Embed Size (px)
Citation preview

Appunti di Teoria dell’Informazione
Filippo Mineo
9 maggio 2012
IndiceDati tecnici 1
1 Codici di sorgente 11.1 B-LV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Codice di Shannon-Fano . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.1.2 Ricerca del codice ottimo – Codice di Huffman . . . . . . . . . . . . . . . . . . . . . 41.1.3 Ricerca del codice universale – Codice multinomiale . . . . . . . . . . . . . . . . . . 6
1.2 LV-B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.2.1 Famiglie complete – Codice di Tunstall . . . . . . . . . . . . . . . . . . . . . . . . . 91.2.2 Codice di Lempel-Ziv (LZ) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 111.2.3 Codice di Lempel-Ziv-Welch (LZW) . . . . . . . . . . . . . . . . . . . . . . . . . . . 131.2.4 Codice di Burrows-Wheeler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2.5 LV-LV . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
1.3 B-B . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151.4 Complessità di Kolmogorov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Codici di canale 192.1 Limitazioni asintotiche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 232.2 Codici algebrici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.2.1 Codice di Hamming . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.2.2 Codice BCH . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 282.2.3 Codici di Reed-Müller . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 292.2.4 Codici ciclici . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 302.2.5 Codice di Reed-Solomon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.3 Codici convolutivi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3 Codici segreti 343.1 Cifrario di Vigenère . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.2 Introduzione all’RSA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.3 Complessità nell’ambito della crittografia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
Questi appunti vengono distribuiti as-is secondo laCreative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
Per eventuali suggerimenti o correzioni scrivetemi a [email protected].

Dati tecniciCorso di laurea: Informatica magistraleNome completo: Teoria dell’Informazione, Crittografia e ComplessitàDocente: Prof. Agostino DovierCFU: 9Modalità di esame: Orale, su appuntamento
1 Codici di sorgenteL’obiettivo è codificare un’informazione generata da un testo (sorgente) nel modo più “compatto”
possibile, senza preoccuparci di errori o nemici, quindi lo scopo è la compressione.
Avremo due alfabeti: A = {a1, . . . , ak} primario (del testo) con k lettere e B = {b1, . . . , bD} secondario(del codice di sorgente) con D lettere.
Le famiglie di codici di sorgente sono 4: B-LV, LV-B, B-B, LV-LV. «B» sta per «blocco» e «LV» sta per«lunghezza variabile». Le sigle della coppia indicano la corrispondenza tra elementi del testo ed elementidel codice di sorgente. Ad esempio l’ASCII è B-B, mentre il codice Morse è B-LV.
Un’idea chiave per comprimere è sfruttare la probabilità di emissione delle lettere da parte della sorgente.
1.1 B-LV
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.1.
• Un codice B-LV è una funzione ϕ : A → B+. Gli elementi di ϕ(A) si dicono parole di codice.
• Un codice ϕ può essere esteso alle stringhe con la ϕ : A∗ → B∗, ϕ(a1 · · · an) := ϕ(a1) · · ·ϕ(an).
• Un codice ϕ si dice univocamente decodificabile (UD) se e solo se ϕ è iniettiva.
• Un codice si dice a prefisso se nessuna sua parola di codice è prefisso di un’altra.
• Il ritardo di decodifica è il numero massimo di caratteri aggiuntivi del codice di sorgente daleggere per compiere un “passo di decodifica”. Un codice si dice istantaneamente decodificabilese il ritardo di decodifica è nullo.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Proposizione 1.2. Se un codice è a prefisso (dunque anche UD) allora è istantaneamente decodificabile.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Esistono i codici UD non a prefisso in cui il ritardo di decodifica non è troppo svantaggioso rispetto allamaggiore compressione che offrono, se confrontati con codici UD a prefisso equivalenti.
D’ora in poi indichiamo con «`i» il valore |ϕ(ai)|, con «`» la massima tra tali lunghezze e con «α» il
valorek∑i=1
D−`i .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Teorema 1.3: Disuguaglianza di Kraft-McMillan. Se un codice è UD allorak∑i=1
D−`i ≤ 1.
Dimostrazione. Sia «N(n, h)» il numero di stringhe di A∗ di lunghezza n a cui corrisponde una stringa diB∗ di lunghezza h. Se un codice è UD allora N(n, h) ≤ Dh.
αn è formata da nk addendi, in cui il generico addendo è nella forma D−(`j1+···+`jn ), con ji ∈ {1, . . . , k}indici. In α ci possono essere addendi di valore uguale, infatti basta che abbiano la stessa somma co-me esponente. È come se con α osservassimo tutte le stringhe di An. Allora possiamo scrivere che
1

∀n : αn =n∑i=1
N(n, i)︸ ︷︷ ︸≤Di
D−i ≤n∑i=1
DiD−i ⇒ ∀n : αn ≤ n` ⇒ α ≤ 1, in cui l’ultimo passaggio discende
dalle proprietà dell’esponenziale.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Questo teorema ha come conseguenze la sufficienza dei codici a prefisso (Lemma 1.4) e il Teorema diShannon (Teorema 1.9).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.4. Dato un codice UD, ne esiste uno a prefisso con la stessa lunghezza.
Dimostrazione. Per semplicità assumiamo che `1 ≤ · · · ≤ `n, senza perdita di generalità.Consideriamo l’albero D-ario di lunghezza ` completo. Partendo da i = 1 e proseguendo fino a i = n,
seguo l’albero per `i passi scegliendo sempre il ramo libero più alto e al termine del cammino pongo l’etichetta«ai».
Se il codice era UD lo spazio è sufficiente, infatti per ogni ai si usano D`−`i nodi, per un totale di
D` ·n∑i=1
D−`i︸ ︷︷ ︸≤1
nodi.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Siano ϕ1 e ϕ2 codici a prefisso per lo stesso alfabeto primario A. Qual è il migliore? Qui entra in giocola probabilità di emissione di un simbolo, che indicheremo con «pi». A ogni alfabeto è quindi associatauna distribuzione di probabilità P := (p1, . . . , pk).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 1.5. La lunghezza media di un codice è EL :=k∑i=1
pi`i.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Naturalmente vogliamo che la lunghezza media sia minore possibile.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 1.6. L’entropia di una distribuzione probabilità P è H(P ) := −k∑i=1
pi log pi.
Se una pi è nulla, per continuità si pone pi log pi = 0. La base del logaritmo è indifferente (purchécoerente col resto dei calcoli), ma la scelta tipica è D.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
L’entropia è una misura della “confusione” nella sorgente. In generale l’entropia è alta quando le pro-babilità sono simili, mentre è bassa quando sono dissimili, ossia uno o più caratteri prevalgono. Il valoremassimo è H
(1k , . . . ,
1k︸ ︷︷ ︸
k volte
)= logD k.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.7. Siano P e Q due distribuzioni di probabilità sullo stesso alfabeto. La divergenza tra P
e Q è D(P �Q) :=k∑i=1
pi log piqi.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Considerando D(P �Q) notiamo che:
• la divergenza è asimmetrica rispetto ai suoi argomenti;
• se P = Q è nulla;
• se esistono pi e qi tali che pi tende a 1 e qi tende a 0, il loro addendo è un numero molto grandepositivo;
• viceversa se pi tende a 0 e qi tende a 1, il loro addendo è un numero molto grande negativo.
2

Estendiamo nei casi limite ponendo:
• 0 log 06=0 ; 0 per continuità;
• ( 6= 0) log 6=00 ; +∞ per continuità;
• 0 log 00 ; 0 per buon senso (non ha senso che accada).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Proposizione 1.8. D(P �Q) ≥ 0.
Dimostrazione. Consideriamo e come base del logaritmo, per cui è facile seguire la via analitica. Si puòdimostrare che vale per qualsiasi base attraverso una dimostrazione combinatoria più difficile.
Confrontando le funzioni log z e 1− 1z abbiamo che ∀z ≥ 0: log z ≥ 1− 1
z . Allora
D(P �Q) =
k∑i=1
pi logpiqi≥
k∑i=1
pi
(1− qi
pi
)=
k∑i=1
pi︸ ︷︷ ︸=1
−k∑i=1
qi︸ ︷︷ ︸=1
= 0 .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 1.9: Teorema di Shannon. Se un codice è UD allora EL ≥ H(P ).
Dimostrazione. Codice UD⇒ α ≤ 1⇒ logα ≤ 0.Definisco una distribuzione “artificiale” Q =
(D−`1
α , . . . , D−`k
α
). Allora
D(P �Q) =
k∑i=1
pi logpiα
D−`i=
k∑i=1
pi(log pi + logα+ `i) =
=
k∑i=1
pi log pi + logα
k∑i=1
pi +
k∑i=1
pi`i = −H(P ) + logα+ EL⇒
⇒ −H(P ) + logα+ EL ≥ 0⇒ EL ≥ H(P )− logα︸ ︷︷ ︸≤0
≥ H(P ) .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Esistono casi in cui EL = H(P ), ossia quando α = 1, anche se comunque non si può fare di meglio.
1.1.1 Codice di Shannon-Fano
Il codice di Shannon-Fano parte dal calcolo della lunghezza delle parole di codice, fissandola pari a`i = d− logD pie. Poi con un algoritmo greedy viene popolato l’albero, sapendo che il posto si trova sempreperché
d− logD pie < − logD pi + 1⇒ d− logD pie = − logD pi + ξi con 0 ≤ ξi < 1⇒
⇒k∑i=1
D−`i =
k∑i=1
DlogD pi−ξi =
k∑i=1
piD−ξi︸ ︷︷ ︸<1
≤ 1 .
EL =
k∑i=1
pid− logD pie =
k∑i=1
pi(− logD pi + ξi) = −k∑i=1
pi logD pi +
k∑i=1
piξi︸ ︷︷ ︸<1
< H(P ) + 1 .
Questo ci dice che il codice ottimo si può cercare tra H(P ) e H(P )+1, infatti in generale Shannon-Fanonon è ottimo.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.10.
3

• Il rapporto Rn := ELn
n si dice tasso di compressione e corrisponde alla lunghezza media percarattere di un codice su un alfabeto An.
• Un codice il cui tasso tende a H(P ) per n che tende a ∞ si dice asintoticamente ottimo.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 1.11. Sia A = {a, b} con P =(
34 ,
14
), da cui H(P ) = ∼0,81. Applicando Shannon-Fano otteniamo
`a = 1, `b = 2 ed EL = 1,25.Invece di considerare A prendiamo A2 = {aa, ab, ba, bb} e calcoliamo P2 in un ottica di processo ber-
noulliano (la lettera appena uscita non influenza la successiva): P2 =(
916 ,
316 ,
316 ,
116
). Applicando di nuovo
Shannon-Fano otteniamo EL2 = 1,93. Nonostante l’apparente peggioramento, ora il tasso è R2 = 0,97. Piùavanti dimostreremo che Shannon-Fano è asintoticamente ottimo.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Siano X e Y variabili aleatorie rispettivamente con valori in {x1, . . . , xk} e {y1, . . . , yh} e distribu-zione di probabilità P = (p1, . . . , pk) e Q = (q1, . . . , qh). Indichiamo con «pij» la probabilità congiuntaP(X = xi∧Y = yj). Avremo kh eventi di questo tipo, la cui sommatoria è ancora 1, quindi possiamo consi-
derare la distribuzione di probabilità congiunta «X∧Y ». La sua entropia è H(X∧Y ) = −k∑i=1
h∑j=1
pij log pij .
Ipotizziamo quindi che X e Y siano indipendenti, ossia pij = piqj , allora
H(X ∧ Y ) = −k∑i=1
h∑j=1
piqj log(piqj) = −k∑i=1
h∑j=1
pjqj log pi −k∑i=1
h∑j=1
piqj log qj =
=
h∑j=1
qj︸ ︷︷ ︸=1
(−
k∑i=1
pi log pi︸ ︷︷ ︸=H(P )
)+
k∑i=1
pi︸ ︷︷ ︸=1
(−
h∑j=1
qj log qj︸ ︷︷ ︸=H(Q)
)= H(P ) +H(Q) ,
oppure, con un leggero abuso di notazione, H(X ∧ Y ) = H(X) +H(Y ).In generale siano X1, . . . , Xn v.a. indipendenti sullo stesso alfabeto e con la stessa distribuzione di
probabilità P . Allora H(X1 ∧ · · · ∧Xn) = nH(P ).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.12. Una sorgente di informazione può essere descritta da una sequenza di v.a. X1, X2, . . .a valori su uno stesso alfabeto. Si dice stazionaria se tutte le distribuzioni di probabilità sono uguali e sidice senza memoria se un simbolo non dipende in nessun modo dal precedente. Se una sorgente di infor-mazione possiede entrambe queste proprietà, le sue v.a. sono indipendenti e si dice anche bernoulliana.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Codifichiamo con un codice UD n-uple provenienti da una sorgente di informazione stazionaria e senzamemoria, quindi abbiamo un alfabeto A e una distribuzione di probabilità Pn. ELn ≥ H(Pn) = nH(P )⇒⇒ Rn ≥ H(P ), che è la versione sulle n-uple del Teorema di Shannon.
Applicando Shannon-Fano otteniamo ELn < H(Pn) + 1 = nH(P ) + 1⇒ Rn < H(P ) + n−1. Da questadisequazione si vede che Shannon-Fano tende asintoticamente all’entropia.
1.1.2 Ricerca del codice ottimo – Codice di Huffman
Per la ricerca del codice ottimo, ossia con EL minima, assumiamo che p1 ≥ · · · ≥ pk, senza perdita digeneralità.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.13.
4

