Embed Size (px)
Citation preview

DIPLOMARBEIT
Agentenbasierte Modellbildung und Simulation auf Basis derFokker-Planck-Gleichung
Ausgeführt am Institut fürAnalysis & Scientific Computing
der Technischen Universität Wienunter der Anleitung von
Ao.Univ.Prof. Dipl.-Ing. Dr.techn. Felix Breiteneckerdurch
Martin Bicher BSc
Untere Weißgerberstraße 6/19-21A-1030 Wien
Wien, am 21. Mai 2013

i
Erklärung zur Verfassung der Arbeit
Martin Bicher, Untere Weißgerberstraße 6/19-21 1030 Wien, Österreich
“Hiermit erkläre ich, dass ich diese Arbeit selbständig verfasst habe, dass ich die verwende-ten Quellen und Hilfsmittel vollständig angegeben habe und dass ich die Stellen der Arbeit -einschließlich Tabellen, Karten und Abbildungen -, die anderen Werken oder dem Internet imWortlaut oder dem Sinn nach entnommen sind, auf jeden Fall unter Angabe der Quelle als Ent-lehnung kenntlich gemacht habe.”
Ort, Datum Unterschrift

ii
Danke
Im Zuge des Abschlusses meiner Diplomarbeit verbleibt, all jenen zu danken, die mich im Um-feld eben dieser unterstützt haben.Herzlichen dank an. . .
. . . Prof. Felix Breitenecker und Niki Popper für die Möglichkeit mein Master-Studiumin der Arbeitsgemeinschaft Simulation abschließen zu können und oftmaliges schmierenvon bürokratischen Zahnrädern.
. . . meine Bürokollegen für ein durchwegs positives Arbeitsklima und lustige Büroabendevoller Krahu, Ironie und Galgenhumor.
. . . alle Freiwilligen für die aufopferungsvolle Unterstützung im Korrekturprozess der Ar-beit.
. . . meine Freunde für das Zurückholen in die Realität nach langen Arbeitstagen.
. . . meine Pfadfindergruppe für das Übermitteln von viel innerer Kraft und Lebensfreude.
. . . meinen Tischtennis und Fußballverein für den für mich lebensnotwendigen sportlichenAusgleich.
Allen voran gilt mein Dank natürlich einerseits meiner Freundin, die es nicht nur trotz, sondernoft auch genau wegen meiner Verrücktheiten mit mir aushält, und andererseits meinem Opa undmeinen Eltern, die mir während der gesamten Zeit des Studiums ein felsenfester Rückhalt warenund mich in all meinen Entscheidungen stets unterstützten.

iii
Abstract Deutsch
Motivation
Bedingt durch immer größer werdende technische Ressourcen und exponentiell wachsende Rech-nerleistungen ist man heutzutage in der Lage, immer komplexere, genauere und Speicher auf-wändigere Simulationen zu berechnen. Die Mikrosimulation ist durch ihre Flexibilität und gerin-ge Abstraktionstiefe zu einem festen Standbein der Modellbildung geworden und stellt in vielenAnwendungsbereichen eine echte Alternative zu altbewährten Modellierungsansätzen wie Dif-ferentialgleichungen dar. Der Preis dafür ist, dass man mit einem Modell arbeitet, das eine aufanalytischer Ebene fast nicht in den Griff zu bekommende Komplexität besitzt.
Inhalt
Anfang der 80er Jahre des vergangenen Jahrhunderts veröffentlichte der niederländische theore-tische Physiker N. G. van Kampen eine Arbeit, wie die stochastischen Größen Erwartungswertund Dichte von Markov-Prozess basierte Mikrosimulationen durch Differentialgleichungen ap-proximiert werden können. Obwohl diese Idee unter Teilchenphysikern unter dem Namen „Dif-fusionsapproximation“ durchaus bekannt ist, findet die Theorie, bis auf wenigen Ausnahmenz.B. im Bereich der Wirtschaftswissenschaften, in anderen Bereichen der Modellbildung kaumAnklang, da Van Kampen das Prinzip seinerzeit für zeitkontinuierliche stochastische agentenba-sierte Modelle entwickelte, die nur selten Anwendung finden.In dieser Arbeit ist erklärt, wie die Diffusionsapproximation unter Inkaufnahme und Abschät-zung von Diskretisierungsfehlern auch auf zeitdiskrete stochastische agentenbasierte Modelleerweiterbar ist und wie die Parameter des Agentenmodells und die Parameter der Differential-gleichung ineinander umzurechnen sind.Grundidee dazu liefert die für Markov-Prozesse gültige Master Gleichung, eine gewöhnlicheDifferentialgleichung, die den zeitlichen Verlauf der Wahrscheinlichkeitsfunktion eines Markov-Prozesses festlegt.
dP
dt(x(t) = i) =
∑j 6=i
P (x(t) = j)ωj,i − P (x(t) = i)ωi,j
Wendet man diese Gleichung auf einen speziellen Zustandsvektor einer aus Markov-Prozessenbestehenden Mikrosimulation mit N Agenten, der aus der Summe von Agenten im selben Zu-stand entsteht und für sich selbst wieder ein Markov-Prozess ist, an und entwickelt die Gleichungauf spezielle Art in eine Taylorreihe, auch als Kramers-Moyal-Entwicklung bekannt, so erhältman nach einen Substitution, bis auf einen Fehler der Ordnung N−
12 , eine gewöhnliche Dif-
ferentialgleichung für den Erwartungswert. Die Wahrscheinlichkeitsdichte lässt sich dann überRücksubstitution als Lösung einer Fokker Planck Gleichung ermitteln.Bemerkenswert ist, dass dafür lediglich der summierte Prozess ein klassischer Markov-Prozesssein muss, womit die Übergangsraten der Agenten sogar vom gesamten Zustandsvektor abhän-gen dürfen und nicht nur von ihrem eigenen. Die Agenten, die durch diese „erweiterten“ Mar-kovprozesse beschrieben werden, dürfen also interagieren. Über ein Diskretisierungsargument

iv
wird daraufhin gezeigt, dass ein zeitdiskret gerechnetes Agentenmodell mit richtig gewähltenÜbergangswahrscheinlichkeiten das zeitkontinuierliche Modell mit einem Fehler, der von derGröße der Übergangsraten abhängt, annähert, womit die Differentialgleichung auch für diesesModell als Approximation verwendet werden kann.
Conclusio
Mit der Berechnung von qualitativen und quantitativen Fehlerabschätzungen wird mit dieserTheorie eine Brücke zwischen zwei grundverschiedenen Modellierungsansätzen gezogen, die invielen Belangen zur Optimierung von all jenen Modellen beitragen könnte, die bislang in ihrerModellierung an einen der beiden Typen gebunden waren.

v
Abstract english
Motivation
Due to exponentially increasing performance of computers, nowadays more and more complexmodels can be simulated in shorter time with less efforts. Thus especially individual-based mod-els, so called microscopic models, requiring lots of memory and fast computation, are gettingmore and more popular. They pose a very well understandable modelling-concept especially tonon-experts and are additionally very flexible regarding change of parameters or model struc-tures. Unfortunately modelling with these, often called agent-based models, is always subjectedto a risk, because the behaviour of the models is hardly predictable and insufficiently studied.Therefore it is often necessary to use reliable, less flexible, methods like differential equationsinstead, which have already been investigated for hundreds of years.
Content
At the end of the 20th century the Dutch physicist N.G. van Kampen published the basis of a the-ory, how the deterministic moments of stochastic agent-based models, in this case continuous-time Markov-process based micro-models, can asymptotically be described by ordinary andpartial differential equations. This method, sometimes known within physicists as “diffusionapproximation“, was formerly mainly used in quantum dynamics before its usage was extendede.g. to economical models by M. Aoki in 2002.Given N identical dynamic agents each described by a Markov-process with a finite numberof states, also the system-vector consisting of the numbers of agents within the same state isdescribed by a Markov-process. Thus the so called Master-equation,
dP
dt(x(t) = i) =
∑j 6=i
P (x(t) = j)ωj,i − P (x(t) = i)ωi,j ,
holds. Taylor-approximation, in this case called Kramers-Moyal-decomposition, and certainsubstitutions on the one hand lead to an ordinary differential equation, solved by an approxima-tion of the mean value, and on the other hand to a special partial differential equation (Fokker-Planck-equation), solved by an approximation of the density function. The resulting curvesdescribe, neglecting an error O(N−
12 ), the temporal behaviour of mean value and variance.
It is important to mention, that the theory does not depend on, whether the agents are indepen-dently described by Markov-processes or are allowed to interact in a memoryless way!Especially the last idea motivates the thought, that the theory can be extended from time-continuous interacting Markov-processes to time-discrete interacting stochastic agent-based mod-els, which are much more commonly used. It shows that this assumption holds consideringcertain errors depending from the size of the transition rates.
Conclusion
Summarizing, formulas were created, how the deterministic system-variables of stochastic agent-based models can asymptotically be described by a system of differential equations. Thus a cer-

vi
tain bijection between a small subspace of agent-based models and a subspace of the set of alldifferential equations is found which could be used to extend the fields of application for bothmodelling-types.

Inhaltsverzeichnis
Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iiiInhalt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . iiiConclusio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ivMotivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vContent . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vConclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
Inhaltsverzeichnis vii
1 Einleitung 11.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21.2 Überblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Grundlagen 52.1 Markov-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.1 Unterschiedliche Typen . . . . . . . . . . . . . . . . . . . . . . . . 92.1.2 Homogenität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102.1.3 Gleichung von Chapman-Kolmogorov . . . . . . . . . . . . . . . . . 102.1.4 Regularität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.1.5 Pfade und Verweildauer . . . . . . . . . . . . . . . . . . . . . . . . 12
2.2 Modellbildung mit Differentialgleichungen . . . . . . . . . . . . . . . . . . . 132.2.1 Gewöhnliche Differentialgleichungen . . . . . . . . . . . . . . . . . 142.2.2 Partielle Differentiagleichungen . . . . . . . . . . . . . . . . . . . . 152.2.3 Zusammenführen der Gedanken . . . . . . . . . . . . . . . . . . . 16
2.3 Micro Modelling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162.3.1 Mikrosimulation mit CT Markov-Modellen . . . . . . . . . . . . . . . 192.3.2 Agentenbasierte Modellierung . . . . . . . . . . . . . . . . . . . . . 202.3.3 Zelluläre Automaten . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3 Master Gleichung 233.1 Existenz von Übergangsraten . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.1.1 Stetigkeit von P . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 243.1.2 Rechtsseitige Differenzierbarkeit von P bei 0 . . . . . . . . . . . . . 25
3.2 Mastergleichung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
vii

viii INHALTSVERZEICHNIS
3.3 Kramers Moyal Entwicklung . . . . . . . . . . . . . . . . . . . . . . . . . . 323.3.1 Voraussetzungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 323.3.2 Taylorentwicklung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
3.4 Fokker-Planck-Gleichung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.4.1 Polynomdarstellung für die Übergangsraten . . . . . . . . . . . . . 353.4.2 Substitution der Variable x . . . . . . . . . . . . . . . . . . . . . . . 363.4.3 Resultierende Gleichungen . . . . . . . . . . . . . . . . . . . . . . 38
3.5 Interpolation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.5.1 Histogramm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 393.5.2 Differenzierbare Approximation . . . . . . . . . . . . . . . . . . . . 423.5.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4 Analyse 494.1 Analyse der Erwartungswertkurve . . . . . . . . . . . . . . . . . . . . . . . 514.2 Analyse der Dichte und der Varianz . . . . . . . . . . . . . . . . . . . . . . 524.3 Stochastische Aussagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5 Mehrdimensionale Probleme 595.1 Mehrdimensionale Mastergleichung . . . . . . . . . . . . . . . . . . . . . . 595.2 Mehrdimensionale Fokker-Planck-Gleichung . . . . . . . . . . . . . . . . . 60
6 Anwendung auf zeitdiskrete agentenbasierte Modelle 636.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 636.2 Voraussetzungen an das DT Agentenmodell . . . . . . . . . . . . . . . . . 646.3 Tempora mutantur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 666.4 Verweildauer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 686.5 Umrechnung auf den summierten Prozess . . . . . . . . . . . . . . . . . . 716.6 Zusammenfassung und letzte Voraussetzungen . . . . . . . . . . . . . . . 73
7 1. Bsp: Ehrenfestsches Urnenproblem 757.1 Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 757.2 Resultierende Differentialgleichungen . . . . . . . . . . . . . . . . . . . . . 77
7.2.1 Überprüfen der Bedingungen . . . . . . . . . . . . . . . . . . . . . 777.2.2 Erwartungswertkurve . . . . . . . . . . . . . . . . . . . . . . . . . . 787.2.3 Equilibrium des Erwartungswertes . . . . . . . . . . . . . . . . . . 787.2.4 Varianz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 807.2.5 Dichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
7.3 Resultate zum konkreten Beispiel . . . . . . . . . . . . . . . . . . . . . . . 817.4 Rück und Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
8 Fehleranalyse 898.1 Gegenüberstellung der Problemstellungen . . . . . . . . . . . . . . . . . . 908.2 Wahrscheinlichkeitsmodell für das DT Agentenmodell . . . . . . . . . . . . 91
8.2.1 Verteilung für einen Zeitschritt . . . . . . . . . . . . . . . . . . . . . 91

INHALTSVERZEICHNIS ix
8.2.2 Erwartungswert nach einem Zeitschritt . . . . . . . . . . . . . . . . 928.2.3 Varianz nach einem Zeitschritt . . . . . . . . . . . . . . . . . . . . . 928.2.4 Zeitliche Entwicklung des Erwartungswertes . . . . . . . . . . . . . 948.2.5 Résumé für das DT Agentenmodell . . . . . . . . . . . . . . . . . . 95
8.3 Vergleich der Resultate mit dem DG Modell . . . . . . . . . . . . . . . . . . 968.3.1 Erwartungswertkurve an der Stelle t = 1 . . . . . . . . . . . . . . . 968.3.2 Abschätzungen für den Erwartungswertfehler . . . . . . . . . . . . 98
8.4 Varianzfehler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1018.5 Interpretation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
9 2. Bsp: SIR Modell 1039.1 Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 104
9.1.1 Reale Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . . 1049.1.2 Problemstellung des Differentialgleichungssystems . . . . . . . . . 1049.1.3 Problemstellung des zellulären Automaten . . . . . . . . . . . . . . 105
9.2 Umsetzung der Theorie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1069.2.1 Übergangswahrscheinlichkeiten . . . . . . . . . . . . . . . . . . . . 1079.2.2 Die entstehenden Differentialgleichungen . . . . . . . . . . . . . . . 109
9.3 Resultate zum konkreten Beispiel . . . . . . . . . . . . . . . . . . . . . . . 1109.4 Résumé . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
10 3. Bsp: Linearisiertes, ungedämpftes Pendel 11510.1 Motivation und Problemstellung . . . . . . . . . . . . . . . . . . . . . . . . 11510.2 Erarbeiten des Agentenmodells . . . . . . . . . . . . . . . . . . . . . . . . 11610.3 Resultate zum konkreten Beispiel . . . . . . . . . . . . . . . . . . . . . . . 118
11 Conclusio 12311.1 Rückblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12311.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124
A Appendix 127
Abbildungsverzeichnis 129
Literaturverzeichnis 131


KAPITEL 1Einleitung
Befindet man sich gemeinsam mit Experten aus aller Welt auf einer Konferenz für Modellbil-dung und Simulation, so fühlt man sich, ob der großen Dichte an Expertise und der enormenVarietät der wissenschaftlichen Kompetenzen, als junger Mathematiker erst einmal leicht fehl-positioniert. Es wird mit Begriffen um sich geworfen, die man vielleicht davor einmal, mögli-cherweise in einer besuchten Vorlesung, gehört hatte und die allesamt dazu verwendet werden,die Idee der eigenen Modelle akkurat, schnell und überblicksartig in einer technischen Sprachezu beschreiben, sodass möglichst jede Fachrichtung damit umgehen kann.Als gelernter Mathematiker lechzt man nach präzisen Definitionen für dieses Fachvokabular, imOptimalfall sogar in Gestalt von Formeln und Gleichungen, da man es einerseits aus der Mathe-matik gewöhnt ist, dass alles zumindest sauber definierbar ist, und man andererseits gelernt hat,dass Begriffe auch nur dann verwendet werden dürfen, wenn entweder bereits eine einheitlicheDefinition existiert, oder man ebendiese selbst gemacht hat. Leider wird man diesbezüglich inder Welt der Modellbildung und Simulation oftmals enttäuscht. Der Umfang des Fachgebietshat sich vor allem innerhalb der letzten Jahrzehnte, insbesondere beeinflusst durch die rasanteWeiterentwicklung der Technologie, insbesondere der exponentiell wachsenden Rechenleistun-gen, in so viele Fachrichtungen und auf so vielfältige Arten vergrößert, dass es fast unmöglichgeworden ist, schnell genug präzise Definitionen zu erstellen, die in allen Fachrichtungen (Infor-matik, Elektrotechnik, Mechanik, Mathematik,. . . ) einheitlich akzeptiert und verwendet werden.Aus diesem Grund entstehen zwar „schwammige“ Begriffsdefinitionen, die von verschiedenenFachgebieten vielleicht sogar unterschiedlich interpretiert werden, aber sie erlauben immerhinden interdisziplinären Diskurs.Diesem Diskurs ist es heutzutage zu verdanken, dass Modelle immer genauer und komplexerund damit die Anwendungsbereiche für Modelle immer vielfältiger werden und sich längst nichtmehr ausschließlich auf Physik, Mechanik oder Elektrotechnik beschränken. U.a. durch Hybri-disierung von unterschiedlichen Modelltypen entstehen regelmäßig neue theoretische Modellie-rungskonzepte, die ob ihrer Effizienz und Genauigkeit schlussendlich altbewährte Algorithmenersetzen, womit man jedoch in Kauf nimmt, dass der neue Algorithmus auf analytischer Ebene
1

2 KAPITEL 1. EINLEITUNG
wesentlich schlechter erforscht ist.
1.1 Motivation
Mittlerweile ist es 11 Jahre her, seit Steven Wolfram mit seinem Buch „A New Kind of Science“die Welt der Modellbildung maßgeblich verändert hat, und das Prinzip des zellulären Automa-ten bzw. das Prinzip der agentenbasierten Modellierung erfreut sich wachsender Beliebtheit. Wardie Tür zur Modellbildung bis zur Erfindung des Computers ausschließlich demjenigen geöffnet,der ein Grundverständnis von der Differentialrechnung hatte, ist mithilfe von agentenbasierterModellierung das Konzept eines Modells sogar einem fachlichen Laien verständlich zu machen,da er deutlich weniger abstrahieren muss, um sein reales Problem im Modell wiederzuerkennen.Auf der theoretischen Ebene büßt man hingegen mit dieser Modellierungsmethode jahrhunder-telange Forschung im Bereich der Differentialrechnung ein und sieht sich teilweise sogar mitProblemen im Bereich der Chaostheorie konfrontiert. In diesem Fall gilt scheinbar:
Je leichter das Modell für Laien verständlich ist (d.h. je geringer das Abstraktionsniveau), umsoschwerer ist es analytisch in den Griff zu bekommen.
Will man nun Grundlagenforschung im Bereich der Modellbildung und Simulation betreiben,muss man entweder versuchen, die komplexe Theorie mit neuen analytischen Methoden in denGriff zu bekommen, oder versuchen, diese zu umgehen, indem man Verbindungen zu bereits gutanalysierten Modelltypen findet. In vielen Arealen der Modellbildung ist das bereits teilweisegelungen. Sieht man die Welt der verschiedenen Simulationstypen als riesiges Venn-Diagrammbezüglich ihrer analytischen Zusammenhänge erstellt, so findet man darin zwar heute immernoch eine Vielzahl an disjunkten Mengen, d.h. nicht oder kaum theoretisch verbundene Modell-typen, doch die Anzahl und Größe der Überscheidungsbereiche steigt stetig an.
In dieser Arbeit wird versucht, einen Beitrag dazu zu leisten, zumindest einen dieserÜberscheidungsbereiche ein wenig zu vergrößern.
Konkret handelt es sich dabei um die Areale der Modelltypen: Differentialgleichungsmodell,Markov-Modell, Mikrosimulation und agentenbasiertes Modell (zellulärer Automat).
1.2 Überblick
Aufbauend auf zwei Bücher des niederländischen Physikers N. G. van Kampen ( [Kam82]und [Kam07]), veröffentlichte Masanao Aoki im Jahr 2002 das Buch „Modeling AggregateBehaviour and Fluctuations in Economics“ ( [Aok02]), in welchem er am Beispiel von Wirt-schaftsmodellen ein Prinzip vorstellte, wie die stochastischen Größen einer zeitstetigen Markov-Modell-basierten Mirkosimulation, d.h. einer stochastischen, zeitkontinuierlichen Simulationmit einer großen Anzahl an individuellen Partikeln, mit einem System von gewöhnlichen bzw.partiellen Differentialgleichungen auf analytischer Ebene zusammenhängen. Im Konkreten wird

1.2. ÜBERBLICK 3
damit gezeigt, dass die stochastischen Größen der Mikrosimulation bis auf einen asymptoti-schen Fehler den Lösungskurven gewisser Differentialgleichungen entsprechen. Obwohl diesesPrinzip in der Fachwelt der Quantenphysik (Teilchenphysik) durchaus unter dem Begriff Dif-fusionsapproximation (diffusion approximation) bekannt ist, fand es bisher kaum Anwendungim Bereich der Grundlagenforschung im Bereich der Modellbildung und Simulation, da vor al-lem zeitstetig gerechnete stochastische Mikrosimulationen eher selten verwendet werden (Vorallem von diesem Gesichtspunkt aus wählte Aoki also einen sehr innovativen Zugang). Zu die-sem Zweck wurde Van Kampens Prinzip im Verlauf dieser Arbeit gleich an mehreren Punktenerweitert:
Unter Inkaufnahme von Diskretisierungsfehlern lässt es sich auch auf zeitdiskrete d.h.zeitlich getaktete, Markov-Prozess basierte Mikrosimulationen anwenden.
Mit dieser Idee lässt es sich auf eine Vielzahl von stochastischen agentenbasierten Model-len und zelluläre Automaten anwenden.
Die Berechnungen wurden auch mehrdimensional durchgeführt.
Für die Erweiterung durch die Diskretisierung wurden neue qualitative, d.h. asymptoti-sche, Fehlerabschätzungen getroffen und damit Konvergenzeigenschaften festgestellt.
Für die Erweiterung durch die Diskretisierung wurden teilweise auch quantitative Fehler-abschätzungen entwickelt.
Schlussendlich wurde die Theorie an einigen neuen Beispielen getestet und verifiziert.


KAPITEL 2Grundlagen
In diesem Kapitel werden die Grundlagen sowie Definitionen der in dieser Arbeit verglichenenModellierungsmethoden zusammengefasst. Die in den Folgekapiteln verwendeten analytischenBetrachtungen bauen auf diese auf, denn das im letzten Kapitel besprochene Ziel dieser Arbeitist gemäß der Übersichtstafel (Abbildung 2.1) nur über gewisse Umwege zu erreichen. Im Fol-genden werden die Grundlagen zu 5 Modellierungsmethoden vorgestellt, die unterschiedlicherkaum sein können, auf Grund dieser Diversität nicht einmal mathematisch zur Gänze auf einengleichen Nenner gebracht werden können, ja teilweise nicht einmal mehr auf mathematischerBasis einheitlich definiert werden.Da sich der Großteil der Theorie des in dieser Arbeit vorgestellten Prinzips zum Vergleich agen-
DT Agentenmodell / stoch. Zellulärer
Automat
CT Markov-Prozess
CT Markov-Prozess basiertes Agentenmodell
Differentialgleichungs
modellZiel
Abbildung 2.1: Übersichtsabbildung - Umweg zum Ziel
5

6 KAPITEL 2. GRUNDLAGEN
tenbasierter und differentialgleichungsbasierter Modelle auf die Markov-Theorie stützt, sind de-ren Grundlagen von besonderer Wichtigkeit. Diese Theorie bildet genauso wie das Modellierenmit Differentialgleichungen aber lediglich ein mathematisch zwar sauber definierbares Konzept,liefert aber keinerlei Vorschriften, wie die Theorie in die Praxis umzusetzen ist. Für Differen-tialgleichungsmodelle lässt sich eine Lösung oft als geschlossene Formel anschreiben, die imOptimalfall sogar mithilfe von Papier und Bleistift lösbar ist. Die Numerik und die sehr alte undgeschlossene Theorie über Differentialgleichungen liefern dann Aussagen über Stabilität undLösbarkeit (Eindeutigkeit). Man hat somit ein sogenanntes deterministisches Modell - d.h. beimehrmaligem Experimentieren unter den selben Bedingungen erhält man das selbe Ergebnis. Esist also aus der Anfangskonfiguration reproduzierbar. Zu dieser gehören neben dem Versuchsauf-bau auch alle während des Experiments einwirkende Einflüsse und Bedingungen.
Definition 2.0.1 (Deterministisch).Ein Modell wird deterministisch genannt, genau dann, wenn mehrmaliges Durchführen des Ex-periments unter den selben Bedingungen, das selbe Resultat hervorbringt.
Im Unterschied zum Differentialgleichungsmodell bezeichnet man z.B. ein Markov-Modellmit dem Begriff stochastisch.
Definition 2.0.2 (Stochastisch).Ein Modell, bei dem der Ausgang des Experiments nicht allein durch die Wahl der Anfangspa-rameter feststeht, bezeichnet man als stochastisch.
Die so gewählten Definitonen für stochastisch und determinischtisch sind disjunkt und derenVereinigung liefert die Menge aller Modelle. D.h. jedes mathematische Modell kann einer dieserKlassen zugeordnet werden.In diesem Zusammenhang kann man sich die Frage stellen, welche der beiden Typen denn dieRealität am besten abbildet? Einerseits ist spätestens seit der Entwicklung der Quantentheoriebekannt, dass jedes Ereignis in der Welt, in der wir leben, mit einem gewissen Zufall verbun-den ist bzw. zumindest mit einer Abweichung, die zumindest zum jetzigen Zeitpunkt noch vonkeinem bekannten Naturgesetz beschrieben werden kann. Da ein Modell im Allgemeinen dazubeitragen soll, die Realität zu imitieren, um zusätzliches Wissen über sie zu erlangen, macht vondiesem Standpunkt aus ein deterministisches Modell kaum Sinn. Es könnte sogar den falschenEindruck vermitteln, dass ein und die selbe Anfangskonfiguration zwangsläufig auch in der Rea-lität immer zum selben Ergebnis führen muss. Andererseits ist dadurch, dass der Modellbildendeohnedies gezwungen ist, Vereinfachungen zu treffen, möglicherweise die in der Theorie verein-fachte Form des Experiments auch, zumindest unter Berücksichtigung des vereinfachten Stand-punktes, in der Realität deterministisch. Man kann sagen, es kommt in diesem Zusammenhangprimär auf die Fragestellung an, wie das folgende Beispiel zeigt:

7
Beispiel 2.0.3 (Gedankenexperiment:).Beobachtung des Ausganges eines Münzwurfes.
Je nach Fragestellung wird sich ein anderer Modelltyp eignen:
Fragestellung deterministisch/stochastisch?Welche Seite liegtbeim Schnipsenmit dem Fingeröfter oben?
Unter diesen Voraussetzungen wird man stochastische Resultate er-halten, da die Anfangskonfiguration trotz alle mechanischen Bemü-hungen quasi nicht reproduzierbar ist und das Modell sehr sensitivdarauf reagiert. Möglicherweise können Faktoren wie die Masseba-lance der Münze auf das Zufallsresultat einwirken. Mithilfe einesstochastischen Modells könnte z.B. ein Erwartungswert bestimmtwerden, der gegebenenfalls für die Seitenwahl vor einem Fußball-spiel interessant sein könnte.
Welche Seite liegtbei bekannten An-fangsparameternoben?
Sind alle Umgebungsparameter bekannt, d.h. herrschen strenge La-borbedingungen, könnte mithilfe von physikalischen Gesetzen dasErgebnis mit einer physikalischen Simulation vorhergesagt werden.Diese Frage stellte sich am Beispiel eines von der Tischkante ge-stoßenen Marmeladebrotes und strahlt seit jeher eine gewisse Fas-ziantion aus.
Welche Seiteliegt bei hoherRotationszahl undbekannten An-fangsparameternöfter oben?
Das Experiment „Münzwurf “ ist von so chaotischer Natur, dassbei hohen und rotationsreichen Würfen sogar quantenmechanischeEffekte eine Rolle spielen, die nachweislich stochastische Resulta-te liefern. Während bei niedrigen Würfen die geringe Varianz derFlugbahn keine Auswirkung auf die resultierende Münzenseite hat,kann diese in diesem Fall sogar bei bekannten Anfangs und Um-gebungsparametern variieren. Ein deterministisches Modell kanndemnach nur Anhaltspunkte geben und muss richtig interpretiertwerden. Ein stochastisches Modell könnte das deterministische un-terstützen.
Je nach Fragestellung ist also einer der beiden Modelltypen sinnvoll und zulässig, manchmalsogar beide. Die Welt ist also, je nach Blickwinkel, stochastisch und deterministisch.Ganz abgesehen von diesem Gedankenexperiment wird aus diesen Fragestellungen, allgemeinfür Modelle betrachtet, einiges deutlich:
⇒ Stochastische Modelle verwendet man bevorzugt (sofern man die Wahl hat) anstelle vondeterministischen, wenn man an den Auswirkungen von Zufallsereignissen interessiert ist.
⇒ Um verwertbare Resultate zu erhalten, muss man diese in der Regel öfter durchführen.Ein einzelner Versuchsausgang ist in der Regel nicht aussagekräftig.
⇒ Die meisten verwertbaren Ergebnisse eines stochastischen Modells, betreffen weniger dasResultat des einzelnen Versuchs, sondern eher die mit dem Modell verbundene Wahr-scheinlichkeitsverteilung.

8 KAPITEL 2. GRUNDLAGEN
⇒ Die Wahrscheinlichkeitsverteilung ist eine deterministische Größe, die mit der Anfangs-konfiguration des Modells definiert ist.
Vor allem der letzte Punkt ist Hauptziel dieser Arbeit. Die Wahrscheinlichkeitsverteilung einesstochastischen Modells ist eine mögliche Brücke, die es erlaubt, deterministische und stochas-tische Modelle zu verknüpfen. Oft wird ein Markov-Modell als deterministisch bezeichnet, daman über die sogenannten Übergangsmatritzen die Wahrscheinlichkeitsverteilung determinis-tisch berechnen kann. Das ändert aber nichts daran, dass das Resultat des Modells immer nochstochastisch ist. Die Computersimulation, d.h. die Implementierung eines stochastischen Mo-dells selbst, ist im Allgemeinen aber wieder deterministisch. Die Quelle, aus der herkömmlicheSimulatoren Zufallszahlen beziehen, hängt mit einem deterministischen Generator zusammen,der bei bekannten Anfangsparametern nachgerechnet werden kann (Sieht man einmal davon ab,dass es tatsächlich Organisationen gibt, die sich darauf spezialisiert haben, aus tatsächlich wei-testgehend stochastischen Vorgängen aus der Natur Zufallszahlen zu gewinnen). Dieser Umstandist auch durchaus nützlich, bedenkt man, dass somit ein Durchlauf der Simulation am Computerjederzeit wieder abrufbar ist. Die Abbildung 2.2 zeigt das gerade Erwähnte graphisch.
Abbildung 2.2: Vergleich stochastisch - deterministisch
2.1 Markov-Modell
Ein Markov-Modell bezeichnet man im Allgemeinen ein Modell, das durch einen sogenanntenMarkov-Prozess beschrieben wird.
Definition 2.1.1 (Markov-Prozess).Ein stochastischer Prozess
X(t) : T → Ω, T ⊆ R+, 0 ∈ T
mit Wahrscheinlichkeitsfunktion
P (t, k) = P (X(t) = k) : T × Ω→ [0, 1]

2.1. MARKOV-MODELL 9
und Zustands (Mess-) Raum Ω wird als Markov-Prozess bezeichnet, dann und genau dann, wennseine bedingte Wahrscheinlichkeitsfunktion
P (X(t2) = k|X(t1) = j) := (P (X(t2) = k) unter der Bedingung dass X(t1) = j)
mit k, j ∈ Ω, t1 < t2 ∈ R+ die sogenannte Markoveigenschaft erfüllt.
Definition 2.1.2 (Markoveigenschaft).Seien t1 < · · · < tm ∈ T eine beliebige endliche, aufsteigende Folge von Zeitpunkten undk1, . . . , km ∈ Ω beliebig, so erfüllt X(t) die Markoveigenschaft, wenn
P (X(tm) = km|X(tm−1) = km−1, . . . , X(t1) = k1) = P (X(tm) = km|X(tm−1) = km−1)
2.1.1 Unterschiedliche Typen
Innerhalb der Klasse der Markov-Prozesse unterscheidet man die Prozesse zunächst anhand ihrerDefinitions und Bildräume:
Definition 2.1.3 (Klassifikation für Markov-Prozesse).Sei tend ∈ R+ ∪ ∞.
Ein Markov-Prozess heißt zeitstetig, wenn T = [0, tend]. Man spricht von einem CTMarkov-Prozess (continous time).
Ein Markov-Prozess heißt zeitdiskret, wenn T = 0, t1, . . . , tend. Man spricht voneinem DT Markov-Prozess (discrete time).
Ein Markov-Prozess heißt ortsstetig oder allgemein, wenn Ω = (S,A) mit einem überab-zählbaren Messraum S mit Sigma-Algebra A. Man spricht von einem CS Markov-Prozess(continous space).
Ein Markov-Prozess heißt ortsdiskret, wenn Ω = (k1, k2, . . . , 2k1,k2,... ) mit derPotenzmengen-Sigma-Algebra (Diese wird i.A. nicht extra angeschrieben). Man sprichtvon einem DS Markov-Prozess (discrete space). In diesem Fall wird auch von sogenann-ten Markov-Ketten gesprochen.

10 KAPITEL 2. GRUNDLAGEN
Zusätzlich kann man noch zwischen diskret-endlichen und diskret-unendlichen (abzählba-ren) Markov-Ketten sprechen, je nachdem, ob der Zustandsraum endlich oder abzählbar un-endlich ist. In dieser Arbeit wird der Begriff diskret stets für endliche Räume Ω ∼= 1, . . . , nverwendet. Die zum Raum gehörige Sigmaalgebra wird in Folge nicht mehr zum Raum dazuangeschrieben, da es sich entweder um eine endliche Potenzmenge oder den Borelmengen aufRn handelt.
2.1.2 Homogenität
Eine weitere wichtige Eigenschaft eines Markovporzesses ist der Begriff der Homogenität.
Definition 2.1.4 (Homogenität eines Markov-Prozesses).Ein Markov-Prozess heißt homogen, wenn für beliebige t1, t2, t2− t1 ∈ T und für alle k, j ∈ Ωgilt:
P (X(t2) = k|X(t1) = j) = P (X(t2 − t1) = k|X(0) = j)
Im weiteren Verlauf wird ausschließlich mit homogenen Markovketten gerechnet, denn nurdiese erfüllen die Gleichung von Chapman-Kolmogorov.
2.1.3 Gleichung von Chapman-Kolmogorov
Diese ist von fundamentaler Wichtigkeit für die Beweise in Kapitel 3. Sie stellt eine Art Pendantzum Satz von der totalen Wahrscheinlichkeit auf der Ebene der stochastischen Prozesse dar.Im weiteren Verlauf der Arbeit werden oft bedingte Wahrscheinlichkeiten in den Beweisen ver-wendet. Es sei also die folgende Kurzschreibweise eingeführt:
Definition 2.1.5 (Kurzschreibweise für bedingte Wahrscheinlichkeiten).
P ((t2, k)|(t1, j)) := P (X(t2) = k|X(t1) = k), t1 < t2 ∈ T, k, j ∈ Ω
Die in der Literatur gebräuchliche, weil kürzere, schreibweise
Pj,k(t) := P ((t, k)|(0, j)) = P (X(t) = k|X(0) = j)
mit der, unter Ausnützung der Homogenität des Prozesses, ebenso jede bedingte Wahrschein-lichkeit beschrieben werden kann, versagt im Falle von komplizierteren Bedingungen, die aberspäter noch benötigt werden. Z.B.:
P ((t2, k)|(t1, 6= k), (t1, 6= j)) := P (X(t2) = k|X(t1) 6= k ∧X(t1) 6= j)

2.1. MARKOV-MODELL 11
Satz 2.1.6 (Gleichung von Chapman-Kolmogorov).Ist X(t) ein Markov-Prozess mit Werten in Ω so gilt ∀t1 < t2 ∈ T und ∀k, j ∈ Ω:
P (X(t2) = k|X(0) = j) =
∫ΩP (X(t2) = k|X(t1) = i)P (X(t1) = i|X(0) = j)di =
=∗
∫ΩP (X(t2 − t1) = k|X(0) = i)P (X(t1) = i|X(0) = j)di
wobei ∗ genau dann gilt, wenn X homogen ist und t2 − t1 ∈ T .
Beweis: 1 Nach dem Satz für bedingte Wahrscheinlichkeiten folgt die Umformung:
P ((t2, k)|(0, j)) =P ((t2, k), (0, j))
P (0, j).
Da der Prozess zum Zeitpunkt t2 < t1 ∈ T einen Zustand gehabt haben muss gilt weiters:
P ((t2, k), (0, j))
P (0, j)=
∫Ω P ((t2, k), (0, j), (t1, i))di
P (t1, k1).
Der Bruch lässt sich erweitern und man erhält:
P ((t2, k)|(0, j)) =
∫Ω
P ((t2, k), (t1, i), (0, j))P ((t1, i), (0, j))
P (0, j)P ((t1, i), (0, j))di =
=
∫Ω
P ((t2, k)|(0, j), (t1, i))P ((t1, i), (0, j))
P (0, j)di =
=
∫ΩP ((t2, k)|(0, j), (t1, i))P ((t1, i)|(0, j))di =
=∗
∫ΩP ((t2, k)|(t1, i))P ((t1, i)|(0, j))di.
Die Gleichheit ∗ folgt nach der Markowbedingung, da t2 > t1 gilt. ist der Markov-Prozess nunauch noch homogen und der Zeitpunkt t2 − t1 ∈ T folgt sogar noch die Gleichheit:
P ((t2, k)|(0, j)) =
∫ΩP ((t2 − t1, k)|(0, i))P ((t1, i)|(0, j))di.
Insbesondere ist die Gleichung natürlich für homogene CT Markov-Prozesse erfüllt, da dortohnedies t2− t1 ∈ T liegt. Für DS Markov-Prozesse erhält man ein Integral bzgl. dem Zählmaßund damit eine endliche oder unendliche Summe:
1Der Beweis ist dem Buch [Aok02] nachempfunden

