Embed Size (px)
Citation preview

Autore Flavio Cerini 1
DEFINIZIONI
PROGRAMMA : Insieme statico di istruzioni (entità passiva) che descrive le azioni da compiere ( un programma viene eseguito ) PROCESSO : Entità attiva che rappresenta l’esecuzione di tali azioni ( un processo viene avanzato ) . Il processo é il job associato alla risorsa che ha richiesto ( rappresenta l’evoluzione dinamica di un programma ) JOB : Una richiesta elementare di utilizzo di una risorsa , presente all’interno del programma in esecuzione . ( una singola istruzione ad alto livello contiene molte operazioni . Per la CPU l’operazione elementare é il JOB PROCESSORE : Dispositivo che consente l’evoluzione e il completamento di un processo ( in genere si intende la CPU ) . In multiprogrammazione ogni utente ha l’impressione di lavorare con un suo processore virtuale . NB : più processi possono essere associati allo stesso programma : ciascuno rappresenta l’esecuzione dello stesso codice con dati diversi ) . THREAD : Termine introdotto in tempi molto recenti ( verso la fine degli anni 80 ) . Un thread rappresenta un segmento di istruzioni di un processo in esecuzione . Un processo é un insieme di thread che rappresentano il suo codice eseguibile . Un processo é composto come minimo da un thread , ma normalmente ad ogni processo ne vengono associati più di uno in base alle capacità di avanzamento concorrente di ciascuno . La dichiarazione e definizione di un thread può avvenire a livello software ( includendo nel programma opportune chiamate a procedure di sistema che gestiscono i thread ) oppure venire generati autonomamente dal S.O quando é in grado di individuare tra i compiti da eseguire quelli che possono essere resi concorrenti . Un processo multithreading in un certo istante ha più parti in esecuzione cioé più zone di programma che avanzano concorrentemente . Il vantaggio principale che si ottiene ricorrendo ai thread é la maggiore velocità di commutazione . Il processo é un’entità più consistente di un thread Il thread viene infatti chiamato anche light process ( processo leggero )
Appunti Di Sistemi Operativi
Prof. Flavio Cerini

Autore Flavio Cerini 2
Definizioni di sistema operativo : 1) Il S.O é il gestore delle risorse del calcolatore , cioé il software di base che serve
all’utente per lavorare con l’hardware . 2) Un S.O può essere definito come un insieme di procedure manuali e automatiche che
consentono all’utente di un sistema di elaborazione di usarlo efficientemente . 3) Un S.O é un insieme di strumenti per lo sviluppo e l’esercizio del software e delle
comunicazioni per un dato sistema hardware nel rispetto dei seguenti principi
a) Visione astratta delle risorse da parte degli utenti , cioé il più possibile indipendente dalle
risorse hardware e dalla loro ubicazione nel sistema hardware b) Gestione corretta , sicura ed efficiente delle risorse
4) Un S.O é un insieme di programmi che assolvono al duplice compito di far vedere
all’utente una macchina virtuale semplificata e di gestire in maniera ottimizzata le risorse del sistema
FUNZIONI SVOLTE DA UN SISTEMA OPERATIVO Le funzioni svolte da un S.O , pur diverse a seconda delle modalità di funzionamento del sistema sono comunque riconducibili ad alcune categorie ben definite . 1) Gestione delle risorse sia hardware ( tempo di cpu , spazio di memoria , dispositivi di
I/O ecc ) che software ( file , strutture dati , ecc ) . Il S.O assegna le risorse ai processi di utente in base a prefissate politiche . 2) Definizione di una macchina virtuale di più semplice uso da parte degli utenti , in grado
di nascondere tutta una serie di particolarità del funzionamento del sistema legate alla struttura del HW ( es gestione interruzioni , utilizzo dei dispositivi di I/O ecc ). La macchina virtuale mette a disposizione dell’utente apposite operazioni ( system calls ) che gli consentono di operare ad un livello di astrazione maggiore . Si noti che le due funzioni rappresentano due modi diversi , ma strettamente connessi , di rappresentare il ruolo di un sistema operativo .

Autore Flavio Cerini 3
RISORSE DEL SISTEMA
Un sistema di elaborazione si può considerare suddiviso in quattro gruppi di elementi ( risorse ) • MEMORIA CENTRALE • PROCESSORE • DISPOSITIVO DI I/O • MEMORIA DI MASSA
struttura di Von Neumann :
Memoria di massa (hard/disk) Le risorse non sono solo hardware ma anche software ( es file presenti in memoria) . Il S.O sarà quindi composto di moduli software che si occupano di gestire una singola classe di risorse , garantendo le seguenti funzioni fondamentali : 1) Conoscere lo stato delle risorse di cui sono responsabili 2) Determinare la politica di allocazione della risorsa ( quale processo deve assumere una
risorsa , quando e per quanto tempo ) 3) Allocare fisicamente la risorsa secondo la strategia prescelta 4) Deallocare la risorsa secondo la strategia prescelta
CONCETTO DI RISORSA RISORSA : Qualsiasi elemento HW oppure SW che viene usato da un processo e che ne condiziona l’avanzamento ( o la creazione )
CPU
MEMORIA CENTRALE
INPUT /OUTPUT
HD

Autore Flavio Cerini 4
PRIMA CLASSIFICAZIONE DEI S.O
1) S.O MONOPROGRAMMATI 2) S.O MULTIPROGRAMMATI 3) S.O DISTRIBUITI 1) S.O MONOPROGRAMMATI : S.O nei quali é possibile eseguire un solo programma per volta ; quindi tutte le risorse sono riservate a questo programma . Il S.O sarà abbastanza semplice , non ci sono problemi di competizione per l’utilizzo delle risorse ( es S.O MS DOS ) problema : Risorse usate in modo poco efficiente con lunghi tempi di inattività 2) S.O MULTIPROGRAMMATI : Gestiscono sistemi di elaborazione in grado di far eseguire più programmi contemporaneamente . Si possono presentare due casi a) Un unico utente fa girare più programmi b) Più utenti lavorano sul loro programma che gira su un elaboratore centrale • In questi ambienti é fondamentale gestire l’assegnazione delle risorse . • Gli utenti non devono attendere troppo • Non si devono creare conflitti fra i processi Vantaggi : - Gestione “ contemporanea “ di più programmi indipendenti presenti nella memoria principale - Migliore utilizzazione delle risorse ( riduzione dei tempi morti ) Svantaggi : - Maggiore complessità del S.O - Algoritmi per la gestione delle risorse ( cpu , memoria , I/O )

Autore Flavio Cerini 5
- Protezione degli ambienti dei diversi programmi ( CPU 286 e successive ) Nei sistemi multiprogrammati si fa riferimento ai concetti di overlapping e interleaving Si faccia riferimento alla Fig Overlapping : Sovrapposizione temporale di processi Interleaving : alternanza temporale di processi PR2 PR1 overlapping interleaving 3) S.O DISTRIBUITI Reti di calcolatori . Un S.O di questo genere deve fare in modo che ogni utente possa connettersi ad una parte qualsiasi del sistema nello stesso modo , come se tutto fosse immediatamente disponibile . Il S.O deve tener conto di molti elementi . La classificazione di cui si é parlato é trasparente per l’utente . I comandi di dialogo , il lancio dei programmi , possono essere identici nei tre sistemi visti 4) S.O TIME SHARING
Tempo di CPU
SERVONO PIU’ CPU
UNA SOLA CPU

Autore Flavio Cerini 6
Processore assegnato ad ogni processo per un quanto di tempo ( time slice ) . Ogni utente ha l’impressione di avere a disposizione tutto il sistema . CLASSIFICAZIONE DEI SISTEMI OPERATIVI L’utente può utilizzare un sistema di elaborazione secondo due modalità fondamentali : A) BATCH ( a lotti ) : non c’é interazione diretta con l’utente . L’obiettivo del S.O é l’ottimizzazione dell’uso delle risorse ( non esistono pregiudiziali verso la multiprogrammazione ) B) INTERATTIVO : l’utente vede una propria macchina vi rtuale con la quale interagire
mediante una serie di comandi Un sistema di elaborazione può essere specializzato dal sistema operativo per particolari applicazioni. S.O real time : generalmente sono sistemi dedicati al controllo di processi industriali. Sono molto importanti i brevi tempi di risposta . In par ticolare si parla di tempo reale stretto ( es processi industriali ) e tempo reale debole ( es prenotazione voli aerei ) . S.O dedicati : previsti per sistemi di elaborazione che devono effettuare delle azioni ripetitive ( es controllo di processi industriali ) . S.O transazionali : Sistemi interattivi che consentono solo accesso e modifica ad archivi di dati ( applicazioni bancarie ) .
Autore Flavio Cerini 7
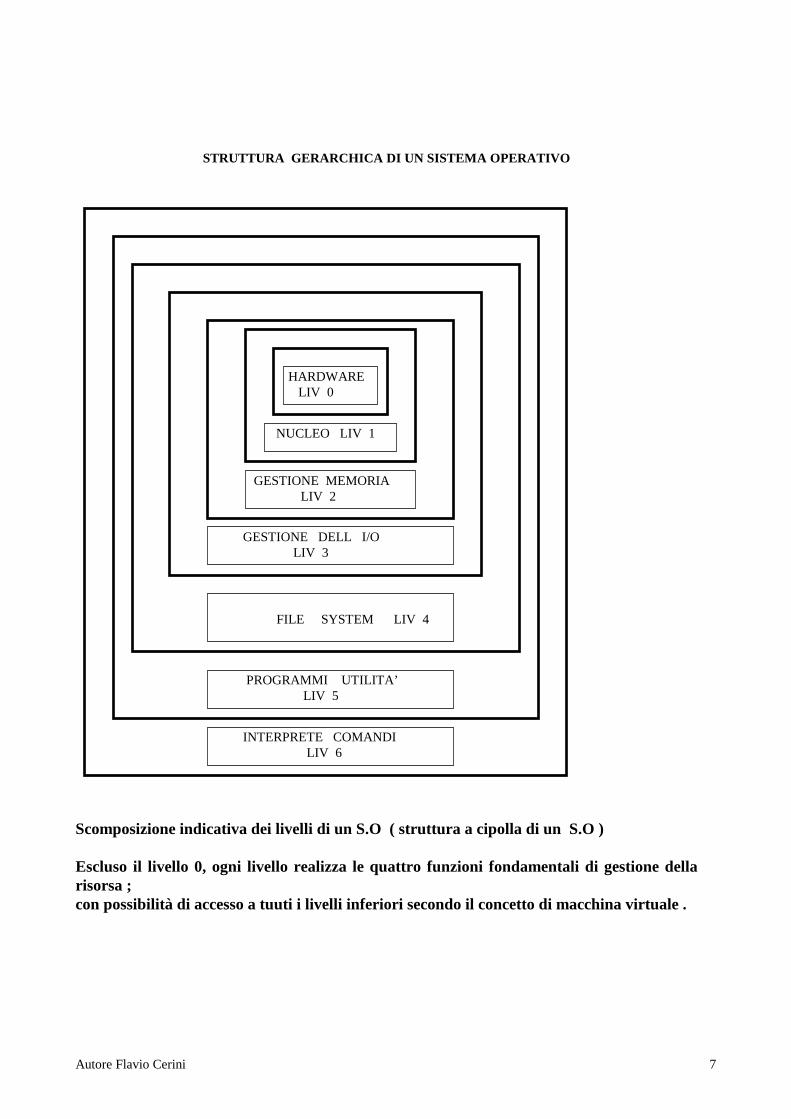
STRUTTURA GERARCHICA DI UN SISTEMA OPERATIVO Scomposizione indicativa dei livelli di un S.O ( struttura a cipolla di un S.O ) Escluso il livello 0, ogni livello realizza le quattro funzioni fondamentali di gestione della risorsa ; con possibilità di accesso a tuuti i livelli inferiori secondo il concetto di macchina virtuale .
HARDWARE LIV 0
NUCLEO LIV 1
GESTIONE MEMORIA LIV 2
GESTIONE DELL I/O LIV 3
FILE SYSTEM LIV 4
PROGRAMMI UTILITA’ LIV 5
INTERPRETE COMANDI LIV 6

Autore Flavio Cerini 8
FUNZIONI DEI LIVELLI Nucleo o Kernel 1) Conoscere lo stato del del processore e dei programmi in attesa ; il programma che si
occupa di ciò é il traffic controller 2) Decidere chi può utilizzare il processore ( job scheduler ) nel caso di
multiprogrammazione ( process scheduler ) 3) Allocare la risorsa secondo indicazioni definite in precedenza 4) Rilasciare il processore secondo indicazioni definite in precedenza GESTIONE DELLA MEMORIA CENTRALE 1) Conoscere lo stato della memoria , quali parti sono in uso e quali sono libere 2) In caso di multiprogrammazione , decidere chi dovrà avere spazio in memoria centrale ,
quando e quanto 3) Allocare la memoria secondo i criteri stabiliti 4) Rilasciare ( deallocare ) la memoria quando non serve più
GESTIONE DELL’ I/O 1) Conoscere lo stato delle periferiche ( I/O traffic controller ) 2) Decidere le modalità di assegnazione delle periferiche ai programmi ( I/O scheduler ) 3) Allocare la risorsa e dare inizio all’operazione di I/O 4) Rilasciare la periferica
GESTIONE DELLA MEMORIA DI MASSA
1) Conoscere lo stato dei dispositivi di memoria di massa , il loro uso , il modo di accesso (
file system ) 2) Decidere chi potrà utilizzare le utility secondo le caratteristiche specifiche del prodotto . 3) Allocare la funzione utility ( es lanciare software relativo ) 4) Rilasciare la risorsa ( es chiudere la funzione )
INTERPRETE COMANDI 1) Conoscere lo stato dei moduli di sistema esistenti e disponibili per le chiamate dell’utente 2) Decidere le tecniche di chiamata delle funzionalità di sistema

Autore Flavio Cerini 9
3) Esaudire la chiamata 4) Rilasciare la risorsa NB non ci sono necessariamente 6 livelli gerarchici . In tutti i sistemi operativi moderni resta pero valido il concetto dei livelli virtuali e le loro assegnazioni ESEMPIO DOS Bios : parte bassa de nucleo ( il colloquio con HW avviene tramite INT software ) Dos rappresenta una sintesi dei livelli di astrazione superiori visti precedentemente ( schema generale ) . Il modulo IBMBIO ( parte inferiore che completa il nucleo e arriva alla gestione dell’ I/O . IBMDOS costituisce fondamentalmente il file system Il livello command del DOS é l’interprete comandio
STATI DI UN PROCESSO Esistono concettualmente due stati per un processo : esecuzione e bloccato a questi si aggiunge uno stato di pronto per motivi di limitazione di risorse ( CPU ) . Un processo transita durante la suia vita tra questi stati . E’ compito del sistema operativo ( nucleo o kernel ) gestire la transizione
CICLO DI VITA DI UN PROCESSO
HARDWARE LIV 0
BIOS LIV 1
DOS LIV 2
Autore Flavio Cerini 10
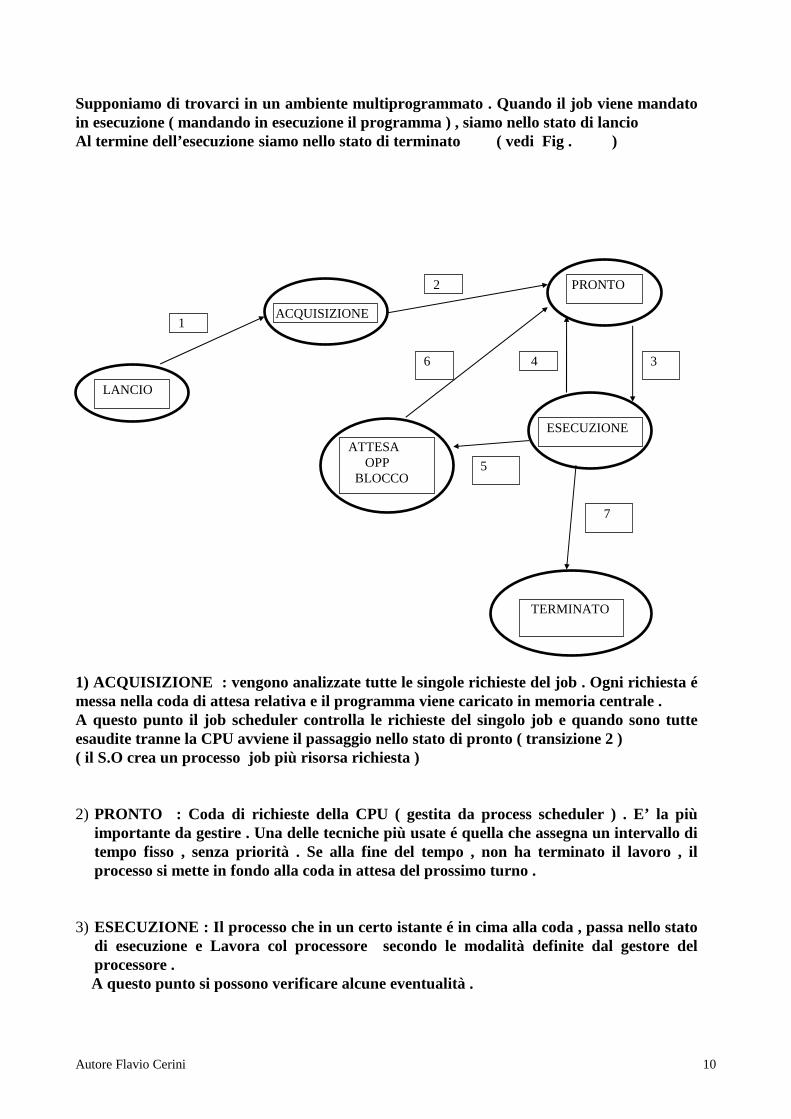
Supponiamo di trovarci in un ambiente multiprogrammato . Quando il job viene mandato in esecuzione ( mandando in esecuzione il programma ) , siamo nello stato di lancio Al termine dell’esecuzione siamo nello stato di terminato ( vedi Fig . ) 1) ACQUISIZIONE : vengono analizzate tutte le singole richieste del job . Ogni richiesta é messa nella coda di attesa relativa e il programma viene caricato in memoria centrale . A questo punto il job scheduler controlla le richieste del singolo job e quando sono tutte esaudite tranne la CPU avviene il passaggio nello stato di pronto ( transizione 2 ) ( il S.O crea un processo job più risorsa richiesta ) 2) PRONTO : Coda di richieste della CPU ( gestita da process scheduler ) . E’ la più
importante da gestire . Una delle tecniche più usate é quella che assegna un intervallo di tempo fisso , senza priorità . Se alla fine del tempo , non ha terminato il lavoro , il processo si mette in fondo alla coda in attesa del prossimo turno .
3) ESECUZIONE : Il processo che in un certo istante é in cima alla coda , passa nello stato
di esecuzione e Lavora col processore secondo le modalità definite dal gestore del processore .
A questo punto si possono verificare alcune eventualità .
LANCIO
1 ACQUISIZIONE
2 PRONTO
ESECUZIONE
3 4
ATTESA OPP BLOCCO
5
6
7
TERMINATO

