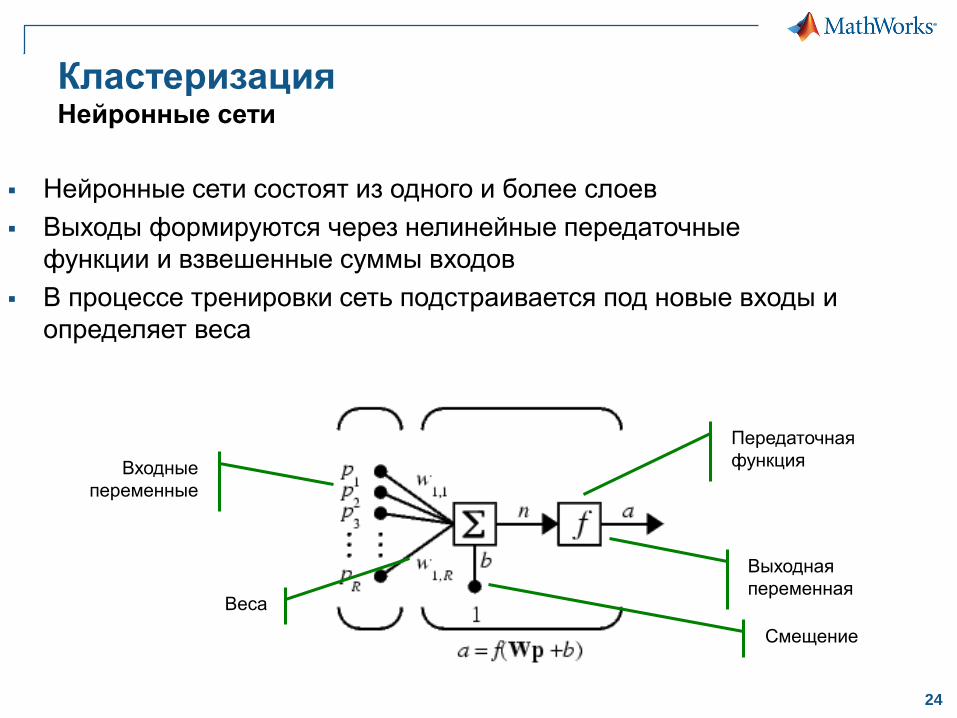
КластеризацияНейронные сети
Нейронные сети состоят из одного и более слоев
Выходы формируются через нелинейные передаточные
функции и взвешенные суммы входов
В процессе тренировки сеть подстраивается под новые входы и
определяет веса
Входные
переменные
Веса
Смещение
Выходная
переменная
Передаточная
функция
25
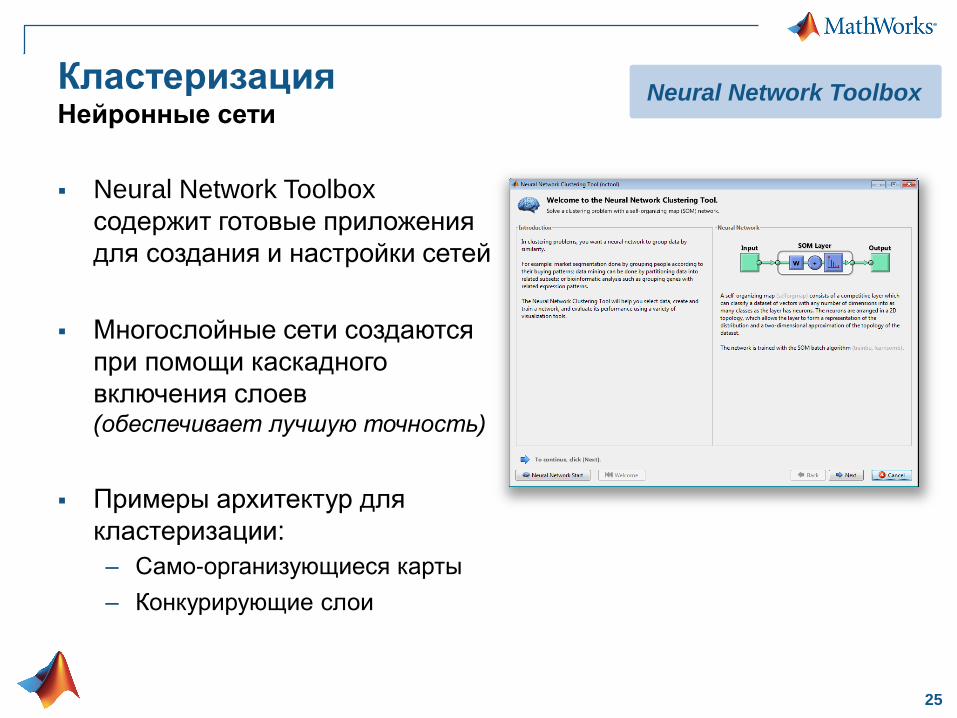
КластеризацияНейронные сети
Neural Network Toolbox
содержит готовые приложения
для создания и настройки сетей
Многослойные сети создаются
при помощи каскадного
включения слоев(обеспечивает лучшую точность)
Примеры архитектур для
кластеризации:
– Само-организующиеся карты
– Конкурирующие слои
Neural Network Toolbox
26
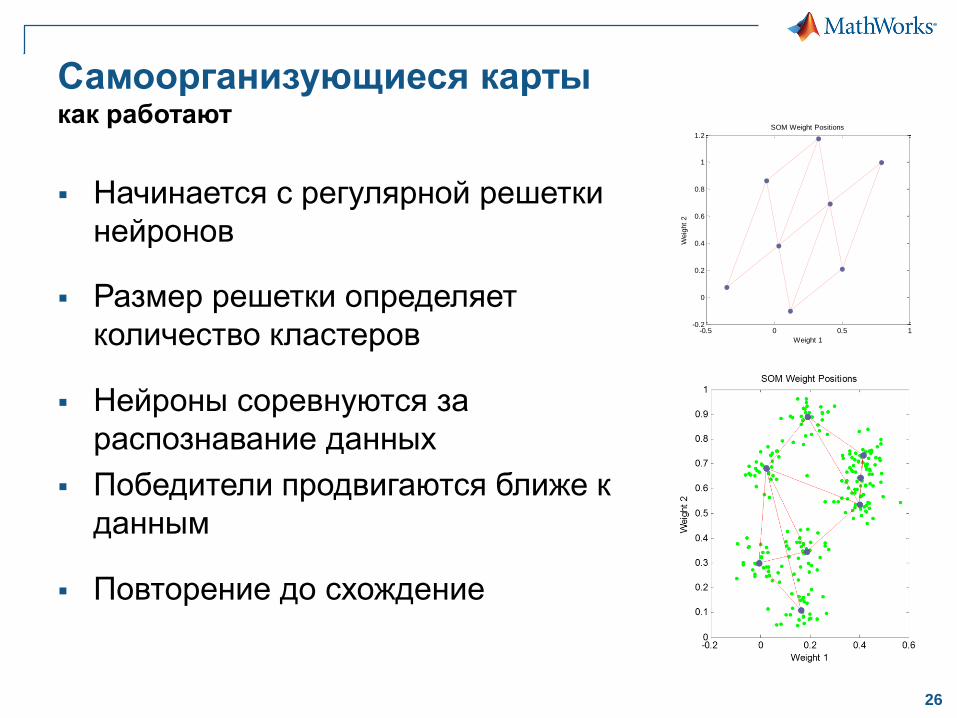
Самоорганизующиеся карты как работают
Начинается с регулярной решетки
нейронов
Размер решетки определяет
количество кластеров
Нейроны соревнуются за
распознавание данных
Победители продвигаются ближе к
данным
Повторение до схождение
-0.5 0 0.5 1-0.2
