Embed Size (px)
Citation preview

確 率 論 第14回-- まとめ --
情報工学科 山本修身
確率論のこれまでの流れ場合の数と組み合せ確率論
• 2項定理などの組み合せ計算の基礎• 確率の定義• 条件付き確率,独立性,ベイズの定理• 確率変数と分布関数• 期待値と分散(モーメント母関数による計算を含む)• 2項分布,ポアッソン分布,正規分布• 複数の確率変数の扱い(同時分布関数や共分散など)• 大数の法則と中心極限定理
ここでの組み合せ計算
順列の数え上げ• 与えられた集合の要素を並べる方法の数• 同じ種類の要素がいくつか与えれたときの並べ方組み合せの数え上げ• 与えられた集合からいくつかを取り出す• 同じ種類の要素をいくらでもとれるとき,総数を限ったときの組み合せ
組み合せ数n個の要素からm個とる組み合せの数を組み合せ数といい,nCmと書く.
nCm =n!
(n ! m)!m!
2項係数について (1)2項係数はn個の要素からr個取り出す組み合せ数のことである.
「2項係数」と呼ぶ理由は,以下の性質が成り立つからである.
nCr =n!
(n ! r)!r!
(x + y)n =n!
r=0
nCrxryn!r
標本空間 (sample space)今注目している確率現象によって起こる結果を集めた集合を標本空間 (sample space)と呼ぶ.標本空間の要素を根元事象と呼ぶ.ここでは普通Ωという記号で表現する.
1 62
53 4 ! = {1, 2, 3, 4, 5, 6}
試行 (trial)
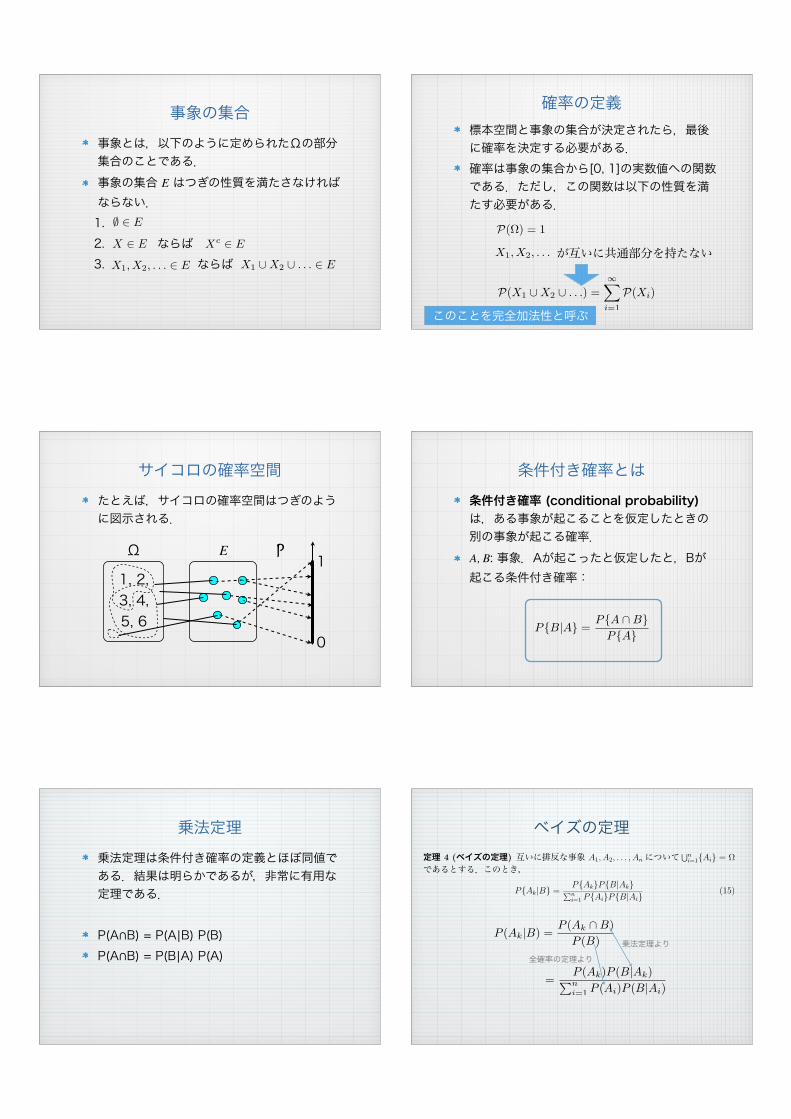
事象の集合事象とは,以下のように定められたΩの部分集合のことである.事象の集合 E はつぎの性質を満たさなければならない.1. 2. ならば3. ならば
! " E
X ! E Xc! E
X1, X2, . . . ! E X1 ! X2 ! . . . " E
確率の定義標本空間と事象の集合が決定されたら,最後に確率を決定する必要がある.確率は事象の集合から[0, 1]の実数値への関数である.ただし,この関数は以下の性質を満たす必要がある.
P(!) = 1
X1,X2, . . . が互いに共通部分を持たない
P(X1 ! X2 ! . . .) =!!
i=1
P(Xi)
このことを完全加法性と呼ぶ
サイコロの確率空間たとえば,サイコロの確率空間はつぎのように図示される.
Ω1, 2, 3, 4,5, 6
E
0
1P
条件付き確率とは条件付き確率 (conditional probability) は,ある事象が起こることを仮定したときの別の事象が起こる確率.A, B: 事象.Aが起こったと仮定したと,Bが起こる条件付き確率:
P{B|A} =
P{A ! B}
P{A}
乗法定理乗法定理は条件付き確率の定義とほぼ同値である.結果は明らかであるが,非常に有用な定理である.
P(A∩B) = P(A|B) P(B)P(A∩B) = P(B|A) P(A)
ベイズの定理
である.さらにBが出てからRでる事象をBRと表現すれば,
P{BR|B} =r
r + b + c(9)
であり,P{B} =
b
r + b(10)
であるので,乗法定理より,
P{BR} = P{BR|B}P{B} =br
(r + c + b)(r + b)(11)
同様にして,Rが連続 2回でる確率は,
P{RR} =(r + c)r
(r + c + b)(r + b)(12)
である.これより,
P{?R} = P{BR} + P{RR} =r
r + b. (13)
ただし,?Rは任意の玉がでてからRがでる事象を表す.
練習問題 一般に P{?nR} =r
r + bであることを示せ.
3 ベイズの定理条件付き確率に関する非常に基本的な定理としてベイズの定理がある.ここで
はベイズの定理を導く.
定理 3 (全確率の定理) 互いに排反な事象 A1, A2, . . . , Anについて!n
i=1{Ai} = !
であるとする.任意の事象Bについて
P{B} =n"
i=1
P{Ai}P{B|Ai}. (14)
さらにこの結果を用いることにより,つぎの定理がなりたつ.
定理 4 (ベイズの定理) 互いに排反な事象 A1, A2, . . . , Anについて!n
i=1{Ai} = !
であるとする.このとき,
P{Ak|B} =P{Ak}P{B|Ak}#ni=1 P{Ai}P{B|Ai}
(15)
がなりたつ.このとき,AiよりもBがあとに起こるとしたとき,左辺を事後確率(存在の確率) 右辺に出現する P{B|Ai}を事前確率(原因の確率)と呼ぶ.事後確率は後に起こった事実から過去の事柄がどうだったかを確率的に推測する手段となる.
3
P (Ak|B) =P (Ak ! B)
P (B)
=P (Ak)P (B|Ak)
!n
i=1P (Ai)P (B|Ai)
全確率の定理より乗法定理より
事象の独立性2つの事象A, Bが独立であるとは,直感的には「関係ない」ということであるが,確率論としては,厳密に数学的な概念である.A, Bが独立であるとは,
ということである.
P (A ! B) = P (A)P (B)
確率変数とは(1)確率変数は厳密には変数ではなく,標本空間から実数への写像である.任意の実数 x について,標本空間の部分集合
が常に事象になることが要求される.
{t ! ! | X(t) " x}
Ωx
確率が計算できる
14
分布関数分布関数はあるxを指定したとき,それに確率P{X ! x}を対応させる関数である.
Ω
x
確率P{X ! x}
F (x) = P{X ! x}
15
分布関数の形しきい値 x が十分大きくなれば,分布関数の値は,ほぼ全部の根元事象を含む事象の確率になる
F (x) = P{X ! x}
x
F(x)
0
1
16
サイコロを振る試行の分布関数(2)確率変数Xの分布関数はつぎのようになる.
1 2 3 4 5 6
1
1/6
0
2/6
3/6
4/6
5/6
x
F(x)
17
F (x) = P{X ! x}
確率密度関数とは確率密度関数とは,確率分布関数の導関数のことである.特に連続的な確率変数については分布関数を眺めるよりも密度関数を眺める方が確率分布の性質を直感的に理解しやすい.定義より,
と書ける.
f(x) =dF (x)
dx
18

確率密度関数と分布関数の関係密度関数は分布関数の導関数であるが,逆に考えれば分布関数は密度関数の積分である.すなわち,つぎのように書ける:
1/2
2
f(x)
x
図 3: 一様分布の確率密度関数
と書く方が自然である.これを解釈すると,確率変数Xが微小区間 [x, x+!x) に入る確率を増分の!xで割った値である.連続分布では,確率変数Xが微小区間[x, x + !x) に入る確率自体は!xを小さくすると限りなく小さくなるが,小さくなる “割合”は一定値に収束することが期待できる.この割合で,確率分布を眺めようとするのが確率密度関数である.直感的に言うと,この関数の値は確率ではないが,分布関数 f(x)は確率変数X が x 辺りの値をとる可能性がどのくらい大きいかを表す指標である.密度関数を用いれば,分布関数は,
F (y) =
! y
!"f(x)dx (12)
と書くことができる.さらに F (!) = 1であることから,! "
!"f(x)dx = 1 (13)
が得られる.離散的な確率分布の場合,分布関数が階段関数になることから,確率が正の場所では密度関数は発散してしまう.そのため,確率密度関数に対応する関数として,確率関数を導入する.確率関数は
p(x) = P (X = x) (14)
と定義する.この関数の値は確率である.図 2に示した分布の確率密度関数は図 3に示すようになる.
4
x
f(x) F(y)
y
19
確率関数離散した確率変数(確率変数で離散した値しかとらないもの)については前述のように分布関数は階段関数になる.従って,分布関数を定理することができない.密度関数に対応するものとして,確率関数を定義することができる.ただし,密度関数とは次元が異なることを注意する必要がある.
p(x) = P (X = x)
20
確率分布の特徴をとらえる確率分布が与えられたとき,その特徴を抽出することによって,その確率分布をおおまかに理解することができる.特徴として一番単純なのは平均(期待値)である.
密度関数 f(x)
期待値とは(連続的確率変数の場合)期待値 (expectation) は,平均 (mean) とも呼ばれる.確率変数 X の密度関数をf(x)としたとき,
と表現される.
山本 修身2008.05.21
確率論 第7回 まとめ— 期待値と分散—
1 平均とは何か確率分布関数や密度関数は,確率分布に関する情報を 100%持っているといえる.確率空間を確率分布から決定することはできないが,ある確率変数に注目した場合,その値がどのように出現するかは分布関数によって完全に記述されている.もちろん,確率現象であるので,確実にどの値が出現するかを言い当てることは不可能である.我々が多くの現象を眺める場合,確率分布をすべて把握する必要の無い場合が多い.たとえば,ある物理現象によって,物理量が観測される場合,大体どのくらい値が出てくるのかということは非常に重要な情報であるが,それぞれの値がどのくらいの割合ででてくるのか(これが分布関数に対応する)を知る必要は無い場合が多い.ここでは,分布のおおまかな状況を把握するための量として平均(mean) を導入する.平均は,期待値 (expectation) という言葉で呼ばれることもある.このため,普通,平均(期待値)を計算するための記号はEを用いる.平均は確率変数を一つ決めるとそれに対して定義される.平均は連続的な確率分布については次のように定義される:
E(X) =
! !
