Embed Size (px)
Citation preview

UNIVERSITÉ DU QUÉBEC À MONTRÉAL
CARACTÉRISATION DE LA PRODUCTION ORALE EN FRANÇAIS L2 DE LOCUTEURS NATIFS DU MANDARIN
RÉALISÉ AU MOYEN D'UNE ANALYSE DES AUTOREFORMULA TIONS AUTOAMORCÉES PRODUITES LORS D'UNE NARRATION
THÈSE
PRÉSENTÉE
COMME EXIGENCE PARTIELLE
DU DOCTORAT EN LINGUISTIQUE
PAR
YONG GANG LIU
DÉCEMBRE 2017

UNIVERSITÉ DU QUÉBEC À MONTRÉAL Service des bibliothèques
Avertissement
La diffusion de cette thèse se fait dans le respect des droits de son auteur, qui a signé le formulaire Autorisation de reproduire et de diffuser un travail de recherche de cycles supérieurs (SDU-522- Rév.10-2015). Cette autorisation stipule que «conformément à l'article 11 du Règlement no 8 des études de cycles supérieurs, [l'auteur] concède à l'Université du Québec à Montréal une licence non exclusive d'utilisation et de publication de la totalité ou d'une partie importante de [son] travail de recherche pour des fins pédagogiques et non commerciales. Plus précisément, [l'auteur] autorise l'Université du Québec à Montréal à reproduire, diffuser, prêter, distribuer ou vendre des copies de [son] travail de recherche à des fins non commerciales sur quelque support que ce soit, y compris l'Internet. Cette licence et cette autorisation n'entraînent pas une renonciation de [la] part [de l'auteur] à [ses] droits moraux ni à [ses] droits de propriété intellectuelle. Sauf entente contraire, [l'auteur] conserve la liberté de diffuser et de commercialiser ou non ce travail dont [il] possède un exemplaire.»

REMERCIEMENTS
Je souhaite exprimer ma profonde gratitude à ma directrice, Madame Daphnée
Simard, qui m'a accompagné tout au long de ces huit années de recherche doctorale,
et sans qui je n'aurais pas pu terminer mes études de doctorat. Son aide infatigable
m'a donné le courage de continuer sans relâche. Son encadrement exemplaire a
contribué énormément à la réalisation de ma thèse. Ses nombreuses lectures et ses
commentaires enrichissants ont été essentiels à mon avancement tout au long de cette
épreuve.
Je tiens à remercier vivement les membres de mon comité d'évaluation, Monsieur
Denis Foucambert, professeur à l'Université du Québec à Montréal, Madame
Véronique Fortier, professeure à l'Université du Québec à Montréal, et Madame
Wynne Wong, professeure à l'Université d'État de l'Ohio, pour leur soutien et leurs
commentaires précieux.
Je voudrais aussi témoigner ma reconnaissance envers Michael Zuniga, Pauline
Palma et Alafia Tahaibaly pour leur aide et leurs conseils pertinents durant la collecte
et le traitement des données.
Je désire aussi exprimer ma gratitude à ma famille qui était présente tout au long de
mes études de doctorat. Ses encouragements m'ont été importants dans la réalisation
de ce projet. Pour terminer, je dois un merci particulier à mon épouse, Kai Liu, qui
m'a offert un soutien inconditionnel pendant toutes ces années d'étude.

TABLE DES MATIÈRES
LISTE DES FIGURES ....................................................................................................... vi
LISTE DES TABLEAUX ................................................................................................. vii
LISTE DES ACRONYMES ............................................................................................ viii
RÉSUMÉ ............................................................................................................................ x
INTRODUCTION .............................................................................................................. 1
CHAPITRE I : PROBLÉMATIQUE .................................................................................. 1
1.0 Introduction ............................................................................................................ 1
1.1 Caractéristiques de la production des apprenants sinophones lors de
l'apprentissage du français L2 .............................................................................. 2
1.2 Identification des caractéristiques de la production orale par 1' observation des
ARAA ...................................................................................................................... 3
1.3 Objectif de recherche .............................................................................................. 5
CHAPITRE II : CADRE THÉORIQUE ............................................................................. 7
2.0 Introduction ............................................................................................................ 7
2.1 Modèles de la production orale .............................................................................. 7
2.1.1 Modèles de la production orale en L 1 ............................................................. 8
2.1.1.1 Modèle de Fromkin .................................................................................. 8
2.1.1.2 Modèle de Garrett ................................................................................... 10
2.1.1.3 Modèle de Levelt. ................................................................................... 11
2.1.2 Modèles de la production orale en L2 ............................................................ 14
2.1.2.1 Modèle de de Bot ....................................................................................... 15

2.1.2.2 Modèle de Kormos .................................................................................... 16
2.1.2.3 Modèle de Segalowitz ............................................................................. 18
2.1.3 Modèle retenu pour 1 'étude ........................................................................... 19
2.2 Autoreformulation autoamorcée ........................................................................... 20
2.2.1 Définitions de l' ARAA dans les études précédentes ...................................... 20
2.2.2 Configurations des reformulations ................................................................. 24
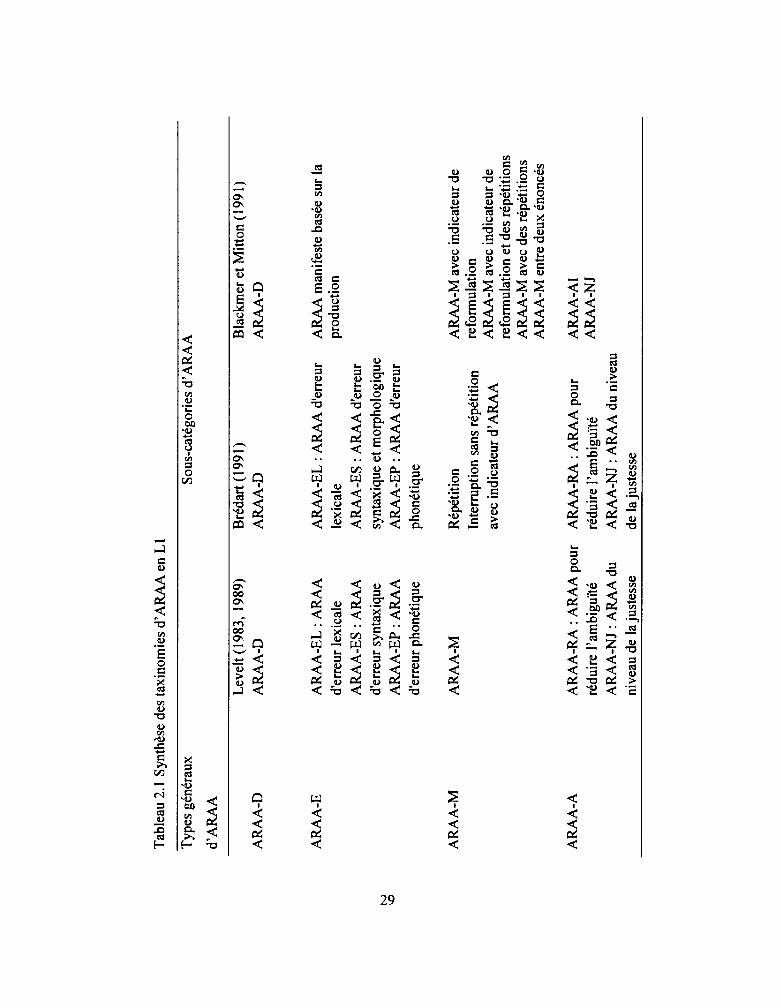
2.2.3 Taxinomies d' ARAA ...................................................................................... 26
2.2.3.1 Taxinomies d' ARAA en L 1 .................................................................... 26
2.2.3.2 Taxinomies d' ARAA en L2 ..................................................................... 31
2.3 Taxinomie retenue pour l'étude ........................................................................... 38
2.4 Synthèse du cadre théorique ................................................................................. 39
CHAPITRE III : RECENSION DES ÉCRITS ................................................................. 41
3.0 Introduction .......................................................................................................... 41
3.1 Études sur les caractéristiques de la production des apprenants sinophones du
français L2 ............................................................................................................ 42
3 .1.1 Étude de Wang ............................................................................................... 4 2
3.1.2 Étude de Yu .................................................................................................... 43
3.1.3 Étude de Sun ................................................................................................... 44
3.1.4 Étude d'Ivanova-Foumier .............................................................................. 45
3.2 Études sur l' ARAA en L2 chez les sinophones .................................................... 48
3.2.1 Étude de Yang ................................................................................................ 48
3.2.2 Étude de Chen et Pu ....................................................................................... 49
3.2.3 Étude de Liu ................................................................................................... 50
3.3 Études sur l' ARAA en L2 chez des locuteurs dont la LI est autre que le
mandarin ............................................................................................................... 51
3.3.1 Étude de Bange et Kem .................................................................................. 52
3.3.2 Étude de van Hest ........................................................................................... 53
ii

3.3.3 Étude de Nagano ............................................................................................ 54
3.3.4 Étude de Kormos ........ ,. ................................................................................... 55
3.3.5 Étude de Kormos ............................................................................................ 56
3.3.6 Étude de Kormos ............................................................................................ 57
3.3.7 Étude de Rieger .............................................................................................. 58
3.3.8 Étude de Simard, Fortier et Zuniga ................................................................ 59
3.3.9 Étude de Simard, Bergeron, Nader, Liu et Redmond ..................................... 60
3.3.10 Étude de Simard, French et Zuniga .............................................................. 61
3.4 Synthèse des études présentées ............................................................................ 62
3.5 Questions de recherche ......................................................................................... 73
CHAPITRE IV : MÉTHODE ........................................................................................... 75
4.0 Introduction .......................................................................................................... 75
4.1 Plan d'expérience ................................................................................................. 76
4.2 Variables ............................................................................................................... 76
4.3 Participants ........................................................................................................... 76
4.4 Instruments de collecte de données ...................................................................... 77
4.4.1 Tâche de narration .......................................................................................... 77
4.4.2 Tâche de texte à trous ..................................................................................... 79
4.4.3 Questionnaire de données sociodémographiques ........................................... 80
4.5 Préparatifs relatifs à la collecte de données .......................................................... 80
4.5.1 Consignes destinées aux participants ............................................................. 80
4.5.2 Recrutement des participants .......................................................................... 81
4.5.3 Planification du calendrier .............................................................................. 81
4.6 Procédure .............................................................................................................. 81
4.6.1 Formulaire d'information et de consentement ............................................... 82
4.6.2 Questionnaire sociodémographique ............................................................... 82
4.6.3 Tâche de texte à trous ..................................................................................... 82
Ill

4.6.4 Tâche de narration .......................................................................................... 83
4.7 Dépouillement des données .................................................................................. 84
4.7.1 Transcription des données .............................................................................. 85
4.7.2 Identification et codage des ARAA ................................................................ 85
4.7.2.1 Codage des éléments linguistiques des ARAA ....................................... 87
4.7.2.2 Codage selon la justesse de l'énoncé-source et de l'énoncé de
reformulation des ARAA ........................................................................ 88
4.7.3 Mesure de compétence langagière en français L2 .......................................... 89
4.7.4 Saisie des données .......................................................................................... 90
4.8 Traitement des données ........................................................................................ 90
CHAPITRE V : PRÉSENT A TION DES RÉSULTATS .................................................. 92
5.1 Réponse à la première question de recherche ....................................................... 92
5.1.1 Description des données ................................................................................. 93
5.1.2 Description des ratios des ARAA .................................................................. 93
5.1.3 Ratios d' ARAA selon la justesse de l'énoncé-source et de l'énoncé de
reformulation .................................................................................................. 95
5.1.4 Première question de recherche: synthèse des résultats ................................ 97
5.2 Réponse à la deuxième question de recherche ..................................................... 98
5.2.1 Constitution des groupes de participants selon le niveau de compétence
langagière ....................................................................................................... 99
5.2.2 Analyses statistiques inférentielles ............................................................... 102
5.3 Deuxième question de recherche: synthèse des résultats .................................. 104
CHAPITRE VI : DISCUSSION DES RÉ SUL TA TS ..................................................... 106
6.1 Première question de recherche .......................................................................... 107
6.1.1 Réponse à la première question de recherche .............................................. 108
6.1.2 Discussion à la lumière des études antérieures ............................................ 109
6.2 Deuxième question de recherche ........................................................................ 116
iv

6.2.1 Réponse à la deuxième question de recherche ............................................. 118
6.2.2 Discussion relative à la deuxième question de recherche ............................ 119
6.3 Profils des participants par niveau de compétence selon les ARAA produites .. 125
6.3.1 Profil des participants du groupe faible ........................................................ 125
6.3.2 Profil des participants du groupe moyen ...................................................... 128
6.3.3 Profil des participants du groupe fort ........................................................... 131
6.3.4 Synthèse ........................................................................................................ 133
6.4 Pistes de recherches futures ................................................................................ 134
CONCLUSION ........................................................................................................ 136
ANNEXE1 QUESTIONNAIRE SUR LES RENSEIGNEMENTS PERSONNELS ......................... 139
ANNEXE2 TEXTE À TROUS .......................................................................................................... 141
ANNEXE3 FORMULAIRE D'INFORMATION ET DE CONSENTEMENT ................................ 142
ANNEXE4 CONSIGNES POUR LA TÂCHE DE NARRATION .................................................. 145
ANNEXES CONVENTIONS DE TRANSCRIPTION ..................................................................... 146
ANNEXE6 GRAPHIQUE P-P DES RÉSIDUS STANDARDISÉS, VARIABLE DÉPENDANTE 147
ANNEXE? DIAGRAMME DE DISPERSION DES V ALE URS, VARIABLE DÉPENDANTE : RATIO DES ARAA ........................................................................................................ 148
ANNEXES PROTOCOLE DE CODAGE DES ÉLÉMENTS LINGUISTIQUES ........................... 149
RÉFÉRENCES ................................................................................................................ 158
v

LISTE DES FIGURES
Figure 1: Structure d' ARAA ............................................................................................. 14
vi

LISTE DES TABLEAUX
Tableau 2.1: Synthèse des taxinomies d' ARAA en L1 ................................................ 29
Tableau 2.2: Synthèse des taxinomies d' ARAA en L2 ................................................ 36
Tableau 2.3: Comparaison de la taxinomie d' ARAA de Levelt et de celle de la
présente étude ............................................................................................. 39
Tableau 3.1: Synthèse des études sur les caractéristiques de la production en
français L2 chez les sinophones ................................................................ 46
Tableau 3.2: Synthèse des études sur les ARAA en L2 ......•..........•..•............••••........... 64
Tableau 3.3: Synthèse des aspects méthodologiques des études sur les ARAA
en L2 .................................................................................. 72
Tableau 5.1: Distribution des ratios d' ARAA: symétrie et aplatissement .•.••..........•• 94
Tableau 5.2: Statistiques descriptives: ratios d' ARAA par 100 mots .........•............. 95
Tableau 5.3: Production d' ARAA selon la justesse de l'énoncé-source et de
l'énoncé de reformulation : symétrie et aplatissement ........................... 96
Tableau 5.4: Statistiques descriptives : ARAA selon la justesse de l'énoncé-source
et de l'énoncé de reformulation ................................................................ 97
Tableau 5.5: Résultats au texte à trous : symétrie et aplatissement ........................... 99
Tableau 5.6: Résultats de la classification par la méthode des nuées dynamiques ... 100
Tableau 5.7: Statistiques descriptives: ARAA selon la compétence langagière ..... 101
Tableau 5.8: Comparaisons intergroupes des ARAA ................................................ 103
Tableau 6.1: Caractéristiques de la production du groupe faible ••.........••.......••••.... 127
Tableau 6.2: Caractéristiques de la production du groupe moyen .......................... 130
Tableau 6.3: Caractéristiques de la production du groupe fort ............................... 132
vii

LISTE DES ACRONYMES
ARAA Autoreformulation autoamorcée
ARAA-A Autoreformulation autoamorcée appropriée
ARAA-AC Autoreformulation autoamorcée de la cohérence
ARAA-AI Autoreformulation autoamorcée appropriée de l'insertion
ARAA-AX Autoreformulation autoamorcée appropriée du temps et de l'aspect
ARAA-D Autoreformulation autoamorcée de différent message
ARAA-E Autoreformulation autoamorcée pour corriger les erreurs
ARAA-EC Autoreformulation autoamorcée pour corriger les erreurs conceptuelles
ARAA-ED Autoreformulation autoamorcée pour corriger les erreurs
dérivationnelles
ARAA-EF Autoreformulation autoamorcée pour corriger les erreurs flexionnelles
ARAA-EG Autoreformulation autoamorcée pour corriger les erreurs
gram mati cales
ARAA-EL Autoreformulation autoamorcée pour corriger les erreurs lexicales
ARAA-EM Autoreformulation autoamorcée pour corriger les erreurs
morphologiques
ARAA-EMP Autoreformulation autoamorcée pour corriger les erreurs
morphophonologiques
ARAA-EP Autoreformulation autoamorcée pour corriger les erreurs phonétiques
ARAA-ES Autoreformulation autoamorcée pour corriger les erreurs syntaxiques
ARAA-EX Autoreformulation autoamorcée pour corriger les erreurs du temps et
de l'aspect
viii

ARAA-LA Autoreformulation autoamorcée appropriée lexicale
ARAA-M Autoreformulation autoamorcée masquée
ARAA-NJ Autoreformulation autoamorcée du niveau de la justesse
ARAA-R Reste d'autoreformulation autoamorcée
ARAA-RA Autoreformulation autoamorcée pour réduire l'ambiguïté
ARAA-RF Autoreformulation autoamorcée de la paraphrase
ARAA-RL Autoreformulation autoamorcée de la recherche lexicale
ARAA-SA Autoreformulation autoamorcée appropriée syntaxique
MICC Ministère de l'Immigration et des Communautés Culturelles
Ll Langue maternelle
L2 Langue seconde
ix

RÉSUMÉ
Plusieurs études suggèrent que les apprenants sinophones du français langue seconde
( désonnais L2) présentent des caractéristiques particulières, notamment, à 1' oral durant
leur apprentissage (p. ex., Ivanova-Fournier, 2009; Sun, 2003, 2008; Tan, 2011: Yu,
1993). Comme les autorefonnulations autoamorcées représentent une infonnation
directe à propos des processus linguistiques dans la production orale en L2 (Konnos.
l999b), il nous semblait pertinent d'étudier les caractéristiques en production orale en
les observant. Des travaux dans le domaine de l'étude des autorefonnulation
autoamorcée portent notamment sur les apprenants de l'anglais L2 (p. ex., Kormos,
2000a; Liu. 2009; van Hest, 1996) et ont entre autres comme objectif de faire la
lumière sur le lien entre les autorefonnulations autoan10rcées et des variables comme
l'attention (Simard, Fortier et Zuniga, 2011 ), la mémoire phonologique (Simard.
Bergeron, Liu, Nader et Redmond, 2016), et sur l'évolution des autorefonnulations
autoamorcées (Simard, French et Zuniga, 20 17). mais peu de chercheurs semblent
sïntéresser aux autorefonnulations autoamorcées chez les apprenants sinophones du
français L2.
Plusieurs de ces études menées auprès d'apprenants de L2 ont exploré les catégories et
x

la fréquence d'autoreformulations autoamorcées produites en L2. et leurs variations
selon la compétence langagière des participants (p. ex., Kormos, 2000a: Liu, 2009; van
Hest. 1996). Cependant, les catégories et la fréquence d'autoreformulations
autoamorcées produites en français L2, et leurs variations en fonction du niveau de
compétence langagière des apprenants sinophones ne sont pas encore explorées. Notre
étude vise donc à déterminer les catégories d'autoreformulations autoamorcées
produites en français L2 et leur fréquence et si elles varient selon le niveau de
compétence langagière des apprenants sinophones lors de la production orale en
français L2. Nous avons formulé les questions de recherche suivantes : 1) Quelles sont
les catégories et la fréquence des autoreformulations autoamorcées produites en
français L2 chez les sinophones? 2) Est-ce que les catégories d'autoreformulations
autoamorcées et leur fréquence en français L2 varient en fonction du niveau de
compétence langagière chez les sinophones?
Afin de répondre à nos questions, nous avons mené une étude empirique auprès de
65 locuteurs sinophones adultes du français L2 de niveaux de compétence variables.
Les participants ont effectué deux tâches. soit une tâche de texte à trous, pour obtenir
un indice de leur compétence en L2, et une tâche de narration, pour obtenir de
l'information sur les autoreformulations autoamorcées. De plus, les participants ont
répondu à un questionnaire de données sociodémographiques. Des analyses ont été
menées sur les données obtenues. Les résultats des analyses nous ont permis
d'affirmer que la compétence langagière contribue de façon significative à la
fréquence de certaines catégories d'autoreformulations autoamorcées en français L2.
Toutefois. la relation entre la compétence langagière et la production
d'autoreformulations autoamorcées s'est révélée non significative. Ces résultats
permettent de dévoiler des caractéristiques particulières et d'établir des profils
d'apprenants sinophones en production orale du français L2 au moyen des
autoreformulations autoamorcées.
xi

Mots clés : autoreformulation autoamorcée. français langue seconde, production orale
en langue seconde.
xii

CHAPITRE I
PROBLÉMATIQUE
1.0 Introduction
Au cours des dernières années, beaucoup de sinophones ont immigré au Québec. En
fait, pour être plus précis, 16053 immigrants sinophones ont été admis au Québec
entre 2007 et 2011, soit 6,5% du total des immigrants, les Chinois occupant la
quatrième place parmi toutes les autres nationalités. En 2011, les immigrants
sinophones constituent la deuxième population immigrante, soit 9,5% du total des
immigrants admis au Québec selon les statistiques publiées par le ministère de
l'Immigration et des Communautés Culturelles (2012) (désormais MICC).
Parmi ces immigrants sinophones, beaucoup ont choisi de s'inscrire dans les
programmes de francisation du MICC ou institutionnels afin d'apprendre le français
ou d'améliorer leur français et de faciliter leur intégration dans la société. Il est à
noter que la plupart de ces immigrants sinophones ne parlaient que très peu le
français à leur arrivée au Québec (Portraits statistiques des groupes ethnoculturels du
Recensement du MICC, 2006, p. 5). Il semble également que cette population
présente des caractéristiques particulières lors de l'apprentissage d'une L2 (p. ex.,
Derwing et Munro, 2013), et notamment, du français L2 en production écrite (p. ex.,

