Embed Size (px)
Citation preview

ESCOLA SUPERIOR DE TECNOLOGIA – EST
ROMILDO PEREIRA EPIFÂNIO JUNIOR
ALGORITMOS PARALELOS COMO TÉCNICA DE DIMINUIÇÃO DO CONSUMO DE ENERGIA – QUICKSORT E CÁLCULO DO PI
Manaus
2008


ROMILDO PEREIRA EPIFÂNIO JUNIOR
ALGORITMOS PARALELOS COMO TÉCNICA DE DIMINUIÇÃO DO CONSUMO DE ENERGIA – QUICKSORT E CÁLCULO DO PI
Monografia submetida ao corpo docente do Curso de Engenharia da Computação da Escola Superior de Tecnologia da Universidade do Estado do Amazonas (EST/UEA) como parte dos requisitos para obtenção do grau de Engenheiro em Computação.
Orientador: Edward David Moreno, Professor Doutor.
Manaus
2008


Epifânio, Romildo Pereira JuniorAspectos de Desempenho do Algoritmo Quicksort em Sistemas Seqüencias e Paralelos. Monografia de Trabalho de Conclusão de Curso, EST/UEA. Manaus, 2008.
Desempenho 2.Algoritmo Quicksort 3. Sistemas Seqüenciais e Paralelos 4.Consumo de Energia

ROMILDO PEREIRA EPIFÂNIO JUNIOR
AGORITMOS PARALELOS COMO TÉCNICA DE DIMINUIÇÃO DO CONSUMO DE ENERGIA – QUICKSORT E CÁLCULO DO PI
Monografia submetida ao corpo docente do Curso de Engenharia da Computação da Escola Superior de Tecnologia da Universidade do Estado do Amazonas (EST/UEA) como parte dos requisitos para obtenção do grau de Engenheiro em Computação.
Manaus, (18 de setembro de 2008)
BANCA EXAMINADORA:
_____________________________________________ Prof. Edward David Moreno, Doutor
OrientadorEST/UEA
_____________________________________________ Prof. Manoel S. Santos Azevedo, Mestre
EST/UEA
_____________________________________________Prof. Salvador Ramos Bernardino da Silva, Especialista
EST/UEA

AGRADECIMENTOS
Agradeço a Deus, pois “até aqui me ajudou o Senhor” (I Sam 7:12). Sem a ajuda do
meu Senhor Jesus Cristo não teria sido possível terminar este trabalho. São tantos os
momentos difíceis que as vezes desanimamos; mas sempre tive Alguém em quem me apoiar.
Agradeço a meus pais, sr Romildo, e em especial minha mãe, Marilene, que nunca
mediu esforços para atender ao menor pedido que fosse feito por mim, ou minhas irmãs e
sempre nos ensinou a seguir em frente. Agradeço também a Deiziane e Natalia – minhas
irmãs – que sempre me animaram, não me deixando desistir.
Agradeço à minha Cláudia, que sempre me apoiou desde o início da minha
monografia, tanto momentos de alegria como de tristeza.
Agradeço também a meu grande professor e orientador Edward, que teve de “me
aturar” por todo esse tempo, sempre muito paciente e disposto a me ajudar.
Agradeço ao sr Cláudio, pai da Cláudia, e ao Benedito (Billy) por me emprestarem
seus computadores, sem hesitar, para que eu pudesse concluir meu curso.

RESUMO
Este trabalho apresenta uma comparação do desempenho (medido através do tempo de execução e consumo de energia) do algoritmo Quicksort em um sistema seqüencial, implementado nas linguagens C e Java, e do cálculo do numero PI em um sistema paralelo, utilizando a biblioteca de troca de mensagem MPICH.
Desta forma, serão feitas algumas explicações sobre conceitos de clusters de computadores, uma breve introdução sobre as diferentes arquiteturas de computadores paralelos, programação paralela, sistemas distribuídos, a conceituação de algumas bibliotecas de troca de mensagens e uma comparação entre elas.
Espera-se então com este projeto realizar um bom trabalho, e também proporcionar ao interessado um bom material de auxílio e experiência em programação, tanto na programação seqüencial tradicional como em programação paralela e distribuída.
Opcionalmente, dedicar-se-á a analisar o impacto do consumo de energia desse algoritmo quando executa nessas plataformas. Além de poder estender-se a uma pesquisa para verificar o comportamento de baterias de dispositivos móveis quando funcionam sob computação paralela, neste caso notebooks e/ou PDAs.
Palavras-chave:Desempenho – Algoritmo Quicksort – Sistemas Seqüenciais e Paralelos – Consumo de Energia

ABSTRACT
This work presents a comparison of performance (measured trough of the running time and consumption of energy) of Quicksort algorithm on a sequential system, implemented on languages C and Java, and calculating the number of IP in a parallel system, using the library of message. passing MPICH.
Therefore, it will be made some explanations on the concepts of clusters of computers, a short introduction about the different parallel computer architectures, parallel programming, distributed systems, the concept of some libraries of message passing and a comparison between them.
So, it is expected with this project to realize a good work, and to proportionate too to the interested a good material aid and experience in programming, both the traditional sequential programming as in parallel and distributed programming.
Optionally, dedicate will be to analyze the impact of consumption of energy this algorithm when run on these platforms. Besides to can extend to a search to verify the comportment of behavior of batteries for mobile devices when operating in parallel computing, on this case notebooks and/or PDAs.
Key-words:Performance – Quicksort Algorithm – Sequential and Parallel Systems – Consumption of Energy

SUMÁRIO
LISTA DE FIGURAS .......................................................................................................................................... 10
LISTA DE TABELAS .......................................................................................................................................... 12
LISTA DE ABREVIATURAS E SIGLAS ......................................................................................................... 13
INTRODUÇÃO .................................................................................................................................................... 14
1.1 MOTIVAÇÃO..................................................................................................................................................15 1.2 OBJETIVOS....................................................................................................................................................17
1.2.1 Geral.....................................................................................................................................................171.2.2 Específicos............................................................................................................................................17
1.3 METODOLOGIA..............................................................................................................................................17 1.4 ORGANIZAÇÃO DA MONOGRAFIA......................................................................................................................18
2 CONCEITOS DE ARQUITETURAS DE MÁQUINAS PARALELAS ...................................................... 19
2.1 COMPUTAÇÃO PARALELO/DISTRIBUÍDA.............................................................................................................212.1.1 Computação Paralela..........................................................................................................................212.1.2 Computação Distribuída......................................................................................................................22
2.2 MPI – MESSAGE PASSING INTERFACE..............................................................................................................23 2.3 PVM – PARALLEL VIRTUAL MACHINE............................................................................................................24 COMPARANDO PVM E MPI.................................................................................................................................25 2.4 BIBLIOTECAS PARALELAS COM JAVA.................................................................................................................26
2.4.1 JavaMPI...............................................................................................................................................262.4.2 mpiJava................................................................................................................................................272.4.3 JPVM....................................................................................................................................................28
2.5 CONSIDERAÇÕES FINAIS DO CAPÍTULO..............................................................................................................28
3 CLUSTERS DE COMPUTADORES .............................................................................................................. 29
3.1 FUNCIONAMENTO E TIPO DE CLUSTERS..............................................................................................................30 3.2 ALTA DISPONIBILIDADE E TOLERÂNCIA A FALHAS..............................................................................................33
3.2.1 Alta disponibilidade ............................................................................................................................333.2.2 Tolerância à Falhas ............................................................................................................................35
3.3 SISTEMAS EMBARCADOS MÓVEIS.....................................................................................................................35 3.4 COMPUTAÇÃO MÓVEL....................................................................................................................................36
3.4.1 Dispositivos Participantes da Comutação móvel.................................................................................363.4.2 Infra-estrutura Necessária para Computação Móvel..........................................................................38
3.5 UM CLUSTER DE CELULARES...........................................................................................................................39
4 UM ESTUDO DE CASO: QUICKSORT ....................................................................................................... 40
4.1 ALGORITMO QUICKSORT.................................................................................................................................41 4.2 IMPLEMENTAÇÃO SEQÜENCIAL.........................................................................................................................43
4.2.1 Quicksort em C.....................................................................................................................................434.2.2 Quicksort em Java................................................................................................................................454.2.3 Análise de resultados do Quicksort .....................................................................................................47
4.3 ANÁLISE DE RESULTADOS DO QUICKSORT E OUTROS ALGORITMOS .........................................................................49 4.4 IMPLEMENTAÇÃO PARALELA COM O MPI..........................................................................................................50 4.5 CONSUMO DE ENERGIA ..................................................................................................................................51 4.6 ANÁLISE DE CONSUMO DE ENERGIA DO ALGORITMO QUICKSORT EM SISTEMAS SEQÜENCIAIS...................................52 4.7 ANÁLISE DE CONSUMO DE ENERGIA DO ALGORITMO DO CÁLCULO DO PI EM SISTEMAS PARALELOS..........................60
CONCLUSÕES .................................................................................................................................................... 62

REFERÊNCIAS BIBLIOGRÁFICAS ............................................................................................................... 64
APÊNDICE A – CONFIGURANDO AS MÁQUINAS DO CLUSTER ......................................................... 68
APÊNDICE B – INSTALAÇÃO DO MPI (MESSAGE PASSING INTERFACE) ....................................... 70
APÊNDICE C – INSTALAÇÃO DO AMBIENTE DE PROGRAMAÇÃO JAVA ....................................... 73
ANEXO A – ALGORITMO QUICKSORT JAVA_1 ...................................................................................... 74
ANEXO B – FUNÇÃO SHELLSORT: LINGUAGEM C (WIKIPÉDIA, 2008) ........................................... 76
ANEXO C – MÉTODO SHELLSORT: LINGUAGEM JAVA (WIKIPÉDIA, 2008) .................................. 77
ANEXO D – FUNÇÃO HEAPSORT: LINGUAGEM C (WIKIPÉDIA, 2008) ............................................. 78
ANEXO E – MÉTODO HEAPSORT: LINGUAGEM JAVA (WIKIPÉDIA, 2008) ..................................... 79

LISTA DE FIGURAS
Figura 2.1 – Modelo SISD................................................................................................... 18
Figura 2.2 – Modelo SIMD.................................................................................................. 18
Figura 2.3 – Modelo MISD.................................................................................................. 19
Figura 2.4 – Modelo MIMD................................................................................................ 19
Figura 2.5 – Típica arquitetura paralela............................................................................... 20
Figura 2.6 – Típica arquitetura distribuída........................................................................... 21
Figura 3.1 – Arquitetura de um cluster Beowuf................................................................... 30
Figura 3.2 – Exemplo de sistema embarcado (MORIMOTO, 2007)................................... 35
Figura 4.1 – Tempo de execução do quicksort em C........................................................... 46
Figura 4.2 – Tempo de execução do quicksort em Java...................................................... 47
Figura 4.3 – Comparação do tempo de execução do quicksort em C e Java....................... 47
Figura 4.4 – Algoritmos de ordenação em C....................................................................... 48
Figura 4.5 – Algoritmos de ordenação em Java................................................................... 48
Figura 4.7 - Consumo de Energia PC
Simple.........................................................................
53
Figura 4.8 - Consumo de Energia PC
HP................................................................................
53
Figura 4.9 - Comparando Consumo de Energia dos PCs HP e Simple............................... 54
Figura 4.10 – Consumo de Energia do Algoritmo Shellsort................................................ 55

Figura 4.11 – Consumo de Energia Heapsort...................................................................... 55
Figura 4.12 – Comparação de Consumo de Energia entre Quicksort, Heapsort e
Sehllsort em C......................................................................................................................
56
Figura 4.13– Comparação de Consumo de Energia entre Quicksort, Heapsort e Sehllsort em Java.................................................................................................................................
56
Figura 4.14 - Coleta de dados do Algoritmo quicksort C.................................................... 57
Figura 4.15 Coleta de dados do Algoritmo quicksort Java.................................................. 58
Figura 4.16 - Coleta de dados do cálculo do número PI em uma máquina......................... 59
Figura 4.17 Coleta de dados do cálculo do número PI no cluste......................................... 59

LISTA DE TABELAS
Tabela 3.1: Evolução da telefonia celular............................................................................ 36
Tabela 4.1: mostra a relação Tempo/Quantidade de elementos........................................... 46
Tabela 4.2: Execução seqüencial do cálculo do número PI................................................. 49
Tabela 4.3: Execução paralela do cálculo do número PI..................................................... 49
Tabela 4.4: Tempo de execução / Consumo de Energia PC Simple.................................... 52
Tabela 4.5: Tempo de execução / Consumo de Energia PC HP.......................................... 52
Tabela 4.6: Consumo de Energia nas Linguagens C e Java nos notebooks HP e Simple... 52
Tabela 4.7:Comparação do Consumo de Energia (mWh) – Algoritmos Quicksort,
Shellsort e Heapsort – PC Simple........................................................................................
54
Tabela 4.8: Utilização de Processador e Memória PC Simple............................................. 58
Tabela 4.9: Consumo de Energia do Cálculo do número PI – PC Simple........................... 58

LISTA DE ABREVIATURAS E SIGLAS
KVM – Kilobyte Virtual Machine – Máquina Virtual KilobytePC – Personal Computer – Computador pessoalPDA – Personal Digital Assistant – Assistente Pessoal DigitalmpiJava – message passing interface Java – Interface de Troca de Mensagem JavaJavaMPI – Java Message Passing Interface – Java Interface de Troca de MensagemJPVM – Java Parallel Virtual Machine – Java Máquina Virtual ParalelaSISD – Single Intruction Single Data – Única Instrução um Único DadoSIMD – Single Instruction Multiple Data – Única Instrução Múltiplos DadosMISD – Multiple Instruction Single Data – Múltiplas Instruções Único DadoMIMD – Multiple Instruction Multiple Data – Múltiplas Instruções Múltiplos DadosNMI – Native Method Interface – Interface de Método NativoJCI – Java-to-C Interface – Interface Java para CDNS – Domain Name System – Sistema de Nomes de DomínioHP – High Performance – Alta PerformanceLB – Load Balance – Balanceamento de CargaMOSIX – Multicomputer Operating System for Unix – Sistema Operacional Multicomputador Para UnixHÁ – High Availability – Alta Disponibilidade LCD – Liquid Crystal Display – Monitor de Cristal LíquidoERB – Estação Rádio-Base

14
INTRODUÇÃO
Com o poder de processamento dos celulares aumentando cada vez mais, torna-se
possível adicionar novas e diversas funcionalidades a estes aparelhos. A maioria dos celulares
vendidos hoje possuem diversos dispositivos integrados como máquinas fotográficas,
tocadores de MP3, rádio AM/FM, Bluetooth, entre outros, que o tornam mais que um celular,
podendo ser chamados de comunicadores móveis.
Mas, a integração destes dispositivos em um único aparelho só foi possível devido ao
extraordinário aumento do poder de processamento do celular. O poder computacional de um
celular de hoje pode ser comparado ao de um computador antigo. Os celulares exigem um
processador de no mínimo 16MHz (CARNIEL; TEIXEIRA, 2005), para que possam executar
a KVM (Kilobyte Virtual Machine). Uma questão que surge neste momento, já que o celular
possui processador, memória e certa capacidade de armazenamento, seria como “aproveitar”
estes momentos de ociosidade do aparelho, quando está no bolso, por exemplo.
Nem sempre tem-se um computador por perto para fazer um teste em um software, ou
obter o resultado de um algoritmo, que em ambos os casos não exijam muitos recursos de
hardware, mas o celular, hoje em dia, já faz parte do nosso cotidiano, e quase sempre está ao
alcance. Em uma oportunidade como essa, o celular poderia fazer este teste, ou executar este
programa, não com o mesmo desempenho de um PC, porém pode-se obter o mesmo
resultado, já que o processamento é feito da mesma forma.
Mas, se a aplicação a ser testada necessitar de um poder de processamento maior que
aquele que o dispositivo em mãos pode alcançar, então pode-se tentar dividir as tarefas a
serem executadas entre os dispositivos que estiverem à disposição. Por exemplo: ocorre uma
interessante idéia, e cria-se um aplicativo, mas este requer recursos que o celular disponível,
por exemplo, não possui. Mas, um parceiro de trabalho, ou um amigo, está ao lado e possui
um celular, ou um PDA, que pode ser colocado em rede com o seu dispositivo. Por que não
dividir as tarefas a serem processadas pelos dispositivos, montando um pequeno cluster com
os celulares ou PDAs, podendo desta forma testar sua aplicação.
Porém, deve-se atentar para o fato de que a bateria de dispositivos móveis é bastante
limitada. Quando em uso contínuo, a bateria destes dispositivos têm, em média, uma duração
entre 3 ou 4 horas. Há pessoas que precisam constantemente do celular: como gerentes de
projetos, empresários ou corretores de imóveis, etc. Por exemplo, ao ficar em uma ligação
continuamente até que a bateria descarregue, o dispositivo não estará utilizando todo o seu

15
poder computacional, pois este não precisa usar todos seus recursos para manter um canal de
comunicação aberto. Mas para executar uma aplicação paralela, que exija controle de
memória, divisão de tarefas e reorganização das tarefas para a obtenção dos resultados, exige-
se muito mais recursos de hardware. Assim, também como na maioria dos jogos que
necessitam de todos os recursos do dispositivo simultaneamente, surge neste ponto a seguinte
questão: como aumentar o tempo de duração da carga de uma bateria até a próxima recarga.
Estes são alguns dos motivos que mostram como é interessante o estudo da
computação paralela para dispositivos embarcados, e também mostra a necessidade do estudo
do comportamento da bateria do dispositivo. Assim, este trabalho tem como objetivo
apresentar uma comparação do desempenho (medido através do tempo de execução) de
algoritmos em sistemas seqüências usando as linguagens C e Java, e do cálculo do número PI
em um sistema paralelo, implementado na linguagem MPICH2. Além disso, este trabalho faz
uma análise do impacto do consumo de energia nos dispositivos utilizados quando executa
esses algoritmos.
1.1 Motivação
Não existe uma comparação de desempenho visando as diferentes linguagens: C, Java
e MPICH2. O algoritmo Quicksort é referência na comunidade acadêmica.
E também, tentar mostrar uma outra forma de utilização do poder computacional
oferecido pelos dispositivos móveis. A maior parte do tempo, estes dispositivos ficam no
bolso, ou em lugar de fácil alcance, ociosos, desperdiçando seu poder computacional.
Partindo do ponto que é possível executar aplicativos nestes dispositivos, pois
possuem processador, memória e capacidade de armazenamento, é necessário
conhecer como se comporta a bateria desse dispositivo.
E como se comportaria esta bateria se estes dispositivos trabalhassem de forma
paralela.
Na fase de pesquisa nota-se que não há material referente ao assunto propriamente
dito, pois este campo de pesquisa está recente. Mas, como os artigos a seguir referem-se a
computação paralela e utilização de bibliotecas que implementam o MP (Message Passing),
ajudarão na melhor compreensão sobre sistemas distribuídos e computação concorrente.
No trabalho “Implementação e Configuração de um Aglomerado de Computadores
Pessoais com Linux”, RÚBIO (2004) montou um cluster com 4 nodos, onde neste foi
instalada a biblioteca MPICH. Como teste final utilizou um algoritmo que gera o valor do

16
número PI, ~3.14..., para constatar o funcionamento do cluster. O trabalho está bem
explicado, de forma que é, aparentemente, simples montar um cluster a partir deste trabalho.
Para este caso, o cluster obteve um tempo de resposta maior que o cálculo executado em uma
única máquina. Neste trabalho nota-se que este não funcionou conforme o esperado de um
cluster, pois a princípio espera-se um tempo de resposta menor. O autor mostra de forma bem
simplificada como montá-lo, e testa seu funcionamento com um algoritmo simples. Neste
trabalho já existem algumas informações de como utilizar os comandos da biblioteca MPICH
para a divisão de tarefas entre os nodos do cluster.
No artigo “Building a Beowulf System”, LINDHEIM (2005) mostra como montar um
cluster com 17 nodos, explicando de forma bastante completa como conFigurar os arquivos
do sistema operacional e todo o hardware e conjuntos de software necessário para
implementar o agrupamento. Este artigo teve como finalidade apenas montar um ambiente
onde a computação paralela e distribuída são possíveis. O autor mostra os detalhes de como
preparar o ambiente para a computação paralela facilitando assim a preparação das máquinas
que foram utilizadas nesta monografia.
No trabalho Macedo (2004) o autor utilizou o algoritmo mergesort, que utiliza a
mesma estratégia de funcionamento do quicksort, dividir para conquistar. Porém o mergesort
possui uma desvantagem, ele utiliza vetores auxiliares, levando a um maior consumo de
memória.
Em Macedo (2004) duas máquinas, uma com um processador Althon XP1800 de
1.6MHz e 256MB de RAM, e a segunda máquina com processador Althon 1.1MHz e 128MB
de RAM, foram colocados em cluster, o qual utiliza a biblioteca MPI, para coordenar os
processos.
Neste trabalho são comparados os resultados dos testes em uma única máquina e no
cluster, executando o algoritmo que gera o valor do PI e o mergesort. Os resultados exibiram
uma diminuição de 31,12% do tempo de resposta quando o algoritmo que gera o valor do PI
executa no cluster.
É visível que utilizar programação paralela na diminuição de tempo é eficaz na
maioria dos casos, mas há aplicativos que podem se mostrar bem menos eficazes quando
executam em um ambiente distribuído. É sempre bom analisar a aplicação antes de paralizá-
la.

