Embed Size (px)
Citation preview

Introducción al Shell
Crear dos archivos de prueba
Comandos en el sistema UNIX
Estructura de Comandos
Expansiones de la línea de comandos
Variables de ambiente
Entrecomillado de argumentos
PS1
Entrada estándar y salida estándar
Fin de flujo
Agregar la salida estándar a un archivo
Error estándar
Interconexión de comandos (entubamiento)
Filtros
Campos y delimitadores
Valores de retorno de los comandos
El operador grave
Secuencias de comandos
Redirección del shell
Fin
Bibliografía y Referencias
El intérprete de comandos o "shell" actúa entre el sistema operativo y el operador.
Provee al usuario una interfaz hacia el sistema operativo. El usuario dialoga con el
intérprete de comandos, y éste transfiere las órdenes al sistema operativo, que las
ejecuta sobre la máquina.
Crear dos archivos de prueba.
Con el comando cat puede crearse un archivo aceptando el teclado como entrada estándar y
direccionando la salida estándar hacia un archivo:
cat >nota
digitar las siguientes líneas, tal cual están, terminando cada línea dando <Enter>; finalizar con
<Ctrl-D>. Digitar con cuidado: una vez pasados al renglón siguiente, no puede volverse atrás
para corregir.
El shell es un intérprete de comandos.
Es también un lenguaje de programación.
Los programas escritos con el shell se llaman scripts.
Digitar <Ctrl-D> para finalizar el ingreso.

cat nota
muestra el contenido digitado.
Crear del mismo modo el archivo LEAME, haciendo
cat > LEAME
con este contenido:
Este es el archivo LEAME.
Recuerde que UNIX diferencia entre mayúsculas y minúsculas.
El archivo LEAME tendrá este contenido.
cat LEAME
para verificar el contenido.
Comandos en el sistema UNIX.
En UNIX, los comandos son programas ejecutables separados. El shell es un intérprete de
comandos: puede expandir y cambiar la manera en que actúan los comandos, admite el uso de
comodines y la interconexión o entubamiento de comandos.
Estructura de comandos.
La estructura general de un comando es la siguiente:
nombre opciones argumentos
nombre es el nombre del comando. Las opciones o banderas controlan la forma en que
actúa el comando; van precedidas por el signo - (menos). Los argumentos son comúnmente
nombres de archivos o nombres de login de usuarios.
pr -l23 nota
pr -l23 LEAME
da formato y muestra el archivo indicado en páginas de 23 líneas de largo para que quepa en la
pantalla.
pr -d -l23 LEAME
muestra el archivo LEAME a doble espacio, largo de página 23.
pr -d -o15 -l23 LEAME

doble espacio, margen izquierdo de 15 espacios, largo de página 23.
pr -l23 nota LEAME | more
muestra los dos archivos uno tras otro, pero los pagina separados.
cat nota LEAME
concatena los archivos; los presenta uno tras otro.
cat nota LEAME | pr -l23
concatena los archivos y luego les da formato a los dos juntos.
Expansiones de la línea de comando.
Los comodines son caracteres que sustituyen cadenas de caracteres.
* secuencia de caracteres cualesquiera, 0 o más.
? caracter cualquiera, uno y uno sólo; debe aparear un caracter.
[...] sustituye los caracteres indicados individualmente.
Variables de ambiente.
Las variables de ambiente son cadenas de caracteres de la forma
nombre=valor
nombre es cualquier cadena de caracteres que no incluya $ ni espacio (\b); valor es cualquier
cadena; puede incluir el espacio si el valor está entre comillas.
MUESTRA="hola chicos"
asigna "hola chicos" a la variable MUESTRA.
echo $MUESTRA
muestra en pantalla el contenido de la variable MUESTRA. Para exhibir el contenido de una
variable de ambiente se escribe echo $nombre-variable. En general, para hacer uso del
contenido de una variable, se escribe $nombre-variable.
Es una costumbre muy arraigada en UNIX usar mayúsculas para los nombres de variable, así
como es una regla usar minúsculas para los comandos. Las opciones pueden ser mayúsculas y
minúsculas; la opción -a no es lo mismo que -A.

Las variables de ambiente pueden ser usadas como nombres de comando o como argumentos
de un comando.
XYZ="cat nota"
$XYZ
la variable XYZ contiene un comando, y al ser invocado su contenido, el comando es ejecutado.
echo hola $MUESTRA chicos
la variable puede usarse en la formación de cadenas.
echo hola${MUESTRA}chicos
la variable puede embeberse en una cadena; las llaves delimitan el nombre de la variable.
env
muestra las variables de ambiente definidas. Muchas son fijadas en el ingreso del usuario al
sistema (variables de login); y otras son propias del shell (variables del shell).
echo $LOGNAME
muestra el nombre de login del usuario.
echo $HOSTNAME
muestra el nombre de la máquina.
echo $NOEXISTE
Las variables no definidas no muestran nada cuando son referenciadas.
Entrecomillado de argumentos en la línea de comandos.
Los espacios separan argumentos. El entrecomillado obliga a tratar una cadena con espacios
como si fuera un solo argumento. Cuando se usan comillas dobles (" ") el shell interpreta las
variables de ambiente incluídas, actuando según su contenido:
MUESTRA="Mi nombre de login es $LOGNAME"
echo $MUESTRA
Cuando se usan comillas simples (' ') el shell no interpreta las variables de ambiente,
tratando sus nombres como cadenas:
MUESTRA='La variable $LOGNAME contiene su nombre de login'
echo $MUESTRA

Las comillas simples permiten usar comillas dobles:
echo '"hola chicos"'
PS1.
Aunque generalmente los omitimos, en los ejemplos de esta sección mostraremos el indicador
de comandos y la salida de ejecución.
La variable símbolo de indicador de comandos nivel 1 PS1 (Prompt Symbol level 1) es
un valor de ambiente que puede no aparecer en la salida de env:
$ echo $PS1
$
responde con el indicador de comandos actual, $.
$ PS1=hola:
hola:
carga un nuevo indicador de comandos; el sistema responde con el nuevo indicador de
comandos, hola:.
hola: MUESTRA="ingrese comando:"
hola: PS1=$MUESTRA
ingrese comando: MUESTRA=hola
ingrese comando: echo $MUESTRA
hola
ingrese comando:
la variable MUESTRA cambió pero el indicador no cambió;
ingrese comando: PS1='$'
$
repone el indicador de comandos.
Entrada estándar y salida estándar.
Los comandos leen como entrada una secuencia de caracteres (flujo de entrada o "input
stream"), y escriben a la salida otra secuencia de caracteres (flujo de salida o "output stream").
Estas secuencias no tienen estructura interna alguna, y se les llama entrada estándar y salida
estándar.
cat nota > nota2

redirige la salida estándar a un archivo que crea o sobreescribe, en vez de a la pantalla.
mail juan < nota
toma la entrada estándar de un archivo en vez del teclado.
pr < nota > nueva.nota
el archivo nota es la entrada, el archivo nueva.nota es la salida.
cat nueva.nota
muestra el archivo donde se grabó la salida con formato.
Los símbolos < y > redirigen entrada y salida estándar:
< nombre_entrada redirige la entrada estándar
> nombre_salida redirige la salida estándar
MUESTRA=/etc/passwd
pr < $MUESTRA > lista.usuarios
more lista.usuarios
Los comandos y los archivos tienen una estructura orientada a caracter. En muchos comandos
se puede intercambiar teclado por archivos o dispositivos de hardware.
cat nota
cat < nota
son comandos equivalentes porque cat opera sobre un archivo y también sobre la entrada
estándar.
cat nota LEAME nueva.nota
cat nota - nueva.nota < LEAME
son comandos equivalentes. El signo menos (-) aislado equivale a tomar en ese punto la
entrada estándar, que usualmente está asignada al teclado.
Fin de flujo.
El ingreso de datos desde el teclado, así como el despliegue en pantalla, se manejan en UNIX
como "flujos de caracteres", una serie de caracteres uno tras otro. Para indicar en el teclado el

fin de un flujo de caracteres se usa Ctrl-D. Este símbolo no forma parte del ingreso;
simplemente indica el final del ingreso, que ya no se escribirá más. En UNIX no hay un caracter
especial para indicar fin de archivo; el sistema sabe cuando termina un archivo por medio de
contadores.
cat nota - nueva.nota > arch.salida
procesa el archivo nota, lee lo que se digite en el teclado hasta recibir un Ctrl-D, procesa
nueva.copia y escribe todo en el archivo arch.salida; se reúnen tres fuentes distintas en una
única salida.
cat arch.salida
muestra todo lo reunido.
Agregar la salida estándar a un archivo.
cat < nota > nota.copia
cat nota nota.copia > doble.nota
rm nota.copia
doble.nota contiene nota dos veces. Se logra lo mismo con
cat nota > dup.nota
cat nota >> dup.nota
El símbolo >> redirige la salida estándar a un archivo, pero agregando al final del mismo en
lugar de reemplazar su contenido.
Error estándar.
Además de los flujos de entrada y salida estándar, existe un tercer flujo de caracteres, el error
estándar, hacia donde se dirigen los mensajes de error. El error estándar está dirigido
habitualmente a la pantalla, pero mediante 2> o 2>> se redirige el error estándar hacia un
archivo de errores. Los flujos estándar se reconocen por los siguientes números:
0 la entrada estándar, usualmente el teclado;
1 la salida estándar, usualmente la pantalla;
2 el error estándar, usualmente la pantalla.
echo Archivo de errores > salida.error
cat noexiste 2>>salida.error
cat salida.error

el archivo salida.error contiene el mensaje inicial y el de error.
ls noexiste 2>>salida.error
rm noexiste 2>>salida.error
cat salida.error
reúne los mensajes de error en el archivo salida.error .
Interconexión de comandos (entubamiento).
El operador | hace que la salida del comando precedente sea la entrada del comando
siguiente, creando un entubamiento o interconexión de comandos.
cat nota LEAME | pr > salida
hace que la concatenacion de los archivos nota y LEAME sea servida al comando pr, cuya
salida está redirigida a un archivo.
cat - LEAME < nota | pr > salida
tiene el mismo efecto. Notar la posicion de redireccion <.
Los operadores < y > redirigen, | conecta comandos.
Filtros.
Muchos comandos están pensados para ser interconectados, pasando simplemente la entrada
hacia la salida, por lo que se les llama habitualmente filtros.
echo 'hola chicos' | tr l p
tr traduce caracteres y produce 'hopa chicos'.
echo 'hola chicos' | tr lo pa
produce 'hapa chicas'.
Campos y delimitadores.
Un campo es una cadena de caracteres separada por un caracter delimitador. El archivo
/etc/passwd tiene en cada línea una serie de campos separados por dos puntos (:) .
more /etc/passwd
muestra el contenido de /etc/passwd.
cut -f1 -d: < /etc/passwd

cut -f1,3,5 -d: < /etc/passwd
muestra los campos pedidos usando el delimitador : (dos puntos).
cut -c1-8 < /etc/passwd
muestra columnas 1 a 8.
ls -l | cut -c56-
corta el listado de archivos desde donde empieza el nombre al final.
sort < /etc/passwd | cut -f1 -d: | more
ordena las líneas, corta el primer campo y presenta los nombres de usuarios habilitados en el
sistema.
env | cut -f1 -d= | sort
muestra nombres de variables de ambiente ordenadas; el separador es =.
Valores de retorno de los comandos.
Los comandos devuelven un código de retorno 0 si el comando termina correctamente, o un
número entre 1 y 255 según la razón de falla. El código de retorno del último comando queda
en una variable llamada '?', que se interroga como $?.
cat noexiste
ERROR=$?
echo $?
echo $ERROR
guarda el código de error; la asignación termina bien, por lo que en $? queda 0, pero en ERROR
quedó el número de error de la operación fallida. $? es una 'variable de shell' mantenida
internamente por el propio intérprete. Otras variables de shell son:
# número de argumentos en el comando para la shell actual
$ número de proceso para el shell actual
Estas variables se interrogan como $# y $$.
El operador grave.
El acento grave (`) asigna a una variable de ambiente la salida estándar de un comando. El
largo de la variable es limitado, pero usualmente > 5120 en SVR4.

MUESTRA=`echo $LOGNAME`
echo $MUESTRA
escribe el nombre de login del usuario.
wc /etc/passw
cuenta líneas, palabras y caracteres.
El comando wc (word count) acepta opciones -l para líneas, -w para palabras y -c para
caracteres.
TOTALPALABRAS=`cat * | wc -w`
echo $TOTALPALABRAS
cuenta las palabras en todos los archivos del directorio. También
echo `cat * | wc -w`
echo Total de palabras en el directorio: `cat * | wc -w`
El acento grave permite ejecutar un comando dentro de otro, encerrando el comando anidado
entre acentos graves.
Secuencias de comandos.
El shell es también un lenguaje de programación. Pueden escribirse varios comandos en una
misma línea separándolos con ; (punto y coma).
date ; echo Hola ; echo $LOGNAME
MUESTRA=`date ; echo Hola ; echo $LOGNAME`;echo $MUESTRA
Redirección del shell.
El shell que atiende los comandos del usuario es el login shell; arranca cuando el usuario
ingresa al sistema y termina cuando sale. Escribir sh como comando invoca una segunda
instancia del shell, que puede terminarse con el comando exit o con <Ctrl-D>.
Puede crearse un archivo de comandos haciendo
cat > datos.usuario
y escribiendo las siguientes líneas. Pueden omitirse los comentarios (de # en adelante)
echo Salida del comando datos.usuario

echo Fecha: `date ` # fecha y hora
echo Usuario: $LOGNAME # nombre de login del usuario
ps # procesos corriendo del usuario
echo Shell actual: $$ # número de proceso para el shell actual
finalizar con <Ctrl-D>. Los # indican comentario.
Para convertir el archivo en ejecutable para el usuario, hacer
chmod u+x datos.usuario
Verificar con ls -l. Los comandos ingresados en el archivo pueden ejecutarse con
sh datos.usuario
Este comando invoca una nueva instancia de shell que no es la del ingreso al sistema.
Agregar una línea más haciendo
cat datos.usuario - >> masdatos.usuario
y escribiendo
cat noexiste # intenta mostrar un archivo inexistente
Finalizar con <Ctrl-D>.
echo "Archivo de errores del usuario" > errores.usuario
coloca una línea descriptiva en el archivo errores.usuario.
cat errores.usuario
verifica su contenido.
sh <masdatos.usuario >salida.usuario 2>>errores.usuario
lee los comandos del archivo masdatos.usuario en la entrada estándar, redirige la salida
estándar al archivo salida.usuario y redirige la salida del error estándar al archivo
errores.usuario.
cat salida.usuario
cat errores.usuario
Fin.

Borrar con el comando rm los archivos auxiliares; conservar para referencia los archivos nota,
LEAME, datos.usuario , masdatos.usuario y eventualmente otros que le interesen.
UNIX y C
El sistema operativo UNIX suele venir acompañado de un compilador para lenguaje C.
Escribiendo programas en lenguaje C es posible crear comandos indistinguibles de los
propios de UNIX. Como ejemplo, puede crearse el siguiente archivo, usando un editor
de texto sencillo como el ae, o el comando cat si se tiene fé en la propia digitación.
Contenido del archivo hola.c:
/* hola.c: programa de saludo */ #include <stdio.h> main() { printf("Hola, mundo\n"); }
Compilar el contenido de este archivo con el comando cc hola.c -o hola
Esto crea el archivo de salida hola, ejecutable en UNIX mediante el comando ./hola Imprime, como es de suponer, la frase "Hola mundo".
Un ejemplo más interesante, con uso de llamadas a la biblioteca del sistema, es el
ejemplo siguiente, una versión muy mínima del comando cat, que llamaremos cati.
Contenido del archivo cati.c:
/* cati: cat versión mínima */ # define LARGO 1024 /* define valor de variable LARGO */
main() { char bufer[LARGO]; /* declara un arreglo de caracteres */ int n; /* para contar caracteres leídos */
/* llamada al sistema para leer caracteres desde la entrada estándar (0), hacia el arreglo bufer, en cantidad igual al tamaño del arreglo bufer */ n = read(0, bufer, sizeof bufer); /* primera lectura */
/* repite mientras haya caracteres leídos, es decir, n>0 */ while (n > 0) { /* llamada al sistema para escribir caracteres en salida estándar (1), en cantidad n, extrayendo desde arreglo bufer */ write(1, bufer, n);

n = read(0, bufer, sizeof bufer); /* siguientes lecturas */ }
exit(0); /* sale devolviendo c¢digo de retorno 0 */ }
Los extensos comentarios explican el funcionamiento. Compilar este programa con el
comando cc cati.c -o cati
Esto crea el archivo de salida cati, ejecutable en UNIX. El comando ./cati <hola.c
muestra el contenido del programa hola.c. Esta versión mínima sólo funciona
redireccionando la entrada estándar. Puede probarse su funcionamiento ingresando
datos desde el teclado, finalizando con Ctrl-D. El programa puede interrumpirse con
Ctrl-C. ¿Qué diferencia hay?
Es un problema de programación algo más complejo asimilar un nombre de archivo
como parámetro y hacer que el programa despliegue el contenido de este archivo.
La razón por la que estos programa se invocan como ./hola y no simplemente hola es
que el directorio actual no está habitualmente en la vía de búsqueda de ejecutables
(variable PATH). Colocando las versiones ejecutables de los programas hola o cati en
un directorio como /bin los haría ejecutables directamente como cualquier comando de
UNIX.
Estos ejemplos muestran la versatilidad de UNIX como sistema operativo: puede uno
ampliarlo con comandos construídos por uno mismo que se integran perfectamente a los
comandos propios del sistema. En las distribuciones de UNIX de dominio público
suelen venir los fuentes en C de todos los comandos, lo cual permite, al usuario con
conocimento suficiente, modificar o corregir estos programas.
Sistema de Archivos Archivos
Directorios
Nombres de Archivo
Directorio Propio. Directorio Actual
Nombres de Directorio
Cambios de directorio
Estructura Interna de los Archivos
Propiedades de los archivos
Tipo y Permisos de achivos

El sistema de archivos en UNIX
Preguntas y Ejercicios
Bibliografía
El sistema UNIX funciona totalmente en base a archivos. Los programas, los datos, los
directorios y aún los controladores de dispositivos tales como discos, modems e
impresoras, son archivos.
El sistema de archivos de UNIX se organiza en una jerarquía de directorios que resulta
en una estructura arborescente.
Archivos.
Cada archivo tiene asociado un nombre, un contenido, un lugar de ubicación e información de
tipo administrativo, tal como dueño y tamaño. El contenido de un archivo puede ser texto,
programas fuente, programas ejecutables, imágenes, sonidos y otros.
Estructuralmente un archivo es una secuencia de bytes de datos que reside en forma
semipermanente en algún medio estable, como ser una cinta magnética o un disco.
Directorios.
Los archivos se agrupan en directorios. Un directorio es un archivo que contiene una lista de
nombres de archivo e información acerca de los mismos. Dentro del sistema de archivos, un
directorio es una localización capaz de contener otros directorios o archivos. Dos archivos que
se encuentren en distinto directorio pueden tener el mismo nombre sin confundirse.
El comando ls permite listar el contenido de un directorio:
ls /var
el argumento es un directorio; la salida son los nombres de archivos y subdirectorios en ese
directorio.
ls nota
el argumento es un archivo, la salida es el nombre del archivo.
ls -l /var
muestra los archivos y subdirectorios contenidos en /var en formato largo.

ls -ld /var
muestra características del directorio /var en lugar de los archivos y subdirectorios
contenidos en él.
Nombres de archivos.
Para el nombre de archivo se puede usar prácticamente cualquier caracter, incluso caracteres
no visibles. Los caracteres $ ; \ & ! * | causan confusión y no conviene usarlos. Se
aconseja usar solamente letras, números, punto, guión y subraya. UNIX diferencia mayúsculas
y minúsculas: el archivo NOTA.TXT es distinto del archivo nota.txt y también de Nota.txt.
No se distingue entre nombre de archivo y extensión: nota.nueva.txt es un nombre de
archivo válido, y LCK..modem también.
Un archivo que comienza por un punto no es visible:
touch .noseve
ls
ls -a
ls no lo muestra, pero sí ls -a.
rm .noseve
lo borra como a cualquier archivo.
Directorio propio. Directorio actual.
Al ingresar al sistema cada usuario entra en su directorio propio, un directorio privado que no
es tocado por el sistema ni por los otros usuarios. El directorio en el cual se encuentra
posicionado el usuario en un momento dado se denomina su directorio actual.
cd /usr/bin
pwd
cambia al directorio /usr/bin; el directorio actual es /usr/bin.
cd
pwd
devuelve al usuario a su directorio propio, que es ahora el directorio actual.
echo $HOME
nuestra el nombre del directorio propio. HOME es una variable de ambiente que contiene el
nombre del directorio propio del usuario.
cd $HOME

tiene el mismo efecto que cd.
Nombres de directorios.
Un directorio puede contener otros directorios así como archivos ordinarios, lo que genera una
jerarquía o árbol de directorios. El directorio superior o directorio raíz se denomina /.
cd /
pwd
el directorio actual es el directorio raíz.
cd
vuelve al directorio propio del usuario.
El caracter / se usa también para separar los componentes de un nombre de archivo
completo: /export/home/usuario1/nota.
La porción /export/home/usuario es la ruta, nota es el nombre del archivo. Si se omite la
ruta, se asume que el archivo se encuentra en el directorio actual. Un nombre tal como
textos/libro/capitulo.1 indica que su ruta comienza a partir del directorio actual. Sería
lo mismo escribir ./textos/libro/capitulo.1 ya que el punto designa el directorio
actual. Dos puntos seguidos designan el directorio de nivel superior al actual. Si el directorio
actual es /home/usuario1
ls ../usuario2
muestra el contenido de los archivos en /home/usuario2
El caracter / separa directorios incluídos como parte de un nombre de archivo o directorio.
ls dir1
es un direccionamiento relativo;
ls /home/esteban/dir1
es un direccionamiento absoluto.
Pueden usarse comodines para referenciar directorios y archivos:
cat /home/esteban/*/*
Cambios en la jerarquía de directorios.

mkdir nuevo.dir
crea un nuevo directorio.
rmdir nuevo.dir
borra un directorio existente; actúa sólo sobre directorios vacíos.
mkdir dir1
mkdir dir1/dir2
touch dir1/dir2/arch2 dir1/arch1
ls -lR
muestra todos los archivos y directorios creados;
rm -r dir1
borra el directorio y todos los archivos y subdirectorios que pueda contener.
Estructura interna de los archivos.
Un archivo es una secuencia de bytes. Un byte es equivalente a un caracter. El sistema no
impone estructura alguna a los archivos ni asigna significado a su contenido; el significado de
los bytes depende totalmente de los programas que interpretan el archivo.
En ningún caso hay ningún byte que no haya sido colocado por el usuario o un
programa. No hay caracter de fin de archivo. El núcleo del sistema UNIX se mantiene al
tanto del tamaño de los archivos sin introducir ningún caracter especial. El caracter
nuevalínea es interpretado por las terminales como nueva línea y retorno de carro (CR
LF, carriage-return y line-feed), necesario para desplegar correctamente los renglones
en la terminal. Al apretar la tecla Enter el núcleo transmite a la terminal CR LF, pero en
un archivo se guarda sólo LF.
¿Qué hay dentro de un archivo? El núcleo no puede decirnos nada del tipo de archivo:
no lo conoce. Todos los archivos tienen la misma estructura interna. El comando file
hace una conjetura: lee algunos bytes y busca indicios sobre el tipo de contenido. En los
sistemas UNIX hay sólo una clase de archivo. Lo único que se requiere para accederlo
es su nombre.
Propiedad de los archivos.
Cada usuario es dueño de los archivos creados por él, hasta que los borre o los ceda a otro
usuario. Cada usuario pertenece a un grupo, y puede compartir archivos con los usuarios de
ese grupo. Cada archivo está asignado a un grupo de usuarios, al cual debe pertenecer su
dueño. El comando ls -l muestra dueño y grupo de los archivos listados.
Tipo y permisos de archivos.

Cada archivo tienen un conjunto de permisos asociados con él que determinan qué puede
hacerse con el archivo y quién puede hacerlo.
Los permisos de un archivo se indican con 10 caracteres:
1 caracter para tipo de archivo,
3 caracteres [rwx] para permisos del dueño,
3 caracteres [rwx] para permisos del grupo,
3 caracteres [rwx] para permisos de otros.
Caracter para tipo de archivo:
d directorio
l enlace simbólico
- archivo normal
b archivo controlador de dispositivo orientado a bloques
c archivo control de dispositivo orientado a caracteres
Caracteres de permisos:
r acceso de lectura (read)
w acceso de escritura (write)
x acceso de ejecución (execute)
cuyo significado varía según se trate de archivos o directorios:
Permiso Archivos Directorios
r leer archivos ver contenido de directorios
w grabar en un archivo crear y borrar archivos
x ejecutar como programa ingresar a un directorio
- sin derechos sin derechos
El ingreso a un directorio (permiso x) permite ejecutar un archivo contenido dentro de
él, o trasladarse a ese directorio; para estas operaciones no es necesario poder ver los
nombres de los archivos contenidos (permiso r).

Un archivo se declara ejecutable dándole permiso de ejecución. Se ejecuta dando su
nombre. Los comandos de UNIX son archivos ejecutables.
Ejemplos de permisos de archivo:
rwxr--r--
rw-rw-r--
rw-------
El sistema de archivos en UNIX.
Un sistema de archivos en UNIX puede contener miles de archivos, cientos de directorios y
cientos de enlaces simbólicos, dependiendo de la distribución y de lo que se haya instalado.
Como referencia, la distribución Debian/GNU 2.1 viene con cerca de 2500 paquetes para
instalar. Una instalación normal puede insumir un 25% en herramientas de administración, y
un 10 % en herramientas de desarrollo. Borrar, alterar o cambiar permisos de archivos puede
conducir a resultados impredecibles.
$ ls -F /
es útil para recorrer el sistema de archivos, bajando luego a los subdirectorios.
Los requerimientos de las redes cambiaron la organización funcional del sistema de archivos.
En un lugar grande, la red se configura con un conjunto de máquinas heterogéneas, cada una
responsable del mantenimento y uso de cada archivo. Los archivos pueden ser específicos para
cierta máquina, compartidos por varias máquinas del mismo tipo, o accesibles a casi cualquier
tipo de máquina en la red. Enlaces simbólicos hacia la anterior localización de los archivos
ayudan al acceso. Un directorio puede ser real o un enlace simbólico a otro; usar /bin/pwd
para si se ha llegado al directorio directamente o a través de un enlace simbólico.
Convenciones en nombres de archivos y directorios. /bin archivos ejecutables, comandos de usuario
/boot archivos de arranque
/cdrom punto de montaje para la uniad de CD-ROM
/dev archivos especiales de dispositivos
[subdirectorios propios de System V]
./dsk dispositivos de disco
./fd dispositivos descriptores de archivo
./kd dispositivos de teclado y despliegue
./kmem memoria
./null dispositivo para descarte de salidas
./osm mensajes de error del núcleo

./pts pseudo ttys; igual que /dev/pts*
./rdsk dispositivos crudos de disco
./term terminales; igual que /dev/tty*
./xt pseudo ttys; para capas DMD
/dosc punto de montaje para la partición DOS
/etc configuración de paquetes, configuración de sistema
./init.d scripts de arranque y detención de programas
./rc?.d enlaces a scripts, con K o S (Kill o Start), y número
de
secuencia para controlar el arranque
./skel archivos de inicialización para nuevos usuarios
/export directorios de usuarios en sistemas grandes
/floppy para montar una unidad de disquete
/home objetos relacionados con los usuarios
/lib bibliotecas de desarrollo y material de apoyo
/lost+found archivos perdidos
/mnt punto de montaje de dispositivos externos
/proc archivos de control de procesos
/root directorio propio para el supervisor (root)
/sbin archivos ejecutables de administración
/tmp archivos temporales
/usr ejecutables, documentación, referencia
./X11R6 sistema X-Windows
./bin más ejecutables
./doc documentos de paquetes de software
./include encabezados .h de bibliotecas en C
./info archivos de info, información de UNIX (GNU)
./lib más bibliotecas en C
./local ejecutables instalados por el administrador
./man subdirectorios de páginas del manual
./sbin más archivos ejecutables de administración

./share compartidos
./src (source) código fuente del kernel
/var archivos de log, auxiliares, archivos que crecen
./backup respaldo de algunos archivos del sistema
./catman páginas man ya formateadas
./lib información propia de programas
./lock control de bloqueos
./log archivos de registro de mensajes (log) del sistema
./spool colas de impresión, intermedios de correo y otros
./run información de procesos (PIDs)
Manejo de Archivos Copia de Archivos
Mover, cambiar de nombre
Enlaces "hard"
Enlaces simbólicos
Opciones del comando ls
Cambio de dueño y grupo
Modos de permisos
Listado de permisos de los directorios
Cambio de permisos
basename, dirname
Archivos de dispositivos
El comando "mesg"
Otros dispositivos
Preguntas y Ejercicios
Bibliografía y Referencias

En los ejemplos siguientes se asume al usuario ubicado en su directorio personal, el cual
contiene los archivos nota y LEAME. El resultado de cada ejemplo debe comprobarse
mediante comandos tales como pwd,ls, cat o more.
Copia de archivos.
cp nota nota.copia
copia el archivo nota en nota.copia. Si el directorio propio del usuario es
/home/usuario1,
cp ./nota /home/usuario1/nota.copia
hace lo mismo indicando las rutas. Si el archivo destino existe lo sobreescribe y realiza la copia
sin comentario ni advertencia.
mkdir dir1
cp nota dir1
si el destino es un directorio, el archivo se copia en ese directorio.
cp nota LEAME dir1
pueden copiarse varios archivos hacia un directorio.
mkdir dir2
touch dir2/arch2 dir2/arch3
ls dir2
cp dir2/* .
copia todos los archivos en dir2 hacia el directorio actual.
Para copiar un directorio es preciso usar la opción -r, de "recursivo":
cp -r dir1 dir3
ls -l dir3
copia el directorio dir1 y todo el contenido en el dir3.

rmdir dir3
fracasa porque dir3 no está vacío.
rm -r dir3
con la opción -r, "recursivo", se puede borrar completamente un directorio y todo su
contenido, sean estos archivos o subdirectorios.
rm -r dir1/* dir2
borra todos los archivos bajo dir1 y dir2; borra también el directorio dir2 pero no el dir1.
rm arch? nota.copia
borra del directorio actual los archivos arch1, arch2, .., y nota.copia.
Mover, cambiar de nombre.
echo "Hola todos" > hola
cat hola
mv hola saludo
cat saludo
mv cambia el nombre del archivo hola por el de saludo.
mv saludo dir1/saludo.1
mueve hacia otro directorio cambiando el nombre.
mv dir1 dirnuevo
cambia de nombre archivos o directorios.
rm -r dirnuevo
elimina dirnuevo y todos sus archivos.
Enlaces "hard".
Un enlace "hard" (hard link) es una nueva referencia a un mismo archivo; consiste en una
nueva entrada de directorio que apunta a un archivo ya existente y apuntado desde otra

entrada de directorio. El contenido se encuentra en un solo lado, pero el archivo puede ser
accedido desde varios lugares, eventualmente con diferentes nombres.
echo 'Hola todos de nuevo!' > adios
ln adios adios.ln0
ln crea un segundo nombre referido al mismo archivo; no se hace copia, crea un enlace (link).
Verificar que
ls -l adios*
muestra un conteo de 2 en la columna de enlaces. Al crear el enlace con el comando ln,
observar que el archivo existente va en primer lugar, luego uno o más nombres de enlaces a
crear.
ln adios adios.ln1
ln adios adios.ln2
ls -l adios*
muestra el conteo de enlaces hard en estos archivos.
mkdir dir2
ln adios dir2/adios
hace aparecer en dir2 un enlace llamado adios hacia el archivo adios del directorio actual.
Un enlace hard puede hacer aparecer un mismo archivo en más de un directorio, con igual o
distinto nombre; el contenido está en un solo lado, no está repetido.
rm adios*
ls -l dir2/adios
Cuando se borra un archivo con varios enlaces, sólo se borra el enlace. El archivo es realmente
borrado sólo cuando desaparece el último enlace.
ln dir2 dir2ln
da error; no se puede crear un enlace hard para un directorio.
Enlaces simbólicos.
Un enlace simbólico (symbolic link) es un archivo que apunta a otro archivo o directorio. El
archivo de enlace simbólico contiene solamente la ruta del otro archivo o directorio.
ln -s nota nota.ls0

crea nota.ls0 como enlace simbólico.
ln -s dir2 dir2ls
crea dir2ls como enlace simbólico hacia un directorio.
ls -l
muestra la letra l en el tipo de archivo para indicar que es un enlace simbólico.
ls dir2
ls dir2ls
muestran el mismo contenido de archivos.
ls -l dir2ls
muestra que es un enlace simbólico e indica hacia donde apunta.
cd dir2ls
ls -l
muestra el contenido de dir2, enlazado desde dir2ls.
pwd
indica el directorio con nombre del enlace, pero
/bin/pwd
muestra el directorio verdadero, no el enlace simbólico; pwd indica la ruta por la que se llegó al
directorio, /bin/pwd indica la ruta de acceso al verdadero directorio. Conviene usar
/bin/pwd para evitar ser engañado por enlaces simbólicos a directorios. El comando pwd es
interno del shell, /bin/pwd es un programa aparte.
cd ..
mv dir2 DIR2
cambia el nombre del directorio real; el enlace simbólico sigue apuntando a dir2, por lo que
cd dir2ls
da error, ya que no existe el objeto real.
mv DIR2 dir2
repone el nombre original al que apunta el enlace.

rmdir dir2ls
da error porque no es un directorio sino un enlace.
rm dir2ls
borra el enlace. Un enlace simbólico se borra con rm, y no con rmdir, puesto que el enlace
simbólico es un archivo y no un directorio, aún cuando sea un enlace simbólico hacia un
directorio.
ls dir2
cuando se borra un enlace simbólico, sólo se borra un archivo puntero, y no el objeto real.
Opciones del comando ls.
ls -1
muestra un item por línea. Cuando ls se usa en interconexiones, la salida de ls presenta un
item por línea por defecto.
ls -C
fuerza el despliegue encolumnado.
ls -a
muestra todos los archivos, incluyendo los que comienzan con punto, normalmente no
mostrados. El directorio corriente . y el directorio padre .. son entidades reales.
ls -F /bin
ls -F
agrega sufijo que indica el tipo de archivo: / directorio, * ejecutable, @ enlace simbólico.
ls -R
muestra recursivamente todos los archivos, subdirectorios y archivos dentro de subdirectorios.
Para ver un listado más largo,
ls -CR /etc | more
ln -s dir2 dir2ls
ln nota nota.ln0
ls -l

listado largo, muestra atributos de los archivos: tipo de archivo (primer caracter), permisos (9
caracteres), enlaces hard (en archivos), dueño, grupo, tamaño en bytes, fecha y hora, nombre.
-rw-r--r-- 1 esteban other 138 Apr 5 19:34 LEAME
drwxr-xr-x 2 esteban other 138 Apr 5 19:34 dir2
lrw-r--r-- 1 esteban other 138 Apr 5 19:34 dir2ls ->./dir2
-rw-rw-rw- 1 esteban other 138 Apr 5 19:34 nota
El símbolo -> indica "apunta hacia" para enlaces simbólicos.
Cambio de dueño y grupo.
chown usuario1 nota
cambia el dueño del archivo nota adjudicándoselo a usuario1.
chown usuario1 arch1 arch2
cambia el dueño de la lista de archivos indicada. No puede revertirse, ya que el usuario actual
dejó de ser dueño de esos archivos. Si el archivo tiene permiso de lectura, es posible copiarlo
para disponer de una copia propia. El cambio de dueño no está permitido a usuarios comunes,
sino reservado al supervisor para evitar que a un usuario se le adjudiquen archivos sin su
consentimiento.
chgrp tecnicos nota
cambia de grupo el archivo notas, adjudicándoselo al grupo tecnicos. El dueño debe
pertenecer al grupo tecnicos.
chgrp tecnicos arch1 arch2
cambia el grupo de la lista de archivos.
Modos de permisos.
Los permisos de archivos y directorios se cambian con el comando chmod. Pueden expresarse
de dos maneras: simbólica y absoluta.
En la forma simbólica, se usa la siguiente sintaxis:
[ugoa...][[+-=][rwxstugo...]

+ agrega permiso a los existentes
- quita permiso de los existentes
= únicos permisos asignados al archivo
r lectura
w escritura
x ejecución, o acceso si es directorio
s usa el id del dueño o grupo del archivo al ejecutar
t fijar "sticky bit" a un directorio: sólo dueños pueden borrar
u usuario (dueño)
g grupo
o otros
a todos (dueño, grupo y otros)
Ejemplos de permisos en notación simbólica:
u+r g+w-r ug+r ugo+w-rx u+rwx,g+r-wx,o-rwx
chmod u+rwx,g+rw-x,o+r-wx arch1
chmod u=rwx,g=rw,o=r arch1
cambian los permisos de los archivos indicados.
En modo absoluto se usa un código de 4 dígitos octales 0..7, en la forma Nnnn.
N, primer dígito:
4 fijar ID del dueño al ejecutar 2 fijar ID del grupo al ejecutar
1 fijar "sticky bit" a un directorio
nnn, 3 dígitos: permisos del usuario, grupo y otros, con el código
4 lectura
2 escritura 1 ejecución, o acceso si es directorio

Ejemplos de permisos en notación absoluta:
0777 0755 0764 0640 0710
chmod 0764 arch1
cambia los permisos como en el ejemplo anterior.
Listado de permisos de los directorios.
ls -l
muestra los permisos y otros atributos.
Para obtener información del directorio dir1 ubicado en el directorio actual,
ls -l
lista todos los archivos, entre los que aparece dir1;
ls -l dir1
lista el contenido del directorio dir1.
ls -ld dir1
trata la entrada dir1 como archivo, sin listar su contenido, y dando sus atributos como
directorio.
ls -ld .
muestra atributos del directorio actual.
Cambio de permisos.
chmod u-w nota
quita permisos de escritura al dueño.
chmod u+w nota
concede permisos de escritura al dueño.
chmod u-w+x nota
chmod u-wx+r nota
cambian varios permisos del dueño al mismo tiempo.

chmod u+w nota
chmod g+w nota
chmod o+w nota
concede permiso de escritura solo al usuario, al grupo o a otros.
chmod u+rw-x,g+r-wx,o+r-wx nota
fija todos los permisos en una sola operación. Los permisos que no se mencionen quedan
como estén.
chmod 0644 nota
realiza lo mismo en notación absoluta.
El comando chmod admite las opciones
-v verboso, describe los permisos cambiados
-f no da error sobre permisos que no pueden cambiarse
-R recursivo, cambia permisos de directorios y sus archivos
chmod -v u+rwx,g+rw-x,o+r-wx arch1
chmod -v 764 arch1
chmod -v 444 arch1
chmod u=rw,go=r arch1
fija permisos en rw-r--r--.
chmod u=rwx,u+s arch1
ejecutará arch1 con permiso del dueño de arch1.
chmod -vR a+r dir1
da permiso de lectura a todos los directorios bajo dir1, anunciando en forma verbosa lo hecho.
chmod ugo+rwx dirtodos
chmod a+t dirtodos
fija "sticky bit": a pesar de tener el directorio permisos totales para todos, sólo pueden
borrarse los archivos propios del usuario, no los ajenos.
chmod 1777 dirtodos

realiza lo mismo.
Los permisos s (setuid, setgid) hacen que un archivo ejecutable ejecute con permisos del
usuario dueño o del grupo dueño del archivo, cualquiera sea el usuario y grupo de quien lo
invoca. El permiso setgid sobre un directorio hace que los archivos y subdirectorios creados en
él pertenezcan al grupo del directorio, y no al grupo primario del usuario, como es normal;
esto es útil para los grupos de trabajo. El permiso t (sticky bit) se aplica a directorios con
permisos totales; limita la operación de borrado al dueño del archivo o subdirectorio. Los
modos S y T, que pueden aparecer en ls -l, indican modos sin sentido: setuid o setgid sobre
archivos no ejecutables, sticky bit sobre directorio sin permisos para todos.
basename, dirname
echo $EDITOR
muestra la variable de ambiente que contiene el nombre del editor por defecto. Si no aparece
nada, inicializarla:
which vi
para obtener la vía hacia el editor vi.
EDITOR=/usr/bin/vi
echo $EDITOR
muestra el nombre del editor a usar por defecto.
MIEDITOR=`basename $EDITOR`
echo "Mi editor es $MIEDITOR"
muestra el nombre del archivo sin ruta; basename quita la ruta a un nombre de archivo
calificado con ruta.
DIREDITOR=`dirname $EDITOR`
dirname separa la ruta del nombre completo.
echo "Mi editor es $MIEDITOR en el directorio $DIREDITOR"
muestra el uso en comandos de variables de ambiente.
echo "Mi editor es "`basename $EDITOR`" en "`dirname $EDITOR`
muestra el uso del operador grave para ejecutar comandos dentro de otros comandos.
Archivos de dispositivos.
El sistema de archivos de UNIX provee una interface estándar entre los dispositivos de
hardware y el sistema operativo que actúa igual que un archivo común: todas las operaciones
de entrada y salida se hacen escribiendo y leyendo sobre un archivo. No se trata de un archivo
común en disco; actúa como una ruta hacia un canal de entrada/salida del hardware. Así como
se redirige la salida de un comando hacia un archivo, puede redirigirse también hacia un disco,
una cinta o un módem con sólo mencionar el nombre del dispositivo correspondiente.
tty
devuelve el nombre del dispositivo asociado al terminal, por ejemplo /dev/tty1. Tomando
ese mismo nombre
ls -l /dev/tty1
obtenemos un listado de atributos del "archivo" controlador de este dispositivo, algo así como
crw-rw-rw- 1 usuario1 otros .... /dev/tty1
El primer caracter indica el tipo de dispositivo: c si es orientado a caracteres, b si es orientado
a bloques. Terminales, impresoras y modems son orientados a caracter, discos y cintas son
orientados a bloque.
cat - < /dev/tty1
para escuchar en la propia sesión de terminal; escribir varias líneas y finalizar con Ctrl-D.
cat - < `tty`
produce el mismo efecto. Luego probar
$ cat - > `tty`
¿puede explicarse el comportamiento?
El comando mesg.
ls -l `tty`
Si otros usuarios pueden leer y escribir en este dispositivo, también pueden ver lo que se está
haciendo o aún escribir directamente en el terminal redirigiendo su salida. Esto se usa en los
comandos wall (write all, escribir a todos) y write (escribir mensajes entre usuarios).
mesg
muestra si está habilitada o no la recepción de mensajes.
mesg y

cambia permisos de grupo y otros en el dispositivo, aceptando mensajes.
mesg n
rechaza mensajes. Verificar con
ls -l `tty`
que muestra los permisos que regulan la terminal del usuario.
ls -l /dev/tty?
muestra los permisos de las terminales principales;
ls -l /dev/tty??
muestra una cantidad de tipos de terminal disponibles.
Otros dispositivos.
cat /etc/passwd
cat /etc/passwd > /dev/null
El dispositivo /dev/null actúa como una papelera de tamaño ilimitado que recibe la salida a
descartar. No guarda nada; lo que allí se envíe se pierde para siempre.
Todos los dispositivos de hardware del sistema tienen una representación en el directorio
/dev.
Expresiones Regulares Expresiones Regulares
Metacaracteres
Expresiones regulares básicas
Expresiones regulares de un sólo caracter
Construcción de expresiones regulares
Ejemplos de expresiones regulares básicas
Expresiones regulares extendidas
Ejemplos de expresiones regulares extendidas
Expresiones Regulares en GNU

Preguntas y Ejercicios
Bibliografía y Referencias
Expresiones Regulares.
La expresiones regulares (ER) son una forma de describir cadenas de caracteres. Se usan en
operaciones de apareamiento o comparación. Las expresiones regulares permiten realizar
búsquedas o sustituciones de gran complejidad.
Las búsquedas en el editor vi con los comandos / y ? aceptan expresiones regulares; esto hace
las búsquedas mucho más potentes y flexibles. Las expresiones regulares son aceptadas en
otros editores y en muchos comandos, si bien con algunas diferencias de sintaxis.
Una expresión regular es un patrón que describe un conjunto de cadenas de caracteres. Por
ejemplo, el patrón aba*.txt describe el conjunto de cadenas de caracteres que comienzan
con aba, contienen cualquier otro grupo de caracteres, luego un punto, y finalmente la cadena
txt. El símbolo * se interpreta como "0, 1 o más caracteres cualesquiera".
Las expresiones regulares se construyen como las expresiones aritméticas, usando operadores
para combinar expresiones más pequeñas. Analizaremos esos operadores y las reglas de
construcción de expresiones regulares, atendiendo siempre al conjunto de cadenas que
representa cada patrón.
Metacaracteres.
La construcción de expresiones regulares depende de la asignación de significado especial a
algunos caracteres. En el patrón aba*.txt el caracter * no vale por sí mismo, como el
caracter asterisco, sino que indica un "conjunto de caracteres cualesquiera". Asimismo, el
caracter ? no se interpreta como el signo de interrogación sino que representa "un caracter
cualquiera y uno solo". Estos caracteres a los que se asigna significado especial se denominan
"metacaracteres".
El conjunto de metacaracteres para expresiones regulares es el siguiente:
\ ^ $ . [ ] { } | ( ) * + ?
Estos caracteres, en una expresión regular, son interpretados en su significado especial y
no como los caracteres que normalmente representan. Una búsqueda que implique
alguno de estos caracteres obligará a "escaparlo" de la interpretación mediante \, como
se hace para evitar la interpretación por el shell de los metacaracteres del shell. En una
expresión regular, el caracter ? representa "un caracter cualquiera"; si escribimos \?,
estamos representando el caracter ? tal cual, sin significado adicional.
Expresiones Regulares Básicas.
Una expresión regular determina un conjunto de cadenas de caracteres. Un miembro de este
conjunto de cadenas se dice que aparea, equipara o satisface la expresión regular.

ERs de un sólo caracter.
Las expresiones regulares se componen de expresiones regulares elementales que aparean
con un único caracter:
Exp.Reg. aparea con
c ER que aparea con el caracter ordinario c
. (punto) ER que aparea con un caracter cualquiera excepto nueva línea
[abc] ER de un caracter que aparea con a, b o c
[^abc] ER de un caracter que no sea a, b o c
[0-9][a-z][A-Z]
ERs de un caracter que aparean con cualquier caracter en el intervalo
indicado. El signo - indica un intervalo de caracteres consecutivos.
\e
ER que aparea con alguno de estos caracteres (en lugar de la e):
. * [ \ cuando no están dentro de [ ]
^ al principio de la ER, o al principio dentro de [ ]
$ al final de una ER
/ usado para delimitar una ER
Los paréntesis rectos [] delimitan listas de caracteres individuales. Muchos
metacaracteres pierden su significado si están dentro de listas: los caracteres especiales
. * [ \ valen por sí dentro de []. Para incluir un caracter ] en una lista, colocarlo al
principio; para incluir un ^ colocarlo en cualquier lugar menos al principio; para incluir
un - colocarlo al final.
Dentro de los conjuntos de caracteres individuales, se reconocen las siguientes
categorías:
[:alnum:] alfanuméricos [:alpha:] alfabéticos [:cntrl:] de control [:digit:] dígitos [:graph:] gráficos [:lower:] minúsculas [:print:] imprimibles [:punct:] de puntuación [:space:] espacios [:upper:] mayúsculas [:xdigit:] dígitos hexadecimales

Por ejemplo, [[:alnum:]] significa [0-9A-Za-z], pero esta última expresión depende
de la secuencia de codificación ASCII, en cambio la primera es portable, no pierde su
significado bajo distintas codificaciones. En los nombres de categorías, los paréntesis
rectos forman parte del nombre de la categoría, no pueden ser omitidos.
Construcción de Expresiones Regulares.
Una Expresión Regular se contruye con uno o más operadores que indican, cada uno, el
caracter a buscar. Los operadores más comunes y aceptados son los siguientes:
Operador Significado
c un caracter no especial concuerda consigo mismo
\c elimina significado especial de un caracter c; el \ escapa el significado especial
^ indica ubicado al comienzo de la línea (cadena nula al principio de línea)
$ indica ubicado al final de la línea (cadena nula al final de línea)
. (punto) un caracter individual cualquiera
[...] uno cualquiera de los caracteres ...; acepta intervalos del tipo a-z, 0-9, A-Z (lista)
[^...] un caracter distinto de ... ; acepta intervalos del tipo a-z, 0-9, A-Z
r* 0, 1 o más ocurrencias de la ER r (repetición)
r1r2 la ER r1 seguida de la ER r2 (concatenación)
Ejemplos de Expresiones Regulares Básicas.
Las expresiones regulares se aprenden mejor con los ejemplos y el uso.
Exp.Reg. aparea con
a.b axb aab abb aSb a#b ...
a..b axxb aaab abbb a4$b ...
[abc] a b c (cadenas de un caracter)
[aA] a A (cadenas de un caracter)
[aA][bB] ab Ab aB AB (cadenas de dos caracteres)

[0123456789] 0 1 2 3 4 5 6 7 8 9
[0-9] 0 1 2 3 4 5 6 7 8 9
[A-Za-z] A B C ... Z a b c ... z
[0-9][0-9][0-9] 000 001 .. 009 010 .. 019 100 .. 999
[0-9]* cadena_vacía 0 1 9 00 99 123 456 999 9999 ...
[0-9][0-9]* 0 1 9 00 99 123 456 999 9999 99999 99999999 ...
^.*$ cualquier línea completa
En el editor vi, las expresiones regulares permiten realizar búsquedas tales como:
/^Desde
busca líneas que empiecen con la cadena Desde
/final$
busca líneas que termine con la cadena final
/\$25
busca líneas que contengan $25; \ escapa el $
Expresiones Regulares Extendidas.
Algunos comandos, como egrep o grep -E, aceptan Expresiones Regulares Extendidas, que
comprenden las Expresiones Regulares Básicas más algunos operadores que permiten
construcciones más complejas. Los operadores incorporados son los siguientes:
Operador Significado
r+ 1 o más ocurrencias de la ER r
r? 0 o una ocurrencia de la ER r, y no más
r{n} n ocurrencias de la ER r
r{n,} n o más ocurrencias de la ER r
r{,m} 0 o a lo sumo m ocurrencias de la ER r

r{n,m} n o más ocurrencias de la ER r, pero a lo sumo m
r1|r2 la ER r1 o la ER r2 (alternativa)
(r) ER anidada
"r" evita que los caracteres de la ER r sean interpretados por el shell
La repetición tiene precedencia sobre la concatenación; la concatenación tiene
precedencia sobre la alternativa. Una expresión puede encerrarse entre paréntesis para
ser evaluada primero.
Ejemplos de Expresiones Regulares Extendidas:
Exp.Reg.Ext. aparea con
[0-9]+ 0 1 9 00 99 123 456 999 9999 99999 99999999 ..
[0-9]? cadena_vacía 0 1 2 .. 9
^a|b a b
(ab)* cadena_vacía ab abab ababab ...
^[0-9]?b b 0b 1b 2b .. 9b
([0-9]+ab)* cadena_vacía 1234ab 9ab9ab9ab 9876543210ab 99ab99ab ...
Expresiones regulares en GNU.
En GNU, no se distinguen expresiones regulares básicas de extendidas; los comandos aceptan
todas las expresiones regulares. En ese caso, como siempre se están usando extendidas, los
metacaracteres ?, +, {, |, (, y ) deben ser escapados cuando se quieren usar como caracteres
normales, escribiendo \?, \+, \{, \|, \(, y \).
Filtros. sort
grep
find
fgrep y egrep
tr
uniq

dd
Preguntas y Ejercicios
Bibliografía y Referencias
Se da el nombe de filtros a un grupo de comandos que leen alguna entrada, realizan una
transformación y escriben una salida. Además de los que veremos aquí, incluye comandos
tales como head, tail, wc, y cut.
sort
La comparación u ordenación puede ser por caracteres ASCII o por valor numérico. La
ordenación ASCII es la más parecida a la alfabética; sigue el orden del juego de caracteres
ASCII. En este ordenamiento, los caracteres idiomáticos (vocales acentuadas, ñ) no se
encuentran en el orden alfabético tradicional. En la ordenación numérica se respeta la
ordenación por valor numérico de la cadena de caracteres: 101 va después de 21; en
ordenamiento ASCII sería al revés.
sort arch1
ordena según el código ASCII.
sort -n arch2.num
ordena numéricamente.
Si no se indican campos de ordenación, la comparación se hace sobre toda la línea. Si se
indican campos, la comparación se hace considerando la cadena de caracteres iniciada en el
primer caracter del primer campo hasta el último caracter del último campo.
sort -t: -k1,3 arch1.txt
ordena por campos separados por ":", tomando en cuenta para la comparación los caracteres
desde el primero del campo 1 hasta el último del campo 3.
sort -t: -k1.3,3.5 arch1.txt
ordena por campos tomando en cuenta desde el 3er. caracter del campo 1 hasta el 5to.
caracter del campo 3.
sort -nr arch2.num
ordena en orden numérico descendente.
sort -k3 arch3.txt

ordena alfabéticamente, usando como cadena de comparación la comprendida desde el
primer caracter del 3er. campo hasta el fin de lína. Como no se indica separador, los campos se
definen por blancos (espacio o tabulador).
find
El comando find explora una rama de directorios buscando archivos que cumplan
determinados criterios. El comando find en GNU es extremadamente potente, permitiendo
criterios de búsqueda tales como:
el nombre contiene cierta cadena de caracteres o aparea con algún patrón: son enlaces a ciertos archivos; fueron usados por última vez en un cierto período de tiempo; tienen un tamaño comprendido dentro de cierto intervalo; son de cierto tipo (regular, directorio, enlace simbólico, etc.); pertenecen a cierto usuario o grupo; tienen ciertos permisos de acceso; contienen texto que aparea con cierto patrón.
Una vez ubicados los archivos, find puede realizar diversas acciones sobre ellos:
ver o editar; guardar sus nombres en otro archivo; eliminarlos o renombrarlos; cambiar sus permisos de acceso; clasificarlos por grupos.
find /var -name *.log -print
busca en el directorio /var los archivos terminados en .log, imprime sus nombres en la salida.
find /tmp -size +200k -print
busca archivos mayores de 200k. En los argumentos numéricos, +N es mayor que N, -N es
menor que N, N es exactamente igual a N.
find /var/spool/mail -atime +30 -print
busca archivos no accedidos hace más de 30 días. La opción -atime se refiere a tiempo
transcurrido desde última lectura, -mtime desde última modificación de estado o permisos, -
ctime de contenido.
find /var/tmp -empty -exec rm {} \;
busca archivos vacíos y los borra.
find /home -nouser -ls
busca archivos en los cuales en lugar del nombre de usuario dueño aparece un número (UID).
Esta situación se da cuando la cuenta de usuario ha sido borrada pero han permanecido los
archivos creados por ese usuario.
grep
El comando grep (Global Regular Expression and Print) permite buscar las líneas que
contienen una cadena de caracteres especificada mediante una expresión regular. Lee la
entrada estándar o una lista de archivos y muestra en la salida sólo aquellas líneas que
contienen la expresión indicada. La sintaxis es
grep patrón archivos
donde el patrón a buscar es una expresión regular.
Crear un archivo con los días de la semana, uno por línea; llamarle dias.
grep martes dias
grep tes dias
muestra las líneas del archivo dias que contienen la cadena "tes".
grep unix01 /etc/passwd
grep unix0[1-9] /etc/passwd
ls -l /usr | grep '^d'
lista sólo los subdirectorios del directorio /usr (la línea empieza con "d").
ls -l / | grep '.......rw'
lista sólo los archivos que otros pueden leer y escribir en el directorio principal.
grep '^[^:]*::' /etc/passwd
busca usuarios sin contraseña; caracteres al principio de línea que no sean ":", y luego "::" (el
segundo lugar, que es el de la contraseña, está vacío).
grep '^[^:]*:\*:' /etc/passwd
busca usuarios que no pueden entrar al sistema; tienen un * en el lugar de la contraseña; \
escapa el significado del segundo *, que vale como caracter a buscar.

Ninguna expresión regular de grep aparea con un caracter nueva línea; las expresiones
se aplican individualmente a cada línea.
Entre las opciones de grep se cuentan -i para evitar distinguir entre mayúsculas de
minúsculas, -n para mostrar el número de línea y -v para buscar líneas que no contengan
la expresión regular indicada.
fgrep y egrep
Hay dos versiones de grep que optimizan la búsqueda en casos particulares:
fgrep (fixed grep, o fast grep) acepta solamente una cadena de caracteres, y no una
expresión regular, aunque permite buscar varias de estas cadenas simultáneamente;
egrep (extended grep), que acepta expresiones regulares extendidas con los operadores
+ ? | y paréntesis.
fgrep no interpreta metacaracteres, pero puede buscar muy eficientemente muchas
palabras en paralelo, por lo que se usa mucho en búsquedas bibliográficas; egrep acepta
expresiones más complejas, pero es más lento; grep es un buen compromiso entre
ambos.
fgrep martes dias
busca la cadena martes en el archivo dias.
En fgrep y egrep puede indicarse la opción -f buscar.exp, donde buscar.exp es un
archivo que contiene la expresión a buscar: cadenas simples para fgrep, expresiones
regulares para egrep, separadas por nueva línea; las expresiones se buscan en paralelo, es
decir que la salida serán todas las líneas que contengan una cualquiera de las expresiones a
buscar.
Crear un archivo buscar.fgrep con las cadenas "tes" y "jue", una por línea. El comando
fgrep -f buscar.fgrep dias
extrae del archivo dias las líneas que contienen estas cadenas.
El comando grep soporta fgrep y egrep como opciones -F y -E, respectivamente.
grep -F -f buscar.fgrep dias
egrep "tes|jue" dias
grep -E "tes|jue" dias
obtienen el mismo efecto del comando anterior.

egrep "([0-9]+ab)*1234" archivo
busca cadenas comenzadas opcionalmente por un dígito y los caracteres ab, todo el paréntesis
0 o más veces, y hasta encontrar la cadena 1234.
Escribir grep -E es similar a egrep, aunque no idéntico; egrep es compatible con el
comando histórico egrep; grep -E acepta expresiones regulares extendidas y es la versión
moderna del comando en GNU. fgrep es idéntico a grep -F.
tr
El comando tr translitera los caracteres de la entrada: sustituye unos caracteres por otros. La
sustitución es caracter a caracter. Entre sus opciones se encuentran -d para borrar caracteres; -
c para sustituir complemento de los caracteres indicados, es decir, que no sean ésos; y -s para
comprimir caracteres repetidos en uno solo.
cat dias | tr a-z A-Z
convierte todo a mayúsculas.
cat dias | tr -d aeiou
borra todas las vocales del archivo dias.
Agregar al archivo dias líneas en blanco, varias seguidas, intercaladas entre los nombres de
los días.
cat dias
cat dias | tr -s "\n*"
convierte varios caracteres nueva línea seguidos en una solo; elimina renglones en blanco.
cat nota | tr -c "[a-zA-Z0-9]" "_"
transforma todos los caracteres que no sean letras o números en subrayas.
cat nota | tr -cs "[a-zA-Z0-9]" "[\n*]"
transforma todos los caracteres que no sean letras o números en nuevalínea, y comprime las
nuevalíneas repetidas en una sola; deja cada palabra sola en un renglón.
ls -l /usr | tr -s " " | cut -f3,4
comprime los blancos en la salida para poder cortar campos.

uniq
El comando uniq excluye todos los renglones adyacentes duplicados menos uno; es decir,
elimina renglones repetidos consecutivos. La opción -c escribe el número de ocurrencias al
comienzo del renglón.
El siguiente ejemplo muestra las 5 palabras más frecuentes en el conjunto de archivos:
cat *.txt | tr -sc A-Za-z '\012' | \
sort | uniq -c | sort -n | tail 5
cat lista todos los archivos, tr comprime el renglón eliminando blancos, sort los ordena,
uniq cuenta las ocurrencias y elimina repetidos, sort -n ordena por cantidad de ocurrencias
y tail muestra las 5 ocurrencias más frecuentes.
dd
El comando dd es un convertidor de datos: convierte de ASCII a EBCDIC y a la inversa, cambia
los tamaños de los bloques de registros, hace ajuste de blancos y otras transformaciones
usuales cuando se manejan transferencias entre sistemas operativos distintos o datos en
bruto, sin formato, como en los respaldos en cinta.
Comandos de Filtro Referencias
dd find grep, fgrep, egrep sort tr uniq
dd
dd OPCION ...
copia un archivo, de entrada estándar a salida estándar por defecto, opcionalmente
cambiando tamaño de bloques de entrada salida y realizando diversas conversiones.
if=ARCHIVO leer la entrada del archivo indicado.
of=ARCHIVO dirigir la salida al archivo indicado.
ibs=BYTES leer la entrada en bloques de BYTES bytes.
obs=BYTES grabar la salida en bloques de BYTES bytes.
bs=BYTES leer y grabar entrada y salida en bloques.
conv=CONVERSION[,CONVERSION]... convertir según argumentos.

