Embed Size (px)
Citation preview

Splunk Splunk ®® Enterprise 7.0.0 Enterprise 7.0.0
Splunk Enterprise DeploymentSplunk Enterprise Deploymentの継承の継承
作成:2017/09/15 午後4時44分
Copyright (c) 2017 Splunk Inc. All Rights Reserved

33333
10131819212627282931
Table of Content sTable of Content s継承したデプロイ作業継承したデプロイ作業
継承したデプロイデプロイの図を描くトポロジをデプロイします。モニターコンソールを使ってトポロジーを判断するトポロジを決定するために設定ファイルを調べるコンポーネントとそれらのネットワークとの関係Splunk デプロイのデータについて学ぶApp やアドオンを確認するユーザー、ロールおよび認証システムセキュリティを確認するライセンスについての学習システム状態をモニターするナレッジオブジェクト問題の調査

継承したデプロイ作業継承したデプロイ作業継承したデプロイ継承したデプロイ
あなたが Splunk ソフトウェアデプロイの責任を継承したシステム管理者である場合、このマニュアルを利⽤してお使いのデプロイのネットワーク特性、データソース、ユーザーについて、ナレッジオブジェクトに関して理解してください。この情報はお使いの環境で実⾏されている Splunk プラットフォームの基本的な概要を把握するのに役⽴ちまう。何が実⾏しているか、どの程度良好に実⾏しているか、誰が使⽤しているか、詳細はどこで確認できるかについての概要を記載しています。
Splunk Enterprise ソフトウェアのハイレベルな説明については、Splunk Enterprise 概要マニュアルをご覧ください。
Splunk ソフトウェアを使⽤したサーチとレポートについては、サーチチュートリアルをご利⽤ください。
Splunk ソフトウェアを始めて使⽤する際に、お役に⽴つリソースがいくつかあります。
Splunk AnswersSplunk EducationSplunk ユーザーグループSplunk ユーザーグループチャット
Splunk Professional Services チームはお使いの Splunk 環境の技術的な評価を実⾏し、お使いのデプロイおよび内部処理がベストプラクティスに従うことを確実にいたします。
デプロイの図を描くデプロイの図を描く
デプロイの図を描くことはデプロイについての詳細を学んだり、将来⾒返す際に、詳細を可視化する便利なツールです。
本マニュアルのトピックを読んで、Splunk デプロイの図を描いてみましょう。詳細を追加します。
最初に描く図は書⾯が好ましいです。Visio または Omnigraffle などの描画ツールが好ましい場合は、以下のアイコンを使⽤できます:
http://wiki.splunk.com/Community:Splunk_Visio_Stencil
図には以下を描く必要があります。
各サーチヘッド各インデクサー追加コンポーネント
クラスタマスター (インデクサークラスタリングがある場合)サーチヘッドデプロイヤー (サーチヘッドクラスタリングがある場合)デプロイサーバーライセンスマスターモニターコンソールKV ストア
フォワーダー、⼤量のフォワーダーの場合は、フォワーダーのセットであるサーバークラス。各インスタンス間の接続。
情報を書き加えるための隙間を図の各ノード間に開けてください。各ノードに、以下の情報を記載します:
実⾏している Splunk Enterprise のバージョン。KV ストアが実⾏されているかどうか。すべての開いているポート。オペレーティングシステム、CPU、物理メモリ、ストレージタイプ、および仮想化などのマシン情報。
コンポーネントの定義については、次のセクション、デプロイテクノロジーをご覧ください。モニターコンソールがある場合は、それを使⽤、モニターコンソールがない場合は、設定ファイル調査のいずれかを使⽤して、以下のトピックを続⾏します。お使いのデプロイにあるサーバークラスおよび KV ストアの情報および検索ステップについては「App およびアドオンのレビュー」をご覧ください。
トポロジをデプロイします。トポロジをデプロイします。
部⾨サイズ環境をサポートするため、単⼀のマシンで実⾏している、単⼀の Splunk Enterprise だけが必要な場合があります。
ただし、多数のマシンからデータが到着し、多数のユーザーがデータをサーチする必要があるような⼤規模な環境に対応するためには、複数のマシンにまたがって Splunk Enterprise インスタンスを分散させ、各インスタンスを特殊なタスクを実⾏するように設定してデプロイをスケールすることもできます。
本トピック、さらに次のトピックの⽬的は、現在のデプロイにある各 Splunk Enterprise インスタンスのどのロールが実⾏されているかを判断する際に役⽴つことです。すでに情報をお持ちの場合、またはお使いのデプロイが単⼀インスタンスだけで構成されている場合は、このトピックをスキップできます。
このトピックは Splunk Enterprise の概要を、デプロイに含まれるトポロジーおよびコンポーネントのタイプの説明とともに提供しています。次に、継承したデプロイの特徴を発⾒するために使⽤できる⼿順を説明します。
3

対象視聴者対象視聴者
本トピックおよび次のトピックで説明しているトポロジー発⾒プロセスは、Splunk Enterprise 経験が全くないまたは少ししかないシステム管理者を⽬的としています。
発⾒するための道は、最も基本的な形式では、ファイルブラウザおよびテキストエディタなどの簡単なシステムツールだけで⼗分です。
Splunk Enterprise モニタリングコンソールを使⽤する他の発⾒プロセスもあります。モニタリングコンソールはお使いのデプロイの全体的なグラフ図を提供するので、新しい Splunk Enterprise 管理者もすぐに使⽤できます。しかし、発⾒ツールとして使⽤するには、以前の Splunk Enterprise 管理者が設定済である必要があります。
経験のある Splunk Enterprise 管理者は、発⾒プロセスをより迅速に⾏うために、CLI コマンド、サーチ、ログファイルの検査などの様々な Splunk 固有のツールの使⽤を好む場合もあります。上記メソッドには SplunkEnterprise の使⽤経験が必要なので、新しい Splunk Enterprise 管理者はすぐに使⽤できません。
Splunk Enterpr ise 環境の拡張Splunk Enterpr ise 環境の拡張
本トピックの内容は⼀般的な Splunk Enterprise デプロイトポロジーの概要、およびそれらを構成しているインスタンスのタイプを提供します。詳細は、分散デプロイマニュアルをご覧ください。
Splunk Enterprise ではデータ処理に際して複数の機能が実⾏されます。これらの機能は以下のカテゴリーに当てはまります:
1.1.ファイル、ネットワーク、またはその他のソースからデータの取り込み
2.2.データをパーシング、インデックス、および保管します。
3.3.インデックスデータでのサーチの実⾏
システムをスケールするために、この機能を Splunk Enterprise の複数の特殊なインスタンスに分配することができます。これらのインスタンスは、処理対象のデータ容量、データにアクセスするユーザー数、その他の環境変数によって、数個から数千個の規模に及びます。
例えば、デプロイはデータを取り込むだけの数百のインスタンス、データをインデックスおよび保管するその他の複数のインスタンス、およびデータでのサーチを管理する単⼀インスタンスから構成されている場合があります。
Splunk Enterpr ise のコンポーネントSplunk Enterpr ise のコンポーネント
Splunk Enterprise コンポーネントコンポーネント とはデータのインデックスなどの特殊なタスクを実⾏する SplunkEnterprise インスタンスです。デプロイにあるタスクのタイプに⼀致する、複数のタイプのコンポーネントがあります。
2 つの幅広いカテゴリーに当てはまるコンポーネント:
処理コンポーネントデータを取り扱います。管理コンポーネント処理コンポーネントのアクティビティをサポートします。
処理コンポーネント処理コンポーネント
処理コンポーネントのタイプは:
フォワーダーインデクサーサーチヘッド
フォワーダーフォワーダーは未加⼯データを取り込み、別のフォワーダーまたはインデクサーのいずれかである、別のコンポーネントにデータを転送します。
フォワーダーは例えばウェブサーバーなどの、データを⽣成するアプリケーションを実⾏するマシンにともに存在しています。
ユニバーサルフォワーダーユニバーサルフォワーダーは最も⼀般的なタイプのフォワーダーです。お使いのデプロイにはヘビーフォワーヘビーフォワーダーダーおよびライトフォワーダーライトフォワーダーも含まれている場合があります。
通常、フォワーダーはデータを取り込み、そのデータを直接インデクサーに転送します。しかし、いくつかのトポロジーでは、フォワーダーのグループがデータを中間フォワーダーに転送し、それが統合データをインデクサーに転送します。いずれのタイプのフォワーダーも中間フォワーダーとして機能します。
インデクサーインデクサーはデータをインデックスおよび保存します。データ全体をサーチもします。
インデクサーは通常専⽤のマシンに設置されます。
インデクサーは独⽴インデクサー (⾮クラスタ) またはクラスタインデクサーのいずれかです。ピアノードピアノードとしても知られるクラスタインデクサーは、インデクサークラスタインデクサークラスタにあるノードです。
サーチヘッドサーチヘッドはサーチを管理します。ユーザーからのサーチリクエストを処理し、ローカルデータでサーチを実⾏する⼀連のインデクサーにリクエストが分散されます。サーチヘッドはすべてのインデクサーからの結果を統合し、ユーザーに返します。サーチを⽀援するため、ここではダッシュボードダッシュボードなどのさまざまなツールが提供されます。
4
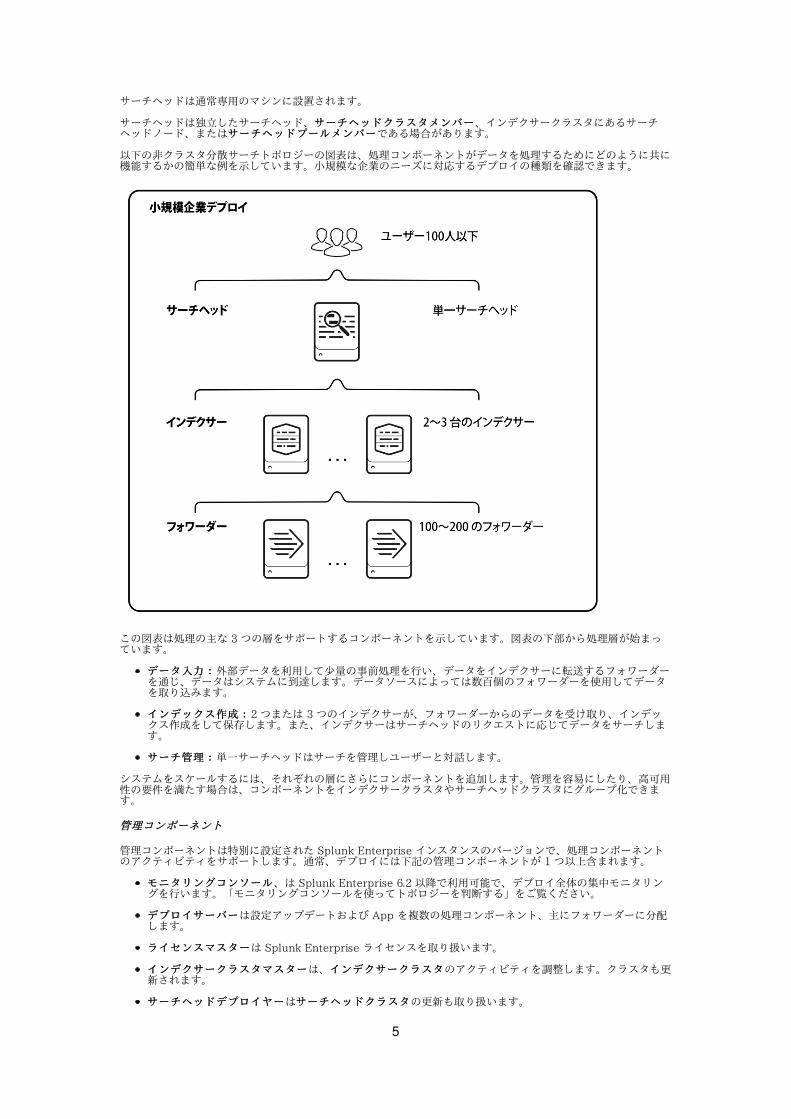
サーチヘッドは通常専⽤のマシンに設置されます。
サーチヘッドは独⽴したサーチヘッド、サーチヘッドクラスタメンバーサーチヘッドクラスタメンバー、インデクサークラスタにあるサーチヘッドノード、またはサーチヘッドプールメンバーサーチヘッドプールメンバーである場合があります。
以下の⾮クラスタ分散サーチトポロジーの図表は、処理コンポーネントがデータを処理するためにどのように共に機能するかの簡単な例を⽰しています。⼩規模な企業のニーズに対応するデプロイの種類を確認できます。
この図表は処理の主な 3 つの層をサポートするコンポーネントを⽰しています。図表の下部から処理層が始まっています。
データ⼊⼒:データ⼊⼒:外部データを利⽤して少量の事前処理を⾏い、データをインデクサーに転送するフォワーダーを通じ、データはシステムに到達します。データソースによっては数百個のフォワーダーを使⽤してデータを取り込みます。
インデックス作成:インデックス作成:2 つまたは 3 つのインデクサーが、フォワーダーからのデータを受け取り、インデックス作成をして保存します。また、インデクサーはサーチヘッドのリクエストに応じてデータをサーチします。
サーチ管理:サーチ管理:単⼀サーチヘッドはサーチを管理しユーザーと対話します。
システムをスケールするには、それぞれの層にさらにコンポーネントを追加します。管理を容易にしたり、⾼可⽤性の要件を満たす場合は、コンポーネントをインデクサークラスタやサーチヘッドクラスタにグループ化できます。
管理コンポーネント管理コンポーネント
管理コンポーネントは特別に設定された Splunk Enterprise インスタンスのバージョンで、処理コンポーネントのアクティビティをサポートします。通常、デプロイには下記の管理コンポーネントが 1 つ以上含まれます。
モニタリングコンソールモニタリングコンソール、は Splunk Enterprise 6.2 以降で利⽤可能で、デプロイ全体の集中モニタリングを⾏います。「モニタリングコンソールを使ってトポロジーを判断する」をご覧ください。
デプロイサーバーデプロイサーバーは設定アップデートおよび App を複数の処理コンポーネント、主にフォワーダーに分配します。
ライセンスマスターライセンスマスターは Splunk Enterprise ライセンスを取り扱います。
インデクサークラスタマスターインデクサークラスタマスターは、インデクサークラスタインデクサークラスタのアクティビティを調整します。クラスタも更新されます。
サーチヘッドデプロイヤーサーチヘッドデプロイヤーはサーチヘッドクラスタサーチヘッドクラスタの更新も取り扱います。
5
お使いのデプロイには、デプロイトポロジーのスケールおよび固有条件により、上記コンポーネントがすべて含まれているか、全く含まれていない場合があります。
複数の管理コンポーネントがしばしば単⼀の Splunk Enterprise インスタンスを処理コンポーネントとともに共有する場合があります。しかし、⼤規模デプロイでは、各管理コンポーネントは専⽤のインスタンスに設置されます。
共通のデプロイトポロジー共通のデプロイトポロジー
分散サーチ分散サーチトポロジーはお使いのデプロイをスケールする柔軟な⽅法を提供します。分散サーチには、デプロイが組織の需要に対応できるように、多くのバリエーションがあります。
すべての Splunk Enterprise デプロイトポロジーは分散サーチごとに異なります。バリエーションはトポロジーがインデクサークラスタリング、サーチヘッドクラスタ、またはその両⽅を組み込むかどうかに関連します。すべての分散トポロジーでは、フォワーダーがデータ⼊⼒を取り扱います。
基本分散サーチ。基本分散サーチ。基本分散サーチでは、独⽴サーチヘッドは⼀群の独⽴インデクサー向けのサーチを管理します。「基本分散サーチ」をご覧ください。インデクサークラスタ。インデクサークラスタ。インデクサークラスタインデクサークラスタでは、⼀群のインデクサーが、⾼いデータ可⽤性を確実にするためにデータを複製します。マスターノードはインデクサーの集中管理を⾏います。基本分散サーチにあるように、フォワーダーおよびサーチヘッドはデータ⼊⼒およびサーチ管理を処理します。「インデクサークラスタ」をご覧ください。サーチヘッドクラスタ。サーチヘッドクラスタ。サーチヘッドクラスタサーチヘッドクラスタでは、⼀群のサーチヘッドがサーチ管理責任を共有しています。サーチを、独⽴インデクサーまたは、インデクサークラスタにあるノードのいずれかに分散します。「サーチヘッドクラスタ」をご覧ください。結合されたインデクサークラスタおよびサーチヘッドクラスタ。結合されたインデクサークラスタおよびサーチヘッドクラスタ。このトポロジーは⼤規模デプロイでは⼀般的です。これは、サーチ管理機能が個々のサーチヘッドではなくサーチヘッドクラスタで処理されることを除いて、インデクサークラスタのパターンに従います。「結合されたインデクサークラスタおよびサーチヘッドクラスタ」をご覧ください。
分散デプロイマニュアルはデプロイトポロジーの詳細な説明および、全範囲の例を提供します。
注記注記: もう⼀つのトポロジー、サーチヘッドプーリングサーチヘッドプーリングがあります。このトポロジーでは、サーチヘッドは設定およびユーザーデータに共有ストレージを使⽤します。このトポロジーは⼀般的ではなく、サーチヘッドクラスタの代わりに廃⽌されていましたが、継承したデプロイがサーチヘッドプーリングを使⽤する場合があります。
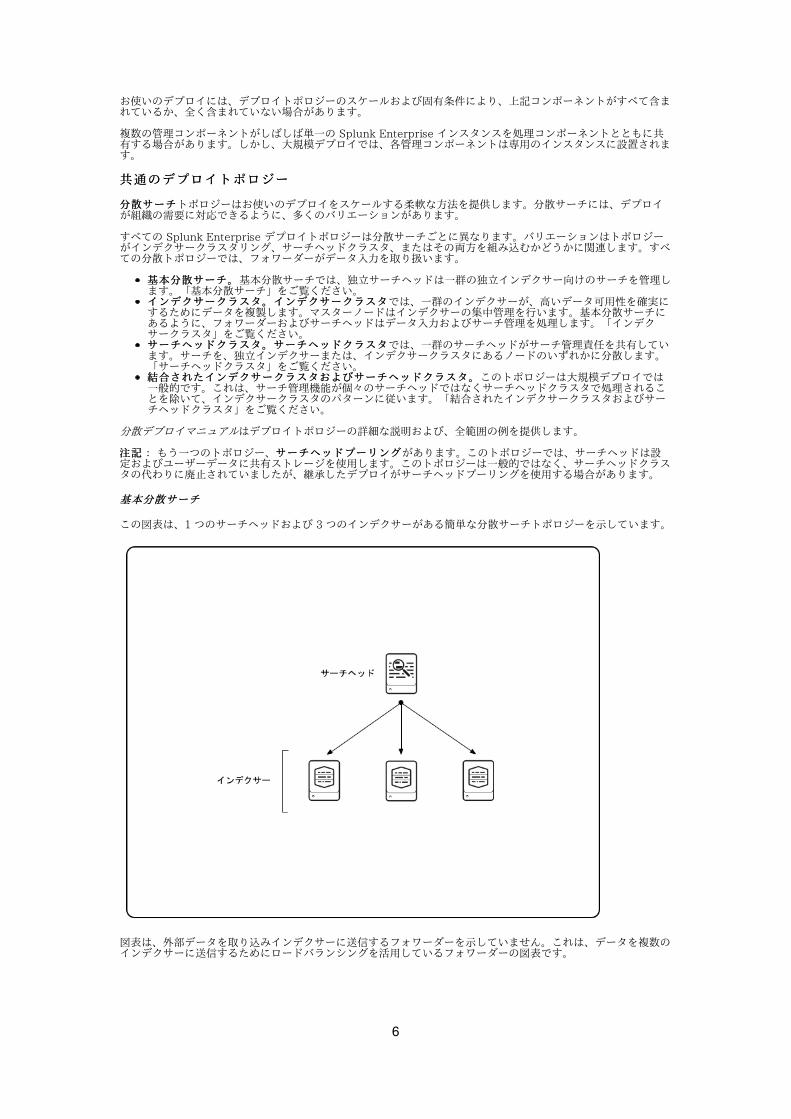
基本分散サーチ基本分散サーチ
この図表は、1 つのサーチヘッドおよび 3 つのインデクサーがある簡単な分散サーチトポロジーを⽰しています。
図表は、外部データを取り込みインデクサーに送信するフォワーダーを⽰していません。これは、データを複数のインデクサーに送信するためにロードバランシングを活⽤しているフォワーダーの図表です。
6
分散サーチの詳細については、分散サーチの「分散サーチ」およびそれに続くトピックをご覧ください。
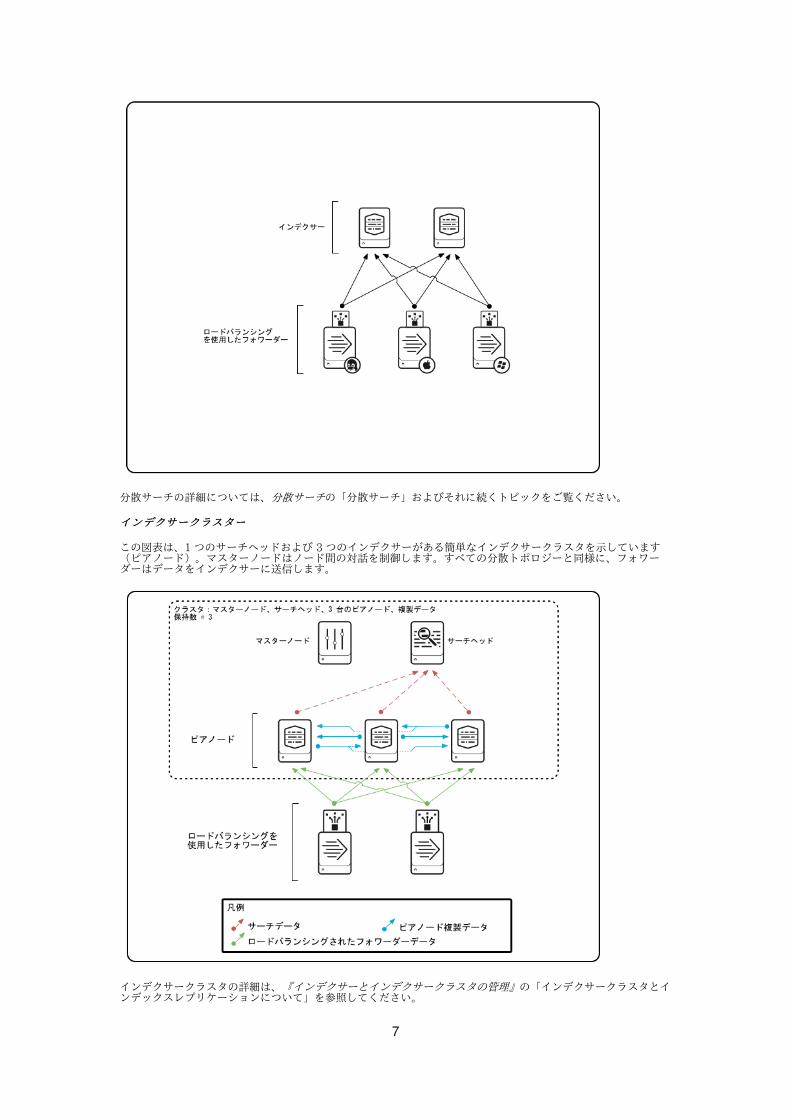
インデクサークラスターインデクサークラスター
この図表は、1 つのサーチヘッドおよび 3 つのインデクサーがある簡単なインデクサークラスタを⽰しています(ピアノード)。マスターノードはノード間の対話を制御します。すべての分散トポロジーと同様に、フォワーダーはデータをインデクサーに送信します。
インデクサークラスタの詳細は、『インデクサーとインデクサークラスタの管理』の「インデクサークラスタとインデックスレプリケーションについて」を参照してください。
7
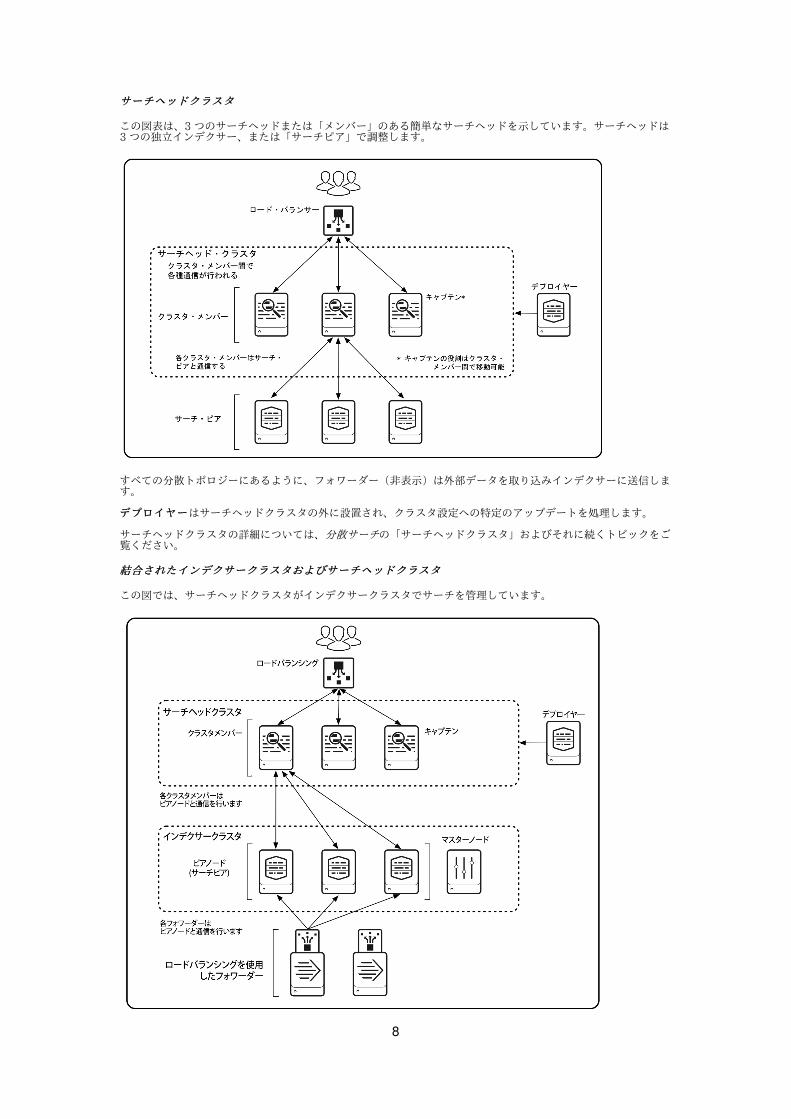
サーチヘッドクラスタサーチヘッドクラスタ
この図表は、3 つのサーチヘッドまたは「メンバー」のある簡単なサーチヘッドを⽰しています。サーチヘッドは3 つの独⽴インデクサー、または「サーチピア」で調整します。
すべての分散トポロジーにあるように、フォワーダー(⾮表⽰)は外部データを取り込みインデクサーに送信します。
デプロイヤーデプロイヤーはサーチヘッドクラスタの外に設置され、クラスタ設定への特定のアップデートを処理します。
サーチヘッドクラスタの詳細については、分散サーチの「サーチヘッドクラスタ」およびそれに続くトピックをご覧ください。
結合されたインデクサークラスタおよびサーチヘッドクラスタ結合されたインデクサークラスタおよびサーチヘッドクラスタ
この図では、サーチヘッドクラスタがインデクサークラスタでサーチを管理しています。
8