Liu, 1989; Wang, 1993; Yu, 1993) et en production orale (p. ex., Camussi-ni, 2005;
Chen, 2003; MICC, 2009; Sun, 2008; Tan, 2011; Wang, 1993; Yu, 1993). Parmi les
caractéristiques observées se trouvent notamment celles portant sur le plan de la
morphologie (p. ex., Camussi-ni, 2005; Chen, 2003; Sun, 2003; Yu, 1993), de la
phonétique (p. ex., Chen, 2003; lvanova-Foumier, 2009; Wang, 1993), de la
temporalité (p. ex., Sun, 2008) et de la référence spatiale (p. ex., Tan, 2011 ).
1.1 Caractéristiques de la production des apprenants sinophones lors de
l'apprentissage du français L2
Des chercheurs (p. ex., Camussi-ni, 2005; Chen, 2003; Wang, 1983) ont formulé, sur
la base de la comparaison entre le français et le mandarin, une liste des
caractéristiques propres aux apprenants sinophones du français L2. Par ailleurs,
plusieurs études (p. ex., lvanova-Foumier, 2009; Sun, 2003, 2008; Tan, 2011; Yu,
1993) ont porté, de façon empirique, sur les caractéristiques en production orale en se
concentrant sur un seul trait langagier à la fois. À titre d'exemple, Yu (1993) a
examiné les différences morphologiques entre les erreurs commises à l'écrit et à
l'oral par les apprenants sinophones du français L2 mesurées au moyen d'un test oral
de type question-réponse. Dans 1' étude de Sun (2008), le développement de la
morphologie chez les apprenants sinophones du français L2 a été étudié au moyen
d'une tâche de narration. À cela s'ajoute Ivanova-Foumier (2009) qui a étudié les
erreurs phonétiques des apprenants sinophones du français L2 au moyen d'une tâche
de lecture à haute voix. Tan (2011) a pour sa part exploré le développement de la
référence spatiale dans la production orale en français L2 chez les apprenants
sinophones au moyen de récits oraux basés sur des bandes dessinées.
Bien que les travaux antérieurs nous fournissent certaines informations sur les
caractéristiques de la production orale des sinophones apprenant le français L2, ils ne
2

se limitent qu'à une description théorique (p. ex., Chen, 2003; Wang, 1983) ou
n'offrent qu'un portrait fragmenté étant donné le regard très précis qu'elles ont sur un
trait langagier à la fois (p. ex., lvanova-Foumier, 2009; Sun, 2003, 2008; Tan, 2011;
Yu, 1993).
Dans le but d'offrir un portrait plus global qui mènera enfin à l'identification de
pistes permettant d'aider les apprenants sinophones du français L2, il convient de
poser un regard plus étendu sur leurs caractéristiques. C'est ce que nous nous
proposons de faire dans le cadre de cette thèse de doctorat.
1.2 Identification des caractéristiques de la production orale par observation des
autoreformulations autoamorcées
Afin d'examiner ce qui caractérise la production orale, il est possible d'observer les
reformulations des apprenants (p. ex., Kormos, 1999a, 2006; Lennon 1990). Les
reformulations sont définies comme étant « des révisions spontanées qui interrompent
des énoncés en cours» 1 (van Hest, Poulisse et Bongaerts, 1997, p. 76) et représentent
un processus de régulation de la production orale, à savoir la vérification par le
locuteur de la justesse de l'énoncé produit par le locuteur (Levelt, 1983).
Dans 1' étude de la production orale en langue maternelle (désormais L 1 ), les
reformulations les plus fréquentes sont celles amorcées et accomplies par l'apprenant
lui-même, à savoir les autoreformulations autoamorcées (désormais ARAA)
(Schegloff, Jefferson et Sacks, 1977). Un des intérêts principaux liés à l'étude des
ARAA réside dans le fait qu'elles constituent un phénomène naturel de production
orale (p. ex., Kormos, 2006; Schegloff et coll., 1977). En effet, il est normal
d'entendre les locuteurs produire des ARAA de façon occasionnelle à l'oral.
1 Notre traduction de« Spontaneous revisions which invo/ve an interruption of the ongoing utterance ».
3

D'ailleurs, les ARAA représentent non seulement une information directe à propos
des processus linguistiques à l'œuvre dans la production orale en L2 (Kormos,
1999b ), mais aussi dévoilent des caractéristiques importantes de la production orale
(Levelt, 1983, 1989, 1999).
Selon Levelt, une ARAA implique trois phases: 1) l'interruption de la production
orale lorsqu'une difficulté survient, 2) la pause et l'emploi de termes de reformulation
{p. ex., « uh ») et 3) l'autoreformulation à proprement dit. En particulier, les termes
de reformulation à utiliser reposent sur la nature des difficultés de la production orale.
Plus concrètement, les modifications, qui ne sont pas nécessairement des erreurs dans
la production orale, sont susceptibles d'entraîner l'emploi de termes de reformulation.
À cet égard, le mot « uh >> représente le terme de reformulation le plus utilisé
lorsqu'une difficulté dans la production orale est signalée rapidement (Levelt, 1983,
p. 41).
Plusieurs études (p. ex., O'Connor, 1988; van Hest, 1996; Yang, 2002) suggèrent que
les apprenants avancés en L2 ne produisent pas d' ARAA de même nature, à savoir du
même niveau (p. ex., lexical versus discours) et du même type (p. ex., ARAA visant à
préciser le discours versus ARAA visant à modifier le discours) que les apprenants
moins avancés lorsqu'ils rencontrent des difficultés en production orale. En effet, les
apprenants avancés font plus fréquemment des ARAA de type anticipatoire et
discursif tandis que les apprenants moins avancés ont tendance à utiliser des ARAA
de type correctif, souvent sur le plan lexical ou grammatical. De plus, van Hest (1996)
constate que les apprenants avancés autoreformulent beaucoup moins fréquemment
que les apprenants débutants ou intermédiaires qui produisent environ le même
nombre d'ARAA. Ces études démontrent que lorsque le niveau de compétence
langagière des apprenants en L2 augmente, la nature et la fréquence d' ARAA en
4

production orale évoluent aussi, ce qui nous permet de dire que les ARAA peuvent
servir d'indicateur de ce qui caractérise la production orale.
Notons aussi que dans les recherches sur la nature et la fréquence des ARAA,
différents types de tâches de production orale sont utilisés afin de déterminer lesquels
aident les apprenants de la L2 à se pencher sur la précision langagière.
En ce qui concerne plus précisément les études sur les ARAA en L2 chez les
sinophones, celles-ci se concentrent principalement sur l'anglais L2. Des études ont
démontré qu'il existait un lien entre la fréquence des ARAA et le niveau de
compétence langagière des apprenants sinophones en anglais L2 (p. ex., Chen et Pu,
2007; Liu, 2009; Yang, 2002). D'ailleurs, la nature des ARAA semble être liée au
niveau de compétence langagière des apprenants (p. ex., van Hest, 1996; Yang, 2002).
Avec l'augmentation de sa compétence langagière en L2, un apprenant produit moins
d' ARAA au niveau grammatical et plus d' ARAA au niveau discursif (Yang, 2002).
Toutes ces études sur les ARAA en anglais L2 nous permettent de mieux connaître
les caractéristiques de la production orale chez les apprenants d'anglais L2.
Cependant, les recherches sur ce sujet dans d'autres langues, en particulier le français,
sont beaucoup plus rares.
1.3 Objectif de la recherche
À notre connaissance, la production orale de sinophones apprenant le français L2 n'a
jamais encore été caractérisée au moyen des ARAA. Pourtant les ARAA sont une
source d'information précieuse permettant un regard sur les aspects langagiers étant
l'objet d'une régulation de la part des apprenants. Nous nous sommes donc proposés
d'étudier des caractéristiques de la production orale en français L2 de locuteurs natifs
5

du mandarin de différents niveaux de compétence en français L2 en observant leurs
ARAA.
6

CHAPITRE II
CADRE THÉORIQUE
2.0 Introduction
Rappelons que notre objectif était d'étudier des caractéristiques de la production orale
en français L2 de locuteurs natifs du mandarin de différents niveaux de compétence
en français L2 par l'observation de leurs ARAA. Ainsi, dans ce chapitre, nous
traiterons de modèles de la production orale (2.1), et des notions principales qui s'y
rattachent (2.2), soit les définitions de l'ARAA (2.2.1), les configurations d'ARAA
(2.2.2), les taxinomies d' ARAA (2.2.3), et finalement nous présenterons notre
synthèse (2.3).
2.1 Modèles de la production orale
Il existe différents modèles expliquant la production orale. Ces modèles peuvent être
regroupés selon deux types de représentation du traitement de 1' information, à savoir
en parallèle ou encore en série (Carroll, 2007).
Parmi les représentations de type «en parallèle», qui proposent une représentation de
la production orale comme étant un ensemble de connexions et d'activation d'unités
d'informations, se trouve, entre autres, le modèle de la propagation d'activation
7

(p. ex., Berg, 1986; Dell, 1986; Dell et O'Seaghda, 1991; Stem berger, 1985) rendant
compte du mécanisme de la production orale. Cependant, en ce qui concerne la
régulation, phénomène à l'étude dans notre thèse, Dell (1986) ne propose pas de
système indépendant et suggère que la régulation soit intrinsèque au mécanisme de
production orale et fonctionne de la même façon que la compréhension des énoncés
d'un interlocuteur, ce qui influence le niveau d'encodage plus bas et ainsi cause un
mélange des deux mots. Par contre, dans l'une des représentations de type« en série»,
dans lesquelles la production orale est conçue comme une séquence de modules, on
retrouve la description d'un mécanisme de régulation dont le produit observable est
les ARAA, pour cette raison, nous nous intéressons plus particulièrement à ceux-ci.
(Une explication de la régulation se trouve en 2.1.1.3).
2.1.1 Modèles de la production orale en L 1
En L1, les modèles de Fromkins (1971, 1973) sur la production d'erreurs, de Garrett
(1975) et de Levelt (1983, 1989, 1999), de loin celui le plus utilisé de ces
représentations en série, visent à expliquer, dans des représentations typiquement en
série, à savoir que l'information circule à sens unique, le processus de la production
orale chez les unilingues. Nous les présentons dans ce qui suit.
2.1.1.1 Modèle de Fromkin
À la suite des analyses de plus de 600 erreurs observées dans des productions orales
(notons que l'auteure ne fournit pas d'informations en ce qui concerne ses
participants), Fromkin (1971, 1973) a proposé un modèle qui divise le processus de la
production orale en six phases. D'abord, l'identification du sens à être transmis dans
laquelle un message est généré a lieu. Ensuite, la structuration syntaxique du message
dans laquelle un squelette syntaxique est construit est mise en place. C'est à ce
8

moment que les traits sémantiques s'attachent à la structure syntaxique et que les
erreurs de transposition telles qu'un nom passant pour un verbe ou vice versa se
produisent. L'output de cette phase correspond à une structure syntaxique avec les
traits sémantiques et syntaxiques spécifiés pour les entrées lexicales. Troisièmement,
la génération du contour intonatif a lieu et la position de l'accent principal est
déterminée pour les mots du message, sans pour autant que la position des syllabes
dans le message ne soit encore spécifiée. Vient ensuite l'insertion des mots. Ainsi,
dans cette phase, les mots lexicaux comme les noms, les verbes et les adjectifs sont
récupérés du lexique et insérés dans les positions assignées. C'est également dans
cette phase que des erreurs telles qu'un mot mal choisi peuvent se produire. À titre
d'exemple, si le mot à produire est li/œ, mais que le mot hale est produit (p. 50},
l'erreur est due à la sélection du mauvais contenu sémantique du mot à produire. La
phase qui suit correspond à la formation des affixes et à 1' insertion des mots
grammaticaux. C'est dans cette phase que les règles morphophonémiques s'imposent
et modifient ou fournissent les éléments phonologiques aux morphèmes. Par
conséquent, les mots grammaticaux ainsi que les préfixes et les suffixes sont ajoutés,
comme la sélection entre a et an et entre s et z de la forme plurielle en anglais (p. 51).
Finalement, la spécification des segments phonétiques se produit au cours de la
dernière phase lorsque les règles phonologiques s'imposent et que le message est
transmis en unités de segments phonétiques convertis en commandes neuromotrices
contrôlant les mouvements des muscles dans le but d'articuler le message. Le modèle
de Fromkin (1973) n'a pourtant trait qu'aux erreurs en production orale et ne prend
pas en considération le processus de régulation de la production orale, ce qui s'avère
moins pertinent pour expliquer les ARAA dans notre étude.
En se basant également sur 1' analyse des erreurs produites lors de la production orale,
Garrett (1975) propose un modèle de production orale structurée en une série de
niveaux distincts. Nous présentons son modèle dans la partie suivante.
9

2.1.1.2 Modèle de Garrett
Garrett (1975) propose un modèle de production orale similaire à celui de Fromkin
(1971, 1973) qui divise le processus, mais cette fois en quatre phases, à savoir a) la
phase de la création du message, b) la phase fonctionnelle, c) la phase positionne lie et
d) la phase phonétique.
À chaque phase, une seule activité se déroule à un moment donné. Cependant, à
chaque niveau, plus d'une activité peut se dérouler simultanément et ces activités de
différents niveaux n'interagissent pas entre elles. La première phase correspond à la
conceptualisation d'un message. Au cours de cette phase, trois éléments contribuent à
la conception du message, à savoir le contenu que le locuteur veut exprimer, l'effet
que le locuteur veut produire sur son interlocuteur et les formes que le message peut
prendre en fonction de structures permises dans la langue cible. Ensuite, au cours de
la deuxième phase se produit la sélection des lemmes, comme des mots lexicaux, et le
cadre syntaxique se construit. Ainsi la forme phonologique des mots lexicaux est
récupérée du lexique et les formes phonologiques sont introduites dans le cadre
syntaxique. C'est dans cette phase que des erreurs de substitution peuvent arriver
parce que le mauvais concept sémantique est sélectionné pour le message. Dans la
troisième phase, les formes phonologiques des affixes et les mots grammaticaux sont
spécifiés; les erreurs de substitution de sons (notre traduction de sound exchange slips)
peuvent se produire parce qu'il est nécessaire d'ajouter des éléments phonologiques
au cadre syntaxique. Enfin, dans la quatrième phase, des règles phonologiques sont
appliquées à la représentation de la forme de la troisième phase et le message est
articulé. C'est dans cette phase que les lapsus peuvent se produire parce que les
lemmes ne correspondent pas aux lexèmes.
10

Tout comme le modèle de Fromkin (1971, 1973), celui de Garrett (1975) se
caractérise par le traitement de l'information en série que la sélection des mots
lexicaux et grammaticaux se produit au cours de phases différentes. Précisons ici que
le modèle ne permet 1' étude des ARAA en production orale et ne prend pas en
compte le processus de régulation de la production orale. Conséquemment nous ne
nous appuierons pas sur ce modèle pour étudier les ARAA dans le cadre de notre
étude. Parmi les modèles en série, celui proposé par Levelt (1983, 1989, 1999)
s'avère légèrement différent de ceux de Fromkin (1971, 1973) et de Garrett (1975),
car Levelt (1983, 1989, 1999) y ajoute la régulation de la production orale. Nous
présentons son modèle dans la section suivante.
2.1.1.3 Modèle de Levelt
Levelt (1983, 1989, 1999), dans son modèle de la régulation du discours, nomme le
processus de la production orale dans un contexte communicatif le plan (notre
traduction de blueprint). Celui-ci comprend cinq phases, à savoir a) la préparation
conceptuelle, b) l'encodage grammatical, c) l'encodage morphophonologique, d)
l'encodage phonétique et e) l'articulation ainsi que trois sources de connaissances,
soit a) les connaissances du monde extérieur et intérieur, b) le lexique mental etc) le
syllabaire.
La première phase correspond à la préparation conceptuelle (notre traduction de
conceptual preparation) dans laquelle un message est préparé au moyen de la
macroplanification et de la microplanification. La macroplanification correspond au
processus dans lequel un locuteur développe son intention communicative et change
le sujet du discours puis décide de ce qui sera dit ensuite. Après l'étape de la
macroplanification vient celle de la microplanification. Durant cette phase, le
locuteur doit incorporer les relations sémantiques dans le message, en particulier, les
11

structures argumentales, tout en donnant un contenu propositionnel au message. De
plus, le locuteur sélectionne le temps et les relations distales pour le message avant la
fin de la microplanification. Le produit de cette microplanification correspond au plan
préverbal, à savoir une structure conceptuelle composée de concepts lexicaux et
contenant toutes les informations nécessaires pour transformer le sens en langue orale.
Ensuite, le message passe à la phase suivante: l'encodage grammatical. Au cours de
cette phase, l'input correspond au message préverbal et l'output, à la structure de
surface. Le locuteur récupère l'information du lexique mental, qui est composée de
lemmes et lexèmes: les lemmes contiennent l'information syntaxique sur une entrée
lexicale et les lexèmes contiennent l'information morphophonologique d'une entrée
lexicale. Les lemmes sont activés par les concepts lexicaux dans le lexique mental.
Lorsque le locuteur sélectionne les lemmes qui correspondent le mieux à
l'information sémantique contenue dans le plan préverbal, la construction du modèle
syntaxique commence, ce qui donne la structure de surface comme l'output. Une
précision doit être apportée ici, la structure de surface est formée d'une chaine de
lexèmes réunis en phrases et en syntagmes.
La phase suivante correspond à l'encodage morphophonologique dans lequel le
locuteur a accès à l'information morphophonologique de l'item lexical lorsque les
lemmes sont sélectionnés. Plus exactement, cette information contient les détails
comme les structures morphologiques et de syllabation du mot, l'intonation et la
prosodie. Les résultats ultimes de l'encodage phonologique sont un modèle
phonologique (notre traduction de phonological score) et «le modèle phonologique
est un modèle incrémentiel de syllabes phonologiques qui sont regroupées
métriquement et sont marquées par les tons dont ils font partie »2 (p. 110). Selon le
modèle phonologique, chaque syllabe doit déclencher des gestes articulatoires. Vient
2 Notre traduction de Levelt, 1989, p. Il 0: « The phonological score is an incrementa/ pattern of phonologica/ sylla bles, metrical/y grouped and mar/œd for the lones they are participating in ».
12

ensuite 1' encodage phonétique, pour lequel le locuteur a accès au répertoire des gestes
articulatoires stockés dans le syllabaire, et génère le modèle articulatoire (notre
traduction de articulatory score).
Finalement, dans la phase de l'articulation, les organes phonatoires du locuteur
exécutent le modèle articulatoire et les mots sont produits, ce qu'on nomme la
production manifeste. Comme le souligne l'auteur, ce processus de production oral
est incrémentiel, automatisé et simultané, et ce afin d'éviter une interruption totale
dans un contexte communicatif, et la présence d'hésitation, de manque d'aisance et
d' ARAA démontrent que le locuteur fait fonctionner la régulation constamment.
Précisons ici que le modèle de Levelt (1983) rend compte également de la régulation
de deux systèmes dans la production orale: le système sémantique/syntaxique et le
système phonologique/phonétique. Dans la régulation, il existe trois boucles : a) le
message du plan préverbal est contrôlé en fonction de l'intention originale de
communication du locuteur concernant la justesse linguistique et contextuelle, b) dans
la seconde boucle, la régulation masquée vérifie le discours interne dans le but de
détecter les erreurs d'encodage sur le plan phonétique, c) la troisième boucle est
externe parce qu'elle vérifie les mots déjà prononcés par le locuteur. La régulation
peut être déclenchée lorsque le locuteur détecte une erreur ou le besoin de modifier sa
production orale. D'ailleurs, ce système de régulation peut intervenir non seulement
pour vérifier la justesse de ses propres paroles, mais aussi celles de l'interlocuteur.
Afin de valider son modèle, Levelt (1983) a constitué un corpus contenant
959 ARAA produites par des participants adultes néerlandais qu'il a analysées. Dans
son étude, Levelt (1983) a distingué deux types d' ARAA : manifestes et masquées.
Les ARAA masquées (désormais ARAA-M) (notre traduction de covert self-repair)
sont produites avant l'articulation et sont des énoncés intérieurs accessibles à
13

l'attention. Dans le cas des ARAA manifestes, elles sont réalisées après qu'un énoncé
erroné ou inapproprié est produit. Les ARAA sont composées de trois
parties principales: a) l'énoncé original qui contient le réparandum, l'item qui sera
reformulé, b) la phase d'autorégulation qui consiste en une période d'hésitation et en
un indicateur de reformulation optionnel, c) l' ARAA même (aussi appelé réparatum
dans van Hest, 1996). La Figure 1 présente un exemple d' ARAA manifeste illustrant
ces trois composants :
Point d'interruption
Énoncé original j Phase d'autorégulation Autoreformulation
Go from left again to uh ... , from pink again to blue ...... ++ .__. .....-. +--+
r r i r 1 Réparandum Délais Indicateur de reformulation Portée de rétraction Réparatum
Figure 1 Structure d' ARAA (Adapté de Levelt, 1983, p. 45)
2.1.2 Modèles de la production orale en L2
Dans les parties ci-dessus, nous avons présenté des modèles de type en série qui nous
aident à mieux comprendre le fonctionnement de la production orale en L 1. À présent,
tournons-nous vers les modèles de production en L2 et examinons trois modèles, à
savoir celui de de Bot ( 1992), celui de Kormos (2006) et celui de Segalowitz (20 1 0).
de Bot ( 1992) a proposé un modèle de la production orale découlant du travail de
Levelt, tandis que Kormos (2006) a proposé un modèle modulaire de la production
orale se basant également sur le modèle de Levelt (1983, 1989, 1999), et que
14

Segalowitz (2010) a proposé un modèle se centrant sur l'aspect cognitif de la
production orale en L2. Nous présentons ces trois modèles dans les parties suivantes.
2.1.2.1 Modèle de de Bot
Tout en se basant sur le modèle de Levelt (1983, 1989, 1999), de Bot (1992) a
proposé un modèle de production pour les bilingues. Il affirme que seules les
modifications absolument nécessaires sont apportées au modèle de Levelt ( 1983,
1989, 1999) étant donné que ce dernier s'avère empiriquement solide. Son modèle
vise à fournir un modèle de production orale non seulement pour les bilingues, mais
aussi pour les multilingues. Selon lui, un modèle de production orale pour les
bilingues doit permettre d'expliquer les cinq phénomènes suivants: 1) le fait qu'un
bilingue est capable de savoir quand l'un des deux systèmes langagiers est utilisé
séparément ou de façon mixte, 2) l'influence interlinguistique, 3) le fait qu'une
décélération importante n'apparaît pas même si un bilingue parle plus d'une langue,
4) le fait que le niveau de la maîtrise de deux langues chez un bilingue s'avère
différent, 5) finalement, ce modèle doit être applicable aux multilingues.
Le modèle de de Bot (1992) se distingue du modèle de Levelt (1983, 1989, 1999) par
plusieurs aspects. D'abord, il faut se rappeler que le modèle de Levelt (1983, 1989,
1999) tente d'expliquer le processus de la production orale chez les unilingues tandis
que celui de de Bot ( 1992) est conçu pour les bilingues et les multilingues. En ce qui
concerne le conceptualiseur, dans le modèle de de Bot (1992), les connaissances
extérieures et intérieures se trouvent dans un seul système unifié au lieu de deux
systèmes chez les bilingues et l'information concernant la langue à choisir est
comprise dans le message préverbal. Il indique que la phase de macroplanification
n'est pas spécifique à une langue tandis que celle de microplanification l'est et que le
fonctionnement du conceptualiseur est spécifique à une langue d'après Levelt (1983).
15

