Embed Size (px)
Citation preview

1
A. UJI NORMALITAS DENGAN SPSS
Uji normalitas data adalah hal yang lazim dilakukan sebelum sebuah metode statistik. Tujuan uji normalitas adalah untuk mengetahui apakah distribusi sebuah data mengikuti atau mendekati distribusi normal, yakni distribusi data yang mampunyai pola seperti distribusi normal (distribusi data tersebut tidak menceng ke kiri atau ke kanan). Misalkan dalam sebuah penelitian pendidikan ingin diketahui apakah data dalam penelitian tersebut berdistribusi normal, data penelitian adalah sebagai berikut:
No. Responden Sex Nilai harian Nilai Rapot
123456789101112131415
121112211221121
506180764073867759566680729583
688678807674708076856069899088
Keterangan sex: 1=laki-laki, 2=perempuan
Cara menganalisisnya adalah sebagai berikut:
1. Buka lembar kerja SPSS
2. Buat semua keterangan variabel di variable view seperti gambar berikut:
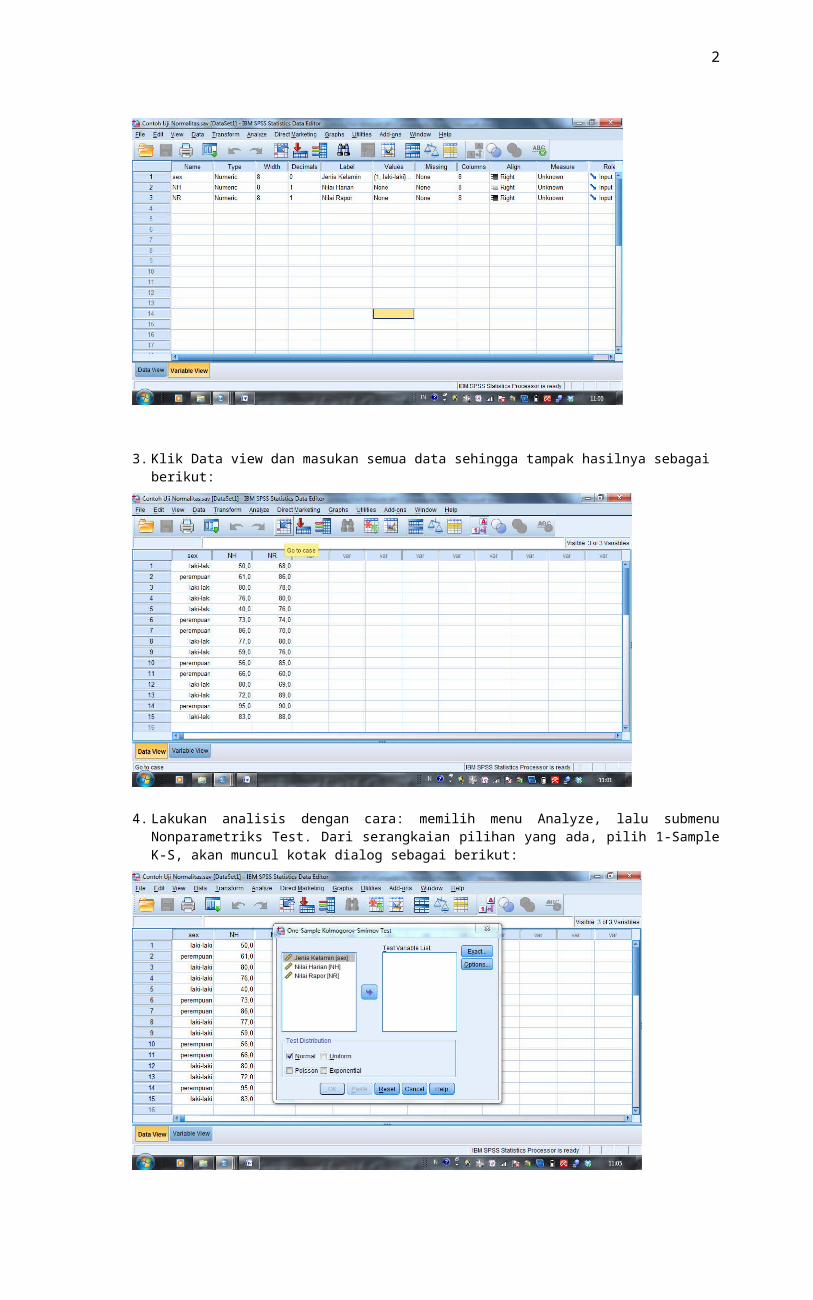
2
3. Klik Data view dan masukan semua data sehingga tampak hasilnya sebagai berikut:
4. Lakukan analisis dengan cara: memilih menu Analyze, lalu submenu Nonparametriks Test. Dari serangkaian pilihan yang ada, pilih 1-Sample K-S, akan muncul kotak dialog sebagai berikut:
5. Pindahkan semua variable ke kotak Test Variable List dengan cara menanadai semua variable kemudian menekan tanda > sehingga kotak dialog menjadi seperti berikut:
