Embed Size (px)
Citation preview

Correction automatique : bilan et perspectives
Coordonné par Séverine VIENNEY et Mounira BIOUD
Revue Annuelle - Année 2004 - N° 29Cré
atio
nA
lain
Gau
dey

Coordination Séverine Vienney et Mounira Bioud
Titre Bulag 29Correction automatique : bilan et perspectives
Résumé Les articles réunis dans ce numéro 29 du Bulag traitent desavancées, des problèmes et des limites rencontrées encorrection automatique. D’origine universitaire et industriel,ils abordent également les progrès envisageables dans cedomaine.
Public. Chercheur, Doctorants
Comité de lecture
Krzysztof Bogacki (Université de Varsovie)Sylviane Cardey (Université de Franche-Comté)André Clas (Université de Montréal)Stéphane Chaudiron (Université de Paris X)Rodolfo Delmonte (Université de Venise)Yves Gentilhomme (Université de Franche-Comté)Peter Greenfield (Université de Franche-Comté)Jean-Michel Hufflen (Université de Franche-Comté)Denis Le Pesant (Université d’Amiens)Henri Madec (Université de Franche-Comté)Igor Mel’cuk (Université de Montréal)Julio Murillo (Université Autonome de Barcelone)
Soutien Ouvrage publié avec le soutien de Centre Lucien Tesnière(UFR SLHS 30, rue Mégevand - 25030 Besançon cedex)
Mots clé Linguistique générale et appliquée - Traitement automatiquedes Langues - Correction automatique - Aide à la rédaction -Université de Franche-Comté - Presses universitaires deFranche-Comté - Publication en ligne
Langue Français, Anglais
Caractéristiques de l’édition papier
Éditeur Presses universitaires de Franche-Comté2, place Saint-JacquesUniversité de Franche-Comté25030 BESANÇON Cedex - France
Année 2004Collection «Revues»,
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Série «Bulag»Format 15 x 21 cm
196 pages recto versosupport papierISSN 0758 6787ISBN 2 -84867-080-0
Mise en pages Marie-Claire RougeotCouverture Alain Gaudey
d’après Luca della Robbia - La grammaticaMusée de l’Opera del Duomo - Florence
Imprimeur Jouve11, bd Sébastopol - BP 273475027 Paris cedex
Dépôt légal 4e trimestre 2004Copyright © Presses universitaires de Franche-Comté,
Université de Franche-Comté - 2004
Anciens numéros
Les anciens numéros encore disponibles peuvent êtrecommandés à l’aide du bon de commande page197-198.
Note de l’éditeur pour l’édition en ligne
Cette publication des Presses universitaires de Franche-Comté est la version intégrale en ligne de l'ouvrage sursupport papier cité en référence. L'accès à cette publicationest libre. Cependant toute reproduction pour publication ouà des fins commerciales de la totalité ou d'une partie del’œuvre devra impérativement faire l'objet d'un accordpréalable avec l’éditeur.Toute reproduction à des fins privées, ou strictementpédagogiques dans le cadre limité d'un enseignement, de latotalité ou d'une partie de l’œuvre est autorisée sous réservede la mention explicite des références éditoriales del'ouvrage (titre, auteur, éditeur, dépôt légal, N° ISBN ouISSN, copyright, adresse du site, pages extraites) et de ladéclaration au Centre Français d’exploitation du droit deCopie (www.cfcopies.com ) conformément à la législation envigueur.
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr


B u l a gCorrection automatique :
bilan et perspectives
Coordonné par
Séverine VIENNEY et Mounira BIOUD
Numéro 29
Revue annuelle – Année 2004
Presses universitaires de Franche-Comté, 2004
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr


SOMMAIRE
3
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Séverine VIENNEYPrésentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Mounira BIOUDUne normalisaton de l’emploi des majuscules pour un systèmede vérification orthographique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Éric BRUNELLEAntidote : Correcteur, Dictionnaire et Plus . . . . . . . . . . . . . . . . . . . . . 25
Frédéric DOLL et Claude COULOMBEL’avenir des correcteurs grammaticaux : un point de vue industriel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Chantal ENGUEHARD et Chérif MBODJDes correcteurs orthographiques pour les langues africaines . . . . . 51
Maryline HERNANDEZ and Ecaterina RASCUChecking and Correcting Technical Documents . . . . . . . . . . . . . . . . . 69
Henri MADECUne approche cognitive de la correction automatique des fautes de syntaxe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
Romain MULLERQuelle politique orthographique pour les correcteurs informatisés ? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105
SOMMAIRE

Mar NDIAYE et Anne VANDEVENTER FALTINCorrecteur orthographique adapté à l’apprentissage du français . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 117
Roger RAINERODébats télévisés en direct du sénat du Canada : correctionautomatique des sous-titres en français . . . . . . . . . . . . . . . . . . . . . . . 135
Myriam THOUETPrise en compte des propriétés sémantiques des unitéslexicales pour améliorer les correcteurs . . . . . . . . . . . . . . . . . . . . . . . 153
Jean-Sébastien TISSERANDParsers, grammaires formalisées et fautes de grammaire du français . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 163
Séverine VIENNEY et Ciprian MELIANLa correction automatique du langage des nouvelles formesde communication écrite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
SOMMAIRE
4
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Séverine VienneyPRÉSENTATION
5
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Nous consacrons le numéro 29 de la revue BULAG à la correctionautomatique. Notre objectif est double. D’une part, nous voulonsétablir un bilan des travaux qui ont été menés dans ce champ d’étude.D’autre part, nous désirons envisager les perspectives de recherchedans ce domaine. Les articles que nous avons collectés répondent à cesdeux attentes.A première vue, la correction automatique semble être un domaineactuellement négligé par les recherches en Traitement Automatiquedes Langues. Nous pouvons avancer deux principales explications.Tout d’abord, depuis plus de quinze ans, la correction automatique aquitté les simples laboratoires de recherche universitaire pour devenirun véritable champ industriel et commercial. Les recherches ne sontdonc pas publiées et les techniques employées restent secrètes. Quelques sociétés se sont donc spécialisées dans ce domaine oudéveloppent entre autres des systèmes de vérification et correctionautomatique, intégrés ou intégrables aux différents logiciels detraitement de texte. Nous aurons trois articles sur ce thème:
a Eric Brunelle aborde certains problèmes majeurs rencontrésen correction automatique et propose une description de l’outilAntidote.a Frédéric Doll et Claude Coulombe, deux des concepteurs duCorrecteur 101, nous dressent un bilan de l’évolution descorrecteurs automatiques avant de nous donner leur point devue industriel sur l’avenir des correcteurs grammaticaux.
PRÉSENTATION
Séverine VIENNEY
Centre de recherche L. TesnièreBesançon, France

a Roger Rainero nous présente une adaptation du correcteurProLexis pour la correction automatique des sous-titres françaisdes débats télévisés en direct du Sénat canadien.
Par ailleurs, une deuxième explication peut être proposée. En réalité,en regard des performances des correcteurs actuellement sur lemarché, nous pouvons constater qu’un certain seuil de qualité decorrection a été atteint et que ce seuil paraît extrêmement difficile àfranchir avec les outils et techniques actuels.Ceci constitue un second aspect abordé dans notre numéro : lesniveaux d’analyse traités par la correction automatique. En effet, ilexiste différents types de fautes qui nécessitent une analyse àdifférents niveaux de la langue : morphologique, syntaxique,sémantique, voire pragmatique et stylistique.Au niveau de la morphologie,
a Mounira Bioud propose un système de correctionautomatique de la majuscule en français. Un problème quinécessite une véritable normalisation avant son traitementautomatique. Doit-on écrire Mont Blanc, Mont blanc, mont blanc oumont Blanc?
a Les bouleversements orthographiques jouent également unrôle dans le développement des correcteurs automatiques. A cesujet, Romain Muller se pose la question de savoir si lescorrecteurs informatisés prennent en compte la politiqueorthographique du français. Un correcteur va-t-il détecter uneerreur si l’on écrit parait ou/et paraît?
Le niveau syntaxique est abordé dans plusieurs articles.
a Henri Madec nous propose un point de vue cognitif de ceproblème en distinguant les notions de « faute » et d’ « erreur ».Il nous expose également une série de problèmes qui ne peuventpas être résolus uniquement par une analyse syntaxique.
Séverine VienneyPRÉSENTATION
6
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Séverine VienneyPRÉSENTATION
7
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
a Parallèlement, Jean-Sébastien Tisserand étudie plusieursphénomènes linguistiques particuliers qui posent desproblèmes syntaxiques en vue d’une correction automatique etmontre qu’une analyse sémantique est indispensable.
En effet, certaines corrections ne peuvent se faire qu’à partir du niveausémantique voire pragmatique du texte. Ce point est également traitépar :
a Myriam Thouet qui défend l’idée d’une nécessaire prise encompte des propriétés sémantiques des unités lexicales pouraméliorer les correcteurs. La grenouille coasse ou croasse-t-elle?
Ainsi, nous pouvons constater que la recherche en correctionautomatique est encore active. Mais quelles sont les perspectives dansce domaine?En réalité, les recherches semblent se diriger vers une voie despécialisation. De nouveaux axes de recherche apparaissent. Les outils de correction sont développés pour un public précis.
a Chantal Enguehard et Cherif Mbodj soulèvent le problèmedu traitement automatique des langues africaines et montrentcomment le développement d’outils électroniques pour ceslangues peut contribuer au développement des pays concernés.a Mar Ndiaye et Anne Vandeventer Faltin présentent leurcorrecteur orthographique adapté à l’apprentissage du français.Toute l’efficacité du système repose sur la prise en compte deserreurs spécifiques à ces utilisateurs.
Un correcteur adapté à une cible particulière semble donc pouvoirobtenir de bons résultats.De nouveaux langages ou de nouvelles langues nécessitent égalementune adaptation des correcteurs automatiques actuels :
a Séverine Vienney et Ciprian Melian proposent un système decorrection automatique du langage texto, ce nouveau langageapparu avec l’évolution des nouvelles formes de communi-cation écrite (e-mail, sms, forums de discussions, etc.) qui ontengendré des bouleversements linguistiques.

Finalement, la correction automatique va-t-elle suivre la voie ouvertepar la traduction automatique ? En effet, elle s’est avérée efficace surles langages contrôlés : le système TAUM de traduction automatiquede bulletins météorologiques en est le meilleur exemple.
a Maryline Hernandez et Ecatarina Rascu proposent sur cethème un système de correction automatique destiné auxrédacteurs techniques. Le type de documents analysé possèdeeffectivement des caractéristiques lexicales, syntaxiques,sémantiques et stylistiques bien particulières et donc peut-êtreplus facile à traiter automatiquement.
Voilà quelques uns des points abordés dans ce numéro du BULAG surLa correction automatique : bilan et perspectives. Nous remercionsles auteurs pour leurs contributions qui ont permis d’envisager ledomaine sous de nombreux aspects.
Séverine VienneyPRÉSENTATION
8
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
9
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
RésuméL’usage des majuscules en français souffre d’une absence de norme fixe et universellequi entraîne inévitablement leur placement aléatoire et souvent injustifié. Cetteabsence fait apparaître des phénomènes appelés majusculite (abus des majuscules) etminusculite (abus des minuscules). Peu à peu on voit le véritable sens des majusculesdisparaître et leur pertinence devenir moins évidente. Tant d’incertitudes,d’hésitations et de flottements dans les règles d’usage, tant de différences de traitementd’un ouvrage à un autre rendent toute tentative d’automatisation très difficile. Cettenormalité bancale touche plus particulièrement les noms propres dits complexes oudénominations. La solution la plus logique, pour que cesse la dérive, est de normaliserl’emploi des majuscules. A partir de règles claires et logiques qui ne laisseraient plusde place à la fantaisie, on pourrait alors élaborer un système automatique vérifiantl’orthographe des dénominations et par là même, la pertinence de la majuscule. Cettesolution verrait ainsi la disparition des variantes orthographiques.
Mots clefsmajuscule ; nom propre ; dénominations ; normalisation ; patrons morpho-syntaxiques ;vérification orthographique
AbstractThe use of capital letters in French suffers from a lack of fixed standardization thatinevitably involves that they are used without methodology. From this absenceappeared two phenomenons called “majusculite” (abuse of capital letters) and“minusculite” (abuse of small letters). Little by little one sees the true direction of thecapital letters disappearing and their relevance to become less obvious. Such anamount of doubts, hesitations and fluctuations in the rules of employment, so muchdifferences between the different authors, between works with anothers returns anyattempt of automatic processing very difficult. This wobbly normality more
UNE NORMALISATION DE L’EMPLOI DESMAJUSCULES POUR UN SYSTEME DEVERIFICATION ORTHOGRAPHIQUE
Mounira BIOUD
Centre de recherche en linguistique Lucien TesnièreUniversité de Franche-Comté, Besançon, France.

particularly touches the proper names known as complex or denominations. The mostlogical solution, so that cease the drift, is to standardize the use of capital letters. Fromclear rules and logics, which would not leave any more a place to imagination, one willbe able to work out an automatic system checking the denominations spelling, checkingthe relevance of the capital letter. Thus, this solution would see the disappearance ofthe spelling variants.
Key-wordsupper-case letter ; proper noun ; denomination ; standardization ; morpho-syntacticpatterns ; spell checking
INTRODUCTION
La majuscule est un signe graphique, pour certains un signe deponctuation, permettant essentiellement de situer les débuts dephrases et de marquer les noms propres. La majuscule, tout autant quele point ou la virgule, est un “baliseur naturel”, un indice doublementutilisé en traitement automatique du langage.D’une part, elle participe à la phase de segmentation du texte, elle adonc un rôle syntaxique. D’autre part, elle permet, si l’on travailledans le domaine de l’extraction d’information par exemple, de repérerles noms propres, ce qui lui vaut de tenir un rôle sémantique.La majuscule a donc l’avantage d’avoir une double fonctionnalité dansla langue et dans le domaine du traitement automatique des langues.
- une fonction démarcative, syntaxique- une fonction distinctive, sémantique
Néanmoins, les choses ne sont pas si simples quant à l’emploi desmajuscules en français. En les étudiant de près, on ne peut manquerd’être surpris par le flottement et l’incertitude qui existent dans leurusage. En effet, les majuscules souffrent d’une absence de norme quirend difficile leur automatisation. Savoir où et quand mettre unemajuscule n’est pas si évident que cela. Le problème est d’autantplus frappant pour l’emploi de la majuscule dans les noms propresdits “complexes” ou “composés” (le mont Blanc, le ministère del’Intérieur) que nous appellerons plus simplement les“dénominations”.
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
10
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
11
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Une dénomination est un groupe de mots dont l’ensemble prend lestatut de nom propre car elle contient toujours au moins unemajuscule. Une dénomination est généralement composée d’ungénérique (très souvent un nom commun) et d’un spécifique (trèssouvent un adjectif). Dans le musée Grévin, le ministère del’Education, la mer Morte, les noms musée, ministère et mer sont lesgénériques, tandis que les mots Grévin, Education et Morte sont lesspécifiques.La question du choix majuscule/minuscule demeure un véritablecasse-tête : doit-on écrire
la Cour Carrée, la Cour carrée, ou la cour Carrée ?La Montagne Noire, la Montagne noire, ou la montagne Noire?
C’est partant de cette incertitude et de ce flottement que nous avonsentrepris, dans le cadre d’une thèse, nos recherches sur la majuscule etles noms propres.Dans un premier temps, nous montrerons pourquoi une normalisationde l’emploi des majuscules est nécessaire avant tout traitementautomatique. Puis dans un second temps, nous présenterons notregrammaire des dénominations et enfin nous dirons en quoi cettegrammaire est indispensable dans un outil de vérificationorthographique.
1. DE LA NÉCESSITÉ D’UNE NORME
La question que nous nous posons est de savoir comment vérifier lebon emploi d’une majuscule à un mot ou à une suite? Sur quelouvrage se baser? Pouvons-nous en automatiser l’usage? Ces diversesquestions ouvrent le champ d’investigation sur la majuscule et parextension, sur les noms propres.
1.1. Absence de norme fixe et contradictionsIl serait faux de dire qu’il n’existe pas de règles régissant l’emploi desmajuscules dans l’écriture des dénominations. Elles existent comme onpeut le constater en consultant des ouvrages tels que les guidestypographiques ou les grammaires. Seulement, le problème en ce qui

concerne ces règles c’est qu’elles ne sont pas absolues et universelles.C’est ce qu’a mis en avant Michel Mathieu-Colas (1998) en observantl’orthographe des noms propres composés du type “nom + adjectif” :
« Certes, il existe des “règles”, aussi précises que contraignantes, etque décrivent minutieusement les dictionnaires orthographiques etautres guides du bon usage. […] on serait donc en droit de penser qu’ilexiste à ce sujet des normes graphiques universelles, […] L’observationmontre qu’il n’en est rien. Si chaque auteur présente ses règles sousune forme impérative, on note un certain nombre de divergences qui,dissipant l’illusion d’une norme universelle, ne font que mettre enévidence l’instabilité du système. »
Dans cet article, Michel Mathieu-Colas montre très bien toutel’étendue de la difficulté à laquelle nous faisons face dans nosrecherches. L’emploi des majuscules relevant plus de l’usage que de la norme, onlaisse souvent le choix à l’auteur d’employer la majuscule comme bonlui semble. Ce qui est également le cas de la ponctuation où les signesservant à la marquer sont utilisés sans beaucoup de méthode et avecbeaucoup de fantaisie. Or une telle liberté aboutit inévitablement à desabus qui font perdre aux majuscules, et à tout autre signe de la langue,leur pertinence et leur validité quant à leurs usages et freine par-làmême, toute tentative de traitement automatique.
1.2. Les variantes orthographiquesEn présence de cette normalité bancale, on voit apparaître deuxphénomènes importants que sont la “majusculite” (abus desmajuscules) et la “minusculite” (abus des minuscules). Ces deuxphénomènes sont la conséquence directe de l’absence d’unification etd’harmonisation des règles d’usage des capitales entre les différentsouvrages. Le scripteur est de plus en plus libre d’écrire selon safantaisie ou sans réel souci de savoir si la majuscule à tel mot estnécessaire ou non. Ainsi, il est de plus en plus courant de trouver destextes où un même mot est orthographié de deux ou trois façonsdifférentes, parfois même plus. Et c’est la présence de ces variantesorthographiques qui va poser de nombreuses difficultés aux systèmesd’extraction d’informations par exemple. En effet, la valeur
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
12
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
13
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
“un signifiant-un signifié” n’est plus du tout respectée. Aujourd’huion trouve plusieurs signifiés associés à un même signifiant. Il n’existepas moins de huit façons différentes d’orthographier Moyen-Age :
moyen âge, moyen-âge, Moyen âge, Moyen-âge, Moyen Age, Moyen-Age, Moyen Âge, Moyen-Âge
Pour un humain, la reconnaissance de ces variantes orthographiquesne pose en général pas de difficultés, mais il en va autrement pourl’ordinateur. Pour ce dernier, chacune de ces huit orthographes vadésigner huit référents différents. On pourrait parler de synonymiedans ce cas là, mais ce ne serait pas tout à fait exact dans la mesure où,entre ces différents mots, il n’existe aucune nuance de sens.Pour éviter l’encombrement des bases de données en les remplissantde “synonymes graphiques” inutiles, il faudrait que la machine sacheque chacune de ces huit suites ne désignent qu’un seul et mêmesignifiant.
1.3. Quelles solutions?
A nos yeux, il n’est pas envisageable de tolérer les variantesorthographiques pour les raisons que nous avons évoqué plus haut.On pourrait céder à la “minusculite” et ne plus utiliser du tout lesmajuscules. Mais cette solution n’est pas envisageable non plus car lesmajuscules sont indispensables à la désambiguïsation sémantique decertains noms propres polysémiques : la Bourse/la bourse, Paris/paris,Pierre/la pierre. Mais également pour désambiguiser certainesdénominations :
- La haute Garonne en parlant du fleuve- La Haute Garonne en parlant du bassin supérieur du fleuve- La Haute-Garonne en parlant du département
On notera ici le rôle important que tient le trait d’union, associé à unemajuscule, dans le processus de désambiguïsation mais aussi dereconnaissance de certaines formes figées.Ne pas céder à la minusculite implique également d’éviter lamajusculite. La majuscule répond à un souci de clarté, mal utilisée elle

ne pourrait provoquer que confusion. Il semblerait que céder à lasimplicité de la minusculite provoquerait plus de ravages que lamajusculite : entre le “trop” et le “trop peu”, il serait plus sage degarder la majuscule mais en réglementant son emploi. En effet, il existerait une solution plus économique encore que ladisparition de la majuscule et qui consisterait à limiter l’écriture d’unedénomination à une seule et unique orthographe. Pour cela, il faudraitdonc normaliser les règles d’usage des majuscules notamment en cequi concerne la majuscule dans les dénominations.Cette dernière solution est la plus logique pour mettre fin à la dérivedes majuscules et voir disparaître l’existence des variantesorthographiques, cela faciliterait par conséquent le travail entraitement automatique des langues.
2. UNE GRAMMAIRE DES DÉNOMINATIONS
Comme nous l’avons montré précédemment, il n’existe pas deconsensus réel entre les divers auteurs pour trancher de l’usage de lacapitale dans la plupart de ses emplois. Dans le cadre de cet article,nous nous focaliserons sur une catégorie de noms propres, lesdénominations, dont l’orthographe instable constitue une réelledifficulté pour le traitement informatique.
2.1. MéthodologieBeaucoup d’auteurs ont mis en évidence l’instabilité du système desmajuscules et sont par conséquent favorables à une normalisation.Nous savons qu’un projet de normalisation est un processus assezlong qui nécessite réflexion, organisation et doit être fait par unecommission de spécialistes (linguistes, auteurs, éditeurs, etc.). Il existeaujourd’hui des systèmes parfaitement capables de vérifier lapertinence des majuscules aux noms. Seulement, ces règles devérification sont élaborées arbitrairement, à partir d’un ouvrage deréférence tel que le Bon usage. Dans le cadre de nos recherches, nousavons décidé que notre travail de “normalisation” aurait pour basenon pas un seul ouvrage mais plusieurs. La démarche choisie répondà un souci d’homogénéisation et de complétude. La consultation de
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
14
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
15
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
plusieurs ouvrages permet d’une part de couvrir tout le champd’application des majuscules et d’autre part d’élaborer des règles dansun réel consensus entre les différents auteurs.Afin de constituer nos règles qui régiraient l’emploi des majuscules,
nous nous sommes donc basés sur une certain nombre d’ouvragessouvent cités comme référence en la matière :
- Le Ramat typographique (RAMAT Aurel, Editions CharlesCorlet 1993) ;- Le Memento typographique (GOURIOU Charles, Editions duCercle de la Librairie, 1990) ;- Le Code typographique : choix des règles à l’usage des auteurset des professionnels du livre (Fédération CGC de lacommunication 1986) ;- Lexique des règles en usage à l’Imprimerie nationale (2002)- LeBon usage (GREVISSE Maurice, 13é éd. ref par André Goose,Duculot 1993) ;- Majuscules, abréviations, sigles et symboles (DOPPAGNEAlbert, Duculot 1998).
Chaque règle a été établie de façon à être la plus simple et la pluslogique possible. Un des premiers objectifs de cette normalisation estde simplifier et d’unifier l’usage des majuscules.
2.2. Classement graphique des dénominations : patronsmorphosyntaxiques
Dans un premier temps, nous avons procédé à un classementmorpholexical des dénominations afin d’en dégager des régularitésqui faciliteront le traitement automatique en générant des règles. Cespatrons morpho-syntaxiques pourront par la suite être utilisés aussibien en extraction d’informations qu’en correction automatique. Nousprésenterons ici quatre grands types de dénominations.
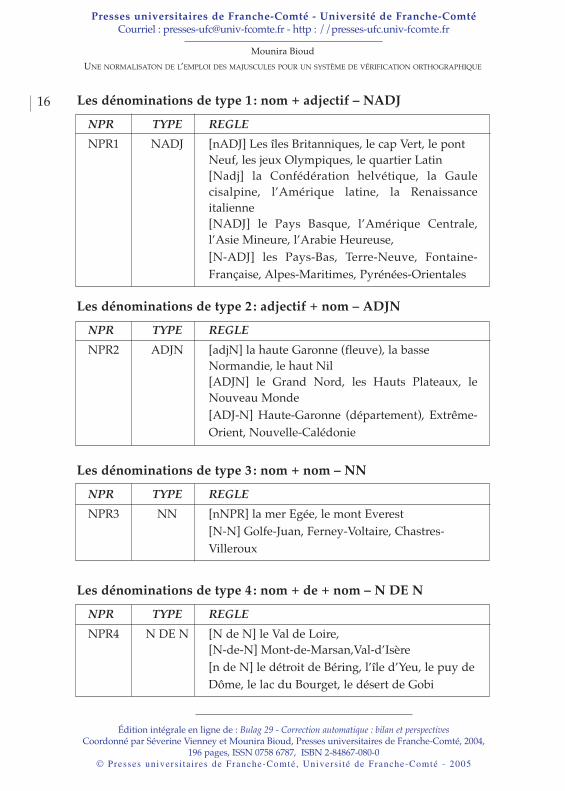
Les dénominations de type 1 : nom + adjectif – NADJNPR TYPE REGLENPR1 NADJ [nADJ] Les îles Britanniques, le cap Vert, le pont
Neuf, les jeux Olympiques, le quartier Latin[Nadj] la Confédération helvétique, la Gaulecisalpine, l’Amérique latine, la Renaissanceitalienne[NADJ] le Pays Basque, l’Amérique Centrale,l’Asie Mineure, l’Arabie Heureuse,[N-ADJ] les Pays-Bas, Terre-Neuve, Fontaine-Française, Alpes-Maritimes, Pyrénées-Orientales
Les dénominations de type 2 : adjectif + nom – ADJNNPR TYPE REGLENPR2 ADJN [adjN] la haute Garonne (fleuve), la basse
Normandie, le haut Nil [ADJN] le Grand Nord, les Hauts Plateaux, leNouveau Monde[ADJ-N] Haute-Garonne (département), Extrême-Orient, Nouvelle-Calédonie
Les dénominations de type 3 : nom + nom – NNNPR TYPE REGLENPR3 NN [nNPR] la mer Egée, le mont Everest
[N-N] Golfe-Juan, Ferney-Voltaire, Chastres-Villeroux
Les dénominations de type 4 : nom + de + nom – N DE NNPR TYPE REGLENPR4 N DE N [N de N] le Val de Loire,
[N-de-N] Mont-de-Marsan,Val-d’Isère [n de N] le détroit de Béring, l’île d’Yeu, le puy de Dôme, le lac du Bourget, le désert de Gobi
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
16
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
17
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
2.3. La normalisationNous venons de dégager, pour chaque catégorie de dénomination, lesproblèmes inhérents à l’emploi de la majuscule. Nous avons essayépar la suite de normaliser, dans la mesure du possible, l’emploi de lacapitale de telle façon que nous puissions tirer des règles logiques,claires et précises qui pourront être utilisées par la suite dans unsystème de vérification orthographique.Malgré les apparences, il existe une règle qui régit les suitesconstituées d’un générique et d’un spécifique. La règle est la suivante :dans les dénominations, le générique prend une minuscule et lespécifique une majuscule.
la mer Rouge, le fleuve Jaune, le pôle Nord, le massif Armoricain, lesmontagnes Rocheuses, la route de Normandie,…
Tous les “spécialistes” s’accordent pour dire que dans lesdénominations, le nom commun d’espèce (le générique) prend uneminuscule. Pour restreindre l’emploi de la majuscule et normaliser sonemploi, on la réservera au mot “maître” (le spécifique), le motcaractéristique, généralement le premier substantif nécessaire àl’identification. Les autres mots servent quant à eux de qualificatifs oude déterminants :
la guerre de Sécession, la mer Morte, le musée Grévin.
Il n’y a qu’une seule mer appelée Morte et qu’un seul musée Grévinmais des milliers de musées. On retrouve ici le rôle essentiel de lamajuscule distinctive : individualiser, singulariser.A partir de cette règle très simple, et très claire, il est possible d’élaborerun système vérifiant l’orthographe des dénominations et les corriger sibesoin est.La réalisation de telles règles ne va pas sans s’accompagner d’uncertain nombre d’exceptions et de phénomènes particuliers quiremettent en cause le caractère “normatif” de nos règles.Il existe des cas qui font exception par tradition et où le génériqueprend une majuscule : le Bassin parisien, le Massif armoricain, le Quartierlatin. Cependant, dans d’autres ouvrages, on constate que ces suitessuivent la règle générale exposée précédemment.

On trouve également des cas où, devant le caractère d’unicité et desingularité que confère la majuscule, on trouve le génériquealternativement en majuscule ou en minuscule selon qu’il soit suivid’un nom commun, d’un adjectif ou d’un nom propre :
la banque Durand mais, la Banque de commerce
Ces diverses exceptions nous confortent dans notre objectif denormalisation. Aussi, dans un souci d’homogénéité et pour pouvoiraboutir à un système automatique, il est indispensable de se libérer detoutes les contraintes qui invalident les règles élaborées. Ainsi, lesexceptions ne seront plus des exceptions car elles suivront toutes larègle générale : majuscule au spécifique et minuscule au générique.
2.4. Les règles
Après avoir dégagé les patrons morpho-syntaxiques qui nous ontpermis de repérer les différents types de dénominations et de procéderà leur classement, nous pouvons dès lors, pour chaque type, élaborerun certain nombre de règles régissant leur orthographe.
11 Dénomination NADJ : “nom + adjectif” :
Û si le nom est un générique alors [nA] :[nA] = minuscule au générique et majuscule au spécifique.
le mont Blanc, la mer Rouge, les îles Britanniques, les jeuxOlympiques, la république Argentine, le pont Neuf, le quartierLatin,...
Û si le nom n’est pas un générique,Û si l’adjectif a une valeur adjectivale précisant la situation,
l’altitude, la dépendance, etc., alors [Na] :
22 [Na] = le nom prend une majuscule et l’adjectif une minuscule.Amérique latine, Italie méridionale, Gaule cisalpine, Colombiebritannique, Assemblée nationale, Cour de cassation,…
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
18
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
19
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Û si l’adjectif n’a pas une valeur adjectivale précisant la situation,l’altitude, la dépendance mais forme avec le nom qu’il accompagneune entité inséparable alors [NA] :[NA] = majuscule aux deux éléments.
Asie Mineure, Pays Basque
Û si le nom et l’adjectif sont reliés par un trait d’union alors [N-A] :[N-A] = majuscule aux deux éléments.
Les Pays-Bas, Terre-Neuve, Alpes-Maritimes, Pyrénées-Orientales
33 Dénomination ADJN: “adjectif + nom”
Û si l’adjectif a une valeur adjectivale précisant la situation, l’altitude,la dépendance, etc., alors [aN] :[aN] = minuscule à l’adjectif et majuscule au nom,
la haute Garonne, basse Normandie, haut Nil, haute Egypte,
Û si l’adjectif n’a pas une valeur adjectivale précisant la situation,l’altitude, la dépendance, etc., alors [AN] :[AN] = majuscule aux deux éléments
le Grand Nord, les Hauts Plateaux, le Nouveau Monde
Û si les deux éléments sont reliés par un trait d’union alors [A-N] :[A-N] = majuscule aux deux éléments reliés par un trait d’union.
Bas-Rhin, Haute-Loire, Sacré-Cœur, Extrême-Orient, Moyen-Atlas,Anti-Liban, Grande-Bretagne, Nord-Américains, Anglo-Saxons,…
44 Dénomination NN: “nom commun + nom propre”
Û si le nom est un générique et qu’il est suivi d’un nom propre alors[nN] :[nN] = minuscule au nom commun
la mer Egée, le mont Everest

Û si les deux noms sont reliés par un trait d’union alors [N-N] :[N-N] = majuscule aux deux éléments reliés par un trait d’union
Golfe-Juan, Ferney-Voltaire, Chastres-Villeroux
55 Dénomination N de N: “nom + de + nom propre”
Û si le nom est un générique et qu’il est suivi d’un nom propreintroduit par “de” alors [n de N] :[n de N] = minuscule au nom commun
le détroit de Béring, l’île d’Yeu, le lac du Bouget, le désert de Gobi
Û si les deux éléments sont reliés par un trait d’union alors [N-de-N] :[N-de-N] = majuscule aux deux éléments reliés par un trait d’union.
Mont-de-Marsan, Val-d’Isère
3. APPLICATIONS
Le but de notre travail de recherche est d’élaborer un modèle théoriquepour automatiser l’emploi des majuscules en français. Ce modèle seraà la base d’un outil d’aide à la rédaction capable de vérifier lapertinence d’une majuscule à un mot ou à une dénomination.
3.1. Notre système
Notre système interviendra après la phase de repérage et d’étiquetagede tous les mots en majuscule à qui on aura donné l’étiquette NPR quisera affiné dans la suite de l’analyse.
Il a gravi le mont Blanc cet été.Pro V PP Det NPR Det N
mont Blanc = NPR complexe (N+Adj) ; “mont” est un génériquedonc minuscule :
Il a gravi le mont Blanc cet été.Pro V PP Det NPR Det N
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
20
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
21
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Comme nous l’avons montré précédemment, les dénominationspeuvent se décliner sous différentes formes, chacune obéissant à desrègles orthographiques spécifiques.Une des finalités de ce projet pourrait être de remettre “aux normes”des textes journalistiques par exemple :
“[…] et confier aux gendarmes les régions rurales les moins peuplées,le ministère de l’intérieur dispose d’une source d’inspiration […]”.
Le Monde (2002).
Le mot “ministère” est un générique mais “intérieur” est unspécifique, il spécifie de quel ministère on parle donc il doit avoir unemajuscule initiale.
“[…] et confier aux gendarmes les régions rurales les moins peuplées,le ministère de l’Intérieur dispose d’une source d’inspiration […]”.
Plusieurs modules sont donc nécessaires à l’élaboration d’un telsystème :
- un module de prétraitement lexical- un module d’étiquetage morpho-syntaxique- un module d’analyse contextuelle : pour lever toutes les
ambiguïtés possibles.- un module de vérification orthographique.
A ces modules sont adjoints un dictionnaire d’amorces qui servirad’une part à la reconnaissance et d’autre part à la correction.En effet, si l’on cherche à repérer les noms propres dans un texte,recourir à de tels lexiques permet un gain de temps considérable. Parexemple la seule présence de termes tels que docteur, professeur, ministreou, etc. supposent très fortement qu’ils seront suivis par un “nompropre”. On peut rechercher dans le texte des séquences de valeur :
nom commun + nom propre = îles Dupas, lac Saint-Pierre, rueLecourbe, etc.
En correction leur présence permet d'établir la limite entre génériqueet spécifique et ainsi de codifier l'emploi des majuscules. Ces listes

d'amorces sont en fait pour la plupart des listes de génériques entrantdans la composition de dénominations. Ces génériques sont des nomscommuns qui ne font qu'introduire le "nom propre" à proprementparler et donc pour cette raison, ne prennent pas de majuscule.
CONCLUSION
Dans cet article, nous avons montré que l'absence d'unification dansles règles d'emploi de la majuscule constituait un obstacle à untraitement automatique. Nous avons vu que cela entraînait desphénomènes tels que les variantes orthographiques (un même motécrit de plusieurs façons différentes) et que cela touchaitparticulièrement les noms propres plus communément appelésdénominations. Une normalisation s'avère donc nécessaire afin deréaliser un outil capable de vérifier, à l'aide de règles claires etlogiques, la pertinence de la majuscule à un mot.
RÉFÉRENCES
BIOUD, M. « Une normalisation de la majuscule pour un système devérification automatique », thèse en cours, Université de Franche-Comté.Code typographique : choix de règles à l'usage des auteurs etprofessionnels du livre (1986), Fédération CGC de la communication.DOPPAGNE, A. (1998), Majuscules, abréviations, symboles et sigles,Paris ; Bruxelles : Duculot.GARY-PRIEUR, M.-N. (1994), Grammaire du nom propre, PressesUniversitaires de France, Paris.GOURIOU, C. (1990), Mémento typographique, Éditions du Cercle dela librairie.GREVISSE, M. (1993), Le Bon usage : grammaire française, 13e éd. ref.par André Goosse, Paris, Louvain-la-Neuve : Duculot.JONASSON, K. (1994), Le nom propre. Construction et interprétations,Duculot Paris.
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
22
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

KLEIBER, G. (1981), Problèmes de référence : descriptions définies etnoms propres, Klincksieck, Paris.MATHIEU-COLAS, M.(1998), La majuscule flottante, remarques surl'orthographe des noms propres composés (type N Adj), BULAG n° 23,PUFC, Besançon.RAMAT, A. (1994), Le Ramat typographique, Editions Charles Corlet.Traitement automatique des noms propres, (2001), Traitementautomatique des langues, Volume 41- n° 3/2000, ATALA/HermesScience Publications, Paris.Le nom propre (1982), Langages n° 66, Larousse, Paris.Syntaxe et sémantique des noms propres, (1991), Langue françaisen° 92, Larousse, Paris.Traitement automatique de la composition nominale, (1993),Traitement automatique des langues, Volume 34- n° 2/1993, ATALA,Paris.
Mounira BioudUNE NORMALISATON DE L’EMPLOI DES MAJUSCULES POUR UN SYSTÈME DE VÉRIFICATION ORTHOGRAPHIQUE
23
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr


25
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS
RésuméAntidote est une suite linguistique commerciale intégrée comportant un correcteurgrammatical avancé du français. Nous présentons l’état d’avancement du correcteur,et certains aspects techniques et commerciaux d’Antidote. Nous évoquons enfin sesperspectives, et notamment l’application de sa technologie à de nouveaux produits.
Mots clefs
Correcteur grammatical ; dictionnaire ; synonymes.
AbstractAntidote is a commercial integrated linguistic suite including a French grammarchecker. We present the state of advancement of the grammar checker as well as sometechnical and commercial aspects of Antidote. We finally evoke Antidote’sperspectives, notably the application of its technology to new products.
Key-words
Grammar checker ; dictionary ; synonyms.
1. INTRODUCTION
La correction automatique du français écrit engendre depuis quinzeans une activité technique et économique non négligeable. À cause dela complexité de ses règles d’écriture, et en particulier de ses accordsmuets, le français suscite en effet un besoin d’aide chez ses scripteurs.
ANTIDOTE: CORRECTEUR,DICTIONNAIRE ET PLUS
Éric BRUNELLE
Druide informatique inc.Montréal, Québec

Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS
26
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Plusieurs entreprises ont vu le jour et ont proposé des produitscommerciaux qui connaissent ou ont connu un certain succès.Les grands logiciels de traitement de texte, notamment ceux deMicrosoft, offrent parfois un correcteur intégré. La diversité de leursmarchés les oblige toutefois à traiter un grand nombre de langues (34à ce jour dans le cas de Microsoft), ce qui limite la profondeur de leurprestation et l’éventail de leurs outils. D’autre part, les texteurs ne sontplus les seuls milieux de rédaction : le courrier électronique, lescollecticiels et d’autres ont pris une place importante.Fait intéressant, l’utilisation des correcteurs a inspiré le besoin d’autresoutils linguistiques d’aide à la rédaction. Pour les scripteurs, en effet,la correction n’est qu’une phase parmi d’autres du processusd’écriture, et l’on perçoit que l’ordinateur pourrait fournir une aideplus complète. Des ouvrages de référence plus ou moins intelligentssont apparus : dictionnaires, conjugueurs, thésaurus et autres.La société Druide informatique, dont l’auteur est fondateur etprésident, conçoit et édite le logiciel Antidote, constitué notammentd’un correcteur grammatical avancé du français. Antidote comporteégalement un dictionnaire multifonction, un dictionnaire desynonymes, un conjugueur et une grammaire. Antidote estcommercialisé depuis 1996 dans la francophonie, et continue d’êtredéveloppé activement. Nous présenterons ici brièvement certainsaspects commerciaux, techniques et linguistiques d’Antidote.
2. QUELQUES DONNÉES COMMERCIALES
Antidote Prisme, paru en octobre 2003, est la 5e édition d’Antidote,résultat de 11 ans de développement, ou 80 années-personnes. Vingtdruides oeuvrent quotidiennement à son évolution, dont dix linguisteset informaticiens.Antidote s’adresse à tous ceux qui écrivent en français sur ordinateur,ce qui lui assure une large distribution. Après sept ans decommercialisation, Antidote compte ainsi plus de 100000 utilisateursdans toute la francophonie, et ailleurs. Parmi ceux-ci, notons plus de1200 licences multipostes (en mai 2004), de 5 à 1200 postes chacune,tant dans l’administration publique que dans l’entreprise privée et lesétablissements d’enseignement. La croissance des ventes dépasse les30 % annuellement.

