Embed Size (px)
Citation preview

Big Data Platform Mission
• Apache Hadoop EcoSystem & Commercial Big Data Platform Support• Vanilla Hadoop, Cloudera CDH, Pivotal HD, Hortonworks
HDP• Pivotal HAWQ, Business Intelligence, Data Source
• Log & Metadata Management• Job Monitoring & Tracking• Workflow Management• Job Management• Auto Provisioning• Analysis Program• Visualization
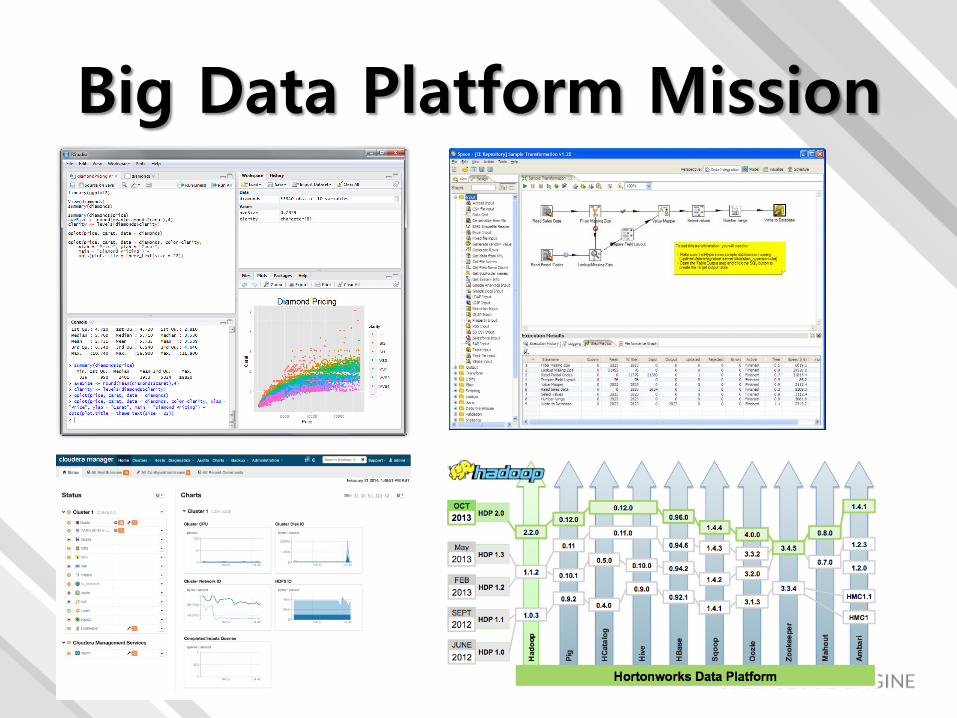
Big Data Platform Mission

Big Data Platform 주요 이슈
• 너무 많은 오픈소스
• 개별 오픈소스의 기능/비기능적 특징
• 배포판별 서로 다른 버전과 호환성 이슈
• 상용 빅데이터 SW와 오픈소스 SW의 조합 이슈
• 데이터를 처리/분석하는 다양한 모듈을 지원 이슈
• 지속적으로 업데이트하는 오픈소스의 통합 이슈
• 데이터 거버넌스
• 로그 데이터의 활용을 위한 기능 제공의 한계
• 전사 조직에 빅데이터 확산을 위한 플랫폼의 역할 정의이슈
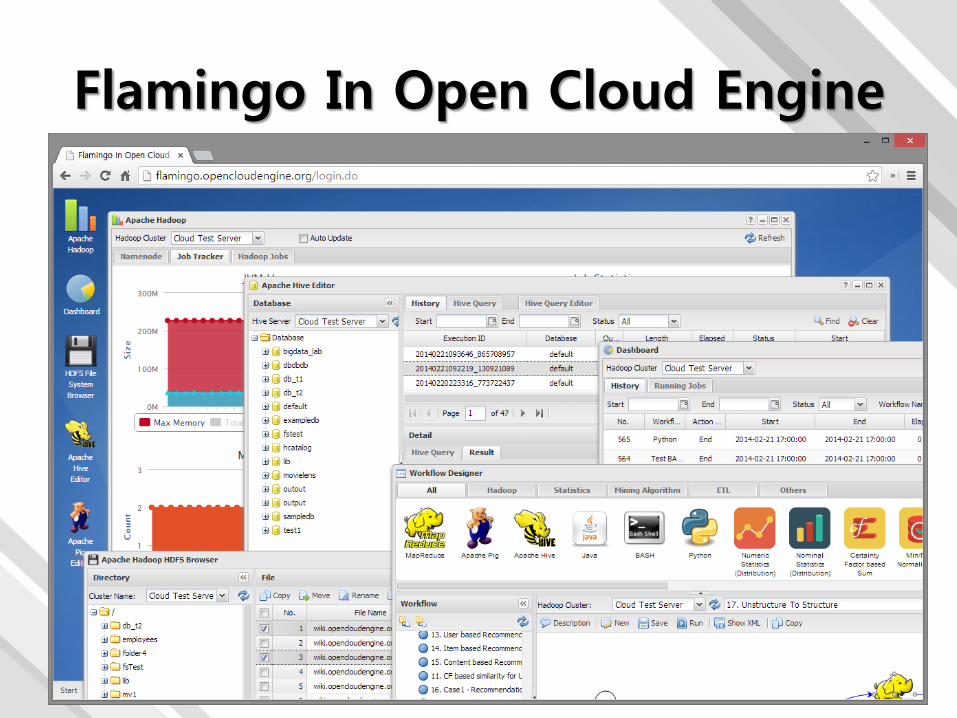
Flamingo In Open Cloud Engine

Flamingo In Open Cloud Engine
• Apache License v2.0 (Server) + GPL v3 (Web UI)
• 다수의 Hadoop Cluster 지원
• 방화벽 밖에서 Hadoop EcoSystem 및 Infra를 활용
• 기 작성한 MapReduce를 재활용 극대화를 위한 프레임워크 내장
• 워크플로우 구성을 위한 그래프 프레임워크 개발
• Hadoop 1/Hadoop 2 모니터링 및 MapReduce Job 추적
• 다양한 데이터 처리 플로우를 구성하는 워크플로우 디자이너 및 다양한 데이터 처리/분석 프로그램 제공
• HDFS 등의 파일 시스템 관리, Audit, 권한 관리
• Hive Metastore 연계 및 데이터베이스/테이블 관리