• Sia ϕ un codice su un alfabeto A con distribuzione di probabilità P . La geminazione di ϕ consiste so-stituire nell’alfabeto un simbolo ai con due nuovi simboli a′i e a′′i tali che p′i+p′′i = pi. Nell’albero di ϕ, lafoglia ai diventa il nodo padre delle nuove foglie a′i e a′′i . Il nuovo alfabeto A = {a1, . . . , a
′i, a′′i , . . . , ak}
viene chiamato sorgente estesa.
• L’operazione inversa della geminazione viene detta taglio.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Siccome EL = c+`ipi e EL = c+(`i+1)(p′i+p′′i ), con c costante che raggruppa gli addendi non coinvolti,
allora in seguito alla geminazione la lunghezza media è aumentata di EL− EL = pi.
Per costruire il codice ottimo, osserviamo alcuni fatti:. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.14.
0. Un codice ottimo esiste.
Dimostrazione. Per individuarlo basta un algoritmo esponenziale che costruisce tutti i codici sull’alberoD-ario di lunghezza k − 1.
1. Non esiste codice ottimo in cui pi > pj ∧ `i > `j .
Dimostrazione. Supponiamo per assurdo che un simile codice ottimo ϕ esista, per qualche i e j.Scambiamo nel suo albero ai e aj , ottenendo così un nuovo codice ϕ′.EL = c + pj`j + pi`i e EL′ = c + pi`j + pj`i (c costante che raggruppa gli addendi non coinvolti),quindi EL− EL′ = (`j − `i)(pj − pi) > 0 con la minimalità di EL.
2. Esiste un codice ottimo in cui `1 ≤ · · · ≤ `k.
Dimostrazione. Supponiamo che `i > `j per qualche i, j con i < j e che il codice sia ottimo. Scambiamonel suo albero ai e aj e vediamo che:
• per pi > pj la lunghezza media cala ;
• quindi l’unica soluzione è che pi = pj .
3. Esiste un codice ottimo tale che nel suo albero ak−1 e ak sono foglie sorelle al livello più basso (formanouna “forchetta”).
Dimostrazione. Consideriamo varie casistiche:
• ak è figlio unico al livello più basso: perché non sarebbe un codice ottimo;
• ak è foglia sorella al livello più basso con ai, per i 6= k − 1, e ak−1 è a un livello superiore: o perché il codice non era ottimo, oppure pi = pk−1 e quindi basta scambiare ai con ak−1 perottenere un codice ottimo con la proprietà desiderata;
• come il caso precedente, solo che ak−1 è allo stesso livello: basta scambiare ai con ak−1 perottenere un codice ottimo con la proprietà desiderata.
4. Se gemino un codice ottimo su un nodo associato a un simbolo che genera due caratteri con probabilitàminimale nella sorgente estesa, allora il codice per la sorgente estesa così ottenuto è ottimo.
Dimostrazione. Sia ¬ l’albero ottimo di partenza. A un simbolo ai sostituisco a′i e a′′i , con probabilitàminimale nel nuovo alfabeto, ottenendo . Supponiamo per assurdo che non sia ottimo, ma alloraesiste un ottimo ® che, tagliando a′i e a′′i , mi porta in un albero ¯ che ha di nuovo ai. Vale cheEL− EL¬ = EL®− EL¯ = pi
® ottimo
}⇒ EL¯ < EL¬ con la minimalità di ¬.
5

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Corollario 1.15. Se A = {a1, a2} il codice ottimo è ϕ(a1) = ‹0›, ϕ(a2) = ‹1›.
Dimostrazione. Discende in particolare dal punto 3. dei Lemmi precedenti.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Pseudocodice 1.16: Huffman – Codifica. Input: Ak = {a1, . . . , ak}, Pk = {p1, . . . , pk}.i := k;F := new Stack;while (i >= 2) do
Scegli a, b in Ai tali che pi(a) e pi(b) siano minime in Pi;Ai−1 :=
(Ai r {a, b}
)∪ {αi}; // αi nuovo simbolo
Pi−1(s) :=
{pi(s) s ∈ Ai r {a, b}pi(a) + pi(b) s = αi
; // per ogni s ∈ Ai−1
F.push(αi, a, b);i--;
odϕ(α2) := "";while (!F.empty()) do
(α, β, γ) := F.pop();ϕ(β) := ϕ(α)·"0";ϕ(γ) := ϕ(α)·"1";
od
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.17. Prima fase:A5 = {a, b, c, d, e} P5 = (20, 15, 10, 5, 3) α5 d eA4 = {a, b, c, α5} P4 = (20, 15, 10, 8) α4 c α5
A3 = {a, b, α4} P3 = (20, 15, 18) α3 b α4
A2 = {a, α3} P2 = (20, 33) α2 a α3
A1 = {α2} P1 = (53)
Seconda fase:ϕ(α2) = ε ϕ(a) = ‹0› ϕ(α3) = ‹1› ϕ(b) = ‹10› ϕ(α4) = ‹11›ϕ(c) = ‹110› ϕ(α5) = ‹111› ϕ(d) = ‹1110› ϕ(e) = ‹1111›.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Ci sono due modi per impiegare il codice di Huffman:
• Scandisco il file, calcolo P , costruisco l’albero e lo memorizzo, comprimo il file. La dimensione finalepotrebbe essere penalizzata dall’albero non compresso contenuto nel file.
• Fisso un albero e uso sempre quello, sconfinando nella semantica. Si comprimono ottimalmente solo ifiles che rispettano la frequenza.
1.1.3 Ricerca del codice universale – Codice multinomiale
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.18. Siano X una v.a. con valori in {x1, . . . , xk} e distribuzione di probabilità P = (p1, . . . , pk)e Y una v.a. generica. Allora l’entropia condizionata di Y |X (leggi «Y data X») viene definita come
H(Y |X) :=k∑i=1
(P(X = xi) ·H(Y |X = xi)
).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
6

Se Y è una v.a. con valori in {y1, . . . , yh} e distribuzione di probabilità Q = (q1, . . . , qh), l’entropia
condizionata viene anche scritta come H(Y |X) =k∑i=1
pi
(−
h∑j=1
qj|i log qj|i
), dove qj|i =
pijpi
, quindi
H(Y |X) = −k∑i=1
h∑j=1
��pipij
��pilog
pijpi
= −k∑i=1
h∑j=1
pij log pij −
(−
k∑i=1
h∑j=1
pij log pi
)=
= H(X ∧ Y )−
(−
k∑i=1
log pi
h∑j=1
pij︸ ︷︷ ︸=pi
)= H(X ∧ Y )−H(X) ,
e similmente H(X | Y ) = H(X ∧ Y )−H(Y ).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.19. La mutua informazione di due v.a. X e Y viene definita come
I(X ∧ Y ) := D(PXY � PXPY ) =
k∑i=1
h∑j=1
pij logpijpiqj
.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Essendo una divergenza, varrà sempre I(X ∧ Y ) ≥ 0. Consideriamo i due casi estremi:
• X e Y indipendenti⇒ pij = piqj ⇒ I(X ∧ Y ) = 0;
• X = Y ⇒ pij =
{0 i 6= j
pi i = j⇒ I(X ∧ Y ) =
k∑i=1
pi logpip2i
= −k∑i=1
pi log pi = H(X).
Per il secondo punto, l’entropia viene anche chiamata autoinformazione.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esercizio 1.20. I(X ∧ Y ) = H(Y )−H(Y |X) = H(X)−H(X | Y ).
Soluzione. Ricordando che qi|j =pijpi
,
I(X ∧ Y ) =
k∑i=1
h∑j=1
pij logpijpiqj
=
k∑i=1
h∑j=1
pij logqi|j
qj=
=
k∑i=1
h∑j=1
pij log qi|j −h∑j=1
log qj
k∑i=1
pij︸ ︷︷ ︸=qj
= H(Y )−H(Y |X) .
La seconda uguaglianza si ottiene per simmetria.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Con il solito A = {a1, . . . , ak}, consideriamo n-uple e le raggruppiamo in classi di permutazioni dette
tipi. Ogni tipo j è identificato univocamente da una k-upla (nj1 , . . . , njk), dovek∑i=1
nji = n e gli nji sono
le occorrenze del simbolo ai nelle n-uple del tipo. Se x ∈ An possiamo anche denotare il suo tipo con «[x]».I tipi sono
(n+k−1n
), abbreviato con «γn» (benché in effetti dipenda anche da k, che però è fissato). La
cardinalità del tipo j è(
n
nj1 , . . . , njk
):=
n!
nj1 ! · · ·njk !(coefficiente multinomiale).
Osserviamo che, nonostante il numero di n-uple in An sia kn, esponenziale rispetto a n, si dimostra (Eser-cizio 1.21) che γn ≤ (n+ 1)k, quindi invece il numero di tipi cresce polinomialmente. Come bilanciamento,qualche tipo dovrà crescere esponenzialmente.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esercizio 1.21. γn ≤ (n+ 1)k.
Soluzione. Per induzione su k:
7

• Lk = 1M(n
n
)= 1 ≤ n+ 1
• Lk > 1M(n+ k
n
)=
(n+ k)!
n!k!=n+ k
k
(n+ k − 1
n
)ind.≤(nk
+ 1)
(n+ 1)k < (n+ 1)k+1.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Il codice multinomiale si basa su questa idea: data x ∈ An, ϕ(x) = ϕp(x)ϕs(x). ϕp è il prefisso,di lunghezza fissa, che individua il tipo; ϕs è il suffisso, di lunghezza variabile a seconda della cardinalitàdel tipo, che identifica la stringa all’interno del tipo selezionato.
Sapendo che |ϕp(x)| = dlogD γne e |ϕs(x)| =⌈logD
(n
nj1 ,...,njk
)⌉possiamo calcolare
Rn =ELnn
=
∑x∈An
Pn(x)|ϕ(x)|
n=
∑x∈An
Pn(x)|ϕp(x)|
n+
∑x∈An
Pn(x)|ϕs(x)|
n,
quindi esaminiamo separatamente
• il prefisso
dlogD γnen
∑x∈An
Pn(x)︸ ︷︷ ︸=1
<logD γn + 1
n≤ logD(n+ 1)k + 1
n= k
logD(n+ 1)
n+
1
n,
che è un infinitesimo;
• il suffisso, che dipende dal tipo. All’interno di un tipo le n-uple hanno la stessa probabilità (nell’ipotesidi una sorgente bernoulliana) e la codifica ha la stessa lunghezza. Indicheremo con «|Tj |» la lunghezzadelle n-uple di Tj e con «P(Tj)» il valore
∑x∈Tj
Pn(x) = Pn(x)|Tj |.
∑x∈An
Pn(x)|ϕs(x)|
n=
γn∑j=1
P(Tj)⌈logD|Tj |
⌉n
<
γn∑j=1
P(Tj) logD|Tj |
n+
1
n, (1.1)
dove il secondo addendo è un infinitesimo.Introduciamo una v.a. “fittizia” J a valori in {1, . . . , γn} con probabilità P(J = j) = P(Tj). Allora
H(Xn | J) =
γn∑j=1
P(J = j)︸ ︷︷ ︸=P(Tj)
·H(Xn | J = j) .
Se J = j, le n-uple sono “determinate”, tutte dello stesso tipo, ognuna permutazione delle altre edequiprobabili, quindi la distribuzione è uniforme e la sua entropia è massima, pari a logD|Tj |, da cui
H(Xn | J) =γn∑j=1
Pn(x)|Tj | logD|Tj |, uguale al numeratore del primo addendo della (1.1). Sappiamo
anche cheH(Xn | J) = H(Xn)︸ ︷︷ ︸
=nH(X)
+H(J |Xn)︸ ︷︷ ︸=0
−H(J)︸ ︷︷ ︸≥0
≤ nH(X) ,
dove il secondo addendo è nullo perché, fissata la n-upla, J è determinata. Allora ripartendo dallafine della (1.1) si ottiene
γn∑j=1
P(Tj) logD|Tj |
n+
1
n≤ H(X) +
1
n.
Rimontiamo prefisso e suffisso e avremo Rn = ELn
n < 2n + k logD(n+1)
n︸ ︷︷ ︸infinitesimi
+H(P ), quindi questo è un codice
asintoticamente ottimo e universale.
8

1.2 LV-BL’idea è quella di avere un vocabolario di parole emesse dalla sorgente.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.22.
• Una famiglia di messaggiM⊆ A+ è un insiemeM := {m1, . . . ,mt}.
• La lunghezza media dell’input è EN :=t∑i=1
P(mi)|mi|.
• M si dice esauriente se ogni sequenza “opportunamente lunga” di caratteri di A ha almeno unprefisso inM.
• M si dice a prefisso se nessun suo messaggio è prefisso di un’altro.
• M si dice completa se è esauriente e a prefisso.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
La codifica per una parola del vocabolario è una parola di codice di lunghezza fissa ` := dlogD te. Iltasso di compressione diventa R := `
EN . Per questo cercheremo di costruire codici con EN grande.Nel caso di una famiglia non a prefisso, si cerca di codificare la parola più lunga, introducendo un ritardo
di codifica. Tuttavia rispetto ai codici B-LV l’assenza di questa proprietà non è così grave.D’ora in poi indichiamo con «ni» la lunghezza del messaggio mi e con «n» la massima tra tali lunghezze.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Teorema 1.23: Controdisuguaglianza di Kraft. Se una famigliaM è esauriente allorat∑i=1
k−ni ≥ 1. Se inoltre
in particolare è completa allora vale l’uguaglianza.
Dimostrazione. Consideriamo l’albero k-ario completo di lunghezza n, le cui foglie sono stringhe di An,ognuna delle quali avente un prefisso inM. mi è prefisso di kn−ni stringhe di A, eventualmente condivise
con altri messaggi. Quindit∑i=1
kn−ni ≥ kn ⇒t∑i=1
k−ni ≥ 1.
Se inoltre M è a prefisso allora non ci sono stringhe di A condivise tra i messaggi, quindi vale l’ugua-glianza.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
1.2.1 Famiglie complete – Codice di Tunstall
Considero uno tra i messaggi più lunghi e lo scompongo in mai. Allora anche ma1, . . . ,mak ∈M perchéM è esauriente e perché m non può contenere messaggi (M è a prefisso). Tagliando in corrispondenzadel nodo m ottengo un nuovo codice completo, ma quindi posso ricominciare, finché arrivo al codice conM0 = {a1, . . . , ak} e albero T0.
Questo fa capire che tutte le famiglie complete si ottengono da T0 mediante una geminazione che rim-piazza un nodo m con ma1, . . . ,mak (chiamata regola «R»). Tutti gli alberi Tj ottenuti con j applicazionidella regola R hanno k + j(k − 1) foglie.
Una sorgente può essere vista sia come sorgente di A sia diM. Allora a una famiglia di messaggi generatacon j applicazioni di R associamo una distribuzione di probabilità Sj , in cui ogni si è il prodotto delleprobabilità dei caratteri che compongono mi. Calcoliamo la differenza tra due lunghezze medie consecutive,isolando il messaggio m su cui avviene la geminazione:
ENj =∑µ∈Mµ 6=m
P(µ)|µ|+ P(m)|m| ,
9

