Embed Size (px)
Citation preview
234262Solving MIPS Exam Problems
21:31
234262 © Dima Elenbogen 2010, Technion
1

LWA Ri, Rj
21:31 234262 © Dima Elenbogen 2010, Technion 2

LWA Ri, Rjקידוד של 21:31 234262 © Dima Elenbogen 2010, Technion
3
• We wish to both read Rj and write there. Hence, an option to encode it as Rt seems tempting.
• But we also wish to use the existing constant 4. MIPS datapath prevents the operation Rt + 4. That’s why Rj should be read as Rs.
• How can we write into it? It’s impossible to write into Rs. Moreover, we need to write into 2 destination registers. Let’s notice, that if we encode the command as R-type, we will have enough space to encode 3 registers. We can encode each of Rj and Ri as either Rd or Rt.
• Thus Rj will appear twice: as Rs and Rd.

LWA Ri, Rjקידוד של 21:31 234262 © Dima Elenbogen 2010, Technion 4
• We wish to both read Rj and write there. Hence, an option to encode it as Rt seems tempting.
• But we also wish to use the existing constant 4. MIPS datapath prevents the operation Rt + 4. That’s why Rj should be read as Rs.
• How can we write into it? It’s impossible to write into Rs. Moreover, we need to write into 2 destination registers. Let’s notice, that if we encode the command as R-type, we will have enough space to encode 3 registers. We can encode each of Rj and Ri as either Rd or Rt.
• Thus Rj will appear twice: as Rs and Rd.

LWA Ri, Rjתוכנית פעולה של
21:31 234262 © Dima Elenbogen 2010, Technion 5
1) Fetch 2) Decode 3) ALUout <= Rs + 4 // Let’s first compute the new value of Rj 4) Rd ← ALUout // Rj ← Rj + 4 5) REG1 <= Rs // ʤhʺʮʤyʥʦʧʮ 6) ALUout <= Rs – 4 // Now we’re computing back the original value of Rj 7) MEMout <= MEM(ALUout) 8) Rt ← MEMout // Ri ← MEM[Rj]

LWA Ri, Rjמימוש 21:31 234262 © Dima Elenbogen 2010, Technion 6
1) Fetch 2) Decode 3) ALUout <= Rs + 4 // Let’s first compute the new value of Rj 4) Rd ← ALUout // Rj ← Rj + 4 5) REG1 <= Rs // ʤhʺʮʤyʥʦʧʮ 6) ALUout <= Rs – 4 // Now we’re computing back the original value of Rj 7) MEMout <= MEM(ALUout) 8) Rt ← MEMout // Ri ← MEM[Rj]
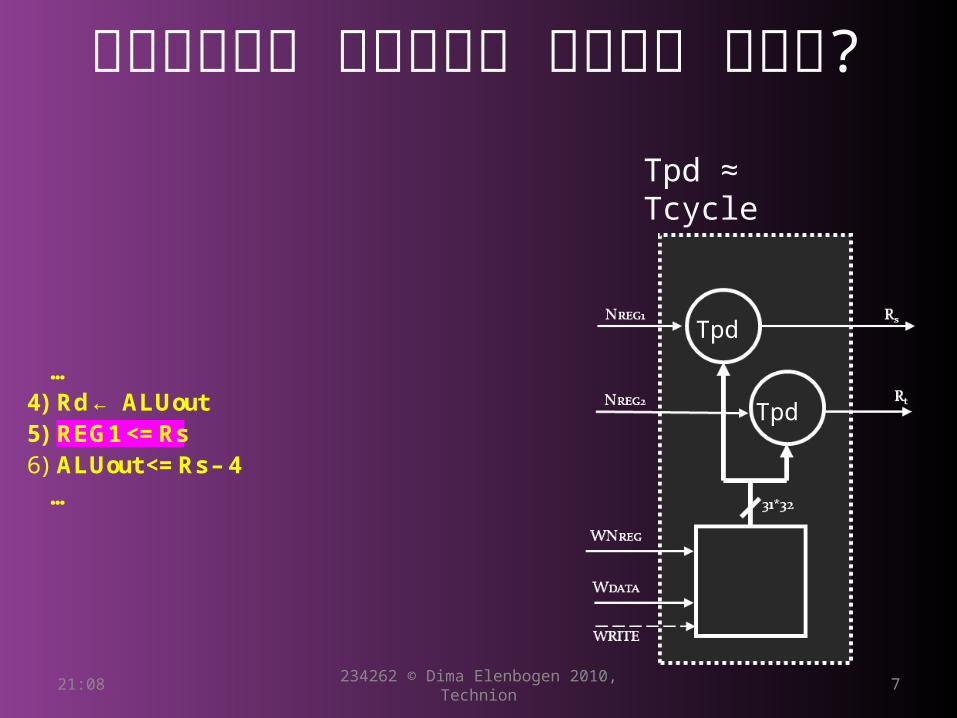
?למה נחוץ מחזור ההמתנה
21:31 234262 © Dima Elenbogen 2010, Technion 7
… 4) Rd ← ALUout 5) REG1 <= Rs 6) ALUout <= Rs – 4
…
Tpd
Tpd
Tpd ≈ Tcycle

