Embed Size (px)
Citation preview

Aprendizado de Máquina para o Processamento de Língua Natural
Arnaldo Candido JuniorArnaldo Candido JuniorCarolina Evaristo ScartonLianet Sepúlveda Torres

Roteiro
� Parte 1: conceitos e exemplos
� Parte 2: processando traços
� Parte 3: geração e avaliação de classificadores
� Parte 4: mão na massa usando o Weka

Roteiro da parte 1: conceitos
� O que é aprendizado de máquina
� Tipos de aprendizado de máquina
� Interpretação gráfica
� Lidando com erros
� Exemplos de traços

Introdução
� Desde quando os computadores foram inicialmente pensados, pergunta-se se eles seriam capaz de aprender
� Seu poder de automatizar diversas tarefas aumentaria
� Apoiariam os humanos a entender tarefas que ainda não foram bem compreendidas
Conceitos Aprendizado de máquina

O que é aprendizado de máquina?
Um programa aprende uma tarefa se seudesempenho avaliado por uma dadamétrica aumenta com a experiência, ouseja, se toma decisões melhoresbaseadas na solução dos problemasanteriores
Conceitos Aprendizado de máquina
anteriores
(Mitchell, 1997)

Usos de aprendizado de máquina
� Dirigir automóveis e veículos não tripuladosDirigir automóveis e veículos não tripulados
� Diagnosticar pacientes com base em seus sintomas
� Detectar fraudes no uso de cartão de crédito
� Identificar estruturas de proteínas
PLN (nosso foco)� PLN (nosso foco)
� E muitos outros
Conceitos Aprendizado de máquina

Tipos de aprendizado de máquina
� Dedução: esses grãos são daquele saco e todos os grãos daquele saco são brancosdaquele saco são brancos
� Logo, esses grãos são brancos
� Indução: Esses grãos são brancos e são daquele saco
� Logo, todos os grãos daquele saco são brancos
� Abdução: Esses grãos são brancos e todos os grãos daquele saco são brancos.
� Logo: esses grãos são daquele saco
Conceitos Aprendizado de máquina
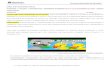
Aprendizado de máquina indutivo
AprendizadoAprendizadoIndutivo
AprendizadoSupervisionado
Aprendizadonão supervisionado
Aprendizadopor reforço
(*) foco deste tutorial
Conceitos Aprendizado de máquina indutivo
Classificação* Regressão

Tipos de aprendizado indutivo
� Aprender é: generalizar
� Supervisionado: um “professor” guia o aprendizado (ex.: detectar spam em e-mails)
� Não supervisionado: não há interferência humana (ex.: recomendar livros que um leitor poderia gostar com base nos livros que comprou)nos livros que comprou)
� Por reforço: um “crítico” diz se o resultado ficou bom ou não, mas não diz como melhorá-lo (ex. jogo de gamão)
Conceitos Aprendizado de máquina indutivo

Aprendizado Supervisionado: a classificação
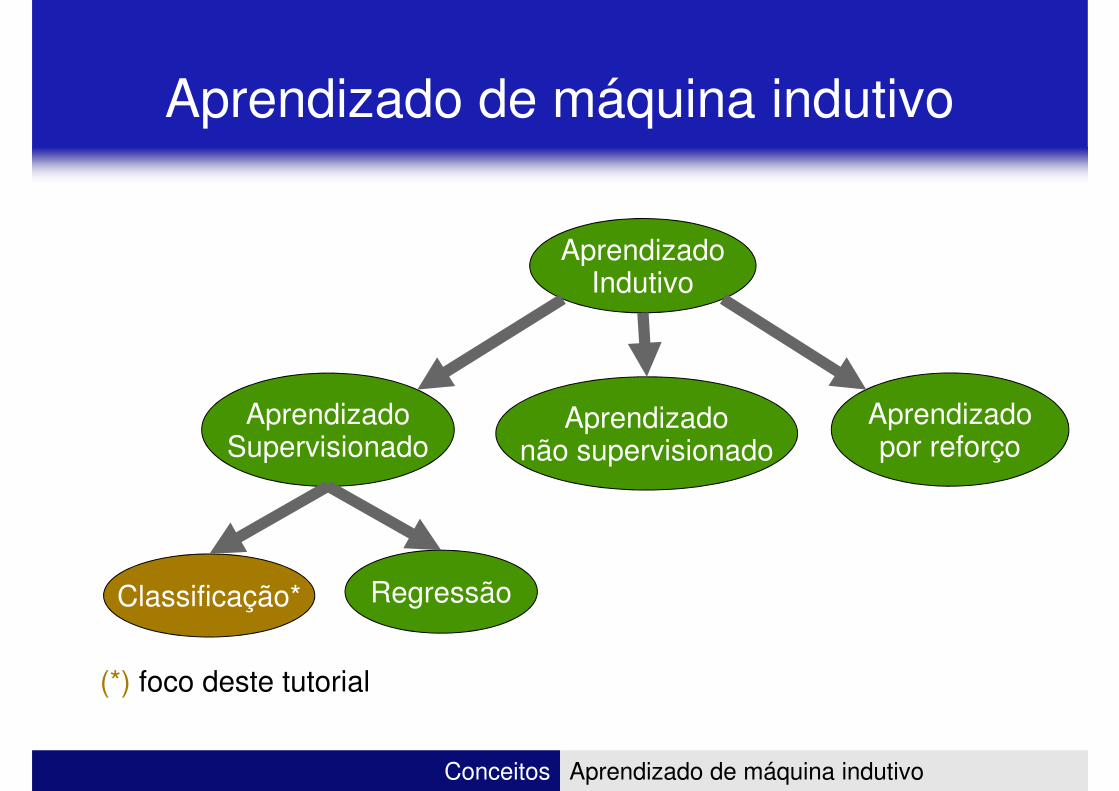
� Exemplo: dizer se um atleta olímpico é halterofilista ou jogador de basquete olhando apenas sua altura e peso
� A máquina deve aprender a predizer um conjunto de classes a partir de uma série de traços (também chamados de atributos)(também chamados de atributos)
� Vamos separar o período de aquisição de experiência (treinamento) do uso do conhecimento apreendido (classificação)
Conceitos Aprendizado de máquina indutivo