"!f(x)xdx (1)
また,離散的な確率分布については,
E(X) =!"
i=1
p(xi)xi (2)
と定義される.
例 サイコロを振る場合,出る目の確率変数をXとしたとき,この変数の期待値は
E(X) = 1·16+2·1
6+3·1
6+4·1
6+5·1
6+6·1
6=
1 + 2 + 3 + 4 + 5 + 6
6=
21
6= 3.5 (3)
と計算することができる.
例 0と 2の間の値を等確率で出す一様分布に従う確率変数Xの期待値は次のように計算できる.この分布の密度関数は f(x) = 1/2 (0 ! x ! 2) である:
E(X) =
! 2
0
1
2xdx =
#x2
4
$2
0
=4" 0
4= 1. (4)
1
期待値とは(離散的確率変数の場合)離散的な確率変数の場合には,積分では表現できない.確率関数をp(x)とおけば,
と表現できる.要は,それぞれの値とそれに対する出現確率を掛け合わせてすべて足せば良い.
山本 修身2008.05.21
確率論 第7回 まとめ— 期待値と分散—
1 平均とは何か確率分布関数や密度関数は,確率分布に関する情報を 100%持っているといえる.
確率空間を確率分布から決定することはできないが,ある確率変数に注目した場合,その値がどのように出現するかは分布関数によって完全に記述されている.もちろん,確率現象であるので,確実にどの値が出現するかを言い当てることは不可能である.我々が多くの現象を眺める場合,確率分布をすべて把握する必要の無い場合が
多い.たとえば,ある物理現象によって,物理量が観測される場合,大体どのくらい値が出てくるのかということは非常に重要な情報であるが,それぞれの値がどのくらいの割合ででてくるのか(これが分布関数に対応する)を知る必要は無い場合が多い.ここでは,分布のおおまかな状況を把握するための量として平均(mean) を導入する.平均は,期待値 (expectation) という言葉で呼ばれることもある.このため,普通,平均(期待値)を計算するための記号はEを用いる.平均は確率変数を一つ決めるとそれに対して定義される.平均は連続的な確率分布については次のように定義される:
E(X) =
! !
"!f(x)xdx (1)
また,離散的な確率分布については,
E(X) =!"
i=1
p(xi)xi (2)
と定義される.
例 サイコロを振る場合,出る目の確率変数をXとしたとき,この変数の期待値は
E(X) = 1·16+2·1
6+3·1
6+4·1
6+5·1
6+6·1
6=
1 + 2 + 3 + 4 + 5 + 6
6=
21
6= 3.5 (3)
と計算することができる.
例 0と 2の間の値を等確率で出す一様分布に従う確率変数Xの期待値は次のように計算できる.この分布の密度関数は f(x) = 1/2 (0 ! x ! 2) である:
E(X) =
! 2
0
1
2xdx =
#x2
4
$2
0
=4" 0
4= 1. (4)
1
分散とは平均は確率変数の分布を端的に示す指標であるが,それだけでは,どのくらいの広がりをもって分布しているのかがわからない.そこで,平均の周りにどの程度分布するかの指標として分散 (variance) がある.平均と合わせて,分布の良い指標となる.
密度関数 f(x)
どの程度広がっているという指標
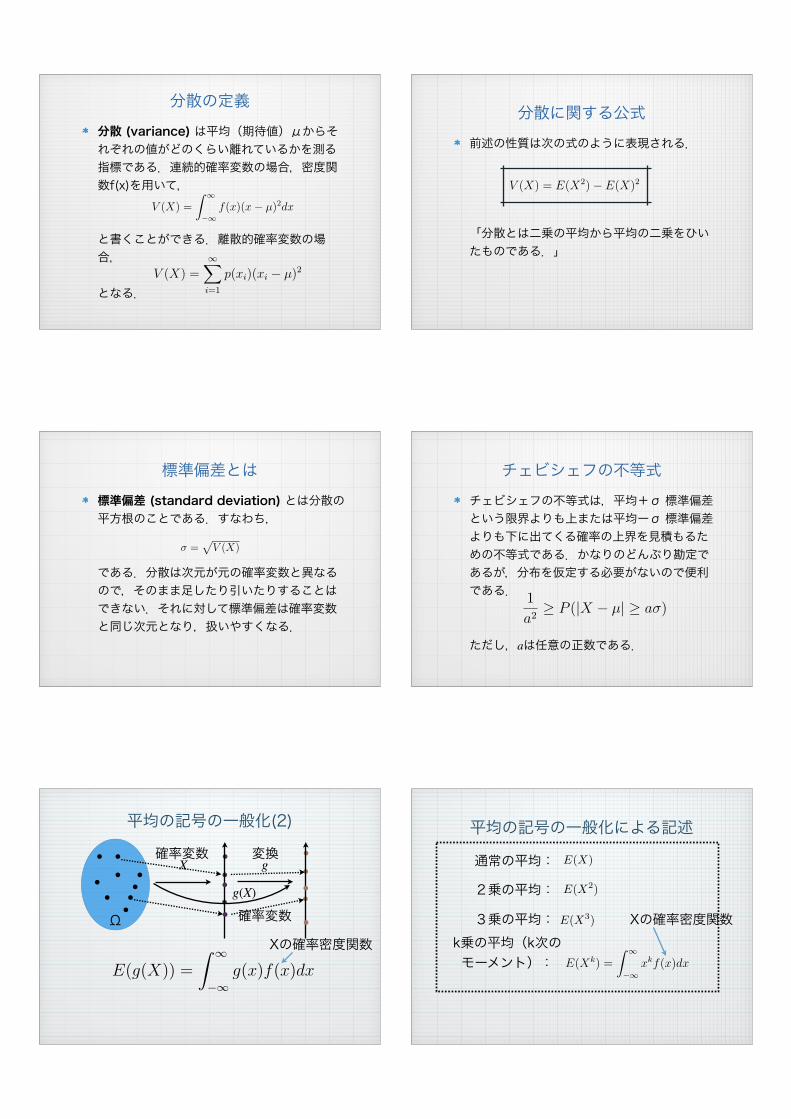
分散の定義分散 (variance) は平均(期待値)μからそれぞれの値がどのくらい離れているかを測る指標である.連続的確率変数の場合,密度関数f(x)を用いて,
と書くことができる.離散的確率変数の場合,
となる.
直感的にいえば,0と 2の間で一様に分布するので,平均をとれば,真ん中である1となる.
例 指数分布に従う確率変数 X の期待値を求めてみる.指数分布の分布関数は,
f(x) = !e!!x (x ! 0) (5)
であることから,期待値は
E(X) =
! "
0
!e!!xxdx (6)
と書ける.ここで部分積分を思い出そう! この積分は,
E(X) =""e!!x · x
#"0
+
! "
0
e!!xdx =
! "
0
e!!xdx =
$"e!!x
!
%"
0
=1
!(7)
と計算することができる.これより,平均 1/!で原子核は崩壊することになる.これは半減期の 1/ ln 2 = 1.443倍である.このずれは,平均とメディアン (中央値)
が異なるということに対応している.
例 幾何分布に従う確率変数の平均について考える.表の出る確率が pのコインを何回も振ったとき,最初に表が出るまでの振った回数は幾何分布に従う.具体的には,確率関数は,
p(k) = pqk!1 (k = 1, 2, · · ·) (8)
である.ただし,q = 1" p である.この定義と期待値の定義より,
E(X) ="&
i=1
pqk!1k ="&
i=1
pdxk
dx
''''x=q
= pd
dx
( "&
i=1
xk
)'''''x=q
= pd
dx
*x
1" x
+''''x=q
= p1
(1" q)2=
1
p(9)
となる.表の出る確率が小さければ小さいほど,表が出るまでに振る回数が大きくなるのがわかる.
2 分散の定義と計算与えられた分布が大体どのあたりにあるのかを示す指標として,期待値を導入
したが,位置の情報だけでは分布を眺めるのに不十分である.そこで,もう一つ指標を導入する.それが分散である.分散は平均の周りに分布どの程度集まっているかということに関する指標である.確率変数X が与えられたとき,この確率変数の分散は
V (X) =
! "
!"f(x)(x" µ)2dx (10)
2
である.ただし,f(x)はこの確率変数の確率密度関数であり,µはこの分布の期待値を表す.また,離散的な確率分布の場合,
V (X) =!!
i=1
p(xi)(xi ! µ)2 (11)
と書ける.ただし,p(x)は確率関数であり,x1, x2, . . .で正の確率をとるものとする.分散が大きいということは,確率変数の値が平均からずれる可能性が大きいことを示している.連続的な確率変数の場合,
V (X) =
" !
"!f(x)(x! µ)2dx =
" !
"!f(x)(x2 ! 2µx + µ2)dx
=
" !
"!f(x)x2dx! 2µ
" !
"!f(x)xdx + µ2
" !
"!f(x)dx (12)
となる.ここで, " !
"!f(x)xdx = µ,
" !
"!f(x)dx = 1 (13)
なので,これを用いれば,
V (X) =
" !
"!f(x)x2dx! µ2 (14)
普通,右辺の第 1項の積分を「二乗の平均」とよび,E(X2)で表す.これを用いれば,
V (X) = E(X2)! E(X)2 (15)
という公式が得られる.同様の公式は離散的な確率変数についても成り立つ (練習問題として導いてみよ).分散 V (X)に対して,! =
#V (X)を標準偏差 (standard deviaiton) と呼ぶ.
分散は平均などとは次元が異なるため,平均値や確率変数の値と同じ次元の標準偏差を用いることが多い.
例 サイコロの目の分布の分散を計算してみる.前述のように分散を計算するには,まず二乗の平均を計算すればよい.そこで,
E(X2) = 12 · 1
6+ 22 · 1
6+ 32 · 1
6+ 42 · 1
6+ 52 · 1
6+ 62 · 1
6
=12 + 22 + 32 + 42 + 52 + 62
6=
91
6(16)
となる.これを用いて,
V (X) = E(X2)! E(X)2 =91
6!
$7
2
%2
=35
12= 2.92 (17)
3
分散に関する公式前述の性質は次の式のように表現される.
「分散とは二乗の平均から平均の二乗をひいたものである.」
である.ただし,f(x)はこの確率変数の確率密度関数であり,µはこの分布の期待値を表す.また,離散的な確率分布の場合,
V (X) =!!
i=1
p(xi)(xi ! µ)2 (11)
と書ける.ただし,p(x)は確率関数であり,x1, x2, . . .で正の確率をとるものとする.分散が大きいということは,確率変数の値が平均からずれる可能性が大きいことを示している.連続的な確率変数の場合,
V (X) =
" !
"!f(x)(x! µ)2dx =
" !
"!f(x)(x2 ! 2µx + µ2)dx
=
" !
"!f(x)x2dx! 2µ
" !
"!f(x)xdx + µ2
" !
"!f(x)dx (12)
となる.ここで, " !
"!f(x)xdx = µ,
" !
"!f(x)dx = 1 (13)
なので,これを用いれば,
V (X) =
" !