インデクサークラスタとサーチヘッドクラスタの結合については、分散サーチの「サーチヘッドクラスタとインデクサークラスタの統合」をご覧ください。
インデックスへのパスインデックスへのパス
デプロイトポロジーを判断するには、コンポーネントおよびその関係を特定する必要があります。
発⾒には以下のステップがあります:
1. Splunk Enterprise およびユニバーサルフォワーダーインスタンスを検索します。
どのマシンにデプロイのインスタンスが含まれているかを判断します。単⼀マシンが複数のインスタンスをホストすることは可能ですが、そのような設定はテスト環境以外では⼀般的ではありません。プロダクション環境では、各 Splunk Enterprise インスタンスは常にそれ⾃⾝のマシンに設置されます。
2. コンポーネントを判断します。
各インスタンスで、ホストにあるコンポーネントを識別します。コンポーネントはインスタンスがデプロイで果たすロールを定義します。単⼀インスタンスをは複数のコンポーネントをホストできます。
3. コンポーネント間の関係を識別します。
コンポーネントがデプロイトポロジー全体にどのように関与しているかを判断します。
ディスカバリープロセスについては、デプロイの図を描くと役に⽴ちます。「デプロイの図を描く」を参照してください。
1.Splunk Enterprise およびユニバーサルフォワーダーインスタンスを検索します。1.Splunk Enterprise およびユニバーサルフォワーダーインスタンスを検索します。
最初のステップは Splunk Enterprise およびユニバーサルフォワーダーインスタンスをマシンで探すことです。以下の事項に注意してください。
ユニバーサルフォワーダーを除く、Splunk Enterprise インスタンスで実⾏されているすべてのコンポーネント。ユニバーサルフォワーダーは Splunk Enterprise の軽量バージョンで、⾃⾝の実⾏可能ファイルがあります。Splunk Enterprise インスタンスは通常専⽤のマシンに設置され、これはベストプラクティスです。しかし、全く異なる機能も実⾏するインスタンスがマシンで実⾏されている場合もあります。ユニバーサルフォワーダーインスタンスは通常、Web サーバーなどの他のアプリケーションをホストしているマシンに設置されます。フォワーダーはこれらのアプリケーションにより⽣成されたデータを取り込みます。単⼀マシンは複数のインスタンスををホストできますが、各インスタンスが⾃⾝のマシンに設置されることがベストプラクティスです。Splunk のグラフィカルユーザーインターフェースである、Splunk WebSplunk Web の不在は、マシンが SplunkEnterprise インスタンスをホストしていないという、信頼できる⽬印ではありません。ほとんどのデプロイでは、サーチヘッドおよび管理コンポーネントのいくつかなどの Splunk Enterprise インスタンスのサブセットだけに、実⾏されている Web インターフェースがあります。
マシンのファイルシステムに Splunk サブディレクトリがあるかを探すことで、Splunk Enterprise およびユニバーサルフォワーダーをホストするマシンを識別できます。
Splunk 説明書では Splunk ファイルシステムの基本ディレクトリを $SPLUNK_HOME と参照しています。
インスタンスは⼀般的にファイルシステムの以下の場所に設置されます。
オペレーティングシオペレーティングシステムステム
Splunk Enterprise の場所Splunk Enterprise の場所$SPLUNK_HOME$SPLUNK_HOME
ユニバーサルフォワーダーの場所ユニバーサルフォワーダーの場所$SPLUNK_HOME$SPLUNK_HOME
Windows
\Program Files\Splunk
C:\Splunk
C:\SPL
\Program Files\SplunkUniversalForwarder
C:\SplunkUniversalForwarder
Linux
SolarisAIXHP-UXFreeBSD
/opt/splunk /opt/splunkforwarder
Mac OS X /Applications/splunk /Applications/splunkforwarder
注意注意: このテーブルは $SPLUNK_HOME のデフォルト、または通常の場所を⽰しています。しかし、インストールプロセスでは、ユーザーは任意の場所にインストール可能で、基本ディレクトリの名称を変更できます。そのため、$SPLUNK_HOME を直ちに識別できない場合は、⼀連の Splunk サブディレクトリを含むディレクトリを探します。上記サブディレクトリには bin, etc, include, lib, openssl, share および以下が含まれます。 var.
splunk, splunkd、btool 実⾏ファイルなどが含まれている bin サブディレクトリを探すことで、マシンが$SPLUNK_HOME をホストしているかを検証できます。その bin サブディレクトリの親は $SPLUNK_HOME です。
インストール済のインスタンスでマシンを識別したら、インスタンスが現在実⾏されていることを確認します。ps
9