Quando usar aprendizado de máquina
� Em situações em que o erro é aceitável� Em situações em que o erro é aceitável
� Subestimando o aprendizado de máquina:
� Deixamos de lado uma ferramenta potencialmente útil para nossa pesquisa
Conceitos Aprendizado de máquina indutivo
� Superestimando o aprendizado de máquina:
� Criaremos sistemas com desempenho muito abaixo do desejado
Exemplo: esporte de atletas olímpicos
Dados reais de atletas de Basquete e Levantamento de peso das seleções masculinas que disputaram as Olimpíadas de Londres em 2012
40
60
80
100
120
140
160
180
Pe
so
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
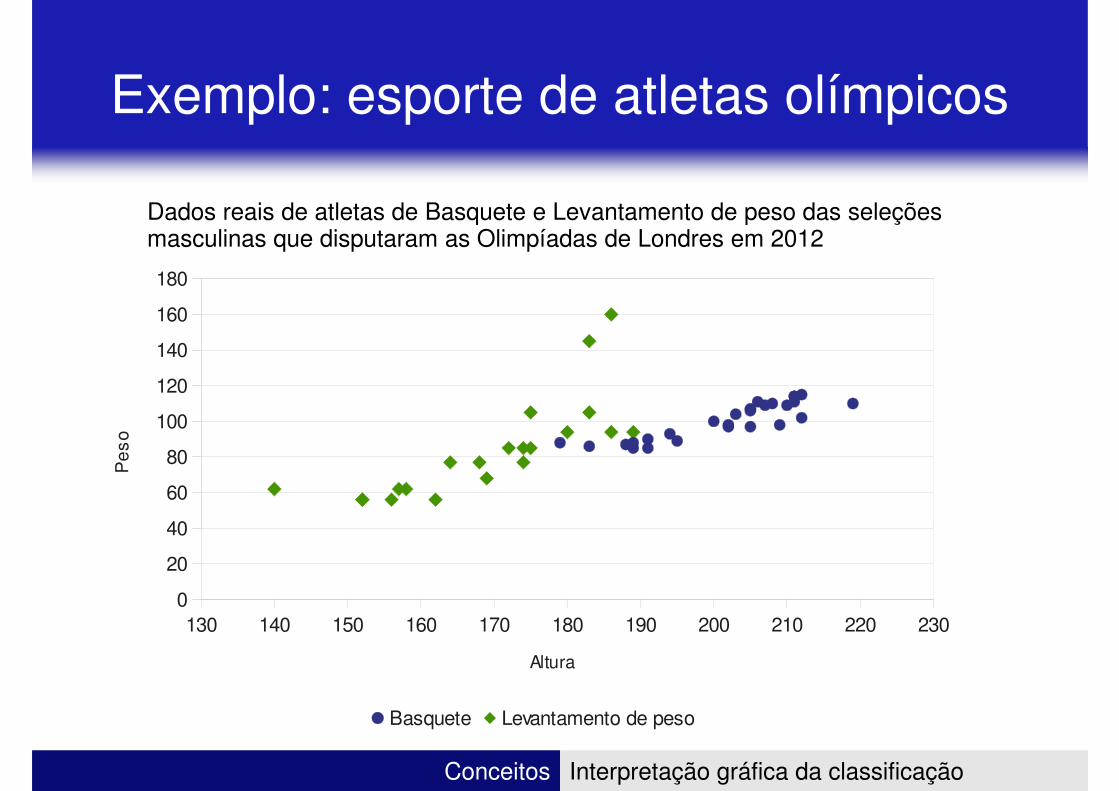
Traços
2 traços
40
60
80
100
120
140
160
180
Pe
so
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
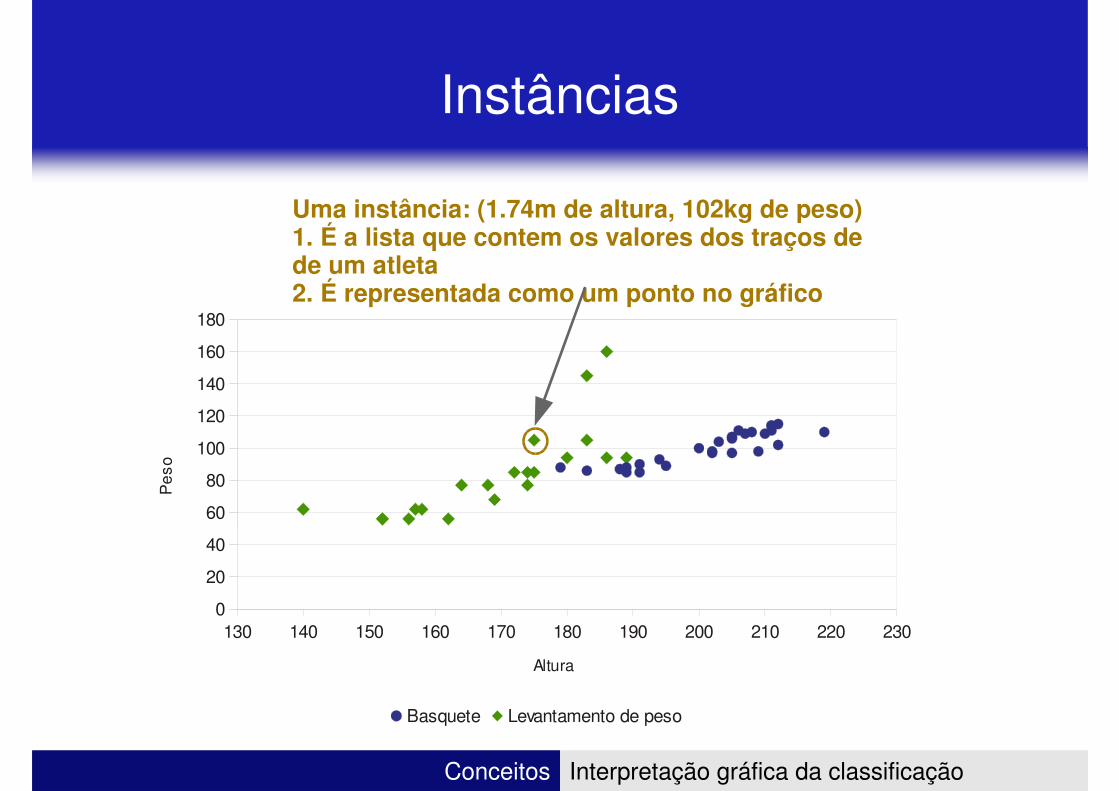
Instâncias
Uma instância: (1.74m de altura, 102kg de peso)1. É a lista que contem os valores dos traços de de um atleta
60
80
100
120
140
160
180
Pe
s o
de um atleta2. É representada como um ponto no gráfico
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
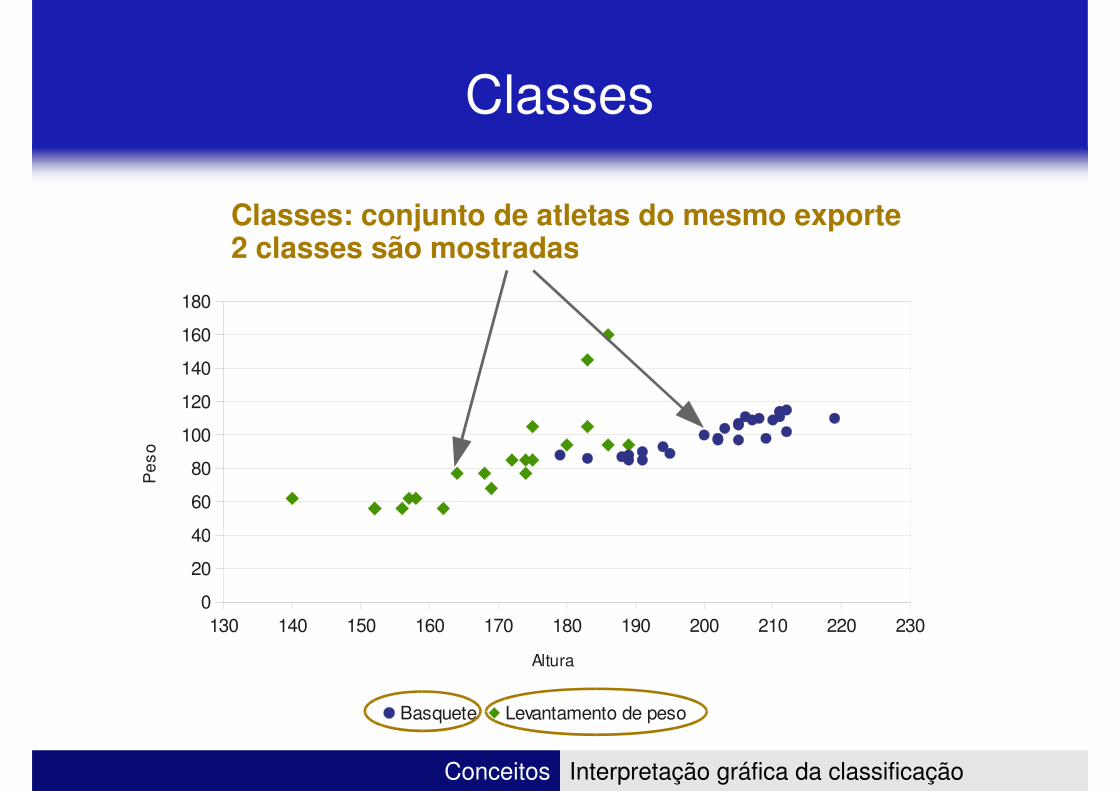
Classes
Classes: conjunto de atletas do mesmo exporte2 classes são mostradas
40
60
80
100
120
140
160
180
Pe
so
2 classes são mostradas
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
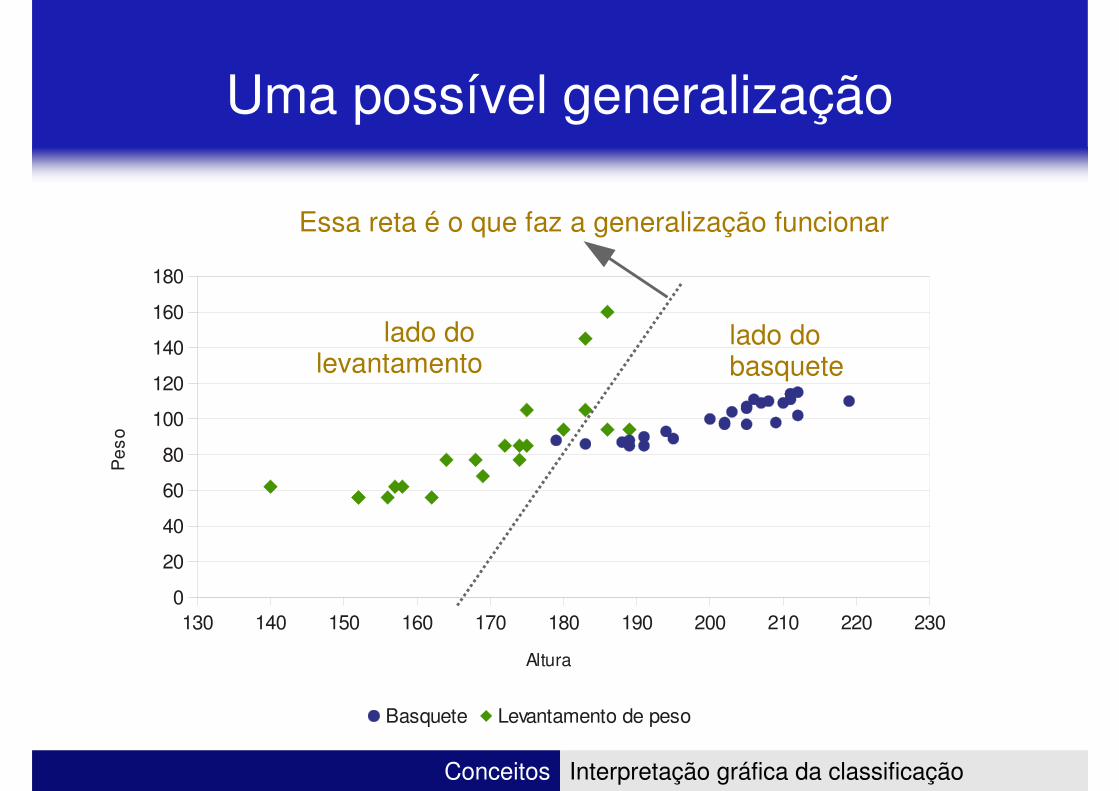
Uma possível generalização
Essa reta é o que faz a generalização funcionar
40
60
80
100
120
140
160
180
Pe
so
lado do levantamento
lado dobasquete
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
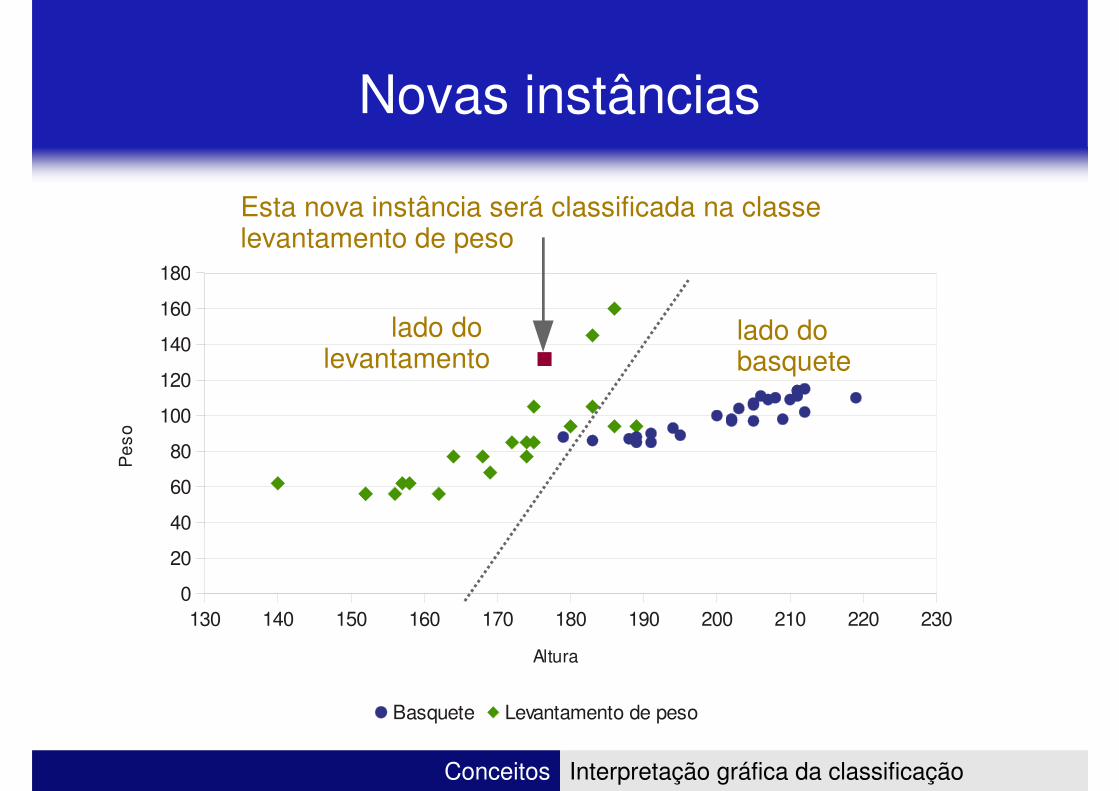
Novas instâncias
180
Esta nova instância será classificada na classe levantamento de peso
40
60
80
100
120
140
160
180
Pe
so
lado do levantamento
lado dobasquete
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
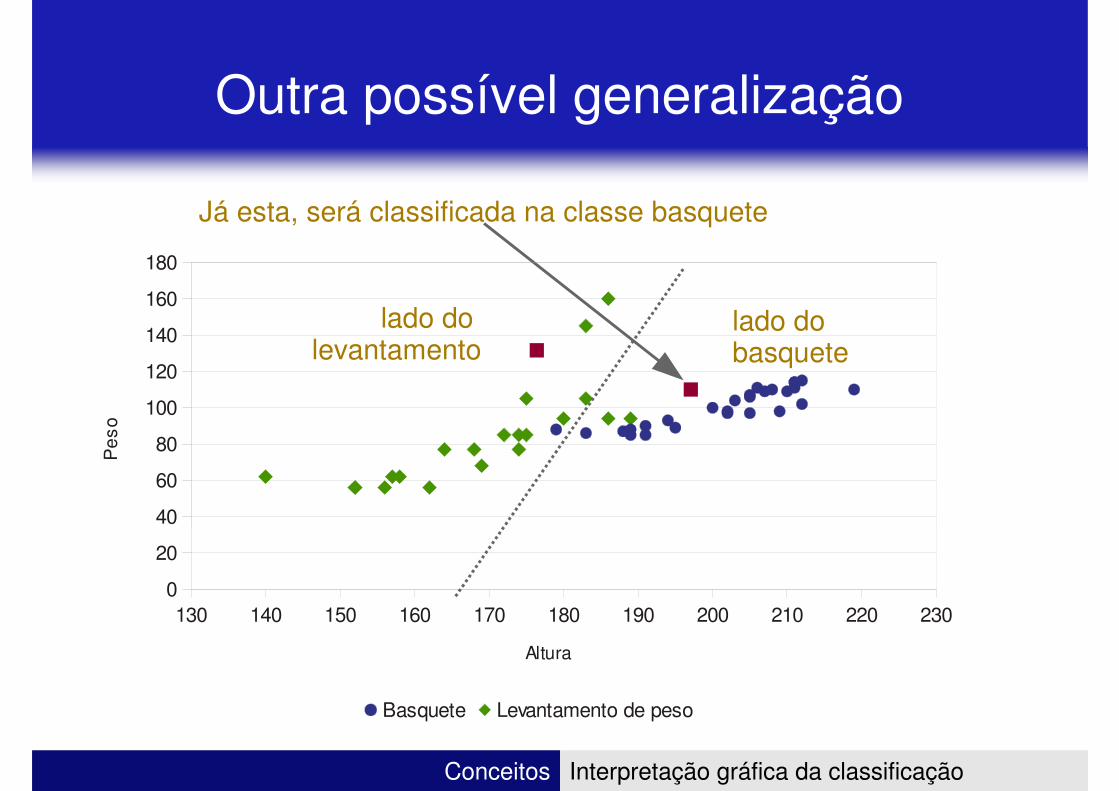
Outra possível generalização
180
Já esta, será classificada na classe basquete
40
60
80
100
120
140
160
180
Pe
so
lado do levantamento
lado dobasquete
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
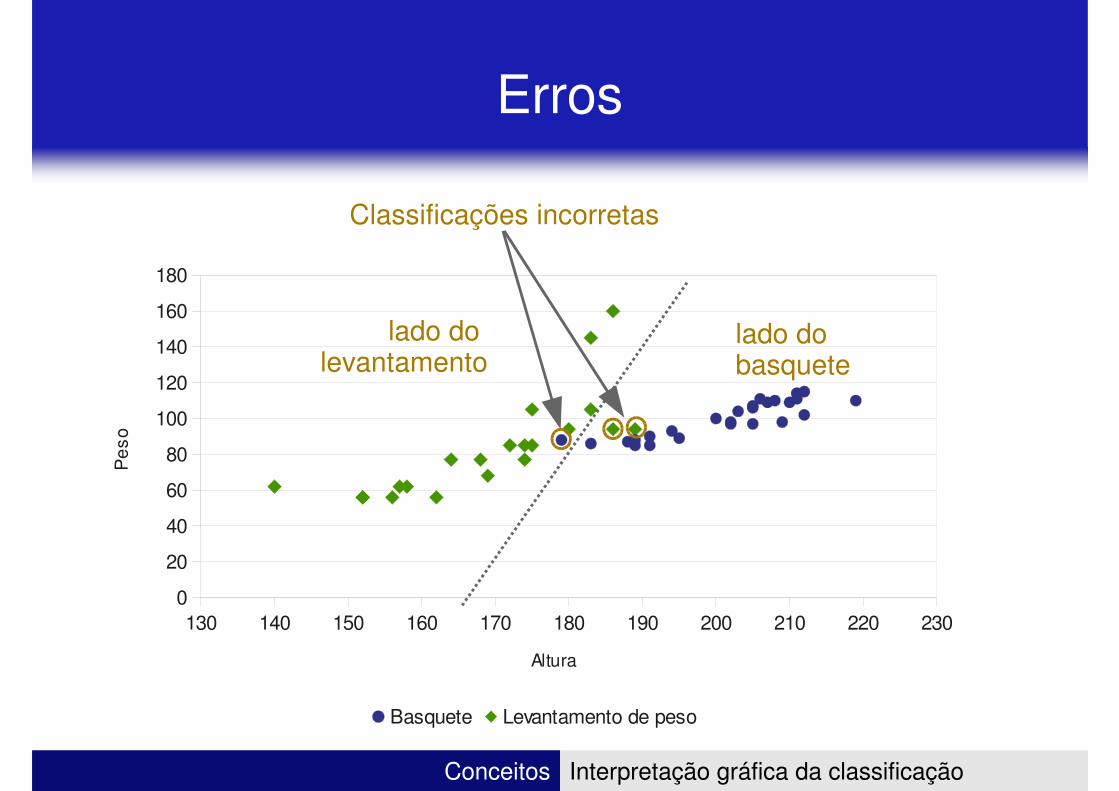
Erros
Classificações incorretas
40
60
80
100
120
140
160
180
Pe
so
lado do levantamento
lado dobasquete
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
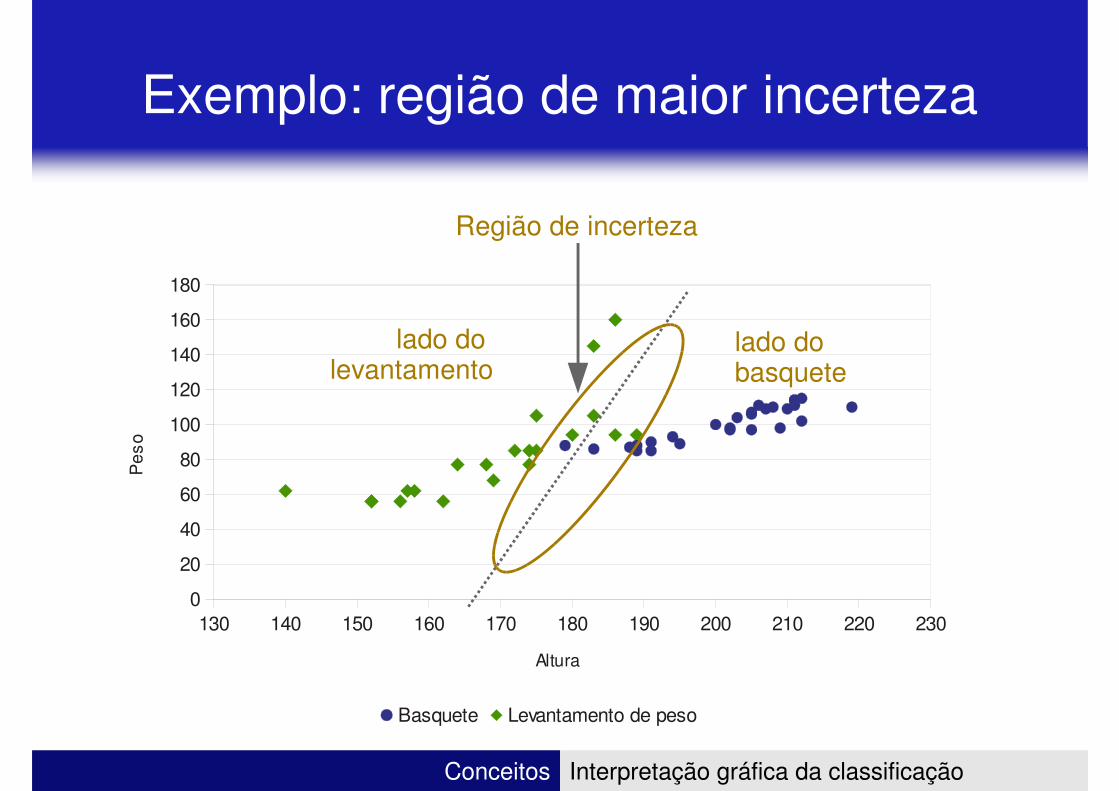
Exemplo: região de maior incerteza
Região de incerteza
40
60
80
100
120
140
160
180
Pe s
o
lado do levantamento
lado dobasquete
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
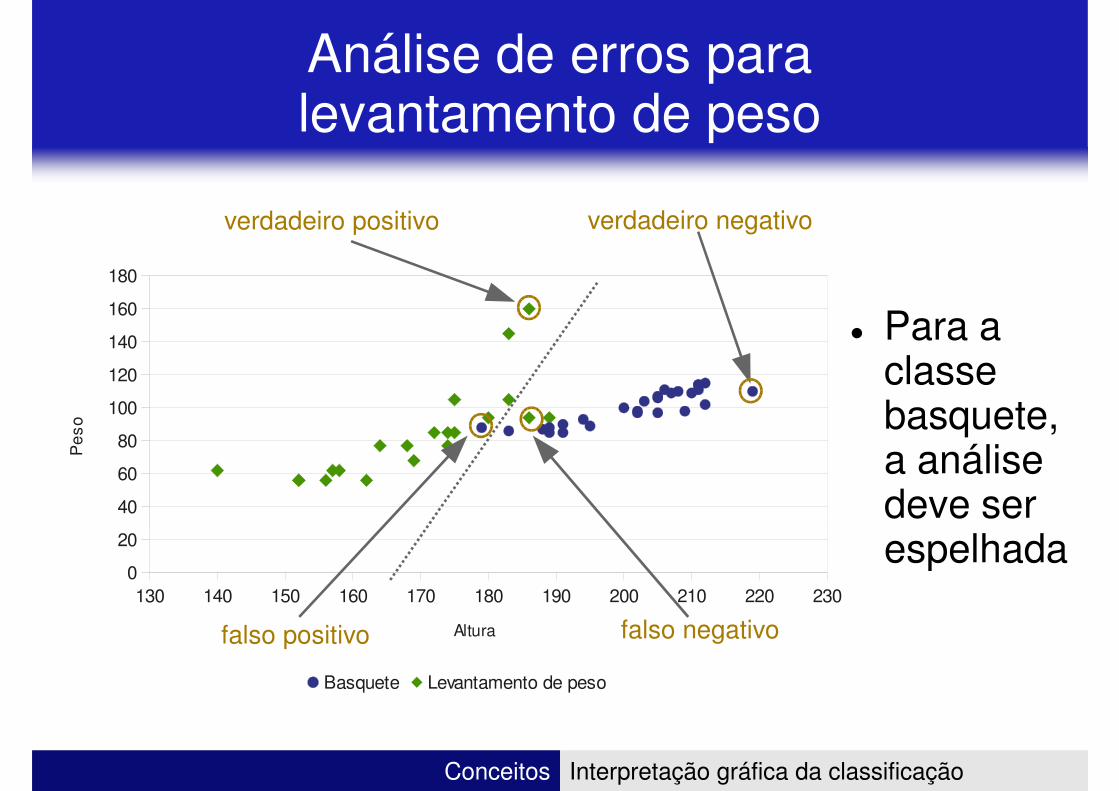
Análise de erros para levantamento de peso
verdadeiro negativoverdadeiro positivo
40
60
80
100
120
140
160
180
Pe
so
� Para a classe basquete, a análise deve ser espelhada
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
Basquete Levantamento de peso
Altura falso negativofalso positivo
espelhada
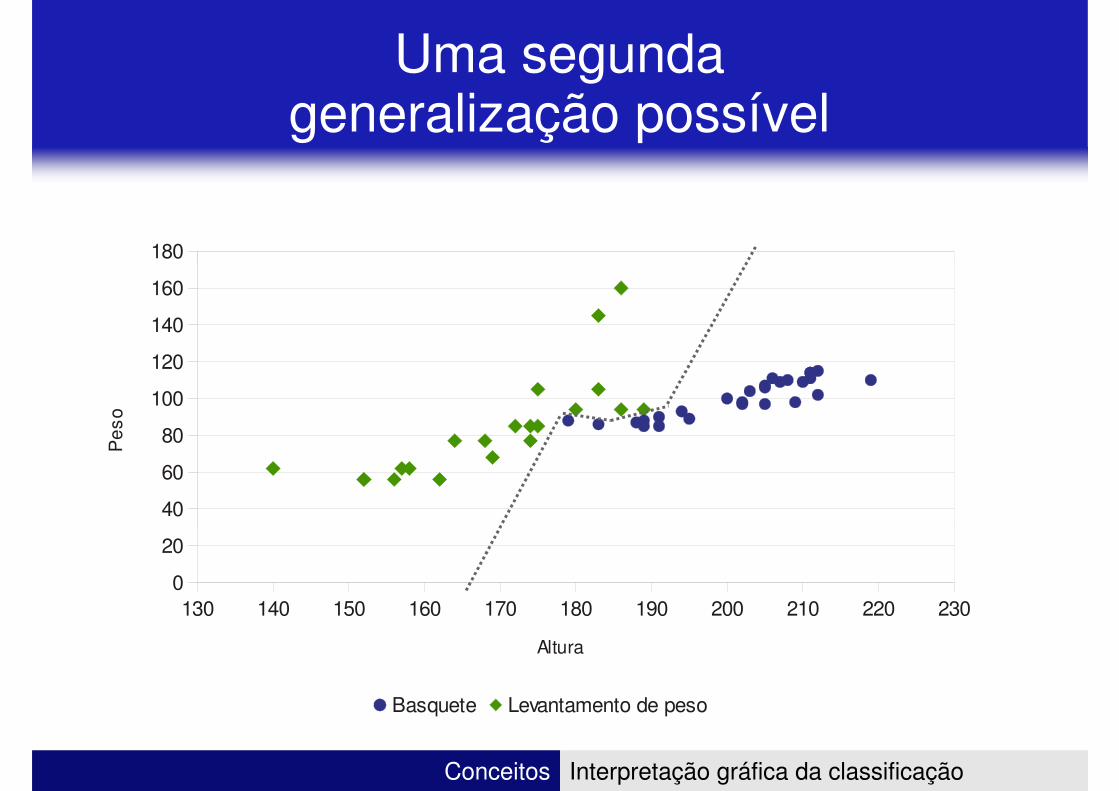
Uma segunda generalização possível
180
40
60
80
100
120
140
160
Pe
so
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
Basquete Levantamento de peso
Altura
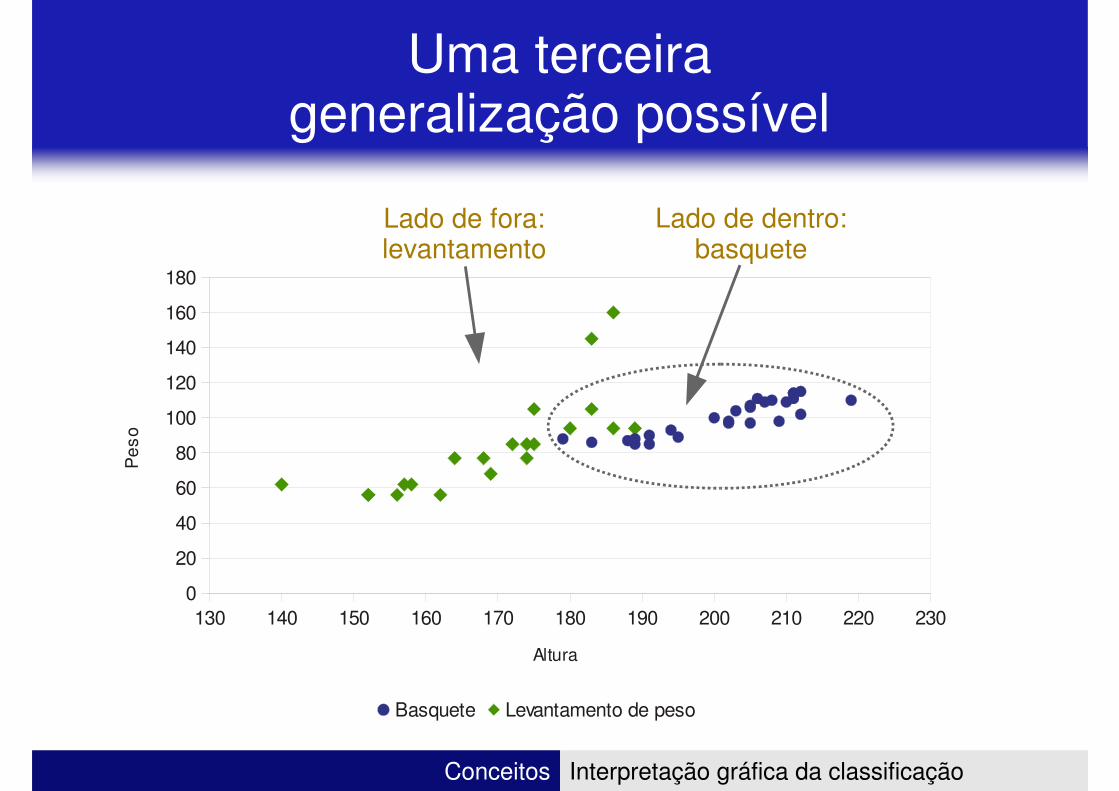
Uma terceira generalização possível
Lado de dentro:basquete
Lado de fora:levantamento
40
60
80
100
120
140
160
180
Pe
so
basquetelevantamento
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Levantamento de peso
Altura
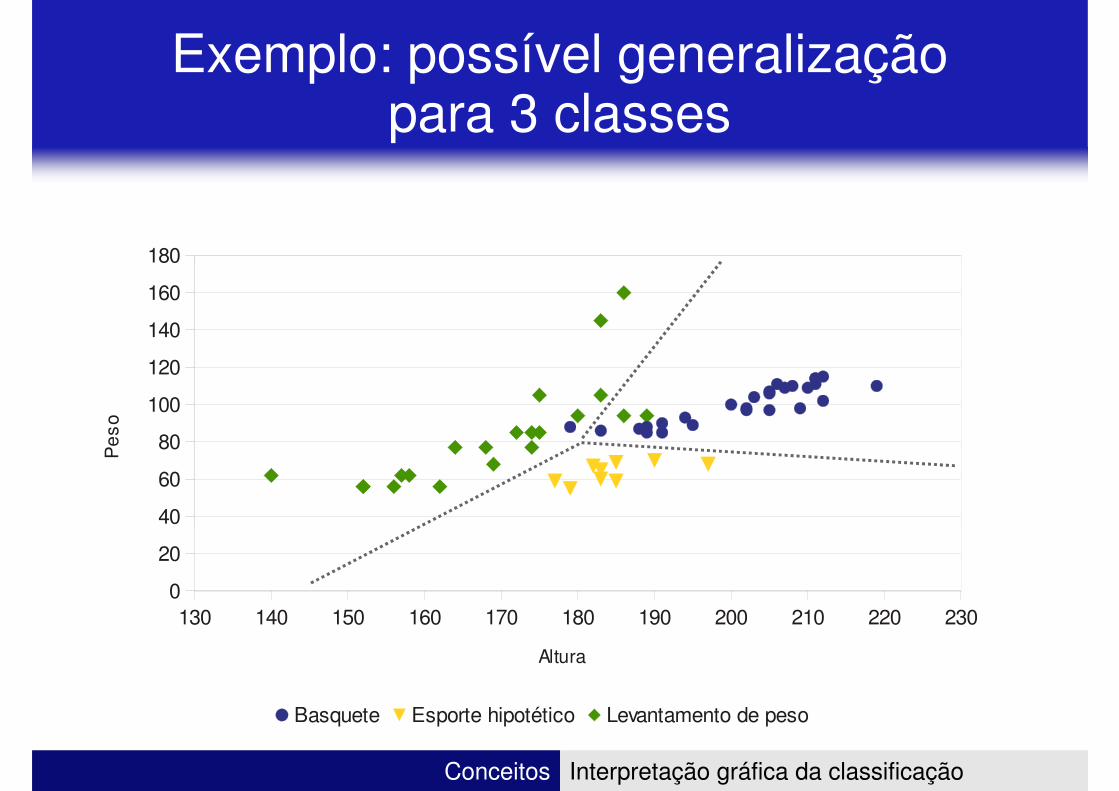
Exemplo: possível generalização para 3 classes
180
40
60
80
100
120
140
160
180
Pe
so
Conceitos Interpretação gráfica da classificação
130 140 150 160 170 180 190 200 210 220 2300
20
40
Basquete Esporte hipotético Levantamento de peso
Altura

Interpretação gráfica no Aprendizado Indutivo
� Para que serve a interpretação gráfica?� Para que serve a interpretação gráfica?
� Ter uma ideia de como os algoritmos trabalham por dentro, suas capacidades e suas limitações
� Ter pistas de como decidir melhor os traços
� É necessário conhecê-la?
Não, podemos usar o aprendizado de máquina
Conceitos Interpretação gráfica da classificação
� Não, podemos usar o aprendizado de máquina bem mesmo mesmo sem saber o que os algoritmos estão fazendo por trás

Interpretação gráfica no Aprendizado Indutivo
� Como fica a interpretação para três traços?� Como fica a interpretação para três traços?
� Ao invés de um gráfico plano, temos um gráfico tridimensional.
� E para quatro ou mais traços?
� Não podemos visualizar, mas importante é que a máquina “pode”
Conceitos Interpretação gráfica da classificação
a máquina “pode”
� Ela manipula as dimensões superiores por meio de equações matemáticas
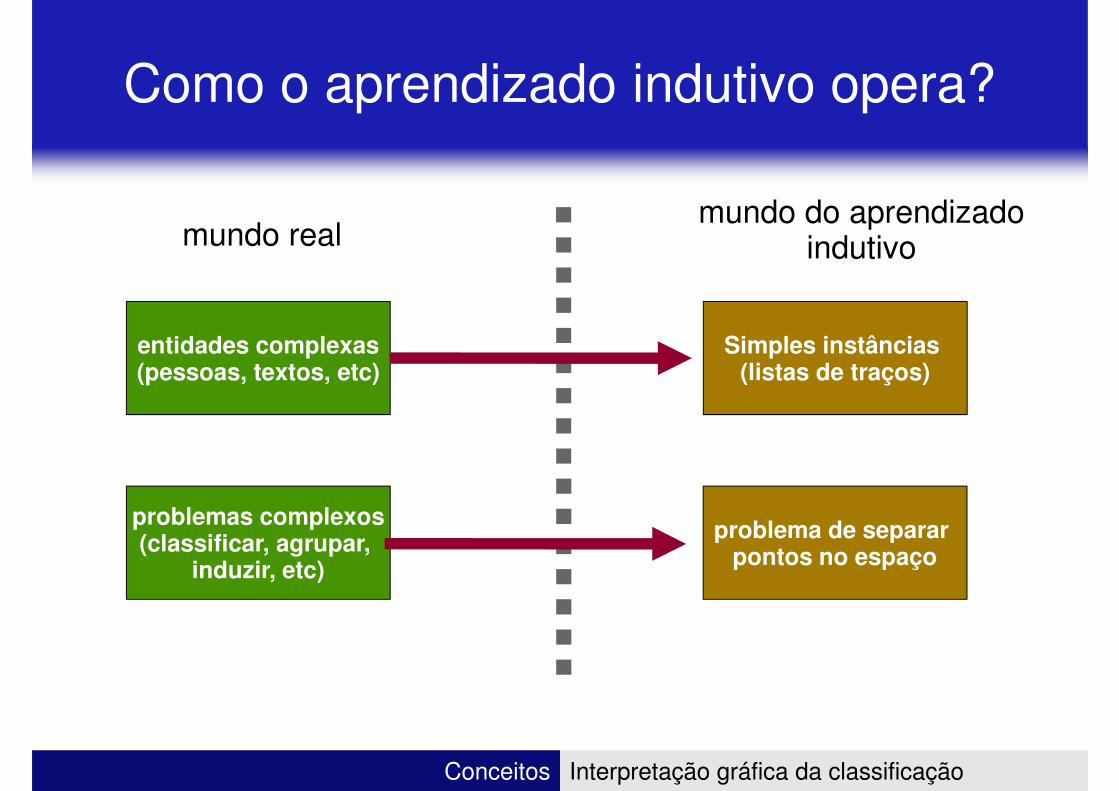
Como o aprendizado indutivo opera?
mundo realmundo do aprendizado
indutivo
entidades complexas(pessoas, textos, etc)
problemas complexos
indutivo
Simples instâncias (listas de traços)
problema de separar
Conceitos Interpretação gráfica da classificação
problemas complexos(classificar, agrupar,
induzir, etc)
problema de separar pontos no espaço