Las opciones numéricas admiten los multiplicadores b para 512, k para 1024.
Los argumentos de conversión se separan por comas sin espacios; incluyen:
ascii convierte EBCDIC a ASCII.
ebcdic convierte ASCII a EBCDIC.
ibm convierte ASCII a EBCDIC alternativo.
block embloca cada línea de entrada en 'cbs' bytes, reemplaza
nueva línea por espacio, rellena con espacios.
unblock reemplaza espacios finales de cada bloque con nueva línea.
lcase convierte mayúsculas a minúsculas
ucase convierte minúsculas a mayúsculas.
notrunc no truncar el archivo de salida.
find
find [DIRECTORIO...] [EXPRESION]
Recorre una jerarquía de directorios buscando archivos seleccionados según cierta
expresión y muestra información sobre los encontrados.
Argumentos numéricos:
+N mayor que N
-N menor que N
N exactamente N.
Criterios de búsqueda:
-name PATRON el nombre aparea con PATRON;
-iname PATRON idem,insensible a mayúculas;
-path PATRON nombre con vía completa;
-ipath PATRON idem, insensible a mayústulas;
-regexp EXP nombre aparea con expresión regular EXP
-iregexp EXP idem, insensible a mayúsculas;
-lname PATRON archivo es un enlace simbólico;
-ilname PATRON idem, insensible a mayúsculas;

-atime N último acceso N*24 horas atrás
-ctime N último cambio de estado N*24 horas atrás
-mtime N última modificación N*24 horas atrás
-amin N último acceso N minutos atrás
-cmin N último cambio de estado N minutos horas atrás
-mmin N última modificación N minutos atrás
-daystart mide tiempos desde las 0 horas de hoy
-size N[bckw] tamaño de N bloques, caracteres, KB o palabras (2
bytes)
-empty archivo vacío, regular o directorio
-user UNAME archivo del usuario UNAME
-group GNAME archivo del grupo GNAME
-uid N archivo del usuario de número N
-gid N archivo del grupo de número N
-nouser archivo sin dueño asignado
-nogroup archivo sin grupo asignado
Acciones:
-print imprime la ruta completa de los archivos encontrados.
-ls lista los archivos encontrados en formato ls -dils
-exec COMANDO {} \; ejecuta COMANDO sobre los archivos encontrados
find /usr/local/doc -name '*.texi'
busca en el directorio indicado los archivos de nombre indicado.
find /usr/src -name '*.c' -size +100k -print
muestra nombres de archivos terminados en .c con tamaño mayor de 100 K.
find . -lname '*sysdep.c'
busca enlaces simbólicos del nombre indicado.
find /u/bill -amin +2 -amin -6
archivos que fueron leídos entre 2 y 6 minutos atrás.
La medición de tiempos se hace desde 24 horas atrás (1 día atrás); para medir tiempos desde
las 0 horas del día de hoy, usar la opción -daystart.

find ~ -daystart -type f -mtime 1
archivos que fueron modificados ayer.
find / -empty -exec rm -rf '{}' ';'
busca archivos o directorios vacíos y los elimina.
find . -name '*.h' -exec diff -u '{}' /tmp/master ';'
compara archivos de "header" (*.h) del directorio corriente contra el archivo /tmp/master.
grep, egrep, fgrep
grep [ -e PATRON | -f ARCHIVO | PATRON ] OPCIONES ARCHIVO ...
recorre los archivos indicados extrayendo las líneas que aparean con un patrón de
cadena de caracteres.
-G el patrón es una expresión regular básica; opción por defecto
-E el patrón es una expresión regular extendida
-F el patrón es una cadena fija
Existen dos variantes: egrep, similar a grep -E, y fgrep, igual a grep -F.
-c sólo muestra la cantidad de líneas
-e PATRON usa el patrón indicado; útil cuando el patrón empieza con -
-f ARCHIVO obtiene los patrones del archivo, uno por línea
-h suprime indicación de archivo cuando se busca en varios archivos
-i ignora mayúsculas y minúsculas en el patrón y en los archivos
-n indicar número de línea
-v muestra las líneas que no aparean con el patrón
-w aparea el patrón como una palabra
-x el patrón aparea con toda la línea
sort
sort [OPCIONES] [ARCHIVO...]
ordena, mezcla o compara todas las líneas de los archivos indicados o de la entrada estándar.
Tiene 3 modos de operación: ordenar, verificar orden, mezclar archivos.

-c verifica si los archivos ya están ordenados
-m mezcla archivos ordenados en uno solo, ordenado
-b ignora blancos adelante en la ordenación
-d ordena considerando sólo letras, números y blancos
-f ordena como si todas fueran mayúsculas
-i ignora caracteres no imprimibles (fuera de 040-0176 octal)
-n ordena como valores numéricos y no como ASCII
-r invertir el sentido de la ordenación
-o arch archivo de salida; puede ser el de entrada
-t usar el caracter indicado como separador de campos
-k POS1[,POS2] campos de ordenación, POS1 hasta POS2 inclusive;
o hasta el final si no hay POS2
Las posiciones POS1 y POS2 son de la forma F.C donde F es el número del campo y C es el
primer caracter desde el comienzo del campo (para POS1) o desde el final del campo (para
POS2); si se omite C se ordena tomando en cuenta el primer caracter del campo.
cat /etc/passwd | sort -t:
cat /etc/passwd | sort -t: +4 -f | cut -d: -f5
cat /etc/passwd | sort -t: +5 | cut -d: -f6
cat /etc/passwd | sort -t: -n -k3,5 | cut -d: -f4,5
tr
tr [OPCION]... CONJ1 [CONJ2]
copia entrada en salida traduciendo, comprimiendo o borrando caracteres. CONJ1 y
CONJ2 definen un conjunto ordenado de caracteres a transformar. La opción -c
reemplaza CONJ1 por su complemento, los caracteres no especificados en el conjunto.
-d elimina los caracteres de CONJ1.
-s comprime caracteres repetidos en CONJ1 en una sola ocurrencia.
-ds primero borra según CONJ1 y después comprime según CONJ2.

El formato de CONJ1 y CONJ2 se parece al de las expresiones regulares, pero son sólo
listas de caracteres. La mayoría de los caracteres se representan a sí mismos, pero
existen las siguientes abreviaturas:
\a Control-G,
\b Control-H,
\f Control-L,
\' Control-J,
\r Control-M,
\t Control-I,
\v Control-K,
\OOO caracter representado por dígitos octales
\\ barra inversa.
M-N intervalo de caracteres desde el M al N (M anterior al N)
0-9 equivale a 0123456789
La notación [:CLASE:] expande a los caracteres predefinidos en las clases:
alnum letras y números.
alpha letras.
blank espacio.
cntrl caracteres de control.
digit números.
graph caracteres imprimibles, excluído el espacio.
lower minúsculas
print caracteres imprimibles, incluído el espacio.
punct signos de puntuación.
space espacio
upper mayúsculas.
xdigit dígitos hexadecimales.
La traducción se realiza cambiando el primer caracter de CONJ1 por el primer caracter

de CONJ2, el 2o. de CON1 por el 2o. de CONJ2, etc. Los caracteres no indicados en
CONJ1 pasan incambiados.
tr abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ
tr a-z A-Z
tr '[:lower:]' '[:upper:]'
convierten minúsculas en mayúsculas.
tr -d '\000'
elimina caracteres nulos (octal 000).
tr -cs '[a-zA-Z0-9]' '[\n*]'
separa las palabras una por línea.
tr -s '\n'
comprime caracteres nueva línea en uno solo (elimina líneas en blanco).
uniq
uniq [OPCION]... [ENTRADA [SALIDA]]
muestra una única línea para una entrada ordenada, eliminando líneas repetidas
sucesivas. Opcionalmente, puede mostrar solo líneas que aparecen una vez, o sólo líneas
que aparecen varias veces. La entrada debe estar ya ordenada; si no lo está, puede usars
sort -u para lograr un efecto similar.
-f N saltear N campos antes de verificar unicidad.
-s N saltear N caracteres antes de verificar unicidad.
-c indicar junto a cada línea el número de veces que aparece.
-i ignorar mayúsculas y minúsculas al comparar.
-d mostrar sólo líneas repetidas.
-u mostrar sólo líneas únicas.
Los campos son cadenas de caracteres separadas por uno o más blancos (espacios o
tabuladores). Si se indican saltear campos y caracteres, los campos se saltean primero.

Programación del Shell Comandos multilínea
El archivo de comandos (script)
Comentarios en los scripts
Comandos de programación
true
false
if
for
case
while
until
exit
expr
test
read
Parámetros
Depuración
Preguntas y Ejercicios
Bibliografía y Referencias
El intérprete de comandos o "shell" de UNIX es también un lenguage de programación
completo. La programación de shell se usa mucho para realizar tareas repetidas con
frecuencia. Los diseñadores de sistemas suelen escribir aplicaciones en el lenguaje de
base del sistema operativo, C en el caso de UNIX, por razones de rapidez y eficiencia.
Sin embargo, el shell de UNIX tiene un excelente rendimiento en la ejecución de
"scripts" (guiones); ésta es la denominación aplicada a los programas escritos en el
lenguaje del shell. Se han creado aplicaciones completas usando solamente scripts.
Comandos multilínea.
Una línea de comando termina con un caracter nuevalínea. El caracter nuevalínea se ingresa
digitando la tecla ENTER. Varios comandos pueden escribirse en una misma línea usando el
separador ";" echo $LOGNAME; pwd; date
Si un comando no cabe en una línea, la mayoría de los intérpretes continúan la digitación en la
línea siguiente. Para establecer específicamente que un comando continúa en la línea
siguiente, hay dos formas, mutuamente excluyentes (se usa una u otra, pero no ambas al
mismo tiempo):
- terminar la primera línea con \ : $ echo $LOGNAME \ > $HOME
que muestra algo como

jperez /home/jperez
- dejar una comilla sin cerrar: $ echo "$LOGNAME > $HOME"
que produce el mismo resultado.
En los ejemplos anteriores hemos escrito los indicadores de comando. Al continuar el
comando en la segunda línea, el indicador de comandos cambia de $ a >, es decir, del
indicador de comando de primer nivel PS1 al indicador de comando de segundo nivel PS2. Si
no se quiere terminar el comando multilínea, puede interrumpirse el ingreso con Ctrl-C,
volviendo el indicador de comando a PS1 inmediatamente.
El archivo de comandos (script).
Es cómodo poder retener una lista larga de comandos en un archivo, y ejecutarlos todos de
una sola vez sólo invocando el nombre del archivo. Crear el archivo misdatos.sh con las
siguientes líneas: # misdatos.sh # muestra datos relativos al usuario que lo invoca # echo "MIS DATOS." echo " Nombre: "$LOGNAME echo "Directorio: "$HOME echo -n "Fecha: " date echo # fin misdatos.sh
El símbolo # indica comentario. Para poder ejecutar los comandos contenidos en este archivo,
es preciso dar al mismo permisos de ejecución: chmod ug+x misdatos.sh
La invocación (ejecución) del archivo puede realizarse dando el nombre de archivo como
argumento a bash bash misdatos.sh
o invocándolo directamente como un comando misdatos.sh
Puede requerirse indicar una vía absoluta o relativa, o referirse al directorio actual, ./misdatos.sh
si el directorio actual no está contenido en la variable PATH.
Comentarios en los scripts.
En un script todo lo que venga después del símbolo # y hasta el próximo caracter nuevalínea se
toma como comentario y no se ejecuta. echo Hola todos # comentario hasta fin de línea
sólo imprime "Hola todos". # cat /etc/passwd
no ejecuta nada, pues el símbolo # convierte toda la línea en comentario.

Los scripts suelen encabezarse con comentarios que indican el nombre de archivo y lo que
hace el script. Se colocan comentarios de documentación en diferentes partes del script para
mejorar la comprensión y facilitar el mantenimiento. Un caso especial es el uso de # en la
primera línea para indicar el intérprete con que se ejecutará el script. El script anterior con
comentarios quedaría así:
#!/bin/bash # misdatos.sh # # muestra datos propios del usuario que lo invoca # echo "MIS DATOS." echo " Nombre: "$LOGNAME echo "Directorio: "$HOME echo -n "Fecha: " date # muestra fecha y hora echo # línea en blanco para presentación # fin misdatos.sh
La primera línea indica que el script será ejecutado con el intérprete de comandos bash. Esta
indicación debe ser siempre la primera línea del script y no puede tener blancos.
Estructuras básicas de programación.
Las estructuras básicas de programación son sólo dos: la estructura repetitiva y la estructura
alternativa. Cada forma tiene sus variaciones, y la combinación de todas ellas generan múltples
posibilidades, pero detrás de cualquiera de ellas, por compleja que parezca, se encuentran
siempre repeticiones o alternativas.
Estructura repetitiva: se realiza una acción un cierto número de veces, o mientras dure
una condición.
mientras haya manzanas, pelarlas; desde i = 1 hasta i = 7 escribir dia_semana(i);
Esta escritura informal se denomina "pseudocódigo", por contraposición al término
"código", que sería la escritura formal en un lenguaje de programación. En el segundo
ejemplo, dia_semana(i) sería una función que devuelve el nombre del día de la
semana cuando se le da su número ordinal.
Estructura alternativa: en base a la comprobación de una condición, se decide una
acción diferente para cada caso.
si manzana está pelada, comerla, en otro caso, pelarla;

# oráculo caso $estado en soltero) escribir "El casamiento será su felicidad"; casado) escribir "El divorcio le devolverá la felicidad"; divorciado) escribir "Sólo será feliz si se vuelve a casar"; fin caso
Funciones: una tarea que se realiza repetidamente dentro del mismo programa puede
escribirse aparte e invocarse como una "función". Para definir una función es preciso
elegir un nombre y escribir un trozo de código asociado a ese nombre. La función suele
recibir algún valor como "parámetro" en base al cual realiza su tarea. Definida así la
función, para usarla basta escribir su nombre y colocar el valor del parámetro entre
paréntesis.
función area_cuadrado (lado) devolver lado * lado; función dia_semana(día_hoy) caso $dia_hoy en 1) devolver "Lunes";; 2) devolver "Martes";; 3) devolver "Miércoles";: 4) devolver "Jueves";; 5) devolver "Viernes;; 6) devolver "Sábado";; 7) devolver "Domingo";; fin caso;
Comandos de programación.
En esta sección veremos los comandos típicos de programación del shell. Obsérvese que el
shell toma la convención inversa de C para cierto y falso: cierto es 0, y falso es distinto de 0. El
shell adopta esta convención porque los comandos retornan 0 cuando no hubo error. Veremos
dos comandos, true y false, que retornan siempre estos valores; se usan en algunas
situaciones de programación para fijar una condición.
true
Este comando no hace nada, sólo devuelve siempre 0, el valor verdadero. La ejecución
correcta de un comando cualquiera devuelve 0. true echo $?
muestra el valor 0; la variable $? retiene el valor de retorno del último comando ejecutado.

false
Este comando tampoco hace nada sólo devuelve siempre 1; cualquier valor diferente de 0 se
toma como falso. Las diversas condiciones de error de ejecución de los comandos devuelven
valores diferentes de 0; su significado es propio de cada comando. false echo $?
muestra el valor 1.
if
El comando if implementa una estructura alternativa. Su sintaxis es if expresión ; then comandos1 ; [else comandos2 ;] fi
o también if expresión then comandos1 [else comandos2] fi
Si se usa la forma multilínea cuando se trabaja en la línea de comandos, el indicador cambia a
> hasta que termina el comando.
La expresión puede ser cualquier expresión lógica o comando que retorne un valor; si el valor
retornado es 0 (cierto) los comandos1 se ejecutan; si el valor retornado es distinto de 0 (falso)
los comandos1 no se ejecutan. Si se usó la forma opcional con else se ejecutan los
comandos2. if true; then echo Cierto ; else echo Falso ; fi
siempre imprime Cierto; no entra nunca en else. if false; then echo Cierto ; else echo Falso ; fi
siempre imprime Falso, no entra nunca en then.
Construcciones más complejas pueden hacerse usando elif para anidar alternativas. Escribir
en un archivo las líneas que siguen
# ciertofalso.sh: escribe cierto o falso según parámetro numérico # if [ $1 = "0" ] then echo "Cierto: el parámetro es 0." else echo "Falso: el parámetro no es 0." fi
Convertir el script en ejecutable. Invocar este script con ./ciertofalso.sh N
donde N es un número entero 0, 1, 2, etc. La variable $1 hace referencia a este parámetro de
invocación. Verificar el resultado.
Crear y ejecutar el siguiente script:

# trabajo.sh: dice si se trabaja según el día # invocar con parámetros: # domingo, feriado, u otro nombre cualquiera # if [ $1 = "domingo" ] then echo "no se trabaja" elif [ $1 = "feriado" ] then echo "en algunos se trabaja" else echo "se trabaja" fi
for
Este comando implementa una estructura repetitiva, en la cual una secuencia de comandos se
ejecuta una y otra vez. Su sintaxis es for variable in lista ; do comandos ; done
Se puede probar en la línea de comandos: for NUMERO in 1 2 3 4 ; do echo $NUMERO ; done for NOMBRE in alfa beta gamma ; do echo $NOMBRE ; done for ARCH in * ; do echo Nombre archivo $ARCH ; done
El caracter * es expandido por el shell colocando en su lugar todos los nombres de archivo del
directorio actual.
Crear y probar el siguiente script.
# listapal.sh: lista de palabras # muestra palabras de una lista interna # LISTA="silla mesa banco cuadro armario" for I in $LISTA do echo $I done # fin listapal.sh
En el siguiente script, el comando expr calcula expresiones aritméticas; notar su sintaxis.
# contarch.sh # muestra nombres y cuenta archivos en el directorio actual # CUENTA=0 for ARCH in * do echo $ARCH CUENTA=`expr $CUENTA + 1` # agrega 1 a CUENTA done

echo Hay $CUENTA archivos en el directorio `pwd` # fin contarch.sh
case
Este comando implementa alternativas o "casos"; elige entre múltiples secuencias de
comandos la secuencia a ejecutar. La elección se realiza encontrando el primer patrón con el
que aparea una cadena de caracteres. Su sintaxis es
case $CADENA in patrón1) comandos1;; patrón2) comandos2;; ... *) comandosN;; esac
El patrón * se coloca al final; aparea cualquier cadena, y permite ejecutar comandosN cuando
ninguna de las opciones anteriores fue satisfecha. Crear el siguiente script:
# diasemana.sh: nombres de los días de la semana # invocar con número del 0 al 6; 0 es domingo case $1 in 0) echo Domingo;; 1) echo Lunes;; 2) echo Martes;; 3) echo Miércoles;; 4) echo Jueves;; 5) echo Viernes;; 6) echo Sábado;; *) echo Debe indicar un número de 0 a 6;; esac
Invocarlo como diasemana.sh N
donde N es cualquier número de 0 a 6, otro número, o una cadena cualquiera. Verificar el
comportamiento.
Crear el archivo estacion.sh con estas líneas:
# estacion.sh # indica la estación del año aproximada según el mes # case $1 in diciembre|enero|febrero) echo Verano;; marzo|abril|mayo) echo Otoño;; junio|julio|agosto) echo Invierno;;

setiembre|octubre |noviembre) echo Primavera;; *) echo estacion.sh: debe invocarse como echo estacion.sh mes echo con el nombre del mes en minúscula;; esac # fin estacion.sh
El valor $1 es el parámetro recibido en la línea de comando. La opción *) aparea con cualquier
cadena, por lo que actúa como "en otro caso"; es útil para dar instrucciones sobre el uso del
comando. En las opciones, | actúa como OR; pueden usarse también comodines * y ?. Invocar
el script: bash estacion.sh octubre bash estacion.sh
¿Cómo podría modificarse el script anterior para que aceptara el mes en cualquier
combinación de mayúsculas y minúsculas?
while
Este comando implementa una estructura repetitiva en la cual el conjunto de comandos se
ejecuta mientras se mantenga válida una condición (while = mientras). La condición se
examina al principio y luego cada vez que se completa la secuencia de comandos. Si la
condición es falsa desde la primera vez, los comandos no se ejecutan nunca. Su sintaxis es while condición ; do comandos ; done
En el guión que sigue la expresión entre paréntesis rectos es una forma de invocar el comando
test, que realiza una prueba devolviendo cierto o falso. El operador -lt, "lower than",
significa "menor que". Observar su sintaxis, sobre todo la posición de los espacios en blanco,
obligatorios.
# crear1.sh # crea archivos arch1....arch9, los lista y luego borra VAL=1 while [ $VAL -lt 10 ] # mientras $VAL < 10 do echo creando archivo arch$VAL touch arch$VAL VAL=`expr $VAL + 1` done ls -l arch[0-9] rm arch[0-9] # fin crear1.sh
until
Este comando implementa una estructura repetitiva en la cual el conjunto de comando se
ejecuta hasta que se cumpla una condición. En cuanto la condición se cumple, dejan de
ejecutarse los comandos. La condición se examina al principio; si es verdadera, los comandos
no se ejecutan. Notar la diferencia con while. Su sintaxis es until condición ; do comandos ; done

Usando until, el script anterior se escribiría
# crear2.sh # crea archivos arch1....arch9, los lista y luego borra VAL=1 until [ $VAL -eq 10 ] # hasta que $VAL = 10 do echo creando archivo arch$VAL touch arch$VAL VAL=`expr $VAL + 1` done ls -l arch[0-9] rm arch[0-9] # fin crear2.sh
exit
Este comando se utiliza en programación de shell para terminar inmediatamente un script y
volver al shell original. exit
en un script, termina inmediatamente el script; en la línea de comando, termina la ejecución
del shell actual, y por lo tanto la sesión de UNIX. exit 6
termina el script devolviendo el número indicado, lo que puede usarse para determinar
condiciones de error. exit 0
termina el script devolviendo 0, para indicar la finalización exitosa de tareas. Escribir sólo exit
también devuelve código de error 0.
El siguiente script ofrece un ejemplo de uso.
#!/bin/bash # exitar.sh: prueba valores de retorno de exit # clear echo "Prueba de valores de retorno" echo " Invocar con parámetros " echo " bien, error1, error2, cualquier cosa o nada" echo " Verificar valor de retorno con" echo ' echo $?' echo VALOR=$1 case $VALOR in bien) echo " -> Terminación sin error." exit 0;; error1) echo " -> Terminación con error 1." ; exit 1;; error2) echo " -> Terminación con error 2." ; exit 2;; *)

echo " -> Terminación con error 3." echo " (invocado con parámetro no previsto o sin parámetro." exit 3;; esac
expr
Este comando recibe números y operadores aritméticos como argumentos, efectúa los
cálculos indicados y devuelve el resultado. Cada argumento debe estar separado por blancos.
Opera sólo con números enteros y realiza las operaciones suma (+), resta (-), multiplicación (*),
división entera (/), resto de división entera (%). Los símbolos * y / deben ser escapados
escribiendo \* y \/, al igual que los paréntesis, que deben escribirse \( y \).
El comando expr usa la convención de C para cierto y falso: 0 es falso, y distinto de 0
es cierto. No confundir con la convención que toma el shell en sus valores true y false,
que es la contraria. expr 4 + 5 devuelve 9 ( 4 + 5 = 9 ). expr 3 \* 4 + 6 \/2
devuelve 15 ( 3 * 4 + 6 /2 = 15 ). expr 3 \* \( 4 + 3 \) \/2 devuelve 10 ( 3 * (4 + 3) / 2 = 10 ).
expr también realiza operaciones lógicas de comparación, aceptando los operadores =,
!=, >, <, >= y <=. El operador != es "no igual"; el ! se usa para negar. Estos
caracteres también requieren ser escapados. echo `expr 6 \< 10`
devuelve 1, cierto para expr. echo `expr 6 \> 10`
devuelve 0, falso para expr. echo `expr abc \< abd`
devuelve 1, cierto para expr.
test
Este comando prueba condiciones y devuelve valor cierto (0) o falso (distinto de 0) según el
criterio de cierto y falso del shell; esto lo hace apto para usar en la condición de if. Tiene dos
formas equivalentes test expresión [ expresión ]
Los blancos entre la expresión y los paréntesis rectos son necesarios.
test devuelve cierto ante una cadena no vacía, y falso ante una cadena vacía: if test "cadena" ; then echo Cierto ; else echo Falso; fi if test "" ; then echo Cierto ; else echo Falso ; fi if [ cadena ] ; then echo Cierto ; else echo Falso; fi if [ ] ; then echo Cierto ; else echo Falso ; fi
test prueba una cantidad de condiciones y situaciones:
if [ -f archivo ]; then echo "Existe archivo"; \ else echo "No existe archivo"; fi

La condición [ -f archivo ] es cierta si archivo existe y es un archivo normal;
análogamente, -r comprueba si es legible, -w si puede escribirse, -x si es ejecutable, -d si es un
directorio, -s si tiene tamaño mayor que 0.
Las condiciones [ $DIR = $HOME ] [ $LOGNAME = "usuario1" ] [ $RESULTADO != "error" ]
comparan cadenas de caracteres; = para igualdad y != para desigualdad.
La condición [ "$VAR1" ]
devuelve falso si la variable no está definida. Las comillas dan la cadena nula cuando VAR1 no
está definida; sin comillas no habría cadena y daría error de sintaxis.
La condición [ expnum1 -eq expnum2 ]
compara igualdad de expresiones que resultan en un número. Pueden ser expresiones
numéricas o lógicas, ya que éstas también resultan en números. Los operadores numéricos
derivan sus letras del inglés, y son -eq (igualdad), -neq (no igual, desigualdad), -lt (menor), -gt
(mayor), -le (menor o igual), -ge (mayor o igual).
El comando test se usa mucho para determinar si un comando se completó con éxito, en
cuyo caso el valor de retorno es 0. El siguiente script crea un archivo si no existe.
# nvoarch.sh # recibe un nombre y crea un archivo de ese nombre; # si ya existe emite un mensaje if [ -f $1 ] then echo El archivo $1 ya existe else touch $1 echo Fue creado el archivo $1 fi echo # fin nvoarch.sh
Para comprobar su acción, bash nvoarch.sh nuevo1 ls -l nuevo1
crea el archivo; ls comprueba que existe; bash nvoarch.sh nuevo1
da mensaje indicando que el archivo ya existe.
Otros operadores aceptados por test son -a (AND) y -o (OR). # rwsi.sh # indica si un archivo tiene permiso de lectura y escritura ARCH=$1 if [ -r $ARCH -a -w $ARCH ] then

echo El archivo $ARCH se puede leer y escribir else echo Al archivo $ARCH le falta algún permiso fi ls -l $ARCH # fin rwsi.sh
read
Este comando tiene como propósito solicitar información al usuario. Su ejecución captura las
digitaciones del usuario, hasta obtener un caracter nueva línea (techa Enter). El ejemplo
siguiente obtiene datos del usuario, los repite en pantalla, solicita confirmación y emite un
mensaje en consecuencia.
# yo.sh: captura datos del usuario # clear echo "Datos del usuario." echo -n "Nombre y apellido: "; read NOMBRE echo -n "Cédula de identidad: "; read CEDULA echo echo "Ha ingresado los siguientes datos:" echo " Nombre y apellido: $NOMBRE" echo " Cédula de Identidad: $CEDULA" echo -n "¿Es correcto?(sN):"; read RESP if [ "$RESP" = "s" -o $RESP = "S" ] then echo "Fin de ingreso." else echo "Debe ingresar sus datos nuevamente." fi
Parámetros.
El siguiente programa muestra los parámetros que recibe al ser invocado:
# ecopars.sh # muestra los parámetros recibidos echo Cantidad de parámetros: $# for VAR in $* do echo $VAR done # fin ecopars.sh ecopars.sh Enero Febrero Marzo
muestra la cantidad y los parámetros recibidos. La variable $* contiene la lista de parámetros,
y $# la cantidad.
Dentro del script, los parámetros recibidos pueden referenciarse con $1, $2, $3, ..., $9, siendo
$0 el nombre del propio programa. Debido a que se los reconoce por su ubicación, se llaman
parámetros posicionales. El siguiente programa se invoca con tres parámetros y muestra sus

valores:
# mostrar3.sh # se invoca con 3 parámetros y los muestra echo nombre del programa: $0 echo parámetros recibidos: echo $1; echo $2; echo $3 echo # fin mostrar3.sh
¿Cómo se podría verificar la invocación con 3 parámetros, y emitir un mensaje de error en caso
contrario (cuando el usuario ingresa menos de 3 parámetros)?
Depuración.
Se llama depuración ("debug") de un programa al proceso de verificar su funcionamiento en
todos los casos posibles y corregir sus errores ("bugs", "pulgas"; del inglés, literalmente,
"chinche"; por extensión, insecto pequeño).
Cuando se está escribiendo un script, puede convenir invocarlo de forma especial para
generar información de comandos ejecutados y errores, para ayudar en la depuración.
Las salidas se imprimen en el error estándar, por lo que pueden direccionarse a un
archivo sin mezclarse con la salida del comando. bash -x ecopars.sh
imprime cada comando en la salida; bash -v ecopars.sh invoca el script obteniendo una salida verbosa con información sobre cada comando
ejecutado. bash -xv ecopars.sh 2>ecopars.err reúne las dos fuentes de información y direcciona el error estándar a un archivo.
Comandos de Usuario Ultima revisión: Set 2001
Propósito
Metalenguaje y convenciones
Referencias
Comandos: apropos banner cal cat cd chmod clear cmp cp cut date diff echo
env exit file head hostname id info less ln ls dir vdir mail man
mesg mkdir more mv passwd pr printenv ps pwd rm rmdir tail talk
touch umask wc whatis which who whoami
Propósito:
Esta guía resume la sintaxis, opciones más frecuentes y ejemplos de uso de los comandos UNIX
de más uso en la práctica. En descripción se presenta nombre del comando, sintaxis resumida,
acción principal, opciones más usuales, ejemplos y observaciones, si las hay.

Esta guía no puede ni pretende sustituir la consulta de las páginas man.
Metalenguaje y convenciones: ... repetición del último item [] item opcional, puede estar o no {A|B} item opcional obligatorio, debe tomarse A o B TAB tecla o caracter tabulador LF caracter nueva línea CR caracter retorno de carro ESPACIO caracter o tecla de barra espaciadora blanco caracter TAB o ESPACIO, delimita palabras UID identificador de usuario (número) GID identificador de grupo (número) (su) requiere permiso de supervisor
Los items en minúsculas van tal cual, los items en MAYUSCULAS deben ser sustituídos
por valores del usuario.
apropos
apropos [OPCIONES] PALABRA-CLAVE ...
busca entre las descripciones cortas de las páginas del manual la presencia de la palabra clave.
-r interpreta cada nombre como una expresión regular
-w interpreta cada nombre como conteniendo caracteres comodines
apropos man
apropos -w man*
banner
banner MENSAJE
Muestra el mensaje (cadena de caracteres) en letras grandes y girado 90°; para imprimir
carteles.
-wN en un ancho de N columnas
banner -w 40 Hola!

banner a
cal
cal [OPCIONES] [[MES]AÑO]
Sin parámetros, muestra calendario del mes actual; el año debe indicarse con centuria, 1-1999;
el mes en número 1 a 12.
-j día juliano, contado desde el 1 de enero
-y calendario del año en curso
cal
cal 1998
cal 11 1997
cal 9 1752
muestra el mes del año en que se saltearon 11 días para compensar años bisiestos.
cat
cat [OPCIONES] [ARCHIVO ...]
Concatena los archivos indicados y los muestra en la salida estándar. Sin argumentos, recibe de
la entrada estándar (-).
-A equivalente a -vET
-b numera las líneas que no están en blanco
-E muestra $ al final de cada línea
-n numera las líneas
-s reemplaza varias líneas en blanco por una sola
-t equivale a -vT
-v muestra caracteres no imprimibles excepto LF y TAB
-T muestra TAB como ^I

cat /etc/group
cat cap1 cap2 cap3
muestra sucesivamente los archivos cap1, cap2 y cap3.
cat cap1 cap2 cap3 > libro
reúne los archivos cap1, cap2 y cap3 en el archivo libro.
cat arch1 arch2 > arch1
hace perder los datos originales en arch1.
cd
cd [DIRECTORIO]
cambia directorio de trabajo; sin parámetros, cambia al directorio propio del usuario como
aparece en $HOME. En Linux, es un comando interno del shell; ver bash(1).
cd /etc
cd
chmod
chmod [OPCION] MODO ARCHIVO ...
cambia los permisos de acceso a los archivos indicados. No cambia los permisos de los enlaces
simbólicos.
-v verboso, describe acción sobre cada archivo.
-R recursivo, cambia permisos de subdirectorios y sus contenidos
chmod -R 0755 documentos/visibles
chmod ug+rw-x,o+r-wx cap*.txt
clear
clear

borra la pantalla del terminal.
cmp
cmp [OPCIONES] ARCH1 ARCH2 [SALTEAR1 [SALTEAR2]]
compara dos archivos. Si son iguales, no dice nada; si difieren, marca el byte y el número de
línea de la primera diferencia.
-l número de byte (decimal) y bytes diferentes (octal) para cada
diferencia.
-s devueve solamente un valor de retorno, sin escribir nada.
Los valores de retorno son 0 si los archivos son iguales, 1 si diferen, >1 si hubo un error. Los
valores decimales SALTEAR1 y SALTEAR2 indican la posición de byte donde comienza la
comparación en ARCH1 y ARCH2; puede expresarse en hexadecimal precediento el número
con 0x, o en octal precediendo con 0.
cp
cp [OPCIONES] ARCH_ORIGEN ARCH_DESTINO
cp [OPCIONES] ARCHIVO ... DIRECTORIO
copia ARCH_ORIGEN hacia ARCH_DESTINO; copia los archivos indicados hacia DIRECTORIO.
Por defecto no copia directorios.
-d copia enlaces simbólicos como tales
-f forzoso, sobreescribe archivos destino si existen
-i avisa antes de sobreescribir archivos existentes
-l crea enlaces hard en lugar de copiar los archivos
-p preserva dueño, grupo, permiso y fecha
-s crea enlaces simbólicos en lugar de copiar los archivos
-R recursivo, copia directorios y sus archivos
-v verboso, escribe el nombre de cada archivo que copia

cp arch1 /dir1/arch1
cp -vi arch1 arch2
cp -dpRv dir1 /dir2/subdir2 dirtodo
mejor forma de copiar exactamente una estructura de directorios, recursivamente,
conservando permisos y manteniendo enlaces simbólicos; verboso puede omitirse.
cut
cut -f CAMPOS [-d DELIM][ARCHIVO ...]
cut -c COLUMNAS [ARCHIVO ...]
extrae partes de cada línea de los archivos indicados o de la entrada estándar. Los campos y
columnas se indican con números 1, 2,... o con intervalos n-m. Intervalos incompletos: -n es 1-
n, m- es m hasta el último campo o columna.
-f campos numerados, por defecto separados por TAB
-c columnas, ubicación posicional de caracteres en la línea
-d fija el caracter delimitador de campos, TAB por defecto
-s con -f para no imprimir líneas que no contengan el delimitador
cat /etc/passwd | cut -d: -f1,3,5-6
cat /etc/passwd | cut -c1-15
ls -l | cut -c57-
corta sólo el nombre del archivo, al final (puede requerir ajuste en el valor de columna).
date
date [OPCION] [+FORMATO]
muestra fecha y hora. Con +FORMATO la presenta según el patrón indicado.
date [-u|--utc|--universal] [ MMDDHHmm [[CC]YY][.SS] ]
fija (su) fecha y hora.
-u --utc --universal hora universal (GMT)

Formato para fijar la hora:
MM mes (01-12)
DD día (01-31)
HH hora (00-23)
mm mminuto (00-59)
CC centuria
YY año
SS segundos (00-59)
Formato para presentar la fecha y la hora (+FORMATO):
'%H' hora (00-23)
'%M' minuto (00-59)
'%S' segundos (00-59)
'%T' hora en 24 horas (hh:mm:ss)
'%X' hora en representación local (%H:%M:S)
'%a' nombre local abreviado del día
'%A' nombre local completo del día
'%b' nombre local abreviado del mes
'%B' nombre local completo del mes
'%c' fecha y hora locales
'%d' día del mes (01-31)
'%m' mes (01-12)
'%w' día de la semana (0-6), 0 es Domingo
'%x' fecha local
'%y' 2 dígitos del año (00-99)
'%Y' 4 dígitos del año (1970....)
diff
diff ARCHIVO1 ARCHIVO2

muestra las diferencias existentes entre dos archivos.
diff nota1 nota2
echo
echo [OPCIONES] MENSAJE ...
escribe en la salida estándar los mensajes, separados con un espacio y con LF al final. Muchos
shells tienen un comando interno del mismo nombre; éste, fuera del shell, debe invocarse
como /bin/echo.
-n suprime LF al final
-e interpreta estos caracteres especiales, dentro de " "
\a campana
\b retroceso
\c suprime LF al final
\f cambio de página
\n nueva línea (LF)
\r retorno de carro (CR)
\t tabulador horizontal
\v tabulador vertical
\\ barra inversa
\nnn caracter ASCII nnn en octal
echo Hola Todos!
echo -n Hola Todos!
echo -e "\a"
echo -e "\101"
muestra la letra A, que es 101 en octal.
env
env [OPCIONES][NOMBRE=VALOR]...[COMANDO [ARGUMENTO ...]]

Sin argumentos, muestra valores de variables de ambiente; con argumentos, corre el comando
indicado con las variables de ambiente modificadas según se indique.
-i comenzar con un ambiente virgen, ignorando el actual
env
env DIR=/etc listadir1
lista el contenido del directorio /etc; listadir es un archivo ejecutable que contiene la línea
ls dir1, para listar contenido del directorio dir1.
echo Directorio $HOME
ls -l $HOME
muestra el directorio propio del usuario, guardado en la variable de ambiente HOME.
exit
exit [N]
produce la salida del shell con estado de terminación N (número); si no se indica retorna con 0.
file
file OPCIONES ARCHIVO
intenta determinar el tipo de archivo de que se trata: texto ASCII, código C, script en
diversos lenguajes, binario, otros.
-z examina archivos comprimidos
file cati.c
este archivo contiene código C. file adduser este archivo es un script en Perl. file /bin/cat
es un ejecutable binario.
head
head [OPCIONES] ARCHIVO ...

muestra la primera parte de un archivo, por defecto 10 líneas. Si son varios archivos muestra
un encabezado con el nombre de cada archivo.
-v verboso, imprime encabezamiento con nombre del archivo
-q silencioso, no imprime encabezado con nombre del archivo
-N imprime primeras N líneas, por defecto 10
-n N imprime primeras N líneas
head -24 /etc/inetd.conf
hostname
hostname [NOMBRE]
sin argumentos, da el nombre de la máquina; con NOMBRE, fija el nombre de la máquina (su).
-h ayuda
-f --fqdn nombre de máquina completo, con dominio DNS
-d --domain nombre de dominio DNS
-i --ip-address dirección (número IP)
-a --alias nombres de alias
-v verboso
id
id [OPCIONES] [NOMBRE_USUARIO]
muestra información sobre un usuario. Muestra nombre, UID, grupo, GID y grupos
suplementarios. Si el id real y el efectivo no corresponden muestra ambos. Las opciones
limitan el despliegue.
-g sólo el grupo primario
-G grupos suplementarios
-n nombre en lugar de número; requiere -u, -g, o -G

-r real en lugar de efectivo; requiere -u, -g o -G
-u sólo el número de usuario (UID)
id
id webmaster
muestra datos del usuario webmaster.
info
info [NOMBRE]
sistema de información de GNU sobre UNIX.
info info
muestra información sobre info, con tutorial para aprender a manejar info.
less
less [OPCIONES] [ARCHIVO]
programa de paginado y búsqueda similar a more, con más opciones y comandos. Permite
movimiento hacia adelante y atrás, pero no lee todo el archivo al principio, por lo que es más
rápido. Sus comandos están tomados de more y vi (ver more).
--help -? muestra ayuda sobre comandos internos
ln
ln [OPCIONES] ORIGEN [DESTINO]
ln [OPCIONES] ORIGEN ... DIRECTORIO
si el último argumento es un directorio, ln crea en ese directorio enlaces a todos los archivos
origen con el mismo nombre; si sólo se indica un nombre de archivo, crea un enlace hacia ese
archivo en el directorio actual; si se indican dos archivos, crea un enlace con el primer nombre
(archivo real) hacia el segundo (enlace). Por defecto, crea enlaces hard y no elimina archivos
existentes.
-f forzoso, elimina archivos destino existentes

-i interactivo, pide confirmación para eliminar archivos
-s simbólico, crea enlaces simbólicos en lugar de hard
-v verboso, da el nombre de cada enlace creado
ln nota nota.ln
ln -s /etc/passwd
ln -s datos.usuario datos.usu.ln
ln -sv datos.usuario LEAME dir2
ls, dir, vdir
ls [OPCIONES] [NOMBRE]
Para cada nombre de directorio, lista contenido de directorio; para cada nombre de archivo,
indica su nombre y datos. La salida está ordenada alfabéticamente por defecto. Sin nombre,
lista el directorio corriente. La opción -l muestra, separados por espacios, los campos tipo
archivo y permisos, cantidad de enlaces hard, dueño, grupo, tamaño, mes, día, hora o año,
nombre.
-1 un nombre de archivo por línea
-a todos los archivos, incluso no visibles comenzados por .
-c ordenar por fecha de estado de último cambio (ctime en inodo)
-C salida en columnas con ordenamiento por columnas
-d lista directorios como archivos, no su contenido
-F indica tipo: / directorio, * ejecutable, @ enlace simbólico
-i inodo, número de índice de cada archivo
-k tamaños en KB
-l listado en formato largo
-r invertir ordenamiento
-R listar recursivamente subdirectorios
-s tamaño en bloques de 1024 bytes
-t ordenar por fecha de última modificación (mtime en inodo)
-u ordenar por fecha de último acceso (atime en inodo)

-U no ordenar
-x salida en columnas con ordenamiento por filas
dir
equivale al ls -C.
vdir
equivale a ls -l.
mail [OPCIONES] [DESTINO ...]
procesador de correo electrónico de UNIX. Sin argumentos, muestra lista de mensajes en la
casilla de entrada y permite manipularlos. Si hay un destino, lee de la entrada estándar hasta
un "." aislado en una línea y envía lo leído como mensaje a destino.
-v verboso, muestra detalles de entrega
-s TEMA especifica el tema (subject) del mensaje
-c LISTA envía copias a LISTA de usuarios, separados por coma
-b LISTA envía copia ciega a LISTA de usuarios
-f [ARCH] lee contenido de archivo propio mbox o el indicado
-u USUARIO equivale a mail -f /var/spool/mail/USUARIO
Comandos internos de mail:
& indicador de comandos de mail
? muestra lista de comandos para manejo de mensajes
d borra mensaje corriente, marcado con '>'
N muestra el mensaje número N
q sale del programa de correo
mail -s "Saludos para todos " -c pedro,[email protected] juan

envía un mensaje al usuario juan, tema "Saludos para todos", con copia a usuarios pedro y
mateo.
man
man [OPCIONES] [SECCION] NOMBRE ...
Da formato y muestra las páginas del manual en línea. Si no se indica sección, muestra sólo la
primera que encuentre; si se indica sección como número 1-9, muestra la página que haya en
la sección indicada. Las páginas están organizadas en secciones, reconocidas por un dígito, y
eventualmente subsecciones indicadas por una o más letras.
-a muestra páginas en todas las secciones
-d muestra información de depuración propia de man
-f equivalente a whatis
-h muestra ayuda para man
-k equivalente a apropos
-w no imprime las páginas, sino las ubicaciones
Secciones del manual:
1 programas ejecutables y guiones (scripts)
2 llamadas al sistema (funciones del núcleo)
3 llamadas a biblioteca (funciones de biblioteca)
4 archivos especiales (generalmente en /dev)
5 formatos de archivos
6 juegos
7 paquetes de macros
8 comandos de administración (su)
man -h
man man
man -a man
mesg

mesg [y|n]
controla acceso de escritura a la terminal propia por otros usuarios, típicamente con
programas tales como talk y write. Sin parámetros, muestra el estado: is y si está
habilitada escritura, is n si no está habilitada escritura.
y permite a otros escribir mensajes en la terminal
n no permite a otros escribir mensajes en la terminal
mesg
mesg y
mesg n
mkdir
mkdir [OPCIONES] [-m MODO] DIRECTORIO ...
crea los directorios indicados. Por defecto, el modo es 0777 menos los bits de umask.
-m MODO permite fijar el modo para el nuevo directorio;
el modo es simbólico y usa el modo por defecto como partida.
-p crea primero todos los directorios padre inexistentes,
con el modo de umask modificado con u+wx
--verbose informa sobre la creación de directorios
mkdir dir1 dir2
mkdir -p ltr/jd/jan
crea la estructura de directorios ltr/jd/jan.
more
more [OPCIONES][-N][+/CADENA[-N] [ARCHIVO ...]

pagina el texto dividiéndolo en pantallas, presentando una por vez.
-N fija tamaño de pantalla en N líneas
-d muestra mensajes de ayuda
-s comprime en una varias líneas en blanco seguidas
-u suprime subrayados
+/cadena busca la cadena antes de mostrar
+N comienza a mostrar a partir de la línea N
Durante el despliegue, reconoce los comandos siguientes, algunos de los cuales pueden ir
precedidos de un número multiplicador:
h muestra resumen de estos comandos
ESPACIO avanza una pantalla
ENTER muestra siguiente línea
f avanza una pantalla; ^F
b retrocede una pantalla; también ^B
^L (Ctrl-L) redibuja la pantalla
= muestra número de línea actual
/PATRON busca hacia adelante la expresión regular PATRON
?/PATRON busca hacia atrás la expresión regular PATRON
n repetir última búsqueda
. repetir el comando anterior
´ ir a lugar de comienzo de última búsqueda
q, Q sale
mv
mv [OPCIONES] ARCH_ORIGNEN ARCH_DESTINO
mv [OPCIONES] ARCHIVO ... DIRECTORIO

cambia de nombre ARCH_ORIGEN, o mueve hacia ARCH_DESTINO si el archivo destino invoca
otro directorio; mueve ARCHIVO y los siguientes archivos hacia DIRECTORIO. Entre sistemas
de archivos sólo puede mover archivos normales.
-f forzoso, sobreescribe archivos destino si existen
-i avisa antes de sobreescribir archivos existentes
-v verboso, escribe el nombre de cada archivo que mueve
-u no mover si existe archivo destino más nuevo o de igual fecha
mv nota notanueva
mv -vi LEAME LEAME2
mv -v arch1 notanueva LEAME /dir2/subdir2
passwd
passwd [OPCIONES] [NOMBRE]
cambia la contraseña del usuario. El superusuario puede cambiar las contraseñas de otros
usuarios. En general, las contraseñas deben tener entre 6 y 8 caracteres, contener mayúsculas,
minúsculas, dígitos 0 a 9 o signos de puntuación; no se admiten contraseñas simples ni
parecidas al nombre del usuario. Si el superusuario asigna contraseñas poco seguras no hay
advertencia.
-x M máximo número de días de validez; luego pide cambiar
-n M mínimo número de días antes de poder cambiar
-n M número de días de advertencia antes de expirar
passwd
permite cambiar la contraseña del usuario invocante
passwd jperez
(su) cambia la contraseña del usuario jperez.
pr
pr [OPCIONES] ARCHIVO ...

escribe en salida estándar un texto con formato, paginado y opcionalmente en varias
columnas.
+P1[:P2] de página P1 a página P2
-C en C columnas
-a escribe las columnas a través y no hacia abajo
-d a doble espacio
-f separar páginas con salto de página
-h reemplazar encabezado con el indicado
-l largo de página en líneas; por defecto 66
-m escribir archivos en paralelo uno en cada columna
-o margen izquierdo; se suma al ancho indicado por -w
-w ancho de página en columnas; por defecto 72
pr -o8 -l23 -h "Lista de usuarios" /etc/passwd
pr -o2 -l22 -h "Lista de servicios" /etc/services | more
ls /etc | pr -2 -b -l23 | more
ls /etc | pr -3 -b -l23 -a | more
printenv
printenv [VARIABLE] ...
muestra el valor de todas las variables de ambiente; si se indica un nombre de variable,
puestra el valor de esa variable.
printenv TERM
ps
ps [OPCIONES] [PID] ...
informa sobre procesos en ejecución. Para las opciones, no debe usarse -, aunque es aceptado.

l formato largo
u formto usuario, muestra nombre, PID, hora inicio, estado
j formato trabajos, muestra PGID y SID
s formato señales
a mostrar también procesos de otros usuarios.
x mostrar también procesos sin terminal de control
w no truncar líneas para caber en un ancho de página;
agregar una w para cada línea más
h sin encabezado
r sólo procesos en ejecución
ps auxwww | more
muestra todos los procesos en ejecución, en formato usuario, aún los sin terminal, admitiendo
hasta 4 líneas por comando.
pwd
pwd
imprime toda la ruta del directorio corriente; todos los componentes mostrados serán los
directorios reales, no enlaces simbólicos. El shell tiene una versión interna de pwd, por lo que
para ejecutar ésta, que es externa, es preciso escribir
ls -l /var/spool/mail
muestra /var/spool/mail como enlace simbólico a /var/mail (Debian).
cd /var/spool/mail
pwd
versión interna del shell, muestra /var/spool/mail, el enlace simbólico.
/bin/pwd
versión externa, muestra /var/mail, el directorio real.

rm
rm [OPCIONES] NOMBRE ...
elimina los archivos indicados; por defecto no elimina directorios.
-f ignora archivos inexistentes y nunca pide confirmación
-i interactivo, pregunta antes de eliminar cada archivo.
-r, -R recursivo, borra directorios y su contenido
-v verboso, muestra nombre de cada archivo eliminado
rm arch1 arch2 dir1/arch3
rm -riv dir1/subdir1
rm -r *
elimina TODOS los archivos y subdirectorios; no avisa. ¡Cuidado!
rmdir
rmdir [OPCIONES] DIRECTORIO ...
elimina directorios vacíos.
-p elimina directorios padre si quedan vacíos
rmdir dir2
rmdir -p dir1/subdir11/subdir111
tail
tail [OPCIONES] ARCHIVO ...
muestra la última parte de un archivo, por defecto 10 líneas. Si son varios archivos muestra un
encabezado con el nombre de cada archivo.

-f continúa tratando de leer; para archivos en crecimiento
-v verboso, imprime encabezamiento con nombre del archivo
-q silencioso, no imprime encabezado con nombre del archivo
-N imprime últimas N líneas
-n N idem
talk
talk USUARIO [TTY]
conversar con otro usuario. Si está en la misma máquina, alcanza con el nombre de login del
usuario; si está en otra máquina, es preciso usar la forma usuario@maquina. Si el usuario
tiene varias sesiones a la vez, puede indicarse la terminal, usualmente en la forma ttyXX.
touch
touch [OPCIONES] ARCHIVO ...
cambia fecha, hora de acceso y/o modificación de los archivos indicados; les pone la fecha y
hora actuales. Si los archivos no existen los crea vacíos.
-a cambia sólo fecha de acceso
-c no crea el archivo si no existe
-m cambiar sólo fecha de modificación
-r arch_ref fija la fecha según fecha del archivo arch_ref
-t MMDDhhmm[[CC]YY][.ss]
fija la fecha indicando mes MM, día DD, hora hh y minuto mm;
puede agregarse también centuria CC y año YY y segundos ss.
touch 01011200 dia1enero.h1
touch ahora.arc
touch -r antes.arch arch1 arch2
umask
umask [-S] [MODO]

fija la máscara para permisos de creación según modo. Si modo se indica con número, es en
octal; si no, es en modo simbólico. En general, los permisos de creación serán, para directorios,
0777 menos los bits de máscara; para archivos 0666 menos los bits de máscara. La máscara
vigente es la fijada por defecto o la que se fije con este comando. Sin parámetros, umask
muestra la máscara vigente. La máscara indica los permisos que se quitan al permiso fijado.
-S muestra la máscara, sin fijarla (por defecto, sin parámetros)
umask
muestra la máscara vigente.
umask 022
fija los permisos de creación de archivos en 0666 - 022, es decir, 0644; los de directorios en
2777 - 022, es decir, 2755 (Debian).
uname
uname [OPCIONES]
muestra información de la máquina y del sistema operativo:
-a toda la información
-m máquina, tipo de hardware
-n nombre de máquina en la red
-p tipo de procesador
-r edición (release) del sistema operativo
-s nombre del sistema operativo
-v versión del sistema operativo
wc
wc [OPCIONES] ARCHIVO ...
cuenta líneas, palabras y caracteres de los archivos indicados o de la entrada estándar. Si son
varios los archivos, imprime una línea por cada uno y un total.

-c sólo caracteres
-w sólo palabras
-l sólo líneas
man pwd | wc -l
wc /etc/passwd /etc/group
whatis
whatis [OPCIONES] NOMBRE ...
muestra una descripción corta de los comandos similares a nombre.
-r interpreta cada nombre como una expresión regular
-w interpreta cada nombre como conteniendo caracteres comodines
whatis man
whatis -w man*
which
which PROGRAMA ...
indica la ruta completa de PROGRAMA, si éste está accesible a través de la variable PATH..
who
who [OPCIONES] [am i]
Quién está en el sistema. Muestra nombre de login, línea de terminal, hora de ingreso, nombre
de máquina remota o display X.
am i máquina y nombre de login del usuario invocante
-H muestra encabezado de columnas

-u tiempo inactivo; "old" es >24 horas; "." activo reciente
-w si el usuario recibe (+) o no (-) mensajes
-m igual que 'who am i'
whoami
whoami
Muestra identificador del usuario efectivo actual. Si se ha usado su para adoptar otro usuario,
whoami muestra el nombre asociado con el usuario adoptado.
Tutorial Emulador de Terminal
Ingreso al sistema (login)
Directorios
Listado de archivos
Manual de UNIX
Contenido de un archivo
Crear y borrar un archivo
Correo electrónico de UNIX
Usuarios en el sistema
Talk
Cambio de contraseña
Fin de Sesión
Otros
Bibliografía y Referencias
Emulador de Terminal.
Para ingresar a un sistema UNIX remoto desde un PC se usa habitualmente un "emulador de
terminal". Este programa permite al PC comportarse como una terminal (teclado y pantalla, sin
procesador) conectada directamente a la máquina UNIX. En el emulador de terminal se deben
fijar los siguientes parámetros:

Nombre descriptivo de la conexión a establecer (arbitrario). Nombre en la red de la máquina a la que se quiere conectar. Tipo de terminal que se emulará (VT100 es el más conocido). Conexión vía TCP/IP, protocolo de comunicación en la red.
Ingreso al sistema (login).
login: id-usuario
password:
id-usuario es el nombre identificador del usuario para ingreso al sistema, proceso que se
denomina "login". Este nombre de usuario suele tener hasta 8 caracteres (letras, números y
algunos símbolos), debe comenzar con minúscula. UNIX distingue entre mayúsculas y
minúsculas. En el ingreso al sistema, no se permiten correcciones.
<mensaje del día>
se despliega siempre después del login, es puesto por el administrador del sistema para
información o bienvenida.
<noticias>
aviso de noticias nuevas. Las noticias se usan para informaciones generales de mayor tiempo
de validez. Las noticias no aparecen más después de haber sido leídas. Para leer las noticias
debe digitarse el comando news.
You have mail
indica que hay mensajes de otros usuarios, o del sistema. El correo electrónico permite a
cualquier usuario enviar y recibir mensajes.
$
es el indicador de comandos del sistema; indica que el sistema está listo y aguarda una orden
del operador, que debe ser escrita a continuación de $ y finalizada con la tecla <Enter>.
En los siguientes ejemplos debe escribirse el comando tal cual se muestra, digitando la tecla
<Enter> al final.
date
comando que muestra la fecha y hora.

who
muestra los nombres de usuarios conectados al sistema en este momento.
hostname
muestra el nombre de la máquina UNIX.
Directorios.
Cada usuario tiene un directorio propio, llamado a veces "directorio home". Cuando el usuario
ingresa al sistema ya está ubicado en su directorio propio. El comando
pwd
muestra el directorio actual.
cd /home
cambia hacia el directorio /home, lo que puede verificarse con el comando pwd.
cd
sin parámetros devuelve al usuario a su directorio propio, desde cualquier lugar donde esté.
Este comando es útil cuando se han hecho varios cambios de directorio y se quiere retornar a
una situación conocida, ubicándose en el directorio propio.
Listado de archivos.
Ensayemos el comando ls:
ls
lista archivos del directorio actual.
ls -l /bin
lista archivos en el directorio /bin; aquí se encuentran los archivos de comandos ejecutables
del sistema. No cambia de directorio; el directorio actual sigue siendo el mismo.
ls -l
lista archivos en formato largo, dando detalles. El -l se llama opción o bandera; se lee "menos
ele".
La salida obtenida consta de renglones parecidos a
-rw-rw-rw- 1 esteban users 138 Apr 5 19:34 leame
y se interpretan así:
-

indica el tipo de archivo de que se trata, con esta convención:
- archivo común,
d directorio,
l enlace o referencia a otro archivo.
rw-rw-rw
son los permisos del archivo;
r (read) permiso para leer el archivo
w (write) permiso para modificar o eliminar el archivo
x (execute) si se trata de un archivo, permiso para ejecutarlo como
programa; si se trata de un directorio, permiso para ingresar
en él y recorrerlo.
Los tres grupos de 3 caracteres indican permisos para el dueño del archivo (esteban), su grupo
(users) y el resto del mundo.
1
cantidad de enlaces, referencias a este archivo desde otros archivos ubicados en diferentes
lugares.
esteban
nombre del usuario dueño del archivo.
users
nombre del grupo al que pertenece el archivo
138
tamaño en bytes del archivo. Si se trata de un directorio, este número es de control del
sistema, sin interpretación inmediata para el usuario.
Apr 5 19:34
fecha y hora de última modificación. Si no aparece el año, se asume el año corriente.
leame

nombre del archivo. Notar que el nombre del archivo está siempre al final.
ls -a
muestra también archivos ocultos, normalmente no visibles en el listado. Los archivos cuyo
nombre empieza con un punto son ocultos, en este sentido. Las entradas . y ..
representan el directorio actual y el directorio padre, respectivamente.
ls -la
formato largo y archivos ocultos.
ls -la /var
listado de archivos visibles y ocultos en formato largo del directorio /var.
Manual de UNIX.
UNIX dispone de un manual en línea o "páginas man" con información sobre comandos,
archivos y otros elementos del sistema operativo. Aunque muy técnicas y a veces difíciles de
comprender, son una referencia obligada para operar con solvencia.
man ls
muestra la página man del comando ls, paginada para poder leer una pantalla por vez. Para
salir antes de terminar, digitar 'q'.
man man
muestra la página man del propio comando man.
man man > man.txt
redirecciona la salida y graba el contenido de la página man en el archivo man.txt, lo que se
puede verificar con ls.
Contenido de un archivo.
cat man.txt
muestra el contenido del archivo. El archivo man.txt, por provenir de una página man,
contiene muchos caracteres de control para regular su despliegue en pantalla. El comando cat
no intrepreta estos caracteres de control. El comando cat permite también concatenar
archivos, según se verá.
head man.txt
muestra las primeras 10 líneas de un archivo.
tail man.txt

muestra las 10 líneas finales de un archivo.
cat man.txt | more
lee una nota larga paginando; la salida de cat es tomada por more, que presenta la
información página por página. Para interrumpir el paginado de more, digitar 'q'. La tecla
espaciadora avanza una pantalla, la combinación de teclas Ctrl-B retrocede una pantalla.
more man.txt
presenta la información de man.txt ya paginada.
ls -l /etc | more
muestra el extenso contenido del directorio /etc paginando la salida.
Crear y borrar un archivo.
touch nota.vacia
crea el archivo nota.vacia, sin contenido alguno.
ls -l nota.vacia
muestra datos del archivo creado.
cat nota.vacia
no muestra nada, el archivo está vacío.
touch .archivo_oculto
crea un archivo vacío y oculto.
ls
no muestra el archivo oculto creado, pero
ls -a
sí lo muestra.
ls -la
muestra datos en formato largo del archivo oculto.
rm nota.vacia
borra el archivo nota.vacia. Como muchos comandos de UNIX, su nombre deriva de
palabras inglesas: rm proviene de "remove", eliminar o borrar.

rm -i man.txt
borrado interactivo, pide confirmación antes de actuar.
rm .archivo_oculto
ls -la
borra el archivo oculto y verifica listando los archivos del directorio.
echo Mensaje en pantalla
muestra en la pantalla la leyenda indicada.
echo Este es el archivo mensaje1 > mensaje1
direcciona la salida del comando echo y graba la leyenda en el archivo mensaje1.
ls -l mensaje1
cat mensaje1
muestra datos del archivo y verifica su contenido.
echo Esta línea es agregada >> mensaje1
echo Esta es otra línea agregada >> mensaje1
cat mensaje1
redirecciona la salida de echo para agregar dos líneas más al archivo ya existente mensaje1.
Verifica el contenido con cat.
Correo electrónico de UNIX.
Para leer el correo, digitar
Este comando ingresa al usuario en el sistema de correo electrónico de UNIX. Revisa la casilla
de entrada de mensajes mostrando la lista de recibidos. De ahora en adelante, sólo se aceptan
los comandos propios de mail. El indicador de comandos de mail es
&
Comandos disponibles dentro del sistema de correo:
d borra mensaje corriente, marcado con '>'
? muestra lista de comandos para manejo de mensajes

5 muestra el mensaje 5
h muestra la lista de mensajes
h 3 muestra la lista de mensajes comenzando en el 3
q sale del programa de correo
Para enviar un correo al usuario juan, desde la línea de comando de UNIX digitar
mail juan
Escribir entonces el texto del mensaje. Antes de llegar al fin de la pantalla, digitar <Enter> para
que cambie al otro renglón. El comando mail no es un editor: no arregla las líneas ni permite
corregir líneas anteriores. Al finalizar de escribir el mensaje, digitar
.
(un punto solo en una línea) y dar <Enter>. Un punto solo en la línea termina el mensaje y
devuelve al usuario a la línea de comandos de UNIX.
El usuario puede probar el correo enviándose un mensaje a sí mismo y luego leyéndolo.
mail juan esteban
envía mensaje al usuario juan y al usuario esteban.
mail -s "Mensaje de prueba" juan
envía un mensaje de prueba al usuario juan con el título "Mensaje de prueba". Es de cortesía
indicar siempre el tema del mensaje, para que el destinatario sepa inmediatamente de qué se
trata.
Existen en UNIX muchos programas para manejo de correo, más potentes y sofisticados; aquí
nos limitamos a mail como ejemplo de un comando de UNIX más bien artesanal, pero
siempre presente y útil para mensajería sencilla.
Usuarios en el sistema.
who
muestra los usuarios que están actualmente en el sistema. Indica identificador de usuario,
terminal en que está conectado, fecha y hora de ingreso al sistema.
who am i
da información sobre el usuario que está trabajando, indicando su máquina y nombre de
usuario, terminal, fecha y hora.
whoami

presenta sólo el nombre del usuario que está operando.
id
proporciona la identificación del usuario invocante, dando el nombre de usuario y su número
(UID), nombre de grupo primario y su número (GID), nombres de otros grupos a los cuales
pertenece (si los hay) y sus números.
id jperez
proporciona datos de identificación del usuario indicado (jperez).
finger
proporciona nombre del usuario en el sistema, nombre en la vida real y otros datos del usuario
invocante, indicando si está en este momento en el sistema, y si tiene correo por leer.
finger jperez
proporciona información sobre el usuario indicado.
Talk.
Talk es un programa que permite a dos usuarios en el sistema comunicarse escribiendo en el
teclado. Al invocar talk la pantalla se divide en dos partes, cada una correspondiente a uno
de los usuarios. Ambos pueden escribir simultáneamente, y ambos ven la salida en su parte
correspondiente de la pantalla.
talk usuario1
solicita apertura de una sesión de talk al usuario1, que debe responder con otro comando
similar cuando recibe el pedido.
Para terminar la sesión de talk, cualquiera de los usuarios puede digitar Ctrl-C.
El comando mesg permite regular si se desea recibir mensajes o no. Para evitar recibir
mensajes de talk es posible bloquear a otros usuarios el acceso a la terminal donde uno está
trabajando; quienes intenten iniciar una sesión recibirán un mensaje indicando que la terminal
destino no está habilitada para recibir mensajes.
mesg n
deshabilita recepción de mensajes,
mesg y
habilita recepción de mensajes.
mesg
muestra el estado: si responde "y" está habilitada la recepción, si responde "n" se rechazan los
pedidos de conexión.

