Embed Size (px)
Citation preview

cenidet
Centro Nacional de Investigación y Desarrollo Tecnológico
Departamento de Ciencias Computacionales
TESIS DE MAESTRÍA EN CIENCIAS
Búsqueda de Páginas Web mediante Ontologías
Presentada por
Ismael Rafael Ponce Medellín Ing. en Sistemas Computacionales por el I. T. de San Luis Potosí
Como requisito para la obtención del grado de:
Maestría en Ciencias en Ciencias de la Computación
Director de tesis: M.C. José Antonio Zárate Marceleño
Co-Director de tesis: Dr. Joaquín Pérez Ortega
Jurado:
Dr. René Santaolaya Salgado – Presidente Dr. Juan Gabriel González Serna – Secretario M.C. José Antonio Zárate Marceleño – Vocal
M.C. Humberto Hernández García – Vocal Suplente
Cuernavaca, Morelos, México. 7 de diciembre de 2006

DedicatoriasDedicatoriasDedicatoriasDedicatorias
A Dios, A Dios, A Dios, A Dios,
por darme vida y guiarme en cada paso de mi vida.
A mis padres, Ismael Ponce y Patricia Medellín,A mis padres, Ismael Ponce y Patricia Medellín,A mis padres, Ismael Ponce y Patricia Medellín,A mis padres, Ismael Ponce y Patricia Medellín,
por respetar mis decisiones, por guiarme en mi educación, por el cariño y confianza que me han dado. Que Dios esté siempre con ustedes.

Agradecimientos Al CoSNET y a la DGEST por el apoyo económico otorgado para la realización de este proyecto. A mi director de tesis, M.C. José Antonio Zárate Marceleño, por brindarme su ayuda y consejo para poder terminar esta tesis, y sobre todo, por ser un amigo en el cuál se puede confiar. Al Centro Nacional de Investigación y Desarrollo Tecnológico y al personal que allí labora, que permitió llevar a cabo mi formación, ser parte de esta institución y lograr una de mis metas. A mis revisores Dr. Juan Gabriel González Serna, Dr. René Santaolaya Salgado y M.C. Humberto Hernández García, por su disposición para la revisión de este trabajo de tesis, y sus valiosos comentarios y observaciones para mejorarlo. A la generación Xoloezcuintle:
A mis compañeros de vicios CeoRaptor y Kuran, por todos los momentos divertidos que pasamos juntos.
A Edgar, Ismael, Jorge, que aunque fueron pocos los momentos que compartimos, nunca quedó en duda la unidad del grupo.
A Jonathan y Carlos, por los momentos amenos y las buenas charlas que tuvimos.
A Chavo, Chio y Kio, por la confianza, las bromas y todo lo que compartimos en este pequeño tiempo que convivimos.
A Pacos y mi no hermanita Miche, por todo lo que me enseñaron, la ayuda en esos momentos pesados y el apoyo que siempre me brindaron.
A los compañeros de la siguiente generación: Ricardo, Zero, Six y a Nenu, por el gran tesoro de la amistad que me brindaron. A los profesores del cenidet, Dr. Pazos, Dr. Máximo, Dra. Azucena. Y a las demás personas que conocí en mi estadía en esta ciudad, y que de una forma u otra me ayudaron a seguir adelante, Vanoye, Morgan, Mirna. Me encuentro sin palabras para poder expresar mi gratitud por todas las vivencias que pasé con todos ustedes, quedo llenó de grandes recuerdos que llevaré siempre en mi mente. Mil gracias.
Ismael Rafael Ponce Medellín

ii
RESUMEN El estudio de las ontologías nace de la filosofía y puede interpretarse como el
estudio del ente o teoría del ser. Las ontologías se encargaban del estudio de las cosas, el qué y cómo son, estableciendo categorías generales donde clasificarlas.
Dentro del enfoque computacional, las ontologías se refieren al desarrollo de un
esquema conceptual sobre un dominio determinado, donde se clasifican conceptos, considerando además las interrelaciones existentes entre ellos, para facilitar la representación de información. En pocas palabras, trata de ser una representación de lo que existe, mostrando un orden para estos conceptos.
En este proyecto se busca la manera de utilizar el orden y la claridad que permite
una ontología, como una manera de guiar al usuario para encontrar información. En particular, el trabajo está centrado en ayudar en la búsqueda de información de páginas Web HTML sobre un dominio particular, como ejemplo se trabajo sobre aspectos generales del dominio del procesamiento del lenguaje natural (PLN).
La característica particular de esta ontología es la consideración de que los
ejemplares que la conforman se tratan de enlaces a páginas Web HTML relacionadas con el concepto al que se hace referencia.
Se menciona el desarrollo de la ontología, formalizándola en OWL (Web Ontology
Language, Lenguaje de Ontologías Web), y el uso de las relaciones que interconectan a los conceptos considerados, la manera en que se puede guiar al usuario para recorrerla y encontrar enlaces a páginas Web que traten sobre el concepto en el cuál se encuentre navegando, logrando ir de un concepto a otro, si hay alguna relación de por medio entre ellos.
Se menciona que proceso se siguió para llenar la ontología con ejemplares, usando
técnicas de clasificación automática mediante un aprendizaje supervisado; las consideraciones tomadas para el desarrollo de la interfaz, así como la manera de consultar sobre la ontología mediante el lenguaje SPARQL (Simple Protocol And RDF Query Language, Protocolo Simple y Lenguaje de Consultas RDF).
Para demostrar que el proyecto no se encuentra limitado a una sola ontología, se
desarrolló otra relacionada con el tema de turismo en el estado de Morelos, México, centrándose en encontrar lugares de visita en los distintos municipios que lo integran.
Con lo anterior se siguieron pruebas de usabilidad, para comprobar qué tan usable
es seguir el enfoque de utilizar una ontología para ayudar al usuario en su navegación para encontrar información.
Finalmente, como trabajos futuros se proponen algunas actividades para mejorar
algunas de las tareas desarrolladas.

ABSTRACT The ontology study born from the philosophy and can be interpreted as the study
of the being or theory of the being. The ontologies were in charge of the study of things, what and how they are, establishing general categories where to classify them.
Inside the computational approach, ontologies are about the development of a
conceptual scheme on a particular domain, where concepts are classified, considering also the existence of interrelations among them, to facilitate the representation of information. Briefly, it tries to be a representation of what it exists, showing an order for these concepts.
In this project is searched the way to use the order and the clarity that an
ontology allows, like a way to guide the user to find information. Particularly, this work was centered in helping in the search of information of Web HTML pages, on a particular domain, which corresponded to general aspects of the natural language process domain (NLP).
The main characteristic of this ontology is that the instances that conform it are
Web HTML page links related to the concept to which reference is made. It is mentioned the ontology development, formalized it in OWL (Web Ontology
Language), and the use of the relations that interconnect to the considered concepts, the way in which it is possible to guide the user to cross the ontology and find Web page links that treat about the concept in which the user is navigating, managing to go from a concept to another one, if there is some relation among them.
The process to populate the ontology with web page links is described, following automatic classification techniques through a supervised learning; the considerations taken for the development of the interface, as well as the way to consult over the ontology using SPARQL language (Simple Protocol And RDF Query Language).
To demonstrate that the project is not limited to a single ontology, another ontology related to the subject of tourism in the state of Morelos, Mexico, was developed, being centered in finding places to visit in the different municipalities that integrate this state..
Considering this, usability tests were followed, to verify how much usability has the approach to use an ontology to help users in their navigation to find information.
Finally, as future works, some activities to improve some of the developed tasks are mentioned.

iii
TABLA DE CONTENIDO TABLA DE CONTENIDO .................................................................................................... iii LISTA DE FIGURAS ..............................................................................................................v LISTA DE TABLAS................................................................................................................v SIGLARIO ..............................................................................................................................vi CAPÍTULO 1 INTRODUCCIÓN............................................................................................1
1.1 Antecedentes...................................................................................................................2 1.2 Descripción del problema...............................................................................................2 1.3 Objetivo ..........................................................................................................................3 1.4 Alcances y limitaciones..................................................................................................3 1.5 Beneficios .......................................................................................................................4 1.6 Organización del documento ..........................................................................................4
CAPÍTULO 2 MARCO TEÓRICO .........................................................................................5
2.1 Buscadores Web .............................................................................................................6 2.2 Ontologías.......................................................................................................................7
2.2.1 Lenguajes para representar de manera formal una ontología ..................................8 2.2.2 Lenguajes de consulta sobre ontologías. .................................................................9 2.2.3 Tecnologías para la consulta sobre ontologías......................................................10
2.3 Métodos de clasificación automática............................................................................11 2.3.1 Modelo del espacio vectorial (MEV) ....................................................................12 2.3.2 Procesamiento de documentos y selección de términos........................................13 2.3.3 Algoritmos de clasificación...................................................................................15 2.3.4 Medidas de desempeño..........................................................................................15
2.4 Lenguaje Natural Acotado (LNA) para la construcción de frases de consulta. ...........17 2.5 Usabilidad.....................................................................................................................17
CAPÍTULO 3 ESTADO DEL ARTE ....................................................................................19
3.1 Motores de búsqueda....................................................................................................20 3.1.1 Motores de búsqueda por palabras clave...............................................................20 3.1.2 Motores de búsqueda por navegación ...................................................................21 3.1.3 Variantes de Motores de búsqueda........................................................................22
3.1.3.1 Motores de búsqueda con clustering..............................................................22 3.1.3.2 Buscadores especializados..............................................................................22
3.1.4 Comparación con el proyecto................................................................................23 3.1.5 Clasificación de documentos.................................................................................24 3.1.6 Trabajos relacionados con ontologías....................................................................25
CAPÍTULO 4 ANÁLISIS Y DESCRIPCIÓN DEL PROBLEMA .......................................27
4.1 Descripción general del problema ................................................................................28 4.2 Diseño general de la propuesta de solución..................................................................28 4.3 Descripción general de las partes desarrolladas como propuesta de solución .............31
4.3.1 Diseño de la ontología ...........................................................................................31

iv
4.3.2 Fase de entrenamiento ...........................................................................................33 4.3.3 Interfaz de usuario siguiendo el modelo OVID.....................................................36
4.3.3.1 Análisis: Fase de descubrimiento ...................................................................37 4.3.3.2 Abstracción del diseño....................................................................................40 4.3.3.3 Realización del diseño....................................................................................44
CAPÍTULO 5 IMPLEMENTACIÓN ....................................................................................46
5.1 Desarrollo de la ontología.............................................................................................47 5.1.1 Creación de clases .................................................................................................47 5.1.2 Establecimiento de propiedades ............................................................................47 5.1.3 Uso de razonadores para comprobar la consistencia lógica de la ontología. ........49 5.1.4 Recolección de documentos de entrenamiento......................................................50
5.2 Entrenamiento y clasificación automática de los documentos. ....................................50 5.2.1 Reducción de la dimensionalidad. .........................................................................51 5.2.2 Selección del algoritmo de clasificación y su ponderación...................................52
5.3 Utilización de la técnica de Lenguaje Natural Acotado (LNA) para la construcción de frases de consulta................................................................................................................53 5.4 Utilización de SPARQL para consultas sobre OWL....................................................54 5.5 Problemas y dificultades encontrados ..........................................................................56
5.5.1 Resultados no deseados con el algoritmo de clasificación....................................56 5.5.2 Errores generados al usar el editor de ontologías Protégé.....................................57 5.5.3 Problemas con la codificación de las páginas a clasificar. ....................................57
5.6 Herramientas utilizadas ................................................................................................59 CAPÍTULO 6 PRUEBAS ......................................................................................................61
6.1 Hipótesis y alcances......................................................................................................62 6.2 Plan de pruebas.............................................................................................................62 6.3 Pruebas de usabilidad ...................................................................................................68
6.3.1 Procedimiento y resultados de las pruebas de usabilidad efectuadas....................68 6.3.2 MRR (Mean Reciprocal Rank)..............................................................................71 6.3.3 Prueba usando otra ontología. ...............................................................................72 6.3.4 Resumen de las pruebas.........................................................................................73
CAPÍTULO 7 CONCLUSIONES..........................................................................................74
7.1 Conclusiones.................................................................................................................75 7.2 Aportaciones.................................................................................................................76 7.3 Trabajos futuros............................................................................................................76 7.4 Publicaciones y reconocimientos .................................................................................77
ANEXO A: DISEÑO DE LA ONTOLOGÍA .......................................................................vii ANEXO B: REPORTE DE PRUEBAS DE USABILIDAD PARA OK............................xxix ANEXO C: MATRIZ DE CONFUSIÓN OBTENIDA DURANTE EL PROCESO ......... xlix ANEXO D: EJEMPLOS DE CONSULTAS EN SPARQL......................................................l Referencias ............................................................................................................................. lii

v
LISTA DE FIGURAS Figura 2-1. Ejemplo de relaciones en una ontología.............................................................. 7 Figura 2-2. Etapas del procesamiento de los documentos de texto ...................................... 14 Figura 4-1 Desarrollo de la ontología................................................................................... 28 Figura 4-2 Etapas generales de desarrollo............................................................................ 29 Figura 4-3 Fase de entrenamiento ........................................................................................ 29 Figura 4-4 Fase de clasificación ........................................................................................... 30 Figura 4-5 Fase de consulta.................................................................................................. 30 Figura 4-6 Interface OK ....................................................................................................... 31 Figura 4-7 Diagrama de casos de uso para el entrenamiento y clasificación. ...................... 33 Figura 4-10. Diagrama de casos de uso para realizar consultas. .......................................... 36 Figura 4-11 Ciclo de vida del desarrollo de interfaz. ........................................................... 36 Figura 4-12 Diagrama de clases de usuario.......................................................................... 38 Figura 4-13 Diagrama de metas de usuario. ......................................................................... 38 Figura 4-14 Modelo actual de tarea de usuario. ................................................................... 39 Figura 4-15 Caso de uso de experiencia del usuario............................................................ 40 Figura 4-16 Modelo de objetos de usuario. .......................................................................... 41 Figura 4-17 Modelo de tareas del diseñador. ....................................................................... 41 Figura 4-18 Diagrama de secuencia de actividades para realizar una consulta directa obteniendo resultados. .......................................................................................................... 42 Figura 4-19 Diagrama de secuencia de actividades cuando se realiza una consulta directa sin obtener resultados. .......................................................................................................... 42 Figura 4-20 Diagrama de secuencia de actividades cuando se usa una consulta guiada y hay subclases por mostrar. .......................................................................................................... 43 Figura 4-21 Diagrama de secuencia de actividades para mostrar enlaces en una consulta guiada. .................................................................................................................................. 43 Figura 4-22 Diagrama de estados de objetos........................................................................ 44 Figura 4-23 Diseño de interfaz. ............................................................................................ 45 Figura 5-1 Clases y subclases............................................................................................... 47 Figura 5-2 Relaciones........................................................................................................... 48 Figura 5-3 Jerarquía inferida por el razonador. .................................................................... 49 Figura 6-1 Relaciones mostradas para un concepto. ............................................................ 66 Figura 6-2 Resultados mostrados para un concepto. ............................................................ 67 Figura 6-3 Buscador usando una ontología de turismo en Morelos ..................................... 73
LISTA DE TABLAS
Tabla 2-1 Ejemplo del MEV. ............................................................................................... 12 Tabla 2-2 Matriz de confusión. ............................................................................................ 16 Tabla 3-1 Buscadores más utilizados .................................................................................. 20 Tabla 3-2 Comparativa entre herramientas de búsqueda...................................................... 24 Tabla 5-1 Porcentaje de instancias bien clasificadas considerando como espacio vectorial palabras con alta GI .............................................................................................................. 52 Tabla 5-2 Porcentajes de recuerdo y precisión..................................................................... 53

vi
Tabla 5-3 Resultados generales. ........................................................................................... 53 Tabla 6-1 Plan de pruebas. ................................................................................................... 62 Tabla 6-2 Palabras con mayor GI. ........................................................................................ 64 Tabla 6-3 Cantidad de tareas terminadas.............................................................................. 69 Tabla 6-4 Tiempo promedio en segundos para terminar cada tarea..................................... 69 Tabla 6-5 Resultados de satisfacción subjetiva. ................................................................... 69 Tabla 6-6 Evolución entre la sesión 1 y 4. ........................................................................... 70 Tabla 6-7 Media geométrica para los principios de usabilidad evaluados. .......................... 70 Tabla 6-8 Usabilidad entre la versión 1 y la 4. ..................................................................... 70 Tabla 6-9 Usabilidad considerando la satisfacción subjetiva, entre ODP y OK Order in Kaos. ..................................................................................................................................... 71 Tabla 6-10 Tabla de valores del MRR.................................................................................. 71 Tabla 6-11 Ubicación de resultados para calcular el MRR. ................................................. 72 Tabla 12. Resultados de satisfacción subjetiva. .................................................................xliv Tabla 13. Puntajes relativos entre las actividades de cada ronda. ......................................xliv Tabla 14. Usabilidad final entre cada ronda. .......................................................................xlv
SIGLARIO Siglas Significado GI Ganancia en la Información. HTML HyperText Markup Language, Lenguaje Marcado de HiperTexto LNA Lenguaje Natural Acotado. MEV Modelo del espacio vectorial. MRR Mean Reciprocal Rank, Rango Recíproco Medio o Rango de la Media
Recíproca. ODP Open Directory Project, Proyecto de Directorio Abierto. OK Order in Kaos (Chaos). Es el prototipo desarrollado. OVID Object, View, Interactive Design, Objeto, Vista, Diseño Interactivo. OWL Web Ontology Language, Lenguaje de Ontologías Web. PLN Procesamiento del Lenguaje Natural. RDF Resource Description Framework, Marco de Descripción de Recursos. SPARQL Simple Protocol And RDF Query Language, Protocolo Simple y Lenguaje de
Consultas RDF. SVM Support Vector Machines, Máquinas de soporte vectorial. tf-idf Term frequency – inverse document frequency, frecuencia de términos,
frecuencia documental inversa. URI Uniform Resource Identifier, Identificador Uniforme de Recursos URL URL significa Uniform Resource Locator, Localizador Uniforme de Recursos. XML eXtensible Markup Language (lenguaje de marcado ampliable o extensible)

Capítulo 1 Introducción
1
CAPÍTULO 1 INTRODUCCIÓN
En este capítulo se explica el contexto del trabajo, el problema que se ataca, el
objetivo y los alcances del mismo, además de la organización en general del documento.

Capítulo 1 Introducción
2
1.1 Antecedentes
La World Wide Web fue fundada entre 1989 y 1990, con la finalidad de que científicos pudieran transmitir resultados e información relacionada con sus investigaciones, a través de todo el mundo; y desde su origen, su crecimiento ha sido sorprendente.
A mediados del 2006, se estimaba la existencia de más de 80 millones de sitios
Web, pero si se considera que en el 2000 sólo había 8 millones de ellos1, queda implícita la manera vertiginosa en que ha aumentado el intercambio de información por este medio, debido principalmente a que cada vez es más sencillo para un usuario común el poder publicar y compartir información. Sin embargo, mientras más información se encuentre disponible, más difícil es encontrar el contenido esperado.
Se han desarrollado diversas formas de ayudar a los usuarios a encontrar
información en la red, que pueden ser a través de consultas o a través de navegación [1]. Las consultas se realizan por medio de la correspondencia de palabras claves, y son útiles cuando el usuario tiene una idea clara de lo que desea encontrar; la navegación se realiza siguiendo una serie de enlaces organizados dentro de una jerarquía, hasta llegar a la información deseada, y por lo mismo, es útil cuando el usuario no puede expresar su necesidad de información de manera clara ni explícita, o bien, cuando lo que se desea es encontrar información general sobre un tema.
Sin embargo la sociedad sigue necesitando alternativas que le ayuden en su
proceso de búsqueda, soluciones enfocadas a temas específicos, que eviten en lo posible contenidos irrelevantes al enfoque sobre el cuál se busque.
En este proyecto se propone el uso de las ontologías como una manera de dar
orden a la información y así poder guiar al usuario a que encuentre contenido sobre el tema que se consulta.
Una ontología, definida como una especificación explícita de una conceptualización
[2], no es más que una abstracción del mundo, en la que se determinan conceptos y las relaciones existentes entre ellos, expresada de manera formal. Se espera que al usar una ontología y sacar provecho del orden que proporciona, así como el mantener interconectados distintos conceptos mediante relaciones, sea una alternativa que guíe al usuario a encontrar información, siguiendo un estilo de navegación.
1.2 Descripción del problema
El problema que se ataca, es la búsqueda y la obtención de información por un usuario. A pesar de que la búsqueda en la red se ha convertido en una tarea cotidiana, aún persiste el problema de que el usuario pueda encontrar la información que desea, y es que, aunque se puede acceder a una gran cantidad de datos, no todos los resultados obtenidos son deseados, puesto que se puede obtener información que abarque otros enfoques distintos al consultado.
1 Netcraft: June 2006 Web Server Survey, disponible en: http://news.netcraft.com/archives/2006/06/04/june_2006_web_server_survey.html.

Capítulo 1 Introducción
3
Aunado a esto, también se presenta el caso de que hay ocasiones en las que el
usuario no sabe con exactitud qué es lo que busca, sólo tiene una idea vaga de lo que espera encontrar, le hace falta una guía que le permita profundizar en las relaciones que pueda tener el concepto que esté buscando.
1.3 Objetivo Objetivo general
Desarrollo de un proceso para ayudar al usuario a encontrar información temática
en páginas Web HTML mediante las relaciones explícitas de una ontología, que es poblada por clasificación automática, probándolo mediante el desarrollo de herramientas para tal fin. Objetivos específicos
• Desarrollo de un módulo de software que permita transformar las páginas Web
a una representación que pueda ser utilizada por un algoritmo de clasificación automática.
• Desarrollo de un módulo de software que permita clasificar automáticamente páginas Web dentro de la ontología.
• Desarrollo de una interfaz que permita recorrer la ontología. • Realización de pruebas de usabilidad para conocer la reacción de los usuarios al
utilizar una ontología como forma de encontrar información.
1.4 Alcances y limitaciones Alcances: 1. El tema que se consideró para la ontología, aborda aspectos relacionados con el
procesamiento del lenguaje natural (PLN). 2. Se probó con otra ontología que se puede guiar al usuario a través de sus
conceptos y relaciones (usando una ontología pequeña sobre turismo de Cuernavaca).
3. La población de la ontología con enlaces a páginas Web, fue usando el clasificador desarrollado y la herramienta WEKA.
4. La interfaz desarrollada permite navegar y recorrer los conceptos que conforman la ontología mediante las relaciones que los enlazan.
Limitaciones: 1. Para fines de prueba, sólo se poblaron 26 de las 165 clases que conforman la
ontología. 2. Sólo se trabajó con páginas HTM y HTML, por motivos de prueba y para facilitar el
procesamiento de los documentos. 3. La ontología desarrollada es estática, tiene sus clases definidas, los elementos que
no formen parte en alguna de estas clases, serán desechados. 4. Sólo se consideraron aquellos métodos de clasificación soportados por la
herramienta WEKA. 5. No se diferencia enlaces distintos que tengan el mismo contenido, como es el caso
de que la misma página Web se encuentre en ubicaciones diferentes.

Capítulo 1 Introducción
4
1.5 Beneficios
1. Se presenta una manera de ayudar al usuario a encontrar información aprovechando la explicites de las relaciones de una ontología.
2. Se presenta una interfaz de guía a los usuarios para navegar dentro de la ontología temática de un concepto a otro.
3. Al trabajar bajo enfoques específicos, se encuentran resultados temáticos, aunado a un ahorro de tiempo.
4. Utilización de herramientas de apoyo, con las cuáles se eviten costo, tiempo y esfuerzo excesivos (Protégé, WEKA, entre otras).
5. Se uso una ontología para el proceso de navegación Web, ante otras herramientas, como los directorios Web.
6. Se automatizó la población de la ontología, haciendo uso de la clasificación automática de textos, en contraste con el proceso manual que se sigue en los directorios Web.
Además de los beneficios arriba listados, se dejan las bases necesarias para poder
trasladar el dominio sobre el cuál se trabajó hacia algún otro, como lo pueden ser de fines turísticos o comerciales.
1.6 Organización del documento La tesis se organiza en los siguientes capítulos: Capítulo 1. Se presenta una introducción para situar al lector en el contexto del trabajo de tesis, indicando además el objetivo, alcances y sus limitaciones. Capítulo 2. Se presenta el marco teórico donde se incluyen conceptos como las ontologías, los métodos de clasificación automática, y otros conceptos relevantes relacionados con la tesis. Capítulo 3. Se describe brevemente el estado del arte que rodea a los buscadores de información en la red, abarcando los que son por consultas y por navegación, así como variantes de los mismos. Capítulo 4. Se describe el análisis y diseño del proyecto. Capítulo 5. Abarca los pasos para la implantación del proyecto. Capítulo 6. Abarca las pruebas realizadas sobre el trabajo desarrollado, los resultados de pruebas de usabilidad efectuados sobre el mismo, además de las herramientas y tecnologías empleadas para esta fase. Capítulo 7. Se plantean las conclusiones del trabajo después de terminar el sistema, además de sugerir los posibles trabajos futuros que pueden ampliar esta investigación.

Capítulo 2 Marco teórico
5
CAPÍTULO 2 MARCO TEÓRICO
En este capítulo se explican conceptos necesarios para la realización de este trabajo, abarcando los buscadores Web, ontologías y métodos de clasificación automática.