Pontos Chaves da Interpretação Gráfica
� Problema a ser resolvido: separar pontos no � Problema a ser resolvido: separar pontos no gráfico (versão muito simplificada de problemas do mundo real)
� Bons traços agrupam melhor os pontos da mesma classe
� Algoritmos fazem separações de forma diferente
Conceitos Interpretação gráfica da classificação
� Algoritmos fazem separações de forma diferente (o melhor varia de acordo com problema a ser resolvido)

Erros no aprendizado de máquina
� Suscetível a erros por natureza: � Suscetível a erros por natureza:
� Novos dados podem ser muito diferentes dos dados de treinamento
� Dois atletas de esportes diferentes podem ter mesmo peso e altura!
� Problemas bem comportados (100% de acerto)
Conceitos Erros
� Problemas bem comportados (100% de acerto) já foram resolvidos de outras formas
� Usa-se quando erros são toleráveis (ex: tradução de máquina pode vir com muitos erros)

Minimizando erros
� Bons traços: fundamental para obter-se boas � Bons traços: fundamental para obter-se boas generalizações
� Bons algoritmos: adequados ao domínio em questão
� Bons parâmetros (se aplicável): determinados algoritmos funcionam melhor quando calibrados
Conceitos Erros
algoritmos funcionam melhor quando calibrados
� Boas generalizações (tarefa do algoritmo): ele tentara escolher estatisticamente uma entre várias possíveis generalizações

Exemplo: jogar tênis
Dia Tempo Temperatura Umidade Vento Jogar tênis?
traços
Dia Tempo Temperatura Umidade Vento Jogar tênis?
1 Sol Quente Alta Fraco Não
2 Sol Quente Alta Forte Não
3 Nublado Quente Alta Fraco Sim
4 Chuva Média Alta Fraco Sim
5 Chuva Frio Normal Fraco Sim
6 Chuva Frio Normal Forte Não
classes
instância
Conceitos Exemplos gerais
7 Nublado Frio Normal Forte Sim
8 Sol Mediana Alta Fraco Não
9 Sol Frio Normal Fraco Sim
10 Chuva Média Normal Fraco Sim
11 Sol Média Normal Forte Sim
instância
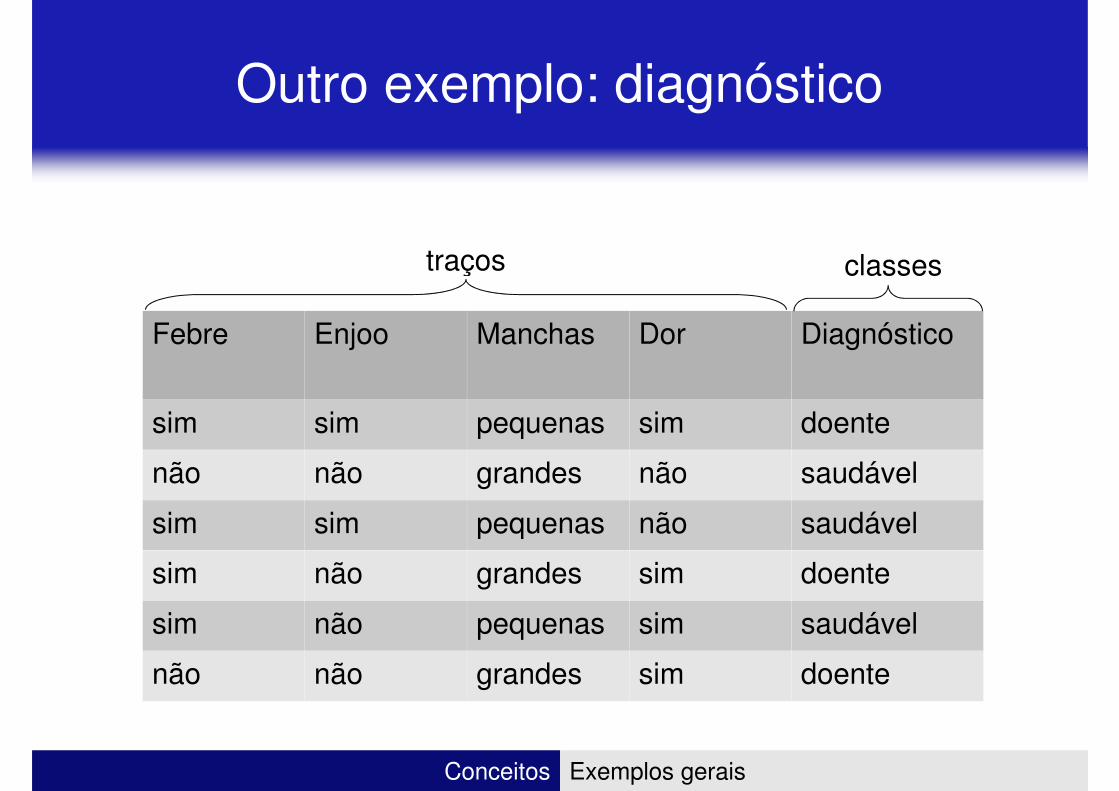
Outro exemplo: diagnóstico
traços classes
Febre Enjoo Manchas Dor Diagnóstico
sim sim pequenas sim doente
não não grandes não saudável
sim sim pequenas não saudável
traços classes
Conceitos Exemplos gerais
sim sim pequenas não saudável
sim não grandes sim doente
sim não pequenas sim saudável
não não grandes sim doente

Traços influenciam os possíveis agrupamentos (2)
Conceitos Exemplos gerais
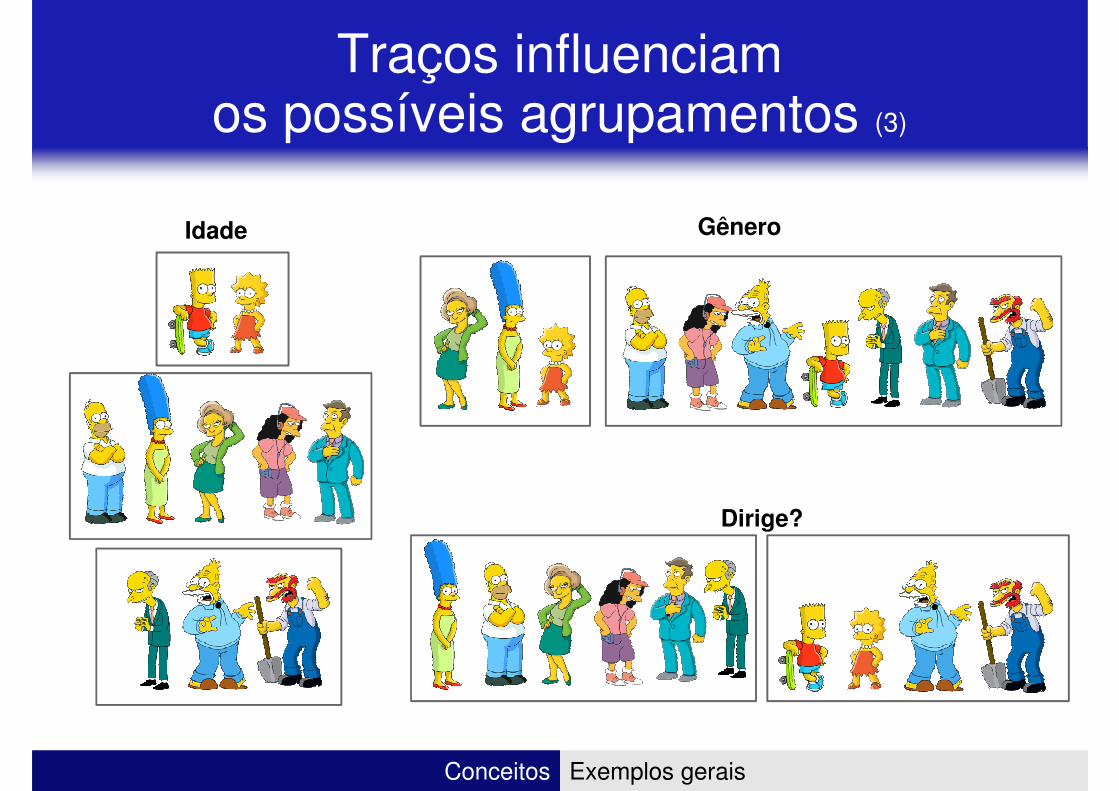
Traços influenciam os possíveis agrupamentos (3)
Idade Gênero
Dirige?
Conceitos Exemplos gerais
Dirige?
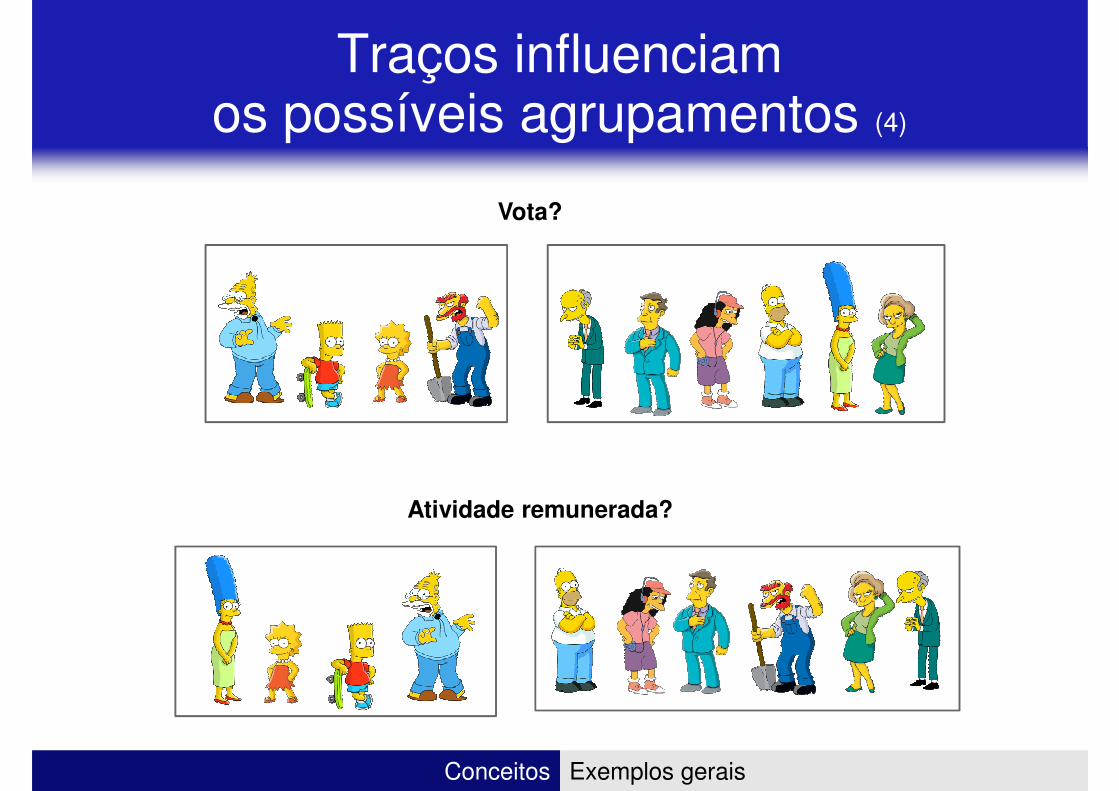
Traços influenciam os possíveis agrupamentos (4)
Vota?
Atividade remunerada?
Conceitos Exemplos gerais

Instâncias no PLN
� As instâncias variam de acordo com a tarefa, � As instâncias variam de acordo com a tarefa, comumente são extraídas:
� Fragmentos de áudio (ex. reconhecimento de fala)
� Orações (ex.: mineração de sentimentos)
� Textos (ex.: identificar domínio, autor, gênero, etc)
� Pares de orações (reconhecimento de paráfrases)
Conceitos Exemplos PLN
� Pares de orações (reconhecimento de paráfrases) ou de textos (alinhamento automático)
� Nesse caso um par vira uma única instância� Entre outros

Traços por nível linguístico
� Baseados nas contagens de palavras� Baseados nas contagens de palavras
� Traço: similaridade entre um par de orações
� Mais 80% de palavras em comum → indicativo de paráfrases
� Baseados nas palavras individuais
Traço: presença da palavra “péssimo” em uma
Conceitos Exemplos PLN
� Traço: presença da palavra “péssimo” em uma oração
� É um indicativo do sentimento negativo do autor

Traços por nível linguístico (2)
� Baseados em sintaxe� Baseados em sintaxe
� Traço: orações na voz passiva em um texto
� Mais de 20% → indicativo de que o texto é complexo (ex.: para portadores de afasia)
� Baseados em semântica
Traço: o sujeito da uma oração é um hiperônimo
Conceitos Exemplos PLN
� Traço: o sujeito da uma oração é um hiperônimo de sua oração predecessora?
� Indicativo que encontramos um fragmento de cadeia de correferência

Traços por nível linguístico (3)
� Estado da arte� Estado da arte
� Traços léxicos predominam
� Traços sintáticos, semânticos e retóricos começarem a se popularizar
� Não sempre a extração pode ser automatizada (principalmente para o Português)
Conceitos Exemplos PLN
� Extração manual é cara � Sem extração automática, cenários de uso são
mais restritos

Traços por nível linguístico (4)
� Linguísticas conhecem a língua profundamente, � Linguísticas conhecem a língua profundamente, mas possuem pouca experiência propondo traços
� “Computeiros” possuem boa experiência com traços, mas não conhecem a língua profundamente
� Pesquisadores podem melhorar sua capacidade
Conceitos Exemplos PLN
� Pesquisadores podem melhorar sua capacidade de propor traços com a experiência e acompanhando as pesquisas relacionadas à sua pesquisa
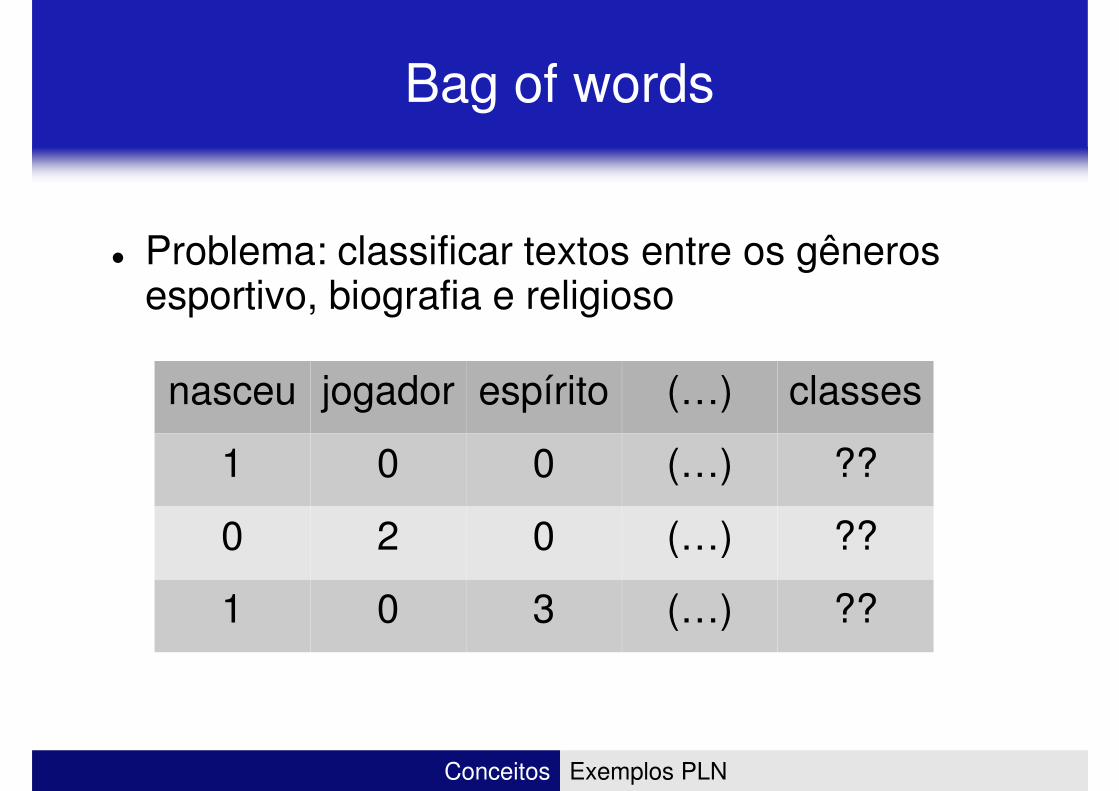
Bag of words
� Problema: classificar textos entre os gêneros � Problema: classificar textos entre os gêneros esportivo, biografia e religioso
nasceu jogador espírito (…) classes
1 0 0 (…) ??
0 2 0 (…) ??
Conceitos Exemplos PLN
0 2 0 (…) ??
1 0 3 (…) ??

Bag of words (2)
� Palavras viram traços
� O número de traços pode ser elevado
� A ordem das palavras não é considerada
� É uma boa ideia remover stopwords (preposições, artigos, entre outras palavras) para facilitar a vida
Seleção de dados Classificação de textos por gênero
artigos, entre outras palavras) para facilitar a vida dos algoritmos

Bag of words (3)
� Variações� Variações
� Usando número de palavras (inteiro) ou presença ausência de palavras (booleano)
� Usando lemas a variação linguística devido a flexões (lematização)
� Usando radicais para remover diferentes variações
Seleção de dados Classificação de textos por gênero
� Usando radicais para remover diferentes variações linguísticas (stemming)

Traços por aplicação de PLN
� Análise de classes gramaticais (Part of Speech � Análise de classes gramaticais (Part of Speech tagging):
� Um classificador por palavra
� Traços são palavras a direita e a esquerda (bag of words)
� Classes são as possíveis classes gramaticais
Conceitos Exemplos PLN
� Classes são as possíveis classes gramaticais de uma palavra ambígua

Traços por aplicação de PLN
� Resolução anafórica� Resolução anafórica
� Instâncias: candidato a correferente (sintagma nominal) + pronome
� Traços:
� Distância entre candidato e o pronomeCandidato tem artigo ou pronome
Conceitos Exemplos PLN
� Candidato tem artigo ou pronome demonstrativo
� Candidato tem nome próprio� Classes: é correferente; não é correferente

Traços por aplicação de PLN
� Sumarização (traços):� Sumarização (traços):
� Posição da oração
� Similaridade da oração com o título
� Ocorrência de nomes próprios
� Ocorrência de anáforas
Conceitos Exemplos PLN
� Similaridade da bag of words da sentença com a bag of words do texto completo
� Classes: incluir no sumário; não incluir

Traços por aplicação de PLN
� Tradução: podemos gerar um classificador para � Tradução: podemos gerar um classificador para cada palavra com mais de uma tradução
� Análogo a análise de PoS
� Traços são palavras que vem antes e depois
� Classes são as possíveis traduções
Desambiguação de sentido
Conceitos Exemplos PLN
� Desambiguação de sentido
� Análogo a tradução

Traços por aplicação de PLN
� Os exemplos são didáticos: traços nem sempre � Os exemplos são didáticos: traços nem sempre são extraídos diretamente dos textos
� Podem originar-se outras representações deles (lógica de predicados, ontologias, grafos, medidas matemáticas diversas, etc)
� O aprendizado de máquina pode corresponder a
Conceitos Exemplos PLN
O aprendizado de máquina pode corresponder a uma etapa de uma tarefa tarefa de PLN
� No exemplo da tradução, ele permite escolher as palavras, mas ainda falta ajustar a ordem delas)

Roteiro da parte 2: processando atributos
� Seleção de dados (instâncias e atributos)
� Preparando instâncias e atributos para o aprendizado
� Problemas com instâncias, atributos e valores
Seleção de Dados
• Selecionar os dados é uma das etapas mais importantes do processoConhecimento processo
• O sucesso ou o insucesso depende da qualidade dos dados escolhidosDados
Informação
Conhecimento
� A maioria dos dados disponíveis não foram coletados para serem utilizados em AM
Seleção de dados Conceitos
utilizados em AM
� Aqui todo o cuidado é pouco! Você pode ser traído pelos seus dados!

Seleção de Dados
� Em PLN, dados (instâncias e atributos) proveem principalmente de copora e recursos linguísticosprincipalmente de copora e recursos linguísticos
� Atentar para: idade do corpus, gênero, autor, etc.
� Textos podem estar repetidos ou duplicados
� Conferir a codificação é importante para evitar problemas (ex: UTF-8, latin-1, etc.)
Seleção de dados Conceitos
� Todas as classes devem estar representadas!

Tipos de atributos
� Escalas� Escalas
� Nominal ou categórica
� Ordinal
� Intervalar
� Razão
Conceitos Tipos de traços
� Alguns algoritmos não aceitam alguns tipos de atributos, é necessário convertê-los

Escala nominal
� Exemplos: cidade, profissão, cor favorita, etc � Exemplos: cidade, profissão, cor favorita, etc
� Podemos comparar a igualdade: a profissão de Maria é a mesma de João?
� Não podemos ordenar: Bombeiro vem antes ou
Conceitos Tipos de traços
� Não podemos ordenar: Bombeiro vem antes ou depois de professor? Vermelho < amarelo?