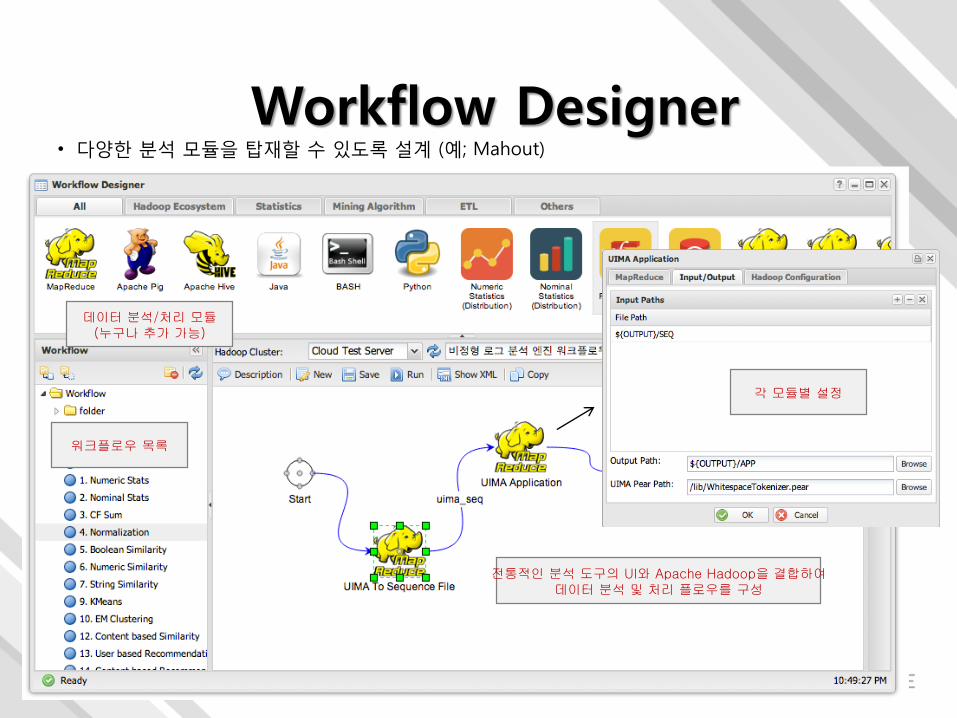
• 다양한 분석 모듈을 탑재할 수 있도록 설계 (예; Mahout)
• UI를 통해 미리 제공하는 분석 및 처리 모듈을 드래그 앤 드롭으로 처리
Workflow Designer
전통적인 분석 도구의 UI와 Apache Hadoop을 결합하여데이터 분석 및 처리 플로우를 구성
각 모듈별 설정
워크플로우 목록
데이터 분석/처리 모듈(누구나 추가 가능)