17
1.2 Objetivos
1.2.1 Geral
O objetivo deste trabalho é realizar uma implementação e apresentar a respectiva
comparação do desempenho, com relação ao tempo de execução e consumo de energia, do
algoritmo Quicksort em um sistema seqüencial (implementado nas linguagens C e Java), e do
cálculo do número PI em um sistema paralelo (implementado utilizando a biblioteca MPICH).
1.2.2 Específicos
Mas para chegar a esta comparação, deve-se antes estudar como tornar possível a
computação paralela nos dispositivos a serem testados. Para isso deve-se:
a) Implementar o algoritmo Quicksort nas linguagens de programação C e Java,
para os testes em sistemas seqüenciais;
b) O estudo sobre sistemas distribuídos embarcados, que envolvem conceitos de
computação concorrente, para dar base teórica à implementação sobre
computação paralela;
c) Montar um cluster, de dois nodos, para testar o algoritmo do cálculo do
número PI na linguagem MPICH.
Além disso, este trabalho analisa o impacto do consumo de energia dos algoritmos
quando executam nessas plataformas. Além de poder estender-se a uma pesquisa para
verificar o comportamento de baterias de dispositivos móveis quando funcionam sob
computação paralela, neste caso notebooks e/ou PDAs.
Também são explicados os conceitos, utilizados neste trabalho, que envolvem o
assunto, na tentativa de conciliar teoria e prática para um entendimento mais simplificado do
projeto.
1.3 Metodologia
A metodologia de implementação deste trabalho foi basicamente pesquisa em fontes
bibliográficas como livros, artigos e materiais disponibilizados na internet. Estudo e
implementação das técnicas e recursos necessários para a configuração dos dispositivos a
serem utilizados. O fato de não estar familiarizado com as linguagens de programação podem
demandou certo tempo de estudo.

18
Para tornar possível a computação paralela com as linguagens de programação
definidas, também foi necessário estudar algumas bibliotecas de troca de mensagem, a saber,
MPI, JavaMPI, mpiJava e JPVM, para que houvesse familiarização com a programação
paralela e conhecer as diferenças entre estas.
1.4 Organização da Monografia
Este trabalho está organizado em 5 capítulos, a saber:
O capítulo 1 faz uma apresentação do assunto, definindo sua importância, e focando
principalmente nos objetivos e organização da monografia.
No capítulo 2 são definidos os principais conceitos que envolvem sistemas
distribuídos e os conceitos de computação paralela.
O capítulo 3 discorre sobre o assunto de clusters de computadores, sua importância e
diferentes arquiteturas, assim como a parte conceitual básica de sistemas móveis.
O capítulo 4 mostra a implementação do algoritmo quicksort nas diferentes linguagens
de programação tais como C, Java e MPICH2, partindo de uma breve análise de seu
funcionamento. Assim como os resultados obtidos da execução dos algoritmos nas diferentes
linguagens, tanto em uma plataforma tradicional seqüencial, como em um sistema paralelo,
em dispositivos móveis.
O capítulo 5 mostra as conclusões do trabalho e propostas para trabalhos futuros.

19
2 CONCEITOS DE ARQUITETURAS DE MÁQUINAS PARALELAS
De acordo com Michael Flynn (MACEDO, 2004) existem dois conceitos que definem
as diferentes arquiteturas de máquinas paralelas: o número de instruções executadas em
paralelo e o número de conjunto de dados tratados em paralelo. Seguem os quatro modelos
classificados (HENNESSY; PATTERSON, 2000):
1. Modelo SISD – Single Intruction Single Data (Uma única instrução, um único dado):
referente às máquinas Desktop e estações de trabalho, onde uma única seqüência de
instruções opera sobre uma única seqüência de dados, que representa o clássico
modelo de Von Neumann (DEMAC, 2007), ver Figura 2.1.
Figura 2.1 – Modelo SISD
2. Modelo SIMD – Single Instruction Multiple Data (Uma única instrução, múltiplos
dados): Este modelo corresponde ao processamento de vários dados sob o comando de
apenas uma instrução. É utilizado para resolver grandes problemas de engenharia e
ciência com dados estruturados e regulares, como vetores e matrizes (TANEMBAUM,
1999). O programa ainda segue uma organização seqüencial. Existe uma única
unidade de controle e diversas unidades funcionais. A esta classe pertencem os
processadores vetoriais e matriciais (DEMAC, 2007), ver Figura 2.2.
Figura 2.2 – Modelo SIMD
3. Modelo MISD – Multiple Instruction Single Data (Múltiplas instruções, um único
dado): neste caso, ver Figura 2.3, múltiplas unidades de controle executando
instruções distintas operam sobre o mesmo dado. Para esta classificação não há
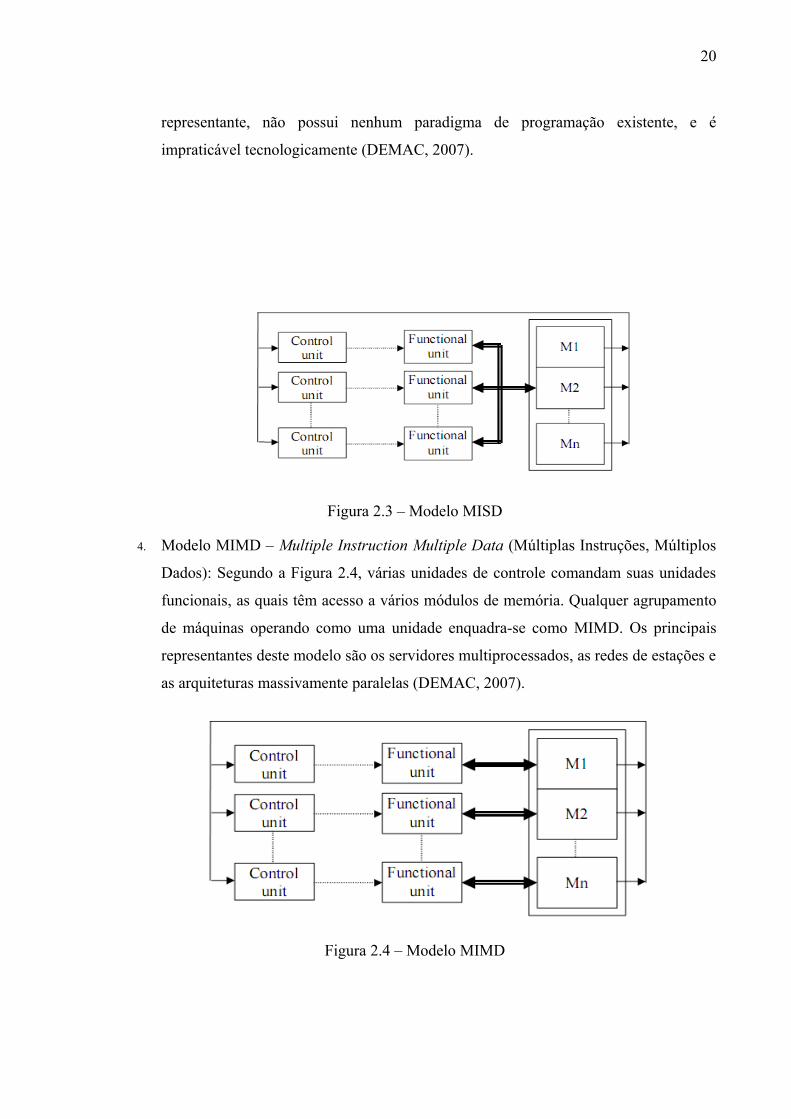
20
representante, não possui nenhum paradigma de programação existente, e é
impraticável tecnologicamente (DEMAC, 2007).
Figura 2.3 – Modelo MISD
4. Modelo MIMD – Multiple Instruction Multiple Data (Múltiplas Instruções, Múltiplos
Dados): Segundo a Figura 2.4, várias unidades de controle comandam suas unidades
funcionais, as quais têm acesso a vários módulos de memória. Qualquer agrupamento
de máquinas operando como uma unidade enquadra-se como MIMD. Os principais
representantes deste modelo são os servidores multiprocessados, as redes de estações e
as arquiteturas massivamente paralelas (DEMAC, 2007).
Figura 2.4 – Modelo MIMD

21
2.1 Computação Paralelo/Distribuída
Antes de explicar os conceitos de computação paralela e distribuída, deve-se explicar
o conceito de concorrência.
Dois eventos são ditos concorrentes quando eles ocorrem no mesmo intervalo de
tempo (HUGHES, 2004). Ou seja, quando duas ou mais tarefas são executadas no mesmo
intervalo de tempo, então elas estão executando concorrentemente. Dizer que duas tarefas
ocorrem sobre o mesmo intervalo de tempo é diferente de dizer que elas ocorrem no
mesmo instante de tempo.
2.1.1 Computação Paralela
O paralelismo é caracterizado por atribuir um trabalho a um programa que tem dois ou
mais processadores dentro de um único computador físico ou virtual. A Figura 2.5 mostra a
arquitetura de uma aplicação paralela. É possível visualizar neta que o programa é dividido
em três tarefas distintas e cada tarefa é executada em processadores diferentes.
Figura 2.5 – Típica arquitetura paralela
O programa que realiza paralelismo pode executar na mesma máquina física ou
virtual. O paralelismo pode dividir o programa em processos ou threads. Um processo é um
programa em execução acompanhado dos valores atuais do contador de programa, dos
registradores e das variáveis (TANEMBAUM, 2006). O thread é como um processo mais
leve, pois, possi algumas propriedades dos processos.
Em suma, os programas projetados para executar paralelamente são geralmente mais
rápidos que os seqüenciais. A computação paralela é geralmente implementada com a
utilização de bibliotecas como, por exemplo, o PVM (Parallel Virtual Machine), MPI –

22
(Message Passing Interface), JavaMPI (Java Message Passing Interface), mpiJava (Message
passing interface Java), JPVM (Java Parallel Virtual Machine), etc. O funcionamento dessas
bibliotecas são explicados mais a frente.
Os programas paralelos visam a execução de diversas tarefas simultaneamente, e
geralmente no mesmo instante. A programação paralela é utilizada principalmente nas áreas
científicas, matemáticas e de inteligência artificial (TANEMBAUM, 2006).
2.1.2 Computação Distribuída
Programação distribuída atribui trabalho a um programa que tem 2 ou mais processos,
sendo que estes processos podem ou não ser executados no mesmo computador (HUGHES,
2004). As diferentes partes desse programa executam em diferentes computadores,
conectados por alguma rede. A Figura 2.6 mostra uma arquitetura distribuída na qual agora
pode-se perceber a diferença entre computação paralela e distribuída. Nesta arquitetura
existem dois computadores conectados em rede, e não apenas uma máquina física ou virtual
como explicado anteriormente.
Figura 2.6 – Típica arquitetura distribuída.
A principal vantagem do programa distribuído é que ele tira vantagens de programas
da internet (HUGHES, 2004). Desta forma pode-se dizer que a programação distribuída
necessita de uma rede de computadores para funcionar. Isso não quer dizer que na
programação paralela não haja a necessidade de uma rede de computadores, e sim, que a
programação distribuída divide seu trabalho em processos e os lança pela rede, geralmente na
internet, ou em uma rede local, sem a necessidade que usuário saiba em que máquina o
processo será executado. Percebe-se então que, não é importante, ou pelo menos vital, a
velocidade do processamento, e sim a execução do processo. A computação distribuída,

23
algumas vezes, implementa o paralelismo. Uma biblioteca que viabiliza a computação
distribuída é a MPI (Message Passing Interface), que é explicada mais a frente.
2.2 MPI – Message Passing Interface
O MPI é um padrão especificado para troca de mensagens (HUGHES, 2004). O MPI
foi criado com os seguintes objetivos (GROPP; LUSK, 2007):
O MPI deveria ser uma biblioteca para escrever aplicativos de programas, e não um
sistema operacional distribuído;
Não daria suporte a thread-safe, ou thread segura, mas em sua especificação está
descrito que é possível implementar esse recurso. Isto implica que pode não haver uma
noção de um buffer “atual”, mensagem, código de erro e assim por diante. Como os
nodos em uma rede se tornam multiprocessadores simétricos, o conceito de thread
segura torna-se muito importante em um ambiente de rede heterogêneo;
O MPI seria capaz de permitir alta performance em sistemas de HP (Hihg
Performance) de alto desempenho. Escalabilidade combinada com precisão, para
operações coletivas que requerem que os grupos sejam estáticos;
Seria modular, para acelerar o desenvolvimento de bibliotecas paralelas portáveis;
Seria extensível, para reunir características necessárias para o desenvolvimento de
aplicações;
Deveria suportar computação heterogênea;
Deveria requerer comportamento bem definido (evitando implementações de
comportamento específico).
As especificações desta interface de programação foram definidas para programas
provenientes das linguagens C, C++ e Fortran (CALIFÓRNIA, 2007). O MPI foi projetado
tanto para computação massivamente paralela como para a criação de clusters em
computadores comuns. Entenda-se por computação massivamente paralela a comunicação e
troca de mensagens em alta escala entre as máquinas do sistema, troca de mensagens acima de
milhões por segundo. O MPI também dá suporte a programação paralela (HUGHES, 2004).
Diversas razões podem ser indicadas para a utilização da biblioteca MPI, como
(CALIFÓRNIA, 2007):
Sua padronização – o padrão MPI é a biblioteca de troca de mensagens padrão
baseada no consenso do Fórum MPI, no qual mais de 40 organizações participantes,

24
incluindo vendedores, pesquisadores, desenvolvedores de bibliotecas de software e
usuários. Além de ser suportada em todas as plataformas de PCs do mercado;
Portabilidade – não há a necessidade de modificar o código fonte quando for utilizá-lo
em outra plataforma;
Sua disponibilidade – uma grande gama de implementações estão disponíveis, tanto
implementações proprietárias como de domínio publico.
Há um nível de segurança bastante grande onde é possível diferenciar as mensagens
das bibliotecas daquelas mensagens usadas pelos usuários. Por possuir uma maior segurança o
MPI é mais utilizado em programação distribuída. O MPI foi projetado para que fosse
portável tanto em arquiteturas SIMD como MIMD (CALIFÓRNIA, 2007).
2.3 PVM – Parallel Virtual Machine
O PVM visa permitir que uma rede heterogênea de computadores de todos os tipos de
arquiteturas sejam programadas como se fossem apenas uma única "Máquina Paralela
Virtual". O objetivo do PVM é permitir que os computadores possam fazer uso da
computação paralela. Assim como o MPI, o PVM utiliza o paradigma de troca de mensagens
como forma de comunicação entre as máquinas. A biblioteca PVM suporta (PINA, 1998):
Máquinas, redes e aplicações heterogêneas, ou seja, arquiteturas heterogêneas –
suporta em uma mesma rede todo o tipo de máquina, desde os modelos já defasados
assim como máquinas MPP (programação massivamente paralela). Porém, problemas
surgem com toda essa flexibilidade como modelos de programação diferentes, pois,
cada máquina possui o seu; uma mesma arquitetura pode utilizar formatos binários
diferentes; e há a necessidade de se compilar as tarefas em cada máquina;
Suporte ao modelo de troca de mensagens – assim como no MPI, o PVM utiliza a
comunicação entre os nodos sob o modelo de troca de mensagens;
Computação baseada em processos – cada processo é dividido em diversas tasks
(tarefas), e cada tarefa é enviada a um nó diferente, se houverem máquinas disponíveis
para isso, da máquina virtual;
Configuração dinâmica de hosts (processadores podem ser adicionados ou removidos
em tempo de execução).
O PVM é um ambiente mais fácil e flexível de configuração para programação
paralela, que também permite a interação entre sistemas operacionais diferentes (HUGHES,

25
2004). O PVM é uma biblioteca que pode ser usada com o C, C++ e Fortran, para
programação. A biblioteca PVM é muito utilizada em clusters de alta performance quando é
exigido grande poder computacional, como por exemplo em cálculos de previsão do tempo,
softwares de simulação, e em diversas áreas onde é necessário grande poder de
processamento.
Segundo Pina (1998), o PVM tem como seus objetivos principais:
Configuração personalizada – cada tarefa pode ser endereçada a um grupo diferente de
máquinas, definidas pelo mantenedor da máquina virtual;
Transparência – como uma máquina virtual é criada, os aplicativos enxergam o
conjunto do hardware como se fosse uma única máquina. Mas, também é possível
separar os aplicativos por um grupo específicos de máquinas;
Heterogeneidade – como dito, permitir o trabalho entre máquinas de arquiteturas
diferentes e topologias de redes diferentes, para que possam trabalhar como uma única
máquina.
Porém, da uma desvantagem que se pode mencionar é a segurança. A biblioteca PVM
pode ser instala por qualquer usuário com nome válido que acesse o sistema (PINA, 1998).
Desta forma não seria muito difícil algum usuário utilizar o processamento das máquinas de
uma rede, sem que os usuários desta soubessem.
Comparando PVM e MPI
A diferença mais marcante inicialmente é que na biblioteca MPI não há a percepção de
uma máquina virtual, como no PVM. Dessa forma a divisão das tarefas deve ser feita de
forma mais explicita, pelo próprio programador. No PVM as máquinas podem ser vistas
como uma única máquina virtual, implementando assim a transparência.
O controle do processamento feito pelo PVM é bem maior em relação ao MPI, pois
pode-se iniciar, interromper e controlar processos em tempo de execução, ao passo que no
MPI apenas é permitido o controle de grupos de tarefas. Há também um critério que pode ser
levado em consideração, que é o de interoperabilidade entre sistemas diferentes. Neste quesito
o PVM supera o MPI, pois permite que sistemas Unix e NT sejam vistos como uma só
máquina (FREITAS, 2007).
No quesito segurança, o MPI é superior, podendo citar, por exemplo, que este foi
projetado de maneira a estabelecer diferencias entre mensagens da biblioteca e de usuário,
impedindo que mensagens de usuários interfiram nos resultados.