Escala ordinal
� Exemplos: notas (A, B, C, D, E), dia da semana, � Exemplos: notas (A, B, C, D, E), dia da semana, tamanho (pequeno, médio e grande), etc
� Podemos comparar a igualdade: o tamanho de Pedro é o mesmo de Henrique?
� Podemos ordenar: a nota de Mateus é maior que
Conceitos Tipos de traços
� Podemos ordenar: a nota de Mateus é maior que a de Antônio?
� Não podemos somar: A + B? E – E?

Escala intervalar
� Exemplos: temperatura (em Celsius), século (XIX, � Exemplos: temperatura (em Celsius), século (XIX, XX, XXI, etc), entre outros
� Podemos comparar a igualdade e ordenar
� Podemos somar: 20 graus + 10 graus = 30 graus
� Não podemos multiplicar: (o zero é relativo)
A temperatura de hoje (20 graus) é o dobro da
Conceitos Tipos de traços
� A temperatura de hoje (20 graus) é o dobro da de ontem (10 graus)???
� Metade do Século XX é o Século X???

Escala da razão
� Exemplos: idade, peso, altura (em metros), � Exemplos: idade, peso, altura (em metros), temperatura (em Kelvins), entre outras
� Nota: temos aqui uma um ordinal modificado (altura) e um intervalar modificado (temperatura)
� Podemos comparar a igualdade , ordenar, somare multiplicar:
Conceitos Tipos de traços
e multiplicar:
� Aqui o zero é absoluto
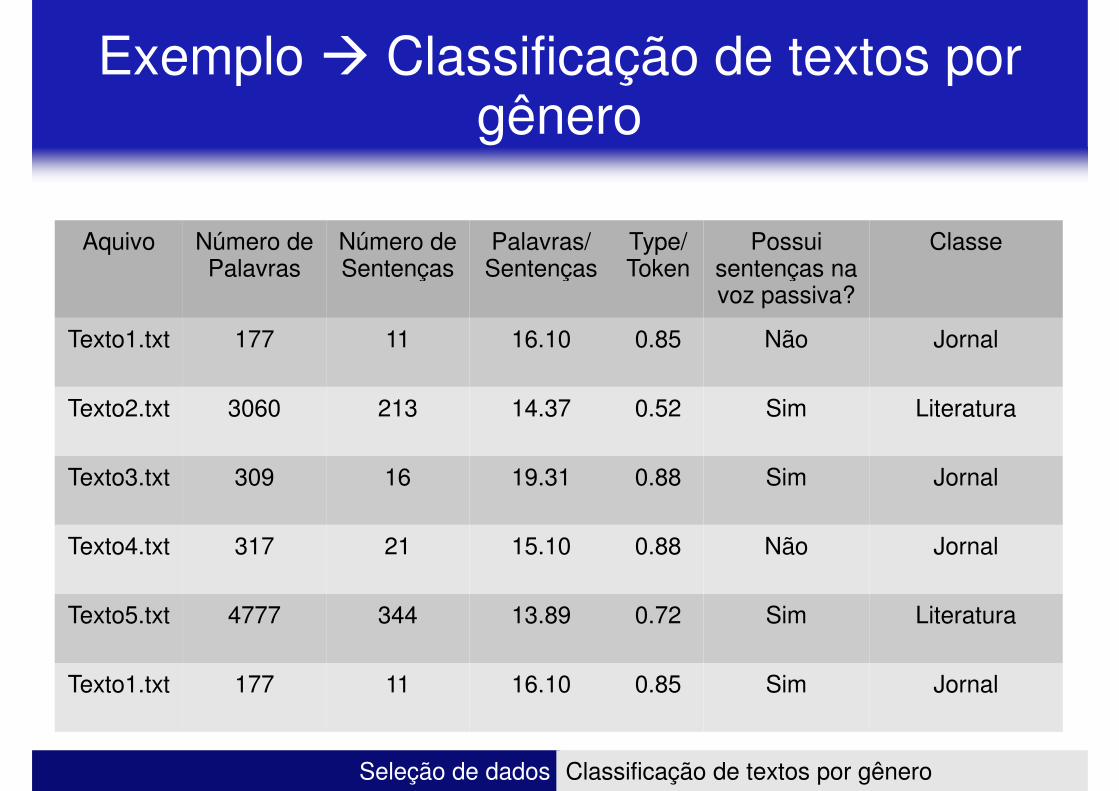
Exemplo � Classificação de textos por gênero
Aquivo Número de Palavras
Número de Sentenças
Palavras/ Sentenças
Type/ Token
Possui sentenças na
ClassePalavras Sentenças Sentenças Token sentenças na
voz passiva?
Texto1.txt 177 11 16.10 0.85 Não Jornal
Texto2.txt 3060 213 14.37 0.52 Sim Literatura
Texto3.txt 309 16 19.31 0.88 Sim Jornal
Seleção de dados Classificação de textos por gênero
Texto4.txt 317 21 15.10 0.88 Não Jornal
Texto5.txt 4777 344 13.89 0.72 Sim Literatura
Texto1.txt 177 11 16.10 0.85 Sim Jornal
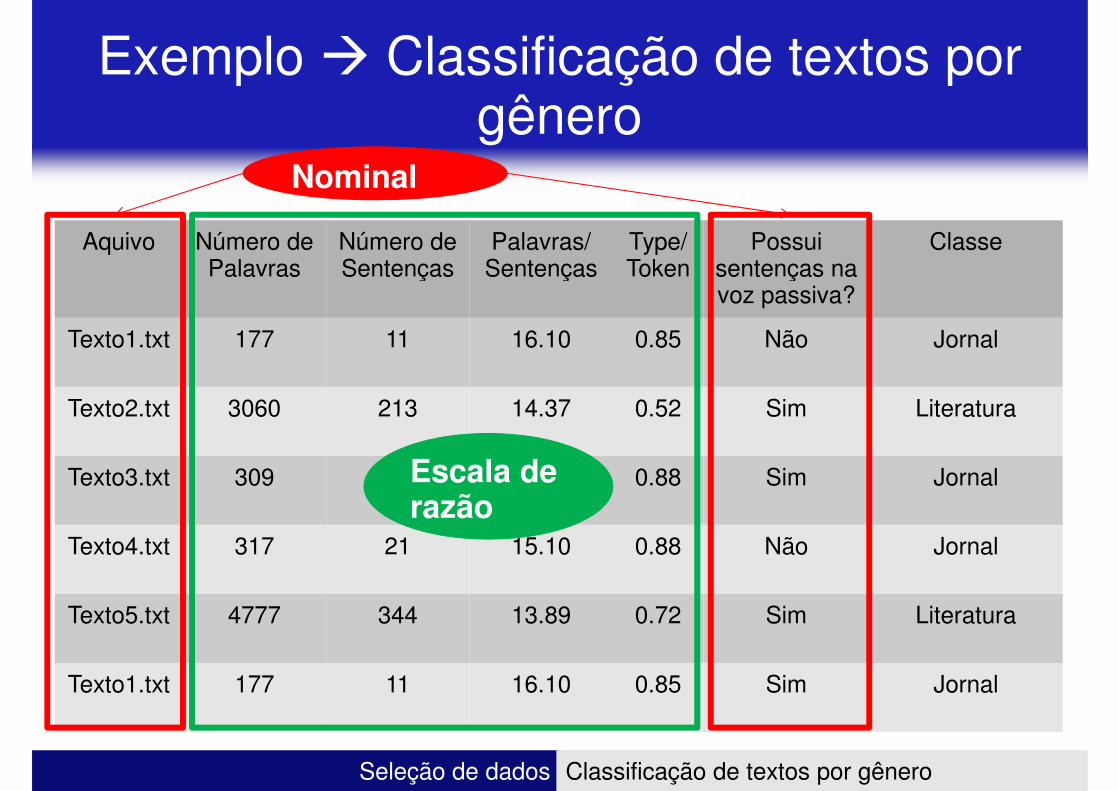
Exemplo � Classificação de textos por gênero
Aquivo Número de Palavras
Número de Sentenças
Palavras/ Sentenças
Type/ Token
Possui sentenças na
Classe
Nominal
Palavras Sentenças Sentenças Token sentenças na voz passiva?
Texto1.txt 177 11 16.10 0.85 Não Jornal
Texto2.txt 3060 213 14.37 0.52 Sim Literatura
Texto3.txt 309 16 19.31 0.88 Sim JornalEscala de razão
Seleção de dados Classificação de textos por gênero
Texto4.txt 317 21 15.10 0.88 Não Jornal
Texto5.txt 4777 344 13.89 0.72 Sim Literatura
Texto1.txt 177 11 16.10 0.85 Sim Jornal

Convertendo atributos para números
� Alguns algoritmos só reconhecem números� Alguns algoritmos só reconhecem números
� Outros apenas categorias nominais
� Como converter ordinais
� Segunda, terça, quarta, … → 1, 2, 3, …
Conceitos Tipos de traços
� A, B, C, … → 5, 4, 3, ...

Convertendo atributos para números (2)
� Convertendo nominais de 2 valores
� Votante: não, sim → 0 (não), 1 (sim)
� Convertendo nominais com 3 ou mais valores
� Esporte: basquete, futebol ou polo
� joga_basquete (0 ou 1), joga_futebol (0 ou 1),
Conceitos Tipos de traços
� joga_futebol (0 ou 1), � joga_polo (0 ou 1)
� 3 valores viraram 3 atributos com 2 valores cada (apenas um traço vale 1 em cada instância)

Convertendo atributos para nomes
� Escala intervalar� Escala intervalar
� 0-10 graus celsius: muito_frio
� 10-20 graus: frio
� 20-25 graus: agradável
� Idem para escala da razão
Conceitos Tipos de traços
� Até 20 palavras: pequeno
� Até 200 palavras: médio
� Mais de 200 palavras: grande

Lidando com ruídos
� Erros podem estar presentes nos dados, são chamados de ruídoschamados de ruídos
� Origem dos ruídos:
� Erros inerentes ao processo de anotação manual
� Erros ocorridos durante a geração automatizada
Seleção de dados Problemas com os dados
Erros ocorridos durante a geração automatizada dos recursos induzem ruído
� Diversos classificadores tem uma tolerância razoável a ruídos, desde que sejam pouco frequentes

• Dados com ruídos � Algumas soluções
– O tratamento de ruídos em geral depende do contexto
Lidando com ruídos
– O tratamento de ruídos em geral depende do contexto
– Dado classificado como “Literatura” que seria bem melhor classificado com “Jornal” � podem ser um erro ou pode ser real
• Em muitos casos não é possível separar os ruídas das instâncias reais � Conviver com os ruídos
Seleção de dados Problemas com os dados
das instâncias reais � Conviver com os ruídos
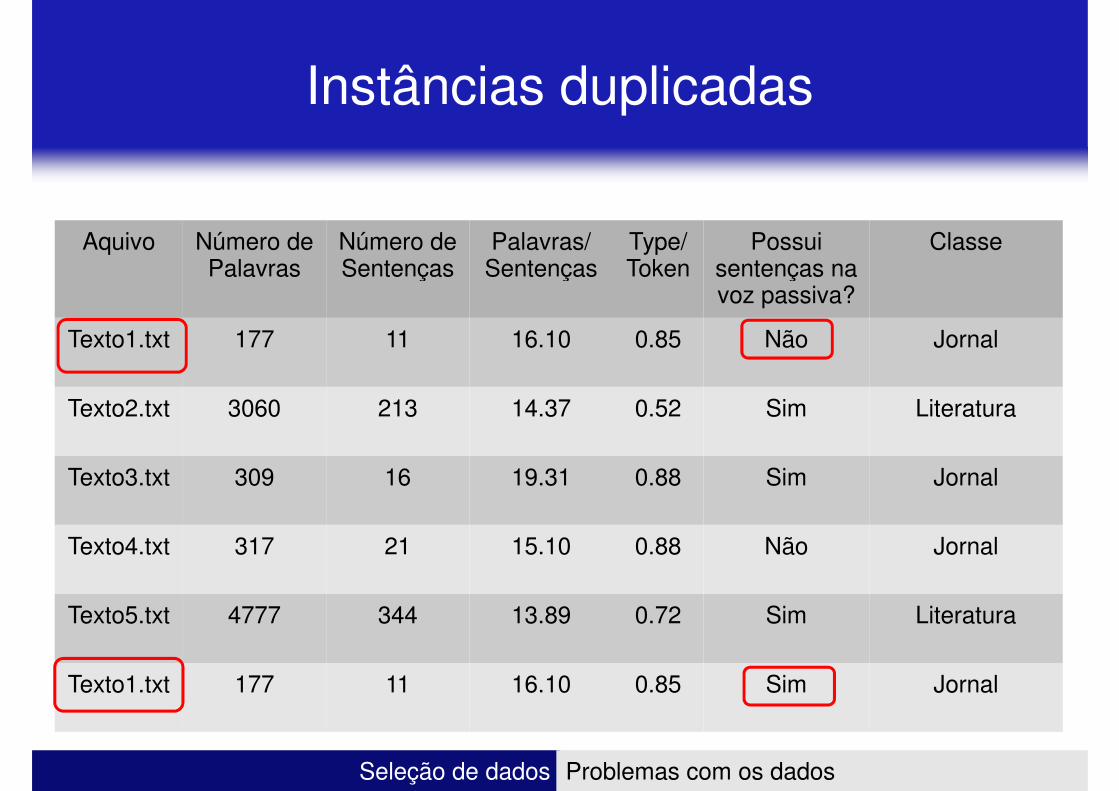
Instâncias duplicadas
Aquivo Número de Palavras
Número de Sentenças
Palavras/ Sentenças
Type/ Token
Possui sentenças na
ClassePalavras Sentenças Sentenças Token sentenças na
voz passiva?
Texto1.txt 177 11 16.10 0.85 Não Jornal
Texto2.txt 3060 213 14.37 0.52 Sim Literatura
Texto3.txt 309 16 19.31 0.88 Sim Jornal
Seleção de dados Problemas com os dados
Texto4.txt 317 21 15.10 0.88 Não Jornal
Texto5.txt 4777 344 13.89 0.72 Sim Literatura
Texto1.txt 177 11 16.10 0.85 Sim Jornal

• Instâncias Duplicadas � Algumas soluções
– Quais são os atributos corretos para o texto1.txt?
Instâncias duplicadas
– Quais são os atributos corretos para o texto1.txt?
– No exemplo aparecem unicamente dois conflitos � E se fossem centenas, milhares??
• Excluir todos os casos
Seleção de dados Problemas com os dados
• Tentar combinar os casos duplicados (poderia pensar na média dos valores)

• Valores inconsistentes � Algumas soluções
– Relação type/token com valores negativos
Valores inconsistentes
– Relação type/token com valores negativos
• Valor inválido para um atributo
– Número de palavra de um texto é maior ou igual ao número de sentenças
• Violação de relações previamente estabelecidas entre atributos
Seleção de dados Problemas com os dados
atributos
• Se a inconsistência é gerada de forma aleatória pode ser considerada um tipo de ruído
• Para corrigir este problema é necessário coletar novamente os dados

• Dados incompletos ou ausentes � Algumas soluções
• Comumente há instâncias que não tem o valor de um ou mais
Dados incompletos ou ausentes
• Comumente há instâncias que não tem o valor de um ou mais atributos
– Descartar instâncias com atributos ausentes � Eficiente se as instâncias remanescentes são representativas e Proibitivo se as instâncias mais significativas possuírem valores ausentes
– Descartar atributos com valores ausentes � Eficiente se os atributos não são significativos para solucionar o problema
Seleção de dados Problemas com os dados
atributos não são significativos para solucionar o problema
– Estimar valores ausentes � média, mediana, moda, etc.

• Outliers � Algumas soluções
Outiliers
• Instâncias que apresentam características diferentes do resto das instâncias ou um atributo com um valor pouco usual com respeito aos valores típicos do atributo.
Seleção de dados Problemas com os dados
• Valores fora do padrão � nem sempre são um problema
– Identificação de catáforas
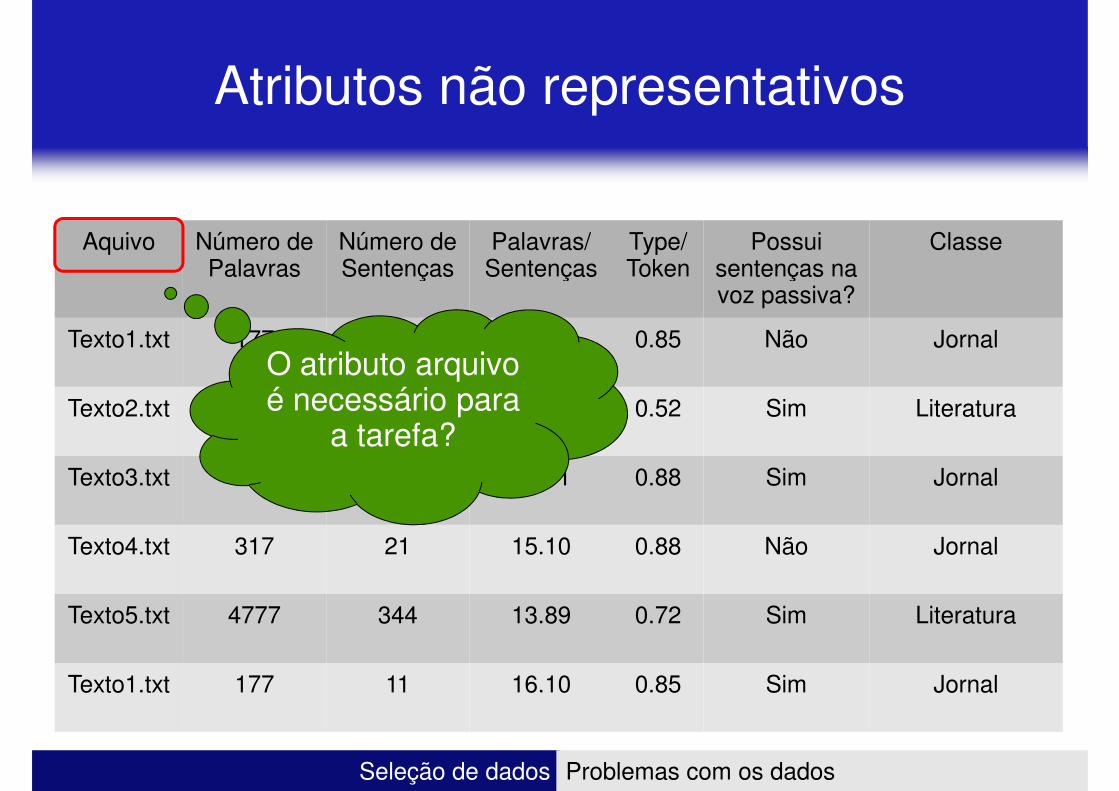
Atributos não representativos
Aquivo Número de Palavras
Número de Sentenças
Palavras/ Sentenças
Type/ Token
Possui sentenças na
ClassePalavras Sentenças Sentenças Token sentenças na
voz passiva?
Texto1.txt 177 11 16.10 0.85 Não Jornal
Texto2.txt 3060 213 14.37 0.52 Sim Literatura
Texto3.txt 309 16 19.31 0.88 Sim Jornal
O atributo arquivo é necessário para
a tarefa?
Seleção de dados Problemas com os dados
Texto4.txt 317 21 15.10 0.88 Não Jornal
Texto5.txt 4777 344 13.89 0.72 Sim Literatura
Texto1.txt 177 11 16.10 0.85 Sim Jornal
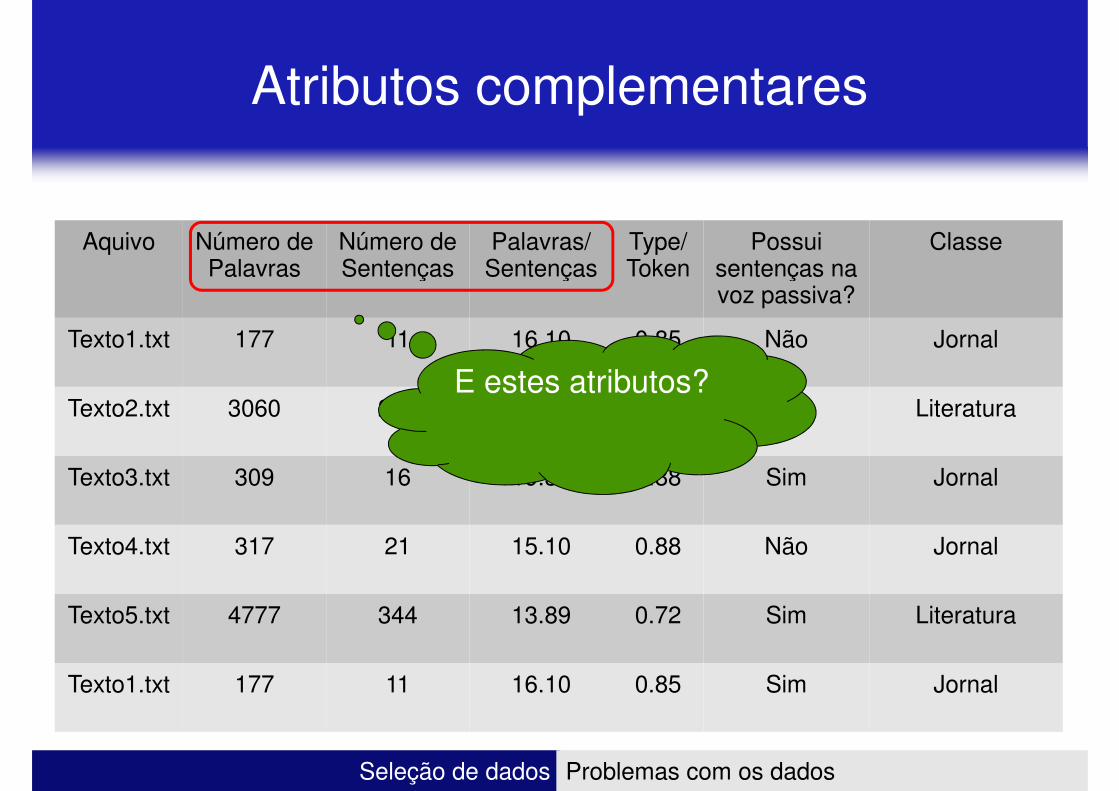
Atributos complementares
Aquivo Número de Palavras
Número de Sentenças
Palavras/ Sentenças
Type/ Token
Possui sentenças na
ClassePalavras Sentenças Sentenças Token sentenças na
voz passiva?
Texto1.txt 177 11 16.10 0.85 Não Jornal
Texto2.txt 3060 213 14.37 0.52 Sim Literatura
Texto3.txt 309 16 19.31 0.88 Sim Jornal
E estes atributos?
Seleção de dados Problemas com os dados
Texto4.txt 317 21 15.10 0.88 Não Jornal
Texto5.txt 4777 344 13.89 0.72 Sim Literatura
Texto1.txt 177 11 16.10 0.85 Sim Jornal

• Algumas soluções
Seleção de Dados
– Atributos desnecessários � Descartar !!!
– Descartar os atributos “número de palavras” e “número de sentenças” � palavras/sentenças é um combinação dos dois
Seleção de dados Conceitos
• Agregação (técnica para redução de dados)• Alguns algoritmos podem ter problemas (Naive
Bayes)

Seleção de Dados
• Nem todos os problemas apresentados tem solução• Nem todos os problemas apresentados tem solução
– Por exemplo: ruídos são difíceis de identificar e/ou corrigir
• Portanto, conhecer a fundo os dados é fundamental para entender o problema
Seleção de dados Conceitos
– E interpretar os resultados!

