Embed Size (px)
Citation preview

Vorlesung Datenbanken Wintersemester 2013/14
3 Datenbankentwurf im Relationenmodell
Entwicklung formaler Kriterien, warum eineGruppierung von Attributen in
Relationenbesser oder schlechter ist als eine andere. Gesichtspunkte:
• logische Ebene: wie gut interpretiert der Benutzer die
Relationenschemata und ihre Attribute,
• Zugriffs–/Speicherungs–Ebene: wie gut sind die Tupel der
Basisrelationen abgespeichert/zugreifbar/änderbar.
Zur Beurteilung einzelner Schemata werdenfunktionale Abhängigkeitenund
Normalformenverwendet.
Zur Beurteilung einer ganzen Menge von Relationenschemata, d.h. von
Datenbankschemata, verwendet man dieverlustfreie Verbund–Eigenschaft
und dieAbhängigkeits–Erhaltungs–Eigenschaft.
Prof. Dr. Dietmar Seipel 194

Vorlesung Datenbanken Wintersemester 2013/14
3.1 Informelle Design–Richtlinien und Update–Anomalien
Richtlinie 1: Semantik der Attribute eines Relationenschemas
Entwerfe ein Relationenschema so, daß seine Bedeutung leicht zu
erklären ist. Es soll einen einfachen Bezug zwischen den Attributen
geben: mische nicht Attribute von unterschiedlichen Entity– oder
Relationship–Typen in einem einzelnen Schema.
Richtlinie 2: Vermeidung von Redundanz und von Update–Anomalien
Entwerfe die Basisrelationenschemata so, daß keine Einfüge–,
Lösch– oder Modifikationsanomalien auftreten. Unvermeidbare
Anomalien sollen gut dokumentiert werden.
Die Vermeidung von Redundanz führt auch zur Minimierung des
Speicherplatzbedarfs für die Basisrelationen.
Prof. Dr. Dietmar Seipel 195

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Lieferant)L: Lieferant, T: Teil, A: Anzahl, O: Ort, K: Entfernung
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
L1
L2
L3
L4
T1
T2
T3
T4
T5
T6
Prof. Dr. Dietmar Seipel 196

Vorlesung Datenbanken Wintersemester 2013/14
Die Tabelle repräsentiert drei Beziehungen:
LTA: zu einem Lieferanten/Teile–Paar wird die gelieferte Teileanzahl
angegeben,
LO : zu jedem Lieferanten wird sein Standort angegeben,
OK : zu jedem Ort wird die Entfernung (in km) angegeben.
Die LO– und dieOK–Beziehung sind hochgradigredundantgespeichert.
Hier tretenUpdate–Anomalienauf:
1. beim Einfügen partieller Tupel zuLTA entstehen Nullwerte,
2. beim Löschen des letzten Eintrages eines Lieferanten geht die
LO–Beziehung verloren,
3. beim Ändern des Ortes zu einem Lieferanten (Umzug) müssenmehrere
Tupel geändert werden.
Prof. Dr. Dietmar Seipel 197

Vorlesung Datenbanken Wintersemester 2013/14
Performance:
Manchmal muß man aus Performance–Gründen gegen einzelne Richtlinien
verstoßen, um gewisse Anfragen effizient beantworten zu können. Im
allgemeinen sollte man Anomalien aber vermeiden.
Views:
Man sollte Views verwenden, welche mit Hilfe von Joins die gewünschten
Attributkombinationen aus verschiedenen Basisrelationen erstellen; diese
können dann auch als Module für komplexe Anfragen verwendetwerden.
Dies bringt Übersichtlichkeit und oft auch einen Performance–Gewinn.
Prof. Dr. Dietmar Seipel 198

Vorlesung Datenbanken Wintersemester 2013/14
Richtlinie 3: Nullwerte
Vermeide weitestgehend Attribute in Relationen, falls die
zugehörigen Attributwerte NULL sein könnten.
Falls eine große Anzahl der Attribute eines Relationenschemas auf viele
Tupel der zugehörigen Relation nicht anwendbar sind, so treten viele
Nullwertein der Relation auf. Konsequenzen:
• Verschwendung von Speicherplatz
• Joins und Aggregatsfunktionen über Nullwerten sind problematisch
• unterschiedliche Interpretationen für Nullwerte:
– das Attribut ist auf das Tupelnicht anwendbar
– der Attributwert ist für das Tupelunbekannt, oder
er ist zwarbekannt, aber nicht eingegeben
Prof. Dr. Dietmar Seipel 199

Vorlesung Datenbanken Wintersemester 2013/14
Richtlinie 4: Überflüssige Tupel
Entwerfe die Relationenschemata so, daß sie mit Hilfe von Joins
(über gleiche Attributwerte) korrekte Sichten auf die Daten liefern.
Dies ist z.B. gewährleistet, falls die Join–Attribute Schlüssel
(Fremdschlüssel) sind.
Falls eine Relationr als ihreProjektionenπU1(r), . . . , πUk
(r) auf mehrere
Attributmengen repräsentiert wird, so gilt für deren Natural Join generell
r ⊆ πU1(r) ⊲⊳ . . . ⊲⊳ πUk
(r).
Es können im Natural Joinüberflüssige Tupelauftreten, welche nicht inr
enthalten waren. Gewünscht wäre aber die Gleichheit der beiden Ausdrücke.
Natural Join: def (ri) = Ui
r1 ⊲⊳ r2 = { t | def (t) = U1 ∪ U2 ∧ t[U1] ∈ r1 ∧ t[U2] ∈ r2 }.
Prof. Dr. Dietmar Seipel 200

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Überflüssige Tupel)
1. Für die folgende Relationr und die Projektionenr1 = πAB(r) und
r2 = πBC(r) gilt r ( πAB(r) ⊲⊳ πBC(r).
r
A B C
1 3 2
2 3 1
→
r1
A B
1 3
2 3
r2
B C
3 2
3 1
→
r1 ⊲⊳ r2
A B C
1 3 1
1 3 2
2 3 1
2 3 2
Hier istU1 = {A,B} undU2 = {B,C}.
Prof. Dr. Dietmar Seipel 201

Vorlesung Datenbanken Wintersemester 2013/14
2. Für dieselbe Relationr und die Projektionenr1 = πAB(r) und
r2 = πBC(r) gilt dagegenr = πAB(r) ⊲⊳ πAC(r).
r = r1 ⊲⊳ r2
A B C
1 3 2
2 3 1
↔
r1
A B
1 3
2 3
r2
A C
1 2
2 1
Hier istU1 = {A,B} undU2 = {A,C}.
Prof. Dr. Dietmar Seipel 202

Vorlesung Datenbanken Wintersemester 2013/14
3. Für die Lieferantenrelation gilt ebenfalls
r = πLTA(r) ⊲⊳ πLO(r) ⊲⊳ πOK(r).
r = r1 ⊲⊳ r2 ⊲⊳ r3
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
↔
r1 = ΠLTA(r)
L T A
L1 T1 300
L1 T2 200
L1 T3 400
L1 T4 200
L1 T5 100
L1 T6 100
L2 T1 300
L2 T2 400
L3 T2 200
L4 T2 200
L4 T4 300
L4 T5 400
r2 = ΠLO(r)
L O
L1 London
L2 Paris
L3 Paris
L4 Brüssel
r3 = ΠOK (r)
O K
London 600
Paris 450
Brüssel 150
Prof. Dr. Dietmar Seipel 203

Vorlesung Datenbanken Wintersemester 2013/14
3.2 Funktionale Abhängigkeiten
Funktionale Abhängigkeiten sind intra–relationale Bedingungen für
Relationenr über einer AttributmengeU . Sie verallgemeinern den
klassischen Schlüsselbegriff.
1. Einefunktionale Abhängigkeit(engl.: functional dependency, fd)
ist gegeben durchX → Y mit X, Y ⊆ U . Sie gilt inr, falls
∀ t1, t2 ∈ r : t1[X ] = t2[X ] ⇒ t1[Y ] = t2[Y ].
Y (rechte Seite) heißt dann funktional abhängig vonX (linke Seite),
und man sagtX geht nachY .
2. Eine fdX → Y heißttrivial , fallsY ⊆ X ; sie gilt in allen Relationen.
FallsX → Y gilt, so definiert die ProjektionΠXY (r) von r eine (partielle)
Funktion, nach der dieY –Werte von denX–Werten abhängen.
Prof. Dr. Dietmar Seipel 204

Vorlesung Datenbanken Wintersemester 2013/14
Die fd X → Y besagt:
∀ t1, t2 ∈ r : t1[X ] = t2[X ] ⇒ t1[Y ] = t2[Y ];
wenn zwei Tupelt1, t2 ∈ r aufX übereinstimmen, dann müssen sie auch auf
Y übereinstimmen.
t1
t2
. . . X . . . Y . . .
. . . . . .
. . . t1[X] . . . t1[Y ] . . .
. . . . . .
. . . t2[X] . . . t2[Y ] . . .
. . . . . .
FallsY = U ist, so bedeutet das, daß die beiden Tupel gleich sind.
Dann gibt es keine unterschiedlichen Tupel, die aufX übereinstimmen.
Prof. Dr. Dietmar Seipel 205

Vorlesung Datenbanken Wintersemester 2013/14
1. EinRelationenschemaR = (U, F ) ist gegeben durch
• eine AttributmengeU und
• eine MengeF von Integritätsbedingungen.
2. Eine Relationr überU , welche alle Integritätsbedingungen ausF
erfüllt, heißt erlaubteInstanzvonR.
Man kann die bekannteSchlüsseleigenschafteiner AttributmengeK als
funktionale AbhängigkeitK → U ausdrücken:
t1[K] = t2[K] ⇒ t1 = t2 ⇒ t1[U ] = t2[U ].
Also wird die bisherige Definition eines Relationenschemasals
R = (U,K,NOTNULL)
mit Ausnahme derNOTNULL–Attribute – die uns in diesem
Zusammenhang nicht interessieren – von der neuen Definitionsubsumiert.
Prof. Dr. Dietmar Seipel 206

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Lieferant)
Wir betrachten das RelationenschemaR = (U, F ) mit
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K }.
L: Lieferant, T: Teil, A: Anzahl,
O: Ort, K: Entfernung
• Die bereits bekannte Relationr
ist eine erlaubte Instanz vonR.
• In r gilt – neben den funktionalen
Abhängigkeiten ausF – auchL → K.
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
Die Redundanz und die daraus folgenden Update–Anomalien liegen offenbar
an den funktionalen AbhängigkeitenL → O undO → K.
Prof. Dr. Dietmar Seipel 207

Vorlesung Datenbanken Wintersemester 2013/14
Die fd LT → A stellt dagegen kein Problem dar, denn die Beziehung
zwischenLT–Paaren und dem geliefertenA ist nicht redundant gespeichert.
In r gilt sogarLT → U , dennLT ist ein Schlüssel: es gibt keine zwei
unterschiedlichen Tupel, die aufLT übereinstimmen.
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
Prof. Dr. Dietmar Seipel 208

Vorlesung Datenbanken Wintersemester 2013/14
In r gilt auch die fdL → K:
t1
t2
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
L → K folgt ausL → O undO → K (Transitivität):
Wenn zwei Tupelt1 undt2 aufL übereinstimmen, dann müssen sie wegen
L → O auch aufO übereinstimmen und somit wegenO → K aufK.
Prof. Dr. Dietmar Seipel 209

Vorlesung Datenbanken Wintersemester 2013/14
• Die partielle Funktion fürO → K ist gegeben durch die Projektion
ΠOK(r) von r (Funktionsgraph):
O K
London 600
Paris 450
Brüssel 150
y = x2:
x y
1 1
2 4
3 9
6
-
Die Funktion ist partiell, da sie z.B. für die Stadt “Berlin”nicht definiert
ist.
• Die fd T → A gilt in r nicht, da es Teile (z.B. T2) gibt, die in
unterschiedlichen Anzahlen (200, 400) geliefert werden.
• Jeder Lieferant liefert jedes Teil allerdings in genau einer Anzahl.
Deswegen gilt die fdLT → A in r. In der erweiterten Relationr ∪ {t},
mit t = (L1,T1,400,London,600), gilt LT → A hingegen nicht.
Prof. Dr. Dietmar Seipel 210

Vorlesung Datenbanken Wintersemester 2013/14
• Man kann die fdL → O z.B. mittels des folgenden SQL–Statements
überprüfen:
SELECT t1.L
FROM Lieferant t1, Lieferant t2
WHERE t1.L = t2.L
AND t1.O != t2.O
Falls die Antwort auf diese Anfrage nicht–leer ist, so ist die fd in der
Relation Lieferant verletzt.
Falls eine fdX → Y in einer Relationr gilt, so giltX → Y auch in allen
Teilmengenr′ ⊆ r. Das Umgekehrte gilt aber – wie bereits gezeigt – nicht.
Prof. Dr. Dietmar Seipel 211

Vorlesung Datenbanken Wintersemester 2013/14
Konventionen:
1. Einzelne Großbuchstaben am Anfang des Alphabets bezeichnen in der
Regel Attribute, einzelne Großbuchstaben am Ende des Alphabets
bezeichnen in der Regel Attributmengen.
2. Wir können eine Attributmenge{A1, . . . , An } auch kurz als
ZeichenketteA1 . . . An schreiben, falls alleAi nur aus einem Zeichen
bestehen.
3. Die VereinigungX ∪ Y zweier AttributmengenX undY kann alsXY
abgekürzt werden.
Prof. Dr. Dietmar Seipel 212

Vorlesung Datenbanken Wintersemester 2013/14
Logische Folgerungen aus funktionalen Abhängigkeiten
SeiF eine Menge von fds überU .
1. Eine fdX → Y überU folgt ausF , fallsX → Y in allenerlaubten
Instanzen von(U, F ) gilt. Dann schreiben wirF |= X → Y .
2. Zwei fd–MengenF undG überU heißenäquivalent, falls (U, F ) und
(U,G) dieselben erlaubten Instanzen haben. Dann schreiben wirF ≡ G.
Offenbar giltF ≡ G, wenn alle fds inG ausF folgen, und umgekehrt.
Die logische Folgerung ist auf der Basis der obigen Definition nur schwierig
zu berechnen, da alle erlaubten Instanzen von(U, F ) zu betrachten wären.
Für einfache Beispiele kann man aber die logischen Folgerungen leicht
ermitteln.
Prof. Dr. Dietmar Seipel 213

Vorlesung Datenbanken Wintersemester 2013/14
Es gibt erlaubte Instanzenr′ des Lieferantenschemas, in denen neben den fds
ausF = {LT → A,L → O,O → K } auch die fdT → A gilt, da jedes Teil
in maximal einer Anzahl geliefert wird:
r′
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 300 London 600
L1 T5 400 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 200 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
T → A ist aber keine logische Folgerung, da es z.B. in der vorherigen
erlaubten Instanzr nicht gilt. L → K ist dagegen eine logische Folgerung.
Prof. Dr. Dietmar Seipel 214

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Logische Folgerung, Äquivalenz)
AusF = {LT → A,L → O,O → K } folgen u.a. die fds
LT → AOK, L → K, L → OK undK → K.
Für zwei Tupelt1, t2 ∈ r einer beliebigen erlaubten Instanzr gilt:
1. Aust1[L] = t2[L] folgt wegenL → O aucht1[O] = t2[O] und wegen
O → K aucht1[K] = t2[K]. Dies zeigtL → K undL → OK.
2. Aust1[LT ] = t2[LT ] folgt natürlicht1[L] = t2[L].
• AusLT → A folgt t1[A] = t2[A].
• AusL → OK folgt t1[OK] = t2[OK].
Damit gilt insgesamtt1[AOK] = t2[AOK]. Dies zeigtLT → AOK.
Die fd L → A folgt offensichtlich nicht, da sie in der obigen erlaubten
Instanzr schon nicht gilt.
Prof. Dr. Dietmar Seipel 215

Vorlesung Datenbanken Wintersemester 2013/14
Also sind die folgenden fd–Mengen äquivalent:F ≡ G1 ≡ G2 ≡ G3.
F = {LT → A,L → O,O → K },
G1 = F ∪ {LT → O,LT → K,L → K },
G2 = {LT → AOK,L → OK,O → K },
G3 = {LT → A,L → OK,O → K }.
G1 nimmt die logischen FolgerungenLT → O, LT → K undL → K zuF
hinzu.
G2 faßt die fds mit den gleichen linken Seiten zusammen und bildet fds ausder Vereinigung der entsprechenden rechten Seiten, denn esgilt
{L → O,L → K } ≡ {L → OK },
{LT → A,LT → O,LT → K } ≡ {LT → AOK }.
G3 verkürztLT → AOK zuLT → A, dennLT → OK folgt bereits ausL → OK.
Prof. Dr. Dietmar Seipel 216

Vorlesung Datenbanken Wintersemester 2013/14
Ableitungsregeln von Armstrong für funktionale Abhängigkeiten
Die folgendenInferenzregeln(Axiome) stammen vonArmstrong(1974).
(F1) Reflexivität (triviale fds):
∅ ⊢ X → Y , fallsY ⊆ X
(F2) Augmentierung:
{X → Y } ⊢ XZ → Y Z
(F3) Transitivität:
{X → Y, Y → Z } ⊢ X → Z
FallsX → Y mittels des Kalküls von Armstrong ausF abgeleitet werden
kann, so schreiben wirF ⊢ X → Y .
Prof. Dr. Dietmar Seipel 217

Vorlesung Datenbanken Wintersemester 2013/14
|= ≡ ⊢
Logische Folgerung und Ableitung sind äquivalent:
die Inferenzregeln (F1), (F2), (F3) von Armstrong bilden einenvollständigen
undkorrektenKalkül für |=.
Vollständigkeit:F |= X → Y ⇒ F ⊢ X → Y
(alle Folgerungen können mittels des Kalküls abgeleitet werden)
Korrektheit:F ⊢ X → Y ⇒ F |= X → Y
(alle mittels des Kalküls abgeleiteten fds folgen)
Durch Anwendung der Inferenzregeln lassen sich also genau alle logischen
Folgerungen aus einer fd–Menge systematisch berechnen.
Prof. Dr. Dietmar Seipel 218

Vorlesung Datenbanken Wintersemester 2013/14
Die Korrektheitder Inferenzregeln von Armstrong ist einfach zu beweisen.
Für zwei Tupelt1, t2 ∈ r einer beliebigen erlaubten Instanzr gilt:
(F1) Reflexivität:X → Y , fallsY ⊆ X .
Aus t1[X ] = t2[X ] undY ⊆ X folgt t1[Y ] = t2[Y ].
(F2) Augmentierung:{X → Y } ⊢ XZ → Y Z.
Aus t1[XZ] = t2[XZ] folgt t1[X ] = t2[X ] undt1[Z] = t2[Z].
WegenX → Y gilt dann aucht1[Y ] = t2[Y ].
Insgesamt gilt alsot1[Y Z] = t2[Y Z].
(F3) Transitivität:{X → Y, Y → Z } ⊢ X → Z.
Aus t1[X ] = t2[X ] undX → Y folgt t1[Y ] = t2[Y ].
WegenY → Z gilt dann aucht1[Z] = t2[Z].
Der Vollständigkeits–Beweis, der auf sogenannten Armstrong–Relationen
basiert, ist kompliziert und kann hier nicht gezeigt werden.
Prof. Dr. Dietmar Seipel 219

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Inferenzregeln)
Aus der Menge
F = {BC → D, D → E, CE → B }
kann man die funktionale AbhängigkeitCD → B ableiten:
D → E Augmentierung
CD → CE CE → B Transitivität
CD → B
R
s ? +
Prof. Dr. Dietmar Seipel 220
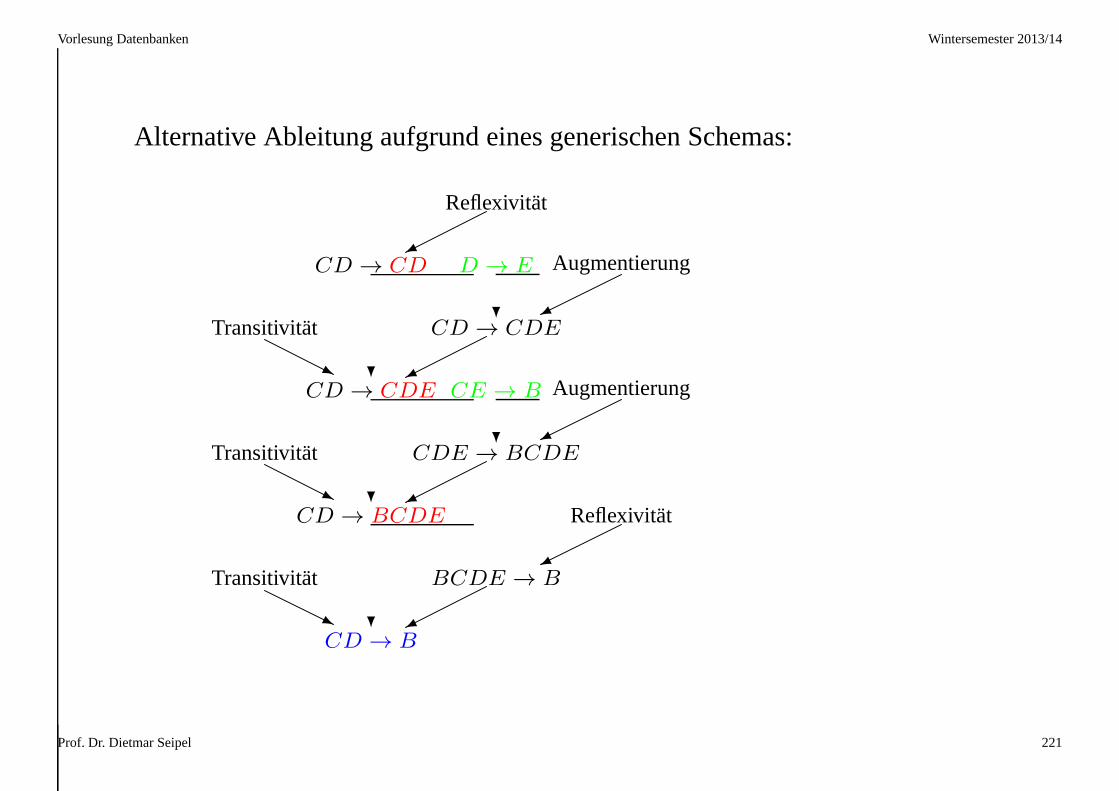
Vorlesung Datenbanken Wintersemester 2013/14
Alternative Ableitung aufgrund eines generischen Schemas:
Reflexivität
�CD → CD D → E Augmentierung
Augmentierung
Reflexivität
CD → CDE
CD → CDE CE → B
CDE → BCDE
Transitivität
Transitivität
Transitivität
CD → BCDE
BCDE → B
CD → B
?
?
?
?
?
�
�
�
�
�
�
j
j
j
Prof. Dr. Dietmar Seipel 221

Vorlesung Datenbanken Wintersemester 2013/14
Weitere Ableitungsregeln für funktionale Abhängigkeiten
Aus (F1)–(F3) können die folgenden weiteren Regeln abgeleitet werden:
(F4) Zerlegung oder Projektion:
{X → YZ } ⊢ X → Y , X → Z
(F5) Vereinigung:
{X → Y, X → Z } ⊢ X → YZ
(F6) Pseudo–Transitivität:
{X → Y, WY → Z } ⊢ WX → Z
(F7) Akkumulation:
{X → WY, Y → Z } ⊢ X → WYZ
Bei Verwendung dieser zusätzlichen Regeln kann man einfachere
Ableitungsbäume erhalten.
Prof. Dr. Dietmar Seipel 222

Vorlesung Datenbanken Wintersemester 2013/14
(F4) Die Projektion ergibt sich durch Verknüpfung von Reflexivität und
Transitivität:{X → YZ } ⊢ X → Y
Reflexivität
Transitivität
X → YZ
YZ → Y
X → Y?
�
�j
(F5) Die Vereinigung ergibt sich durch Verknüpfung von Augmentierung
(zweimal) und Transitivität:{X → Y, X → Z } ⊢ X → YZ
X → Y X → ZAugmentierung
XY → YZX → XY
X → YZ
Transitivität??
?
�
�j
�
Prof. Dr. Dietmar Seipel 223

Vorlesung Datenbanken Wintersemester 2013/14
(F6) Die Pseudo–Transitivität ergibt sich durch Verknüpfung vonAugmentierung und Transitivität:{X → Y, WY → Z } ⊢ WX → Z
X → Y Augmentierung
WX → WY WY → Z Transitivität
WX → Z
R
s ?+
(F7) Die Akkumulation ergibt sich durch Verknüpfung von Augmentierungund Transitivität:{X → WY, Y → Z } ⊢ X → WYZ
X → WY Y → Z Augmentierung
WY → WYZ
X → WYZ
Transitivität?
?
�
�j
Prof. Dr. Dietmar Seipel 224

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Inferenzregeln)
Aus der Menge
F = {BC → D, D → E, CE → B }
kann man die funktionale AbhängigkeitCD → B nun einfacher ableiten:
D → E CE → B Pseudo–Transitivität
CD → Bs ? +
Anstelle von Augmentierung und Transitivität (2 Schritte,siehe weiter oben)
verwenden wir nun einfach die Pseudo–Transitivität.
Prof. Dr. Dietmar Seipel 225

Vorlesung Datenbanken Wintersemester 2013/14
Auch die alternative Ableitung aufgrund des generischen Schemas können
wir vereinfachen:
Reflexivität
�CD → CD
D → E
CD → CDE
CE → B
Akkumulation
Akkumulation
Projektion
CD → BCDE
CD → B
?
?
?
�
�
j
j
j
Prof. Dr. Dietmar Seipel 226

Vorlesung Datenbanken Wintersemester 2013/14
Einfachere Formulierung der Inferenzregeln
1. Augmentierung:
{X → Y } ⊢ X ′ → Y , fallsX ⊆ X ′ (links vergrößern).
2. Zerlegung oder Projektion:
{X → Y } ⊢ X → Y ′, fallsY ′ ⊆ Y (rechts verkleinern).
3. Vereinigung:{X → Y, X → Y ′ } ⊢ X → Y ∪ Y ′.
4. Reflexivität: ∅ ⊢ X → Y , fallsY ⊆ X (triviale fds).
5. Akkumulation: {X → Y, Y ′ → Z } ⊢ X → Y ∪ Z, fallsY ′ ⊆ Y .
Als Spezialfall der Akkumulation erhält man fürY = Y ′ mittels der
Projektion die Transitivität:{X → Y, Y → Z } ⊢ X → Z.
Für die Relation< über den reellen Zahlen gilt die Transitivität z.B. auch:
für alleX, Y, Z ∈ IR mit X < Y ∧ Y < Z gilt X < Z.
Prof. Dr. Dietmar Seipel 227