26
O PVM foi criado com a intenção de que fosse de simples programação e também que
tornasse possível a computação entre máquinas de arquiteturas diferentes e também permitisse
a computação de máquinas que fazem parte de redes de topologias diferentes. É um padrão
mais antigo, e mais difundido também. O PVM foi lançado no verão de 1989 (PINA, 1998),
e foi bem aceito pelos usuários, dessa forma difundindo-se rapidamente. O padrão MPI foi
criado para ser uma biblioteca de troca de mensagens mais robusta, e com maior nível de
segurança que o PVM. Porém, o MPI é um pouco mais complexo em termos de utilização, o
que acaba se tornando certo entrave no momento de escolha em um projeto. O próprio fato de
ter que aprender um outro padrão a ser utilizado desestimula alguns usuário a testar essa
biblioteca de troca de mensagens.
2.4 Bibliotecas Paralelas com Java
2.4.1 JavaMPI
O JavaMPI é o resultado obtido da primeira tentativa de combinar Java com o padrão
MPI-1, utilizando o JDK1.0.2 (MORIN, 2000). O JavaMPI é um conjunto de funções que
provê acesso a uma implementação nativa do MPI existente, como o MPICH e o LAM,
usando o NMI (Native Method Interface), disponibilizado pelo JDK1.0.2. Os programadores
têm acesso a outras funções e bibliotecas desenvolvidas em outras linguagens de programação
por meio do NMI, como por exemplo C ou Fortran (MORIN, 2000). O encapsulamento de
funções foi gerado com o JCI (Java-to-C Interface), um conjunto para tornar automático o
desenvolvimento de funções para métodos nativos do Java.
As duas principais classes do JavaMPI são a MPIconst e a MPI. A classe MPIconst
contém as declarações de todas as constantes MPI e o MPI_Init(), que inicializa o ambiente
MPI. A classe MPI contém todas as outras funções. A combinação do MPI com a linguagem
de programação C inclui diversas funções que requerem que argumentos sejam passados por
referência, para que se obtenha o retorno de informação. O Java não possui suporte a chamada
por referência (MORIN, 2000). Entretanto, quando se trabalha com objetos é necessário
chamar uma função MPI com um parâmetro de chamada, passado por referência. Devido a
este fato, o desenvolvimento de uma aplicação é dificultado de duas formas: o objeto precisa
ser instanciado com um construtor new() antes de ser usado na chamada de uma função MPI,
e o valor da variável é acessada através de um campo, como em rank.val (MORIN, 2000).
Em Java não há suporte para trabalho com ponteiros, desta forma os elementos de um array1
1 Em programação de computadores, um array é também conhecido como vetor ou lista (para arrays uni-dimensionais) ou matriz (para arrays bi-dimensionais), e é uma das mais simples estruturas de dados.

27
não podem ser passados à funções como argumentos, assim como em C ou Fortran. O
programador pode usar uma função do JCI, JCI.section(arr,i) (MORIN, 2000), para passar o
iésimo elemento do array arr. O Java não da suporte a passagem por parâmetro de parte de um
array . Se o programador desejar enviar parte de um array a outro processo, a aplicação deve
criar primeiro um dado tipado derivado do MPI, e depois enviar este dado derivado MPI.
A junção do Java com o MPI, como é proposta pelo JavaMPI, altera
significativamente a estrutura do programa de uma aplicação MPI. Como resultado, portar
uma aplicação MPI existente requer uma modificação significativa da estrutura do código
original.
O grande problema visto neste padrão, que é uma combinação do Java com o MPI, é
que o Java perde sua portabilidade. A linguagem Java foi criada com o intuito de ser
multiplataforma. Analisando desta forma, um programa criado seguindo a idéia de combinar
recursos do Java com o MPI, o Java perderia seu principal propósito, que é a portabilidade do
código.
Basta apenas analisar que para que um aplicativo criado no padrão JavaMPI, seria
necessário que a biblioteca que implementa o MPI, MPICH ou LAM, por exemplo, e o JDK
estivessem instalados simultaneamente, o que quebra o principal princípio do Java.
2.4.2 mpiJava
O mpiJava permite o acesso a implementações nativa MPI por meio do Java Native
Interface (MORIN, 2000). A aproximação feita na implementação mpiJava definiu uma
combinação que permite seu uso na linguagem Java nativa. O mpiJava combina o Java tão
próximo quanto possível à estrutura do C++, como definida no padrão MPI-2. A hierarquia de
classes no mpiJava é organizada como no C++, e está definida na especificação MPI-2, e suas
principais classes são: MPI, Group, Comm, Datatype, Status e Request (MORIN, 2000). A
classe MPI é responsável pela inicialização e constantes globais.
A classe Comm define todo o método de comunicação do MPI como enviar e receber.
O mpiJava espera a passagem de um objeto como parâmetro. Este objeto é um array de um ou
mais elementos de tipo primitivo. Devido ao fato do Java não suportar o trabalho com
ponteiro, todo o método de comunicação definido na mpiJava leva um parâmetro adicional
offset, que é usado para especificar o elemento inicial em um array (MORIN, 2000).
No que se refere a programação, o mpiJava prove um suporte melhor que o JavaMPI,
podendo utilizar diversos padrões MPI como base (SCHEPKE, 2005).

28
2.4.3 JPVM
A biblioteca PVM (Parallel Virtual Machine) possibilita a computação paralela de
forma simples (FERRARI, 1999). Permite que computadores com arquiteturas diferentes e até
mesmo com sistemas operacionais diferentes, possam ser colocados em rede para que formem
uma única máquina virtual. Mas, há diversas implicações em se permitir a utilização de
arquiteturas ou sistemas diferentes como performance, e principalmente portabilidade do
código.
O JPVM surgiu na tentativa de resolver estes problemas. Foi então criada uma API
totalmente implementada em Java, que tem como base a biblioteca PVM, que usa o padrão de
troca de mensagem. Desta forma o JPVM possui um suporte à programação paralela de forma
mais completa que o próprio PVM, pois combina os recursos computacionais da linguagem
Java e da biblioteca PVM. O JPVM é uma combinação de fácil programação em Java com o
suporte ao paralelismo do PVM (FERRARI, 1999).
Se apenas fosse feita uma combinação do padrão PVM com o Java não seria ruim. Um
exemplo disso seria a biblioteca JavaPVM. O JavaPVM utiliza funcionalidades de métodos
nativos permitindo aos programas Java acessar os padrões da biblioteca PVM. A razão de não
se fazer isso no JPVM é simples, a portabilidade do código (FERRARI, 1999).
A utilização de métodos nativos restringe as tarefas derivadas da divisão dos processos
a executarem apenas em sistemas que possuem as duas plataformas simultaneamente, o Java e
o PVM. A principal finalidade de criação desta API é permitir que diferentes arquiteturas de
computador possam trabalhar com a computação paralela utilizando o ambiente Java.
2.5 Considerações Finais do Capítulo
Neste capítulo foram vistas as definições das diferentes arquiteturas de computadores,
e a quais sistemas computacionais se referem, seqüenciais ou paralelos; também foram
discutidos os conceitos de Programação Paralelo/Distribuída, e suas diferenças. Também
foram citadas, e brevemente explicadas, algumas das bibliotecas que permitem um ambiente
de programação paralelo e/ou distribuído ao programador. Todos os conceitos estudados neste
capítulo formam uma base de conhecimento necessário para que se inicie um estudo sobre
clusters de computadores. A definição de cluster e outros conceitos importantes que
envolvem este sistema computacional são explicados no próximo capítulo.

29
3 CLUSTERS DE COMPUTADORES
A palavra cluster vem do inglês e significa grupo. Com a necessidade de grande poder
de processamento, e poucos recursos para investir, uma alternativa torna-se a grande salvação
para pesquisadores ou empresas com poucos recursos para investimento: os clusters.
Os clusters são os agrupamentos de computadores comuns, desktop ou mesmo os já
ultrapassados, para a realização de tarefas que um único computador não conseguiria realizar.
Porém, existem supercomputadores, que são dotados de vários processadores, capazes de
realizar diversas tarefas simultaneamente sem a necessidade de dividir tarefas com outros
computadores. Mas, a grande vantagem do cluster em relação aos supercomputadores é o
custo.
Um supercomputador chega a custar milhões de dólares, enquanto um cluster com
poder de processamento semelhante, ou talvez melhor, dependendo de como for programado,
geralmente custa muito menos, justamente por usar computadores comuns e não
computadores de grande porte. Um exemplo clássico é o primeiro cluster já montado, por
Donald Becker e Thomas Sterling, para a NASA, que possuía 16 processadores 486DX4, e
custava 10% do preço de um supercomputador da época com quase o mesmo poder de
processamento (MERKEY, 2008). Outro exemplo de cluster é o Avalon composto de 140
máquinas Alpha 533 MHz, localizado no Laboratório Nacional de Los Alamos, nos Estados
Unidos (MANIKA, 2008). No fim de 1993, os pesquisadores Donald Becker e Thomas
Sterling começaram a esboçar um projeto que tinha como objetivo interligar máquinas de
menor poder de processamento para que juntas pudessem realizar tarefas que apenas um
supercomputador era capaz de fazer (MERKEY, 2008).
Outros fatores que contribuem para o aumento das pesquisas nesta área são a
necessidade e a dependência dos sistemas computadorizados serem imensuráveis. A prestação
de serviços de redes, como servidores proxies, DNSs, de arquivos, banco de dados, etc., são
simplesmente indispensáveis. Estes são alguns dos serviços básicos, críticos e indispensáveis
para o bom funcionamento de uma rede, e que não podem parar.
Estes serviços são indispensáveis mesmo para pequenas empresas, com 5 ou 6
estações de trabalho. Este se torna também importante em uma grande empresa com centenas
de micros em uma rede, ou um grande portal web, sites de vendas online e serviços de e-mail,
são outros exemplos que devem permanecer ativos sempre. Neste momento, a qualidade na
prestação de serviço é o assunto chave. Tentar manter esses serviços sempre ativos é a
intenção de todos que dependem destes. Com base nestas informações, os pequenos

30
escritórios, ou grandes empresas, tentam encontrar uma forma de manter seus serviços o
máximo de tempo possível ainda em funcionamento. Uma possível solução para este
problema também seria montar um cluster.
Mas o fator marcante para o desenvolvimento dos clusters é a grande necessidade por
máquinas mais poderosas, e pouco poder aquisitivo, o que torna o estudo da computação
paralelo-distribuída essencial para pequenas e médias empresas prestadoras de serviços web,
por exemplo, que recebem solicitações, em alguns casos do mundo inteiro, simultaneamente,
e devem permanecer no ar em tempo integral, e respondendo às solicitações em tempo
aceitável.
Cada computador de um cluster é denominado nó ou nodo. Todos devem ser
interconectados, de maneira a formarem uma rede. Essa rede precisa ser criada de uma forma
que permita o acréscimo ou a retirada de um nó em casos de defeitos por exemplo, mas sem
interromper o seu funcionamento.
3.1 Funcionamento e tipo de Clusters
No inicio o funcionamento é simples. Existe um servidor que divide as tarefas em
partes independentes, em seguida distribuí estas tarefas entre os clientes que são os
computadores que fazem parte do cluster. As tarefas são processadas e então os resultados são
enviados para o servidor. Esse processo necessita de uma biblioteca para troca de mensagens
que deve conter um conjunto de funções para executar o funcionamento em todas as máquinas
do cluster e cabos para conexão via rede dos diversos computadores. O servidor distribui o
processamento para os clientes. As placas de rede, switchs e cabos devem ter capacidade para
transferir os dados do servidor para os clientes com maior rapidez e eficiência. Cada
computador recebe as mensagens e um conjunto de dados a serem processados e seus
resultados são enviados para o servidor.
São diferentes os tipos de estruturas utilizadas para implementar o processamento do
cluster: Como o Beowulf (LINDHEIM, 2005), uma tecnologia de cluster que agrupa
computadores executando GNU/Linux para formar um supercomputador virtual via
processamento paralelo-distribuído. Esse tipo de cluster, voltado à computação paralela, foi
fundamentado em 1994, pela NASA, com a finalidade de processar as informações espaciais
que a entidade recolhia. Existe um servidor responsável por controlar todo o cluster,
principalmente quanto a distribuição de tarefas e processamento, pode haver mais de um
servidor, dedicado a tarefas específicas, como monitoração de falhas. Existem alguns outros
requisitos para se ter esse tipo de cluster como o sistema operacional e a necessidade de se ter

31
as bibliotecas para Parallel Virtual Machine (PVM) ou para Message Passing Interface
(MPI).
O Beowulf é usado na ciência, engenharia e finanças para atuarem em projetos de
desdobramento de proteínas, dinâmica de fluídos, redes neurais, analise genética, estatística,
economia, astrofísica e etc. (PITANGA, 2003). O Beowulf é um projeto bem sucedido e a
opção feita por seus criadores de usar hardware popular e software aberto tornou-o fácil de
copiar e modificar. Um exemplo disso é a grande quantidade de sistemas construídos desse
tipo em diversas universidades, empresas americanas e européias e até residenciais. Assim, o
que era um experimento tornou-se um sistema de uso prático que continua sendo aperfeiçoado
constantemente. A Figura 3.1 exibe a arquitetura de um cluster Beowulf.
Existem vários tipos de cluster. Segundo Pitanga (2003) um que se destaca é o cluster
de alta disponibilidade, que quer dizer o tempo em que determinado sistema permanece ativo
e em condições de uso, são sistemas que não param de funcionar e costumam ter meios
eficientes de proteção e de detecção de falhas. Para processar em um cluster de alta
disponibilidade, uma aplicação deve satisfazer alguns requisitos: deve haver uma forma mais
fácil de iniciar, parar, interromper e verificar o estado da aplicação. A aplicação deve conter
uma interface por linha de comando e deve ser capaz de utilizar armazenamento
compartilhado. O principal é que a aplicação deve salvar a maior quantidade possível de
estados do seu armazenamento compartilhado. Um cluster de Alta Disponibilidade tem como
objetivo manter a disponibilidade dos serviços prestados por um sistema computacional
fazendo uma cópia de serviços e servidores, por meio da menor quantidade de hardware e
reconfiguração de software.
Figura 3.1 – Arquitetura de um cluster Beowulf

32
Segue uma breve classificação dos diferente tipos de clusters (PITANGA, 2003):
O Cluster de Alto Desempenho (High Performance - HP), conhecido como cluster de
alta performance, funciona permitindo que ocorra uma grande carga de processamento
com um volume alto de gigaflops em computadores comuns e utilizando sistema
operacional gratuito, o que diminui seu custo.
O Cluster de Balanceamento de Carga (Load Balance - LB) é o controle e execução
da distribuição equilibrada de processamento às máquinas do cluster. É usado na web,
em servidores de e-mail, comércio eletrônico, em provedores de acesso a internet que
necessitam resolver diferenças de carga provenientes de múltiplas requisições de
entrada em tempo real, em sistemas de lojas, entre outros. Neste cluster é necessário
que haja monitoração constante da comunicação e mecanismos de diminuição de
excesso, senão qualquer falha pode interromper o funcionamento do cluster. Existem
três modelos básicos de algoritmos para balanceamento: o Least Connections que é
um método cuja função é redirecionar as requisições para o servidor baseado no menor
número de requisições/conexões: O Round Robin é um método que usa a técnica de
sempre direcionar as requisições para o próximo servidor disponível de uma forma
circular: O Weighted Fair é um método que usa a técnica que dirige os pedidos para
os servidores baseados na carga de requisições de cada um e na capacidade de resposta
dos mesmos, como por exemplo aquele que trabalha mais rápido é aquele que recebe
mais pedidos.
E o Cluster Combo, Balanceamento de carga e Alta Disponibilidade, que é a
combinação de cluster de alta disponibilidade e do tipo balanceamento de carga. Esta
solução prove alta performance aliada à possibilidade da não existência de paradas
críticas.
Outro tipo de estrutura é o MOSIX (Multicomputer Operating System for Unix) que é
um conjunto de ferramentas de cluster para Linux com implementação transparente, voltado
ao tipo balanceamento de Carga. Por ser um sistema operacional voltado para sistemas
multicomputadores, este não há a necessidade de aplicativos ou recursos de software inerentes
a clusters comuns, como, por exemplo, bibliotecas de troca de mensagens, para que sejam
feitas as divisões de tarefas, o próprio MOSIX faz essa divisão de forma transparente
(BARAK; SHILOH, 2007). O MOSIX é eficiente na tarefa de distribuição dinâmica de

33
processamento entre os computadores do cluster. O MOSIX precisa de recompilação do
kernel, com sua inclusão ou instalação de novo kernel.
Assim, percebe-se a importância dos clusters de alta disponibilidade e balanceamento
de carga. Estas máquinas influem diretamente na qualidade dos serviços computacionais
prestados pela empresa e na garantia de prestação de serviços dos mesmos. Este sistema
computacional tem a função de manter-se ativo com base na eliminação dos pontos únicos de
falha, onde o primeiro ponto único de falho a ser visto é uma única máquina para a realização
de um serviço. De modo que se esta máquina precisar realizar uma parada, para manutenção,
por exemplo, o serviço deixaria de ser prestado.
Porém, existem diversos aspectos relevantes ao funcionamento destes agrupamentos
de computadores, que são o assunto do próximo tópico.
3.2 Alta Disponibilidade e Tolerância a Falhas
3.2.1 Alta disponibilidade
Na primeira parte deste capítulo foi dito qual a principal finalidade de sistemas de alta
disponibilidade, que é a de tentar manter o sistema sempre ativo. Neste capítulo discorreremos
sobre outros conceitos que envolvem alta disponibilidade, e também Tolerância a Falhas.
O termo High Availability – HA (Alta Disponibilidade) está diretamente ligado a
crescente dependência dos sistemas computacionais. Com o avanço das atividades que
necessitam desses sistemas computacionais, é cada vez maior o transtorno causado pela
eventual falha dos mesmos. Dos supermercados até os sistemas bancários, os computadores
têm papel fundamental. Mas não somente em tais tipos de serviços, mas, principalmente, em
empresas prestadoras de serviços computacionais, como o comércio eletrônico (e-business),
notícias, sites web, etc.
A Disponibilidade de um sistema computacional é a probabilidade de que este sistema
esteja funcionando e pronto para uso em um determinado instante de tempo t. Esta
disponibilidade pode ser enquadrada em três classes, de acordo com a faixa de valores desta
probabilidade. As três classes são: Disponibilidade Básica, Alta Disponibilidade e
Disponibilidade Contínua (SZTOLTZ; TEIXEIRA; RIBEIRO, 2003):
Disponibilidade Básica: é aquela encontrada em máquinas comuns, sem nenhum
mecanismo especial, em software ou hardware, que vise de alguma forma mascarar as
eventuais falhas destas máquinas. Costuma-se dizer que máquinas nesta classe
apresentam uma disponibilidade de 99% a 99,9%. Isto equivale a dizer que em um ano

