Embed Size (px)
Citation preview

MC852 – TURMA A
Cap. 2: Programação Paralela
Luís Felipe Souza de Mattos – RA: 107822
11/13/2012

Introdução:
A paralelização de algoritmos pode ajudar muito no desempenho, seja para
economizar tempo e/ou dinheiro. Alguns processos de paralelização podem levar tempo,
serem muito complicados e torna o programa sujeito a erros. A utilização de várias
ferramentas tem sido feita nesses últimos anos , principalmente compiladores paralelos ou
pré-processadores para tornar um código de um programa serial em paralelo.
Existem duas maneiras de se paralelizar um programa, manualmente, através de
diretivas para o compilador que o programador utiliza em seu programa para indicar o
paralelismo desejado, ou então através de ferramentas automáticas que tornar o processo
mais rápido. Tais ferramentas são utilizadas para identificar partes paralelizáveis no programa,
como loops, identificar os inibidores de paralelismo
O processo de paralelização de um problema, requer que este seja realizado ao
mesmo tempo por diferentes unidades de processamento. Para isso, o algoritmo que deve ser
paralelizado deve passar por alguns passos para que isso aconteça.
Análise:
Antes de iniciar a paralelização de qualquer programa devemos analisar o problema
que deve ser resolvido. Entender o problema é um passo crucial para realizar a paralelização
de um algoritmo e devemos ter a capacidade de determinar quando um programa pode ou
não ser paralelizado. Um programa que pode ser paralelizado deve ter uma pequena ou
nenhuma dependência entre os dados calculados independentemente nos núcleos de
processamento. Um programa que necessita de dados calculados anteriormente, como a
sequência Fibonacci, não pode ser paralelizado, pois cada cálculo depende dos dois valores
anteriores.
Algumas técnicas são utilizadas para determinar se um algoritmo pode ou não ser
paralelizável, primeiramente o programador deve identificar qual parte do seu programa é a
maior responsável pelo uso do processador, ou seja, onde a maior parte dos cálculos está
sendo feita, já que a maior parte dos programas de cálculo científico e técnico concentram
seus cálculos em alguns pontos do programa. Estes pontos de maior demanda de
processamento são as principais partes que devem ser paralelizadas, já que grande parte da
execução do programa se concentra nelas.
Outro fator importante para determinar a paralelização do programa é identificar os
pontos onde o trabalho realizado pelo programa é mais lento ou causam problemas com a
paralelização, como por exemplo o I/O, que costuma ser mais lento do que o resto do
programa. Para tentar resolver este problema, deve-se recorrer à reestruturação do programa
ou o uso de outros algoritmos que utilizem em menor quantidade e evite acessos
desnecessários à essas partes lentas do programa.
Identificar no programa partes que causem o bloqueio do paralelismo, como por
exemplo a dependência de dados entre núcleos de processamento. Este problema pode é
vísivel no algoritmo da sequência Fibonacci, onde um número não pode ser calculado até que

os dois anteriores tenham sido calculados. Essa dependência faz com que o processamento
fique bloqueado e não seja realizado o paralelismo. Outra maneira é utilizar outros algoritmos,
principalmente se for um algoritmo pensado para a programação paralela e também deve-se
utilizar bibliotecas que otimizem o uso do hardware, como por exemplo o uso de bibliotecas
matemáticas do fabricante do próprio hardware.
Decomposição:
Passada a fase de análise do algoritmo e do problema a ser paralelizado, deve-se
começar a programação do algoritmo em si. Para isso, é necessário que haja a decomposição,
ou seja, a divisão do problema em tarefas menores que podem ser atribuídas para cada
núcleos de processamento independentemente. Para particionar o problema em blocos
existem duas maneiras que podem ser utilizadas dependendo do tipo de problema a ser
tratado.
Podemos dividir o problema em blocos em que são realizados a mesma tarefa em
todos os blocos, porém para conjuntos de dados diferentes e que somados resultam no
conjunto de dados completo a ser calculado, conhecida como decomposição por domínio.
A figura abaixo mostra como pode ser feita a decomposição por este método.
Figura 1: Decomposição de um problema por domínio.
Como exemplo de problemas que podem ser decompostos por esta maneira temos os
algoritmos que envolvem cálculos independentes utilizando vetores e matrizes e que podem
ser dividos de várias maneiras, alguns desses modos são mostrados na figura 2.