Antidote est offert sur Mac OS 9, Mac OS X et Windows (de 98 à XP),où il coopère intimement (lecture et correction directe dans le texte)avec plus de 50 applications populaires : texteurs, mise en page etcourrier électronique.Des mises à jour regroupant ajouts linguistiques, nouvellescoopérations avec les logiciels, corrections de coquilles et autres sontoffertes en téléchargement gratuit environ tous les six mois, jusqu’à laparution d’une nouvelle édition.De nombreux utilisateurs nous signalent leur grande satisfaction,voire leur étonnement face à l’efficacité d’Antidote et à la richesse deses services. Ils sont aussi nombreux à le prouver en se procurant lesmises à niveau payantes aux éditions successives environ tous lesdeux ans.
3. QUELQUES DONNÉES TECHNIQUES
Antidote est généré par la compilation de cinq couches de code source :les données linguistiques, les algorithmes linguistiques (programmésdirectement par les linguistes dans un métalangage orienté-objetopérant sur les mots et les arbres), les algorithmes généraux (codés enC++), les modules d’interface aux logiciels externes (codés en diverslangages d’interface comme AppleScript, VBA et autres) et l’interface-utilisateur (recodée nativement pour chaque plateforme). Les donnéeslinguistiques représentent 28 Mo de code source ; les autres couchestotalisent 46 Mo. Une fois compilées et indexées, les donnéesreprésentent environ 20 Mo de binaire, et les autres couches pèsentenviron 10 Mo par plateforme.En date du 31 mai 2004, le dictionnaire d’Antidote compte 113000mots, dont 8200 verbes et 10000 noms propres.L’une des complexités d’Antidote est la maintenance continue. Il luifaut à la fois suivre l’évolution des systèmes d’exploitation (parexemple, la montée actuelle de Linux, mais aussi les versionssuccessives de Windows) et celle des logiciels externes, sans oubliercelle de la langue. Pour suivre l’évolution linguistique, nous avonsnotamment mis au point des outils de veille automatique et d’étudeterminologique sur Internet. Sans cette mise à jour continue,l’obsolescence s’installerait rapidement.
27
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS

Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS
28
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
4. ÉTAT LINGUISTIQUE DU CORRECTEUR
Le correcteur d’Antidote est capable d’analyses complexes. Il gèrenotamment la coordination, l’extraposition, la corrélation, laponctuation (correcte et incorrecte) et autres phénomènes non triviaux.Il utilise une grammaire de dépendances qui génère elle-même desarbres de dépendances. Sur un texte du Monde, par exemple, il seragénéralement en mesure d’analyser de façon satisfaisante environ90 % des phrases.Étant donné la grande variété de ses utilisateurs, la couverture del’analyseur est très large. Cela implique une vaste nomenclature, maisaussi des structures syntaxiques particulières à certains domaines,comme les énoncés numériques des articles financiers et certainesformules juridiques. Chacun des 113000 mots de sa nomenclature afait l’objet d’une description formelle poussée, faite entièrement à lamain par un linguiste, et vérifiée par un compilateur. La grammairecompte environ 2000 règles syntaxiques. Plus de 1200 types d’erreursdistincts sont corrigés.L’analyseur gère l’ambiguïté de bout en bout, et peut présenterplusieurs analyses pour une même phrase. Les variantes graphiquessont alors affichées dans une ou plusieurs infobulles à choix multiples.L’utilisateur peut choisir une alternative ; les autres variantes sontajustées en conséquence. Les variantes d’analyse sont présentées à lafois dans les bulles de nature et fonction sur chaque mot et dans lafenêtre d’analyse détaillée.Le figement a fait l’objet d’un traitement soigné, avec plus decinquante mille collocations répertoriées et traitées directement parl’analyseur syntaxique.Le dictionnaire et le correcteur gèrent les variantes nationales dufrançais, tant lexicales que syntaxiques. En outre, ils connaissent lesrectifications du français proposées par le Conseil de la languefrançaise en 1990, et peuvent alterner entre graphies traditionnelles etrectifiées, ou accepter les deux.L’analyseur reconnaît les passages non français, même à l’intérieurd’une phrase, et ne les analyse pas. Ceci évite les surcorrections sur lescitations en langue étrangère.

Antidote Prisme tire son nom d’un nouvel outil, le prisme, que nousavons ajouté au correcteur. Le prisme révèle visuellement, ensurlignant les passages correspondants, plusieurs des rouages d’untexte ; on peut ainsi en évaluer la justesse, la pertinence et ladistribution. Certains filtres du prisme s’attaquent à la pragmatique enreconnaissant, par leur description syntaxico-sémantique et leurfonction dans la phrase, les éléments désignant des personnes(physiques ou morales), des lieux (physiques ou virtuels, comme lesURL), des quantités (monétaires ou autres) et des éléments temporels(absolus ou relatifs). D’autres aident à réviser le style en identifiant lesrépétitions, les phrases sans verbe principal et les tournuresimpersonnelles, passives, négatives ou autres.
5. DU CORRECTEUR À LA SUITE LINGUISTIQUE
Antidote n’est pas un correcteur. Dès le début, nous avons appliqué unprincipe : transférer à l’utilisateur le maximum d’information. Chaquefois que nous encodons formellement un type d’information àl’intention du correcteur, nous étudions comment présenter cetteinformation à l’utilisateur sous une forme compréhensible et utile. Nous avons ainsi créé un dictionnaire multifonction, qui affiche lesdéfinitions complètes des mots, accompagnées de notes qui signalentles homophones, les paronymes, les anglicismes, et autres difficultésreconnues par le correcteur. Capitalisant sur la puissance de nos outilslexicaux, nous y avons ajouté la famille morphosémantique, lesanalogies et l’onomastique.Le conjugueur présente les tableaux de conjugaison de chaque verbe,pour les temps simples et composés.La grammaire énonce en 375 articles chacune des règles qu’applique lecorrecteur, ainsi que les notions de style et de pragmatique que traquele prisme.Ainsi armé, l’utilisateur peut non seulement vérifier les diagnostics ducorrecteur, mais aussi profiter lui-même de ces informations pourapprendre et se perfectionner.Enfin, les utilisateurs nous ont demandé un dictionnaire desynonymes pour compléter les outils lexicaux d’Antidote. Nous avonsdonc conçu un dictionnaire de synonymes original, comportant prèsde 60000 entrées, paru avec la troisième édition.
29
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS

Les outils sont intégrés intelligemment. Du correcteur, on passedirectement à l’article de la grammaire qui décrit la règle transgressée.Du dictionnaire, on accède à la conjugaison du verbe ou à l’article dela grammaire qui énonce une particularité grammaticale du mot. Departout, on double-clique sur un mot pour que le dictionnaire enaffiche la définition. Et les synonymes présentent leur définition enparallèle, pour faciliter la sélection.Du point de vue des utilisateurs, la correction n’est qu’une partie de latâche d’écriture. Or l’intégration des outils facilite la manipulation etl’appréhension, et augmente la cohésion et l’efficacité.Même si le correcteur est intrinsèquement plus complexe, nousaccordons le même soin à chacun des ouvrages d’Antidote ; nousmaintenons chacun à jour, et nous nous efforçons de les améliorer tousavec chaque nouvelle édition d’Antidote.
6. PERSPECTIVES
Nous envisageons le développement de plusieurs nouveaux filtrespour le prisme, dont plusieurs réalisant des fonctions encore inédites.Le prisme a en effet inspiré de nombreuses suggestions originales à sesutilisateurs.Nous augmentons constamment la couverture de l’analyseur,notamment sur les suggestions des utilisateurs et les constats de nosoutils de veille automatique.Nous travaillons à étendre les capacités de l’analyse multiphrase.L’utilisation d’éléments extraphrastiques présente en effet plusieurspossibilités intéressantes.Nous continuons d’augmenter la vitesse d’analyse. Elle a déjà été plusque décuplée depuis la première édition, et est aujourd’hui fortsatisfaisante, surtout en considérant que l’utilisateur peut traiter lespremiers résultats pendant que l’analyse se poursuit.Nous envisageons d’autres applications de la technologie d’Antidoteet de ses multiples services. Nous avons ainsi conçu et développé leprojet Druidemestre, une application Web inédite qui est aujourd’huiau stade des premiers essais en externe et que nous comptonscommercialiser à court terme.
Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS
30
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

7. CONCLUSION
Antidote est un produit mûr, utilisé par un très large public, et encroissance constante. De ce fait, nous estimons que l’utilité et laviabilité de la correction grammaticale en français sont prouvées.Bien qu’ils cherchent d’abord un correcteur, les utilisateurs apprécientles autres ouvrages de référence. Il faut considérer le correcteurcomme partie d’un ensemble d’outils d’aide à l’écriture, répondant àdes besoins variés mais interreliés, et non pas comme une fin en soi.Même après onze ans, Antidote continue d’être développéintensivement. L’analyse multiphrase a ouvert de nouvellesperspectives. Le prisme s’est attaqué à de nouveaux problèmes, et ainspiré la solution de plusieurs autres.Enfin, la technologie d’analyse d’Antidote est suffisamment avancéepour nous permettre d’envisager d’autres applications inédites ; l’uned’entre elles, le projet Druidemestre, devrait être commercialisée àcourt terme.
31
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Éric BrunelleANTIDOTE : CORRECTEUR, DICTIONNAIRE ET PLUS


33
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
RésuméDepuis quinze ans, la correction de texte assistée par ordinateur est passée dulaboratoire au terrain commercial. On peut distinguer l’évolution des correcteursorthographiques en plusieurs générations. L’idée de départ de la première générationconsistait à supposer que si un mot était absent du lexique, il devait être mal écrit. Ladeuxième génération de correcteurs s’appuyait sur une analyse syntaxique locale.L’analyse de la phrase complète est l’innovation principale de la troisième génération.On assiste présentement à un lent plafonnement des systèmes de troisième génération.Après des progrès spectaculaires, le piétinement des dernières années montre qu’unobstacle majeur reste à franchir : la barrière de la sémantique. Quel sera alors l’avenirdes correcteurs ? Nous croyons que l’évolution technologique des correcteursdemanderait des travaux de sémantiques difficilement réalisables au plan économiquepour les seuls besoins de la correction. Nous entrevoyons donc une période despécialisation des outils de correction en attendant qu’une percée ait lieu du côté de lasémantique sous la poussée plus probable des logiciels de traduction.
Mots clefsCorrection automatique ; correction assistée ; correcteur orthographique ; correcteurgrammatical ; analyse grammaticale ; analyse syntaxique ; sémantique ; langagecontrôlé.
AbstractOver the last fifteen years, computer-assisted grammar checking left the laboratory toreach the market. The technical evolution of grammar checkers can be divided intoseveral generations. One of the ideas at the origin of the first generation of spellingcheckers was to assume that if a word is missing from a large lexicon, then this word
L’AVENIR DES CORRECTEURSGRAMMATICAUX: UN POINT DE VUE
INDUSTRIELFrédéric DOLL et Claude COULOMBE
Lingua Technologies Montréal (Québec)[email protected]

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
34
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
must be written incorrectly. The second generation was based on local syntacticanalysis. The detailed analysis of complete sentences was the main innovation of thethird generation. Today, these systems have nearly peaked. After a period ofspectacular progress, the stagnation of the recent years shows that a major obstaclemust now be overcome : the semantic barrier. What will then be the future of grammarcheckers ? We think that further technological advancement would require research insemantics that would be overly expensive when considering the specific needs ofgrammar checking. We thus anticipate a period of specialisation of current grammarchecking tools until a breakthrough happens in the field of semantics, due to pressurefrom translation software developers.
Key-wordsAutomatic spelling correction ; assisted spelling correction ; spelling checker ; grammarchecker ; grammatical analysis ; semantic ; controlled language.
ARTICLE
Cet article est rédigé par deux des concepteurs du Correcteur 101, undes produits phare pour la langue française, qui fut le premier àproposer une analyse syntaxique complète de la phrase. Nous pensonscontribuer par notre expérience industrielle de plus d’une décennie aubilan de cette technologie et à la réflexion sur ses perspectives d’avenir.Nous limiterons notre propos aux seuls aspects linguistiques de cettetechnologie tout en soulignant que l’évolution passée et future requiertégalement beaucoup d’efforts au niveau de l’intégration de latechnologie aux outils de traitement de texte (éditeurs de courriel,logiciels de microédition, etc.), au niveau des outils connexes commeles dictionnaires de définitions et de l’ergonomie des interfacesutilisateurs. La correction orthographique et grammaticale par ordinateur estsûrement la technologie du traitement automatique des langues (TAL)la plus répandue à travers le monde en tant que composante des outilsde traitement de texte.Depuis environ quinze ans, la correction de texte assistée parordinateur (terme que nous préférons à celui de correctionautomatique) est passée du laboratoire au terrain commercial ce quiexplique en partie qu’elle semble négligée par les recherches en

35
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
Traitement Automatique des Langues (TAL). En effet, les chercheursindustriels publient très peu pour des raisons de secret commercial. Deplus, le monopole de la suite Office de Microsoft dans le monde dutraitement de texte entraîne un manque d’intérêt pour ce typed’application, qui est perçu comme la chasse gardée de lamultinationale. Enfin, la performance des systèmes commerciauxactuels est satisfaisante compte tenu de l’effort qui serait requis pourl’améliorer d’une manière significative. Nous pouvons affirmer que, malgré ses lacunes, un bon correcteurgrammatical, bien utilisé, peut apporter une aide précieuse dans lacorrection de texte. Les bancs d’essais qui s’ingénient à piéger leslogiciels de correction, en leur soumettant des exemples fabriqués àcette intention, sont d’une utilité limitée puisqu’ils ne reflètent en rienl’expérience d’un utilisateur qui coopère avec le logiciel.
1. UNE ÉVOLUTION PAR GÉNÉRATION
Une séparation des différentes technologies en “générations” permetde préciser simplement les apports technologiques particuliersdécelables dans plusieurs logiciels de correction et d’en extraire lesprincipes de correction propres à chacun. Ne s’excluant nullement, cestechnologies sont à chaque fois réutilisées à différents niveaux dans leprocessus de correction. Les problèmes que se sont posés lesconcepteurs sont des problèmes de langue et sont communs à chaquegénération. Cependant l’évolution des technologies a permis dedépasser certaines limites pour en atteindre d’autres que la générationsuivante fera disparaître.
1.1. Génération 1 : le motLa première génération de correcteurs, appelés avec justessecorrecteurs orthographiques, se contentait de vérifier si un mot d’untexte faisait partie d’un lexique de référence le plus souvent stocké surdisque [Kukich92]. L’idée de départ, très simple, consistait à supposerque si un mot était absent du lexique, il devait être mal écrit.L’algorithme de base s’écrit en moins d’une journée deprogrammation et le plus gros du travail est de créer le lexique deréférence. Le critère principal de la qualité de ces outils est la

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
36
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
couverture lexicale : le nombre de mots courants, la prise en comptedes variantes orthographiques, le traitement des locutions, les nomspropres, les régionalismes, les emprunts aux langues étrangères, lesabréviations, les sigles, les acronymes, et les autres éléments dulexique comme les nombres, les symboles, les unités de mesure, lesunités monétaires, les dates, les adresses, les équations, etc.Le fonctionnement de ces premiers correcteurs orthographiquesrépondait aux impératifs technologiques du moment : espace mémoireminime (tout au plus quelques centaines de kilo-octets) et lenteurd’exécution (processeurs à quelques MHz). Il est important desouligner que cette première génération d’outils de correction ne faitappel à pratiquement aucune connaissance linguistique. C’est unsimple traitement de chaînes de caractères. Les insuffisances de cessystèmes étaient évidentes, particulièrement en langue française où letaux de correction avoisinait les 40 %. Cette performance estcomparable aux résultats d’une étude réalisée au Québec qui indiquaitqu’en moyenne 39 % des fautes commises sont des fautesd’orthographe [Bureau85].
1.2. Génération 2 : le mot et son contexte immédiatLa deuxième génération de correcteurs s’appuie sur une analysesyntaxique locale. Le correcteur prend en compte l’environnementimmédiat du mot à vérifier. Profitons de l’occasion pour rendrehommage à deux produits pionniers d’origine québécoise dans cedomaine : Hugo de Logidisque et GramR d’Edit.La faute type recherchée est la faute d’accord et principalementl’erreur de nombre ou de genre. La liste de formes orthographiquesprésente dans la première génération fait place à un dictionnaire demots contenant des informations supplémentaires permettantd’étiqueter la catégorie grammaticale de chaque mot et de définir legenre et le nombre des noms, pronoms, des adjectifs et desdéterminants ainsi que la ou les personnes pour les verbes. Unensemble de règles de constructions locales est consulté. La présenced’une construction entraîne la vérification de certaines conditionsdéclenchant alors une alerte de déviance d’accord grammatical. Cettedeuxième génération est la première à utiliser des connaissanceslinguistiques. Les progrès sont évidents, on atteint les 60 % de bonnescorrections.

37
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
1.3. Génération 3 : la phrase complèteL’analyse de la phrase complète est l’élément le plus visible de latransition vers la troisième génération. Cette génération fait intervenirun analyseur morphosyntaxique à large couverture. Le dictionnaire demots devient alors une véritable base de données de référencecomprenant des informations syntaxiques servant à valider laconstruction du groupe ainsi que sa dépendance. Seules lesconstructions couvrant la phrase entière sont retenues. Dans le cas duCorrecteur 101, on s’appuiera sur les lexiques grammaires de MauriceGross [Gross75] pour le dictionnaire et sur les grammaires dedépendance et la théorie Sens-Texte d’Igor Melcuk [Mel’cuk88] pour leformalisme de la grammaire.Cette génération nous amène à la frontière des 80 % de bonnescorrections, seuil pour lequel la correction peut être considérée commesatisfaisante pour un usager moyen. Le principe de l’analysesyntaxique comme préalable à toutes propositions de correction étaitdéjà présent dans la deuxième génération. Les manuelsd’apprentissage de l’orthographe ont poussé naturellement dans cettevoie. La réponse aux explications de type “le nom s’accorde en genreet en nombre avec son déterminant” ne pouvait être que celle desaccords locaux dans un groupe syntaxique précis. Mais pour proposerdes corrections mettant en jeu des éléments grammaticaux répartis surl’ensemble de la phrase, comme la règle de l’accord du participe passéqui fait intervenir la position du complément d’objet direct par rapportau verbe, il a fallu se tourner vers des solutions faisant intervenirl’analyse syntaxique complète de la phrase.
2. L’HÉRITAGE DES GÉNÉRATIONS PRÉCÉDENTES
Si chaque génération a contourné les limites de la précédente, lestechnologies employées n’ont pas été mises à l’écart. Bien au contraire,elles ont été réintégrées et réutilisées dans divers outils livrés avecl’outil principal de correction.
2.1. Autour du motOn constate que les applications actuelles de correction grammaticaleproposent toutes un outil pour “balayer” le texte complet afin de

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
38
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
repérer des mots inconnus ou partiellement connus, des motscommençant par une majuscule, des erreurs de typographie, desrépétitions de mots ou de famille de mots et même des ensemblesappartenant à une même famille sémantique. Ce type d’outilappartient à la première génération c’est-à-dire se composantuniquement d’un test graphique et d’une comparaison entre un mot etune liste de mots étiquetés ou non d’informations morphologiques,syntaxiques, sémantiques. Sans aucune analyse syntaxique, lerepérage des catégories suivantes est possible :
- Les fautes d’orthographe à l’aide d’une comparaison de liste.- Les noms propres et les signes typographiques à l’aide d’une
analyse graphique se limitant à détecter la présence d’unemajuscule dans un mot ou la présence ou l’absence d’uneespace avant et après le signe.
- Les mots collés et les néologismes possibles à l’aide d’uneanalyse morphologique se limitant à détecter la présence d’unélément collé à un autre compatible ou non.
- Les doublons et les répétitions à l’aide d’un ensemble devariables qui mémorisent les mots soumis à la correction.
S’ajoute à cette liste un certain nombre d’informations comme lacatégorie probable des mots, des groupes d’adverbes identifiés “detemps ou de lieu” ou encore parfois les modes des verbes. Cesinformations restent partielles et certaines peuvent apparaître erronéesaprès analyse.
L’enfant a [été paisible dans la campagne un soir de lune et plusieursen profitent pour prendre l’air]
Un [été paisible dans la campagne un soir de lune et plusieurs enprofitent pour prendre l’air]
D’autre part, il arrive, malgré les efforts des concepteurs, que l’analysecomplète de la phrase échoue et le système ne dispose alors que d’unesérie d’analyses partielles de la phrase. Cette situation peut être soitignorée soit exposée à l’utilisateur, mais le principe qui sous-entendque les corrections sont valables et ne peuvent être proposées qu’à lacondition que l’analyse de la phrase soit complète n’est plus de miseen cas d’échec. D’un point de vue industriel, même sans analyse

39
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
complète, un maximum d’erreurs doit être proposé à la révision durédacteur. Les correcteurs bureautiques doivent-ils présenter les pointsd’achoppement de l’analyse ou seulement les groupes syntaxiquesconstruits par une analyse de contexte immédiat? Bien que la premièresolution offre de meilleures pistes pour la réécriture de certainesstructures défaillantes, la seconde répond plus efficacement à lademande de la correction automatique professionnelle.
2.2. Autour du groupeOn pourrait croire également que l’analyse complète de la phrase aéliminé l’analyse de contexte immédiat. Or, l’analyse de contexteimmédiat, ou encore la détection de groupes syntaxiques liés a un rôletrès important à jouer dans la correction automatique de troisièmegénération.Sur le plan algorithmique d’une part, une pré-analyse de contextedétectant des groupes syntaxiques non ambigus, améliore grandementla vitesse et la construction d’une analyse complète de la phrase etévite certaines explosions combinatoires sans issues. Dans la phrasesuivante, la branche de recherche construite sur le nom “été” peut êtrecoupée grâce à une analyse contextuelle à gauche mettant en évidencela catégorie “auxiliaire” de “été”.
3. QUELQUES PROBLÈMES PARTIELLEMENT RÉSOLUS
La distinction des différents logiciels de correction professionnels entrois générations ne doit pas cacher la persistance de certainsproblèmes de langue qui se retrouvent dans chacun d’eux, et lesmoyens pour les régler sont restés souvent inchangés.
3.1. Le rétablissement orthographiqueLa détection d’une faute d’orthographe demeure encore liée àl’absence du mot dans une liste. Les techniques de rétablissementorthographique n’ont pas connu de développement très important. Onconstate encore que les quatre procédés classiques de rétablissementorthographique [Damerau64] sont utilisés avec quelques variantesdans les logiciels : insertion de lettres, retranchement de lettres,substitution de lettres, inversion de lettres. Souvent très efficaces, ces

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
40
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
techniques génèrent aussi des propositions inadéquates. Lesalgorithmes utilisés, même agrémentés de système de pondération enfonction de la position dans le mot ou de transformations phonétiqueset phonologiques d’équivalence graphiques demeurent identiques.Des règles d’équivalence de lettre basées sur la proximité des touchesaux claviers donnent autant de résultats positifs que négatifs. Unevraie amélioration est à prévoir dans ce domaine avec des solutionsbasées moins sur la manipulation graphique que sur la probabilité dela présence d’un mot dans un texte.
3.2. Le découpage en phraseMalgré une apparente simplicité, dans la pratique, le découpageautomatique d’un texte en phrases ne peut pas être considéréaujourd’hui comme un processus parfaitement robuste et fiable.L’explication est que les marqueurs de fin de phrase sont fréquemmentambigus et variables. Par exemple, le point, est tantôt un séparateur dephrase, un marqueur d’abréviation (M.) ou de l’initiale d’un pronom,une partie d’un sigle (R.A.T.P.), en plus de se retrouver dans les pointsde suspension (...). Comment traiter les abréviations en fin de phrase?Doit on considérer les “;” ou les “:” comme des fins de phrases ou desfins de syntagmes?Le découpage du texte en phrase est une préoccupation plus évidentepour la troisième génération des correcteurs, puisque l’élément detravail de base est la phrase. Or, la moindre erreur lors du découpageen phrases peut avoir des conséquences désastreuses pour la suite dutraitement.Malgré son importance, le découpage en phrases est souvent négligé.Avec une bonne liste d’abréviations et de noms propres, un algorithmeà bases de règles ou d’automates à états finis sera capable de découperun texte en phrases avec une efficacité entre 95 % et 97 %.Ici encore, les nouvelles générations ont fait peu d’avancée dans cedomaine. Les solutions les plus évidentes sont restées au fil desgénérations.
Le “retour de chariot” : terminal de phrases non ambigu.Toutefois l’opération délicate de “copier/coller” d’une pageWeb dans un logiciel de correction automatique a tendance àremettre en question ce principe encore unanimement utilisé.

41
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
Le point d’interrogation, le point d’exclamation : terminaux nonambigus sauf dans le cas de discours rapporté à l’intérieur deguillemet.
Le point : terminal ambigu à cause de son utilisation dans lessigles et les abréviations connus ou construits.
Le point virgule, les deux-points : terminaux ou introducteurs?
Ils sont considérés plus intuitivement comme des introducteurs liantune partie de la phrase à une autre et mettant en évidence des lienssémantiques et syntaxiques. Dans la phrase suivante, la partie à droitedes deux-points est Complément d’objet direct du verbe à gauche.
Le président déclare : “Je suis là !”.
Étant donné le peu d’interférence graphique entre des éléments dechaque côté du signe de ponctuation, les concepteurs ont souvent préféréle statut de terminal non ambigu pour chacun de ces signes gagnant ainsisur la combinatoire dans la construction syntaxique de la phrase.
Les parenthèses, crochets, guillemets, ouvrants et fermantsrenferment-ils des éléments internes à la phrase ou des élémentsdevant être traitées comme indépendants?
Les barres obliques à droite et à gauche, les tildes, étoiles, dièses,arobas, perluète et tout autre bidule s’insèrent-ils dans la phrase,la découpent-ils de manière non ambiguë?
Une approche à explorer serait de créer un découpeur de textes àpartir d’un algorithme d’apprentissage et d’un corpus où les phrasessont séparées et marquées comme telles. Le problème de créer undécoupeur de texte revient à faire apprendre à un programmed’apprentissage automatique comment découper un texte en phrasesà partir d’exemples.
3.3. Les indices de lisibilité
Les outils d’évaluation de lisibilité des textes ont, eux, subis quelquesaméliorations dues à l’évolution de la technologie d’analyse du texte.Ces outils étaient surtout utilisés par les logiciels de correction de

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
42
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
l’anglais qui avaient à leur disposition des références précisesd’évaluation de la lisibilité. Ces outils étaient essentiellement basés surla longueur des phrases et les mots qui la constituent. Les critèressyntaxiques qui rentrent en ligne de compte de ces calculs étaient plusdéduits que construits. La présence de constructions passives étaitdétectée par des “mots clés”.Grâce à l’analyse complète de la phrase, les outils de calcul de lisibilitéont pu élargir leurs critères et affiner les pronostics qu’ils posaient. Siles deux principaux critères de la lisibilité de texte sont restés lesmêmes : la longueur de la phrase et les mots “rares”, d’autres critèresissus des études sur le langage contrôlé [Allen2000] [AECMA89] sontvenus enrichir ces outils. Un critère comme “l’écran linguistique” quise définit par la présence d’un groupe syntaxique autonome entre lesujet et le verbe n’aurait pu être détecté avec une analyse de contexteimmédiat. Les constructions complexes de comparaison ou decoordination sont des indices qui n’ont été disponibles qu’à partir dela troisième génération.Toutefois, plusieurs règles du langage contrôlé relèvent de lasémantique et ne peuvent être implantées avec des techniquessyntaxiques de la troisième génération. Par exemple, comment vérifierque le rédacteur ne s’éloigne pas trop de son sujet ou qu’uncommentaire est superflu.
3.4. La correction des accords
Les erreurs d’accord véhiculent un paradoxe qui a été rarement mis enévidence, mais que les concepteurs de logiciels de correctionprofessionnels ont dû résoudre. L’erreur d’accord met en jeu auminimum 2 mots : le déterminant et le nom, l’adjectif et le nom, le sujetet le verbe, l’attribut et le sujet. Or, une fois que l’analyse syntaxique adéterminé la relation grammaticale comprenant un accord nonsatisfait, l’interrogation persiste sur le choix de l’élément qui doitrecevoir l’alerte. Les grammaires de référence optent implicitementpour l’accord du noyau du groupe :
“Le nom s’accorde avec son déterminant”, “l’attribut s’accordeavec le sujet du verbe”.

43
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
Ce choix, incontestable au niveau de la grammaticalité de laproposition de correction n’est pas toujours le plus ergonomique.Lorsque la proposition de correction entraîne plusieurs rectificationsgraphiques dans la même phrase ou pire encore des modificationsphonologiques, ce choix de correction n’est peut-être pas le mieuxadapté. C’est pourquoi, nous avons proposé d’introduire desmécanismes pour minimiser le nombre de corrections proposées.
3.5. La résolution des anaphoresLes langues naturelles utilisent des mots différents (pronoms, groupesnominaux, etc.) pour reprendre (ou référer) des mots déjà utilisés dansle texte. Par exemple, dans une même phrase on aura : Jean enlaceSuzanne et embrasse l’élue de son coeur. Le « l’ » se rapporte ici à Suzanne.Par contre dans : « Jean enlace Suzanne qui embrasse l’élu de son cœur. »,ici « l’» se rapporte à Jean. Un exemple impliquant deux phrases : Jeanse promène. Il regarde le paysage. Il s’agit d’une anaphore dudiscours. La première phrase crée un contexte pour la suivante. Onvoit ici clairement que le problème de l’anaphore déborde du cadre dela sémantique de la phrase pour celui du texte dans son entier. Unautre exemple dans le roman de Gustave Flaubert : “Madame Bovary”,“la Bovary”, “la femme de Charles” et “la maîtresse de Rodolphe” réfèrenttoutes à la même personne.La résolution des anaphores (ou résolution des références) n’est pasabordée par les systèmes de correction actuels. La première raison estque la résolution des anaphores n’aurait pas un très grand impact auniveau de la correction grammaticale de textes généraux. La deuxièmeraison est que souvent la résolution d’une “chaîne de références”demande de considérer le texte dans son entier. Or les correcteurs detroisième génération se limitent à une seule phrase. Enfin, il n’existepas de solution simple et fiable à 100 %. Les cas les plus difficilesdemanderaient un traitement sémantique poussé difficilementjustifiable par la seule amélioration des performances de correction.Il existe pourtant des heuristiques simples qui pourraient fonctionnerdans la plupart des cas. Par exemple, on définit quatre variables deréférences de base (masculin-singulier, masculin-pluriel, féminin-singulier, féminin-pluriel) que l’on remplace par des choixheuristiques au gré de l’évolution du discours.

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
44
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
4. GÉNÉRATION EN CRISE
Tout comme les générations précédentes, la troisième génération delogiciels de correction, qui fonde son principe de fonctionnement surl’analyse syntaxique complète de la phrase, c’est-à-dire surl’identification des groupes et des liens qui régissent leurs membres, setrouve face à des situations qui ne peuvent être surmontées sansl’introduction de nouveaux critères distinctifs. On assiste à un plafonnement des systèmes de troisième génération.La courbe des performances se stabilise pour atteindre un quasi-plateau. L’amélioration ne progresse que très lentement aux prixd’efforts de plus en plus importants. Typiquement pour arriver à 80 %,il aura fallu 15 années-personnes et 85 % ne sera atteint qu’au prixd’un effort de 30 années-personnes. Chaque point d’améliorationrequiert un effort difficile à justifier au plan économique.Une analyse permettant l’extraction d’éléments sémantiques, unalgorithme de calcul d’inférence à partir de ces éléments et des règlesde déduction d’accord pourraient sans doute aider à résoudre desproblèmes qui font encore aujourd’hui défaut à la correction de texteet plus généralement à l’analyse de texte. Les problèmes suivants nesont que des exemples de limites atteintes par l’analyse syntaxique.
4.1. La distinction entre coordination implicite des noms etl’apposition des noms
La description de la coordination implicite n’occupe que très peu deplace dans les manuels de grammaires classiques. Elle apparaîtpresque comme une construction déviante et rare, mais elle restefréquemment utilisée et dans des domaines très diversifiés. Elle n’estpas non plus une marque d’écriture soutenue et littéraire, on laretrouve tout aussi bien dans les livres pour de très jeunes enfants quedans des plaquettes publicitaires et des rapports d’activités.
“Madame Catastrophe glisse, tombe, pleure”
“Les assiettes, les cuillères, les fourchettes se retrouvent par terre”

45
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
Les coordinations implicites se retrouvent dans les mêmesconstructions, avec les mêmes catégories grammaticales que lescoordinations avec préposition. Le nombre d’éléments de lacoordination n’est pas non plus distinctif.Les appositions des noms se reconnaissent intuitivement maisprésentent les mêmes caractéristiques syntaxiques que lescoordinations implicites.
“Couverts, fourchettes, cuillères se retrouvent par terre”
“Mon père, mon géniteur, mon inspirateur disparaît à tout jamais”
“Alain Delon, l’acteur surprend encore”
Les deux derniers exemples posent un réel problème pour lacorrection automatique puisque la détection de l’une ou l’autreconstruction influence l’accord du verbe.Souvent enfin, ces constructions proches apparaissent imbriquées lesunes dans les autres, multipliant ainsi les analyses qui peuvent en êtrefaites :
“Robert, monsieur le ministre, mon grand ami, homme de talent,directeurs et simples ouvriers, nous vous remercions.”
4.2. L’acceptabilité de certaines formes conjointes
Les formes conjointes peuvent potentiellement apparaître avec tous lesverbes transitifs. Certaines tournures semblent tout à fait acceptablesd’autres appartenant à un registre de langue familier, d’autres encoreseront jugées agrammaticales. Or, on ne retrouve pas d’informationssignificatives sur le verbe qui pourraient faire accepter ou refuser cesstructures. Les exemples suivants peuvent être paraphrasés enremplaçant la forme conjointe par un complément en “pour”.
“Enfilez moi ces vêtements et partez!”
“Enfilez-les moi!”
“Je vous prends un rendez-vous pour 5 H 00”

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
46
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
“Nous te lui préparons une fête mémorable pour ses 20 ans”
“Goûtez moi ça et dites-m’en des nouvelles”
La distinction entre un complément indirect et une forme conjointe estparfois difficile à faire et celle-ci pourrait éventuellement se substituerau pronom indirect en donnant à la phrase un sens différent.
“je vous colle une contravention”
“Les activistes vont nous coller 500 affiches pour la manifestation dedemain”
“je vous envoie cette lettre” (à vous)
“je vous envoie cette lettre” (pour vous)
4.3. Les constructions particulières impliquant les parties d’un tout
Les groupes nominaux non introduits par des prépositions servent àformer principalement des sujets, des compléments directs et desattributs. Certains compléments de temps se passent aussi depréposition. “la nuit venue, le lendemain matin”. Mais on retrouveégalement dans cette catégorie un ensemble de termes appartenant àun champ sémantique particulier : les vêtements et les parties ducorps.
“Il est arrivé la queue entre les jambes”
“Cousteau, le bonnet noir enfoncé jusqu’au yeux ...”
“le nez au vent… les cheveux hérissés… les bras ballants… lepantalon déchiré”
Pour être plus exact, le champ sémantique doit être adapté aux partiesdu “thème” de la phrase qu’il soit sujet ou complément. Les parties dece tout et les compléments acceptables sont dépendants d’une analyseparticulière mettant en jeu les caractéristiques de l’objet divisé. Ainsi,nous devons accepter des constructions comme:

47
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
“Il faut entreposer les artichauts, la tige dans l’eau”
“Il entrepose les artichauts, la tête ailleurs”
“Les feuillets devront être présentés au client, le logo en évidence” etrefuser
“*Il faut entreposer les artichauts, le jardin en friche”
“*Les feuillets devront être présentés au client, le bureau en ordre”
“*Il faut entreposer les artichauts, la tige”
“*les feuillets devront être présentés, le logo”
5. L’AVENIR : LA SÉMANTIQUE OU LA SPÉCIALISATION
Après le mot, le groupe et la phrase, c’est l’étude du texte au completqui semble être l’étape naturelle suivante. Avec le texte vientégalement, bien qu’il ne soit pas exclu de la phrase, l’analyse du senset des relations sémantiques qui subsistent en dehors de la phrase. Lesgénérations précédentes ne faisaient que consulter un ensemble dedonnées complexes non modifiables. Les informations recueillies parl’analyse étaient perdues à la fin du traitement de la phrase. Laquatrième génération devrait permettre le stockage d’informationsconstruites et l’utilisation de ces informations pourrait entraîner unealerte de déviance d’un type particulier.Les outils de correction commerciaux qui se lancent dans cette voien’en sont qu’aux balbutiements et ne présentent que très peud’avancée sur le plan scientifique. Les informations recueillies surl’ensemble du texte ressemblent plus à une accumulation de donnéessimples de type deuxième génération qu’à de véritables élémentsservant à un calcul du sens. Une des applications immédiates de laprise en compte du texte au complet est sans doute la résolution desanaphores. Le pronom utilisé dans la phrase en cours de traitementcorrespond à un élément cité ailleurs dans le texte. L’analyse sémantique du texte et de la phrase doit servir à dépasser leslimites que la syntaxe seule ne pourra franchir. La plupart des

Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
48
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
problèmes maintenant rencontrés en correction sont des candidats àun traitement amélioré grâce à une analyse sémantique.Nous croyons que l’évolution technologique des correcteursdemanderait des travaux de sémantiques difficilement réalisables surle plan économique pour les seuls besoins de la correction et pour lesgains de performance attendus. Après des progrès spectaculaires, le piétinement des dernières annéesmontre qu’un obstacle majeur est à franchir : la barrière de lasémantique. C’est ce qui explique que l’effort de développement desindustriels s’oriente vers le perfectionnement des outils existants :l’ajout de dictionnaires, l’amélioration de l’ergonomie, l’intégration demodules de correction à davantage d’outils textuels et le traitement delangues encore peu informatisées.Compte tenu de ces contraintes économiques, l’évolution la plusprobable des outils de correction devrait être la spécialisation. Nous entrevoyons donc une période de spécialisation des outils decorrection en attendant qu’une percée ait lieu du côté de la sémantiquesous la poussée probable des logiciels de traduction qui présentent unpotentiel économique suffisant pour entraîner ce progrès. Cela dit,examinons quelles formes pourrait prendre cette spécialisation. Parexemple, la correction de textes rédigés en langue seconde. Dans le casd’utilisateurs qui travaillent dans une autre langue que leur languematernelle, les fautes seront fortement dépendantes de la languematernelle de l’utilisateur. Par exemple, les mots similaires (faux-amis)poseront souvent des problèmes : actuellement-actually, blesser-bless,journée-journey, librairie-library, etc.D’autres directions de spécialisation sont celles des outils de correctionpour l’enseignement ou encore les outils de langage contrôlé (oulangage simplifié).L’avenir de la quatrième génération pourrait coïncider avec un autretype d’analyse pour les logiciels professionnels de correctionautomatique. On peut remettre en cause la position didactiqueadoptée par les développeurs, qui consiste d’une part à analyser laphrase pour d’autre part être en mesure d’expliquer l’erreurgrammaticale commise et de pointer la règle enfreinte selon

49
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
les manuels de grammaire traditionnelle. Le résultat d’une analyseautomatique de texte servant à la génération de propositions decorrection n’est pas l’unique solution aux problèmes posés par lacorrection automatique. Les outils de traduction automatique ontouvert la voie à une nouvelle approche : les “mémoires” de traduction.La traduction d’une phrase correspond à celle qui a déjà été faite. Ces“mémoires” de phrase peuvent être des phrases complètes ou descanevas partiels à reconstituer. La correction automatique peut tireravantage de ces techniques en interrogeant une cache de correction eten proposant à l’utilisateur ce qui a déjà été écrit.
Doit-on écrire : “je me permet” ou “je me permets”?
En utilisant n’importe quel moteur de recherche sur Internet, laréponse est immédiate : 18500 réponses pour le premier, 56300 pour lesecond.
RÉFÉRENCES
[AECMA89] AECMA (1989), A Guide for the Preparation of AircraftMaintenance Documentation in the Aerospace Maintenance Language :AECMA Simplified English, Bruxelles, AECMA, document : PSC-85-16598, Issue 1. [Allen2000] ALLEN, J., HOGAN, C. (2000), Toward the development of apost-editing module for Machine Translation raw output : a new productivitytool for processing controlled language, Presented at the ThirdInternational Controlled Language Applications Workshop(CLAW2000), held in Seattle, Washington, 29-30 April 2000.[Bureau85] BUREAU, C. (1985), Le français écrit au secondaire : uneenquête et ses implications pédagogiques, Ed. Officiel du Québec,Montréal. [Coulombe91] COULOMBE, C. (1995), Les qualités attendues d’uncorrecteur orthographique et syntaxique, dans les Actes du colloque«Problématiques 1995», Traitement automatique de la langue etindustries de l’information, OFIL (Observatoire français des industriesde la langue), Paris.