"!f(x)x2dx! µ2 (14)
普通,右辺の第 1項の積分を「二乗の平均」とよび,E(X2)で表す.これを用いれば,
V (X) = E(X2)! E(X)2 (15)
という公式が得られる.同様の公式は離散的な確率変数についても成り立つ (練習問題として導いてみよ).分散 V (X)に対して,! =
#V (X)を標準偏差 (standard deviaiton) と呼ぶ.
分散は平均などとは次元が異なるため,平均値や確率変数の値と同じ次元の標準偏差を用いることが多い.
例 サイコロの目の分布の分散を計算してみる.前述のように分散を計算するには,まず二乗の平均を計算すればよい.そこで,
E(X2) = 12 · 1
6+ 22 · 1
6+ 32 · 1
6+ 42 · 1
6+ 52 · 1
6+ 62 · 1
6
=12 + 22 + 32 + 42 + 52 + 62
6=
91
6(16)
となる.これを用いて,
V (X) = E(X2)! E(X)2 =91
6!
$7
2
%2
=35
12= 2.92 (17)
3標準偏差とは
標準偏差 (standard deviation) とは分散の平方根のことである.すなわち,
である.分散は次元が元の確率変数と異なるので,そのまま足したり引いたりすることはできない.それに対して標準偏差は確率変数と同じ次元となり,扱いやすくなる.
である.ただし,f(x)はこの確率変数の確率密度関数であり,µはこの分布の期待値を表す.また,離散的な確率分布の場合,
V (X) =!!
i=1
p(xi)(xi ! µ)2 (11)
と書ける.ただし,p(x)は確率関数であり,x1, x2, . . .で正の確率をとるものとする.分散が大きいということは,確率変数の値が平均からずれる可能性が大きいことを示している.連続的な確率変数の場合,
V (X) =
" !
"!f(x)(x! µ)2dx =
" !
"!f(x)(x2 ! 2µx + µ2)dx
=
" !
"!f(x)x2dx! 2µ
" !
"!f(x)xdx + µ2
" !
"!f(x)dx (12)
となる.ここで, " !
"!f(x)xdx = µ,
" !
"!f(x)dx = 1 (13)
なので,これを用いれば,
V (X) =
" !
"!f(x)x2dx! µ2 (14)
普通,右辺の第 1項の積分を「二乗の平均」とよび,E(X2)で表す.これを用いれば,
V (X) = E(X2)! E(X)2 (15)
という公式が得られる.同様の公式は離散的な確率変数についても成り立つ (練習問題として導いてみよ).分散 V (X)に対して,! =
#V (X)を標準偏差 (standard deviaiton) と呼ぶ.
分散は平均などとは次元が異なるため,平均値や確率変数の値と同じ次元の標準偏差を用いることが多い.
例 サイコロの目の分布の分散を計算してみる.前述のように分散を計算するには,まず二乗の平均を計算すればよい.そこで,
E(X2) = 12 · 1
6+ 22 · 1
6+ 32 · 1
6+ 42 · 1
6+ 52 · 1
6+ 62 · 1
6
=12 + 22 + 32 + 42 + 52 + 62
6=
91
6(16)
となる.これを用いて,
V (X) = E(X2)! E(X)2 =91
6!
$7
2
%2
=35
12= 2.92 (17)
3
チェビシェフの不等式チェビシェフの不等式は,平均+σ 標準偏差という限界よりも上または平均ーσ 標準偏差よりも下に出てくる確率の上界を見積もるための不等式である.かなりのどんぶり勘定であるが,分布を仮定する必要がないので便利である.
ただし,aは任意の正数である.
という不等式が成り立ち,さらに,X ! µ"a!, X # µ+a!においては,(X"µ)2 !a2!2が成立する.これより,被積分関数をこの不等式で置き換えることによって
!2 #! µ!a!
"a2!2f(x)dx +
! "
µ+a!
a2!2f(x)dx (24)
= a2!2 {P (X ! µ" a!) + P (X # µ + a!)} (25)
と書ける.これより,!2 # a2!2P (|X " µ| # a!) (26)
であり,両辺を !2で割ることにより,1
a2# P (|X " µ| # a!) (27)
という不等式が得られる.このとき,正の数として aは任意に選ぶことができる.この不等式をチェビシェフの不等式と呼ぶ.a = 2とすれば,
1
4# P (|X " µ| # 2!) (28)
平均から 2!以上離れている確率は 1/4以下であることがわかる.この不等式は確率分布を仮定していないので,あらゆる確率分布について成り立つ.
例 0から 2の間から一様にランダムに実数を出力する確率変数X について考えると,平均は µ = 1であり,標準偏差は
$3/3 であるから,
µ + 2! = 1 + 2
$3
3> 2, µ" 2! = 1" 2
$3
3< 0, (29)
となり,この範囲には出現する確率は 0となる.チェビシェフの不等式では 1/4以下であるが,それよりも小さくなっており,チェビシェフの不等式は成り立っている.
5
平均の記号の一般化(2)
Ω
X g
g(X)
確率変数 変換
確率変数
山本 修身2008.05.28
確率論 第8回 まとめ— モーメントと変数変換—
1 モーメントと母関数平均や分散は与えられた確率分布の特徴をとられるための指標である.これを一般化するとモーメントという概念が得られる.まず,平均という考え方を一般化して,確率変数を適当な関数 g(x)で変換したものを考える.これも確率変数と見なすことができる.すなわち,標本空間の要素(根元事象)e ! !に対して確率変数によって実数値 X(e)が定義されるわけだが,この eに対して,g(X(e))を対応させる確率変数を考えることができる.これを模式的に,g(X) と書くことができる.この確率変数の平均は,
E(g(X)) =
! !
"!g(x)f(x)dx (1)
と書くことができる.この書き方を用いれば,前回述べた「二乗の平均」はそのままE(X2)と書いてよいことになる.この書式を用いて,確率変数Xの k次のモーメントを
E(Xk) =
! !
"!xkf(x)dx (2)
と書くことができる.離散的な確率変数の場合は,確率関数を f とおいて,
E(Xk) =!"
i=1
xki f(xi) (3)
と書ける.前回示したように,分散は 1次のモーメントと 2次のモーメントを用いて,
V (X) = E(X2)" E(X)2 (4)
と書くことができる.また,このように考えると,E(eXt)を考えることができる.ここで tは実変数であるとする.この場合,exのTaylor展開を用いて,
E(eXt) = E
# !"
n=0
(Xt)n
n!
$(5)
と変形することができる.さらに平均を求めるという作用素Eの線形性1 から,
E(eXt) =!"
n=0
E(Xn)tn
n!(6)
1これについては後で述べる.一般にどのような場合でも任意の確率変数X, Y についてE(X +Y ) = E(X) + E(Y )という式が成り立つ.
1
Xの確率密度関数
平均の記号の一般化による記述通常の平均:
2乗の平均: E(X2)
E(X)
3乗の平均: E(X3)
山本 修身2008.05.28
確率論 第8回 まとめ— モーメントと変数変換—
1 モーメントと母関数平均や分散は与えられた確率分布の特徴をとられるための指標である.これを
一般化するとモーメントという概念が得られる.まず,平均という考え方を一般化して,確率変数を適当な関数 g(x)で変換した
ものを考える.これも確率変数と見なすことができる.すなわち,標本空間の要素(根元事象)e ! !に対して確率変数によって実数値 X(e)が定義されるわけだが,この eに対して,g(X(e))を対応させる確率変数を考えることができる.これを模式的に,g(X) と書くことができる.この確率変数の平均は,
E(g(X)) =
! !
"!g(x)f(x)dx (1)
と書くことができる.この書き方を用いれば,前回述べた「二乗の平均」はそのままE(X2)と書いてよいことになる.この書式を用いて,確率変数Xの k次のモーメントを
E(Xk) =
! !
"!xkf(x)dx (2)
と書くことができる.離散的な確率変数の場合は,確率関数を f とおいて,
E(Xk) =!"
i=1
xki f(xi) (3)
と書ける.前回示したように,分散は 1次のモーメントと 2次のモーメントを用いて,
V (X) = E(X2)" E(X)2 (4)
と書くことができる.また,このように考えると,E(eXt)を考えることができる.ここで tは実変数であるとする.この場合,exのTaylor展開を用いて,
E(eXt) = E
# !"
n=0
(Xt)n
n!
$(5)
と変形することができる.さらに平均を求めるという作用素Eの線形性1 から,
E(eXt) =!"
n=0
E(Xn)tn
n!(6)
1これについては後で述べる.一般にどのような場合でも任意の確率変数X, Y についてE(X +Y ) = E(X) + E(Y )という式が成り立つ.
1
k乗の平均(k次のモーメント):
Xの確率密度関数

モーメントの加重平均を作ると…
1 + E(X)t +E(X2)
2!t2 +
E(X3)
3!t3 + · · ·
= E
!
1 + Xt +X2
2!t2 +
X3
3!t3 + · · ·
"
= E!
eXt
"
!(t) =
tは純粋に変数1回微分すると…
1 + E(X)t +E(X2)
2!t2 +
E(X3)
3!t3 + · · ·!(t) =
!!(t) = E(X) +E(X2)
1!t +
E(X3)
2!t2 + · · ·
!!(0) = E(X)
もう1回微分すると…!!(t) = E(X) +
E(X2)
1!t +
E(X3)
2!t2 + · · ·
!!!(t) = E(X2) +E(X3)
1!t + · · ·
!!!(0) = E(X2)
V (X) = !!!(0) ! (!!(0))2
2項分布の定義2項分布はn回振るベルヌーイ試行において表の出る回数を確率変数としたものである.
H T H H T H T H
H: pT: q = 1 - p
n回振る
1 2 3 4 5 6 7 8
この場合X = 5
p(k) = nCkpkqn!k (k = 0, 1, . . . , n)
Bin(p, n)
2項分布のグラフ2項分布は,確率pとコインを振る回数nに依存する.このグラフは p = 0.6, n = 20のときの確率関数の様子.
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
平均= 12
σσ
μ
2項分布の平均母関数が求まると,平均や分散は幾何的に求めることができる.まず,平均については,以下のようになる:
!(t) = (pet + q)n
山本 修身2008.06.04
確率論 第9回 まとめ— 2項分布—
1 2項分布とは2項分布はもっとも単純でありながら,種々の分布の基礎となり,応用範囲の広
い確率分布である.2項分布は,ベルヌーイ試行 (Bernoulli trial) に基づいている.ベルヌーイ試行とは,
表の出る確率が pであるコインを n回振る試行である.ただし,毎回の結果は互いに独立であるとする.すなわち,ある回に出た結果が後の結果に影響を及ぼさない.2項分布の場合,この試行によって注目するのは表の出た回数である.コインを振る回数は全部で n回であるので,表の出る回数は高々nであり,最も少ない場合 0回である.2項分布は明らかに離散的な確率分布である.この分布に従う確率変数をXとおくとき,この変数の確率関数はつぎのように表現される.
p(k) = nCkpkqn!k (k = 0, 1, . . . , n) (1)
ここで nCkは n個から k個を選ぶ組み合せ数であり,q = 1! pである.コインの表の出る確率が pで n回コインを振るベルヌーイ試行による 2項分布を Bin(p, n)
と記号で表すことがある.2項分布の確率関数を図 1に示す.この場合,n = 20とし,p = 0.6 とする.