34
de operação a máquina pode ficar indisponível por um período de 9 horas a quatro
dias. Estes dados são empíricos e os tempos não levam em consideração a
possibilidade de paradas planejadas, porém, na literatura da área são aceitas como o
senso comum.
Alta Disponibilidade: adicionando-se mecanismos especializados de detecção,
recuperação e mascaramento de falhas, pode-se aumentar a disponibilidade do
sistema, de forma que este venha a se enquadrar na classe de Alta Disponibilidade.
Nesta classe as máquinas tipicamente apresentam disponibilidade na faixa de 99,99%
a 99,999%, podendo ficar indisponíveis por um período de pouco mais de 5 minutos
até uma hora em um ano de operação. Aqui se encaixam grande parte das aplicações
comerciais de Alta Disponibilidade, como centrais telefônicas.
Disponibilidade Contínua: neste caso obtém-se uma disponibilidade cada vez mais
próxima de 100%, diminuindo o tempo de inoperância do sistema de forma que este
venha a ser desprezível ou mesmo inexistente. Chega-se então na Disponibilidade
Contínua, o que significa que todas as paradas planejadas e não planejadas são
mascaradas, e o sistema está sempre disponível.
Existem fatores, tanto previsíveis como imprevisíveis, que fazem recorrer à sistemas
redundantes, como os clusters HA. Tanto problemas em nível de hardware, como um defeito
na placa de rede, e também problemas que não estão relacionados à empresa ou às próprias
máquinas do sistema, mas sim a um mau fornecimento de energia, por exemplo. Segue então
uma breve descrição dos fatores que nos levam a recorrer a estes sistemas redundantes
(SZTOLTZ; TEIXEIRA; RIBEIRO, 2003):
Falha: Uma falha acontece no universo físico, ou seja, no nível mais baixo do
hardware. Uma flutuação da fonte de alimentação, por exemplo, é uma falha. Uma
interferência eletromagnética também. Estes são dois eventos indesejados, que
acontecem no universo físico e afetam o funcionamento de um computador ou de
partes dele.
Erro: A ocorrência de uma falha pode acarretar um erro, que é a representação da
falha no universo informacional. Um computador trabalha com bits, cada um podendo
conter 0 ou 1. Uma falha pode fazer com que um (ou mais de um) bit troque de valor
inesperadamente, o que certamente afetará o funcionamento normal do computador.
Uma falha, portanto, pode gerar um erro em alguma informação.
Defeito: Já esta informação errônea, se não for percebida e tratada, poderá gerar o que

35
se conhece por defeito. O sistema simplesmente trava, mostra uma mensagem de erro,
ou ainda perde os dados do usuário sem maiores avisos. Isto é percebido no universo
do usuário.
Uma falha no universo físico pode causar um erro no universo informacional, que por
sua vez pode causar um defeito percebido no universo do usuário. A Tolerância a Falhas visa
exatamente acabar com as falhas, ou tratá-las enquanto ainda são erros. Já a Alta
Disponibilidade permite que máquinas travem ou errem, contanto que exista outra máquina
para assumir seu lugar, e continuar o oferecimento do serviço prestado.
Para que uma máquina assuma o lugar de outra, é necessário que descubra de alguma
forma que a outra falhou. Isso é feito através de testes periódicos, cujo período deve ser
configurável, nos quais a máquina secundária testa não apenas se a outra está ativa, mas
também fornecendo respostas adequadas a requisições de serviço. Um mecanismo de
detecção equivocado pode causar instabilidade no sistema. Por serem periódicos, nota-se que
existe um intervalo de tempo durante o qual o sistema pode estar indisponível sem que a outra
máquina o perceba.
Portanto, como uma falha pode levar a um erro, e este a um defeito, estes sistemas são
conFigurados de forma tal que possam ser tolerantes a estas eventuais falhas.
3.2.2 Tolerância à Falhas
Uma definição simples de um sistema Tolerante a Falhas, é um sistema que continue
funcionando, de forma confiável, mesmo em decorrência de possíveis falhas. Geralmente,
parte destas falhas é prevista, e tratada diretamente no algoritmo por meio de exceções. Estas
falhas também podem ser tratadas por meio de redundância de hardware, ou software e, por
replicação de disco, com o intuito principal de tornar a falha transparente ao usuário. Este
conceito se assemelha muito à Alta Disponibilidade.
3.3 Sistemas Embarcados Móveis
Embedded system – Sistema Embarcado é um sistema computacional microprocessado
que tem a característica de ser dedicado ao dispositivo que controla. Estes sistemas são
projetados com o intuito que realizem tarefas pré-definidas, geralmente com requisitos bem
definidos, diferentes de computadores pessoais, com o intuito de otimizar o projeto
diminuindo o tamanho, seus recursos e também os custos. A Figura 3.2 mostra um exemplo

36
de sistema embarcado, caracterizado por ser um hardware limitado e de funcionalidades e
comportamento bem definidos.
Figura 3.2 – Exemplo de sistema embarcado (MORIMOTO, 2007)
O high-end destes sistemas são os celulares, os mais modernos, e os PDAs (Personal
digital assistants), assistentes pessoais digitais, devido à característica limitada de seu
hardware, porém os softwares que gerenciam estes dispositivos são mais flexíveis.
3.4 Computação Móvel
Computação móvel pode ser definida como um novo modelo computacional que
permite aos usuários deste ambiente um acesso transparente a serviços sem se importar com
sua localização. A idéia da computação móvel é ter acesso à alguma informação de forma
constante, e até mesmo em movimento. Porém, diversos aspectos e implicações estão
envolvidos neste paradigma. A computação móvel já é uma realidade, mas ainda não como se
almeja.
3.4.1 Dispositivos Participantes da Comutação móvel
Para que um dispositivo seja caracterizado como móvel ele deve possuir uma
capacidade de processamento (proveniente de um sistema embarcado), trocar informações via
rede e ser facilmente transportado pelo usuário (FIGUEIREDO; NAKAMURA, 2003). Estes
dispositivos devem ser de tamanho reduzido, sem que haja a necessidade de utilização de
cabos para conectar-se a uma rede de dados ou rede elétrica.
Assim seguem exemplos de dispositivos que são enquadrados nesta classificação
(FIGUEIREDO; NAKAMURA, 2003):
Laptops (também chamado de notebook) – é um computador portátil, leve, com a
finalidade de poder ser transportado e utilizado em diversos lugares com facilidade.
Geralmente um laptop contém tela de LCD, teclado, mouse (geralmente um touchpad,

37
área onde se desliza o dedo), uma unidade de disco rígido, além dos dispositivos de
entrada e saída (E/S) padrão;
Palmtop – é um computador que cabe na palma da mão. O nome palm serve para
diferenciá-lo de laptop (que cabe no colo) e de desktop (em cima da mesa). Foi
desenvolvido para trabalhos específicos. O palmtop não tem teclado nem mouse, uma
caneta especial os substitui;
Personal digital assistants (PDAs ou Handhelds) – são o Assistente Pessoal Digital, é
um computador de dimensões reduzidas, com mais poder de processamento,
exercendo as funções de agenda e sistema de informação de escritório, com
possibilidade de se conectar com um PC desktop e uma rede de dados sem fios
wireless, 802.11, com suporte a bluetooth, por exemplo;
Celular: estes dispositivos logo que lançados tinham a finalidade apenas para
conversação por voz. Com o grande investimento em comunicação de dados sem fio a
quantidade de dados que se pode transmitir desta forma aumentou muito, e também
em paralelo com o avanço da tecnologia para celulares, estes dispositivos adquiriram a
grande capacidade de processamento e de se comunicarem com redes de dados e
também com a internet. A Tabela 3.1 mostra uma evolução na taxa de transmissão de
dados destes aparelhos.
Tabela 3.1 – Evolução da telefonia celular (FIGUEIREDO, NAKAMURA; 2003)
Geração 1ªG 2ªG 2,XªG 3ªG 4ªGCaracteríst
icas
- Transmissão
de dados
analógica
(AMPS);
- Taxas de
9600bps.
- Transmissão
digital de dados
(TDMA,
CDMA e
GSM);
- Taxas de
9600bps a
14400bps;
- Surgimento
de aplicações
WAP.
- Disponibili-
zação de
aplicações
pré-3ªG
- Evolução
CDMA e
GSM;
- Taxas de até
2Mbps;
- Surgimento
de aplicações
multimídia.
- Elevação das
taxas de
transmissão
de dados;

38
Todos os dispositivos apresentados possuem a mobilidade como fator comum, mas
diferem em usabilidade. Os telefones celulares, hoje, diferem dos PDAs na forma de
interação, pois os celulares possuem uma interface muito mais restrita. Os SmartPhones são
aparelhos que dispõem de funcionalidades dos celulares e PDAs de forma integradas, deste
modo tentando limitar os problemas de interação entre usuário e dispositivo.
3.4.2 Infra-estrutura Necessária para Computação Móvel
Sem a necessidade de se aprofundar no tema, este tópico visa mostrar alguns dos
fatores que tornam a computação móvel possível.
Percebe-se que o padrão de rede sem fio é o que atende às necessidades destes
dispositivos. Porém, estas redes, geralmente, possuem suporte de uma rede fixa, que pode ou
não usar comunicação sem fio. Estas redes recebem o nome de redes infra-estruturadas, e são
a partir delas que é feita a comunicação entre os dispositivos (FIGUEIREDO; NAKAMURA,
2003).
Existem dois tipos de infra-estruturas de rede: a interna e a externa. Estas diferem
basicamente na área de cobertura.
A infra-estrutura de rede interna tem uma área de cobertura menor, restrita, geralmente
a pequenos ambientes, por exemplo, redes empresariais, e até mesmo pequenas redes
pessoais. Dentre os padrões de rede que se encontram nesta infra-estrutura estão
(FIGUEIREDO, NAKAMURA; 2003):
Infravermelho – com baixa largura de banda e com difícil comunicação em ambientes
com obstáculos, como paredes, por exemplo;
Laser – possibilita alta largura de banda, mas necessita bom alinhamento entre os
dispositivos, devido ao feixe ser extremamente direcionado.
As infra-estruturas de redes externas não se restringem a pequenas áreas, podem se
estender desde a cobertura de pequenas cidades, rádios AM e FM, por exemplo, a continentes,
como na transmissão via satélite. Alguns exemplos desta tecnologia são:
Rádio freqüência – são fáceis de gerar, capacidade de percorrer longas distâncias e
penetram facilmente em prédios; são boas para a utilização tanto em ambientes abertos
como fechados e são omnidirecionais, ou seja, se propagam em todas as direções, isso
permite que o emissor e o receptor não necessitem estar alinhados (TANEMBAUM,
2003);
Satélites – alguns podem cobrir até um terço da terra em sua área de alcance.

39
Importantes na comunicação de longa distância;
Telefonia celular – são chamadas dessa forma devido a sua tecnologia. As áreas de
cobertura são chamadas de células, e cada célula é controlada por uma estação rádio-
base (ERB), e cada ERB se comunica por uma rede de fibra óptica, permitindo a
comunicação entre as células.
Ainda há duas tecnologias de rede sem fio que devem ser citadas, as quais são as
principais e modernas tecnologias de rede sem fio, a saber:
Bluetooth – elimina os cabos usados para conectar os dispositivos digitais. Se baseia
em um link de rádio de curto alcance, normalmente distâncias até 10m, e baixo custo.
Desta forma pode-se conectar vários, e diversos tipos de dispositivos sem a
necessidade de cabos, proporcionando uma maior mobilidade;
802.11 – O IEEE (Institute of Electrical and Electronics Engineers) padronizou esta
tecnologia. Também são conhecidas como redes Wi-Fi ou wireless, e vem recebendo
grandes investimentos nos últimos anos. Atualmente, são o padrão para conexão sem
fio para redes locais. Este padrão já está bastante difundido. Percebe-se este fato ao
ver que essas interfaces de rede são quase um item de série de computadores portáteis.
A computação móvel já é realidade, e é uma área em crescente expansão. É um ramo
da computação que necessita de bastante investimento, pois, com a explosão destes
dispositivos móveis capazes de se conectarem sem a necessidade de cabos, os seus usuários
também necessitam de uma infra-estrutura que possibilite o uso desta poderosa tecnologia.
3.5 Um Cluster de Celulares
Os celulares mais modernos já vêm com suporte a Buetooth, ou seja, capaz de se
conectar a qualquer rede sem fio próxima. Pensando nestes elementos, pode-se supor que uma
das indústrias que mais lucrariam com a programação paralela e distribuída para estes
dispositivos seria a de entretenimento, mais especificamente jogos.
Supondo que bons servidores destas empresas fossem dispostos em locais
“estratégicos” como shoppings, e outros locais de entretenimento público, e colocassem a
disposição jogos que os visitantes pudessem jogar nesses servidores com os seus próprios
dispositivos como celulares, PDAs, etc., e que estes servidores montassem uma rede para que
os participantes pudessem jogar uns com os outros seria uma boa idéia. Poderia se imaginar
algo como um fliperama. Quem se aproximasse, e tivesse suporte a bluetooth, seria detectado

40
pelo servidor, recebendo uma mensagem convidativa para testar um dos jogos. Mas, se os
usuários pudessem fazer o download do jogo e jogar entre si, deste modo sem ter de ir a outro
lugar, seria melhor ainda. A programação paralela e distribuída seria uma solução para o
proposto acima.
O primeiro cluster do mundo, o Beowulf, foi montado com 16 486DX4 (MERKEY,
2008) e cada nó tinha um processador de, no máximo, 100MHz de clock (INTEL, 2007). Há
Smartphones hoje sendo lançados no mercado com um processador de 312 MHz de clock, por
exemplo, o Treo 650 da Softsite Mobile que vem com o processador Intel™ PXA270, ou seja,
já possuem uma boa capacidade de processamento (SOFTSITE MOBILE, 2007).
Com a utilização da programação paralelo-distribuída é possível utilizar, de forma
mais abrangente, as funcionalidades deste dispositivos, e não apenas para jogos, mas também
para diversas áreas de interesse.
Com o conhecimento teórico mínimo, referente à computação paralela e distribuída,
além de uma breve abordagem sobre clusters, e suas diferentes arquiteturas, e computação
móvel, é possível implementar um aplicativo para a análise da teoria estudada. Nesta
monografia trabalhamos o algoritmo quicksort como um estudo de caso, executando em um
dispositivo móvel do tipo leptop e deixamos a idéia de computação paralela e distribuída em
móveis modernos para trabalhos futuros.
4 UM ESTUDO DE CASO: QUICKSORT
Para testar o funcionamento paralelo em computadores móveis foi utilizado o
algoritmo quicksort, por ser um algoritmo de ordenação simples. O quicksor foi criado por
Charles Antony Richard Hoare, é um algoritmo de ordenação simples, onde os elementos a
serem ordenados são dispostos em um vetor. Este algoritmo adota a estratégia de dividir para
conquistar (MATHIAS, 2007), ou seja, o vetor que contém os elementos é dividido com base
em um pivô, um elemento tomado como base.
Este algoritmo funciona da seguinte maneira (CELES, CERQUEIRA, RANGEL, 2004):
Primeiro é escolhido um elemento pivô, que serve de base para a divisão do vetor;
O vetor original é subdivido, com base no pivô, de forma que os elementos são todos
realocados, sendo reunidos juntos os elementos menores ou iguais ao pivô em um sub-
vetor e os elementos maiores em outro sub-vetor. Quando este processo termina o pivô
está em sua posição final;
Depois de feita a divisão do vetor, com base em seus elementos, então os sub-vetores
são ordenados de forma recursiva.

41
O nível de complexidade de tempo pode ser medido a partir da fórmula (MATHIAS,
2007):
Ө(n log n) para casos de média complexidade, sendo “n” o número de elementos;
Ө(n2) no pior caso.
Esta complexidade também pode ser medida em ambientes distribuídos, com a
fórmula: Ө((n/p) log (n/p)), sendo “p” o número de processadores que estão
trabalhando na solução do problema.
4.1 Algoritmo Quicksort
O elemento arbitrário x – o pivô – deve ocupar uma posição i do vetor, com relação a
ordenação, sendo esta então sua posição definitiva. Esse fato pode ser observado, mesmo sem
que o vetor esteja ordenado, quando todos os elementos das posições v[0]...v[i-1] são menores
que x, e todos os elementos das posições v[i+1]...v[n-1] são maiores que x.
Esse algoritmo pode ser muito eficiente, e essa é a sua grande vantagem. O melhor
caso do quicksort ocorre quando o pivô é o elemento mediando do vetor. Desta forma, quando
o pivô é colocado em sua posição final ficam restando apenas dois sub-vetores, geralmente do
mesmo tamanho. Para este caso, o esforço computacional é igual a n log(n), e é dito que o
algoritmo é O(n log(n)), o que representa um desempenho superior ao O(n2) que apresenta o
algoritmo bubblesort (CELES, CERQUEIRA, RANGEL, 2004).
O bubblesort, ou ordenação por flutuação (por bolha), é um algoritmo de ordenação
bastante simples. O plano é que o vetor seja percorrido várias vezes, fazendo com que o
menor elemento encontrado “flutue” para o topo da seqüência. Esta característica lembra a
forma de bolhas subindo em um tanque de água, procurando seu próprio nível, e daí o nome
bubblesort (CELES, CERQUEIRA, RANGEL, 2004).
O exemplo a ser utilizado supõe que o pivô é o primeiro elemento do vetor, x=v[0],
sendo este elemento a ser realocado no seu devido lugar. É feita uma comparação com os
elementos v[1], v[2], v[3],..., até que seja encontrado um elemento v[a]>x. E partindo do
final do vetor, é feita uma comparação com os elementos v[n-1], v[n-2],..., até que seja
encontrado um elemento v[b]<=x. Quando esta situação é atingida, os elementos v[a] e v[b]
são trocados de lugar e a busca continua, para cima a partir de v[a+1] e para baixo a partir de
v[b-1]. Desta forma em algum momento a busca deve terminar, pois os parâmetros de busca
se encontrarão (b<a). Então, x deverá ser colocado em sua posição correta, e os valores
armazenados em v[0] e v[b] são trocados.