LWC Rn, const
21:31 234262 © Dima Elenbogen 2010, Technion 8
Pay attention that this command occupies 2 words!
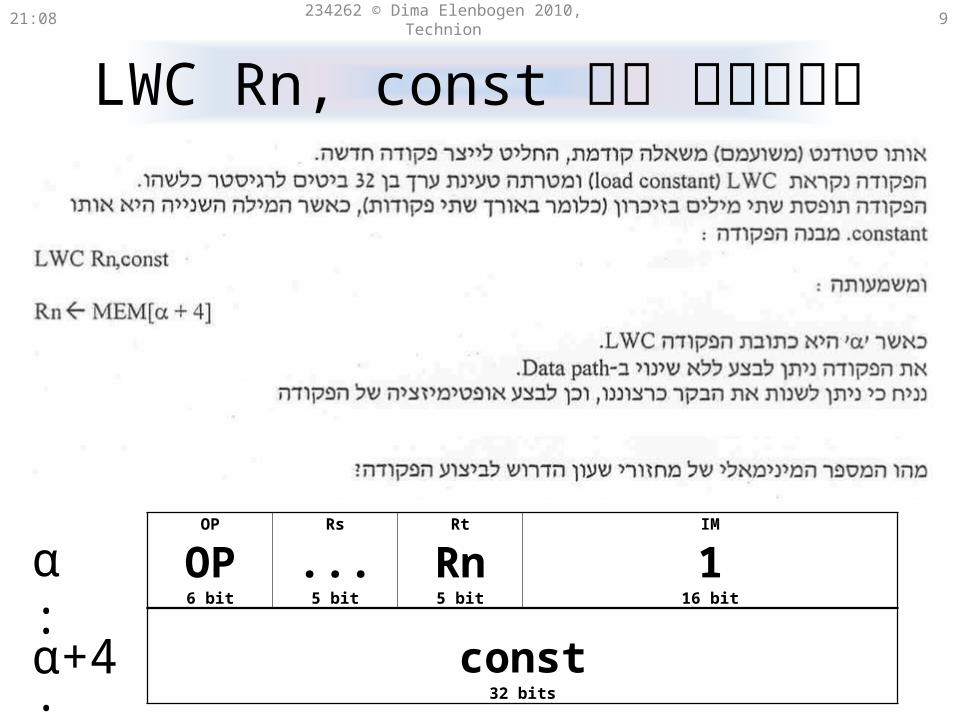
LWC Rn, constקידוד של 21:31 234262 © Dima Elenbogen 2010, Technion 9
OP Rs Rt IM
OP ... Rn 16 bit 5 bit 5 bit 16 bit
const32 bits
α:
α+4:
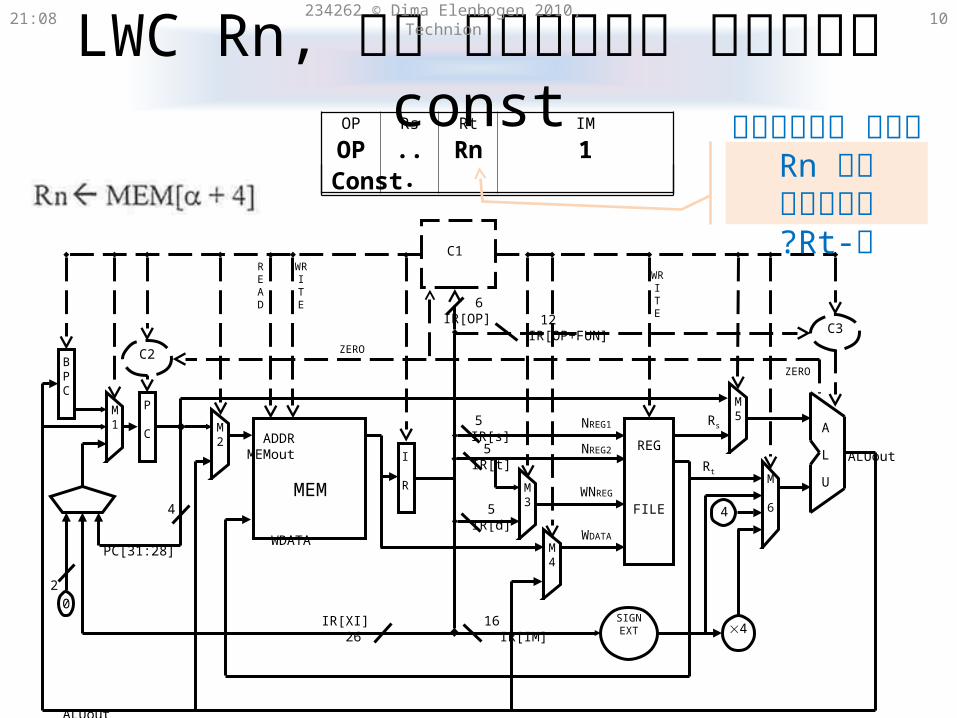
LWC Rn, constרעיון למימוש של 21:31 234262 © Dima Elenbogen 2010, Technion 10
I
R
M3 5 IR[d]
5 IR[t]
5 IR[s]
M4
NREG1
WDATA
M5 Rs
Rt
M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
REG
FILE 4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
P
C
M1
M2
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
ADDR MEMout
MEM
WDATA
A
L
U
OP Rs Rt IM
OP ... Rn 1Const
קידדנו למה דווקה Rnאת
?Rtב-
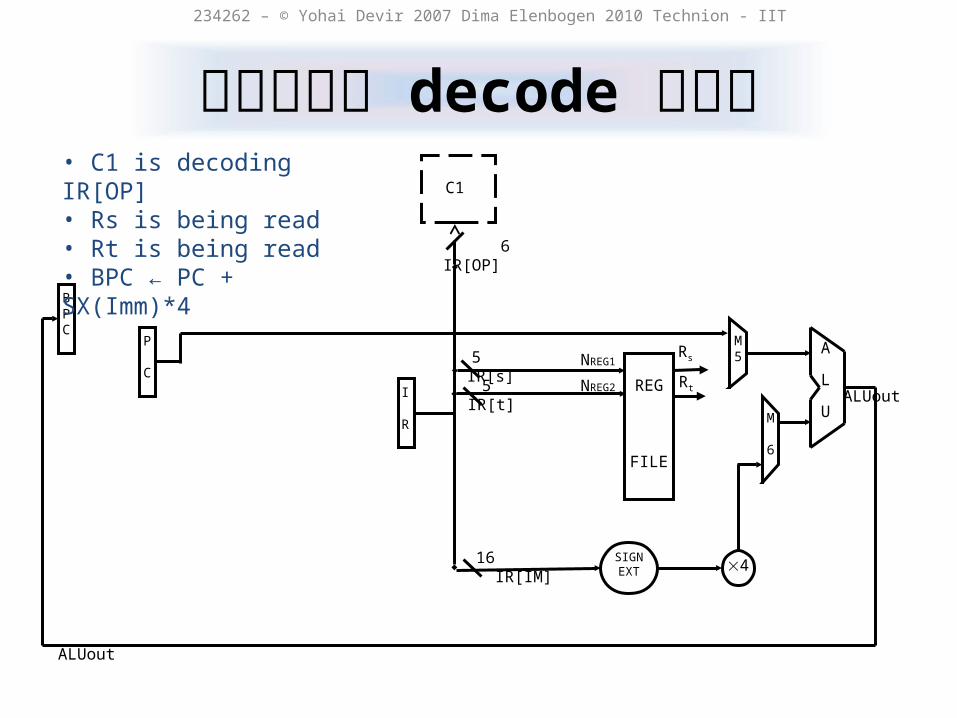
מקוריdecodeשלב
234262 – © Yohai Devir 2007 Dima Elenbogen 2010 Technion - IIT
I
R
5 IR[t]
5 IR[s] NREG1Rs
Rt
M5
M
6
A
L
U
NREG2
REG
FILE
16 IR[IM] 4
SIGNEXT
C1
6 IR[OP]
ALUout
BPC
P
C
ALUout
• C1 is decoding IR[OP]• Rs is being read• Rt is being read• BPC ← PC + SX(Imm)*4
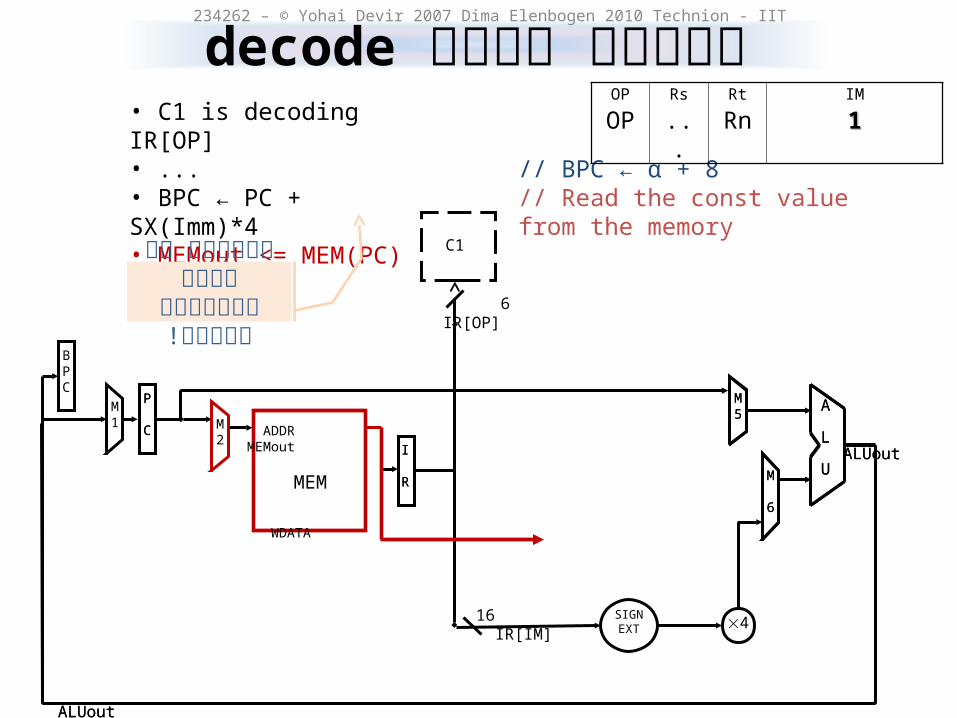
decodeתוספת בשלב 234262 – © Yohai Devir 2007 Dima Elenbogen 2010 Technion - IIT
