Embed Size (px)
Citation preview

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 106
9.4. 대응 표본 분석
학생들의 통계학에 대한 이해 정도(통계 시험 점수)가 정보와 통계 수강 전과 후에 차이가
있는지 알아보고자 한다. 이런 경우 수강 전 통계학 점수 평균과 수강 후 통계학 점수
평균의 차이를 검정하는 두 모집단 평균 차이 검정인 t-검정(대표본일 때는 z-검정)을
사용할 수 없다. 왜냐하면 전후 통계학 점수는 서로 짝을 이루고 있으므로 독립 집단이
아니다 . 그러므로 측정치가 개체, 사람에 종속되어 있고 “before and after”, “pre and post”
개념으로 자료가 서로 짝을 이룬 경우는 짝 이룬 표본에 대한 검정 방법을 사용해야 한다.
환자들의 혈압을 낮추는 약의 효과가 (treatment effect) 있는지 알아보기 위하여 약 복용
전 혈압과 약 복용 후 혈압을 측정하여 그 차이가 있는지 알아보는 경우와 같이 관측치가
측정형인 경우 짝진 t-검정을 사용하면 된다.
운전자들의 안전벨트 착용 여부가 벌금 부여 전후에 차이가 있는지 알아보는 경우와 같이
사건 전후의 관측치가 분류형인 경우 짝진 분할표 검정 방법인 McNemar 검정 방법을
사용해야 한다.
9.4.1. 짝이룬 t-검정 (paired t-test)
통계학 점수, 혈압 등과 같이 자료가 측정형인 경우 짝 이룬 t-검정(paired t-test) 방법을
사용하면 된다.
관측치
짝 이룬 경우 관측치 자료는 다음과 표현된다. ),(,),,(),,( 2211 nn yxyxyx K
짝진 표본의 경우 사건(교육, 처리, … ) 전후 관측치 차이가 있다는 말은 사건 전 관측치
평균과 사건 후 관측치 평균의 차이가 있느냐 하는 것이다. 이렇게 표현하면 마치 독립인
두 모집단 평균 차이 검정 방법(7.2.절)을 사용할 수 있을 것 같으나 잘못된 것이다.
짝진 표본의 경우 우선 짝 이룬 관측치의 차이를 구한 후 )( iii yxd −= 이것의 평균의 차
이가 있는지를 검정하면 된다. 즉 id 의 평균이 0인지 검정하는 것과 동일하므로 모집단
이 하나인 경우 모집단 평균에 대한 검정과 동일하다. 차이가 있다면 두 짝진 관측치의
차이에 대한 평균 검정이라는 것뿐이다.
가설 (hypothesis)
귀무가설: 0=dµ (처리 효과의 차이가 없다, 짝진 집단의 평균 차이가 없다)
대립가설: 0≠dµ (양측 검정) 0>dµ 혹은 0<dµ (단측 검정)

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 107
검정 통계량 (test statistic)
쌍을 이룬 관측치에 대해 )( iii yxd −= 계산한다.
id 의 평균( d )을 구한다 . 이제 이를 이용하여 일변량 모집단 평균에 대한 가설 검정을
시행하면 된다.
검정통계량 ns
dTd /
= ~ )1,0(Normal (대표본) ~ )1( −nt (소표본)
결정 (decision rule)
정규분포나 t-분포표를 이용하여 p-value 를 구하거나 기각역 을 이용하여 가설을 검정하면
된다.
;EXAMPLE;
다음은 두 차량 정비소의 차량 정비 예상 가격에 차이가 있는지 알아보기 위하여 사고 난
차 7 대를 각 정비소에 가져가 예상 가격을 조사한 자료이다. 두 정비소의 차량 예상
가격에 차이가 있는지 가설 검정하시오. (유의수준=0.05) (단위 만원)
차량 1 2 3 4 5 6 7
정비소 A 7.1 9 11 8.9 9.9 9.1 10.3
정비소 B 7.9 10.1 12.2 8.8 10.4 9.8 11.7
차이 id -0.8 -1.1 -1.2 0.1 -0.5 -0.7 -1.4
1) 가설 (hypothesis)
§ 귀무가설: 정비소간 차량 정비 예상 가격 차이는 없다. 0=dµ
§ 대립가설: 차이가 존재한다. 0≠dµ (양측 검정)
2) 검정 통계량 (test statistic)
① 쌍을 이룬 관측치에 대해 )( iii yxd −= 계산한다. (표 참조)
② id 의 평균( 8.0−=d )과 표준 편차( 1902.07/5033.0/ ==nsd )를 구한다.
③ 검정통계량 205.41902.0
8.0
/−=−==
ns
dTd