などのシステムツールまたはタスクマネージャーを使⽤して splunkd プロセスを探します。
2.コンポーネントを識別します。2.コンポーネントを識別します。
コンポーネントは以下のいずれかの⽅法で識別できます:
モニタリングコンソールを使う。各インスタンスの設定ファイルを試す。
お使いの Splunk Enterprise デプロイでモニタリングコンソールが実⾏されている場合、それを使⽤してコンポーネントとその関係を発⾒します。「モニタリングコンソールを使ってトポロジーを判断する」をご覧ください。
お使いの Splunk Enterprise デプロイにモニタリングコンソールがない場合は、各インスタンスの設定を確認する必要があります。すべてのインスタンスの設定を保持しているテキストファイルである、設定ファイルを閲覧します。「トポロジを決定するために設定ファイルを調べる」をご覧ください。
「Splunk Enterprise のコンポーネント」をご覧ください。
3.コンポーネント間の関係を識別します。3.コンポーネント間の関係を識別します。
コンポーネントを理解したら、それらの間の関係は通常明らかです。例えば、⾮クラスタ環境にサーチヘッドおよび 3 つのインデクサーがある場合、各インデクサーはサーチヘッドのサーチピアサーチピアです。つまり、そのインデクサーはサーチヘッドに対するサーチリクエストを処理します。同様に、インデクサークラスタのコンポーネントがある場合、デプロイにはインデクサークラスタが含まれます。
デプロイにモニタリングコンソールがある場合、それを使⽤して関係、およびコンポーネント⾃体を特定できます。
デプロイトポロジーは通常これらの幅広いカテゴリーに当てはまります:
基本分散サーチインデクサークラスターサーチヘッドクラスタ結合されたインデクサークラスタおよびサーチヘッドクラスタ
「共通のデプロイトポロジー」をご覧ください。
コンポーネントタイプのサマリーコンポーネントタイプのサマリー
このサマリーはコンポーネント発⾒プロセスを実⾏する際に留意するべき主要なポイントを概説しています。
Splunk Enterprise デプロイは処理コンポーネントおよび管理コンポーネントとして機能するインスタンスから構成されています。デプロイは通常可能なコンポーネントタイプのサブセットしか含みません。発⾒プロセスで、各インスタンスに設置されるコンポーネントを特定します。
インスタンスは通常単⼀の処理コンポーネントです。処理コンポーネントは第⼆の処理機能も実⾏できます。例えば、内部データをインデクサーに転送するサーチヘッドもあります。サーチヘッドの転送機能はその主要機能の第⼆機能ですが、内部データのみが転送に関与します。
管理コンポーネントはしばしば処理コンポーネントまたはその他の管理コンポーネントと⼀緒に存在します。
バリエーションがある処理コンポーネントもあります。例えば、インデクサーは独⽴またはインデクサークラスタのピアノードである場合があります。
これらは処理コンポーネントとそのバリエーションです。
サーチヘッドは以下の任意のタイプです:サーチヘッドの独⽴インデクサークラスタのサーチヘッドノードサーチヘッドクラスタのメンバーインデクサークラスタのサーチヘッドノードおよびサーチヘッドクラスタのメンバーサーチヘッドプーリングのメンバー
インデクサーは以下の任意のタイプです:独⽴インデクサーインデクサークラスタのピアノード
フォワーダーは以下の任意のタイプです:ユニバーサルフォワーダー:ヘビーフォワーダー:ライトフォワーダー中間フォワーダー (任意のタイプのフォワーダーの⼆次的特徴)
これらは管理コンポーネントです:
モニターコンソールデプロイサーバーライセンスマスターインデクサークラスタマスターサーチヘッドクラスタデプロイヤー
モニターコンソールを使ってトポロジーを判断するモニターコンソールを使ってトポロジーを判断する
10
モニタリングコンソール (以前の名称は分散管理コンソール、DMC) についての情報が残された場合は、これを使⽤してデプロイトポロジーを発⾒できます。
前提条件前提条件
「トポロジをデプロイします」をお読みください。このトピックでは、Splunk Enterprise デプロイの要素について説明し、デプロイトポロジーを検出する⽅法についての基本的な指針を解説しています。
モニタリングコンソールへのアクセスモニタリングコンソールへのアクセス
以前の管理者または御社組織提供の情報を参照します。
モニタリングコンソールはそれ⾃⾝のインスタンスでホストされるか、またはクラスタマスターと同⼀場所に配置される場合があります。あまり⼀般的ではありませんが、別の管理コンポーネントと同⼀場所に配置されることもあります。『Splunk Enterprise のモニタリング』の「コンソールを利⽤するインスタンス」を参照してください。
モニタリングコンソールと思われるノードで Splunk Web にログインします。どのノードがモニタリングコンソールか不明な場合は、クラスタマスターを試⾏します。結果が得られない場合は、サーチヘッドを試⾏します。
モニタリングコンソールを実⾏しているノードを⾒つけたら、モニタリングコンソールに進みます:
1. Splunk Web の任意の場所から設定設定をクリックします。2. パネルの左にあるモニターコンソールをクリックしてモニタリングコンソールを開きます。
モニターコンソールの概要モニターコンソールの概要
モニターコンソールのホームページは概要ページです。
モニターコンソールにはスタンドアローンおよび分散の 2 つのノードがあります。以下のスクリーンショットに基づいて、お使いのインスタンスのモニターコンソールがスタンドアローンまたは分散モードで設定されているかどうかを判断します。
スタンドアローンモードでの概要:
分散モードでの概要:
11
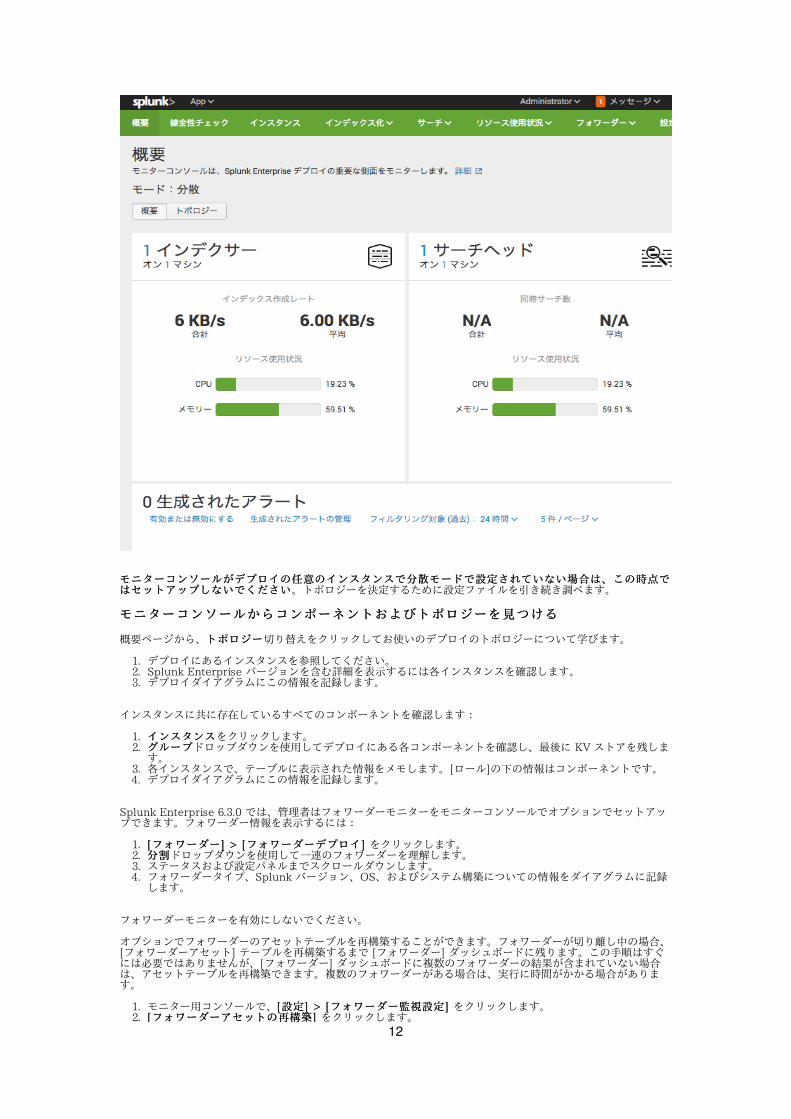
モニターコンソールがデプロイの任意のインスタンスで分散モードで設定されていない場合は、この時点でモニターコンソールがデプロイの任意のインスタンスで分散モードで設定されていない場合は、この時点ではセットアップしないでくださいはセットアップしないでください。トポロジーを決定するために設定ファイルを引き続き調べます。
モニターコンソールからコンポーネントおよびトポロジーを⾒つけるモニターコンソールからコンポーネントおよびトポロジーを⾒つける
概要ページから、トポロジートポロジー切り替えをクリックしてお使いのデプロイのトポロジーについて学びます。
1. デプロイにあるインスタンスを参照してください。2. Splunk Enterprise バージョンを含む詳細を表⽰するには各インスタンスを確認します。3. デプロイダイアグラムにこの情報を記録します。
インスタンスに共に存在しているすべてのコンポーネントを確認します:
1. インスタンスインスタンスをクリックします。2. グループグループドロップダウンを使⽤してデプロイにある各コンポーネントを確認し、最後に KV ストアを残しま
す。3. 各インスタンスで、テーブルに表⽰された情報をメモします。[ロール]の下の情報はコンポーネントです。4. デプロイダイアグラムにこの情報を記録します。
Splunk Enterprise 6.3.0 では、管理者はフォワーダーモニターをモニターコンソールでオプションでセットアップできます。フォワーダー情報を表⽰するには:
1. [フォワーダー] > [フォワーダーデプロイ][フォワーダー] > [フォワーダーデプロイ] をクリックします。2. 分割分割ドロップダウンを使⽤して⼀連のフォワーダーを理解します。3. ステータスおよび設定パネルまでスクロールダウンします。4. フォワーダータイプ、Splunk バージョン、OS、およびシステム構築についての情報をダイアグラムに記録
します。
フォワーダーモニターを有効にしないでください。
オプションでフォワーダーのアセットテーブルを再構築することができます。フォワーダーが切り離し中の場合、[フォワーダーアセット] テーブルを再構築するまで [フォワーダー] ダッシュボードに残ります。この⼿順はすぐには必要ではありませんが、[フォワーダー] ダッシュボードに複数のフォワーダーの結果が含まれていない場合は、アセットテーブルを再構築できます。複数のフォワーダーがある場合は、実⾏に時間がかかる場合があります。
1. モニター⽤コンソールで、[設定] > [フォワーダー監視設定][設定] > [フォワーダー監視設定] をクリックします。2. [フォワーダーアセットの再構築][フォワーダーアセットの再構築] をクリックします。
12

3. 時間範囲を選択するか、デフォルトの 24 時間をそのままにします。4. [再構築の開始][再構築の開始] をクリックします。
「お使いの App およびアドオンのレビュー」で後ほどサーバークラスと呼ばれる⼀群のフォワーダーを調査します。
モニターコンソールのセットアップを検証しますモニターコンソールのセットアップを検証します
モニターコンソールを使⽤してダイアグラムを記⼊している場合は、ほとんど完成しています。
精度を保証するために、そのモニターコンソールが以前の管理者により正確に設定されていたかを検証します。以下の、設定ファイルメソッドを使⽤します。モニターコンソールのセットアップを検証するには:
1. 複数のサーバーロールのあるインスタンス、つまりコンポーネントの 1 つまたは 2 つをテストします。2. モニターコンソールのインスタンスインスタンスページで、そのインスタンスに表⽰されているサーバーロールが収集し
た情報と⼀致しているかを、設定ファイルメソッドを使⽤して検証します。3. ⼀致しない場合は、他の設定ファイルの設定を調査して、その情報でデプロイダイアグラムを作成します。4. 本マニュアルにあるオリエンテーションタスクの残りを完了し、モニターシステムの正常性に達したら、モ
ニターコンソールセットアップを修正します。
トポロジを決定するために設定ファイルを調べるトポロジを決定するために設定ファイルを調べる
この検出⽅法では、各 Splunk Enterprise インスタンスに存在する特定の設定ファイルを調べます。ファイルには、存在または不在が、インスタンスがどのようなコンポーネントコンポーネントとして機能するかを判断するのに役⽴つ設定が含まれています。これらの設定は、コンポーネント間の関係、したがってトポロジ全体の関係を決定する際にも役⽴ちます。
検出プロセスは、各コンポーネントタイプの特徴的な設定を検出します。
ディスカバリープロセスについては、デプロイの図を描くと役に⽴ちます。「デプロイの図を描く」を参照してください。
前提条件前提条件
次の資料をお読みください:
『管理』マニュアル の「設定ファイルを使った Splunk Enterprise の管理」を参照してください。この章のトピックでは、設定ファイルの概要、設定ファイルの場所、および設定ファイルの階層構造について説明します。
トポロジーをデプロイします。このトピックでは、Splunk Enterprise デプロイの要素について説明し、デプロイトポロジーを検出する⽅法についての基本的な指針を解説しています。
設定ファイルの場所設定ファイルの場所
設定ファイルのコピーは、システムディレクトリと App ディレクトリを含む複数の場所に置くことができます。設定ファイルに複数箇所のコピーがある場合、ファイル内の各設定の有効値は、優先順位に基づいて、ファイルの階層化のプロセスによって決定されます。
設定ファイルの優先度の詳細は、『管理』マニュアルの「設定ファイルの優先度」を参照してください。設定ファイル層における複数箇所のコピー⽅法については、『管理』マニュアルの「構成ファイルの優先順位」を参照してください。
server.conf のようなコンポーネント設定はシステムレベルの設定であり、App 依存とならないために、通常は$SPLUNK_HOME/etc/system/local 下にのみ存在します。しかし、確実に設定を⾏うためには、それぞれの関連ファイルのコピーの可能な場所をすべて調べる必要があります。
設定ファイルを調べる⽅法設定ファイルを調べる⽅法
設定ファイルを調べる⼿段として、テキストエディターまたは btool ユーティリティを使⽤できます。
注意注意:テキストエディターを使⽤する場合は、ファイルを変更しないでください。
この $SPLUNK_HOME/bin 内の btool ユーティリティは、設定ファイルのすべてのコピーをすばやく調べる⽅法を提供します。btool のメリットは、ファイルのすべてのコピーをレイヤーした後に最終的な設定のレポートが返されることです。構⽂およびその他の詳細については、『トラブルシューティング』マニュアルの「btool を使⽤した設定のトラブルシューティング」を参照してください。
処理コンポーネントを検出する処理コンポーネントを検出する
まず、各インスタンスを調べて、処理コンポーネントをホストしているかどうかを確認します。その後、インスタンスを調べて、管理コンポーネントをホストしているかどうかを確認します。
処理コンポーネントを検出するには、次の 2 つの⼿順に従います:
1. サーチヘッドサーチヘッドとインデクサーインデクサーを特定する2. フォワーダーフォワーダーを特定します。
インスタンスは、通常、多くとも 1 つの処理コンポーネントを含みます。したがって、インスタンスごとに、各インスタンスに含まれる処理コンポーネントがある場合はそれらを特定するまで、各プロシージャを順番に実⾏し
13

ます。
処理中の処理コンポーネントは太字で⽰されています。
サーチヘッドとインデクサーを特定するサーチヘッドとインデクサーを特定する
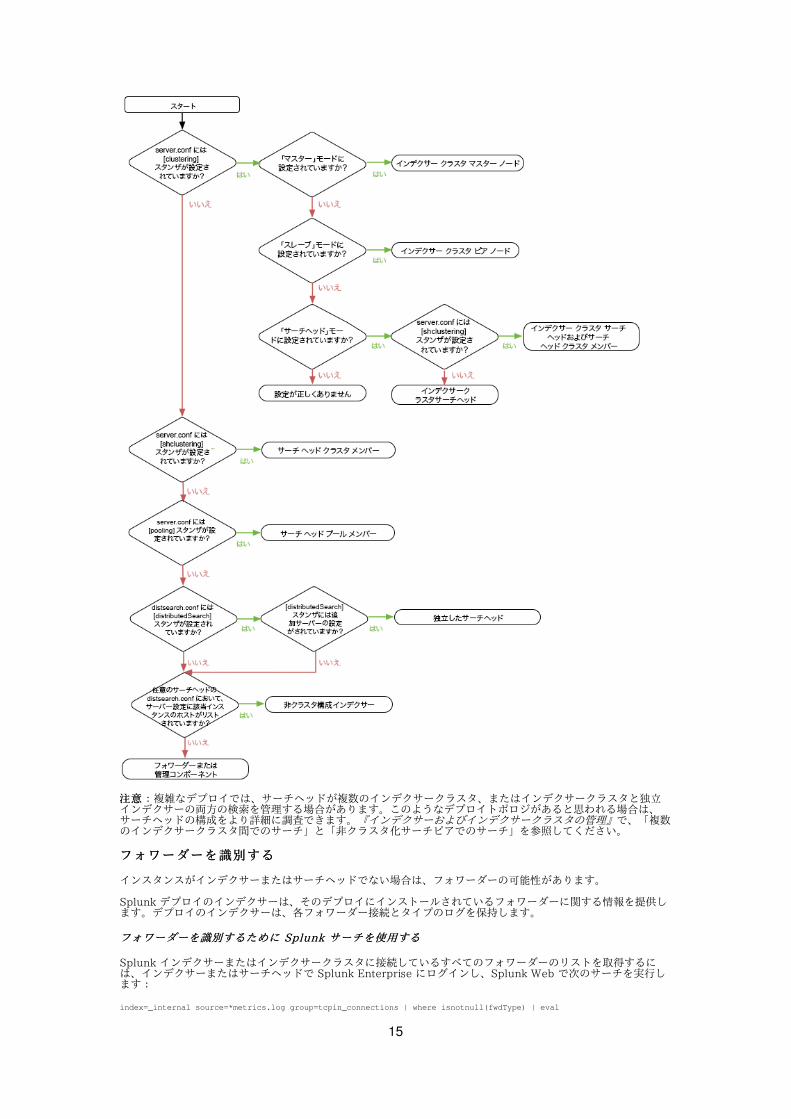
インスタンスがサーチヘッドかインデクサーかを判断し、存在する場合は、サーチヘッドまたはインデクサーのタイプを決定します。
1. $SPLUNK_HOME/etc/system/local 内の server.conf で調査します。1. [clustering] スタンザを探します。⾒つかった場合、このインスタンスはインデクサークラスタインデクサークラスタの
ノードです。
インデクサークラスタノードの種類を確認するには、mode の設定を調べます:1. mode = master、このインスタンスがインデクサークラスタマスターノードインデクサークラスタマスターノードの場合。ここで停⽌
します。
注意注意:マスターノードは、管理コンポーネントであり、処理コンポーネントではありません。マスターノードは、server.conf 内において設定されているため、処理コンポーネントのためにserver.conf を調べることは理にかなっています。
2. mode = slave の場合、このインスタンスがインデクサークラスタピアノードインデクサークラスタピアノードであり、クラスタクラスタ化インデクサー化インデクサーとも呼ばれます。ここで停⽌します。
3. mode = searchhead 、このインスタンスがインデクサークラスタサーチヘッドノードインデクサークラスタサーチヘッドノードの場合。次のステップに進み、このインデクサークラスタサーチヘッドがサーチヘッドクラスタサーチヘッドクラスタのメンバーでもあるかどうかを判断します。
2. [shclustering] スタンザを探します。⾒つかった場合、このインスタンスはサーチヘッドクラスタメサーチヘッドクラスタメンバーンバーです。ここで停⽌します。
注意注意:デプロイトポロジによっては、サーチヘッドクラスタメンバーをインデクサークラスタ内のサーチヘッドノードにすることも可能です。
3. [pooling] スタンザを探します。⾒つかった場合、このインスタンスはサーチヘッドプールメンサーチヘッドプールメンバーバーです。ここで停⽌します。
2. $SPLUNK_HOME/etc/system/local 内の distsearch.conf で調査します。1. [distributedSearch] スタンザ内において事前に設定された servers の設定を探します。⾒つかった場
合、このインスタンスは独⽴サーチヘッド独⽴サーチヘッドです。ここで停⽌します。
注意注意:サーチヘッドクラスタまたはサーチヘッドプールのメンバーであるサーチヘッドにも事前に設定された servers の設定が適⽤されます。ただし、この⼿順の初期段階で既にこのようなサーチヘッドを特定しているため、この時点で特定されたままの事前に設定された servers の設定のサーチヘッドは、独⽴サーチヘッドでなければなりません。
3. 以前にサーチヘッドクラスタメンバー、サーチヘッドプールメンバー、または独⽴したサーチヘッドとして識別されたすべてのインスタンスで servers 内の、distsearch.conf の設定を調べます。
servers のアドレスリストは、このサーチヘッドが接続するインデクサーのホストを指定します。このリストを使⽤して、デプロイ内のどのインスタンスが独⽴ (⾮クラスタ化) インデクサー独⽴ (⾮クラスタ化) インデクサーであるかを判断します。ここで停⽌します。
注意注意:インデクサークラスターでは、サーチヘッドは servers のリストを使⽤してインデクサーを指定しません。したがって、このリストにインデクサーが表⽰される場合、それは⾮クラスタ化インデクサーです。
サーチヘッドとインデクサーを特定すると、残りのインスタンスはフォワーダーまたは管理コンポーネントのいずれかになります。
次のフローチャートは、上記の⼿順をカプセル化します:
14
注意注意:複雑なデプロイでは、サーチヘッドが複数のインデクサークラスタ、またはインデクサークラスタと独⽴インデクサーの両⽅の検索を管理する場合があります。このようなデプロイトポロジがあると思われる場合は、サーチヘッドの構成をより詳細に調査できます。『インデクサーおよびインデクサークラスタの管理』で、「複数のインデクサークラスタ間でのサーチ」と「⾮クラスタ化サーチピアでのサーチ」を参照してください。
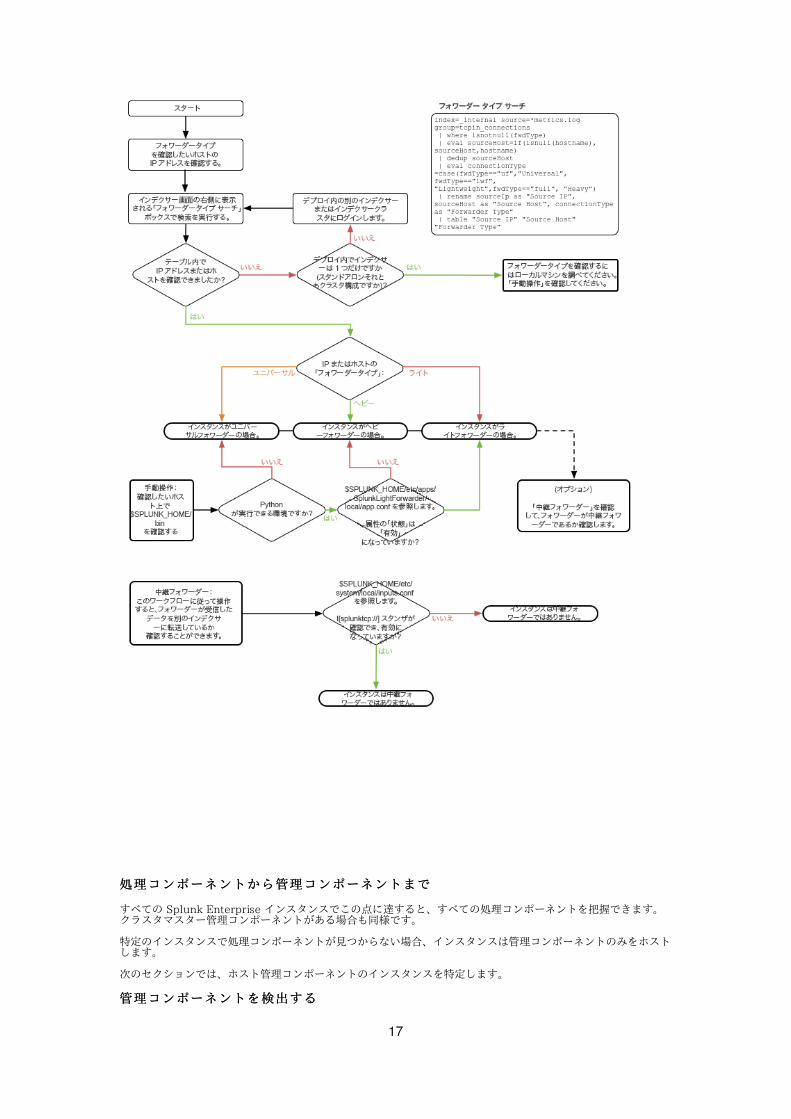
フォワーダーを識別するフォワーダーを識別する
インスタンスがインデクサーまたはサーチヘッドでない場合は、フォワーダーの可能性があります。
Splunk デプロイのインデクサーは、そのデプロイにインストールされているフォワーダーに関する情報を提供します。デプロイのインデクサーは、各フォワーダー接続とタイプのログを保持します。
フォワーダーを識別するために Splunk サーチを使⽤するフォワーダーを識別するために Splunk サーチを使⽤する
Splunk インデクサーまたはインデクサークラスタに接続しているすべてのフォワーダーのリストを取得するには、インデクサーまたはサーチヘッドで Splunk Enterprise にログインし、Splunk Web で次のサーチを実⾏します:
index=_internal source=*metrics.log group=tcpin_connections | where isnotnull(fwdType) | eval
15