Capítulo 2 Marco teórico
6
2.1 Buscadores Web
• Existen dos maneras principales de realizar búsquedas en la red, por navegación (que se realiza siguiendo enlaces) y por motores de consulta (consultas que se realizan mediante palabras clave que hacen referencia al tema sobre el cuál se busca) [1].
• Los motores de consulta Web mantienen un índice de palabras de los
documentos que encuentran en la red, y con base en las consultas que realizan los usuarios, devuelven una lista de resultados ordenados; sin embargo, no todos los resultados devueltos le son útiles al usuario. Estos buscadores se encuentran entre los sitios más accedidos por los cibernautas ¡Error! No se encuentra el origen de la referencia., pero ante el crecimiento descomunal que ha tenido la red, se enfrentan a varios problemas, siendo el principal no poder indexar todos los documentos existentes, ya que a cada segundo se generan más de ellos.
• La navegación se realiza a través de una jerarquía de enlaces que llevan hacia
un tema específico; este tipo de búsquedas resulta especialmente útil cuando el usuario no tiene totalmente claro qué es lo que busca, ni las palabras clave necesarias para encontrar algo, o simplemente, es útil cuando se busca información general sobre un tema.
En [1] se identifican tres tipos principales de buscadores: • Arañas Web. Buscan en la red páginas para agregar a su índice, comenzando
con un conjunto de direcciones predefinidas, y de cada una de ellas, extrae las direcciones a otras páginas que allí aparezcan, para después también agregarlas; de estas páginas va guardando las palabras que aparecen, para ser usadas cuando los usuarios realicen sus consultas. Así, cuando un usuario realice su consulta, en realidad está buscando sobre el índice que tenga el buscador.
Estos buscadores son buenos para encontrar información específica, más no común, ya que si se pregunta por algo muy general, la cantidad de resultados que devuelve es inmensa. Ejemplo: Google2.
• Directorios Web. Son sitios que organizan la información por temas, y son
construidos y mantenidos manualmente; algunos directorios permiten realizar consultas como si se tratara de arañas Web, sin embargo estas búsquedas solamente se restringen a las descripciones y a los títulos que tienen las páginas guardadas en el directorio. Las páginas que almacenan son obtenidas mediante instituciones, compañías o sugerencias de usuarios. Los directorios son útiles para encontrar información general, pero no son buenos para encontrar información específica. Ejemplo: Open Directory Project3.
2 Google http://www.google.com. 3 Open Directory Project, http://www.dmoz.org

Capítulo 2 Marco teórico
7
• Metabuscadores. Son sitios que procesan las consultas que reciben de los usuarios, enviándolas a varios motores de búsqueda, mostrando un compilado de los resultados obtenidos por todos ellos. Ejemplo: Metacrawler4.
2.2 Ontologías
Una ontología se define como una especificación explícita de una conceptualización [2]. Es una descripción formal de conceptos pertenecientes a un dominio, así como las relaciones existentes entre ellos. El estudio de las ontologías nace de la filosofía y proviene de las etimologías griegas “ontos” (el ser) y “logos” (estudio), que significaría el estudio del ser.
En el enfoque computacional, las ontologías abordan el desarrollo de un esquema
conceptual sobre un dominio determinado [4] donde se clasifican conceptos y las interrelaciones existentes entre ellos. La definición de clases generalmente es el tema central de la mayoría de las ontologías.
Las clases describen a los conceptos dentro de un dominio. Por ejemplo,
consideremos una conceptualización en que la clase vehículos representa a todas las marcas de vehículos; en este ejemplo, las subclases serían cada una de las marcas; se llama ejemplar de una clase cuando se habla de un elemento específico y particular que representa a una clase, siguiendo el mismo ejemplo, el Volkswagen rojo con matrícula X sería un ejemplar que pertenece a la clase Volkswagen.
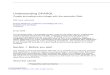
Dos de las relaciones más utilizadas en una ontología para interrelacionar
conceptos son: la relación de generalización o especialización, llamadas de hiperonimía (relación es un), y la relación de pertenencia, conocida como meronimía (relación parte
de o tiene). Un ejemplo se muestra en la Figura 2-1, donde se muestran las partes que
contiene una obra de texto, así como algunos tipos de obras que puede haber.
Figura 2-1. Ejemplo de relaciones en una ontología.
El uso de ontologías cada vez está tomando mayor auge, gracias a que por medio
de ellas se puede hacer referencia hacia una misma conceptualización, logrando unificar y formalizar los conceptos de un dominio, clasificarlos y darles un orden.
Existen una serie de consideraciones necesarias a tomar en cuenta al momento de
desarrollar una ontología [5]: • No existe una manera correcta única de modelar un dominio. • El diseño de una ontología es un proceso iterativo.
4 Metacrawler, http://www.metacrawler.com
obra
periódico
revista
libro
título autor contenido fecha
es un
parte de

Capítulo 2 Marco teórico
8
• Los conceptos de una ontología, lógicos o físicos, así como las relaciones entre ellos, deben ser relevantes al dominio de interés.
Con respecto al primer punto, hay que considerar que existen distintos puntos de
vista y consideraciones hacia un mismo tema, por lo que es lógico pensar que un mismo dominio puede ser conceptualizado de diferentes maneras, sin implicar que alguna de ellas esté bien o mal, por que son maneras distintas de interpretar el mundo.
La mejor opción a considerar dependerá del objetivo por el cuál se desea construir
la ontología.
2.2.1 Lenguajes para representar de manera formal u na ontología Una ontología formal se compone de un vocabulario controlado, expresado en un
lenguaje de representación ontológica. Se han desarrollado una serie de lenguajes de descripción, algunos de los cuales se describen a continuación.
RDF (Resource Description Framework)5 es una recomendación del W3C (World Wide Web Consortium) para la representación de metadatos dentro de la Web.
Es una especificación que proporciona una manera sencilla de intercambiar conocimiento por medio de la Internet, tomando como base a XML como medio de transporte.
RDF es un lenguaje de etiquetado que define un modelo de datos para describir recursos, mediante enunciados en forma de tripletas recurso – propiedad – enunciado, donde recurso es cualquier cosa que pueda nombrarse mediante una URI (mecanismo propuesto por el W3C, para identificar recursos en la red, su subconjunto más conocido son las URL); propiedad es una característica o atributo de un recurso, el cual lleva asociada una URI y puede relacionarse con otras propiedades; por último, el enunciado se encarga de asociar el valor de una propiedad a un recurso. Estos tres elementos son llamados también sujeto, predicado y objeto, respectivamente. Por ejemplo:
Recurso Propiedad Enunciado
http://www.paginapersonal.com/ponce.html Autor “Rafael Ponce”
<?xml version=“1.0”> <rdf:RDF> <rdf:Description about=“http://www.paginapersonal.com/ponce.html”> <s:autor>Rafael Ponce</s:autor> </rdf:Description> </rdf>
Partiendo de RDF, se han desarrollado otros lenguajes para la representación de
ontologías: OIL (Ontology Inference Layer)6, basado en estándares del W3C y usando
sintaxis de XML, representa el conocimiento siguiendo la lógica descriptiva (declaración
5 Resource Description Framework (RDF) / W3C Semantic Web Activity, http://www.w3.org/RDF/

Capítulo 2 Marco teórico
9
de axiomas o reglas) así como sistemas basados en marcos (taxonomías de clases y atributos). DAML+OIL7 es una propuesta de lenguaje de representación de ontologías, fruto
del trabajo conjunto de los grupos de trabajo de OIL y DARPA (que previamente habían desarrollado DAML, otro lenguaje para el uso de ontologías), cuyo objetivo es el de extender la expresividad del RDF pero que presentó cierta complejidad conceptual de uso. OWL (Web Ontology Language) 8 es un trabajo del grupo WebOnt del W3C, el
cual trata de un lenguaje derivado de DAML+OIL, a su vez cimentado sobre RDF, que busca solucionar la complejidad conceptual que manejaba su antecesor. OWL permite definir clases (conceptos), propiedades y ejemplares; además contiene una serie de predicados predefinidos que ayudan en la definición de ontologías. OWL es el lenguaje estándar propuesto por el W3C al 2004 para el diseño de ontologías. OWL se divide en tres sublenguajes:
• OWL Full. Es la unión de la sintaxis OWL y RDF, sin restricciones, lo que permite
una alta expresividad, a costo de una mayor dificultad para trabajar con las ontologías, en cuanto a la conceptualización, decisiones y consultas que se le puedan hacer.
• OWL DL (Description Logics). En este sublenguaje se limita la expresividad en favor
de las decisiones; la gran mayoría de las herramientas que trabajan sobre ontologías soportan este sublenguaje, siendo un gran punto a su favor.
• OWL Lite. Es un subconjunto de OWL DL más sencillo de implementar, mediante el
manejo de una menor complejidad formal en comparación de los otros sublenguajes mencionados.
2.2.2 Lenguajes de consulta sobre ontologías. Para poder recuperar la información almacenada en ontologías, se requieren de
lenguajes especiales que permitan aprovechar las ventajas que estas brindan. En general, los lenguajes existentes siguen el modelo de tripletas sujeto, objeto, predicado, heredado de RDF. A continuación se mencionan algunos de los lenguajes más conocidos.
RDQL (RDF Data Query Language)9 es un lenguaje de consulta para RDF de
Hewlett Packard, diseñado originalmente dentro del entorno de Jena, enfocado a recuperar información de un modelo que se encuentre en la forma de tripletas directamente.
RQL (RDF Query Language)10 o SeRQL (Sesame RDF Query Language)11
son otros lenguajes, que surgieron ha raíz de proyectos específicos, pero ninguno de ellos llegó a consolidarse como estándar.
6 OIL, http://www.ontoknowledge.org/oil/ 7 DAML+OIL (March 2001), http://www.daml.org/2001/03/daml+oil-index.html 8 OWL Web Ontology Language Overview, W3C Recommendation, http://www.w3.org/TR/owl features/ 9 RDQL – A Query Language for RDF, http://www.w3.org/Submission/RDQL/ 10 The RDF Query Language (RQL), http://139.91.183.30:9090/RDF/RQL/

Capítulo 2 Marco teórico
10
SPARQL (Simple Protocol And RDF Query Language)12 es un lenguaje de
consulta y un protocolo de acceso de datos para la Web semántica. En abril de 2006, SPARQL se encontraba como candidato a recomendación, por parte del W3C [6], sin embargo, a inicios de octubre del mismo año, nuevamente se encuentra en revisión para posibles mejoras [7]. SPARQL se encuentra definido bajo el modelo RDF y puede trabajar con cualquier tipo de datos que pueda ser representado bajo esta manera. Una de sus ventajas es que su sintaxis trata de asemejarse a SQL, permitiendo consultas de tipo SELECT. Parte sus consultas al considerar tripletas que consideran a un sujeto, un objeto y una relación entre ellos. Para realizar una consulta, solamente se deben definir los nombres de espacio que incluyan las relaciones que se utilizan dentro del documento de Web semántica y establecer la ontología sobre la que se realizará la consulta. Un ejemplo sencillo se muestra a continuación, en donde se consulta por las clases hijas que parten directamente de la clase general owl:Thing.
PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX : <http://mx.briefcase.yahoo.com/rafaxzero/pln.owl#> SELECT ?y WHERE { ?y rdfs:subClassOf owl:Thing } ORDER BY ?y Se usan prefijos, donde se indican los nombres de espacio con los cuales se
trabaja; se indican las variables que se quieren mostrar, siendo variables genéricas que hacen referencia a elementos de la ontología, y por último se expresan las condiciones que deben cumplir tales variables, como por ejemplo que se enlacen mediante un tipo determinado de relación (en el código de ejemplo se pide la relación subclase rdfs:subClassOf). Una instrucción de suma utilidad que proporciona SPARQL es OPTIONAL, la cuál permite dentro de la cláusula WHERE establecer condiciones no obligatorias; además, con la instrucción UNION se pueden juntar los resultados de distintas condiciones en una sola, brindando una mayor flexibilidad al momento de su uso.
2.2.3 Tecnologías para la consulta sobre ontologías Así como en SQL existen diversos gestores de base de datos para manipularlo,
algo semejante se requiere para trabajar con los lenguajes de consulta mencionados en la sección anterior. Existen varias herramientas que soportan distintos lenguajes, e inclusive algunas implementan los propios. Un breve panorama de algunos se menciona a continuación.
KAON213 es una herramienta que brinda una infraestructura para poder trabajar
con ontologías codificadas en OWL-DL, por medio de una API. Entre otras características, proporciona una interfaz DIG (es una interfaz estándar de XML para Lógica de Descripciones) que le permite comunicarse con otras herramientas como editores de ontologías, además de tener un motor de inferencia que permite responder consultas expresadas según la sintaxis de SPARQL. Sin embargo KAON2 es un
11 The SeRQL query language, http://www.openrdf.org/doc/sesame/users/ch06.html 12 SPARQL Query Language for RDF, http://www.w3.org/TR/2004/WD-rdf-sparql-query-20041012/ 13 KAON2 – Ontology Management for the Semantic Web, http://kaon2.semanticweb.org/

Capítulo 2 Marco teórico
11
proyecto aún en desarrollo, adolece algunas deficiencias, una de ellas en el sentido de la documentación, ya que no tiene, solamente se proveen de momento algunos ejemplos de su uso en su página principal. Además, no soporta del todo las especificaciones de SPARQL, dejándose notar serias restricciones en su uso, como por ejemplo el no poder utilizar la instrucción OPTIONAL.
Siguiendo los ejemplos que se dan como documentación, se encontraron
problemas para poder efectuar consultas siguiendo las diferentes relaciones incluidas en la ontología. Para consultar por subclases hay suficientes ejemplos, pero se muestra un tanto confuso navegar a través de otras relaciones.
KPOntology14 es una librería que permite gestionar ontologías, presentando un
nivel de abstracción de alto nivel que libera al usuario de muchos detalles, facilitando su tarea y logrando realizar consultas de una manera más directa. Entre sus ventajas se encuentra que puede ser fácilmente integrada a entornos como Jena y Sesame. Es una utilidad muy prometedora, desgraciadamente como sucede con KAON2, no hay mucha documentación disponible, ya que se trata de un proyecto particular de un grupo de participantes, así que se encuentra un poco descuidado.
Joseki15 es un motor HTTP y SOAP que soporta el protocolo y lenguaje SPARQL,
para ser usado directamente como un servidor; sin embargo para abril del 2006, se encontraba disponible para su descarga solamente una versión beta, la cuál tiene varios errores, rutas equivocadas, entre otros problemas, por lo que simplemente ponerlo en funcionamiento se vuelve una tarea compleja.
Sesame16 es una arquitectura para el almacenamiento y consulta de información
en RDF y RDF Schema (RDFS), además de contar con soporte para los lenguajes RQL. Jena17 es un marco de trabajo construido en Java, usado para la construcción de
aplicaciones de Web Semántica, que permite trabajar con RDF, RDFS y OWL y usar el lenguaje de consulta RDQL, gracias a las APIs que proporciona, lo cuál la hace manejable y sencilla de utilizar.
ARQ18, el cuál es un motor de consulta que corre bajo Jena, y que soporta los
lenguajes SPARQL, RDQL y ARQ (éste último es propio de esta implementación y aún se encuentra en pruebas). Cuenta con bastantes ejemplos de su uso, en particular para su ejecución en consultas con SPARQL, aparte de documentación y otros archivos de ayuda, lo que facilita en gran medida su uso.
2.3 Métodos de clasificación automática
El aprendizaje automático se define como “El uso de la experiencia de modo que el desempeño de una tarea dada resulte mejor con experiencia que sin ella” [8]. Se considera que un programa aprende si, al desarrollar una tarea después de haberle proporcionado experiencia, el sistema puede desempeñarse aceptablemente bien bajo nuevas situaciones.
14 KPOntology, http://kpontology.isoco.net/ 15 Joseki – A SPARQL Server for Jena, http://www.joseki.org/ 16 openRDF.org, home of Sesame, http://www.openrdf.org/ 17 Jena Semantic Web Framework, http://jena.sourceforge.net/ 18 ARQ – A SPARQL Processor for Jena, http://jena.sourceforge.net/ARQ/

Capítulo 2 Marco teórico
12
Dentro del aprendizaje automático existen varios enfoques, pero las dos vertientes
principales son el aprendizaje supervisado (como los métodos de clasificación automática) y el aprendizaje no supervisado, como las técnicas de agrupamiento (clustering).
La clasificación automática de textos es aquella tarea en la que un documento o
parte del mismo es marcado como perteneciente a una determinada clase [9]. En otras palabras, consiste en clasificar un conjunto de documentos en clases predefinidas. Para ello, siguiendo un enfoque de aprendizaje automático supervisado, se entrena a cada clase con un conjunto de documentos de entrenamiento, los cuáles son usados para aprender a clasificar nuevos textos que se presenten.
Para poder trabajar con los textos, tanto para el entrenamiento como para su
clasificación, se debe seguir una serie de pasos, que permitan representarlos en una forma que pueda ser utilizada por algún algoritmo de clasificación automática. Para poder llevar a cabo esta representación, se puede usar el modelo del espacio vectorial.
2.3.1 Modelo del espacio vectorial (MEV)
El modelo del espacio vectorial (MEV) [10], consiste en manejar una tabla o matriz donde se representen los documentos y las palabras que estos contienen, asignándoles un peso a cada palabra. Cada vector que conforma la matriz representa un documento y la distribución de las palabras que en él aparecen. En pocas palabras, se trata de una matriz de dimensiones m x n, donde m son los documentos y n las palabras
registradas en ellos (un ejemplo de esta idea se puede apreciar en la Tabla 2-1).
Tabla 2-1 Ejemplo del MEV.
palabra 1 palabra 2 palabra 3 … palabra n
D1 0 1 1 … 1
D2 1 1 0 … 0
… … … … … …
Dn 1 1 1 … 0
Un aspecto importante en esta representación es la asignación de un peso a cada
palabra, lo que es usado para indicar la relevancia de la palabra en cada documento. La ponderación más sencilla y rápida utilizada, es el ponderado booleano, que se basa en considerar si una palabra aparece o no en un documento, asignándole un peso de 0 ó 1, según sea el caso.
Otras ponderaciones comunes son el ponderado por frecuencia de aparición
(considera cuantas veces aparece una palabra en el documento) o el ponderado tf-idf (frecuencia de términos – frecuencia inversa en documentos), que es una técnica estadística usada para determinar la importancia de una palabra en un documento, considerando la frecuencia de aparición de los términos, así como la frecuencia documental que tiene la palabra en todos los documentos.

Capítulo 2 Marco teórico
13
El MEV puede ser utilizado para llevar a cabo el proceso de clasificación automática, ya que se puede usar para lograr una representación tanto de los documentos que se usen como entrenamiento, así como de los que vayan a ser clasificados.
Como se puede apreciar, la dimensionalidad de la tabla que se maneje en el MEV
depende de la cantidad de palabras distintas que se consideren y que aparezcan en los documentos que se vayan a usar como parte del entrenamiento; sin embargo, la cantidad de palabras distintas que pueden aparecer, puede ser inmensamente exagerada, lo que no hace viable el considerarlas todas, ya que la dimensionalidad del MEV podría llegar a miles de columnas. Para reducir esta posible dimensionalidad, se pasa cada documento por un procesamiento que ayude a eliminar palabras poco relevantes, y a seleccionar aquellas que presenten un mayor poder discriminatorio para llevar a cabo la clasificación.
2.3.2 Procesamiento de documentos y selección de té rminos.
Para poder representar los documentos dentro del MEV, primero se les tiene que normalizar, siendo como primer paso, la eliminación de los signos de puntuación, recordando que lo que se va a representar es la ocurrencia de palabras, por lo que estos símbolos y otros elementos que no son relevantes son eliminados. También se considera para su eliminación las etiquetas HTML de las páginas Web, ya que si bien indican la forma en que se presente la información, no influyen en el contenido del documento, desde un punto de vista estadístico, que es en lo que se centra el MEV.
Además se eliminan palabras vacías (llamadas en inglés stopwords), también
conocidas como listas de parada, y que son aquellas palabras que se considera tienen poco aporte al contenido del documento, al ser términos de uso frecuente y por consiguiente, de escaso poder discriminatorio. Dentro de estas palabras se incluyen a los artículos, conjunciones, preposiciones, entre otras.
Una vez eliminadas las palabras vacías, se puede seguir un proceso de
lematización, el cual consiste en llevar a las palabras a sus lemas base, es decir, a su raíz, partiendo de que aunque distintas palabras tengan diversas terminaciones, comparten una misma base, haciendo referencia al mismo concepto; por ejemplo, las palabras nacionalidad y nacional, aunque distintas, parten del término nación.
Por último, se sigue un proceso de normalización, en el cuál se consideran
sinónimos, siglas y palabras distintas que hacen referencia a un mismo concepto dentro de la ontología, para representarlas bajo un mismo término.
Siguiendo este procesamiento (resumido en la Figura 2-2), se reduce
significativamente la cantidad de palabras que se consideran relevantes para clasificar el contenido del documento.

Capítulo 2 Marco teórico
14
Figura 2-2. Etapas del procesamiento de los documentos de texto
A pesar de la depuración de los documentos que reducen la posible
dimensionalidad resultante para el MEV, es común que las medidas mencionadas anteriormente no sean suficientes. Para ayudar a reducir aún más esta alta dimensionalidad, existen distintos tipos de técnicas, entre las cuales se encuentran, las basadas en la selección de términos, que en cierta forma, buscan aquellas palabras que más aporte y relevancia tengan en los documentos. En esta vertiente se encuentran la frecuencia documental y la ganancia de la información [11].
La frecuencia documental básicamente consiste en determinar un valor mínimo de
apariciones que debe tener una palabra dentro del total de documentos; con esto se logra discriminar aquellas palabras cuya frecuencia de aparición sea muy pequeña, y de la misma forma, los términos más valiosos a tomar en cuenta para la categorización son aquellos que tengan una frecuencia documental mayor.
Para este tipo de problemas de clasificación, la ganancia de la información consiste
en calcular la entropía19 que presenta un sistema (en este caso, el conjunto de documentos de entrenamiento), y la entropía que tiene cada una de las palabras que lo integran; la diferencia entre ambas será el indicador de que tan relevante y cuanta información aporta la palabra como factor determinante para llevar a cabo la clasificación.
La fórmula general de la entropía está dada por:
∑=
−=n
iii ppSH
1
log*)(
(1)
Donde n indica los distintos estados o valores que pueden existir en el sistema (en
este caso, las distintas clases), y pi es la probabilidad de que ocurra el estado i. Debe tomarse en cuenta una consideración muy especial, para evitar problemas con los cálculos, considerando que 0*log0=0 si fuera el caso.
La entropía que genera un atributo (o en el caso, una palabra), y que divide al
conjunto S en m estados, está dada por:
19 Entropía. Desestructuración o desorden presente en un conjunto.
Eliminar stopwords
Normalización
Eliminar signos de puntuación, acentos
y otros símbolos Documento
Documento depurado

Capítulo 2 Marco teórico
15
∑=
=m
iii SHSPatributoSH
1
)(*)(),(
(2)
Donde: m es la cantidad de estados en los que puede estar el atributo (que puede ser
si aparece o no la palabra en un documento), H(Si) es la entropía del subconjunto Si, que es el subconjunto donde el atributo se encuentra en el estado m, y P(Si) es la probabilidad de que el atributo se encuentre en ese estado. Al final, la ganancia de la información de una palabra estará dada por:
),()(),( atributoSHSHatributoSGI −= (3)
Se consideran las palabras que mayor GI presenten, y hecho esto, se puede
determinar la representación del MEV. Después se puede someter el conjunto de documentos de entrenamiento ya representado y, mediante el uso de un algoritmo de clasificación automática, clasificar nuevos documentos.
2.3.3 Algoritmos de clasificación Algunos algoritmos representativos de clasificación se mencionan a continuación: • Naive Bayes. Es un método de clasificación probabilística, cuya clasificación es llevada a cabo dependiendo de la probabilidad de que un documento pertenezca a una categoría determinada [12]. • k-vecinos más cercanos (kNN). Es un método de aprendizaje basado en ejemplos, donde la idea central es almacenar el conjunto de entrenamiento, para buscar en los ejemplos casos similares a un nuevo elemento a clasificar [13]. • Máquinas de soporte vectorial (SVM). Busca la construcción de un hiperplano como frontera de decisión entre clases, como intento de encontrar una superficie que separe los elementos positivos y negativos de una clase, por el margen más amplio posible [14]. • Naive Bayes Multinomial. Supone que la aparición de los atributos de una clase es independiente de la aparición de los demás, y la probabilidad de que un elemento pertenezca a una clase, corresponde a una distribución multinomial [15].
2.3.4 Medidas de desempeño.
Para ver qué tan bien funciona un sistema de aprendizaje, se han tomado en cuenta distintas métricas, como lo son la exactitud (accuracy), la precisión y el recuerdo (recall) [16]. Para poder calcularlas, se recurre a una tabla conocida como
matriz de confusión, como la que se muestra por ejemplo en la Tabla 2-2:

Capítulo 2 Marco teórico
16
Tabla 2-2 Matriz de confusión. Predicción a Predicción b Clasificado en a A (aciertos) B (fallos) Clasificado en b C (fallos) D (aciertos)
En las columnas etiquetadas como Predicción a y Predicción b se hace referencia a
la cantidad de elementos que tras haber efectuado el proceso de clasificación, se encuentren en las clases a o b. En las filas Clasificado en a y Clasificado en b, se encuentra la cantidad de documentos que se esperaba se encontrarán en las clases a o b.
En otras palabras, en A se encuentran aquellos elementos que pertenecían a la
clase a y que se predijo que pertenecían a la clase a, y en D los elementos que pertenecían a la clase b y que se predijo que pertenecían a la clase b, es decir, aquellos elementos que fueron bien clasificados. En el caso de B y C, se encuentran aquellos elementos que no fueron bien clasificados, que pertenecían a una clase y la predicción los marcó en otra.
La exactitud se obtiene considerando los elementos que fueron bien clasificados,
con respecto al total de elementos, es decir, la parte de la predicción que fue correcta. Considerando la matriz de confusión, la exactitud se calcula según la fórmula (4):
DCBA
DAexactitud
++++=
(4)
El recuerdo se refiere a la proporción de documentos relevantes correctamente
predichos, de entre el total de los documentos relevantes para determinada clase. Por ejemplo, para la clase a se tendría que su recuerdo está dado, según la fórmula (5):
BA
Aarecuerdo
+=)(
(5)
Y para la clase b, fórmula (6):
DC
Dbrecuerdo
+=)(
(6)
Mientras que la precisión hace referencia a la proporción de documentos predichos
de manera correcta de entre el total de documentos predichos para determinada clase. La precisión para la clase a queda indicada en la fórmula (7):
CA
Aaprecisión
+=)(
(7)
Y para la clase b, fórmula (8):
DB
Dbprecisión
+=)(
(8)

Capítulo 2 Marco teórico
17
2.4 Lenguaje Natural Acotado (LNA) para la construc ción de frases de consulta.
El lenguaje natural acotado (LNA) [17] es una técnica enfocada a disminuir la
ambigüedad de las expresiones de consulta que un usuario pueda realizar, mediante la utilización de un conjunto de frases en lenguaje natural, con espacios o huecos, las cuáles el usuario debe seleccionar y rellenar, siendo el conjunto de frases rellenadas la consulta que el usuario realice.
Se encuentra enfocado a que mientras menos tenga que escribir el usuario, menos
errores debe contener su consulta. Se parte de que sucede que el usuario puede escribir por descuido algún dato que desea buscar de forma errónea, ya sea confundir alguna letra, omitir o cambiar otra, etc., lo cuál ocasionaría que obtuviera resultados no deseados.
Una gran ventaja percibida a través de este enfoque, consiste en que el usuario
debe rellenar frases que ya se encuentran en lenguaje natural, es decir, frases cotidianas con las cuáles puede encontrarse familiarizado, por lo que pueden ser llenadas de forma intuitiva.
Los tipos de espacios o huecos que se consideran son cuadros de texto, cajas de
listado, botones de opción, así como casillas de verificación.
2.5 Usabilidad.
La usabilidad es una metodología de medida cualitativa que indica que funciona y que no funciona, dentro del campo de la experiencia del usuario [18]. La usabilidad es un atributo cualitativo que verifica qué tan fácil de usar es una interfaz de usuario [19]. En este tipo de pruebas, un grupo de usuarios prueban un sitio Web o aplicación, y se van anotando los problemas de uso que se vayan encontrando, para su posterior solución.
Realizar pruebas de usabilidad demasiado elaboradas es una perdida de tiempo.
Los mejores resultados vienen de probar con no más de cinco usuarios en múltiples pruebas, como lo demuestran pruebas efectuadas por Nielsen en [20], además de determinar que se necesitan por lo menos 15 usuarios para descubrir la mayoría de los problemas de usabilidad; es por ello que se recomiendan pruebas pequeñas considerando de cuatro a cinco usuarios, aprovechando que tras identificar un error, éste se pueda corregir inmediatamente, en vez de seguir arrastrándolo durante pruebas largas y seguir mostrando lo malo que es.
En este tipo de pruebas, se pide a los usuarios que realicen una serie de tareas
representativas y observar lo que hacen, no basta con escuchar lo que dicen, hay que ver como lo hacen.
Algunas medidas básicas con respecto a la usabilidad son: • Grado de aciertos (success rate). Se refiere a la cantidad de tareas que el
usuario ha logrado realizar [21]. Si el usuario no puede completar sus actividades, todo lo demás resulta irrelevante.
• El tiempo que requiere una tarea. • Rango de errores.