Vorlesung Datenbanken Wintersemester 2013/14
Generisches Ableitungsschema: RA∗P–Ableitung
Um eine fdX → Y aus einer fd–MengeF herzuleiten, konstruieren wir
induktiv eine fd–FolgeX → Xi, für 1 ≤ i ≤ n:
(R) Wir setzenX1 = X : X → X gilt wegen der Reflexivität.
(A∗) i → i+ 1: Falls wirYi → Zi ∈ F finden, mitYi ⊆ Xi, so kann
X → Xi ∪ Zi ausX → Xi mittels Akkumulation gewonnen werden,
und wir setzenXi+1 = Xi ∪ Zi.
(P) FallsY ⊆ Xn gilt, dann erhält man ausX → Xn mittels Projektion die
gewünschte fdX → Y .
Damit gilt {Yi → Zi | 1 ≤ i ≤ n } ⊢ X → Y. Am Ende gilt offensichtlich
Xn = X ∪ Z1 ∪ . . . ∪ Zn.
Prof. Dr. Dietmar Seipel 228
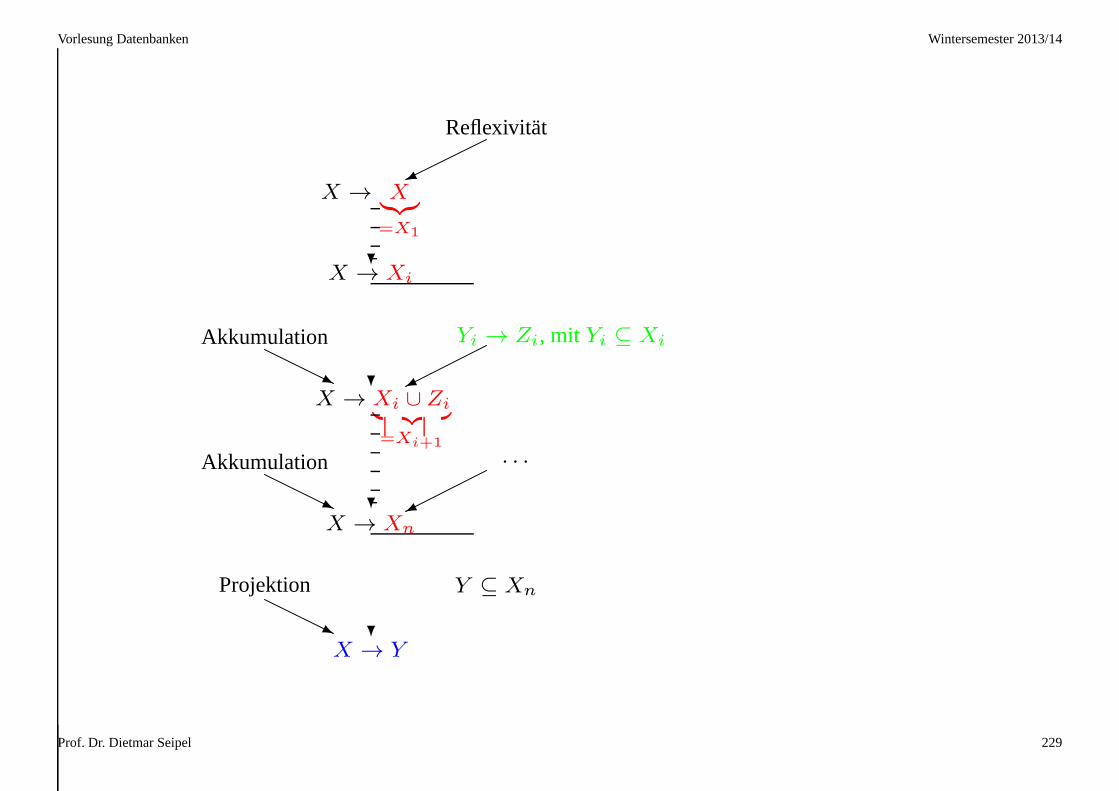
Vorlesung Datenbanken Wintersemester 2013/14
Reflexivität
�X → X
︸︷︷︸
=X1
X → Xi
Yi → Zi, mit Yi ⊆ Xi
. . .
Y ⊆ Xn
X → Xi ∪ Zi︸ ︷︷ ︸
=Xi+1
Akkumulation
Akkumulation
Projektion
X → Xn
X → Y
?
?
?
?
�
�
j
j
j
Prof. Dr. Dietmar Seipel 229

Vorlesung Datenbanken Wintersemester 2013/14
FD–Hülle, Attributhülle
SeiR = (U, F ) ein Relationenschema undX ⊆ U .
1. DieFD–HülleF+ vonF besteht aus allen fds überU , die ausF folgen:
F+ = {X → Y | F |= X → Y }.
2. DieAttributhülleX+F vonX besteht aus allen AttributenA ∈ U , welche
bezüglichF funktional vonX abhängig sind:
X+F = {A ∈ U | F |= X → A }.
Prof. Dr. Dietmar Seipel 230

Vorlesung Datenbanken Wintersemester 2013/14
Eigenschaften:
• Die FD–HülleF+ besteht aus allen logischen Folgerungen.
Sie ist immer sehr groß, denn sie enthält z.B. auch alle trivialen fds
X → Y , mit Y ⊆ X , und sie enthält damit exponentiell viele fds.
• Man kann den Implikationstest auf die AttributhülleX+F stützen ohne
die sehr große FD–HülleF+ zu berechnen:
X → Y ∈ F+ ⇐⇒ F |= X → Y ⇐⇒ Y ⊆ X+F .
• Die AttributhülleX+F kann mit einem einfachen Algorithmus berechnet
werden. Sie enthält immer auchX , d.h.
X ⊆ X+F .
Wegen der Reflexivität gilt nämlich für alleA ∈ X auchF |= X → A.
Prof. Dr. Dietmar Seipel 231

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Hülle)
SeiU = {L, T,A,O,K } und
F = {LT → A,L → O,O → K }.
Dann gilt
{L, T }+ = U,
{L }+ = {L,O,K } ( U,
{T }+ = {T } ( U.
Also istX = {L, T } eine minimale Menge von Attributen mitX+ = U .
Für die beiden um ein Attribut kleineren MengenX gilt X+ ( U .
Weiter gilt
{O }+ = {O,K } ( U.
Prof. Dr. Dietmar Seipel 232

Vorlesung Datenbanken Wintersemester 2013/14
Die AttributhülleX+F kann entsprechend der RA∗P–Ableitung effizient
berechnet werden, indem man lediglich die rechten Seiten der berechnetenfd–Folge betrachtet.
Algorithmus zur Berechnung der Attributhülle
Input: Eine fd–MengeF und eine AttributmengeXOutput:X+ = X+
F
X+ := X ;REPEAT
X∗ := X+;FOR EACH (Y → Z ∈ F ) DO
IF Y ⊆ X+ THEN X+ := X+ ∪ Z;UNTIL X∗ = X+;
Komplexität: O(|F | · |U |2 · log |U |)
X → X+
Y → Z
X → X+ ∪ Z
Akkumulation
? �j
Prof. Dr. Dietmar Seipel 233

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Berechnung der Attributhülle)
FürF = {LT → A,L → O,O → K } undX = {L, T } ist folgendeBerechnungsfolge möglich:
X+1 = {L, T },
X+2 = {L, T,A }, mittelsY → Z = LT → A,
X+3 = {L, T,A,O }, mittelsY → Z = L → O,
X+4 = {L, T,A,O,K } = U, mittelsY → Z = O → K.
• Die Berechnung erfordert in diesem Falle nur eine Iteration.
• Für die ReihenfolgeLT → A, O → K, L → O, gibt es zweiIterationen, daO → K erst in Iteration 2 angewendet werden kann,nachdemL → O in Iteration 1 angewendet wurde.
• Unabhängig von der Reihenfolge der fds erhält man immer dasselbeEndergebnis, in diesem Falle{L, T }+F = U.
Prof. Dr. Dietmar Seipel 234

Vorlesung Datenbanken Wintersemester 2013/14
L T A O K
• Aufgrund der fdLT → A kann manX+1 = {L, T } zu
X+2 = {L, T,A } erweitern.
• Dieses wird mittelsL → O zuX+3 = {L, T,A,O }.
• Abschließend kann man mittelsO → K zu
X+4 = {L, T,A,O,K } = U erweitern.
• Also gilt {L, T }+F = U.
Prof. Dr. Dietmar Seipel 235

Vorlesung Datenbanken Wintersemester 2013/14
Wir betrachten nunX = {L }.
L O K T A
• Aufgrund der fdL → O kann manX+1 = {L } zuX+
2 = {L,O }
erweitern.
• Dieses kann man mittelsO → K zuX+3 = {L,O,K } erweitern.
• Also gilt {L }+F = {L,O,K }.
Prof. Dr. Dietmar Seipel 236

Vorlesung Datenbanken Wintersemester 2013/14
Eine fdX → Y folgt ausF , genau dann wennY ⊆ X+F gilt.
• Wegen{L, T }+F = {L, T,A,O,K } folgen ausF u.a. die fds
LT → A, LT → O, LT → K, LT → OK, LT → L.
• Die fd LT → L ist trivial, da die rechte Seite eine Teilmenge der linken
ist. Diese fd gilt in allen Relationen über der AttributmengeU .
• Wegen{L }+F = {L,O,K } folgen ausF u.a. die fds
L → K, L → OK.
• Die fdsL → A undT → A folgen nicht ausF . UmA zu erhalten
braucht manL undT zusammen.
Insbesondere folgen ausF natürlich auch alle fds, die bereits inF enthalten
sind.
Prof. Dr. Dietmar Seipel 237
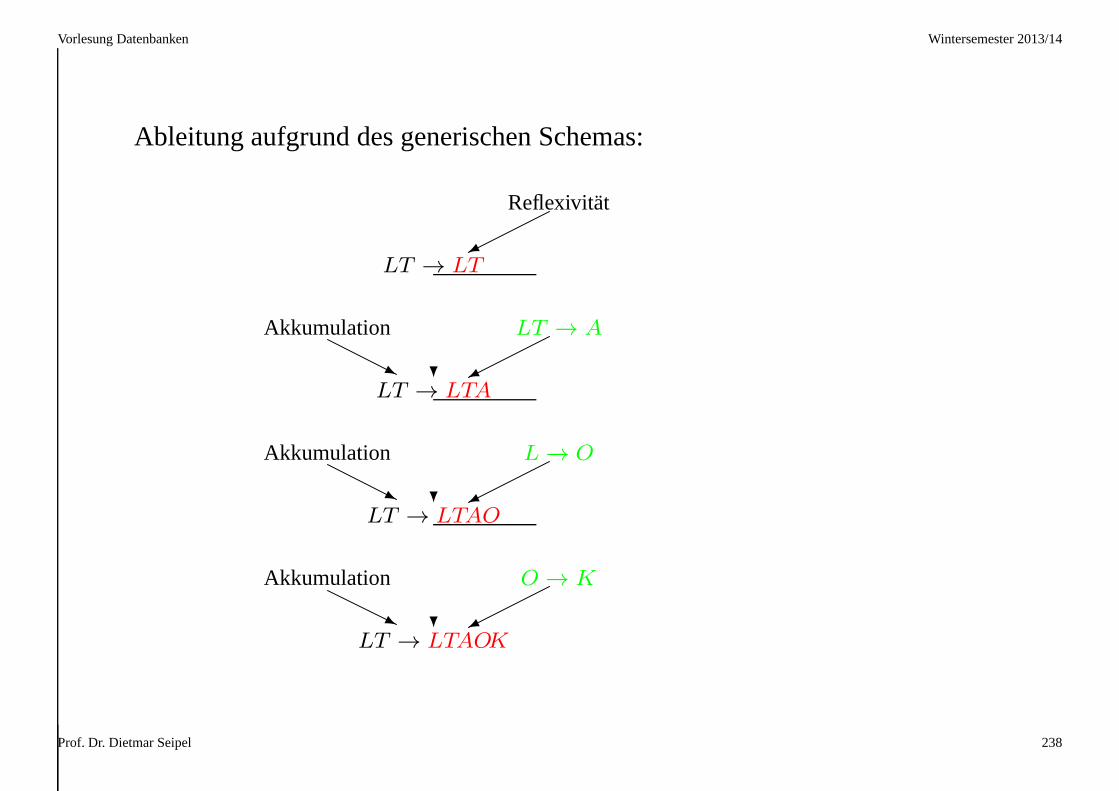
Vorlesung Datenbanken Wintersemester 2013/14
Ableitung aufgrund des generischen Schemas:
Reflexivität
�LT → LT
LT → A
LT → LTA
L → O
O → K
Akkumulation
Akkumulation
Akkumulation
LT → LTAO
LT → LTAOK
?
?
?
�
�
�
j
j
j
Prof. Dr. Dietmar Seipel 238

Vorlesung Datenbanken Wintersemester 2013/14
Schlüssel, Oberschlüssel
SeiR = (U, F ) ein Relationenschema undX ⊆ U .
1. X heißtOberschlüsselvonR, fallsX+F = U ,
2. Ein minimaler OberschlüsselX heißtSchlüsselvonR(d.h., es gibt keinen kleineren OberschlüsselX ′ ( X).
Ein Schlüssel ist also eine minimale AttributmengeX mit X → U .
Beispiel (Schlüssel, Oberschlüssel)
Sei wiederF = {LT → A,L → O,O → K }.
• L undT müssen in jedem Schlüssel vorkommen, da sie in keiner fd aufder rechten Seite vorkommen.
• X = {L, T } ist wegenX+F = U bereits ein Oberschlüssel, und somit
dereindeutige SchlüsselvonR.
Prof. Dr. Dietmar Seipel 239

Vorlesung Datenbanken Wintersemester 2013/14
Algorithmus K EY
Input: Ein RelationenschemaR = (U, F ) mit U = {A1, . . . , Am }.
Output: Ein SchlüsselK ⊆ U für R
K := U ;
FOR (i := 1 tom) DO
K′ := K \ {Ai};
IF (K′ ist Oberschlüssel vonR)
THEN K := K′;
Unterschiedliche ReihenfolgenA1, . . . , Am der Attribute können
verschiedene Schlüssel liefern.
Jedes Attribut, das nicht in der rechten Seite einer fd auftritt,
ist in jedem Schlüssel enthalten.
Prof. Dr. Dietmar Seipel 240

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Algorithmus KEY)
SeiR = (U, F ) mit
U = {A,B,C },
F = {AB → C,C → B }.
Es gibt zwei Schlüssel:K1 = {A,C }, K2 = {A,B }. Offensichtlich kannmanA nicht weglassen, da es nicht auf der rechten Seite einer fd auftritt.
• Für die ReihenfolgeA1 = A, A2 = B, A3 = C, wird der SchlüsselK1
berechnet, daA1 nicht weggelassen werden kann,A2 dann aber schon,undA3 dann wieder nicht.
• Für die ReihenfolgeA1 = A, A2 = C, A3 = B, wird der SchlüsselK2
durch Weglassen vonC berechnet.
Ebenso hatR = (U, F ) mit U = {A,B } undF = {A → B,B → A } zweiSchlüssel:K1 = {A }, K2 = {B }.
Prof. Dr. Dietmar Seipel 241

Vorlesung Datenbanken Wintersemester 2013/14
A B D E C G
+?
−
SeiR = (U, F ) mit
U = {A,B,C,D,E,G },
F = {AB → C,ACD → EG,ACE → DG }.
Offensichtlich sindA undB in jedem Schlüssel enthalten, da sie nicht auf
der rechten Seite einer fd auftreten. WegenC ∈ {A,B }+F ist C in keinem
Schlüssel enthalten. AuchG ist in keinem Schlüssel enthalten, da es auf der
rechten Seite von fds und nur da auftritt.
Also kann manA undB nicht weglassen,C undG muß man dagegen
weglassen. Wir setzen also immerA1 = A, A2 = B, A3 = C, A4 = G.
• FürA5 = D, A6 = E wird der SchlüsselK1 = {A,B,E } berechnet.
• FürA5 = E, A6 = D wird der SchlüsselK2 = {A,B,D } berechnet.
In beiden Fällen kannA5 weggelassen werden, und danachA6 nicht.
Prof. Dr. Dietmar Seipel 242

Vorlesung Datenbanken Wintersemester 2013/14
Vereinfachung von fd–Mengen
Manchmal können fd–MengenF durch Verkleinerung der rechten bzw.
linken Seiten vereinfacht werden.
Definition (Rechts– und links–minimale fds)
Eine fdX → Y ∈ F heißt
1. rechts–minimal, fallsY = {A} einelementig ist.
2. links–minimal, falls es keinX ′ ( X mit X ′ → Y ∈ F+ gibt.
Beispiel (Minimalität)
Alle fds inF = {LT → A,L → O,O → K } sind rechts– und
links–minimal.
Prof. Dr. Dietmar Seipel 243

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Zerlegung und Vereinigung)
1. Aufgrund der Zerlegungs– und der Vereinigungsregel ist die MengeF
äquivalent zur MengeG von rechts–minimalen fds:
F = {X → A1 . . . Am },
G = {X → A1, . . . , X → Am }.
2. Man darf also die rechte Seite einer fd aufsplitten:
X → AB ist äquivalent zu zwei rechts–minimalen fds
X → A undX → B.
3. Die linke Seite einer fd darf man aber nicht aufsplitten:
AB → Y ist schwächer alsA → Y undB → Y .
Sowohl ausA → Y als auch ausB → Y folgt AB → Y ,
aber nicht umgekehrt.
Prof. Dr. Dietmar Seipel 244

Vorlesung Datenbanken Wintersemester 2013/14
4. Manchmal kann man die linke Seite einer fd im Kontext einerfd–Menge
verkleinern:
Die fd AB → C ist nicht links–minimal in
F = {AB → C, A → B }.
Sie kann zuA → C verkleinert werden, daA → B gilt.
Die Menge
G = {A → C, A → B }
von links–minimalen fds ist äquivalent zuF .
Alle fds inF undG sind rechts–minimal.
Zu jeder fd–MengeF gibt es (mindestens) eine äquivalente MengeG von
rechts– und links–minimalen fds.
Prof. Dr. Dietmar Seipel 245

Vorlesung Datenbanken Wintersemester 2013/14
Links–Minimalität
Analog zur Schlüsselberechnung kann man eine fdX → Y ∈ F mit
X = {A1, . . . , Am }
wie folgt links–minimal machen:
X ′ := X ;
FOR (i := 1 tom) DO
X ′′ := X ′ \ {Ai};
IF F |= X ′′ → Y
THEN X ′ := X ′′;
Am Ende istX ′ → Y ∈ F+ links–minimal undX ′ ⊆ X .
Genau wie bei der Schlüsselberechnung können wir – je nach der
Reihenfolge derAi – unterschiedliche Ergebnisse erhalten.
Prof. Dr. Dietmar Seipel 246

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Links–Minimalität)
SeiR = (U, F ) mit
U = {A,B,C },
F = {AB → C,A → B, B → A }.
Die fd AB → C ist nicht links–minimal.
• Für die ReihenfolgeA1 = A, A2 = B wird die links–minimale fd
B → C berechnet, daA1 weggelassen werden kann, undA2 dann aber
nicht.
• Für die ReihenfolgeA1 = B, A2 = A wird die links–minimale fd
A → C berechnet, daA1 weggelassen werden kann, undA2 dann aber
nicht.
Prof. Dr. Dietmar Seipel 247

Vorlesung Datenbanken Wintersemester 2013/14
Projektion von Relationenschemas
Definition (Projektion)
Die ProjektionΠV (R) = (V,ΠV (F )) eines RelationenschemasR = (U, F )
auf eine AttributmengeV ⊆ U ist gegeben durch
ΠV (F ) = {X → Y ∈ F+ | XY ⊆ V }.
Eigenschaften (Projektion)
1. FallsF in einer Relationr überU gilt, so giltΠV (F ) in ΠV (r).X → Y gilt in R, fallsX ein Oberschlüssel vonΠXY (R) ist.
2. Im schlechtesten Fall ist die Berechnung vonΠV (F ) sehr aufwendig – genau so
komplex wie die vonF+. In der Praxis ist sie aber meist nicht so schwierig.
Es genügt z.B., zu jedemX ⊆ V , das Obermenge der linken Seite einer fd ausF
ist, die fdX → Y , mit Y = (X+
F \X) ∩ V , zu berechnen, um eine zuΠV (F )
äquivalente Menge zu erhalten.
Prof. Dr. Dietmar Seipel 248

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Projektionen von Lieferant)
In der ProjektionΠLK(r) der Lieferantenrelationr gilt die fdL → K. Man
erhält sie durch transitive Verknüpfung vonL → O undO → K.
ΠLK (r) :
L K
L1 600
L2 450
L3 450
L4 150
L ist ein Oberschlüssel vonΠLK (R) = (LK,ΠLK(F )). In R ist L kein
Oberschlüssel, da ein Lieferant in der Regel mehrere Teile liefert.
Es giltΠLK (F ) ≡ {L → K }.
Prof. Dr. Dietmar Seipel 249

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Projektionen von Lieferant)
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K }.
3 Projektionen
ΠLTA(F ) ≡ {LT → A },
ΠLO(F ) ≡ {L → O },
ΠLK (F ) ≡ {L → K }.
Hier wurden triviale fds weggelassen, da sie redundant sind.
• FürV = LTA undX = L gilt X+F = LOK und(X+
F \X) ∩ V = ∅.
• FürV = LK erhalten wir die fdL → K ausL → O undO → K.
Die fd O → K ist in keiner der drei Projektionen erhalten. Man könnte sie
aber im Join der beiden Projektionen aufLO bzw.LK überprüfen.
Prof. Dr. Dietmar Seipel 250

Vorlesung Datenbanken Wintersemester 2013/14
V
E
B
CA
D
-N
Beispiel (Projektion einer fd–Menge)
U = {A,B,C,D,E, I },
F = {A → E,BE → C }.
FürV = {A,B,C,D } erhält man die Projektion
ΠV (F ) ≡ {AB → C }.
Es genügt die MengeX = {A,B} ⊆ V zu betrachten:
• Zur Ableitung einer fd ausΠV (F ) muß man mit einer fd starten,
deren linke Seite inV liegt. Die einzige solche fd istA → E.
• Wenn man{A}+F = {A,E} umB erweitert, so kann man die zweite fd
BE → C anwenden.
• Man erhält{A,B}+F = {A,B,C,E}, d.h.AB → C ∈ ΠV (F ).
Um AB → C abzuleiten muß man zwischenzeitlichV verlassen.
Prof. Dr. Dietmar Seipel 251

Vorlesung Datenbanken Wintersemester 2013/14
3.3 Normalformen
Definition (1NF)
Ein RelationenschemaR = (U, F ) ist in erster Normalform(1NF),fallsU nur atomare Attribute enthält, d.h. keine mehrwertigen oderzusammengesetzten Attribute.
Ein Relationenschema, das nicht in 1NF ist, und eine Ausprägung davon:
DMGRSSNDNAME DLOCATIONSDNUMBER
DEPARTMENT
DEPARTMENT
DNAME DNUMBER DMGRSSN DLOCATIONS
Headquarters 1 111111111 {Houston}
Administration 4 333333333 {Stafford}
Research 5 222222222 {Bellaire, Sugarland, Houston}
Prof. Dr. Dietmar Seipel 252

Vorlesung Datenbanken Wintersemester 2013/14
Normalisierung auf 1NF
Relation in 1NF mit Redundanz:
DEPARTMENT
DNAME DNUMBER DMGRSSN DLOCATION
Headquarters 1 111111111 Houston
Administration 4 333333333 Stafford
Research 5 222222222 Bellaire
Research 5 222222222 Sugarland
Research 5 222222222 Houston
Der eindeutige Schlüssel istK = {DNUMBER, DLOCATION }.
Es gilt die fd{DNUMBER} → {DNAME, DMGRSSN}, obwohl die linkeSeite kein Oberschlüssel ist. Deswegen sind die Werte zu denAttributen ausder rechten Seite redundant gespeichert.
Prof. Dr. Dietmar Seipel 253

Vorlesung Datenbanken Wintersemester 2013/14
Wir werden später sehen, daß man diese Relation verlustfreiin die folgenden
zwei Relationen zerlegen kann, um die Redundanz zu beseitigen:
DEPARTMENT
DNAME DNUMBER DMGRSSN
Headquarters 1 111111111
Administration 4 333333333
Research 5 222222222
DEPT_LOCATIONS
DNUMBER DLOCATION
1 Houston
4 Stafford
5 Bellaire
5 Sugarland
5 Houston
In der Tabelle DEPT_LOCATIONS werden lediglich die Werte des Attributs
DNUMBERrepliziert (z.B. der Wert 5), das die Verbindung zum Schlüssel
der Tabelle DEPARTMENT herstellt (Fremdschlüsselbedingung).
Prof. Dr. Dietmar Seipel 254

Vorlesung Datenbanken Wintersemester 2013/14
Weitere Normalformen
Definition (Schlüsselattribut)
SeiR = (U, F ) ein Relationenschema.
1. A ∈ U heißtSchlüsselattribut, bzw.prim,falls es einen SchlüsselK für R gibt mit A ∈ K.
2. Andernfalls heißt ANichtschlüsselattribut(NSA).
Beispiel (Schlüssel von Lieferant)
Der eindeutige Schlüssel für das LieferantenschemaR = (U, F ) mit
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K },
istK = {L, T }. Deswegen sind die AttributeL undT prim, undA, O undK sind Nichtschlüsselattribute.
Prof. Dr. Dietmar Seipel 255

Vorlesung Datenbanken Wintersemester 2013/14
Definition (2NF)
Ein 1NF–RelationenschemaR = (U, F ) ist in zweiter Normalform(2NF),
falls für jedesNSAA ∈ U und jeden SchlüsselK für R gilt, daß die fd
K → A links–minimalist.
Beispiel (2NF)
Das Lieferantenschema
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K },
ist nicht in2NF, da die fdLT → O zum eindeutigen SchlüsselK = {L, T }
wegenL → O nicht links–minimal ist, und daO ein NSA ist.
Prof. Dr. Dietmar Seipel 256

Vorlesung Datenbanken Wintersemester 2013/14
Definition (Normalformen: 3NF, BCNF)
SeiR = (U, F ) ein Relationenschema in 1NF.
1. Eine nicht–triviale fdX → Y heißt3NF–verletzend,
fallsX kein Oberschlüssel vonR ist, d.h. fallsX+F 6= U gilt,
und falls es ein NichtschlüsselattributA ∈ Y \X gibt.
2. R ist in dritter Normalform(3NF),
falls es keine 3NF–verletzende fdX → Y ∈ F gibt.
3. Eine nicht–triviale fdX → Y heißtBCNF–verletzend,
fallsX kein Oberschlüssel vonR ist, d.h. fallsX+F 6= U gilt.
4. R ist in Boyce–Codd–Normalform(BCNF),
falls es keine BCNF–verletzende fdX → Y ∈ F gibt.
Da jede 3NF–verletzende fd auch BCNF–verletzend ist, folgtaus der BCNF
die 3NF. Später zeigen wir auch, daß aus der 3NF die 2NF folgt.
Prof. Dr. Dietmar Seipel 257

Vorlesung Datenbanken Wintersemester 2013/14
Beispiele (Normalformen: Vergleich und Abgrenzung)
1. SeiR = (U, F ) mit U = ABCD undF = {AB → C,BC → D }.
Dann istAB der eindeutige Schlüssel.
• Die fdsAB → C undAB → D zu den NSAs sindlinks–minimal,
• aberBC → D ist 3NF–verletzend.
Deshalb istR zwar in2NF, aber nicht in3NF.
2. SeiR = (U, F ) mit U = ABC undF = {AB → C,C → B }.
Dann gibt es die zwei SchlüsselAB undAC.
• Folglich sind alle Attributeprim.
• AberC → B ist BCNF–verletzend.
Deshalb istR zwar in3NF, aber nicht inBCNF.
Prof. Dr. Dietmar Seipel 258