Pré-processamento
• Conjunto de estratégias e técnicas para melhorar o desempenho (tempo, custo e qualidade da solução) de algoritmos de AM
– Seleção de dados
– Amostragem (instâncias)
– Redução de dimensionalidade
• Agregação (atributos)
• Extração de características (atributos)
É muito caro trabalhar com os dados
completos e o consumo de tempo é elevado
Pré-processamento Conceitos
• Seleção de atributos (atributos)
– Transformação de variáveis (valores)

Amostragem
• Técnica da estatística também muito útil para AM
• Seleção de um subconjunto de instâncias (amostra)• Seleção de um subconjunto de instâncias (amostra)
• Geralmente chega a resultados similares ao do conjunto
• A amostra precisa ser representativa!!!
– Aproximadamente mesmas propriedades do conjunto
– Deve fornecer uma estimativa da informação desejada contida na população original
Pré-processamento Amostragem
contida na população original
– Deve permitir tirar conclusões de um todo a partir de uma parte

Redução de dimensionalidade
• Conjuntos da dados com um número muito grande de atributos pode atrapalhar a tarefa
• Exemplos: text mining � cada atributo é uma palavra com sua frequência
• Traz benefícios:
– Melhora eficácia e eficiência dos algoritmos
– Reduz o tamanho necessário da amostra
Pré-processamento Redução de dimensionalidade
– Reduz o tamanho necessário da amostra
– Facilita interpretação e visualização dos dados
• Exemplos: Processamento de textos � Eliminação das stop-words e emprego de lematizadores

Maldição de dimensionalidade
• A medida que o número de atributos aumenta � aumenta o número de generalizações ruins, MAS que parecem o número de generalizações ruins, MAS que parecem boas
– 1 atributo com 10 possíveis valores � 10 objetos
– 5 atributos com 10 possíveis valores �105 objetos
Pré-processamento Redução de dimensionalidade
• Enquanto o número de atributos cresce suavemente � o número instâncias necessárias para uma boa generalização explode
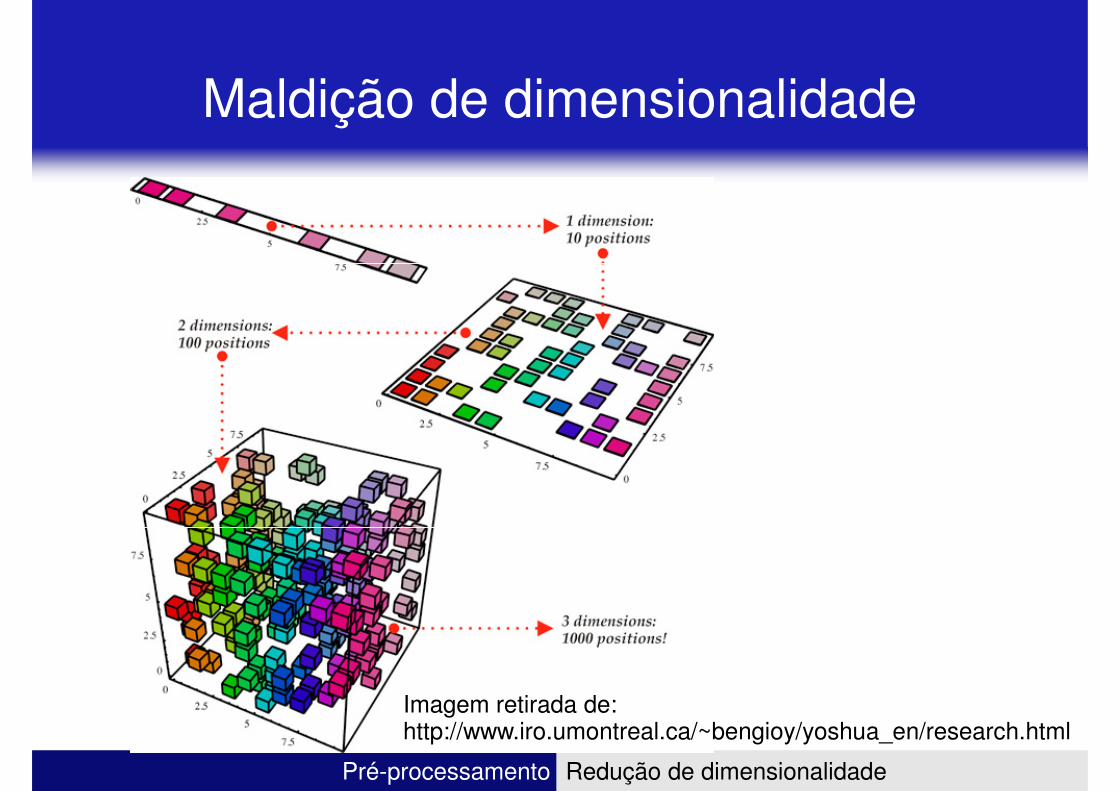
Maldição de dimensionalidade
Pré-processamento Redução de dimensionalidade
Imagem retirada de:http://www.iro.umontreal.ca/~bengioy/yoshua_en/research.html

Técnicas para reduzir dimensionalidade
• Agregação• Agregação
• Extração de Características
• Seleção de Atributos
Pré-processamento Redução de dimensionalidade
• Seleção de Atributos

Agregação
• Combinação de instâncias e atributos
– Redução dos dados
– Dados mais estáveis (menos variabilidade)
• Exemplos:
– Stemming/lematização em text mining
Pré-processamento Redução de dimensionalidade
– Stemming/lematização em text mining
– Combinar os atributos – número de palavras e número de sentença no lugar de trabalhar com os dois atributos

Extração de Características
• Parte dos atributos definidos podem ser desnecessários ou redundantes
– Em text mining � muitos atributos podem ser irrelevantes – Em text mining � muitos atributos podem ser irrelevantes (palavras sem conteúdo (artigos, preposições) ou marcas de pontuação)
– Reconhecimento de Fala � Áudio bruto não é um bom atributo para reconhecimento de voz � uso de harmônicas de frequência
• O problema é selecionar o conjunto de atributos que representam
Pré-processamento Redução de dimensionalidade
• O problema é selecionar o conjunto de atributos que representam melhor os dados
• Problema: pode ser impossível interpretar os atributos
• Técnica muito utilizada para domínios em que não é necessário interpretar os atributos (ex: reconhecimento de imagens)

Seleção de Atributos
• Seleção por ordenação � ordena os atributos de acordo com sua relevância (para discriminar classes individualmente) e seleciona segunda uma medida
– Emprega medidas Estatísticas ou da Teoria da Informação
Pré-processamento Extração de Características
• Seleção de subconjunto � seleciona de acordo a relevância mutua do subconjunto

Seleção de Atributos
• Filtros � realizado a priori e não envolve o algoritmo de classificação (algoritmo alvo)
• Wrappers � algoritmo alvo é usado para guiar a seleção de atributos
Pré-processamento Extração de Características
• Embedded � seleção ocorre internamente e como parte do algoritmo

Filtros
• Fácil e rápido
• Baseado em medidas de informação mútua ou correlação entre os atributos
• Apenas propriedades intrínsecas dos dados são consideradas
Extração de Características Seleção de Atributos
consideradas
• Seleção indireta � pode levar a resultados inferiores

Filtros
• Mais utilizado no WEKA:
– InfoGain � por ordenação– CfsSubsetEval � subconjunto
• Podemos utilizar filtros como este para verificar quais atributos possuem melhor desempenho
Extração de Características Seleção de Atributos
• Exemplo: Classificação de textos por gênero usando atributos de inteligibilidade � quais atributos apresentam o melhor desempenho?

Wrappers
• Guiado pelo algoritmo alvo• Guiado pelo algoritmo alvo
• Seleciona os atributos que maximizam a performance do algoritmo
• Pode ser custuso demais
Extração de Características Seleção de Atributos
• Pode ser custuso demais

Embedded
• Seleção de atributos faz parte da estratégia do algoritmo• Seleção de atributos faz parte da estratégia do algoritmo
• Exemplo clássico: Árvores de decisão!!
• Veremos árvores mais adiante...
Extração de Características Seleção de Atributos

Ajustando os dados
• Além das transformações dos atributos, as vezes é necessário ajustar os valores
• Normalização
• Dados numéricos com grande variação
• Ex: menor valor – 500 milhões e maior valor + 900 milhões• Propriedades estatística indesejadas (não Gaussiana)
– Os dados são transformados para o intervalo [0,1] � o maior valor
Pré-processamento Transformação de dados
– Os dados são transformados para o intervalo [0,1] � o maior valor será 1, o menor 0, e os outros são calculados por regra de três.
• Alterar as unidades de medida dos atributos � Adicionar ou subtrair uma constante e dividir ou multiplicar pela constante
• Para dados com distribuição Gaussiana � Subtrair a média e dividir pelo desvio padrão

Pré-processamento
• Esta etapa é muito importante pois interfere diretamente na • Esta etapa é muito importante pois interfere diretamente na etapa posterior
• Conhecer bem os dados e saber aplicar corretamente as técnicas de pré-processamento é, algumas vezes, mais importante do que a escolha do próprio algoritmo!
Pré-processamento Conclusão
• Cuidado para não ser traído pelos próprios dados!!!

Roteiro da parte 3: processando traços
� Algoritmos de classificação
� Avaliando resultados

Algoritmos de classificação
• Classificação
– Classificação é feita com base nos atributos dos objetos– Classificação é feita com base nos atributos dos objetos
– Exemplo: diagnóstico de um paciente é feito com base nos sintomas observados e os exames realizados
– Associar objetos a uma categoria ou classe
– Exemplo: diagnóstico de pacientes (saudável ou doente), classificação de textos (simples ou complexo)
Algoritmos de Classificação
– Quando são duas classes � classificador binário
– Aprendemos a classificar melhor com o tempo à medida que observamos novos exemplos

Algoritmos de classificação
• Classificação
– Existem várias técnicas, para diferentes contextos...
• O sucesso de cada técnica depende da tarefa que está sendo desenvolvida
– Métodos simples, geralmente, funcionam bem e apresentam bons resultados
– Algoritmos caixa branca são usados quando explicitar o
Algoritmos de Classificação
– Algoritmos caixa branca são usados quando explicitar o conhecimento é importante.
– Algoritmos caixa preta é usado para otimizar desempenho do classificador.

Algoritmos de Classificação
• Baseado em regras• Baseado em regras
• Probabilísticos
• Baseados em funções matemáticas
• Baseados em instâncias
• Baseado em árvores
Algoritmos de Classificação Tipos
• Baseado em árvores

Baseado em regras
• Simples, mas capaz de alcançar bons resultados
• Para cada atributo são elaboradas regras de acordo com os valores deste atributo
• Uma boa estratégia para começar! • “Try the simplest thing first”
Algoritmos de Classificação Baseados em Regras
• É possível entender o processo (o resultado é interpretável)
• 1-rule � WEKA: OneR

Baseado em regras
• r1: Emprego=Não � Crédito = Emprego Estado Renda Crédito
Sim Solteiro 9500 Sim• r1: Emprego=Não Crédito = Não
Emprego=Sim�Crédito=Sim
•r2: Emprego=Sim e Estado = Solteiro e Renda > 6000 � Crédito =Sim
Sim Solteiro 9500 Sim
Não Casado 8000 Não
Não Solteiro 7000 Não
Sim Casado 12000 Sim
Não Divorciado 9000 Sim
Não Casado 6000 Não
Sim Divorsiado 4000 Não
Baseado em Regras Exemplo
• r3: Emprego=Sim e Renda > 12000 �Crédito=Sim
Não Solteiro 8500 Sim
Não Casado 7500 Não
Não Solteiro 9000 Não

Probabilísticos
• Relação entre atributos de entrada e a classe éprobabilísticaprobabilística
• Exemplo: Predizer se uma pessoa terá problemas decoração � Duas classes Doente e Saudável
• Atributos de Entrada: peso e frequência de exercíciosfísicos
Algoritmos de Classificação Probabilísticos
físicos
• Modelam relacionamento probabilístico entre atributos deentrada e atributo alvo (classe)

Probabilísticos
• Usam todos os atributos• Assumir que todos contribuem igualmente• Assumir que todos contribuem igualmente• Assumir que são independentes entre si
• Atributos independentes? � praticamente impossível•Porém, apresentam resultados consideravelmente bons
• Considera teoria de probabilidade para definir as
Algoritmos de Classificação Probabilísticos
• Considera teoria de probabilidade para definir ascontribuições de cada atributo
• Algoritmo mais famoso: NaiveBayes �WEKA: mesmo nomeBaseado na teoria de Bayes

Baseados em funções matemáticas
• Utilizam métodos lineares e não lineares para classificação
• Adequado para dados numéricos
• Algoritmo mais famoso: SVM� WEKA: SMO
• Não é possível interpretar o
Algoritmos de Classificação Baseados em funções matemáticas
• Não é possível interpretar oresultado (caixa preta)

Baseados em instâncias
• Utiliza uma medida de distância para definir quais instânciasdos dados de treinamento está mais próxima de um dado dedos dados de treinamento está mais próxima de um dado deteste (desconhecido)
•Conhecidos como algoritmo “preguiçoso”• Não geram um modelo previamente• Para classificar um novo objeto olha os dados
Algoritmos de Classificação Baseados em distância
• Medidas mais utilizadas: Distancia Euclidiana e DistanciaCoseno
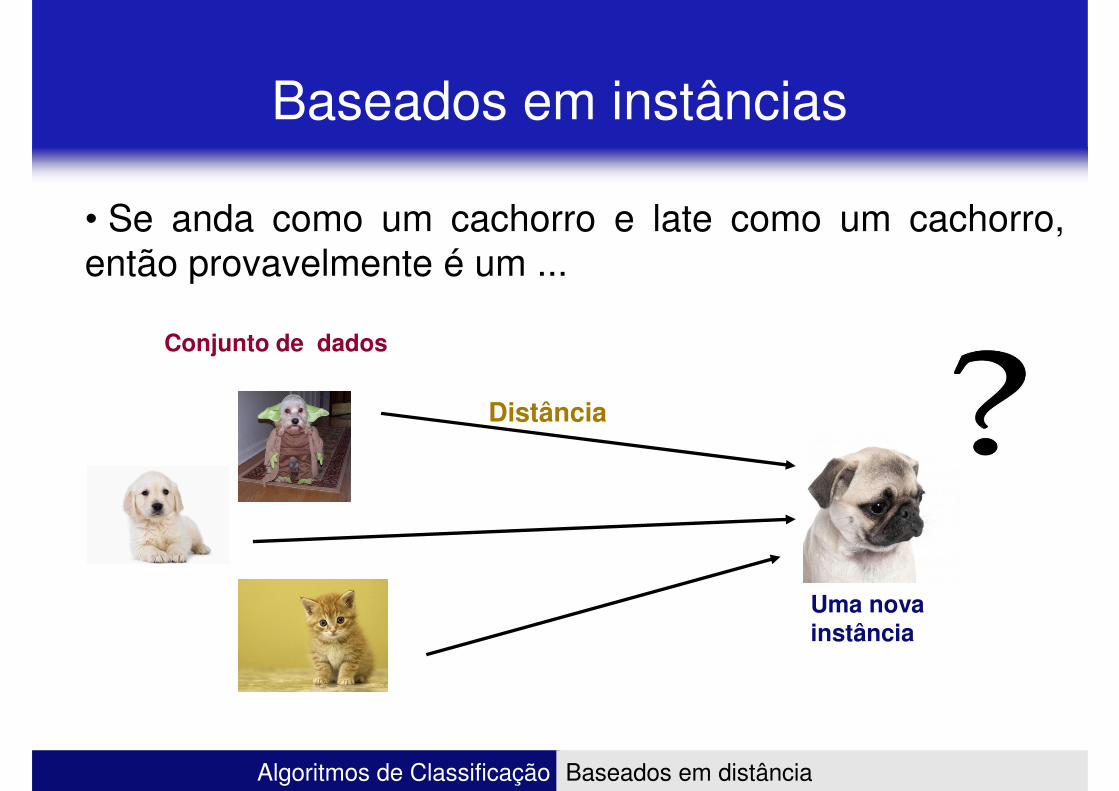
Baseados em instâncias
• Se anda como um cachorro e late como um cachorro,então provavelmente é um ...então provavelmente é um ...
Conjunto de dados
Distância
Algoritmos de Classificação Baseados em distância
Uma nova instância
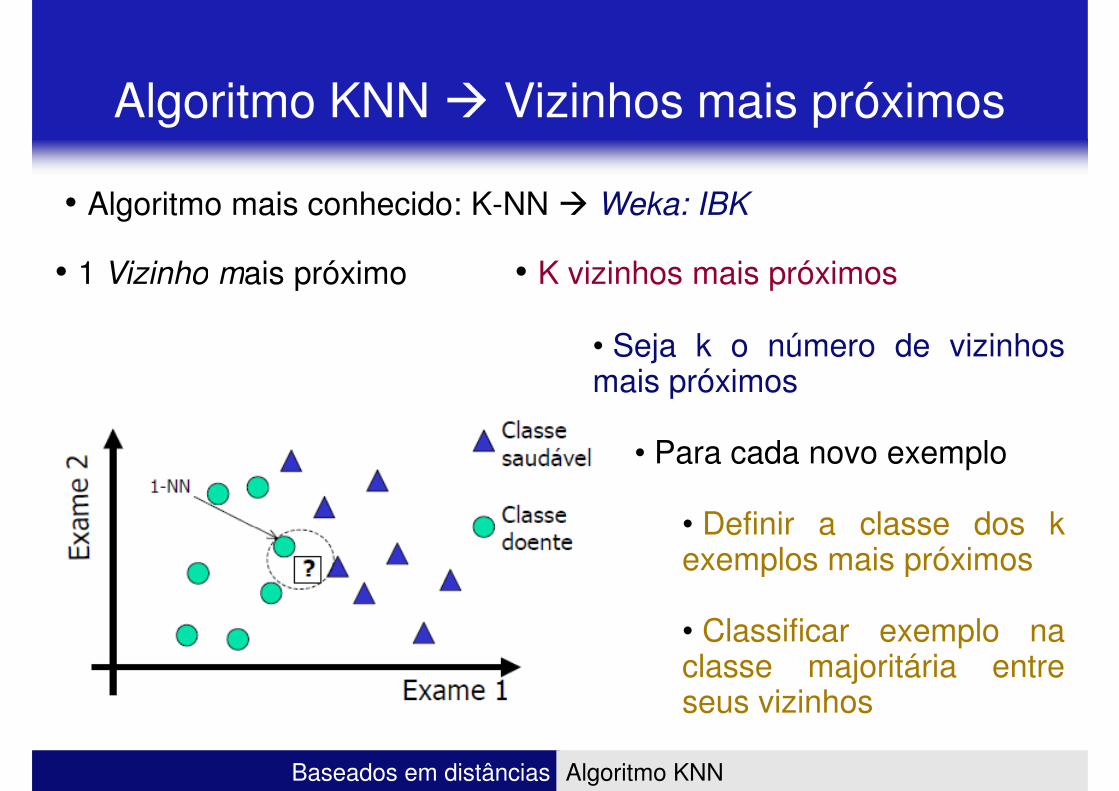
Algoritmo KNN � Vizinhos mais próximos
• 1 Vizinho mais próximo • K vizinhos mais próximos
• Algoritmo mais conhecido: K-NN � Weka: IBK
• 1 Vizinho mais próximo • K vizinhos mais próximos
• Seja k o número de vizinhosmais próximos
• Para cada novo exemplo
• Definir a classe dos k
Baseados em distâncias Algoritmo KNN
• Definir a classe dos kexemplos mais próximos
• Classificar exemplo naclasse majoritária entreseus vizinhos

Algoritmo KNN
• Quantidade de vizinhos?
• Se K muito grande � os vizinhos podem ser muito• Se K muito grande � os vizinhos podem ser muitodiferentes
• Se K muito pequeno � não há informação suficiente
Baseados em distâncias Algoritmo KNN

Baseados em árvores
• Dividir para Conquistar!
• Um problema complexo é dividido em problemasmenores e mais simples
• Repete o processo recursivamente para cada novoproblema
Algoritmos de classificação Baseados em árvores
• Eficaz, eficiente e produz modelos interpretáveis
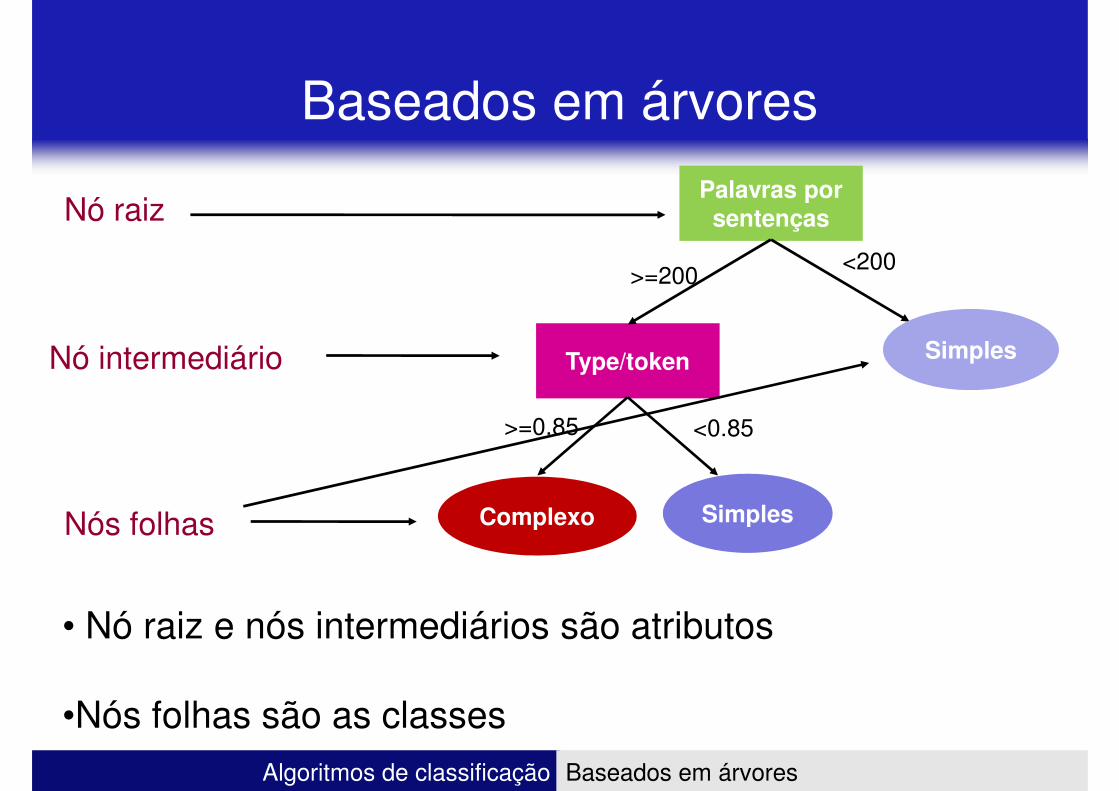
Baseados em árvores
Palavras por sentenças
<200>=200
Nó raiz
Type/token Simples
<200>=200
>=0.85 <0.85
SimplesComplexo
Nó intermediário
Nós folhas
Algoritmos de classificação Baseados em árvores
• Nó raiz e nós intermediários são atributos
•Nós folhas são as classes
SimplesComplexoNós folhas