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 108
3) 결정 (decision rule)
소표본이므로 447.2)025.0,61( ==−= ndft 과 비교하면 된다. 계산된 검정 통계량이
크므로 귀무가설을 기각하고 정비소간 예상 가격의 차이는 존재하며 계산된 검정
통계량 값이 음수이므로 정비소 B 의 예상 가격을 높다고 결론 낼 수 있다.
;HOMEWORK; [optional]
다음은 10 명에 대해 광고 전후 상품에 대한 선호도를 조사한 자료이다. 광고 전과 공고
후의 상품 선호도가 차이가 있는지 분석하시오. 유의수준=0.05
사람 1 2 3 4 5 6 7 8 9 10
광고 전 50 25 30 50 60 80 45 30 65 70
광고 후 53 27 38 55 61 85 45 31 72 18
9.4.2. 교차표의 수준이 짝을 이룬 경우 (McNemar 검정 )
수준이 짝을 이루었다는 것은 무슨 뜻인가? 측정형 변수가 짝진 경우와는 달리 응답자들
의 성향(수준)이 사건 전후에 어떻게 바뀌었는지를 알아보는 것이다. 예를 들어 보자. 벌
금 부여 전 운전자들의 안전벨트 착용 여부를 조사하고(착용, 미착용) 벌금 부여 후에 안
잔 벨트 착용 여부를 조사한 후 착용 여부에 차이가 있는지 조사한다면 이런 경우
McNemar 방법을 사용해야 한다.
McNemar 방법을 사용하려면 반드시 동일 실험 대상이 전후에 사용되어야 하고 같은 개
념을 묻거나 실험해야 한다. McNemar는 이 방법을 수준이 2개(Yes, No)인 경우만 제안했
으나 Bennett & Underwood가 3개 이상인 경우로 확대하였다. 편의를 위하여 수준이 2개
인 경우를 가설 검정 순서를 살펴보기로 하자.
사건 후
예 아니오 Total
예 A B A+B 벌금 부과 전
아니오 C D C+D
Total A+C B+D N
N=응답자 총수
A=실험 전후 모두 YES인 응답자
D=실험 전후 모두 NO인 응답자
B=실험 전 YES, 실험 후 NO
D=실험 전 No, 실험 후 YES

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 109
가설 (hypothesis)
귀무가설: 21 pp = (사건 전 예 응답 비율과 사건 후의 예 응답 비율이 같다)
대립가설: 21 pp ≠ (양측 검정) 21 pp > 혹은 21 pp < (단측 검정)
검정 통계량 (test statistic)
표본 추정치: N
BAp +=1ˆ , N
CAp +=2ˆ 표본 추정치 차이: N
CBpp −=− 21 ˆˆ
귀무가설이 맞다면 0/)( =− NCB 이므로 이를 이용하여 McNemar 는 검정 통계량으로
다음을 제안하였고 이가 성립하기 위해서는 (B+C)가 적어도 10 이상이어야 한다.
)1,0(~ NormalCB
CBz
+
−=
;EXAMPLE;
안전벨트 미착용 벌금 효과를 알아보기 위하여 85 명을 임의로 선택하여 벌금 부과 전
벨트 작용 여부와 부과 후 벨트 작용 여부를 조사하여 아래 표를 만들었다. 벌금 효과가
있는지 검정하시오
벌금 부과 후
착용 미착용 Total
착용 7 26 33 벌금 부과 전
미착용 48 4 52
Total 55 30 85
1) 가설 (hypothesis)
귀무가설: 21 pp = (벌금 부과 전후 벨트 착용 비율은 동일하다)
대립가설: 21 pp ≠ (벌금 부과 후 벨트 착용 비율에 차이가 있다)
2) 검정 통계량 (test statistic): 56.24826
4826−=
+
−=z
3) 96.1)025.0( ±==αz 이므로 기각 값보다 적으므로 귀무가설이 기각되고 벌금 부과에
따른 차이가 있다고 결론 지을 수 있다. 부과 후 착용 비율은 647.085/55 = 으로 부과 전
388.085/33 = 에 비해 높아졌다고 결론 지을 수 있다.