ENj+1 =∑µ∈Mµ6=m
P(µ)|µ|+k∑i=1
P(mai)|mai| =
=∑µ∈Mµ6=m
P(µ)|µ|+k∑i=1
P(m)P(ai)(|m|+ 1) =
=∑µ∈Mµ 6=m
P(µ)|µ|+ P(m)(|m|+ 1) ,
da cui ∆EN = P(m).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.24. H(Sj) = H(P ) · ENj .
Dimostrazione. Per induzione su j.
LBM S0 = P e EN0 = 1.
LPM H(Sj+1) = −∑
µ∈Mj+1
µ 6=mai
P(µ) logP(µ)−k∑i=1
P(mai) logP(mai)︸ ︷︷ ︸espanso di seguito
k∑i=1
P(m)P(ai)(logP(m) + logP(ai)
)=
k∑i=1
P(m)P(ai) logP(m)
k∑i=1
k∑i=1
P(m)P(ai) logP(ai) = P(m) logP(m)
k∑i=1
P(ai)︸ ︷︷ ︸=1
− P(m)H(P )
H(Sj+1) = −∑
µ∈Mj+1
µ6=mai
P(µ) logP(µ)− P(m) logP(m)
︸ ︷︷ ︸=H(Sj)
+ P(m)H(P ) =
= H(Sj) + P(m)H(P )ind.= H(P ) · ENj + P(m)H(P ) =
= H(P )(ENj + P(m)
)= H(P ) · ENj+1 .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Tornando a esaminare il tasso, abbiamo che Rj =dlogD|Mj |eH(P )
H(Sj) . In generale 0 ≤ H(Sj) ≤ log|Mj |,quindi Rj ≥ dlogD|Mj |e
logD|Mj | H(P ) ≥ H(P ), che è la forma LV-B del teorema di Shannon.
Se la regola R è applicata a un nodo con probabilità massima, la chiameremo regola di Tunstall ela scriveremo come «RT».. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.25. Sia Tj un albero ottenuto con j applicazioni di R. Allora esiste una sequenza di j applicazionidi R sui messaggi m1, . . . ,mj tale che P(m1) ≥ · · · ≥ P(mj).
Dimostrazione. Una volta costruito Tj basta riordinare le applicazioni di R in modo tale da rispettare laproprietà. Si può sempre fare perché la probabilità di un sottoalbero è strettamente minore di quella delnodo a cui appartiene.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Una sequenza con questa proprietà è detta regolare. Possiamo quindi concentrarci sulle famigliegenerate da sequenze regolari.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.26. Sia T un albero ottenuto da T0 con una sequenza regolare di j applicazioni di R. Se in un
10

passo non è stata usata RT allora esiste un albero T ′ ottenuto da T0 con j applicazioni regolari tale cheEN(T ′) > EN(T ).
Dimostrazione. Sia u + 1 il primo passo in cui non ho usato RT . Siano m ed n messaggi in Tu tali cheP(m) > P(n), con n nodo geminato. Poiché T deriva da una sequenza regolare, m è ancora una foglia inT . Al passo u + 1 gemino su m e ripeto nel sottoalbero di m le applicazioni di R che prima avevo fattonel sottoalbero di n. Allora EN(T ′) − EN(T ) = P(m) − P(n) > 0 ⇒ EN(T ′) > EN(T ), infatti l’unicadifferenza non viene “recuperata” nei passi successivi, che sono identici in entrambe le costruzioni.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Per il prossimo lemma introduciamo alcune notazioni: «Πj» sarà maxm∈Mj
P(m), «πj» sarà minm∈Mj
P(m) e
infine «p∗» è π0 = mina∈AP(a). L’idea è mostrare che per i codici di Tunstall Πj e πj sono “simili”:
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Lemma 1.27.Πj
πj≤ 1
p∗ .
Dimostrazione. Per induzione su j.
LBM Π0 ≤ 1 e π0 = p∗.
LPM Se in Tj c’era un solo massimo allora Πj+1 < Πj , altrimenti Πj+1 = Πj . In generale Πj+1 ≤ Πj .
πj+1 = min{πj ,Πjp1, . . . ,Πjpk} = min{πj ,Πjp∗}. Se πj+1 = πj allora Πj+1
πj+1≤ Πj
πj
ind.≤ 1
p∗ . Altrimenti
se πj+1 = Πjp∗ allora Πj+1
πj+1≤ ��Πj
��Πjp∗= 1
p∗ .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Corollario 1.28. Il codice di Tunstall, che si ottiene applicando sempre RT , è asintoticamente ottimo.
Dimostrazione.
H(Sj) = −|Mj |∑i=1
P(mi) logP(mi)︸ ︷︷ ︸≤Πj
≥ −|Mj |∑i=1
P(mi) log Πj = − log Πj ≥ log p∗ − log πj .
Siccome πj ≤ 1|Mj | ⇒ log πj ≤ − log|Mj | allora H(Sj) ≥ log p∗ + log|Mj | ⇒ Rj =
log|Mj |log p∗+log|Mj |H(P ),
quindi all’aumentare di j il tasso tende all’entropia.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.29. Dato un alfabeto A = {a, b, c} e la sua distribuzione di probabilità P = (pa, pb, pc), conpa > pb ∧ pa > pc, costruiamo
• il codice di Tunstall: M = {aa, ab, ac, b, c} con EN = 1 + pa;
• un codice esauriente ma non a prefisso: M = {a, aa, aaa, b, c} con EN = 1 + p2a + p3
a, infattiS =
(pa(1− pa), p2
a(1− pa), p3a(1− pa), pb, pc
).
Poiché 1 + p2a + p3
a > 1 + pa per pa > −1+√
52 , in tal caso Tunstall non è ottimo. Ciò significa che
rinunciando alla proprietà del prefisso di può fare meglio di Tunstall.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
1.2.2 Codice di Lempel-Ziv (LZ)
Abbiamo un buffer V diviso in due parti [1 ..M−1] e [M ..N ]. Dato i ∈ {1, . . . ,M−1}, definiamo «L(i)»come il massimo intero tale che V [i .. i+L(i)− 1] = V [M ..M +L(i)− 1]. Questo è un banale algoritmo diricerca di sottostringhe quadratico sulla lunghezza di mezzo buffer (ma si può anche fare lineare). Inoltredefiniamo «p» come un indice tale che L(p) = max{L(1), . . . , L(M − 1)} e «L» come L(p).
L’algoritmo di compressione consiste nelle seguenti operazioni:
11

• predispongo il buffer con zeri nella prima parte e l’inizio del file nella seconda;
• finché il file non è finito:
I calcolo p e L;
I guardo il simbolo x := V [M + L];
I memorizzo la tripla 〈L, p, x〉;I faccio uno shift a sinistra di L+ 1 posizioni, facendo entrare un nuovo pezzo di file nel buffer.
Anche se non abbiamo una famiglia di messaggi, LZ è LV-B. Misurando lo spazio in bits, le componentidelle triple occupano:
• L ∈ {0, . . . , N −M + 1} ⇒ |L| = dlog2(2 +N −M)e bit (che denotiamo con «`1»);
• p ∈ {1, . . . ,M − 1} ⇒ |p| = dlog2(M − 1)e bit («`2»);
• |x| = 1 bit.
Riusciremo quindi a comprimere se “mediamente” L+ 1 > `1 + `2 + 1⇒ L > `1 + `2.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.30: LZ – Codifica. Codifichiamo la stringa ‹0011010010000111› con un buffer da 4 + 4 bit.
buffer 〈L, p, x〉 shift
0 0 0 0 0 0 1 12 2 2 2
〈2, 1, 1〉 3
0 0 0 1 1 0 1 00 0 0 1
〈1, 4, 0〉 2
0 1 1 0 1 0 0 10 1 2 0
〈2, 3, 0〉 3
0 1 0 0 1 0 0 00 3 0 0
〈3, 2, 0〉 4
1 0 0 0 0 1 1 10 1 1 1
〈1, 2, 1〉 2
0 0 0 1 1 10 0 0 1
〈1, 4, 1〉 2
Quando mi fermo alla fine del file ho una configurazione particolare.La stringa codificata è ‹010001 001110 010100 011010 001011 001111›, quindi notiamo che in questo esem-
pio la stringa iniziale era troppo breve per poter essere compressa.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.31: LZ – Decodifica. I simboli che escono dal buffer con lo shift vengono aggiunti alla stringadecodificata.
buffer 〈L, p, x〉 shift
0 0 0 0 0 0 1 〈2, 1, 1〉 3
0 0 0 1 1 0 〈1, 4, 0〉 2
0 1 1 0 1 0 0 〈2, 3, 0〉 3
0 1 0 0 1 0 0 0 〈3, 2, 0〉 4
1 0 0 0 0 1 〈1, 2, 1〉 2
0 0 0 1 1 1 〈1, 4, 1〉 2
12

Ciò che resta alla fine nel buffer viene riversato direttamente nella stringa.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Quanto posso comprimere nel caso migliore possibile (file di soli zeri)? Se prendiamo un buffer con dueparti di pari lunghezza uguale a ` e un file lungo f , la dimensione compressa è circa f 2 log `+1
` , dove lafrazione rappresenta il rapporto di compressione.
LZ è universale e l’idea è che le stringhe frequenti vengono catturate con un’unica tripla. Si dimostrainfatti che LZ tende all’entropia, ossia è ottimo.
Di questo algoritmo esiste la variante deflate, che prevede di applicare Huffman all’output a blocchidi LZ, focalizzandosi sulla componente L delle triple.
1.2.3 Codice di Lempel-Ziv-Welch (LZW)
Assumiamo di avere una struttura dati string table (un vettore di stringhe).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Pseudocodice 1.32: LZW – Codifica. Partiamo con una string table table vuota.
string := read(); // Supponiamo di lavorare con files non vuoti.while (ci sono caratteri) do
char := read();if (string·char ∈ table) then
string := string·char;else
write(il codice di string);table.add(string·char);string := char;
fiodwrite(il codice di string);
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Supponendo di avere un alfabeto primario a 8 bit, possiamo decidere di costruire una string table da10 bit. I caratteri mantengono il loro codice, mentre le coppie, triple, . . . assumono un codice man mano chevengono scoperte.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.33: LZW – Codifica. Codifichiamo la stringa ‹ABAABAAABA›.
char string·char ∈ table write table.add string‹A›
‹B› % 65 256 ; ‹AB› ‹B›‹A› % 66 257 ; ‹BA› ‹A›‹A› % 65 258 ; ‹AA› ‹A›‹B› ! ‹AB›‹A› % 256 259 ; ‹ABA› ‹A›‹A› ! ‹AA›‹A› % 258 260 ; ‹AAA› ‹A›‹B› ! ‹AB›‹A› ! ‹ABA›
259
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Il codice LZW è un codice LV-B non a prefisso in cui il vocabolario viene costruito passo per passo.Fatto interessante è che non serve memorizzare la string table.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Pseudocodice 1.34: LZW – Decodifica. Partiamo con la string table table con le prime 256 celle riempitecon i caratteri ASCII.
13
oc := read();string := table[oc];write(string);while (ci sono caratteri) do
nc := read();string := table[nc];write(string);ch := string[0];table.add(oc·ch);oc := nc;
od
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.35: LZW – Decodifica. Decodifichiamo la sequenza di numeri (stringa) 65, 66, 65, 256, 258, 259.
nc & oc string & write ch table.add65 ‹A›66 ‹B› ‹B› 256 ; ‹AB›65 ‹A› ‹A› 257 ; ‹BA›256 ‹AB› ‹A› 258 ; ‹AA›258 ‹AA› ‹A› 259 ; ‹ABA›259 ‹ABA› ‹A› 260 ; ‹AAA›
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
1.2.4 Codice di Burrows-Wheeler
Il file viene diviso in blocchi (anche grandi), ognuno dei quali costituirà una stringa «x». Per ogni xseparatamente, si scrivono le permutazioni cicliche, le si ordina lessicograficamente e le si mette in unamatrice quadrata di lato |x| × |x|.
Data una colonna, posso ricostruire l’intera matrice? Con una qualsiasi colonna diversa dalla prima, pos-so ottenere in modo deterministico la prima, che è la versione ordinata di una qualunque colonna. L’ultimacolonna, in particolare, è sia la più lontana dalla prima, sia quella che la precede. Quindi posso calcolare lecoppie (ultima, prima), che concatenate alfabeticamente alla prima colonna mi forniscono la seconda. Alloraposso iterare il ragionamento per ottenere le triple (ultima,prima, seconda) con cui ricostruire la terza, ecosì via. In fase di decodifica quindi ci bastano l’ultima colonna (che scriveremo come L) e l’indice di rigain cui si trova la stringa originale.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 1.36. Sia x = ‹pippi›. La sua matrice è
i p i ppipp ipp ip ipp ipp ipp ip i
.
Partendo dall’ultima colonna L =
pppii
otteniamo subito la prima:
iippp
. Le coppie che consentono di calcolare
la seconda colonna sono ‹pi›, ‹pi›, ‹pp›, ‹ip›, ‹ip›. Quando vengono applicate in ordine alfabetico alla
prima colonna, formano la matrice incompleta
i p??pip??pp i ??pp i ?? ipp?? i
. Iterando con le triple e le quadruple si ottiene la
matrice completa.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
14