0
0.2
0.4
0.6
0.8
1
1.2SOM Weight Positions
Weight 1
Weig
ht
2
27
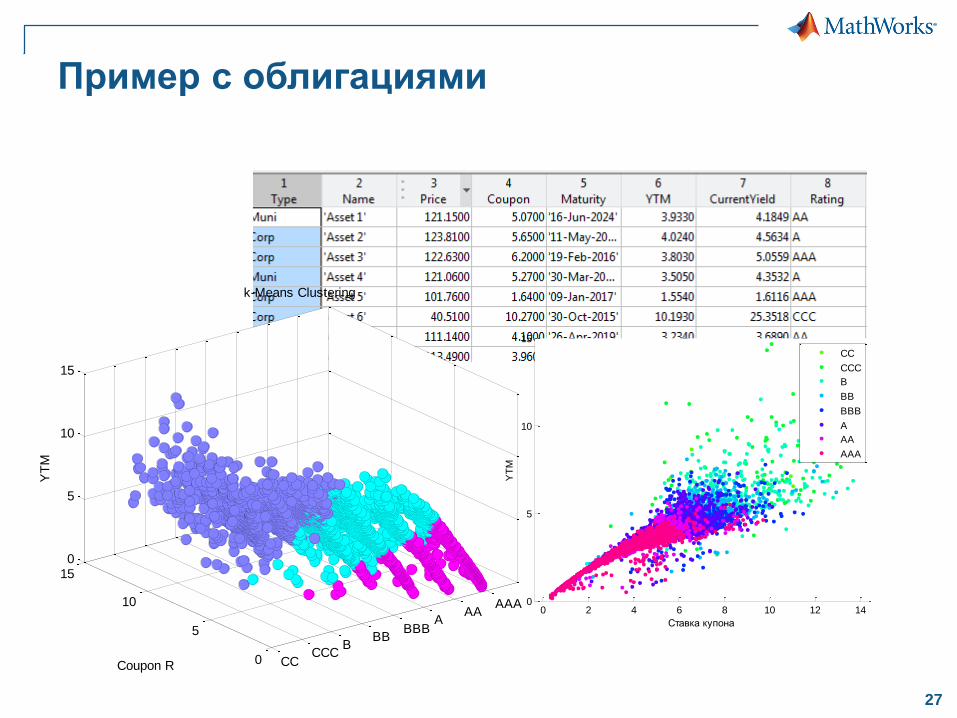
Пример с облигациями
CCCCC
BBB
BBBA
AAAAA
0
5
10
150
5
10
15
YT
M
k-Means Clustering
Coupon R
0 2 4 6 8 10 12 140
5
10
15
Ставка купона
YT
M
CC
CCC
B
BB
BBB
A
AA
AAA
28
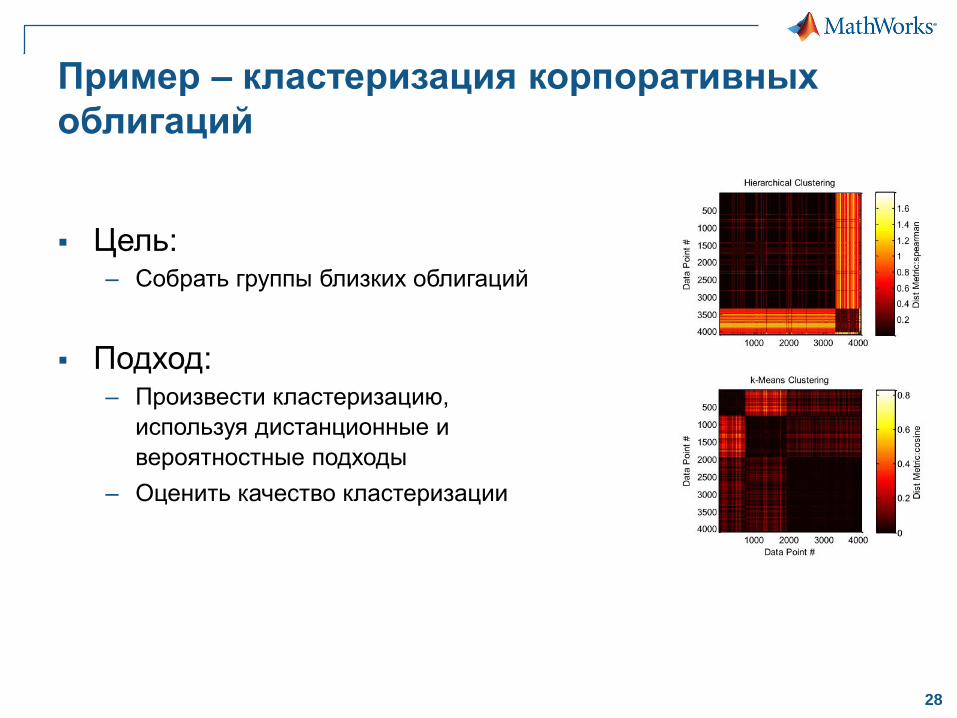
Пример – кластеризация корпоративных
облигаций
Цель:– Собрать группы близких облигаций
Подход:– Произвести кластеризацию,
используя дистанционные и
вероятностные подходы
– Оценить качество кластеризации
29
Пример – кластеризация корпоративных
облигаций
Множество функций
кластеризации с богатой
документацией
Интерактивная визуализация
для проведения исследований
Виден исходный код, не
черный ящик
Быстрое исследование и
разработка
30
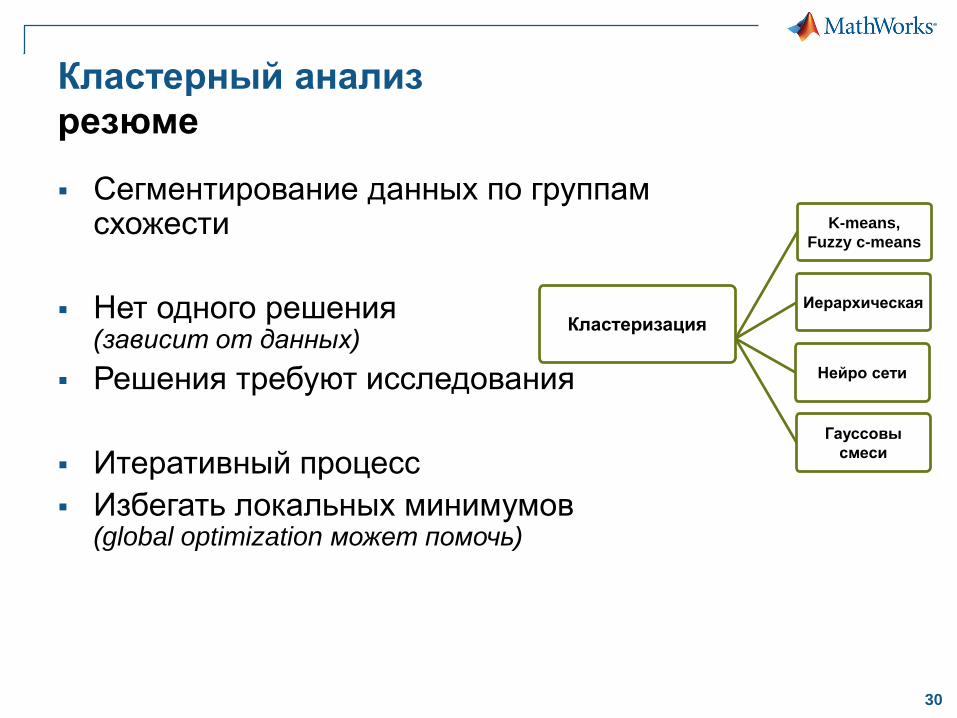
Кластерный анализ
резюме
Сегментирование данных по группам схожести
Нет одного решения(зависит от данных)
Решения требуют исследования
Итеративный процесс
Избегать локальных минимумов(global optimization может помочь)