Autore Flavio Cerini 11
a) Il processo ha finito il suo lavoro col processore prima dello scadere dell’intervallo di tempo a sua disposizione
b) Il processo non ha terminato il suo lavoro allo scadere dell’intervallo a sua disposizione . c) Il processo deve bloccare temporaneamente il lavoro col processore perché ha bisogno ,
per poter continuare , di eventi di tipo diverso ( es letture opp operazioni di I/O ) a) In questo caso il processo passa tramite la freccia ( 7 ) nello stato di terminato
rilasciando tutte le risorse in suo possesso b) Il processo é costretto a rilasciare il processore , ne ha comunque ancora bisogno ,
quindi tramite la freccia ( 4 ) torna a mettersi in coda per l’uso del processore c) Tramite la freccia ( 5 ) passa nello stato di attesa dove resta congelato finché il modulo (
I/O traffic controller ) non gli consente di riprendere il lavoro facendolo passare nello stato di pronto ( 6 )
Esistono tre code ( acquisizione , pronto , attesa ) e il processo cicla fra pronto ,esecuzione attesa .
PROCESSI E RISORSE Un Job che acquisisce la propria risorsa diventa un processo. Il numero di risorse è limitato , quindi é compito del S .O garantire l’avanzamento di tutti i processi senza che si generino sovrappposizioni e ambiguità . PROCESSI SEQUENZIALI Tutti i job vengono eseguiti nello stesso ordine in cui si trovano nel programma originale . Le risorse vengono acquisite secondo l’ordine di richiesta . Il tempo di esecuzione complessivo è pari alla somma dei tempi di esecuzione dei vari job . Vantaggi : - SEMPLICITA’ DELLA SOLUZIONE
- LINEARITA’ “ “ “ “ Svantaggi: - LUNGHI TEMPI DI INATTIVITA’ PER LE RI SORSE
-ATTESE DEI SINGOLI JOB prima di acquisire la loro risorsa e diventare sottoprocessi ( vedi Fig 1 )

Autore Flavio Cerini 12
J1 J2 J3 J4 J1 W J2 J3 W J4 t
Fig.1 W = wait Si supponga di poter scomporre un processo in più job ( es : Li , Ei , Si ) che eseguono rispettivamente una lettura , eseguono una elaborazione e scrivono i risultati su di un supporto di memorizzazione . ( vedi Fig 2 ) L1 E1 S1 L2 E2 S2 L3 E3 S3 Fig 2 ESEMPIO DI PROCESSO Si può prevedere una organizzazione in processi non sequenziali. Per esempio si può eseguire l’elaborazione E2 prima di S1 ma non prima di L2 . Si deve tener conto di un diagramma delle precedenze . ( vedi Fig 3 )

Autore Flavio Cerini 13
L1 L2 E1 L3 E2 S1 L4 E3 S2 S3 Fig.3 DIAGRAMMA DELLE PRECEDENZE I processi non sequenziali ,ordinati secondo dei diagrammi di precedenza , allargano il concetto di esecuzione sequenziale . Nel senso che certe operazioni , legate a risorse distinte , possono essere eseguite contemporaneamente con un evidente risparmio di tempo di esecuzione totale . PROGRAMMAZIONE PARALLELA Una tecnica che prevede la realizzazione di processi non sequenziali , si chiama PROGRAMMAZIONE PARALLELA e si può definire attrav erso i seguenti costrutti linguistici : • COROUTINE • FORK / JOIN • COBEGIN / COEND COROUTINE : Assomiglia molto al salto a procedura . La differenza sta nel fatto che non c’è l’obbligo di ritorno dalla procedura chiamante alla chiamata . L’istruzione RESUME consente il passaggio da una COROUTINE ad un’altra . Quando si incontra una istruzione di RESUME il controllo passa alla COROUTINE indicata e la precedente si blocca . NB : tale costrutto non realizza una vera programmazione parallela ma un INTERLEAVING
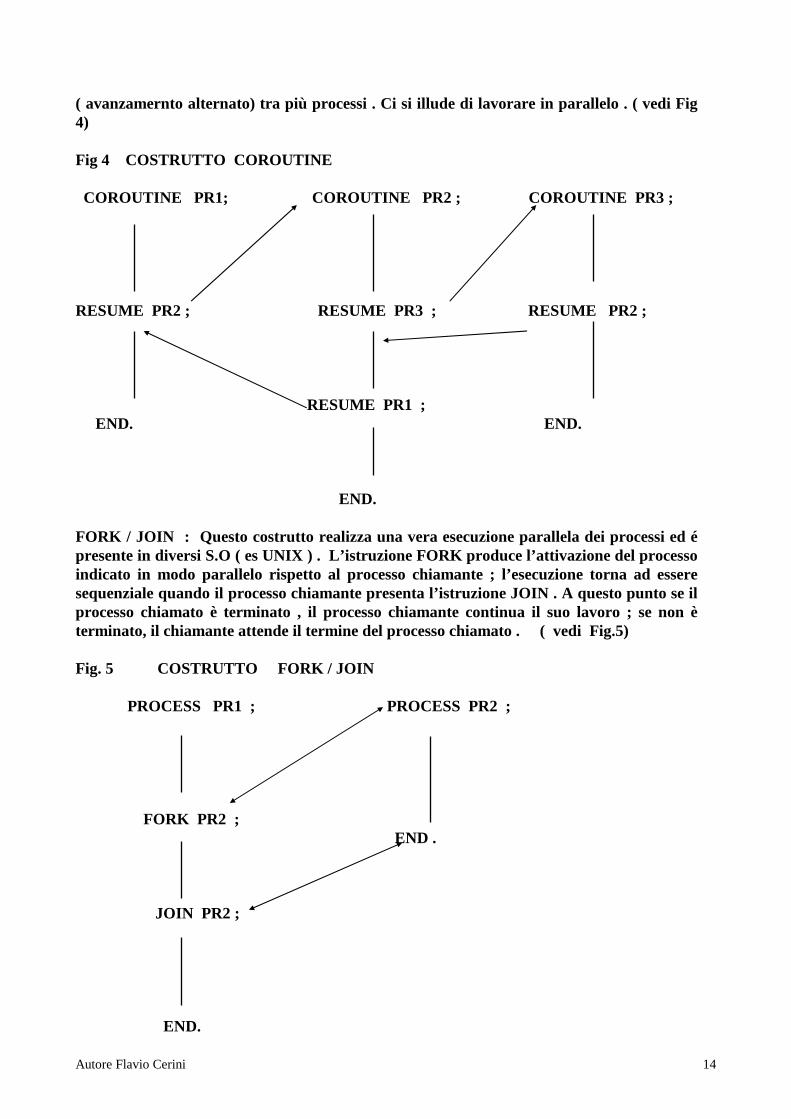
Autore Flavio Cerini 14
( avanzamernto alternato) tra più processi . Ci si illude di lavorare in parallelo . ( vedi Fig 4) Fig 4 COSTRUTTO COROUTINE COROUTINE PR1; COROUTINE PR2 ; COROUTINE PR3 ; RESUME PR2 ; RESUME PR3 ; RESUME PR2 ; RESUME PR1 ; END. END. END. FORK / JOIN : Questo costrutto realizza una vera esecuzione parallela dei processi ed é presente in diversi S.O ( es UNIX ) . L’istruzione FORK produce l’attivazione del processo indicato in modo parallelo rispetto al processo chiamante ; l’esecuzione torna ad essere sequenziale quando il processo chiamante presenta l’istruzione JOIN . A questo punto se il processo chiamato è terminato , il processo chiamante continua il suo lavoro ; se non è terminato, il chiamante attende il termine del processo chiamato . ( vedi Fig.5) Fig. 5 COSTRUTTO FORK / JOIN PROCESS PR1 ; PROCESS PR2 ; FORK PR2 ; END . JOIN PR2 ; END.

Autore Flavio Cerini 15
Una tipica applicazione del costrutto FORK / JOIN riguarda le operazioni che coinvolgono periferiche distinte ( vedi Fig 6) . Si può pensare di dover leggere dei dati da un file su disco e di dover fare dei calcoli statistici su di essi e dover riportare tutto su stampante Si può pensare di effettuare la lettura dei dati ed eseguire parallelamente i calcoli e la stampa dei dati letti , successivamente si possono stampare i risultati . PR_A Fig . 6 Leggi da disco FORK B PR_A PR_B PR_A PR_B stampa dati Leggi dati Stampa dati calcola risultati disaggregati FORK B END JOIN B Calcola risultati stampa risultati JOIN B PR_A Stampa risultati COBEGIN / COEND Tale costrutto prevede l’esecuzione parallela di singole istruzioni . La sintassi generale é la seguente : program PR ; Istruzione I0; cobegin I1;I2;.....;In; coend

Autore Flavio Cerini 16
end NB: E’ possibile indicare le singole istruzioni che devono essere eseguite in modo parallelo. In questo caso si parla di parallelizzazione di singole istruzioni all’interno di un unico processo e non di esecuzione contemporanea di parti di processi distinti . Il problema maggiore a questo punto è la SINCRONIZZAZIONE . E’ fondamentale la gestione della programmazione concorrente
CONCORRENZA Quando si parla di concorrenza , si fa riferimento a processi che si trovano a competere ( a concorrere ) per aggiudicarsi una stessa risorsa . Con il termine programmi concorrenti si intendono dei processi che richiedono la stessa risorsa nello stesso istante . A volte la risorsa può essere condivisa tra tutti i richiedenti , ma nella maggior parte dei casi il sistema deve utilizzare delle tecniche e degli strumenti ( fondamentalmente software ) per regolare le assegnazioni . I processi concorrenti si possono trovare in una di queste relazioni : • a) COOPERAZIONE • b) COMPETIZIONE • c) INTERFERENZA a) COOPERAZIONE (vedi Fig 7) : due processi si dicono in cooperazione se tra di loro c’è un legame logico ;
caso classico : PRODUTTORE-CONSUMATORE . Un processo P produce dei dati che vengono inseriti in un’area di buffer ( BUFF) , un secondo processo C legge i dati dall’area buffer e li elabora ottenendo dei risultati . Ovviamente il processo C deve leggere da BUF solo dopo che P ha inserito dei dati . Tale operazione può essere ciclica ma deve essere ripetuta nell’ordine giusto altrimenti le operazioni non avvengono correttamente . Sequenza giusta : PCPCPCPC... .Sequenza errata : PPCC... Fig . 7 Processi PRODUTTORE e CONSUMATORE

Autore Flavio Cerini 17
Generazione Lettura da dati BUFFER Scrittura in Operazioni BUFFER sui dati PRODUTTORE CONSUMATORE b) COMPETIZIONE : Due processi in competizione sono indipendenti da un punto di vista logico , sono invece dipendenti avendo la necessità di appropriarsi di una risorsa comune (con molteplicità limitata ) I tempi di completamento del lavoro possono dipendere sensibilmente da tale competizione . Un esempio può essere quello della mutua esclusione nella quale l’acquisizione di una risorsa é esclusiva di un processo con conseguente attesa di tutti gli altri processi richiedenti. c) INTERFERENZA : Questo caso rappresenta una degenerazione della COMPETIZIONE . Ci troviamo in tale situazione quando il risultato dei processi dipende dalla sequenza temporale di utilizzo di certe risorse del sistema da parte di tutti i processi che le richiedono . Si deve fare in modo che i processi si aggiudichino la risorsa solo in istanti precisi ,e non la rilascino in momenti critici del loro lavoro . Nessun processo deve togliere una risorsa ad un altro processo in modo incontrollato ( pensare ad ad una operazione di stampa interrotta da un’altra operazione di stampa) . Se le risorse sono acquisite in modo disordinato , può capitare che i processi lavorino su dati elaborati da altri e quindi facendo eseguire il programma più volte , gli utenti ottengano risultati sempre diversi . Gli erori di questo tipo sono difficili da identificare perché il lavoro é sintatticamente corretto . NB : si devono sincronizzare tutte le operazioni sulle risorse a rischio .

Autore Flavio Cerini 18
IL NUCLEO ( kernel ) Il nucleo é il livello più vicino alla macchina ( hardware ) . Le sue funzioni sono fondamentali per il funzionamento complessivo del sistema . Le funzionalità del nucleo sono richieste principalmente nei seguenti stati : PRONTO , ATTESA , ESECUZIONE . FUNZIONI PRINCIPALI SVOLTE DAL NUCLEO • Implementazione della sincronizzazione , tramite funzioni primitive, per consentire
le transizioni di stato dei job e dei processi • Scelta del processo destinato a passare dalla coda di “ PRONTO “ allo stato di “
ESECUZIONE “ in base alla strategia scelta dal gestore del processore . • Gestione delle interruzioni con salvataggio e ripristino dello stato della macchina .
Il JOB-SCHEDULER sceglie il job che deve acquisire il processore tra quelli presenti nella coda di “ PRONTO “ : viene recuperato il valore del puntatore al processo in modo da identificarne l’indirizzo reale . Il PROCESS-SCHEDULER applica la strategia di allocazione . La tecnica più semplice è quella FIFO ( rispetta l’ordine di arrivo delle richieste ) .
INTERRUZIONI LEGATE AL SISTEMA OPERATIVO 1) I/O INTERRUPT : comando di I/O errato,canale o dispositivo non correttamente
connesso 2) PROGRAM INTERRUPT: istruzione errata di CPU , overf low,violazione delle aree
di memoria protette 3) SUPERVISOR CALL INTERRUPT : chiamata asincrona da un modulo
supervisore di priorità superiore 4) EXTERNAL INTERRUPT : fine del tempo a disposizione , tasto di interruzione da
da operatore ; 5) HARDWARE INTERRUPT : interruzione causata da guasto hardware
I SEMAFORI

Autore Flavio Cerini 19
Quando ci sono problemi di competizione , servono dei meccanismi di sincronizzazione . Non ci sarebbe nessun problema se ogni processo tenesse una risorsa per tutta la durata del lavoro , ma non sarebbe conveniente . La competizione , può essere relativa a certe zone di programma che vanno preservate da interruzioni indesiderate . Tali zone di programma vengono chiamate : ZONE CRITICHE ( esempi di zone critiche : non si può interrompere una operazione di stampa per eseguirne un’altra ; non si può leggere un file mentre si sta modificando il suo contenuto ; oppure la scrittura in un’area buffer prima che sia terminata la lettura del blocco di dati scritto nel buffer precedentemente . La tecnica principale per gestire una zona critica é basata sul principio del SEMAFORO . IL SEMAFORO :utilizza due procedure elementari ( primitive di sincronizzazione vedi Fig 8 ) Tali procedure utilizzano una variabile S il cui valore viene sempre controllato prima di accedere alla risorsa critica ( risorsa il cui uso può generare delle zone critiche) . Se la variabile - semaforo ha il valore giusto , la risorsa può essere allocata e il processo può proseguire , in caso contrario , il processo si porrà in stato di attesa Fig. 8 Le primitive di semaforo P(S) V(S) False True
S = 1
S: = 0
S : = 1

Autore Flavio Cerini 20
Il “semaforo “ é rappresentato dalla variabile binaria S che negli schemi funge da parametro per le due procedure P(S) e V(S) . Se la variabile S = 0 la risorsa critica é occupata e si deve attendere che venga rilasciata . Se S= 1 la risorsa può essere allocata . La procedura P(S) viene richiamata dal processo che richiede una risorsa , se S= 1 la risorsa é libera e viene allocata al processo richiedente e il semaforo viene impostato al valore “0” . Se S = 0 , la procedura ripete il controllo finché non trova il valore 1 . La procedura V(S) viene richiamata da un processo che vuole rilasciare una risorsa in suo possesso . La Procedura pone S = 1 ed incarica il SO del rilascio della risorsa PRODUTTORE CONSUMATORE Si può risolvere con utilizzo di due semafori S1 e S2 ( vedi Fig 9 ) Si deve fare attenzione , oltre all’accesso esclusivo alla risorsa, si deve anche fare in modo che non si legga dal buffer prima di aver terminato la scrittura . Si può considerare un semaforo S1 che controlla l’accesso in scrittura e un semaforo S2 che controlla l’accesso in lettura . Fig. 9 Scrittura - Lettura in un buffer Inizializzazione : S1: = 1 ; S2 : = 0 PRODUTTORE CONSUMATORE
P(S2)
LETTURA DAL BUFFER
V(S1)
OPERAZIONI SUI DATI
GENERAZIONE DATI
P(S1)
SCRITTURA NEL BUFFER
V(S2)