I
R
M5
M
6
A
L
U
16 IR[IM] 4
SIGNEXT
C1
6 IR[OP]
ALUout
BPC
P
C
ALUout
I
R
M5
M
6
A
L
U
ALUout
P
C
M1
M2
ALUout
ADDR MEMout
MEM
WDATA
• C1 is decoding IR[OP]• ...• BPC ← PC + SX(Imm)*4• MEMout <= MEM(PC)
// BPC ← α + 8// Read the const value from the memory
השינוי לא פוגע בפקודות אחרות!
OP Rs Rt IM
OP ... Rn 11
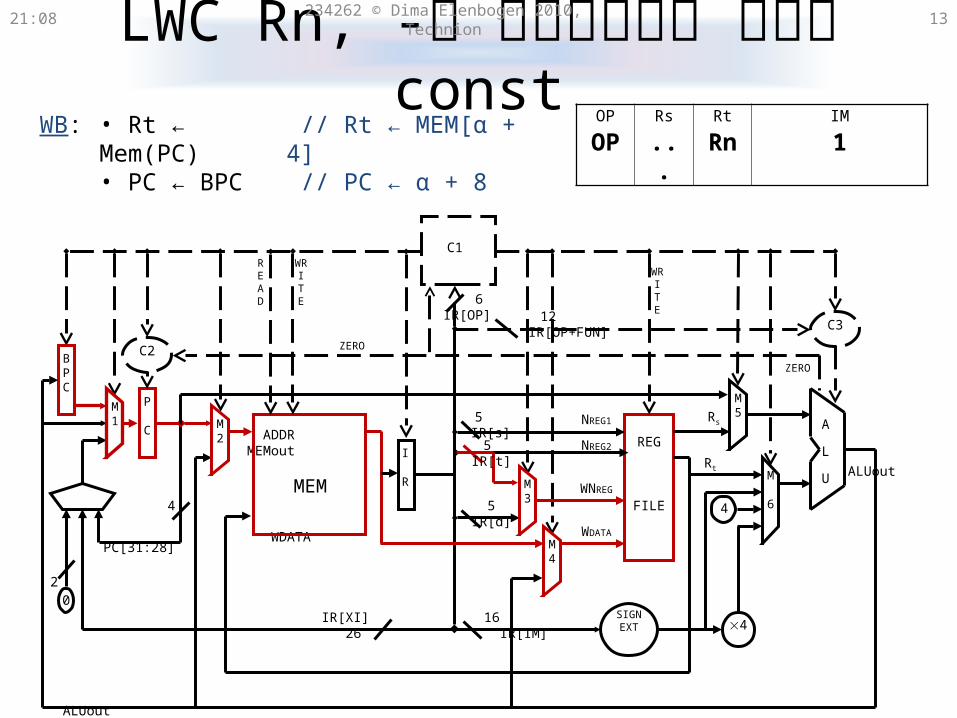
LWC Rn, constשלב ייחודי ל-
M2
5 IR[d]
REG
FILE
ADDR MEMout
MEM
WDATA
P
C
M1
21:31 234262 © Dima Elenbogen 2010, Technion 13
• Rt ← Mem(PC)• PC ← BPC
WB: // Rt ← MEM[α + 4] // PC ← α + 8
I
R
M3
5 IR[t]
5 IR[s]
M4
NREG1
WDATA
M5 Rs
Rt
M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
A
L
U
OP Rs Rt IM
OP ... Rn 1
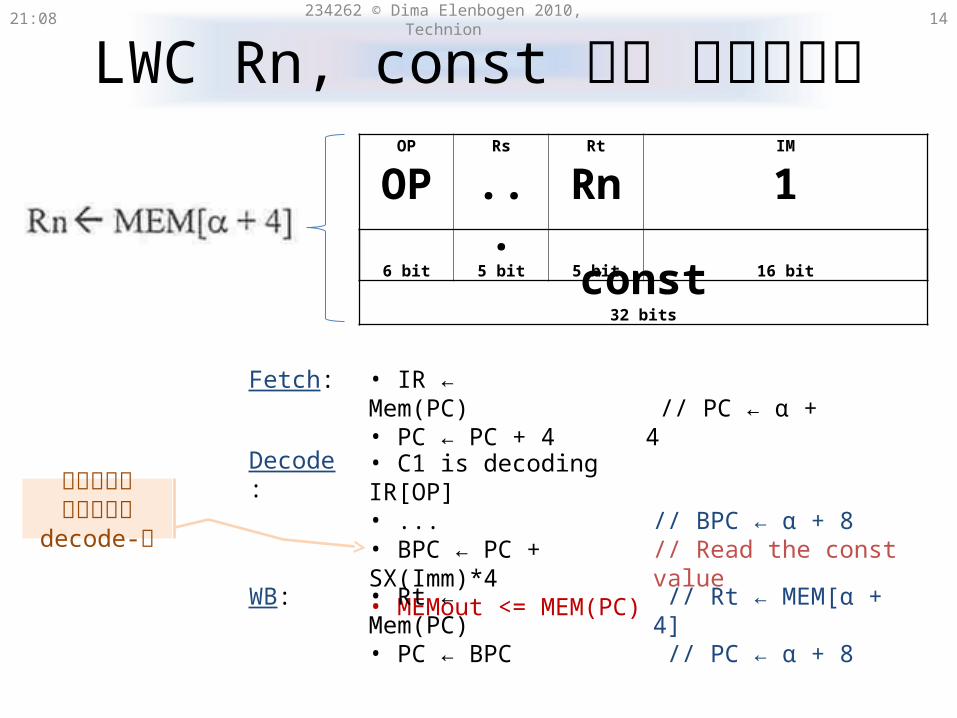
LWC Rn, constמימוש של 21:31 234262 © Dima Elenbogen 2010, Technion 14
OP Rs Rt IM
OP ... Rn 16 bit 5 bit 5 bit 16 bit
const32 bits
• IR ← Mem(PC)• PC ← PC + 4
Fetch: // PC ← α + 4
• C1 is decoding IR[OP]• ...• BPC ← PC + SX(Imm)*4• MEMout <= MEM(PC)
// BPC ← α + 8// Read the const value
Decode:
• Rt ← Mem(PC)• PC ← BPC
WB: // Rt ← MEM[α + 4] // PC ← α + 8
פעולה נוספת decodeב-