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 110
9.5. 회귀분석(optional)
두 측정형 변수들의 관계를 살펴보는 방법은 상관 분석(correlation analysis)과 회귀
분석(regression analysis)으로 나뉜다. 상관 분석은 두 변수간의 선형(linear) 관계 정도를
알아보는 것이고 회귀분석은 두 변수간의 인과 관계(casual relationship)가 있는지(주로
선형 인과 관계) 알아보는 분석 방법이다.
예를 들면, 키와 몸무게의 상관 관계, 부모와 자녀 IQ 간의 상관 관계를 보는 경우 상관
분석, 키가 큰 사람은 몸무게가 많이 나가는가? 부모의 IQ 는 자식의 IQ 에 영향을
미치는가?를 알아보려면 회귀분석을 시행해야 한다. 회귀분석에서 원인이 되는 변수를
독립변수 (independent variable) 혹은 설명 변수(explanatory variable)라 하고 (키, 부모 IQ)
결과로 나타나는 변수를 반응 변수 (response variable) 혹은 종속 변수 (dependent
variable)라 한다. (몸무게, 자녀 IQ)
상관 분석이나 회귀 분석에 이용되는
관측치는 쌍으로 이루어져 있다.
),( ii yx è ),( 11 yx ),( 22 yx … ),( nn yx
오른쪽에 있는 자료는 키와 몸무게의
관계를 분석하기 위하여 자료를 엑셀에
입력한 화면이다

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 111
9.5.1. 산점도
두 변수간의 관계를
보기 위하여 종속
변수를 y 축으로 설명
변수를 X 축으로 하여
이차원 그래프를
그리게 되는데 이를
산점도라 한다.
40
60
80
100
120
140
160
50 55 60 65 70 75
엑셀에서 산점도 그리기
Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 112
9.5.3. 선형 회귀 모형 및 추정
설명변수가 하나인 단순 선형 회귀 모형은 다음과 같다.
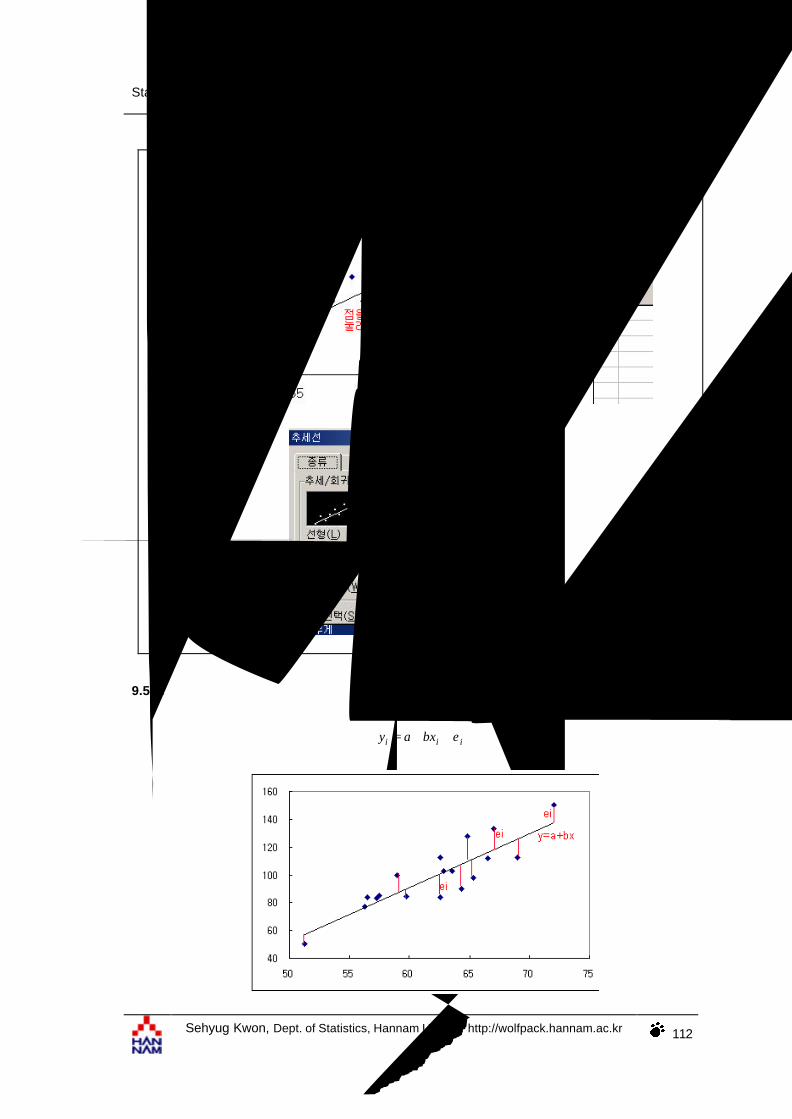
iii ebxay ++=