Autore Flavio Cerini 21
L’inizializzazione permette al processo produttore di accedere al buffer ( S1=1) e preclude la lettura (S2=0) . Il processo produttore lavora , generando dei dati , S1 diventa 0 con l’esecuzione di P(S1) alla fine si apre la possibilità di lettura bloccando la scrittura . Il processo Consumatore , ottenuto il permesso di accesso , legge dal buffer e , prima di iniziare la elaborazione dei dati acquisiti , libera l’accesso in scrittura ( con procedura V(S1) ) , in tal modo si risparmia tempo poichè mentre si fa elaborazione dati ne possono essere inseriti altri nel buffer
SEMAFORO GENERALIZZATO Se il sistema deve gestire una risorsa che é oggetto di contesa , si può ricorrere alla tecnica del semaforo generalizzato . La variabile semaforo non é più binaria ma é un semplice contatore delle unità disponibili della risorsa . Se il valore della variabile é 0 nessuna unità della risorsa é disponibile , altrimenti é possibile effettuare un’allocazione . Il numero massimo che può assumere la variabile semaforo coincide con il numero di unità presenti nel sistema . Nel caso di un produttore-consumatore con tre buffer , i due semafori hanno valore massimo tre . ( vedi Fig 10 ) . Nel caso di quattro stampanti che consentono il lavoro di otto persone in multiutenza ; un semaforo generalizzato impostato al valore 4 regola l’accesso ai dispositivi . Si utilizzano ancora le procedure P(S) e V(S) ( vedi Fig 11 ) . La procedura P(S) contiene un test che controlla il valore del contatore ; se S > 0 ci sono ancora unità libere . L’allocazione comporta un decremento del numero di unità disponibili . La procedura V(S) , relativa al rilascio della risorsa , contiene l’incremento del numero di unità disponibili . Le procedure P(S) e V(S) sono le operazioni di base per la gestione dei meccanismi di sincronizzazione degli accessi . Fig. 10 Semafori generalizzati P(S) V(S) False True
S >0
S : = S - 1
S : = S + 1

Autore Flavio Cerini 22
PRINCIPI DI PROGRAMMAZIONE CONCORRENTE DEFINIZIONE DI STALLO ( nel gioco degli scacchi : nessuno dei giocatori da scacco matto ) : Un sistema di elaborazione si dice in condizione di STALLO se nessuno dei processi in corso riesce a portare a termine il suo lavoro . Supponiamo di avere due processi P1 e P2 ( vedi Fig 12 ) . che lavorano rispettivamente con le risorse RISORSA_1 e RISORSA_2 .Ad un certo istante il processo P1 ha bisogno di dati prodotti dalla RISORSA_2 e si mette in stato di attesa . Contemporaneamente il processo P2 necessita della RISORSA_1 e aspettando che si liberi si mette in stato di attesa . I due processi sono in attesa a tempo indeterminato. Fig 12 Processi in stato di stallo Le frecce che vanno dalla risorsa al processo indicano che la risorsa é assegnata al processo , mentre le frecce che vanno dal processo alla risorsa indicano che la risorsa é stata richiesta dal processo . Questo modo di rappresentare la relazione tra processi e risorse si chiama GRAFO DI ALLOCAZIONE delle risorse .
PROCESSO P1
PROCESSO P2
RISORSA R1
RISORSA R2

Autore Flavio Cerini 23
IL PROBLEMA DELLO STALLO ( DEADLOCK )
Un problema fondamentale che deve affrontare un sistema operativo é quello relativo al controllo delle zone critiche ( contengono delle azioni indivisibili e le risorse richieste vengono rilasciate solo a fine esecuzione ) . In questa situazione insorgere uno stato di DEADLOCK . Lo stato di deadlock si può presentare anche nel caso di superamento della molteplicità di una risorsa ( semaforo generalizzato ) , cioé il numero massimo di processi che possono lavorare contemporaneamente con la risorsa stessa oppure il numero di esemplari presenti di una risorsa che non può essere condivisa .
SITUAZIONI NELLE QUALI SI PUO’ GENERARE UN DEADLOC K • Mutua esclusione ( nelle zone critiche le risorse vengono rilasciate solo a fine lavoro ) • Superamento della molteplicità di una risorsa • Allocazione parziale : il processo non impegna , all’inizio del blocco critico, tutte le
risorse di cui avrà bisogno ma le richiederà via via che serviranno • Negazione del prerilascio forzato : il sistema non é abilitato a sottrarre forzatamente la
risorsa al processo per evitare uno stallo • Attesa circolare : esiste una lista di processi ognuno dei quali é in attesa di acquisire una
risorsa che é in possesso del seguente . Il risultato é un deadlock del sistema .
GESTIONE DEL PROBLEMA DELLO STALLO • PREVENZIONE : Il sistema deve capire quando esistono le condizioni per la nascita di
un deadlock . In effetti un eccessivo controllo produce un rallentamento del sistema forse non giustificato considerato che il DEADLOCK si verifica molto raramente .

Autore Flavio Cerini 24
• RICONOSCIMENTO : Il sistema deve riconoscere quando il sistema di elaborazione si trova in una situazione di stallo . Una volta effettuata la rilevazione si deve effettuare un recupero ( recovery ) dello stato del sistema subito prima dello stallo . Il riconoscimento e il recovery sono operazioni molto complesse PREVENZIONE : la prevenzione propone le seguenti tecniche : a) Allocazione globale delle risorse b) Allocazione gerarchica c) Algoritmo del banchiere a) Le risorse necessarie ad un processo gli vengono assegnate tutte insieme solo quando
sono tutte libere ; in mancanza di tale situazione il sistema resta in attesa . In questo modo però qualche processo che ha urgenza di una risorsa può restare in attesa molto a lungo e si possono avere anche rallentamenti notevoli nell’esecuzione di un processo.
b) Si considera un ordine gerarchico delle risorse . Se un processo possiede una risorsa di un certo livello , può acquisire solo risorse di livello superiore . se deve acquisire una risorsa a livello inferiore , deve prima rilasciare quella che possiede e richiederla successivamente .
c) Questo algoritmo consiste nello scegliere un’allocazione che consente ad almeno un processo di poter lavorare e concludere .
LA GESTIONE DELLA MEMORIA AMBIENTE MONOPROGRAMMATO ( monoprogrammazione ) In ambiente monoprogrammato é possibile far girare un solo programma per volta . Tutte le risorse sono dedicate all’unico programma residente in memoria . Non esiste il problema della concorrenza e il S.O risulta abbastanza semplice . Abbastanza semplice risulta anche la gestione della memoria centrale . La memoria centrale é divisa in non più di tre aree : a) Area contenente i moduli software del S.O b) Area contenente il programma utente da eseguire c) Area differenza fra Area totale a disposizione dell’utente e Area occupata dal
programma caricato . Tale Area resta vuota e non utilizzabile .
ALLOCAZIONE SINGOLA CONTIGUA ( vedi Fi g . 13 )

Autore Flavio Cerini 25
Il modo più semplice di gestione della memoria , in questo caso , consiste nel riservare una prima parte della memoria , ad accesso controllato, contenente le procedure del S.O . L’utente ha quindi a disposizione la parte rimanente della memoria che inizia da un indirizzo definito staticamente . In questo caso il calcolo dall’indirizzo è estremamente semplice , in quanto l’indirizzo iniziale è fissato staticamente , quindi il passaggio dal nome simbolico all’indirizzo rilocabile e fisico é immediato
S.O Programma
Fig.13 FUNZIONI CHE IL S.O DEVE GARANTIRE PER IL GESTORE DI MEMORIA :
1) Mantenere traccia dello stato di memoria (tutta la memoria é dedicata interamente all’unico lavoro) 2) Definire la strategia di allocazione ( se la memoria é sufficiente si può allocare ) 3) Effettuare l’allocazione ( programma allocato a partire dalla prima locazione libera dal
S.O ) 4) Deallocare la memoria ( finito il lavoro , il programma rilascia la risorsa memoria ) NB : Un programma di dimensione superiore a quella fisicamente disponibile ( memoria utente ) ,non ha nessuna possibilità di essere eseguito . Facendo riferimento al ciclo di vita del processo , il programma non supera la fase di lancio . Il S.O verifica che non ci sono le condizioni per farlo diventare processo ( verrà visualizzata una condizione di errore ). SVANTAGGI PRINCIPALI : a) Utilizzazione ridotta della memoria b) Inefficiente uso del processore ( resta in attesa durante le operazioni di I/O)

Autore Flavio Cerini 26
c) Il programma utente deve avere una dimensione limitata compatibilmente con la memoria disponibile
AMBIENTE MULTIPROGRAMMATO ( multiprogrammazione ) In questo caso il sistema di elaborazione deve gestire più programmi contemporaneamente presenti in memoria centrale . Quindi la memoria diventa una risorsa soggetta a condivisione . Un problema rlevante é quello degli accessi fuori area ; il S.O deve controllare che ogni programma faccia riferimento soltanto agli indirizzi facenti parte dell’area di memoria ad esso dedicata ( protezione degli accessi fuori area ). Il sistema deve provvedere ad un ricalcolo degli indirizzi fisici secondo tecniche molto più sofisticate rispetto al caso precedente ( ci saranno dei registri che tengono traccia degli indirizzi di soglia fra le varie aree di memoria. Le aree in cui si considera divisa la memoria centrale fisica vengono chiamate partizioni . ( vedi Fig 14)
S.O Prog_1 Prog_2 Prog_3

Autore Flavio Cerini 27
Fig.14
FUNZIONI FONDAMENTALI SVOLTE DA UN GESTORE DI MEMORIA 1) Mantenere traccia dello stato della memoria ( conoscenza dello stato delle singole
partizioni . es in uso/non in uso , dimensione , indirizzo iniziale ecc ). 2) Definire la strategia di allocazione : se c’é una partizione libera che può contenere il
programma questo può essere allocato secondo dei criteri realizzati principalmente dal job scheduler 3) Effettuare l’allocazione : ilpèrogramma é allocato nella partizione prescelta a partire
dall’indirizzo indicato dal S.O 4) Deallocare la memoria : quando il lavoro é finito , il programma rilascia la partizione
che torna nello stato di disponibilità .
ALLOCAZIONE PARTIZIONATA L’allocazione partizionata prevede due modalità fondamentali : partizionamento statico e dinamico
PARTIZIONAMENTO STATICO
L a memoria centrale é divisa a priori in partizioni di dimensione prefissata e le informazioni relative allo stato della risorsa vengono inseritae in una tabella delle partizioni secondo la struttura di Fig 15 NUMERO DIMENSIONE INDIRIZZO STATO 1 8 K 312 K IN USO 2 32 K 320 K IN USO 3 32 K 352 K NON “ “ 4 120 K 384 K NON “ “ 5 520 K 504 K IN USO

Autore Flavio Cerini 28
Fig 15 Nell’esempio indicato ci sono cinque partizioni a disposizione degli utenti . Tali partizioni variano fra gli 8 e i 520 K . Soltanto le N 1,2 5 sono occupate . I primi 312 K sono occupati dal S.O. In questo esempio la memoria totale é composta da 1024 K bytes. Questa tabella serve per conoscere lo stato della risorsa memoria e per la costruzione del meccanismo di protezione. ( per ogni partizione viene indicato lo spazio di indirizzi riservato ). Quando un nuovo programma vuole accedere alla memoria , il S.O consulta la tabella alla ricerca di una partizione sufficientemente ampia par contenere il programma ; se la ricerca ha successo,il programma viene caricato e nella tabella viene indicato “ partizione in uso “ . Questo meccanismo di allocazione funziona bene quando si conosce , statisticamente, la frequenza e la dimensione dei programmi che richiedono la memoria . Sarà utile sapere se l’elaboratore lavora con tanti piccoli programmi oppure con pochi grossi programmi . ( nel primo caso servono molte piccole partizioni nel secondo poche grandi ) .
FRAMMENTAZIONE Questa tecnica produce lo spiacevole fenomeno definito : frammentazione . Come indicato anche in Fig. 15 , i programmi non occupano interamente la partizione che viene loro assegnata ma resterà sempre un piccolo spazio non utilizzato e non utilizzabile da altri utenti . Se si ha un programma di piccole dimensioni e si è costretti ad assegnargli una partizione di dimensioni notevoli , la parte che resta inutilizzata non può essere occupata da un altro programma anche se lo spazio libero risulta sufficiente . Svantaggi del partizionamento statico: a) Rallentamento del lavoro b) Sfruttamento inefficiente della risorsa memoria
PARTIZIONAMENTO VARIABILE
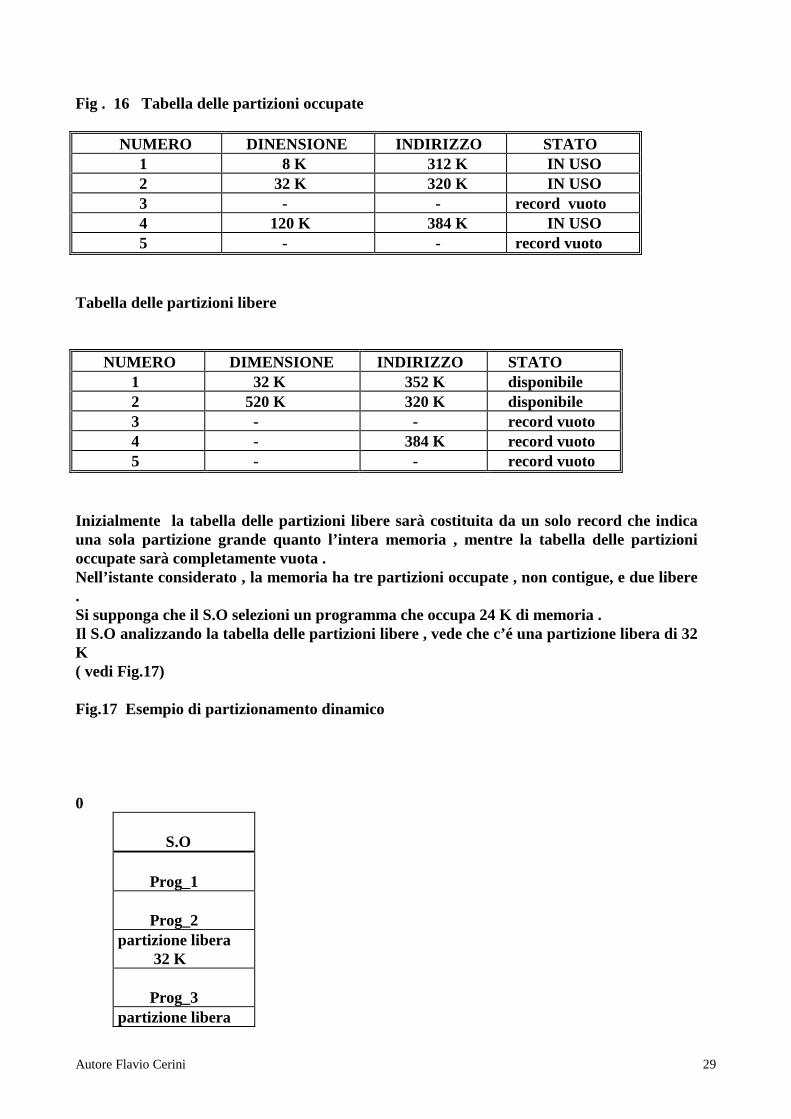
Secondo questa tecnica il S.O crea partizioni della esatta dimensione necessaria a contenere il programma che si sta caricando . Tale tecnica utilizza due tabelle ; una tabella delle partizioni occupate e una tabella delle partizioni libere Esempio : (vedi Fig 16 )
Autore Flavio Cerini 29
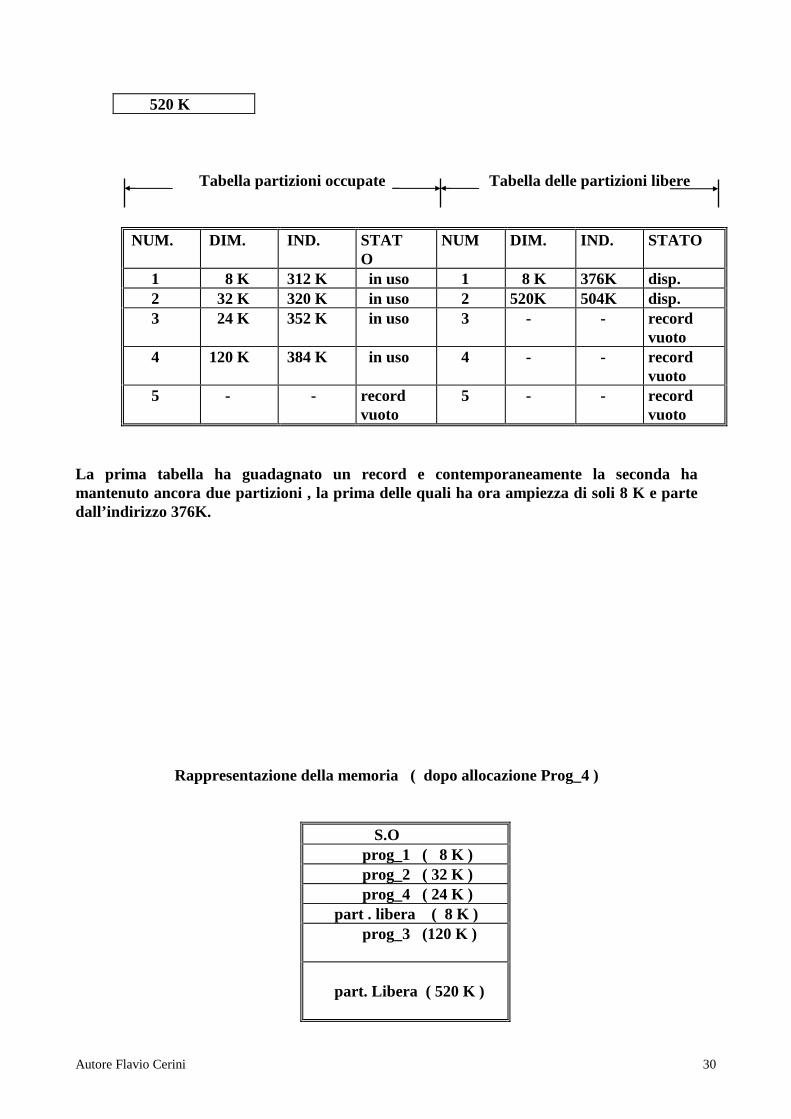
Fig . 16 Tabella delle partizioni occupate NUMERO DINENSIONE INDIRIZZO STATO 1 8 K 312 K IN USO 2 32 K 320 K IN USO 3 - - record vuoto 4 120 K 384 K IN USO 5 - - record vuoto Tabella delle partizioni libere NUMERO DIMENSIONE INDIRIZZO STAT O 1 32 K 352 K disponibile 2 520 K 320 K disponibile 3 - - record vuoto 4 - 384 K record vuoto 5 - - record vuoto Inizialmente la tabella delle partizioni libere sarà costituita da un solo record che indica una sola partizione grande quanto l’intera memoria , mentre la tabella delle partizioni occupate sarà completamente vuota . Nell’istante considerato , la memoria ha tre partizioni occupate , non contigue, e due libere . Si supponga che il S.O selezioni un programma che occupa 24 K di memoria . Il S.O analizzando la tabella delle partizioni libere , vede che c’é una partizione libera di 32 K ( vedi Fig.17) Fig.17 Esempio di partizionamento dinamico 0
S.O Prog_1 Prog_2 partizione libera 32 K Prog_3 partizione libera
Autore Flavio Cerini 30
520 K Tabella partizioni occupate Tabella delle partizioni libere
NUM. DIM. IND. STATO
NUM DIM. IND. STATO
1 8 K 312 K in uso 1 8 K 376K disp. 2 32 K 320 K in uso 2 520K 504K disp. 3 24 K 352 K in uso 3 - - record
vuoto 4 120 K 384 K in uso 4 - - record
vuoto 5 - - record
vuoto 5 - - record
vuoto La prima tabella ha guadagnato un record e contemporaneamente la seconda ha mantenuto ancora due partizioni , la prima delle quali ha ora ampiezza di soli 8 K e parte dall’indirizzo 376K.
Rappresentazione della memoria ( dopo allocazione Prog_4 )
S.O prog_1 ( 8 K ) prog_2 ( 32 K ) prog_4 ( 24 K ) part . libera ( 8 K ) prog_3 (120 K ) part. Libera ( 520 K )