Notiamo che nell’ultima colonna ci sono molte ripetizioni contigue, fatto che viene sfruttato nell’algoritmodi codifica.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Pseudocodice 1.37: Burrows-Wheeler – Codifica. Sia A l’alfabeto primario. Abbiamo l’ultima colonna Lcome input. Il seguente frammento è solo la preparazione per la codifica.
for i := 1 to |L| doR[i] := indice di L[i] in A;Porta l’R[i]-esimo carattere di A in posizione 0 e sposta a destra tutti gli altri;
od
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Grazie al frammento precedente, le lettere probabili staranno sempre “all’inizio” di A, quindi si puòcreare un codice di Huffman “fisso”.
1.2.5 LV-LV
Alcuni dei codici reali che abbiamo incontrato coniugano una prima parte LV-B con un postprocessingB-LV. Allora possiamo costruire un codice
LV−−→ Tunstall B−→ Huffman LV−−→
sfruttando i codici ottimi delle due tipologie. Il tasso sarà R = ELEN , che è la forma più generale.
Partendo da un A con distribuzione di probabilità P , applicando j volte Tunstall, otterremo unMj condistribuzione Sj . Allora
Rj =ELjENj
=H(Sj) + ξ
ENjper qualche 0 ≤ ξ < 1⇒
⇒ Rj =ENj ·H(P ) + ξ
ENj= H(P ) +
ξ
ENj< H(P ) +
1
ENj,
quindi questo codice tende all’entropia.
1.3 B-BIl codice sarà una funzione ϕ : An → B`, quindi il tasso è R = `
n . Se n è fissato, affinché tutte len-uple possano essere codificate, deve valere D` ≥ kn ⇒ ` ≥ n logD k ⇒ ` = dn logD ke (perché lo vogliamominimo). Un codice B-B è solo una riscrittura, non una compressione.
Shannon non si fermò qui e andò oltre: se accettassi qualche errore? Ammetto che ϕ non sia iniettiva.Sia ψ l’inversa di ϕ, definita “bene” dove possibile.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 1.38. La probabilità di errore «perr» è definita come perr := P(ψ ◦ ϕ(X) 6= X
).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Ammettendo la probabilità di errore, introduciamo «C», sottoinsieme di An contenente le n-uple corret-tamente codificate. Inoltre passiamo a considerare un tasso semplificato R := log|C|
n , in cui rispetto a quellonormale si ignora la base del logaritmo e si elimina la parte estremo superiore.
Cerco allora il più piccolo C tale P(C) sia alta. La soluzione si ottiene ordinando le n-uple di An perprobabilità decrescente e scegliendo il minimo numero di n-uple altamente probabili tali che la somma delleloro probabilità sia maggiore o uguale a 1− perr, con perr fissata in partenza.
Sia F = (f1, . . . , fk) una distribuzione di probabilità. Partizioniamo An in tipi. Fissiamo un tipo Tcaratterizzato dalle probabilità (n1, . . . , nk).
Fn(T ) =∑x∈T
Fn(x) = Fn(∈Tx )|T |. Fn(x) = fn1
1 · · · fnk
k = exp2
(k∑i=1
ni log fi
).
15

Ciò vale per ogni F , in particolare per F =(n1
n , . . . ,nk
n
), ossia la frequenza del tipo T . Allora
Fn(x) = exp2
(n
k∑i=1
nin
log fi
)= exp2
(n
k∑i=1
fi log fi
)= 2−nH(F ) ⇒
⇒ Fn(T ) = 2−nH(F )|T | ≤ 1⇒ |T | ≤ 2nH(F ) .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Lemma 1.39.n!
m!≤ nn−m.
Dimostrazione.
• Ln ≥ mM n!
m!=
n−m fattori︷ ︸︸ ︷n (n− 1) · · · (m+ 1)��m!
��m!≤ nn−m;
• Ln < mMn!
m!=
��n!
m (m− 1) · · · (n+ 1)︸ ︷︷ ︸m− n fattori
��n!≤ nn−m.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Consideriamo il tipo T caratterizzato da (n1, . . . , nk), il tipo Tj caratterizzato da (m1, . . . ,mk) e ladistribuzione F = (f1, . . . , fk) =
(n1
n , . . . ,nk
n
).
Fn(Tj)
Fn(T )=|Tj | · Fn(
∈Tj
y )
|T | · Fn( x∈T
)=
��n!
m1! · · ·mk!· fm1
1 · · · fmk
k
��n!
n1! · · ·nk!· fn1
1 · · · fnk
k
=n1! · · ·nk!
m1! · · ·mk!·
(n1
n
)m1
· · ·(nkn
)mk(n1
n
)n1
· · ·(nkn
)nk=
=
(n1!
m1!· n(m1−n1)
1
)︸ ︷︷ ︸
≤1
· · ·(nk!
mk!· n(mk−nk)
k
)︸ ︷︷ ︸
≤1
· n(n1+···+nk)
n(m1+···+mk)︸ ︷︷ ︸=1
≤ 1⇒ Fn(Tj) ≤ Fn(T ) ,
ossia se uso la probabilità uguale alla frequenza di un tipo T , allora T ha probabilità massima. Allora
1 =
γn∑j=1
Fn(Tj) ≤ γnFn(T ) ≤ (n+ 1)k · 2−nH(F )|T | =
= exp2
(−n(H(F )− k
n log(n+ 1)))|T | ⇒ |T | ≥ 2n(H(F )−ξ) ,
con ξ infinitesimo. Complessivamente si ha |T | ≈ 2nH(F ).
Rammentiamo che una v.a.X ha distribuzione binomiale se P(X = x) =(nx
)px(1−p)n−x, con p ∈ ]0, 1[.
Il valore atteso «µX» vale np e la varianza «σ2X» vale np(1− p).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Lemma 1.40: Disuguaglianza di Čebyšëv. ∀ε > 0: P(|X − µX | ≥ ε
)≤ σ2
X
ε2.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Indichiamo con «N(ai ‖ x)» la v.a. che rappresenta il numero di occorrenze di ai nella n-upla x. Essaavrà valore atteso npi e varianza npi(1− pi). La v.a. derivata N(ai‖x)
n avrà di conseguenza valore atteso pie varianza pi(1−pi)
n .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.41. Sia «δ» una successione di numeri reali positivi δ1, δ2, δ3, . . . tale che lim
n→+∞δn = 0 e che
limn→+∞
δn√n = +∞. Definiamo l’insieme «Tn» delle n-uple di δ-tipiche nel seguente modo:
Tn =
{x ∈ An : ∀i :
∣∣∣∣N(ai ‖ x)
n− pi
∣∣∣∣ ≤ δn} .
16

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Quando δn è piccolo (n è grande), essere δ-tipico significa che la frequenza dei simboli è circa uguale allaprobabilità.
P(∣∣∣∣N(ai ‖ x)
n− pi
∣∣∣∣ > δn
)Čeb.≤ pi(1− pi)
n δ2n
=
parabola︷ ︸︸ ︷pi(1− pi)(√n δn)2
≤ 1
4
1
(√n δn)2
,
che tende a 0 per n che tende a +∞. Allora P(x /∈ Tn) ≤ k4
1(√n δn)2
e P(x ∈ Tn) ≥ 1− k4
1(√n δn)2
.
Preso un An e il suo Tn, un tipo Tj sta o tutto dentro o tutto fuori a Tn. Sia «In» l’insieme degli indici
dei tipi inclusi in Tn. |Tn| =
∣∣∣∣ ⋃j∈In
Tj
∣∣∣∣ disg.=
∑j∈In
|Tj | ≤∑j∈In
2nH(Fj). Poiché se Tj ⊆ Tn ⇒ Fj ≈ P allora
|Tn| ≤ (n+ 1)k 2nH(P ) = 2n(H(P )+ξ), con ξ infinitesimo. Inoltre vale 2n(H(P )−ξ′) ≤ |Tn|, con ξ′ infinitesimo.Allora complessivamente R = log|Tn|
n ≈ �nH(P )
�n= H(P ).
Questa è la parte diretta del 2º Teorema di Shannon. Anche usando un codice B-B con errore nonpossiamo fare meglio dell’entropia.
1.4 Complessità di Kolmogorov
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.42. Sia U un calcolatore universale (o l’interprete di un linguaggio di programmazione). SeP è un programma per U , denotiamo con «JP KU ()» l’esecuzione, con eventuale output, di P su U . Lacomplessità di Kolmogorov di una stringa x rispetto a U è KU (x) := min
{|P | : JP KU () = x
}.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Supponiamo che P sia un programma che genera x, ossia JP K() = x. Come faccio a capire se è ilpiù piccolo? Dovrei provare JQK() per ogni Q di lunghezza inferiore a P , ma non lo posso fare, a causadell’halting problem. Per colpa di questo problema, della complessità di Kolmogorov avremo solo unalimitazione superiore, salvo rarissimi casi. L’idea è comunque quella di usare la complessità di Kolmogorovper comprimere.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.43. Se A e B sono due l.d.p. allora ∀x : KA(x) ≤ KB(x) + cAB , dove cAB è una costante chedipende solo dai due linguaggi.
Dimostrazione. Supponiamo KB(x) = k, ovvero esiste un programma P nel linguaggio B tale cheJP KB() = x ∧ |P | = k. So che esiste un programma I scritto in A che fa l’interprete del linguaggio B,ossia ∀Q programma in B, y input : JIKA(Q, y) = JQKB(y). Il programma “composto” (I, P ) è un program-ma in A, lungo |I|+ |P | e che genera x. Allora KA(x) ≤ |I|+KB(x).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Corollario 1.44. Se A e B sono l.d.p. allora∣∣KA(x)−KB(x)
∣∣ ≤ c, dove c è costante.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
D’ora in poi astrarremo dal l.d.p., poiché è indifferente. Inoltre tutte le «c» denoteranno costanti semprediverse e fissiamo «n» pari alla lunghezza della stringa x di volta in volta considerata.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 1.45. La complessità di Kolmogorov condizionata di una stringa x è definita comeK(x | n) := min
{|P | : JP K(n) = x
}.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 1.46. La stringa x = ‹01 . . . 01› può essere generata dal programma
17

for i := 1 to � dowrite("01");
od
Al posto di «�» il programma senza input avrà il valore n2 in forma di stringa, mentre il programma con la
lunghezza in input avrà semplicemente «n / 2». Quindi K(x) ≤ c+ log n2 mentre K(x | n) ≤ c.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 1.47.
1. ∀x : K(x | n) ≤ n+ c.
2. ∀x : K(x) ≤ K(x | n) + 2 log n+ c.
Dimostrazione.
1. Sia x una stringa “senza struttura”. Allora il programma che la genera è banalmente «write(x);»,che ha lunghezza c+ 8n, perché i bits salvati sono bytes.Allora si può creare un comando «writeb(n, x)» che stampa bit per bit una stringa codificata informa di bytes. In questo modo il programma ha finalmente lunghezza n+ c.Si noti che è necessario scrivere il numero di bits da leggere perché nella sequenza di bits codificaticome bytes ci potrebbe essere un byte che si confonde col delimitatore della stringa.
2. Sfruttiamo il punto precedente. Il programma senza input è nella forma
n := n;writeb(n, x);
la cui lunghezza è tuttavia 8 log n+ c.Allora similmente a prima possiamo creare un comando «bass(n, n)» (binary assignment) in cui lastringa che rappresenta n è scritta di nuovo in bits codificati come bytes. Per capire dove finisce lastringa possiamo rappresentare n raddoppiando ogni singolo bit e aggiungere ‹01› come segnale.Ora il programma ha finalmente lunghezza K(x) ≤ K(x | n) + 2 log n+ c.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Possiamo migliorare le prestazioni della codifica di n nel secondo punto del teorema precedente:
2 3 4 10 n = 1023 valore decimale10 11 100 1010 0 1111111111 stringa2 2 3 4 10 bits della rappresentazione
in cui lo ‹0› isolato è il segnale di fine. Questa stringa è lunga
log n+ log log n+ log log log n+ · · ·+ 3 ≈ log∗ n ≤ 2 log n .
Prendiamo A = {0, 1} alfabeto binario e consideriamo An, che dividiamo in tipi. Allora γn = n + 1esattamente. La cardinalità di un tipo identificato da (n1, n2) è
(nn1
)=(
nn1,n2
)=(nn2
)e sappiamo anche
2nH(F )
γn≤ |T | ≤ 2nH(F ), con F =
(n1
n ,n2
n
)=(n1
n , 1−n1
n
)frequenza del tipo T .
L’entropia di una distribuzione binaria H(x, 1 − x) viene spesso denotata con «H0(x)» o con «hx».
Abbreviamo con «u» il numero di ‹1› di un tipo T fissato, esprimibile anche come u :=n∑i=1
xi. Vale che
2nH0(u/n)
n+ 1≤(n
u
)︸︷︷︸=|T |
≤ 2nH0(u/n) .
18

Un programma che dice «Genera tutte le stringhe di n elementi con u ‹1›, ordinale lessicograficamente,stampa la i-esima» è sicuramente più compatto di un write se n è grande. Studiamo quindi K(x | n) peril nuovo programma.
K(x | n) ≤ c︸︷︷︸resto
+ log(n+ 1)︸ ︷︷ ︸u
+ log
(n
u
)︸ ︷︷ ︸
i
≤ c+ log(n+ 1) + nH0
(un
).
Confrontando questa complessità con quella del Teorema 1.47, abbiamo che per u ≈ n2 ⇒ H0
(un
)≈ 1
quindi conviene la write, altrimenti conviene la nuova codifica.
Proveremo ora a usare le idee impiegate per K come algoritmo di compressione. Associamo ϕ(x) al piùpiccolo programma che stampa x. L’algoritmo ottenuto è B-LV e non realizzabile, sempre per l’impossibilitàdi determinare il programma più breve.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Proposizione 1.48. H(P ) ≤ ELn ≤ H(P ) + ξn, con ξn infinitesimo.
Dimostrazione. Programmi che generano stringhe diverse non possono essere uno prefisso dell’altro, quindiquesto codice è a prefisso, è UD e dunque EL
n ≥ H(P ).
Innanzitutto valeEL
n=
∑x∈An
Pn(x)K(x | n)
n. Usando una meta-notazione, scriviamo che
EK(x | n) ≤ E
(c+ log(n+ 1) + nH0
(∑ni=1Xi
n
))= c+ log(n+ 1) + nEH0
(∑ni=1Xi
n
),
dove ogni Xi è una v.a. che è ‹1› con probabilità p. Allora, per la disuguaglianza di Jensen, si ha che
EH0
(∑ni=1Xi
n
)≤ H0
(E∑ni=1Xi
n
)= H0
(�np
�n
)= H(p, 1− p) = H(P ) ,
da cui
EK(x | n) ≤ c+ log(n+ 1) + nH(P )⇒ EL
n≤ c+ log(n+ 1)
n+�nH(P )
�n= H(P ) + ξn .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
2 Codici di canaleL’obiettivo è proteggere l’informazione da errori casuali, ossia non provocati da malintenzionati. L’idea
generale consiste nell’introdurre delle ridondanze sistematiche.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 2.1. Il tasso di trasmissione è R := log|C|n , dove C è l’alfabeto del codice e n è in numero di
simboli del messaggio codificato.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
In generale il metodo di decodifica è quello di massima verosimiglianza con un insieme di valoriammissibili. Il problema «Trovare un insieme di n-uple con e elementi che differiscono ognuno per almenod bits» è NP-completo.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.2.
• Nel bit di parità si aggiunge un bit corrispondente allo xor degli altri bit. Con un alfabeto di n-upledi bits, noi inviamo n+ 1 bit, con un tasso R = 7
8 . Se nella trasmissione avviene un numero dispari dierrori si riconosce che c’è stato un errore, ma non lo si può correggere.
19