LWC Rn, constשלב ייחודי אלטרנטיבי ל- 21:31 234262 © Dima Elenbogen 2010, Technion 15
• Rt ← Mem(PC)• PC ← PC + 4
WB: // Rt ← MEM[α + 4] // PC ← α + 8
OP Rs Rt IM
OP ... Rn ...
I
R
M3 5 IR[d]
5 IR[t]
5 IR[s]
M4
NREG1
WDATA
M5 Rs
Rt M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
REG
FILE 4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
P
C
M1
M2
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
ADDR MEMout
MEM
WDATA
A
L
U

ADDMEM Ri, Rj, Imm21:31 234262 © Dima Elenbogen 2010, Technion 16
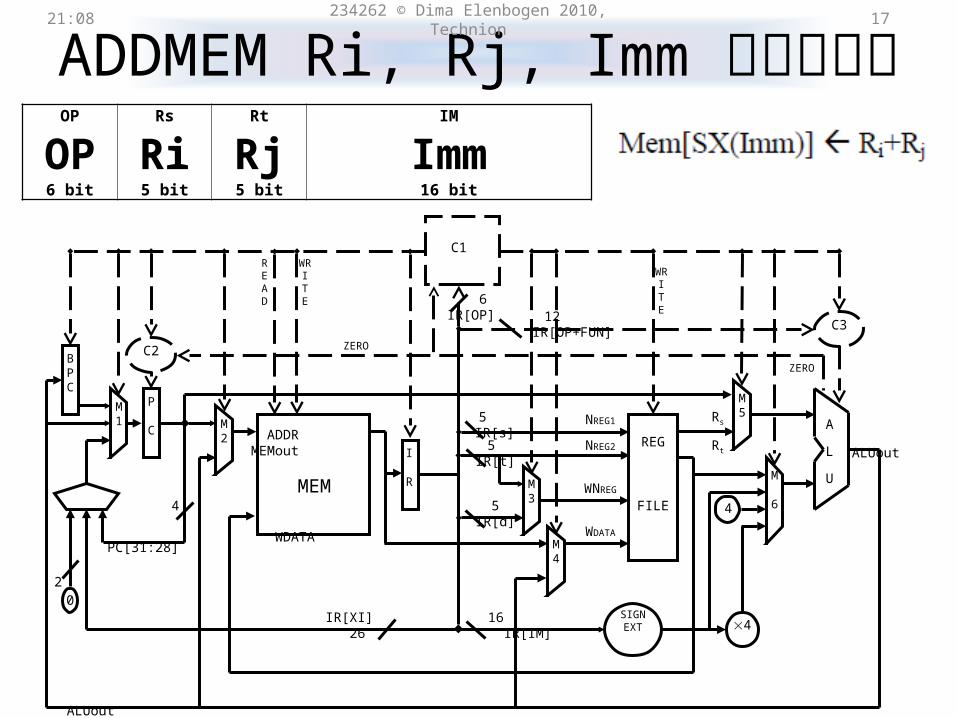
ADDMEM Ri, Rj, Immקידוד 21:31 234262 © Dima Elenbogen 2010, Technion 17
OP Rs Rt IM
OP Ri Rj Imm6 bit 5 bit 5 bit 16 bit
I
R
M3 5 IR[d]
5 IR[t]
5 IR[s]
M4
NREG1
WDATA
M5 Rs
Rt M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
REG
FILE 4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
P
C
M1
M2
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
ADDR MEMout
MEM
WDATA
A
L
U
I
R
M3 5 IR[d]
5 IR[t]
5 IR[s]
M4
NREG1
WDATA
M5 Rs
Rt
M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
REG
FILE 4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
P
C
M1
M2
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
ADDR MEMout
MEM
WDATA
A
L
U
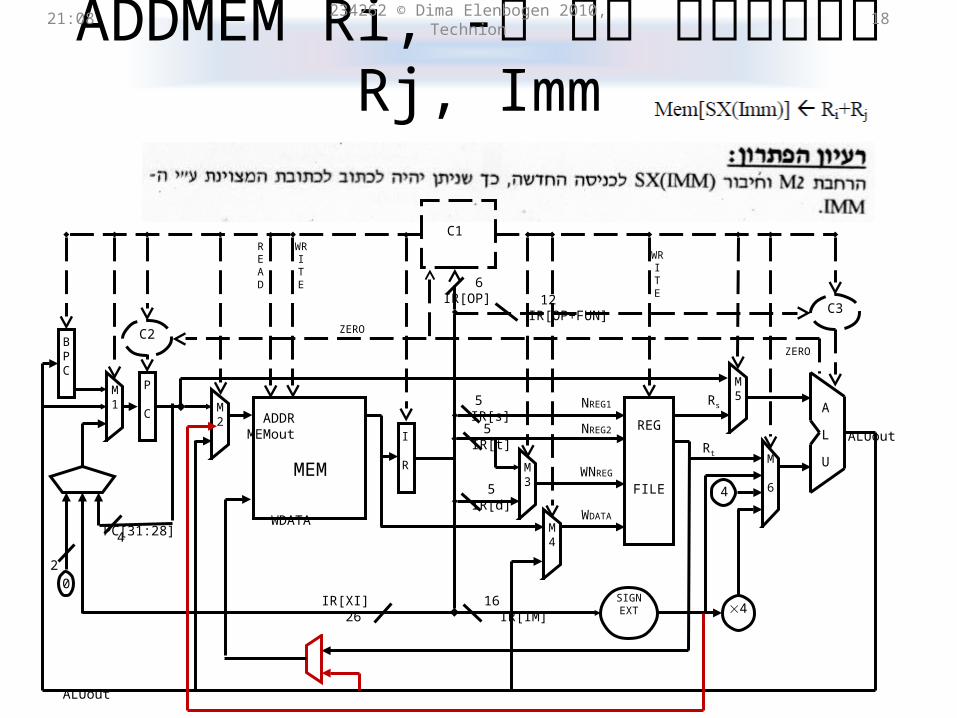
ADDMEM Ri, Rj, Immפיתרון קל ל- 21:31 234262 © Dima Elenbogen 2010, Technion 18
I
R
M3 5 IR[d]
5 IR[t]
5 IR[s]
M4
NREG1
WDATA
M5 Rs
Rt M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
REG
FILE 4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
P
C
M1
M2
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
ADDR MEMout
MEM
WDATA
A
L
U
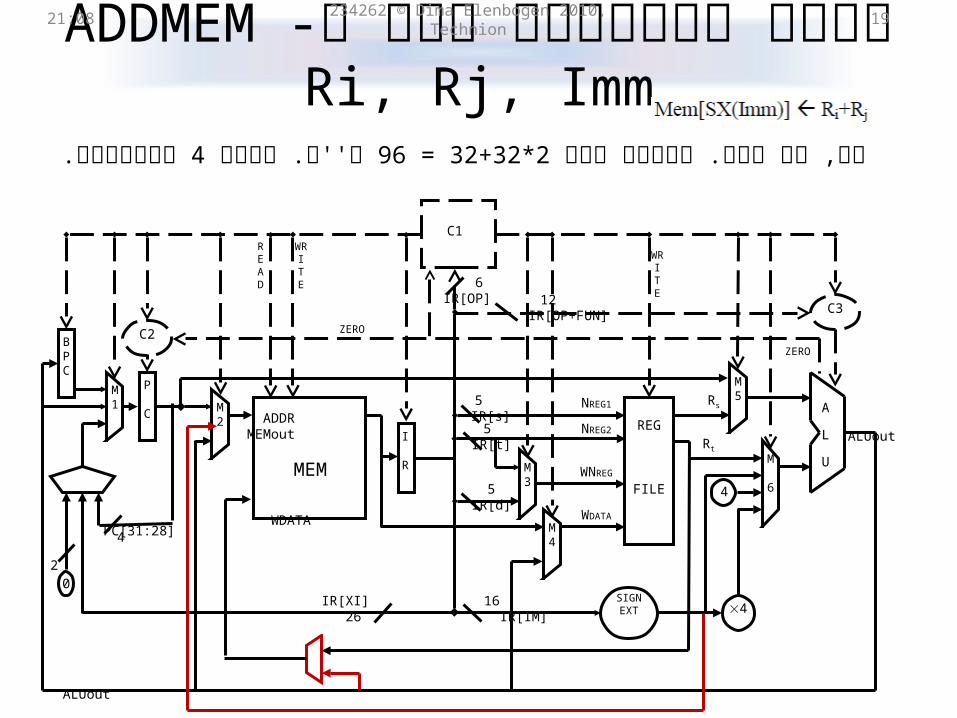
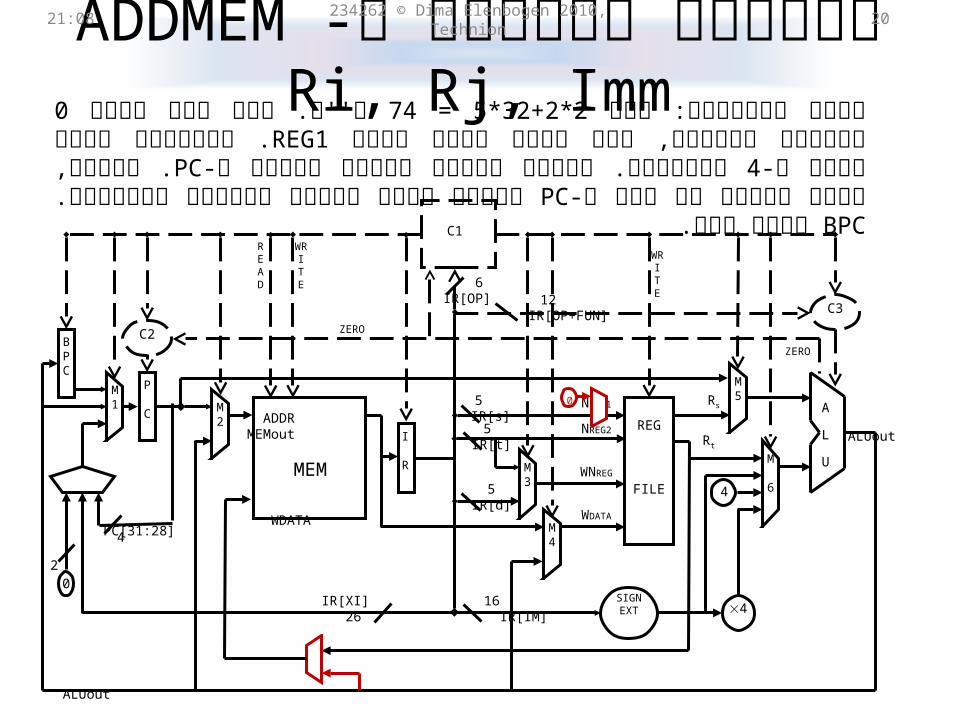
ADDMEM Ri, Rj, Immעלות הפיתרון הקל ל- 21:31 234262 © Dima Elenbogen 2010, Technion 19
מחזורים.4 ש''ח. דורש 96 = 32+32*2קל, אך יקר. עלותו היא
NREG1 0
I
R
M3 5 IR[d]
5 IR[t]
5 IR[s]
M4
WDATA
M5 Rs
Rt M
6
12 IR[OP+FUN]
NREG2
16 IR[IM]
WNREG
ZERO
REG
FILE 4
4
SIGNEXT
C1
C3
WRITE
6 IR[OP]
ALUout
BPC
P
C
M1
M2
ZERO
IR[XI] 26
PC[31:28]
C2
2
0
4
WRITE
READ
ALUout
ADDR MEMout
MEM
WDATA
A
L
U
,ADDMEM Ri, Rjפיתרון בינוני ל- Imm
21:31 234262 © Dima Elenbogen 2010, Technion 20
בקידוד הפקודה, לכן נדרש 0 ש''ח. אין לנו קבוע 74 = 5*32+2*2עלות בינונית: היא לפני מ-REG1בורר יותר דורש נכתוב נשמרת 4. הפיתרון מחזורים. כתובת שאליה
BPC הקודם לאחר השלמת עידכון הזיכרון. PC. כמובן, חובה לשחזר את ערך ה-PCב-ישמש לכך.

