Embed Size (px)
Citation preview

1
CAPITULO1:INTRODUCCIO� N
1.1. LENGUAJES DE PROGRAMACIÓN (COMUNICACIÓN HOMBRE -MAQUINA)
En la comunicación hombre-máquina existe una dificultad real: las computadoras operan sobre bits (ceros y unos) y los hombres se entienden por medio de idiomas (lenguaje na-tural). El vehículo de comunicación entre el hombre y la computadora son los lenguajes de programación. Un lenguaje de programación es un conjunto de símbolos junto a un conjunto de reglas para combinar dichos símbolos que permite al usuario crear programas que serán enten-didos por la computadora (directa o indirectamente) con el objetivo de realizar alguna ta-rea. Podemos clasificar los lenguajes de programación en dos categorías:
• lenguajes de bajo nivel • lenguajes de alto nivel
Lenguajes de bajo nivel Son lenguajes totalmente dependientes de la máquina, es decir no se pueden migrar o uti-lizar en otras máquinas. Al estar prácticamente diseñados a medida del hardware, aprove-chan al máximo las características del mismo.
Cada instrucción corresponde a una acción ejecutable por la computadora.
Dentro de este grupo se encuentran: • Lenguaje de máquina: Las instrucciones se representan por medio de códigos nu-
méricos (binario). Cada cifra binaria del código se corresponde con un pulso eléc-trico; los circuitos de la máquina están diseñados para activar sus señales de acuerdo con este código. Cada operación requiere una determinada combinación de señales. Por eso deci-mos que este código numérico binario (que no es más que la representación numé-rica de las posibles combinaciones de estados opuestos de las señales) es el “len-guaje” que la computadora “entiende” y por eso lo conocemos como lenguaje de máquina. Su estructura está totalmente adaptada a los circuitos de la máquina, por eso es de bajo nivel. Los datos se referencian por medio de las direcciones de memoria donde se en-cuentran y las instrucciones realizan operaciones simples. Estos lenguajes están íntimamente ligados a la CPU y por eso no son transferibles de uno otro tipo de procesador (baja portabilidad). Para los programadores es posible escribir progra-mas directamente en lenguaje de máquina, pero las instrucciones son difíciles de recordar y los programas resultan largos y laboriosos de escribir y también de co-rregir y depurar.
• Lenguaje ensamblador: Las instrucciones se presentan por medio palabras en re-emplazo de los códigos numéricos (se trata de abreviaturas en letras o mnemotéc-nicos de las acciones correspondientes); es decir, las instrucciones se presentan en forma simbólica (no numérica binaria) por lo que son más fáciles de escribir y

2
recordar por las personas. Dada su correspondencia estrecha con las operaciones elementales de las máquinas, las instrucciones de los lenguajes ensambladores obligan a programar cualquier función de una manera minuciosa e iterativa. De cualquier forma para cada acción se necesita una instrucción y dependen comple-tamente del hardware (baja portabilidad). A pesar de que el lenguaje ensamblador es propio de una máquina, resulta muy fácil de manejar. Ejemplo de algunos códigos mnemónicos son: STO para guardar un dato, LOA para car-
gar algo en el acumulador, ADD para adicionar un dato, INP para leer un dato, STO para guardar
información, MOV para mover un dato y ponerlo en un registro, END para terminar el programa, etc.
De cualquier forma el programa así escrito debe ser traducido a lenguaje de má-quina. En los inicios (principios de la década del 50) se traducían manualmente y luego fueron las propias máquinas las que realizaran el proceso mecánico de la tra-ducción. A este trabajo se le llama ensamblar el programa.
Lenguajes de alto nivel Son aquellos que se encuentran más cercanos al lenguaje natural humano que al len-guaje máquina. Se trata de lenguajes independientes de la máquina. Por lo que, en principio, un programa escrito en un lenguaje de alto nivel, se puede migrar de una máquina a otra sin ningún tipo de problema.
Cada instrucción suele corresponder a varias acciones ejecutables por la computadora.
Estos lenguajes permiten al programador olvidarse por completo del funcionamiento in-terno de la máquina para la que se está diseñando el programa.
Es así que un programa fuente escrito en un lenguaje de programación necesita pasar por ese proceso de traducción al lenguaje de máquina que entiende la computadora. A ese proceso de conversión se le llama proceso de compilación o simplemente com-pilación . Y al programa capaz de realizar ese proceso se le llama compilador o tra-ductor . Un lenguaje de programación es un conjunto de símbolos + un conjunto de reglas que gobiernan las distintas maneras de combinar dichos símbolos. Decimos entonces que: Un lenguaje de programación tiene un léxico (símbolos permitidos o vocabulario), una sintaxis (reglas de construcción) y una semántica (significado de las construcciones).
Las instrucciones escritas en un lenguaje de alto nivel necesitan de un traductor que entienda tanto al lenguaje en sí como a las características de la máquina.
De qué forma se relacionan las palabras que apare-cen en una misma frase o párrafo (reglas que go-biernan la forma de combinarse las palabras). Ej. Un adjetivo puede ser complemento de un sus-tantivo o cumplir otra función.
Tiene que ver con el signi-ficado de la palabra Ej. Un adjetivo es una cualidad del sustantivo