Vorlesung Datenbanken Wintersemester 2013/14
Definition (Transitive Abhängigkeit) X/←→ Y → A
SeiR = (U, F ) ein Relationenschema undX → A ∈ F+, mit A ∈ U .
1. X → A heißttransitiv, falls es eine nicht–triviale fdY → A ∈ F+ gibt,so daßX → Y ∈ F+ undY → X /∈ F+. Dann heißtA auchtransitiv
abhängigvonX , undX/←→ Y → A heißttransitive Kette.
2. Ansonsten heißt die fdX → A direkt.
Beispiel (Lieferant, Department)
1. LT → A ist direkt.
LT/←→ L → O ist eine transitive Kette.
LT/←→ O → K ist eine transitive Kette.
2. {DNUMBER, DLOCATION }/←→ {DNUMBER} → A
ist für A = DNAME undA = DMGRSSNeine transitive Kette.
Prof. Dr. Dietmar Seipel 259

Vorlesung Datenbanken Wintersemester 2013/14
Die MengeF ∗ aller rechts–minimalen fdsX → Ai zu den fds
X → {A1, . . . , An } ∈ F ist äquivalent zuF .
BCNF–verletzende fds ausF ∗ und transitive Ketten korrelieren:
1. Bei einer transitiven KetteX/←→ Y → A ist die fdY → A
BCNF–verletzend, sie muß aber nicht inF ∗ liegen.
Es gibt aber eine fdY ′ → A ∈ F ∗, so daßY ′ ⊆ Y +F , z.B. diejenige fd,
die bei der Hüllenberechnung vonY +F = Y +
F∗ verwendet wird, so daßA
hinzukommt. Dann giltY ′ → X 6∈ F+, sonst wäreY → X ∈ F+.
Also istX/←→ Y ′ → A ebenfalls eine transitive Kette, und
Y ′ → A ∈ F ∗ ist BCNF–verletzend.
2. Für jede BCNF–verletzende fdY → A ∈ F ∗ istX/←→ Y → A eine
transitive Kette.
Prof. Dr. Dietmar Seipel 260

Vorlesung Datenbanken Wintersemester 2013/14
Redundanz und Update–Anomalien
Seir eine erlaubte Instanz eines RelationenschemasR = (U, F ).
• Eine BCNF–verletzende fdX → Y ∈ F bereitet ein Problem.
Dasselbe gilt auch, fallsX → Y nur inF+ enthalten ist.
• DaX kein Oberschlüssel ist, kann es inr verschiedene Tupel mit
denselbenX–Werten geben.
Dann müssen auch dieY –Werte gleich sein, und es kommt zu
Redundanz und zu den bekannten Update–Anomalien.
• FallsY \X allerdings nur Schlüsselattribute enthält, so ist das Problem
nicht ganz so groß, da diese weniger häufig geändert werden.
Dann ist die fd nicht 3NF–verletzend.
Prof. Dr. Dietmar Seipel 261

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Lieferant)
U = {L, T,A,O,K }, F = {LT → A,L → O,O → K }.
Die 3NF–verletzende fdO → K führt zu den bekannten Update–Anomalien.
DaO kein Oberschlüssel ist, gibt es verschiedene Tupel mit denselben
O–Werten, und diese müssen dann auch dieselbenK–Werte haben.
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
Prof. Dr. Dietmar Seipel 262

Vorlesung Datenbanken Wintersemester 2013/14
Aus der Korrelation zwischen BCNF/3NF–verletzenden fds und transitivenKetten ergibt sich der folgende Satz.
Satz (Normalformen)
SeiR = (U, F ) ein Relationenschema in 1NF.
1. R ist in 3NF, falls für jedesNSAA ∈ U und jeden SchlüsselK gilt,daß die fdK → A direkt ist.
2. R ist in BCNF, falls für jedesAttribut A ∈ U und jeden SchlüsselK gilt,daß die fdK → A direkt ist.
Da direkte fds auch links–minimal sind, folgt weiter:
Satz (Normalformen)
SeiR = (U, F ) ein Relationenschema in 1NF.
1. IstR in BCNF, so istR auch in 3NF.
2. IstR in 3NF, so istR auch in 2NF.
Prof. Dr. Dietmar Seipel 263

Vorlesung Datenbanken Wintersemester 2013/14
Beispiele (Normalformen: Vergleich und Abgrenzung)
1. SeiR = (U, F ) mit U = ABCD undF = {AB → C,BC → D }.
Dann istAB der eindeutige Schlüssel.R ist zwar in2NF, aber wegen
der folgenden transitiven Kette nicht in3NF:
AB/←→ BC → D.
2. SeiR = (U, F ) mit U = ABC undF = {AB → C,C → B }.
Dann gibt es die zwei SchlüsselAB undAC, und alle Attribute sind
prim. R ist zwar in3NF, aber wegen der folgenden transitiven Ketten
nicht inBCNF:
AB/←→ C → B, AC
/←→ C → B.
Prof. Dr. Dietmar Seipel 264

Vorlesung Datenbanken Wintersemester 2013/14
Satz (3NF–Test, BCNF–Test)
SeiR = (U, F ) ein Relationenschema in 1NF.
Das Problem zu entscheiden,
1. ob ein AttributA ∈ U prim ist, istNP–vollständig.
2. obR in 3NF ist, istNP–vollständig.
3. obR in BCNF ist, ist in polynomieller Zeit lösbar.
In praktischen Beispielen ist die Anzahl|U | der Attribute und die Anzahl|F |
der funktionalen Abhängigkeiten aber nicht sehr groß.
Deswegen stellen die (asymptotischen) Komplexitätsresultate zur
NP–Vollständigkeit kein Problem dar.
Prof. Dr. Dietmar Seipel 265

Vorlesung Datenbanken Wintersemester 2013/14
Wir werden später sehen, wie wir ein RelationenschemaR = (U, F )
aufgrund seiner fds verlustfrei in kleinere Relationenschemata in 3NF bzw.
BCNF zerlegen können.
Dazu verwenden wir
1. 3NF–kompatible bzw.
2. BCNF–verletzende fds.
Definition (3NF/BCNF–Kompatibilität)
SeiR = (U, F ) ein Relationenschema.
Eine fdX → Y heißt3NF–kompatibel(BCNF–kompatibel),
falls das RelationenschemaΠXY (R) in 3NF (BCNF) ist.
Prof. Dr. Dietmar Seipel 266

Vorlesung Datenbanken Wintersemester 2013/14
Satz (3NF–Kompatibilität)
Jedelinks–minimaleundrechts–minimalefd X → A ∈ F+ in einemRelationenschemaR = (U, F ) ist 3NF–kompatibel.
Beweis.AngenommenR′ = ΠXA(R) ist nicht in 3NF.
Dann gibt es eine transitive KetteXA/←→ Y → A′ zu einem NSAA′ ∈ XA,
mit A′ /∈ Y . WegenY 6→ XA folgt Y A′ ( XA.
Wir betrachten zwei Fälle:
1. A = A′: Es folgtY ( X , und es gilt die fdY → A.Also istX → A nicht links–minimal.�
2. A 6= A′: In diesem Fall folgtA′ ∈ X . DaA′ ein NSA undX einOberschlüssel vonR′ ist, existiert ein SchlüsselK ( X mit A′ /∈ K.Es gilt dannK → A, d.h.X → A ist nicht links–minimal.�
Also ist das SchemaR′ in 3NF, d.h.X → A ist 3NF–kompatibel.
Prof. Dr. Dietmar Seipel 267

Vorlesung Datenbanken Wintersemester 2013/14
3.4 Mehrwertige und Verbund–Abhängigkeiten
Die Join–Bedingung⊲⊳ (U1, . . . , Uk) besagt, daß man eine Relationr
verlustfrei in die ProjektionenΠUi(r) zerlegen kann:
r = ΠU1(r) ⊲⊳ . . . ⊲⊳ ΠUk
(r)
r
ΠU1(r) ΠUk
(r). . .� ^
Eine mehrwertige Abhängigkeit ist eine Join–Bedingung mitk = 2.
Wir können sie alsX →→ Y |Z schreiben, wobei
X = U1 ∩ U2, Y = U1 \ U2, Z = U2 \ U1.
Eine Menge{X →→ Y1, . . . , X →→ Ym } von mvds mit derselben linken
SeiteX kann alsX →→ Y1 |Y2 | . . . |Ym abgekürzt werden.
Prof. Dr. Dietmar Seipel 268

Vorlesung Datenbanken Wintersemester 2013/14
Mehrwertige Abhängigkeiten sindintra–relationale Abhängigkeiten,
Verbund–Abhängigkeiten sindinter–relational.
Falls ein Relationenschemamehrwertige Attributeenthält,
so gelten in der 1NF–Normalisierung mehrwertige Abhängigkeiten.
Beispiel (Mehrwertige Abhängigkeit)
Wir betrachten ein Relationenschema mit der AttributmengeU = ABC und
zwei mehrwertigen AttributenB undC:
r′:
A B C
a1 { b1, b2 } { c1, c2, c3 }
a2 { b3 } { c3, c4 }
Prof. Dr. Dietmar Seipel 269

Vorlesung Datenbanken Wintersemester 2013/14
1. Dann ist die 1NF–Normalisierung vonr′ gegeben durchr.
ZwischenB undC besteht inr eigentlich keindirekter Zusammenhang.
Dies wird durch die mvd{A} →→ {B} | {C} ausgedrückt.
r:
A B C
a1 b1 c1
a1 b1 c2
a1 b1 c3
a1 b2 c1
a1 b2 c2
a1 b2 c3
a2 b3 c3
a2 b3 c4
r1:
A B
a1 b1
a1 b2
a2 b3
r2:
A C
a1 c1
a1 c2
a1 c3
a2 c3
a2 c4
2. Äquivalent kann manr undr′ mit den zwei Relationenr1 = ΠAB(r)
undr2 = ΠAC(r) repräsentieren. Man erhältr dann als deren Natural
Join: r = r1 ⊲⊳ r2.
Prof. Dr. Dietmar Seipel 270

Vorlesung Datenbanken Wintersemester 2013/14
Man kann die Relationr′, die nicht in 1NF ist, zuerst zu einer 1NF–Relation
r normalisieren. Dann kann manr mittels einer Dekompositions–Methode,
die wir im nächsten Abschnitt kennen lernen werden, verlustfrei in zwei
kompaktere Relationenr1 undr2 zerlegen:
r′
r r1, r2
Dekomposition
Normalisierung ER 7→ relational
?-R
Alternativ können wir die beiden Relationenr1 undr2 auch durch die bereits
bekannte Abbildung vom ER–Modell ins relationale Modell erhalten.
Schließlich könnte manr′ auch zuerst inr′1 undr′2 zerlegen, und diese dann
zu r1 undr2 normalisieren.
Prof. Dr. Dietmar Seipel 271

Vorlesung Datenbanken Wintersemester 2013/14
Die verlustfreie Zerlegbarkeit einer Relationr in zwei Projektionen
r1 = ΠU1(r) undr2 = ΠU2
(r) bedeutet, daßr = r1 ⊲⊳ r2 gilt.
• In unserem Beispiel sind die beiden mvds{A} →→ {B} bzw.
{A} →→ {C}, die inr gelten, verantwortlich für die verlustfreie
Zerlegbarkeit. Wir werden sehen, daß die beiden mvds äquivalent sind.
• Wir werden zeigen, daß sich eine Relation genau dann verlustfrei in zwei
ProjektionenΠU1(r) undΠU2
(r) zerlegen läßt, wenn die beiden
äquivalenten mvdsU1 ∩ U2 →→ U1 \ U2 undU1 ∩ U2 →→ U2 \ U1
gelten.
• Solche Datenabhängigkeiten nennen wir auch binäre
Verbundabhängigkeiten (Join Dependencies, jds),
und wir schreiben⊲⊳ (U1, U2).
• In unserem Beispiel gilt die jd⊲⊳ ({A,B}, {A,C}) in r.
Prof. Dr. Dietmar Seipel 272

Vorlesung Datenbanken Wintersemester 2013/14
Definition (Mehrwertige Abhängigkeit, mvd)
SeiU eine Attributmenge, sowieX, Y ⊆ U undZ = U \XY .
1. Einemehrwertige Abhängigkeit(engl.: multivalued dependency, mvd)
X →→ Y gilt für eine Relationr überU , falls
∀µ, ν ∈ r : ( µ[X ] = ν[X ] ⇒
( ∃ρ ∈ r : ρ[X ] = µ[X ] = ν[X ] ∧
ρ[Y ] = µ[Y ] ∧ ρ[Z] = ν[Z] ) ).
2. Eine mvdX →→ Y heißt trivial, fallsY ⊆ X oder fallsX ∪ Y = U ;
sie gilt in allen Relationen.
Logische Folgerung: SieΣ eine Menge von Datenabhängigkeiten undδ
eine einzelne Datenabhängigkeit:
Σ |= δ, falls in jeder Relationr, in welcherΣ gilt, auchδ gilt.
Prof. Dr. Dietmar Seipel 273

Vorlesung Datenbanken Wintersemester 2013/14
• Während eine fdX → Y mit X ∪ Y = U ausdrückt, daßX ein
Oberschlüssel ist, ist eine entsprechende mvdX →→ Y trivial.
Zum Beweis nehme manρ = µ: dann giltρ[Y ] = µ[Y ], und da
Z = U \XY = ∅ ist, gilt automatisch auchρ[Z] = ν[Z].
• Eine Relationr überU mit einer mvdX →→ Y , wobeiZ = U \XY ,
könnte man besser als eineNF 2–Relationr′ repräsentieren,
r:
µ
ν
ρ
ρ′
X Y Z
x y1 z1
x y2 z2
x y1 z2
x y2 z1
r′:X Y Z
x { y1, y2 } { z1, z2 }
oder als zwei RelationenΠXY (r) undΠXZ(r).
Prof. Dr. Dietmar Seipel 274

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Dekomposition)
SeienX, Y ⊆ U undZ = U \XY .
Dann gilt die mvdX →→ Y in einer Relationr überU , g.d.w.
r = ΠXY (r) ⊲⊳ ΠXZ(r).
D.h. die Zerlegung inU1 = XY undU2 = XZ ist verlustfrei:
U = XYZ
U1 = XY U2 = XZ
X →→ Y R
Der folgende Beweis verwendet wiederholt eine – triviale – Eigenschaft von
Tupelnt: (t[X1])[X2] = t[X2], falls X2 ⊆ X1 ⊆ def (t).
Prof. Dr. Dietmar Seipel 275

Vorlesung Datenbanken Wintersemester 2013/14
Beweis.
“⇒”: AngenommenX →→ Y gilt in r.
Es genügt zu zeigen:r ⊇ ΠXY (r) ⊲⊳ ΠXZ(r).
Sei alsoρ ∈ ΠXY (r) ⊲⊳ ΠXZ(r). Dann existieren Tupel
µ′ = ρ[XY ] ∈ ΠXY (r),
ν′ = ρ[XZ] ∈ ΠXZ(r).
Somit existieren auch Tupelµ, ν ∈ r mit µ′ = µ[XY ], ν′ = ν[XZ].
Nun folgt
µ[X ] = µ′[X ] = ρ[X ] = ν′[X ] = ν[X ],
µ[Y ] = µ′[Y ] = ρ[Y ],
ν[Z] = ν′[Z] = ρ[Z].
Aus der Gültigkeit vonX→→Y in r folgt nunρ ∈ r.
Prof. Dr. Dietmar Seipel 276

Vorlesung Datenbanken Wintersemester 2013/14
“⇐”: Angenommenr = ΠXY (r) ⊲⊳ ΠXZ(r).
Seienµ, ν ∈ r mit µ[X ] = ν[X ], und sei
µ′ = µ[XY ] ∈ ΠXY (r),
ν′ = ν[XZ] ∈ ΠXZ(r).
Sei das Tupelρ gegeben durch
ρ[X ] = µ[X ] = ν[X ],
ρ[Y ] = µ[Y ],
ρ[Z] = ν[Z].
Dann giltρ ∈ ΠXY (r) ⊲⊳ ΠXZ(r) = r.
Also gilt die mvdX →→ Y in r.
Prof. Dr. Dietmar Seipel 277

Vorlesung Datenbanken Wintersemester 2013/14
Inferenzregeln für mvds
Das folgende Regelsystem (M1)–(M4) ist vollständig und korrekt für mvds.
SeienX, Y, Z,W,W ′ ⊆ U :
(M1) Komplement:
{X →→ Y } ⊢ X →→ U \ Y, X →→ U \ (XY ).
(M2) Reflexivität (triviale mvd):
∅ ⊢ X →→ Y , fallsY ⊆ X .
(M3) Erweiterung:
{X →→ Y } ⊢ XW →→ YW ′, fallsW ′ ⊆ W .
(M4) Pseudo–Transitivität:
{X →→ Y, Y →→ Z } ⊢ X →→ Z \ Y .
Prof. Dr. Dietmar Seipel 278

Vorlesung Datenbanken Wintersemester 2013/14
Inferenzregeln für fds und mvds
SeienX, Y,X ′, Y ′ ⊆ U
(FM1) Replikation:
{X → Y } ⊢ X →→ Y.
(FM2) Koaleszenz:
{X →→ Y, X ′ → Y ′ } ⊢ X → Y ∩ Y ′, fallsX ′ ∩ Y = ∅.
Satz (Kalkül für fds und mvds)
SeiΣ = F ∪M eine Menge von fds und mvds. Dann ist die Regel–Menge
{ (F1),(F2),(F3), (M1),(M2),(M3),(M4), (FM1),(FM2)}
vollständig und korrekt zur Ableitung der ausΣ folgenden fds und mvds.
Prof. Dr. Dietmar Seipel 279

Vorlesung Datenbanken Wintersemester 2013/14
Weitere Inferenzregeln für mvds, Vergleich mit fds
1. Man kann die rechte und linke Seite einer mvd disjunkt machen,
denn ausX →→ Y folgt X →→ Y \X.
2. Partitions–Regel: Man kann die rechten Seiten von mvds zur selben
linken SeiteX disjunkt machen, denn ausX →→ Y |Z folgt
X →→ Y ∩ Z |Y \ Z |Z \ Y.
Y Z
Y \ Z
Y ∩ Z
Z \ Y
� 6 K
3. Vereinigungs–Regel: Man kann die rechten Seiten von mvdszur selben
linken SeiteX vereinigen, denn ausX →→ Y |Z folgt X →→ Y ∪ Z.
Prof. Dr. Dietmar Seipel 280

Vorlesung Datenbanken Wintersemester 2013/14
4. Wegen der Vereinigungs–Regel folgt aus
X →→ Y ∩ Z |Y \ Z |Z \ Y
auchX →→ Y |Z, denn
Y = (Y ∩ Z) ∪ (Y \ Z),
Z = (Y ∩ Z) ∪ (Z \ Y ).
5. Also istX →→ Y |Z äquivalent zuX →→ Y ∩ Z |Y \ Z |Z \ Y.
Z.B. istA →→ BC |CD äquivalent zuA →→ B |C |D, denn für
Y = BC undZ = CD gilt Y ∩ Z = C, Y \ Z = B, Z \ Y = D.
6. Die Zerlegungs–Regel gilt für mvds nicht:
X →→ Y ∪ Z ist schwächer alsX →→ Y |Z.
Dagegen ist eine fdX → Y ∪ Z wegen der Zerlegungs– und der
Vereinigungs–Regel zur Menge{X → Y, X → Z } von fds äquivalent.
Prof. Dr. Dietmar Seipel 281

Vorlesung Datenbanken Wintersemester 2013/14
X Y1. . . Ym
AbhängigkeitsbasisDEPG(X)
SeiG eine Menge von mvds undX = {A1, . . . , An} ⊆ U.
1. Aus der Reflexivitäts– und der Partitions–Regel folgt, daß es eine
eindeutige Partition
DEPG(X) = {
Ym+1
︷ ︸︸ ︷
{A1}, . . . ,
Ym+n
︷ ︸︸ ︷
{An}, Y1, . . . , Ym }
vonU gibt, so daßG |= X →→ Y gilt, genau dann wenn
• es MengenYi1 , . . . , Yik ∈ DEPG(X) gibt
• mit Y = Yi1 ∪ . . . ∪ Yik .
2. Wir schreiben dannX →→ Y1 |Y2 | . . . |Ym.
Prof. Dr. Dietmar Seipel 282

Vorlesung Datenbanken Wintersemester 2013/14
Vergleich von fds und mvds
Für eine AttributmengeX entspricht die AbhängigkeitsbasisDEPG(X) für
mvds der AttributhülleX+F für fds:
1. Für eine mvd–MengeG undX, Y ⊆ U gilt
G |= X →→ Y ⇐⇒
∃Yi1 , . . . , Yik ∈ DEPG(X) :
Y = Yi1 ∪ . . . ∪ Yik .
2. Für eine fd–MengeF undX, Y ⊆ U gilt
F |= X → Y ⇐⇒
∃Bi1 , . . . , Bik ∈ X+F :
Y = {Bi1 , . . . , Bik }.
FürYi = {Bi } könnte man auch wiederY = Yi1 ∪ . . . ∪ Yik schreiben.
Prof. Dr. Dietmar Seipel 283

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Abhängigkeitsbasis)
SeienX = {A1, A2}, Y1 = {B1, B2}, Y2 = {B3} undU = X ∪ Y1 ∪ Y2.Dann erhalten wir fürG = {X →→ Y1 } folgende Abhängigkeitsbasis:
DEPG(X) = { {A1}, {A2}, Y1, Y2 }.
A1
A2
B1 B2 B3
X Y1 Y2
1. AusG folgen die mvdsX →→ {A1, B3} undX →→ {B1, B2, B3},wohingegenX →→ {B2, B3} nicht folgt, daB2 nur zusammen mitB1
auf der rechten Seite auftreten darf.
2. Insgesamt gibt es genau 16 mvds der FormX →→ Y , die ausG folgen.Man erhält die MengenY als VereinigungY = Yi1 ∪ . . . ∪ Yik
kompletter BlöckeYij ∈ DEPG(X).
Prof. Dr. Dietmar Seipel 284

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Abhängigkeitsbasis)
FürG = {A →→ BC,DE →→ C } undU = ABCDE, X = A gilt
DEPG(X) = { {A}, {B}, {C}, {D,E} }.
A B C D E
X Y1 Y2 Y3
1. AusA →→ BC folgt A →→ U \ (ABC) = DE mittels derKomplement–Regel.
2. AusA →→ DE undDE →→ C folgt A →→ C mittels derPseudo–Transitivitäts–Regel.
3. AusA →→ BC undA →→ C folgt A →→ (BC) \ C = B.
Prof. Dr. Dietmar Seipel 285

Vorlesung Datenbanken Wintersemester 2013/14
Definition (Verbundabhängigkeit, Join Dependency, jd)
SeiR = (U,Σ) ein Relationenschema zu einer AttributmengeU = ∪ni=1Ui
und einer MengeΣ eine Menge von Datenabhängigkeiten überU .
Die Verbundabhängigkeit
⊲⊳ (U1, . . . , Un)
gilt in R, falls für alle erlaubten Instanzenr vonR gilt:
r = ΠU1(r) ⊲⊳ . . . ⊲⊳ ΠUn
(r).
U1 . . .Un
U1. . . Un
⊲⊳ (U1, . . . , Un) R
Prof. Dr. Dietmar Seipel 286

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (jd)
Wir betrachten die folgenden beiden Relationenr1 undr2,
und die jd δ = ⊲⊳ (AB,BC,CD). In der ersten Relationr1 gilt δ.
r1 :
A B C D
1 1 1 1
1 1 1 2
1 1 2 2
1 2 2 2
2 2 2 2
r2 :
A B C D
1 1 1 1
1 1 1 2
2 1 2 2
In r2 gilt δ nicht, daΠAB(r2) ⊲⊳ ΠBC(r2) ⊲⊳ ΠCD(r2) ) r2 die drei angegebenen
überflüssigen Tupel enthält:
A B
1 1
2 1
B C
1 1
1 2
C D
1 1
1 2
2 2
A B C D
1 1 2 2
2 1 1 1
2 1 1 2
. . . .
Prof. Dr. Dietmar Seipel 287

Vorlesung Datenbanken Wintersemester 2013/14
Folgerung aus dem Dekompositionssatz:
Satz (mvds sind binäre jds)
Es seienX, Y ⊆ U , Z = U \ (XY ) undr eine Relation überU .
Dann gilt die mvdX →→ Y in r, g.d.w. die jd ⊲⊳ (XY,XZ) in r gilt.
Binäre jds
1. Folglich ist jede mvd über paarweise disjunkten MengenX, Y, Z
äquivalent zu einer binären jd:
X →→ Y |Z ⇐⇒ ⊲⊳ (XY,XZ),
2. und umgekehrt:
⊲⊳ (U1, U2) ⇐⇒ U1 ∩ U2 →→ U1 \ U2 | U2 \ U1.
Prof. Dr. Dietmar Seipel 288

Vorlesung Datenbanken Wintersemester 2013/14
Allgemeine jds
1. Eine mvd über paarweise disjunkten MengenX, Y1, . . . , Ym,
X →→ Y1 | Y2 | . . . | Ym,
ist ebenfalls äquivalent zu einer (azyklischen) Join–Dependency
⊲⊳ (XY1, XY2, . . . , XYm),
XY1 . . .Ym
XY1. . . XYm
X →→ Y1 |Y2 | . . . |Ym
RX
Y1
Ym
...
aber nicht jede Join–Dependency ist äquivalent zu einer mvd.
2. Nicht jede jd ist äquivalent zu einer Menge von mvds,denn es gibt Relationen, die verlustfrei in drei (oder mehr)Projektionenzerlegbar sind, aber nicht in zwei.
Prof. Dr. Dietmar Seipel 289

Vorlesung Datenbanken Wintersemester 2013/14
Definition (4NF, 5NF)
Es seiR = (U,Σ) ein Relationenschema in 1NF undΣ eine beliebige Menge
von Datenabhängigkeiten.
1. K ⊆ U heißtOberschlüsselvonR, falls die fdK → U ausΣ folgt.
Ein minimaler Oberschlüssel ist einSchlüssel.
2. K → U heißtSchlüsselabhängigkeit, fallsK ein Schlüssel fürR ist.
3. FallsΣ nur fds und mvds enthält, so istR in vierter Normalform (4NF),
falls die linke SeiteX jeder nicht–trivialen mvd mitΣ |= X →→ Y ein
Oberschlüssel ist, d.h.Σ |= X → U.
4. R ist in fünfter Normalform (5NF)bzw.Projekt–Join–Normalform
(PJNF), falls jede jd mitΣ |= ⊲⊳ (X1, . . . , Xn) alleine aus den
SchlüsselabhängigkeitenK → U vonR folgt.
Prof. Dr. Dietmar Seipel 290

