Embed Size (px)
Citation preview

© 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
アマゾン ウェブサービス ジャパン 株式会社
エコシステム ソリューション部
パートナーソリューションアーキテクト
相澤恵奏
Amazon Redshift Ecosystem

自己紹介
名前:相澤 恵奏
外資系コンピューターベンダーにて、OLTP DBを10年
DWHを4年、プリセールスを担当。
得意領域はPOC/ベンチマーク。
現在:APNパートナー様をサポートするソリューションアーキテクト
好きなAWSサービス
RedshiftAmazonRedshift
• コスト
• パフォーマンス
• アジリティー
(俊敏性)

Ecosystem

AmazonRedshift
可視化データ連携
ETL BI
ユースケース
移行、構築、運用

本日のアジェンダ
Redshift 概要
Redshift Ecosystem

Redshift概要

DWHの時代遷移

DWHの時代による遷移
DWHアプライアンス
OLTP向けRDBMS
列指向型データベース
ソフトウェア
遅い
高い
■フルマネージド
運用のオフロード
■初期投資不要
使いたい時に
すぐに始められる。
■時間課金
■列指向、MPP
Amazon
Redshift

一般的な構成例
可視化保存 分析
S3 Redshift
一括ロード
BIツール
ETL
テキストファイル1,Book,100⏎2,Pen,50⏎…n,Eraser,10⏎
Webアクセス・ログ2013-06-05 12:00:00 192.168.0.2 http://www.amazon.com2013-06-05 12:00:01 …
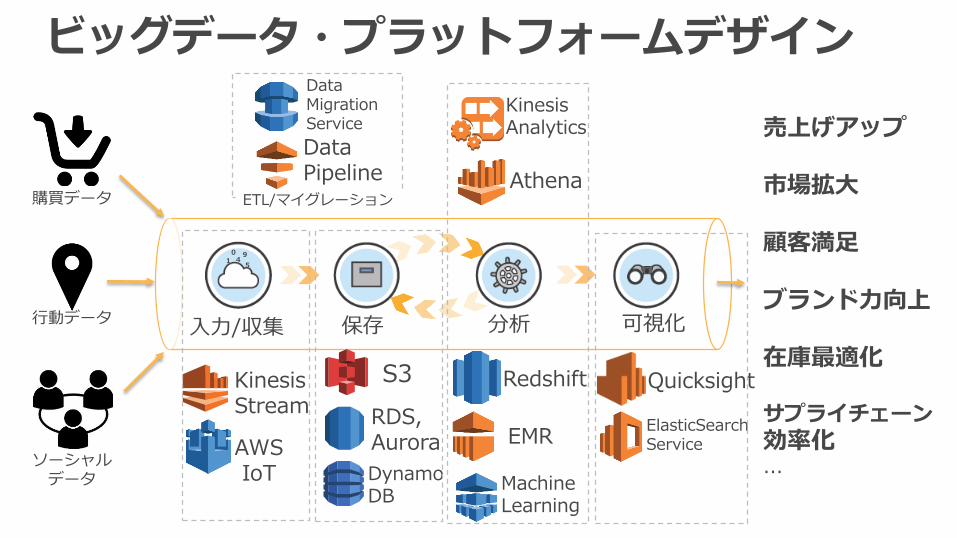
ビッグデータ・プラットフォームデザイン
購買データ
行動データ
ソーシャルデータ
入力/収集 可視化保存 分析
1 40 9
5
売上げアップ
市場拡大
顧客満足
ブランド力向上
在庫最適化
サプライチェーン
効率化...
KinesisStream
AWSIoT
S3
RDS, Aurora
DynamoDB
Redshift
EMR
DataPipeline
Quicksight
MachineLearning
DataMigrationService
ETL/マイグレーション
ElasticSearchService
Athena
KinesisAnalytics

クラウド上のデータウェアハウス
ペタバイト級までスケールアウト
フルマネージド(運用のオフロード)
多数の周辺ソフト; PgSQL互換性
$1,000/TB/年; 最小$0.314/時から
Amazon Redshift
より速くよりシンプルにより安価に
※費用は2017年6月時点での東京リージョンのものです

最大128ノードスケールアウト可能
1〜128台 伸縮性
10Gb Ether
JDBC/ODBC
Redshift

列指向型(カラムナ)
・行指向型 ・列指向型(Redshift)
orderid name price
1 Book 100
2 Pen 50
…
n Eraser 70
orderid name price
1 Book 100
2 Pen 50
…
n Eraser 70
DWH用途に適した格納方法

