Embed Size (px)
Citation preview

INFERENCIA ESTADÍSTICA
MATEMÁTICAS aplicadas a las CC. SS. II Alfonso González
IES Fernando de Mena Dpto. de Matemáticas

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
I) REPASO de ESTADÍSTICA ELEMENTAL
El concepto de variable estadística es bastante intuitivo y fácil de comprender. Existen los siguientes tipos de variables o caracteres: 1. Caracteres cualitativos: Se describen mediante palabras y no se pueden medir, es decir, no se les puede
asignar un número; más bien, presentan modalidades. Ejemplos : el estado civil, la nacionalidad, el nivel de estudios, el color del pelo, etc.
2. Caracteres cuantitativos: Se describen mediante números, es decir, son medibles. A su vez, se dividen
en:
2.1 Caracteres cuantitativos discretos: Sólo toman valores puntuales aislados. Ejemplos : número de hijos, número del calzado, nota de la evaluación de Matemáticas, etc.
2.2 Caracteres cuantitativos continuos: Pueden tomar cualquier valor intermedio entre dos cualesquiera. Ejemplos : estatura, peso, nota en un examen, etc.
Nosotros vamos a tratar en este tema generalmente variable estadística continua.
Supongamos que, en vísperas de unas elecciones, queremos tener una idea sobre las intenciones de voto del electorado. Evidentemente, no podemos preguntárselo al conjunto de todos los votantes (eso ocurrirá más bien el día de las elecciones), por lo cual tendremos que limitarnos a hacer un sondeo a una parte, naturalmente lo más representativa posible. Surgen así los siguientes conceptos:
Población: Conjunto de todos los individuos objeto del estudio.
Muestra: Subconjunto extraído de la población, cuyo estudio sirve para inferir características de toda la población.
La elección de la muestra (lo que se conoce como muestreo ) debe realizarse con cuidado para que la muestra sea lo más representativa posible; para ello hay dos factores fundamentales a tener en cuenta: el tamaño de la muestra –es evidente que si ésta es demasiado pequeña no será representativa, pero se pueden obtener estimaciones muy certeras con sondeos muy ajustados– y el cómo se lleva a cabo el muestreo: condición indispensable para que una muestra sea representativa es que el muestreo sea aleatorio1. Los años 30 del siglo pasado vieron el nacimiento de la Estadística Inductiva, que permite obtener conclusiones válidas para toda la población a partir del estudio de una muestra.
■ Para poder manejar cómodamente datos estadísticos se suelen construir tablas de frecuencias. Veámoslo, en primer lugar, para un ejemplo sencillo de variable discreta: Ejemplo 1: Las edades de los 25 alumnos de una clase de 2º de Bachillerato son las siguientes:
17, 17, 17, 18, 17, 17, 19, 17, 17, 18, 18, 17, 17, 20, 19, 17, 18, 17, 17, 17, 18, 17, 18, 17, 17 Con estos datos, construimos la siguiente tabla:
x i f i h i % 17 16 0,64 64 18 6 0,24 24 19 2 0,08 8 20 1 0,04 4
Σ=25 Σ=1 Σ=100
1 Pueden verse con más profundidad todos estos conceptos en conceptos en
http://www.alfonsogonzalez.es/asignaturas/1_bach_ccss/unidades_didacticas_1_bach_ccss.html
• La 1ª columna contiene los valores que toma la variable aleatoria xi, en este caso la edad, por orden creciente.
• La 2ª columna muestra el recuento de cada valor; se llama frecuencia absoluta , y se designa como f i
• Dividiendo las frecuencias absolutas entre el número total de individuos (25) se obtienen las frecuencias relativas (3ª columna), que se designan como h i
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
• La última columna son las frecuencias relativas expresadas en tanto por ciento.
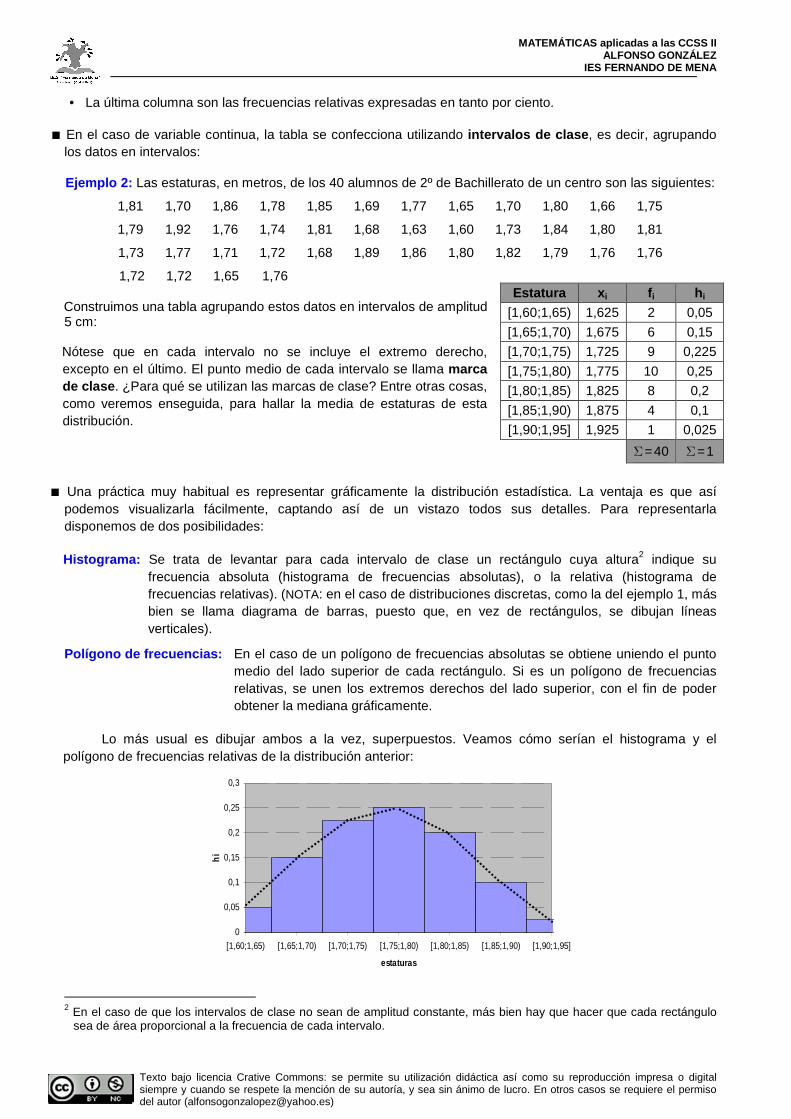
■ En el caso de variable continua, la tabla se confecciona utilizando intervalos de clase , es decir, agrupando los datos en intervalos: Ejemplo 2: Las estaturas, en metros, de los 40 alumnos de 2º de Bachillerato de un centro son las siguientes:
1,81 1,70 1,86 1,78 1,85 1,69 1,77 1,65 1,70 1,80 1,66 1,75
1,79 1,92 1,76 1,74 1,81 1,68 1,63 1,60 1,73 1,84 1,80 1,81
1,73 1,77 1,71 1,72 1,68 1,89 1,86 1,80 1,82 1,79 1,76 1,76
1,72 1,72 1,65 1,76 Construimos una tabla agrupando estos datos en intervalos de amplitud 5 cm:
■ Una práctica muy habitual es representar gráficamente la distribución estadística. La ventaja es que así podemos visualizarla fácilmente, captando así de un vistazo todos sus detalles. Para representarla disponemos de dos posibilidades:
Histograma: Se trata de levantar para cada intervalo de clase un rectángulo cuya altura2 indique su frecuencia absoluta (histograma de frecuencias absolutas), o la relativa (histograma de frecuencias relativas). (NOTA: en el caso de distribuciones discretas, como la del ejemplo 1, más bien se llama diagrama de barras, puesto que, en vez de rectángulos, se dibujan líneas verticales).
Polígono de frecuencias: En el caso de un polígono de frecuencias absolutas se obtiene uniendo el punto medio del lado superior de cada rectángulo. Si es un polígono de frecuencias relativas, se unen los extremos derechos del lado superior, con el fin de poder obtener la mediana gráficamente.
Lo más usual es dibujar ambos a la vez, superpuestos. Veamos cómo serían el histograma y el polígono de frecuencias relativas de la distribución anterior:
2 En el caso de que los intervalos de clase no sean de amplitud constante, más bien hay que hacer que cada rectángulo
sea de área proporcional a la frecuencia de cada intervalo.
0
0,05
0,1
0,15
0,2
0,25
0,3
[1,60;1,65) [1,65;1,70) [1,70;1,75) [1,75;1,80) [1,80;1,85) [1,85;1,90) [1,90;1,95]
estaturas
hi
Estatura x i f i h i [1,60;1,65) 1,625 2 0,05
[1,65;1,70) 1,675 6 0,15
[1,70;1,75) 1,725 9 0,225
[1,75;1,80) 1,775 10 0,25
[1,80;1,85) 1,825 8 0,2
[1,85;1,90) 1,875 4 0,1
[1,90;1,95] 1,925 1 0,025
Σ=40 Σ=1
Nótese que en cada intervalo no se incluye el extremo derecho, excepto en el último. El punto medio de cada intervalo se llama marca de clase . ¿Para qué se utilizan las marcas de clase? Entre otras cosas, como veremos enseguida, para hallar la media de estaturas de esta distribución.
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
Por último, para poder definir correctamente la distribución, también se acostumbra a definir una serie de parámetros estadísticos; los más importantes son dos: la media aritmética y la desviación típica.
El concepto de media aritmética es bastante intuitivo: la media aritmética de una serie de valores se
obtiene sumándolos, y dividiendo la suma por el número de valores. Se designa3 mediante o µµµµ. En el caso de datos agrupados en intervalos, se escoge como valor de cada intervalo el punto medio o marca de clase. En el ejemplo anterior, puede comprobarse que sale 1,765 m de estatura media.
El otro parámetro aludido es la desviación típica , que se designa4 como s o σσσσ. Su significado lo veremos más adelante (apdo. VI.4); baste decir, por el momento, que está relacionada con la forma de la distribución: cuando mayor es σ en relación con µ, más dispersos son los datos, y viceversa.
II) IDEA INTUITIVA DE DISTRIBUCIÓN NORMAL
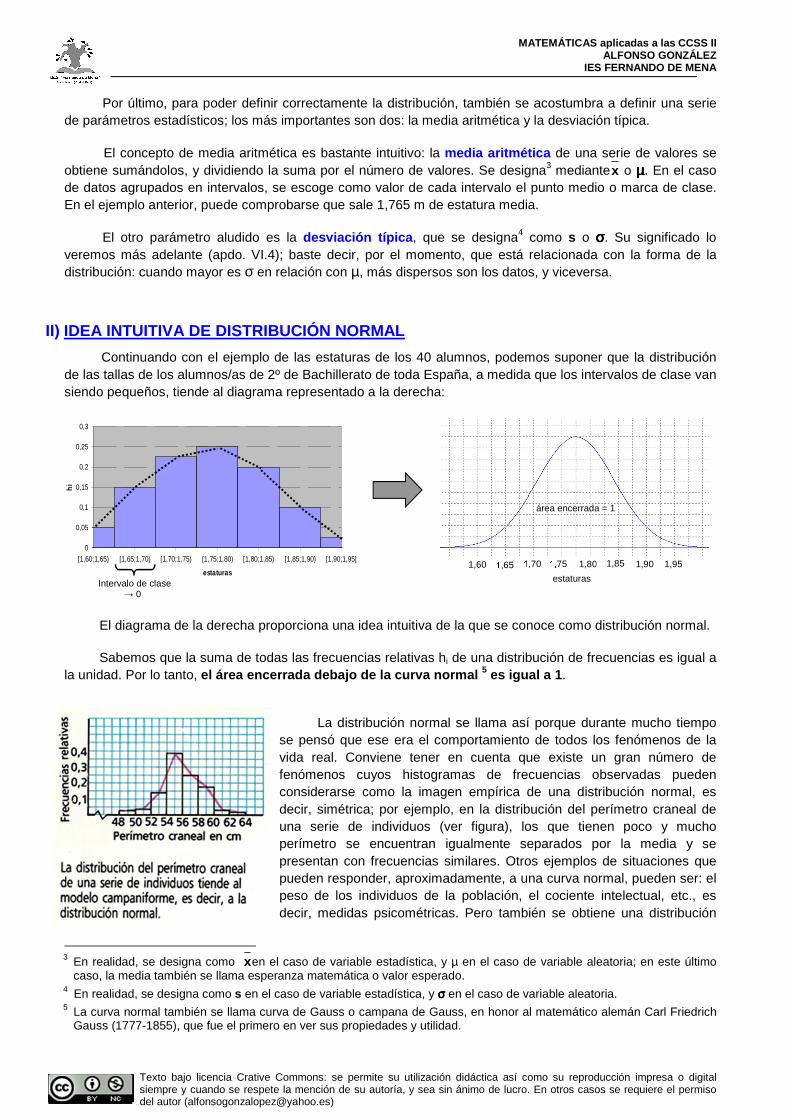
Continuando con el ejemplo de las estaturas de los 40 alumnos, podemos suponer que la distribución de las tallas de los alumnos/as de 2º de Bachillerato de toda España, a medida que los intervalos de clase van siendo pequeños, tiende al diagrama representado a la derecha:
El diagrama de la derecha proporciona una idea intuitiva de la que se conoce como distribución normal. Sabemos que la suma de todas las frecuencias relativas hi de una distribución de frecuencias es igual a
la unidad. Por lo tanto, el área encerrada debajo de la curva normal 5 es igual a 1 .
La distribución normal se llama así porque durante mucho tiempo
se pensó que ese era el comportamiento de todos los fenómenos de la vida real. Conviene tener en cuenta que existe un gran número de fenómenos cuyos histogramas de frecuencias observadas pueden considerarse como la imagen empírica de una distribución normal, es decir, simétrica; por ejemplo, en la distribución del perímetro craneal de una serie de individuos (ver figura), los que tienen poco y mucho perímetro se encuentran igualmente separados por la media y se presentan con frecuencias similares. Otros ejemplos de situaciones que pueden responder, aproximadamente, a una curva normal, pueden ser: el peso de los individuos de la población, el cociente intelectual, etc., es decir, medidas psicométricas. Pero también se obtiene una distribución
3 En realidad, se designa como en el caso de variable estadística, y µ en el caso de variable aleatoria; en este último
caso, la media también se llama esperanza matemática o valor esperado. 4 En realidad, se designa como s en el caso de variable estadística, y σσσσ en el caso de variable aleatoria. 5 La curva normal también se llama curva de Gauss o campana de Gauss, en honor al matemático alemán Carl Friedrich
Gauss (1777-1855), que fue el primero en ver sus propiedades y utilidad.
1,75 1,80 1,85 1,90 1,95 1,70 1,65 1,60
estaturas
área encerrada = 1
0
0,05
0,1
0,15
0,2
0,25
0,3
[1,60;1,65) [1,65;1,70) [1,70;1,75) [1,75;1,80) [1,80;1,85) [1,85;1,90) [1,90;1,95]
estaturas
hi
Intervalo de clase → 0
x
x