Capítulo 2 Marco teórico
18
• Satisfacción subjetiva del usuario. Generalmente se requiere que en un sitio se evite el gasto innecesario de dinero en
diseños vistosos, y al contrario, es mejor enfocarse en la sencillez y a las necesidades del usuario.
La ventaja que ofrecen las pruebas de usabilidad frente a otro tipo de evaluaciones
es que por un lado es una demostración con hechos, por lo que sus resultados son fiables, y por otro porque posibilitan el descubrimiento de errores de diseño, imposibles o difíciles de descubrir mediante una evaluación heurística [22].
Realizar una prueba formal con usuarios puede requerir personal especializado,
entre otros factores, lo que lo puede volver un estudio muy costoso; en cambio, se pueden realizar pruebas informales, también conocidas como test de guerrilla, que son económicas y de resultados muy similares a los otros.
En [23] se encuentran algunas sugerencias para realizar este tipo de pruebas, que
abarca desde conseguir a los participantes, el lugar donde se efectuarán y el equipo a usar (consideraciones como una computadora, y las hojas donde anotar las observaciones), denotando que se realiza una prueba a cada participante por separado. Se sugiere elaborar un guión orientativo sobre las actividades que se espera realice el usuario y la manera en que se espera las haga, todo en un ambiente amigable, invitando a que el sujeto de prueba se exprese oralmente, que diga todo lo que esté pensando, los problemas que tenga, dudas o explicaciones de lo que significa lo que esté observando. La primera información que se espera obtener es el grado de entendimiento que el usuario sienta con el sitio, y lo siguiente va encaminada a la facilidad de uso, la cuál se obtiene mediante la ejecución de una serie de tareas concretas.
Por último, lo observado y anotado durante la prueba, debe ser resumido en un
reporte final, como se muestra en el anexo B. Dentro de las pruebas de usabilidad, se aplican cuestionarios a los usuarios, en los
cuáles se tratan principios como consistencia, control del usuario, presentación visual, manejo de errores y reducción de la carga de memoria [23].
Para medir muchos de estos aspectos cualitativos, se puede usar lo que se conoce
como la escala de Likert. Una escala consiste en presentar una serie de ítems o frases que permitan construir un criterio que pueda medir de alguna manera fenómenos sociales, como una actitud. En estas escalas, los usuarios señalan su grado de acuerdo o desacuerdo con cada una de las frases que se le presentan, asignándosele una puntuación a cada respuesta [24].

Capítulo 3 Estado del arte
19
CAPÍTULO 3 ESTADO DEL ARTE
A continuación se mencionan algunas herramientas que se han desarrollado para consultas por Internet, sus características más sobresalientes y las diferencias que presentan con el presente trabajo.

Capítulo 3 Estado del arte
20
3.1 Motores de búsqueda
3.1.1 Motores de búsqueda por palabras clave
En esta sección se hace una comparación entre los motores de búsqueda por clave y los motores de búsqueda tradicional, ya que estos son los más comunes y utilizados en el medio de la recuperación de información.
Un motor de búsqueda es un software que realiza búsquedas de archivos
almacenados en algún lugar; por ejemplo, los ya conocidos buscadores de Internet. Las búsquedas generalmente se hacen por medio de palabras clave y los resultados obtenidos son un listado de direcciones de Web, en donde se mencionan temas relacionados con las palabras clave buscadas. Generalmente se puede acceder a ellos desde una página Web.
Según estadísticas en Nielsen NetRating20, a julio de 2006, los cuatro motores de
búsqueda más utilizados, así como sus porcentajes de uso, son:
Tabla 3-1 Buscadores más utilizados
Buscador Porcentaje de uso
49.2 %
23.8 %
search 9.6 %
AOL search 6.3 %
Google. Autoproclamado el mejor motor de búsquedas del mundo, sosteniendo tal
afirmación no sólo por ser el sitio de búsqueda con más tráfico, sino que también es uno de los diez sitios más populares de Internet [25].
Google recibe cada día cerca de 200 millones de consultas a través de sus múltiples
servicios; hasta junio del 2005 tenía indexado cerca de 8.05 mil millones de páginas Web21. En una consulta básica Google buscará aquellas palabras que fueron introducidas. En
la búsqueda avanzada se restringen los resultados esperados mediante operadores booleanos. Además, incorpora una autocorreción ortográfica para los usuarios que se lleguen a equivocar al escribir las palabras de sus consultas.
El funcionamiento del motor de búsqueda de Google se describe a continuación: Google relaciona las páginas en su índice de búsqueda usando un robot de búsqueda
para inspeccionar la Web. Luego, conforme encuentra las páginas, son automáticamente
20 http://searchenginewatch.com/showPage.html?page=2156451 21 http://en.wikipedia.org/wiki/Google_search

Capítulo 3 Estado del arte
21
añadidas a su base de datos y así cuando un usuario efectúa una consulta en Google, en realidad está buscando sobre esta base de datos de páginas Web.
Los resultados de la consulta están clasificados en base a la tecnología PageRank [26]
de Google. Esta tecnología mide cuántos enlaces existen de otras páginas a una página en particular, es decir, a mayor cantidad de enlaces a una página, mayor será su puntuación y eso determinará qué lugar ocupa en los resultados que se muestran. PageRank asigna un mayor peso a los enlaces que vienen de páginas con altas puntuaciones. En otras palabras, esto se puede llegar a considerar un concurso de popularidad.
Yahoo! Search. Originalmente las consultas hechas a Yahoo! eran realizadas tras
bambalinas por otros motores de búsqueda, sin embargo a inicios del 2004, Yahoo! desarrolló un buscador propio utilizando la tecnología de varias compañías que poseía (Inktomi, AlltheWeb y AltaVista), dando pie a Yahoo! Slurp, tratando con esto de convertirse en un serio competidor ante Google [27].
AlltheWeb. AlltheWeb es un motor de búsqueda, originalmente propiedad de una
compañía llamada FAST. A principios de 2003, Overture adquirió el motor de búsqueda de alltheweb de FAST, y después ese mismo año Yahoo! adquirió Overture (y por consiguiente alltheweb).
AlltheWeb permite además búsquedas de imágenes, noticias, audio y video. También
permite especificar una serie de criterios para obtener mejores resultados, como restringir las búsquedas a un sitio específico, definir el idioma en que se esperan los resultados, y obtener páginas hasta un determinado tamaño, pero no reconoce palabras semejantes [25].
3.1.2 Motores de búsqueda por navegación
Un directorio de Web, o motor de búsqueda por navegación, es una tecnología que permite realizar búsquedas por temas o categorías jerarquizadas; son bases de datos de direcciones Web elaboradas manualmente; es decir, la asignación de cada página Web a una categoría o tema en cuestión es efectuada por personas.
Ejemplos de este tipo de directorios son LookSmart22, Gimpsy (cuya característica
principal es que en vez de categorizar por medio de conceptos, lo hace definiendo actividades23), el directorio de Yahoo!24 y uno de los más importantes, el Open Directory Project.
Open Directory Project (ODP)25. El Open Directory Project, llamado también
Dmoz (por Directory Mozilla), es un proyecto colaborativo de editores voluntarios, los cuales listan y categorizan enlaces a páginas Web. Cualquier persona puede sugerir un enlace dentro de una categoría determinada, la cual después deberá ser aprobada por un editor.
22 http://search.looksmart.com/ 23 http://www.gimpsy.com/ 24 http://dir.yahoo.com/ 25 http://www.dmoz.org

Capítulo 3 Estado del arte
22
Fundada primero como Gnuhoo, por Rich Skrenta y Bob Cruel en 1998, que
después cambio de nombre a Newhoo, hasta llegar a ser ODP cuando fue adquirida por Netscape.
Hasta julio del 2005, ODP contenía cerca de 4.6 millones de páginas categorizadas
en cerca de 580, 000 categorías, gracias a la contribución de casi 69, 000 editores voluntarios (siendo editores activos solamente entre 9, 000 y 10, 000 de ellos).
Para su organización, ODP utiliza el esquema de una ontología jerárquica, donde
los enlaces de temas semejantes son agrupados en categorías, las cuales a su vez se pueden dividir en más subcategorías.
Gnuhoo comenzó su ontología con las siguientes categorías de nivel superior:
adultos, artes, ciencia, compras, computadoras, deportes, entretenimiento, hogar, juegos, negocios, noticias, referencia, región, salud, sociedad.
Sin embargo, para poder dar de alta una página, debe pasar por una seria
revisión, para cuidar que no se trate de basura, que esté bien clasificada, entre otras características; dada la gran cantidad de páginas que existen hoy en día, la aceptación de una página puede tardarse, desde horas, hasta en el peor de los casos, un par de años.
3.1.3 Variantes de Motores de búsqueda
3.1.3.1 Motores de búsqueda con clustering
El “clustering” es la clasificación de objetos similares en diferentes grupos, en otras palabras, es particionar un conjunto en otros subconjuntos donde los elementos que los conformen compartan características comunes.
Las ventajas de trabajar de esta manera es que permite tener una panorámica
general de los temas disponibles para la consulta, además de que en cada grupo brindado se encontrarían resultados similares, ayudando en gran manera al usuario ahorrando su tiempo.
Este tipo de buscadores devuelven su conjunto de resultados acomodados en
clusters (grupos), ejemplos de ellos son Clusty26, Vivisimo27 o qksearch28.
3.1.3.2 Buscadores especializados Este tipo de buscadores temáticos se centran más que nada en brindar al usuario
enlaces a documentos técnicos y científicos, como medio de ayuda a la comunidad de investigadores y estudiantes, dejando de lado enlaces a páginas que se desvíen de la intención del usuario (ya sea páginas comerciales y otras no deseadas, como spam, entre otras).
Citeseer. Citeseer fue creado por el Dr. Steve Lawrence, Kurt Bollacker y el Dr.
Lee Giles, para ser un buscador de documentos académicos y científicos, enfocado
26 http://clusty.com/ 27 http://vivisimo.com/ 28 http://www.qksearch.com/

Capítulo 3 Estado del arte
23
principalmente sobre los campos de la computación e informática, contando con alrededor de 700, 000 documentos [28].
Su peculiaridad es servirse de las citas bibliográficas para efectuar sus consultas,
de esta manera, considera los artículos que son referenciados y hacen referencia a uno en particular [29].
Google Scholar29. A finales del 2004, Google liberó un nuevo servicio conocido
como Google Scholar, el cuál está enfocado en la búsqueda de literatura académica de varias disciplinas, mostrando sus resultados por relevancia, considerando el número de citas que hacen referencia a los artículos mostrados, dejando en indudable manifiesto la influencia de Citeseer para este funcionamiento.
Scirus30. Es un buscador enfocado a información científica, semejante a Citeseer,
sin embargo no se enfoca solamente al tema de computación; además, los resultados que devuelve pueden ir mezclados entre aquellos que se pueden acceder gratuitamente junto con aquellos que requieren algún tipo de suscripción para poder ser visualizados. Desgraciadamente al utilizarse, queda denotado que dan preferencia a aquéllos artículos que son de paga, por lo que la intención de un usuario de encontrar información, puede quedar abrumada ante la imposibilidad de acceder a los resultados que le son mostrados.
Para mostrar sus resultados, se basa en la relevancia de los mismos; esto lo
calcula mediante la frecuencia de las palabras en el documento, así como la cantidad de enlaces que le hacen referencia [30].
Para la clasificación de los documentos se basa en una clasificación por tema
(actualmente maneja 20 áreas para la selección) que parte del tipo de vocabulario que se puede esperar de un documento técnico; además, también se basa en una clasificación por el tipo de información, usando un algoritmo propio que analiza la estructura y vocabulario de una página para asignarla a una de las áreas mencionadas; esto último es usado para las páginas de investigadores y otras afines. Sin embargo, aparte de las clases temáticas que utiliza, no profundiza en otras subclases.
3.1.4 Comparación con el proyecto
Se presenta a continuación un cuadro comparativo entre algunos de los buscadores
mencionados con anterioridad con respecto al proyecto presentado (Tabla 3-2). El
nombre dado al proyecto desarrollado en este trabajo es OK Order on Kaos y los aspectos usados como medidas de comparación se explican a continuación:
• Búsquedas temáticas indica si de alguna manera la consulta realizada se centra en
un enfoque particular.
• El uso de ontologías trata de indicar a aquellas herramientas, que de manera directa o indirecta las utilicen como medio para ayudar a realizar o seguir una consulta.
29 http://scholar.google.com/ 30 http://www.scirus.com/

Capítulo 3 Estado del arte
24
• Intervención humana se refiere a la cantidad de esfuerzo humano que se debe invertir como parte de la configuración de la herramienta para su total funcionamiento.
• Orientación al usuario se refiere a que de alguna manera se guíe y ayude al usuario a encontrar lo que desea. Con la independencia de fuentes se hace alusión a que no se limite de alguna
manera el origen de las fuentes de información que utilizan los buscadores. Por ejemplo, en el caso de ODP sólo se mostrarán aquellos resultados que se hayan sugerido por los editores, y Citeseer solamente los artículos que tengan dados de alta.
Tabla 3-2 Comparativa entre herramientas de búsqueda.
Buscadores Búsquedas temáticas
Uso de ontologías
Intervención humana
Orientación al usuario
Independencia de fuentes
Google No No Sí No Sí
ODP Sí Sí No
Sí, según lo permite la
jerarquía que presenta
No
Clusty No No Sí Sí, al mostrar los resultados
en grupos Sí
CiteSeer Sí No No, se necesita dar de alta los
artículos
Sí, muestra artículos
relacionados con el
resultado mostrado
No
OK Sí Sí
Requiere una ontología
específica para el tema a consultar.
Sí, según lo permitan las relaciones de la ontología
Sí
3.1.5 Clasificación de documentos
A continuación se presentan algunos artículos que tratan sobre el tema de la clasificación automática de textos.
De antemano se menciona que estos trabajos se centran sobre todo en el proceso
de la clasificación de textos, siendo que tal actividad es solamente una parte del trabajo aquí presentado, como medio, no como fin del mismo. Esta panorámica de trabajos mostrados permitió proporcionar las pautas a seguir para esta etapa del desarrollo.
Clasificación Automática de Textos de Desastres Naturales en México [31]
Este trabajo busca clasificar automáticamente un conjunto de páginas de HTML
sobre fenómenos naturales, para crear un almacén de información que permita tener un mejor conocimiento de los desastres naturales, prevenirlos y minimizar sus efectos.
Para lograr esto, han hecho pruebas usando técnicas de clasificación estadísticas
sobre el texto para conseguir un aprendizaje automático, mediante un conjunto de

Capítulo 3 Estado del arte
25
documentos previamente clasificados, es decir, un conjunto de entrenamiento. Para ello utilizan los métodos de clasificación de Bayes y de vecinos más cercanos. Con esto logran una identificación de documentos relevantes (que tratan sobre el tema de desastres naturales) y los que son irrelevantes (que pueden llegar a incluir palabras que puedan ser usadas para describir sucesos naturales, pero que sin embargo son utilizadas en otro contexto, por ejemplo, al referirse a un huracán, puede que hagan alusión a que “el presidente está en el ojo del huracán”).
Los resultados obtenidos en las pruebas de este trabajo han sido alentadores, con
cerca de un 97% de elementos correctamente clasificados, por lo que la diferenciación de documentos ha sido muy positiva, lo cual indica que mediante métodos de clasificación estadísticos se pueden obtener resultados razonables.
Experimentos en Clasificación Automática de Noticias en Español Utilizando el Modelo Bayesiano [32]
Este trabajo consistió en una serie de experimentos donde se utilizó el modelo
Naive Bayes para la clasificación de un conjunto de noticias en español de Usenet. Una de las conclusiones más relevantes a las que llegaron por medio de su experimentación, fue que el proceso de lematización no afecta en demasía el desempeño del clasificador Naive Bayes.
3.1.6 Trabajos relacionados con ontologías
A continuación se presentan una serie de artículos y productos que tratan sobre el uso de ontologías.
A Comparative Study for Domain Ontology Guided Feature Extraction [33]
Este artículo muestra la factibilidad de utilizar ontologías para ayudar en el proceso
de selección de características que representen a los documentos, dentro del proceso de clasificación de textos.
Parten del hecho de que solamente un número muy pequeño de características es
útil en la clasificación de documentos. Así que para determinar la manera de reducir la dimensionalidad de los vectores que se utilizan para representar a los documentos, proponen que mediante una ontología de un dominio específico, se manejen los conceptos generales que a su vez agrupen los términos que hagan alusión al mismo concepto.
Trabajan sobre un dominio médico, y la única relación que utilizan en su ontología
es la relación de es_un (ISA).
ONTOBROKER: Ontology based Access to Distributed and Semi-Structured Information [34]
Ontobroker es un trabajo que por medio de la utilización de ontologías, persigue
conseguir información dentro de páginas HTML publicadas en la Web o de una Intranet. Define una ontología donde se anota y clasifica ciertos documentos Web, para que después un usuario use los servicios de interrogación avanzada que permite y consulte el conocimiento incluido en dichos documentos.

Capítulo 3 Estado del arte
26
Para lograr esto, proponen un ligero añadido a las etiquetas HTML que conforman una página, por medio de las cuáles pueden establecer los conceptos y relaciones que serán considerados dentro de una ontología central, que será utilizada por Ontobroker.
Este añadido no afecta la visualización normal de las páginas, además de que se
pueden ir incorporando paulatinamente a la misma, por lo que la conversión puede ser gradual.
Ya con las especificaciones anteriores, Ontobroker utiliza su propio motor de
inferencia, el cuál busca responder preguntas específicas realizadas sobre la ontología, así como brindar información que se encuentre solamente implícita.
Tomando por ejemplo una serie de páginas sobre investigadores, Ontobroker
podría responder preguntas sobre que mostrará aquellos investigadores que tuvieran tal nombre, que tengan ciertos temas de interés, entre otras, siempre y cuando esto se haya especificado en las páginas HTML con las etiquetas adecuadas.
Ontobroker fue mejorado a otra versión llamada On2broker, que básicamente
consistió en algunos cambios a su arquitectura [35]. Las diferencias con respecto a este trabajo, más que nada se basan en el enfoque.
Mientras que el desarrollo presentado en este documento busca responder con una serie de enlaces ante las consultas de un usuario, Ontobroker en cambio busca dar datos concretos a preguntas específicas, enfocado por ejemplo a un ambiente más empresarial, donde se requiere que la información que se planea mostrar esté previamente etiquetada o estructurada para que Ontobroker pueda localizar y trabajar sobre ella.
Swoogle31
Swoogle es un buscador de documentos de Web semántica. Básicamente puede
encontrar ontologías en la red, usando para ello otros motores de búsqueda convencionales, como Google.
Cuando encuentra un documento de Web semántica, Swoogle explora el sitio
donde lo localizó, tratando de encontrar más archivos afines. Con los sitios que haya encontrado, los guardará en una lista que servirá de guía para nuevas y futuras búsquedas sobre este tipo de documentos [36].
31 http://swoogle.umbc.edu/

Capítulo 4 Análisis y descripción del problema
27
CAPÍTULO 4 ANÁLISIS Y DESCRIPCIÓN DEL
PROBLEMA
El capítulo aborda un análisis más detallado de la problemática a la que se hizo frente, abarcando las distintas etapas realizadas, la construcción de la ontología, la clasificación de elementos dentro de ella y la navegación a través de la misma.

Capítulo 4 Análisis y descripción del problema
28
4.1 Descripción general del problema La búsqueda de información en Internet se ha convertido en una actividad
cotidiana, sin embargo existe el problema de que el encontrar lo que uno desea es una tarea complicada, debido a que medios, como los buscadores, devuelven una gran cantidad de información, que va desde resultados útiles hasta basura, siendo para el usuario una tarea difícil el tener que seleccionar de entre este mar de información. Este obstáculo se acrecienta si la información buscada pertenece a un dominio particular, al recurrir a buscadores generales que llegan a abarcar varios enfoques para una misma consulta, ocasionando que el usuario perderá tiempo divagando que camino tomar. El problema al que hace frente el usuario, es poder encontrar lo que desea.
La hipótesis de la que se parte, es de que con objetos de alguna manera
ordenados (como en una ontología), es de ayuda al usuario en su proceso de búsqueda de información sobre un dominio particular.
Con fines de prueba y para demostrar la hipótesis, se desarrolló principalmente
una ontología sobre el dominio del procesamiento del lenguaje natural (PLN), sin embargo, el procedimiento puede ser aplicado a cualquier otro dominio, como lo muestra otra prueba efectuada sobre el dominio del Turismo de Morelos.
4.2 Diseño general de la propuesta de solución El trabajo realizado se puede apreciar en distintas etapas, cada una de las cuáles
lleva implícito todo un procedimiento para poder llevarse a cabo. Para lograr todo el proceso que conlleva la realización de este proyecto, se recurrió a la programación de herramientas de soporte y al diseño de una interfaz, como el medio para probar la idea de esta tesis. • Creación de la ontología de prueba. • Entrenamiento del clasificador de documentos. • Clasificación de documentos. • Realización de consultas sobre la ontología poblada.
La primera de ellas corresponde a la creación de la ontología de prueba utilizada,
en la que se tuvo que investigar sobre el dominio, seguir una metodología para el desarrollo de ontologías y un editor que permitiera formalizarla en un lenguaje estándar (¡Error! No se encuentra el origen de la referencia.).
Figura 4-1 Desarrollo de la ontología
Ontología
Investigación sobre el dominio
Metodología de Uschold & King

Capítulo 4 Análisis y descripción del problema
29
Una vez contando con la ontología, se debe seguir el proceso de entrenamiento para aprender a clasificar páginas, así como la clasificación misma, y posteriormente proceder a hacer consultas sobre la ontología (
Figura 4-2).
Figura 4-2 Etapas generales de desarrollo En la Figura 4-3 se muestra más a detalle en qué consiste la etapa de
entrenamiento. Usando una colección de documentos que servirán como entrenamiento, se les depura según los pasos de la sección 2.3.2 , así como la selección de los términos que servirán como factor para llevar a cabo la clasificación Tomados estos términos, mediante una ponderación, se puede representar cada documento bajo el modelo del espacio vectorial.
Figura 4-3 Fase de entrenamiento
A partir de esto, siguiendo la misma depuración de documentos ya mencionada, la
herramienta WEKA, la cuál contiene un conjunto de algoritmos de clasificación, y haciendo uso del entrenamiento previo, se obtiene la clase a la que pertenece un documento HTML a clasificar, guardando esta información dentro de la ontología
(Figura 4-4).
Entrenamiento
Clasificación
Consulta
HTML Procesamiento
Frecuecia documental
Ganancia en la información
MEV
Selección de variables
Colección procesada
Representación MEV
Términos con alta GI

Capítulo 4 Análisis y descripción del problema
30
Figura 4-4 Fase de clasificación
Una vez que la ontología es poblada con enlaces a las páginas clasificadas, se
guarda dentro de un servidor, y mediante páginas programadas en JSP y usando API´s brindadas por las librerías ARQ que permiten trabajar el lenguaje de consulta SPARQL,
la ontología pueda ser consultada desde un explorador Web (Figura 4-5).
Figura 4-5 Fase de consulta
OK
Consulta: Navega por conceptos
Resultados: páginas relacionadas con la búsqueda
Servidor local
Búsqueda mediante OK desde cualquier navegador
Usuario
Ontología
Internet
HTML
Procesamiento
Eliminación de palabras vacías y conversión a raíz
Documentos normalizados
Clasificación de
MEV
Ontología

Capítulo 4 Análisis y descripción del problema
31
Por último, siguiendo la metodología OVID (Object, View, Interactive Design,
Objeto, Vista, Diseño Interactivo) para diseño de interfaces [37], así como principios de lógica visual, se desarrolló una interfaz que mediante frases que el usuario puede seleccionar, se puede navegar a través de la ontología, mostrando para cada concepto las relaciones que tiene con otros, sirviendo de guía al usuario para saber cómo se
encuentran interrelacionados y poder encontrar información sobre ellos (Figura 4-6).
Figura 4-6 Interface OK
4.3 Descripción general de las partes desarrolladas como propuesta de solución
En esta sección se describen brevemente las actividades que se siguieron para
este proyecto.
4.3.1 Diseño de la ontología Para el desarrollo de la ontología, se siguió la metodología propuesta por Uschold y
King [38], en la cuál está basado el desarrollo de Enterprise Ontology, una ontología utilizada para el modelado de procesos de una empresa.
Los pasos que se siguieron con base en esta metodología se enumeran a
continuación: a). Identificación del propósito. La intención de realizar una ontología sobre el procesamiento del lenguaje natural
(PLN), es con el propósito de tener con un medio donde sea posible colocar y clasificar los enlaces hacia páginas de Web que traten sobre temas del PLN.
Se propone una ontología ya que dada la naturaleza de ésta, permite tener un
orden sobre la distribución de conceptos que la integran, con lo que se asegura que los nodos finales u hojas puedan ser accedidos desde conceptos de nivel superior o más generales.