3
Evidentemente cada lenguaje de programación requiere de un compilador específico. El compilador traduce todo el programa, a un código binario (lenguaje de máquina). Los compiladores son, pues, PROGRAMAS de traducción, insertados en la memoria por el sistema operativo y como tales responden a un algoritmo (bastante complejo) que está codificado en un lenguaje de programación. Un compilador queda entonces definido por tres lenguajes:
- el lenguaje del código que compila (programa fuente) - el lenguaje del código que genera (programa objeto) - el lenguaje en el que está escrito (lenguaje de implantación). Aunque puede servir
cualquier lenguaje, generalmente se eligen lenguajes orientados a sistemas como es el C
Una vez finalizada la compilación y obtenido el programa objeto, este es sometido a otro proceso para llegar al programa ejecutable. Es así que podemos decir que un compilador no es un programa que funcione de manera aislada, sino que necesita ser asistido por otros programas para llegar a obtener el ejecu-table. Algunos de esos programas son.
- el preprocesador: se ocupa (dependiendo del lenguaje) de incluir archivos, expan-dir macros, eliminar comentarios, y otras tareas similares.
- el enlazador o editor de enlace (linker): se encarga de construir el archivo ejecuta-ble, añadiendo al archivo que contiene al programa objeto generado por el compila-dor las funciones de librería utilizadas por el programa fuente.
- el depurador (debuger): permite, si el compilador ha generado adecuadamente el programa objeto, seguir paso a paso la ejecución de un programa.
- el ensamblador: muchos compiladores, en vez de generar código objeto, generan un programa en lenguaje ensamblador que debe después convertirse en un ejecu-table mediante un programa ensamblador.
Las herramientas para la construcción de software facilitan la creación de un compilador que, generalmente, está formado por un conjunto de módulos interactuantes. Por lo tanto, podemos destacar que para construir un compilador hay que integrar concep-tos referidos a:
• Los lenguajes de programación • La arquitectura del computador • La teoría de lenguajes • La algoritmia • La ingeniería de software
compilador
Programa
objeto
Programa
fuente
Mensaje
de error

4
En el idioma castellano las palabras se clasifican en verbos, sustantivos, adjetivos, etc.
1.2. COCEPTOS PREVIOS A TENER EN CUENTA Componentes léxico o token = elemento básico propios del lenguaje (en el idioma caste-llano son las palabras). Es una cadena de caracteres que se ajusta a un patrón determi-nado y que tiene un significado en el lenguaje. Se los puede considerar agrupados en ca-tegorías (o tipos). Las categorías de tokens pueden variar de un lenguaje a otro, pero en general se distinguen las siguientes: � palabras reservadas � identificadores � constantes numéricas y literales � operadores
(el nombre que le demos a los tipos de tokens depende de nosotros)
Ejemplo: Son componentes léxico del Pascal las cadenas: Son componentes léxico del C las cadenas:
A cada token le corresponde una estructura lexicológica de la forma <tipo del token, va-lor léxico>. Por lo tanto en la estructura lexicológica del token distinguimos: - Tipo de token: es una categoría léxica (“constante”, “identificador”, “operador”, etc.). - Valor léxico: datos relacionados con el token en particular (valor de la constante, índice
del símbolo en la tabla de símbolos, etc.).
En el idioma castellano sería: La flor es blanca
Cada una de estas cadenas
tiene un significado para el
lenguaje
while
if son palabras reservadas
readln
= es operador de relación
:= es operador de asignación
+ es operador aritmético de
suma
Artículo LA Sustantivo FLOR Verbo ES Adjetivo BLANCO
while
if
= = es operador de relación
= es operador de asignación
+ es operador aritmético de suma
+ = es operador de asignación especial suma (no sería un componente léxico para
el Pascal)
son palabras reservadas
categorías Componente léxico

5
Atributo = característica propia de cada tipo de token.
Patrón = es la regla de generación de la secuencia de caracteres que podría representar a determinado token. La definición formal de la descripción de un patrón se realiza con una herramienta lingüística especial denominada expresión regular. Ejemplo:
Para Pascal, el identificador de una variable debe ser “cualquier combinación de letras, dígitos y guión bajo siempre
que la primera sea una letra”. Habrá una expresión regular (tema que se verá más adelante) que represente lo dicho.
Lexema (valor léxico) = cadena que se encuentra en el programa fuente que es posible identificarla como un token; es decir, concuerda con el patrón que describe al token Po-dríamos sintetizar diciendo que, el patrón es una definición formal y el lexema es la ca-dena que encaja en esa definición.
En el idioma castellano sería: flor es una palabra; rosa, clavel,
margarita (si bien son palabras del castellano, en este caso) serían lexe-
mas de flor pues sirven para referirse a una determinada flor. Cuando
decimos flor nos referimos a cualquiera.
Los componentes elementales de un programa fuente son los lexemas, que pueden ser reconocidos como token del lenguaje (si está correctamente escrito). Además a un token le puede corresponder uno o más lexemas. Algunos tokens y sus posibles lexemas serían:
Ejemplo:
Para Pascal:
- son lexemas del token de categoría identificador : A12, sub_total
- son lexemas del token de categoría palabra reservada : if, read, begin
Estudiaremos:
EXPRESION REGULAR
(para especificar patrones)