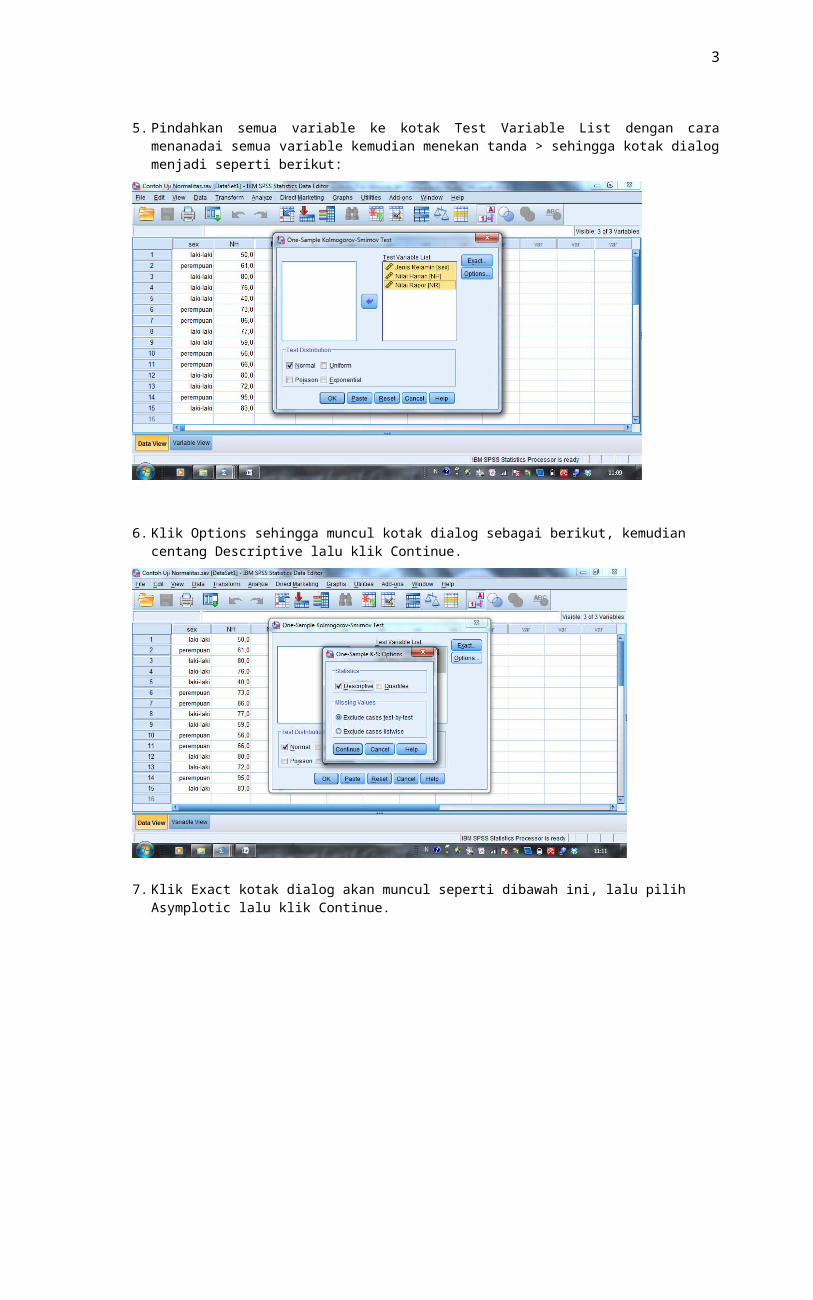
3
6. Klik Options sehingga muncul kotak dialog sebagai berikut, kemudian centang Descriptive lalu klik Continue.
7. Klik Exact kotak dialog akan muncul seperti dibawah ini, lalu pilih Asymplotic lalu klik Continue.
8. Klik OK sehingga akan muncul Output sebagai berikut:
NPar Tests
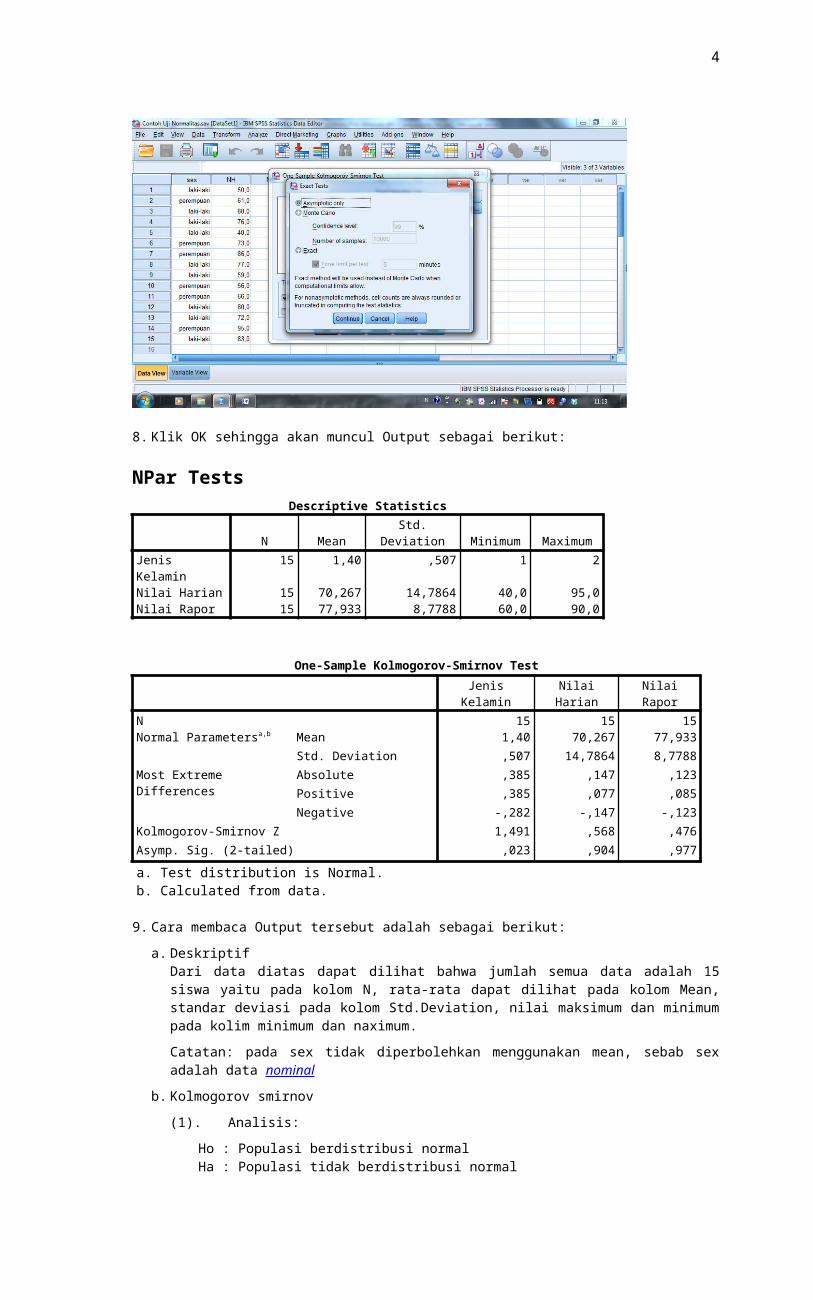
4
Descriptive Statistics
N Mean Std. Deviation Minimum MaximumJenis Kelamin 15 1,40 ,507 1 2Nilai Harian 15 70,267 14,7864 40,0 95,0Nilai Rapor 15 77,933 8,7788 60,0 90,0
One-Sample Kolmogorov-Smirnov Test
Jenis Kelamin Nilai Harian Nilai RaporN 15 15 15Normal Parametersa,b Mean 1,40 70,267 77,933
Std. Deviation ,507 14,7864 8,7788Most Extreme Differences Absolute ,385 ,147 ,123
Positive ,385 ,077 ,085Negative -,282 -,147 -,123
Kolmogorov-Smirnov Z 1,491 ,568 ,476Asymp. Sig. (2-tailed) ,023 ,904 ,977
a. Test distribution is Normal.b. Calculated from data.