Autore Flavio Cerini 31
A questo punto , se il prog_2 termina , viene liberato lo spazio di memoria centrale e quindi viene liberato un record nella tabella delle partizioni occupate ed occupato un record nella tabella delle partizioni libere . se viene liberata una partizione adiacente ad un’altra partizione libera , allora ne verrà costruita una unica che le comprende entrambe . Quando termina il prog_4 viene creata un’unica partizione ampia 64 K a partire dalla locazione 320 K .
STRATEGIE DI ALLOCAZIONE DEL GESTORE DI MEMORIA Il problema consiste nello scegliere la partizione più idonea per allocare unprogramma . I metodi più comuni sono i tre seguenti : 1) FIRST FIT : il programma viene inserito nella prima partizione di dimensione
sufficiente a contenerlo 2) BEST FIT : Il programma viene inserito nella partizione la cui dimensione è più vicina a
quella richiesta, in modo da ridurre al minimo la dimensione dei frammenti 3) WORST FIT : Il programma viene inserito nella partizione più grande disponibile in
quel momento , in modo da generare dei frammenti della dimensione massima possibile . Nessuna di queste tre tecniche é la migliore in assoluto . I progettisti di sistemi operativi le ritengono tutte valide . Nella seconda tecnica ( BEST FIT ) il vantaggio principale é dovuto al fatto che si hanno frammenti molto piccoli e quindi minor spreco di spazio . Lo svantaggio principale , in partizionamento dinamico, consiste nella difficoltà di allocare programmi in partizioni molto piccole ( frammenti ). Nella terza tecnica ( WORST FIT ) i frammenti sono abbastanza grandi per essere riutilizzati . Le due tecniche suddette richiedono che la tabella delle partizioni libere sia ordinata per dimensione delle partizioni crescente , in modo da facilitare l’operazione di ricerca . Le tre tecniche suddette possono essere usate sia in partizionamento statico che dinamico .
PARTIZIONAMENTO RILOCABILE
Per risolvere il problema della frammentazione si possono ricompattare tutte le aree libere di memoria in modo da avere a disposizione un’unica grande area , posta nella memoria bassa oppure alta , e nuovamente utilizzabile per altri programmi . In linea di principio il

Autore Flavio Cerini 32
procedimento sembra abbastanza semplice ; praticamente invece si presentano notevoli problemi dato che il sistema deve trattare delle operazioni o istruzioni legate agli indirizzi delle locazioni ; si pensi alle strutture di dati che utilizzano puntatori . Poiché il ricompattamento implica uno spostamento di un programma in altra zona di memoria , si deve mettere in atto una tecnica che riaggiusti tutti i riferimenti alla memoria . il S.O deve essere in grado di lavorare con partizionamento dinamico. Con partizionamento statico non é pensabile un compattamento dei programmi . 1) Prima soluzione : si ricaricano tutti i programmi presenti in memoria centrale in modo contiguo lasciando così un unico spazio in fondo alla memoria . Tale operazione comporta una ripartenza di tutti i programmi . In questo modo non ci sono problemi di ricalcolo degli indirizzi fisici . Svantaggi :
a) Ovviamente non è possibile procedere in tal modo se il programma ha prodotto dei risultati (anche una sequenza di modifica di un file ).
b) se , mentre avviene il ricaricamento , si presenta un nuovo programma , il S.O deve decidere se caricarlo insieme agli altri ( magari a danno di altri precedentemente presenti in memoria ) oppure costringerlo ad attendere .
c) Il procedimento é lungo e complesso e può rallentare in modo consistente il lavoro dell’elaboratore
2) Seconda soluzione : si effettua un ricaricamento limitato al minimo necessario . Qualche programma può non richiedere di essere spostato .
Per ogni partizione é prevista una coppia di registri chiamati : registro base di rilocazione
e registro limite. Nel registro base di rilocazione viene memorizzato il numero di bytes di cui avviene lo
spostamento . Il registro limite memorizza la dimensione della partizione . Il programma in questo modo non viene modificato ( con risparmio di tempo e risorse ). Ad ogni riferimento a memoria viene sommato ( compattamento verso la parte alta della memoria ) o sottratto ( compattamento verso la parte bassa della memoria ) il contenuto del registro base di rilocazione ESEMPIO : ( vedi Fig 18 ) Il prog_X é stato caricato in una partizione ampia 20 K a partiredalla locazione 51200 della memoria centrale . Dalla locazione 20480 fino al programma suddetto si é generato uno spazio libero che si vuole compattare verso la parte bassa degli indirizzi di memoria . ( Reg_lim = 20480 ( dim part)) , (Reg_base_riloc = 30720 (51200-20480)) .

Autore Flavio Cerini 33
Fig 18 Esempio di compattamento
S.O
S.O
Prog_X
Prog_X
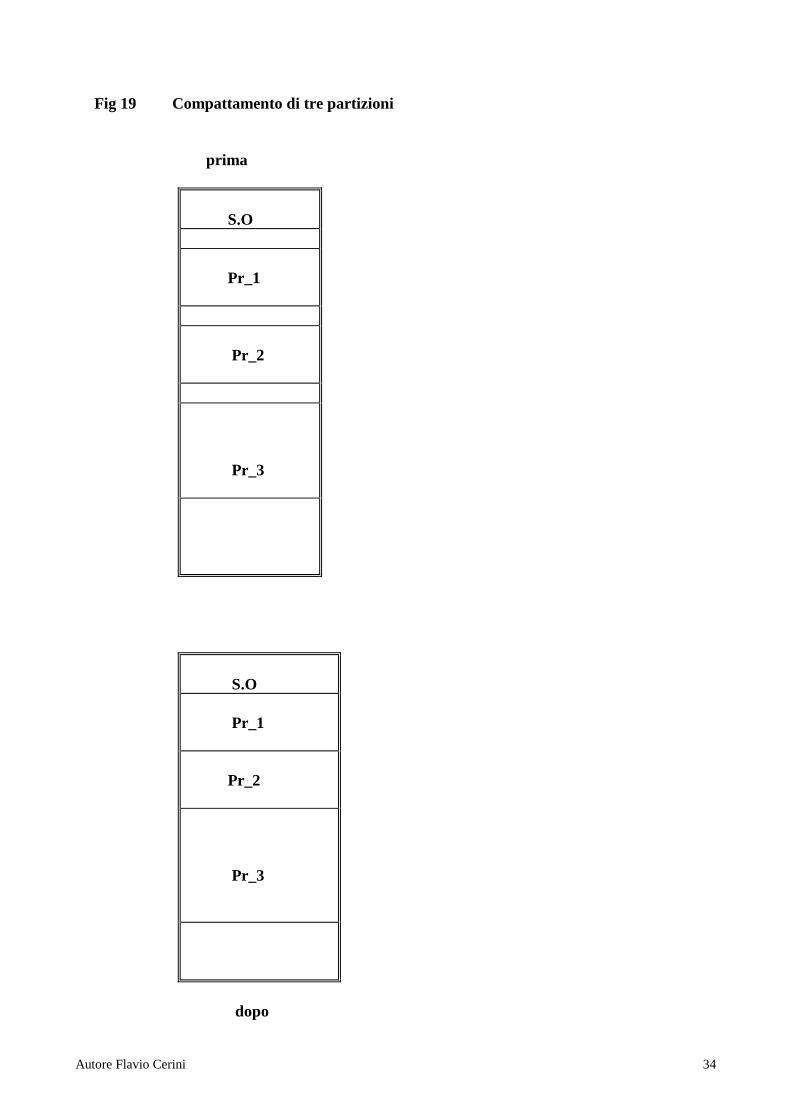
prima dopo Il valore del Reg_base viene sottratto ( compattamento verso il basso ) a tutti i riferimenti a memoria riscontrati nel programma dur ante l’esecuzione . Per esempio se un’istruzione fa riferimento alla locazione 60350 , dopo il compattamento il riferimento sarà modificato in 29630 ( 60350-30720). La funzione principale del registro limite riguarda la protezione degli accessi . Anche a compattamento avvenuto non devono esserci riferimenti non consentiti alla memoria ESEMPIO : compattamento di tre partizioni . ( vedi Fig. 19 ) Supponiamo di voler spostare verso l’alto tre partizioni intervallate da un frammento ognuna . La nuova posizione del primo programma si ottiene sottraendo la dimensione del primo frammento che viene elimiminato ( valore de Reg_base ) al vecchio indirizzo iniziale . Il valore del Reg_base del secondo programma é calcolato sommando al valore del registro di rilocazione precedente l’ampiezza del secondo frammento . Il valore del terzo Reg_base di rilocazione si ottiene sommando al valore del secondo la dimensione del terzo frammento . Il S.O quindi provvede ad aggiornare il valore di ogni reg_base di rilocazione sommando il contenuto del registro base precedente alla dimensione dell’ultimo frammento da eliminare .
Autore Flavio Cerini 34
Fig 19 Compattamento di tre partizioni prima
S.O Pr_1 Pr_2 Pr_3
S.O Pr_1 Pr_2 Pr_3
dopo

Autore Flavio Cerini 35
Quando risulta conveniente effettuare un ricompattamento della memoria ? Si potrebbe fare ogni volta che viene liberata una partizione in modo da avere sempre un’unica grande area vuota a disposizione senza frammentazione . In questo modo si avrebbe una notevole semplificazione della tabella delle aree libere ( partizionamento dinamico ) a spese però di maggiori costi di gestione ( tempo e realizzazione ) . Una seconda soluzione consiste nell’effettuare l’operazione di compattamento periodicamente . Il sistema lavora , in questo caso, come in un normale partizionamento dinamico ma periodicamente c’é questa riorganizzazione delle aree libere e delle relative tabelle . Nessuna delle due soluzioni é in assoluto la migliore . Fra le tecniche viste finora , il partizionamento rilocabile é la soluzione migliore in termini di utilizzo della risirsa memoria . Gli svantaggi sono relativi ai costi , alla complessità e alla limitatezza alla sola memoria fisica .
LA PAGINAZIONE Questo meccanismo cerca di ridurre il fenomeno della frammentazione superando il vincolo della contiguità . Nella gestione paginata della memoria , si considera lo spazio di indirizzi di un programma diviso in pagine di una dimensione predefinita che é la stessa per tutti i programmi girano nell’elaboratore . La memoria é divisa in blocchi tali da contenere esattamente una qualsiasi pagina di programma . Le pagine di programma vengono smistate in memoria nei blocchi che sono liberi in quell’istante . Non c’è contiguità fisica fra gli indirizzi del programma ma tramite certe tabelle si riesce a stabilire una contiguità logica . PAGE BREAKAGE : con questo termine si indica il fenomeno della frammentazione limitato all’ultima pagina . Se per esempio definiamo dei blocchi di memoria di 4 K , non tutti i programmi richiedono un multiplo esatto di 4 K , per cui l’ultima pagina occuperà meno spazio lasciando pertanto un frammento inutilizzabile . ( es un programma di 17 K che viene caricato in una memoria divisa in blocchi di 4 K , necessita di 5 blocchi dei quali l’ultimo produrrà un frammento di 3 K ) . La dimens ione ottimale dei blocchi di memoria é generalmente intorno ai 4 K . I blocchi non devono essere molto grandi ( possono generare grossi frammenti ) e nemmeno troppo piccoli perché ogni programma ne richiederebbe un numero alto con conseguente difficoltà di gestione da parte del S.O .
FUNZIONI FONDAMENTALI DEL GESTORE
1) Mantenere traccia dello stato della memoria . ( per mettere in relazione le pagine con i
blocchi della memoria , si utilizzano due tabelle ).

Autore Flavio Cerini 36
• PAGE MAP TABLE ( PMT ) : una per ogni programma , con tanti elementi quante sono le sue pagine , contiene la corrispondenza tra il numero della pagina ed il numero di blocco di memoria che la contiene .
• MEMORY BLOCK TABLE ( MBT ) : unica nel sistema , con tanti elementi quanti sono i blocchi di della memoria , e contenente lo stato dei blocchi ( liberi, occupati).
2) Definire la strategia di allocazione dei blocchi : a carico del job scheduler ; consiste nel
ricercare nella MBT i blocchi liberi e disponibili per il programma in attesa ; 3) Effettuare l’allocazione : le pagine del programma sono caricate nei blocchi prescelti dal
S.O che provvede anche all’aggiornamento delle PMT e MBT ; 4) Deallocare la memoria ; quando il lavoro é finito, il programma rilascia i blocchi di
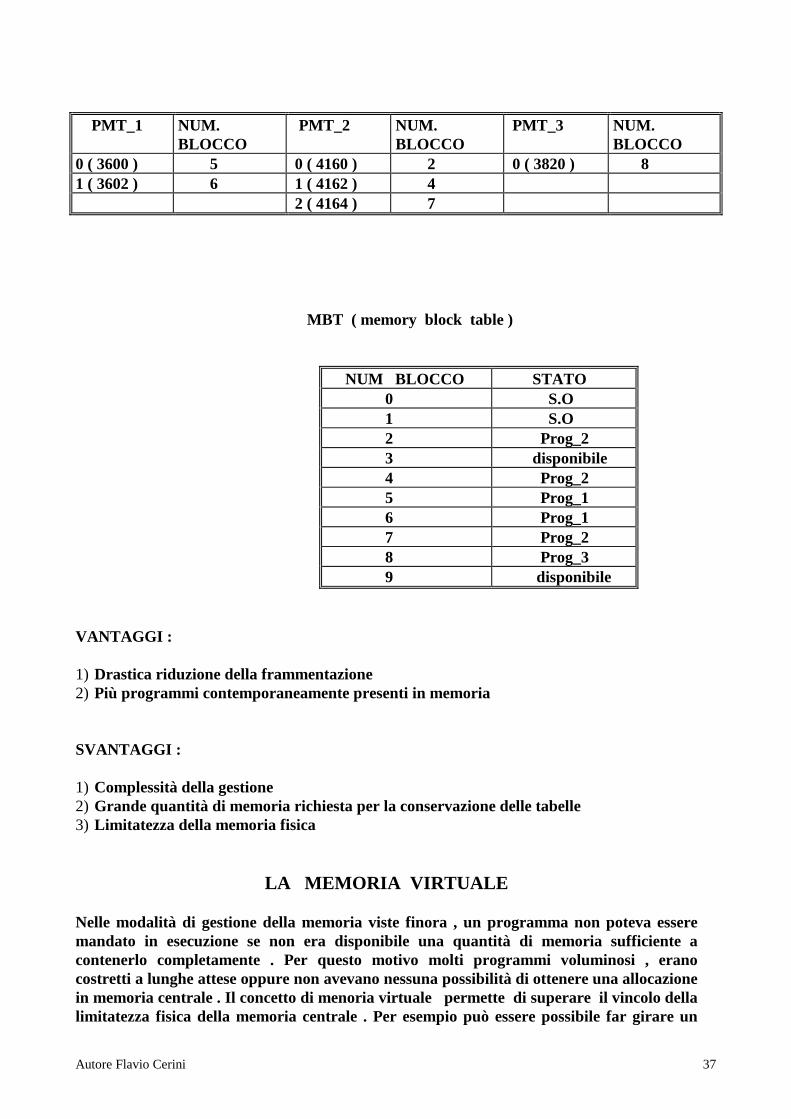
memoria che tornano nello stato di disponibilità ( aggiornamento della MBT ) . Le tabelle suddette possono essere implementate in diversi modi : in modo abbastanza semplice attraverso un gruppo di registri dedicati che vengono caricati e gestiti come i registri dei programmi ma rispetto a questi ultimi hanno una gestione prioritaria . Tale tecnica é efficace se la tabella ha dimensioni limitate . Se le tabelle sono grandi vengono utilizzate memorie di tipo associativo (come la CACHE ) dove il registro si compone di due parti : chiave e valore . Se il numero di elementi delle tabelle é alto , solo una parte può essere conservato nella CACHE ( tempo ridotto ) altrimenti si deve accedere alla memoria centrale co conseguente tempo medio di ritrovamento alto . Alle tabelle PMT e MBT viene associata la JT ( job table ) che contiene l’identificatore del programma , la sua dimensione e l’indirizzo di memoria a partire dal quale é memorizzata la sua PMT . ESEMPIO : ( vedi Fig.18 ) In questo esempio si considerano delle pagine di 4 K ( lo stesso per i blocchi ) . Dalle tabelle si vede che sono presenti in memoria tre programmi ognuno con la sua PMT e restano ancora due blocchi liberi . Fig. 18 Tabelle di paginazione JT ( job table ) PROG.ID DIMENSIONE IND.PMT STATO 1 8 K 3600 allocato 2 12 K 4160 allocato 3 4 K 3820 allocato
Autore Flavio Cerini 37
PMT_1 NUM.
BLOCCO PMT_2 NUM.
BLOCCO PMT_3 NUM.
BLOCCO 0 ( 3600 ) 5 0 ( 4160 ) 2 0 ( 3820 ) 8 1 ( 3602 ) 6 1 ( 4162 ) 4 2 ( 4164 ) 7 MBT ( memory block table )
NUM BLOCCO STATO 0 S.O 1 S.O 2 Prog_2 3 disponibile 4 Prog_2 5 Prog_1 6 Prog_1 7 Prog_2 8 Prog_3 9 disponibile
VANTAGGI : 1) Drastica riduzione della frammentazione 2) Più programmi contemporaneamente presenti in memoria SVANTAGGI : 1) Complessità della gestione 2) Grande quantità di memoria richiesta per la conservazione delle tabelle 3) Limitatezza della memoria fisica
LA MEMORIA VIRTUALE Nelle modalità di gestione della memoria viste finora , un programma non poteva essere mandato in esecuzione se non era disponibile una quantità di memoria sufficiente a contenerlo completamente . Per questo motivo molti programmi voluminosi , erano costretti a lunghe attese oppure non avevano nessuna possibilità di ottenere una allocazione in memoria centrale . Il concetto di menoria virtuale permette di superare il vincolo della limitatezza fisica della memoria centrale . Per esempio può essere possibile far girare un