Cambio de contraseña.
passwd
pide la vieja contraseña y luego la nueva; la nueva contraseña deberá ingresarse dos veces,
para evitar posibles errores de digitación. En sistemas con servicio de información de red (NIS),
el comando es
yppasswd
El administrador del sistema indicará cuál de estos comandos debe usar.
Fin de sesión.
exit
termina la sesión con UNIX, vuelve a presentar el mensaje inicial
login:
habilitando a un nuevo usuario a ingresar al sistema. Las teclas <Ctrl-D> también terminan la
sesión.
Otros.
Las teclas Ctrl-C interrumpen la ejecución de un comando. Las teclas Ctrl-D indican un fin
de ingreso; si se dan en el indicador de comandos, termina la sesión UNIX. En UNIX no hay un
caracter reservado para fin de archivo; Ctrl-D simplemente indica la terminación de un flujo
de datos.
En UNIX, la tecla <Enter> coloca un caracter nueva línea, que en ASCII es <Ctrl-J>;
con la tecla <Enter> DOS o MS-Windows colocan dos caracteres al final de una línea:
un nueva línea <Ctrl-J> y un retorno <Ctrl-M>. Al mirar un archivo creado en DOS o
MS-Windows con algunos programas UNIX se pueden llegar a ver caracteres '^M' al
final por esta razón.
Algunas terminales adminten un control instantáneo de la salida, con las teclas
<Ctrl-S> detiene despliegue.
<Ctrl-Q> continúa despliegue.
En las máquinas UNIX, el terminal de la propia máquina UNIX se denomina
"consola"; se usa preferentemente para administración del sistema. Todas las teclas de
control funcionan bien en la consola; el funcionamiento en los emuladores de terminal
depende de la construcción del programa de emulación.

ADMINISTRACION UNIX
Políticas, Procedimientos, Ética.
Políticas
Procedimientos
Etica y actitud
Políticas.
En la administración de sistemas, la inmensa mayoría de los especialistas aconsejan
disponer de una política administrativa escrita y firmada. En muchos casos, las
instituciones legales y sociales se encuentran muy atrasadas respecto a las implicancias
de las nuevas tecnologías de comunicación, dejando vacíos en aspectos tales como
privacidad, derechos de autor, propagación de mensajes obscenos u ofensivos, etc. Las
políticas y procedimientos de una institución deben consignarse por escrito, someterse a
la aprobación de la dirección y a la verificación del departamento legal.
Las políticas definen los criterios por los que se rige la institución. La documentación
de políticas debe incluir:
servicios de administración brindados o excluídos;
derechos y responsabilidades de los usuarios;
derechos y responsabilidades de los administradores (usuarios con privilegios);
acceso a personas invitadas.
Procedimientos.
Los procedimientos describen, en forma de lista o receta, la forma en que se realizan las
diferentes tareas. Son útiles tanto para los administradores nuevos como para los
experientes. Entre sus múltiples ventajas, se destacan:
las tareas se realizan siempre del mismo modo;
se reducen las probabilidades de error;
es más rápido trabajar siguiendo una receta;
los cambios quedan documentados en el propio procedimiento;
existe un estándar de correctitud definido.
Las redes basadas en UNIX han ido sustituyendo los mainframe (computadoras de gran
porte) para aplicaciones de misión crítica en el mundo corporativo, alcanzando
proporciones considerables. En estos lugares los procedimientos son creados por un
nivel de administración por encima de quienes los ejecutan; se organizan en un libro que
se mantiene impreso y en línea. Deben existir procedimientos para las siguientes tareas:
agregar, eliminar, bloquear una cuenta de usuario;
agregar una máquina;

localizar una máquina;
instalar "TCP wrappers" para registro y control de accesos vía TCP (telnet, ftp,
finger);
instalar respaldos para una máquina nueva;
configurar la seguridad de una máquina nueva;
prever el rearranque de piezas complejas de software;
revivir un sitio web que no responde o no sirve las páginas;
destrabar y rearrancar una impresora;
actualizar el sistema operativo;
instalar un paquete de software;
instalar software desde la red;
actualizar paquetes críticos de software (sendmail, gcc, named, etc.);
respaldar y restaurar archivos;
definir condiciones y alcance en bajadas de emergencia.
Algunas políticas surgen de manera forzosa por el entorno; otras deben manejarse en
forma centralizada, como ser los números IP, nombres de máquinas, UIDs, GIDs,
nombres de grupos y de usuarios.
Las cuentas compartidas son un inconveniente para el cumplimiento de las políticas, ya
que las responsabilidades se diluyen. Es preferible disponer de un esquema de
asignación de cuentas más liberal, limitando en horario, tiempo de conexión u otros.
Otros aspectos, que pueden trascender del grupo local de administradores, incluyen:
manejo de las violaciones de seguridad;
control de exportación de sistemas de archivos;
criterios de selección de contraseñas;
bloqueo de cuentas por incumplimientos;
uso de material protegido por derechos de autor (MP3s, DVDs);
piratería de software.
En un lugar grande, la comunicación y coordinación entre los distintos grupos de
administradores es esencial.
Etica y actitud.
El administrador de sistemas es una persona con poder: dispone de la contraseña de
supervisor, puede leer el correo de los usuarios, borrar o alterar sus archivos,
distorsionar intencional o accidentalmente el sistema hasta dejarlo inutilizable, producir
pérdida de datos, trabajo y respeto por los individuos y la institución. La persona
elegida para administrar un sistema debe tener firmes convicciones éticas. Alguien con
tendencia a presumir de su condición privilegiada debe ser invitado prontamente a
cambiar de ocupación.
Las condiciones de un buen administrador son un tanto contradictorias: debe ser
innovador en la búsqueda de soluciones, pero cuidar de no arriesgar el sistema; debe
ayudar a los usuarios pero sin resentir la atención comunitaria; debe ser amable, pero
firme en los momentos críticos. En algunas organizaciones, los administradores de
sistemas son vistos como gente capaz, trabajadora, bien paga, orientada a brindar
servicio. En otras, se los trata como peones informáticos útiles para todo. Los

administradores maltratados desarrollan una oposición no formulada, una actitud de
agresividad pasiva muy inconveniente para la organización.
Las tareas de administración crecen muy rápidamente: en cuanto los usuarios descubren
a alguien capaz de resolver problemas, los pedidos proliferan. Si la persona tiene otras
tareas asignadas, debe pensar a dónde le llevará su nuevo rol. Puede ser muy difícil
convencer a la gerencia sobre el tiempo, recursos y riesgos de la operación del sistema.
Los registros escritos de tareas y tiempos pueden ser una ayuda invalorable para
solicitar recursos, colaboradores, cambios de función... o un traslado a otra sección.
El trabajo de administración de sistemas implica más cambios de tarea, y con mayores
consecuencias, en un sólo día, de lo que muchos trabajos requieren en un año. No debe
sorprender que estas personas parezcan a veces distraídas o descorteses.
El sistema de archivos
Concepto
Rutas y nombres
Montaje
Organización
Tipos de archivo
Permisos de un archivo
Propiedad de un archivo
Inodos
Ejercicios e Investigación.
Concepto. Es frecuente decir que en UNIX "todo es un archivo". Efectivamente, programadores y
desarrolladores han encontrado conveniente colocar en el espacio de nombres de
archivo entidades que no son propiamente archivos de datos: puertos seriales,
controladores de dispositivos, canales de comunicación entre procesos, porciones de
memoria compartida son vistos como archivos de datos, y en muchos casos manejados
con los mismos comandos. La ventaja de este enfoque reside, entre otras cosas, en la
posibilidad de usar llamadas al sistema uniformes cualquiera sea el dispositivo de
entrada salida referido. La redirección de entrada o salida de comandos es un ejemplo
de esta capacidad. Una extensión en otro sentido permite integrar a ese mismo espacio
de nombres unidades de almacenamiento masivo ubicadas en otras máquinas accesibles
a través de una red.
Tradicionalmente, el sistema de archivos es una abstracción usada por el kernel para
representar y organizar el almacenamiento de datos. Los dispositivos de
almacenamiento masivo de datos pueden ser de diferentes tipos: discos fijos, disquetes,
discos compactos. Los diferentes medios se integran en una estructura jerárquica única.
Esta estructura arranca en un directorio raíz designado con / y se extiende hacia abajo en
diversos niveles de subdirectorios. Las entidades no propiamente archivos se integran
en esta estructura jerárquica con naturalidad.

Un sistema de archivos comprende todas estas cosas:
un espacio de nombres: una forma de identificar entidades y organizarlas en una
estructura jerárquica;
una interfaz de programación de aplicaciones (API, Application Programming
Interface): un conjunto de llamadas al sistema para recorrer y manipular los
nodos de la estructura jerárquica. Una API es un conjunto de rutinas contenidas
en una biblioteca, un sistema operativo o un paquete de software, disponibles
para los programadores de aplicaciones a través de llamadas de función.
un modelo de seguridad: una forma de proteger, esconder, compartir
información con quienes deban disponer de ella, y solo con ellos.
una implementación: una forma de soportar el modelo lógico (los datos) sobre el
medio físico (los discos).
Los sistemas operativos actuales soportan diferentes formas de implementación de
sistemas de archivos, ya sea para leer y grabar en formatos propios de otros sistemas de
archivos (DOS, Windows, otros UNIX), como para acceder a diferentes medios (discos
compactos).
La expresión sistema de archivos puede referirse tanto a la estructura jerárquica
completa como a cada una de las partes de implementación homogénea que lo
componen. El árbol de directorios está formado por una o más de estas partes
homogéneas. En el caso de los discos, un sistema de archivos es una partición sobre la
cual se ha creado la estructura (el sistema de archivos) necesaria para contener los
archivos de datos.
Rutas y nombres.
La sucesión de directorios atravesados hasta alcanzar un nombre de archivo se
denomina ruta o vía (path). Ejemplo: /home/alberto/documentos/carta01.txt.
Una ruta es absoluta cuando arranca del directorio raíz: /bin/elvis. El directorio donde
está trabajando un usuario en el momento se denomina directorio actual. Una ruta es
relativa cuando arranca del directorio actual: documentos/carta01.txt.
No existen limitaciones para dar nombre a los archivos, salvo no usar el carácter / o
caracteres nulos. Para usar espacios en blanco, los nombres deben encerrarse entre
comillas, ya que el espacio en blanco actúa como separador en los comandos. touch "nuevo archivo"
crea un archivo del nombre indicado, con un espacio en blanco entre las dos palabras.
Para realizar cualquier operación sobre este archivo será necesario usar las comillas, o
escapar el carácter en blanco usando \: rm "nuevo archivo" rm nuevo\ archivo Ambos comandos borran el archivo.
Montaje.
Un sistema de archivos contiene un directorio principal, subdirectorios y archivos
soportados en un área de disco. Pueden adjuntarse otros sistemas de archivos al árbol de

directorios principal aplicando sobre un directorio del árbol principal el directorio
superior del sistema de archivos que se adjunta. El punto del árbol principal donde se
"cuelga" el sistema de archivos adjuntado se llama punto de montaje. Este artificio
permite disponer de un árbol único de directorios formado por partes en distintos
soportes locales o remotos. El comando mount habilita la operación de "colgar" un
sistema de archivos a un directorio del árbol principal.
mount /dev/sda0 /usuarios coloca el sistema de archivos almacenado en el disco /dev/sda0 bajo el directorio
/usuarios; para ver el contenido del sistema de archivos en disco, en lo sucesivo se hará ls /usuarios.
Un sistema de archivos se desvincula del árbol principal con el comando umount: umount /usuarios
desmonta el sistema de archivos anterior del directorio /usuarios, impidiendo el acceso a
los archivos contenidos en el disco. Para poder ejecutar umount no debe haber archivos
abiertos, ni usuarios en directorios de la rama a desmontar, ni procesos corriendo cuyos
ejecutables residan en él.
En la extensión semántica ya indicada, el término sistema de archivos se emplea así
para designar la totalidad del árbol de directorios, formado en realidad por partes de
diferente organización lógica y naturaleza física.
La lista de archivos montados en un sistema UNIX figura en el archivo /etc/fstab,
/etc/vfstab o /etc/checklist según la variedad de UNIX. Esto permite realizar tareas
sobre todos los sistemas de archivos, generalmente en el momento del arranque: fsck -p
verifica la integridad de todos los sistemas de archivos según figuran en /etc/fstab (o su
equivalente); mount -a monta todos los sistemas de archivos en /etc/fstab (o su equivalente).
Si el intento de desmontar un sistema de archivos fracasa por encontrarse éste ocupado,
el comando fuser indicará los números de proceso y los nombres de usuario que lo
ocupan. En FreeBSD, fstat hace algo similar.
Organización.
A través de las diferentes versiones de UNIX ha habido cierta confusión en cuanto a la
organización en directorios de los sistemas de archivos. No obstante, existen criterios
más o menos uniformes en cuanto a la ubicación de cada cosa. Es preferible respetar las
ubicaciones clásicas para evitar reconfigurar las aplicaciones.
Tipos de archivos.
Archivos comunes (regular files). Un archivo común es una secuencia de bytes. Su
contenido puede ser cualquiera: texto, imágenes, binarios ejecutables. UNIX no asigna
estructura alguna a los archivos comunes, aunque soporta acceso secuencial y aleatorio.
No hay caracter reservado para fin de archivo.

Directorios. Un directorio es un continente para nombres de archivos de cualquier tipo.
Las entradas . y .. designan el directorio actual y el directorio padre, respectivamente;
son visibles con ls -a. Un directorio se crea con mkdir; se borra con rmdir si está
vacío, y con rm -r si está lleno.
Un directorio puede contener dos nombres diferentes apuntando a la misma área de
datos, creando la ilusión de haber dos archivos cuando en realidad son solo uno con dos
entradas en el directorio. Este tipo de enlace se denomina enlace hard, enlace duro o
hard link, para distinguirlo del enlace simbólico explicado más adelante.
ln arch1 arch1.ln2 crea un segundo nombre arch1.ln2 dirigido a la misma área de datos del archivo arch1. rm arch1
borra la entrada de directorio arch1, pero no el área de datos. Esta permanece mientras
exista alguna entrada de directorio que la referencie. rm arch1.ln2 borra la entrada de directorio arch1.ln2 y el área de datos, ya que ésta era la última
referencia a ella.
Los "enlaces duros"solo actúan dentro de un mismo sistema de archivos. UNIX
mantiene un conteo de enlaces duros para no eliminar el archivo hasta que ha
desaparecido el último enlace a él. Este número es visible en la salida de ls -l,
después de los permisos.
Los enlaces hard no pueden hacerse sobre directorios, ni sobre otros sistemas de
archivos locales o remotos (no atraviesan "fronteras físicas").
Archivos de dispositivos de bloque y de caracter. UNIX se comunica con el hardware
y sus periféricos mediante módulos especializados en su manejo llamados controladores
de dispositivos (device drivers). Un controlador de dispositivo es visto en el sistema
como un archivo; esto provee una interfaz normalizada. Para dirigirse a un dispositivo
de hardware, el kernel solo debe referenciar el archivo controlador de dispositivo
correspondiente. Los controladores de dispositivos son de caracter cuando realizan por
sí mismos el manejo de emblocamiento (buffering). Los dispositivos de bloque manejan
porciones mayores de datos, dejando al kernel el manejo de emblocamiento. Los discos
y cintas pueden ser manejados por los dos tipos de controlador; un mismo dispositivo
físico puede tener así más de un controlador, operando de diferente forma según se lo
solicite a través de un controlador u otro.
Puede haber varias instancias de un mismo dispositivo. Los archivos de dispositivo se
definen a través de dos números un "mayor" para indicar el tipo de dispositivo, y un
"menor" para indicar la unidad física referida. Un terminal, por ejemplo, puede tener
mayor 12; entonces, ttya se describirá por 12 0, y ttyb por 12 1. Algunos dispositivos
usan el menor para indicar características del dispositivo. Un archivo de dispositivo se
crea con mknod y se elimina con rm. Suele existir un script llamado MAKEDEV,
usualmente en /dev, para crear los archivos de dispositivo correspondientes para
dispositivos comunes de hardware. Leer cuidadosamente este script antes de invocarlo;
no hacerlo si no se entiende bien como trabaja.

Sockets de dominio (BSD). Los "sockets" o "enchufes" permiten la comunicación entre
procesos, muchas veces a través de la red. Los sockets de dominio son propios de una
máquina; se los referencia como objetos de un sistema de archivos y no como puertos
de red. Los archivos "socket" sólo pueden ser leídos o escritos por los procesos
involucrados en la comunicación, aunque son visibles como entradas de directorio. Los
sockets de dominio se crean con la llamada al sistema socket(); se eliminan con rm, o
con la llamada al sistema unlink() si ya no tienen usuarios.
Interconexiones nominadas ("Named pipes"). Al igual que los sockets de dominio,
las "interconexiones nominadas" ("named pipes") permiten la comunicación entre
procesos no relacionados corriendo en la misma máquina. Las interconexiones
nominadas se crean con mknod y se borran con rm.
Enlaces simbólicos. Los enlaces simbólicos ("symbolic links", "symlinks") es el
nombre de un puntero hacia un archivo. El enlace simbólico contiene la ruta hacia el
archivo; existe como tal, independiente del archivo al que apunta. Puede referenciar
archivos en otro sistema de archivos, o aún archivos inexistentes. Los enlaces
simbólicos pueden formar lazos, referenciándose mutuamente. Un enlace simbólico se
crea con ln -s y se borra con rm.
ln -s carta.txt /grupos/trabajos/carta12.txt crea en /grupos/trabajos un pequeño archivo llamado carta12.txt que solo apunta al
archivo carta.txt en el directorio actual. rm carta.txt
borra el archivo carta.txt; el enlace simbólico carta12.txt queda apuntando al vacío. rm /grupos/trabajos/carta12.txt borra el archivo enlace simbólico.
Pueden crearse enlaces simbólicos con rutas relativas; esto permite trasladar los
directorios superiores sin alteraciones: ln -s ../../ufs /usr/include/bsd/sys/ufs permite trasladar /usr/include sin afectar el enlace simbólico. Cuando se cambia a un
directorio que es un enlace simbólico, el comando pwd indica el nombre de directorio
del enlace, pero /bin/pwd indica el nombre del directorio real.
Los enlaces simbólicos pueden referirse a archivos en otros sistemas de archivos, o a
directorios.
Propiedad de archivos.
Todos los archivos están asignados a un dueño y un grupo. El dueño de un archivo es el
usuario que lo crea; el grupo de un archivo es el grupo primario al cual pertenece el
usuario que lo crea. El comando para modificar el dueño de un archivo es chown
(change owner). El comando para modificar el grupo asignado a un archivo es chgrp.
Permisos de archivo.
Los permisos de un archivo se refieren a la posibilidad de leer, escribir y ejecutar el
archivo. Existen 9 bits de permiso, más 3 que afectan el modo de operación de los
programas ejecutables. Este conjunto de 12 bits es el modo del archivo. El tipo de

archivo, fijado al momento de su creación, ocupa 4 bits más, completando una palabra
de 16 bits. Los bits de modo se modifican con chmod; los permisos se visualizan con ls
-l.
Setuid, setgid. Los valores octales 4000 y 2000 son los bits setuid y setgid. El bit setuid
permite ejecutar el programa con el dueño del archivo como propietario del proceso; el
bit setgid permite ejecutarlo con el grupo dueño del archivo como grupo propietario del
proceso. En algunos sistemas el bit setgid se usa en directorios para fijar el grupo dueño
igual al del directorio cuando se crea un nuevo archivo.
Sticky bit. El valor octal 1000 es el "sticky bit". Originalmente indicaba procesos que
debían permanecer en memoria; actualmente se usa en algunos sistemas para conferir a
los directorios compartidos la propiedad de impedir borrar archivos a otros que no sean
el dueño del directorio, el dueño del archivo o el superusuario.
Bits de permiso. Se agrupan en conjuntos de tres bits, representando permisos de
lectura, escritura y ejecución. Existen tres grupos de 3 bits, con los respectivos permisos
para el usuario, el grupo y otros. El significado de los permisos varía según se trate de
un archivo o un directorio:
Permiso Símbolo Binario Archivo Directorio
ninguno - 000 ninguno ninguno
lectura r 100 ver contenido ver nombres de archivos y
subdirectorios
escritura w 010 modificar contenido,
permisos
crear y eliminar archivos y
subdirectorios en el directorio
ejecución x 001 ejecutar el archivo
como programa
acceder al directorio (posicionarse en
él o invocar programas)
El uso del sistema octal permite codificar el grupo de permisos de 3 bits en un único
dígito octal para todas las combinaciones posibles de permisos:
Octal Binario Permisos
0 000 ---
1 001 --x
2 010 -w-
3 011 -wx
4 100 r--
5 101 r-x
6 110 rw-
7 111 rwx

Los permisos que recibe efectivamente un usuario se definen por uno de los tres
conjuntos de permisos: se verifica primero su condición de dueño (permisos de usuario,
primer conjunto de 3 bits): si el usuario es el dueño, recibe los permisos de dueño; si no
lo es, se examina su condición de integrante del grupo al que está asignado el archivo o
directorio (permisos de grupo, segundo conjunto de 3 bits); si el usuario pertenece al
grupo del archivo o directorio, recibe los permisos de grupo; si no es dueño ni pertenece
al grupo, recibe los permisos de otros (tercer conjunto de 3 bits).
El cambio de permisos se hace mediante el comando chmod. Este comando acepta tanto
la notación en octal como la notación simbólica mediante letras. Solo el dueño o el
superusuario pueden cambiar permisos.
Es posible fijar permisos por defecto para nuevos archivos o directorios al momento de
su creación, mediante el comando umask. Este comando acepta 3 dígitos octales que
representan los permisos a quitar. El valor por defecto suele ser 022: plenos permisos al
dueño, prohibe escritura a grupo y otros. No es posible imponer una umask a los
usuarios: éstos siempre pueden cambiarla. Es posible colocar una umask por defecto
inicial, en los archivos de inicialización del intérprete de comandos, por ejemplo .cshrc
o .profile.
Permisos recibidos por cada nuevo archivo o directorio según el valor de umask:
Octal Binario Permisos
0 000 rwx
1 001 rw-
2 010 r-x
3 011 r--
4 100 -wx
5 101 -w-
6 110 --x
7 111 ---
Inodos.
Parte
Indica
- tipo de archivo
rwxr-xr-x permisos de dueño, grupo y otros
1 cantidad de enlaces hard
root dueño

El núcleo mantiene la
información de archivos en
estructuras llamadas inodos.
La tabla de inodos se crea
cuando se crea el sistema de
archivos; su tamaño y
ubicación en el disco son fijos.
Los items de mayor interés contenidos en un inodo son cuenta de enlaces, dueño, grupo,
modo, tamaño, fecha de último acceso, fecha de última modificación, tipo de archivo.
Estos datos se hacen visibles con el comando ls -l. Una línea típica de salida para este
comando podría ser:
-rwxr-xr-x 1 root bin 279352 Mar 31 1997 /bin/bash
El primer caracter, para tipo de archivo, admite los siguientes significados:
Tipo de archivo Símbolo Creado por Eliminado por
archivo regular - editores, copia, comando touch rm
directorio d mkdir rmdir, rm -r
dispositivo de caracteres c mknod rm
dispositivo de bloques b mknod rm
socket s socket rm
interconexión nominada (named pipe) p mknod rm
enlace simbólico l ln -s rm
En los bits de permisos, si el setuid está puesto, la x del dueño aparece como s; si el
setgid está puesto, la x del grupo aparece como s; si el "sticky bit" está puesto, la x de
otros aparece como t; si en algún caso el permiso x está ausente, se muestran como S o
T, respectivamente, indicando la anomalía.
La salida del comando ls -l difiere cuando se trata de archivos de dispositivo; en este
caso se indican los números mayor y menor en lugar del tamaño: crw-rw-rw- 1 root tty 3, 176 May 20 1996 /dev/ttya0
La salida de ls -l para un enlace simbólico tiene este aspecto: lrwxrwxrwx 1 root root 279352 4 Aug 22 17:52 /bin/sh -> bash
El dueño se cambia con el comando chown, y el grupo con chgrp.
Manejo de discos.
UNIX maneja el espacio en disco en bloques; según los sistemas, un bloque tiene
típicamente 512 bytes o 1024 bytes. Un mismo disco puede contener varios sistemas de
archivos, incluso de distinto tipo, pero un mismo sistema de archivos no puede abarcar
varios discos. UNIX hace este hecho transparente al usuario: la jerarquía de directorios
bin grupo
279352 tamaño en bytes
Mar 31
1997 fecha
/bin/bash ruta y nombre

se ve como algo homogéneo. La confiabilidad del sistema aumenta si se definen
sistemas de archivos diferentes para /, /var, /usr, /home, /export:. el agotamiento de
espacio en un sistema de archivos diferente de / no produce un error fatal.
Especialmente /home y /var son propensos a llenarse. Es parte de las tareas rutinarias de
administración gestionar el espacio en disco.
El espacio libre en disco puede monitorarse por el comando df. Este comando muestra
el espacio utilizado y libre en cada sistema de archivos. Para determinar el espacio
utilizado por archivos o directorios, se dispone del comando du.
El siguiente comando permite encontrar los archivos mayores que 200 bloques: find / -size +200 -exec ls -l {} \;
La falla de un comando o aplicación genera un archivo denominado core. Estos archivos
pueden ser grandes. Denotan algún tipo de error en el sistema; su ubicación puede dar
una pista del origen, pero en general no son útiles para el usuario no especializado. El
siguiente comando lista los archivos core en el sistema: find / -name core -print
El comando siguiente los busca y borra sin preguntar nada: find / -name core -exe rm {} \;
Los archivos en /tmp pueden acumular espacio. Este directorio se reserva para archivos
temporales; un usuario o una aplicación no puede asumir la permanencia de estos
archivos. El administrador puede, en forma manual o automática, borrar los archivos
con más de cierta antigüedad. El siguiente comando encuentra los archivos de /tmp
modificados hace más de 10 días: find /tmp -mtime +10 -print
Ejercicios e Investigación.
1. Si su sistema dispone de algún programa de administración de archivos; explore con
él los primeros niveles del sistema de archivos. Los comandos ls y cd bastan a este
propósito.
2. Determine la situación de montajes en su sistema, usando mount.
3. Estudie los tipos de sistema de archivos que soporta su versión de UNIX, en
particular con soporte sobre disquete. Realice el montaje de un disquete sobre el punto
/mnt u otro; verifique que puede acceder a los archivos; luego desmonte el disquete.
4. Con el comando ln, experimente la creación de enlaces hard y simbólicos,
verificando con ls las características del enlace (ls -ld directorio) y su contenido
(ls -l directorio).
5. Experimente cambiar permisos con el comando chmod, tanto usando notación
numérica como simbólica.

6. Verifique el valor por defecto de umask. Cambie el valor de umask; verifique creando
archivos con touch.
7. Con los comandos ls y cd, explorar el directorio /dev o su equivalente, buscando
visualizar características de archivos de dispositivo.
8. Determine si su sistema soporta uso de sticky bit: cree un directorio, active el sticky
bit, verifique luego si otros usuarios pueden crear y borrar archivos en ese directorio.
9. Estudiar los comandos df y du, sus opciones y la forma en que dan la salida (bloques
o Kb).
10. Determine en qué archivo guarda sus sistema la lista de sistemas de archivos a
montar (/etc/fstab, /etc/vfstab, /etc/checklist, otro). Visualice el archivo con more.
Compare la situación de montajes con el contenido de ese archivo. ¿Puede interpretar
todos sus campos? Busque una página man sobre la estructura interna de este archivo.
Superusuario y usuarios especiales.
Control admnistrativo del sistema
Propiedad en UNIX
Propiedad de archivos
Propiedad de procesos
El Superusuario
Contraseña de root
Acceso a root
Usuarios especiales
Ejercicios e investigación
Control administrativo del sistema.
Salvo en los sistemas operativos para uso personal (MS-DOS, Windows, Macintosh), en todos
los sistemas operativos el control administrativo del sistema está fuera de las posibilidades de
acceso de los usuarios comunes. En los sistemas UNIX, una cuenta de usuario especial llamado
"superusuario" tiene los privilegios necesarios para realizar tareas tales como control de
procesos, creación de usuarios, agregado de dispositivos, fijar permisos de acceso a la
información y toda otra tarea que implique cambios en el sistema.

Propiedad en UNIX.
En UNIX, los procesos y archivos tienen asociado un usuario como dueño. El dueño de un
archivo es el usuario que lo crea. Un proceso es un programa en ejecución; el dueño del
proceso es el usuario que lo arranca. Los derechos del dueño sobre sus archivos y procesos
sólo pueden ser subrrogados por el superusuario. Tanto para archivos como para procesos
existe también un grupo al que ese proceso o archivo pertenece. Un grupo es un conjunto de
usuarios; un usuario puede pertenecer a varios grupos. Un archivo o proceso pertenece al
grupo primario o grupo principal del usuario que crea el archivo o arranca el proceso.
Propiedad de archivos.
Todo archivo tiene un usuario propietario y un grupo propietario. El propietario de un archivo
puede controlar los permisos de su archivo. Existe un juego de permisos de usuario para el
propietario de un archivo.
Todo archivo tiene también un grupo propietario. Existe un juego de permisos de grupo
para el grupo propietario de un archivo. Cualquier usuario miembro del grupo puede
realizar sobre el archivo las operaciones permitidas por los permisos de grupo asignados
a ese archivo.
Existe también un juego de permisos de otros para usuarios en general, que no sean
dueños del archivo ni pertenezcan al grupo del archivo.
El propietario y grupo de un archivo aparecen en la salida larga del comando ls: ls -l .
muestra dueño, grupo, permisos y otros datos de archivos en el directorio actual.
UNIX reconoce internamente a los usuarios y grupos mediante números. El número
idenfiticador de usuario se llama UID. La equivalencia entre UID y nombre de usuario
consta en el archivo /etc/passwd, donde figura también el grupo primario al que
pertenece el usuario. El grupo primario es el grupo al que se asigna al usuario en el
momento de su creación. El grupo primario es único para cada usuario.
El número identificador de grupo se llama GID. La equivalencia entre GID y nombre de
grupo consta en el archivo /etc/group, donde figuran también los integrantes de cada
grupo secundario. Los grupos secundarios son otros grupos a los que puede pertenecer
el usuario además de su grupo primario. Un usuario puede pertenecer a varios grupos
secundarios.
Propiedad de procesos.
El kernel (núcleo) de UNIX asocia a cada proceso cuatro números: UID real, UID efectivo, GID
real y GID efectivo. UID y GID reales se usan para fines contables; UID y GID efectivos para
determinar permisos de acceso. Generalmente los números reales y efectivos son los mismos.
No obstante, cuando un proceso ejecuta un nuevo programa haciendo uso de alguna de las
llamadas al sistema de la familia exec, el nuevo proceso generado puede correr con UID y GID
del archivo, eventualmente diferentes del UID y GID del usuario que invocó el proceso original.

Los bits setgid y setuid fijados en los archivos permiten correr procesos con los
permisos del dueño y grupo del archivo, y no de quien los invoca. Un ejemplo es el
comando passwd: para cambiar una contraseña se requiere permiso de superusuario: ls -l /usr/bin/passwd muestra los siguientes permisos -rwsr-xr-x 1 root root 28896 jul 17 1998 /usr/bin/passwd
Por tener fijado setuid, el proceso passwd correrá con permiso real del usuario que lo
invoca, pero con permiso efectivo de supervisor.
El Superusuario.
La administración del sistema requiere desconocer las medidas de protección de UNIX. Para
ello existe una cuenta especial con UID 0, por convención asociada a una cuenta de usuario de
nombre "root". El nombre puede ser cualquiera; lo decisivo es el UID 0.
El superusuario puede realizar cualquier operación posible sobre archivos y procesos;
muchas llamadas al sistema sólo pueden ser realizadas por el superusuario o tienen
opciones especiales para el superusuario no disponibles para los usuarios comunes. Las
llamadas al sistema son formas de solicitar servicios al kernel.
Ejemplos de operaciones restringidas al superusuario:
Montar y desmontar sistemas de archivos. Cambiar el directorio raíz de un proceso con chroot. Crear archivos de dispositivos. Fijar la hora del sistema Cambiar propiedad de archivos. Fijar límites al uso de recursos; fijar prioridades de procesos. Fijar el nombre propio de la máquina donde reside el sistema. Configurar interfaces de red. Cerrar el sistema.
Como ejemplo, el programa login, antes de recibir nombre y contraseña del usuario, corre
como root; una vez que el usuario es reconocido, el proceso cambia su UID y GID a los del
usuario y arranca el intérprete de comandos (shell) del usuario. Una vez que un proceso
adquiere UID y GID de usuario común no puede ya retornar a sus privilegios anteriores.
Contraseña de root.
En la contraseña de root reside toda la seguridad del sistema. Debe elegirse una contraseña
difícil de adivinar o descubrir. Una buena contraseña debe tener al menos 8 caracteres,
mezclar letras con números o símbolos, o combinar mayúsculas y minúsculas. Solía
recomendarse el uso de dos palabras al azar separadas por un símbolo como compromiso
entre la seguridad y la memorización; actualmente este esquema no ofrece seguridad. La
receta actual consiste en inventar una frase "de chocante sinsentido" fácil de recordar para el
usuario y armar la contraseña con las primeras letras de cada palabra. Agregar algún número o
carácter de puntuación aumenta mucho la seguridad de este tipo de contraseñas. Un ejemplo:
"No Pagar Software En 2001" genera la contraseña "npse2k1", muy difícil de violar, aunque la

frase no es chocante ni sinsentido. Estas "cualidades" se recomiendan para facilitar el recuerdo
de la frase.
La contraseña de root debe cambiarse:
al menos cada tres meses; cada vez que se retire alguien que la conoce; siempre que se sospeche una situación de inseguridad.
El olvido de la contraseña de root es un problema mayor: puede requerir ingresar al sistema
vía CD de instalación o disquete de arranque. Esto implica, obviamente, bajar el sistema.
Acceso a root.
La forma más inmediata de acceder a root es ingresar al sistema como el usuario root. Es
mejor usar el comando su, que permite asumir la identidad de root luego de pedir contraseña,
pero deja constancia del usuario que la asumió. Una buena medida de seguridad es
deshabilitar el acceso directo a root desde todas las terminales excepto la consola. La forma
segura de operar como root es ingresar al sistema como usuario común, hacer su solo para
realizar tareas administrativas, finalizando con exit enseguida de terminar, continuando la
sesión como usuario común. El comando su nombre_usuario permite asumir la identidad
de cualquier usuario si se conoce su contraseña; si ya se es root no pide contraseña. El uso de
su puede requerir pertenecer al grupo wheel, o estar limitado a ciertas terminales.
La sentencia sudo comando permite ejecutar el comando con privilegios de root, si el
nombre del usuario figura en el archivo /etc/sudoers. Este archivo lista nombres de
usuarios, comandos autorizados y máquinas donde pueden correrlos. Si estos datos
validan, se pide al usuario su contraseña y el comando ejecuta con privilegios de
supervisor.
# /etc/sudoers
#
# Alias para grupos de máquinas
Host_Alias LABSOFT=pino,aromo,ceibo,acacia
Host_Alias MEDIDAS=ombu,girasol,alamo
# Alias para comandos de respaldo
Cmd_Alias RESP=/usr/etc/dump, /usr/etc/restore
# usuario, máquinas, comandos permitidos
marcos LABSOFT=ALL,MEDIDAS=RESP
edgard LABSOFT=/usr/local/bin/tcpdump
mendez ALL=ALL

El archivo /etc/sudoers se modifica usando el comando visudo, capaz de validar la sintaxis
antes de grabar los cambios. Los comandos ejecutados con sudo se registran vía syslogd. Los
comandos a ejecutar vía sudo deben escribirse en /etc/sudoers con la ruta completa, para
evitar una posible sustitución fraudulenta.
Ventajas de sudo:
mejor contabilidad y registro; los operadores pueden trabajar sin privilegios ilimitados; la contraseña de root la conocen pocas personas; pueden revocarse privilegios sin cambiar contraseña de root;
es más rápido usar sudo que usar su o ingresar al sistema como root; existe una lista restringida de usuarios con privilegios; disminuye la probabilidad de dejar una sesión de root abierta; como depende de las máquinas, un sólo archivo sirve para controlar el acceso en toda
la red.
Riesgos:
la seguridad de un usuario puede comprometer la de root; sudo csh o sudo su evitan el registro de comandos; no deben habilitarse.
Usuarios especiales.
En UNIX existen cuentas de usuarios no humanos usadas por el sistema; suelen tener un
asterisco * en el campo de la contraseña en el archivo /etc/passwd o /etc/shadow, lo que
impide el ingreso por estas cuentas.
daemon: propietario de archivos y procesos propios del sistema operativo no
privilegiados, que sería inseguro conceder a root. Con el mismo propósito existe un
grupo daemon.
bin: propietario de directorios de comandos y de muchos de los propios archivos de
comandos. Actualmente existe la tendencia a dejar los archivos y directorios de
comandos propiedad de root.
sys: propietario de imágenes del kernel y la memoria, tales como /dev/kmem (espacio
de direcciones del kernel), /dev/mem (memoria física del sistema), /dev/drum o
/dev/swap (imagen del área de intercambio del sistema). Los programas que acceden
estos archivos lo hacen setuid a sys (corren con sys como dueño).
nobody: UID -1 o -2; -1 puede aparecer como 32767, lo que confunde a los programas
adduser cuando determinan el siguiente UID libre. En Linux la cuenta nobody tiene
UID 65534. Este usuario sin privilegios es útil para acceder archivos remotos vía red
usando NFS, el sistema de exportación de archivos de UNIX, así como para correr otros
comandos como finger donde sería riesgoso conceder privilegios aún de usuario común.
Usuarios habilitados a hacer uso de algún servicio del sistema sin estar registrados en él,
como en los servidores web, reciben la identidad nobody. La cuenta nobody no debe ser
propietaria de ningún archivo.

Creación de Usuarios
El archivo /etc/passwd
El archivo /etc/shadow
El archivo /etc/group
Crear usuarios
Edición de archivos.
Fijar contraseña inicial
Directorio propio del usuario
Copiar archivos de inicialización
Casilla de correo
Editar /etc/group
Información contable
Tabla de usuarios y guía telefónica
Fijar cuotas
Verificar la nueva cuenta
Eliminar usuarios
Inhabilitar cuentas.
Caducidad de contraseñas. Pseudo-logins.
Herramientas de administración de usuarios
Ejercicios e Investigación.
Bibliografía y referencias.
La creación y remoción de usuarios es una tarea de rutina en la administración de sistemas.
Suele ser realizada a través de programas asistentes de administración, usualmente de
interface gráfica, o a través de scripts o guiones de comandos. Aquí se describen las tareas
paso a paso en su realización manual. Finalmente se hace referencia a comandos existentes en
algunos sistemas para facilitar y asegurar la ejecución de estos procesos. El mantenimiento de
usuarios es un tema de importancia para la seguridad del sistema; las cuentas poco usadas, o
de contraseña trivial, son el blanco preferido de los violadores de sistemas.
Existen servicios especiales para el manejo de cuentas a nivel de red, simplificando la
administración y permitiendo el ingreso del usuario en cualquier máquina de la red.

Estas facilidades tienen sus propios problemas de seguridad; son un tema aparte; no se
tratan aquí.
El archivo /etc/passwd.
El archivo /etc/passwd contiene la lista de usuarios en el sistema, una línea por usuario. Es
consultado cuando el usuario ingresa al sistema para determinar su UID; en muchos casos,
contiene también la contraseña encriptada, aunque la tendencia actual es retener la
contraseña encriptada en otro archivo, /etc/shadow, con permisos de acceso más restringidos.
En este último caso, el proceso de login consulta ambos archivos, /etc/passwd y /etc/shadow.
Los campos de /etc/passwd y /etc/shadow están separados por ":", al igual que la
mayoría de los archivos de configuración en UNIX.
Ejemplo de entradas en /etc/passwd:
root:x:0:0::/root:/bin/bash
bin:x:1:1:bin:/bin:
ftp:x:404:1::/home/ftp:/bin/bash
daemon:x:2:2:daemon:/sbin:
adm:x:3:4:adm:/var/adm:
lp:x:4:7:lp:/var/spool/lpd:
mail:x:8:12:mail:/var/spool/mail:
postmaster:x:14:12:postmaster:/var/spool/mail:/bin/bash
news:x:9:13:news:/usr/lib/news:
uucp:x:10:14:uucp:/var/spool/uucppublic:
man:x:13:15:man:/usr/man:
guest:x:405:100:guest:/dev/null:/dev/null
nobody:x:65534:100:nobody:/dev/null:
jperez:x:1000:100:Juan PEREZ,,,:/home/jperez:/bin/bash
mmendez:x:1001:100:Mario MENDEZ,,,:/home/mmendez:/bin/bash
gmartin:x:1002:100:Gerardo MARTIN,,,:/home/mmendez:/bin/bash
En su versión clásica, el archivo /etc/passwd contiene los siguientes campos:
nombre de login: nombre único, no más de 8 caracteres, sin signos de puntuación;
generalmente en minúscula para compatibilidad con todos los agentes transporte de
correo. Evitar nombres totalmente en mayúsculas, porque: el sistema asumirá que el
terminal no soporta minúsculas y abrirá una sesión totalmente en mayúsculas. El

nombre de login es un dato público; deben elegirse nombres que favorezcan el
reconocimiento de los usuarios en la vida real. En el acceso a diferentes máquinas, es
conveniente asignar a un mismo usuario el mismo nombre de login. Conviene asimismo
evitar el uso del mismo nombre para usuarios diferentes en distintas máquinas; los
agentes transporte de correo y los usuarios pueden caer en confusión. También debe
asegurarse no usar un nombre de login que sea a la vez un alias de correo para otro
usuario.
contraseña encriptada: la contraseña se encripta con un algoritmo llamado DES; debe
ser fijada por el comando passwd (o yppasswd si se usa NIS), o copiar una contraseña
ya encriptada de otra cuenta. Si este campo está en blanco, el acceso es sin contraseña;
esto es una gran brecha de seguridad. Si se coloca un asterisco en este campo, la cuenta
no puede accederse hasta que el supervisor asigne una contraseña (comando passwd, o
yppasswd si se usa NIS). En sistemas que usan /etc/shadow, la contraseña se encuentra
en este archivo y no en /etc/passwd. Los archivos /etc/passwd y /etc/shadow deben
mantenerse consistentes; existen comandos que atienden esta situación específicamente.
número UID: número identificatorio del usuario, generalmente entre 0 y 32767 o
65535, según se usen enteros con o sin signo. Muchos sistemas han pasado ya a
números de 32 bits. Debe ser único en toda la red local. Los números de 0 a 99 se
reservan para usuarios no humanos; 0 para root, 1 para bin, 2 para daemon, etc. Debe
evitarse la reutilización de números de usuarios que han dejado la institución, para
evitar confusiones si han quedado archivos del usuario anterior en el sistema o al
restaurar desde respaldo; recordar que los usuarios en el sistema son reconocidos por
número y no por nombre.
número GID por defecto: número identificatorio de grupo, también entre 0 y 32767 o
65535. Los números bajos se reservan para grupos del sistema: 0 para el grupo root o
wheel, 1 para el grupo daemon. Los grupos se definen en el archivo /etc/group. El
número GID define el grupo de pertenencia de los archivos creados por el usuario, o de
procesos iniciados por él. La pertenencia a grupo de un nuevo archivo es la del
directorio donde se encuentra si éste directorio tiene fijado setgid. El uso de la opción
grpid en el comando mount también obliga a los archivos nuevos a tomar como
grupo el del directorio donde son creados. El comando newgrp permite a un usuario
cambiar su grupo primario hacia otro al cual también pertenezca; el comando sg
permite ejecutar un comando como perteneciendo al grupo indicado en el propio
comando.
información de usuario (campo "GECOS"): históricamente usado para transferir
trabajos en batch desde una máquina UNIX hacia un mainframe corriendo GECOS. Se
usa ahora, sin una sintaxis fija, para contener información del usuario. El comando
finger interpreta este campo como una lista separada por comas conteniendo: 1)
nombre en la vida real, 2) edificio y número de oficina, 3) teléfono interno, 4) teléfono
domiciliario. El comando chfn permite al usuario cambiar su información propia.
directorio propio (home): cuando el usuario ingresa al sistema, es colocado en su
directorio propio; si éste no existe, algunos sistemas impiden el ingreso; otros emiten un
mensaje de error, aceptan el ingreso y colocan al usuario en el directorio raíz. El
directorio propio del usuario suele tener su mismo nombre de login; se ubica (o se
monta) habitualmente bajo /home.

shell de login: al ingresar al sistema, el usuario dispone de un intérprete de comandos
por defecto, generalmente /bin/sh o /bin/csh; también pueden ser /bin/bash, /bin/ksh,
/bin/tcsh, u otros. El usuario puede cambiar su intérprete con el comando chsh, o a
veces simplemente invocando el nuevo shell; el archivo /etc/shells contiene los
intérpretes habilitados para elección de los usuarios con chsh. Al editar/etc/shells, en los
nombres de invocación de los shell debe figurar la vía completa.
El archivo /etc/shadow.
El archivo /etc/passwd las contraseñas encriptadas, una línea por usuario; solo es visible al
supervisor. Provee además información relativa a cambio de contraseñas y expiración de la
cuenta.
Ejemplo de entradas en /etc/shadow:
root:1eklLr8RdBuao:10461:0:::::
bin:*:9797:0:::::
ftp:*:9797:0:::::
daemon:*:9797:0:::::
adm:*:9797:0:::::
lp:*:9797:0:::::
mail:*:9797:0:::::
postmaster:*:9797:0:::::
news:*:9797:0:::::
uucp:*:9797:0:::::
man:*:9797:0:::::
guest:*:9797:0:::::
nobody:*:9797:0:::::
jperez:Uq54ay2A4F6MY:10461:0:99999:7:::
mmendez:dp079LiquZhwo:10454:0:99999:7:::
gmartin:Gr989KumerAdf:10231:0:99999:7:::
Contiene los siguientes campos:
nombre de login: el mismo nombre que en /etc/passwd; este nombre conecta las
entradas en /etc/passwd y /etc/shadow.
contraseña encriptada: bajo las mismas condiciones que en /etc/passswd; la
contraseña encriptada es desplazada del /etc/passwd al /etc/shadow, dejando en
/etc/passwd una x en este campo.

fecha de úlimo cambio de contraseña: registra la fecha en que el usuario cambió por
última vez su contraseña.
mínima cantidad de días entre cambios de contraseña: una vez cambiada una
contraseña, el usuario no puede volver a cambiarla hasta que haya transcurrido esta
cantidad de días como mínimo. No se recomienda fijar este valor; si ha habido una
violación de seguridad puede ser necesario cambiar la contraseña de inmediato, sin
tener que esperar.
máxima cantidad de días entre cambios de contraseña: obliga a los usuarios a
cambiar su contraseña periódicamente. En Linux, este valor se suma al campo de
inactividad antes de bloquear la cuenta.
cantidad de días de adelanto para avisar expiración de contraseña: avisa al usuario
de la necesidad del cambio de contraseña, a partir de esta cantidad de días antes de la
fecha límite.
cantidad de días de inactividad antes de expirar la cuenta: en Solaris, si pasa esta
cantidad de días sin login del usuario se bloquea la cuenta; en Linux, son días de gracia
después del máximo sin cambiar contraseña y antes de bloquear la cuenta.
fecha de expira de la contraseña: día contado a partir del 1-1-1970, en que la cuenta
expirará. Si el campo está en blanco, la cuenta no expira nunca. Si ha transcurrido esta
fecha, el campo debe ser repuesto por el administrador para rehabilitar la cuenta.
banderas: reservado para usos futuros.
El archivo /etc/group.
El archivo /etc/group contiene los nombres de los grupos UNIX definidos en el sistema y una
lista de sus miembros. Hay una línea por cada grupo. Los campos están separados por ":".
Ejemplo de entradas en /etc/group:
root::0:root
bin::1:root,bin,daemon
daemon::2:root,bin,daemon
sys::3:root,bin,adm
adm::4:root,adm,daemon
tty::5:
disk::6:root,adm
lp::7:lp
mem::8:
kmem::9:

wheel::10:root
floppy::11:root
mail::12:mail
news::13:news
uucp::14:uucp
man::15:man
usuarios::100:jperez,mmendez,gmartin
nogroup::-2:
Cada línea contiene:
nombre del grupo: algunos sistemas piden 8 caracteres o menos.
contraseña encriptada: histórico, no se usa. El comando newgrp no cambia el grupo
por defecto de un usuario si su nombre no está listado en el grupo al que quiere cambiar,
aún cuando este campo esté en blanco (lo usual).
número GID: número único identificador del grupo. Para mantener coherencia en un
sistema heterogéneo es recomendable no usar como grupo por defecto de los usuarios
un grupo del sistema o del proveedor (por ejemplo, users, o staff), sino un grupo creado
por el administrador (por ejemplo, usuarios), ya que diferentes sistemas pueden asignar
diferente GID a los mismos grupos del sistema.
lista de integrantes: nombres de login de los integrantes del grupo separados por
comas, sin blancos.
Crear usuarios.
Antes de abrir una cuenta a un nuevo usuario, éste debe fechar y firmar su conformidad con el
documento descriptivo de política de uso del sistema local. La experiencia demuestra ser
mucho más difícil de conseguir una firma de conformidad después de haber sido abierta y
concedida la cuenta.
La creación de usuarios se realiza en tres fases: dos para establecer el ambiente del
usuario y una tercera para objetivos administrativos.
Requeridos:
definir la cuenta del usuario, ingresándola en los archivos /etc/passwd y /etc/shadow; fijar una contraseña inicial; crear el directorio propio (home) del usuario.
En beneficio del usuario:

copiar hacia el directorio personal del usuario archivos de inicialización; fijar la casilla de correos del usuario y establecer alias de correo.
Para administración:
agregar el usuario al archivo /etc/group; registrar información contable, si es necesario; ingresar al usuario en la base de datos global del sistema; ingresar información de contacto con el usuario (dirección, teléfono); configurar cuotas de disco; verificar el establecimiento correcto de la cuenta.
Edición de archivos.
Si estas herramientas existen en el sistema, la edición de /etc/passwd debe hacerse con vipw,
que bloquea el archivo para evitar interferencias si un usuario está cambiando su contraseña
simultáneamente. Con vipw -s se edita /etc/shadow. Se insiste en la necesidad absoluta de
mantener coordinados los archivos /etc/shadow y /etc/passwd. La edición de /etc/group se
hace con vigr. Con vigr -s se edita /etc/shadow-group o /etc/gshadow, en caso de que
exista un archivo shadow para grupos. Si el sistema provee scripts para crear, modificar o
borrar usuarios, éstos se ocupan de mantener la coherencia y bloquear los archivos antes de
modificarlos. El siguiente análisis de creación manual de un usuario muestra el procedimiento
subyacente en las herramientas habituales de adminstración.
Fijar contraseña inicial.
El superusuario puede cambiar en cualquier momento la contraseña de cualquier usuario
mediante el comando
passwd nombre_usuario.
Un usuario común puede cambiar su propia contraseña digitando solamente passwd. El
comando passwd suele exigir un mínimo de largo o uso de caracteres de puntuación,
números, mezcla de mayúsculas y minúsculas, para alcanzar un cierto nivel de inviolabilidad.
No debe dejarse nunca una cuenta sin contraseña, especialmente en ambientes de red o con
acceso a Internet.
Crear directorio propio del usuario.
La siguiente secuencia de comandos crea un directorio para el usuario jperez: mkdir /export/home/jperez chown jperez /export/home/jperez chgrp usuarios /export/home/jperez chmod 700 /export/home/jperez
En ambientes menos restrictivos, los permisos de los directorios propios pueden ser
755, lo que permite a todos los usuarios del sistema ver los directorios personales. Los
usuarios siempre pueden limitar el acceso sobre los subdirectorios contenidos en su
directorio personal.
Copiar archivos de inicialización.
Algunos comandos y utilitarios admiten personalización colocando archivos en el directorio
propio del usuario. Estos archivos generalmente empiezan con punto, lo que los hace

normalmente ocultos, y terminan con rc, por "run command". Siguen algunos ejemplos
comunes:
Comando Archivo Usos
csh .login fija tipo de terminal, variables de ambiente, opciones para biff y mesg
.cshrc
fija alias de comandos, rutas de búsqueda, valor de umask, cdpath para
búsqueda de nombres de archivo; fija variables promtp, history, savehist
.logout imprime recordatorios, borra la pantalla
sh .profile
fija tipo de terminal, variables de ambiente, opciones para biff y mesg; fija
alias de comandos, rutas de búsqueda, valor de umask, cdpath para búsqueda
de nombres de archivo, etc.
vi .exrc opciones para el editor vi
emacs .emacs_pro Opciones y asignación de teclas para el editor emacs
mailx .mailrc aliases personales para correo, opciones para el lector de correo
tin .newsrc especifica grupos de interés para noticias
xrdb .Xdefaults fija configuración de X11 (sistema de ventanas): tipos de letra, colores, etc.
startx .xinitrc fija ambiente inicial para X11
xdm .xsession fija ambiente inicial para X11
Suele haber un conjunto ya preparado de archivos de inicialización, usualmente en
/erc/skel; también pueden crearse, en /etc/skel o en /usr/local/lib/skel, editándolos para
reflejar configuraciones útiles al usuario corriente. Se debe proveer un ambiente
razonable para usuarios no calificados, sin "sobreprotección": evitar cosas tales como
crear alias de comandos para emular DOS, u obligar a uso interactivo en el borrado.
La siguiente secuencia de comandos instala los archivos de inicialización en el
directorio propio del usuario: cp /usr/local/lib/skel/.[a-zA-Z]* /export/home/jperez chmod 644 /export/home/.[a-zA-Z]* chown jperez /export/home/.[a-zA-Z]* chgrp usuarios /export/home/.[a-zA-Z]*
No es posible usar el comando chown jperez /export/home/.* ya que ello cambiaría la propiedad del directorio padre, /export/home, dándosela al
usuario jperez, debido a que el directorio padre ".." queda incluído en ".*"; éste es un
error común y peligroso.

Casilla de correo.
Es conveniente limitar la lectura de correo por parte de un usuario a una máquina única,
aquella en la cual habitualmente trabaja. Para ello, se crea en el archivo /etc/aliases una
entrada que dirige el correo del usuario hacia una máquina específica. Las líneas jperez: jperez@alamo juanperez: jperez
redirigen el correo de jperez hacia la máquina alamo y fijan juanperez como alias de jperez. En
ambientes de red suele resolverse este problema eligiendo una máquina como servidor de
correo y montando el directorio /var/spool/mail de esta máquina vía NFS en el /var/spool/mail
de las restantes máquinas.
Editar /etc/group.
Si bien no es necesario asignar el usuario a su grupo por defecto en /etc/group, conviene
igualmente hacerlo para tener actualizada la lista de integrantes del grupo. Sí debe editarse
/etc/group para incluir al usuario en grupos secundarios. Algunos sistemas requieren que el
usuario figure en el grupo wheel para poder hacer su.
Información contable.
Muchos sitios controlan o aún facturan servicios informáticos por uso. En estos casos, al crear
un usuario debe registrarse la información pertinente, tal como nombre, número de cuenta,
calendario de pago, dirección de cobro.
Tabla de usuarios y guía telefónica.
Es fácil crear una tabla de usuarios y números telefónicos extrayendo la información del campo
GECOS del archivo /etc/passwd, sobre todo si se tomaron en cuenta las recomendaciones para
uso de comas en este campo. Esta tabla puede luego interrogarse con un script simple tal
como: #!/bin/sh # telefono: devuelve línea con datos del usuario grep $1 /usr/local/pub/telefonos
que se invoca simplemente como telefono jperez
y devuelve una línea con los datos del usuario indicado en el parámetro.
Fijar cuotas.
Si en el sistema se utilizan cuotas para controlar el uso de disco, es preciso fijar la cuota para el
nuevo usuario con el comando edquota. Este comando admite diversos parámetros para fijar
límites en el uso de disco, pero en la creación de usuarios es más frecuente usarlo en modo
prototipo, copiando el perfil de cuota de algún usuario tomado como modelo:
edquota -p usuario-modelonuevo-usuario
Verificar la nueva cuenta.
Para verificar la validez de la nueva cuenta, ingresar al sistema como el nuevo usuario y
ejecutar los comandos pwd ls -la
para verificar la ubicación inicial en el directorio propio y la existencia de los archivos de inicialización.

El usuario debe ser notificado por algún medio seguro de su nombre de login y
contraseña. Este momento es oportuno para entregarle documentación descriptiva del
sistema. Ya debe haber firmado su conformidad con el documento de recomendaciones
de uso y comportamiento esperado; solo resta recordarle la necesidad de cambiar su
contraseña en cuanto ingrese al sistema.
Eliminar usuarios.
Cuando un usuario abandona la institución, su cuenta debe ser inmediatamente bloqueada. Se
procederá luego a eliminar la cuenta de los archivos de contraseñas y grupos, la casilla de
correo, las referencias en la tabla de usuarios, listados telefónicos y otros, conservando los
datos históricos que la institución especifique. Los archivos podrán transferirse en propiedad a
otro usuario o ser eliminados. En definitiva, todo rastro del nombre de login debe ser
eliminado, pero debe recordarse la recomendación de no reutilizar los números UID.
Una lista de control incluiría:
Fijar cuotas del usuario en 0, si se está usando cuotas; Eliminar al usuario de guías telefónicas, bases de datos o listas; Eliminar al usuario del archivo de aliases, o redirigir su correo a otra dirección;
Eliminar el archivo de procesos diferidos (crontab) y trabajos pendientes con at. Eliminar procesos del usuario que se hallen aún corriendo. Eliminar archivos temporales del usuario en /tmp y /var/tmp. Eliminar al usuario de los archivos passwd, shadow, group. Eliminar el directorio propio del usuario. Eliminar el archivo de distribución de correo del usuario en /var/spool/mail.
Inhabilitar cuentas.
Cuando una cuenta debe ser temporalmente inhabilitada, por ejemplo por ausencia del titular,
se solía colocar simplemente un asterisco en el lugar de la contraseña en /etc/passwd. En la
era de las redes, esto no es suficiente; entonces, se sustituye el intérprete de comandos de
login por un programa que imprime un mensaje indicando la inhabilitación de la cuenta.
Caducidad de contraseñas.
Los UNIX modernos disponen de una facilidad para obligar al usuario a cambiar su contraseña
periódicamente. Esta práctica está un tanto cuestionada, ya que el usuario obligado a disponer
de varias contraseñas se ve fácilmente tentado hacia elecciones menos seguras. Sí se insiste o
aún obliga a los usuarios a cambiar su contraseña cuando han habido violaciones de seguridad
o sospechas fundadas.
Pseudo logins.
Son cuentas de usuario que no corresponden a personas. Es el caso de bin y daemon. Es
posible crear otras cuentas de pseudo login, como shutdown, halt, who; estas cuentas tienen
como shell un programa que sólo ejecuta el comando indicado.

Herramientas de administración de usuarios.
useradd
comando con opciones para agregar usuarios; modifica los archivos passwd y shadow
coherentemente.
usermod
comando con opciones para modificar diversos ajustes de una cuenta de usuario.
userdel
comando con opciones para eliminar un usuario.
adduser
es un script en Perl u otro lenguaje de scripting, ofrece opciones de menú para facilitar
el ingreso de datos y luego invoca el comando useradd con los parámetros ingresados.
groupadd, groupmod, groupdel
comandos con opciones para agregar, modificar o borrar un grupo del archivo de
grupos; análogos a sus contrapartidas para usuarios.
Aunque útiles, estos comandos y scripts rara vez implementan todas las políticas de uso
locales. Es aconsejable reescribir o adaptar los scripts adduser y rmuser para
realizar vía scripts todo el proceso de creación y remoción de usuarios.
Ejercicios e investigación.
1. Determine si su sistema dispone de herramientas de administración para la creación,
modificación y remoción de usuarios. Estudie la herramienta y pruébela críticamente en todas
sus posibilidades, asegurándose de su éxito o anotando sus fallas o carencias.
2. Determine si su sistema usa el archivo shadow. Verifique si existen las herramientas
vipw y vigr; estudie sus páginas man y pruébelas con sumo cuidado, asegurando
siempre el retorno a la situación original y la coherencia entre /etc/passwd y
/etc/shadow.
3. Construya un script para crear una lista de usuarios del sistema con sus datos
personales que pueda actuar como listín telefónico. Construya luego un script que reciba
como parámetro el nombre de usuario y responda con los datos personales
adecuadamente presentados o con un mensaje que indique la inexistencia de tal usuario.
Estudie la posibilidad de que esta lista se regenere automáticamente.
4. Determine si en su institución se respeta la "política de comas" para el campo
GECOS de /etc/passwd. Verifique el comportamiento del comando finger en esta
situación. Evalúe la conveniencia de respetar o imponer dicha política.
5. Cree un usuario de prueba. Construya un script que emita un mensaje o realice alguna
tarea sencilla. Asigne este script como shell por defecto en el usuario de prueba.
Verifique los resultados.