2 2項分布の平均と分散2項分布に従う確率変数Xの平均と分散について考える.平均と分散は定義に
戻って計算することも可能であるが,ここでは母関数によって計算する.素朴な計算方法については,教科書 pp. 71-72 を参照すること.まず,2項分布の母関数を以下のように求める:
!(t) = E[eXt] =n!
k=0
nCkpkqn!kekt =
n!
k=0
nCk(pet)kqn!k = (pet + q)n (2)
この式の変形では (a + b)n ="n
i=0 nCiaibn!iという公式を用いている.母関数が求まってしまうと,平均と分散は機械的に計算できる.まず,平均は,
E(X) = !"(0) = n(pet + q)n!1pet##t=0
= n(p + q)np = np (3)
1
山本 修身2008.06.04
確率論 第9回 まとめ— 2項分布—
1 2項分布とは2項分布はもっとも単純でありながら,種々の分布の基礎となり,応用範囲の広
い確率分布である.2項分布は,ベルヌーイ試行 (Bernoulli trial) に基づいている.ベルヌーイ試行とは,
表の出る確率が pであるコインを n回振る試行である.ただし,毎回の結果は互いに独立であるとする.すなわち,ある回に出た結果が後の結果に影響を及ぼさない.2項分布の場合,この試行によって注目するのは表の出た回数である.コインを振る回数は全部で n回であるので,表の出る回数は高々nであり,最も少ない場合 0回である.2項分布は明らかに離散的な確率分布である.この分布に従う確率変数をXとおくとき,この変数の確率関数はつぎのように表現される.
p(k) = nCkpkqn!k (k = 0, 1, . . . , n) (1)
ここで nCkは n個から k個を選ぶ組み合せ数であり,q = 1! pである.コインの表の出る確率が pで n回コインを振るベルヌーイ試行による 2項分布を Bin(p, n)
と記号で表すことがある.2項分布の確率関数を図 1に示す.この場合,n = 20とし,p = 0.6 とする.
2 2項分布の平均と分散2項分布に従う確率変数Xの平均と分散について考える.平均と分散は定義に
戻って計算することも可能であるが,ここでは母関数によって計算する.素朴な計算方法については,教科書 pp. 71-72 を参照すること.まず,2項分布の母関数を以下のように求める:
!(t) = E[eXt] =n!
k=0
nCkpkqn!kekt =
n!
k=0
nCk(pet)kqn!k = (pet + q)n (2)
この式の変形では (a + b)n ="n
i=0 nCiaibn!iという公式を用いている.母関数が求まってしまうと,平均と分散は機械的に計算できる.まず,平均は,
E(X) = !"(0) = n(pet + q)n!1pet##t=0
= n(p + q)np = np (3)
1

2項分布の分散2項分布の分散については,まず,2次のモーメントを求めると,つぎのようになる.
この結果を用いて,
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
! =
!
npq
標準偏差
2項分布の例 (2)Bin(1/5, 20)に従うことから,平均は,
となる.また,分散は,
となる.これより,標準偏差は,
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
0
0.05
0.1
0.15
0.2
0 5 10 15 20
"example.dat"
図 1: n = 20, p = 0.6の場合の 2項分布の様子
となる.一方,2次のモーメント(2乗の平均)は,
E(X2) = !!!(0) = n(n! 1)(pet + q)n"2p2e2t + n(pet + q)n"1pet!!t=0
(4)
= n(n! 1)p2 + np (5)
これより,分散は,
V (X) = E(X2)! (E(X))2 = n(n! 1)p2 + np! n2p2 (6)
= !np2 + np = npq (7)
となる.したがって,標準偏差は"npqである.2項分布のこの性質は非常に重要である.
3 2項分布の例5つの選択肢から1つ正解を選ぶ問題が 20個用意されているとする.これらの
問題をサイコロを振って解答するとする.このとき正解の個数に対応する確率変数をXとおけば,この確率変数はBin(1/5, 20)に従う.この確率変数の期待値は,前節の議論から,
µ = E(X) = np = 20# 1
5= 4 (8)
である.また,分散が
V (X) = npq = 20# 1
5# 4
5=
16
5(9)
2
であることから,標準偏差は ! =!
16/5 = 4!
5/5 = 1.79. この結果から,この確率変数が µ + 2!よりも大きい値をとることはまれであること1から,
µ + 2! = 4 + 2" 1.79 = 7.58 (10)
となることはまれである.すなわち,20問のうち,8問以上正解できることは極めてまれな現象であると言える.すなわち,100点満点だとすると,この方法で 40
点とることは極めて難しいということになる.どの面も同じ確率で出現するサイコロを 30回振るとき,1の目のでる確率は,
1/6であり,1の目の出る回数 XはBin(1/6, 30)に従う.よって,Xの平均は,
E(X) = np = 30" 1
6= 5 (11)
であり,分散がV (X) = npq = 30" 1
6" 5
6=
25
6(12)
であり,これより,標準偏差は ! =!
25/6 = 2.04となる.従って,1の目の出る回数が,5 + 2" 2 = 9 回以上になることは,極めてまれであると言える.
4 大数の法則 – 経験的確率と確率空間の関係 –
ある現象が起こる確率を定義する場合に,n回試みた場合にそのうち何回その現象が起こったかによって確率を定義するという考え方に基づいた確率の定義を「経験的な確率」と定義した.このような確率の定義は採用しなかったが,ここでは,2項分布の結果をもとにして,「経験的な確率」を意味付けする.まず,それぞれの試行について,ある確率 pで起こる現象があるとする.このとき,この試行を n回繰り返したとき,この現象が起こる回数を確率とすれば,XはBin(n, p)に従う.この場合の「経験的確率」は,起こった現象の回数を試した試行の回数で割ればよいので,X/nに等しい.この確率変数の平均は,
E
"X
n
#=
E(X)
n=
np
n= p (13)
であり,分散は,V
"X
n
#=
V (X)
n2=
npq
n2=
pq
n(14)
である2.これより,この確率変数の標準偏差は ! =!
pq/nとなる.チェビシェフの不等式を用いると,
P
"$$$$X
n# p
$$$$ < a
%pq
n
#> 1# 1
a2(15)
1これは,正規分布と中心極限定理による.これについては,第 13回の講義で解説する.また,この現象は前述のチェビシェフの不等式からもある程度伺い知ることができる.しかし,チェビシェフの不等式は非常に荒い限界しか与えない.
2これは後述する内容であるが,E(aX) = aE(X), V (aX) = a2V (X)が成り立つ.
3
大数の法則 (3)まず,平均は,
である.また,分散は,
である.この結果から,つぎのようになる.
であることから,標準偏差は ! =!
16/5 = 4!
5/5 = 1.79. この結果から,この確率変数が µ + 2!よりも大きい値をとることはまれであること1から,
µ + 2! = 4 + 2" 1.79 = 7.58 (10)
となることはまれである.すなわち,20問のうち,8問以上正解できることは極めてまれな現象であると言える.すなわち,100点満点だとすると,この方法で 40
点とることは極めて難しいということになる.どの面も同じ確率で出現するサイコロを 30回振るとき,1の目のでる確率は,
1/6であり,1の目の出る回数 XはBin(1/6, 30)に従う.よって,Xの平均は,
E(X) = np = 30" 1
6= 5 (11)
であり,分散がV (X) = npq = 30" 1
6" 5
6=
25
6(12)
であり,これより,標準偏差は ! =!
25/6 = 2.04となる.従って,1の目の出る回数が,5 + 2" 2 = 9 回以上になることは,極めてまれであると言える.
4 大数の法則 – 経験的確率と確率空間の関係 –
ある現象が起こる確率を定義する場合に,n回試みた場合にそのうち何回その現象が起こったかによって確率を定義するという考え方に基づいた確率の定義を「経験的な確率」と定義した.このような確率の定義は採用しなかったが,ここでは,2項分布の結果をもとにして,「経験的な確率」を意味付けする.まず,それぞれの試行について,ある確率 pで起こる現象があるとする.このとき,この試行を n回繰り返したとき,この現象が起こる回数を確率とすれば,XはBin(n, p)に従う.この場合の「経験的確率」は,起こった現象の回数を試した試行の回数で割ればよいので,X/nに等しい.この確率変数の平均は,
E
"X
n
#=
E(X)
n=
np
n= p (13)
であり,分散は,V
"X
n
#=
V (X)
n2=
npq
n2=
pq
n(14)
である2.これより,この確率変数の標準偏差は ! =!
pq/nとなる.チェビシェフの不等式を用いると,
P
"$$$$X
n# p
$$$$ < a
%pq
n
#> 1# 1
a2(15)
1これは,正規分布と中心極限定理による.これについては,第 13回の講義で解説する.また,この現象は前述のチェビシェフの不等式からもある程度伺い知ることができる.しかし,チェビシェフの不等式は非常に荒い限界しか与えない.
2これは後述する内容であるが,E(aX) = aE(X), V (aX) = a2V (X)が成り立つ.
3
であることから,標準偏差は ! =!
16/5 = 4!
5/5 = 1.79. この結果から,この確率変数が µ + 2!よりも大きい値をとることはまれであること1から,
µ + 2! = 4 + 2" 1.79 = 7.58 (10)
となることはまれである.すなわち,20問のうち,8問以上正解できることは極めてまれな現象であると言える.すなわち,100点満点だとすると,この方法で 40
点とることは極めて難しいということになる.どの面も同じ確率で出現するサイコロを 30回振るとき,1の目のでる確率は,
1/6であり,1の目の出る回数 XはBin(1/6, 30)に従う.よって,Xの平均は,
E(X) = np = 30" 1
6= 5 (11)
であり,分散がV (X) = npq = 30" 1
6" 5
6=
25
6(12)
であり,これより,標準偏差は ! =!
25/6 = 2.04となる.従って,1の目の出る回数が,5 + 2" 2 = 9 回以上になることは,極めてまれであると言える.
4 大数の法則 – 経験的確率と確率空間の関係 –
ある現象が起こる確率を定義する場合に,n回試みた場合にそのうち何回その現象が起こったかによって確率を定義するという考え方に基づいた確率の定義を「経験的な確率」と定義した.このような確率の定義は採用しなかったが,ここでは,2項分布の結果をもとにして,「経験的な確率」を意味付けする.まず,それぞれの試行について,ある確率 pで起こる現象があるとする.このとき,この試行を n回繰り返したとき,この現象が起こる回数を確率とすれば,XはBin(n, p)に従う.この場合の「経験的確率」は,起こった現象の回数を試した試行の回数で割ればよいので,X/nに等しい.この確率変数の平均は,
E
"X
n
#=
E(X)
n=
np
n= p (13)
であり,分散は,V
"X
n
#=
V (X)
n2=
npq
n2=
pq
n(14)
である2.これより,この確率変数の標準偏差は ! =!
pq/nとなる.チェビシェフの不等式を用いると,
P
"$$$$X
n# p
$$$$ < a
%pq
n
#> 1# 1
a2(15)
1これは,正規分布と中心極限定理による.これについては,第 13回の講義で解説する.また,この現象は前述のチェビシェフの不等式からもある程度伺い知ることができる.しかし,チェビシェフの不等式は非常に荒い限界しか与えない.
2これは後述する内容であるが,E(aX) = aE(X), V (aX) = a2V (X)が成り立つ.
3
! =
!
pq
n
稀に起こる現象について考える出てくるメカニズムは2項分布と同じであるが,起こる確率が非常に小さく,なおかつ試行の回数が非常に多い場合を考える.
結果的に,出現する平均値はそれほど小さくない.1年間に世界中でロトで億万長者になった人の人数の分布など.
Bin(p, n)小
大
ポアッソン分布の確率関数 (4)結局,以下のようになる.