K-means,
Fuzzy c-means
Иерархическая
Нейро сети
Гауссовы
смеси
Кластеризация
31
Процесс разработки модели
ИсследованиеМоделирова
ниеАнализ Внедрение
32
Обучение с учителемКлассификация для прогнозирующего моделирования
Обучение без
учителя
Разработка прогнозирующих
моделей по входу и выходу
Machine
Learning
Обучение с
учителем
Дерево
принятия
решений
Ансамбли
Нейронные
сети
Метод
опорных
векторов
Классификация
33
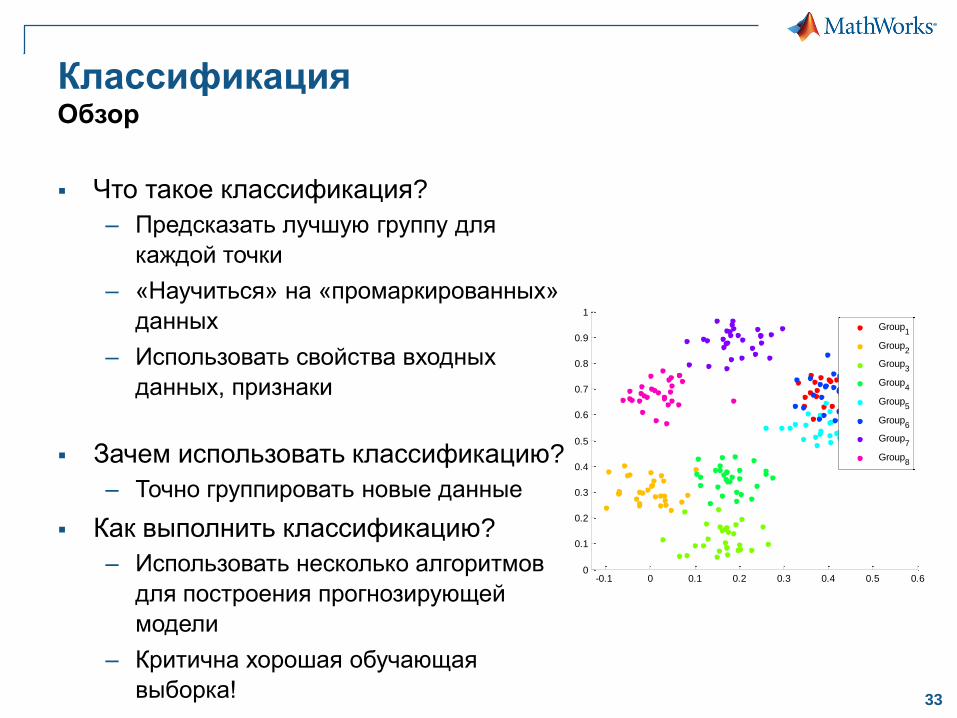
КлассификацияОбзор
Что такое классификация?
– Предсказать лучшую группу для
каждой точки
– «Научиться» на «промаркированных»
данных
– Использовать свойства входных
данных, признаки
Зачем использовать классификацию?
– Точно группировать новые данные
Как выполнить классификацию?
– Использовать несколько алгоритмов
для построения прогнозирующей
модели
– Критична хорошая обучающая
выборка!
-0.1 0 0.1 0.2 0.3 0.4 0.5 0.60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Group1
Group2
Group3
Group4
Group5
Group6
Group7
Group8