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Normalformen)
SeiR = (U,Σ) ein Relationenschema:
R ist in 5NF⇒ R ist in 4NF⇒ R ist in BCNF.
Die Datenabhängigkeiten in einem 4NF– bzw. 5NF–Relationenschema sind
also äquivalent zu Schlüsselabhängigkeiten.
Deswegen reicht das Konzept der
• Primär– bzw.
• Sekundär–Schlüsselbedingungen
aus SQL (CREATE TABLE ) zur Datenmodellierung aus.
Prof. Dr. Dietmar Seipel 291

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (4NF)
SeiR = (U,Σ) ein Relationenschema mitU = ABC und
Σ = {A →→ B,A →→ C }.
Dann giltΣ |= A →→ B, aberΣ 6|= A → U .
• Deshalb ist Rnicht in 4NF.
• Man kannR aber anhand vonA →→ B |C verlustfreizerlegen in zwei
4NF–Relationenschemata:
ABC
AB AC
A →→ B |C R
Prof. Dr. Dietmar Seipel 292

Vorlesung Datenbanken Wintersemester 2013/14
Ein Instanzr vonR, in derA →→ B undA →→ C gelten, nicht aber
A → U , haben wir bereits gesehen:
r:
A B C
a1 b1 c1
a1 b1 c2
a1 b1 c3
a1 b2 c1
a1 b2 c2
a1 b2 c3
a2 b3 c3
a2 b3 c4
r1:
A B
a1 b1
a1 b2
a2 b3
r2:
A C
a1 c1
a1 c2
a1 c3
a2 c3
a2 c4
Man kannr in die zwei Relationenr1 = ΠAB(r) undr2 = ΠAC(r)
zerlegen, so daß für den Natural Join gilt:r = r1 ⊲⊳ r2.
Prof. Dr. Dietmar Seipel 293

Vorlesung Datenbanken Wintersemester 2013/14
Der HypergraphH zur mvd A →→ B |C bzw. zur entsprehenden jd
⊲⊳ (AB,AC)
ist azyklisch:
H:
A B
C
Ein Hypergraph entspricht einem Mengendiagramm. In einem folgenden
Abschnitt werden wir zyklische bzw. azyklische Hypergraphen definieren.
Prof. Dr. Dietmar Seipel 294

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (4NF, 5NF)
Das Relationenschema
R = (ABC, { ⊲⊳ (AB,AC,BC) })
• ist in 4NF, aber nicht in 5NF:
• es gelten weder nicht–triviale fds noch mvds, und
• der einzige Schlüssel ABC impliziert nicht die jd.
• R kann verlustfrei zerlegt werden in drei 5NF–Relationenschemata:
ABC
AB AC BC
⊲⊳ (AB,AC,BC) R?
Prof. Dr. Dietmar Seipel 295

Vorlesung Datenbanken Wintersemester 2013/14
Der HypergraphH zur Join Dependency
⊲⊳ (AB,AC,BC)
ist zyklisch:
H:
A B
C
Die jd entspricht keiner Menge von mvds.
Prof. Dr. Dietmar Seipel 296

Vorlesung Datenbanken Wintersemester 2013/14
3.5 Verlustfreie Zerlegungen
Definition (Relationales Datenbankschema)
1. Ein relationalesDatenbankschemaD ist eine Menge vonRelationenschemata.
2. D ist in 2NF (3NF, BCNF),falls jedesR ∈ D in 2NF (3NF, BCNF) ist.
ZerlegungvonR in D = {ΠUi(R) | 1 ≤ i ≤ k } :
R
ΠU1(R) ΠUk
(R). . .� ^
r
ΠU1(r) ΠUk
(r). . .� ^
Eine erlaubte Instanzr vonR wird entsprechend zerlegt in eine Datenbankd = {ΠUi
(r) | 1 ≤ i ≤ k } zuD.
Prof. Dr. Dietmar Seipel 297

Vorlesung Datenbanken Wintersemester 2013/14
Definition (Zerlegung)
SeiR = (U, F ) ein Relationenschema undD = { (U1, F1), . . . , (Uk, Fk) }
ein Datenbankschema.
1. D heißtZerlegungvonR, falls gilt:
a) U = U1 ∪ . . . ∪ Uk, und
b) Fi ≡ ΠUi(F ), für alle1 ≤ i ≤ k.
2. Eine ZerlegungD vonR heißt
a) verlustfrei, falls fürR die Join–Bedingung⊲⊳ (U1, . . . , Uk) gilt,
d.h., falls für alle erlaubten Instanzenr überR gilt
r = ΠU1(r) ⊲⊳ . . . ⊲⊳ ΠUk
(r).
b) unabhängig, falls
F ≡ F1 ∪ . . . ∪ Fk.
Prof. Dr. Dietmar Seipel 298

Vorlesung Datenbanken Wintersemester 2013/14
1. Zerlegung:
Alle Attribute ausU bleiben in mindestens einem Relationenschema
(Ui, Fi) erhalten, und die fd–MengenFi sind äquivalent zu den
Projektionen ausF .
2. a) Verlustfreiheit:
Jede erlaubte Instanzr zuR kann als Join der Projektionen
ri = ΠUi(r) rekonstruiert werden.
b) Unabhängigkeit:
Falls eine der Abhängigkeiten vonF nicht in einem der Schemas
(Ui, Fi) ∈ D repräsentiert ist, dann können wir diese Abhängigkeit
nicht in einer einzelnen Relation einer erlaubten Datenbankinstanz
d = { r1, . . . , rk } zuD testen.
In diesem Falle muß man zuerst den Join mehrerer Relationen
ausd berechnen um die Abhängigkeit darin testen zu können.
Prof. Dr. Dietmar Seipel 299

Vorlesung Datenbanken Wintersemester 2013/14
Falls eine Zerlegung
D = { (U1, F1), . . . , (Uk, Fk) }
zwei Relationenschemata(Ui, Fi) und(Uj , Fj) mit sich enthaltenden
AttributmengenUj ( Ui enthält, so kann man das Relationenschema
(Uj , Fj) zur kleineren Attributmenge ausD entfernen.
AusUj ( Ui folgt nämlich für alle Relationenr überU
ΠUi(r) ⊲⊳ ΠUj
(r) = ΠUi(r).
Deswegen gilt für alle erlaubten Instanzenr überR
r = ΠU1(r) ⊲⊳ . . . ⊲⊳ ΠUk
(r) = ⊲⊳1≤i≤k, i 6=j ΠUi(r).
Also istD \ { (Uj , Fj) } immer noch eine verlustfreie Zerlegung.
Prof. Dr. Dietmar Seipel 300

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Zerlegung von Lieferant)
R = (U, F ):
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K }.
1. Die Zerlegung inU1 = LTA, U2 = LO, U3 = OK, mit Fi = ΠUi(F ),
ist verlustfrei und unabhängig. Die Zerlegung ist unabhängig, da jede fd
ausF in einer der drei Projektionen erhalten ist.
2. Die Zerlegung inU1 = LTA, U2 = LO, U3 = LK, mit Fi = ΠUi(F ),
ist verlustfrei. Sie ist aber nicht unabhängig, da die fdO → K in keiner
der drei Projektionen erhalten ist.
Die Verlustfreiheit werden wir später zeigen.
Prof. Dr. Dietmar Seipel 301

Vorlesung Datenbanken Wintersemester 2013/14
r :
L T A O K
L1 T1 300 London 600
L1 T2 200 London 600
L1 T3 400 London 600
L1 T4 200 London 600
L1 T5 100 London 600
L1 T6 100 London 600
L2 T1 300 Paris 450
L2 T2 400 Paris 450
L3 T2 200 Paris 450
L4 T2 200 Brüssel 150
L4 T4 300 Brüssel 150
L4 T5 400 Brüssel 150
Prof. Dr. Dietmar Seipel 302

Vorlesung Datenbanken Wintersemester 2013/14
1. Zerlegung: r = r1 ⊲⊳ r2 ⊲⊳ r3r1 = ΠLTA(r) :
L T A
L1 T1 300
L1 T2 200
L1 T3 400
L1 T4 200
L1 T5 100
L1 T6 100
L2 T1 300
L2 T2 400
L3 T2 200
L4 T2 200
L4 T4 300
L4 T5 400
r2 = ΠLO (r) :
L O
L1 London
L2 Paris
L3 Paris
L4 Brüssel
r3 = ΠOK (r) :
O K
London 600
Paris 450
Brüssel 150
Prof. Dr. Dietmar Seipel 303

Vorlesung Datenbanken Wintersemester 2013/14
2. Zerlegung: r = r1 ⊲⊳ r2 ⊲⊳ r3r1 = ΠLTA(r) :
L T A
L1 T1 300
L1 T2 200
L1 T3 400
L1 T4 200
L1 T5 100
L1 T6 100
L2 T1 300
L2 T2 400
L3 T2 200
L4 T2 200
L4 T4 300
L4 T5 400
r2 = ΠLO (r) :
L O
L1 London
L2 Paris
L3 Paris
L4 Brüssel
r3 = ΠLK (r) :
L K
L1 600
L2 450
L3 450
L4 150
Prof. Dr. Dietmar Seipel 304

Vorlesung Datenbanken Wintersemester 2013/14
3.5.1 BCNF–Dekomposition
Satz (Dekomposition)
Es seiR = (U, F ) mit X → Y ∈ F+ undZ = U \ (XY ).
Dann ist die ZerlegungD = {ΠXY (R),ΠXZ(R) } verlustfrei.
U = XYZ
U1 = XY U1 = XZ
X → Y R
Folglich kann man jede erlaubte Instanzr vonR aus den Projektionen
rekonstruieren alsr = ΠXY (r) ⊲⊳ ΠXZ(r).
Dieser Satz folgt aus dem Dekompositionssatz für mvds,
da jede fdX → Y die entsprechende mvdX →→ Y impliziert.
Prof. Dr. Dietmar Seipel 305

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Dekomposition von Lieferant)
Es seiR = (U, F ) mit
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K }.
FürX → Y = L → O erhalten wirZ = TAK und
R1 = (LO, {L → O }+ ),
R2 = (LTAK , {LT → A,L → K }+ ).
Die fd O → K ∈ F geht bei der Dekomposition verloren, da die AttributeO
undK getrennt werden.
Prof. Dr. Dietmar Seipel 306

Vorlesung Datenbanken Wintersemester 2013/14
Algorithmus D EKOMPOSITION
Input: ein UniversalrelationenschemaR = (U, F )
Output: eine verlustfreie BCNF–ZerlegungD vonR
D := {R };WHILE (D ist nicht in BCNF) DO
{wähleS = ΠV (R) = (V,ΠV (F )) ∈ D
mit einer nicht–trivialen fdX → Y ∈ ΠV (F ),so daßXY ( V ;
ersetzeS in D durchΠXY (S) undΠXZ(S),wobeiZ = V \ (XY );
}
Die Verlustfreiheit zeigt man induktiv aufgrund des Dekompostionssatzes.
Prof. Dr. Dietmar Seipel 307

Vorlesung Datenbanken Wintersemester 2013/14
Alle RelationenschemataS ∈ D sind Projektionen vonR.
• Am Anfang giltD = {R } = {ΠU (R) }.
• Später giltΠW (S) = ΠW (ΠV (R)) = ΠW (R), dennW ⊆ V , fürW = XY undW = XZ.
Wir wollen eine ZerlegungD mit möglichst wenigen Relationenschemataerhalten.
1. Deswegen zerlegt man nur solange, bis alle RelationenschemataS ∈ D
in BCNF sind.
2. Falls bei der Zerlegung RelationenschemataS1 = ΠV1(R) und
S2 = ΠV2(R) mit sich enthaltenden AttributmengenV1 ( V2 entstehen,
so kann man das enthaltene RelationenschemaS1 ausD entfernen.
3. Außerdem kann man zur ZerlegungBCNF–verletzendefds verwenden:Das sind nicht–triviale fdsX → Y ∈ ΠV (F ) mit F 6|= X → V .
Prof. Dr. Dietmar Seipel 308

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Dekompositionen von Lieferant)
Es seiR = (U, F ) mit
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K }.
D1:
LTAOK
LO LTAK
LK LTA
L → O
L → K
R
R
D2:
LTAOK
LTA LTOK
OK LTO
LT → A
O → K
R
R
Prof. Dr. Dietmar Seipel 309

Vorlesung Datenbanken Wintersemester 2013/14
Die erzeugten Zerlegungen vonR = (U, F ) sindverlustfrei:
D1 = {ΠLO(R), ΠLK (R), ΠLTA(R) },
D2 = {ΠLTA(R), ΠOK (R), ΠLTO(R) }.
• D1 ist in BCNF aber nicht unabhängig, denn
O → K /∈ {L → O,L → K,LT → A }+.
Die fd O → K muß inΠLO(r) ⊲⊳ ΠLK (r) getestet werden.
• D2 ist unabhängig aber nicht in BCNF, dennL → O ist
BCNF–verletzend inΠLTO(R).
• Man kannD2 mittelsL → O weiter zuD3 zerlegen:
D3 = {ΠLTA(R), ΠOK (R), ΠLO(R), ΠLT (R) }.
ΠLT (R) ist redundant, da es inΠLTA(R) enthalten ist.
D3 ist in BCNF und unabhängig.
LTO
LO LT
L → O R
Prof. Dr. Dietmar Seipel 310
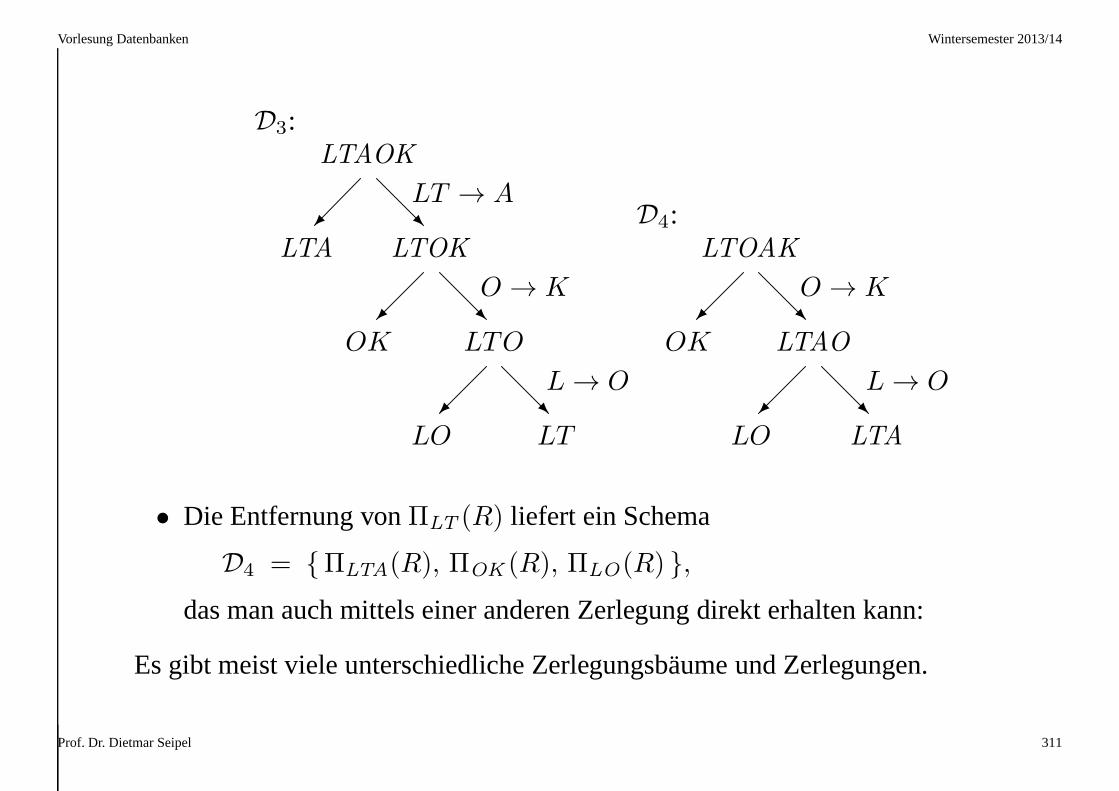
Vorlesung Datenbanken Wintersemester 2013/14
D3:LTAOK
LTA LTOK
OK LTO
LO LT
LT → A
O → K
L → O
R
R
R
D4:LTOAK
OK LTAO
LO LTA
O → K
L → O
R
R
• Die Entfernung vonΠLT (R) liefert ein Schema
D4 = {ΠLTA(R), ΠOK (R), ΠLO(R) },
das man auch mittels einer anderen Zerlegung direkt erhalten kann:
Es gibt meist viele unterschiedliche Zerlegungsbäume und Zerlegungen.
Prof. Dr. Dietmar Seipel 311

Vorlesung Datenbanken Wintersemester 2013/14
Wenn man bei der Berechnung des Natural Joins dem Zerlegungsbaum folgt,
dann sind je zwei zu verbindende Relationen mittels der AttributmengeX
aus der zerlegenden fdX → Y verbunden:
LTOAK
U3 = OK LTAO
U2 = LO U1 = LTA
O → K
L → O
R
R
⊲⊳
r3 ⊲⊳
r2 r1
� I
� I
FallsX 6= ∅, so tritt bei der Berechnung des Natural Joins kein kartesisches
Produkt auf. Hier berechnen wir
r = r1 ⊲⊳ r2 ⊲⊳ r3 = ( r1 ⊲⊳ r2 ) ⊲⊳ r3.
Prof. Dr. Dietmar Seipel 312

Vorlesung Datenbanken Wintersemester 2013/14
Prinzipiell kann man jede nicht–triviale fdX → Y ∈ F+ zur Zerlegungeines RelationenschemasR = (U, F ) heranziehen, fallsX ∪ Y 6= U .
Falls z.B.K ein Schüssel ist undU \K = {A1, . . . , An }, so kann manmittels der fdsK → Ai eine verlustfreie Zerlegung erhalten:
KA1 . . .An
KA2 . . .An
KAn−1An
KAn
KA1
KA2
KAn−1
K → A1
K → An−1
R
R
R
Für einen Schlüssel mit minimaler Kardinalität|K|, sind viele der SchemataΠKAi
(R) schon in BCNF; die restlichen kann man weiter zerlegen. Imfolgenden Beispiel wären = 1, undKAn = U müßte weiter zerlegt werden.
Prof. Dr. Dietmar Seipel 313

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Unvereinbarkeit von BCNF und Unabhängigkeit)
SeiR = (U, F ) mit
U = {A,B,C },
F = {AB → C,C → B }.
Dann istR in 3NF, aber nicht in BCNF.
ABC
BC AC
C → B R
1. Dekomposition mittels der BCNF–verletzenden fdC → B liefert eine
verlustfreie BCNF–ZerlegungD, die abernicht unabhängigist:
D = { (BC, {C → B}), (AC, ∅) }.
2. Dekomposition mittelsAB → C liefert eine Zerlegung, die wieder
R = ΠABC(R) enthält (und das darin enthaltene, redundanteΠAB(R)).
3. Man kann sogar zeigen, daß es für dieses BeispielR keine unabhängige
BCNF–Zerlegunggibt.
Prof. Dr. Dietmar Seipel 314

Vorlesung Datenbanken Wintersemester 2013/14
ER–Modellierung:
Ein n : m–Relationship–TypR = (E,F, VR) zwischen zwei Entity–TypenE = (VE , KE) undF = (VF , KF ) könnte alternativ auch im ersten Schrittals eine Relation mit der AttributmengeKEV
′EKFV
′FVR und den fds
KE → V ′E , KF → V ′F und – je nach Interpretation –KEKF → VR
repräsentiert werden, wobeiV ′E = VE \KE undV ′F = VF \KF .
E R Fn m
KE V ′E VR KF V ′F
KE V ′E KF V ′F VR
. . . . . . . . . . . . . . .
Prof. Dr. Dietmar Seipel 315

Vorlesung Datenbanken Wintersemester 2013/14
Diese Relation könnte dann im zweiten Schritt mittels desDekompositionsalgorithmusin die bekannten Relationen zerlegt werden.
KEV′EKFV
′FVR
KEV′E KEKFV
′FVR
KFV′F KEKFVR
KE → V ′E
KF → V ′F
R
R
KE V ′E
. . . . . .
KE KF VR
. . . . . . . . .
KF V ′F
. . . . . .
Prof. Dr. Dietmar Seipel 316

Vorlesung Datenbanken Wintersemester 2013/14
Die optionale Bedingung( r(E) = r′(E) ∧ r(F ) = r′(F ) ⇒ r = r′ ) fürn : m–Beziehungen entspricht der fdKEKF → VR.
Im Prüfungsbeispiel mitKE = { TID }, V ′E = {NAME }, KF =
{SNR }, V ′F = {NAME }, VR = {DATE, GRADE }, gilt diese fd nicht,da ein Student mehrere Prüfungen beim selben Dozenten habenkann.
TEACHER EXAM STUDENTn m
TID NAME DATE GRADE SNR NAME
Aber es gilt{ TID, SNR, DATE } → {GRADE }, falls ein Student beimselben Dozenten an einem Tag nur eine Prüfung haben kann.Dies wird durch das Unterstreichen von DATE angezeigt.
Prof. Dr. Dietmar Seipel 317

Vorlesung Datenbanken Wintersemester 2013/14
3.5.2 3NF–Synthese
Bei der 3NF–Synthese wird eine fd–MengeF zuerst zu einer BasisG
vereinfacht, und dann wird jeder fd ausG ein Relationenschema zugeordnet.
Definition (Basis)
SeiF eine fd–Menge.
1. Eine fdf ∈ F heißtredundant, falls f schon ausF \ { f } folgt.
2. EineBasisfür F ist eine zuF äquivalente,
a) MengeG von rechts– und links–minimalen fds,
b) die keine redundanten fds enthält.
Es gibt immermindestens eineBasis, und es gibt manchmal mehrere Basen.
Prof. Dr. Dietmar Seipel 318

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Basis)
1. SeiG = {A → B, B → C } undF = G ∪ {A → C }.
• Dann ist die fdA → C redundant inF ,
da sie aus der transitiven Verkettung der beiden anderen fdsfolgt.
• G ist die eindeutige Basis fürF .
2. SeiG = {A1 → A2, A2 → A1 } undF = G ∪ {A1 → B, A2 → B }.
Dann gibt es die zwei BasenGi = G ∪ {Ai → B }, 1 ≤ i ≤ 2, für F .
A1
A2
B*j
?6
3. F = {LT → A,L → O,O → K } ist bereits eine Basis.
Prof. Dr. Dietmar Seipel 319

Vorlesung Datenbanken Wintersemester 2013/14
Algorithmus B ASIS
SeiF eine fd–Menge.
Um eine Basis vonF zu bestimmen, gehen wir wie folgt vor:
1. Wir zerlegen die fdsX → A1 . . . An mit mehrelementigen rechten
Seiten in einzelne, rechts–minimale fdsX → Ai.
2. Wir verkleinern die linken Seiten der erhaltenen fdsX → Ai,
so daß wir links–minimale fdsX ′ → Ai, mit X ′ ⊆ X , erhalten.
3. Wir entfernen schrittweise redundante fds.
Die erhaltene fd–MengeG ist eine Basis vonF .
Prof. Dr. Dietmar Seipel 320

Vorlesung Datenbanken Wintersemester 2013/14
Algorithmus B ASIS
Input: eine fd–MengeF
Output: eine BasisG vonF
% macheF rechts–minimal
G := {X → A |X → Y ∈ F, A ∈ Y };
% macheG links–minimal
FOR EACH X → A ∈ G DO
ersetzeX → A in G durch
eine links–minimale fdX ′ → A ∈ G+, mit X ′ ⊆ X ;
% entferne redundante fds ausG
FOR EACH f ∈ G DO
IF G \ {f} |= f THEN G := G \ {f};
Prof. Dr. Dietmar Seipel 321

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Basis)
SeiF = {AB → BC }.
• Wir zerlegen die fds inF zunächst in zwei rechts–minimale fds
AB → B undAB → C.
• Die erste fdAB → B ist trivial, und damit auch redundant. Nach
unserem obigen Algorithmus ist sie nicht links–minimal, und sie wird
zuerst zur – ebenfalls trivialen und redundanten – fdB → B verkleinert.
• Die zweite fdAB → C ist links–minimal.
• Nach dem Entfernen der redundanten fdB → B erhält man die Basis
G = {AB → C }.
Prof. Dr. Dietmar Seipel 322

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Basen mit unterschiedlicher Kardinalität)
F = {BC → D, D → E, ACD → B, CE → BD }
1. Die fd CE → BD ist nicht rechts–minimal, sie kann aber in zwei
rechts–minimlae fdsCE → B undCE → D gesplittet werden.
2. AusD → E undCE → B folgt CD → B. Deshalb ist die fd
ACD → B nicht links–minimal; ihre linke Seite könnte zuCD
verkleinert werden. Wir reduzierenACD → B also zuCD → B.
3. Dann kann manCE → B weglassen, oder man kannCE → D und
CD → B weglassen. Man erhält somit zwei Basen:
G1 = G ∪ {CD → B, CE → D },
G2 = G ∪ {CE → B },
mit dem gemeinsamen SchnittG = {BC → D, D → E }.
Prof. Dr. Dietmar Seipel 323
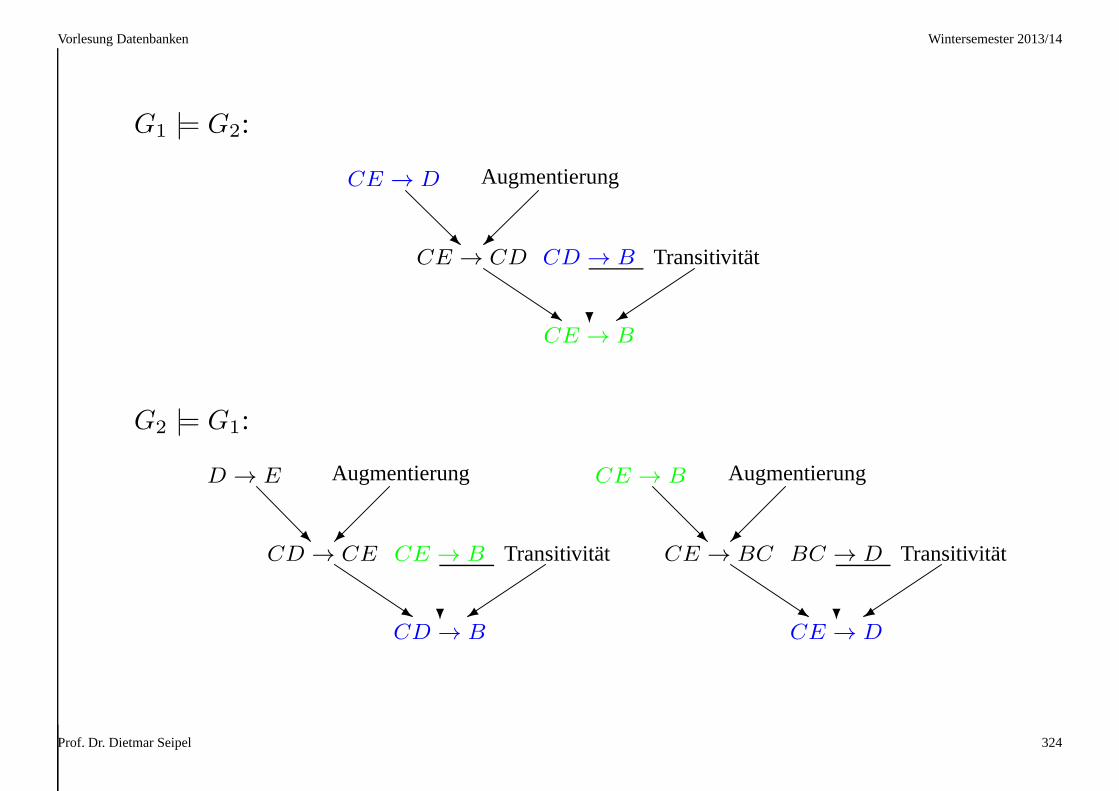
Vorlesung Datenbanken Wintersemester 2013/14
G1 |= G2:
CE → D Augmentierung
CE → CD CD → B Transitivität
CE → B
R
s ?+
G2 |= G1:
D → E Augmentierung
CD → CE CE → B Transitivität
CD → B
R
s ?+
CE → B Augmentierung
CE → BC BC → D Transitivität
CE → D
R
s ?+
Prof. Dr. Dietmar Seipel 324