山本 修身2008.06.11
確率論 第10回 まとめ— ポアッソン分布—
1 ポアッソン分布とは2項分布において,コインの表のでる確率が非常に低く,コインを振る回数が非
常に多い場合,必ずしも平均は大きくなったり小さくなったりしない.ここでは,コインを振る回数 nが非常に大きくなおかつ,表の出る回数E(X) = np が一定値になるような「極限の分布」について考える.これは基本的には 2項分布と同じようなメカニズムによる確率分布であるが,それぞれの発生確率が極端に低い場合に確率分布に対応する.たとえば,プロシャの部隊で 20年間に馬に蹴られて死んだ兵士の数を調べると,「馬に蹴られて死ぬ」という事象が起こる確率は極めて小さいので,非常に多くの回数(もしくは非常に多くの事例)について調べないと,値が出てこない.このようなケースについてここでは考える.
2項分布の確率関数は,f(x) = nCxp
xqn!x (1)
と書けるが,ここで,平均 µ = npが一定であると考える.すると,p = µ/nと書けるので,
f(x) =n(n! 1)(n! 2) · · · (n! x + 1)
x(x! 1)(x! 2) · · · 1 pxqn!x
=n(n! 1)(n! 2) · · · (n! x + 1)
x(x! 1)(x! 2) · · · 1
!µ
n
"x !1! µ
n
"n!x
(2)
=1
x!
#1! 1
n
$#1! 2
n
$· · ·
#1! x! 1
n
$µx
!1! µ
n
"n!x
(3)
=1
x!
#1! 1
n
$#1! 2
n
$· · ·
#1! x! 1
n
$µx
!1! µ
n
"n !1! µ
n
"!x
(4)
ここで,lim
n"#
#1! k
n
$= 1 (k = 1, . . . , x! 1) (5)
であり,さらに,lim
n"#
!1! µ
n
"!x
= 1 (6)
であるから,
f(x) =µx
x!
%lim
n"#
!1! µ
n
"n/µ&µ
=µx
x!
'e!1
(µ=
µxe!µ
x!(7)
1
山本 修身2008.06.11
確率論 第10回 まとめ— ポアッソン分布—
1 ポアッソン分布とは2項分布において,コインの表のでる確率が非常に低く,コインを振る回数が非
常に多い場合,必ずしも平均は大きくなったり小さくなったりしない.ここでは,コインを振る回数 nが非常に大きくなおかつ,表の出る回数E(X) = np が一定値になるような「極限の分布」について考える.これは基本的には 2項分布と同じようなメカニズムによる確率分布であるが,それぞれの発生確率が極端に低い場合に確率分布に対応する.たとえば,プロシャの部隊で 20年間に馬に蹴られて死んだ兵士の数を調べると,「馬に蹴られて死ぬ」という事象が起こる確率は極めて小さいので,非常に多くの回数(もしくは非常に多くの事例)について調べないと,値が出てこない.このようなケースについてここでは考える.
2項分布の確率関数は,f(x) = nCxp
xqn!x (1)
と書けるが,ここで,平均 µ = npが一定であると考える.すると,p = µ/nと書けるので,
f(x) =n(n! 1)(n! 2) · · · (n! x + 1)
x(x! 1)(x! 2) · · · 1 pxqn!x
=n(n! 1)(n! 2) · · · (n! x + 1)
x(x! 1)(x! 2) · · · 1
!µ
n
"x !1! µ
n
"n!x
(2)
=1
x!
#1! 1
n
$#1! 2
n
$· · ·
#1! x! 1
n
$µx
!1! µ
n
"n!x
(3)
=1
x!
#1! 1
n
$#1! 2
n
$· · ·
#1! x! 1
n
$µx
!1! µ
n
"n !1! µ
n
"!x
(4)
ここで,lim
n"#
#1! k
n
$= 1 (k = 1, . . . , x! 1) (5)
であり,さらに,lim
n"#
!1! µ
n
"!x
= 1 (6)
であるから,
f(x) =µx
x!
%lim
n"#
!1! µ
n
"n/µ&µ
=µx
x!
'e!1
(µ=
µxe!µ
x!(7)
1
μは2項分布における平均
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
平均μ=3のポアッソン分布
ポアッソン分布の平均と分散 (2)平均の計算
もともとμを一定にするように確率関数を変形させたので当然の結果である.
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
図 1: µ = 3の場合のポアッソン分布
ここで,この確率分布の総和を計算すれば,!!
x=0
f(x) =!!
x=0
µxe"µ
x!= e"µ
!
x=0
µx
x!= e"µeµ = 1 (8)
となり,確率分布として矛盾はない.この確率分布のことをポアッソン分布 (Pois-
son distribution)と呼ぶ.この分布はもともと,2項分布の平均値 µ = pnを一定にするようにして確率分布を定めているので,平均値は µ であることが予想される.この関数の母関数を計算してみるとつぎのようになる:
!(t) = E(eXt) =!!
x=0
µxe"µ
x!ext = e"µ
!!
x=0
(µet)x
x!= e"µeµet
= eµet"µ = eµ(et"1).
(9)
この結果より,平均は,
E(X) = !#(0) = eµ(et"1)µet"""t=0
= µ (10)
となる.さらに,2乗の平均は,
E(X2) = !##(0) = eµ(et"1)µetµet + eµ(et"1)µet"""t=0
= µ2 + µ (11)
この結果より,分散は,
V (X) = E(X2)! (E(X))2 = µ2 + µ! µ2 = µ (12)
となる.従って,標準偏差は " ="
µとなる.図 1に µ = 3の場合のポアッソン分布の様子を示す.
2
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
図 1: µ = 3の場合のポアッソン分布
ここで,この確率分布の総和を計算すれば,!!
x=0
f(x) =!!
x=0
µxe"µ
x!= e"µ
!
x=0
µx
x!= e"µeµ = 1 (8)
となり,確率分布として矛盾はない.この確率分布のことをポアッソン分布 (Pois-
son distribution)と呼ぶ.この分布はもともと,2項分布の平均値 µ = pnを一定にするようにして確率分布を定めているので,平均値は µ であることが予想される.この関数の母関数を計算してみるとつぎのようになる:
!(t) = E(eXt) =!!
x=0
µxe"µ
x!ext = e"µ
!!
x=0
(µet)x
x!= e"µeµet
= eµet"µ = eµ(et"1).
(9)
この結果より,平均は,
E(X) = !#(0) = eµ(et"1)µet"""t=0
= µ (10)
となる.さらに,2乗の平均は,
E(X2) = !##(0) = eµ(et"1)µetµet + eµ(et"1)µet"""t=0
= µ2 + µ (11)
この結果より,分散は,
V (X) = E(X2)! (E(X))2 = µ2 + µ! µ2 = µ (12)
となる.従って,標準偏差は " ="
µとなる.図 1に µ = 3の場合のポアッソン分布の様子を示す.
2
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
図 1: µ = 3の場合のポアッソン分布
ここで,この確率分布の総和を計算すれば,!!
x=0
f(x) =!!
x=0
µxe"µ
x!= e"µ
!
x=0
µx
x!= e"µeµ = 1 (8)
となり,確率分布として矛盾はない.この確率分布のことをポアッソン分布 (Pois-
son distribution)と呼ぶ.この分布はもともと,2項分布の平均値 µ = pnを一定にするようにして確率分布を定めているので,平均値は µ であることが予想される.この関数の母関数を計算してみるとつぎのようになる:
!(t) = E(eXt) =!!
x=0
µxe"µ
x!ext = e"µ
!!
x=0
(µet)x
x!= e"µeµet
= eµet"µ = eµ(et"1).
(9)
この結果より,平均は,
E(X) = !#(0) = eµ(et"1)µet"""t=0
= µ (10)
となる.さらに,2乗の平均は,
E(X2) = !##(0) = eµ(et"1)µetµet + eµ(et"1)µet"""t=0
= µ2 + µ (11)
この結果より,分散は,
V (X) = E(X2)! (E(X))2 = µ2 + µ! µ2 = µ (12)
となる.従って,標準偏差は " ="
µとなる.図 1に µ = 3の場合のポアッソン分布の様子を示す.
2

ポアッソン分布の平均と分散 (3)2次モーメントの計算:
分散の計算:
標準偏差:
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
図 1: µ = 3の場合のポアッソン分布
ここで,この確率分布の総和を計算すれば,!!
x=0
f(x) =!!
x=0
µxe"µ
x!= e"µ
!
x=0
µx
x!= e"µeµ = 1 (8)
となり,確率分布として矛盾はない.この確率分布のことをポアッソン分布 (Pois-
son distribution)と呼ぶ.この分布はもともと,2項分布の平均値 µ = pnを一定にするようにして確率分布を定めているので,平均値は µ であることが予想される.この関数の母関数を計算してみるとつぎのようになる:
!(t) = E(eXt) =!!
x=0
µxe"µ
x!ext = e"µ
!!
x=0
(µet)x
x!= e"µeµet
= eµet"µ = eµ(et"1).
(9)
この結果より,平均は,
E(X) = !#(0) = eµ(et"1)µet"""t=0
= µ (10)
となる.さらに,2乗の平均は,
E(X2) = !##(0) = eµ(et"1)µetµet + eµ(et"1)µet"""t=0
= µ2 + µ (11)
この結果より,分散は,
V (X) = E(X2)! (E(X))2 = µ2 + µ! µ2 = µ (12)
となる.従って,標準偏差は " ="
µとなる.図 1に µ = 3の場合のポアッソン分布の様子を示す.
2
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
図 1: µ = 3の場合のポアッソン分布
ここで,この確率分布の総和を計算すれば,!!
x=0
f(x) =!!
x=0
µxe"µ
x!= e"µ
!
x=0
µx
x!= e"µeµ = 1 (8)
となり,確率分布として矛盾はない.この確率分布のことをポアッソン分布 (Pois-
son distribution)と呼ぶ.この分布はもともと,2項分布の平均値 µ = pnを一定にするようにして確率分布を定めているので,平均値は µ であることが予想される.この関数の母関数を計算してみるとつぎのようになる:
!(t) = E(eXt) =!!
x=0
µxe"µ
x!ext = e"µ
!!
x=0
(µet)x
x!= e"µeµet
= eµet"µ = eµ(et"1).
(9)
この結果より,平均は,
E(X) = !#(0) = eµ(et"1)µet"""t=0
= µ (10)
となる.さらに,2乗の平均は,
E(X2) = !##(0) = eµ(et"1)µetµet + eµ(et"1)µet"""t=0
= µ2 + µ (11)
この結果より,分散は,
V (X) = E(X2)! (E(X))2 = µ2 + µ! µ2 = µ (12)
となる.従って,標準偏差は " ="
µとなる.図 1に µ = 3の場合のポアッソン分布の様子を示す.
2
0
0.05
0.1
0.15
0.2
0.25
0 2 4 6 8 10 12
"poisson.data"
図 1: µ = 3の場合のポアッソン分布
ここで,この確率分布の総和を計算すれば,!!
x=0
f(x) =!!
x=0
µxe"µ
x!= e"µ
!
x=0
µx
x!= e"µeµ = 1 (8)
となり,確率分布として矛盾はない.この確率分布のことをポアッソン分布 (Pois-
son distribution)と呼ぶ.この分布はもともと,2項分布の平均値 µ = pnを一定にするようにして確率分布を定めているので,平均値は µ であることが予想される.この関数の母関数を計算してみるとつぎのようになる:
!(t) = E(eXt) =!!
x=0
µxe"µ
x!ext = e"µ
!!
x=0
(µet)x
x!= e"µeµet
= eµet"µ = eµ(et"1).