Figura 2: Modos de decomposição de vetores e matrizes.
Existe também outro tipo de decomposição que pode ser feita para problemas que
exigem a realização de diferentes tarefas para o mesmo conjunto de dados. Cada conjunto de
tarefas é realizado paralelamente com as outras tarefas, porém para diferentes conjuntos de
dados. Este processo chamado de decomposição funcional é mostrado na figura abaixo.
Figura 3: Decomposição funcional de um problema.

Este método de decomposição é utilizado para paralelizar problemas que exigem a
realização de diversas tarefas sobre um mesmo conjunto de dados, o exemplo mais comum
para este método é o processamento de sinais, onde um sinal é passado por diversos filtros
até que se chegue ao resultado esperado, como é mostrado na figura 4.
Figura 4: Processamento de um sinal utilizando decomposição funcional do algoritmo.
Na prática é comum encontrar modelos de decomposição híbridos, que misturam
tanto a decomposição por domínios como a decomposição funcional.
Podemos encontrar tanto modelos que utilizam a decomposição por domínios dentro
dos blocos de um problema que foi separado utilizando a decomposição funcional como
modelos que utilizam a decomposição funcional dentro dos blocos de um problema separado
utilizando decomposição por domínios.
Comunicação:
Apesar da decomposição, nem sempre é possível dividir o problema sem que haja
dependências entre os dados calculados em diferentes núcleos de processamento. Para isso,
deve haver algum modo de transferir esses dados calculados entre as tarefas de cada núcleo,
seja pela memória compartilhada ou pela passagem de mensagens, há necessidade de
processamento para verificar se o dado está no local correto e caso esteja, transferir para o
destino correto.
Isto gasta tempo do processador, que poderia estar realizando outras tarefas, além
disso, perde-se mais tempo de processamento caso o dado ainda não esteja pronto para ser
utilizado. O destino do dado deve ficar esperando o dado ao invés de poder continuar com
outros cálculos. Outro problema é a concorrência entre os núcleos de processamento para
colocar seus dados no barramento ou na rede entre os outros núcleos, isto pode saturar a rede
caso a banda e a latência de transferência não sejam suficientes para o trabalho exigido.
Para controlar essas transferências no barramento, pode-se utilizar o modelo de
comunicação síncrono, que necessita um “handshaking” entre a origem e o destino, porém
este tipo de comunicação pode bloquear os núcleos de processamento, e aumentar a espera,
pois além de tranferir o dado, deve-se esperar antes o resultado do “handshaking”, o que pode

aumentar ainda mais o tempo de bloqueio não somente de um núcleos, mas sim de ambos os
núcleos que trocam esses dados.
O modelo assíncrono ainda tem o problema de bloquear um núcleo que necessita de
um dado que não está pronto ainda, porém deixa mais rápido todo o processo de troca de
dados, já que não necessita do “handshaking” e o processador pode utilizar os dados para o
cálculo assim que o recebem do outro núcleo de processamento.
Do ponto de vista do programador, a comunicação pode ser explícita ou transparente
dependendo do modelo de programação que é utilizado. Como explicado mais para frente,
caso o modelo seja o message passing, deve ser explicitado pelo programador no código do
programa. Caso seja utilizado o modelo data parallel pode ou não ser explicitado, dependendo
do modelo de conexão utilizado (SMP ou memória distribuída).
Sincronização:
Para que haja a sincronização entre os núcleos de processamento é necessário que
haja algum modo de garantir a consistência sequencial. Para isso, existem diferentes modos
que são utilizados pelos programadores para que haja a sincronização entre os núcleos de
processamento. Um desses modos é a barreira, que bloqueia a execução de alguns processos
até que o último processo chegue à barreira, sinalizando que todos os processos bloqueados
podem continuar sem que haja problemas para a consistência sequencial.
Um grande problema deste método é o bloqueio, que faz com que todos os processos
que estão na barreira não possam executar nenhuma tarefa até que o último processo chegue
à barreira. Outro problema é o grande número de transações de barramento geradas para
verificar se a barreira ainda está bloqueando os processos.