42
A seguir um exemplo de como o algoritmo deverá se comportar. Seja um vetor de 8
posições (CELES, CERQUEIRA, RANGEL, 2004):
(0-7) 25 48 37 12 57 86 33 92
Onde (0-7) indica o valor do índice do vetor, de v[0] a v[7]. O algoritmo começa verificando
a posição correta de x = v[0] = 25. Neste momento já ocorre a primeira comparação, 48>25
(a=1). Buscando também a partir do fim do vetor, tem-se que 25<92, 25<33, 25<86, 25<57 e
12<=25 (b=3).
(0-7) V[0] v[1] v[2] v[3] v[4] v[5] v[6] v[7]25 48 37 12 57 86 33 92
a↑ b↑São trocados os valores de v[a] e v[b], 48 e 12, respectivamente, incrementando o
valor de a e decrementando o valor de b. O novo esquema fica da seguinte forma:
(0-7) v[0] v[1] v[2] v[3] v[4] v[5] v[6] v[7]25 12 37 48 57 86 33 92
a,b↑Nesta situação tem-se 37>25 (a=2), pois a foi incrementado, e partindo do outro lado
tem-se a mesma situação, 37>25, e 12<=25. Isto indica que os índices de a e b se cruzaram,
com b<a.
(0-7) v[0] v[1] v[2] v[3] v[4] v[5] v[6] v[7]25 12 37 48 57 86 33 92
b↑ a↑Desta forma, todos os elementos a partir do 37, o sub-vetor a direita, incluindo o 37,
são maiores que o pivô, 25, e os elementos do sub-vetor a esquerda, a partir do 12, incluindo o
12, são menores que o pivô. Neste momento troca-se então o pivô com o último dos valores
encontrado. Onde v[b]=12.
(0-7) v[0] v[1] v[2] v[3] v[4] v[5] v[6] v[7]12 25 37 48 57 86 33 92
O pivô assume sua posição final, restando apenas dois sub-vetores a serem ordenados,
o que possui valores menores que 25, e o de valores maiores que 25. Neste caso o vetor de
valores menor que o pivô já se encontra ordenado, pois só possui um valor:
(0-0) v[0]12
Porém, o outro sub-vetor, o de valores maiores que o pivô, deverá ser ordenado da
mesma forma:

43
(2-7) v[2] v[3] v[4] v[5] v[6] v[7]37 48 57 86 33 92
O pivô passa então a ser o 37, e sua posição correta deve ser localizada. Procura-se o
próximo elemento maior que 37, o 48, e a partir do final do vetor busca-se um elemento
menor que 37, o 33.
(2-7) v[2] v[3] v[4] v[5] v[6] v[7]37 48 57 86 33 92
a↑ b↑Os elementos são trocados de posição, e os valores de a e b são incrementado e
decrementado, respectivamente:
(2-7) v[2] v[3] v[4] v[5] v[6] v[7]37 33 57 86 48 92
a↑ b↑É verificado que 37<57 e 37<86, porém 37>=33. Então a e b se cruzam;
(2-7) v[2] v[3] v[4] v[5] v[6] v[7]37 33 57 86 48 92
b↑ a↑Neste momento v[b] é a correta posição de 37, então os elemento são trocados de
posição:
(2-7) v[2] v[3] v[4] v[5] v[6] v[7]33 37 57 86 48 92
Os vetores restantes a serem ordenados são:
(2-2) v[2] e (4-7) v[3] v[4] v[5] v[6] v[7]33 37 57 86 48 92
A ordenação continua até que todo o vetor seja percorrido, atingindo o resultado:
(0-7) v[0] v[1] v[2] v[3] v[4] v[5] v[6] v[7]12 25 33 37 48 57 86 92
4.2 Implementação Seqüencial
4.2.1 Quicksort em C
A seguir um exemplo de implementação do quicksort em linguagem C. É uma
implementação simples, onde um vetor recebe seus valores de um gerador de números
aleatórios, para depois poder ordená-los. A função void rapida (long int n, long int* v),

44
tirada de Celes, Cerqueira, Rangel (2004), exibe uma – de várias – forma de implementar o
quicksort.
#include <stdio.h>#include <stdlib.h>#include <time.h>
void rapida (long int n, long int* v);
int main (){
#define NUM 2000000
clock_t inicio, fim;
long int v[NUM];long int i;double j=0;
for (i=0; i<NUM; i++)v[i] = rand() %NUM;
inicio = clock();rapida(NUM, v);fim = clock();
j = (fim - inicio)/3.0e9;
printf(" \n \n O tempo total de ordenacao e %.20e segundos! \n \n", j);return 0;
}

45
4.2.2 Quicksort em Java
Segue um exemplo de implementação do quicksort em código, com adaptações, Java
(WIKIPÉDIA, 2008).
void rapida (long int n, long int* v){
if (n <= 1)return;
else{ long int x = v[0];
long int a = 1;long int b = n-1;do {
while (a < n && v[a] <= x) a++;
while (v[b] > x) b--;
if (a < b) { /* faz a troca */long int temp = v[a];v[a] = v[b];v[b] = temp;a++; b--;
}} while (a <= b);
/* troca o pivo */
v[0] = v[b];v[b] = x; /*ordena os subvetores restantes*/ rapida(b,v);rapida(n-a,&v[a]);
}}
import java.util.Date;import java.util.Random;
public class Ordena {public static final Random RND = new Random();
public static void main(String[] args) {
final int VETOR = 45000;Integer v[] = new Integer[VETOR];int i;

46
int n = VETOR;for (i = 0; i < VETOR; i++) {
v[i] = RND.nextInt(n + 1);}Date inicio = new Date();sort(v, 0, v.length);Date fim = new Date();
System.out.println("Tempo em milisegundos é: "+(fim.getTime()-inicio.getTime()));for (i = 0; i < 10; i++) {
System.out.println(v[i]);}}private static void swap(Object[] array, int i, int j) {Object tmp = array[i];array[i] = array[j];array[j] = tmp;}public static int compare(Integer arg0, Integer arg1) {if (arg0< arg1)
return -1;else if (arg0>arg1)
return 1;else return 0;
}private static int partition(Integer[] array, int begin, int end) {int index = begin;Integer pivot = array[index];swap(array, index, end);for (int i = index = begin; i < end; ++i) {
if (compare(array[i], pivot) <= 0) {swap(array, index++, i);
}}swap(array, index, end);return (index);}private static void qsort(Integer[] array, int begin, int end) {if (end > begin) {
int index = partition(array, begin, end);qsort(array, begin, index - 1);qsort(array, index + 1, end);
}}
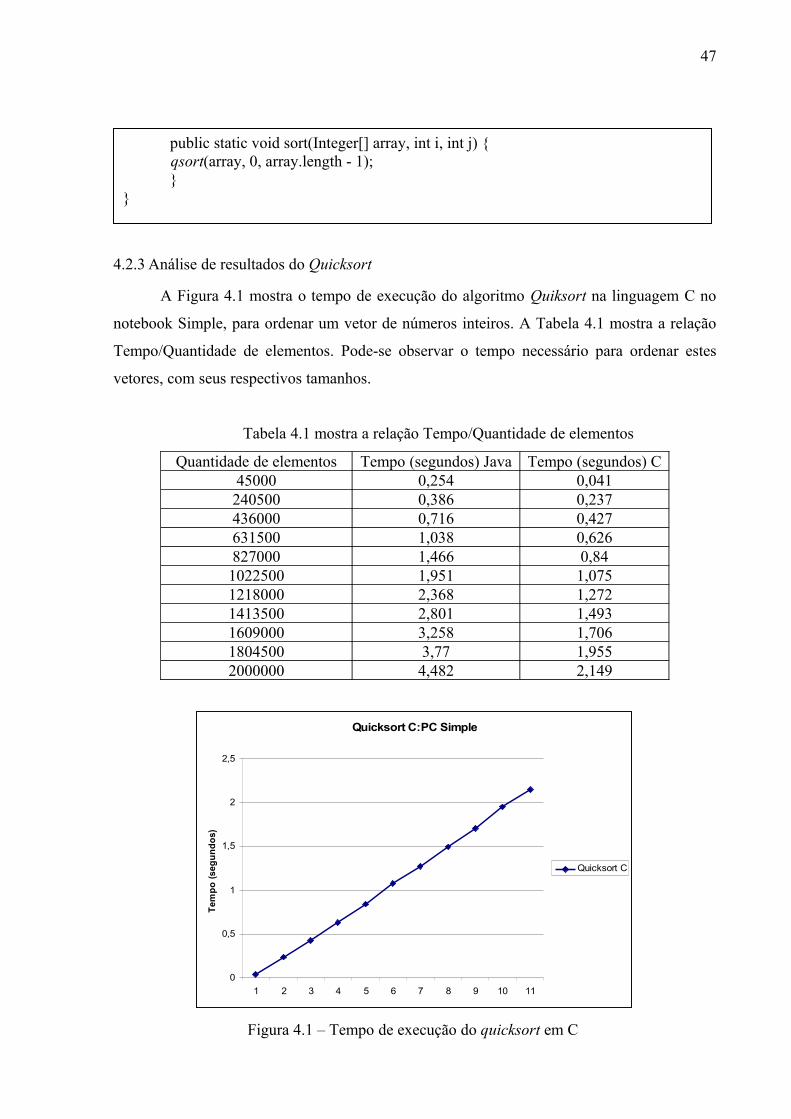
47
4.2.3 Análise de resultados do Quicksort
A Figura 4.1 mostra o tempo de execução do algoritmo Quiksort na linguagem C no
notebook Simple, para ordenar um vetor de números inteiros. A Tabela 4.1 mostra a relação
Tempo/Quantidade de elementos. Pode-se observar o tempo necessário para ordenar estes
vetores, com seus respectivos tamanhos.
Tabela 4.1 mostra a relação Tempo/Quantidade de elementos
Quantidade de elementos Tempo (segundos) Java Tempo (segundos) C45000 0,254 0,041240500 0,386 0,237436000 0,716 0,427631500 1,038 0,626827000 1,466 0,841022500 1,951 1,0751218000 2,368 1,2721413500 2,801 1,4931609000 3,258 1,7061804500 3,77 1,9552000000 4,482 2,149
Quicksort C:PC Simple
0
0,5
1
1,5
2
2,5
1 2 3 4 5 6 7 8 9 10 11
Tem
po (s
egun
dos)
Quicksort C
Figura 4.1 – Tempo de execução do quicksort em C
public static void sort(Integer[] array, int i, int j) {qsort(array, 0, array.length - 1);}
}
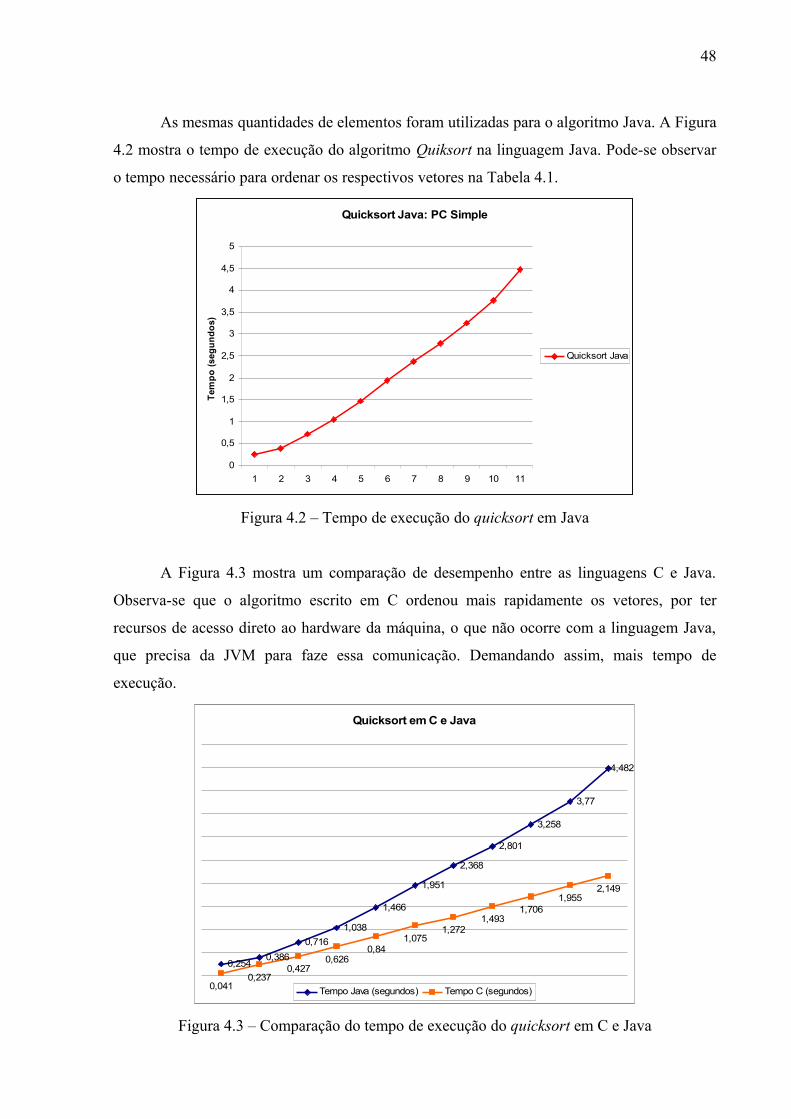
48
As mesmas quantidades de elementos foram utilizadas para o algoritmo Java. A Figura
4.2 mostra o tempo de execução do algoritmo Quiksort na linguagem Java. Pode-se observar
o tempo necessário para ordenar os respectivos vetores na Tabela 4.1.
Quicksort Java: PC Simple
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
5
1 2 3 4 5 6 7 8 9 10 11
Tem
po (s
egun
dos)
Quicksort Java
Figura 4.2 – Tempo de execução do quicksort em Java
A Figura 4.3 mostra um comparação de desempenho entre as linguagens C e Java.
Observa-se que o algoritmo escrito em C ordenou mais rapidamente os vetores, por ter
recursos de acesso direto ao hardware da máquina, o que não ocorre com a linguagem Java,
que precisa da JVM para faze essa comunicação. Demandando assim, mais tempo de
execução.
Quicksort em C e Java
0,2540,386
0,7161,038
1,466
1,951
2,368
2,801
3,258
3,77
4,482
0,0410,237
0,4270,626
0,841,075
1,2721,493
1,7061,955
2,149
Tempo Java (segundos) Tempo C (segundos)
Figura 4.3 – Comparação do tempo de execução do quicksort em C e Java
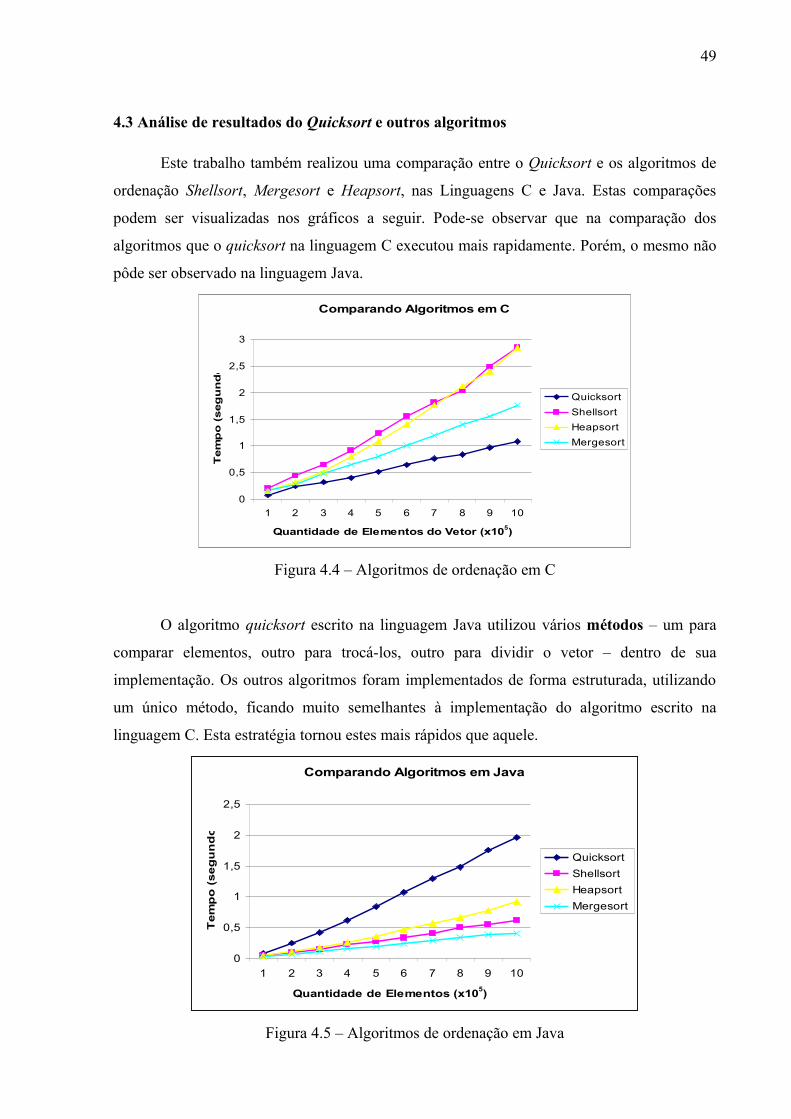
49
4.3 Análise de resultados do Quicksort e outros algoritmos
Este trabalho também realizou uma comparação entre o Quicksort e os algoritmos de
ordenação Shellsort, Mergesort e Heapsort, nas Linguagens C e Java. Estas comparações
podem ser visualizadas nos gráficos a seguir. Pode-se observar que na comparação dos
algoritmos que o quicksort na linguagem C executou mais rapidamente. Porém, o mesmo não
pôde ser observado na linguagem Java.
Comparando Algoritmos em C
0
0,5
1
1,5
2
2,5
3
1 2 3 4 5 6 7 8 9 10
Quantidade de Elementos do Vetor (x105)
Tem
po
(seg
un
do
s)
QuicksortShellsortHeapsortMergesort
Figura 4.4 – Algoritmos de ordenação em C
O algoritmo quicksort escrito na linguagem Java utilizou vários métodos – um para
comparar elementos, outro para trocá-los, outro para dividir o vetor – dentro de sua
implementação. Os outros algoritmos foram implementados de forma estruturada, utilizando
um único método, ficando muito semelhantes à implementação do algoritmo escrito na
linguagem C. Esta estratégia tornou estes mais rápidos que aquele.
Comparando Algoritmos em Java
0
0,5
1
1,5
2
2,5
1 2 3 4 5 6 7 8 9 10
Quantidade de Elementos (x105)
Tem
po
(se
gu
nd
os)
Quicksort Shellsort HeapsortMergesort
Figura 4.5 – Algoritmos de ordenação em Java

50
O algoritmo quicksort descrito no APÊNDICE A mostrou-se ainda mais lento que sua
implementação descrita no item 4.2.2. Isto se deve ao fato de que além de vários métodos,
este possui outras duas classes. Desta forma, quando o algoritmo precisa acessá-las, será
necessário instruções em outro arquivo, ao invés de tê-las no mesmo arquivo.
4.4 Implementação Paralela com o MPI
O APÊNDICE A deste projeto apresenta a explicação de preparação do sistema para a
implementação do cluster, assim como o APÊNDICE B apresenta uma explicação de
instalação e configuração do ambiente de troca de mensagens com o MPICH2-1.0.7.
Foram utilizados dois Notebooks. Segue a configuração das máquinas, com relação ao
hardware:
Notebook Simpel – Pentium M, 1800 GHz de clock, 1 GB de memória RAM com
Linux Kurumin 7.0, kernel 2.6.18;
Notebook HP – AMD Turion 64 X2, 2600 GHz de clock, 3 GB de memória RAM
com o Linux Kurumin 7.0, kernel 2.6.18;
Como forma de teste, o programa que calcula o valor de PI foi executado nas
máquinas do cluster. O programa CPI é um dos aplicativos de teste que acompanham o pacote
MPICH e pode ser encontrado em ~/mpich2-1.0.7/examples.
A Tabela 4.2 mostra os resultados obtidos com a execução do programa CPI
individualmente em cada máquina, e depois uma execução paralela, com 2 notebooks. É
possível observar que há um ganho de tempo de execução quando se tem uma máquina
paralela, como exibe-se na Tabela 4.3.
Tabela 4.2 Execução seqüencial do cálculo do número PI
Notebook Tempo (segundos)Simple 4,48HP 3,67
Tabela 4.3 Execução paralela do cálculo do número PI
Notebook Tempo (segundos) SpeedupSimple 4,48 1,69HP 3,67 1,38Paralelo 2,65 ----------
Após a verificação do funcionamento correto do MPI, pode-se então passar para os
testes de consumo de energia nas máquinas. A próxima seção mostra esses resultados.