6
1.3. MODELO DE ANALISIS Y SINTESIS DE LA COMPILACIO N Ya mencionamos que el trabajo de un compilador consiste en tomar la cadena del pro-grama fuente, determinar si es válida para el lenguaje y, a la vez, generar un programa equivalente en un lenguaje que la computadora entienda; debemos agregar que si, a lo largo de este proceso de traducción, encuentra en el texto, errores que tengan que ver con el uso del lenguaje, los informará al usuario y no completará la traducción. El proceso de compilación que se realiza sobre el programa fuente puede considerárselo como integrado por dos tareas principales: el análisis de su texto y la síntesis en un có-digo que, cuando se ejecute, realice correctamente las actividades descritas en el pro-grama. El proceso es irreversible e inclusive puede considerarse destructivo, ya que no hay forma de reconstituir el programa fuente a partir del ejecutable. En el siguiente es-quema se presenta el proceso con las etapas que componen a cada fase perfectamente diferenciadas y separadas, pero en la práctica las etapas se entremezclan.
1.4. LAS FASES DE UN COMPILADOR Desde otro punto de vista se lo puede ver como formado por dos etapas: etapa inicial en la que el proceso depende del lenguaje fuente y es completamente independiente de la máquina y una etapa final en la que el proceso se hace dependiente de la máquina e in-dependiente del lenguaje fuente. De cualquier manera para el estudio de un compilador es apropiado considerar el proceso total que lleva a cabo, como que se cumple en fases; cada una de ellas iría transformando al código original, pasando de una a otra representación, hasta convertirlo en pulsaciones eléctricas ejecutables (lenguaje de máquina). En general, estas fases no son estrictas, se entrelazan mediante distintos procesos, defi-niendo un programa bastante complejo; y esta complejidad va en aumento en función de la riqueza del lenguaje que compila. Para un compilador en particular, el orden de los pro-cesos puede variar y, en muchos casos, varios procesos pueden combinarse en una sola fase. Los módulos generales son seis:
Compilación
Generación
de código Léxico: separación
de cada elemento
componente del
programa (“token”)
Sintáctico: separa-
ción de cada instruc-
ción o sentencia del
lenguaje, que agrupa
varios componentes
léxicos o “tokens”
Semántico:
comprueba que
las reglas se-
mánticas del
lenguaje se
cumplan
Análisis Síntesis

7
1. Análisis léxico (rastreo o scanner)
2. Análisis sintáctico (parser)
3. Análisis semántico
4. Generación de código intermedio
5. Optimización de código intermedio
6. Generación de código ejecutable
En estas seis fases interactúan también otros procesos, que no son fases en sentido estricto, pero muchas veces, para describirlas se las menciona como tales; son los módulos de:
7. Administración de la tabla de símbolos y tipos
8. Gestión de errores Normalmente el centro del proceso de compilación gira alrededor del analizador sintác-tico, el cual es el encargado de activar cada una de las restantes fases según sea nece-sario. Como el trabajo será “traducir” un determinado lenguaje, deberá formar parte del compila-dor: las especificaciones léxicas del lenguaje que traduce (sus tokens), las especificacio-nes sintácticas (el ordenamiento válido de sus tokens) y las semánticas (significado de cada token y las reglas que deben cumplir). El proceso de análisis no se detiene ante el primer error encontrado. En cada fase se pueden encontrar errores, sin embargo, cada uno será procesado (sin corregirlo) en el momento de ser detectado, de manera tal que el compilador pueda continuar. De esta forma, le será posible encontrar errores posteriores. Todos los errores se informan al final de la etapa de análisis y recién ahí se detiene la compilación. La detección de un error no siempre se hace en la fase de análisis que le corresponde, a veces se detectan en fases posteriores e inclusive sólo se hacen visibles en tiempo de ejecución. El tratamiento de los errores durante el proceso de compilación (en cualquiera de sus fa-ses) debe cumplir al menos los requisitos siguientes: - reportar su presencia de manera clara y precisa - recuperarse lo suficientemente rápido como para ser capaz de detectar los errores si-guientes - no demorar significativamente el procesamiento de los programas correctos. Análisis léxico (AL) El AL reconoce, para cada cadena del programa fuente, si concuerda o no con alguna de las que pertenecen al léxico especifico del lenguaje (token), y la clasifica por su catego-ría. Es decir lee los lexemas y le hace corresponder un significado propio. Entrada: cadena de caracteres (el texto completo del programa fuente).
ETAPA DE ANALISIS
ETAPA DE SINTESIS
ETAPA INICIAL
front-end
ETAPA FINAL
back-end

8
Proceso: se agrupan los caracteres, separando en subcadenas que tienen un significado elemental. Es decir, se separan los componentes léxicos o tokens. En este proceso va ignorando las partes que no son esenciales para la siguiente fase; es así que elimina los comentarios, los espacios en blanco, etc. (z:=A+23 es descompuesto de la misma forma que se haría con z := A + 23 o con z:= a + 23 ). Salida: la secuencia de tokens correspondientes, expresados por su estructura lexicoló-gica.
Cuando el AL detecta un identificador o una constante, almacena su lexema y sus atribu-tos principales, de manera que en cualquier momento se pueda recurrir a ellos. Se usa para esto una estructura de datos conocida como tabla de símbolos. Los tokens se alma-cenan en ella a medida que van apareciendo. Ejemplo 1:
Entrada: A := BT * C + 3;
Proceso: Se reconocen y agrupan los siguientes tokens
A := BT * C + 3 ;
Tabla de símbolos: Salida: <Identificador, A> <Operador Asig> <Identificador, BT> <Operador aritm, *> <Identificador, C><Operador aritm, +> <Cte.numer., 3 >
Si la entrada fuera: ZETA := X * M_T + 273; tendrá la misma estructura de salida (son los mismos tipos de to-
ken) pero con distinto valor de lexema
Ejemplo 2:
Entrada: if (A = B) then Z := 0 else Z := 1; Salida: <Palabra reserv., if > <Paréntesis abre, ( > <Identificador, A > <Operador relación,= > ………………….
El AL opera bajo petición del AS, devolviendo un token, cuando el AS lo va necesitando para avanzar en la gramática.
Funcionamiento detallado del AL:
Operador asignación
Este es un lexema que corresponde al to-ken de categoría “operador relacional”.
A variable entera
BT variable entera
C variable entera
3 constante entera
Identificador
Constante numérica Estudiaremos:
AUTOMATAS FINITOS (modelo que
se usa para describir el proceso de
reconocer patrones en cadenas de
entrada)
Operador aritmético