[Compagnion96] COMPAGNION, H. (1996 septembre), Les correcteursorthographiques : Caractéristiques, mesures et méthodes, Observatoiresuisse des industries de la langue. http://www.osil.ch/eval/.[Damerau64] DAMERAU, F. (1964), A technique for computer detectionand correction of spelling errors, Communications of the ACM 7(3): 659-664.[Doll95] DOLL, F. (1995), Du correcteur orthographique au correcteurgrammatical intelligent, dans États généraux de la Francophoniescientifique, AUPELF/UREF, Montréal.[Gross75] GROSS, M. (1975), Méthodes en syntaxe, Hermann Editeur,Paris.[Kukich92] KUKICH, K. (1992), Techniques for automatically correctingwords in text, ACM Computing Surveys 24(4).[Mel’cuk88] MEL’CUK, I. (1988), Dependency Syntax : Theory andPractice, SUNY, New-York.
Frédéric Doll et Claude CoulombeL’AVENIR DES CORRECTEURS GRAMMATICAUX : UN POINT DE VUE INDUSTRIEL
50
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

51
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
Résumé Nous rappelons brièvement l’histoire récente des grandes langues africaines, ainsi queles contraintes techniques et surtout économiques qui freinent leur expression dans lasphère de l’information écrite et électronique. Cette situation a des conséquencesnéfastes sur le développement des pays concernés, en particulier une grande partie dela population est analphabète.Un environnement logiciel adapté, s’appuyant sur des connaissances linguistiquesmémorisées dans un lexique électronique, pourrait répondre en partie aux besoinsspécifiques de ces langues. Nous montrons comment un correcteur orthographiques’appuyant sur ce lexique peut participer à la diffusion de connaissances linguistiques,et comment, symétriquement, des outils logiciels doivent aider les linguistes àcapitaliser des connaissances dans ce même lexique.Nous examinons la mise en pratique de ce programme avec le développement effectifd’un correcteur orthographique, la spécification du logiciel de constitution deconnaissances linguistiques et la constitution initiale de quelques lexiques.
Mots clefsCorrecteur orthographique ; langues africaines ; outils électroniques pour les languesafricaines ; lexique électronique.
AbstractThe recent history of the west-African languages and the lack of technical, economicaldevelopment of the involved countries have considerably hindered their electronicdevelopment, with the consequences of the massive analphabetism of the population.
DES CORRECTEURS ORTHOGRAPHIQUESPOUR LES LANGUES AFRICAINES
Chantal ENGUEHARDLaboratoire d’Informatique de Nantes-Atlantique – Nantes- France
[email protected]érif MBODJ
Centre de Linguistique appliquée de DakarUniversité Cheikh Anta Diop – Dakar-Fann-Sénégal

An adjusted software environment could help for the compilation and distribution oflinguistic knowledge. We plan the development of such a software and detail the firststeps of this project.
Key-wordsSpelling correction for african languages ; softwares for african languages ; africanlanguages ; electronic lexicon.
INTRODUCTION
Les langues africaines sont peu présentes sur Internet, pourtant certainessont parlées par une importante population, même si ce n’est pas toujoursleur langue maternelle. Ainsi, le bambara au Mali, le wolof au Sénégal etle swahili en Afrique de l’Est sont des exemples de grandes langues decommunication (elles sont dites véhiculaires car elles permettentl’intercompréhension entre des personnes de langues maternellesdifférentes) [Calvet 1981]. Malgré leur importance au sein du continentafricain, il apparaît que ces langues sont globalement peu informatisées[Diki-Kidiri 2003]. Plusieurs facteurs (techniques, économiques, sociaux)expliquent cette désaffection mais le poids de l’histoire ne peut être passésous silence si l’on souhaite comprendre la situation.
1. SITUATION
1.1. Contexte historique et socialLes colonisateurs des pays africains ont eu des attitudes différentes ence qui concerne les langues locales. Dans l’ex-Congo belge(aujourd’hui RDC1), certaines langues africaines étaient enseignéesalors qu’au même moment elles n’avaient aucun droit de cité dans lescolonies françaises. Il était même formellement interdit aux élèvesd’utiliser leurs langues maternelles, y compris dans la cour derécréation, lorsqu’ils étaient entre eux, sous peine de subir des sévicescorporels. Ces comportements ont certainement eu des effetspsychologiques très négatifs dans le développement de la personnalitéde ces jeunes créatures humaines (qui ont notamment appris que leurlangue n’est pas digne de l’école).
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
52
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
1 - République Démocratique du Congo.

La scolarisation dans les langues européennes n’a pas été un succès, etil faut bien constater qu’elle a contribué à aggraver le sous-développement de l’Afrique dans les secteurs économiques et sociauxen maintenant une grande partie de la population dansl’analphabétisme. Cette période est aussi marquée par l’apparition denombreuses monographies sur les langues africaines, œuvres demissionnaires ou d’administrateurs coloniaux, c’est-à-dire depersonnes certes de bonne volonté mais sans aucune qualification enlinguistique2. Il faut souligner que ces travaux d’amateurs ont fini parimposer l’utilisation de l’alphabet latin alors qu’il existait déjà desalphabets autochtones bien adaptés aux langues locales. Citonsl’écriture des Bamum que le roi Njoya crée et fait prospérer à la fin dudix-neuvième siècle au Cameroun, ou les syllabaires mandé quiapparaissent entre 1833 et 1930 [Dalby 1986].Les intellectuels africains ont identifié le péril que représente cettesituation de négation des langues et cultures africaines car ilsconnaissent l’importance primordiale des langues3. Ils ont égalementcompris très tôt que l’alphabétisation de la population est un facteuressentiel pour développer un pays, et qu’il est nécessaired’alphabétiser la population dans une langue qu’elle comprend, et nonplus dans une langue totalement étrangère comme celle ducolonisateur4. Il faut donc que le travail de description scientifique deslangues africaines soit mené par des linguistes de métier afin de mettreau point des systèmes de transcription susceptibles de fixer les langueslocales et d’aider à leur introduction dans le système éducatif. Nous ne pouvons évoquer les circonstances de ce nécessaire effortlinguistique pour chacune des langues de chacun des pays d’Afriquede l’Ouest et nous restreignons pour cet article au cas du Sénégal.
53
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
2 - Ainsi, le même son [u] est transcrit ‘u’ par les colonisateurs anglophones, et ‘ou’ parles francophones.
3 - Une langue qui disparaît s’accompagne de la disparition de la culture partagée parla population dont c’était la langue maternelle [Calvet 1987].
4 - Rappelons, à cet effet, que dès 1817, Jean Dard (cf. Gaucher 1968), instituteur françaisen poste à l’école mutuelle de Saint-Louis du Sénégal dont il était le directeur, avaitessayé d’utiliser le wolof comme langue d’enseignement, après avoir constaté« l’échec d’un enseignement unilingue français amenant les élèves à lire et à écrire lefrançais sans le comprendre » (cf. Dumont 1983) . Malheureusement, la commissionscolaire que le gouverneur Dubelin envoya, le 25 mars 1829, à l’école mutuelle deSaint-Louis condamna et mit fin à cette innovation pédagogique qui desservait lapolitique assimilationniste de la France d’alors.

Le 10 septembre 1937, lors de sa conférence à la Chambre de commercede Dakar, le futur Président de la République, Léopold Sédar Senghor,préconisa l’enseignement des langues maternelles. Après l’accessionde son pays à la souveraineté internationale, il donna des instructionsafin que dans, une première étape, six des langues africaines parléesau Sénégal (wolof, sereer, jóola, manding (malinke) et soninke) soientélevées au statut de langues nationales et fassent l’objet de décretsréglementant leur transcription et le découpage des mots en leur sein.Malheureusement, il convient de remarquer qu’aujourd’hui lessystèmes orthographiques officiels ne sont pas harmonisés d’un paysà un autre pour les mêmes langues, voire à l’intérieur d’un même Etat ;ce qui a conduit, naturellement, à l’existence d’usages différents àl’intérieur d’une même langue. On pourrait illustrer cette situation parplusieurs exemples empruntés au wolof5 : l’énoncé [nja :y]6 est transcritndiaye au Sénégal, et njie en Gambie7. Une telle situation a été évitéeentre la Mauritanie et le Sénégal, dont les systèmes de transcriptionétaient respectivement fondés sur des principes d’ordremorphophonologique ou phonologique grâce à un projet de l’ACCT8
(actuelle AIF9) qui a permis, dans les années 90, à des expertssénégalais et mauritaniens de se réunir, à Dakar comme à Nouakchott,et d’harmoniser le système de transcription du wolof dans les deuxpays concernés. A ce problème d’harmonisation il s’ajoute que, faute d’avoir été rendusobligatoires par des mesures législatives coercitives, les systèmes detranscription officiels ne sont pas toujours respectés et les décrets sontgénéralement laissés pour compte.Mais que constate-t-on, en outre, à l’heure des TIC10 ? Que nonseulement les systèmes de transcription ne sont pas harmonisés, maiségalement que la représentation électronique usuelle des caractères
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
54
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
5 - Le wolof est une langue parlée à la fois au Sénégal et en Mauritanie, colonisés parles Français, et en Gambie, colonisée par les Anglais.
6 - Nom de famille wolof.7 - Ainsi, une unique langue est transcrite de deux manières différentes suivant le pays
où elle est parlée ce qui complique de manière absurde la communication écrite ausein d’une même communauté linguistique [Mbodj 2002].
8 - Agence de Coopération culturelle et technique.9 - Agence intergouvernementale de la Francophonie.10 - Technologies de l’Information et de la Communication.
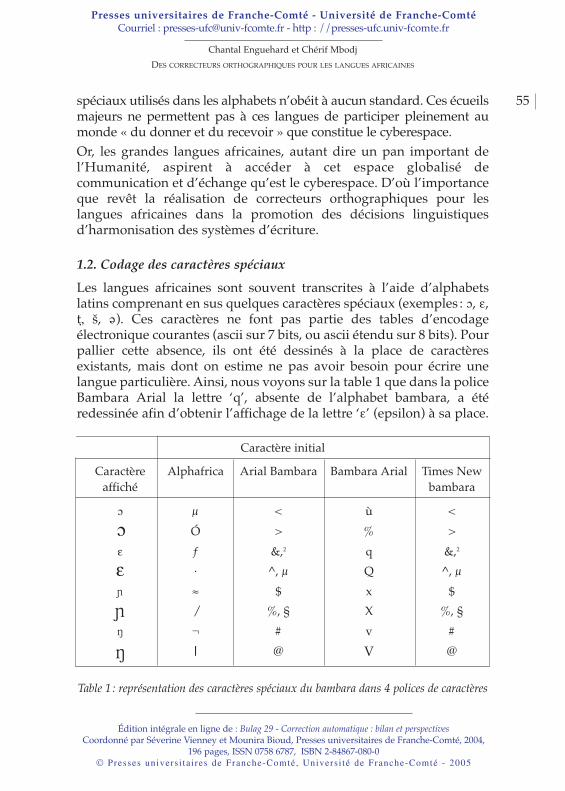
spéciaux utilisés dans les alphabets n’obéit à aucun standard. Ces écueilsmajeurs ne permettent pas à ces langues de participer pleinement aumonde « du donner et du recevoir » que constitue le cyberespace.Or, les grandes langues africaines, autant dire un pan important del’Humanité, aspirent à accéder à cet espace globalisé decommunication et d’échange qu’est le cyberespace. D’où l’importanceque revêt la réalisation de correcteurs orthographiques pour leslangues africaines dans la promotion des décisions linguistiquesd’harmonisation des systèmes d’écriture.
1.2. Codage des caractères spéciauxLes langues africaines sont souvent transcrites à l’aide d’alphabetslatins comprenant en sus quelques caractères spéciaux (exemples : O, E,9t, ôs, ê). Ces caractères ne font pas partie des tables d’encodageélectronique courantes (ascii sur 7 bits, ou ascii étendu sur 8 bits). Pourpallier cette absence, ils ont été dessinés à la place de caractèresexistants, mais dont on estime ne pas avoir besoin pour écrire unelangue particulière. Ainsi, nous voyons sur la table 1 que dans la policeBambara Arial la lettre ‘q’, absente de l’alphabet bambara, a étéredessinée afin d’obtenir l’affichage de la lettre ‘E’ (epsilon) à sa place.
55
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
Caractère initial
Caractère Alphafrica Arial Bambara Bambara Arial Times New affiché bambara
O µ < ù <O Ó > % >E ƒ &,2 q &,2
Q · ^, µ Q ^, µN ≈ $ x $X ⁄ %, § X %, § ù ¬ # v #V | @ V @
E
N
ù
O
Table 1 : représentation des caractères spéciaux du bambara dans 4 polices de caractères

Cette solution s’est largement développée puisqu’elle a longtempsreprésenté la seule possibilité pour écrire avec les outils électroniquesdisponibles, mais elle présente de nombreux inconvénients. Toutd’abord, elle complique l’échange de fichiers de textes à cause del’absence de consensus dans la mise au point de telles polices decaractères alternatives. Ainsi, un texte écrit avec un ordinateurdisposant de la police A et affiché sur un autre ordinateur, avec lapolice B, sera illisible (cf. Table 2). Tout envoi de fichiers doit donc êtreaccompagné des polices de caractères utilisées par ces fichiers 11.
En second lieu, cette représentation interdit tout traitementautomatique des langues puisque le code de chaque caractère n’est pasfixé, le même code pouvant être utilisé par plusieurs caractères (sur latable 1, par exemple, nous voyons que ‘E’ (epsilon) occupe la place du‘&’ dans la police Arial Bambara et celle du ‘q’ dans la police BambaraArial).En 1992, a émergé le standard Unicode, fruit d’une concertation entreindustriels membres du Consortium Unicode et les représentants del’Organisation internationale de normalisation (ISO) [Andries 2002]. Ils’agit d’un système de codage qui peut être étendu sur 2, 3 ou 4 octets.Il permet de représenter plus d’un million de caractères différents,c’est-à-dire tous les caractères de toutes les langues. La mise au point et la diffusion de ce standard constituent un progrèsconsidérable puisqu’il autorise toutes les langues à franchir la
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
56
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
11 - Il est fréquent qu’un fichier utilise plusieurs polices de caractères puisque lescaractères redessinés ne sont plus affichables. Ainsi, un texte mathématique écrit enbambara, à l’aide de la police de caractères Alphafrica, et dans lequel est utilisé ‘µ’(lettre grecque mu), devra obligatoirement utiliser une autre police de caractères pourafficher ‘µ’ puisque ce caractère est redessiné O (o ouvert) dans la police Alphafrica.
Alphafrica CEnimusoya ye jENOgOnya wale ye min kOnO cEnimuso bE jE fo den bE se ka bO a kOnO.
Bambara Arial Cƒnimusoya ye jƒ≈µgµnya wale ye min kµnµcƒni muso bƒ jƒ fo den bƒ se ka bµ a kµnµ.
Table 2 : affichage d’un même texte avec les polices de caractères Alphafrica etBambara Arial

première étape de l’informatisation d’une langue : le stockage desdocuments sous une forme électronique qui permette leur traitementanalytique [Chanard 2001]. De nombreux outils adaptés à unicode commencent à apparaître.
1.3. Outils électroniques ll Claviers
La plupart des caractères spéciaux ne figurent pas sur les clavierscouramment distribués. Il est possible de les saisir en utilisant leurcode, mais cette solution manque évidemment d’ergonomie (il faut sesouvenir des codes, appuyer sur plusieurs touches pour obtenir uncaractère). Dans le cadre d’une action de recherche en réseau de l’AUFréunissant l’Université de Nouakchott, l’Université de Dakar et l’ISTI,des claviers virtuels Unicode ont été développés en balante, bambara,pulaar, sereer et wolof12. Ces claviers permettent d’obtenir directementles caractères spéciaux requis par la frappe de touches du clavier ; lecode généré est le code Unicode du caractère.
ll Editeurs de textesLes éditeurs de textes couramment disponibles (comme Word ou OpenOffice) sont réalisés dans des langues de statut international (anglais,français, espagnol, etc.), il est évidemment possible d’utiliser de telséditeurs pour écrire d’autres langues malgré quelques difficultés.Tout d’abord, il faut maîtriser la langue dans laquelle est rédigée soninterface. L’utilisateur est obligé de fonctionner en mode bilingue, cequi n’est peut-être pas sans conséquence sur son fonctionnementcognitif, l’une des langues pouvant influencer les mots et structuressyntaxiques choisis pour la rédaction dans l’autre langue. Ensuite, lesfonctionnalités linguistiques complémentaires, comme la correctionautomatique de l’orthographe, sont inexistantes pour certaineslangues (même imparfait, il est évident qu’un correcteurorthographique représente un soutien appréciable pour améliorer laqualité d’un texte). Enfin, les textes produits sont codés en ascii etaffichés à l’aide de polices de caractères éventuellement redessinées.Les progrès récents permettent d’envisager le développement
57
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
12 - http://www.termisti.refer.org/ltt/ltt.htm

d’éditeurs de textes adaptés aux langues africaines et produisant destextes au format unicode.
1.4. Ressources linguistiques raresEcrire dans une langue africaine, avec ou sans ordinateur, reste unexercice difficile. Dans la grande majorité des cas, il n’existe pas deressources linguistiques imprimées permettant de trancher lesquestions sémantiques ou syntaxiques. Ainsi, la plupart des languesne bénéficient d’aucun dictionnaire monolingue13, ce qui est unesituation paradoxale puisque qu’elles sont souvent dotées de plusieursdictionnaires bilingues.Bien que cruciales, les étapes de production et de distribution deressources linguistiques paraissent hors de portée. La production d’undictionnaire monolingue représente un travail titanesque, or lespersonnes qualifiées sont rares en Afrique et généralement déjàmobilisées sur des tâches également importantes comme la productionde manuels d’éducation ou de santé. De plus, la diffusion desouvrages produits est confidentielle car ils restent onéreux, et lapopulation est globalement peu alphabétisée !Face à ce décourageant constat, l’utilisation systématique desordinateurs lors de la production de textes (qu’il s’agisse de saisie oumême d’élaboration directe) représente une opportunité à saisir carelle offre la possibilité de diffuser et de recueillir des connaissanceslinguistiques via un éditeur de texte adapté, et plus particulièrementgrâce à un correcteur orthographique adapté.
2. SPÉCIFICATION D’UN CORRECTEUR ORTHOGRAPHIQUE ADAPTÉ
2.1. Bref état de l’artLes correcteurs orthographiques constituent un axe de recherchedepuis les années 1960 [Kukich 1992]. Ils sont maintenant courammentutilisés par le grand public car les éditeurs de textes courants enintègrent souvent un, et qu’ils apportent un confort non négligeablelors de la rédaction de textes. Ces correcteurs fonctionnent selon un
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
58
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
13 - Nous pouvons citer un dictionnaire monolingue zarma : Isufi Alzuma Umaru,Kaamuusu Kayna, éd. Alpha, 1996.

mode interactif dans lequel intervient l’utilisateur, contrairement auxcorrecteurs orthographiques complètement automatiques commedans le domaine de la reconnaissance optique de caractères (et dontnous ne nous préoccupons pas ici).Un correcteur orthographique interactif fonctionne en suivantplusieurs étapes :
- détection des erreurs ;- sélection des corrections possibles ;- ordonnancement des corrections possibles et proposition à
l’utilisateur ;- correction effective du texte respectant le choix de l’utilisateur.
l La détection des erreurs s’effectue souvent en considérant un à unles mots du texte à corriger, de manière isolée. Chacun des mots dutexte est comparé aux mots du lexique (qui contient les mots de lalangue, ainsi que leurs flexions). Tout mot non trouvé dans le lexiqueest considéré comme erroné. Cette technique est très simple à mettreen œuvre mais présente l’inconvénient de ne pas détecter les erreurstransformant un mot en un autre mot présent dans le lexique commedans la phrase « le livre est sue la table ». Le mot « sur » (préposition),a été transformé en « sue » (verbe suer), ce qui est manifestementerroné. Le taux de telles erreurs non détectées augmente avecl’accroissement de la taille du lexique, car plus celui-ci contient demots, plus il est possible qu’une erreur transforme un mot en un autremot du lexique. L’augmentation de la taille du lexique contribue donc,paradoxalement, à dégrader les performances du correcteurorthographique. Seule la prise en compte du contexte d’apparition desmots peut aider à éviter cet écueil majeur. Les premières expériencesdans ce sens étaient fondées sur le calcul de trigrammes (sur les mots).Cette approche théoriquement valide présente l’inconvénient majeurde nécessiter un énorme corpus d’entraînement qu’il n’est pas toujourspossible de constituer [Mays 1991]. Les plus récents travauxs’inscrivent dans le domaine de la cohésion lexicale. Tester simplementles chaînes lexicales sur une phrase aboutit à ce que le système détectedes erreurs qui, pour les neuf dixièmes, n’en sont pas [Hirst 1998]. Unnouvel algorithme exploitant les relations sémantiques diverses que
59
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES

peuvent entretenir les mots (synonymie, méronymie, fréquence decooccurrences élevée, etc.), et étendant la notion de voisinage,autrefois restreinte à la phrase à un ou plusieurs paragraphes, semblecapable de bien meilleures performances [Hirst 2003].l Quand une erreur est détectée, le correcteur sélectionne une sériede mots susceptibles d’être la version correcte de la chaîne à corriger.Ces mots sont choisis selon différentes techniques (calcul de ladistance minimale d’édition, clé de similarité, ou encore mesure de ladistance phonologique).l L’ordonnancement des chaînes candidates à la correction prend encompte la mesure utilisée lors de l’étape de sélection, ainsi que desmesures statistiques (comme la fréquence d’apparition des mots, oubien le mot le plus fréquemment choisi lors de rencontres préalablesavec la même erreur).l Enfin, une étape interactive permet à l’utilisateur de superviser lacorrection. Il peut adopter l’une des trois attitudes suivantes :
- corriger le mot erroné en sélectionnant un des candidatsproposés par le correcteur ;
- modifier le mot erroné ;- ne pas corriger ; dans ce dernier cas, il peut rajouter ce mot à
son dictionnaire personnel. Les correcteurs orthographiques rencontrent deux difficultés majeures.Tout d’abord, les concaténations intempestives de mots, ou l’insertiond’un délimiteur (caractère espace, ponctuation) à l’intérieur d’un motrendent très délicate la sélection de candidats pour la correction. Cettedifficulté n’est cependant pas trop gênante dans le cadre d’unfonctionnement interactif car ces erreurs de frappe sont facilementcorrigées par l’utilisateur. La mise à jour du lexique constitue un écueilplus important : les langues évoluent assez vite comme le montre legrand nombre d’ajouts et de suppressions de mots lors des révisionsannuelles des dictionnaires destinés au grand public, l’utilisation d’uncorrecteur fondé sur un lexique vieux de plusieurs années révèle quenombre de mots couramment utilisés sont faussement diagnostiquéscomme erronés car ce sont des emprunts, des néologismes, ou denouvelles dérivations de mots.
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
60
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

2.2. Inadéquation des correcteurs orthographiques existants pour leslangues africaines
Il existe déjà des correcteurs orthographiques pour certaines languesafricaines, mais ils sont généralement très simples : il s’agit d’utiliserdes correcteurs orthographiques existants en leur fournissant unlexique correspondant à la langue visée [Van der Veken 2003]. Cescorrecteurs orthographiques localisent les erreurs en scrutant les motsdu texte de manière isolée et, même s’ils rendent des servicesappréciables, ils rencontreront fatalement les problèmes précédem-ment soulignés. Nous pensons qu’un correcteur orthographiqueadapté aux langues africaines doit prendre en compte les contextes desmots afin de ne pas limiter inévitablement ses performances.Par ailleurs, il doit posséder des fonctionnalités supplémentaires parrapport aux correcteurs orthographiques habituels afin de prendre encompte le contexte de dénuement linguistique des langues africaines.D’une part, il peut participer à la diffusion de connaissanceslinguistiques en accompagnant les propositions de correctionsd’informations linguistiques supplémentaires, d’autre part, il peutaider à la constitution de ressources linguistiques en recueillant desdonnées destinées à des linguistes.
2.3. Spécification d’un correcteur orthographique adaptéNous avons choisi de réaliser un correcteur orthographique simple,compatible avec le standard Unicode, et fonctionnant avec desressources linguistiques limitées et incomplètes. Nous avons définideux fonctionnalités supplémentaires pour, d’une part, communiquerdavantage d’informations linguistiques à l’utilisateur et, d’autre part,encourager la capitalisation de ressources linguistiques. l Lors de la correction d’un mot détecté comme erroné, le correcteurpropose des mots candidats à la correction. Comme les languesafricaines sont peu standardisées et présentent de nombreusesvariantes dialectales, en particulier phonologiques, il est possible quel’utilisateur n’identifie pas certains mots proposés car ils sontorthographiés d’une manière qui lui est peu familière (mais qui estofficielle) ou qu’il n’a jamais rencontrée. La communicationd’informations supplémentaires sur les mots (comme leur(s)
61
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES

définition(s), leur catégorie grammaticale, des exemples d’usage, etc.)pourraient l’aider à choisir le mot adéquat et à l’utiliser correctement.l Un correcteur orthographique rencontre, par définition, denombreux textes, et est muni d’un lexique qui lui permet d’identifierles mots absents du lexique (mots désignés comme a priori erronés).Son fonctionnement prévoit qu’un utilisateur peut ajouter des motscorrects, mais absents du lexique général, à son lexique personnel.Nous souhaitons exploiter ce processus d’enrichissement afin d’aiderles institutions en charge des langues à augmenter le lexique officieldisponible pour une langue. Lors de l’ajout d’un mot au lexiquepersonnel, le correcteur orthographique peut mémoriser ce mot dansun fichier, ainsi que la phrase dans laquelle il apparaît. L’utilisateur estvivement encouragé à transmettre ce fichier à l’institution en charge dela langue. Celle-ci peut utiliser les informations contenues dans ce typede fichiers pour enrichir le lexique de la langue (cf. aide à la productionde ressources linguistiques).Ce correcteur orthographique est, dans une certaine mesure,indépendant de la langue puisque nous décrivons les traitementsdépendants de la langue (comme le calcul des flexions et dérivationsdes mots par exemple) dans des modules génériques qui utilisent lesinformations contenues dans les ressources linguistiques rassembléesdans le lexique électronique de la langue. Pour adapter ce correcteurorthographique à une nouvelle langue, il suffit donc de changer delexique.
2.4. Le lexique
Le lexique est placé au centre de notre démarche car il est utilisé par lecorrecteur orthographique comme ressource, qu’il doit être maintenuet enrichi par l’institution en charge de la langue et, qu’en l’absence deressources linguistiques imprimées, il est souhaitable que l’utilisateurpuisse le consulter directement. Donc, il peut contenir desinformations qui ne sont pas directement exploitables par uncorrecteur orthographique, mais qui sont importantes pour unutilisateur humain. De manière symétrique, il contient desinformations statistiques qui ne sont pas directement utilisables par unutilisateur.
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
62
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

La diversité des usages d’un tel lexique nous a poussés à spécifier plusprécisément les interactions auxquelles il participe et à proposer desaides logicielles adéquates :
- Lors de la correction d’un texte, l’utilisateur manipule uncorrecteur orthographique qui consulte le lexique.
- L’utilisateur peut souhaiter consulter le lexique hors de toutetâche de correction. Il a besoin dans ce cas d’un logicielpermettant de feuilleter le lexique. La transformationautomatique du lexique en un document hypertexte répond àcette préoccupation.
- L’institution en charge de la langue doit enrichir le lexique soiten introduisant de nouveaux mots, soit en complétant lesinformations sur les mots qui en font déjà partie. Nous avonsdéjà décrit une voie d’enrichissement possible avec laproposition de nouveaux mots par les utilisateurs ducorrecteur orthographique. Les mots nouveaux pourraientégalement être suggérés par l’analyse de corpus. L’institutionen charge du lexique doit donc disposer d’un logiciel luioffrant le plus d’aide possible pour la maintenance du lexique.Nous décrivons ce logiciel en détail dans la partie suivante.
Un lexique est défini comme un ensemble d’items. Chaque itemregroupe un ensemble d’informations dont le radical de la forme, lacatégorie grammaticale, le mode de flexion, une définition, un ouplusieurs exemples d’usage. D’autres informations peuvent êtreajoutées, qui ne seront pas forcément utilisées par le correcteurorthographique (phonétique, synonymes, etc.).
63
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
Utilisateur Lexique
InstitutionCorrecteurorthographique
Transformationen hypertexte
Logiciel demaintenance
Interactions entre le lexique, l’utilisateur et l’institution en charge de la langue

Exemple d’item (wolof) :radical de la forme : aayphonétique : [a :y]catégorie grammaticale : v.i.mode de flexion : 2définition : Être mauvais, être malexemples d’usage : Lu aay ci li ma wax. (Qu’est-ce
qu’il y a de mal dans ce que j’ai dit ?)
synonyme: bon
Dans notre approche, le lexique n’est pas statique mais estperpétuellement « en cours d’élaboration » : plusieurs personnespeuvent intervenir à différents moments pour l’enrichir, le modifier. Ilconvient donc de mentionner, pour chaque champ, la source del’information, l’identité de la personne l’ayant validée, ainsi que ladate de validation. Ces méta-informations sont très classiques dans ledomaine de la lexicographie et permettront d’avoir un retourd’expérience sur la constitution du lexique.Le lexique est mémorisé au format XML, ce qui laisse la possibilité del’adapter à différentes normes (comme la norme : « lexiques pour leTAL » en cours de définition14).Le lexique apparaît ici comme centralisant l’ensemble desinformations sur la langue, et cette tendance devrait s’accentuer avecl’introduction d’expressions lexicales et d’informations syntaxiquesplus précises.
2.5. Aide à la production de ressources linguistiquesNous faisons l’hypothèse que l’enrichissement du lexique au sein del’institution en charge de la langue peut être facilité par ledéveloppement d’un logiciel adéquat. Ce logiciel a plusieurs objectifs :
- intégration des contributions des utilisateurs ;- enrichissement des items du lexique (catégorie grammaticale,
définitions, exemples d’usage, etc.) ;
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
64
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
14 - Dans le cadre de l’action SYNTAXE de l’INRIA, du projet RNTL -Outilex, del’action Normalangue et du groupe de travail AFNOR: « lexiques pour le TAL ».

- intégration de corpus pour calculer des informationsstatistiques (trigrammes sur les symboles, fréquenced’apparition des mots, etc.), observer les contextes d’usage(concordancier), etc.
Les personnes chargées de la maintenance des ressourcesélectroniques verraient leur tâche facilitée par l’utilisation d’un tellogiciel leur permettant d’observer les mots en contexte (grâce à laprise en compte d’un corpus) et de noter de nouvelles informations(telles la catégorie grammaticale, une définition, etc.) dans desformulaires adaptés.
3. RÉALISATION
3.1. Recueil de données linguistiquesNous avons pour projet de développer des correcteurs orthographiquespour plusieurs langues africaines (dans un premier temps: bambara,kanuri, tamajaq, fulfulde (peul), wolof, hausa et zarma). Pour chacunede ces langues, nous avons recueilli des ressources textuelles15 auprèsd’institutions, de journalistes et de maisons d‘édition afin d’initialiser lelexique électronique de chacune des langues. Des linguistes spécialistesde ces langues ont vérifié que ces textes sont écrits conformément auxrègles de transcription et d’orthographe en vigueur afin de ne pasbiaiser la qualité de notre correcteur.
Langue Nombre de motsbambara 89684kanuri 79336
tamajaq 350010fulfulde 24088hausa 139239zarma 74398wolof en cours d’évaluationTable 3 : corpus
recueillis
65
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
15 - Il faut remarquer que les textes recueillis dans 7 langues (cf. Table 3) utilisent 25polices de caractères différentes ! Leur exploitation nécessite donc de lestransformer en conformité avec le standard unicode.

Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
66
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Ces ressources textuelles sont complétées par quelques lexiquesgénéralement bilingues (lexique du droit en bambara-français, parexemple), et des dictionnaires également bilingues (bambara-français,hausa-français, wolof-français) ou monolingues (zarma).Les dictionnaires constituent une ressource particulièrement précieusecar de nombreux liens sémantiques utiles pour une correctionorthographique de qualité y sont notés (synonymie, antonymie,analogie)
3.2. LogicielLe correcteur orthographique lui-même est en développement àl’Université de Nantes. Il procède par l’observation du texte mot àmot, où chaque mot est comparé aux mots présents dans le lexique(après calcul des formes fléchies). Les candidats proposés à lacorrection sont les mots du lexique les plus proches de la chaîneerronée au sens de la distance minimale d’édition [Wagner 1974]. Larecherche de ces candidats est facilitée par la représentation interne dulexique comme un arbre lexicographique [Oflazer 1996] décoré, lesdécorations correspondants aux informations utiles lors de lacorrection (mode de flexion, définition, exemples d’usage, etc.). Dans une seconde version, le contexte des mots sera pris en comptegrâce aux liens sémantiques issus des dictionnaires, et à des mesureseffectuées en corpus (fréquences de cooccurrences).Le correcteur traite des textes sauvegardés au format HTML. Ce modede fonctionnement présente l’avantage de le rendre compatible avecde nombreux éditeurs de texte puisque les fonctionnalités « sauver auformat HTML » et « lire un texte écrit en HTML » sont largementrépandues dans les éditeurs courants. Ce format présente l’avantagede mentionner explicitement les polices de caractères utilisées lors del’élaboration du texte, et donc de rendre possible le recodage d’untexte ascii utilisant une police redessinée en un texte respectant lestandard unicode. Le développement de la première version du correcteurorthographique et du logiciel de maintenance du lexique devrait êtreachevé en 2004. Les tests qui seront effectués au début de l’année 2005déboucheront sur la réalisation de la version finale. Celle-ci devraitêtre disponible, et gratuitement téléchargeable, en 2005.

67
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
CONCLUSION
Nous pouvons déjà prévoir une période de transition jusqu’à unenvironnement logiciel entièrement compatible avec unicode. Cettepériode délicate verra cohabiter des outils anciens avec des outils“unicodisés” : un texte entièrement codé selon le standard Unicodesera illisible par les anciens outils, les claviers Unicode serontinutilisables avec les anciens outils, etc. Il convient donc de développerdes passerelles entre ces deux environnements permettant, enparticulier, de convertir facilement les anciens documents au nouveaustandard, mais également de faire l’opération inverse afin de continuerà bénéficier des outils anciens pendant cette période de transition.Nous soulignons que certaines innovations décrites, comme laprésentation d’informations supplémentaires à l’utilisateur d’uncorrecteur orthogra-phique, seraient utilisables dans d’autres languesoù elles rendraient des services, notamment aux rédacteurs écrivantdans une langue qui n’est pas leur langue maternelle. Les languesafricaines jouent donc un rôle stimulant en nous obligeant à faire faceà des situation extrêmes. Nous pouvons mettre en parallèle ce transfertd’innovation d’un environnement sociétal à un autre avec l’inventionde la télécommande pour télévision inventée en premier lieu pourrépondre à un besoin des handicapés, et largement appréciée del’ensemble de la population.
RÉFÉRENCES
ANDRIES, P. (2002), Introduction à Unicode et à l’ISO 10646, Documentnumérique, vol.6, n° 3-4, pp.51-88.CALVET, L.-J. (1981), Les langues véhiculaires, P.U.F. coll. Que sais-je ?CALVET, L.-J. (1987), La guerre des langues et les politiques linguistiques,Payot.CHANARD, C. et A. POPESCU-BELIS (2001), Encodage informatiquemultilingue : application au contexte du Niger, Les cahiers du RIFAL,n° 22, pp.33-45.DALBY, D. (1986), L’Afrique et la lettre, Centre Culturel Français, Lagos& Fête de la Lettre, Paris.