9. Cara membaca Output tersebut adalah sebagai berikut:
a. DeskriptifDari data diatas dapat dilihat bahwa jumlah semua data adalah 15 siswa yaitu pada kolom N, rata-rata dapat dilihat pada kolom Mean, standar deviasi pada kolom Std.Deviation, nilai maksimum dan minimum pada kolim minimum dan naximum.
Catatan: pada sex tidak diperbolehkan menggunakan mean, sebab sex adalah data nominal
b. Kolmogorov smirnov
(1). Analisis:
Ho : Populasi berdistribusi normalHa : Populasi tidak berdistribusi normal
(2). Dasar pengambilan keputusan adalah berdasarkan probabilitasJika nilai probabilitas > 0,05 maka Ho diterimaJikan nilai probabilitas ≤ 0,05 maka Ho ditolak
(3). Keputusan
(a). Sex: Terlihat bahwa pada kolom signifikan (Asymp. Sig (2-tailed)) adalah 0,023 atau probabilitas kurang dari 0,05 maka Ho ditolak yang berarti populasi tidak berdistribusi normal.
(b). Terlihat bahwa pada kolom signifikan (Asymp. Sig (2-tailed) adalah 0,904 atau probabilitas lebih dari 0,05 maka Ho diterima yang berarti populasi berdistribusi normal.
(c). Terlihat bahwa pada kolom signifikan (Asymp. Sig (2-tailed)) adalah 0,977 atau probabilitas lebih dari 0,05 maka Ho diterima yang berarti populasi berdistribusi normal.
B. UJI VALIDITAS DENGAN SPSS
Sumber data sebuah penelitian ada kalanya menggunakan data dari hasil kuesioner. Tentunya dalam penyusunan kuesioner harus benar-benar bisa menggambarkan tujuan dari penelitian (valid). Uji validitas untuk mengukur kelayakan butir-butir pertanyaan dalam kuesioner tersebut dapat mendefinisikan suatu variabel. Daftar pertanyaan pada umumnya untuk mendukung suatu kelompok variabel tertentu. Uji validitas dilakukan pada setiap butir pertanyaan. Hasilnya dibandingkan dengan r tabel | df=n-k dengan tingkat kesalahan 5%. Jika r tabel Jika r tabel < r hitung, maka butir soal disebut valid.