Vorlesung Datenbanken Wintersemester 2013/14
Verlustfreie und unabhängige 3NF–Zerlegungen
SeiR = (U, F ) ein Relationenschema.
1. Wir erzeugen eine BasisG und bilden für jede fdX → A ∈ G ein
RelationenschemaΠXA(R) = (XA,ΠXA(F )).
2. Falls keine der AttributmengenXA ein Oberschlüssel vonR ist,
so bilden wir ein zusätzliches Relationenschema(K, ∅) zu einem
beliebigen SchlüsselK.
Dann ist das DatenbankschemaD, das die gebildeten Relationenschemata
enthält, eine verlustfreie und unabhängige 3NF–ZerlegungvonR.
Für einen SchlüsselK ist ΠK(F ) ≡ ∅.
Prof. Dr. Dietmar Seipel 325

Vorlesung Datenbanken Wintersemester 2013/14
Algorithmus SYNTHESE
Input: ein RelationenschemaR = (U, F )
Output: eine verlustfreie und unabhängige 3NF–ZerlegungD vonR
G := BASIS (F );
D := {ΠXA(R) |X → A ∈ G };
IF (für keinΠV (R) ∈ D ist V ein Oberschlüssel vonR)
THEN D := D ∪ { (KEY(U, F ), ∅) };
Für einen SchlüsselK ist ΠK(F ) ≡ ∅,
• denn es gibt es keine nicht–triviale fdX → Y ∈ ΠK(F ).
• Sonst würdeK′ → K gelten, fürK′ = K \ (Y \X), dennX ⊆ K′.
WegenY \X 6= ∅ wäreK′ ( K, und folglichK kein Schlüssel.
Prof. Dr. Dietmar Seipel 326

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Synthese vs. Dekomposition für Lieferant)
Der Synthese–Algorithmus angewandt auf
U = {L, T,A,O,K },
F = {LT → A,L → O,O → K },
liefert die BasisG = F und die Zerlegung inΠUi(R) mit
U1 = {L, T,A },
U2 = {L,O },
U3 = {O,K }.
LTAOK
OK LTAO
LO LTA
O → K
L → O
R
R
Diese Zerlegung könnte man auch durch Dekomposition mit Hilfe der fds
O → K undL → O erhalten.
Prof. Dr. Dietmar Seipel 327

Vorlesung Datenbanken Wintersemester 2013/14
Datendefinition in SQL
In den Relationenschemata der Zerlegung kann man die fds ausG mit Hilfe
von PRIMARY KEY–Klauseln ausdrücken, denn die linken Seiten der
entsprechenden fds ausG sind darin Schlüssel.
CREATE TABLE LTA (
L VARCHAR(9),
T VARCHAR(9),
A INT(6),
PRIMARY KEY (L,T) );
Die linke SeiteLT der fdLT → A war bereits ein Schlüssel im
Ausgangsrelationenschema zuU = {L, T,A,O,K }.
Prof. Dr. Dietmar Seipel 328

Vorlesung Datenbanken Wintersemester 2013/14
Die fdsO → K undL → O, die man im Relationenschema zu
U = {L, T,A,O,K } nicht in SQL ausdrücken konnte, kann man nun
ebenfalls in SQL ausdrücken.
CREATE TABLE LO (
L VARCHAR(9),
O VARCHAR(12),
PRIMARY KEY (L) );
CREATE TABLE OK (
O VARCHAR(12),
K DECIMAL(7,2),
PRIMARY KEY (O) );
BezüglichU sindL undO keine Oberschlüssel, bezüglichU2 = {L,O } und
U3 = {O,K } sindL bzw.O Schlüssel.
Prof. Dr. Dietmar Seipel 329

Vorlesung Datenbanken Wintersemester 2013/14
Außerdem kann man noch folgende Fremdschlüsselbedingungen hinzufügen:
• zuLTA:
FOREIGN KEY (L)
REFERENCES LO(L)
• zuLO:
FOREIGN KEY (O)
REFERENCES OK(O)
Die TabelleLTA wird nicht referenziert.
Prof. Dr. Dietmar Seipel 330

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Synthese)
In F = {L → O,O → K,L → K } ist die fdL → K redundant.O → K
ist 3NF–verletzend.F ist äquivalent zu seiner BasisG = {L → O,O → K }.
L O K
L1 London 600
L2 Paris 450
L5 Prag 600
• Nach dem Synthese–Algorithmus würde man die obige Relationr
mittelsπLO(r) undπOK(r) repräsentieren. Eine weitere RelationπLK(r) wäre hier redundant.
• Man könnter aber auch mittelsπLO(r) undπLK(r) repräsentieren.
• Man kannr aber nicht mittelsπOK(r) undπLK(r) repräsentieren, dennπOK(r) ⊲⊳ πLK(r) enthält das Tupel (L1, Prag, 600)6∈ r.
Prof. Dr. Dietmar Seipel 331

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Synthese vs. Dekomposition)
1. Das RelationenschemaR = (U, F ) mit
U = {A,B,C },
F = {AB → C,C → B },
ist bereits in 3NF, und es gibt bekanntlich keine verlustfreie
BCNF–Zerlegung, die auch noch unabhängig wäre.
• F ist bereits eine Basis.
• Der Synthese–Algorithmus würdeU zerlegen in
U1 = ABC undU2 = BC.
Das redundante Schema zuU2 würde man wieder fallen lassen.
• Der Dekompositions–Algorithmus würdeU zerlegen in
U1 = BC undU2 = AC.
Prof. Dr. Dietmar Seipel 332

Vorlesung Datenbanken Wintersemester 2013/14
2. Das erweiterte RelationenschemaR = (U, F ) mit
U = {A,B,C,D },
F = {AB → C,C → B,C → D },
hat die zwei SchlüsselAB undAC, und es ist wegenC → D nicht in
3NF.
• F ist bereits eine Basis.
• Der Synthese–Algorithmus würdeU zerlegen in
U1 = ABC, U2 = BC undU3 = CD.
Das redundante Schema zuU2 würde man wieder fallen lassen.
• Der Dekompositions–Algorithmus könnteU zerlegen in
U1 = BC, U2 = CD undU3 = AC.
Prof. Dr. Dietmar Seipel 333

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Synthese vs. Dekomposition)
Das RelationenschemaR = (U, F ) mit U = {A,B,C,D,E } und
F = {BC → D, D → E, ACD → B, CE → BD }
mit den zwei Basen
G1 = G ∪ {CD → B, CE → D },
G2 = G ∪ {CE → B },
mit dem gemeinsamen Schnitt
G = {BC → D, D → E }
hat die drei SchlüsselACB, ACD undACE.
Da alle Attribute prim sind, istR in 3NF.
Prof. Dr. Dietmar Seipel 334

Vorlesung Datenbanken Wintersemester 2013/14
1. Der Synthese–Algorithmus würde (unnötigerweise) zerlegen in
D1 = {ΠBCD(R), ΠDE(R), ΠCDE(R), ΠK(R) } oder
D2 = {ΠBCD(R), ΠDE(R), ΠBCE(R), ΠK(R) },
für einen beliebigen SchlüsselK.
2. Der Dekompositions–Algorithmus könnte z.B. das reduzierte Schema
D′1 = {ΠBCD(R), ΠCDE(R), ΠK(R) }
für den SchlüsselK = ACE erzeugen.
ABCDE
BCD ACDE
CDE ACE
CD → B
CE → D
R
R
Prof. Dr. Dietmar Seipel 335

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Synthese)
1. SeiR = (U, F ) mit
U = {A,B,C,D,E },
F = {AB → CD, BC → D }.
R ist nicht in 3NF wegenBC → D, undAB → D ist redundant.
• Der eindeutige SchlüsselvonR ist K = ABE .
Die eindeutige BasisvonR ist G = {AB → C,BC → D }.
• Der 3NF–SYNTHESE–Algorithmus liefert eineunabhängigeund
verlustfreie 3NF–ZerlegungD in drei Relationenschemata
R1 = ΠABC (R), R2 = ΠBCD(R), R3 = (ABE , ∅).
• Ohne das SchemaR3 zum SchlüsselK = ABE wäre das AttributE
nicht inD enthalten.
Prof. Dr. Dietmar Seipel 336

Vorlesung Datenbanken Wintersemester 2013/14
2. SeiR = (U, F ) mit
U = {A,B,C,D },
F = {A → B, C → D }.
R ist nicht in 3NF wegenA → B und wegenC → D.
• Der eindeutige SchlüsselvonR ist K = AC.
Die eindeutige BasisvonR ist G = F .
• Der 3NF–SYNTHESE–Algorithmus liefert eineunabhängigeund
verlustfreie 3NF–ZerlegungD in drei Relationenschemata
R1 = ΠAB (R), R2 = ΠCD(R), R3 = (AC, ∅).
• Ohne das SchemaR3 zum SchlüsselK = AC wäreD
unzusammenhängend.
Prof. Dr. Dietmar Seipel 337

Vorlesung Datenbanken Wintersemester 2013/14
r :
A B C D
a1 b c1 d1
a2 b c2 d2
ΠAB(r) :
A B
a1 b
a2 b
ΠCD(r) :
C D
c1 d1
c2 d2
ΠAC(r) :
A C
a1 c1
a2 c2
r ( ΠAB(r) ⊲⊳ ΠCD(r) :
A B C D
a1 b c1 d1
a1 b c2 d2
a2 b c1 d1
a2 b c2 d2
ΠAB(r) ⊲⊳ ΠCD(r)
ist ein kartesisches Produkt, da die Rela-
tionen keine Attribute gemeinsam haben
(unzusammenhängend sind).
ΠAB(r) ⊲⊳ ΠAC(r) ⊲⊳ ΠCD(r) = r,
dennAC stellt einen geeigneten Zusam-
menhang her –BC wäre ungeeignet.
Prof. Dr. Dietmar Seipel 338

Vorlesung Datenbanken Wintersemester 2013/14
Da der SYNTHESE–Algorithmus eine Basis verwendet, enthält die Zerlegung
D möglichst wenige Relationenschemata mit wenigen Attributen.
Wir haben bereits gesehen, daß manchmal einzelne Relationenschemata der
Zerlegung redundant sind, da ihre Attributmengen in anderen
Relationenschemata enthalten sind.
Ein RelationenschemaR = (U, F ) ohne fds wird effektiv nicht zerlegt.
Beispiel (Synthese)
Ein RelationenschemaR = (U, F ) mit F = ∅ ist schon in 3NF.
1. Die Basis istG = ∅ undK = U ist der eindeutige Schlüssel.
2. Also wird die ZerlegungD = { (K, ∅) } = { (U, F ) } erzeugt,
d.h.R wird faktisch nicht zerlegt.
Prof. Dr. Dietmar Seipel 339

Vorlesung Datenbanken Wintersemester 2013/14
Nachweis der Verlustfreiheit
Definition (Schema–Tableau)
Wir betrachten ein DatenbankschemaD = {R1, . . . , Rk } mit
Ri = (Ui, Fi), für 1 ≤ i ≤ k, und setzenU = ∪ki=1Ui = {A1, . . . , Am }.
1. DasSchema–TableauTD zuD ist eine Tabelle mitm = |U | Spalten und
k Zeilenwi = (wi,1, . . . , wi,m), die den SchemataRi entsprechen:
wi,l =
a, fallsAl ∈ Ui
bi, fallsAl /∈ Ui
Dabei sinda, b1, . . . , bk paarweise verschiedene Symbole.
2. wi heißta–Zeile, fallswi,l = a, für alle1 ≤ l ≤ m.
Man schreibt die AttributeA1, . . . , Am in eine zusätzliche Kopfzeile.
Prof. Dr. Dietmar Seipel 340

Vorlesung Datenbanken Wintersemester 2013/14
Tableau–Algorithmus LJP (Lossless Join Property)
Input: eine ZerlegungD eines RelationenschemasR = (U, F )
Output: true, fallsD verlustfrei ist, false, sonst
konstruiereTD;
WHILE (TD läßt sich verändern) DO
FOR EACH (X → Y ∈ F ) DO
FOR EACH (wi, wj in TD, i 6= j: wi[X ] = wj [X ]) DO
identifizierewi undwj für alleAl ∈ Y :
◦ istwi,l = a, so setzewj,l := a,
◦ istwj,l = a, so setzewi,l := a,
◦ andernfalls setze (o.B.d.A.)wj,l := wi,l
IF (∃ a–Zeile) THEN RETURN true ELSE RETURN false;
Satz: D ist verlustfrei, genau dann wenn LJP(R,D) = true gilt.
Prof. Dr. Dietmar Seipel 341

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (LJP–Algorithmus)
LJP liefert für die ZerlegungD vonR = (U, F ), mit
U = {L, T,A,O,K},
F = {LT → A,L → O,O → K },
in die AttributmengenU1 = {L, T,A}, U2 = {L,O} undU3 = {O,K}
folgende Tableaus:
L T A O K
w1 a a a b1 b1
w2 a b2 b2 a b2
w3 b3 b3 b3 a a
Prof. Dr. Dietmar Seipel 342

Vorlesung Datenbanken Wintersemester 2013/14
Operationen:
1. Die Anwendung vonL → O aufw1, w2, und danach
2. die Anwendung vonO → K aufw1, w3,
liefern einea–Zeile inw1:
L T A O K
w1 a a a a b1
w2 a b2 b2 a b2
w3 b3 b3 b3 a a
L T A O K
w1 a a a a a
w2 a b2 b2 a b2
w3 b3 b3 b3 a a
Die AttributmengeU1 zuw1 enthält einen Schlüssel vonR. Die fehlenden
a’s werden aus den beiden anderen Zeilen geholt.
Diese zeigt die Verlustfreiheit der ZerlegungD.
Prof. Dr. Dietmar Seipel 343

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (LJP–Algorithmus)
Anwendung des LJP–Algorithmusauf die Bank–Anwendung:
K = Kunde, N = Kontonummer, S = Saldo, Z = Zweigstelle,
F = {K → S,N → SZ }.
DasSchema–Tableauzur Zerlegung inU1 = KS undU2 = NSZ wird von
LJPnicht verändert.
K N S Z
w1 a b1 a b1
w2 b2 a a a
Die Zerlegung istnicht verlustfrei.
Prof. Dr. Dietmar Seipel 344

Vorlesung Datenbanken Wintersemester 2013/14
Die Hinzunahme eines Relationenschemas zum SchlüsselU3 = KN liefert
eineverlustfreie Zerlegung, denn die Anwendung vonN → SZ aufw2, w3
liefert das zweite Tableau mit einera–Zeile inw3:
K N S Z
w1 a b1 a b1
w2 b2 a a a
w3 a a b3 b3
K N S Z
w1 a b1 a b1
w2 b2 a a a
w3 a a a a
Die AttributmengeU3 zuw3 enthält einen Schlüssel vonR. Die fehlenden
a’s werden aus der Zeilew2 geholt.
Das Schema zuU1 = KS ist also für die Verlustfreiheit der Zerlegung
unerheblich. OhneU1 wäre die Zerlegung allerdings nicht unabhängig, denn
die fdK → S ginge verloren.
Prof. Dr. Dietmar Seipel 345

Vorlesung Datenbanken Wintersemester 2013/14
Satz (3NF–Synthese)
SeiR = (U, F ) ein Relationenschema.
Dann liefert SYNTHESE (R) eineverlustfreieundunabhängige
3NF–ZerlegungvonR.
Beweis.
SeiD = {R1, . . . , Rk } mit Ri = (Ui, Fi) die betrachtete Zerlegung.
1. Unabhängikeit:
Nach Konstruktion werden alle in der BasisG enthaltenen fds an die
KomponentenRi vererbt. Deshalb gilt
F+ = G+ =
(k⋃
i=1
Fi
)+
,
d.h. die ZerlegungD ist unabhängig.
Prof. Dr. Dietmar Seipel 346

Vorlesung Datenbanken Wintersemester 2013/14
2. Verlustfreiheit:
Nach Konstruktion existiert ein SchemaRi = (Ui, Fi) ∈ D mit einem
OberschlüsselUi, d.h.Ui → U ∈ F+.
Wir wenden nun den Algorithmus LJPaufR undD an und beobachten
speziell die Veränderungen in der Zeilewi zuRi.
• Insbesondere interessieren wir uns für die Anwendung jenerfds
X → Y ∈ Fj auf das TableauTD, welche zur Hüllenberechnung von
U = (Ui)+G verwendet werden.
• Diese fds werden in derselben Reihenfolge, in der sie bei der
Hüllenberechnung verwendet werden, auf die Zeilenwi undwj des
Tableaus angewendet. Eine fdX → Y ∈ Fj wird also auf die zugehörige
Zeilewj sowie die Zeilewi zum OberschlüsselUi angewendet.
Per Induktion kann man zeigen, daß vor der Anwendung vonX → Y in
allenX–Spalten vonwi nura–Einträge stehen.
Prof. Dr. Dietmar Seipel 347

Vorlesung Datenbanken Wintersemester 2013/14
Da auch in denX–Spalten vonwj nura–Einträge stehen, können diea–Einträge derY –Spalten vonwj nachwi übertragen werden:
Ui X \ Ui Y
wi a . . . a a . . . a
↑ ↑
wj a . . . . . . . . . a a . . . a
Nach der Anwendung aller fdsX → Y aus der Hüllenberechnung aufdas Tableau gilt folglich:
es stehen nura–Einträge in den(Ui)+G–Spalten vonwi.
Wegen der Unabhängigkeit vonD gilt aber für den OberschlüsselUi:
(Ui)+G = (Ui)
+F = U,
d.h.wi ist einea–Zeile.
Folglich ist die ZerlegungD verlustfrei.
Prof. Dr. Dietmar Seipel 348

Vorlesung Datenbanken Wintersemester 2013/14
3. 3NF:
Wir betrachten 2 Fälle fürS ∈ D:
• Falls das Schema
S = (K, ∅)
zu einem SchlüsselK für R explizit inD aufgenommen wurde,so istS trivialerweise in 3NF.
• Falls
S = ΠXA(R)
ein Schema ist, welches durch eine fdX → A ∈ G aus der BasisGerzeugt wurde, so gilt:
– X → A ist links–minimal und rechts–minimal, und somit– 3NF–kompatibel.
Also ist auch dieses SchemaS in 3NF.
Somit ist die gesamte ZerlegungD in 3NF.
Prof. Dr. Dietmar Seipel 349

Vorlesung Datenbanken Wintersemester 2013/14
Algorithmus SYNTHESE ’
Input: R = (U, F )
Output: Eine verlustfreie und unabhängige ZerlegungD vonR
G := BASIS(F ); D := ∅;
FOR EACH (linke SeiteX einer fd ausG) DO {
Y := { A ∈ U |X → A ∈ G };
D := D ∪ {ΠXY (R) } };
IF (für keinΠV (R) ∈ D ist V ein Oberschlüssel vonR)
THEN D := D ∪ { (KEY(U, F ), ∅) };
Auch der Algorithmus SYNTHESE’(R) liefert für alle RelationenschemataR
eineverlustfreieundunabhängige 3NF–Zerlegung.
Prof. Dr. Dietmar Seipel 350

Vorlesung Datenbanken Wintersemester 2013/14
Da SYNTHESE’ eine Basis verwendet, enthält die ZerlegungD möglichstwenige Relationenschemata mit wenigen Attributen, die dann zusätzlichnoch geeignet zusammengefaßt werden, ohne die 3NF zu verletzen.
X → A1, . . . , X → Ak ∈ G
ΠXA1(R), . . . ,ΠXAk
(R)
ΠXA1...Ak(R)
Basis
SYNTHESE
SYNTHESE ’
? ?
R
Prinzip “one fact in one place”:
Jede linke SeiteX einer fd aus der BasisG wird als ein Konzept augefaßtund die abhängigen Attribute inY = {A1, . . . , Ak } als dessenEigenschaften;X undY werden in einem Schema zusammengefaßt.
Prof. Dr. Dietmar Seipel 351

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (SYNTHESE vs. SYNTHESE ’)
Das RelationenschemaR = (U, F ) mit
U = {A,B,C,D,E } undF = {AB → CD }
ist nicht in 3NF. Dieeindeutige BasisvonR ist
G = {AB → C,AB → D },
und der eindeutige Schlüssel vonR ist {A,B,E}.
1. Der Algorithmus SYNTHESE liefert die Zerlegung in drei
Relationenschemata:
R1 = ΠABC(R), R2 = ΠABD(R), R3 = (ABE, ∅).
2. Der Algorithmus SYNTHESE’ liefert dagegen eine Zerlegung in nur zwei
RelationenschemataR1,2 undR3, in derR1 undR2 zusammen ein
Schema bilden:R1,2 = ΠABCD(R).
Prof. Dr. Dietmar Seipel 352

Vorlesung Datenbanken Wintersemester 2013/14
ER–Modellierung:
Der Algorithmus SYNTHESE’ kann auch für einenn : m–Relationship–TypR = (E,F, VR) zwischenE = (VE , KE) undF = (VF , KF ) angewendetwerden. FürV ′E = VE \KE , V ′F = VF \KF , undU = KEV
′EKFV
′FVR ist
G = {KE → V ′E , KF → V ′F , KEKF → VR }
bereits eine Basis, und wir erhalten auch hier wieder die Zerlegung in
U1 = KEV′E , U2 = KFV
′F , U3 = KEKFVR.
E R Fn m
KE V ′E VR KF V ′F
Dies gilt auch, falls wir die fdKEKF → VR nicht annehmen, denn dannkommtU3 als Relation zum eindeutigen Schlüssel hinzu.
Prof. Dr. Dietmar Seipel 353

Vorlesung Datenbanken Wintersemester 2013/14
3.6 Azyklische Datenbankschemata
Wir gehen von einem DatenbankschemaD = {R1, . . . , Rn }, mitRelationenschemataRi = (Ui, Fi), und einer zugehörigen, erlaubtenDatenbankinstanzd = { r1, . . . , rn } aus.
Wir definierenR = (U, F ) = ⊲⊳ni=1 Ri mittelsU = ∪ni=1Ui, F = ∪n
i=1Fi.
R = ⊲⊳ni=1 Ri
R1 Rn. . .
� ]
r = ⊲⊳ni=1 ri
r1 rn. . .
� ]
Die Relationr heißtUniversalrelation.
Universalrelationen–Anfragen der Formq = ΠX(r) über AttributmengenX ⊆ U solleneffizientdurchJoinsüber geeignete, möglichst kleineTeilmengen der Relationenri beantwortet werden – ohner komplett zuberechnen.
Prof. Dr. Dietmar Seipel 354

Vorlesung Datenbanken Wintersemester 2013/14
Bei der Berechnung des Natural Joins
⊲⊳ d = ⊲⊳ { r1, . . . , rn } = r1 ⊲⊳ . . . ⊲⊳ rn
muß man auch berücksichtigen, daß die Relationenri an unterschiedlichen
Standorten gespeichert sein können.
r1
r2
r3
r4R
I
IR
�
�?
6-�
Dann sollen dieKommunikationskostenbeim Join minimiert werden.
Prof. Dr. Dietmar Seipel 355

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (COMPANY–Datenbank)
Wir betrachten den Ausschnittd = { r1, r2, r3, r4, r5 } mit
r1 = EMPLOYEE,
r2 = WORKS_ON,
r3 = PROJECT.
r4
SSN ESSN
111111111 111111111
222222222 222222222
. . . . . .
r5
PNO PNUMBER
1 1
2 2
. . . . . .
Da die Relationenr1, r2, r3, keine gemeinsamen Attribute haben, erfordert
der Natural Join⊲⊳ d zur Berechnung des Views E_WORKS_ON_P virtuelle
Relationenr4 undr5 zur Repräsentation der Join–Bedingungen
r1.SSN = r2.ESSNundr2.PNO = r3.PNUMBER
(hier: Fremdschlüsselbeziehungen) zwischenr1 undr2 bzw.r2 undr3.
Prof. Dr. Dietmar Seipel 356

Vorlesung Datenbanken Wintersemester 2013/14
Bei der Berechnung des eingeschränkten Views entsprechend
SELECT FNAME, LNAME, PNAME, HOURS
FROM EMPLOYEE, PROJECT, WORKS_ON
WHERE SSN=ESSNAND PNO=PNUMBER
AND BDATE >= ’1960-01-01’AND HOURS >= 10AND DNUM = 4
mittels des Natural Joinsr = re ⊲⊳ r4 ⊲⊳ rw ⊲⊳ r5 ⊲⊳ rp und der Projektion
ΠX(r), für X = { FNAME, LNAME, PNAME, HOURS}, enthalten die
eingeschränkten Relationenre = σBDATE ≥ ’1960-01-01’(EMPLOYEE),
rw = σHOURS≥ 10(WORKS_ON), rp = σDNUM = 4(PROJECT), dangling tuples.
EMPLOYEE WORKS_ON PROJECT
r4 r5
FNAME
LNAMESSN ESSN
HOURS
PNOPNUM-
BER PNAME
Prof. Dr. Dietmar Seipel 357

Vorlesung Datenbanken Wintersemester 2013/14
Man kannΠX(r) entlang der Join–Kette(re, r4, rw, r5, rp) wie folgt
berechnen:
s1 = ΠFNAME , LNAME , SSN(re),
s2 = ΠFNAME , LNAME , ESSN(s1 ⊲⊳ r4) = {SSN 7→ ESSN}(s1),
s3 = ΠFNAME , LNAME , HOURS, PNO(s2 ⊲⊳ rw),
s4 = ΠFNAME , LNAME , HOURS, PNUMBER(s3 ⊲⊳ r5) = {PNO 7→ PNUMBER}(s3),
s5 = ΠFNAME , LNAME , HOURS, PNAME(s4 ⊲⊳ rp).
Dann giltΠX(r) = s5.
• Die Anfrage–Attribute ausX werden aufgesammelt.
• Die Join–Attribute werden weg–projeziert,
sobald sie nicht mehr weiter benötigt werden.
Diese Join–Strategie wollen wir im folgenden auf komplexere
Join–Ausdrücke mit nicht–linearen Join–Ketten verallgemeinern.
Prof. Dr. Dietmar Seipel 358
Vorlesung Datenbanken Wintersemester 2013/14
O: ΠFNAME , LNAME , PNAME , HOURS
⊲⊳
ΠFNAME , LNAME , PNO, HOURS
{PNO7→PNUMBER}
{SSN7→ESSN}
ΠFNAME , LNAME , SSN
σBDATE ≥ ’1960-01-01’
EMPLOYEE
⊲⊳
σHOURS≥ 10
WORKS_ON
σDNUM = 4
PROJECT
I
�
I�
�
�
6
6
6 6
6
6
Prof. Dr. Dietmar Seipel 359