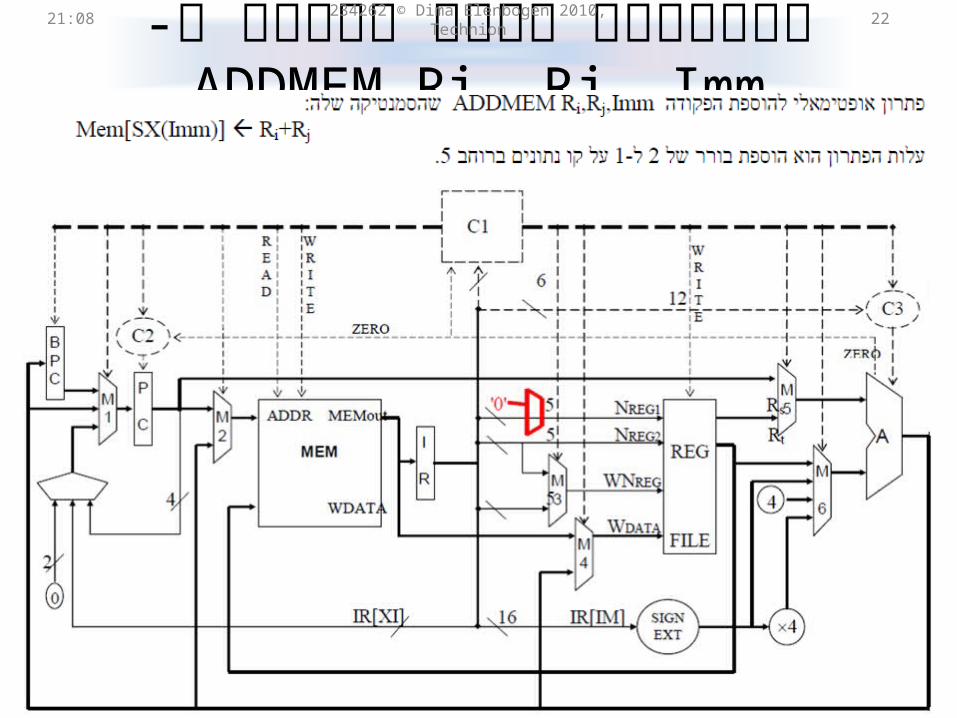
,ADDMEM Ri, Rjהפיתרון הזול ביותר ל- Imm
21:31 234262 © Dima Elenbogen 2010, Technion 21
OP Rs Rt IM
OP Ri Rj Imm
,ADDMEM Ri, Rjהפיתרון הזול ביותר ל- Imm
21:31 234262 © Dima Elenbogen 2010, Technion 22
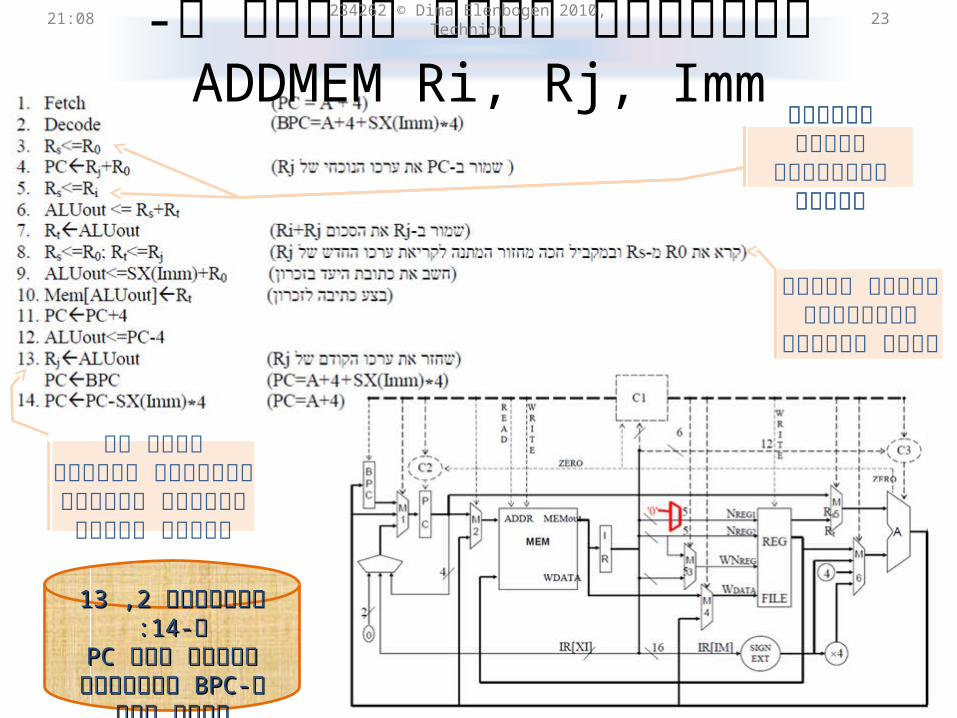
,ADDMEM Ri, Rjהפיתרון הזול ביותר ל- Imm
21:31 234262 © Dima Elenbogen 2010, Technion 23
מחזורי קריאת רגיסטרים
חדשים
מחזור קריאת רגיסטרים אחרי
עידכון
מחזורי קריאת רגיסטרים
חדשים
שימו לב לכתיבות שנעשות במקביל
במחזור הלפני אחרון
::1414ו-ו- 1313, , 22מחזורים מחזורים BPCBPC ב- ב-PCPCגיבוי ערך גיבוי ערך
ושיחזור הערך משםושיחזור הערך משם