(9)
この結果より,平均は,
E(X) = !#(0) = eµ(et"1)µet"""t=0
= µ (10)
となる.さらに,2乗の平均は,
E(X2) = !##(0) = eµ(et"1)µetµet + eµ(et"1)µet"""t=0
= µ2 + µ (11)
この結果より,分散は,
V (X) = E(X2)! (E(X))2 = µ2 + µ! µ2 = µ (12)
となる.従って,標準偏差は " ="
µとなる.図 1に µ = 3の場合のポアッソン分布の様子を示す.
2
複数の確率変数による分布関数2つの確率変数 X, Yが与えられたとき,同時分布関数を定義する.
2 ポアッソン分布の例ポアッソン分布はまれに起こる現象によくマッチする.たとえば,50ページのの本があり,1ページに平均 2個の間違いが存在すると仮定する.間違いの個数はポアッソン分布に従うとしよう.この場合,1ページに存在する間違いの個数は,
f(k) =2ke!2
k!(13)
に従う.あるページに1個も間違いが無い確率は f(0) = e!2 = 0.135 であり,ちょうど 1個だけ間違いがある確率は,f(1) = 2e!2 = 0.271 である.同様にして,ちょうど 2個および 3個間違いがある確率は,それぞれ f(2) = 2e!2 = 0.271,
f(3) = 4e!2/3 = 0.180である,以上より,1ページに 4個以上の間違いが出てくる確率は,1! f(0)! f(1)! f(2)! f(3) = 0.143である.したがって,すべてのページに間違いが 4個以上ない確率は,0.85750 = 0.000448となり,非常に小さな確率であることがわかる.
3 いくつかの確率変数による分布関数これまで,それぞれのケースである一つの確率変数に注目してその確率変数の
分布関数を解析してきた.ここで,複数の確率変数を同時に扱うための枠組みについて考えてみる.2つの確率変数 X, Y が定義されているとする.このとき,同時分布関数 (simultanous distribution function) F (x, y)はつぎのように定義される:
F (x, y) = P (X " x かつ Y " y). (14)
このように定義すると,このように定義すると,
limy"#
F (x, y) = limy"#
P (X " x かつ Y " y) = P (X " x) = FX(x) (15)
であり,
limx"#
F (x, y) = limx"#
P (X " x かつ Y " y) = P (Y " y) = FY (y) (16)
である.ただし,FX , FY はそれぞれ X, Y の分布関数とする.この結果より,limy"# F (x, y)と limy"# F (x, y)のことを,周辺分布 (marginal distribution)
と呼ぶことがある.1変数について確率密度関数を考えたのと同様にして,多変数についても密度関
数を考える.この場合,f(x, y) =
!2F (x, y)
!x!y(17)
3
2 ポアッソン分布の例ポアッソン分布はまれに起こる現象によくマッチする.たとえば,50ページのの本があり,1ページに平均 2個の間違いが存在すると仮定する.間違いの個数はポアッソン分布に従うとしよう.この場合,1ページに存在する間違いの個数は,
f(k) =2ke!2
k!(13)
に従う.あるページに1個も間違いが無い確率は f(0) = e!2 = 0.135 であり,ちょうど 1個だけ間違いがある確率は,f(1) = 2e!2 = 0.271 である.同様にして,ちょうど 2個および 3個間違いがある確率は,それぞれ f(2) = 2e!2 = 0.271,
f(3) = 4e!2/3 = 0.180である,以上より,1ページに 4個以上の間違いが出てくる確率は,1! f(0)! f(1)! f(2)! f(3) = 0.143である.したがって,すべてのページに間違いが 4個以上ない確率は,0.85750 = 0.000448となり,非常に小さな確率であることがわかる.
3 いくつかの確率変数による分布関数これまで,それぞれのケースである一つの確率変数に注目してその確率変数の
分布関数を解析してきた.ここで,複数の確率変数を同時に扱うための枠組みについて考えてみる.2つの確率変数 X, Y が定義されているとする.このとき,同時分布関数 (simultanous distribution function) F (x, y)はつぎのように定義される:
F (x, y) = P (X " x かつ Y " y). (14)
このように定義すると,このように定義すると,
limy"#
F (x, y) = limy"#
P (X " x かつ Y " y) = P (X " x) = FX(x) (15)
であり,
limx"#
F (x, y) = limx"#
P (X " x かつ Y " y) = P (Y " y) = FY (y) (16)
である.ただし,FX , FY はそれぞれ X, Y の分布関数とする.この結果より,limy"# F (x, y)と limy"# F (x, y)のことを,周辺分布 (marginal distribution)
と呼ぶことがある.1変数について確率密度関数を考えたのと同様にして,多変数についても密度関
数を考える.この場合,f(x, y) =
!2F (x, y)
!x!y(17)
3
2 ポアッソン分布の例ポアッソン分布はまれに起こる現象によくマッチする.たとえば,50ページのの本があり,1ページに平均 2個の間違いが存在すると仮定する.間違いの個数はポアッソン分布に従うとしよう.この場合,1ページに存在する間違いの個数は,
f(k) =2ke!2
k!(13)
に従う.あるページに1個も間違いが無い確率は f(0) = e!2 = 0.135 であり,ちょうど 1個だけ間違いがある確率は,f(1) = 2e!2 = 0.271 である.同様にして,ちょうど 2個および 3個間違いがある確率は,それぞれ f(2) = 2e!2 = 0.271,
f(3) = 4e!2/3 = 0.180である,以上より,1ページに 4個以上の間違いが出てくる確率は,1! f(0)! f(1)! f(2)! f(3) = 0.143である.したがって,すべてのページに間違いが 4個以上ない確率は,0.85750 = 0.000448となり,非常に小さな確率であることがわかる.
3 いくつかの確率変数による分布関数これまで,それぞれのケースである一つの確率変数に注目してその確率変数の
分布関数を解析してきた.ここで,複数の確率変数を同時に扱うための枠組みについて考えてみる.2つの確率変数 X, Y が定義されているとする.このとき,同時分布関数 (simultanous distribution function) F (x, y)はつぎのように定義される:
F (x, y) = P (X " x かつ Y " y). (14)
このように定義すると,このように定義すると,
limy"#
F (x, y) = limy"#
P (X " x かつ Y " y) = P (X " x) = FX(x) (15)
であり,
limx"#
F (x, y) = limx"#
P (X " x かつ Y " y) = P (Y " y) = FY (y) (16)
である.ただし,FX , FY はそれぞれ X, Y の分布関数とする.この結果より,limy"# F (x, y)と limy"# F (x, y)のことを,周辺分布 (marginal distribution)
と呼ぶことがある.1変数について確率密度関数を考えたのと同様にして,多変数についても密度関
数を考える.この場合,f(x, y) =
!2F (x, y)
!x!y(17)
3
Xの分布関数
Yの分布関数周辺分布関数
複数の確率変数による密度関数多変数の密度関数はやはり分布関数の微分である.
2 ポアッソン分布の例ポアッソン分布はまれに起こる現象によくマッチする.たとえば,50ページのの本があり,1ページに平均 2個の間違いが存在すると仮定する.間違いの個数はポアッソン分布に従うとしよう.この場合,1ページに存在する間違いの個数は,
f(k) =2ke!2
k!(13)
に従う.あるページに1個も間違いが無い確率は f(0) = e!2 = 0.135 であり,ちょうど 1個だけ間違いがある確率は,f(1) = 2e!2 = 0.271 である.同様にして,ちょうど 2個および 3個間違いがある確率は,それぞれ f(2) = 2e!2 = 0.271,
f(3) = 4e!2/3 = 0.180である,以上より,1ページに 4個以上の間違いが出てくる確率は,1! f(0)! f(1)! f(2)! f(3) = 0.143である.したがって,すべてのページに間違いが 4個以上ない確率は,0.85750 = 0.000448となり,非常に小さな確率であることがわかる.
3 いくつかの確率変数による分布関数これまで,それぞれのケースである一つの確率変数に注目してその確率変数の
分布関数を解析してきた.ここで,複数の確率変数を同時に扱うための枠組みについて考えてみる.2つの確率変数 X, Y が定義されているとする.このとき,同時分布関数 (simultanous distribution function) F (x, y)はつぎのように定義される:
F (x, y) = P (X " x かつ Y " y). (14)
このように定義すると,このように定義すると,
limy"#
F (x, y) = limy"#
P (X " x かつ Y " y) = P (X " x) = FX(x) (15)
であり,
limx"#
F (x, y) = limx"#
P (X " x かつ Y " y) = P (Y " y) = FY (y) (16)
である.ただし,FX , FY はそれぞれ X, Y の分布関数とする.この結果より,limy"# F (x, y)と limy"# F (x, y)のことを,周辺分布 (marginal distribution)
と呼ぶことがある.1変数について確率密度関数を考えたのと同様にして,多変数についても密度関
数を考える.この場合,f(x, y) =
!2F (x, y)
!x!y(17)
3
表 1: 2つのサイコロを振ったときのそれぞれの状態と確率変数X, Y の値.ただし,a/bは確率変数X, Y がそれぞれ a, b であることを表す.
1 2 3 4 5 6
1 1/2 1/3 1/4 1/5 1/6 1/7
2 1/3 2/4 2/5 2/6 2/7 2/8
3 1/4 2/5 3/6 3/7 3/8 3/9
4 1/5 2/6 3/7 4/8 4/9 4/10
5 1/6 2/7 3/8 4/9 5/10 5/11
6 1/7 2/8 3/9 4/10 5/11 6/12
と定義し,同時確率密度関数 (simultanous probability density function) と呼ぶ.このように定義すると,
F (x, y) =
! x
!"
! y
!"f(s, t)dtds (18)
と書くことができる.離散的な確率変数についても同様に定義することができる.離散的な確率変数
の場合,同時確率関数 (simultanous probability function) を定義することができ,
p(x, y) = P (X = x かつ Y = y) (19)
と書くことができる.
例 2つのサイコロを同時にふる場合に,2つのサイコロのうち小さい方をとった確率変数をX, 2つサイコロの目の和の確率変数を Y とおく.それぞれのサイコロの目の数と,その場合の確率変数の値を表にすると,表 1のようになる.これより,同時確率関数の値は表 2のようになる.
4 平均値をとる演算子Eと分散をとる演算子V の性質について
まず,平均をとる演算子E(·)について考える.この演算子のいくつかの性質について考える.2つの確率変数 X, Y について,その和の確率変数X + Y の平均を考える.連続的なケースでは,
E(X + Y ) =
! "
!"
! "
!"(x + y)f(x, y)dxdy (20)
4
x
y
2 ポアッソン分布の例ポアッソン分布はまれに起こる現象によくマッチする.たとえば,50ページのの本があり,1ページに平均 2個の間違いが存在すると仮定する.間違いの個数はポアッソン分布に従うとしよう.この場合,1ページに存在する間違いの個数は,
f(k) =2ke!2
k!(13)
に従う.あるページに1個も間違いが無い確率は f(0) = e!2 = 0.135 であり,ちょうど 1個だけ間違いがある確率は,f(1) = 2e!2 = 0.271 である.同様にして,ちょうど 2個および 3個間違いがある確率は,それぞれ f(2) = 2e!2 = 0.271,
f(3) = 4e!2/3 = 0.180である,以上より,1ページに 4個以上の間違いが出てくる確率は,1! f(0)! f(1)! f(2)! f(3) = 0.143である.したがって,すべてのページに間違いが 4個以上ない確率は,0.85750 = 0.000448となり,非常に小さな確率であることがわかる.