IOの削減が高速化のポイント
301
610
列指向カラムナーフォーマット
圧縮 ゾーンマップ

マネージドサービスでアプリケーション作成に注力
電源・ネットワーク
ラッキング
HWメンテナンス
OSパッチ
ミドルウェアパッチ
定形運用設計
スケールアウト設計
ミドルウェア導入
OS導入
アプリケーション作成
オンプレミス DWH DWH on EC2 Redshift
お客様がご担当する作業 AWSが提供するマネージド機能
電源・ネットワーク
ラッキング
HWメンテナンス
OSパッチ
ミドルウェアパッチ
定形運用設計
スケールアウト設計
ミドルウェア導入
OS導入
アプリケーション作成
電源・ネットワーク
ラッキング
HWメンテナンス
OSパッチ
ミドルウェアパッチ
定形運用設計
スケールアウト設計
ミドルウェア導入
OS導入
アプリケーション作成

マネージメントコンソール

フルマネージドサービス
設計・構築・運用の手間を削減
数クリックで起動
1時間単位の費用
ノード数やタイプは後から変更可能
バックアップ(Snapshot)やモニタリング機能を内蔵• GUI(マネジメントコンソール)
• API経由で操作も可能
パッチ適用も自動的• メンテナンスウィンドウでパッチの時間帯を指定可能

Redshift Ecosystem

AmazonRedshift
可視化データ連携
ETL BI
ユースケース
移行、構築、運用
ELT先にRedshiftにロードするケースもあります。

Redshiftと連携できる、ETL/BIツールは?
・ 今使っているものをそのまま使いたい・ 新しいものを構築したい

Amazon Redshift パートナー
https://aws.amazon.com/jp/redshift/partners/2017年6月現在

ESPカタログ(Ecosystem Solution Pattern)
270以上の、AWS上で稼働が確認されているソフトウェア製品のカタログです。PDFのダウンロードが可能ですので、是非ご活用ください。
https://aws.amazon.com/jp/solutions/partner-central/esp-catalog/

Redshift / ETL
Amazon Redshift

Redshift / BI/BA
Amazon Redshift
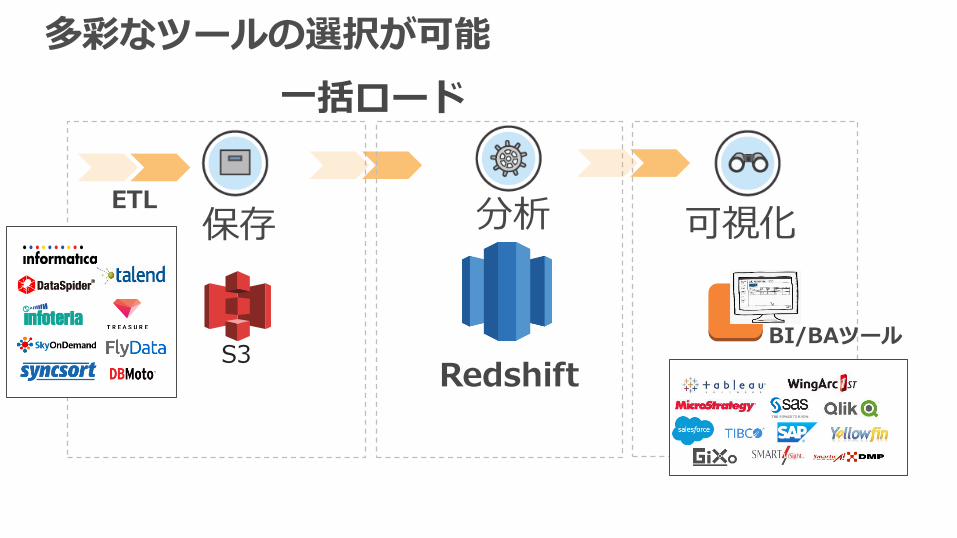
多彩なツールの選択が可能
可視化保存 分析
S3Redshift
一括ロード
BI/BAツール
ETL