Vorlesung Datenbanken Wintersemester 2013/14
Anfragen in verteilten Datenbanken
Es soll der Natural Join
⊲⊳ d = ⊲⊳ { r1, . . . , rn } = r1 ⊲⊳ . . . ⊲⊳ rn
über eine Datenbankinstanzd = { r1, . . . , rn } berechnet werden,
wobei jede Relationri an einem anderen Ort gespeichert sein kann.
1. Man kann zuerst alle Tupel einer Relationri eliminieren, die keine
Join–Partner in den anderen Relationen haben (dangling tuples).
2. Für diereduziertenRelationenr∇i ⊆ ri gilt dann immer noch
⊲⊳ d = r1 ⊲⊳ . . . ⊲⊳ rn = r∇1 ⊲⊳ . . . ⊲⊳ r∇n .
3. FürazyklischeDatenbankschemata gibt es effiziente Methoden zur
Reduktion mit Hilfe von Semi–Join–Programmen.
Dieses Vorgehen minimiert dieKommunikationskostenbeim Join.
Prof. Dr. Dietmar Seipel 360

Vorlesung Datenbanken Wintersemester 2013/14
Vollständige Reduktion
Die vollständige Reduktion vonri bezüglichd ist
r∇i = ΠUi(⊲⊳ d),
und die vollständige Reduktion vond ist d∇ = { r∇1 , . . . , r∇n }.
Bekanntlich gilt immerr∇i ⊆ ri undr ⊆ ΠU1(r) ⊲⊳ . . . ⊲⊳ ΠUn
(r).
1. Die globale Konsistenz fordertri = r∇i , für 1 ≤ i ≤ n.
r1, . . . , rn⊲⊳−→ ⊲⊳ d
Π−→ r1, . . . , rn :
2. Die Verlustfreiheit bedeutet dagegenr = ΠU1(r) ⊲⊳ . . . ⊲⊳ ΠUn
(r).
rΠ
−→ r1, . . . , rn⊲⊳−→ r :
d∇ reicht aus, um den Join zu berechnen:⊲⊳ d = ⊲⊳ d∇.
Die vollständige Reduktion ist idempotent:(d∇)∇ = d∇.
Prof. Dr. Dietmar Seipel 361
Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Vollständige Reduktion)
Wir betrachten die Datenbankinstanz
d = { r1, r2, r3, r4 }
mit folgenden Relationen:
r1 : r2 : r3 : r4 :
A B C
0 3 2
0 1 2
3 1 2
1 1 3
B C D E
3 2 1 0
1 2 3 0
1 3 1 0
B C D G
3 2 1 4
1 2 3 2
1 3 1 0
1 3 1 1
C D E F
2 1 1 4
2 3 0 1
3 1 0 2
3 1 0 3
A CB D
E
G
F
Prof. Dr. Dietmar Seipel 362

Vorlesung Datenbanken Wintersemester 2013/14
Die Universalrelation
r = r1 ⊲⊳ r2 ⊲⊳ r3 ⊲⊳ r4
ist gegeben durch:
A B C D E F G
0 1 2 3 0 1 2
3 1 2 3 0 1 2
1 1 3 1 0 2 0
1 1 3 1 0 2 1
1 1 3 1 0 3 0
1 1 3 1 0 3 1
Prof. Dr. Dietmar Seipel 363

Vorlesung Datenbanken Wintersemester 2013/14
In der Relationr gilt die jd
⊲⊳ (ABC,BCDE,BCDG,CDEF ).
Die reduzierten Relationen bilden eine konsistente Zerlegung vonr:
r∇1
: r∇2
: r∇3
: r∇4
:
A B C
0 1 2
3 1 2
1 1 3
B C D E
1 2 3 0
1 3 1 0
B C D G
1 2 3 2
1 3 1 0
1 3 1 1
C D E F
2 3 0 1
3 1 0 2
3 1 0 3
Jeweils das erste Tupel einer jeden Relationri konnte nicht am Join
teilnehmen (dangling tuples).
Prof. Dr. Dietmar Seipel 364

Vorlesung Datenbanken Wintersemester 2013/14
Konsistenz
SeiD = {R1, . . . , Rn } ein Datenbankschema sowied = { r1, . . . , rn }
eine entsprechende Datenbankinstanz zuD, so daßri eine erlaubte InstanzvonRi = (Ui, Fi), für 1 ≤ i ≤ n, ist.
1. Zwei Relationenri, rj ∈ d heißenkonsistent, falls es eine RelationrüberUi ∪ Uj gibt mit ri = ΠUi
(r) undrj = ΠUj(r). In diesem Fall
kann manr = r1 ⊲⊳ r2 wählen.
2. Die Datenbankinstanzd heißt
a) paarweise konsistent, falls je zwei Relationenri, rj ∈ d konsistentsind.
b) global konsistent, falls es eine Relationr überU gibt mitri = ΠUi
(r), für 1 ≤ i ≤ n.
Die vollständige Reduktiond∇ = { r∇1 , . . . , r∇n } vond ist global konsistent.
Prof. Dr. Dietmar Seipel 365

Vorlesung Datenbanken Wintersemester 2013/14
Bemerkungen (globale Konsistenz)
Seid = { r1, . . . , rn } eine Datenbankinstanz.
1. Fallsd global konsistent ist, so gilt insbesondereri = ΠUi(r), für
1 ≤ i ≤ n, wenn man die Universalrelationr = ⊲⊳ d wählt.
2. d ist genau dann global konsistent, wennd mit seiner vollständigen
Reduktion übereinstimmt:d∇ = d.
3. d ist genau dann global konsistent, wenn es durch Zerlegung einer
fiktiven Relationr in Relationenri = ΠUi(r), für 1 ≤ i ≤ n, entsteht.
• Für solche Zerlegungen gilt also immerd∇ = d.
• Neben der Universalrelation⊲⊳ d kann es weitere Relationenr geben,
aus denend entstanden sein kann.
• Für diese erzeugenden Relationen muß aber immerr ⊆ ⊲⊳ d gelten.
Prof. Dr. Dietmar Seipel 366
Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (globale Konsistenz)Die global konsistente Datenbankinstanzd = { r1, r2 } kann durch Zerlegungunterschiedlicher Relationen, z.B.r = r1 ⊲⊳ r2, r′ undr′′, erzeugt werden:
r1 : r2 :
A B
a b
a′ b
B C
b c
b c′
r : r′ : r′′ :
A B C
a b c
a b c′
a′ b c
a′ b c′
A B C
a b c
a′ b c′
A B C
a b c′
a′ b c
d entsteht auch aus allen Obermengens vonr′ oderr′′, mit s ⊆ r.
Prof. Dr. Dietmar Seipel 367

Vorlesung Datenbanken Wintersemester 2013/14
Semi–Join–Reduktion
Seienr, s zwei Relationen über den AttributmengenUr, Us.
Der Semi–Joinvon r mit s ist
r⋉s = ΠUr(r ⊲⊳ s).
r :
. . . . . . . . . . . .
︸ ︷︷ ︸
Ur∩Us
s :
. . .
︸ ︷︷ ︸
Ur∩Us
. . . . . . . . .
Folgerung (Semi–Joins)
Für r′ = r⋉s unds′ = s⋉r gilt:
1. r′ ⊆ r unds′ ⊆ s,
2. r′ unds′ sind konsistent,
3. r′ = r ⊲⊳ ΠUr∩Us(s) = { t ∈ r | t[Ur ∩ Us] ∈ ΠUr∩Us
(s) },
4. r ⊲⊳ s = r′ ⊲⊳ s = r ⊲⊳ s′ = r′ ⊲⊳ s′.
Der kleine TeilΠUr∩Us(s) vons reicht aus umr⋉s ausr zu berechnen.
Prof. Dr. Dietmar Seipel 368

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Semi–Joins)
Zur Semi–Join–Reduktion vonr mit s kann manΠUr∩Us(s) verwenden:
r: s: r⋉s: s⋉r:
A B
a1 b1
a2 b2
a3 b3
B C
b2 c2
b3 c3
b4 c4
A B
a2 b2
a3 b3
B C
b2 c2
b3 c3
ΠB(r): ΠB(s):
B
b1
b2
b3
B
b2
b3
b4
Es giltUr ∩ Us = {B }.
1. WegenΠB(r) 6= ΠB(s),
sindr unds nicht konsistent.
2. NurΠB(s) muß vons zur geschickt
werden, um dortr⋉s zu berechnen.
Prof. Dr. Dietmar Seipel 369

Vorlesung Datenbanken Wintersemester 2013/14
Folgerung (globale und paarweise Konsistenz)
1. Die Datenbankinstanzd ist global konsistent, g.d.w. für die Relation⊲⊳ d = ⊲⊳ni=1 ri gilt ri = ΠUi
(⊲⊳ d), d.h. wennri = r∇i , für 1 ≤ i ≤ n.
2. Zwei Relationenr, s sind konsistent, g.d.w. die Datenbankd = { r, s }
global konsistent ist. Dies ist der Fall, wenn
r = r⋉s und s = s⋉r,
und es ist äquivalent zur Inklusionsabhängigkeit
ΠUr∩Us(r) = ΠUr∩Us
(s).
3. Aus der globalen Konsistenz folgt die paarweise Konsistenz.
Konsistenztests (paarweise, global)
1. Der Test auf paarweise Konsistenz kann in polynomieller Zeit erfolgen.
2. Der Test auf globale Konsistenz istNP–vollständig.
Prof. Dr. Dietmar Seipel 370

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Konsistenz)
1. Die Datenbankinstanzd = { r1, r2, r3 } mit den Relationen
r1 : r2 : r3 :
A B
a b
a′ b′
B C
b c
b′ c′
C A
c a′
c′ a
ist zwarpaarweisekonsistent, abernicht global. Es gilt
a) ri⋉rj = ri, für alle1 ≤ i 6= j ≤ n,
b) r1 ⊲⊳ r2 ⊲⊳ r3 = ∅, und
c) r∇i = ∅, für alle1 ≤ i ≤ n.
Man kannd nicht mit Hilfe von Semi–Joins reduzieren.
Prof. Dr. Dietmar Seipel 371

Vorlesung Datenbanken Wintersemester 2013/14
2. Gegeben sei wieder folgende Datenbankinstanzd = { r1, r2, r3, r4 }.
r1 : r2 : r3 : r4 :
A B C
0 3 2
0 1 2
3 1 2
1 1 3
B C D E
3 2 1 0
1 2 3 0
1 3 1 0
B C D G
3 2 1 4
1 2 3 2
1 3 1 0
1 3 1 1
C D E F
2 1 1 4
2 3 0 1
3 1 0 2
3 1 0 3
a) r1 ist konsistent mitr2, r3, r4,
b) r2 ist nicht konsistent mitr4.
c) r3 ist konsistent mitr2 undr4.
Deshalb istd weder paarweise konsistent noch konsistent.
Prof. Dr. Dietmar Seipel 372

Vorlesung Datenbanken Wintersemester 2013/14
Semi–Join–Programme
SeiD ein Datenbankschema.
1. EinSemi–Join–ProgrammP = (a1, . . . , am) für eine Datenbankinstanz
d = { r1, . . . , rn } ist eine Folge von Anweisungenak, für 1 ≤ k ≤ m,
der Form
rik := rik⋉rjk .
2. P reduziertd voll, falls esd in die global konsistente Datenbankinstanz
d∇ überführt.
3. P heißtvoll reduzierend, falls es jede Datenbankinstanzd vonD voll
reduziert.
Mit Hilfe eines Semi–Join–Programms versucht man eine Datenbankinstanz
zu reduzieren, ohne den kompletten Join berechnen zu müssen.
Prof. Dr. Dietmar Seipel 373

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Semi–Join–Reduktion)
Gegeben sei die Datenbankinstanzd = { r1, r2, r3 } :
r1 : r2 : r3 :
L T A
L2 T1 300
L2 T2 400
L O
L1 London
L2 Paris
L3 Paris
L4 Brüssel
O K
London 600
Paris 450
Brüssel 150
Dann reduziert das folgende Semi–Join–ProgrammP1 die Instanzd voll:
r2 := r2⋉r1, r3 := r3⋉r2, r2 := r2⋉r3, r1 := r1⋉r2.
Wir werden später sogar sehen, daßP1 jede Datenbankinstanz desselben
Datenbankschemas voll reduziert.
Prof. Dr. Dietmar Seipel 374

Vorlesung Datenbanken Wintersemester 2013/14
Da die Relationr1 nur Teilelieferungen des Lieferanten L2 enthält,
• müssen ausr2 alle Tupel zu anderen Lieferanten entfernt werden, und
• entsprechend bleibt inr3 nur das Tupel zum Ort Paris übrig.
Die reduzierte Datenbankinstanzd∇ ist gegeben durch
r∇1
: r∇2
: r∇3
:
L T A
L2 T1 300
L2 T2 400
L O
L2 Paris
O K
Paris 450
Das folgende Semi–Join–ProgrammP2 reduziert die Instanzd nicht voll:
r3 := r3⋉r2, r2 := r2⋉r3, r1 := r1⋉r2, r2 := r2⋉r1.
Hier wird die Datenbankinstanz{r∇1 , r∇2 , r3} erzeugt;r3 bleibt unverändert,
da es vonr2 reduziert wird, bevorr2 vonr1 reduziert wird.
Prof. Dr. Dietmar Seipel 375

Vorlesung Datenbanken Wintersemester 2013/14
Eine Kante vonri nachrj drückt aus, daß der Semi–Joinrj := rj⋉ri
berechnet wird. Die Markierung gibt den Index des Rechenschritts im
Semi–Join–Programm an.
Das Semi–Join–ProgrammP1 ist voll reduzierend:
r1 r2 r3- -��1 2
34
Das Semi–Join–ProgrammP2 ist nicht voll reduzierend:
r1 r2 r3- -��4 1
23
In beiden Fällen durchlaufen die Semi–Joins den Graphen zyklisch.
Prof. Dr. Dietmar Seipel 376

Vorlesung Datenbanken Wintersemester 2013/14
Die etwas kleinere Datenbankinstanzd = { r1, r2, r3 } mit
r1 : r2 : r3 :
L T A
L2 T1 300
L2 T2 400
L O
L2 Paris
L3 Paris
O K
London 600
Paris 450
Brüssel 150
wird aber vom Semi–Join–ProgrammP2 voll reduziert:
r3 := r3⋉r2, r2 := r2⋉r3, r1 := r1⋉r2, r2 := r2⋉r1.
Hier kannr3 kann vonr2 geeignet reduziert werden.
Wir sind nur an voll reduzierenden Semi–Join–Programmen – wie P1 –
interessiert, nicht aber an Semi–Join–Programmen, die nurmanche Instanzen
voll reduzieren – wieP2.
Prof. Dr. Dietmar Seipel 377

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Semi–Join–Reduktion)
Gegeben sei wieder die Datenbankinstanzd = { r1, r2, r3, r4 }
r1 : r2 : r3 : r4 :
A B C
0 3 2
0 1 2
3 1 2
1 1 3
B C D E
3 2 1 0
1 2 3 0
1 3 1 0
B C D G
3 2 1 4
1 2 3 2
1 3 1 0
1 3 1 1
C D E F
2 1 1 4
2 3 0 1
3 1 0 2
3 1 0 3
Dann reduziert das folgende Semi–Join–Programmd voll:
r2 := r2⋉r4, r2 := r2⋉r3, r1 := r1⋉r2,r2 := r2⋉r1, r3 := r3⋉r2, r4 := r4⋉r2.
Das ProgrammP entfernt aus jeder Relationri die erste Zeile.P ist sogar voll reduzierend für das gegebene Datenbankschema.
r1
r2
r3 r4
16
25
34 ?6
R� I
Prof. Dr. Dietmar Seipel 378

Vorlesung Datenbanken Wintersemester 2013/14
Hypergraphen
Ein Hypergraphist ein PaarH = (V, E) mit
1. einer MengeV von Knoten und
2. einer MengeE ⊆ 2V von Hyperkanten.
Der HypergraphH = (V, E) zu einem Datenbankschema
D = {R1, . . . , Rn } mit RelationenschemataRi = (Ui, Fi), für 1 ≤ i ≤ n,
ist gegeben durch
1. die KnotenmengeV =n⋃
i=1
Ui,
2. die KantenmengeE = {U1, . . . , Un }.
Prof. Dr. Dietmar Seipel 379
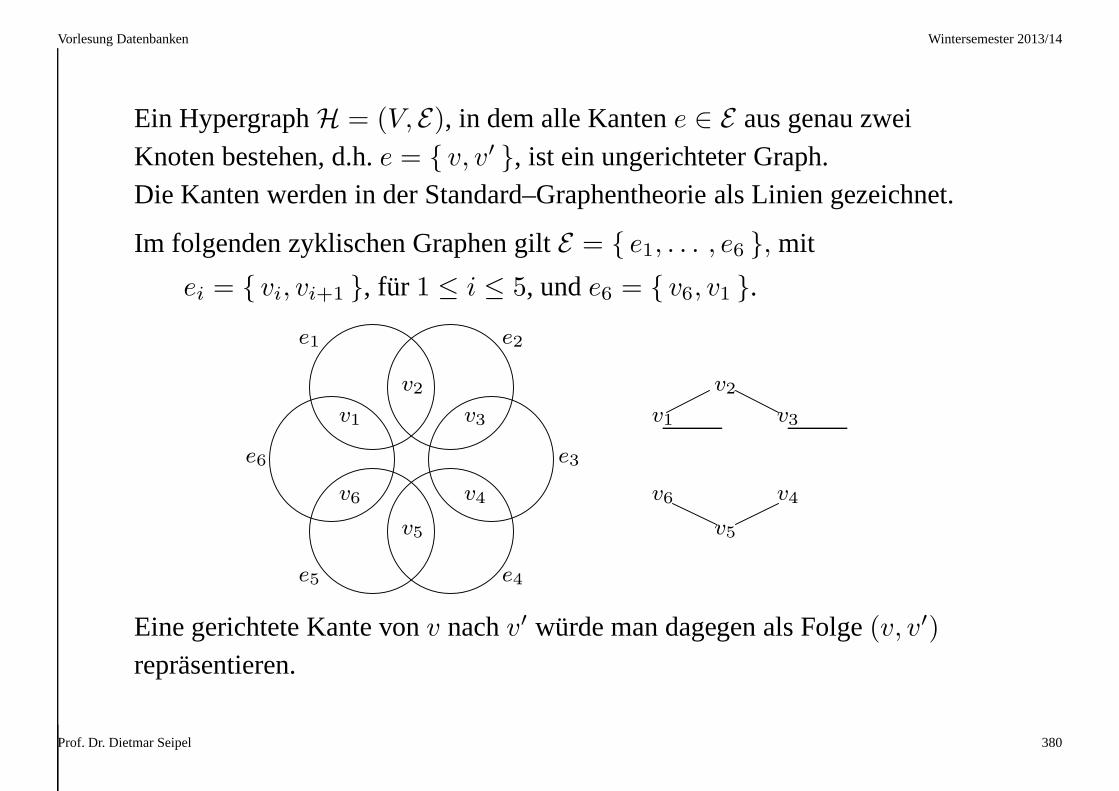
Vorlesung Datenbanken Wintersemester 2013/14
Ein HypergraphH = (V, E), in dem alle Kantene ∈ E aus genau zweiKnoten bestehen, d.h.e = { v, v′ }, ist ein ungerichteter Graph.Die Kanten werden in der Standard–Graphentheorie als Linien gezeichnet.
Im folgenden zyklischen Graphen giltE = { e1, . . . , e6 }, mit
ei = { vi, vi+1 }, für 1 ≤ i ≤ 5, unde6 = { v6, v1 }.
v1
v2
v3
v4
v5
v6
e1 e2
e3
e4e5
e6
v1
v2
v3
v4
v5
v6
Eine gerichtete Kante vonv nachv′ würde man dagegen als Folge(v, v′)repräsentieren.
Prof. Dr. Dietmar Seipel 380

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Lieferant)
Der HypergraphH = (V, E) zuRi = (Ui, Fi) mit
U1 = {L, T,A}, U2 = {L,O}, U3 = {O,K}
ist gegeben durch
V = {L, T,A,O,K },
E = { {L, T,A}, {L,O}, {O,K} }.
Mengen–Diagramm:
LTA O K
Prof. Dr. Dietmar Seipel 381

Vorlesung Datenbanken Wintersemester 2013/14
Die folgende alternative Repräsentation eines HypergraphenH als bipartider
Inzidenz–GraphG ist dagegen nicht zielführend:
A T L O K
e1 e2 e3
Für jede Kantee ∈ E gibt es einen neuen Knoten, der mit allen Knotenv ∈ e
verbunden ist.
Diese Darstellung ist zwar äquivalent zum Mengen–Diagramm.
• FallsG azyklisch ist, so ist auchH azyklisch.
• Zykel in G besagen aber nicht, daßH zyklisch ist.
Prof. Dr. Dietmar Seipel 382
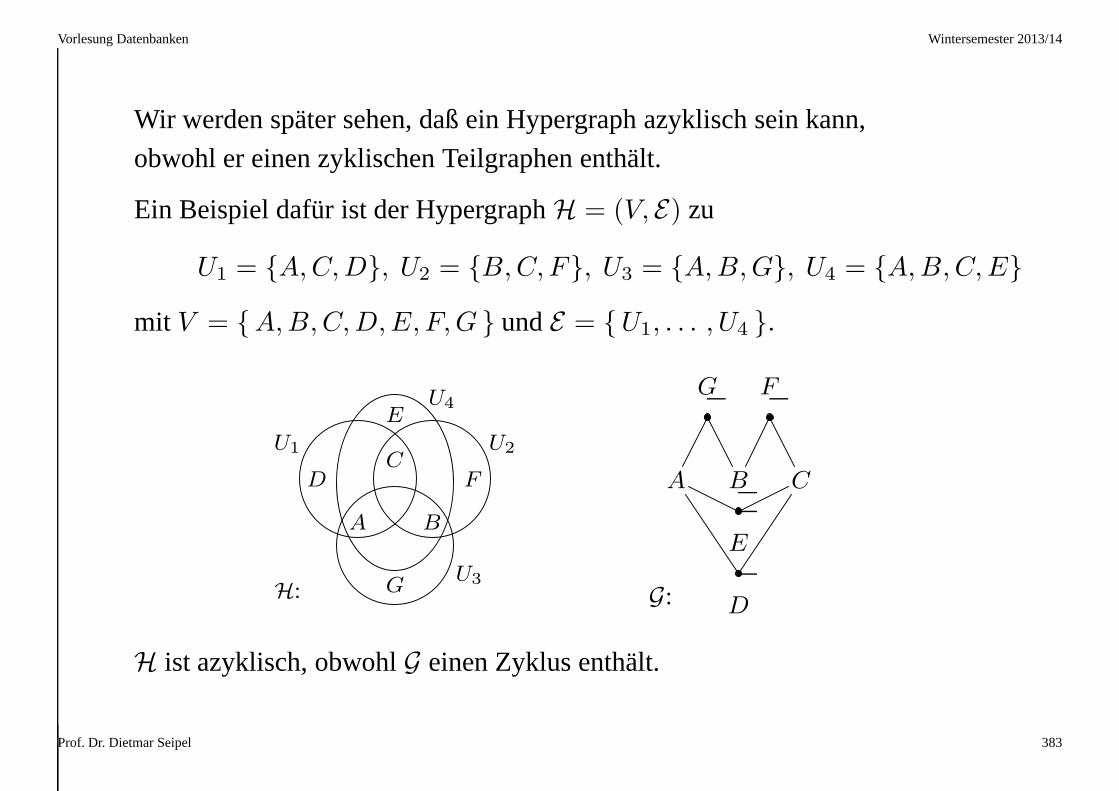
Vorlesung Datenbanken Wintersemester 2013/14
Wir werden später sehen, daß ein Hypergraph azyklisch sein kann,
obwohl er einen zyklischen Teilgraphen enthält.
Ein Beispiel dafür ist der HypergraphH = (V, E) zu
U1 = {A,C,D}, U2 = {B,C, F}, U3 = {A,B,G}, U4 = {A,B,C,E}
mit V = {A,B,C,D,E, F,G } undE = {U1, . . . , U4 }.
H:
A B
C
G
D F
E
U1 U2
U3
U4
A B C
G F
E
DG:
H ist azyklisch, obwohlG einen Zyklus enthält.
Prof. Dr. Dietmar Seipel 383

Vorlesung Datenbanken Wintersemester 2013/14
Reduktion eines Hypergraphen
SeiH = (V, E) ein Hypergraph.
1. DieReduktionvonH ist der HypergraphH∇ = (V, E∇) mit
E∇ = { e ∈ E |6 ∃e′ ∈ E : e ( e′ }
2. H heißtreduziert, fallsH = H∇ gilt.
Kanten, die Teilmengen anderer Kanten sind, werden entfernt:
H:
A B C D
H∇:
A B C D
Prof. Dr. Dietmar Seipel 384

Vorlesung Datenbanken Wintersemester 2013/14
Zusammenhangskomponente
SeiH = (V, E) ein Hypergraph.
1. EinPfadvon einem Knotenv zu einem Knotenv′ ist eine Folge
(e1, . . . , ek), für k ∈ IN+, von Hyperkanten mit
a) v ∈ e1, v′ ∈ ek,
b) ei ∩ ei+1 6= ∅, für alle1 ≤ i ≤ k − 1.
2. Zwei Hyperkantene, e′ ∈ E heißenzusammenhängend,
falls es einen Pfad(e1, . . . , ek) mit e = e1 unde′ = ek gibt.
3. Eine TeilmengeF ⊆ E heißtzusammenhängend,
falls je zwei Hyperkantene, e′ ∈ F zusammenhängend sind.
4. F heißtZusammenhangskomponentevonH,
fallsF eine maximale, zusammenhängende Teilmenge vonE ist.
Prof. Dr. Dietmar Seipel 385

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Zusammenhangskomponenten)
AB
C
D
G
E F
H
e1
e2
e3
e4
e5
e6
J
I
K
1. (e1, e2, e3) und(e1, e2, e4) sind Pfade.
2. Die Zusammenhangskomponenten sind
F1 = { e1, e2, e3, e4 } und F2 = { e5, e6 }.
Prof. Dr. Dietmar Seipel 386