9
• A partir de la lectura carácter a carácter de la entrada, construye un token válido. • Pasa el token válido, al AS • Gestiona el manejo de la entrada • Ignora espacios en blanco, comentarios y caracteres innecesarios • Avisa de los errores encontrados • Lleva la cuenta del número de línea (para incluirlo en el informe de errores)
Cada carácter leído es guardado en un buffer. Cuando encuentra uno que no le sirve para construir un token se detiene y envía los caracteres acumulados al AS, quedando a la es-pera de una nueva petición de lectura. Cuando esto ocurra, limpia el buffer y vuelve a leer el carácter donde paró la vez anterior (ese no fue enviado porque no pertenecía al token). Ejemplo: Para el siguiente fragmento de código Pascal:
real x;
begin end.
entrada buffer acción
r r Leer otro carácter
e re Leer otro carácter
a rea Leer otro carácter
l real Leer otro carácter
Espacio en blanco real Enviar token y limpiar buffer
x x Leer otro carácter
; x Enviar token y limpiar buffer
; ; Leer otro carácter
b ; Enviar token y limpiar buffer
b b Leer otro carácter
e be Leer otro carácter
g beg Leer otro carácter
i begi Leer otro carácter
n begin Leer otro carácter
Espacio en blanco begin Enviar token y limpiar buffer
e e Leer otro carácter
n en Leer otro carácter
d end Leer otro carácter
. end Enviar token y limpiar buffer
. . Leer otro carácter
Fin de entrada . Enviar token y finaliza proceso
Errores detectados por el AL: Descubre un error cuando los caracteres que toma del buffer de entrada no forman un to-ken válido para el lenguaje.
En síntesis:
LEE CARACTERES HASTA COM-
PLETAR UN TOKEN Y EMITE EL
PAR token-lexema

10
Ejemplo:
Si encuentra una coma como separador de la parte decimal de un número, si en un identificador hay un
símbolo no permitido, etc.
Análisis sintáctico (AS) La escritura de un programa en un lenguaje de alto nivel se rige por un reducido conjunto de reglas gramaticales. Este conjunto de reglas se denomina la sintaxis del lenguaje y es lo que permite determinar, matemáticamente, si un programa es correcto o no desde el punto de vista sintáctico
En los lenguajes naturales (castellano, inglés, etc.) una frase gramaticalmente incorrecta puede ser comprendida por la persona a la que se dirige; con los lenguajes de programa-ción no ocurre lo mismo
Cada lenguaje posee su propia sintaxis. Las reglas que rigen para Pascal, no son las mis-mas que para Fortran o para C. La sintaxis de un lenguaje se basa en la existencia de categorías sintácticas. Son catego-rías sintácticas las instrucciones, los identificadores, las constantes, las expresiones, las asignaciones, los operadores, etc.
En el idioma castellano serían categorías sintácticas: - verbos - sustantivos - adjetivos - ………
Cuando una regla gramatical especifica que en tal contexto debe ir tal categoría sintáctica, significa que ahí puede y debe ir cualquier construcción del lenguaje que sea considerada de esa categoría.
La tarea del AS es determinar si la estructura sintáctica del programa es correcta para ese lenguaje. Para ello hace un análisis gramatical del texto.
En el idioma castellano sería verificar que se cumplan las reglas de, por ej.: - concordancia entre sustantivos y adjetivos (en género y nú-mero) - concordancia entre sujeto y verbo (el verbo concuerda con el núcleo de su sujeto, en número y persona)
Entrada: los sucesivos tokens producido por el AL (no maneja la secuencia de caracte-res).