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
Miles de € al mes
que tiende a la normal en otro tipo de medidas: duración media de una bombilla, esperanza de vida de una mascota, etc… Por supuesto, todo esto no se puede demostrar, pero es algo que se comprueba estadísticamente…
¡Cuidado!: No todas las distribuciones se comportan según el modelo normal. Consideremos el siguiente contraejemplo: supongamos que clasificamos a los ciudadanos españoles según su nivel de renta (ver figura). Evidentemente, son muy pocos los que poseen niveles de rentas altas y en cambio son muchos los que poseen niveles de rentas bajas. Por tanto, la distribución ya no es simétrica y, en consecuencia, no se adapta al modelo normal.
III) DEFINICIÓN DE DISTRIBUCIÓN NORMAL: CURVA DE GA USS
Volviendo al ejemplo 2, si el número de alumnos/as crece indefinidamente y vamos haciendo cada vez más pequeña la amplitud de los intervalos, el polígono de frecuencias tomará entonces la forma de la distribución normal, es decir, de una campana de Gauss. La variable en este caso sería continua y su recorrido sería, en principio, el intervalo [1,60;1,95], aunque teóricamente sería desde 0 hasta ∞.
Vamos a definir la distribución normal teórica: Una variable aleatoria continua X sigue una distribución normal de media µµµµ y desviación típica σσσσ, y se
designa por N(µ ,σ ), si cumple:
1º) La variable recorre toda la recta real, es decir ( -∞ ,∞ )
2º) La distribución tiene la forma de la curva de Gauss, cuya ecuación6 es:
Observaciones: 1º) µµµµ y σσσσ se llaman parámetros de la distribución normal, y cumplen: -∞<µ<∞ y σ>0
2º) El significado de µ es intuitivo; el de σ lo veremos más adelante, en el apartado VI.4) La forma de la curva de Gauss es la siguiente:
Se trata de una curva simétrica respecto a X =µ.
Precisamente, tiene su máximo en X=µ. Por otra parte, ya podemos empezar a ver el significado de la desviación típica, la cual nos indica la forma de la curva: una desviación típica σ a ambos lados de la media µ nos marca la posición de los dos puntos de inflexión7 simétricos de la curva. Por último, y muy importante: recordar que el área total encerrada en el histograma de frecuencias relativas era 1 ⇒ el área encerrada bajo la curva de Gauss es 1
¿Qué representa la curva de Gauss? Por ejemplo, el área sombreada de la curva de la figura representa la frecuencia relativa de individuos con estatura comprendida entre 1,80 y 1,85, es decir, representa la probabilidad de que un individuo elegido al azar tenga una talla comprendida entre dichos valores .
6 e ≅ 2,7182818… es un número irracional llamado constante de Euler, en honor al matemático suizo Leonhard Euler
(1707-1783) 7 Recordar: los puntos de inflexión de una curva son los puntos donde cambia la curvatura de ésta.
2x21
e2
1)x(f
σµ−−
πσ=
1,80 X=µ
1,85 µ+σ µ σ