Workflow Designer :: 주요 이슈
• 데이터 프로세싱을 위한 워크플로우 디자인
• 각 노드간 의존성 관리
• 다양한 MapReduce의 파라미터 처리• hadoop jar test.jar wordcount –input in.txt –output out.txt
• hadoop jar test.jar wordcount input.txt output.txt
• 스케줄러에 등록한 워크플로우가 실행할 때 경로 처리
• 복잡한 워크플로우의 해석 및 실행 (예; 분기 처리)
• 워크플로우 스케줄링시 변수값 변경
• 기 개발한 MapReduce의 UI화를 통해 재사용하기 위한통합 방안
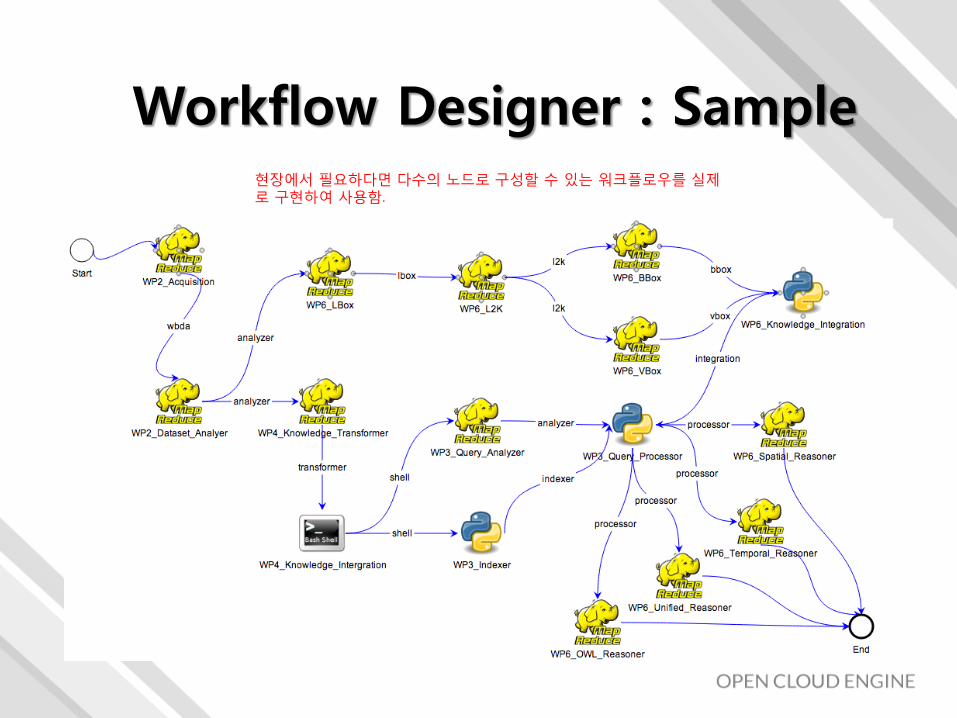
현장에서 필요하다면 다수의 노드로 구성할 수 있는 워크플로우를 실제로 구현하여 사용함.
Workflow Designer : Sample
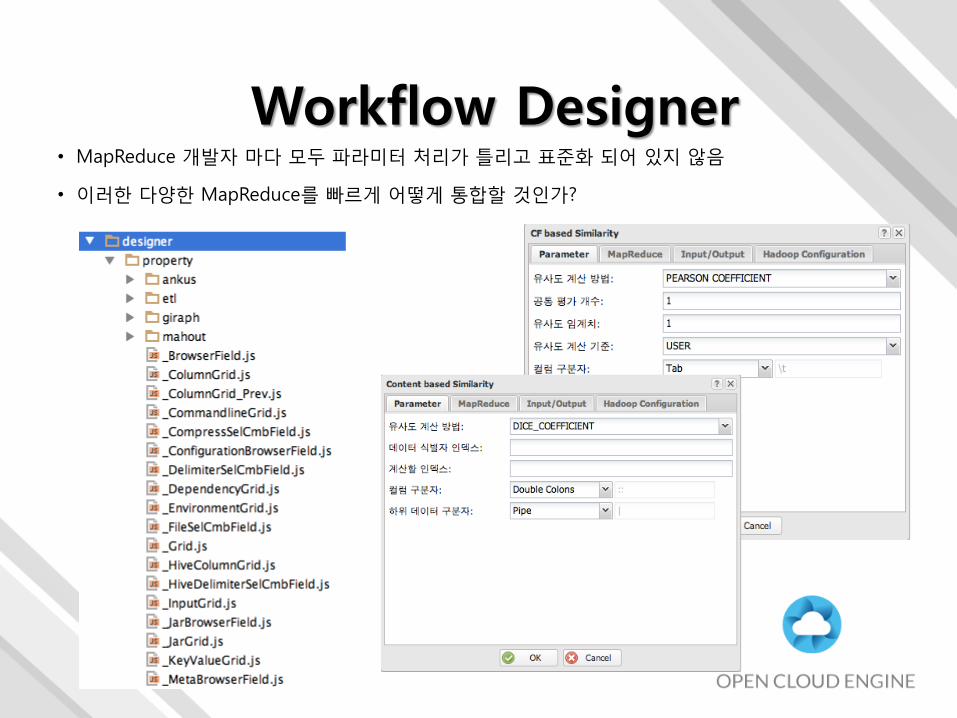
• MapReduce 개발자 마다 모두 파라미터 처리가 틀리고 표준화 되어 있지 않음
• 이러한 다양한 MapReduce를 빠르게 어떻게 통합할 것인가?
Workflow Designer
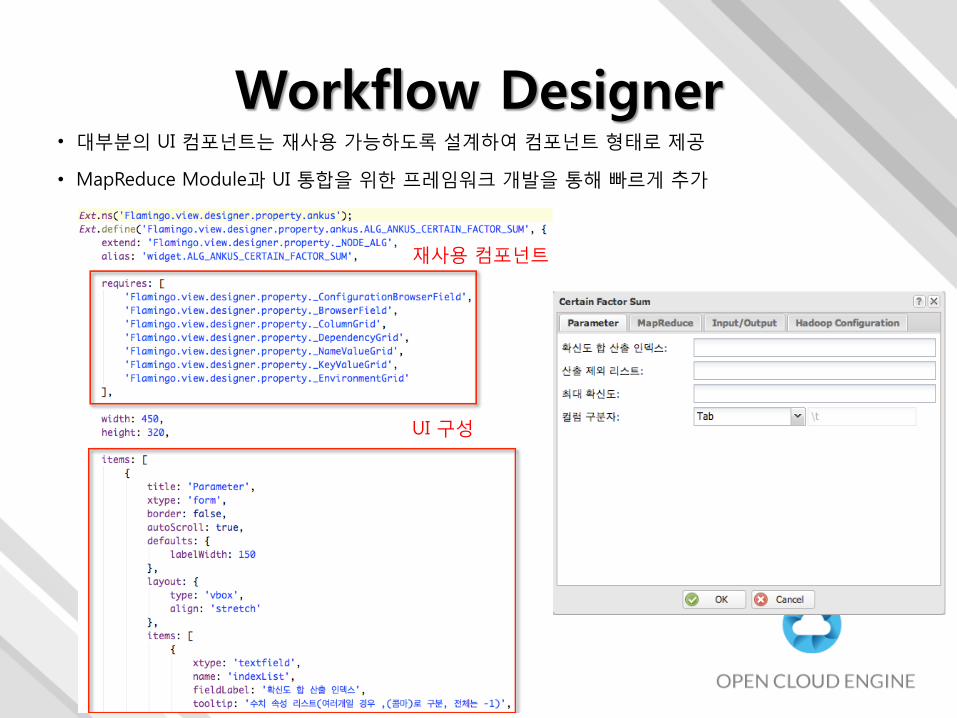
Workflow Designer• 대부분의 UI 컴포넌트는 재사용 가능하도록 설계하여 컴포넌트 형태로 제공
• MapReduce Module과 UI 통합을 위한 프레임워크 개발을 통해 빠르게 추가
재사용 컴포넌트
UI 구성

Workflow Designer• 모듈의 아이콘도 메타 데이터를 통해서 정의하여 별도 코드 작성을 최소화하고
• 관련 기능을 통합 프레임워크로 위임하고 사용자는 메타 데이터만으로 핸들링

Workflow Designer :: 현재분류 내용 주요 출력 결과 MapReduce 처리 내용
수치/범주데이터
기초 통계 분석
수치 데이터 기초 통계합계, 평균(4종) 분산, 표준편차
최대/최소/중앙값• 데이터의 분할 및 분할 데이터의 통계 산출• 분할 산출된 통계의 합산 및 최종 통계 산출
범주 데이터 기초 통계 발생빈도, 발생비율• 데이터의 속성값 별 빈도수 산출• 빈도에 대한 전체 데이터 대비 비율 산출
수치 데이터 확신도 기반합계
확신도(Certainty Factor) 기반 합계• 데이터의 분할 및 분할 데이터의 확신도 산출• 분할 산출된 통계의 합산 및 최종 확신도 산
출
전처리수치 데이터 Min/Max 기반
정규화Min/Max 정규화 값
• 데이터의 Min/Max 수치 산출• Min/Max 값 기반 데이터 정규화
유사/상관분석
이진 벡터 데이터 기반 Hamming, Jaccard/Tanimoto, Dice• 데이터의 속성별 분해 레코드 생성• 분해된 속성별 데이터 레코드를 이용한 유사
/상관 수치 계산수치 벡터 데이터 기반 Euclidean, Manhattan, Cosine, Pearson
문자열 데이터 기반 Hamming, Edit(Levenshtein)
마이닝기계학습
Clustering K-Means, EM• 데이터 최근접 할당 (거리/확률 빌도)• 군집별 할당 데이터를 이용한 군집 중심 정보
갱신 (거리 평균/데이터 분포)
Classification ID3• 의사결정 트리의 분류 노드 선택을 위한 속성
별 정보량 계산
RecommendationCollaborative Filtering
Item/Use based Recommendation
• 사용자 및 아이템 간 상관계수 도출• 아이템 속성별 이진 유사도 계산• 사용자별 추천 아이템 생성
공통Hadoop EcoSystem MapReduce, Hive, Pig,
Program Java, Python, Bash