Outro método para garantir a sincronização é o uso de locks, onde somente uma das
tarefas pode realizar seu trabalho enquanto todas as outras tarefas devem esperar o unlock
para que possam continuar. Ocasionalmente muitas tarefas podem querer acessar serialmente
uma região crítica, o que faz com que todas tenham que esperar o lock ser liberado para tentar
travar o lock para poderem entrar na região crítica também. Isto gera uma situação de corrida,
onde somente uma tarefa pode ter o lock no mesmo instante e muitas outras tarefas queiram
pegar o lock.
O programador deve evitar essas situações de corrida explorando os diferentes tipos
de lock existentes, o lock simples, que somente carrega o valor da variável da memória,
compara e caso esteja livre, faz o lock e realiza a parte do código na região crítica, não é
atômico o suficiente para garantir que somente um processo tenha acesso à região crítica do
programa, pois entre carregar o valor da memória e gravar, outros processos podem realizar o
carregamento da variável da memória antes que o processo que deseja o lock consiga gravar
na variável.
Para isso, existe o outro tipo de lock, uma instrução que realiza este processo
atomicamente, o Test&Set. Esta instrução é utilizada pelo programador para garantir a
atomicidade do lock, porém existe um problema com ela, caso muitos processos queiram
entrar na região crítica, o Test&Set não é uma escolha boa. Isso porque ao ler o valor da

variável e ver que está travada, o processo espera um tempo não muito longo a ponto de
gastar tempo que poderia ser utilizado para processamento, mas também não muito curto a
ponto de realizar muitas transações de barramento inúteis quando o lock ainda não foi
liberado.
Para resolver este problema, existe um outro tipo de lock, o Test-and-Test&Set, que
carrega para o cache o valor da variável e só tenta pegar o lock quando a cópia do cache é
invalidada, ou seja, quando o valor na memória é alterado. Outro método é utilizar o LL-SC, ou
seja, Load-Locked e Store-Conditional. Apesar de serem transações não atômicas, resolvem o
problema de ler valor errado da variável de lock. O LL carrega o valor da variável de lock da
memória para um registrador, então a comparação é feita, caso esteja livre, armazena na
variável o novo valor do lock caso não tenha nenhuma modificação no valor da variável entre a
leitura e a escrita, caso contrário, volta a tentar ler o valor da variável.
Outros métodos de lock podem ser usados pelo programador, como o ticket lock, que
faz com que a corrida após a liberação do lock não aconteça. O processo entra em uma fila
para pedir o lock e quando chega sua vez é servido. Este método tem a desvantagem de todos
os processos lerem a mesma posição da memória para ver se chegou a sua vez de pegar o lock.
Há também o array-based-lock, onde cada processo verifica uma posição diferente da
memória para verificar se chegou sua vez.
Além dos lock, o programador pode fazer o uso de operações de comunicação
síncronas, que envolve somente as tarefas que enviam e recebem o dados, neste método o
programador deve sincronizar o envio e recebimento de dados, através de envio de
mensagens no código do programa, além disso, é necessário que haja uma coordenação do
modo como essas mensagens são passadas, havendo a necessidade de troca de sinais de
controle para início de operação, para sinalizar que o processo que deve receber o dado está
pronto para receber e para sinalizar que o dado foi recebido corretamente.
Este método envolve um número maior de transações de barramento entre os
processos e um overhead para realizar e interpretar tais transações.
Dependência de dados:
A dependência de dados em programas paralelos é a principal barreira para o
paralelismo, já que várias tarefas dependem da ordem em que são realizadas operações sobre
um mesmo dado na memória ou no meio de armazenamento. Caso esta ordem seja alterada, a
consistência sequencial deixa de ocorrer e o programa não realiza aquilo que o programador
teve a intenção que o programa realizasse.
Um uso muito comum em programas técnicos e científicos que dejesa-se o paralelismo
é o uso de uma variável que acumula sobre si mesma. Não há como o processo 2 realize a
próxima iteração sem que o processo 1 termine a iteração atual. Isso faz com que o processo 2
fique bloqueado esperando o término do cálculo do processo 1, como é visto no exemplo da
sequência Fibonacci. Outro exemplo de dependência de dados é quando dois processos
alteram a mesma posição da memória e então ambos utilizam esta variável para algum
cálculo. A ordem em que são realizadas tais tarefas altera o resultado esperado pelo

programador, já que não se sabe a ordem em que serão realizadas tais tarefas. Para isso, o
programador deve eliminar o máximo possível essas dependências de dados, seja alterando o
algoritmo de seu programa ou então agrupando essas dependências num mesmo processo.