AmazonRedshift
可視化データ連携
ETL BI
ユースケース
移行、構築、運用

多種多様な業界/業種で活用されております。
NTT Docomo | Telecom FINRA | Financial Svcs Philips | Healthcare Yelp | Technology NASDAQ | Financial Svcs
The Weather Company | Media Nokia | Telecom Pinterest | Technology Foursquare | Technology Coursera | Education
Coinbase | Bitcoin Amazon | E-Commerce Etix | Entertainment Spuul | Entertainment Vivaki | Ad Tech
Z2 | Gaming Neustar | Ad Tech SoundCloud | Technology BeachMint | E-Commerce Civis | Technology
https://aws.amazon.com/jp/redshift/customer-success/

AWSパートナー事例大全集 Vol.2
★注力ソリューション
マイグレーション、ERP、ビッグデータ、
IoT★注力業種
金融、製造、メディア
・175事例、約400ページのボリューム
・アライアンスブースで配布しています!!!

Data Lake

データレイク
センターデータ
非構造化ファイルテキストファイル
RDBMS
データレイク
API呼び出しによる連携
多様なデータを一元的に保存
決められた方法(API)ですぐにアクセスできる
サイズ制限からの開放

Amazon S3
データ分析
Elastic MapReduce Redshift
データバックアップ
EC2 RDS
Storage Gateway
EBS
Redshift
コンテンツ配信
CloudFront
データアクセスGW
Storage Gateway
コンテンツトランスコード
Elastic Transcoder
データアーカイブ
Glacier
データ交換
Data Pipeline
S3にデータを保存 各種AWSサービスとの連携が容易に
Athena

S3によるデータレイク実現のメリット
• 上限無し:サイジング不要
• 高い耐久性:99.999999999%
• 安価な費用:
• APIアクセス
• 多様な言語にライブラリを提供
• AWS各種サービスと連携
データレイク
Amazon EMR(Hadoop)
Amazon Redshift
Amazon API
Gateway
Amazon S3
センターデータ 非構造化ファイルテキストファイル
RDBMS
AmazonAthena

ビッグデータ・プラットフォームデザイン
可視化保存 分析
S3 Redshift
一括ロード
BIツール
ETL
データレイク

S3上のデータを、Redshiftにロードすることなく外部表として直接アクセスしたい。

Amazon Redshift Spectrumがその課題を解決します
スケールアウトでエクサバイト級に対応
高速 オンデマンド、
クエリ毎の費用
オープンファイル
フォーマットデータを移動させずに
クエリ
フルマネージド
大規模スケールアウトの処理層を使い、S3上のデータに対してSQLを実行する

Amazon Redshift Spectrum
Data Catalog
2 CREATE EXTERNAL SCHEMA でクラスターと、データカタログもしくはHive Meta Storeを接続
3CREATE EXTERNALTABLE で外部表としてS3データを定義
Amazon S3
1S3にParquet / CSV 等の形式でファイルを作成(もしくは既存をそのまま)
4 クエリを実行SELECT COUNT(*)FROM S3.EXT_TABLEGROUP BY…
Redshift Cluster(s)
Spectrum層1 2 3 4 ... N
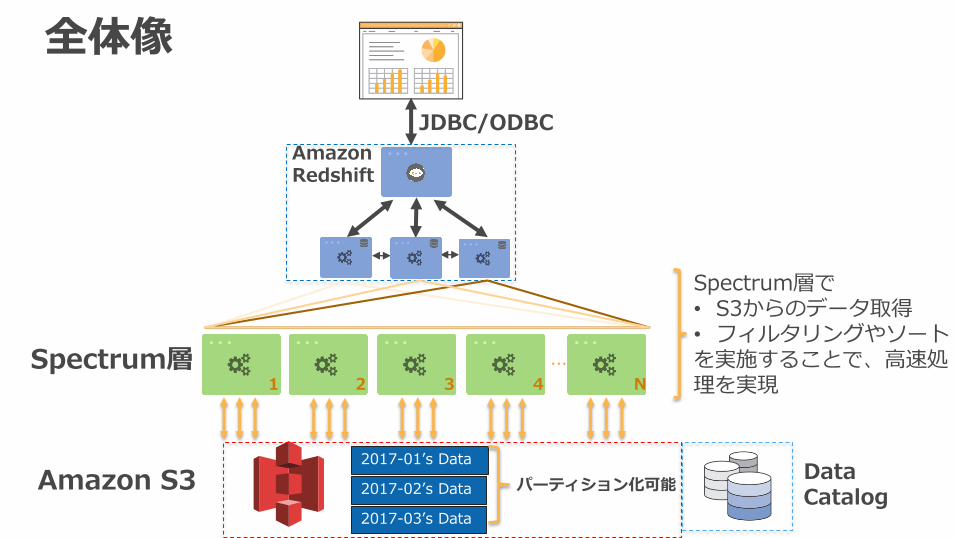
全体像
Amazon Redshift
JDBC/ODBC
...
1 2 3 4 N
Amazon S3 Data Catalog
Spectrum層
Spectrum層で• S3からのデータ取得• フィルタリングやソートを実施することで、高速処理を実現
2017-01’s Data
2017-02’s Data
2017-03’s Data
パーティション化可能