Capítulo 4 Análisis y descripción del problema
32
Dentro de esta etapa, se aprovechó para definir el compromiso intencional y de extensión de la ontología. El primero alude a que se trata de una ontología semi-independiente, no está atada únicamente al trabajo de tesis a desarrollar, si no que bien pudiera ser utilizada por alguien más con algún otro fin. Para ello se eligió desarrollarla bajo el estándar OWL.
Con respecto a la extensión de la misma, se consideraron los siguientes tipos de
relaciones, tieneTrabajosCon (hasWoksWith), conformadoPor (hasPartOf), haOriginado (hasOrigin), siendo esta última, una relación compuesta por las relaciones haProducido (hasProduced) y haDesarrollado (hasDeveloped), junto con las relaciones inversas esTrabajadoPor (isWorkedBy), esParteDe (isPartOf) y fueOriginado (wasOriginated, compuesto por esProducido -isProduced y esDesarrollado -isDeveloped), respectivamente; la relación es_un (isA), se considera por default al determinar las clases y sus subclases correspondientes. Considerar más relaciones puede volverse una tarea complicada, además de que con las mencionadas, resultan más que suficientes para los fines deseados. Las relaciones anteriores dependen directamente del dominio con el que se trabajó, excepto la relación hasPartOf e isA.
Se considera que abarque conceptos generales al tema del procesamiento del
lenguaje natural (PLN), como aplicaciones, investigadores, instituciones, entre otros, con la limitante de que se está diseñando con propósitos de prueba para el proyecto en cuestión, por lo que el alcance de los conceptos considerados no es exhaustivo.
El motivo de la elección del tema del PLN fue debido a petición de un investigador
de la institución donde se llevó a cabo esta tesis. b). Construcción de la ontología. b.1) Captura Este paso se compone de tres etapas, la primera se refiere a la captura, la cuál
consiste en la identificación de conceptos clave y sus relaciones del tema deseado, obtenidos a partir de un análisis del dominio. En este paso se efectuó una recopilación general de conceptos, tomándolos de documentos afines al tema del procesamiento del lenguaje natural, a manera de lluvia de ideas, estableciendo de manera burda una taxonomía general. Este tipo de captura de conceptos se llama de middle out, ya que a partir de los conceptos tomados, se buscan clases superiores e inferiores, partiendo, como dice su nombre, de “en medio” hacia fuera.
Después se procede a eliminar la ambigüedad de los conceptos, esto es, efectuar
una limpieza de aquellos conceptos que bien, no son necesarios o abarcan otros temas y se alejan del tema principal, o en general que admitan interpretaciones que den motivo a dudas, incertidumbre o confusión.
Por último, la metodología de Uschold y King indica la identificación de los
términos que se refieran a los conceptos localizados, con el fin de obtener una clasificación dada por una generalización (gracias a la relación de es_un) y una especialización (por medio de la relación de pertenencia, conformadoPor).
b.2) Codificación. El siguiente paso dentro de la construcción de la ontología está relacionado con la
codificación, lo que involucra representar el conocimiento adquirido por medio del proceso de captura anterior, en un lenguaje formal.

Capítulo 4 Análisis y descripción del problema
33
El lenguaje elegido para la representación de la ontología fue OWL, que es un estándar aceptado por el W3C, con el fin de que la ontología pueda ser fácilmente adaptada, distribuida y reutilizada por cualquier otra persona. Para esta etapa se utilizó el editor de ontologías Protégé32.
La siguiente etapa de la metodología es la integración con ontologías existentes,
sin embargo, al momento de realizar la ontología sobre PLN, no se encontró alguna afín que pudiera servir.
4.3.2 Fase de entrenamiento
Una vez creada la ontología, para poblarla se siguió un enfoque de aprendizaje supervisado, en el cuál es necesario realizar un entrenamiento para poder clasificar nuevos elementos.
El diagrama de casos de uso de esta fase se muestra en la Figura 4-7. Para llevar a
cabo esta fase, es necesario contar con una colección de documentos de entrenamiento para cada una de las clases que se desea entrenar. Se sigue una depuración o limpieza de tales documentos, para su representación dentro del MEV, y se almacene esta información dentro de un archivo llamado de entrenamiento.
Así, con este archivo de entrenamiento, cuando se presente una página HTML a
clasificar, tras someterla a la misma depuración y representación, se pueda obtener a qué posibles clases puede pertenecer, y finalmente guardar esta información dentro de la ontología.
Figura 4-7 Diagrama de casos de uso para el entrenamiento y clasificación.
32 The Protégé Ontology Editor and Knowledge Acquisition System, http://protege.stanford.edu/

Capítulo 4 Análisis y descripción del problema
34
La etapa del tratamiento para depurar los documentos, sigue el esquema
mostrado en la sección 2.3.2 . Para la representación del documento bajo el MEV, es necesario seleccionar los
términos más relevantes para la clasificación, siguiendo las técnicas de frecuencia documental y ganancia en la información, mencionadas en la sección ¡Error! No se encuentra el origen de la referencia.. Después, se calcula el peso para cada término de cada documento a entrenar, para al final crear la representación de cada documento. La ponderación que se utilizó son pesos booleanos. Como última parte del entrenamiento, cada representación es almacenada en un archivo.
De manera semejante a la etapa de entrenamiento, los pasos para clasificar
nuevos documentos también se muestran en la Figura 4-7. Tras el mismo tratamiento
y representación a un documento a clasificar, y utilizando el documento de entrenamiento generado con anterioridad y un algoritmo de clasificación, se obtiene por resultado las clases a las que puede pertenecer tal documento, guardando las clases que presenten mayor probabilidad como ejemplares dentro de la ontología.
Los escenarios para el caso del tratamiento del documento, corresponden a los
siguientes: Escenario Acción a tomar
Aparición en el documento de signos de puntuación y símbolos.
Eliminación en el documento de cada símbolo distinto a caracteres y números.
Aparición de caracteres acentuados. Si se trata de una letra acentuada, cambiarla por la misma sin acentuar; si se trata de una instrucción HTML para indicar que una letra se debe acentuar, se cambia por la letra correspondiente sin acentuar.
Aparición de etiquetas HTML Eliminación de etiquetas dentro del documento.
Aparición de stopwords. Eliminación de stopwords en el documento, usando una lista de las más comunes de ellas.
Normalización de las palabras Cambiar palabras y siglas que hagan alusión al mismo concepto, a una misma palabra base, en base a una lista de las mismas. Seguir un proceso de lematización en base a reglas generales tomadas del algoritmo de Porter.
Casos de éxito para el tratamiento de documentos: Un documento que puede ser
depurado, independientemente de la codificación en la que éste se encuentre. Casos de fracaso para el tratamiento de documentos: Páginas con etiquetas HTML
no cerradas; palabras que al estar mal escritas o en otro idioma, no pueden ser eliminadas ni normalizadas.
Los escenarios para el caso de la representación del documento, corresponden a
los siguientes:

Capítulo 4 Análisis y descripción del problema
35
Escenario Acción a tomar Gran cantidad de palabras distintas en la colección de entrenamiento.
Utilización de técnicas de selección de términos, como la frecuencia documental y la ganancia en la información.
Ponderación de las palabras. Utilización del ponderado booleano para las palabras que aparecen en cada documento depurado, tomando como base las palabras relevantes obtenidas a partir de la selección de términos.
Representación de cada documento Registrar la ponderación obtenida de cada palabra relevante del documento, a manera de vector.
Casos de éxito para la representación de documentos: Se obtiene una lista de
palabras relevantes, se calcula el peso de cada palabra en cada documento y se obtiene un vector que representa cada documento con las palabras que contiene y su peso.
Casos de fracaso para la representación de documentos: Que la cantidad de
palabras relevantes obtenidas sea muy pequeña o muy grande, ya que de ello depende la dimensionalidad que tendrá el modelo del espacio vectorial de los documentos. En caso de presentarse esta situación, deben modificarse los parámetros usados en las técnicas de selección de términos.
Los escenarios para el caso de obtener las clases a las que puede pertenecer un
documento clasificado, corresponden a los siguientes: Escenario Acción a tomar
El documento no pertenece a ninguna clase de la ontología.
El documento es indicado como perteneciente a la clase nulo, por lo que no se guarda la referencia a esa página dentro de la ontología.
El documento clasificado pertenece a una clase dentro de la ontología.
Se guarda la URL del documento clasificado, se indica la clase a la que pertenece y la probabilidad que tuvo de pertenecer a ella, dentro de la ontología.
Un documento clasificado puede pertenecer a más de una clase.
Si se presentan una o más clases, con una probabilidad igual o cercana, para cada una de ellas se guarda la URL del documento clasificado, la clase y su probabilidad correspondiente, dentro de la ontología.
Casos de éxito para la clasificación de un documento: Se guardan como
ejemplares el enlace a páginas HTML con mayor probabilidad de pertenecer a alguna o algunas de las clases de la ontología.
Casos de fracaso para la clasificación de un documento: Que la mejor probabilidad
de pertenecer a una clase sea muy baja, en la práctica, menor de 70%; es por estos casos que se guarda la probabilidad obtenida de cada página, para que al momento en que se realice una consulta, se muestren primero los resultados con mayor probabilidad.

Capítulo 4 Análisis y descripción del problema
36
4.3.3 Interfaz de usuario siguiendo el modelo OVID
Cuando el usuario realiza una consulta (Figura 4-8), ésta se debe representar de
alguna manera, para luego ser procesada de una manera que se pueda obtener información de la ontología; después de que la consulta ha sido realizada, se deben mostrar la serie de enlaces que satisfagan la solicitud.
Figura 4-8. Diagrama de casos de uso para realizar consultas.
OVID es una metodología formal para el proceso del desarrollo de una interfaz,
basada en el análisis de los objetivos y las tareas que el usuario debe realizar, obteniendo al final un diagrama abstracto que describe la arquitectura del diseño deseado, desde el punto de vista del usuario.
Se maneja que el ciclo de vida del desarrollo de interfaces, es muy semejante al
modelo en espiral para el desarrollo de software. En la Figura 4-9 se muestra tal ciclo.
Figura 4-9 Ciclo de vida del desarrollo de interfaz.
1. Análisis. En el análisis se busca definir cuál es el propósito, determinar a qué usuarios va
dirigido el desarrollo y qué tareas se esperan realizar por medio de la interfaz. Básicamente se busca:
• Definir el propósito: El propósito será crear una página Web que funja como motor de búsqueda
especializado, utilizando una ontología de por medio, para la localización de documentos de Web de HTML que traten sobre el tema procesamiento del lenguaje natural (PLN), que es el tema abordado por la ontología.
• Definir la audiencia a quien va dirigido:

Capítulo 4 Análisis y descripción del problema
37
¿Quiénes pueden estar interesados en los contenidos mostrados? En el ámbito de este proyecto, estudiantes y docentes dentro del área de la informática, y más precisamente de aquellos que, necesiten obtener información relacionada con el PLN.
• Análisis de los competidores. Consiste en ver qué hacen los demás, saber sus virtudes y hacerlas propias, saber sus
debilidades para no caer en ellas. En este caso, en la sección del estado del arte se mencionan distintos tipos de buscadores.
• Establecer una estrategia. Se debe establecer qué mensaje es el que se desea dar, en este caso, que mediante el
uso de ontologías, se ayuda al usuario a encontrar temas relacionados con el PLN, con menor esfuerzo de su parte. Para que este mensaje llegue, se planea permitir que el usuario navegue a través de la ontología por las diferentes categorías que la integran.
• Contenido a mostrar. ¿Qué se desea mostrar al usuario? Tras la consulta efectuada, se mostrarán enlaces
valorados a páginas Web así como los conceptos relacionados con el concepto sobre el que se pregunta.
2. Diseño Esta etapa se divide en dos partes, la primera determina los elementos que el usuario
espera para llevar a cabo su tarea, y en la segunda, se abstraen en una representación que permita establecer la comunicación entre el usuario y el sistema.
3. Implementación o desarrollo En esta se llevan a cabo los detalles técnicos para poner en funcionamiento el sistema,
lo más fiel posible al diseño desarrollado en el punto anterior. 4. Validación y mantenimiento Consiste en probar el comportamiento del sistema, que realice las acciones esperadas
de la forma esperada. De esta etapa se obtiene retroalimentación del usuario, que le gustó, que no le gustó, que esperaba, entre otra información igual de valiosa; con base en los datos recibidos, se procede a reformular desde la etapa de análisis, en un proceso que es iterativo.
En las siguientes secciones de este documento se abarcará cada una de ellas, aplicada a
la interfaz desarrollada para este trabajo.
4.3.3.1 Análisis: Fase de descubrimiento Primero se define para qué tipo de usuarios se trabajará, identificando sus
objetivos, es decir lo que ellos esperan. Un usuario se define como todo individuo que interactúa directamente con el sistema. Primero se identifican los individuos que de una forma u otra interactuarán con el sistema, así como algunas características que tengan, como se ilustra en la Figura 4-10. Así, se encuentra el usuario principal, el que realizará las consultas (denotado como asker), que a su vez puede tratarse de un docente o de un estudiante.

Capítulo 4 Análisis y descripción del problema
38
Figura 4-10 Diagrama de clases de usuario.
Una vez identificados los individuos, se procede a encontrar sus metas cualitativas.
Una meta es un resultado que debe ser logrado, sin importar cómo se logra. En el modelado se deben incluir las metas buscadas, así como los criterios para alcanzarlas. Se debe tomar en cuenta, que aunque hay una meta común, existen submetas que deben ser alcanzadas (Figura 4-11).
Docente
Estudiante
Encontrar información para investigaciones y trabajos
Medida1 : Enlaces encontrados = BuenosMedida2 : Investigación completa = Sí
<<Meta cualitativa >>
Encontrar información para tareas y tesisMedida1 : Enlaces encontrados = BuenosMedida2 : Tarea completa = Sí
<<Meta cualitativa>>
Encontrar resultados de una consulta por medio de una ontología
Medida1 : Rapidéz = BuenaMedida2 : Resultados = RelevantesMedida3 : Satisfacción = Buena
<<Meta cualitativa>>
Figura 4-11 Diagrama de metas de usuario.
Para comprender cómo realizaría el usuario sus tareas, se procede a realizar una
descripción de tales pasos. Una tarea es definida como el conjunto de pasos a desarrollar para lograr una meta. Las tareas en forma general que puede realizar el usuario se denotan en la Figura 4-12, donde se indica que el usuario accede al sistema, puede realizar sus consultas y espera obtener algún tipo de resultado.
Asker
Estudiante
Grado de conocimientos = "Media" Memoria = "Media"
Capacidad visual = "Alta" Habilidad resolviendo problemas = "Media"
Docente
Grado de conocimientos: = "Alto" Memoria = "Alta"
Capacidad visual = "Media" Habilidad resolviendo problemas = "Alta"

Capítulo 4 Análisis y descripción del problema
39
Acceder al Sistema de Consulta
Idealización de una consulta
Elegir tipo de consulta
Revisar los resultados
Consulta finalizada
Expresar consulta
Mostrar pantalla de inicio
Procesar consulta
Obtener resultados
Tipo de consulta
Consulta directa
Generar campos BNL
Consulta guiada
Sistema de consultaAsker
Figura 4-12 Modelo actual de tarea de usuario.

Capítulo 4 Análisis y descripción del problema
40
Especificar criterios de búsqueda
Navegar a través de la ontología
Representar consulta
Consultar sobre una ontología
Recibir resultados
Formular consultas
Revisar resultados
Asker
Recibir consultas
Procesar consultas
Mostrar resultados
Sistema de consulta
<<include>>
<<include>>
<<include>>
<<include>>
<<include>>
Figura 4-13 Caso de uso de experiencia del usuario.
4.3.3.2 Abstracción del diseño En esta etapa el primer paso es modelar los objetos de usuario, que incluyen
conceptos (concretos o abstractos) que el usuario percibe y con los que interactúa. En este caso, para que una persona consulte al buscador deberá llenar un formulario de consulta, y en base a los criterios seleccionados se obtendrá de la ontología los enlaces que los satisfagan (Figura 4-14).

Capítulo 4 Análisis y descripción del problema
41
Figura 4-14 Modelo de objetos de usuario.
Después se prosigue con el modelo de tareas del diseñador, que consiste en una
descripción más detallada de la estructura de la secuencia de actividades que el sistema debe de permitir al usuario, definiendo el diagrama de flujo a seguir, como se ilustra en la Figura 4-15.
Llenar campos de BNL para expresar consulta
¿Seguir navegando?
Expresar consulta
Observar resultados
¿Terminar?
Elegido el tipo de consulta
Consulta finalizada
Sí
Terminar
Navegación a través de las clases de la ontología
¿Hay subclases por mostrar?
Sí
Generar campos BNL
Tipo de consulta
Consulta guiada
Continuar
Búsqueda de enlaces
Listo para recibir consulta
Consulta directa
Mostrar campos a llenar BNL
Mostrar enlaces encontrados
No
No
Sistema de consultaAsker
Figura 4-15 Modelo de tareas del diseñador.

Capítulo 4 Análisis y descripción del problema
42
El siguiente paso consiste en identificar exactamente cual es la secuencia de las
interacciones que existen entre el sistema y el usuario, modelando un flujo de tareas, como se muestran en los diagramas de secuencias de actividades de la Figura 4-16 a la Figura 4-19.
Por último, se modela los estados que mostrará la interfaz, según sea la
interacción con el usuario (Figura 4-20).
: Asker
: Formulario de consulta
: Buscador : Ontología
1: Escribe consulta directa2: Envia consulta
5: Despliega resultados
3: Procesa consulta
4: Obtiene enlaces6: Obtiene resultados
Figura 4-16 Diagrama de secuencia de actividades para realizar una consulta directa obteniendo
resultados.
: Asker
: Formulario de consulta
: Buscador : Ontología
1: Escribe consulta directa2: Envia consulta 3: Procesa consulta
4: No hay enlaces relacionados5: Despliega no
encontró resultados6: Recibe mensaje de no resultados
Figura 4-17 Diagrama de secuencia de actividades cuando se realiza una consulta directa sin obtener
resultados.

Capítulo 4 Análisis y descripción del problema
43
: Asker
: Formulario de consulta
: Buscador : Ontología
1: Llena consulta guiada
2: Envia consulta3: Procesa consulta
4: Obtiene relaciones y clases5: Genera campos BNL6: Muestra campos para
realizar la consulta
Figura 4-18 Diagrama de secuencia de actividades cuando se usa una consulta guiada y hay subclases
por mostrar.
: Asker : Formulario de consulta
: Buscador : Ontología
1: Llena consulta guiada 2: Envia consulta
5: Genera visualización de resultados6: Obtiene resultados
4: Obtiene enlaces
3: Procesa consulta
Figura 4-19 Diagrama de secuencia de actividades para mostrar enlaces en una consulta guiada.

Capítulo 4 Análisis y descripción del problema
44
Diagrama de estados para el Formulario de consulta
Recibir orden de tipo de consulta
Abrir
Muestra campo de consulta
[ Consulta directa ]
Recibe entrada
Entrada
Notifica no hay resultados
Volver a consultar
[ No hay resultados ]
Terminar
Cerrar
Muestra campos BNL
[ Consulta guiada ]
Recibe entradas
Entrada
Navegar por la contología
[ Existen subclases por
mostrar ]
[ Seguir navegando ]
Mostrar resultados
Cerrar
[ No existen subclases
por mostrar ]
[ Terminar navegación ]
[ Hay resultados ]
Volver a consultar
Figura 4-20 Diagrama de estados de objetos.
4.3.3.3 Realización del diseño En esta fase se realizan vistas de presentación, las cuáles se componen de
distintas visualizaciones de los objetos modelados; en cada vista de presentación, los objetos visuales pueden tener distintas ubicaciones y tamaños con respecto a otros, dependiendo del impacto que quieran causar al usuario.
Como recomendación, primero se sugiere realizar esbozos en lápiz y papel sobre lo
que se espera sea el diseño visual para el sistema; una vez revisados que se hayan incluido los aspectos necesarios a visualizar de los objetos, se puede proceder a un esbozo más detallado y estilizado, usando alguna herramienta que permita el manejo
gráfico de lo que se espera sea la representación visual del sistema (Figura 4-21). Esta etapa se basa sólo en la representación visual, quedando la implementación
para el siguiente paso del desarrollo.

Capítulo 4 Análisis y descripción del problema
45
Figura 4-21 Diseño de interfaz.

Capítulo 5 Implementación
46
CAPÍTULO 5 IMPLEMENTACIÓN
Este capítulo aborda detalles de la implementación de este trabajo, comenzando por la creación de la ontología, los pasos de la clasificación y consultas sobre la ontología.

Capítulo 5 Implementación
47
5.1 Desarrollo de la ontología
5.1.1 Creación de clases
Tomando en cuenta los pasos mencionados en la sección 4.3.1 , se buscaron ontologías que pudieran servir de base para desarrollar la propia, sin mucho éxito en su momento; debido a esto, mediante entrevistas, documentos y diccionarios relacionados con el PLN se tomaron conceptos generales considerando aspectos desde investigadores, instituciones, herramientas, entre otros.
Utilizando el editor de ontologías Protégé se realizó la jerarquía de clases y
subclases (Figura 5-1).
Figura 5-1 Clases y subclases.
5.1.2 Establecimiento de propiedades Las propiedades representan una relación entre dos individuos; los dos tipos de
propiedades principales son las propiedades de objetos y las propiedades de tipos de datos [39]. En este trabajo se centra prácticamente en las propiedades de objetos, en las cuales se enlazan un individuo con otro (como en clase con clase). Las propiedades de tipos de datos se refieren a cuando se asigna un valor a una clase (por ejemplo, asignarle una cadena, un valor numérico, etc.).
Como ya se mencionó con anterioridad, las relaciones que se tomaron en cuenta
(Figura 5-2) son: hasWoksWith, hasPartOf y hasOrigin (compuesta por hasProduced y

Capítulo 5 Implementación
48
hasDeveloped), la relación is_a, y las relaciones inversas isWorkedBy, isPartOf y wasOriginated (con isProduced e isDeveloped), respectivamente. Una relación inversa consiste en que si existe una relación que enlaza un elemento a con uno b, también existe una relación que sería inversa, y que enlaza a b con a. Por ejemplo, si el investigador x trabaja con el tema z (a hasWoksWith z), también se puede decir que z es trabajado por a (z isWorkedBy a).
Las propiedades pueden presentar una serie de características, como lo son las
propiedades transitivas, en estas, si una relación enlaza un elemento a con uno b, y a su vez, b enlaza por la misma relación a c, se puede inferir que para esa misma relación, a enlaza a c. En el caso particular de este proyecto, se puede considerar que la relación hasPartOf es del tipo transitiva, y por ende, su relación inversa isPartOf también lo es.
Otra consideración a tener en cuenta con respecto a las propiedades, es el rango y
dominio sobre el cuál tienen acción; esto se puede explicar considerando el qué o quién ejerce una relación (el dominio) y sobre qué o quién tiene efecto tal relación (el rango). Cabe aclarar que cuando se define el dominio y rango para una relación, por ejemplo dominio_a relacionado_con rango_b, se infiere que un elemento a es miembro de la clase que conforma al dominio_a, y a la vez, un elemento b es miembro de la clase que conforma el rango_b.
Considerando las propiedades inversas, el dominio de una relación se convierte en
el rango de su relación inversa, y a la vez, el rango de una relación, es el dominio de su inversa. Sea dominio_a relación rango_b, entonces rango_b relación_inversa dominio_a.
Las relaciones consideradas para especificar un dominio y rango, son
hasWorksWith, cuyo dominio se encuentra comprendido por los elementos de la clase Investigador, y el rango se especificó con los elementos de la clase Aspecto_Pln; hasDeveloped con Investigador por dominio y Herramienta por rango; por último, hasProduced con Institución por dominio y Herramienta por rango. Para las relaciones inversas, solo se intercambian el dominio por su rango, y viceversa.
Figura 5-2 Relaciones.

Capítulo 5 Implementación
49
5.1.3 Uso de razonadores para comprobar la consiste ncia lógica de la ontología.
Los razonadores utilizados para comprobar la consistencia y clasificación de los conceptos dentro de la ontología fueron FaCT++33 y OntoRacer34. Un razonador permite encontrar la posición correcta para una clase dentro de la jerarquía que se haya desarrollado, usando para ello la definición de las clases y restricciones que se hayan establecido, además de encontrar errores de lógica que impidan que una clase pueda llegar a tener ejemplares, ya que una clase se determina inconsistente si se considera que no puede albergar ejemplares.
Para poder utilizar los razonadores, es necesario que la formalización de la
ontología se encuentre en OWL-DL. Esta actividad generalmente se conoce como clasificando la ontología.
Además de tener una representación jerárquica de la ontología desarrollada bajo
Protégé, como resultado de aplicar un razonador se obtiene otra clasificación inferida, en la cuál se muestra como considera el razonador la clasificación que debe tener la ontología.
En la Figura 5-3, en la parte izquierda se muestra la clasificación original de los
conceptos, en la derecha, la inferida por el razonador. Como se puede ver en la izquierda, el concepto Mineria_de_Texto aparece como clase hermana de Procesamiento_de_Texto, y a la vez, como subclase del mismo, por lo que en la ontología inferida se sugiere que sólo se considere como subclase.
Figura 5-3 Jerarquía inferida por el razonador.
33 OWL FaCT++, http://owl.man.ac.uk/factplusplus/ 34 Racer Pro, http://www.franz.com/products/racer/

Capítulo 5 Implementación
50
5.1.4 Recolección de documentos de entrenamiento. Para poder llevar a cabo el aprendizaje supervisado para la clasificación
automática de documentos, se requiere de una colección de documentos de entrenamiento.
Los documentos que conforman la colección de entrenamiento corresponden a una
selección de un subconjunto de las clases presentes en la ontología. Esto es debido principalmente a que se trata de una prueba, además de que si se recolectarán documentos de entrenamiento para todas las clases, sería una actividad que excedería el tiempo disponible para este proyecto de tesis.
Un primer intento por conseguir estos documentos, fue tratar de que fuera de
forma automática, sirviéndonos de consultas complejas elaboradas bajo Google. Para ello, se estudiaron los parámetros que se manejan en las consultas de Google, y se desarrollo un programa que usando la herramienta wget y un archivo de entrada que incluyera las consultas pudiera descargar los resultados encontrados.
Desgraciadamente los resultados que se obtenían no fueron del todo deseados,
demostrándonos una vez más lo difícil que es encontrar información dentro de la Web; entonces partiendo de esto, se procedió a una discriminación manual de los mismos.
También se realizó la búsqueda de documentos que nada tuvieran que ver con el
tema, para utilizarlos como documentos “no deseados” y que sirvieran para identificar a una clase nulo, es decir, una clase que se refiera a elementos ajenos a los considerados dentro de la ontología.
5.2 Entrenamiento y clasificación automática de los documentos.
En esta sección se abordarán las actividades relacionadas para llevar a cabo el
entrenamiento, así como el desarrollo del clasificador automático de páginas HTML. Inicialmente, se eligieron tres medidas de ponderación, con el fin de determinar
para este trabajo cuál es la que mejor resultados proporciona; estas ponderaciones son la booleana, por frecuencia de aparición y ponderación tf-idf. De igual manera, los algoritmos de clasificación probados fueron Naive Bayes, k vecinos más cercanos, máquinas de soporte vectorial y por último Naive Bayes Multinomial.
Una vez obtenida la colección de entrenamiento, a cada uno de los documentos
que la conforman se le somete al proceso de depuración. Con esto, se considera cada palabra distinta resultante para llevar a cabo la representación del MEV, sin embargo, como se hace frente a una gran cantidad de palabras, se recurre a técnicas que permitan reducir la dimensionalidad que tendrá el MEV.