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
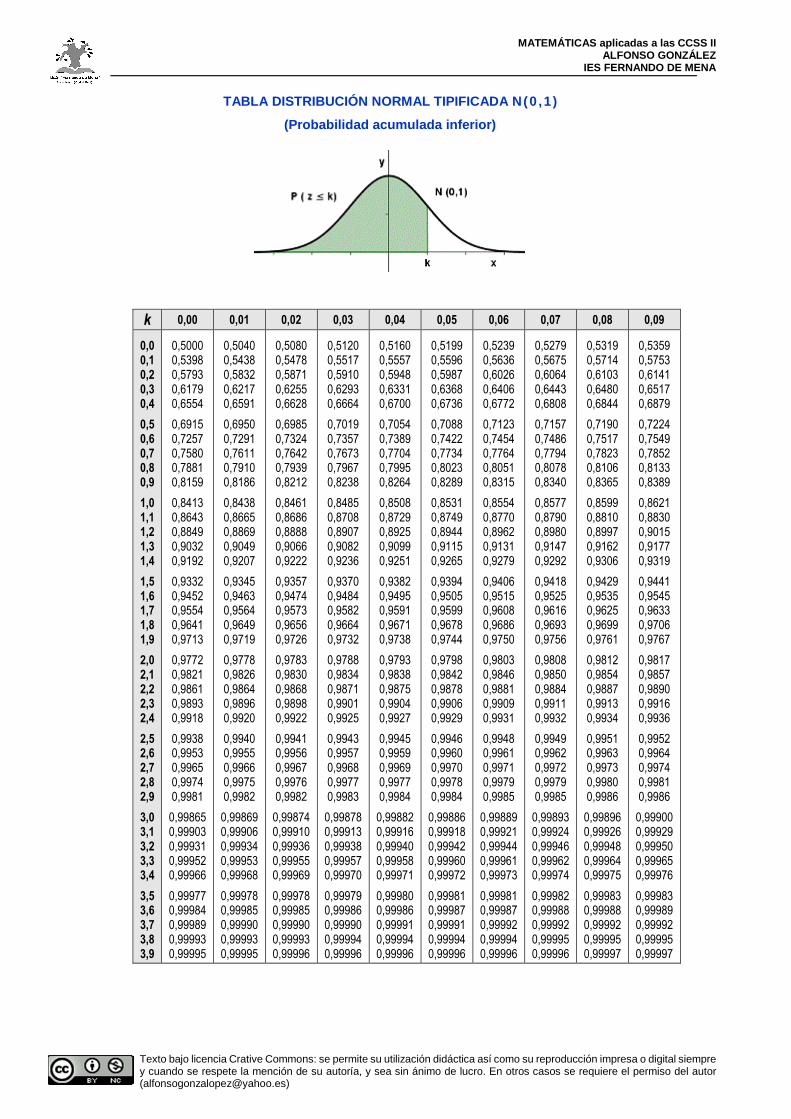
IV) DISTRIBUCIÓN NORMAL ESTÁNDAR: N(0,1)
A la vista de lo anterior, es evidente que para cada valor de µ y σ tendremos una curva de Gauss distinta. Pero de las infinitas distribuciones normales posibles tiene interés la distribución N(0,1), llamada distribución normal estándar , distribución normal reducida, distribución normada o tipificada. Corresponde a la ecuación:
2
2x
e2
1)x(f
−
π=
, cuya representación gráfica se muestra al margen. Decimos que tiene interés pues el área que deja está tabulada (ver tabla suministrada en la PAEG), y además toda distribución se puede poner en función de la N(0,1), como veremos en el siguiente apartado.
V) TIPIFICACIÓN DE LA VARIABLE
Consiste en transformar la variable X que sigue una distribución N( µµµµ ,σσσσ ) en otra variable Z que siga una distribución N(0 ,1) , la cual está tabulada . Para ello, hay que hacer dos pasos:
1º) CENTRAR: Trasladar la media de la distribución al origen de coordenadas, haciendo x-µ (esto equivale a hacer µ=0)
2º) CONTRAER la gráfica de la distribución σ unidades, lo cual se consigue dividiendo por σ (esto equivale a hacer σ=1)
Estos dos pasos se consiguen simultáneamente haciendo el cambio de variable σ
µ−= XZ (1)
En resumen:
En el próximo apartado haremos uso de la expresión (1).
VI) MANEJO DE TABLAS (Cálculo de áreas bajo la curva de gauss)
Para hallar áreas (y por lo tanto probabilidades) bajo la curva normal mediante tabla a menudo tendremos en cuenta que dicha curva es simétrica y por lo tanto deja un 50 % de observaciones a ambos lados del origen. Además, no debe olvidarse que el área encerrada total es 1, es decir el 100 % de observaciones, o lo que es lo mismo, la probabilidad del suceso seguro. Vayamos por pasos:
VI.1) Cálculo de probabilidades en una distribución N(0,1)
Vamos a ver todos los 4 casos que se pueden presentar, desde el más fácil hasta el último, el más “complicado”. Sea Z una variable que sigue una distribución normal N(0 ,1 ) . Veamos algunos ejemplos, utilizando la tabla más usual, que es una tabla de frecuencias –es decir, de probabilidades– acumuladas (precisamente la suministrada en la PAEG), como la que figura al margen. Esta tabla nos proporciona la
(NOTA: Se acostumbra a modificar la escala del eje y para conseguir una forma más acampanada de la curva)
0,4
4,02
1 ≅π
N(µ ,σ ) de variable X
CAMBIO
σµ−= X
Z
N(0 ,1 ) de variable Z
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
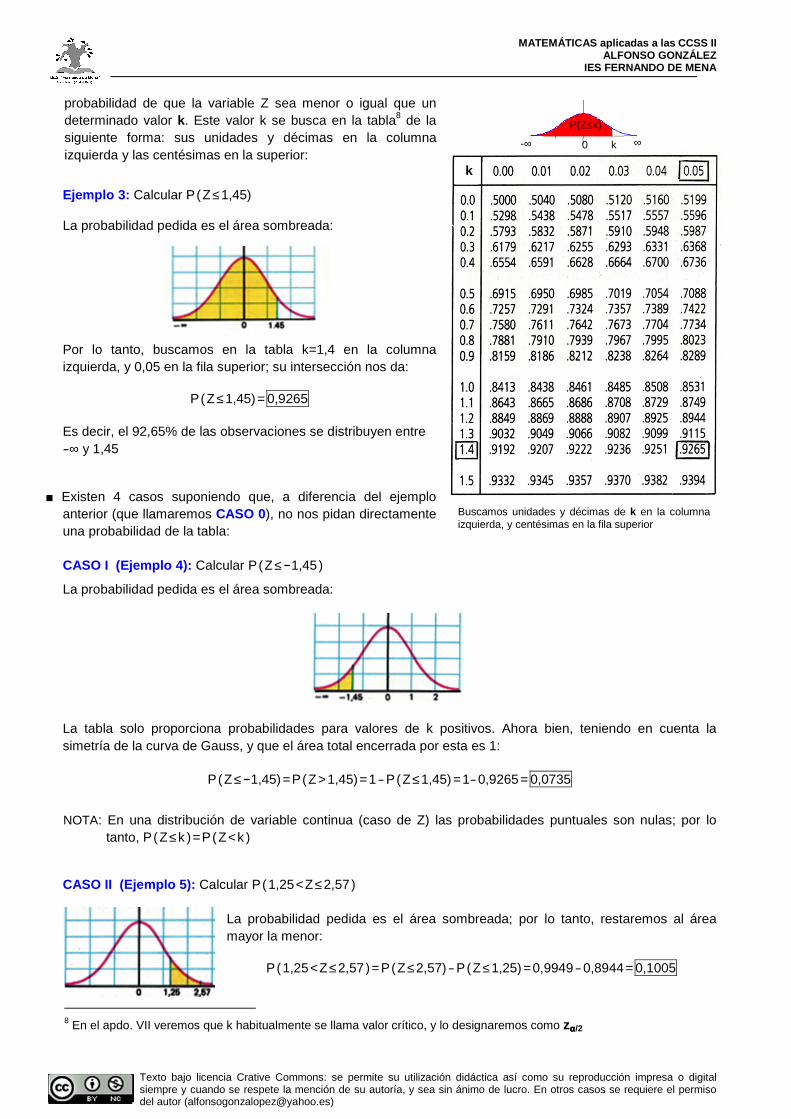
probabilidad de que la variable Z sea menor o igual que un determinado valor k. Este valor k se busca en la tabla8 de la siguiente forma: sus unidades y décimas en la columna izquierda y las centésimas en la superior:
Ejemplo 3: Calcular P(Z≤1,45) La probabilidad pedida es el área sombreada: Por lo tanto, buscamos en la tabla k=1,4 en la columna izquierda, y 0,05 en la fila superior; su intersección nos da:
P(Z≤1,45)= 0,9265
Es decir, el 92,65% de las observaciones se distribuyen entre -∞ y 1,45
■ Existen 4 casos suponiendo que, a diferencia del ejemplo anterior (que llamaremos CASO 0), no nos pidan directamente una probabilidad de la tabla:
CASO I (Ejemplo 4): Calcular P(Z≤-1,45)
La probabilidad pedida es el área sombreada: La tabla solo proporciona probabilidades para valores de k positivos. Ahora bien, teniendo en cuenta la simetría de la curva de Gauss, y que el área total encerrada por esta es 1:
P(Z≤-1,45)=P(Z>1,45)=1-P(Z≤1,45)=1-0,9265= 0,0735
NOTA: En una distribución de variable continua (caso de Z) las probabilidades puntuales son nulas; por lo tanto, P(Z≤k )=P(Z<k )
CASO II (Ejemplo 5): Calcular P(1,25<Z≤2,57)
La probabilidad pedida es el área sombreada; por lo tanto, restaremos al área mayor la menor:
P(1,25<Z≤2,57)=P(Z≤2,57)-P(Z≤1,25)=0,9949-0,8944= 0,1005
8 En el apdo. VII veremos que k habitualmente se llama valor crítico, y lo designaremos como zαααα/2
k
Buscamos unidades y décimas de k en la columna izquierda, y centésimas en la fila superior
P(Z≤k)
0 k -∞ ∞
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
CASO III (Ejemplo 6): Calcular P(-2,57<Z≤-1,25)
La probabilidad pedida es el área sombreada; por lo tanto, por simetría de la curva normal:
P(-2,57<Z≤-1,25)=P(1,25<Z≤2,57)= 0,1005
CASO IV (Ejemplo 7): Calcular P(-0,53<Z≤2,46)
La probabilidad pedida es el área sombreada. Este es el caso más general, y se resuelve teniendo en cuenta todo lo anterior:
P(-0,53<Z≤2,46)=P(Z≤2,46)-P(Z≤-0,53)=P(Z ≤2,46)-P(Z≥0,53)
=P(Z≤2,46)- [1-P(Z<0,53) ]=0,9931- (1-0,7019)= 0,695
Ejercicios final tema: 1 a 3
■ Por otra parte, tenemos el problema inverso (muy importante de cara a lo que se pide en PAEG, es decir,
hallar el intervalo de confianza): dada una determinada probabilidad, hallar el valor de k asociado. También hay 4 casos posibles: CASO I (Ejemplo 8): Calcular el valor de k (exacto o aproximado) tal que P(Z≤ k )=0,85
En las tablas encontramos que P(Z≤1,03)=0,8485 y P(Z≤1,04)=0,8508; por lo tanto, asignaremos a k el valor intermedio de 1,03 y 1,04, es decir k =1,035
NOTA: Habitualmente k no aparece exactamente en la tabla, en cuyo caso se hace la media de los dos más cercanos, por exceso y por defecto.
NOTA: Sólo el caso I es necesario posteriormente para el intervalo de confianza.
CASO II (Ejemplo 9): Calcular el valor de k (exacto o aproximado) tal que P(Z≤ k )=0,33
En la tabla no aparecen valores de la probabilidad menores que 0,5. Pero, por simetría (ver dibujo), tomamos un k' simétrico a k, tal que P(Z≤k ' )=0,67 ⇒
k '=0 ,44 ⇒ k =-0,44
CASO III (Ejemplo 10): Calcular el valor de k (exacto o aproximado) tal que P(Z>k )=0,12
También por simetría: P(Z>k )=0,12 ⇒ P(Z≤k )=0,88 ⇒ k =1,175
como en el ejemplo 5
como en el ejemplo 4
k
0,85
0,33 k k '
0,67
0,88
0,12 k
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
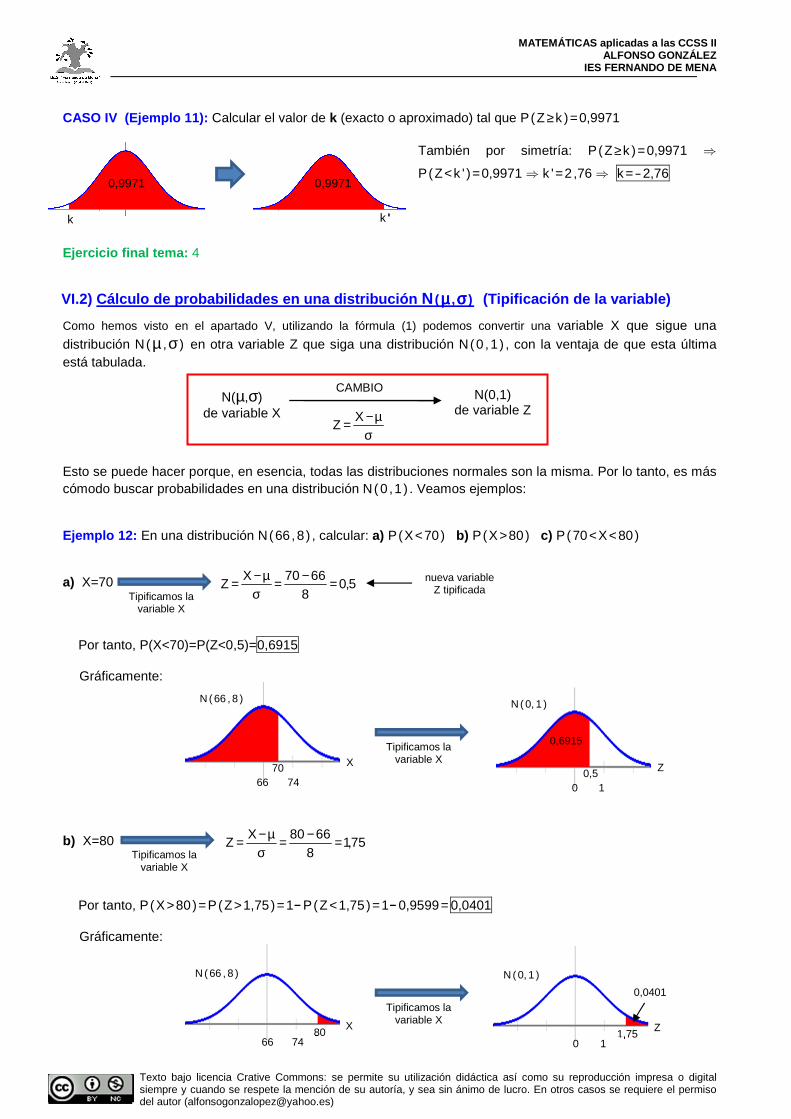
CASO IV (Ejemplo 11): Calcular el valor de k (exacto o aproximado) tal que P(Z ≥k )=0,9971
También por simetría: P(Z≥k )=0,9971 ⇒
P(Z<k ' )=0,9971 ⇒ k '=2 ,76 ⇒ k =-2,76
Ejercicio final tema: 4
VI.2) Cálculo de probabilidades en una distribución N ( µµµµ ,σσσσ ) (Tipificación de la variable)
Como hemos visto en el apartado V, utilizando la fórmula (1) podemos convertir una variable X que sigue una distribución N(µ ,σ ) en otra variable Z que siga una distribución N(0 ,1) , con la ventaja de que esta última está tabulada.
Esto se puede hacer porque, en esencia, todas las distribuciones normales son la misma. Por lo tanto, es más cómodo buscar probabilidades en una distribución N(0 ,1) . Veamos ejemplos:
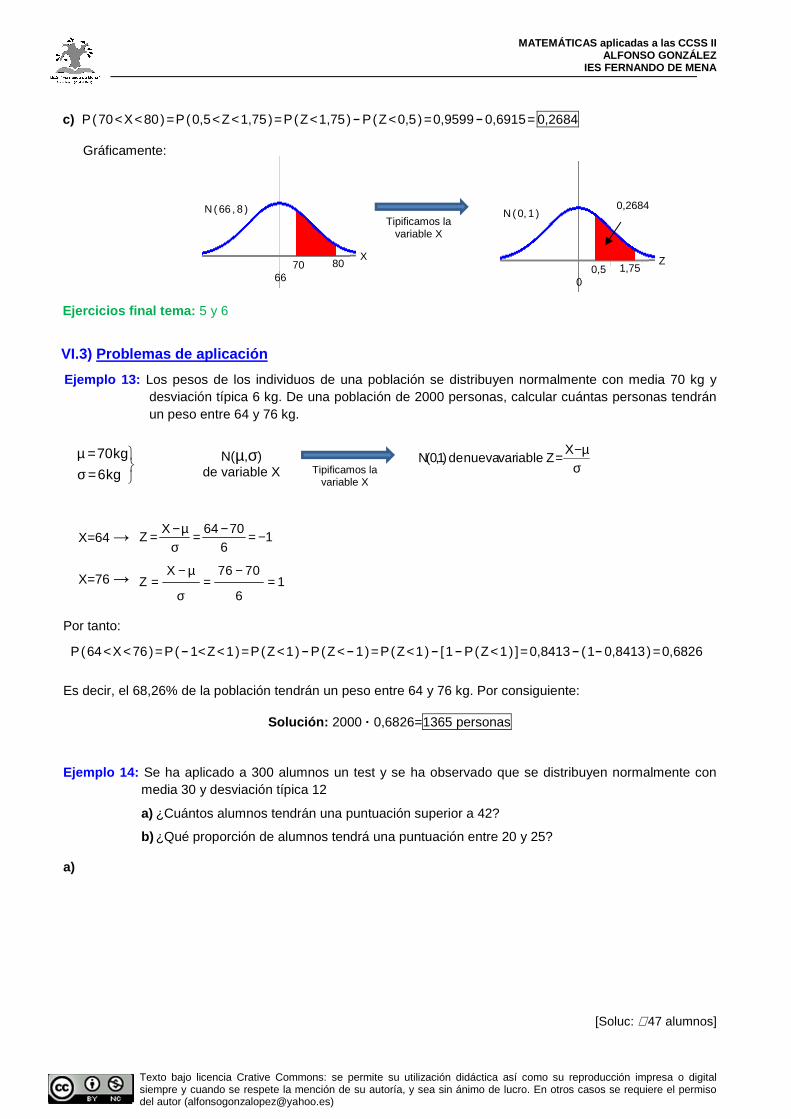
Ejemplo 12: En una distribución N(66,8) , calcular: a) P(X<70) b) P(X>80) c) P(70<X<80)
a) X=70
Por tanto, P(X<70)=P(Z<0,5)=0,6915 Gráficamente:
b) X=80
Por tanto, P(X>80)=P(Z>1,75)=1-P(Z<1,75)=1-0,9599= 0,0401 Gráficamente:
N(µ,σ) de variable X
CAMBIO
σµ−= X
Z
N(0,1) de variable Z
5,08
6670XZ =−=
σµ−=
75,18
6680XZ =−=
σµ−=
66 70
74
N ( 66 , 8 )
X
0 0,5
1
N ( 0, 1 )
0,6915
Z
nueva variable Z tipificada
Tipificamos la variable X
Tipificamos la variable X
Tipificamos la variable X
N ( 66 , 8 )
80 66 74
X
Tipificamos la variable X
N ( 0, 1 )
0,0401
1,75 0 1
Z
0,9971
k
0,9971
k '
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
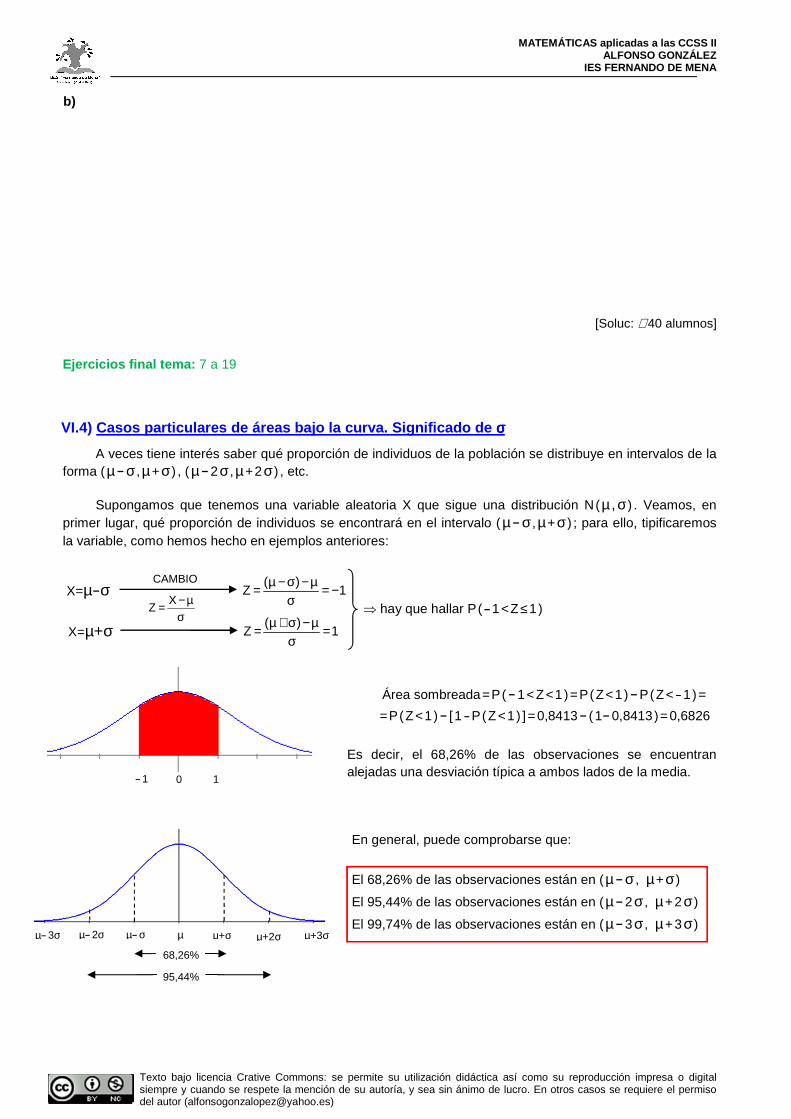
c) P(70<X<80)=P(0,5<Z<1,75)=P(Z<1,75)-P(Z<0,5)=0,9599-0,6915= 0,2684
Gráficamente:
Ejercicios final tema: 5 y 6
VI.3) Problemas de aplicación
Ejemplo 13: Los pesos de los individuos de una población se distribuyen normalmente con media 70 kg y desviación típica 6 kg. De una población de 2000 personas, calcular cuántas personas tendrán un peso entre 64 y 76 kg.
X=64 →
X=76 →
Por tanto:
P(64<X<76)=P(-1<Z<1)=P(Z<1)-P(Z<-1)=P(Z<1)- [1-P(Z<1) ]=0,8413- (1-0,8413)=0,6826
Es decir, el 68,26% de la población tendrán un peso entre 64 y 76 kg. Por consiguiente:
Solución: 2000 · 0,6826=1365 personas
Ejemplo 14: Se ha aplicado a 300 alumnos un test y se ha observado que se distribuyen normalmente con media 30 y desviación típica 12
a) ¿Cuántos alumnos tendrán una puntuación superior a 42?
b) ¿Qué proporción de alumnos tendrá una puntuación entre 20 y 25? a)
[Soluc: ≅ 47 alumnos]
N(µ,σ) de variable X σ
µ−= XZiablevarnuevade)1,0(N
=σ=µ
kg6
kg70
16
7064XZ −=−=
σµ−=
X 76 70Z 1
6
− µ −= = =
σ
N ( 66 , 8 )
66 70 80
X
Tipificamos la variable X
N ( 0, 1 )
0 0,5 1,75
Z
0,2684
Tipificamos la variable X
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
b)
[Soluc: ≅ 40 alumnos]
Ejercicios final tema: 7 a 19
VI.4) Casos particulares de áreas bajo la curva. Si gnificado de σσσσ
A veces tiene interés saber qué proporción de individuos de la población se distribuye en intervalos de la forma (µ-σ ,µ+σ ) , (µ-2σ ,µ+2σ ) , etc.
Supongamos que tenemos una variable aleatoria X que sigue una distribución N(µ ,σ ) . Veamos, en
primer lugar, qué proporción de individuos se encontrará en el intervalo (µ-σ ,µ+σ ) ; para ello, tipificaremos la variable, como hemos hecho en ejemplos anteriores:
Área sombreada=P(-1<Z<1)=P(Z<1)-P(Z<-1)=
=P(Z<1)- [1-P(Z<1) ]=0,8413- (1-0,8413)=0,6826
Es decir, el 68,26% de las observaciones se encuentran alejadas una desviación típica a ambos lados de la media.
En general, puede comprobarse que:
El 68,26% de las observaciones están en (µ-σ , µ+σ )
El 95,44% de las observaciones están en (µ-2σ , µ+2σ )
El 99,74% de las observaciones están en (µ-3σ , µ+3σ )
X=µ-σ CAMBIO
σµ−= X
Z1
)(Z −=
σµ−σ−µ=
X=µ+σ 1)(
Z =σ
µ−σ+µ=
⇒ hay que hallar P( 1<Z ≤1)
0 1 1
µ σ µ 2σ µ 3σ µ µ+σ µ+2σ µ+3σ
68,26%
95,44%