12 KAPITEL 2. GRUNDLAGEN
Satz 2.1.7 (Gleichung von Chapman-Kolmogorov für DS Markov-Prozesse).SeiΩ := k1, k2, . . . und t2 > t1, t2 − t1 ∈ T folgt:
P ((t2, k)|(0, j)) =∑i∈Ω
P ((t2 − t1, k)|(0, i))P ((t1, i)|(0, j))
Beweis: Man modifiziere den Beweis (vor allem den zweiten Schritt unter Verwendung desSatzes für bedingte Wahrscheinlichkeiten) für die allgemeine Chapman-Kolmogorov Gleichung,sodass er für diskrete Zustandsräume gilt.
2.1.4 Regularität
Des weiteren unterscheidet man homogene CT Markov-Prozesse in reguläre und nicht reguläreMarkov-Prozesse.
Definition 2.1.8 (Regularität eines CT Markov-Prozesses).Ein homogener CT Markov-Prozess X heißt regulär, wenn für alle k, j ∈ Ω gilt
limh→0
P ((h, k)|(0, j)) =
0, k 6= j1, k = j
Diese Eigenschaft ist von sehr intuitiver Natur. Sie besagt, dass ein regulärer Markov-Prozesszumindest eine gewisse Zeit in einem Zustand verbringen muss, bevor er zum nächsten übergeht,da die Wahrscheinlichkeit, dass er den Zustand in dem Augenblick wieder verlässt, in dem er ihnerreicht hat, gegen Null geht. Die Regularität wird im Kapitel 3 noch eine sehr wichtige Rollespielen denn der Begriff der Übergangsrate baut darauf auf. Man erhält für reguläre Markov-Prozesse rechtsstetige Pfade.
2.1.5 Pfade und Verweildauer
Definition 2.1.9 (Pfad).Als Pfad eines Markov-Prozesses bezeichnet man den Graph
Γ(X) := (t,X(t)), t ∈ [0, T ]
der Abbildung X(t).
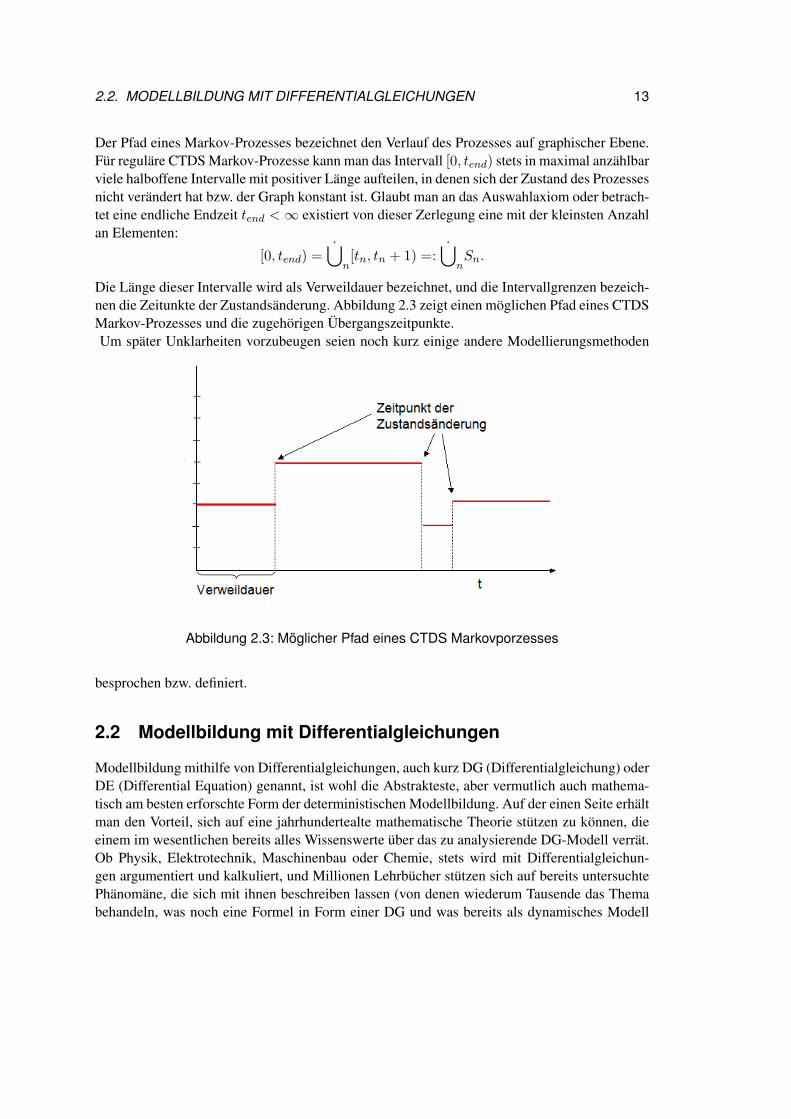
2.2. MODELLBILDUNG MIT DIFFERENTIALGLEICHUNGEN 13
Der Pfad eines Markov-Prozesses bezeichnet den Verlauf des Prozesses auf graphischer Ebene.Für reguläre CTDS Markov-Prozesse kann man das Intervall [0, tend) stets in maximal anzählbarviele halboffene Intervalle mit positiver Länge aufteilen, in denen sich der Zustand des Prozessesnicht verändert hat bzw. der Graph konstant ist. Glaubt man an das Auswahlaxiom oder betrach-tet eine endliche Endzeit tend <∞ existiert von dieser Zerlegung eine mit der kleinsten Anzahlan Elementen:
[0, tend) =⋃
n[tn, tn + 1) =:
⋃nSn.
Die Länge dieser Intervalle wird als Verweildauer bezeichnet, und die Intervallgrenzen bezeich-nen die Zeitunkte der Zustandsänderung. Abbildung 2.3 zeigt einen möglichen Pfad eines CTDSMarkov-Prozesses und die zugehörigen Übergangszeitpunkte.Um später Unklarheiten vorzubeugen seien noch kurz einige andere Modellierungsmethoden
Abbildung 2.3: Möglicher Pfad eines CTDS Markovporzesses
besprochen bzw. definiert.
2.2 Modellbildung mit Differentialgleichungen
Modellbildung mithilfe von Differentialgleichungen, auch kurz DG (Differentialgleichung) oderDE (Differential Equation) genannt, ist wohl die Abstrakteste, aber vermutlich auch mathema-tisch am besten erforschte Form der deterministischen Modellbildung. Auf der einen Seite erhältman den Vorteil, sich auf eine jahrhundertealte mathematische Theorie stützen zu können, dieeinem im wesentlichen bereits alles Wissenswerte über das zu analysierende DG-Modell verrät.Ob Physik, Elektrotechnik, Maschinenbau oder Chemie, stets wird mit Differentialgleichun-gen argumentiert und kalkuliert, und Millionen Lehrbücher stützen sich auf bereits untersuchtePhänomäne, die sich mit ihnen beschreiben lassen (von denen wiederum Tausende das Themabehandeln, was noch eine Formel in Form einer DG und was bereits als dynamisches Modell

14 KAPITEL 2. GRUNDLAGEN
gilt). Diese doch sehr flächendeckenden Theorie, vor allem im Bereich der Naturwissenschaf-ten, wird in gängigen Simulatoren wie DYMOLA oder SIMULINK ausgenützt, in denen mansein Modell aus einem großen Pool an bereits validierten Differentialgleichungsmodellen die füreinzelne Teilprobleme geeignet sind zusammensetzen kann.Leider fallen in den Bereich der Modellbildung heuzutage nicht nur Problemstellungen aus denNaturwissenschaften, sondern auch aus Bereichen wie Wirtschaft oder Soziologie, in denen mansich nicht auf eine Axiomatik berufen kann, die aus Formeln besteht. Zunächst muss man dieAufgabenstellung hinreichend abstrahieren, um sie überhaupt mit mathematischen Werkzeugenin den Griff zu bekommen, insbesondere wenn man sie mit Differentialgleichungen beschreibenwill. Da Abstrahieren in diesen Bereichen stets auch Vereinfachungen mit sich bringt, kann espassieren, dass man, um ein geschlossenes Differentialgleichungsmodell zu erhalten, wesentli-che Parameter vernachlässigen muss und man dadurch das Modell komplett entwertet. Zusätz-lich darf man nicht vergessen, dass derartige Abstraktionen für Aufgabensteller (Kunden) ausden erwähnten Bereichen kaum nachzuvollziehen sind, und dadurch das Modell an Glaubwür-digkeit einbüßt - nicht umsonst nennt man diesen Bereich der Modellbildung auch „Black-Box-Modelling“.Ist der Abstraktionsvorgang abgeschlossen und hat man einmal eine geschlossene mathemati-sche Formulierung des Problems in Form von Differentialgleichungen erlangt, kann man dasSystem im Wesentlichen zu einer von zwei unterschiedlichen Klassen zuordnen.
2.2.1 Gewöhnliche Differentialgleichungen
Auch kurz ODEs (Ordinary Differential Equations) genannt, bezeichnet man mit diesem Begriffdie einfachste Form der Differentialgleichung.
Definition 2.2.1 (ODE).Sei ~x(t) : D ⊆ R→ R
n, x ∈ Cd, so nennt man eine Differentialgleichung der Form
f(~x(d)(t), ~x(d−1)(t), . . . , ~x′(t), ~x(t), t
)= 0
gewöhnlich. Der Grad der höchsten Ableitung, die in der DG auch tatsächlich auftritt, nennt mandie Ordnung der DG.
Ohne zu sehr in die Theorie eingehen zu wollen, seien noch einige Begriffe erklärt:Lässt sich die Differentialgleichung (gemäß dem Hauptsatz über implizite Funktionen) schrei-ben als
x(d)1 (t) = g
(x
(d)2 (t), . . . , x(d)
n (t), ~x(d−1)(t), . . . , ~x′(t), ~x(t), t),
so nennt man die ODE explizit, andernfalls implizit. Tritt in der Differentialgleichung die Fun-tion mit der höchsten Ableitung nur linear auf, so ist die DG insbesondere explizit. Man sprichtin diesem Fall von einer quasiliearen DG. Gilt dies nicht nur für den Term mit der höchsten

2.2. MODELLBILDUNG MIT DIFFERENTIALGLEICHUNGEN 15
Differentiationsordnung, sondern für alle, so nennt man die Differenzialgleichung sogar linear(mit Störterm h(t)):
~ad · ~x(d)(t) + ~ad−1 · ~x(d−1)(t) + · · ·+ ~a0 · ~x(t) = h(t)
Jede explizite gewöhnliche Differentialgleichung, insbesondere jede lineare, lässt sich über ein-fache Variablensubstitutionen in ein (dementsprechend großes) System erster Ordnung überfüh-ren, womit für lineare DG ausschließlich die Form
~x′(t) = A(t)~x(t) +~b(t)
untersucht werden muss.Die Theorie über ODEs ist sehr weit fortgeschritten und liefert auf die meisten einfacheren Fra-gestellungen, insbesondere für lineare ODEs, sogar analytische Antworten für die unbekannteFunktion x(t). Dieser Umstand wird natürlich ausgenützt, denn kaum etwas ist so leicht ana-lysierbar und validierbar, wie eine explizite Lösungsformel für ein Modell. Ist andernfalls eineanalytische Lösung nicht bestimmbar, so lassen sich explizite Systeme auch leicht numerischbehandeln. Besonders hervorgehoben seien an dieser Stelle die expliziten und impliziten Ver-fahren von Euler, Heun und Runge-Kutta, sogenante ODE-Solver, deren Konvergenzverhaltenund Stabilität bereits seit Jahrzehnten bekannt sind und auf fast alle, also insbesondere auch aufnicht analytisch lösbare, explizite gewöhnliche Differentialgleichungen im Allgemeinen sehrbefriedigende Lösungsantworten geben.
2.2.2 Partielle Differentiagleichungen
Auch kurz PDEs (Partial Differential Equations) genannt, bezeichnet die wesentlich schwierigerzu behandelnde Klasse der Differentialgleichungen.
Definition 2.2.2 (PDE).Sei u ∈ Cd(Rn,Rm) so bezeichnet man eine Differerentialgleichung der Form
f
(Ld~i1d
(~u), . . . ,Ld~ind(~u),Ld−1
~i1d−1
(~u) . . . ,Ld−1~ind−1
(~u), . . . , L1~i11
(~u), . . . ,L1~in1
(~u), ~u, ~x
)= 0
mit sogenannten Differentialoperatoren:
Lk~i (~u) =∂k~u
∂xi11 , ∂xi22 , . . . , ∂x
in=k−(i1+i2+···+in−1)n
als partiell, wenn Ableitungen nach mindestens zwei unterschiedlichen Variablen tatsächlichauftreten (d.h. nichtverscheindende Koeffizientenfunktionen haben).
Mit ähnlichen Kriterien wie bei ODEs unterscheident man auch hier zwischen nicht-linearen,quasilieraren und linearen PDEs. Auch wenn die analytische Betrachtung der Lösung sogar

16 KAPITEL 2. GRUNDLAGEN
schon bei linearen PDEs sehr schwer ist und kaum verallgemeinerte Lösungsmethoden be-kannt sind, gibt es doch gut erforschte Mittel und Wege, solche Probleme zu analysieren. Ei-nerseits lassen sich sehr viele, häufig auftretende Probleme, auf bereits gut erforschte Spezial-fälle zurückführen (Transportgleichung, Wärmeleitungsgleichung, Schrödingergleichung, Max-wellgleichungen, . . . ). Andererseits gibt es auch auf diesem Gebiet gut erforschte numerischeMethoden, die es erlauben, auch Lösungen von analytisch nicht behandelbaren Problemen mitgut abschätzbaren Fehlern zu approximieren. Zu den wichtigsten Vertretern aus dieser Familiegehören das Verfahren der finiten Differenzen und die Methode der finiten Elemente (FEM).
2.2.3 Zusammenführen der Gedanken
Berücksichtigt man diese Überlegungen erhält man, grob gesprochen, die Conclusio:Hat man das DG Modell einmal erstellt, d.h. die Realität sinnvoll abstrahiert, ist (zumindestbei ODEs) die Simulation des Modells nicht mehr schwierig, da man sich auf gut erforschtemTerrain befindet.Dieser Umstand ist jener, der das DG Modell so wertvoll macht und den Gedanken anregt, nichtso gut erforschte Gebiete der Modellbildung auf das DG Modell zurückführen zu wollen. Manerhält den Konflikt:
DG ModellSehr abstrakt
Gut analysierbar⇔
Anderes ModellEvt. realitätsnäher
Schlecht analysierbar
Denkt man z.B. an Bevölkerungsmodelle, so kann man sich nach der Simulation des Modellsmittels Differentialgleichungen durchaus berechtigt fragen, warum 17.42 Personen zum Zeit-punkt t ein gültiges Resultat des Modells sein soll, und wie man dieses Ergebnis richtig deutensoll? Die imaginäre 0.42-te Person existiert nicht und wird auch nie existieren, doch will manvon diesem Resultat Gebrauch machen, um z.B. eine Bugdetkalkulation zu erstellen, macht esu.U. durchaus Sinn, mit ihr zu rechnen. Das Modell kann sich für diesen Zweck also sehr wohlals das Richtige herausstellen.Gerade in solchen Bereichen, wo in der Realität nur eine endliche Anzahl an Zuständen alsLösung des Problems in Frage kommt, ist das Modellieren mit DG oftmals sehr umstritten, daeinfach missverstanden. Zu diesem Zweck bieten sich sogenannte Mikrosimulationen an.
2.3 Micro Modelling
Setzt sich ein zu simulierendes System S bzw. eine zu simulierende Zustandsvariable Z in derRealität aus einer Anzahl an Subsystemen si mit eigenen Zustandsvariablen zi zusammen,
S =⋃N
i=1si, Z = f(z1, . . . , zN )
so macht es oft Sinn, anstelle einer ganzheitlichen Simulation des Gesamtsystems S mit einemModell für Z, die einzelnen Bestandteile des Systems einzeln zu simulieren und schlussendlichdie Zustandsvariable Z mit dem Wissen über die Funktion f , d.h. mit dem Wissen darüber, wie

2.3. MICRO MODELLING 17
sich die Systeme zusammensetzten, aus den einzelnen Systemvariablen zi zu berechnen.Einerseits ist dieses, hier sehr abstrakt beschriebene, Konzept ein sehr natürlicher Zugang zueiner Problemstellung. Z.B. besagt das Konzept, dass in einem Bevölkerungsmodell jede Per-son einzeln simuliert werden kann, anstatt die gesamte Bevölkerung mit einer z.B. kontinuierli-chen Größe zu beschreiben, was im Vergleich einen bedeutend weniger abstrakten Zugang zurProblemstellung darstellt. Jedermann, auch ein modellbildungstheoretischer Laie, kann nach-vollziehen, dass sich eine Bevölkerungszahl als Summe der Individuen ergibt, die agieren undmiteinander kommunizieren.Andererseits ist gerade die Kommunikation zwischen den einzelnen Subsystemen si ein oftschwer umzusetzender Stolperstein in der Modellierung und Implementierung. Überhaupt konn-te dieser Zugang zur Modellbildung erst mit der (weiter-)Entwicklung des Computers entstehen,da ob des großen Aufwands i.A. keine händischen Berchnungen mehr möglich sind. Während al-so Lotka und Volterra bereits 1925/26 mithilfe ihrer berühmten Differentialgleichungen Räuber-Beute Modelle mit durchaus großem Erfolg und Nutzen für die Gesellschaft berechnen konnten,wäre damals ein Individuen-basiertes Modell zu dieser Problemstellung (z.B. das Modell Wa-Tor von Dewdney und Wiseman, 1984) noch gar nicht möglich gewesen. In der heutigen Zeiterfreuen sich solche, Individuen-basierte, Modelle, klarerweise bedingt durch die immer größerwerdenden technologischen Ressourcen, immer größer werdender Beliebtheit. Diese Entwick-lung geht so weit, dass oftmals sogar krampfhaft eine Zerlegung eines Systems S in Bestandteilesi gesucht wird, obwohl sie eigentlich in der Realität gar nicht da sind, weil auf diese Art dasModell deutlich flexibler wird. Diese, ungerechtfertigt negativ behaftet ausgedrückte, Idee könn-te man auch mit dem Begriff „Diskretisierung“ bezeichnen. (Unter diesem Gesichtspunkt kannman z.B. die Methode der Finiten Elemente auch als Mikrosimulation bezeichnen.)
Definition 2.3.1 (Mikrosimulation / Makrosimulation 2).Wird, um ein System S zu simulieren, jedes einzelne Subsystem si mit S =
⋃N
i=1si sowie dieKommunikation zwischen diesen individuell Simuliert, und schlussendlich die SystemvariableZ = f(z1, . . . , zN ) aus den einzelnen Systemvariablen zi berechnet so bezeichnet man diesesModell, unabhängig von der Art der Simulation der Subsysteme, als mikroskopisch (Mikromo-dell, Mikrosimulation, Micro Model, Micro Simulation).Wird andererseits ein, sich aus Subsystemen zusammensetztendes System S =
⋃N
i=1si, alsgesamtes, d.h. ohne Berücksichtigung der Submodelle, mithilfe eines Modells für die Zustands-variable Z direkt simuliert, so nennt man das Modell makroskopisch (Makro Modell, Makrosi-mulation, Macro Model, Macro Simulation).
Meist kommt der Begriff der Makrosimulation nur im Kontext zusammen mit einer Mikro-simulation vor. Besteht das System also nicht aus Subsystemen, stellt sich die Frage nach demTypus i.A. nicht.Es folgen, zusammenfassend und ergänzend, einige Eigenschaften von Mikrosimulationen imVergleich zu Makrosimulationen.
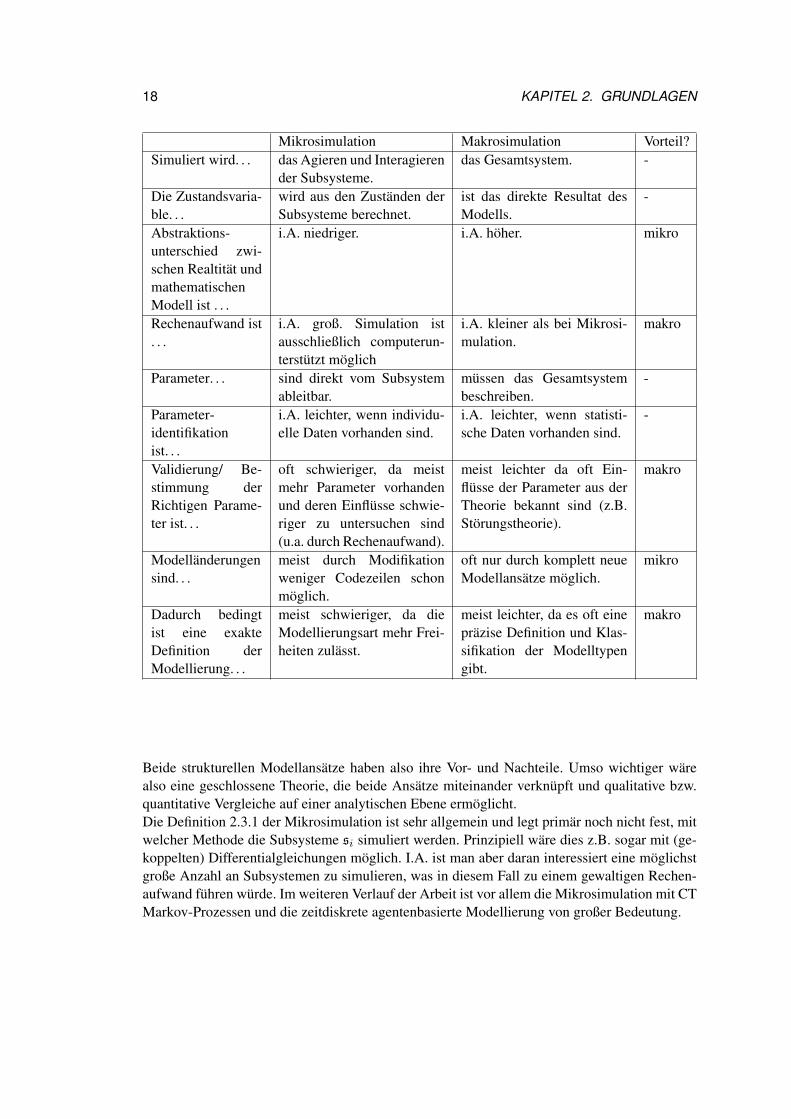
18 KAPITEL 2. GRUNDLAGEN
Mikrosimulation Makrosimulation Vorteil?Simuliert wird. . . das Agieren und Interagieren
der Subsysteme.das Gesamtsystem. -
Die Zustandsvaria-ble. . .
wird aus den Zuständen derSubsysteme berechnet.
ist das direkte Resultat desModells.
-
Abstraktions-unterschied zwi-schen Realtität undmathematischenModell ist . . .
i.A. niedriger. i.A. höher. mikro
Rechenaufwand ist. . .
i.A. groß. Simulation istausschließlich computerun-terstützt möglich
i.A. kleiner als bei Mikrosi-mulation.
makro
Parameter. . . sind direkt vom Subsystemableitbar.
müssen das Gesamtsystembeschreiben.
-
Parameter-identifikationist. . .
i.A. leichter, wenn individu-elle Daten vorhanden sind.
i.A. leichter, wenn statisti-sche Daten vorhanden sind.
-
Validierung/ Be-stimmung derRichtigen Parame-ter ist. . .
oft schwieriger, da meistmehr Parameter vorhandenund deren Einflüsse schwie-riger zu untersuchen sind(u.a. durch Rechenaufwand).
meist leichter da oft Ein-flüsse der Parameter aus derTheorie bekannt sind (z.B.Störungstheorie).
makro
Modelländerungensind. . .
meist durch Modifikationweniger Codezeilen schonmöglich.
oft nur durch komplett neueModellansätze möglich.
mikro
Dadurch bedingtist eine exakteDefinition derModellierung. . .
meist schwieriger, da dieModellierungsart mehr Frei-heiten zulässt.
meist leichter, da es oft einepräzise Definition und Klas-sifikation der Modelltypengibt.
makro
Beide strukturellen Modellansätze haben also ihre Vor- und Nachteile. Umso wichtiger wärealso eine geschlossene Theorie, die beide Ansätze miteinander verknüpft und qualitative bzw.quantitative Vergleiche auf einer analytischen Ebene ermöglicht.Die Definition 2.3.1 der Mikrosimulation ist sehr allgemein und legt primär noch nicht fest, mitwelcher Methode die Subsysteme si simuliert werden. Prinzipiell wäre dies z.B. sogar mit (ge-koppelten) Differentialgleichungen möglich. I.A. ist man aber daran interessiert eine möglichstgroße Anzahl an Subsystemen zu simulieren, was in diesem Fall zu einem gewaltigen Rechen-aufwand führen würde. Im weiteren Verlauf der Arbeit ist vor allem die Mikrosimulation mit CTMarkov-Prozessen und die zeitdiskrete agentenbasierte Modellierung von großer Bedeutung.

2.3. MICRO MODELLING 19
2.3.1 Mikrosimulation mit CT Markov-Modellen
Definition 2.3.2 (Microsimulation mit CT Markov-Modellen).Gegeben sei ein dynamisches System S, d.h. ein System, bei dem die Zustandsvariable Z(t) ∈ Ωals Funktion in der Zeit auftritt, bestehend aus N ∈ N Subsystemen si. Die Zustandsvariablejedes Subsystems folgt einem CT Markov-Prozess
zi(t) : [0, tend]→ Ωi.
Die Zustandsvariable Z(t) ergibt sich über eine Funktion aus den Zuständen der Subsysteme:
Z(t) := f(z1(t), . . . , zN (t)) :N
×i=1
Ωi → f(N
×i=1
Ωi) ⊆ Ω
Im weiteren Verlauf der Arbeit werden für CTDS Markov-Prozesse Funktionen f der Form
Zj(t) = f(z1(t), . . . , zN (t)) :=N∑i=1
Ij(z(t))
mit der Indikatorfunktion I als Zustandsvariablen benutzt. Damit ergibt sich als Zustandsvektordes Systems zeilenweise die Anzahl aller Agenten im selben Zustand.Es sei an dieser Stelle bemerkt und auch bewiesen, dass Z ebenfalls einem Markov-Prozess folgt.
Satz 2.3.3 (Kombination von Markov-Prozessen).Werden xi(t), i ∈ I mit |I|maximal abzählbar unendlich, von CT/DT CS/DS Markov-Prozessenbeschrieben, so folgt auch für jede Funktion f mit
Z(t) := f(z1(t), . . . , zN (t)) :N
×i=1
Ωi → f(N
×i=1
Ωi),
dass der Prozess Z(t) ebenso einem CT/DT CS/DS Markov-Prozess folgt.
Beweis: Zunächst folgt Z(t) auf jeden Fall einem zeitabhängiger stochastischer Prozess (Ist dieFunktion Konstant, so hat er einfach Varianz 0).Seien nun tend ≥ ti > ti−1 > · · · > t0 ≥ 0 Zeitschritte so gilt durch die Markoveigenschaft
P (zk(ti) = ai|(zk(tj) = aj)j∈0,...,i−1) = P (zk(ti) = ai|zk(ti−1) = ai−1), ∀k ∈ 1, . . . , N
die Gedächtnislosigkeit des Prozesses für jedes Subsystem. Da nun aber
Z(t) := f(z1(t), . . . , zN (t))

20 KAPITEL 2. GRUNDLAGEN
gilt, gibt es eine messbare Funktion G (im Falle der einfachen Summe wäre das z.B. die Faltungder Wahrscheinlichkeitsfunktionen), sodass sich die Wahrscheinlichkeitsfunktion
P (Z(t) = Z) = G
(N
×i=1
(×k∈Ωi
P (zi(t) = k)
))
und natürlich auch die bedingte Wahrscheinlichkeitsfunktion
P(Z(ti) = Zi| (Z(tj) = Zj)j∈0,...,i−1
)=
= G
(N
×u=1
(×
k1,...,i∈Ωu
P(zu(ti) = ki| (zu(tj) = kj)j∈0,...,i
)))=
= G
(N
×u=1
(×
ki−1,i∈Ωu
P (zu(ti) = ki|zu(ti−1) = ki−1)
))als Funktion in den einzelnen Wahrscheinlichkeitsfunktionen schreiben lässt, und sich somitauch der Prozess Z(t) als gedächtnislos herausstellt.
Satz 2.3.4 (Interagierende Agenten).Der eben geführte Beweis bleibt gültig, wenn die bedingten Wahrscheinlichkeiten der einzel-nen Agenten nicht nur vom Zustand des einzelnen Agenten abhängen, wie es bei klassischenMarkov-Prozessen üblich ist, sondern auch noch vom Zustandsvektor des aktuellen Zeitpunktesabhängen dürfen. D.h. die Agenten dürfen auf gewisse Weise mit ihrer Umgebung kommuni-zieren. Diese Beobachtung ist eine der wichtigsten der ganzen Arbeit.
Manchmal wird eine zeitkontinuierliche Simulation dieser Art auch Agentensimulation ge-nannt. Historisch gesehen, bzw. auch vom informatischen Standpunkt aus, soll in Folge aberunter Agentenmodellierung etwas anderes verstanden sein.
2.3.2 Agentenbasierte Modellierung
Ein spezieller Subtypus unter den Mikromodellen wird als agentenbasierte Modellierung (oderAgent-Based Modelling) bezeichnet. In Kapitel 1 wurde angesprochen, dass oftmals Fachvo-kabular im Bereich der Modellbildung und Simulation nicht einheitlich definiert und demnachvon Fachrichtung zu Fachrichtung unterschiedlich interpretiert wird. Der Begriff der agentenba-sierten Modellierung ist genau ein solcher und ist dadurch bedingt unter Modellbildungsexper-ten heiß diskutiert. Während der implementations-fokussierte Informatiker unter diesem Begriffstets einen Raster oder ein rechteckiges Gebiet mit sich darauf bewegenden und interagieren-den Individuen im Kopf hat, definieren sich Mathematiker den Begriff teilweise auch ohne eineräumliche Geometrie bzw. Topologie.Auf Grund dieser Diversität wird an dieser Stelle auch keine präzise Definition dafür angegeben,

2.3. MICRO MODELLING 21
was ein agentenbasiertes Modell ist, oder was keines ist, sondern lediglich beschrieben, welcheEigenschaften ein, für die Anwendung der Theorie in den Folgekapiteln taugliches Agentenmo-dell mindestens zu erfüllen hat (genauere Restriktionen folgen in den Theoriekapiteln). DieseGrundeigenschaften sind sinngemäß aus der Definition eines Agenten aus [Mik12, 5-14] moti-viert.
Definition 2.3.5 (Eigenschaften eines agentenbasierten Modells).Hat eine Mikrosimulation die folgenden Eigenschaften, so wird sie im Verlauf der Arbeit alsagentenbasiertes Modell bezeichnet:
Die endlich vielen Subsysteme werden Agenten genannt
Jeder Agent ist eindeutig identifizierbar und handelt eigenständig.
Jeder Agent hat einen Zustand (Eigenschaft) in einem gemeinsamen endlichen Zustands-raum, der sich ändern kann.
Handelt nach Regeln, die es ihm erlauben, auch mit seiner Umgebung zu kommunizieren.
Da es im Laufe der weiteren Arbeit notwendig ist, wird die zeitliche Änderung hier präzisiert:
Das Modell wird zeit-diskret, d.h. in endlich vielen Zeitschritten, gerechnet.
Jeder Agent ist gedächtnislos. D.h. die Entscheidung über die Änderung des Zustandswird ausschließlich anhand des aktuellen Zustandes bzw. der Zustände der anderen Agen-ten getroffen.
Vor allem die letzte Eigenschaft stellt eine enorme Restriktion dar, ist aber für die Modell-vergleiche notwendig.Das so definierte Modell ist ansonsten sehr frei definiert und umfasst fast alle gängigen Defini-tionen eines agentenbasierten Modells. Ein wenig präziser und auch einheitlicher lässt sich einzellulärer Automat definieren.
2.3.3 Zelluläre Automaten
Was im Fall des agentenbasierten Modells noch untergeordnete Rolle hatte, steht bei diesemModellierungstyp im Vordergrund : Der Raum selbst. Der Zwischenschritt des Agenten, der denRaum besetzt und den Zustand mit sich trägt, fällt nun weg und dem Raum selbst wird im zellu-lären Automaten (englisch cellular Automata oder kurz CA genannt) der Zustand zugeordnet.Obwohl es auch in diesem Bereich der Simulation unterschiedliche Definitionen gibt, differie-ren diese nicht so extrem, wie im Falle des Agentenmodells. Die Grundprinzipien der meistenDefinitionen sind hier sinngemäß wiedergegeben (siehe [PK12]).

22 KAPITEL 2. GRUNDLAGEN
Definition 2.3.6 (zellulärer Automat).Sei Ω ein ein, in endlich viele vernetzte Parzellen ωi,j geteiltes, Gebiet so wird ein Modellzellulärer Automat genannt, wenn gilt:
Das Modell wird zeitdiskret gerechnet.
Jeder Parzelle sei zu jedem Zeitpunkt ein Zustand ωi,j(t) ∈ 0, . . . , d =: I zugeordnet
Jede Zelle besitzt ob der Vernetzung des Raumes eine gewisse Anzahl an Nachbarzellen.Formal: es existiert eine Nachbarschaftsfunktion n(ωi,j) mit
n : Ω→ Ik : ωi,j 7→(ωi1,j1(t) . . . ωik,jk
),
die die sogenannte Nachbarschaft der Zelle definiert und als Rückgabewert die Zuständeder Nachbarzellen hat.
Der Zustand der Zelle ωi,j im Folgezeitschritt wird durch eine deterministische Überfüh-rungsfunktion U beschrieben, die von der Werten der Nachbarschaftsfunktion abhängt:
U : Ω→ I : ωi,j 7→ U(n(ωi,j)) =: ωi,j(t+ 1)
Für viele Bereiche der Modellbildung ist sogar diese sehr offene Definition zu streng undwird oft erweitert. Z.B. lässt man oft auch stochastische Übergangsfunktionen, die von Zufalls-variablen abhängen, zu. Das ändert schlussendlich auch den Modelltyp von deterministisch aufstochastisch und der Automat wird für die Theorie in den späteren Kapiteln interessant und ver-wendbar.Da zelluläre Automaten jedoch nicht zum eigentlichen Kerngebiet der Arbeit gehören, wird hiernicht näher darauf eingegangen.

KAPITEL 3Master Gleichung
In diesem Kapitel wird der Kern jener Theorie erklärt, mit der im Anschluss agentenbasierte Mo-delle und Differentialgleichungsmodelle approximativ ineinander übergeführt werden. Als Basisdient dazu die Theorie über CT Markov-Prozesse und Mikrosimulationen, insbesondere die imKapitel 2.1 besprochene Chapman-Kolmogorov Gleichung, auf der in Folge alles konstruktivaufbaut. Das wichtigste Werkzeug dazu wird die Taylorentwicklung sein, die es gestattet, einebeliebige, hinreichend oft differenzierbare Funktion in ein Polynom bzw. in eine konvergenteReihe zu entwickeln. Um Abschätzungen zu vereinfachen, bedient man sich der sogenanntenLandau Symbole:
Definition 3.0.7 (Landau Symbole).
f(h) = O(h)⇔ ∃C :f(h)
h≤ C
f(h) = o(h)⇔ limh→0
f(h)
h= 0
Bevor man jedoch mit den Umformungen der Chapman-Kolmogorov Gleichung beginnenkann fehlt noch der Begriff der Übergangsrate. Dieser ist eine zeitunabhängige Größe für dieWechselwahrscheinlichkeit eines CTDS Markov-Prozesses von einem Zustand in einen anderen.
3.1 Existenz von Übergangsraten
Als Basis für die Umformungen werden für das Kapitel 3 zunächst feste Variablennamen undVoraussetzungen definiert. Diese Liste wird im weiteren Verlauf der Arbeit verändert und erwei-tert und dient der Übersicht.
23

24 KAPITEL 3. MASTER GLEICHUNG
Bedingung 3.1.1.(Voraussetzungen für Kapitel 3.1 und 3.2.)
Bezeichnung DefinitionX(t) CTDS Markov-Prozess (regulär, homogen)
t, t1, t2, h ∈ [0, tend] Endliches Zeitintervalli, j, k ∈ Ω = 0, 1, . . . , n Endlicher Zustandsraum des Markov-Prozesses
P ((t2, k)|(t1, j)) Wahrscheinlichkeit für X(t2) = k bedingt durch j bei t1.k0 ∈ Ω Anfangszustand des Markov-Prozesses
P ((t, k)|(0, k0)) =: P (t, k) Kurzschreibweise
Die grundelegende Idee zur Einführung der sogenannten Übergangsrate ist, dass die, ohne-hin stets zumindest durch dessen Anfangswert bedingte, Wahrscheinlichkeitsfunktion P eineshomogenen Markov-Prozesses nicht von der Zeit selbst abhängt, sondern lediglich von der Zeit-differenz zwischen dem Zeitpunkt der Bedingung und dem aktuellen Zeitpunkt.
P ((t2, k)|(t1, j)) = P ((t2 − t1, k)|(0, j))
Es liegt also Nahe die Wahrscheinlichkeitsfunktion bzgl. der Zeitdifferenz nach Taylor entwi-ckeln zu wollen:
P ((t, k)|(0, j)) = P ((0, k), (0, j)) + tP ′((0, k)|(0, j)) + . . .
Man überlegt sich zunächst die Stetigkeit bzgl. der Zeit.
3.1.1 Stetigkeit von P
Satz 3.1.2.Die bedingte Wahrscheinlichkeit P eines Markov-Prozesses, der die Bedingungen 3.1.1 erfüllt,ist bzgl der Zeitdifferenz t zwischen Bedingung und aktuellem Zeitpunkt stetig.
Beweis: Einerseits ist der Prozess gemäß Vorraussetzung regulär. Damit gilt schon
limt→0
P ((t, k)|(0, j)) = δk,j ,
und es folgt schon die Stetigkeit von P bzgl. der Zeitdifferenz bei t = 0. Diese würde zumtaylorentwickeln 0-ter Ordnung bereits genügen. Man kann jedoch auch einen Schritt weitergehen:Sei ε > 0 beliebig, so folgt:
limε→0|P ((t, k)|(0, j))− P ((t+ ε, k)|(0, j))| =
∗

3.1. EXISTENZ VON ÜBERGANGSRATEN 25
=∗
limε→0
∣∣∣∣∣P ((t, k)|(0, j))−∑i∈Ω
P ((ε, k)|(0, i))P ((t, i)|(0, j))
∣∣∣∣∣ ≤≤ lim
ε→0
∑i 6=k|P ((ε, k)|(0, i))|+ |P ((ε, k)|(0, k))| · |P ((t, k)|(0, j))− P ((t, k)|(0, j))︸ ︷︷ ︸
=0
| = 0.
Die Gleichheit ∗ gilt durch die Chapman-Kolmogorov Gleichung. Damit ist die Funktion sogarüberall rechtsseitig stetig. Die linksseitige Stetigkeit folgt ganz analog.
3.1.2 Rechtsseitige Differenzierbarkeit von P bei 0
Um die Entwicklung fortzusetzen werden die Ausdrücke
limh→0+
P ((h, k)|(0, j))− P ((0, k)|(0, j))h
= limh→0+
P ((h, k)|(0, j))− δj,kh
untersucht.Was ad hoc nicht klar ist, existieren diese Ausdrücke und werden gemeinhin Übergangsratengenannt. Es gilt der folgende Satz:
Satz 3.1.3 (Existenz von Übergangsraten).Ist X(t) ein homogener, regulärer CTDS Markov-Prozess, insbesondere also wenn er die Be-dingungen 3.1.1 erfüllt, so gilt:Die Limiten
ωi,j := limh→0+
P ((h, j)|(0, i))h
und
ωi,i := limh→0+
P ((h, i)|(0, i))− 1
h
existieren und werden als Übergangsraten bezeichnet.Damit gilt
P ((h, j), (0, i)) = hωi,j +O(h2) und P ((h, i), (0, i)) = 1− hωi,i +O(h2).
Die Übergangsraten erfüllen überdies ∑j
ωi,j = 0.
Beweis: Der Beweis dazu (Großteils entnommen aus [Sch05]) ist sehr technischer Natur undwird zu Übersichtszwecken in mehreren Schritten geführt.
S 1 Sei zunächst i 6= j betrachtet:

26 KAPITEL 3. MASTER GLEICHUNG
S 1.1 Bevor der Beweis geführt wird wollen (nur für diesen Beweis) einige Abkürzungen ge-troffen werden:
pi,j(t) := P ((t, j)|(0, i)) = P (X(t) = j|X(0) = i)
pki,j(v, h) := P (X(vh) = j,X(uh) 6= k∀1 ≤ k < j|X(0) = i)
Letztere ist für v ∈ N definiert.Um gerade diesen Audruck ein wenig besser zu verstehen, kann man sich den Prozess mith zeitgetaktet in einer Art „Slot“-Notation vorstellen:
pi,j(vh) := P (X(kh)k∈1,...,v = [j, ·, ·, . . . , ·|i])
Wobei die zentralen Punkte illustrieren, dass diese Slots frei wählbar sind.
pki,j(vh) := P (X(kh)k∈1,...,v = [j,¬k,¬k, . . . ,¬k|i])
Ziel ist es nun, eine Formel zu finden, um pi,j(nh) alternativ auszudrücken. Klarerweiseist
pi,j(nh) = P ([j, ·, . . . , ·|i]) =
n−2∑u=0
P ([j, ·, . . . , ·, k,¬k,¬k, . . . ,¬k︸ ︷︷ ︸u
|i])+
+P ([j,¬k, . . . ,¬k|i]).
Die einzelnen Summanden lassen sich über den Satz für bedingte Wahrscheinlichkeit aus-drücken:
P (X(nh) = j|X(uh) = k,X((u− 1)h) 6= k, . . . ,X(h) 6= k,X(0) = i) =
=P (X(nh) = j,X(uh) = k,X((u− 1)h) 6= k, . . . ,X(h) 6= k|X(0) = i)
P (X((u+ 1)h) = k,X(uh) 6= k, . . . ,X(h) 6= k|X(0) = i).
Die linke Seite der eben beschriebenen Gleichung wird nach der Markov-Eigenschaft nurnoch vom letzten Zustand bedingt. Umformung liefert:
P ([j, ·, . . . , ·, k,¬k,¬k, . . . ,¬k︸ ︷︷ ︸u
|i]) = pk,j((n− u− 1)h)pki,k(u+ 1, h)
Man kann somit ersetzen:
pi,j(nh) =
n−2∑u=0
pk,j((n− u− 1)h)pki,k(u+ 1, h) + pki,j(n, h) (3.1)
Diese Formel gilt nun für beliebiges k ∈ Ω. Für k = j lässt sich der letzte Summanddurch pj,j(0) = 1 in die Summe ziehen:
pi,j(nh) =n−1∑u=0
pj,j((n− u− 1)h)pji,j(u+ 1, h).