sourceHost=if(isnull(hostname), sourceHost,hostname) | dedup sourceHost | eval connectionType
=case(fwdType=="uf","Universal", fwdType=="lwf", "Lightweight", fwdType=="full","Heavy") | rename sourceIp as
"Source IP", sourceHost as "Source Host", connectionType as "Forwarder Type" | table "Source IP" "Source Host"
"Forwarder Type"
フォワーダーのステータスとタイプを確認するマシンの IP アドレスまたはホスト名がある場合は、サーチを変更してホスト名、 IP アドレスを指定できます:
index=_internal source=*metrics.log group=tcpin_connections [sourceIp=<ip address>|hostname=<host name>] | where
isnotnull(fwdType) | eval sourceHost=if(isnull(hostname), sourceHost,hostname) | dedup sourceHost | eval
connectionType =case(fwdType=="uf","Universal", fwdType=="lwf", "Lightweight", fwdType=="full", "Heavy") | rename
sourceIp as "Source IP", sourceHost as "Source Host", connectionType as "Forwarder Type" | table "Source IP" "Source
Host" "Forwarder Type"
これらのサーチで⽣成されるテーブルに情報が必要なマシンの情報が表⽰されない場合や、Splunk Web にアクセスできない場合は、マシン⾃体を調べてフォワーダータイプを判断できます。
⼿動でフォワーダーを識別する⼿動でフォワーダーを識別する
1. 状態を確認したいマシンで、$SPLUNK_HOME/bin ディレクトリを調べます。python 実⾏可能ファイル (python.exeが Windows の場合) がこのディレクトリに存在するかどうかを確認します。
1. 存在しない場合、このインスタンスはユニバーサルフォワーダーユニバーサルフォワーダーです。ここで停⽌するか、次のセクションで中間フォワーダーを識別することができます。
2. 存在する場合は、$SPLUNK_HOME/etc/apps/SplunkLightForwarder/local/app.conf において、ファイルの state の設定が enabled に設定されているかどうかを確認します。
1. その場合、インスタンスはライトフォワーダーライトフォワーダーです。いずれの場合も、次のセクションで中間フォワーダーの識別に進みます。
2. そうでない場合、次のセクションでヘビーフォワーダーヘビーフォワーダーの識別に進みます。いずれの場合も、次のセクションで中間フォワーダーの識別に進みます。
中間フォワーダーを識別する中間フォワーダーを識別する
中間フォワーダーは、他のフォワーダーからデータを受信してインデクサーに送信します。いずれのフォワーダーも中間フォワーダーにすることが可能です。
1. $SPLUNK_HOME/etc/system/local/inputs.conf のフォワーダーを確認します。splunktcp:// のスタンザがあり、有効になっていますか?
存在する場合、インスタンスは中間フォワーダーです。存在しない場合、インスタンスは中間フォワーダーではありません。
フォワーダーの検出の仕組みについては、次のフローチャートを参照してください:
16
処理コンポーネントから管理コンポーネントまで処理コンポーネントから管理コンポーネントまで
すべての Splunk Enterprise インスタンスでこの点に達すると、すべての処理コンポーネントを把握できます。クラスタマスター管理コンポーネントがある場合も同様です。
特定のインスタンスで処理コンポーネントが⾒つからない場合、インスタンスは管理コンポーネントのみをホストします。
次のセクションでは、ホスト管理コンポーネントのインスタンスを特定します。
管理コンポーネントを検出する管理コンポーネントを検出する
17

管理コンポーネントは、専⽤の Splunk Enterprise インスタンスに配置することも、プロセッシングコンポーネントと⼀緒に配置することも、他の管理コンポーネントと⼀緒に配置することもできます。したがって、SplunkEnterprise インスタンスには管理コンポーネントが含まれている可能性があります。
ただし、ユニバーサルフォワーダーインスタンスには管理コンポーネントを含めることはできません。
また、通常、デプロイ全体の管理コンポーネントは最⼤でも 1 つです。たとえば、デプロイサーバーをホストするインスタンスが特定された場合は、他のデプロイサーバーインスタンスの検索を中⽌できます。
この表は、管理コンポーネントごとに、キーインジケータと、インジケータに関連する設定ファイルがある場合は、それらを⽰しています。
コンポーネントタイプコンポーネントタイプ 設定ファイル設定ファイル キーインジケータキーインジケータ
モニターコンソール$SPLUNK_HOME/etc/apps/splunk_monitoring_console
/splunk_management_console_assets.conf
既存のsplunk_management_console_assets.conf
デプロイサーバーデプロイサーバー $SPLUNK_HOME/etc/system/local/serverclass.conf [serverClass:<name>] スタンザ
ライセンスマスターライセンスマスター $SPLUNK_HOME/etc/system/local/server.conf[license] スタンザと master_uri =self
インデクサークラスタインデクサークラスタマスターマスター
$SPLUNK_HOME/etc/system/local/server.conf [cluster] スタンザと mode = master
サーチヘッドクラスタサーチヘッドクラスタデプロイヤーデプロイヤー N/A
事前に設定された$SPLUNK_HOME/etc/shcluster/ ディレクトリ
このトピックのすべての⼿順を完了したのち、Splunk Enterprise トポロジの仕様を理解することをお勧めします。各インスタンスの場所と機能、およびインスタンス間の関係を把握しておくことをお勧めします。
コンポーネントとそれらのネットワークとの関係コンポーネントとそれらのネットワークとの関係
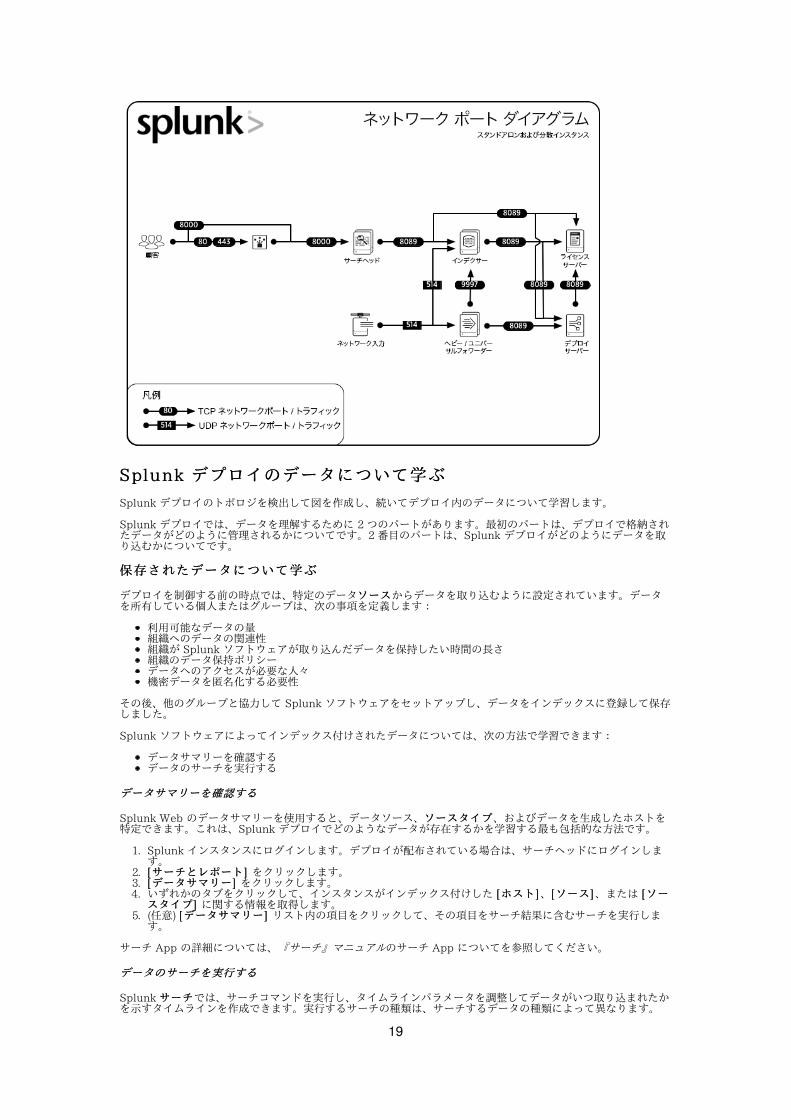
Splunk Enterprise コンポーネントが複数のマシンにわたって分散している場合、さらにコンポーネントが 1 台のマシンにある場合でも、適切に動作するためにネットワーク接続が必要です。
Splunk コンポーネントは TCP および UDP ネットワークプロトコルを使ってお互いに通信しています。これらのポートが開けるようには設定されていないファイアウォールが、Splunk インスタンス間の通信をブロックします。
Splunk ソフトウェアはデフォルトまたは慣例的に以下のネットワークポートを使⽤してコンポーネント間で通信しています。ポートで待機しているかどうか判断するためにホストでネットワークポートスキャンを実⾏できます。オープンポート番号をデプロイプログラムに記録します。
コンポーネントコンポーネント ⽬的⽬的 通信通信 待機待機
全コンポーネント* 管理 / REST API N/A TCP/8089
サーチヘッド / インデクサー Splunk Web アクセス いずれでも可 TCP/8000
サーチヘッド App キー・バリュー・ストア
いずれでも可
TCP/8065、TCP/8191
インデクサー フォワーダーからデータ受信 N/A TCP/9997
インデクサークラスタピアノード / サーチヘッドクラスタメンバー クラスタ複製 N/A TCP/9887
インデクサー / フォワーダー ネットワーク⼊⼒(syslog) N/A UDP/514
ダイアグラムダイアグラム
以下のダイアグラムは Splunk ソフトウェアが待機するネットワークポートを⽰しています。
18
Splunk デプロイのデータについて学ぶSplunk デプロイのデータについて学ぶ
Splunk デプロイのトポロジを検出して図を作成し、続いてデプロイ内のデータについて学習します。
Splunk デプロイでは、データを理解するために 2 つのパートがあります。最初のパートは、デプロイで格納されたデータがどのように管理されるかについてです。2 番⽬のパートは、Splunk デプロイがどのようにデータを取り込むかについてです。
保存されたデータについて学ぶ保存されたデータについて学ぶ
デプロイを制御する前の時点では、特定のデータソースソースからデータを取り込むように設定されています。データを所有している個⼈またはグループは、次の事項を定義します:
利⽤可能なデータの量組織へのデータの関連性組織が Splunk ソフトウェアが取り込んだデータを保持したい時間の⻑さ組織のデータ保持ポリシーデータへのアクセスが必要な⼈々機密データを匿名化する必要性
その後、他のグループと協⼒して Splunk ソフトウェアをセットアップし、データをインデックスに登録して保存しました。
Splunk ソフトウェアによってインデックス付けされたデータについては、次の⽅法で学習できます:
データサマリーを確認するデータのサーチを実⾏する
データサマリーを確認するデータサマリーを確認する
Splunk Web のデータサマリーを使⽤すると、データソース、ソースタイプソースタイプ、およびデータを⽣成したホストを特定できます。これは、Splunk デプロイでどのようなデータが存在するかを学習する最も包括的な⽅法です。
1. Splunk インスタンスにログインします。デプロイが配布されている場合は、サーチヘッドにログインします。
2. [サーチとレポート][サーチとレポート] をクリックします。3. [データサマリー][データサマリー] をクリックします。4. いずれかのタブをクリックして、インスタンスがインデックス付けした [ホスト][ホスト]、[ソース][ソース]、または [ソー[ソー
スタイプ]スタイプ] に関する情報を取得します。5. (任意) [データサマリー][データサマリー] リスト内の項⽬をクリックして、その項⽬をサーチ結果に含むサーチを実⾏しま
す。
サーチ App の詳細については、『サーチ』マニュアルのサーチ App についてを参照してください。
データのサーチを実⾏するデータのサーチを実⾏する
Splunk サーチサーチでは、サーチコマンドを実⾏し、タイムラインパラメータを調整してデータがいつ取り込まれたかを⽰すタイムラインを作成できます。実⾏するサーチの種類は、サーチするデータの種類によって異なります。
19