DIKI-KIDIRI, M. et E. ATIBAKWA BABOYA (2003), Les languesafricaines sur la toile, Les cahiers du RIFAL - Le traitement informatiquedes langues africaines, n° 23, pp.5-32.DUMONT, P. (1983), Le français et les langues africaines au Sénégal, Paris,Acct-Karthala.GAUCHER, J. (1968), Les débuts de l’enseignement en Afrique francophone,Jean Dard et l’école mutuelle de Saint-Louis du Sénégal, Paris, Le livreafricain.HIRST, G. et D. ST-ONGE (1998), Lexical chains as representationsof context for the detection and correction of malapropisms, Fellbaum,pp.305-332.HIRST, G. et A. BUDANITSKY (2003). “Correcting real-word spellingerrors by restoring lexical cohesion”,http://www.cs.toronto.edu/compling/Publications/Abstracts/Papers/Hirst+Budanitsky-2001-abs.html.KUKICH K. (1992), Techniques for automatically correcting words in text,Computing Surveys, 24(4): 377–439.MAYS, E., DAMERAU, F. J. et R. L. MERCER (1991), Context basedspelling correction, Information Processing and Management, 27(5),pp.517-522.MBODJ, C. (2002), Orthographe commune et législations nationales,Writing African – The Harmonisation of Orthographic Conventions inAfrican Languages, ed. Kwesi Kwaa Prah, pp. 55-64.OFLAZER, K. (1996), Error-tolerant Finite-state Recognition withApplications to Morphological Analysis and Spelling Correction,Computational Linguistics, vol. 22, n° 1, pp.73-98.VAN DER VEKEN A. et A. DE SCHRYVER (2003), Les langues africainessur la Toile : études des cas haoussa, somali, lingala et isixhosa, Les cahiersdu RIFAL n° 23, pp.33-45.WAGNER, R.A. et M.J. FISCHER (1974), The string-to-string correctionproblem, Journal of the Association for Computing Machinery, vol.21,n° 1, p. 168-173.
Chantal Enguehard et Chérif MbodjDES CORRECTEURS ORTHOGRAPHIQUES POUR LES LANGUES AFRICAINES
68
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

69
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
RésuméCet article présente MULTILINT, la version allemande de CLAT, un outil de contrôlede la langue destiné aux rédacteurs techniques. MULTILINT regroupe différentsoutils de contrôle : orthographe, grammaire, terminologie et style. Nous expliquons lesfonctions de contrôle ainsi que les stratégies de correction implémentées puisprésentons un module en développement pour la reformulation automatique dephrases stylistiquement défectueuses. Nous abordons également l’aspect del’organisation du travail dans des entreprises utilisant cet outil.
Mots cléscontrôle de l’orthographe ; contrôle de la grammaire ; contrôle du style ; outil devérification de langue contrôlée ; aide à la rédaction ; reformulation automatique.
AbstractIn this paper we present MULTILINT, a language checking tool designed to assisttechnical writers in producing high quality documentation in various domains.MULTILINT integrates multiple checking functionalities such as spell, grammar,terminology, and style checking. Besides presenting these checking functionalities, wealso outline the correcting strategies integrated in MULTILINT and report on ongoingwork to implement an automatic paraphrasing module able to reformulate stylisticallyinappropriate sentences. Moreover, we discuss the use of such a tool within theworkflow of a company.
Key-wordsspell checking ; grammar checking ; style checking ; controlled language checker ;authoring tool ; automatic paraphrasing.
CHECKING AND CORRECTINGTECHNICAL DOCUMENTS
Maryline HERNANDEZ and Ecaterina RASCU
Institut für Angewandte InformationsforschungMartin-Luther-Str. 14, Saarbrücken, Germany

1. INTRODUCTION
The growing importance of technology in every-day life has led to anincreasing demand for high quality technical documentation in anyindustry and business. High quality in this case is measurable in termsof correct information, comprehensible presentation as well as user-friendly layout. There are national and international standards, forexample DIN EN 62079 and DIN EN 12100-2, that regulate content,form, and language of technical documentation in order to ensure safeusage of products. From a linguistic point of view, standard language,consistent use of terminology, unambiguous linguistic structures arethus required to increase the readability, comprehensibility andtranslatability of technical documentation. In addition to the abovementioned standards, company specific regulations may imposefurther restrictions on texts in order to promote a corporate identity. Various tools such as document management systems, terminologicaldatabases or language checkers have been developed in order tofacilitate the authoring process and ensure conformance to standards.In this paper we present MULTILINT1, the German version of CLAT2,a tool designed to assist technical writers in producing high qualitydocuments by checking terminological consistency, spelling, grammar,and style. In Section 2 we present similar work carried out in the fields of bothgeneral language checking and language checking for specialdomains. Subsequently, in Section 3, we describe the checkingfunctionalities of MULTILINT and discuss the correcting strategiesimplemented in the system. Moreover, we present ongoing research inthe field of automatic paraphrasing for style correction. In Section 4,we discuss issues concerning the use of MULTILINT in the actualworkflow of a company.
2. RELATED WORK
Language checking may involve spell, grammar, terminology andstyle checking, depending on the domain for which the respective toolhas been developed. General purpose checkers usually cover spell andgrammar checking whereas those designed for special fields such astechnical communication may also include terminology or style
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
70
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
1 - Multilingual Intelligence for Technical Documentation.2 - Controlled Language Authoring Tool.

checking. Most commercial editors incorporate general languagechecking facilities. Alternatively, commercial language checkers suchas Corrigo, DUDEN-Korrektor, Deutsch Korrekt 2000, or Orthograph forGerman can be integrated into various text editors. Some of these toolsonly offer spell checking whereas others also include grammarchecking facilities.Controlled language (CL) checkers have been developed in order tofacilitate the authoring process in particular technical fields. Besideschecking texts with respect to general language correctness, CL checkersmay also verify conformance to authorised terminology and approveduse of language. For instance, the commercial tool MAXit checks ifdocuments follow the specification of Controlled English or AECMASimplified English. Further examples of CL checkers are: Boeing SimplifiedEnglish Checker (BSEC), KANT Controlled Language Checker etc. All theabove mentioned CL checkers adopt a prescriptive approach, i.e. theyonly allow structures that are written in accordance with the respectiveCL and mark any other sentence as improper. Conversely, MULTILINTadopts a proscriptive approach by detecting linguistic structures that arepredefined as incorrect or inappropriate. Mitamura and Nyberg (2001)describe this process as partial checking, since a text still might have otherproblems which are not covered by the rules of the system.Language checkers ideally have two components, a checker and acorrector, which either automatically corrects the text or suggestsrewrites to the user (Mitamura & Nyberg, 2001). Whereas MicrosoftWord or KANT contains such correction modules, other checkers donot. Typical reasons for not integrating a corrector are for example thewish to keep error reports simple and to avoid possible wrongsuggestions which would only annoy the technical writer (Wojcik &Holmback, 1996). Besides reformulating inappropriate structures,checkers might integrate various other strategies meant to support therewriting process such as detailed problem diagnosis or trainingthrough typical reformulation examples (cf. Section 3.2.).
3. CHECKING AND CORRECTING WITH MULTILINT
MULTILINT is a language checking tool developed at IAI3 within theframework of several R&D projects. The first of these projects,MULTILINT (1995-1998), was funded by the German Federal Ministry
71
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
3 - Institut für Angewandte Informationsforschung, Saarbrücken, Germany

of Economy with the BMW Group as the main industry partner. Theaim was to develop a linguistically intelligent system to assist theproduction of multilingual technical documentation, especially in thefield of service and repair methods for the automotive industry. Theprototype was improved during follow-up projects, focusing onEnglish, French and Swedish (MULTIDOC, 1996-2000) and later,focusing on German (TETRIS, 1999-2002). In the meanwhile,MULTILINT has become an application that supports technical writersin producing high quality documents in terms of both general andcorporate language correctness. It is also available under the nameCLAT for English, and in less developed forms for French, Italian,Spanish or Swedish. On the level of general language, MULTILINT provides spell andgrammar checking functionalities. On the level of corporate language,the terminology and style checking modules verify if a text complieswith company specific terminology as well as stylistic requirementsconcerning technical writing in general and corporate identity inparticular. MULTILINT is designed for tagged input (SGML, XML,HTML) allowing the system to make use of metainformation bound totags marking particular text parts during processing. Hence, listelements and titles that are marked accordingly undergo a slightlydifferent checking process compared to the rest of the document. In thefollowing section we present the checking and correctingfunctionalities of MULTILINT in more detail.
3.1. Checking FunctionalitiesSince the process of checking terminological accuracy and consistencywith MULTILINT has been described in detail in (Carl et al., 2002), inthis paper we focus on spell, grammar and style checking. In Sections3.1.1. – 3.1.3. we outline for each functionality the linguistic processingsteps involved and illustrate the checking process.
3.1.1. Spell CheckingThe German Spelling Reform introduced in 1998 changes the spellingfor given word classes such as loan words, derivative variants ofnouns, compound words etc. It also introduces progressive andconservative writing variants for given patterns. Although both newvariants are allowed in general language, it is recommended not tomix progressive and conservative spelling in a document intended for
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
72
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

publication. Consequently, companies producing technical documen-tation have to decide upon one of the alternatives. Corporatelanguage, on the other hand, may also include word constructs that arein contradiction to the general spelling rules. For example, the Germanrailway company Deutsche Bahn AG uses compounds with capitalletters within the word, like NachtZug (night-train) instead of Nachtzug.The spell checking functionality of MULTILINT detects words that donot conform to the requirements of the German Spelling Reform andother typical spelling mistakes. Moreover, it can be tuned to cope withthe particular problems of corporate language correctness. The spellchecker is actually a component of MPRO, a morphological analyserdeveloped at IAI (Maas, 1996). The tokeniser in MPRO first identifiessentence and word boundaries in the text. The words are thenmorphologically analysed against several lexicons, mainly a phraselexicon and a morpheme lexicon that is combined with word buildingrules. The phrase lexicon contains morphologically non-productiveelements such as prepositions and articles whereas the morphemelexicon contains roots, flexions and derivative elements (Maas, 1996).For an unrestricted German text, the morphological module producesmore than 95 % correct analyses (Schmidt-Wigger, 1998). If no analysiswas found for a word, a correction module tries to determine the rightspelling based on resemblance criteria and weighing operations.The words in the examples (1) – (4) were checked according to theprogressive paradigm. The results are given in form of attribute-valuepairs grouped in a feature bundle. The attributes in the exampleanalyses have the following meaning:
-ori original input word -c part-of-speech-lu lexical unit -s semantics-ls lexical structure -control error category-ns correct spelling -problem error type
In (1) the analysis shows that Prozeß is written according to the oldspelling rules (problem = alt) and is, according to the Spelling Reform,a mistake. The correct spelling is given in the attribute-value pair ns= Prozess. In (2) the analysis indicates that the word is indeed writtenaccording to the new spelling, but in the conservative way of writing(problem = kon). Here too, the value of the attribute ns, Geografie,indicates the right spelling. In example (3), Unterfuehrung, thesequence ue is used instead of the letter ü. Even though such writing
73
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS

variants may be appropriate in certain contexts, they have to beavoided in technical writing (problem = nie). The word Plattentechtonik(4) is misspelled and thus unknown to the system (problem = unknown).Consequently the value of ns is calculated using a word form lexiconand the above mentioned correction algorithm.
(1) Prozeß(process){ori=Prozeß, lu=prozess, ls=prozess, ns=Prozess,c=noun, s=process, control=orth, problem=alt}
(2) Geographie(Geography){ori=Geographie, lu=geographie, ls=geographie,ns=Geografie, c=noun, s=science, control=orth,problem=kon}
(3) *Unterfuehrung(underpass){ori=Unterfuehrung, lu=unterführung, ls=unter$führen,ns=Unterführung, c=noun, s=massnahme, control=orth,problem=nie}
(4) *Plattentechtonik(plate tectonics){ori=Plattentechtonik, lu=Plattentechtonik,ls=plattentechtonik, ns=Plattentektonik; Plattenstecherin,c=noun, s=n, control=orth, problem=unknown}
Certain spelling problems like capitalisation mistakes4 can only bedetected during grammar checking, since they involve worddisambiguation according to the immediate context.
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
74
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
4 - In German, nouns have to be capitalised.

3.1.2. Grammar CheckingThe grammar checking component aims at detecting ungrammaticalconstructions with respect to Standard German. It detects: misplacedcommas5, capitalisation mistakes, misspelled compounds, agreementmistakes, misplaced relative clauses, word repetition, etc. Wrongstructures are flagged with error codes which trigger appropriatemessages in the user interface.In order to detect grammar mistakes the output of the morphologicalanalysis is parsed using an ordered set of grammar rulesimplemented in KURD6, a flat pattern matching formalism (Carl &Schmidt-Wigger, 1998). With KURD, word clusters are described,permitting to disambiguate, recognise and mark first smallerstructures, for example nominal or prepositional phrases, thenfunctional units such as subject or verb group, main and subordinateclauses. Certain word clusters may be marked as a phrase even if theresulting phrase is not entirely correct. This enables the recognition offunctional units. The recognition modules strongly interact with theerror tagging modules. Thus, some error codes are attributed on theevidence that particular structures could be recognised. If, on theother hand, structure recognition fails, other error codes are assigned.Example (5) illustrates the former case while (6) the latter.
(5) *Ein 64 KBit EPROM dient als Read-Only Memory undDatenspeicher.(A 64 kbit EPROM serves as Read-Only Memory and DataMemory){ori=Ein, lu=ein, ls=ein, c=w, sc=art, s=nil},{ori=64, lu=64, ls=64, c z, s=integer, gram=3162de,gramprop=w; c-},{ori=KBit, lu=KBit, ls=KBit, c=noun, s=measure, w=1,gram=3162de, gramprop=w; c-},{ori=EPROM, lu=eprom, ls=eprom, c=noun, s=instr,gram=3162de, gramprop=w}
75
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
5 - In German, commas have to separate main clauses from subordinate clauses. 6 - KURD is an acronym representing the first letters of the basic actions of the
formalism: Kill, Unify, Replace, Delete.

(6) *Der Computer mit den neuen Bildschirm ist aus.(The computer with the new monitor is off.),{ori=mit, lu=mit, ls=mit, c=w, sc=p, s=nil},{ori=den, lu=d_art, ls=d_art, c=w, sc=art, s=nil,gram=4211de},{ori=neuen, lu=neu, ls=neu, c=adj, s=nil, gram=4211de},{ori=Bildschirm, lu=bildschirm, ls=bild#schirm, c=noun,s instr, gram=4211de}
In example (5) ein 64 KBit EPROM is marked as a noun phrase basedon the order of constituents and the agreement between the article einand the last noun EPROM. Therefore the latter is the head of acompound in the structure of which the hyphens are missing. For thisreason, the problematic part of the noun phrase is flagged with errorcode gram = 3162de. The attribute gramprop encodes in this case theinformation that is necessary for generating a correction (cf. Section3.2.1.). In example (6) the sequence preposition – article – noun is notmarked as a prepositional phrase because there is no agreementamong the elements of the structure7. Consequently the structure isflagged with error code gram = 4211de.The disambiguated output of the grammar analysis is transmitted tothe next checking components: terminology and style checking.
3.1.3. Style CheckingIn addition to checking documents with respect to general languagecorrectness, MULTILINT also checks if they conform to specificstylistic requirements concerning technical writing in general. Thestyle checking functionality identifies phrase structures that areambiguous or difficult to understand. Besides, company specificstylistic requirements are also checked in order to ensure compliancewith corporate identity. The style constraints in MULTILINT wereinitially formulated with the help of experts in the field of technicaldocumentation (Schmidt-Wigger, 1998). During subsequentexperiences with the system and implementations for the industry, therules were tuned according to the needs of technical writers. Presently
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
76
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
7 - In German, prepositions require case agreement with the following noun or nounphrase.

there are 33 so-called core rules checking conformance to generalstylistic standards and 40 optional rules. Hence, the user may activatedifferent sets of style rules in different configurations, i.e. he8 cancustomise the application according to his needs. As in case of grammar checking, an ordered set of style rulesimplemented in KURD is applied to the morphologically analysed andgrammatically disambiguated input (cf. Section 3.1.2.). In case therules apply, the respective structures are marked with an error code.Style constraints in MULTILINT address the following issues: layout,lexical problems, ambiguity, ellipsis, complexity, order of sentenceconstituents as well as other stylistic problems. Example (7) presents asentence which disregards the lexical constraint according to whichthe indefinite pronoun man (one) should be avoided. The sentence in(8) violates the syntactic constraint restricting the use of the verb sein(to be) followed by a zu infinitive.
(7) # Um sich anzumelden, gibt man das Passwort ein.9
(To log in, one types in one’s password.)(8) # Die Schrauben sind zu ersetzen.
(The bolts are to be replaced.)
Even though the constraints presented in examples (7) and (8) belongto different formal categories, the underlying problems are similar.Both sentences express instructions that have to be carried out by thereader of the document. Nevertheless, the indefinite pronoun man inthe former example and the lack of subject of the passive-likeconstruction in the latter are both quite vague formulations. Thereader may not feel addressed and fail to grasp the message. In orderto avoid such situations, MULTILINT marks the respective structuresand prompts the technical writer to reformulate the sentence. Thevarious means supporting the user in reformulating incorrect orinappropriate sentences are discussed in the next section.
3.2. Correcting StrategiesIn this section we discuss the various correcting strategiesimplemented in MULTILINT and report on ongoing researchconcerning the stylistic optimisation of texts.
77
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
8 - Please note that we address both male and female technical writers and authors.9 - The symbol ”#” marks a stylistically inappropriate sentence.

3.2.1. Implemented Strategies
MULTILINT integrates multiple strategies that help the author tocorrect a text. In case of spell checking, MULTILINT proposes a rewriteif a correction can be found by resorting to the linguistic resources ofthe tool. For instance, in (1) or (2) the value of the attribute ns, Prozessrespectively Geografie, is offered as correction. In case of (4) theattribute ns has two values, i.e. ns = Plattentektonik ; Plattenstecherin,and the author must resolve the ambiguity by choosing the propercorrection.
Figure 1 : MULTILINT interface - Grammar mistake identification andcorresponding rewrite
In case of grammar mistakes, the system offers a rewrite only if theproblem is unambiguous. For example, in (5) the system highlights thesequence 64 KBit EPROM and suggests the writer to replace it with 64-KBit-EPROM (cf. Figure 1). This correction is automatically generatedby the system on the basis of the gramprop feature (cf. Section 3.1.2.).The values of this feature indicate that the words in the structureshould be linked by hyphens until the headword is reached. Whenseveral rewrites are possible, MULTILINT only identifies the grammar
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
78
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

problem and prompts the author to reformulate the sentence. Forinstance, in case of the agreement problem in example (6) either thedeterminer has the wrong case or the noun the wrong number. Here,the system only displays an appropriate error message signalling theproblem. The error messages can be customised according to theuser’s level of linguistic knowledge and professional background. During style checking, stylistically inappropriate phrases arehighlighted and the technical writer is provided with an error messageexplaining the problem. Besides, a typical example illustrating theproblem and its stylistically adequate reformulation are also providedas illustrated in example (9).
(9) So nicht : An dieser Stelle sind die Einstellungennochmals zu überprüfen.Sondern so : Überprüfen Sie an dieser Stelle nochmalsdie Einstellungen.(Wrong : At this stage, the settings are to be rechecked)(Right : Recheck the settings at this stage)
As in case of error messages, the user can choose among several sets ofexamples designed for different domains such as automotive industry,telecommunication, software etc. The examples and the errormessages have didactic functions: they help the user to reformulatesentences by clearly identifying problems and by offeringreformulation patterns. Moreover, in time, authors learn how to avoidproblematic structures. This leads to a more efficient individualwriting style and is consequently profitable for the company.
3.2.2. Ongoing DevelopmentIn the remainder of this section we report on ongoing work to developan automatic paraphrasing component capable of optimisingstylistically inadequate structures. The proposed reformulations takeinto account pragmalinguistic criteria formulated in relevant researchaddressing comprehensibility and style in technical documentation(Lehrndorfer, 1996 ; Sandig, 1986 etc.). Therefore, integrating such aparaphrasing component into MULTILINT would further increase theefficiency of the checker by providing adequate reformulations to thetechnical writer.
79
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS

Our method for generating stylistic paraphrases relies on amethodology developed in transfer-based Machine Translation (MT).In MT, source language structures are mapped onto target languageequivalents with the help of transfer rules. Similarly, the rewritingalgorithm makes use of an ordered set of paraphrasing rules whichdescribe the necessary rearrangement of the input structure in order toproduce a stylistically appropriate sentence. The algorithm tries toapply the paraphrasing rules to every input sentence flagged duringstyle checking. If a rule applies successfully, the set of paraphrasingrules is applied to the transformed sentence once again till no moretransformations are possible. At present, only one reformulation canbe produced for a given sentence since the algorithm does not performbacktracking.For instance, the stylistically inappropriate sentence in (7) can bereplaced by a lexical paraphrase in which man is replaced by Sie, thepolite form of the personal pronoun. The corrected sentence is given in(10). Even though (10) resolves a lexical constraint the transformationsinvolved are not exclusively lexical, since the number of the finite verbalso needs to be changed into the plural. In order to reformulatesentence (8) the structure sein followed by a zu infinitive is replaced bythe verb in the infinitive as shown in example (11).
(10) Um sich anzumelden, geben Sie das Passwort ein.(To log in, type in your password.)
(11) Die Schrauben ersetzen.(Replace the bolts.)
However, stylistic inappropriateness is not confined to sentence level.Therefore, the module needs to be extended in order to cope with suchphenomena as anaphora resolution.
4. MULTILINT IN USE
The traditional document production process includes qualityassurance steps like proofreading and correction after the writingphase. When the technical writer finishes the first version of thedocument, he sends it for proofreading to the reviewer. At this stage,mistakes and inappropriate structures that can be easily corrected – for
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
80
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

example spelling or terminology problems – are rectified on the spot.In this case the author receives no or little feedback. Only if the textpresents a considerable number of deficiencies, it is sent back to theauthor for revision. The use of a language checker like MULTILINT has multiple effects onthe workflow within a company. First, the author becomes moreinvolved in the quality assurance process. He is now responsible forcorrecting spelling and terminology mistakes as well as grammaticallyand stylistically inappropriate sentences, which leads in time to theimprovement of his writing style. The learning effect is furtherenhanced by the fact that feedback is immediate and that the mistakesare pointed out by a system and not by a person, so it is easier to acceptthe criticism. Second, the use of MULTILINT makes translation easierby ensuring higher consistency of text and terminology. Thus matchrates are higher when using Translation Memories and as a result,translators have fewer uncertainties that need to be resolved. Third,the use of MULTILINT contributes to building a positive image of thecompany. On the one hand, by respecting corporate guidelines, thedocuments better reflect corporate identity. On the other hand,documentation that is easier to understand and consequently morecustomer-friendly increases client satisfaction regarding the product inparticular and the company in general. However, MULTILINT is only a tool designed to support technicalwriters and cannot entirely replace experienced human reviewers(Böhler & Ceglarek, 2003). Users often wish MULTILINT to carry outan automatic correction of the text. But as the system relies only onlinguistic resources, it has certain limitations the user needs to beaware of. Therefore, the technical writer has to consider and decideupon each reported problem and take the responsibility for thecorrections.MULTILINT has been in use at the BMW Group, in the automotiveindustry, since 1998 and at Heidelberger Druckmaschinen, in thedomain of printing machines, since 2001. Both companies benefit fromthe system and still request for enhancements involving furtheraspects of the authoring process.
81
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS

5. CONCLUSIONS AND FUTURE WORK
In this paper we presented MULTILINT, a language checker designedto support the production of documentation in various technicalfields. MULTILINT checks spelling, grammar, terminology and stylein order to increase readability, comprehensibility and translatabilityof a text. It facilitates the work of technical writers and reviewers sinceit carries out a rigorous checking by applying the same filter to allstructures in a text. Correcting is essentially interactive: MULTILINThighlights the mistake, describes the problem and in certain casessuggests a rewrite or provides an example illustrating the rewritingprocess. It is up to the technical writer to accept or reject thereformulation as well as to rewrite incorrect or inappropriatesentences. Interactivity is also crucial in case of style correction, wherean utterance might be reformulated differently depending on the typeof the text and the communicative intention involved. A current study,on which we reported in Section 3.2.2., addresses the issue ofgenerating possible rewrites in order to support style correction.
AcknowledgementThroughout the years, there have been many persons involved in thedevelopment of MULTILINT at IAI. Therefore, we would like toacknowledge their work and thank them for providing the basis forthis paper. We would also like to thank our reviewers for their valuablecomments.
REFERENCES
BÖHLER, K. and CEGLAREK, R., (2001), Evaluierungsbericht Lektorat,TETRIS Projektdokumentation 01/02, pp. 7-21.CARL, M., HALLER, J., HORSCHMANN, C., MAAS, H.-D. andSCHÜTZ, J., (2002), The TETRIS Terminology Tool, In TraitementAutomatique des Langues, Vol.43:1.CARL, M. and SCHMIDT-WIGGER, A., (1998), Shallow PostMorphological Processing with KURD, In Proceedings of the Conferenceon New Methods in Natural Language Processing, NeMLaP’98,Sydney.
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS
82
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

FOTTNER-TOP, C., (2002), Maschineller Lektor, In technischekommunikation 1/02, pp. 26-29.HALLER, J. and FOTTNER-TOP, C., (2001), Multilint - eine toolgestützteLösung für die Kontrolle von Textqualität, In tekom-Frühjahrstagung2001.LEHRNDORFER, A., (1996), Kontrolliertes Deutsch. Linguistische undsprachpsychologische Leitlinien für eine (maschinell) kontrollierte Sprache, inder Technischen Dokumentation, Gunter Narr Verlag, Tübingen.MAAS, H.-D., (1996), MPRO-Ein System zur Analyse und Synthesedeutscher Wörter, In Hausser, R. (ed). Linguistische Verifikation Spracheund Information, Max Niemeyer Verlag, Tübingen.MITAMURA, T and NYBERG, E., (2001), Automatic Rewriting forControlled Language Translation, In Proceedings of the NLPRS 2001.Workshop on Automatic Paraphrasing: Theory and Application.REUTHER, U., (1998), Controlling Language in an Industrial Application,In Proceedings of CLAW’98.SANDIG, B., (1986), Stilistik der deutschen Sprache. Walter de Gruyter,Berlin/New York.SCHMIDT-WIGGER, A., (1998), Grammar and Style Checking forGerman, In Proceedings of CLAW’98.WOJCIK, R. H. and HOLMBACK, H., (1996), Getting a ControlledLanguage Off the Ground at Boeing, In Proceedings of CLAW’96, pp. 22-31.
83
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Maryline Hernandez and Ecaterina RascuCHECKING AND CORRECTING TECHNICAL DOCUMENTS


85
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
RésuméLes outils d’aide à la création et à l’édition de textes représentent un marché d’avenirdans lequel vont être utilisées les technologies de TALN (traitement automatique dulangage naturel). Le problème est de créer des correcteurs “sensibles au texte” c’est àdire qui ne considèrent plus le texte comme une suite de caractères mais comme desmots et des phrases produisant des effets sémantiques et pragmatiques.Le traitement de la grammaire est le but visé aujourd’hui par ces technologies. Maisquelle théorie faut-il adopter? Comment constituer des analyseurs syntaxiques à la foisfins et robustes pour prendre en compte les mots inconnus et les structuressyntaxiques nouvelles ?Mais ce n’est pas qu’une question d’analyseurs syntaxiques. Il faut que le systèmeexplique que sa proposition de correction est la bonne. Comment faire comprendre àl’utilisateur les raisons des modifications d’une manière acceptable?Ceci amène à admettre qu’il faudra avoir recours aux technologies les plus avancées duTAL, si on veut obtenir des résultats notables. Fabriquer des outils et définir desconceptualisations adéquates et adaptées sont en jeu. Nous optons pour une approchecognitive.
Mots clésLogiciel d’aide ; création de texte ; édition ; correcteur orthographique ; correcteurgrammatical ; parseur ; sensitivité au texte ; cognition ; traitement de texte ;intelligence textuelle
AbstractComputer assistance in text creation and editing represents a market with prospects inwhich we can ask how natural language processing technologies can apply. Theproblem is to add language sensitivity, enabling the software not to see a text as asequence of characters anymore - as in word spelling technologies - but as words andsentences producing semantic and pragmatic effects.
UNE APPROCHE COGNITIVE DELA CORRECTION AUTOMATIQUE
DES FAUTES DE SYNTAXEHenri MADEC
MCF HDRCentre L. Tesnière, Université de Franche-Comté
Besançon, France

Grammar checking is really the aim of these technologies today. But what are thelinguistic approaches to be prefered? How can we design powerful syntactic parserswhich will be subtle and robust enough to accept sentences with unknown nouns andnew syntactic structures?Yet, it is not only a question of parsing: it is the problem of helping to understand whythe solution of the software is the good one. How is the user to understand the reasonsof the system’s proposed revisions? How to match the view of the system and the user’sone in an acceptable way?That induces to take into account the most advanced technologies in NLP if we wantgood revisions. Designing convenant and adapted approaches and making up highquality tools are at stake.We choose a cognitive model.
Key-wordsAssistance software ; text creation ; editing ; spelling checker ; grammar checker ;parser ; text sensitivity ; cognition ; word processor ; text intelligence
INTRODUCTION
L’usage des correcteurs orthographiques s’est répandu dans le mondede l’édition. On ne trouve plus de PC dont les traitements de texte ensoient dépourvus. La correction s’est imposée dans le milieuindustriel, la composition des journaux, dans l’édition en général. Onles trouve dans les langages contrôlés où ils aident à la rédaction nonambiguë de textes scientifiques et techniques. Ils soulignent les motsestimés défectueux, et aussitôt la bonne forme trouvée, lesoulignement disparaît. Que c’est pratique! Mais le traitement secantonne à l’orthographe du mot. On a construit des dictionnaires deréférence les plus complets possibles. Ils intègrent les mots de lalangue standard, des langues de spécialité, les néologismes les plusrécents, les expressions figées, les collocations, les proverbes, les nomspropres de lieux, de pays, de personnes, de sociétés, d’évènementshistoriques, les sigles, les troncations etc.On souhaite aller au-delà, les correcteurs doivent prendre en compteles fautes de grammaire. Il est possible aujourd’hui de voir affichéesles formes possibles, voire une règle de grammaire avec un exemplepour aider l’utilisateur. Mais ce qu’il faudrait, ce sont des correcteursintelligents capables de rectifier à coup sûr le passage défectueux, dedonner une explication et être aussi efficaces que le correcteur expert.
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
86
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Ceci exige des analyseurs syntaxiques de haut niveau, des systèmes decompréhension de langage naturel, d’interprétation de textes. Or cesdomaines sont toujours au-delà des possibilités des technologiesdéveloppées par le TAL. Il est intéressant de déterminer quellestechnologies mettre en œuvre et ce qu’il est permis d’en attendre.
1. UN CORRECTEUR ORTHOGRAPHIQUE CORRIGE-T-IL LES FAUTES ?
Il ne s’agit pas de chercher à identifier correcteurs orthographiques etcorrecteurs humains. Les uns sont des programmes informatiques, lesautres sont des experts. Ceci amène à s’interroger sur ce qu’on appelle“corriger les fautes d’orthographe”. La notion de faute dans cedomaine est plus complexe qu’on ne croit. Il importe de distinguerl’erreur et la faute. Si l’on se fie aux correcteurs existants, celui qui est implanté dansWORD par exemple, on constate que l’outil ne souligne que les erreursprésentes dans les chaînes de caractères. Si l’on écrit :
*inatentifpour :
inattentifon constate l’efficacité du produit proposé.
Si une règle d’espacement n’est pas respectée, un soulignementapparaît :
*Qu’ondit
Ce n’est qu’une question de dixième de millimètres. Dans un texteécrit à la main, le regard rectifierait automatiquement. Le sujet n’a pasrelevé assez longtemps sa main entre les deux mots. Mais si on écrit :
*? Qu ‘ on ditle correcteur accepte la séquence de caractères or l’espacement n’estpas correct. Le groupe aurait dû être souligné.
Il y a encore soulignement quand il manque une lettre ou s’il y a unelettre en trop. Ceci est dû à l’inertie ou à la trop grande sensibilité destouches du clavier. C’est une erreur produite par le matériel, ce n’estmême pas de l’inattention.
87
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

Il y a aussi le cas des mots doublés qui sont soulignés :*chat chat
Il ne peut y avoir répétition de la même forme à moins qu’elles nesoient séparées par une virgule :
le chat, chat dont nous avons déjà parlé
Cependant la chaîne suivante est acceptée :nous nous
alors que :*très très
est souligné. Pourtant la répétition est fréquente dans la langue.Le soulignement dépend des listes de tolérances fixées dans une basede règles.
Quel degré de fiabilité peut-on accorder au soulignement d’unechaîne? On peut dire que le correcteur a localisé une forme qu’ilignore. Le système contient une liste d’orthographes possibles pour unmot donné et compare le mot sous le collimateur avec la ou les formesstockées en mémoire. Ceci va poser le problème des orthographes nonretenues par les logiciels. On ne va pas insister sur ce point et onrestera en dehors des querelles des éditeurs de dictionnaires. Robert,Larousse et autres n’ont pas les mêmes “idées” sur la manière d’écrireles mots. Ceci est dû à l’histoire littéraire et aux décisions changeantesdes Académies. Les variations sont considérables tant dans laconjugaison que dans l’orthographe, si l’on tient compte des époqueset des auteurs. On ne peut pas non plus admettre toutes lesorthographes des mots. Beaucoup ont totalement disparu de la langueet ce serait incongru de les accepter aujourd’hui sous prétexte qu’ellesont existé. Il y a des choix à faire! On supposera donc qu’il existe uneorthographe moderne qui est un point de convergence pour tous ceuxqui veulent écrire en français d’aujourd’hui et que l’on est capable dediscerner avec une certaine scientificité le passé du présent, lavariation subjective et la forme stabilisée d’un mot. Sans conteste,l’orthographe reste une affaire d’expert.
Plus gênant, les logiciels de correction ne soulignent pas les erreurs desegmentation, quand les deux segments existent dans lesdictionnaires :
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
88
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

*dé cèdeau lieu de :
décèdeni celles liées aux homophones non homographes :
*Les paires attendaient devant la clinique l’annonce de la naissance deleurs fils.
On voulait écrire les “pères”. Le système a trouvé un mot qu’il connaît“paires”, donc il ne souligne rien… En ce sens :
Les pairs attendaient devant la cliniqueserait une “faute moins grave” du point de vue du sens que la premièrebien qu’il n’y ait toujours pas de soulignement… Un correcteur humainy verrait une faute d’orthographe très grave car il y a des fautes à4 points, des fautes à 2 points, des fautes à 1 point, des fautes à un demi-point et des fautes où il n’y a pas de faute du tout. Il y a des passages oùl’on peut comprendre les choses différemment de l’auteur et tout aussilégitimement. Ceci est laissé à l’appréciation du Maître!
La grammaire, censée régir jusqu’aux rois, pose des problèmes plusgraves à ces correcteurs automatiques. Il y a bien faute dans un accordnon respecté.
*Les chiens que Paul a caresséIl manque un “s” à “caressé”. Une règle de grammaire n’a pas étéappliquée : l’accord du participe se fait avec le complément d’objetdirect placé devant le verbe. Les correcteurs orthographiques nesavent pas corriger une faute de grammaire, faire un accord sujet-verbe, par exemple.
Il faudra distinguer les fautes de non application de règle comme au-dessus et les fautes qui viennent d’une mauvaise application de règle.
*Marie a chantée une chansonL’accord du participe a été fait avec le sujet du verbe, alors qu’il auraitdû se faire avec le COD s’il avait été placé devant le verbe. Ce cas estrelativement simple. Les corrections de BEPC donnent lieu à des joutesorthographiques. Les fautes de grammaire en général impliquent unemauvaise compréhension du texte.
Le chien de Marie que Paul a soignée
89
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

La phrase dit que c’est Marie que Paul a soignée et non le chien commela phrase :
Le chien de Marie que Paul a soigné
C’est en ce sens que les fautes d’accord sont de vraies fautes. On rejointsensiblement ici le problème de paires/pairs/pères.
Il ne suffit pas d’avoir des analyseurs syntaxiques performants.L’accord relève d’une lecture des événements et exige lacompréhension du texte.
La chienne des enfants que Paul a tenus en laissePaul n’a pas pu “tenir les enfants en laisse”, c’est étonnant, hautementimprobable. Il y a faute de compréhension. “Tenir en laisse” doit êtreappliqué aux animaux et non aux hommes. Mais l’emploi pourrait êtremétaphorique. La dictée est une introduction à la connaissance de lalangue et à la manière dont le bon écrivain sait ou ne sait pas exprimerou interpréter dans sa langue le monde extérieur. Dans les petitesclasses, on a le cas de la dictée à la première personne, avec nombre departicipes y renvoyant, mais ce n’est que lorsque le nom de l’auteur estannoncé, George sans le “s”, qu’il faut comprendre que l’auteur estune femme et l’accord des participes est à reprendre… Quel plaisiréprouve aussi M. Bernard Pivot, auteur de sa “dictée” de dire:
“Il fallait penser à ma personnalité, à mes goûts pour faire l’accordcorrectement”.
Il ne s’agit plus seulement de dictionnaire et de grammaire normative.C’est l’aspect intelligence du texte, “sensibilité” à ce qui est écrit, qu’ilfaut pouvoir intégrer dans le logiciel correcteur. C’est tout l’enjeu dutraitement de la faute d’orthographe.
On peut donc penser que la correction automatique, sous forme delocalisation de formes ignorées par un dictionnaire et une base derègles, peut rendre des services. C’est une question d’automates à étatsfinis, d’expressions rationnelles s’appuyant sur des dictionnaires oud’analyseurs morphologiques. Mais dès que le sens du texte est enquestion, les logiciels correcteurs sont inopérants et deviennent desoutils inefficaces, utopiques, sur lesquels le TAL est destiné à faire debeaux rêves.
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
90
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

2. LA TECHNOLOGIE EN SYNTAXE DES CORRECTEURS ORTHOGRAPHIQUES
Parlons sérieusement. Les correcteurs orthographiques existent, etrendent des services considérables. Qui a un article à écrire entre20 heures 30 et minuit est bien content de voir toutes les imperfectionsorthographiques apparaître en souligné sur son texte. Que de tempsde gagné, d’efforts épargnés à ne pas vérifier l’orthographe lettre àlettre, dans le cas où deux lettres seraient inversées ou un accent inutilese serait glissé quelque part… Le problème de l’industrie des languesest de produire des outils utiles, efficaces, peu importent les subtilitésorthographiques et syntaxiques de la langue française. Maintenant que l’on sait “traiter l’orthographe des mots”, les industrielsdu secteur s’attèlent à la correction syntaxique pour pouvoir prendre encharge un autre niveau de fautes et par la suite des niveaux plus subtilsencore des langues naturelles, le style par exemple…Dans le traitement automatique des fautes de grammaire, on peutdistinguer deux niveaux. Les fautes d’accord locales et les fautesd’accord à distance. Les premières seraient simples à traiter. Par exemple:
*Les belles hortensiassera corrigé :
Les beaux hortensias
Des analyseurs qui corrigent les fautes locales, en contact,apparaissent. Les accords de verbes, d’adjectifs, de déterminants…doivent tenir compte des traits associés aux catégories grammaticalesdes mots voisins.
*Les enfant chantesera facilement corrigé :
Les enfants chantent
Quelques règles s’appuyant sur de bons analyseurs morphologiquessoulignent ces formes fautives et proposent des corrections. Mais peut-on dire que deux mots en contact entraînent un accord local :
*Nous, les enfants nous chanteron -s/t des chansonsimpose deux analyses :
Les enfants vont nous chanter des chansonset :
Nous qui sommes enfants, nous allons chanter des chansons
91
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

Il faut étudier le contexte pour savoir laquelle des orthographes duverbe “chanter” convient.
Si on veut tenir compte de la ponctuation, on crée autant de problèmesqu’on en résout :
Les enfants de nos rues(,) en congés( ) prolongé/s(,) très ensoleillé/e/scette année-là(,) bronzé/s(,) étaient heureux.
La ponctuation aide-t-elle à lever les ambiguïtés? Il faudrait évaluer lacohésion du lien établi entre les noms et les participes par laprobabilité des bi-grammes constitués… mais sans certitude.
Examinons maintenant le traitement des fautes dans les accords àdistance. Ce sont ceux qui posent les problèmes les plus difficiles. Onen a recensé des centaines : les négations, les temps et les modes, lesconcordances, les participes-passés-adjectifs, les dislocationsauxiliaire-verbe, le calcul de la co-référence etc. On ne peut pas - àmoins d’un analyseur syntaxique du niveau de l’ATN, c’est à dire unegrammaire équivalente à une grammaire sensible au contexte - obtenirde résultats acceptables. Prenons l’accord du participe passé conjuguéavec l’auxiliaire “avoir”. Le traitement de :
La chienne du boucher que Paul a caressésuppose de descendre les informations sur les antécédents du pronomrelatif, de la principale dans la subordonnée par une fonction send etde mettre dans une send list les mots susceptibles d’être antécédents :“chienne” et “boucher”. Ensuite on consultera un dictionnaire poursavoir que “caresser” sous-catégorise un humain comme N1 et unanimal en N2 avec de fortes chances.
On peut toujours se dire que les parseurs mis au point en TAL peuventêtre utilisés dans les correcteurs syntaxiques. On peut ensuite réduirele nombre d’arborescences possibles pour chaque phrase en tenantcompte des cas (sujet/objet), des genres et des nombres, de lacohérence des traits sémantiques, des contraintes liées à la sous-catégorisation. Les techniques d’héritage et d’unification apportent debons résultats. Les technologies TAL peuvent rendre d’énormesservices dans la réalisation de correcteurs syntaxiques de haut niveau.
Il faut quand même souligner que la correction des fautes degrammaire dépasse les possibilités des analyseurs syntaxiques. Un très
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
92
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

grand nombre de structures analysées par les parseurs TAL n’a aucunintérêt pour la correction des fautes car ces structures ne génèrent pasde fautes : les bridge verbs, les it-cleft, etc.En revanche, il y a des structures syntaxiques qui génèrent des fautes,que les analyseurs ne prennent pas en compte car ils reconstruisent lesstructures profondes plus qu’ils ne cherchent à justifier les décisionsorthographiques normatives qu’ont prises les Académies tout au longde l’histoire de la langue. On pourrait prendre le cas des règlesd’accord de participes dans le cas des verbes pronominaux : remplacerl’auxiliaire “être” par l’auxiliaire “avoir” et rechercher le COD, etc.De telles règles n’apparaissent pas dans les parseurs. Il n’est paspossible de prendre un analyseur conçu pour la traductionautomatique ou la recherche d’informations, et dire qu’il servira pourfaire de la correction automatique.
Ces difficultés techniques supposées résolues, le problème de l’accordest-il pour autant réglé ? Il faut souvent faire intervenir desconnaissances pragmatiques :
Le pare-brise de la voiture que nous avons lavé(?) avec Ajax-vitre.On a pu laver la voiture et/ou le pare-brise, mais Ajax-vitre contraintà faire l’accord avec le “pare-brise”. S’il faut consulter une base dedonnées contenant tous les produits vaisselles et tous les shampoingsvoiture de tous les supermarchés, la tâche sera immense.
La chienne du boucher que Marie a toiletté(?)Peut-on admettre que Marie ait toiletté une personne ? On n’est pas enmesure de faire des systèmes qui aient un degré de réflexion linguis-tique du niveau d’un enfant de 12 ans, l’âge auquel on découvre lesjoies de la dictée !
On pourrait procéder comme pour l’orthographe et se dire qu’unegrammaire superficielle, aménagée, ou même une grammaire très fine,pourrait rendre des services autant qu’un correcteur orthographiquetraitant les chaînes de caractères. Mais chaque accord amène uneinterprétation sémantico-pragmatique qui a besoin d’être examinéepar un expert, dans notre cas l’utilisateur.
93
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

3. LA CHARGE COGNITIVE DANS L’AIDE À LA CORRECTION SYNTAXIQUE
Il faut donc tenir compte de la charge mentale associée à la correctionchez un humain. Si aucune faute n’est signalée par le logiciel, est-ceque la compréhension générée correspond à celle que l’utilisateur adans son esprit? Rien n’est sûr. Si une faute est signalée, peut-être est-ce une structure syntaxique que le logiciel ignore, ou un effet que tientà maintenir l’utilisateur. Dans tous les cas, l’utilisateur se doit decontre-vérifier les solutions de la machine.
Dans le cas de la correction de :*inatention
la charge mentale pour supprimer le soulignement est faible. Onadmet facilement que le premier “t” est à doubler. Il est vrai que cen’est pas toujours le cas. On peut hésiter sur la correction à apporter àcertains mots mal orthographiés :
*continuement*continument continûment
Il suffit d’essayer plusieurs orthographes. Rapidement et sans tropd’effort le problème est résolu. Il arrive cependant que l’on restequelque temps à essayer des solutions.
Il y a aussi les mots que le système ne connaît pas et qui serontsoulignés. Le dictionnaire qui accompagne un correcteur ne peut pasconnaître toutes les formes existant dans une langue à un momentdonné de son développement, par exemple :
existentialité
Les termes de la philosophie moderne, les néologismes de la languecourante, les noms propres de marques, des emprunts à l’anglais etaux langues les plus diverses par l’intermédiaire de la presse et de latélévision, les termes des nouvelles technologies, etc. Comment fairepour savoir si c’est une forme que le système ignore ou une forme quenous ne savons pas écrire correctement ? Le mot existe dans ledictionnaire sous une orthographe très différente, dont nous n’avonspas idée :
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
94
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

redingotePour :
ridingcoat
C’est le même problème qui va se poser en syntaxe. On est amené àreprendre l’analyse que fait la machine et à rechercher quels élémentson a soi-même pris en compte dans l’accord que l’on a fait. Or dans cecas, la machine n’est pas capable de dire pourquoi elle ne se trompepas, alors qu’on n’est pas sûr d’avoir appliqué la bonne règle :
Elles se sont ri(?) de luiElles se sont plu(?) à chanterElles se sont parlé(?)Elles se sont rencontrées(?)Elles se sont peignées(?)Elles se sont peigné(?) les cheveux
On est obligé de prendre connaissance des règles de grammaire àappliquer et de trouver une explication. Ceci implique différentesopérations cognitives exigeant une charge mentale considérable :
— compréhension du texte (mise en forme logique desprédicats verbaux),
— vérification des règles de grammaire concernées (rule basedsystem),
— analyse grammaticale des éléments du texte nécessaires àl’application des règles,
— application des règles aux éléments grammaticaux dans letexte,
— calcul du résultat et de l’élaboration de l’accord,— vérification de la cohérence de l’analyse et des résultats
obtenus par rapport au contexte. Et tout ceci doit être calculé de plusieurs points de vue :
— celui du logiciel correcteur,— celui de l’utilisateur,— celui du logiciel qui analyse la faute de l’utilisateur,— celui de l’utilisateur qui cherche à comprendre les
corrections proposées par le logiciel.
95
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