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
VII) INTERVALOS CARACTERÍSTICOS
Definición: Dada una variable X que sigue una distribución de media µ, se llama intervalo característico correspondiente a una probabilidad p a un intervalo centrado en la media, (µ-k, µ+k), tal que la probabilidad de que X pertenezca a dicho intervalo es p:
P(µ-k<X<µ+k)=p
Ejemplo 15: Hallar el intervalo característico de una distribución normal N(0,1) correspondiente a la probabilidad p=0,9
Viendo la figura adjunta, si dentro del intervalo tiene que haber un área de 0,9, fuera de él habrá por tanto 0,1; ahora bien, como el intervalo es, por definición, simétrico, el área de las dos colas será 0,05. Por tanto, se trata de buscar k tal que P(Z≤k)=0,95 Este es una situación idéntica a la ya vista en el ejemplo 8; en las
tablas encontramos que P(Z≤1,64)=0,9495 y P(Z≤1,65)=0,9505; por lo tanto, asignaremos a k el valor intermedio 1,645. Solución: el intervalo característico pedido es (-1,645;1,645); se trata de un intervalo simétrico respecto al
origen y en el que se sitúan el 90% de las observaciones.
Ejemplo 16: Hallar razonadamente el intervalo característico a una probabilidad de p=0,6 para una distribución N(0,1). Interpretarlo. (Soluc: (-0,845;0,845))
Definición: En una distribución N(0,1), si (-k,k) es el intervalo característico correspondiente a una probabilidad p, diremos que k es el valor crítico correspondiente a p
Habitualmente, el valor crítico se suele denominar zαααα/2, siendo p=1-α (ver figura).
p
µ µ+k µ k
intervalo característico
0,9
0 k k
0,05 0,05
p=1-α
0 k=zα/2 k
α/2 α/2