1 -
Ensuite, de Bot (1992) propose deux scénarios pour le fonctionnement du fonnulateur
et du lexique : a) il existe un fonnulateur et un lexique pour chaque langue chez les
bilingues, b) il existe un seul système qui comprend toutes les infonnations, qui sont
étiquetées sur le plan linguistique, pour toutes les langues chez les bilingues; mais
plus tard, il décide de proposer un troisième scénario selon lequel certains éléments
des deux langues sont stockés ensemble, d'autres séparément dépendamment des
facteurs comme la distance typologique et le niveau de compétence langagière des
bilingues. En ce qui concerne l'encodage phonologique et l'articulation, de Bot (1992)
propose qu'il existe une réserve commune pour les syllabes des deux langues chez les
bilingues, et que les modèles articulatoires sont stockés seulement une fois s'ils sont
identiques et de façon individuelle s'ils sont différents dans la réserve. Par ailleurs, le
modèle de de Bot (1992) ne précise pas le fonctionnement du processus de la
régulation de la production orale et n'offre pas d'explication pour le phénomène
d'ARAA.
2.1.2.2 Modèle de Konnos
Konnos (2006) a proposé un modèle modulaire de production orale chez les bilingues
en se basant sur celui de Levelt (1989, 1999). Tout comme Levelt (1989, 1999),
Konnos a pensé un modèle qui comprend trois modules: a) le conceptualiseur, b) le
fonnulateur etc) l'articulateur. Selon Konnos (2006), le processus de la production
orale en L2 est similaire à celle en Ll parce que la production en L2 peut aussi
fonctionner de façon progressive, ce qui veut dire que les processus d'encodage
peuvent être déclenchés par un fragment de l'input dans un module donné.
L'encodage fonctionne seulement en série tant que les processus d'encodage exigent
un contrôle conscient de l'attention. De plus, l'activation en cascade peut passer du
niveau lexical au niveau phonologique, mais pas inversement. Il est à noter que la
16

régulation dans ce modèle se fait à l'aide du système de compréhension de production
orale.
Au lieu de proposer trois réserves comme le fait le modèle de Levelt (1989), Kormos
(2006) a proposé une réserve de mémoire nommée mémoire à long terme qui
comprend quatre composantes : a) la mémoire épisodique qui correspond à la réserve
d'événements organisés temporairement ou les épisodes vécus, b) la mémoire
sémantique qui comprend le lexique mental, les concepts linguistiques, et non
linguistiques, et les traces de mémoire liées à ces événements, c) le syllabaire qui
stocke les modèles gestuels automatisés utilisés pour produire des syllabes et d) une
réserve pour les connaissances déclaratives des règles de la L2. Dans ce modèle, les
réserves des connaissances sont partagées entre L 1 et L2.
Selon le modèle de Kormos (2006), le processus de production orale commence par
la conceptualisation du message pour laquelle les concepts pertinents à encoder sont
activés et le choix de la langue du message est déterminé. Parmi tous les concepts
pertinents, seul le concept visé est sélectionné pour le traitement à la prochaine étape.
Le concept sélectionné active non seulement l'item lexical qui correspond au concept,
mais aussi les lemmes reliés sémantiquement, y compris les unités langagières
préfabriquées stockées et récupérées en tant qu'unités langagières. Lorsque le
message est généré, il passe à 1' encodage lexical, ce qui correspond au rapprochement
des spécifications conceptuelles et des indices de langage (notre traduction de
language eues) avec les entrées lexicales appropriées dans le lexique mental; l'étape
qui suit correspond à l'encodage syntaxique comportant deux phases principales:
l) l'activation des traits syntactiques des lemmes correspondant à l'unité conceptuelle
de message, ainsi que la construction des phrases et propositions et l'arrangement des
phrases. Ensuite l'encodage phonologique commence et correspond à l'activation de
la forme du mot à encoder, à la syllabation et à la définition des paramètres tels que
17

l'intensité, le ton, etc. 2) la phase suivante correspond à l'encodage phonétique dans
lequel des gestes articulatoires des syllabes sont récupérés. Enfin un énoncé est
produit au cours de la phase articulatoire.
Tout comme le modèle de Levelt (1983, 1989), Kormos (2006) propose trois boucles
pour la régulation de la production orale. La première boucle correspond à la
vérification du plan préverbal contre l'intention initiale du locuteur, la deuxième, à la
vérification du plan phonétique avant l'articulation et la troisième, à la vérification de
l'énoncé après qu'il est produit, qui est la boucle externe de régulation. Au cas où une
erreur ou une expression inappropriée dans la production est perçue dans une des trois
boucles, un signal est lancé qui déclenche le mécanisme de production pour la
deuxième fois en commençant par la phase de conceptualisation. Même Kormos
(2006) a proposé son modèle en se basant sur celui de Level (1983), elle n'a pourtant
pas offert une explication explicite sur le mécanisme sous-jacent des ARAA. De plus,
le modèle de Kormos (2006) n'a pas été validé par d'autres études.
2.1.2.3 Modèle de Sega1owitz
Segalowitz (2010) a proposé un modèle sur les liens dynamiques entre les facteurs
qui influencent l'aisance en L2 tout en reconnaissant les travaux antérieurs dans ce
domaine comme celui de Levelt (1983, 1989, 1999) et de de Bot (1992). Dans ce
modèle, Segalowitz (2010) a suggéré qu'au moins quatre facteurs exercent une
influence sur la production orale en L2, à savoir les systèmes de traitement cognitif
perceptuel, les expériences cognitives et perceptuelles reliées à l'aisance, le contexte
social et la motivation de communiquer.
Le premier facteur, soit les systèmes de traitement cognitif-perceptuel, est caractérisé
par l'aisance cognitive, qui renvoie à la vitesse de traitement, à la stabilité et à la
18

flexibilité dans la planification, la préparation et l'exécution d'un énoncé au niveau de
l'accès lexical et de l'usage de ressources langagières. Ensuite, ces dernières sont
utilisées pour exprimer des sens, pour satisfaire les normes sociolinguistiques et pour
atteindre des buts psychosociaux (p. ex., être écouté). Le deuxième facteur, à savoir
les expériences cognitives et perceptuelles reliées à l'aisance, comprennent une
gamme d'éléments (p. ex., la fréquence d'exposition dans un milieu favorable au
développement de la L2, des occasions de pratiquer la L2). Le troisième facteur
correspond au contexte social, qui établit la demande de la tâche cognitive
relativement à la communication. Il est à noter que ce facteur contribue à la
compréhension de ressources langagières. Finalement, la motivation de communiquer
renvoie à la volonté de communiquer, à la croyance en la communication, à l'identité
et à la notion de L2. Ces quatre facteurs interagissent l'un avec l'autre et contribuent
à la création d'un système changeant, à savoir le système dynamique.
La production orale en L2 est aussi caractérisée par 1' aisance de production qui
interagit avec l'aisance cognitive et cette interaction caractérise l'aisance de la
production orale en L2.
2.1.3 Modèle retenu pour l'étude
Dans le cadre de la présente étude, nous avons décidé d'adopter le modèle de Levelt
(1983, 1989, 1999) afin d'expliquer le phénomène à l'étude, soit l'ARAA, qui sert
également d'indicateur manifeste du processus de la régulation dans la production
orale. D'une part, cette décision est basée sur les travaux antérieurs (p. ex., de Bot,
1992; van Hest, 1996) qui démontrent que le modèle de Levelt ( 1983) peut être
adopté afin d'expliquer le processus de la régulation dans la production orale en L2
sans modifications qualitatives. D'autre part, comme nous l'avons mentionné dans la
section précédente, d'autres modèles comme celui de Fromkin (1973), de Garret
19

(1975), de de Bot (1992) et de Kormos (2006) s'avèrent moins pertinents afin
d'expliquer les ARAA dans le cadre de notre étude. Ainsi dans la partie suivante,
nous présentons ce phénomène langagier, à savoir l' ARAA dans la production orale
et les notions qui s'y attachent.
2.2 Autoreformulation autoamorcée
De façon générale, l' ARAA est conçue comme étant une modification de la production
orale réalisée par le locuteur. De façon plus précise, l'ARAA est définie comme un
processus de régulation dans lequel le locuteur reformule ce qu'il considère
inapproprié ou erroné dans un contexte donné (Kormos, 1999a; O'Connor, 1988).
Tout en reconnaissant ces deux grandes lignes de conception d' ARAA, nous
présentons quelques définitions par différents auteurs et essayons de définir cette
notion.
2.2.1 Définitions de l' ARAA dans les études précédentes
À notre connaissance, Schegloff et ses collaborateurs (1977) présentent la première
définition de l' ARAA3• Les auteurs définissent l'ARAA comme« l'achèvement d'une
procédure d'ARAA par un locuteur »4 (p. 363). Plus tard, Schegloff (1997b) donne
une autre définition de l' ARAA, à savoir « les pratiques permettant de régler des
3 Dans la présente étude, afin d'être cohérent, nous appellerons toute autoreformulation self-repair et re pair, sauf pour other-repair que nous appellerons hétéroreformulation. 4 Notre traduction de Schegloff et ses collaborateurs, 1977, p. 363: « [ ... ] the suc cess of a re pair procedure ». Il est à noter que selon la personne qui a amorcé et complété une autoreformulation, Schegloff et ses collaborateurs, (1977) ont classifié les reformulations en quatre types (voir la configuration d'autoreformulation pour plus de détails).
20

problèmes ou des difficultés de parole, d'écoute et de compréhension dans une
conversation (et dans d'autres formes de discours à cet effet)» (p. 503)5•
Levelt (1983), pour sa part, propose de considérer l' ARAA comme étant une activité
de régulation dans une boucle perpétuelle. Il définit l'ARAA comme étant «une
boucle perpétuelle dans laquelle la production intérieure et manifeste est perçue,
analysée et vérifiée pour sa justesse intentionnelle et contextuelle, la concordance
entre le message conçu et le message produit, et la justesse linguistique. Lorsqu'un
problème est détecté, une action corrective venant du central est prise» (p. 50)6•
À la suite du travail de Levelt (1983, 1989) sur la production orale, plusieurs
chercheurs ont tenté de définir l' ARAA dans leurs études. C'est notamment le cas de
Bange et Kem (1996) selon qui l' ARAA constitue la résolution d'un problème par le
locuteur.
Les autoreformulations qui ont la structure qu'on a vue réparandumlréparans ont pour fonction de résoudre un problème sur lequel l'attention du locuteur s'était focalisée et cette résolution de problème est assurée par le locuteur luimême sous son propre contrôle. Les autoreforrnulations manifestent la résolution autonome d'un problème par le locuteur (p. 80).
Pour leur part, van Hest, Poulisse et Bongaerts (1997) mettent plutôt l'accent sur
1' aspect « spontanéité » de 1 'ARAA qu'ils définissent comme « des révisions
5 Notre traduction de Schegloff et ses collaborateurs, 1977, p. 503: « By 'repair ·. we refer to practices for dealing with problems or troubles in speaking, hearing and understanding the talk in conversation (and in other forms oftalk-in-interaction.jor thal matter)». 6 Notre traduction de Levelt, 1983, p. 50:«[ ... ] repairing speech involves a perceptual/oop: the selfproduced inner or overt speech is perceived, parsed and checked with respect to intentional and contextual appropriateness, agreement of intended and delivered message, and linguistic correctness. When trouble is detected, central corrective action is laken>>.
21

spontanées qui interrompent des énoncés en cours » 7 • Salonen et Laakso (2009)
adoptent une définition similaire de l'ARAA : «les révisions d'énoncés que les
locuteurs ont débutées et achevées» 8• Pour Baker et Ellece (2011), l'ARAA
correspond à une correction de l'énoncé:
La reformulation est un terme utilisé dans l'analyse conversationnelle qui renvoie aux modèles de conversation spontanée dans laquelle un locuteur doit répéter ou reformuler une partie de son énoncé afin de «corriger» ce qu'il a dit. Cela se produit souvent lorsqu'un ou plusieurs participants ont de la difficulté à parler, à entendre ou à comprendre. La reformulation peut être effectuée par le locuteur, ou l'interlocuteur peut essayer de clarifier ou de reformuler ce que le locuteur a dit (p. 115)9
•
Dans les études sur les ARAA en L2, plusieurs chercheurs ont aussi essayé de
circonscrire les ARAA selon le but de leurs études respectives. À titre d'exemple,
citons les cas de Tarone (1980) et de O'Connor (1988). D'un côté, Tarone (1980)
définit l'ARAA dans une perspective de stratégie de communication: «L' ARAA est
vue comme une deuxième tentative de communiquer ce qu'un locuteur voulait dire.
Comme nous le savons, les ARAA se produisent habituellement lorsqu'un locuteur
perçoit que l'énoncé original contient une structure linguistique ou sociolinguistique
qui ne transmet pas ce qu'il voulait dire de sorte que 1' interlocuteur puisse
7 Notre traduction de van Hest, Poulisse et Bongaerts, 1997, p. 76: « Spontaneous revisions which invo/ve an interruption of the ongoing utterance ». 8 Notre traduction de Salonen et Laakso, 2009, p. 859: « [ ... ] revisions of speech thal the speakers themselves had initiated and completed) » 9 Notre traduction de Baker et Ellece, 2011, p. 115: « Repair is a lerm used in Conversation Analysis to re fer to patterns of naturally occurring conversation where a speaker needs to repeat or reformulate part of hislher utterance in order to "correct' what helshe had previously said. This can often occur when one or more has difficulty with speaking, hearing or understanding. Repair can involve selfrepair, or another speaker can attempt to c/arify or correct the first speaker 's utterance )).
22

comprendre» 10• D'un autre côté, O'Connor (1988) définit I'ARAA en L2 comme
« l'une des stratégies communicatives utilisées par un apprenant d'une L2 » 11•
Quant à Kormos ( 1999a}, elle relie 1' ARAA à la régulation. Pour elle, « 1' ARAA
correspond à une manifestation du processus de la régulation. Une reformulation
autoamorcée et autoaccomplie se produit lorsqu'un locuteur se rend compte que sa
production est erronée ou inappropriée, qu'il arrête sa production et opère une
révision »12• En suivant la même conceptualisation de l'ARAA, Rieger (2003) définit
I'ARAA comme étant «une correction d'erreur, une recherche lexicale et l'usage
d'une pause d'hésitation, d'une pause de remplissage lexical, quasi lexical ou non
lexical, d'une modification lexicale immédiate, d'un faux départ et de répétitions
instantanées>> 13• Finalement, Kaur (2011) considère I'ARAA comme étant un
mécanisme autorégulateur dans une conversation pour améliorer la clarté de
communication. Dans son étude, I'ARAA se définit comme étant «un mécanisme
puissant d'autorégulation qui permet à un locuteur de non seulement corriger les
erreurs linguistiques ou factuelles, mais aussi de rendre son discours plus précis,
explicite et clair »14•
10 Notre traduction de Tarone, 1980, p. 425 : « Repairs. as we sha/1 see, occur primarily when the speaker perceives thal the first-attempt utterance contains a linguistic or sociolinguistic structure which does not communicate an intended meaning x close/y enough to ensure that there will be shared meaning». 11 Notre traduction de O'Connor, 1988, p. 251 :«Second-language repairs are usual/y considered one of severa/ types of communicative strategies employed by a language /earner ». 12 Notre traduction de Kormos, 1999a, p. 315: « Self-corrections are overt manifestations of the regulation processes. A self-initiated self-completed correction cornes about when the speaker detects thal the output has been erroneous or inappropriate, halts the speech flow, and final/y executes a co"ection ». 13 Notre traduction de Rieger, 2003, p. 48 : « [ ... ] error correction, the searchfor a word, and the use of hesitation pauses, lexical, quasi-lexical, or non-lexical pause fil/ers, immediate lexical changes, fa/se starts, and instantaneous repetitions ». 14 Notre traduction de Kaur, 2011, p. 2712 : « [ ... ] a powerful self-regu/ating mechanism thal allows the speaker to not on/y make corrections when linguistic andfactua/ errors occur but to a/so make ta/k more specifie, explicit and c/ear ».
23

Enfin, dans leurs études comparatives entre plusieurs langues sur l' ARAA, Fox,
Wouk, Hayashi, Fincke, Tao, Sorjonen et Hemandez (2009) et Fox, Maschler et
Uhmann (201 0) proposent deux définitions de l' ARAA selon lesquelles il s'agit d'un
processus. La première définition dit que « l' ARAA du même tour est un processus
dans lequel un locuteur arrête un énoncé en cours puis l'abandonne, le remanie ou le
refait» 15; la deuxième correspond au «processus selon lequel un locuteur s'arrête,
abandonne, répète ou change son tour de parole avant que ce processus soit
terminé »16•
D'une part, chacune des définitions qui viennent d'être présentées met en lumière un
aspect particulier de l' ARAA, que ce soit l'aspect de la stratégie de communication
(O'Connor, 1988; Rieger, 2003) ou encore l'aspect processuel (Fox et coll., 2009;
Fox et coll., 2010). D'autre part, ces définitions indiquent que l'ARAA représente
une sorte de difficulté auquel le locuteur fait face et qu'il essaye de résoudre d'une
certaine manière.
Dans la présente étude, l' ARAA sera considérée avant tout comme un processus de
régulation. Par conséquent, nous retenons la définition suivante pour l'ARAA:
1 'ARAA est définie comme étant un processus de régulation qui implique
1 'autorévision de la production par le locuteur.
2.2.2 Configurations des reformulations
La reformulation présente différentes configurations. Dans la présente étude, les
configurations de reformulation revoient à qui amorce et qui accomplit une
15 Notre traduction de Fox et ses collaborateurs, 2009, p. 60: « Same-turn self-repair is the process by which speakers stop an utterance in progress and then abort, recast or redo thal utterance ». 16 Notre traduction de Fox et ses collaborateurs, 2010, p. 2487 : « Same-turn self-repair is the process by which speakers of a language stop, abort, repeat, or alter the ir turn before il cornes to completion ».
24

reformulation lorsqu'une difficulté de la production orale arrtve. Cette notion
correspond en général aux sous-catégories de reformulations de Schegloff et ses
collaborateurs (1977, p. 384-385). Les quatre configurations principales sont:
autoreformulation autoamorcée, autoreformulation hétéroamorcée,
hétéroreformulation autoamorcée et hétéroreformulation hétéroamorcée (Schegloff
et coll., 1977). Plus concrètement, 1 'auto re formulation autoamorcée est une
reformulation amorcée et accomplie par le locuteur lui-même lorsqu'une difficulté de
la production orale arrive dans son tour de parole tandis que l' autoreformulation
hétéroamorcée est une reformulation amorcée par le locuteur lorsqu'une difficulté de
la production orale arrive dans son tour de parole, mais accomplie par l'interlocuteur;
par contre, l' hétéroreformulation autoamorcée est une reformulation amorcée par
l'interlocuteur, mais accomplie par le locuteur et I'hétéroreformulation
hétéroamorcée est celle qui est amorcée et accomplie par l'interlocuteur. N'oublions
pas que Schegloff et ses collaborateurs (1977) ont observé que les participants dans
une conversation avaient préféré l'autoamorce et l'autoreformulation à
l'hétéroamorce et à l'hétéroreformulation. Dans les études antérieures, une des
configurations de la reformulation a été étudiée en particulier: l' ARAA.
Il existe également d'autres types de configuration de reformulations proposés par les
chercheurs. À titre d'exemple, citons la reformulation prépositionnée (notre
traduction de prepositionned repair) et la reformulation postpositionnée (notre
traduction de postpositioned repair) (Hennoste, 2005) 17• De plus, Fox et Jasperson
(1995) proposent la reformulation de première position (notre traduction de first
position repair) 18 et Schegloff et ses collaborateurs (1977) proposent la reformulation
du même tour (notre traduction de same tum repair), également étudiée par Fox,
17 Voir Hennoste (2005) pour une description plus détaillée. 18 Ce type d'autoreformulation a aussi fait l'objet d'études par Hayashi ( 1994).
25

Hayashi et Jasperson (1996) et par Fox et ses collaborateurs (2009, 2010) 19• Dans
notre étude, nous nous concentrerons sur le premier type de reformulation, soit
l'ARAA.
2.2.3 Taxinomies d' ARAA
La taxinomie d' ARAA concerne la classification des ARAA. En général, la
taxinomie d' ARAA en L2 est empruntée de celle de LI, puisque les recherches sur
l' ARAA dans l'approche psycholinguistique en L2 sont moins avancées qu'en LI
(Kormos, 1998).
2.2.3.1 Taxinomies d' ARAA en L 1
La première taxinomie systématique des ARAA produites en L l est celle proposée
par Levelt (1983 ). En s'appuyant sur ses données, Levelt (1983) a créé trois types
d'ARAA:
ARAA de différent message (désormais ARAA-D) (notre traduction de D-repairs,
different repair), ARAA appropriée (désormais ARAA-A) (notre traduction de A
repairs, appropriateness repairs), ARAA pour corriger les erreurs (désormais
ARAA-E) (notre traduction de error repairs,). Ces trois types d'ARAA sont les
ARAA manifestes (en anglais, overt self-repairs). Il convient d'examiner ces trois
types d' ARAA afin de savoir de quoi il s'agit.
Premièrement, une ARAA-D se produit «lorsqu'un locuteur se rend compte qu'il y a
une erreur dans la phase de la préparation conceptuelle et qu'une autre idée doit être
19 Voir Fox et ses collaborateurs (1996, 2009, 2010) et Schegloff et ses collaborateurs (1977) pour plus d'information sur ces types de reformulation.
26

exprimée avant celle en cours, et interrompt son discours pour commencer à nouveau.
Par la suite, le message en cours est remplacé par un message différent »20•
Les ARAA-A portent pour leur part sur la modification de la manière dont un locuteur
s'exprime. Les ARAA-A se subdivisent en trois catégories en fonction du but de
l'ARAA: a) pour réduire l'ambiguïté b) pour ajuster le niveau de la justesse et
c) pour garder la cohérence. L'ARAA-RA, l' ARAA-A pour réduire l'ambiguïté, se
produit afin de clarifier toute ambiguïté de référence. L'ARAA-NJ, l' ARAA-A du
niveau de la justesse, se produit lorsqu'un locuteur change un terme moins spécifique
à un terme plus spécifique. L'ARAA-AC, l'ARAA pour l'ajustement de la cohérence,
s'utilise afin qu'un terme soit cohérent avec ce qui est utilisé précédemment. De plus,
il existe une autre sorte d' ARAA-A, à savoir ARAA-A pour respecter les coutumes
sociales (Levelt, 1989), qui correspond à 1 'ARAA pour le bon usage de la langue telle
que définie par Brédart (1991). Le dernier type d'ARAA manifeste, à savoir ARAA-E
porte sur la correction des erreurs lexicales, syntaxiques ou phonétiques, codées
ARAA-EL, ARAA-ES et ARAA-EP respectivement. L'ARAA-EL est le remplacement
d'un terme lexical erroné par le bon terme tandis que l'ARAA-ES est une
modification de la mauvaise construction syntaxique qui aboutit à une impasse. Enfin,
Levelt (1983) a codé tout le reste d' ARAA comme ARAA-R.
En ce qui concerne ARAA-M, elle n'a pas fait l'objet d'études approfondies par
Levelt ( 1983), qui 1 'a considérée comme problématique et parce qu'il était difficile de
déterminer ce qu'un locuteur surveillait dans son discours. Par conséquent, au lieu
d'avoir approfondi ce type d' ARAA, Levelt (1983) a mentionné au passage qu'une
ARAA-M est marquée soit par une interruption avec un indicateur de reformulation,
soit par une répétition d'items lexicaux. De plus, une ARAA-M indique que la
20 Notre traduction de Levelt, 1983, p. 51 : « The speaker reali=es thal another idea than the current one has to be expressedfirst and interrupts his speech to start anew. The current message is rep/aced by a different one ».
27

régulation sert à surveiller le discours avant qu'un énoncé soit produit. Par la suite,
Blackmer et Mitton (1991) ont divisé la ARAA-M en quatre sous-catégories: avec un
indicateur de refonnulation, avec des répétitions, avec un indicateur de refonnulation
et des répétitions, et entre deux énoncés. Certains chercheurs (p. ex., Blackmer et
Mitton, 1991; Levelt, 1983, 1989; Postma et Kolk, 1992) s'entendent sur l'idée que
les ARAA manifestes et masquées fonctionnent de la même façon.
Le Tableau 2.1 offre une synthèse des taxinomies d' ARAA en L 1 que nous venons de
présenter.
28
N
\C)
Tab
leau
2.1
Syn
thès
e de
s ta
xino
mie
s d'
AR
AA
en
LI
Typ
es g
énér
aux
d'A
RA
A
AR
AA
-D
AR
AA
-E
AR
AA
-M
AR
AA
-A
Lev
elt (
198
3, 1
989)
A
RA
A-D
AR
AA
-EL
: A
RA
A
d'er
reur
lex
ical
e
AR
AA
-ES
: A
RA
A
d'er
reur
syn
taxi
que
AR
AA
-EP
: A
RA
A
d'er
reur
pho
néti
que
AR
AA
-M
AR
AA
-RA
: A
RA
Ap
ou
r ré
duir
e l'a
mbi
guït
é A
RA
A-N
J : A
RA
A d
u ni
veau
de
la ju
stes
se
Sou
s-ca
tégo
ries
d' A
RA
A
Bré
dart
(19
91)
AR
AA
-D
AR
AA
-EL
: A
RA
A d
'err
eur
lexi
cale
AR
AA
-ES
: A
RA
A d
'err
eur
synt
axiq
ue e
t m
orph
olog
ique
A
RA
A-E
P :
AR
AA
d'e
rreu
r ph
onét
ique
Rép
étit
ion
Inte
rrup
tion
san
s ré
péti
tion
av
ec i
ndic
ateu
r d
' AR
AA
AR
AA
-RA
: A
RA
A p
our
rédu
ire
l'am
bigu
ïté
AR
AA
-NJ
: AR
AA
du
nive
au
de l
a ju
stes
se
B la
ckm
er e
t Mit
ton
( 199
1)
A R
AA
-D
AR
AA
man
ifes
te b
asée
sur
la
prod
ucti
on
AR
AA
-M a
vec
indi
cate
ur d
e re
form
ulat
ion
AR
AA
-M a
vec
indi
cate
ur d
e re
form
ulat
ion
et d
es r
épét
itio
ns
AR
AA
-M a
vec
des
répé
titi
ons
AR
AA
-M e
ntre
deu
x én
oncé
s
AR
AA
-AI
AR
AA
-NJ