Bibliografía y Referencias.
Comandos: vi (editor), passwd, yppasswd, newgrp, sg, chsh, chfn, useradd, userdel, usermod,
adduser, groupadd, groupdel, groupmod, edquota, quot.
Archivos: /etc/passwd, /etc/shadow, /etc/group, /etc/shells.
Procesos.
Procesos Información almacenada por el kernel
o IDentificadores Process ID (PID) Parent Process ID (PPID) UID y EUID GID y EGID
o Información de ambiente Directorio actual Variables de ambiente globales. Variables de ambiente locales. Terminal de control.
o Información de E/S o Espacio de direcciones virtual o Estado de un proceso
Ciclo de vida de un proceso Threads Señales (signals) Prioridad de ejecución y valor "nice" Supervisión de procesos
o Averiguando qué pasa Comando ps (process status) Comando top Comando pstree Carga del sistema reportada por w o uptime Comando vmstat (virtual memory stats)
o Tomando acciones Ejercicios e investigación Bibliografía y Referencias
Procesos
Se le llama proceso en Unix a un programa en ejecución y al objeto abstracto que crea
el sistema operativo para manejar el acceso de ese programa a los recursos del sistema
(memoria, CPU, dispositivos de E/S). Pueden coexistir varias instancias de un mismo
programa ejecutando en forma simultánea. Cada una de ellas es un proceso diferente.
Unix es un sistema multiproceso por tiempo compartido. A los ojos de un usuario en un

momento dado hay múltiples programas en ejecución, cada uno de ellos avanzando en
su tarea. Sin embargo en una máquina con un solo procesador hay en cada instante
solamente un proceso ejecutando. Es el sistema operativo el que va rotando el uso del
procesador a intervalos breves (alguna decena de milisegundos) entre los procesos
definidos en el sistema de forma que se crea la ilusión que todos avanzan
simultáneamente.
El administrador del sistema dispone de herramientas para supervisar el estado de los
procesos y eventualmente tomar acciones para suspender o detener la ejecución de un
proceso o simplemente modificar su comportamiento.
Información almacenada por el kernel
Para cada proceso definido en el sistema, el kernel del sistema operativo almacena y
mantiene al día varios tipos de información sobre el proceso. Esta información podemos
ordenarla de la siguiente forma:
* Información general. Identificadores de proceso, usuario y grupo
* Ambiente (variables, directorio actual, etc.)
* Información de E/S
* Información de Estado
* Espacio de direcciones del proceso. Areas de trabajo (código ("text"), datos, stack)
IDentificadores
Process ID (PID)
Al crearse un nuevo proceso se le asigna un identificador de proceso único. Este número
debe utilizarse por el administrador para referirse a un proceso dado al ejecutar un
comando.
Los PID son asignados por el sistema a cada nuevo proceso en orden creciente
comenzando desde cero. Si antes de un reboot del sistema se llega al nro. máximo, se
vuelve a comenzar desde cero, salteando los procesos que aún estén activos.
Parent Process ID (PPID)
La creación de nuevos procesos en Unix se realiza por la vía de duplicar un proceso
existente invocando al comando fork(). Al proceso original se le llama "padre" y al
nuevo proceso "hijo". El PPID de un proceso es el PID de su proceso padre.
El mecanismo de creación de nuevos procesos en Unix con el comando fork() se ve con
más detalle en el apartado "Ciclo de vida de un proceso".
UID y EUID
Normalmente estos dos identificadores coinciden pero hay excepciones.
El User ID (UID) del proceso identifica al creador del proceso, esto es a la persona que
lo lanzó a correr. Este usuario y root son los únicos que pueden modificar al proceso. El
UID se utiliza con fines de tarificación o accounting. El sistema de accounting carga a la
cuenta del usuario identificado por el UID del proceso por los recursos del sistema que
el proceso utilice (tiempo de CPU, impresoras, terminales, etc.).

El Effective User ID (EUID) en cambio se utiliza para determinar si el proceso tiene
permiso para acceder a archivos y otros recursos del sistema.
La forma más habitual de hacer que el EUID de un proceso sea el de un usuario
diferente del que lanza a correr el programa es activando el flag setuid en el archivo del
programa. Un ejemplo de esto son los comandos que permiten a un usuario modificar su
password, en que se debe modificar el archivo passwd o equivalente del sistema sobre el
cual el usuario obviamente no tiene permiso de escritura. Habitualmente ese comando
es un archivo de root con setuid y el proceso corre con EUID de root.
GID y EGID
Es totalmente análogo a los identificadores de usuario pero para grupos de usuarios. El
GID se hereda del proceso padre. El EGID puede utilizarse igual que el EUID para
controlar el acceso del proceso a archivos.
En la mayoría de los sabores actuales de Unix el proceso puede estar en varios grupos y
se chequea contra toda la lista de grupos para definir si el proceso puede acceder o no a
un recurso.
Información de ambiente
Directorio actual
El proceso mantiene actualizado cual es su directorio de trabajo.
Variables de ambiente globales.
Son heredadas por los procesos hijos.
Variables de ambiente locales.
Solamente existen en el proceso que las define.
Terminal de control.
En general los procesos están asociados a una terminal de control. Esta terminal
determina el valor por defecto de los archivos stdin, stdout y stderr del proceso.
Una excepción a esto son los procesos llamados daemons, que una vez lanzados se
desvinculan de su terminal de control y siguen ejecutando inclusive después de cerrada
la sesión de usuario desde la cual se lanzaron a correr.
Información de E/S
El kernel mantiene descriptores de los archivos abiertos por el proceso.
Están siempre definidos los archivos de entrada, salida y error estándar (stdin, stdout y
stderr). Por defecto están asociados con el teclado y la pantalla del terminal de control
del proceso pero pueden ser redireccionados a un archivo cualquiera. Todos los shells
prevén un mecanismo para hacer este redireccionamiento en el momento de lanzar a
correr un programa.

Espacio de direcciones virtual
En la mayoría de los sistemas multiproceso como Unix, cada proceso tiene la ilusión de
disponer para si el espacio de direcciones completo del procesador. En realidad el
procesador ve un espacio de direcciones virtual. Este espacio está organizado en
secciones para el código (text), datos, stack y otras y generalmente está dividido en
páginas. En un instante dado una página puede estar residiendo en la memoria física del
procesador o puede estar almacenada en disco en un procedimiento llamado
"swapping". El sistema operativo, con el auxilio del hardware, mantiene al día una tabla
con el estado de cada página de memoria del proceso.
Estado de un proceso
Los estados básicos en los que puede estar un proceso son los siguientes:
* Durmiendo (asleep). En general a la espera de algún recurso compartido.
* Listo para ejecutar (runnable). A la espera que le toque el turno en el uso de la CPU.
* Ejecutando (running). Puede estar ejecutando en modo kernel o en modo usuario.
A su vez el proceso (o partes del espacio de memoria virtual del proceso) puede estar
cargado en memoria o "swapped" a disco.
Además de estos estados básicos un proceso puede estar detenido (stopped). En este
caso se le prohibe ejecutar al proceso. Hay mecanismos para detener y rearrancar un
proceso a través de las señales STOP y CONT que veremos más adelante.
El estado stopped es el estado en que queda un proceso lanzado a correr desde un
interprete de comandos (shell) cuando se presiona <Control-Z> o la tecla configurada
como "suspend" en el terminal que estemos utilizando.
Finalmente el otro estado en que a menudo un administrador encuentra a un proceso es
el estado zombie o exiting. Un proceso en este estado está en proceso de terminación.
Este caso se discute más en detalle en el apartado "Ciclo de vida de un proceso".
Ciclo de vida de un proceso
El mecanismo de creación de un proceso en Unix es un poco peculiar. Un proceso se
crea invocando a una función del sistema operativo llamada fork(). La función fork()
crea una copia idéntica del proceso que la invoca con excepción de:
* El nuevo proceso tiene un PID diferente
* El PPID del nuevo proceso es el PID del proceso original
* Se reinicia la información de tarificación del proceso (uso de CPU, etc.)
Al retorno de fork() se siguen ejecutando las siguientes sentencias del programa en

forma concurrente. Para distinguir entre los dos procesos la función fork() devuelve un
cero al proceso hijo y el PID del nuevo proceso al proceso padre. Normalmente el
proceso hijo lanza luego un nuevo programa ejecutando alguna variante de comando
exec(). En el recuadro puede verse un ejemplo del uso de fork.
kidpid = fork()
if (kidpid==0) {
/* soy el hijo, p. ej. lanzo un nuevo prog. */
exec(...)
}
else{
/* soy el padre */
...
wait() /* espero exit() del hijo */
}
Si este es el mecanismo para crear un proceso, entonces ¿quién lanza a correr el primer
proceso? Luego del boot del sistema el kernel instala y deja corriendo un proceso llamado init
con PID=1. Una de las funciones principales de init es lanzar mediante fork() intérpretes de
comandos que a su vez lanzarán los scripts de inicialización del sistema y los procesos de los
usuarios. Además de init el kernel lanza algunos procesos más cuyo nombre y función varía en
los diferentes sabores de Unix. A excepción de estos procesos lanzados por el kernel al inicio,
todos los demás son descendientes de init.
Normalmente un proceso termina invocando a la función exit() pasando como parámetro un
código de salida o exit code. El destinatario de ese código de salida es el proceso padre. El
proceso padre puede esperar la terminación de su proceso hijo invocando la función wait().
Esta función manda al padre a dormir hasta que el hijo ejecute su exit() y devuelve el exit code
del proceso hijo.
Cuando el proceso hijo termina antes que el padre, el kernel debe conservar el valor del exit
code para pasarlo al padre cuando ejecute wait(). En esta situación se dice que el proceso hijo
está en el estado zombie. El kernel devuelve todas las áreas de memoria solicitadas por el
proceso pero debe mantener alguna información sobre el proceso (al menos su PID y el exit
code).
Cuando el proceso padre termina primero el kernel encarga a init la tarea de ejecutar el wait()
necesario para terminar todo en forma ordenada. A menudo init falla en esta función y suelen
quedar procesos en estado zombie hasta un nuevo reboot. Dado que un proceso zombie no
consume recursos fuera de su PID, esto por lo general no provoca problemas.
Threads
Cambio de contexto entre procesos:
* código ("text")
* datos
* stack
* tablas varias
Varias secuencias de ejecución (threads) pueden agruparse en un proceso y compartir
algunos segmentos

Ventajas:
* simplifica cambio de contexto y comunicación
* facilita el uso de múltiples procesadores
Soportado por la mayoría de los SO actuales (Digital Unix, DEC OSF/1, Solaris 2, AIX,
HP-UX, SGI Irix, Linux)
Posix standard
Bibliotecas provistas por terceros
Señales (signals)
Las señales de Unix son un mecanismo para anunciar a un proceso que ha sucedido
cierto evento que debe ser atendido. La lista de posibles señales a comunicar a los
procesos está fija, con algunas variaciones de un sabor a otro de Unix.
La recepción de una señal en particular por parte de un proceso provoca que se ejecute
una subrutina encargada de atenderla. A esa rutina se le llama el "manejador" de la señal
(signal handler). Un proceso puede definir un manejador diferente para sus señales o
dejar que el kernel tome las acciones predeterminadas para cada señal.
Cuando un proceso define un manejador para cierta señal se dice que "captura" (catch)
esa señal.
Si se desea evitar que determinada señal sea recibida por un proceso se puede solicitar
que dicha señal sea ignorada o bloqueada. Una señal ignorada simplemente se descarta
sin ningún efecto posterior. Cuando alguien envía a cierto proceso una señal que está
bloqueada la solicitud se mantiene encolada hasta que esa señal es explícitamente
desbloqueada para ese proceso. Cuando la señal es desbloqueada la rutina de manejo de
la señal es invocada una sola vez aunque la señal haya sido recibida más de una vez
mientras estaba bloqueada.
Si bien un proceso tiene ciertas libertades para configurar como reacciona frente a una
señal (capturando, bloqueando o ignorando la señal), el kernel se reserva ciertos
derechos sobre algunas señales. Así, las señales llamadas KILL y STOP no pueden ser
capturadas, ni bloqueadas, ni ignoradas y la señal CONT no puede ser bloqueada.
La señal KILL provoca la terminación de un proceso. La señal STOP provoca la
detención del proceso que queda en el estado "stopped" hasta que alguien le envíe la
señal CONT.
Una señal puede enviarse desde un programa utilizando llamadas al sistema operativo, o
desde la línea de comandos de un shell utilizando el comando kill. Al comando kill se le
pasa como parámetro el número o nombre de la señal y el PID del proceso. El uso más
habitual del comando es para enviar una señal TERM o KILL para terminar un proceso,
de ahí su nombre.
Para muchas de las señales la acción predeterminada consiste en terminar el proceso. En
algunos casos se genera además un core dump. Un core dump es un archivo con una
imagen del estado del sistema que permite al desarrollador de un programa diagnosticar
problemas con la ayuda de un debugger. Al usuario final de un programa esta imagen
rara vez le sirve de ayuda.
La lista de posibles señales puede obtenerse para cada sistema a través del man del
comando kill o de la función kill() del sistema operativo. En la tabla se listan las
utilizadas más a menudo por un administrador.
ID Nombre Uso habitual
1 SIGHUP Usualmente para releer configuración

9 SIGKILL El kernel destruye el proceso
15 SIGTERM Terminación "elegante", en general termina enviándose un KILLL a sí
mismo
SIGSTOP El kernel pasa el proceso a stopped
SIGCONT
SIGUSR Definidas por el usuario o más bien por quien programó el proceso
Prioridad de ejecución y valor "nice"
Cuando hay más de un proceso en el estado "listo para ejecutar", el kernel le asigna el
uso de la CPU al de mayor prioridad en ese momento. En el caso de Unix esta prioridad
varía dinámicamente. Las diferentes versiones y sabores de Unix utilizan diferentes
algoritmos de planificación del uso de la CPU (algoritmos de scheduling), pero en todos
los casos tienen características similares:
- procuran ser justos con los diferentes procesos
- procuran dar buena respuesta a programas interactivos
Para eso los algoritmos consideran parámetros como cuanto uso de CPU ha hecho el
proceso recientemente, si pasa mucho tiempo dormido a la espera de un evento de
teclado (sería un proceso interactivo), etc..
El administrador del sistema o el usuario dueño de un proceso pueden influir en el
algoritmo de scheduling a través del llamado valor nice. Este es un número que se
asigna a cada proceso e indica que tan "nice" es el proceso para con los demás.
Este valor es considerado por el algoritmo de scheduling de manera que un proceso con
valor nice alto estará en desventaja frente a otro con valor nice menor a la hora de
decidir a quien asignar la CPU. Como ejemplo veamos el algoritmo utilizado por alguna
versión de AIX:
P = min + nice + (0.5 x recent)
Donde P indica la prioridad dinámica (a menor P mayor prioridad) y recent es una
medida de cuanto ha recibido la CPU el proceso recientemente. Recent se calcula de la
siguiente forma:
* Inicialmente vale 0
* Al final de cada time slice (aprox. 10 milisegundos) recent se incrementa en 1 para el
proceso que está usando la CPU
* Una vez por segundo se divide por dos el valor recent para todos los procesos
Normalmente el valor nice se hereda del proceso padre. El dueño del proceso o el
propio proceso pueden elevar su valor nice (menor prioridad). El superusuario puede
modificar el valor nice de todos los procesos a gusto.
En los sistemas "a la BSD" el valor del número nice puede variar entre -20 y +20,
siendo por defecto 0.
En System V en cambio los valores posibles van de 0 a 39, siendo 20 el valor por
defecto.
Se puede modificar el valor nice por defecto en el momento de lanzar un programa
lanzándolo a correr con el comando nice, o posteriormente utilizando el comando
renice.

Supervisión de procesos
Averiguando qué pasa
Comando ps (process status)
La herramienta básica para diagnosticar problemas relacionados con procesos es el
comando ps. Este comando genera un reporte de un renglón por cada proceso,
brindando abundante información sobre cada uno.
El comando ps en los dos sabores básicos de Unix (BSD y System V) difiere en el
nombre y función de los parámetros, en la información que brindan sobre cada proceso
y en los criterios de ordenación de los procesos.
En ambos casos si ejecuto ps sin parámetros solamente se listará información básica
sobre los procesos que pertenecen a mi usuario. A través del uso de parámetros
adecuados puedo agregar más columnas (más información sobre cada proceso) o más
filas (más procesos) al reporte. Un conjunto de parámetros que permite ver todos los
procesos con un grado de detalle que en general es adecuado es:
ps -uax (BSD)
ps -elf (System V)
Los campos de información más importantes desplegados por ps para cada proceso son:
* Usuario (USER)
* Identificadores de proceso (PID, PPID)
* Uso de recursos reciente y acumulado (%CPU, %MEM, TIME)
* Estado del proceso (STAT, S)
* comando invocado (COMMAND)
Comando top
El comando top actualiza un reporte similar al generado por ps a intervalos periódicos.
Normalmente top ordena los procesos por uso de CPU en forma decreciente. Permite
además de manera amigable invocar los comandos kill y renice sobre el proceso.
Comando pstree
En algunos sistemas está disponible el comando pstree, que lista los procesos y sus
descendientes en forma de árbol. Esto permite visualizar rápidamente los procesos que
están corriendo en el sistema.
Carga del sistema reportada por w o uptime
Los comandos w (who) y uptime reportan tres números que indican la carga promedio
del sistema en un intervalo de 1, 5 y 15 minutos respectivamente. Más precisamente el
parámetro reportado es el promedio de la cantidad de procesos listos para correr. Este
valor es un indicador rápido de la actividad del sistema y suele vigilarse para detectar
sobrecargas en el mismo, o registrarse periódicamente para un análisis posterior en caso
de problemas. La relación entre este número y que tan "pesado" se vuelve el sistema
para los usuarios varía fuertemente dependiendo de las características del sistema (de la
cantidad de procesadores p. ej.) y de los procesos que se están ejecutando.

Comando vmstat (virtual memory stats)
El comando vmstat reporta varias estadísticas que mantiene el kernel sobre los
procesos, la memoria y otros recursos del sistema. Se puede tomar una instantánea de
esas estadísticas o repetirlo cierta cantidad de veces a intervalos de algunos segundos.
Alguna de la información reportada por vmstat es la siguiente:
* Cantidad de procesos en diferentes estados (listo para correr, bloqueado, "swapeado" a
disco.
* Valores totales de memoria asignada a procesos y libre.
* Estadísticas sobre paginado de memoria (page faults, paginas llevadas o traídas a
disco, páginas liberadas)
* Operaciones de disco
* Uso de CPU reciente clasificado en inactivo, ejecutando en modo usuario y
ejecutando en modo kernel
Tomando acciones
A menudo, por algún bug en el programa o por algún error de operación, los procesos
no terminan correctamente y es necesario terminarlos por algún método más violento.
El procedimiento usual en estos casos es obtener el PID del proceso con la ayuda de ps
y luego terminarlo con el comando kill. Enseñarle a los usuarios a hacer estas
operaciones con sus procesos colgados es una muy buena inversión de tiempo para un
administrador de sistema.
También suele suceder que algún proceso quede fuera de control y comience a acaparar
algún recurso del sistema (memoria, disco o CPU). Esto puede suceder por un error de
programación, por un error de configuración, por intentar correr algún proceso que
necesita más recursos que los disponibles o directamente por mala intención.
Sea cual sea el caso se hace necesario que el dueño del proceso o el administrador del
sistema tomen medidas para frenar o terminar a ese proceso.
En general el primer síntoma es "el sistema está muy pesado" (o el teléfono sonando
con reclamos de los usuarios). El primer paso será identificar a el o los procesos
problemáticos utilizando las herramientas ya vistas. Si la situación es tan grave que
dificulta la operación del administrador, puede ser recomendable lanzar un shell de root
con prioridad alta utilizando el comando nice.
Si no está claro por qué el proceso puede estar acaparando recursos se puede intentar
detenerlo con la señal STOP hasta ubicar al usuario dueño del proceso. Una vez ubicado
al usuario si se considera necesario que el proceso continúe se le puede bajar la
prioridad de ejecución con el comando renice.
Las siguientes opciones son o bien pedirle al proceso que tenga a bien terminar con la
señal TERM (kill -15 PID) o bien terminarlo por la fuerza con la señal KILL (kill -9
PID)
Ejercicios e investigación
* Use el comando ps y analice la información obtenida. Experimente las diferentes
opciones de ps en su sistema.
* Experimente el comando kill. Ejecute comandos en background para tener "materia
prima" con qué jugar. Utilice ps junto con grep para averiguar el PID

* Consulte el man para saber como reacciona algún proceso daemon (p. Ej. named)
frente a diferentes signals
Bibliografía y Referencias
* man page de:
* ps, top, kill, nice, renice, vmstat
* Nemeth, "UNIX System Administration Handbook", cap 5. El libro rojo/violeta
* Frisch, "Essential Unix Administration", cap. 7. El libro "de la mulita"
Syslog y Archivos de registro de eventos.
Syslog y Archivos de registro de eventos o Rotación de archivos de log o ¿Dónde están los logfiles? o Algunos archivos importantes
wtmp y el comando who messages
o Syslog El daemon syslogd
Configuración de syslogd Limitaciones y depuración de errores
Ejercicios e Investigación Referencias y Bibliografía
Syslog y Archivos de registro de eventos
Tanto el propio kernel del sistema operativo como los servicios de red o aplicaciones
que están corriendo en forma permanente en un sistema Unix mantienen archivos de
registro de eventos (logfiles) para reportar sucesos relevantes.
Estos registros son de gran utilidad para determinar a posteriori qué ha sucedido en un
sistema en caso de un malfuncionamiento y para detectar en forma temprana eventuales
fallas en el sistema. Forma parte de las tareas del administrador revisar periódicamente
estos logs.
Una particularidad común a todos los archivos de registro de eventos es que crecen, lo
que obliga a definir alguna política para el manejo de estos archivos para evitar que
llenen el espacio en disco. La política a seguir puede variar de acuerdo al esfuerzo de
administración y la importancia que la organización preste a temas como la seguridad.
Las políticas más comunes son:
No almacenar
Resetearlos periódicamente
Rotarlos, manteniendo datos por un período fijo de tiempo hacia atrás
Archivar en cinta u otro medio de respaldo toda la historia

El primer método no es para nada recomendable dado que los logs son una de las principales
herramientas para determinar la causa de un malfuncionamiento y para detectar algún acceso
no autorizado al sistema.
La política de borrar los archivos de log cada vez que toman un tamaño que los hace molestos,
si bien en la mayoría de los casos nos permite disponer de información, no nos garantiza
disponer de los registros de un tiempo hacia atrás. Por otra parte si el tamaño de los logs crece
excesivamente puede hacerse inmanejable extraer de ellos información o incluso pueden
llegar a llenar el disco.
Rotación de archivos de log
La práctica más usual consiste en ir "rotando" los nombres de archivo diariamente o
semanalmente, de manera de ir descartando los archivos más antiguos y mantener
información de una cantidad fija de días anteriores. Un ejemplo elemental de un script
que se podría lanzar desde cron para realizar esto es el que sigue:
#!/bin/sh
cd /var/log
rm logfile.3
mv logfile.2 logfile.3
...
mv logfile logfile.0
cat /dev/null > logfile
La mayoría de los sistemas Unix traen instalado alguna variante de un script como el de arriba
para ser ejecutados desde el cron. Como habitualmente se utilizan para rotar los registros de
eventos de syslog, el administrador de registros de eventos que estudiamos más adelante en
este documento, los scripts de este tipo suelen llevar por nombre newsyslog.
Una versión más compleja de este script es el comando newsyslog de FreeBSD o el comando
logrotate de algunas versiones de Linux. Se describe a continuación newsyslog, logrotate tiene
prestaciones similares.
Esta versión "potenciada" de newsyslog es lanzada periódicamente con cron y lee de un
archivo de configuración (/etc/newsyslog.conf) cuáles son los archivos que debe rotar. Para
cada familia de archivos se configura si la rotación se realiza cada un lapso fijo o cuando el
archivo de log alcanza un determinado tamaño.
Un archivo no termina de desaparecer hasta que se cierran todas las referencias a él desde los
procesos que están corriendo. Si un programa abre el archivo de log al inicio y luego lo
mantiene abierto, aunque borremos el archivo, la referencia que mantiene el programa sigue
apuntando al antiguo archivo que ya no existe.
Para instalar un nuevo logfile, dependiendo del programa, puede ser necesario enviarle algún
signal en particular o matar al programa y volverlo a arrancar para lograr que el programa
comience a escribir en el nuevo archivo de log (por ej. para syslogd es necesario hacer kill -1
pid). Algunos programas necesitan que el archivo al cual escriben esté previamente creado. El
comando newsyslog descripto anteriormente permite especificar un nombre de archivo del
cual tomar un Process ID para enviar un kill -1 a ese proceso para que reabra los archivos de
log luego de la rotación.
A menudo los archivos de log más antiguos son poco consultados por lo que pueden
comprimirse para ahorrar espacio en disco. Los programas de compresión más comunmente

utilizados son compress y gzip. Un ejemplo típico puede ser rotar los archivos diariamente,
manteniendo los dos días anteriores sin comprimir y los siguientes comprimidos con gzip hasta
completar una semana.
Por motivos de auditoría o seguridad algunas organizaciones optan por no destruir la
información de los logs antiguos. En esos casos en general los archivos de cierta antigüedad se
almacenan en algún medio removible (cinta o CD) y se archivan por la eventualidad de que
sean requeridos más adelante.
¿Dónde están los logfiles?
Dado que no existe un lugar fijo en el cual se creen los archivos de log, enfrentados a un
sistema Unix que no conocemos no siempre es sencillo encontrarlos. Se enumeran a
continuación las situaciones más frecuentes.
Una buena parte de los programas manejan sus logs utilizando syslogd.
A otros programas se les especifica con parámetros en la línea de comando donde
dejar los logs que generen durante su funcionamiento. En otros casos esto es una opción
de compilación.
Algunos sistemas como OSF/1 y AIX almacenan los errores del sistema en archivos
binarios y proveen alguna herramienta para listarlos (comando uerf en OSF/1). En
general estos comandos aceptan alguna opción para filtrar u ordenar los mensajes con
algún criterio.
¿Cómo averiguar dónde están los logs entonces?
en el archivo /etc/syslog.conf para ver donde se almacenan los mensajes reportados a
syslogd.
en los scripts de arranque para ver cómo son invocados los daemons que almacenan
directamente los mensajes en archivos propios.
en el man de los programas para ver donde almacenan los logs cuando no es esto una
opción de línea de comando.
Algunos de los lugares más usuales son:
/var/log
/var/adm o /usr/adm
/var/<nombre_de_daemon>/log
/var/spool/<nombre_de_daemon>/log
Algunos archivos importantes
wtmp y el comando who
Para cada usuario del sistema Unix mantiene un registro en los archivos utmp y lastlog
que indica entre otra información si está logueado en el sistema o no, y en caso

afirmativo en cuál terminal y desde que fecha/hora. Estos archivos son actualizados en
cada login y logout y consultados por ejemplo por los comandos w, who y lastlog.
En cada login y logout además de actualizarse el registro del usuario en el archivo
utmp, se hace un append del mismo en un archivo llamado wtmp. Este archivo
entonces es un registro histórico de los login y logout al sistema. Va creciendo con cada
login y logout por lo que debe ser administrado con alguna de las políticas vistas.
El archivo está en formato binario, pero puede observarse con el comando who. Este
comando por defecto despliega los usuarios logueados al sistema consultando al archivo
utmp, pero se le puede pasar como parámetro el nombre del archivo wtmp y en ese
caso nos va a listar la secuencia de login y logout.
La ubicación de estos archivos varía de un sisetma a otro. El archivo utmp
habitualmente está en el directorio /etc o /var/run, el archivo wtmp suele estar en
/var/log o /var/adm.
Si bien tienen algunas similitudes con los archivos de log, debe evitarse manipular los
archivos utmp y lastlog. El archivo lastlog está indexado por UID. Si en la asignación
de UIDs a los usuarios del sistema se saltea algún intervalo, pueden quedar "huecos" en
el archivo que nunca son escritos y a los que nunca se les llega a asignar sectores del
disco. Algunos programas (ls -l) reportan el tamaño completo del archivo, otros
comandos (du) reportan solamente el tamaño efectivamente utilizado por clusters
asignados. Un problema que puede aparecer es que al copiar un archivo con huecos se le
asigne lugar en disco para los registros correspondientes a los UID que no existen. Esto
puede hacer que el archivo destino de la copia sea mucho mayor que lo esperado,
eventualmente llenando el disco.
messages
Por lo general la mayoría de los mensajes procesados por el daemon syslog que se ve
más adelante se almacenan en un archivo llamado messages, de modo que este archivo
es uno de los primeros lugares a los que recurrir en busca de información cuando se ha
detectado un problema.
Syslog
El syslog es un sistema que procura centralizar (y en buena medida lo logra) el manejo
de los registros de eventos que generan los diversos programas que corren en una
máquina Unix. Por un lado facilita a los desarrolladores de aplicaciones la generación y
el manejo de mensajes a registrar, y por otro lado facilita a los administradores de
sistema el manejo en forma centralizada de los mensajes provenientes de diferentes
aplicaciones. Permite, clasificando los mensajes por origen e importancia, enviarlos a
diferentes destinos como archivos, a la terminal de un operador, o eventualmente a un
comando que lo reenvíe a direcciones de correo electrónico o pagers.
El syslog tiene además capacidad para manejar mensajes originados en diferentes
computadores en una red.
Los componentes más importantes de syslog son:
syslogd: el daemon que recibe los mensajes y los almacena de acuerdo a la
configuración almacenada en el archivo /etc/syslog.conf

openlog(), syslog() y closelog(): rutinas de la biblioteca C estándar para comunicarse
con syslog desde un programa.
logger: comando de usuario para agregar un mensaje a un log
El daemon syslogd
El daemon syslogd es uno de los primeros que se lanza a correr en los scripts de
arranque del sistema. Una vez arrancado queda esperando recibir mensajes para
procesarlos de acuerdo a la configuración en /etc/syslog.conf.
Syslogd reponde a la signal 1 (HUP) cerrando los logs, releyendo la configuración y
reiniciando la operación. Es por eso que si realizamos algún cambio en la configuración,
o si rotamos o movemos los archivos de log, es necesario enviarle una señal HUP a
syslogd. Para facilitar esto syslogd guarda al arrancar en un archivo de nombre
predeterminado (/etc/syslog.pid) el PID que le tocó en suerte, de manera que el
siguiente comando rearranca a syslogd:
kill -1 `/bin/cat /etc/syslog.pid`
Configuración de syslogd
La configuración de syslogd se hace a través del archivo de texto /etc/syslogd.conf. A
través de este archivo se especifica hacia dónde se deben enrutar los diferentes
mensajes. Se pueden dejar líneas en blanco o comentar líneas enteras con el carácter "#"
como primer carácter no blanco. Cada línea tiene el siguiente formato:
selector <Tab> action
La acción especificada se aplicará a todos los mensajes que verifiquen las condiciones
que se especifican con el selector. En algunos sistemas solamente puede utilizarse
tabuladores como separador entre el selector y la acción, generándose un error muy
difícil de descubrir si al editar el archivo syslog.conf se insertan espacios en lugar de
tabuladores.
El selector se especifica como un par facility.level. Cuando un programa envía un
mensaje al syslog, lo hace especificando un valor de "facility" y un valor de "level".
El campo facility procura identificar al programa que originó el mensaje, mientras que
el campo level busca clasificar el nivel de importancia o severidad del mismo.
Los valores posibles de facility están prefijados en cada sistema. Básicamente permiten
identificar mensajes del kernel, de varios de los deaemons y servicios de mayor prosapia
en Unix (mail, daemon, lpr, news, uucp, cron, syslog, ftp), mensajes que tienen que ver
con seguridad y autenticación de usuarios y una serie de valores que pueden ser usados
con cierta libertad para diferentes aplicaciones (local0 a local7, user).
Los valores posibles de level son en general 8 y van en orden de severidad creciente
desde DEBUG hasta EMERG. La acción especificada se aplica a todos los mensajes del
nivel especificado o mayor.
Se puede combinar varios selectores en una línea separándolos por el carácter punto y
coma (";").
Se pueden especificar varias facilities para un mismo nivel separándolas con el carácter
coma (",").
La clave especial "*" puede utilizarse para especificar todos los niveles o todas las
facilities (excepto la facility "mark").
La clave especial "none" en el campo level puede especificarse para excluir todos los

niveles de una cierta facility al combinar varios selectores.
La facility "mark" recibe mensajes a intervalos de 20 minutos. Esto permite, en caso que
el sistema se "cuelgue", determinar de manera bastante precisa la hora a la que sucedió
el problema aunque esto haya sido a una hora de baja actividad en el syslog.
La acción puede ser una de las siguientes:
guardar en un archivo. Es la acción más habitual. El archivo debe estar creado de
antemano. Se especifica simplemente escribiendo el nombre del archivo con su path
completo.
reenviar hacia el syslogd de otra máquina. Se especifica escribiendo @<nombre de
máquina o dirección IP>. El nombre de la máquina origen se agrega al comienzo del
mensaje junto con el timestamp, pero solamente se conserva por un salto. En el syslog
original el nombre de la máquina que generó el mensaje no interviene en el selector,
de manera que no es posible desencadenar diferentes acciones según la máquina que
originó el mensaje. Esto último se ha modificado en versiones más nuevas de syslog.
reenviar a la terminal de un usuario si es que está logueado. Se puede especificar una
lista de usuarios separados por el carácter coma (",") o un carácter "*" para especificar
todos los usuarios logueados.
en algunos sistemas es posible pasar el texto del mensaje como entrada estándar a un
comando, escribiendo el comando precedido por el carácter pipe ("|").
Los siguientes ejemplos tomados del man de syslogd.conf ilustran la mayoría de los casos.
# Log anything (except mail) of level info or higher.
# Don't log private authentication messages!
*.info;mail.none;authpriv.none /var/log/messages
# Everybody gets emergency messages, plus log them on another
# machine.
*.emerg *
*.emerg @arpa.berkeley.edu
El esquema descripto hasta ahora es estándar en la mayoría de los syslog y permite con un
esquema simple configurar el sistema para las necesidades de cada lugar. Para ello se utilizan
en general los valores local0-7 de facility. Estos valores deberán administrarse asignándolos a
las diferentes fuentes de mensajes que no están previstas en los daemons originales. Estos
programas por lo general permiten configurar el valor de facility con el que etiquetan sus
mensajes. Así por ejemplo en un sitio podría asignarse el valor local0 a los mensajes del popper
(consultas de casillas de correo electrónico con pop3) y el valor local1 para los mensajes de los
routers de la red, dispositivos que por lo general no tienen disco y permiten ser configurados
para enviar los mensajes al syslog de otra máquina.
En un sistema grande puede llegar a agotarse los valores disponibles de facilities localx. Esto ha
influido para que en nuevas versiones de syslog aparezcan extensiones que hagan más flexible
la especificación de los selectores. En ese sentido algunas versiones de syslog identifican a la
primera palabra en el texto del mensaje como el nombre del programa que lo originó, y
permiten utilizar ese nombre de programa para seleccionar la acción a aplicar sobre el
mensaje.

Para ello en el archivo syslog.conf se definen secciones especiales para cada programa que
comienzan con una línea de la forma #!programa o !programa. En los casos en que el syslog
del sistema acepta estas extensiones hay que ser cuidadoso al agregar líneas al archivo
syslog.conf para estar seguro que la línea insertada no queda dentro del bloque definido para
un programa en particular.
Otra mejora introducida en nuevas versiones de syslog es que es posible agregar el
modificador "=" al comienzo del nivel para especificar que el nivel de severidad sea igual
estricto en lugar de mayor o igual al nivel especificado. En forma similar pueden usarse los
modificadores "!" (diferente) y "-" (menor). Esto puede verse en el siguiente ejemplo:
# Log daemon messages at debug level only daemon.=debug /var/log/daemon.debug
Limitaciones y depuración de errores
Luego de realizar alguna modificación en el archivo syslog.conf y de enviar una señal
HUP a syslogd para que relea la configuración, debe testearse el funcionamiento
enviando mensajes de test con el comando logger.
Un error común es olvidar enviar la señal HUP. Otro error bastante común cuando la
acción es guardar los mensajes en un archivo es no crear el archivo previamente. Si el
archivo destino no está creado syslogd no lo crea.
En la mayoría de las implementaciones de sylog solamente se aceptan tabuladores como
separador entre el selector y la acción. Algunas versiones más nuevas permiten
indistintamente espacios y tabuladores.
Algunas versiones de syslog tienen limitado la cantidad de acciones a especificar en
syslog.conf a un valor constante fijo NLOGS que usualmente era 20. En otras versiones
hay una limitación en la cantidad de usuarios a los que es posible reenviar los mensajes
a la consola.
Una herramienta bastante potente para depurar errores en la configuración de syslog es
ejecutarlo en modo debug con el flag -d (syslog -d). Ejecutado de este modo syslog
despliega una tabla con una columna por cada facility y un renglón por cada acción. Los
números en la tabla indican a partir de cual nivel se aplica la acción para cada facility.
En el ejemplo se muestran 4 acciones diferentes (desplegar en la consola, almacenar en
el archivo /var/cron/log, reenviar a la máquina de nombre ohm, desplegar en el terminal
en que esté logueado el usuario root). En los sistemas que tienen limitado a NLOGS la
cantidad de acciones, la tabla tiene NLOGS renglones y aparecen los últimos con la
acción UNUSED.
7 3 2 3 5 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 X X CONSOLE:
/dev/console X X X X X X X X X 8 X X X X X X X X X X X X X X X FILE: /var/cron/log X X X X X X X X X X X X X X X X X X X X X X X 8 X FORW: ohm 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 X USERS: root,
Cuando se ejecuta en modo debug syslogd no libera el terminal. Después de desplegar
la tabla con el resumen de acciones queda desplegando en pantalla cada mensaje que
recibe y las acciones que se le aplican.
Una precaución a tener cuando se envían mensajes a la consola es que si alguien
presiona la tecla de pausa del terminal (habitualmente <Control-S>), entonces cada
intento de syslog de sacar un mensaje en consola queda bloquedo. Esto por lo general

produce el efecto de enlentecer violentamente el funcionamiento de la máquina,
situación que se revierte si desbloqueamos el terminal con <Control-Q>.
Ejercicios e Investigación Determine en su sistema donde están los diferentes archivos de registro de eventos
Averigüe quién y desde qué terminal trabajo en el sistema el día anterior
Identifique que política de rotación de archivos de tiene configurada su máquina
(identifique el script periódico que se encarga de eso, si utiliza algún comando especial
para eso (newsyslog p. ej.) lea el man de ese comando.
Modifique /etc/syslog.conf para hacer que determinados mensajes se escriban
también en la consola de su usuario. Pruébelo usando el comando logger. Retorne
luego a la configuración inicial!!!
Referencias y Bibliografía
Nemeth, Evi, "UNIX System Administration Handbook", cap. 12
Comandos: who, wtmp, utmp, newsyslog, compress, gzip, syslogd, syslog.conf, logger.
Arranque y Detención del Sistema.
Estudio de caso: Linux Debian/GNU
Arranque y detención "System V".
Niveles de arranque: /etc/inittab.
Algunos subdirectorios de /etc.
Plantilla para script rc.
Un script rc real: network.
Bibliografía y Referencias.
Arranque y detención "System V".
El esquema de arranque y detención del sistema en Linux Debian/GNU es del tipo
"system V". Todos los scripts que ejecutan tareas en el arranque o detención del sistema
se encuentran en el directorio /etc/init.d. Los directorios /etc/rcS.d, /etc/rc0.d, /etc/rc1.d,
/etc/rc2.d y /etc/rc6.d corresponden a cada uno de los posibles niveles o estados de
funcionamiento del sistema. Estos directorios sólo contiene enlaces simbólicos hacia los
scripts en /etc/init.d. Los nombres de estos enlaces simbólicos son significativos: la
primera letra es S o K, luego sigue un número de 2 cifras, y finalmente el nombre de un
script en /etc/init.d. Algunos ejemplos: K18netbase K20ppp K20exim S15netbase S20exim S25nfs-server

Dentro de un directorio, los scripts K se ejecutan primero. La K (de "kill", matar)
indica que el script correspondiente en /etc/init.d debe ejecutarse con la opción de
detención, "stop". Luego de ejecutados todos los scripts K, se ejecutan los scripts S. La
S (de "start", arrancar) indica que el script correspondiente en /etc/init.d debe ejecutarse
con la opción de arranque ("start").
El número de 2 dígitos regula el orden en que se ejecutan los distintos scripts; el número
puede estar repetido, cuando importa la precedencia.
Los distintos niveles en que puede funcionar el sistema se definen en el arthivo
/etc/inittab.
Niveles de arranque: /etc/inittab.
# /etc/inittab: init(8) configuration. # $Id: inittab,v 1.8 1998/05/10 10:37:50 miquels Exp $
# The default runlevel. id:2:initdefault:
# Boot-time system configuration/initialization script. # This is run first except when booting in emergency (-b) mode. si::sysinit:/etc/init.d/rcS
# What to do in single-user mode. ~~:S:wait:/sbin/sulogin
# /etc/init.d executes the S and K scripts upon change # of runlevel. # # Runlevel 0 is halt. # Runlevel 1 is single-user. # Runlevels 2-5 are multi-user. # Runlevel 6 is reboot.
l0:0:wait:/etc/init.d/rc 0 l1:1:wait:/etc/init.d/rc 1 l2:2:wait:/etc/init.d/rc 2 l3:3:wait:/etc/init.d/rc 3 l4:4:wait:/etc/init.d/rc 4 l5:5:wait:/etc/init.d/rc 5 l6:6:wait:/etc/init.d/rc 6 # Normally not reached, but fallthrough in case of emergency. z6:6:respawn:/sbin/sulogin
# What to do when CTRL-ALT-DEL is pressed. ca:12345:ctrlaltdel:/sbin/shutdown -t1 -a -r now
# Action on special keypress (ALT-UpArrow). kb::kbrequest:/bin/echo "Keyboard Request--edit /etc/inittab to let
this work."
# What to do when the power fails/returns. pf::powerwait:/etc/init.d/powerfail start pn::powerfailnow:/etc/init.d/powerfail now po::powerokwait:/etc/init.d/powerfail stop
# /sbin/getty invocations for the runlevels. #

# The "id" field MUST be the same as the last # characters of the device (after "tty"). # # Format: # <id>:<runlevels>:<action>:<process> 1:2345:respawn:/sbin/getty 38400 tty1 2:23:respawn:/sbin/getty 38400 tty2 3:23:respawn:/sbin/getty 38400 tty3 4:23:respawn:/sbin/getty 38400 tty4 5:23:respawn:/sbin/getty 38400 tty5 6:23:respawn:/sbin/getty 38400 tty6
# Example how to put a getty on a serial line (for a terminal) # #T0:23:respawn:/sbin/getty -L ttyS0 9600 vt100 #T1:23:respawn:/sbin/getty -L ttyS1 9600 vt100
# Example how to put a getty on a modem line. # #T3:23:respawn:/sbin/mgetty -x0 -s 57600 ttyS3
Algunos subdirectorios de /etc.
init.d rc0.d rc2.d rc4.d rc6.d rc1.d rc3.d rc5.d rcS.d Contenido de /etc/rcS.d: README S20modutils S40network S55bootmisc.sh S05keymaps.sh S30checkfs.sh S45mountnfs.sh S55urandom S10checkroot.sh S35mountall.sh S50hwclock.sh S70nviboot S15isapnp S40hostname.sh Contenido de /etc/rc0.d: K01xdm K20gpm K20quota S20sendsigs K11cron K20isdnutils K25nfs-server S25hwclock.sh K12kerneld K20logoutd K30netstd_misc S30urandom K15netstd_init K20lprng K89atd S40umountfs K18netbase K20ppp K90sysklogd S90halt K20exim Contenido de /etc/rc1.d: K01xdm K20exim K20lprng K30netstd_misc K11cron K20gpm K20ppp K89atd K12kerneld K20isdnutils K20quota K90sysklogd K15netstd_init K20logoutd K25nfs-server S20single K18netbase Contenido de /etc/rc2.d: S10sysklogd S20gpm S20ppp S89atd S12kerneld S20isdnutils S20quota S89cron S15netstd_init S20logoutd S25nfs-server S99rmnologin S18netbase S20lprng S30netstd_misc S99xdm S20exim Contenido de /etc/rc6.d: K01xdm K20gpm K20quota S20sendsigs K11cron K20isdnutils K25nfs-server S25hwclock.sh K12kerneld K20logoutd K30netstd_misc S30urandom K15netstd_init K20lprng K89atd S40umountfs K18netbase K20ppp K90sysklogd S90reboot K20exim

Scripts en /etc/init.d: README hwclock.sh netbase reboot atd isapnp netstd_init rmnologin bootmisc.sh isdnutils netstd_misc sendsigs checkfs.sh kerneld network single checkroot.sh keymaps.sh nfs-server skeleton cron logoutd nviboot sysklogd exim lprng ppp umountfs gpm modutils quota urandom halt mountall.sh rc xdm hostname.sh mountnfs.sh rcS
Plantilla para script rc.
En la distribución Debian se exige que todos los paquetes de software tengan un script
rc con las opciones "start", "stop", "restart" y mensaje informativo de uso si no se dan
opciones. Se provee una plantilla modelo para la creación de estos scripts, a partir de la
cual el responsable de cada paquete estructura el script rc, que residirá en /etc/init.d, y
con el cual se gobierna el paquete.
#! /bin/sh # # skeleton example file to build /etc/init.d/ scripts. # This file should be used to construct scripts for
/etc/init.d. # # Written by Miquel van Smoorenburg <[email protected]>. # Modified for Debian GNU/Linux # by Ian Murdock <[email protected]>. # # Version: @(#)skeleton 1.8 03-Mar-1998 [email protected] #
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin DAEMON=/usr/sbin/daemon NAME=daemon DESC="some daemon"
test -f $DAEMON || exit 0
set -e
case "$1" in start) echo -n "Starting $DESC: " start-stop-daemon --start --quiet --pidfile /var/run/$NAME.pid \ --exec $DAEMON echo "$NAME." ;; stop) echo -n "Stopping $DESC: " start-stop-daemon --stop --quiet --pidfile /var/run/$NAME.pid \ --exec $DAEMON echo "$NAME." ;; #reload) #

# If the daemon can reload its config files on the fly # for example by sending it SIGHUP, do it here. # # If the daemon responds to changes in its config file # directly anyway, make this a do-nothing entry. # # echo "Reloading $DESC configuration files." # start-stop-daemon --stop --signal 1 --quiet --pidfile \ # /var/run/$NAME.pid --exec $DAEMON #;; restart|force-reload) # # If the "reload" option is implemented, move the "force-
reload" # option to the "reload" entry above. If not, "force-reload" is # just the same as "restart". # echo -n "Restarting $DESC: " start-stop-daemon --stop --quiet --pidfile \ /var/run/$NAME.pid --exec $DAEMON sleep 1 start-stop-daemon --start --quiet --pidfile \ /var/run/$NAME.pid --exec $DAEMON echo "$NAME." ;; *) N=/etc/init.d/$NAME # echo "Usage: $N {start|stop|restart|reload|force-reload}" >&2 echo "Usage: $N {start|stop|restart|force-reload}" >&2 exit 1 ;; esac
exit 0
Un script rc real: network.
No todos los scripts rc requieren las opciones "start" y "stop"; algunos realizan tareas
siempre requeridas para el funcionamiento del sistema. El script rc "network" inicializa
la máquina para su entrada en la red
#! /bin/sh # # network Establish the network connection. # # Version: @(#)network 1.2 14-Nov-1996 [email protected] #
# Configure the loopback device. ifconfig lo 127.0.0.1 route add -net 127.0.0.0 dev lo
# Configure the ethernet device or start SLIP/PPP below. IPADDR="192.168.1.1" # Your IP address. NETMASK="255.255.255.0" # Your netmask. NETWORK="192.168.1.0" # Your network address. BROADCAST="192.168.1.255" # Your broadcast address (blank if

none). GATEWAY="" # Your gateway address.
/sbin/ifconfig eth0 ${IPADDR} netmask ${NETMASK} broadcast
${BROADCAST} /sbin/route add -net ${NETWORK} [ ! -z "$GATEWAY" ] && /sbin/route add default gw ${GATEWAY}
Bibliografía y Referencias.
Sistema instalado Linux Debian/GNU 2.1.
Debian Policy Manual , http://www.debian.org/doc/debian-policy/
Páginas "Como" (HOWTO), en español, en el sitio web de Debian Argentina,
http://www.debian.org.ar/. Una excelente fuente de información para múltiples aspectos
de instalación y configuración, desde nivel elemental hasta nivel técnico muy
especializado.
Procesos Periódicos y Cron
Estilos de cron
Formato de archivos crontab
Precauciones y errores comunes
Aplicaciones más usuales
Limpieza de archivos (/tmp, core, otros)
Accounting
Manejo de archivos de registro de eventos (logs)
Chequeos periódicos de seguridad y de disponibilidad de recursos de red
Ejecución de procesos pesados fuera de horario más cargado
Otros comandos
Ejercicios e investigación
Comandos y archivos
Bibliografía y referencias.
Procesos periódicos y cron El "daemon" cron en Unix permite lanzar comandos de sh con un calendario predeterminado y es la
herramienta estándar para el manejo de tareas periódicas. cron usualmente se lanza como un daemon
en algún script de arranque del sistema.
Para determinar qué comandos debe ejecutar y en que momento hacerlo, cron lee uno o varios archivos
de configuración denominados crontabs (de "cron table").
Estilos de cron
Existen dos estilos de implementar el cron originados en los dos "sabores" principales de Unix.
En un cron "a la BSD" existe un crontab único para todo el sistema, usualmente en /etc/crontab o en
/usr/lib/crontab. Dado que el archivo es único para todo el sistema debe ser administrado por el usuario

root editando el archivo crontab con un editor de texto. En este caso cada renglón del crontab, además de
indicar qué comando ejecutar y cuándo hacerlo debe especificar a nombre de qué usuario debe ejecutarse
el comando.
Los cron "a la ATT" brindan una flexibilidad mayor al permitir que exista un archivo crontab diferente
para cada usuario del sistema. De esta manera cada usuario puede configurar sus propias tareas repetitivas
sin intervención del administrador. Este puede todavía controlar cuales usuarios pueden utilizar el cron a
través de dos archivos de configuración adicionales: cron.allow y cron.deny.
Normalmente los archivos crontab se encuentran bajo un directorio común, y cada uno lleva como
nombre de archivo el nombre del usuario. Para manejar estos archivos habitualmente se utiliza el
comando crontab, que permite crear, examinar y editar el archivo de configuración del usuario que lo
invoca.
La mayoría de los Unix modernos, inclusive los de origen BSD, tienen un cron "a la AT&T". Algunos
inclusive pueden manejar archivos crontab de los dos tipos simultáneamente como es el caso del "vixie
cron", un paquete independiente que puede instalarse en varias plataformas.
Formato de archivos crontab
Los archivos crontab son archivos de texto en que se lista una tarea repetitiva por cada renglón. Salvo
pequeñas diferencias como la necesidad o no de especificar el nombre de usuario, el formato es el
mismo en todos los sistemas con los siguientes 7 campos:
minuto hora día mes día_de_la_semana [usuario] comando
Campo
Minuto Minuto de la hora 0 a 59
Hora Hora del día 0 a 23
Día Día del mes 1 a 31
Mes Mes en el año 1 a 12
Dia_de_la_semana Día de la semana 1 a 7 o 0 a 6
Atención!! con el campo día_de_la_semana no todos los cron se comportan igual:
lunes siempre es el día 1 el domingo casi siempre es el dia 7, pero en algunos casos es el dia 0 (RTFM) algunos cron modernos (vixie cron) aceptan los dos valores (0 y 7) para especificar domingo

En todos los campos se puede especificar, además de un valor exacto, rangos (separando con un guión '-
'), listas (separando con una coma ',') y un comodín con el carácter '*'.
Por ejemplo, en la siguiente línea:
30 07 * * 1-5 comando
Se indica que se ejecute 'comando' de lunes a viernes a las 7:30hs
Si en una línea se especifica tanto el campo día como el campo día_de_la_semana, entonces es suficiente
con que se satisfaga una sola de las dos condiciones. Para mayor claridad, en el ejemplo:
0,15,30,45 * 13 * 2 comando
se está especificando la ejecución cada cuarto de hora en todos los días 13 y en todos los días martes.
En los rangos y comodines también se puede especificar el paso de incremento, como en los siguientes
ejemplos.
# cada 15 minutos
*/15 * * * * comando1
# cada 2 horas entre las 8 y las 12, idem 8,10,12
* 8-12/2 * * * comando2
Precauciones y errores comunes
Un comando o script puesto a ejecutar automáticamente por cron puede comportarse de manera
diferente que cuando ejecutamos el mismo script desde una sesión interactiva de usuario. Hay que
tener en cuenta varios aspectos:
El comando va a ser lanzado por cron utilizando sh como interpretador de comandos. Debemos tener en cuenta esto si utilizamos habitualmente otro shell (csh, ksh, bash, tcsh) ya que presentan diferencias de sintaxis, variables de ambiente, etc..
No se ejecutan los scripts de inicialización del shell (.login, .profile, .cshrc por ejemplo) que normalmente se ejecutan al iniciarse una sesión de usuario, por lo que no estarán inicializadas ciertas variables de ambiente. El caso más común de esto es la variable PATH: o bien debe inicializarse explícitamente o bien escribirse el camino completo en el sistema de archivos de cada comando que se utilice.
Dado que un comando lanzado por cron no corre en un terminal, toda la salida estándar y la salida de error del comando se envía por e-mail al usuario. Es práctica usual redireccionar la salida a /dev/null una vez que han sido depurados los scripts utilizados.
Un error habitual tiene que ver con que en las líneas del crontab no se especifica el año. Es común que
se agende un comando para ejecutarse una sola vez pero luego se olvide borrar el comando del crontab.
En esos casos el olvido suele notarse un año más tarde cuando vuelve a ejecutarse el comando. Otra
opción para agendar trabajos por una única vez es utilizar el comando at.
Aplicaciones más usuales
El grueso de las aplicaciones lanzadas desde cron tienen que ver la realización de tareas repetitivas de
administración. El agendar estas tareas para su realización automática minimiza la probabilidad de

errores y olvidos y automatiza a favor del administrador algunas de las tareas más tediosas. A
continuación se enumeran algunas de las aplicaciones más habituales de cron.
Limpieza de archivos (/tmp, core, otros)
En los sistemas Unix (y también en otros sistemas) suelen generarse archivos que son de poca o ninguna
utilidad para los usuarios y a menudo ocupan un área del disco no despreciable. El caso más notorio es
el de los "core dumps" que se generan cuando un programa falla. Un core dump es un archivo que se
guarda en el directorio actual del proceso que "hace crash" con el nombre de core, y contiene una copia
de la memoria y el estado del procesador en el momento del "crash". Con la ayuda de un debugger, el
archivo core permite al desarrollador del programa que falla reconstruir la situación en el momento de
la falla y detectar cual fue el problema. Para los usuarios finales sin embargo el archivo core solamente
significa malgastar espacio en disco. Se utiliza el comando find para recorrer el sistema de archivos y
borrar los archivos no deseados. En el siguiente ejemplo:
find / -xdev -name core -atime +7 -exec rm -f {} \;
se borran todos los archivos de nombre "core" que no han sido accedidos en los últimos 7 días. El
parámetro -xdev impide que la búsqueda se extienda más alla del sistema de archivos donde se inicia la
búsqueda.
Por diversos problemas las aplicaciones suelen dejar sin borrar archivos temporales. El administrador
debe estar atento a detectar situaciones de este tipo que se den en su sistema, identificar los nombres de
los archivos a borrar y agregar una línea similar en el crontab.
Otros archivos candidatos a ser borrados periódicamente por el administrador son el contenido de /tmp o
/var/tmp.
Accounting
Si se trabaja en un entorno en que se cobra a cada usuario por la utilización de los recursos, la
información de accounting debe resumirse y archivarse periódicamente. Incluso en sistemas donde no
se cobra por uso de recursos la información de accounting puede utilizarse para diagnosticar problemas
o hacer previsiones de necesidades de ampliaciones del sistema.
Manejo de archivos de registro de eventos (logs)
La mayoría de los servicios que corren en un sistema Unix dejan un registro de los eventos importantes
que van sucediendo en archivos de texto. El tamaño de estos archivos está siempre creciendo por lo que
se deben tomar acciones para borrar o archivar los datos más antiguos.
Chequeos periódicos de seguridad y de disponibilidad
de recursos de red
Dependiendo de la importancia que tenga para la organización la seguridad, suelen ejecutarse chequeos
diarios buscando posibles brechas en la seguridad del sistema. Así por ejemplo puede mantenerse una
lista de los archivos con setuid y en caso de detectar un cambio reportarlo vía e-mail al administrador.