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
Ejemplo 17: Calcular razonadamente el valor crítico correspondiente a una probabilidad de 0,95
En la figura se ve que obviamente α/2=0,025; por tanto, zα/2 será tal
que la probabilidad que acumule sea 0,95+0,025=0,975:
P(z≤zα/2)=0,975
De la tabla deducimos que, entonces, zα/2=1,96
Ejercicios final tema: 20 Intervalos característicos en distribuciones N( µµµµ,σσσσ):
Acabamos de ver que en una variable Z que siga una distribución N(0,1) el intervalo característico correspondiente a la probabilidad p=1-α (ver figura) es (-zα/2, zα/2). Esto significa que:
-zα/2<z<zα/2 (2)
con una probabilidad p=1-α. Ahora bien, esto es para el caso particular de una distribución N(0,1); pero, ¿qué
pasa en el caso general de una N(µ,σ)? Para pasar de una a otra, sustituyamos en (2) el cambio de variable
ya utilizado, :
σ+µ<<σ−µ⇒σ<µ−<σ−⇒<σ
µ−<− αααααα ·zx·z·zx·zzx
z 2/2/2/2/2/2/
Es decir, el intervalo ( µµµµ-zαααα/2·σσσσ, µµµµ+zαααα/2·σσσσ) es el intervalo característico correspondiente a u na probabilidad p=1 -αααα para una variable x que sigue una distribución N( µµµµ,σσσσ); se trata de un intervalo centrado respecto a la media µ:
Ejemplo 18: En una distribución N(66,8), obtener el intervalo característico para el 90%. Interpretarlo.
90% ⇒ p=0,9=1-α ⇒ α=0,1⇒ α/2=0,05
0,9+0,05=0,95 → hay que buscar el valor crítico zα/2 tal que:
P(z≤zα/2)=0,95
De la tabla deducimos que zα/2≅1,645. Por lo tanto, el intervalo característico pedido será:
(µ-zα/2·σ, µ+zα/2·σ)=(66-1,645 ·8,66 ;66+1,645 ·8,66)=(52,84;79,16)
0,95
0,025 0,025
zα/2 zα/2
p=1-α
0 zα/2
α/2 α/2
zα/2
σµ−= x
z
p=1-α
µ µ+zα/2 ·σ
α/2 α/2
µ zα/2
0,9 0,05 0,05
zα/2 zα/2 0

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
Es decir, el 90% de los individuos están en ese intervalo, o lo que es igual, P(52,84<x<79,16)=0,9
Ejemplo 19: En una distribución N(66,8), obtener el intervalo característico para el 95% y el 99%.
Interpretarlos. a)
[Soluc: (50,32;81,68)] b)
[Soluc: (45,4;86,6)]
Ejercicios final tema: 21 a 26
VIII) DISTRIBUCIÓN DE LAS MEDIAS MUESTRALES. TEOREM A CENTRAL DEL LÍMITE
Está demostrado estadísticamente que si en una distribución (no necesariamente normal, se entiende) extraemos muestras de tamaños n=2, n=3, n=4, etc.… la distribución de sus correspondientes medias se va pareciendo a una distribución normal a medida que aumenta n. Además, la media se mantiene constante, mientras que la desviación típica va disminuyendo. Comprobémoslo con un ejemplo:
Ejemplo 20: Consideremos la distribución de probabilidad correspondiente al lanzamiento de un dado:
x i p i p i x i p i x i2
1 1/6 1/6 1/6
2 1/6 2/6 4/6
3 1/6 3/6 9/6
4 1/6 4/6 16/6
5 1/6 5/6 25/6
6 1/6 6/6 36/6
Σpi=1 Σpixi=21/6 Σ pixi2 =91/6
90% 5% 5%
79,16 52,84 66
n
i ii 1
n2 2 2
i ii 1
p x 21/ 6 3,5
p x 91/ 6 3,5 2,92 1,7
=
=
µ = = =
σ = − µ = − = ≅
∑
∑
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
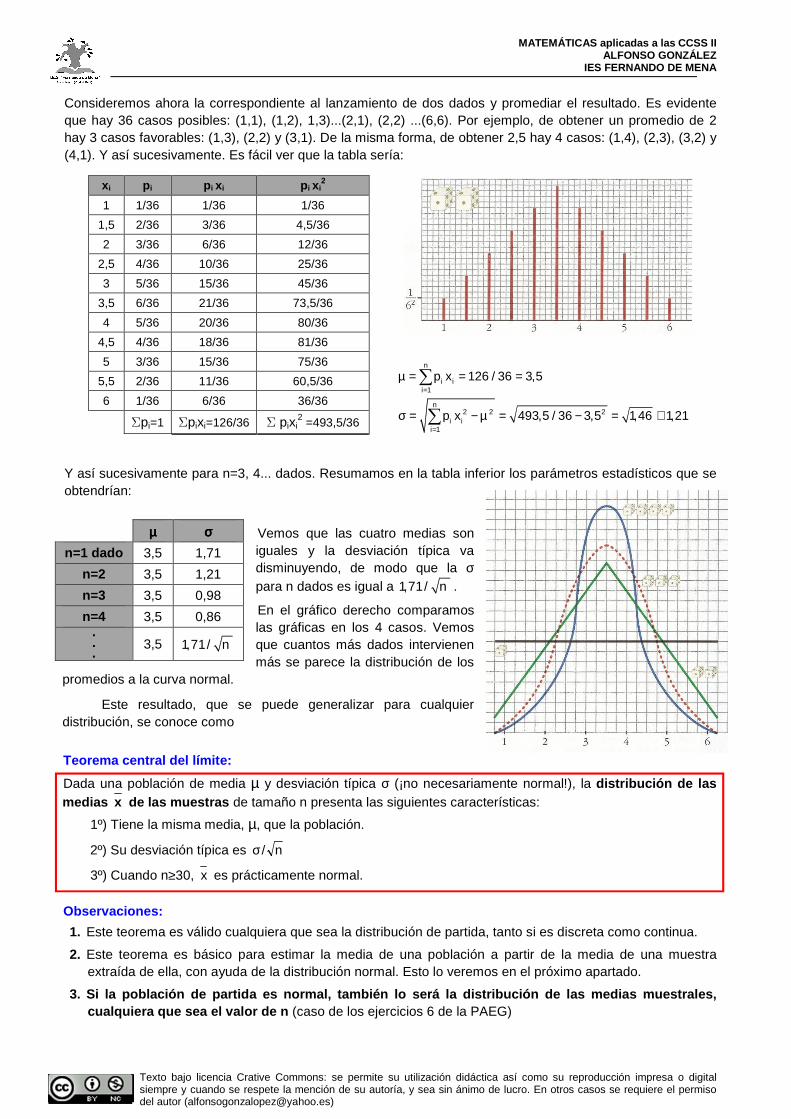
Consideremos ahora la correspondiente al lanzamiento de dos dados y promediar el resultado. Es evidente que hay 36 casos posibles: (1,1), (1,2), 1,3)...(2,1), (2,2) ...(6,6). Por ejemplo, de obtener un promedio de 2 hay 3 casos favorables: (1,3), (2,2) y (3,1). De la misma forma, de obtener 2,5 hay 4 casos: (1,4), (2,3), (3,2) y (4,1). Y así sucesivamente. Es fácil ver que la tabla sería:
Y así sucesivamente para n=3, 4... dados. Resumamos en la tabla inferior los parámetros estadísticos que se obtendrían:
Vemos que las cuatro medias son iguales y la desviación típica va disminuyendo, de modo que la σ para n dados es igual a 1,71/ n .
En el gráfico derecho comparamos las gráficas en los 4 casos. Vemos que cuantos más dados intervienen más se parece la distribución de los
promedios a la curva normal.
Este resultado, que se puede generalizar para cualquier distribución, se conoce como
Teorema central del límite:
Dada una población de media µ y desviación típica σ (¡no necesariamente normal!), la distribución de las medias x de las muestras de tamaño n presenta las siguientes características:
1º) Tiene la misma media, µ, que la población.
2º) Su desviación típica es n/σ
3º) Cuando n≥30, x es prácticamente normal.
Observaciones:
1. Este teorema es válido cualquiera que sea la distribución de partida, tanto si es discreta como continua.
2. Este teorema es básico para estimar la media de una población a partir de la media de una muestra extraída de ella, con ayuda de la distribución normal. Esto lo veremos en el próximo apartado.
3. Si la población de partida es normal, también lo será la distribución de las medias muestrales, cualquiera que sea el valor de n (caso de los ejercicios 6 de la PAEG)
x i p i p i x i p i x i2
1 1/36 1/36 1/36
1,5 2/36 3/36 4,5/36
2 3/36 6/36 12/36
2,5 4/36 10/36 25/36
3 5/36 15/36 45/36
3,5 6/36 21/36 73,5/36
4 5/36 20/36 80/36
4,5 4/36 18/36 81/36
5 3/36 15/36 75/36
5,5 2/36 11/36 60,5/36
6 1/36 6/36 36/36
Σpi=1 Σpixi=126/36 Σ pixi2 =493,5/36
µµµµ σσσσ
n=1 dado 3,5 1,71
n=2 3,5 1,21
n=3 3,5 0,98
n=4 3,5 0,86 . . .
3,5 1,71/ n
n
i ii 1
n2 2 2
i ii 1
p x 126 / 36 3,5
p x 493,5 / 36 3,5 1,46 1,21
=
=
µ = = =
σ = − µ = − = ≅
∑
∑