11
Proceso: examina los tokens según van apareciendo, analizando solamente la 1er. com-ponente (la 2da. se usará en otros pasos); y comprueba si van llegando en el orden espe-cificado por la gramática del lenguaje. Si no cumple con las reglas que rigen la correcta vinculación entre las distintas categorías sintácticas, genera el informe de error correspon-diente. Para esto construye, con lo devuelto por el AL, un agrupamiento jerárquico conocido como árbol1 y verifica que su constitución responda a un agrupamiento aceptable por el lenguaje. El árbol que se utiliza, es un árbol especial llamado árbol sintáctico o árbol de análisis gra-matical que se caracteriza por ser una representación compacta de las operaciones y sus argumentos. En este tipo de estructura jerárquica se encontrarán:
• los nodos interiores los operadores (que son los símbolos que definen a la operación correspondiente, por ej. en Pascal: + para una suma, := para una asig-nación,…)
• los hijos del nodo los operandos (que son los argumentos con los
que se resuelve la operación) Para que un árbol sintáctico sea válido se necesita que, para cada bifurcación exista una regla sintáctica. Ejemplo:
El principio básico de la sintaxis consiste en que una construcción corresponde a una ca-tegoría sintáctica determinada, sí y solo sí es posible construir un árbol sintáctico en
1 En lingüística, un árbol es una forma de visualizar la estructura de una oración. Es una notación puramente formal, sin sustancia alguna. Debe mostrar todas las relaciones relevantes en la oración sin confusión. Las palabras están en sucesión lineal de izquierda a derecha, y en el mismo orden en que aparecen en la oración. La idea es que de-bemos poder leer la oración de izquierda a derecha sin tener que volver los ojos hacia la izquierda en ningún punto.
ocupados por…
ocupados por…
23
X := Z * 23
Z
NODO
Esta hoja puede ser el nodo
de otra categoría sintáctica
Describe a una categoría sintáctica (si es
una expresión o una asignación, etc.)
*
:=
X

12
donde en la raíz aparezca la categoría sintáctica pretendida y la lectura secuencial de las hojas corresponde a la construcción dada. Salida: árbol sintáctico Ejemplo:
Si en un lenguaje existe una regla sintáctica que dice:
una expresión puede ser construida a partir de otra expresión se-
guida de un operador binario y luego una tercera expresión
esta regla se podría expresar esquemáticamente como:
expresion → expresion operador aritmético expresión
con esta regla, no es suficiente para el ejemplo, pues deberá tenerse en cuenta otras reglas más; por ejemplo, la que
define qué es una expresión (seguramente en ella estará considerado si se trata de un identificador o de una constante),
qué es un operador binario aritmético (en ella se mencionará, seguramente a los símbolos +, -, *, /, etc.)
el árbol sintáctico válido sería:
<Identificador> <Operador aritm> <Identificador>
Es así que para la construcción B + * C (en Pascal)
- el AL devuelve la secuencia: <Identificador, B> <Operador aritm, +> <Operador ar itm, *> <Identificador, C>
- el AS toma las categorías de esos tokens: <Identificador> <Operador aritm> <Operador aritm> <Identificador>
y analiza si concuerda o no con la regla .
∴ concluye que NO CUMPLE CON LA ESPECIFICACION SINTACTICA DEL LENGUAJE – E R R O R
En cambio para la construcción B + 15 (en Pascal)
- el AL devuelve la secuencia: <Identificador, B> <Operador aritm, +> <Constante, 15>
- el AS toma las categorías de esos tokens: <Identificador> <Operador aritm> <Constante> y analiza si con-
cuerda o no con la regla .
∴ concluye que SI CUMPLE CON LA ESPECIFICACION SINTACTICA DEL LENGUAJE
Los dos analizadores (AL y AS) trabajan juntos e incluso, el AL suele ser una subrutina del AS. El accionar de estos analizadores apunta a comproba r que el programa está bien construido respecto a las reglas impuestas por el lenguaje (las que definen el lé-xico y las que definen la sintaxis).
categorías sintácticas distintas
1
1
1
Identificador Identificador
Operador aritm

13
Es el AS el que guía la mayor parte del proceso de compilación ya que, mientras por un lado va pidiendo los tokens al AL, al mismo tiempo va dirigiendo el proceso del Ase y ge-nerando el código inter-medio. Errores detectados por el AS: Descubre un error cuando los tokens no cumplan con las reglas estructurales (sintaxis) del lenguaje. Ejemplo:
En una expresión aritmética los paréntesis no están balanceados. Administración de la tabla de símbolos y tipos Los lenguajes de programación tienen tipos de datos primitivos y permiten crear, a partir de ellos, nuevos tipos. Por otro lado, el programador puede crear variables que pertenezcan a cualquiera de esos tipos, y también crear subprogramas. Estos recursos y otros objetos del texto fuente constituyen una información importante para el compilador; los llamaremos símbolos y en general, consideraremos entre ellos a las constantes, los nombres de variables, las eti-quetas del programa, los nombres de subprogramas y sus parámetros. Por todo esto resulta evidente que, en el proceso de compilación deberá mantenerse, de alguna manera, la información referida a los tipos del lenguaje y a los símbolos del mismo, a medida que van apareciendo. Una forma de hacer esto, es usando tablas:
- Tabla de tipos - Tabla de símbolos
Para que la compilación sea eficiente, estas tablas deben estar implementadas con es-tructuras de datos que hagan fácil el acceso, ya que durante todo el proceso las diferentes fases harán uso de ellas (especialmente el AS y Ase). El compilador debe incluir entonces, una serie de funciones relativas a la gestión de estas tablas tales como, permitir insertar un nuevo elemento en ella, consultar la información re-lacionada con un símbolo, borrar un elemento, etc. Tabla de tipos Es esencial para que el Ase pueda trabajar. Estas se inicializan con los tipos primitivos y se van agregando los tipos definidos por el usuario. Se guardarán en la tabla, fundamentalmente, información referida a:
- identificador del tipo