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 113
ie 는 선형 회귀 직선( bxa + )에 의해 설명되지 못하는 부분이다. 그러므로 설명되지 못하는
부분이 적을수록 선형 회귀모형의 정도는 높을 것이다.
22 )(,
min,
miniii
bxayba
eba
−−= è xbyaxx
yyxxS
Sb
xx
xy ˆˆ,)(
))((ˆ2
−=∑ −
∑ −−==
)ˆ()ˆ()( yyyyyy iiii −+−=− è ∑ −+∑ −=∑ − 222 )ˆ()ˆ()( yyyyyy iiii
SSRSSESST −=
))2,1((~/ −== ndfFMSEMSRF : 모형에 대한 유의성 검정
asat ˆ/ˆ= ( 0:0 =aH ) : 절편에 (상수 항) 대한 유의성 검정
bsbt ˆ/ˆ= ( 0:0 =bH ) 기울기에 대한 유의성 검정: F-검정과 동일( 2tF = : 단순회귀)
자료로부터 추정된 회귀 모형은 xy 899.302.143ˆ +−= 이다. 즉 몸무게=-143.02+3.899*(키)가
성립하고 이로부터 다음 사실을 알 수 있다.
§ 키는 몸무게에 영향을 미친다.
§ 키가 1inch 커지면 몸무게는 3.899(pound)만큼 증가함을 알 수 있다. (기울기 해석)
§ 키가 5feet 10inch(70inch=178cm)인 사람 몸무게는
9.13970*899.302.143 =+− (pound)일 것으로 추정된다.

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 114
9.5.4. 상관 계수
두 변수간의 선형 상관 관계 정도를 나타내는 상관 계수 계산식은
SSTSSR
SS
byyxx
yyxx
SS
Sr
yy
xx
ii
ii
yyxx
xy ==∑ ∑ −−
∑ −−== ˆ
)()(
))((22
귀무가설: 두 변수간의 상관 관계는 없다. 상관 계수는 0 이다. 0=ρ
대립가설: 두 변수간의 상관 관계가 존재한다. 0≠ρ

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 115
)2(~12.4)219/()878.01(
878.0
)2/()1( 22−==
−−=
−−= ndft
nr
rt
t-분포 표에 의해 자유도 17, 유의수준이 0.05 인 (0.025 로 참조) 경우 2.11 이다. 검정
통계량의 값이 4.12 이므로 기각역에 속하므로 귀무가설은 기각되고 몸무게와 키 변수에는
선형 상관 관계가 있음을 알 수 있다.
9.6. 분산분석 (optional)
분산분석이란 분류형 변수의 수준(범주)에 따른 측정형 변수의 평균의 차이가 있는지
알아보기 위한 분석 방법이다 . 분산분석에서 집단을 분류하는 분류형 변수를 요인(이를
처리 효과라 부르기도 함)이라 하고 측정형 변수를 반응변수(response variable) 혹은 종속
변수라 (dependent variable) 한다.