Workflow Designer :: 계획분류 내용 주요 출력 결과 예정 일정
전처리
MapReduce ETL Grep, Filter, Encrypt, Group By, Remove 등등
• Flamingo 1.3에서 지원
형태소 분석 한글 형태소 분석 • 완료
마이닝기계학습
Clustering Canopy • Flamingo 1.4에서 지원
ClassificationLogistic Regression, Random Forest
Naïve Bayes• Flamingo 1.4에서 지원
Graph Apache Giraph, GraphBuilder • Flamingo 1.4에서 지원
공통
Hadoop EcoSystemSqoop • Flamingo 1.2에서 지원
Apache Spark & Shark • Flamingo 1.4에서 지원
ProgramPL/Java • Flamingo 1.4에서 지원
R Statistics • Flamingo 1.3에서 지원
Commercial SQL On Hadoop Pivotal HAWQ • Flamingo 1.5에서 지원
기타
Input Format Binary File Format • Flamingo 1.3에서 지원
File FormatPDF Text Extractor • Flamingo 1.3에서 지원
Excel Text Processor • 현재 적용 완료
Framework 비정형 처리 Apache UIMA Framework • 현재 적용 완료
Log 처리 Apache Web Server Access Log To CSV • 현재 적용 완료

HDFS File System Browser
• 빅 데이터 플랫폼의 주요 기능 중 핵심은 로그 및 데이터를 다루는 것
• 인프라에 직접 접근하지 않고 통제된 환경에서 로그 및데이터에 접근
• 로그 및 데이터를 저장하기 위한 다양한 기능 필요
• 로그 및 데이터 핸들링시 행위 모니터링