[データサマリー] を使⽤して、インスタンスにインデックス付けされたものとサーチ可能なものを知ることができます。
1. Splunk インスタンスにログインします。2. [サーチとレポート][サーチとレポート] をクリックします。3. 表⽰させたいデータを表すサーチを⼊⼒します。持っているデータがわからない場合は、データサマリーを
使⽤できます。4. (任意) イベントのタイムラインを使⽤して、イベントがどの程度巻き戻るかを判断します。5. (任意) 時間ピッカーを異なる時間範囲に設定して、その範囲内でのみ発⽣するイベントを表⽰します。6. サーチパラメータを変更するか、その項⽬に基づいて新しいサーチを実⾏するには、結果の個々の項⽬をク
リックします。
検索の詳細については、『サーチ』マニュアルの「サーチの詳細な分析」を参照してください。
デプロイのデータジェネレータについて学ぶデプロイのデータジェネレータについて学ぶ
Splunk ソフトウェアがデータを受信するためには、データ⼊⼒データ⼊⼒にて設定する必要があります。⼊⼒は Splunk インデクサーで設定できますが、ほとんどのデプロイでは、フォワーダーフォワーダーは⼊⼒で設定され、データコレクションを⾏います。データはフォワーダーからインデクサーに流れ、Splunk ソフトウェアはデータをサーチ、レポーレポートト、ダッシュボードダッシュボードの基礎となるイベントイベントに分割したり、組織内のデータコンシューマのニーズに合わせて変更することができます。
Splunk ソフトウェアは、さまざまな種類のマシンデータを取り込むことができます。『データの取り込み』マニュアル には、Splunk ソフトウェアが取り込むことができるマシンデータに関する情報が含まれていますが、これに限定されません:
ログファイルスクリプトと処理からのデータHTTP イベントコレクタによる TCP、UDP、HTTP トラフィックのモニタリングを含むネットワークストリームWindows イベントログ、レジストリ変更、およびパフォーマンスモニタリングのメトリックを含むWindows データ
Splunk ソフトウェアが⼊⼒設定を使ってデータを取得する⽅法についての学習Splunk ソフトウェアが⼊⼒設定を使ってデータを取得する⽅法についての学習
Splunk デプロイトポロジーを検出した後で、世代データの⽣成場所を指定できます。デプロイトポロジーを検出する過程でこれを⾏うこともできますが、デプロイトポロジーが検出された後で設定に関する情報を収集する⽅が簡単です。
フォワーダーとインデクサーは、データ⼊⼒やその他の設定をいくつかの⽅法で取得できます:
ローカルでは、inputs.conf 設定ファイル設定ファイルを使⽤します。これは、Splunk インスタンスが設定情報を取得する⽅法の最も⼀般的な⽅法ですインスタンスにインストールされている AppApp またはアドオンアドオンを介してフォワーダーまたはインデクサーが接続しているデプロイサーバーデプロイサーバーから
デプロイサーバーは、このトピックの範囲外の⾼度な設定トピックです。デプロイサーバーとその動作の詳細については、『Splunk Enterprise インスタンスの更新』の「デプロイサーバーとフォワーダー管理について」を参照してください。
inputs.conf ファイルは、データ⼊⼒を定義し、フォワーダーまたはインデクサーのデータコレクションの側⾯を制御します:
いつデータを収集するか収集するデータの種類データの収集頻度収集したデータをどこにインデックスするか収集したデータをインデックス付けする⽅法
フォワーダーでは、フォワーダーがデータを送信する場所を制御するファイル outputs.conf があります。inputs.conf のように、スタンドアロン設定、App またはアドオンの⼀部である設定、またはデプロイサーバーから取得された設定です。
Splunk ソフトウェアは、設定ファイル優先順位と呼ばれる⽅式を使⽤して、複数のデータコレクションおよび転送シナリオを処理するためのマスター設定ファイルを構築します。『管理』マニュアルの「設定ファイルの優先度」を参照してください。
Splunk データコレクション設定を検出するSplunk データコレクション設定を検出する
次の⼿順は、Splunk デプロイへの⼊⼒を決定するための⾼度なガイダンスを⽰しています。
1. デプロイでインデクサーとフォワーダーを⾒つけた後、データ⼊⼒⽤のローカル設定があるかどうかを確認し、App またはアドオンから設定を取得するか、デプロイサーバーから設定を取得します。
2. フォワーダーがデプロイサーバーに接続するように設定されている場合は、デプロイサーバをチェックして設定を確認します。このサーバーに接続するフォワーダーは、これらの設定を取得します。設定はスタンドアロン、App やアドオンにも含まれます。
3. inputs.conf 設定ファイルを確認して、収集されているデータを確認します。これらのファイルは以下の場所にあります:
1. 単体の場合は、 $SPLUNK_HOME/etc/system/local2. App やアドオンでは、 $SPLUNK_HOME/etc/apps/<name of app>/local3. デプロイサーバーでは、 $SPLUNK_HOME/etc/deployment_apps/<name of app>/local
4. 各インスタンスが収集するデータの種類については、『データの取り込み』マニュアル を参照してくださ
20

い。5. Splunk デプロイのダイアグラムがある場合は、ダイアグラム内のデータ収集インスタンスの場所と収集す
るデータを指定します。
次のステップ次のステップ
データ⼊⼒の場所を確認したのち、以下の操作を実⾏できます:
ビジネス⽬的またはデータコレクションパフォーマンスの向上に応じて、⼊⼒設定を追加、変更、または削除する必要があるかどうかを判断します。モニター⽤コンソールをまだ設定していない場合は、設定するかどうかを決定します。データを取得するための Splunk のベストプラクティスに従って、データのインデックスを変更する必要があるかどうかを判断します。
App やアドオンを確認するApp やアドオンを確認する
⼤規模な組織向けに Splunk Enterprise のデプロイを継承した場合、多くの App とアドオンがシステム上で実⾏されている可能性があります。このトピックでは、Splunk App とアドオンの概要を説明し、Splunk Enterpriseインスタンスにインストールされている App とアドオンの識別を⼿助けします。
システム上で実⾏されている Splunk Premium Solution App を特定することが重要です。これらの App は、IT運⽤やセキュリティなどの特定のユースケースに関する包括的なデータ分析を提供し、追加のリソースと管理が必要となる場合があります。
Splunk App とアドオンの概要Splunk App とアドオンの概要
Splunk App とアドオンは、Splunk Enterprise インスタンスにインストールする設定ファイルのパッケージ化されたセットです。App とアドオンは次のように定義されています:
AppApp:Splunk App は、データを扱うためのユーザーインターフェイスを提供します。App は、多くの場合、1つ以上のアドオンを使⽤してさまざまなタイプのデータを取り込みます。Splunk Enterprise 『管理』マニュアルの「Apps とアドオン」を参照してください。
アドオンアドオン:アドオンは Splunk Enterprise または Splunk App での特定の種類のデータの取り込みやマッピングを可能にします。『Splunk アドオン』マニュアルの「Splunk アドオンについて」を参照してください。
すべての Splunk App とアドオンは Splunk Enterprise 上で動作します。Splunk Enterprise には SplunkSearch and Reporting App が含まれています。この App は、Splunk Enterprise のコア検索環境を提供し、保保存済みサーチ存済みサーチ、レポートレポート、アラートアラート、ダッシュボードダッシュボード、データセットデータセットなどの Splunk ナレッジオブジェクナレッジオブジェクトトを作成および管理することができます。
デプロイの要件と考慮事項デプロイの要件と考慮事項
Splunk App とアドオンは、シングルインスタンス、分散、クラスター、およびクラウド環境を含む、サポートされている Splunk Enterprise デプロイトポロジで実⾏されます。既存の Splunk Enterprise デプロイトポロジの詳細については、このマニュアルの「デプロイトポロジ」を参照してください。
App やアドオンの特別な要件や考慮事項を理解するには、特定の App やアドオンのドキュメントを確認してください。サポートされているすべての Splunk App とアドオンのドキュメントにアクセスするには、「Splunk ドキュメント」を参照してください。
多くの Splunk App は Splunk Cloud 上でのデプロイのために認定されています。Splunk クラウドでの App のデプロイに問題が発⽣した場合や、Splunk クラウドに追加の App をデプロイする場合は、Splunk サポートにお問い合わせください。
詳細は、以下の項⽬を参照してください。
『管理』マニュアルの App デプロイの概要。Splunk アドオンの 『Splunk アドオン』マニュアルへのインストール箇所。
App やアドオンを調べるApp やアドオンを調べる
Splunk Enterprise UI である Splunk Web を使⽤するか、コマンドラインを使⽤してサーチヘッド上のファイルシステムをナビゲートすることで、システムにインストールされているすべての App とアドオンを表⽰できます。
Splunk Web で App とアドオンを表⽰するSplunk Web で App とアドオンを表⽰する
Splunk Web の [Manage apps] ページでは、デプロイにインストールされているすべての App とアドオンにアクセスできます。App 名、フォルダ名、バージョンなど、アプリに関する情報を表⽰できます。また、App を有効または無効にすることや、ロールベース・アクセス制御を使⽤した App の権限の設定、プロパティの編集やオブジェクトの表⽰などの操作を実⾏することもできます。
1. Splunk Webを開きます。有効なアプリはすべて、左側の [App] 列に表⽰されます。
2. [Apps]> [App の管理][Apps]> [App の管理] をクリックします。[App の管理] ページが開きます。
3. Splunk Enterprise インスタンスにインストールされている App とアドオンのリストを確認します。
詳細は、以下の項⽬を参照してください。
21

このトピックの App とアドオンオブジェクトを表⽰します。『管理』マニュアルの App とアドオンのプロパティを編集します。
サーチヘッド上のファイルシステムを使⽤して App とアドオンを表⽰するサーチヘッド上のファイルシステムを使⽤して App とアドオンを表⽰する
1. サーチヘッドにログインします。2. $SPLUNK_HOME/etc/apps ディレクトリに移動します。
システムにインストールされているすべての App とアドオンは、apps ディレクトリにあります。3. App やアドオンを確認します。
App およびアドオンの命名規則App およびアドオンの命名規則
Splunk App のフォルダ名は、App の商品名のバリエーションまたは省略形を使⽤します。次の表にいくつかの例を⽰します。
App の名前App の名前 App フォルダ名App フォルダ名
Splunk Enterprise のセキュリティ SplunkEnterpriseSecuritySuite
Splunk IT のサービスインテリジェンス itsi
Splunk のアドオンフォルダ名は、通常、次の接頭辞のいずれかを使⽤します:
アドオンプレフィックスアドオンプレフィックス アドオンの説明アドオンの説明 名前例名前例
TA Splunk テクノロジーアドオン Splunk_TA_stream
SA Splunk をサポートするアドオン SA-ITOA
DA Splunk ドメインアドオン (ITSI モジュール) DA-ITSI-OS
App とアドオンオブジェクトを表⽰するApp とアドオンオブジェクトを表⽰する
App またはアドオンを作成すると、Splunk Enterprise は App またはアドオンを構成するオブジェクトのコレクションを作成します。これらのオブジェクトには、ビュー、コマンド、ナビゲーション項⽬、イベントタイプ、保存済みサーチ、レポートなどが含まれます。
さらに、各 App オブジェクトには、オブジェクトを表⽰または編集できるユーザーを決定するロールベースの権限が関連付けられています。デフォルトでは、Splunk Enterprise の管理ユーザーは書き込み権限を持ち、システム全体のすべてのオブジェクトを編集できます。
Splunk Web を使⽤して、特定の App またはアドオンに関連するすべてのオブジェクトを次のように表⽰します。
1. Splunk Web で、[設定] > [すべての設定][設定] > [すべての設定] をクリックします。2. [App コンテキスト][App コンテキスト] メニューで、オブジェクトを表⽰する App の名前を選択します。3. [この App コンテキストで作成されたオブジェクトのみを表⽰する][この App コンテキストで作成されたオブジェクトのみを表⽰する] チェックボックスをオンにしま
す。
詳細は、以下の項⽬を参照してください。
『管理』マニュアルの App とアドオンオブジェクトを管理します。『管理』マニュアルの App アーキテクチャとオブジェクトの所有権。
KV ストアを使⽤する App を特定するKV ストアを使⽤する App を特定する
KV ストアKV ストア は、デフォルトですべての Splunk Enterprise バージョン 6.2 以降のインスタンスに存在し、サーチヘッドで有効になることがよくあります。KV ストアは App に関する状態情報を保持することができます。さらに、Enterprise Security のような⼀部の App は、ルックアップに KV ストアを使⽤します。KV ストアは、デフォルトでポート 8191 を使⽤してサーチヘッドにデータを複製します。KV ストアプロセスは、サーチヘッドクラスタのプロセスとは独⽴しています。
Splunk コマンドラインインターフェイスを使⽤して KV ストアのメンバーを検出します。『管理』マニュアルの「CLI について」を参照してください。
1. サーチヘッドにログインします。2. タイプ ./splunk show kvstore-status
次のことに注意してください:
無効にするかどうかは 1 または 0 です。どのノードが KV ストアクラスタのメンバーであるか。KV ストアが使⽤しているポート番号。
デプロイ図に KV ストアのメンバーとポート番号を追加します。このコマンドは、どのノードがキャプテンであるかの情報も返しますが、この段階ではこの情報は役に⽴ちません。キャプテンシーは変わる可能性があるので、この詳細に関しては、ダイアグラムを残しておいてください。
次に、KV ストアを使⽤する App があればそれを決定します。22

⼀般的に KV ストアを使⽤する App には、$SPLUNK_HOME/etc/apps/<app name>/default に collections.conf が定義されています。加えて、transforms.conf は、external_type = kvstore でコレクションを参照しています。
コレクションが定義されている App のリストについては:
1. サーチヘッドにログインします。2. コマンドラインで、Splunk のインストールディレクトリから次のように⼊⼒します ./splunk btool
collections list --debug
3. 結果では、次からアイテムを探します $SPLUNK_HOME/etc/apps
詳細は、以下の項⽬を参照してください。
開発者ポータルのキー値ストアを使⽤して状態を管理します。『ナレッジ管理』マニュアルの KV ストアルックアップを設定する『管理』マニュアルの App Key Value Store について。『管理』マニュアルの KV ストアのトラブルシューティングツール。
デプロイ App を特定するデプロイ App を特定する
分散型 Splunk Enterprise デプロイでは、デプロイサーバーデプロイサーバーを使⽤して、フォワーダー、⾮クラスタ化インデクサー、サーチヘッドなどの Splunk Enterprise コンポーネントのグループに、App および設定ファイルの更新を配布します。これらの App と設定ファイルはデプロイ Appデプロイ App と呼ばれます。デプロイ App は、デプロイサーバーのロールが割り当てられた Splunk Enterprise インスタンスに存在し、$SPLUNK_HOME/etc/deployment-apps ディレクトリにあります。
Splunk Web でデプロイ App を表⽰する:
1. どの Splunk Enterprise インスタンスにデプロイサーバーのロールが割り当てられているかを特定します。正しい Splunk Enterprise インスタンスの検出については、このマニュアルの「管理コンポーネントの検出」を参照してください。
2. デプロイサーバーにログインします。3. [設定] > フォワーダー管理][設定] > フォワーダー管理] をクリックします。4. [フォワーダー管理] ページでは、次の点に注意してください。
AppApp:App は、現在デプロイサーバによって配布されているデプロイ App です。クライアントクライアント:クライアントは、デプロイサーバーがデプロイ App を配布するリモートの SplunkEnterprise インスタンスです。サーバークラスサーバークラス:サーバークラスは、デプロイクライアントのグループです。サーバークラスは、App 更新を受信するクライアントの特定のセットを定義します。
5. デプロイダイアグラムにサーバークラスを記録します。
デプロイサーバー上のファイルシステムを使⽤して、デプロイ App を表⽰します。
1. デプロイサーバーをホストしているマシンにログインします。2. 次に移動: $SPLUNK_HOME/etc/deployment-apps3. デプロイサーバーによって現在配布されている App をメモします。
詳細は、以下の項⽬を参照してください。
『Splunk Enterprise インスタンスの更新』のデプロイサーバーとフォワーダー管理について『Splunk Enterprise インスタンスの更新』で、クライアントに App をデプロイします。
サーチヘッドクラスタサーチヘッドクラスタ、インデクサーインデクサー、およびインデクサークラスタインデクサークラスタへの App のデプロイについては、以下を参照してください:
『分散サーチ』の「デプロイヤーを使った App と設定更新の配布」を参照してください。詳細は、『インデクサーとインデクサーのクラスタの管理』の「共通のピア設定と App の更新」を参照してください。
App は Splunkbase からダウンロードできます。App は Splunkbase からダウンロードできます。
Splunk は、データの取り込み、サーチ、分析機能を拡張するのに役⽴つ、無料で購⼊できる多数の App とアドオンを提供しています。Splunk App とアドオンは Splunkbase からダウンロードできます。
Splunk P remium Solutions の概要Splunk P remium Solutions の概要
Splunk Premium Solutions は、Splunk によって開発された App で、IT オペレーションの分析やセキュリティの脅威の検出や分析などの特定のユースケースに対して包括的なデータサーチと分析機能を提供します。
Splunk は以下のプレミアムソリューションを提供しています:
Splunk Enterprise のセキュリティSplunk IT のサービスインテリジェンスSplunk ユーザー⾏動分析 (UBA)
ES と ITSI の要件と考慮事項ES と ITSI の要件と考慮事項
Splunk ES および ITSI プロダクションデプロイは、リソースを⼤量に消費する可能性があります。同時サーチ23