14
- tipo base, si se tratara de un tipo compuesto definido por el usuario - dimensión (cantidad de elementos, 1 para los primitivos), alcance, etc.
Es habitual contar con un campo adicional que contenga un código para el tipo, la finali-dad de esto es hacer más práctica la referencia a un tipo determinado. Tabla de símbolos La tabla de símbolos es una estructura de datos contenedora de la información que el programa procese, por lo tanto estarán en la memoria donde corre el programa compi-lado. A lo largo de la ejecución del programa, alguno de esos símbolos podrá ir cam-biando su valor, pero la dirección de memoria donde ello ocurre es fija y se define en la etapa de compilación. Por todo esto, en la tabla de símbolos se mantendrá el símbolo (en un campo) y la direc-ción donde se guardará el o los valores que asuma (en otro campo). Para las siguientes fases de compilación será necesario incluir otros datos en la tabla de símbolos. En esta fase son necesarios:
- Nombre (nombre de una variable, nombre de una función, etc.) - Categoría (según ella el significado de algunos campos será distinto) - Tipo (debe estar en la tabla de tipos, para los subprogramas es el tipo de retorno) - Cantidad de parámetros (sólo cuando el símbolo es un subprograma) - Lista de parámetros (estructura de datos que contiene a la lista de los tipos de los pa-
rámetros, si es que existen) - Dirección (lugar de memoria donde estará el valor; si se trata de una estructura de da-
tos es la que corresponde al valor del primer elemento) En estas tablas se guardan también otros datos que tienen que ver con los símbolos y los tipos, y son los que el diseñador del compilador considere relevantes para el funciona-miento del programa.
Ejemplo:
Si trabajáramos con un lenguaje Pascal que tuviera sólo dos tipos primitivos (integer y char) y suponemos que las varia-
bles se guardan desde la dirección de memoria 9000 en adelante y que cada entero ocupa 2 direcciones y cada carác-
ter ocupa 1, la formación de las tablas será como se indica luego para el siguiente fragmento de código:
Type Ar = array [0..9] of integer; Var
x: Ar; car: char; z: integer;
1º sólo la tabla de tipos se inicializará:
TABLA DE TIPOS TABLA DE SIMBOLOS
Código del tipo nombre dimensión Código del símb. nombre categoria tipo dirección
0 char 1
1 integer 1
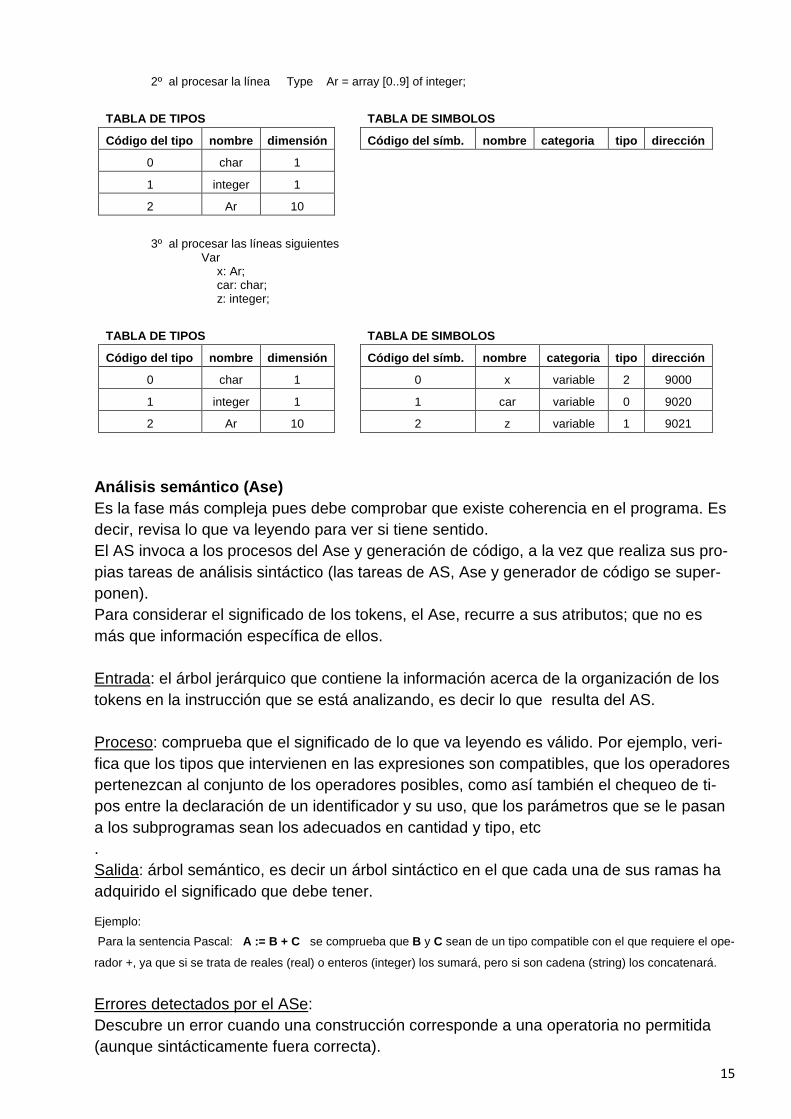
15
2º al procesar la línea Type Ar = array [0..9] of integer;
3º al procesar las líneas siguientes
Var x: Ar; car: char; z: integer;
Análisis semántico (Ase) Es la fase más compleja pues debe comprobar que existe coherencia en el programa. Es decir, revisa lo que va leyendo para ver si tiene sentido. El AS invoca a los procesos del Ase y generación de código, a la vez que realiza sus pro-pias tareas de análisis sintáctico (las tareas de AS, Ase y generador de código se super-ponen). Para considerar el significado de los tokens, el Ase, recurre a sus atributos; que no es más que información específica de ellos. Entrada: el árbol jerárquico que contiene la información acerca de la organización de los tokens en la instrucción que se está analizando, es decir lo que resulta del AS. Proceso: comprueba que el significado de lo que va leyendo es válido. Por ejemplo, veri-fica que los tipos que intervienen en las expresiones son compatibles, que los operadores pertenezcan al conjunto de los operadores posibles, como así también el chequeo de ti-pos entre la declaración de un identificador y su uso, que los parámetros que se le pasan a los subprogramas sean los adecuados en cantidad y tipo, etc . Salida: árbol semántico, es decir un árbol sintáctico en el que cada una de sus ramas ha adquirido el significado que debe tener. Ejemplo:
Para la sentencia Pascal: A := B + C se comprueba que B y C sean de un tipo compatible con el que requiere el ope-
rador +, ya que si se trata de reales (real) o enteros (integer) los sumará, pero si son cadena (string) los concatenará. Errores detectados por el ASe: Descubre un error cuando una construcción corresponde a una operatoria no permitida (aunque sintácticamente fuera correcta).
TABLA DE TIPOS TABLA DE SIMBOLOS
Código del tipo nombre dimensión Código del símb. nombre categoria tipo dirección
0 char 1
1 integer 1
2 Ar 10
TABLA DE TIPOS TABLA DE SIMBOLOS
Código del tipo nombre dimensión Código del símb. nombre categoria tipo dirección
0 char 1 0 x variable 2 9000
1 integer 1 1 car variable 0 9020
2 Ar 10 2 z variable 1 9021