Porém, mesmo com essas precauções não é possível eliminar todas as dependências,
para isso, o programador deve fazer o uso de mecanismo de sincronização já explicados, como
barreiras, locks ou através de operações síncronas em seu programa. Outros mecanismos
podem ser utilizados, dependendo da arquitetura do sistema, como por exemplo em sistemas
com memória distribuída pode-se realizar sincronizações em certos pontos do programa apra
garantir que os dados estejam corretos, ou então para sistemas com memória compartilhada
pode-se sincronizar todas as operações de leitura e escrita entre as tarefas para garantir a
consistência sequencial.
Balanceamento:
O programa para ser executado em paralelo, deve ser bem balanceado, ou seja, as
tarefas realizadas por cada processo devem ser bem distribuídas, para que em pontos onde
haja barreiras, muitos processos não fiquem bloqueados esperando o processo mais lento
chegar até a barreira.
O programador deve procurar particionar igualmente as tarefas entre os processos,
seja através da divisão de vetores e matrizes ou iterações de um loop entre os processos de
forma igual, mas também em tarefas onde esta divisão pode ser feita usando ferramentas de
análise do desempenho para evitar processamento desigual no programa.
Alguns desses problemas, como cálculos usando matrizes esparsas ou simulações
entre n partículas causam um desbalanceamento do processamento. Nesses casos onde pode-
se prever que haverá desbalanceamento, o uso de uma fila pode resolver este problema. Cada
processo ao terminar uma tarefa entra na fila para que seja atribuída uma nova tarefa para
ele. Assim, cada processo, ao terminar sua tarefa requisita uma nova tarefa até que o
programa seja terminado. Este método conhecido como scheduler-task pool pode utilizar
também um algoritmo que detecta e dinamicamente modifica esta balança para que o
programa fique igualmente balanceado entre os processos.
Implementações:
A seguir serão mostrados os diferentes métodos de programação para cada tipo de
arquitetura paralela:
- Shared Memory sem threads:
Neste tipo de arquitetura, os núcleos de processamento são conectados à uma
memória compartilhada entre todos eles através de barramentos, seja utilizando a arquitetura
UMA (Uniform Memory Access) [Figura 5] ou a arquitetura NUMA (Non-Uniform Memory
Access) [Figura 6], os núcleos compartilham a memória e todos os núcleos enxergam todos os
dados da memória compartilhada e podem fazer alterações.
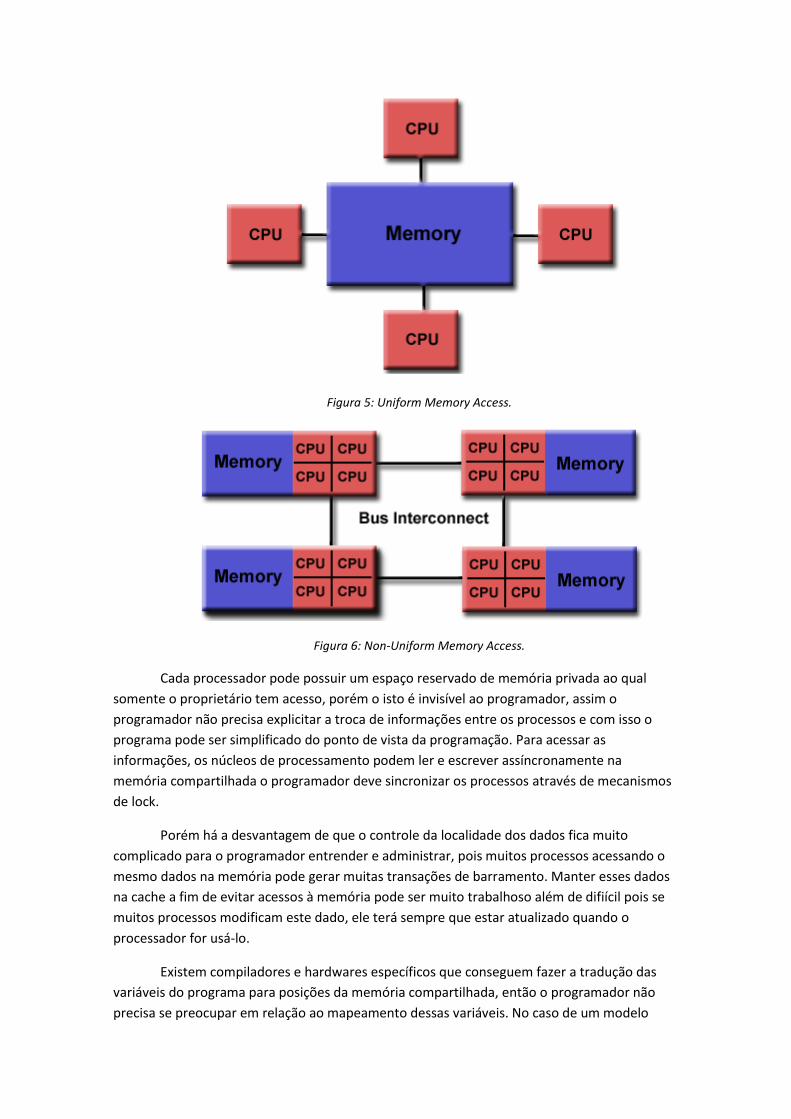
Figura 5: Uniform Memory Access.