Baseados em árvores
• Indica quais atributos são mais importantes para a• Indica quais atributos são mais importantes para aclassificação � FILTRO
• C4.5 � um dos algoritmos mais usados
• No WEKA: J48
Algoritmos de classificação Baseados em árvores
• No WEKA: J48

Algoritmos de classificação
• Mais utilizados
• SMO
• J48
• Naive Bayes
Algoritmos de classificação Baseados em árvores

Avaliação dos resultados
• Desempenho do classificador• Desempenho do classificador• Dados para treino/validação• Dados para teste
• Métodos de Amostragem• Hold-out
Algoritmos de classificação Avaliação dos resultados
• Cross-validation

Desempenho de um classificador
• O classificador deve manter um desempenho adequado para• O classificador deve manter um desempenho adequado paranovos conjuntos de dados
• Estimar a capacidade de generalização do classificador
• Avaliar a variância (estabilidade) do classificador
• O conjunto de dados é separado em conjunto de treinamento e
conjunto de teste
Avaliação dos resultados Desempenho de um classificador
conjunto de teste
• Vários métodos de amostragem dos dados

Métodos de amostragem
• Empregados para avaliar o desempenho de umclassificador � separar em amostras de treinamento eclassificador � separar em amostras de treinamento eteste
• Usando os mesmos dados para treinamento e teste pode-se obter resultados muito otimistas e não reais
Avaliação dos resultados Métodos de amostragem
• Principais métodos• Hold-out• Cross validation

Métodos de amostragem
Hold-out
• Técnica mais simples• Técnica mais simples
• Divide o conjunto de dados em:• Conjunto de treinamento: comunmente 1/2 ou 2/3
dos dados• Conjunto de teste: os dados restantes
Avaliação dos resultados Métodos de amostragem
• Conjuntos de treinamento e teste não sãoindependentes
• Usado em grandes conjuntos de dados

Métodos de amostragem
• Utilizam várias partições do conjunto original de dados paraconstituir os conjuntos de treinamento e teste
• Cross-Validation (Validação Cruzada)
• Divide conjunto de dados em k partições mutuamenteexclusivas
• A cada iteração, uma das k partições é usada para testar omodelo
Avaliação dos resultados Métodos de amostragem
modelo
• As outras k – 1 são usadas para treinar o modelo
• Taxa de erro é tomada como a média dos erros de teste dask partições

Métodos de amostragem• Cross-Validation (Validação Cruzada)
Avaliação dos resultados Métodos de amostragem
Modificada de: http://genome.tugraz.at/proclassify/help/pages/XV.html

Métodos de amostragem
• Geralmente utiliza-se k = 10 (10-fold cross-validation) �• Geralmente utiliza-se k = 10 (10-fold cross-validation) �
padrão do WEKA
• Hold-out no WEKA � Supplied test set (deve-se dividir oARFF antes)
Avaliação dos resultados Estimativa de erros

Desempenho de um classificador
• Treinamento pode ser insuficiente levando ageneralização ruins (undertraining), ou mais que o idealgerando memorização dos padrões de treinamento(overtraining).
• Conjunto de teste é usado para prevenir isso.
Avaliação dos resultados Estimativa de erros
• Conjunto de teste é usado para prevenir isso.

Avaliação dos resultados
• Matriz de confusão
•Tipos de erros
• Precisão
• Cobertura
• Medida F
Avaliação dos resultados
• Medida F
• Acurácia
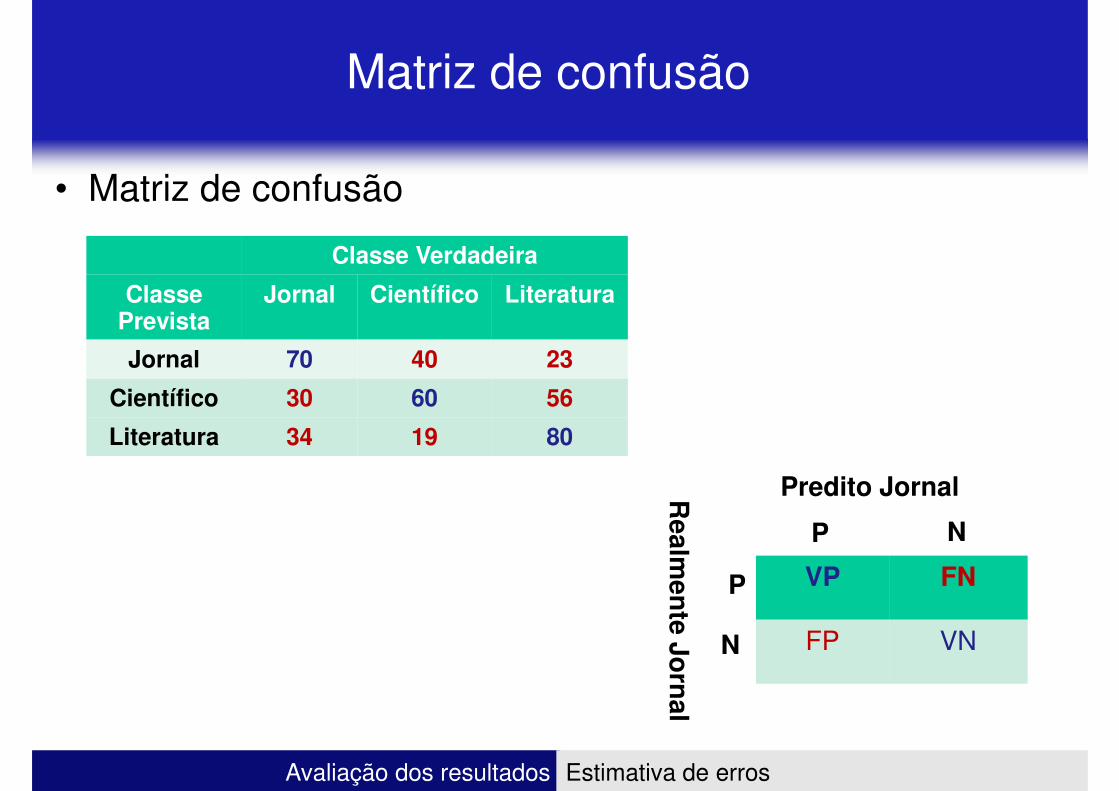
Matriz de confusão
• Matriz de confusão
Classe VerdadeiraClasse Verdadeira
Classe Prevista
Jornal Científico Literatura
Jornal 70 40 23
Científico 30 60 56
Literatura 34 19 80
P N
Predito JornalRealm
ente Jo
rnal
Avaliação dos resultados Estimativa de erros
VP FN
FP VN
P N
P
N
Realm
ente Jo
rnal

Tipos de erros
• Para duas classes, em geral se adota a convenção de• Para duas classes, em geral se adota a convenção derotular os exemplos da classe de maior interesse comopositivos (+)
• Classe rara ou minoritária
• Demais exemplos são rotulados como negativos (–)
Avaliação dos resultados Estimativa de erros
• Demais exemplos são rotulados como negativos (–)
• Exemplo: diagnóstico negativo para indivíduo doente...

Tipos de erros
• Falso Positivo (FP) � Um exemplo N foi classificado• Falso Positivo (FP) � Um exemplo N foi classificadocomo P
• Exemplo: Diagnosticado como doente (classe +)mas está saudável (classe -)
• Falso Negativo (FN) � Um exemplo P foi classificadocomo N
Avaliação dos resultados Estimativa de erros
como N
• Exemplo: Diagnosticado como saudável (classe -),mas está doente (classe +)
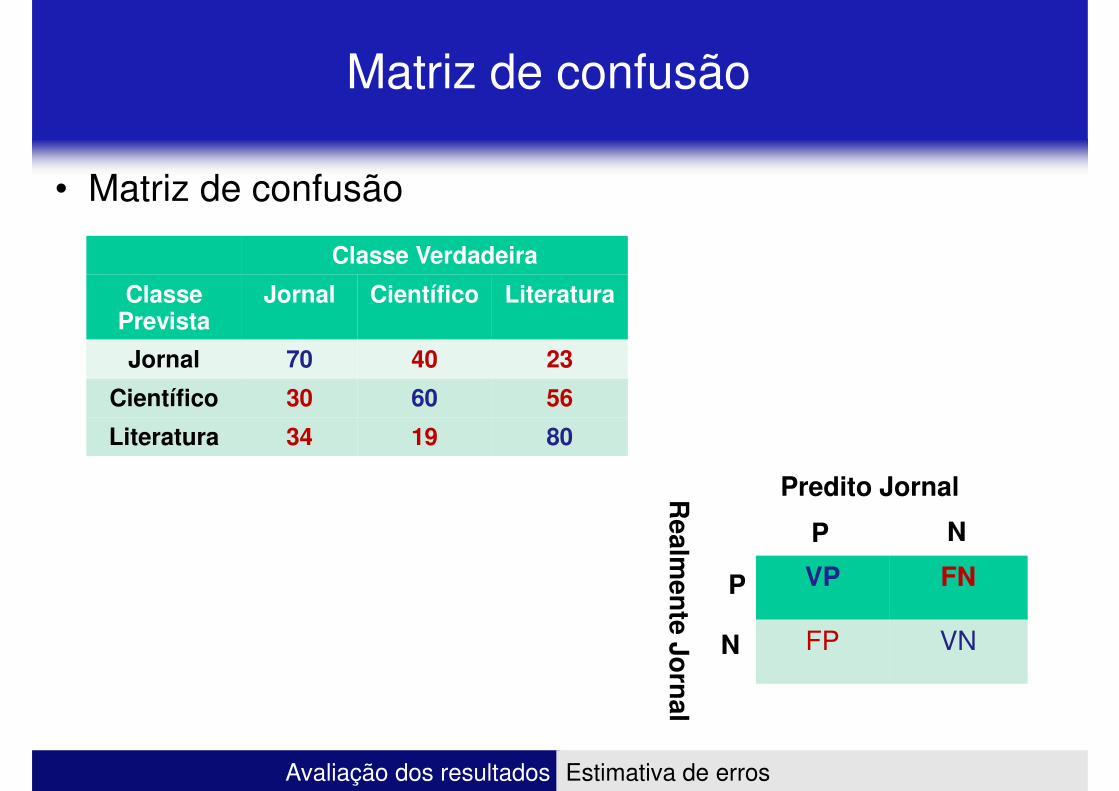
Matriz de confusão
• Matriz de confusão
Classe VerdadeiraClasse Verdadeira
Classe Prevista
Jornal Científico Literatura
Jornal 70 40 23
Científico 30 60 56
Literatura 34 19 80
P N
Predito JornalRealm
ente Jo
rnal
Avaliação dos resultados Estimativa de erros
VP FN
FP VN
P N
P
N
Realm
ente Jo
rnal

Cobertura & Precisão
• Cobertura (recall)• Taxa com que classifica como positivos todos os• Taxa com que classifica como positivos todos os
exemplos que são positivos• Nenhum exemplo positivo é deixado de fora• Tudo o que é relevante foi recuperado?
• Todos os exemplos da classe X foramclassificados como X?
Avaliação dos resultados Avaliação de desempenho

Cobertura & Precisão
•Precisão• Taxa com que todos os exemplos classificados como
positivos são realmente positivos• Nenhum exemplo negativo é incluído• Tudo o que foi recuperado é relevante?
• Todos os exemplos classificados como X são daclasse X
Avaliação dos resultados Avaliação de desempenho
classe X

Precisão
Primeira classe: primeiro item dadiagonal dividido pela soma da primeira÷ diagonal dividido pela soma da primeiracoluna
Segunda classe: segundo item divididopela soma da segunda coluna
÷
÷
Avaliação dos resultados Avaliação de desempenho
Terceira classe: terceiro item divididopela soma da terceira coluna
÷
÷

Cobertura
Primeira classe: primeiro item dadiagonal dividido pela soma da primeira÷ diagonal dividido pela soma da primeiralinha
Segunda classe: segundo item divididopela soma da segunda linha
÷
÷
Avaliação dos resultados Avaliação de desempenho
Terceira classe: terceiro item divididopela soma da terceira linha
÷
÷

Cobertura & Precisão
• São medidas locais:
• Avaliam classe a classe
Avaliação dos resultados Avaliação de desempenho

Medida-F
• Média harmônica da precisão e da cobertura• Procura otimizar precisão e cobertura � a média• Procura otimizar precisão e cobertura � a média
harmônica é mais influenciada pela pior medida
• Também é uma medida local
• Versão não ponderada da medida:
Avaliação dos resultados Avaliação de desempenho
cob+prec
cobprec ∗*2

Medida-F
• Em verde: classificado como a classe X• Em azul: classificado com as demais classes (U –• Em azul: classificado com as demais classes (U –universo)
XU
XU
XU
IdealQuando pensamos só na precisão
Quando pensamos só na cobertura
Avaliação dos resultados Avaliação de desempenho
XX X
exemplos classificados como positivos são realmente positivos
classifica como positivos todos os exemplos que são positivos

Acurácia
Soma da diagonal dividida pela somade todos os elementos÷ de todos os elementos÷
• É uma medida global• Avalia todas as classes juntas
• Cuidado!! Pode ser enganosa em classesdesbalanceadas
Avaliação dos resultados Avaliação de desempenho
desbalanceadas• Nesse caso pode ser melhor utilizar as médias das
coberturas, médias das precisões e a medida Fcorrespondente

Hands-on: WEKA

Roteiro do hands-on
� Arquivos .ARFF� Arquivos .ARFF
� Classificação de textos por complexidade
� Seleção de atributos
� Classificação de textos por domínio
� Métricas de complexidade
� Bag-of-words (com seleção de atributos)

Download
� Fazer o download do arquivo EBRALC_ARFF.zip� Fazer o download do arquivo EBRALC_ARFF.zip
� Site:
� Minicursos � Aprendizado de Máquina para tarefas de PLN � Arquivos .ARFF
http://nilc.icmc.usp.br/elc-ebralc2012/

Arquivos .ARFF
� Arquivos de entrada do WEKA
� Tem duas partes:
� Cabeçalho
� Nome da relação� Lista de atributos com os tipos
� Dados
� Dados separados por vírgula e seguindo a ordem em que os atributos são definidos no cabeçalho
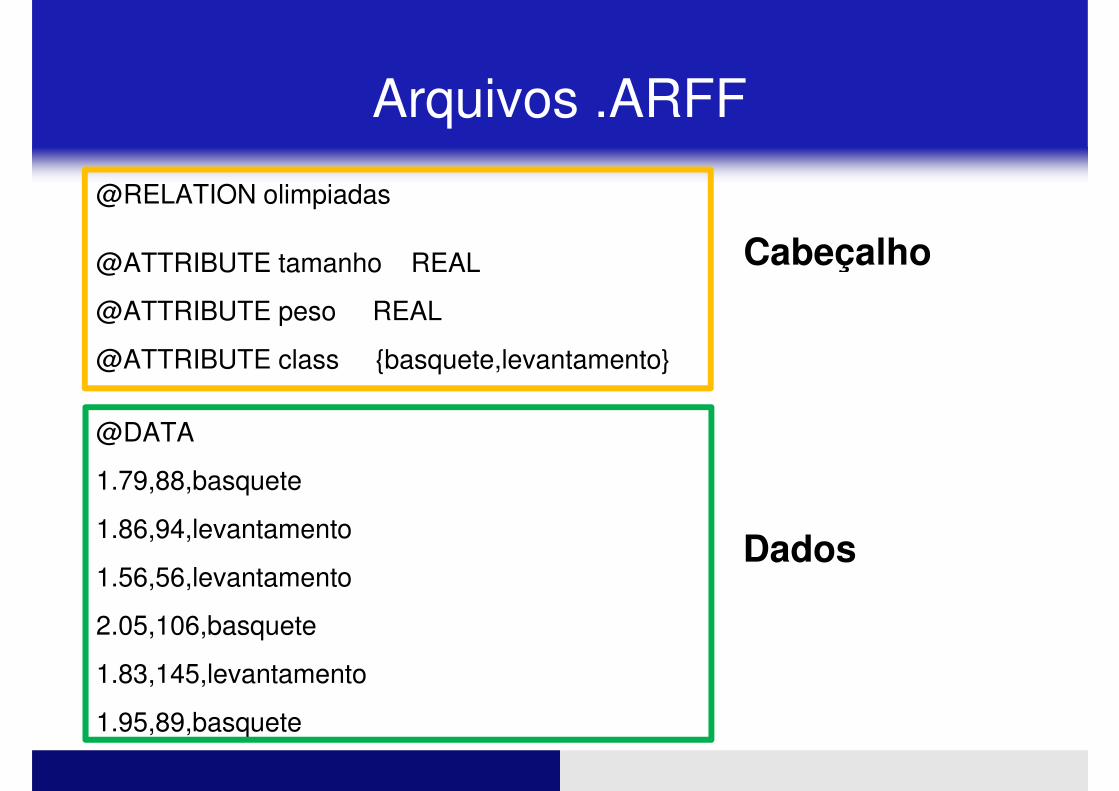
Arquivos .ARFF
@RELATION olimpiadas
@ATTRIBUTE tamanho REAL Cabeçalho@ATTRIBUTE tamanho REAL
@ATTRIBUTE peso REAL
@ATTRIBUTE class {basquete,levantamento}
@DATA
1.79,88,basquete
1.86,94,levantamento
Cabeçalho
Dados1.86,94,levantamento
1.56,56,levantamento
2.05,106,basquete
1.83,145,levantamento
1.95,89,basquete
Dados

Arquivos .ARFF
� Importante manter a estrutura do ARFF
Sem esta estrutura o WEKA não funciona!!� Sem esta estrutura o WEKA não funciona!!
� Os atributos podem ser dos tipos:
� Numeric (inteiros ou reais)
� <nominal-specification> (classe � entre { })
� String
� Date [<date-format>]
Primeiros passos
� Selecione a opção “Explorer”
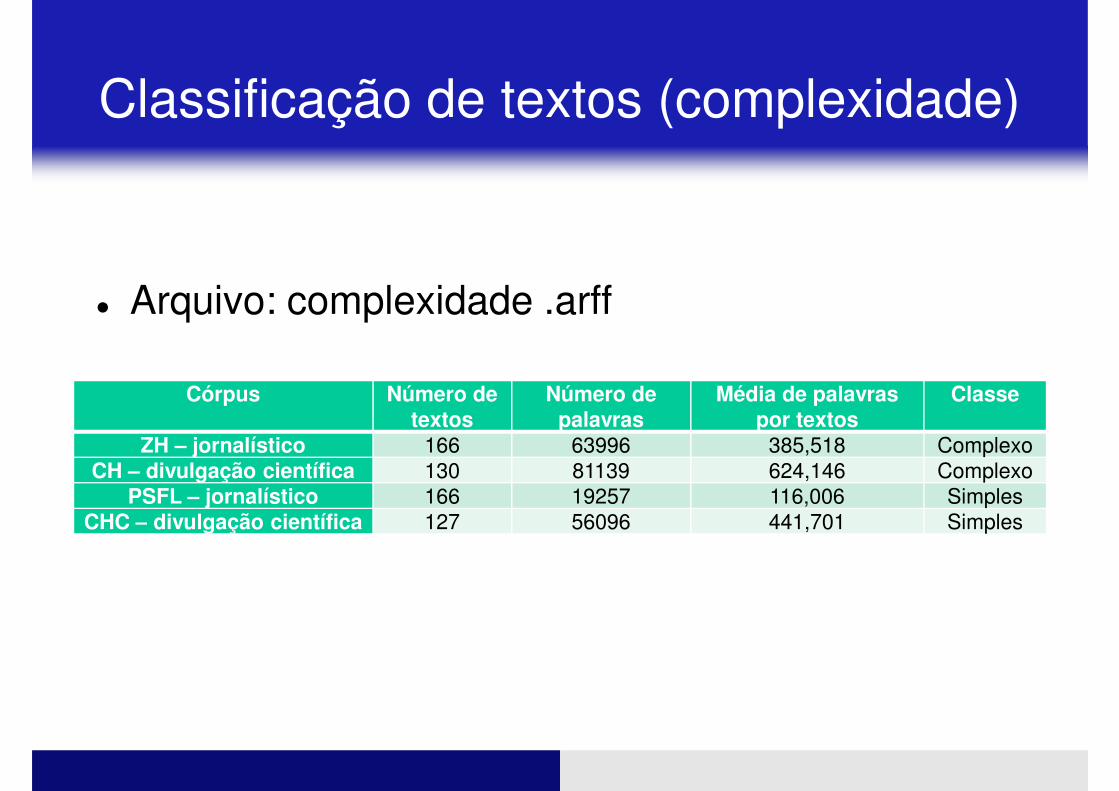
Classificação de textos (complexidade)
� Arquivo: complexidade .arff
Córpus Número de textos
Número de palavras
Média de palavras por textos
Classe
ZH – jornalístico 166 63996 385,518 ComplexoCH – divulgação científica 130 81139 624,146 Complexo
PSFL – jornalístico 166 19257 116,006 SimplesCHC – divulgação científica 127 56096 441,701 SimplesCHC – divulgação científica 127 56096 441,701 Simples