AR
AA
-AC
: A
RA
A d
e la
A
RA
A-A
C :
AR
AA
de
la
cohé
renc
e A
RA
A p
our
resp
ecte
r le
s
cout
umes
soc
iale
s
cohé
renc
e A
RA
A p
our
le b
on u
sage
de
la l
angu
e

2.2.3.2 Taxinomies d' ARAA en L2
Dans les études de l' ARAA en L2, des chercheurs comme Fathman (1980),
Verhoeven (1989), Bange et Kern (1996), van Hest (1996), Kormos (1998), et Simard
et ses collaborateurs (2011) ont contribué à l'établissement de taxinomies d'ARAA
en se basant sur celle de Levelt (1983).
Fathman (1980) est parmi les premiers chercheurs à avoir étudié les ARAA et les
répétitions chez des apprenants de L2. Dans son étude, l'auteure a classifié les ARAA
selon cinq catégories : phonologique, morphologique, syntaxique, sémantique et
lexicale. Toutefois, bien que des exemples soient fournis pour chacune des catégories,
certaines d'entre elles ne sont pas définies de façon explicite. Quant à l'étude de
Verhoeven (1989), trois catégories d'ARAA ont été établies, à savoir l'ARAA
phonologique, qui concerne une modification phonologique des mots prononcés,
l'ARAA syntaxique, qui contribue à l'amélioration de la structure syntaxique d'un
énoncé et qui peut prendre la forme d'un changement de l'ordre des mots, l'emploi
des mots grammaticaux corrects ou la sélection de terminaisons morphologiques, et
1 'ARAA sémantique, qui vise à améliorer la cohérence d'un énoncé par le
remplacement de mots lexicaux (p. 146). Dans leur étude, Bange et Kern (1996) ont
ajouté une nouvelle catégorie, ARAA-RL (recherche lexicale) et une nouvelle sous
catégorie, ARAA d'erreur sur le genre à ARAA-E. De plus, ils ont divisé ARAA-EL
en deux sous-catégories : EL lapsus pour les ARAA en L 1 et EL expression correcte
pour les ARAA en L2.
Dans la taxinomie d' ARAA qu'elle a établie en se basant sur la classification
d' ARAA de Levelt (1983), van Hest (1996) a ajouté plusieurs types d' ARAA à la
taxinomie d' ARAA. Dans la catégorie ARAA-A, les catégories suivantes ont été
ajoutées: ARAA-AI (notre traduction de appropriateness repairs: insertion), ARAA-
31

LA (notre traduction de appropriateness repairs: lexical), ARAA-SA (notre traduction
de appropriateness repairs: syntactic), ARAA-AX (notre traduction de
appropriateness repairs for tense or aspect). En ce qui concerne I'ARAA-E,
quelques sous-catégories ont été ajoutées : ARAA-EX (notre traduction de repairs for
tense or aspect) et ARAA-EC (notre traduction de conceptual error repairs) qui
correspond à des erreurs de traitement conceptuel de bas niveau et qui provient du
mauvais plan conceptuel attribuable à une interprétation erronée (van Hest, 1996,
p. 41). Également, les ARAA morphologiques ont été divisées en trois sous
catégories: ARAA-EF (notre traduction de inflectional error repairs), ARAA-ED
(notre traduction de derivational error repairs) et ARAA-EMP (notre traduction de
morphological/phonological error repairs). Même si les taxinomies que nous avons
vues sont importantes pour le perfectionnement de la taxinomie d' ARAA en L2, il
n'empêche qu'elles ne sont pas sans faiblesse. L'une des critiques formulées à l'égard
de ces taxinomies concerne le fait qu'elles ne prennent pas en compte les mécanismes
psycholinguistiques sous-jacents (Kormos, 1998, p. 47).
En s'appuyant sur une étude des ARAA chez des participants hongrois, Kormos
( 1998) a ajouté une nouvelle catégorie et quelques nouvelles sous-catégories à la
taxinomie d'ARAA en L2. La nouvelle catégorie ARAA-RF (notre traduction de
rephrasing repairs), qui est une révision du plan préverbal, se définit comme une
modification d'un énoncé et une partie d'énoncé par un ajout ou une paraphrase
parce qu'un locuteur n'est pas certain de la justesse de 1 'énoncé (Kormos, 1998,
p. 63). En outre, la ARAA-D est divisée en trois sous-catégories : ARAA de 1 'erreur
de 1 'ordre (notre traduction de ordering error repair) qui correspond à un nouvel
arrangement des énoncés produits par un locuteur, ARAA de 1 'information
inappropriée (notre traduction de inappropriate information repair) qui vise à
rectifier l'information encodée de façon inappropriée, et ARAA du remplacement de
message (notre traduction de message replacement repair) avec laquelle un message
32

est interrompu et est remplacé par un nouveau message. Quant à l' ARAA-E, une
nouvelle sous-catégorie a été ajoutée : ARAA de la justesse pragmatique (notre
traduction de pragmatic appropriacy repair) qui a pour but de corriger des erreurs
pragmatiques. D'après Kormos (1998), l' ARAA de la justesse pragmatique est
différente de celle pour le bon usage de la langue proposée par Brédart (1991) parce
que cette dernière vise à reformuler les énoncés qui sont acceptables
pragmatiquement, mais jugés inappropriés selon le niveau de registre utilisé par le
locuteur. La dernière catégorie d' ARAA comprend ARAA-EL, ARAA-EG (notre
traduction de grammatical error repairs) et ARAA-EP. Kormos a argumenté que le
nom des trois catégories est inspiré du processus de la production orale développé par
Levelt (1983) et de la grammaire procédurale incrémentielle (notre traduction de
Incrementa/ Procedural Grammar) (Kempen et Hoenkamp (1987). C'est pour cette
raison que la définition des trois sous-catégories reflète le mécanisme de la
production orale de Levelt (1983, 1999). En ce qui concerne l'ARAA-EL, elle se
définit comme étant «la révision d'un lemme activé par accident »21 (p. 59), ce qui
est produit durant la première phase de la production orale. Ainsi, une ARAA-EG se
produit dans la deuxième phase de la production orale, soit 1' encodage grammatical,
et par conséquent, se définit comme étant« la correction d'une erreur qui se produit
lors de la phase d'encodage grammatical »22 (p. 61).
Kormos (1998) a proposé que les ARAA des morphèmes dérivationnels et
flexionnels, et de certains mots grammaticaux et de certains verbes auxiliaires doivent
être codées de façon différente parce qu'elles sont traitées différemment dans la
production orale. Les ARAA des morphèmes dérivationnels sont codées ARAA-EL
tandis que celles flexionnelles sont codées ARAA-EG parce que les premières se
21 Notre traduction de Korrnos, 1998, p. 59: « [ ... ] the correction of an accidenta/ly erroneously activated lemme». 22 Notre traduction Korrnos, 1998, p. 61: « [ ... ] the correction of a lapse, which occurs in the grammatical encoding phase ».
33

produisent durant 1' encodage lexical et les dernières durant 1 'encodage grammatical.
En suivant le même raisonnement, elle a codé des mots grammaticaux et des verbes
auxiliaires soit ARAA-EL, soit ARAA-EG. Enfin, une ARAA-EP se produit dans la
phase de 1 'encodage phonologique et de 1 'articulation. Ainsi les corrections des
erreurs dans ces deux phases sont codées ARAA-EP.
Dans l'étude de Liu (2009) qui portait sur l' ARAA en anglais L2 chez des
participants sinophones, la répétition a été renommée ARAA de la même information
(notre traduction de same information repair), et l'ARAA de type retour à l'erreur
(notre traduction de back-to-error repair) a aussi été examinée. Finalement, selon
Simard et ses collaborateurs (20 Il), bien que les études antérieures disent établir
leurs catégories sur la base des travaux de Levelt, « dans les faits, leurs catégories
varient d'une étude à l'autre, et souvent, ne sont pas opérationnalisées exactement de
la même façon » (p. 8). Selon les auteurs, le point commun entre les catégories
correspond à l'objet de l' ARAA, à savoir la forme ou le choix de mots ou le groupe
de mots. Pour terminer cette section du chapitre, le Tableau 2.2 présente une synthèse
des taxinomies d' ARAA en L2 que nous venons de mentionner selon les auteurs qui
les ont proposées.
34
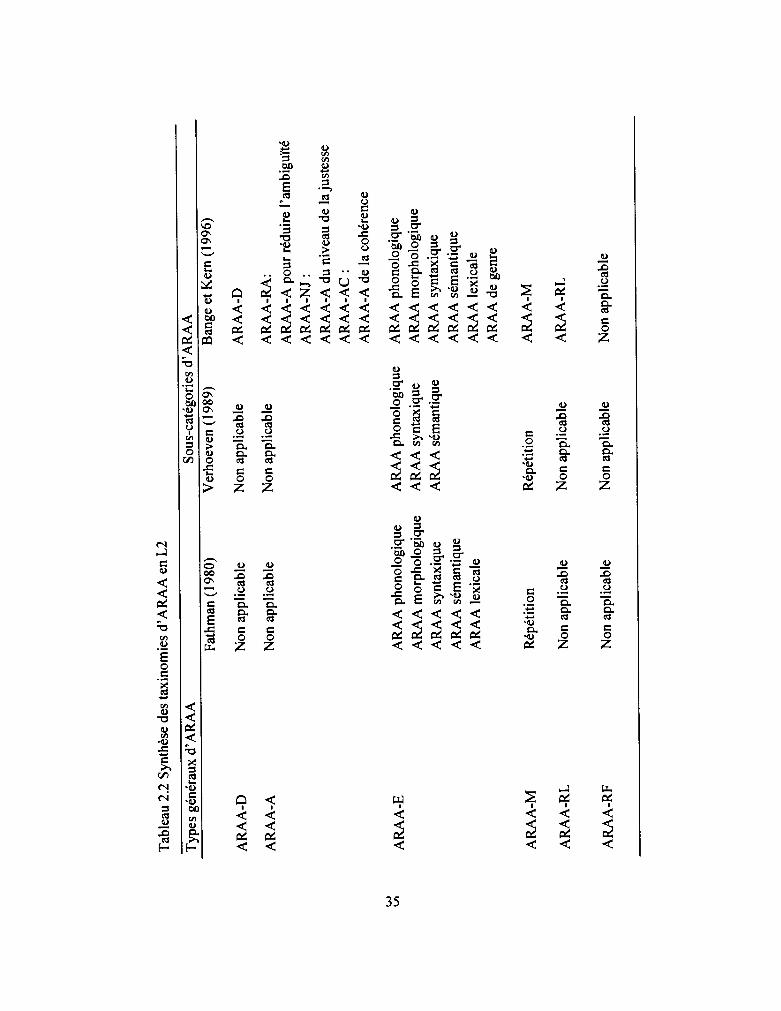
Tab
leau
2.2
Syn
thès
e de
s ta
xino
mie
s d
' AR
AA
en
L2
Typ
es g
énér
aux
d' A
RA
A
Sou
s-ca
tégo
ries
d' A
RA
A
Fat
hman
(19
80)
Ver
hoev
en (
1989
) B
ange
et K
ern
( 199
6)
AR
AA
-D
Non
app
lica
ble
Non
app
lica
ble
AR
AA
-D
AR
AA
-A
Non
app
lica
ble
Non
app
lica
ble
AR
AA
-RA
: A
RA
A-A
pou
r ré
duir
e l'a
mbi
guït
é
AR
AA
-NJ:
A
RA
A-A
du
nive
au d
e la
just
esse
AR
AA
-AC
: A
RA
A-A
de
la c
ohér
ence
w
Vl
AR
AA
-E
AR
AA
pho
nolo
giqu
e A
RA
A p
hono
logi
que
AR
AA
pho
nolo
giqu
e
AR
AA
mor
phol
ogiq
ue
AR
AA
syn
taxi
que
AR
AA
mor
phol
ogiq
ue
AR
AA
syn
taxi
que
AR
AA
sém
anti
que
AR
AA
syn
taxi
que
AR
AA
sém
anti
que
AR
AA
sém
anti
que
AR
AA
lex
ical
e A
RA
A l
exic
ale
AR
AA
de
genr
e
AR
AA
-M
Rép
étit
ion
Rép
étit
ion
AR
AA
-M
AR
AA
-RL
N
on a
ppli
cabl
e N
on a
ppli
cabl
e A
RA
A-R
L
AR
AA
-RF
N
on a
ppli
cabl
e N
on a
ppli
cabl
e N
on a
ppli
cabl
e
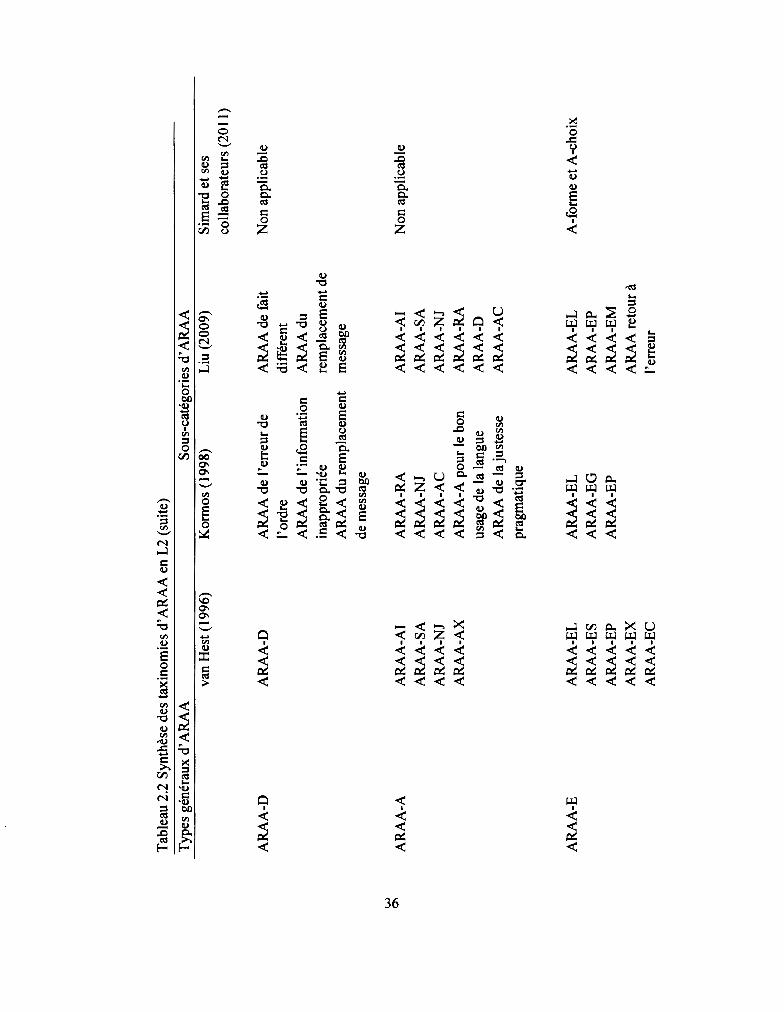
Tab
leau
2.2
Syn
thès
e de
s ta
xino
mie
s d
' AR
AA
en
L2
(sui
te)
Typ
es g
énér
aux
d' A
RA
A
Sou
s-ca
tégo
ries
d' A
RA
A
van
Hes
t ( 1
996)
K
orm
os (
199
8)
Liu
(20
09)
Sim
ard
et s
es
coll
abor
ateu
rs (
20 I
l)
AR
AA
-D
AR
AA
-D
AR
AA
de
1 'er
reur
de
AR
AA
de
fait
Non
app
lica
ble
l'ord
re
diff
éren
t
AR
AA
de
l'inf
orm
atio
n A
RA
Ad
u
inap
prop
riée
re
mpl
acem
ent d
e
AR
AA
du
rem
plac
emen
t m
essa
ge
de m
essa
ge
w
0\
AR
AA
-A
AR
AA
-AI
AR
AA
-RA
A
RA
A-A
I N
on a
ppli
cabl
e
AR
AA
-SA
A
RA
A-N
J A
RA
A-S
A
AR
AA
-NJ
AR
AA
-AC
A
RA
A-N
J A
RA
A-A
X
AR
AA
-A p
our
le b
on
AR
AA
-RA
usag
e de
la
lang
ue
A R
AA
-D
AR
AA
de
la ju
stes
se
AR
AA
-AC
prag
mat
ique
AR
AA
-E
AR
AA
-EL
A
RA
A-E
L
AR
AA
-EL
A
-for
me
et A
-cho
ix
AR
AA
-ES
A
RA
A-E
G
AR
AA
-EP
A
RA
A-E
P
AR
AA
-EP
A
RA
A-E
M
AR
AA
-EX
A
RA
A r
etou
r à
AR
AA
-EC
l'e
rreu
r

AR
AA
-EM
A
RA
A-E
F
AR
AA
-ED
AR
AA
-EM
P
AR
AA
-M
AR
AA
-M
AR
AA
-M
AR
AA
de
la m
ême
Non
app
lica
ble
info
rmat
ion
RL
N
on a
ppli
cabl
e N
on a
ppli
cabl
e N
on a
ppli
cabl
e N
on a
ppli
cabl
e
AR
AA
-RF
N
on a
ppli
cabl
e A
RA
A-R
F
Non
app
lica
ble
Non
app
lica
ble
VJ
-....)

2.3 Taxinomie retenue pour l'étude
Dans les parties ci-dessus, nous avons présenté les définitions, les configurations et
les taxinomies d' ARAA utilisées dans les études en LI et en L2. Dans le cadre de
notre étude, nous adoptons la taxinomie de Levelt (1983). D'une part, la taxinomie
d' ARAA proposée par Levelt (1983) est adoptée par plusieurs études (p. ex., Bange
et Kem, 1996; Chen et Pu, 2007; Kormos, 2000a; Liu 2009; Nagano, 1997; Yang,
2002), d'autre part, elle s'avère empiriquement solide comme le démontrent les
études citées. De plus, il nous semble que les taxinomies utilisées dans les études en
L2 soient moins sophistiquées que celle en L 1 proposée par Leve tt.
Toutefois, nous y apportons certaines modifications que nous jugeons mineures. En
effet, nous partageons l'avis de Kormos (1998) selon qui certaines catégories de la
taxinomie de Levelt (1983) pourraient ne pas convenir à la recherche d' ARAA en L2
puisqu'elles ont été élaborées d'après des données de production orale en Ll. De plus,
il est difficile de catégoriser certains cas d' ARAA-E, notamment les ARAA
morphologiques, selon la taxinomie de Levet (1983). Ainsi dans le cadre de notre
étude, nous avons gardé seulement les ARAA-A dans la catégorie d' ARAA-A, ajouté
ARAA morphologique dans la catégorie d' ARAA-E et décidé d'inclure les
répétitions dans les ARAA-M. Puisque notre étude porte sur les caractéristiques de la
production orale en français L2 au moyen des ARAA, nous avons choisi les
catégories d' ARAA jugées pertinentes afin de mener des analyses dans les prochaines
sections, à savoir les ARAA-D, les ARAA-A, les ARAA-E comprenant les ARAA
phonologiques, morphologiques, syntaxiques et lexicales.
Nous présentons dans le Tableau 2.3 une comparaison entre la taxinomie de Levelt et
celle que nous avons utilisée pour notre étude.
38

Tableau 2.3 Comparaison de la taxinomie d' ARAA de Levelt et de celle de la
présente étude
Types d' ARAA principaux Sous-catégories d' ARAA Levelt (1983, 1989)
ARAA-D ARAA-D
ARAA-A ARAA-RA : ARAA-A
Notre étude ARAA-D
ARAA-A : ARAA-A pour réduire l'ambiguïté pour réduire l'ambiguïté
ARAA-E
ARAA-M
ARAA-NJ : ARAA-A du niveau de la justesse ARAA-AC : ARAA-A de la cohérence ARAA pour respecter les coutumes sociales
ARAA-EL : ARAA d'erreur lexicale ARAA-ES : ARAA d'erreur syntaxique ARAA-EP : ARAA d'erreur phonétique
ARAA-M
ARAA phonologique ARAA morphologique ARAA syntaxique ARAA lexicale
Répétition
Dans ce qui suit, nous offrons une synthèse du cadre théorique.
2.4 Synthèse du cadre théorique
Dans la présente étude, nous nous proposons de présenter des caractéristiques de la
production orale en français L2 des locuteurs natifs du mandarin au moyen d'une
analyse de leurs ARAA. D'abord, nous avons présenté six modèles de production
orale, celle de Fromkin (1971, 1973), de Garrett (1975), de Levelt (1983, 1989, 1999),
de de Bot (1992), de Kormos (2006) et de Segalowitz (20 1 0). Les cinq modèles
39

Fromkin (1971, 1973), Garrett (1975), Levelt (1983, 1989, 1999), de Bot (1992) et
Kormos (2006) correspondent aux représentations de type en série. Nous avons
décidé de baser notre étude sur le modèle de Levelt (1983, 1989, 1999). Ensuite, nous
avons exposé les différentes définitions de 1 'ARAA et avons donné notre définition
de 1 'ARAA en mettant 1 'accent sur l'aspect de régulation de l' ARAA. Par la suite,
nous avons présenté les différentes configurations et les taxinomies de l' ARAA en L1
et en L2. Dans le chapitre suivant, nous présentons une recension des écrits portant
sur les caractéristiques des productions orales des apprenants sinophones du français
L2, sur les ARAA en anglais L2 chez les sinophones et dans d'autres langues.
40

CHAPITRE III
RECENSION DES ÉCRITS
3.0 Introduction
Dans le chapitre précédent, nous avons présenté le cadre dans lequel s'inscrit notre
étude ainsi que les définitions des notions principales qui s'y rattachent. Nous
exposons dans ce qui suit les études sur les caractéristiques de la production des
apprenants sinophones du français L2 (3 .1) et les études sur les ARAA en L2 chez les
sinophones (3.2). Nous poursuivrons cette présentation avec d'autres études sur les
ARAA qui ne portent pas directement sur les apprenants sinophones de L2, mais que
nous jugeons néanmoins pertinentes pour notre étude (3.3). Dans notre recension,
nous précisons l'objet, les participants, la méthode de la collecte de données,
l'analyse des données et les conclusions principales des études que nous rapportons.
Ensuite, nous présentons un sommaire des études sur l' ARAA (3.4). Enfin, nous
formulons nos questions de recherche (3.5).
41

1 !
3.1 Études sur les caractéristiques de la production des apprenants sinophones du
français L2
Comme nous l'avons mentionné dans la problématique, les productions orales en
français L2 des sinophones présentent des caractéristiques particulières entre autres,
sur le plan morphologique, syntaxique, phonologique, lexical et sur le plan de la
conception de la temporalité. Très peu d'études ont, à notre connaissance, fait état des
caractéristiques chez ce groupe d'apprenants en production orale. Dans ce qui suit,
nous présentons ces études.
3.1.1 Étude de Wang (1993)
Wang (1993) a décrit de façon théorique certaines difficultés d'apprentissage
auxquels pourraient faire face les apprenants sinophones immigrants au Québec.
L'auteure met en évidence le fait que peu d'immigrants sinophones sont capables de
se débrouiller en français même après une période de formation intensive de plus de
six mois en français dans un programme de francisation au Québec. L'auteure dresse
une liste de problèmes d'apprentissage présentées par les apprenants sinophones et les
catégorise en cinq groupes, soit la phonétique, les articles, les formes verbales, les
choix des mots et la syntaxe. Rappelons-nous que l'étude n'a eu recours à aucune
expérience impliquant des participants, et qu'il s'agit d'un travail purement théorique.
L'auteure a conclu que, sur le plan phonétique, à cause des différences entre les deux
langues, les apprenants sinophones ne sont pas capables de distinguer certains
phonèmes en français, ainsi ils n'entendent pas ce qui leur est dit et ne sont pas
capables de prononcer certains phonèmes de façon correcte. En ce qui concerne les
articles, l'un des principaux problèmes se trouve dans l'usage des articles en fonction
du genre et du nombre de noms qu'ils qualifient pour les apprenants sinophones.
42