Figura 6: Non-Uniform Memory Access.
Cada processador pode possuir um espaço reservado de memória privada ao qual
somente o proprietário tem acesso, porém o isto é invisível ao programador, assim o
programador não precisa explicitar a troca de informações entre os processos e com isso o
programa pode ser simplificado do ponto de vista da programação. Para acessar as
informações, os núcleos de processamento podem ler e escrever assíncronamente na
memória compartilhada o programador deve sincronizar os processos através de mecanismos
de lock.
Porém há a desvantagem de que o controle da localidade dos dados fica muito
complicado para o programador entrender e administrar, pois muitos processos acessando o
mesmo dados na memória pode gerar muitas transações de barramento. Manter esses dados
na cache a fim de evitar acessos à memória pode ser muito trabalhoso além de difiícil pois se
muitos processos modificam este dado, ele terá sempre que estar atualizado quando o
processador for usá-lo.
Existem compiladores e hardwares específicos que conseguem fazer a tradução das
variáveis do programa para posições da memória compartilhada, então o programador não
precisa se preocupar em relação ao mapeamento dessas variáveis. No caso de um modelo

híbrido de Shared Memory e Distributed Memory [Figura 7] apesar da memória ser distrbuída,
ela é vista como global para o programador e para o programa através de hardwares e
softwares específicos para este fim.
Figura 7: Híbrido de Shared Memory e Distributed Memory.
- Shared Memory com threads:
Apesar do uso de threads na programação paralela não ser uma novidade, seus
princípios podem ser transportados para uma arquitetura paralela.
Assim como na memória compartilhada, uma thread possui memória local, mas
compartilha dados através de uma memória global, assim como a Shared Memory. Porém os
métodos que existem para a programação paralela com threads exigem que o programador
explicite isto no código do programa, seja pelo uso de funções de bibliotecas especializadas ou
então o uso de diretivas para um compilador que podem ser inseridas no código serial ou
então nas partes do código a serem executadas em paralelo.
Como no passado as implementações de threads variavam muito de desenvolvedor
para desenvolvedor, foram padronizados as duas maneiras de se implementar programação
paralela com o uso de threads. Seja através da utilização de biblioteca foi definido o POSIX
threads (IEEE POSIX 1003.1c standard) de 1995 para a linguagem C ou então através de
diretivas para o compilador com o OpenMP que foi definido primeiramente para o Fortran em
1997 e posteriormente para C e C++ em 1998.
O POSIX threads conhecido como Pthreads utiliza rotinas do processo que podem ser
executadas paralelamente através de chamadas de funções da biblioteca pthread. Os
benefícios que uma thread pode oferecer em relação tempo são muitos, não só podem
executar algoritmos em paralelo como também são mais rápidas do que criar um novo
processo através do fork(), como mostrado na tabela 1.