Vorlesung Datenbanken Wintersemester 2013/14
Azyklizität
SeiH = (V, E) ein Hypergraph.
1. DieEinschränkungvonH auf eine KnotenmengeV ′ ⊆ V ist
H|V ′ = (V ′, E ′), mit E ′ = { e ∩ V ′ | e ∈ E , e ∩ V ′ 6= ∅ }.
2. Seiene, e′ ∈ E zwei verschiedene Hyperkanten unde∗ = e ∩ e′ ⊆ V .
e∗ ist eineArtikulationsmengevonH, falls die Anzahl der
Zusammenhangskomponenten vonH|V \e∗ größer ist als die Anzahl der
Zusammenhangskomponenten vonH.
3. H heißtazyklisch, falls für alleV ′ ⊆ V gilt:
falls die ReduktionH′ = (H|V ′)∇ zusammenhängend ist und mehr als
eine Hyperkante enthält, so hatH′ eine Artikulationsmenge.
Ein ungerichteter Graph ist azyklisch, g.d.w. er als Hypergraph azyklisch ist.
Prof. Dr. Dietmar Seipel 387

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Artikulationsmengen)
AB
C
D
G
E F
H
e1
e2
e3
e4
J
I
K e5
e6
SeiW = {A,B,C,D,E, F,G }.Der zusammenhängende, reduzierte HypergraphH|V ′ hat
• für V ′ = W keine Artikulationsmenge,
• für V ′ = W ∪ {H } dagegen schon, nämliche∗ = {F}, und
• für V ′ = { I, J,K } auch, nämliche∗ = {I}.
Prof. Dr. Dietmar Seipel 388

Vorlesung Datenbanken Wintersemester 2013/14
H ist azyklisch, falls es für jede KnotenteilmengeV ′ ⊆ V undjede ZusammenhangskomponenteF , mit |F| ≥ 2, der ReduktionH′ = (H|V ′)∇, zwei verschiedene Kantene, e′ ∈ F gibt, so daß dieEinschränkungH′|V ′\(e∩e′) unzusammenhängend ist.
1. Man muß die EinschränkungH|V ′ vonH auf beliebige Knotenteilmengen
V ′ ⊆ V zulassen, da eine zyklische Zusammenhangskomponente azyklische
Teile – und damit eine Artikulationsmenge – enthalten kann.
AB
C
D
G
E F
H
e1
e2
e3
e4
“Zykel”: { e1, e2, e3 }Artikulationsmenge:
e∗ = e2 ∩ e4 = {F }trennte4 vom Zykel ab
Es reicht dann nicht aus nur die HypergraphenH|V ′ zu den Knotenmengen
V ′ = ∪f∈Ff der ZusammenhangskomponentenF vonH zu betrachten.
Prof. Dr. Dietmar Seipel 389

Vorlesung Datenbanken Wintersemester 2013/14
2. Die Betrachtung eingeschränkter Kantenmengen des HypergraphenH = (V, E)
bringt ebenfalls nichts, da eine KantenteilmengeE ′ ⊆ E zyklisch sein kann,
obwohlH azyklisch ist.
H:
A B
C
G
D F
Ee1 e2
e3
e4
E ′ = { e1, e2, e3 }
Nach dem Löschen der isolierten KnotenD,E, F,G, sind alle Kanten in
e′4 = {A,B,C } enthalten, d.h.H ist azyklisch.
3. Man muß die Reduktion(H|V ′)∇ betrachten, da sonst ein nicht–reduzierter
HypergraphH = (V, { e, e′ }) mit zwei Kanten∅ 6= e′ ( e zyklisch wäre.
H′ = H|V ist zusammenhängend, abere∗ = e ∩ e′ = e′ ist keine
Artikulationsmenge vonH′, daH|V \e∗ nur die eine Kantee \ e′ enthält und
somit ebenfalls zusammenhängend ist.
A B
Prof. Dr. Dietmar Seipel 390

Vorlesung Datenbanken Wintersemester 2013/14
Standard–Graphentheorie:
1. Das erste Problem tritt in ungerichteten Graphen genausoauf.
Die folgende zyklische Zusammenhangskomponente
F = { {A,B}, {B,C}, {A,C}, {C,D} }
besitzt einer Artikulationsmengee∗ = {B,C} ∩ {C,D} = {C}.
C
A B
D
2. Das zweite und das dritte Problem treten in ungerichtetenGraphen nichtauf, da dort Kanten immer zwei Knoten haben und es keineeingebetteten Kanten gibt.
Ein ungerichteter Graph ist zyklisch, wenn er eine zyklischeKantenteilmenge enthält, egal welche Kanten er sonst noch enthält.
Prof. Dr. Dietmar Seipel 391

Vorlesung Datenbanken Wintersemester 2013/14
Der Reduktionsalgorithmusvon Graham, Yannakakis und Ozoyoglu (GYO–Algorithmus)
Input: ein HypergraphH = (V, E)
Output: ein HypergraphH′ = (V,F)
Methode: Starte mitF = E , und wende folgende Regeln aufF solangewiederholt an, bis keine der Regeln mehr anwendbar ist.
isolierte Knoten löschen: Falls ein Knotenv in genau einer Kantef ∈ F
vorkommt, so löschev ausf : d.h.F = (F \ { f }) ∪ { f \ {v} }.
Kantenmenge reduzieren: Falls eine Kantef ∈ F eine Teilmenge eineranderen Kantef ′ ∈ F ist, f ( f ′, oder fallsf = ∅, so löschef ausF :d.h.F = F \ { f }.
Satz: H ist azyklisch, genau dann wenn der GYO–Reduktionsalgorithmusmit dem HypergraphenH′ = (V, ∅) ohne Hyperkanten terminiert.
Prof. Dr. Dietmar Seipel 392

Vorlesung Datenbanken Wintersemester 2013/14
Zur Visualisierung des GYO–Reduktionsalgorithmus verwenden wir wieder
ein Tableau, das – analog zum Schema–Tableau aus dem LJP–Algorithmus –
eine Zeile pro Hyperkante enthält.
Für den HypergraphenH mit der KantenmengeE = {U1, U2, U3 } zu den
AttributmengenU1 = {L, T,A}, U2 = {L,O} undU3 = {O,K} erhalten
wir folgendes GYO–Tableau:
L T A
L O
O K
Zum Vergleich das Schema–Tableau aus dem LJP–Algorithmus:
L T A O K
w1 a a a b1 b1
w2 a b2 b2 a b2
w3 b3 b3 b3 a a
Prof. Dr. Dietmar Seipel 393

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (GYO–Reduktionsalgorithmus)
1. Der HypergraphH = (V, E) mit E = {AB,BC,AC } ist zyklisch:
A B
C
Beim GYO–Algorithmus wird die Kantenmenge nicht verändert:
A B
B C
A C
Auch als ungerichteter Graph betrachtet istH zyklisch.
Prof. Dr. Dietmar Seipel 394
Vorlesung Datenbanken Wintersemester 2013/14
2. SeiH = (V, E) der Hypergraph mitV = {A, . . . , G } und
E = {ABC,BCDE,BCDG,CDEF }.
A CB D
E
G
F
a) Der GYO–Algorithmus startet mit der Kantenmenge
A B C
B C D E
B C D G
C D E F
Prof. Dr. Dietmar Seipel 395

Vorlesung Datenbanken Wintersemester 2013/14
b) Durch Löschen der isolierten KnotenA,F,G erhalten wir
B C
B C D E
B C D
C D E
c) Durch Löschen der HyperkantenBC,BCD,CDE als Teilmengen von
BCDE erhalten wir
B C D E
d) Durch Löschen der isolierten KnotenB,C,D,E und durch
darauffolgendes Löschen der leeren Hyperkante erhalten wir einen leeren
Hypergraphen.
e) Also istH azyklisch.
Prof. Dr. Dietmar Seipel 396

Vorlesung Datenbanken Wintersemester 2013/14
Alternativ könnte man in den Schritten a) und b) wie gerade eben
verfahren, und dann aber in anderer Weise weitermachen:
c) Durch Löschen der HyperkantenBCD,CDE als Teilmengen von
BCDE erhalten wirB C
B C D E
d) Durch Löschen der isolierten KnotenD,E erhalten wir
B C
B C
e) Durch Löschen der zweiten Zeile (doppelte HyperkanteBC) erhalten wir
B C
f) Durch Löschen der isolierten KnotenB,C und durch darauffolgendes
Löschen der leeren Hyperkante erhalten wir einen leeren Hypergraphen.
Prof. Dr. Dietmar Seipel 397
Vorlesung Datenbanken Wintersemester 2013/14
3. Der folgende HypergraphH ist azyklisch, obwohl er eine zyklische
KantenteilmengeE ′ = { e1, e2, e3 } enthält:
A B
C
G
D F
E
e1 e2
e3
e4
a) Der GYO–Algorithmus startet mit der Kantenmenge
A C D
B C F
A B G
A B C E
Prof. Dr. Dietmar Seipel 398

Vorlesung Datenbanken Wintersemester 2013/14
b) Durch das Löschen der isolierten KnotenD,E, F,G erhalten wir
A C
B C
A B
A B C
c) Nun sind alle resultierenden Hyperkanten Teilmengen dievierten
Hyperkante, und sie können somit gelöscht werden:
A B C
d) Durch Löschen der isolierten KnotenA,B,C und durch darauffolgendes
Löschen der leeren Hyperkante erhalten wir einen leeren Hypergraphen.
Ohne die Schutzkantee4 (letzte Zeile des Tableaus) wäre der
Hypergraph zyklisch, da die Schritte c) und d) nicht möglichwären.
Prof. Dr. Dietmar Seipel 399
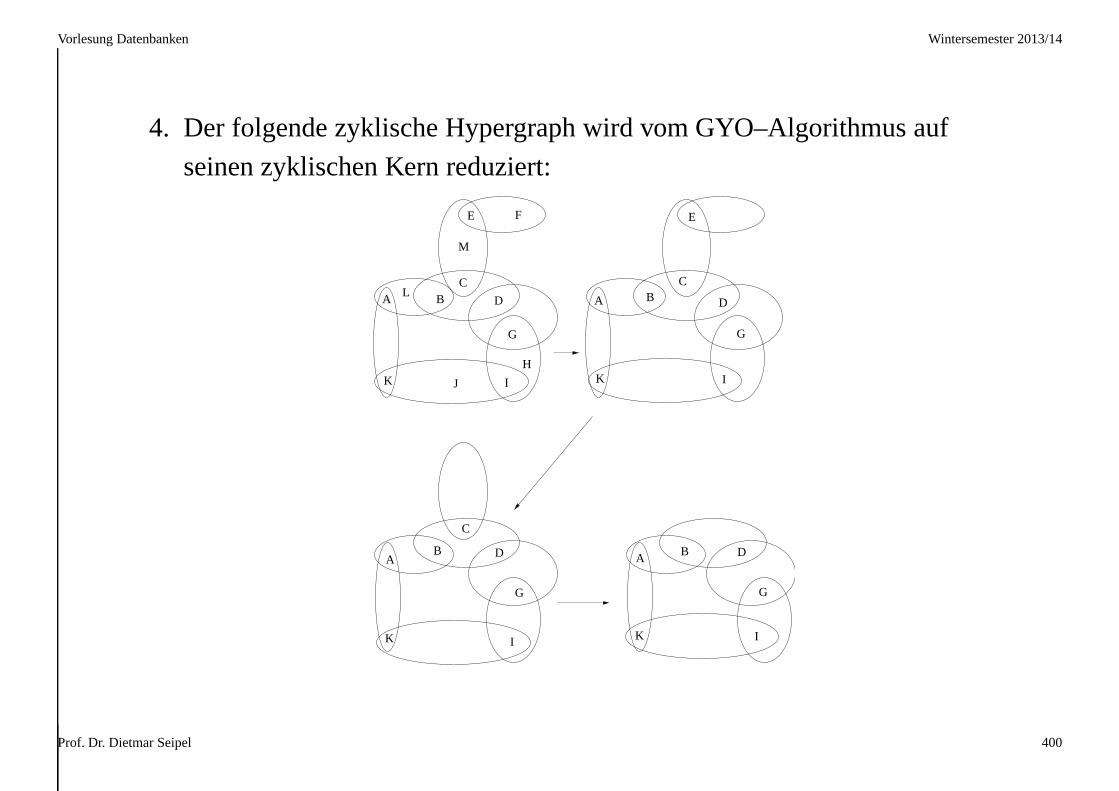
Vorlesung Datenbanken Wintersemester 2013/14
4. Der folgende zyklische Hypergraph wird vom GYO–Algorithmus auf
seinen zyklischen Kern reduziert:
FE
M
C
D
G
H
AL
B
K IJ
E
CBA
K I
G
D
C
D
G
I
BA
K K
G
DBA
I
Prof. Dr. Dietmar Seipel 400

Vorlesung Datenbanken Wintersemester 2013/14
Join Trees
Ein Join Treefür einen HypergraphenH = (V, E) ist ein ungerichteter Baum
T = (E ,F) mit den Hyperkanten vonH als Knoten,
so daß für jedes Paare, e′ ∈ E von Knoten vonT und für jeden Knotenf auf
dem (eindeutigen) Pfad vone nache′ in T gilt: e ∩ e′ ⊆ f .
e′f
e
Prof. Dr. Dietmar Seipel 401
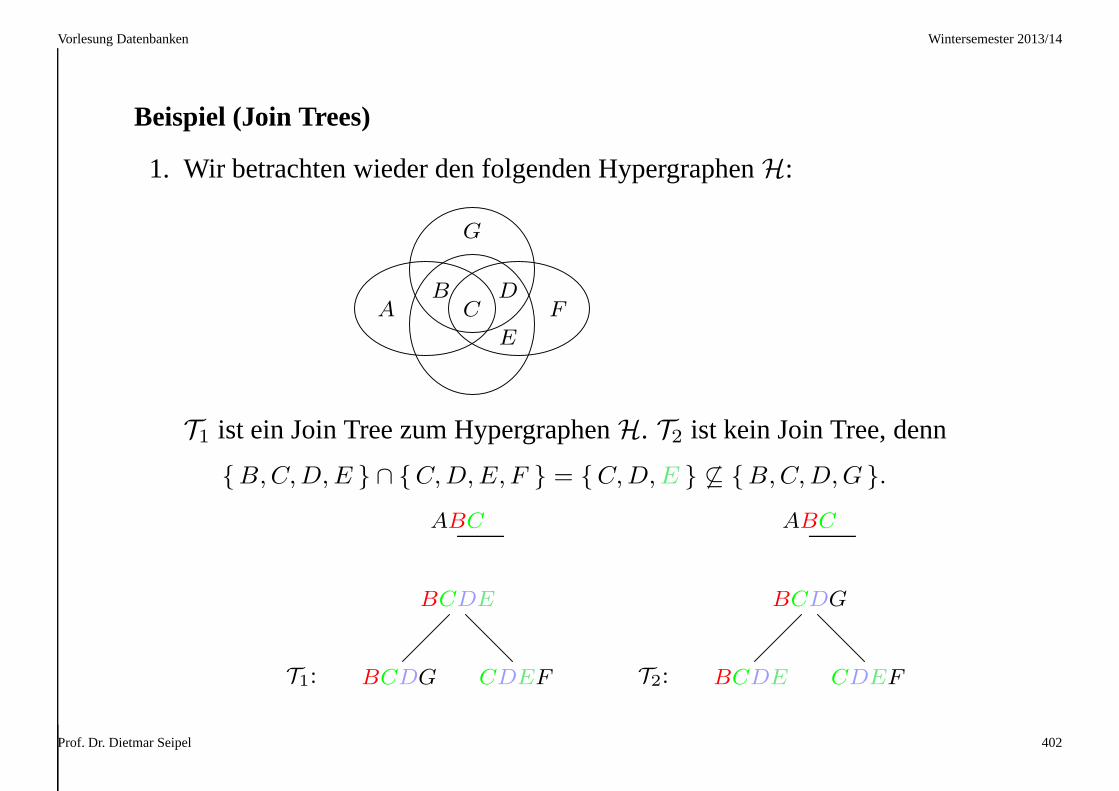
Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Join Trees)
1. Wir betrachten wieder den folgenden HypergraphenH:
A CB D
E
G
F
T1 ist ein Join Tree zum HypergraphenH. T2 ist kein Join Tree, denn
{B,C,D,E } ∩ {C,D,E, F } = {C,D,E } 6⊆ {B,C,D,G }.
T1:
ABC
BCDE
BCDG CDEF T2:
ABC
BCDG
BCDE CDEF
Prof. Dr. Dietmar Seipel 402
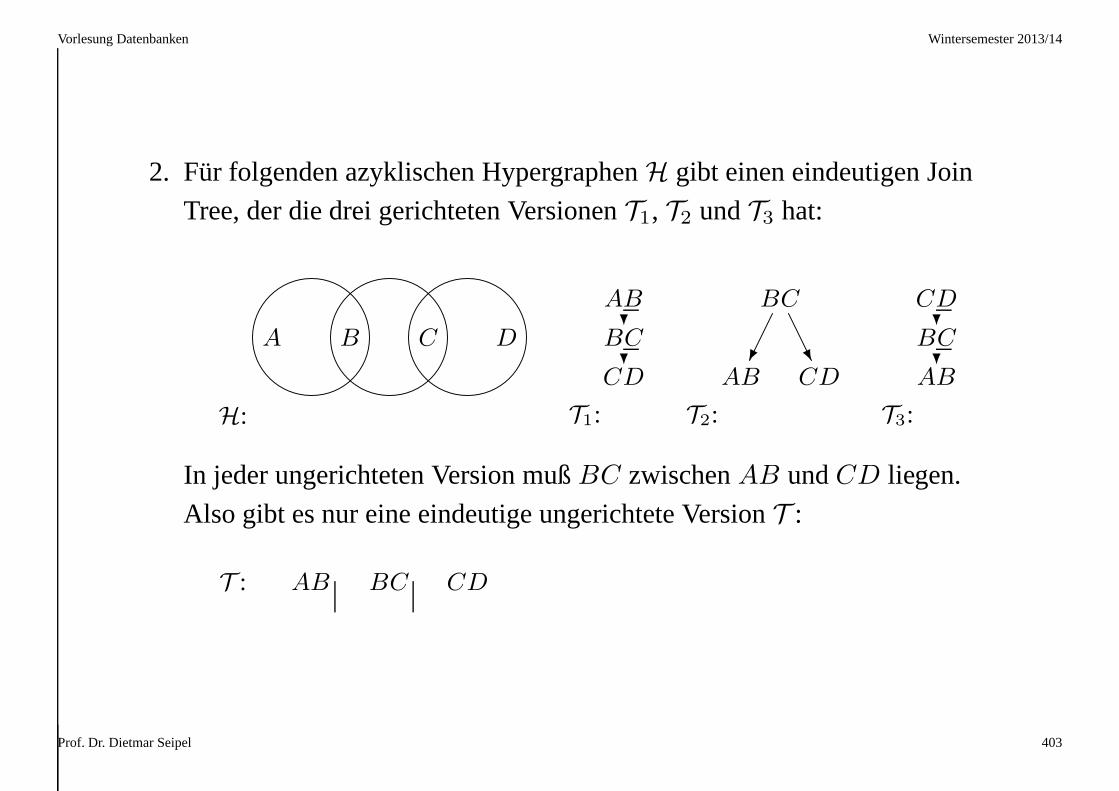
Vorlesung Datenbanken Wintersemester 2013/14
2. Für folgenden azyklischen HypergraphenH gibt einen eindeutigen Join
Tree, der die drei gerichteten VersionenT1, T2 undT3 hat:
H:
A B C D
T1:
CD
BC
AB
??
T2:
BC
AB CD� U
T3:
AB
BC
CD
??
In jeder ungerichteten Version mußBC zwischenAB undCD liegen.
Also gibt es nur eine eindeutige ungerichtete VersionT :
T : AB BC CD
Prof. Dr. Dietmar Seipel 403

Vorlesung Datenbanken Wintersemester 2013/14
3. Für folgenden azyklischen HypergraphenH gibt es16 unterschiedliche
ungerichtete Join Trees:
H:
A
B
C
D
E
T1: T2: T3:AB
AC
AD
AE
AB
AD
AC
AE
AD AE
AC
AB
Da sich alle Kanten im selben KnotenA schneiden, ist hier jeder Baum
ein Join Tree. 12 der Join Trees sind Ketten (wieT1 undT2), und 4 sind
Sterne (wieT3).
Prof. Dr. Dietmar Seipel 404

Vorlesung Datenbanken Wintersemester 2013/14
4. Für folgenden zyklischen HypergraphenH gibt es keinen Join Tree:
H:
A B
C
T :
AC
BC
AB
Da das Beispiel inA, B undC voll symmetrisch aufgebaut ist,
gäbe es – bis auf Isomorphie – nur eine AlternativeT .
T ist aber kein Join Tree, denn es gilt
{A,B } ∩ {A,C } = {A } 6⊆ {B,C }.
Prof. Dr. Dietmar Seipel 405

Vorlesung Datenbanken Wintersemester 2013/14
Join–Berechnung
Ein gerichteter Join TreeT kann in einen geeigneten relationalenOperatorbaumO zur Berechnung des Joins⊲⊳ d einer Datenbankinstanzdverwandelt werden.
Dabei wird der TeilbaumTr zu einem Knotenr des Join Trees in einenOperatorbaumOr verwandelt:
• Für einen Blattknotenr bestehtOr nur ausr.
• Sonst ergibt sichOr als (k + 1)–Wege–Join vonr mit denOperatorbäumenOrij
zu den TeilbäumenTrij der Söhnerij von r:
Tr: r
ri1 rik
Tri1 . . . Trik
R
Or: ⊲⊳
r ⊲⊳ ⊲⊳
Ori1. . . Orik
61 i
Prof. Dr. Dietmar Seipel 406
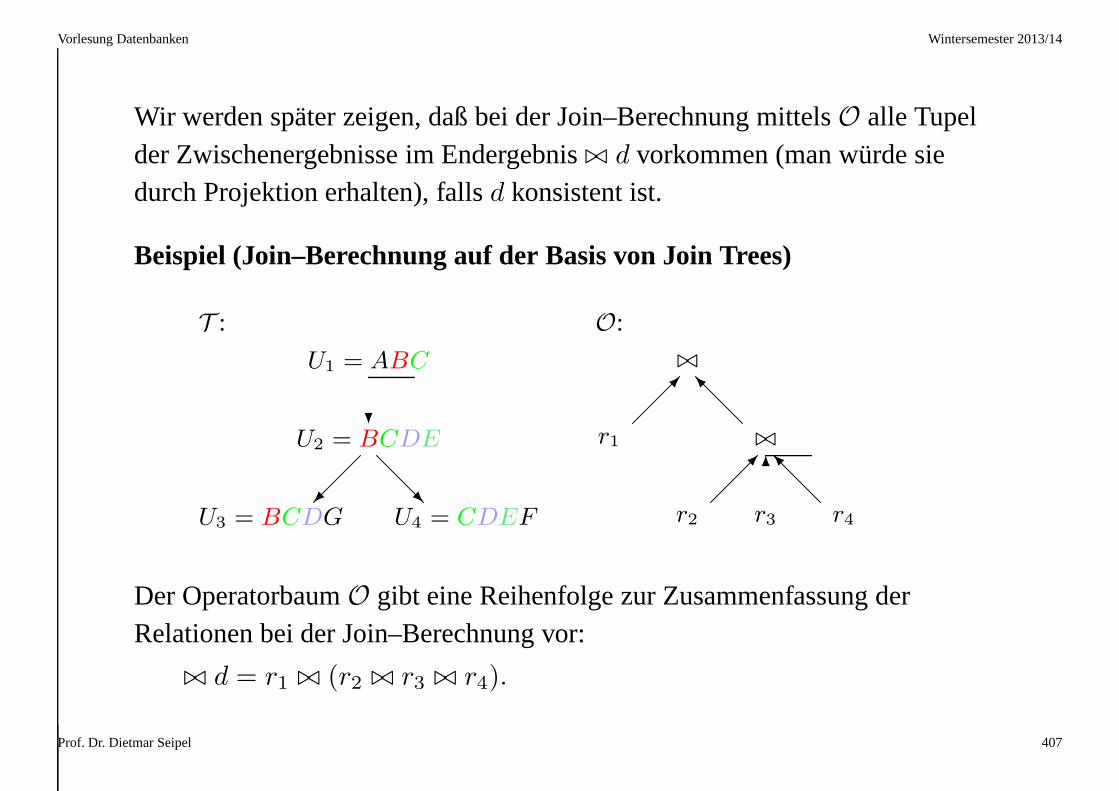
Vorlesung Datenbanken Wintersemester 2013/14
Wir werden später zeigen, daß bei der Join–Berechnung mittels O alle Tupelder Zwischenergebnisse im Endergebnis⊲⊳ d vorkommen (man würde siedurch Projektion erhalten), fallsd konsistent ist.
Beispiel (Join–Berechnung auf der Basis von Join Trees)
T :
U1 = ABC
U2 = BCDE
U3 = BCDG U4 = CDEF
?
R
O:
⊲⊳
r1 ⊲⊳
r2 r3 r4
I�
6I�
Der OperatorbaumO gibt eine Reihenfolge zur Zusammenfassung derRelationen bei der Join–Berechnung vor:
⊲⊳ d = r1 ⊲⊳ (r2 ⊲⊳ r3 ⊲⊳ r4).
Prof. Dr. Dietmar Seipel 407

Vorlesung Datenbanken Wintersemester 2013/14
Für den Join TreeT1 werden zuerstr2 undr3 verbunden, und das Ergebnis
dann mitr1:
T1:U1 = AB
U2 = BC
U3 = CD?
?
O1:⊲⊳
r1 ⊲⊳
r2 r3
I�
I�
Join–Berechnung:
⊲⊳ d = r1 ⊲⊳ (r2 ⊲⊳ r3).
Prof. Dr. Dietmar Seipel 408