Capítulo 5 Implementación
51
5.2.1 Reducción de la dimensionalidad. Para reducir la alta dimensionalidad que se pudiera presentar al momento de
realizar el MEV de la representación de los documentos, se siguieron las técnicas de umbral de frecuencia y ganancia en la información.
Se desarrollo un programa que calculará la ganancia de la información de cada
palabra que pasara la frecuencia documental. Para ello, primero se calcula la entropía del sistema en general, lo cuál se consigue con la fórmula (9), aplicada a este problema de clasificación de documentos:
∑=
−=
n
i
ii
totaldocs
categoríadocs
totaldocs
categoríadocssH
12 _#
_#log*
_#
_#)(
(9)
Donde: H(s) es la entropía del sistema. n es la cantidad de categorías. #docs_categoríai es la cantidad de documentos que pertenecen a la categoría i. #docs_total es la cantidad total de documentos que integran la colección. Luego se debe calcular la entropía que presenta cada palabra, lo que se consigue
mediante la fórmula (10):
∑=
−=
n
i p
pi
p
pip
palabracondocs
palabracondocs
palabracondocs
palabracondocs
totaldocs
palabracondocspH
12 __#
__#log*
__#
__#*
_#
__#)(
∑=
−+
n
i p
pi
p
pip
palabradocs
palabradocs
palabradocs
palabradocs
totaldocs
palabradocs
12 sin__#
sin__#log*
sin__#
sin__#*
_#
sin__#
(8)
Donde: H(p) representa la entropía que tiene una palabra p. n es la cantidad de categorías. #docs_total es la cantidad total de documentos que integran la colección. #docs_con_palabrap es la cantidad de documentos dentro de la colección, donde la
palabra p aparece. #docs_sin_palabrap es la cantidad de documentos dentro de la colección, donde la
palabra p no aparece. # docs_con_palabrapi es la cantidad de documentos de la categoría i en los que la
palabra p aparece. # docs_sin_palabrapi es la cantidad de documentos de la categoría i en los que la
palabra p no aparece. La entropía de cada palabra se obtiene con la diferencia de la entropía del sistema
y la entropía de la palabra. Un valor muy pequeño en ganancia de información indicará que la palabra en cuestión no aporta gran información dentro de la colección.
Terminada la representación MEV de todo el entrenamiento, se guarda, dándole el
formato adecuado para que pueda tratarse como un documento arff, que pueda ser tratado por WEKA.

Capítulo 5 Implementación
52
5.2.2 Selección del algoritmo de clasificación y su ponderación.
WEKA proporciona varios métodos para evaluar los clasificadores. En las pruebas se consideraron:
• Usar el mismo conjunto de entrenamiento: Evalúa al clasificador, tomando en
cuenta los mismos ejemplares con los que se ha efectuado el entrenamiento. • Validación cruzada de 10 corridas (10 fold cross validation): En este tipo de
validación se divide el conjunto de entrenamiento en diez partes, efectuando la corrida del algoritmo de aprendizaje diez veces, siendo el resultado final un promedio de todas las corridas; en cada una, se consideran nueve de las partes de la división, y se prueba el algoritmo de aprendizaje contra la parte de las diez que no se consideró. Por ejemplo, sean las partes 1, 2,… 10, en la primer corrida se considerarían las partes 1, 2,… 9 para el clasificador y se evaluaría contra la parte 10; en la segunda corrida se considerarían las partes 1, 2,… 8, 10 y se evaluaría contra la 9, y así sucesivamente [40].
Un resumen de los resultados obtenidos se aprecia en la Tabla 5-1.
Tabla 5-1 Porcentaje de instancias bien clasificadas considerando como espacio vectorial palabras con alta GI
Tipo de ponderación Validación cruzada 10 corridas Validación con el conjunto entrenamiento boleano Tf Tfidf boleano Tf tfidf
Naive Bayes 61.66 47.55 51.84 88.96 82.51 97.24 kNN 52.15 51.84 49.01 97.24 97.55 97.55 SVM 65.34 47.24 65.64 97.23 70.55 92.33
Naive Bayes Multinomial 67.79 70.86 15.34 92.94 90.8 15.34
Inicialmente sólo se habían considerado los algoritmos de Naive Bayes, kNN y
SVM, obteniendo como mejor resultado SVM con ponderado booleano; sin embargo, como se explica en una sección siguiente dedicada a los problemas encontrados, en la práctica, los resultados distaban mucho de ser aceptables, esto motivo a que se revisara nuevamente todo el proceso, volviendo a revisar cada una de las etapas involucradas con la clasificación. Entre estas actividades se utilizó el algoritmo Naive Bayes Multinomial, obteniendo los resultados ya mostrados, usando nuevamente el ponderado booleano. Considerando las métricas explicadas en la sección 2.3.4 , para Naive Bayes Multinomial, bajo ponderación boleana, se muestra la matriz de confusión correspondiente en el anexo D de esta tesis, así como los resultados de recuerdo y precisión que de ella se desprenden (Tabla 5-2 y Tabla 5-3).

Capítulo 5 Implementación
53
Tabla 5-2 Porcentajes de recuerdo y precisión. Precisión Recuerdo Clase
91% 100% Allen_James 100% 100% Brill_Eric 93% 100% Charniak_Eugene
100% 100% Chomsky_Noam 100% 100% Clasificacion_de_Documentos 92% 75% Comprension_del_Lenguaje
100% 90% Corpus_Linguistico
100% 100% Diccionario_Electronico
100% 89% Extraccion_de_Informacion 84% 89% Farquhar_Adam 83% 100% Gelbukh_Alexander 93% 100% Guarino_Nicola
100% 60% INAOE 100% 100% Interfaz_en_Lenguaje_Natural 100% 100% IPN 89% 100% Marcu_Daniel 85% 85% Mineria_de_Contenido
100% 78% Mineria_de_Estructura 89% 89% Mineria_de_Texto
100% 92% Mineria_de_Uso 88% 88% Mineria_de_Web 79% 92% Montes_Manuel
100% 100% Motor_de_Busqueda_Web
93% 100% Nulo 100% 92% Procesamiento_del_Lenguaje_Natural 71% 63% Rice_James
100% 100% Sager_Naomi
Tabla 5-3 Resultados generales.
Elementos bien clasificados 303 92.95% Elementos mal clasificados 23 7.05% Raíz del error medio cuadrático 0.0663
Usando el algoritmo de Naive Bayes Multinomial y el entrenamiento efectuado, se
pobló un conjunto de clases de la ontología, con enlaces a páginas Web. Una vez poblada la ontología, se busca la manera de poder navegar a través de ella.
5.3 Utilización de la técnica de Lenguaje Natural A cotado (LNA) para la construcción de frases de consulta.
En [41] se encuentran algunas propuestas para la construcción de frases en LNA,
las cuáles se tomaron como base para definir las propias. Enfocados a las relaciones presentes en nuestra ontología, se construyeron las siguientes frases.
Para preguntar por subclases se tiene la frase:
<<Deseo consultar la subcategoría: de [concepto]>> Para la relación isWorkedBy:

Capítulo 5 Implementación
54
<<Quiero consultar sobre el investigador: quien trabaja con [concepto]>>
Para la relación haspartof: <<De las partes que conforman a [concepto], deseo consultar sobre:
>> Para la relación ispartof:
<< [concepto] forma parte de: >> Para la relación hasWorksWith: <<De las áreas en que participa [concepto], deseo consultar sobre:
>> Para la relación hasDeveloped: <<De las herramientas desarrolladas por [concepto] deseo consultar sobre:
>> Para la relación isDeveloped e isProduced: <<De los desarrolladores de [concepto], deseo consultar sobre:
>> Para la relación hasProduced: <<De las herramientas producidas en [concepto], deseo consultar sobre:
>>
5.4 Utilización de SPARQL para consultas sobre OWL Para poder realizar consultas sobre la ontología, se utilizaron las librerías de ARQ
para poder trabajar con el lenguaje de consulta SPARQL. El código necesario se llevó a cabo dentro de páginas JSP, por medio de las cuáles, se consulta la ontología de PLN, y dependiendo de lo solicitado, se muestra un concepto y las relaciones que tiene con otros conceptos.
En el siguiente código, se muestra un ejemplo de la manera de realizar una
consulta en SPARQL, con los requisitos necesarios para ello. En esta consulta, lo primero que se muestra son los conceptos raíz que conforman la ontología, es decir, aquellas clases que no son subclases de ninguna otra.
El primer paso es establecer una conexión con el archivo que comprende la
ontología.
<% // declarando y creando objetos globales InputStream in = null; ServletContext app = getServletContext(); String path = app.getRealPath("/pln.owl"); //nombre de la ontología in = new FileInputStream(path);

Capítulo 5 Implementación
55
// Crear un modelo vacío para llenarlo Model model = ModelFactory.createMemModelMaker().cr eateModel(); model.read(in,null); try { in.close(); } catch (IOException exc) { return;}
En la siguiente parte, se guarda la consulta dentro de una variable. Esta consulta se encuentra en SPARQL, el resto del código mostrado corresponde a los comandos necesarios para poder trabajar con las librerías de ARQ, en este caso bajo JSP. En primer lugar se definen los nombres de espacio que van a ser utilizados, es decir, se indica que tipos de relaciones van a ser utilizados, y se identifica el lugar al que pertenecen, mediante un prefijo; por ejemplo, si en la consulta se va a preguntar por la relación subclase de (subClassOf), la cuál forma parte de la definición del lenguaje rdfs, se indica, poniendo un nombre como prefijo (en este mismo caso, según lo muestra el ejemplo, se uso como prefijo la misma palabra rdfs). Dentro de esta parte de definición de prefijos, se debe indicar también la ontología que va a ser consultada, principalmente, en el código mostrado, no se indico ningún nombre como prefijo, solamente se dejó el signo de “:”, lo cuál también es válido. // Crear una consulta String queryString = "PREFIX owl: <http://www.w3.org/2002/07/owl#> " + "PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schem a#> " + "PREFIX : <http://mx.briefcase.yahoo.com/rafaxzero /pln.owl#> " + "SELECT ?y " + "WHERE {" + " ?y rdfs:subClassOf owl:Thing " + " } ORDER BY ?y ";
Como se puede apreciar, la sintaxis trata de asemejarse a SQL, donde se indica primero un nombre general para las variables sobre las cuáles se solicitará algo (parte de la cláusula del SELECT); dentro de la cláusula del WHERE se indican las condiciones necesarias de la consulta, en forma de tripletas concepto – relación – concepto, (se pueden enlazar varias de estas condiciones mediante un signo de punto “.”), en donde se puede especificar si concepto se trata de una variable o una constante, y de igual manera, la relación puede hacer alusión a una relación específica o a cualquier relación. En el ejemplo se indica ?y rdfs:subClassOf owl:Thing, donde ?y serán los conceptos por los que se está solicitando, rdfs:subClassOf indica que se trata de una relación de subclase, y por último, se maneja la constante owl:Thing, que es un valor general de toda ontología, y que hace alusión a la clase superior absoluta. En otras palabras, la consulta está preguntando por: todos los conceptos ?y que sean subclase de owl:Thing.
La siguiente etapa consiste en ejecutar la consulta, y recorrer cada uno de los resultados que arroja. Se obtiene el valor de cada variable ?y obtenida, y al convertirla a cadena, se puede desplegar su valor sin mayor complicación dentro de un formulario HTML.
Query query = QueryFactory.create(queryString); // Ejecutar la consulta y obtener resultados QueryExecution qe = QueryExecutionFactory.create(qu ery, model);

Capítulo 5 Implementación
56
ResultSet results = qe.execSelect(); //Se recorren los resultados, y se ponen dentro del formulario for ( ; results.hasNext() ; ) { QuerySolution rb = results.nextSolu tion() ; RDFNode x = rb.get("y") ; String var = x.toString(); String var1 = var.substring(var.indexOf('#') + 1, var.length()); out.println("<input type='radio' na me='eleccion' value='"+var1+"'>" + var1.replace('_',' ') + "<br>" ) ; } // Cerrar la conexión qe.close(); %>
5.5 Problemas y dificultades encontrados
5.5.1 Resultados no deseados con el algoritmo de cl asificación Inicialmente, tras los primeros resultados arrojados al utilizar los algoritmos de
clasificación Naive Bayes, k-vecinos y máquinas de soporte, la opción que se había elegido para clasificar las páginas, fue el algoritmo de máquinas de soporte vectorial, sin embargo para fines prácticos, además de ser muy lento, al momento de determinar las clases más probables a las que podía pertenecer un documento, manualmente se comprobó que los resultados dejaban mucho que desear, puesto que los documentos que entraban a alguna de las clases eran exageradamente pocos, además de poco o nada relevantes.
Un primer intento de mejorar tal situación, fue confrontar los resultados brindados
por máquinas de soporte junto con k-vecinos más cercanos, para que aquellas clases en las que se obtuviera una mayor probabilidad de manera conjunta, fueran las elegidas. Desgraciadamente el proceso resultó ser mucho más lento, y de malos resultados, devolviendo en general pocas páginas, y de muy poca relevancia al concepto al cuál se suponía debían pertenecer.
Además, para la parte de las consultas directas, el texto que escribe el usuario es
procesado para saber a qué posible clase puede pertenecer, lo deseable sería que el tiempo de respuesta no sea tan lento, lo cuál máquinas de soporte no facilita, y en cuanto a los resultados devueltos, ni máquinas ni k-vecinos ayudaban mucho.
Sin embargo, el algoritmo Naive Bayes Multinomial, también incorporado en
WEKA, emergió como la mejor elección. Con este algoritmo, y usando una validación cruzada de 10 corridas y el mismo conjunto de entrenamiento mediante WEKA, se obtuvo como resultado que el porcentaje de los elementos correctamente clasificados era de cerca del 68% y del 93% respectivamente. Sin embargo ya en la práctica, los resultados se mostraban mejores que usando los otros algoritmos ya mencionados; además, se debe considerar que tales porcentajes corresponden al primer resultado arrojado por WEKA, pero revisando cada uno de los elementos marcados como erróneamente clasificados, se puede apreciar que las veces que hay empates en que

Capítulo 5 Implementación
57
un elemento pertenezca a más de una clase, WEKA lo asigna a la primera que aparece, esto sucede en caso de que se determine que un documento tenga la misma probabilidad de pertenecer a más de una clase.
Otra ventaja de usar Naive Bayes Multinomial, es que al momento de realizar una
consulta directa, con muy pocas palabras es capaz de determinar a que posible clase puede pertenecer lo solicitado. Esto sucede por que en este tipo de clasificadores bayesianos, se supone que la aparición de una palabra es independiente de la aparición de las demás, y la probabilidad de que un documento pertenezca a una clase, corresponde a una distribución multinomial, en la cuál las probabilidades asociadas a cada uno de los posibles resultados (pertenecer a una clase) son constantes.
5.5.2 Errores generados al usar el editor de ontolo gías Protégé. A pesar de que Protégé es uno de los mejores editores para el desarrollo de
ontologías, presenta una serie de problemas al momento de realizar modificaciones a ontologías ya desarrolladas, ya que no cuida del todo los cambios que se efectúan a unas clases y que pueden afectar a otras.
El ejemplo particular de esto, fue cuando se intentó realizar una modificación a la
clase Aplicaciones_del_Pln, que era subclase de otro concepto, se intentó ponerla como subclase de owl:Thing (la cuál es la clase base a partir de la cuál parten todas las demás). Al querer realizar esta tarea, en el editor mostraba que la realizaba de manera correcta, y sin ningún otro cambio, se guardaba la ontología modificada; sin embargo al utilizar la ontología para realizar consultas sobre ella, la sorpresa fue que muchas de las clases que partían de owl:Thing habían desaparecido, o más precisamente, aunque estaban referenciadas internamente en el código de la ontología, faltaba la referencia explícita que indicara la relación de dichas subclases. Específicamente, la etiqueta que faltaba para indicar esta dependencia como subclase, era:
<rdfs:subClassOf rdf:resource="http://www.w3.org/2002/07/owl#Thing"/> Esto motivo a que se tuviera que modificar la ontología de manera manual, con un
editor de textos ordinario, agregando la etiqueta mostrada a aquellas clases en las que hiciera falta; además de tener que actualizar etiquetas que indicaran los cambios realizados por mover de lugar la clase mencionada.
Otra desventaja que demostró el uso de Protégé es que no soporta escribir
nombres de conceptos o relaciones con letras acentuadas; sin embargo, al realizar consultas mediante SPARQL vemos que no es una limitante el tener dentro de una ontología este tipo de caracteres, ya que al procesar las consultas, se encuentran los resultados esperados sin ningún inconveniente.
Nuevamente, usando un editor de textos tradicional, se reemplazaron aquellas
palabras que debían llevar acentos.
5.5.3 Problemas con la codificación de las páginas a clasificar. Sin razón aparente se suscitaban varios errores, por ejemplo, cuando se quería
encontrar palabras exactas dentro de las páginas que estaban siendo procesadas (como en la etapa de eliminación de stopwords), y pese a que las palabras se encontraban allí, el uso de comandos como el grep de UNIX indicaban lo contrario. Además, esta situación repercutía al momento de representar los documentos dentro del modelo del espacio vectorial, ya que al no encontrar también las palabras que se

Capítulo 5 Implementación
58
consideraban para formar dicho modelo, se les asignaba pesos de cero, lo cuál repercutía al momento de realizar la clasificación.
Otro suceso semejante ocurría cuando se creaba la ontología que almacenaba
todos los ejemplares, ya que al realizar consultas sobre dicha ontología, los resultados devueltos eran sospechosamente muy pocos, y es que, comprobando directamente sobre el código, se pudo comprobar que existían más resultados que no se estaban mostrando, y que a partir de un determinado ejemplar, se dejaban de mostrar. Curiosamente, cuando se ejecutan las consultas sobre el servidor Web utilizado (en este caso Tomcat 5.0), se devolvía un pequeño grupo de resultados, abarcando como ya se mencionó, hasta un ejemplar determinado, pero al realizar la misma consulta directamente bajo línea de comandos, los resultados arrojados eran directamente errores, es decir, la consulta ni siquiera se podía procesar.
Otro problema encontrado se presentó al momento de poblar la ontología, cuando
se guardaba el título de la página que estaba siendo almacenada, este era una cadena vacía, situación que se repetía demasiadas veces; es cierto que hay algunas páginas que por alguna razón no tienen las etiquetas HTML correspondientes, pero al comprobar en algunas páginas que presentaban este caso, estas etiquetas si aparecían, es decir, si tenía título el documento, pero nuevamente, por alguna razón no se detectaba.
Estas situaciones y otras semejantes se originan a partir de un problema común, y
la solución radica en la codificación empleada para las páginas procesadas y los documentos creados. Algo aparentemente sin importancia a simple vista, pero que como se puede ver en los contratiempos mencionados, repercute directamente en los resultados.
El primer síntoma que se puede apreciar es la aparición de caracteres extraños,
que al verse por ejemplo en un editor de textos, se muestran de una manera, al verse en un explorador, de otra, e incluso, desde línea de comandos pueden simplemente no verse.
La razón de que suceda esto, radica en la internacionalización existente a raíz de
que en Internet se pueden compartir documentos de todas partes del mundo, y que no en todos los lugares se escribe con los mismos caracteres.
Para tratar de mantener un orden, alrededor de 1963 se desarrollo un estándar
para el intercambio de información, el ASCII, sin embargo, de estándar no tenía mucho, ya que se creo particularmente para el idioma inglés, considerando en total hasta 128 caracteres. Parcialmente el estándar ASCII solucionaba el problema de las codificaciones, pero al popularizarse las PC por todo el mundo, estos 128 caracteres resultaban insuficientes (no se consideran letras acentuadas ni la letra ñ, por solo poner unos ejemplos); ante esto, los fabricantes de equipos ampliaban el conjunto ASCII, dependiendo de la región donde se vendieran los equipos, pero esto no hizo mas que generar caos a la larga, ya que dio origen a que comenzaran las incompatibilidades, puesto que el código ASCII que usaban unos caracteres en un país, diferían de los usados en otro, por lo que los mensajes escritos de un lugar a otro se volvían ininteligibles.
Ante esta nueva situación, se volvió a intentar desarrollar una codificación común,
como el proyecto Unicode (el cuál solucionaba el problema asignándole un valor escalar único a cada caracter), o también el juego de caracteres ISO-8859-1 (el cuál

Capítulo 5 Implementación
59
definía el alfabeto latino, y que fue utilizado ampliamente en occidente tras el surgimiento de Internet).
Sin embargo, en el caso de ISO-8859-1 se presentaba nuevamente el mismo
problema, funcionaba para codificar aquellas páginas occidentales, pero fallaba para mostrar caracteres orientales.
Esta limitación no se hace presente en Unicode. Una de las representaciones más
comunes de Unicode es UTF-8 (Unicode Transformation Format-8). Entre las ventajas de usar UTF-8 se pueden mencionar: soporte a todos los caracteres, sin importar el idioma, y compatibilidad entre páginas y programas, brindando un soporte de internacionalización.
Para poder convertir un documento a UTF-8, se puede realizar mediante un editor
de textos que permita especificar la codificación a utilizar, como el editor gedit de Linux. Sin embargo esta solución no se muestra del todo viable para este proyecto, ya que no se podría que por cada documento HTML descargado, abrirlo con el editor y guardarlo con la nueva codificación.
Pero nuevamente en Linux, se puede disponer de otra herramienta. Se trata del
comando iconv, en el cuál, indicando el archivo y la codificación en que se encuentra, permite transformarlo a otra codificación que se le especifique. Su sintaxis es:
iconv -f codificación_origen -t codificación_final documento_entrada -o documento_salida
Desgraciadamente la teoría es distinta de la práctica; en el ejercicio realizado, el
comando iconv no siempre funcionaba, por lo que antes de utilizarlo para cambiar la codificación de las páginas, primero se procesan dichos documentos con otro comando, el recode, que brinda funciones similares a iconv. Con la utilización de ambas instrucciones, así como unos filtros usando el comando sed fue solucionado el problema.
5.6 Herramientas utilizadas
La siguiente es una lista de las herramientas y tecnologías utilizadas de las que se dispuso para realizar este trabajo. • WEKA 3.4.635
WEKA36 es una completa herramienta enfocada al aprendizaje máquina y minería de datos. Uno de sus mayores fuertes recae en la clasificación de datos, ya que cuenta con varias implementaciones hechas en Java para este tipo de aprendizaje. Además, se utilizó una clase llamado callClassifier.class que sirve para obtener las probabilidades de que un elemento pertenezca a cada clase, al momento de llevar a cabo un proceso de clasificación; dicho archivo se encuentra disponible en http://alex.seewald.at/WEKA/callClassifier.java.
35 http://prdownloads.sourceforge.net/weka/weka-3-4-6.zip?download 36 http://www.cs.waikato.ac.nz/ml/weka

Capítulo 5 Implementación
60
• J2SDK 1.4.2_1037 Java 2 SDK Standard Edition (J2SE) es un entorno de desarrollo proporcionado por
Sun Micro Systems. • wget 1.10.238
Wget39 es un software libre para recuperar paquetes utilizando los protocolos de Internet más usados. Es una herramienta no interactiva desde línea de comandos. • recode 3.640
Recode es un programa que se encarga de convertir archivos en diferentes conjuntos de caracteres. • Jakarta Tomcat 5.0.2841
Apache Tomcat es un servidor de servlets, en el que pueden ser utilizados implementaciones tanto de servlets de java como páginas JSP (JavaServer Pages). • ARQ 1.342
ARQ es un motor de consultas en Jena, que soporta el lenguaje SPARQL, lenguaje usado para realizar consultas sobre recursos de Web lingüística, como las ontologías. Documentos utilizados:
Para la ejecución de los programas desarrollados, son necesarios un conjunto de documentos que sirven como entrada, además, las salidas de unos se convierten en las entradas de otros. Dentro de estos documentos se tienen: • Documentos para eliminar elementos de una página HTML. Entre estos se
encuentran: un documento con patrones para eliminar símbolos, signos de puntuación y etiquetas HTML, un documento con patrones para eliminar palabras de parada (stopwords), un documento con patrones para realizar una lematización básica y por último, un documento con patrones para normalizar palabras (como sinónimos, siglas, etc.).
• Documento arff de entrenamiento. Una vez realizado el entrenamiento, y en base a la ponderación elegida, se utiliza este archivo para clasificar nuevos elementos.
• Lista de clases. Documento que contiene un listado de las clases que se encuentran entrenadas para el proceso de clasificación.
• Lista de palabras con alta ganancia en la información. Documento que contiene las palabras que mayor ganancia en la información presentaron al realizar el entrenamiento; es usado para ver la ocurrencia de estas palabras en un nuevo documento a clasificar.
• Documentos de entrenamiento. Conjunto de páginas HTML relacionados con las distintas clases que se consideraron para poblar la ontología.
37 http://java.sun.com/products/archive/j2se/1.4.2_10/index.html 38 http://ftp.gnu.org/pub/gnu/wget/wget-1.10.2.tar.gz 39 http://www.gnu.org/software/wget/ 40 ftp://ftp.gnu.org/pub/gnu/recode/recode-3.6.tar.gz 41 http://apache.downlod.in/tomcat/tomcat-5/v5.0.28/bin/jakarta-tomcat-5.0.28.tar.gz 42 http://prdownloads.sourceforge.net/jena/ARQ-1.3.zip?download

Capítulo 6 Pruebas
61
CAPÍTULO 6 PRUEBAS
A continuación se describen las pruebas efectuadas a las partes desarrolladas para poner en marcha el sistema OK (Order in Kaos), sistema utilizado para comprobar la hipótesis de este trabajo de tesis, que si mediante elementos de alguna manera ordenados, es más fácil encontrar información.