L'auteure a aussi mentionné que la conjugaison verbale du français pose des
problèmes aux apprenants sinophones puisqu'elle n'existe pas en mandarin, et que les
différences sur le plan de la syntaxe entre les deux langues résident essentiellement
dans la position des mots et dans le rapport entre eux sur lesquels la syntaxe du
français repose tandis que c'est la juxtaposition qui caractérise la syntaxe du
mandarin23 •
3.1.2 Étude de Yu (1993)
Yu (1993) a pour sa part étudié les difficultés relatives à la morphologie du français
L2 à l'oral et à l'écrit chez les apprenants sinophones en Chine. Les corpus
consistaient en des données orales et écrites provenant de quatre groupes d'une
vingtaine d'apprenants étudiant chacun dans une université à Beijing. Les apprenants
étaient inscrits dans un programme de formation d'études de la première année à la
quatrième année afin de devenir des maitres de langue ou de travailler dans le
domaine de la traduction. En ce qui concerne la partie expérimentale de 1 'étude, les
participants devaient accomplir une tâche de composition écrite et une tâche d'exposé
oral dont les données ont été enregistrées, transcrites et traitées par analyses
statistiques. Il est à noter que les caractéristiques observées dans les productions
orales ont été opérationnalisées au moyen des erreurs commises (sans attention
particulière portée sur les reformulations).
L'auteur a conclu qu'il existe une interférence de la LI lors de l'apprentissage du
français L2 chez les apprenants sinophones et que cette interférence est plus
importante à l'oral qu'à l'écrit. En outre, il a observé que les erreurs portant sur le
verbe sont plus nombreuses que celles portant sur le nom ou l'adjectif dans la
production orale des participants. Finalement, l'étude montre qu'il n'existe pas de
23 Nous tenons à préciser que très peu d'informations sont fournies dans le texte de Wang (1993).
43

différence significative entre le nombre d'erreurs portant sur le nom et le nombre
d'erreurs portant sur l'adjectif dans la production orale.
3.1.3 Étude de Sun (2008)
Sun (2008) a examiné la conceptualisation de la temporalité des apprenants
sinophones du français langue étrangère. Le corpus est composé de narrations
réalisées à partir du film muet Les temps modernes par deux groupes d'apprenants
sinophones: un groupe en Chine et l'autre en France. Le groupe en Chine est
composé de trois niveaux: débutant (n = 3), intermédiaire (n = 6) et avancé (n = 3) et
le groupe en France : intermédiaire (n = 6) et avancé (n = 3). Les données de la
production orale ont été enregistrées, transcrites et traitées par analyses statistiques.
Notons que dans son étude Sun ne s'est pas concentrée sur les erreurs commises. Elle
a plutôt regardé l'émergence de la temporalité dans les productions orale.
L'auteure a observé que les participants sinophones tendent à regrouper des actions et
à les conceptualiser en fonction de leur simultanéité, mais cette conceptualisation ne
nuit pas à la logique de l'histoire dans le film. En outre, la morphologie verbale des
participants se développe dans l'ordre suivant: forme de l'indicatif présent, du passé
composé, du futur simple et du plus-que-parfait. Cependant, la conceptualisation
étendue du temps topique (à savoir, l'intervalle temporel à propos duquel le locuteur
fait une déclaration) 24 se manifeste à travers différents stades d'apprentissage, à
savoir 1) forme du présent de l'indicatif, 2) forme du passé composé, 3) forme du
futur simple et 4) forme du plus-que-parfait. Finalement, les résultats de l'étude
mettent en relief le fait que les apprenants sinophones ne changent pas la manière
24 Notre traduction de Klein, 1994, p. 4: « Topic lime is the lime span to which the speaker's c/aim on this occasion is confined ».
44

dont ils perçoivent les actions et les événements même lorsqu'ils maitrisent des
moyens linguistiques du français L2.
3.1.4 Étude d'Ivanova-Foumier (2009)
lvanova-Foumier (2009) a examiné les difficultés de la production orale des
apprenants sinophones du français L2. Les 24 participants de l'étude dont le niveau
du français est intermédiaire suivent un programme du français L2 dans une
université en Chine. Le corpus est composé de 24 transcriptions d'une dictée. Les
caractéristiques de la production orale ont été opérationnalisées au moyen des erreurs
phonétiques. Il est à noter que les données n'ont pas été traitées statistiquement. Elles
ont plutôt fait l'objet d'une description.
Parmi les 218 erreurs identifiées, la confusion des consonnes sourdes/sonores occupe
le premier rang (n = 120), puis viennent l'omission d'un son ou d'un groupe de sons
(n = 62), la liaison non respectée (n = 20) et finalement la faute d'aperture (n = 16).
L'auteure explique que les différences phonétiques entre les deux langues contribuent
principalement à ces fautes chez les apprenants. Notamment, l'absence d'opposition
sourde/sonore entre [b]/[p], [d]/[t], [g]/[k] en mandarin est source de confusion entre
ces consonnes sourdes/sonores chez les apprenants sinophones.
Nous présentons une synthèse des quatre études sur les caractéristiques de la
production des apprenants sinophones du français L2 dans le Tableau 3.1.
45

Tab
leau
3.1
Syn
thès
e de
s ét
udes
sur
les
cara
ctér
isti
ques
de
la p
rodu
ctio
n en
fra
nçai
s L2
che
z le
s si
noph
ones
Aut
eurs
L
I/L
2 P
arti
cipa
nts
N
Âge
Wan
g (1
993)
Yu
(199
3)
Man
dari
n N
on a
ppli
cabl
e L
I et
fr
ança
is L
2
Man
dari
n In
conn
u In
conn
u L
I et
fr
ança
is L
2
Inst
rum
ents
de
mes
ure
Non
ap
plic
able
Exp
osés
or
aux
et
com
posi
tion
s
Tra
item
ent
de d
onné
es
Obj
ecti
f P
rinc
ipal
es c
oncl
usio
ns
Non
ap
plic
able
Enr
egis
tré
et
tran
scri
t et
an
alys
e st
atis
tiqu
e
Dre
sser
une
lis
te
Les
ci
nq
caté
gori
es
de
de
diff
icul
té
diff
icul
tés
chez
le
s
pote
ntie
lles
de
la
appr
enan
ts
sino
phon
es
prod
ucti
on
des
corr
espo
nden
t à
: la
ap
pren
ants
ph
onét
ique
, le
s ar
ticle
s,
les
sino
phon
es
form
es
verb
ales
, le
s ch
oix
des
mot
s et
la s
ynta
xe.
Com
para
ison
L
'inte
rfér
ence
du
m
anda
rin
entr
e er
reur
s L
1
est
plus
im
port
ante
à
mor
phol
ogiq
ues
l'ora
l q
u'à
l'é
crit
ch
ez
les
à l'o
rale
et
à
appr
enan
ts
sino
phon
es.
Les
l'écr
it
erre
urs
port
ant
sur
le
verb
e so
nt
plus
no
mbr
euse
s qu
e ce
lles
por
tant
sur
le
nom
ou
sur
l'adj
ecti
f da
ns
la
prod
ucti
on o
rale
.

Sun
Man
dari
n 21
In
conn
u R
écits
ora
ux
Enr
egis
tré
L'a
cqui
siti
on
de
La
mor
phol
ogie
ve
rbal
e se
(200
8)
LI
et
et
tran
scri
t la
m
orph
olog
ie
déve
lopp
e da
ns
l'ord
re
fran
çais
L2
et
anal
yse
verb
ale
du
suiv
ant
: fo
rme
de l
'indi
cati
f
stat
isti
que
fran
çais
L2
prés
ent,
du
pass
é co
mpo
sé,
du f
utur
si
mpl
e et
du
plus
-
que-
parf
ait.
La
conc
eptu
alis
atio
n ét
endu
e du
te
mps
top
ique
se
man
ifes
te à
tr
aver
s di
ffér
ents
st
ades
d'ap
pren
tiss
age.
Ivan
ova-
Man
dari
n 24
ad
ulte
s D
icté
e E
nreg
istr
é E
xam
iner
de
s L
es
diff
éren
ces
phon
étiq
ues
""" -.....
) F
ourn
ier
LI
et
et tr
ansc
rit
diff
icul
tés
de
la
entr
e le
s de
ux
lang
ues,
(200
9)
fran
çais
L2
prod
ucti
on o
rale
no
tam
men
t, l'a
bsen
ce
prés
enté
es
chez
d'
oppo
siti
on
sour
de/s
onor
e
les
appr
enan
ts
entr
e [b
)/[p
],
[d]/
[t],
[g
]/[k
]
sino
phon
es
en
man
dari
n co
ntri
buen
t
fran
çais
L2
prin
cipa
lem
ent
à de
s fa
utes
phon
étiq
ues
chez
le
s
appr
enan
ts.

Dans le cadre de notre étude, nous pourrons au moyen de 1' observation des ARAA
vérifier s'il s'avère que les domaines (phonétique, morphologie, syntaxe et lexique
chez les apprenants sinophones) mentionnés dans ces études sont en effet des lieux
de vulnérabilité. Dans ce qui suit, nous examinons quelques études sur les ARAA
produites par des apprenants sinophones afin de mieux connaître leurs pratiques
d' ARAA en production orale en L2.
3.2 Études sur l' ARAA en L2 chez les sinophones
Certaines études se sont centrées sur les ARAA produites en anglais L2 par des
sinophones. Ces études menées fournissent non seulement des informations
concernant les caractéristiques de la production orale, mais aussi des informations
sur la nature et la fréquence des ARAA ainsi que sur le lien entre le niveau de
compétence langagière en L2 et les ARAA produites par les apprenants sinophones
de L2. Nous présentons ces études dans ce qui suit.
3.2.1 Étude de Yang (2002)
Yang (2002) a examiné l'influence du niveau de compétence langagière sur la
production d' ARAA chez les étudiants universitaires en Chine. Les données ont été
collectées à l'aide d'une tâche de narration. Les 40 participants ont reçu la consigne
de raconter une histoire à partir de deux séries de bandes dessinées. Les narrations
ont été enregistrées et transcrites. Seules les ARAA manifestes ont été catégorisées
selon la taxinomie de Levelt (1983). Des Chi deux ont été utilisés afin de
déterminer le lien entre le niveau de compétence langagière et les pratiques
d'ARAA.
48

Les résultats ont révélé que le niveau de compétence langagière a influencé de
manière importante la production d' ARAA, en particulier la fréquence et les types
d' ARAA. Les participants plus avancés ont formulé des ARAA moins
fréquemment que ceux moins avancés. Toutefois, les participants plus avancés ont
produit plus d' ARAA au niveau du discours alors que ceux moins avancés ont fait
plus d' ARAA au niveau grammatical. Quant à la nature des ARAA, on observe que
le groupe plus avancé a eu tendance à faire des ARAA de type commencement
d'une nouvelle phrase (notre traduction de fresh starts)25, tandis que celui moins
avancé a eu tendance à faire des ARAA de type ARAA instantanée (notre traduction
de instant repairing) et de type rétraction par anticipation (notre traduction de
anticipatory retracing), notion qui renvoie au fait que « le locuteur retourne à un
élément qui anticipe le réparandum » (Levelt, 1983, p. 85)26•
3.2.2 Étude de Chen et Pu (2007)
Chen et Pu (2007) ont étudié la nature des ARAA et leur fréquence chez les
étudiants universitaires chinois. Les participants de leur étude ont été sélectionnés
dans un département autre que celui des études anglaises 27 • Les données
proviennent du corpus de l'anglais oral des étudiants universitaires (notre traduction
de Co/lege Learners' Spolœn English Corpus (COLSEC), un corpus oral de
25 En ce qui concerne ce type d' ARAA, Levelt (1983) le définit comme étant les ARAA au cours desquelles « le locuteur ne remplace pas immédiatement un mot problématique ou encore ne retourne pas à un mot déjà produit dans le discours original, mais il commence une nouvelle phrase » (notre traduction de Levelt, 1983, p. 85 : « The speaker neither instant/y replaces a trouble word, nor retraces to an earlier word in the OU, but restarts with fresh mate rial » ). 26 Notre traduction de Levelt, 1983, p. 85: « [ ... ] the speaker retraces to an element which anticipa/es the reparandum ». 27 En Chine, les étudiants universitaires qui se spécialisent en études anglaises sont différents des étudiants qui ne se spécialisent pas en études anglaises par la façon dont ils sont formés. Leur formation est plus systématique et plus poussée, et ils deviennent souvent maitres de langue ou traducteurs une fois leurs études finies (http://gaokao.chsi.com.cn/gkxx/zytb/20 1207/20120713/328313174.htrnl). Donc, les études en
acquisition des L2 en Chine ayant recours à des participants fournissent généralement cette information.
49
---------~~- ~--- -~------

l'anglais L2 constitué de tests oraux que des étudiants universitaires en Chine ont
passés. Ce type de test oral est composé de trois parties totalisant 20 minutes : une
période de questions/réponses, un monologue et une autre période de questions
/réponses. Au total, 500 minutes d'enregistrement ont été utilisées pour l'étude à
laquelle 21 étudiants et 55 étudiantes ont participé. Les données ont été transcrites
et analysées.
Parmi les 3160 ARAA identifiées, les ARAA de la même information ont
représenté 60,4 %, une proportion plus importante que les autres types d' ARAA, à
savoir ARAA-E (18,9 %}, ARAA-D (11,4 %) et ARAA-A (9,2 %). Pour la même
information, la majorité des ARAA ont été la répétition d'un mot (57,8 %), suivi
par la répétition de deux mots (24 %), la répétition d'une syllabe ou d'une consonne
(9,3 %) et finalement la répétition de plus de deux mots (8,9 %). Dans les ARAA-E,
38,6 % ont été syntaxiques, 36,3 % lexicales, 20,7 % morphologiques et 4,2 %
phonologiques. En moyenne, les participants ont fait 6,32 ARAA par minute et une
ARAA tous les 15 mots. Les auteurs ont remarqué que le taux d'ARAA était élevé,
ce qui indique que les étudiants ont fait très attention à la bonne forme de leur
production orale en L2. De plus, les auteurs ont observé que la fréquence élevée
d' ARAA de la même information a nui à l'aisance de la production orale en L2.
Cependant, les auteurs n'ont pas exploré chaque type d' ARAA de façon
approfondie. Ce manque de profondeur ne permet pas de connaitre le mécanisme
sous-jacent de l'organisation des ARAA.
3.2.3 Étude de Liu (2009)
Liu (2009) a mené une étude sur les pratiques d' ARAA chez les apprenants
intermédiaires sinophones de l'anglais L2. Les 36 participants, 21 femmes et
15 hommes, étaient des étudiants sélectionnés dans un département autre que celui
50

d'études anglaises dans une université en Chine. Les données ont été collectées à
partir d'un test d'anglais oral pour lequel les étudiants pouvaient parler d'un sujet
de leur choix. Les participants avaient trois minutes pour se préparer avant de parler
pendant trois minutes. Les participants pouvaient parler d'un autre sujet s'ils en
avaient fini avec le premier sujet avant la fin des trois minutes. Un total de
120 minutes d'enregistrement a été transcrit et analysé.
L'auteur a identifié 912 ARAA dans son corpus et a adopté les méthodes de
classification d'ARAA de van Hest (1996), de Kormos (1999, 2000a), de Chen, Li
et Zhao (2005) et de Chen et Pu (2007). Parmi 912 ARAA, les ARAA de la même
information comptent le pourcentage le plus important (78,3 %), puis viennent les
ARAA-D (9 %), les ARAA-E (7,8 %) et les ARAA-A (4,6 %). Parmi les ARAA de
la même information, voici les taux de répétition: répétition d'un mot (48,1 %),
répétition de deux mots (32,2 %), répétition de plus de deux mots (14,8 %) et
répétition d'une syllabe (4,8 %). Pour les ARAA-E, les taux sont les suivants:
ARAA-EM (58,3 %), ARAA-EL (19,5 %) et ARAA-EP (8,3 %). L'auteur a
constaté que les participants dans son étude ont effectué une ARAA de la même
information tous les neuf mots, comparé à une ARAA de la même information tous
les 15 mots dans 1' étude de Chen et Pu (2007).
Dans la section suivante, nous faisons état des études portant sur les ARAA
produites par des locuteurs non natifs ayant une L 1 autre que le mandarin.
3.3 Études sur l' ARAA en L2 chez des locuteurs dont la LI est autre que le
mandarin
Bien que notre étude porte sur les caractéristiques de la production orale des
sinophones apprenant le français L2 par 1 'observation de leurs ARAA, il est
51

néanmoins nécessaire de prendre connaissance des études portant sur les ARAA
dans d'autres langues afin de disposer d'un aperçu global du phénomène à l'étude.
3.3.1 Étude de Bange et Kern (1996)
Bange et Kern ( 1996) ont étudié la régulation du discours et 1 'ARAA en français L 1
et allemand L2 en s'appuyant sur le modèle de régulation de Levelt (1983, 1989).
Dans leur étude, 12 locuteurs natifs adultes du français ont été invités à accomplir
une tâche de narration après avoir lu une bande dessinée de 24 images en français et
en allemand. En adoptant les catégories d'ARAA de Levelt (1983, 1989), les
auteurs ont répertorié plusieurs nouvelles catégories d' ARAA, à savoir l' ARAA
d'erreur de genre, d'erreur morphologique, d'erreur de codage syntaxique, d'erreur
phonologique et d'erreur lexicale.
Leur étude a démontré que le nombre d' ARAA en L2 (262) a été six fois supérieur
à celui des ARAA produites en LI (46). Parmi toutes les ARAA-E en L2, celles de
genre, de morphologie et de syntaxe ont représenté 61 %, soit 130 tandis que
seulement un cas d'ARAA d'erreur syntaxique a été relevé en LI. Les auteurs ont
attribué cette différence importante d' ARAA-E entre LI et L2 à deux facteurs :
l'apprentissage guidé et une méthode d'enseignement qui a accordé trop
d'importance à ces aspects de langue dans l'enseignement. Bien que leur étude ait
aussi abordé d'autres types d' ARAA, par exemple, ARAA de cohérence, il serait
intéressant d'examiner chaque type d' ARAA de façon plus approfondie et d'établir
un lien entre l' ARAA et la typologie linguistique de chaque langue étudiée. De plus,
les résultats seraient plus convaincants si une analyse corrélationnelle était
appliquée aux données.
52

3.3 .2 Étude de van Hest ( 1996)
Dans son étude, van Hest (1996) a examiné les différences dans les pratiques de
l' ARAA en LI et L2, et le lien entre l' ARAA et le niveau de compétence
langagière en L2 chez 30 participants néerlandais dont la L2 était l'anglais en
s'appuyant sur le modèle de la régulation du discours de Levelt (1983). Les
participants ont été répartis en trois groupes selon leur niveau d'anglais :
1) participants âgés de 14 à 15 ans, niveau d'anglais débutant avec expérience
d'apprentissage de l'anglais de quatre ans, 2) participants âgés de 16 à 17 ans,
niveau d'anglais intermédiaire avec expérience d'apprentissage de l'anglais de six
ans, 3) participants âgés de 20 à 23 ans, niveau d'anglais avancé avec expérience
d'apprentissage de l'anglais de huit ans. L'auteure a utilisé deux tâches: la
narration d'après des images et une entrevue. Les données ont été enregistrées et
transcrites, et une analyse statistique ANOV A a été faite sur les données.
Au total, 2079 ARAA ont été identifiées en L 1 et 2623 en L2. Parmi ces ARAA,
244 ARAA-E ont été répertoriées en LI et 590 en L2, 973 ARAA-A en LI et 1042
en L2, 413 ARAA-D en LI et 264 en L2, 274 ARAA-R en LI et 322 en L2,
177 ARAA conceptuelles (notre traduction de conceptual self-repair) en LI et 405
en L2. L'auteure a conclu qu'il n'y avait pas de différences qualitatives entre les
ARAA en L 1 et en L2 sauf que le temps pris pour effectuer une ARAA a été plus
long en L2 qu'en L 1. Les résultats de cette étude ont démontré que le modèle de la
régulation de discours en L 1 était également applicable à la régulation en L2. De
plus, l'étude a démontré que le développement du mécanisme de l' ARAA était
réparti en deux phases au lieu de trois. L'auteure a remarqué que les participants
débutants et intermédiaires ont non seulement eu tendance à faire plus d'ARAA-EL
et moins d'ARAA-NJ en L2 qu'en LI, mais ils ont utilisé aussi plus d'indicateurs
de reformulation de la LI et interrompu leur discours plus tôt en L2 qu'en LI afin
53

d'effectuer une ARAA, tandis que les participants de niveau avancé se sont
comportés différemment dans tous les aspects mentionnés ci-dessus.
Étant donné que le néerlandais et l'anglais appartiennent à la même famille de
langues, il serait pertinent d'ajouter à cette étude une autre langue éloignée de
celles-ci afin de les comparer entre elles et de pouvoir observer les différences des
ARAA en LI et en L2, ce qui permettrait de tirer des conclusions plus
convaincantes. Il faudrait également augmenter le nombre de participants dans
chaque groupe afin de dégager plus clairement le lien entre le niveau d'une L2 et
l'ARAA.
3.3.3 Étude de Nagano (1997)
Nagano (1997) a comparé l' ARAA chez les locuteurs natifs du japonais apprenants
de l'anglais L2 avec celle de Levelt (1983). L'auteur a utilisé le modèle de la
régulation de Levelt (1983) pour tester, dans une université au Japon, quatre
étudiants universitaires en génie dont le niveau d'anglais était avancé. Les quatre
participants ont dû décrire cinq images colorées en anglais et leurs descriptions ont
été enregistrées et transcrites sur une cassette.
L'auteur a relevé 45 ARAA dont 15 étaient les ARAA-A de son étude
comparativement à 290 ARAA-A sur 689 ARAA dans l'étude de Levelt (1983). Le
taux d' ARAA est similaire dans les deux études, 50 % chez les locuteurs japonais
et 46 % chez les locuteurs néerlandais. Pourtant cette étude indique que les
participants ont utilisé les indicateurs de reformulation moins fréquemment que
ceux de l'étude de Levelt (1983). De plus, les participants de cette étude ont
procédé à des rétractions par anticipation, que mentionne l'étude de Levelt (1983).
Les résultats de l'étude ont partiellement confirmé l'hypothèse de l'auteur, à savoir
54

le modèle de la régulation du discours proposé par Levelt (1 983) est applicable à
I'ARAA en L2. Cependant, le nombre restreint des participants de l'étude a rendu
les conclusions moins convaincantes, ainsi une étude comprenant plus de
participants serait nécessaire pour en valider les conclusions.
3.3.4 Étude de Kormos (1998)
En s'appuyant sur le modèle de la régulation du discours de Levelt (1983, 1989),
Kormos (1 998) a revu les taxinomies de l' ARAA en LI et L2, et a proposé une
nouvelle taxonomie de l' ARAA en L2 en se basant sur une analyse de l' ARAA
chez 30 participants hongrois dont la L2 était l'anglais. Les participants ont été
répartis en trois groupes selon leur niveau d'anglais: 1) participants âgés de 16 à
22 ans, niveau d'anglais intermédiaire, 2) participants âgés de 25 à 35 ans, niveau
d'anglais intermédiaire à avancé, 3) participants dont l'âge n'est pas précisé, niveau
d'anglais avancé. L'auteure a utilisé deux tâches: les jeux de rôle de cinq minutes
en L2 et une entrevue rétrospective en L 1 avec les participants. Les données ont été
enregistrées et transcrites, mais aucune analyse statistique n'a été effectuée avec les
données.
Comme nous l'avons mentionné dans le chapitre Il, Kormos (1998) a réorganisé la
taxinomie d' ARAA en L2 en ajoutant une nouvelle catégorie ARAA-RF et quelques
nouvelles sous-catégories à la taxinomie d' ARAA en L2. En outre, la ARAA-0 est
divisée en trois sous-catégories : ARAA de 1 'erreur de 1 'ordre, ARAA de
1 'information inappropriée et ARAA du remplacement de message. Quant à
l' ARAA-E, elle comprend ARAA-EL, ARAA-EG, ARAA-EP et une nouvelle
sous-catégorie: ARAA de la justesse pragmatique. Cette nouvelle taxinomie de
l' ARAA contribue à l'établissement d'un système plus fin de catégorisation des
ARAA ainsi qu'aux futures études dans le domaine de l' ARAA.
55