HDFS File System Browser :: 주요 이슈
• 하나의 디렉토리에 수없이 많은 파일 및 디렉토리• 아주 많이 존재하는 경우 UI 표현의 문제 발생 (예; 20만개)
• 대용량 파일의 업로드 및 다운로드 그리고 통제
• 사용자의 등급별 접근 제어 및 표시 여부• 특정 등급의 사용하는 사용자는 해당 경로의 디렉토리/파일이
보이지 않아야 함
• 파일의 내용 표시• 압축 파일, 사용자만의 Writable을 사용한 바이너리 파일은 표시
가 어려움
• Object Storage가 백엔드인 경우 파일 처리 레이어의 추상화가 매우 어려움 (파일 방식 자체가 상이)
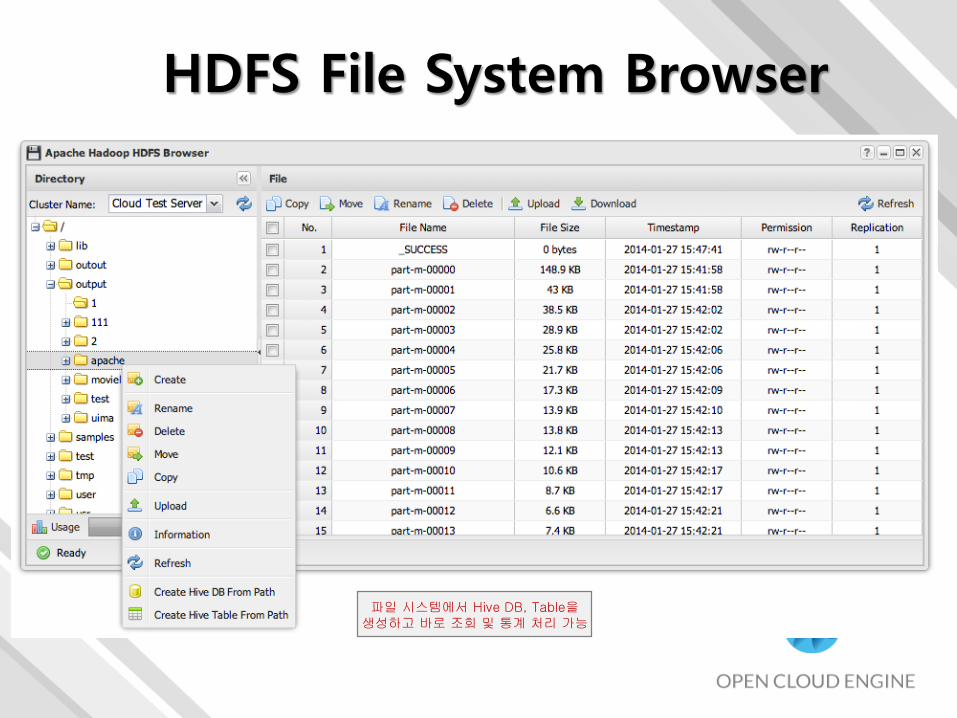
HDFS File System Browser
파일 시스템에서 Hive DB, Table을생성하고 바로 조회 및 통계 처리 가능
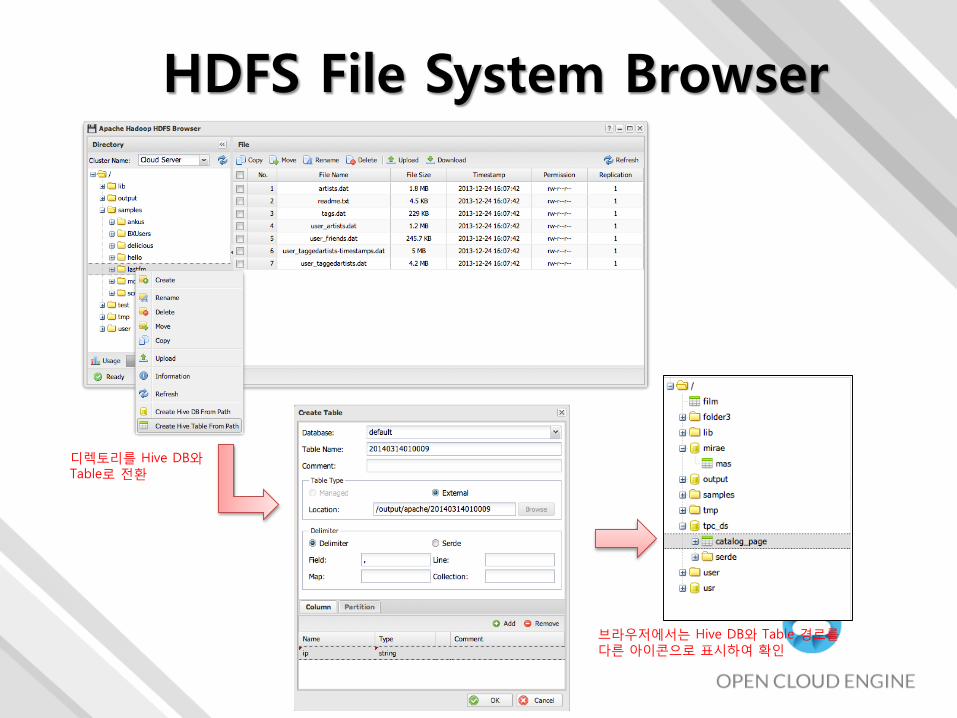
HDFS File System Browser
디렉토리를 Hive DB와Table로 전환
브라우저에서는 Hive DB와 Table 경로를다른 아이콘으로 표시하여 확인
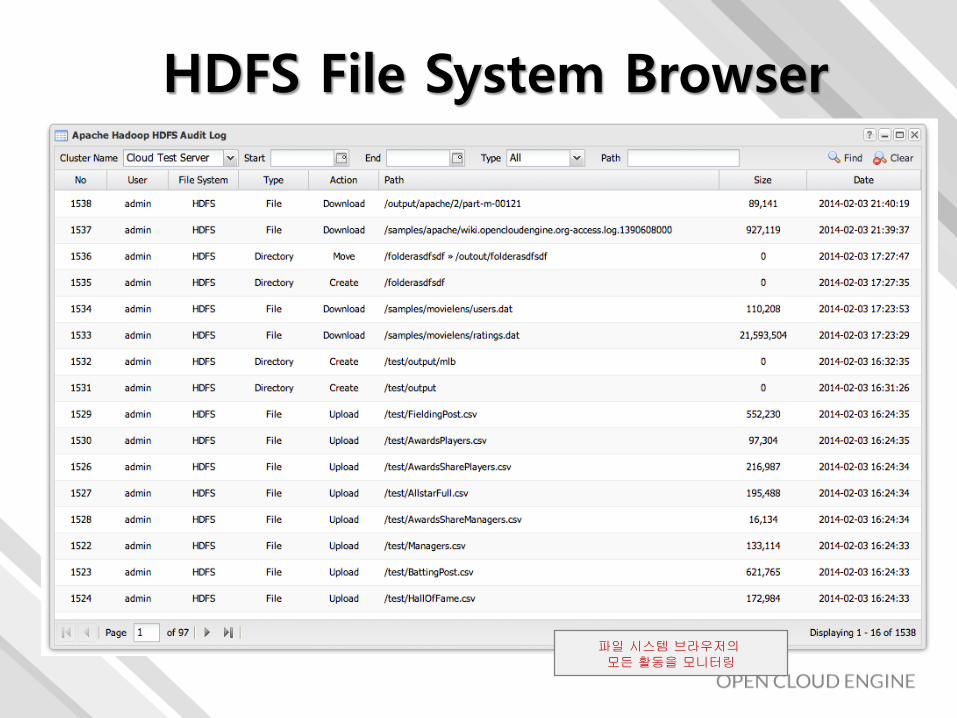
HDFS File System Browser
파일 시스템 브라우저의모든 활동을 모니터링
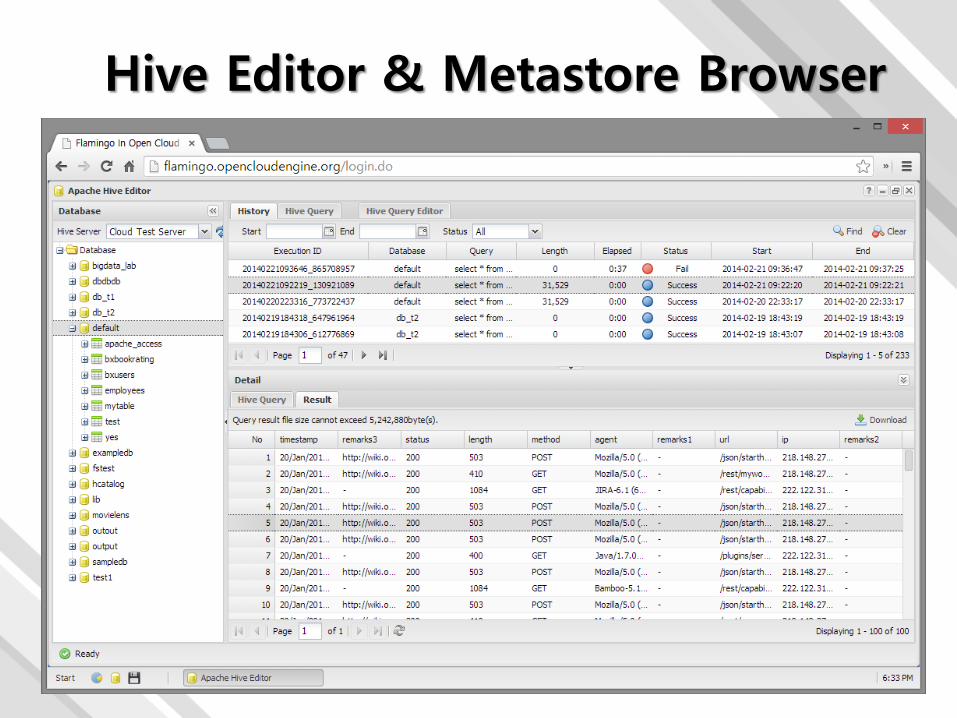
Hive Editor & Metastore Browser