3.1. EXISTENZ VON ÜBERGANGSRATEN 27
Für den letzten Term lässt sich eine ähnliche Aussage treffen wie der Satz von Chapman-Kolmogorov, was hier, sehr ähnlich zum Beweis des Originalsatzes mit Integralen, in„Slot“ Notation gezeigt ist. Es gilt
pji,j(n, h) = P ([j,¬j, . . . ,¬j|i︸ ︷︷ ︸n
]) =P ([j,¬j, . . . ,¬j, i])
P ([i])=
=∑k 6=j
P ([j, k,¬j, . . . ,¬j, i])P ([i])
=∑k 6=j
P ([
n−1︷ ︸︸ ︷k,¬j, . . . ,¬j, i])P ([j|k])
P ([i]),
nach dem Satz für bedingte Wahrscheinlichkeiten. Somit folgt
pji,j(n, h) =∑k 6=j
pji,k((n− 1)h)pk,j(h).
Setzt man dieses Resultat ein erhält man
pi,j(nh) =n−1∑u=0
pj,j((n− u− 1)h)∑k 6=j
pji,k(u, h)pk,j(h) ≥ (3.2)
≥ pi,j(h)n−1∑u=0
pj,j((n− u− 1)h)pji,i(u, h). (3.3)
Aus (3.1) folgt außerdem
pi,i(uh) =u∑v=1
pj,i((u− v)h)pji,j(v, h) + pji,i(u, h). (3.4)
Diese Resultate (3.3) und (3.4) waren das Ziel des ersten Unterpunkts.
S 1.2 Aus der Regularitätseigenschaft der Wahrscheinlichkeiten kann man nun für ein beliebi-ges ε > 0 ein h0 finden, dass die Eigenschaften:
pi,j(h) < ε, 1− pi,i(h) < ε, 1− pj,j(h) < ε
für alle h < h0 gelten. Kombiniert man nun die Endaussagen aus Punkt [1.1] und wähltnh < h0, erhält man
pi,j(nh) ≥ pi,j(h)
n−1∑u=0
pj,j((n− u− 1)h)pji,i(u, h) ≥
≥ pi,j(h)n−1∑u=0
(1− ε)pji,i(u, h). (3.5)

28 KAPITEL 3. MASTER GLEICHUNG
Aus Aussage (3.4) folgt
pji,i(u, h) = pi,i(uh)−u∑v=1
pi,j((u− v)h)pji,i(v, h) ≥
≥ pi,i(uh)− maxv∈1,...,u
(pj,i((u− v)h))
u∑v=1
pji,j(v, h) ≥
≥ 1− ε− εu∑v=1
pji,j(v, h) ≥ 1− 2ε.
Die letzte Summe ist stets kleiner gleich 1 da sogar∑v∈N
pji,j(v, h) = P (Zustand j wird irgendwann angenommen|i)
stets kleiner gleich eins ist. Setzt man diese Abschätzung nun in (3.5) ein, so erhält man
pi,j(nh) ≥ pi,j(h)n−1∑u=1
(1− ε)(1− 2ε) ≥ pi,j(h)n(1− 3ε).
Damit ist man bereits fast am Ziel. Division durch nh liefert die Aussage:Für alle ε > 0 existiert ein h0 sodass ∀h < h0 und alle n ∈ N gilt
pi,j(nh)
nh≥ pi,j(h)
h(1− 3ε)
S 1.3 Sei nun ε und, ohnehin davon abhängig, h0 fest und angenommen, dass limh→0 pi,j(h)/h =∞ so kann pi,j(h)/h durch Variation von h beliebig groß gemacht werden. Somit wirdnach der gezeigten Abschätzung auch pi,j(nh)/(nh) beliebig groß, unabhängig von derWahl von n. Sei nun n so gewählt, dass h0/2 ≤ nh < h0 so folgt
pi,j(hn)/(hn) < ε/(hn) < 2ε/h0.
Man erhält durch Widerspruch somit Beschränktheit und die Existenz von lim infh→0 undlim suph→0 des Ausdrucks, definiert nun als ai,j und bi,j . Gemäß Definition von lim supund lim inf erhält man sie als Limes zweier Teilfolgen
ai,j := limk→∞
pi,j(hak)/hak , bi,j := limk→∞
pi,j(hbk)/hbk
mit Nullfolgen hak und hbk . Gemäß Annahme gilt für den Quotienten
ai,jbi,j
= limk→∞
pi,j(hak)hbkpi,j(hbk)hak
.
Klarerweise kann man sich die beiden Folgen streng monoton fallend und hbk < hakdefinieren. Genauso sei der Quotient hak/hbk = O(1) definiert (z.B. über Teilfolgen).Man kann nun Chapman-Kolmogorov benutzen und erhält:
ai,jbi,j
= limk→∞
∑m
pi,m(hbk)pm,j(hak − hbk)hbkpi,j(hbk)hak
=

3.1. EXISTENZ VON ÜBERGANGSRATEN 29
= limk→∞
hbkhak
∑m 6=j
pi,m(hbk)pm,j(hak − hbk)
pi,j(hbk)+ pj,j(hak − hbk)
Da alle Limiten existieren müssen, kann man den Ausdruck zerlegen und getrennt zumLimes übergehen.
ai,jbi,j
= limk→∞
hbkhak
∑m 6=j
pi,m(hbk)pm,j(hak − hbk)
pi,j(hbk)
+ 1 =
= limk→∞
∑m 6=j
pi,m(hbk)pm,j(hak − hbk)
pi,j(hbk)+ 1 ≥ 1
Man erhält somit ai,j/bi,j ≥ 1. Da aber stets lim inf ≤ lim sup gilt folgt hier ai,j =bi,j . Somit muss lim sup = lim inf = lim gelten und damit ist die Existenz des Limesbewiesen. Da er als Quotient zweier positiver Zahlen entsteht, muss er auch positiv sein.Man erhält die Existenz einer positiven Übergangsrate ωi,j .
S 2 Ausgehend von der Existenz der Übergangsraten ωi,j mit i 6= j ist nun die Existenz derRate ωi,i zu zeigen.
pi,i(h)− 1
h=
1−∑
j 6=i pi,j(h)− 1
h= −
∑j 6=1
pi,j(h)
h
Da die Limiten aller Summanden existieren, folgt einerseits die Existenz des Limeslimh→0+
pi,i(h)−1h und andererseits sofort die Formel
ωi,i = −∑j 6=i
ωi,j < 0. (3.6)
Die Aussage (3.6) ist wichtig und wird in den Folgekapiteln noch des öfteren verwendet.Mithilfe von
limh→0
pi,j(h)− pi,j(0)− hωi,jh
= 0
folgt schon pi,j(h) = δi,j + hωi,j + o(h). Für die Folgerung
pi,j(h) = δi,j + hωi,j +O(h2)
sei auf die Literatur ( [Sch05]) verwiesen.
Bemerkung 3.1.4.Anzumerken ist, dass hier ob des Definitionsbereiches der Funktion nur ein einseitiger Grenz-wert gefordert ist. Die Eigenschaft, die zu zeigen war, ist somit nicht äquivalent zur stetigenDifferenzierbarkeit der bedingten Wahrscheinlichkeit bei 0 und schon gar nicht zur Differen-zierbarkeit der Funktion P selbst. Sie ist aber dennoch nicht trivial (vgl. Wurzelfunktion).

30 KAPITEL 3. MASTER GLEICHUNG
Ist eine Übergangsrate ωj,k von einem Zustand in einen anderen groß, so bedeutet das, dassder Prozess stark tendiert, in diesen Zustand zu wechseln. Ist sie klein, ist wohl eher ein andererZustand bevorzugt, oder der Prozess wird länger in seinem Zustand bleiben. Ist die Übergangs-rate ω·,k = 0 so wird der Prozess fast sicher nicht in den Zustand k übergehen. Ist andererseitsωk,k = 0 so wird der Prozess diesen Zustand fast sicher nicht mehr verlassen. Ist im Gegenteildazu ωk,k << 0 stark negativ, wird der Zustand k mit hoher Wahrscheinlichkeit bereits nachsehr kurzer Zeit wieder verlassen.
Bemerkung 3.1.5.Der Begriff der Übergangsrate lässt sich auch auf CS Markov-Prozesse erweitern. Man bezeich-net die resultierende stetige Funktion ω(i, j) in diesem Fall Übergangskern.
Man kann schon erkennen, dass die Übergangsraten allein bereits den Verlauf des Markov-Prozesses bestimmen. Mehr noch wird das in der sogenannten Mastergleichung deutlich.
3.2 Mastergleichung
Mit den Voraussetzungen 3.1.1 und dem Wissen über die Existenz von Übergangsraten ωi,jlässt sich nun die Chapman-Kolmogorov Gleichung umformen. Es folgt daraus die sogenannteMastergleichung.
Satz 3.2.1 (Mastergleichung/ Master Equation).Die Wahrscheinlichkeitsfunktion P (t, j) eines homogenen, regulären, CT Markov-Prozesses iststetig nach der Zeit differenzierbar.Die Ableitung erfüllt im ortskontinuierlichen Fall
dP (t, j)
dt=
∫ΩP (t, k)ωk,j − P (t, j)ωj,kdk, j ∈ Ω, t > 0,
wobei die Übergangsraten hier als Übergangskerne verstanden sein mögen, oder im ortsdiskretenFall
dP (t, j)
dt=
n∑k=0
P (t, k)ωk,j − P (t, j)ωj,k, j ∈ Ω = 0, . . . , n, t > 0
die sogenannte Mastergleichung.
Beweis: In diesem Abschnitt ist nur der ortsdiskrete Fall bewiesen da in Folge nur noch dieserbenötigt wird. 1 Den ortskontinuierlichen Fall kann man analog zeigen.
1Der Beweis ist dem Buch [Aok02] nachempfunden

3.2. MASTERGLEICHUNG 31
Nach der Gleichung von Chapman-Kolmogorov und dem Satz der totalen Wahrscheinlichkeitgilt
P (t+ h, j) =∑k∈Ω
P ((h, j)|(0, k))P (t, k) =
=∑k 6=j
P ((h, j)|(0, k))P (t, k) + P ((h, j)|(0, j))P (t, j) =
=∑k 6=j
P ((h, j)|(0, k))P (t, k) +
1−∑k 6=j
P ((h, k)|(0, j))
P (t, j) =
= P (t, j) +∑k 6=j
P (t, k)P ((h, j)|(0, k))− P (t, j)P ((h, k)|(0, j)).
Geht man zur Schreibweise mit Übergangsraten über, so erhält man
P (t+ h, j)− P (t, j) =∑k 6=j
P (t, k)hωk,j − P (t, j)hωj,k +O(h2).
Division durch h und der Limes h → 0 liefert den rechtsseitigen Differenzialquotienten. DaP (t, k)ωk,k −P (t, k)ωk,k = 0 gilt, kann man den ausgeklammerten Summanden optional nochdazunehmen, da es die Schreibweise vereinheitlicht.Geht man von P (t, j) aus und führt die Chapman-Kolmogorov Gleichung für P (t − h, ·) aus,erhält man, unter Ausnutzung der Stetigkeit von P , den linksseitigen Differenzialquotienten, dermit dem rechtsseitigen übereinstimmt.
Bemerkung 3.2.2.Im ortsdiskreten Fall lässt sich diese Differentialgleichung auch wie folgt in Matrixform schrei-ben.
P ′(t) = QP (t)
Dabei gilt P := [P (t, 0), P (t, 1), . . . , P (t, n)]T und
Q := (qi,j) :=
ωi−1,j−1, i 6= j
−∑
k 6=i−1 ωi−1,k = ωi−1,i−1, i = j.
(Kolmogorov’sche Rückwärtsgleichung)Lösungen dieser erfüllen überdies
P ′(t) = P (t)Q.
(Kolmogorov’sche Vorwärtsgleichung)Die Matrix Q wird klassisch als Übergangsmatrix bezeichnet.
Man erhält die vermutete Aussage, dass Markov-Prozesse von ihren Übergangsraten ein-deutig bestimmt sind. Ausgehend von einer Anfangsdichte kann man also für jeden Zustand undjede Zeit durch das DG-System die Wahrscheinlichkeitsdichte berechnen und benötigt lediglichWissen über die Anfangskonfiguration und die Übergangsraten. Man befindet sich an dem in

32 KAPITEL 3. MASTER GLEICHUNG
Kapitel 2 erwähnten Punkt, dass mit rein analytischen Mitteln die Verteilung des stochastischenModells errechnet werden könnte.Leider ist im allgemeinen die Anzahl der Zustände sehr groß und die Differentialgleichung starkgekoppelt, womit sie kaum lösbar wird. Nachdem das Prinzip im Anschluss auf agentenbasierteModellierungen angewendet werden soll, kann man aber die Gleichung sowie die Bedingungen3.1.1 weiterentwickeln.
3.3 Kramers Moyal Entwicklung
3.3.1 Voraussetzungen
Man betrachtet nun ein mikroskopisches Modell bestehend aus N Agenten A1, . . . , AN mitgemeinsamen endlichen Zustandsraum 0, 1, . . . , d, wobei der Zustand jedes dieser Agenteneinem CTDS Markov-Prozess m1(t), . . . ,mN (t) folgt.
mi(t) : [0, tend]→ 0, 1, . . . , d
Nachdem als Ergebnis der stochastischen Mikrosimulation kaum der Pfad eines einzelnen Markov-Prozesses von Interesse ist, sei die ZustandsvariableXk(t) definiert als die Summe aller Agentenim selben Zustand zum Zeitpunkt t.
Xk(t) :=
N∑i=1
δmi(t),k
Wie bewiesen, ist auch dieser Prozess markovsch, und gemäß Satz 2.3.4 dürften die Übergangs-raten dieser Agenten auch vom Zustandsvektor abhängen. Es sind also Markov-Prozesse mitbedingten Wahrscheinlichkeiten der Form
P (mi(t+ h) = j) = P (mi(t+ h) = j|mi(t), ~X(t))
zulässig. D.h. insbesondere dürfen auch die Übergangsraten vom Zustandsvektor abhängen.Es gilt nun
Xk : [0, tend]→ 0, . . . , N.
Des weiteren wird in Folge bevorzugt der zugehörige normierte Markov-Prozess betrachtet
xk(t) =Xk(t)
N: [0, tend]→ 0, N−1, . . . , 1,
dessen Wahrscheinlichkeitsfunktion bzw. Dichte pk nun „fast“ schon stetig auf [0, 1] ist.In Folge wird die eben erwähnte Dichte pk des normierten Prozesses nach allen Regeln der Kunstauf vielerlei Arten Taylor-entwickelt und umgeformt, ohne das tatsächlich tun zu dürfen. DieDichte (Wahrscheinlichkeitsfunktion) ist für endliches, wenn auch großes, N immer noch le-diglich auf einer diskreten Menge definiert und dementsprechend natürlich nirgends bzgl. derOrtsvariablen differenzierbar. Diese Probleme lassen sich zwar mit Interpolationsargumentenunter Inkaufnahme von gewissen Fehlern außer Kraft setzen, doch verwirren diese an dieser

3.3. KRAMERS MOYAL ENTWICKLUNG 33
Stelle nur. Dafür sei auf das Kapitel 3.5 verwiesen. Man setzt also zum jetzigen Zeitpunkteinfach hinreichende Regularität der Dichte vorraus, womit die Interpolationsbedingungenhinterher auf natürliche Weise entstehen und nachvollziehbarer sind.Zusätzlich wird der Beweis bzw. die Entwicklung dem Buch [Aok02] nachempfunden, zunächstfür ein eindimensionales Problem geführt - d.h.mk(t) = 0 oder 1 D.h. es existieren genau zweiZustände, wobei der Zustandsvektoreintrag des zweiten Zustandes aus jenem des Ersten folgt.Der mehrdimensionale Fall ist unübersichtlich, funktioniert aber analog. Diese Resultate werdenim Kapitel 5 behandelt.
Bedingung 3.3.1.(Voraussetzungen für Kapitel 3.3.)
Bezeichnung DefinitionN Anzahl der Agenten/Markov-Prozesse
A1, . . . , AN Agentenm1(t), . . . ,mN (t) Markov-Prozesse
mk(t) : [0, tend]→ 0, 1 Raum der ProzesseX(t) =
∑Ni=1 δmi(t),1 Anzahl der Agenten im Zustand 1
P (k, t) : 0, 1, . . . , N × [0, tend]→ [0, 1] Wahrscheinlichkeitsfunktion von X(t)
x(t) := X(t)N normierter Prozess
p(kN−1, t) ∈ C∞([0, 1]× [0, tend], [0, 1]) Dichte des normierten Prozessesunter Vorraussetzung von Regularität
und Anfangswerti, j, k ∈ 0, 1, . . . , N Variablen aus dem Zustandsraum
x, y, z ∈ [0, 1] Variablen aus dem erweiterten,normierten Raum
ωk,j Übergangsraten der Zustandvariable X(t)ωk,j = ω(k, j) : 1, . . . , N2 → R Definitions/Zielbereich der RatenX(0) = k0, x(0) = k0
N = x0 Anfangswert der Prozesse
Nutzt man nun die Eigenschaft, dass p, wie in 3.5 definiert 2, immer noch Wahrscheinlich-keitsfunktion eines DS Markov-Prozesses ist, gilt für diese genauso die Mastergleichung
p′(t, x) =∑
y 6=x,y∈0,N−1,...,1
p(t, y)ωy,x − p(t, x)ωx,y, ∀x ∈ 0, N−1, . . . , 1. (3.7)
Hierbei steht ω für die Übergangsraten des normierten Prozesses.
Bemerkung 3.3.2.Überdies ist hier, sowie auch in Folge, die Variable x nicht mit dem Prozess selbst zu ver-wechseln. Die Wahl der Variable führt darauf zurück, dass x am besten den Raum-Unterschiedverdeutlicht, da es nun im Gegensatz zu k für eine kontinuierliche Größe steht.
2d.h. die Werte der interpolierten Dichte und der diskreten Wahrscheinlichkeitsfunktion stimmen bei allenN−1k bis auf einen sich kürzenden Faktor N überein

34 KAPITEL 3. MASTER GLEICHUNG
Überlegt man sich nun, dass
P (X(t) = k|X(0) = k0) = P
(X(t)
N=
k
N|X(0)
N=k0
N= x0
)= p
(x(t) = N−1k|x(0) = x0
)gilt, lassen sich die Übergangsraten des normierten und des ursprünglichen Markov-Prozessestrivial ineinander überführen.
ωx,y = ωNx,Ny
Es gilt somit
p′(t, x) =∑
y 6=x,y∈0,N−1,...,1
p(t, y)ωNy,Nx − p(t, x)ωNx,Ny, ∀x ∈ 0, N−1, . . . , 1.
3.3.2 Taylorentwicklung
Gegen Mitte des 19.Jahrhunderts entwickelten der niederländische Physiker Hendrik Kramersund der in Jerusalem geborene Australier José Enrique Moyal die Idee, die Dichtefunktion inihrer Mastergleichung (dort in Integralform), die bei deren Arbeit durch Aufenthaltswahrschein-lichkeiten von „Random-Walk“-Teilchen entstand, bzgl. der Sprungweite in eine Taylorreihe zuentwickeln.
Definition 3.3.3 (Sprungweite).Die Sprungweite R für einen CTDS Markov-Prozess, der in einem Zeitpunkt die Möglichkeithat, vom Zustand k in den Zustand j überzugehen, ist definiert als
R := k − j
Damit erhält man für Nx−Ny = R die Taylorreihenentwicklung:
p(t, y)ωNy,Ny+R =
= p(t, x)ωNx,Nx+R +−RN
∂p(t, x)ωNx,Nx+R
∂x+
(−R)2
2N2
∂2p(t, x)ωNx,Nx+R
∂x2+ . . .
Die Taylorreihenentwicklung kann man im Fall von Kramers und Moyal auch sinngemäß recht-fertigen, da nicht anzunehmen ist, dass sich Teilchen innerhalb eines kleinen Zeitintervalls sehrweit von ihrem Ausgangspunkt entfernen. Auch hier ist diese Rechtfertigung durchaus zutref-fend, wenn man annimmt, dass sich die Zustandsvariable der Mikrosimulation weitestgehendstabil verhält. Später wird dieser Gedanke sogar noch erweitert.Setzt man die Taylorentwicklung in die Mastergleichung ein, so erhält man
p′(t, x) =∑R 6=0
∑m≥0
(−R)m
m!Nm
∂mp(t, x)ωNx,Nx+R
∂xm
− p(t, x)ωNx,Nx−R =

3.4. FOKKER-PLANCK-GLEICHUNG 35
= p(t, x)∑R 6=0
(ωNx,Nx+R − ωNx,Nx−R)︸ ︷︷ ︸I
+∑R 6=0
∑m>0
(−R)m
m!Nm
∂mp(t, x)ωNx−R,Nx∂xm︸ ︷︷ ︸
II
.
I Da über alle R 6= 0 Summiert wird vereinfacht sich Ausdruck I zu∑R 6=0
(ωNx,Nx+R − ωNx,Nx−R) =∑R 6=0
ωNx,Nx+R −∑R 6=0
ωNx,Nx+R = 0.
II Der einzig übrige Teil der Gleichung ist dann∑R 6=0
∑m>0
(−R)m
m!Nm
∂mp(t, x)ωNx,Nx+R
∂xm=
=∑m>0
1
m!Nm
∂mp(t, x)∑
R 6=0(−R)mωNx,Nx+R
∂xm.
Die Gleichung
p′(x, t) =∑m>0
1
m!Nm
∂mp(t, x)∑
R 6=0(−R)mωNx,Nx+R
∂xm, ∀x ∈ 0, N−1, . . . , 1 (3.8)
war das Ziel dieser Entwicklung. Man beachte hier for allem, wie das N in negativer Potenzvorkommt, und geschlossene Momentenfunktionen mit den Übergangsraten entstehen.Ähnlich wie für die Dichte selbst, muss ab sofort auch von den Übergangsraten stetige Differen-zierbarkeit bzgl. x verlangt werden. D.h.:
ωNx,Nx+R = ω(x,R) : [0, 1]× R1, R2, . . . , RN → R, ω ∈ C∞([0, 1],R).
Sinngemäß seien die Voraussetzungen 3.3.1 erweitert. Rechtfertigung für die Differenzierbarkeitliefert ein Interpolationsargument, welches in Kapitel 3.5 zu finden ist.
3.4 Fokker-Planck-Gleichung
3.4.1 Polynomdarstellung für die Übergangsraten
Ziel dieses Unterkapitels ist es nun, die komplette Abhängigkeit von N aus den Übergangsratenherauszuziehen. Hierzu verlangt man von den mittlerweile als stetig differenzierbar vorausge-setzten Übergangsraten die folgende Darstellungsform:
Bedingung 3.4.1.
ωNx,Nx+R = f(N)(Φ1(x,R) +N−1Φ2(x,R) +N−2Φ3(x,R) + . . . )
mit f(N) > 0 und Φi(x,R) mindestens zweimal stetig differenzierbar, beschränkt und unab-hängig von N . In den meisten Fällen gilt f(N) = N oder f(N) = 1.

36 KAPITEL 3. MASTER GLEICHUNG
Diese Bedingung ist nicht besonders scharf. Meistens treten die Raten ohnehin als Polynomein N auf und lassen sich dementsprechend nach N−1 Taylor-entwickeln.Einsetzen in die umgeformte Mastergleichung 3.8 liefert:
p′(x, t) =∑m>0
f(N)
m!Nm
∂mp(t, x)∑
R 6=0(−R)m(Φ1(x,R) +N−1Φ2(x,R) + . . . )
∂xm.
Mittlerweile wird der Grundgedanke, mit dem diese Umformungen verbunden sind, klar. Ei-nerseits sind für große Agentenzahlen N die Ausdrücke N−k, k ∈ N klein, und durch die be-schränkten und vonN unabhängigen Funktionen kann man Abschätzungen mitO(N−k) durch-führen. Andererseits entwickelt man auf diese Art und Weise Gleichungen, die nur noch direktvon der Agentenzahl abhängen, sodass deren Lösungen für unterschiedliche Agentenzahlen ver-gleichbar werden.Den gegebenenfalls störenden Term f(N) eliminiert man mit der Zeittransformation:
τ =f(N)
Nt. (3.9)
Da die entstehende Ableitung nur auf der linken Seite durch die innere Ableitung einen neuenTerm hervorbringt, der sich mit einem Term auf der rechten Seite kürzt, erhält man:
∂p(x, τ)
∂τ=∑m>0
1
m!Nm−1
∂mp(τ, x)∑
R 6=0(−R)m(Φ1(x,R) +N−1Φ2(x,R) + . . . )
∂xm
(3.10)Selbst, wenn man nun Terme mit negativer Potenz in N vernachlässigte, erhielte man „ nur “eine partielle Differenzialgleichung. Um das in den Griff zu bekommen, bedient man sich einesTricks.
3.4.2 Substitution der Variable x
Man definiere eine Funktion (Zufallsvariable) ξ(τ) und eine Hilfsfunktion φ(τ), beide mindes-tens einmal stetig differenzierbar, durch
x = φ(τ) +N−12 ξ
Die bislang unabhänige Variable wird damit auf einmal zeitabhängig. Um die Zerlegung eindeu-tig zu definieren, müssen zunächst die Startwerte φ(0), ξ(0) bestimmt werden. Da zum Zeitpunkt0 der Markov-Prozess den Wert x0 fast sicher annimmt gilt auf jeden Fall x0 = φ(0)+N−
12 ξ(0).
Es macht also Sinnφ(0) = x0, und ξ(0) = 0 fast sicher
zu definieren. Die Dichte p(τ, x) wird nun unter
Π(τ, ξ) := p(τ, φ(τ) +N−12 ξ(τ))

3.4. FOKKER-PLANCK-GLEICHUNG 37
weitergeführt. Zusätzlich gilt die Gleichung:
0 =∂φ(τ)
∂τ+N−
12∂ξ(τ)
∂τ.
Vor den allerletzten Umformungen werden noch einmal die gesammelten Voraussetzungen undBedingungen zusammengefasst.
Bedingung 3.4.2.(Voraussetzungen für Kapitel 3.4.2.)
Bezeichnung DefinitionN Anzahl der Agenten/Markov-Prozesse
A1, . . . , AN Agentenm1(t), . . . ,mN (t) Markov-Prozesse
mk(t) : [0, tend]→ 0, 1 Raum der ProzesseX(t) =
∑Ni=1 δmi(t),1 Anzahl der Agenten im Zustand 1
P (k, t) : 0, 1, . . . , N × [0, tend]→ [0, 1] Wahrscheinlichkeitsfunktion von X(t)
x(t) := X(t)N normierter Prozess
p(kN−1, t) ∈ C∞([0, 1]× [0, tend], [0, 1]) Dichte des normierten Prozessesunter Vorraussetzung von Regularität
und Anfangswerti, j, k ∈ 0, 1, . . . , N Variablen aus dem Zustandsraum
x, y, z ∈ [0, 1] Variablen aus dem erweiterten,normierten Raum
R := k − j = Ny −Nx Sprungweiteωk,j Übergangsraten der Zustandvariable X(t)
ωk,j = f(N)(Φ1(x,R) +N−1Φ2(x,R) + . . . ) Polynomdarstellung der RatenΦi(x,R) : [0, 1]× R1, . . . → [−c, c] beschränkt und
Φi ∈ C∞([0, 1], [−c, c]) stetig differenzierbarX(0) = k0, x(0) = k0
N = x0 Anfangswert der Prozesseτ = N−1f(N)t Zeittransformation
x = φ(τ) +N−12 ξ(τ) Substitution
Π(τ, ξ) := p(τ, x) neue Dichteφ(0) = x(0), ξ(0) = 0 Anfangswert
Nach der Kettenregel lassen sich die Ableitungen nun neu bestimmen
∂p(φ(τ) +N−12 ξ(τ), τ)
∂τ=∂Π(ξ, τ)
∂ξ
∂ξ(τ)
∂τ+∂Π(ξ, τ)
∂τ=
= −√N∂Π(ξ, τ)
∂ξ
∂φ(τ)
∂τ+∂Π(ξ, τ)
∂τ.

38 KAPITEL 3. MASTER GLEICHUNG
Die letzte Gleichheit ist der Schlüssel dazu, eine gewöhnliche Differentialgleichung von derpartiellen DG 3.10 abzuspalten. Desweiteren gilt
∂mp(φ(τ) +N−12 ξ(τ), τ)
∂xm=∂mΠ(ξ, τ)
∂ξm
(∂√N(x− φ)
∂x
)m=
=∂mΠ(ξ, τ)
∂ξmN
m2 .
Einsetzen in 3.10 liefert
−√N∂Π(ξ, τ)
∂ξ
∂φ(τ)
∂τ+∂Π(ξ, τ)
∂τ=
=∑m>0
Nm2
m!Nm−1
∂mΠ(τ, ξ)∑
R 6=0(−R)m(Φ1(x,R) +N−1Φ2(x,R) + . . . )
∂ξm=
=∑m>0
N−m2
+1
m!
∂mΠ(τ, ξ)∑
R 6=0(−R)m(Φ1(x,R) +N−1Φ2(x,R) + . . . )
∂ξm.
Man erkennt leider immer noch störende x Terme innerhalb der Übergangsraten. Diese werdenebenfalls mittels Taylorentwicklung von x bei φ(τ) eliminiert:
Φi(x,R) = Φi(φ(τ), R) +N−12 ξ(τ)(Φi)x(φ(τ), R) +O(N−1)
Ab dieser Stelle kann man die Gleichung auf Grund ihres Umfanges nicht mehr in ihrer Ge-samtheit betrachten. Man erkennt innerhalb der unendlichen Summen genau einen Term, sowohllinks, als auch rechts, der eine postive Potenz inN , genauer
√N , als Faktor hat, und einen Term
links sowie zwei Terme rechts der Ordnung N0. Alle weiteren Terme sind zu einem O(N−12 )
zusammengefasst:
−√N∂Π
∂ξ
∂φ
∂τ+∂Π
∂τ=√N
∂Π
ξ
∑R 6=0
Φ1(φ,R)(−R)
+
+
∂Π
∂ξ
∑R 6=0
(Φ1)x(φ,R)(−R) +∂2Πξ
∂ξ2
∑R 6=0
Φ1(φ,R)(−R)2
+O(N−12 )
3.4.3 Resultierende Gleichungen
Die wichtigste Aussage dieser Gleichung ist nun, dass bei einem Koeffizientenvergleich bzgl.Nder Terme höchster Ordnung die partielle Ortsableitung der Dichte Π wegfällt und nur noch derTerm
∂φ
∂τ=∑R 6=0
Φ1(φ,R)R (3.11)

3.5. INTERPOLATION 39
übrig bleibt. Die Lösung dieser ODE erster Ordnung liefert nun den zeitlichen Verlauf der Kurveφ mit Anfangswert φ(0) = x0 bei bekannten Übergangsraten für X . Die Bedeutung und Wich-tigkeit dieser Kurve wird im Kapitel 4 besprochen.Hat man die Lösung der Gleichung 3.11 gefunden, so dominieren in der partiellen DG nur nochdie Terme 0-ter Ordnung. Man erhält
∂Π
∂τ=∂Π
∂ξ
∑R 6=0
(Φ1)x(φ,R)(−R) +∂2Πξ
∂ξ2
∑R 6=0
Φ1(φ,R)(−R)2. (3.12)
Diese partielle Differentialgleichung erlaubt es nun, sofern sie lösbar ist, eine mit OrdnungN−
12 approximative Lösung der Dichte p(t, x) zu ermitteln, indem man hinterher die Argu-
mente rücksubstituert. Gleichungen dieser, bzw. erweitert definiert sogar der Form
∂u(x, t)
∂t=∂u(x, t)a(x, t)
∂x+∂2u(x, t)b(x, t)
∂x2
werden klassischerweise Fokker-Planck-Gleichung genannt. Es seien aus diesem Anlass dieGrößen:
α(φ) :=∑R 6=0
Φ1(φ,R)R⇒ φτ = α(φ)
undαx(φ) := −
∑R 6=0
(Φ1)x(φ,R)R, β(φ) :=1
2
∑R 6=0
Φ1(φ,R)R2
definiert.⇒ Πτ = (Πξ)ξξβ(φ) + Πξαx(φ)
Es ist nun an der Zeit, die durchgeführten Umformungen, respektive die Bedingungen 3.3.1 und3.4.2 zu rechtfertigen.
3.5 Interpolation
3.5.1 Histogramm
Geht man lediglich von den Bedingungen 3.1.1 aus, sind sämtliche Umformungen der Master-gleichung, die im Anschluss vorgenommen wurden, schlichtweg falsch. Einerseits wurde diegemäß 3.1.1 als diskrete Wahrscheinlichkeitsfunktion definierte Dichte p(t, x) als beliebig oftstetig bzgl. der Ortsvariable differenzierbar angenommen. Andererseits wurde selbiges in 3.4.2auch von den Raten gefordert. Es wird nun gezeigt, dass die Mastergleichung nicht zwingendauf die diskrete Dichte p angewandt werden muss, damit das Resultat schlussendlich für allediskreten Werte aus dem Zustandsraum von x(t) korrekt ist und trotzdem Aussagen über diediskrete Wahrscheinlichkeitsfunktion zulässig sind. Es wird in Folge das Zeitargument, da nichtvon Bedeutung, in diesem Kapitel meist weggelassen.Im Allgemeinen führt der Weg von der diskreten Wahrscheinlichkeitsfunktion zu einer kontinu-ierlichen Dichte nicht an der Diracverteilung bzw. dem Begriff der Deltadistibution vorbei.Ist
p : 20,N−1,...,1 → [0, 1] : A 7→ p(A)

40 KAPITEL 3. MASTER GLEICHUNG
eine diskrete Wahrscheinlichkeitsfunktion, so ist
pd : [0, 1]→ [0, 1] : x 7→ pd(x) :=∑
k∈0,N−1,...,1
p(k)δ0(x− k)
die zugehörige Dichtefunktion auf dem erweiterten kontinuierlichen Bereich [0, 1], denn es gilt∫A⊆0,N−1,...,1
pd(x)dx =∑x∈A
p(x) = p(A).
In diesem Fall wählt man jedoch einen anderen Zugang. Man definiere:
pcont : [− 1
2N, 1 +
1
2N]→ [0, 1] :
x 7→ pcont(x) :=∑
k∈0,N−1,...,1
1[k− 12N
,k+ 12N
](x)Np(x)
Die so definierte, kontinuierliche (wenn auch noch lange nicht differenzierbare) Funktion erfüllt∫ kN−1+ 12N
kN−1− 12N
pcont(x)dx = p(kN−1)
sowie ∫ 1+ 12N
− 12N
pcont(x)dx = 1 =N∑k=0
p(kN−1) = p(Ω).
Sie ist also eine Wahrscheinlichkeitsdichte. Am leichtesten stellt man sich dieses Konstrukt inForm eines Histogrammes dar. Eine Skizze dazu findet sich in Abbildung 3.1.Um die weitere Vorgehensweise rechtzufertigen sei noch einmal daran erinnert, dass das Zieldes Verfahrens ist, ein besseres Verständnis der Verteilung zu gewinnen. Insbesondere also sinddie Größen Erwartungswert und Varianz von Bedeutung.
Definition 3.5.1 (Erwartungswert einer Zufallsvariable).Sei X eine Zufallsvariable auf Ω verteilt mit Dichte (Wahrscheinlichkeitsfunktion) P so be-zeichnet man die deterministische Größe
E(X) :=
∫ΩP (X)XdX
als Erwartungswert der Zufallsvariable. Ist Ω diskret, so geht das Integral bzgl. dem Zählmaß ineine Summe über.