CREATE EXTERNAL SCHEMA s3 FROM DATA CATALOG
DATABASE 'spectrum_test'
IAM_ROLE 'arn:aws:iam::999999999999:role/spectrum-s3-athena'
CREATE EXTERNAL DATABASE IF NOT EXISTS;
create external schema
CREATE EXTERNAL TABLE s3.customer(
c_custkey integer,
c_nation varchar(15),
c_name varchar(25))
PARTITIONED BY (cusdate date)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
LOCATION 's3://redshift-test1-virginia/customer/’;
create external table

s3://redshift-test1-virginia/customer
----- /cusdate=2017-01/customer201701.gz
----- /cusdate=2017-02/customer201702.gz
----- /cusdate=2017-03/customer201703.gz
ALTER TABLE s3.customer
ADD PARTITION(custdate='2017-01-01')
LOCATION 's3://redshift-test1-virginia/customer/cusdate=2017-01/';
ALTER TABLE s3.customer
ADD PARTITION(custdate='2017-02-01')
LOCATION 's3://redshift-test1-virginia/customer/cusdate=2017-02/';
ALTER TABLE s3.customer
ADD PARTITION(custdate='2017-03-01')
LOCATION 's3://redshift-test1-virginia/customer/cusdate=2017-03/';
alter table partition

Partition化することにより不要な部分は読まない
SELECT c_nation,count(*) FROM s3.customer
WHERE cusdate='2017-03-01'
GROUP BY c_nation ORDER BY 2 LIMIT 4;
c_nation | count
-----------------+-------
JAPAN | 19708
JORDAN | 19749
BRAZIL | 19774
CHINA | 19811
(4 rows)
2017-03’s Data
2017-01’s DataPartitionの設定により読み込まない
2017-02’s Data

実行計画
EXPLAIN SELECT c_nation,count(*) FROM s3.customer WHERE cusdate='2017-03-01' GROUP BY c_nation ORDER BY 2 LIMIT 4;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------- XN Limit (cost=1000300017023.64..1000300017023.65 rows=4 width=48)
-> XN Merge (cost=1000300017023.64..1000300017024.14 rows=200 width=48)
Merge Key: sum(*)
-> XN Network (cost=1000300017023.64..1000300017024.14 rows=200 width=48)
Send to leader
-> XN Sort (cost=1000300017023.64..1000300017024.14 rows=200 width=48)
Sort Key: sum(*)
-> XN HashAggregate (cost=300017015.50..300017016.00 rows=200 width=48)
-> XN Partition Loop (cost=300000000.00..300012015.50 rows=1000000 width=48)
-> XN Seq Scan PartitionInfo of s3.customer (cost=0.00..12.50 rows=5 width=0)
Filter: (cusdate = '2017-03-01'::date)
-> XN S3 Query Scan customer (cost=150000000.00..150002000.50 rows=200000 width=48)
-> S3 HashAggregate (cost=150000000.00..150000000.50 rows=200000 width=40)
-> S3 Seq Scan s3.customer location:"s3://redshift-test-virginia/customer" format:TEXT (cost=0.00..100000000.00 rows=10000000000 width=40)

S3上のデータを外部表として参照が可能に
可視化保存 分析
S3 Redshift外部表
Spectrum

毎朝、9:00にDWHへの負荷が集中する。

RDS(PostgreSQL)前面配置がその課題を解決します
dblink、マテリアライズドビューなどを使い、キャッシュとしてRDSを利用する。
http://aws.typepad.com/sajp/2016/06/join-amazon-redshift-and-amazon-rds-postgresql-with-dblink.html

全体像
Amazon Redshift
JDBC/ODBC
RDS PostgreSQL
すでにRDS上にマートがあるのでRDSへアクセス
dblink定期的にMV(マテリアライズドビュー)を更新