Otro chequeo periódico puede hacerse para generar alarmas en caso de detectar que un recurso en la red
no está disponible. Así por ejemplo puede hacerse ping a intervalos de 15 minutos hacia los servidores
importantes de una organización y en caso de detectar una falla reportar una alarma a un pager.
Ejecución de procesos pesados fuera de horario más
cargado
Un ejemplo de esto es la realización de respaldos durante la madrugada, en horarios de baja actividad
del sistema de archivos. Otro ejemplo es agendar el download de algún archivo muy grande desde
Internet para ser ejecutado en horarios en que la utilización del ancho de banda de los enlaces sea
menor.
Otros comandos
Otros comandos que permiten lanzar un comando o programa automáticamente son el comando at y el
comando batch.
El comando at permite agendar la ejecución de una tarea para que sea realizada una única vez. En la línea
de comando debe pasarse la fecha y hora a la que debe ser ejecutada la tarea. El uso del comando at es
preferible frente al uso del cron cuando el comando se ejecutará solamente una vez. También puede
usarse at para poner a punto un comando que luego se va a incorporar al crontab para su ejecución
periódica.
Por medio del comando batch se puede encargar la ejecución de una tarea. En este caso no se especifica
fecha y hora de ejecución sino que la tarea será atendida cuando el sistema se encuentre suficientemente
descargado.
Ejercicios e investigación
Determinar que estilo de cron está instalado en su sistema. Examinar el man del comando crontab e incluir un comando (p. ej. un mail a sí mismo) para la
siguiente noche. Ponerlo a punto utilizando el comando at. No olvidar quitar el comando del crontab al día siguiente
Comandos y archivos
/etc/crontab y /var/cron/tabs comandos cron y crontab at, batch
Respaldo.
El respaldo de datos
Dispositivos y medios
Régimen de respaldo incremental

Respaldo de un sistema de archivos
Niveles de respaldo incremental
Esquema de respaldo
Elección de un esquema
Recomendaciones generales
Restaurar archivos
Restaurar sistemas de archivos
Otros comandos de respaldo
Amanda
Ejercicios e Investigación
Bibliografía y referencias.
El respaldo de datos.
En la inmensa mayoría de los sistema informáticos, los datos almacenados en el sistema tienen
mucho mayor costo y son mucho más difíciles de recuperar que el sistema en sí. Entre los
riegos de pérdida de datos se cuentan los errores en el software, la falla de equipos, el error
humano, el daño intencional, las catástrofes naturales. El respaldo de datos es la generación
de una copia, en un momento determinado, de los datos del sistema, con vistas a su eventual
reposición en caso de pérdida. Todos los sistemas informáticos deben respaldarse
cuidadosamente, en momentos predeterminados, siguiendo un cronograma preestablecido.
Dispositivos y medios.
Las causas de pérdida de datos generan los siguientes requisitos de respaldo:
uso de un medio removible, utilizable en otra máquina; los daños o fallas pueden afectar varias partes de hardware al mismo tiempo, impidiendo la utilización de la máquina original.
conservación de los respaldos en un lugar físico suficientemente apartado. Existen actualmente empresas para realizar respaldos vía Internet, pero la mayoría de las instituciones conservan sus respaldos localmente.
La inmensa mayoría de los dispositivos de respaldo son de tipo magnético. Esto los hace
vulnerables a la proximidad de elementos generadores de campos magnéticos. Los respaldos
deben mantenerse apartados de dispositivos tales como parlantes de audio, transformadores
de pared, acondicionadores de línea, unidades de potencia ininterrumpida (UPSs), unidades de
disco o disquetera no confinados en gabinetes metálicos, monitores aún apagados, detectores
de metales como los usados en los aeropuertos. El campo magnético terrestre termina, con el
tiempo, afectando los medios magnéticos de grabación; esto limita la duración efectiva de los

respaldos; para períodos largos, se aconseja usar medios ópticos o regrabar periódicamente.
Puede asumirse una duración de 3 años para los medios magnéticos.
Muchos fabricantes de unidades de respaldo proveen compresión incorporada, citando
el almacenamiento y la velocidad de transferencia en la presunción optimista de un 2 a
1. En términos reales sólo puede asumirse la capacidad real en bytes de la cinta, y la
velocidad de transferencia de esa misma cantidad de bytes. En principio no puede
asegurarse compresión alguna sin conocimiento previo del tipo de datos.
Características de los principales medios de respaldo, en orden de capacidades
crecientes:
Medio Capacidad Reuso Acceso
aleatorio Comentarios
Disquete 1.44/2.8
MB Sí Sí
muy común; poca capacidad, incómodo; poca
duración (2 años); útil para respaldo de archivos de
configuración o transferencia de archivos chicos; alto
costo por MB
Zip 100/250
MB Sí Sí
bastante común; varias interfaces de conexión; alto
costo por MB
CD-R 650 MB No Sí
muy común; varias interfaces de conexión; menor
duración que CDs pregrabados, mucho mayor que los
medios magnéticos; buenos para datos permanentes,
incómodo para respaldos regulares
CD-RW 650 MB Sí Sí ventajas del CD-R; limitado en capacidad
DVD-R 4.7 a 17
GB No Sí Aún poco común; U$S 5 el de 4.7GB.
Jaz, Orb ~2 GB Sí Sí discos removibles; buena velocidad de transferencia
Cinta 8 mm 7 GB Sí No cinta video formato chico; las unidades suelen ser
llamadas Exabyte
Cinta 4 mm
DAT/DDS 20 GB Sí No
DDS (Digital Data Storage) es similar al DAT (Digital
Audio Tape) para audio; original 2 GB, DDS-4 en 20
GB; buena velocidad de transferencia; tamaño
reducido
Disco fijo 40 GB Sí Sí muy común; excelente transferencia, bajo costo; apto
para crear espejos de discos; menor transportabilidad

Existen cintas de nueva tecnología, con mejoras en capacidad, precio, transferencia o
duración: Travan (varios fabricantes), ADR (OnStream), DLT (Quantum), AIT (Sony),
Mammoth (Exabyte); verificar soporte para el hardware en la versión de UNIX a
utilizar. DAT y Exabyte son soluciones baratas para la mayoría de las empresas chicas y
medianas; DLT, AIT y Mammoth están orientadas a grandes corporaciones o
universidades.
Existen diversos tipos de equipo para cambio automático de volúmenes, de alto costo y
con software propio, en capacidades de terabytes. Una adecuada partición en sistemas
de archivo, un cronograma adecuado y un poco de paciencia permiten respaldar un
sistema con razonable esfuerzo.
Régimen de respaldo incremental.
Los comandos tradicionales de respaldo y recuperación son dump y restore. Según los
sistemas, pueden tener nombres similares (ufsdump, ufsrestore en Solaris). Otros
comandos también tradicionales son tar y cpio, con múltiples opciones de control
adaptables a variadas necesidades.
Respaldo de un sistema de archivos.
El comando dump recorre el sistema de archivos haciendo una lista de los archivos modificados
o nuevos desde una corrida anterior de dump; luego empaqueta todos esos archivos en uno
solo y lo vuelca en un dispositivo externo tal como una cinta. Exhibe estas características:
soporta multivolumen; soporta todo tipo de archivo, incluso de dispositivos; conserva permisos, dueños y fecha de modificación; maneja nombres largos y rutas de anidamiento profundo; maneja bien los archivos con huecos (bloques sin datos) producidos por algunos
programas (bdm, nbdm); en una copia común estos archivos se agrandan desmesuradamente;
admite respaldo incremental.
dump maneja el sistema de archivos en crudo, leyendo la tabla de inodos para decidir qué
archivos deben respaldarse. Esto aumenta su eficiencia, pero obliga a manejar cada sistema de
archivos en forma independiente, e impide el respaldo de sistemas de archivos remotos tipo
NFS. No obstante, es posible respaldar un sistema de archivos sobre una unidad de respaldo
remota usando rdump.
Niveles de respaldo incremental.
El respaldo incremental se implementa asignando un nivel a cada respaldo, de 0 a 9. Un
respaldo nivel 0 copia todos los archivos; un respaldo nivel 1 copia sólo los archivos
modificados luego de la fecha del último respaldo nivel 0; un respaldo nivel 7 copia sólo los
archivos modificados luego del último respaldo nivel 6. La recuperación de un sistema de
archivos requiere reponer primero el respaldo nivel 0 y luego sucesivamente el último nivel 1,
el último de nivel 2, y siguientes. Los números de niveles pueden no ser contiguos: se toma el
nivel anterior más próximo existente como referencia. La información de dump se guarda en el
archivo /etc/dumpdates; en caso necesario, este archivo puede ser editado manualmente.

dump 0uf /dev/st0 /usr
crea un respaldo nivel 0 del sistema de archivos /usr usando el dispositivo de cinta con
rebobinado /dev/st0 (opción f) actualizando /etc/dumpdates (opción u).
dump 3uf /dev/st0 /usr
análogo para un nivel 3.
dump 0uf /dev/nst0 /usr crea un respaldo nivel 0 del sistema de archivos /usr usando el dispositivo de cinta no
rebobinado /dev/nrst0, para reiterar el comando y colocar varios respaldos en una
misma cinta. Los dispositivos de cinta suelen tener dos archivos de dispositivo, uno con
rebobinado automático (/dev/st0) y otro sin rebobinado (/dev/nst0); ambos se refieren al
mismo dispositivo físico. El manejo de la unidad de cinta se hace con el comando mt.
rdump 0uf pino:/dev/rtape /usr crea un respaldo nivel 0 del sistema de archivos /usr usando el dispositivo remoto
/dev/rtape en la máquina pino. El acceso a la cinta remota es controlado por el archivo
.rhosts de la máquina remota. Si no se confía en la privacidad de la red puede
convenir más implementar un túnel seguro con ssh.
El respaldo en cinta requiere conocer su tamaño y características. El fin de cinta (EOT,
End Of Tape) es generalmente detectado, para habilitar los respaldos multivolumen. Un
error en el largo de cinta o en la elección de dispositivo rebobinado puede arruinar el
respaldo.
dump 5usdf 60000 6250 /dev/st0 /trabajos
indica un largo de cinta ficticio de 60000 pies (opción s, size), densidad de grabación
6250 dpi (opción d, densidad), para engañar una versión dump incapaz de reconocer
cintas de más de 1.5 GB (DAT DDS-1); como además se comprime, se confía en la
capacidad de dump para recibir la señal EOT en una cinta con capacidad en exceso.
ufsdump 0uf /dev/rmt2 /dev/rdsk/c0t3d0s5
crea un respaldo nivel 0 con el comando ufsdump (Solaris), del sistema de archivos
sobre el dispositivo crudo /dev/rdsk/c0t3d0s5; algunas versiones no aceptan el punto de
montaje. Desgraciadamente, el comando dump en Solaris existe, pero su propósito es
examinar archivos objeto, lo cual induce a error a muchos administradores honestos.
Esquemas de respaldo.
Los niveles de respaldo pueden elegirse arbitrariamente; sólo tienen sentido respecto de un
respaldo de nivel menor. Un esquema de respaldo se define en función de
actividad de cada sistema de archivos; capacidad del dispositivo de respaldo; redundancia deseada; cantidad de volúmenes; complejidad operativa.
Si el sistema de archivos cabe en un volumen, puede hacerse un nivel 0 diario (o semanal), con
un grupo de cintas que se va reutilizando; cada N días, la cinta se conserva. Este esquema
presenta redundancia masiva y es fácil para restaurar

Un esquema más optimizado consiste en realizar un nivel 9 diario (7 cintas), un nivel 5
semanal (5 cintas), un nivel 3 mensual (12 cintas), un nivel 0 cuando ya no alcanza un
volumen o al menos una vez al año.
El esquema clásico más completo de respaldo tiene conexión con el algoritmo
matemático de las Torres de Hanoi. Equilibra la aspiración de retener la mayor
información posible por el mayor tiempo posible con limitaciones prácticas como el
número de cintas y el tiempo disponible. Emplea los 9 niveles, el 0 se conserva, y
reitera el ciclo cada 45 días. Este esquema suele ser demasiado complicado aún para
sistemas grandes, aunque provee excelente redundancia; también es complicado
restaurar.
>> 0 > 3 > 2 > 5 > 4 > 7 > 6 > 9 > 8
> 1A > 3 > 2 > 5 > 4 > 7 > 6 > 9 > 8
> 1B > 3 > 2 > 5 > 4 > 7 > 6 > 9 > 8
> 1C > 3 > 2 > 5 > 4 > 7 > 6 > 9 > 8
> 1D > 3 > 2 > 5 > 4 > 7 > 6 > 9 > 8
Elección de un esquema.
Dado que una gran parte de los archivos no cambian, el esquema incremental más simple ya
elimina un gran volumen del respaldo diario. La inserción de niveles divide aún más finamente
en grupos los archivos activos. El respaldo incremental permite respaldos más frecuentes con
menos cintas, más alguna redundancia por repetición de archivos. El esquema de respaldo
elegido surge de evaluar estas condiciones.
Recomendaciones generales.
Las siguientes recomendaciones no son universales ni infalibles, pero surgen de la experiencia.
Respaldar todo desde la misma máquina: aunque es más lento, la facilidad de
administración y la posibilidad de verificar la corrección del respaldo en todas las
máquinas justifica su realización a través de la red. Se corre rdump en la máquina
remota a respaldar, vía rsh, dirigiendo la salida hacia la unidad de respaldo en la
máquina local. Al restaurar, deben tomarse en cuenta eventuales diferencias de sistema
operativo; en algunos casos hay inversión de bytes, que pueden arreglarse con dd; esto
no resuelve diferencias entre versiones de rdump.
Etiquetar las cintas: fecha, hora, máquina, sistema de archivos, número serial
constituyen el mínimo absoluto. Una cinta no identificada sólo sirve para ser regrabada.
Los sistemas de archivos / y /usr deben poder restaurarse sin referencia alguna a scripts
o información en línea; la sintaxis exacta de los comandos, densidades, opciones y otros
valores deben figurar en la documentación de la cinta. Un registro más completo se hace
imprescindible cuando se respaldan muchos sistemas de archivos en un mismo
volumen.
Intervalo de respaldos razonable: el sistema de archivos de usuarios puede
respaldarse a diario en sistemas grandes, o semanalmente en sistemas chicos; la

frecuencia de respaldo para otros sistemas de archivos dependerán del uso y la
criticidad. El respaldo consume recursos y tiempo de operador; es responsabilidad del
administrador del sistema balancear costos y riesgos al definir frecuencias de respaldo
sobre cada sistema de archivos.
Elegir sistemas de archivo: según el movimiento, cada sistema de archivos puede tener
un esquema diferente. Un grupo de archivos muy activo en un sistema de archivos
inactivo puede copiarse diariamente hacia otro sistema de archivos con respaldo diario.
Sistemas de archivos de noticias, o el sistema de archivos /tmp, no deben respaldarse;
las noticias son efímeras, y /tmp no debe contener nada importante.
Respados diarios en un solo volumen: buscar un esquema o un medio para que el
respaldo diario quepa en un solo volumen; es la única forma simple de realizar un
respaldo diario, cargando la cinta a última hora y ejecutando el respaldo en cron.
Recordar: el respaldo de varios sistemas de archivos en una cinta única requiere usar el
dispositivo no rebobinado y documentar bien las cintas.
Crear sistemas de archivo acordes con el tamaño del medio de respaldo: con las
capacidades actuales, es posible crear sistemas de archivo de tamaño razonable que
quepan en una cinta. Debe haber una buena razón para crear sistemas de archivo muy
grandes.
Mantener las cintas fuera del lugar: pero realmente en otro lugar, apartado del lugar
de la instalación; hay innúmeras historias sobre pérdida de los respaldos conjuntamente
con el sistema. El volumen actual de medios es suficientemente reducido como para
trasladar un montón de información en un portafolios. Puede recurrirse a una institución
especializada en conservación de datos o llevar las cintas a casa del gerente.
Seguridad del respaldo: el robo de un respaldo equivale al robo de toda la información
vital de una organización. Las precauciones de seguridad con los respaldos debe ser
tanta como la dispensada al propio sistema, con el agravante de que es más fácil llevarse
unas cintas que la información en disco.
Limitar la actividad durante dump: la actividad en los archivos mientras se ejecuta
dump puede ocasionar confusión en el momento de restaurar. Esto no es tan crítico en
niveles superiores, pero sí en el nivel 0. Puede hacerse el respaldo en horas de escasa
actividad, nocturnas o en fin de semana. Es preciso cuidar de no coincidir con los
programas del sistema que modifican el sistema de archivos; éste debe permanecer
estacionario mientras se realiza el respaldo. La solución más segura es hacer el respaldo
en monousuario. En ocasiones especiales, como al encarar una actualización del sistema
operativo, deberá uno armarse de paciencia, bajar la máquina a monousuario y respaldar
el sistema en nivel 0. Existen programas especiales (archivadores o "filers") capaces de
tomar un registro periódico del estado del sistema y resincronizar el respaldo. Debe
considerarse esta posibilidad cuando no sea posible reducir la actividad del sistema en
ningún momento.
Verificar el respaldo: hay también historias de respaldos tomados cuidadosamente que
nunca pudieron restaurarse. Releer la cinta con restore para generar la tabla de
contenido es una prueba razonable; probar recuperar un archivo en particular obliga a
recorrer partes más alejadas de la cinta, ofreciendo una comprobación más sólida. Debe

verificarse también que es posible restaurar desde varias cintas, que se pueden leer
cintas grabadas tiempo atrás, y que es posible leer en otras unidades además de la
habitual.
Vida útil de las cintas: como todo en el mundo, las cintas tienen una vida limitada,
indicada por los fabricantes en cantidad de pasadas. Un respaldo, una restauración o un
salto de archivos representan, cada uno, una pasada.
Crecimiento del sistema: el bajo precio de discos tiende a generar un aumento
desordenado de la capacidad de almacenamiento. Imponer un criterio ordenado de
crecimiento, con calificación de datos por criticidad y actividad, su separación racional
en distintos sistemas de archivos, la concentración de información vital en un servidor
confiable, son algunas medidas coactivas para alcanzar un respaldo confiable y
humanamente posible.
Restaurar archivos.
En este apartado se trata la restauración de un archivo o un grupo de archivos, en
contraposición a la restauración de un sistema de archivos completo.
1. Determinar en qué cinta se encuentran los archivos a restaurar. Los usuarios
generalmente buscan la última versión del archivo, pero no siempre es así. La existencia
y ubicación del archivo dependen del esquema de respaldo empleado. Si se conservan
catálogos (listas con todos los archivos respaldados en una fecha), la búsqueda se
simplifica: basta con verificar si el archivo buscado se encuentra en el catálogo. Si no es
así, se deberán revisar las cintas más probables según la fecha indicada por el usuario, o
recorrer todo el conjunto desde el respaldo nivel 0 inmediato anterior.
2. Crear un directorio donde recuperar los archivos. Muchas versiones de restore
requieren reponer la ruta entera de directorios para recuperar el archivo. No usar /tmp;
su contenido será borrado en un rearranque imprevisto.
3. Si se han colocado varios archivos de respaldo en una misma cinta, se deberá
consultar la documentación de ubicación de cada uno, determinar el lugar en que se
encuentra el de interés, y usar el comando mt para ubicar el comienzo del archivo de
respaldo.
4. Restaurar el archivo. Usar el comando complementario del respaldo: si se usó dump
para respaldar, usar restore; si se usó rdump, usar rrestore.
5. Entregar el archivo al usuario. Se puede copiar el archivo hacia el directorio del
usuario, verificando que no exista ya un archivo con ese nombre. En ningún caso debe
sobreescribirse un archivo de otro usuario. Otra alternativa es dejarlo en el lugar de
recuperación para que el usuario lo copie. En este caso, será preciso limpiar
regularmente el directorio de recuperación.
6. Notificar al usuario.
Ejemplo completo de recuperación del archivo perdido.arch del usuario juanpe, con
la cinta en la máquina roble:

Montar la cinta en la unidad de la máquina roble.
$ su
ingresa como supervisor, pide contraseña.
# cd /var/tmp
la recuperación se hará en el directorio /var/tmp.
# rsh roble mt -f /dev/nrst1 fsf 3
salta hasta el 4o. archivo de respaldo en la cinta.
# rrestore xf roble:/dev/nrst1
> /usr/users/juanpe/docs/perdido.arch
ejecuta el comando e imprime mensajes; observar continuación del comando en la segunda
línea.
# ls /var/tmp/usr/users/juanpe/docs
perdido.arch
muestra la presencia del archivo recuperado.
# ls /usr/users/juanpe/docs
otro1.arch otro2.arch
verifica que el archivo recuperado no existe en el directorio propio del usuario, para no
reescribirlo.
# cp -p /var/tmp/usr/users/juanpe/docs/perdido.arch
/usr/users/juanpe/docs
copia el archivo recuperado hacia el directorio propio del usuario.
# mail -s "Archivo recuperado" juanpe
Su archivo perdido.arch fue recuperado.
Se encuentra en su directorio, bajo docs.
Saludos,
El Administrador.
.
Envía correo al usuario avisando la recuperación.
# exit
$

Fin de la tarea.
restore admite la opción i, para uso interactivo: el comando lee el catálogo de la cinta;
se recorren los archivos como si se tratara de un árbol de directorios común, usando ls,
cd y pwd; se van seleccionando los archivos a restaurar con add; cuando se han
seleccionado todos, indicando extract se los recupera de la cinta.
Ejemplo de recuperación interactiva. El indicador de supervisor # cambia a restore> al
operar dentro del comando.
# rrestore if roble:/dev/nrst1
restore> ls
.:
arnoldo/ beiro/ juanpe/ lost+found/ vega/
restore> cd juanpe
restore> ls
carta01.txt core docs/ mbox perdido.arch varios/
restore> add perdido.arch
El archivo se agrega a la lista de archivos a recuperar. Agregar un directorio agrega todo su
contenido.
restore> ls
carta01.txt core docs/ mbox perdido.arch* varios
El asterisco indica que está marcado para recuperar.
restore> extract
Muestra mensajes; si no se sabe en qué volumen está el archivo, debe comenzarse por el
último y proceder hacia el principio; aquí asumimos saber que está en el primer volumen.
Specify next volume #: 1
Se realiza la extracción; pregunta si el directorio raíz de la cinta debe intepretarse como
directorio corriente; se usa sólo al restaurar sistemas de archivo completos.
set owner mode for '.'? [yn] n
#
Sale de restore, fin de la tarea.
Restaurar sistemas de archivos.

Antes de restaurar un sistema de archivos completo, se debe estar seguro de haber eliminado
las causas que provocaron su destrucción.
1. Crear un sistema de archivos en la partición donde se va a restaurar; montarlo.
2. Cambiar al directorio raíz (punto de montaje) del nuevo sistema de archivos. Montar la
primera cinta del último respaldo nivel 0. Arrancar la restauración con restore r. El
comando pedirá las cintas sucesivas.
3. Al terminar de restaurar el nivel 0, continuar con los diferentes niveles en el mismo orden
del esquema de respaldos empleado.
Ejemplo de restauración de un sistema de archivos a partir de un respaldo de 3 niveles.
# newfs /dev/dsk/c201d6s0 QUANTUM_PD1050S
# mount /dev/dsk/c201d6s0 /home
# cd /home
Crea el sistema de archivos, lo monta y se posiciona en él. Montar ahora la cinta 1 del último
respaldo nivel 0 de /home.
# restore r
Montar las restantes cintas del respaldo nivel 0. Montar luego la primer cinta del respaldo
nivel 1 siguiente.
# restore r
Montar las siguientes cintas del respaldo nivel 1. Montar luego la primer cinta del respaldo
nivel 2 siguiente.
# restore r
Montar las siguientes cintas del respaldo nivel 2. Montar luego la primer cinta del respaldo
nivel 3 siguiente.
# restore r
Esta secuencia repone el sistema de archivos a su estado original más cercano al
momento de pérdida. En el esquema de respaldos empleado, la única diferencia es la
mágica aparición de los archivos que fueron borrados. Hay versiones de restore que
llevan registro de los archivos borrados.
En una actualización del sistema operativo, debe hacerse un respaldo nivel 0 antes de la
actualización, efectuar luego la actualización cuidando de reponer los archivos de
configuración necesarios en los sistemas de archivos afectados por la actualización. Una
vez que todo esté funcionando, realizar inmediatamente un nuevo respaldo nivel 0. Esto

es imprescindible para asegurar la coherencia de los siguientes niveles, ya que la
actualización puede haber modificado fechas de archivos preexistentes.
Otros comandos de respaldo.
Los clásicos comandos tar (BSD) y cpio (System V) sirven para respaldar archivos, directorios
y grupos diversos de archivos y directorios. Se usan frecuentemente para trasladar
información, distribuir software o aún copiar árboles de directorios dentro de un mismo
sistema, sobre todo por su capacidad de conservar dueños, permisos y fechas, no siempre
posible con cp.
Copia de un árbol de directorios usando tar:
tar cf - dir_origen | ( cd dir_destino ; tar xfp - )
Copia de un árbol de directorios usando cpio:
find dir_origen -depth -print | cpio -pdm dir_destino
Este comando es poco usado, habiendo cedido lugar a tar.
Al usar estos comandos verificar estas posibles limitaciones: soporte multivolumen,
nombres de ruta largos, recuperación de errores, fijación de factor de bloqueo (20 por
defecto). Muchas han sido levantadas, en particular en las versiones de GNU, pero
conviene verificar en la documentación y comprobar en la práctica.
Cuando es preciso realizar transformaciones de datos es útil el comando dd (data
duplicator). Sin parámetros, este comando sólo copia entrada en salida. Admite un
cierto número de opciones que permiten cambiar formato de los datos o transferir entre
distintos medios.
Copia de una cinta entre dos unidades:
dd if=/dev/rmt8 of =/dev/rmt9 cbs=16b
Copia de una cinta en una sola unidad:
dd if=/dev/rmt8 of =/tmp/cinta.archdev cbs=16b
cambiar la cinta;
dd if=/tmp/cinta.arch of =/dev/rmt8 cbs=16b
Conversión desde cinta con diferente orden de byte:
dd if=/dev/rst8 conv=swab | tar xf -

volcopy permite realizar una copia exacta de un sistema de archivos completo hacia
otro dispositivo, eventualmente con cambio en el bloqueo. Está disponible en Solaris,
HP-UX y Linux.
Para el control de la unidad de cinta, se usa el comando mt, especialmente útil cuando
se graba más de un archivo en la misma cinta. Su sintaxis básica es
mt [-f dispositivo_cinta] comando [cantidad]
Los comandos de respaldo en cinta graban una señal de fin de archivo (EOF, End Of
File) al terminar de ejecutar; esto permite ubicar un respaldo en particular
desplazándose en la cinta. Entre los comandos admitidos por mt se destacan:
rew rebobinado de la cinta
offline saca de línea la unidad de cinta; en los modelos que lo permiten, eyecta el
casete.
status muestra información de la cinta.
fsf [cantidad] avanza la cinta la cantidad de archivos indicada, 1 por defecto.
bsf [cantidad] retrocede la cinta la cantidad de archivos indicada, 1 por defecto.
Amanda.
Amanda (Advanced Maryland Automatic Network Disk Archive) es un software para respaldo
de red capaz de actuar en una LAN hacia una unidad de cinta ubicada en un servidor,
cumpliento todas las exigencias deseables para un administrador. Usa dump y restore como
comandos de base, pero también puede manejar tar de GNU y smbtar de Samba para
respaldar datos de máquinas Windows. Corre en muchas versiones de UNIX, soporta extensa
variedad de hardware, permite compresión sobre el cliente antes de la transferencia, graba
registros completos del respaldo en la cinta. Amanda es software libre, escala bien, es muy
configurable, evoluciona rápido; está siendo usado extensamente en todo el mundo.
Ejercicios e Investigación.
1. Imagine la peor contingencia posible para su organización: la destrucción total del lugar.
Considere su disponibilidad de respaldos: determine qué información puede recuperar, con
qué esfuerzo, y en cuánto tiempo podría tener el sistema de nuevo en marcha, incluyendo la
necesidad eventual de adquirir hardware. ¿Está satisfecho con las respuestas?
2. Estudie los comandos de respaldo disponibles en su sistema. Realice una prueba
sobre la unidad de respaldo de que disponga. Si se dispone de un sistema de archivos
separado para /var puede ser conveniente usarlo, sobre todo si no es muy grande.
Restaure sobre un directorio borrador, cuidando no alterar el original.
3. Estudiar los comandos tar y/o cpio disponibles en su sistema. Estos comandos
tienen muchas opciones, diferentes según los sistemas. Aún la misma opción puede
actuar diferente en distintos sistemas. Probar con un grupo de archivos pequeño. No se
requiere disponer de una unidad de cinta o específica de respaldo, ya que se pueden usar
archivos en disco o aún la unidad de disquete. Asegurarse de poder respaldar, listar los
archivos de un archivo de respaldo, recuperar todos o uno de los archivos contenidos en
el archivo de respaldo.

4. Estudiar el comando dd y sus opciones de conversión. Probarlo para copiar un
archivo, o para tranferirlo hacia una cinta o un disquete.
5. Diseñe una estrategia para implementar un esquema de respaldo incremental en base
a tar o cpio. Algunos sistemas no disponen de dump/restore; en esos casos, tar y/o
cpio ofrecen facilidades para implementar el respaldo incremental manualmente o a
través de scripts. Algunos sitios que disponen de dump/restore igualmente prefieren
usar tar o cpio por la mayor tolerancia a actividad en el sistema
TCP/IP y Enrutamiento
TCP/IP
Paquetes
Direccionamiento de paquetes
Direcciones en Internet
ARP, RARP, BootP, DHCP - Relación entre direcciones
Enrutamiento
Protocolos de enrutamiento
Redirecciones ICMP
Subredes
CIDR: Classless Inter-Domain Routing
Elección de una estrategia de enrutamiento
Configuración de una red
Obtener y configurar las direcciones IP
Configurar las interfaces de red: ifconfig
Configurar rutas estáticas: route
Configuración dinámica estándar: routed
Configuración para el arranque automático
Diagnóstico de fallas de red
Ver si las máquinas están vivas: ping
Estado de la red: netstat
Encaminamiento de paquetes: traceroute

Monitores de tráfico: tcpdump, snifit, snoop, etherfind.
Inspección de tablas de ARP
TCP/IP y Enrutamiento
El TCP/IP es el software básico de red utilizado en Internet y fue desarrollado en los
primeros sistemas UNIX.
Incluye básicamente los siguientes componentes:
Internet Protocol (IP). Es el protocolo de capa de red (capa 3) y se encarga de transportar paquetes crudos de una máquina a otra.
Internet Control Message Protocol (ICMP). Proporciona funciones de soporte de bajo nivel a IP, por ejemplo mensajes de error.
Address Resolution Protocol (ARP). Relaciona direcciones de capa 2 y capa 3 en una LAN.
User Datagram Protocol (UDP) y Transmission Control Protocol (TCP). Se usan para enviar datos desde un programa a otro utilizando IP. UDP es un servicio no confiable y sin conexión y TCP es un servicio confiable y orientado a conexión. Ambos son protocolos de capa de transporte (capa 4)
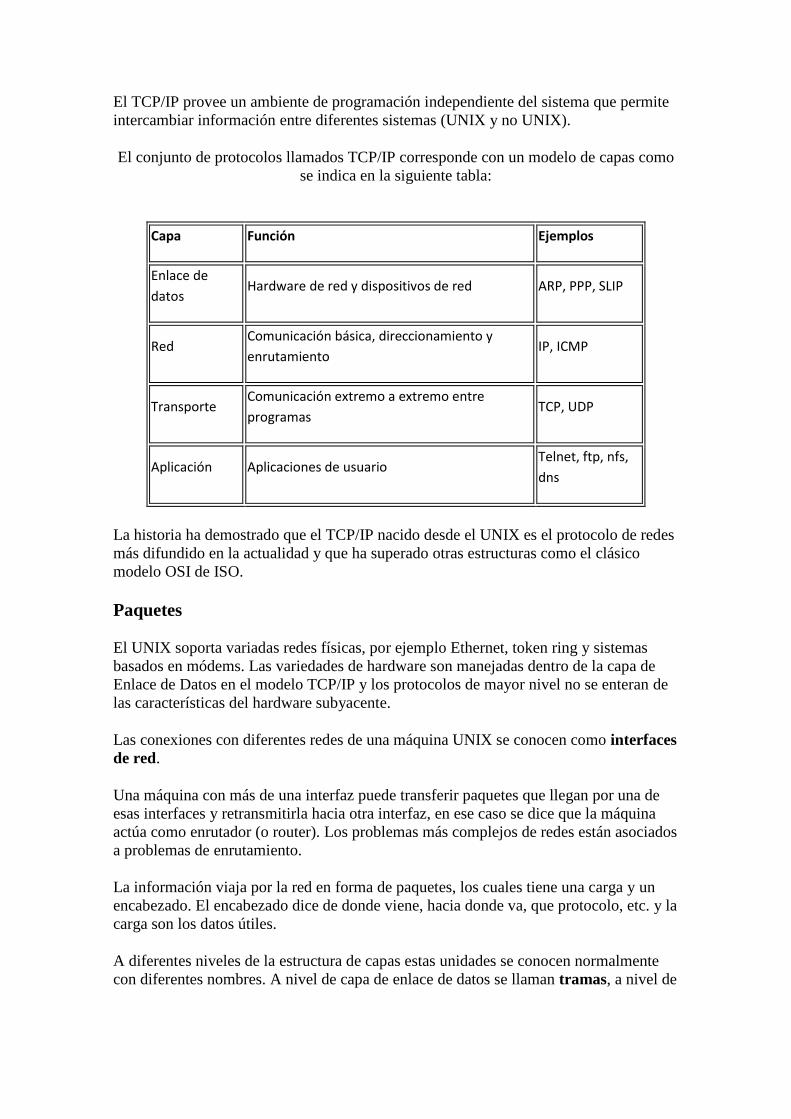
El TCP/IP provee un ambiente de programación independiente del sistema que permite
intercambiar información entre diferentes sistemas (UNIX y no UNIX).
El conjunto de protocolos llamados TCP/IP corresponde con un modelo de capas como
se indica en la siguiente tabla:
Capa Función Ejemplos
Enlace de
datos Hardware de red y dispositivos de red ARP, PPP, SLIP
Red Comunicación básica, direccionamiento y
enrutamiento IP, ICMP
Transporte Comunicación extremo a extremo entre
programas TCP, UDP
Aplicación Aplicaciones de usuario Telnet, ftp, nfs,
dns
La historia ha demostrado que el TCP/IP nacido desde el UNIX es el protocolo de redes
más difundido en la actualidad y que ha superado otras estructuras como el clásico
modelo OSI de ISO.
Paquetes
El UNIX soporta variadas redes físicas, por ejemplo Ethernet, token ring y sistemas
basados en módems. Las variedades de hardware son manejadas dentro de la capa de
Enlace de Datos en el modelo TCP/IP y los protocolos de mayor nivel no se enteran de
las características del hardware subyacente.
Las conexiones con diferentes redes de una máquina UNIX se conocen como interfaces
de red.
Una máquina con más de una interfaz puede transferir paquetes que llegan por una de
esas interfaces y retransmitirla hacia otra interfaz, en ese caso se dice que la máquina
actúa como enrutador (o router). Los problemas más complejos de redes están asociados
a problemas de enrutamiento.
La información viaja por la red en forma de paquetes, los cuales tiene una carga y un
encabezado. El encabezado dice de donde viene, hacia donde va, que protocolo, etc. y la
carga son los datos útiles.
A diferentes niveles de la estructura de capas estas unidades se conocen normalmente
con diferentes nombres. A nivel de capa de enlace de datos se llaman tramas, a nivel de

red se llaman paquetes, a nivel de transporte se llaman segmentos y a nivel de
aplicación se llaman mensajes.
A medida que la información pasa por la estructura de capas cada una de ellas le agrega
información de cabecera e incluye la unidad de la capa superior dentro de la carga. Por
ejemplo un segmento UDP se transmite en un medio Ethernet:
------------------------- Segmento UDP (108 bytes) --------------
----------- Paquete IP (128 bytes) -----------
Ethernet Header IP Header UDP Header Datos de la aplicación Ethernet Trailer
14 Bytes 20 Bytes 8 Bytes 100 Bytes 4 Bytes
Trama Ethernet (146 bytes)
El tamaño del paquete puede limitarse por causas de hardware o por convenciones del
protocolo. Por ejemplo la carga de una trama Ethernet no puede ser superior a 1500
bytes, el largo máximo de un paquete IP es de 64 Kbytes pero en general hay
limitaciones que no permiten ese tamaño. La limitación de una red o protocolo en el
tamaño del paquete se llama MTU (Maximun Transfer Unit).
La capa IP es la responsable de fragmentar los paquetes para adecuarse a la MTU de
una red en particular.
Direccionamiento de paquetes
Para que los paquetes lleguen a destino es necesario que contengan direcciones. Las
direcciones existen a varios niveles en la estructura de capas.
En el nivel de capa de enlace, existen direcciones Ethernet que son de 6 bytes, que están
pre-configuradas por el fabricante de la tarjeta y son únicas en el mundo. En Token
Ring existen también direcciones de capa de enlace y en enlaces PPP y SLIP como son
conexiones punto a punto no es necesario utilizar direcciones.
En el nivel IP, existen direcciones IP que son cuatro bytes asignados a la interfaz de red,
únicas en el mundo y no asociadas al dispositivo hardware. Son asignadas para permitir
el encaminamiento de los paquetes de una máquina origen a otra destino.
Son asignadas por InterNIC.
La correlación entre direcciones de capa de enlace y direcciones de capa de red es
necesaria en las redes de difusión y para hacer esta relación existe el protocolo arp. Este
protocolo permite implementar esta correlación en forma automática o sea sin la

intervención del administrador. Esto tiene importantes ventajas pues es posible cambiar
la tarjeta de red a una computadora sin necesidad de configurar a mano el cambio de
dirección de capa de enlace.
Las direcciones IP se escriben por convención de la forma: 164.73.224.40 y claramente
no son fáciles de recordar y por eso los sistemas UNIX permiten asociar nombres a las
direcciones para poder referirse a máquinas por su nombre y no por su dirección.
El UNIX posee varios mecanismos de implementar esa conversión de nombres a
números. La forma más básica es mediante el archivo /etc/hosts que tiene esa relación y
la más usada en Internet es a través del servicio de Servidor de Nombres DNS.
Es de destacar que el software de red no conoce de nombres sin de direcciones y el
servicio de relación entre números y nombres es una aplicación de usuario y no parte
del software de red.
Las direcciones IP identifican máquinas pero no servicios dentro de esas máquinas. Para
identificar servicios existe el concepto de PUERTOS que son las direcciones de capa de
transporte. Los números de puertos son de 2 bytes y hay un conjunto de puertos
llamados "bien-conocidos" ("well-known ports") que se han estandarizado para los
diferentes servicios. Por ejemplo el servidor de telnet atiende en el puerto 23, el servidor
de correo electrónico en el puerto 25, etc. La asignación de puertos puede verse en un
archivo que relaciona números con nombres de servicios y que se llama /etc/services.
Direcciones en Internet
Las direcciones Internet tienen cuatro bytes y se dividen en una parte de numeración de
red y otra de numeración de máquina.
En las decisiones de enrutamiento se utiliza esta división para saber si una máquina está
en la propia red o por qué camino debe encaminarse para llegar a destino.
Por convención se anotan en decimal separados por puntos entre los 4 bytes. Ejemplo
164.73.224.40
Hay varias clases de direcciones IP. Difieren en como se asigna la frontera entre parte
de red y parte de máquina.
Clase Primer byte Formato Comentario
A 1-126 R.M.M.M
B 128-191 R.R.M.M Normalmente con subredes
C 192-223 R.R.R.M
D 224-239 - Multicast

E 240-254 - Experimental
Si en los bits reservados para números de máquina de una red colocamos ceros,
entonces nos estaremos refiriendo a toda esa red. Es el nombre de la red y por lo tanto
los ceros están reservados a esta identificación. Si todos los bits de la parte de máquina
son unos, entonces se considera una dirección de broadcast dentro de esa red por lo que
todas las máquinas de la red deben escuchar esa dirección.
Si el primer byte de una dirección es el 127, se refiere a una red ficticia llamada
"loopback" y que no se refiere a una interfaz física. Tiene sentido dentro de una misma
máquina y los paquetes enviados a esa dirección no salen de la propia máquina, recorren
la pila de protocolos del TCP/IP y vuelven a la máquina como si hubieran sido recibidos
por ésta a través de alguna de las interfaces físicas.
ARP- Relación entre direcciones
Los paquetes IP se enrutan usando las direcciones IP, sin embargo, en redes de difusión
(particularmente Ethernet) es necesario tener una relación entre direcciones IP y
direcciones de capa de enlace de datos. Este relacionamiento se realiza mediante el
protocolo ARP.
La idea es que si estoy en una red Ethernet y tengo que enviar un paquete IP a una
máquina de mi misma red, debo enviar ese paquete encapsulado en una trama Ethenet.
Para saber a que dirección de capa de enlace debo enviar dicha trama, tengo que
averiguar cuál es la dirección de capa de enlace que se corresponde con la dirección IP a
la cual quiero enviar el paquete.
El ARP mantiene una tabla en memoria con la correspondencia entre direcciones de
capa de red y direcciones de capa de enlace de datos. Si ARP tiene en su tabla la
dirección de capa de enlace asociada a la dirección IP a la cual quiero referirme, se
forma una trama Ethernet con dicha dirección ethernet como destino.
Si ARP no posee en su tabla dicha correspondencia, es el encargado de averiguarlo. A
estos efectos genera una trama de difusión "Broadcast" de capa de enlace preguntando:
¿ Quién tiene la dirección IP 22.22.22.22 ?
Ese broadcast de capa de enlace es obviamente escuchado por todas las máquinas de la
red Ethernet y entonces aquella que tenga configurada esa dirección IP, responderá
diciendo:
Yo tengo esa dirección IP y mi dirección de capa de enlace es: 8:0:20:0:fb:6a
Ahora entonces la máquina que hizo la consulta ARP tiene la información de
correspondencia para la dirección IP deseada y la puede agregar en su tabla y así
generar la trama ethernet dirigida a la máquina deseada.

A su vez, la máquina que recibió la consulta original, tiene la correspondencia de la
máquina origen y también la incluye en su tabla pues es altamente probable que deba
dirigirse próximamente (para enviar una respuesta) a la máquina origen.
La trama de broadcast con la pregunta original incluye la dirección de capa de enlace de
la máquina origen, así como su dirección IP, por lo que terceras máquinas que no
participen del diálogo, podrían aprender de la pregunta la correspondencia de
direcciones correspondiente a la máquina origen. En realidad solamente tienen en
cuenta ese dato aquellas máquinas que ya tenían una entrada en su tabla referente a la
máquina origen y lo que hacen es actualizarla con la nueva información.
Esto es así para que las máquinas no agranden demasiado su tabla con información de
máquinas con las cuales quizá no tengan que hablar.
Las tablas además tienen tiempo de expiración con lo cual entradas no usadas van
liberando espacio en la tabla.
Existe en UNIX un comando arp que permite manejar el cache del protocolo ARP para
debugging.
RARP, BootP, DHCP
A veces existe la necesidad de conocer a partir de una dirección ethernet la dirección IP
asignada. Esto se utiliza en máquinas sin disco que arrancan cargando lo necesario de
un servidor. Para que todas las máquinas en este modo puedan cargar la misma imagen
del sistema operativo y no tener necesidad de disponer de una imagen por máquina, se
utiliza el protocolo RARP que consulta un servidor al cual se le pregunta:
¿ Que dirección IP corresponde a la dirección ethenet 8:0:20:0:fb:6a ?0
El servidor tiene una tabla de las direcciones IP asociadas a las diferentes máquinas
según su dirección de capa de enlace de datos y la máquina sin disco configura la
imagen con la dirección IP brindada por el servidor.
El protocolo RARP ha quedado obsoleto con el advenimiento del protocolo BOOTP
(Boot Protocol) que brinda más datos de configuración además de la dirección IP.
En la actualidad el DHCP (Dynamic Host Configuration Protocol) permite a una
máquina obtener toda la configuración a partir de un servidor en su red de área local.
Enrutamiento
Enrutamiento es el proceso de dirigir un paquete a través de la red desde una máquina
origen a otra destino.
La idea es enviar los paquetes a algún sitio donde pueden tener más información de
cómo llegar al destino deseado.
La información de enrutamiento se construye en una tabla de reglas del tipo:

Para ir a la red A (número de red y máscara), envíe los paquetes a la máquina B, con
un costo de 1 salto.
Asimismo existe una ruta por default donde se envían todos los paquetes destinados a
redes para las cuales no tenemos rutas explícitas.
La tabla de ruteo se recorre de lo más específico a lo más general. Si no hay ruta
específica para dirigirse a un destino y no hay ruta default, el sistema enviará un
mensaje de "network unreacheable". Esta especificidad se determina por el largo de la
máscara. Cuanto más cantidad de unos tenga la máscara, más específica será la ruta.
Desde el punto de vista del enrutamiento IP, toda la información necesaria se almacena
en la tabla de ruteo, el problema es determinar si la tabla tiene la información adecuada.
La tabla de ruteo de una máquina puede examinarse con el comando netstat. La opción
-r del mismo muestra la tabla de ruteo (la opción -n es para no convertir números en
nombres).
En un FreeBSD, por ejemplo la salida resumida del comando netstat -rn sería
# netstat -rn
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif
Expire
default 164.73.224.28 UGSc 33 36932 ed1
127.0.0.1 127.0.0.1 UH 16 45450 lo0
.....
164.73.224/25 link#1 UC 0 0
164.73.224.1 8:0:2b:14:a1:21 UHLW 5 198078
ed1 1039
164.73.224.40 48:54:e8:26:db:69 UHLW 1 1908914 lo0
164.73.224.60 0:0:21:95:90:34 UHLW 4 0
ed1 840
164.73.224.128 164.73.224.60 UGHD 0 2 ed1
164.73.224.130 164.73.224.60 UGHD 0 801 ed1
.....
En un Linux RedHat, por ejemplo la salida del comando netstat -rn sería de la forma:
17 ludmilla ~ >netstat -rn
Kernel IP routing table
Destination Gateway Genmask Flags MSS Window
irtt Iface
164.73.224.76 0.0.0.0 255.255.255.255 UH 0 0
0 eth0
164.73.224.0 0.0.0.0 255.255.255.128 U 0 0
0 eth0
127.0.0.0 0.0.0.0 255.0.0.0 U 0 0
0 lo
0.0.0.0 164.73.224.28 0.0.0.0 UG 0 0
0 eth0

Las rutas pueden ser estáticas o dinámicas. Las rutas estáticas se establecen
manualmente con el comando route, por ejemplo:
route add -net 222.222.222.0 164.73.224.28 1
Las rutas estáticas son una solución confiable en redes pequeñas pero el administrador
debe conocer la topología de la red.
Dinámicamente las rutas pueden modificarse a través de un demonio que se comunican
con otros enrutadores intercambiándose información para actualizar las tablas.
En UNIX está disponible el routed en forma estándar y existe también el gated que
tiene más potencia.
Protocolos de enrutamiento
Los protocolos de enrutamiento son el lenguaje en que los demonios de ruteo
intercambian información acerca de la red.
Se clasifican en protocolos de enrutamiento exterior (IGP) y protocolos de enrutamiento
exterior (EGP). Los IGP se usan al interior de lo que se llaman sistemas autónomos que
son un conjunto de máquinas administradas por una autoridad común. Los EGP se usan
entre sistemas autónomos. La diferencia es que los IGP tratan de optimizar el
enrutamiento entre una red compleja con muchos caminos alternativos y los EGP tratan
de optimizar el enrutamiento teniendo en cuenta que los caminos son normalmente
pocos porque los sistemas autónomos se interconectan entre si con pocos enlaces.
Los diferentes protocolos utilizan distintas métricas para estimar el costo de cada ruta.
Los costos pueden medirse en saltos, retardo, etc. Los EGP en general no toman
demasiado en cuenta los costos porque normalmente no hay demasiadas rutas
alternativas pero si tratan de optimizar la posibilidad de alcanzar una determinada red.
Hay varios protocolos utilizados comunmente. Algunos de ellos son:
RIP - Routing Information Protocol
OSPF - Open Shortest Path First
IGRP - Interior Gateway Routing Protocol
EGP - Exterior Gateway Protocol
BGP - Border Gateway Protocol
RIP es el protocolo usado por el demonio routed estándar en UNIX. El costo de las rutas
se mide en saltos, donde cada salto es un enrutador por el cual pasan los paquetes. Hay
dos versiones: la 1 no tiene soporte para máscaras y la 2 sí.
OSPF funciona bien en redes grandes y es más difícil de configurar. IGRP es un
protocolo propietario de Cisco previo al OSPF.

El estándar actual de EGP es el protocolo BGP en su versión 4.
Redirecciones ICMP
Aunque IP no se encarga del manejo de la tabla de ruteo tiene algunas funciones para
facilitar la configuración de enrutamiento.
Si un enrutador envía un paquete a una máquina cuya dirección IP de origen es de la
misma red que el destino, es claro que algo no funciona muy bien, ya que la máquina
origen podría haber enviado directamente el paquete a la máquina destino sin pasar por
el enrutador.
El enrutador puede concluir que las tablas de ruteo de la máquina origen no están muy
ajustadas. En este caso el enrutador puede notificar al originador de este problema
mediante un paquete ICMP del tipo redirect. Ese paquete dice: "Para dirigir paquetes a
la máquina XX, debería enviarlos a través a router YY"
Si el originador es bien comportado, debería introducir en sus tablas la información
indicada, para que los próximos paquetes dirigidos hacia XX sean enviados por YY, es
decir por el camino directo.
Este sistema permite configurar las máquinas con solamente una ruta por defecto y dejar
que por el mecanismo de los ICMP redirects vayan aprendiendo las rutas alternativas.
Obviamente no es muy eficiente porque hay un tráfico extra para transmitir la
información de redirección.
Subredes
Las clases A y B permiten respectivamente redes de 16 millones y 64 mil máquinas
respectivamente, pero es muy raro que existan redes con esa cantidad de máquinas.
Entonces se utiliza un mecanismo para dividirlas que se llama "subnetting".
El método consiste en pedir prestados bits de la parte correspondiente a la numeración
de máquina para extender la parte de numeración de red. Para especificar hasta donde
va la parte de red y cual es la parte de máquina, se utiliza la máscara de subred. La
máscara son 32 bits que van en 1 los correspondientes a la parte de red y en 0 los de la
parte de máquina.
La configuración de la máscara de red se utiliza en el momento de configurar la interfaz
de red mediante el comando ifconfig. Si no ponemos máscara el sistema la toma según
las normas para las clases A, B o C. Si se especifica la máscara, se sobreescribe el valor
por defecto.
La ventaja es que para el resto de la red se sigue siendo por ejemplo una clase B y
solamente al interior de la organización es necesario conocer como se llega a las
diferentes subredes.

CIDR: Classless Inter-Domain Routing
Con el crecimiento de Internet, se produce el fenómeno que las tablas de ruteo a nivel
del backbone, crecen mucho porque hay muchísimas clases C para cada una de las
cuales se requiere una entrada en la tabla.
La idea del CIDR es extender el concepto de máscara para agrupar ahora varias redes
clase C por ejemplo en una sola entrada en la tabla de ruteo.
La idea es que si por ejemplo las redes 199.128.0, 199.128.1, 199.128.2 y 199.128.3 se
acceden por la misma salida, puedo poner una sola entrada para una red que tiene la
primer parte igual o sea con una máscara FFFFFC00.
Elección de una estrategia de enrutamiento
Hay en principio cuatro estrategias de enrutamiento:
Ninguno Rutas estáticas Rutas estáticas pero escuchando mensajes de RIP Enrutamiento dinámico
La topología de la red tiene una influencia muy importante en la estrategia a tomar. Las
diferentes topologías tienen diferentes requerimientos.
Las siguientes reglas pueden ayudar a tomar la decisión de qué estrategia seguir.
Una red aislada no requiere reglas de enrutamiento Si hay una sola salida de esa red al mundo, las máquinas pueden tener solamente una
ruta por defecto hacia el enrutador que comunica la red con el mundo. Un enrutador con pocas redes hacia un lado y con una salida al mundo por otro, puede
configurarse con rutas estáticas, aunque si hay más de una alternativa sería deseable que escuchara mensajes de enrutamiento dinámico.
Aunque se utilice RIP, tratar de que no envíe actualizaciones a intervalos muy cortos para reducir el tráfico. El routed normalmente hace eso y es posible entonces utilizar gated al cual puede configurársele que envíe información a determinados enrutadores y no por difusión.
Para que los clientes escuchen información de ruteo en forma pasiva (sin informar de sus rutas) puede usarse el routed con la opción -q. También puede configurarse el gated en esa modalidad.
El routed cree todo lo que escucha, con lo cual es más confiable usar gated configurado en forma más controlada.
El enrutamiento dinámico debe ser usado donde hay fronteras políticas o administrativas de la red.
Configuración de una red
Para configurar una red se requieren los siguientes pasos:
Planificar la estructura física y lógica de la red

Asignación de direcciones IP Instalación del hardware de red Configurar los equipos para que reconozcan y configuren las conexiones de red en
tiempo de arranque Configurar las rutas estáticas necesarias o los demonios de enrutamiento
Se abarca la configuración en una red ethernet. Los aspectos de las conexiones punto a
punto quedan fuera de este tema.
Se supondrá que ya se tiene configurada la interfaz desde el punto de vista hardware y
se hará referencia a la configuración desde el punto de vista lógico del sistema.
Obtener y configurar las direcciones IP
Las direcciones IP deben ser únicas en Internet, por lo que son asignadas por un
organismo central llamado IANA (Internet Assigned Numbers Authority) normalmente
a través de un proveedor de servicio (ISP).
Hay que tener en cuenta que las direcciones IP no se asignan a máquinas sino a
interfaces, por lo que una máquina con varias interfaces requerirá varias direcciones IP.
Además de asignarle una dirección IP es recomendable asignar un nombre y
configurarlo por lo tanto en el DNS (Domain Name Server).
Configurar las interfaces de red: ifconfig
El comando ifconfig se utiliza para configurar las direcciones IP, máscaras y
direcciones de difusión de las interfaces de red.
Normalmente es ejecutado en tiempo de arranque pero puede ejecutarse a mano para
hacer cambios al vuelo de la configuración de las interfaces.
La sintaxis más común es:
ifconfig interfaz [familia] direccion_ip opciones
por ejemplo:
ifconfig en0 128.138.240.1 netmask 255.255.255.0 broadcast 128.138.240.255
interfaz indica el nombre del driver asignado por el sistema operativo a la interfaz de
red. Para determinar las interfaces presentes (detectadas) en una máquina puede
utilizarse el comando netstat -i.
familia indica el tipo de protocolo de red que queremos asociar a la interfaz. En general
lo que nos interesa es el tipo IP por lo que se especifica inet como opción. La mayoría
de los UNIX toman inet por defecto por lo que es común no poner nada en el campo de
familia.

direccion_ip es la dirección IP asociada. Puede ser un nombre o una dirección en la
notación de puntos de Internet (Ejemplo: 128.138.240.1). Se recomienda poner las
direcciones como número para evitar que la máquina no arranque por no poder
averiguar la correspondencia entre nombre y número.
opciones más comunes:
netmask Para especificar la máscara de la red. Puede ser notación decimal o
hexadecimal.
broadcast Para indicar la dirección IP de difusión, normalmente el default es
todos 1 en la parte de máquina de la dirección IP de acuerdo a la máscara. Puede
ser notación decimal o hexadecimal.
ifconfig interfaz Presenta la configuración actual de la interfaz. En muchos sistemas
también ifconfig -amuestra la configuración de todas las interfaces.
Configurar rutas estáticas: route
Para configurar rutas estáticas se utiliza el comando route que permite agregar y borrar
rutas. Además de las rutas agregadas a mano en la tabla de ruteo, puede estar corriendo
algún demonio para mantener rutas dinámicas.
Normalmente hay una red que siempre hay que configurar a mano y es la ruta por
defecto.
El comando route tiene la siguiente sintaxis simplificada:
route operación [tipo] destino enrutador saltos
El argumento operación dice que estamos haciendo (add, delete), el destino es el
número de una red o una máquina o la palabra default. El enrutador es la máquina a la
que hay que enviarle los paquetes dirigidos a esa red o máquina destino. Los saltos es la
cantidad de saltos necesarios para llegar al destino.
El tipo es para decir que tipo es el destino. Puede ser una red o una máquina. En algunas
máquinas el tipo se indica con las palabras clave net o host y en otras con -net y -host.
Hay otra opción que es para borrar la tabla de ruteo que según el sistema puede ser
route -f o route flush.
La configuración actual de la tabla de ruteo puede verse con el comando netstat -rn.
Configuración dinámica estándar: routed
El demonio routed es el estándar en UNIX como demonio de ruteo dinámico. Es muy
simple pero es consumidor de recursos. La tendencia debería ser a pasarse al gated pero
no todos los sistemas lo traen aunque está disponible en forma pública para la mayor
parte de las plataformas.

El routed solo sabe hablar RIP que es un protocolo simple que usa los saltos como
métrica para medir el costo de las diferentes rutas. Es un protocolo que funciona
enviando paquetes de difusión "broadcast" cada 30 segundos publicando las rutas que
conoce. La información que recibe de sus vecinos, la junta con las que posee y con las
tablas de ruteo del kernel.
El routed puede funcionar en modo servidor (invocado con -s) o en modo "quiet"
(invocado con -q). En ambos modos escucha la información de RIP que le llega pero
solo en modo servidor informa de las rutas que posee hacia los demás enrutadores. Si la
máquina tiene más de una interfaz, por defecto funciona en modo servidor y si tiene una
sola por defecto funciona en modo "quiet".
El routed no requiere configuración y dinámicamente escucha RIP y actualiza las tablas
de ruteo. Si se tiene solo un camino para salir al mundo puede ejecutarse con la opción -
g para que propague la ruta hacia el mundo como ruta por defecto.
Se puede usar el archivo /etc/gateways cuando se tiene más de una salida. El archivo
tiene líneas similares a comandos route.
Configuración para el arranque automático
En los sistemas más viejos, la configuración de la red se hacía directamente
modificando los archivos básicos de arranque (/etc./rc o /etc./rc.local), actualmente casi
todos los sistemas tienden a que no se modifiquen los scripts de arranque sino que se
modifiquen algunos archivos de los cuales los scripts de arranque toman variables.
En todos los sistemas se llaman diferente los archivos de configuración o los scripts
donde se encuentran las configuraciones de red.
Diagnóstico de fallas de red
Hay muchas herramientas para determinar problemas de red TCP/IP en UNIX. En
general la información que brindan es de bajo nivel por lo que es necesario saber como
funciona el TCP/IP y como se realiza el enrutamiento.
Ver si las máquinas están vivas: ping
El comando ping utiliza el mensaje ECHO_REQUEST del protocolo ICMP para pedir a
una máquina que responda con un mensaje ECHO_REPLY del mismo protocolo para
verificar que dicha máquina esta viva.
Esto es solo una función de bajo nivel que no requiere procesamiento en la máquina
destino. Sirve para probar:
Que la máquina este encendida Que tenga configurado el protocolo TCP/IP Que existan rutas para llegar desde la máquina origen a la destino y de la máquina
destino a la origen.

Si alguna de estas condiciones no se cumple el comando ping informará que la máquina
no responde.
A su vez, que el comando ping informe que una máquina está viva solamente indica
que se cumplen las condiciones establecidas pero no indica que funcionen o no otros
protocolos de nivel superior u otros servicios que esa máquina deba o pueda brindar.
Hay una versión más vieja del comando ping que solamente dice si la máquina está viva
o no. Las versiones más modernas, quedan en un loop infinito hasta que se presione
Control-C. En la versión vieja es posible que exista alguna opción para entregar una
salida extendida modo loop. Ejemplo ping -s (SunOS) o ping -l (Ultrix).
Las salidas de la vieja versión del ping (Ejemplo en SunOS) son del tipo:
# ping ampere
ampere.iie.edu.uy is alive
#
En la versión moderna del ping, las salidas son del tipo:
# ping maxwell
PING maxwell.iie.edu.uy (164.73.224.30): 56 data bytes
64 bytes from 164.73.224.30: icmp_seq=0 ttl=255 time=0.614 ms
64 bytes from 164.73.224.30: icmp_seq=1 ttl=255 time=0.568 ms
64 bytes from 164.73.224.30: icmp_seq=2 ttl=255 time=0.573 ms
64 bytes from 164.73.224.30: icmp_seq=3 ttl=255 time=0.570 ms
^C
--- maxwell.iie.edu.uy ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.568/0.581/0.614/0.019 ms
#
Cuando la máquina destino no responde, el reporte de las dos versiones del ping se
pueden ver en los siguientes ejemplos
# ping acer
no answer from acer.iie.edu.uy
#
# ping acer
PING acer.iie.edu.uy (164.73.224.3): 56 data bytes
ping: sendto: Host is down
ping: sendto: Host is down
ping: sendto: Host is down
ping: sendto: Host is down
ping: sendto: Host is down
ping: sendto: Host is down
^C
--- acer.iie.edu.uy ping statistics ---
7 packets transmitted, 0 packets received, 100% packet loss
#
La salida detallada en caso de éxito, contiene la dirección IP de la máquina destino, la
secuencia de los paquetes ICMP y el tiempo de ida y vuelta de las respuestas.

Además, luego del Control-C da las estadísticas de paquetes enviados y respuestas
recibidas.
Es interesante notar que si bien el IP no garantiza entrega de paquetes, normalmente a
menos que la red esté muy cargada, todos los paquetes deberían llegar a destino. Si se
pierden paquetes puede ser por exceso de carga y es posible que los protocolos de
mayor nivel igual funcionen aunque deberán utilizar retransmisiones haciendo que las
cosas funcionen más lentamente.
En caso de paquetes perdidos es importante tratar de detectar el motivo ya que puede
deberse a problemas físicos en la red y sería deseable poder solucionarlos.
Estado de la red: netstat
El comando netstat despliega informaciones varias sobre el estado de la red. En
realidad de acuerdo a las opciones con que se invoque brinda información de diferentes
aspectos de la red.
Veremos los cuatro usos más frecuentes del netstat.
Estado de las conexiones de red Configuración de las interfaces de red Estado de la tabla de ruteo Estadísticas de los diferentes protocolos de red
Estado de las conexiones de red
Sin argumentos el comando netstat despliega el estado de los puertos TCP y UDP
activos (Con la opción -a) despliega además los inactivos.
La salida es algo del estilo:
FreeBSD
# netstat
Active Internet connections
Proto Recv-Q Send-Q Local Address Foreign
Address (state)
tcp 0 0 ampere.1946
obelix.unicamp.b.http ESTABLISHED
tcp 0 0 ampere.3128
plata.1116 ESTABLISHED
tcp 0 0 ampere.1945
obelix.unicamp.b.http ESTABLISHED
tcp 0 0 ampere.1944
obelix.unicamp.b.http ESTABLISHED
tcp 0 0 ampere.pop3
chui.1065 TIME_WAIT
....
....
Linux RedHat
# netstat

Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address
State
tcp 0 252 ludmilla.iie.edu.uy:ssh
ampere.iie.edu.uy:3690 ESTABLISHED
tcp 1 0 ludmilla.iie.edu.u:1431
ampere.iie.edu.uy:3128 CLOSE_WAIT
tcp 1 0 ludmilla.iie.edu.u:1430
ampere.iie.edu.uy:3128 CLOSE_WAIT
tcp 0 0 ludmilla.ii:netbios-ssn
cachimba.iie.edu.u:1135 ESTABLISHED
Las direcciones son indicadas en la modalidad máquina:puerto. Los nombres de
máquinas se obtienen a partir del Servidor de Nombres (DNS) y los nombres de puertos
a partir del archivo /etc/services. Si se especifica al netstat la opción -n no se hace la
traducción de números a nombres ni de las máquinas ni de los puertos.
Recv-Q y Send-Q son los tamaños de las colas para dicha conexión en la máquina local.
Deberían tender a 0.
El estado de la conexión solo tiene sentido para TCP puesto que UDP es un protocolo
no orientado a conexión. Los estados posibles son: ESTABLISHED (conexión
establecida), LISTENING (para servicios que están esperando por conexiones,
normalmente no aparecen a menos que usemos la bandera -a) o TIME_WAIT (para
conexiones en proceso de cierre). Hay otros estados posibles en caso de fallas, como por
ejemplo SYN_SENT que significa que estamos tratando de establecer una conexión con
una máquina que seguramente no responde.
Configuración de las interfaces de red
Invocado con la opción -i el comando netstat muestra la información de las interfaces
de red.
Ejemplos:
FreeBSD
# netstat -i
Name Mtu Network Address Ipkts Ierrs
Opkts Oerrs Coll
ed1 1500 <Link> 48.54.e8.26.db.69 9665343 525
8972011 2 269894
ed1 1500 164.73.224/25 ampere 9665343 525
8972011 2 269894
lp0* 1500 <Link> 0 0
0 0 0
tun0* 1500 <Link> 0 0
0 0 0
sl0* 552 <Link> 0 0
0 0 0
ppp0* 1500 <Link> 155934 1719
159304 0 0
lo0 16384 <Link> 3857677 0
3857677 0 0
lo0 16384 your-net localhost 3857677 0
3857677 0 0

#
Linux RedHat
# netstat -i
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP
TX-OVR Flg
eth0 1500 0 2450985 0 0 0 1969656 0 0
0 BRU
lo 3924 0 148 0 0 0 148 0 0
0 LRU
Las direcciones se brindan en formato simbólico (nombres) a menos que usemos la
opción -n. Las colisiones indican estado de carga de la red (deberían ser menores de un
3% de los paquetes procesados en una red poco cargada). Los Ierrs y Oerrs se deben
normalmente a problemas de cables.
Las interfaces indicadas con un asterisco (*) después de su nombre indican que no están
configuradas.
Si se especifica un número luego del netstat -i número se brinda la estadística en el
número de segundos indicado de los paquetes entrantes, salientes, colisiones y errores.
Se puede hacer que la salida refiera solamente a una interfaz de red utilizando la
bandera -I interfaz.
Estado de la tabla de ruteo
El comando netstat -r brinda información de la tabla de ruteo del kernel.
El siguiente ejemplo muestra la salida en un FreeBSD, ejecutado con la opción -n para
que brinde la salida en forma numérica.
# netstat -rn
Routing tables
Internet:
Destination Gateway Flags Refs Use Netif
Expire
default 164.73.224.28 UGSc 19 29342 ed1
127.0.0.1 127.0.0.1 UH 13 9712 lo0
164.73.224/25 link#1 UC 0 0
164.73.224.28 0:40:95:15:89:d UHLW 20 33
ed1 864
164.73.224.29 link#1 UHLW 1 3081
164.73.224.30 8:0:2b:bc:f2:2a UHLW 4 32305
ed1 1121
164.73.224.40 48:54:e8:26:db:69 UHLW 1 2164094 lo0
164.73.224.60 0:0:21:95:90:34 UHLW 2 0
ed1 952
164.73.224.127 ff:ff:ff:ff:ff:ff UHLWb 1 3291 ed1
164.73.224.130 164.73.224.60 UGHD 0 524 ed1
164.73.224.255 164.73.224.60 UGHD 1 2009 ed1
....