51
4.5 Consumo de Energia
Antes de exibir os resultados faz-se necessário uma breve explicação de como é
possível extrair esses dados do sistema. O processo de análise de energia desse projeto foi
baseado em Costa (2007).
Os dados do consumo de energia foram coletados a partir de parâmetros fornecidos
pelo sistema operacional. Os mesmos foram coletados de arquivos virtuais presentes no
arquivo /proc.
O diretório /proc é uma interface entre o sistema operacional e os dispositivos de
hardware. O kernel controla o acesso a esses dispositivos e gerencia a interação entre os
componentes físicos do sistema (COSTA, 2007).
Os dados de análise da bateria são coletados nos arquivos
/proc/acpi/battery/BAT0/info e /proc/acpi/battery/BAT0/state que apresentam informações
relativas à bateria do dispositivo. Sendo o último arquivo que de fato interessa neste projeto.
Segue um exemplo do arquivo state.
kurumin@escravo2:~$ cat /proc/acpi/battery/BAT0/state present: yescapacity state: okcharging state: dischargingpresent rate: 11511 mWremaining capacity: 29220 mWhpresent voltage: 12029 mV
O valor de Remaining capacity é utilizado para calcular o valor de energia gasto. O
valor da energia consumida é fornecido através da equação (COSTA, 2007):
Remaining capacity (antes) - Remaining capacity (depois) = Energia Consumida (mWh)
De posse dessas informações, um shell script criado por Costa (2007) foi adaptado,
para que simplesmente imprimisse no konsole os valores coletados. A seguir o shell script
para a coleta dos dados:
#!/bin/sh echo `cat /proc/acpi/battery/BAT0/state | grep "voltage"` echo `cat /proc/acpi/battery/BAT0/state | grep "present rate"` echo `cat /proc/acpi/battery/BAT0/state | grep "remaining"`
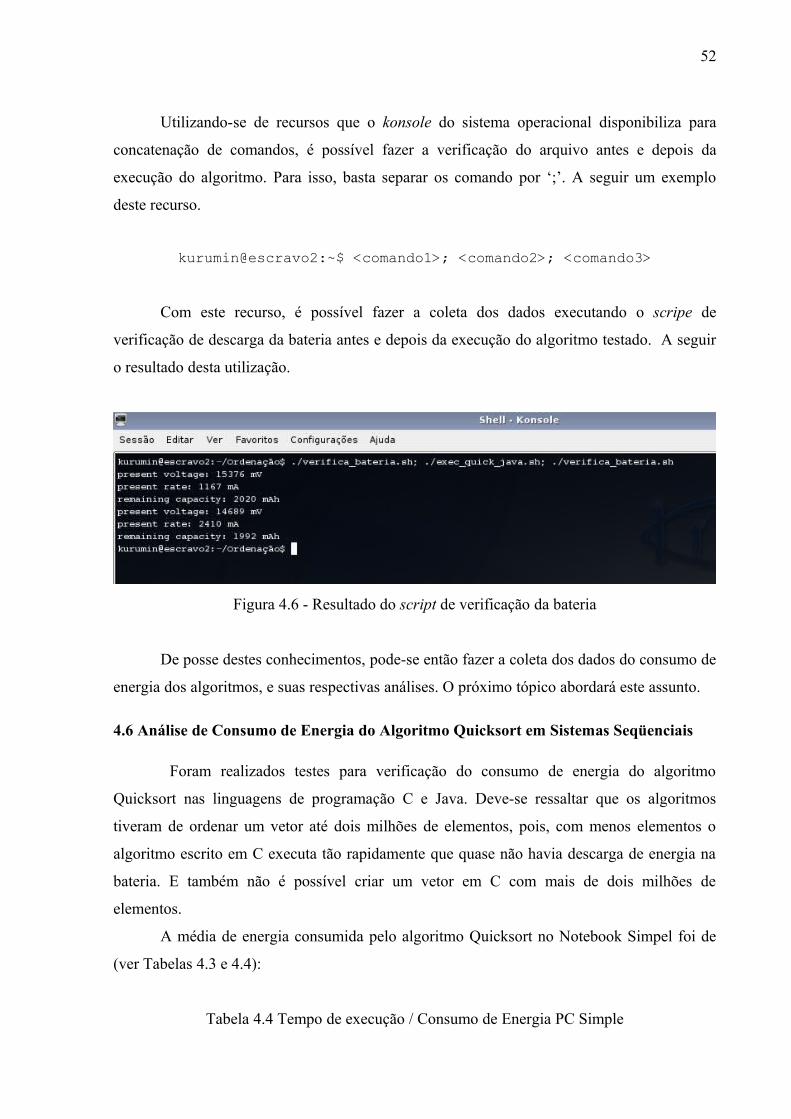
52
Utilizando-se de recursos que o konsole do sistema operacional disponibiliza para
concatenação de comandos, é possível fazer a verificação do arquivo antes e depois da
execução do algoritmo. Para isso, basta separar os comando por ‘;’. A seguir um exemplo
deste recurso.
kurumin@escravo2:~$ <comando1>; <comando2>; <comando3>
Com este recurso, é possível fazer a coleta dos dados executando o scripe de
verificação de descarga da bateria antes e depois da execução do algoritmo testado. A seguir
o resultado desta utilização.
Figura 4.6 - Resultado do script de verificação da bateria
De posse destes conhecimentos, pode-se então fazer a coleta dos dados do consumo de
energia dos algoritmos, e suas respectivas análises. O próximo tópico abordará este assunto.
4.6 Análise de Consumo de Energia do Algoritmo Quicksort em Sistemas Seqüenciais
Foram realizados testes para verificação do consumo de energia do algoritmo
Quicksort nas linguagens de programação C e Java. Deve-se ressaltar que os algoritmos
tiveram de ordenar um vetor até dois milhões de elementos, pois, com menos elementos o
algoritmo escrito em C executa tão rapidamente que quase não havia descarga de energia na
bateria. E também não é possível criar um vetor em C com mais de dois milhões de
elementos.
A média de energia consumida pelo algoritmo Quicksort no Notebook Simpel foi de
(ver Tabelas 4.3 e 4.4):
Tabela 4.4 Tempo de execução / Consumo de Energia PC Simple
53
Linguagem de
programação
Número de
elementos ordenados
Tempo (segundos) Energia média
(mWh)C 2*106 2,149 0,601Java 2*106 4,485 2,9
A média de energia consumida pelo algoritmo Quicksort no Notebook HP foi de:
Tabela 4.5 Tempo de execução / Consumo de Energia PC HP
Linguagem de
programação
Número de
elementos ordenados
Tempo (segundos) Energia média
(mWh)C 2*106 1,731 0,53Java 2*106 3,916 2,61
No notebook Simple, o algoritmo em C ordenou o vetor 52,05% mais rapidamente
que o algoritmo em Java, e foi 79,30% mais econômico que o mesmo em Java; e no notebook
HP, o algoritmo em C foi 55,80% mais rápido que o algoritmo em Java, e foi 79,70% mais
econômico que o mesmo em Java. Estes dados podem ser comprovados pelo fato de a
linguagem de programação C possuir recursos de uma linguagem de programação de baixo
nível, que possibilitam ter acesso direto ao hardware da máquina. Contudo, a linguagem Java
não dispõe desse recurso de acesso direto aos dispositivos físicos da máquina, tendo sua
comunicação pela JVM – Java Virtual Machine. A JVM além de tornar o aplicativo mais
lento, também demanda mais recursos de máquina (memória RAM, por exemplo),
explicando, então, a economia de energia ao se utilizar a linguagem de programação C. Segue
uma comparação do consumo de energia no PC Simple. Nos gráficos abaixo, Figuras 4.7 e
4.8, foram exibidos os resultados da ordenação de vetores com seus valores na Tabela 4.6.
Tabela 4.6 Consumo de Energia nas Linguagens C e Java nos notebooks HP e Simple
Número de elementos
Quicksort C (mWh) - HP
Quicksort Java (mWh) - HP
Quicksort C (mWh) - Simple
Quicksort Java (mWh) - Simple
500000 0,064 0,43 0,1375 0,575800000 0,08 0,91 0,175 1,075
1100000 0,102 1,43 0,2375 1,5751400000 0,177 1,87 0,345 2,051700000 0,355 2,31 0,408 2,62000000 0,533 2,67 0,601 2,9
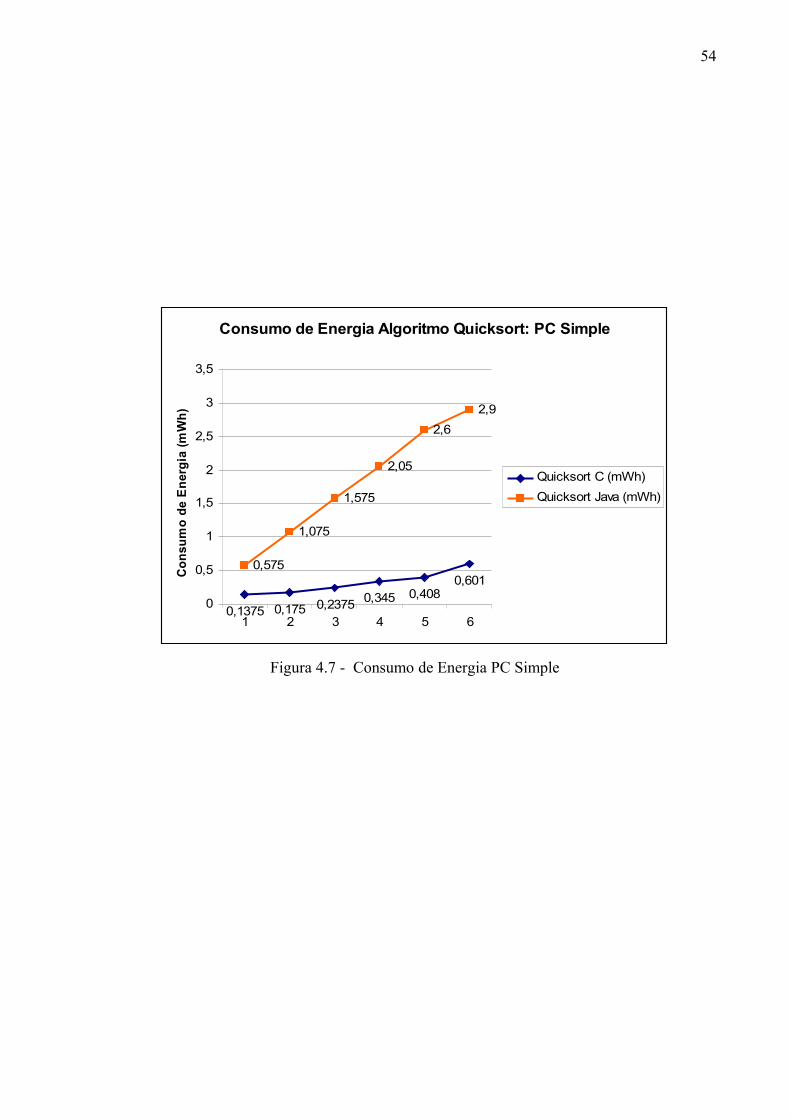
54
Consumo de Energia Algoritmo Quicksort: PC Simple
0,1375 0,175 0,2375 0,345 0,4080,601
0,575
1,075
1,575
2,05
2,62,9
0
0,5
1
1,5
2
2,5
3
3,5
1 2 3 4 5 6
Con
sum
o de
Ene
rgia
(mW
h)
Quicksort C (mWh)Quicksort Java (mWh)
Figura 4.7 - Consumo de Energia PC Simple
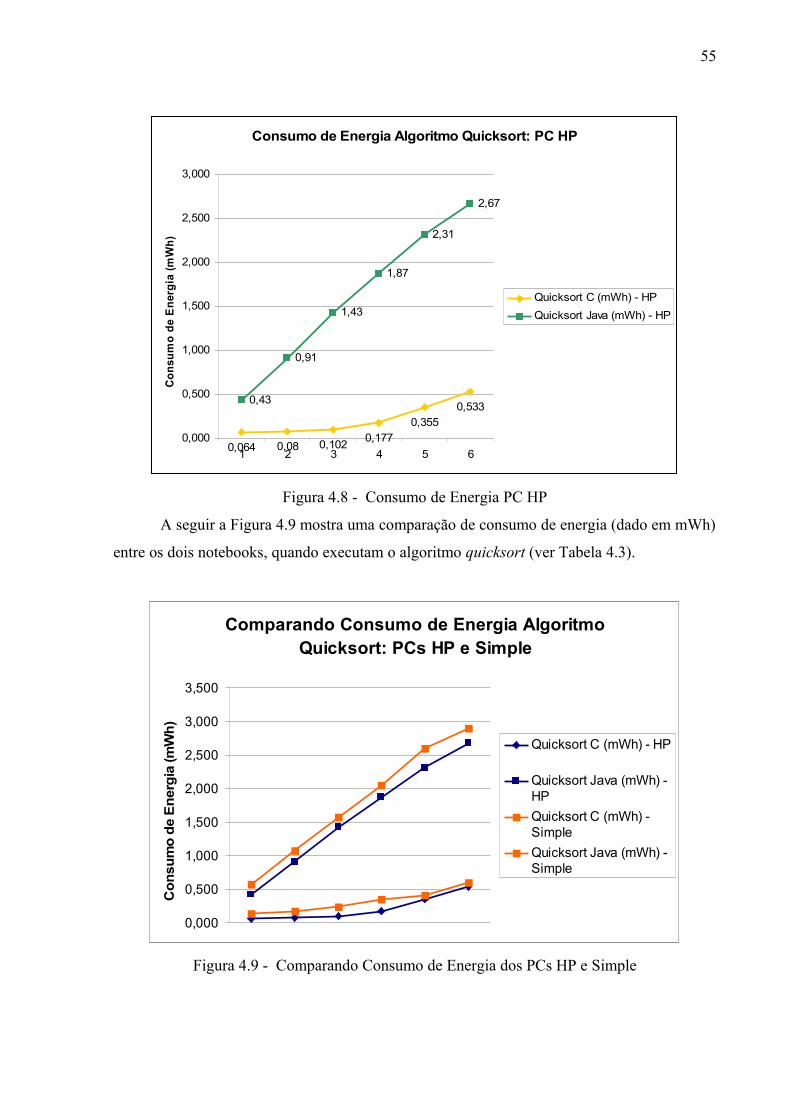
55
Consumo de Energia Algoritmo Quicksort: PC HP
0,064 0,08 0,102 0,1770,355
0,5330,43
0,91
1,43
1,87
2,31
2,67
0,000
0,500
1,000
1,500
2,000
2,500
3,000
1 2 3 4 5 6
Con
sum
o de
Ene
rgia
(mW
h)
Quicksort C (mWh) - HP Quicksort Java (mWh) - HP
Figura 4.8 - Consumo de Energia PC HP
A seguir a Figura 4.9 mostra uma comparação de consumo de energia (dado em mWh)
entre os dois notebooks, quando executam o algoritmo quicksort (ver Tabela 4.3).
Comparando Consumo de Energia Algoritmo Quicksort: PCs HP e Simple
0,000
0,500
1,000
1,500
2,000
2,500
3,000
3,500
Con
sum
o de
Ene
rgia
(mW
h)
Quicksort C (mWh) - HP
Quicksort Java (mWh) -HPQuicksort C (mWh) -SimpleQuicksort Java (mWh) -Simple
Figura 4.9 - Comparando Consumo de Energia dos PCs HP e Simple
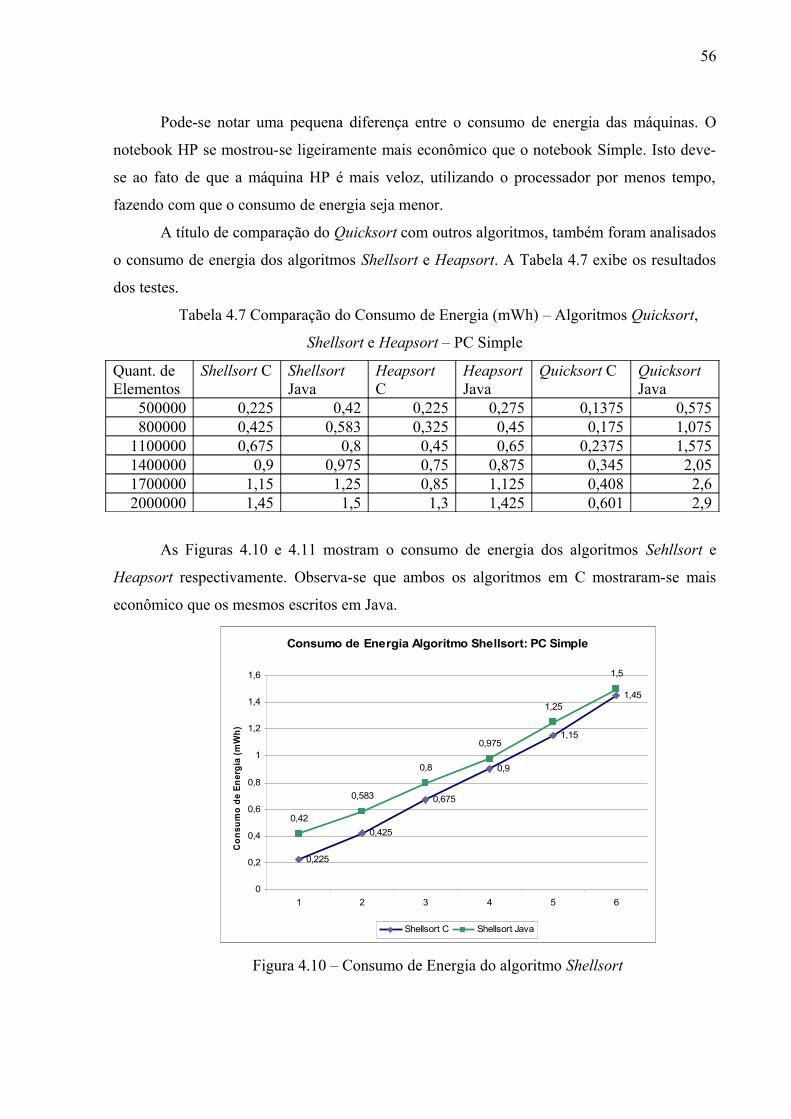
56
Pode-se notar uma pequena diferença entre o consumo de energia das máquinas. O
notebook HP se mostrou-se ligeiramente mais econômico que o notebook Simple. Isto deve-
se ao fato de que a máquina HP é mais veloz, utilizando o processador por menos tempo,
fazendo com que o consumo de energia seja menor.
A título de comparação do Quicksort com outros algoritmos, também foram analisados
o consumo de energia dos algoritmos Shellsort e Heapsort. A Tabela 4.7 exibe os resultados
dos testes.
Tabela 4.7 Comparação do Consumo de Energia (mWh) – Algoritmos Quicksort,
Shellsort e Heapsort – PC Simple
Quant. de Elementos
Shellsort C Shellsort Java
Heapsort C
Heapsort Java
Quicksort C Quicksort Java
500000 0,225 0,42 0,225 0,275 0,1375 0,575800000 0,425 0,583 0,325 0,45 0,175 1,075
1100000 0,675 0,8 0,45 0,65 0,2375 1,5751400000 0,9 0,975 0,75 0,875 0,345 2,051700000 1,15 1,25 0,85 1,125 0,408 2,62000000 1,45 1,5 1,3 1,425 0,601 2,9
As Figuras 4.10 e 4.11 mostram o consumo de energia dos algoritmos Sehllsort e
Heapsort respectivamente. Observa-se que ambos os algoritmos em C mostraram-se mais
econômico que os mesmos escritos em Java.
Consumo de Energia Algoritmo Shellsort: PC Simple
0,225
0,425
0,675
0,9
1,15
1,45
0,42
0,583
0,8
0,975
1,25
1,5
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1,6
1 2 3 4 5 6
Con
sum
o de
Ene
rgia
(mW
h)
Shellsort C Shellsort Java
Figura 4.10 – Consumo de Energia do algoritmo Shellsort
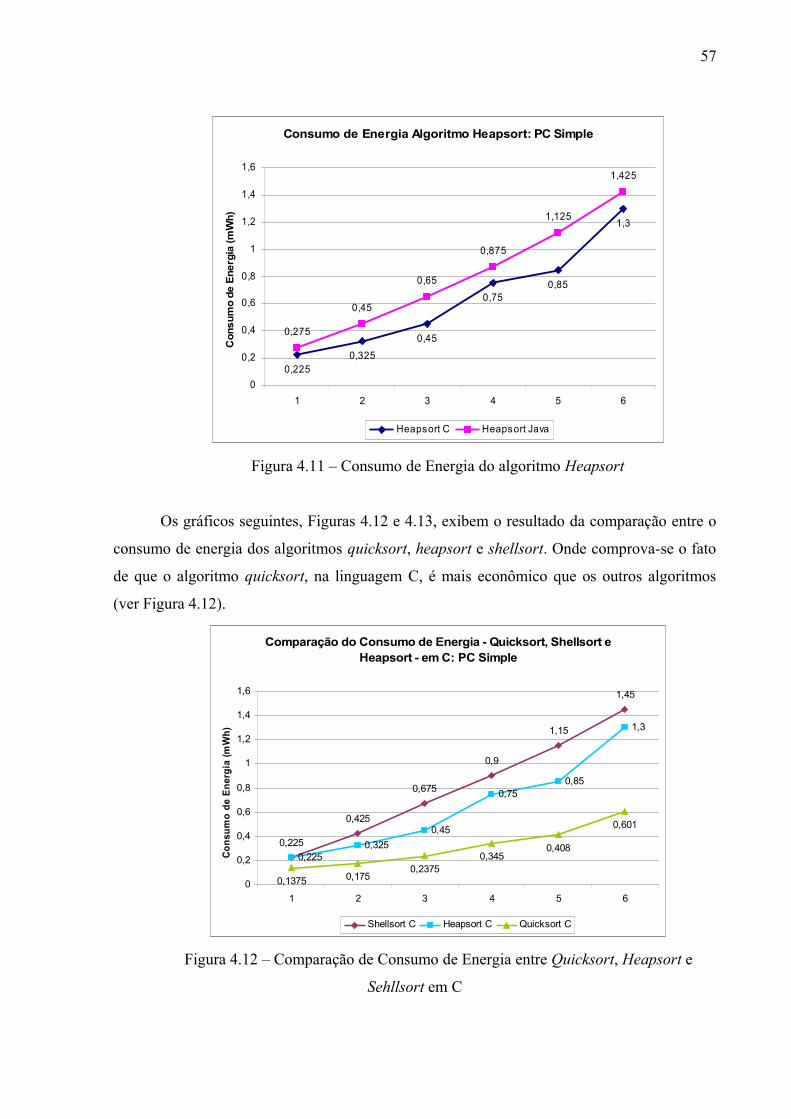
57
Consumo de Energia Algoritmo Heapsort: PC Simple
0,2250,325
0,45
0,750,85
1,3
0,275
0,45
0,65
0,875
1,125
1,425
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1,6
1 2 3 4 5 6
Con
sum
o de
Ene
rgia
(mW
h)
Heapsort C Heapsort Java
Figura 4.11 – Consumo de Energia do algoritmo Heapsort
Os gráficos seguintes, Figuras 4.12 e 4.13, exibem o resultado da comparação entre o
consumo de energia dos algoritmos quicksort, heapsort e shellsort. Onde comprova-se o fato
de que o algoritmo quicksort, na linguagem C, é mais econômico que os outros algoritmos
(ver Figura 4.12).
Comparação do Consumo de Energia - Quicksort, Shellsort e Heapsort - em C: PC Simple
0,225
0,425
0,675
0,9
1,15
1,45
0,2250,325
0,45
0,750,85
1,3
0,1375 0,1750,2375
0,3450,408
0,601
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1,6
1 2 3 4 5 6
Cons
umo
de E
nerg
ia (m
Wh)
Shellsort C Heapsort C Quicksort C
Figura 4.12 – Comparação de Consumo de Energia entre Quicksort, Heapsort e
Sehllsort em C
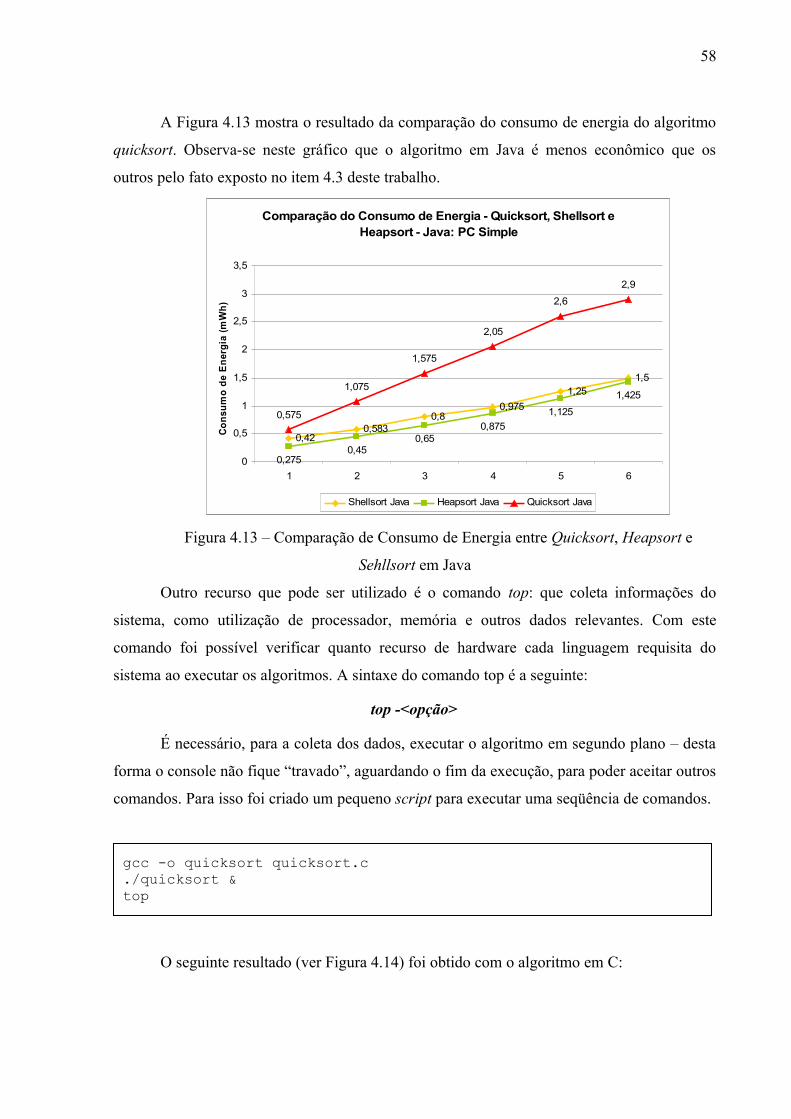
58
A Figura 4.13 mostra o resultado da comparação do consumo de energia do algoritmo
quicksort. Observa-se neste gráfico que o algoritmo em Java é menos econômico que os
outros pelo fato exposto no item 4.3 deste trabalho.
Comparação do Consumo de Energia - Quicksort, Shellsort e Heapsort - Java: PC Simple
0,420,583
0,80,975
1,251,5
0,2750,45
0,650,875
1,125
1,425
0,575
1,075
1,575
2,05
2,6
2,9
0
0,5
1
1,5
2
2,5
3
3,5
1 2 3 4 5 6
Cons
umo
de E
nerg
ia (m
Wh)
Shellsort Java Heapsort Java Quicksort Java
Figura 4.13 – Comparação de Consumo de Energia entre Quicksort, Heapsort e
Sehllsort em Java
Outro recurso que pode ser utilizado é o comando top: que coleta informações do
sistema, como utilização de processador, memória e outros dados relevantes. Com este
comando foi possível verificar quanto recurso de hardware cada linguagem requisita do
sistema ao executar os algoritmos. A sintaxe do comando top é a seguinte:
top -<opção>
É necessário, para a coleta dos dados, executar o algoritmo em segundo plano – desta
forma o console não fique “travado”, aguardando o fim da execução, para poder aceitar outros
comandos. Para isso foi criado um pequeno script para executar uma seqüência de comandos.
O seguinte resultado (ver Figura 4.14) foi obtido com o algoritmo em C:
gcc -o quicksort quicksort.c./quicksort &top
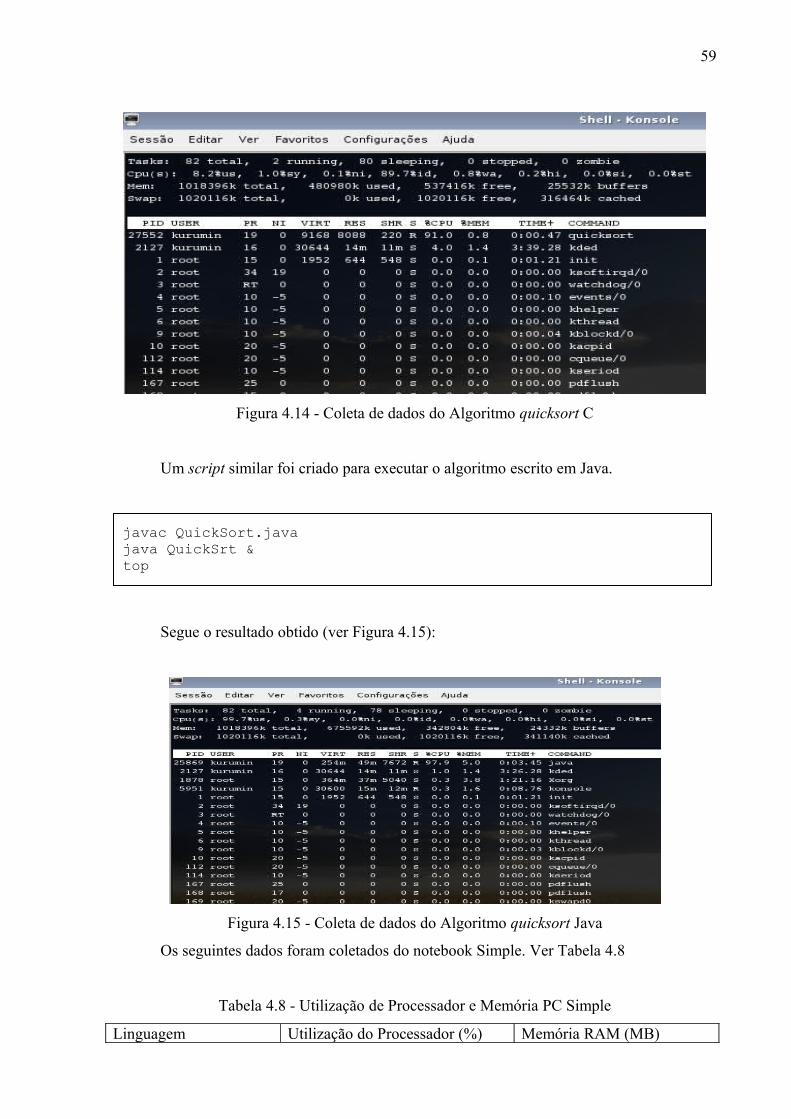
59
Figura 4.14 - Coleta de dados do Algoritmo quicksort C
Um script similar foi criado para executar o algoritmo escrito em Java.
Segue o resultado obtido (ver Figura 4.15):
Figura 4.15 - Coleta de dados do Algoritmo quicksort Java
Os seguintes dados foram coletados do notebook Simple. Ver Tabela 4.8
Tabela 4.8 - Utilização de Processador e Memória PC Simple
Linguagem Utilização do Processador (%) Memória RAM (MB)
javac QuickSort.javajava QuickSrt &top