3.5. INTERPOLATION 41
Definition 3.5.2 (Varianz einer Zufallsvariable).SeiX eine Zufallsvariable auf Ω verteilt mit Dichte(Wahrscheinlichkeitsfunktion) P so bezeich-net man die deterministische Größe
V(X) :=
∫ΩP (X)(X − E(X))2dX
als Varianz der Zufallsvariable. Ist Ω diskret, so geht das Integral bzgl. dem Zählmaß in eineSumme über.
Das Besondere an der Wahl der, auf diese Art kontinuierlich definierten, Dichte ist nun, dassErwartungswert und Varianz mit nur kleinen Fehlern (N sei weiterhin als „groß“ angenommen)erhalten bleibt: Sei xcont eine mit der Dichte pcont Verteilte, kontinuierliche Zufallsvariable mitWerten in [− 1
2N , 1 + 12N ] so gilt:
E(xcont) =
∫ 1+ 12N
− 12N
pcont(x)xdx =N∑k=0
∫ kN−1+ 12N
kN−1− 12N
xNp(kN−1)dx =
=
N∑k=0
p(kN−1)N
∫ kN−1+ 12N
kN−1− 12N
xdx =
N∑k=0
p(kN−1)kN−1 = E(x).
Um Ähnliches für die Varianz zu erhalten, wird der Verschiebungssatz von Steiner definiert undbewiesen.
Satz 3.5.3 (Verschiebungssatz von Steiner).Sei X eine Zufallsvariable so gilt
V(X) = E(X2)− E(X)2
sofern beide Ausdrücke existieren.
Beweis:V(X) = E((X − E(X))2) = E(X2 − 2E(X)X + E(X)2) =
= E(X2)− 2E(E(X)X) + E(E(X)2) = E(X2)− 2E(X)E(X) + E(X)2E(1) =
= E(X2)− 2E(X)2 + E(X)2 = E(X2)− E(X)2

42 KAPITEL 3. MASTER GLEICHUNG
Gemäß dem Verschiebungssatz von Steiner 3.5.3 gilt für die Varianz:
E(x2cont) =
N∑k=0
p(kN−1)N
∫ kN−1+ 12N
kN−1− 12N
x2dx =∗
=∗
N∑k=0
p(kN−1)(kN−1)2 +O(N−2) = E(x2) +O(N−1)
⇒ V(xcont) = V(x)+O(N−1)
Die Gleichheit ∗ rechnet sich leicht nach:
N
∫ kN−1+ 12N
kN−1− 12N
x2dx = N(kN−1 + 1
2N )3 − (kN−1 − 12N )3
3=
= NN−1
((kN−1 + 1
2N )2 + (kN−1 + 12N )(kN−1 − 1
2N ) + (kN−1 − 12N )2
)3
=
=(kN−1)2 + 1
4N2 + (kN−1)2 − 14N2 + (kN−1)2 + 1
4N2
3= (kN−1)2 +
1
12N2
Man sieht, dass die wesentlichen Größen, die zum Arbeiten mit einer Verteilung von Nöten sind,bis auf ein O(N−1) erhalten bleiben. Kennt man also Erwartungwert und Varianz von xcont, soauch approximativ von x.Die definierte Funktion pcont ist also eine kontinuierliche Dichte, die die wichtigsten Parameterder diskreten Verteilung approximiert.
3.5.2 Differenzierbare Approximation
Ausgehend von der Histogramm-artigen, stückweise konstanten Dichte, kann man versuchen,diese mit einer hinreichend oft differenzierbaren Funktion zu approximieren. Man überlegt zu-nächst, welche Bedingungen an die Approximationsfunktion pi gestellt werden müssen:
Bedingung 3.5.4.(Interpolationsbedingungen).
pi sei hinreichend (beliebig) oft differenzierbar.Die Bedingung wird für die Kramers-Moyal Entwicklung benötigt.
pi : [− 12N , 1 + 1
2N ]→ [0, 1]
pi(x) = Np(x), ∀x ∈ 0, N−1, . . . , NDa die Dichte pi (noch nicht einmal die Dichte pcont) keinen Markov-Prozess beschrei-ben muss, gilt auch nicht zwingend die Mastergleichung. Die hier geforderte Relation zwi-schen pi und p erlaubt das Einsetzen immerhin für gewisse diskrete Punkte (0, N−1, . . . , 1).
∫ kN−1+ 1
2N
kN−1− 12N
pi(x)dx = p(kN−1)
Mit dieser Bedingung ist die Funktion pi erst eine Dichte.
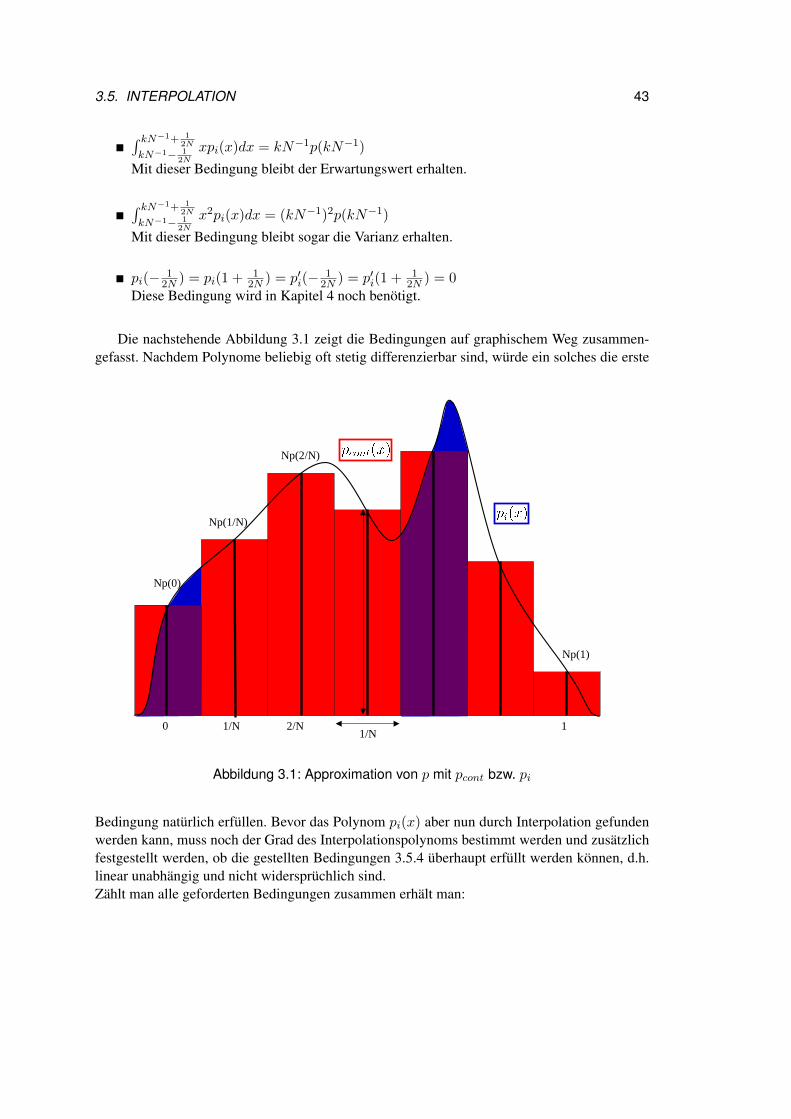
3.5. INTERPOLATION 43
∫ kN−1+ 1
2N
kN−1− 12N
xpi(x)dx = kN−1p(kN−1)
Mit dieser Bedingung bleibt der Erwartungswert erhalten.
∫ kN−1+ 1
2N
kN−1− 12N
x2pi(x)dx = (kN−1)2p(kN−1)
Mit dieser Bedingung bleibt sogar die Varianz erhalten.
pi(− 12N ) = pi(1 + 1
2N ) = p′i(− 12N ) = p′i(1 + 1
2N ) = 0Diese Bedingung wird in Kapitel 4 noch benötigt.
Die nachstehende Abbildung 3.1 zeigt die Bedingungen auf graphischem Weg zusammen-gefasst. Nachdem Polynome beliebig oft stetig differenzierbar sind, würde ein solches die erste
0 1/N 2/N 1
Np(2/N)
Np(1/N)
Np(0)
Np(1)
1/N
Abbildung 3.1: Approximation von p mit pcont bzw. pi
Bedingung natürlich erfüllen. Bevor das Polynom pi(x) aber nun durch Interpolation gefundenwerden kann, muss noch der Grad des Interpolationspolynoms bestimmt werden und zusätzlichfestgestellt werden, ob die gestellten Bedingungen 3.5.4 überhaupt erfüllt werden können, d.h.linear unabhängig und nicht widersprüchlich sind.Zählt man alle geforderten Bedingungen zusammen erhält man:

44 KAPITEL 3. MASTER GLEICHUNG
Anzahl Bedingungen Typ der BedingungN klassische InterpolationspunkteN Bedingungen an die Stammfunktion von pi(x)N Bedingungen an die mit x multiplizierte SF von pi(x)N Bedingungen an die mit x2 multiplizierte SF von pi(x)4 Bedingungen an den Rand
4N + 4 Polynomgrad des Interpolationspolynoms
Damit folgt formal angeschrieben
pi(x) =4N+4∑n=0
anxn.
Es werden nun für alle Typen von Bedingungen die resultierenden Gleichungen aufgestellt, umsicherzustellen, dass die Forderungen konform sind.
Für die Interpolationspunkte gilt die Gleichung
4N+4∑n=0
xnan = Np(x),∀x ∈ 0, N−1, . . . , 1.
Die erste Integralbedingung führt zu:[4N+4∑n=0
yn+1
nan
]y=x+ 12N
y=x− 12N
= xp(x),∀x ∈ 0, N−1, . . . , 1.
⇒4N+4∑n=0
(x+ 12N )n+1 − (x− 1
2N )n+1
nan = x2p(x),∀x ∈ 0, N−1, . . . , 1
Die weiteren Intergralbedingungen führen auf
4N+4∑n=0
(x+ 12N )n+2 − (x− 1
2N )n+2
n+ 1an = p(x), ∀x ∈ 0, N−1, . . . , 1,
sowie
4N+4∑n=0
(x+ 12N )n+3 − (x− 1
2N )n+3
n+ 2an = p(x), ∀x ∈ 0, N−1, . . . , 1.
Die letzten vier Bedingungen liefern
4N+4∑n=0
(− 1
2N)nan =
4N+4∑n=0
(1 +1
2N)nan = 0

3.5. INTERPOLATION 45
4N+4∑n=1
n(− 1
2N)n−1an =
4N+4∑n=1
n(1 +1
2N)n−1an = 0.
Unschwer zu erkennen, erzeugen die Divisionen durch n, n+1 und n+2 sowie die Multiplikati-on mit n stets linear unabhängige Gleichungen, womit die linke Seite des 4N+4 dimensionalenGleichungssystems vollen Rang hat und damit invertierbar ist. Das LGS ist demnach lösbar undliefert die Existenz eines (sogar eindeutigen) Interpolationspolynoms vom Grad 4N+4, welchesdie Bedingungen 3.5.4 erfüllt.Es verbleibt die Differenzierbarkeitsvorraussetzung an die Übergangsraten zu rechtfertigen. Die-ses ist aber, verglichen mit der Differenzierbarkeit der Dichte selbst, ein Leichtes. Man definiere
ωi(y,R) := IN (ω(x,R) := ωNx,Nx+R)(y,R), R 6= 0,
mit dem in dieser Kurzschreibweise angedeuteten Interpolationsoperator N -ten Grades. Nach-dem nicht mehr, als die Differenzierbarkeit an den x-Werten gefordert wird, ist dieser durch dieN verschiedenen Punkte wohldefiniert (Dort woNx+R 6∈ 0, 1, . . . , N gilt, sei ωNx,Nx+R :=0).Durch die Forderung 3.4.1, dass die Übergangsraten bzgl. N−1 in eine Reihe entwickelbar sind,sind diese meist ohnehin auch bzgl. x differenzierbar und die Interpolation ist meist gar nichtmehr notwendig.
Bemerkung 3.5.5.Da ωi,i < 0 obwohl ωi,j > 0 ist nicht zu erwarten, dass der Interpolant im GrenzfallN →∞ beiR = 0 stetig sein wird. Da innerhalb der Mastergleichung aber ohnehin nur die Übergangsratenmit von 0 unterschiedlicher Sprungweite betrachtet werden, spielt das keine Rolle.
3.5.3 Zusammenfassung
Zusammenfassend gibt es also eine für jedes t beliebig oft differenzierbare Dichte pi(t, x) (eineszeitabhängigen Prozesses xi(t)) auf [− 1
2N , 1 + 12N ] sodass die Bedingungen 3.5.4 erfüllt sind
und demnach
E(xi) =
∫ 1+ 12N
− 12N
p(x)xdx =
N∑k=0
p(kN−1)kN−1 = E(x)
E(x2i ) = E(x2)⇒ V(xi) = V(x)
für jedes t ≥ 0 gilt. Für jeden Wert x aus der diskreten Menge 0, N−1, . . . , 1 ist der Funktions-wert pi(t, x) mit dem N -fachen des Funktionswertes der diskreten Wahrscheinlichkeitsfunktionp(t, x) identisch und kann damit in die Mastergleichung 3.7 eingesetzt werden.
p′(t, x) =∑y 6=x
p(t, y)ωNy,Nx − p(t, x)ω(Nx,Ny)
⇔ p′i(t, x)
N=∑y 6=x
pi(t, y)
NωNy,Nx −
pi(t, x)
NωNx,Ny

46 KAPITEL 3. MASTER GLEICHUNG
⇔ p′i(t, x) =∑y 6=x
pi(t, y)ωNy,Nx − pi(t, x)ωNx,Ny
Die diskreten Übergangsraten können, falls nicht ohnedies bereits stetig bzgl. x differenzierbar,getrost durch deren Interpolanten ersetzt werden:
p′i(t, x) =∑R 6=0
pi(t, y)ωi(x,R)− pi(t, x)ωi(x,R)
Damit sind die Bedingungen 3.3.1 bzw. 3.4.2 durch ein Interpolationsargument mit einer Funk-tion pi erfüllt (die Einschränkung des Definitionsbereiches von [− 1
2N , 1 + 12N ] auf [0, 1] spielt
keine Rolle), die immerhin die wichtigsten Eigenschaften der diskreten Dichte p erhält.Mit einem Fehler mit negativem Exponenten in N ergeben sich die beiden Gleichungen 3.11und 3.12.Die Gleichung 3.12 ist eine partielle DG zweiter Ordnung. Zur eindeutigen Lösung dieser sindRand/Anfangsbedingungen notwendig, die nun nach den Überlegungen in diesem Unterkapitelbestimmt werden können.Gemäß der Definition des Anfangswertes des stochastischen Prozesses ist
p(0, x) =
0, ∀x0 6= x ∈ 0, N−1, . . . , 1
1, ∀x0 = x,
und gemäß der Definition der kontinuierlichen Dichte gilt
pcont(0, x) =
0, ∀x0 6= x ∈ 0, N−1, . . . , 1
N, ∀x0 = x.
Definiert man nun die Funktionenfolge (pcont(0, x))N , so ist diese Folge eine sogenannte Di-racfolge. D.h. sie erfüllt
limN→∞
(pcont)N = δx0(x).
Als stetige Approximation der Diracfolge ist auch
limN→∞
(pi)N = δx0(x)
und damit ebenfalls eine Diracfolge.
Satz 3.5.6 (Anfangswert der Fokker-Planck-Gleichung 3.12).Für großes N kann also die Dirac’sche Deltadistribution δx0 als approximative Näherung fürden Anfangswert pi(0, x) herangezogen werden. Sie erhält (schwach) die L1 Norm, den Erwar-tungswert E(xi) = x0 und die Varianz V(xi) = 0. Somit gilt
Π(0, ξ) := δ0(ξ).

3.5. INTERPOLATION 47
Beweis:
||δx0 ||L1 =
∫ 1+ 12N
− 12N
δx0(x) · 1dx =
∫ ∞−∞
δx0(x) · 1dx = 1(0) = 1
E(pi(0, x)) =
∫ 1+ 12N
− 12N
δx0(x)xdx =
∫ ∞−∞
δ0(x)x0dx = x0
V(pi(0, x)) =
∫ 1+ 12N
− 12N
δx0(x)(x− x0)2dx =
∫ ∞−∞
δ0(x)(x− x0)2dx = (x0 − x0)2 = 0
Π(0, ξ) = pi(0, x0 +N−12 ξ)⇒ Π(0, ξ) = δx0(x0 +N−
12 ξ) = δ0(N−
12 ξ) = δ0(ξ)


KAPITEL 4Analyse
In Kapitel 2 wurde bereits erwähnt, dass vor allem die zwei Parameter Erwartungswert und Va-rianz die Gestalt einer Verteilung maßgeblich bestimmen. (Überhaupt ist eine Verteilung genaudann bekannt, wenn ihre momenterzeugende Funktion bekannt ist, was äquivalent zur Tatsacheist, dass tatsächlich alle Momente bekannt sind). Es wird in diesem Kapitel gezeigt, dass aus denresultierenden Gleichungen aus Kapitel 3 genau diese beiden Größen mit einer Fehlergenauig-keit von O(N−
12 ) abgeleitet werden können. Diese Fehlerbreite wird zunächst vernachlässigt,
und es wird davon ausgegangen, dass p(x, t), gewonnen aus 3.12, bereits die zu betrachtendeDichte des Prozesses ist. Im weiteren Verlauf der Analyse wird natürlich auch auf den Fehlerzur tatsächlichen, agentenabhängigen, ortsdiskreten Dichte p(x, t) mit tatsächlicher Mittelwert-kurve φ(t) und Varianzkurve σ2(t) eingegangen (siehe 6 und 8).Zunächst sei ein wenig auf die Theorie der Fokker-Planck-Gleichungen eingegangen.Die Lösung einer Fokker-Planck-Gleichung der Gestalt
∂u(x, t)
∂t=∂u(x, t)a(x, t)
∂x+∂2u(x, t)b(x, t)
∂x2
wird für sinnvolle Anfangsbedingungen (z.B. wie in diesem Fall δ0(x)) im Allgemeinen durchdie zwei zeitabhängigen Größen Drift und Diffusion bestimmt.Erstere gibt jene Funktion an, mit der sich der Anfangspeak in der Zeit verschiebt bzw. drif-tet. Als Beispiel dazu kann als Spezialfall für eine diffusionslose Fokker-Planck-Gleichung diesogenannte Transportgleichung betrachtet werden:
∂u(x, t)
∂t=∂u(x, t)a(x, t)
∂x+∂2u(x, t)b(x, t)
∂x2:= c
∂u(x, t)
∂x
Deren Lösung sind sogenannte stehende Wellen (siehe Abbildung 4.1).Unter dem Begriff Diffusion bezeichnet man die qualitative Veränderung des Peaks selbst (hö-
her, flacher, breiter, schmäler). Ein Beispiel für eine Fokker-Planck-Gleichung ohne Drift wäredie sogenannte Diffusionsgleichung:
∂u(x, t)
∂t=∂u(x, t)a(x, t)
∂x+∂2u(x, t)b(x, t)
∂x2:= −c∂
2u(x, t)
∂x2
49

50 KAPITEL 4. ANALYSE
Abbildung 4.1: Beispiel für die Lösungskurven einer Transportgleichung
Die Lösungen dieser diffundieren, bei deltadistributioneller Anfangsbedingung, mit fortlaufen-der Zeit auseinander (Siehe Abbildung 4.2).Der Nutzen des Wissens über Diffusion und Drift liegt in diesem Fall klar auf der Hand. Ist die
Abbildung 4.2: Beispiel für die Lösungskurven einer Diffusionsgleichung
Lösungskurve der Fokker-Planck-Gleichung Dichtefunktion eines zeitabhängigen Prozesses, soist der Driftparameter hauptverantwortlich für die zeitliche Entwicklung des Mittelwertes, unddie Diffusion beschreibt großteils die Entwicklung der Varianz.Im Beispiel der Transportgleichung mit dem Setting aus Abbildung 4.1, verläuft der Erwar-tungswert der Verteilung entlang einer linearen Funktion. Die Varianz hingegen, bliebe gleich.Im Beispiel der Diffusionsgleichung bleibt der Erwartungswert konstant (= 0) und die Varianzvergrößert sich (im einfachsten Fall sogar linear).Des weiteren soll nun für die Lösung der Fokker-Planck-Gleichung, die aus den Differenti-algleichungen (3.11,3.12) ermittelt werden kann, zunächst der Driftparameter/Erwartungswertbestimmt werden.

4.1. ANALYSE DER ERWARTUNGSWERTKURVE 51
4.1 Analyse der Erwartungswertkurve
Die heuristische Überlegung, dass durch x = N−12 ξ + φ(τ) und N → ∞, x → φ(τ) konver-
giert, würde φ(τ) als Erwartungswert des Prozesses mit verschwindender Varianz im Limesfallkennzeichnen. Man kann sich nun die berechtigte Frage stellen, warum die Anzahl der Agentenden Erwartungswert des normierten Prozesses mit endlichem N überhaupt beeinflussen soll?
Satz 4.1.1 (Erwartungswert der Dichte p).Ist φ Lösung von 3.11 und Π Lösung von 3.12 mit deltadistributioneller Anfangsdichte δ0 so gilt
E(ξ, τ) = 0.
Mit p(x(τ)) := Π(N12 (x(τ)− φ(τ))) gilt damit
E(x, τ) = φ(τ).
Beweis: Mit Ω := [−∞,∞] gilt nach Definition des Erwartungswertes
E(ξ, τ) =
∫Ω
Π(ξ, τ)ξdξ.
Desweiteren verwendet man den Taylorschen Lehrsatz und erhält Π(τ) = Π(0) +∫ τ
0∂Π∂t (s)ds.
Durch Π(0) = δ0 und ξ(0) = 0 gilt∫Ω
Π(ξ, τ)ξdξ =
∫Ωδ0ξ +
∫ τ
0
∂Π
∂t(s)ξdsdξ =
= 0 +
∫ τ
0
∫Ω
∂Π(ξ, s)ξβ(s)
∂xξ +
∂2Π(ξ, s)αx(s)
∂x2ξdξds =
=
∫ τ
0β(s)
∫Ω
Π(ξ, s)ξξ2︸ ︷︷ ︸
Ia
+ Π(ξ, s)ξdξ︸ ︷︷ ︸Ib
+αx(s)
∫Ω
Π(ξ, s)ξξξdξ︸ ︷︷ ︸II
ds.
Term II wird mit partieller Integration zu∫Ω
Π(ξ, s)ξξξdξ = −∫
ΩΠ(ξ, s)ξdξ = [−Π(ξ, s)]∂Ω = 0,
da Gemäß der Randbedingungen die Randterme wegfallen. Term I ist ein wenig unhandlicher.Der Ausdruck Ib ist gemäß Definition∫
ΩΠ(ξ, s)ξdξ = E(ξ, s).

52 KAPITEL 4. ANALYSE
Ähnlich lässt sich Term Ia umformen.∫Ω
Π(ξ, s)ξξ2dξ = −
∫Ω
Π(ξ, s)2ξdξ = −2E(ξ, s)
Somit gilt
E(ξ, τ) =
∫ τ
0−β(s)E(s)ds.
Der Erwartungswert von ξ löst also die lineare DG
E(ξ, τ)′ = −β(τ)E(ξ, τ), E(ξ, 0) = 0,
da ξ(0) = 0 fast sicher. Klar ersichtlich ist er auch Ruhelage der DG, womit
E(ξ, τ) = 0
folgt.Ist nun
p(x(τ)) := Π(N12 (x(τ)− φ(τ))),
so gilt nach der Linearität für Erwartungswerte
E(x, τ) = E(φ(τ) +N−12 ξ, τ) =
= E(φ(τ), τ) +N−12E(ξ, τ) = φ(τ) +N−
12 · 0 = φ(τ),
was zu zeigen war.
Man erhält damit eine sehr starke Aussage. Unabhängig von N beschreibt die Funktion φ(t)den Drift der Verteilung aus Gleichung 3.12. Außerdem approximiert die in Gleichung 3.11 er-haltene Funktion φ den Erwartungswert des stochastischen Modells, das die Bedingungen 3.4.2erfüllt, bis auf ein O(N−
12 ).
Bemerkung 4.1.2.Darauf, wie die Lösung der i.A. recht komplizierten gewöhnlichen Differentialgleichung 3.11gefunden werden kann, wird hier nicht eingegangen. Ist sie nicht ohnehin analytisch lösbar, solässt sich eine Approximation der Lösung recht genau z.B. mit einem Runge-Kutta-Verfahrenfinden, da sie bereits in expliziter Form vorliegt.
4.2 Analyse der Dichte und der Varianz
Es verbleibt die partielle Fokker-Planck-Gleichung 3.12 zu lösen, um hinterher die Varianz zuermitteln. Man wählt dazu einen sehr heuristische Zugang, der eigentlich genau die umgekehrte

4.2. ANALYSE DER DICHTE UND DER VARIANZ 53
Richtung einschlägt. Da die Größe X(t) als Summe von Zufallszahlen entsteht, liegt die Ver-mutung nahe, X bzw. x sei in jedem Zeitschritt näherungsweise um den Erwartungswert φ(t)normalverteilt. Somit wäre auch ξ um 0 mit einer Varianzfunktion σ2(τ) normalverteilt.
Ansatz: ξ(τ) ∼ Π(ξ, τ) :=1√
2πσ2(τ)e− ξ2
2σ2(τ)
So einfach und naheliegend der Ansatz mit der noch zu ermittelnden Funktion σ2(t) erscheinenmag, führt er zum Ziel. Einsetzen in die Fokker-Planck-Gleichung
∂Π
∂τ=∂Π
∂ξαx(φ(τ)) +
∂2Πξ
∂ξ2β(φ(τ))
mitαx(φ(τ)) =
∑R 6=0
(Φ1)x(φ(τ), R)(−R), β(φ(τ)) =∑R 6=0
Φ1(φ(τ), R)(−R)2
liefert für σ2 6= 0 die gewöhnliche, sogar lineare DG
∂σ2(τ)
∂τ= −2αx(φ(τ))σ2(τ) + 2β(φ(τ)). (4.1)
Diese ist in manchen Fällen sogar analytisch lösbar:
σ2(τ) = 2e−2∫ τ0 αx(φ(s))ds
∫ τ
0β(φ(u))e2
∫ u0 αx(φ(s))dsdu
Gemäß der Variablensubstitution gilt nun für die Dichte p(x, τ) nach dem Transformationssatzfür Dichten (Integrale)
p(x, τ) =
√N√
2πσ2(τ)e−N(x−φ(τ))2
σ2(τ) ,
bzw. mitsamt der Zeittransformation Nf(N) t = τ
p(x, t) =
√N√
2πσ2(
Nf(N) t
)e−N
(x−φ
(N
f(N)t
))2
σ2(
Nf(N)
t
).
Man erhält also eine um den Erwartungswert φ(t) verschobene Normalverteilung mit zeitabhän-giger Varianz
V(x, τ) =σ2(τ)
N,
die somit durch die Funktion σ2(τ) beschrieben wird.

54 KAPITEL 4. ANALYSE
4.3 Stochastische Aussagen
Die im letzten Kapitel (3) hergeleiteten Gleichungen liefern jeweils Aussagen, die unter Vor-raussetzung der Bedingungen 3.4.2 mit einer Genauigkeit von mindestens O(N−
12 ) zutreffen.
Folgende Aussagen können also zusammenfassend gemacht werden:
Für N → ∞ konvergiert die normierte Zustandsvariable des CT Markov-Prozess basier-ten Mikromodells gegen die Mittelwertkurve φ(t), die durch die Gleichung 3.11 beschrie-ben wird und aus den Übergangsraten des Mikromodells ermittelt werden kann.
Für N →∞ geht die Varianz σ2 des CT Markov-Prozess basierten Mikromodells, wobeiσ2 mit einem Fehler der OrdnungN−
12 durch die Gleichung 4.1 und deren LösungN−1σ2
ermittelt werden kann, gegen 01.
Bis auf einen Fehler der Ordnung O(N−12 ) beschreibt die Kurve φ(t) den zeitlichen Ver-
lauf des Mittelwerts der Zustandsvariable des Mikromodells.
|φ(t)− φ(t)| = O(N−12 )
Bevor Aussagen für das wiederholte Durchführen des Experiments gemacht werden, seien sto-chastische Grundlagen ergänzt.
Satz 4.3.1 (Starkes Gesetz der Großen Zahlen).Es sei (Xi)i∈I eine beliebig verteilte aber unabhängige Folge von Zufallszahlen mit Erwartungs-wert µ und beschränkter Varianz, so gilt
limM→∞
1
M
M∑i=1
XiP stark→ µ⇔ lim
M→∞P
(1
M
(M∑i=1
Xi − µ
)= 0
)= 1.
Für den Beweis sei auf Grundlagenliteratur für Wahrscheinlichkeitstheorie verwiesen.Führt man nun das Mikromodell M -mal wiederholt, unabhängig voneinander aus, sind die Vor-aussetzungen erfüllt und es gilt:
Nach dem Starken Gesetz der Großen Zahlen konvergiert der Mittelwert der Ergebnisseder wiederholten Hintereinanderausführung des CT Markov-Prozess basierten Mikromo-dells stark in der Wahrscheinlichkeit gegen eine Mittelwertkurve, die mit einem Fehler derOrdnung O(N−
12 ), wobei N die Agentenzahl beschreibt, durch die Kurve φ(t) approxi-
miert werden kann.
1Da σ2 Lösung einer von N unabhängigen DG ist, hat die Funktion keine Auswirkung auf die Konvergenz.

4.3. STOCHASTISCHE AUSSAGEN 55
Nach direkter Folgerung aus dem Starken Gesetz der Großen Zahlen konvergiert die Va-rianz des empirischen Mittelwerts2 der Ergebnisse der M -maligen Hintereinanderausfüh-rung des CT Markov-Prozess basierten Mikromodells für M →∞ gegen 0.
Diese beiden Aussagen sind theoretisch sinnvoll, doch numerisch schlecht verwertbar. Man be-nötigt noch eine weitere stochastische Aussage, um die Konvergenzgeschwindigkeit unter Kon-trolle zu bekommen.
Satz 4.3.2 (von Hartman-Wintner).Sei Xi eine identisch verteilte aber unabhängige Folge von Zufallszahlen mit Mittelwert 0 undVarianz 1 so gilt:
lim supM→∞
∑Mi=1Xi√
2M ln(ln(M))= 1, fast sicher
lim infM→∞
∑Mi=1Xi√
2M ln(ln(M))= −1, fast sicher
Für den Beweis wird auf die Literatur verwiesen ( [Sto70, 2158-2160]).Nun folgt daraus direkt, dass für alle Xi, die den Satz erfüllen gilt:
1
M
M∑i=1
Xi = O
(√ln(ln(M))
M
)
Ist nun Xi verteilt mit Mittelwert µ und endlicher Varianz σ2, so ist Xi := (Xi−µ)σ so verteilt,
dass der Satz anwendbar ist. Es folgt:
1
M
M∑i=1
Xi − µ = σO
(√ln(ln(M))
M
)
Ganz im Unterschied zum Mittelwert ist die Konvergenzgeschwindigkeit der Varianz des Mit-telwerts der wiederholten Durchführung gegen 0 deutlich einfacher zu berechnen:
V(1
M
M∑i=1
Xi) =1
M2V(
M∑i=1
Xi) =M
M2V(X1) =
σ2
M= O(M−1)
Somit ergeben sich zwei weitere Aussagen:
2Man sollte im Hinterkopf behalten, dass der empirische Mittelwert der Ergebnisse der einzelnen Durch-läufe als das eigentliche Simulationsergebnis betrachtet werden muss, was die Betrachtung dessen Varianzrechtfertigt.

56 KAPITEL 4. ANALYSE
Der Fehler | 1M
∑Mi=1Xi(t) − φ(t)| der empirischen Mittelwertkurve gegen die tatsäch-
lichen Mittelwertkurve des Experiments φ(t) (damit ist nicht die in 3.11 beschriebene
Kurve gemeint) ist bei M -fach wiederholter Durchführung einO(√
ln(ln(M))M
)bzw. ge-
nauer
|| 1
M
M∑i=1
Xi(t)− φ(t)|| ≤ O
(√ln(ln(M))
M
)||Xi(t)− φ(t)||∞.
Die Varianz der Mittelwertkurve ist nach M unabhängigen Experimenten genau 1M σ
2(t)der tatsächlichen Varianzkurve σ2 bei einmaligem Durchlauf.
Für die Konvergenzgeschwindigkeit der Varianz gegen 0 liefert das Verdoppeln der Agen-tenzahl sowie das zweifache Hintereinanderausführen und Mitteln des Experimentes das-selbe Resultat. Es hängt also vom Rechenaufwand bzw. den Ergebnissen des Experimentsab, welches der zwei bevorzugt eingesetzt wird um die Varianz zu verringern. Sie konver-giert in beiden Fällen linear.
Wie man aus den letzten drei Punkten bereits herauslesen konnte, ist die Aussage, dassM -fachesHintereinanderausführen des Experiments mitN -Agenten dieselben Resultate liefert wie einma-liges Ausführen mit N ·M Agenten, nicht korrekt. Die Konvergenz des empirischen Mittelwer-tes gegen den tatsächlichen Mittelwert hängt i.A. nicht mit der Konvergenz des tatsächlichenMittelwertes der Mikrosimulation gegen die in 3.11 hergeleitete Kurve zusammen.
Bemerkung 4.3.3.Die Ausnahmen in dieser Regel bilden agentenbasierte Markov-Modelle, in denen die Über-gangsraten der Agenten nicht von den Zuständen des Systems abhängen. In diesem Fall ist jadas Durchführen der Mikrosimulation und das Normieren äquivalent zum Mitteln über mehrereDurchläufe, da die Agenten nicht voneinander abhängen, d.h. nicht miteinander „kommunizie-ren“.
Zusätzlich sind die Aussagen wichtig, denn:
Zusammenfassend gilt für die aus Gleichung 3.11 bestimmbare Kurve bei N Agenten ei-ner CT Markov-Prozess basierten Mikrosimulation und M -fachen Mitteln des erhaltenenErgebnisses
| 1
M
M∑i=1
Xi − φ(t)| ≤ | 1
M
M∑i=1
Xi − φ(t)|+ |φ(t)− φ(t)| =
= O
(√ln(ln(M))
MN−
12
)+O(N−
12 ) = O
(N−
12
(1 +
√ln(ln(M))
M
)).
Die Varianz des Ergebnisses geht mit Ordnung O( 1N ·M ) gegen 0.

4.3. STOCHASTISCHE AUSSAGEN 57
Mehrmaliges Durchführen des Versuches reicht also i.A. allein nicht aus, um Konvergenz gegendie berechnete Kurve zu erhalten. Jedoch ist es notwendig, um schlussendlich die Erwartungs-wertkurven, die meist das Ziel einer stochastischen Simulation sind, überhaupt bestimmen zukönnen. Will man andererseits die Lösung der Differentialgleichung mit einem adäquat zu Ka-pitel 3 gewählten Agentenmodell approximieren, macht einerseits die mehrfache Ausführungdes Experiments in Anbetracht des reinen Fehlers kaum Sinn, andererseits jedoch glättet es be-kanntermaßen die Lösungskurve.Alle in diesem Kapitel gebrachten Analysen, sowie die Entwicklung der Differentialgleichun-gen, lassen sich auch für mehrdimensionale Probleme durchführen. Da die weiteren ernstzuneh-menderen Fehlerbetrachtungen auch für vektorwertige Zustandsvariablen ihre Gültigkeit behal-ten sollen, wird nun diese Lücke gefüllt, und die mehrdimensionale Diffusionsapproximationvorgestellt.


KAPITEL 5Mehrdimensionale Probleme
Um Problemstellungen mit mehr als nur zwei Zuständen analysieren zu können, wie z.B. dasSIR-Modell im Kapitel 9, ist es notwendig, die Mastergleichung und die Kramers-Moyal-Entwicklungmehrdimensional durchzuführen und die entstehenden Differentialgleichungen für Erwartungs-wert und Dichte herzuleiten. Fast alle Berechnungen, die eindimensional durchgeführt werdenkönnen, lassen sich analog auf den mehrdimensionalen Fall erweitern.
5.1 Mehrdimensionale Mastergleichung
Wie im Kapitel 3.2 nutzt man ein Interpolationsargument und verwendet die mittlerweile mehr-dimensionale Dichte, als wäre sie beliebig of stetig differenzierbar.
Es sei X : R+ → 0 . . . Nd, t 7→ ~K ein Vektor aus Markov-Prozessen auf dem Raum
0, . . . , N.
Der Vektor X ist verteilt mit der diskreten Dichte
P : (0 . . . N)d × R+ → [0, 1], ~K × t 7→ P (X(t) = ~K|X(0) = ~K0).
Der normierte Prozess x := XN−1 ist demnach verteilt mit
p : (0, N−1 . . . 1)d × R+ → [0, 1], ~KN−1 =: ~k × t 7→ P (x(t) = ~k|x(0) = ~k0).
Die Übergangsraten sind ebenfalls definiert als
ω(~k, ~R) := limh→0
P (x(h) = ~k + ~RN−1|x(0) = ~k)
h
und
ω(~k,~0) := 1− limh→0
P (x(h) = ~k|x(0) = ~k)
h.
59

60 KAPITEL 5. MEHRDIMENSIONALE PROBLEME
Die Definitions- und Zielbereiche der als differenzierbar vorausgesetzten Dichte und Ra-ten haben die Form
p : [− 1
2N, 1 +
1
2N]d × R
+ → [0, 1] : ~k × t 7→ I(2N+4)d(p)(~k, t)
ω : [− 1
2N, 1 +
1
2N]d × ~R1, ~R2 . . . ~Rl → R : ~k × ~R 7→ INd(ω)(~k, ~R)
mit dem Interpolationsoperator I.
Da die Zeit immer noch ein eindimensionaler Parameter ist, lässt sich wie auch im eindimensio-nalen Fall, die Chapman-Kolmogorov Gleichung herleiten, und der Ansatz
p(~j, t+ h)− p(~j, t)h
liefert, da die Mehrdimensionalität des Problems hier noch nicht zu tragen kommt, durch Limes-bildung analog die Mastergleichung:
p(~j, t)′ =∑~k 6=~j
p(~k, t)ω~k,~j − p(~j, t)ω~j,~k
5.2 Mehrdimensionale Fokker-Planck-Gleichung
Da in Folge die Kettenregel verwendet wird, entstehen Ableitungen nach der Ortsvariablen unddadurch, statt einfach Ableitungen nach x, vektorwertige Nabla-Operatoren. Vor allem bei dermehrdimensionalen Dichte liefert das unangenehm zu behandelnde Terme.Weil die Dichte, gemäß Voraussetzung, beliebig oft stetig differenzierbar ist, lässt sich dieKramers-Moyal-Entwicklung (Taylorentwicklung nach dem Sprung ~R) durchführen, hier dar-gestellt bis zum quadratischen Term.
p(~j, t)′ =∑~k 6=~j
p(~j, t)ω~k,~j +∇(p(~j, t)ω~k,~j
)· ~R 1
N+
+1
2N2~RTH
(p(~j, t)ω~k,~j
)~R+O(N−3)− p(~j, t)ω~j,~k =
=∑~k 6=~j
∇(p(~j, t)ω~k,~j
)· ~R 1
N+
1
2N2~RTH
(p(~j, t)ω~k,~j
)~R+O(N−3)
Dabei wurden Kürzel für Hessematrix (H), Nablaoperator (∇) und das Skalarprodukt (·) ver-wendet.Die Substitution ~k = ~φ + N−1/2~ξ und die Zwangsbedingung ~φ′ = −N−1/2~ξ′ liefert mit derKettenregel
p(~k, t)′ = Π(~ξ, t)′ +∇ξΠ · ~ξ′ = Π(ξ, t)′ +N1/2∇Π · ~φ′
und∇p =
√N∇ξΠ, H(p) = NHξ(Π).

5.2. MEHRDIMENSIONALE FOKKER-PLANCK-GLEICHUNG 61
Gemäß Voraussetzung sind die Raten als Polynom in N−1 schreibbar.
ω(~k,R) = f(N)(Φ1(~k,R) +N−1Φ2(~k,R) + . . . )
Die Entwicklung von Φ1(~φ+N−1/2~ξ, ~R) um ~φ liefert
Φ1(~k, ~R) = Φ1(~φ+N−1/2~ξ, ~R) = Φ1(~φ, ~R) +N−1/2~ξ · ∇Φ1(~φ, ~R) +O(N−1).
Aus der Substitution der Zeit von t nach τ = tf(N)/N folgt schlussendlich die Gleichung
Π(ξ, t)τ +N1/2∇ξΠ · ~φτ =
=∑~R 6=0
N1/2∇ξ(
Π(~j, t)Φ1(~φ, ~R))· ~R+
+∑~R 6=0
(∇ξ(
Π(~ξ, t)(~ξ · ∇Φ1(~φ, ~R)))· ~R+
+1
2~RTHξ
(Π(~ξ, t)Φ1(~φ, ~R)
)~R
)=
= N1/2∇ξΠ ·∑~R 6=0
Φ1(~φ, ~R)~R+
+∇ξΠ ·∑~R 6=0
(ξ · ∇Φ1(~φ, ~R))~R+ Π∑~R 6=0
∇Φ1(~φ, ~R) · ~R+
+1
2
∑~R 6=0
~RTHξ(Π)~RΦ1(~φ, ~R).
Vergleiche der jeweiligen Potenzen vonN liefern schlussendlich die gewünschten Gleichungen.
Satz 5.2.1 (Mehrdimensionale Lösungsgleichungen der Kramers Moyal Entwicklung).Auch für d > 2 gilt nun
~φτ =∑~R 6=0
Φ1(~φ, ~R)~R
Π(ξ, t)τ = Πf(~ξ, ~φ) +∇ξΠ · ~F (~φ) + g(Hξ(Π), ~φ)
mit skalaren Funktionen f und g sowie einer vektorwertigen Funktion ~F , die wie folgt definiertsind.
f(~ξ, ~φ) :=∑~R 6=0
∇Φ1(~φ, ~R) · ~R
g(Hξ(Π), ~φ) :=1
2
∑~R 6=0
~RTHξ(Π)~RΦ1(~φ, ~R)
~F (~φ) :=∑~R 6=0
(ξ · ∇Φ1(~φ, ~R))~R

62 KAPITEL 5. MEHRDIMENSIONALE PROBLEME
Das Finden von Lösungen ist für die partielle Differentialgleichung der Dichte im Mehrdi-mensionalen jedoch bedeutend schwieriger als im eindimensionalen Fall.