Platform fork() pthread_create()
real user sys real user sys
Intel 2.6 GHz Xeon E5-2670 8.1 0.1 2.9 0.9 0.2 0.3
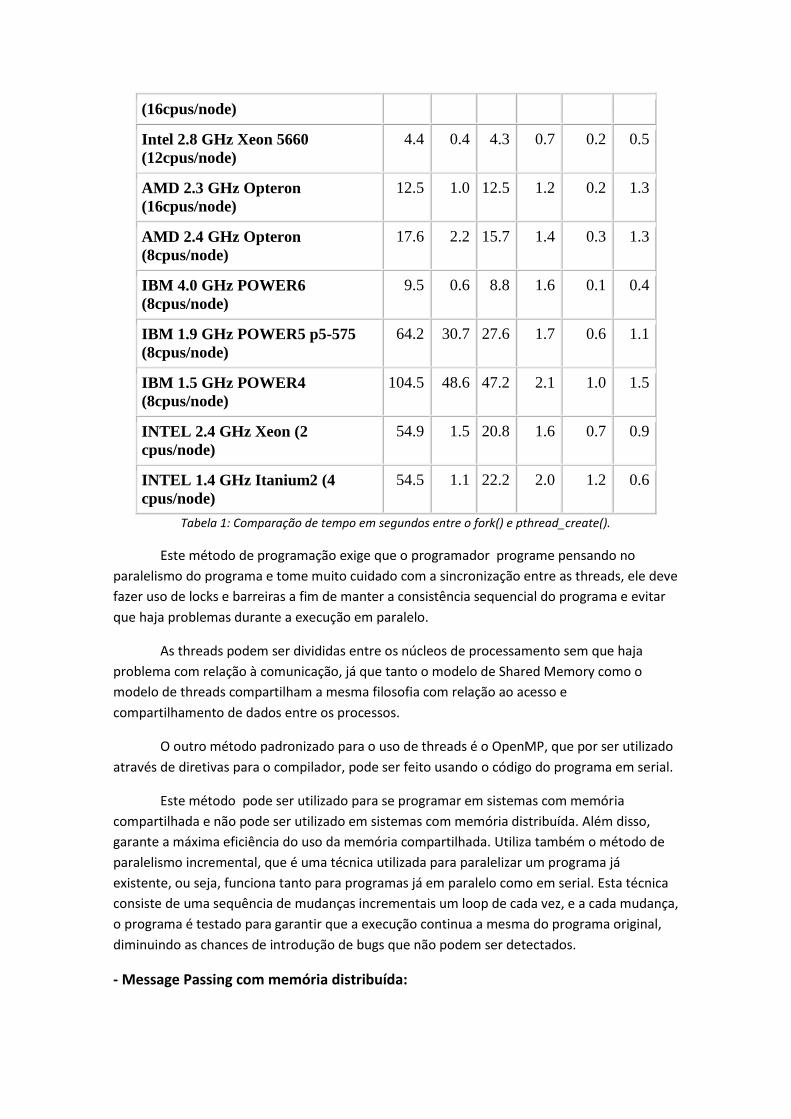
(16cpus/node)
Intel 2.8 GHz Xeon 5660
(12cpus/node)
4.4 0.4 4.3 0.7 0.2 0.5
AMD 2.3 GHz Opteron
(16cpus/node)
12.5 1.0 12.5 1.2 0.2 1.3
AMD 2.4 GHz Opteron
(8cpus/node)
17.6 2.2 15.7 1.4 0.3 1.3
IBM 4.0 GHz POWER6
(8cpus/node)
9.5 0.6 8.8 1.6 0.1 0.4
IBM 1.9 GHz POWER5 p5-575
(8cpus/node)
64.2 30.7 27.6 1.7 0.6 1.1
IBM 1.5 GHz POWER4
(8cpus/node)
104.5 48.6 47.2 2.1 1.0 1.5
INTEL 2.4 GHz Xeon (2
cpus/node)
54.9 1.5 20.8 1.6 0.7 0.9
INTEL 1.4 GHz Itanium2 (4
cpus/node)
54.5 1.1 22.2 2.0 1.2 0.6
Tabela 1: Comparação de tempo em segundos entre o fork() e pthread_create().
Este método de programação exige que o programador programe pensando no
paralelismo do programa e tome muito cuidado com a sincronização entre as threads, ele deve
fazer uso de locks e barreiras a fim de manter a consistência sequencial do programa e evitar
que haja problemas durante a execução em paralelo.