Capítulo 6 Pruebas
62
6.1 Hipótesis y alcances
La hipótesis que se persigue demostrar es que presentando al usuario información sobre un tema de forma ordenada, como lo permite una ontología, le ayude a encontrar lo que busca.
De manera más particular, una hipótesis es si es de ayuda la explicites de las
relaciones manejadas en una ontología para guiar al usuario en su navegación; otra es si sirve el poner un orden usando una ontología para realizar búsquedas de información.
Los alcances que se persiguieron con las pruebas realizadas, consistieron en
probar los procedimientos desarrollados para demostrar tal hipótesis, para los procesos que abarcan desde el preprocesamiento de los documentos hasta su clasificación, como partes necesarias para poder llevar a cabo el proceso de búsqueda de páginas Web mediante una ontología; el uso de la ontología mediante una interfaz que permita recorrer sus conceptos mediante las relaciones que los interconectan, además de un conjunto de pruebas de usabilidad que prueban que tan sencillo de usar resulta esta interfaz con una ontología de por medio.
6.2 Plan de pruebas
El plan de pruebas seguido se muestra en la Tabla 6-1; los casos del 1 al 3 corresponden a parte del proceso de entrenamiento, el caso 4 para la población de la ontología, y por último, del 5 a 7 conciernen al uso de la interfaz para recorrer la ontología.
Tabla 6-1 Plan de pruebas. Caso de prueba Descripción
1 Preparación y depuración de los documentos a entrenar y clasificar.
2 Cálculo de la ganancia en la información
3 Representación al MEV de un documento, con una ponderación.
4 Población de la ontología
5 Recorrido de los conceptos de una ontología mediante sus relaciones, por una interfaz que usa consultas en SPARQL.
6 Obtención de resultados de las clases pobladas de la ontología, mediante una interfaz que usa consultas en SPARQL.
7 Realización de una consulta directa para determinar la posible clase a la que puede pertenecer.

Capítulo 6 Pruebas
63
Evaluación experimental Prueba 1. Depuración de los documentos. Objetivo: Filtrar el documento de signos de puntuación, símbolos, etiquetas HTML, palabras de parada, así como una fase de lematización, con el fin de hacer más manejables los documentos para su procesamiento, eliminando dichos elementos y ayudar a su representación dentro del modelo del espacio vectorial. La entrada es una página HTML, el sistema comienza primero pasando de la codificación en que se encuentra la página a UTF-8, después se pasan todas las letras a minúscula, se eliminan símbolos y etiquetas HTML, palabras de parada, se cambian por sinónimos palabras consideradas dentro de la ontología y se lleva a cabo la lematización. Descripción:
1. Se le proporciona una ruta con la ubicación física del documento a procesar. Este código depurador es llamado por un programa encargado de procesar la colección de entrenamiento.
2. El sistema realiza las actividades de eliminación y conversión mencionadas. 3. El sistema guarda el archivo modificado en un documento temporal.
Entrada: El documento HTML a ser depurado y los documentos con los patrones para eliminación de elementos de las páginas. Salida: El documento HTML en codificación UTF-8, sin etiquetas HTML, palabras de parada y lematizado. Análisis de resultados. Tras esta depuración, la colección de entrenamiento fue depurada en promedio hasta alrededor del 70% de su tamaño original. Se utilizó una colección de 275 documentos, distribuidos para las 26 clases a entrenar, con un total de 733 945 palabras; al final del procesamiento, se contaron 354 873 palabras totales, un 48% del tamaño original, siendo de estas solamente 27 531 palabras distintas (un 3.7% de la cantidad original). El tiempo promedio para llevar a cabo esta etapa es de 13 segundos para una página de 20.8Kb. Prueba 2. Cálculo de la ganancia en la información. Objetivo: Seleccionar aquellas palabras que mayor poder discriminatorio proporcionen. Dada la gran cantidad de palabras distintas resultantes, no es viable considerarlas todas para la posterior representación del modelo del espacio vectorial. La entrada es la cantidad de palabras distintas que se obtuvieron de la etapa anterior, a las que se calcula su frecuencia de aparición, se discriminan las palabras que tuvieron una aparición mínima, y después, mediante cálculos matemáticos, se obtiene la entropía del sistema y por consiguiente, se puede calcular la ganancia de la información (GI) de cada palabra. Al final, se consideran aquellas palabras que mayor GI presentaron. Descripción:
1. El sistema lee las palabras distintas encontradas y se contabiliza su frecuencia de aparición.
2. Se eliminan las palabras que menor aparición tuvieron.

Capítulo 6 Pruebas
64
3. Se calcula la entropía del sistema. 4. Se calcula la GI para cada palabra.
Entrada: El archivo con las palabras distintas encontradas. Salida: Un documento con las palabras que mayor GI obtuvieron. Análisis de resultados: La entropía del sistema calculada fue de 4.625, y algunas de las palabras que mayor
GI presentaron se muestran en la Tabla 6-2; en general, las palabras mostradas tienen
relación con el dominio con el que se está trabajando. El tiempo llevado para esta etapa fue de 146 minutos.
Tabla 6-2 Palabras con mayor GI.
Palabra GI mining 0.663 Nlp 0.555 farquhar 0.446 ontolog 0.437 fikes 0.385 Web 0.371
Prueba 3. Representación al MEV de un documento, bajo una ponderación. Objetivo: Representar los documentos de entrenamiento dentro del modelo del espacio vectorial, guardando el resultado en un archivo tipo .arff que pueda ser utilizado por WEKA. Descripción:
1. Se toman las versiones temporales de los documentos de entrenamiento, y se encuentran en cada documento que palabras existen, de las palabras que mayor GI tuvieron.
2. Se guarda la información anterior, indicando a que clase pertenece el documento, y la distribución de palabras consideradas que en el aparecen.
Entrada: Las versiones temporales ya procesadas de los documentos de entrenamiento, la lista de palabras con mayor GI y la lista de clases que se consideraron para el entrenamiento. Salida: Un documento arff que puede ser utilizado por WEKA para clasificar nuevos documentos. Análisis de los resultados: Cada documento representa una línea en el documento .arff creado, algo similar a: 0,0,0,1,1, … 0,0,1,1,Clase donde se va indicando si aparece o no cada una de las palabras consideradas (ponderado booleano, 0 si no aparece, 1 si aparece), y al final, se indica a qué clase pertenece el documento procesado. El tiempo promedio llevado a cabo para esta etapa fue de 4 segundos por documento.

Capítulo 6 Pruebas
65
Prueba 4. Población de la ontología. Objetivo: Con páginas de la red, las cuáles son procesadas y clasificadas, llenar la ontología con ejemplares que sean enlaces a esas páginas. Utilizando Google, se obtuvieron documentos de la red que traten sobre las clases consideradas a poblar dentro de la ontología, obteniendo desde páginas acordes con el tema hasta páginas no deseadas. A cada una de estas páginas se les aplica un procesamiento semejante al del caso de prueba 1, se realiza una representación del modelo del espacio vectorial para la página procesada y se clasifica utilizando WEKA, del cuál se obtienen las clases más probables a las que puede pertenecer. Por último, se guarda en una ontología que almacena sólo ejemplares, el enlace a la página y la probabilidad que tuvo de pertenecer a su clase. Descripción:
1. A partir de una lista de consultas generales, se obtienen páginas de Google, a manera de prefiltrado, esto por problemas de tiempo principalmente, ya que tratar de obtener las páginas directamente de la red, tomaría demasiado tiempo.
2. Con cada página encontrada, se les somete al procesamiento de eliminación de etiquetas HTML, palabras de parada y lematización.
3. Se crea la representación del modelo del espacio vectorial para la página procesada, guardándola en un archivo en formato .arff.
4. Mediante WEKA y usando el archivo .arff de entrenamiento, se obtienen las clases más probables a las que puede pertenecer la página clasificada.
5. Se guarda información de la página (título, probabilidad y clase a la que pertenece) en una ontología donde se almacenan únicamente los ejemplares, siempre y cuando la clase a la que se determino pertenece, sea distinta de nulo.
Entrada: Páginas HTML, documento .arff de entrenamiento, lista de las clases, lista de palabras con alta GI, y los documentos con los patrones para eliminación de elementos de las páginas. Salida: Documento OWL (la ontología) poblada con las páginas que mayor probabilidad obtuvieron de pertenecer a las clases consideradas. Análisis de los resultados: La ontología resultante cuenta con 5 321 ejemplares, es decir, referencias de enlaces a páginas Web. Como a cada página se le depura y luego se clasifica, el tiempo promedio conjunto para esta etapa fue de 17 segundos, por documento, siendo de este tiempo solamente 4 segundos para llevar a cabo la clasificación. Prueba 5. Recorrido de la ontología mediante sus relaciones. Objetivo: Que mediante la selección de enlaces en una página Web, el usuario pueda recorrer los conceptos que conforman la ontología. Mediante consultas en SPARQL, se puede ir recorriendo los conceptos que conforman la ontología, mediante las relaciones que los entrelazan; según sea el concepto seleccionado, se consulta que relaciones tiene, y según el caso, se muestra con qué conceptos se tiene esa relación.

Capítulo 6 Pruebas
66
Descripción: 1. Se recibe el concepto por el cuál se está buscando. 2. Mediante consultas en SPARQL, se determinan la clase padre del concepto, y a
su vez, el padre de éste, y así repetitivamente hasta que no haya más padres. 3. Del padre inmediato del concepto, se pregunta en SPARQL sobre todos los hijos
de ese concepto, mostrando así sus hermanos. 4. Se pregunta en SPARQL por las relaciones que tiene el concepto. 5. Por cada una de las relaciones, se pregunta por los conceptos con los que se
encuentra interconectados mediante dicha relación. Entrada: Concepto por el que se esté navegando (se obtiene según la elección del usuario sobre la página con la que interactúa), ontología de clases. Salida: Se despliegan las relaciones asociadas a un concepto, y los conceptos con los que se
encuentra interconectado por ellas (Figura 6-1). Esta etapa fue ampliamente probada
en las pruebas de usabilidad, también incluidas en este documento.
Figura 6-1 Relaciones mostradas para un concepto.
Prueba 6. Obtención de los ejemplares de las clases pobladas de la ontología. Objetivo: Si una clase se encuentra poblada, mostrar sus resultados. Cuando el usuario en su navegación, encuentre clases que tengan ejemplares, los resultados de estos se le muestran, funcionando el sistema como un directorio Web. Los resultados se muestran en base a la probabilidad que tuvieron de pertenecer a la clase en la cuál se encuentran. Descripción:
1. Se recibe el concepto por el cuál se está buscando. 2. Se pregunta en la ontología con ejemplares si hay resultados para ese
concepto. 3. Si hay resultados, se cuenta la totalidad de ellos. 4. Se muestran los resultados de 10 en 10.

Capítulo 6 Pruebas
67
5. Se calcula cuántas páginas de 10 en 10 se pueden mostrar; cuando se accede a alguna de ellas, se manda el parámetro de cuantos resultados había, para no volver a efectuar la cuenta de ellos (es decir, omitir el paso 3).
Entrada: Concepto por el que se esté navegando (por parte del usuario), la ontología con ejemplares, y opcionalmente, la cantidad de resultados que tiene el concepto (se obtiene por parte del sistema, en cada ocasión que el usuario navega por el concepto). Salida: Una lista de los ejemplares para el concepto poblado en que se encuentre el usuario, ordenados según su probabilidad, así como enlaces numerados a páginas para poder
ver el resto de los resultados, de 10 en 10 (Figura 6-2).
Figura 6-2 Resultados mostrados para un concepto.
Prueba 7. Realización de una consulta directa para determinar la posible clase a la que puede pertenecer. Objetivo: Cuando el usuario realice una consulta escribiendo directamente palabras para su búsqueda, devolver las clases más probables para su petición. Se trabaja la consulta escrita por el usuario como un nuevo documento al cuál se le somete al proceso de clasificación, pasando por su depuración y representación, mostrando al final las clases más probables a las que puede pertenecer su consulta. Descripción:
1. Se recibe la cadena de consulta del usuario. 2. Se guarda la cadena en un archivo, nombrado aleatoriamente para evitar
repeticiones y comprobando que dicho archivo no exista previamente. 3. Con el archivo creado, se sigue un proceso similar al caso 1 y 3, para poder
clasificar su consulta. 4. Se obtienen las clases más probables, y se muestran al usuario, excepto si se
tratase de la clase nulo.

Capítulo 6 Pruebas
68
Entrada: La cadena de consulta introducida por el usuario, documento .arff de entrenamiento, lista de las clases, lista de palabras con alta GI, y los documentos con los patrones para eliminación de elementos de las páginas. Salida: Las clases más probables a las que puede pertenecer la consulta.
6.3 Pruebas de usabilidad
6.3.1 Procedimiento y resultados de las pruebas de usabilidad efectuadas.
Se siguieron cuatro sesiones con cinco usuarios cada una, siendo los usuarios de la primer y tercer sesión, y de la segunda y cuarta, los mismos. Esto fue realizado de dicha manera, para que los participantes vieran los cambios que sugirieron en las primeras fases, y vieran los cambios realizados en base a sus comentarios, además de llevar un registro sobre el cambio de actitud de los participantes a través de la evolución del sistema que fue probado.
Se realizaron sesiones individuales, en las cuáles se mostró al usuario el sistema,
para que lo probaran y realizaran una serie de tareas, grabando en audio todos sus comentarios, dudas y sugerencias. Así mismo, se tomaron notas de los aspectos relevantes que comentaban los participantes.
Cuando cada persona terminaba las tareas que se le indicaban, se les entregaba
un cuestionario, siguiendo la escala de Likert, para que fuera llenado, en base a su experiencia usando OK Order in Kaos.
Para la elaboración de los ítems en los cuestionarios de usabilidad, se tomaron en
cuenta algunos ejemplos encontrados en WAMMI standarized questions43, y en Computer System Usability Questionnaire44.
En la sección de anexos se presenta un reporte del procedimiento y resultados
generales obtenidos en las pruebas de usabilidad realizadas. A continuación se muestra un análisis a partir de lo obtenido, considerando tanto tiempo, rango de aciertos y satisfacción subjetiva, entre la primer versión de OK Order in Kaos y la última presentada, en el que se puede ver un progreso y mejora, que quedan denotadas por los cuestionarios y comentarios brindados por los participantes.
Con cada participante, se siguieron seis tareas. El estilo de las tareas realizadas
corresponde a las siguientes:
# Tarea 1 Que el usuario navegue y comente los cambios a la interfaz. 2 Que el usuario navegue por los conceptos y relaciones de la clase Aplicaciones
del PLN y seleccione una de las relaciones que se muestran. Si la categoría a la que llega tiene enlaces a páginas, pruebe alguno.
43 http://www.wammi.com/samples/index.html, visitado en mayo 2006. 44 http://www.acm.org/~perlman/question.cgi, visitado en mayo 2006.

Capítulo 6 Pruebas
69
3 Que el usuario encuentre enlaces sobre el investigador Eric Brill . 4 Que el usuario encuentre un investigador que trabaje con Comprensión del
Lenguaje. 5 Que el usuario realice una consulta directa escribiendo palabras clave
relacionadas con alguna de las categorías pobladas, y escoja de las clases resultantes la que crea mejor hace referencia a lo consultado.
6 Que el usuario pruebe la interfaz con la ontología de turismo y comente los cambios positivos y negativos que perciba.
Considerando el grado de aciertos, tenemos la Tabla 6-3, donde se resume la
cantidad de actividades completada para cada ronda, considerando las tareas efectuadas de la 2 a la 5, ya que las tareas 1 y 6 eran más de reconocimiento.
Tabla 6-3 Cantidad de tareas terminadas.
Tareas % global % tareas 2-5 Sesión:
2 3 4 5 1 3 4 5 5 90% 85% 2 5 5 5 5 100% 100% 3 5 5 5 4 97% 95% 4 5 5 4 5 97% 95%
La cantidad de tiempo en promedio, necesario para terminar cada tarea
considerando las cuatro sesiones se muestran en la Tabla 6-4; habiendo medido en minutos cada tarea, el promedio se encuentra expresado en segundos.
Tabla 6-4 Tiempo promedio en segundos para terminar cada tarea.
Tarea Sesión 1 Sesión 2 Sesión 3 Sesión 4 2 192 156 108 96 3 204 120 108 120 4 132 120 120 120 5 144 120 108 108
Para la satisfacción subjetiva, se consideraron varios aspectos de los mencionados
en [42], correspondiendo varios de estos a preguntas efectuadas a los usuarios cuando terminaban de realizar las tareas propuestas, mediante un cuestionario realizado mediante la escala de Likert en base 7 (es decir, siete posibles campos de respuesta a cada pregunta, que van desde total desagrado a total acuerdo); también se busco determinar la aceptación general que tuvo el sistema y el uso de relaciones que permite la ontología para la búsqueda. Los resultados se expresan en la Tabla 6-5.
Tabla 6-5 Resultados de satisfacción subjetiva.
Principio Ronda 1 Ronda 2 Ronda 3 Ronda 4 Consistencia 6.8 6 5.6 7 Control del usuario 6.4 6.53 6.6 6.467 Presentación visual 6.1 6.3 6.5 6.4 Manejo de errores y recuperación 6.8 6.8 6.6 7 Reducción de carga de memoria 6.6 5.4 6.4 7 Satisfacción general 6.267 6.2 6.67 6.93 Guía y ayuda 5.467 5.867 6.6 6.867 Uso de relaciones 6.6 6.7 6.5 6.6

Capítulo 6 Pruebas
70
En este caso, se desea comparar la usabilidad que se obtuvo comparando el
sistema probado en la primera sesión, contra el modificado utilizado en la cuarta. Para este tipo de cálculos, es recomendable realizarlos por cada tarea de manera independiente, para obtener resultados más realistas. Un simple promedio puede dar resultados poco confiables. Se considera por ejemplo, que para realizar la tarea 2, de la sesión uno a la cuatro, hubo un puntaje relativo del 200% (un 100% de mejora), para la 3 de 170% (un 70% de mejora), y así sucesivamente para cada una de los aspectos que se están tomando en cuenta. Un resumen de lo anterior, entre la sesión uno y la cuatro, se muestra en la Tabla 6-6.
Tabla 6-6 Evolución entre la sesión 1 y 4.
Ronda 1 Ronda 4 Puntaje relativo entre 1-4
Mejora
2 192 96 200% 100% 3 204 120 170% 70% 4 132 120 110% 10%
Tiempos de cada tarea
5 144 108 133% 33% Grado de acierto 0.85 0.95 112% 12%
Consistencia 6.8 7 103% 3% Control del usuario 6.4 6.467 101% 1% Presentación visual 6.1 6.4 105% 5% Manejo de errores y
recuperación 6.8 7 103% 3%
Reducción de carga de memoria
6.6 7 106% 6%
Satisfacción general 6.267 6.933 111% 11% Guía y ayuda 5.467 6.867 126% 26%
Satisfacción
Uso de relaciones 6.6 6.6 100% 0%
Después, tanto para los tiempos de cada tarea, el grado de aciertos y la
satisfacción, se calcula la media geométrica, siendo estos tres aspectos los que se considerarán para evaluar la usabilidad obtenida de una versión a la otra. El resultado de la media geométrica para estos 3 casos se muestra en la Tabla 6-7. La media geométrica se calcula mediante la raíz enésima del producto de N valores; así, para el tiempo por ejemplo, se multiplica 2.0*1.7*1.1*1.33, y se le saca raíz cuarta.
Tabla 6-7 Media geométrica para los principios de usabilidad evaluados.
Media geométrica Tarea (tiempo) 1.49435088 Satisfacción 1.0650659 Grado de acierto 1.11764706
Por último, considerando nuevamente los tres aspectos mostrados de la tabla
anterior, nuevamente se calcula la media geométrica; en este ejercicio se está dando un peso igual a los tres aspectos. El resultado final de usabilidad entre la primera y última versión se ve en la Tabla 6-8.
Tabla 6-8 Usabilidad entre la versión 1 y la 4.
Ronda 1 – 4 Usabilidad final: 1.21165203

Capítulo 6 Pruebas
71
De lo anterior, se puede ver que la usabilidad de la última versión es del 121%
sobre el 100% de la primera, es decir, el nuevo diseño tiene 21% mayor usabilidad que el primero. Aunque es un incremento pequeño, es significativo, pues denota que hubo un avance.
También, de manera breve, se efectuó una prueba de usabilidad sobre el Open
Directory Project, con el objetivo de comparar que tan bien se sentían un grupo de cinco usuarios con su uso, y poder comparar tales resultados con los obtenidos con OK Order in Kaos. Usando el mismo cuestionario (excepto por la pregunta concerniente al uso de relaciones), se determinó la satisfacción subjetiva de los usuarios, la cuál se comparó contra la determinada en la última ronda de OK Order in Kaos, y entre ambas, se calculó su usabilidad, según se muestra en la Tabla 6-9, donde se obtuvo un incremento del 37% sobre el 100% base que representa ODP.
Tabla 6-9 Usabilidad considerando la satisfacción subjetiva, entre ODP y OK Order in Kaos.
ODP Ronda 4 OK Puntaje relativo
Mejora
Consistencia 5.8 7 120% 20% Control del usuario 4.27 6.467 151% 51% Presentación visual 4.8 6.4 133% 33% Manejo de errores y recuperación
5.4 7 129% 29%
Reducción de carga de memoria
5.4 7 129% 29%
Satisfacción general 4.67 6.93 148% 48% Guía y ayuda 4.33 6.867 158% 58% Usabilidad en cuanto a satisfacción: 1.37
6.3.2 MRR (Mean Reciprocal Rank). El MRR es una métrica estándar de desempeño para sistemas de pregunta
respuesta [43], en donde para cada consulta se consideran las primeras cinco respuestas, y dependiendo del lugar donde se encuentre la mejor respuesta, se le asigna un valor. Este valor corresponde a:
Tabla 6-10 Tabla de valores del MRR. Lugar de la respuesta Puntos
1 1 2 0.5 3 0.33 4 0.25 5 0.2
6 o posteriores 0 El MRR se calcula de la siguiente forma:

Capítulo 6 Pruebas
72
n
rMRR
n
i i
∑=
=1
1
donde n es el número total de preguntas y ri es el puntaje determinado, en base a
el lugar donde se encuentra la primera respuesta correcta del grupo de repuestas. En nuestro experimento, consideramos los primeros cinco resultados
correspondientes a cada clase poblada. Considerando las 26 clases pobladas, y los 6 lugares posibles de respuesta, tenemos la siguiente tabla:
Tabla 6-11 Ubicación de resultados para calcular el MRR.
Lugar de la respuesta Cantidad de clases
1 13 2 8 3 1 4 0 5 0
6 o posteriores 4 De lo anterior, el MRR queda determinado por:
( ) 66.02.0*025.0*033.0*15.0*81*13*26
1 =++++=MRR
El resultado anterior indica que el rango de respuestas correctas se encuentra
entre los lugares 1 y 2; es importante destacar que no solamente importa que los elementos relevantes sean recuperados, sino también la posición con que estos se muestran al usuario.
6.3.3 Prueba usando otra ontología. Para demostrar que el trabajo desarrollado puede ser trasladado a otro dominio,
se buscó un tema totalmente diferente, y se desarrollo una ontología sobre lugares turísticos del estado de Morelos, México.
En el lapso de una semana se desarrolló manualmente la ontología, manejando
como conceptos distintos atractivos (desde balnearios y bares, hasta cines y restaurantes), correspondiendo como los ejemplares de esta ontología a los lugares y negocios en si, junto con información relacionada a ellos (ubicación, teléfono, página Web en caso de contar con una, entre otros).
Para esta ontología no se siguió ningún proceso de clasificación, se pobló de
manera manual, pues la información con la que se llenó así lo ameritaba. En este experimento se busca que el usuario encuentre un lugar de su interés, pasando por las clases que se le van mostrando.
Retomando lo realizado para OK Order on Kaos con la ontología del PLN, el único
cambio que se realizó fue con respecto a las frases que se mostraban en la interfaz usada para guiar al usuario, y en las consultas en SPARQL para las mismas.

Capítulo 6 Pruebas
73
La interfaz seguida es muy semejante a la usada para la ontología de PLN,
tomando sólo algunos cambios en el diseño, para adecuarla más al enfoque turístico al
cuál va orientada (Figura 6-3).
Figura 6-3 Buscador usando una ontología de turismo en Morelos
Los resultados de usabilidad obtenidos indican una aceptación por parte de los
usuarios, además de que mostraron un mayor interés por este experimento, más que nada por el tema del que se trataba. Los comentarios y modificaciones en este caso, por parte de las personas que lo probaron, se centraron más que nada en el aspecto visual de la interfaz, resultándoles intuitiva la manera de desplazarse y consultar sobre la ontología.
6.3.4 Resumen de las pruebas. En este capítulo se menciona cómo funcionan cada una de las partes
desarrolladas, y los resultados obtenidos dentro de cada etapa; además, el prototipo desarrollado fue probado con usuarios mediante las pruebas de usabilidad efectuadas, en varias rondas que ayudaron a ir mejorando y adecuándolo a lo que los usuarios esperarían de una aplicación de este tipo. De la primera versión a la última realizada, se nota un aumento en la usabilidad percibida por los usuarios, a la vez que se demostró una mayor usabilidad al usar OK con respecto a una aplicación semejante, como lo es el Open Directory Project. Por último, siguiendo la métrica del MRR en general, se obtuvo un buen resultado, al indicar que la relevancia de los resultados mostrados es buena, al obtener un valor de 0.66 (la relevancia de los resultados se encuentra en promedio en las dos primeras respuestas arrojadas por OK).

Capítulo 7 Conclusiones
74
CAPÍTULO 7 CONCLUSIONES
En este capítulo se presentan las conclusiones obtenidas a través de todo el proceso de investigación desarrollado para llevar a cabo este proyecto, las aportaciones más relevantes que surgen a través de éste, y algunos posibles trabajos futuros que le pueden complementar.