KAPITEL 6Anwendung auf zeitdiskrete
agentenbasierte Modelle
In den Kapiteln 3,5 und 4 wurde ein theoretisches Konzept erarbeitet, wie näherungsweise Va-rianz, Dichte und Mittelwert eines agentenbasierten CTDS Markov-Modells mittels Differen-zialgleichungen bestimmt werden können. Der diskrete Zustandsraum der Agenten konnte alsobereits in einen kontinuierlichen übergeführt werden. Um schlussendlich den Bogen zu klassi-schen, zeitdiskreten Agentenmodellen spannen zu können, fehlt nicht mehr viel.
6.1 Motivation
Eine zeitdiskrete Herangehensweise an mathematische Probleme ist spätestens seit der Erfin-dung des Computers bzw. dessen Anwendung in mathematischen Forschungsbereichen unum-gänglich geworden. Große Bereiche der Numerik beschäftigen sich ausschließlich mit Proble-men, auf welche Weise die, klassischerweise im Alltag als kontinuierlich angenommene, Zeitoptimal diskretisiert werden kann, um den sogenannten Diskretisierungsfehler, d.h. den Fehlerder im Zuge der Vereinfachung durch die getaktete Zeit entstanden ist, möglichst gering zu hal-ten. Was in der abstrakten Theorie als selbstverständlich genommen wird, nämlich das Perfekte,Kontinuierliche (evt. sogar Stetige, Glatte,. . . ) mit dem Diskreten zu approximieren, verliert seiteinigen Jahren immer mehr an Generalität, wenn man die Situation nicht (nur) mehr mit den Au-gen des theoretischen Mathematikers, sondern mit den Augen eines Modellbildners betrachtet.In diesem Zusammenhang kann man nämlich, im Unterschied zur theoretischen Mathematik,die Begriffe
zeitdiskret ↔ zeitdiskretisiert
klar unterscheiden. Auf der einen Seite muss man ein Modell zeitdiskretisiert rechnen, wenn einkontinuierliches (analytisches) Rechnen des Modells nicht mehr möglich ist (oder es Vorteileanderer Art mit sich bringt). Auf der anderen Seite tauchen im Alltag sehr wohl Prozesse auf,
63

64 KAPITEL 6. ANWENDUNG AUF ZEITDISKRETE AGENTENBASIERTE MODELLE
die zu simulieren keine Diskretisierung mehr bedürfen, da sie selbst bereits diskret sind. Klarer-weise rechnet man diese Modelle dann zeitdiskret, ohne sie diskretisiert zu haben. Ein Beispieldazu könnte ein Raumbelegungsmodell einer Universität sein, wenn man davon ausgeht, dassVorlesungen oder Übungen nur im Viertelstunden-Takt beginnen oder enden können.In diesem Kapitel wird davon ausgegangen, dass die in Kapitel 3 erarbeitete Theorie auf einzeitdiskretes Modell angewandt werden soll, ohne darauf Rücksicht zu nehmen, ob es ein dis-kretisiertes Modell ist, oder nicht. Da all die erarbeitete Theorie auf zeitkontinuierliche agenten-basierte Markov-Modellen basiert, muss das Prinzip der Diskretisierung diesmal in die entge-gengesetzte Richtung erfolgen. 1
6.2 Voraussetzungen an das DT Agentenmodell
Untersucht man die Voraussetzungen 3.3.1, unter welchen das Kapitel 3.3 gültig ist, so erhältman weitestgehend natürlich und ohne Umschweife bereits Voraussetzungen, unter welchenein zeitdiskretes Agentenmodell überhaupt in ein zeitkontinuierliches agentenbasiertes Markov-Modell überführt werden kann.Gegeben ist ein agentenbasiertes Modell bestehend aus N Agenten A1, . . . , AN mit einem ge-meinsamen endlichen Zustandsraum 0, 1, . . . , d. Der Zustand jedes Agenten ist zu einem derfesten Zeitpunkte t ∈ 0, 1, . . . , T, T ∈ N+ genau ein Element des Zustandsraumes.Die wichtigste Voraussetzung unter welcher die Überführung überhaupt erst möglich ist, istklarerweise die Voraussetzung der Gedächtnislosigkeit. D.h. die Wahrscheinlichkeit, dass derAgent seinen Zustand ändert bzw. ihn beibehält, darf nicht von den Zuständen des Systems inden bereits vergangenen Zeitschritten abhängen:
P ((t+ 1, k)|(t, jt), (t− 1, tj−1), . . . , (0, j0)) = P ((t+ 1, k)|(t, jt))
mit jn ∈ 0, 1, . . . , d, ∀n und t ∈ 0, 1, . . . , T. Anders gesagt bedeutet diese Definitiongleichsam, dass zu jedem Zeitpunkt jeder Agent eine gewisse Wahrscheinlichkeit (ggf. auch 0)haben muss, in einen anderen Zustand überzugehen, der nicht von den Zuständen des Agenten inder Vergangenheit abhängt. Sehr wohl aber darf diese Wahrscheinlichkeit gem. Satz 2.3.4 vomZustandsvektor abhängen! Gleichsam muss natürlich auch die Homogenität gefordert werden.
P ((t, k)|(t− 1, j)) = P ((1, k)|(0, j))
Mit dieser Definition muss der Zustand xi jedes Agenten also einem homogenen (evt. um dieAbhängigkeit vom Zustandsvektor erweiterten) DTDS Markov-Prozess mi folgen.Somit kann, in Analogie zu den letzten Kapiteln, auch eine Liste an Voraussetzungen erstelltwerden, die zumindest einmal notwendige Bedingungen für eine erfolgreiche Überführung einesagentenbasierten DTDS Modells in ein, für die Theorie taugliches, CT Mikromodell sind.
Bedingung 6.2.1.(Voraussetzungen für das Kapitel 6.1.)
1Wie ungewöhnlich diese Idee ist, zeigt sich darin, dass es zumindest in deutscher Sprache nicht einmalein Wort dafür gibt.

6.2. VORAUSSETZUNGEN AN DAS DT AGENTENMODELL 65
Bezeichnung DefinitionN Anzahl der Agenten/DTDS Markov-Prozesse
A1, . . . , An Agentenm1, . . . , mn DTDS Markov-Prozesse
X(t) =∑N
i=1 δmi(t),1, t ∈ 0, . . . , T Anzahl der Agenten im Zustand 1
P : 0, . . . , N × 0, . . . , T → [0, 1] Wahrscheinlichkeitsfunktion von X(t)i, j, k ∈ 0, 1, . . . , d Variablen aus dem Zustandsraum von mi, ∀i
mi(0) = ki, ki ∈ 0, . . . , d Anfangswert der Prozesse
Die weiteren Beobachtungen sind auf einen dieser N (ohnedies äquivalenten) Markov-Prozesse konzentriert.Viele Tatsachen lassen sich natürlich aus dem kontinuierlichen Fall übernehmen:
Die Summe X(t) der DTDS Markov-Prozesse, die schlussendlich die Systemvariable er-gibt, ist für sich selbst auch ein DTDS Markov-Prozess.
Jeder einzelne Markov-Prozess wird mit einer Übergangsmatrix Q beschrieben, die fürjeden Agenten gleich ist:
Q :=
P ((1, 0)|(0, 0)) P ((1, 1)|(0, 0)) . . . P ((1, d)|(0, 0))P ((1, 0)|(0, 1)) P ((1, 1)|(0, 1)) . . . P ((1, d)|(0, 1))
......
. . ....
P ((1, 0)|(0, d)) P ((1, 1)|(0, d)) . . . P ((1, d)|(0, d))
bzw., wenn der Markov-Prozess auch von den Zustandsvektoren abhängen darf, muss mandiese erweitern:
Q =
P ((1, 0)|(0, 0), ~Xk) P ((1, 1)|(0, 0), ~Xk) . . . P ((1, d)|(0, 0), ~Xk)
P ((1, 0)|(0, 1), ~Xk) P ((1, 1)|(0, 1), ~Xk) . . . P ((1, d)|(0, 1), ~Xk)...
.... . .
...P ((1, 0)|(0, d), ~Xk) P ((1, 1)|(0, d), ~Xk) . . . P ((1, d)|(0, d), ~Xk)
k ∈ 1, . . . , (N − 1)d
(d− 1)!2.
Die Zeilensummen der Übergangsmatrix sind immer 1 und ihre Einträge stets ∈ [0, 1].
Die Übergangsmatrix ist zwar nicht zeitabhängig, sehr wohl kann sie aber wie erwähntzustandsabhängig sein. Dennoch ist sie auf jedem ganzem Zeitintervall [t, t + 1), t ∈0, . . . , T− konstant, da sich die Zustände des Systems nur zum Zeitschritt ändern.
Bemerkung 6.2.2.Der hier verwendete Begriff der Übergangsmatrix ist nicht mit dem Begriff der Übergangsmatrixim zeitkontinuierlichen Fall (siehe 3.2.2) äquivalent. Hier sind die Einträge stets positiv und dieZeilensummen konstant 1 - im kontinuierlichen Fall stets 0, da Qi,i = ωi,i = −
∑j 6=i ωi,j < 0.
2Diese Zahl gibt die Menge aller möglichen Zustandsvektoren an. Sie entspricht der Anzahl der Möglich-keiten, d− 1-Grenzen zwischen N aneinandergereihten Agenten zu platzieren, dividiert durch die Anzahl ihrerPermutationen.

66 KAPITEL 6. ANWENDUNG AUF ZEITDISKRETE AGENTENBASIERTE MODELLE
6.3 Tempora mutantur
Man definiere nun mittels
Definition 6.3.1 (Zeitkontinuierlicher Markov-Prozess zu gegebenen zeitdiskretenAgentenmodell gem. 6.2.1).
ωi,j : = P ((1, j)|(0, i)), i 6= j
ωi,i : = −∑j 6=i
ωi,j = P ((1, i)|(0, i))− 1
m(0) : = m(0)
einen zeitkontinuierlichen Markov-Prozess. Man darf nun nicht fälschlicherweise davonausgehen, dass auch hier die Übergangsraten dieses Prozesses auf jedem vollen Zeitintervall[t, t+ 1), t ∈ 0, . . . , T− konstant sind, da sich der Zustand des Systems auch währenddessenändern kann. Es wird nun kurz die bereits in den vergangenen Kapiteln erwähnte, Vermutunggezeigt, dass dieser durch den Anfangswert, die Übergangsraten und die Bedingung der Homo-genität eindeutig bestimmt ist.
Satz 6.3.2 (Eindeutigkeit des CTDS Markov-Prozesses).Ein regulärer, homogener CTDS Markov-Prozess ist eindeutig durch Übergangsraten und denAnfangswert bestimmt
Beweis: Die Summenform der Mastergleichung 3.2.1 für CTDS Markov-Prozesse bzw. auchdie Kolmogorov’sche Rückwärtsgleichung 3.2.2 ist eine gewöhnliche Differentialgleichung ers-ter Ordnung. Im Falle von konstanten Übergangsraten ist die Differentialgleichung sogar linearund besitzt gemäß der Theorie über lineare Differentialgleichungen eine eindeutige Lösung. Istnun der Markov-Prozess regulär, können innerhalb eines infinitesimalen Zeitschrittes nur end-lich viele Zustandswechsel stattfinden, womit es um jeden Punkt, der nicht gerade Zeitpunktdes Zustandswechsels ist, eine offene Umgebung gibt, auf der die Raten konstant und damit dieLösung eindeutig ist. Ändern sich die Raten auf Grund einer Zustandsänderung des Systemszu einem gewissen Zeitpunkt, so war der Prozess bis zu diesem Punkt eindeutig bestimmt. DerWert des Prozesses an diesem Punkt liefert einen neuen Anfangswert für eine ebenfalls eindeutiglösbare, durch die neuen Raten veränderte, Differentialgleichung.
Gemäß Definition der Übergangsraten erhält man
P (m(1) = j|m(0) = i) = 1 · ωi,j +O(12) = P (m(1) = j|m(0) = i) +O(1)

6.3. TEMPORA MUTANTUR 67
bzw.
P (m(1) = i|m(0) = i) = 1 · (1 + αi,i) +O(12) = P (m(1) = i|m(0) = i) +O(1).
Diese Aussage mag auf den ersten Blick enttäuschend sein, doch verbirgt sich hinter dem O(1)doch ein wenig mehr. Um das einzusehen kann man die Kolmogorov’sche Rückwärtsgleichung3.2.2 verwenden:
P (t)′ = QP (t), P (0) =
I0(m(0))I1(m(0))
...Id(m(0))
Da die Übergangsmatrix über einen gewissen Zeitraum konstant bleibt, lässt sie sich gemäß derTheorie über Matrixexponentialfunktionen auf diesem Intervall lösen (ei bezeichne in Folge deni-ten Einheitsvektor der Länge d).
P (m(t) = 0|m(0) = i)P (m(t) = 1|m(0) = i)
...P (m(t) = d|m(0) = i)
= eQt
0...
1 [i-te Stelle]...0
=: eQtei ⇒
P (m(t) = 0|m(0) = i)P (m(t) = 1|m(0) = i)
...P (m(t) = d|m(0) = i)
= ei + tQei +∞∑n=2
1
ntnQnei =
= ei +
tαi,0
...tαi,i
...tαi,d
+
∫ t
0Q2eτQeidτ =
tP (m(1) = 0|m(0) = i)
...tP (m(1) = i|m(0) = i)
...tP (m(1) = d|m(0) = i)
+
∫ t
0Q2eτQeidτ︸ ︷︷ ︸
I
Term I ist das Restglied in Integralform der Taylorentwicklung der beliebig oft differenzierbarenFunktion eQtei.Teilt man nun das Intervall [0, 1] mit einer endlichen Zerlegung in diejenigen n Punkte ein, indenen sich der Zustand des Systems respektive die Übergangsmatrix ändert, so lässt sich dieWahrscheinlichkeitsfuntkion zum Zeitpunkt 1 schreiben als:
P (m(1) = 0|m(0) = i)P (m(1) = 1|m(0) = i)
...P (m(1) = d|m(0) = i)
= eQntneQn−1tn−1 . . . eQt0ei =:

68 KAPITEL 6. ANWENDUNG AUF ZEITDISKRETE AGENTENBASIERTE MODELLE
=: e
(tn + · · ·+ t0)︸ ︷︷ ︸1
(Q+R(Q′))
ei = e(Q+R(Q′))ei
mit einer Fehlermatrix R(Q′), die von der Größe der Änderung der Übergangsmatrix in die-sem Zeitschritt abhängt. Der gemachte Fehler pro Zeitschritt lässt sich, setzt man in die obigeUmformung t = 1, mit
||P (m(t) = ·|m(0) = i)− P (m(1) = ·|m(0) = i)||2 =
= ||eQ+R(Q′)ei − P (m(1) = ·|m(0) = i)||2 ≤≤ ||eQ+R(Q′) − eQ||2||ei||2 + ||eQei − P (m(1) = ·|m(0) = i)||2 ≤
≤ ||R(Q′)||2e||Q||2e||R(Q′)||2 + ||∫ 1
0Q2etQeidt||2 ≤
≤ ||R(Q′)||2e||Q||2e||R(Q′)||2 + ||Q||22∫ 1
0||etQ||2dt ≤
≤ ||R(Q′)||2e||Q||2e||R(Q′)||2 + ||Q||22∫ 1
0et||Q||2dt =
= ||R(Q′)||2e||Q||2e||R(Q′)||2 +||Q||22e||Q||2 − 1
||Q||2= ||R(Q′)||2e||Q||2e||R(Q′)||2 +||Q||2(e||Q||2−1)
abschätzen.
||P ((1, ·)|(0, i))− P ((1|·)|(0, i))||2 ≤ ||R(Q′)||2e||Q||2e||R(Q′)||2 + ||Q||2(e||Q||2 − 1) (6.1)
Diese Fehleranalyse untermauert den Verdacht, dass der „Diskretisierungsfehler“, bzw. eigent-lich der Fehler, der gemacht wird, wenn man das zeitdiskrete Modell mit einem Kontinuierlichenapproximiert, von der Größe der Übergangsraten sowie deren „Ableitungen“, d.h. deren maxi-malen Abweichungen innerhalb eines Zeitschrittes, abhängt. Je kleiner die Raten, umso geringersind natürlich auch die Eigenwerte der Übergangsmatrix und damit die Matrixnorm.Der tatsächliche Fehler sowie das Erarbeiten handfester Fehlerschranken wird in Kapitel 8 be-handelt.
6.4 Verweildauer
Als zusätzliche Motivation für die Wahl des CT Markov-Prozesses wird noch der folgende Satzüber homogene reguläre Markov-Prozesse bewiesen und hinterher angewendet.
Satz 6.4.1 (Verweildauer für CTDS Markov-Prozesse).Die Verweildauer, d.h. die Zeit, die ein CT Markov-Prozess in einem bestimmten Zustand jverweilt, ist stets lokal um einen gewissen Zeitpunkt exponentialverteilt mit Parameter αj,j . ZumÜbergangszeitpunkt geht der Markov-Prozess mit Wahrscheinlichkeit −αj,i/αj,j vom Zustandj in den Zustand i über.

6.4. VERWEILDAUER 69
Beweis: Betrachtet man die Wahrscheinlichkeit, dass ein Markov-Prozess zum Zeitpunkt t0seinen Zustand wechselt, so erhält man den Ausdruck
P (j →6= j bei t0) = limh→0
P
((t0 +
h
2, 6= j)|([0, t0 −
h
2], j)
)=
= 1− limh→0
P
((t0 +
h
2, j)|([0, t0 −
h
2], j)
).
Die Wahrscheinlichkeitsfunktion in der letzten Zeile beschreibt einen Markov-Prozess und er-füllt somit die Mastergleichung (hier mit der Rate αj,j geschrieben)
∂P((t+ h
2 , j)|([0, t0 −h2 ], j)
)∂t0
=∑k
P
((t+
h
2, k)|([0, t0 −
h
2], j)
)αk,j .
Da bekannt ist, dass sich der Zustand des Prozesses für t ∈ [0, t0 − h2 ] nicht ändert, gilt
P ((t+h
2, k)|([0, t0 −
h
2], j)) = 0, P ((t+
h
2, j)|([0, t0 −
h
2], j)) = 1,
für alle t ∈ [0, t0 − h]. Damit fallen alle Summanden weg, bis auf jenen mit Faktor αj,j . Esbleibt
∂P((t+ h
2 , j)|([0, t0 −h2 ], j)
)∂t0
= P
((t+
h
2, j)|([0, t0 −
h
2], j)
)αj,j .
Die Lösung der resultierenden Gleichung lässt sich ermitteln:
P
((t+
h
2, j)|([0, t0 −
h
2], j)
)= e(t+h
2)αk,j
Insbesondere gilt damit die Gleichung
P
((t0 − h+
h
2, j)|([0, t0 −
h
2], j)
)= P
((t0 −
h
2, j)|([0, t0 −
h
2], j)
)= e(t0−h2 )αk,j .
Man erhält
limh→0
P
((t0 +
h
2, j)|([0, t0 −
h
2], j)
)= lim
h→0P
((t0 −
h
2, j)|([0, t0 −
h
2], j)
)= et0αk,j
und damitP (j →6= j bei t0) = 1− et0αj,j
Auf der rechten Seite erkennt man nun die Verteilungsfunktion der Exponentialverteilung mitParameter αj,j .Ist dieser Zeitpunkt t0 erreicht, so gilt ∀h > 0, dass sich die Wahrscheinlichkeit, dass sichder Prozess nach dem Zeitpunkt im Zustand i befindet, unter der Bedingung, dass er davor im

70 KAPITEL 6. ANWENDUNG AUF ZEITDISKRETE AGENTENBASIERTE MODELLE
Zustand j war und bekannt ist, dass er sich nachher nicht mehr in diesem Zustand befindet, aufden folgenden Ausdruck beläuft:
P (j → i|t0) = P ((t0 +h
2, i)|(t0 +
h
2, 6= j), (t0 −
h
2, j)) =
= P ((h, i)|(h, 6= j), (0, j)) =P ((h, i), (h, 6= j)|(0, j))P ((h, 6= j)|(0, j))
=hP ((h, i)|(0, j))
h∑
k 6=j P ((h, k)|(0, j))Da der Ausdruck für alle beliebig kleinen h gilt, gilt er auch für den Limes h→ 0:
P (j → i|t0) =αj,i∑k 6=j αj,k
= −αj,iαj,j
Dieser Satz liefert nun u.a. eine Methode, wie ein zeitkontinuierlicher ortsdiskreter regulärerMarkov-Prozess bzw. eine Markov-Prozess basierte Mikrosimulation sogar ohne Diskretisie-rung simuliert werden kann, indem man exponentialverteilte Zufallszahlen erstellt.Man untersucht nun die Verteilung der Verweildauer für einen DSDT Markov-Prozess, bzw.für einen Agenten aus einem Agentenmodell, das die Bedingungen 6.2.1 erfüllt.
Satz 6.4.2 (Verweildauer für einen DTDS Markov-Prozess).Die Verweildauer eines durch die Übergangsmatrix Q definierten Zustandes j eines Markov-Prozesses ist geometrisch verteilt mit Parameter 1 − P ((1, j)|(0, j)). Die Wahrscheinlichkeitdass der Prozess zum Zeitpunkt t ∈ 0, . . . T den Zustand ändert, beläuft sich zu
P ((t, 6= j)|(0, . . . , t− 1, j)) = Qt−1j,j (1−Qj,j) = P ((1, j)|(0, j))t−1(1− P ((1, j)|(0, j))).
Zum Zeitpunkt der Zustandsänderung geht der Prozess mit Wahrscheinlichkeit
P ((1, i)|(1, 6= j), (0, j)) =P ((1, i)|(0, j))
1− P ((1, j)|(0, j))
vom Zustand j in den Zustand i über.
Beweis: Beide Aussagen sind von sehr elementarer Natur. Erstere folgt, arbeitet man die Ereig-nisse der t Zeitschritte schrittweise ab:
P ((t, 6= j)|(0, . . . , t− 1, j)) =
= P (Prozess bleibt in j) · · · · · (Prozess bleibt in j)︸ ︷︷ ︸t−1
P (Prozess bleibt nicht in j).
Zweitere folgt direkt aus dem Satz über bedingte Wahrscheinlichkeiten:
P ((1, i)|(1, 6= j), (0, j)) =P ((1, i) ∩ (1, 6= j)|(0, j))
P ((1, 6= j)|(0, j))=
P ((1, i)|(0, j))1− P ((1, j)|(0, j))
.

6.5. UMRECHNUNG AUF DEN SUMMIERTEN PROZESS 71
Nun gilt dieser Satz natürlich nur für konstant bleibende Übergangsmatritzen und damit nurfür nicht-interagierende Agenten. Immerhin ist aber die Übergangsmatrix für einen Zeitschrittkonstant, womit die Verteilungsfunktion eines DT Agenten, der die Bedingungen 6.2.1 erfüllt,immerhin für einen Zeitschritt eine geometrische ist.Gemäß der Definition 6.3.1 folgt, dass der aus dem zeitdiskreten Agentenmodell definierte zeit-kontinuierliche Markov-Prozess mit genau den selben Parametern exponentialverteilt ist, mitdenen der zeitdiskrete Agent, zumindest für einen Zeitschritt, geometrisch verteilt ist. Nun giltaber der Satz:
Satz 6.4.3 (Konvergenzeigenschaft der Geometrischen- gegen die Exponentialvertei-lung).Ist Xn ∼ Geom(λ/n) folgt
limn→∞
Xn
n∼ Exp(λ).
Für den Beweis sei auf Grundlagenliteratur für Wahrscheinlichkeitstheorie verwiesen.Der Satz liefert nun die Aussage:
Zeitskalierung + inverse Parameterskalierung ⇒ Konvergenz des DT Agenten gegenden CT Markov-Prozess
Bemerkung 6.4.4.Tatsächlich gilt für die Lösungskurven der Differentialgleichungen 3.11 bzw. 4.1 mit s := Ctund νi,j :=
ωi,jC mit C ∈ R
∂φ(t)
∂t=∑R 6=0
(Φ1)ω(φ(t), R)R⇒ ∂φ(s)
∂sC =
∑R 6=0
C(Φ1)ν(φ(t), R)R
⇒ φω(t) = φν(s),
bzw. genausoσ2ω(t) = σ2
ν(s), pω(t, x) = pν(s, x).
D.h. bleibt ωi,jt konstant, ändert sich der Verlauf der Approximationskurven nicht.
6.5 Umrechnung auf den summierten Prozess
Nachdem im letzten Kapitel gezeigt wurde, wovon der Diskretisierungsfehler abhängt, der ge-macht wird, wenn man den Zustand eines einzelnen Agenten gemäß Definition 6.3.1 approxi-miert, muss man sich nun die Frage stellen, wie man die für das Kapitel 3 erforderlichen Über-gangsraten ω~x,~x+~R des summierten und normierten Prozesses, ausgehend von den einzelnenÜbergangsraten des agentenbasierten Markov-Modells und in Konsequenz von den Übergangs-wahrscheinlichkeiten des Agentenmodells, findet.

72 KAPITEL 6. ANWENDUNG AUF ZEITDISKRETE AGENTENBASIERTE MODELLE
Von diesem Zeitpunkt an gelte wieder der RaumX ∈ 0, . . . , Nd als der Zustandsraum, da derüber die Indikatorfunktionen summierte Prozess beobachtet wird. Für den klassisch auftretendenFall ~R = ~ei − ~ej kann man geschlossen eine Umrechnungsformel angeben.
Satz 6.5.1.[Umrechnungsformel] Es gilt
ω(~x,~ei − ~ej) = ω ~X,~ei−~ej := ~xjωj,i := ~xjP ((1, i)|(0, j))
mit den kanonischen, d-dimensionalen Einheitsvektoren ~ei und ~ej .
Beweis: Sei ~R := ~ei − ~ej so gilt gemäß Definition der Übergangsraten
ω ~X,~ei−~ej = limh→0
P ((h, ~X + ~R)|(0, ~X))
h.
Gemäß einfacher Kombinatorik lässt sich die Wechselwahrscheinlichkeit von genau einem der~Xj identischen Agenten berechnen:
P ((h, ~X + ~R), (0, ~X)) = ~XjP ((h, i)|(0, j))(1− P ((h, i)|(0, j))) ~Xj−1
Ein einzelner Markov-Prozess geht nun mit Wahrscheinlichkeit ωj,ih + O(h2) vom Zustand jin den Zustand i über.
P ((h, ~X + ~R), (0, ~X)) = ~Xjωj,ih(1− hωj,i)~Xj−1 +O(h2)
Damit gilt für die Übergangsrate
ω ~X,~ei−~ej = limh→0
~Xjωj,i(1− hωj,i)~Xj−1 +O(h) = ~Xjωj,i.
In diesem Sinne sind Übergangsraten also in gewissem Maße linear. Da
P ((1, ~X + ~R)|(0, ~X) = P ((1, ~x+N−1 ~R)|(0, ~x))
gilt die Gleichheitω(~x, ~R) = ω ~X,~R.
Bemerkung 6.5.2.Da man das Zeitintervall h durch den Limes beliebig klein machen kann, muss man nicht be-rücksichtigen, dass innerhalb des beobachteten Zeitintervalls ggfs. noch zusätzliche Prozesseden Zustand wechseln und damit die Übergangsraten beeinflussen. Alle den Zustand verlassen-de [betretende] Prozesse müssen tatsächlich gleichzeitig den Zustand wechseln. Somit ist ~ei− ~ejmeist die einzige mögliche Zustandsänderung, die man berücksichtigen muss.Ein Beispiel, in dem es aber doch Zustände gibt, die ~R 6= ~ei− ~ej erlauben, wäre ein Populations-modell, welches auf Eheschließungen abzielt. Den Zustand „verheiratet“ kann man ja schließlichnicht alleine betreten oder verlassen.

6.6. ZUSAMMENFASSUNG UND LETZTE VORAUSSETZUNGEN 73
6.6 Zusammenfassung und letzte Voraussetzungen
Im letzten Kapitel wurde gezeigt, dass unter der Vorraussetzung von kleinen Übergangswahr-scheinlichkeiten eines Agenten, diese direkt als Übergangsraten für ein CT Markov-Modell ver-wendet werden können und wie sich auf einfache Weise Übergangsraten für den Markov-Prozessder Zustandsvariablen ergeben. Somit kann ein Agentenmodell gemäß Definition 6.3.1 mit ei-nem CT Markov-Prozess basierten Mikromodell approximiert werden. Um das Agentenmodellnun mit der Mastergleichung bzw. der Kramers-Moyal-Entwicklung behandeln zu können, mussman die Voraussetzungen aus 6.2.1 noch gemäß 3.4.2 erweitern.
Bedingung 6.6.1.(Voraussetzungen für ein für die Theorie aus Kapitel 3 taugliches DT Agentenmodell)
Bezeichnung DefinitionN Anzahl der Agenten/DTDS Markov-Prozesse
A1, . . . , An Agentenm1, . . . , mn (erweiterte) DTDS Markov-Prozesse
Xa(t) =∑N
i=1 Iam(t), t ∈ 0, . . . , T Anzahl der Agenten im Zustand aP : 0, . . . , N × 0, . . . , T → [0, 1] Wahrscheinlichkeitsfunktion von X(t)
xa(t) := Xa(t)N normierter Prozess
~X(0) = ~k0, ~x(0) =~k0N = x0 Vektorwertiger Anfangswert der Prozesse
~k0 ∈ 0, . . . , Nd, ||k0||1 = N mit Summe N über alle ElementeP (m(1) = a|b) = g(N)(
∑∞n=0N
−nΦn(x)) Polynomdarstellungsmöglichkeit
Da die für die Umformung zu DG-System notwendigen Übergangsraten des zeitkontinu-ierlichen Prozesses x(t) auf lineare Weise aus den Übergangswahrscheinlichkeiten des Agen-tenmodells entstehen, ist, um die Polynomdarstellung der Übergangsraten zu sichern, auch einepolynomielle Darstellung für die Übergangswahrscheinlichkeiten, die ja auch von Systempara-metern abhängen können, gefordert.Es folgt nach allem Gezeigten der Satz:
Satz 6.6.2.Erfüllt ein agentenbasiertes Modell die Bedingungen 6.6.1, so approximiert der in 6.3.1 und in6.5.1 definierte CT-Markov-Prozess das Agentenmodell (bzgl. des Zustandsvektors x) und kanngemäß der Theorie aus Kapitel 3 bzw. 5 mit einem System aus Differentialgleichungen beschrie-ben werden.Der Fehler der Dichten bzw. Wahrscheinlichkeitsfunktionen ist von den Größen der Übergangs-raten, der Anzahl der Agenten und der Anzahl der Durchläufe des Experiments abhängig.


KAPITEL 71. Bsp: Ehrenfestsches
Urnenproblem
Zu Beginn des 20. Jhdt entwickelte der österreichische Quantenphysiker Paul Ehrenfest ein sto-chastisches Gedankenexperiment, welches hier, ob seiner Einfachheit, als Modellproblem die-nen soll. Es handelt sich dabei um das berühmte Ehrenfest’sche Urnenmodell, nachzulesen imBuch „The Encyclopaedia Britannica“ unter „Ehrenfest model of diffusion“ [Enc07], mit wel-chem Ehrenfest seinerzeit versuchte, das zweite Gesetz der Thermodynamik zu veranschauli-chen.
7.1 Problemstellung
Definition 7.1.1 (Ehrenfestsches Urnen Problem).Gegeben seien N unabhängige Partikel Pn mit Zustand 1 oder 0. Jedes Partikel folgt einem CTMarkov-Prozess. Die Übergangsraten, mit denen ein Partikel von Zustand i zu j wechselt seienkonstant und definiert mit:
ω(0, 1) = λ ω(1, 0) = µ.
Visualisieren lässt sich das Modell am besten mithilfe eines Raumes, der in der Mitte durch eineMembran in zwei Teilbereiche getrennt ist. Auf die beiden Bereiche werden nun N Teilchenverteilt, die ihrerseits während jedes Zeitintervalls eine gewisse Wahrscheinlichkeit haben, durchdie Membran in den anderen Bereich durchzudringen (siehe Abbildung 7.1). Während Ehrenfestdamals mit diesem Experiment das Prinzip der Entropie veranschaulichen wollte, dient es hierals das Modellproblem für ein agentenbasiertes CT Markov-Modell. Ausgehend von diesemkann man auch ein klassisches DT Agentenmodell definieren.
75

76 KAPITEL 7. 1. BSP: EHRENFESTSCHES URNENPROBLEM
µ
µ
λ
1 0
Abbildung 7.1: Skizze des Ehrenfest’schen Urnenproblems
Definition 7.1.2 (DT Urnen Problem).Gegeben seien N unabhängige Partikel Pn im Zustand 1 oder 0. In jedem Zeitschritt geht einAgent im Zustand 0 mit Wahrscheinlichkeit
P ((1, 1)|(0, 0)) := λ ≤ 1
in den Zustand 1 über. Umgekehrt geht ein Agent im Zustand 1 mit
P ((1, 0)|(0, 1)) := µ ≤ 1
in den Zustand 0 über.
Die beiden Definitionen unterscheiden sich grundlegend vor allem anhand der Bedingungλ(µ)≤ 1. Was im Falle von Wahrscheinlichkeiten eine notwendige Bedingung ist, spielt beiÜbergangsraten keine Rolle. Gemäß der Analyse des Diskretisierungsfehlers muss sogar
λ 1, µ 1
verlangt werden, damit das diskrete Urnenmodell ähnliche Ergebnisse liefert, wie das CT Markov-Modell. Um also die Theorie aus Kapitel 3 auf das DT Agentenmodell anwenden zu können,seien die Übergangswahrscheinlichkeiten ab sofort 1.

7.2. RESULTIERENDE DIFFERENTIALGLEICHUNGEN 77
7.2 Resultierende Differentialgleichungen
7.2.1 Überprüfen der Bedingungen
Um das Modell nun theoretisch zu analysieren, müssen zunächst die Übergangsraten des auf-summierten und normierten Markov-Prozesses
x(t) := x1(t) :=1
N
N∑i=0
I1(Pn(T ))
bestimmt werden.
Bemerkung 7.2.1.Obwohl das Modell zwei Zustände 0 und 1 hat ist es eindimensional, da bei bekannter Anzahlder AgentenX(t) im Zustand 1, die Anzahl der Agenten im zweiten Zustand 0 auf triviale Weisedirekt durch N −X(t) folgt. Selbiges folgt natürlich auch für den normierten Prozess, wo mit1− x(t) der Wert des normierten Prozesses für den Zustand 0 eindeutig aus dem Wert x(t) desProzesses für den Zustand 1 bestimmt ist.
Gemäß Gleichung 6.5.1 erhält man auf einfache Weise die für die Differentialgleichungnotwendigen Raten:
ωX,X+1 = (N −X)λ⇒ ωx,1 = N(1− x)λ (= ω~x,~e1− ~e2)
ωX,X−1 = Xµ⇒ ωx,−1 = Nxµ (= ω~x,~e2− ~e1)
Da in diesem Experiment Übergänge von mehreren Agenten fast sicher nicht gleichzeitig ver-laufen können, verschwinden alle anderen Übergangsraten (vgl. Bemerkung 6.5.2).
ωx,x+R = 0, ∀|R| > 2
Die Übergangsrate ωx,x berechnet sich gemäß Definition der Übergangsraten zu
ωx,x = −ωx,x+1 − ωx,x−1 = −Nxµ−N(1− x)λ = N(x(λ− µ)− λ).
Leicht zu sehen sind alle Übergangsraten
ωx,y : 0, N−1, . . . , 12 → R
auf triviale Weise nachωx,y : [0, 1]2 → R
erweiterbar und nach der Variable x differenzierbar. Die Darstellung als Polynom liefert
ωx,x+R = f(N)(Φ1(x,R) +N−1Φ2(x,R) . . . )⇒
ωx,x+1 = Nλ(1− x)⇒ f(N) := N,Φ1(x, 1) = λ(1− x)
ωx,x = N(x(λ− µ)− λ)⇒ f(N) := N,Φ1(x, 0) = x(λ− µ)− λωx,x−1 = Nµx⇒ f(N) := N,Φ1(x,−1) = µx
ωx,x+R = 0, ∀|R| > 1.

78 KAPITEL 7. 1. BSP: EHRENFESTSCHES URNENPROBLEM
7.2.2 Erwartungswertkurve
Gemäß Gleichung 3.11 folgt der Erwartungswert des Modells näherungsweise der Kurve φ, diedurch die Differentialgleichung
∂φ(τ)
∂τ=∑R 6=0
Φ1(φ(τ), R)R = 1 · λ(1− φ(τ)) + (−1) · µφ(τ) =
= −φ(τ)(λ+ µ) + λ,
mit φ(0) = x0 = N−1∑N
n=0 I1Pn(0) als Anfangswert beschrieben wird. Die Zeitvariable τfolgt der Substitution τ = f(N)
N t = t (d.h. die Zeit muss nicht substituiert werden).Die entstende Differentialgleichung ist linear und analytisch lösbar:
φ′ = −φ(τ)(λ+ µ) + λ⇒
φ(t) = φh(t) + φp(t) = Ce−t(λ+µ) +λ
λ+ µ
Durch φ(0) = x0 folgt
x0 = C +λ
λ+ µ⇒
φ(t) =
(x0 −
λ
λ+ µ
)e−t(λ+µ) +
λ
λ+ µ. (7.1)
7.2.3 Equilibrium des Erwartungswertes
Von großem Interesse ist an dieser Stelle auch das Langzeitverhalten der Lösung. Da λ und µals Wahrscheinlichkeiten stets positiv (≥ 0) sind, folgt
limt→∞
φ(t) =λ
λ+ µ.
(Sind µ und λ beide gleich 0 so ändert sich das Agentenmodell genauso wenig, wie die Differen-tialgleichung. Man erhielte die konstante Lösung x0 in beiden Modellen mit Varianz konstant 0;d.h. eine entartete Dichtekurve.)Betrachtet man im Gegenzug das Langzeitverhalten des Erwartungswertes für das aufsummierteAgentenmodell x(t), t ∈ 0, 1, . . . , so muss man den Ausdruck
limt→∞
E(x(t)|x(0) = x0) =: E(x(∞)|x(0) = x0)
betrachten, sofern der Limes existiert. Gemäß der Gleichung von Chapman-Kolmogorov (Satz2.1.6), die hier ohne Einschränkung gilt, da die Agenten nicht interagieren, lässt sich der Erwar-tungswert mit endlicher Zeit t umschreiben.
E(x(t+ 1)|x(0) = x0) =∑x
(x∑y
P ((1, x)|(0, y))P ((t, y)|(0, x0))) =

7.2. RESULTIERENDE DIFFERENTIALGLEICHUNGEN 79
=∑y
P ((t, y)|(0, x0))∑x
xP ((1, x)|(0, y)) =∑y
P ((t, y)|(0, x0))E(x(1)|x(0) = y)∗=
Als Summe über sogenannte Bernoulli-Ereignisse sind sowohl die yN Agenten im Zustand 1,also auch die N(1− y) Agenten im Zustand 0 über einen Zeitschritt hinweg binomialverteilt:
X1 ∼ Binom(Ny, (1− µ))
X2 ∼ Binom(N(1− y), λ),
mit (X(1)|X(0) = Ny) ∼ X1 +X2. Somit gilt für den normierten Erwartungswert über einenZeitschritt die Gleichung
E(x(1)|x(0) = y) =E(X1)
N+E(X2)
N= y(1− µ) + (1− y)λ = y(1− µ− λ) + λ. (7.2)
Setzt man also die Umformung für den Erwartungswert an der Stelle t+ 1 fort, so gilt
∗=∑y
P ((t, y)|(0, x0))(y(1− µ− λ) + λ) =
= (1− µ− λ)
(∑y
P ((t, y)|(0, x0))y
)+ λ
∑y
P ((t, y)|(0, x0))︸ ︷︷ ︸=1
=
= (1− µ− λ)E(x(t)|x(0) = x0) + λ.
Durch diese Umformung erhält man eine rekursive Darstellung für die explizite Folge(E(x(t)|x(0) = x0))t. Als Grenzwert kann, gemäß dem Fixpunktsatz von Banach, ausschließ-lich der Ausdruck E(x(∞)|x(0) = x0) mit
E(x(∞)|x(0) = x0) = (1− µ− λ)E(x(∞)|x(0) = x0) + λ
⇒ E(x(∞)|x(0) = x0) =λ
λ+ µ
in Frage kommen. Die Rekursion
at+1 = (1− λ− µ)at + λ
ist aber, wie man leicht nachrechnet, für jedes offene Intervall (al, ar) ∈ [0, 1] das λλ+µ enthält
und für 0 < λ + µ < 1 sowie 0 < λ < 1, eine strikte Kontraktion, womit der im Fixpunktsatzbestimmte Grenzwert angenommen wird. (Eine sehr ähnliche Rechnung wird später im Kapitel8 für die analoge, verallgemeinerte Aussage durchgeführt.)Der Grenzwert des Erwartungswertes im Agentenmodell entspricht also dem Equilibriumzu-stand der Lösung der Differentialgleichung 3.11.

80 KAPITEL 7. 1. BSP: EHRENFESTSCHES URNENPROBLEM
7.2.4 Varianz
Gemäß Gleichung 4.1 lässt sich auch eine Approximation an die Varianz des agentenbasiertenModells ermitteln.
∂σ2(τ)
∂τ= −2αx(φ(τ))σ2(τ) + 2β(φ(τ)) =
= −2σ2(τ)∑R 6=0
(Φ1)x(φ(τ), R)(−R) + 2∑R 6=0
Φ1(φ(τ), R)(−R)2 =
= −2σ2(τ)((−1) · (−λ) + 1 · µ) + 2(1 · λ(1− φ(τ)) + 1 · µφ(τ)) =
= −2σ2(τ)(λ+ µ) + 2(λ+ φ(τ)(µ− λ)) =
= −2σ2(τ)(λ+ µ) + 2(λ+
((x0 −
λ
λ+ µ
)e−τ(λ+µ) +
λ
λ+ µ
)(µ− λ))
Auch diese gewöhnliche, lineare Differentialgleichung mit Störfunktion ist, wenn auch nichttrivial, analytisch lösbar. Der Vollständigkeit halber ist hier die Lösung mit t = τ angegeben:
σ2(t) = e−2(µ+λ)t
(−λ2 + x0(λ2 − µ2)
(λ+ µ)2+
µλ
(λ+ µ)2e2t(λ+µ)
)+ (7.3)
+2e−2(µ+λ)t
((λ− µ)(−x0(µ+ λ) + λ)
(λ+ µ)2et(λ+µ)
)Mittels V(x)(t) = σ2(t)
N lässt sich somit die Varianz des Agentenmodells approximieren.Wie im Fall des Erwartungswertes ist auch hier das Langzeitverhalten der Funktion interessant.Man erkennt, dass die Varianz zwar mit t monoton wachsend, aber sogar beschränkt ist. DerGrenzwert beträgt N−1 µλ
(λ+µ)2 , womit das Modell in diesem Sinne zeitlich stabil bleibt.
Bemerkung 7.2.2.Dass diese Tatsache nicht trivial ersichtlich ist, sieht man, vergleicht man das Modell (mit derFokker-Planck-Gleichung 3.12) mit einer klassischen Diffusions- (Wärmeleitungs-) gleichung
Πt −Πξξα = 0,
mit den Randbedingungen Π(0, ·) = δ0(ξ) und
Π(·,−∞) = Π(·,∞) = Πξ(·,−∞) = Πξ(·,∞) = 0.
Eine Fundamentallösung ist mit
Π(ξ, t) = (4απt)−1/2e−ξ24αt
gegeben. Da diese ohnedies bereits Lösung zur Diffusionsgleichung mit Delta-distributionellerAnfangsbedingung bei 0 ist, erfüllt sie die Zeit-RB und ebenso, wie sich zeigt, die Orts-RB.Um die Analogie zum Agentenmodell deutlich zu machen, sei für diese Dichte die analogeSubstitution durchgeführt:
p(x, t) = (4απt)−1/2e−N(x−φ(t))2
4αt c.