CREATE EXTENSION postgres_fdw;
CREATE EXTENSION dblink;
CREATE SERVER foreign_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'tests.cvjywiabyocg.us-east-1.redshift.amazonaws.com',
port ’5439', dbname ’testspectrum', sslmode 'require');
CREATE USER MAPPING FOR dbadmin
SERVER foreign_server
OPTIONS (user ’dbadmin', password ’xxxxxxxxxx');
PostgreSQLサーバー側での作業
オレンジ文字は環境に合わせて変更ください。

SELECT *FROM dblink('foreign_server',$REDSHIFT$
SELECT c_nation,count(*) countFROM s3.customerGROUP BY c_nationORDER BY 2
$REDSHIFT$) AS t1 (c_nation varchar(20), count int);
Redshift で実行されるクエリー
PostgreSQL経由でRedshiftへのSQL

CREATE MATERIALIZED VIEW EVERY_9AM_VIEW AS
SELECT *
FROM dblink('foreign_server',$REDSHIFT$
SELECT aaaa, bbbb, cccc
FROM tablea,tableb, tablec
WHERE Join条件
$REDSHIFT$) as t1 (z1 varchar(20), z2 varchar (20),z3 bigint);
マテリアライズドビュー作成分析に時間が掛かるクエリー、朝9時に負荷が集中するクエリーをマテリアライズド
ビューとしてPostgreSQL側に持たせる。
REFRESH MATERIALIZED VIEW EVERY_9AM_VIEW;
SELECT * FROM EVERY_9AM_VIEW; マテリアライズドビューへのアクセス
定期的なマテリアライズドビューの更新(※大量データがあるケースなどでは、MVではなく、dblink関数を利用してPostgreSQL上の表にInsert intoで最新データのコピーも要検討)
PostgreSQL側にマテリアライズドビュー作成

全体像
Amazon Redshift
JDBC/ODBC
RDSPostgreSQL
朝のラッシュは前面のPostgreSQLで対応する。
dblink定期的にMV(マテリアライズドビュー)を更新
AWS Lambda

Lambda連携var pg = require("pg");
exports.handler = function(event, context) {var conn = "pg://username:password@host:port/dbname";var client = new pg.Client(conn);client.connect(function(err) {
if (err) {context.fail("Failed" + err);
}client.query('REFRESH MATERIALIZED VIEW EVERY_9AM_VIEW', function (err, result) {
if (err) {context.fail("Failed to run query" + err);
}client.end();context.succeed("Successfully Refreshed.");
});});
};
AWSLambda

全体像
RDS PostgreSQL
テーブルごとに振り分ける為、ロードバランサーを定義する。
pgbouncer-rr
Amazon Redshift
http://aws.typepad.com/sajp/2016/06/join-amazon-redshift-and-amazon-rds-postgresql-with-dblink.html
Redshiftへのアクセス キャッシュ層

RDSを前面において、負荷を分散するパターン
可視化保存 分析
S3Redshift
RDS PostgreSQL
マテリアライズドビュー

S3上のデータを複数のRedshiftで参照パターン
可視化保存 分析
S3 Redshift外部表
Spectrum

AmazonRedshift
可視化データ連携
ETL BI
ユースケース
移行、構築、運用

既存DWHからRedshiftへ移行したい。
Bigdata新規基盤を構築したい。
既存のRedshiftのチューニングしたい。

Legacy BI Solution New BI Solution
既存DWH
ソースデータ 新規ソースデータ
共通データ
ダウンタイムをできるだけ少なくRedshiftへ移行
POC &スモールスタート
Amazon Redshift
開発
スケールアウト