Los destinos (destination) y enrutadores (gateway) se indican en números IP o
nombres según se utilice la opción -n o no.
Las banderas (Flags) caracterizan la ruta y sus significados son:
U - (Up) Activa
G - (Gateway) El destino es un enrutador
H - (Host) El destino es una máquina.
D - Resultado de un ICMP Redirect
G y H juntas significa que es una ruta a una máquina pasando por un enrutador.
El campo Refs es el número de conexiones TCP que están usando esa ruta.
El campo Use es el número de paquetes enviados por esa conexión.
El campo Netif o If es la interfaz usada para esa ruta.
En la implementación del FreeBSD pueden observarse entradas asociadas con
direcciones de capa de enlace de datos. Esto es porque el sistema usa la misma tabla
para almacenar la información de ruteo y la tabla de ARP.
Estadísticas de los diferentes protocolos de red
El comando netstat -s muestra estadísticas de diferentes protocolos IP, ICMP, TCP y
UDP desplegando los valores de algunos contadores existentes en el código de los
protocols de red.
Ejemplo OSF/1 3.2c:
# netstat -s
ip:
152480 total packets received
0 bad header checksums
0 with size smaller than minimum
0 with data size < data length
0 with header length < data size
0 with data length < header length
1356 fragments received
0 fragments dropped (dup or out of space)
4 fragments dropped after timeout
0 packets forwarded
722 packets not forwardable
0 redirects sent
icmp:
11 calls to icmp_error
0 errors not generated 'cuz old message was icmp
Output histogram:
echo reply: 2

destination unreachable: 11
0 messages with bad code fields
0 messages < minimum length
0 bad checksums
0 messages with bad length
Input histogram:
destination unreachable: 84
source quench: 1
routing redirect: 3
echo: 2
time exceeded: 3
address mask request: 3
2 message responses generated
igmp:
0 messages received
0 messages received with too few bytes
0 messages received with bad checksum
0 membership queries received
0 membership queries received with invalid field(s)
0 membership reports received
0 membership reports received with invalid field(s)
0 membership reports received for groups to which we belong
0 membership reports sent
tcp:
78664 packets sent
67591 data packets (20378697 bytes)
1005 data packets (1073929 bytes) retransmitted
8432 ack-only packets (8247 delayed)
0 URG only packets
3 window probe packets
1489 window update packets
144 control packets
76819 packets received
51806 acks (for 20382773 bytes)
2125 duplicate acks
0 acks for unsent data
55295 packets (7943243 bytes) received in-sequence
92 completely duplicate packets (4815 bytes)
56 packets with some dup. data (249 bytes duped)
172 out-of-order packets (22545 bytes)
0 packets (0 bytes) of data after window
0 window probes
618 window update packets
3 packets received after close
0 discarded for bad checksums
0 discarded for bad header offset fields
0 discarded because packet too short
29 connection requests
91 connection accepts
120 connections established (including accepts)
131 connections closed (including 13 drops)
3 embryonic connections dropped
48215 segments updated rtt (of 49036 attempts)
484 retransmit timeouts
0 connections dropped by rexmit timeout
2 persist timeouts
0 keepalive timeouts
0 keepalive probes sent
0 connections dropped by keepalive
udp:
61324 packets sent

73826 packets received
0 incomplete headers
0 bad data length fields
0 bad checksums
0 full sockets
5082 for no port (5071 broadcasts, 0 multicasts)
Encaminamiento de paquetes: traceroute
El comando traceroute permite ver la secuencia de enrutadores por los que pasa un
paquete IP para alcanzar un determinado destino.
Hay muchas máquinas que lo brindan como herramienta en el sistema operativo (IRIX,
OSF/1, BSDi, FreeBSD) pero existen fuentes disponibles para muchos sistemas. La
instalación puede requerir una modificación del núcleo.
La sintaxis es:
traceroute máquina
La máquina puede estar indicada mediante su número IP o su nombre. Es posible
además incorporar la opción -n en la línea de comando con la cual no se hace la
correspondencia entre nombres y números IP de las máquinas involucradas. Hay
además otra cantidad de opciones de uso menos frecuente.
La salida del traceroute es algo del estilo:
# traceroute seciu.edu.uy
traceroute to seciu.edu.uy (164.73.128.5), 30 hops max, 40 byte
packets
1 IIE-FING-GW (164.73.224.28) 1.720 ms 1.812 ms 1.630 ms
2 FING-RAU-GW.fing.edu.uy (164.73.32.121) 3.643 ms 3.627 ms 3.726
ms
3 164.73.162.113 (164.73.162.113) 286.303 ms 111.015 ms 28.714 ms
4 seciu.uy (164.73.128.5) 33.604 ms 26.355 ms 33.572 ms
En la salida se observa por un lado los nombres y direcciones IP de los enrutadores por
los que pasa un paquete originado en la máquina que corre el tcpdump y el destino
especificado en la línea de comandos.
Además de nombres y direcciones IP, aparecen tres valores del tiempo de ida y vuelta
(round-trip time, RTT) para alcanzar los enrutadores de la lista.
El comando funciona enviando un paquete a destino con un tiempo de vida de 1 salto.
Al llegar al primer enrutador, este deberá descartarlo y enviar un mensaje ICMP al
origen indicando que este paquete fue descartado. De esta forma el originador obtiene la
dirección IP del primer salto. Ahora construye un paquete con tiempo de vida 2 que será
descartado por el segundo enrutador y así sucesivamente.
Para cada salto, el traceroute envia 3 paquetes y da el tiempo de ida y vuelta de cada
uno (ver ejemplo). Si algún enrutador no responde igual puede seguir al siguiente salto
y pone asteriscos. Si los 3 paquetes vuelven de diferentes enrutadores, se despliegan las
direcciones de cada uno de ellos.

Monitores de tráfico: tcpdump, snifit, snoop, etherfind, etherreal.
Estos programas son conocidos como espías de red y lo que hacen es mirar los paquetes
que pasan por una conexión IP. Se pueden establecer criterios de inspección basados en
máquinas, protocolos, servicios, etc.
El tcpdump es una herramienta muy potente disponible en casi todas las variedades de
sistemas BSD y es distribuido dentro del sistema en varios UNIX.
El etherfind es un comando disponible en SunOS y la versión de solaris es el snoop.
Ambos son similares al tcpdump.
Como los espías deben poder ver los paquetes dirigidos a otras máquinas de la red el
sistema de base debe dar los mecanismos para que esto pueda realizarse. Para esto debe
existir la posibilidad que el hardware de red pueda ver todos los paquetes. Esto, en un
medio de difusión tipo Ethernet es posible.
Otro mecanismo adicional que debe proveer el sistema es el pasaje de los paquetes que
no están dirigidos a la máquina a las capas superiores de la red. Normalmente una
máquina define a nivel de hardware si los paquetes son para ella o no (contienen su
dirección IP o son broadcasts) y si no lo son los descarta. Para que el tcpdump pueda
acceder a todos los paquetes de la red, es necesario que la interfaz de red se configure en
modo promiscuo lo cual significa que pasará a las capas superiores los paquetes
destinados a ella así como los que no están destinados a ella de forma tal que el
tcpdump pueda verlos.
Estas herramientas son muy útiles para detectar problemas en la red.
Inspección de tablas de ARP
El comando arp permite ver la tabla de correspondencia del kernel del protocolo ARP.
Estas tablas se actualizan automáticamente.
Opciones:
arp -a permite ver la totalidad de la tabla.
arp -d máquina borra la entrada de una máquina.
arp -s máquina dirección agrega una entrada en la tabla.
arp -f archivo agrega entradas desde un archivo de configuración.
arp máquina muestra la entrada para esa máquina.
En general en una Ethernet no tiene demasiada utilidad para detectar problemas, pero si
puede ayudar en caso de tarjetas de red con problemas.

Distribución de archivos - NIS.
Administración de máquinas en red
Archivos de configuración
Distribución de archivos
rdist
rsync
expect
NIS, servicio de información de red
Netgroups
NIS y archivos locales
Ventajas y desventajas de NIS
Funcionamiento de NIS
Comandos y demonios de NIS
Implantación de un domino NIS
NIS+
LDAP
Ejercicios e Investigación
Bibliografía y referencias.
Administración de máquinas en red.
La configuración de una máquina UNIX depende de un cierto número de archivos de texto.
Mantener la configuración de un sistema formado por una red de máquinas UNIX equivale a
mantener coordinados los ajustes de estos archivos de configuración en todas las máquinas.
En cuanto el número de máquinas involucradas aumenta un poco la tarea empieza a hacerse
difícil. En organizciones medianas o grandes suele haber grupos de máquinas de configuración
similar, lo cual permite usar archivos de configuración similares entre máquinas del mismo
grupo.
Existen dos enfoques básicos para manener la configuración de máquinas en una red:
instalar una copia maestra de los archivos de configuración en una máquina y distribuírla hacia las otras por copia. Esto es simple y funciona en todos los sistemas, pero es preciso distribuir los archivos periódicamente o ante cada modificación.

prescindir de los archivos de configuración locales e implementar un servidor central de configuraciones al cual se referirán todas las máquinas. No es una solución simple, pero no hay problemas de actualización, ya que todas las máquinas toman su configuración del servidor central. En contrapartida, el mal funcionamiento del servidor central puede colgar toda la red.
Han habido múltiples intentos de crear bases de datos para la administración de máquinas en
una red. Ninguna es aún completamente satisfactoria: cuando son seguras y escalables
resultan difíciles de implementar; las soluciones simples no ofrecen buena seguridad y tienen
un alcance limitado.
Archivos de configuración.
De la multiplicidad de archivos de configuración existentes en una máquina UNIX, sólo pueden
ser compartidos entre diferentes máquinas algunos de ellos. Los archivos más comúnmente
compartidos son:
Archivo Función
/etc/passwd base de datos de información de cuentas de usuarios
/etc/shadow1 contraseñas encriptadas de usuarios, caducidad de contraseñas
/etc/group definición de grupos UNIX
/etc/hosts mapeo de nombres a direcciones IP de máquinas
/etc/networks1 asocia nombres en texto con direcciones de red IP
/etc/services lista los números de puerto para servicios de red bien conocidos
/etc/protocols mapeo de nombres en texto a números de protocolos
/etc/ethers1 mapeo entre direcciones Ethernet y nombres de máquinas
/etc/aliases nombres usados como alias para correo electrónico
/etc/rpc lista los números de identificación de servicios RPC (Remote Procedure
Control)
/etc/netgroup1 define colecciones de usuarios, máquinas y redes
/etc/printcap base de datos de información de impresoras
/etc/termcap base de datos de tipos de terminal
1. No usado en todos los sistemas.

El uso de estos archivos se implementa a través de funciones definidas en la biblioteca
estándar de C. El archivo /etc/passwd es accedido por las funciones getpwuid,
getpwnam, getpwent; estas funciones manejan el archivo /etc/passwd devolviendo al
programa de usuario la información solicitada. Para pasar de un sistema de consulta
directa de archivos a una base de datos compartida alcanza con modificar estas rutinas
de la biblioteca.
Distribución de archivos.
La solución de copiar los archivos de configuración a todas las máquinas puede no ser
elegante, pero es simple, funciona en todo tipo de máquinas, es fácil de implementar y
mantener, minimiza la interdependencia entre máquinas, se adapta bien a grupos de
máquinas de configuración similar (secciones, departamentos, institutos). Cuando un
problema puede resolverse de manera simple debe haber buenas razones para implementar
una solución compleja.
El procedimiento de distribución consiste en copiar periódicamente los archivos de
configuración desde un servidor maestro hacia todas las demás máquinas. Existen dos
esquemas posibles:
por empuje (push): el servidor maestro copia periódicamente los archivos modificados hacia las restantes máquinas, lo quieran éstas o no. Mantiene los archivos en un sólo lugar, permitiendo un buen control de su contenido. Las máquinas cliente deben permitir al servidor maestro el acceso; esto deja una brecha de seguridad.
por descarga (pull): las máquinas cliente se actualizan a voluntad desde el servidor maestro. Es menos centralizado, pero es más seguro y funciona aún a través de fronteras con diferentes políticas o autoridades administrativas.
rdist
El comando rdist funciona en base a un archivo de texto donde se establecen los archivos a
distribuir; la ejecución de rdist copia hacia los destinatarios los archivos desactualizados,
optimizando la transferencia y conservando los atributos. Permite incluso ejecutar comandos
en la máquina remota para activar los cambios incluídos en el archivo recientemente copiado.
rdist ofrece problemas de seguridad: corre sobre rsh, confiando en su esquema de
autenticación. Debe implementarse, al menos, un "TCP wrapper", para limitar el
contacto con rlogind a una lista de máquinas. rlogind es el servidor para rsh, rcp y
rlogin, necesario también para rdist. Correr rlogind abre las máquinas a diversos
tipos de ataque. En Linux es posible sustituir rsh por ssh, aunque corriendo sin
contraseña; no es lo mejor, pero ofrece dos ventajas: ssh usa criptografía de clave
pública para autenticar el anfitrión maestro, y encripta todo el intercambio realizado por
rdist, eliminando la posibilidad de espionaje sobre la transferencia.
Ejemplo de archivo de distribución:

# definición de variables ARCH_SIST = (/etc/passwd /etc/group /etc/mail/aliases) MAQS_TODO = (alamo pino baobab) MAQS_ALGO = (gingko arauca)
# máquinas que reciben todos los archivos todo: {$ARCH_SIST} -> ${MAQS_TODO} notify jperez; special /etc/mail/aliases "/usr/bin/newaliases";
# máquinas que reciben algunos archivos algo: {$ARCH_SIST} -> ${MAQS_ALGO} except /etc/mail/aliases notify mlopez@alamo;
Bajo el rótulo todo se indica copiar los archivos en ARCH_SIST hacia las máquinas
MAQS_TODO, notificando por correo electrónico a jperez en las máquinas destino, y
ejecutando luego el comando /usr/bin/newaliases. Bajo el rótulo algo se copian los
archivos en ARCH_SIST menos /etc/mail/aliases, y se notifica al usuario mlopez en la
máquina alamo.
rsync
rsync es una versión potenciada de rcp capaz de conservar enlaces, permisos y fechas de
modificación. Es más seguro que rdist: permite restringir acceso remoto a ciertos directorios,
y exigir al maestro una contraseña; puede correrse desde inetd, o también usando ssh. Por
ejemplo, el comando rsync -gopt --passwdord-file=/etc/rsync.pwd \ /etc/passwd gingko::/etc
transfiere el archivo /etc/passwd a la máquina gingko conservando permisos, dueño y fechas
de modificación (-gopt); el doble :: en gingko::/etc obliga a contactar a rsync en el
servidor remoto directamente en el puerto 873 en lugar de usar rsh; la conexión se autentica
por la contraseña contenida en el archivo /etc/rsync.pwd.
La configuración de rsync demanda varias tareas, tanto en servidores como en clientes.
En Linux viene con la distribución; los fuentes pueden bajarse de rsync.samba.org.
expect
Un sistema de actualización por parte del cliente puede implementarse colocando los archivos
en un directorio accesible vía ftp y empleando el comando expect para automatizar el
proceso. expect es un conjunto de extensiones para el lenguaje de scripts Tcl (Tool Command
Language), de sintaxis relativamente simple; no se requiere mucho conocimiento de Tcl para
usar expect.
Ejemplo de srcript Tcl para expect:
spawn /usr/bin/ftp servidor_red while 1 { expect {
"Name: " {send "cliente_red\r"}
"Password: " {send "cliente_contraseña\r"} "ftp> " {break} "failed" {send_user "Login rechazado.\r"; exit 1}

timeout {send_user "Tiempo inactivo.\r"; exit 2} }} send "lcd /etc\r" expect "ftp> " {send "cd pub/sisarchs\r"} expect "ftp> " {send "get passwd\r"} expect "ftp> " {send "quit\r"; send_user "\r"} exit 0
El script arranca un proceso ftp sobre el servidor de red, iniciando el login de un cliente
con contraseña; se capturan e informan errores de login e inactividad; finalmente, se
emiten comandos ftp uno a uno hasta cerrar la sesión.
Los fuentes de expect están disponibles en expect.nist.gov.
NIS, servicio de información de red.
NIS fue la primera base de datos administrativa para sistemas informáticos. Lanzado por Sun
en los '80 con el nombre de Yellow Pages (páginas amarillas, en análogo con las de la guía
telefónica), hubo de cambiar este nombre por ser marca registrada en Inglaterra, pero muchos
comandos siguen comenzando por yp. A comienzos de los '90 Sun implementó NIS+ como
sustituto de NIS, agregando mayor seguridad. No obstante la similitud de nombres, se trata de
dos sistemas totalmente diferentes, incompatibles entre sí. NIS+ puede dar servicio limitado a
clientes NIS si se le indica, aunque se pierde la seguridad intrínseca de NIS+. Linux y FreeBSD
no soportan NIS+; Solaris y HP-UX soportan NIS+; todos soportan NIS.
NIS proporciona el mismo nivel de control que la copia de archivos. Se designa una
máquina como servidor maestro NIS. Allí se mantienen como copias autoritativas los
archivos de configuración, en el mismo formato y lugar, editándolos con un editor de
texto como habitualmente.Un proceso servidor hace disponibles el contenido de estos
archivos hacia la red. El conjunto de un servidor maestro NIS y sus clientes se
denomina un "dominio NIS". No debe confundirse con el "dominio DNS", algo
totalmente distinto, y menos con el concepto de dominio en Windows NT/2000.
Para mejorar la eficiencia en las búsquedas, los mapas NIS son preprocesados por las
rutinas de "hashing" ndbm (gdbm en GNU): luego de editar los archivos en el servidor
maestro, NIS los convierte al formado ndbm; esto se hace invocando make en el
directorio de NIS, o un script llamado ypmake en algunos UNIX. El formato ndbm
admite sólo una clave para cada entrada, por lo que un archivo de sistema puede dar
lugar a varios mapas NIS: el archivo /etc/passwd genera los mapas passwd.byuid,
ordenada por uid, y passwd.byname, ordenada por nombre de usuario.
NIS permite replicar sus mapas en uno o más servidores esclavos. Esto aligera la tarea
del servidor maestro y mantiene la red en funcionamiento cuando el servidor maestro no
está disponible. Cuando se modifican los mapas en el servidor maestro, éstos son
empujados hacia los servidores esclavos. Para el cliente, un servidor esclavo es
indistinguible de un servidor maestro. Los clientes ubican los servidores NIS por
difusión. Debe haber un servidor NIS por cada subred. Si no hay servidor NIS activo en
una red, los clientes pueden quedar colgados. El comando ypset permite apuntar un
cliente hacia un servidor específico.

Grupos de red ("netgroups").
Los grupos de red, "netgroups" o "netgrupos" son una forma abreviada de designar un
conjunto de usuarios, máquinas y redes para su referencia en otros archivos del sistema. Se
definen en /etc/netgroup; son compartidos como un mapa NIS de prioridad global. El
formato de una entrada en /etc/netgroup es
nombre_grupo lista_miembros
La lista de miembros es un conjunto de tríadas (máquina, usuario, dominio) separadas por
espacios; la ausencia de máquina, usuario o dominio implica todos; un signo - indica ninguno.
La situación típica en la realidad es definir los grupos por máquinas:
oficina15 (valizas,,) (lantis2,,)
oficina17 (colorado,,)
servidores (ampere,,) (maxwell,,) (gauss,,) (ohm,,)
admins oficina15 oficina17
Los netgrupos pueden usarse en /etc/exports, /etc/hosts.equiv y .rhosts; en
/etc/passwd puede usarse incluyendo +@netgrupo en una línea aislada. Colocar + en
/etc/hosts.equiv es una enorme brecha de seguridad, como puede también serlo el uso
de netgrupos en este archivo y en .rhosts. El uso más frecuente es en /etc/exports, para
definir conjuntos de máquinas habilitadas para montar recursos vía NFS.
NIS y archivos locales.
En la mayoría de los sistemas NIS puede ser suplementado por la información local del cliente,
al menos para algunos archivos. El enfoque tradicional admite dos tipos de situación:
prioridad local: los archivos locales tienen precedencia sobre NIS; prioridad global: NIS tiene precedencia sobre los archivos locales.
Usualmente, sólo /etc/passwd y /etc/group tienen precedencia sobre NIS. En estos casos,
el contenido de los mapas NIS para usuarios y grupos debe ser incluídos en los archivos locales
a través de una convención: un signo + aislado en una línea de /etc/passwd o /etc/group
incorpora todo el mapa NIS a los usuarios o grupos locales; una línea con +@netgroup
incorpora solo ese netgroup; una línea con +nombre incorpora sólo ese nombre. El archivo
/etc/hosts es consultado en el arranque, cuando todavía no hay NIS activo. Los restantes
archivos locales son ignorados por NIS.
La tendencia actual es definir en un archivo centralizado, /etc/nsswitch.conf, las fuentes
de información para cada tipo de entidad, con entradas tales como passwd: files nis hosts: files dns group: files donde las fuentes se prueban en orden hasta la primera que valida el pedido. Según estas
líneas, un login de usuario se contrasta primero contra /etc/passwd y luego, si éstos no
contienen al usuario, contra el mapa NIS correspondiente; un nombre de máquina se
busca primero en /etc/hosts, y si este fracasa se interroga al servicio DNS. El archivo
nsswitch.conf permite configurar acciones en casos de falla: continuar buscando en la
siguiente fuente (continue) o retornar en falta (return) si la fuente presente no

responde en algunas de las opciones previstas: UNAVAIL (fuene no disponible o baja),
NOTFOUND (la fuente no reconoce el pedido), TRYAGAIN (fuente ocupada), SUCCESS (el
pedido fue contestado). Ejemplo: hosts: files dns [NOTFOUND=return] nisplus
busca en /etc/hosts, si éste falla busca en DNS, si éste falla vuelve sin reconocer el
pedido, ni buscar en NIS+. Este archivo es una forma segura y prolija de controlar las
fuentes de validación.
Ventajas y desventajas de NIS.
es entendible por humanos: se siguen editando los mismos viejos archivos, sólo hay que aprender unos comandos nuevos, no requiere conocer la estructura interna de los mapas.
no admite enlace de dominios: una red grande puede dividirse en dominios, pero cada uno debe ser administrado separadamente.
NIS consume un cierto ancho de banda: no tiene capacidad de cache, toda consulta debe realizarse a un servidor; los mapas modificados deben distribuírse.
un servidor esclavo fuera de servicio puede perder una actualización; debe implementarse una rutina de control de actualización; aún así, dos versiones diferentes de un mapa pueden estar siendo servidas al mismo tiempo, con los clientes viendo una u otra aleatoriamente.
NIS no es seguro: cualquier máquina puede manifestarse como servidor de un dominio, cualquier usuario puede leer los mapas NIS.
Funcionamiento de NIS.
Los mapas de NIS están contenidos habitualmente en /var/yp, donde se crea un directorio
con el nombre del dominio NIS para contener los archivos. Cada mapa NIS comprende dos
archivos, uno de extensión .dir y el otro de extensión .pag. En el dominio instituto los
archivos ndbm para /etc/passwd serían
/var/yp/instituto/passwd.byname.dir
/var/yp/instituto/passwd.byname.pag
/var/yp/instituto/passwd.byuid.dir
/var/yp/instituto/passwd.byuid.pag
Para crear estos archivos ndbm, generalmente basta con los comandos cd /var/yp make
que invoca un archivo Makefile. Los archivos ndbm contienen "agujeros"; pueden
expandirse significativamente al ser copiados.
Esquema de consulta NIS:

Comandos y demonios de NIS
M: servidor NIS maestro;
S: servidor NIS esclavo;
C: cliente NIS
Programa En Descripción
ypserv MS demonio servidor NIS, se activa en el arranque de la máquina; recibe y
contesta consultas de clientes
ypbind MSC
demonio cliente NIS, se activa en el arranque de la máquina; consultado
por la biblioteca C para ubicar un servidor NIS en el dominio; la bilioteca
contacta luego ypserv directamente; las máquinas se mantienen fieles al
primer servidor ubicado
domainname MSC fija el nombre de dominio NIS en que se encuentra la máquina; corre en el
arranque
ypxfr S baja mapa desde el servidor maestro; sólo si está desactualizado
ypxfrd M demonio en el servidor maestro que atiende ypxfr
yppush M avisa a los servidores esclavos que deben actualizarse ejecutando ypxfr
makedbm M crea mapa ndbm desde archivo llano; corrido por make
ypmake M reconstruye mapas ndbm de los archivos modificados; en otras versiones,

se debe invocar make en el directorio NIS
ypinit MS configura una máquina para ser servidor maestro o esclavo
ypset MSC hace que ypbind se conecte a un servidor NIS específico
ypwhich MSC determina qué servidor NIS está usando la máquina local
yppoll MS determina la versión de un mapa que está usando un servidor
ypcat MSC muestra valores contenidos en un mapa NIS
ypmatch MSC muestra entradas para una clave indicada en un mapa NIS
yppasswd MSC cambia la contraseña de usuario en el servidor maestro NIS
ypchfn MSC cambia información de usuario en el servidor maestro NIS
ypchsh MSC cambia shell de login de usuario en el servidor maestro NIS
yppasswdd MSC servidor para yppasswd, ypchfn, ypchsh
ypupdate MS servidor para actualizar mapas NIS, manejado por inetd
El mapa especial ypservers es construído automáticamente al implantarse el dominio;
sirve para conocer los servidores esclavos a los que deben distribuírse los mapas.
Implantación de un dominio NIS.
NIS debe iniciarse en el servidor maestro, luego en cada servidor esclavo. El nombre de
dominio NIS debe fijarse en todas las máquinas, así como ajustar el archivo nsswitch.conf para
consultar los mapas.
Configuración de servidor NIS.
Para configurar el servidor NIS, ejecutar los comandos cd /var/yp # directorio NIS domainname iie-nis # fija el nombre de dominio NIS ypinit -m # inicializa como servidor maestro ypserv # arranca servidor NIS
Al inicializar el servidor maestro con ypinit -m, ya pide la lista de servidores esclavos
que incluirá en el archivo ypservers.
Iniciar servidores esclavos.
En los servidores esclavos, ejecutar los comandos cd /var/yp # directorio NIS ypinit -s ampere # fija servidor maestro, obtiene mapas ypserv # arranca servidor esclavo NIS

En cada esclavo deben ingresarse entradas en crontab para obtener copias actualizadas
de los mapas del servidor maestro. Como no todos los mapas cambian con la misma
frecuencia, si se quiere preservar el ancho de banda, debe implementarse una agenda
diferencial. Este script trasfiere todos los mapas:
#!/bin/csh -f
set eldominio = `/usr/bin/domainname`
cd /var/yp/$eldominio
foreach map (`/bin/ls`)
/usr/lib/yp/ypxfr $map
end
Algunos sistemas proveen scripts tales como ypxfr_1perday, ypxfr_2perday,
ypxfr_1perhour para transferir mapas NIS a diferentes intervalos. Para permitir a los
usuarios cambiar sus contraseñas NIS con yppasswd debe correrse el demonio
yppasswd en el servidor maestro del dominio.
Configuración de Cliente NIS.
Los servidores de un dominio generalmente son también clientes; el dominio NIS se fija u
obtiene con el comando domainname. Todos los clientes deben disponer de una versión
mínima de los archivos passwd, group y hosts con los usuarios y grupos habituales; hosts debe
existir para el arranque, cuando aún no hay NIS ni DNS. Todos los clientes deben asimismo
tener una configuración adecuada en nsswitch.conf, para saber qué deben consultar al validar,
o en su defecto contener las entradas con + en passwd y group. El servidor maestro del
dominio no debe contener entradas con +.
El arranque manual de un cliente NIS puede hacerse con los comandos domainname iie-nis # fija el nombre de dominio NIS ypbind # arranca demonio cliente NIS
Para el arranque automático, las máquinas deben ser informadas que pertenecen a un
dominio NIS. Esto puede hacerse con el comando domainname o nisdomainname
corrido desde algún script de arranque. Algunas versiones verifican la existencia del
archivo /etc/defaultdomain; si existe toman el nombre de dominio desde él. La forma de
arranque de NIS varía entre sistemas. Las líneas siguientes proveen un ejemplo de
comandos a incluir en un script de arranque; el nombre del dominio ya fue fijado para
esta máquina; se obtiene con el comando domainname.
# verificar si esta máquina sirve el dominio if [ -f /usr/sbin/ypserv -a -d /var/yp/`domainname`]; then /usr/sbin/ypserv; (echo -n ' ypserv') > /dev/console fi # arrancar ypbind if [ -f /usr/sbin/ypbind ]; then /usr/sbin/ypbind; (echo -n ' ypbind') > /dev/console fi

NIS+.
NIS+ corrige algunas deficiencias de NIS y agrega otras propias. Está orientado a redes grandes,
implementa seguridad, maneja eficientemente las actualizaciones, permite administrar
diversos dominios desde cualquier punto de la red. Es una base de datos distribuída de alta
complejidad, difícil de administrar, soportada por algunos proveedores mayores; no ha
migrado hacia las versiones de dominio público. Aún organizaciones grandes evitan usarlo.
Características de NIS+:
emplea un sistema jerárquico de dominios y subdominios, permitiendo delegar autoridad administrativa. Una máquina pertenece a un dominio, pero puede obtener información de máquinas en otros dominios.
emplea "tablas" en lugar de "mapas", permitiendo búsquedas por diferentes campos; por cada archivo de sistema se genera sólo una tabla.
no emplea archivos llanos; una vez transferidos los archivos al formato NIS+, los cambios en los archivos llanos no tienen influencia; es preciso editar las tablas de NIS+ con comandos especiales.
maneja mejor los servidores esclavos, llamados réplicas; las réplicas son actualizadas en forma incremental, con un esquema autenticación similar al de login para entrar en contacto con el servidor maestro.
se basa en el RPC seguro de Sun: autentica en base al encriptado de claves públicas. Los objetos NIS+ pueden ser tablas, columnas o entradas; todos los objetos tienen dueño y grupo; los permisos se fijan para el dueño, el grupo, el mundo y la categoría especial "nobody" para quienes no pueden exhibir credenciales, como ser clientes NIS. Tanto los usuarios como las máquinas pueden ser "principales RPC", entidades capaces de exhibir credenciales. Al acceder a NIS+ como root, se usan las credenciales de la máquina en lugar de las personales.
Desde el punto de vista del cliente, NIS+ se comporta como es habitual en UNIX, sin
transparentar su complejidad. Aunque no es lo mismo, NIS+ se parece mucho a DNS, con quien
comparte la organización jerárquica en dominios. Los nombres de dominio NIS+ y DNS suelen
ser el mismo; esto aumenta la confusión entre ambos. Un dominio NIS+ es un directorio con
subdirectorios org_dir y groups_dir; en org_dir van las tablas administrativas y en
groups_dir las credenciales de los principales del dominio.
LDAP.
Además de los archivos del sistema existe otro tipo de información cuya distribución debe ser
amplia: guías telefónicas, direcciones de correo electrónico, información a compartir con el
mundo exterior. Estas necesidades pueden ser respondidas por un servicio general de
directorios; éste debe ser capaz de asimilar cualquier conjunto de datos con ciertas
características:
objetos de datos relativamente chicos; extensa replicación y almacenamiento en caché; información basada en atributos; lectura frecuente, modificación escasa;

la búsqueda como operación frecuente y preferente.
El procotolo LDAP (Lightweight Directory Access Protocol), otrora parte del conjunto de
protocolos de red de OSI, está siendo promovido como servicio de directorios. Actualmente
(año 2000) en su versión 3 experimental, está lejos aún de proveer universalidad suficiente.
Las aplicaciones reales son todavía escasas como para recomendar su instalación en
producción. No obstante, existe considerable trabajo de investigación y desarrollo en torno a
este tema; en el futuro puede llegar a sustituír con ventaja los modos tradicionales de
compartir archivos.
Ejercicios e investigación.
1. Analice la necesidad de compartir archivos de configuración en su red. ¿Cuántos servidores
tiene? ¿Los usuarios deben ingresar a todos? ¿Sería posible el mantenimento manual? ¿Qué
riesgos se corren?
2. Estudie y proponga un esquema de copia de archivos con comandos habituales de
UNIX, incluyendo una actualización periódica. Analícelo luego críticamente,
atendiendo especialmente a la posibilidad de mantener versiones desactualizadas,
complejidad de administración, consumo de ancho de banda.
3. Reconsidere la situación anterior estudiando las prestaciones ofrecidas por los
comandos rdist, rsync, expect o similares existentes en su sistema.
4. Estudie los scripts de arranque de su máquina. Es posible que encuentre en ellos,
comentadas, las sentencias para arrancar la máquina como servidor NIS y como cliente
NIS. Esto no es suficiente para implantar un dominio NIS. Determine las acciones
complementarias.
5. Suponga que implementa un dominio NIS en su sistema. ¿Qué información debe
hacer llegar a los usuarios para su mejor conocimiento y uso? ¿Qué precauciones de
seguridad tiene que tomar como administrador?
6. Si su sistema soporta NIS+, es posible que cuente con scripts para realizar la mayor
parte de las tareas de administración. Investigue la existencia de dichos scripts, su forma
de uso individual y el esquema de aplicación para la implantación de un dominio.
7. Si dispone de un programa administrador para la creación de usuarios, investigue si
actualiza automáticamente las tablas de NIS (NIS+). Si tiene su dominio NIS ( NIS+)
activo, verifíque la actualización de los mapas NIS (tablas NIS+) al crear usuarios. Si la
herramienta administrativa no contempla el servicio, defina los procedimientos
complementarios para actualizar las tablas o mapas.
8. Investigue la situación anterior para el caso de la incorporación de máquinas.
9. Estudie en su sistema la relación entre NIS (NIS+) y DNS. ¿Cuál tiene precedencia?
¿Es posible controlar esto? Recuerde que los dominios NIS y DNS son conceptualmente
distintos.

Bibliografía y Referencias.
Comandos: rdist, rsync, expect, ypserv, ypbind, domainname, ypinit, ypxfr, yppush, yppoll, ypset, ypcat, yppasswd, ypwhich, ypmatch,
ypchfn, ypchsh, ypupdate.
Network File System (Sistema de archivos de red)
Introducción
El "Sistema de Archivos de Red" (NFS) es un protocolo para compartir archivos a través de una
red TCP/IP. Este sistema, originalmente introducido por Sun Microsystems en 1985, es el
protocolo más utilizado por máquinas UNIX para la compartición de archivos, y practicamente
todos los sistemas modermos lo proveen.
NFS es casi transparente para los usuarios, y es un protocolo "sin estado", en el sentido que si
un servidor NFS se cuelga, no se pierde información. Los clientes pueden esperar a que el
servidor retorne y continuar trabajando como si nada hubiera sucedido.
NFS consta de varios componentes, incluyendo un protocolo de montaje y su correspondiente
servidor, un protocolo de "locking" de archivos y su correspondiente servidor, y daemons que
coordinan el servicio de archivos básico.
NFS utiliza los servicios RPC de Sun ("Remote Procedure Call", llamada a procedimientos
remotos)
NFS desde el lado del servidor
Bajo BSD, se dice que un servidor "exporta" un filesystem cuando lo hace disponible para su
uso por parte de otras máquinas. En ATT se dice que lo "comparte".
Un cliente NFS debe explicitamente "montar" un filesystem antes de utilizarlo. El servidor
examina el pedido para asegurarse que el cliente tiene la autorización correcta, y luego le da al
cliente una "magic cookie" (un número aleatorio) que el cliente deberá utilizar para obtener
acceso en el futuro.
El esquema de "magic cookies" permite que el servidor funcione "sin estado", ya que no
precisa mantener información de qué clientes han sido autorizados. Usualmente, desmontar y
volver a montar un filesystem cambia la cookie.
Como un caso especial, las cookies se mantienen en un reboot para que un servidor que se
cuelga pueda volver a su anterior estado (siempre y cuando no se haya pasado por single-user
y modificado los filesystems).
Una vez que un cliente tiene una "magic cookie", utiliza RPC para solicitar operaciones sobre el
filesystem como crear un archivo o leer un bloque de datos. Como el protocolo es sin estado,
el servidor no se preocupa de recordar qué operaciones realiza un cliente. Es responsabilidad
del cliente asegurarse que el servidor de su confirmación en las operaciones de escritura antes
de borrar su copia de los datos.

RPC y el proceso portmap: mapeo de servicios.
RPC de Sun es un conjunto de protocolos para ejecutar servicios remotamente. Los distintos
servicios disponibles se distinguen por un número de servicio y un número de versión.
Para evitar tener que asignar un puerto TCP o UDP fijo a cada servicio, se utiliza el programa
portmap (a veces rpc.portmap) para mapear los números de servicio a puertos en el servidor.
Esto permite que a cada servicio se le asigne un puerto arbitrario en el servidor (aunque
normalmente NFS utiliza el puerto 2049). Por supuesto, portmap requiere que se le asigne un
puerto bien conocido (sunrpc/111). Antes de contactar cualquier servicio RPC, los clientes
deben consultar al servicio portmap en qué puerto está escuchando el servicio dado.
Cuando arrancan los demás programas (nfsd, mountd, etc.), se registran con portmap para
poder ser accesibles desde la red.
En versiones nuevas de solaris, este proceso se llama rpcbind
El proceso mountd: respuesta a pedidos de montar filesystems.
Los pedidos para montar filesystems son atendidos por el demonio mountd (a veces llamado
rpc.mountd). En los sistemas BSD (y muchos que no lo son, por ejemplo Linux), mountd lee el
archivo /etc/exports para obtener información de las máquinas que tienen acceso a cada
filesystem, y las restricciones que puedan tener.
El archivo exports contiene una lista de los directorios exportados y sus correspondientes
opciones y atributos.
Cada línea en el archivo exports especifica un directorio exportado, los permisos para los
distintos clientes que puedan utilizar este filesystem, y la descripción de que máquinas pueden
usarlo.
P. Ej:
/discos/users -maproot=root maquina1.iie.edu.uy
/discos/man -ro maquinasunix_iie
Permite que /discos/users sea montado desde maquina1.iie.edu.uy, permitiendo el
acceso de root (por defecto, los accesos de root via NFS se realizan como si el usuario
que estuviera realizando el acceso fuera nobody), y el acceso de solo lectura a
/discos/man de las máquinas en el "netgroup" maquinasunix_iie (asumiendo que este es
un netgroup).
NFS se maneja con la vision lógica de los filesystems, no con la capa física. Se puede
exportar cualquier subdirectorio, aunque no sea la raiz de un filesystem. Sin embargo,
por razones de seguridad, NFS requiere que cada dispositivo sea exportado
independientemente, por ejemplo en una máquina con una particion montada como
/users, el directorio / se puede exportar sin que se brinde acceso a /users.
El formato y los atributos que pueden ser especificados en /etc/exports varian entre
sistemas. En la tabla se muestran los atributos para algunos sistemas.
-
access=lista
Lista los hosts que pueden montar el filesystem (dados como una lista de
máquinas y netgroups separados por :)

-ro Especifica que solo se debe permitir el acceso de lectura, no de escritura.
-rw (=lista) Lista especiffica los hosts que pueden montar el filesystem con permiso de
escritura, los demás solo lo pueden montar read-only
-root=lista lista de hosts a los que se les permite acceder al filesystem como root (para los
demas, el acceso como root se mapea al acceso del usuario nobody)
-anon=n Especifica el uid (número de usuario) que debe utilizarse para los pedidos
provenientes de un usuario desconocido. (Por defecto, es nobody)
Si no se especifica que hosts pueden montar el filesystem, TODAS las maquinas pueden
hacerlo. Esto puede ser un grave problema de seguridad, y debe evitarse en lo posible.
Después de modificar /etc/exports, se le debe decir al demonio mountd que lo relea.
Algunos sistemas proveen un comando llamado exportfs que cumple esta función (con
la flag -a, o la flag -r en algunas versiones de Linux), mientras que en otros hay que
enviarle la señal SIGHUP al demonio mountd (mediante kill).
En Linux, las opciones con las cuales se exporta un filesistem se especifican entre
paréntesis DESPUÉS de la especificación del equipo o equipos que pueden montar el
filesystem.
P. Ej.
# sample /etc/exports file
/ master(rw) trusty(rw,no_root_squash)
/projects proj*.local.domain(rw)
/usr *.local.domain(ro) @trusted(rw)
/home/joe pc001(rw,all_squash,anonuid=150,anongid=100)
/pub (ro,insecure,all_squash)
Por el detalle de las distintas opciones, ver man exports.
Solaris
Solaris sustituyó el archivo /etc/exports con el archivo /etc/dfs/dfstab, el cual es un script de
shell que ejecuta el comando share para cada uno de los filesystems exportados.
Por ejemplo:
share -F nfs -o rw=maq:fing:ferrari,root=ferrari /export/home
comparte el directorio /export/home con las máquinas maq, fing y ferrari, permitiendo
acceso de root a la máquina ferrari.
Luego de editar el archivo dfstab, se deben ejecutar los comandos share nuevos o
modificados para que las modificaciones tomen efecto, o ejecutar el comando shareall.
Por mas información, consultar el man de share.

nfsd : Proceso que acepta los pedidos de los clientes
Una vez validado el pedido de montar un filesystem por parte de un cliente, se le permite
realizar una serie de operaciones sobre el filesystem. Los pedidos para realizar estas
operaciones son manejados por nfsd (o rpc.nfsd).
nfsd recibe un parámetro que indica la cantidad de copias de si mismo que iniciar (mediante
fork, o como threads independientes en sistemas más modernos). Esta cantidad puede afectar
la performance del servidor (tanto si son muy pocos como si son demasiados), y no existe una
regla general para determinar dicho número. El valor por defecto es 4 en la mayoría de los
casos, y se recomienda para servidores que no sean muy utilizados. Este es el número máximo
de pedidos que el servidor puede procesar simultaneamente.
(En versiones nuevas de solaris y algunos linux, en lugar de iniciar multiples copias de nfsd, se
utilizan distintos threads de ejecución, y la cantidad por defecto que inicia el sistema al
bootear es de 16 en solaris y 1 en Linux).
lockd y statd : locking remoto
Los demonios lockd y statd (rpc.lockd y rpc.statd) proveen locking (control de acceso a los
archivos) para los filesystems compartidos mediante NFS, y son necesarios para que muchos
programas sean capaces de arbitrar el acceso concurrente a un mismo archivo.
Versiones viejas de Linux y FreeBSD no proveen locking.
rquotad : quotas en filesystems remotos
El demonio rpc.rquotad en algunos sistemas permite que otros sistemas obtengan información
sobre los límites de uso de un filesystem por parte de un usuario remotamente.
NFS desde el lado del cliente.
Extensiones al comando mount.
En las máquinas que soportan NFS, el comando mount acepta la notación maquina:directorio
para referirse al directorio directorio en la máquina maquina.
Es decir, para montar el directorio /ext de la máquina servidor en el directorio local /mnt se
ejecuta el comando:
mount servidor:/ext /mnt
biod : demonio que provee cache del lado del cliente.
Para mejorar la performance de NFS, la mayoría de los sistemas proveen el demonio biod
(llamado a veces nfsiod o rpciod), que realiza tareas básicas de lectura anticipada (read ahead)
y escritura retardada (write-behind) sobre el filesystem. Este demonio es opcional, pero
altamente recomendado ya que provee una mejora apreciable en la performance de NFS. (No
en Solaris).
biod, al igual que nfsd, recibe como parámetro la cantidad de copias de si mismo que
debe arrancar.

Montando filesystems remotos.
Los filesystems remotos que se deban montar de forma permanente deben o listarse en
/etc/fstab (/etc/vfstab en Solaris) o ser manejados por un servicio de montaje automático
como ser automount o amd.
Ejemplo:
# Device Mountpoint FStype Options Dump Pass#
ohm:/discos/ext /ext nfs rw,bg,intr,hard 0 0
ampere:/discos/users /usr/users nfs ro,bg,intr,soft 0 0
Las opciones mas usuales para NFS son:
rw Montar el filesystem read-write (debe estar exportado read-write en el servidor)
ro Solo lectura
bg Si la operación de montaje falla (el servidor no responde), continuar reintentando
en background.
hard Si un servidor no responde, hacer que las operaciones que intenten accederlo se
bloqueen hasta que el servidor reviva
soft
Si un servidor cae, hacer que las operaciones que traten de accederlo fallen y
retornen un error. Eso evita que los procesos se "cuelguen" en filesystems "no
esenciales". Debe usarse con cuidado.
retrans=n Numeros de reintentos antes de devolver un error en un filesystem montado
"soft"
timeo=n timeout (en décimas de segundo) para los pedidos.
intr Permite que los usuarios interrumpan operaciones bloqueadas (retornando un
error)
rsize=n Cambiar el tamaño del buffer de recepción a n bytes
wsize=n Cambiar el tamaño del buffer de transmisión a n bytes
nosuid Ignorar el bit de suid en los ejecutables en esta partición
nfsv2/nfsv3 Utilizar la versión de NFS especificada
Los nombres específicos pueden variar de sistema en sistema
Los filesystems montados "hard" causan que los procesos que lo usan se bloqueen
cuando los servidores caen (retornando a la normalidad al volver los servidores),
mientras que esto no sucede si está montado "soft". Pese a ser más cómodo el

funcionamiento "soft", puede ocasionar que procesos de larga duración aborten por un
problema transitorio en la red, y también puede llegar a generar archivos corruptos si el
corte se produce durante operaciones de escritura. Por ello normalmente se recomienda
no utilizar esta opción.
La opción intr, junto con la hard, permite que las operaciones bloqueadas sean
interrumpidas (enviandole al proceso una señal de QUIT (mediante kill , o <CTRL> C
si es el proceso activo en la terminal)). Esto permite que sea el usuario el que decida si
se debe interrumpir el proceso o no.
La elección de estas opciones es un compromiso entre seguridad de la información y
comodidad de uso que debe resolverse en cada caso.
Algunas utilidades de montaje automático, como amd, proveen algunos remedios para
esta situación.
Las opciones rsize y wsize son muy útiles en algunas versiones de linux, que por
defecto utilizan buffers muy chicos (1024 bytes). En estas versiones, especificar valores
entre 4096 y 8192 puede mejorar sustancialmente la performance de NFS.
Convenciones administrativas para NFS.
Manejo de usuarios en NFS
En NFS, el acceso a los archivos desde una máquina cliente se autoriza o nó de acuerdo al
número de usuario (UID) con el cual la máquina cliente informa que se está intentando el
acceso. Esto impone algunas decisiones administrativas.
Cualquier usuario que quiera acceder a un archivo en la red debe tener una cuenta de usuario
en la máquina donde se encuentra el filesystem. No es necesario que el usuario pueda
loguearse en esa cuenta, pero debe existir en los sistemas de autentificación. Además, los
números de usuario y de grupo deben ser únicos a través de todas las máquinas que
comparten filesystems (preferiblemente en toda la red).
También es conveniente tener un esquema de nombres de filesystems común a toda la red,
para simplificar el mantenimiento.
Interacciones entre NFS y las redes
NFS tradicionalmente ha utilizado UDP como protocolo de transporte. Aunque NFS hace su
propio chequeo de errores y retransmisión de paquetes erroneos y perdidos, ni UDP ni NFS
proveen ningún protocolo de control de congestión. Esto hace que NFS sobre UDP sea una
mala elección para redes de area extensa (WAN). También puede ocasionar problemas en
redes de area local, dada la capacidad de los servidores actuales.
Varios sistemas modernos ofrecen versiones de NFS que funcionan sobre TCP, siendo
mucho más adecuados para redes de area extensa y redes locales muy utilizadas.
Servidores NFS dedicados.
NFS sufre algunos problemas de performance debido a su diseño "sin estado" (parte de estos
problemas son mitigados en las últimas versiones de NFS). En particular, como el cliente asume

que una operación de escritura se completa una vez que recibe el acuse de recibo del servidor,
el servidor debe asegurarse de escribir cada bloque a disco antes de responder, para evitar
discrepancias en el caso de una caida. Esto introduce un retardo significativo en el caso de
escrituras NFS. Esto está en vías de solución en las nuevas versiones de NFS (v4, parcialmente
v3).
Además, los filesystems NFS tienden a ser grandes, lo que los hace suceptibles a problemas de
confiabilidad y dificultades para el respaldo.
Existen soluciones comerciales para estos problemas, tanto desde el punto de vista de tarjetas
que se pueden agregar a sistemas existentes para mejorar su performance (por ejemplo,
grabando la información en RAM no volatil hasta que se tenga tiempo de grabar a disco), como
sistemas dedicados con software y hardware especializados que solucionan tanto los
problemas de performance como los de confiabilidad.
Montaje automático
Montar los filesystems uno por vez listándolos en el archivo /etc/fstab introduce serios
problemas en redes grandes.
Primero, el mantenimiento de /etc/fstab en un número considerable de equipos puede
convertirse rápidamente en una pesadilla, especialmente si no todos son idénticos.
En segundo lugar, si se depende fuertemente de filesystems remotos, especialmente si se
montan filesystems de varios hosts, se genera un gran problema cuando cualquiera de ellos
falla, ya que cualquier comando que utilice los filesystems no disponibles se bloqueará.
En tercer lugar, si un servidor importante no está disponible, los usuarios pueden ver sus
posibilidades de trabajar disminuidas al no estar disponibles particiones importantes. En esta
situación sería muy util si se pudiera montar una copia de la particion de un servidor de
backup.
Un demonio de montaje automático conecta filesystems cuando son accedidos y los
desconecta cuando ya no son necesarios. Esto minimiza la cantidad de puntos de
montaje activos y es mayormente transparente a los usuarios. En la mayoría de los
servidores de montaje automático es posible dar una lista de filesystems replicados que
utilizar si el servidor primario no funciona.
Para implementarlo, el programa de conexión automática aparece como un servidor
NFS, pero en lugar de compartir un filesystem hacia la red, "inventa" un filesystem de
acuerdo a las especificaciones en su archivo de configuración.
Cuando un usuario hace referencia a un directorio dentro del filesystem "fantasma"
creado por el automounter, este intercepta la referencia, monta el filesystem que el
usuario está tratando de utilizar y continúa con la operación. Usualmente hay un solo
directorio donde realmente se montan los filesystems, y la ilusión de que dichos
filesystems están en otras ramas del filesystem se crea utilizando links simbólicos.
La idea original de los programas de montaje automático es de Sun. Su implementación,
automount, se encuentra en casi todos los sistemas NFS derivados de Sun. Sin
embargo, automount tuvo varios bugs y defectos de diseño en varias de sus versiones
que han hecho muy popular a una de sus alternativas gratuitas, amd.
amd (Am-Utils) es el resultado de una tesis doctoral (de Jan-Simon Pendry del Colegio
Imperial, Londres), que expande la idea de Sun, corrige las fallas mas graves de
automount, y es más portable que este último.
El sistema autofs implementado en linux puede utilizarse con el mismo cometido.
AUTOMOUNT: el demonio de montaje automático de Sun
automount entiende tres tipos de archivos de configuración (llamados "mapas"): mapas
directos, mapas indirectos, y mapas maestros. Los mapas directos e indirectos dan información
acerca de los filesystems que deben ser montados automáticamente. Un mapa maestro es una
lista de mapas directos e indirectos que automount debe manejar. No es necesario tener un
mapa maestro para correr automount, ya que se pueden pasar los mapas directos e indirectos
en la línea de comando.
Mapas indirectos
Los mapas indirectos se utilizan para montar varios filesystems bajo un directorio común. El
path al directorio se especifica en el mapa maestro, no en el propio mapa indirecto. En el
siguiente ejemplo, la primera columna indica el subdirectorio donde cada filesystem debe ser
montado (relativo al directorio indicado en el mapa maestro), y las siguientes columnas
indican las opcionesde montaje y el directorio de origen del filesystem.
users chimchim:/chimchim/users
devel chimchim:/chimchim/devel
info -ro chimchim:/otros/info
Mapas directos
Los mapas directos listan filesystems que no tienen un prefijo común. automount conecta cada
filesystem en un directorio temporal, y crea un link simbólico en el punto de destino
Ejemplo:
/usr/man chimchim:/usr/man
/cs/tools anchor:/cs/tools
En este ejemplo, automount conectaría los filesystems chimchim:/usr/man y
anchor:/cs/tools en un directorio temporal (por defecto tmp_mnt) y crearía un link
simbólico de /usr/man y /cs/tools a los puntos de montaje correspondientes.
Mapas maestros
Un mapa maestro lista mapas directos e indirectos. Para cada mapa indirecto, también
especifica el directorio base utilizado por las conexiones definidas en el mapa.
Por defecto, automount utiliza el mapa maestro definido en la NIS (excepto en Solaris, que por
defecto utiliza /etc/auto_master y requiere una línea +auto_master en este archivo para usar
los datos de la NIS).
Por ejemplo:
#Directory Map
/chimchim /etc/auto.chim
/- /etc/auto.direct

La primer columna indica el directorio local para un mapa indirecto, o /- para un mapa
directo. La segunda indica el nombre del archivo en el cual se encuentra el mapa. Puede
haber varios mapas de cada tipo.
Automount se puede ejecutar de dos formas: utilizando un mapa maestro (ya sea el por
defecto auto.master de la NIS o uno dado en la línea de comandos), o listando los mapas
directos e indirectos en la línea de comando.
Ej: automount /- /etc/auto.direct /chimchim /etc/auto.chim &
Filesystems replicados utilizando automount
En algunos casos, un filesystem read-only como /usr/man puede ser idéntico en varios
servidores. En ese caso, se le puede decir a automount que elija el servidor que responda mas
rápido.
Algunas consideraciones:
- Los filesystems replicados DEBEN ser de solo lectura. El demonio de automount no puede
sincronizar escrituras en varios servidores.
- automount NO puede desmontar un filesystem activo y reemplazarlo con un respaldo
cuando un servidor se cuelga. Solo puede elegir un servidor que responda cuando se monta el
filesystem.
- No se puede indicar qué servidores son primarios y cuales backup. automount selecciona el
servidor basado en su idea de cercania.
- Los filesystems replicados DEBEN ser idénticos.
Por ejemplo, un mapa directo que define que /usr/man es un filesystem replicado puede
ser:
/usr/man chimchim,band:/usr/man
Nuevas versiones de automount permiten montar RW filesystems replicados.
Deteniendo automount
Como automount funciona como un servidor NFS, terminarlo con kill -9 puede dejar el sistema
bloqueado. Si se precisa matar o reiniciar automount, se debe asegurar de utilizar la señal
TERM (kill -15) para que automount pueda devolver el filesystem local a su estado original.
AMD (AM-UTILS)
amd es técnicamente superior al automount original de Sun. Algunas de sus ventajas:
- amd nunca se va a bloquear si un servidor remoto se cuelga.
- amd envía pedidos de "keep-alive" a los servidores remotos a intervalos regulares y
mantiene una lista de los servidores accesibles, que utiliza para montar, desmontar y
reemplazar filesystems. Si un servidor se cuelga, futuros accesos al filesystem devuelven el
error "operation would block" en lugar de bloquearse.
- amd no contiene código propietario y ha sido portado a muchas versiones de UNIX.
- amd soporta una cantidad de tipos de montaje no soportados por automount.

- los mapas de amd pueden ser guardados en varios formatos de base de datos, incluyendo
NIS, NIS+, Hesiod, ndbm y otros
- posee una herramienta de manipulación y consulta (amq) que permite su monitoreo y el
envio de comandos al servidor.
- La sintaxis de usu mapas es mas genérica que la de automount.
- amd está basado en el concepto de que cada servidor tiene uno o mas filesystems, con
cada filesystem conteniendo uno o mas volúmenes (un conjunto coherente de archivos). Esto
hace que el manejo de subdirectorios sea mas directo que con automount.
Mapas de AMD
El formato de los mapas de amd es extremadamente flexible, y permite que un mismo archivo
de configuración sea utilizado en varias máquinas. Cada filesystem listado en un mapa de amd
debe tener asociado un tipo de montaje. Los tipos mas comunes se muestran en la tabla.
nfs Acceso básico a un servidor NFS
ufs Acceso básico a un filesystem local
host Acceso a todo el arbol exportado por un servidor (se le pregunta al mountd en el
servidor cuales son sus filesystems exportados)
nfsx Acceso a un grupo de filesystems en un servidor NFS con una sola entrada en el
mapa.
program Corre un programa cada vez que se debe montar o desmontar el filesystem. Se utiliza
para tipos de montaje que amd no conozca.
link Crea un link simbólico que apunta a un punto de montaje físico (permite que
cualquier directorio se pueda acceder via amd).
auto Crea un nuevo punto de montaje debajo de uno existente, algunas veces utilizado
para replicar el árbol de montaje de un servidor.
direct Casi idéntico a los mapas directos de automount
union Permite que el contenido de varios directorios aparezca como un único directorio
Las entradas en los mapas pueden contener condicionales, que permiten que se activen
solo en contextos específicos (por ejemplo en un determinado host o tipo de máquina).
Los condicionales utilizan varias variables automáticamente asignadas con una serie de
información acerca del entorno en que amd está corriendo. Los selectores mas comunes
se muestran en la tabla.
arch Arquitectura de la máquina

autodir Directorio por defecto donde montar filesystems.
byte Orden de los bytes en la máquina (big- o little-endian)
cluster Nombre del cluster local de la máquina, por defecto domain
domain Dominio NIS local
host nombre de la máquina
hostd nombre de la máquina concatenado con el dominio
karch arquitectura del kernel (por defecto igual a arch)
key Nombre del volumen que se está resolviendo
map Nombre del mapa siendo utilizado
os Sistema Operativo
Wire Nombre de red de la interfase primaria de la máquina
Ejemplo:
/default opts:=rw,soft,timeo=10,retrans=5
usr/man host==chimchim;type:=ufs,dev:=/dev/sd1f
host!=chimchim;rhost=chimchim;rfs:=/${key};type=nfs;fs:=${autodir}/${key}
cs/tools host==anchor;type:=ufs;dev:=/dev/sd3c
host!=anchor;rhost=anchor;rfs:=/${key};type=nfs;fs:=${autodir}/${key}
Las entradas de la forma nombre:=valor definen varios atributos del montaje. Por
ejemplo, la primera línea fija las opciones por defecto en "rw,soft,timeo=10,retrans=5".
Los elementos de la forma nombre==valor o nombre!=valor son condicionales: los
siguientes elementos solo son utilizados si el condicional es verdadero (En el ejemplo
para /usr/man, se utilizan para tomar acciones distintas dependiendo de si estamos en
chimchim o no).. Notaciones como ${autodir} o ${key} insertan el valor del selector
adecuado.
Algunas opciones en los mapas de amd que indican filesystems remotos son:
rhost host remoto donde se encuentra el filesystem
rfs Nombre del filesystem remoto

type Tipo de montaje
fs Punto local de montaje.
Arrancando amd
amd se puede arrancar con un script como:
#!/bin/csh -f
cd /usr/local/etc/amd
exec /usr/local/bin/amd -x fatal,error,user -r -l syslog -a /tmp_mnt /amd
amd.master.map >& /dev/console.
Opción Descripción
-x Fija las opciones de error
-r "Adopta" los puntos de montaje ya existentes
-l Especifica el archivo de log o syslog para los mensajes de error
-a Especifica una ubicación alternativa para los puntos de montaje (por defecto,
/a)
/amd Especifica el nombre del directorio del mapa
amd.master.map Especifica el archivo conteniendo las opciones de montaje.
Cuando un usuario referencia un filesystem definido en el mapa de amd, amd monta el
filesystem y monitorea el uso del mismo. Después de haber estado inactivo por un
período de tiempo (usualmente 5-15 minutos), amd desmonta el filesystem hasta que
sea accedido nuevamente.
Filesystems replicados utilizando amd
amd permite que se listen varios servidores para un filesystem particular. A diferencia de
automount, en la mayoría de los casos es capaz de desconectar filesystems activos de
servidores caidos y montar sus reemplazos "on the fly"
Por ejemplo:
usr/man host==chimchim;type:=ufs;dev;=/dev/sd1f ||
host==band;type:=ufs;dev:=/dev/sd3c ||
rhost=chimchim rhost=band;rfs:=/${key};
type=nfs;fs:=${autodir}/${key}

Deteniendo amd
amd debe ser notificado de que debe irse para que tenga opción de retirarse de la estructura
del filesystem. Para ello hay que enviarle una señal SIGTERM.
NFS y la seguridad
NFS provee una forma conveniente de acceder a archivos a través de una red, pero es una
fuente importante de problemas de seguridad. Para un sitio "normal", una protección
adecuada se obtiene con un control estricto de /etc/exports (o /etc/dfs/dfstab), y un manejo
adecuado del archivo /etc/hosts.allow (en los sistemas que permiten limitar los servicios RPC
en este archivo). El mayor riezgo proviene de máquinas locales a las cuales se les permite
montar un filesystem (obviando los casos de fallas en la implementación de los protocolos, que
históricamente fueron comunes).
La seguridad de NFS se basa en la confianza entre máquinas. Una vez que el servidor le
permite a un equipo montar un filesystem, la seguridad de los archivos en el servidor depende
también de la seguridad en la máquina cliente. Es el cliente el que indica como qué usuario
debe realizarse cada operación (dando el número de usuario), por lo que es importante que
solo exportemos filesystems a máquinas "confiables", y que compartan la misma base de datos
de usuarios.
Si un usuario es capaz de obtener acceso de root en una máquina cliente, hay varios métodos
para acceder a archivos pertenecientes a otros usuarios, aun cuando en el /etc/exports no se
permita el acceso de root. Si alguien en quien no se confía tiene acceso de root en una
máquina cliente, no se debe exportar ningun filesystem a esa máquina.
Hubo intentos de hacer NFS mas seguro. Por ejemplo, a través de la utilización de Kerberos
para la validación, o de "secure RPC", un protocolo más seguro de invocación de procesos
remotos. Sin embargo, no es tanta la mejora de seguridad que se obtiene comparado con una
buena administración, y dichas extensiones no son mayormente utilizadas.
Monitoreo y "tunning" de NFS
La mayoría de los sistemas proveen un comando llamado nfsstat que despliega varias
estadísticas mantenidas por los sistemas NFS. nfsstat -s muestra estadísticas de los procesos
de servidor NFS, mientras que nfsstat -c muestra información de las operaciones como cliente.
Los principales parámetros a monitorear son los timeouts y los errores.
Bibliografía Adicional
http://www.linuxdoc.org/HOWTO/NFS-HOWTO/ http://www.am-utils.org/
http://www.am-utils.org/am-utils.html
http://www.linuxdoc.org/HOWTO/mini/Automount.html
http://www.linux-consulting.com/Amd_AutoFS/autofs-HOWTO.html
man de los comandos descriptos.