34
-0.4 -0.2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6-0.5
0
0.5
1
1.5
x1
x2
group1
group2
group3
group4
group5
group6
group7
group8
Классификация «метод k
ближайших соседей»
Один из простейших
классификаторов
Взять K ближайших точек из
обучающей выборки и определить
доминирующий класс среди K точек
Нет тренировочной фазы – вся
работа делается в процессе
применения модели
Statistics Toolbox

35
Дискриминантный анализ
Подбор многомерной нормальной плотности для
каждого класса
class = classify(sample,training,group,'type')
– linear— подбор многомерной нормальной плотности для
каждой группы с суммарной оценкой ковариации. По
умолчанию
– diaglinear — как и в линейной, но с диагональной оценкой
ковариационной матрицы (наивный Байесовский
классификатор)
– quadratic — подбор многомерной нормальной плотности с
ковариационной оценкой с разбивкой по группам
– diagquadratic —как и в квадратичной, но с диагональной
оценкой ковариационной матрицы (наивный Байесовский
классификатор).
Классифицировать новую точку за счет оценки вероятности
для каждого распределения и определения класса по
наибольшему значению

36
Пример классификацииДерево принятия решений
Построение дерева из
обучающей выборки
– Моделью является дерево, каждый
узел которого является логическим
тестом на предиктор
Спускаемся по дереву,
сравнивая признаки с
пороговыми значениями
«Листья» дерева определяют
группу
Statistics Toolbox

37
Ансамбли алгоритмовобзор
Деревья решений -“слабые” алгоритмы
– Хорошая классификация на обучающей
выборке
– Часто плохой результат на новых
данных
– Заметные прямоугольные группы
(ящики)
Ансамбли алгоритмов
– Комбинация нескольких деревьев для
создания «сильного» алгоритма
– Использовать “бутстрап аггрегацию”
Зачем использовать ансамбли?
– Большая мощность классификатора
– Заметное улучшение в форме
кластеров
Statistics Toolbox
-0.4 -0.2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6-0.5
0
0.5
1
1.5
x1
x2
group1
group2
group3
group4
group5
group6
group7
group8

38
Метод опорных векторов
(support vector machine)Обзор
Хорошо работает для сложных
разделяющих поверхностей
между классами
– Может быть очень точным
– Нет ограничений на предикторы
Как работает?
– Использует нелинейное «ядро»
для определения границ
– Может быть вычислительно
затратным
Statistics Toolbox поддерживает
классификацию только на 2
группы
Statistics Toolbox
-3 -2 -1 0 1 2 3-2
-1
0
1
2
3
4
1
2
Support Vectors

39
Распознавание образов с Neural Network
Двуслойная (с одним скрытым слоем) сеть прямого
распространения
При заданном количестве нейронов в скрытом слое
может отображать любую зависимость вход-выход
Нет ограничений на предикторы