3.3.5 Étude de Kormos (1999b)
Kormos (1999b) a exploré 1 'effet de la manière de parler sur les ARAA chez les
apprenants hongrois de l'anglais L2. Les 30 participants ont été répartis en trois
groupes selon leur niveau d'anglais : préintermédiaire, intermédiaire supérieur et
avancé. L'auteure a eu recours à deux tâches: les jeux de rôle de cinq minutes en
L2 et une entrevue rétrospective de 25-35 minutes en LI. De plus, l'auteure a utilisé
un questionnaire d'auto-évaluation afin de recueillir des informations concernant le
style de locuteur qu'étaient ses participants et de savoir s'ils attribuaient une plus
grande importance à la précision de leur message (orienté vers la précision) ou à la
production plus rapide et plus aisée de leur message (orienté vers l'aisance). Les
données ont été enregistrées puis transcrites et analysées.
Les résultats de cette étude ont démontré que la fréquence globale des ARAA chez
les deux types d'apprenants reste similaire, mais di fière pour le type d' ARAA
impliquant l'incertitude de l'exactitude des énoncés et en ce qui concerne le taux de
correction des fautes lexicales et les fautes en général. L'auteure a suggéré que,
d'une part, cette différence pourrait être due au fait que les deux types d'apprenants
utilisent leurs ressources attentionnelles de façon différente. De plus, les
participants orientés vers la précision centrent leur attention plutôt sur la forme
tandis que ceux orientés vers la rapidité de la production orale font plus attention au
sens du message et donc filtrent les fautes. D'autre part, les participants orientés
vers l'aisance pourraient décider de ne pas corriger les fautes qu'ils ont remarquées
plus fréquemment que ceux orientés vers la précision.
56

3.3.6 Étude de Kormos (2000a)
Kormos (2000a) a examiné le rôle de l'attention dans la régulation de la production
orale en LI et en L2 au moyen d'une analyse de la nature et de la fréquence
d' ARAA et du taux de correction des fautes. Parmi 40 participants, 30 Hongrois
apprenants de l'anglais L2 ont été répartis en trois groupes selon leur niveau
d'anglais: intermédiaire, intermédiaire supérieur et avancé, et les dix autres ont
exécuté la même tâche en hongrois. L'auteure a eu recours à deux tâches: les jeux
de rôle de cinq minutes en L2 et une entrevue rétrospective en L 1. Les données ont
été enregistrées, transcrites et analysées.
Les résultats de cette étude ont démontré que les participants ont produit des
ARAA-E plus fréquemment en L2 qu'en LI. De plus, parmi toutes les ARAA, le
nombre des ARAA-E en L2 s'est révélé plus important en LI. D'autre part, les
participants ont corrigé le contenu de l'information de message plus fréquemment
en LI qu'en L2. Par ailleurs, les fautes lexicales ont été corrigées plus fréquemment
en LI qu'en L2. Une comparaison de la fréquence et du type des ARAA a révélé
que les participants du niveau avancé se comportaient de manière similaire à ceux
de la LI. Les participants plus avancés ont corrigé leurs fautes langagières
beaucoup moins fréquemment que les participants préintermédiaires, mais ont
amélioré la justesse du contenu d'information plus fréquemment que ces derniers.
Finalement, les participants de la L 1 ont corrigé un pourcentage de fautes plus
important que ceux de la L2 et ont corrigé presque deux fois plus de fautes lexicales
que de fautes grammaticales tandis que ceux de la L2 ont corrigé un pourcentage
similaire de fautes lexicales et grammaticales.
57

3.3.7 Étude de Rieger (2003)
Rieger (2003) a examiné les répétitions comme étant des stratégies
conversationnelles chez les bilingues germanophones et anglophones. Parmi les
huit participants adultes bilingues parlant l'anglais et l'allemand, cinq étaient
locuteurs natifs de l'anglais et trois de l'allemand. L'auteure a eu recours à une
tâche de conversation pour obtenir des données de production orale totalisant
420 minutes. Les conversations ont été enregistrées, transcrites et analysées.
L'auteure a identifié 749 répétitions parmi 2873 ARAA dans les données de
l'anglais comprenant 31333 mots, et 622 répétitions parmi 3516 ARAA dans les
données de 1 'allemand comprenant 31028 mots. Les répétitions ont été
principalement réparties dans les catégories suivantes : les pronoms personnels, les
conjonctions, les combinaisons de pronom-verbe, les prépositions, les articles
définis, les pronoms démonstratifs et les articles indéfinis.
Les résultats de cette étude montrent que les participants ont répété les pronoms
personnels, les combinaisons de pronom-verbe et les prépositions plus
fréquemment en anglais qu'en allemand. L'auteure a attribué cette différence au fait
que la majorité des combinaisons de pronom-verbe en anglais correspondaient à des
unités inséparables tandis qu'en allemand les formes contractées de pronom-verbe
n'existaient pas. De plus, c'est pour cette raison qu'en anglais le recyclage se fait
souvent au début d'une unité, par exemple, au début d'une phrase. En outre,
l'auteure a expliqué que les pronoms démonstratifs ont été répétés plus
fréquemment en allemand qu'en anglais en citant le fait qu'un pronom démonstratif
répété se sépare facilement du verbe conjugué qui suit en allemand. Cependant, les
répétitions de pronoms personnels sont moins nombreuses en allemand qu'en
anglais parce que l'allemand est une langue V2 et que le recyclage se produit
souvent au début d'une unité.
58

Ainsi, l'auteure a conclu que les différences de structures morphosyntaxiques entre
l'anglais et l'allemand pourraient expliquer la variation du nombre de répétitions
entre ces langues. Bien que cette étude soutienne le lien qui existe entre les
structures morphosyntaxiques d'une langue et les pratiques d' ARAA des locuteurs
de cette même langue, il serait plus pertinent de prendre en considération le niveau
de compétence langagière des participants tout en mesurant la compétence
langagière afin de démontrer l'influence de cette dernière sur les répétitions. De
plus, l'auteure a mentionné au début de son étude qu'il s'agit d'une étude
sociolinguistique sur les répétitions en tant que stratégies d' ARAA, pourtant, les
résultats et les conclusions montrent qu'il s'agit plutôt d'une étude faite dans le
cadre de l'analyse de discours.
3.3.8 Étude de Simard, Fortier et Zuniga (2011)
Simard et ses collaborateurs (20 11) ont étudié le lien entre la capacité attentionne Ile
et les ARAA d'apprenants adultes du français L2. Les 23 participants de l'étude,
dont 1 0 sinophones, 1 0 hispanophones, un russophone, un arabophone et un
bulgarophone, étaient inscrits dans un programme de français L2 de niveau avancé
dans une université à Montréal. Les auteurs ont eu recours à une tâche de narration
à effectuer à partir d'images données, au test d'attention D2 et à un questionnaire
de données sociodémographiques. Dans les données contenant 4012 mots,
149 ARAA ont été observées puis codées selon qu'elles étaient liées à la forme (A
forme) ou au choix d'un élément langagier (A-choix).
Les résultats de l'étude n'ont pas permis aux auteurs d'établir un lien entre les deux
variables à l'étude, à savoir la capacité attentionnelle et la production d' ARAA, ce
qui est aussi confirmé dans l'étude de Fincher (2006). De plus, les résultats des
analyses ont révélé qu'il n'existe pas de différence statistiquement significative
59

entre A-forme et A-choix, et ce contrairement aux résultats obtenus dans les études
de Griggs (2002) et Arroyo (2003), qui mettent en lumière des différences entre les
fréquences pour chacun des deux types d' ARAA. Même si l'étude n'a pas pu
établir de lien entre la production d' ARAA et la capacité attentionnelle, selon les
auteurs, elle ne leur a pas permis non plus d'affirmer que l'attention n'est pas
associée à la production d' ARAA. Enfin, les auteurs suggèrent qu'une étude
impliquant les participants de la même L 1 soit entreprise afin de neutraliser la
variable « LI » et qu'une étude sur la relation entre l'attention et le nombre
d'ARAA des participants au moyen d'une mesure de type processuelle de
l'attention contribuerait à augmenter les connaissances dans ce domaine.
3.3.9 Étude de Simard, Bergeron, Liu, Nader et Redmond (2016)
Dans la continuité de l'étude menée en 2011 par Simard et ses collaborateurs,
Simard et ses collaborateurs (2016) ont examiné le rôle de l'attention et de la
mémoire phonologique dans la production d' ARAA en L2. Les trente participants
de l'étude, soit 24 femmes et six hommes dont la LI était le français, étaient tous
étudiants universitaires et avaient l'anglais comme L2. Pour la collecte des données,
les auteurs ont eu recours à une tâche de narration à effectuer à partir d'une bande
dessinée, à un test d'attention, à une tâche de mémoire phonologique et à un
questionnaire de données sociodémographiques.
Les résultats de l'étude ont démontré, d'une part, qu'il existe un lien entre la
capacité de commutation de l'attention et la production d' ARAA, et d'autre part,
entre la mémoire phonologique et la production d' ARAA. Ce lien se manifeste dans
les types d' ARAA étudiées. D'après les résultats obtenus, la capacité de
commutation de l'attention et les ARAA de type A-choix, et la mémoire
phonologique et les ARAA de type A-forme se corrèlent négativement de façon
60

significative. Ainsi quand un participant possède une meilleure capacité de
commutation de l'attention, il produit moins d' ARAA de type A-choix et quand un
participant possède une meilleure mémoire phonologique, il produit moins
d' ARAA de type A-forme. Comme les participants dans l'étude possèdent un
niveau d'anglais L2 relativement élevé, les auteurs suggèrent que d'autres études
soient menées afin d'examiner ce même lien chez des participants qui possèdent un
niveau de compétence langagière en L2 moins élevé. Ils suggèrent aussi qu'« une
mesure des ARAA en L 1 doive être prise, un peu à la manière de Mojavezi et
Ahmadian »(p. 2014).
3.3.1 0 Étude de Simard, French et Zuniga (2017)
Enfin, Simard et ses collaborateurs (2017) ont étudié l'évolution d' ARAA en
production orale en français L2 sur une période de cinq semaines. Les
50 participants, dont 18 femmes et 32 hommes, étaient des apprenants anglophones
adultes du français L2 inscrits dans un programme de cinq semaines d'immersion
en français dans une université à Québec. Les participants ont reçu 21 heures
d'enseignement formel par semaine et ont participé à des activités socioculturelles
pendant 35 heures au total. Le test de classement a indiqué que la maîtrise du
français des participants correspondait à un niveau faible-moyen au début du
programme. Les auteurs ont eu recours à une tâche de narration à effectuer à partir
d'images afin d'obtenir des données de production orale au début (désormais Tl) et
à la fin (désormais T2) du programme.
Les auteurs ont codé les ARAA identifiées dans leur corpus en deux catégories : les
ARAA de type A-choix et celles de type A-forme. Les deux sous-catégories dans
les A-choix correspondaient aux ARAA de mot (notre traduction de word repairs) et
aux ARAA de déterminant (notre traduction de determiner repairs). Les A-forme
61

ont été catégorisées comme suit : 1) les ARAA de genre, 2) les ARAA de nombre,
3) les ARAA de conjugaison, 4) les ARAA phonologiques et 5) les ARAA
syntaxiques. De plus, les auteurs ont codé les ARAA en quatre catégories selon la
justesse du réparandum et du réparatum des ARAA dans leur corpus :
1) réparandum correct et réparatum incorrect (correcte-incorrecte), 2) réparandum
incorrect et réparatum correct (incorrecte-correcte), 3) réparandum incorrect et
réparatum incorrect (incorrecte-incorrecte), 4) réparandum correct et réparatum
correct (correcte-correcte).
Les résultats ont démontré qu'au Tl, les participants ont effectué en moyenne
3,55 ARAA par 100 mots tandis qu'au T2, ils ont effectué 2, 15 ARAA par
lOO mots. Les diminutions du taux d'ARAA par 100 mots et des A-forme et des A
choix entre le Tl et le T2 étaient significatives. Parmi les sous-catégories des A
forme, la diminution des ARAA de genre entre le Tl et le T2 s'est avérée
significative et a contribué de façon importante à la diminution des A-formes entre
le Tl et le T2. En ce qui concerne la diminution des sous-catégories des A-choix
entre le Tl et le T2, seule celle des ARAA de déterminant était significative. Sur le
plan de l'évolution des ARAA selon lajustesse du réparandum et du réparatum, les
diminutions des ARAA incorrecte-correcte et incorrecte-incorrecte, et
l'augmentation des ARAA correcte-correcte entre le Tl et le T2 étaient
significatives. Finalement, les auteurs ont conclu que la fréquence des ARAA
pouvait changer au cours d'une courte période et que ce changement semblait se
produire notamment dans les A-forme.
3.4. Synthèse des études présentées
Dans le Tableau 3.2, nous présentons une synthèse des études faites sur l' ARAA.
Huit éléments y figurent, à savoir le nom de l'auteur, les langues à l'étude, le
62

nombre et l'âge de participant, les instruments de mesure, le traitement de données,
le nombre ou pourcentage et le type d' ARAA, et les principales conclusions.
63
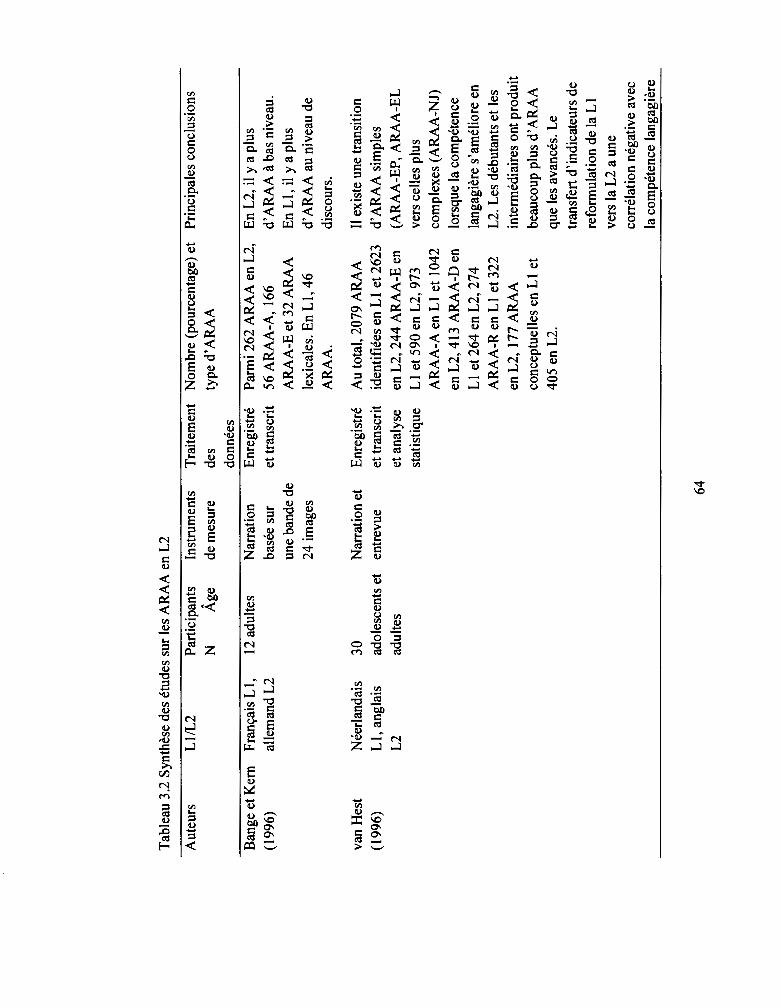
Tab
leau
3.2
Syn
thès
e de
s ét
udes
sur
les
AR
AA
en
L2
Aut
eurs
L
l/L
2 P
arti
cipa
nts
N
Âge
In
stru
men
ts
de m
esur
e
Ban
ge e
t K
ern
Fra
nçai
s L
1,
12 a
dult
es
Nar
rati
on
basé
e su
r un
e ba
nde
de
24 i
mag
es
( 199
6)
alle
man
d L
2
van
Hes
t (1
996)
N
éerl
anda
is
LI,
ang
lais
L
2
30
Nar
rati
on e
t ad
oles
cent
s et
en
trev
ue
adul
tes
64
Tra
item
ent
Nom
bre
(pou
rcen
tage
) et
de
s ty
pe d
'AR
AA
do
nnée
s
Enr
egis
tré
Par
mi
262
AR
AA
en
L2,
et
tran
scri
t 56
AR
AA
-A,
166
AR
AA
-E e
t 32
AR
AA
le
xica
les.
En
Ll,
46
AR
AA
.
Enr
egis
tré
Au
tota
l, 20
79 A
RA
A
et tr
ansc
rit
iden
tifi
ées
en L
1 e
t 262
3 et
ana
lyse
en
L2,
244
AR
AA
-E e
n st
atis
tiqu
e L
1 e
t 590
en
L2,
973
A
RA
A-A
en
L1 e
t 10
42
en L
2, 4
13 A
RA
A-D
en
LI
et 2
64 e
n L
2, 2
74
AR
AA
-R e
n L1
et 3
22
en L
2, 1
77 A
RA
A
conc
eptu
elle
s en
L 1
et
405
en L
2.
Pri
ncip
ales
con
clus
ions
En
L2,
il y
a p
lus
d'A
RA
A à
bas
niv
eau.
E
n L
l, il
y a
plu
s d
' AR
AA
au
nive
au d
e di
scou
rs.
Il e
xist
e un
e tr
ansi
tion
d
' AR
AA
sim
ples
(A
RA
A-E
P,
AR
AA
-EL
ve
rs c
elle
s pl
us
com
plex
es (
AR
AA
-NJ)
lo
rsqu
e la
com
péte
nce
lang
agiè
re s
'am
élio
re e
n L
2. L
es d
ébut
ants
et
les
inte
rméd
iair
es o
nt p
rodu
it
beau
coup
plu
s d
' AR
AA
qu
e le
s av
ancé
s. L
e tr
ansf
ert d
'indi
cate
urs
de
refo
rmul
atio
n de
la
L 1
ve
rs l
a L
2 a
une
corr
élat
ion
néga
tive
ave
c
la c
ompé
tenc
e la
ngag
ière
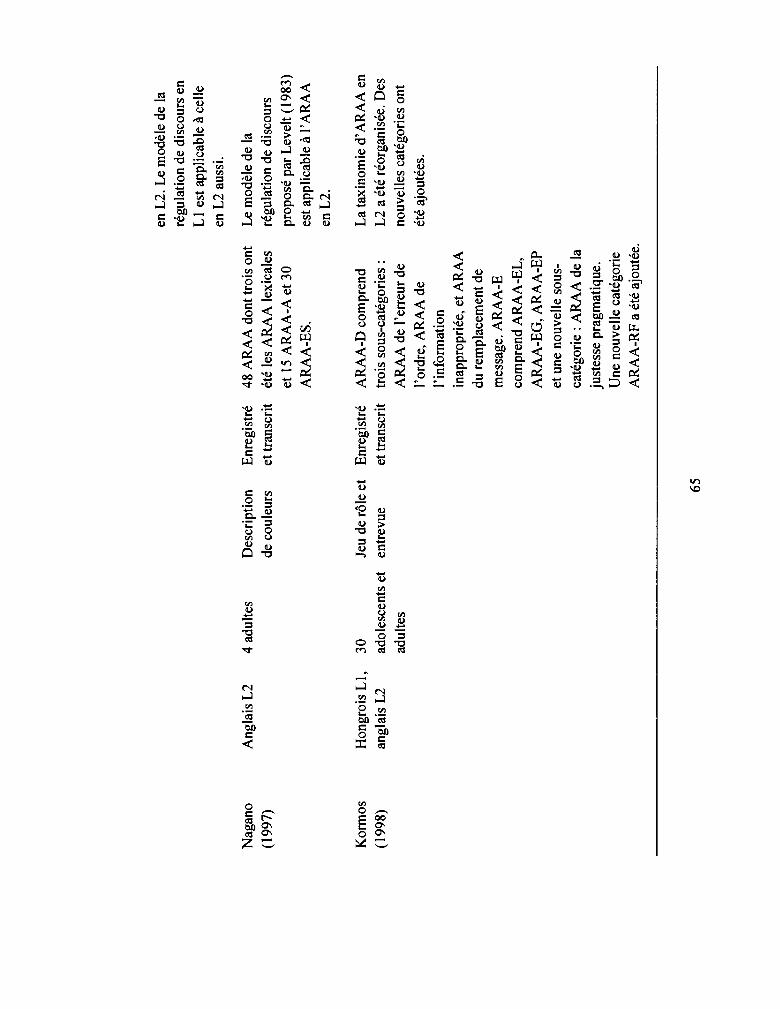
--------------
Nag
ano
(199
7)
Kor
mos
(199
8)
Ang
lais
L2
Hon
groi
s L
1,
angl
ais
L2
4 ad
ulte
s D
escr
ipti
on
de c
oule
urs
Enr
egis
tré
48 A
RA
A d
ont t
rois
ont
et tr
ansc
rit
été
les
AR
AA
lex
ical
es
et 1
5 A
RA
A-A
et
30
AR
AA
-ES
.
30
Jeu
de r
ôle
et
Enr
egis
tré
AR
AA
-D c
ompr
end
troi
s so
us-c
atég
orie
s :
adol
esce
nts
et
entr
evue
adul
tes
65
et tr
ansc
rit
AR
AA
de
1' er
reur
de
1' or
dre,
AR
AA
de
1' in
form
atio
n
inap
prop
riée
, et
AR
AA
du r
empl
acem
ent
de
mes
sage
. A
RA
A-E
com
pren
d A
RA
A-E
L,
AR
AA
-EG
, A
RA
A-E
P
et u
ne n
ouve
lle
sous
caté
gori
e : A
RA
A d
e la
just
esse
pra
gmat
ique
.
Une
nou
vell
e ca
tégo
rie
AR
AA
-RF
a é
té a
jout
ée.
en L
2. L
e m
odèl
e de
la
régu
lati
on d
e di
scou
rs e
n
L 1
est
app
lica
ble
à ce
lle
en L
2 au
ssi.
Le
mod
èle
de l
a
régu
lati
on d
e di
scou
rs
prop
osé
par
Lev
elt (
1983
)
est
appl
icab
le à
l' A
RA
A
en L
2.
La
taxi
nom
ie d
' AR
AA
en
L2
a ét
é ré
orga
nisé
e. D
es
nouv
elle
s ca
tégo
ries
ont
été
ajou
tées
.
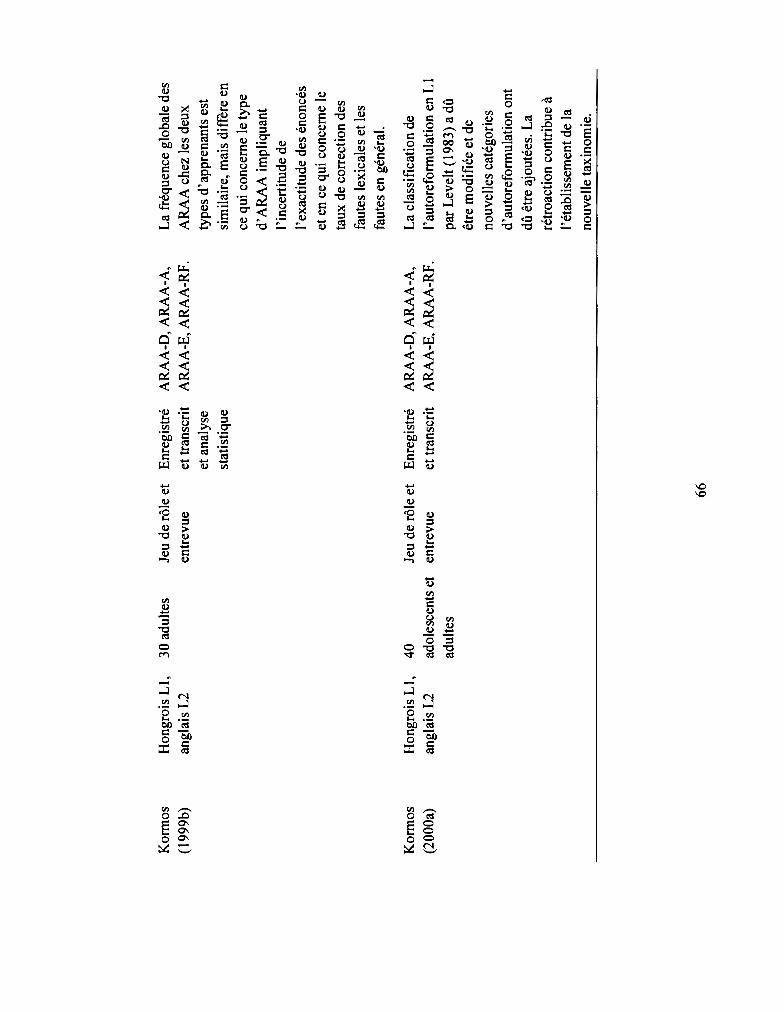
Kor
mos
H
ongr
ois
L 1,
30
adu
ltes
Je
u de
rôl
e et
E
nreg
istr
é A
RA
A-D
, A
RA
A-A
, L
a fr
éque
nce
glob
ale
des
(199
9b)
angl
ais
L2
entr
evue
et
tran
scri
t A
RA
A-E
, AR
AA
-RF
. A
RA
A c
hez
les
deux
et
ana
lyse
ty
pes
d'ap
pren
ants
est
stat
isti
que
sim
ilai
re,
mai
s di
ffèr
e en
ce
qui
con
cern
e le
typ
e d
' AR
AA
im
pliq
uant
l'i
ncer
titu
de d
e 1'
exac
titu
de d
es é
nonc
és
et e
n ce
qui
con
cern
e le
ta
ux d
e co
rrec
tion
des
fa
utes
lex
ical
es e
t le
s fa
utes
en
géné
ral.
Kor
mos
H
ongr
ois
Ll,
40
Je
u de
rôl
e et
E
nreg
istr
é A
RA
A-D
, A
RA
A-A
, L
a cl
assi
fica
tion
de
(200
0a)
angl
ais
L2
adol
esce
nts
et
entr
evue
et
tran
scri
t A
RA
A-E
, A
RA
A-R
F.
l'aut
oref
orm
ulat
ion
en L
l
adul
tes
par
Lev
elt (
1983
) a
dû
être
mod
ifié
e et
de
nouv
elle
s ca
tégo
ries
d'
auto
refo
rmul
atio
n on
t dû
êtr
e aj
outé
es.
La
rétr
oact
ion
cont
ribu
e à
l'éta
blis
sem
ent d
e la
no
uvel
le ta
xino
mie
.
66