En tout cas, la charge mentale impliquée par toutes ces opérations estconsidérable, ainsi que le temps passé à faire les calculs, tout ceci pourl’accord d’un mot. Autant supprimer le correcteur syntaxiqueautomatique, on divise par quatre l’effort mental! Il vaut mieux passerdu temps tous les mois à approfondir la grammaire française, qued’acheter le logiciel. Si on ne peut avoir totale confiance dansl’analyseur, et ce ne sera jamais le cas, autant ne pas chercher à yrecourir et ne pas chercher à en réaliser.Il faut aussi prendre en compte le temps de traitement de toutes cesopérations par une machine. La correction doit se faire au fur et àmesure que l’utilisateur écrit son texte. Il ne peut pas y avoir decorrection décalée. L’utilisateur ne pourrait supporter longtempsd’avoir à avancer et à reculer sans arrêt dans le texte qu’il rédige. Les concepts de fiabilité et de qualité, de convivialité, d’ergonomie quisont liés à tous les logiciels et à leurs applications semblent mettre encause la possibilité d’un traitement syntaxique automatique. Lesystème doit justifier ses analyses et pouvoir les expliquer. Cecirappelle les interfaces de systèmes experts des années 80, qui devaientêtre capables de justifier leurs raisonnements. Il ne s’agit pas dedonner la liste des règles qui ont été appliquées. Cette approche estconnue pour être très largement insuffisante.
4. QU’EST-CE QU’UNE EXPLICATION GRAMMATICALE ?
La question devient alors : qu’est-ce qu’expliquer? Qu’est-ce qu’uneexplication grammaticale?On est alors obligé de passer par les travaux de psychologiedéveloppementale. Comment des règles de grammaire sont-ellesapprises ? Comment sont-elles retenues ? Comment sont-ellesappliquées? Comment les explique-t-on? Comment se les explique-t-on? Ce sont toutes ces informations dont il faut disposer pourproduire des réponses correctes et les explications que l’utilisateurattend.On connaît les rengaines des pédagogues : “Il faut que l’enfantconnaisse ses règles par cœur et les applique les yeux fermés”. Tous lesenfants connaissent leurs règles de participes par coeur et peu saventles appliquer. “Ils ne font pas attention, les adultes eux fontattention…” Ce n’est pas le problème! L’observation des
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
96
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

apprentissages montre que l’on doit intégrer un très grand nombre deparamètres qui vont de la catégorisation grammaticale à la sous-catégorisation, aux thêta-rôles, à la compréhension de la structure dela phrase : inversion, formes orthographiques des participes (permis,fait, construit, ri…), à la transitivité du verbe, à l’ergativité, aux fauxpassifs, à l’agentivité, etc.
En fait une masse d’informations linguistiques doit converger avantque l’accord ne soit pleinement maîtrisé. Il ne s’agit pas de modulessyntaxiques, mais de l’équilibre d’une très grande quantité deparamètres sémantico-syntaxiques et d’opérations linguistico-cognitives. Or tant que le traitement de ces éléments ne sera pasacquis, l’enfant ne prendra en compte que quelques uns des élémentset se trompera. C’est ce qui explique que l’enfant progresse et régressedans l’application des règles d’accord et que souvent il se trompe plussouvent à la fin de l’année qu’au début. Cet apprentissage est facile àmodéliser par des réseaux de neurones. Le nombre d’erreurs nedécroît pas linéairement avec l’augmentation des ticks. Avant l’instantoù l’apprentissage est achevé, le nombre d’erreurs peut encore êtreimportant, alors qu’à l’instant qui précédait, il était proche de zéro.
On est en face d’un apprentissage qui conduit à l’acquisition d’uneexpertise. Un système expert en tant que collection de règles nemodélise pas cette approche. Donner les règles qui ont été appliquées,sans expliquer les raisons de l’accord, ne sert à rien. L’explication esten soi impossible parce que les paramètres dont dispose l’utilisateursont inconnus de la machine et réciproquement. Si l’utilisateur ne saitpas avec certitude identifier un COD, quel intérêt de dire que l’accordse fait avec le COD et donner le COD dans la phrase en question ?L’utilisateur prenait un complément de quantité ou de durée, oumême un sujet pour un COD. Identifier un COD suppose d’avoircompris la notion de transitivité, peu importe le contenu sémantiqueou pragmatique en question. Il peut être parfois suffisant, il ne l’est pastoujours. Si l’on ne dispose pas d’un modèle du traitement syntaxiquede l’utilisateur, comment lui expliquer la faute? La machine peutimposer un accord, elle ne dispose pas des moyens pour prouver queson accord est juste aux yeux de celui qui en envisageait un autre. Tousdeux, machine et utilisateur, peuvent appliquer la règle officielle, maisle contexte de l’application n’être pas le même. Quelles solutionsenvisager pour ce type de problème?
97
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

5. L’EIAO ET LES CORRECTEURS ORTHOGRAPHIQUES ÉVOLUÉS
S’il y avait un outil de correction syntaxique à mettre au point et si l’ondisposait d’analyseurs complexes type ATN pour le français, ce quin’est pas le cas, il faudrait envisager le rajout d’une architecture demodules de type EIAO (Enseignement Intelligent Assisté parOrdinateur). Au correcteur orthographique et au parseur seraientassociés les éléments suivants :
— un module utilisateur : modélisant les connaissances ensyntaxe, les heuristiques, les connaissances du mondeextérieur de l’utilisateur ;
— un module expert : connaissant les règles canoniques de lagrammaire, ayant des connaissances sur le monde extérieuret sachant appliquer ces règles ;
— un module enseignement : sachant comment enseigner lagrammaire en général
— un module didactique : sachant faire le lien entre le moduleutilisateur et le module enseignement avec la création d’uneséquence spécifique et comment présenter les informations àl’apprenant qui a été modélisé ;
— un module interface : sachant expliquer par des dialogues,par des dessins à l’utilisateur pourquoi il se trompe etcomment il va corriger sa faute.
On est en face d’une structure beaucoup plus complexe que celle d’undictionnaire ou d’une base de règles. Mais la réalisation d’un tel outilreste hypothétique. Pour se faire une idée, il faudrait reprendre lesgrands logiciels d’EIAO: WHY, SOPHIE, WEST, etc. De tels produitsn’ont jamais dépassé l’état de maquette. Or dans les traitements detexte, il faut fonctionner dans un monde ouvert et prendre en comptetous les profils cognitifs possibles. Ceci relèverait du rêve éveillé.En matière d’ergonomie et de processus cognitif de traitementd’information, une autre difficulté apparaît et plus délicate encore.Quand on rédige un article ou un rapport, est-on prêt à recevoir unedemi-heure de leçon de grammaire et d’explications diverses sur lefonctionnement des accords des verbes pronominaux parce qu’onvient de se tromper sur un cas un peu subtil d’accord de participepassé? La réponse est non. La charge mentale que demande unecréation textuelle exclut qu’on perde du temps et dépense de l’énergieà comprendre pourquoi il y a une divergence entre deux possibilités
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
98
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

d’accord et d’interprétations dans un texte. Une langue estl’accumulation d’une myriade de petits évènements linguistiques sansrapport, certains ont des effets bénéfiques dans des cas limités,amenant à des précisions sémantiques ou pragmatiques, d’autresencombrent le fonctionnement linguistique de l’écrit et de l’oral. On ahésité longtemps pour savoir s’il fallait créer un point d’ironie commeil y a des points d’exclamation ou d’interrogation. Jusqu’à quel pointfaut-il vouloir traiter automatiquement les fautes de grammaire?Un logiciel de correction de fautes n’est pas un didacticiel. Il seraitdommage de vouloir tout expliquer pour les rares fois où l’explicationest stratégique. C’est bien là un des paradoxes des langues naturelles.
6. OUTILS LINGUISTICO-COGNITIFS EN VUE D’UN TRAITEMENT DES FAUTESDE SYNTAXE
Une architecture de correction de fautes de syntaxe, dans uneapproche cognitive, exigerait différents modules modélisant les pointsde vue que nous avons dégagés, pour prendre en charge pleinement la“faute d’orthographe”.On a d’abord un module qui identifie l’utilisateur. Il importe de savoirsoit directement, soit indirectement qui est celui qui utilise le systèmede correction : un novice, un professionnel de l’édition…? Il y auraitune dizaine de catégories. Selon le niveau de connaissance de lalangue et de la culture française, on doit s’attendre à trouver un typede faute donné et pouvoir produire des explications et des messagesadéquats à l’utilisateur identifié. Ceci se fait en demandantdirectement à l’utilisateur qui il est ; soit indirectement en testant sespossibilités ou en modélisant ses traitements syntaxiques pendantquelque temps. On étudie ses fautes et les corrections qu’il a apportéeslui-même avec l’aide du système.On a ensuite un module qui modélise l’apprentissage de l’utilisateur.A partir des fautes qu’il a déjà commises, il est facile de déterminer lafaçon par laquelle il va apprendre et prévoir ses fautes. Cettemodélisation est obtenue par apprentissage automatique desinformations contextuelles liées à la faute. Il y a un profil type pourchaque catégorie d’utilisateur et l’apprentissage de l’utilisateurlambda est modélisé de façon à entrer dans une catégorie. On sait queltype de faute il commet, comment il les corrige. On peut donc l’aider.On sait alors quelles explications, quelles règles on peut lui proposerpour qu’il comprenne les fautes que le système a repérées.
99
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

Il faut ensuite modéliser le domaine des fautes d’orthographe et degrammaire commises en français. Ceci est possible à partir d’uncorpus général des fautes commises. Ce corpus considérable peut êtretraité comme un tout ou structuré pour constituer des sous-corpusrespectant les profils d’utilisateurs et de fautes commises : fautes surles conjugaisons, sur les adjectifs, les accords sujet-verbe, etc. Ce corpus fait l’objet d’un important taggage tant lexical quesyntaxique ou sémantique. Il permet de dégager les contextes desfautes, grammaticales, sémantiques, selon les types d’utilisateurs. Letaggage peut s’appuyer sur des traitements par automates à états finis,par n-grammes, dans notre cas de tri-grammes ou plus, mais aussi pararborescences, partielles ou complètes. Cela veut dire que lorsqu’il y aune subordonnée relative introduite par “que”, l’accord du participese fait en retenant les traits genre et nombre des catégories nominalesprécédant le pronom relatif, à moins que ce soit un complément denom, un complément circonstanciel, un adverbe, etc. Le système apprend lui-même les règles et les exceptions. A chaquetype de faute est associée l’explication syntaxique de la faute :méconnaissance des participes irréguliers, confusion de l’ordre desmots avec les fonctions, connaissance insuffisante de ce qu’est latransitivité verbale. Il faut distinguer les fautes qui relèvent d’unmanquement à un traitement automatique de celles qui relèvent d’uneanalyse d’un contexte complexe. Dans un tel cas, le système secontente de suggérer plus que d’imposer des corrections. Les typesd’erreurs, des heuristiques d’apprentissage orientent le traitement. Lesystème peut aussi se comporter comme un didacticiel. Il est capablede prédire que l’utilisateur va se tromper, donc d’anticiper la faute enenvoyant un message. On se sépare totalement d’un modèle systèmeexpert par règles pour envisager un traitement heuristique.On prend en compte l’état psychologique du sujet. Est-il en train detravailler depuis des heures sur sa machine? Est-ce une fin de journée?Présente-t-il un état d’excitation, de fatigue qui peut-être calculé aunombre de fautes de frappe par exemple, etc. Les messages envoyésdoivent bien sûr tenir compte de tous ces éléments.Un système de correction automatique est capable d’intégrer lesvariations de la progression de l’utilisateur, de l’accompagner vers lastabilisation que son profil construit dans le traitement des fautes desyntaxe. Une telle approche implique de travailler sur le traitementréel des données par l’utilisateur, d’utiliser des technologies psycho-
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
100
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

cognitives, psycholinguistiques, sans prendre pour modèle l’appren-tissage scolaire. Il n’est pas sûr que les fautes de grammaire soient lereflet d’un manquement aux règles de la grammaire traditionnelle. Lameilleure preuve est qu’on constate que certains apprenants corrigentsur intuition, sans se préoccuper d’appliquer des règles.L’interface n’est pas seulement un système qui envoie du texte, en toutcas jamais de longues phrases de type canned text. Le style de laconversation doit être respecté de part en part, comme dans le systèmed’EIAO. De plus elle peut envoyer des images, des dessins, desarborescences de phrases. Elle peut corriger en posant une question ouen utilisant des icônes. Ce sont là toutes les technologies que l’ontrouve dans les interfaces actuelles. Le système de correction peut aussi être mis en veille. Il se contented’effectuer les corrections et rien de plus. A l’utilisateur de faire ce qu’ilveut du passage corrigé. Mais cette dernière façon de résoudre leproblème de l’explication est dangereuse et sera toujours insatis-faisante d’un point de vue utilisateur. Il ne pourra jamais accepter lesyeux fermés l’accord proposé. A la limite, le correcteur syntaxique nelui servira à rien.
Par exemple :Le quart de la facture que l’acheteur aura réglé(e), lui sera remboursé.
Ce n’est pas le même contrat que l’on signe selon l’accord que l’on fait ;“réglé” implique que l’objet sera acquis sans bourse déliée. Il n’y aaucune chance qu’un mot mal écrit ait de telles conséquences.
CONCLUSION
On s’attend à voir apparaître des perfectionnements du côté dutraitement des textes considérés comme des chaînes de caractères. Onpeut encore avoir de meilleurs dictionnaires. Mais c’est en syntaxe quedes avancées sont attendues, la première étape vers un traitementintelligent du texte. Des outils, des analyseurs syntaxiques ne vont pastarder à prendre en compte les phrases les plus complexes et de façonassez sûre. Mais comment expliquer les corrections proposées? Cesont, à notre avis, les solutions apportées par l’EIAO et sonarchitecture modulaire distinguant divers “modèles” (utilisateur,expert, enseignant, didactique, etc.) qui semblent devoir êtreappliquées.
101
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE

On ne voit pas comment la mise au point de technologiesd’exploration de la compréhension de textes et d’explication de faitsde syntaxe pourra ne pas recourir aux concepts, aux méthodes, auxalgorithmes des sciences cognitives, de la psycholinguistique et auxoutils linguistiques constitués dans ces domaines.
RÉFÉRENCES BIBLIOGRAPHIQUES
Proceedings of the 14th International Conference on ComputationalLinguistics, (1992), ACL, Nantes, France.Proceedings of the 32nd Annual Meeting of the Association forComputational Linguistics, (1994), Association for ComputationalLinguistics, Las Cruces, New Mexico.AECMA Simplified English: A Guide for the Preparation of AircraftMaintenance Documentation in the International Aerospace MaintenanceLanguage, (1995), AECMA, Brussels.ADRIAENS, G. and SCHREUERS, D., (1992), From COGRAM toALCOGRAM: Toward a controlled English grammar checker, In COLING,pages 595—601. BROGLIO, J. CALLAN, J. and CROFT, W.B., (1993), The INQUERYsystem, In R. Merchant, editor, Proceedings of the TIPSTER TextProgram, Phase I, San Mateo, California, Morgan Kaufmann. CHURCH, K., GALE, W., HANKS, P. and HINDLE, D., (1991), Usingstatistics in lexical analysis, In U. Zernik, editor, Lexical Acquisition: UsingOn-Line Resources To Build A Lexicon. Lawrence Earlbaum, Hillsdale,New Jersey.ENDRES-NIGGEMEYER,B., HOBBS, J., and SPARCK JONES, K.,(1995), Summarizing text for intelligent communication, Technical ReportDagstuhl Seminar Report 79, 13.12-19.12.93 (9350), IBFI, Dagstuhl.FAGAN, J.-L., (1989), The effectiveness of a nonsyntactic approach toautomatic phrase indexing for document retrieval, Journal of the AmericanSociety for Information Science, 40(2):115—132. GALICHET, G. & R., (1971-1982), Dictées préparées dictées de contrôle,Charles-Lavauzelle Hatier Paris.
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE
102
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

GREVISSE, A., (1964), Le bon usage, Duculot Bruxelles.HAHN, U., (1990), Topic parsing: accounting for text macro structures infull-text analysis, Information Processing and Management, 26(1):135—170.HOARD, J., WOJCIK, R. and HOLZHAUSER, K., (1992), An automatedgrammar and style checker for writers of simplified English, In P. Holt andN. Williams, editors, Computers and Writing. Kluwer AcademicPublishers, Boston .JACOBS, P., KRUPKA, G., RAU, L., MAULDIN, M., MITAMURA, T.,KITANI, T., SIDER, I. and CHILDS, L., (1993), The TIPSTER/SHOGUNproject, In Proceedings of the TIPSTER Phase I, Final Meeting, SanMateo, California, Morgan Kaufmann. LANDGACKER, R.W., (1987), Foundations of cognitive grammar,Stanford University Press Stanford.LIDDY, D. et al., (1993), Development, implementation and testing of adiscourse model for newspaper texts, In Proceedings of the 1993 ARPAHuman Language Technology Workshop, pages 159—164, Princeton,New Jersey, Advanced Research Projects Agency, Morgan Kaufmann. RUGE, G., (1992), Experiments in linguistically based term associations,Information Processing and Management, 28(3).SLEEMAN, D., BROWN, J. S., (1982), Intelligent tutoring systems,Academic Press New York.The Boeing simplified English checker, (1993), Language IndustryMonitor, (13).PEREIRA, F., (1990), Finite-state approximations of grammars, InProceedings of the Third DARPA Speech and Natural LanguageWorkshop, pages 20—25, Hidden Valley, Pennsylvania, DefenseAdvanced Research Projects Agency, Morgan Kaufmann. WOJCIK, R., HARRISON, P. and BREMER, J., (1993), Using bracketedparses to evaluate a grammar checking application, In Proceedings of the31st Annual Meeting of the Association for Computational Linguistics,pages 38—45, Columbus, Ohio, ACL.
103
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Henri MadecUNE APPROCHE COGNITIVE DE LA CORRECTION AUTOMATIQUE DES FAUTES DE SYNTAXE


105
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
RésuméLes correcteurs informatiques font pleinement partie du « paysage informatique ».Quelle est la politique orthographique des maisons éditant ces logiciels ? Globalement,il semble qu’elles soient attentives aux évolutions, comme le montrent les moyens misen œuvre pour intégrer les rectifications orthographiques.
Mots clefsAntidote ; Cordial ; correcteur(s) ; correcticiel(s) ; féminisation ; nouvelle orthographe ;orthographe ; langue ; politique orthographique ; ProLexis ; rectificationsorthographiques ; vérificateur(s).
AbstractSpelling checkers are fluently used today. What is the “spelling policy” of the editorsof these softwares? It seems that they are attentive to the evolutions, as the integrationof the new French spelling shows.
Key-wordsAntidote; Cordial; French language; new French spelling; ProLexis; spelling;spelling checker; spelling policy.
1. INTRODUCTION
Alors que des logiciels de correction orthographique sont désormaisinclus dans la majorité des programmes de traitement de texte, lesvérificateurs informatiques avancés ont aujourd’hui toute leur placechez les professionnels, que ceux-ci soient journalistes, éditeurs,traducteurs, ou même correcteurs-réviseurs. Ils peuvent être paramétrés
QUELLE POLITIQUE ORTHOGRAPHIQUEPOUR LES CORRECTEURS INFORMATISÉS ?
Romain MULLER
membre du groupe de modernisation de la langue (Paris)directeur de publication du site orthographe-recommandee.info

de manière à tenir compte d’une norme typographique particulière…Mais qu’en est-il sur le plan de l’orthographe et de l’analysegrammaticale ? Quelles sont les références des correcteursinformatiques ? Comment évoluent-ils ? Dans cet article, après un retoursur l’importante évolution accomplie en dix ans, nous nous intéresseronsen particulier à la politique orthographique – et, plus largement, à la« politique de la langue » – des maisons qui éditent de tels outils, autravers, notamment, des rectifications orthographiques qu’a proposées leConseil supérieur de la langue française de Paris, appuyé par l’Académiefrançaise et les instances francophones compétentes1.
2. LA CORRECTION INFORMATIQUE : RÉVOLUTION PUIS ÉVOLUTION
L’apparition, voilà à peu près deux décennies, des premiersvérificateurs informatiques, fut une véritable révolution : on disposaitd’un système qui vérifiait la graphie de chaque mot d’un texte etdécelait ainsi immédiatement le t de trop ou le l simple qui aurait dûêtre redoublé ! Le fonctionnement était en fait fort simple : chaqueélément du texte corrigé était recherché dans une longue liste contenantdes dizaines de milliers de mots et toutes leurs formes fléchies. Chaquegraphie qui n’était pas trouvée dans la liste était présumée fautive, etune ou plusieurs suggestions de remplacement, générées par desalgorithmes, étaient proposées. Ce système permettait donc de nevérifier que l’orthographe lexicale, mais, malgré tous ses inconvénients(mots trop techniques ou noms propres inconnus du vérificateur,suggestions de remplacement trop nombreuses…), constituait unenouveauté d’un intérêt tout particulier. Et, le progrès ne s’arrêtant pas,sont apparus assez rapidement les premiers correcteurs « avancés », quiprétendaient aussi vérifier la typographie et, surtout, l’orthographegrammaticale. Mais les critiques ont promptement fusé… Il est vrai queles performances de ces outils laissaient souvent à désirer. Ainsi unchercheur du Centre national de la recherche scientifique2 a-t-ilcomparé en 1989 les différents correcteurs sur le marché et est arrivé à
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
106
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
1 - Les instances francophones compétentes ont en effet proposé un nombre modéré demodifications orthographiques, selon lesquelles il est désormais correct d’écrire,par exemple, évènement (plutôt que événement) comme avènement, ou paraître sansaccent circonflexe. Pour plus d’informations à ce sujet, on se reportera au sitewww.orthographe-recommandee.info ainsi qu’au Vadémécum de l’orthographerecommandée publié par le Réseau pour la nouvelle orthographe du français (voir labibliographie). Note : cet article applique les rectifications orthographiques.
2 - Fabrice Jejcic (article cité).

la conclusion que bien des erreurs n’étaient pas relevées, maiségalement que les programmes détectaient des erreurs… qui n’enétaient pas. Il est intéressant, en 2004, de relire de telles comparaisonseffectuées voilà quinze ans.Il faut toutefois noter qu’en 1989, les correcteurs informatiques étaientplutôt peu utilisés des professionnels, et étaient carrément inconnusdu grand public (faut-il rappeler que les ordinateurs domestiques –que l’on appelait encore « microordinateurs » – étaient de loin bienmoins répandus qu’aujourd’hui ?).C’est précisément à cette époque que Roger Rainero créait la firmefrançaise Diagonal, aujourd’hui connue pour ses produits ProLexis etMyriade, fort employés dans le monde de la presse et de l’édition : lepremier, vérificateur orthographique, grammatical et typographique,et le second, dictionnaire très étoffé, sont utilisés notamment par lesrédactions du Monde, du Figaro, de Libération et par les éditeursFlammarion, Hachette ou encore Nathan.Début 1993, Druide informatique inc., entreprise québécoise, étaitfondée par trois associés : deux informaticiens, Éric Brunelle (cepassionné de la langue venait de quitter Machina Sapiens, où il avaitdéveloppé, avec d’autres, le Correcteur 101, largement dépassé depuis)et Bertrand Pelletier (professeur titulaire d’informatique), ainsi qu’unavocat, André d’Orsonnens ; en novembre 1996, elle lançait au Canadala première version d’Antidote – commercialisée en Europe quelquesmois plus tard –, programme aussi bien destiné aux spécialistes qu’aux« simples » usagers qui était plutôt présenté comme « le premiervéritable logiciel d’aide à la rédaction du français »3.L’année suivante, en 1994, voyait le jour Synapse France – l’un desmembres fondateurs du Natural Language Understanding Consortium –,compagnie toulousaine dont les linguistes sont tous parfaitementbilingues et dont les développeurs avaient élaboré Le Rédacteur,traitement de texte pour la plateforme Atari initialement destiné auxjournalistes de Libération puis vendu à plus de quarante mille
107
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
3 - Antidote est en fait un correcteur avancé dont la première version étaitaccompagnée d’un dictionnaire de définitions, d’un conjugueur (c’est un « logicielpermettant de conjuguer les verbes », nous dit son dictionnaire ; il faut préciser quechaque verbe est conjugué, sans abréviations – il n’y a donc pas de renvoi à unmodèle) et d’un mémento grammatical. Depuis la version parue en 2000, unimpressionnant dictionnaire de synonymes (augmenté d’antonymes en 2003) estégalement disponible. Bien des nouveautés sont apparues d’édition en édition.

exemplaires. Elle commercialise aujourd’hui Cordial, et c’est égalementelle qui a développé le vérificateur incorporé à plusieurs produits deMicrosoft (dont Word).Actuellement, les trois principaux correcteurs avancés4 pour le françaissont donc Antidote, Cordial et ProLexis. Ceux-ci, utilisés par nombre deprofessionnels – journalistes et autres rédacteurs, traducteurs… – etaussi par certains particuliers soucieux de l’aspect « formel » desdocuments qu’ils rédigent, sont vendus séparément des logiciels detraitement de texte et de mise en pages auxquels ils s’intègrent. Ilsparaissent périodiquement dans de nouvelles versions : Antidote en està sa cinquième édition, Cordial à sa dixième et ProLexis à sa quatrième.(On notera qu’à côté des mises à niveau [nouvelles éditions, versionscomportant des nouveautés majeures] sont proposées régulièrementdes mises à jour, en principe gratuites.) Depuis les débuts de lacorrection informatique, les progrès ont été considérables, et n’ont pascessé ces dernières années – bien au contraire.Parallèlement, des correcteurs beaucoup plus simples sont proposésau grand public. Ceux-ci, bien que s’améliorant quelque peu, ontbeaucoup moins changé en dix ans que les correcteurs avancés : ils nevérifient, au fond, que l’orthographe lexicale – comme le faisaient tousles prototypes dans les années quatre-vingt –, bien que certains soientcapables d’émettre des alertes enregistrées en rencontrant par exempleune certaine locution5 ou offrent quelques autres fonctions, sommetoute assez sommaires6. Ces correcteurs-ci sont notamment intégrés
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
108
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
4 - On entend par « correcteurs avancés » les correcticiels qui vérifient non seulementl’orthographe lexicale, mais aussi l’orthographe grammaticale et la typographie.
5 - Par exemple, certains de ces correcteurs peuvent émettre une alerte en rencontrantbien que, pour rappeler à l’utilisateur qu’il doit utiliser ensuite le subjonctif. Cesalertes sont souvent inutiles (elles s’affichent quel que soit le mode employé aprèsla conjonction, qu’il y ait erreur ou non) et parfois même malvenues (dans « Jecomprends bien que c’est nécessaire », on n’a pas affaire à la conjonction bien que).
6 - Une fonction ajoutée au correcteur inclus à Word 2003 nous parait toutefoisintéressante (bien que techniquement très simple) : il s’agit des filtres d’exclusion. Lescripteur peut demander au programme de ne tolérer que clé et de considérer clefcomme incorrect (alors que, par défaut, les deux graphies sont admises par lecorrecteur, lequel ne bronche pas, même s’il trouve dans un même paragraphetantôt l’une des deux graphies, tantôt l’autre), ou inversement. Cette fonction n’estpas disponible dans les correcteurs avancés mentionnés plus haut, mais les éditionsDiagonal proposent à leurs clients de développer des dictionnaires « maison » pourProLexis.

dans des programmes de traitement de texte (Word de MicrosoftCorporation, StarOffice de Sun Microsystems…), et aussi dans des« webmails », sites Web faisant office de messagerie, permettant deconsulter et d’envoyer des messages de courrier électronique(caramail.com, laposte.net…).Les utilisations des correcticiels sont multiples. Au-delà des particuliers,des secrétaires… qui se réjouissent de pouvoir faire confiance àl’informatique pour savoir si, dans le message de courrier électroniquequ’ils sont en train de rédiger, époustouflant prend un ou deux f, bien descorrecteurs-réviseurs ont aujourd’hui recours à des vérificateursavancés. C’est en particulier le cas dans de nombreuses rédactions, oùles articles des journalistes subissent une première vérification – celle del’ordinateur –, avant d’être relus par deux correcteurs, humains cettefois-ci… pour autant que les délais le permettent. On notera d’ailleursque les cours dispensés aux journalistes français incluent désormais uneformation à l’emploi de ProLexis. Il semble en effet que de tels outils sontencore fréquemment mal utilisés. Bien des utilisateurs en ignorent larichesse. Mais il arrive aussi que le correcticiel pointe du doigt unpassage qu’il croit incorrect mais qui est en fait parfaitement juste, ouencore qu’il relève une erreur, mais que la correction proposée ne soitpas la bonne… Bien que ces situations soient actuellement assez rares –elles l’étaient bien moins voilà à peine quelques années –, il faut en effetgarder à l’esprit que le vérificateur informatique ne comprend pas lesens de ce qu’il corrige. Comme le relève la Posologie (mode d’emploi)qui accompagne Antidote : « S[i le correcteur] peut analyser un textegrammaticalement et en détecter les erreurs d’orthographe et degrammaire, il n’en comprend pas le sens pour autant. Il ne peut doncpas détecter les erreurs de sens. » Le même fascicule note d’ailleurs unpoint très intéressant : le correcteur « constitue une aide riche etprécieuse pour le rédacteur, mais il ne remplace pas le correcteurhumain, et vice versa ».On remarquera aussi que les correcteurs – essentiellement lescorrecteurs simples, ceux intégrés aux programmes de traitement detexte courants – sont de plus en plus utilisés par les élèves. Lesprogrammes scolaires français7 y font notamment référence. Ainsi, pourle troisième cycle, ils recommandent: « D’une manière générale, danschaque activité mettant en jeu l’écriture, on conduit les élèves à utiliser
109
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
7 - Voir la bibliographie.

tous les instruments nécessaires (répertoires, dictionnaires, correcteursinformatiques, etc.) pour vérifier et corriger l’orthographe lexicale. »Au Québec, le ministère chargé de l’Éducation a récemment introduitla notion de correction automatique dans les programmes scolaires.
3. LA POLITIQUE ORTHOGRAPHIQUE DES MAISONS D’ÉDITION
On l’aura aisément compris, créer un vérificateur informatique avancén’est pas une mince affaire : faire analyser à un système informatiquedes phrases souvent complexes dans la langue romane qu’est lefrançais relève ni plus ni moins du défi. Or, aussi bien dans le cas d’uncorrecteur lexical que dans le cas d’un correcteur orthographique etgrammatical, il faut définir une politique orthographique et même,plus largement, une « politique de la langue ».Un exemple intéressant sont les rectifications orthographiquesproposées par le Conseil supérieur de la langue française (Paris) etl’Académie française, avec le concours des instances francophonescompétentes de Belgique et du Québec8. Celles-ci ne sont pasimposées, mais officiellement recommandées. Les ouvrages deréférence perçus comme étant plus « traditionnels » – en d’autrestermes, les dictionnaires et les grammaires sur papier – les intègrent,parfois de manière progressive : la dernière édition du DictionnaireHachette signale toutes les nouvelles graphies et présente les nouvellesrègles dans ses annexes, tandis que les éditions les plus récentes duPetit Robert et du Petit Larousse enregistrent déjà respectivement 60 %et 40 % de la « nouvelle orthographe ».Et les correcteurs informatiques ? La situation peut se résumer ainsi :dans leur ensemble, les correcteurs lexicaux sont en train d’être mis àjour, mais les nouvelles versions9 ne sont pas encore disponibles ; lestrois principaux correcteurs avancés cités dans cet article ont tous étérectifiés récemment de manière à connaître les nouvelles graphies. Enpratique, le choix est laissé à l’utilisateur.
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
110
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
8 - Voir la note 1.9 - On notera que les correcteurs lexicaux courants sont bien plus rarement mis à jour
que les correcteurs avancés. C’est pourquoi il est courant que des néologismes nesoient pas reconnus par des traitements de texte comme Word alors qu’ils sontparfaitement connus d’un programme tel Antidote.

Cordial est donc le seul outil à ne pas permettre l’emploi des seulesnouvelles graphies. Antidote est celui qui propose le plus d’options.
Image 1. L’un des multiples réglages d’Antidote Prisme (dernière éditiond’Antidote). Si l’utilisateur souhaite que les deux orthographes – l’ancienne et la
nouvelle – soient acceptées, il doit procéder à un choix subalterne, de manière que lecorrecteur, les dictionnaires et le conjugueur sachent quelle forme privilégier, le cas
échéant (par exemple, si l’infinitif étiqueter est entré dans le conjugueur, celui-ci doit-il donner il étiquète [nouvelle orthographe] ou il étiquette [ancienne orthographe]?).
111
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
ProduitProLexis(dernièreédition)
Cordial(dernièreédition)
Antidote(dernière édition)
Intégrationde la
nouvelleorthographe
Correcteur :•N’accepterque lanouvelle
ortho-graphe.•N’accepterquel’ancienneortho-graphe.
Correcteur :•N’accepterquel’ancienneortho-graphe.•Accepter lesdeux ortho-graphes(ancienne etnouvelle).
Correcteur :• N’accepter que la nouvelleorthographe.• N’accepter que l’ancienneorthographe.• Accepter les deux orthographes(ancienne et nouvelle).Le dictionnaire signale les deuxorthographes en note, maisprivilégie l’une ou l’autre enfonction du réglage del’utilisateur. Le conjugueurconjugue en ancienne ou ennouvelle orthographe enfonction du même réglage.La grammaire présente chaquenouvelle règle.
Tableau 1. Choix laissés à l’utilisateur face à la nouvelle orthographe.

On voit donc que les maisons éditant de tels logiciels ont à cœur desuivre constamment et au plus près l’évolution de la langue et de sonorthographe. N’est-ce pas là une nouvelle fort réjouissante ?
Image 2. Alerte du correcteur d’Antidote s’il détecte la graphie ancienne « eczéma »alors que les réglages demandent que soit imposée la nouvelle orthographe.
Il faut noter aussi qu’un label de qualité spécifique a été créé pour lescorrecteurs informatiques prenant en compte la nouvelle orthographe.Pour l’obtenir, les éditeurs desdits vérificateurs doivent soumettre àun groupe d’experts indépendants les versions rectifiées de leurproduit, lesquelles sont testées avant la mise sur le marché, pours’assurer que toutes les nouvelles graphies aient été correctementintégrées. Antidote et ProLexis ont déjà reçu ce label10.Par ailleurs, on remarque que, globalement, les correcteurs necraignent pas de mentionner (et d’accepter) toutes les variantesgraphiques. Ce semble être, là encore, une constatation plaisante.
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
112
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
10 - On trouvera plus d’informations sur ce label et sur les produits l’ayant reçu souswww.orthographe-recommandee.info/label.
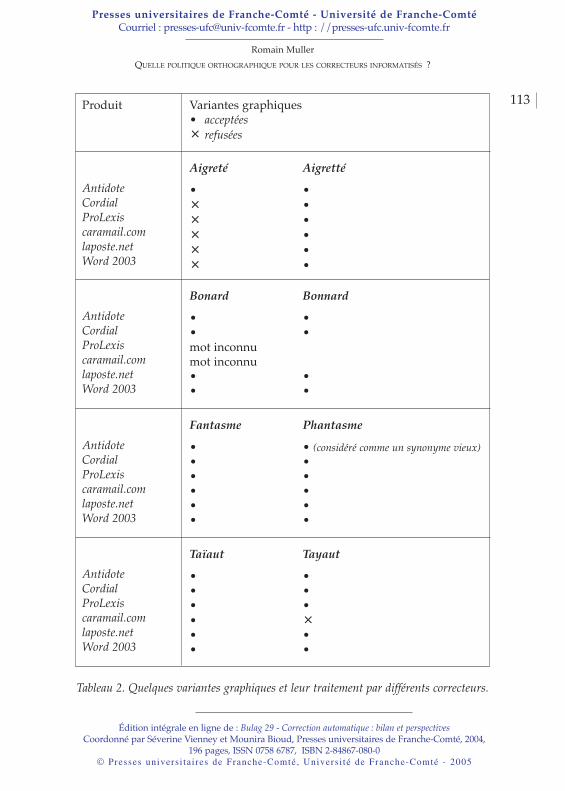
Tableau 2. Quelques variantes graphiques et leur traitement par différents correcteurs.
113
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
Produit Variantes graphiques• acceptéesÍÍ refusées
AntidoteCordialProLexiscaramail.comlaposte.netWord 2003
Aigreté Aigretté
• •ÍÍ •ÍÍ •ÍÍ •ÍÍ •ÍÍ •
AntidoteCordialProLexiscaramail.comlaposte.netWord 2003
Bonard Bonnard
• •• •mot inconnumot inconnu• •• •
AntidoteCordialProLexiscaramail.comlaposte.netWord 2003
Fantasme Phantasme
• • (considéré comme un synonyme vieux)• •• •• •• •• •
AntidoteCordialProLexiscaramail.comlaposte.netWord 2003
Taïaut Tayaut
• •• •• •• ÍÍ• •• •

Au-delà de la politique orthographique, on peut se demander quelleest la « politique de la langue » des éditeurs de correcteurs avancés. Onse rend compte qu’en matière d’orthographe grammaticale, Le BonUsage de Maurice Grevisse revu par André Goosse estsystématiquement retenu comme étant « la » référence. Toutefois, onpeut constater qu’Antidote et, apparemment, ProLexis refusent l’accorddu participe passé lorsque en joue le rôle de COD, alors que Le BonUsage est moins strict sur ce point…Un autre point intéressant est la manière dont a été intégrée laféminisation des titres. Antidote est celui qui s’en est le mieux tiré ;l’utilisateur peut lui demander de tolérer les titres non féminisés(« madame le ministre »), sans quoi le correcteur ne les accepte pas. Lesformes ont été, dans leur ensemble, bien féminisées :
– une agente ;– une chercheuse ;– une maçonne ; – une officière ;– une sapeuse-pompière ; – une substitut(e)…
Toutefois, des améliorations seraient encore nécessaires :– Les formes en -eure (une professeure) sont les seules enregistrées. Il estvrai qu’elles sont courantes au Québec et de plus en plus fréquentes enEurope, mais on peut regretter que le correcteur d’Antidote n’accepte pasune professeur, à moins qu’on lui demande de tolérer la non-féminisation,auquel cas il admettra du même coup « madame le ministre ».– À côté de sculpteure, seule la forme sculptrice est retenue ; sculpteuseest rejeté. Cela vient probablement du fait que sculpteuse tend à êtremoins utilisé, surtout au Québec, en raison du suffixe -euse qui paraitquelquefois péjoratif ; or, il n’en reste pas moins que cette forme estparfaitement acceptable…Cela dit, le logiciel québécois a bien intégré la féminisation, surtout sion le compare à Cordial, à ProLexis ou aux correcteurs lexicaux commecelui de Word, lesquels accusent un sérieux retard.Il est fort dommage, enfin, qu’aucun des vérificateurs consultés netienne compte de la masculinisation ; les mots que cela concerne sontpourtant très peu nombreux (moins de dix probablement). Ainsi, unsagehomme est toujours un mot inconnu pour tous ces logiciels.
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
114
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

4. EN GUISE DE CONCLUSION
« Ce que nous appelons aujourd’hui vérificateur ou correcteurinformatique, termes élogieux supposant une certaine intelligencemachine, devrait, si l’on pèse bien les mots, ne s’appeler que détecteursde mots mal orthographiés ou contrôleurs orthographiques de mots isolés »,notait Fabrice Jejcic en 198911. Force est de constater que la situation aénormément évolué depuis. Pourtant, si, aujourd’hui, un correcteurpurement lexical est intégré à chaque logiciel de traitement de textecourant, les vérificateurs avancés sont encore peu employés par le grandpublic. On peut le regretter quand on sait tout ce que permettent de telsoutils ; mais sans doute les correcticiels intégrés aux texteurs vont-ils seperfectionner dans les prochaines années. Toujours est-il que, d’unemanière générale, la politique orthographique des éditeurs de telsproduits est presque toujours basée sur des références incontestées etpour ainsi dire universellement reconnues. On peut d’autant plus s’enréjouir que les linguistes-informaticiens semblent globalement trèsattentifs aux évolutions de la langue, quelles qu’elles soient.
RÉFÉRENCES ET BIBLIOGRAPHIE
Antidote Prisme, (2003), cinquième édition d’Antidote, édité par Druideinformatique inc.
Cordial 10 Pro, (2004), dixième édition de Cordial, édité par SynapseFrance.
ProLexis 4.2, (2004), quatrième édition de ProLexis, édité par Diagonal.
Word 2003, (2003), inclus dans la suite Office, édité par MicrosoftCorporation.
Cycle des approfondissements et cycle 3, (2002), programmes scolaires, inBulletin officiel de l’Éducation nationale française, hors série no 1 du14 février 2002.
115
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
11 - Article cité.