40
Оценка модели классификатора
Три стратегии
– Повторная подстановка (resubstitution) – тест модели на
тренировочных данных
– Кросс-валидация (перекрестная проверка)
– Отложенный тест (holdout test) – на новом наборе данных
Использовать кросс-валидацию для оценки таких параметров
модели, как число листьев дереве или количество скрытых
нейронов
Требуется Statistics Toolbox
Применение кросс-валидации на модели классификатора>> cp = cvpartition(y,'k',10);
>> ldaFun= @(xtrain,ytrain,xtest)(classify(xtest,xtrain,ytrain));
>> ldaCVErr = crossval('mcr',x,y,'predfun',ldaFun,'partition',cp)
41
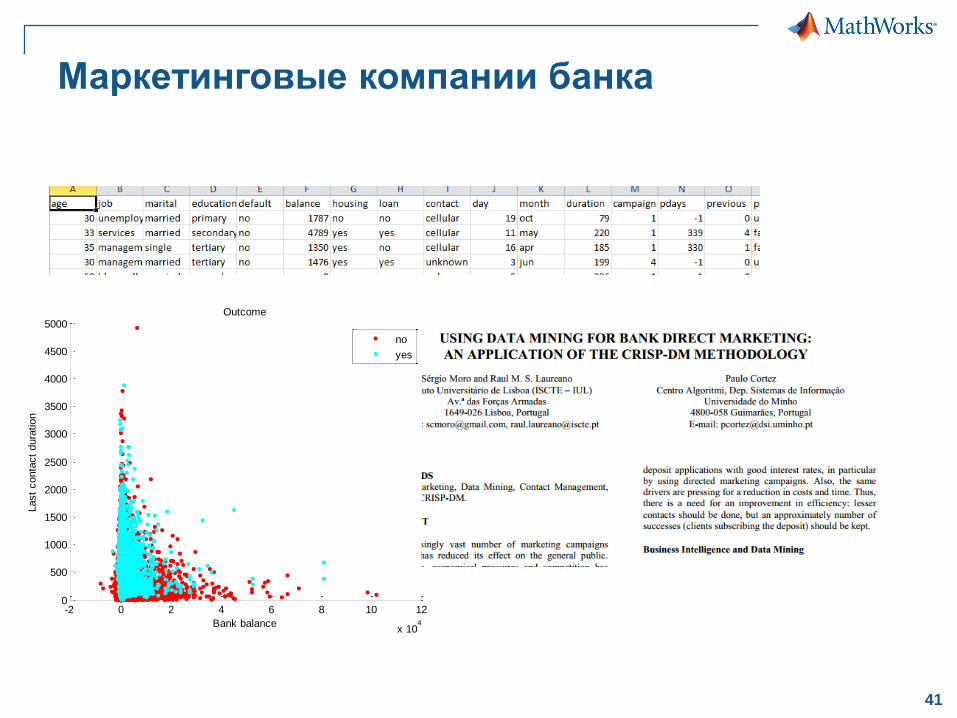
Маркетинговые компании банка
-2 0 2 4 6 8 10 12
x 104
0
500
1000
1500
2000
2500
3000
3500
4000
4500
5000
Bank balance
Last
conta
ct
dura
tion
Outcome
no
yes
42
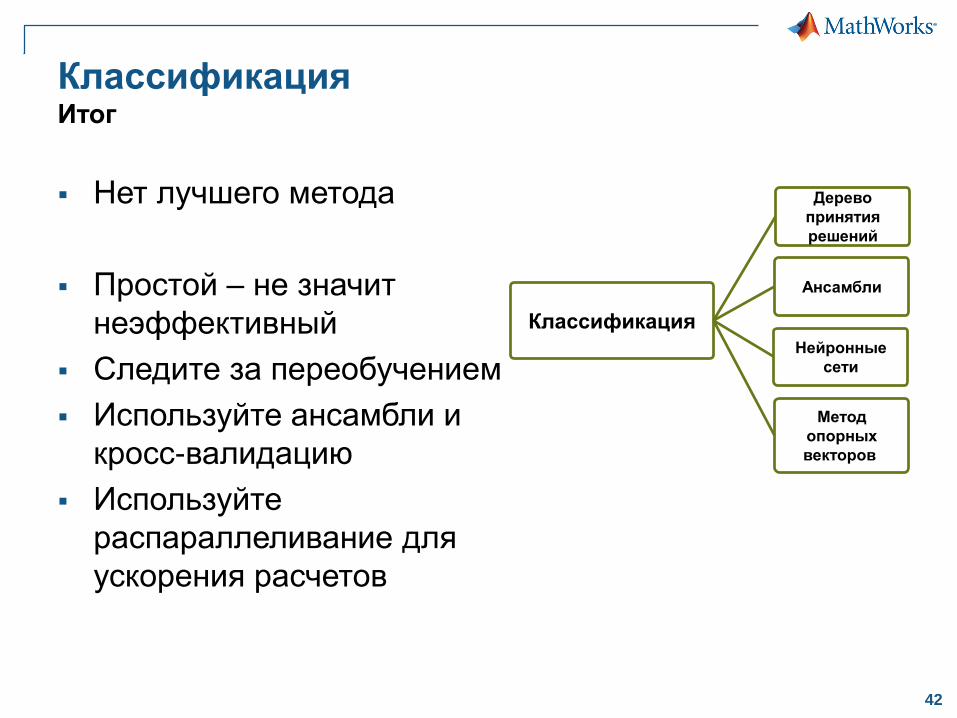
КлассификацияИтог
Нет лучшего метода
Простой – не значит
неэффективный
Следите за переобучением
Используйте ансамбли и
кросс-валидацию
Используйте
распараллеливание для
ускорения расчетов
Дерево
принятия
решений
Ансамбли
Нейронные
сети
Метод
опорных
векторов
Классификация
43
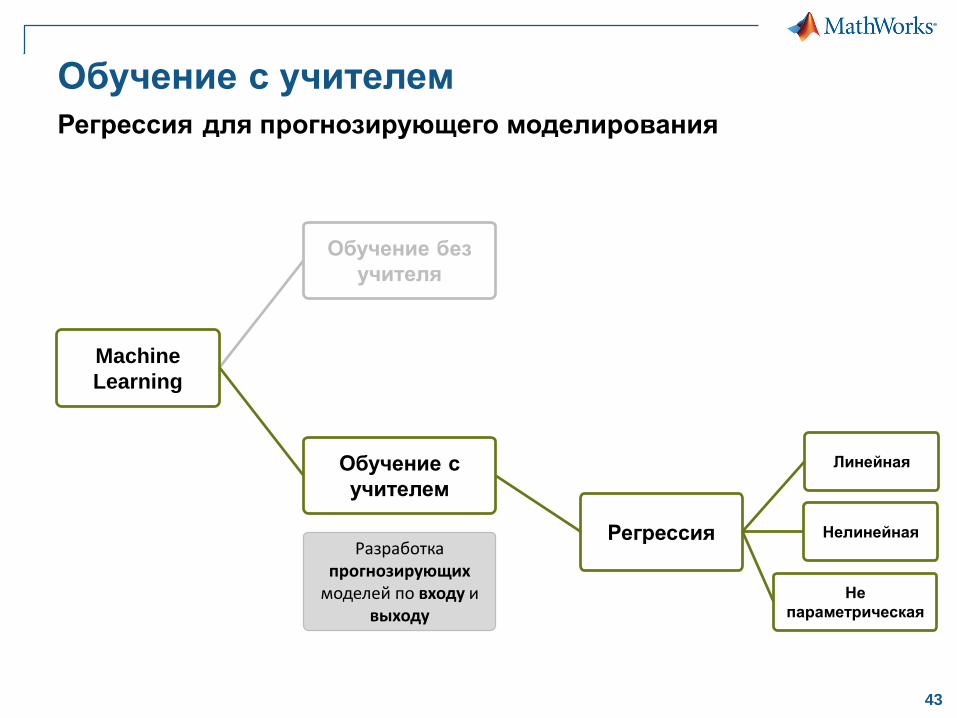
Обучение с учителем
Регрессия для прогнозирующего моделирования
Обучение без
учителя
Разработка прогнозирующих
моделей по входу и выходу
Machine
Learning
Обучение с
учителем
Линейная
Нелинейная
Не
параметрическая
Регрессия
44
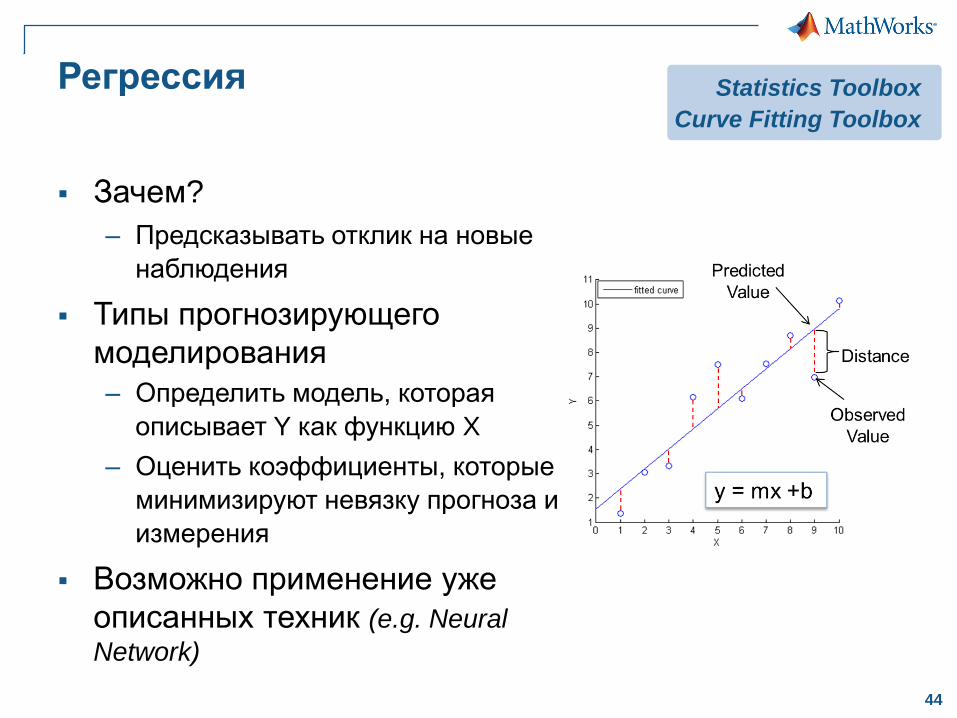
Регрессия
Зачем?
– Предсказывать отклик на новые
наблюдения
Типы прогнозирующего
моделирования
– Определить модель, которая
описывает Y как функцию X
– Оценить коэффициенты, которые
минимизируют невязку прогноза и
измерения
Возможно применение уже
описанных техник (e.g. Neural
Network)
Statistics Toolbox
Curve Fitting Toolbox