Yan
g (2
002)
Rie
ger
(200
3)
Man
dari
n L
1,
40 a
dult
es
angl
ais
L2
Bil
ingu
e al
lem
and
et
angl
ais
8 ad
ulte
s
Nar
rati
on
basé
e su
r de
ux b
ande
s de
ssin
ées
Enr
egis
tré
et tr
ansc
rit
et a
naly
se
L' A
RA
A d
e ty
pe
com
men
cem
ent d
'une
no
uvel
le p
hras
e, d
e ty
pe
stat
isti
que
inst
anta
né,
de t
ype
rétr
acti
on p
ar
anti
cipa
tion
.
Con
vers
atio
n E
nreg
istr
é R
épét
itio
ns:
749
répé
titi
ons
parm
i 28
73
AR
AA
en
angl
ais
et 6
22
répé
titi
ons
parm
i 3 5
16
AR
AA
en
alle
man
d.
spon
tané
e
67
et tr
ansc
rit
et a
naly
se
stat
isti
que
Les
par
tici
pant
s pl
us
avan
cés
font
des
AR
AA
m
oins
fré
quem
men
t qu
e ce
ux m
oins
ava
ncés
. Il
s fo
nt p
lus
d' A
RA
A a
u ni
veau
de
disc
ours
; ce
ux
moi
ns a
vanc
és f
ont
plus
d'
AR
AA
au
nive
au
gram
mat
ical
.
Les
pro
nom
s pe
rson
nels
, le
s co
mbi
nais
ons
de
pron
om-v
erbe
et
les
prép
osit
ions
rép
étée
s pl
us
fréq
uem
men
t en
ang
lais
qu
'en
alle
man
d. D
e pl
us,
le r
ecyc
lage
en
angl
ais
se
fait
souv
ent a
u dé
but
d'un
e un
ité,
p. e
x.,
au
débu
t d'
une
phra
se.
En
outr
e, l
es p
rono
ms
dém
onst
rati
fs o
nt é
té
répé
tés
plus
fré
quem
men
t en
all
eman
d qu
'en
angl
ais.
Moi
ns d
e ré
péti
tion
s de
s pr
onom
s

Che
n et
Pu
(200
7)
Liu
(20
09)
Man
dari
n L
1,
angl
ais
L2
Man
dari
n L
l,
angl
ais
L2
76 a
dult
es
36 a
dult
es
Tes
t ora
l
Tes
t d'
angl
ais
oral
68
Enr
egis
tré
et tr
ansc
rit
et a
naly
se
stat
isti
que
Enr
egis
tré
et tr
ansc
rit
et a
naly
se
stat
isti
que
3160
AR
AA
: A
RA
A d
e
la m
ême
info
rmat
ion
60,4
%,
AR
AA
-E
18,9
%,
AR
AA
-D
11
,4%
et
AR
AA
-A
9,2
%.
912
AR
AA
ide
ntif
iées
:
AR
AA
de
la m
ême
info
rmat
ion
78,3
%,
AR
AA
-D 9
%,
AR
AA
-E
7,8
% e
t A
RA
A-A
4,
6 %
.
pers
onne
ls s
e pr
odui
sent
en
all
eman
d qu
'en
angl
ais.
Ain
si,
les
diff
éren
ces
de s
truc
ture
s m
orph
osyn
taxi
ques
ent
re
l'ang
lais
et
l'all
eman
d ex
pliq
uera
ient
ces
diff
éren
ces
dans
les
ré
péti
tion
s.
Les
par
tici
pant
s fo
nt u
ne
AR
AA
tou
s le
s 15
mot
s.
Les
par
tici
pant
s fo
nt
beau
coup
att
enti
on à
la
bonn
e fo
rme
de l
eur
prod
ucti
on o
rale
en
L2.
Les
par
tici
pant
s fo
nt u
ne
AR
AA
tou
s le
s ne
uf m
ots
et e
ffec
tuen
t pl
us
d' A
RA
A d
e la
mêm
e
info
rmat
ion
que
ceux
da
ns 1
'étu
de d
e C
hen
et
Pu (
2007
) qu
i fo
nt u
ne
AR
AA
de
la m
ême
info
rmat
ion
sur
15 m
ots.
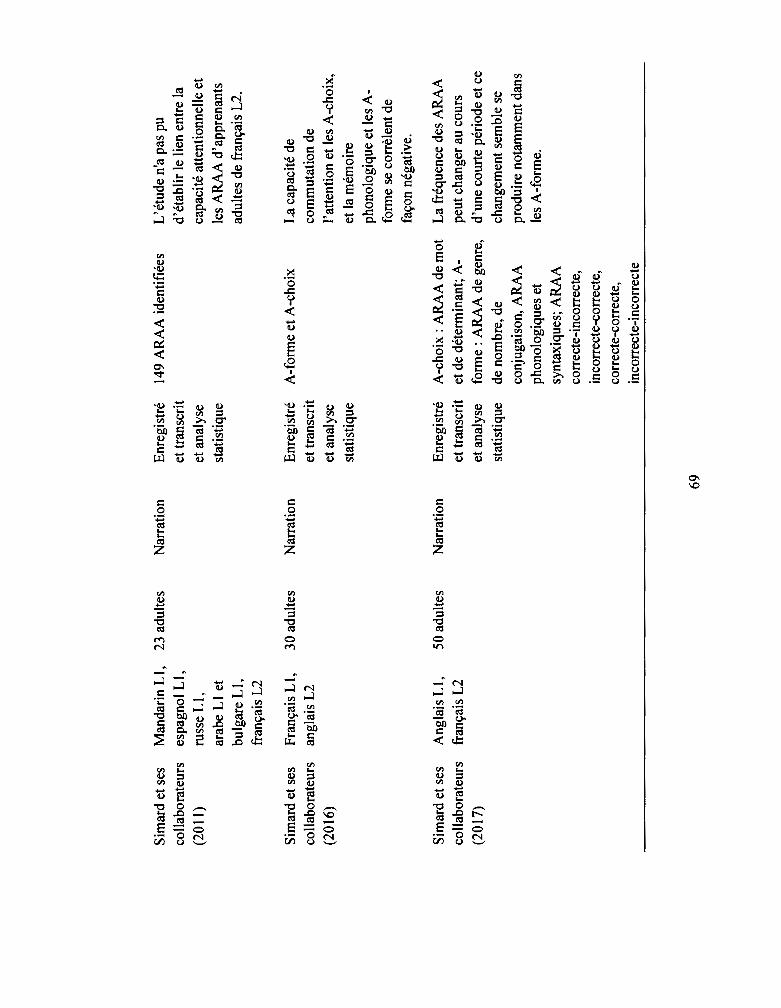
Sim
ard
et s
es
Man
dari
n L
I,
23 a
dult
es
Nar
rati
on
Enr
egis
tré
I49
AR
AA
ide
ntif
iées
L
'étu
de n
'a p
as p
u
coll
abor
ateu
rs
espa
gnol
LI,
et
tran
scri
t d'
étab
lir
le l
ien
entr
e la
(20
Il)
russ
e L
I,
et a
naly
se
capa
cité
att
enti
onne
lle
et
arab
e L
I et
st
atis
tiqu
e le
s A
RA
A d
'app
rena
nts
bulg
are
LI,
ad
ulte
s de
fra
nçai
s L
2.
fran
çais
L2
Sim
ard
et s
es
Fra
nçai
s L
I,
30 a
dult
es
Nar
rati
on
Enr
egis
tré
A-f
orm
e et
A-c
hoix
L
a ca
paci
té d
e
coll
abor
ateu
rs
angl
ais
L2
et tr
ansc
rit
com
mut
atio
n de
(2
016)
et
ana
lyse
l'a
tten
tion
et
les
A-c
hoix
,
stat
isti
que
et la
mém
oire
ph
onol
ogiq
ue e
t le
s A
-fo
rme
se c
orrè
lent
de
faço
n né
gati
ve.
Sim
ard
et s
es
Ang
lais
LI,
50
adu
ltes
N
arra
tion
E
nreg
istr
é A
-cho
ix:
AR
AA
de
mot
L
a fr
éque
nce
des
AR
AA
coll
abor
ateu
rs
fran
çais
L2
et tr
ansc
rit
et d
e dé
term
inan
t; A
-pe
ut c
hang
er a
u co
urs
(20I
7)
et a
naly
se
form
e : A
RA
A d
e ge
nre,
d'
une
cour
te p
ério
de e
t ce
stat
isti
que
de n
ombr
e, d
e ch
ange
men
t sem
ble
se
conj
ugai
son,
AR
AA
pr
odui
re n
otam
men
t dan
s ph
onol
ogiq
ues
et
les
A-f
orm
e.
synt
axiq
ues;
AR
AA
co
rrec
te-i
ncor
rect
e,
inco
rrec
te-c
orre
cte,
co
rrec
te-c
orre
cte,
in
corr
ecte
-inc
orre
cte
69

En guise de synthèse, mentionnons d'entrée de jeu que les études sur les erreurs
produites par les sinophones en français L2 permettent de dégager un certain nombre
de conclusions. Premièrement, les apprenants sinophones présentent cinq catégories
de difficultés dans l'apprentissage du français L2 : la phonétique, les articles, les
formes verbales, les choix des mots et la syntaxe (Wang, 1993). Deuxièmement,
l'interférence du mandarin LI s'avère plus importante à l'oral qu'à l'écrit, et les
verbes posent plus de problèmes que les noms et les adjectifs dans la production
orale (Yu, 1993). Troisièmement, le développement de la morphologie verbale suit
une trajectoire fixée: forme de l'indicatif présent, du passé composé, du futur simple
et du plus-que-parfait (Sun, 2008). Finalement, comme l'a observé Wang (1993),
certaines erreurs phonétiques chez les apprenants sont principalement dues aux
différences phonétiques entre les deux langues (Ivanova-Fournier, 2009).
Ensuite, la recension des écrits sur les ARAA chez les sinophones nous permet de
formuler les conclusions suivantes : les apprenants sinophones plus avancés font des
ARAA moins fréquemment que les apprenants moins avancés, et ces derniers font
plus d'ARAA grammaticales (Yang, 2002). Ce résultat est similaire à ceux observés
dans autres études (p. ex., Kormos, 1999b; van Hest, 1996). Les apprenants prêtent
beaucoup d'attention à la bonne forme de leur production orale en L2 (Chen et Pu,
2007). La fréquence des ARAA varie d'une étude à l'autre, allant d'une ARAA tous
les neuf mots à une ARAA tous les 15 mots (Liu, 2009).
Quant aux études sur les ARAA dans d'autres langues, bien qu'il soit difficile de
présenter toutes les conclusions de toutes les études recensées, il est possible de
dégager certains points importants afin d'en avoir une idée globale. Notamment, il
est observé: a) qu'il existe un lien entre les structures morphosyntaxiques d'une
langue et les pratiques d' ARAA d'un locuteur de cette langue (Rieger, 2003), b) qu'il
existe un lien entre le niveau de compétence langagière et la nature et la fréquence
70

des ARAA en L2 (discours versus grammatical), y compris la répétition (Bange et
Kem, 1996; van Hest, 1996), c) qu'il existe des différences entre la pratique
d' ARAA en L 1 et en L2 (Bange et Kem, 1996; Nagano, 1997; Rie ger, 2003), d) qu'il
existe des différences en matière d'usage des indicateurs de reformulation entre la LI
et la L2 (Nagano, 1997; van Hest, 1996), e) que le modèle d'ARAA en LI est
applicable aux ARAA en L2 (Nagano, 1997; van Hest, 1996), f) qu'il n'existe pas de
lien entre la capacité attentionnelle et les ARAA, g) qu'il existe un lien entre la
capacité de commutation de l'attention et les ARAA de type A-choix, et entre la
mémoire phonologique et les ARAA de type A-forme, et h) que la fréquence des
ARAA peut changer au cours d'une courte période et que ce changement semble se
produire notamment dans les A-forme. Voici une synthèse des aspects cités dans la
recension des écrits, voir le Tableau 3.3.
71

Tableau 3.3 Synthèse des aspects méthodologiques des études sur les ARAA en L2
Aspect
Langues étudiées
Participants
Instruments de mesure
Traitement des données
Nombre (pourcentage) et typed'ARAA
Principales conclusions
Faits saillants
Anglais, la plus étudiée, d'autres langues comme le français, l'allemand et le chinois moins étudiées.
Dans la plupart de cas, adultes; dans certaines études, adultes et adolescents.
Conversation spontanée, test oral, description, narration à partir de bandes dessinées, commentaire et entrevue.
Enregistrement, transcription et analyse statistique. Seules quelques études utilisent les trois méthodes, par exemple, van Hest (1996) et Tseng (2006).
Le nombre varie beaucoup d'une étude à l'autre. Les principaux types d' ARAA : ARAA-E, ARAA-A, ARAA-D, ARAA-RF, ARAA-M, A-forme et Achoix, ARAA correcte-incorrecte, ARAA incorrectecorrecte, ARAA incorrecte-incorrecte et ARAA correcte-correcte.
a) Lien entre les structures morphosyntaxiques d'une langue et les pratiques d' ARAA. b) Lien entre le niveau de compétence langagière en L2 et la nature et la fréquence des ARAA. c) Des différences entre la pratique d' ARAA et l'usage des indicateurs de reformulation en L1 et en L2. d) Différences en matière de l'usage des indicateurs de reformulation entre L 1 et L2 e) Le modèle d' ARAA en L1 est applicable aux ARAAen L2. f) Pas de lien entre la capacité attentionnelle et les ARAA.
72

3.5 Questions de recherche
g) Lien entre La capacité de commutation de l'attention et les ARAA de type A-choix, et entre la mémoire phonologique et les ARAA de type Aforme h) L'évolution des ARAA, notamment dans les Aforme, au cours d'une courte période
La recension des écrits nous a permis d'exposer les éléments suivants qui n'ont pas
encore fait l'objet d'études approfondies: a) les catégories, soit la nature des ARAA
produites en français L2 chez les sinophones ne sont pas examinées, b) la fréquence
des ARAA produites en français L2 chez les sinophones n'est pas explorée, c) les
variations des catégories des ARAA et leur fréquence en français L2 en fonction du
niveau de compétence langagière chez les sinophones ne sont pas explorées.
Étant donné que les éléments mentionnés ci-dessus n'ont pas fait l'objet d'études
approfondies, nous formulons nos questions de recherche ainsi :
1. Quelles sont les catégories et la fréquence des ARAA produites en
français L2 chez les sinophones?
2. Est-ce que les catégories d' ARAA et leur fréquence en français L2
varient en fonction du niveau de compétence langagière chez les sinophones?
Afin de répondre à nos questions de recherche, nous avons conçu une étude pour
collecter les ARAA produites en français L2 par les locuteurs natifs sinophones.
73

Dans le chapitre IV, nous présentons la méthode de cette étude en précisant les
variables, les participants, les tâches, les préparatifs pour l'expérimentation, les
instruments de collecte de données, les étapes de la collecte de données, le
dépouillement et l'analyse des données.
74

CHAPITRE IV
MÉTHODE
4.0 Introduction
Comme nous l'avons indiqué dans les chapitres précédents, notre étude de nature
empirique et descriptive vise à présenter des caractéristiques de la production orale
des locuteurs natifs du mandarin au moyen d'une analyse des ARAA produites en
français L2. De façon plus précise, nous souhaitons répondre aux deux questions
suivantes : 1) Quelles sont les catégories et la fréquence des ARAA produites en
français L2 chez les sinophones? 2) Est-ce que les catégories d' ARAA et leur
fréquence en français L2 varient en fonction du niveau de compétence langagière
chez les sinophones?
Nous consacrons ce chapitre à la description des démarches suivies afin de répondre
à nos deux questions de recherche. Ce chapitre s'organise de la façon suivante: nous
exposons le plan d'expérience (4.1), les variables (4.2); ensuite, nous spécifions les
participants (4.3), les instruments de collecte de données (4.4), les préparatifs
relativement à la collecte de données ( 4.5). Finalement, nous présentons la procédure
(4.6), le dépouillement des données (4.7) et le traitement des données (4.8).
75

-----------
4.1 Plan d'expérience
Nous avons élaboré un plan d'expérience qui comporte un seul moment de mesure,
au cours duquel les participants devaient réaliser une tâche de narration après le
visionnement d'un extrait d'un film muet visant à recueillir les ARAA, une tâche de
texte à trous permettant de mesurer la compétence langagière en français L2 chez nos
participants et enfin un questionnaire de données sociodémographiques à remplir.
4.2 Variables
Dans cette étude, la variable indépendante correspond au niveau de compétence en
français L2 de nos participants et la variable dépendante, aux ARAA, et plus
précisément, au nombre d'ARAA dans chacune des catégories évoquées
précédemment.
4.3 Participants
Notre échantillon était composé de 65 locuteurs natifs adultes sinophones apprenant
le français L2 à Montréal. De ce nombre, 18 étaient des hommes et 47 étaient des
femmes. Tous nos participants étaient nés en Chine et leur âge variait entre 21 et
52 ans (M = 35,1). Le recrutement des participants s'est fait dans une école de
langues et dans des classes de francisation à Montréal. En moyenne, au moment de
l'étude, les participants avaient étudié le français pendant 4,5 ans. Parmi les
65 participants, six avait obtenu un diplôme collégial, 25 un diplôme universitaire de
premier cycle, 30 un diplôme universitaire de deuxième cycle et quatre un diplôme
universitaire de troisième cycle.
76

4.4 Instruments de collecte de données
Dans le cadre de cette étude, les instruments de collecte de données sont une tâche de
narration ( 4.4.1) effectuée après le visionnement d'un extrait du film muet Les temps
modernes de Charlie Chaplin, sorti en 1936, un texte à trous (4.4.2) et un
questionnaire de données sociodémographiques (4.4.3). Nous les présentons dans les
sections suivantes.
4.4.1 Tâche de narration
Tenant compte du but de notre étude, nous avons choisi une tâche connue pour
encourager les participants à parler aussi longtemps que possible tout en évitant
l'intervention du chercheur. Ainsi, nous avons choisi la tâche de narration utilisée
dans plusieurs études antérieures portant sur les ARAA (p. ex., Bange et Kern, 1996;
Sun, 2008; van Hest, 1996; Yang, 2002). En outre, cette tâche a été validée dans
d'autres études antérieures (p. ex., Simard et coll., 2011; Sun, 2008; van Hest, 1996).
Dans le cadre de notre étude, les participants devaient produire une narration en
français après le visionnement d'un extrait d'un film de quatre minutes. Ce choix
méthodologique est justifié par les études antérieures dans le domaine de la
recherche en acquisition des L2 qui ont utilisé une tâche de narration après le
visionnement d'un film afin de recueillir des données de production orale (p. ex.,
Gass, Mackey, Alvarez-Torres et Fernândez-Garcia, 1999; Skehan et Poster, 1999;
Sun, 2008). En plus, 1 'étude de Bada (20 1 0), qui examine les répétitions et les
ARAA en anglais L2 et en français L2, a eu recours à ce type de tâche dans le but de
cueillir ses données. Par ailleurs, la tâche de narration basée sur le visionnement d'un
film permet aux participants de parler en se basant sur un message-guide identique
(Mackey et Gass, 2005, p. 88).
77