60
C 91 0,8Java 97,9 5,0
Estes dados apenas reforçam o fato de que a linguagem de programação C além de
mais rápida necessita de menos recursos de hardware. Os testes realizados até aqui foram em
sistemas seqüenciais. O próximo tópico exibirá os resultados dos testes realizados no cluster,
executando o algoritmo que calcula o número PI.
4.7 Análise de Consumo de Energia do Algoritmo do Cálculo do PI em Sistemas
Paralelos
Os testes de consumo de energia foram realizados em um cluster montado com os dois
notebooks descritos no item anterior. Os resultados obtidos são mostrados na Tabela 4.9.
Tabela 4.9 Consumo de Energia do Cálculo do número PI – PC Simple
Quantidade de máquinas Número de iterações Consumo de energia (mWh)Uma Máquina 108 2,67Duas Máquinas 108 0,75
Analisando os resultados nota-se que houve uma redução no consumo de energia,
quando o cluster executou o algoritmo. Esta economia foi de 71,91%. Esse resultado pode ser
confirmado pelo fato de que quando as máquinas dividem o processo, além do tempo, todo o
processamento é reduzido, tanto memória como processador são menos usados. Seguem os
resultados obtidos com o recurso do comando top, em uma máquina e no cluster.
Resultado em uma máquina:
Figura 4.16 - Coleta de dados do cálculo do número PI em uma máquina

61
Resultado no cluster (ver Figura 4.17):
Figura 4.17 - Coleta de dados do cálculo do número PI no cluster
Nota-se uma substancial redução na utilização do processador quando o algoritmo é
executado paralelamente. Essa foi de 96,5% para 49,8%. Ou seja, além da redução de tempo
houve também uma redução na carga de processamento. Podendo-se afirmar que é justificável
o uso de programação paralela para redução do consumo de energia.

62
CONCLUSÕES
No capítulo 1 foram discorridos assuntos iniciais ao trabalho como o avanço da
tecnologia de dispositivos móveis e sua importância em nosso dia-a-dia. No capítulo 2 foram
exibidos conceitos de arquitetura de computadores e também sobre diferentes bibliotecas de
troca de mensagens, que tornam possível a computação paralela. Conceitos envolvendo
cluster e suas diferentes arquiteturas, foram discutidos no capítulo 3. No capítulo 4 foram
vistos os conceitos e implementações do algoritmo Quicksort nas linguagens de programação
C e Java, e seus respectivos resultados. Como também foram vistos os resultados obtidos com
o algoritmo do cálculo do número PI.
Atualmente vê-se o crescente avanço no desenvolvimento de processadores com dois
núcleos: Core Duo ou Core 2 Duo. Essa nova arquitetura de processadores é
comprovadamente mais veloz, eficaz e econômica.
O estudo da programação paralela traz diversos benefícios, desde o próprio
aprendizado, às vantagens que podem ser agregadas a sua utilização: maior poder
computacional, redução significativa de custos no projeto, redução no consumo de energia –
de grande importância para dispositivos móveis – e outros fatores que não foram discutidos
neste trabalho.
Um dos problemas que podem ser encontrados na fase de projeto, na programação
paralela, é o fato de que praticamente não há muito material de qualidade disponível,
livremente, que sirva de base para o estudo de programação paralela propriamente dita.
Percebe-se claramente a grande vantagem no uso de programação paralela: a redução
no consumo de energia. Fato esse que foi comprovado neste trabalho.
O quicksort C mostrou-se mais rápido e econômico que os outros, comprovando sua
eficácia na ordenação. O quicksort Java mostrou-se mais lento e menos econômico que os
outros algoritmos, mostrando que nem sempre – dependendo da maneira que foi
implementado – este é o mais rápido.
Pode-se afirmar que nem sempre quando um algoritmo é mais rápido ele será mais
econômico. A Figura 4.13 mostra que o heapsort é mais econômico que o shellsort, apesar de
ser mais lento. Esta informação nos permite, por exemplo, afirmar que é mais vantajoso
utilizar o heapsort ao quicksort, no que se refere à economia no consumo de energia em
dispositivo móvel.

63
Ao utilizar-se da programação paralela nota-se que houve uma redução no consumo de
energia, quando o cluster executou o algoritmo. Esta economia foi de 71,91%. Esse resultado
pode ser confirmado pelo fato de que quando as máquinas dividem o processo, além do
tempo, todo o processamento é reduzido, tanto memória como processador são menos usados.
Desta forma, confirmam-se os resultados ao ver que o percentual de utilização do processador
foi reduzida de 96,5% para 49,8%. Sendo esta uma substancial diferença entre uma execução
seqüencial e uma paralela. Podendo-se afirmar que é justificável o uso de programação
paralela para redução do consumo de energia.
Como neste projeto foi estudado o consumo de energia em um ambiente paralelo que é
implementado na linguagem de programação C, uma proposta para um trabalho futuro seria a
montagem de um ambiente paralelo que utilizasse a linguagem de programação Java, e fazer
uma comparação tanto de desempenho como de consumo de energia. Podendo-se também
considerar um estudo mais aprofundado da linguagem, estudando sua estrutura, funções,
rotinas, para saber qual trecho do código demanda mais energia, e se possível reescrevê-lo,
para uma maior economia.
Uma possível continuação para este trabalho seria verificar quão significativa seria a
redução no consumo de energia de um celular ou PDA com a utilização da programação
paralela.
Como proposta de continuação deste trabalho, poder-se-ia verificar como se comporta
o consumo da bateria dos dispositivos quando mais máquinas são adicionadas ao cluster.