45
Линейная регрессия
Y линейная функция коэффициентов регрессии
Обычные примеры:
Прямая 𝑌 = 𝐵0+ 𝐵1𝑋1
Плоскость 𝑌 = 𝐵0+ 𝐵1𝑋1+𝐵2𝑋2
Полиномы 𝑌 = 𝐵0+ 𝐵1𝑋13+ 𝐵2𝑋1
2 +𝐵3𝑋1
𝑌 = 𝐵0+ 𝐵1𝑋12+ 𝐵2(𝑋1 ∗ 𝑋2) + 𝐵3 𝑋2
2

46
Fourier Series 𝑏0+ 𝑏1 cos 𝑏3𝑋 + 𝑏2 sin 𝑏3𝑋
Exponential Growth 𝑁 = 𝑁0𝑒
Logistic Growth 𝑃 𝑡 =𝑏0
1 + 𝑏1𝑒−𝑘𝑡
Нелинейная регрессия
Y нелинейная функция коэффициентов регрессии
Синтаксис формул:
y ~ b0 + b1*cos(x*b3) +
b4*sin(x*b3)
y ~ b0 + b1*cos(x*b3) +
b4*sin(x*b3)
@(b,t)(b(1)*exp(b(2)*t)
y ~ b0 + b1*cos(x*b3) +
b4*sin(x*b3)
@(b,t)(b(1)*exp(b(2)*t)
@(b,t)(1/(b(1) + exp(-
b(2)*x)))