Autore Flavio Cerini 38
programma che richiede 50 K di memoria avendone a disposizione soltanto 20 K . Il principio consiste nell’immaginare di avere a disposizione una memoria ipotetica “ virtuale “ teoricamente infinita . VANTAGGI : 1) Non c’é più la limitazione dovuta alla dimensione della memoria fisica , quindi diventa
possibile eseguire programmi di qualsiasi dimensione 2) Si eleva notevolmente il livello di multiprogrammazione del sistema 3) Si possono sfruttare , come conseguenza , in modo più efficiente tutte le altre risorse
procurate dall’elaboratore .
PRINCIPI DI LOCALITA’ : Il concetto di memoria virtuale trae origine dai seguenti due principi di località : 1) Principio di località temporale : Le locazioni di memoria usate recentemente é probabile
che saranno riutilizzate molto presto ( es programmi con istruzioni cicliche , sottoprocedure strutture di dati composte ) 2) Principio di località spaziale : Se é stata indirizzata una certa locazione di memoria , é probabile che saranno indirizzate presto anche le locazioni adiacenti ad essa . ( programmi con struttura sequenziale oppure strutture dati lineari come i vettori ) . Da questi due principi si evince che , quando é in esecuzione una certa parte del programma , non é necessario che siano presenti in memoria anche tutte le altre istruzioni . Si possono conservare solo quelle parti di programma interessate dall’esecuzione secondo i criteri probabilistici enunciati con i due principi . Gestione di una memoria virtuale : 1) Si deve spezzettare un programma ( tecniche di paginazione e di segmentazione ) 2) Caricamento in memoria di alcuni pezzi del programma lasciando il resto su memoria di
massa 3) Se durante l’esecuzione di un programma viene richiesta una pagina ,non presente in
memoria, si dovrà provvedere al caricamento con eventuale rimozione di un blocco ( algoritmi di rimozione della pagina ) . Questi criteri sono seguiti dalle tre strategie principali per la gestione della memoria virtuale :
• Gestione virtuale paginata • Gestione segmentata • Gestione segmentata-paginata

Autore Flavio Cerini 39
GESTIONE VIRTUALE PAGINATA Questa tecnica sfrutta la politica di gestione a pagine , tenendo comunque conto del nuovo concetto di memoria virtuale . Pertanto , se le pagine che servono non sono in memoria centrale , bisogna provvedere a caricarle e si devono eventualmente rimuovere altre pagine che al momento non servono ( algoritmo di rimozione ). FUNZIONI FONDAMENTALI DEL GESTORE : 1) Mantenere traccia dello stato della memoria ( si devono mettere in relazione le pagine
con i blocchi di memoria e con i dispositivi di massa , per questo vengono usate tre tabelle ) :
• Page Map Table ( PMT ) : una per ogni programma , con tanti elementi quante sono le
sue pagine , contiene la corrispondenza tra il numero della pagina e il numero di blocco di memoria che la contiene ;
• Memory Block Table ( MBT ) : unica nel sistema , con tanti elementi quanti sono i blocchi della memoria , e contenente lo stato dei blocchi ( liberi / occupati ) ;
• File Map Table ( FMT ) : una per ogni programma , mette in relazione le pagine del programma col loro indirizzo fisico sul dispositivo di memoria di massa ;
2) Definire la strategia di allocazione dei blocchi : questa gestione é sviluppata dal JOB SCHEDULER che deve ricercare nella MBT dei blocchi liberi per il programma in attesa . Se la memoria centrale é occupata , parte il meccanismo di rimozione delle pagine . 3) Effettuare le allocazioni : Le pagine del programma vengono caricate nei blocchi
prescelti dal S.O ( dopo eventuale rimozione ) che provvede anche all’aggiornamento delle tabelle . 4) Deallocare la memoria : quando il lavoro é finito , il S.O rende di nuovo disponibili i
blocchi di memoria che tornano così disponibili . La paginazione virtuale , rispetto alla paginazione semplice , introduce qualche modifica alle tabelle (vedi esempio in Fig 19 ) • MBT : mantiene la stessa struttura ( Num_blocco / stato ) e viene interrogata per accesso
a memoria • PMT : oltre ai campi Num_pag , Num_blocco contiene un bit che indica se la pagina é
presente o non presente in memoria centrale • FMT : contiene due campi ( Num_pagina , Indirizzo_file ) e serve a mettere in relazione
la singola pagina con l’indirizzo della sua copia su disco .

Autore Flavio Cerini 40
FMT PMT PAGINA INDIRIZZO PAGINA NUM BLOCCO STAT O 0 5000 0 2 in 1 4600 1 4 in 2 5340 2 - out Fig.19 Nell’esempio indicato , viene considerato un programma composto da 3 pagine inizialmente residenti su disco nelle locazioni indicate dalla FMT . Le pagine 0 e 1 sono state caricate in memoria centrale nei blocchi 2 e 4 . La pagina 2 non è presente in memoria . Se successivamente ci sarà necessità di tale pagina, il S.O dovrà accedere alla locazione 5340 ( indicata dalla FMT ) e caricare la pagina nel blocco individuato tramite la MBT . Vengono utilizzati due bit ( reference bit e change bit ) associati ad ogni blocco della memoria fisica ( abbinati ad ogni record della MBT ) e vengono utilizzati nella procedura di rimozione delle pagine dai blocchi . • Reference bit : viene impostato ad 1 quando viene effettuato un riferimento ad una
qualsiasi locazione del blocco • Change bit : viene impostato ad uno quando viene effettuata una modifica ad una
qualsiasi locazione del blocco relativo Processo sviluppato dal S.O : Inizio esecuzione istruzione ; Calcolo Num_pag di programma da utilizzare; IF < Num_pag in memoria centrale > THEN begin completa l’istruzione ; passa alla prossima istruzione ; end ELSE IF < esiste un blocco libero > THEN carica la pagina nel blocco libero ( usa FMT ) ; ELSE begin scegli il blocco da liberare; se la pagina é stata modificata ( Change bit = 1 ) riscrivila sul disco ; aggiorna le MBT e PMT ; carica la pagina nel blocco liberato ( usa la FMT ) ; end aggiorna le MBT e PMT ; continua l’istruzione interrotta .

Autore Flavio Cerini 41
PAGE FAULT ( fallimento dell’operazione di ricerca della pagina ) : quando il sistema deve caricare una pagina si genera un page fault , se non viene recuperato un blocco libero , parte il meccanismo di rimozione di una pagina dalla memoria centrale . Vengono usati i seguenti algoritmi : 1) FIFO ( first in first out ) 2) LRU ( least recently used ) 3) NUR ( not used recently ) 1) Questo algoritmo é molto semplice : viene eliminata dalla memoria la pagina che , tra
quelle presenti in un certo istante , é stata caricata per prima .Il metodo é semplice ma produce molti page fault . Se una pagina é usata frequentemente ( es pagina di menu principale ) , diventerà presto la più vecchia e quindi viene eliminata , ma essendo sempre richiesta viene immediatamente ricaricata rallentando così il sistema . ( vedi esempio pag 201 Sistemi 2 )
2) Tale algoritmo seleziona la pagina che non é stata referenziata da più tempo ( non necessariamente si tratta di quella in memoria da più tempo ).Tale tecnica si basa sul principio di località : si suppone che se una pagina é stata richiesta di recente , é probabile che presto serva nuovamente ( le informazioni per la rimozione di una pagina sono contenute nel reference bit e ne change bit ) . L’efficienza di tale metodo é superiore a quella del FIFO 3) Tale metodo parte dagli stessi principi del metodo LRU . Si cerca di eliminare una
pagina non utilizzata di recente ( non necessariamente quella non usata da più tempo . In questo modo la gestione si semplifica . Si prevede un azzeramento periodico dei reference bit , se al momento della selezione della pagina viene trovato ad 1 , significa che é stato fatto un accesso recente se viene trovato a 0 ,non é stato fatto un accesso recente e quindi può avvenire la rimozione . La scelta della pagina da eliminare , fra quelle che hanno il reference bit = 0 , é casuale. L’efficacia di tale tecnica é vicina alla precedente ma é di più semplice implementazione . La tecnica della gestione virtuale paginata mantiene tutti i vantaggi legati alla gestione della memoria centrale in modo virtuale ( memoria teoricamente infinita , alto livello di multiprogrammazione ... ) e gli svantaggi dovuti alla complessità ed al volume delle tabelle da gestire . Per quanto riguarda la frammentazione , viene conservato quel minimo relativo al Page breakage ( resto nell’ultima pagina di ogni programma ) .

Autore Flavio Cerini 42
GESTIONE VIRTUALE SEGMENTATA Quando si parla di memoria virtuale , si intende che i programmi non sono caricati per intero in memoria centrale . Si deve quindi pensare ad una eventuale suddivisione da operare su ogni programma . La tecnica della paginazione é deterministica e legata alla dimensione predefinita staticamente per i blocchi di memoria . Con la gestione virtuale segmentata i programmi vengono divisi in segmenti di dimensione variabile secondo la logica del programma . Nella paginazione si fa una suddivisione in pagine indipendentemente da quello che contengono ( criterio fisico ) . Nella segmentazione , la suddivisione in segmenti viene fatta a seconda del significato del contenuto (criterio logico ) . Tutto questo viene fatto nel rispetto dei principi di località . La paginazione, essendo legata, alle dimensioni del programma, poteva anche spezzare su due pagine una stessa funzione e generare quindi un numero notevole di page faults fra le due durante l’esecuzione . Il problema si elimina se tutte le istruzioni che concorrono alla realizzazione di una funzione restano adiacenti anche in memoria centrale . La segmentazione virtuale consiste nella suddivisione della memoria centrale in una entità simile alla partizione : cioè uno spazio di dimensione variabile creato dinamicamente e gestito tramite tabelle che indicano le aree libere e quelle occupate . Oltre alle tabelle che realizzano il partizionamento, ci saranno dei meccanismi che realizzano la virtualizzazione . Funzioni fondamentali svolte dal gestore della memoria 1) Mantenere traccia dello stato della memoria ; si deve conoscere lo stato delle aree di
memoria (libere e occupate) e lo stato di ogni programma ( quanta parte é in memoria di massa e quanta in memoria centrale ) . Vengono utilizzate due tabelle principali :
• Segment Map Table ( SMT ) : una per ogni programma , con tanti elementi quanti sono
i suoi segmenti , che contiene la corrispondenza tra le aree di memoria e il segmento e l’indicazione sul tipo di accesso consentito ;
• Unallocated Area Table ( UAT ) : unica nel sistema , elenca i dati sulle aree libere della memoria centrale
Esiste un’altra tabella che realizza il meccanismo di condivisione dei segmenti da parte di più programmi : Active Segment Table ( AST ) 2) Definire la strategia di allocazione della memoria ( a carico del job scheduler ), si deve
ricercare nella UAT se esistono aree libere per il segmento richiesto del programma in esecuzione , Se la ricerca non va a buon fine, parte il meccanismo di rimozione per creare spazio in memoria centrale
3) Effettuare l’allocazione : i segmenti del programma sono caricati nelle aree libere prescelte dal S.O ( eventualmente dopo intervento del meccanismo di rimozione ) che provvede anche all’aggiornamento delle tabelle
4) Deallocare la memoria : a lavoro finito il programma rilascia le aree di memoria occupate ( se non sono condivise con altri programmi ) che tornano disponibili ed eventualmente aggiorna i dati posti sul disco .

Autore Flavio Cerini 43
La tabella SMT ha una struttura più complessa rispetto alla equivalente PMT ( usata nella paginazione ) . ( vedi Fig. 20 ).
NUM . SEGM. DIMENSIONE ACCESSO STATO LOCAZIONE 0 160 E In 4000 1 340 E In 3460 2 100 R In 3800 3 60 RW Out -
Fig. 20 SMT • Primo campo : numero del segmento • Secondo campo : dimensione del segmento che serve per la ricerca dell’area libera nellaUAT • Terzo campo : tipo di accesso consentito al programma nel segmento specifico ( R lettura, W: scrittura, E: esecuziona ); • Quarto campo : stato ( In : in memoria centrale, Out : in memoria di massa ) • Quinto campo : locazione iniziale del segmento all’interno della memoria centrale (
ha senso se il segmento é già in memoria ) La tabella delle aree libere (UAT) ha la stessa struttura di un meccanismo semplicemente partizionato . In Fig. 21 viene rappresentata lo stato della memoria
S.O
SEG_1
SEG_2
SEG_0
0 3000 3460 3800 3900 4000 4160

Autore Flavio Cerini 44
Fig.21 Stato della memoria
Vantaggi principali del metodo segmentato : • Elimina frammentazione : muovendo i segmenti in aree della dimensione esatta, si
elimina il problema dei frammenti inutilizzabili ( grazie anche al compattamento periodico )
• Permette la crescita dinamica del segmento : nel caso in cui il segmento subisce delle modifiche di dimensione , non si presentano problemi poiché la dimensione del segmento non é definita a priori . Nella paginazione, una modifica della dimensione di una pagina comporta la risuddivisione di tutto il programma
• Facilita la condivisione dei segmenti : la suddivisione del programma é logica e non fisica é quindi possibile consentire la condivisione di alcuni segmenti che contengono funzioni che possono essere utili a più programmi
• Controllo degli accessi più rigoroso : l’accesso ad ogni segmento é controllato • Linking e loading dinamico : i programmi voluminosi e complessi possono essere
composti da centinaia di procedure e funzioni distinte . Poiché é costoso linkarle e caricarle tutte in memoria nello stesso tempo , viene caricato in memoria solo il programma principale, mentre le altre parti vengono richiamate quando servono .
Tabella AST : contiene informazioni sui segmenti attivi ( residenti in memoria centrale ) . Quando un programma richiama un segmento, le coordinate del segmento vengono inserite in tale tabella . Un programma che ha bisogno di una funzione consulta prima la AST per controllare che sia già in memoria, nel caso non ci sia il S.O provvede al caricamento . Quando un segmento viene rimosso dalla memoria centrale devono essere aggiornate tutte le SMT e le AST . I meccanismi di rimozione del segmento sono simili a quelli della paginazione, in più c’é il vincolo della dimensione del segmento . Non basta che l’area da liberare sia la più vecchia o la meno usata,é importante che la sua dimensione sia sufficiente.
Svantaggi principali : • La necessità del compattamento aumenta la complessità della gestione ; • La dimensione non fissa dei segmenti del programma non garantisce i vantaggi di
memorizzazione guadagnata nell’organizzazione a blocchi della memoria di massa • La dimensione massima di un segmento é limitata alla dimensione della memoria fisica • Le tecniche per ridurre il segment fault sono più complesse dell’equivalente nella
gestione paginata .
GESTIONE VIRTUALE SEGMENTATA - PAGINATA Questa é una tecnica di tipo segmentato ; in aggiunta ogni segmento é suddiviso in pagine di uguale dimensione . Si ottengono buoni risultati a scapito di una maggiore difficoltà di gestione. L’indirizzo di una locazione di memoria é composto di tre parti : un numero di
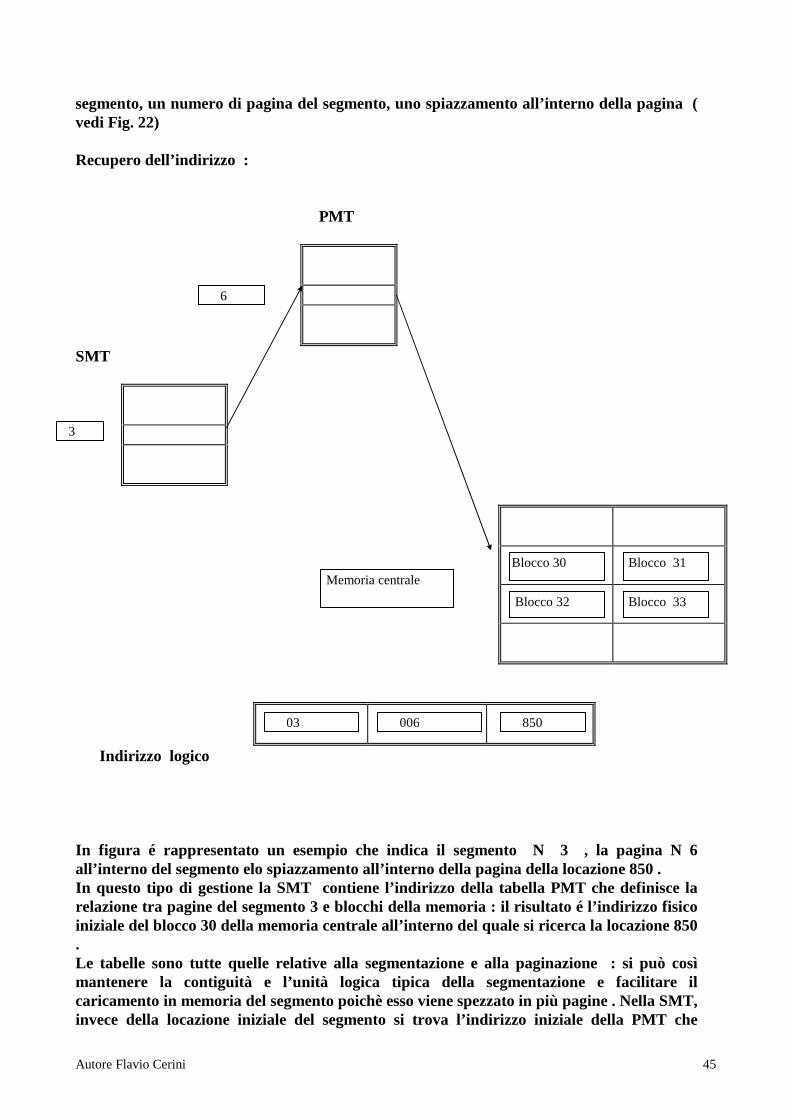
Autore Flavio Cerini 45
segmento, un numero di pagina del segmento, uno spiazzamento all’interno della pagina ( vedi Fig. 22) Recupero dell’indirizzo : PMT
SMT
Indirizzo logico In figura é rappresentato un esempio che indica il segmento N 3 , la pagina N 6 all’interno del segmento elo spiazzamento all’interno della pagina della locazione 850 . In questo tipo di gestione la SMT contiene l’indirizzo della tabella PMT che definisce la relazione tra pagine del segmento 3 e blocchi della memoria : il risultato é l’indirizzo fisico iniziale del blocco 30 della memoria centrale all’interno del quale si ricerca la locazione 850 . Le tabelle sono tutte quelle relative alla segmentazione e alla paginazione : si può così mantenere la contiguità e l’unità logica tipica della segmentazione e facilitare il caricamento in memoria del segmento poichè esso viene spezzato in più pagine . Nella SMT, invece della locazione iniziale del segmento si trova l’indirizzo iniziale della PMT che
03
3
006
6
850
Blocco 30 Blocco 31
Blocco 32 Blocco 33
Memoria centrale