数、1 ⽇のインデックス量、使⽤していない容量など、いくつかの要因によって、Splunk Enterprise ハードウェアの上に追加のハードウェアが必要になることがあります。最新の Splunk Enterprise ハードウェア要件については、Splunk Enterprise 『キャパシティプランニング』マニュアル の「リファレンスハードウェア」を参照してください。
ES や ITSI のパフォーマンスに影響する要因、実⾏中の相関や KPI サーチの回数、システム上の同時ユーザー数などに習熟する必要があります。これらは、システムのパフォーマンスを評価し、デプロイの⽅法と時期を決定するために役⽴ちます。
デプロイの構成に影響を与える可能性のあるサーチヘッドおよびインデクサーに関する考慮事項に習熟することが重要です。たとえば、Splunk ES は専⽤のサーチヘッドを必要としますが、ITSI は必要としません。
ES パフォーマンスと容量計画、サーチヘッドとインデクサーの考慮事項については、Splunk EnterpriseSecurity 『インストールおよびアップグレード』マニュアルの「デプロイプランニング」を参照してください。
ITSI のパフォーマンスと容量計画、サーチヘッドとインデクサーに関する考慮事項については、Splunk ITSI 『インストールおよび設定マニュアル』の「デプロイプランニング」を参照してください。
Splunk Enterpr ise Secur i ty の概要Splunk Enterpr ise Secur i ty の概要
Splunk Enterprise Security (ES) は、データ内のパターンを検出し、相関検索を使⽤してセキュリティに関連するインシデントのイベントを評価します。相関サーチ相関サーチにより不審なパターンが検出されると、新しい重要イベン重要イベントトが⽣成されます。この App では、セキュリティインシデントの識別、分類、分析に使⽤できる特殊なダッシュボードとビジュアライゼーションを提供しています。
Splunk Enterprise のシステム要件をご覧ください。
ES 相関サーチを表⽰するES 相関サーチを表⽰する
Splunk Enterprise Security で利⽤可能な相関サーチと、Splunk Enterprise Securityが検出に使⽤しているユースケースをよりよく理解できるサーチを表⽰します。Splunk Enterprise Security で有効になっている相関サーチのリストを取得するために、REST サーチを使⽤して表内の情報を表⽰することができます。『SplunkEnterprise Security の管理』の Splunk Enterprise Security「相関サーチの作成」を参照してください。
コンテンツプロファイルダッシュボードコンテンツプロファイルダッシュボード
Enterprise Security は、CIM 特有のデータモデルまたは ES 固有のデータモデルにマッピングされたデータを使⽤し、⾼速化されて幅広いテクノロジセットでより⾼速なサーチ結果を⽣成します。ご使⽤の環境で使⽤中のデータモデルを確認し、[コンテンツプロファイル] ダッシュボードのデータモデルに対応するナレッジオブジェクトの概要を確認します。「Splunk Enterprise Security を使⽤する」の「コンテンツプロファイル」を参照してください。
データモデルの監査ダッシュボードデータモデルの監査ダッシュボード
さらに、[データモデルの監査] ダッシュボードおよびデータモデルの保持およびアクセラレーション設定で、データモデルのステータスを確認できます。完全に加速されていないデータモデルは、Splunk Enterprise Securityのダッシュボードや重要なイベントに関する情報が失われたり古いものになる可能性があります。『SplunkEnterprise Securityのインストールと更新』マニュアル内、「Splunk エンタープライズセキュリティを使⽤する」の「データモデル監査」および「Splunk エンタープライズセキュリティのデータモデルを設定する」を参照してください。
Splunk Enterprise Security についての詳細はこちらSplunk Enterprise Security についての詳細はこちら
重要な Splunk Enterprise Security の概念と機能の詳細については、以下を参照してください:
『Splunk Enterprise Security の管理』のインシデントレビュー。『Splunk Enterprise Security の管理』の相関サーチ概要。『Splunk Enterprise Security の管理』のアセットと ID データを Splunk Enterprise Security に追加する。『Splunk Enterprise Security の管理』の Splunk Enterprise Security に脅威インテリジェンスを追加する。『Splunk Enterprise Security を使⽤する』におけるリスク分析。『Splunk Enterprise Security を使⽤する』においてセキュリティインテリジェンスによる調査を迅速化する。『Splunk Enterprise Security を使⽤する』においてセキュリティドメインアクティビティをモニターする。
Splunk IT Service Intelligence の概要Splunk IT Service Intelligence の概要
Splunk IT Service Intelligence (ITSI) は、ITパフォーマンスメトリクスの重⼤度レベルを追跡する主要業績評価指標 (KPI) を使⽤して、IT サービスの健全性をモニターします。KPI 値がしきい値条件を満たすと、ITSI は重要なイベントを⽣成します。この App は、重要なイベントを集約し分析する機能と、IT サービスを継続的にモニターし根本原因の調査を実⾏できるダッシュボードとビジュアライゼーション機能を提供します。
Splunk IT Service Intelligence のドキュメントを参照してください。
ITSI サービスとサービス KPI を表⽰するITSI サービスとサービス KPI を表⽰する
サービスとサービスに含まれる KPI を確認します。これらは、サービスが監視している IT 運⽤とビジネスプロセスを理解し、サービスの状態を評価するために使⽤されているパフォーマンスメトリクスを特定するために役⽴ちます。また、KPI の状態を決定するソースサーチタイプ (データモデル、アドホック、ベースサーチ)、計算 (サー
24

チ頻度と計算された統計)、重⼤度レベルのしきい値など、KPI のサーチプロパティを理解するために役⽴ちます。
サービスとサービス KPI を表⽰するには:
1. ITSI の [メイン] メニューで、[設定]> [サービス][設定]> [サービス] の順にクリックします。2. サービスの⼀覧を確認します。3. 任意のサービスをクリックします。たとえば、データベースサービスなどです。サービス設定ワークフロー
が表⽰されます。4. サービスに含まれる KPI の⼀覧を確認します。各 KPI は、CPU 使⽤率、メモリフリー %、応答時間など
の IT パフォーマンスメトリックを表します。5. リスト内の任意の KPI をクリックします。6. [サーチと計算] パネルを開きます。7. [ソース] で、[しきい値] フィールド[しきい値] フィールドをメモします。これは、KPI サーチで値が返されるデータ内のフィー
ルドです。たとえば、cpu_load_percent などです。ソースサーチの詳細を調べるには、[編集][編集] をクリックします。ITSI モジュールによって提供されるようなベースサーチは、最良のサーチパフォーマンスを提供する傾向にあることに注意してください。
8. エンティティについては、エンティティエイリアスフィルタの設定に注意してください。これにより、KPIサーチが実⾏されるエンティティが決定されます。
9. 計算の場合は、KPI が計算する統計値、たとえば Average をメモします。また、KPI の頻度と時間範囲にも注意してください。KPI は、1 分、5 分、または 15 分ごとに実⾏できます。
10. [しきい値] パネルを開きます。11. [しきい値] プレビューグラフで、KPI に設定されている重⼤度レベルのしきい値を確認します。KPI 値がし
きい値条件を満たしている場合、KPI の正常性ステータスは、たとえば⾼から重⼤に変化します。
詳細は、以下の項⽬を参照してください。
ITSI 『インストールおよび設定』マニュアルでサービスを作成します。ITSI 『インストールおよび設定』マニュアルで ITSI サービスを設定します。
関連するエンティティを確認する関連するエンティティを確認する
サービスに関連するエンティティを特定します。エンティティは、ITSI サービスのプライマリデータソースとして機能する IT コンポーネントです。KPI サーチは、定義したフィルタリング条件に基づいてエンティティに対して実⾏されます。より複雑な ITSI デプロイでは、単⼀のエンティティを複数のサービスに関連付けることができ、複数の異なる KPI を実⾏することができます。
サービスに関連付けられたエンティティを表⽰するには:
1. ITSI の [メイン] メニューで、[設定] > [エンティティ][設定] > [エンティティ] の順にクリックします。2. エンティティのリストを確認します。[サービス] 列で、各エンティティに関連付けられているサービスをメ
モします。3. リスト内の任意のエンティティに対して、[ビュー ヘルス][ビュー ヘルス] をクリックします。4. エンティティが関連付けられているすべてのサービスと、エンティティに対して実⾏されているすべての
KPI を⽰すエンティティの詳細ページを確認します。
詳細については、ITSI 『インストールおよび設定マニュアル』の「エンティティの定義」を参照してください。
すべての ITSI KPI を表⽰するすべての ITSI KPI を表⽰する
Splunk Web を使⽤して、サーチヘッドで実⾏されているすべての KPI 検索を表⽰します。これにより、サーチ負荷に寄与する同時サーチ数を知ることができます。最近の KPI サーチジョブの KPI サーチ⽂字列、サーチ頻度、時間範囲、実⾏時間などの追加情報を表⽰できます。
1. Splunk Web で、[設定] > [検索、レポート、および アラート][設定] > [検索、レポート、および アラート] をクリックします。2. [このアプリケーションコンテキストで作成されたオブジェクトのみを表⽰する][このアプリケーションコンテキストで作成されたオブジェクトのみを表⽰する] チェックボックスをオ
ンにします。
ITSI App コンテキストで作成されたすべての App がリストに表⽰されます。KPI サーチ名の構⽂は次のとおりです:
Indicator - <KPI_id> - ITSI Search
たとえば、
Indicator - 3bee62acf7f4de2a095e475f - ITSI Search
3. KPI サーチで、最近のビュー最近のビューをクリックします。KPI の実⾏時間に注意してください。4. KPI サーチの名前をクリックします。KPI サーチ⽂字列、時間範囲、およびスケジュールを確認します。
平均 KPI 実⾏時間、KPI 頻度、および KPI ごとに参照されるエンティティの数、システムで実⾏されている同時サーチ総数は、パフォーマンスに著しく影響することに注意してください。詳細については、ITSI 『インストールおよび設定マニュアル』の「パフォーマンスに関する考慮事項」を参照してください。
Splunk ITSI についての詳細はこちらSplunk ITSI についての詳細はこちら
Splunk ITSI の詳細については、ITSI 『インストールおよび設定マニュアル』の ITSI の概念と機能を参照してください。
Splunk ユーザ⾏動分析についてSplunk ユーザ⾏動分析について
25

Splunk User Behavior Analytics (UBA) は、既知、未知、および隠れている脅威を環境内で⾒つけるために役⽴ちます。Splunk UBA を使⽤して、内部および外部の脅威と異常を視覚化して調査することができます。SplunkUBA は Splunk Enterprise Security と統合され、Splunk イベントを活⽤し、組織内の重要なイベントとともにUBA の脅威を調査します。
Splunk User Behavior Analytics のドキュメントを参照してください。
ユーザー、ロールおよび認証ユーザー、ロールおよび認証
Splunk の設定とデータが習熟された場合、ユーザ、ロール、および認証⽅法を確認してください。
Splunk Enterprise は複数のユーザー認証システムに対応しています。
ロールベースのユーザーアクセスによる Splunk の内部認証LDAPここで説明する、PAM や RADIUS などの外部認証システムを使⽤するための、スクリプト認証 API。マルチファクタ認証シングルサインオン
内部認証とロールベースのユーザーアクセス内部認証とロールベースのユーザーアクセス
ロールベースのアクセス制御により、ユーザーの管理や、Splunk Enterprise データを制限または共有することができます。Splunk Enterprise は、リレーショナルデータベースによるロールベース・アクセス制御の管理と同様の⽅法で、ユーザーにデータをマスクします。
既存の設定を検出または変更する既存の設定を検出または変更する
既存のユーザーとその割り当てられたロールに習熟します。ロールは、ユーザーのデータアクセスレベルとユーザーが実⾏できる操作を定義します。
Splunk Web で、[設定][設定]> > [アクセスコントロール][アクセスコントロール] をクリックして、Splunk ユーザー全員を表⽰します。[アクセス制御] ページでは、ロールとユーザーをクリックし、権限の調査や編集が⾏えます。このページを使⽤して、各ユーザーまたはユーザーのグループが使⽤できるデータのリストを作成できます。『Splunk Enterprise のセキュリティ』の「アクセス制御を使⽤して Splunk データを保護する」を参照してください。
特定のユーザーをサーチする際には、CLI を使⽤してユーザーとロールをサーチします。詳細は、『SplunkEnterprise のセキュリティ』の「既存のユーザーとロールの検索について」を参照してください。
LDAP 認証LDAP 認証
管理者が LDAP で動作するように Splunk を設定した場合、「LDAP ストラテジー」が作成されます。LDAP ストラテジーは、Splunk が LDAP 設定を操作するために使⽤する設定データのコレクションです。Splunk は、LDAP ユーザーをサーチする際に、特定の順序でこれらの「ストラテジー」を照会するように指⽰できます。『Splunk Enterprise のセキュリティ』の「LDAP によるユーザー認証の設定」を参照してください。
既存の LDAP 設定を検出または変更する既存の LDAP 設定を検出または変更する
すべてのストラテジーを確認し、既存の LDAP グループとアクセス権限のマッピングに習熟します。既存のLDAP 戦略を表⽰または編集するには、以下のステップに従います。
1.[ユーザーと認証][ユーザーと認証] セクションで、[アクセス制御][アクセス制御] をクリックします。
2.LDAPLDAP をクリックします。
3.このページから、ストラテジーを選択して情報を表⽰し、Splunk のロールに対する LDAP マッピングを追跡できます。
『Splunk Enterprise のセキュリティ』で「Splunk Web を使⽤した LDAP の設定」を参照してください。
マルチファクタ認証マルチファクタ認証
Splunk Enterprise は現在、Duo Security を使⽤してマルチファクタ認証をサポートしています。『SplunkEnterprise のセキュリティ』の「デュアルセキュリティによる2要素認証について」を参照してください。
既存の設定を検索または変更する既存の設定を検索または変更する
システムが Splunk Web 経由で Duo Factor 認証を使⽤しているかどうかを調べます。
1.[設定][設定] 配下の [ユーザー認証][ユーザー認証] をクリックします。
2.[認証⽅法][認証⽅法] で [Duo Security][Duo Security] を選択します。
3.このページでは、システムにマルチファクタ認証が設定されているかどうかを確認できます。『SplunkEnterprise のセキュリティ』で Duo Security ⼆要素認証を使⽤する場合は、「Splunk Enterprise の設定」を参照してください。
SAML を使⽤する SSOSAML を使⽤する SSO
26

Splunk ソフトウェアは、外部 ID プロバイダ (IdP) によって提供される情報を使⽤して、シングルサインオン(SSO) ⽤の SAML 認証を活⽤できます。『Splunk Enterprise のセキュリティ』の「SAML でのシングルサインオンを使⽤した認証」を参照してください。
既存の設定を検索または変更する既存の設定を検索または変更する
ユーザーが SAML SSO ⽤に設定されているかどうかを確認します。
1.[設定][設定] で [アクセス制御][アクセス制御] を選択します。
2.[認証⽅法][認証⽅法] 配下で [SAML] を選択します。
3.新しい SAML 設定が表⽰されます。このページを閉じて既存の設定を表⽰できます。
このページでは、ユーザーのグループに対して SSO 認証が設定されているかどうかを確認できます。そこからIdP 情報、マップされたグループ、およびそのグループに割り当てられたユーザーまでドリルダウンすることができます。
P roxySSO 認証:P roxySSO 認証:
ProxySSO では、リバースプロキシサーバーを介して Splunk インスタンスのシングルサインオン (SSO) を設定できます。SSO を使⽤してログインしたユーザーは Splunk Web に⼀貫してアクセスすることができます。
既存の設定を⾒つける既存の設定を⾒つける
プロキシサーバーが Splunk Web に送信する既存の HTTP 要求ヘッダーを表⽰できます:
web.conf の enableWebDebug=true を settings のスタンザ配下に設定します。
http://<ProxyServerIP>:<ProxyServerPort>/debug/sso
ProxySSO ログインイベントが var/log/splunkd.log にログインしています。
システムセキュリティを確認するシステムセキュリティを確認する
Splunk ソフトウェアには、⼀連のデフォルト証明書が同梱されています。デフォルトの証明書は、起動時に⽣成/設定され、$SPLUNK_HOME/etc/auth/ に保管されます。Splunk では、管理者がこれらのデフォルト証明書を⾃社または第三者署名付き証明書に置き換えることを推奨しています。
もっとも⼀般的なシナリオと、デフォルトの SSL 設定を以下の表に⽰します。
やり取りの種やり取りの種類類
クライアントクライアント機能機能
サーバー機サーバー機能能 暗号化暗号化 証明書認証証明書認証 共通名の共通名の
チェックチェックやり取りされるデータやり取りされるデータ
の種類の種類
ブラウザとSplunk Web ブラウザ Splunk Web
デフォルトでは無効
クライアント (ブラウザ) が記述
クライアント (ブラウザ) が記述
⽤語のサーチ結果
Splunk 間通信 Splunk Web splunkd
デフォルトで有効
デフォルトでは無効
デフォルトでは無効 ⽤語のサーチ結果
転送splunkd フォワーダーとして
splunkd インデクサーとして
デフォルトでは無効
デフォルトでは無効
デフォルトでは無効 インデックス対象データ
デプロイサーバーからインデクサー
splunkd フォワーダーとして
splunkd インデクサーとして
デフォルトでは無効
デフォルトでは無効
デフォルトでは無効
推奨しません。代わりにPass4SymmKey を使⽤します。
Splunk 間通信
splunkd デプロイクライアントとして
splunkd デプロイサーバーとして
デフォルトで有効
デフォルトでは無効
デフォルトでは無効 設定データ
Splunk 間通信
splunkd サーチヘッドとして
splunkd サーチピアとして
デフォルトで有効
デフォルトでは無効
デフォルトでは無効 サーチデータ
SSL 設定を確認するSSL 設定を確認する
Splunk WebSplunk Web
Splunk Web で SSL 接続を確認するには、次のコマンドを使⽤します。
index=_internal source=*metrics.log* group=tcpin_connections | dedup hostname | table _time hostname version
sourceIp destPort ssl
インデクサーとフォワーダーインデクサーとフォワーダー
27