16
Ejemplo:
Si se presenta la operación suma entre dos identificadores, uno el nombre de un arreglo y el otro el nombre de un
procedimiento, si un identificador se declara de un tipo y se lo usa como si fuera de otro, si el índice de un arreglo es
de tipo real (esto sólo para algunos lenguajes).
Ejemplo de una etapa de análisis: Para el siguiente fragmento de código Pascal:
Var car: char; num: integer; …… …… car := num + 4; …….
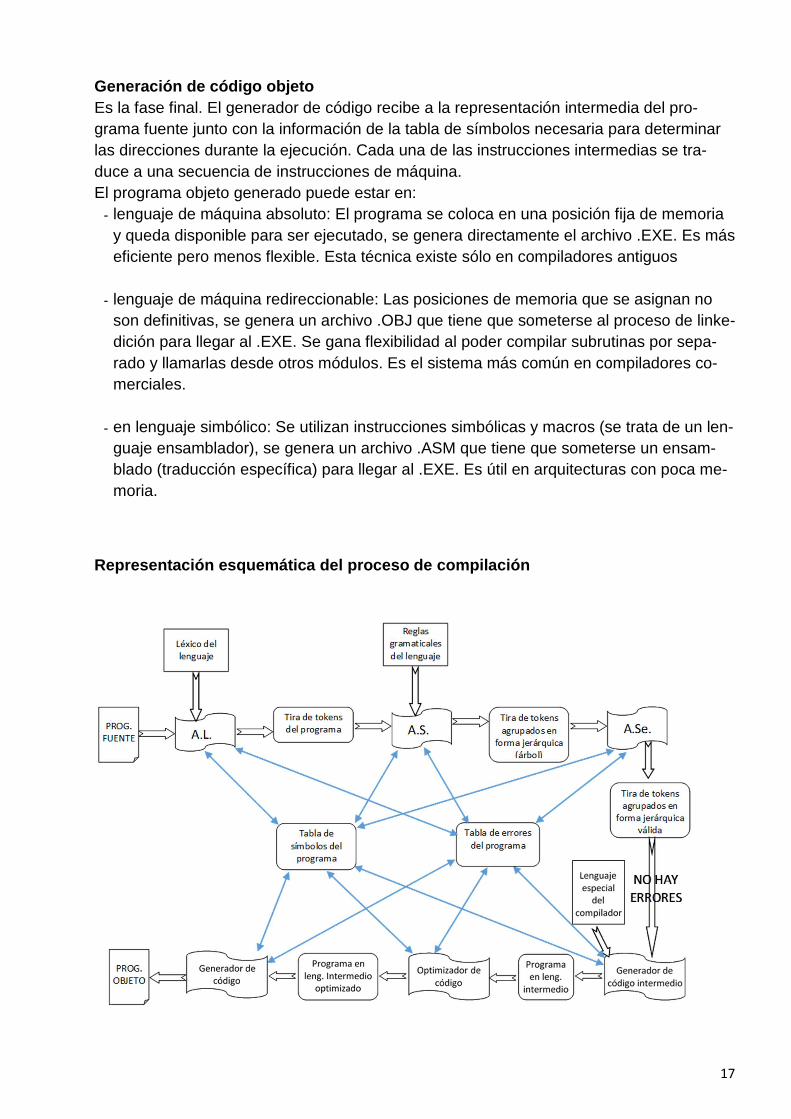
Generación de código intermedio Después de AS y ASe, algunos compiladores generan una representación intermedia ex-plícita del programa fuente. El código intermedio corresponde a un lenguaje sencillo (generalmente inventado por el desarrollador del compilador). Se trata de un lenguaje cercano a una máquina abstracta y no a una concreta como sería el que le corresponde al verdadero procesador con que está armada la máquina. El código generado responde a la secuencia real de las opera-ciones que se harán como resultado de las fases anteriores.
Este código intermedio es de fácil traducción al lenguaje de máquina al que responde un determinado procesador, de esta forma el esfuerzo de crear un compilador para uno u otro modelo de procesador se minimiza pues el proceso anterior al código intermedio (largo y complejo) será común para todos. Optimización de código intermedio En esta fase se trata de mejorar el código intermedio, de modo que resulte un código de máquina más rápido de ejecutar. Se toma el código intermedio de forma global y lo adapta a las características del procesador al que va dirigido.
Analizador léxico: genera la secuencia de tokens <Identif, car> <Asig> <Identif, num> <Op aritm, +> <Constante, 4>