Samba Qué es Samba
Versiones, obtener Samba
Instalación
Arranque de los demonios
Configuración
Acceder directorio UNIX desde Windows
Acceder directorio Windows desde UNIX
Compartir una impresora UNIX
Compartir una impresora Windows
Protocolos SMB y CIFS
Protocolo SMB
Protocolo CIFS
Localización de recursos o "browsing"
Conceptos y objetivos de una red SMB/CIFS
Conceptos de red SMB/CIFS
Grupos de trabajo y Dominios
Localizadores maestros
Controlador de dominio
Seguridad de los servicios compartidos en Grupo de Trabajo
Modo de autenticación de servicios por Dominio
Esquemas de autenticación
Bibliografía y referencias.
Qué es Samba
Samba es un conjunto de programas que permite a sistemas cliente acceder archivos e
impresoras en un servidor usando el protocolo SMB (Server Message Block). El servidor puede
ser una máquina UNIX, Netware, OS/2 o VMS. Los clientes pueden ser Lan Manager, Windows
3.11/95/98/NT/2000, Linux, OS/2. Concretamente, Samba permite hacer uso de archivos e
impresoras ubicados en una máquina UNIX desde máquinas Windows; también desde

máquinas DOS con Lan Manager. Como parte del conjunto, viene un programa que permite a
una máquina UNIX actuar como cliente de otros servidores SMB.
Con Samba pueden realizarse las siguientes cosas:
compartir un directorio de UNIX hacia máquinas Windows; acceder un directorio Windows desde máquinas UNIX; compartir una impresora UNIX hacia máquinas Windows; acceder una impresora Windows desde máquinas UNIX.
El conjunto de programas contenidos en el paquete Samba comprende:
smbd, el servidor SMB; maneja las conexiones de los clientes, incluyendo permisos y
validación de usuarios.
nmbd, el servidor de nombres NetBIOS; permite a los clientes ubicar los servidores
mostrando una lista e incorporando aspectos de manejo de dominio.
smbclient, programa cliente UNIX; permite a UNIX actuar como cliente de otro servidor
SMB.
smbrun, permite al servidor correr aplicaciones en máquinas SMB.
testprns, para comprobar el acceso a impresoras.
testparms, para verificar la configuración de Samba.
smb.conf, el archivo de configuración de Samba.
smbprint, un script para que una máquina UNIX pueda usar smbclient para imprimir en un
servidor SMB.
documentación, abundante cantidad de información cuya lectura puede ahorrar mucho
tiempo y frustración.
El conjunto se entrega con todo el código, es de uso público, y se encuentra protegido bajo la
licencia GPL (General Public License) de GNU.
Versiones, obtener Samba.
Linux y FreeBSD incluyen Samba entre sus paquetes; para Solaris o HP-UX pueden bajarse los
fuentes, o aún versiones en binario, desde www.samba.org. Samba es considerado muy
estable y seguro, condiciones logradas en base a la política de abundar en versiones de
dominio público para favorecer la corrección del software. Las versiones alfa, que contienen la
palabra "alpha" en el nombre del paquete, están destinadas a detección de fallas; no se las
consideran estables como para el uso en producción. Al obtener una versión nueva, debe
buscarse el número más alto que no contenga la palabra "alpha".
Instalación.
Las siguientes son las ubicaciones habituales de comandos y archivos:

demonios smbd y nmbd en /sbin; comandos de usuario en /bin; archivo de configuración en /etc/smb.conf; archivo de registro en /var/log; los archivos smb y nmb retienen mensajes originados
por los demonios smbd y nmbd; pueden configurarse archivos de mensajes distintos por máquina cliente, por ejemplo en /var/log/samba/%m.log, donde %m es una variable que contiene el nombre de la máquina;
directorio para bloqueos en /var/lock/samba.
El archivo de configuración /etc/smb.conf es la parte crucial de la instalación. En la distribución
viene un ejemplo con abundantes comentarios. La página man smb.conf explica las muchas
opciones disponibles.
Arranque de los demonios.
Los demonios smbd y nmbd pueden ser corridos desde inetd o como procesos autónomos.
Para arrancarlos desde inetd, si se está configurando un servidor permanente, deben ser
configurados para arrancar de nuevo si mueren. El archivo /etc/inetd.conf debe
contener líneas similares a éstas: # servicios NetBIOS de Samba netbios-ssn stream tcp nowait root /usr/sbin/smb smbd netbios-ns dgram udp wait root /usr/sbin/nmbd nmbd
Después de editar el archivo, reinicializar inetd con
kill -1 id-proceso-inetd
para que la configuración tome efecto. El número de proceso de inetd puede obtenerse
con ps auxw | grep inetd
Para arrancar los demonios como procesos autónomos, incluir su invocación a través de
los scripts de arranque, como se muestra en el siguiente script /etc/rc.d/init.d/smb:
#!/bin/sh
#
# /etc/rc.d/init.d/smb - arranca y detiene servicios SMB.
#
# Establecer los siguientes enlaces simbólicos hacia este script
# para el arranque en el nivel 3 (red en multiusuario):
# /etc/rc.d/rc0.d/K35smb - destruye servicio SMB en shutdown
# /etc/rc.d/rc1.d/K35smb - destruye servicio SMB en monousuario
# /etc/rc.d/rc3.d/S91smb -arranca servicio SMB en multiusuario
# /etc/rc.d/rc6.d/K35smb -destruye servicio SMB en reboot

# parámetros de invocación.
case "$1" in
start)
echo -n "Iniciando servicios SMB: "
/sbin/smbd -D
/sbin/nmbd -D
echo
touch /var/lock/subsys/smb
;;
stop)
echo -n "Cerrando servicios SMB: "
killproc smbd
killproc nmbd
rm -f /var/lock/subsys/smb
echo
;;
*)
echo "Usage: smb {start|stop}"
exit 1
esac
En algunas distribuciones el arranque de Samba viene ya incluído en los scripts de
arranque, a veces comentado. Distribuciones como Debian traen ya su script
/etc/init.d/samba y crean los enlaces simbólicos al instalar el paquete.
Configuración.
La configuración de Samba se controla con un único archivo, /etc/smb.conf. Aquí se determina
qué recursos serán compartidos y bajo qué condiciones. El archivo está dividido en secciones,
cada una de las cuales comienza con un encabezado tal como global, homes, printers, etc. La
sección "global" define variables de acción global sobre todos los recursos compartidos. La
sección "printers" define la configuración general de impresoras reconocidas por ese servidor.
La sección "homes" permite a un usuario, y sólo a él, acceder su directorio propio en la

máquina UNIX. El ejemplo siguiente permitirá a usuarios Windows acceder sus directorios
propios en la máquina UNIX y usar libremente un directorio temporal en la máquina UNIX.
; /etc/smb.conf
;
[global]
guest account = guest
log file = /var/log/samba/%m.log
lock directory = /var/lock/samba
share modes = yes
[homes]
comment = Directorios propios
browseable = no
read only = no
create mode = 0755
[temporal]
comment = Espacio para archivos temporales
path = /tmp
read only = no
public = yes
Para compartir un directorio público con permisos de escritura:
[publico]
comment = Public Stuff
path = /home/public
public = yes
writable = yes
Para que este directorio sea legible por todo público pero solo modificable por
integrantes del grupo "tecnicos":

[tecnopub]
comment = Directorio Público del grupo Técnicos
path = /home/tecnopub
public = yes
writable = yes
printable = no
write list = @tecnicos
Acceder directorio UNIX desde Windows.
Una vez instalado y configurado Samba en la máquina UNIX, quedarán disponibles para los
clientes Windows los servicios compartidos. Esto es, será posible montar directorios de la
máquina UNIX en una máquina Windows. Para ello, se realiza la operación de montaje como
siempre: si se trata de Windows 95/98/NT/2000 puede usarse el Explorador, indicando en la
opción de montar unidad de red el nombre de la unidad de disco, y luego el nombre de la
máquina UNIX seguido del nombre del recurso compartido, en la notación habitual,
\\máquina_UNIX\nombre_recurso. También puede hacerse la operación desde una ventana de
comandos, indicando el nombre de la unidad: net use K: \\gingko\tecnopub
monta sobre la unidad K: el recurso llamado tecnopub compartido vía Samba en la máquina
UNIX llamada gingko.
Una vez asegurado el éxito de la operación, puede accederse desde la máquina cliente al
directorio de la máquina UNIX en la letra de unidad indicada. Si el recurso compartido
requiere autenticación del usuario, este debe poseer una cuenta en la máquina UNIX o
en otra máquina que haya sido designada para la autenticación de seguridad. En este
caso, el acceso sólo será concedido si el usuario es autenticado por quien tenga la
autoridad de hacerlo, y si dispone de los permisos adecuados. La autoridad para
autenticación de usuarios se designa en el archivo smb.conf de Samba.
Acceder directorio Windows desde máquinas UNIX con Samba.
Samba trae un programa cliente, smbclient, para que las máquinas UNIX puedan acceder
recursos compartidos vía SMB en máquinas Windows o en otras máquinas UNIX/Samba. Este
programa provee una interface similar a ftp, lo que permite transferir archivos desde y hacia
un recurso compartido desde una máquina Windows.
/usr/sbin/smbclient -L winntmaq
muestra los recursos compartidos en la máquina winntmaq, ya sean directorios o
impresoras, generalmente pidiendo una contraseña.
/usr/sbin/smbclient \\\\winntmaq\\g_tmp <contraseña> Aquí el caracter \ debe "escaparse" con otro \, escribiendo \\ para que tome \. Este
comando conecta al directorio g_tmp habilitando una línea de comandos de tipo ftp: Server time is Sat Aug 10 15:58:44 1996 Timezone is UTC+10.0 Domain=[WORKGROUP] OS=[Windows NT 3.51] Server=[NT LAN Manager 3.51] smb: \>

Para obtener la lista de comandos disponibles en smbclient:
smb: \> h
ls dir lcd cd pwd
get mget put mput rename
more mask del rm mkdir
md rmdir rd prompt recurse
translate lowercase print printmode queue
cancel stat quit q exit
newer archive tar blocksize tarmode
setmode help ? !
smb: \>
El programa smbclient es también útil para determinar el funcionamiento correcto de
Samba en una máquina UNIX, invocándolo desde ella misma o desde otra máquina
UNIX.
Compartir una impresora UNIX.
Como toda impresora en UNIX, la impresora a compartir debe tener una entrada en el archivo
/etc/printcap. Una vez seguros de que la impresora funciona bien en la máquina UNIX, para
compartirla hacia las máquinas Windows agregar en smb.conf algo similar a esto:
; parámetros globales para imprimir
[global]
printing = bsd
printcap name = /etc/printcap
load printers = yes
log file = /var/log/samba/%m.log
lock directory = /var/lock/samba
; parámetros para todas las impresoras
[printers]
comment = Todas las Impresoras
security = server
path = /var/spool/lpd/lp

browseable = no
printable = yes
public = yes
writable = no
create mode = 0700
; configuración de una impresora
[ljet]
comment = Impresora HP laserjet
security = server
path = /var/spool/lpd/lp
printer name = hpljet
writable = yes
public = yes
printable = yes
print command = lpr -r -h -P %p %s
Compartir una impresora Windows.
Para poder compartir una impresora en un servidor Windows remoto vía Samba, debe
disponerse de una entrada para ésta en el /etc/printcap de la máquina UNIX. Las convenciones
de printcap usadas significan:
cm - comentario
lp - nombre del dispositivo de impresión
sd - directorio de spool de la impresora, en la máquina local
af - archivo de contabilidad
mx - tamaño máximo de archivo; si se pone 0, no hay límite
if - nombre del filtro de entrada, si lo hay (un script)
Ejemplo de entrada en /etc/printcap.
# /etc/printcap
#
# \\winntmaq\imppost5 via smbprint
#

lpwin|immpost5:\
:cm=HP 5MP Postscript imppost5 en winntmaq:\
:lp=/dev/null:\
:sd=/var/spool/lpd/imppost5:\
:af=/var/spool/lpd/imppost5/acct:\
:mx#0:\
:if=/usr/bin/smbprint:
smbprint es un filtro de entrada para impresoras definidas en /etc/printcap. Usa el
programa smbclient para imprimir un archivo en una impresora servida por una
máquina basada en SMB. El nombre del servidor y la impresora se leen del archivo de
configuración /var/spool/lpd/nombre_impresora/.config; para el ejemplo anterior,
# /var/spool/lpd/imppost5/.config # # configuración para impresora imppost5 en servidor winntmaq server=winntmaq service=imppost5 password=""
El script imprime hacia el servicio de impresión en la máquina remota mediante un comando
similar a cat archivo.txt | /usr/bin/smbclient \\servidor\impresora \ contraseña -U servidor -N -P >> logfile
Protocolos CIFS y SMB.
En las secciones siguientes se resumen algunos conceptos útiles para comprender la
instalación de una red basada en máquinas UNIX/Samba sirviendo archivos e impresión a
máquinas Windows y NT. Cada nueva versión de Samba implementa más cercanamente el
esquema de red Microsoft, haciendo la máquina UNIX cada vez más indistinguible de un
servidor Microsoft en lo que a clientes se refiere.
Protocolo SMB.
SMB (Server Message Block, bloque de mensajes de servidor) es un protocolo para compartir
archivos, base de los sistemas de red LAN Manager y Microsoft Networking. SMB fue aplicado
por Microsoft a DOS como una extensión para dirigir entrada salida de disco hacia NetBIOS
(Network BIOS), un sistema diseñado por IBM y Sytec para actuar como interfaz cruda entre
red y aplicación. Modernamente, los paquetes SMB son transportados en una extensión de
NetBIOS denominada NBT, NetBIOS sobre TCP/IP.

Protocolo CIFS.
CIFS (Common Internet Filesystem, sistema de archivos común para Internet) es una tentativa
de implementar un protocolo de dominio público para transferencia de archivos en forma
simple y potente, ampliando las capacidades de SMB, en el cual se basa.
CIFS define un protocolo de acceso a sistemas de archivos remotos normalizado para
uso en redes, permitiendo a los grupos de usuarios trabajar juntos y compartir
documentos ya sea a través de Internet o dentro de sus intranets corporativas. Es una
tecnología multiplataforma, abierta, basada en los protocolos para compartir archivos de
MS Windows y otros sistemas operativos comunes, soportada por UNIX y otros
sistemas operativos. En su máxima expresión, CIFS permitiría a millones de usuarios
compartir sus archivos sin instalar nuevo software o cambiar su forma de trabajo
habitual.
Localización de recursos o "browsing".
La localización de recursos o "browswing" es la parte de los protocolos SMB/CIFS que permite
ubicar recursos en la red tal como se hace en la sección "Entorno de Red" para las máquinas de
un mismo grupo en el Explorador de Windows 95/98/NT/2000. Tocando con el ratón sobre el
nombre de una máquina, ésta muestra sus recursos compartidos (impresoras y directorios), a
los que puede hacerse conexión. CIFS aspira a realizar esto a través de la Internet.
Conceptos y objetivos de una Red SMB/CIFS.
Al instalar en una red LAN o WAN servicios de archivo e impresión las decisiones cruciales
implican:
Cómo y dónde se almacena la información de nombres de usuario, contraseñas y seguridad;
Qué método se usará para ubicar los recursos que los usuarios tienen habilitados;
Qué protocolos hablan (soportan) los clientes.
Las redes Netware, Windows NT o cualquier producto para servicio de archivos encierra al
usuario en el marco de las respuestas de ese producto a las preguntas anteriores. Esto es
inconveniente aún cuando se tiene una red homogénea, pero más cuando se tiene diversos
tipos de máquinas y sistemas operativos. Samba intenta superar estas restricciones
admitiendo la mayor combinación posible de clientes, servidores, sistemas operativos y
protocolos.
Conceptos de red SMB/CIFS.
Para la implementación de redes, Dominio y Grupo de Trabajo son exactamente lo mismo,
excepto por la secuencia de ingreso del cliente (logon). En los dominios, existe una base de
datos de autenticación distribuída; esto da mayor alcance y flexibilidad al concepto de
dominio. Para Samba, cuando un cliente se conecta a un servicio, lo hace presentando una
cadena de autenticación; si ésta es válida, el acceso le es permitido, sin importar cómo ha sido
generada esa cadena. En el caso de ingresar a un dominio, sin embargo, el cliente SMB espera
que todos los demás servidores del dominio acepten la misma información de autenticación.
En cuanto a la localización de recursos ("browsing"), no hay diferencia entre dominio y grupo
de trabajo. Windows 95/98 puede ser miembro tanto de un dominio como de un grupo de
trabajo; Windows NT no. Samba puede sólo ser miembro de un único grupo de trabajo o
dominio, aunque las nuevas versiones de Samba están ya dando soporte de dominio NT.
Grupos de Trabajo y Dominios.
El grupo de trabajo (Workgroup) designa un conjunto de máquinas que mantienen una base de
datos común para la localización de sus recursos compartidos. No necesariamente tienen en
común información de seguridad; si ésto acontece, estamos en presencia de un dominio. El
mantenimiento de la lista de servidores y recursos es dinámica: se altera toda vez que entra o
sale un servidor de la red, o que incorpora o elimina un recurso compartido. El término
"browsing" o localización se refiere al acceso a recursos por parte del usuario, usando una
interfaz cualquiera, tal como el Explorador de Windows. Los servidores SMB acuerdan entre
ellos cuales mantienen la base de datos de localización de recursos. Los grupos de trabajo
pueden estar en cualquier punto de una red interconectada TCP/IP, aún en diferentes
subredes o en la internet; esto es algo muy difícil de implementar para SMB.
Localizadores maestros.
Los localizadores maestros o "master browsers" son máquinas que tienen la base de datos
maestra de localización de recursos en un dominio o grupo de trabajo. Hay dos clases de
localizadores maestros:
Localizador Maestro de Dominio ("Domain Master Browser"): retiene la base de datos
maestra de localización de todo el dominio, eventualmente atravesando varias subredes
TCP/IP.
Localizador Maestro Local ("Local Master Browser"): retienen la base de datos maestra de
localización de la subred en la que se encuentran; se comunican con el localizador maestro de
dominio para obtener información de otras subredes.
Las subredes son un caso especial porque la localización de recursos se basa en difusión, y la
difusión no atraviesa los ruteadores. Los localizadores maestros, ya sean de dominio o locales,
son elegidos dinámicamente según un algoritmo que considera la habilidad de la máquina para
sostener la carga de localización. Samba puede configurarse para actuar siempre como
localizador maestro; esto equivale a ganar siempre la elección, incluso frente a sistemas
actuando como controladores primarios de dominio Windows NT, que aspiran ellos mismos a
ganar la elección.
Controlador de Dominio.
El término Controlador de Dominio (Domain Controller) está unido a la autenticación de
usuarios en un dominio. El método de autenticación de usuarios en un dominio usado por
Windows NT es el más difundido, pero no es el único.
Seguridad de los servicios compartidos en Grupo de Trabajo.
El ajuste de seguridad de Samba "security = SHARE", fue la implementación inicial de Samba,
en la cual en base a la contraseña asociada al recurso se infería el usuario, pudiendo incluso
hacerse que el usuario fuera "todos". Esto se considera mala práctica, pero en los orígenes
estaba ligado a grupos chicos, alrededor de los años '80, en los cuales las consideraciones de
seguridad no eran prioritarias. El criterio resucitó en 1992 con Windows for Workgroups.

Modo de autenticación de servicios por Dominio.
Con el ajuste de seguridad de Samba "security = USER" o "security = SERVER" todos los
accessos a los recursos son verificados por el par nombre de usuario / contraseña de modo
más riguroso. Para el cliente, esto emula el comportamiento de ingreso a un dominio
Microsoft. Para el cliente es indiferente si Samba consulta la base de datos de seguridad SAM
de Windows NT o autentica al usuario de algún otro modo, como ser consultando a la máquina
UNIX. Si los nombres de usuario existen en la máquina UNIX, conviene usar "security = user"; si
no, convendrá "security = share" para ambientes chicos donde la seguridad no es un problema;
con "security = server" las duplas nombre de usuario / contraseña son transferidas a otro
servidor SMB para su autenticación, como ser una máquina NT.
Esquemas de autenticación.
En el caso más simple, la información necesaria para la autenticación de un usuario
reside en uno o más archivos en un servidor único. Cuando el usuario debe acceder más
de un servidor, se requiere algún tipo de base de datos distribuída para evitar obligar al
usuario a tener una contraseña en cada contexto. Tal esquema debe ser capaz de
soportar cambios de contraseña y grupos de usuarios con permisos en un mismo nivel.
Por estas razones Samba implementa en muchos casos directamente el modelo de
dominio.
Existen diversos esquemas de autenticación posibles utilizables por Samba, tales como
NIS; para máquinas Windows 95/98 y muchos otros clientes Samba puede comportarse
como controlador maestro de dominio compartiendo la base de datos de autenticación
vía NIS en forma transparente para los clientes. El soporte de dominio para Windows
NT está ya disponible en las nuevas versiones. El soporte para perfiles de usuario es
soportado por Samba para clientes Windows 95/98/NT desde tiempo atrás.
Samba: ejemplo de archivo de configuración.
; ; =========================================== ; Archivo de configuración simple para Samba. ; =========================================== ; archivo: smb.conf ; ; Provee: ; - acceso a directorios propios de usuarios ; - acceso a todas las impresoras en /etc/printcap ; ; Verificar: ; 1: Ruta a printcap; en general, /etc/printcap (BSD). ; 2: Validez del comando "print", que debe aceptar un archivo %s ; para una impresora %p y luego eliminar el archivo. ; 3: Ajuste "printing =" para el sistema: sysv, bsd, aix ; 4: Validez del comando "lpq" para el sistema. ; 5: El usuario en la cuenta "guest" debe existir; "nobody" da
problemas ; en algunos sistemas; una opción es "ftp". ; 6: Ajustar la opción "security =": "share", "user", "server". ; 7: Limitar acceso con "hosts.allow", sobre todo en Internet. ; [global]

server string = Máquina %h con Samba %v printing = bsd printcap name = /etc/printcap load printers = yes guest account = pcguest hosts allow = 10.137.0.0 localhost ;Para tener un archivo de registro para cada cliente ; log file = /usr/local/samba/var/log.%m ;Para permitir acceso múltiple a los mismos archivos se requiere ;un directorio de bloqueos con permisos de lectura para todos ; lock directory = /usr/local/samba/var/locks ; share modes = yes ;Para autenticar contraseñas por una máquina NT ; security = server ; password server = <Servidor-NT> ;Para autenticar con esta máquina UNIX; ;no colocar en este caso "password server" security = user ;Para incluir configuraciones específicas para cada máquina ; include = /usr/local/samba/var/lib/smb.conf.%m ;En algunas situaciones, este ajuste aumenta el rendimiento ; socket options = TCP_NODELAY ;Si se tienen varias interfaces de red en esta máquina ; interfaces = 10.137.107.200/24 10.137.109.200/24 ;o alternativamente ; interfaces = 10.137.107.200/255.255.255.0 \ ; 10.137.109.200/255.255.255.0 ;Para que Samba se anuncie en subredes o redes remotas ; remote announce = 10.137.105.255 192.168.1.255/GR-SAMBA ;Localizador Maestro de Dominio para manejar listas de subredes; ;no debe haber ya un servidor NT haciendo esta tarea domain master = yes ;Para dar ventaja en elección inicial de localizador a Samba preferred master = yes ;Si se tiene un servidor NT como Primary Domain Controller, ; domain master = no ; preferred master = no ; domain controller = <Servidor-NT-PDC> ;Para configurar servicio WINS (única máquina) wins support = yes ;Si ya hay un servidor WINS, para referirse a él ; wins support = no ; wins server = 10.137.137.230 ;Para descargar y ejecutar un archivo de comandos .BAT en Win95 ;o .CMD en WinNT, por máquina %m o por usuario %U. ;Requiere servicio netlogon. ;El archivo de comandos debe estar escrito con cr/lf, estilo DOS. ; logon script = /usr/local/samba/lib/netlogon/%m.bat ;Directorios propios de usuarios, mapeo automático al conectar [homes]

comment = Directorios propios de Usuarios browseable = no read only = no create mode = 0750 ;Para logon a dominio, scripts de logon ;[netlogon] ; comment = Servicio Netlogon ; path = /usr/local/samba/lib/netlogon ; guest ok = yes ; writable = no ; share modes = no ;Todas las impresoras definidas en esta máquina [printers] comment = Todas las Impresoras path = /tmp browseable = no printable = yes public = no writable = no create mode = 0700 ;Directorio accesible a todos sin contraseña, sólo lectura [aplics] comment = Directorio Público sólo lectura path = /export/softaplic writable = no public = yes ;Impresora privada del usuario freddy, quien debe tener permiso de ;escritura sobre el directorio de spool. [fredimp] comment = Impresora de Freddy valid users = freddy path = /homes/freddy printer = fred_imp public = no writable = no printable = yes ;Directorio privado del usuario Fred, quien debe tener permiso de ;escritura sobre el directorio. [freddir] comment = Directorio de Freddy path = /export/privados/freddy valid users = freddy public = no writable = yes printable = no ;Directorio público sólo lectura excepto para el grupo "personal" [interno] comment = Directorio uso interno path = /export/publico/interno public = yes writable = no printable = no write list = @personal ;Un directorio diferente para cada máquina, con la variable %m;

;igual puede hacerse para cada usuario, con %u. [maquinas] comment = Directorios por máquina path = /usr/pc/%m public = no writeable = yes ;Directorio público, lectura escritura para todos; ;los archivos quedan en propiedad del dueño del directorio; ;todos pueden borrar archivos ajenos. [publico] path = /export/pub public = yes only guest = yes writable = yes printable = no
Configuración del kernel
El núcleo o "kernel"
Tipos de kernel
Cuándo configurar el kernel
Configurar kernel en Solaris
Configurar kernel en Linux
Bibliografía
El núcleo o "kernel".
En el sistema operativo UNIX se reconocen tres niveles de abstracción:
- el hardware;
- el núcleo del sistema operativo (kernel);
- los programas de usuario (aplicaciones).
El kernel presenta al usuario o los programas de aplicación una interfaz de
programación de alto nivel, implementando la mayoría de las facilidades requeridas por
éstos. Reúne el manejo de una serie de siguientes conceptos ligados al hardware de
nivel más bajo:
- procesos (tiempo compartido, espacios de direccionamiento protegidos);
- señales y semáforos;
- memoria virtual ("swapping", paginado);
- sistema de archivos;
- tubos ("pipes") y conexiones de red.
Una parte del kernel es independiente de los dispositivos presentes en el sistema, pero
otra contiene los controladores necesarios para manejar partes específicas del hardware.
El kernel intrepreta los pedidos de los programas y los traduce en secuencias de bits
que, presentadas a los registros de los controladores, operan sobre los dispositivos
físicos.
El kernel está escrito casi todo en C, salvo una pequeña parte en lenguaje ensamblador
para los procesos de bajo nivel. El tamaño puede ir desde unos 400 KB hasta más de 15
MB.
Tipos de kernel.

Todos los sistemas permiten indicar al kernel qué hardware encontrará, o cuál no debe
buscar; algunos kernels pueden explorar el sistema por sí solos.
Solaris usa un kernel totalmente modular, y puede cargar los controladores de
dispositivos al momento que se necesitan, gracias a la coherencia de la arquitectura
propietaria de Sun, mucho mayor que la de un computador personal. HP-UX también
puede determinar su hardware sin intervención del administrador. FreeBSD y los UNIX
BSD en general requieren indicación explícita del hardware del equipo; esto resulta a
veces difícil por la poca información técnica que los fabricantes de partes PC proveen a
los usuarios. Linux compila los controladores en el kernel como los BSD, pero también
maneja módulos a la manera de Solaris, aunque no tan limpiamente, debido a las
limitaciones de la arquitectura PC.
En la siguiente tabla se muestra el nombre del directorio donde se compila el kernel
(directorio de compilación), así como nombre y ubicación del kernel para algunos
sistemas ejemplo:
Sistema Directorio de compilación Kernel
Solaris (usa módulos) /kernel/unix
HP-UX /stand /stand/vmunix
Linux /usr/src/linux /vmlinux o /boot/vmlinuz
FreeBSD /usr/src/sys /kernel
Cuando configurar el kernel.
Para la instalación las distribuciones proveen uno o más kernels típicos, adaptados a
grandes grupos de hardware corriente, con muchos controladores y paquetes opcionales
que no se usarán en nuestro sistema particular. Aunque no interferirán con el uso del
sistema, un kernel adaptado a nuestro hardware será más chico, ocupará menos
memoria, y ejecutará más rápido. Si bien los kernels modernos pueden descartar en
parte los controladores innecesarios, sus opciones quedarán activadas. Reconfigurar el
kernel para el hardware específico tiende a optimizar el rendimiento del sistema.
Otras razones para reconfigurar el kernel son la actualización de versiones y el agregado
de nuevos dispositivos físicos. Incorporar un nuevo controlador requiere actualizar las
tablas y estructuras de datos del kernel. En muchas distribuciones esto implica
reconfigurar el kernel; en otras puede bastar correr un programa de inserción de
módulos cargables en tiempo de ejecución.
Configurar kernel en Solaris.
En el arranque el kernel de Solaris sondea los dispositivos e inicializa un controlador
por cada uno de los que encuentra. Mediante la técnica de módulos cargables incorpora
sólo el código correspondiente a los dispositivos físicamente presentes. No obstante, en
algunos casos este automatismo puede fallar, por errores o por no estar previsto ese
dispositivo en particular, haciendo necesaria la configuración manual.
Solaris maneja la siguiente estructura de directorios para la carga de módulos:

/kernel
módulos comunes a máquinas con el mismo conjunto de instrucciones.
/platform/nombre-plataforma/kernel
módulos específicos para un tipo de máquina (reconocido en nombre-
plataforma). Por ejemplo, "Ultra Enterprise". Puede determinarse con uname -i.
/platform/clase-hardware/kernel
módulos específicos para una clase de hardware (reconocido en clase-
hardware). Por ejemplo, sun4u. Puede determinarse con uname -m.
/usr/kernel
similar a /kernel.
Solaris busca el kernel en las vías /platform/nombre-plataforma/kernel:/kernel:/usr/kernel
El nombre del kernel buscado es "unix", y si no se encuentra, "genunix", un kernel más
genérico conteniendo sólo la parte independiente de dispositivos. Los directorios de la
vía contienen una serie de subdirectorios de clasificación de módulos, tales como drv,
misc, cpu, strmod, sparcv9, fs, exec, sched, sys, genunix, unix. Normalmente no es
preciso tocar ningún archivo de estos subdirectorios, a no ser que el fabricante de un
dispositivo lo establezca en forma específica.
El kernel de Solaris se configura en un archivo maestro de nombre /etc/system,
consistente en una serie de variables (fijadas con set) y directivas (palabras reservadas).
Manejar mal este archivo puede impedir el arranque. Con boot -a se intenta arrancar
desde una copia respaldo si se la ha creado previamente.
Un ejemplo de archivo /etc/system simple contendría algo así (excluyendo los
comentarios): rootfs:ufs
sistema de archivos tipo ufs. rootdev:/sbus/@1,f800000/esp@0,800000/sd@3,0:a
dispositivo de arranque sd3a; /dev/sd3a es un enlace al nombre largo usado aquí. moddir: /platform/SUNW/Ultra-Enterprise/kernel:/platform/sun4u/kernel: /kernel:/usr/kernel
vía de búsqueda para los módulos; va en una línea única. forceload: drv/superplotter
fuerza la carga del módulo indicado; exclude fuerza la exclusión de un módulo. set maxusers=64
dimensiona las tablas del kernel para atender un máximo de 64 usuarios
simultáneos.
Una serie de comandos ayudan a encontrar fallas de configuración: prtconf
imprime la configuración general de la máquina, incluyendo las dependencias
entre controladores. sysdef
descripción muy pormenorizada de la configuración de la máquina. Incluye todo
lo mostrado por prtconf. Un impreso de la salida de este comando debe formar
parte de la documentación de máquina. modinfo
informa sobre los módulos cargables dinámicamente; es normal hallar 50 o más.

Esta breve descripción no es suficiente para configurar un kernel Solaris. En la mayoría
de los casos la técnica de módulos cargados dinámicamente hace innecesario
reconfigurar el kernel Solaris, pero si debiera hacerse, leer cuidadosamente la
documentación antes de emprender la tarea.
Configurar kernel en Linux.
La configuración del kernel en Linux se basa en un archivo /usr/src/linux/.config de
críptico contenido. Existen no obstante interfaces más comprensibles basadas en el
comando make: make config
pide una respuesta para cada opción de configuración; no permite corrección;
poco flexible, conviene usar alguna de las otras. make menuconfig
presenta las opciones de configuración en forma de menú con interfaz gráfica en
terminal de caracteres, clasificadas por grupos y con ayuda explicativa sobre
cada una. Cada opción puede compilarse en el kernel (marcada con *) o cargarse
como módulo (marcada con M). Cuando la opción sólo puede tomarse
compilada la propia interfaz así lo hace. make xconfig
como make menuconfig pero en X-Windows. Requiere autorización para root
en el uso del ambiente gráfico.
Los pasos para una compilación de kernel en Linux incluyen: cd /usr/src/linux
trasladarse al directorio de compilación. Puede tener un nombre más específico,
como /usr/src/kernel-source-2.2.17, indicando la versión de kernel a que
corresponden los fuentes; /usr/src/linux suele ser un enlace simbólico al nombre
más específico. make menuconfig
corre la interfaz de configuración. Fijar las opciones deseadas, ya sea internas o
como módulos. La ayuda describe extensamente el significado de cada una,
sugiriendo en muchos casos el ajuste. make dep
resuelve las dependencias entre módulos de compilación en C (código objeto y
encabezados), a más de otras. make clean
asegura el inicio de la compilación en un ambiente limpio de rastros de
compilaciones anteriores (elimina archivos intermedios). Se usa cuando quiere
arrancarse una compilación desde cero, sin reutilizar el código objeto. make bzImage
compila un kernel comprimido de nombre bzImage. Puede crearse un kernel en
disquete sustituyendo este comando por make bzdisk, una opción segura para
probar un nuevo kernel. make modules
compila los módulos marcados en la configuración. make modules_install
instala los módulos compilados. cp /usr/src/linux/arch/i386/boot/bzImage /boot/vmlinuz
copia el kernel generado hacia donde se espera encontrarlo en el arranque. Si se
creó en disquete bastará arrancar el equipo con el disquete. vi /etc/lilo.conf

LILO (LInux LOader) es el programa de carga del kernel. Se configura en el
archivo /etc/lilo.conf. Entre sus opciones mínimas debe encontrarse el
dispositivo de arranque (p.ej. /dev/hda3), la ruta y nombre del kernel a arrancar
(usualmente /boot/vmlinuz o /vmlinuz). /sbin/lilo
Instala LILO según la configuración de LILO recientemente ajustada.
Esta breve descripción no es suficiente para configurar un kernel Linux. Debe leerse la
documentación, especialmente el archivo README ubicado en el directorio de
compilación.
Es conveniente disponer de un modo alternativo de arrancar el sistema, por ejemplo en
disquete, antes de recompilar el kernel. Alternativamente, compilar el kernel en
disquete, probarlo y recién después de verificar el correcto funcionamiento de todos los
servicios copiar hacia la ubicación definitiva en disco. Un disquete de arranque se crea
simplemente haciendo cp /usr/src/linux/arch/i386/boot/bzImage /dev/fd0
Un disquete de arranque con el kernel actual se crea igualmente haciendo cp /boot/vmlinuz /dev/fd0
No confiar en estos disquetes hasta no probarlos.
Aún con error de LILO, si disponemos de un kernel sano puede indicarse a LILO su
ubicación, así como otros parámetros. Al aparecer el prompt LILO: escribir algo así
como
vmlinuz root=/dev/hda3 ether=0,0,eth0 ether=0,0,eth1 donde se indica el arranque del kernel vmlinuz ubicado en la partición /dev/hda3, e
intentar reconocer 2 tarjetas de red Ethernet.
Puede existir la opción make install para instalar el kernel en su ubicación definitiva
y correr LILO; esto deja la máquina lista para arrancar con el nuevo kernel. Debe
hacerse sólo después de haber probado el nuevo kernel compilado en disquete.
Impresión
Impresión en UNIX
Términos usuales en impresión
Tipos de impresoras
Impresoras seriales y paralelas
Impresoras de red
Sin PostScript
Impresión BSD
Proceso de impresión BSD
El archivo /etc/printcap

Variables de printcap
Control del ambiente de impresión
Impresión System V
Proceso de impresión System V
Comandos de impresión System V
Eliminar una impresora
Agregar una impresora (BSD)
LPRng
Las impresoras PostScript
Sugerencias
Bibliografía y referencias.
Impresión en UNIX.
En el estado actual de la tecnología las impresoras de matriz de puntos sólo sobreviven en
aplicaciones empresariales, sobre todo cuando son necesarias varias copias; las impresoras
láser, cada vez más accesibles, ofrecen velocidad a buena calidad como impresoras de red; la
impresión barata es chorro de tinta, aunque el alto precio de los cartuchos hace más rentable
la impresión láser cuando se trata de cantidad. El sistema de impresión UNIX, sin embargo, ha
permanecido casi constante frente a estos cambios: la mayoría de los sistemas siguen usando
el esquema típico BSD (lpd, lpc, lpr, ...) o System V (lpsched, lpadmin, lp, ...). Muchos
sistemas proveen comandos cruzados para el manejo de colas de impresión; la manera de
determinar el sistema de impresión es viendo qué demonio está presente: lpd para BSD,
lpsched para System V.
Términos usuales en impresión.
spooler o servidor de impresión: software que recibe los trabajos a imprimir, los almacena en
cola, les asigna prioridades y los envía secuencialmente hacia la impresora. Usa un directorio
de "spool" o almacenamiento intermedio donde se ubican en espera los trabajos a imprimir.
dpi (Dots Per Inch, puntos por pulgada): medida de la resolución o capacidad de
presentación de la impresora, expresada en la cantidad de puntos impresos por pulgada.
Cuanto más cantidad de puntos, mejor se ve el impreso. Suele expresarse como 360 x
720, indicando 360 dpi en la horizontal y 720 dpi en la vertical.
PDL (Page Description Language, lenguaje descriptor de página): lenguaje
comprendido por las impresoras usado para definir una imagen de la página a imprimir.
El PDL hace más eficiente la transmisión, facilita el trabajo de las aplicaciones, es

independiente de dispositivos y de la resolución en dpi. Los más conocidos son
PostScript y PCL.
bitmap: imagen gráfica expresada mediante un conjunto de datos que indican el color
de punto de la imagen. Todo PDL soporta al menos un tipo de bitmap. Los más
conocidos son JPEG, PNG, TIFF y GIF.
RIP (Raster Image Processor, procesador de imagen de barrido): sistema que convierte
PDL a bitmap, apropiado para un dispositivo de impresión en particular. El RIP suele
residir en la impresora.
filtros: programas intercalados en la secuencia del proceso de impresión para realizar
transformaciones en los datos: conversión de formatos de archivo, contabilidad,
comunicación con la impresora. La impresión de un trabajo en PostScript en una
impresora incapaz de interpretar PostScript requiere un filtro específico para la marca y
modelo de la impresora.
PostScript: el PDL más común en UNIX, original de Adobe Systems; muchas
impresoras aceptan PostScript directamente; todas las aplicaciones para diseño de
páginas y publicación generan PostScript . Es un lenguaje completo de programación;
su código puede ser visto con cualquier procesador de texto.
PCL (Printer Command Language): alternativa de Hewlett-Packard para PostScript,
usado en impresoras HP, común en computadores personales. UNIX no genera PCL;
requiere un filtro para convertir desde otros formatos.
roff: no es un PDL, sino un lenguaje para formato de textos, surgido en la época de los
terminales de caracteres. No se usa en documentos nuevos, pero existe mucho ya hecho,
en particular las páginas man de UNIX. GNU produce groff, una versión sin costo de
roff.
Tipos de impresoras.
Las impresoras se clasifican por el tipo de conexión (serie, paralelo, red) y por el formato de
datos que comprenden (texto, PostScript, PCL, otro).
Existen actualmente impresoras baratas con escasa o ninguna inteligencia limitadas para
su uso con Windows (WinPrinters). No convienen ni siquiera usando Windows: cargan
al computador con tareas propias de la impresora. Pasa lo mismo con los WinModem.
Impresoras seriales y paralelas.
Las impresoras seriales requieren intrincados detalles de configuración, como velocidad de
transferencia y otros; es preciso consultar la información de la impresora. La interfaz paralela
de los PCs requieren poca configuración y son más rápidas. La interfaz serial permite cables de
hasta 15 m; la paralela sólo hasta 6 m. USB, una tecnología serial nueva, está apareciendo ya
en las versiones estables de FreeBSD y Linux.

Impresoras de red.
Las impresoras de red disponen de una tarjeta y conexión completa a la red. Dirigir trabajos a
una impresora de red es más rápido que dirigirlos a una impresora local serie o paralela. Como
cualquier máquina puede mandar trabajos a la impresora de red, aparecen problemas de
contención. Conviene mantener el manejo de todas las impresoras bajo unos pocos servidores;
las máquinas restantes envían a los servidores. Hay impresoras láser de red con demonio lpd
incluído, capaces de manejar un spool como cualquier máquina UNIX. Hay impresoras de red
viejas que requieren enviar trabajos de impresión al puerto TCP 9100; ofrecen dificultades de
configuración con BSD y SysV, pero no con LPRng, un nuevo diseño de servidor de impresión
basado en BSD.
Sin PostScript.
Aunque todos los sistemas UNIX generan PostScript la mayoría de las impresoras de chorro de
tinta y las láser de poco precio no lo soportan. El paquete abierto GhostScript es capaz de
convertir PostScript al PDL propio de cientos de impresoras. Al especificar GhostScript como
filtro se debe indicar el nombre del filtro correspondiente a la impresora disponible; hay
documentación y ejemplos en el propio paquete.
Impresión BSD.
El sistema de impresión BSD ha escalado para soportar las impresoras y PDLs actuales,
incluyendo soporte para impresoras compartidas en redes heterogéneas. FreeBSD y Linux
soportan el sistema de impresión BSD.
El proceso de impresión.
En BSD, el acceso a las impresoras es controlado por el demonio lpd: recibe los trabajos
enviados por los usuarios u otros lpd remotos, los procesa y los transfiere a la impresora. lpd
lee la configuración de las impresoras en el archivo /etc/printcap.
Los usuarios envían trabajos de impresión usando el comando lpr. lpr y lpd se
comunican usando el enchufe (socket) /dev/printer. El usuario puede indicar la
impresora destino en el propio comando lpr con la opción -P impresora; si no se
indica, se usa la impresora indicada en la variable de ambiente PRINTER; si ésta no
existe, se usa la impresora por defecto configurada en el sistema (en /etc/printcap).
Una vez determinada la impresora, lpr busca en /etc/printcap la entrada
correspondiente a esa impresora, de la cual obtiene entre otros datos el directorio de
spool donde debe colocar el trabajo, usualmente /var/spool/lpd/nombre_impresora. lpr
crea por cada trabajo dos archivos, uno de control, de nombre cf seguido del número de
trabajo, con información de manejo, y otro con los datos a imprimir, de nombre df
seguido del mismo número. Una vez colocado el trabajo en el directorio de spool, lpr
notifica a lpd la llegada de un trabajo de impresión.
Ante un nuevo trabajo, lpd vuelve a leer /etc/printcap para saber si la impresora referida
es local o remota; si es local, verifica la existencia de un demonio para manejo de la
cola donde se encuentra el trabajo, y si no está lo crea como copia de sí mismo; si es
remota, abre una conexión al lpd de la máquina remota, le transfiere los archivos de
control y datos, y luego borra las copias locales de ambos archivos.

Los trabajos se procesan en orden de llegada. La prioridad puede ser cambiada con lpc
sobre un trabajo en particular; no hay manera de fijar prioridades por máquina origen o
usuario.
Cuando un trabajo está listo para imprimir, lpd crea una serie de tuberías (pipes) UNIX
entre el archivo en spool y el hardware de impresión por las cuales son transferidos los
datos, eventualmente pasando a través de un proceso de filtro capaz de dar formato o
implementar un protocolo específico de la impresora.
El archivo /etc/printcap.
El archivo /etc/printcap es la base de datos maestra del sistema de impresión. Una impresora
debe estar descrita aquí antes de poder recibir trabajos. El formato es el mismo de
/etc/termcap y /etc/remote: el primer item de entrada es una lista de nombres posibles para
la impresora, separados por "|"; luego siguen un conjunto de ajustes separados por ":" , cada
uno de los cuales es de la forma xx=cadena o xx#número, donde xx es un código de 2
caracteres. Los comentarios comienzan con #; una entrada puede abarcar varias líneas si se
usa \ como caracter de continuación.
# Impresora Laser remota en máquina roble en Ingeniería roble-lj4|lping|l-56|HP Laserjet 4 de Ingenieria: \ :lp=:/var/spool/lpd/roble-lj4/.null: \ :rw: \ :sd=/var/spool/lpd/roble-lj4: \ :rm=roble: \ :rp=roble-lj4: \ :lf=/var/adm/lpd-errs:
Los nombres de la primera línea reflejan la práctica de disponer de 3 nombres como
mínimo para cada impresora, con este criterio: un nombre corto para uso en la práctica
(lping); un nombre identificatorio de la máquina anfitrión y tipo de impresora (roble-
lj4); una descripción larga con información adicional (HP laserjet 4 de Ingenieria).
El nombre de impresora lp designa una impresora por defecto a la cual se dirigen todos
los trabajos sin indicación de impresora específica. No conviene usar lp como nombre
primario de una impresora; esto dificulta el cambio de impresora por defecto. En
ausencia de impresora llamada lp la primera en /etc/printcap será la impresora por
defecto si la variable de ambiente PRINTER no indica otra cosa.
Variables de printcap.
La descripción completa de las muchas variables de usadas en el archivo de control de
impresión /etc/printcap se encuentran en la página man printcap. Pueden agruparse en
estas categorías básicas:
especificaciones de archivos y directorios; información para acceso remoto; filtros de impresión; ajustes de comunicaciones; información de página.

sd: (spool directory), directorio de spool o almacenamiento intermedio. Cada impresora debe
tener su directorio de almacenamiento intermedio, aún si la impresora es remota; los trabajos
se almacenan localmente hasta ser transmitidos. El directorio de spool debe crearse a mano,
con permisos 755, dueño y grupo daemon. El directorio de spool contiene, además del trabajo
a imprimir, dos archivos de estado: status y lock. El archivo status contiene una descripción del
estado de la impresora; es mantenido por lpd y consultado por lpq. El archivo de lock existe
para evitar el arranque de más de un demonio lpd para atender la misma cola, y para
mantener información del trabajo en curso.
lf: (log file), archivo de registro de errores. Un archivo común para errores de impresión
basta para todas las impresoras; aún las remotas deben disponer de un archivo de
registro de errores, para registrar fallas de comunicación. Los procesos filtro dirigen sus
errores a otros archivos, según lo especificado en syslog, no en el indicado por este
parámetro.
rw: si la impresora es capaz de emitir información de estado a través de su archivo de
dispositivo, debe especificarse lectura escritura sobre él incluyendo este parámetro en su
descripción.
lp: nombre del dispositivo de impresión. Para impresoras locales debe especificarse el
archivo /dev correspondiente al puerto al que se encuentra conectada. Las impresoras de
red (diferentes de las remotas, se conectan a la LAN, no tienen máquina anfitrión) deben
apuntar a un archivo falso (dummy) para permitir a lpd el bloquear ese archivo como
indicación de que la impresora está en uso. Ejemplo: lp:/var/spool/lpd/roble-lj4/.null
af: (accounting file): la especificación de este archivo permite llevar contabilidad de los
trabajos de impresión, ya sea para cobrar o sólo para conocer la carga sobre el sistema
de impresión. El comando pac resume esta información contable; los números de
página son inciertos, salvo si el filtro es capaz de interrogar a la impresora por su
número de copias antes y después del trabajo, y la impresora es capaz de responder.
mx: tamaño máximo de archivo; no permite inferir nada para archivos PostScript o
PDL. Puede ser necesario colocar mx#0 para habilitar impresiones de tamaño ilimitado.
rm y rp: acceso remoto. rm indica la máquina a la que debe enviarse el trabajo, rp el
nombre de la impresora remota en la máquina donde está conectada. Aún una impresora
de red debe definirse con un único servidor habilitado para enviarle trabajo; un único
demonio lpd maneja la cola en forma más eficiente, evitando el problema de contención
cuando muchas máquinas envían hacia la misma impresora de red. Definir en la
máquina que contiene la impresora una entrada para "remota" que refiera a una entrada
"local" en la propia máquina, con directorios de spool diferentes, es un artificio para
poder usar siempre el nombre de la remota, ya sea en la máquina local o en otra
máquina cualquiera, simplificando la administración y la detección de fallas.
of, if, nf: filtros de impresión. Los filtros son usualmente scripts en lenguaje de shell
que invocan programas de traducción, aceptando el trabajo a la entrada, efectuando la
transformación y devolviéndolo en la salida. El filtro if se invoca una vez por cada
trabajo; es el más común. El filtro of recibe toda la cola de trabajos en una invocación

única; es útil para dispositivos lentos para conectar, actualmente escasos. La presencia
simultánea de ambos hace que of imprima una página de anuncio (banner) e if procese
el archivo. El siguiente ejemplo es un filtro if para imprimir PostScript en una impresora
Epson Stylus, de naturaleza "no PostScript", usando el convertidor de dominio público
ghostscript (gs) para intepretar el PostScript:
#!/usr/local/bin/bash # filtro de entrada para postscript en impresora común /usr/local/bin/gs -q -dNOPAUSE -sPAPERSIZE=a4 -sDEVICE=stccolor -sOutputFile=- -
stccolor es el nombre de controlador para una impresora Epson Stylus Color. Este otro
ejemplo es para una impresora PostScript:
#!/bin/csh -f /usr/local/bin/textps $* | /usr/local/bin/psreverse
El programa textps determina si el contenido a imprimir es PostScript, y si no lo es lo
convierte a PostScript, usando los filtros que se indiquen como parámetros, a través de
$*. Luego, psreverse invierte el orden de las páginas para entregar el trabajo ordenado.
Estos ejemplos son scripts; deben tener permiso de ejecución.
br: (baud rate), velocidad en bauds. Para impresoras seriales, indica la velocidad de la
puerta serial. Ejemplo: br#9600
fc, fs (flag bits), bits de bandera. Para impresoras seriales. Fijan paridad, control de
flujo, duplex, retardos. Funcionan combinados para fijar/quitar bits correspondientes a
cada ajuste; la información se encuentra en la página man tty sección 4. fc es "flag
clear" para apagar bits, fs es "flag set" para prender bits, y la suma octal de fs y fc da
como resultado los bits prendidos.
sh: (suppress header), suprime impresión de página de encabezado.
El archivo printcap admite extensiones: si son necesarias variables no previstas,
interpretadas por los controladores de la impresora, pueden colocarse en
/etc/printcap sin afectar el funcionamiento de lpd ni lpr. Variables no citadas en la
página man deben aparecer en la documentación del controlador de la impresora.
También es posible usar el sistema de impresión como spool para otros tipos de archivo:
Nemeth[2000] cita un caso de uso para música en MP3.
#
#/etc/printcap
#
lx810|lp|lp0|Impresora matriz de puntos LX-810:\
:lp=/dev/lpt1:\
:sd=/var/spool/lx810:\
:mx#0:\

:pl#72:\
:pw#80:\
:sh:\
:hl:\
:lf=/var/spool/lx810/lp-err:\
:af=/var/spool/lx810/lp-acct:
#
hplaser|Impresora HP Laserjet 4 texto:\
:lp=/dev/lpt0:\
:sd=/var/spool/hplaser:\
:mx#0:\
:pl#72:\
:pw#80:\
:sh:\
:sf:\
:lf=/var/spool/hplaser/lp-err:\
:tr=\033&l0H:\
:af=/var/spool/hplaser/lp-acct:
#
pslaser|ps|Impresora HP Laserjet 4 PostScript:\
:lp=/dev/lpt0:\
:sd=/var/spool/pslaser:\
:mx#0:\
:pl#72:\
:pw#80:\
:sh:\
:sf:\
:lf=/var/spool/pslaser/lp-err:\
:if=/var/spool/pslaser/ps_input_filter:\
:tr=\033&l0H:\

:af=/var/account/pslaser-acct:
#
hp550c|Impresora HP Deskjet 550C remota en máquina ohm:\
:lp=:\
:mx#0:\
:rm=ohm:\
:rp=hp550c:\
:sd=/var/spool/hp550c:
#
Control del ambiente de impresión.
Los comandos lpq, lprm y lpc son los más usados en el manejo diario de las tareas de
impresión.
lpq, normalmente acompañado de la opción -Pimpresorau otra que restrinja la salida,
muestra los trabajos en la cola de impresión, en el orden de prioridad asignado, arriba el
que será impreso primero. Otros datos incluyen el dueño del trabajo, el número de
trabajo (jobid), nombre del archivo, tamaño; la opción -l da más detalles. El número de
trabajo importa para el manejo del mismo con lprm o lpc.
lprm, en su forma más común lprm nro_trabajo, elimina de la cola el trabajo de
número indicado; como lprm usuario elimina todos los trabajos enviados por ese
usuario; lprm sin opciones elimina el trabajo activo; lprm - elimina todos los del
usuario invocante, o todos los trabajos si el usuario es root. El éxito de la operación es
denunciado con el aviso de la eliminación del trabajo indicado por su número;
curiosamente, no indica cuando falla. En algunos sistemas la remoción de un trabajo
puede producir confusión en un filtro, dejando la impresora bloqueada e impidiendo su
uso; identificar el proceso filtro con ps y eliminarlo desbloquea la impresora;
rearrancando lpd se soluciona este problema; en este caso, la manipulación con lpc es
inútil. El rearranque del equipo también lleva la impresión a estado de sanía, pero una
medida tan drástica no es simpática para ningún adiministrador; antes de llegar a eso,
detener lpd, eliminar a mano con rm todos los trabajos en el directorio de spool y
arrancar de nuevo lpd.
lpc: comando administrativo, usado para habilitar/deshabilitar la cola de impresión,
habilitar/deshabilitar la impresión en sí, eliminar todos los trabajos de la cola, mover un
trabajo hacia el principio de la cola, manipular el demonio lpd, obtener información de
estado. No es capaz de resolver problemas cuando hay filtros de por medio, no funciona
a través de la red, ni dice siempre la verdad: puede aparentar arreglar todo pero nada
funciona. Se usa normalmente en modo interactivo, disponiendo de diversos comandos:
help muestra una lista de comandos internos de lpc

help comando muestra ayuda del comando interno indicado
enable impresora habilita puesta en cola de trabajos
disable impresora deshabilita puesta en cola de trabajos
start impresora habilita impresión en la impresora indicada
stop impresora deshabilita impresión, permite puesta en cola
abort impresora detiene impresión, aún del trabajo en curso
down impresora mensaje coloca la impresora fuera de servicio, muestra mensaje
up impresora vuelve la impresora al servicio
clean impresora elimina todos los trabajos de la cola
topq impresora id_trabajo mueve un trabajo hacia el principio de la cola
topq impresora usuario aumenta prioridad de trabajos de usuario
restart impresora rearranca demonio de impresión; la falta de lpd la indica lpq
status impresora indica estado de cola, impresión, demonio y entradas en cola
La opción restart no desbloquea una impresora con un filtro corriendo; usar stop y luego
start; asegurarse de eliminar también el proceso filtro.
La falta de un demonio de impresión para una impresora determinada es normal cuando
no hay trabajos para imprimir: el demonio se activa para imprimir los trabajos y luego
desaparece.
Impresión System V.
System V no fue diseñado para redes; no ha escalado bien, los fabricantes lo han modificado
bastante, a veces sin razón. Solaris y HP-UX se basan en System V, con muchas particularidades
propias.
Proceso de impresión System V.
Un usuario usa el comando lp para imprimir, ya sea en forma directa o no; lp recibe la
entrada y la coloca en un archivo en el directorio de spool. El demonio lpsched determina
cuando debe imprimirse el archivo, ejecuta el programa de interfaz que da formato al archivo
y lo envía hacia la impresora correspondiente.
En System V se habla de "clases" y "destinos", nombres de hasta 14 caracteres
alfanuméricos y subrraya. Un destino es generalmente una impresora, pero podría ser
otra cosa, por ejemplo un archivo de texto donde todos los usuarios pudieran agregar
trozos, resolviendo así el problema de concurrencia originado en el acceso simultáneo.
Una clase es un conjunto de destinos sirviendo a un propósito común, por ejemplo todas

las impresoras de una sección o un local; el demonio lpsched puede dirigir un trabajo
hacia una clase, asignando el destino más conveniente según los trabajos en cola.
Comandos de impresión System V.
Los comandos más usuales en impresión System V son los siguientes:
accept comienza a aceptar trabajos para un dispositivo
cancel cancela un trabajo en cola o en ejecución
disable deshabilita la impresión en un dispositivo
enable habilita la impresión en un dispositivo
lp coloca trabajos en cola para imprimir
lpadmin configura el sistema de impresión
lpmove mueve trabajos de un dispositivo de impresión a otro
lpsched demonio que maneja la agenda de trabajos de impresión
lpshut deshabilita lpsched
lpstat muestra estado del sistema
reject detiene la aceptación de trabajos para un dispositivo
lp: comando a nivel de usuario para enviar trabajos a la cola de impresión. El directorio
de spool para una impresora suele ser /var/spool/lp/request/destino, donde
destino es la impresora en cuestión o una clase de impresoras. La opción -ddestino
permite direccionar hacia una impresora o una clase; si se omite, se consulta la variable
de ambiente LPDEST, o en su defecto el dispositivo de impresión por defecto, asignable
con lpadmin -d.
lpsched: demonio que toma los archivos en el directorio de spool, ordenadamente, y los
envía hacia el dispositivo de impresión, cuando esté disponible. Si el destino es una
clase, se dirige al primero que se encuentre disponible. Los errores suelen registrarse en
/usr/spool/lp/log, registrando identificador de trabajo (jobid), usuario, impresora
pedida, impresora asignada, hora de encolado.
lpshut: elimina lpsched, algo necesario para correr lpadmin. Pueden seguirse
enviando trabajos a la cola aunque lpsched no esté presente, pero no serán impresos.
Los trabajos interrumpidos se reimprimirán completos al restaurarse lpsched. Para
arrancar de nuevo correr lpsched.
lpadmin: define la configuración de impresión local. Permite asignar nombre a las
impresoras, crear clases, especificar impresora por defecto. Mantiene la configuración
creando archivos de texto en /usr/spool/lp, pero éstos no deben ser manejados
directamente, ya que son altamente sensibles a formato. La mayoría de los comandos de

lpadmin requieren que lpsched no esté actuando, por lo que es buena práctica eliminar
lpsched antes de usar lpadmin. Como ejemplo, para agregar una impresora, se requiere
un comando de este tipo:
/usr/sbin/lpadmin -pimpresora -vdispositivo { -eimpresora | -mmodelo | -iinterfaz } [ -cclase ... ] [{ -l | -h}]
donde impresora es el nombre a asignar a la impresora, dispositivo el nombre de un
archivo en /dev. Las banderas -e (para impresora existente), -m (modelo del que se tiene
interfaz), -i (ruta al programa de interfaz), son diferentes formas de indicar el programa
de interfaz encargado de dar formato a los trabajos antes de imprimirlos. Para eliminar
una impresora,
lpadmin -ximpresora
No debe tener trabajos en cola. Existen muchas otras banderas aceptadas por lpadmin.
lpstat: da información sobre el estado del sistema de impresión. Sin argumentos, da el
estado de todos los trabajos de impresión del usuario; -pimpresora los de una
impresora, -r el estado de lpsched. Hay muchas otras opciones.
Eliminar una impresora.
A veces, intentar configurar o reconfigurar una impresora puede dejar el sistema de impresión
en estado de confusión irrecuperable, al punto de que el proceso de eliminación de la
impresora con lpadmin no funcione. Los siguientes comandos eliminan una impresora por la
fuerza:
lpshut lpadmin -xdestino find /usr/spool/lp -name destino rm -rf {} \; lpsched lpstat -t
Se eliminan por la fuerza los archivos de configuración de la impresora destino. Si se
trata de una clase, se estará eliminando toda la clase! El comando final, lpstat -t,
muestra el estado completo, para verificar que se han eliminado todas las referencias a
la impresora destino. Obviamente, esta receta será utilizada sólo cuando los
procedimientos normales hayan fallado.
Agregar una impresora (BSD).
Resumimos los pasos para agregar una impresora en forma manual. En muchas distribuciones
existen utilitarios para realizar esta tarea.
Impresora local. o crear la entrada en /etc/printcap; o crear el directorio de spool; fijar dueño, grupo permisos; o probar la impresora: arrancar la cola (lpc start), enviar un archivo corto (lpr),
mostrar la cola de impresión (lpq). Impresora remota.

o crear la entrada en /etc/printcap para impresora remota (rm, rp); o crear directorio de spool; fijar dueño, grupo, permisos; o habilitar en /etc/hosts.lpd del servidor la nueva máquina cliente.
Impresora de red. o fijar número IP de la impresora, según se indique en el manual de la
impresora. o verificar conectividad: la impresora debe responder a ping. o instalar la impresora en un servidor de impresión, como impresora remota. o crear el archivo falso, ajustar su dueño, grupo y permisos.
LPRng.
Basado en BSD, es un nuevo servidor de impresión, incorpora también lo mejor de System V.
Todos los comandos BSD están disponibles, pero sustituídos por los de LPRng, más potentes y
confiables. Los más importantes comandos System V están implementados como enlaces a sus
versiones BSD; LPRng examina como fueron invocados, y se comportan según lo esperado.
LPRng prescinde de la necesidad de correr procesos como root e implementa muchas
precauciones de seguridad. Tiene buenas rutinas de diagnóstico, produce mensajes útiles y
claros en caso de error. Implementa redirección dinámica de colas de impresión, soporta
varias impresoras en una misma cola, balancea la carga entre varias impresoras y otras
maravillas, muchas de ellas inspiradas en System V.
En ambientes chicos de pocos usuarios y pocas impresoras puede no jusficarse el
esfuerzo de configuración, pero puede aún valer la pena colocar LPRng en el servidor:
resuelve muchos de los problemas tradicionales en los sistemas de impresión UNIX.
Las impresoras PostScript.
Algunos detalles relativos a las impresoras PostScript:
Las impresoras PostScript contiene una CPU. La velocidad de impresión depende no sólo de la parte mecánica sino de la CPU, que puede no estar usando al máximo la capacidad mecánica de impresión al procesar imágenes complicadas.
Conectar las impresoras PostScript a interfaces bidireccionales, para permitir al software controlador de la impresora informar errores.
Los intérpretes PostScript requieren mucha memoria, que puede agotarse al imprimir archivos PostScript complejos.
Las impresoras PostScript tienen tipos de letra nativos; otros pueden ser cargados en memoria. Si el trabajo a imprimir contiene un tipo de letra no disponible en la impresora ni en la memoria, el trabajo se imprimirá en Courier (generalmente).
Una intefaz serial puede no ser eficiente para una impresora color o para imprimir bitmaps.
Si un trabajo PostScript no imprime, usar una aplicación tal como GhostView para visualizarlo en pantalla, como forma de asegurar la integridad del archivo.
Algunas aplicaciones generan ocasionalmente comandos PostScript inválidos; los mensajes de error pueden ser diferentes ante un mismo tipo de error según el intérprete PostScript.
Sugerencias.