As threads podem ser divididas entre os núcleos de processamento sem que haja
problema com relação à comunicação, já que tanto o modelo de Shared Memory como o
modelo de threads compartilham a mesma filosofia com relação ao acesso e
compartilhamento de dados entre os processos.
O outro método padronizado para o uso de threads é o OpenMP, que por ser utilizado
através de diretivas para o compilador, pode ser feito usando o código do programa em serial.
Este método pode ser utilizado para se programar em sistemas com memória
compartilhada e não pode ser utilizado em sistemas com memória distribuída. Além disso,
garante a máxima eficiência do uso da memória compartilhada. Utiliza também o método de
paralelismo incremental, que é uma técnica utilizada para paralelizar um programa já
existente, ou seja, funciona tanto para programas já em paralelo como em serial. Esta técnica
consiste de uma sequência de mudanças incrementais um loop de cada vez, e a cada mudança,
o programa é testado para garantir que a execução continua a mesma do programa original,
diminuindo as chances de introdução de bugs que não podem ser detectados.
- Message Passing com memória distribuída:

Este método de programação deve utilizar bibliotecas com subrotinas que são
responsáveis por toda a comunicação entre os processos através da passagem de mensagens.
Neste modelo de memória distribuída [Figura 8], as tarefas são divididas nos vários
núcleos de processamento e utilizam a memória local para realizar os cálculos, havendo
comunicação pela rede entre os núcleos para o compartilhamento de dados entre os núcleos
de processamento localizados em diferentes blocos. Para realizar essa troca de informações é
necessário que haja a sincronização, pois é preciso que haja não somente o envio da
informação, mas também o alvo do dado deve realizar uma operação receive compatível com
o send que possui o dado.
Figura 8: Sistema com memória distribuída (Distributed Memory).
Para que isso aconteça, o programador é responsável pelas chamadas das rotinas que
fazem essa troca de informações, ou seja, o paralelismo deve ser completamente explícito no
código do programa. O programador também é responsável por sincronizar essas passagens
de mensagens a fim de evitar bloqueios de processos ou para o caso de uso de buffers evitar
que fique cheio.
O message passing foi desenvolvido em duas partes, a parte 1 (MPI1), lançada em
1994 e a parte 2 (MPI2) em 1996 com o objetivo de padronizar o método de programação
utilizando passagem de mensagens, já que até esta época existiam diversas implementações
diferentes de bibliotecas do MPI. Atualmente o MPI é o padrão para o modelo de passagem de
mensagens principalmente nas liguangens C e Fortran.
Para facilitar a programação de códigos utilizando o MPI pode ser utilizado o conceito
de topologia virtual, que mapeia “geometricamente” ou ordena os processos do MPI em
formatos mais compreensíveis para o programador, como uma grade ou um grafo. Esta
topologia é totalmente virtual e pode ou não ter relação com a estrutura física do computador
e devem ser programadas pelo desenvolvedor.
Programar utilizando topologias virtuais pode facilitar e muito em alguns algoritmos
que utilizam uma topologia semelhante de grade ou grafo. Este mapeamento pode otimizar e
facilitar a comunicação entre nós de processamento do ponto de vista do programador, já que
dependendo da topologia física do sistema, fica muito complexo de se tentar entender. Além
disso o mapeamento para uma topologia virtual depende da implementação do MPI.

- Data Parallel:
Nesta implementação, o problema é constituído por uma estrutura como um array ou
matrizes n-dimensionais que podem ser divididas em partições e cada núcleo de
processamento executa um mesmo algoritmo sobre partições diferentes do conjunto de
dados, como mostrado na figura 9.
Figura 9: Modelo Data Parallel.
Este tipo de programação pode ser aplicado em vários tipos de arquiteturas paralelas,
em modelos de memória compartilhada todas as tarefas têm acesso à estrutura de dados na
memória compartilhada, apesar que só rode o algoritmo na partição que lhe foi atribuída.
Para equilibrar o programa e evitar o desbalanceamento entre as partições, essas
atribuições de partições pode ser feita dinamicamente à medida que tarefas vão sendo
concluídas por cada núcleo.
No modelo de memória distribuída cada partição fica localizada na memória local de
cada núcleo de processamento e caso haja necessidade de troca de informações é utilizada a
passagem de mensagens. A passagem de mensagens éproduzida pelo compilador e é
totalmente invisível para o programador, porém pode-se utilizar diretivas para especificar a
distribuição e alinhamento dos dados na estrutura utilizada ou então rotinas de bibliotecas.