? סוגים2מחזורי קריאה (המתנה) מ-
21:31 234262 © Dima Elenbogen 2010, Technion 24
Tpd
Tpd
Tpd ≈ Tcycle
מחזורי קריאת רגיסטרים
חדשים
מחזורי קריאת רגיסטרים
חדשים
מחזור קריאת רגיסטרים אחרי
עידכון
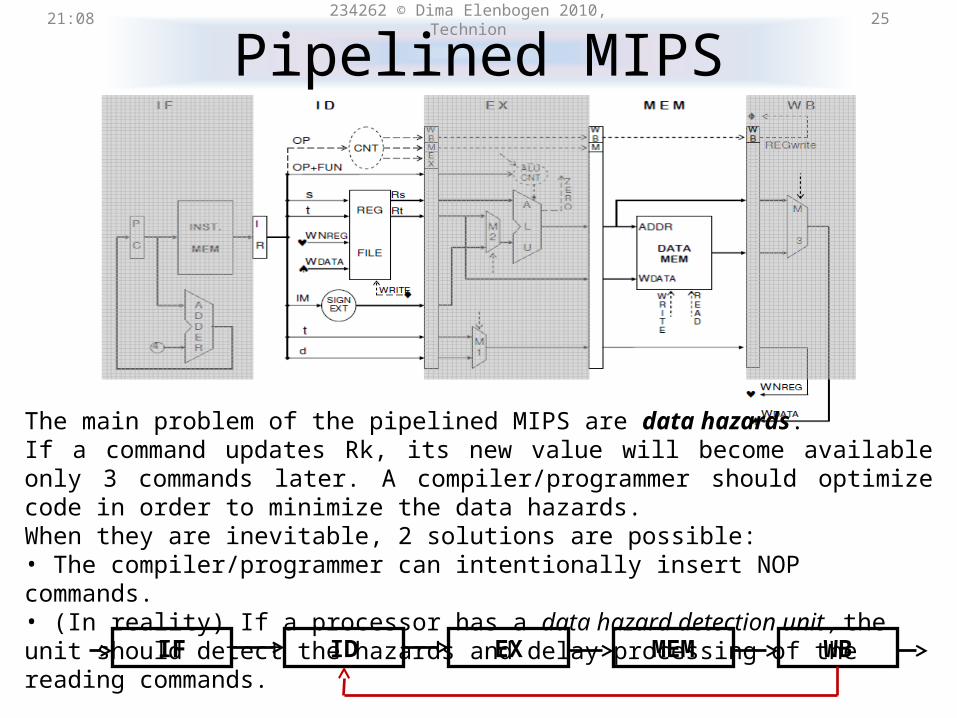
Pipelined MIPS21:31 234262 © Dima Elenbogen 2010, Technion 25
IF ID EX MEM WB
The main problem of the pipelined MIPS are data hazards. If a command updates Rk, its new value will become available only 3 commands later. A compiler/programmer should optimize code in order to minimize the data hazards.When they are inevitable, 2 solutions are possible:• The compiler/programmer can intentionally insert NOP commands.• (In reality) If a processor has a data hazard detection unit , the unit should detect the hazards and delay processing of the reading commands.