JEJCIC, F. (1989), Zerro faute avec mon micro ?, in Liaisons HESO,publication de l’équipe Histoire et structure de l’orthographe duCentre national de la recherche scientifique (France) no 16-17.MULLER, R. (2004), Nouvelle orthographe et correcteurs informatiques, inDyalang, L’orthographe en questions, sous la direction de RenéeDucrocq-Honvault, Presses universitaires de Rouen [À paraitre.]RENOUVO (2004), Le Millepatte sur un nénufar. Vadémécum del’orthographe recommandée, [Cette publication peut être obtenue pourquelques euros auprès de l’Association pour la nouvelle orthographe(Boite postale 106, CH-1680 Romont, Suisse).]
Romain MullerQUELLE POLITIQUE ORTHOGRAPHIQUE POUR LES CORRECTEURS INFORMATISÉS ?
116
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
117
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
RésuméCet article présente un système de détection et de correction orthographiqueprincipalement caractérisé par son adaptation aux besoins spécifiques des apprenantsdu français. Il utilise trois méthodes pour corriger les fautes d’orthographes : (i) laméthode des alpha-codes, (ii) la réinterprétation phonétique pour corriger les fautesd’orthographe phonétiques, et (iii) une méthode ad hoc pour traiter certains typesd’erreurs morphologiques en attendant d’implémenter une composante de traitementmorphologique plus complète. Le système a été testé et comparé avec un correcteurcommercialisé.
Mots clefsCorrection orthographique ; alpha-code ; réinterprétation phonétique ; distancelexicographique.
AbstractThis paper presents a spell checker catering to the specific needs of langage learners.Three methods for retrieving correction proposals are discussed : (i) the alpha-codemethode which is often used in spell checkers and which is particularly adequate formissing discritics and many typing errors ; (ii) the phonological reinterpretationmethod, which retrieves corrections for words written phonetically ; and (iii) an adhoc method treating a specific type of morphological error, pending theimplementation of a more complete morphological treatement. Tests of the system wereperformed and compared to the results of a commercially available spell checker.
Key-wordsSpell checker ; Alpha-code ; Phonological reinterpretation ; lexicographic Distance.
CORRECTEUR ORTHOGRAPHIQUEADAPTE A L’APPRENTISSAGE DU
FRANÇAISMar NDIAYE et Anne VANDEVENTER FALTIN
Laboratoire d’analyse et des technologies du langage, Département de linguistique, Université de Genève.
{mar.ndiaye, anne.vandeventer}@lettres.unige.ch

1. INTRODUCTION
La correction orthographique consiste à vérifier si chaque mot d’untexte fait partie du lexique de la langue dans laquelle le texte est écritet de proposer au besoin des corrections possibles lorsqu’un mot esterroné. Le principe de détection d’erreur consiste à se servir d’undictionnaire supposé contenir tous les mots de langue dans leursdifférentes formes et de considérer comme erreur tout mot qui ne faitpas partie du dictionnaire. En plus d’erreurs d’insertion, de transposition, de suppression et desubstitution de caractères, les apprenants d’une langue font aussi deserreurs spécifiques, par exemple morphologiques ou dues à l’écriturephonétique des mots. Or, en français, comme dans d’autres langues,plusieurs séquences de mots peuvent avoir la même prononciation.La section 2 présente l’architecture générale du système, la section 3décrit la méthode des alpha-codes ainsi que la stratégie de filtrage desalternatives. La section 4 concerne la réinterprétation phonétique. Letraitement de certaines erreurs morphologiques est présenté dans lasection 5. La section 6 présente les résultats des tests effectués. Lasection 7 conclut cet article.
2. ARCHITECTURE
Le système de détection et de correction d’erreurs orthographiques quiest proposé utilise trois méthodes différentes pour tenter de trouver labonne orthographe d’un mot considéré comme erroné. La premièreméthode est celle dite des alpha-codes, la seconde consiste en uneréinterprétation phonétique du mot erroné et la troisième méthodepermet de traiter certaines erreurs morphologiques.
L’architecture générale du système correspond à ces troiscomposantes. La stratégie de correction privilégie la méthode ad hoc, etsi une alternative est proposée par cette méthode, la recherche s’arrêteici. Lorsque aucune alternative n’est proposée par cette méthode, laréinterprétation phonétique est déclenchée en premier et la méthodedes alpha-codes est activée ensuite.
Le système, nommé FipsCor, utilise un dictionnaire de 200000formes lexicales. Chaque forme lexicale contient, entre autres, del’information catégorielle, l’alpha-code du mot et sa représentationphonétique.
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
118
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
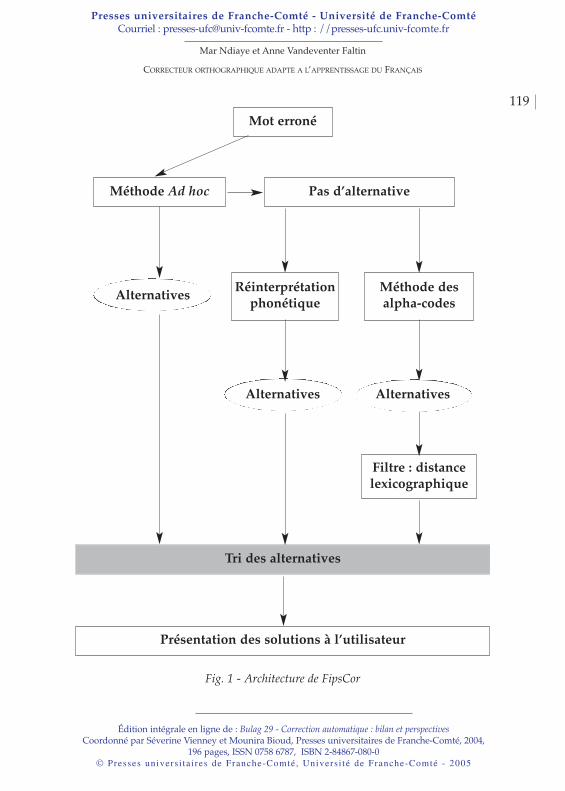
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
119
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Fig. 1 - Architecture de FipsCor
Mot erroné
Présentation des solutions à l’utilisateur
Tri des alternatives
Méthode Ad hoc Pas d’alternative
Méthode desalpha-codes
Réinterprétationphonétique
Filtre : distancelexicographique
AlternativesAlternatives
Alternatives

Lorsqu’un mot est considéré comme erroné, il est soumis à la méthodead hoc pour voir s’il s’agit d’une erreur morphologique ou pas. Ce n’estque lorsque qu’aucune alternative n’est proposée par cette méthode quele mot est soumis à la réinterprétation phonétique ainsi qu’à la méthodedes alpha-codes. Les résultats fournis par cette dernière méthodesubissent un filtrage sur la base de leur distance lexicographique avec lemot erroné. En d’autres termes, seuls les mots les plus proches du moterroné sont proposés à l’utilisateur. Les résultats obtenus par laphonétique sont directement soumis à l’utilisateur. Le tri de la liste desalternatives suit l’ordre d’arrivée des résultats, c’est-à-dire, lescorrections par phonétisation sont en tête de liste s’il en existe, et lescorrections par alpha-code viennent après. Les alternatives issues desdeux méthodes simultanément sont éliminées de la liste.
3. ALPHA-CODE
L’alpha-code permet de représenter de manière abstraite un mot enutilisant les caractères qui le composent. Appelé aussi clé squelette(skeletton key) (voir Pollock & Zamora, 1984), l’alpha-code permet decorriger les erreurs de duplication de caractères, de suppression etd’insertion de certaines occurrences de caractères, ainsi que les fautesd’accent. Il existe plusieurs façons de calculer l’alpha-code d’un motdont celle décrite ci-dessous utilisée par FipsCor :
1. Tous les accents sont retirés ;2. Les lettres sont mises en minuscule ;3. Les lettres sont ordonnées en commençant par les consonnes,
suivies des voyelles, chaque groupe étant classéalphabétiquement ;
4. Les doublons sont retirés.L’algorithme utilisé par la méthode des alpha-codes est le suivant :
1. Les alpha-codes de tous les mots sont calculés et stockésdans le dictionnaire.
2. Le dictionnaire est également indexé par alpha-code afin defaciliter la recherche.
3. Lorsqu’un mot est considéré comme erroné,a. On calcule son alpha-code ;
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
120
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

b. On extrait du dictionnaire le sous-ensemble des mots quiont le même alpha-code ;
c. On filtre cet ensemble afin d’éliminer les mots qui ont peude probabilité d’être une alternative valide.
Considérons l’exemple donné en (1a), le mot *prèferrer est erroné, il nefigure pas dans le dictionnaire. Son alpha-code est donné en (1b). Surla base de cet alpha-code, le système récupère les quatre mots en (1c)ayant le même alpha-code que le mot erroné *prèferrer .
(1a) *prèferrer1
(1b) fpre(1c) préférer, préféré, préfère, préférée
3.1. Modification de la technique des alpha-codes
Les erreurs d’inversion de caractères, de duplication de caractères, dediacritiques, ainsi que certaines erreurs de suppression lorsque lecaractère supprimé figure toujours dans le mot erroné sont facilementtraitées par la méthode des alpha-codes. En revanche, lorsqu’il s’agitd’ajout d’une lettre ou de suppression d’une lettre qui ne figure plusdans le mot erroné, alors la méthode des alpha-codes telle que décritejusqu’à présent ne permet pas de retrouver le mot correct. La stratégieutilisée dans ces deux cas consiste à prendre une lettre dans la liste deslettres ne figurant pas dans l’alpha-code et de la rajouter dans l’alpha-code (dans le cas d’une suppression) ou de supprimer une lettre del’alpha-code (dans le cas d’une insertion) et d’essayer de retrouver desmots sur la base des nouveaux alpha-codes créés. L’apha-code modifié permet ainsi de traiter la plupart des erreurs maispeut entraîner une surgénération des solutions. Afin d’éviter d’avoirdes alternatives trop distantes du mot erroné, le système ne proposeque les mots qui sont à une distance convenable du mot erroné. Pource faire, FipsCor utilise la distance lexicographique décrite ci-après.
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
121
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
1 - L’étoile * indique que le mot est faux.

3.2. Distance lexicographique
La distance lexicographique calcule le nombre minimum d’insertion,de suppression et de substitution de lettres nécessaires pourtransformer un mot en un autre. La distance utilisée dans FipsCor estune variante de la distance de Levenshtein selon laquelle l’insertion etla suppression d’une lettre coûtent 1 alors que la substitution a un coûtégal à 2. L’algorithme est programmé dynamiquement avec unecomplexité d’ordre O(m*n), m et n correspondent aux longueursrespectives des deux séquences de mots (voir Jurafsky et Martin (2000,pp.155-157) pour une description de cet algorithme). Seuls les mots quise situent à une distance inférieure ou égale à un seuil fixé d’avancesont proposés. Reprenons l’exemple donné en (1a), le mot préférer seraproposé comme alternative car c’est le seul qui est à une distance de 1du mot erroné *prèferrer. Les autres mots sont à des distances de 2(préféré et préfère) ou de 3 (préférée). La difficulté d’utilisation d’unedistance lexicographique se situe au niveau du choix d’un seuilconvenable, qui conserve les corrections plausibles tout en éliminantles autres.
4. RÉINTERPRÉTATION PHONÉTIQUE
La réinterprétation phonétique est basée sur le constat que certainesséquences de lettres ou de mots se prononcent de la même manière etqu’une séquence erronée pourrait être corrigée par une autre séquencephonétiquement similaire. La longueur des séquences peut varier d’unsimple mot à plusieurs. La réinterprétation phonétique repose surdeux étapes essentielles. (i) Une séquence erronée est tout d’abordtransformée en sa contrepartie phonétique, une séquence dephonèmes. (ii) Cette séquence de phonèmes est ensuite réinterprétéeen une chaîne orthographique. Les erreurs qui peuvent être détectées,diagnostiquées et éventuellement corrigées par la technique deréinterprétation phonétique sont de plusieurs types et touchent desdomaines plus larges que la seule phonétique. Nous nous limitonsdans cet article aux erreurs sur les mots inconnus du dictionnaire.
1. Au niveau lexical, certains mots inconnus du dictionnairepeuvent trouver une correction pour autant qu’un mot ayant une
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
122
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

même sonorité existe. Il s’agira essentiellement d’erreurs dues à uneécriture phonétique, comme en (2).
(2) a. *fenaitreb. fenêtre
2. Il est également possible de retrouver des propositions decorrection pour des mots agglutinés les uns aux autres (3), phénomènequi arrive relativement fréquemment mais qui est fort mal traité parles correcteurs orthographiques actuels.
(3) * plustôt (au lieu de « plus tôt »)L’utilisation de la réinterprétation phonétique telle que définie ci-dessusimplique d’avoir à disposition un certain nombre d’outils de traitementautomatique du langage qui possèdent certaines caractéristiques bienprécises. Cette section explicite ces différents pré-requis.Le dictionnaire utilisé par le correcteur orthographique doit posséderdeux critères liés qui sont loin d’être courants pour ce type d’outils : (i)L’information présente pour chaque mot du dictionnaire doit contenirla représentation phonétique de ce mot. C’est la manière la plus rapideet la plus sûre d’obtenir la transcription phonétique des mots àréinterpréter. (ii) Pour la deuxième étape, c’est-à-dire pour retrouverune version orthographique à partir de la chaîne phonétique, il fautpouvoir faire une recherche dans ce même dictionnaire sur les entréesphonétiques. Sans ces deux conditions sur le contenu et l’accessibilitédu dictionnaire, la réinterprétation phonétique ne peut avoir lieu.Lorsque l’on cherche à traiter le niveau lexical et que l’on se retrouveface à des mots qui ne figurent pas dans le dictionnaire, parce qu’ilssont le résultat soit d’une agglutination soit d’une orthographephonétique, il faut un autre mécanisme que l’accès au dictionnairepour obtenir la chaîne phonétique de ces mots inconnus. Unphonétiseur remplit justement cette tâche. Un phonétiseur peut êtreconsidéré comme un système expert contenant les règles detranscription permettant, pour une langue donnée, de passer d’uneséquence de graphèmes à une séquence de phonèmes correspondants :« Un système expert de conversion graphèmes-phonèmes à base derègles ordonnées (environ 500) propose une solution alternative en casde recherche infructueuse dans le lexique» (Gaudinat et Goldman1998 : 140).
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
123
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

L’’algorithme de réinterprétation est le suivant :1. Le mot inconnu est proposé au phonétiseur afin d’obtenir
une transcription phonétique. 2. La transcription phonétique sert de clé de recherche dans le
dictionnaire afin de retrouver toutes les orthographescorrespondant à la même séquence de sons.
3. Si aucun mot n’est trouvé avec la transcription phonétiqueentière, on considère toutes les possibilités pour lesquelles lachaîne phonétique recouvrirait plusieurs motsorthographiques.
4. Le mot (ou les mots) ainsi réinterprété(s) est (sont) utilisé(s)comme proposition(s) de correction.
Ainsi, dans l’exemple (6), le mot erroné en (6a) est transcrit par lephonétiseur en (6b). Les mots du dictionnaire ayant commereprésentation phonétique (6b) sont en (6c). Ils pourront donc êtreproposés aux utilisateurs comme possibilités de correction.
(6) a. *puitb. /pyi/c. puis, puits
La réinterprétation phonétique présente certains avantages commetechnique de diagnostic d’erreurs. Bien qu’elle ne couvre qu’unnombre relativement restreint de types d’erreurs, son utilisation esttoutefois intéressante dans le domaine de l’ELAO2 car les typescouverts sont plus fréquents dans les textes d’apprenants que dans lestextes de locuteurs natifs.
5. LE TRAITEMENT MORPHOLOGIQUE
Les deux techniques précédemment décrites (alpha-code etréinterprétation phonétique) permettent de traiter de nombreuseserreurs orthographiques. Il existe néanmoins d’autres types d’erreursplus ou moins morphologiques qui ne sont pas récupérables ni par
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
124
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
2 - Enseignement des Langues Assisté par Ordinateur

l’alpha-code ni par la réinterpretation phonétique. C’est le cas parexemple lorsque l’apprenant écrit *animals au lieu de animaux ou*changeage au lieu de changement. La stratégie utilisée pour corriger cestypes d’erreurs consiste à repérer dans la forme erronée le suffixe« als » ou « ails » ou « age » et de le remplacer par le suffixe appropriérespectivement « -aux » et « -ment ». D’autres cas sont beaucoup moinsfaciles à traiter, il s’agit par exemple de certaines conjugaisonsirrégulières comme *allerons au lieu de irons.Le traitement de ces types d’erreurs se fera par le repérage des traitsflexionnels du mot erroné (première personne du pluriel, futur) ainsique de la racine du mot. La difficulté du traitement des erreursmorphologiques est surtout liée au repérage de ces traits morpho-syntaxiques ainsi qu’à l’extraction du lexème correspondant au moterroné. Dans le cas d’un verbe conjugué, par exemple, il faut extrairedu mot erroné le lexème verbal ainsi que les traits de flexion. Or, larécupération d’un lexème verbal n’est pas triviale compte tenu del’irrégularité de certains verbes. Considérons le verbe devoir dont leparticipe passé est dû, si l’apprenant applique la règle de calcul desparticipes passés des verbes du premier groupe au verbe devoir, il estfort probable qu’il considère *devé comme participe passé au lieu de dû(Mogilevski, 1998, p. 188). Le traitement de telles erreurs nécessite leuridentification en amont afin de faciliter leur repérage. Les informationsflexionnelles sont calculables sur la base de la terminaison du moterroné. Ainsi, à partir de ces informations, le générateurmorphologique calcule la bonne forme et la propose à l’utilisateur.Toutefois, dans son état actuel, FipsCor ne fait pas appel à un véritablecorrecteur morphologique. Seule une méthode ad hoc est implémentée.Cette méthode repère les mots erronés se terminant par –als ou –ails etvérifie que le mot ainsi créé est bien valide avant de le proposer àl’utilisateur.
6. RÉSULTATS
Les résultats du test de FipsCor sont comparés avec le correcteurorthographique inclus dans le logiciel Word 2000. Le système est testésur un corpus réparti de la sorte :
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
125
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

- 20 authentiques erreurs prises dans la littérature selon ledécompte suivant :m 3 dans Burston (1998)m 17 dans Mogilevski (1998)
- 144 erreurs non authentiques tirées de Dinnematin et Sanz(1990)
Les résultats du traitement des erreurs authentiques sont présentésdans la table 2. Le système FipsCor n’a pas pu corriger les fautes *emploiés au lieu deemployés,*devé au lieu de dû. Il a manqué la correction du mot erroné*emploiés parce qu’il s’agit d’une substitution de caractère non traitépar l’alpha-code. L’erreur *devé est de type morphologie et sontraitement n’est pas implémenté pour l’instant. Le mot erroné qui netrouve aucune alternative est le mot *raissonable au lieu du mot correctraisonnable. En réalité, la méthode des alpha-codes a pu trouvé le motcorrect, raisonnable ; seulement ce dernier est rejeté par le filtre car il està une distance lexicographique de 2 par rapport au mot erroné. Lesrésultats de la table 3 sont plutôt favorables au correcteur deWord 2000 qui propose 94.44 % de bonnes corrections pendant queFipsCor n’en donne que 77.78 %. Il convient tout de même de préciserque seul un mot n’a pas pu être détecté par FipsCor alors que lecorrecteur de Word 2000 en rate 7. De plus, FipsCor ne trouve pas debonnes solutions dans de nombreux cas car le mot attendu ne setrouve pas dans son dictionnaire, ce qui pourra facilement être corrigé.
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
126
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Erreurs FipsCor Word 2000Number % Number %
Détectées Propositions correctes 17 85 19 95Propositions incorrectes 2 10 1 5Pas de propositions 1 5 0 0
Non détectées 0 0 0 0Total 20 100 20 100
Table 2 : Résultats sur des erreurs authentiques
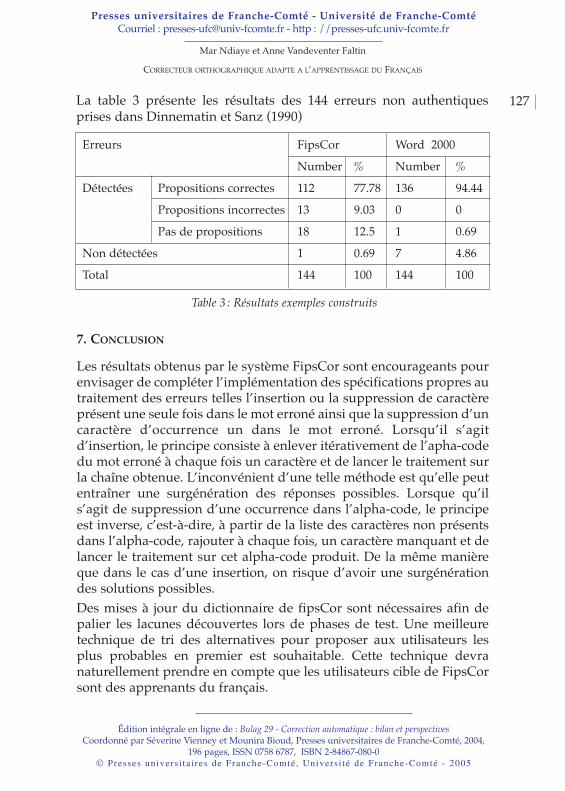
7. CONCLUSION
Les résultats obtenus par le système FipsCor sont encourageants pourenvisager de compléter l’implémentation des spécifications propres autraitement des erreurs telles l’insertion ou la suppression de caractèreprésent une seule fois dans le mot erroné ainsi que la suppression d’uncaractère d’occurrence un dans le mot erroné. Lorsqu’il s’agitd’insertion, le principe consiste à enlever itérativement de l’apha-codedu mot erroné à chaque fois un caractère et de lancer le traitement surla chaîne obtenue. L’inconvénient d’une telle méthode est qu’elle peutentraîner une surgénération des réponses possibles. Lorsque qu’ils’agit de suppression d’une occurrence dans l’alpha-code, le principeest inverse, c’est-à-dire, à partir de la liste des caractères non présentsdans l’alpha-code, rajouter à chaque fois, un caractère manquant et delancer le traitement sur cet alpha-code produit. De la même manièreque dans le cas d’une insertion, on risque d’avoir une surgénérationdes solutions possibles. Des mises à jour du dictionnaire de fipsCor sont nécessaires afin depalier les lacunes découvertes lors de phases de test. Une meilleuretechnique de tri des alternatives pour proposer aux utilisateurs lesplus probables en premier est souhaitable. Cette technique devranaturellement prendre en compte que les utilisateurs cible de FipsCorsont des apprenants du français.
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
127
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Erreurs FipsCor Word 2000Number % Number %
Détectées Propositions correctes 112 77.78 136 94.44Propositions incorrectes 13 9.03 0 0Pas de propositions 18 12.5 1 0.69
Non détectées 1 0.69 7 4.86Total 144 100 144 100
Table 3 : Résultats exemples construits
La table 3 présente les résultats des 144 erreurs non authentiquesprises dans Dinnematin et Sanz (1990)

Le travail futur le plus intéressant pour ce correcteur orthographiqueconcerne l’implémentation d’un traitement morphologique completqui passe par l’utilisation d’un générateur morphologique.Finalement, des tests sur un large corpus comprenant de véritableserreurs d’apprenants sont indispensables afin d’affiner le système etde comparer avec les correcteurs existants.
8. RÉFÉRENCES
COURTIN, J., DUJARDIN, D., KOWARSKI, I., GENTHIAL, D., et DELIMA, V.L. (1991), Towards a complete detection/correction system,Proceedings of the International Conference on Current Issues inComputational Linguistics, Penang, Malaysia. pp. 158-173.DINNEMATIN, S., et SANZ, D. (1990 décembre), Sept correcteurs pourl’orthographe et la grammaire, Science et Vie Micro, 78, 118-130.JURAFSKY, D., et MARTIN, J.H. (2000), Speech and language Processing :An introduction to natural language processing, Computational linguistics,and Speech Recognitio,. Upper Saddler River, NJ : Prentice-Hall.MODGILEVSKI, E. (1998), Le correcteur 101, CALICIO Journal, 16 (2),183-196.PETRSON, J.-L. (1980), Computer programs for detecting and correcting inscientific and scholarly text, Communication of the ACM, 27(4), 358-368.GRANGER, S., et MEUNIER, F. (1994), Towards a grammar checker forlearners of English, In Fries, Tottie et Schneider Eds. Creating and UsingEnglish Language Corpora. Rodopi, Amsterdam. pp. 79-91.HEIDORN, G. E. (2000), Intelligent Writing Assistance, In Dale, Moisl etSomers Eds. Handbook of Natural Language Processing, MarcelDekker. New York. p. 181-207.TSCHICHOLD, C. (1999), Grammar Chec king for CALL : Strategies forimproving foreign language grammar checkers, In Cameron Ed. CALL :Media, Design and Applications, Swets & Zeitlinger. Lisse. pp. 203-222.
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
128
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

VANDEVENTER, A. (1998), An automatic systeme for error diagnostic inCALL, proceedings of NLP+IA/TAL+AI 98 (pp. 77-83) M, Monton,Canada, August 18-21.
VANDEVENTER, A. (2001), Creating a grammar checker for CALL byconstraint relaxation : a feasibility study, ReCALL, Vol. 13(1). pp. 110-120.
VANDEVENTER, A. (1999), FIPSGram: A tool to create sentence structurerepresentations for CALL, Actes des journées internationales delinguistique appliquée JILA’99, Nice, France, pp.272-275.
VOSS, T. (1992), Detecting and Correcting Morpho-Syntaxtic Errors in RealTexts, Proceedings of the Third Conference on Applied NaturalLanguage Processing, ACL, Trento, Italie. pp.111-118.
WEHRLI, E. (1997), L’analyse syntaxique des langues naturelles : problèmeset méthodes, Mason. Paris.
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
129
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

9. ANNEXE 1 :
Données authentiques (Burston, 1998, p. 209)Mot CorrectionPremiere premièreVidettes vedetteEmploiés employés
Données authentiques (Mogilevski, 1998, p. 188)Mot Correctiondevé dûecrire écrireraissonnable raisonnable
Données authentiques (Mogilevski, 1998, p. 188)Mot CorrectionPlutot plutôtRéctangle rectangleReussi réussiAnnee annéeSceance séanceFormalite formalitéTres trèsCharctere caractèreRole rôleEtait étaitScenes scèneEvenement événementRemarqable remarquableRelévé révélé
Données non authentiques (Dinnematin et Sanz, 1990, p. 119)Mot Correctionasfaltées asphaltéeseucaliptus eucalyptusaccacias acaciastuyas thuyas
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
130
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

décriptent décryptentpannonceaux panonceauxdédalles dédalespromennées promenéscosmopolytes cosmopolitesengoufrés engouffréspènétrants pénétrantsalizée alizéaquillon aquilonamitiée amitiédéfaît défaitschôquants choquantssussurés susurrésmarmonés marmonnéslançés lancéscantonnade cantonadehupés huppéspopulaçières populacièresponnant ponantbadaus badaudsdéléctés délectéslanguissament languissammentensaignes enseigneseffourceaux éfourceauxéchôppes échoppesabbaitiales abbatialesfronttons frontonslezardés lézardésfoisson foisonvennelles venellesruélles ruellesmaïls mailsplû plunonctambulles noctambuleségarrés égaréspoêtes poètesailleur ailleurscourrent courent
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
131
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Données non authentiques (Dinnematin et Sanz, 1990, p. 121)Mot Correctionabsorpsion absorptionacessit accessitacceuil accueilacolite acolyteaddresse adresseaigüe aiguëalgorythme algorithmeappats appâtsappogiature appoggiatureaéropage aréopagearome arômeasujettir assujettirattrapper attraperazalé azaléebarette barrettebéquée becquéebifteek bifteckboîter boiterboursouffler boursouflerbraîment braimentcelà celacharriot chariotcharette charrettechrysalyde chrysalideschrysantème chrysanthèmecomparition comparutioncomcombre concombreconcurent concurrentcongruement congrûmentconnection connexionconsonnant consonantcontigüe contiguëcontrole contrôleconvaint convainc
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
132
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

coordonateur coordonnateurcourier courriercoutumace contumacecyprés cyprèsdébarasser débarrasserdéclancher déclencherdéguingandé dégingandéderilection dérélictiondevot dévotdilemne dilemmedisfonctionnement dysfonctionnementdisgrâcier disgracierdisparâte disparatedrôlatique drolatiquedislexie dyslexieéchaufourée échauffouréeantropie entropieerronné erronéeéthymologique étymologiquefiligramme filigranegaité gaietégheto ghettohalucination hallucinationhypothénuse hypoténuseimbécililité imbécillitéinfractus infarctusinommé innoméinommable innommableinsassiable insatiableintensemment intensémentmacchiavélique machiavéliquemalaîse malaisemalapris malapprismalgrès malgrémapemonde mappemondemarâsme marasmenégligeamment négligemment
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
133
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

occurrence occurrencepannacée panacéepantomine pantomimepécunière pécuniairepélerine pèlerinepiqure piqûreprécéde précèdeprofesionnel professionnelprotége protègepsychadelique psychédélique râtisser ratisserrecoit reçoitréddhibitoire rédhibitoireremerciment remerciementrenumération rémunérationshéma schémaséborhée séborrhéesoufle soufflesubbit subitsubcidiaire subsidiairesubstanciel substantielsuccint succinctsuperfètatoire superfétatoiresimptomatique symptomatiquesynthése synthèsesizygie syzygietraditionnaliste traditionalistetroglodite troglodyte
Mar Ndiaye et Anne Vandeventer Faltin
CORRECTEUR ORTHOGRAPHIQUE ADAPTE A L’APPRENTISSAGE DU FRANÇAIS
134
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
135
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
RésuméLe Sénat du Canada diffuse certains de ses débats en direct sur une chaîne de télévisionspécialisée. Ces débats sont sous-titrés en temps réel en français par sténotypie. Lesystème utilisé génère un français très correct mais présente de nombreuses fautesd’accord dues aux syllabes finales muettes, fréquentes en français. Le taux moyen defautes est de l’ordre de 7 pour 100 mots.La société Diagonal a développé et livré en 2003 un automate de correction en tempsréel de la majorité de ces fautes. Grâce à lui, le taux d’erreurs est passé de 7 à 1,7 %.Dans une prochaine version, ce taux pourra chuter sous la barre de 1 %.
Mots clefscorrection automatique ; temps réel ; analyse syntaxique ; propagation de contraintes ;évaluation à grande échelle.
AbstractA large number of the debates of the Senate of Canada are broadcast live on aspecialised television channel. These debates are subtitled in French in real time bystenotypy. The system employed generates acceptable French but produces numerouserrors of agreement on mute final syllables which are very frequent in French. Theaverage rate of mistakes is in the order of 7 per 100 words.In 2003 the company Diagonal developed and delivered a real-time correctionautomaton for the majority of these mistakes. Thanks to this tool, the rate of errors hasgone from 7 to 1.7 %. In a new version, this rate could drop below the 1 % mark.
Key-wordsautomatic correction ; real time ; syntactic analysis ; constraint propagation ; largescale evaluation.
DEBATS TELEVISÉS EN DIRECT DU SENATDU CANADA: CORRECTION AUTOMATIQUE
DES SOUS-TITRES EN FRANÇAISRoger RAINERO
Auteur du logiciel ProLexisDirecteur Technique de la société Diagonal
1, Traverse des Brucs – Valbonne - Sophia Antipolis

1. EXPOSÉ DU PROBLÈME
Le Sénat du Canada diffuse certains de ses débats en direct sur unechaîne de télévision spécialisée.Chaque Sénateur pouvant s’exprimer dans sa langue maternelle(français ou anglais), les interventions se succèdent indifféremmentdans ces deux langues.Les téléspectateurs ont la possibilité d’afficher des sous-titres, soit enfrançais, soit en anglais, mais lorsqu’une langue est choisie, la totalitédes débats est transcrite dans cette langue (fonction légale pour lesmalentendants).Les sous-titrages français sont obtenus par retranscription sténotypée soitdirecte (locuteur français) soit indirecte (locuteur anglais traduitsimultanément en français, la sténotypiste enregistrant alors la traduction).Les sténotypistes francophones et anglophones utilisent la mêmeméthode de saisie mise au point en Amérique du Nord, trèsperformante pour les langues globalement phonétiques (où la majoritédes lettres se prononcent). Cette méthode donne ainsi d’excellentsrésultats en anglais.Mais pour le français qui comporte de nombreuses syllabes finalesmuettes, les ajustements ont été longs et fastidieux, et la mise en ondesa été maintes fois repoussée, à la recherche d’un taux acceptable detranscription exacte.Les résultats ont régulièrement progressé jusqu’en 2002, où ce taux aplafonné aux alentours de 93 % (sur 100 mots, seuls 93 étaient corrects).Bien que ce taux paraisse très élevé, il génère un nombre d’incidents delecture très au-delà de ce qui est acceptable. Il suffit, pour s’enconvaincre, de constater qu’il correspond à 8 fautes par minute delecture.Le Sénat du Canada a alors fait un appel d’offres international dans lebut de trouver une solution automatique susceptible d’améliorer cettesituation. La solution proposée devait permettre de corrigerautomatiquement le plus grand nombre de fautes résiduellespossibles, sans ajouter de fautes là où il n’y en a pas.D’autre part, l’automate devait s’intercaler dans le processusd’acquisition du texte sténotypé (logiciel Eclipse déjà installé) sans leralentir de façon notable. (En clair, l’automate ne devait pasconsommer plus d’un millième de seconde par mot.)
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
136
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

La société Diagonal a soumissionné en proposant une adaptationspécifique de ses moteurs d’analyse déjà utilisés dans les logiciels decorrection ProLexis et Myriade. Cette solution retenue par le Sénat aété livrée en octobre 2003.
2. TYPOLOGIE DES FAUTES À CORRIGER
Dans l’état actuel de performance des analyseurs de syntaxe dumarché, la correction automatique n’est possible que dans certainescirconstances : il faut nécessairement limiter la liberté de langagequelque part : soit sur le vocabulaire, soit sur les tournuressyntaxiques, soit sur les types de fautes à corriger.Dans notre cas de figure, le langage est totalement libre tant d’un pointde vue du vocabulaire que des formes syntaxiques utilisées.Ce qui a rendu la chose envisageable ici est le prétraitement humain dessténotypistes qui normalise le texte. Les fautes résiduelles ne sont pas libresmais contraintes par les faiblesses du système Eclipse d’acquisition.Pour vérifier la faisabilité de notre automate, nous avons étudié endétail la retranscription d’un débat récent de 25 minutes contenant2719 mots, que nous avons limités dans une phase initiale aux 2000premiers mots. Ce passage recelait 149 fautes, soit un taux detranscription correcte de 92,5 %: ce texte était bien conforme auxdonnées avancées par le Sénat.Les 149 fautes se décomposaient ainsi :
Fautes d’orthographe :Ces fautes sont théoriquement absentes des textes obtenus parretranscription sténotypique. Mais en pratique, surtout en français,il en reste toujours. En voici deux exemples :
- je concluerait (au lieu de « conclurais »)- je craignerait (au lieu de « craindrais »)
Accords simples du groupe nominal (faute sur le nom) :Ces fautes sont les plus fréquentes mais aussi parmi les plusgênantes. En voici quelques exemples :
- les espèce- certaines préoccupation- de ces disposition
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
137
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
3
49
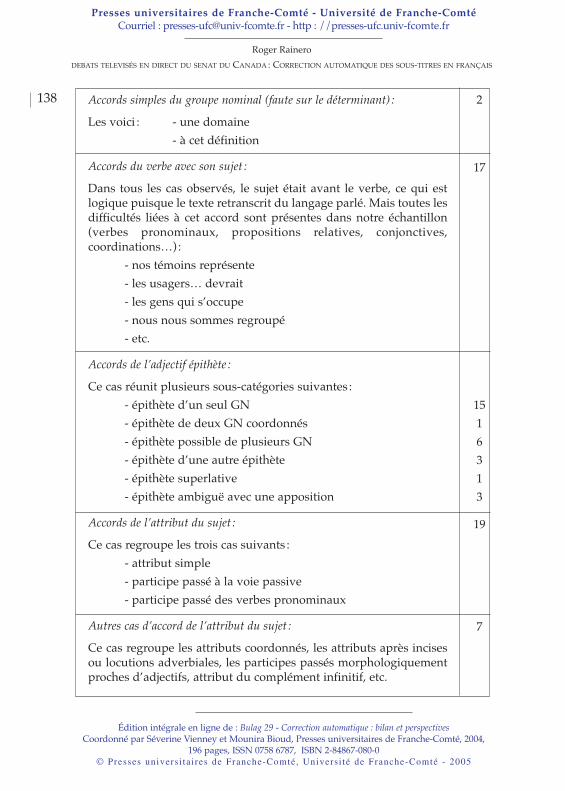
Accords simples du groupe nominal (faute sur le déterminant) :
Les voici : - une domaine- à cet définition
Accords du verbe avec son sujet :
Dans tous les cas observés, le sujet était avant le verbe, ce qui estlogique puisque le texte retranscrit du langage parlé. Mais toutes lesdifficultés liées à cet accord sont présentes dans notre échantillon(verbes pronominaux, propositions relatives, conjonctives,coordinations…) :
- nos témoins représente- les usagers… devrait- les gens qui s’occupe- nous nous sommes regroupé- etc.
Accords de l’adjectif épithète :
Ce cas réunit plusieurs sous-catégories suivantes :- épithète d’un seul GN- épithète de deux GN coordonnés- épithète possible de plusieurs GN- épithète d’une autre épithète- épithète superlative- épithète ambiguë avec une apposition
Accords de l’attribut du sujet :
Ce cas regroupe les trois cas suivants :- attribut simple- participe passé à la voie passive- participe passé des verbes pronominaux
Autres cas d’accord de l’attribut du sujet :
Ce cas regroupe les attributs coordonnés, les attributs après incisesou locutions adverbiales, les participes passés morphologiquementproches d’adjectifs, attribut du complément infinitif, etc.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
138
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
2
17
1516313
19
7

Autres cas d’erreurs :- tournures idiomatiques- homophones grammaticaux (délie/délit, tu/tue, affaibli/affaiblit)- répétitions (que que, que qu’)- accord avec le locuteur (oratrice : je suis arrivée)- faute de frappe sténotypique- autres
Quatre grands groupes de fautes (49 + 17 + 15 + 19 = 100) représentent2/3 du total. Ce sont les fautes les plus visibles et donc les plusgênantes à la lecture des sous-titres. D’autres fautes comme les fautesd’orthographe (3) ou les cas spécifiques d’accord de l’attribut du sujet(7) méritaient également un traitement prioritaire.C’est sur ces fautes qu’il faudrait porter nos efforts en priorité.
3. APTITUDE DES PRODUITS COMMERCIAUX À CORRIGER CES FAUTES
À ce stade de l’analyse, il était impératif d’évaluer les capacitésactuelles des technologies de détection de fautes et de correctionutilisées par nos produits (essentiellement ProLexis).Nous avons donc pour cela tenté de corriger le texte des 2000 motsavec ProLexis et avons observé les résultats suivants :
(1) ProLexis a détecté et corrigé correctement 114 des 149 fautesque contenait le document. Dans certains cas, plusieurscorrections étaient proposées et ProLexis a laissé le choix àl’utilisateur humain. Mais nous avons estimé qu’il nous étaitpossible d’automatiser ce choix par un développementspécifique tenant compte de l’origine sténotypée desdocuments analysés.
(2) ProLexis a détecté de manière directe ou indirecte 22 autresfautes, sans pour autant faire la bonne proposition decorrection, mais de façon suffisamment précise pour quenous puissions compter sur une correction possible de cesfautes avec un autre développement spécifique.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
139
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
532166