Hive Editor & Metastore Browser :: 주요 이슈
• 다양한 배포판 간 호환성• Protocol Buffer, Thrift 호환성은 동일 배포판도 버전에 따라서
매우 상이
• 배포판에 따라서 관련 기능이 커스터마이징되어 있어서 연계 어려움
• Hive QL 처리시 장시간 실행하는 Hive QL의 경우 웹 세션 종료 문제
• Hive에서 제공하는 SERDE 지원 문제
• Hive QL을 실행하는 Hive Server ½의 접근 방식의 차이와 호환성
• Managed/External Table과 Complex Data Type 지원
• Table Partitioning 지원
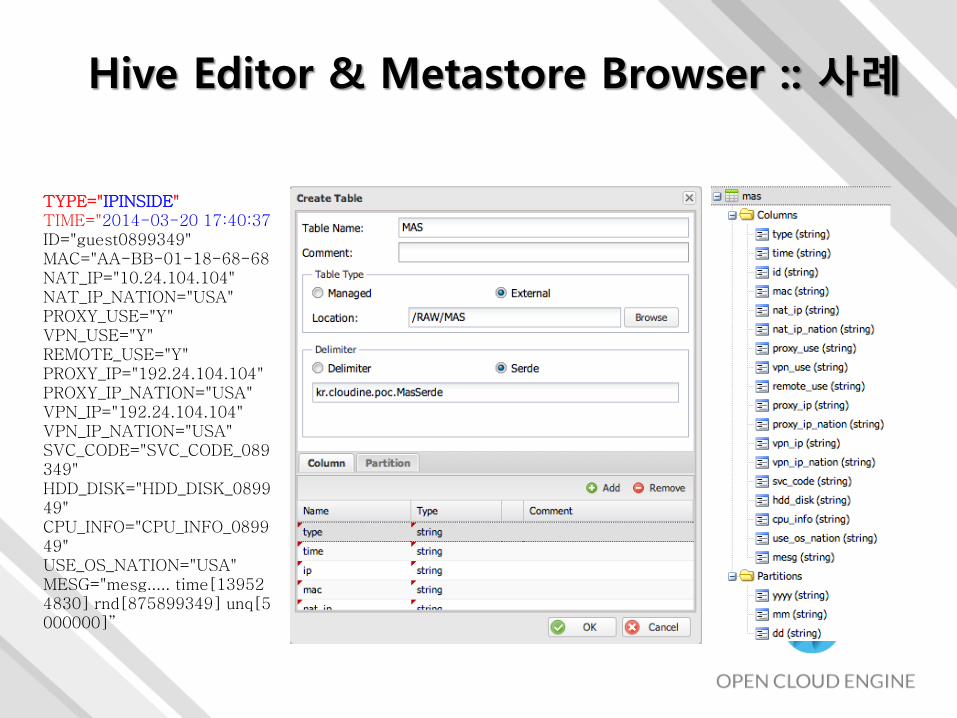
Hive Editor & Metastore Browser :: 사례
TYPE="IPINSIDE" TIME="2014-03-20 17:40:37ID="guest0899349" MAC="AA-BB-01-18-68-68NAT_IP="10.24.104.104" NAT_IP_NATION="USA" PROXY_USE="Y" VPN_USE="Y" REMOTE_USE="Y" PROXY_IP="192.24.104.104" PROXY_IP_NATION="USA" VPN_IP="192.24.104.104" VPN_IP_NATION="USA" SVC_CODE="SVC_CODE_089349" HDD_DISK="HDD_DISK_089949" CPU_INFO="CPU_INFO_089949" USE_OS_NATION="USA" MESG="mesg..... time[139524830] rnd[875899349] unq[5000000]”

Expression Language
• 로그 수집은 보통 YYYY MM DD HH 등과 같이 일정한 주기를 가지며 데이터 처리 또한 일정한 주기를 가짐
• 동적인 값들을 얻고자 할 때 Workflow Designer에서 활용
• 예) 오늘 날짜 : dateFormat(‘yyyyMMdd’) dateFormat(‘yyyy-MM-dd’)
• 워크플로우가 실행할 때 특정한 값들은 해당 시간으로 대체되어야하는 경우가 발생
• 예) 오늘 실행하는 워크플로우는 어제 날짜의 디렉토리에 기록 (일배치)
• 제공하는 Expression Language
• dateFormat(‘DATE FORMAT’) dateFormat(‘yyyyMMddHHmmss’)
• hostname, escapeString,
• yesterday, tommorow
• month, day, hour, minute, … day(‘yyyyMMdd’, -1) :: 어제 날짜(20131111)
• trim, concat 등등
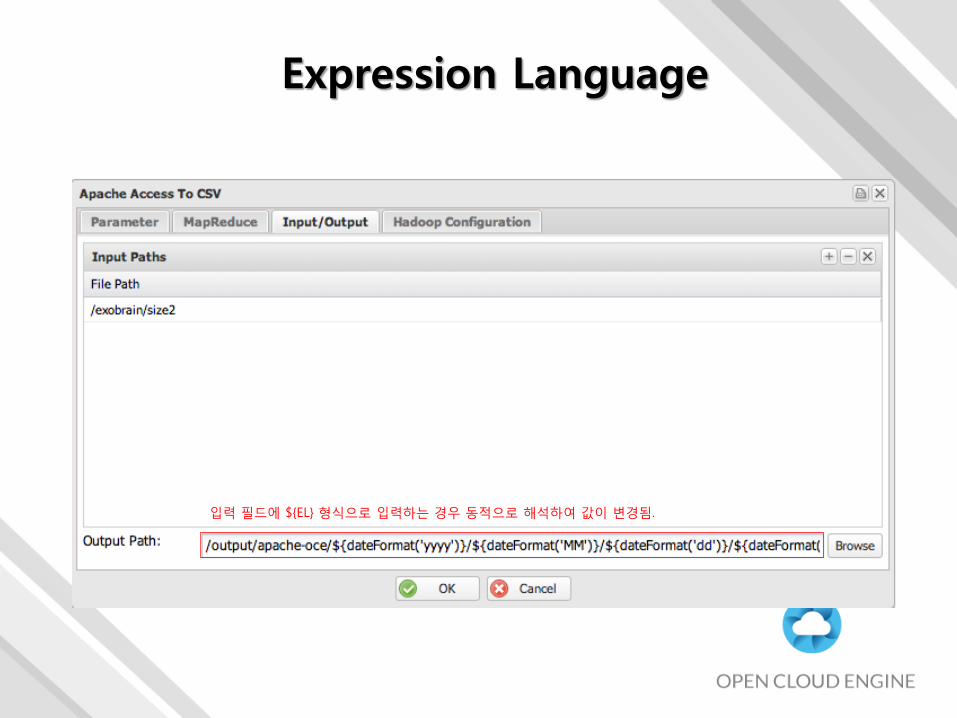
Expression Language
입력 필드에 ${EL} 형식으로 입력하는 경우 동적으로 해석하여 값이 변경됨.