Vorlesung Datenbanken Wintersemester 2013/14
Für den Join TreeT2 werden die Relationen in einem 3–Wege–Join
verbunden:
T2:
U1 = AB
U2 = BC
U3 = CD R
O2:⊲⊳
r1 r2 r3
I6�
Join–Berechnung:
⊲⊳ d = r1 ⊲⊳ r2 ⊲⊳ r3.
Man sollte hier auf keinen Fall zuerstr1 ⊲⊳ r3 berechnen;
daU1 undU3 nicht verbunden sind, würde das zu einem kartesischen
Produkt führen.
Prof. Dr. Dietmar Seipel 409
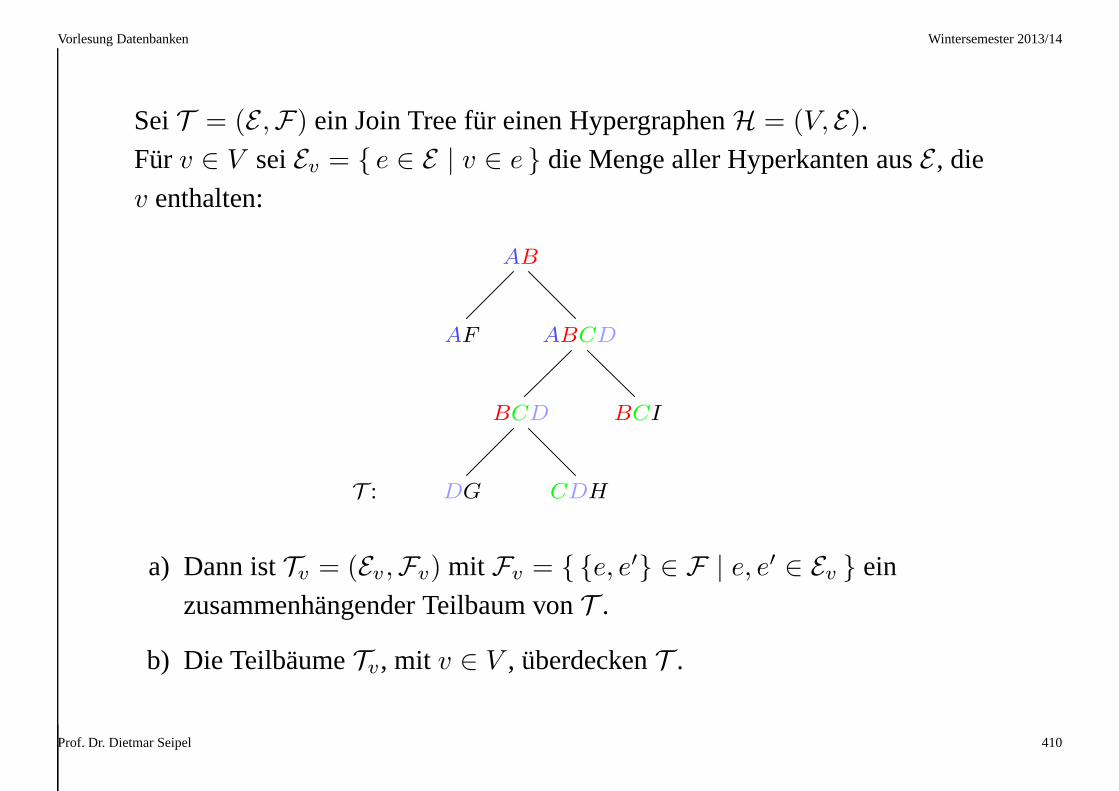
Vorlesung Datenbanken Wintersemester 2013/14
SeiT = (E ,F) ein Join Tree für einen HypergraphenH = (V, E).
Fürv ∈ V seiEv = { e ∈ E | v ∈ e } die Menge aller Hyperkanten ausE , die
v enthalten:
T :
AB
AF ABCD
BCD BCI
DG CDH
a) Dann istTv = (Ev,Fv) mit Fv = { {e, e′} ∈ F | e, e′ ∈ Ev } ein
zusammenhängender Teilbaum vonT .
b) Die TeilbäumeTv, mit v ∈ V , überdeckenT .
Prof. Dr. Dietmar Seipel 410

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Join Tree⇔ Azyklizität)
Ein HypergraphH = (V, E) hat einen Join Tree, g.d.w.H azyklisch ist.
Beweis.“⇒” zeigt man durch Induktion nachn = |E|.Die Verankerung fürn = 0, 1 ist klar.Der Schrittn → n+ 1, n ≥ 1, ist wie folgt:
1. SeiH ein Hypergraph mitn+ 1 Kanten,und seiT = (E ,F) ein gerichteter Join Tree zuH.
2. Seie ∈ E ein Blatt inT , und seif ∈ E der Vater vone in T .Dann gilt für alle anderen Knotene′ ∈ E des Baumese ∩ e′ ⊆ f ,dennf liegt auf dem ungerichteten Pfad vone nache′.
3. Folglich sind alle Elemente ause \ f in H isoliert, und sie können beimGYO–Reduktionsalgorithmus entfernt werden. Danach ist dieeingeschränkte Kantee \ (e \ f) = e ∩ f eine Teilmenge vonf .
e′f
e
RR
RR
R R
Prof. Dr. Dietmar Seipel 411

Vorlesung Datenbanken Wintersemester 2013/14
4. Also kann jetzt die eingeschränkte Kantee ∩ f entfernt werden.
Der eingeschränkte Baum
T ′ = (E \ {e},F \ {(f, e)})
ist ein Join Tree für den eingeschränkten Hypergraphen
H′ = (V, E \ {e}), der nurn = |E \ {e}| Hyperkanten hat.
Nach Induktionsannahme kann manH′ zuH′′ = (V, ∅) reduzieren.
WegenH → H′ → H′′ ist H azyklisch.
“⇐” zeigt man durch Konstruktion eines gerichteten Join Trees:
H kann mittels des GYO–Algorithmus zuH′ = (V, ∅) reduziert werden.
1. Seien, . . . , e1 die Reihung vonE , nach der die Elemente vonE gelöscht
wurden. Seiei′ ∈ E der Grund für die Löschung vonei.
Dann gilt1 ≤ i′ ≤ i− 1, daei′ nachei gelöscht wurde.
Prof. Dr. Dietmar Seipel 412

Vorlesung Datenbanken Wintersemester 2013/14
2. Für alle1 ≤ j < i ≤ n gilt
ei ∩ ej ⊆ ei′ .
3. Damit istT = (E ,F), mit F = { (ei′ , ei) | 2 ≤ i ≤ n }, ein gerichteter
Join Tree fürH.
e1 : A B C
. . .
ei′ : B C D E
. . .
ei−1 : B C D G
ei : C D E F
GYO–Algorithmus Join Tree
e1
ei′
ei−1 eiR
?
Prof. Dr. Dietmar Seipel 413

Vorlesung Datenbanken Wintersemester 2013/14
GYO–Algorithmus → Join Tree
Aus der Löschreihenfolge der Tableau–Zeilen beim GYO–Algorithmus
ergibt sich ein (gerichteter) Join TreeT = (E ,F) :
• Seien, . . . , e1 die Reihenfolge, in der die Tableau–Zeilen gelöscht
wurden.
• Sei die Tableau–Zeileei′ der Grund für die Löschung vonei. Dann
enthält der Join Tree eine Kante vonei′ nachei.
• Die Kantenmenge des Join Trees ergibt sich also als
F = { (ei′ , ei) | 2 ≤ i ≤ n }.
Prof. Dr. Dietmar Seipel 414

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (GYO–Algorithmus → Join Tree)
1. Für die Löschreihenfolgee4, e3, e2, e1 erhalten wir den gerichteten Join
TreeT1.
2. Für die Löschreihenfolgee4, e3, e1, e2 erhalten wir den gerichteten Join
TreeT2.
T1:
U1 = ABC
U2 = BCDE
U3 = BCDG U4 = CDEF
?
R
T2:
U2 = BCDE
U1 = ABC U3 = BCDG U4 = CDEF?) q
Prof. Dr. Dietmar Seipel 415

Vorlesung Datenbanken Wintersemester 2013/14
Topologische Sortierung
Eine topologische Sortierung eines gerichteten GraphenG = (V,E) ist eineSortierung
v1, . . . , vn
der KnotenmengeV , so daß für alle Kanten(vi, vj) ∈ E gilt i < j. Es gibtalso nur Kanten von kleineren Indizes zu größeren.
Man kannG genau dann topologisch sortieren, wennG azyklisch ist.
Zur algorithmischen Bestimmung einer topologischen Sortierung sucht manzunächst nach einem Knotenv1 ohne eingehende Kanten und entfernt diesenzusammen mit seinen ausgehenden Kanten aus dem Graphen.Danach bestimmt man (rekursiv) eine topologische Sortierungv2, . . . , vndes Restgraphen.
Für die obigen Join Trees erhält man z.B.U1, U2, U3, U4 (für T1) bzw.U2, U1, U4, U3 (für T2). Die Reihenfolge der BrüderU3 undU4 ist beliebig.
Prof. Dr. Dietmar Seipel 416

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Azyklizität ⇒ Semi–Join–Programm)
SeiD ein Datenbankschema mit einem azyklischen HypergraphenH.
Dann hatD hat einvoll reduzierendesSemi–Join–Programm.
Beweis.Wir konstruieren ein voll reduzierendes Semi–Join–Programm.
Sei (o.B.d.A.) der HypergraphH = (V, E) zusammenhängend,
und seiT = (E ,F) ein gerichteter Join Tree fürH.
T : U1 = ABC
U2 = BCDE
U3 = BCDG U4 = CDEF
?
R
Prof. Dr. Dietmar Seipel 417

Vorlesung Datenbanken Wintersemester 2013/14
1. Topologisches Sortieren vonE liefert eine FolgeU1, . . . , Un von
Attributmengen, wobei natürlichU1 die Wurzel vonT ist.
2. Sei nund = { r1, . . . , rn } eine Datenbankinstanz zuD mit
ri ∈ Rel(Ui), für 1 ≤ i ≤ n.
3. SeiUi′ der Vater vonUi in T undsi = ri′ ∈ Rel(Ui′) die entsprechende
Vaterrelation vonri, für 2 ≤ i ≤ n.
T :
r1 = s2
r2 = s3 = s4
r3 r4
?
R
Prof. Dr. Dietmar Seipel 418

Vorlesung Datenbanken Wintersemester 2013/14
Dann ist folgendes Semi–Join–ProgrammP für D voll reduzierend:
allgemein:
sn := sn⋉rn...
s3 := s3⋉r3
s2 := s2⋉r2
r2 := r2⋉s2
r3 := r3⋉s3...
rn := rn⋉sn
Beispiel:
r2 := r2⋉r4
r2 := r2⋉r3
r1 := r1⋉r2
r2 := r2⋉r1
r3 := r3⋉r2
r4 := r4⋉r2
T :
r1 = s2
r2 = s3 = s4
r3 r4
?
R
P besteht aus2 · (n− 1) Semi–Join–Reduktionsschritten.
Prof. Dr. Dietmar Seipel 419

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Join Tree→ Semi–Join–Programm)
T1: U1 = ABC
U2 = BCDE
U3 = BCDG U4 = CDEF
?
R
T2:
U2 = BCDE
U1 = ABC U3 = BCDG U4 = CDEF?) q
Jeder gerichtete Join TreeTi erzeugt ein Semi–Join–ProgrammPi:
P1 : r2 := r2⋉r4r2 := r2⋉r3r1 := r1⋉r2
r2 := r2⋉r1r3 := r3⋉r2r4 := r4⋉r2
P2 : r2 := r2⋉r4r2 := r2⋉r3r2 := r2⋉r1
r1 := r1⋉r2r3 := r3⋉r2r4 := r4⋉r2
P1 undP2 unterscheiden sich nur in den mittleren beiden Operationen.
Prof. Dr. Dietmar Seipel 420

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Azyklizität)
Für ein DatenbankschemaD und seinen HypergraphenH sind folgendeAussagen äquivalent:
1. H ist azyklisch.
2. Jedepaarweisekonsistente Datenbankinstanz vonD
ist auchglobal konsistent.
3. D hat einvoll reduzierendesSemi–Join–Programm.
4. H hat einenJoin Tree.
Beweis.(teilweise) “1.⇔ 4.” und “4. ⇒ 3.” wurden oben bewiesen.
“3. ⇒ 2.” gilt, da eine paarweise konsistente Datenbankinstanzd durch einSemi–Join–Programm nicht verändert wird. Deswegen istd identischmit seiner vollständigen Reduktiond∇, und somit global konsistent.
1
4 3
26?
6-
Prof. Dr. Dietmar Seipel 421

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Azyklische Joins)
SeiD = {R1, . . . , Rn } ein azyklischesDatenbankschema.
Dann kann man für jede erlaubte Datenbankinstanzd = { r1, . . . , rn }
vonD den AusdruckΠX(⊲⊳ d) in polynomieller Zeit berechnen,
und zwar polynomiell in der Größe der EingabeD, d, und der Ausgabe.
Beweis.(Skizze)
Da die Berechnung in den einzelnen Zusammenhangskomponenten des
HypergraphenH zuD separat ausgeführt werden kann, können wir o.B.d.A.
annehmen, daßH zusammenhängendist.
1. Wir könnend zuerst in polynomieller Zeit mit einem voll reduzierenden
Semi–Join–Programm auf die global konsistente Datenbankinstanz
d∇ = { r∇1 , . . . , r∇n } reduzieren, so daß⊲⊳ d = ⊲⊳ d∇ gilt.
Prof. Dr. Dietmar Seipel 422
Vorlesung Datenbanken Wintersemester 2013/14
2. Sei nunRi = (Ui, Fi), für 1 ≤ i ≤ n, undT ein gerichteter Join Tree
für den HypergraphenH = (V, E) zuD, mit
V =n⋃
i=1
Ui und E = {Ui | 1 ≤ i ≤ n }.
SeiTi der Teilbaum eines KnotenUi mit den SöhnenUi1 , . . . , Uik .
Vi1Xi1
Ti1
· · ·
VikXik
Tik
Vi Xi
Vij = Uij ∩ Ui
R
R
K K
Prof. Dr. Dietmar Seipel 423

Vorlesung Datenbanken Wintersemester 2013/14
3. SeienXi die Anfrage– undVi die Join–Attribute vonTi:
Xi = X ∩ ∪Uj∈TiUj ,
Vi = Ui ∩ Ui′ ,
wobeiUi′ der Vater vonUi in T ist.
4. Dann kann induktiv zuTi die Relation
si = ΠXiVi
(⊲⊳Uj∈Ti r
∇j
)
wie folgt konstruiert werden:
a) Für ein BlattUi vonT ist si = ΠXiVi(r∇i ).
b) Für einen VaterknotenUi ausT erhält man die Relationsi = ΠXiVi(s)
aus dem Join
s = r∇i ⊲⊳ si1 ⊲⊳ . . . ⊲⊳ sik
der Relationr∇i mit den Relationensij aller SöhneUij vonUi.
Prof. Dr. Dietmar Seipel 424

Vorlesung Datenbanken Wintersemester 2013/14
5. Am Ende gilt für die Relations1 an der Wurzel des Baumes:
X1 = X ∩ ∪Uj∈T1Uj = X ∩ U = X,
V1 = ∅.
Deshalb folgt
s1 = ΠX
(⊲⊳Uj∈T1 r∇j
)= ΠX(⊲⊳ d∇) = ΠX(⊲⊳ d).
6. Wegen
a) der paarweisen Konsistenz vond∇ und
b) der Join Tree–Eigenschaft vonT
ist die Tupelanzahl|si| in jedem Zwischenstadium durch dieTupelanzahl|s1| des Endresultats beschränkt.
Also kann man den AusdruckΠX(⊲⊳ d) in polynomieller Zeit berechnen.
Prof. Dr. Dietmar Seipel 425

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Azyklische Joins)
U = {A,B,C,D,E, F,G },
U1 = {A,B,C }, U2 = {B,C,D,E },
U3 = {B,C,D,G }, U4 = {C,D,E, F },
X = {A,D, F }.
Datenbankausprägungd = { r1, r2, r3, r4 }
Vollständige Reduktion:
r∇1
: r∇2
: r∇3
: r∇4
:
A B C
0 1 2
3 1 2
1 1 3
B C D E
1 2 3 0
1 3 1 0
B C D G
1 2 3 2
1 3 1 0
1 3 1 1
C D E F
2 3 0 1
3 1 0 2
3 1 0 3
Prof. Dr. Dietmar Seipel 426

Vorlesung Datenbanken Wintersemester 2013/14
Join Tree: die Pfeile geben hier den Berechnungsfluß an
U1 = ABC
U2 = BCDE
U3 = BCDG U4 = CDEF
6
� I
V1 = ∅, X1 = ADF
V2 = BC, X2 = DF
V3 = BCD
X3 = D
V4 = CDE
X4 = DF
6
� I
Join–Programm:
s4 = ΠCDEF (r∇4 ),
s3 = ΠBCD(r∇3 ),
s2 = ΠBCDF (r∇2 ⊲⊳ s3 ⊲⊳ s4),
s1 = ΠADF (r∇1 ⊲⊳ s2).
Prof. Dr. Dietmar Seipel 427
Vorlesung Datenbanken Wintersemester 2013/14
OperatorbaumO mit Joins und Projektionen:
⊲⊳
r∇1
⊲⊳
r∇2 πBCD
r∇3
πCDEF
r∇4
πBCDF
πADF
I�
6I�
6 6
6
6
Prof. Dr. Dietmar Seipel 428

Vorlesung Datenbanken Wintersemester 2013/14
Berechnete Relationen:
r∇2 ⊲⊳ s3 ⊲⊳ s4:
B C D E F
1 2 3 0 1
1 3 1 0 2
1 3 1 0 3
s2 = ΠBCDF (r∇2 ⊲⊳ s3 ⊲⊳ s4):
B C D F
1 2 3 1
1 3 1 2
1 3 1 3
r∇1 ⊲⊳ s2:
A B C D F
0 1 2 3 1
3 1 2 3 1
1 1 3 1 2
1 1 3 1 3
Resultat:s1 = ΠADF (r∇1 ⊲⊳ s2):
A D F
0 3 1
3 3 1
1 1 2
1 1 3
Prof. Dr. Dietmar Seipel 429

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Zyklische Joins)
U = {A,B,C } = X,
U1 = {A,B }, U2 = {B,C }, U3 = {A,C }.
Die Datenbankinstanzd = { r1, r2, r3 } mit den Relationen
r1 : r2 : r3 : r1,2 :
A B
a b
a′ b′
B C
b c
b′ c′
C A
c a′
c′ a
A B C
a b c
a′ b′ c′
ist zwar paarweise konsistent, aber nicht global, und⊲⊳ d = ∅.
Bei der Join–Berechnung enthalten die Zwischenrelationenmehr Tupel alsdas Endergebnis⊲⊳ d. Der Joinr1,2 = r1 ⊲⊳ r2 enthält z.B. 2 Tupel, während⊲⊳ d = r1,2 ⊲⊳ r3 = ∅ keine Tupel enthält.
Prof. Dr. Dietmar Seipel 430

Vorlesung Datenbanken Wintersemester 2013/14
Satz (Azyklische Joins)
Für eine Datenbankinstanzd = { r1, . . . , rn } zu einem azyklischenDatenbankschemataD und eine AttributmengeX ist der Test
t ∈ ΠX(⊲⊳ d)
polynomiell in der Größe der EingabenD undd.
Beweis.
Berechne die Relationen
σt(ri) = { ti ∈ ri | ti[X ∩ Ui] = t[X ∩ Ui] },
und mache diese mit polynomiellem Aufwand mittels einesvoll–reduzierenden Semi–Join–Programms global konsistent: si = σt(ri)
∇.
Falls eine der Relationensi – und damit alle – nicht–leer ist,so istt ∈ ΠX(⊲⊳ d).
Prof. Dr. Dietmar Seipel 431

Vorlesung Datenbanken Wintersemester 2013/14
Allgemeine Joins
Für eine Datenbankinstanzd = { r1, . . . , rn } zu einem allgemeinen
DatenbankschemataD und eine AttributmengeX ist der Test
t ∈ ΠX(⊲⊳ d)
NP–vollständig in der Größe der EingabenD undd.
Der Join⊲⊳ d kann exponentiell viele Tupel enthalten:
Im folgenden Beispiel mit insgesamt4 · n Tuplen enthält der Join die2n+1
Tupel(ai11 , . . . , ain+1
n+1 ), für (i1, . . . , in+1) ∈ {1, 2}n+1.
ri :
a1i a1i+1
a1i a2i+1
a2i a1i+1
a2i a2i+1
a11
a21
a12
a22
a13
a23
a1n
a2n
a1n+1
a2n+1
-
-R�
-
-R�
-
-R�
-
-
�R
Prof. Dr. Dietmar Seipel 432

Vorlesung Datenbanken Wintersemester 2013/14
Join
Obige Datenbankinstanzd = { r1, . . . , rn } zeigt, daß der Join⊲⊳ d selbst für
azyklische DatenbankschemataD exponentiell viele Tupel enthalten kann,
denn das zugehörige DatenbankschemaD = { (Ui, Fi) | 1 ≤ i ≤ n } mit den
AttributmengenUi = {Ai, Ai+1 } ist azyklisch.
Test
• Für azyklische Datenbankschemata kann der Testt ∈ ΠX(⊲⊳ d) auf der
Basis eines Semi–Join–Programms in polynomieller Zeit durchgeführt
werden, ohne den Join⊲⊳ d zu berechnen.
• Für allgemeine Datenbankschemata ist dies nicht möglich,
denn der Test istNP–vollständig.
Prof. Dr. Dietmar Seipel 433

Vorlesung Datenbanken Wintersemester 2013/14
Wünschenswerte Eigenschaften für Datenbankschemata
3NF BCNF Verlustfreiheit Unabhängigkeit Azyklizität Methode
+ + + Synthese
+ + Dekomposition
– –
– – –
? ? ?
vereinbar: +
unvereinbar: –
nicht bekannt, ob vereinbar: ?
Prof. Dr. Dietmar Seipel 434

Vorlesung Datenbanken Wintersemester 2013/14
Unvereinbarkeit von BCNF, Verlustfreiheit und Azyklizitä t
Für manche Relationenschemata gibt es keine verlustfreie und azyklische
BCNF–Zerlegung.
Beispiel (Unvereinbarkeit)
Das folgende RelationenschemaR = (U, F ) ist nicht in BCNF:
U = {A,B,C,G,H, I },
F = {AGH → B, BHI → C, CGI → A }.
Es gibt keine verlustfreie und azyklische BCNF–Zerlegung vonR.
Bereits früher hatten wir gezeigt, daß es für manche Relationenschemata
auch keine unabhängige BCNF–Zerlegung gibt.
Prof. Dr. Dietmar Seipel 435
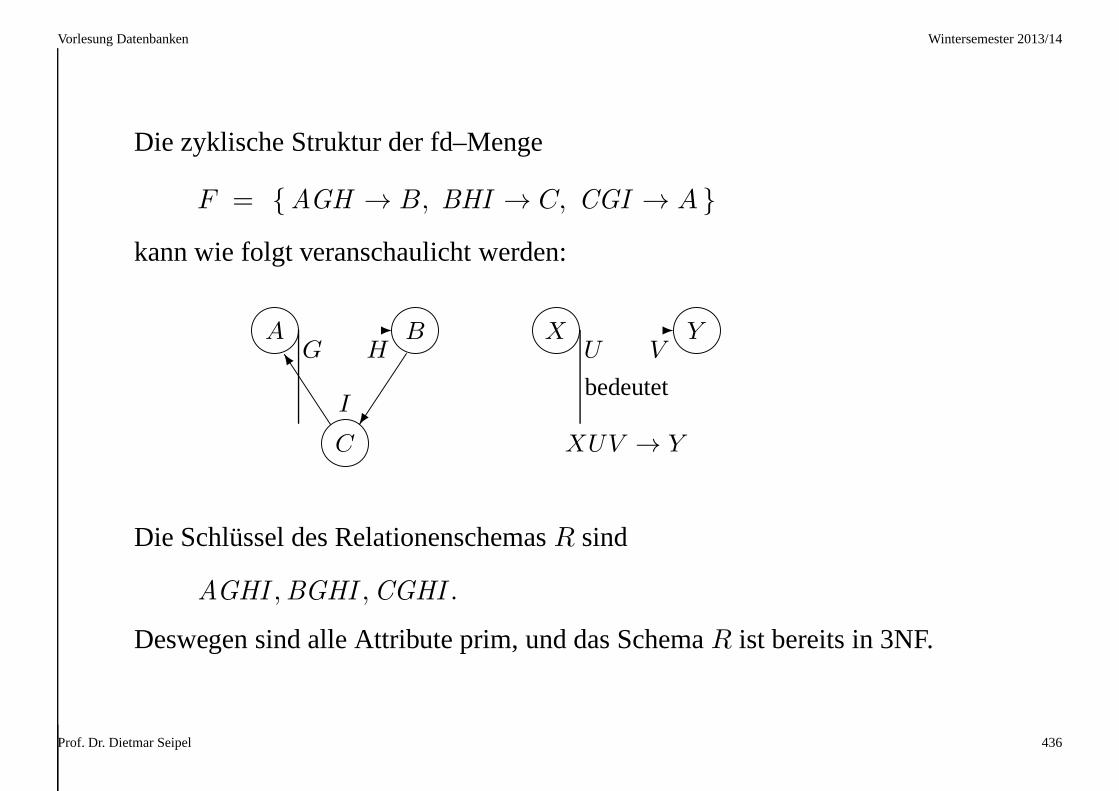
Vorlesung Datenbanken Wintersemester 2013/14
Die zyklische Struktur der fd–Menge
F = {AGH → B, BHI → C, CGI → A }
kann wie folgt veranschaulicht werden:
A B
C
G H
I
-
�
]
X YU V
-
bedeutet
XUV → Y
Die Schlüssel des RelationenschemasR sind
AGHI ,BGHI ,CGHI .
Deswegen sind alle Attribute prim, und das SchemaR ist bereits in 3NF.
Prof. Dr. Dietmar Seipel 436

Vorlesung Datenbanken Wintersemester 2013/14
Anwendung auf zyklische Datenbankschemata
Die Konzepte der Semi–Join–Reduktionen und der polynomiellen
Join–Berechnung kann man auch auf zyklische Datenbankschemata
übertragen.
• Indem man zyklische, zusammenhängende Teilmengen des zugehörigen
Hypergraphen zu jeweils einer einzigen Kante kollabiert, erhält man
azyklische Hypergraphen.
• Auf der Datenbankseite bedeutet dies, daß man die entsprechenden
Relationen zu jeweils einer einzigen Relation mittels eines Natural Join
zusammenfaßt.
Das neu entstandene Datenbankschema kann jetzt mittels
Semi–Join-Reduktionen bei Join–Berechnungen effizient behandelt werden.
Prof. Dr. Dietmar Seipel 437

Vorlesung Datenbanken Wintersemester 2013/14
Beispiel (Clusterung)
Wenn man die zyklische, zusammenhängende Teilmenge{ e1, e2, e3 } zueiner einzigen Kantee1,2,3 kollabiert (Clusterung), dann erhält man einenazyklischen Hypergraphen mit der neuen KantenmengeE ′ = { e1,2,3, e4, e5, e6 }.
AB
C
D
G
E F
H
e1
e2
e3
e4J
I
K e5
e6
-
AB
C
D
G
E F
He1,2,3
e4J
I
K e5
e6
Auf der Datenbankseite faßt man die entsprechenden Relationen mittels einesNatural Joins zu einer einzigen Relationr1,2,3 = r1 ⊲⊳ r2 ⊲⊳ r3 zusammen.Dadurch erhält man eine neue Datenbankinstanzd′ = { r1,2,3, r4, r5, r6 }.
Prof. Dr. Dietmar Seipel 438

Vorlesung Datenbanken Wintersemester 2013/14
Zusammenfassung
Für azyklische Datenbankschemata kann man Joins effizienter berechnen.
Semi–Join–Programme können eine Datenbankinstanz durch Entfernung der
dangling tuplesauf eineglobal konsistenteDatenbankinstanz reduzieren.
Die Azyklizität kann man mit Hilfe des GYO–Algorithmus feststellen:
• Aus der Löschreihenfolge der Tableau–Kanten ergibt sich ein Join Tree.
Unterschiedliche Join Trees sind möglich.
• Aus einem Join Tree kann man einSemi–Join–Programmableiten.
• Ein Join Tree gibt eine geeigneteJoin–Reihenfolgean.
Manchmal ist die Azyklizität nicht mit den anderen wünschenswerten
Eigenschaften für Datenbankschemata vereinbar.
Prof. Dr. Dietmar Seipel 439





