47
Регрессионные деревья?
Деревья принятия решения с бинарным разделением для
регрессии. Объект класса регрессионного дерева может
предсказывать отклик на новые данные.
Любые предикторы (категории, порядковые, с разрывами)
48
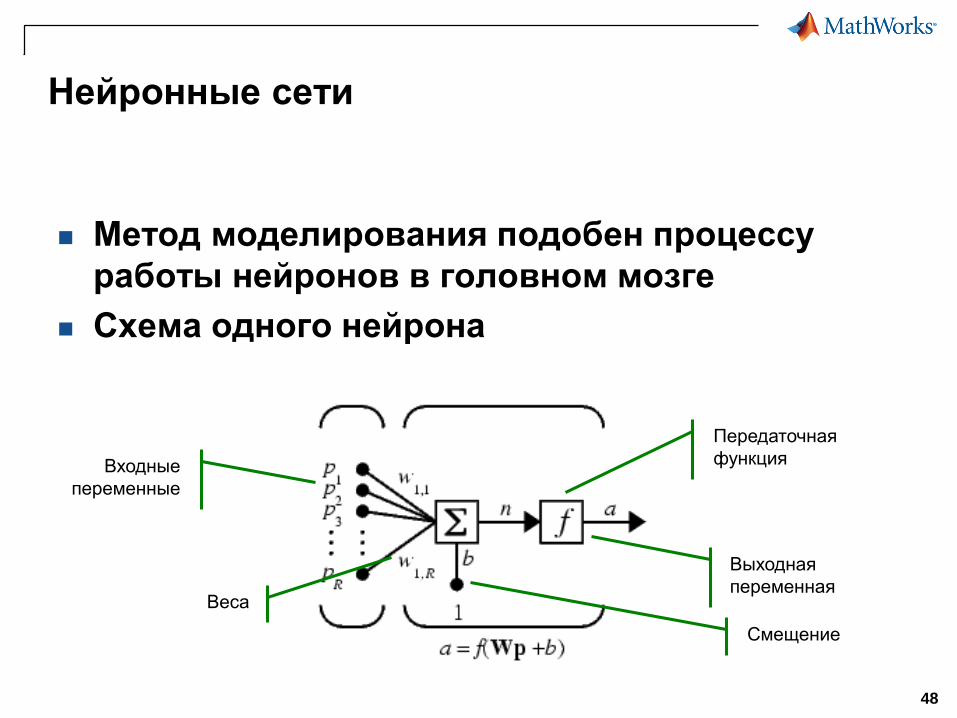
Нейронные сети
Метод моделирования подобен процессу
работы нейронов в головном мозге
Схема одного нейрона
Входные
переменные
Веса
Смещение
Выходная
переменная
Передаточная
функция
49
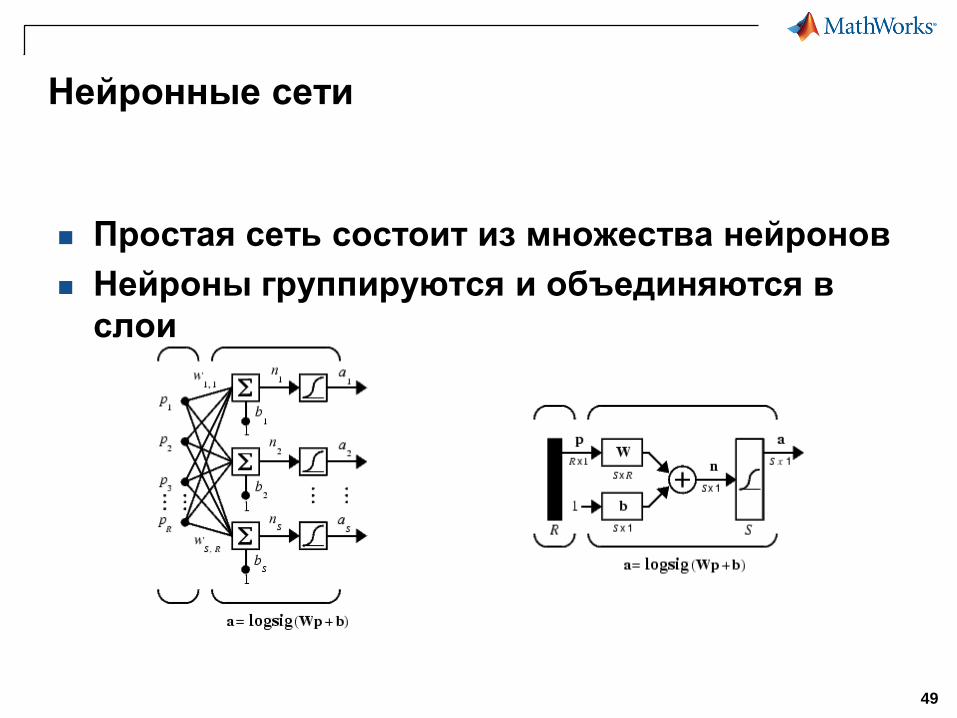
Нейронные сети
Простая сеть состоит из множества нейронов
Нейроны группируются и объединяются в
слои
50
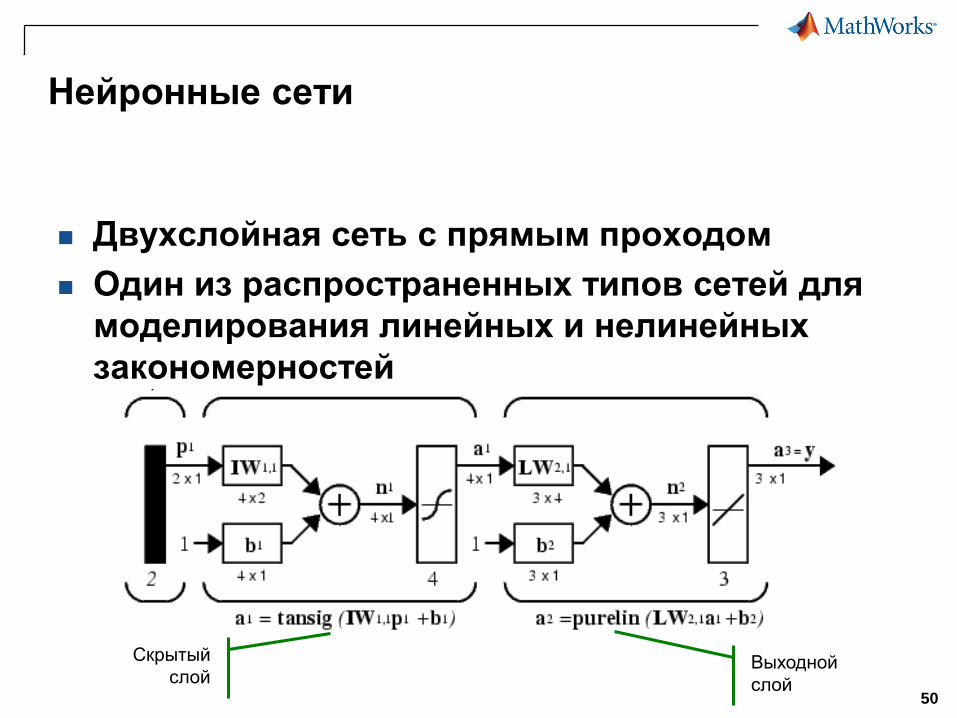
Нейронные сети
Двухслойная сеть с прямым проходом
Один из распространенных типов сетей для
моделирования линейных и нелинейных
закономерностей
Скрытый
слойВыходной
слой