Autore Flavio Cerini 46
contiene i dati relativi a tutte le pagine di quel segmento . I vantaggi e gli svantaggi sono quelli della paginazione e della segmentazione sommati. Il meccanismo della segmentazione paginata é abbastanza efficiente e flessibile con un buon livello di protezione degli accessi ma é piuttosto gravosa la gestione da parte del S.O . Come svantaggio si ha la ricomparsa della frammentazione dovuta al page breakage .
GESTIONE DEL PROCESSORE Il livello di S.O richiamato con maggior frequenza, direttamente o da altri gestori, é quello che si occupa della gestione del processore . Vengono evidenziati i seguenti tre moduli : 1) Job scheduler : seleziona il job che può essere eseguito ( transizione fra gli stati di
acquisizione e pronto ) 2) Process scheduler : decide tutte le modalità di accesso al processore ( transizione tra gli
stati pronto ed esecuzione ) 3) Traffic controller : mantiene traccia dello stato del processo, coordina i meccanismi di
sincronizzazione e comunicazione tra i processi (transizioni in stati di attesa e terminazione e pronto)
In ambiente monoprogrammato il job scheduler ed il process scheduler coincidono in quanto il job selezionato dal job scheduler è anche l’unico che otterrà l’uso del processore . Scheduler : con tale termine si intende un gestore di una risorsa che esegue il suo lavoro secondo certe regole e priorità . Vengono evidenziate le seguenti classi di scheduling : • Short term scheduling : gestisce un utilizzo della risorsa di durata molto breve ( frazioni
di secondo ) ; si tratta del process sheduler che gestisce i tempi di utilizzo della CPU ( millisecondi). Si parla anche di dispatcher o schedulatore di basso livello ( rappresenta il pro- cesso con cui il nucleo di un S.O fa passare un processo tra quelli presenti nella ready list dallo stato di pronto allo stato di esecuzione . • Medium term scheduling : Le operazioni di gestione della risorsa fanno riferimento a
tempi di media lunghezza ( le operazioni interne al calcolatore sono comunque velocissime per l’uomo )
un esempio può essere il job scheduler che gestisce operazioni meno frequenti e che richiedono più tempo . E’ più importante ottimizzare l’uso della risorsa (tramite algoritmo ) piuttosto che la velocità di esecuzione. • Long term scheduling : ( detto semplicemente scheduler ) riguarda un controllo delle
richieste a livello ancora più alto . ( può essere la fase in cui si decide se un programma può essere accolto all’interno della macchina in attesa di essere scelto dal job scheduler .

Autore Flavio Cerini 47
Da quanto detto si intuisce che, passando dallo scheduling a basso livello allo scheduling ad alto livello vengono trattate operazioni sempre meno legate al processore fisico ; quindi si passa da problematiche relative alla riduzione dei tempi di esecuzione a problematiche relative alla ottimizzazione dell’uso e della condivisione delle risorse. Un esempio di gestione a lungo termine é lo spooler che si occupa di gestire le richieste di stampa di più utenti in ambiente multiprogrammato .
JOB SCHEDULER Il job scheduler é un piccolo gestore che deve assegnare le risorse del sistema ai job (o programmi) selezionati. Deve pertanto svolgere le quattro funzioni fondamentali di un gestore : • prendere nota dello stato dei job richiedenti ; • applicare la strategia prescelta per selezionare i job da portare allo stato di pronto • assegnare le risorse richieste dai job che sono arrivati in stato di pronto • sovrintendere alle operazioni di deallocazione delle risorse Per mantenere traccia dei job che richiedono di essere eseguiti é necessario avere una tabella per ogni job chiamata job control block che contiene le informazioni circa le richieste temporali e di risorse . L’insieme di tutte le tabelle JCB costituisce la coda dei job in stato di acquisizione ( vedi fig.23 ) Fig. 23 JCB ( job control block )
...........................
JOB ID
STATO CORRENTE
PRIORITA’
TEMPO PREVISTO

Autore Flavio Cerini 48
Alcune informazioni, come la priorità dell’utente o il tempo previsto per l’esecuzione dipendono dalle dichiarazioni o dalle stime dell’utente, altre, come lo stato corrente sono impostate dal sistema operativo. Per quanto riguarda la strategia di selezione dei job da portare dallo stato di acquisizione allo stato di pronto. Per selezionare i job da portare dallo stato di acquisizione allo stato di pronto vengono utilizzati principalmente due criteri : • Ottimizzazione dell’uso delle risorse a costi limitati ( complessità degli algoritmi di
gestione ) • Minimizzazione dei tempi di attesa dei job Facendo riferimento alla minimizzazione dei tempi di attesa si definisce la seguente grandezza : Average Turnaround Time ( ATT : tempo medio di esecuzione ) così definito : n ∑∑∑∑ Ti i=1 dove Ti = Fi - Ai ATT = n Fi = istante finale Ai= istante iniziale ( istante di arrivo job) n = numero dei job Il problema consiste nell’individuare delle strategie che mediamente comportano le minori attese per i programmi e quindi per gli utenti. Sistema monoprogrammato : Siccome é possibile eseguire un solo programma per volta , alcuni job saranno costretti ad attendere il loro turno. ( vedi esempio pag 223 Sistemi 2 ). Si possono individuare tre strategie: • FIFO ( programmi eseguiti nell’ordine in cui vengono lanciati ) . ( nell’esempio visto
ATT = 2.63 ore ). • Shortest Job First ( SJF ) prevede una precedenza di esecuzione per il job che ha il
tempo previsto minimo ( nell’esempio ATT = 2.38 ) c’é quindi un risparmio di tempo rispetto alla tecnica FIFO.
• Future Knowledge ( conoscenza futura ) é utilizzabile se il sistema conosce a priori la sequenza di job che si presenteranno per essere eseguiti ; si possono fare delle scelte che permettono di migliorare il tempo medio
Sistema multiprogrammato : Si possono utilizzare gli algoritmi visti con la variante che possono lavorare più job contemporaneamente . Se per esempio viene usata la tecnica

Autore Flavio Cerini 49
FIFO, il S.O farà eseguire i primi N job acquisiti ( se N é il livello di multiprogrammazione )
IL PROCESS SCHEDULER Questo modulo si incarica di assegnare il processore ai processi che sono stati inseriti nella coda di pronto dal job scheduler. Anche in questo caso il modulo può essere considerato come un piccolo gestore di risorse. Si possono ancora individuare le quattro funzioni fondamentali dei gestori. Process Control Block ( PCB ) : sono delle tabelle contenenti le informazioni fondamentali relative ad un processo in esecuzione. L’insieme delle PCB é organizzato come lista di record ( ogni PCB é un record ). ( vedi fig 24 ) Fig 24 Process Control Block
Il traffic controller viene richiamato ogni volta che un processo cambia stato ( attesa - pronto - esecuzione ecc ..) e va a modificare il contenuto del campo relativo allo stato all’interno della della corrispondente PCB. Le PCB organizzate nella lista che si trova nello stato di pronto costituiscono la coda che prende il nome di ready list e rappresentano le richieste dei job pronti a ricevere la CPU . Altre PCB si trovano nelle code relative agli altri stati che compongono il ciclo di esecuzione di un processo. Strategie di assegnazione del processore : • FCFS ( First Come First Served ) • Round Robin ( RR) • Inverso del time slice residuo • Priorità definita
PROCESS ID
STATO CORRENTE
PRIORITA’
COPIA REGISTRI ATTIVI
PUNTATORE LISTA PROCESSI

Autore Flavio Cerini 50
• Shortest Elapsed Time ( SET ) FCFS : é basata sul principio del FIFO. Il primo processo che entra nella ready list é il primo che ottiene l’utilizzo della CPU che mantiene per tutto il tempo necessario al completamento del lavoro. ROUND ROBIN (Fig.25 ) : é una tecnica molto importante sulla quale si basano molte altre . Ogni processo mantiene il processore per un certo tempo ( time slice ). Se il processo non ha finito il suo lavoro, deve essere inserito di nuovo nella coda nella posizione definita dalla particolare strategia adottata dal S.O . La tecnica round robin prevede che la ready list venga gestita in modo FIFO perché ad ogni processo in coda venga assegnato a turno un intervallo di tempo di CPU uguale per tutti.Se il processo, al termine del suo time slice, non ha terminato il suo lavoro, deve rilasciare forzatamente la CPU ( preemption ) e viene inserito in fondo alla ready list. In questo modo i processi brevi non sono soggetti a lunghe attese, mentre i processi lunghi allungano i loro tempi di lavoro. La scelta del time slice é molto importante ; se il tempo é troppo breve rispetto alla durata dei processi, il numero di interruzioni risulta molto alto e si abbassano le prestazioni del sistema. Se il tempo é troppo lungo quasi tutti i processi terminano il loro lavoro e si ricade così nella tecnica FCFS. Fig. 25 Round Robin Inverso del time slice residuo : La tecnica del tempo residuo di CPU prevede una gestione con priorità della ready list . Il S.O fa una prima assegnazione della CPU secondo la strategia Round Robin pura, poi inserisce i processi nella lista in ordine inverso rispetto al tempo di CPU non utilizzato. Si vuole cioé dare priorità maggiore ai processi che usano poco la CPU e che quindi lasciano un grande residuo di time slice. In questo modo si raggiungono due obiettivi : • Si abbrevia il tempo medio di esecuzione ( si velocizzano i processi brevi )
P1 P5 P4 P3 P2 PRONTO
ESECUZIONE

Autore Flavio Cerini 51
• Si intensificano le operazioni sulle periferiche ( aumenta la percentuale di utilizzo ) infatti se un processo interrompe il suo lavoro col processore é molto probabile che lo faccia anche per svolgere delle operazioni di I/O.
Processi I/O bound : processi che presentano una notevole quantità di operazioni di I/O Processi CPU bound : processi per i quali predomina il lavoro con la CPU Priorità definita : si può pensare di ordinare la coda secondo delle priorità prestabilite, per cui ogni processo prende posto nella ready list secondo la propria priorità. Si possono definire anche tante code, una per ogni livello di priorità in modo che tutti i processi della stessa importanza siano nella stessa struttura ( priorità multilista ). Ogni coda viene poi gestita con tecnica FCFS oppure Round Robin. I processi a priorità più alta accederanno per primi ; i processi a priorità inferiore potrannno accedere alla CPU solo quando non c’é nessun processo nelle code superiori. Il lavoro di una coda viene interrotto quando si presenta un nuovo processo di priorità superiore. Tale tecnica potrebbe produrre il fenomeno deenominato starvation ( attesa infinita ) di processi a bassa priorità. Shortest Elapsed Time ( SET ) : tale tecnica é una sintesi delle precedenti. E’ ancora una organizzazione multilista ( gestita in Round Robin ) che sfrutta dinamicamente le richieste temporali dei processi. I processi che arrivano in stato di pronto vengono automaticamente inseriti nella coda di priorità maggiore ottenendo quindi la CPU entro breve tempo. Se terminano il lavoro prima della fine del time slice escono dalla struttura, altrimenti regrediscono di un livello di priorità passando alla coda immediatamente inferiore. Tale procedimento si applica a tutti i processi della lista finché non resta vuota. A questo punto viene assegnata la CPU alla seconda lista con le stesse regole e così via fini all’ultima. Se arriva un processo, mentre si sta scandendo una lista inferiore,al termine del time slice, il controllo passa alla prima lista della struttura. In pratica, a regime, il sistema da priorità massima alla lista contenente i processi che richiedono brevi periodi di CPU e penalizza i processi CPU bound che acquistano il processore raramente. S.O XENIX : privilegia i processi interattivi definendo un time slice breve e assegna ad ogni processo un numero di priorità ( numero basso corrisponde a priorità alta ) che gestisce dinsmicamente per evitare lo starvation ( causato dalla priorità statica ) . S.O OS2 : prevede una strategia di assegnazione secondo una priorità di tipo multilista GESTIONE DEI DISPOSITIVI Nei sistemi di elaborazione l’accesso ai dispositivi periferici avviene tramite i “ device drivers “ cioè attraverso dei moduli software che fanno da interfaccia fra il S.O e i dispositivi. Ogni dispositivo periferico ha il suo device driver. Nei sistemi multiprogrammati può capitare che più processi richiedano di accedere ad uno stesso dispositivo o che tale dispositivo non sia disponibile al momento della richiesta. I device drivers, presenti in ogni S.O non sono concepiti per risolvere tali problemi. Un S.O deve quindi prevedere una serie di moduli software, affiancati ai device drivers, atti ad implementare una politica di gestione delle periferiche. ( gestore I/O livello 3 ).