O exemplo mais comum de compilador que utiliza este método de programação é o
HPF (High Performance Fortran), uma extensão para o Fortran 90 que contém diretivas para o
compilador para dividir as tarefas e serem executadas paralelamente.
- Outros modelos:
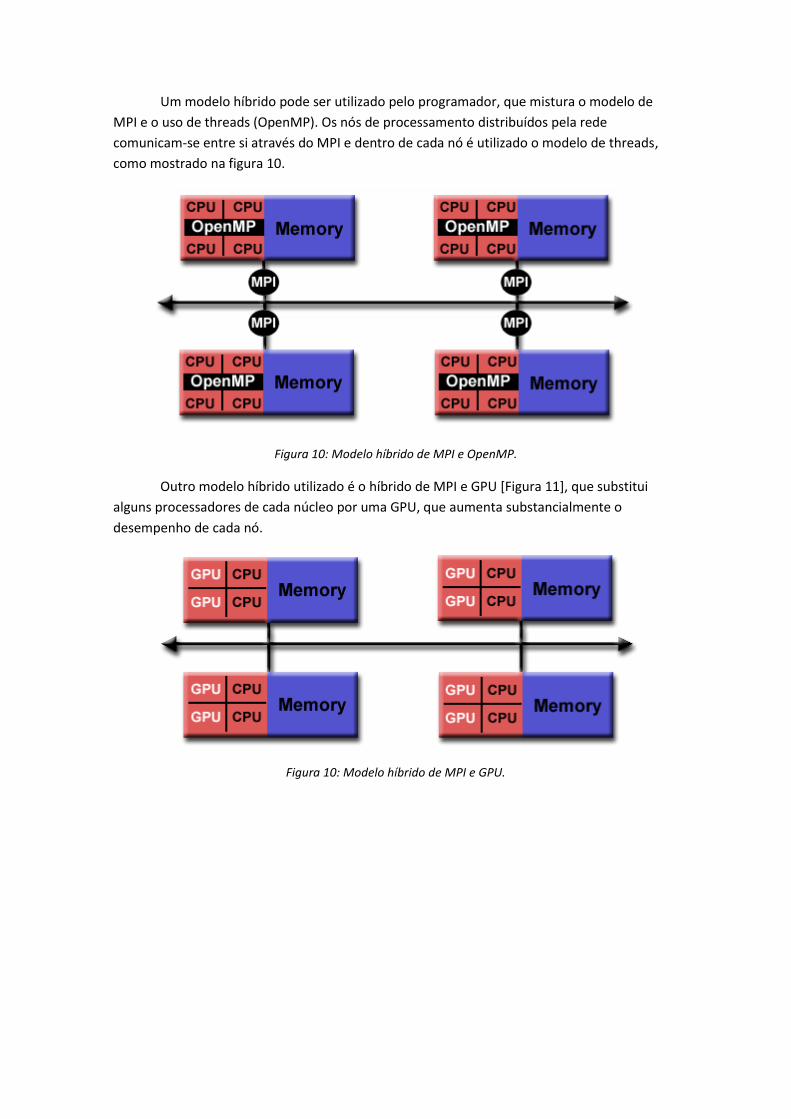
Um modelo híbrido pode ser utilizado pelo programador, que mistura o modelo de
MPI e o uso de threads (OpenMP). Os nós de processamento distribuídos pela rede
comunicam-se entre si através do MPI e dentro de cada nó é utilizado o modelo de threads,
como mostrado na figura 10.
Figura 10: Modelo híbrido de MPI e OpenMP.
Outro modelo híbrido utilizado é o híbrido de MPI e GPU [Figura 11], que substitui
alguns processadores de cada núcleo por uma GPU, que aumenta substancialmente o
desempenho de cada nó.
Figura 10: Modelo híbrido de MPI e GPU.

Referências:
- "Parallel Computer Architecture", David E. Culler, Jaswinder Pal Singh, Morgan
Kaufmman, 1999, ISBN 1-55860-343-3
- https://computing.llnl.gov/tutorials/parallel_comp/
- http://www.cise.ufl.edu/research/ParallelPatterns/glossary.htm