• Nel codice a ripetizione si ripete ogni bit r volte. Con un alfabeto di n-uple inviamo rnbit, con untasso R = 1
r . Anche se “sprechiamo” più bits, possiamo correggere fino a b r2c errori per ogni gruppodi r bit.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 2.3. Una matrice quadrata di lato n è di Hadamard se Hij ∈ {−1, 1} e HHT = nIn.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 2.4.(1)e(−1)sono di Hadamard.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Lemma 2.5. Se H è di Hadamard allora(H HH −H
)è di Hadamard.
Dimostrazione. Se H è di Hadamard (di lato n) allora Hij ∈ {−1, 1} e ciò vale anche per la nuova matrice.(H HH −H
)(HT HT
HT −HT
)=
(HHT +HHT HHT −HHT
HHT −HHT HHT +HHT
)=
(2nIn 0
0 2nIn
)= 2nI2n .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Indichiamo con «H2n» la matrice di Hadamard ottenuta dalla matrice(1)con n applicazioni del lemma
precedente.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 2.6. Due qualsiasi righe distinte di H2n si differenziano in 2n−1 punti.
Dimostrazione. Prendiamo due righe a caso (a1, . . . , a2n) e (b1, . . . , b2n) distinte. PoichéH2n(H2n)T = 2nI2n ,
sappiamo che2n∑i=1
aibi può valere 0 oppure 2n, il secondo dei quali vale solo quando la riga è la stessa. Ma
siccome le righe sono diverse per ipotesi, la sommatoria è nulla. Affinché questo accada a una somma diprodotti di 1 e −1, significa che metà sono uguali e metà diversi.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Allora alla NASA hanno pensato di costruire la matrice(H32
−H32
), che ha 64 righe e 32 colonne. Pren-
dendo una riga di quella sopra e una di quella sotto, possono differire in 16 o 32 punti. In questo modohanno scelto un codice C di 64 elementi per il quale vengono usati 32 bit. Allora R = 6
32 ≈15 , potendo però
correggere fino a 7 errori consecutivi.
Consideriamom−→ CC x−→ canale y−→ DC m−→
con x ∈ X := {a1, . . . , ak} e y ∈ Y := {b1, . . . , bh}. Gli alfabeti sono teoricamente diversi perché in Ypotrebbero esserci valori che indicano «indefinito», ma tipicamente k = h = 2. Un canale viene descrittocon una matrice stocastica Γ tale che Γij := P(Y = bj |X = ai).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 2.7. Il canale simmetrico binario (CSB) ha X = Y = {0, 1} e Γ =
(1− ε εε 1− ε
), con ε
probabilità di errore.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
20

Scriveremo «Γn(x |y)» per indicare P(Y n = y |Xn = x). Nell’ipotesi di assenza di memoria di un canale,la probabilità della concatenazione è il prodotto delle probabilità. Scriveremo anche Γ
({x1, . . . , xt}
∣∣ y)»per intendere
t∑i=1
Γn(xi | y).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.8. Dato un insieme di messaggi «M», il codificatore di canale (CC) è una f : M→ Xne il decodificatore di canale (DC) è una g : Yn →M∪ {⊥} (codifica morbida) oppure g : Yn →M(codifica rigida). Il simbolo «⊥», opzionale, indica che non ho saputo decodificare.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Quindi R := log|M|n e il C usato prima non è altro che f(M) ⊆ Xn. Ci piacerebbe che R fosse alto (il
valore massimo è 1).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.9. La probabilità di errore di un messaggio m è
perr(f, g,m) := P(g(Y ) 6= m
∣∣X = f(m))
= P(Y /∈ g−1(m)
∣∣X = f(m))
= 1− Γn(g−1(m)
∣∣ f(m)).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Per la probabilità di errore di un codice possiamo scegliere il massimo, la media o la media pesata delleprobabilità di errore dei messaggi. Quest’ultima è improponibile perché non possiamo conoscere a priori leprobabilità dei messaggi. Per il CSB sono tutte uguali. Quindi in generale non viene definita.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.10. Come canale consideriamo il CSB.
• f(x) = x g(x) = x
R = 1 perr(f, g, ‹0›) = Γ(‹1› | ‹0›) = ε perr(f, g, ‹1›) = Γ(‹0› | ‹1›) = ε
• f(x) = xxx
perr(f, g, ‹0›) = Γ3({‹110›, ‹011›, ‹101›, ‹111›}
∣∣ ‹000›)
=
= Γ3(‹110› | ‹000›) + Γ3(‹011› | ‹000›) + Γ3(‹101› | ‹000›) + Γ3(‹111› | ‹000›) =
= 3ε2(1− ε) + ε3 = ε2(3− 2ε) = perr(f, g, ‹1›) .
Rispetto al caso precedente, la probabilità di errore è calata.
• Con 5 ripetizioni abbiamo R = 15 e perr = ε3(6ε2 − 15ε+ 10), che cala ulteriormente.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Possiamo migliorare la probabilità di errore, ferma restando Γ, senza perdere troppa velocità?. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.11. La capacità di un canale Γ si definisce come C(Γ) := max
PI(X ∧ Y ), dove P è la
distribuzione di probabilità di X.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 2.12: Teorema di Shannon (per i codici di canale).
1. Esiste una famiglia di codici tale che la sua probabilità di errore tende a 0 per R che tende a C(Γ).
2. Se un codice ha R > C(Γ) allora perr > η, con η > 0.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.13.
21

• Sia Γ =
(0.4 0.60.4 0.6
). Questa matrice ha le righe tutte uguali e a somma 1. L’uscita è indipendente
dall’ingresso, infatti questo canale viene detto inutile (o “cavo rotto”). Poiché
pij = P(X = ai ∧ Y = bj) = P(Y = bj |X = ai)P(X = ai) = Γijpi
e Γij = qj (non dipende da i) allora
I(X ∧ Y ) =∑i
∑j
pij logpijpiqj
=∑i
∑j
log ��Γij��pi
��pi��qj︸ ︷︷ ︸=1
= 0
e in definitiva C(Γ) = 0.
• Sia Γ =
(0 0.35 0.651 0 0
). Questa matrice ha in ogni colonna al più un elemento non nullo. Un canale
simile viene detto senza rumore, infatti dall’uscita posso determinare sempre l’ingresso. Indichiamocon «Ni» l’insieme degli indici di Y che sono “nomi” per ai. Poiché pij = pi|jqj allora
I(X ∧ Y ) =∑i
∑j
logpijpiqj
=∑i
∑j∈Ni
pij logpijpiqj
=
=∑i
∑j∈Ni
qj log1
pi= −
∑i
pi log pi = H(P ) .
da cui C(Γ) = maxP
H(P ) = 1.
• Sia Γ =
1 01 00 10 10 1
. Questa matrice ha in ogni riga esattamente un elemento non nullo. Un canale
simile viene detto deterministico. Pur non avendo rumore, introduce errore in decodifica. Poichévale il ragionamento simmetrico rispetto al caso precedente, abbiamo I(X ∧ Y ) = H(Q), da cuiC(Γ) = max
PH(Q) = log|X ||Y|.
• Consideriamo il CSB e sfruttiamo I(X ∧ Y ) = H(Y )−H(Y |X).Abbiamo H(Y |X) =
∑x∈{0,1}
P (x)H(Y |X = x) e
H(Y |X = ‹0›) = −P(Y = ‹0› |X = ‹0›) logP(Y = ‹0› |X = ‹0›)−−P(Y = ‹1› |X = ‹0›) logP(Y = ‹1› |X = ‹0›) =
= −(1− ε) log(1− ε)− ε log ε = hε = H(Y |X = ‹1›) ,
quindi H(Y | X) = P (‹0›)hε + P (‹1›)hε = hε. Allora I(X ∧ Y ) = H(Y ) − hε e inoltre C(Γ) == max
P
(H(Y )− hε
), che è massima per Q uniforme e vale C(Γ) = 1− hε.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esercizio 2.14. Dimostrare che nel canale simmetrico q-ario (CSq) la capacità vale C(Γ) = 1 − hε −− ε log(q − 1) con
Γ =
1− ε η · · · ηη 1− ε · · · η...
.... . .
...η η · · · 1− ε
︸ ︷︷ ︸
q×q
,
22

dove η = εq−1 .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Abbiamo un messaggio m che diventa x = f(m), che a sua volta diventa y passando attraverso ilcanale. La f è solo una riscrittura, quindi devo trovare x che massimizza P(Y = y | X = x) oppureP(Y = y | X = x)P(X = x), ossia Γn(y | x) oppure Γn(y | x)P (x) in termini di Γ. Questi due criteri sichiamano rispettivamente massima verosimiglianza e massima probabilità a posteriori. La secondaè più precisa, ma siccome non abbiamo P (x), l’unica decodifica possibile può essere quella a massimaverosimiglianza (come già accennato).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.15. La distanza di Hamming «dH(x, y)» è definita come il numero di simboli diversi tra xe y.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Allora nel CSB P(Y = y | X = x) = εdH(x,y)(1 − ε)n−dH(x,y) = (1 − ε)n(
ε1−ε)dH(x,y), in cui il primo
fattore è costante e il secondo è un esponenziale con base minore di 1, quindi devo minimizzare l’esponentedH(x, y).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.16. Definiamo la distanza minima di un codice C come dmin(C) := min
x,y∈Cx 6=y
dH(x, y).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Se il codice è fissato, scriveremo in breve «dmin».. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 2.17. Se dmin ≥ 2t+ 1 (per t ∈ N) allora so correggere tutte le configurazioni con t errori.
Soluzione. Sia y una stringa uscita dal canale, con dH(x, y) ≤ t per qualche x ∈ C. Per ogni altra x′ ∈ Cvale dH(x′, y) > t, altrimenti dH(x, x′) < 2t+ 1, contro l’ipotesi di minimalità di dmin.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
L’inverso di questo lemma afferma che se dmin ≤ 2t allora esiste almeno una configurazione di t erroriche non viene corretta.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esercizio 2.18. Nel CSB con decodifica a minima dH, se dmin
n > 2ε allora so correggere tutte le n-upleδ-tipiche, ovvero perr tende a 0.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
2.1 Limitazioni asintoticheCi concentriamo su X e su C ⊆ Xn, indicando con «q» e «M» le rispettive cardinalità.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 2.19. Il tasso di correzione è definito come λ := dmin
n .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Naturalmente vogliamo sia R che λ alti.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 2.20. Parità Ripetizione HadamardR n−1
n1n
632
λ 2n 1 1
2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
23

Singleton Prese tutte le n-uple di C e considerandone solo i primi n − (dmin − 1) caratteri, sono tuttediverse. Infatti, se così non fosse, il codice avrebbe distanza minima pari a dmin − 1, che non ha senso.Allora qn−(dmin−1) ≥M affinché valga la considerazione precedente. Asintoticamente vale
qn−(dmin−1) ≥M ⇒ log qn−(dmin−1) ≥ logM ⇒ n−(dmin−1) ≥ logM ⇒ 1−dmin
n+
1
n≥ logM
n⇒ R ≤ 1−λ.
Plotkin Denotiamo con «D» il valore∑
xi,xj∈CdH(xi, xj), contenente anche i doppioni. Sicuramente vale
D ≥ M(M − 1). Immaginiamo di incolonnare tutte le n-uple di C e denotiamo con «uij» il numero disimboli della colonna i uguali al j-esimo simbolo. Allora
D =
n∑i=1
q∑j=1
uij(M − uij) = M
n∑i=1
q∑j=1
uij︸ ︷︷ ︸=M
−n∑i=1
q∑j=1
u2ij = nM2 −
n∑i=1
q∑j=1
u2ij .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Lemma 2.21: Disuguaglianza di Cauchy-Schwartz.∑i
a2i
∑i
b2i ≥
(∑i
aibi
)2
.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Esaminiamo il secondo addendo:
n∑i=1
q∑j=1
u2ij =
n∑i=1
q∑j=1
12
q
q∑j=1
u2ij ≥
1
q
n∑i=1
(q∑j=1
uij︸ ︷︷ ︸=M
)2
=nM2
q.
Allora D ≤ nM2 q−1q e dunque asintoticamente
M(M − 1)dmin ≤ nM2 q − 1
q⇒ dmin
n≤ M
M − 1
q − 1
q⇒ λ ≤ qnR
qnR − 1
q − 1
q⇒ λ ≤ q − 1
q.
Hamming. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.22. La sfera di Hamming di centro x e raggio r è definita come S(x, r) := {y ∈ Xn :
dH(x, y) ≤ r}. Il suo “volume” «∣∣S(x, y)
∣∣» valer∑i=0
(ni
)(q − 1)i.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Notiamo che le sfere di raggio t =⌊d−1
2
⌋con elementi di C come centro non si intersecano mai. Dunque
M∣∣S(x, t)
∣∣ ≤ qn = M
t∑i=0
(n
i
)(q − 1)i ≤ qn ⇒
⇒ logM + log
t∑i=0
(n
i
)(q − 1)i ≤ n⇒ R ≤ 1− 1
nlog
t∑i=0
(n
i
)(q − 1)i .
Gilbert Con un algoritmo greedy scelgo una n-upla x1 e costruisco S(x1, d−1), per qualche d. Poi scelgoun’altra n-upla x2 tra quelle non appartenenti alla sfera e reitero fermandomi quando i
∣∣S(x, d − 1)∣∣ > qn,
per qualche x. Questa limitazione afferma che qualunque codice con dmin = d è migliore o uguale a questo,
ossia Md−1∑i=0
(n
i
)(q − 1)i ≥ qn ⇒ · · · ⇒ R ≥ 1− 1
nlog
d−1∑i=0
(n
i
)(q − 1)i.
24