Autore Flavio Cerini 52
Funzioni del gestore dell’I/O • Controllare lo stato delle periferiche ( può essere necessario un data base utilizzato come
mappa delle periferiche ) • Decidere la politica di assegnazione del dispositivo ai programmi • Allocare la risorsa e dare inizio all’operazione di I/O • Rilasciare la periferica ( deallocare la risorsa ) La gestione dei dispositivi si compone di due moduli ( vedi Fig. 26 ) richieste di accesso alla periferica stato rilevato dalle periferiche al driver del dispositivo Fig 26 Gestione dei dispositivi • I/O Traffic Cotroller : controlla lo stato dei disp ositivi per avere sempre presente la
situazione delle periferiche ( disponibili oppure occupate ) . • I/O Scheduler : in base alle informazioni fornite dall’I/O traffic controller , decide a
quale processo assegnare il dispositivo libero predisponendo il percorso ( path ) che conduce al dispositivo stesso. Il driver della risorsa permette infine al processo che ha fatto richiesta di accedere fisicamente al dispositivo.
Canali ed unità di controllo Il S.O si deve incaricare della gestione dei canali e lelle unità di controllo. Un canale
INPUT OUTPUT TRAFFIC CONTROLLER
INPUT OUTPUT SCHEDULER
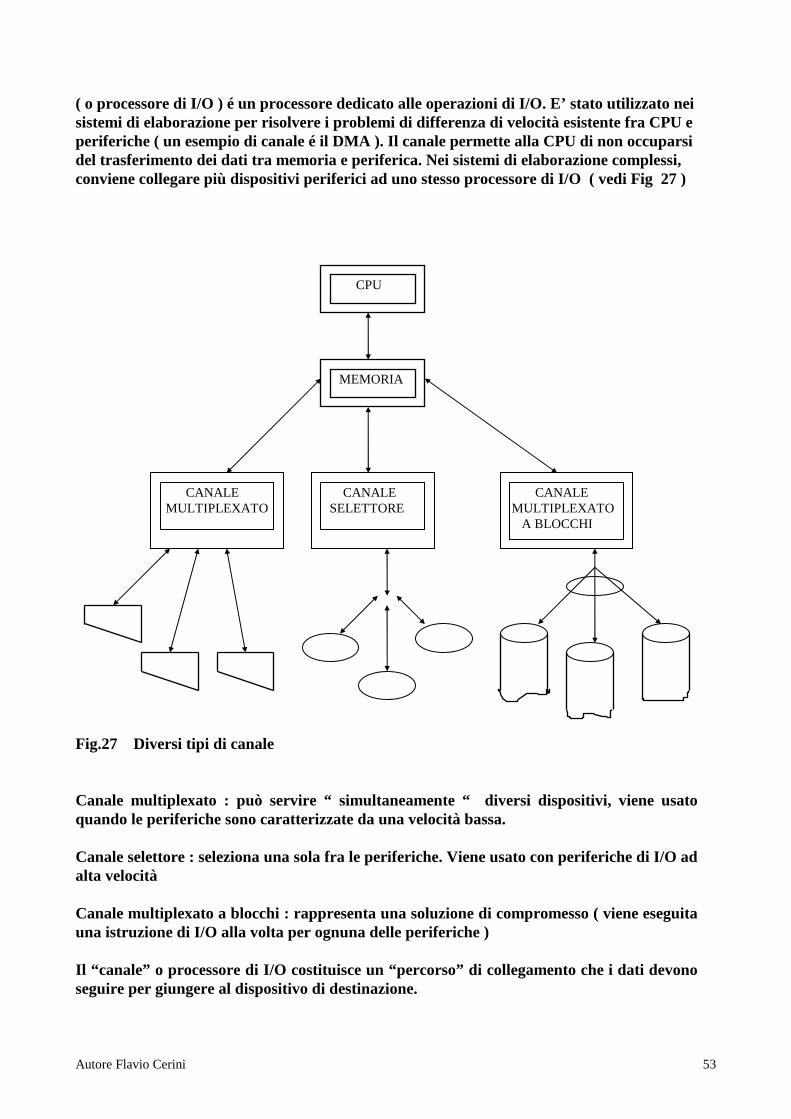
Autore Flavio Cerini 53
( o processore di I/O ) é un processore dedicato alle operazioni di I/O. E’ stato utilizzato nei sistemi di elaborazione per risolvere i problemi di differenza di velocità esistente fra CPU e periferiche ( un esempio di canale é il DMA ). Il canale permette alla CPU di non occuparsi del trasferimento dei dati tra memoria e periferica. Nei sistemi di elaborazione complessi, conviene collegare più dispositivi periferici ad uno stesso processore di I/O ( vedi Fig 27 ) Fig.27 Diversi tipi di canale Canale multiplexato : può servire “ simultaneamente “ diversi dispositivi, viene usato quando le periferiche sono caratterizzate da una velocità bassa. Canale selettore : seleziona una sola fra le periferiche. Viene usato con periferiche di I/O ad alta velocità Canale multiplexato a blocchi : rappresenta una soluzione di compromesso ( viene eseguita una istruzione di I/O alla volta per ognuna delle periferiche ) Il “canale” o processore di I/O costituisce un “percorso” di collegamento che i dati devono seguire per giungere al dispositivo di destinazione.
CPU
MEMORIA
CANALE MULTIPLEXATO
CANALE SELETTORE
CANALE MULTIPLEXATO A BLOCCHI

Autore Flavio Cerini 54
Unità di controllo : é un apparato elettronico che controlla la parte meccanica dei dispositivi periferici. In genere vengono accomunate più periferiche uguali ad una sola unità di controllo che può eesere collegata al dispositivo prescelto. Il canale é collegato all’unità di controllo a cui il dispositivo é associato ( vedi Fig 28 ) Il driver della risorsa deve conoscere il path da seguire es : canale B U.C. stampanti stampante 2 controllore della risorsa : scheda su cui vengono montati canali e unità di controllo Fig. 28 Canali ed unità di controllo
IL CONTROLLO DEL TRAFFICO L’ I/O traffic controller deve essere sempre a conoscenza dello stato dei dispositivi , unità di controllo e canali per determinare l’esistenza di path disponibili. Il problema é complesso poiché potrebbero essere liberi canale e unità di controllo e non il dispositivo terminale ; questo si verifica poiché il processore di I/O e l’unità di controllo possono essere usati soltanto nella parte iniziale e la periferica può restare impegnata per tutto il tempo necessario. L’I/O traffic controller deve occuparsi della seguente attività : • Determinare se esiste un path disponibile per servire una richiesta di I/O • Determinare se più paths sono disponibili contemporaneamente • Determinare quando un path si libererà, nel caso non ce ne fosse neanche uno
disponibile
MEMORIA
Disco A
Disco B
Disco C
Disco D
Disco E
Stampante 1
Stampante 2
Monitor 1
Monitor 2
Canale A
Canale B
U.C Dischi 1
U.C Dischi 2
U.C Dischi 3
U.C Dischi 4

Autore Flavio Cerini 55
L’I/O traffic controller si avvale di un data base che fornisce una mappa degli stati e delle connessioni. Tale data base é costituito dalle seguenti strutture • UNIT CONTROL BLOCK ( UCB) ( data base relativo alle singole unità periferiche ) • CONTROL UNIT CONTROL BLOCK ( CUCB ) (data base rela tivo alle unità di
controllo) • CHANNEL CONTROL BLOCK ( CCB ) ( data base relativo ai canali ) L’ I/O traffic controller esegue una interrogazione a ritroso di tutte le sue tabelle per trovare un path libero. Un altro controllo che deve effettuare é relativo alla ricerca di più percorsi disponibili contemporaneamente. Tale verifica deve essere fatta quando l’apparato di I/O é organizzato secondo la cosiddetta “ configurazione asimmetrica “ ( vedi Fig 29 ) Fig 29 Configurazione asimmetrica Per accedere alla periferica Y si possono scegliere cinque percorsi diversi. La scelta di un certo path potrebbe bloccarne un altro; bisogna quindi scegliere i percorsi in modo oculato. Può capitare che non ci siano percorsi disponibili, in questo caso l’I/O traffic controller deve memorizzare la richiesta in attesa che si liberi un path ; all’interno del data base ci sarà una lista di processi in attesa.
L’allocazione dei dispositivi I/O Scheduler : questo modulo software si occupa di associare ai processi che ne fanno richiesta, i dispositivi individuati come liberi ( path libero ) dal modulo traffic controller. Se le richieste sono inferiori al numero di dispositivi, non si presentano problemi; in caso contrario l’I/O scheduler dovrà provvedere ad una assegnazione stabilendo una gerarchia fra le richieste inoltrate. Molti concetti espressi a proposito del job scheduling, si possono applicare anche in questo caso. In questo contesto, a differenza di quanto avviene per i processi non si possono sospendere le attività di I/O per poi riprenderle in un secondo tempo ( pensare ad una operazione di stampa ).
Memoria CANALE B
CANALE C
CANALE A Unità di controlo 1
Unità di controllo 2
Unità di controllo 3
Periferica x
Periferica y
Periferica z

Autore Flavio Cerini 56
Politiche di schedulazione : le politiche di schedulazione applicate dall’I/O scheduler, possono variare da sistema a sistema. Può essere una buona politica, in generale, quella di associare ad un processo la stessa priorità assegnatagli dal process scheduler. Dopo che si é identificato il processo da servire e la periferica da assegnare é necessario procedere alla allocazione della risorsa. Si deve attivare il driver della risorsa che deve creare il “programma di canale “ per inizializzare il dispositivo di I/O, abilitarne le interruzioni e predisporlo ad eseguire la funzione richiesta. A questo punto si procede con l’I/O fisico. A fine operazione si ha il rilascio della periferica ( deallocazione ). Allocazione e deallocazione : l’I/O scheduler si deve occupare della politica di gestione della allocazione/deallocazione ; le tecniche adottate variano a seconda del sistema, si possono comunque raggruppare in tre classi principali a seconda del tipo di dispositivi collegati. • Dispositivi dedicati : sono dispositivi che non possono essere utilizzati
contemporaneamente da più utenti ( es stampante ), vengono allocati ad un processo e conservati fino a fine lavoro. Il processo richiedente aspetta il suo turno per ottenere l’uso esclusivo della risorsa.. L’uso delle risorse risulta abbastanza inefficiente. Un processo potrebbe usare poco una risorsa e tenerla comunque allocata per molto tempo a discapito di altri processi. Si potrbbero anche creare intasamenti dovuti al blocco di certi paths ( configurazione asimmetrica dell’I/O ).
• Dispositivi condivisi : sono dispositivi il cui accesso é permesso contemporaneamente a più processi ( es dischi o nastri magnetici ). La politica di gestione consiste nel suddividere logicamente il dispositivo ( es il disco ) in diverse aree di utilizzo ognuna delle quali viene assegnata ad un particolare processo. In questo modo ogni processo ha l’impressione di disporre di un dispositivo dedicato. Ovviamente risulta appesantita la parte hardware ( canali e unità di controllo ) e la parte software del S.O. In particolare é l’I/O traffic controller che deve accollarsi la gestione delle partizioni ricavate dalle risorse oltre alla gestione delle normali risorse ( controllore e periferica ).
• Dispositivi virtuali : La virtualizzazione delle periferiche é indubbiamente la tecnica preferibile.
Viene simulata la presenza di periferiche reali utilizzando dispositivi di memoria sui quali i processi possono immagazzinare o prelevare dati come se avessero a disposizione degli effettivi organi di I/O. Il S.O eseguirà le operazioni di I/O fisico “ in differita “ rispetto all’I/O logico eseguito dai processi. La tecnica dei dispositivi virtuali é divenuta praticamente uno standard “ de facto ” nei moderni sistemi operativi. DISPOSITIVI VIRTUALI : buffering e sistemi di spool Con le tecniche di allocazione dedicata e condivisa non si risolve il problema della sincronizzazione fra processi e periferiche. Spesso capita che i processi lavorino ad una velocità superiore a quella dei dispositivi periferici ( potrebbe capitare anche il contrario ma raramente ). Il S.O deve cercare di ottimizzare il proprio lavoro cercando di ridurre il più possibile i tempi morti che si vengono a creare. Per sincronizzare le attività dei processi

Autore Flavio Cerini 57
con quelle dei dispositivi, si utilizza generalmente la tecnica della virtualizzazione delle periferiche. Viene utilizzato un dispositivo di memoria ad alta velocità ( normalmente un disco ) per simulare la periferica. Il processo selezionato dall’I/O scheduler invia ( o preleva ) i dati in un’area del disco e non direttamente alla periferica potendo così sfruttare una maggiore velocità di trasferimento. In un secondo tempo il driver della periferica legge i dati dal disco per inviarli al dispositivo di uscita oppure legge i dati dal dispositivo di ingresso per inviarli al disco. Vengono così differenziati i tempi di accesso alle risorse. Il processo ha la sensazione di avere a disposizione un dispositivo dedicato e si comporta come se stesse trasferendo dati direttamente ad una periferica reale.
BUFFERING
La tecnica del buffering consiste nel riservare , ad ogni processo che necessita di un dispositivo, in memoria centrale un buffer attraverso il quale transita il flusso dei dati. ( vedi Fig.30 ) Fig. 30 Buffering in ingresso BUFFER La figura fa riferimento ad una operazione di input : il controllore della risorsa esegue il programma di canale impostato dal driver della periferica per leggere i dati dall’esterno e memorizzarli nel buffer. Al termine dell’operazione di lettura, sarà sempre il controllore a segnalare il buon esito dell’operazione al processo richiedente, il quale inizierà a prelevare i dati dal buffer. Ora il dispositivo di ingresso può essere allocato ad un altro processo.
SISTEMI DI SPOOL
Controllore del dispositivo
Disp. input I/O Scheduler
P1
P2
Pn

Autore Flavio Cerini 58
Il metodo del buffering presenta alcuni limiti . Il buffer é una struttura rigida in memoria centrale. La dimensione del buffer, una volta fissata, resta costante. Si può rischiare di sottodimensionare il buffer ( insufficiente per il lavoro del processo ) oppure di sovradimensionarlo ( spreco di memoria). La soluzione migliore sarebbe quella di utilizzare una struttura dinamica. Tale soluzione viene adottata nei sistemi di spool ( Simultaneous Peripheral Operation On Line). In tali sistemi, a differenza del buffering, ad ogni processo che deve eseguire operazioni di I/O viene associato un file su disco nel quale si memorizzano temporaneamente i file su disco. Il buffer é costituito da un numero di files pari al numero di processi attivati dall’I/O ; di solito questi files vengono organizzati in una unica directory ( vedi Fig 31 ). Come si può notare in Fig 31 sono presenti due particolari processi detti spooler. Lo spooler di uscita ha il compito di prelevare i dati dai files ed inviarli alla periferica. Lo spooler di ingresso ha il compito di leggere i dati in input e memorizzarli nel file del processo che ha richiesto la lettura . La schedulazione dei files da parte degli spoolers dipende dal particolare sistema utilizzato.( files relativi a processi con alto livello di privilegio oppure evasi per primi files più corti ). Dopo che un processo é stato servito, il relativo file verrà tolto dalla directory e lo spazio liberato verrà utilizzato da un altro processo. Vantaggi dello spooling : • Viene utilizzata una struttura dinamica che non richiede un preventivo
dimensionamento • Consente di implementare una politica di gestione dei lavori da svolgere, non possibile
con una struttura sequenziale come quella del buffer • Non volatilità dei dati memorizzati sotto forma di file. Se si spegne improvvisamente il
sistema i files memorizzati su disco non vanno persi. Fig 31 Sistema di Spool
P1
P2
Pn
I/O SCHEDULER
SPOOLER DI USCITA
SPOOLER DI INGRESSO
F1
F2
Fn
Dispositivo di uscita
Dispositivo di ingresso

Autore Flavio Cerini 59
Fn = file relativo al processo Pn
GESTIONE DELLE INFORMAZIONI Il S.O si deve occupare anche dalla gestione delle informazioni memorizzate sulla memoria secondaria ( memooria di massa) . la gestione dei dispositivi di memoria deve essere assolutamente trasparente per l’utente. Il dodulo di S.O che si occupa di tale gestione viene chiamato File System. Il file system si deve occupare dei seguenti compiti : • Mantenere aggiornata una directory, cioè una mappa di tutte le informazioni
memorizzate nel sistema • Decidere una politica di immagazzinamento e di accesso alle informazioni, tenendo
conto sia delle esigenze degli utenti, sia di quelle relative ad un uso ottimale dei dispositivi di memoria
• Allocare le risorse informazioni ( ad esempio aprire un file in seguito ad una richiesta da parte di un processo)
• Deallocare la risorsa ( chiusura di un file ). Un generico file system può essere composto dai seguenti moduli software ( vedi Fig. 32) Fig 32 File System
FILE SYSTEM SIMBOLICO
BASIC FILE SYSTEM
VERIFICA CONTROLLI ACCESSO
FILE SYSTEM LOGICO
FILE SYSTEM FISICO

Autore Flavio Cerini 60
Un file system è organizzato gerarchicamente su più livelli : ogni livello dipende da quelli sottostanti, e solo a questi può inviare chiamate. ORGANIZZAZIONE FISICA DELLE INFORMAZIONI Consideriamo l’organizzazione del dispositivo di memoria floppy disk . ( vedi Fig. 33 ) Fig.33 Floppy disk Il floppy disk su entrambe le facce ( se è a doppia faccia ) è ricoperto da materiale magnetico . Con l’operazione di formattazione vengono ricavate un certo numero di tracce ( piste ) e di settori. Ogni faccia contiene un numero fisso di tracce concentriche sulle quali, tramite una testina magnetica, vengono effettuate le operazioni di lettura e scrittura dei dati. Tutte le tracce hanno la stessa capacità di memorizzazione. Le tracce vengono suddivise in settori della stessa lunghezza ( solitamente un settore contiene un multiplo di 512 bytes ). Ogni settore rappresenta un’area della memoria di massa con una capacità di memorizzazione costante, che può variare da sistema a sistema.
DEVICE STRATEGY
Settore
Traccia

Autore Flavio Cerini 61
Hard Disk : Il disco fisso ( hard disk ) può essere visto come un insieme di dischi ( piatti ) sovrapposti. Ogni piatto è organizzato come un floppy disk. L’insieme delle tracce che, su piatti diversi occupano la stessa posizione, viene detto cilindro. Tra un piatto e l’altro viene posta una testina di lettura/scrittura che può accedere alla faccia inferiore del piatto sovrastante e a quella superiore del piatto sottostante. Occorre un movimento combinato del disco ( movimento rotatorio) e del braccio ( supporto delle testine ) che compie un movimento trasversale. I files ( strutture permanenti ) a livello fisico, vengono memorizzati in blocchi ( records fisici ). I blocchi hanno generalmente lunghezza fissa ( dimensione del settore o multiplo). Ogni record fisico è identificato da un indirizzo determinato dai parametri che ne indicano la posizione in memoria ( traccia,settore,piatto…) oppure da un numero progressivo. I blocchi che compongono uno stesso file possono essere allocati sul disco secondo due diverse strategie : 1) Allocazione contigua : tutti i blocchi che costituiscono un file vengono allocati
consecutivamente a partire da un certo settore. In questo modo il file è “ compattato “ e facilmente raggiungibile . Per allocare un file si deve trovare un numero di settori sufficientemente grande per contenere tutti i blocchi. Quando si cancella un file si liberano dei settori , bisognerebbe allora trovare un altro file delle stesse dimensioni e non sempre si trova ( utilizzo non ottimale del disco).
2) Allocazione dinamica : i blocchi che compongono un file sono sparsi in memoria . Il file si
presenta così in modo frammentato e il file system deve occuparsi di trovare tutte le varie parti del file allocate sul disco. L’allocazione dinamica consente un utilizzo del disco sicuramente più efficiente dell’allocazione contigua.
ORGANIZZAZIONE LOGICA DELLE INFORMAZIONI L’organizzazione fisica delle informazioni deve essere trasparente all’utente. L’utente deve poter accedere al file semplicemente facendo riferimento al suo nome simbolico. Il file sistem fa riferimento ad un descrittore del file. Tale descrittore può essere pensato come una tabella contenente il nome simbolico del file e il suo indirizzo fisico o i parametri necerssari per calcolarlo. I files sono strutture a lungo termine e anche i loro descrittori devono essere memorizzati su file. Viene chiamato directory un file contenente i descrittori. Generalmente alla directory viene associata una struttura ad albero. Il vertice della struttura viene chiamato radice o root e il suo indirizzo è noto al file system. In questa organizzazione logica delle informazioni, ogni file è raggiungibile tramite un path name ( vedi Fig 34 ) Fig 34 Albero delle directories
ROOT
LINGUAGGI PROVE VARIE
File
directory