インデクサーの場合は、スタートアップシーケンス内の以下のようなメッセージをチェックして、接続が正常に⾏われているかどうかを確認します。
02-06-2011 19:19:01.552 INFO TcpInputProc - using queueSize 1000
02-06-2011 19:19:01.552 INFO TcpInputProc - SSL cipherSuite=ALL:!aNULL:!eNULL:!LOW:!EXP:RC4+RSA:+HIGH:+MEDIUM
02-06-2011 19:19:01.552 INFO TcpInputProc - supporting SSL v2/v3
02-06-2011 19:19:01.555 INFO TcpInputProc - port 9997 is reserved for splunk 2 splunk (SSL)
02-06-2011 19:19:01.555 INFO TcpInputProc - Port 9997 is compressed
02-06-2011 19:19:01.556 INFO TcpInputProc - Registering metrics callback for: tcpin_connections
フォワーダーの場合は、スタートアップシーケンス内の以下のようなメッセージをチェックして、接続が正常に⾏われているかどうかを確認します。
02-06-2011 19:06:10.844 INFO TcpOutputProc - Retrieving configuration from properties
02-06-2011 19:06:10.850 INFO TcpOutputProc - Using SSL for server 10.1.12.112:9997,
clientCert=/opt/splunk/etc/aut/server.pem
02-06-2011 19:06:10.854 INFO TcpOutputProc - ALL Connections will use SSL with sslCipher=
02-06-2011 19:06:10.859 INFO TcpOutputProc - initializing single connection with retry strategy for 10.1.12.112:9997
接続が成功した場合、splunkd.log のインデクサー上では以下のようになります:
02-06-2011 19:19:09.848 INFO TcpInputProc - Connection in cooked mode from 10.1.12.111
02-06-2011 19:19:09.854 INFO TcpInputProc - Valid signature found
02-06-2011 19:19:09.854 INFO TcpInputProc - Connection accepted from 10.1.12.111
接続が成功した場合、splunkd.log のフォワーダー上では以下のようになります:
02-06-2011 19:19:09.927 INFO TcpOutputProc - attempting to connect to 10.1.12.112:9997...
02-06-2011 19:19:09.936 INFO TcpOutputProc - Connected to 10.1.12.112:9997
分散環境のセキュリティについて分散環境のセキュリティについて
サーチヘッドとピア間の通信には、公開鍵暗号を使⽤しています。
Splunk ソフトウエアは起動時に、秘密鍵と公開鍵を Splunk 設定に⽣成します。サーチヘッドに分散サーチを設定した場合、公開鍵がピアに配布されて、それらの鍵が通信の保護に⽤いられます。このデフォルト設定は、パフォーマンスを向上するビルトインの暗号/データ圧縮機能を提供しています。「分散サーチマニュアル」 のキーファイルの配布を参照してください。
分散構成を保護するための公開鍵暗号化。ただし、サーチヘッドクラスタの各メンバーを設定することで、サーチヘッドクラスタに SSL を設定することは可能です。デプロイメントに、サーチヘッドクラスタの各メンバーがSSL ⽤に構成されているかどうかを判断するには、 requireClientCert 属性を server.conf にチェックします。[Splunk Enterprise のセキュリティ] の「証明書認証を使⽤してデプロイメントサーバーとクライアントを保護する」を参照してください。
splunk.secret キーによる暗号化 キーによる暗号化
splunk.secret ファイルには、設定ファイル内の⼀部の認証情報を収集し暗号化するために使⽤される鍵が含まれています。
web.conf:各インスタンスの SSL パスワードauthentication.conf:LDAP パスワード (ある場合)inputs.conf:SSL パスワード (を使⽤している場合) splunktcp-ssloutputs.conf:SSL パスワード (を使⽤している場合) splunktcp-sslserver.conf:ある場合は、pass4symmkey
初回起動時に Splunk Enterprise は $SPLUNK_HOME/etc/auth/ にこのファイルを作成します。上記リストに作成したパスワードはこのファイルに保存されます。暗号化されていないパスワードを⼿動で追加すると、Splunk ソフトウェアは起動時にこれらのパスワードを上書きします。
詳細詳細
Splunk Web の保護について
フォワーダーからのデータの保護について
Splunk から Splunk への通信のセキュリティについて
独⾃の証明書を使った Splunk Web の保護
独⾃の証明書を使⽤するための、Splunk 転送の設定
Splunk 間通信の保護について
ライセンスについての学習ライセンスについての学習
Splunk Enterpr ise ライセンスの仕組みSplunk Enterpr ise ライセンスの仕組み
28

Splunk Enterprise は指定されたソースからデータを取り込んで、それを分析⽤に処理します。このプロセスは、インデックス作成と呼ばれています。正確なインデックス作成のプロセスについては、『データの取り込み』マニュアルの「Splunk ソフトウェアによるデータの取り扱い」を参照してください。
Splunk Enterprise ライセンスは、暦⽇当たり (ライセンスマスターライセンスマスターの時計による午前 0 時から翌午前 0 時まで)にインデックスを作成できるデータ量を⽰します。
インデックス作成を⾏う Splunk Enterprise インスタンスには、そのためのライセンスが必要です。ローカルにライセンスをインストールしたスタンドアロンのインデクサーを実⾏するか、またはいずれかの SplunkEnterprise インスタンスをライセンスマスターライセンスマスターとして設定し、ライセンスプールライセンスプールを作成して、他のライセンスライセンススレーブスレーブとして設定されたインデクサーがそこからライセンスを利⽤できるようにすることができます。
ある 1 暦⽇にライセンスで許可されている⽇次ボリュームを超えた場合、違反の警告が通知されます。連続 30 ⽇間の間に Enterprise で 5 つ以上の警告がある場合、ライセンス違反の状態にあります。Splunk Enterprise6.5.0 以降の⾮強制型ライセンスを使⽤している場合を除き、違反のあるプールプールでのサーチが無効になります。すべてのプールからのライセンス使⽤合計が当該ライセンスのライセンスクォータ合計以下である限り、その他のプールはサーチ可能です。
インデックス量の制限の他にも、⼀部の Splunk Enterprise 機能を利⽤するには、Enterprise ライセンスが必要になります。
ライセンスのタイプは以下のとおりです:
Enterprise ライセンス:認証や分散サーチなど、すべての Enterprise 機能を利⽤できます。SplunkEnterprise 6.5.0 以降、新しい Enterprise ライセンスは⾮強制型のライセンスになりました。Free ライセンス:制限されたインデックスを作成できます。認証を含む⼀部の機能は無効になります。Forwarder ライセンス:データを転送できますが、インデックスを作成することはできません。認証機能は有効になります。Beta ライセンス:⼀般的には、Enterprise 機能が有効になりますが、Splunk ベータリリースにのみ限定されています。App の機能をアクセスするためには、Enterprise または Cloud ライセンスを併せてプレミアム App のライセンスが使⽤されます。
ライセンスの種類については、管理マニュアルの「Splunk ソフトウェアライセンスの種類」を参照してください。
⾃分のライセンスを把握します。⾃分のライセンスを把握します。
持っているライセンスを調査:
1. Splunk Web のライセンスマスターにログインします。2. [設定] > [ライセンス][設定] > [ライセンス] をクリックします。3. Enterprise および App ライセンス、さらにその有効期限をメモします。
ライセンス使⽤状況を確認:
1. Splunk Web のライセンスマスターにログインします。2. [設定] > [ライセンス][設定] > [ライセンス] をクリックします。3. ライセンス使⽤状況レポートライセンス使⽤状況レポートをクリックします。
詳細は、管理マニュアルの「ライセンス使⽤状況レポート・ビュー」を参照してください。このビューはモニターコンソールのインデックスインデックスタブからもアクセス可能です。
ライセンス使⽤状況をモニターライセンス使⽤状況をモニター
ライセンス違反を防ぐには、有効期限切れライセンスおよびライセンスに近いクォータのアラートをセットアップします。モニターコンソールに含まれる 2 つのプラットフォームアラートを使⽤できます。
詳細は、以下の項⽬を参照してください。
Splunk Enterprise のモニタリング の「プラットフォームアラート」をご確認ください。管理マニュアルのライセンス違反について。
システム状態をモニターするシステム状態をモニターする
モニター⽤コンソールが設定されている場合は、プラットフォームアラートとヘルスチェックを使⽤してシステムの状態をモニターできます。
モニター⽤コンソールが設定されていない場合、このトピックでは設定を開始するためのいくつかのツールを紹介します。しかし、これまでのいくつかのトピックの内容を読んで理解していれば、モニタリング コンソールを設定することは可能です。
モニター⽤コンソール有りモニター⽤コンソール有り
ヘルスチェックを実⾏するヘルスチェックを実⾏する
モニター⽤コンソールには、事前設定されたプラットフォームアラートに加えて、事前設定されたヘルスチェックが⽤意されています。既存のヘルスチェックを変更するか、新規で作成することができます。
詳細は、[Splunk Enterprise のモニタリング] の「ヘルスチェックへのアクセスとカスタマイズ」をご確認ください。
29

プラットフォームアラートを理解するプラットフォームアラートを理解する
プラットフォームアラートは、モニター⽤コンソールに含まれる、保存されたサーチです。プラットフォームアラートは、Splunk Enterprise 環境に問題を引き起こす可能性がある状況を、Splunk 環境の管理者に通知します。通知はモニター⽤コンソール ユーザーインターフェイス上に表⽰され、メールなどのアラートアクションを追加で開始できます。
有効なプラットフォームアラートを確認する:
1. モニター⽤コンソールで [概要][概要] をクリックします。2. ダッシュボードを下にスクロールし、[アラートのトリガー] パネルが表⽰されるまで待ちます。3. [有効または無効][有効または無効] をクリックし、プラットフォームアラート設定ページを表⽰します。4. 有効なアラートを探します。5. [⾼度な編集][⾼度な編集] をクリックし、アラートに対してどのようなアラートアクションが存在するかを確認します。
電⼦メールアラートを受信する場合は、電⼦メールアドレスを追加します。[電⼦メールを送信する][電⼦メールを送信する] のようなアラートアクションを設定しない場合は、モニター⽤コンソールの [概要] ダッシュボードでトリガされたアラートを表⽰します。
アラートアクションの追加⽅法と使⽤可能なプラットフォームアラートのリストについては、[SplunkEnterprise のモニタリング] の「プラットフォームアラート」を参照してください。
フォワーダーのアセットテーブルの再構築フォワーダーのアセットテーブルの再構築
フォワーダーが切り離し中の場合、[フォワーダーアセット] テーブルを再構築するまで [フォワーダー] ダッシュボードに残ります。この⼿順はすぐには必要ではありませんが、[フォワーダー] ダッシュボードに複数のフォワーダーの結果が含まれていない場合は、アセットテーブルを再構築できます。
1. モニター⽤コンソールで、[設定] > [フォワーダー監視設定][設定] > [フォワーダー監視設定] をクリックします。2. [フォワーダーアセットの再構築][フォワーダーアセットの再構築] をクリックします。3. 時間範囲を選択するか、デフォルトの 24 時間をそのままにします。4. [再構築の開始][再構築の開始] をクリックします。
モニター⽤コンソール無しモニター⽤コンソール無し
内部ログをサーチ可能にする内部ログをサーチ可能にする
デプロイでは、$SPLUNK_HOME/var/log/splunk および $SPLUNK_HOME/var/log/introspection の両⽅で、内部ログを、他のすべてのインスタンスタイプのインデクサーに転送することをベストプラクティスとしてお勧めします。ベストプラクティスとして『分散サーチ』マニュアルの「サーチヘッドデータの転送」を参照してください。他のインスタンスタイプには以下が挙げられます。
サーチヘッドライセンスマスタークラスタマスターデプロイサーバー
Splunk Enterprise の内部ログファイルの概要については、「Splunk Enterprise のトラブルシューティング」の 「Splunk ソフトウェアのログとは何か」を参照してください。
既存のモニタリング アプリケーションを調査する既存のモニタリング アプリケーションを調査する
Splunkbase または以前の管理者が開発したカスタム App から、システムの状態をモニタリングするアプリケーションのデプロイを調査します。
Fire Brigade App は、インデクサーの状態を把握します。⼀般的であった Splunk on Splunk App (SoS) は、Splunk Enterprise 6.3.0 においてサービスを終了し、機能のほとんどは監視コンソールに組み込まれました。モニタリングストラテジーが SoS に依存している場合は、モニター⽤コンソールにアップグレードすることを検討してください。
デフォルトのモニタリングツールを使⽤するデフォルトのモニタリングツールを使⽤する
モニター⽤コンソールがない場合においても、Splunk Enterprise には、システムの健全性をチェックするために、いくつかのリソースが含まれています。インデクサクラスタリング、サーチヘッドクラスタリング、KV ストア、および Splunk ソフトウェアが内部的に記録するエラーに関するいくつかのステータス情報を表⽰できます。
[インデクサークラスタリング] ダッシュボードの詳細については、「インデクサーとインデクサーのクラスタの管理」の「マスターダッシュボードと次の2つのトピックの表⽰」を参照してください。
サーチヘッドクラスタリングや KV ストアなどの Splunk コマンドラインを使⽤して、デプロイの⼀部についてステータスチェックを実⾏できます。
コマンドラインからサーチヘッドクラスタのコンポーネントを確認できます。『分散サーチ』マニュアルのサーチヘッドクラスタに関する情報を表⽰するには、「CLI の使⽤」を参照してください。
KV ストアのステータスを確認する:
1. サーチヘッドにログインします。2. ターミナルウィンドウで、Splunk インストールディレクトリ内の bin ディレクトリに移動します。3. タイプ ./splunk show kvstore-status
Splunk CLI の使⽤⽅法については、『管理マニュアル』の「CLI について」を参照してください。
30

⼀般的なエラーのレポートを⽣成する:
1. クラスタマスターまたはサーチヘッドで Splunk Web にログインします。2. [Apps] > [検索とレポート][Apps] > [検索とレポート] をクリックします。3. [レポート] > [過去24時間の Splunk エラー][レポート] > [過去24時間の Splunk エラー] をクリックします。
カスタム モニタリングツールを探すカスタム モニタリングツールを探す
以前の管理者は、カスタムモニタリング App に加えて、システム状態に関するカスタムレポートまたはアラートを作成している可能性があります。カスタムレポートまたはアラートを探す:
1. クラスタマスタまたはサーチヘッド上の Splunk Web で、[設定] > [検索、レポート、アラート][設定] > [検索、レポート、アラート] の順に選択します。
2. アラートアクションが要件を満たしているかを確認します。3. (オプション)メールアドレスまたはカスタムスクリプトを追加します。
モニタリング ストラテジーを計画するモニタリング ストラテジーを計画する
Splunk Enterprise のデプロイには、ダウンタイムやその他の問題を最⼩限に抑えるために堅牢で積極的なモニタリングが必要です。
Splunk Enterprise のモニタリングストラテジーでは、次の点に対処する必要があります。モニタリングの内容は、モニター⽤コンソールに含まれています。
CPU 負荷、メモリ使⽤率、ディスク使⽤率*nix システムでは、THP や ulimits などの OS レベルの設定インデックス作成レートスキップされたサーチ正しくないデータ⼊⼒習慣
モニタ―⽤コンソールの設定を検討してください。これは新しいマシンのプロビジョニングで構成される予定です。「Splunk Enterprise のモニタリング」の「マルチインスタンスのデプロイメント」の「モニター⽤コンソールの設定⼿順」を参照してください。
ナレッジオブジェクト問題の調査ナレッジオブジェクト問題の調査
ナレッジオブジェクトナレッジオブジェクトは既存のデータを豊かにするユーザー定義エンティティです。以下のオブジェクトを含んでいます:
レポートレポートアラートアラートダッシュボードダッシュボードデータセットデータセットフィールド抽出フィールド抽出計算済みフィールド計算済みフィールドイベントタイプイベントタイプルックアップルックアップtagstagsエイリアスエイリアス
ほとんどのナレッジオブジェクトはサーチおよびレポートビューの⼀覧ページから、または設定設定メニューにあるナレッジナレッジに⼀覧されているページから管理します。
⼤規模な Splunk Enterprise デプロイのある組織にはナレッジ管理ナレッジ管理があり、その役割は他の Splunk Enterpriseユーザー向けにナレッジオブジェクトを作成し、整理し、維持することです。『ナレッジ管理』マニュアルを参照してください。
ナレッジオブジェクトランドスケープの調査ナレッジオブジェクトランドスケープの調査
Splunk Enterprise デプロイのナレッジオブジェクトコレクションを確認する。設定設定にあるナレッジオブジェクトページを使⽤して、インストール済のすべての app にわたって各ナレッジオブジェクトを確認できます。例えば、保存済みサーチを⾒たい場合は、 設定 > サーチ、レポート、アラート設定 > サーチ、レポート、アラートを選択します。
ナレッジオブジェクトを確認しながら、その名前、App 提携、所有者、および権限ステータスをメモします。名前または権限に⽭盾がある、冗⻑であり、またはオルファンのあるナレッジオブジェクトを特定します。
ナレッジオブジェクトの名前の⽭盾ナレッジオブジェクトの名前の⽭盾
ナレッジオブジェクトのカテゴリーを確認しながら、2 種類の命名⽭盾を探します。
同じ名前ではあるが、異なる定義を持つオブジェクト同じ定義ではあるが、異なる名前を持つオブジェクト
同じ名前、異なる定義同じ名前、異なる定義
ナレッジオブジェクトカテゴリー内のすべてのオブジェクトには固有名称が必要です。例えば、設定設定のサーチ、レポート、およびアラート⼀覧ページにある保存済みサーチには重複する名前はないはずです。これらのナレッジオブジェクトのほとんどはサーチ時にサーチ結果に適⽤されます。同じ名前を持つ同じカテゴリーの 2 つのオブジェクトがある場合は、それらの 1 つだけが適⽤されます。
31