Calcoli finali Abbiamo lasciato in sospeso le ultime due limitazioni in cui il membro di destra della
disuguaglianza è nella formaz∑i=0
(ni
)(q − 1)i, per un certo z.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 2.23. L’entropia q-aria si definisce come Hq(p) := H
(1− p, p
q − 1, . . . ,
p
q − 1︸ ︷︷ ︸q − 1 elementi
).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Dalla definizione si ricava che l’entropia q-aria vale
Hq(p) = −(1− p) log(1− p)−����(q − 1)p
���q − 1log
p
q − 1=
= −(1− p) log(1− p)− p log p︸ ︷︷ ︸hp
+ p log(q − 1) = hp + p log(q − 1) .
Sappiamo che qnH(F )
n+1 ≤(ni
)≤ qnH(F ), con F =
(in ,
n−in
), e possiamo riscrivere (q − 1)i come
expq(n in log(q − 1)
). Allora
expq
(n(H0( in ) + i
n log(q − 1)))
n+ 1≤(n
i
)(q − 1)i ≤ expq
(n(H0( in ) + i
n log(q − 1)))⇒
⇒ qnHq( in )
n+ 1≤(n
i
)(q − 1)i ≤ qnHq( i
n ) .
Considerando la sommatoriaz∑i=0
(ni
)(q−1)i, l’idea è che l’argomento cresce fino a n
2 , ma non ci si arriva.
Nell’approssimazione in cui d non può essere troppo grande rispetto a n, per i = z avremo il massimo,quindi
qnHq( zn )
n+ 1≤
z∑i=0
(n
i
)(q − 1)i ≤ (z + 1)qnHq( z
n ) ⇒
⇒�nHq
(zn
)�n
− log(n+ 1)
n︸ ︷︷ ︸infinitesimo
≤log
z∑i=0
(ni
)(q − 1)i
n≤ log(z + 1)
n︸ ︷︷ ︸infinitesimo
+�nHq
(zn
)�n
⇒
⇒ 1
nlog
z∑i=0
(n
i
)(q − 1)i ≈ Hq
( zn
).
Hq(y) è massima quando 1 − y = yq−1 ⇒ y = q−1
q , per cui le due limitazioni che avevamo lasciato insospeso diventano R . 1−Hq
(d−12n
). 1−Hq
(λ2
)e R & 1−Hq
(d−1n
)& 1−Hq(λ), rispettivamente.
Uno schema riassuntivo è presentato in Figura 2.1. Non ci si lasci ingannare dal fatto che nel graficoesemplificativo la limitazione À non intervenga attivamente.
2.2 Codici algebriciUn codice algebrico è un codice che trasforma k-uple diM in n-uple di Xn utilizzando una matrice
«G» (di dimensione k × n), ossia x = mG.Sorgono subito alcune domande:
• Sarà UD?
• Corregge? Quanto corregge?
• Se X = {‹a›, ‹b›, . . . , ‹z›}, cosa significa ‹a› · ‹b›? Posso invertirlo?
25
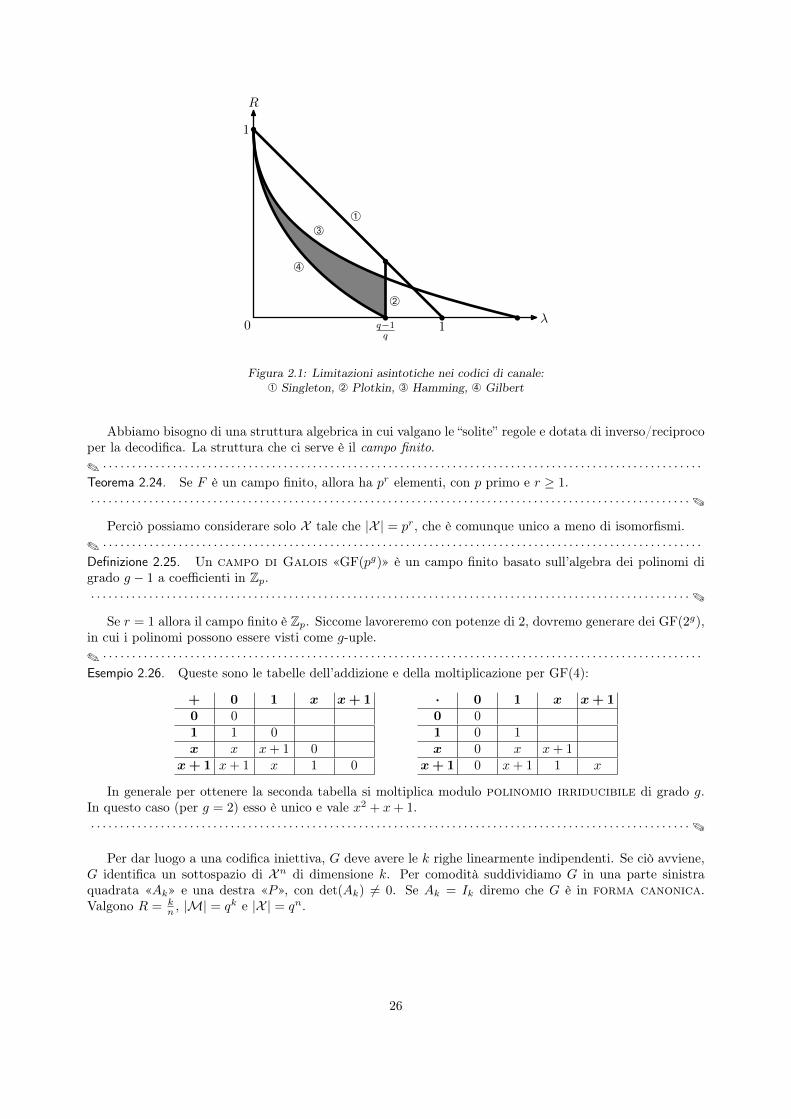
λ
R
0 1
1
q−1q
À
Á
Â
Ã
Figura 2.1: Limitazioni asintotiche nei codici di canale:À Singleton, Á Plotkin, Â Hamming, Ã Gilbert
Abbiamo bisogno di una struttura algebrica in cui valgano le “solite” regole e dotata di inverso/reciprocoper la decodifica. La struttura che ci serve è il campo finito.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 2.24. Se F è un campo finito, allora ha pr elementi, con p primo e r ≥ 1.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Perciò possiamo considerare solo X tale che |X | = pr, che è comunque unico a meno di isomorfismi.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.25. Un campo di Galois «GF(pg)» è un campo finito basato sull’algebra dei polinomi digrado g − 1 a coefficienti in Zp.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Se r = 1 allora il campo finito è Zp. Siccome lavoreremo con potenze di 2, dovremo generare dei GF(2g),in cui i polinomi possono essere visti come g-uple.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.26. Queste sono le tabelle dell’addizione e della moltiplicazione per GF(4):
+ 0 1 x x+ 10 01 1 0x x x+ 1 0
x+ 1 x+ 1 x 1 0
· 0 1 x x+ 10 01 0 1x 0 x x+ 1
x+ 1 0 x+ 1 1 x
In generale per ottenere la seconda tabella si moltiplica modulo polinomio irriducibile di grado g.In questo caso (per g = 2) esso è unico e vale x2 + x+ 1.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Per dar luogo a una codifica iniettiva, G deve avere le k righe linearmente indipendenti. Se ciò avviene,G identifica un sottospazio di Xn di dimensione k. Per comodità suddividiamo G in una parte sinistraquadrata «Ak» e una destra «P», con det(Ak) 6= 0. Se Ak = Ik diremo che G è in forma canonica.Valgono R = k
n , |M| = qk e |X | = qn.
26

Se non c’è errore, per decodificare bisogna invertire G. Trovo k colonne linearmente indipendenti, leinverto e seleziono le componenti di x corrispondenti.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.27. (
0 1 1)︸ ︷︷ ︸
m
1 1 10 1 10 0 1
0 00 11 0
︸ ︷︷ ︸
G=(A|P )
=(0 1 0 1 1
)︸ ︷︷ ︸x
(0 1 0
)︸ ︷︷ ︸parte di x
1 1 00 1 10 0 1
︸ ︷︷ ︸
A−1
=(0 1 1
)︸ ︷︷ ︸m
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Osserviamo che se x1, x2 ∈ C allora sia x1 + x2 ∈ C sia x1 − x2 ∈ C, infattiM è fatto in modo tale dacontenere tutte le k-uple. Inoltre 0 ∈ C sempre.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 2.28. Il peso di un codice è w(C) := minx∈Cr{0}
dH(x, 0).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Osserviamo che 0 ∈ C ⇒ w(C) ≥ dmin(C) (la premessa serve affinché funzioni anche nei codici nonalgebrici) e in particolare nei codici algebrici w(C) = dmin(C). Supponendo infatti che la distanza minimadel codice si ottenga come dmin = dH(x1, x2), poiché x1 − x2 ∈ C allora dH(x1 − x2, 0) = dmin.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.29.
• G =
1 · · · 0...
. . ....
0 · · · 1
1...1
è il bit di parità, che ha w = dmin = 2.
• G =(1 1 · · · 1
)︸ ︷︷ ︸n colonne
è il codice a ripetizione, che ha w = dmin = n.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Come esempio di riferimento della prossima parte consideriamo
(m1 m2 m3
)︸ ︷︷ ︸m
1 0 00 1 00 0 1
1 10 11 0
︸ ︷︷ ︸
G=(I3|P )
=(x1 x2 x3 x4 x5
)︸ ︷︷ ︸x
,
notando che G è in forma canonica. Allora xi = mi per i ∈ {1, 2, 3}, x4 = m1 + m3 = x1 + x3 ⇒⇒ x1 +x3−x4 = 0 e x5 = m1 +m2 = x1 +x2 ⇒ x1 +x2−x5 = 0. Le ultime due sono dette equazioni dicontrollo e danno luogo alla matrice di controllo, solitamente denotata con «H», con n−k righe ed
n colonne. In questo esempio abbiamo H =
(1 0 11 1 0
−1 00 −1
). Poiché G era in forma canonica, vale
infatti che H = (PT | −In−k).
Siccome HxT =
(x1 + x3 − x4
x1 + x2 − x5
), allora HxT = 0 ⇔ x ∈ C, anche se HxT = 0 non implica assenza di
errore.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 2.30. La sindrome di y si definisce come s(y) := HyT .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
27

Quando una x entra nel canale, ne esce una y = x+ e, con e errore. Siccome
HyT = H(x+ e)T = H(xT + eT ) = HxT︸ ︷︷ ︸=0
+HeT = HeT
si può costruire un algoritmo di decodifica basato sulle sindromi (metodo di Slepian), provando a risalirea x da s(y).
2.2.1 Codice di Hamming
Consideriamo G =
1 0 0 00 1 0 00 0 1 00 0 0 1
1 1 11 1 00 1 11 0 1
e la sua H =
1 1 0 11 1 1 01 0 1 1
1 0 00 1 10 0 1
, con k = 4, n = 7,
R = 47 . Indichiamo «hi» l’i-esima colonna di H.
In questa H le colonne sono tutte diverse, quindi se c’è stato 1 errore non solo me ne accorgo ma soanche dove è avvenuto e lo correggo calcolando x = y − e. Se invece ci sono stati 2 o più errori sbaglierei,perché e = hi per qualche i, pur essendo la somma di più colonne. In sintesi, questo codice corregge 1errore.
Permutando le colonne di H in modo da ottenere H ′ =
0 0 0 1 1 1 10 1 1 0 0 1 11 0 1 0 1 0 1
si ottiene un codice
equivalente, col vantaggio che H ′yT mi dice in binario il bit con l’errore, rendendo più facile l’implementa-zione. Quest’ultimo è il codice di Hamming, che ha dmin = 3 e λ = 3
7 .In generale un codice di Hamming ha H matrice r × qr−1, da cui R = qr−1−r
qr−1 e λ = rqr−1 .
Sia H =
1 1 1 1 1 1 1 10 0 0 1 1 1 1 00 1 1 0 0 1 1 01 0 1 0 1 0 1 0
, dove la parte inferiore sinistra è la H ′ di poco fa. Mi aspetto un
x in cui l’ultimo bit è di parità. HyT può essere nella forma(
10
),(
00
),(
0
hi
)oppure
(1
hi
). Con 1 errore
ottengo(
1
hi
)oppure
(10
)e posso correggere. Con 2 errori ottengo
(0
hi
)e me ne accorgo.
2.2.2 Codice BCH
Sia H2 =
(h1 · · · hnk1 · · · kn
), dove le colonne ki provengono da una matrice «K» in stile Hamming.
Con 1 errore nel bit i, H2yT =
(hiki
), riconosciamo la colonna di H2 e correggiamo. Con 2 errori nei
bits i, j, H2yT =
(hi + hjki + kj
). Siamo in grado di risalire a i, j? Se H = K no. In alternativa K potrebbe
essere una permutazione di H, quindi con 2 errori H2yT non corrisponderebbe ad alcuna colonna di H2.
Per trovare la giusta K esprimiamo ki in funzione di hi. Se proviamo con ki = h2i si ha
(hi + hjki + kj
)=
=
(hi + hjh2i + h2
j
). Indicando con «s» la somma e con «q» la somma dei quadrati abbiamo s2 = q, che non
fornisce alcuna informazione aggiuntiva.Con ki = h3
i invece funziona, perché (hi + hj)3 = h3
i + h3j + h2
i hj + hih2j ⇒ s3 = q + ps ⇒
⇒ p = (s3 − q)s−1, dove stavolta «q» denota la somma dei cubi e «p» il prodotto. Resta ora da ca-pire cosa siano il cubo e l’inverso di un vettore-colonna, ma possiamo considerare le colonne di H comeelementi di GF(n + 1) r {0}. In questo esempio, prendendo x3 + x + 1 come polinomio irriducibile per
28