Berikut langkah-langkah uji validitas, dengan menggunakan contoh data sebagai berikut:
No x11 x12 x13 total x
1 2 4 3 9
2 1 2 2 5
3 4 4 2 10

5
4 3 4 3 10
5 2 2 3 7
6 4 2 4 10
7 4 4 3 11
8 1 1 1 3
9 2 2 1 5
10 3 5 5 13
11 3 4 4 11
12 2 4 5 11
13 5 2 4 11
14 2 4 2 8
15 4 4 4 12
16 1 4 2 7
17 1 4 1 6
18 2 2 4 8
19 1 2 1 4
20 1 3 3 7
21 4 4 5 13
22 2 2 2 6
23 2 2 2 6
24 2 1 1 4
25 5 4 5 14
26 4 3 5 12
27 5 5 5 15
28 2 4 4 10
29 3 3 5 11
30 5 5 4 14
31 1 3 3 7
32 2 4 3 9
33 2 2 4 8
34 5 1 3 9
35 2 4 3 9
6
36 1 4 2 7
37 2 4 3 9
38 1 1 3 5
39 2 3 3 8
40 2 3 2 7
41 2 4 5 11
42 3 3 3 9
43 3 5 3 11
44 2 2 3 7
45 3 4 5 12
46 1 2 3 6
47 1 3 3 7
48 2 4 4 10
49 1 2 2 5
50 5 4 3 12
Keterangan: x11 (tingkat pendidikan) : 1. Tidak pernah sekolah, 2. SD, 3. SMP, 4 SMA, 5 Perguruan Tinggix12 (jenis pekerjaan) : 1. Petani, 2. Pedagang, 3. Pegawai Swasta, 4. PNS, 5 TNI-POLRIx13 (status Sosial Ekonomi : 1. Miskin sekali, 2. Miskin, 3. Cukup, 4. Kaya, 5. Kaya sekali
Langkah 1 : Masukkan data ke dalam data editor SPSS. Untuk memberikan nama/label variabel klik Variable view (x11, x12, x13 dan total_x)