3 いくつかの確率変数による分布関数これまで,それぞれのケースである一つの確率変数に注目してその確率変数の
分布関数を解析してきた.ここで,複数の確率変数を同時に扱うための枠組みについて考えてみる.2つの確率変数 X, Y が定義されているとする.このとき,同時分布関数 (simultanous distribution function) F (x, y)はつぎのように定義される:
F (x, y) = P (X " x かつ Y " y). (14)
このように定義すると,このように定義すると,
limy"#
F (x, y) = limy"#
P (X " x かつ Y " y) = P (X " x) = FX(x) (15)
であり,
limx"#
F (x, y) = limx"#
P (X " x かつ Y " y) = P (Y " y) = FY (y) (16)
である.ただし,FX , FY はそれぞれ X, Y の分布関数とする.この結果より,limy"# F (x, y)と limy"# F (x, y)のことを,周辺分布 (marginal distribution)
と呼ぶことがある.1変数について確率密度関数を考えたのと同様にして,多変数についても密度関
数を考える.この場合,f(x, y) =
!2F (x, y)
!x!y(17)
3
同時密度関数
f(x, y) =1
!
2!e!(x2+y2)/2
2つの確率変数の和について
表 1: 2つのサイコロを振ったときのそれぞれの状態と確率変数X, Y の値.ただし,a/bは確率変数X, Y がそれぞれ a, b であることを表す.
1 2 3 4 5 6
1 1/2 1/3 1/4 1/5 1/6 1/7
2 1/3 2/4 2/5 2/6 2/7 2/8
3 1/4 2/5 3/6 3/7 3/8 3/9
4 1/5 2/6 3/7 4/8 4/9 4/10
5 1/6 2/7 3/8 4/9 5/10 5/11
6 1/7 2/8 3/9 4/10 5/11 6/12
と定義し,同時確率密度関数 (simultanous probability density function) と呼ぶ.このように定義すると,
F (x, y) =
! x
!"
! y
!"f(s, t)dtds (18)
と書くことができる.離散的な確率変数についても同様に定義することができる.離散的な確率変数
の場合,同時確率関数 (simultanous probability function) を定義することができ,
p(x, y) = P (X = x かつ Y = y) (19)
と書くことができる.
例 2つのサイコロを同時にふる場合に,2つのサイコロのうち小さい方をとった確率変数をX, 2つサイコロの目の和の確率変数を Y とおく.それぞれのサイコロの目の数と,その場合の確率変数の値を表にすると,表 1のようになる.これより,同時確率関数の値は表 2のようになる.
4 平均値をとる演算子Eと分散をとる演算子V の性質について
まず,平均をとる演算子E(·)について考える.この演算子のいくつかの性質について考える.2つの確率変数 X, Y について,その和の確率変数X + Y の平均を考える.連続的なケースでは,
E(X + Y ) =
! "
!"
! "
!"(x + y)f(x, y)dxdy (20)
4
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5
XとYのそれぞれの密度関数
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5
2つの確率変数の積について2つの確率変数X, Yは独立であると仮定する.
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5

確率変数の定数倍の平均について確率変数の定数倍の平均は,平均の定数倍となる.
表 2: 確率変数Xと Y の同時確率関数.表の中の値はすべて 1/36倍する.
X Y 2 3 4 5 6 7 8 9 10 11 12
1 1 2 2 2 2 2 0 0 0 0 0
2 0 0 1 2 2 2 2 0 0 0 0
3 0 0 0 0 1 2 2 2 0 0 0
4 0 0 0 0 0 0 1 2 2 0 0
5 0 0 0 0 0 0 0 0 1 2 0
6 0 0 0 0 0 0 0 0 0 0 1
と書ける.ここで,f(x, y)はXと Y の同時密度関数であるとする.ここで,この式は以下のように変形することができる:
E(X + Y ) =
! !
"!
! !
"!xf(x, y)dxdy +
! !
"!
! !
"!yf(x, y)dxdy. (21)
しかし,ここで,Xの密度関数を hX , Y の密度関数を hY とおけば,! !
"!f(x, y)dy = hX(x),
! !
"!f(x, y)dx = hY (y) (22)
と書けるので,
E(X + Y ) =
! !
"!hX(x)xdx +
! !
"!hY (y)ydy = E(X) + E(Y ) (23)
を得る.これより,平均値をとる演算子Eは線形であることがわかる.この性質はいつでも成り立つ.また,2つの確率変数の積については,2つの変数が独立であることを仮定する.このとき,f(x, y) = fX(x)fY (y)と書けるので,
E(XY ) =
! !
"!
! !
"!xyfX(x)fY (x)dxdy (24)
この場合,積分を2つの因子に分けることができるので,
E(XY ) =
! !
"!xfX(x)dx
! !
"!yfX(y)dy = E(X)E(Y ) (25)
と書くことができる.また,確率変数を定数倍した確率変数については,
E(aX) =
! !
"!axfX(x)dx = a
! !
"!xfX(x)dx = aE(X) (26)
である.
5
確率変数の和の分散2つの確率変数は独立であると仮定する.つぎに,分散について考えてみる.分散は平均の記号を用いて以下のように表
現できる.ここで,確率変数X, Y は独立であるとする.
V (X + Y ) = E((X + Y )2)! (E(X + Y ))2
= E(X2 + 2XY + Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
= E(X2) + 2E(XY ) + E(Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
(27)
ここで2つの確率変数が独立であるということから,E(XY ) = E(X)E(Y )であることから,
V (X + Y ) = E(X2) + E(Y 2)! E(X)2 ! E(Y )2 = V (X) + V (Y ). (28)
また,確率変数の定数倍については,
V (aX) = E((aX)2)! E(aX)2 = a2E(X2)! a2E(X)2 = a2V (X) (29)
となる.
例 2項分布の平均と分散について再び考える.1回だけコインを振る試行で,表が出たら 1, 裏がでたら 0とするような n個の確率変数をX1, X2, . . . , Xnとおく.それぞれは独立であるとする.2項分布に従う確率変数はX =
!ni=1 Xiと書くこ
とができる.まず,それぞれの確率変数の平均は,
E(Xi) = p (30)
であり,分散はE(X2i ) = 12 " p + 02 " (1! p) = pより,
V (Xi) = E(X2i )! E(Xi)
2 = p! p2 = p(1! p) = pq (31)
である.ただし,q = 1! pとする.この結果より,
E(X) =n"
i=1
E(Xi) = np (32)
であり,
V (X) = V
#n"
i=1
Xi
$=
n"
i=1
V (Xi) = npq (33)
となる.
6
=0
つぎに,分散について考えてみる.分散は平均の記号を用いて以下のように表現できる.ここで,確率変数X, Y は独立であるとする.
V (X + Y ) = E((X + Y )2)! (E(X + Y ))2
= E(X2 + 2XY + Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
= E(X2) + 2E(XY ) + E(Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
(27)
ここで2つの確率変数が独立であるということから,E(XY ) = E(X)E(Y )であることから,
V (X + Y ) = E(X2) + E(Y 2)! E(X)2 ! E(Y )2 = V (X) + V (Y ). (28)
また,確率変数の定数倍については,
V (aX) = E((aX)2)! E(aX)2 = a2E(X2)! a2E(X)2 = a2V (X) (29)
となる.
例 2項分布の平均と分散について再び考える.1回だけコインを振る試行で,表が出たら 1, 裏がでたら 0とするような n個の確率変数をX1, X2, . . . , Xnとおく.それぞれは独立であるとする.2項分布に従う確率変数はX =
!ni=1 Xiと書くこ
とができる.まず,それぞれの確率変数の平均は,
E(Xi) = p (30)
であり,分散はE(X2i ) = 12 " p + 02 " (1! p) = pより,
V (Xi) = E(X2i )! E(Xi)
2 = p! p2 = p(1! p) = pq (31)
である.ただし,q = 1! pとする.この結果より,
E(X) =n"
i=1
E(Xi) = np (32)
であり,
V (X) = V
#n"
i=1
Xi
$=
n"
i=1
V (Xi) = npq (33)
となる.
6
確率変数の定数倍の分散について確率変数の定数倍aの分散はその二乗a2倍となる.
つぎに,分散について考えてみる.分散は平均の記号を用いて以下のように表現できる.ここで,確率変数X, Y は独立であるとする.
V (X + Y ) = E((X + Y )2)! (E(X + Y ))2
= E(X2 + 2XY + Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
= E(X2) + 2E(XY ) + E(Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
(27)
ここで2つの確率変数が独立であるということから,E(XY ) = E(X)E(Y )であることから,
V (X + Y ) = E(X2) + E(Y 2)! E(X)2 ! E(Y )2 = V (X) + V (Y ). (28)
また,確率変数の定数倍については,
V (aX) = E((aX)2)! E(aX)2 = a2E(X2)! a2E(X)2 = a2V (X) (29)
となる.
例 2項分布の平均と分散について再び考える.1回だけコインを振る試行で,表が出たら 1, 裏がでたら 0とするような n個の確率変数をX1, X2, . . . , Xnとおく.それぞれは独立であるとする.2項分布に従う確率変数はX =
!ni=1 Xiと書くこ
とができる.まず,それぞれの確率変数の平均は,
E(Xi) = p (30)
であり,分散はE(X2i ) = 12 " p + 02 " (1! p) = pより,
V (Xi) = E(X2i )! E(Xi)
2 = p! p2 = p(1! p) = pq (31)
である.ただし,q = 1! pとする.この結果より,
E(X) =n"
i=1
E(Xi) = np (32)
であり,
V (X) = V
#n"
i=1
Xi
$=
n"
i=1
V (Xi) = npq (33)
となる.
6
つぎに,分散について考えてみる.分散は平均の記号を用いて以下のように表現できる.ここで,確率変数X, Y は独立であるとする.
V (X + Y ) = E((X + Y )2)! (E(X + Y ))2
= E(X2 + 2XY + Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
= E(X2) + 2E(XY ) + E(Y 2)! E(X)2 ! 2E(X)E(Y )! E(Y )2
(27)
ここで2つの確率変数が独立であるということから,E(XY ) = E(X)E(Y )であることから,
V (X + Y ) = E(X2) + E(Y 2)! E(X)2 ! E(Y )2 = V (X) + V (Y ). (28)
また,確率変数の定数倍については,
V (aX) = E((aX)2)! E(aX)2 = a2E(X2)! a2E(X)2 = a2V (X) (29)
となる.
例 2項分布の平均と分散について再び考える.1回だけコインを振る試行で,表が出たら 1, 裏がでたら 0とするような n個の確率変数をX1, X2, . . . , Xnとおく.それぞれは独立であるとする.2項分布に従う確率変数はX =
!ni=1 Xiと書くこ
とができる.まず,それぞれの確率変数の平均は,
E(Xi) = p (30)
であり,分散はE(X2i ) = 12 " p + 02 " (1! p) = pより,
V (Xi) = E(X2i )! E(Xi)
2 = p! p2 = p(1! p) = pq (31)
である.ただし,q = 1! pとする.この結果より,
E(X) =n"
i=1
E(Xi) = np (32)
であり,
V (X) = V
#n"
i=1
Xi
$=
n"
i=1
V (Xi) = npq (33)
となる.
6
正規分布の導出 (6)結局,求める確率密度関数は以下のとおり.
とおけば,
R2 =
! !
"!e"x2/2dx
! !
"!e"y2/2dy =
! !
"!
! !
"!e"(x2+y2)/2dxdy (21)
=
! !