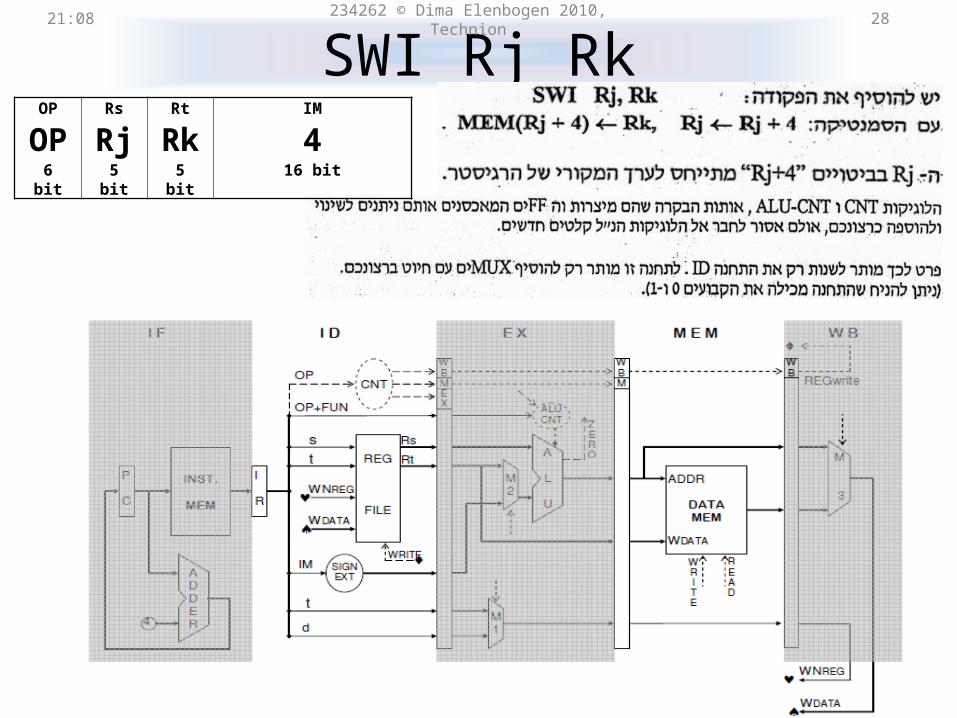
SWI Rj Rk21:31 234262 © Dima Elenbogen 2010, Technion 26

SWI Rj Rkקידוד של 21:31 234262 © Dima Elenbogen 2010, Technion 27
OP Rs Rt IM
OP Rj Rk 4
6 bit 5 bit 5 bit 16 bit
SWI Rj Rk21:31 234262 © Dima Elenbogen 2010, Technion 28
OP Rs Rt IM
OP Rj Rk 46 bit 5 bit 5 bit 16 bit
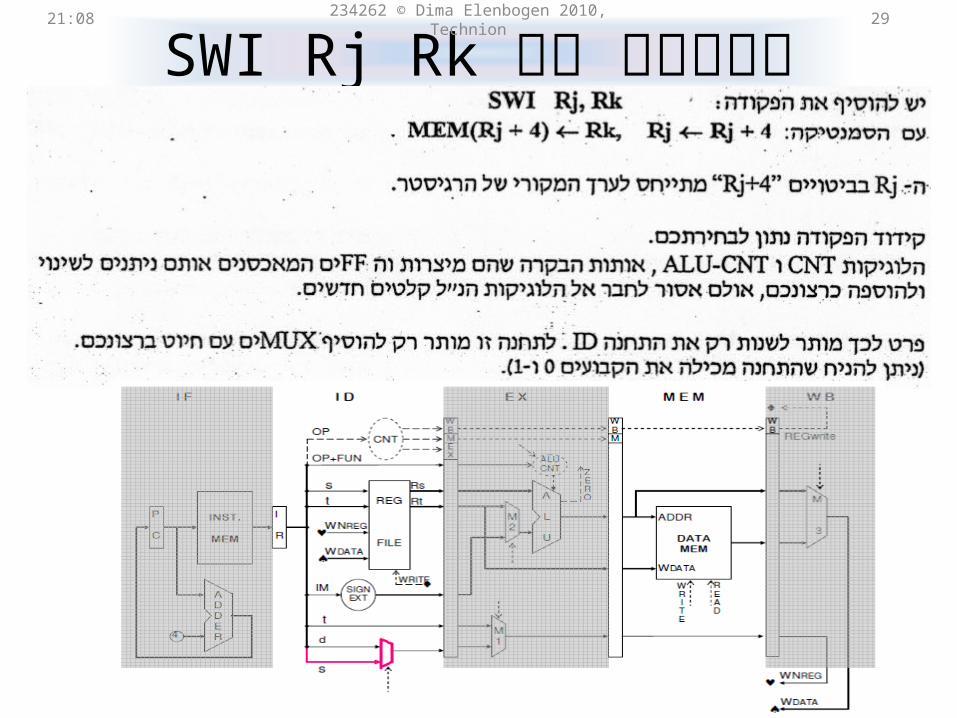
SWI Rj Rkמימוש של 21:31 234262 © Dima Elenbogen 2010, Technion 29
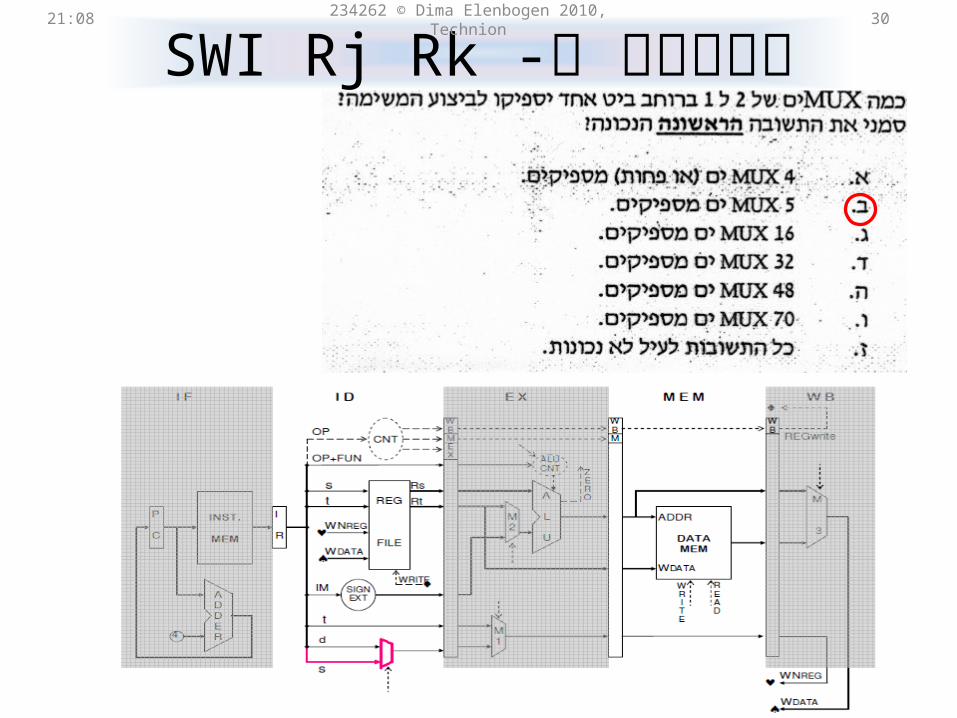
SWI Rj Rkתשובה ל- 21:31 234262 © Dima Elenbogen 2010, Technion 30