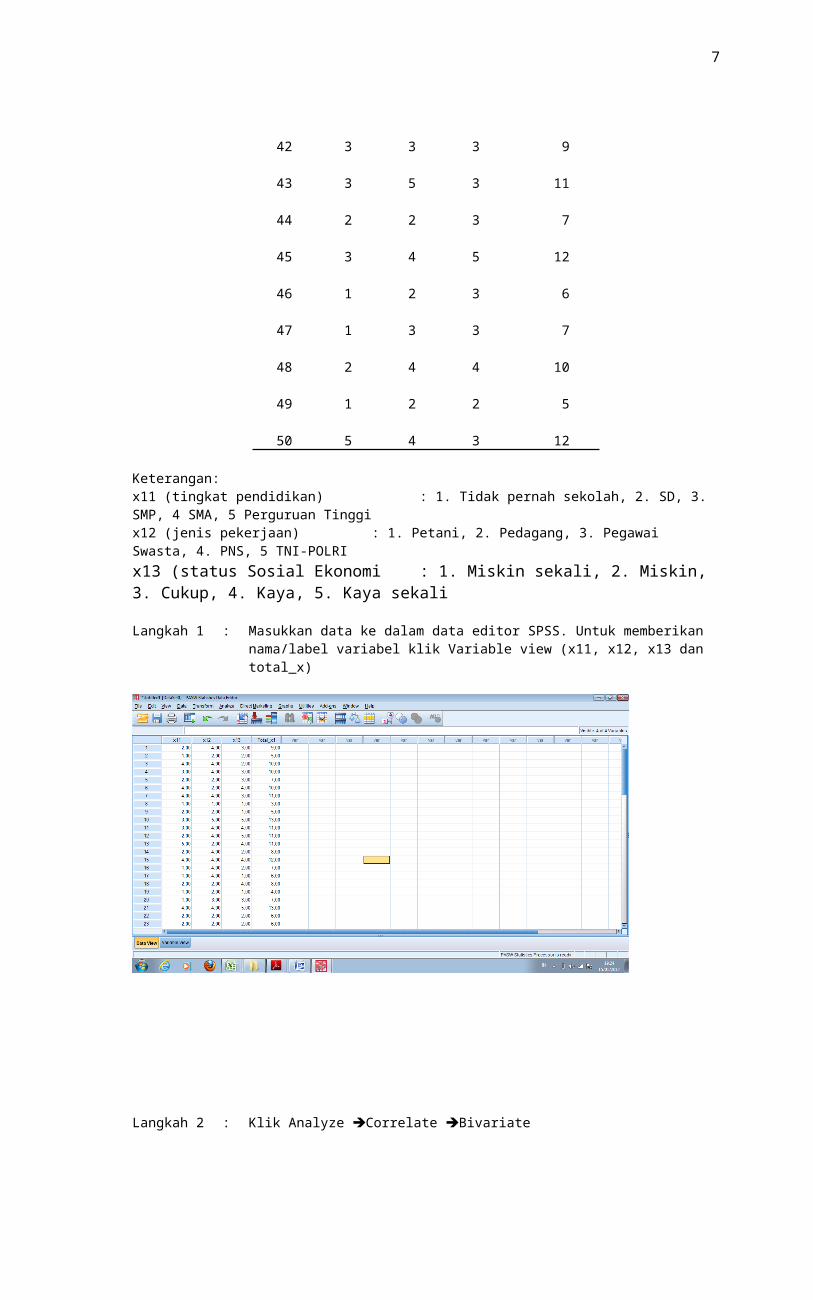
Langkah 2 : Klik Analyze Correlate Bivariate
7
Langkah 3 : Selanjutnya akan tampak kotak Bivariate Correlations seperti ini
Langkah 4 : Selanjutnya pindahkan masing-masing indikator x11, x12, x13 dan total_x ke sebelah kanan pada kolom variables dengan cara memblok masing-masing indikator kemudian klik tanda panah tengah.
Langkah 5 : Klik OK. Setelah itu akan tampak kota seperti berikut
Correlations
x11 x12 x13 Total_x1x11 Pearson Correlation 1 ,311* ,523** ,800**
Sig. (2-tailed) ,028 ,000 ,000
N 50 50 50 50
x12 Pearson Correlation ,311* 1 ,419** ,717**
Sig. (2-tailed) ,028 ,002 ,000
N 50 50 50 50
x13 Pearson Correlation ,523** ,419** 1 ,828**
Sig. (2-tailed) ,000 ,002 ,000
8
N 50 50 50 50
Total_x1 Pearson Correlation ,800** ,717** ,828** 1
Sig. (2-tailed) ,000 ,000 ,000
N 50 50 50 50
*. Correlation is significant at the 0.05 level (2-tailed).
**. Correlation is significant at the 0.01 level (2-tailed).
Pada tabel di atas tampak bahwa seluruh indikator (X11, X12, X13) dikatakan valid karena memiliki nilai korelasi di atas 0,3 yakni X11=0,800, X12=0,717 dan X13=0,828.