64
REFERÊNCIAS BIBLIOGRÁFICAS
BARAK, A.; SHILOH, A. The MOSIX2 Management System for Linux Clusters:
A White Paper. 2007. 8p. Disponível em: <http://www.mosix.org/txt_pub.html>.
Acesso em: 16 jan. 2008;
CALIFÓRNIA - ESTADOS UNIDOS DA AMÉRICA. Lawrence Livermore National
Laboratory (LLNL). National Nuclear Security Administration (NNSA) (Org.).
Message Passing Interface (MPI). Atualizado em 27 jun 2007. Disponível em:
<http://www.llnl.gov/computing/tutorials/mpi/>. Acesso em: 26 mai. 2008;
CELES, Waldemar; CERQUEIRA, Renato; RANGEL, José Lucas. Introdução a
Estrutura de Dados, com técnicas de programação em C. Elsevier Editora Ltda.
São Paulo, 2004;
COSTA, Ricardo Augusto Gomes da. Desenpenho e Consumo de Energia de
Algorítmos Criptográficos do MIBENCH em Sistemas Móveis. 2007. 64 f.
Trabalho de Conclusão de Curso (Engenheiro da Computação) - Curso de Engenharia
da Computação, Escola Superior de Tecnologia, Manaus, 2007;
DEMAC – Departamento de Estatística, Matemática Aplicada e Computação.
Introdução ao Processamento Paralelo e de Alto Desempenho. 3p. Disponível em:
<demac.rc.unesp.br/.../Arquiteturas.pdf>. Acesso em: 12 jan. 2008;
FERRARI, Adam. JPVM - The Java Parallel Virtual Machine. Virginia - Eua.
Material Eletrônico. 1999. Disponível em:
<http://www.cs.virginia.edu/~ajf2j/jpvm.html>. Acesso em: 26 dez. 2007;
FREITAS, Evandro Luiz de. Uma comparação entre os modelos de Message
Passing MPI e PVM: Introdução ao Processamento Paralelo Distribuído.
Universidade Federal do Rio Grande do Sul, Rio Grande do Sul, 2004. Disponível em:
<http://www.inf.ufrgs.br/procpar/disc/cmp134/trabs/T2/981/mpi.html>. Acesso em:
22 abr. 2008;
GROPP, William; LUSK, Ewing. Goals Guiding Design: PVM and MPI.
Universidade de Chicago – Eua. 2000. 9 p. Disponível em: <http://www-
unix.mcs.anl.gov/~gropp/bib/papers/2002/mpiandpvm.pdf>. Acesso em: 14 jun. 2007;

65
HENNESSY, John L; PATTERSON, David A. Organização e Projeto de
Computadores: A Interface Hardware/Software. 2.ed. Rio de Janeiro: Livros
Técnicos e Científicos, 2000;
HUGHES, Cameron. Parallel and Distributed Programming Using C++. Person
Education, Inc, 2004;
INTEL (Estados Unidos da América). Intel486™ Processors. Disponível em: <http://
www.intel.com/design/intarch/intel486/index.htm>. Acesso em: 17 ago. 2007;
LINDHEIM, Jan. Building a Beowulf System. Atualizado em 05 mar 2005.
Disponível em: <http://www.cacr.caltech.edu/beowulf/tutorial/building.html>. Acesso
em: 12 maio 2008;
MACEDO, Jeferson Augusto Matos de. Implementação de Cluster de
Computadores. 2004. 59 f. Trabalho de Conclusão Dse Curso (Graduação) - Curso
de Engenharia da Computação, Universidade de Tecnologia do Amazonas, Manaus,
2004;
MANIKA, Guilherme Wünsch. Supercomputador a preço de banana. Disponível
em: <http://augustocampos.net/revista-do-linux/002/beowulf.html>. Acesso em: 26
maio 2008.
MATHIAS, Elton Nicoletti. Introdução ao Processamento Paralelo e Distribuído.
Disponível em: <www.inf.ufrgs.br/procpar/disc/cmp134/trabs/T2/061/t2-enmathias-
pquick-mpi.pdf>. Acesso em: 26 dez. 2007;
MERKEY, Phil. Beowulf History. Disponível em:
<http://www.beowulf.org/overview/history.html>. Acesso em: 24 ago. 2008;
MORIMOTO, Carlos E. Entendendo os sistemas embarcados. Atualizado em 20 fev
de 2007. Disponível em: <http://www.guiadohardware.net/artigos/entendendo-
sistemas-embarcados/>. Acesso em: 17 fev. 2008;
MORIN, Steven Raymond. JMPI: IMPLEMENTING THE MESSAGE PASSING
INTERFACE STANDARD IN JAVA. 2000. 66 p. Dissertação (Mestre em Ciência
Eletrônica e Engenharia da Computação) - Graduate School of the University of
Massachusetts Amherst, Massachusetts - EUA, 2000. Disponível em:
<www.ecs.umass.edu/ece/realtime/publications/steve-thesis.pdf>. Acesso em: 09 fev.
2008;

66
PINA, António M. Máquina Paralela Virtual (PVM). Universidade do Minho,
Campus de Gualtar. Departamento de Informática. Braga, Portugal. 1998. Disponível
em: <http://www.di.uminho.pt/~amp/textos/pvm/pvm.html>. Acesso em: 17 jul. 2008;
PITANGA, Marcos. Computação em cluster. Última Atualização em 30 de maio de
2003. Disponível em: <http://www.clubedohardware.com.br/artigos/153>. Acesso em:
23 jul. 2008;
RÚBIO, Guilherme Messas. Implementação e configuração de um aglomerado de
computadores pessoais com Linux. Monografia (Bacharel) - Curso de Ciência da
Computação, Fundação de Ensino Eurípides Soares da Rocha -, Marília, 63 f, 2004;
SAITO, Priscila Tieme Maeda. Otimização do processamento de imagens mádicas
utilizando computação paralela. 2007. 159 f. Trabalho de Conclusão de Curso
(Baicharel) - Curso de Ciência da Computação, Centro Universitário Eurípides de
Marília, Marília - São Paulo, 2007.
SCHEPKE, Claudio. Implementação de MPI em Java. Instituto de Informática -
Universidade Federal do Rio Grande do Sul. Programação com Objetos Distribuídos.
2005. 8p. Disponível em:
<http://www.inf.ufrgs.br/~cschepke/mestrado/ArtigoMpiJava.pdf>. Acesso em: 09
ago. 2008;
SOFTSITE MOBILE (Brasil). Dispositivos Homologados. Fundada em 1996.
Disponível em: <http://www.softsite.com.br/index.php?
option=com_content&task=blogcategory&id=13&Itemid=30>. Acesso em: 18 fev.
2007.
SZTOLTZ, Lisiane; TEIXEIRA, Roberto Selbach; RIBEIRO, Evelyne de Oliveira
Ferraz. Guia do Servidor Conectiva Linux. Editado por Conectiva S.A. 2003.
Disponível em:
<http://www.dimap.ufrn.br/~aguiar/Livros/Conectiva9Server/book.html>. Acesso em:
14 maio 2007;
TANEMBAUM, Andrew S. Redes de Computadores. CAMPUS, 4a edição, 2003;
TANEMBAUM, Andrew S. Sistemas Operacionais Modernos. Person, 2a edição,
2006;

67
TANEMBAUM, Andrew S. Structured Computer Organization. Prentice Hall, 4a
edição, 1999;
WIKIPÉDIA. Quick sort. Disponível em:
<http://pt.wikipedia.org/wiki/Quicksort#Java>. Acesso em: 07 abr. 2008;
WIKIPÉDIA. Shell sort. Disponível em: <http://pt.wikipedia.org/wiki/Shell_sort>.
Acesso em: 11 set. 2008;
WIKIPÉDIA. Heapsort. Disponível em: <http://pt.wikipedia.org/wiki/Heap_sort>.
Acesso em: 11 set. 2008.

68
APÊNDICE A – CONFIGURANDO AS MÁQUINAS DO CLUSTER
As máquinas do cluster precisam se comunicar sem que haja necessidade de
autenticação entre elas. Dessa forma, alguns arquivos devem ser alterados e/ou criados para
que a senha de autenticação exigida pelo protocolo rsh(remote shell) deixe de ser exigida. É
necessário que estes arquivos sejam alterados em todas as máquinas do cluster.
A.1 Configuração do Arquivo hosts
O arquivo hosts está localizado no diretório /etc. Este arquivo deve conter os IPS
(Internet Protocols), os nomes e os apelidos atribuídos às máquinas que fazem parte do
cluster. Um exemplo de configuração do arquivo hosts é representado a seguir.
Configuração do arquivo hosts
A.2 Configuração do Arquivo hosts.equiv
O arquivo hosts.equiv encontra-se no diretório /etc. Os nome atribuídos às máquinas
devem ser colocados neste arquivo.
A.3 Configuração do Arquivo .rhosts
Esse arquivo deverá existir em cada diretório de trabalho do usuário, tanto o /home
como o /root. Este arquivo é utilizado pelo protocolo rsh para a execução de comandos
remotos. A seguir o formato do arquivo.
A.4 Configuração do Arquivo securetty
# IP hostname hostname127.0.0.1 localhost.localdomain localhost192.168.0.1 mestre mestre192.168.0.2 escravo escravo
# hostnamemestreescravo
mestreescravo

69
O arquivo securetty encontra-se no diretório /etc. Deve-se acrescentar ao final do
arquivo rsh e rlogin, conforme observado a seguir.
A pós as conFigurações, o próximo passo é a instalação e configuração MPI nas
máquinas, que pode ser visto no Apêndice B.
tty1tty2tty3tty4...rsh
rlogin

70
APÊNDICE B – INSTALAÇÃO DO MPI (MESSAGE PASSING INTERFACE)
Para a construção deste cluster foi utilizada a versão MPICH2-1.0.7.
Feito o download do arquivo mpich2-1.0.7.tar.gz é necessária sua descompactação. O
comando a seguir pode ser utilizado:
tar –zxvf mpich2-1.0.7.tar.gz
Um subdiretório mpich2-1.0.7 é criado. Nesse diretório deve-se conFigurar a
biblioteca de passagem de mensagens do MPI. A configuração pode ser feita com o seguinte
comando:
./configure –prefix=/usr/local
O configure analisa se todos os requisitos para a instalação estão disponíveis para a
compilação e conFigura os parâmetros de compilação de acordo com o sistema;
O prefix serve para especificar o diretório onde o o pacote será instalado;
/usr/local é o caminho onde deverá ser instalada a aplicação.
Obs:é aconselhável instalar o MPI na mesma paste em que for descompactado.
Em seguida deve-se compilar o software utilizando o comando make. Para compilar os
arquivos gerados na compilação deve-se utilizar o comando make install. Após a instalação,
deve-se acrescentar ~/mpich2-1.0.7/bin à variável de ambiente PATH, conforme pode ser
observado abaixo. Tal variável pode ser editada no arquivo .bash_profile ou /etc/profile,
dependerá da versão Linux a ser usada.
Para que as modificações nas variáveis de ambiente sejam permanentes, deve-se
reinicializar o Linux.
É necessária a criação de um arquivo contendo o
MPD_SECRETWORD=<secretword>. Como usuário root, o nome do arquivo deve ser
mpd.conf e estar localizado em /root. Como usuário qualquer, o nome do arquivo deve ser
MPI_HOME=/usr/local/mpich2-1.0.7PATH=$MPIR_HOME/bin:$PATH
export PATH

71
.mpd.conf (com o ponto antes do nome) e estar localizado no diretório /home. Pode-se
observar abaixo da criação do arquivo mpd.conf, em que mpipass é a senha escolhida.
Escolhida a senha, deve-se conFigurar as permissões do arquivo mpd.conf para que
somente o proprietário possa visualizá-lo ou modifica-lo. Para isso pode ser utilizado o
seguinte comando:
chmod 600 mpd.conf
Para testar se o sistema está conFigurado corretamente até o momento, é aconselhável
verificar se o servidor foi inicializado corretamente por meio dos comandos:
mpd &
mpdtrace
mpdallexit
Em que:
mpd & inicia a execução do servidor MPI;
mpdtrace mostra as conexões ativas que no caso é apenas um servidor;
mpdallexit fecha o servidor MPI;
Antes de executar qualquer aplicação é necessário iniciar a execução dos servidores
em todas as máquinas que participarão do processo.
No mestre: mpd &;
No escravo: mpd –h hostname –p port &.
Em que:
hostname é o hostname do servidor mestre;
port é a porta em que ele está sendo executado.
Essas informações podem ser encontradas por meio dos comandos hostname e
mpdtrace –l, respectivamente.
Alguns aplicativos de teste acompanham o pacote MPICH, podendo ser executados
para verificar se tudo está funcionando de forma correta.
Este teste de troca de mensagem pode ser realizado utilizando-se o programa para o
cálculo do PI paralelizado e compara com o valor 3,14159265358979. O programa CPI é um
MPD_SECRETWORD=mpipass

72
dos aplicativos de teste que acompanha m o pacote MPICH e pode ser encontrado em
~/mpich2-1.0.7/examples.
A compilação e a execução podem ser realizadas com os seguintes comandos:
mpicc –o cpi cpi.c
mpirun –n 2 cpi
Na execução dos programas, erros podem vir a ocorrer, caso isso aconteça, as
conFigurações do sistema relacionados às regras de segurança devem ser verificadas.
Configure o firewall para que ele permita a comunicação sem restrições entre as máquinas.
O resultado da execução do programa é apresentado abaixo:
mpicc -o cpi cpi.cmpirun -n 2 cpiProcess 0 of 2 is on mestre2Process 1 of 2 is on escravo2para 100000000 iterações pi é aproximadamente 3.1415926535900001,Erro é 0.0000000000002069tempo total = 2.65281

73
APÊNDICE C – INSTALAÇÃO DO AMBIENTE DE PROGRAMAÇÃO JAVA
Recomenda-se a utilização de versões superiores a 1.4 do JDK. Nesse caso foi
utilizada a versão jdk-1.0.5_13-i586.bin para Linux.
Antes de instala-lo é necessário transforma-lo em executável. Isso é possível com o
seguinte comando:
chmod +x jdk-1.0.5_13-i586.bin
Após isso é necessário apenas executa-lo. Isso é possível com o seguinte comando:
./ jdk-1.0.5_13-i586.bin
Após a instalação do JDK, deve-se adicionar ~/jdk-1.0.5_13/bin à variável de
ambiente PATH.
Um exemplo de configuração da variável de ambiente PATH é demonstrada abaixo,
considerando-se que jdk-1.0.5_13 é um subdiretório de /usr/local/java.
Para que as modificações nas variáveis de ambiente sejam permanentes, deve-se
reinicializar o Linux.
Realizadas as modificações, é possível verificar se as variáveis de ambiente foram
conFiguradas de forma correta pelo comando java –version. A versão exibida deve
corresponder a versão instalada.
JAVA_HOME=/usr/local/java/jdk1.0.5_13PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH

74
ANEXO A – ALGORITMO QUICKSORT JAVA_1
Apenas a classe QuickSort foi tirada de Wikipédia (2008).
import java.util.Comparator;
import java.util.Random;
public class QuickSort {
public static final Random RND = new
Random();
private static void swap(Object[] array, int
i, int j) {
Object tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
private static int partition(Object[] array,
int begin, int end, Comparator cmp) {
int index = begin; //+ RND.nextInt(end -
begin + 1);
Object pivot = array[index];
swap(array, index, end);
for (int i = index = begin; i < end; ++i) {
if (cmp.compare(array[i], pivot) <= 0) {
swap(array, index++, i);
} }
swap(array, index, end);
return (index);
}
private static void qsort(Object[]
array, int begin, int end, Comparator cmp) {
if (end > begin) {
int index =
partition(array, begin, end, cmp);
qsort(array, begin,
index - 1, cmp);
qsort(array, index + 1,
end, cmp);
}
}
public static void sort(Object[] array,
int i, int j, Comparator cmp) {
qsort(array, 0, array.length - 1,
cmp);
}
}
------------------------------------------------------

75
import java.util.Comparator;
public class ComparadorInteiro implements
Comparator<Integer> {
public int compare(Integer arg0, Integer
arg1) {
if (arg0< arg1)
return -1;
else if (arg0>arg1)
return 1;
else return 0;
}
}
------------------------------------------------------
import java.util.Comparator;
import java.util.Random;
import java.util.Date;
public class Principal {
public static final Random RND = new
Random();
/**
* @param args
*/
public static void main(String[] args) {
Integer v[] = new Integer[NUM];
int i;
int n = NUM;
for (i = 0; i < NUM; i++) {
v[i] = RND.nextInt(n + 1);
}
Comparator cmp = new ComparadorInteiro();
Date inicio = new Date();
QuickSort.sort(v, 0, v.length - 1, cmp);
Date fim = new Date();
System.out.println("Tempo em
milisegundos eh: "+(fim.getTime()-
inicio.getTime()));
}
}

76
ANEXO B – FUNÇÃO SHELLSORT: LINGUAGEM C (WIKIPÉDIA, 2008)void shellSort( long int size , long int * vet ) {
int i , j , value;
int gap = 1;
do {gap = 3*gap+1;} while ( gap < size );
do {
gap /= 3;
for ( i = gap; i < size; i++ ){
value =vet[i];
j = i - gap;
while ( j >= 0 && value < vet[j] ){
vet [j + gap] =vet[j];
j -= gap;
}
vet [j + gap] = value;
}
} while ( gap > 1);
}

77
ANEXO C – MÉTODO SHELLSORT: LINGUAGEM JAVA (WIKIPÉDIA, 2008)private static void shellSort ( int [ ] v )
{
int i , j , h = 1, value ;
do { h = 3 * h + 1; } while ( h < v.length );
do {
h /= 3;
for ( i = h; i < v.length; i++) {
value = v [ i ];
j = i - h;
while (j >= 0 && value < v [ j ])
{
v [ j + h ] = v [ j ];
j -= h;
}
v [ j + h ] = value;
}
} while ( h > 1 );
}
}

78
ANEXO D – FUNÇÃO HEAPSORT: LINGUAGEM C (WIKIPÉDIA, 2008)
void heapsort (long int n, long int* a)
{
long int i = n/2, pai, filho;
long int t;
for (;;)
{
if (i > 0)
{
i--;
t = a[i];
}
else
{
n--;
if (n == 0)
return;
t = a[n];
a[n] = a[0];
}
pai = i;
filho = i*2 + 1;
while (filho < n)
{
if ((filho + 1 < n) && (a[filho + 1] >
a[filho]))
filho++;
if (a[filho] > t)
{
a[pai] = a[filho];
pai = filho;
filho = pai*2 + 1;
}
else
break;
}
a[pai] = t;
}
}

79
ANEXO E – MÉTODO HEAPSORT: LINGUAGEM JAVA (WIKIPÉDIA, 2008)
public static void heapSort(int v [])
{
buildMaxHeap(v);
int n = v.length;
for (int i = v.length - 1; i > 0; i--)
{
swap(v, i , 0);
maxHeapify(v, 0, --n);
}
}
private static void buildMaxHeap(int v[])
{
for (int i = v.length/2 - 1; i >= 0; i--)
maxHeapify(v, i , v. length );
}
private static void maxHeapify(int v [], int pos,
int n)
{
int max = 2 * pos + 1, right = max + 1;
if (max < n)
{
if ( right < n && v[max] < v[right])
max = right;
if (v[max] > v[pos])
{
swap(v, max, pos);
maxHeapify(v, max, n);
}
}
}
public static void swap ( int [ ] v, int j, int
aposJ )
{
int aux = 0;
aux = v [ j ];
v [ j ] = v [ aposJ ];
v [ aposJ ] = aux;
}
}