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
4. Aunque la población de partida no sea normal, pa ra n>30 es seguro que se consigue una gran aproximación a la normal.
Tabla resumen:
IX) INTERVALO DE CONFIANZA PARA LA MEDIA
En este apartado veremos cómo, a partir de una muestra aleatoria de tamaño n de la cual conocemos su media, podemos estimar el valor de la media de toda la población dando un intervalo, llamado intervalo de confianza , dentro del cual confiamos que esté dicha media. Este es el objetivo final al que ha ido encaminado todo lo visto en los apartados anteriores.
Para ello, disponemos del siguiente teorema:
Se desea estimar la media, µ, de una población cuya desviación típica σ es conocida.
Para ello se recurre a una muestra de tamaño n en la cual se obtiene una media muestral, x .
Si la población de partida es normal, o si el tamaño de la muestra es n≥30, entonces el intervalo de confianza de µ con un nivel de confianza p=1-α viene dado por:
σ+σ− ααn
·zx,n
·zx 2/2/ (3)
Observaciones:
1. La justificación de este hecho es bastante sencilla, y se basa en el teorema central del límite. En efecto, en el apartado VII obtuvimos que el intervalo (µ-zα/2·σ, µ+zα/2·σ) es el intervalo característico correspondiente a una probabilidad p=1-α para una variable x que sigue una distribución N(µ,σ).
Por tanto, por el teorema central del límite, en dicho intervalo podemos reemplazar µ por x , y σ por
n/σ , obteniendo así el intervalo dado por (3).
2. Podemos ahora completar definitivamente la tabla resumen del apartado anterior:
población de
partida
(x)
distribución de las medias de las muestras
de tamaño n
( x )
media µ µ
desviación típica σ n/σ
será normal si n≥30
población de partida
(x)
distribución de las medias de las muestras
de tamaño n
( x )
media µ x =µ
desviación típica σ n/σ
será normal si n≥30
intervalo característico:
(µ-zα/2·σ, µ+zα/2·σ)
intervalo de confianza:
σ+σ− ααn
·zx,n
·zx 2/2/

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
3. Como ya hemos dicho al principio de este apartado, el significado del intervalo de confianza obtenido es que podemos afirmar que existe (ya no hablamos de probabilidad) un nivel de confianza p=1 -αααα (en %) de que la media de toda la población esté en dic ho intervalo:
4. Los ejercicios 6 de las últimas convocatorias de la PAEG siempre presentan el mismo esquema:
DATOS DE PARTIDA: Tamaño de la muestra, n
Media de la muestra, x
Desviación típica de la muestra, σ
Nivel de confianza, p=1-α
(Además, se supone siempre que la población de partida es normal)
¿QUÉ NOS PIDEN?: El intervalo de confianza al p=1-α (en %) para la media de toda la población.
PASOS A SEGUIR: Se trata de obtener todos los términos del intervalo dado por (3):
σ+σ− ααn
·zx,n
·zx 2/2/
Para ello:
1. Obtenemos el valor crítico zαααα/2 correspondiente a la probabilidad p=1-α, de acuerdo con lo visto en el apdo. VII, para lo cual se recomienda un gráfico explicativo.
2. Sustituimos en el intervalo mencionado arriba el zα/2 recién obtenido, así como
los datos n, x y σ
3. Finalmente, se interpreta el intervalo obtenido con una sencilla frase.
Ejemplo 21: (UCLM, 4B junio 2007) Para determinar cómo influye en la osteoporosis una dieta pobre en calcio, se realiza un estudio sobre 100 afectados por la enfermedad, obteniéndose que toman una media de calcio al día de 900 mg. Suponemos que la toma de calcio en la población de afectados por la enfermedad se distribuye normalmente con una desviación típica de 150. a) Encontrar un intervalo de confianza al 99 % para la media de calcio al día que toma toda la población afectada. b) Interpretar el significado del intervalo obtenido.
a) Del enunciado deducimos que los datos son: Tamaño de la muestra: n=100
Media de la muestra: x =900 mg
Desviación típica de la muestra: σ=150 mg
Nivel de confianza, p=1-α=0,99
Vamos a obtener el valor crítico zα/2 correspondiente a la probabilidad p=1-α, tal y como hacíamos en el apdo. VII:
p=1-α
α/2 α/2
x /2x zn
α
σ+
/2x zn
α
σ−
/2zn
α
σ
x

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
99% ⇒ p=0,99=1-α ⇒ α=0,01⇒ α/2=0,005
0,99+0,005=0,995 → zα/2 será el valor crítico que acumule una
probabilidad de 0,995, es decir:
P(z≤zα/2)=0,995
De la tabla deducimos que, entonces, zα/2≅2,575
Sustituimos todo lo anterior en el intervalo de confianza:
+−=
σ+σ− αα 10150
·575,2900,10150
·575,2900n
·zx,n
·zx 2/2/ = (861,375;938,625)
b) Podemos asegurar con un nivel de confianza del 99% que la media de calcio al día en mg que toma toda la población afectada está en el intervalo anterior.
■ En ocasiones nos dan el intervalo de confianza y hay que obtener otro parámetro: el tamaño de la muestra utilizada (n), el valor de la media muestral ( x ), el nivel de confianza... en ese caso simplemente hay que despejar
en la fórmula del intervalo de confianza. Veamos un ejemplo:
Ejemplo 22: (UCLM, 6A junio 2014) Una empresa produce dispositivos electrónicos con pantalla HD. La resolución de estas pantallas sigue una distribución normal de media desconocida y desviación típica σ=20 píxeles. Se tomó una muestra aleatoria de 100 dispositivos electrónicos y mediante un estudio estadístico se obtuvo un intervalo de confianza (1076,08;1083,92) para la resolución media de las pantallas elegida s al azar.
a) Calcular el valor de la resolución media de las pantallas de los 100 dispositivos electrónicos elegidos para la muestra. (0,25 ptos.)
b) Calcular el nivel de confianza con el que se ha obtenido dicho intervalo. (0,75 ptos.)
c) ¿Cómo podríamos aumentar o disminuir la amplitud del intervalo? Sin calcular el intervalo de confianza, ¿se podría admitir que la media poblacional sea µ=1076,08 píxeles con un nivel de confianza del 90%. Razonar las respuestas. (1 pto.)
a) Del enunciado deducimos que los datos son: Tamaño de la muestra: n=100
Intervalo de confianza: (1076,08;1083,92
Desviación típica de la muestra: σ=20 píxeles
Nos piden: Media de la muestra: x
Nivel de confianza, p=1-α
a) La media x es el punto medio del intervalo de confianza:
1076,08 1083,92x 1080 píxeles
2
+= =
0,99
0,005 0,005
zα/2 0,995
99%
938,625 mg 861,375 mg =900 mg
p=1-α
α/2 α/2
/2x zn
α
σ− x
/2x zn
α
σ+
/2zn
α
σ

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
b) El radio del intervalo de confianza será (ver figura):
/21083,92 1080 3,92 zn
α
σ− = =
Sustituímos los datos:
/2 /2
203,92 z z 1,96
100α α= ⇒ =
Llevamos este valor crítico a la tabla suministrada en la PAEG:
Observamos que P(Z<zα/2)=P(Z<1,96)=0,9750 ⇒ α/2=P(Z>1,96)=1-0,9750=0,025 ⇒ α=0,05
⇒ p=1-0,05=0,95 ⇒ nivel de confianza=95%
c) Como el radio del intervalo de confianza es /2zn
α
σ, podemos disminuirlo (o aumentarlo):
1º) Aumentando (reduciendo) el tamaño de la muestra, n, al mismo nivel de confianza.
2º) Reduciendo el nivel de confianza p, pues también disminuiría zα/2.
En cuanto a la 2ª pregunta, acabamos de ver que la media que toma toda la población está en el intervalo (1076,08;1083,92) con un nivel de confianza del 95%. Por tanto, como 1076,08 está en uno de los extremos, si rebajamos el nivel de confianza al 90% se quedará fuera del intervalo.
Error máximo admisible:
En ocasiones piden el error máximo admisible de estimación de la media para un determinado nivel de confianza, o bien hallar el tamaño mínimo de la muestra para un determinado error máximo admisible. Vamos a explicar este concepto:
‹‹Se define el error máximo admisible E como el radio del intervalo de confianza: /2E zn
α
σ= ›› (4)
Por tanto, en (4) podemos jugar con tres parámetros: nivel de confianza (que tiene que ver con zα/2), tamaño de la muestra (n) y error máximo admisible (es decir, amplitud de la estimación), y concluir que:
p=1-α
α/2 α/2
x /2x zn
α
σ+
/2x zn
α
σ−
α/2α/2α/2α/2
σσσσz =Ez =Ez =Ez =E
nnnn
x