Autore Flavio Cerini 62
MODELLO GENERALE DI UN FILE SYSTEM Si consideri un’istruzione generica : Leggi ( Agenda,Persona,3) Che richiede di prelevare il terzo record di Agenda e memorizzarlo nella variabile persona. Si faccia l’ipotesi che Agenda sia formato da 5 record logici ( creati dal programmatore ). Il record può contenere diversi campi ( es nome, cognome, indirizzo, telefono … ) ; si consideri inoltre che ogni record sia lungo 512 bytes. Il file agenda sia memorizzato in memoria secondaria in maniera contigua a partire dal quarto settore, la dimensione di ogni blocco sia di 1 Kbyte; ogni blocco coincide con un settore. Ogni settore contiene due record logici, per allocare il file servono tre settori. Il file system simbolico si incarica della scansione dell’albero delle directories per cercare il descrittore di agenda. Il basic file system estrae quindi dal descrittore le informazioni relative al file agenda.Il modulo verifica dei controlli d’accesso verificherà appunto la correttezza della richiesta in base ai livelli di protezione del file ricavati dal descrittore. Se il file è accessibile in lettura, il file system logico dovrà trasformare l’indirizzo del record logico ( nell’esempio = 3 ) nell’indirizzo del byte logico. A questo punto il file system fisico deve trasformare l’ indirizzo suddetto in un indirizzo fisico. Come ultima cosa deve essere letto il record e losi deve copiare nella variabile che l’utente ha indicato con il nome “ persona “. Questa operazione deve essere effettuata dalla gestione dei dispositivi. Il modulo device strategy deve passare al driver del disco le informazioni necessarie per costruire il programma di canale.
FILE SYSTEM SIMBOLICO Il compito di questo modulo del file system è quello di prendere in ingresso il nome simbolico del file ( assegnato dall’utente ) e fornire al basic file system la posizione del descrittore del file. Per fare questo deve percorrere l’albero delle directories. Nell’esempio considerato, se si parte dalla root attraverso il path VARIE\ Agenda, il file system simbolico accede alla directory VARIE che contiene i descrittori di alcuni files fra cui
PASCAL
C++
Prova1
Prova2
Prova3
Prova1
Agenda
lettera
giochi
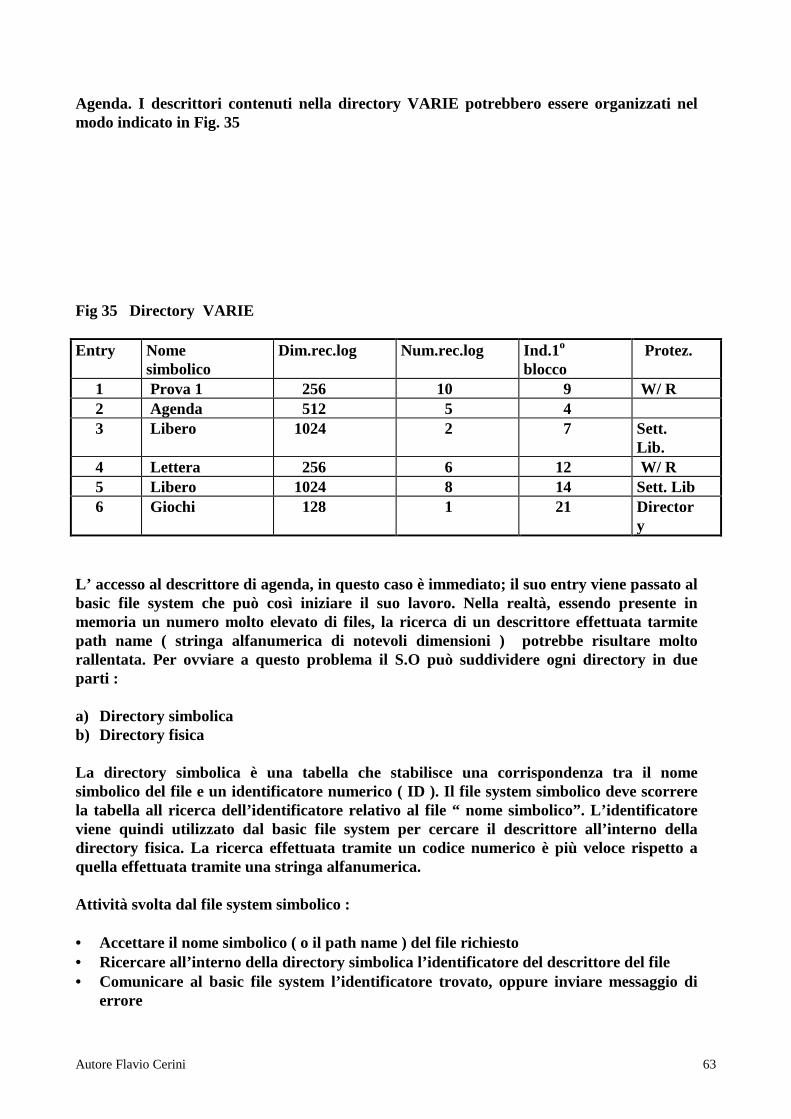
Autore Flavio Cerini 63
Agenda. I descrittori contenuti nella directory VARIE potrebbero essere organizzati nel modo indicato in Fig. 35 Fig 35 Directory VARIE Entry Nome
simbolico Dim.rec.log Num.rec.log Ind.1o
blocco Protez.
1 Prova 1 256 10 9 W/ R 2 Agenda 512 5 4 3 Libero 1024 2 7 Sett.
Lib. 4 Lettera 256 6 12 W/ R 5 Libero 1024 8 14 Sett. Lib 6 Giochi 128 1 21 Director
y L’ accesso al descrittore di agenda, in questo caso è immediato; il suo entry viene passato al basic file system che può così iniziare il suo lavoro. Nella realtà, essendo presente in memoria un numero molto elevato di files, la ricerca di un descrittore effettuata tarmite path name ( stringa alfanumerica di notevoli dimensioni ) potrebbe risultare molto rallentata. Per ovviare a questo problema il S.O può suddividere ogni directory in due parti : a) Directory simbolica b) Directory fisica La directory simbolica è una tabella che stabilisce una corrispondenza tra il nome simbolico del file e un identificatore numerico ( ID ). Il file system simbolico deve scorrere la tabella all ricerca dell’identificatore relativo al file “ nome simbolico”. L’identificatore viene quindi utilizzato dal basic file system per cercare il descrittore all’interno della directory fisica. La ricerca effettuata tramite un codice numerico è più veloce rispetto a quella effettuata tramite una stringa alfanumerica. Attività svolta dal file system simbolico : • Accettare il nome simbolico ( o il path name ) del file richiesto • Ricercare all’interno della directory simbolica l’i dentificatore del descrittore del file • Comunicare al basic file system l’identificatore trovato, oppure inviare messaggio di
errore

Autore Flavio Cerini 64
Il file system simbolico deve inoltre tenere aggiornato l’albero delle directories. Tale struttura può essere modificata in seguito alle seguenti operazioni : • Aggiunta di un nuovo file • Cancellazione di un file • Spostamento di un file • Rinominazione di un file La creazione di un nuovo file richiede l’aggiunta, nella directory simbolica cui il file è destinato, di un entry con il nuovo nome simbolico e il relativo identificatore assegnatogli dal file system simbolico. Nella directory fisica verrà inserito un nuovo descrittore. La cancellazione di un file esistente comporta la rimozione del suo descrittore e del suo entry. Analogamente le operazioni di spostamento fra directories o di cambiamento di nome comportano operazioni sul descrittore e sull’entry del file in oggetto.
BASIC FILE SYSTEM Il basic file system esegue una ricerca all’interno della directory fisica, per individuare il descrittore del file; quando viene individuato, viene copiato nella tabella dei files attivi cioè dei files aperti. Tale tabella serve ad evitare continui accessi in memoria secondaria da parte di diversi programmi che vogliono accedere ad uno stesso file. Prima di iniziare la ricerca nella directory fisica, il basic file system fa una ricerca nella tabella dei files attivi per verificare se il file richiesto è già aperto: in caso affermativo non occorre eseguire una ricerca in memoria secondaria. Un file condiviso da più utenti implica un ulteriore problema : un programma per eseguire operazioni di scrittura e lettura su di un file, deve aprirlo e dopo aver ultimato le operazioni lo deve chiudere. L’apertura richiede l’allocazione del descrittore nella tabella dei files attivi, la chiusura ne richiede la deallocazione. Per evitare queste operazioni di allocazione e deallocazione, il basic file system aggiunge al descrittore del file, nella tabella dei files attivi, un campo numerico con funzione di contatore delle aperture. Ad ogni richiesta di apertura del file il contatore viene incrementato; ad ogni richiesta di chiusura viene decrementato. Il file viene chiuso ( descrittore deallocato dalla memoria centrale ) soltanto quando il contatore delle aperture si annulla. ( Flow chart del basic file system Fig. 36 )
Autore Flavio Cerini 65
Fig. 36
Messaggio = “ OK “ Da FS simbolico
Cerca ID nella tabella dei files attivi
Aggiorna il contatore Degli accessi
Cerca ID nella directory fisica
Trovato
Messaggio = “errore” Copia il descrittore nella Tabella dei files attivi
START
Trovato
NO SI
NO
SI

Autore Flavio Cerini 66
VERIFICA DEI CONTROLLI D’ACCESSO L’accesso ai files per operazioni di lettura , scrittura , esecuzione non deve essere concesso a tutti gli utenti ; esistono problemi di sicurezza e di privatezza .Il S.O deve pertanto garantire dei meccanismi di protezione delle informazioni presenti nel sistema. Le tecniche utilizzate per realizzare i meccanismi di protezione variano da sistema a sistema. Nel caso in cui il numero di files presenti in memoria e il numero di utenti che vi accedono non sia elevato si può pensare ad una matrice degli accessi ( vedi Fig. 37 ) Fig 37 Matrice degli accessi U1 U2 U3 ………. Um
R R RWE R RW E RE RW
Ogni colonna della matrice rappresenta un utente ( soggetto ), ogni riga rappresenta un file ( oggetto ) ; nella generica casella vengono indicate le possibili operazioni ( R = lettura ; W = scrittura ; E = esecuzione ) che l’utente Ui può effettuare sul file fj . Tale soluzione è adottabile se la matrice non è di dimensioni eccessive. Una soluzione analoga ma che richiede minor spazio è rappresentata dalla lista delle capability ( vedi Fig. 38 ) Fig. 38 Lista delle capability
Invia messaggio ( int software ) al FS simbolico
END
Soggetti Oggetti
F1 F2 F3 . . Fn

Autore Flavio Cerini 67
Ogni colonna della matrice degli accessi viene trasformata in una lista. Per ogni utente viene predisposta una lista nella quale ogni elemento rappresenta un file con le relative modalità di accesso da parte del soggetto ( utente ). In certi casi si preferisce organizzare la struttura partendo dagli oggetti ( righe della matrice degli accessi ) : ad ogni file si associa una lista in cui compaiono i soggetti che vi possono accedere con le relative modalità di accesso , tale lista viene definita : lista degli accessi . Un’altra tecnica utilizzata e quella delle passwords ( codici alfanumerici associati al file e noti all’utente ); è di facile implementazione ma non è molto sicura. Un’altra tecnica è quella della crittografia : traduzione di un file in un codice segreto la cui chiave di lettura sia nota solo all’utente; sono richiesti programmi aggiuntivi, per codificare e decodificare, che appesantiscono l’attività del file system. In definitiva il modulo del file system chiamato verifica dei controlli di accesso confronta la richiesta dell’utente con le modalità di accesso al file. Se l’operazione richiesta è compatibile con quelle permesse, l’attività del file system prosegue con il file system logico, viceversa viene inviato al basic file system un segnale di interruzione con un messaggio di accesso negato.
FILE SYSTEM LOGICO Il file system logico trasforma l’indirizzo logico del record nell’indirizzo fisico, cioè nell’indirizzo del blocco, in memoria secondaria, che lo contiene. Questa trasformazione viene suddivisa in due parti; inizialmente è il file system logico che trasforma l’indirizzo del record logico nell’indirizzo del byte logico. Il file system fisico trsforma poi questo indirizzo nell’indirizzo fisico. Il file system logico permette di trasformare l’insieme di records che costituiscono il file in un insieme lineare di bytes ( organizzazione byte stream ) . Le tecniche utilizzate per operare tale trasformazione variano a seconda dell’organizzazione dei files e del loro metodo di accesso. Metodo di accesso : modalità secondo la quale è possibile accedere ad un singolo elemento ( record logico ) del file. Si fa una distinzione tra files ad accesso sequenziale e files ad accesso diretto . Accesso sequenziale : per accedere ad un record è necessario scorrere sequenzialmente quelli che lo precedono
F2 R F3 RW nil U1
F1 R F2 RWE Fn RE U2 nil
F3 E
F2 R
nil
Fn RW nil
U3
Um

Autore Flavio Cerini 68
Accesso diretto : un puntatore consente di posizionarsi direttamente sull’elemento desiderato,senza dover scorrere l’intero file Si fa anche una distinzione in base alla caratteristica dei records che costituiscono il file : record a lunghezza fissa, record a lunghezza variabile, record ad accesso indicizzato . FILE A RECORD DI LUNGHEZZA FISSA : La struttura più semplice di un file di record è quella in cui tutti i records hanno la stessa dimensione. ( vedi Fig. 39 ) Fig 39 Records di lunghezza fissa LR In caso di accesso sequenziale, per passare da questo tipo di organizzazione all’organizzazione byte stream si può applicare la seguente formula : IBC = IBC + LR IBC indica l’indirizzo del byte corrente, ed LR la lunghezza del record espressa in bytes. Quando il file viene aperto per la prima volta, l’indirizzo del byte corrente viene azzerato: in seguito ad ogni richiesta, IBC viene aggiornato sommandogli la lunghezza di ogni record. Nel caso di accesso diretto, il numero di record indicato dall’utente ( NR ) viene utilizzato per calcolare l’indirizzo del byte secondo la seguente formula : IBC = ( NR-1 ) x LR Nell’esempio (Agenda) la richiesta di leggere il terzo record di Agenda si trasforma nall’accesso al byte logico di indirizzo : IBC = ( NR – 1 ) x LR ( 3 – 1 ) x 512 = 1024 ( 512 byte è la dimensione del record logico di agenda ) FILE A RECORD DI LUNGHEZZA VARIABILE :
Record 1 1
Record 2 …………. Record n

Autore Flavio Cerini 69
I records costituenti i files possono avere dimensioni diverse ( vedi Fig. 40 ) Fig 40 Records di lunghezza variabile L L L Anche per i files organizzati in questo modo, la trasformazione in byte stream avviene diversamente a seconda delle modalità di accesso. Se l’accesso è sequenziale, l’indirizzo del byte corrente ( IBC ) si può calcolare con la formula vista precedentemente, aggiungendo la lunghezza L del campo numerico : IBC = IBC + L +LRn La costante L rappresenta la lunghezza del campo numerico contenente la dimensione LR del record successivo. Tale campo deve essere sufficientemente grande per contenere la lunghezza massima dei records ; se il record più lungo è di 64 K , L dovrà avere avere una lunghezza di 2 bytes. Dalla formula si vede che l’indirizzo del byte corrente viene calcolato sommando all’attuale indirizzo sia la dimensione del campo L, sia la dimensione LR del record interessato ( espresse in byte ). Se si accede direttamente all’n-esimo record, si può organizzare il file in byte stream sommando a tutte le lunghezze LR dei records che precedono quello specificato, lo spazio occupato da tutti i campi di lunghezza costante L secondo la seguente formula : IBC = L + LR1 + L + LR2 +….+ L + LRn-1 = LR1 + ….+ LRn-1 + L x (n-1) FILE A RECORD CON ACCESSO INDICIZZATO In questo tipo di organizzazione ( ISAM: Indexed Sequential Access Method ) ogni record è provvisto di un campo chiave numerico o alfanumerico che lo identifica all’interno del file ( vedi Fig 41 ) Fig 41 Records ad accesso indicizzato Record 1 Record 2 Record n Il record non è identificato da un indirizzo ma dal contenuto di un suo campo. All’interno del file, i records sono organizzati in modo crescente in base al valore della rispettiva
LR1 Record 1 LR2 Record 2 ……………… LRn Record n
K1 K2 ………… Kn

Autore Flavio Cerini 70
chiave. La corrispondenza tra questa organizzazione e quella byte stream è stabilita da una tabella degli indici ( vedi Fig 42 ) Fig 42 Tabella degli indici
CHIAVE INDIRIZZO K1 Indirizzo 1 K2 Indirizzo 2 ………. …………. Kn Indirizzo n
La tabella fissa una relazione tra la chiave che identifica il record e l’indirizzo lineare di quest’ultimo. Il file system logico deve risolvere un problema di ricerca tabellare tramite algoritmi standard ( ricerca lineare, dicotomica …. ).
![Giancarlo Cerini Valutazione di sistema Un quadro di ... · • PDCA [ciclo di Deming]: Plan, Do,Check, Act) Giancarlo Cerini ... 28 marzo 2014 Slide elaborate da Mariella Spinosi](https://img.pdfslide.tips/doc/110x75/5c65e67509d3f252168b85fc/giancarlo-cerini-valutazione-di-sistema-un-quadro-di-pdca-ciclo-di.jpg)




