7.3. RESULTATE ZUM KONKRETEN BEISPIEL 81
D.h. man erhält eine zeitabhängige Gauss Verteilung mit Mittelwert φ(t) und eine Normierungs-konstante c, die sich zu c =
√N bestimmen lässt.
Somit gilt
p(x, t) =
√N
4απte−N(x−Φ(t))2
4αt .
Die von Zeit und N abhängige Varianz der Kurve beträgt 4αtN . Sie wird mit t linear größer (und
geht mit N →∞ gegen 0). Die Varianz bleibt somit für festes N mit der Zeit unbeschränkt.
7.2.5 Dichte
Der Ansatz zur Lösung der Differentialgleichung 3.12 liefert nach Bestimmung der Varianz eineDichtefunktion Π mit
Π : [0, tend]× [−∞,∞]
Π(t, ξ) =
√N√
2πσ2(t)e−N(ξ)2
2σ2(t)
und nach der Variablensubstitution ξ → x die Dichtefunktion
p(x, t) =
√N√
2πσ2(t)e−N(x−φ(t))2
σ2(t) ,
die schlussendlich die Dichte des Agentenmodells annähert.
7.3 Resultate zum konkreten Beispiel
Es folgen nun einige Plots, die abschließend zu diesem Modellbeispiel die Theorie untermauernsollen. Zu diesem Zweck gibt die folgende Tabelle zunächst einen Überblick über die für dieeinzelnen Abbildungen verwendeten Parametersätze.
Abb. Typ N M λ µ x0
7.2 DT Agent 200, 1000, 2000 1 0.05 0.1 0.17.3 Vergleich: Mittelwerte 1000 1000 0.05 0.1 0.17.4 Vergleich: Varianz 1000 1000 0.05 0.1 0.17.5 Vergleich: Dichte 1000 5000 0.05 0.1 0.17.6 Fehler für mehrere N ·M 10 1 + 10 · C 0.05 0.1 0.17.7 Fehler mit Skalierung 10000 1 0.2
C0.1C 0.1
Abbildung 7.2 zeigt die Graphen von mehreren Durchläufen des Agentenmodells mit unter-schiedlichen Agentenzahlen. Man sieht sehr schön, dass für hohe Agentenzahlen die Abwei-chung zum Mittelwert stets kleiner wird.Nach dem Mitteln über M Durchläufe erhält man stochastisch gute Approximationen an Erwar-tungswert durch
E(X(t)) ≈ X(t) :=1
M
M∑i=1
Xi(t)
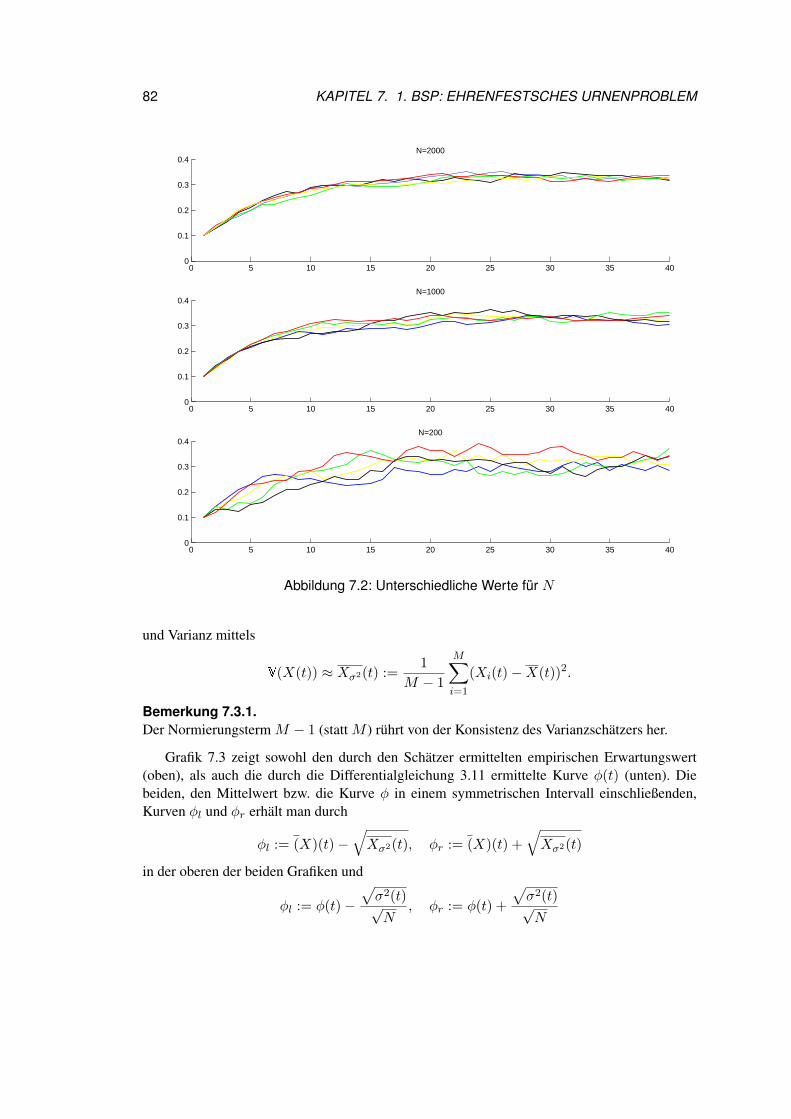
82 KAPITEL 7. 1. BSP: EHRENFESTSCHES URNENPROBLEM
0 5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4N=2000
0 5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4N=1000
0 5 10 15 20 25 30 35 400
0.1
0.2
0.3
0.4N=200
Abbildung 7.2: Unterschiedliche Werte für N
und Varianz mittels
V(X(t)) ≈ Xσ2(t) :=1
M − 1
M∑i=1
(Xi(t)−X(t))2.
Bemerkung 7.3.1.Der Normierungsterm M − 1 (statt M ) rührt von der Konsistenz des Varianzschätzers her.
Grafik 7.3 zeigt sowohl den durch den Schätzer ermittelten empirischen Erwartungswert(oben), als auch die durch die Differentialgleichung 3.11 ermittelte Kurve φ(t) (unten). Diebeiden, den Mittelwert bzw. die Kurve φ in einem symmetrischen Intervall einschließenden,Kurven φl und φr erhält man durch
φl := (X)(t)−√Xσ2(t), φr := (X)(t) +
√Xσ2(t)
in der oberen der beiden Grafiken und
φl := φ(t)−√σ2(t)√N
, φr := φ(t) +
√σ2(t)√N
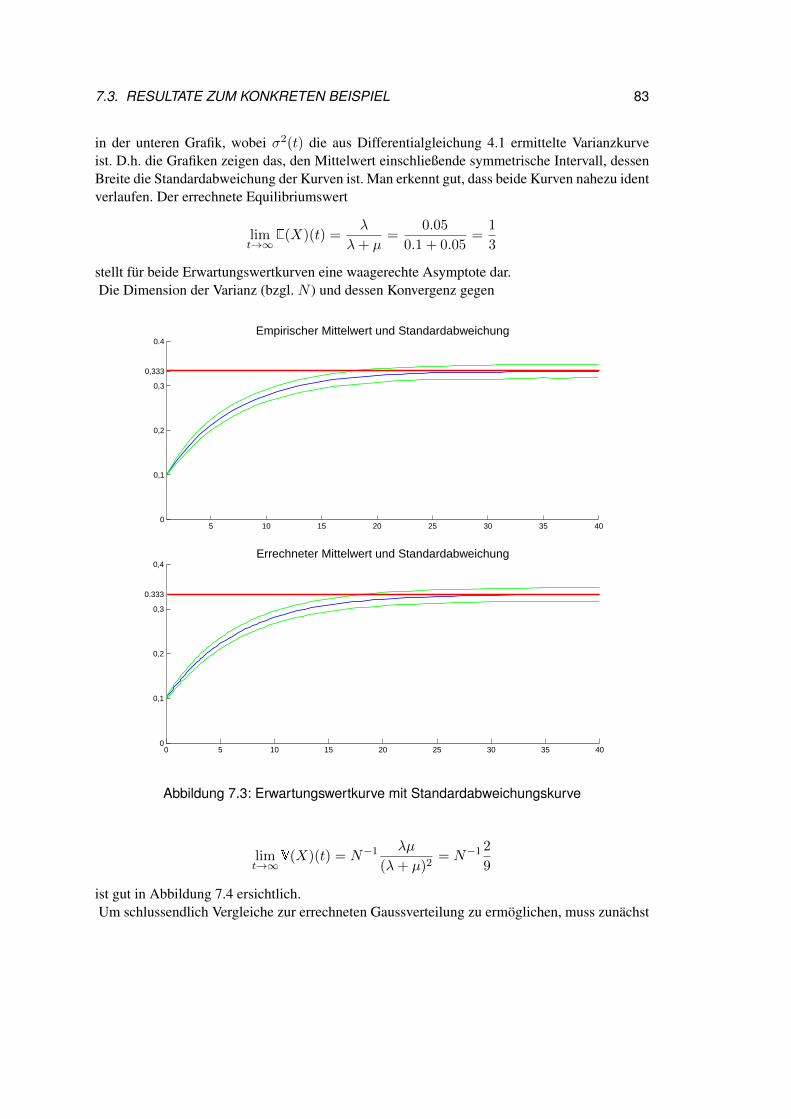
7.3. RESULTATE ZUM KONKRETEN BEISPIEL 83
in der unteren Grafik, wobei σ2(t) die aus Differentialgleichung 4.1 ermittelte Varianzkurveist. D.h. die Grafiken zeigen das, den Mittelwert einschließende symmetrische Intervall, dessenBreite die Standardabweichung der Kurven ist. Man erkennt gut, dass beide Kurven nahezu identverlaufen. Der errechnete Equilibriumswert
limt→∞
E(X)(t) =λ
λ+ µ=
0.05
0.1 + 0.05=
1
3
stellt für beide Erwartungswertkurven eine waagerechte Asymptote dar.Die Dimension der Varianz (bzgl. N ) und dessen Konvergenz gegen
5 10 15 20 25 30 35 400
0,1
0,2
0,3
0,333
0.4Empirischer Mittelwert und Standardabweichung
0 5 10 15 20 25 30 35 400
0,1
0,2
0,3
0.333
0,4Errechneter Mittelwert und Standardabweichung
Abbildung 7.3: Erwartungswertkurve mit Standardabweichungskurve
limt→∞
V(X)(t) = N−1 λµ
(λ+ µ)2= N−1 2
9
ist gut in Abbildung 7.4 ersichtlich.Um schlussendlich Vergleiche zur errechneten Gaussverteilung zu ermöglichen, muss zunächst
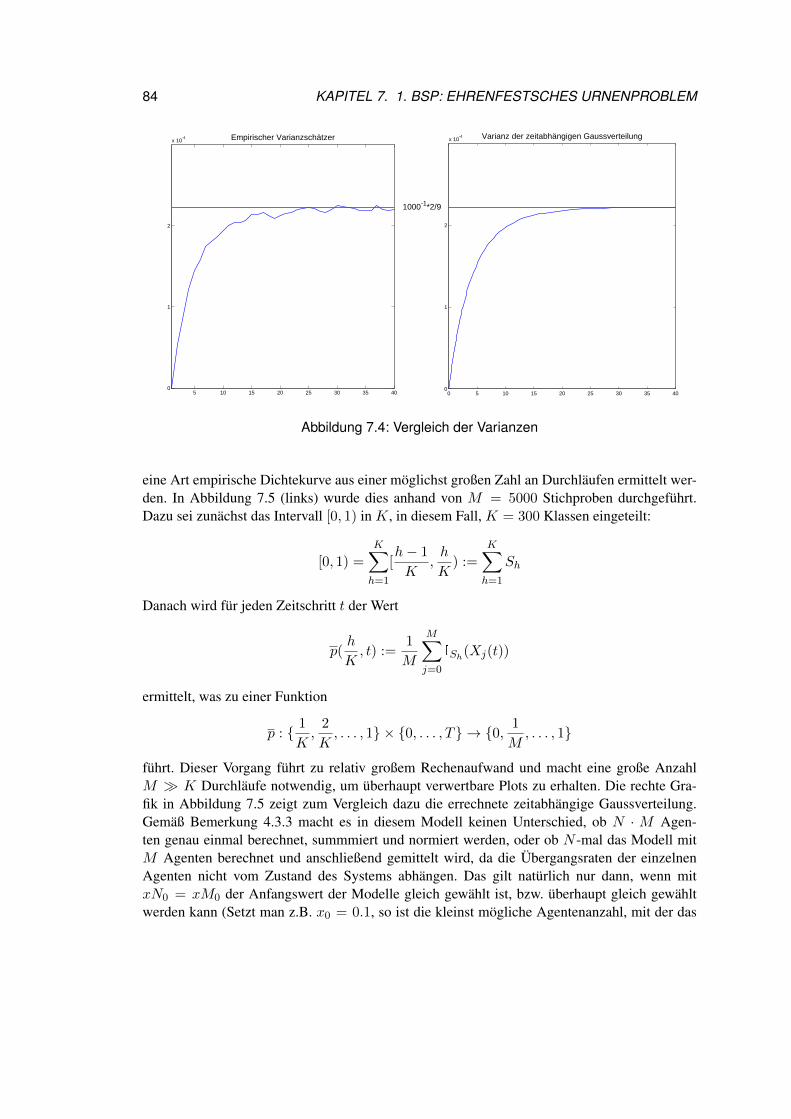
84 KAPITEL 7. 1. BSP: EHRENFESTSCHES URNENPROBLEM
5 10 15 20 25 30 35 400
1
2
x 10-4 Empirischer Varianzschätzer
0 5 10 15 20 25 30 35 400
1
2
x 10-4 Varianz der zeitabhängigen Gaussverteilung
1000-1*2/9
Abbildung 7.4: Vergleich der Varianzen
eine Art empirische Dichtekurve aus einer möglichst großen Zahl an Durchläufen ermittelt wer-den. In Abbildung 7.5 (links) wurde dies anhand von M = 5000 Stichproben durchgeführt.Dazu sei zunächst das Intervall [0, 1) in K, in diesem Fall, K = 300 Klassen eingeteilt:
[0, 1) =K∑h=1
[h− 1
K,h
K) :=
K∑h=1
Sh
Danach wird für jeden Zeitschritt t der Wert
p(h
K, t) :=
1
M
M∑j=0
ISh(Xj(t))
ermittelt, was zu einer Funktion
p : 1
K,
2
K, . . . , 1 × 0, . . . , T → 0, 1
M, . . . , 1
führt. Dieser Vorgang führt zu relativ großem Rechenaufwand und macht eine große AnzahlM K Durchläufe notwendig, um überhaupt verwertbare Plots zu erhalten. Die rechte Gra-fik in Abbildung 7.5 zeigt zum Vergleich dazu die errechnete zeitabhängige Gaussverteilung.Gemäß Bemerkung 4.3.3 macht es in diesem Modell keinen Unterschied, ob N · M Agen-ten genau einmal berechnet, summmiert und normiert werden, oder ob N -mal das Modell mitM Agenten berechnet und anschließend gemittelt wird, da die Übergangsraten der einzelnenAgenten nicht vom Zustand des Systems abhängen. Das gilt natürlich nur dann, wenn mitxN0 = xM0 der Anfangswert der Modelle gleich gewählt ist, bzw. überhaupt gleich gewähltwerden kann (Setzt man z.B. x0 = 0.1, so ist die kleinst mögliche Agentenanzahl, mit der das
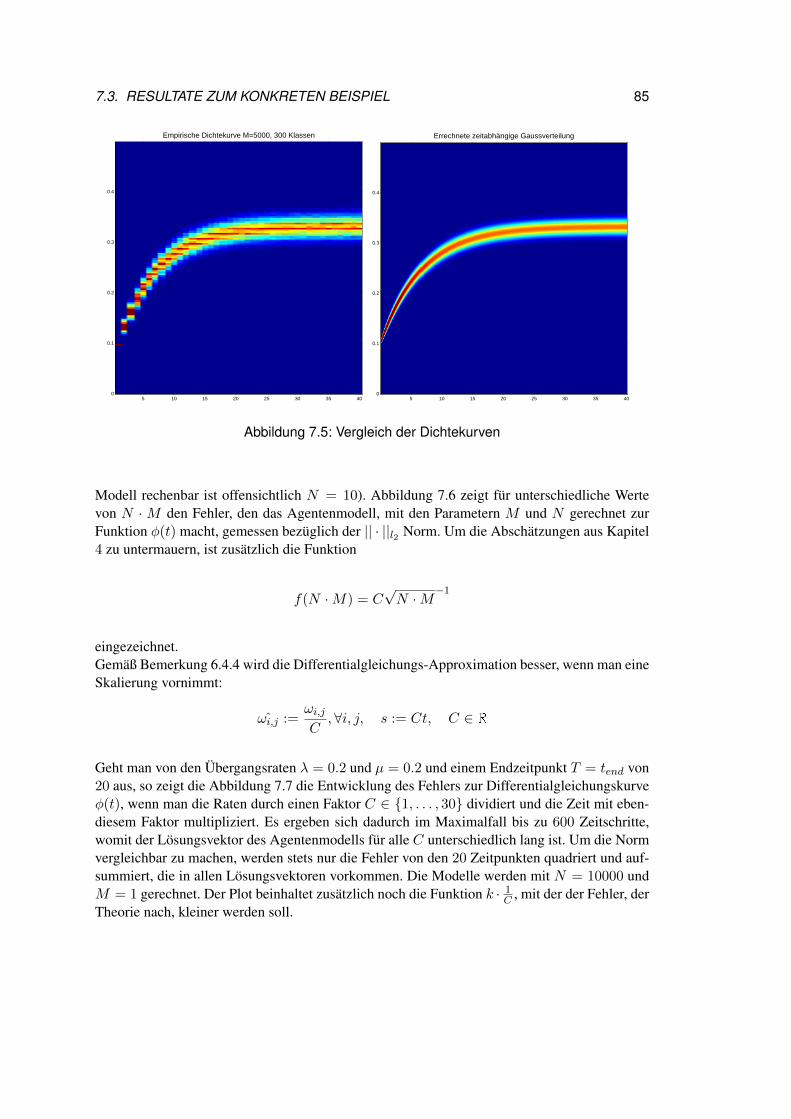
7.3. RESULTATE ZUM KONKRETEN BEISPIEL 85
Empirische Dichtekurve M=5000, 300 Klassen
5 10 15 20 25 30 35 40
0.4
0.3
0.2
0.1
0
Errechnete zeitabhängige Gaussverteilung
5 10 15 20 25 30 35 40
0.4
0.3
0.2
0.1
0
Abbildung 7.5: Vergleich der Dichtekurven
Modell rechenbar ist offensichtlich N = 10). Abbildung 7.6 zeigt für unterschiedliche Wertevon N ·M den Fehler, den das Agentenmodell, mit den Parametern M und N gerechnet zurFunktion φ(t) macht, gemessen bezüglich der || · ||l2 Norm. Um die Abschätzungen aus Kapitel4 zu untermauern, ist zusätzlich die Funktion
f(N ·M) = C√N ·M
−1
eingezeichnet.Gemäß Bemerkung 6.4.4 wird die Differentialgleichungs-Approximation besser, wenn man eineSkalierung vornimmt:
ωi,j :=ωi,jC,∀i, j, s := Ct, C ∈ R
Geht man von den Übergangsraten λ = 0.2 und µ = 0.2 und einem Endzeitpunkt T = tend von20 aus, so zeigt die Abbildung 7.7 die Entwicklung des Fehlers zur Differentialgleichungskurveφ(t), wenn man die Raten durch einen Faktor C ∈ 1, . . . , 30 dividiert und die Zeit mit eben-diesem Faktor multipliziert. Es ergeben sich dadurch im Maximalfall bis zu 600 Zeitschritte,womit der Lösungsvektor des Agentenmodells für alle C unterschiedlich lang ist. Um die Normvergleichbar zu machen, werden stets nur die Fehler von den 20 Zeitpunkten quadriert und auf-summiert, die in allen Lösungsvektoren vorkommen. Die Modelle werden mit N = 10000 undM = 1 gerechnet. Der Plot beinhaltet zusätzlich noch die Funktion k · 1
C , mit der der Fehler, derTheorie nach, kleiner werden soll.
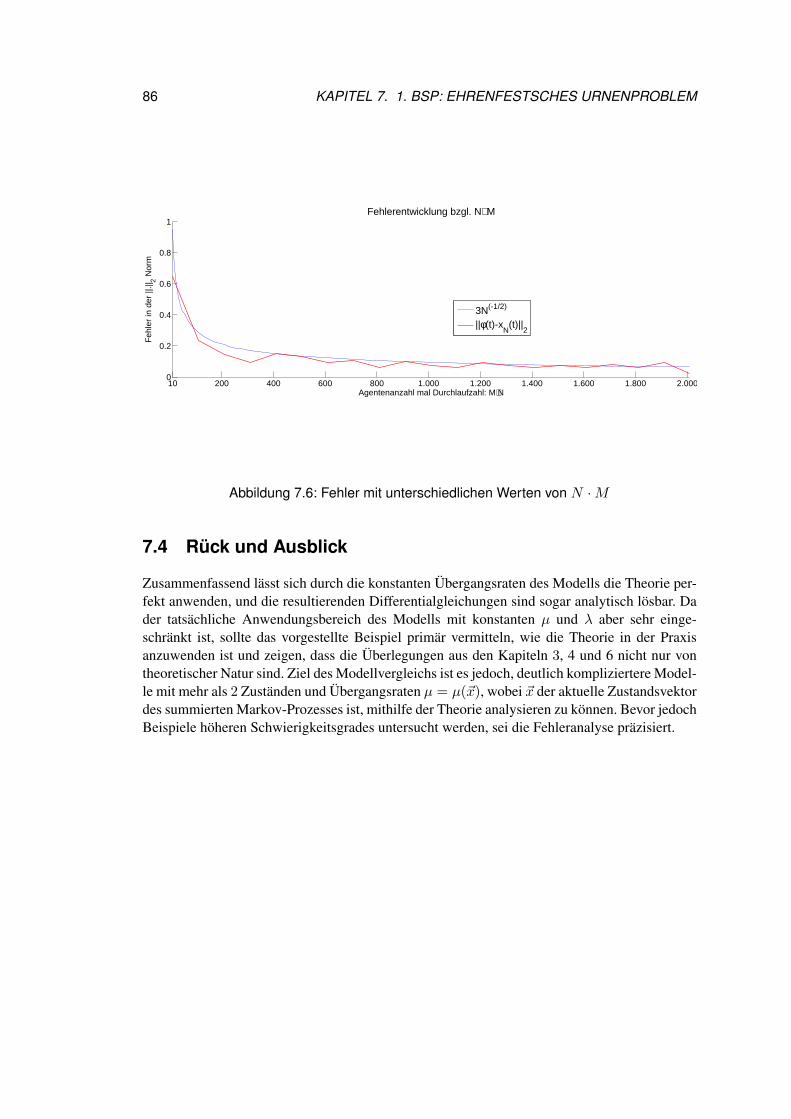
86 KAPITEL 7. 1. BSP: EHRENFESTSCHES URNENPROBLEM
10 200 400 600 800 1.000 1.200 1.400 1.600 1.800 2.0000
0.2
0.4
0.6
0.8
1
Agentenanzahl mal Durchlaufzahl: M⋅N
Feh
ler
in d
er ||
.||2 N
orm
Fehlerentwicklung bzgl. N⋅ M
3N(-1/2)
||φ(t)-xN
(t)||2
Abbildung 7.6: Fehler mit unterschiedlichen Werten von N ·M
7.4 Rück und Ausblick
Zusammenfassend lässt sich durch die konstanten Übergangsraten des Modells die Theorie per-fekt anwenden, und die resultierenden Differentialgleichungen sind sogar analytisch lösbar. Dader tatsächliche Anwendungsbereich des Modells mit konstanten µ und λ aber sehr einge-schränkt ist, sollte das vorgestellte Beispiel primär vermitteln, wie die Theorie in der Praxisanzuwenden ist und zeigen, dass die Überlegungen aus den Kapiteln 3, 4 und 6 nicht nur vontheoretischer Natur sind. Ziel des Modellvergleichs ist es jedoch, deutlich kompliziertere Model-le mit mehr als 2 Zuständen und Übergangsraten µ = µ(~x), wobei ~x der aktuelle Zustandsvektordes summierten Markov-Prozesses ist, mithilfe der Theorie analysieren zu können. Bevor jedochBeispiele höheren Schwierigkeitsgrades untersucht werden, sei die Fehleranalyse präzisiert.
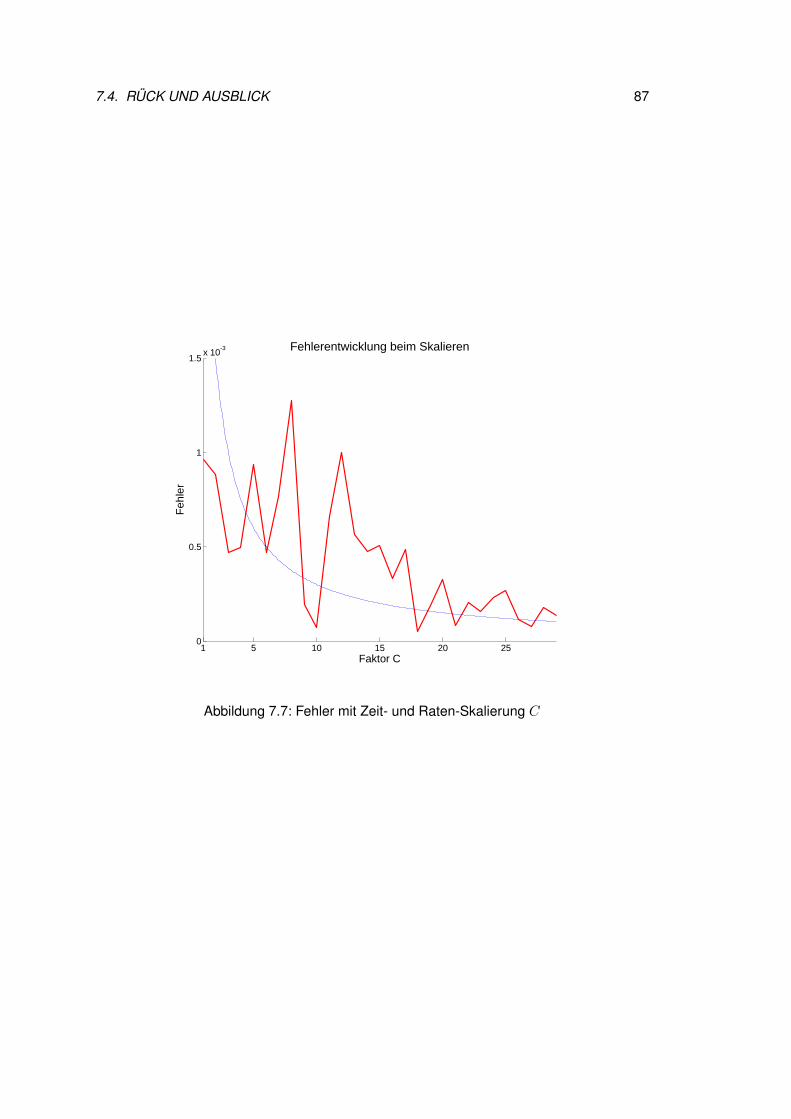
7.4. RÜCK UND AUSBLICK 87
1 5 10 15 20 250
0.5
1
1.5x 10
-3
Faktor C
Feh
ler
Fehlerentwicklung beim Skalieren
Abbildung 7.7: Fehler mit Zeit- und Raten-Skalierung C


KAPITEL 8Fehleranalyse
In den letzten Kapiteln wurden bereits einige Fehleranalysen durchgeführt, beziehungsweise dieGrößenordnung von einigen Fehlern bestimmt. Was aber leider alle bis zu diesem Punkt durch-geführten Fehleranalysen gemeinsam haben ist, dass es sich lediglich um qualitative Analysendes Fehlers in Form von Landau Symbolen handelt, aber nicht um handfeste, verwertbare Ab-schätzungen.Zudem wurde der Fehler stets schrittweise, d.h. sich aufsummierend von Modelltyp zu Modell-typ (siehe Abbildung 8.1) ermittelt, anstatt direkt das agentenbasierte zeitdiskrete Modell mitdem Differentialgleichungsmodell zu vergleichen.Diese zwei Lücken zu füllen ist nun Ziel dieses Kapitels.
DT Agentenmodell
DT Agentenmodell Stoch. Größe
CT Agentenmodell Stoch. Größe
Differentialgleichung
Durchlaufzahl M
Diskretisierungsfehler ||W||
Kramers Moyal
Entwicklung N
Ziel der Fehlerabschätzung
Abbildung 8.1: Überblick über bisherige Abschätzungen
89

90 KAPITEL 8. FEHLERANALYSE
8.1 Gegenüberstellung der Problemstellungen
Wie in den vergangenen Kapiteln erwähnt, ist mit der Definition eines zeitdiskreten agentenba-sierten Modells über Übergangswahrscheinlichkeiten, Anfangswert und Agentenzahl eine, diestochastischen Größen des Zustandsvektors des Agentenmodells approximierende, Differenti-algleichung (Differentialgleichungssystem) bereits eindeutig definiert. Gemäß 6.3.1 und 6.5.1bzw. Kapitel 5 ergibt sich die Umrechnung, wie sie in der vereinfachten Skizze 8.2 zu sehen ist.Da in einem zeitdiskreten Modell innerhalb eines Zeitschrittes maximal N Agenten ihren Zu-stand ändern können, kann man davon ausgehen, dass bei einem, das zeitdiskrete Modell ap-proximierenden, CT Markov-Modell mit nicht-verschwindender Wahrscheinlichkeit nie mehrals ein Agent gleichzeitig den Zustand ändert (Vergleich 6.5.2). Selbst wenn das DT Modellrein theoretisch vorsähe, dass einige Zustandswechsel von mehreren Agenten gleichzeitig zuerfolgen haben, kann man sich die Zustandswechsel im kontinuierlichen Modell innerhalb desZeitschrittes auch mit nicht verschwindendem Zeitabstand, hintereinander, vorstellen. Basierendauf dieser Überlegung wird in Folge genau einer der d Zustände, nämlich oBdA der Zustand 1mit ~X1 =: X , welcher als Beobachtungszustand bezeichnet wird, betrachtet, wobei dieser genauzwei nicht-verschwindende Raten besitzt.
Definition 8.1.1 (Exit/Entry Rate für Zustand 1).Der Beobachtungszustand 1 der CT Approximation des Agentenmodells besitzt nun genau eineExit Rate ωex
ωex := ωex(X, ~X) := ωX,X−1 = X∑a6=1
P ((1, a)|(0, 1), ~X)
und eine Entry Rate ωen
ωen := ωen(X, ~X) := ωX,X+1 =∑a6=1
XaP ((1, 1)|(0, a), ~X),
wobei beide Raten vom Zustandsvektor ~X sowie insbesondere vom ZustandX abhängen dürfen.Die Entry Rate lässt sich umschreiben zu
ωen = (N −X)λ( ~X)
mit dem gewichteten Mittel
λ( ~X) :=N∑a=2
Xa
N −XP ((1, 1)|(0, a), ~X) ∈ [0, 1],
welches als Entry Wahrscheinlichkeit bezeichnet wird. Analog dazu wird mit
µ( ~X) :=N∑a=2
P ((1, a)|(0, 1), ~X)
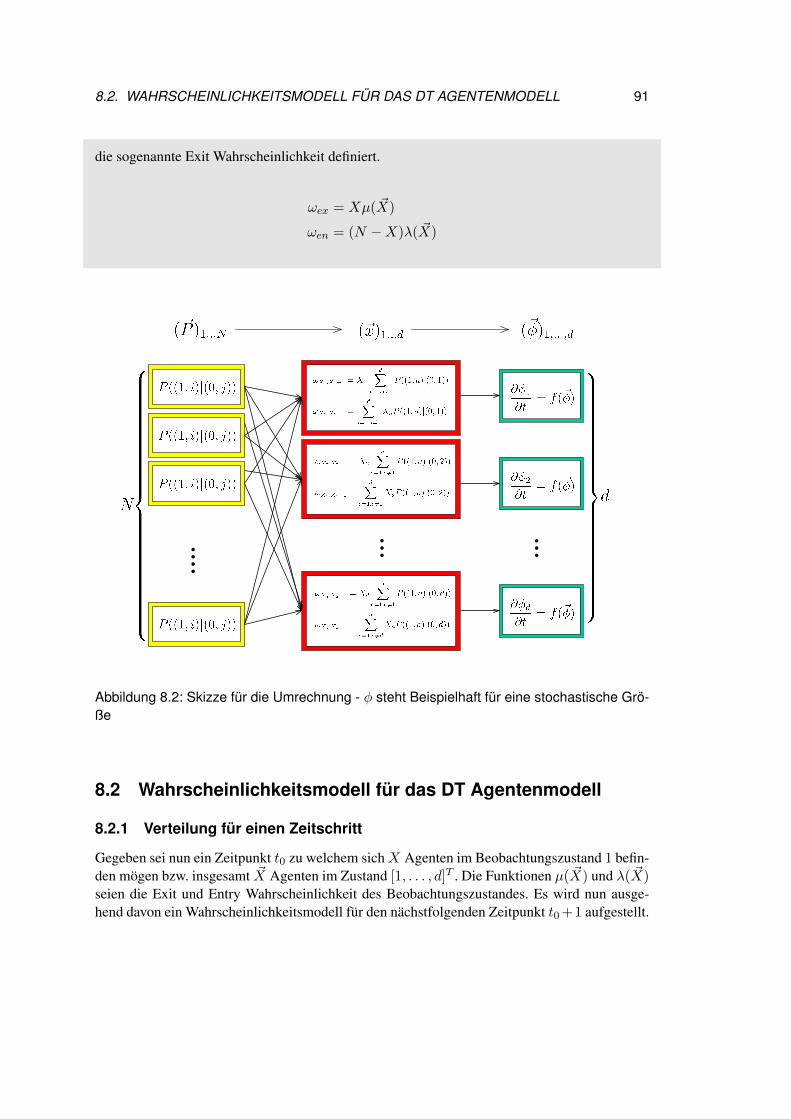
8.2. WAHRSCHEINLICHKEITSMODELL FÜR DAS DT AGENTENMODELL 91
die sogenannte Exit Wahrscheinlichkeit definiert.
ωex = Xµ( ~X)
ωen = (N −X)λ( ~X)
....
... ...
Abbildung 8.2: Skizze für die Umrechnung - φ steht Beispielhaft für eine stochastische Grö-ße
8.2 Wahrscheinlichkeitsmodell für das DT Agentenmodell
8.2.1 Verteilung für einen Zeitschritt
Gegeben sei nun ein Zeitpunkt t0 zu welchem sichX Agenten im Beobachtungszustand 1 befin-den mögen bzw. insgesamt ~X Agenten im Zustand [1, . . . , d]T . Die Funktionen µ( ~X) und λ( ~X)seien die Exit und Entry Wahrscheinlichkeit des Beobachtungszustandes. Es wird nun ausge-hend davon ein Wahrscheinlichkeitsmodell für den nächstfolgenden Zeitpunkt t0 +1 aufgestellt.