Job & Workflow Monitoring
• 워크플로우는 다수 노드로 구성되며 각 노드는MapReduce Job으로 실행 가능
• 관리자 및 사용자는 자신의 MapReduce Job, Workflow의 진행 상태를 확인하기를 원함

Job & Workflow Monitoring :: 이슈
• Workflow가 실행하는 Job을 추적할 수 없음• Pig Latin/Hive QL은 다수의 Hadoop Job을 생성
• 워크플로우가 얼마나 많은 자원을 사용했는지 파악이 매우 어려움
• Hadoop의 Job Tracker, History Server를 외부에 공개하는데보안상 이슈가 있음
• Job Tracker, History Server를 별도 API로 추출하는데 상당한한계가 있고, 정보도 완전히 수집되지 않음

Job & Workflow Monitoring
MapReduce의 처리 현황 그래프
데이터 검증을 위한MapReduced의 Counter 정보
MapReduce Job Configuration검색 및 다운로드 기능
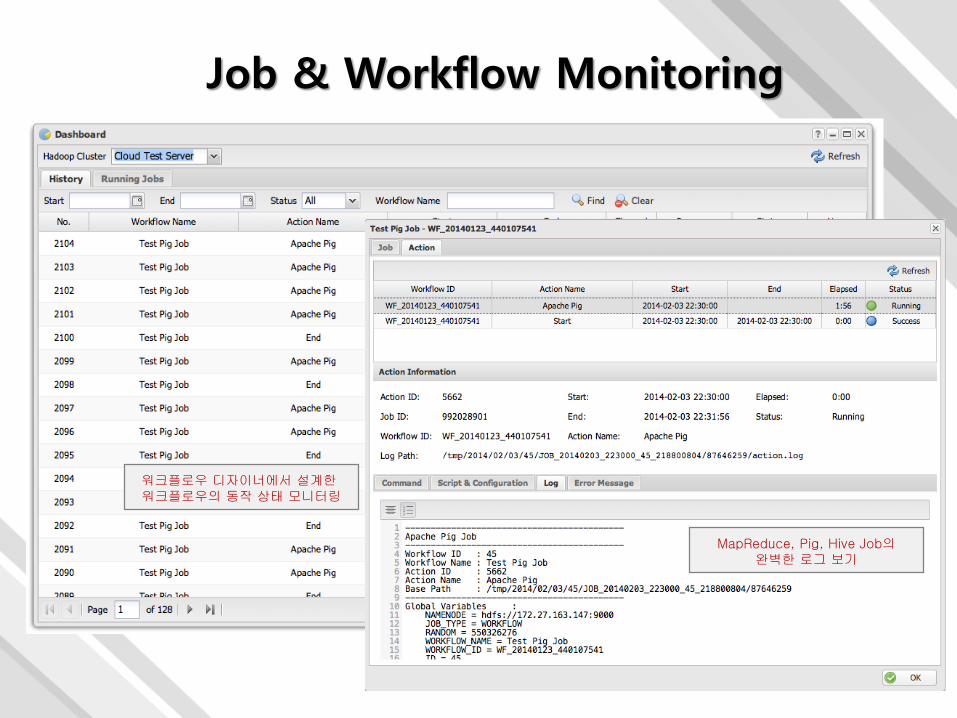
Job & Workflow Monitoring
워크플로우 디자이너에서 설계한워크플로우의 동작 상태 모니터링
MapReduce, Pig, Hive Job의완벽한 로그 보기
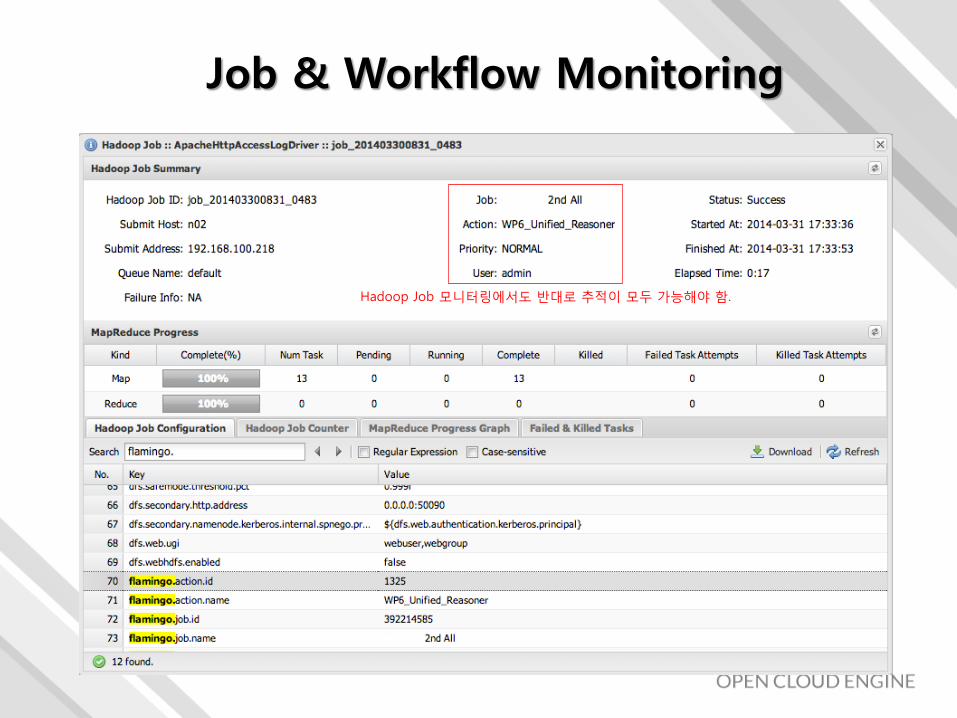
Job & Workflow Monitoring
Hadoop Job 모니터링에서도 반대로 추적이 모두 가능해야 함.
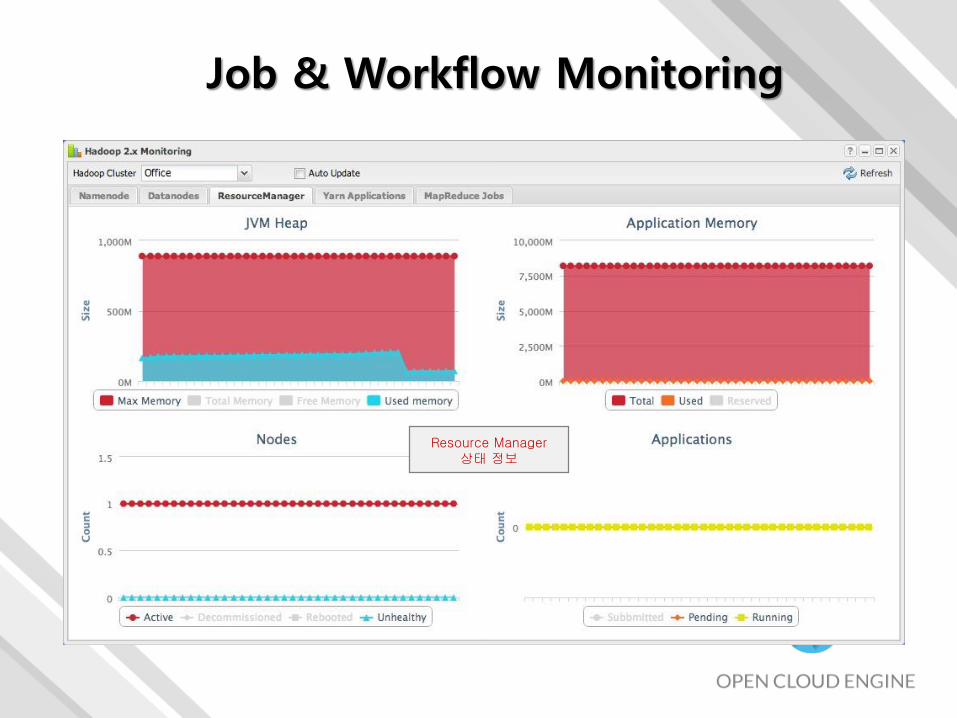
Job & Workflow Monitoring
등록되어 있는배치 작업 현황
Resource Manager상태 정보