Capítulo 7 Conclusiones
75
7.1 Conclusiones
En el presente trabajo se realizó la investigación para utilizar una ontología como una manera de ordenar la información y facilitar las búsquedas realizadas por los usuarios. Para este trabajo se uso una ontología temática, cuyos ejemplares fueran enlaces a páginas HTML que tratarán sobre el concepto al cuál hacían referencia, enlazando los conceptos con relaciones explícitas, y mediante una interfaz que permitiera recorrer la ontología, el usuario pudiera ser guiado para encontrar información sobre alguno de dichos conceptos.
Fue necesaria la construcción de una ontología temática, la investigación de
técnicas de selección de términos, clasificación automática supervisada, algoritmos de clasificación y ponderaciones de términos, diseño de interfaces, consultas en SPARQL y pruebas de usabilidad, para lograr el objetivo de guiar al usuario en su proceso de búsqueda.
Se pudo probar la hipótesis de que es más fácil encontrar información, si ésta se
encuentra ordenada, como en una ontología, mediante las pruebas de usabilidad efectuadas, en las cuáles se demostró la aceptación de los usuarios ante este tipo de navegación.
La hipótesis anterior se acepta cuando se trata de búsquedas temáticas, ya que
existe un control sobre el enfoque de los conceptos que se pueden buscar; sin embargo, al tratar con dominios generales, vuelve a suceder el problema origen, un caos en la cantidad y variedad de la información que puede existir.
Además, en nuestro experimento se probó que al centrarse en búsquedas
temáticas, la relevancia de los documentos recuperados es mayor (documentos con cerca de un 93% de probabilidad de pertenecer a una clase en cuestión, según los resultados arrojados por medio del algoritmo de clasificación Naive Bayes Multinomial utilizado), y como lo indican los resultados obtenidos de la métrica MRR, la recuperación de los documentos relevantes se encuentra entre las dos primeras posiciones de los resultados recuperados.
Con este trabajo se dejan asentadas las bases para trasladar el desarrollo
realizado y poder usar ontologías de otros temas, como quedó demostrado al utilizar una ontología que abordaba el tema de turismo en el estado de Morelos, México, con lo cuál se demuestra la flexibilidad de la aplicación, no quedando limitado a un tema particular.
De entre las conclusiones obtenidas, se encontró que existe mucha discrepancia en
cuanto a la forma de buscar información por parte de los usuarios, pues se enfrentan a la dificultad de encontrar dentro del caos de información existente. Es por ello que con este trabajo se pretende dar un orden a ese caos.
Algunos comentarios con respecto al lenguaje natural acotado, pueden poner en
entredicho su utilidad, ya que, a menos que situaciones muy específicas lo ameriten, su uso en vez de ayudar al usuario, lo pueden limitar. Esto es, si bien es cierto que una frase descriptiva podría ayudar al usuario a comprender mejor el contexto en el cuál se encuentra, también le lleva tiempo leerla y comprenderla, y dado que la cultura actual de la sociedad se enfoca en querer resultados lo más rápido posible, sin leer tanto, esto puede convertirse en una limitación. Dentro de las pruebas de usabilidad, un

Capítulo 7 Conclusiones
76
aspecto que se observó fue que cuando se les solicitaba una tarea a algunos usuarios, estos simplemente daban clic en las listas desplegables, no se entretenían en leer la frase, simplemente buscaban el concepto que más se acercara o que los pudiera guiar a lo que buscaban.
La utilización del algoritmo Naive Bayes Multinomial resulto útil para este ejercicio,
debido principalmente a la teoría que tiene de fondo, en la que considera a cada atributo que se toma en cuenta para la clasificación, de manera independiente uno de otro, por lo que con pocas palabras relevantes a una clase, se puede determinar si pertenece o no a ella. Esto además resulta útil cuando se manejan consultas que incluyen pocas palabras, problema no manejado a si se utilizara alguno de los otros métodos de clasificación analizados, como SVM, KNN o Naive Bayes.
Gracias a los resultados arrojados por las pruebas de usabilidad, se puede apreciar
la ayuda que les representa el tener una manera de guiarlos de clases generales a subclases, o bien, de un concepto a otro mediante una relación existente entre ellos, dando una panorámica general al usuario de lo que rodea a un determinado concepto, y poder navegar hasta él. A diferencia de los directorios Web tradicionales, esto es posible gracias a la explicites de las relaciones de las ontologías.
7.2 Aportaciones
Resultado de este trabajo de tesis, se obtuvo el conocimiento de poder utilizar una ontología como un medio de organizar información, además de poder aprovechar la explicites de sus relaciones, como una manera de poder guiar a los usuarios en su proceso de búsqueda.
Como parte de esta investigación, también se obtuvieron una serie de herramientas, que ayudaron a llevar a cabo este proyecto:
• Se proporciona una herramienta que permite procesar un conjunto de
documentos para obtener sus palabras más representativas, siguiendo la técnica de la ganancia en la información.
• A partir de un previo entrenamiento, se permite clasificar páginas HTML dentro
de una ontología. • Se presenta una interfaz que permite recorrer la ontología mediante las
relaciones que interconectan los conceptos que la conforman. • Con la utilización de las herramientas desarrolladas, se pueden probar
ontologías de otros dominios, para distintas aplicaciones. • Mediante las pruebas de usabilidad, se demostró la ayuda que resulta de
aprovechar lo explícito de las relaciones de una ontología, para poder guías a un usuario en su proceso de búsqueda general.
7.3 Trabajos futuros
En este apartado se sugieren algunos trabajos que pueden ayudar a complementar el trabajo de investigación desarrollado, en distintos aspectos:

Capítulo 7 Conclusiones
77
• Automatizar la creación de la ontología. Dado que el proceso de creación de la ontología temática se efectuó de manera manual, es un proceso que requiere tiempo y esfuerzo.
• Probar otras maneras de llevar a cabo la clasificación de las páginas dentro de
la ontología. En este trabajo se siguió un enfoque probabilístico basado en algoritmos de clasificación automática (Bayes), pero bien se puede seguir otro enfoque automático o semiautomático, como puede ser un análisis semántico del contenido de cada documento para saber a que clase puede pertenecer.
• Considerar otros tipos de formatos para los documentos que pueden ser
clasificados. Como una limitante, para fines de prueba en este proyecto, sólo se trabajaron páginas html, pero siguiendo la misma base, se podría trabajar con otro tipo de documentos (.doc, .pdf, entre otros).
• Mejorar la interfaz de usuario para que incorpore algunos elementos de ayuda
para realizar consultas (uso de operadores lógicos, restricciones en los criterios de búsqueda, etc.) que tienen buscadores como Google, Yahoo!, etc.
• Usar a las ontologías como la base del diseño de sitios Web que faciliten la
búsqueda de información en ellos.
7.4 Publicaciones y reconocimientos
Este tema de tesis ha permitido tener las siguientes publicaciones, tanto a nivel nacional como internacional; en cada una de ellas el objetivo fue mostrar la idea de la manera en que se puede usar una ontología para guiar al usuario en su proceso de búsqueda y la manera propuesta para lograrlo.
Las publicaciones son las siguientes:
• “Recuperación de Información de Páginas Web mediante una Ontología que es poblada usando Clasificación Automática de Textos” para la revista electrónica Looking Forward en su rama estudiantil de la IEEE, Vol 13, 2006.
• “Búsqueda de páginas Web mediante una ontología poblada por clasificación
automática de textos”, dentro de la XXXII Conferencia Latinoamericana de Informática CLEI 2006, celebrada en Santiago de Chile.
• “Order on Chaos: Looking for Web Pages through an Ontology Populated by
Automatic Text Classification”, aceptado para el 13vo. International Congress on Computer Science Research (CIICC'06), en México.
• “Consideración de Aspectos Visuales para el Diseño de Interfaces Web”,
aceptado para el Séptimo Congreso Internacional de las Ciencias Computacionales CICC2006, celebrado en Colima, México.
Además, dentro del desarrollo del trabajo, se participó en el XXI Concurso de
Creatividad, Fase Local, celebrado en el Centro Nacional de Investigación y Desarrollo Tecnológico (cenidet), en el año 2006, obteniendo el segundo lugar, dentro del área de Computación.

Anexo A: Diseño de la ontología
vii
ANEXO A: DISEÑO DE LA
ONTOLOGÍA Las siguientes imágenes corresponden al diseño de la ontología, mostrando la
interconexión de los conceptos mediante las relaciones consideradas.
A.1 Relación subclase

Anexo A: Diseño de la ontología
viii

Anexo A: Diseño de la ontología
ix

Anexo A: Diseño de la ontología
x

Anexo A: Diseño de la ontología
xi

Anexo A: Diseño de la ontología
xii

Anexo A: Diseño de la ontología
xiii

Anexo A: Diseño de la ontología
xiv

Anexo A: Diseño de la ontología
xv

Anexo A: Diseño de la ontología
xvi
A.2 Relación hasDeveloped
A.3 Relación hasOrigin

Anexo A: Diseño de la ontología
xvii
A.4 Relación hasPartOf

Anexo A: Diseño de la ontología
xviii
A.5 Relación hasProduced
A.6 Relación hasWorksWith

Anexo A: Diseño de la ontología
xix

Anexo A: Diseño de la ontología
xx
A.7 Relación wasOriginated

Anexo A: Diseño de la ontología
xxi
A.8 Relación isWorkedby

Anexo A: Diseño de la ontología
xxii

Anexo A: Diseño de la ontología
xxiii
A.9 Relación isProduced
A.10 Relación isDeveloped

Anexo A: Diseño de la ontología
xxiv
A.11 Relación isPartOf

Anexo A: Diseño de la ontología
xxv

Anexo A: Diseño de la ontología
xxvi

Anexo A: Diseño de la ontología
xxvii

Anexo A: Diseño de la ontología
xxviii

Anexo B: Reporte de pruebas de usabilidad para OK
xxix
ANEXO B: REPORTE DE PRUEBAS
DE USABILIDAD PARA OK
Fecha del reporte: Agosto, 2006 Fecha de la prueba: Julio, 2006 Lugar de la prueba: Cuernavaca, Morelos Realizado por: Ismael Rafael Ponce Medellín Email: [email protected]

Anexo B: Reporte de pruebas de usabilidad para OK
xxx
Sumario ejecutivo
El presente reporte abarca el desarrollo de cuatro rondas de pruebas de usabilidad, con cinco usuarios cada una, efectuadas sobre el sistema OK Order in Kaos, tanto para una versión que trataba sobre el tema del procesamiento del lenguaje natural, como para otra que era relacionada con el turismo en el estado de Morelos. Las tareas desarrolladas abarcan desde una familiarización con la interfaz, hasta una serie de actividades específicas que se pueden desarrollar en el sistema. Después de la primer sesión, se fueron realizando parte de los cambios sugeridos por los usuarios, lo que esperaban obtener y lo que les molestaba; así, para las siguientes sesiones se apreciaban las modificaciones, y por ende, los comentarios y opiniones que surgían. Se pudo apreciar que para las últimas sesiones las críticas fueron menores, el usuario se sentía más satisfecho, y una característica importante que se pudo demostrar: una vez que el usuario ha manejado el sistema, los usos subsecuentes le son más sencillos, es decir, batalla menos en realizar las tareas. Las primeras dos sesiones fueron totalmente supervisadas, las últimas dos se dio más libertad al usuario, pues se esperaba ya hubiera aprendido a usar el sistema. Otros aspectos observados, en un principio fue la incertidumbre de lo que podían o no realizar. Varios usuarios mostraron dificultades en comprender el enfoque que usa OK Order in Kaos, ya que la mayoría desconocía lo que eran los directorios Web; pero tras una serie de sugerencias y modificaciones, se logró ayudar en el manejo del sistema por parte de los usuarios, según lo indican los resultados de usabilidad arrojados por la última ronda de pruebas.
Metodología
¿Qué pasó durante las pruebas de usabilidad?
La evaluación de usabilidad de OK Order in Kaos fue conducida por Ismael Rafael Ponce Medellín, como parte de su trabajo relacionado con el desarrollo de su tesis. Esta evaluación se llevó a cabo en la ciudad de Cuernavaca, Morelos, desde el 17 de julio al 25 de julio de 2006. Para las pruebas de usabilidad, considerando las investigaciones de Jakob Nielsen, se consideraron cuatro sesiones, con cinco usuarios cada una; los participantes pasaron cerca de una hora probando el sistema, durante la cual ellos:
� Contestaron preguntas sobre la impresión inicial del sistema � Realizaron tareas reales mientras pensaban en voz alta

Anexo B: Reporte de pruebas de usabilidad para OK
xxxi
� Contestaron preguntas sobre su satisfacción general
¿Quiénes participaron?
Once (11) participantes diferentes, estudiantes a nivel postgrado, con las siguientes características, evaluaron el sistema.
Edad
<=25 4
>25 7
TOTAL 11
Género
Mujer 6
Hombre 5
TOTAL 11
¿Qué hicieron los participantes?
Durante la evaluación, se les solicitó a los participantes realizar seis (6) actividades sobre el sistema. Durante las dos primeras rondas se pidieron un conjunto de tareas, grabando en audio sus comentarios y auxiliándolos en caso de ser necesario, y durante las últimas dos rondas las tareas fueron similares, cambiando únicamente en los conceptos que el usuario debía encontrar, dirigiéndose los usuarios por sí mismos sin supervisión directa. A los participantes se les explicó brevemente en que consiste el sistema OK Order in Kaos, explicando la forma en que se llevaría a cabo la sesión e indicando que el objetivo de la prueba era ver el comportamiento y reacción del usuario. También se les explico las limitantes con las que contaba el sistema, en el caso de la prueba sobre el dominio del procesamiento del lenguaje natural, que sólo se contaba con 26 clases pobladas, y que para el tema de turismo, la ontología no se encontraba poblada totalmente, pero lo suficiente para hacer una demostración. Las tareas efectuadas durante las primeras dos rondas correspondan a las mostradas a continuación.
# Tarea 1 Que el usuario navegue y se familiarice con la interfaz. 2 Que el usuario navegue por los conceptos y relaciones de la clase Investigador,
seleccione una relación y regrese a la clase de la cuál partió. 3 Que el usuario encuentre enlaces sobre el investigador Noam Chomsky. 4 Que el usuario navegue hasta el concepto Aplicaciones del PLN � Recuperación
de información, encuentre qué investigadores trabajan con tal concepto, y seleccione uno.
5 Que el usuario realice una consulta directa y escoja de las clases resultantes la que

Anexo B: Reporte de pruebas de usabilidad para OK
xxxii
mejor haga referencia a lo consultado. 6 Que el usuario pruebe la interfaz con la ontología de turismo.
Las tareas efectuadas para las últimas rondas son las siguientes.
# Tarea 1 Que el usuario navegue y comente los cambios a la interfaz. 2 Que el usuario navegue por los conceptos y relaciones de la clase Aplicaciones
del PLN y seleccione una de las relaciones que se muestran. Si la categoría a la que llega tiene enlaces a páginas, pruebe alguno.
3 Que el usuario encuentre enlaces sobre el investigador Eric Brill . 4 Que el usuario encuentre un investigador que trabaje con Comprensión del
Lenguaje. 5 Que el usuario realice una consulta directa escribiendo palabras clave
relacionadas con alguna de las categorías pobladas, y escoja de las clases resultantes la que crea mejor hace referencia a lo consultado.
6 Que el usuario pruebe la interfaz con la ontología de turismo y comente los cambios positivos y negativos que perciba.
Las tareas se corresponden mutuamente, por lo que son consideradas como iguales, para fines prácticos.
¿Qué información se obtuvo?
Dentro de la retroalimentación proporcionada por los usuarios, entre los comentarios favorables, se pudo apreciar un agrado por la forma de navegar a través de los conceptos que se mostraban (la ontología). En general sintieron que la interfaz les era amigable, y que conforme realizaban las tareas solicitadas, iban aprendiendo a usar el sistema y les era más fácil moverse a través de él. También hubo muchas sugerencias, tanto en la forma de presentar la información como en la ubicación de varios elementos, no hacer tan tediosa la navegación, sino que se mostrara lo que el usuario buscaba lo más rápido posible, sin seguir tanto enlace, así como tener cuidado con el lenguaje utilizado, que este fuera lo más sencillo posible. Fue notoria la necesidad de una ayuda, ya que el usuario primerizo no está totalmente conciente de lo que el sistema puede hacer y la manera en que lo hace.
¿Dónde se llevaron a cabo las pruebas?
Lo siguiente es una recapitulación del equipo con el que se contó:
URLs utilizadas http://192.168.190.31/pelene http://192.168.190.31/turistar http://192.168.190.31/pelene1.5 http://192.168.190.31/turistar1.5 http://192.168.190.31/pelene2.1

Anexo B: Reporte de pruebas de usabilidad para OK
xxxiii
http://192.168.190.31/turistar2.1 Plataformas utilizadas
Laptops y PCs de escritorio, con Pentium IV, con memoria desde los 256MB en RAM hasta los 512MB.
Navegador Firefox 1.5, Opera e Internet Explorer.
Resolución de pantalla 800 X 600, 1024 X 768, 1280 X 768
Sistema operativo de los usuarios
Windows XP
Sistema operativo del servidor
Linux Fecora Core 1.3
Servidor Web Tomcat 5.0
¿Cuáles fueron las impresiones generales del sitio?
Algunos acuerdos a favor que se observó tuvieron en común los usuarios, así como aspectos que no les gustaron, por rondas, fueron: Primer ronda Les agradó:
� Interfaz agradable. � Los mensajes y letreros mostrados ayudan a entender el sitio. � Al usuario le llama la atención la forma en que se interconectan los distintos
conceptos. No les agradó:
� Comportamiento errático cuando algunas palabras tienen acentos. � Comentarios sobre el diseño visual (en particular, el fondo empleado y que algunos
elementos cambiaban su centrado aleatoriamente). � El usuario presenta confusión con parte de la terminología usada. � Frustrante el tener que marcar cada botón de selección, el usuario esperaba que esa
tarea se realizara automáticamente. � Cuando se indicaba que había resultados por mostrar, el usuario no se percataba del
mensaje. � La relación de hermanos de la ontología, causa confusión. � Se solicita que haya más letreros que indiquen el estado en que se encuentra el
sistema, ya que el tiempo de respuesta es lento, se sugiere que al usuario se le indique que se está procesando la orden.
� Confusión con los porcentajes presentados para los resultados de cada concepto. � En Turismo, se esperaba que la ontología estuviese más poblada. � En Turismo, el usuario nuevamente no se percata de que hay resultados por mostrar.
Segunda ronda: Les agradó:

Anexo B: Reporte de pruebas de usabilidad para OK
xxxiv
� Sin comentarios relevantes. No les agradó:
� Aunque los botones de radio se seleccionan automáticamente al modificar alguna de las relaciones mostradas, se espera que también con sólo hacer clic en el texto, dichos botón se marque; además, que se tenga una opción marcada por default al momento de escoger una relación.
� Se pide agilizar la navegación, no tener que hacer tantos clic para ver los resultados de las clases que se encuentren pobladas, si estás se encuentran pobladas, que se muestre directamente sus resultados.
� Usar un lenguaje más sencillo. � En Turismo, mantener constantes las opciones que se pueden consultar.
Previamente, cuando se entraba a un concepto, se podía acceder a un menú que permitía seleccionar otros conceptos, pero quitando el concepto en el cuál el usuario se encuentre en ese momento. No limitar al usuario.
Terer ronda: Les agradó:
� Mejoró la interfaz para Turismo, así como cambió favorablemente la forma de mostrar los resultados.
� Detalle corregido, botón de selección se marca automáticamente al seleccionar una relación, y hay un botón marcado por default.
� Los resultados de la búsqueda son más visibles. � Se agregó una ventana de ayuda, la cuál es útil.
No les agrado:
� Hace falta revisar el aspecto de visual de Turismo y la forma en que está poblado. Cuarta ronda: Les agradó:
� Mejoró la interfaz de Turismo. � Se facilitó la navegación y la búsqueda. � Los letreros agregados ayudan a entender lo que sucede. � Interfaz agradable y amigable. � Ayuda el haber utilizado antes el sistema, pues la navegación resulta más fácil.
No les agradó:
� Se habían eliminado los porcentajes de los resultados que se mostraban, pero en unas secciones el usuario los siente necesarios.
� Incluir en la taxonomía mostrada, niveles más profundos. � Si no se conoce del tema, la navegación se puede complicar. � Hace falta poblar más la ontología de Turismo. � Ajustar detalles visuales en las nuevas imágenes puestas para Turismo.

Anexo B: Reporte de pruebas de usabilidad para OK
xxxv
Descubrimientos y recomendaciones Resulta curioso que lo que a algunos participantes les agradaba, a otros no, no cabe duda de la diversidad de opiniones, sin embargo, en general, el realizar consultas usando una ontología de por medio, fue del agrado de los usuarios. Cabe destacar que muy pocos de ellos habían utilizado previamente lo que son los directorios Web, por lo que este primer acercamiento fue muy bueno, para conocer este tipo de navegación, diferente a lo que muchos están acostumbrados por utilizar motores de consulta basados en palabras clave. En gran medida, muchas de las recomendaciones efectuadas se refieren a la forma en que se presentan los elementos en pantalla, sugerencias de realce y una mayor sencillez en los textos mostrados. Sin embargo, algo relevante fue que el usuario quiere que movimientos triviales se realicen de manera automática, como se pudo apreciar con las sugerencias efectuadas con los botones de radio, usados para seleccionar las relaciones que se mostraba tenía un concepto, ya que para el usuario resultaba tedioso tener que marcar exactamente el lugar donde el botón se encontraba, pues en numerosas ocasiones se le pasaba por alto, y obtenía resultados no esperados. Otro detalle corresponde a que el usuario desea realizar la menor cantidad de clics posible para llegar a lo que desea, ya que en las primeras versiones del sistema para PLN, si una clase se encontraba poblada, se indicaba al usuario con un mensaje y se presentaba un botón que lo llevaba a otra página donde estaban los resultados. Varios de los sujetos de prueba concordaron en que esto era innecesario, que si había resultado, que estos se mostraran directamente sin tener que dar tanto rodeo. Otras recomendaciones efectuadas, aunque se toman en cuenta, no se ven viables, por ejemplo, en el caso de aumentar la taxonomía que se muestra en el sistema de PLN, la cuál indica lo que hay alrededor del concepto en el cuál el usuario se encuentra (que corresponde a la relación de tipo hermana, que fue adaptada de esta manera); esto no se ve viable, ya que sobrecargaría de contenido la pantalla, principalmente por el tamaño de la ontología; a cambio de esto, mediante la serie de ligas que indican la serie de conceptos y subconceptos que preceden al concepto sobre el cuál el usuario se encuentra, se brinda una manera rápida de regresar y visitar niveles superiores que le brinden una panorámica general de la forma en que se compone la ontología. El ejercicio también sirvió para detectar errores que pasaron desapercibidos. Uno de ellos fue al principio, en el caso del uso de palabras acentuadas, y es que este detalle afectaba al momento de manejar enlaces, ya que en los enlaces Web no se puede manejar este tipo de caracteres, para ello se tienen que mandar bajo una codificación distinta. Por ejemplo, la letra á le corresponde el código %A1, a la é el %A9, por mencionar algunos. A continuación se detallan las tareas que los usuarios realizaron y las observaciones individuales para cada una de ellas. Le sigue un análisis de usabilidad, en base a los cuestionarios llenados por los usuarios al término de cada sesión.

Anexo B: Reporte de pruebas de usabilidad para OK
xxxvi
Escenario #1
Escenario #1 Tarea 1: Que el usuario navegue y se familiarice con la interfaz / Que el
usuario navegue y comente los cambios a la interfaz
Evidencia Recomendaciones / Comentarios Notas tomadas, registro en audio
Ronda 1: Hubo problemas con algunos enlaces que llevaban palabras acentuadas; sienten la interfaz agradable, aunque sugieren cambios en el fondo. Causa confusión la relación hermanas, por terminología. Se sugiere revisar el centrado de varios elementos. Cuando una clase tiene resultados para mostrar, no se destaca el mensaje que lo indica, pasa desapercibido. Se considera de utilidad el mostrar letreros que indican que un concepto no cuenta con relaciones, pero se sugiere otro letrero para indicar que el sistema está trabajando, ya que responde algo lento. Ronda 2: Hacer más sencillos los textos que se utilizan para guiar al usuario, se pide que se agilice la navegación cuando una categoría tiene resultados mostrándolos directamente, pues seguir varios botones para ello

Anexo B: Reporte de pruebas de usabilidad para OK
xxxvii
es una pérdida de tiempo. Ronda 3: Se agradece la página de ayuda agregada, que los botones de radio se seleccionen automáticamente al realizar una modificación de las opciones que se muestran y que uno de los botones se encuentre seleccionado por default. En la taxonomía que se muestra, se realza el concepto donde el usuario se encuentra con la imagen de una palomilla y también el que los resultados se encuentren más visibles. Ronda 4: No hubo aparentemente cambios visibles; se agradece que cuando una categoría tiene enlaces para mostrar, estos se pongan directamente.
Escenario #2
Escenario #2 Tarea 2: Que el usuario navegue por los conceptos y relaciones de la
clase Investigador, seleccione una relación y regrese a la clase de la cuál partió. / Que el usuario navegue por los conceptos y relaciones de la clase Aplicaciones del PLN y seleccione una de las relaciones que se muestran. Si la categoría a la que llega tiene enlaces a páginas, pruebe alguno.
Ronda % cumplido 1 60% 2 100% 3 100% 4 100%

Anexo B: Reporte de pruebas de usabilidad para OK
xxxviii
Evidencia Recomendaciones / Comentarios Notas tomadas, registro en audio
Ronda 1: Algunos elementos se encuentran mal centrados; se pide que se seleccione una relación por default, ya que fue común el error de dar clic en el botón buscar, sin haber seleccionado el botón de radio correspondiente. También hubo confusión en los términos, lo que provocó que el usuario no terminara la tarea y navegara indefinidamente. Ronda 2: La tarea se completo correctamente. Pero hubo necesidad de aclarar algunos términos empleados. Ronda 3: La tarea se completó correctamente. Ronda 4: La tarea se completó correctamente. Agrada el hecho de haber eliminado el botón que indicaba que una categoría tiene resultados, y mostrarlos directamente.
Escenario #3
Escenario #3 Tarea 3: Que el usuario encuentre enlaces sobre el investigador Noam
Chomsky / Que el usuario encuentre enlaces sobre el investigador Eric Brill.
Ronda % cumplido 1 80% 2 100% 3 100% 4 100%

Anexo B: Reporte de pruebas de usabilidad para OK
xxxix
Evidencia Recomendaciones / Comentarios Notas tomadas, registro en audio
Ronda 1: Al usuario le gusta la interconexión entre conceptos; sin embargo se tienen problemas para identificar el mensaje que indica que una categoría tiene resultados, pues pasa desapercibido, se pierde con el fondo, lo que provocó que el usuario siguiera recorriendo otras relaciones sin nunca entrar a ver los enlaces de resultado. Ronda 2: Se pide simplificar el texto de las relaciones, pues no son del todo claras, y que una se encuentre seleccionada por default. Se pide que los resultados se muestren directamente. Ronda 3: La tarea se completó correctamente. Ronda 4: El usuario sintió la tarea más sencilla, pues ya lo había hecho antes y no tuvo mucha dificultad para realizarla. Se agradece que se automatizara el marcado automático de los botones de radio de las relaciones. Se habían quitado los porcentajes que indicaban la

Anexo B: Reporte de pruebas de usabilidad para OK
xl
probabilidad que tienen las páginas de pertenecer a una categoría, se solicita volver a incluirlas.
Escenario #4
Escenario #4 Tarea 4: Que el usuario navegue hasta el concepto Aplicación del PLN
� Recuperación de información, encuentre que investigadores trabajan con tal concepto, y seleccione uno. / Que el usuario encuentre un investigador que trabaje con Comprensión del Lenguaje.
Ronda % cumplido 1 100% 2 100% 3 100% 4 80%
Evidencia Recomendaciones / Comentarios Notas tomadas, registro en audio
Ronda 1: La tarea se complete correctamente. Ronda 2: Se pide que se automatice la selección de los botones de radio. Ronda 3: La tarea se completó correctamente. Ronda 4: Al dejar que el usuario se condujera totalmente solo, si no se imagina que el concepto buscado es subconcepto de otro, no le es tan claro la manera de llegar a lo solicitado, esto posiblemente por que no hay una gran familiarización con el tema que se pidió. Un usuario resolvió esta situación usando primero una consulta directa, y de los resultados que se le presentaban, seleccionó el concepto por el cuál preguntaba, de allí pudo navegar a Investigadores gracias a las relaciones que se mostraban.