92 KAPITEL 8. FEHLERANALYSE
Für i ∈ 0, . . . , N, i =: X +R ergibt sich
P ((t0 + 1, i)|(t0, ~X)) = P ((t0 + 1, X +R)|(t0, ~X))∗=
∗=
minX,N−X−R∑m=0
(N −XR+m
)(Xm
)µm(1− µ)X−mλR+m(1− λ)N−X−R−m
für R ≥ 0 und
∗=
minX+R,N−X∑m=0
(N −Xm
)(X
m−R
)µm−R(1− µ)X−m+Rλm(1− λ)N−X−m
für R < 0.Diese sehr unansehnlichen Formeln lassen sich nachvollziehen, überlegt man folgendes:Ist R = 0 bedeutet das, dass sich die Zustandsvariable innerhalb des Zeitschrittes nicht verän-dert hat, was aber noch nicht bedeutet, dass alle Agenten selbst ihren Zustand beibehalten haben.Wichtig ist nur, dass für jeden Agenten, der seinen Zustand verändert hat, ein komplementärerAgent ebenfalls seinen Zustand verändert haben muss. Die Summe über alle Möglichkeiten,Agentenpaare auszuwählen, multipliziert mit der Wahrscheinlichkeit der paarweisen Zustands-änderung, ergibt nun die gewünschte Wahrscheinlichkeit für R = 0. Die anderen Wahrschein-lichkeiten ergeben sich analog dazu, indem man zusätzliche R Agenten ohne komplementärenGegenpart den Zustand ändern lässt.
8.2.2 Erwartungswert nach einem Zeitschritt
Trotz dieses sehr komplizierten Wahrscheinlichkeitsmodells lässt sich ähnlich zur Rechnung 7.2der Erwartungswert dieser Verteilung relativ leicht ermitteln, definiert man für jeden Agentenmit Zufallsvariable mi die Schreibweise yi(t) := I1(Pi(t)).
E(X(t0 + 1)| ~X) = E(N∑n=0
yn(t0 + 1)| ~X) =N∑n=0
E(yn(t0 + 1)| ~X) =
=∑
n:yn(t0)=0
0 · P (0|0) + 1 · P (1|0) +∑
n:yn(t0)=1
0 · P (0|1) + 1 · P (1|1) =
= (N −X)λ+X(1− µ) = X + ((N −X)λ−Xµ)
D.h. man erhält E(R) = (N −X)µ−Xλ (Vergleich Rechnung 7.2).
8.2.3 Varianz nach einem Zeitschritt
Die Varianz lässt sich auf ähnliche Weise über den Verschiebungssatz bestimmen:
V(X(t0 + 1)| ~X) = E(X2(t0 + 1)| ~X)− E(X(t0 + 1)| ~X)2

8.2. WAHRSCHEINLICHKEITSMODELL FÜR DAS DT AGENTENMODELL 93
E(X2(t0 + 1)| ~X) = E((
N∑n=1
yn)(
N∑n=1
yn)| ~X) = E(
N∑n=1
n∑i=1
yn−iyi| ~X) =
=∑
n,i:yn(t0)=yi(t0)=1
E(yiyn) + 2∑
n,i:yn(t0)=0,yi(t0)=1
E(yiyn) +∑
n,i:yn(t0)=yi(t0)=0
E(yiyn) =
= (X2 −X)E(yiyj |1, 1) + 2X(N −X)E(yiyj |0, 1) + ((N −X)2 − (N −X))E(yiyj |0, 0)+
+XE(yiyi|1) + (N −X)E(yiyi|0)
Die Schreibweise (. . . |1, 1) bedeutet hier (. . . |yi(t0) = 1, yj(t0) = 1). Ebenso ist die Notationin der folgenden Rechnungen gewählt. Man beachte, dass in der Summe die Produkte gleicherZufallsvariablen andere Erwartungswerte haben und deshalb gesondert betrachtet werden müs-sen.
E(yiyj |1, 1) = 1 · P (1, 1|1, 1) + 0 · P (1, 0|1, 1) + 0 · P (0, 1|1, 1) + 0 · P (0, 0|1, 1) = (1− µ)2
E(yiyj |1, 0) = P (1, 1|1, 0) = (1− µ)λ
E(yiyj |0, 0) = P (1, 1|0, 0) = λ2
E(yiyi|1) = P (1|1) = (1− µ)
E(yiyi|0) = P (1|0) = λ
Man erhält somit zusammengefasstE(X2| ~X) =
= (X2−X)(1−µ)2+2X(N−X)(1−µ)λ+((N−X)2−(N−X))λ2+X(1−µ)+(N−X)λ =
= (X(1− µ) + (N −X)λ)2 − (X(1− µ)2 + (N −X)λ2) +X(1− µ) + (N −X)λ =
= (X(1− µ) + (N −X)λ)2 +Xµ(1− µ) + (N −X)(λ(1− λ)).
Somit erhält man für die Varianz nach dem Verschiebungssatz
V(X| ~X) =
= (X(1−µ)+(N −X)λ)2 +Xµ(1−µ)+(N −X)(λ(1−λ))− ((N −X)λ+X(1−µ))2 =
= Xµ(1− µ) + (N −X)λ(1− λ).
Trotz des sehr unansehnlichen Wahrscheinlichkeitsmodells ergeben sich doch recht eleganteWerte für Erwartungswert und Varianz der Zufallsvariable X(t0 + 1) - d.h. des aufsummiertenzeitabhängigen agentenbasierten Prozesses nach Ablauf eines Zeitschrittes.
E(X(t0 + 1)| ~X(t0)) = ~X) = X(1− µ) + (N −X)λ
V(X(t0 + 1)| ~X(t0)) = ~X) = X(1− µ)µ+ (N −X)(1− λ)λ
Aus der Linearität des Erwartungswertes bzw. der Formel V(cX) = c2V(X) erhält man für den
normierten Prozess
E(x(t0 + 1)|~x(t0)) = ~x) = x(1− µ( ~x(t0))) + (1− x)λ( ~x(t0))

94 KAPITEL 8. FEHLERANALYSE
V(x(t0+1)|~x(t0)) = ~x) = N−1(x(1− µ( ~x(t0)))µ( ~x(t0)) + (1− x)(1− λ( ~x(t0)))λ( ~x(t0))
).
Man beachte an dieser Stelle erneut, dass die Übergangswahrscheinlichkeiten µ und λ nur fürdiesen Zeitschritt konstant sind, da sie allgemein von ~x, insbesondere nicht nur von x = x1,abhängen. Selbst wenn sich x1 innerhalb des Zeitschrittes nicht geändert hat, so können sich dieÜbergangswahrscheinlichkeiten ändern. Diese Tatsache ist für Berechnungen, die über einenZeitschritt hinaus gehen sehr hinderlich.
8.2.4 Zeitliche Entwicklung des Erwartungswertes
Man steht also vor dem Problem, dass man ohne das Wissen über die weiteren Zustandsvektor-Einträge keine Voraussagen über die folgenden Zeitschritte machen kann. D.h. man muss sichzwangsläufig mit dem Erwartungswert
E(~x(t)|~x(t0) = ~x)
auseinandersetzen; also die Berechnungen vektorwertig durchführen.Aus den Tatsachen für einen Zeitschritt kann man den weiteren Verlauf des Erwartungswerteszumindest als Rekursion darstellen. Man benutzt dazu die Tatsache, dass das Modell gedächt-nislos ist und damit die (diskrete Form der) Gleichung von Chapman-Kolmogorov 2.1.6 gilt.
E(~x(t)|(0, ~x)) =∑~k
P ((t,~k)|(0, ~x))~k =∑~k
∑~i
P ((t,~k)|(t− 1,~i))P ((t− 1,~i)|(0, ~x))~k =
=∑~i
P ((t− 1,~i)|(0, ~x))∑~k
P ((1,~k)|(0,~i))~k =∑~i
P ((t− 1,~i)|(0, ~x))E(~x(1)|(0,~i)) =
=
∑~i P ((t− 1,~i)|(0, ~x))(i1(1− µ1(~i)) + (1− i1)λ1(~i))∑~i P ((t− 1,~i)|(0, ~x))(i2(1− µ2(~i)) + (1− i2)λ2(~i))
...∑~i P ((t− 1,~i)|(0, ~x))(id(1− µd(~i)) + (1− id)λd(~i))
Hierbei steht λk(µk) für die Exit und Entry Rate des Zustands k. Man erhält also die Rekursi-onsformel:.
E( ~x(t)|(0, ~x0)) = F F · · · F︸ ︷︷ ︸t×
( ~x0), F (~x) :=
x1(1− µ1(~x)) + (1− x1)λ1(~x)...
xd(1− µd(~x)) + (1− xd)λd(~x)
. (8.1)
Man kann an dieser Stelle anmerken, dass durch F , mit sinnvollen Parametern (Funktionen) µund λ, das Intervall [0, 1]d auf das „Intervall“ [ ~λ(0),
(1, . . . , 1
)T − ~µ(1)] abgebildet wird. Es gilt
|F (~x)−F (~x′)| = |(xi(1− µi(~x)) + (1− xi)λi(~x)− x′i(1− µi(~x′))− (1− x′i)λi(~x′)
)i=1...d
| =
= |(xi − x′i + (µi(~x
′)x′i − µi(~x)xi) + (x′iλi(~x′)− xiλi(~x)) + λi(~x)− λi(~x′)
)i=1...d
| ≤

8.2. WAHRSCHEINLICHKEITSMODELL FÜR DAS DT AGENTENMODELL 95
≤ |(xi − x′i + µi(x
′i − xi) + λi(x
′i − xi) + (λi(~x)− λi(~x′))
)i=1...d
| ≤
≤ |(
(xi − x′i)(1− λi − µi))i=1...d
|+ |(λ(x)− λ(x′))| ≤
≤ (1− µ− λ+ L)|x− x′|,
sofern λ(·) lipschitzstetig bzgl. ~xmit Konstante L ist. Zusätzlich seien µi = minµi(~x′), µi(~x)und λi = minλi(~x′), λi(~x), sowie µ = mini=1...dµi und λ = mini=1...dλi definiert. FürFunktionen mit µ + λ − L > 0 ist der geklammerte Wert positiv und betragsmäßig kleinerals 1. Damit läge eine Kontraktion vor. Gemäß dem Banachschen Fixpunktsatz konvergiert dierekursive Folge und geht gegen einen Grenzwert (von möglicherweise mehreren), der die Fix-punktgleichung
~x = (xi(1− µi(~x)) + (1− xi)λi(~x))di=1 = (xi(1− µi(~x)− λi(~x))di=1 + λ(~x) =
= Diag(1− µi(~x)− λi(~x))di=1~x+ λ(~x),
alsoDiag(µi(~x) + λi(~x))di=1~x = λ(~x)
⇒ ~x =(Diag(µi(~x) + λi(~x))di=1
)−1λ(~x)
⇒ ~x = Diag
(1
µi(~x) + λi(~x)
)di=1
λ(~x)
⇒ ~x =(
λ1(~x)µ1(~x)+λ1(~x) . . . λd(~x)
µd(~x)+λd(~x)
)T,
erfüllt. Man erhält also unter der Vorraussetzung µ + λ > L eine Kontraktion und damit die(garantierte) Existenz eines Fixpunktes.
8.2.5 Résumé für das DT Agentenmodell
Im folgenden Unterkapitel sollen ähnliche, vergleichbare Aussagen für das Zeit und Raum-kontinuierliche Differentialgleichungsmodell gemacht werden. Zu diesem Zweck seien nocheinmal die wichtigen Aussagen des letzten Unterkapitels zusammengefasst:
Die Berechnung von Erwartungswert und Varianz über mehrere Zeitschritte hinweg istschwierig, da die Übergangswahrscheinlichkeiten λ(~x) und µ(~x) vom kompletten Zu-standsvektor abhängen dürfen.
Nach einem Zeitschritt erhält man als Erwartungswert
E(~x(1)| ~x0) = (xi(1− µ( ~x0)) + (1− xi)λ( ~x0))di=1 . (8.2)
Nach einem Zeitschritt erhält man als Varianz von xi
V(xi(1)| ~x0) = N−1(xi(1− µ( ~x0))µ( ~x0) + (1− xi)(1− λ( ~x0))λ( ~x0)). (8.3)

96 KAPITEL 8. FEHLERANALYSE
Unter der Bedingung µ+ λ > L mit
µ := min~x
mini=1...d
µi(~x)
λ := min~x
mini=1...d
λi(~x)
L := sup~x,~x′
|λ(~x− ~x′)||~x− ~x′|
lässt sich der Banachsche Fixpunktsatz anwenden und man erhält als Grenzwert für denErwartungswert einen Fixpunkt von
~x =(
λ1(~x)µ1(~x)+λ1(~x) . . . λd(~x)
µd(~x)+λd(~x)
)T.
(Vgl. dieses Resultat mit dem Langzeitverhalten des Erwartungswertes im Ehrenfestmo-dell)
8.3 Vergleich der Resultate mit dem DG Modell
Um die Resultate handfest vergleichen zu können, muss auch die Lösung des, dem Agentenmo-dell entsprechenden Differentialgleichungssystems zum Zeitpunkt 1 ausgewertet werden.
Bemerkung 8.3.1.An dieser Stelle sei der enorme Raumunterschied der beiden Modelle angemerkt. Das (aufsum-mierte) Agentenmodell einerseits ist rein orts- und zeitdiskret, wohingegen das Differentialglei-chungsmodell sogar auf beiden Skalen kontinuierlich ist.
8.3.1 Erwartungswertkurve an der Stelle t = 1
Als Start der Analyse bietet sich die Differentialgleichung 3.11 an:
φ(τ)′ = −∑R 6=0
~Φ1(φ(t), R)R, φ(0) = ~x0
Sofern die Lösung dieser Differentialgleichung überhaupt existiert, wovon in Folge ausgegan-gen wird, sei sie entweder (bezüglich der Zeit) zweimal differenzierbar oder mindestens durchzweifach differenzierbare Funktionen approximierbar. Für den weiteren Verlauf wird angenom-men, dass sie Ersteres ist - ansonsten kann man die Analyse analog mit konvergenten Folgendurchführen, worauf hier nicht eingegangen wird.Gemäß dieser Annahme lässt sich eine Taylorentwicklung der Lösungsfunktion φ(t) an der Stel-le t = 1 (d.h. τ = f(N)N−1) durchführen.
~φ(1) = ~φ(0) + ~φ′(0) +1
2~φ′′(ξ) =

8.3. VERGLEICH DER RESULTATE MIT DEM DG MODELL 97
Es gilt nun mit den am Anfang des Kapitels gebrachten Ideen∑R 6=0
Φ1(~φ(0), R)R =∑
1≤i 6=j≤dΦ1(~φ(0), ei − ej)(ei − ej),
mit den Einheitsvektoren ei :=
(0, . . . , 1︸︷︷︸
i
, . . . , 0)T
, da innerhalb eines infinitesimalen Zeit-
schrittes genau ein Agent seinen Zustand ändern kann (er verlässt j und wechselt zu i). Setztman nun φ := ~φk als Beobachtungszustand, erhält man für die korrespondierende Zeile im DGSystem den Ausdruck
~φ′k(τ) =∑j 6=k
Φ1(~φ(τ), ek − ej)− Φ1( ~φ(τ), ej − ek).
Gemäß der Definition der Reihenentwicklung der Übergangsraten,
ωx,R = f(N)(Φ1(·) +N−1Φ2(·) + . . . ),
formt man um,
Φ1(~φ, ek − ej) =1
f(N)ω~φ,ek−ej
−N−1Kj,k,
mitKj,k := Φ2(~φ, ek − ej) +N−1Φ3(·) + . . .
und erhält, eingesetzt
~φ′k(τ) =N
f(N)
1
N
∑j 6=k
ω~φ,ek−ej(~φ)−N−1f(N)Kj,k − ω~φ,ej−ek(~φ) +N−1f(N)Kk,j .
Mit der Zeittransformation τ → t fällt der Term Nf(N) weg und man erhält mitsamt der definier-
ten Umrechnung zwischen den Modellen
~φ′k(t) =
=
1
N
∑j 6=k
ω~φ,ek−ej(~φ)
− 1
N
∑j 6=k
ω~φ,ej−ek(~φ)
+N−1
∑j 6=k
f(N)
N(Kk,j −Kj,k)
︸ ︷︷ ︸
=:C
=
=
1
N
∑j 6=k
N~φj(t)P ((1, k)|(0, j), ~φ)
− 1
N
∑j 6=k
N~φk(t)P ((1, j)|(0, k), ~φ)
+N−1C =
=
(1− ~φk)∑j 6=k
~φj
1− ~φkP ((1, k)|(0, j), ~φ)
−~φk∑
j 6=kP ((1, j)|(0, k), ~φ)
+N−1C.

98 KAPITEL 8. FEHLERANALYSE
Linker Hand erkennt man die Entry Wahrscheinlichkeit, rechter Hand, mit negativem Vorzei-chen, die Exit Wahrscheinlichkeit des Zustands k.
= (1− ~φk)λ(~φ)− ~φkµ(~φ) +N−1C
Setzt man nun in die Taylorentwicklung ein, erhält man
~φk(1) = ~φk(0)− (1− ~φk(0))λ(~φ) + ~φk(0)µ(~φ)−N−1C +1
2~φ′′k(ξ) =
=(
(1− ~φk(0))λ(~φ) + ~φk(0)(1− µ(~φ)))−N−1C +
1
2~φ′′k(ξ).
Der geklammerte Ausdruck entspricht dem errechneten Erwartungswert im diskreten Modell -die übrigen beiden Terme gilt es abzuschätzen.
||φ(1)− E(x, 1)|| = || −N−1C +1
2φ′′(ξ)|| ≤ N−1||C||+ 1
2||φ′′(ξ)||
8.3.2 Abschätzungen für den Erwartungswertfehler
Zunächst wird der Ausdruck
||C|| = f(N)
N||∑j 6=k
(Kk,j −Kj,k)|| ≤
≤ f(N)
N
∑j 6=k||Φ2(·)j,k +N−1Φ3(·)j,k + · · · − Φ2(·)k,j −N−1Φ3(·)k,j − . . . || =
=f(N)
N
∑j 6=k||(Φ2(·)j,k − Φ2(·)k,j) +N−1(Φ3(·)j,k − Φ3(·)k,j) +N−2 . . . ||
mit Φi(·)j,k := Φi(~φ, ek−ej) untersucht. Gemäß der Definition der Reihenentwicklung müssendie Φn(·) unabhängig von N und stetig sein. Da die Übergangsraten kompakten Träger haben,haben auch die einzelnen Φn kompakten Träger (womit alle Normen äquivalent sind). Es sei nun
αj,k := supn≥2||Φn(·)j,k − Φn(·)k,j || <∞
definiert. Damit konvergiert die geometrische Reihe innerhalb der Norm und es gilt die Abschät-zung
||C|| = f(N)
N
∑j 6=k||(Φ2(·)j,k − Φ2(·)k,j) +N−1(Φ3(·)j,k − Φ3(·)k,j) +N−2 . . . || ≤
≤ 2f(N)
N
∑j 6=k
(αj,k +N−1αj,k +N−2αj,k . . . ) =

8.3. VERGLEICH DER RESULTATE MIT DEM DG MODELL 99
=2f(N)
N
∑j 6=k
αj,k1
1−N−1≤
≤ 2f(N)
N(d− 1) sup
j 6=k(αj,k)
1
1−N−1=
=2f(N)
N − 1(d− 1) sup
j 6=k(αj,k) =: C1.
Im klassischen Fall f(N) = O(N) erhält man eine von N unabhängige Konstante, die imFehler sogar mit N−1 multipliziert wird. Der durch N−1C1 hervorgerufene Fehler ist also sogarein O(N−1).
Bemerkung 8.3.2.Ist die Übergangsrate ωxk,xk±1 (Exit und Entry Rate) aus dem diskreten Agentenmodell durchUmrechnung definiert, so hat sie stets die Form
ωxk,ej−ek := N(1− xk)λ, ωx,ek−ej := Nxkµ
mit Exit und Entry Wahrscheinlichkeiten λ bzw µ ≤ 1. Aus diesem Grunde kann die Funktionf(N) maximal Ordnung f(N) = O(N) haben.Diese Tatsache ist im Rahmen der Kramers-Moyal-Entwicklung nicht notwendig gewesen, daman zeitkontinuierliche, Markov-Prozess-basierte Mikrosimulationen mit Differentialgleichun-gen vergleichen wollte, wobei durchaus auch größere Übergangsraten entstehen konnten. Diesemüssen und können innerhalb dieser Fehlerabschätzung auf diese Weise aber auch nicht behan-delt werden.
Es verbleibt den Fehler ||φ′′(ξ)|| abzuschätzen. Einsetzen in die Differentialgleichung liefertzeilenweise
||~φ′′k(ξ)|| = ||
∑R 6=0
Φ1(~φ, ~R)~R
′ || ≤≤ ||
((1− ~φk)λk(~φ)− ~φkµk(~φ)
)′+N−1C ′(ξ)||.
Das für die Abschätzung unangenehme Problem ist, dass die 1. Ableitung nur zeilenweise ange-schrieben werden kann, da jeder Zustand eigene Exit und Entry Raten hat. Definiert man mittels
||~φ′′(ξ)|| ≤ λ(~φ) := maxk
(λk(~φ))
µ(~φ) := mink
(µk(~φ))
skalare Funktionen, lässt sich der ganze Ausdruck auch vektorwertig abschätzen.
≤ ||(
(~1− ~φ)λ(~φ)− ~φµ(~φ))′||+ ||N−1C ′(ξ)||

100 KAPITEL 8. FEHLERANALYSE
Der rechte TermC ′(ξ) lässt sich ganz analog mit den Ableitungen von Φn abschätzen und lieferteine Konstante C2. Den linken Term kann man mit Produkt und Kettenregel ableiten.(
(~1− ~φ)λ(~φ)− ~φµ(~φ))′
=
= −~φ′λ+ (~1− ~φ)∇λ · ~φ′ − ~φ′µ− φ(∇µ · ~φ′) =
= ~φ′(−λ− µ) + (~1− ~φ)(∇λ · ~φ′) + ~φ(∇(µ) · ~φ′)
Abschätzen liefert für die Norm davon
≤ |λ+ µ|||~φ′||+ ||(~1− ~φ)(∇λ · ~φ′) + ~φ(∇µ · ~φ′)|| ≤ ∗.
Der rechte Term ist nun zeilenweise eine Konvexkombination (da φ ≤ 1 elementweise) derAusdrücke ∇λ · ~φ′ und ∇µ · ~φ′. Demnach kann man den Term mit dem Maximum der beidenAusdrücke abschätzen.
∗ ≤ |λ+ µ|||~φ′||+ max||∇λ · φ′||, ||∇µ · φ′|| ≤
≤ |λ+ µ|||~φ′||+ max||∇λ||, ||∇µ||||~φ′|| ≤
≤ (2 max|λ|, |µ|+ max||∇λ||, ||∇µ||) ||~φ′|| ≤ ∗
Neuerliches Einsetzen für ~φ′ liefert schlussendlich eine Abschätzung, die nur φ, λ und µ enthält.Die Funktion ~φ wird erneut durch φ ≤ 1 für einen Konvexkombination benutzt.
∗ ≤ (2 max|λ|, |µ|+ max||∇λ||, ||∇µ||)(||(1− ~φ)λ+ ~φµ||+N−1||C(ξ)||
)≤
≤ (2 max|λ|, |µ|+ max||∇λ||, ||∇µ||) ||(max|λ|, |µ|) +N−1C3.
Das Resultat ist (berücksichtigt man die Zwischenstelle ξ) also die Fehlerabschätzung:
|~φ(1)− E(~x)| ≤
≤(
2 max~v∈[0,1]d
|λ(~v)|, |µ(~v)|+ max~v∈[0,1]d
||∇λ(~v)||, ||∇µ(~v)||)
max~v∈[0,1]d
|λ(~v)|, |µ(~v)|+N−1C4
mit den skalaren Funktionen
λ(~φ) := maxk
(λk(~φ)), µ(~φ) := mink
(µk(~φ)).
Die Normen der Übergangsraten und deren Ableitungen treten also sogar quadratisch auf.
Bemerkung 8.3.3.Die Konstanten Ci treten natürlich nur dann in den Abschätzungen auf, wenn die Übergangsrateauch Terme niederer Ordnung in N hat, als den führenden. Das ist z.B. dann der Fall, wenn mangewisse Randwahrscheinlichkeiten (z.B. bei zellulären Automaten) berücksichtigen müsste, dieum eine Dimension in N geringere Auswirkung haben, als die Wahrscheinlichkeiten im Innerendes Gebiets und dann in der DG-Modellierung nicht mehr auftreten.

8.4. VARIANZFEHLER 101
Bemerkung 8.3.4.An dieser Stelle sei bemerkt, dass diese Fehlerabschätzung primär auf die Größe der Übergangs-raten abzielt und der Fehler, der bei zu geringen Agentenzahlen N gemacht wird, bereits darinabsorbiert ist. Nichtsdestotrotz gilt immer noch die (nicht quantitative Aussage), dass der Fehlerder Erwartungswerte bei Vergrößerung der Agentenzahlen mit Ordnung N−
12 kleiner wird. D.h.
unter anderem, es gilt im Falle des Ehrenfestmodells (Ci = 0) die gezeigte Abschätzung für denFehler ||φ(1)− E(x(1))|| sogar bei N = 1.
Es verbleibt den Limes der Erwartungswertkurve zu analysieren und zu vergleichen. Gemäßder Differentialgleichung erhält man als stationären Punkt,
0 = (1− φk)λk(~φ)− φkµk(~φ) +N−1C,
also
φk =λk(~φ)
λk(~φ) + µk(~φ)+N−1C,
für die Exit und Entry Rate des Zustandes k.Im Grenzwert erfüllen die errechnete Erwartungswertkurve des DG Modells und der Grenzwertder Fixpunktgleichung für das diskrete Modell (asymptotisch bzgl. N , aber unabhängig von denRaten) die selbe Fixpunktgleichung. Für den selben Anfangswert müssen die beiden Kurven alsomit eine Fehler ≤ C1N
−1 zum selben Fixpunkt gehen.
8.4 Varianzfehler
Genauso, wie beim Erwartungswert ließe sich auch eine analoge, noch aufwändigere, Abschät-zung für den Fehler in der Varianz eines einzelnen Zustandes nach einem Zeitschritt durchfüh-ren. Da aber die Differentialgleichung, aus der die Varianz folgten würde, für d > 2 kaum nochlösbar ist (siehe Kapitel 5), wird hier nur das (sehr grob abgeschätzte) Resultat für das eindi-mensionale Problem (d = 2) angegeben.
|V(1)− σ2(1)| ≤
≤ N−1
(4 max~v∈[0,1]
|λ′(~v)|, |µ′(~v)|+ 6 max~v∈[0,1]
|λ(~v)|, |µ(~v)|)
max~v∈[0,1]
|λ(~v)|, |µ(~v)|+N−2C
8.5 Interpretation
Die im Kapitel vorgestellten Abschätzungen sind leider kaum verwertbar, da sie viel zu grobsind und nur für einen Zeitschritt gelten. Man könnte z.B. über Multiplikation mit der Anzahlder Zeitschritte, den Fehler linear wachsend für den Zeitschritt t abschätzen. Experimente zei-gen jedoch, dass der Fehler einerseits deutlich kleiner ist, als die gewählte Abschätzung undzusätzlich nicht einmal monoton wächst. Das Modell korrigiert sich also selbst, was man sogaranalytisch anhand der asymptotischen Äquivalenz der Ruhelagen der Erwartungswertkurven derbeiden Modelle erkennt.

102 KAPITEL 8. FEHLERANALYSE
In beiden Fällen, Erwartungswert sowie Varianz, kann man dennoch einige wichtige Schlüsseziehen:
Es existieren quantitative Abschätzungen für den Fehler. Die in diesem Kapitel Vorge-stellten sind solche, jedoch mit Sicherheit nicht die Besten.
Es gilt die Folgerung limn→∞(ωi,jn , tn,Nn) ⇒ ||φ(t) − E(x)|| → 0 sowie ||σ2(t) −
V(x)|| → 0. D.h. Skalieren von Zeit und Raten, sowie Vergrößern der Agentenzahlenführt zu Konvergenz. Das erkennt man direkt aus den Abschätzungen, da die Raten in derFormel quadratisch vorkommen, der Fehler aber nur linear in der Zeit wächst.
Der ErwartungswertfehlerErr(t) ist eine positive, beschränkte Funktion auf R+ mit min-destens einem Maximum und limt→∞,N→∞Err(t) = 0.

KAPITEL 92. Bsp: SIR Modell
Das klassische SIR (Susceptible-Infected-Recovered) Modell ist ein, Anfang des 20. Jahrhun-derts (Kermack und McKendrick, 1927, [KM27]) entwickeltes Modell zum einfachen mathe-matischen Beschreiben eines Krankheitsverlaufs. Zu dieser Zeit wurde das Modell als Systemvon Differentialgleichungen beschrieben, die heutzutage vorwiegend in Grundlagenvorlesungenüber Modellbildung und Simulation bzw. Epidemiologie Anwendung finden. Es handelt sichdabei um ein gekoppeltes, nichtlineares Differentialgleichungssystem 1. Ordnung, welches trotzder enormen Modellvereinfachung (das Modell kommt mit lediglich zwei Parametern aus), kei-ne analytischen Lösungen mehr besitzt. Ende der 30er Jahre des vergangenen Jahrhunderts wardiese Tatsache enorm hinderlich, denn, obwohl Näherungsmethoden von Euler et al. längst be-kannt waren, war die Umsetzung dieser ohne Computertechnologie äußerst zeitaufwändig undressourcenintensiv.In der heutigen Computer-unterstützten Zeit schafft es beinahe sogar ein numerischer bzw. ma-thematischer Laie eine approximative Lösung der drei Gleichungen immerhin zeichnen zu las-sen, sofern er/sie über die richtige Software verfügt. Die Forschung schreitet also voran. Wäh-rend Anfang des 20. Jahrhunderts eine Epidemie offensichtlich noch mit zwei Parametern zubeschreiben war, ist die Welt heutzutage scheinbar deutlich komplexer geworden. Auf jedenFall sind es die Anforderungen an das jeweilige Modell. Aus einem Projekt des Modellbil-dung und Simulations Unternehmen „dwh GmbH“ resultierte vor einiger Zeit ein Influenza-Infektionsmodell (siehe [MZP+12]) mit mehr als 40 Parametern. Auf Grund der fehlenden Fle-xibilität des Modelltypus war es unmöglich, dieses Modell in Form von Differentialgleichungenzu formulieren, also verwendete man agentenbasierte Modellierung (Es wäre 1927 noch deutlichillusorischer gewesen, solch eine umzusetzen, als die numerische Lösung des Differentialglei-chungssystems selbst).Im Zuge von Arbeiten im Umfeld dieses Projekts entstand auch ein sehr vereinfachter stochasti-scher zellulärer Automat mit zwei bis vier Parametern (je nachdem, was man unter dem BegriffParameter verstehen will), der sehr ähnliche Ergebnisgraphen (Mittelwertkurven) lieferte, wiedas Differentialgleichungssystem aus dem Jahr 1927.Ziel dieses Kapitels wird es sein, diesen zellulären Automaten zu analysieren, in interagierende
103

104 KAPITEL 9. 2. BSP: SIR MODELL
Markov-Prozesse zu zerlegen und mithilfe der hergeleiteten Theorie zu untersuchen. Es stellensich folgende Fragen:
Liefert die Theorie ähnliche Differentialgleichungen wie das klassische SIR-Modell?
Falls ja: Lassen sich die Parameter ineinander umrechnen?
9.1 Problemstellung
Um die Aufgabenstellung zu verdeutlichen, wird die Problemstellung in drei Unterkapitel zer-legt.
9.1.1 Reale Problemstellung
Gegeben ist eine Gesamtbevölkerung eines Gebiets (Staat, Stadt, Region, etc.), die über denVerlauf der Krankheit als konstant angesehen wird (natürliche Geburten oder Todesfälle werdenalso nicht berücksichtigt oder gleichen einander aus). Unter der Bevölkerung bricht schlagartigeine Krankheit aus, sodass man jede Person genau einer der folgenden Klassen zuordnen kann:
Susceptible (S) - Die Person ist anfällig für die Krankheit.
Infected (I) - Die Person ist infiziert und stellt eine Ansteckungsgefahr dar.
Recovered (R) - Die Person ist genesen (verfügt also über Antikörper), von vorn hereinimmun (geimpft) oder tot. Sie ist keine Ansteckungsgefahr mehr und kann (in diesemModell) auch nicht mehr infiziert werden.
9.1.2 Problemstellung des Differentialgleichungssystems
Im Bereich der Medizin bzw. Soziologie ist sogar der Mathematiker dazu gezwungen, sich vonseinem hohen Ross herab zu bewegen und sich auf Heuristiken einzulassen, um ein Modellherzuleiten, da man sich im Bereich des sogenannten „Black Box Modelling“ befindet. Manüberlegt, beobachtet und kommt schlussendlich zu folgenden Ideen:
Je mehr Individuen infiziert (I) sind, umso mehr Individuen werden angesteckt.
Je weniger Individuen empfänglich (S) sind, umso weniger können angesteckt werden.
Die Ansteckungsgeschwindigkeit I ′ ist also proportional zu einer Funktion f , die positivvon I und S abhängt. Man verwendet klassisch
I ′ = αIS.
Je mehr Individuen Infiziert sind, umso mehr Individuen genesen.

9.1. PROBLEMSTELLUNG 105
Die GenesungsgeschwindigkeitR′ ist also positiv von der Anzahl der Infizierten abhängig.Im klassischen SIR Modell wird sie als direkt proportional angenommen.
R′ = βI
Der Fluss der Suszeptiblen zu den Infizierten muss in Summe 0 sein.
S′ = −αIS
Mit der selben Überlegung erhält man
I ′ = αIS − βI.
Es folgt somit das DG System:
dS
dt= −αIS
dI
dt= αIS − βI
dR
dt= βI.
9.1.3 Problemstellung des zellulären Automaten
Die Idee des zellulären Automaten beruht auf stochastischen Individuen-basierten Überlegun-gen. Dieses Konzept bietet neben einer deutlich größeren Flexibilität den Vorteil, dass es fach-fremden Personen, wie bereits mehrfach erwähnt, deutlich leichter verständlich gemacht werdenkann. Da in diesem Modell die Anzahl aller Zellen, die mit dem Zustand S,I oder R belegt sind,konstant bleibt, lässt sich die Idee des CAs besser mithilfe von, sich auf einem diskreten Gitterbewegenden Agenten erklären. Es ist eine Philosophiefrage und eine Implementationsfrage, obman das Modell als stochastischen zellulären Automaten, oder als Agentenmodell betrachtenwill.
Das als rechteckig angenommene Beobachtungsgebiet sei aufgeteilt in n ·m benachbarteZellen. Jede dieser Zellen ist wiederum in 4 Unterzellen geteilt und bietet theoretisch Platzfür maximal 4 Agenten, wobei jeder Agent für ein Individuum steht, welches einen derdrei erwähnten Zustände (S,I,R) hat 1.
Es sei N < 4mn die Anzahl der Individuen.
Das Modell wird Zeit getaktet (diskret) gerechnet.
1Hier wird der enge Zusammenhang zwischen agentenbasierten Modellen und zellülären Automaten sicht-bar. Zwar trägt die Zelle direkt den Zustand, doch lässt sich die Aufgabenstellung durch die Gleichgewichtsbe-dingung der Zellen (Summe ≡ N ) besser mithilfe von Agenten begreiflich machen.

106 KAPITEL 9. 2. BSP: SIR MODELL
Befindet sich innerhalb einer Parzelle zu einem Zeitpunkt ein Agent im suszeptiblen Zu-stand und einer im infizierten Zustand, so hat der suszeptible Agent eine gewisse Wahr-scheinlichkeit sich am kranken „anzustecken“. Diese Wahrscheinlichkeit λ ≤ 1 wird alsInfektionswahrscheinlichkeit bezeichnet.
Jeder infizierte Agent hat während eines Zeitschrittes eine gewisse Wahrscheinlichkeit,zu genesen (d.h. in den R Zustand überzugehen). Die Wahrscheinlichkeit µ ≤ 1 wird alsGenesungswahrscheinlichkeit bezeichnet.
Am Ende eines Zeitschrittes bewegen sich die Agenten nach gewissen Regeln am Gitter.
Die Anzahl der Agenten pro Zustand dient schlussendlich als Zustandsvariable, die mitdem DG Modell verglichen werden soll.
So definiert ist das CA (bzw. Agenten) Modell noch lange nicht eindeutig.An dieser Stelle wird einer der großen Unterschiede zwischen der Individuen-basierten Mo-dellierung und dem Modellieren mit Differentialgleichungen am praktischen Beispiel deutlich:Es ist kaum möglich das Modell zu definieren, ohne zumindest die Grundzüge der Implemen-tierung des Modells vorzugeben. Allein um die Bewegungsregeln, die die Position des Agentenzum nächsten Zeitpunkt bestimmen, zu beschreiben, muss man fast schon auf Indexschreibweisevon Matrizen zurückgreifen, bedenkt man z.B. das Verhalten der Agenten am Rand des Gebietsoder das Problem des sequenziellen Bewegens der Agenten auf freie Felder. Die enorme Fle-xibilität in der Modellierung fordert so ihren Tribut, indem die Beschreibung des Modells auchfür einfache Probleme sehr detailliert sein muss, um insofern vollständig zu sein, als dass manreproduzierbare Ergebnisse erhalten will. Die numerische Lösung der SIR Differentialgleichungauf der anderen Seite sieht heute, trotz modernster numerischer Hilfsmittel, kaum anders aus,als vor 80 Jahren.Im weiteren Verlauf des Analyse wird nicht, und muss auch nicht näher auf die angesproche-nen Bewegungsregeln eingegangen werden, sofern diese eine gewisse „Durchmischung“ derBevölkerung verursachen. Man verdankt das dem Umstand, dass bereits im ersten Schritt deranalytischen Analyse des zellulären Automaten das räumliche Konzept aufgelöst und in einWahrscheinlichkeitsmodell übersetzt wird. Man erweitert damit sogar die Fragestellung von
Ist genau dieser zelluläre Automat ein diskretes Pendant zu den SIR Gleichungen?
auf
Sind alle diese zellulären Automaten, die gewisse Bewegungsregeln erfüllen, ein diskretesPendant zu den SIR Gleichungen?
9.2 Umsetzung der Theorie
Bevor man zu einer Schreibweise mit Übergangsraten übergehen kann, ist zunächst zu über-prüfen, ob man die Bedingungen 6.6.1 mit dem so definierten Modell überhaupt erfüllen kann.Zunächst kann ein Agent in diesem Fall genau einen von drei Zuständen annehmen (S, I oder R).

9.2. UMSETZUNG DER THEORIE 107
Das Problem ist also dreidimensional. Es ist also genau dann für eine Analyse tauglich, wenn es3× 3 = 9 verschiedene Übergangswahrscheinlichkeiten gibt, die nur von den Zustandsvektoren(also nicht von der Zeit) abhängen, und in eine Reihe bzw. in ein Polynom (bzgl. der Agenten-zahl) entwickelt werden können.
9.2.1 Übergangswahrscheinlichkeiten
Diese werden nun eine nach der anderen untersucht.
P ((1, R)|(0, S))Diese Wahrscheinlichkeit ist 0, da ein suszeptibler Agent nicht sofort in den Zustand Im-mun übergehen kann.
P ((1, S)|(0, R)), P ((1, I)|(0, R)), P ((1, S)|(0, I))Auch diese drei Wahrscheinlichkeiten belaufen sich auf 0, da ein immunes Individuumweder suszeptibel noch krank wird. Genauso geht ein Agent im Zustand I nicht wiedernach S zurück. Als direkte Folgerung erhält man
P ((1, R)|(0, R)) = 1.
P ((1, R)|(0, I))Die Genesungswahrscheinlichkeit ist direkt aus dem Modell gegeben. Es giltP ((1, R)|(0, I)) =µ.
P ((1, I)|(0, S))Um diese Wahrscheinlichkeit zu definieren, muss man sich einiger Tricks bedienen. Zu-nächst kann man die Wahrscheinlichkeit aufschlüsseln:
P ((1, I)|(0, S)) = P ((Agent trifft auf I) ∧ (Agent steckt sich dann an )|(0, S))
Eine Überlegung zeigt, dass diese beiden Wahrscheinlichkeiten unabhängig voneinandersind und demnach als Multiplikation aufgelöst werden können. Mithilfe der Ansteckungs-wahrscheinlichkeit λ erhält man den Ausdruck
P ((1, I)|(0, S)) = P (( Agent trifft auf I )|(0, S)) · λ.
Um die erste Wahrscheinlichkeit zu bestimmen, wird zunächst der Begriff der Dichte ρals Anzahl der Agenten pro Feld definiert.
ρ :=N
4nm
Diese ist, genauso wie die Agentenzahl, im Modell konstant.Verweilt nun ein Agent mit suszeptiblem Zustand für einen Zeitschritt in einer Parzelle,so kann er sich genau dann anstecken, wenn sich in zumindest einer der 3 Nachbarzellenein Agent mit infiziertem Zustand befindet. Würde man nun zufällig alle Infizierten auf

108 KAPITEL 9. 2. BSP: SIR MODELL
dem Gebiet verteilen, so wäre die Wahrscheinlichkeit, auf einem bestimmten Feld, einenvon ihnen anzutreffen genau
P ( I auf best. Feld) = Dichte × Anteil der Infizierten unter den Agenten = ρI
N.
Für drei Nachbarfelder entspricht die Wahrscheinlichkeit also genau dem Dreifachen die-ses Wertes.
P (( Agent trifft auf I )|(0, S)) = 3ρI
N
Natürlich fordert das eine gleichmäßige zufällige Vermischung der Agenten auf demRaum. Nachdem i.A. aber ein Regelwerk keine vollkommen wirren, zufälligen Bewe-gungen erlaubt, kann man folgende Bedingung formulieren.
Bedingung 9.2.1 (Zulässige Bewegungsregeln).Für die weitere Theorie des Modells sind nur Bewegungsregeln zugelassen, die eine sochaotische Vermischung der Agenten hervorrufen, dass
P (( Agent trifft auf I )|(0, S)) = 3ρI
N+O(N−1)
I.A. ist diese Bedingung für vernünftige Regelwerke erfüllt. Der AusdruckO(N−1) fängtvereinzelte etwaige Cluster-Bildungen von ähnlichen Agenten oder ungewöhnliche Be-wegungen von vereinzelten Agenten am Rand ab.Insgesamt erhält man somit
P ((1, I)|(0, S)) = 3λρI
N+O(N−1).
P ((1, I)|(0, I)), P ((1, S)|(0, S))Als Folgerung aus dem Satz für totale Wahrscheinlichkeit erhält man schlussendlich
P ((1, I)|(0, I)) = 1− µ
undP ((1, S)|(0, S)) = 1− 3λρ
I
N−O(N−1).
Aus der Definition der Übergangswahrscheinlichkeiten definiert man nun direkt die Raten fürdie einzelnen Agenten ω.
ωA,B := P ((1, B)|(0, A))
Bevor nun die Raten des summierten Prozesses betrachtet werden, sei eine Vektorschreibweiseeingeführt (ai(t) bezeichne den Zustand des Agenten i zum Zeitpunkt t):
~X(t) :=(∑N
i=1 IS(ai),∑N
i=1 II(ai(t)),∑N
i=1 IR(ai(t)))T
~x(t) := N−1 ~X(t)

9.2. UMSETZUNG DER THEORIE 109
Somit erhält man einen normierten Vektor (||x||1 = 1), wobei jeder Eintrag Aufschluss über dieAnzahl der gesunden, kranken und immunen Individuen zum Zeitpunkt t gibt. Es folgt nun ana-log zur Aufschlüsselung der Übergangswahrscheinlichkeiten P ((1, B)|(0, A)) die Berechnungder Übergangsraten ω(~x, ~R) = ω(~x, ei − ej). Gemäß der Analyse der Übergangswahrschein-lichkeiten sind lediglich zwei dieser Übergangsraten nicht = 0, nämlich jene von den Vektoren−1
10
→ ein Gesunder wird krank
und 0−11
→ ein Kranker wird immun.
Gemäß der hergeleiteten Theorie belaufen sich diese auf
ω
x1
x2
x3
,
−110
= X1(3λρI
N+O(N−1)) = N
(3λρx1x2 +O(N−1)
)und
ω
x1
x2
x3
,
0−11
= X2 · µ = N(x2µ).
9.2.2 Die entstehenden Differentialgleichungen
Man erkennt sofort f(N) = N und die Entwicklung der Raten nach der Agentenzahl:
Φ1(~x, e2 − e1) = 3λρx1x2, Φ2(~x, e2 − e1) = O(1)
Φ1(~x, e3 − e2) = x2µ
Es ergibt sich also keine Zeittransformation und die Differentialgleichung:
~φ′(t) =∑R 6=0
Φ1(~x, ~R)R = 3λρx1x2
−110
+ µx2
0−11
=
=
−3λρx1x2
3λρx1x2 − µx2
µx2
.
Die wohlbekannten klassischen SIR Gleichungen entstehen auf ganz natürliche Art und Weiseund liefern die Antwort auf beide zu Anfang gestellten Fragen:
Ja, unter den Voraussetzungen der gut mischenden Bewegungsregeln erhält man die klassischenSIR-Gleichungen.