オブジェクトの権限が変更した場合に、名称の重複が⽣じる場合があります。例えば、同じ名前の 2 つの別のApp にルックアップを含むことができます。それらは App レベルで共有されている場合はお互いに⽭盾しません。しかし、それらルックアップの 1 つの権限が変更されたため、グローバルで共有されると、それらのルックアップの 1 つが他のルックアップの代わりに適⽤される可能性があります。
ナレッジ管理マニュアルで「ナレッジオブジェクトに同じ名前を付ける」をご覧ください。
命名規則を設定してこの問題を避けます。ナレッジ管理マニュアルの「ナレッジオブジェクトの命名規則を開発」をご覧ください。
同じ定義、異なる名前同じ定義、異なる名前
同じまたは類似定義を持つが、名前が異なる複数のナレッジオブジェクトが 1 つのカテゴリーにある場合、正規化の問題が⽣じます。これは、抽出されたフィールドで特に問題になります。複数のソースタイプからのデータをインデックスする場合、名前は異なるが同じ種類のデータを表す複数のフィールドを持つことが可能です。これは、インデックスデータの誤解を招きます。不注意でキャプチャしたい情報の⼀部を構成するサーチをビルドする場合があります。
お使いの Splunk Enterprise デプロイにデータの正規化問題がある場合、Splunk Common Information Modelアドオンをインストールします。CIM アドオンは複数のソースタイプからのデータを正規化するのに役⽴ちます。これにより、レポート、相関サーチ、ダッシュボードを開発し、データドメインの統⼀のとれたビューを⽰すことができます。
Splunk Common Information アドオンマニュアルをご覧ください。
オブジェクト権限を理解するオブジェクト権限を理解する
継承したナレッジオブジェクトを管理する際、ロールロール、機能機能、および権限権限が Splunk デプロイにセットアップされる⽅法を理解するようにします。
ユーザーがナレッジオブジェクトを作成する場合、デフォルトによりその権限はそのユーザー固有のものです。お使いの Splunk Enterprise デプロイのセットアップにより、ユーザーはそのオブジェクトを他のユーザーやロールと共有するために、他のユーザーの管理者権限またはパワーユーザ権限を必要とする場合があります。
権限およびナレッジオブジェクトの相互依存権限およびナレッジオブジェクトの相互依存
すべてのオブジェクトが同じ権限である場合は、ナレッジオブジェクト間の依存性問題は簡単に解決できます。例えば、outputlookup コマンドを使⽤して広く使⽤されているルックアップをグローバル権限で更新する個⼈的にスケジュールされたレポートがあるとします。時として、ユーザーはそのルックアップが予想に反して挙動することに気づきますが、個⼈的なナレッジオブジェクトはほとんどのユーザーには⾒えないため、問題の原因をトラブルシューティングして解決することが困難です。
その他の例は、オブジェクト相互依存考慮事項、をご覧ください。
権限のその他の使⽤権限のその他の使⽤
ナレッジオブジェクトの可視性の拡張または制限よりも権限の様相のほうが多いです。権限機能を以下のタスクに使⽤できます:
ナレッジオブジェクトの作成および編集機能を制限または拡張するユーザーロールベースの機能管理者およびパワーユーザー以外のロールへの権限の設定とオブジェクトの共有の許可ナレッジオブジェクトカテゴリの権限設定例えば、特定のロールの権限をすべてのイベントタイプを使⽤するまたはすべてのルックアップを使⽤するように制限できます。
ロールおよび権限についての詳細は、Splunk Enterprise の保護マニュアルの「ロールベースのユーザーアクセス設定について」をご覧ください。
ナレッジオブジェクト権限の管理については、『ナレッジ管理』マニュアルの「ナレッジオブジェクト権限の管理」を参照してください。
オブジェクトの相互依存性考慮事項オブジェクトの相互依存性考慮事項
オブジェクトグループ間に⼤きな相互依存性がある場合があります。オブジェクト変更または削除は、そのオブジェクトに依存する他のオブジェクトに影響を及ぼす場合があります。例えば、カスタムフィールドの抽出参照定義を伴うルックアップを設定できます。フィールドの抽出⽅法を変更すると、ルックアップの精度に影響します。ルックアップがデータモデルデータセットへのフィールドの追加に使⽤される場合、変更はその⼦データモデルデータセットにまで伝播します。
多くの場合、ナレッジオブジェクトの相互依存性を明らかにする唯⼀の⽅法はオブジェクト定義の調査、または上流オブジェクトが変更、無効化、または削除された場合に起きる下流オブジェクトの破壊を分析することです。ナレッジ管理マニュアルの「ナレッジオブジェクトの無効化または削除」をご覧ください。
サーチ時操作の順序サーチ時操作の順序
相互依存性のあるナレッジオブジェクトがある場合、サーチ時操作の順序を理解することが重要です。サーチ時、Splunk ソフトウェアはナレッジオブジェクトをサーチ結果に特定の順番で適⽤します。これはつまり、定義されていないオブジェクトに依存するナレッジオブジェクト相互依存性をセットアップできないことを意味します。いくつかの相互依存性ナレッジオブジェクトが動作しない場合、それが考えられる理由です。
例えば、Splunk ソフトウェアはカスタムフィールドの抽出を、ルックアップを処理する前にサーチ結果に適⽤します。これはつまり、ルックアップにはサーチ時に抽出されたフィールドを参照する定義があることを意味します。しかし、カスタムフィールドの抽出はルックアップ派⽣フィールドをその定義では使⽤できません。なぜな
32

ら、ルックアップフィールドはまだ存在しないからです。カスタムフィールドの抽出が処理された後にのみ派⽣します。
ナレッジ管理マニュアルのサーチ時操作の順番をご覧ください。
ルックアップオブジェクトの相互依存性ルックアップオブジェクトの相互依存性
ルックアップルックアップは設計によりナレッジオブジェクトの相互依存性を引き起こす場合があります。
以下はルックアップに関連する 3 つのナレッジオブジェクトカテゴリーです:
ルックアップ定義ルックアップ テーブル ファイル⾃動ルックアップ
上記カテゴリーのオブジェクトは⾃⾝の権限および共有ステータスを割り当てられる場合があります。
それらのナレッジオブジェクトカテゴリーを活⽤して以下のルックアップタイプを作成できます。
CSV ルックアップ外部ルックアップKV ストアルックアップ地理空間ルックアップ
ルックアップタイプにはルックアップ定義が必要です。2 つのルックアップタイプである、CSV および地理空間には、ルックアップテーブルファイルが必要です。すべてのルックアップタイプに⾃動ルックアップをオプションで作成できます。
ルックアップオブジェクトを参加または修正する場合は注意してください。ルックアップテーブルファイルには複数のルックアップ定義を関連づけることができます。ルックアップ定義は複数の⾃動ルックアップも関連づけることができます。
ルックアップで権限の問題にぶつかることがあります。ルックアップテーブルファイルに関連する定義よりもさらに厳しい権限がある場合、ルックアップは動作しません。ルックアップ定義および⾃動ルックアップにも同じことが⾔えます。
ルックアップテーブルファイルの権限は、それが関連するルックアップ定義の権限と同等またはより幅広い必要があります。ルックアップ定義の権限は、それが関連する⾃動ルックアップの権限と同等またはより幅広い必要があります。
ナレッジ管理マニュアルのルックアップ定義の説明をご覧ください。
データモデルのデータセットヒエラルキーデータモデルのデータセットヒエラルキー
データモデルは、親/⼦関係を備えたデータモデルデータセットのヒエラルキー順のコレクションである場合があります。親データセットの変更は、そこから派⽣する⼦データセットすべてに伝播します。この関係はデータモデータモデルエディターデルエディターで閲覧できます。
『ナレッジ管理』マニュアルの「データモデル」を参照してください。
データセット拡張データセット拡張
すべてのデータセットタイプ、ルックアップ、データモデル、およびテーブルはテーブルデータセットテーブルデータセットとして拡拡張張できます。拡張されると、元のデータセットは拡張元のテーブルデータセットの親関係を備えます。元のデータセットへの変更は拡張元のデータセットに影響します。データセットの拡張元のデータセットを⾒るには、データセット⼀覧ページにある⾏を拡張します。
詳細は、『ナレッジ管理』マニュアルの「データセットの拡張」を参照してください。
孤⽴オブジェクトの検索孤⽴オブジェクトの検索
ナレッジオブジェクトの Splunk アカウントが無効である場合、それが所有するナレッジオブジェクトはシステム内に残ります。これらのオブジェクトは孤⽴していて、問題を引き起こします。孤⽴オブジェクトは、相互依存性のあるオブジェクトに悪影響を及ぼします。
孤⽴スケジュールレポートが特に問題です。サーチスケジューラーは存在しないユーザーの代わりにスケジュール済レポートを実⾏できません。これはスケジュール済レポートを使⽤するダッシュボードパネルおよび埋め込みレポートに影響します。レポートの結果が電⼦メールで意思決定者に送信されると、電⼦メールは停⽌します。
Splunk Enterprise は孤⽴ナレッジオブジェクト、特に孤⽴スケジュール済みサーチを検出する複数のメソッドを提供します。孤⽴ナレッジオブジェクトを⾒つけたら、ナレッジオブジェクトの再割り当てページを使⽤して 1つまたは複数のナレッジオブジェクトを新しい所有者に再割り当てします。
ナレッジ管理マニュアルにある「孤⽴ナレッジオブジェクトの管理」をご覧ください。
スケジュール済みサーチおよびサーチの同時並⾏性スケジュール済みサーチおよびサーチの同時並⾏性
お使いの Splunk Enterprise デプロイが⼤量のスケジュール済レポートおよびアラートに依存する場合は、サーチ同時並⾏性問題が⽣じていないか確認します。
Splunk Enterprise デプロイが並⾏に実⾏できるスケジュール済みサーチの数には制限があります。この制限に達
33

すると、サーチスケジューラーサーチスケジューラーと呼ばれるバックグラウンド処理が超過レポートを優先させ、分析が完了したその他のスケジュール済レポートおよびアラートとして実⾏します。
サーチスケジューラーのゴールは、それぞれのスケジュール済レポートおよびアラートを、もともと実⾏を予定していた時間範囲の⼀定期間内のある時点で実⾏させることです。しかし、特定のレポートがスケジュール済実⾏を定期的にスキップする場合があります。
モニターコンソールを使⽤してスケジューラー問題を特定します。モニターコンソールを使⽤してスケジューラー問題を特定します。
モニターコンソールを使⽤して、頻繫にスキップする、または他のサーチの頻繫なスキップを引き起こしているサーチを特定することができます。システム全体の同時サーチ制限を確認するためにモニターコンソールを使⽤することもできます。Splunk Enterprise のモニタリングの [スケジューラーアクティビティ] を参照してください。
スキップしたレポート数を減らす。スキップしたレポート数を減らす。
スケジュールウィンドウスケジュールウィンドウまたはスケジュール優先度スケジュール優先度設定のいずれかをスケジュール済レポートに適⽤することで、スキップするスケジュール済レポートの数を減らすことができます。これらの設定は⼿動で除外することができます。スケジュールウィンドウスケジュールウィンドウを重要度が低いレポートに適⽤して他のレポートを先に実⾏できるようにします。[スケジュール優先度][スケジュール優先度]を使⽤して、⾼価値のレポートの実⾏優先度を向上させます。ナレッジ管理マニュアルの Splunk Web で「並⾏スケジュール済レポートの優先度」をご覧ください。
レポート、データモデル、データセットの⾼速化レポート、データモデル、データセットの⾼速化
⾼速化を使⽤してレポート、データモデル、およびテーブルデータセットのパフォーマンスを改善する SplunkEnterprise デプロイを継承する場合もあります。お使いのデプロイにはデフォルトで⾼速化データモデルおよびレポートに同梱された App が含まれている場合があります。例えば、Splunk Enterprise Security、Splunk ITService Intelligence、および Common Information Model アドオンなどです。
お使いのデプロイに App およびアドオンが提供したもの以外の⾼速化がある場合には、それらが適切に機能しているかを検証し、サマリーが貴重なディスク容量を無駄に使⽤していないかを判断します。
レポート、データモデル、およびテーブルデータセットの⼀覧ページで、⾼速化は⻩⾊の点滅ボルト記号で⽰されています。
Splunk 提供のサマリーベースの⾼速化オプションの概要については、ナレッジ管理マニュアルのサマリーベースのサーチの⾼速化の概要をご覧ください。
レポート⾼速化サマリーの確認レポート⾼速化サマリーの確認
レポート⾼速化サマリー統計には設定 > レポート⾼速化サマリー設定 > レポート⾼速化サマリーを選択してアクセスできます。
対処対処 詳細詳細
不要なサマリーを特定する
設定のレポート⾼速化サマリーページで、サマリー負荷サマリー負荷が⾼くアクセス数アクセス数が低いサマリーを探します。
これらのサマリーの削除を検討します。統計によると、それらは多くのシステムリソースを使⽤するが、頻繫にはアクセスされていません。
特定のサマリーのディスク容量ディスク容量を⾒るにはそのサマリー詳細をクリックします。多くの領域を使⽤しているが、滅多にしか使⽤されないサマリーも削除の候補です。
機能不全サマリーの特定
設定のレポート⾼速化サマリーページで、サマリーステータスサマリーステータスが保留中またはサマリーする⼗分サマリーする⼗分なデータがないなデータがないである場合は、サマリーに解決すべき問題がある場合があります。Splunk ソフトウェアは、⼤きくなりすぎると判断した場合、サマリーを作成しない場合があります。
サマリー問題を解決する。
1. [設定] > [レポート⾼速化サマリー][設定] > [レポート⾼速化サマリー] を選択します を選択します。2. 削除すべきサマリーを検索しサマリー IDサマリー ID をクリックしてその詳細ページを開きます。3. (任意) サマリーに⽭盾するデータが含まれている可能性がある場合は検証検証をクリックしま
す。4. (任意) サマリーが⻑期間更新されていず、最新にしたい場合は更新更新をクリックします。5. (任意) 検証に失敗、またはデータロスの問題がある可能性があるサマリーを再構築するに
は再構築再構築をクリックします。⾮常に⼤きなサマリーの再構築には時間がかかる場合があります。
不要なサマリーを削除します。
1. [設定] > [レポート⾼速化サマリー][設定] > [レポート⾼速化サマリー] を選択します を選択します。2. 削除すべきサマリーを検索しサマリー IDサマリー ID をクリックしてその詳細ページを開きます。3. サマリーを削除するには削除削除をクリックします。
ナレッジ管理マニュアルの「レポート⾼速化の管理」をご覧ください。
データセットモデルとデータセットサマリーの調査データセットモデルとデータセットサマリーの調査
データモデル⾼速化とテーブルデータは、設定のデータモデルページから管理できます。データモデルおよびテーブルデータセットの⾏を拡張してその状態を確認します。
34

アクセスカウントアクセスカウント数が低く ディスク容量ディスク容量数が⾼いサマリーを探します。⼤量のディスク容量を締めないように、上記サマリーの削除、またはサマリーウィンドウの削減を検討します。
完了していないビルドプロセスがあるサマリーについては、ナレッジ管理マニュアルの「⾼速化データモデル」を参照します。これらの問題の解決に役⽴つ詳細設定について記載しています。
サイズベースのサマリー保持ルールを確認するサイズベースのサマリー保持ルールを確認する
レポート、データモデル、およびテーブルデータセットサマリーについて、サイズベースの保持ルールがあるデプロイは、ディスク容量を無制限に使⽤する場合があります。お使いのデプロイには上記を防ぐための、サイズベースの保持ルールが設定されている場合があります。
これらの設定を確認し、影響を受けるサマリーを特定して、設定を更新または削除する必要があるかを評価します。
レポート⾼速化サマリー保持設定についての詳細は、ナレッジ管理マニュアルの「レポート⾼速化の管理」をご覧ください。
データモデルおよびテーブルデータセットサマリー保持設定の詳細は、ナレッジ管理マニュアルの「データモデルの⾼速化」を参照してください。
データモデルおよびテーブルデータセットの並⾏サマリーを確認データモデルおよびテーブルデータセットの並⾏サマリーを確認
並⾏サマリーとはバックグラウンド処理で、Splunk ソフトウェアがデータモデルおよびテーブルデータセットの⾼速化サマリーをビルドする速度を上げます。これは、サマリーをビルドする並⾏サーチを実⾏することで可能です。これはデフォルトによりすべての Splunk Enterprise デプロイで可能です。
サーチ同時並⾏性やサーチパフォーマンス問題が継続する場合は、前任者が並⾏サマリー設定を、デフォルトよりも引き上げていなかったかどうかを確認します。システムの対応能⼒以上の同時並⾏サーチを実⾏している場合があります。
『ナレッジ管理』マニュアルの「データモデルの⾼速化」を参照してください。
サマリーインデックスの評価サマリーインデックスの評価
サマリーインデックスはレポート⾼速化メソッドで、レポート⾼速化の要件を満たさないレポートに使⽤できます。デプロイがサマリーインデックスを使⽤している場合は、特にサマリーインデックスに使⽤されるインデックスがあります。これらのサマリーインデックスと、それらにデータを⼊⼒するサーチを確認し、それらがレポート⾼速化サマリーに置換できるかどうかを評価します。
『ナレッジ管理』マニュアルの「サマリーベースのサーチ⾼速化の概要」をご覧ください。
35