Job Scheduling
• 작성한 워크플로우는 운영시 배치 스케줄링 필요
• 스케줄링 작업이 증가하는 경우 노드 증가시 스케줄러용량도 증가
• Cron Expression 기반 스케줄링 요구
• 워크플로우 작성시 워크플로우 변수를 스케줄링 시점에서 변경하여 적용 (예; HR 부서 코드)
• 배치 작업의 생명 주기 관리

Job Scheduling
등록되어 있는배치 작업 현황
작업 스케줄링 현황엔진의 메모리 상태
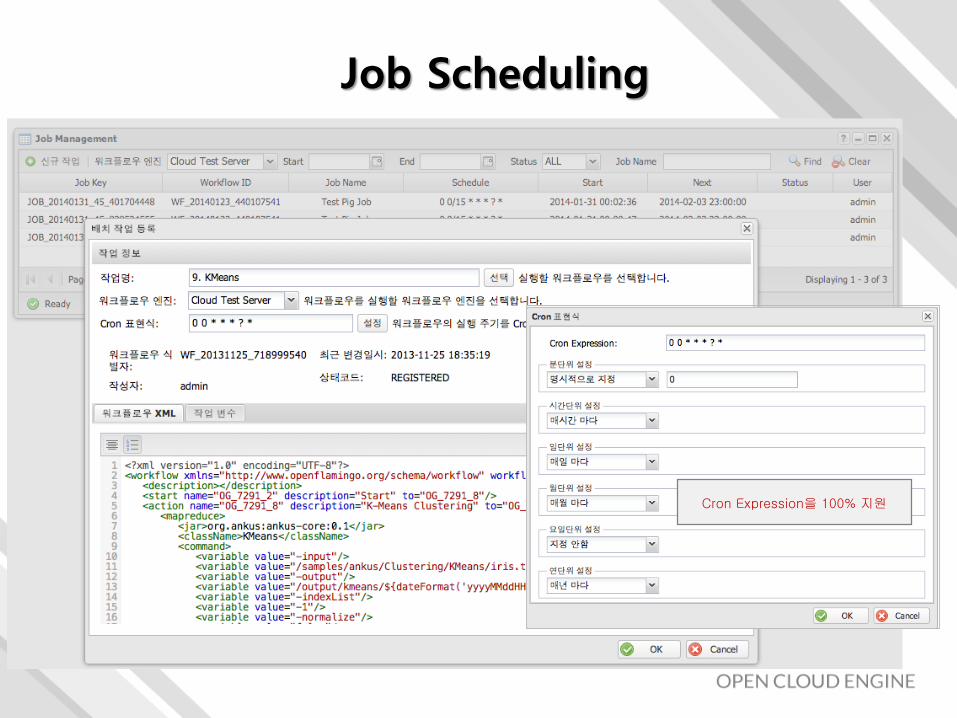
Job Scheduling
Cron Expression을 100% 지원

Flamingo Project
• Spring IO• Spring Framework 4, Spring Boot 1, Spring Web MVC
• Web Rich UI Framework• Sencha ExtJS 4 (GPL v3)
• Persistence : MyBATIS
• Hadoop EcoSystem : Hadoop 1.x & 2.x
• MySQL5.1 or higher
• JDK 1.7
• Hadoop Distribution• Vanilla Hadoop
• Cloudra CDH
• Pivotal HD (With HAWQ)
유사 프로젝트 : HUE

결론
• 데이터를 다루는 사용자의 행위를 이해하고 과거에 사용했던 도구를 철저하게 분석하여 Hadoop에 최적화
• UI 기술이 절대적으로 필요하며 인프라 SW에 대한 이해도도 높아야 함
• 빠르게 변하는 오픈소스에 대한 지속적인 지원이 필요하므로 전담 개발 인력이 계속 유지되어야 함
• 배포판별 호환성 문제가 심각하고 배포판이 많으므로 검증 작업은 배포판이 릴리즈될 때 마다 즉시 수행

Flamingo Project 관련 사이트
• Source Forge (다운로드)– http://www.sourceforge.net/projects/hadoop-manager
• 위키 (설명서 및 각종 기술자료)– http://wiki.opencloudengine.org/pages/viewpage.action?pageId=819205
• 이슈 관리 (버그 및 신규 기능)– http://jira.opencloudengine.org
• 빌드 서버– http://build.opencloudengine.org
• 구글 그룹스 : [email protected]
• Facebook : https://www.facebook.com/groups/flamingo.workflow

Flamingo Project의 미래
• Big Data On Cloud :: OpenStack + Flamingo
• Big Data All In One Package
• Apache Hadoop PaaS (Platform as a Service)

















![[SW 아키텍처 컨퍼런스] 클라우드 아키텍처 개론](https://img.pdfslide.tips/doc/110x75/5469d9d7af7959cb768b63e6/sw-5469d9d7af7959cb768b63e6.jpg)