(3) ProLexis a analysé les 2000 mots et détecté toutes ces fautesen 35 centièmes de secondes sur un Pentium 2 à 500 MHz,soit une consommation totale de 0,2 millième de secondepar mot.
Au total, ProLexis s’est avéré capable de détecter 136 fautes sur 149soit 91 % des fautes qui nous intéressent. Il ne les corrigeait pas toutesau moment de l’étude parce qu’il a été conçu pour collaborer avec unhumain qui le pilote, et qu’il préfère donc lui demander son avis dèsqu’il doute d’une situation.Mais sa vitesse de traitement très confortable nous permettait depenser que nous disposerions de la réserve de capacité suffisante pourdoter son moteur des automates complémentaires adaptés auxcorrections demandées.À ce stade de l’étude, il était très difficile d’évaluer le taux desurdétection du produit fini, car il intégrerait de nombreux automatescomplémentaires dont le comportement n’était pas nécessairementextrapolable à partir de nos connaissances.Nous n’avions donc pas d’autre choix que d’introduire cette donnéecomme une contrainte complémentaire dans l’écriture des nouvellesfonctions : ne pas dégrader le taux actuel de surdétection, soit unefaute tous les 2000 mots.
4. CONTRAINTES DYNAMIQUES DE LA CORRECTION AUTOMATIQUE DESSOUS-TITRAGES EN TEMPS RÉEL
Le système demandé par le Sénat imposait de faire les corrections aufur et à mesure de la saisie, c’est-à-dire sans que l’on puisse attendre lafin des phrases.Cette contrainte vient essentiellement du direct : les sous-titres suiventà peu près les paroles des orateurs. En théorie donc, les correctionsdoivent être faites quasi immédiatement après les fautes.
En pratique, nous disposions des souplesses suivantes : – les diffusions sont en léger différé d’une à deux secondes,– les sous-titres sont découpés en lignes. Celles-ci ne partent à
l’antenne que lorsqu’elles sont pleines.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
140
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Exemple avec la phrase :« Les filles jouent aux billes, les garçons jouent au ballon. »
Voici ce que saisit la sténotypiste par tranche de 0,5 seconde :0,5 s Les1,0 s Les fille1,5 s Les fille joue2,0 s Les fille joue au2,5 s Les fille joue au bille,3,0 s Les fille joue au bille, les3,5 s Les fille joue au bille, les garçon4,0 s Les fille joue au bille, les garçon joue4,5 s Les fille joue au bille, les garçon joue au5,0 s Les fille joue au bille, les garçon joue au ballon.
Et voici ce que doit voir le téléspectateur :0 s (rien)
3 s Les filles jouent aux billes,
6 s Les filles jouent aux billes,les garçons jouent au ballon.
L’automate doit corriger les fautes de la 1re ligne au plus tard au temps5,0 (temps réel 3,0 + 2 secondes de différé), c’est-à-dire lorsque le 4e
mot de la ligne suivante vient d’arriver.Pour la première faute (fille), il dispose d’un retard de 7 mots, maispour la dernière faute (bille), il ne bénéficie plus que d’un retard de 4mots.
L’automate ignorant totalement à quel moment les lignes sontdéclarées « pleines », il est obligé de s’astreindre à faire toutesses corrections avec un maximum de quatre mots de retard !
C’était bien là la plus grande difficulté à laquelle nous allions êtreconfrontés.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
141
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

5. CE QUI A RENDU LA CHOSE POSSIBLE
Notre moteur d’analyse syntaxique est basé sur une technologie depropagation de contraintes. Chaque nouveau mot dans une phraseapporte son lot de variantes possibles, mais aussi son lot de contraintespour toutes les variantes établies depuis le début de la phrase. Et ainside suite jusqu’à la fin de la phrase:
(1) En apportant son lot de variantes, chaque nouveau motfabrique son bosquet dans la forêt des arborescences.
(2) Mais en propageant ses nouvelles contraintes aux variantesantérieures, chaque nouveau mot coupe également ungrand nombre d’arbustes dans cette forêt naissante.
Cette autorégulation des naissances est un facteur qui lutteefficacement contre l’explosion combinatoire de l’analyse arbores-cente. C’est lui qui explique en grande partie les performances devitesse de ProLexis.Mais son plus gros avantage, dans le cadre de la correctionautomatique en temps réel provient de sa capacité à délivrer uneanalyse pondérée des variantes après chaque mot. Bien sûr, l’analyseest réputée optimale lorsque tous les mots de la phrase sont connus,mais cette analyse est néanmoins disponible en phase intermédiaireaprès chaque mot.Il nous fallait donc vérifier que pour les corrections de fautes visées,nous disposions effectivement de suffisamment d’indices pour déciderde leur correction au maximum 4 mots après chacune d’elles.En théorie, en effet, tout nouveau mot dans une phrase peut changertotalement son analyse. C’est un exercice bien connu auquel se livrentvolontiers les professionnels de l’analyse syntaxique. Et c’est aussiavec de tels exemples que l’on peut démontrer que ce que nous avonsfait est impossible. En voici quelques-uns :
Début : Le chien regarde le chat et la souris…Suite : Le chien regarde le chat et la souris rigole…
Et si le mot d’après est encore ambigu, l’analyse est impossible tantque la suite n’est pas connue :
Début : Le chien regarde le chat et la souris prise…Suite 1: Le chien regarde le chat et la souris prise… (au piège ?)Suite 2: Le chien regarde le chat et la souris prise… (du tabac ?)
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
142
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
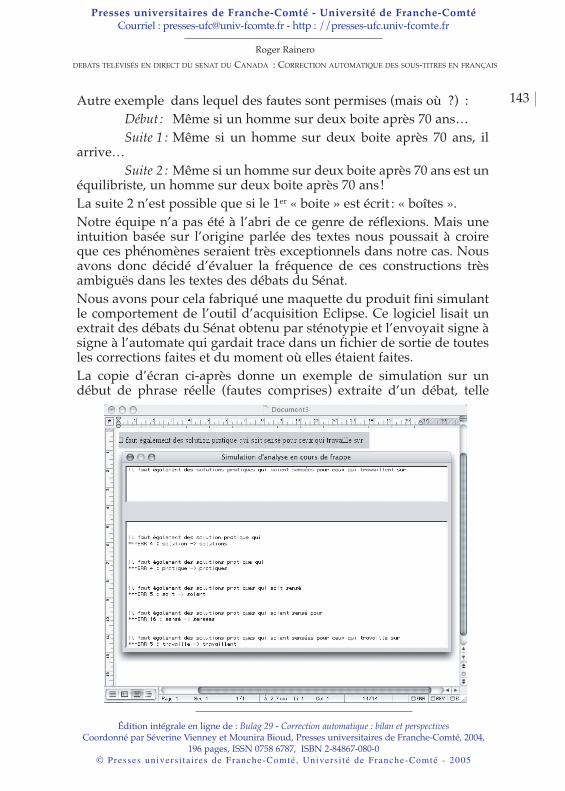
Autre exemple dans lequel des fautes sont permises (mais où ?) :Début : Même si un homme sur deux boite après 70 ans…Suite 1 : Même si un homme sur deux boite après 70 ans, il
arrive…Suite 2 : Même si un homme sur deux boite après 70 ans est un
équilibriste, un homme sur deux boite après 70 ans !La suite 2 n’est possible que si le 1er « boite » est écrit : « boîtes ».Notre équipe n’a pas été à l’abri de ce genre de réflexions. Mais uneintuition basée sur l’origine parlée des textes nous poussait à croireque ces phénomènes seraient très exceptionnels dans notre cas. Nousavons donc décidé d’évaluer la fréquence de ces constructions trèsambiguës dans les textes des débats du Sénat.Nous avons pour cela fabriqué une maquette du produit fini simulantle comportement de l’outil d’acquisition Eclipse. Ce logiciel lisait unextrait des débats du Sénat obtenu par sténotypie et l’envoyait signe àsigne à l’automate qui gardait trace dans un fichier de sortie de toutesles corrections faites et du moment où elles étaient faites.La copie d’écran ci-après donne un exemple de simulation sur undébut de phrase réelle (fautes comprises) extraite d’un débat, telle
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
143
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

qu’elle est délivrée par Eclipse : « Il faut également des solutionpratique qui soit sensé pour ceux qui travaille sur… ».La fenêtre en arrière-plan est celle de Word dans lequel les textes desdébats sont ouverts et où sont faites manuellement les sélections desparties de texte à simuler.Au premier plan, la fenêtre du simulateur affiche en temps réel danssa partie haute chaque caractère au fur et à mesure des transcriptionssimulées. Chaque caractère est simultanément transmis à l’automatequi corrige aussitôt les fautes (si besoin, et quand bon lui semble). Lesmots ayant fait l’objet de corrections passent en gras.En bas de la fenêtre de simulation, l’automate consigne chaquecorrection en reportant la phrase concernée dans l’état où elle étaitjuste avant la correction. Puis il indique clairement la correction faiteen précisant la nature de l’erreur par un code numérique.On peut voir que la première erreur concerne « solution » et qu’elle estcorrigée dès la saisie de « qui ». La correction en « solutions » entraînedans la foulée la correction de « pratique » en « pratiques ».Regardons de plus près les analyses qui sont faites à ce stade : le mot« pratique » est ambigu, comme le montre un extrait du dictionnairede ProLexis ci-dessous :
Ce peut être un nom féminin ausingulier, un adjectif au masculinou féminin singulier, ou un verbeaux 1re et 3e personnes du présentde l’indicatif et du subjonctif, ou unverbe à l’impératif (2e personne dusingulier).
Toutes ces formes génèrent théorique-ment à peu près autant devariantes, globalement réparties en deux grandes catégories : lesvariantes nominales et les variantes verbales. Pour-tant, l’apparitiondu mot « qui » suffit à tuer dans l’œuf toutes les variantes verbales,comme le montre le mouchard d’analyse ci-après :
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
144
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

La flexion verbale de « pratique » est à la racine d’une arborescence devariantes parmi lesquelles la plus probable suppose que ce mot est unimpératif, comme dans la phrase :
« Il faut également des solutions, pratique ce sport et tuverras ! »
Bien sûr, la virgule semble obligatoire mais un analyseur syntaxiquedestiné à la correction ne peut s’appuyer totalement sur laponctuation, certaines fautes étant liées à sa présence abusive ou à sonabsence. Un tel analyseur est obligé de considérer que la virgule a puêtre oubliée : potentiellement, elle est donc là !L’arrivée du mot suivant « qui » est déterminante : la flexion verbalepour le mot « pratique » devient quasiment impossible. En théorie, ellene peut être totalement exclue sans analyse sémantique, mais lesréglages actuels des seuils de probabilités dans ProLexis font qu’elleest rejetée catégoriquement ici.La conséquence immédiate est que toutes les variantes restantes ont encommun le fait que « des solution pratique » est un groupe nominal,complément d’objet direct du verbe « faut ».Le groupe étant fautif sur l’accord GN, deux formes correctes sontpossibles : « une solution pratique » et « des solutions pratiques ».C’est là qu’interviennent les automates spécialisés dans la correctionautomatique spécifique du Sénat du Canada : ces automateschoisissent de façon probabiliste la correction au pluriel. Les deuxmises au pluriel sont alors faites en rafale.Nous verrons au chapitre suivant les différences de comportemententre ProLexis qui est démuni de ces automates spécialisés etl’automate du Sénat du Canada.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
145
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

De façon analogue, le mot « soit » est ambigu entre une conjonction decoordination, un adverbe et le verbe « être » au subjonctif. Lapropagation de ses contraintes propres sur les variantes antérieures,ainsi que l’application des contraintes du mot suivant permettentd’éliminer de manière quasi absolue les formes non verbales de « soit ».Les automates spécialisés du Sénat transforment la quasi-certitude encertitude. Le verbe « soit » est alors contrôlé avec son sujet connu « qui »dont le seul antécédent possible est « solutions » (déterminé et corrigéau pluriel trois mots avant). La correction s’impose au pluriel : « soient ».L’adjectif « sensé » qui suit est déjà déterminé « attribut du sujet ».Pourtant, il n’est pas mis tout de suite au pluriel. L’automate attendsystématiquement l’apparition du mot qui suit une faute connue pourla valider. Simple principe de précaution. Rien ne presse !En effet, tant qu’un mot reste le dernier transcrit, les sténotypistespeuvent le corriger (le supprimer ou le compléter par une syllabe).Donc, mieux vaut attendre sagement que le mot suivant vienne…Dans notre simulation, l’automate était libre de décider du moment oùil pouvait faire les corrections sur la seule considération des scores depondération des variantes à tout instant.La simulation sur le texte de 2000 mots a donné les résultats suivants(sur les 110 fautes que nous nous proposions de corrigerautomatiquement) :
Nombre de fautes corrigées avec un retard de :89 1 mot17 2 mots3 3 mots1 4 mots
L’intuition sur la faible fréquence des situations ambiguës dans lelangage parlé des débats du Sénat du Canada paraissait doncconfirmée, au moins sur le texte étudié.Et la propagation de contraintes montrait là une capacité tout à faitétonnante à résoudre le problème posé. Restaient à démontrer sonefficacité et sa stabilité à grande échelle.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
146
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

6. CE QU’IL A FALLU CHANGER POUR LES BESOINS SPÉCIFIQUES DU CLIENT.
Nous avons déjà vu au point 4 comment l’automate devait corriger« Les fille joue au bille… » en « Les filles jouent aux billes… »Prenons l’exemple de « au bille ». Un correcteur de type « papier »comme ProLexis qui suppose que le texte a été saisi par un humain surun clavier d’ordinateur ne peut trancher entre les deux corrections « àla bille » ou « aux billes ».Pour la première correction, il y a un indice phonétique « primaire »qui tend à le rendre improbable, mais qui ne résiste pas à l’usage, parl’examen d’un très grand nombre de textes « tout venant » où il estpossible d’observer que ce type de fautes est fréquent, soit parcopier/coller, soit dû à la méconnaissance par le locuteur du genreexact du mot utilisé, soit dû à la langue maternelle de l’auteur(anglaise par exemple), etc.La deuxième correction possible est phonétiquement probable, maisest desservie statistiquement par la double faute.Au total, le logiciel hésite entre les deux corrections et propose d’abordl’une (celle qu’il estime la plus probable), tout en laissant la possibilitéà l’utilisateur de choisir quand même l’autre.Un automate de correction de type « Sénat du Canada » sait que letexte provient de la transcription phonétique d’un discours, via unprocessus de sténotypie. Certes, l’influence de l’anglais au Canada estforte et les confusions de genre sont fréquentes. Mais les sténotypistesfrancophones effectuent un prétraitement cérébral qui corrige lamajorité de ces cas.De toute manière, l’automate de correction n’a pas le choix : il doitcorriger dans un sens ou dans l’autre, ou laisser la faute ! Seule uneétude statistique à grande échelle a permis de trancher : dans un cassemblable, la correction phonétique s’impose.Pour traiter tous les cas de ce type, nous avons conçu un ensembled’automates spécialisés auxiliaires qui viennent propager descontraintes spécifiques adaptées aux comportements statistiquesobservés sur les textes réels du client.Dans d’autres cas, comme les fautes d’orthographe par exemple, lesfautes faites par Eclipse sont très typées et très reconnaissables,contrairement aux fautes faites par les humains.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
147
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

En voici quelques exemples : « je concluerait », « je craignerait »…Il s’agit là de bugs des algorithmes de conjugaison d’Eclipse quipourraient très bien être corrigés par les développeurs du logiciel,mais qu’il était plus rapide de traiter à notre niveau.Nous avons construit un automate spécialisé dans la reconnaissancede ces formes conjuguées inventées par algorithme. Rien n’était plusfacile alors que de les corriger.
7. SYSTÈME D’ÉVALUATION DE L’AUTOMATE.
Le simulateur conçu pour l’étude de faisabilité et décrit au point 5 étaitl’outil idéal pour l’évaluation de l’automate finalisé, à condition quel’on puisse le tester sur un grand nombre de textes.Après avoir été choisis par le Sénat du Canada pour exécuter lemarché, nous avons donc lancé en parallèle les deux réalisationssuivantes :
– d’une part, le logiciel lui-même (bien entendu),– d’autre part, l’étalonnage d’un corpus de 50000 mots destiné
à valider les tests d’usine du logiciel, avant sa livraison chezle client.
Ce corpus a été extrait des transcriptions sténotypées de débats récentsreprésentant un peu plus de 10 heures d’antenne.On ne s’est limité à cette taille que pour des contraintes de temps.Deux personnes ont travaillé pendant un mois pour sélectionner lestextes, éliminer les passages en double, détecter les fautes et les baliserdans le texte.Quelque 3500 fautes y ont été repérées.
8. RÉSULTATS ANNONCÉS ET RÉSULTATS OBSERVABLES.
Nous nous étions engagés par contrat à porter le taux de transcriptionscorrectes à 98,25 %.Nous avions indiqué notamment que sur le texte de référence de2000 mots contenant 149 fautes, nous corrigerions (dans la premièrephase contractuelle) 114 fautes réparties dans les catégories suivantes :
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
148
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

accords simples du groupe nominal 49(faute de nombre sur le nom)
accords du verbe avec son sujet 17
accords de l’adjectif épithète 15
accords de l’attribut du sujet 19
problèmes divers : 14(répétitions, orthographe phonétique, etc.)
Total 114
La version que nous avons livrée corrige en fait 118 erreurs : les 114initialement prévues, plus quatre nouvelles fautes que les évolutionsrégulières du moteur de ProLexis dont est équipé l’automatepermettent désormais de corriger en standard.L’automate n’introduit qu’une seule faute sur ce même texte, ce quiabouti au taux de transcription correcte de :
(2000 – 149 + 118 – 1) / 2000 = 98,40 %Quant au temps pris par l’automate pour faire son travail, il est trèsinférieur au 1/1 000e de seconde par mot.L’application de l’automate sur le corpus de 50000 mots a corrigé plusde 2500 fautes sur 3500, établissant un taux de reconnaissance àgrande échelle stable à 98,31 %.Sur ce même corpus, l’automate n’a introduit que 23 fautes, soit untaux moyen de surcorrection de 1/2 100. Notre objectif de maintenir cetaux au niveau moyen actuel de surdétection du moteur de ProLexis(1/2 000) a été atteint.Afin de mieux appréhender l’impact réel des corrections faites sur lalisibilité générale des sous-titres, nous avons mis en page la totalité dutexte de 2000 mots dans le format suivant, très proche des sous-titrestels qu’ils sont perçus par les téléspectateurs :À chaque instant, trois lignes de sous-titrage sont visiblessimultanément, une nouvelle ligne apparaît tous les 10/3 de secondes(soit 3 nouvelles lignes toutes les 10 secondes), et chaque nouvelleligne chasse la plus ancienne des trois déjà présentes.
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
149
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
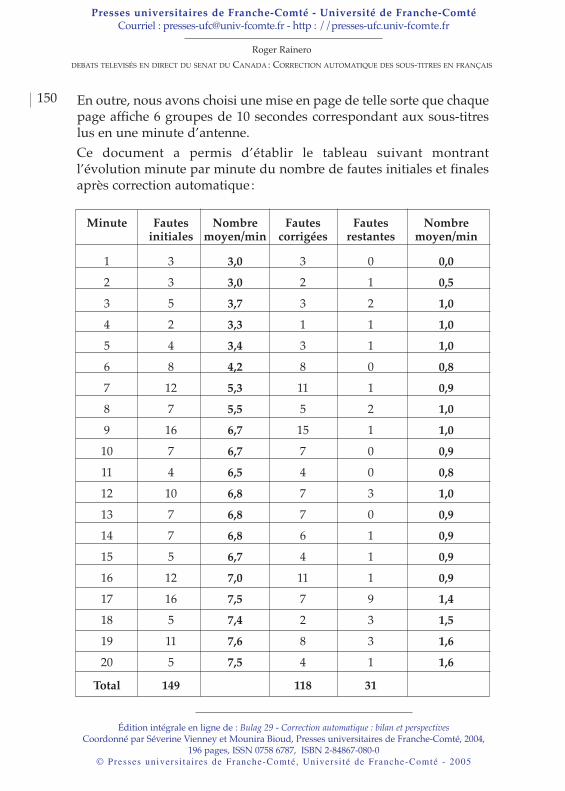
En outre, nous avons choisi une mise en page de telle sorte que chaquepage affiche 6 groupes de 10 secondes correspondant aux sous-titreslus en une minute d’antenne.Ce document a permis d’établir le tableau suivant montrantl’évolution minute par minute du nombre de fautes initiales et finalesaprès correction automatique :
Minute Fautes Nombre Fautes Fautes Nombre initiales moyen/min corrigées restantes moyen/min
1 3 3,0 3 0 0,02 3 3,0 2 1 0,53 5 3,7 3 2 1,04 2 3,3 1 1 1,05 4 3,4 3 1 1,06 8 4,2 8 0 0,87 12 5,3 11 1 0,98 7 5,5 5 2 1,09 16 6,7 15 1 1,010 7 6,7 7 0 0,911 4 6,5 4 0 0,812 10 6,8 7 3 1,013 7 6,8 7 0 0,914 7 6,8 6 1 0,915 5 6,7 4 1 0,916 12 7,0 11 1 0,917 16 7,5 7 9 1,418 5 7,4 2 3 1,519 11 7,6 8 3 1,620 5 7,5 4 1 1,6
Total 149 118 31
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
150
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Le nombre moyen de fautes par minute de lecture passe de 7,5 (avantcorrections) à 1,6 (après corrections). Il y avait donc, avant correctionautomatique, plus d’un incident de lecture par groupe de trois lignes.Après correction, il n’y en a plus qu’un seul tous les quatre groupes detrois lignes.La photo d’écran ci-dessous montre l’automate à l’œuvre, en tâche defond dans le logiciel Eclipse :
À droite, les signes saisis par les sténotypistes, à gauche (sur fond gris)le texte transcrit par le logiciel Eclipse, et sur fond blanc, les correctionsautomatiques faites par le moteur de ProLexis appuyé de sesautomates spécialisés.
La photo d’écran ci-contre montreles bandes de sous-titres produitesen temps réel par Eclipse le8 octobre 2003 après correctionautomatique par ProLexis.On constate à la fois l’efficacité ducorrecteur automatique et leslimites de l’analyseur syntaxique :1. …qui… apporte(nt),2. …à leur(s) parent(s).
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
151
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

9. PERSPECTIVES
Le calendrier très serré imposé par le Sénat nous a limités dans lestypes d’erreurs à traiter.Nos études initiales, confirmées par les résultats obtenus dans lapremière phase de travaux, ont montré qu’il nous était possible deporter le taux de reconnaissance à 99,25 %, par simple ajoutd’automates spécialisés à la technologie générale actuelle.Au-delà, nous allons vite atteindre les limites de l’analyse syntaxiquepure. L’extrait réel de la page précédente en donne deux exemples.L’amélioration des performances passera alors nécessairement par laprise en compte de données sémantiques.
10. CONCLUSION
La correction automatique en temps réel n’est plus une fiction ou unprojet. Elle est non seulement possible mais déjà opérationnelle (danscertains cas et moyennant certains seuils de tolérance).Dans les dix ans à venir, ces seuils devraient se réduire considérable-ment. L’introduction prochaine des analyseurs sémantiques dans leprocessus de décision des automates devrait élargir le champ d’appli-cation actuellement restreint de cette technique.Désormais, un peu comme dans les années 70 avec les automates dejeu d’échec, chaque année verra naître de meilleurs produits, plusperformants, moins sensibles au contexte.Et comme pour les automates de jeu d’échec, cette course à laperformance serait certainement accélérée s’il existait un concoursnational de correction automatique du français, une sorte de « Dictéede Pivot » pour automates. L’idée est lancée à qui veut la saisir !
Pour contacter l’auteur : [email protected] contacter la société en France : [email protected] contacter la société au Canada : [email protected]
Roger RaineroDEBATS TELEVISÉS EN DIRECT DU SENAT DU CANADA : CORRECTION AUTOMATIQUE DES SOUS-TITRES EN FRANÇAIS
152
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Myriam ThouetPRISE EN COMPTE DES PROPRIETES SÉMANTIQUES DES UNITÉS LEXICALES POUR AMÉLIORER LES CORRECTEURS
153
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Cet article n’est pas repris sur la version en lignemais est disponible sur la version papier
Bulag 29
Correction automatique : bilan et perspectiveCoordonné par Séverine Vienney et Mounira BioudPresses universitaires de Franche-Comté, 2004
ISBN 2-84867-080-0
pages 153 à 162
PRISE EN COMPTE DES PROPRIETESSEMANTIQUES DES UNITES LEXICALESPOUR AMELIORER LES CORRECTEURS
Myriam THOUET
Laboratoire d’Ingénierie Linguistique et de Linguistique AppliquéeUniversité de Nice – Sophia Antipolis Nice, France


Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
163
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
RésuméLa technologie des correcteurs grammaticaux nous amène à penser qu’il n’est paspossible de séparer traitement syntaxique et traitement sémantique. Ce que nousappelons structure syntaxique apparaît dans des phrases artificielles, que l’on peutconsidérer comme de bons exemples de structures grammaticales.En fait, syntaxe et sémantique vont ensemble et sont profondément liées. Aussi quandnous voyons les résultats de parseurs de type ATN ou TAG, nous constatons qu’ilsmettent à jour les relations logiques présentes dans la phrase : sujets des infinitives,liage, bornage… en d’autres termes, tous les éléments qui permettent de construire lesrelations prédicatives du texte.Mais pour les correcteurs grammaticaux, nous sommes obligés de traiter sémantiqueet syntaxe ensemble. Les outils existant ne prennent que partiellement en charge cesaspects. Des systèmes distribués ou parallèles ne sont pas disponibles pour le moment,et les parseurs ne savent pas faire intervenir des informations sémantiques oupragmatiques dans le traitement syntaxique.Ainsi quelles informations doit-on utiliser - où, quand et comment ? - au cours del’analyse syntaxique automatique d’une phrase ?
Mots clésGrammaire formalisée ; correcteur grammatical ; analyseur syntaxique ; parseur ; fauted’orthographe
AbstractThe technology of grammatical checkers leads us to think that it is impossible toseparate syntax from semantics if we want to achieve good results. What we callsyntactic structure appears in artificial sentences, that we can consider as “goodgrammar examples”.
PARSERS, GRAMMAIRES FORMALISEES ETFAUTES DE GRAMMAIRE DU FRANCAIS
Jean-Sébastien TISSERAND
Centre L. TesnièreUniversité de Franche-Comté
Besançon - France

In reality, syntax and semantics go together and are intrinsically linked. Thus whenwe see what kind of results parsers like ATN and TAG carry out, we realise that theybring to light the logical relations of the sentence: control, binding, bounding… inother words, all the elements that allow us to build the predicative relations of the text.As far as syntax checkers are concerned, the only solution is to process semantics andsyntax together. But such parsers do not allow any semantic or pragmatic processingunless in very limited aspects. Distributed or parallel systems are not available for themoment. We do not know how to control the semantic information during syntaxprocessing.So the question is to know what kind of information - where, when and how? - are tobe used during the syntactic structure’s analysis of a sentence?
Key-wordsFormalised grammar; grammatical checker; syntactical analyser; parser; spellingmistake
INTRODUCTION
La hiérarchie des grammaires de Chomsky établit l’échelle desgrammaires formelles et des automates correspondant, partant desautomates à états finis équivalents des langages rationnels, auxmachines de Turing équivalentes d’une grammaire zéro. Les langagesrationnels sont jugés insuffisants pour rendre compte des structuressyntaxiques des langues naturelles. Les context free ne tiennent passuffisamment compte des traits sémantiques et de la lexicologie. Ons’arrête généralement aux grammaires de niveau supérieur comme lesATN (Augmented Transition Network) et les TAG (Tree AdjoiningGrammar). On n’envisagera pas les grammaires comme les HPSG(Head-Driven Phrase Structure Grammar) ou GPSG (GeneralizedPhrase Structure Grammar) dont la puissance est proche desprécédentes.Avec ces analyseurs syntaxiques, on dispose d’outils très puissants -trop puissants peut-être - pour analyser les langues naturelles. Lesgrammaires décrites engendrent une grammaire formalisée,permettant de traiter la plupart des structures syntaxiques répertoriéesen français (Cf. les travaux de A.K. Joshi).
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
164
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

On peut penser qu’il va de soi que de telles grammaires formaliséessont susceptibles de servir dans des correcteurs orthographiques.Nous aimerions montrer dans cet article que le problème est pluscomplexe qu’on peut le penser. Les règles d’accord, par exemple,suivent une logique issue des normes linguistiques du français,résultat d’une histoire spécifique et le traitement automatique de cettegrammaire pose encore des problèmes très particuliers. Nous nousarrêterons sur quelques phénomènes.
1. QU’EST-CE QUE LA GRAMMAIRE D’UNE LANGUE ET SA PRATIQUE ?
On a l’impression communément que la grammaire est un ensemblede règles que l’on appliquerait aveuglément aussitôt que l’ondisposerait de tous les éléments linguistiques nécessaires. Or cepréjugé résiste difficilement à une analyse un tant soit peuapprofondie. On a ici un certain nombre de phénomènes très fins quel’on aimerait mettre en évidence. Une fois les grandes structuressyntaxiques du français décrites, il suffirait de les reconnaître dans lestextes. Cette démarche impliquerait une bijection entre la grammaireformalisée et la grammaire mentale, ce qui est loin d’être établi.
a) On prendra d’abord comme exemple le mode dans lessubordonnées. Ce domaine est connu de toutes les grammaires et a étémaintes fois étudié. On dit qu’après certains verbes, on aautomatiquement l’indicatif ; après d’autres on a le subjonctif :
Paul veut que Pierre vienne (subjonctif obligatoire).Paul pense que Jean viendra (indicatif obligatoire).
Et que dans d’autres cas, les deux sont possibles :Je ne dis pas qu’il est bête.Je ne dis pas qu’il soit bête, mais je crois…
le subjonctif marquant une nuance subjective de doute, d’hypothèse.Le problème orthographique se posera quand même dans les cassuivants :
Je ne pense pas qu’il soit aveugle ou qu’il voie double.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
165
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

On a une contrainte sur le mode qui doit être le même dans les deuxphrases :
*Je ne pense pas qu’il voit double ou soit aveugle.Le mode ne dépend pas du verbe principal, mais de la construction dela suite de la phrase. Le mode peut aussi être déterminé par la présence d’expressionsmodalisantes :
Je ne pense pas, Dieu soit loué, qu’il soit aveugle.Toute valeur de souhait ou de volonté entraîne le subjonctif. Leproblème est alors de repérer l’existence de faits amenant à un modeplus qu’à un autre, une valeur sémantique quelconque. Il faut dans untel cas prendre en compte de nombreux éléments dans la phrase pourfaire le calcul, et pas seulement le verbe.
Mais il y a des cas où on doit déterminer le mode pour progresser dansl’analyse :
Je ne pense pas qu’il est/ait habité par hasard dans ce quartier d’espritde revanche.
On est obligé d’avoir un traitement syntaxique et sémantique parallèlepour lever les ambiguïtés. Le système est obligé de construire deuxreprésentations et d’évaluer laquelle est la meilleure. Encore faut-ilque le système continue l’analyse du texte pour valider lareprésentation qu’il a construite. Cela suppose que les architectures detraitement de fautes soient à plusieurs niveaux.
Faudra-t-il attendre la fin du roman pour savoir quel accord on doiteffectuer ? C’est l’enjeu de La jalousie de Robbe-Grillet : on ne saurajamais comment désambiguïser le titre même arrivé à la dernière page.On risque dans un pareil cas de construire des milliers dereprésentations sans pouvoir trouver de solution définitive. On seretrouve dans les problèmes de compréhension de texte,d’interprétation de sens de mots ou de situations. La dimensionsyntaxique est largement dépassée.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
166
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

b) On peut prendre ensuite le cas de l’accord des participes passés desverbes pronominaux.La règle simplifiée est la suivante : on remplace l’auxiliaire “être” parl’auxiliaire “avoir” et on cherche le COD (Complément d’ObjetDirect) ; si le pronom réfléchi a valeur de COD ou si un nom ou unpronom COD est devant le verbe, on accorde avec le COD; dans lesautres cas, on ne fait pas l’accord ; si le pronom “se” n’est ni COD niCOI (Complément d’Objet Indirect), l’accord se fait avec le sujet.
Elles s’étaient plu = Elles avaient plu à elles-mêmes.“s’” est COI donc il n’y a pas d’accord.
Il suffit de vérifier si le verbe a le trait transitif direct ou indirect dansle dictionnaire.
Elles s’étaient regardées dans le miroir.Elles s’étaient regardé le visage avec attention.
Mais :Elles s’étaient attaquées.Elles s’étaient attaqué.
Les deux sont possibles : quelque chose attaque quelque chose ;quelqu’un s’attaque à quelqu’un. Mais le sens n’est pas le même.
Attaquer quelque chose = détruire.S’attaquer à quelqu’un = agresser quelqu’un.
Autre cas où les deux accords sont possibles avec des nuances de sens :Elles s’étaient persuadées que…Elles s’étaient persuadé que…
C’est donc un problème sémantique à solution pragmatique. On distingue deux accords selon l’expression qui est jugée COD, sansdifférence de sens.
Elles s’étaient senties mourir.Elles s’étaient senti piquer par les moustiques.
On tombe sur la difficulté classique :Les violons que j’ai entendus jouer.Les airs que j’ai entendu jouer.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
167
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Et bien sûr selon le sens que l’on donne à “musiciens", on écrira :Les musiciens que j’ai vu(s) jouer/jouer.
Ce que l’on appelle règle syntaxique est la représentation d’unphénomène sémantique qui se structure syntaxiquement. C’est leproblème du passif et de l’actif, de la manière par laquelle l’action estsentie par le sujet, selon les langues naturelles. On est ramené à LeeWhorf et au relativisme linguistique.
La faute de grammaire met profondément en cause la construction dusens. Elle est rarement une faute de structure pure qui se “répare” parun procédé automatique de calcul. On se retrouve en train de calculerdes interprétations dans les grands domaines de la grammaire quesont : la modalité, la diathèse.
2. QUE PROPOSENT LES GRAMMAIRES FORMALISÉES ET LES ANALYSEURS ?
Les analyseurs syntaxiques ne vont pas dans ces directions sémantico-syntaxiques. Ils calculent les structures possibles de la phrase étantdonné les catégories grammaticales des mots qui la composent.L’analyseur n’est pas un outil qui travaille en parallèle sur la syntaxe,la sémantique, la lexicologie. Il calcule la structure possible étantdonné les éléments en surface.
Prenons le cas de ce que la tradition des grammaires formaliséesappelle “bridge verbs” :
Il a dit à Paul de sauter.Il a promis à Paul de sauter.
Le but de l’analyseur est d’obtenir le résultat suivant :Dire à (X Y) & Sauter (Y)Promettre à (X Y) & Sauter (X)
C’est très important d’avoir ces analyses car elles permettent desavoir :
Qui a dit quoi à qui ?Qui doit faire quoi ?
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
168
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Et donc en lisant le texte, on vérifie si X ou Y a fait ce qu’il était attenduqu’il fasse.On sait depuis les premiers grands projets informatiques que laconnaissance des contenus des variables des prédicats verbaux étaittrès importante dans les systèmes de réponses à des questions(question-answering).Mais ces informations, qu’elles soient obtenues par un ATN ou par uneTAG, n’ont aucune pertinence dans le cas du traitement des fautesd’orthographe car il n’y aucune raison de commettre une faute danscette suite.
Si l’on examine la grammaire de Chomsky et son traitement de la co-référence dans la théorie du gouvernement et du liage (l’anaphore, lepronom, la référence libre), on constate que les définitions qui sontdonnées ne règlent aucun problème d’orthographe. Elles précisent ledomaine où rechercher l’antécédent du pronom ou de l’expressionréférentielle :
Il se lave.“Se” a son antécédent dans la proposition (entre le verbe et le sujet).
Pour le reste, il faut continuer l’analyse : verbe transitif ou intransitif ;il, personnel ou impersonnel…
Il le lave.“Le” ne peut être co-référentiel de “il”. Il faut aller chercherl’antécédent au-delà de la proposition (au-delà du groupe sujet-verbe-COD).Il en va de même pour :
Le vainqueur d’Austerlitz savoura sa victoire.Il s’agit de Napoléon, mais métaphoriquement il peut s’agir den’importe qui à condition qu’il ait un lien avec Austerlitz, fût-ce la gareou le pont.
Si nous parcourons l’ensemble de la grammaire formelle qui est priseen charge par les TAG, il n’y a presque pas de structures qui puissent
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
169
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

servir au traitement des fautes de grammaire, sinon sous des aspectsminimes, annexes. C’est la plupart du temps se donner beaucoup depeine pour rien…Citons quelques structures :
Le “se” moyen : Les oranges se sont bien vendues.Ce ne sont pas elles qui se vendent.
Le “se” réfléchi ou réciproque : Elles se sont blessées.Elles se sont blessées elles-mêmes ou entre elles.Les comparatives dites propositionnelles et celles ditesmétalinguistiques :
Jean est plus fatigué que Paul.Je connais plus de français que d’anglais.
Le pied piping :A qui est-il plus facile d’avouer sa faute ?
Etc.
La notion de grammaire formalisée apparaît très éloignée de lagrammaire normative proche de la correction grammaticale, del’expertise permettant d’écrire ou de comprendre les phrasescanoniques dotées de sens dans la langue, et écrites ou prononcéesselon les règles de la langue. Elle ne prend pas en charge lesconstructions qui permettent de construire la logique des propositions.
La notion de grammaire française s’appuie sur la connaissance destravaux historiques, par exemple la construction de la préposition“avec” depuis la chute de l’empire romain à travers le moyen âge etjusqu’aux temps modernes. A-t-on le droit de dire ?
Ca se mange avec.*?Ca je m’appuie sur.*Je mets cela sur (dessus).
On admet des constructions en post-position avec la préposition“avec” mais pas avec “sur”. L’histoire de la grammaire justifielargement cette démarche. “Avec” a toujours été considéré pouvantavoir des valeurs adverbiales.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
170
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Pourtant il y a des cas où une grammaire formalisée permet derésoudre certaines difficultés. Prenons le cas de cyclicité :
Jean croit que Marie pense que Paul a frappé Sylvie.Qui Jean croit-il que Marie pense que Paul a frappée ?
Si on prend un ATN pour faire l’analyse, on peut reprendre letraitement classique :
The drivers were thought to have been shot.Some thought that some shot the drivers.On croyait qu’on avait tué les chauffeurs.
Les déplacements qui sont calculés interviennent dans la correction defautes d’orthographe : l’accord du participe “frappée”, qui renvoie auCOD “Sylvie”, placé devant sous la forme de “qui”. Pour des raisonssyntaxiques, ce COD ne peut être “Marie”. Dans ce cas un peu exceptionnel, on se rend compte qu’une grammaireformalisée peut rendre des services dans la correction de fautes degrammaire. Selon nos investigations, le nombre de fois où cela seproduit est rare. La plupart du temps, ces grammaires donnent accès àla structure logique des phrases et à l’organisation profonde desgroupes qui les constituent.
3. REPROFILER LES ANALYSEURS SYNTAXIQUES POUR QU’ILS PUISSENTTRAITER LES FAUTES D’ORTHOGRAPHE
Cette démarche est tout à fait légitime. Les parseurs, les analyseurssyntaxiques, les grammaires formalisées qui leur sont associées sontlargement en dehors des problèmes posés par les fautes. Peut-êtreserait-il possible de modifier les parseurs de telle manière qu’ilsprennent en charge les difficultés soulevées par la grammairenormative. Il importe de graduer les difficultés et de distinguer ce quiest faisable de ce qui le sera peut-être à plus longue échéance.
a) Il serait possible de faire les accords dépendant de contrainteslocales sans trop de difficultés.Les accords sujets-verbes, noms-adjectifs, déterminants-noms, quandil est vérifié que les éléments sont en contact, se font sans difficultéavec des automates à états finis ou une base de règles.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
171
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Il est sûrement possible d’améliorer les correcteurs existant à l’aide deces traitements, d’indiquer des fautes possibles, de rappeler des règlesexistantes.Il est certain que les accords complexes exigeront d’autrestechnologies.
b) Prenons le problème de l’accord du participe passé ave l’auxiliaire“avoir” :
Les pommes que Jean a mangées étaient belles.
Un ATN effectue le traitement sans difficulté. Quand le système voitapparaître “que” suivant un nom, il en infère que c’est un relatif objet.A ce moment, il descend dans la subordonnée (SENDR) l’informationque “pomme” (nom commun, féminin, singulier) est le COD de laphrase suivante. Ceci permet de reconstruire :
Jean a mangé les pommesLes pommes étaient belles
et par la même occasion de faire un accord correct sur “mangées”.Certains accords à distance trouveront ainsi des solutions.
c) Le problème des accords à distance des participes passés employéscomme adjectifs dans un certain nombre de cas peuvent être résolus :
Effrayé(e) par un chien énorme qui avait surgi de derrière les haies,Marie prit peur.
Le participe passé sans sujet a pour sujet celui du verbe principal.
Que ce soit en position anaphorique ou cataphorique, le problème estfacile à résoudre. Dans un ATN, le registre SUBJ d’un participe sanssujet (Graphe fils) reste vide tant que le registre SUBJ de la principale(Graphe père) n’est pas rempli, et la sortie (S) de phrase ne peut êtreeffectuée. Pour ce faire, le registre SUBJ du participe est affecté de lavaleur du registre SUBJ de la principale (SENDR).
On se rend compte que l’analyse syntaxique effectuée par des outilscomme les ATN ou les TAG peut donner quelquefois de bons résultats.Les ATN sont équivalents en capacité générative faible à des machines
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
172
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

de Turing. Rien n’empêche d’y programmer tous les traitements quel’on désire. Il resterait ensuite les problèmes de sémantique et depragmatique.
d) On pourrait à ce sujet parler des “cascaded ATN” ou des systèmesavec agents. Il s’agit, lorsqu’une difficulté est rencontrée au niveausyntaxique, d’appeler le module lexicologique ou le modulesémantique afin de résoudre le problème. Ce module peut à son tourdemander des traitements syntaxiques, etc. Et on redescend ensuite lesinformations au niveau de la phrase traitée.
De telles architectures n’ont pas connu de grands développementspour différentes raisons. Il faut retenir la grande quantitéd’informations qu’un tel système exige : à toute informationsyntaxique est liée une grande quantité d’informations sémantiques.On se trouve en train de gérer des systèmes énormes d’informations,ce qu’on ne sait pas faire. Ensuite, il faut programmer la constructionà plusieurs niveaux de profondeur pour pouvoir remonter lesinformations pertinentes. Les parcours sont complexes et supposentde gérer un très grand nombre de piles, et l’effacement desinformations ayant contribué à produire un résultat amène à détruiredes données que l’analyse ultérieure de la phrase peut exiger. Quandon progresse dans l’analyse de la phrase, les différentes informationscollectées - au lieu d’amener une seule solution - conduisent à unequantité de traitements, dans toutes les directions…
Rapidement ce type d’outil s’est révélé inopérant, alors qu’il semblaittrès approprié pour traiter la sémantique, la pragmatique, faire descalculs en avant et en arrière dans la phrase analysée, donc prendre encharge le traitement des fautes de grammaire…
Peut-être aurait-il fallu faire des efforts et progresser dans la réalisationde ce type d’outil ? Les anglais et les japonais ont beaucoup investidans ces technologies. Mais les outils mis au point dans lestechnologies agent allaient révéler les mêmes faiblesses. On ne sait pastraiter des quantités d’informations considérables. Rapidement on adécouvert que certains problèmes syntaxiques résistaient auxanalyseurs.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
173
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