Usar contabilidad de impresión, aunque no se cobre por el uso. No penaliza mucho el sistema, permite conocer la carga sobre la impresora, el origen de los trabajos, quiénes la usan. Todo esto ayuda cuando es preciso decidir tipo, características y ubicación de una nueva impresora.
No usar páginas de encabezado (banner) si no es imprescindible. Proveer facilidades para la reutlización del papel, o su reciclado. Proveer a los usuarios visualizadores en pantalla para disminuir las impresiones
"borrador". Un buen uso de la contabilidad es detectar trabajos impresos repetidamente.
No gastar en impresoras "caras": la tecnología de impresión es madura; considerar calidad de impresión realmente requerida, producción (páginas promedio por minuto), costo de insumos, fortaleza mecánica. Una impresora de 10 páginas por minuto es suficiente para al menos 5 escritores a tiempo completo.
Mantener en stock cartuchos de tinta o toner; los cartuchos siempre se terminan cuando uno está imprimiendo :-). Una sacudida amable puede redistribuir el toner de un cartucho de impresora láser "gastado" y obtener unas 100 páginas más.
Asegurar la impresora de red: al ser accesibles vía telnet para cambiar su configuración, las impresoras de red proveen control por contraseña; fijarla.
Espacio en disco
El espacio en disco
Aspectos políticos
Monitoreo del espacio en disco
Compresión de datos
"Skulker scripts"
Cuotas de disco
Funcionamiento de las cuotas
Habilitación de cuotas
Fijar cuotas sobre un sistema de archivos
edquota
quota, repquota
Cuotas en NFS
Ejercicios e Investigación
Bibliografía y referencias.
El espacio en disco.

El abaratamiento de los discos ha reducido considerablemente la incidencia del espacio
ocupado por los usuarios. No obstante, los discos requieren administración: hay que
instalarlos, darles formato, montarlos en otras máquinas, respaldarlos, monitorarlos. Aunque
el espacio en disco sea suficiente, es preciso insistir ante los usuarios para hacer un uso
racional del recurso.
Aspectos políticos.
Existe una natural, y en parte justificada, tendencia a "conservarlo todo" en materia de
archivos: es trabajoso seleccionar qué se debe guardar, todo puede servir algún día. En una
máquina personal, el usuario simplemente borra cuando se quedó sin espacio. En una red,
siempre se espera que sea otro quien lo haga. Las recomendaciones generales dan poco
resultado. Para un efectivo control del espacio en disco, es preciso determinar quienes son los
usuarios más consumidores y hacerles saber a ellos mismos que son fuente de problemas. Un
script automático puede recorrer los directorios personales, calcular el espacio consumido y
publicar los "top 10", los 10 usuarios con más espacio en disco ocupado. Enviar un correo
automático a los ofensores da resultado la primera vez, luego la novedad decae y los mensajes
son borrados sin leer. La publicación ante toda la comunidad de usuarios del espacio insumido
por los mayores consumidores tiene un efecto mucho mayor. Si esta "presión social" no da
resultado, es preciso enviar un cortés mensaje personal al usuario; esto tiene mucho mayor
efecto que un correo automático. Proveer un medio de almacenamiento fuera de línea (cinta,
zip drives, grabadoras de CD), fácilmente disponible, con instrucciones claras, es una buena
ayuda para usuarios y administradores.
Monitoreo del espacio en disco.
El comando quot informa sobre el espacio en disco consumido por los usuarios en cada
sistema de archivos:
quot -f /dev/hda2
da una lista de la cantidad de bloques y archivos a nombre de cada usuario. Este comando no
tiene nada que ver con el sistema de cuotas, analizado más adelante. No está disponible en
todas las versiones de UNIX.
El comando du da un resumen del uso de disco en una rama de directorios.
du -s /export/home/*
da el total para cada rama de subdirectorio bajo /export/home; esto no es efectivo para ver el
consumo total de cada usuario si los usuarios tienen archivos en otras partes del sistema.
El comando df da un resumen del uso del espacio a nivel de todo el sistema:
df

muestra el espacio utilizado en cada sistema de archivos, incluso a veces en los que están
montados vía NFS. Si se indica uno en particular, da el espacio utilizado en ese sistema de
archivos:
df /dev/hda2
Estos comandos informan el espacio en "bloques"; los bloques tienen diferente tamaño
según las versiones de UNIX, generalmente 512 b o 1 KB (1024 B); suele haber
opciones para controlar la salida.
Compresión de datos.
Los sistemas UNIX suelen proveer al menos un conjunto de herramientas de compresión de
archivos. El conjunto comprende, mínimamente: un programa para comprimir, un programa
para descomprimir y un programa para visualizar comprimidos (u opciones de un mismo
programa).
compress: tradicional en Uniz, compresión menor que gzip, algo más rápido. Usa
codificacion Lempel-Ziv adaptativa. Comandos: compress, uncompress, zcat.
gzip: la mejor compresión, más lento, alguna incompatibilidad entre versiones distintas
de gzip. Esencial para descomprimir paquetes bajados por Internet. Algoritmo de
compresión Lempel-Ziv (LZ77). Comandos: gzip, gunzip, zcat.
zip: versión Unix del conocizo PKZIP de MS-DOS y Windows; análogo a la acción
combinada de los comandos tar y gzip. PKZIP (MS-DOS) y zip (Unix) crean archivos
compatibles en tanto las versiones en uno y otro sistema operativo se correspondan.
Comandos: zip, unzip.
bzip2: comprime archivos con el algoritmo de compresión por reordenamiento de
bloques de Burrows-Wheeler y codificación Huffman. Obtiene generalmente mejor
compresión que los programas basados en algoritmos LZ77/LZ78. Comandos: bzip2,
bunzip2, bzcat, bzip2recover.
Puede esperarse una reducción de un 50% a un 75% en archivos de texto o binarios; los
archivos encriptados no comprimen, o aún se agrandan: sus datos son aleatorios, de
distribución uniforme; los programas de compresión no encuentran brechas para actuar.
Lo mismo pasa al intentar comprimir archivos ya comprimidos.
"Skulker scripts".
Este nombre se aplica a los scripts que recorren el sistema buscando archivos innecesarios
para borrar: temporales viejos, archivos "core", archivos "dead_letter", respaldos de edición,
etc. Los nombres de los archivos a borrar dependerán de cada sistema; deben ser publicados,

para hacer saber a los usuarios que no deben emplear estos nombres, ni sorprenderse cuando
sus archivos desaparezcan. Los scripts "skulker" suelen correrse semanalmente, por root, vía
cron.
Cuotas de disco.
Ante una falta de espacio en disco, la primera pregunta que cabe hacerse hoy día es si no será
necesario agregar discos. Si esto no es posible, mientras se logre mantener bajo control el
espacio en disco usando la persuasión y la presión social de de los pares, no se hallará método
mejor. Muchos administradores consideran obsoleto el control de espacio en disco por cuotas,
sobre todo por la baja de costo de los discos y la frecuencia de uso de discos locales en las
estaciones de trabajo de los usuarios. En las unidades compartidas, cuando la comunidad de
usuarios es propensa a consumos desmedidos o incontrolables, puede ser necesario
implementar cuotas de uso de disco para forzar a los usuarios a mantenerse dentro de límites
prefijados de uso.
El sistema de cuotas permite limitar tanto el número de inodos como la cantidad de
bloques que un usuario puede ocupar. La cantidad de inodos está directamente
relacionada con la cantidad de archivos; la cantidad de bloques, con el espacio ocupado.
Cada uno de estos límites tiene dos valores: un valor soft y un valor hard. Superar el
valor soft origina una advertencia; el valor hard impide ocupar más disco. Un lapso
prolongado (más de 3 días, por ejemplo), superando el valor soft, lo impone
rígidamente, tal como el hard, hasta que el usuario borra, momento en que se reinicia el
conteo de tiempo. Muchas versiones implementan cuotas también sobre grupos,
permitiendo controlar el espacio que insume un proyecto o equipo de trabajo.
Un beneficio colateral de las cuotas es que impiden a los programas descontrolados
llenar el disco: se trancan en cuanto se supera la cuota correspondiente al usuario
invocante.
Los inconvenientes esenciales de las cuotas son el mantenimiento administrativo y la
carga que imponen sobre el sistema: un sistema de archivos puede perder hasta un 30 %
de rendimiento al estar procesando cuotas. Como las cuotas se imponen por sistema de
archivo, es preciso tener una adecuada división en sistemas de archivo diferentes, para
no poner cuotas sobre aquellos donde los usuarios no tienen derechos, evitando así
detrimentar su rendimiento.
Las cuotas se asignan por sistema de archivos, y dentro de un mismo sistema de
archivos, por usuario: un usuario habilitado a grabar en dos sistemas de archivo
diferentes obliga a fijar su cuota en ambos. Si no se fija cuota para un usuario, se
entiende que no tiene límite. Lo mismo vale para cuotas de grupo.
Funcionamiento de las cuotas.
La información de cuotas para un sistema de archivos se encuentra en el archivo quotas del
directorio raíz del sistema de archivos. Si se soportan cuotas para usuarios y grupos, los
archivos suelen ser dos: quota.user y quota.group. El kernel actualiza el archivo quotas toda
vez que una operación altera la cantidad de bloques ocupados por un usuario. Los comandos
usuales para el manejo de cuotas son los siguientes:

edquota: permite editar los archivos quota.* para fijar las cuotas.
quota, repquota: muestran información de cuotas y espacio insumido para usuarios y
grupos.
quotacheck: recorre todo el sistema de archivos bloque a bloque calculando el espacio
utilizado; luego actualiza el archivo quotas. Suele corrérselo en el arranque del sistema
con la opción -a para que verifique todos los sistemas de archivo montados que tengan
activado el sistema de cuotas. Con -v muestra una lista de usuarios y sus consumos. La
opción -p examina los sistemas de archivos en paralelo, a la manera de fsck.
Habilitación de cuotas.
Para habilitar el sistema de cuotas, esta opción debe estar compilada en el kernel. En muchas
versiones ésto ya viene hecho; de no ser así, habrá que habilitar la opción y recompilar el
kernel o activar el módulo cargable. Además de ésto, es preciso habilitar explícitamente el
sistema de cuotas al arrancar el sistema y después de montados los sistemas de archivos; esto
se hará desde un script rc o desde inittab, según la versión de UNIX. Una secuencia típica de
comandos de arranque puede ser:
/sbin/mount -a
echo -n 'verificando cuotas...'
/sbin/quotacheck -avug
echo ' hecho.'
/sbin/quotaon -avug
donde las opciones significan: a recorrer todos los sistemas de archivos registrados en
/etc/fstab, v mensajes verbosos, u habilitar cuotas para usuarios, g habilitar cuotas para
grupos. La habilitación de cuotas debe hacerse siempre después que los sistemas de archivos
han sido montados; de otro modo, no funcionará.
Fijar cuotas sobre un sistema de archivos.
Requiere crear y configurar el o los archivos de cuotas, y declarar el uso de cuotas en el
sistema de archivos en la tabla de sistemas de archivos.
cd /usuarios # directorio raíz de la partición
touch quota.user
touch quota.group
chmod 600 quota.user quota.group
Operando como root, estos comandos crean un archivos de cuotas vacíos para usuarios y
grupos en el sistema de archivos montado sobre /usuarios.

Para activar las cuotas, en el archivo /etc/fstab (BSD), se agrega a la línea de montaje
del sistema de archivos las opciones userquota y groupquota; otros sistemas sustituyen
la opción rw en este archivo por rq, lectura-escritura con cuotas.
# /etc/fstab con cuotas
/dev/hda1 / ext2 defaults 1 1
/dev/hda2 /usuarios ext2 defaults,usrquota,grpquota 1 2
Este ejemplo habilita cuotas para grupos y usuarios sobre la partición montada sobre el
directorio /usuarios.
Luego de fijar las cuotas para cada usuario, con el comando edquota, estos archivos se
poblarán corriendo el comando quotacheck sobre la partición en cuestión.
edquota.
El comando
edquota -u nombre_usuario
permite editar el valor de cuota para el usuario indicado. El comando edquota suele correr
una versión de vi (o el editor especificado en la variable EDITOR) mostrando un formato
base para la edición, referenciando todos los sistemas de archivos en el cual el usuario tenga
cuota habilitada:
Quotas for user jperez
/dev/hda2: blocks in use: 2594, limits (soft = 5000, hard = 6500)
inodes in use: 356, limits (soft = 1000, hard = 1500)
Para grupos es análogo, usando el comando
edquota -g nombre_grupo
La forma de trabajo usual el definir algunos "usuarios prototipo", fijarles cuota
individualmente con el comando edquota, y luego asignar cuotas a los restantes usuarios
conforme alguno de los usuarios prototipo. El comando
edquota -p nombre_usuario_prototipo nombre_usuario
permite fijar la cuota de usuario al valor de cuota de un usuario prototipo.

Un esquema práctico es disponer de 3 usuarios prototipo: chico, medio y grande, para
así fijar fácilmente los valores de cuota de los usuarios reales según los de estos
usuarios prototipo.
Para fijar cuotas a los grupos puede seguirse un esquema análogo, con el comando:
edquota -p nombre_grupo_prototipo nombre_grupo
Puede fijarse un tiempo de gracia durante el cual se permite al usuario mantener un consumo
por encima del límite soft antes de forzar su cumplimiento, mediante el comando
edquota -t usuario
que abre el editor con algo similar a ésto:
Time units may be: days, hours, minutes or seconds
Grace period before enforcing soft limits for users:
/dev/hda2: block grace period: 0 days, file grace period: 0 days
donde es habitual cambiar el 0 por 7 para dar una semana de gracia a los usuarios.
quota, repquota. quota nombre_usuario
informa al usuario sobre cuota en el sistema de archivos en que se encuentra; con -v informa
en todos los sistemas de archivos. Sólo el superusuario puede ver cuotas ajenas. login corre
quota cada vez que el usuario ingresa; esto puede producir retardos, sobre todo para
sistemas de archivos remotos.
repquota produce un informe similar al de quot o quotacheck -v; también informa
de cuotas para usuarios individuales.
Cuotas sobre NFS.
La implementación de cuotas es local al sistema de archivos; los sistemas cliente no hacen
verificación de cuota, pero los límites son verificados en el servidor en todas las operaciones
que afectan el consumo de disco, por lo que la limitación es efectiva. Muchos sistemas
proveen rquotad para responder información de cuota a través de la red mediante el
comando quota, advertiendo a los usuarios sobre uso de espacio en sistemas de archivos
montados vía NFS.
Ejercicios e Investigación.

1. Determine si su sistema dispone del comando quot, quota o alguna forma de determinar el
espacio en disco ocupado por cada usuario. Verifique su funcionamiento con y sin el sistema
de cuotas activado.
2. Investigue la asignación de derechos de sus usuarios en su sistema: si pueden escribir
en otros directorios además del propio, o en más de un sistema de archivos. No olvide
los archivos públicos, como suele ser /tmp, donde puede escribir todo el mundo. Evalúe,
según los resultados, la dificultad para determinar el espacio en disco ocupado por los
usuarios, sobre todo si no dispone de un comando similar a quot.
3. Investigue si su sistema provee algún tipo de "skulker script". Si es así, examine la
documentación o el código para determinar exactamente qué hace. ¿Qué información
debería publicar ante los usuarios antes de utilizar este script?
4. Si su sistema no dispone de "skulker script", ¿cuáles serían los lineamientos para
escribir uno? ¿Con qué privilegios y de qué forma debería correr? ¿Cuáles son sus
riesgos potenciales, ya sea por omisión (no borrar lo que se debiera) o por exceso
(borrar lo que no se debe)?
5. Investigue la disponibilidad de cuotas en su sistema. Estudie sus comandos y realice
una prueba, limitando el uso de disco de un usuario irreal. Verifique el funcionamiento,
si existen los límites soft y hard, el tiempo de permanencia por encima del límite soft.
6. Intente efectuar medidas de la influencia del sistema de cuotas sobre el rendimiento
en el servicio de archivos. A modo de sugerencia, puede escribirse un script que realice
una serie de operaciones de copia imprimiendo la hora al principio y al final, y luego
correrlo con y sin cuotas habilitadas. ¿Se obtiene algún resultado significativo? ¿Cómo
puede mejorarse la medida? ¿Qué factores pueden estar falseando los resultados?
7. ¿Dispone sus sistema de alguna facilidad para el almacenamiento de datos fuera de
línea? ¿Es accesible a todos los usuarios? ¿Es difícil de manejar? ¿Es complicado
recuperar datos? ¿Existe algún instructivo? ¿Los usuarios saben que existe? ¿Lo
utilizan? Determine si es posible mejorar las respuestas a estas preguntas.
Bibliografía y Referencias.
Páginas man: quot, df, du; gzip, compress, zip, bzip2; quota, edquota, repquota, quotacheck,
quotaon, quotaoff, rquotad.
Archivos: quota, quota.user, quota.group, /etc/fstab (BSD), etc/vfstab (system V).

Nociones de Seguridad
Introducción
Daremos una muy breve introducción a algunos de los temas que deben ser tomados en
cuenta para planificar la seguridad de nuestros sistemas. Debe quedar claro que, como
introducción que es, solo pretende motivar al lector sobre la necesidad de estudiar la
seguridad de nuestros sistemas.
El primer hecho a tener en cuenta es que el sistema operativo UNIX no fue diseñado pensando
en la seguridad, sino en la conveniencia y la facilidad de uso en un ambiente de confianza
relativa, y por ello es imposible hacerlo 100% seguro. Sin embargo, muchas cosas pueden
hacerse para hacer que nuestros sistemas sean más resistentes a los ataques.
Siempre existe un compromiso entre la seguridad que ofrece un sistema y la facilidad y
conveniencia de su uso.
En cada caso, es necesario evaluar cuál es el nivel de seguridad requerido y actuar en
consecuencia. No son iguales los requerimientos de seguridad de un sistema personal ubicado
en nuestro hogar, a los de un sistema militar, o a los de un equipo controlando procesos
industriales. En cada caso, es necesario plantear políticas de seguridad adecuadas tanto para
los administradores como para los usuarios del sistema.
Enfoque del problema
Lo primero que debe tener claro un administrador es qué es lo que debe ser protegido, y qué
se puede perder. Las pérdidas pueden ser tanto pérdidas monetarias (directas, como pérdida
del equipo, si este es robado o inutilizado completamente, o indirectas, por pérdida de
confiabilidad de la empresa, pérdida de negocios, etc.), pérdida de información (secretos de
empresa, información personal, etc.), o pérdida de "uso" (el costo de no poder brindar el
servicio). En cada caso las soluciones serán distintas.
También debemos pensar de quién lo debemos proteger, y las rutas de acceso existentes.
Podemos tener tanto amenazas externas (directas o a través de redes) como internas a
nuestra organización (tanto usuarios maliciosos, como usuarios inexpertos o herramientas con
bugs que causan daño inintencionalmente, como programas trojanos que dicen realizar una
tarea y en realidad realizan otras).
Una buena estrategia de seguridad es un conjunto de políticas que prevengan todas las
amenazas relevantes, en la medida que puedan ser prevenidas, y en la medida en que nuestra
organización y nuestros usuarios estén dispuestos a aceptar los inconvenientes que presenten
dichas medidas de seguridad; y que nos permita recuperarnos en el caso en que lo peor
suceda.
La seguridad debe verse como un proceso y no como algo que se puede instalar y olvidar.
Reglas de sentido común
No poner en nuestro sistema archivos que sean interesantes para hackers o usuarios entrometidos. En caso que sea necesario tenerlos disponibles, redoblar los esfuerzos de seguridad, de ser posible encriptando los datos o haciendolos inaccesibles o inutilizables externamente.

Eliminar los agujeros de seguridad que puedan ser utilizados para ganar acceso a nuestro sistema. Para ello, debemos estar al tanto de los boletines de seguridad correspondientes a nuestro sistema y otras fuentes de información.
No permitir sitios donde los hackers tengan acceso. Eso incluye cuentas públicas, directorios de ftp público con permiso de escritura, cuentas grupales, etc.
Poner "trampas" básicas en sitios accesibles (especialmente desde internet). Utilizar herramientas como tripwire, COPS, etc para ser capaces de detectar intrusiones en sus primeras fases.
Monitorear los reportes de estas herramientas. No confiar en "recetas mágicas". Aprender acerca de la seguridad en UNIX y no dejarse
atrapar por recetas mágicas de "consultores en seguridad" que muchas veces lo único que nos dejan es un falso sentimiento de seguridad. No es que todos los consultores nos vayan a engañar, pero debemos desconfiar si nos prometen que una única acción nos dejará protegidos "para siempre".
Minimizar los servicios que brinda nuestra máquina, no habilitando servicios innecesariamente, especialmente en los equipos expuestos a un ambiente hostil.
Ser "curioso", investigar toda actividad fuera de lo común en nuestro sistema, mensajes extraños en los logs, actividad de usuarios que se encuentran de vacaciones, etc.
Planear de antemano qué hacer en caso de un compromiso a la seguridad, y disponer de respaldos confiables del sistema en un estado conocido.
Líneas de defensa
Acceso físico a la computadora.
La primer línea de defensa es el acceso físico a la propia máquina. Esto puede variar desde
mínimas prevenciones para que no nos roben la máquina o la rompan, pasando por evitar el
acceso de personal no autorizado a la consola y la CPU (por ejemplo para evitar que se pueda
apagar y prender la máquina para reiniciarla en modo "single-user"), hasta aquellas
instalaciones en que el acceso a las computadoras está limitado por varios sistemas de
seguridad y guardias armados, como puede suceder en algunas instalaciones militares.
Aunque en la mayoría de las instalaciones no es necesaria tanta "paranoia", al menos es
necesario evitar que nos apaguen la máquina, y es conveniente que las consolas y terminales
esten "a la vista", para que los posibles "hackers" vean su accionar mas controlado.
Validación de usuarios y passwords.
La siguiente línea de defensa, una vez que se obtuvo acceso a la máquina (permitido o no) es la
validación de acceso a los usuarios. Esta validación tiene como objeto verificar que quien
pretende dar comandos a la máquina es un usuario autorizado para hacerlo.
Normalmente, esta validación se realiza solicitando al usuario un nombre de cuenta y una
contraseña, que son chequeadas contra las que el sistema tiene guardadas. Tradicionalmente
los datos del usuario (su cuenta y su contraseña encriptada) se guardaban en el archivo
/etc/passwd, donde son legibles por todos los usuarios (esto es necesario para el
funcionamiento de varias utilidades del sistema). El método de encriptación es "en un solo
sentido", es decir que no existe un algoritmo conocido que permita obtener la contraseña
original a partir de la encriptada (otro que probar hasta que se encuentre la correcta). Sin
embargo, hoy en día en que con computadoras de muy bajo costo se pueden probar varios
miles de encriptaciones por segundo, el hecho de que la password encriptada esté disponible

para cualquiera se presta a ataques mediante "metodos de fuerza bruta", encriptando
palabras de un diccionario y comparándolas con la password encriptada.
Para que estos ataques no sean exitosos, es necesario que las passwords de los usuarios sean
bien elegidas. Son malas elecciones las passwords muy cortas, aquellas que contienen palabras
que se encuentran en un diccionario, modificaciones triviales de estas, palabras que se
encuentran en los datos del usuario en el sistema, datos personales del usuario, y cualquier
otra información fácilmente relacionable con el usuario.
Para mitigar este problema, la mayoría de los sistemas modernos proveen el mecanismo de
"shadow passwords", en donde el archivo /etc/passwd contiene los datos del usuario EXCEPTO
la contraseña, y existe otro archivo, con permisos mucho mas restrictivos, donde se encuentra
la contraseña e información adicional del usuario. El único acceso a estas contraseñas es para
verificar la validez de una contraseña dada a través de funciones del sistema, las cuales son
artificialmente lentas para minimizar el riezgo de un ataque por la fuerza bruta.
Otro problema que puede presentarse es el de la existencia de cuentas colectivas (es decir
cuentas utilizadas por varias personas) y cuentas "públicas" (cuentas de usuario sin password
que supuestamente pueden realizar muy pocas cosas). Estas se deben evitar en la medida de
lo posible.
Otro tema importante a tener en cuenta es cómo se eligen las contraseñas, especialmente la
de root, y cada cuanto estas son cambiadas. Muchos sistemas proveen opciones para forzar a
los usuarios a no utilizar contraseñas triviales, a cambiarlas a intervalos de tiempo regulares
(password aging), y a no reutilizar contraseñas anteriores.
El sistema de validación debe ser monitoreado regularmente para verificar que no ha sido
modificado ilegalmente. Especialmente deben buscarse usuarios con UID 0 (superusuario,
independientemente de como se llame), usuarios sin contraseñas, etc.
Existen sistemas de validación avanzados para necesidades específicas, que se pueden agregar
a varios sistemas. Estos varían desde sistemas con multiples niveles de passwords, a sistemas
con acceso mediante tarjetas o reconocimiento biométrico. Muchos de estos sistemas,
extremadamente caros hace unos años, son cada día más accesibles económicamente.
Protegiendo archivos y el filesystem.
Una vez que se tiene acceso al sistema, la siguiente línea de defensa es la protección brindada
por los permisos en los archivos y filesystems. Esto es válido tanto para minimizar el daño que
pueda ocasionar alguien que logró acceder ilegalmente a nuestro sistema, como para
protegernos de nuestros propios usuarios.
En general, el objetivo de toda medida de seguridad en un sistema es evitar que la gente haga
cosas que no debería. Esto principalmente significa evitar acceso a la cuenta de root (directa o
indirectamente) y a los archivos del sistema.
En UNIX clásico, la seguridad es "ON/OFF". Existe un único usuario con permisos globales para
realizar cualquier tarea sobre el sistema (el usuario con UID 0, usualmente llamado root), y los
demás usuarios tienen solamente permisos correspondientes a las tareas específicas que
pueden realizar, otorgados mediante permisos en los archivos del filesystem. No es posible
fácilmente delegar tareas de administración puntuales (aunque existen utilidades como "sudo"
que nos permiten delegar ciertas tareas). Eso hace que el acceso a la cuenta de root deba ser
extremadamente controlado.

En algunas variedades de UNIX existen agregados que permiten dividir la responsabilidad con
una mejor granularidad, usualmente mediante permisos más granulares en el filesystem (Listas
de control de acceso, ACL's), y mediante la separación de los poderes "omnipotentes" de root
en un conjunto de "capabilities" que se pueden asignar independientemente.
Problemas con el path
Una forma de subvertir la seguridad del sistema es hacer que root u otros usuarios ejecuten
comandos inadvertidamente. Una forma de lograr esto es colocar programas con el mismo
nombre que algún comando del sistema en un directorio que se encuentre antes en el path
que el directorio del programa original (y que pueda ser escrito).
Por ello, es importante que en el path el directorio actual (".") y los directorios relativos no se
encuentren en el path, o que se encuentren al final del path.
Además, es importante que ninguno de los directorios en el path de root se pueda escribir por
alguien que no sea root, nuevamente para evitar que se pueda sustituir un comando estandard
por otro programa.
Permisos en los archivos del sistema
Los sistemas UNIX dependen de una cantidad de archivos para su correcto funcionamiento, y
los permisos en dichos archivos deben ser adecuados. Algunas áreas a ser tomadas en
consideración son:
Los archivos de arranque del sistema. En ellos se ejecutan todos los comandos necesarios para el funcionamiento normal multiusuario del sistema, y normalmente se arrancan los servicios que el equipo brinda. Estos archivos se ejecutan con permisos de root cada vez que se inicia el sistema, y por lo tanto deben ser de escritura solo para root (así como el directorio donde están contenidos) (en algunos sistemas el grupo system o similar puede tener permiso de escritura).
Los archivos de configuración de los distintos servicios que brinda el sistema. Cambiando la configuración de los programas que brindan determinados servicios (muchas veces corriendo como root) se los puede obligar a cambiar su comportamiento en forma no esperada, dar servicio a usuarios o máquinas en los que normalmente no se confía, o hacer que no funcionen.
Los archivos relativos a la validación de usuarios. Tanto el archivo de passwords (que debe ser solo de escritura para root) como los archivos adicionales de otros sistemas (como las "shadow passwords" que para cumplir su cometido no deben tener permisos de lectura para ningún usuario excepto root) deben tener los permisos adecuados. Recordemos que en casi todos los sistemas de validación alcanza con que un usuario tenga uid=0 para que tenga los mismos derechos de acceso total sobre el sistema que root.
Los archivos del directorio /dev. En el directorio /dev están representados todos los dispositivos del sistema, y el acceso a varios de ellos permite el acceso "directo" al hardware de la máquina. Por ejemplo, en muchos sistemas el archivo /dev/kmem o /dev/mem representa la memoria del sistema, es decir que el poder leer dicho dispositivo nos permite ver toda la información que el sistema tenga en la memoria (como por ejemplo la password que acabamos de teclear). Otros dispositivos que pueden darnos acceso a datos "sensitivos" son los correspondientes a los discos y particiones. Con el suficiente conocimiento teniendo acceso a dichos dispositivos se puede leer cualquier archivo del filesystem.

Otro grupo de archivos a ser tomado en especial consideración es el de los archivos setuid y
setgid, especialmente los programas setuid cuyo dueño sea root. El sistema setuid y setgid
permite, bien administrado, dar acceso limitado al sistema en forma temporal, comando por
comando (por ejemplo, el comando passwd, setuid a root, permite que el usuario modifique el
archivo de passwords, pero solo para cambiar su contraseña). Sin embargo, también pueden
representar un serio compromiso a la seguridad, tanto por problemas de diseño como por
problemas de programación. Los comandos suid no deben permitir realizar ninguna otra
operación además de la que fueron diseñados para realizar.
Esta lista no es en absoluto exhaustiva, se debe investigar cuales son los archivos
"importantes" en nuestro sistema.
Uno de los puntos importantes, en un sistema que deba ser seguro, es minimizar los
servicios y programas instalados, para disminuir la probabilidad de que se encuentre una
vulnerabilidad en un servicio que tengamos instalado.
Permisos en otros archivos
Muchos otros archivos deben tener permisos adecuados. En particular los archivos de
inicialización (.login y .cshrc o .profile) del shell que el usuario ejecute normalmente no debe
poderse escribir por otros usuarios (para evitar que se puedan agregar ahi comandos por parte
de otros usuarios).
Por supuesto, debe también ponerse cuidado en los permisos de los archivos sensibles que
podamos tener en nuestro sistema, y proteger la privacidad de nuestros usuarios. Por ejemplo,
los permisos en los mailboxes de los usuarios no deben poder ser leídos por ningún usuario
que no sea el dueño
Otras medidas
Existen algunas medidas para minimizar los daños en caso que la seguridad del sistema sea
violada.
Una forma de evitar que los datos que alguien nos pueda "robar" puedan ser utilizados
es mediante encriptación. Si se elige un algoritmo adecuado (y no se guardan las claves
en el sistema), se puede tener una razonable certeza que los datos robados no podrán ser
utilizados por otros. La mayoría de los sistemas proveen programas de encriptación
básicos, y existen múltiples programas de dominio público para implementar los
algoritmos mas conocidos de encriptación.
La otra medida importante en muchos casos para minimizar los daños es tener una
buena política de backup, que nos permita recuperar rápidamente los servicios perdidos
(y restaurar nuestro sistema a un estado conocido).
La Seguridad y las Redes
Cuando una máquina está conectada a una red, se agregan un conjunto de posibles problemas
a la seguridad, especialmente si no tenemos control sobre todas las partes de dicha red (como
es el caso en una red pública como puede ser Internet).

Hay diversas clases de ataques que pueden provenir de una red. Principalmente los podemos
dividir en aquellos en que se compromete la seguridad de los datos contenidos en el sistema o
el sistema en sí, y aquellos en lo que se compromete es el servicio que el equipo brinda (denial
of service attacks). Estos últimos se basan ya sea en explotar errores en los programas que
atienden dichos servicios, errores en el sistema en sí, o deficiencias en los protocolos que se
utilizan en la red, y no los trataremos aquí.
Relaciones de confianza y las utilidades r*
Todas las utilidades r* (rlogin, rexec, rsh, rcp) hoy en día se consideran inseguras, solamente
aptas para su utilización en redes locales no expuestas a amenazas de seguridad.
Por defecto, cuando un usuario desea acceder otros hosts en la red, se le solicita una
password. Esto es así tanto si se desea loguearse de forma remota (mediante rlogin)
como si se desea ejecutar comandos remotos mediante rsh. Además, no se puede utilizar
rcp, ya que este no sabe como pedir passwords.
Para permitir el acceso remoto sin passwords, existe un sistema de "equivalencia de
hosts" conectados mediante TCP/IP. El sistema determina el permiso para que un
usuario remoto se conecte mirando en dos archivos, /etc/hosts.equiv y el archivo .rhosts
en el directorio home del usuario. Dichos archivos deberán ser construidos de acuerdo a
la seguridad requerida del sistema.
Equivalencia entre máquinas: /etc/hosts.equiv
El primer nivel de equivalencia es a nivel de máquinas. Cada máquina tiene un archivo
/etc/hosts.equiv, el cual es simplemente una lista de máquinas, uno por línea, que
consideramos equivalentes a la nuestra en cuanto a los usuarios y su seguridad.
En este archivo se pueden poner todas las máquinas de nuestra red, ninguna, o aquellas que
nosotros queramos. Cuando un usuario de un equipo remoto intenta un acceso mediante
rlogin, rsh o rcp, el sistema verifica si la máquina pidiendo acceso se encuentra en el archivo
/etc/hosts.equiv. Si así es, y hay una cuenta de usuario en el sistema con el mismo nombre que
el usuario remoto, se permite el acceso sin solicitar contraseña. Esto funciona para todas las
cuentas EXCEPTO la de root.
Esta equivalencia efectivamente significa que las cuentas con el mismo nombre en el sistema
remoto que en el local son equivalentes. Por ello, solo se debe utilizar este sistema si los
usuarios son los mismos en ambos sistemas, y si podemos confiar plenamente en la seguridad
del sistema remoto.
Los sistemas de equivalencia entre máquinas, y en especial los servicios de rlogin, rsh y rcp,
están siendo paulatinamente sustituidos con servicios con mejores prestaciones de seguridad
(mayormente SSH), y solo se deben utilizar en redes locales en las que no tengamos equipos
potencialmente maliciosos (es decir, un ambiente de alta confianza).
Equivalencia entre cuentas: el archivo .rhosts
La equivalencia a nivel de cuentas se obtiene utilizando el archivo .rhosts en el directorio home
del usuario en el equipo destino. Cada línea de este archivo consiste de un nombre de host y,
opcionalmente, una lista de nombres de usuario.
maquina [usuario. . .]
Cada línea significa que usuario tiene permitido conectarse a esta cuenta desde máquina.
Si usuario no esta presente, solo el mismo nombre de usuario puede conectarse desde
máquina.
Si se intenta un acceso remoto, primeramente se verifica la equivalencia a nivel de
máquina, y de no pasar este acceso se intenta con el archivo .rhosts del directorio home
del usuario hacia el cual se está intentando el acceso.
Se recomienda NUNCA utilizar la equivalencia de cuentas para el superusuario.
Vale el mismo comentario anterior, sobre la paulatina desaparición de los comandos r*
Implicaciones de la confianza
Una relación de confianza entre máquinas siempre implica un riezgo. Sin embargo, en este
caso ese riezgo va más allá del equipo en el cual explícitamente estamos confiando. La
confianza actua en forma transitiva, ya que si máquina1 confía en máquina2, y esta a su vez
confia en máquina3, implícitamente máquina1 está confiando en máquina3, y transitivamente
en todos los hosts en que máquina3 confíe.
Esta es una razon por la cual las relaciones de confianza deben ser establecidas con mucho
cuidado.
Sustitución de los comandos r*
Hoy en día, la utilización de los comandos r* (rcp, rsh, rcp, etc.) se desaconseja en cualquier
servicio que se encuentre accesible desde una red no confiable.
Usualmente, se utilizan protocolos más seguros, como los utilizados por ssh, para mejorar la
seguridad de los sistemas. Los protocolos ssh (hoy en día, versión 2), proveen:
- Encriptación de los datos que circulan en la red. En ningún momento pasan en claro
por la red ni datos ni contraseñas.
- Validación de los equipos servidores mediante claves públicas.
- Validación de los usuarios ya sea por pares usuario/contraseña, como (opcionalmente),
mediante certificados de clave pública.
Además, este protocolo está diseñado teniendo en cuenta la seguridad desde el
principio, a diferencia de los comandos r*.
No es conveniente utilizar los protocolos SSN versión 1, ya que además de ser mas
débiles desde el punto de vista de la seguridad, existen ataques contra versiones viejas
de los servidores ssh de versión 1.
Seguridad y la NIS
NIS, por su propia naturaleza de servicio de información de facil acceso y por su
implementación, es un servicio inherentemente inseguro. Aun NIS+, que fue pensado como un
reemplazo para NIS con mayor seguridad (y otras mejoras), es también un servicio con
problemas de seguridad.
No debería permitirse el acceso a la NIS a máquinas de las cuales no confiemos en su seguridad
o máquinas donde tengamos usuarios no confiables.

Seguridad y NFS
NFS, como la mayoría de los servicios, requiere de una adecuada configuración para ser
seguro. Se debe prestar atención al archivo /etc/exports, donde se configura a qué máquinas
les permitimos acceder a nuestros discos (implícitamente, confiando en la seguridad de dichos
equipos).
En tiempos no tan lejanos, también ha habido algunos ataques a implementaciones de NFS con
bugs, y se debe verificar estar corriendo una versión que sea segura.
Seguridad y sendmail
Tradicionalmente, Sendmail ha sido blanco de muchos ataques, los cuales explotaban diversas
vulnerabilidades y bugs en el mismo. Las últimas versiones de Sendmail se consideran
relativamente seguras, pero hay que asegurarse de estar razonablemente actualizados.
Seguridad y DNS
Idem al sendmail, hay que mantenerse actualizados.
Firewalls.
Un firewall es una estructura de red pensada para minimizar los riezgos a los equipos de
nuestra red.
La estructura clásica de un firewall presenta 3 zonas con diferentes niveles de seguridad,
separadas por filtros a los paquetes IP:
- Una zona pública, accesible directamente desde las redes "no confiables". Idealmente
en esta zona se encuentran solamente los equipos que nos unen a otras redes.
- Una zona desmilitarizada, donde se encuentran aquellos equipos que precisan tener
comunicación con las redes "no confiables", por ejemplo los servicios que brindamos
hacia el exterior, y aquellos servidores que nos permiten obtener servicios desde las
redes "no confiables" (servicios proxy, servidores de correo, DNS, etc.)
- Una zona privada, donde se encuentran nuestras máquinas, las cuales (idealmente) no
tienen ningún contacto directo con las redes "no confiables", sino que obtienen todos
sus servicios a través de los servidores proxy.
Muchas veces, al armar un Firewall, se utilizan equipos UNIX para uno o varios de
estos equipos (tanto los filtros como los servicios en la zona desmilitarizada). Es
EXTREMADAMENTE IMPORTANTE maximizar los cuidados en la configuración de
estos equipos y en la configuración de los filtros.
Instalando una máquina UNIX
- Instalar solamente aquellas aplicaciones necesarias.
- Deshabilitar todos los servicios de red que no precisemos.
- Hacer uso de las utilidades de "hardening" que algunos sistemas proveen.
- Utilizar herramientas como Tripwire para poder detectar cambios maliciosos en nuestro

sistema.
- Si estamos expuestos a redes no confiables, utilizar las utilidades de filtrado de paquetes y
conexiones que provea nuestro sistema (packet filtering, tcp_wrappers, etc.)
- Familiarizarnos con el funcionamiento normal de nuestro sistema.
Ejercicio:
Ejecute "netstat -a" en un equipo unix que usted administre. ¿Puede usted describir qué
programa tiene abiertos cada uno de los puertos TCP y UDP habilitados sobre interfaces de red
(no loopback)?
Algunas herramientas para ayudarnos a administrar la seguridad.
COPS crack tcpd tcp_wrappers tripwire Kerberos Satan ssh
Monitoreo del sistema
Es necesario monitorear el sistema regularmente tanto para detectar intentos de
comprometer nuestra seguridad, como para minimizar los daños de una intrusión en curso.
No existen reglas absolutas acerca de qué se debe monitorear. Eso depende mucho de que
sistemas y servicios tenemos funcionando, y que es lo "normal" en nuestro sistema. La
principal recomendación es que debemos familiarizarnos con el funcionamiento normal de
nuestro sistema, y verificar cualquier actividad o cambio "sospechoso".
Algunas cosas a monitorear:
Cambios en los archivos del sistema Actividad extraña o en horarios extraños REVISAR LOS LOGS DEL SISTEMA Muchos reintentos para loguearse. Usuarios haciendo su. Saber que es normal y que no.
Manteniéndose informado.
Nuevos bugs y problemas cert advisories. (www.cert.org) ciac (www.ciac.org) bugtraq ([email protected]) sun-managers ([email protected]) http://www.ers.ibm.com/ (IBM) Otros

Arranque y detención
Arranque del sistema
Arranque automático y arranque manual
Pasos del proceso de arranque
Inicialización del núcleo (kernel)
Configuración del hardware
Procesos del sistema
Intervención del operador (solo en arranque manual)
Archivos de arranque (scripts rc)
Operación en multiusuario
Scripts rc
Scripts rc estilo System V
Problemas de arranque
Problemas de hardware
Problemas en el cargador del sistema operativo
Problemas en el sistema de archivos
Problemas de configuración del núcleo (kernel)
Errores en los scripts de arranque
Detención del sistema
Apagar la llave del equipo
shutdown
halt
reboot
Enviar al proceso init la señal TERM
Cambiar el nivel de ejecución (System V)
Matar el proceso init
El sistema operativo UNIX es un sistema complejo; los procesos de arranque y detención de
una máquina UNIX implican muchas tareas; deben realizarse correctamente si se desea

mantener la sanía del sistema. No basta con prender o apagar un interruptor. La pluralidad de
configuraciones introducidas por el advenimiento de los computadores personales al mundo
UNIX ha extendido los alcances y complicaciones de estos procesos.
Aunque lo dicho aquí es aplicable en general, los procesos de arranque y detención son
dependientes de hardware: puede haber diferencias para un equipo en particular.
Arranque del sistema.
El arranque del sistema suele llamarse "booting" o "booteo" en la jerga informática, propensa
a castellanizaciones crueles.
Durante el arranque no están disponibles las facilidades del sistema; éste debe
levantarse a sí mismo iniciando todos sus servicios (bootstrapping). Cuando una
máquina se enciende, ejecuta un programa de carga cuyas instrucciones se encuentran
almacenadas en ROM. Este programita determina como cargar en memoria el núcleo
del sistema operativo (kernel) y comenzar a ejecutarlo. El kernel examina el hardware
probando todos los dispositivos conectados, e inicia un proceso llamado init, siempre
con identificador de proceso PID 1. Se verifican los sistemas de archivos, se montan, se
arrancan los demonios del sistema, siguiendo los dictados de una serie de scripts en
lenguaje de shell llamados archivos o scripts rc (rc = run command). El contenido y
estructura de los scripts rc determinan la situación final del sistema.
Arranque automático y arranque manual.
La mayoría de los sistemas operativos tienen un modo de arranque manual y otro automático.
En modo automático, el sistema operativo realiza las tareas correspondientes al proceso
de arranque en forma autónoma, sin necesidad de intervención del administrador,
ejecutando todos los scripts de arranque e iniciando todos los procesos necesarios para
brindar los servicios habituales a los usuarios.
En modo manual el sistema operativo ejecuta una primera parte del proceso de arranque
pero casi enseguida transfiere el control al administrador. Se ejecutaron sólo unos pocos
scripts, hay pocos procesos corriendo, sólo el superusuario puede acceder al sistema: se
está ejecutando en modo monousuario (single-user mode).
En la operativa diaria el sistema arranca en modo automático con sólo encender el
equipo. Algunas fallas pueden obligar al arranque en monousuario: una falla en una
tarjeta de red o un sistema de archivos corrupto. Es preciso conocer bien el proceso de
arranque para configurar el arranque automático de los servicios requeridos o intervenir
en caso de falla.
Pasos del proceso de arranque.
El proceso de arranque tiene varios pasos que en general son los siguientes:
Carga e inicialización del núcleo (kernel). Detección y configuración de dispositivos. Creación automática de procesos base. (Intervención del administrador - solo en modo monousuario).

Ejecución de archivos de comandos de arranque (scripts rc). Operación en multi-usuario.
El administrador tiene poco control de esta secuencia, pero sí puede alterar los scripts rc,
donde se arrancan los procesos capaces de brindar servicios a los usuarios.
Inicialización del núcleo (kernel).
El núcleo del UNIX es un programa, y como todo programa debe cargarse previamente en
memoria para poder ejecutarse. El núcleo reside en un archivo llamado unix, vmunix, vmlinuz
o similar. Al encender el equipo comienzan a ejecutarse instrucciones en ROM cuyo objeto es
transferir a memoria un pequeño programa de arranque (boot program) encargado de cargar
el kernel en memoria y comenzar a ejecutarlo. Esta primera parte del proceso, hasta alcanzar
la ejecución del kernel, la realiza el hardware de la máquina. Una vez iniciado, el kernel verifica
la cantidad de memoria, separa una parte para sí mismo e informa la cantidad de memoria
total, lo reservado para sí y lo disponible para procesos de usuario.
Configuración del hardware.
Al comenzar su ejecución el núcleo intenta localizar e inicializar los dispositivos que le hayan
sido asignados en su construcción. Prueba estos dispositivos uno por uno, intentando
determinar parámetros de funcionamiento no especificados interrogando al propio
dispositivo. Los dispositivos no hallados o que no responden son inhabilitados. Una vez
completado este proceso, el agregado de un nuevo dispositivo deberá esperar el próximo
arranque del sistema para ser reconocido. Los sistemas UNIX suelen venir con uno o más
núcleos genéricos donde están preconfigurados los dispositivos más comunes, pero es posible
reconstruir el núcleo optimizándolo estrictamente al hardware disponible. También es posible
prever el agregado dinámico de módulos complementarios del kernel, cargándolos en
memoria solo al detectarse la presencia del dispositivo físico o solicitarse su acceso.
Procesos del sistema.
Una vez completada la inicialización básica el núcleo crea algunos procesos espontáneos,
llamados así por no haber sido creados por fork, el mecanismo habitual en UNIX. Los
procesos espontáneos difieren entre sistemas; en BSD son:
swapper - Proceso 0
init - Proceso 1
pagedaemon - Proceso 2
En los descendientes de System V son:
sched - Proceso 0
init - Proceso 1
varios manejadores de memoria y procesos del núcleo

En Linux no hay un proceso visible con PID 0, sino varios procesos de manejo además de init,
diferentes según la versión del kernel:
init - Proceso 1
varios manejadores de memoria y procesos del núcleo (kflushd,
kupdate, kpiod, kswapd).
De todos estos proceos solo inites un proceso de usuario; los restantes son partes del núcleo
enmascaradas como procesos a para agendar su ejecución (scheduling) o por razones de
arquitectura. Aquí finaliza el núcleo sus tareas de arranque; los restantes procesos del sistema
serán arrancados directa o indirectamente por init.
Intervención del operador (solo en arranque manual).
Si el sistema fue arrancado en modo monousuario el procesoinites invocado por el núcleo con
un parámetro indicativo, pidiendo la contraseña de superusuario y arrancando un intérprete
de comandos (shell); al finalizar la ejecución del intérprete initcontinúa con el proceso
normal de arranque. Digitando Ctrl-D en lugar de la contraseña del supervisor continúa el
arranque sin invocar el shell.
En el shell monousuario el supervisor puede trabajar como en cualquier sesión, pero
solo dispondrá de comandos existentes en la partición raíz, la única montada. Esta
partición puede, además, haber sido montada en solo lectura para ser verificada; si /tmp
está en la partición raíz, programas necesitados de archivos temporales como vi no
funcionarán. Volver a montar la partición raíz en modo lectura escritura puede diferir
entre sistemas, pero en general mount / leerá de nuevo /etc/fstab para montar / en el
modo habitual. Otros sistemas de archivos, como /usr, pueden ser montados a mano si
es necesario. Una falla habitual de arranque son sistemas de archivos con
inconsistencias; en este caso, deberá correrse fsck en forma manual antes de montar el
recurso. En el modo automático los sistemas de archivos son verificados como parte del
proceso de arranque; no así en monousuario.
Archivos de arranque (scripts rc).
Al momento de correr los scripts rc el sistema ya es un UNIX típico, con pocos servicios pero
sin magias de arranque; todos los pasos posteriores se gobiernan mediante los propios scripts
rc. La ubicación exacta y la organización de esos archivos depende del sistema.
Operación en multiusuario.
Una vez ejecutados los scripts de arranque el sistema se encuentra operativo, pero para
aceptar el ingreso de usuarios (login)initdebe arrancar un procesos getty de escucha en cada
una de las líneas de conexión de terminales. Esto completa el proceso de arranque. En los
sistemas configurados para usar login en ambiente gráfico init arranca estos servicios (xdm,
gdm, dtlogin u otro).
El proceso init sigue desempeñando un rol importante durante todo el período de
funcionamiento del sistema, arrancando procesos y recibiendo en herencia procesos sin
padre. En BSD init tiene solo dos estados, monousuario y multiusuario; en System V

existen diferentes estados mono y multiusuario (run levels), cada uno con diferente
espectro de recursos y servicios.
Scripts rc.
En BSD, los scripts rc se ubican bajo /etc, con nombres comenzados por "rc"; pueden invocarse
unos a otros. En System V los scripts se guardan bajo /etc/init.d, con enlaces hacia ellos en
directorios /etc/rc0.d, /etc/rc1.d, ..., correspondientes cada uno a un nivel de arranque.
Usualmente los scripts rc realizan, entre otras, las siguientes tareas:
Fijar el nombre de la máquina. Fijar la zona horaria. Verificar los discos con fsck (en arranque automático). Montar los discos del sistema. Eliminar archivos del directorio /tmp. Configurar las interfaces de red. Arrancar los demonios del sistema y los servicios de red.
Scripts rc estilo System V.
El estilo System V es el más usado actualmente. Se definen en él 7 niveles de arranque (run
levels), cada uno con un conjunto de servicios particular:
Nivel 0: sistema bajo, no hay nada corriendo.
Nivel 1 o S: monousuario.
Niveles 2 a 5: diversos (o idénticos) niveles multiusuario.
Nivel 6: rearranque (reboot), el sistema se detiene y vuelve a arrancar.
Como nivel multiusuario se usa únicamente el nivel 2, o el 2 y el 3 para configuración sin y con
red, por ejemplo; los niveles 4 y 5 no suelen ser usados. Los niveles 1 y S difieren según los
sistemas. Los niveles 0 y 6 no son en realidad estados de funcionamiento, sino transitorios.
El nivel 1 es el monousuario por excelencia; el S fue creado para pedir la contraseña del
supervisor. En Solaris S es el monousuario, pero en Linux se usa 1 como monousuario y
S para pedir la contraseña del supervisor.
Los niveles se definen en el archivo /etc/inittab. Aunque el formato varía, el propósito
de este archivo es definir los comandos a correr en cada nivel; uno de ellos define el
nivel por defecto que ha de alcanzar el sistema. Los scripts se ejecutan pasando
ordenadamente por cada nivel, creciendo en el arranque y decreciendo en la detención.
Los scripts de cada nivel detienen los servicios correspondientes a niveles superiores y
arrancan los servicios correspondientes al nivel propio. No suele ser necesario tocar el
archivo /etc/inittab; el control puede realizarse totalmente a través de los scripts rc
correspondientes a cada nivel, confiando en el sistema para la invocación ordenada de
los scripts rc de cada nivel según el directorio en que se encuentran.

Los scripts colocados en /etc/init.d manejan cada uno un demonio, servicio o aspecto
particular del sistema. Todos los scripts deben entender al menos los parámetros start
(arrancar), stop (detener); muchos entienden también restart, un stop seguido de un
start. Esto permite al administrador gobernar un servicio manualmente con comandos
tales como /etc/init.d/sshd start /etc/init.d/sshd stop
El conjunto de servicios a detener y arrancar en cada nivel se controla disponiendo de
un directorio para cada nivel y estableciendo en él enlaces hacia los scripts en init.d,
según la siguiente convención de nombres:
[K|S][0-9][0-9]nombre_script
nombre de enlace iniciado en K invoca el script en init.d con parámetro "stop";
nombre de enlace iniciado en S invoca el script en init.d con parámetro "start";
el número de 2 cifras que sigue a K o S indica el orden de ejecución;
sigue el nombre del script en init.d.
Ejemplos: S34named, K29bind.
Los directorios para cada nivel siguen la convención de nombres rcN.d, donde N es el
número de nivel. Ejemplos: rc0.d, rc2.d, rcS.d. Cuando el sistema está subiendo, se
ejecutan los scripts S; cuando está bajando se ejecutan los scripts K, siempre en el orden
definido por los números en los nombres de sus enlaces simbólicos. Los comandos ln -s /etc/init.d/sshd /etc/rc2.d/S99sshd ln -s /etc/init.d/sshd /etc/rc2.d/K25sshd ln -s /etc/init.d/sshd /etc/rc6.d/K13sshd
crean los enlaces simbólicos necesarios para arrancar y detener el servicio sshd en el
nivel multiusuario 2. La colocación del enlace en el nivel 6, reboot, es un reaseguro para
la detención del servicio en el rearranque, si el sistema no recorre por sí en forma
ordenada los niveles de detención.
Las distribuciones de Linux usan distintos esquemas de scripts rc: Debian sigue el
esquema System V descrito, en forma similar a Solaris y HP-UX; Slackware usa el
esquema BSD, como FreeBSD; Redhat usa un híbrido System V y BSD con algunas
complicaciones de propia cosecha.
Problemas de arranque.
Las dificultades de arranque pueden deberse a diferentes causas:
Problemas de hardware. Problemas en el cargador del sistema operativo. Problemas en el sistema de archivos. Problemas de configuración del núcleo (kernel). Errores en los scripts de arranque (scripts rc).

Problemas de hardware.
Antes de diagnosticar un problema de hardware es preciso descartar fehacientemente errores
en la configuración del software; muchos de esos errores sugieren fallas de hardware a los ojos
inexpertos. Un mensaje de error específico proveniente directamente de un dispositivo es un
buen indicador de falla de hardware (error de memoria, error de controlador de disco).
Siempre es conveniente verificar aspectos de instalación tales como
Alimentación de corriente para todas las partes del equipo: gabinete principal, gabinetes externos con discos, cinta u otros periféricos.
Alimentación de dispositivos internos (discos, disqueteras, unidades de cinta, CDROM). Conexiones entre diferentes dispositivos (cables de señal de discos, disqueteras,
puertos). Conexiones de red, sobre todo si la máquina depende de recursos externos (estación
sin disco, sistemas de archivos montados de otro servidor de red). Si existen, revisar e interpretar las luces indicadoras de estado de los dispositivos. Si la máquina comienza el arranque, verificar la aparición de todos los dispositivos
conectados; cada uno emite un mensaje de una línea al ser reconocido. Un mensaje de error o la falta de detección de un dispositivo conectado correctamente puede indicar una falla de hardware en ese dispositivo, en su plaqueta controladora o en la plaqueta principal.
Cuando sea posible, usar programas de diagnóstico; los hay para dispositivos, independientes del sistema operativo. Las máquinas de hardware propietario disponen de rutinas de diagnóstico de hardware en ROM. En los computadores personales la BIOS ejecuta en el arranque una prueba de autoverificación llamada POST (Power On Self Test) que prueba la memoria, presencia de discos y otros elementos básicos; los periféricos suelen traer programas DOS para diagnóstico (tarjetas de red, de video, impresoras).
Al detectarse una falla conviene dejar el equipo apagado unos 30 segundos y luego arrancarlo, para asegurarse de llevar el hardware a un estado conocido.
Problemas en el cargador del sistema operativo.
En las máquinas de arquitectura propietaria existe un programa de carga del sistema operativo
almacenado en ROM. Una falla común es la alteración o borrado de una variable de ambiente
almacenada en memoria no volátil. En este y otros casos es preciso seguir las indicaciones del
fabricante para reponer el arranque.
Los sistemas UNIX para computadores personales vienen programas de carga tales
como LILO para Linux o BootEasy para FreeBSD. Estos cargadores permiten arrancar
electivamente Linux u otros sistemas operativos instalados en diferentes particiones de
un mismo disco. Una falla, alteración o borrado del programa cargador obliga a arrancar
el sistema con un medio alternativo (disquete, CD), y reinstalar el programa de carga o
corregir y reponer su configuración correcta.
Las fallas de carga pueden darse en un sistema operativo instalado correctamente; la
reposición del esquema de arranque recupera el sistema completamente.
Problemas en el sistema de archivos.
Un sistema de archivos puede fallar por razones físicas (superficie dañada, disco roto), o
lógicas (inconsistencias en las estructuras de almacenamiento). En caso de falla física habrá

que cambiar el disco o al menos realizar una detección de bloques defectuosos para evitar su
uso, crear nuevamente el sistema de archivos y reponer desde respaldos. Una falla lógica
puede ser reparable con fsck, eventualmente con alguna pérdida; de no ser así, será preciso
recrear el sistema de archivos y reponer desde respaldo. La verificación deberá realizarse
arrancando en modo monousuario, con el sistema de archivos en falta desmontado y sobre el
dispositivo, ejecutando fsck reiteradamente en modo forzoso hasta no obtener errores.
Si la falla es en el sistema de archivos raíz el sistema no podrá arrancar. Si se dispone de
una partición de arranque alternativa, puede levantarse el sistema desde ella y reponer el
servicio rápidamente. Según los sistemas, esto puede hacerse con comandos de ROM o
del programa de carga; es preciso tener muy clara esta secuencia, y haber probado el
arranque al crear la partición alternativa, así como mantener permanentemente
sincronizadas (idénticas) ambas particiones de arranque, mediante copia cruda con dd.
Estas particiones deben estar en discos distintos para obtener una confiabilidad
razonable. En ausencia de partición de arranque alternativa será preciso reinstalar el
sistema operativo, eventualmente reponiendo desde respaldo los archivos de datos.
Una falla lógica en el sistema de archivos raíz puede intentar repararse arrancando el
sistema desde un medio alternativo (CD, disquete de rescate o disquete de instalación) y
correr fsck sobre el sistema de archivos raíz, no montado por el arranque desde medio
alternativo.
Problemas de configuración del núcleo (kernel).
Cuando se genera un nuevo núcleo debe mantenerse siempre un respaldo del núcleo anterior,
y saber como levantar el sistema con él; un núcleo recientemente generado puede muy bien
no funcionar. En Linux es posible generar el nuevo núcleo en disquete, para fines de prueba, y
recién después copiar la nueva versión sobre la anterior en disco.
Errores en los scripts de arranque.
Los errores en los scripts de arranque son la causa más frecuente de falla en el arranque; son
también las de más fácil solución: basta arrancar el sistema en monousuario, editar los scripts
rc, corregir los errores y continuar con el arranque normal. Es preciso verificar qué editor hay
disponible en modalidad monousuario y saber manejarlo; algunos sistemas requieren montar
/usr para disponer de vi. El editor ed, poco amigable, suele estar disponible en todos los
UNIX. En Linux, el disquete de rescate ofrecido por las distintas distribuciones suele tener un
conjunto de herramientas razonables para lidiar con estas dificultades; puede dar mejores
resultados recurrir al disquete de rescate que intentar el arranque monousuario.
Detención del sistema
En otros sistemas operativos es práctica común arrancar de nuevo el sistema operativo como
primer intento para resolver cualquier problema. Los sistemas UNIX suelen realizar tareas
críticas, atender múltiples usuarios o soportar redes de datos; no puede pensarse en arrancar
de nuevo el sistema así sin más; es imprescindible pensar primero e intentar solucionar los
problemas sin bajar la máquina. Esto no es una aspiración quimérica; es posible en muchos
casos. Es normal para una máquina UNIX pasar meses sin detenerse. Solo en casos de agregar
un dispositivo, sufrir una falla de hardware, un estado de confusión del sistema o la

imposibilidad de acceder, puede pensarse en rearrancar. En suma, cuando realmente no hay
otra solución.
Si se han hecho cambios en los scripts de arranque conviene rearrancar el sistema para
verificar el funcionamiento correcto de los cambios efectuados sin esperar el próximo
arranque, que puede darse en un momento donde el autor de los cambios no esté
presente o ya no recuerde lo hecho.
Hay diferentes formas de bajar un sistema o arrancarlo de nuevo:
Apagar la llave del equipo. Usar el comando shutdown. Usar el comando halt y reboot (BSD, Linux). Enviar al proceso init la señal TERM. Usar telinit para cambiar el nivel de ejecución del proceso init (System V). Matar el proceso init.
Apagar la llave del equipo.
Ni siquiera en sistemas UNIX personales es aceptable bajar el equipo apagando la llave:
pueden perderse datos o corromperse lógicamente los sistemas de archivos. Apagar la llave
puede ser inevitable en caso de catástrofe natural o de bloqueo total del sistema.
shutdown
El comando shutdown es el método más prolijo, seguro y completo de bajar un sistema UNIX.
Dispone de una variedad de opciones, variables según los UNIX, pero en general permite fijar
anticipadamente el momento de la bajada, enviar avisos a los usuarios, decidir si será un
apagado, un rearranque o una bajada a monousuario. Procede enviando señales de
terminación a todos los procesos en forma ordenada, sincroniza y desmonta los sistemas de
archivos, avisa cuando terminó ("System halted", "Power down", o similar).
shutdown -r now
en Linux rearranca (-r) la máquina en forma inmediata (now). La opción -h detiene; la
opción -f no realiza verificación de discos en el siguiente arranque.
halt
El comando halt realiza las tareas esenciales mínimas para bajar el sistema ordenadamente:
registra la bajada, termina los procesos no esenciales, sincroniza los discos y termina la
ejecución. La opción -n no sincroniza discos; se usa cuando se ha hecho un fsck sobre la
partición raíz para impedir al kernel sobreescribir el superbloque reparado con el defectuoso
que retiene en memoria.
reboot
El comando reboot procede como al halt pero arranca de nuevo el sistema después de
bajarlo. Tiene también opción -n, como halt.
Enviar al proceso init la señal TERM.
Esta señal obliga al proceso init a terminar; según la variedad de UNIX puede causar la
bajada del sistema. Es un método crudo; no sincroniza discos. Como init tiene siempre PID 1,
la secuencia
sync; sync kill -TERM 1
ejecuta la acción. Consultar la documentación antes de emplear este método.
Cambiar nivel de ejecución (System V).
El comando telinit permite avisarle al procesoinitque cambie a otro nivel de ejecución. telinit S
pasa el sistema a modo monousuario en Solaris y HP-UX; en Linux telinit 1
realiza la misma acción (S solo abriría un nuevo shell). No hay período de gracia ni
advertencias. shutdown -i1
es una forma más elegante de pasar a monousuario. telinit es útil para probar cambios al
archivo /etc/inittab: telinit -q
obliga a init a releer el archivo inittab.
Matar el proceso init.
El proceso init es esencial para el funcionamiento del sistema; matar este proceso
rearranca el sistema inmediatamente, pero en algunos sistemas el kernel entra en pánico.
Es un método salvaje; usar shutdown o reboot.





