Classificação de textos (complexidade)
� Atributos
� 49 métricas do Coh-Metrix-Port
� Métricas de complexidade textual
� Exemplos: índice Flesch, Pronomes por sintagmas, número de palavras de conteúdo, sintagmas, número de palavras de conteúdo, referência anafórica adjacente...
Classificação de textos (complexidade)
Selecione “Open file...”
Classificação de textos (complexidade)
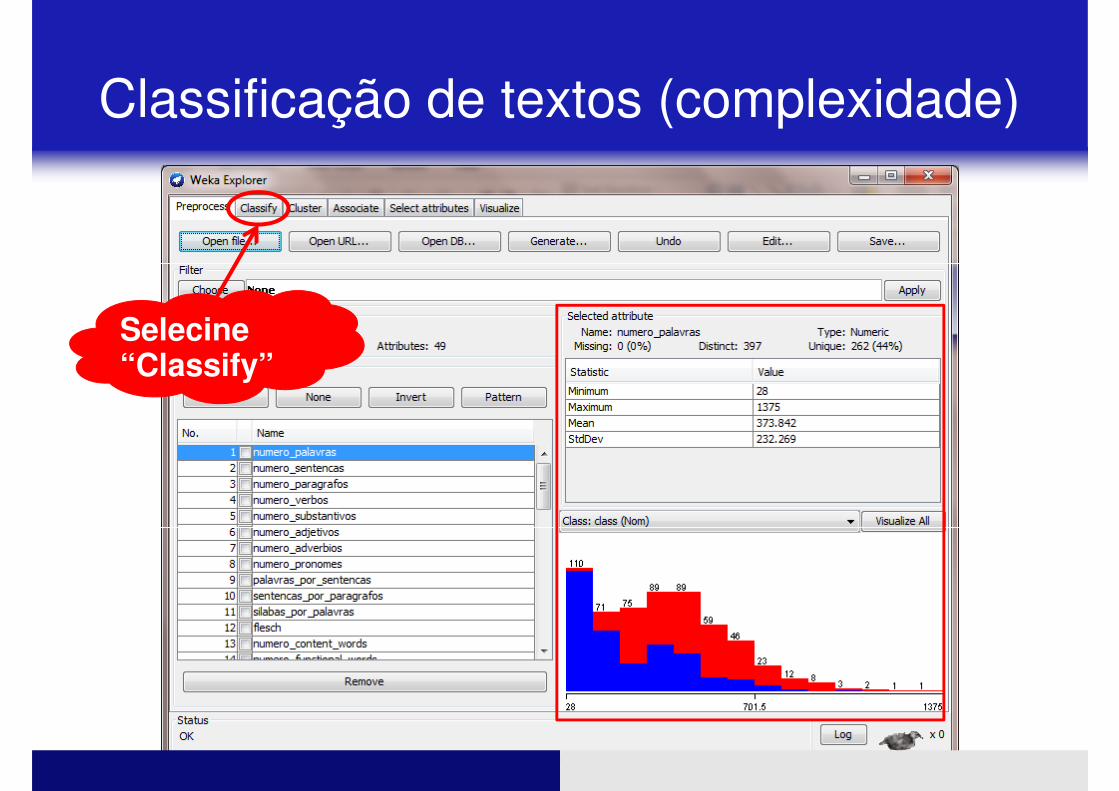
Selecine “Classify”
Classificação de textos (complexidade)
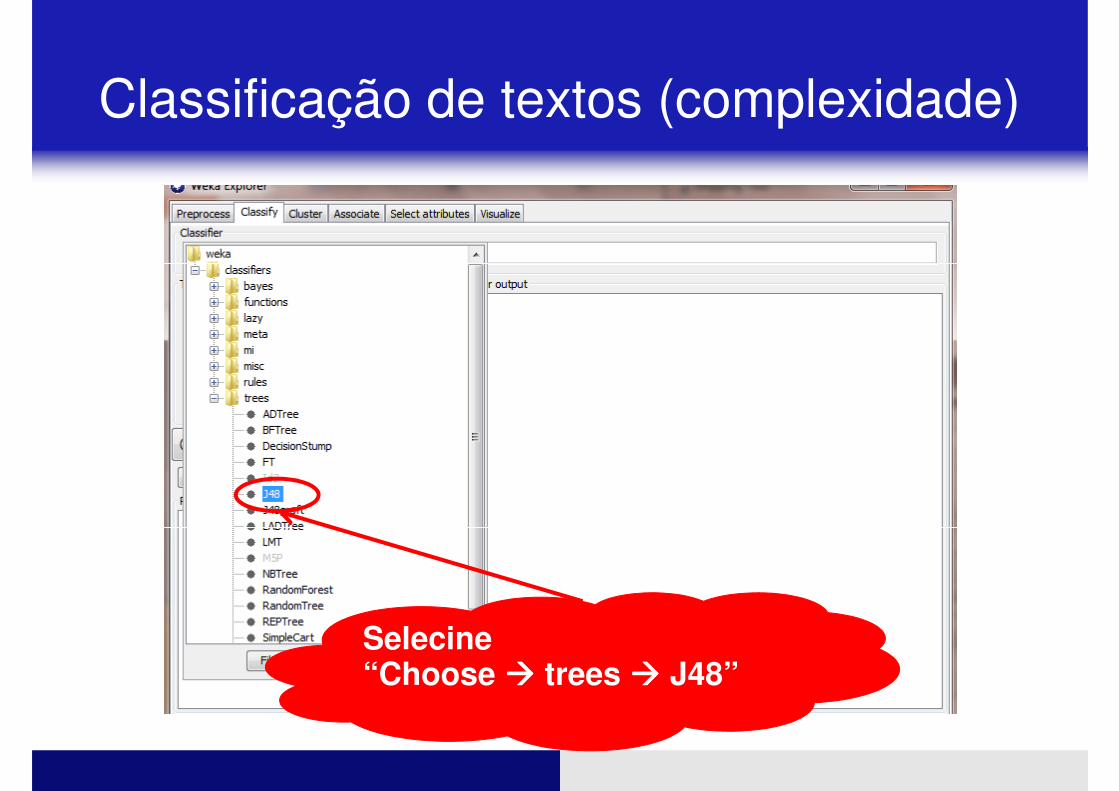
Selecine “Choose ���� trees ���� J48”
Classificação de textos (complexidade)

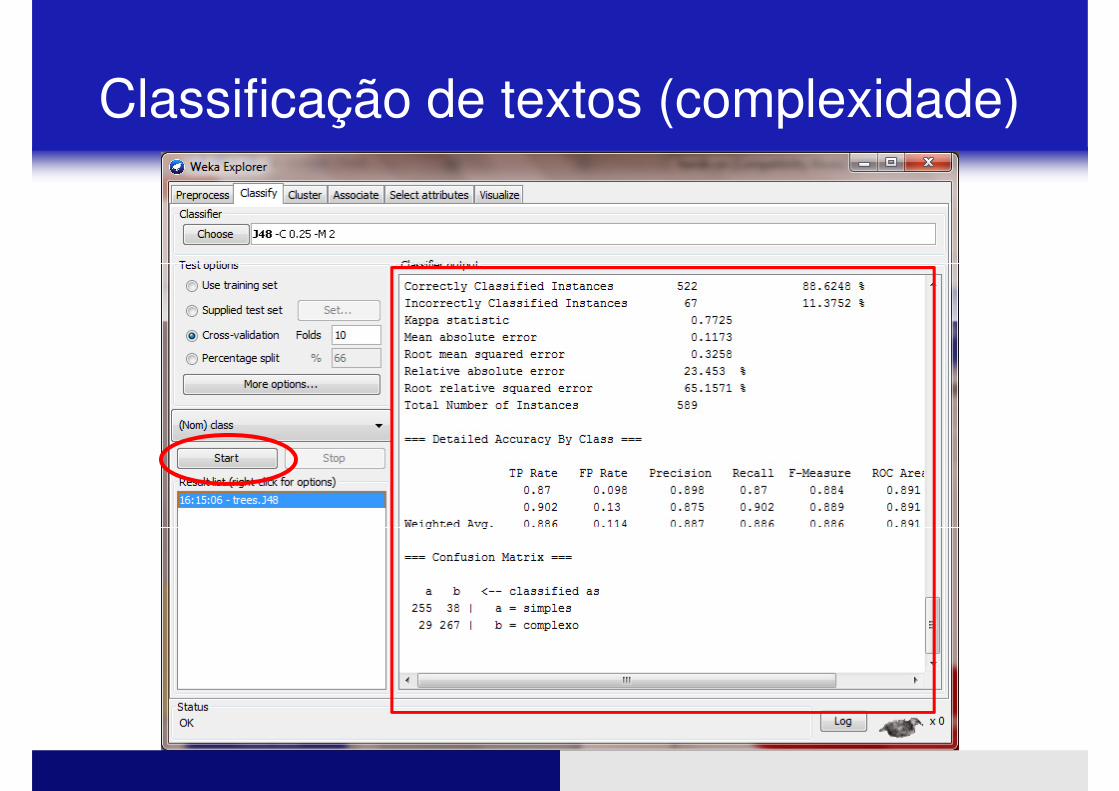
Classificação de textos (complexidade)
� Repitam o processo:
� Selecionem “Choose � functions � SMO”
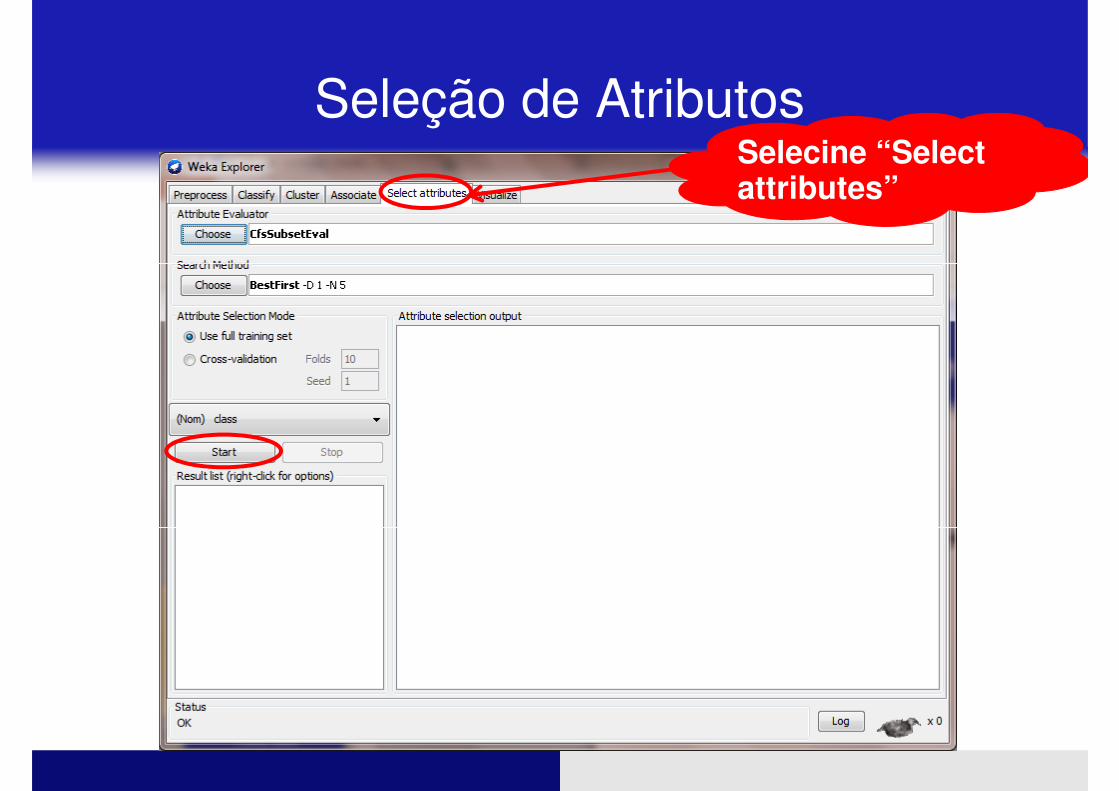
Seleção de AtributosSelecine “Select attributes”
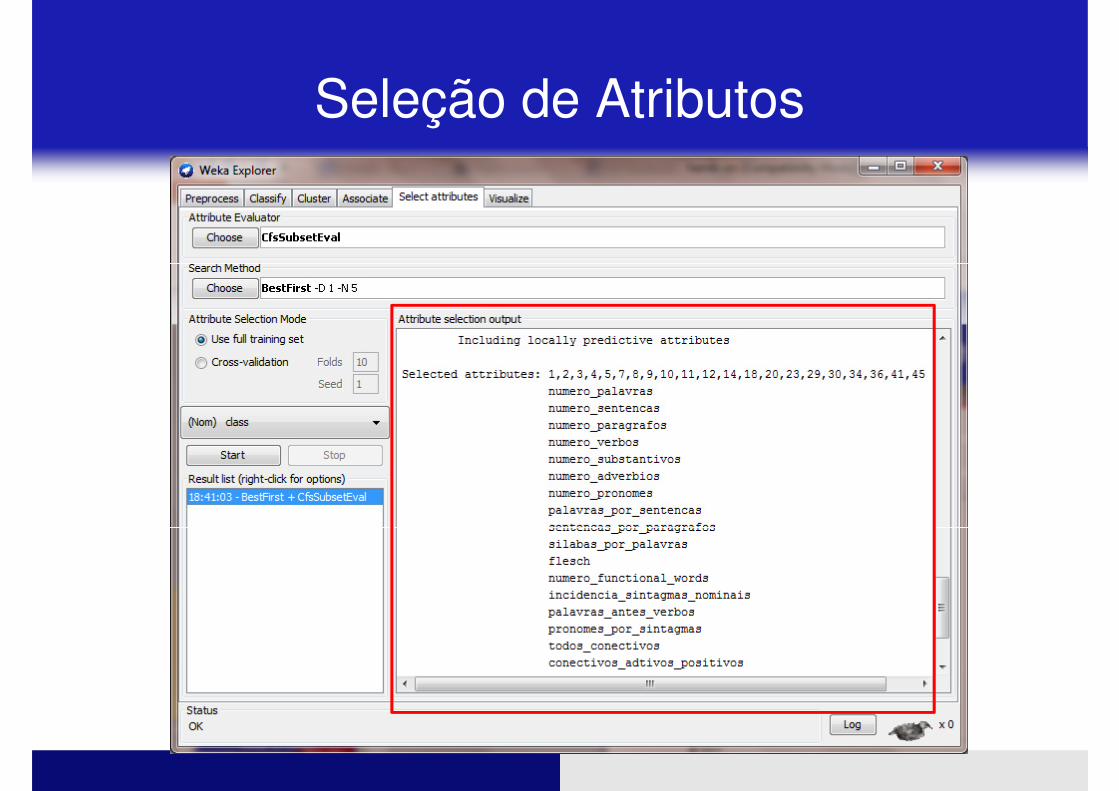
Seleção de Atributos
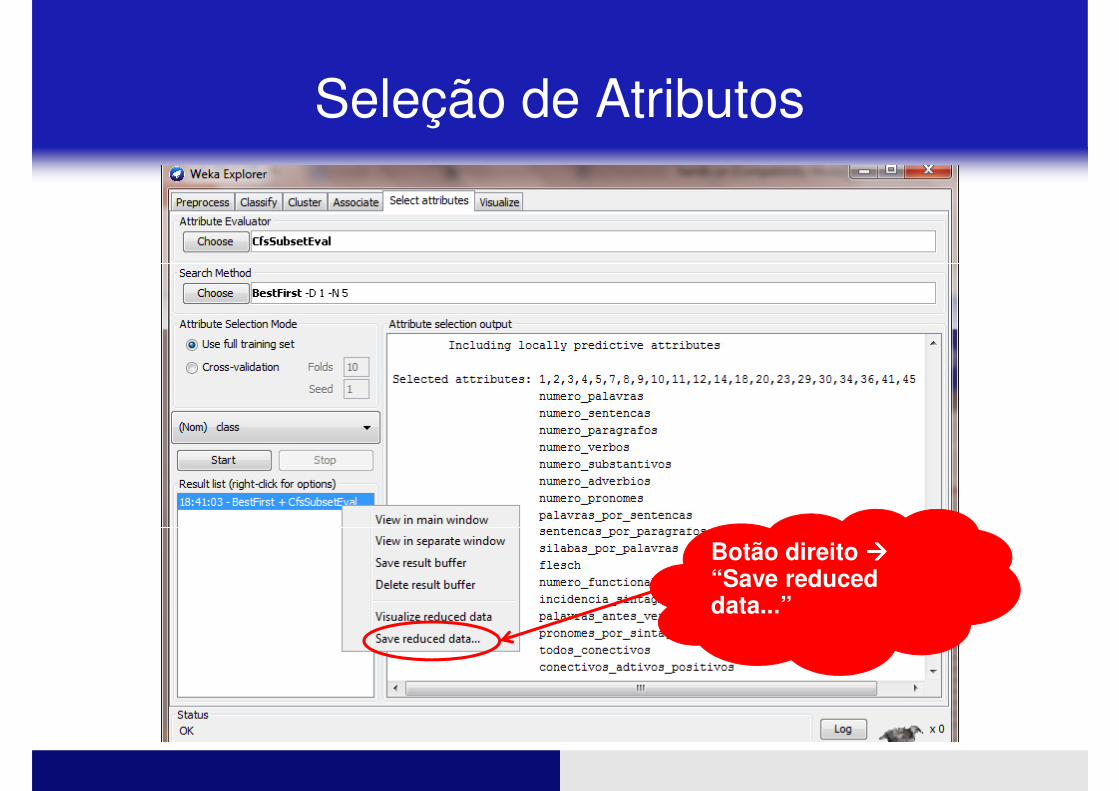
Seleção de Atributos
Botão direito ����“Save reduced data...”

Classificação de textos (complexidade)
� Repitam o processo:
� Utilizem o novo arquivo
� Classificação
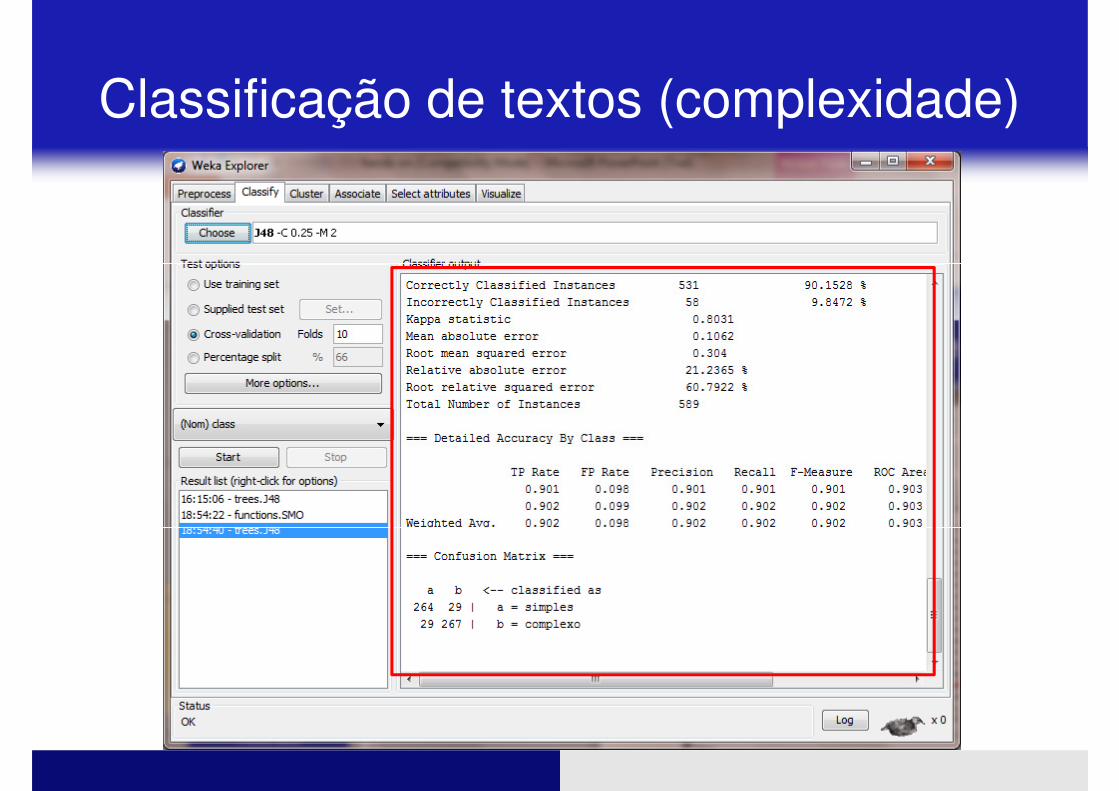
Classificação de textos (complexidade)