Single-Cycle MIPS21:31 234262 © Dima Elenbogen 2010, Technion 31
מבצע כל פקודה במחזור •אחד.
הבקר צירופי.• אינו מותנה.PC האוגר היחיד • המסלול הצירופי הארוך•
יח' איטיות. 5 ביותר באורך
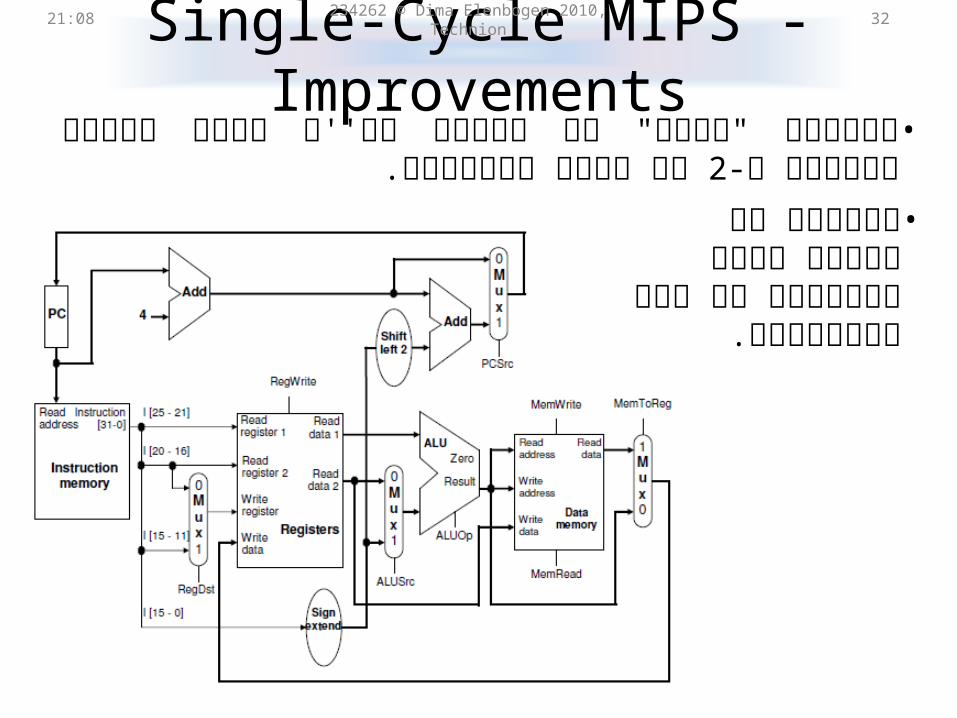
Single-Cycle MIPS - Improvements21:31 234262 © Dima Elenbogen 2010, Technion 32
ל-• בפקודה טיפול מפרק בד''כ המעבד את "לשפר" או 2ניסיון יותר מחזורים.
לפעמים זה אפילו •פוגע בישימות של
חלק מהפקודות.
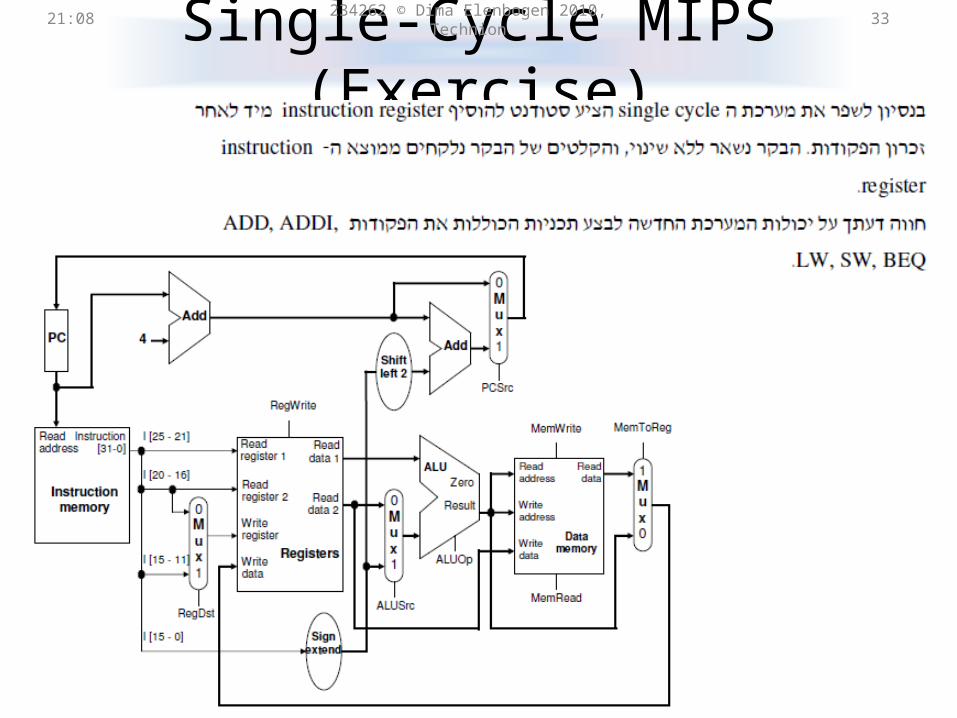
Single-Cycle MIPS (Exercise)21:31 234262 © Dima Elenbogen 2010, Technion 33
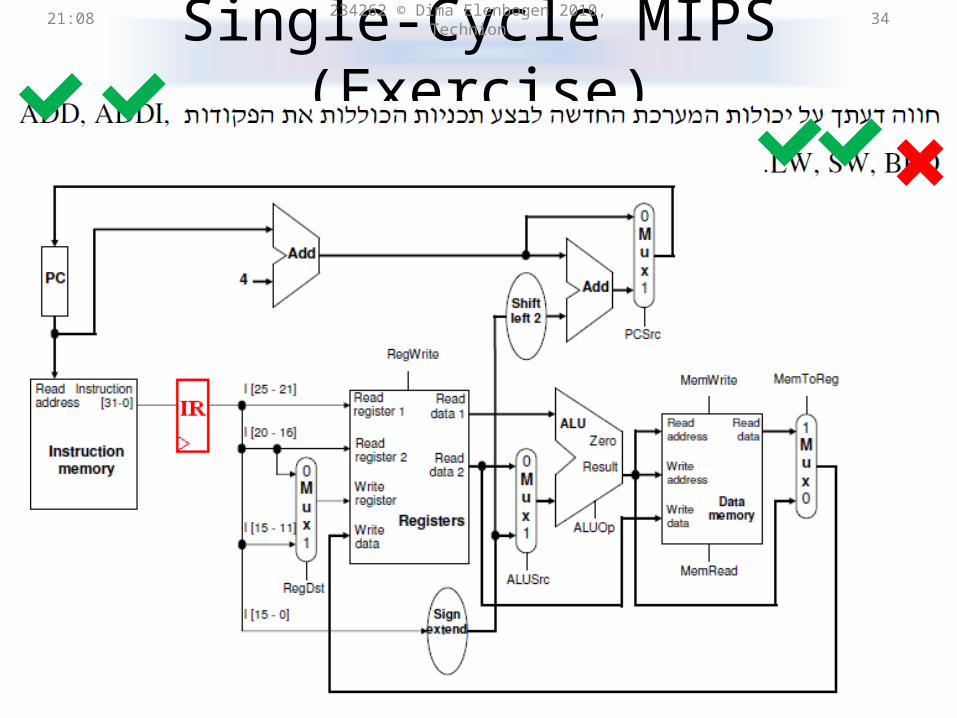
Single-Cycle MIPS (Exercise)21:31 234262 © Dima Elenbogen 2010, Technion 34

ואל תעשו בהן טעויות מטופשות!© Dima Elenbogen 2010, Technion – Israel Institute of Technology






![Higgs PhysicsShaouly Bar-Shalom1 arXiv/1405.2924 [PRD 2015] SBS (Technion), A. Soni (BNL) & J. Wudka (UCR) Shaouly Bar-Shalom Technion, Israel (shaouly@physics.technion.ac.il)](https://img.pdfslide.tips/doc/110x75/5697bf891a28abf838c8a1df/higgs-physicsshaouly-bar-shalom1-arxiv14052924-prd-2015-sbs-technion.jpg)