4. DES STRUCTURES SYNTAXIQUES QUI RÉSISTENT AUX ANALYSEURS
Il y a de nombreuses structures que les analyseurs ne peuvent prendreen charge pour différentes raisons que l’on peut aborder maintenant.
a) Les antécédents de pronoms sont calculables. C’est une nécessitépour instancier les variables d’un prédicat :
Jean est venu, je l’ai rencontré. “le” = Jean RENCONTRER (Je, Jean)Jean est venu, je le sais. “le” = que Jean est venu.
Mais il y a des cas où le référent n’est pas calculable. Il s’agit despronoms pro-string. La détermination de cette chaîne demeureimpossible :
Vous avez bien trouvé la maison de Mme Dupont…Ca a été facile.Vous n’avez pas pu vous tromper, vous l’avez vu. Vous avez tourné àgauche. Vous avez continué le long de la rue, jusqu’à la grande toursombre. Là après avoir fait cent mètres vous êtes entré dans une cour.C’était là.
A quoi renvoie “ça” de “ça a été facile”?- c’est un simple embrayeur. L’expression est à prendre telle
qu’elle.- à trouver la maison de Mme Dupont.- à comprendre à partir de l’explication qui suit où se trouve
cette maison.- à comprendre ou à mémoriser les étapes.Etc.
Prenons l’autre pronom qui posera des problèmes d’orthographe :A quoi renvoie “le” de “vous l’avez vu” :A la maison? (vous l’avez vue)Où se trouve la maison? (vous l’avez vu) La recherche de la maison de Mme Dupont? (vous l’avez vue)Que vous ne pouvez pas vous tromper? (vous l’avez vu.)Vous tournez à gauche et chacune des expressions qui suiventou l’ensemble de ces expressions? (vous l’avez vu)Etc.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
174
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Il y a des textes où il y a une infinité de référents possibles pour un motdonné. Généralement ce sont des pronoms : “ça”, “le”, “il”… mais cepeut être aussi des mots-valises. Quand on s’exprime, il n’est pasnécessaire de tout préciser, l’interlocuteur comprend implicitement. Lalangue s’entoure de flou, d’indétermination. Or les analyseurs ontpour fonction de déterminer le sens, la portée des mots d’un texte. Il ya des cas où il est nécessaire de les programmer de façon à ne pasrechercher les antécédents. Quand, pourquoi, et comment faireprendre une telle décision à l’analyseur?
b) Le problème des noms composés est aussi redoutable pour lesparseurs. La technologie est parfaitement au point, les grammairesformalisées sont bonnes. Les TAG ont de bonnes solutions pour cetype de problèmes :
Paul a pris une veste.
La difficulté vient des informations du texte ou du monde extérieur.Des connaissances pragmatiques doivent servir à faire les accords.Mais le fait d’accorder ou de ne pas accorder change complètement lesens :
des (armoires à linge sale)des (armoires à linges sales)des (armoires à linge) salesdes armoires à (linge sale)
Selon le sens que l’on veut donner à la suite de mots, les accords neseront pas les mêmes. Dans certains cas, l’accord n’a pas d’importanceen français :
Les nains de jardin(s)
Mais parfois, l’accord amène deux représentations totalementdifférentes. Il importe dans ce cas de savoir de quel objet on parle. Soitle texte ou le contexte permettent de lever l’ambiguïté et desélectionner un accord, soit le contexte ne dit rien. Mais dans ce cas,choisir de ne pas faire l’accord privilégie une des représentations audétriment de l’autre, alors que l’on n’a aucune raison de choisir celle-
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
175
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

là même. Donc la solution recourant à des listes de mots composésmatérialise la difficulté plus qu’elle ne la résout.
C’est un peu le même problème que l’attachement du groupeprépositionnel. La difficulté est qu’on est ici en face d’un très grandnombre d’expressions, impossibles à recenser toutes.
c) On peut prendre encore le cas des ellipses impossibles à calculer :Pierre mange une pomme, Jean aussi.
C’est à dire :Pierre mange une pomme, Jean (mange) aussi (une pomme).
Il y a des cas plus délicats :Jean a acheté une grande auto verte, Paul une rouge.
On peut rechercher à reconstruire la phrase mais plusieurs possibilitéssont offertes :
Paul a acheté une grande auto rouge.Ou:
Paul a acheté une auto rouge.
On a plusieurs possibilités, ce qui est un mal mais ce n’est pas le piredes maux.Parfois le calcul de l’ellipse conduit à “planter” l’analyseur. Il fautqu’on puisse, s’il y a ellipse, savoir quelles structures ont été effacées.
Or dans de nombreux cas, il est impossible de le dire. Prenons le textesuivant extrait d’une dictée :
Mais qu’un peu de chagrin vînt, une maladie, et le bois qui lesentourait(?) semblait(?) resserrer sur eux sa poigne hostile pour lespriver des secours du monde, le bois et ses acolytes : les mauvaischemins où les chevaux s’enfoncent jusqu’au poitrail, les tempêtes deneige en plein avril
Louis Hémon Maria Chapdelaine
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
176
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

L’accord de “entourait” et de “semblait” exige que l’analysesyntaxique de la phrase soit faite avec exactitude.
L’explication sémantique n’est pas concluante : il est difficiled’admettre qu’une maladie puisse entourer ces personnes. En tout cas,elle ne le fait pas de la même façon que le bois (la forêt). Lacoordination ne serait pas possible sauf dans le cas de l’attelage, ce quiest difficilement le cas ici.Il y a une explication syntaxique : “le bois” est le seul sujet des deuxverbes à cause de “sa poigne”, sinon on aurait eu “leur poigne”. “et”n’est pas une coordination, mais un marqueur de conséquence. On est donc amené à dire que “maladie” comporte une ellipse :
Mais qu’un peu de chagrin vînt, (qu’) une maladie (vînt), et le bois…
Le problème est que l’analyseur doit reconstruire le reste de la phrase.Il ne peut pas y avoir parsage local pour un analyseur de type ATN.Comment construira-t-il “le bois et ses acolytes” dans la suite de laphrase ?
La construction pour le locuteur français standard est la suivante :Mais qu’un peu de chagrin vînt, (qu’)une maladie (vînt), et le bois— lebois et ses acolytes : les mauvais chemins où les chevaux s’enfoncentjusqu’au poitrail, les tempêtes de neige… —qui les entourait semblaitresserrer sur eux sa poigne hostile pour les priver des secours du monde.
Le fait de rejeter en fin de phrase le groupe :le bois et ses acolytes : les mauvais chemins où les chevaux s’enfoncentjusqu’au poitrail, les tempêtes de neige…
permet d’échapper à la dislocation conduisant à une difficulté decompréhension chez le lecteur.
En revanche, il sait que “le bois” est à interpréter sémantiquementcomme la forêt canadienne, un être unique, spécifique, comme on dit“le soleil”. Il comprend que “le bois et ses acolytes” reprend “le boisqui”. C’est une apposition. Ce n’est pas un autre bois défini commeayant des acolytes. Cette interprétation va de soi à cause de la chargesémantique accompagnant l’expression “le bois” dans le contextecanadien.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
177
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Mais l’analyseur automatique qui prend les mots à la suite traite “lebois et ses acolytes” comme un nouveau groupe nominal introduisantune nouvelle structure syntaxique et essaiera de construire des ellipsesétant donné qu’il n’y a pas dans la suite de structure verbale. Ce quiamène à boucler indéfiniment dans le reste de la phrase.
L’homme échappe à cette boucle par un traitement sémantique del’information au niveau de “le bois et ses acolytes”. L’analyseurautomatique ne dispose pas d’un traitement sémantique parallèle, etcela d’ailleurs n’est pas possible du fait qu’il prend les mots à la suite. Le lecteur est obligé de reconstruire une phrase canonique qui seradifférente de celle qui est écrite et que nous avons donnée plus haut,pour valider sa lecture.
Nombreux sont les cas de constructions syntaxiques qui sont jugéeshors de portée des analyseurs quels qu’ils soient. L’existence derécursivité dans les langues humaines amène obligatoirement à cetype de conséquences. La machine va se bloquer ou tourner à l’infiniconstruisant toutes sortes de structures… Et même s’il devaitreprendre l’analyse par une fonction de type “on error go to”,l’analyseur ne sait pas sur quel point il s’est trompé, l’analyse étantrécursive.
Dans un pareil cas, il vaut mieux ne pas utiliser d’analyseur syntaxiquecomplexe, mais procéder à l’aide de simples automates à états finis quirepèrent les prédicats et éliminent ce qui n’est pas pertinent. Mais alorsle traitement de “sa poigne” ne pourra pas se faire…
CONCLUSION
Traiter ensemble la syntaxe et la sémantique dans la correction desstructures se révèle absolument nécessaire. Les analyseurs sémantico-syntaxiques existants, parfois efficaces dans les petits domaines, sontinopérants dans les mondes ouverts.
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
178
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

On est contraint d’avoir recours à des analyseurs puissants de typegrammaires sensibles au contexte (ATN, TAG…). Cependant cesanalyseurs ont de par leur puissance un défaut majeur : leur puissancede calcul les aveugle. On est alors obligé de construire des systèmes qui mêlent untraitement syntaxique et des traitements sémantiques et pragmatiquesen parallèle. Ceci permettrait de revenir sur des parties d’analyses déjàfaites, ou entraînerait des regards en avant, ou des regards en arrièreet en avant pour éviter des chemins qui ne mènent nulle part.Des essais ont été faits en ce sens grâce à des architectures distribuées,des systèmes par agents. Mais les résultats sont très peu concluants.Alors que le backtrack est possible dans les structures syntaxiques, ilse révèle impossible à contrôler dans la circulation d’informationsentre les niveaux sémantique, pragmatique et syntaxique. Comment fait l’homme pour jongler entre ces différents niveaux, pourne pas se perdre dans les dédales des informations sémantiques etpragmatiques, et pour se servir seulement des informationspertinentes ? On ne le sait pas. De nombreuses recherches dans desdirections cognitives ont été entreprises sans donner de résultatstangibles. Les traitements à partir d’un niveau méta ne se sont pasrévélés viables.Ces points peuvent être secondaires pour des parseurs de corpusimportants, mais dans le cas de la correction syntaxique, ils sontstratégiques. Un système qui ne corrige pas les fautes avec exactitudeest sans valeur.
RÉFÉRENCES BIBLIOGRAPHIQUES
BOLC, L. (1983) : Augmented Transition Networks, Springer Verlag,BerlinBRADY, M. & BERWICK, C. (1984): Computational Models of Discourse,MIT Press, Cambridge, MassachusettsBRESNAN, J. (1982) : The Mental Representation of Grammatical Relations,MIT Press, Cambridge, Massachusetts
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
179
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

BRISCOE, E.J. (1994): “Prospects for practical parsing: robuststatistical techniques” in P. de Haan and N. Oostdijk, Corpus-BasedResearch into Language: A Feschrift for Jan Aarts, pages 67-95. Rodopi,AmsterdamCHOMSKY, N. (1987) : Generative Grammar: Its Basis, Development andProspects. Studies in English Linguistics and Literature, Special Issue,Kyoto: Kyoto University of Foreign StudiesEARLEY, J.-C. (1968) : An Efficient Context-Free Parsing Algorithm, PhDthesis, Computer Science Department, Carnegie-Mellon UniversityGREENE, B.B. & RUBIN, G.M. (1971): Automatic Grammatical Tagging ofEnglish, Technical report, Brown UniversityHADDOCK, J.N., KLEIN, E. & MORRILL, G. (1987) : UnificationCategorical Grammar, Unification Grammar and Parsing, University ofEdinburghHARRIS, H.D. (1985): Introduction to Language Processing, RestonPublishing Company, New YorkHEMON, L. (1916) : Maria Chapdelaine: récit du Canada français,Montréal, J.-A. Lefebvre éditeurJACOBS, P.-S. & RAU, L.F. (1993): Innovations in Text Interpretation,Artificial Intelligence, 63(1-2):143-191JONES, S.K. & WILLKS, Y. (1983): Automatic Natural Language Parsing,Ellis Horwood John Wiley and sons, New YorkJOSHI, A.K. & SCHABES, Y. (1992): “Tree-Adjoining Grammars andLexicalized Grammars” in Tree Automata and LGS, Elsevier Science,AmsterdamJOSHI, A.K., LEVY, L.S. & TAKAHASHI, M. (1975) : “Tree adjunctgrammars” in Journal of Computer and System Sciences, 10(1)JOSHI, A.K., VIJAY-SHANKER, K. & WEIR, D.J. (1991): “Theconvergence of mildly context-sensitive grammatical formalisms” inPeter Sells, Stuart Shieber, and Tom Wasow, editors, Foundational Issuesin Natural Language Processing, MIT Press, Massachusetts
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
180
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

KAPLAN, R.M. & BRESNAN, J. (1982) : Lexical-Functional Grammar: AFormal System for Grammatical Representation
KUPIEC, J. (1992) : “Robust Part-of-Speech Tagging Using a HiddenMarkov Model” in Computer Speech and Language, 6MARCUS, M.P. (1980): A Theory of Syntactic Recognition for NaturalLanguage, MIT Press, Cambridge, MassachusettsPEREIRA, F.C.N. (1985): “A New Characterization of AttachmentPreferences” in David R. Dowty, Lauri Karttunen, and ArnoldM. Zwicky, editors, Natural Language Parsing—-Psychological,Computational and Theoretical perspectives, pages 307—319, CambridgeUniversity PressPOLLARD, C. & SAG, I.A. (1994): Head-driven Phrase StructureGrammar, Center for the Study of Language and Information (CSLI),Lecture Notes, Stanford University Press and University of ChicagoPressROBBE-GRILLET, A. (1957) : La jalousie, Les Editions de Minuit, ParisSIMMONS, R.F. (1984): Computation from the English, Prentice Hall,New YorkTENNANT, H. (1981) : Natural Language Processing, PBI Petrocellibook, New YorkTOMITA, M. (1987) : An Efficient Augmented Context-Free ParsingAlgorithm, Computational Linguistics, 13(1):31-46WHORF, B.L. (1956): Language, Thought and Reality, Cambridge, MITPress, MassachusettsYOUNGER, D.H. (1967): Recognition and parsing of context-free languagesin time, Information and Control, 10(2):189-208ZEEVAT, H., KLEIN, E. & CALDER, J. (1987) : “An introduction tounification categorical grammar” in J. Nicholas Haddock, Ewan Klein,and Glyn Morrill, editors, Edinburgh Working Papers in CognitiveScience, volume 1: Categorial Grammar, Unification Grammar, andParsing, volume 1 of Working Papers in Cognitive Science. Centre forCognitive Science, University of Edinburgh
Jean-Sébastien TisserandPARSERS, GRAMMAIRES FORMALISÉES ET FAUTES DE GRAMMAIRE DU FRANÇAIS
181
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr


Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
183
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
RésuméCet article traite du langage « texto », le langage apparu avec l’essor des nouvellesformes de communication écrite (NFCE). Couramment utilisé sur Internet et dans les« sms » sur téléphone portable, ce langage a engendré un besoin de nouveaux outilsT.A.L. adaptés. Nous proposons ici un système de correction automatique de celangage.
Mots clefsCorrection automatique, langage texto, nouvelles formes de communication écrite(NFCE).
AbstractThis article deals with the “texto” language which came out with the emergence of thenew written communication forms. Used fluently on Internet and in the SMS on cellphones, this language generates a need of new adapted NLP tools. We propose here asystem of automatic spell checking of this language.
Key-wordsSpell checking; « texto » language; new written communication forms.
INTRODUCTION
La contribution que nous proposons se place dans le cadre de notreactuelle étude sur ce nouveau langage apparu avec l’essor desnouvelles formes de communication écrite que sont les sms, les e-mails, les chats, les forums de discussion sur Internet, etc. Malgré
LA CORRECTION AUTOMATIQUE DULANGAGE DES NOUVELLES FORMES DE
COMMUNICATION ECRITESéverine VIENNEY et Ciprian MELIAN
Centre de recherche L. Tesnière - Besançon, [email protected] - [email protected]

l’ampleur considérable de ce phénomène (plus de huit milliards deSMS ont été envoyés en 2003), et le bouleversement linguistique qu’ila engendré, peu de recherches ont été faites sur ce sujet.
7 artikl trèt D nouvL form 2 komunikacion ékritVoici un exemple de phrase écrite en langage texto. A première vue, lalangue française y semble véritablement maltraitée. C’est pourquoi,notre objectif est la mise au point d’un système de correctionautomatique qui transposera notre phrase de départ en « françaisstandard » :
Cet article traite des nouvelles formes de communication écrite.Nous exposons tout d’abord la problématique, en définissantprécisément le langage texto et ses caractéristiques. Nous développonsensuite l’architecture générale de notre système de correctionautomatique. Enfin, nous concluons sur les résultats et les perspectivesd’un tel système.
1. PROBLÉMATIQUE : LANGAGE TEXTO ET CORRECTION AUTOMATIQUE
Dans ce chapitre, nous décrivons dans un premier temps le langagetexto, en exposant toutes ses particularités. Dans un deuxième temps,nous expliquons toute l’utilité d’un système de correction automatiquede ce langage.
1.1. Le langage textoApparu il y a quelques années avec l’essor des nouvelles formes decommunication écrite, le langage texto est désormais utiliséquotidiennement par des millions de « texteurs ». Deux technologiesont favorisé son développement, appelées généralement les« nouvelles formes de communication écrite ». Ce sont :
� sur Internet : les chats, les forums de discussion (sites dédiés àun thème ou un sujet d’actualité, où les internautes posent desquestions, apportent des réponses ou des commentaires), lese-mails, etc.� sur téléphone portable : les SMS (Short Message Servicing),
appelés également « textos ». Ce sont des messages courts (160caractères maximum) reçus sur téléphone portable.
Ce sont donc des millions d’utilisateurs, qui communiquent ainsiquotidiennement.
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
184
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Ces nouvelles formes de communication écrite correspondent en fait àun dialogue écrit entre au moins deux personnes. C’est pourquoi, lelangage texto, que l’on peut qualifier de langage « abrégé », répond aubesoin de rapidité caractéristique à ces échanges. Le but est deretrouver une sorte de « cadence orale », d’où une forte tendance àl’oralisation de la langue. De plus, le message écrit est habituellementà échéance rapide (Anis, 2001) et a donc une durée de vie limitée. Unsms est généralement reçu, lu et effacé quelques minutes seulementaprès son envoi. Un e-mail est rarement stocké une fois que sa réponsea été envoyée.Toutefois, l’oralisation de la langue n’est qu’un des différentsphénomènes linguistiques observés dans le langage texto. L’ensemblede ces phénomènes est regroupé par Jacques Anis sous le terme de« néographies » (les graphies s’écartant de la norme orthographique).Nous présentons ici les principaux types de néographies utilisées dansles NFCE (Anis, 2002) :
a Les graphies phonétisantes :A. Réductions graphiques :
- Réduction de « qu » dans : ki, ke, koi, kel, kan = qui, que, quoi,quel(le), quandtu as kel age? = tu as quel âge?
- Substitution de « k » à « c » et de « z » à « s », ce qui provoqueun effet de phonétisme :kom = commekler = clairbiz = bises
- Chute des ‘e’ instables : grav = grave courag = courage
- Chute des mutogrammes en finale :cour = coursé = etpa = passalu = salut
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
185
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

- Simplification des digrammes et trigrammes : ossi = aussivréman = vraimentocun = aucunebo = beau
- Combinaisons des deux phénomènes : forfè = forfaitjamé = jamais
- Ces simplifications ne sont pas réservées aux noms, ellestouchent également la morphologie verbaleé = esrépondé = répondezpe = peux… c toi qui ma dit que je pouvé te trouver ici = c’est toi qui m’as dit que jepouvais te trouver iciÇa me fé plaisir ke t’ait pensé à moi = ça me fait plaisir que t’aies pensé à moi
- Déconstruction de « oi »moua = moi
- Emprunt du digramme « oo » de l’anglaisbizoo = bisou
- Réductions avec compactage, lequel dissout les frontières demots et évoque le mot phonique.cé = c’estmapelé = m’appelervérépa = verrai pasjsui = je suis
B. Réductions avec variantes phonétiquesmoa = moitoa = toipo = pa
- Écrasements phonétiqueschais = je sais
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
186
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

a Les squelettes consonantiques:tt = touttjs = toujourslgtps = longtempspb, prb = problèmevs = vous
a Les syllabogrammes et rébus à transfertLes lettres et les chiffres sont utilisés pour la valeur phonétique deleurs noms, sans tenir compte des frontières de mots.
l = ellec = c’est, sais/sait, s’est, c’é[tait]d = desg = j’aim = aimev = vaisC T COOL = c’était coolg jamais vu ca encore = j’ai jamais vu ça encore
oqp = occupénrv = énervé
1 = « in », « un », etc.2 = « de »2m1 = demain abi1to = à bientôtkoi de 9 = quoi de neuf
1 = un2 = deux+ = plusa+ ça a été très émouvant = a plus (tard) ça a été très émouvantte lé di en +!! = (je) te l’ai dit en plus !!
Le mot est réduit à l’initialej = jed = dev = vaisj suis libre = je suis libre
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
187
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Les sigles :lol = laughing out loud (je rigole)brb = be right backasv = âge sexe villemdr = mort de rire
a Les étirements graphiquesje t’aiiiiiiiiiime
a Caractéristiques du fonctionnement global des graphies - Hétérogénéité :Un mot peut être transcrit par la combinaison de plusieurs procédés :
kelk1 = quelqu’un (phonétisme + logographie)ptdr = pété de rire (syllabogramme + siglaison)pkoi = pourquoi (squelette consonantique + phonétisme)k = que (logographie après réduction phonétique)
L’étirement graphique peut se surimposer aux autres procédés.On peut avoir ainsi :
ptdrr = pété de rire
- Polyvalence et même polysémie :Un même élément peut être lu de différentes façons, par exemple leslettres isolées, comme dans ce message où v transcrit vais puis veux :
je v o sport dans une demi heure. […] tu v une douch froid?= je vais au sport dans une demie heure [...] tu veux une douche froide?
- VariationNon seulement les unités lexicales peuvent être transcrites dedifférentes façons par différents scripteurs, mais il peut arriver qu’unmême scripteur n’emploie pas constamment les mêmes graphies.
Tout : « tou », « tt », « tout »Demain : « 2m1 », « 2main », « 2min »
Bien entendu, tous ces phénomènes linguistiques ne sont pasnouveaux. On retrouve dans les premiers écrits des formes simplifiées.Par exemple, dans le papyrus d’Egerton, daté du IIe siècle, J. Véronis(2004) a relevé quelques uns de ces phénomènes :
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
188
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Par ailleurs, depuis de nombreuses années, les collégiens, lycéens etétudiants prennent leurs cours sous forme de « notes » en utilisant desabréviations, des signes particuliers. Les secrétaires suivent des coursde sténographie, définit comme « l’art de se servir de signesconventionnels pour écrire d’une manière aussi rapide que la parole ».Cette technique s’est développée dès la fin du XIXe siècle et est encoreutilisée couramment. Elle permet de gagner du temps pour la dictéedu courrier qui sera dactylographié par la suite.
Ainsi, ces formes d’écriture ont une origine lointaine. En réalité, lanouveauté réside dans le fait qu’elles sont maintenant utilisées dansun but de communication interpersonnelle et non plus pour un seulusage personnel. En effet, une personne qui envoie un sms doit êtresûr qu’il emploie des abréviations que son destinataire pourraretranscrire. Un internaute qui laisse un message sur un forum dediscussion, doit employer un langage qui sera compris par les autress’il désire obtenir une réponse.
1.2. La correction automatique appliquée au langage textoNous comprenons à partir de tous ces exemples que le langage texto,malgré son objectif de simplification, n’est pas simple à analyser.La lecture d’un message écrit en langage texto peut ne pas êtreévidente pour un utilisateur novice. En effet, on remarque qu’il existeplusieurs niveaux d’utilisateurs. Un usager expérimenté, qui a acquisdes automatismes, aura beaucoup plus d’aisance qu’un utilisateuroccasionnel pour lire le texte reçu.Par ailleurs, l’utilisation du langage texto dans certaines circonstancessemble totalement déplacée. En effet, que pensera un chef d’entreprisequi reçoit d’un de ses employés, un e-mail écrit en langage texto?
Je vou pri 2 bi1 vlr… = Je vous prie de bien vouloir…
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
189
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

Ce phénomène a déjà été remarqué dans certaines copies d’examensde collégiens, de lycéens (premiers utilisateurs de ce langage) et mêmed’étudiants. D’un point de vue du Traitement Automatique des Langues, peud’outils traditionnels semblent être adaptés à cette nouvelle forme delangage. En effet, comment un taggeur, par exemple, pourrait-il étiqueter unephrase telle que : kestufé (= Qu’est-ce que tu fais ?) ? Quels résultats unanalyseur syntaxique pourrait-il obtenir sur cette “phrase” : HT du p1et D poiro (= acheter du pain et des poireaux) ?Ainsi, de nouveaux outils appropriés à ce nouveau langage doiventêtre développés.C’est pourquoi, un système de correction automatique apparaît tout àfait utile. Il permet de retrouver un « français standard » qui sera alorscompris de tous. En effet, le temps gagné par l’utilisateur qui a entréson texte en langage texto, risque de se transformer en perte de tempspour l’utilisateur qui n’arrive pas à le « déchiffrer » et qui risque mêmed’abandonner au bout de quelques secondes d’incompréhension.
2. PRÉSENTATION DE L’ARCHITECTURE DU SYSTÈME
Nous exposons ici les différents modules qui constituent notre systèmede correction automatique. Ces modules ne sont pas indépendants lesuns des autres, mais, au contraire, ils interagissent continuellement aucours de l’analyse.
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
190
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
Figure 1 - Architecture générale du système
Lecture du texte source
Texte cible : texte source corrigé
Segmentationdu texte
Analysesmorphologiques
syntaxiquessémantiques
Transcription en françaisstandard

2.1. Lecture du texte sourceLa première étape du système consiste en la lecture du texte saisi parl’utilisateur. Ainsi, le « chateur », le « texteur », le « smseur », ou encorele « maileur » entre son message en langage texto.Nous trouverons des différences de saisie suivant le support utilisé. Eneffet, un message écrit par la même personne mais à partir d’un clavierd’ordinateur ou à partir d’un clavier de téléphone portable ne sera pasidentique. Il suffit de penser que la lettre « f » par exemple, correspondà une pression de l’index gauche sur un clavier d’ordinateur mais àtrois pressions sur la touche « 3 » d’un clavier de téléphone portable. Pour un sms, la saisie se fait en règle générale, à partir du clavierréduit du téléphone mobile (peu ergonomique et qui implique le plussouvent la frappe répétée d’une touche pour chaque caractère). Sur cesupport, l’accès aux caractères accentués est particulièrement long, cequi explique l’absence générale des diacritiques dans ces messages.Par ailleurs, un utilisateur expérimenté n’aura aucune difficulté àsaisir son texte, mais un novice devra chercher la bonne touche puisfaire très attention d’appuyer sur cette touche à la bonne cadence et lebon nombre de fois. Pour réduire encore le temps de frappe, il existe une option de saisieintuitive qui permet d’obtenir une liste de mots à partir des deux outrois premières lettres entrées. L’utilisateur valide ensuite le mot qu’ildésire. Cependant, cette option n’est pas véritablement utilisée car iloblige l’usager à regarder son écran, ce qu’un utilisateur expérimenténe fait pas.
2.2. La segmentation du texteComme dans toute application en Traitement Automatique desLangues, la segmentation du texte constitue une étape fondamentalepour la suite de l’analyse. Elle consiste en la séparation des unitésminimales du texte entré.La segmentation des textes issus des NFCE pose un certain nombre deproblèmes qui viennent des phénomènes de néographiepréalablement évoqués. Les principales difficultés sont de trouver des « frontières » desegmentation, de séparer et d’interpréter des graphies. Nous avons à
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
191
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

faire à des problèmes de présence ou d’absence de ponctuation ouencore de son utilisation abusive :
on est sur la plage !!!!!!!!!!Nous sommes également face à des phénomènes d’agglutination :
a chuila = je suis pas làa jattend son cou 2fil = j’attends son coup de fil
ou encore à des sigles :a mdr = mort de rirea tvb = tout va bien a bcp = beaucoup
sans oublier les structures liées à des tours syntaxiques habituellementassociés à l’oral familier :
a tufékoi = tu fais quoi?Enfin, l’utilisation des séparateurs entre les mots n’est passystématique et ces séparateurs ne sont pas toujours « l’espace » :
a je sui malad-jiré pa o licé-a+ = Je suis malade. J’irai pas au lycée. Aplus tard.
Un autre problème de segmentation est celui des smileys quicorrespondent généralement à une utilisation détournée des signes deponctuation. Ce ne sont pas des mots mais des marques d’expressionde visage de celui qui écrit. Comment peut-on traduire l’expression dejoie représentée par : -)) dans cet exemple?
- g gagné o loto : -))Nous pouvons ajouter une phrase telle que « je suis content », ou « jesuis très content » s’il y a deux parenthèses fermantes qui insistent surle sourire : J’ai gagné au loto. je suis très content.Mais alors que faire des autres signes plus ambigus comme le « clind’oeil : ; -) » ? Il peut effectivement exprimer de nombreux sentimentstelles que la connivence, la complicité, l’ironie. Ces problèmesnécessiteront une analyse fine au niveau pragmatique.La segmentation du texte n’est donc pas une étape évidente. C’estpourquoi ce module travaille en parallèle avec les deux modulessuivants, la transcription et l’analyse, afin de valider ou d’invaliderdes hypothèses de segmentation en fonction d’un ensemble de règles.
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
192
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

2.3. La transcription en français standardCe module « traduit » ou « transcrit » à proprement parler le langagetexto en français standard. Il est basé sur un ensemble de règles detranscription traitant l’ensemble des phénomènes de néographiesdécrits précédemment. Les rôles de ce module sont multiples. Il valide ou non des hypothèsesde segmentation puis il calcule des hypothèses de transcription avecune analyse lexicale et combinatoire. Ces hypothèses sont ensuitevalidées ou invalidées par l’analyse morpho-syntaxique et, si besoin,par l’analyse sémantique. La grande difficulté d’analyse est liée à la gestion des procédésdynamiques de création de graphies ainsi qu’à l’ambiguïté desgraphies abrégées. Par exemple la lettre « c » peut correspondre à :
a ‘c’ : slt, c’est moi : salut, c’est moia ‘c’est ’ : C ton problem : c’est ton problèmea ‘sais’ : j c pa si jviens : je sais pas si je viensa ‘ses’ : 1 2 c amis : un de ses amisa mais encore ‘sait’, ‘ces’, ‘s’est’, etc.
On comprend donc qu’un réel travail contextuel est indispensablepour désambiguïser les formes saisies par l’utilisateur.
2.4. L’analyse morpho-syntaxique et sémantiqueCe module correspond à la vérification et validation des formesobtenues par les analyses précédentes. En effet, pour le texte de départsuivant : G 1 IDle résultat obtenu par les deux premiers modules sera :
G - > jé, jet, jei, jai, jais, jay, j’é, j’ai, etc.1 - > un, ein, ain, in, une, hune, etc.ID - > idé, idée, idai, idés, etc.
Le module de validation lexicale va dégager les différentescombinaisons possibles en français, au niveau morphologique. Onobtient donc les quatre structures suivantes :
a Geai un/une idée(s)a J’ai un/une idée(s)a Jais un/une idée(s)a Jet un/une idée(s)
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
193
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

L’analyse syntaxique et sémantique (si nécessaire) va ensuite détecterla structure correcte. Pour notre exemple, le résultat sera donc :
J’ai une idée
2.5. Le texte cibleL’utilisateur obtient donc le texte source corrigé, écrit en françaisstandard. La plupart des textes des NFCE ont une structure syntaxique correcte,ce qui facilite la génération du texte en français. Les principalesdifficultés viendront donc de la prise en compte de toutes lesnéographies et phénomènes linguistiques relevés, qui nécessitent desanalyses précises et fines.De plus, comme nous l’avons vu précédemment, une difficultés’ajoute avec l’utilisation des smileys qui devront être remplacés parune structure sémantique équivalente ou alors simplement suppriméss’ ils sont utilisés pour « signer » le texte : je viens 2m1 ; -)Par ailleurs, le système peut avoir à traiter un message ambigu pourlequel nous obtiendrons plusieurs interprétations possibles. Si nousprenons le célèbre exemple : lépwasonvR, suivant la segmentation dutexte, le système proposera les deux structures suivantes :
les pois sont verts / les poissons vertsNous retrouvons ici les problèmes rencontrés par les systèmes detraitement automatique de l’oral, de reconnaissance et synthèse de laparole.Mais, en réalité, dans le cas d’un message texto, sauf si l’utilisateurveut réellement jouer sur l’ambiguïté, le message sera plutôt saisiainsi :
a lé poi son vR = les pois sont vertsa lé poicon vR = les poissons verts
En effet, le texteur segmente généralement son texte de façon àsimplifier au maximum sa lecture. Un tel cas d’ambiguïté sera doncexceptionnel mais notre système en tiendra tout de même compte.
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
194
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

CONCLUSIONS ET PERSPECTIVES
Ainsi, après avoir exposé toutes les caractéristiques du langage texto,ce langage utilisé quotidiennement par des millions d’internautes etde texteurs, nous avons vu qu’un système de correction automatiqueen « français standard » serait d’une grande utilité. En effet, lacommunication se base sur la compréhension des messages échangés.Un système de correction automatique du langage texto serait doncune aide non négligeable pour un texteur néophyte.
Notre système est en cours d’implémentation. Les premiers résultatsobtenus à partir d’un prototype sont encourageants. De plus, denombreuses applications sont envisageables. Nous pouvons penser àun téléphone-traducteur, qui transcrirait en français le message entréen langage texto ou encore un correcteur automatique intégré auxforums de discussion, aux chats ou aux systèmes de messagerieélectronique.
RÉFÉRENCES BIBLIOGRAPHIQUES
ANIS J., (Ed.) 1999, Internet, communication et langue française. Paris,Hermès.
ANIS J., 2001, Parlez-vous texto? Guide des nouveaux langages du réseau,Le cherche-midi éditeur.
ANIS J., 2002, Communication électronique scripturale et formeslangagières : chats et SMS, Actes des journées « S’écrire avec les outilsd’aujourd’hui », Université de Poitiers.
CRYSTAL D., 2001, Language and the Internet. Cambridge UniversityPress.
LIENARD F., 2004, Analyse linguistique et sociopragmatique d’unepratique scripturale particulière, communication présentée lors des 18èmes
Journées de Linguistique de l’Université Laval, 11-12 mars 2004,Québec, Canada.
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
195
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr

VERONIS J., GUIMIER DE NEEF E., 2004, Les NFCE: 1 pw1 sr lakestion, communication présentée lors de la Journée d’Etude del’ATALA du 5 juin 2004 « Le traitement automatique des nouvellesformes de communication écrite », Paris.VIENNEY S., MELIAN C., 2004, Vers un système de traductionautomatique du langage « texto », communication présentée lors de laJournée d’Etude de l’ATALA du 5 juin 2004 « Le traitementautomatique des nouvelles formes de communication écrite », Paris.
Séverine Vienney et Cirpian MelianLA CORRECTION AUTOMATIQUE DU LANGAGE DES NOUVELLES FORMES DE COMMUNICATION ÉCRITE
196
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
197
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
BULAGBulletin de Linguistique Appliquée et Générale.
Liste des numéros disponibles :
18 1992 Les industries de la langueCoordonné par S. Cardey 15 Euros 7 Euros
21 1996 L’ambiguïtéCoordonné par S. Cardey 15 Euros 7 Euros
22 1997 TAL et Sciences CognitivesCoordonné par H. Madec 15 Euros 7 Euros
23 1998 Figement et TALCoordonné par P.-A. Buvet 15 Euros 7 Euros
24 1999 Génie Linguistique et Génie LogicielCoordonné par P. Greenfield 15 Euros 7 Euros
25 2000 La Traduction et le Traite-ment Automatique des LanguesCoordonné par S. Cardey et R. Mandic 15 Euros 7 Euros
26 2001 T.A.L. et InternetCoordonné par H. Madec 15 Euros 7 Euros
27 2002 Les mots, leur sens, leurforme leur création et leurreconnaissanceCoordonné par D. Limame,I. Skouratov, I. Thomas 15 euros 7 euros
28 2003 Modélisation, systémique,traductibilitéCoordonné par S. Cardey 15 euros 7 euros
Frais de port : 7,5 Euros ( hors communauté européenne)
Contact : Presses universitaires de Franche-Comté2, place Saint Jacques - 25030 Besançon cedexTél. (33) 03 81 66 59 70 – Fax (33) 03 81 66 59 80
Retrouvez les dernières parutions sur le site internet à l’adresse suivante :
http://tesniere.univ-fcomte.fr
Numéro Année Titre Prix Prix Etudiant

198
Édition intégrale en ligne de : Bulag 29 - Correction automatique : bilan et perspectivesCoordonné par Séverine Vienney et Mounira Bioud, Presses universitaires de Franche-Comté, 2004,
196 pages, ISSN 0758 6787, ISBN 2-84867-080-0© Presses univers i ta i res de Franche-Comté, Universi té de Franche-Comté - 2005
Presses universitaires de Franche-Comté - Université de Franche-ComtéCourriel : [email protected] - http : //presses-ufc.univ-fcomte.fr
BULAGBON DE COMMANDE
à adresser àPresses Universitaires de Franche-Comté
2, place Saint Jacques25030 Besançon cedex
NOM ............................……… PRENOM………………………..
ADRESSE: N°……………….. Rue………………………………
CODE POSTAL……………… VILLE………………………….
Je désire recevoir :
Numéro Exemplaires Prix
Frais de port :____________________
TOTAL :____________________
Règlement par chèque bancaire ou postal à l'ordre de :
l'Agent comptable de l'Université de Franche-ComtéCCP 340 367 C Dijon


![H20youryou[2] · 2020. 9. 1. · 65 pdf pdf xml xsd jpgis pdf ( ) pdf ( ) txt pdf jmp2.0 pdf xml xsd jpgis pdf ( ) pdf pdf ( ) pdf ( ) txt pdf pdf jmp2.0 jmp2.0 pdf xml xsd](https://img.pdfslide.tips/doc/110x75/60af39aebf2201127e590ef7/h20youryou2-2020-9-1-65-pdf-pdf-xml-xsd-jpgis-pdf-pdf-txt-pdf-jmp20.jpg)


