Catatan: ada beberapa buku yang menggunakan nilai korelasi diatas 0,3. Tetapi ada juga yang menentukan nilai korelasi diatas 0,5. Batas keduanya diakui dan bisa diterima.
C. UJI RELIABILITAS DENGAN SPSS
Selain harus valid, kuesioner sebagai alat ukur harus konsisten bila pertanyaan tersebut dijawab dalam waktu yang berbeda (reliabel). Untuk menilai kestabilan ukuran dan konsistensi responden dalam menjawab kuesioner. Kuesioner tersebut mencerminkan konstruk sebagai dimensi suatu variabel yang disusun dalam bentuk pertanyaan. Uji reliabilitas dilakukan secara bersama-sama terhadap seluruh pertanyaan. Jika nilai alpha>0.60, disebut reliable. Dengan menggunakan data yang sama, langkah uji reliabilitas adalah sebagai berikut:
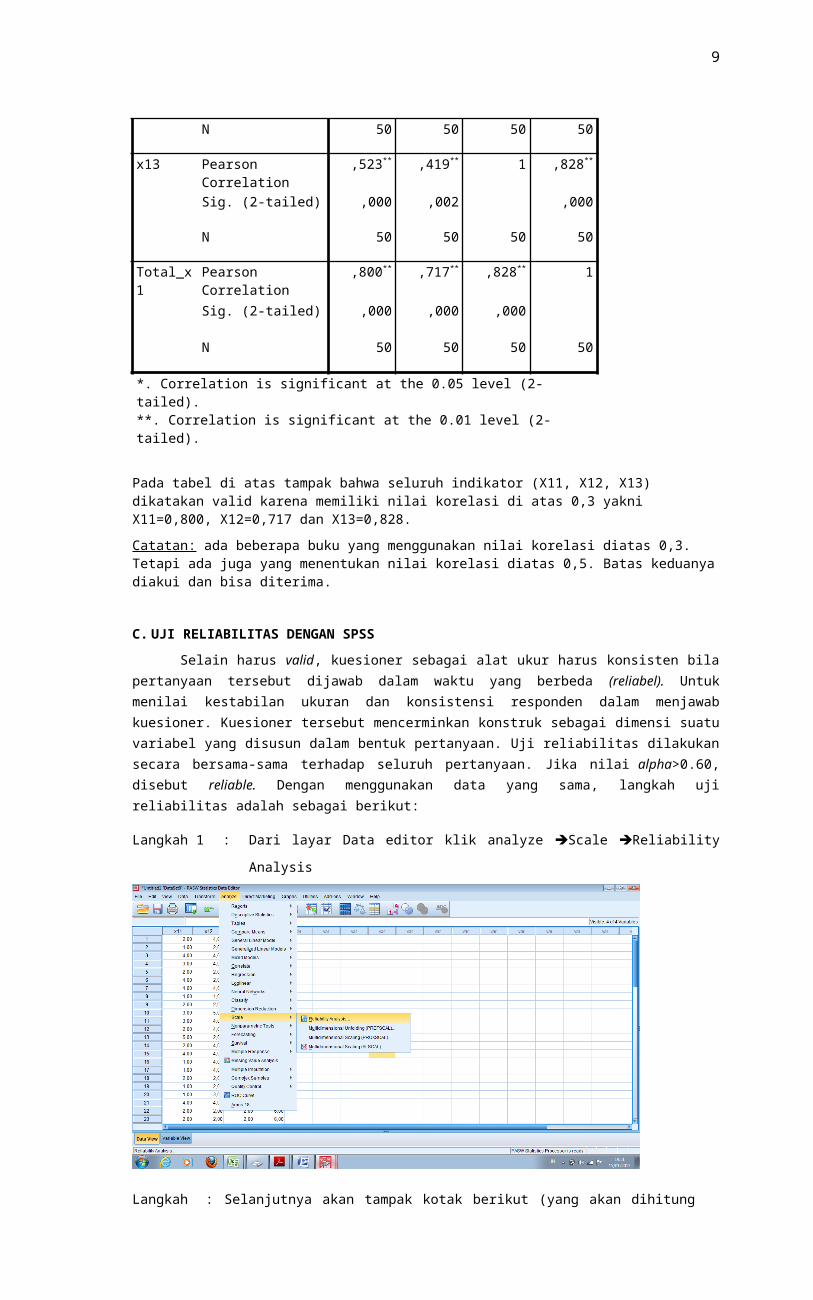
Langkah 1 : Dari layar Data editor klik analyze Scale Reliability Analysis