Analizador sintáctico: define que el orden de los tokens es válido Analizador semántico: detecta que el tipo de variables asignadas es incorrecta
Si fuera el análisis de un compilador C, para la misma devolución del AL el ASe hubiera dado como válida la asignación
PROG.
FUENTE
CODIGO
INTERMEDIO
PRCESADOR
xx
PRCESADOR
YY
yy
PRCESADOR
ZZ
Se traduce para …
17
Generación de código objeto Es la fase final. El generador de código recibe a la representación intermedia del pro-grama fuente junto con la información de la tabla de símbolos necesaria para determinar las direcciones durante la ejecución. Cada una de las instrucciones intermedias se tra-duce a una secuencia de instrucciones de máquina. El programa objeto generado puede estar en:
- lenguaje de máquina absoluto: El programa se coloca en una posición fija de memoria y queda disponible para ser ejecutado, se genera directamente el archivo .EXE. Es más eficiente pero menos flexible. Esta técnica existe sólo en compiladores antiguos
- lenguaje de máquina redireccionable: Las posiciones de memoria que se asignan no
son definitivas, se genera un archivo .OBJ que tiene que someterse al proceso de linke-dición para llegar al .EXE. Se gana flexibilidad al poder compilar subrutinas por sepa-rado y llamarlas desde otros módulos. Es el sistema más común en compiladores co-merciales.
- en lenguaje simbólico: Se utilizan instrucciones simbólicas y macros (se trata de un len-
guaje ensamblador), se genera un archivo .ASM que tiene que someterse un ensam-blado (traducción específica) para llegar al .EXE. Es útil en arquitecturas con poca me-moria.
Representación esquemática del proceso de compilaci ón
18
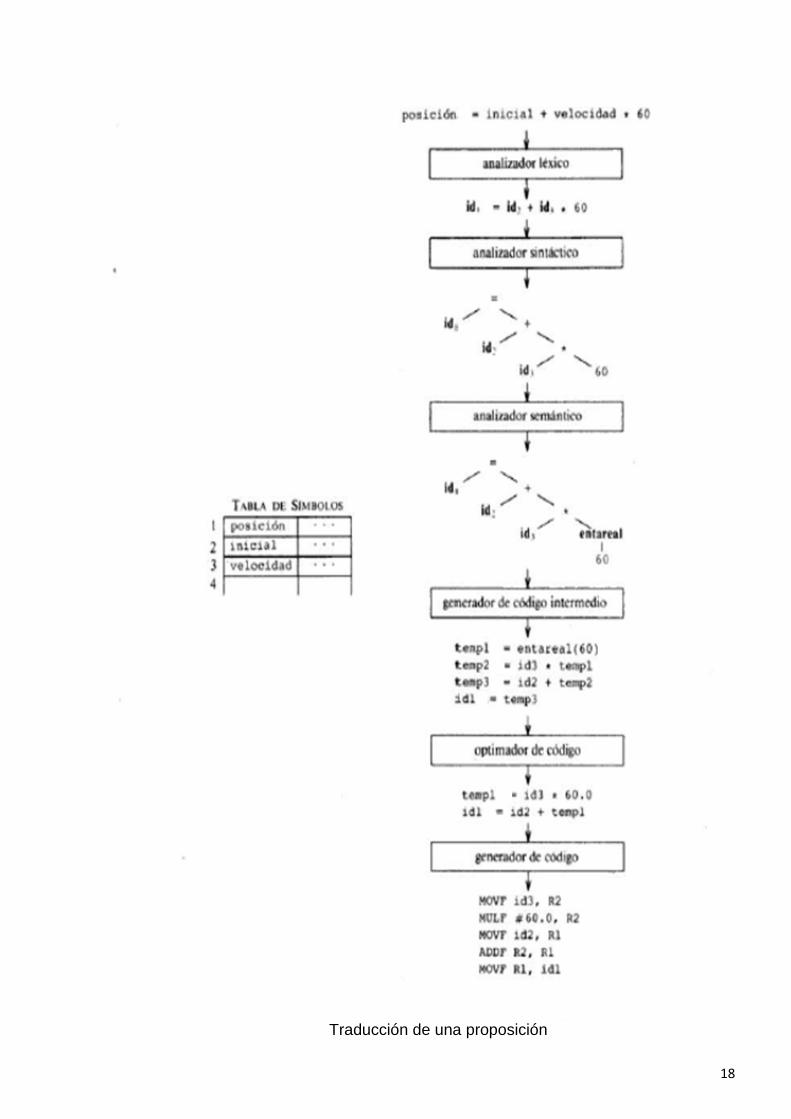
Traducción de una proposición





