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
1º) Cuanto mayor es el tamaño de la muestra, n, menor es E (al mismo nivel de confianza), es decir, más estrecho es el intervalo, o lo que es igual, afinaremos más en la estimación.
2º) Cuanto mayor sea el nivel de confianza (p=1-α, es decir, zα/2), mayor es E.
Esto se ve fácilmente en la tabla al margen, que recoge los niveles de confianza más habituales:
3º) Para aumentar el nivel de confianza (i.e. aumentar zα/2) debemos aumentar el tamaño de la muestra, n.
Etc.
NOTA: Si nos piden hallar el tamaño mínimo de la muestra para un determinado error máximo admisible, dado que n ha de ser entero, tomaremos el entero inmediatamente superior al número obtenido al despejar en (4).
Veamos un ejemplo de todo lo anterior, en el que, además, tenemos que calcular previamente la media:
Ejemplo 22: (UCLM, 6B sept 2013) En un centro de investigación se está estudiando el tiempo de eliminación de una toxina en la sangre mediante un fármaco. Se sabe que el tiempo de eliminación de esta toxina sigue una distribución normal de media desconocida y desviación típica 6 horas. Se toma una muestra aleatoria de 10 pacientes y se concluye que el tiempo que tardan en eliminar dicha toxina es: 39, 41, 42, 44, 48, 50, 53, 54, 59 y 60 horas respectivamente.
a) Hallar un intervalo de confianza para la media poblacional del tiempo de eliminación de dicha toxina con un nivel de confianza del 97%. (1,25 ptos.)
b) ¿Cuál debería ser como mínimo el tamaño de la muestra para que el error máximo admisible de estimación de la media sea inferior a 2 horas, con un nivel de confianza del 97%? (0,75 ptos.)
a) En primer lugar, tenemos que hallar la media de la muestra:
N
ii 1
_ x39 41 42 44 48 50 53 54 59 60 490
x 49 hN 10 10
= + + + + + + + + += = = =∑
Por tanto, los datos son: Tamaño de la muestra: n=10
Media de la muestra: x =49 h
Desviación típica de la muestra: σ=6 h
Nivel de confianza, p=1-α=0,97
Obtenemos el valor crítico zα/2 correspondiente a la probabilidad p=1-α
97% ⇒ p=0,97=1-α ⇒ α=0,03⇒ α/2=0,015
0,97+0,015=0,985 → zα/2 será el valor crítico que acumule una
probabilidad de 0,985, es decir:
P(z≤zα/2)=0,985
De la tabla deducimos que, entonces, zα/2=2,17
Sustituimos todo lo anterior en el intervalo de confianza:
Nivel de confianza
1-αααα αααα
Valor crítico
zαααα/2
0,90 0,10 1,645
0,95 0,05 1,96
0,99 0,01 2,575
0,99
0,005 0,005
zα/2 0,995

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
/2 /2
6 6x z · , x z · 49 2,17· , 9 2,17·
n n 10 10α α
σ σ − + = − +
= (44,88;53,12)
b) /2
6E z 2,17 2 6,51 n 42,38 n n 43
n nα
σ= ⇒ < ⇒ < ⇒ < ⇒ =
(Nótese que, dado que n ha de ser entero, hemos tomado el entero inmediatamente superior al valor decimal obtenido)
Ejercicios final tema: 27 a 30
Ejercicios PAEG: 4B jun 2009; 4B sept 2009; 4B jun 2008; 4B sept 2008; 4B jun 2007; 4B sept 2007; 4B jun 2006; 4B sept 2006; 4B jun 2005; 4B sept 2005; 4B jun 2004; 4B sept 2004 ← intervalo confianza
6A jun 2015; 6A jun 2013; 6B sept 2013; 6B jun 2011; 6A sept 2011 ← hallar previamente la media
6B jun 2015; 6A jun 2014; 6B jun 2013 ← dado el intervalo confianza, hallar otro parámetro
(6A jun 2015); 6B jun 2014; 6A sept 2014; (6A jun 2013); 6A sept 2013; 6A jun 2012; 6B jun 2012; 6A sept 2012; 6A jun 2011; (6B jun 2011); (6A sept 2011); 6B sept 2011; 4A jun 2010; 4B jun 2010; 4A sept 2010; 4B sept 2010; ← intervalo confianza + preguntas
(6B jun 2015); 6B sept 2014; (6B sept 2013), 6B sept 2012; ← intervalo confianza + error

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
RESUMEN de INFERENCIA ESTADÍSTICA Ejemplo: Calcular razonadamente el valor crítico correspondiente a una probabilidad de 0,95
En la figura se ve que obviamente α/2=0,025; por tanto, zα/2 será tal
que la probabilidad que acumule sea 0,95+0,025=0,975:
P(z≤zα/2)=0,975
De la tabla deducimos que, entonces, zα/2=1,96
■ Obtención del intervalo de confianza (ejercicio 6 de las últimas convocatorias de la PAEG):
DATOS DE PARTIDA: Tamaño de la muestra, n
Media de la muestra, x
Desviación típica de la muestra, σ
Nivel de confianza, p=1-α
(Además, se supone siempre que la población de partida es normal)
¿QUÉ NOS PIDEN?: El intervalo de confianza al p=1-α (en %) para la media de toda la población.
PASOS A SEGUIR: Se trata de obtener todos los términos del intervalo dado por:
σ+σ− ααn
·zx,n
·zx 2/2/
Para ello:
1. Obtenemos el valor crítico zαααα/2 correspondiente a la probabilidad p=1-α, de acuerdo con lo visto en el ejemplo de arriba (para lo cual se recomienda un gráfico explicativo).
2. Sustituimos en el intervalo mencionado arriba el zα/2 recién obtenido, así como los datos n, x y σ
3. Finalmente, se interpreta el intervalo obtenido con una sencilla frase.
Significado del intervalo de confianza: podemos afirmar que existe un nivel de confianza p=1 -αααα (en %) de que la media de toda la población esté en dicho intervalo.
Error máximo admisible E: es el radio del intervalo de confianza: /2E zn
α
σ=
Nivel de confianza 1-αααα
αααα Valor crítico
zαααα/2
0,90 0,10 1,645
0,95 0,05 1,96
0,99 0,01 2,575
p=1 α =0,95
α/2=0,025
zα/2 zα/2 0
α/2=0,025
p=1-α
α/2 α/2
x/2x z
nα
σ+
/2x zn
α
σ−
α/2α/2α/2α/2
σσσσz =Ez =Ez =Ez =E
nnnn
MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
TABLA DISTRIBUCIÓN NORMAL TIPIFICADA N(0 ,1)
(Probabilidad acumulada inferior)
k 0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
1,1
1,2
1,3
1,4
1,5
1,6
1,7
1,8
1,9
2,0
2,1
2,2
2,3
2,4
2,5
2,6
2,7
2,8
2,9
3,0
3,1
3,2
3,3
3,4
3,5
3,6
3,7
3,8
3,9
0,5000
0,5398
0,5793
0,6179
0,6554
0,6915
0,7257
0,7580
0,7881
0,8159
0,8413
0,8643
0,8849
0,9032
0,9192
0,9332
0,9452
0,9554
0,9641
0,9713
0,9772
0,9821
0,9861
0,9893
0,9918
0,9938
0,9953
0,9965
0,9974
0,9981
0,99865
0,99903
0,99931
0,99952
0,99966
0,99977
0,99984
0,99989
0,99993
0,99995
0,5040
0,5438
0,5832
0,6217
0,6591
0,6950
0,7291
0,7611
0,7910
0,8186
0,8438
0,8665
0,8869
0,9049
0,9207
0,9345
0,9463
0,9564
0,9649
0,9719
0,9778
0,9826
0,9864
0,9896
0,9920
0,9940
0,9955
0,9966
0,9975
0,9982
0,99869
0,99906
0,99934
0,99953
0,99968
0,99978
0,99985
0,99990
0,99993
0,99995
0,5080
0,5478
0,5871
0,6255
0,6628
0,6985
0,7324
0,7642
0,7939
0,8212
0,8461
0,8686
0,8888
0,9066
0,9222
0,9357
0,9474
0,9573
0,9656
0,9726
0,9783
0,9830
0,9868
0,9898
0,9922
0,9941
0,9956
0,9967
0,9976
0,9982
0,99874
0,99910
0,99936
0,99955
0,99969
0,99978
0,99985
0,99990
0,99993
0,99996
0,5120
0,5517
0,5910
0,6293
0,6664
0,7019
0,7357
0,7673
0,7967
0,8238
0,8485
0,8708
0,8907
0,9082
0,9236
0,9370
0,9484
0,9582
0,9664
0,9732
0,9788
0,9834
0,9871
0,9901
0,9925
0,9943
0,9957
0,9968
0,9977
0,9983
0,99878
0,99913
0,99938
0,99957
0,99970
0,99979
0,99986
0,99990
0,99994
0,99996
0,5160
0,5557
0,5948
0,6331
0,6700
0,7054
0,7389
0,7704
0,7995
0,8264
0,8508
0,8729
0,8925
0,9099
0,9251
0,9382
0,9495
0,9591
0,9671
0,9738
0,9793
0,9838
0,9875
0,9904
0,9927
0,9945
0,9959
0,9969
0,9977
0,9984
0,99882
0,99916
0,99940
0,99958
0,99971
0,99980
0,99986
0,99991
0,99994
0,99996
0,5199
0,5596
0,5987
0,6368
0,6736
0,7088
0,7422
0,7734
0,8023
0,8289
0,8531
0,8749
0,8944
0,9115
0,9265
0,9394
0,9505
0,9599
0,9678
0,9744
0,9798
0,9842
0,9878
0,9906
0,9929
0,9946
0,9960
0,9970
0,9978
0,9984
0,99886
0,99918
0,99942
0,99960
0,99972
0,99981
0,99987
0,99991
0,99994
0,99996
0,5239
0,5636
0,6026
0,6406
0,6772
0,7123
0,7454
0,7764
0,8051
0,8315
0,8554
0,8770
0,8962
0,9131
0,9279
0,9406
0,9515
0,9608
0,9686
0,9750
0,9803
0,9846
0,9881
0,9909
0,9931
0,9948
0,9961
0,9971
0,9979
0,9985
0,99889
0,99921
0,99944
0,99961
0,99973
0,99981
0,99987
0,99992
0,99994
0,99996
0,5279
0,5675
0,6064
0,6443
0,6808
0,7157
0,7486
0,7794
0,8078
0,8340
0,8577
0,8790
0,8980
0,9147
0,9292
0,9418
0,9525
0,9616
0,9693
0,9756
0,9808
0,9850
0,9884
0,9911
0,9932
0,9949
0,9962
0,9972
0,9979
0,9985
0,99893
0,99924
0,99946
0,99962
0,99974
0,99982
0,99988
0,99992
0,99995
0,99996
0,5319
0,5714
0,6103
0,6480
0,6844
0,7190
0,7517
0,7823
0,8106
0,8365
0,8599
0,8810
0,8997
0,9162
0,9306
0,9429
0,9535
0,9625
0,9699
0,9761
0,9812
0,9854
0,9887
0,9913
0,9934
0,9951
0,9963
0,9973
0,9980
0,9986
0,99896
0,99926
0,99948
0,99964
0,99975
0,99983
0,99988
0,99992
0,99995
0,99997
0,5359
0,5753
0,6141
0,6517
0,6879
0,7224
0,7549
0,7852
0,8133
0,8389
0,8621
0,8830
0,9015
0,9177
0,9319
0,9441
0,9545
0,9633
0,9706
0,9767
0,9817
0,9857
0,9890
0,9916
0,9936
0,9952
0,9964
0,9974
0,9981
0,9986
0,99900
0,99929
0,99950
0,99965
0,99976
0,99983
0,99989
0,99992
0,99995
0,99997

Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
30 EJERCICIOS de INFERENCIA ESTADÍSTICA 2º BACH . CC. SS.
NOTA: En algunos ejercicios conviene identificar el rango de valores y el significado de la variable aleatoria continua X, y
acompañar el planteamiento con una gráfica explicativa. Los señalados con son los más recomendados. Cálculo de áreas:
1. Utilizando la tabla de la curva normal tipificada, calcular las siguientes áreas: a) Área entre 0 y 0,25 b) Área desde –∞ hasta 1,32 c) Área entre –2,23 y 1,15 (Soluc: 0,0987; 0,9066; 0,862)
2. Sea Z una variable aleatoria N(0 ,1). Calcular: a) P(Z ≥1,32) b) P(Z≤2,17) c) P(1,52<Z≤2,03)
(Soluc: 0,0934; 0,9850; 0,0431)
3. Sea Z una variable aleatoria N(0 ,1) . Calcular: a) P(Z ≥-1,32) b) P(Z≤-2,17) c) P(-2,03<Z≤1,52)
d) P(Z>2,8) e) P(Z≤-1,8) f) P(Z>-1,8) g) P(1,62≤Z<2,3) h) P(1≤Z<2) i) P(-0,61<Z≤1,4)
j) P(-1<Z≤2) k) P(-2,3<Z≤-1,7) l) P(-2≤Z≤-1)
(Soluc: a) 0,9066; b) 0,015; c) 0,9145; d) 0,0026; e) 0,0359; f) 0,9641; g) 0,0419; h) 0,1359; i) 0,6483; j) 0,8185; k) 0,0339; l ) 0,1359)
Problema inverso:
4. Calcular el valor de k (exacto o aproximado) en cada uno de los siguientes casos:
a) P(Z≤k )=0,5
b) P(Z≤k )=0,8729
c) P(Z≤k )=0,9
d) P(Z≤k )=0,33
e) P(Z≤k )=0,2
f) P(Z>k )=0,12
g) P(Z≥k )=0,9971
h) P(Z≥k )=0,6
(Soluc: a) k =0; b) k =1,14; c) k ≅1,28; d) k =-0,44; e) k ≅-0,84; f) k ≅1,175; g) k =-2,76; h) k ≅-0,25)
Tipificación de la variable:
5. En una distribución N(18,4), hallar las siguientes probabilidades: a) P(X≤20) b) P(X≥16,5) c) P(X≤11) d) P(19≤X≤23) e) P(11≤X<25)
(Soluc: a) 0,6915; b) 0,6461; c) 0,0401; d) 0,2957; e) 0,9198)
6. En una distribución N(6 ;0 ,9), calcular k para que se den las siguientes igualdades: a) P(X≤k )=0,9772 b) P(X≤k )=0,8 c) P(X≤k )=0,3 d) P(X≥k )=0,6331 (Soluc: a) k=7,8; b) k≅6,756; c) k≅5,532; d) k=5,694)

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
Problemas de aplicación:
7. Las tallas de los individuos de una población se distribuyen normalmente con media igual a 175 cm y desviación típica igual a 8 cm. Calcular la probabilidad de que un individuo tenga una talla: a) Mayor que 180 cm. b) Menor que 170 cm. c) Entre 170 y 180 cm. (Soluc: 0,27; ídem; 0,4648)
8. Los opositores que se presentan a unas plazas de cierto organismo se distribuyen normalmente con una
puntuación media igual a 70,5 y con una desviación típica igual a 9 ¿Cuántas plazas se adjudicarán en la oposición de este año, si el tribunal ha decidido de antemano dejar sin plaza a todos aquellos que obtengan una puntuación inferior a 80? (Soluc: consiguen plaza ≅ 14,5 % de los opositores)
9. En un determinado examen la media de las calificaciones es 6 y la desviación típica 1,2. Calcular la probabilidad de que un alumno tenga una calificación: a) Mayor que 7 b) Menor que 5 c) Entre 5,5 y 7 (Soluc: 0,2633; ídem; 0,46)
10. El Ministerio de Educación ha hecho una encuesta sobre la distribución de las edades del profesorado de Educación Especial, y ha observado que se distribuyen normalmente con media de 38 años y desviación típica 6. De un total de 500 profesores, a) ¿Cuántos profesores hay con edades menores o iguales a 35 años? b) ¿Cuántos mayores de 55 años? (Soluc: ≅ 154 profesores; 1 profesor)
11. Los pesos de los individuos de una población se distribuyen normalmente con media 70 kg y desviación típica 6 kg. De una población de 2000 personas, calcular cuántas tendrán un peso comprendido entre 65 y 75 kg. (Soluc: 1187)
12. El peso teórico de una tableta de cierto medicamento es de 324 mg. Si suponemos que los pesos de las tabletas siguen una normal de desviación típica 10 mg por tableta, calcular: a) ¿Cuál será el porcentaje de tabletas con peso menor o igual a 310 mg? b) ¿Cuál será el porcentaje de tabletas con peso superior a 330 mg?
13. La duración media de un determinado modelo de televisor es de ocho años, con una desviación típica de medio año. Si la vida útil del televisor se distribuye normalmente, hallar la probabilidad de que un televisor cualquiera dure más de nueve años. (Soluc: ≅ 2 % de los televisores)
14. Se llama cociente intelectual (C.I.) al cociente entre la edad mental y la edad real. Supongamos que la distribución del C.I. de 2000 personas sigue una distribución normal de media 0,8 y desviación típica 0,2. Calcular: a) El número de personas con C.I. superior a 1,4 b) El número de personas con C.I. inferior a 0,9 (Soluc: 2 personas; 1383 personas)
15. La duración de un determinado modelo de pila se distribuye según una normal con media 70 horas y desviación típica de 2 horas. A un establecimiento le quedan del pedido anterior 20 pilas. a) ¿Cuántas tendrán una duración superior a 70 horas? b) ¿Cuántas tendrán una duración entre 75 y 82 horas?
16. Por estudios realizados sobre un gran número de niñas al nacer, se ha determinado que su talla se distribuye según una normal de media 50 cm y desviación típica 1,8 cm. a) Hallar la probabilidad de que una niña al nacer tenga una talla superior a 54 cm. b) Si durante un mes en una maternidad nacen 100 niñas, ¿cuántas tendrán al nacer una talla entre 48,2 y 51,8? (Soluc: 0,0132; 68 niñas)
17. Un almacén de camisas ha determinado que el cuello de los varones adultos se distribuye normalmente con media 38 cm y desviación típica 1,5 cm. Con el fin de poder preparar la próxima temporada, y teniendo en cuenta que su producción está en 10 000 camisas, ¿cuántas camisas de los números 35, 36, 37, 38 y 39 tendrá que fabricar? (Soluc: 376 camisas del 35; 1112 del 36; 2120 del 37; 2586 del 38)

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
18. Continuando con el problema anterior, ¿cuántas camisas habrá que fabricar del 43? ¿Y del 33?
19. En una población de 1 000 individuos se establecen dos grupos, A y B. Los cocientes intelectuales (C.I.) de ambos grupos se distribuyen según N(100,30) y N(120,35), respectivamente. Elegido, aleatoria e independiente, un individuo de cada grupo, se pide: a) ¿Cuál es la probabilidad de que el individuo del grupo A tenga un C.I. superior a 90? b) ¿Cuál es la probabilidad de que el individuo del grupo B tenga un C.I. superior a 90? c) ¿Cuál es la probabilidad de que ambos tengan un C.I. superior a 90?
(Soluc: 0,6293; 0,8051; el producto de las dos anteriores)
Intervalo característico:
20. Calcular los valores críticos correspondientes: a) α=0,09 b) α=0,21 c) α=0,002
(Soluc: zα/2≅1,70; zα/2≅1,25; zα/2≅3,08)
21. En una distribución N(173,6) hallar los intervalos característicos para el 90%, el 95% y el 99%.
(Soluc: (163,13;182,87); (161,24; 184,76); (157,55; 188,45))
22. En una distribución N(18,4) hallar los intervalos característicos para el 95% y el 99,8%.
(Soluc: (10,16;25,84); (5,68; 30,32))
23. En las distribuciones normales cuyos parámetros se dan, hallar el intervalo característico que en cada caso se indica:
a b c d e f g h i media: µµµµ 0 0 0 0 112 3512 3512 3512 3512
desv. típica: 1 1 1 1 15 550 550 550 550 probab.: 1 -αααα 0,95 0,99 0,90 0,80 0,95 0,99 0,95 0,90 0,80
(Soluc: a) (-1,96;1,96); b) (-2,575;2,575); c) (-1,645;1,645); d) (-1,28;1,28); e) (82,6;141,4); f) (2095,75;4928,25); g) (2434;4590); h) (2607,25;4416,75); i) (2808;4216))
24. En una distribución normal con media µ=25 y desviación típica σ=5,3, obtener un intervalo centrado en la
media, (µ-k,µ+k), de forma que el 95% de los individuos estén en ese intervalo. (Soluc: (14,612;35,388))
25. En una distribución N(10,4), obtener un intervalo centrado en la media, (µ-k,µ+k), tal que:
P(µ-k<x<µ+k)=0,90
(Soluc: (3,42;16,58))
26. En una distribución normal de media µ=9,5 y varianza σ2=1,44, hallar el intervalo característico para el 99%. (Soluc: (6,41;12,59))
Intervalo de confianza
27. Deseamos valorar el grado de conocimientos en historia de una población de varios miles de alumnos. Sabemos que σ=2,3. Nos proponemos estimar µ pasando una prueba a 100 alumnos, obteniéndose una media x 6,32= . Hallar el intervalo de confianza de µ con un nivel de confianza del 95% (Sol: (5,87;6,77))
28. Para estimar la media de los resultados que obtendrían al resolver un cierto test los alumnos de 4º de
ESO de toda una comunidad autónoma, se les pasa dicho test a 400 de ellos escogidos al azar. Los resultados obtenidos vienen dados en la siguiente tabla:

MATEMÁTICAS aplicadas a las CCSS II ALFONSO GONZÁLEZ
IES FERNANDO DE MENA
Texto bajo licencia Crative Commons: se permite su utilización didáctica así como su reproducción impresa o digital siempre y cuando se respete la mención de su autoría, y sea sin ánimo de lucro. En otros casos se requiere el permiso del autor ([email protected])
xi 1 2 3 4 5
fi 24 80 132 101 63
A partir de ellos, estimar con un nivel de confianza del 95% el valor de la media de la población. (Sol: (3,14;3,36))
29. De una variable estadística conocemos la desviación típica, σ=8, pero desconocemos la media, µ. Para estimarla, extraemos una muestra de tamaño n=60 cuya media obtenemos: x 37= . Estimar µ mediante un intervalo de confianza del 99%. (Sol: (34,34;39,66))
30. Un ganadero de reses bravas quiere estimar el peso medio de los toros de su ganadería con un nivel de
confianza del 95%. Para ello, toma una muestra de 30 toros y los pesa. Obtiene una media x 507kg= y una desviación típica s=32 kg. a) ¿Cuál es el intervalo de confianza para la media µ de la población? b) ¿Cuál será el intervalo si queremos que el nivel de confianza sea del 99%?
(Sol: a) (495,55;518,45); b) (492;522))



