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 116
한남대학교 학생들 중 학년별로 월 용돈의 차이는 있는가를 알아보는 경우 학년이
요인(독립변수)이 되고 월 용돈이 종속변수가 된다. 이를 다시 표현하면 학년별 월 용돈
평균의 차이가 있는가를 알아보는 것이다.
요인이 하나인 경우를 일원(one-factor, one-way) 분산분석 , 두 개인 경우를 이원(two-factor,
two-way) 분산분석 , 그리고 3 개 이상이면 다원(multi-factor, multi-way) 분산 분석이라 한다.
분산 분석의 개념은 실험 계획으로부터 시작되었다.
9.6.1. 통계적 기초
모형 ijiijiij eeuy +=++= µτ injki ,,2,1 ,2,1 KK == SStr
추정치: )()()( yyyyyy iiijij −+−=− SSE
변동: ∑ ∑∑∑∑ ∑ −+−=− 222 )()()( yyyyyy iiijij
SStrSSESST +=
è 총변동=설명 안된 부분 + 설명 되는 부분
범주 1 2 3
ijy = i 범주(집단)의 j 번째 관측치,
iµ = i 범주의 평균 (즉 i 집단 평균에 의해 설명되는 부분)
ije = 집단 평균에 의해 설명되지 않는 부분
분산분석표 (ANOVA Table)
변동
Source
자유도
DF
자승합
Sum of Square
평균 자승합
Mean of SS F-검정
Treatment
처리효과 1−t ∑∑ −= 2)( yySStr i )1/( −= tSStrMStr
Error
오차 tn − SStrSSTSSE −= )/( tnSSEMSE −=
MSEMStrF =
Total
총합 1−n ∑ ∑ −= 2)( yySST ij ~ ),1( tntF −−
그러므로 F 검정 통계량의 값이 커지면 처리 효과가 존재한다고 할 수 있다. 만약 범주가
2 개인 경우는 (예를 들면 우리 설문 예제에서 성별에 따른 시설물 만족도 차이가
있는가?) 독립인 두 집단 평균 비교를 위한 모평균 차이 t-검정과 분산 분석은 동일하다 .
( )),1(()(2 ndfFndft ===

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 117
9.6.2. 예제
다음은 3 개 호수의 산소량의 차이가 있는지 알아보기 위하여 각 호수의 중앙에서 깊이
1m 의 물로부터 산소량(ppm)을 측정한 자료이다.
Lake Observation
1 0 2 1 3 1 2 3 4 1 5
2 1 3 4 6 8 7 5 3 4 5
3 14 26 25 18 19 22 21 16 20 30
요약표
인자의 수준 관측 수 합 평균 분산
호수 1 10 22 2.2 2.4
호수 2 10 46 4.6 4.2666667
호수 3 10 211 21.1 23.433333
분산 분석
변동의 요인 제곱합 자유도 제곱 평균 F 비 P-값 F 기각치
처리 2117.4 2 1058.7 105.51827 1.73E-13 3.3541312
잔차 270.9 27 10.03333
계 2388.3 29
( =α 0.05)
유의수준
0.05
3.35 105.5
산소량은 호수에 따라 차이가 있다. 물론 각 호수간 평균 차이에 대한 검정은 Post-Hoc
검정(사후 검정)에 살펴보아야 한다. 방법으로는 Scheffe, Tukey 방법 등이 있는데
여기서는 다루지 않기로 한다.

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 118
9.6.3. 엑셀 이용하기
1) 자료를 입력한 후 도구메뉴에서 데이터 분석을 선택한다.
2) 데이터 분석 설정 창에서 “분산분석: 일원 배치법”을 선택한다.
3) 분산분석: 일원 배치법의 설정을 다음과 같이 하고 “확인”을 누른다.

Statistics for Business ;Fall, 2001; Ch. 9 변수가 2개 이상인 경우
Sehyug Kwon, Dept. of Statistics, Hannam Univ. ; http://wolfpack.hannam.ac.kr 119
page 101 과 같은 분산분석 결과가 나타난다 . 요인 각 수준(호수 1, 호수 2, 호수 3)의
평균과 표준 편차 값이 요약되는데 이를 이용하여 각 수준 평균에 대한 막대 그래프를
그리면 정보가 잘 요약된다.
2.2
4.6
21.1
0
5
10
15
20
25
1호수1 호수2 호수3





![Chapter03.ppt [호환 모드] - hnuwolfpack.hnu.ac.kr/Spring_2013/Biz_Math13/Chapter03_BM.pdf · 2013. 3. 25. · © 2012 Cengage Learning. All Rights Reserved. May not be scanned,](https://img.pdfslide.tips/doc/110x75/600de7da55df910b2212324b/-eeoe-hnuwolfpackhnuackrspring2013bizmath13chapter03bmpdf.jpg)