51
Нейронные сети – как работать с ними в
MATLAB?
Создать сеть с одним скрытым слоем и 5
нейронами. X и Y содержат построчно
переменные, образцы содержатся в
колонках Для преобразования можно использовать транспонирование
>> net = newff(X,Y,5);
Тренируем>> net = train(net,X,Y);
Применяем на новых данных>> Y = sim(net,newdata);
Или используем инструмент
nntool
52
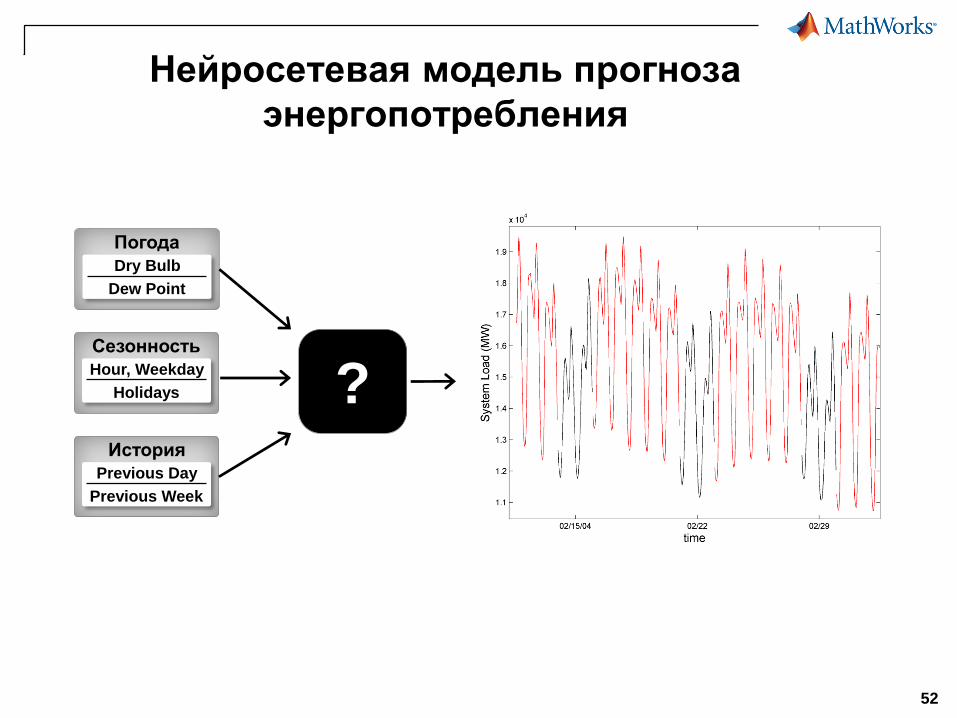
Нейросетевая модель прогноза
энергопотребления
Dry Bulb
Dew Point
Погода
?Hour, Weekday
Holidays
Сезонность
Previous Day
Previous Week
История
53
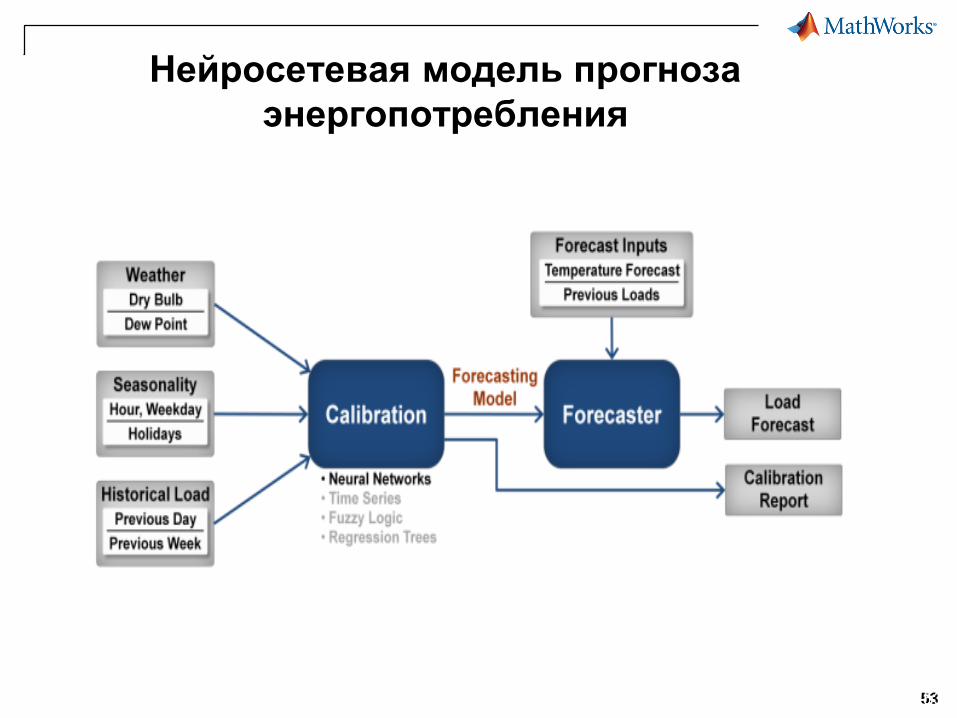
Нейросетевая модель прогноза
энергопотребления
53

54
MATLAB для Machine Learning
Задача/Проблемы Решение
Потери в производительности Быстрый анализ и разработка приложенияВысока производительность подготовки
данных, интерактивного исследования и
визуализации
Извлечение пользы данных Алгоритмы машинного обучения в обработке
данных (Video, Image, Financial и тд)
Скорость расчета Быстрое обучение и вычисление
Распараллеливание, оптимизированные
библиотеки
Время на развертывание и интеграцию Готовые решения на уровне «нажать на
кнопку»
Технологические риски Высококачественные библиотеки и поддержка

55
Машинное обучение с MATLAB
Интерактивная среда
– Визуальные инструменты для проведения
исследовательского анализа данных
– Удобство в оценке и выборе лучшего алгоритма
– Приложения для быстрого старта(e.g,. neural network tool, curve fitting tool)
Множество алгоритмов для
– кластеризации
– классификации
– регрессии

56
Что дальше: Machine Learning with MATLAB
Classification
with MATLAB
Credit Risk Modeling with
MATLAB
Multivariate Classification in
the Life Sciences
Electricity Load and
Price Forecasting
http://www.mathworks.com/discovery/
machine-learning.html
Data Driven Fitting
with MATLABRegression
with MATLAB

57
Support and Community

58
Источники/ссылки
http://www.mathworks.com/machine-learning
http://www.machinelearning.ru
Дьяконов А.Г. СРЕДА ДЛЯ ВЫЧИСЛЕНИЙ И ВИЗУАЛИЗАЦИИ
MATLAB/«ШАМАНСТВО» В АНАЛИЗЕ ДАННЫХ
Kaggle.com
58

59
Обзор доступных тренингов
Начальный уровень:
MLBE Основы работы в MATLAB
MLBE-F Основы работы в MATLAB для финансистов
Средний уровень:
MLVI MATLAB для обработки и визуализации данных
MLPR Методы программирования в MATLAB
MLGU Разработка графических интерфейсов пользователя в MATLAB
MLST Статистические методы в MATLAB
MLEX Интеграция MATLAB c внешними приложениями
MLJA Развертывание приложений на базе MATLAB – Java
MLNE Развертывание приложений на базе MATLAB -.NET
MLOP Методы оптимизации в MATLAB
MLPC Параллельные вычисления в MATLAB

60
Ресурсы MathWorks на русском языке
Сайт matlab.ru Семинары и вебинары (в том числе записи
вебинаров)
Истории успеха
Статьи
Youtube канал
youtube.com/user/MATLABinRussia Видео
Списки видео по темам
Форум Экспоненты
matlab.exponenta.ru/forum Живое общение
Ответы на вопросы