110 KAPITEL 9. 2. BSP: SIR MODELL
Unter diesen Voraussetzungen erhält man(αβ
)=
(3λρµ
)für die Umrechnung der Parameter
ineinander.
Als Dichtekurve erhält man
Π(ξ, t)τ = Πf(~ξ, ~φ) +∇ξΠ · ~F (~φ) + g(Hξ(Π), ~φ)
mit
f(~ξ, ~φ) :=∑~R 6=0
∇Φ1(~φ, ~R) · ~R = 3λ(φ1 − φ2)− µ
g(Hξ(Π), ~φ) :=1
2
∑~R 6=0
~RTHξ(Π)~RΦ1(~φ, ~R) =
(H1,1ξ − 2H2,1
ξ +H2,2ξ )3ρλφ1φ2 + (H2,2
ξ − 2H3,2ξ +H3,3
ξ )µφ2
~F (~φ) :=∑~R 6=0
(ξ · ∇Φ1(~φ, ~R))~R =
−3λρ(φ1ξ2 + φ2ξ1)3λρ(φ1ξ2 + φ2ξ1)− µξ2
µξ2
.
Obwohl das Problem also „nur“ dreidimensional ist, entsteht eine sehr komplexe partielle Diffe-rentialgleichung zweiter Ordnung, in welcher die Koeffizienten-Funktionen sehr ungleichmäßigvon den Variablen abhängen. Jeglicher Versuch über eine Parametrisierung zur Lösung zu ge-langen ist somit zum Scheitern verurteilt.
9.3 Resultate zum konkreten Beispiel
Wie im Kapitel 7 folgen nun einige Grafiken, die die angewendeten Umformungen bestätigensollen. Es folgt aus Gründen der Übersicht eine Tabelle, die die verwendeten Parametersätze fürdie Plots zusammenfasst. In diesem Kapitel werden die Parameter Ansteckungswahrscheinlich-keit (λ), Genesungswahrscheinlichkeit µ und die Dichte ρ verwendet.
Abb. Typ N M λ µ ρ x0
9.1 Vergleich: Mittelwerte 4000 300 0.7 0.2 0.5 (0.9, 0.1, 0)T
9.2 Vergleich: Mittelwerte 4000 300 0.8 0.1 0.5 (0.9, 0.1, 0)T
9.3 Vergleich: Mittelwerte 4000 300 0.7 0.05 0.5 (0.9, 0.1, 0)T
9.4 Vergleich: Fehler 4000 300
0.70.70.35
0.5
304560
(0.9, 0.1, 0)T
Die ersten 3 Abbildungen (9.1,9.2,9.3) zeigen linker Hand das Resultat des agentenbasiertenModells (zellulären Automats) gemittelt über 300 Durchläufe - also den empirischen Mittel-wertschätzer E(x) ≈ 1
M
∑Mi=1 xi. Gerechnet wurde ein Raster von 40 × 50 Zellen (d.h. 2000
Zellen, von denen jede wiederum in 4 weitere Parzellen unterteilt ist). Mit der Dichte ρ = 0.5
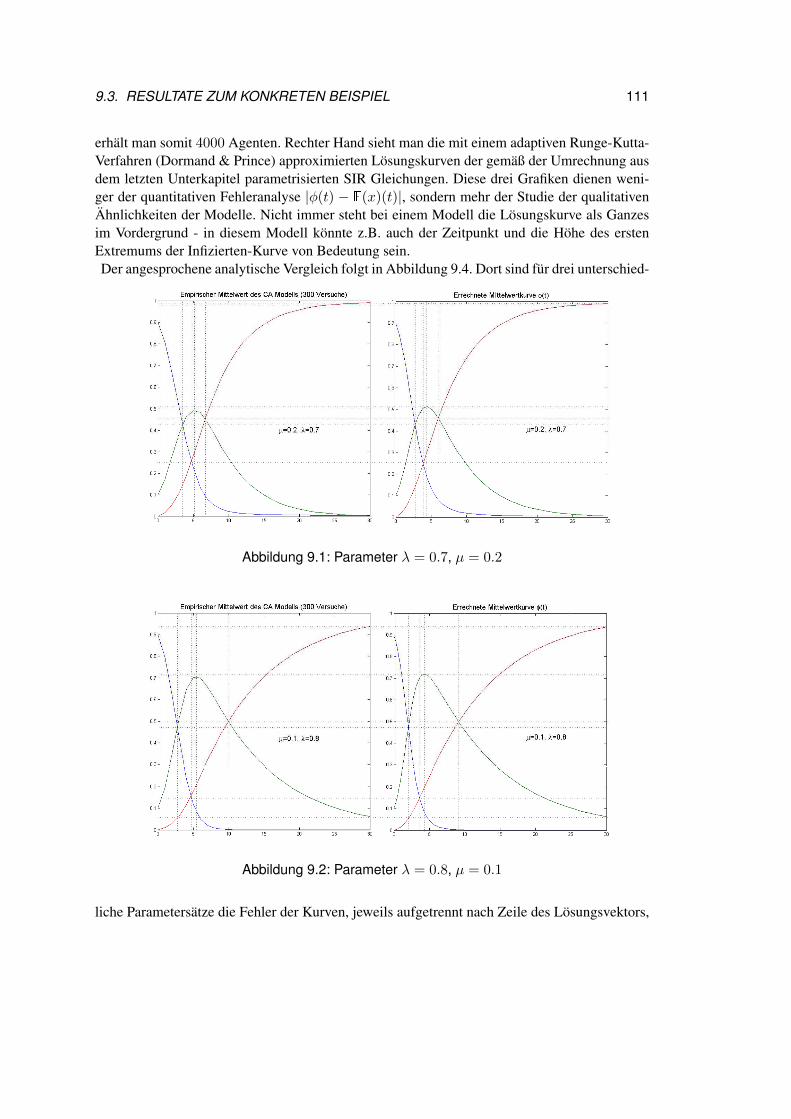
9.3. RESULTATE ZUM KONKRETEN BEISPIEL 111
erhält man somit 4000 Agenten. Rechter Hand sieht man die mit einem adaptiven Runge-Kutta-Verfahren (Dormand & Prince) approximierten Lösungskurven der gemäß der Umrechnung ausdem letzten Unterkapitel parametrisierten SIR Gleichungen. Diese drei Grafiken dienen weni-ger der quantitativen Fehleranalyse |φ(t) − E(x)(t)|, sondern mehr der Studie der qualitativenÄhnlichkeiten der Modelle. Nicht immer steht bei einem Modell die Lösungskurve als Ganzesim Vordergrund - in diesem Modell könnte z.B. auch der Zeitpunkt und die Höhe des erstenExtremums der Infizierten-Kurve von Bedeutung sein.Der angesprochene analytische Vergleich folgt in Abbildung 9.4. Dort sind für drei unterschied-
Abbildung 9.1: Parameter λ = 0.7, µ = 0.2
Abbildung 9.2: Parameter λ = 0.8, µ = 0.1
liche Parametersätze die Fehler der Kurven, jeweils aufgetrennt nach Zeile des Lösungsvektors,

112 KAPITEL 9. 2. BSP: SIR MODELL
Abbildung 9.3: Parameter λ = 0.7, µ = 0.05
aufgetragen. D.h. die oberste Grafik zeigt den Fehler, den die beiden Modelle zueinander ma-chen, für die Anzahl der suszeptiblen Individuen. Man erkennt, z.B. mithilfe der punktiertenLinie, die in jede der drei Grafiken eingezeichnet ist, dass die Halbierung der Raten und dieVerdoppelung der Zeit, was für das ODE Modell lediglich eine Transformation in der Zeit be-deutet, den Fehler invers linear verringert. Der überraschende Effekt, dass der Fehler für die Rateµ = 0.1 anstelle von µ = 0.2 (wobei λ unverändert) im Plot für die gesunden und kranken Indi-viduen sogar größer ist, als der Fehler des Ausgangsmodells 0.7/0.2, lässt sich z.B. so erklären:Die Exit Rate für den Zustand I wurde verkleinert. Demnach wächst der Zustand I schneller,was die Entry Rate (die ja von I abhängt) des Zustandes I , sowie auch die Exit Rate des Zustan-des S vergrößert. Demnach nimmt der Fehler, trotz Verringerung einer Rate, für diese beidenZustände, sogar zu. Diese Rate wirkt sich gem. der Gleichungen nicht mehr direkt auf die dritteKomponente (R) aus. Dort nimmt der Fehler durch die Halbierung der Rate zwar ein weniglangsamer als für den dritten Parametersatz, aber dennoch, ab.
9.4 Résumé
Das SIR-Modell reizt, im Gegensatz zum Ehrenfestmodell, die Theorie an zwei entscheidendenPunkten aus:
Das Problem ist mehrdimensional.
Die Übergangsraten der Agenten, hängen von den Zustandsvektoren ab (hier dem ZustandI).
Vor allem der zweite Punkt ist von besonderem Interesse, denn er bedeutet, dass die Agentenmiteinander interagieren dürfen. Die Fehlergrafiken zeigen, genauso wie die Fehlerabschätzun-
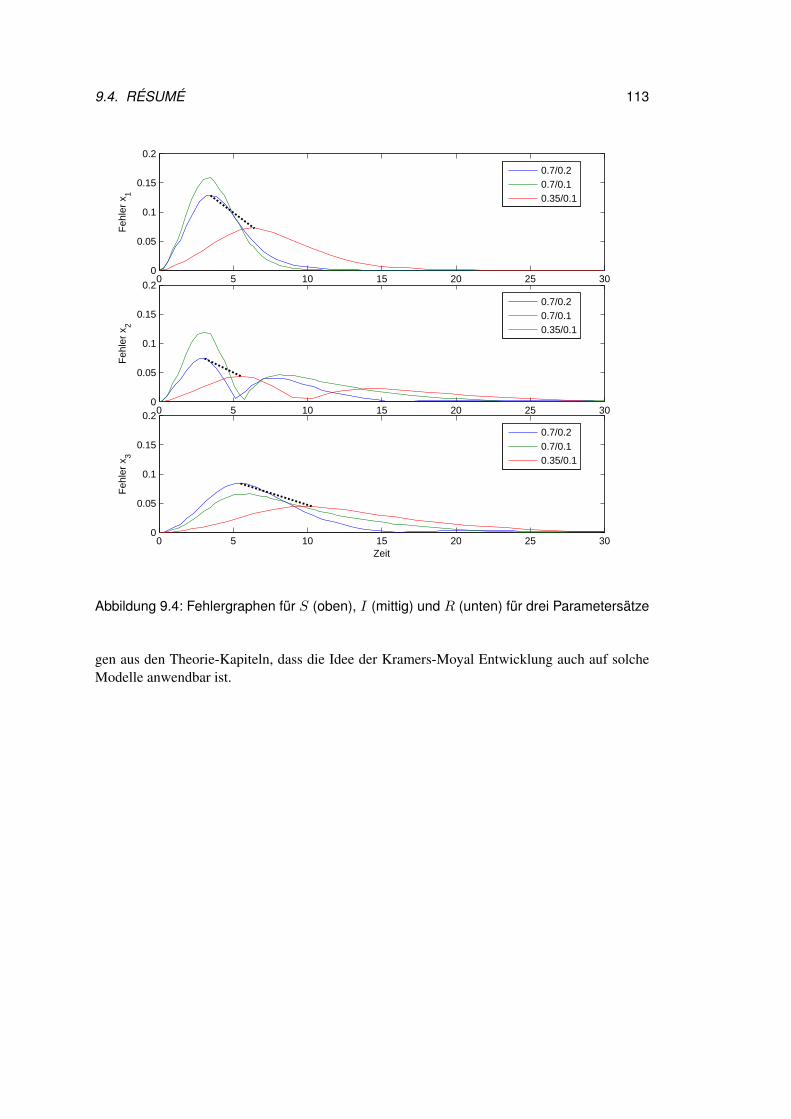
9.4. RÉSUMÉ 113
0 5 10 15 20 25 300
0.05
0.1
0.15
0.2
Zeit
Feh
ler
x 1
0 5 10 15 20 25 300
0.05
0.1
0.15
0.2
Zeit
Feh
ler
x 2
0 5 10 15 20 25 300
0.05
0.1
0.15
0.2
Zeit
Feh
ler
x 3
0.7/0.20.7/0.10.35/0.1
0.7/0.20.7/0.10.35/0.1
0.7/0.20.7/0.10.35/0.1
Abbildung 9.4: Fehlergraphen für S (oben), I (mittig) und R (unten) für drei Parametersätze
gen aus den Theorie-Kapiteln, dass die Idee der Kramers-Moyal Entwicklung auch auf solcheModelle anwendbar ist.


KAPITEL 103. Bsp: Linearisiertes, ungedämpftes
Pendel
10.1 Motivation und Problemstellung
An diesem, letzten, Beispiel soll schlussendlich illustriert sein, dass die erarbeitete Theoriedurchaus auch in die umgekehrte Richtung, d.h das Erstellen eines agentenbasierten Modellsauf Basis einer Differentialgleichung, anwendbar ist. Ausgangspunkt dieses Beispiels ist diewohlbekannte linearisierte Pendelgleichung
u′′ = −ku, u(0) = u0, u′(0) = u′0
mit k > 0. Es sei für dieses Beispielkapitel sogar k < 1 gefordert. Die Lösung ist wohlbekanntund leicht analytisch anzugeben:
u(t) =u′0√k
sin(√kt) + u0 cos(
√kt)
Gemäß der Lösungstheorie über lineare Differentialgleichungen kann die Differentialgleichung
zweiter Ordnung mithilfe der Substitution(u1
u2
):=
(uu′
)in ein System erster Ordnung ge-
schrieben werden. (u1
u2
)′=
(u2
−ku1
)Sei also in Folge die Differentialgleichung
~φ0′=
(0 1−k 0
)~φ0 (10.1)
eine Approximation des Mittelwertes eines stochastischen agentenbasierten Modells, dessen Pa-rameter und Übergangswahrscheinlichkeiten zu bestimmen sind.
115

116 KAPITEL 10. 3. BSP: LINEARISIERTES, UNGEDÄMPFTES PENDEL
10.2 Erarbeiten des Agentenmodells
Zunächst stellt man fest, dass als Output des in den Theoriekapiteln beschriebenen Verfahrens,stets eine Differentialgleichung der Form
~φ′ =∑i,j
ω~φ,~ei−~ej (~ei − ~ej)
resultiert. D.h. Differentialgleichungen die∑
i~φ′i = 0 und damit eine gewisse Erhaltungsglei-
chung erfüllen. Die beschriebene Modellgleichung 10.1 ist demnach in dieser Form noch nichtverwendbar. Man löst das Problem z.B., indem man einen fiktiven dritten Zustand, der das Ver-halten der ursprünglichen Differentialgleichung direkt noch nicht beeinflusst, in Form einer drit-ten Differentialgleichung dazu modelliert.φ1
φ2
φ3
′ = φ2
−kφ1
−φ2 + kφ1
=
10−1
φ2 +
0−11
kφ1 (10.2)
Mit der Taylorentwicklung ω~x,R = NΦ~x,R und der Formel ~φ′ =∑
R Φ~φ,RR erhält man
ω~x, ~e1− ~e3 = Nx2, ω~x, ~e3− ~e2 = Nkx1.
Das größte Problem für die Anwendung der Theorie ist nun das Problem, dass die Werte derZustände auch negativ sein können, was negative Übergangsraten verursachen würde. Man istalso gezwungen, Fallunterscheidungen zu machen:
ω~x, ~e1− ~e3 := max(0, Nx2), ω~x, ~e3− ~e1 := max(0,−Nx2)
ω~x, ~e3− ~e2 := kmax(0, Nx1), ω~x, ~e2− ~e3 := kmax(0,−Nx1)
Nun soll aber Nxi einer Agentenzahl entsprechen, womit eben diese aber nicht negativ seinkann. Um dieses Problem zu lösen, muss man noch einmal zum Anfang springen und dieDifferentialgleichung umskalieren. Bekanntermaßen schwingt das Pendel u1 auf dem IntervallC[−1, 1] und die Ableitung des Pendels u2 auf dem Intervall C[−
√k,√k], mit einer von den
Anfangswerten abhängigen Konstante C. Verwendet man stattdessen also die Differentialglei-chung φ1
φ2
φ3
′ = φ2
−kφ1
−φ2 + kφ1
+
CCC
,
so schwingen die Lösungen für auf [0, 2C] bzw auf C[1−√k, 1+
√k]. Um zu garantieren, dass
x1 + x2 + x3 = 1 bzw. überhaupt x1 + x2 < 1 kann man z.B.
C :=1
4

10.2. ERARBEITEN DES AGENTENMODELLS 117
setzen. Damit erhält man die Differentialgleichungφ1
φ2
φ3
′ = φ2
−kφ1
−φ2 + kφ1
+
141414
, (u0 −1
4)2 +
1
k(u′0 −
1
4)2 = (≤)
1
4
Die resultierenden Übergangsraten sind demnach
ω~x, ~e1− ~e3 := max(0, Nx2 −N
4), ω~x, ~e3− ~e1 := max(0,−Nx2 +
N
4)
ω~x, ~e3− ~e2 := kmax(0, Nx1 −N
4), ω~x, ~e2− ~e3 := kmax(0,−Nx1 +
N
4).
Die Umrechnungsformel
ω~x, ~ej−~ei = N~xiωi,j = XiP ((1, j)|(0, i))
liefert schlussendlich die Übergangsmatrix
P ((1, j)|(0, i)) := cωi,j := c
· 0
max(0,−Nx2+N4
)
Nx1
0 · kmax(0,Nx1−N4 )
Nx2max(0,Nx2−N4 )
Nx3k
max(0,−Nx1+N4
)
Nx3·
=
= c
· 0
max(0,−X2+N4
)
X1
0 · kmax(0,X1−N4 )
X2max(0,X2−N4 )
X3k
max(0,−X1+N4
)
X3·
.
Da i.A. die definierten Wahrscheinlichkeiten nicht einmal kleiner als 1 sein müssen, bietet sichhier die Skalierung mit einem kleinen c > 0 an, womit auch die Zeit skaliert werden muss.Mithilfe dieser Matrix ist das agentenbasierte Modell bereits definiert und kann implementiertwerden. Mithilfe von Relationen zwischen den Zuständen könnte man zusätzlich noch versu-chen, die Wahrscheinlichkeiten aus einem räumlichen Modell über Kontaktwahrscheinlichkeitenzu erzeugen. In jedem Zeitschritt hängt die Veränderung der Zustandsvektors von der Positivitätder Ausdrücke X1 − N
4 bzw. X2 − N4 ab. Je nach Vorzeichen haben entweder die Agenten im
(unbedeutenden) Zustand 3 die Möglichkeit, in den Zustand „Funktion“ (1) oder „Ableitung“ (2)überzugehen und damit die jeweilige Zustandsvariable zu erhöhen, oder die Agenten aus demZustand 1 oder 2 haben die Chance in den Zustand „Ruhe“ (3) überzugehen. Wie hier schonherausgelesen werden kann, ist eine logische Deutung des definierten Agentenmodells fast nichtmöglich. Umso interessanter ist die Tatsache, dass das in dieser Form definierte Modell über-haupt entwickelt werden konnte.So verrückt und abstrakt die Verwendung eines agentenbasierten Modells in diesem Fall aucherscheinen mag, baut sie doch auf einem erst zunehmenden Hintergrund auf. So ausgereift dieForschung auch im Bereich der Physik ist, liefert sie keinerlei Antworten darauf, wie die in derPhysik hergeleiteten Differentialgleichungen bzw. Differentialgleichungsmodelle gelöst werden
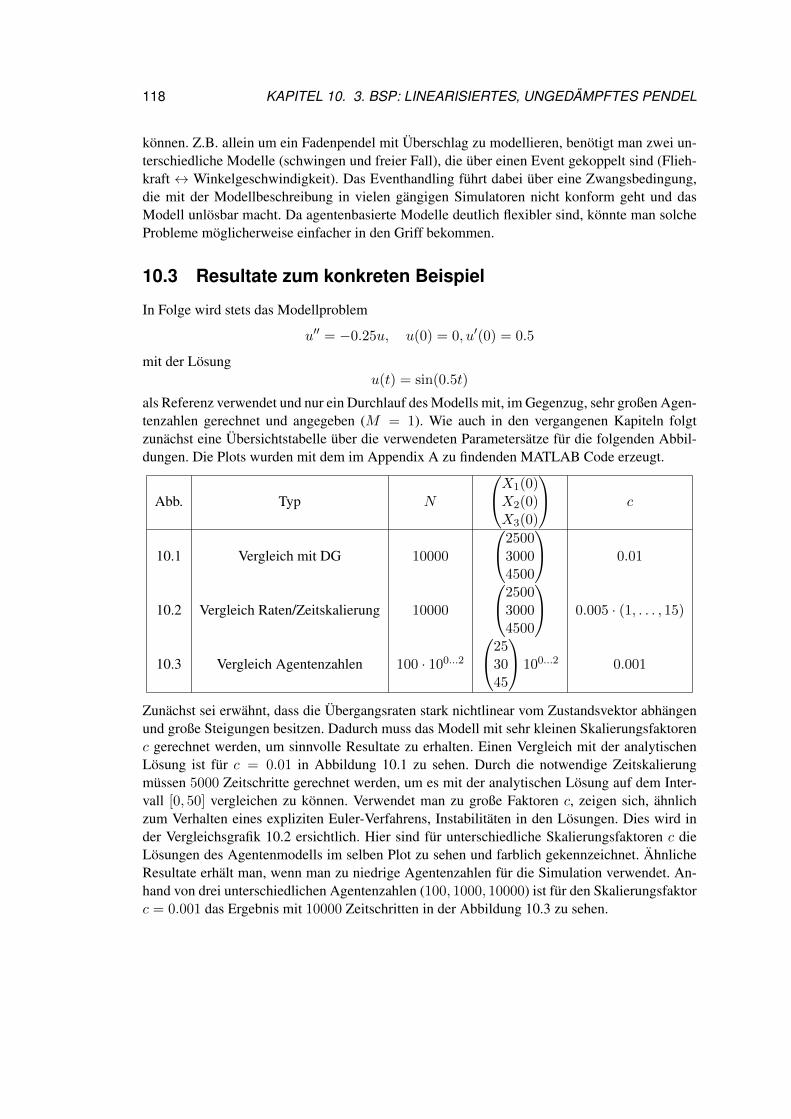
118 KAPITEL 10. 3. BSP: LINEARISIERTES, UNGEDÄMPFTES PENDEL
können. Z.B. allein um ein Fadenpendel mit Überschlag zu modellieren, benötigt man zwei un-terschiedliche Modelle (schwingen und freier Fall), die über einen Event gekoppelt sind (Flieh-kraft ↔ Winkelgeschwindigkeit). Das Eventhandling führt dabei über eine Zwangsbedingung,die mit der Modellbeschreibung in vielen gängigen Simulatoren nicht konform geht und dasModell unlösbar macht. Da agentenbasierte Modelle deutlich flexibler sind, könnte man solcheProbleme möglicherweise einfacher in den Griff bekommen.
10.3 Resultate zum konkreten Beispiel
In Folge wird stets das Modellproblem
u′′ = −0.25u, u(0) = 0, u′(0) = 0.5
mit der Lösungu(t) = sin(0.5t)
als Referenz verwendet und nur ein Durchlauf des Modells mit, im Gegenzug, sehr großen Agen-tenzahlen gerechnet und angegeben (M = 1). Wie auch in den vergangenen Kapiteln folgtzunächst eine Übersichtstabelle über die verwendeten Parametersätze für die folgenden Abbil-dungen. Die Plots wurden mit dem im Appendix A zu findenden MATLAB Code erzeugt.
Abb. Typ N
X1(0)X2(0)X3(0)
c
10.1 Vergleich mit DG 10000
250030004500
0.01
10.2 Vergleich Raten/Zeitskalierung 10000
250030004500
0.005 · (1, . . . , 15)
10.3 Vergleich Agentenzahlen 100 · 100...2
253045
100...2 0.001
Zunächst sei erwähnt, dass die Übergangsraten stark nichtlinear vom Zustandsvektor abhängenund große Steigungen besitzen. Dadurch muss das Modell mit sehr kleinen Skalierungsfaktorenc gerechnet werden, um sinnvolle Resultate zu erhalten. Einen Vergleich mit der analytischenLösung ist für c = 0.01 in Abbildung 10.1 zu sehen. Durch die notwendige Zeitskalierungmüssen 5000 Zeitschritte gerechnet werden, um es mit der analytischen Lösung auf dem Inter-vall [0, 50] vergleichen zu können. Verwendet man zu große Faktoren c, zeigen sich, ähnlichzum Verhalten eines expliziten Euler-Verfahrens, Instabilitäten in den Lösungen. Dies wird inder Vergleichsgrafik 10.2 ersichtlich. Hier sind für unterschiedliche Skalierungsfaktoren c dieLösungen des Agentenmodells im selben Plot zu sehen und farblich gekennzeichnet. ÄhnlicheResultate erhält man, wenn man zu niedrige Agentenzahlen für die Simulation verwendet. An-hand von drei unterschiedlichen Agentenzahlen (100, 1000, 10000) ist für den Skalierungsfaktorc = 0.001 das Ergebnis mit 10000 Zeitschritten in der Abbildung 10.3 zu sehen.
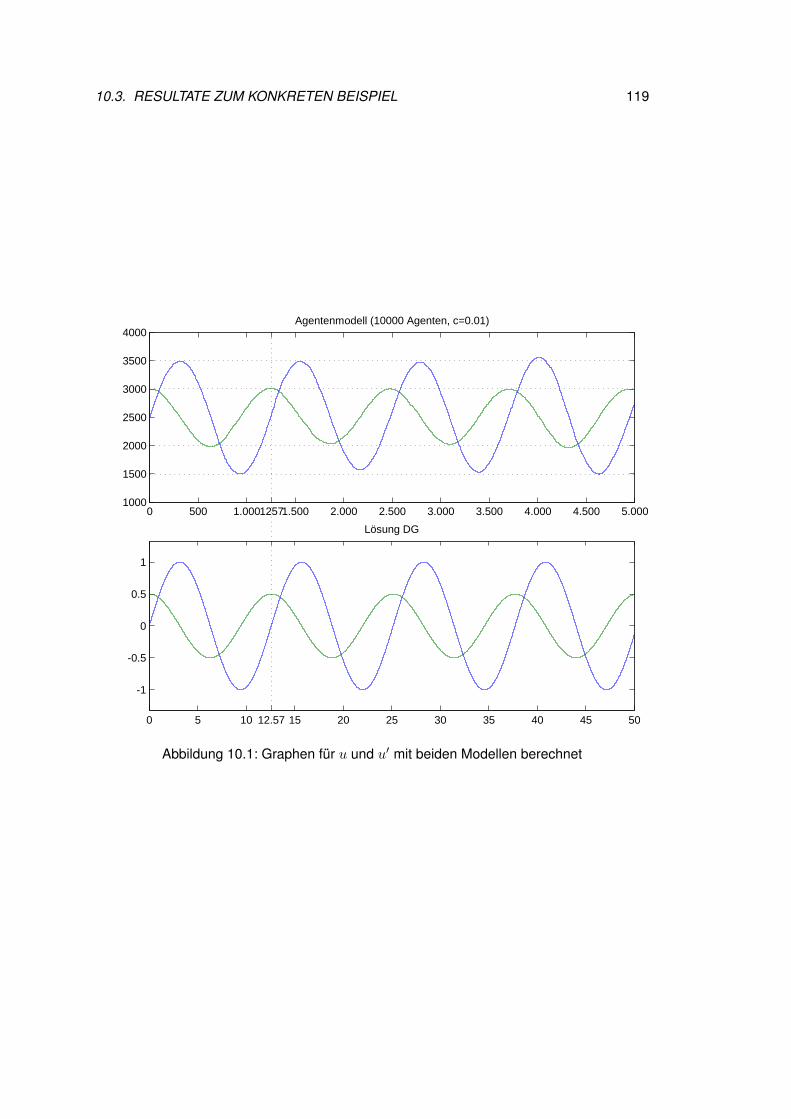
10.3. RESULTATE ZUM KONKRETEN BEISPIEL 119
0 500 1.00012571.500 2.000 2.500 3.000 3.500 4.000 4.500 5.0001000
1500
2000
2500
3000
3500
4000Agentenmodell (10000 Agenten, c=0.01)
0 5 10 12.57 15 20 25 30 35 40 45 50
-1
-0.5
0
0.5
1
Lösung DG
Abbildung 10.1: Graphen für u und u′ mit beiden Modellen berechnet
120 KAPITEL 10. 3. BSP: LINEARISIERTES, UNGEDÄMPFTES PENDEL
0 5 10 15 20 25 30 35 40 45 500
500
1000
1500
2000
2500
3000
3500
4000
4500
u mit 0.005u mit 0.075
0 5 10 15 20 25 30 35 40 45 500
1000
2000
3000
4000
5000
u' mit 0.005u' mit 0.075
Abbildung 10.2: Lösungen u (oben) und u′ für unterschiedliche Raten/Zeitskalierungsfakto-ren

10.3. RESULTATE ZUM KONKRETEN BEISPIEL 121
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
10
20
30
40
50N=100
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100000
100
200
300
400
500N=1000
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 100001000
2000
3000
4000
5000N=10000
Abbildung 10.3: Agentensimulation für N = 100, 1000 und 10000


KAPITEL 11Conclusio
11.1 Rückblick
In den vergangenen Kapiteln wurde gezeigt, wie mit rein mathematischen Mitteln auf analyti-scher Ebene, Modelltypen ineinander übergeführt werden können, und wie im Endeffekt sogarKonvergenzresultate folgen. Vor allem bedingt durch die theoretische Komplexität einer Mikro-simulation waren viele Zwischenschritte notwendig, um vom DG Modell schlussendlich eineBrücke zum zeitdiskreten - raumdiskreten Agentenmodell zu gelangen. Es seien nun ein letztesMal die wichtigsten Aussagen der Arbeit zusammengefasst:
Die Zustandsvektoren (Summe aller Agenten im selben Zustand) von stochastischen agen-tenbasierten Modellen, in denen die Übergangswahrscheinlichkeiten eines Agenten voneinem Zustand in den anderen maximal von dem Zustandsvektor selbst abhängen, habenstochastische Größen, die approximativ mit Differentialgleichungen beschreibbar sind.
Die Kurve des Mittelwerts der agentenbasierten Modelle kann durch ein System von ge-wöhnlichen, evtl. nichtlinearen, Differentialgleichungen approximiert werden.
Die Varianz lässt sich im Fall von maximal zwei Zuständen ebenfalls durch eine gewöhnli-che Differentialgleichung annähern. Sie ist nicht zwingend monoton wachsend. In diesemFall lässt sich damit sogar eine Approximation an die Wahrscheinlichkeitsdichte ermitteln.
Eine Approximation an die diskrete Wahrscheinlichkeitsverteilung erhält man mit einerDichtefunktion, die als Lösung einer Fokker-Planck-Gleichung auftritt.
Im eindimensionalen Fall entspricht diese Dichte einer zeitabhängigen Gauss-Verteilungmit Mittelwert φ(t) und Varianz σ2(t).
Die Varianz ist auch für eine beliebige Anzahl an Zuständen stets ein O(N−1) und kon-vergiert gegen 0.
123

124 KAPITEL 11. CONCLUSIO
Im Vergleich der DG mit einem zeitkontinuierlichen agentenbasierten Markov-Modellentsteht ein Orts-Diskretisierungs-Fehler, der von der Agentenzahl bzw. der Anzahl derDurchläufe des Agentenmodells abhängt.
Im Vergleich des zeitkontinuierlichen Markov-Modells und des stochastischen zeitdiskre-ten agentenbasierten Modells entsteht ein Zeit-Diskretisierungs-Fehler der von der Größeder Übergangsraten bzw. deren Ableitungen abhängt.
Die Konvergenz, zumindest der Erwartungswertkurven, erhält man mit dem Parameter-setting
limn→∞
(nTend,ω
n,Nn)
Die zu verwendenden Umrechnungen vom Agentenmodell zur Differentialgleichung lau-ten
ωj,i := P ((1, i)|(0, j)) = P (Agent wechselt von j zu i)
ω~x,~ei−~ej := N~xjωi,j
f(N)(Φ1(~x, ~ei − ~ej) +N−1Φ2(~x, ~ei − ~ej) + . . . ) := ω~x,~ei−~ej
~φ′ =∑i 6=j
Φ1(~φ, ~ei − ~ej)(~ei − ~ej),
oder mithilfe der Exit und Entry Rate definiert
(ωex(~x))j := N~xj∑i 6=j
ωj,i =: N~xjµj
(ωen(~x))j := N∑i 6=j
~xiωi,j =: N(1− ~xj)λj
~φ′j := (Φ1en(~φ))j − (Φ1
ex(~φ))j .
Der Fehler, den beide Modelle zueinander machen, ist auch quantitativ abschätzbar.
Das Resultat ist ein fertiges, wenn auch noch nicht perfekt ausgereiftes Konzept zur Erstellungvon Differentialgleichungs bzw. agentenbasierten Modellen aus dem jeweils anderen.
11.2 Ausblick
Die vorgestellte Theorie könnte durchaus langfristig in Bereichen der Modellbildung in Simula-tion helfen, die Anwendungsbereiche von Modellen weiter zu vergrößern. Ist z.B. durch eine ge-ringe Modelländerung ein Differentialgleichungsmodell unrechenbar geworden, z.B. durch einekomplizierte Zwangsbedingung oder einen Event, könnte das Problem vielleicht im korrespon-dierende agentenbasierten Modell leicht zu lösen sein. Auf der anderen Seite könnten genauereAnalysen des Konzepts überdies dazu beitragen, mithilfe der ausgereiften Theorie über Diffe-rentialgleichungen das Verhalten von sich selbst korrigierenden mikroskopischen Systemen, die

11.2. AUSBLICK 125
ob ihres chaotischen Verhaltens stets schwer zu analysieren sind, besser zu verstehen und vor-hersagen zu können. Die vorliegende Arbeit kratzt diesbezüglich gerade erst an der Wurzel, unddie Theorie bietet noch viel Potenzial (genauere Fehleranalysis, Untersuchen von Stabilität vonLösungen, Rechenzeitanalysen, etc.).Sowohl das Modellieren mit Differentialgleichungen, als auch die agentenbasierte Modellierungleisten gerade in einer Zeit, in der es immer notwendiger wird, auf ihrem jeweiligen Anwen-dungsgebiet sehr gute Dienste. Wenn mithilfe von Ideen wie dieser die beiden Anwendungs-gebiete immer weiter überlappen und man weniger an einen Modelltyp gefesselt ist, kann dieModellbildung, denke ich, nur profitieren und mit ihr natürlich auch der Mensch.


ANHANG AAppendix
Matlab Code für das agentenbasierte Pendel Modell:
function [M] = pendel(N,x0,tt,k,c)% Ausgangspunkt: x’’=-kx bzw (x_1,x_2)’=(x_2,-kx_1)% N - Anzahl an Agenten% x0 - (X1(0),X2(0))% tt - Anzahl der Schritte% k - Frequenzkonstante% c - Skalierungsfaktor fuer die Wahrscheinlichkeiten%% ------Definition der Anfangskonfiguration-------P(1:N)=0;P(1:x0(1))=1;P(x0(1)+1:x0(1)+x0(2))=2;x(1)=x0(1);xx(1)=x0(2);% ------Schleife ueber die Zeit -------------------for t=2:tt
x(t)=x(t-1);xx(t)=xx(t-1);Q(1:N)=0;W=WW(x(t-1),xx(t-1)); % Aufruf der Ratenfunktion
% ------Schleife ueber die Agenten -----------------for i=1:N
if P(i)==0r=rand();if r<W(3,1)Q(i)=1;x(t)=x(t)+1;
elseif r<W(3,1)+W(3,2)Q(i)=2;xx(t)=xx(t)+1;
elseQ(i)=0;
end;
127

128 ANHANG A. APPENDIX
elseif P(i)==1r=rand();
if r<W(1,3)Q(i)=0;x(t)=x(t)-1;
elseif r<W(1,3)+W(1,2)Q(i)=2;x(t)=x(t)-1; xx(t)=xx(t)+1;
elseQ(i)=1;
end;else
r=rand();if r<W(2,3)
Q(i)=0;xx(t)=xx(t)-1;
elseif r<W(2,3)+W(2,1)Q(i)=1;x(t)=x(t)+1; xx(t)=xx(t)-1;
elseQ(i)=2;
end;end;
end;M(t,1:N)=P(1:N);
P=Q; % Updateschrittend;% ------Plotbefehl-------------------------------A=[x;xx];plot(1:tt,A);% ------Ratenfunktion----------------------------
function omega = WW(x,xx)omega=zeros(3);omega(1,3)=c*max(0,-xx+N/4)/x;omega(3,1)=c*max(0,xx-N/4)/(N-x-xx);omega(2,3)=c*k*max(0,x-N/4)/xx;omega(3,2)=c*k*max(0,-x+N/4)/(N-x-xx);
end;end

Abbildungsverzeichnis
2.1 Übersichtsabbildung - Umweg zum Ziel . . . . . . . . . . . . . . . . . . . . . . 52.2 Vergleich stochastisch - deterministisch . . . . . . . . . . . . . . . . . . . . . . 82.3 Möglicher Pfad eines CTDS Markovporzesses . . . . . . . . . . . . . . . . . . 13
3.1 Approximation von p mit pcont bzw. pi . . . . . . . . . . . . . . . . . . . . . . . 43
4.1 Beispiel für die Lösungskurven einer Transportgleichung . . . . . . . . . . . . . 504.2 Beispiel für die Lösungskurven einer Diffusionsgleichung . . . . . . . . . . . . 50
7.1 Skizze des Ehrenfest’schen Urnenproblems . . . . . . . . . . . . . . . . . . . 767.2 Unterschiedliche Werte für N . . . . . . . . . . . . . . . . . . . . . . . . . . . 827.3 Erwartungswertkurve mit Standardabweichungskurve . . . . . . . . . . . . . . 837.4 Vergleich der Varianzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 847.5 Vergleich der Dichtekurven . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 857.6 Fehler mit unterschiedlichen Werten von N ·M . . . . . . . . . . . . . . . . . 867.7 Fehler mit Zeit- und Raten-Skalierung C . . . . . . . . . . . . . . . . . . . . . 87
8.1 Überblick über bisherige Abschätzungen . . . . . . . . . . . . . . . . . . . . . 898.2 Skizze für die Umrechnung - φ steht Beispielhaft für eine stochastische Größe . 91
9.1 Parameter λ = 0.7, µ = 0.2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1119.2 Parameter λ = 0.8, µ = 0.1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1119.3 Parameter λ = 0.7, µ = 0.05 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1129.4 Fehlergraphen für S (oben), I (mittig) und R (unten) für drei Parametersätze . . 113
10.1 Graphen für u und u′ mit beiden Modellen berechnet . . . . . . . . . . . . . . . 11910.2 Lösungen u (oben) und u′ für unterschiedliche Raten/Zeitskalierungsfaktoren . 12010.3 Agentensimulation für N = 100, 1000 und 10000 . . . . . . . . . . . . . . . . . 121
129


Literaturverzeichnis
[Aok02] Masanao Aoki. Modeling Aggregate Behavior and Fluctuations in Economics: Sto-chastic Views of Interacting Agents. Cambridge University Press, New York, 2002.
[Enc07] Encyclopaedia Britannica, inc. The New Encyclopaedia Britannica. EncyclopaediaBritannica, Chicago, 15th edition, 2007.
[Kam82] N. G. van Kampen. The Diffusion Approximation for Markov Processes. Thermo-dynamics and kinetics of biological processes. Walter de Gruyter and Co., 1982.
[Kam07] N. G. van Kampen. Stochastic processes in physics and chemistry. North-Hollandpersonal library. Elsevier, Amsterdam ; Boston, 3rd ed edition, 2007.
[KM27] W.O. Kermack and W.G. McKendrick. A contribution to the mathematical theoryof epidemics. 1927.
[Mik12] F. Miksch. Mathematische Modelle für neue Erkenntnisse über Epidemien mittelsHerdenimmunität und Serotypenverschiebung. Dissertation, Inst. f. Analysis undScientific Computing, Vienna University of Technology, Vienna, 2012.
[MZP+12] Florian Miksch, Günther Zauner, Philipp Pichler, Christoph Urach, and Niki Popper.Endbericht. Technical Report Endbericht des Influenza Projekts, Vienna, February2012.
[PK12] C. Pöll and A. Körner. A different kind of modelling: Cellular automata. In F. Brei-tenecker and I. Troch, editors, Preprints MATHMOD 2012 Vienna – Abstract Volu-me, volume 38 of ARGESIM Report, page 402, Vienna, Austria, 2012. ARGESIM /ASIM.
[Sch05] Volker Schmidt. Vorlesungsskript Wahrscheinlichkeitstheorie. Universität Ulm,SS2005, Juli 2005. Vorlesung SS2005.
[Sto70] William F. Stout. The hartman-wintner law of the iterated logaroithm for martinga-les. The Annals of Mathematical Statistics, 41(6), 1970.
131





