既存DWHからRedshiftへの移行時の考慮点
業務の最適化(移行すべき箇所の洗い出し)
スキーマ/データ構造
クエリー(SQL文)
既存アプリ(ストアドプロシージャなど)
パフォーマンスを意識したテーブル設計
データ移行
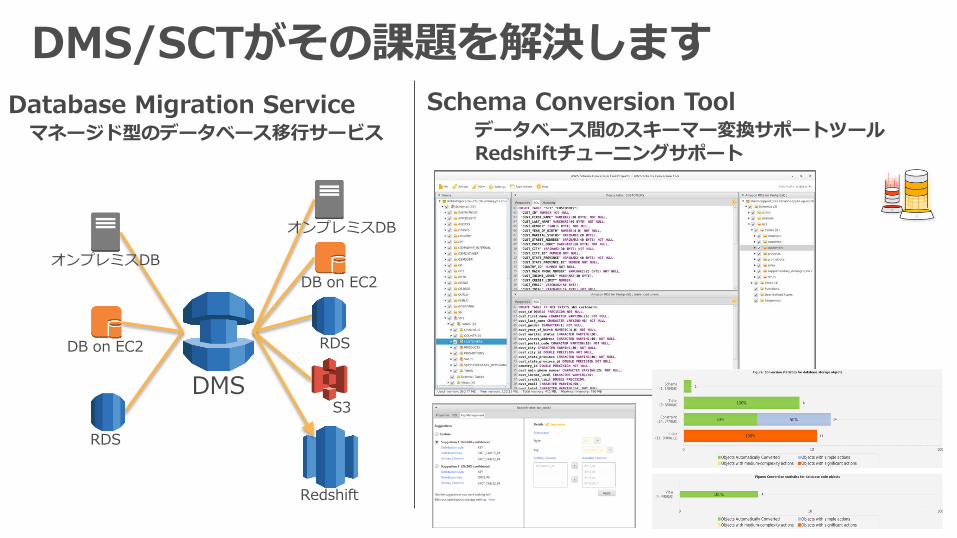
Database Migration Serviceマネージド型のデータベース移行サービス
オンプレミスDB
DB on EC2
RDS
オンプレミスDB
DB on EC2
RDS
DMSS3
Redshift
DMS/SCTがその課題を解決しますSchema Conversion Tool
データベース間のスキーマー変換サポートツールRedshiftチューニングサポート

スキーマー変換のサポートに加え、データ移行にも対応
MicrosoftSQL Server
Netezza
Redshift
SCT
Teradata
Oracle
Greenplum
Source Database
Greenplum Database (version 4.3 and later)
Microsoft SQL Server (version 2008 and later)
Netezza (version 7.2 and later)
Oracle (version 11 and later)
Teradata (version 14 and later)
Vertica (version 7.2.2 and later)
http://docs.aws.amazon.com/SchemaConversionTool/latest/userguide/Welcome.html
Vertica

既存DWHからRedshiftへの移行をサポートして欲しい
Bigdata新規基盤の構築をサポートして欲しい
既存のRedshiftのチューニングをサポートして欲しい

AmazonRedshift
可視化データ連携
ETL BI
ユースケース
移行、構築、運用

https://aws.amazon.com/jp/partners/competencies/
習熟した技術を持ち、専門的なソリューションエリアでお客様を成功に導いた実績を持つ APNパートナーに付与されます。

複数の案件のサポート実績に加えて、対象サービスに関するソリューションを公開しているなど、厳しい要件をクリアしたAPNパートナーを認定する制度です。
https://aws.amazon.com/partners/service-delivery/

Redshift Service Delivery Program取得パートナー様
Redshift 案件がございましたら、是非ともご相談ください。
Amazon Redshift

まとめ
• クラウドの上のDWH Amazon Redshift
• 列指向、MPP、フルマネージド、RDS PostgreSQL との連携
• Amazon Redshift Spectrum
• S3上のデータを外部表としてアクセスできる新機能
• ESPカタログ
• Redshiftと連携できるツールの確認
• Amazon Redshift Service Delivery Program• Redshiftの案件を依頼するならこのパートナー!

AWS ソリューション Day 2017- Database Day ~すでに始まっている!「クラウドへのデータベース移行」と「データレイクを軸としたビッグデータ活用」~
Database Dayとは?
ユーザー企業/パートナー/AWSによる導入事例や活用動向また技術情報をご紹介するIT部門(エンジニア・管理者など)向けのカンファレンス
開催日時・会場
• 2017年7月5日(水) 10:00~17:30 (9:30開場予定)
• 大崎ブライトコアホール(JR大崎駅より徒歩5分)
セッション
①基調講演 ②ブレイクアウトセッション – 2トラック構成
トラック1:データベース移行 (事例セッションあり)
トラック2:データレイク(JAWSUG-BigData支部 事例セッションあり)
お申込みhttps://aws.amazon.com/jp/about-aws/events/2017/solutiondays20170705/

本セッションのFeedbackをお願いします
受付でお配りしたアンケートに本セッションの満足度やご感想などをご記入くださいアンケートをご提出いただきました方には、もれなく素敵なAWSオリジナルグッズをプレゼントさせていただきます
アンケートは受付、パミール3FのEXPO展示会場内にて回収させて頂きます

Thank you!