Langkah 2 : Selanjutnya akan tampak kotak berikut (yang akan dihitung hanya indikator x11, x12 dan x13 sehingga total_x harus diabaikan atau dipindahkan ke kolom sebelah kiri dengan cara memblok Total_x kemudian klik tanda panah tengah:
9
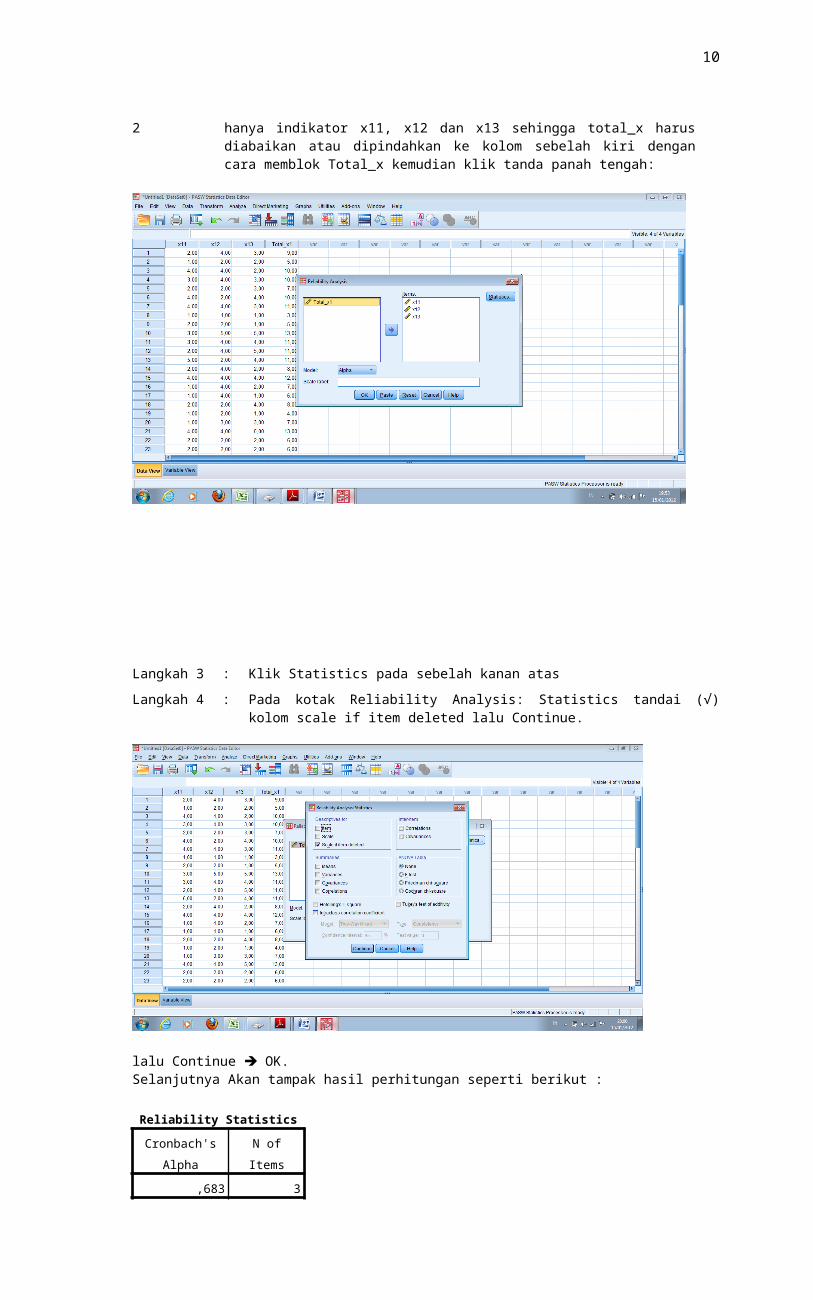
Langkah 3 : Klik Statistics pada sebelah kanan atas
Langkah 4 : Pada kotak Reliability Analysis: Statistics tandai (√) kolom scale if item deleted lalu Continue.
lalu Continue OK.Selanjutnya Akan tampak hasil perhitungan seperti berikut :
Reliability Statistics
Cronbach's
Alpha N of Items
,683 3
Hasil perhitungan menunjukkan nilai Cronbach’s Alpha = 0,683 yang lebih besar dari 0,60 berarti instrumen penelitian dikatakan reliabel
Catatan: ada beberapa buku yang menggunakan batas nilai reliabilitas di atas 0,6. Tetapi ada juga yang menentukan nilai reliabilitas diatas 0,7. Batas keduanya diakui dan bisa diterima.
10
Item-Total Statistics
Scale Mean if Item Deleted
Scale Variance if Item Deleted
Corrected Item-Total Correlation
Cronbach's Alpha if Item
Deletedx11 6,3200 3,977 ,499 ,589x12 5,6600 4,882 ,416 ,686x13 5,6600 3,984 ,585 ,471





