l’algebra in GF(8), dopo qualche calcolo otteniamo K =
0 0 1 1 1 1 00 1 0 0 1 1 11 1 0 1 0 1 0
. Per quanto riguarda
gli inversi valgono (x+ 1)(x2 + x) = 1, x(x2 + 1) = 1 e x2(x2 + x+ 1) = 1.Ora dovremmo risolvere z2 − sz + p = 0, ma poiché in un campo finito di polinomi a coefficienti in
Z2 la formula risolutiva delle equazioni di secondo grado non funziona, è necessario riscriverla nella forma(αx2 + βx+ γ)2 − s(αx2 + βx+ γ) + p = 0 e “semplificarla”.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 2.31. Supponiamo di avere errori nel bit 2 e 4. Allora s = q =
110
= x2 + x (casualmente
uguali).p =
((x2 + x)3 − (x2 + x)
)(x2 + x)−1 = (x2 + x+ 1− x2 − x)(x+ 1) = x+ 1 .
(αx2 + βx+ γ)− (x2 + x)(αx2 − βx+ γ) + (x+ 1) = 0⇒
{γ = 0
α+ β = 1 ,
da cui le soluzioni attese h2, h4.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Nel caso particolare utilizzato in questa sezione, H2 era 6 × 7, quindi la G corrispondente è 1 × 7, chenon è altro che il codice a ripetizione.
In generale il codice BCH corregge 1 errore di più della matrice H da cui viene generato.
2.2.3 Codici di Reed-Müller
Ogni funzione booleana B : {0, 1}m → {0, 1} può essere identificata univocamente con un vettore(a1, . . . , a2m) di elementi in {0, 1}. La possiamo allora scrivere nella cosiddetta forma normale algebricaB(X1, . . . , Xm) = a1 + a2X1 + a3X2 + · · ·+ a2mX1 · · ·Xm, dove le operazioni sono in Z2.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.32. Per m = 3 costruiamo la seguente tabella (omettendo gli ‹0›):
0 1 2 3 4 5 6 71 1 1 1 1 1 1 1 1
X1 1 1 1 1X2 1 1 1 1X3 1 1 1 1
X1X2 1 1X1X3 1 1X2X3 1 1
X1X2X3 1
in cui la prima riga è semplicemente riempita di ‹1›, la fascia delle variabili singole è la rappresentazionebinaria dei numeri soprastanti e le fasce successive sono compilate con la congiunzione delle variabili diciascuna riga.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Parte della matrice dell’esempio precedente può essere usata per codificare, considerando come G laparte di tabella dalla cima fino alle r-uple, con r ∈ {1, . . . ,m − 1}. La G avrà allora n = 2m colonne e
k =r∑i=0
(mi
)righe.
Per ogni grado i abbiamo 2m−1 equazioni di controllo, con il minimo per i = r. Allora la capacità dicorrezione di questo codice è 2m−r−2.
29

2.2.4 Codici ciclici
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.33. Un codice C ⊆ Xn è ciclico se è un codice algebrico e se per ogni x ∈ C anche tutte lepermutazioni cicliche di x sono in C.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Esempio 2.34. C = {‹000›, ‹101›, ‹110›, ‹011›} è un codice ciclico con G =
(1 1 00 1 1
).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Sia (c0, c1, · · · , cn−2, cn−1) ∈ C e applichiamo le seguenti trasformazioni:
• interpreto la n-upla come un polinomio (attenzione che già le ci sono elementi del campo finito X ):c0 + c1x+ · · ·+ cn−2x
n−2 + cn−1xn−1;
• lo moltiplico per x: c0x+ c1x2 + · · ·+ cn−2x
n−1 + cn−1xn;
• applico il modulo xn − 1: cn−1 + c0x+ c1x2 + · · ·+ cn−2x
n−1;
• lo reinterpreto come n-upla: (cn−1, c0, c1, . . . , cn−2).
Così facendo abbiamo ottenuto la prima permutazione ciclica della n-upla iniziale. Riassumendo, sec ∈ C considero il polinomio associato c(x), di grado n− 1. Allora xc(x), . . . , xn−2c(x) mod xn − 1 sono lesue permutazioni cicliche.
Nei codici algebrici vale anche la proprietà che a ∈ X ∧ x ∈ C ⇒ ax ∈ C. Per questo motivo, nelcodici ciclici vale che se c(x) ∈ C e p(x) è un qualunque polinomio a coefficienti in X allora
(c(x)p(x) mod
xn − 1)∈ C.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.35. Un polinomio è monico se il coefficiente del termine di grado massimo è 1.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemmi 2.36.
• In un codice ciclico c’è un unico polinomio «g(x)» monico di grado r 6= 0 minimo.
Dimostrazione. Se fossero due distinti, sottraendoli otterrei un polinomio di grado minore non nullo.
• C =⟨g(x)
⟩, ovvero se c(x) ∈ C allora esiste f polinomio di grado minore di n tale che c(x) = f(x)g(x)
mod xn − 1.
• g(x) è fattore di xn − 1, ovvero ∃h : g(x)h(x) = xn − 1.
Dimostrazione. xn − 1 = g(x)h(x) + s(x), con s di grado minore di r. Allora g(x)h(x) ≡ −s(x)mod xn − 1, ma g(x) ∈ C ⇒ g(x)h(x) ∈ C ⇒ s(x) = 0, perché lo zero è l’unico polinomio del codicedi grado minore di r.
• |C| = qn−r.
• Ogni c(x) ∈ C può essere scritto univocamente come c(x) = f(x)g(x), con f polinomio di grado minoredi n− r.
• Il codice che si ottiene ha
G =
g0 · · · gr · · · 0...
. . .. . .
. . ....
0 · · · g0 · · · gr
, H =
0 · · · hn−r · · · h0
... . ..
. ..
. .. ...
hn−r · · · h0 · · · 0
,
rispettivamente con n− r ed r righe, dove g = (g0, . . . , gr, 0, . . . , 0) e h = (h0, . . . , hn−r, 0, . . . , 0) sonon-uple.
30

• c(x) ∈ C ⇒ c(x)h(x) ≡ 0 mod xn − 1.
Dimostrazione.
c(x) ∈ C ⇒ c(x) = f(x)g(x)⇒ c(x)h(x) = f(x)g(x)h(x)︸ ︷︷ ︸≡0
⇒ c(x)h(x) ≡ 0 mod xn − 1 .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.37. Sia n = 1 e X = Z2. Siccome x7 − 1 = (x+ 1)(x3 + x2 + 1)(x3 + x+ 1), abbiamo vari modiper scegliere g e h.
• g(x) = x3 + x2 + 1, h(x) = x4 + x3 + x2 + 1
G =
1 0 1 1 0 0 00 1 0 1 1 0 00 0 1 0 1 1 00 0 0 1 0 1 1
, H =
0 0 1 1 1 0 10 1 1 1 0 1 01 1 1 0 1 0 0
.
Questa H la conosciamo già: è il codice di Hamming.
• g(x) = x+ 1, h(x) = x6 + x5 + x4 + x3 + x2 + x+ 1
G =
1 1 0 0 0 0 00 1 1 0 0 0 00 0 1 1 0 0 00 0 0 1 1 0 00 0 0 0 1 1 00 0 0 0 0 1 1
, H =(1 1 1 1 1 1 1
).
Questo è ancora una volta il codice di parità.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Come si fattorizza xn − 1? Che relazioni ci sono tra g, h e la capacità di correzione?. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 2.38. Un elemento a di un campo finito di cardinalità n si dice radice primitiva dell’unitàse an−1 ≡ 1.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Il Teorema 3.8 ci dice che se n = pr− 1, ogni elemento non nullo di GF(pr) è radice primitiva dell’unità.Inoltre, preso un qualsiasi elemento a, tutti gli elementi del campo di ottengono come potenza di a.
Scomporre xn − 1 significa scrivere (x − α1) · · · (x − αn) avendo le soluzioni α1, . . . , αn di xn = 1. Ciòsembra contrapporsi alla presenza di polinomi irriducibili, secondo quanto visto sopra. L’“imbroglio” sta nelfatto che gli αi sono coefficienti in GF(pr), non in Zp.
Tuttavia, se abbiamo un polinomio ` e α è radice di `, allora anche αp1
, αp2
, . . . sono radici di `.Nel nostro campo di riferimento GF(8), se a è radice di x7 − 1, i due polinomi irriducibili sono proprio(x− a)(x− a2)(x− a4) = x3 + x+ 1 e (x− a3)(x− a6)(x− a5) = x3 + x2 + 1 (infatti 5 ≡7 12).
Prendiamo g(x) = x3 + x+ 1, le cui radici sono a, a2, a2 + a. Allora
c(x) ∈ C ∧ a radice di g ⇒ c(a) = 0⇒
⇒ c(a) =(1 a · · · an−1
)
c0c1...
cn−1
=
0 0 1 1 1 0 10 1 1 1 0 1 01 1 1 0 1 0 0
︸ ︷︷ ︸
H di Hamming
c0c1...
cn−1
.
31

Naturalmente vale anche c(a2) =(1 a2 · · · a2(n−1)
)
c0c1...
cn−1
. Se però uniamo le due matrici di
controllo otteniamo(
1 a · · · an−1
1 a2 · · · a2(n−1)
), che il primo tentativo di BCH. Come sappiamo, esso corregge
esattamente come quello singolo, proprio perché le radici “coniugate” non aumentano la capacità di corre-zione. Dunque possiamo arricchire g(x) = (x3 + x+ 1)(x3 + x2 + 1), ottenendo così la matrice di controllo(
1 a · · · an−1
1 a3 · · · a3(n−1)
), in grado di correggere 1 errore in più.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Teorema 2.39. Se g(x) ammette radici αb, αb+1, . . . , αb+δ−2︸ ︷︷ ︸δ − 1 radici consecutive
(dove α è un elemento del campo) allora con
H =
1 αb (αb)2 · · · (αb)n−1
1 αb+1 (αb+1)2 · · · (αb+1)n−1
......
.... . .
...1 αb+δ−2 (αb+δ−2)2 · · · (αb+δ−2)n−1
il codice ha dmin ≥ δ.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.40. Rivediamo alcuni codici alla luce del teorema appena enunciato:
• g(x) = x3 +x+ 1 ha radici a, a2, a4, di cui solo le prime 2 consecutive, per cui il codice avrà dmin ≥ 3.Noi sappiamo che questo codice è Hamming e possiamo notare a posteriori che 1 delle 2 righe generateè ridondante.
• g(x) = (x3 + x + 1)(x3 + x2 + 1) ha radici a, a2, a3, a4, a5, a6, per cui il codice avrà dmin ≥ 7. Noisappiamo che questo codice è BCH e possiamo notare a posteriori che 4 delle 6 righe generate sonoridondanti.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Per quanto riguarda i tassi, λ ≥ δn e R ≥ n−r(δ−1)
n . La prima ha un «≥» perché dmin ≥ δ, la secondaperché nella H potrebbero esserci righe superflue.
2.2.5 Codice di Reed-Solomon
Supponiamo di avere una matrice di controllo H =
1 α α2 · · ·1 α2 α4 · · ·1 α3 α6 · · ·...
......
. . .
1 αδ α2δ · · ·
con n = 2r − 1 colonne.
Si correggono δ2 errori e i tassi valgono R = (2r−1)−rδ
2r−1 e λ = δ+12r−1 . L’idea di Reed e Solomon fu quella
di prendere i coefficienti da GF(2t), invece che in Z2. Si ottiene così una matrice formata da t-ple di bits,quindi il numero di colonne effettivo diventa t(2r − 1). I tassi diventano R = ? e λ = ? da chiedere, percui anche se si va più veloce sembra che la capacità di correzione sia diminuita. In realtà questo codicecorregge non solo δ
2 errori lontani, ma anche t δ2 errori vicini, perché agisce all’interno del byte.Nel Reed-Solomon effettivo abbiamo n = 216 − 1 (∼ 64 k), δ = 512, t = 16, quindi corregge 256 errori
sparsi e 4096 errori contigui in 1 M.
2.3 Codici convolutiviImmaginiamo di avere un circuito sequenziale come quello in Figura 2.2. I «+» sono in Z2 e le lettere sono
registri che memorizzano i risultati precedenti. Ogni circuito introduce 3 parametri: numero di uscite «u»
32

x
c1
c2
A B
+
+
Figura 2.2: Esempio di circuito che descrive un codice convolutivo
(R = 1u ), numero di memorie «k» (influisce sulla difficoltà della decodifica) e collegamenti/forma (studiati
insieme per costruire un buon codice).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Esempio 2.41: Viterbi.
• Codifica – Sia ‹1011101› la stringa in ingresso.La stringa che esce sarà ‹11 01 00 10 01 10 00 | 01 11›.I bits dopo la barra verticale sono ottenuti in una fase finale di “svuotamento” dei registri, simulandol’ingresso di ulteriori k ‹0›. Ciò peggiora lievemente il tasso di trasmissione.
• Decodifica in assenza di errore – Si usa un automa a stati finiti con output, dotato di 2k stati (Fi-gura 2.3). Notiamo che questa particolare rete sequenziale ha la proprietà che le uscite da ciascunostato differiscono sempre di 2 bit. Per la decodifica si usa questo stesso automa scambiando l’inputcon l’output.
00
01 10
11
1/110/11
1/100/10
0/00
1/01
1/00
0/01
Figura 2.3: L’automa a stati finiti che corrisponde al circuito
Facendo un unfolding parziale dell’automa si ottiene un trellis («traliccio») di altezza 2k.
• Decodifica in presenza di errore – Costruiamo il trellis completo, di lunghezza proporzionale allalunghezza della stringa. Percorriamo ipoteticamente tutte le strade, segnando gli errori su ciascunastrada. Se un nodo è raggiungibile da più di una strada, il percorso a partire da esso terrà conto solodella strada col minimo numero di errori; se la strada con numero minimo di errori non è unica, se nesceglie una a caso.
• Capacità di correzione – Si considera un qualsiasi percorso chiuso del trellis. Se esso ha lunghezza ` ele due stringhe che individua hanno distanza d, diremo che la capacità di correzione è di
⌊d−1
2
⌋su `bit.
La capacità di correzione è dunque variabile in funzione della lunghezza del percorso considerato.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
33