Anexo B: Reporte de pruebas de usabilidad para OK
xli
Escenario #5
Escenario #5 Tarea 5: Que el usuario realice una consulta directa y escoja de las
clases resultantes la que mejor haga referencia a lo consultado. / Que el usuario realice una consulta directa escribiendo palabras clave relacionadas con alguna de las categorías pobladas, y escoja de las clases resultantes la que crea mejor hace referencia a lo consultado.
Ronda % cumplido 1 100% 2 100% 3 80% 4 100%
Evidencia Recomendaciones / Comentarios Notas tomadas, registro en audio
Ronda 1: Los usuarios realizaron sus consultas en base a los conceptos que conformaban la ontología. Ronda 2: No hubo comentarios destacables. Sucedió lo mismo que en la ronda anterior. Ronda 3: Hubo confusión con los porcentajes mostrados como resultados de las posibles categorías a las que podría pertenecer la consulta efectuada; el usuario divagaba sobre la opción que podía elegir. Ronda 4: La tarea se completo.

Anexo B: Reporte de pruebas de usabilidad para OK
xlii
Escenario #6 Escenario #6 Tarea 6: Que el usuario pruebe la interfaz con la ontología de turismo. /
Que el usuario pruebe la interfaz con la ontología de turismo y comente los cambios positivos y negativos que perciba.
Evidencia Recomendaciones / Comentarios Notas tomadas,
Ronda 1: Falta poblar más la ontología; los resultados pasan

Anexo B: Reporte de pruebas de usabilidad para OK
xliii
registro en audio
desapercibidos. Se debe revisar el diseño visual. Ronda 2: Es necesario poblar más la ontología, para las consultas directas. No quitar la opción de volver a checar el mismo concepto, pero bajo distinta ubicación. Ronda 3: La interfaz es más amigable y entendible, al cambiar tanto diseño como la forma de presentar resultados. Pesé a que es un sistema más sencillo, también se sugiere agregar una ayuda. Ronda 4: Son agradables los dibujos agregados para Turismo, pero falta editarlos.
Análisis de usabilidad Comparando los cuatro diseños utilizados para cada una de las rondas, se consideró el tiempo que tardaba cada tarea en realizarse, el grado de éxito (success rate, es cuando el usuario termina una tarea) y la satisfacción subjetiva del usuario. Considerando el grado de aciertos, tenemos la Tabla Anexo 1, donde se resume la cantidad de actividades completada para cada ronda. Sin embargo, dado que las tareas de mayor peso son de la 2 a la 5, el porcentaje considerado corresponde a estas, ya que las tareas 1 y 6 eran más de reconocimiento.
Tabla Anexo 1. Cantidad de tareas terminadas Tareas
Ronda: 1 2 3 4 5 6
% global % tareas 2-5
1 5 3 4 5 5 5 90% 85% 2 5 5 5 5 5 5 100% 100% 3 5 5 5 5 4 5 97% 95% 4 5 5 5 4 5 5 97% 95%
La cantidad de tiempo en promedio, necesario para terminar cada tarea considerando las cuatro rondas se muestran en la Tabla Anexo 2; habiendo medido en minutos cada tarea, el promedio se encuentra expresado en segundos.
Tabla Anexo 2. Tiempo promedio en segundos para terminar cada tarea. Tarea Ronda 1 Ronda 2 Ronda 3 Ronda 4
2 192 156 108 96 3 204 120 108 120 4 132 120 120 120 5 144 120 108 108
Para la satisfacción subjetiva, se consideraron aspectos como la consistencia (correspondiente a la pregunta 14 del cuestionario que los usuarios llenaron), el control del usuario (preguntas 2, 6 y 10), presentación visual (pregunta 13), manejo de errores y recuperación (pregunta 7), reducción de la carga de memoria (pregunta 9), guía y ayuda mostrada (preguntas 4, 11 y 12), así como la

Anexo B: Reporte de pruebas de usabilidad para OK
xliv
aceptación general que tuvo el sistema (preguntas 1, 5 y 8) y tratar de determinar la aceptación que tuvo el uso de relaciones que permite la ontología (preguntas 3 y 15). Estos aspectos quedan resumidos en la Tabla 6-5 los resultados mostrados en dicha tabla corresponden al promedio con el que los usuarios contestaron las preguntas, siguiendo una escala de Likert de siete campos de respuesta, por lo que los valores permitidos van desde 1 (en desacuerdo, para todas las cuentas) hasta 7 (de acuerdo, para todas las cuentas).
Tabla 12. Resultados de satisfacción subjetiva. Principio Ronda 1 Ronda 2 Ronda 3 Ronda 4
Consistencia 6.8 6 5.6 7 Control del usuario 6.4 6.53 6.6 6.467 Presentación visual 6.1 6.3 6.5 6.4 Manejo de errores y recuperación
6.8 6.8 6.6 7
Reducción de carga de memoria
6.6 5.4 6.4 7
Satisfacción general 6.267 6.2 6.67 6.93 Guía y ayuda 5.467 5.867 6.6 6.867 Uso de relaciones 6.6 6.7 6.5 6.6
Para poder medir el avance obtenido tras cada ronda, se utilizó la media geométrica, la cuál se calcula sacando la raíz enésima del producto de N números. Para ello, se computan las mejoras relativas para cada uno de los aspectos analizados, entre una ronda y otra, como se muestra en la Tabla 13.
Tabla 13. Puntajes relativos entre las actividades de cada ronda.
Ronda 1-
2 Ronda 2-
3 Ronda 3-
4 2 123% 144% 113% 3 170% 111% 90% 4 110% 100% 100%
Tarea (tiempos)
5 120% 111% 100% Grado de acierto:
118% 95% 100%
Consistencia 88% 93% 125% Control del usuario 102% 101% 98% Presentación visual 103% 103% 98% Manejo de errores y
recuperación 100% 97% 106%
Reducción de carga de memoria 82% 119% 109% Satisfacción general 99% 108% 104%
Guía y ayuda 107% 113% 104%
Satisfacción subjetiva
Uso de relaciones 102% 97% 102% Así, por ejemplo, para la tarea 2, de la ronda 1 a la 2, se ve una mejora del 23%, de la 2 a la 3, la misma tarea tiene una mejora del 44%, y de la 3 a la 4 de tan sólo 13%. De la tabla anterior, se obtiene la media geométrica tanto para los tiempos, aciertos y satisfacción, una vez calculadas, se realiza la media geométrica de estas tres consideraciones, obteniendo finalmente la usabilidad

Anexo B: Reporte de pruebas de usabilidad para OK
xlv
generada entre cada versión probada del sistema OK Order in Kaos, cuyos resultados se muestran en la Tabla 14.
Tabla 14. Usabilidad final entre cada ronda. Ronda 1-2 Ronda 2-3 Ronda 3-4 Usabilidad final
1.14 (114%)
1.04 (104%)
1.02 (102%)
En general, se puede apreciar que la mayor mejora se dio entre la ronda 1 y la ronda 2, con un 114% sobre el 100% base, y que de la ronda 3 a la 4, de sólo un 102% sobre el 100% base, lo que indica que el nuevo diseño tuvo prácticamente la misma usabilidad que el diseño anterior.
Reacciones después del test Al final de cada sesión preguntamos a los participantes un conjunto de preguntas, de entre ellas:
� Comentarios positivos de lo que le haya gustado. � Comentarios negativos sobre lo que no le gustó. � ¿Sugerencias para mejorarlo?
Se muestran un resumen de los comentarios que más se repitieron para cada ronda, también para ver aquellos comentarios que se mantuvieron constantes y los que fueron cambiando.
Resumen de comentarios positivos de lo que le haya gustado Primer ronda:
� Interfaz sencilla de aprender y agradable. � Presentación agradable. � Interesante la forma de recorrer los conceptos y ver sus relaciones. � La barra de categorías es útil para regresar y no perderse.
Segunda ronda:
� Interfaz sencilla de aprender y agradable. � Poder ver en todo momento en que parte se encuentra el usuario. � Fácil navegación. � Buenos resultados. � Ayuda clara.
Tercer ronda:
� Interfaz sencilla de aprender y agradable. � Ayuda clara y útil. � Al ya conocerlo, es más fácil realizar las tareas..

Anexo B: Reporte de pruebas de usabilidad para OK
xlvi
Cuarta ronda: � Los cambios efectuados facilitan la búsqueda. � El sistema funciona bien, es amigable. � Las imágenes utilizadas en Turismo realzan mucho y llaman la atención.
Comentarios negativos sobre lo que no le gustó
Primer ronda:
� Se olvida marcar los botones de selección. � Letras pequeñas. � Respuesta lenta.
Segunda ronda:
� La distribución de los elementos en pantalla. � Botones sobrantes, se debe buscar una manera de agilizar la navegación al usuario. � Detalles en el aspecto visual de Turismo, como el fondo. � Respuesta lenta. � Simplificar el lenguaje de los textos utilizado.
Tercer ronda:
� Mejorar el diseño visual. � La navegación se puede volver tediosa al aumentar los niveles de profundidad en la
navegación. Cuarta ronda:
� Dificultad para navegar si no se conoce del tema.
¿Sugerencias para mejorarlo?
Primer ronda:
� Automatizar el marcar los botones de selección. � Poner textos más grandes y visibles. � Cuidar centrado de elementos. � Poner una ventana de ayuda de cómo usar la aplicación. � Poner porcentajes reales, no redondeados. � Resaltar cuando se encuentran resultados disponibles. � Poner letreros que indiquen que el sistema está cargando.
Segunda ronda:
� Que la taxonomía de relaciones hermanas sea más constante, que no varíe tanto, si no que todos los elementos se muestren igual.
� Agilizar la navegación con menos movimientos por parte del usuario (si una clase está poblada, mostrar los resultados directamente).
� Resaltar la aparición del concepto en que se encuentra el usuario, dentro del texto de las relaciones mostradas.

Anexo B: Reporte de pruebas de usabilidad para OK
xlvii
� Tener cuidado en las consultas directas, pues los porcentajes mostrados pueden dar ideas erróneas.
� Hacer más visual la interfaz de Turismo, con imágenes alusivas a los conceptos que determinan cada clase.
Material usado
El cuestionario de usabilidad contestado por los usuarios, corresponde a las siguientes preguntas.
Cuestionario después del uso de OK Instrucciones: De acuerdo a su experiencia al utilizar el sistema OK, sírvase contestar el siguiente cuestionario, marcando el número según considere responde mejor a cada pregunta. 1. En general, estoy satisfecho con lo fácil que es usar el sistema. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
2. Me sentí en control mientras navegaba. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
3. Pude encontrar rápidamente lo que deseaba. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
4. El sitio necesita explicaciones extra. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
5. Fue fácil aprender a usar el sistema. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
6. Usar el sitio por primera vez es sencillo. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
7. Es muy difícil moverse alrededor del sitio. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
8. Cuando cometo un error puedo recuperarme rápidamente. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
9. No me gustó usar el sitio. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
10. Es difícil decir si el sitio tiene lo que deseo. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
11. El sitio tiene características molestas. En desacuerdo 1 2 3 4 5 6 7 De acuerdo

Anexo B: Reporte de pruebas de usabilidad para OK
xlvii i
12. Recordar donde estoy en el sitio es difícil. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
13. Obtuve lo que esperaba cuando hacía clic en los objetos del sitio. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
14. La información proporcionada por el sistema es fácil de entender. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
15. El lenguaje usado en el sistema es comprensible. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
16. La organización de la información en la pantalla es clara. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
17. Hay consistencia en la forma en que se presenta la información. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
18. ¿Considera de utilidad las relaciones que interrelacionan los conceptos? En desacuerdo 1 2 3 4 5 6 7 De acuerdo
19. La interfaz del sistema es cómoda. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
20. Me gustó usar la interfaz del sistema. En desacuerdo 1 2 3 4 5 6 7 De acuerdo
21. Mencione tres comentarios positivos sobre el sistema:
22. Mencione tres comentarios negativos sobre el sistema:
23. Sugerencias para mejorarlo.

Anexo C: Matriz de confusión
xlix
ANEXO C: MATRIZ DE CONFUSIÓN OBTENIDA DURANTE EL PROCESO
a b c d e F g h i j k l m n o p q r s t u v w x y z aa <-- clasificado como 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 a=Allen_James 0 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b=Brill_Eric 0 0 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 c=Charniak_Eugene 0 0 0 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 d=Chomsky_Noam 0 0 0 0 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 e=Clasif…_de_Documentos 1 0 1 0 0 12 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 f=Comprension_del_Leng… 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 g=Corpus_Linguistico 0 0 0 0 0 0 0 6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 h=Diccionario_Electro… 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 i=Extraccion_de_Inform… 0 0 0 0 0 0 0 0 0 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 j=Farquhar_Adam 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 k=Gelbukh_Alexander 0 0 0 0 0 0 0 0 0 0 0 14 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 l=Guarino_Nicola 0 0 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 1 0 1 0 0 0 m=INAOE 0 0 0 0 0 0 0 0 0 0 0 0 0 10 0 0 0 0 0 0 0 0 0 0 0 0 0 n=Interfaz_en_LN 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 o=IPN 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8 0 0 0 0 0 0 0 0 0 0 0 p=Marcu_Daniel 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 0 0 0 1 1 0 0 0 0 0 q=Mineria_de_Contenido 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 7 0 0 1 0 0 1 0 0 0 r=Mineria_de_Estructura 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8 0 0 1 0 0 0 0 0 s=Mineria_de_Texto 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 1 0 0 0 t=Mineria_de_Uso 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 0 14 0 0 0 0 0 0 u=Mineria_de_Web 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 11 0 0 0 0 0 v=Montes_Manuel 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 0 w=Motor_de_Busqueda_Web 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 50 0 0 0 x=nulo 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 0 0 y=Procesamiento_del_LN 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 z=Rice_James 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 aa=Sager_Naomi

Anexo D: Ejemplos de consultas en SPARQL
l
ANEXO D: EJEMPLOS DE
CONSULTAS EN SPARQL Las siguientes son una serie de consultas base para los casos generales que fueron
necesarios dentro del desarrollo del proyecto.
Para saber si una clase está poblada, es decir, tiene ejemplares (enlaces a páginas Web), se sigue una consulta como la siguiente: String queryinstance = "PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schem a#> " + "PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syn tax-ns#> " + "PREFIX owl: <http://www.w3.org/2002/07/owl#> " + "PREFIX submodel: <http://www.owl-ontologies.com/s ubmodel.owl#> " + "PREFIX : <http://mx.briefcase.yahoo.com/rafaxzero /instances.owl#> " + "ASK" + "{" +
" ?url rdfs:comment ?title . ?url :peso ?peso s . ?url rdf:type submodel:"+variable+" }";
En esta, con ASK se pregunta si en una consulta normal se devolverían valores, y
la palabra variable es usada para indicar el concepto por el cuál se está preguntando. La consulta para determinar las relaciones con las que cuenta un concepto se
muestra en el siguiente código, donde nuevamente, variable se trata del concepto por el cuál se consulta:
queryString =
"PREFIX owl: <http://www.w3.org/2002/07/owl#> " + "PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schem a#> " + "PREFIX : <http://mx.briefcase.yahoo.com/rafaxzero /pln.owl#> " + "SELECT DISTINCT ?z " + "WHERE {" + " ?y owl:onProperty ?z . :" + variable + " rd fs:subClassOf ?y " +
" } ORDER BY ?z "; Para encontrar los conceptos que se encuentran relacionados con uno en particular
(variable), mediante una relación, es abordada mediante la siguiente consulta:
String queryStringrela = "PREFIX rdfs: <http://www.w3.org/2000/01/rdf-sc hema#> " + "PREFIX owl: <http://www.w3.org/2002/07/owl#> " + "PREFIX : <http://mx.briefcase.yahoo.com/rafaxz ero/pln.owl#> " + "SELECT DISTINCT ?x " +

Anexo D: Ejemplos de consultas en SPARQL
li
"WHERE { " + " ?y owl:onProperty :" + var1xyz + " . :" + var iable + " rdfs:subClassOf ?y . ?y ?p ?x " + " . FILTER ( ?p = owl:someValuesFrom || ?p = ow l:allValuesFrom ) " + " . FILTER isUri(?x) " +
" } ORDER BY ?x ";

Referencias
lii
Referencias
[1] A. A. Barfourosh, M. L. Anderson, Information Retrieval on the World Wide Web and Active Logia: A Survey and Problem Definition, 2001.
[2] T. Gruber, A Translation Approach to Portable Ontology Specifications, Knowledge Acquisition, 1993.
[3] S. Mizzaro, Relevance: The whole history, Journal of the American Society for Information Science, 48(9), referenciado en [1].
[4] http://es.wikipedia.org/wiki/Ontolog%C3%ADa_%28Inform%C3%A1tica%29, visitado en junio de 2006.
[5] N. F. Noy, D. L. McGuinness, Ontology Development 101: A Guide to Creating your First Ontology, Universidad de Stanford, EUA, 2004.
[6] SPARQL Query Language for RDF, http://www.w3.org/TR/2006/CR-rdf-sparql-query-20060406/, visitado en octubre de 2006.
[7] SPARQL Query Language for RDF, http://www.w3.org/TR/2004/WD-rdf-sparql-query-20041012/, visitado en octubre de 2006.
[8] T. M. Mitchell, Machine Learning, McGraw-Hill International Editions, 1997. [9] V. Fresno F., Clasificación Bayesiana de textos y páginas Web, Curso de doctorado, disponible en
línea: http://www.escet.urjc.es/~rmartine/ClasificacionBayesiana.pdf, visitado en abril de 2006. [10] G. Salton, A. Wong, C. S. Yang, A vector space model for automatic indexing, Communications of
the ACM Vol. 18 No. 11, EUA, 1975. [11] F. Sebastiani, Machine Learning in Automated Text Categorisation, ACM Computing Surveys,
Italia, 1999. [12] Naïve Bayes classifier, http://en.wikipedia.org/wiki/Naive_Bayesian_classifier, visitado en octubre
de 2006. [13] K-nearest neighbor algorithm, http://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm, visitado
en octubre 2006. [14] T. Joachims, Text categorization with support vector machines: Learning with many relevant
features, Universidad de Dortmund, Alemania, 1998. [15] A. Juan, H. Ney, Reversing and Smoothing the Multinomial Naïve Bayes Text Classifier,
Universidad Politécnica de Valencia, España; Universidad de Tecnología, Alemania, 2002. [16] M. A. Serrano, Almacenamiento y recuperación de la información, Universidad de la Castilla – La
Mancha, Quinto Curso 2006 - 2007, disponible en línea en: http://alarcos.inf-cr.uclm.es/doc/ARI/ari.htm, última visita octubre 2006.
[17] Saavedra M., Arquitectura para Federación de Bases de Datos Documentales basada en Ontologías, Tesis doctoral, Universidade da Coruña, enero 2003.
[18] Jakob Nielsen, Usability: Empiricism or Ideology (Jakob Nielsen’s Alert Box), 27 junio de 2005. Disponible en línea: http://www.useit.com/alertbox/20050627.html.
[19] Jakob Nielsen, Usability 101: Fundamentals and Definitions – What, Why, How (Jakob Nielsen’s Alert Box), 25 de agosto 2003. Disponible en línea: http://www.useit.com/alertbox/20030825.html.
[20] Jakob Nielsen, Usability Testing With 5 Users (Jakob Nielsen’s Alert Box), 19 de marzo de 2000. Disponible on-line: http://www.useit.com/alertbox/20000319.html.
[21] Jakob Nielsen, Success Rate: The Simplest Usability Metric, 18 de febrero de 2001. Disponible en: http://www.useit.com/alertbox/20010218.html.
[22] http://www.hipertext.net/web/pag206.htm. [23] Hassan M., Martín F., Método de test con usuarios, 2003, disponible en:
http://www.nosolousabilidad.com/articulos/test_usuarios.htm, visitado en julio 2006. [24] Fernández I., Construcción de una escala de actitudes tipo Likert, Centro de Atención y Asistencia
Técnica, Barcelona, España, disponible en: http://www.mtas.es/insht/ntp/ntp_015.htm, visitado en julio de 2006.
[25] M. Miller, 501 Web Site Secrets: Unleash the Power of Google, Amazon, eBay, and More, Whiley Publishing, Inc. EUA, 2004.

Referencias
liii
[26] S. Brin, L. Page, The Anatomy of a Large-Scale Hypertextual Web Search Engine, Computer Science Department, Stanford University, Stanford, disponible en línea: http://www.db.stanford.edu/~backrub/google.html.
[27] Yahoo! Search Engine Analysis, http://www.seologic.com/guide/yahoo.php, visitado en octubre 2006.
[28] http://en.wikipedia.org/wiki/CiteSeer [29] C. L. Giles, K. D. Bollacker, S. Lawrence, CiteSeer: An Automatic Citation Indexing System, 1998. [30] Scirus White Paper – How Scirus Works, 2004, disponible en línea:
http://www.scirus.com/press/pdf/WhitePaper_Scirus.pdf. [31] A. Téllez V., M. Montes y G., M. Fuentes C., Clasificación Automática de Textos de Desastres
Naturales en México, Memoria del CIICC’03, México, 2003. [32] F. R.A. Bordignon, J. A. Peri, G. Tolosa, D. Villa y L. Paoletti, Experimentos en Clasificación
Automática de Noticias en Español Utilizando el Modelo Bayesiano, Universidad Nacional de Luján. Depto. de Ciencias Básicas Luján, Argentina, 2004, disponible en línea: http://www.unlu.edu.ar/~tyr/TYR publica/paper-unlu-bayes-2004.doc.
[33] B. B. Wang, R. I. Mckay, H. A. Abbass, and M. Barlow. A comparative study for domain ontology guided feature extraction. Del 26vo. Australian Computer Science Conference (ACSC-2003), Págs. 69-78. Australian Computer Society, 2003.
[34] S. Decker, M. Erdmann, D. Fensel, R. Studer, ONTOBROKER: Ontology based Access to Distributed abd Semi-Structured Information, Universidad de Karlsruhe, Alemania, 1998.
[35] D. Fensel, J. Angele, S. Decker, M. Erdmann, R. Studer, A. Witt, On2broker: Semantic-Based Access to Information Sources at the WWW, Universidad de Karlsruhe, Alemania, 1999.
[36] L. Ding, T. Finin, A. Joshi, Y. Peng, R. Pan, P. Reddivari, Search on the Semantic Web, Computer Vol. 38, No. 10, EUA, 2005.
[37] IBM Ease of Use – Object, view and interaction design, disponible en línea en: http://www-306.ibm.com/ibm/easy/eou_ext.nsf/publish/589, última visita el 24 de febrero de 2006.
[38] Fernández M. Overview Of Methodologies For Building Ontologies. Estocolmo, Suecia. Agosto 1999. Disponible en línea en http://sunsite.informatik.rwth aachen.de/Publications/CEUR-WS/Vol-18/4-fernandez.pdf
[39] Horridge M., Knublauch H., Rector A., Stevens R., Wroe C., A Practical Guide To Building OWL Ontologies Using The Protégé-OWL Plugin and CO-ODE Tools Edition 1.0, Universidad de Manchester – Universidad de Stanford, 2004.
[40] What are cross-validation and bootstrapping? Disponible en línea en http://www.faqs.org/faqs/ai-faq/neural-nets/part3/section-12.html, última visita el 21de febrero del 2006.
[41] Saavedra M., Arquitectura para Federación de Bases de Datos Documentales basada en Ontologías, Tesis doctoral, Universidade da Coruña, enero 2003.
[42] Keinonen T., One-dimensional usability - influence of usability on consumers' product preference, publicación A21 de la UIAH, Helsinki, 1998. Traducción por Routtio P. disponible en http://www2.uiah.fi/projects/metodi/258.htm.
[43] Text Retrieval Conference (TREQ) QA Data, disponible en http://trec.nist.gov/data/qa.html, visitado en agosto de 2006






![14 רועיש linked data rdf/owl sparql - BGUdss152/wiki.files/class14.rdf.sparql[1].pdf · linked data rdf/owl sparql םיילטיגידה חורה יעדמ רצנ לעי And some](https://img.pdfslide.tips/doc/110x75/5b4ef9337f8b9a206e8b4f11/14-linked-data-rdfowl-sparql-bgu-dss152wikifiles-1pdf-linked.jpg)