Classificação de textos (domínio) –atributos de complexidade
� Arquivo: dominio .arff
� Textos extraídos da Wikipedia
� 13 domínios: arte, biografias, ciências exatas, ciências da natureza, ciências sociais, cultura e ciências da natureza, ciências sociais, cultura e sociedade, desporto, geografia, história, literatura, musica, religião, tecnologia
� Cada classe com 12 textos (total: 156)
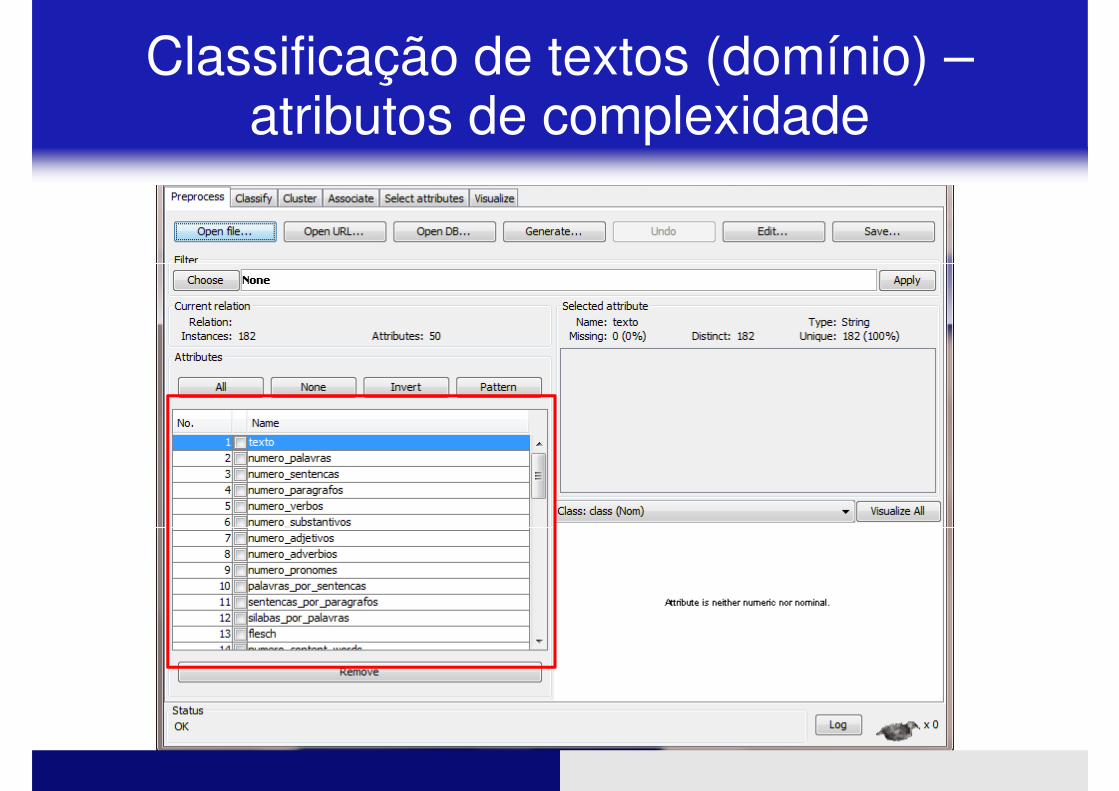
Classificação de textos (domínio) –atributos de complexidade
Classificação de textos (domínio) –atributos de complexidade
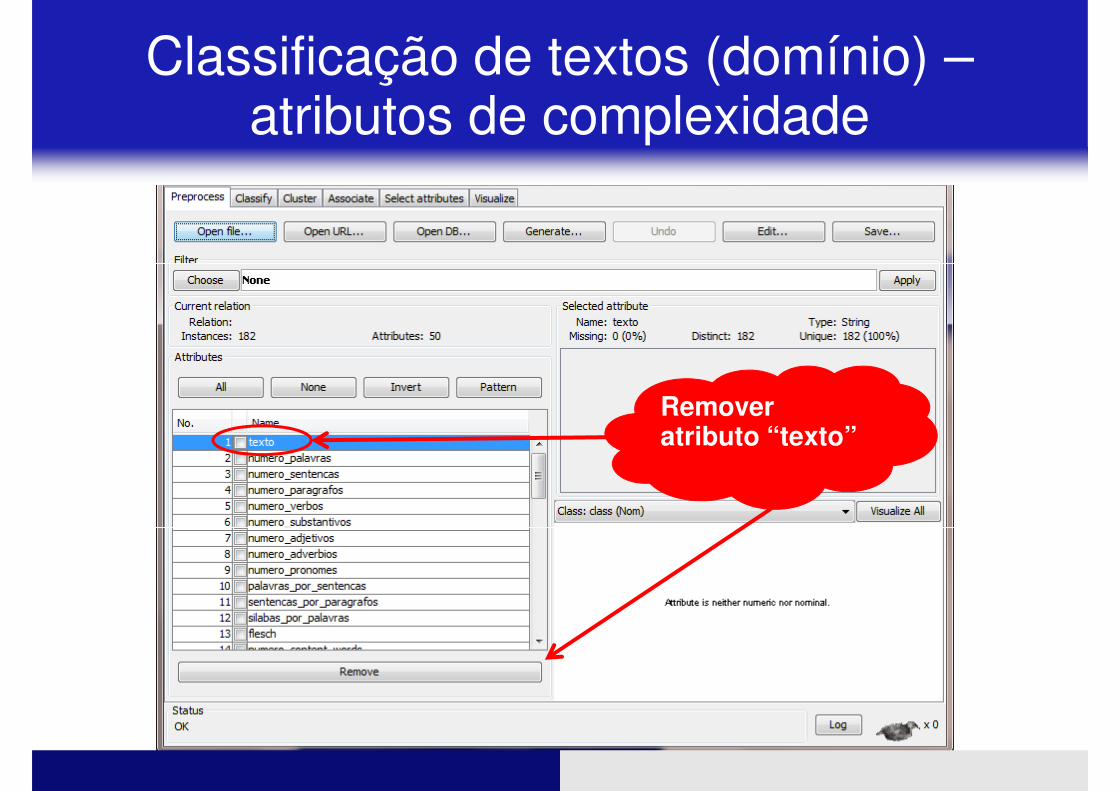
Remover atributo “texto”
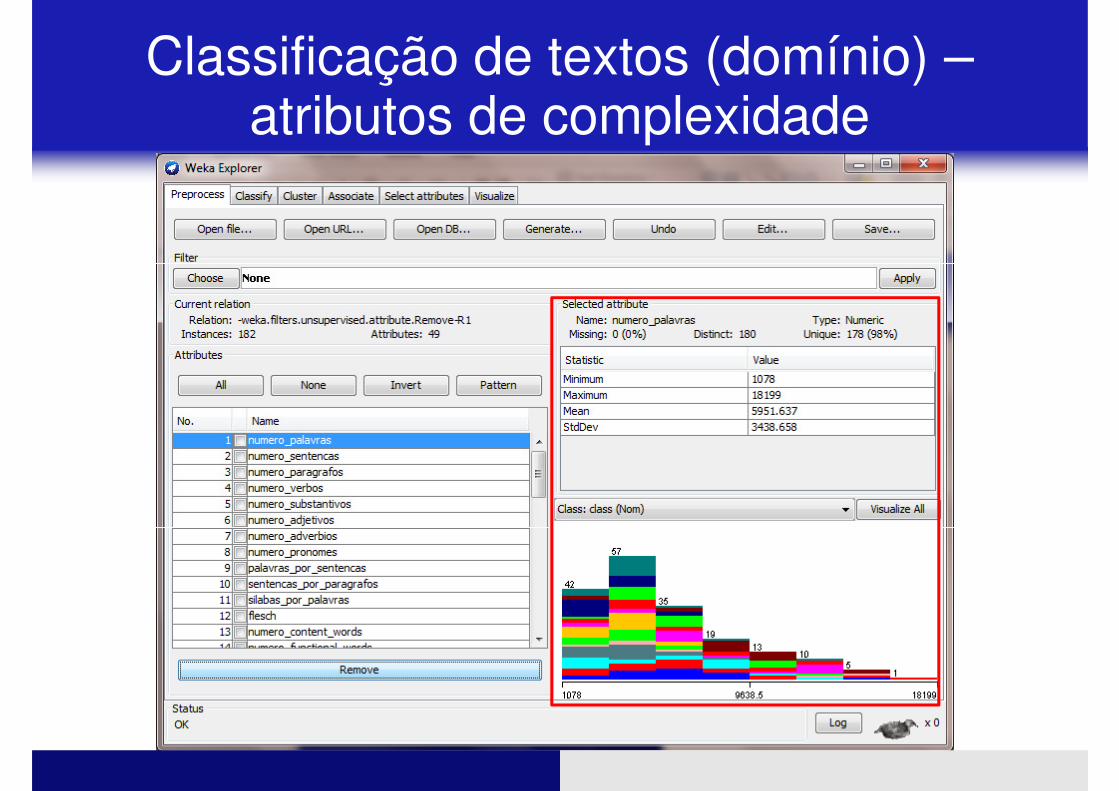
Classificação de textos (domínio) –atributos de complexidade

Classificação de textos (domínio) –atributos de complexidade
� Repitam o processo:
� Utilizem os classificadores nos novos dados
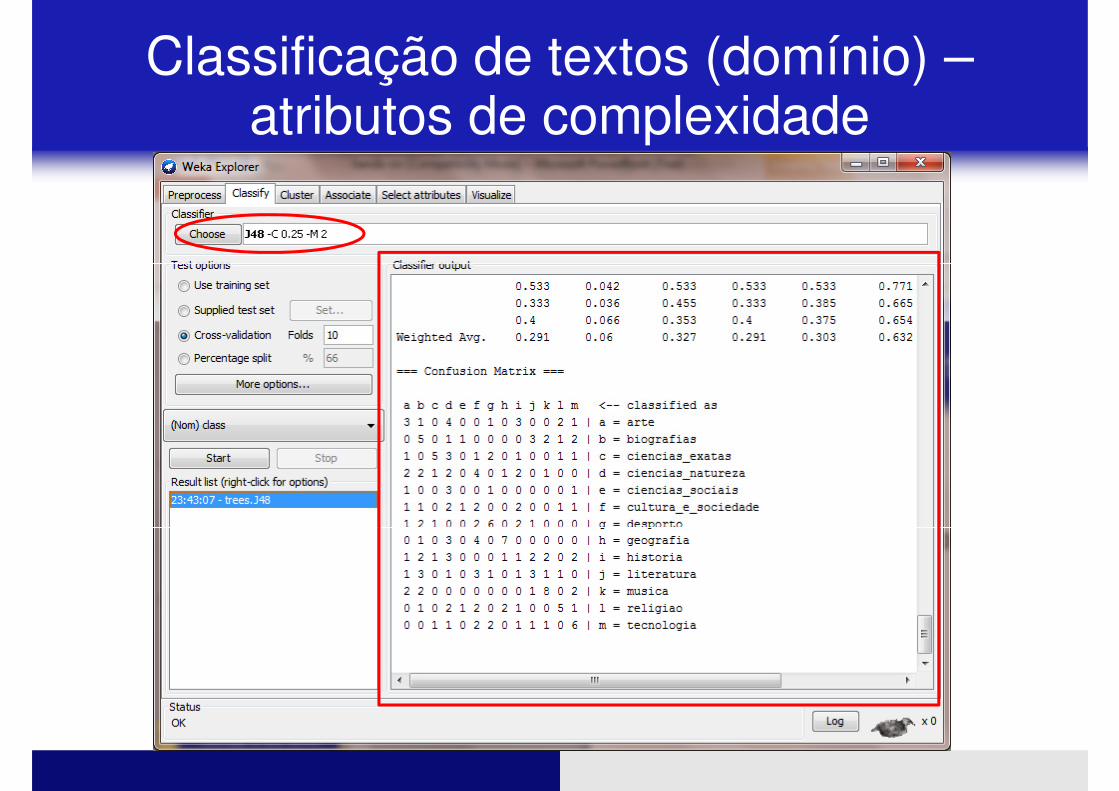
Classificação de textos (domínio) –atributos de complexidade

Seleção de Atributos
� Repitam o processo:
� Apliquem seleção de atributos para os novos dados
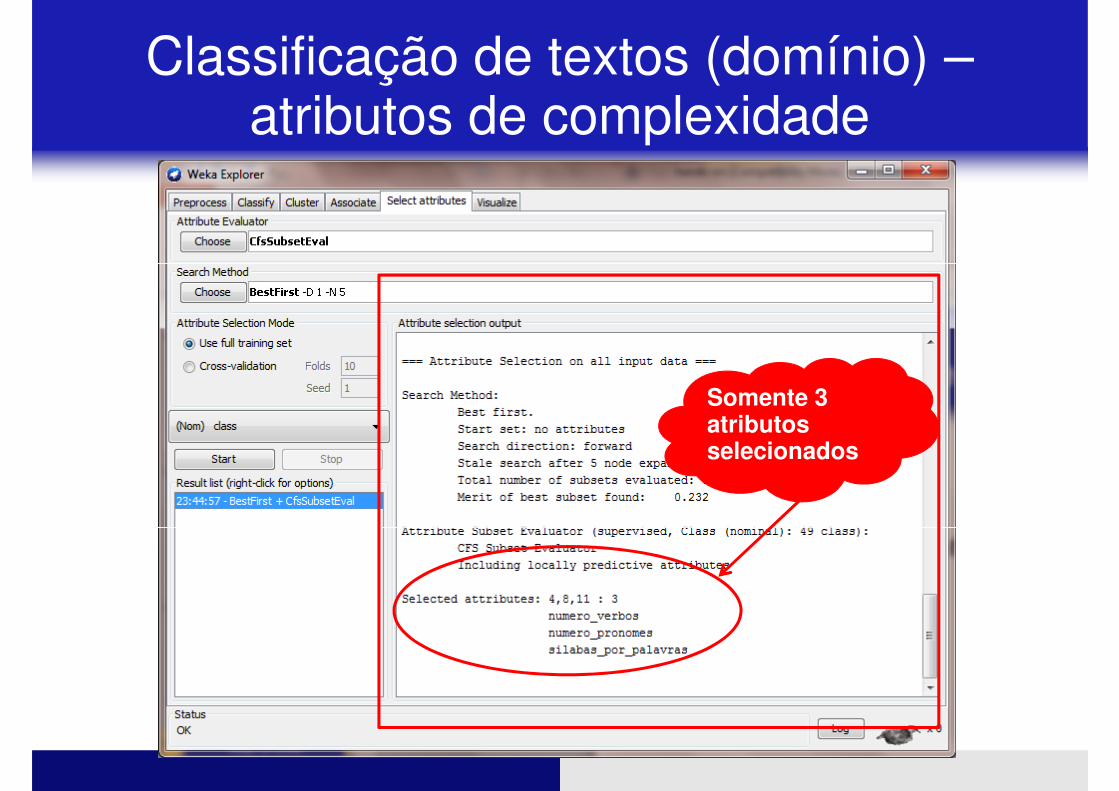
Classificação de textos (domínio) –atributos de complexidade
Somente 3 atributos selecionados

Seleção de Atributos
� Repitam o processo:
Guardem o arquivo .arff somente com os 3 � Guardem o arquivo .arff somente com os 3 atributos
� Realizem a classificação novamente
� Resultados???
� Pior com seleção de atributos!!!� Por isso, conhecer os atributos e os
domínios é muito importante!!!

� Utilizando o WEKA para geração dos atributos
Classificação de textos (domínio) – bag-of-words
� Atributos são as próprias palavras
� Passos:
� Abrir um prompt de comando do Windows ou um Shell do Linuxum Shell do Linux
� Entrar na pasta do WEKA
� Digitar o comando:java -cp weka.jar weka.core.converters.TextDirectoryLoader -dir text_example > bag.arff

� Abrir o arquivo bag.arff no WEKA
Classificação de textos (domínio) – bag-of-words
� Necessário a aplicação do filtro StringtoVector do WEKA
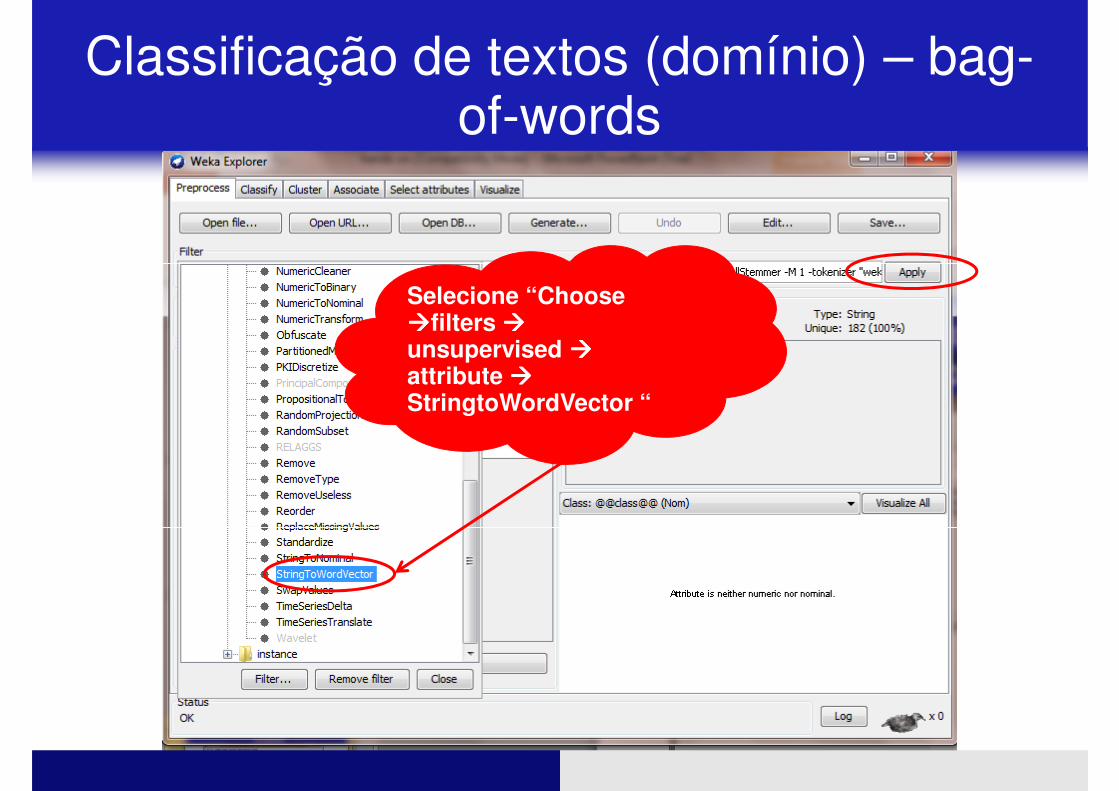
Classificação de textos (domínio) – bag-of-words
Selecione “Choose ����filters ����unsupervised ����attribute ����StringtoWordVector “

� Usar os dados e repetir o processo:
Aplicar classificação
Classificação de textos (domínio) – bag-of-words
� Aplicar classificação
� Realizar seleção de atributos
� Aplicar classificação novamente
� Resultados??Resultados??
� Melhor do que as métricas de complexidade
� Conclusão: nem sempre as métricas mais robustas são as melhores para a aplicação!!
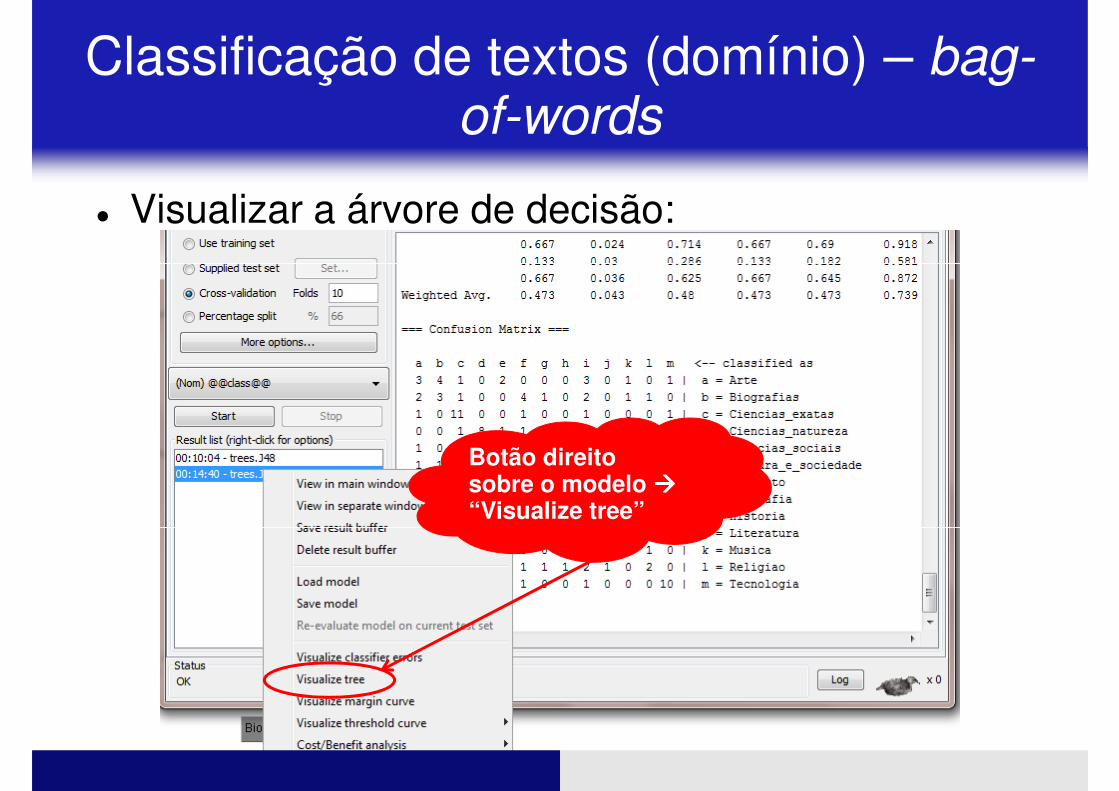
� Visualizar a árvore de decisão:
Classificação de textos (domínio) – bag-of-words
Botão direito sobre o modelo ����“Visualize tree”
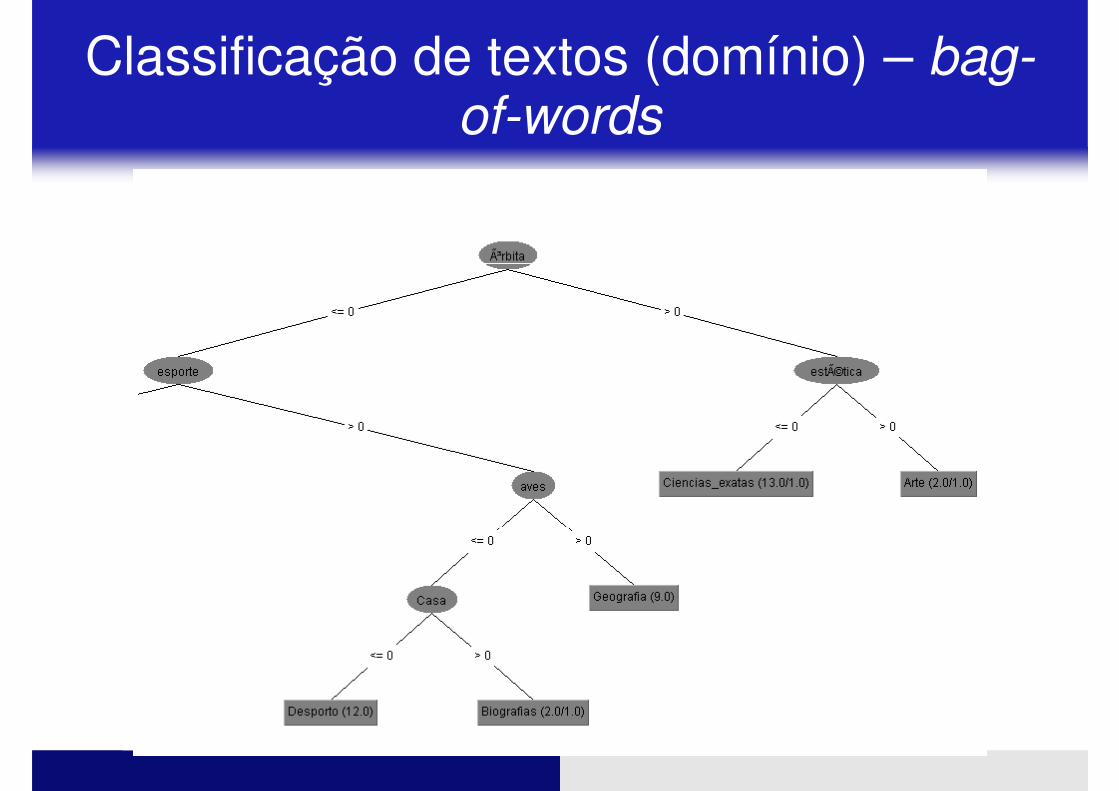
Classificação de textos (domínio) – bag-of-words

Créditos
� Slides baseados nas notas de aula dos Professores:
– Ricardo Campello
– André C. P. L. F. de Carvalho