3 Codici segreti[1]
3.1 Cifrario di Vigenère: decrittazione(Cifrari a sostituzione polialfabetica)
L’idea chiave per decrittare il cifrario di Vigenère è quella di trovare µ tale che tra il testo in cifra e sestesso traslato di µ ci sia il massimo numero di simboli coincidenti.
Sia «k» la cardinalità dell’alfabeto. Associato ad esso ci sarà una distribuzione di probabilitàP 0 := (p0, . . . , pk−1). Siano X,Y v.a. che rappresentano rispettivamente il simbolo in chiaro e quelloin cifra. Definiamo inoltre «P i» come P 0 spostato a destra ciclicamente di i passi. Allora, riassumendo,P(X = xi) = pi = P 0
i e P(Y = yi) = P δi , dove δ è la differenza tra yi e il simbolo in chiaro che l’ha generato.Se consideriamo Y ′ v.a. che indica il simbolo corrispondente a Y nel testo in cifra traslato di µ, abbiamo
P(Y = yi) = P δ1i e P(Y ′ = yi) = P δ2i per ogni i. Allora P(Y = Y ′) =k−1∑i=0
P δ1i Pδ2i = P δ1 · P δ2 . Poiché
P δ1 ·P δ2 = p0p|δ1−δ2|+ · · ·+pk−1p|δ1−δ2|+k−1, questo prodotto scalare dipende solo da |δ1−δ2|, il cui valoremassimo è per δ1 = δ2. Ciò succede quando allineo i due testi in cifra con un µ multiplo della lunghezzadella chiave.
3.2 Introduzione all’RSA
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Pseudocodice 3.1: Euclide. MCD(a, b), con a ≥ b:if (b = 0) then
return a;else
return MCD(b, a mod b);fi
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
L’algoritmo funziona perché c | a ∧ c | b⇔ c | b ∧ c | a mod b.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 3.2. Se MCD(a, b) esegue più di k ≥ 1 chiamate ricorsive, allora a ≥ Fk+1 e b ≥ Fk, con «Fi»i-esimo numero di Fibonacci.
Dimostrazione.
LBM k = 1⇒ b > 0 ∧ a ≥ b⇒ b ≥ 1 = F1 ∧ a ≥ 1 = F2.
LPM Per ipotesi induttiva vale b ≥ Fk ∧ a mod b ≥ Fk−1, da cui otteniamo banalmente b ≥ Fk. Poichéa = qb+ (a mod b), se valesse q ≥ 1 saremmo a posto perché a ≥ b+ (a mod b) ≥ Fk + Fk−1 = Fk+1;ma in effetti a ≥ b⇒ q ≥ 1.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
[1]Ecco i link ai PDF preparati dal docente:1. Storia e terminologia. Cifrari a sostituzione monoalfabetica. Cifrari omofonici e nomenclatori.
2. Cifrari polialfabetici: tecniche per scoprire lunghezza della chiave e chiave. Esempio pratico di cifrazione Vigenèree sua decrittazione.
3. Cifrari polialfabetici “algebrici”. One-time-pad: perfezione. Automazione della crittografia. Il rotore di Jefferson.Enigma: storia, funzionamento, debolezze.
4. Codici a trasposizione. Data Encryption Standard (DES): funzionamento e decrittazione.
5. Advanced Encryption Standard (AES).
6. Crittografia a chiave pubblica. Diffie e Hellman e il logaritmo finito. Diffie e Merkle e il cifrario del fusto. Il cifrarioRSA (Rivest Shamir Adlemann).
Quanto esposto in questa sezione comprende solo i contenuti non presenti nei PDF.
34

. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 3.3: Teorema di Lamé. Se a ≥ b ≥ 0 e b ≤ Fk allora MCD(a, b) impiega meno di k chiamatericorsive.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Poiché i numeri di Fibonacci crescono esponenzialmente, il numero di passi è dell’ordine log b, che èanche il numero di cifre b.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Pseudocodice 3.4: Euclide esteso. EE(a, b), con a ≥ b:if (b = 0) then
return (a, 1, 0);else
(d, x, y) := EE(b, a mod b);return (d, y, x - (a div b) * y);
fi
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
L’algoritmo di Euclide esteso (EE) permette di trovare i coefficienti d, x, y tali che ax + by = d == MCD(a, b). La sua complessità è la stessa di Euclide “semplice”.
Se siamo in Zb (b primo) e scegliamo a ∈ Zbr{0}, a e b sono sempre primi tra loro ed EE(a, b) = (1, x, y),con x inverso di a in Zb.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 3.5. ab ≡n ac ∧MCD(a, n) = 1⇒ b ≡n c.Dimostrazione. Per EE esistono x, y tali che ax+ ny = 1 ⇒ (ab− ac)x+ n(b− c)y = b− c quindi b− c èmultiplo di n perché ab− ac è multiplo di n.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Corollario 3.6. ab ≡n 0 ∧MCD(a, n) = 1⇒ b ≡n 0.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 3.7: Piccolo teorema di Fermat. Se p è primo e p - a allora ap−1 ≡p 1.
Dimostrazione. Sia S = Zp r {0}. Definiamo ψ(x) = ax mod p con x ∈ S e mostriamo che è una biiezione
ψ : S → S. Sicuramente ψ(x) ∈ Zp, ma se fosse ψ(x) = 0⇒ ax ≡p 0p-a⇒ x ≡p 0 con l’ipotesi che x ∈ S.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Corollario 3.8. In Zp (p primo) ogni elemento a non nullo è tale che ap−1 ≡p 1, ossia è radice primitivadell’unità.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Definizione 3.9. La funzione di Eulero è Φ(n) :=∣∣{x ∈ {1, . . . , n−1} : MCD(n, x) = 1
}∣∣, ossia restituisceil numero di numeri minori di n coprimi con n.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Calcolando Φ(n), se p è primo e p | n allora MCD(kp, n) 6= 1 per ogni k tale che kp < n. Dunque
Φ(n) = n∏
p primop|n
(1− 1
p
).
35

In particolare se p è primo Φ(p) = p−1. Inoltre se n = pq, con p, q primi, allora Φ(n) = pq(1− 1
p
)(1− 1
q
)=
= (p− 1)(q − 1) = Φ(p)Φ(q).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Teorema 3.10: Teorema di Eulero. MCD(a, n) = 1⇒ aΦ(n) ≡n 1.
Dimostrazione. Sia S ={x ∈ {1, . . . , n − 1} : MCD(n, x) = 1
}, per cui vale Φ(n) = |S|. Definiamo
ψ(x) = ax mod n e mostriamo che è una biiezione ψ : S → S. Sicuramente ψ(x) ∈ {0, . . . , n − 1}, ma
se fosse ψ(x) = 0 ⇒ ax ≡p 0p-a⇒ x ≡p 0 con l’ipotesi che x ∈ S. Poi MCD(a, x) = 1 (per ipotesi) e
MCD(x, n) = 1 (perché x ∈ S) implicano MCD(ax, n) = 1 ⇒ ax mod n ∈ S. Inoltre ax ≡n ay ⇒ x ≡n yquindi è iniettiva e dunque biiettiva.
Ciò premesso, scrivendo S = {x1, . . . , xΦ(n)}, possiamo scrivere
x1 · · ·xΦ(n) = ψ(x1) · · ·ψ(xΦ(n)) ≡n ax1 · · · axΦ(n) ≡n aΦ(n)x1 · · ·xΦ(n) ⇒ aΦ(n) ≡n 1 ,
poiché nell’ultimo passo dividiamo di volta in volta per x1, . . . , xΦ(n).. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Lemma 3.11. Se p e q sono primi diversi e a ≡p b ∧ a ≡q b allora a ≡pq b.Dimostrazione.
a ≡p b⇒ a− b = pha ≡q b⇒ a− b = qk
}⇒ ph = qk ⇒ h = qα ∧ k = pα⇒ a− b = pqα⇒ a ≡pq b .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
L’esponenziale finito consente di calcolare in maniera efficiente ba mod n. I passi sono i seguenti:
• Calcolo b20
, . . . , b2k
con k = blog2 ac. In questa fase i numeri crescono temporaneamente fino a (n−1)2,ma ne devo calcolare solo un numero logaritmico.
• Scrivo a in base 2, che posso denotare come (ck, . . . , c0).
• Calcolo ba =k∏i=0
cib2i
, facendo ogni moltiplicazione in modulo n.
Il numero di operazioni è dunque nell’ordine di log a. Al contrario, il calcolo del logaritmo finitologb a mod n è difficile (secondo le conoscenze attuali).
3.3 Complessità nell’ambito della crittografia[2]
Una MdT può servire per decidere o per calcolare una funzione. Ad esempio, a SAT è strettamenteassociato un problema funzionale FSAT, ossia trovare (se esiste) un assegnamento di verità. Se ho unalgoritmo per FSAT, allora lo posso usare anche per SAT, il che è banale.
Tuttavia se ho M che decide SAT, posso costruire M ′ per FSAT. Infatti sia ϕ una formula con variabilix1, . . . , xn. SeM(ϕ) = no allora subitoM ′(ϕ) = no. Altrimenti provoM
(ϕ[x1/0]
)e a seconda del risultato
scopro l’assegnamento per x1. Procedo quindi similmente per stabilire le altre variabili.
Secondo le conoscenze attuali, non è però sempre vero che il problema esistenziale risolve facilmentequello funzionale. Infatti nella coppia
• ¬PRIMES (esistenziale) – dato n, stabilire se esiste p primo tale che p | n;
• ONE-FACTOR (funzionale) – dato n, calcolare p primo (ma non necessariamente) tale che che p | n(se esiste);
[2]Questa sezione dà per noti i concetti di complessità ivi utilizzati.
36

la negazione del primo è in P, mentre non sappiamo dire nulla del secondo, che è alla base della crittografiaa chiave pubblica.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 3.12. La classe di complessità «FP» è definita come l’insieme delle funzioni f calcolate da unaMdT che opera in tempo polinomiale.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 3.13. Una relazione R ⊆ Σ∗ × Σ∗ si dice:
• polinomialmente decidibile se esiste una MdT deterministica che decide (x, y) ∈ R in tempopolinomiale;
• polinomialmente bilanciata se ∃h : ∀(x, y) ∈ R : |y| ≤ |x|h.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 3.14. Sia L ∈ Σ∗. L ∈ NP se e solo se esiste una relazione RL polinomialmente decidibile epolinomialmente bilanciata tale che L =
{x : ∃y : (x, y) ∈ RL
}.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
È proprio questo teorema che caratterizza NP come l’insieme dei problemi “guess-and-verify”, ossia chepossono essere verificati in tempo polinomiale conoscendo un assegnamento.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 3.15. La classe di complessità «FNP» viene definita come l’insieme dei problemi formulati nelseguente modo:Sia L ∈ NP. Dato x ∈ Σ∗ trovare y ∈ Σ∗ tale che (x, y) ∈ RL se x ∈ L, altrimenti rispondere negativamente.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Notiamo che FP non è altro che la restrizione di FNP per problemi in P . Inoltre si ottiene facilmenteche FP = FNP⇔ P = NP.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 3.16. Una funzione f si dice one-way (ossia monodirezionale) se:
0. f è iniettiva;
1. ∃k : ∀x ∈ Σ∗ : k√|x| ≤
∣∣f(x)∣∣ ≤ |x|k;
2. f ∈ FP;
3. f−1 /∈ FP (con f−1 definita laddove possibile).
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Osserviamo che una conseguenza della definizione è che se f è one-way allora f−1 ∈ FNP. Inoltre non èdetto che esistano funzioni one-way, infatti possiamo solo presumere che il logaritmo finito e ONE-FACTORnon siano in FP. Più precisamente vale che esistono funzioni one-way solo se P 6= NP.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Definizione 3.17. La classe di complessità UP (la «U» sta per «unambiguous») è definita come l’insiemedei linguaggi L decisi da una ND-MdT che opera in tempo polinomiale e tale che per ogni x ∈ L esisteun’unica computazione accettante.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
Chiaramente UP ⊆ NP, ma si sospetta che l’inclusione sia stretta. Inoltre P ⊆ UP, infatti in una MdTdeterministica c’è al più una computazione.. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .Teorema 3.18. UP = P se e solo se non ci sono funzioni one-way.
Dimostrazione. Per la dimostrazione consideriamo la formulazione equivalente: esiste una funzione one-wayse e solo se UP 6= P.
37

L⇒M Sia f una funzione one-way e sia k il grado del polinomio che collega la dimensione dell’input con quelladell’output. Consideriamo una relazione d’ordine tra stringhe x ≺ y ⇔ |x| < |y| ∨
(|x| = |y| ∧ x <lex y
).
Sia Lf ={
(x, y) : ∃z � x : f(z) = y}.
Se voglio risolvere (x, y) ∈ Lf genero nondeterministicamente tutte le z � x, escludendo eventualmentequelle che non rispettano i vincoli di lunghezza. Tra le z rimaste lancio f (che è polinomiale), ottenendoal più un valore uguale a y, perché f è iniettiva. Allora Lf ∈ UP.Supponiamo per assurdo che Lf ∈ P. Allora esiste una MdT deterministicaM che decide Lf in tempopolinomiale, che possiamo usare per calcolare f−1. Se abbiamo f−1(y) lancio M(‹1 · · · 1›︸ ︷︷ ︸
|y|k, y) cercando
l’eventuale soluzione per bisezione. Ma allora col fatto che f−1 non sia polinomiale.
L⇐M Sia L ∈ UP r P e sia M la ND-MdT (che per semplicità supporremo a un nastro) che lo decide.Chiamiamo stringhe di tipo ¬ quelle che descrivono una computazione accettante di M per unaqualche stringa y e di tipo tutte le altre.
Allora definiamo fM (x) =
{(1, y) se x è di tipo ¬
(0, x) se x è di tipo e procediamo con il controllo dei punti della
Definizione 3.16:
0. Date due stringhe x1, x2 distinte: se sono di tipo diverso allora le rispettive fM hanno prefissodiverso; se sono entrambe di tipo differiscono nel suffisso; se infine sono entrambe di tipo ¬,la y a cui si riferiscono è necessariamente diversa per l’unicità della computazione accettante.
1. |fM (x)| < |x| per le stringhe di tipo ¬ e |fM (x)| = c + |x| per quelle di tipo . Dopo qualchecalcolo di ottiene anche che |fM (x)| ≥ k
√|x|.
2. Posso determinare il tipo di x e costruire l’output in tempo polinomiale.
3. Supponiamo di voler calcolare f−1(z). Se z è nella forma «(0, z)» basta restituire z. Altrimenti seè «(1, y)» devo restituire la descrizione dell’unica computazione accettante per y conM . Tuttaviain tal caso M opererebbe in tempo polinomiale, con l’ipotesi iniziale.
Abbiamo dunque trovato una funzione one-way.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 0
38





