0
! 2!
0
e"r2/2rd!dr = 2""!e"r2/2
#!0
= 2" (22)
となる.ただし,r =$
x2 + y2 であり,! = tan"1(y/x) である.これより,R ="2"を得る.これより,
h(x) =1"2"
e"x2/2. (23)
この関数をもとにZ = aX + bによって変換すれば,
E(Z) = aE(X) + b = b, V (X) = a2V (X) = a2 (24)
であるので,平均µ,分散#とするには,b = µ, a = #とすれば良い.X = (Z!µ)/#
という関係になるので,Zの確率密度関数は,
g(z) = lim!z#0
P (z # Z # z + !z)
!z(25)
= lim!z#0
P (x # X # x + !z/a)
!z(26)
=1
alim
!z#0
P (x # X # x + !z/a)
!z/a(27)
=1
ah
%z ! µ
#
&(28)
=1"2"#
e"(z!µ)2
2!2 (29)
となる.この密度関数によって表される確率分布のことを一般の正規分布と呼び,N(µ,#)で表す.正規分布は工学の色々な場面に出現する.また,色々な量の確率分布を正規分布であると仮定することがある.
3 共分散と相関係数ここでは再び複数の確率変数の扱いについて考える.特に,2つの確率変数の関係について考える.2つの確率変数がどのように連動しているのかということが問題になる場合がある.特に2つの確率変数の間に線形もしくはアフィン的な関係があるかどうかを探る場合,共分散や相関係数を計算することはある程度有効である.まず,2つの確率変数X, Y の共分散は,
#XY = E((X ! µX)(Y ! µY )) (30)
4
!!
"!
e"
x2
2 dx =!
2!
正規分布の形正規分布の形は良く研究されている.特に平均値からはずれたところの確率は良く知られている.正規分布は2項分布の近似になっているので2項分布の見積りに用いることができる.
-4 -2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
95.4%
99.7%
正規分布の応用教科書の例:1000点満点のテストで600点が平均であり,標準偏差は100点であった.正規分布にしたがっているとして,800点以上は何パーセントいるか?
800 ! 600
100= 2
-4 -2 0 2 4
0.0
0.1
0.2
0.3
0.4
x
y
95.4%
99.7%
2.3%教科書のp. 213を参照

2つの確率変数の関係2つの確率変数の関係を調べる量
これを共分散 (covariance) と呼ぶ.
とおけば,
R2 =
! !
"!e"x2/2dx
! !
"!e"y2/2dy =
! !
"!
! !
"!e"(x2+y2)/2dxdy (21)
=
! !
0
! 2!
0
e"r2/2rd!dr = 2""!e"r2/2
#!0
= 2" (22)
となる.ただし,r =$
x2 + y2 であり,! = tan"1(y/x) である.これより,R ="2"を得る.これより,
h(x) =1"2"
e"x2/2. (23)
この関数をもとにZ = aX + bによって変換すれば,
E(Z) = aE(X) + b = b, V (X) = a2V (X) = a2 (24)
であるので,平均µ,分散#とするには,b = µ, a = #とすれば良い.X = (Z!µ)/#
という関係になるので,Zの確率密度関数は,
g(z) = lim!z#0
P (z # Z # z + !z)
!z(25)
= lim!z#0
P (x # X # x + !z/a)
!z(26)
=1
alim
!z#0
P (x # X # x + !z/a)
!z/a(27)
=1
ah
%z ! µ
#
&(28)
=1"2"#
e"(z!µ)2
2!2 (29)
となる.この密度関数によって表される確率分布のことを一般の正規分布と呼び,N(µ,#)で表す.正規分布は工学の色々な場面に出現する.また,色々な量の確率分布を正規分布であると仮定することがある.
3 共分散と相関係数ここでは再び複数の確率変数の扱いについて考える.特に,2つの確率変数の関係について考える.2つの確率変数がどのように連動しているのかということが問題になる場合がある.特に2つの確率変数の間に線形もしくはアフィン的な関係があるかどうかを探る場合,共分散や相関係数を計算することはある程度有効である.まず,2つの確率変数X, Y の共分散は,
#XY = E((X ! µX)(Y ! µY )) (30)
4と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
XとYが独立のとき,E(XY) = E(X)E(Y)となるので,σxyは0となる
2つの確率変数の関係相関係数 (2)
この確率変数は0以上の値しかとらないので,平均も0以上になる.したがって,λの2次式としてみたとき,判別式は0以上となる.
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
実際の相関係数実際にシミュレートしてみる
と定義する.ここでこれを展開して計算すると,
!XY = E((X!µX)(Y!µY )) = E(XY )!µXE(Y )!µY E(X)+µXµY = E(XY )!µXµY
(31)
となる.共分散と通常の分散の関係を求めるために,Z = ("(X!µX)+(Y !µY ))2
の平均について考える.この確率変数の平均E(Z)を以下のように計算する.
E(Z) = E[("(X ! µX) + (Y ! µY ))2]
= "2E((X ! µX)2) + "E((X ! µX)(Y ! µY )) + E((Y ! µY )2)
= "2!2X + 2"!XY + !2
Y (32)
ここで,この量は常に正であることから,最後に導出した式は負にはならない.すなわち,この式を 0にするような 2次方程式の判別式は 0以下である.すなわち,
D/4 = !2XY ! !2
X!2Y " 0 (33)
である.これより, !!XY
!X!Y
"2
" 1 (34)
を得る.これより,!1 " !XY
!X!Y" 1 (35)
となる.この量をことを相関係数と呼び,2つの確率変数がいかに連動しているかの指標となる.そもそも,2つの確率変数が独立である場合,共分散は,
E((X ! µX)(Y ! µY )) = E(X ! µX)E(Y ! µY ) = 0# 0 = 0 (36)
であるから,相関係数は 0である.また,Y = aX + bという関係があれば,
E((X ! µX)(Y ! µY )) = E((X ! µX)(aX + b! aµX ! b))
= aE((X ! µX)(X ! µX)) = aV (X) (37)
である.これより,相関係数は,!XY
!X!Y=
aV (X)
!X |a|!X= ±1 (38)
となる.このように2つの確率変数に線形な関係があると,相関係数は 1となる(傾きが負の場合には!1になる).実際にY = X +0.2N(0, 1), Z = X +0.2N(0, 1)
とおいて,2つの量 Y , Z をプロットすると図 2のようになる.ただし,2つの正規分布は互いに独立であるとし,Xは [0, 1] の間の一様分布であるとする.この分布の相関係数を計算すると,0.80となる.このような相関係数によって
関係の度合いを測るということは,実験などでは頻繁に行われることである.
5
互いに独立
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
-0.4 -0.2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6
"workx.dat"
相関係数=0.8
中心極限定理とは (3)確率変数
とすれば,平均0, 標準偏差1の分布となり,これは,nを大きくすると正規分布に近づく.この場合,Xiはそれぞれ1回コインを振る試行であるが… 他の分布の場合はどうなるか?
山本 修身2008.07.02
確率論 第13回 まとめ— 中心極限定理と大数の法則—
1 中心極限定理1回だけコインを振るという試行を考える.この試行では,コインの表がでたら
1,裏がでたら 0という値を確率変数Xに与えるものとする.当然,平均は,
E(X) = 1! p + 0! (1" p) = p, E(X2) = 12 ! p + 02 ! (1" p) = p (1)
であり,分散は,
V (X) = E(X2)" E(X)2 = p" p2 = p(1" p) = pq (2)
となる.この分布を何回も繰り返して(それぞれの試行は独立である),確率変数を足し合わせたものが,2項分布である.この場合,繰り返す回数が大きくなると平均や分散が大きくなってしまうので,繰り返す回数 nで割って,
Z =X1 + X2 + · · · + Xn
n(3)
とすれば,平均と分散は,
E(Z) =np
n= p, V (Z) =
npq
n2=
pq
n(4)
となるので,ある程度 nが大きくなると,平均が一定で,分散が小さくなり,非常に高い確率で平均(これがこの試行の確率である)に近づくことになる.これが大数の法則である.これに対して,確率変数 U を
U =X1 + X2 + · · · + Xn " np
#npq
(5)
とおけば,この確率変数の平均と標準偏差は常にそれぞれ 0と 1になる.第 11回で解説したように,この確率変数はnが大きくなるとともに正規分布に近づく(正規分布はそもそも U の極限分布として定義されていた).この場合には,コインを振るという特殊な形の確率分布を元にそれらを足し合わせ確率分布である.ここで,元とする確率分布を別のものに変えてしまったら,どのような確率分布に近づくだろうか?実は多くの場合,確率分布はやはり正規分布に近づく.この現象のことを中心極限定理 (central limit theorem)と呼ぶ.
1
中心極限定理ほとんど確率分布ついて正規分布に近づく.
一様分布を足し合わせると一様分布についても正規分布に急速に近づく
0
0.0005
0.001
0.0015
0.002
0.0025
0.003
0.0035
0.004
0.0045
-3 -2 -1 0 1 2 3
"data1.dat"
"data2.dat"
"data3.dat"
"data4.dat"
"data5.dat"
"data6.dat"
"data7.dat"
n=1
n=2
n"3
チェックポイント(1)• 場合の数が計算的,それを用いて確率が計算できるか?特に同じものがある場合の順列やいくつかの組にわける組み合せなどが計算できるか?
• 2項係数の計算ができるか?2項係数nCkと2項定理が理解できているか?
• 確率空間の定義が理解できているか?標本空間,事象の集合,確率の• 3つ組による確率空間の定義に基づいて確率を理解できるか?• 条件付き確率 P(E1|E2)の意味が理解できているか.• ベイズの定理の意味が理解でき,ベイズの定理を用いて事後確率が計算できるか?
• 独立性について意味が理解できているか?• 確率変数の意味が理解でき,それに基づいて,分布関数や密度関数の意味が理解できるか?

チェックポイント(2)• 期待値と分散の定義が理解でており,分布が与えられたとき,その平均や分散,標準偏差を計算することができるか?特にV(X) = E(X2) - (E(X))2を利用して分散が計算できるか?
• モーメント母関数 f(t) = E(eXt)を用いた平均や分散の計算が理解できているか?
• 2項分布Bin(n, p)の定義を知っているか?2項分布の平均 (np)や分散 (npq) の計算結果を知っておりそれを用いて問題が解けるか?
• ポアッソン分布の定義を知っているか?ポアッソン分布の結果(平均,分散ともにλ) を知っており,それを用いて問題が解けるか?
• 正規分布の定義を知っており,それを用いて問題が解けるか.特に任意の正規分布を標準正規分布N(0, 1)へ変数変換して,確率を計算するやり方を理解できているか?正規分布表は使えるか?
チェックポイント(3)• 指数分布の定義を知っており,それを用いて問題が解けるか?• 同時分布関数や同時密度関数についてその定義や意味を理解しているか?特に,共分散や相関係数の計算ができるか?
• チェビシェフの不等式を用いて,確率を見積もることができるか?• 大数の法則や中心極限定理について理解できているか?







![第3章 確率論の基礎 - web.econ.keio.ac.jpweb.econ.keio.ac.jp/staff/ito/pdf05/FM05prob.pdf · 4 第3章 確率論の基礎 ただし[0,1]= x∈ R 0 ≤ 1 である 演習5](https://img.pdfslide.tips/doc/110x75/5e5b8436a3f32a7b540be7fd/c3c-ccec-webeconkeioacjpwebeconkeioacjpstaffitopdf05.jpg)





