De façon plus précise, nous avons retenu la méthode mise au point par Sun (2008)
dans laquelle un montage du film muet Les temps modernes de Charlie Chaplin a été
utilisé pour obtenir des données en production orale des apprenants sinophones du
français L2. La raison pour laquelle nous avons choisi d'utiliser le même film que
Sun (2008) au lieu d'un autre film réside dans le fait que ce film est généralement
connu du public en Chine28 et que le contenu du film est neutre culturellement, et
facile à comprendre pour un participant adulte (Mackey et Gass, 2005).
Nous avons retenu l'extrait du film à visionner pour notre étude sur la base des
critères suivants : a) plusieurs actions se passent pendant la scène sélectionnée,
b) l'extrait dure deux à quatre minutes, ce qui offre aux participants une quantité
d'information leur permettant d'organiser leur narration (Mackey et Gass, 2005,
p. 88).
L'extrait sélectionné représente une scène où l'action se déroule dans la cantine
d'une prison. Quand le personnel commence à servir le repas, Charlot se penche et
cherche quelque chose sous la table. Il se demande d'où vient le repas. Il se trouve à
côté d'un autre grand détenu qui maintient que le pain de Charlot lui appartient.
Charlot essaie de reprendre le pain du détenu par une ruse, mais en vain. Le détenu
menace Charlot avec force. C'est à ce moment que deux agents de police se
présentent dans la cantine et le détenu assis en face de Charlot se dépêche de cacher
sa drogue dans la salière qu'il repose sur la table. Les deux agents le sortent de la
cantine. Ensuite, Charlot met du sel dans sa nourriture et sur son pain avec la salière
dans laquelle se trouve la drogue. Il se sent un peu bizarre après avoir consommé le
sel, mais il n'en fait pas cas. Sous 1 'emprise de la drogue, Charlot change
soudainement de comportement et s'empare du pain. Lorsque le grand détenu le
menace, Charlot ne se laisse pas faire. À ce moment-là, un policier signale qu'il est
28 Pour plus de détails sur la popularité du film Les temps modernes en Chine, voir le site web de la Télévision Centrale de Chine (http://jishi.cntv.cn/speciaUzjzx/Chaplin/index.shtml).
78

temps de retourner dans les cellules. Tous les détenus s'exécutent sauf Charlot qui se
retrouve, sous l'effet de drogue, dans le jardin de la prison. Lorsqu'il essaie de
retourner dans sa cellule, il constate que trois criminels ont maîtrisé les agents de
prison et essaient de faire sortir un détenu. Encore sous l'effet de la drogue, Charlot
n'a pas peur du danger et réussit à renverser deux des criminels alors que le troisième
se fait maîtriser par les policiers dans sa cellule. Charlot ouvre la porte de la cellule
afin de laisser sortir les policiers. Finalement, le chef de la prison le remercie pour
son courage.
4.4.2 Tâche de texte à trous
Afin de mesurer la compétence langagière en français, nous avons eu recours à une
tâche de texte à trous (voir l'Annexe 2). Dans ce genre de tâche, les participants
doivent compléter des phrases en remplissant des espaces laissés vides avec les bons
mots. Les études antérieures (Brown, 1980; Olier, 1973; Stubbs et Tucker, 1974) ont
démontré que les résultats de ce type de tâche sont un indicateur de la compétence
langagière d'un apprenant de L2. En outre, certaines recherches ont établi des
corrélations entre ces résultats et ceux de tests standardisés de compétence langagière
tels que le TOFEL en anglais L2 (p. ex., Tremblay et Garrison, 201 0).
Dans le cadre de la présente étude, nous nous sommes servis de la tâche de texte à
trous utilisé par Tremblay et Garrison (20 1 0). Le texte à trous créé à partir d'un
article du journal Le Monde (2007) sur le réchauffement climatique et comprenant
314 mots et 45 trous à compléter permettait d'évaluer la compétence langagière des
participants en français. Parmi les 45 mots à remplir, 23 étaient des mots lexicaux et
22 des mots grammaticaux. Les participants devaient trouver le mot manquant pour
chaque trou et ne devaient pas laisser un seul trou vide.
79

4.4.3 Questionnaire de données sociodémographiques
Le questionnaire de 12 questions a été conçu pour recueillir des renseignements
personnels tels que 1 'âge, le sexe, la LI, la L2 et les autres langues parlées, les
langues parlées à la maison, les années d'étude en anglais et en français et le niveau
de scolarité (voir l'Annexe 1). Les informations recueillies dans le questionnaire
nous serviraient, le cas échéant, à expliquer certains écarts potentiels du groupe de
participants dans cette étude ou à tirer des conclusions générales selon les résultats
obtenus.
4.5 Préparatifs relatifs à la collecte de données
Dans cette partie, nous présentons les étapes que nous avons élaborées pour la
collecte de données. Ces étapes comprennent la rédaction des consignes à l'intention
des participants (4.5.1), le recrutement des participants (4.5.2) et la planification du
calendrier (4.5.3).
4.5.1 Consignes destinées aux participants
Afin de nous assurer que les participants comprennent au mieux les consignes de
réalisation des tâches, nous les avons rédigées en français et en chinois. Les
consignes ont été présentées aux participants avant qu'ils commencent à exécuter les
tâches. De plus, les consignes ont été vérifiées verbalement auprès des participants
afin d'éliminer tout malentendu et doute.
80

4.5.2 Recrutement des participants
Afin de recruter nos participants, nous avons fait passer une annonce dans les écoles
de langues des universités de Montréal et dans les classes de francisation à Montréal.
Ces annonces précisaient le temps que la réalisation des différentes tâches devrait
prendre et le montant que les participants recevraient comme compensation. Les
participants intéressés étaient priés de communiquer avec nous par courriel ou par
téléphone.
4.5.3 Planification du calendrier
La planification du temps consacré à la collecte des données s'est effectuée selon la
disponibilité et l'emploi du temps des participants. Un mois a été nécessaire pour
collecter les données, soit le mois de décembre 2015.
4.6 Procédure
La procédure a consisté en quatre étapes: 1) remplir le formulaire d'information et
de consentement, 2) remplir le questionnaire sociodémographique, 3) accomplir la
tâche de texte à trous, 4) accomplir la tâche de narration. La collecte de données s'est
déroulée dans un laboratoire de recherche universitaire à Montréal.
Les consignes présentées aux participants pour chacune des quatre étapes sont
spécifiées en détail dans les parties suivantes.
81

4.6.1 Formulaire d'information et de consentement
Les participants ont lu et signé le formulaire d'information et de consentement (voir
l'Annexe 3). Nous les avons invités à poser des questions sur la procédure à suivre
pour cette étape de notre étude. Cependant nous n'avons répondu qu'à des questions
concernant le déroulement normal de notre expérience.
4.6.2 Questionnaire sociodémographique
Après avoir rempli le formulaire d'information et de consentement, les participants
ont été invités à remplir le questionnaire sociodémographique. La consigne de cette
étape était formulée comme suit :
« Ce questionnaire sert à obtenir des informations générales sur vous. Les
réponses données resteront confidentielles et ne serviront qu'à des fins de
recherche. Votre nom ne sera pas utilisé, car nous utiliserons à la place un
numéro pour permettre d'identifier les résultats à l'individu correspondant.
Vous pouvez répondre en français ou en mandarin ».
Les participants ont été invités à poser des questions concernant l'information
demandée dans le questionnaire avant de procéder à l'accomplissement de la tâche.
4.6.3 Tâche de texte à trous
Après avoir terminé le questionnaire, les participants ont été invités à lire la consigne
suivante pour la tâche de texte à trous :
82

« Maintenant, pour cette tâche, vous allez remplir chaque trou par un mot en
français dans le paragraphe. Il ne faut laisser aucun trou non rempli. Vous
pouvez deviner et y insérer un mot de votre choix. Vous avez 25 minutes
pour accomplir cette tâche ».
Lorsque les participants n'avaient plus de questions à poser et qu'ils étaient prêts à
commencer, nous commencions à chronométrer le temps relatif à la tâche.
4.6.4 Tâche de narration
Nous avons fourni aux participants les consignes de la tâche de narration sur papier
en français et en chinois (voir l'Annexe 4). Notons que la consigne fournie en
français est traduite en chinois par un traducteur agréé. Voici les consignes en
français:
«Dans cette étape, vous visionnerez un extrait d'un film muet qui s'intitule
Les temps modernes et cet extrait du film dure environ quatre minutes. Vous
êtes encouragé-e à prendre des notes pendant le visionnement du film afin de
vous aider à organiser la narration pour la prochaine étape.
Après le visionnement, vous aurez trois minutes pour vous préparer à la tâche
de narration. Vous pourrez vous servir de vos notes. Notez que vous n'aurez
pas accès à vos notes lorsque vous effectuez la narration en français.
Après la préparation, vous raconterez l'extrait du film que vous aurez
visionné tout en décrivant chaque détail dont vous vous souvenez. La
narration devra durer cinq à dix minutes et sera enregistrée sur un appareil
d'enregistrement».
83

Après avoir terminé la lecture des consignes, les participants ont été invités à
regarder l'extrait de film sans interruption sur un ordinateur portable. Il est à noter
que les participants ont été encouragés à prendre des notes pendant le visionnement
du film afin de les aider à structurer la narration. Cependant, les participants devaient
effectuer la tâche de narration sans leurs notes. Nous avons donné trois minutes aux
participants afin qu'ils puissent préparer la narration en français, puisque les études
antérieures ont démontré que ce temps alloué à la préparation d'une tâche de
narration non seulement facilite la production orale, mais aussi augmente la
complexité grammaticale de la production orale (Poster et Skehan, 1996; Mackey et
Gass, 2005; Yuan et Ellis, 2003). Donc, pendant cette période de préparation, les
participants ont organisé leurs idées à l'aide des notes qu'ils ont prises pendant le
visionnement du film. Les notes des participants étaient rédigées sous la forme de
mots-clés ou de courtes phrases qui les aidaient à rappeler des scènes ou des actions
dans l'extrait du film lors de la narration. Quant à la durée maximale de la narration,
nous avons décidé de ne pas être très clairs, soit cinq à dix minutes pour ne pas
limiter la quantité de production orale, comme dans l'étude de Simard et ses
collaborateurs (20 Il). Étant donné de la nature de notre étude, il convient de préciser
ici que les participants ont passé le test un à la fois et qu'ils ont été informés que
leurs narrations seraient écoutées par un locuteur qui comprenait seulement la langue
de narration. Leurs narrations ont été enregistrées sur bande audio afin d'être
analysées plus tard.
4. 7 Dépouillement des données
Après avoir terminé la collecte des données, nous avons procédé au dépouillement de
nos données. Le dépouillement des données s'est déroulé comme suit:
a) transcription des données (4.7.1), b) identification et codage des ARAA (4.7.2),
84

c) mesure de compétence écrite en français L2 (4.7.3), et d) saisie des données
(4.7.4).
4. 7.1 Transcription des données
Nous avons d'abord transcrit les trois premières minutes et 15 secondes des
65 narrations à partir de la quinzième seconde. Les 15 premières secondes étaient
considérées comme une période d'échauffement. Donc une transcription durait trois
minutes, ce qui fournissait suffisamment de données pour une analyse statistique.
Parce que l'instrument de mesure dans notre étude était sous forme de narration,
nous avons utilisé les conventions de transcription de Jefferson (1984), que nous
avons adaptées 29• À cet égard, nous avons transcrit non seulement les éléments
verbaux, mais aussi les éléments extralinguistiques comme les pauses, les sons
prolongés et l'accentuation. Par contre, nous avons omis certains éléments considérés
comme non pertinents pour notre étude, par exemple, les inhalations et les
exhalations. La transcription des 65 narrations a été d'abord faite par le chercheur à
l'aide du logiciel Audacity et a été vérifiée ensuite par une étudiante à la maitrise en
linguistique qui est un locuteur natif de la langue de narration afin d'assurer sa
fiabilité.
4.7.2 Identification et codage des ARAA
Afin d'identifier les ARAA, nous nous sommes appuyés sur les outils utilisés
notamment par Schegloffet ses collaborateurs (1977), Levelt (1983), van Hest (1996)
et Rieger (2003). En général, les chercheurs conviennent qu'une ARAA est
composée d'un réparandum, d'une phase d'autorégulation qui peut comprendre une
29 Voir la liste complète des conventions de transcription utilisées dans cette étude dans l'Annexe 5 et consulter Jefferson ( 1984) pour la liste de conventions de transcription de conversation.
85

interruption et un indicateur optionnel, et finalement d'un réparatum. Par ailleurs,
comme nous l'avons mentionné dans le chapitre Il, les répétitions étaient considérées
comme un type d' ARAA dans lequel le réparandum et le réparatum étaient
identiques. Ainsi les ARAA dans la présente étude comprenaient les répétitions. Il
est à noter que la présente étude se limitait aux ARAA manifestes et aux répétitions
et ne traitait pas des ARAA-M.
En ce qui concerne la borne d'une ARAA, nous avons emprunté ce qui a été défini
dans l'étude de Levelt (1983). L'énoncé original qui contient le réparandum débute à
partir de la borne finale de la proposition précédente avant le réparandum et se
termine au point d'interruption. Ce dernier peut se situer immédiatement après le
réparandum, au milieu du réparandum ou même dans une position qui est loin du
réparandum. Ce dernier type de point d'interruption s'appelle point d'interruption
reportée (notre traduction de delay of interruption). Enfin, l' ARAA même se termine
normalement à la borne finale de la proposition contenant le réparatum (Levelt, 1983,
p. 44-45).
Cependant, une mise en garde s'impose parce que la structure d'une ARAA peut
varier dans certains cas, comme 1 'ont mentionné Blackmer et Mitton (1991 ). Dans
leur étude, on trouve certaines ARAA sans phase d'autorégulation. En somme,
l'identification d'une ARAA se faisait à l'aide de la présence du réparandum, de la
phase d'autorégulation facultative et du réparatum. Tenant compte de ce critère, nous
avons examiné les 65 narrations et identifié tous les cas d' ARAA, y compris les
répétitions. Afin de vérifier la fiabilité de la méthode utilisée dans l'identification des
ARAA, un second juge a vérifié 15 narrations une deuxième fois et le coefficient
d'accord entre les deux juges a été vérifié, ce qui déterminerait si la méthode
d'identification des ARAA utilisée était fiable ou non. Ensuite, un troisième juge a
86

tranché sur les items au sujet desquels il y avait désaccord entre les deux premiers
juges.
En ce qui concerne le codage des ARAA dans le corpus, nous avons établi deux
protocoles. Le premier protocole, conçu à partir de Levelt (1983), que nous avons
légèrement modifié, a été utilisé afin de coder les éléments linguistiques étant l'objet
des ARAA produites (4.7.2.1). Pour le second protocole, nous nous sommes basés
sur Simard et ses collaborateurs (2017) afin de coder la justesse de l'énoncé-source et
de l'énoncé de reformulation (4.7.2.2).
De cette manière, le chercheur a codé les 65 narrations deux fois selon les deux
protocoles établis. Parallèlement, un second juge a codé 15 narrations selon les deux
protocoles qui représentent 23% du corpus (voir Mackey et Gass, 2005). Comme
nous l'avons indiqué dans l'identification des ARAA, un troisième juge a tranché sur
les items au sujet desquels il y avait désaccord entre les deux premiers juges. Le
coefficient d'accord entre les deux juges a été vérifié. Les résultats de fiabilité
interjuges pour l'identification et le codage ont été calculés au moyen du coefficient
alpha de Cronbach (,953). Les résultats que nous présenterons dans le chapitre V sont
ceux obtenus à la suite de l'intervention du troisième juge.
4.7.2.1 Codage des éléments linguistiques des ARAA
En ce qui concerne les éléments linguistiques à l'étude, nous avons codé la catégorie
grammaticale du réparandum dans une ARAA et celle du dernier élément lexical
avant le point d'interruption dans une répétition (voir l'Annexe 8 pour plus de détail).
Dans ce qui suit, nous donnons deux exemples illustrant l'identification et le codage
desARAA.
87

1. il !! tombé [p] il est tombé ...
L'exemple 1 représentait une ARAA, dans laquelle le point d'interruption
correspondait à une pause et il n'y avait pas d'indicateur de reformulation. Le
réparandum correspondait à« a» et le réparatum à« est». Puisque le mot« a» a été
remplacé par« est », l' ARAA a été codée ARAA syntaxique.
2. il y a un grenouillie/p/ grenouille ...
L'exemple 2 contenait aussi une ARAA, dans laquelle le point d'interruption
correspondait également à une pause et il n'y avait pas d'indicateur de reformulation.
Le réparandum correspondait à « grenouillie » et le réparatum à « grenouille ».
Puisque le mot « grenouillie » a été remplacé par « grenouille » et la prononciation
du réparandum a été corrigée, l' ARAA a été codée ARAA phonologique.
3. il regard à: le grand monsieur regard à droite ....
L'exemple 3 comportait une ARAA, dans laquelle le point d'interruption
correspondait aussi à une pause et il n'y avait pas d'indicateur de reformulation. Le
réparandum correspondait à « il » et le réparatum à « le grand monsieur ». Puisque le
mot « il » a été remplacé par « le grand monsieur » et 1 'ambiguïté de référence a été
clarifiée, l' ARAA a été codée ARAA-A.
4.7.2.2 Codage selon la justesse de l'énoncé-source et de l'énoncé de reformulation
desARAA
Enfin, afin d'obtenir plus d'information à partir des ARAA produites, nous avons
88

effectué un deuxième codage. Pour cette deuxième étape de codage, à l'instar de
Simard et ses collaborateurs (2017), toutes les ARAA recensées ont été codées selon
quatre catégories de justesse de l'énoncé-source et de l'énoncé de reformulation, à
savoir 1) énoncé-source correct et énoncé de reformulation incorrect (correcte
incorrecte), 2) énoncé-source incorrect et énoncé de reformulation correct
(incorrecte-correcte), 3) énoncé-source incorrect et énoncé de reformulation incorrect
(incorrecte-incorrecte) et 4) énoncé-source correct et énoncé de reformulation correct
(correcte-correcte). Nous avons décidé que les répétitions seraient catégorisées en
fonction de la justesse de l'énoncé-source puisque dans une répétition, l'énoncé
source est identique à l'énoncé de reformulation. Donc, elles ont été placées dans les
catégories 3 ou 4 selon la justesse de l'énoncé-source.
4.7.3 Mesure de compétence langagière en français L2
Rappelons que nous nous sommes servis du texte à trous de Tremblay et Garrison
(20 1 0) afin de mesurer la compétence langagière en français L2 de nos participants.
Pour coder les réponses fournies pour cette tâche, nous nous sommes également
servis de la méthode proposée par Tremblay et Garrison (20 1 0), soit la méthode de la
base de réponses acceptables (par opposition à la méthode de réponses strictes). Par
base de réponses acceptables, les auteurs réfèrent à une liste de mots acceptables qui
sont jugés comme possibles dans le contexte par un locuteur natif du français (p. ex.,
le mot « globale » utilisé dans « économie globale » au lieu de « économie
mondiale» est jugé acceptable et se trouve dans la base de réponses acceptables).
Ainsi, nous avons accordé un point à chaque réponse correspondant à une réponse
dans la base. Par ailleurs, si une réponse ne se trouvait pas dans la base, mais qu'elle
semblait être néanmoins acceptable, nous avons consulté un locuteur natif du
français et des dictionnaires ou des sites Internet pour pouvoir déterminer
89
- 1 1

l'acceptabilité de la réponse. Si la réponse était retenue, nous avons accordé un point.
Nous avons donné zéro point à une mauvaise réponse ou pour un trou non rempli. Un
second juge a également calculé les notes de 15 des participants ayant effectué la
tâche du texte à trous afin de déterminer la fiabilité de calcul du chercheur. Comme
l'identification et le codage des ARAA, les résultats de fiabilité interjuges de la
mesure de compétence écrite ont été calculés au moyen du coefficient
d'intercorrélation des mesures moyennes (,998).
4.7.4 Saisie des données
À la suite du codage des données et de la mesure de la compétence écrite, nous avons
procédé à la saisie des données au moyen du logiciel EXCEL. Les renseignements
personnels tels que le nom, l'âge et la scolarité des participants ont été saisis sur une
feuille de calcul, les données sur les ARAA tels que le nombre total d' ARAA
produites par participant, le total de mots produits par participant, le nombre
d' ARAA de chaque sous-catégorie ainsi que les résultats de la compétence
langagière, sur une autre feuille de calcul. Nous avons calculé non seulement le
nombre d' ARAA pour chacune des sous-catégories, mais aussi le ratio d' ARAA sur
les mots totaux produits par participant.
4.8 Traitement des données
Afin de répondre à nos questions de recherche, nous avons d'abord vérifié la
normalité de la distribution de nos données. Pour ce faire, nous avons procédé avec
les statistiques descriptives en calculant les pourcentages, les moyennes et les écarts
types pour les ratios des ARAA par 100 mots (pris globalement et par type de
catégories). Ensuite, nous avons calculé les ratios de symétrie en divisant l'indice de
symétrie (en anglais, skewness) par son erreur type. Les ratios de l'indice de symétrie
90

et de l'indice d'aplatissement 30 sont présentés comme test de la normalité de la
distribution. En effet, un ratio se situant entre -2 et +2 (Larson-Hall, 2010, p. 78) est
considéré comme étant un indicateur de données normalement distribuées. Nous
avons confirmé la normalité des distributions par l'observation des histogrammes.
Nous avons ensuite effectué une classification des 65 participants au moyen de la
méthode des nuées dynamiques (en anglais, K-means) sur les résultats obtenus à la
tâche de texte à trous. La classification nous a permis de regrouper les 65 participants
en trois groupes, à savoir faible, moyen et fort. Cette étape était nécessaire pour
identifier les variations intergroupes sur le plan de la catégorie et de la fréquence des
ARAA dans les analyses inférentielles.
Finalement nous avons mené une série d'analyses inférentielles qui correspondait au
test de Kruskal-Wallis afin de tester l'effet global de groupe de compétence
langagière en fonction des ARAA produites. Nous avons privilégié le test de
Kruskal-Wallis parce que la distribution de la plupart de nos données n'était pas
normale (Larson-Hall, 2010, p. 273). Les résultats du test de Kruskal-Wallis nous ont
permis de déterminer si les résultats du test étaient significatifs. Dans les cas où les
résultats du test se sont avérés significatifs, nous avons effectué des comparaisons
multiples (test post hoc) au moyen de la méthode de Dunn-Bonferroni. Enfin, le
degré de confiance a été établi à 95%.
30 Les ratios de l'indice de symétrie et de l'indice d'aplatissement sont calculés en divisant l'indice de symétrie, « skewness ». et d'aplatissement, « kurtosis », par son erreur type.
91

CHAPITRE V
PRÉSENTATION DES RÉSULTATS
Dans le chapitre précédent, nous avons exposé la méthode préconisée pour obtenir
les données nous permettant de répondre à nos questions de recherche. Dans ce
chapitre, nous présentons d'abord les résultats qui nous permettent de répondre à la
première question de recherche (5.1), puis ceux qui nous permettent de répondre à la
deuxième question de recherche (5.2).
5.1 Réponse à la première question de recherche
Rappelons que notre première question de recherche était formulée comme suit :
Quelles sont les catégories et la fréquence des ARAA produites en français L2 chez
les sinophones?
Pour répondre à la première question de recherche, nous offrons une description des
ARAA produites par les participants lors de la tâche de narration, en détaillant la
distribution, les moyennes et les écarts types des ratios des ARAA.
92

5 .1.1 Description des données
Dans la présente partie de notre chapitre, nous présentons un portrait des données des
ARAA en français L2 produites par nos participants sinophones. Le corpus contient
195 minutes d'enregistrement audio de narrations. Chaque participant a produit une
narration d'environ trois minutes, qui a été transcrite puis codée, et le total des mots
produits dans ces 195 minutes est de 11799.
5.1.2 Description des ratios des ARAA
Puisque les données brutes des ARAA ne prennent pas en considération les
variations individuelles concernant 1' aisance (p. ex., les faux départs, hésitations et
reformulés compris dans les séquences de reformulations) parmi les participants,
nous les avons transformées en ratio pour chaque type d' ARAA. Pour ce faire, nous
avons divisé le nombre d' ARAA par le nombre de mots obtenus après avoir appliqué
la procédure de Griggs (1997). Selon la méthode utilisée par Griggs (1997, p. 41 0),
« seulement les mots qui apportent une information nouvelle sont inclus dans le
calcul. Ainsi les secondes parties de répétitions, les faux départs et les mots répétés et
reformulés dans une séquence de reformulations sont exclus, comme le sont les
métacommentaires en français )) 31 •
Nous présentons dans ce qui suit les statistiques descriptives des ratios d' ARAA. De
façon plus précise, le Tableau 5.1 présente l'indice de symétrie, l'indice
d'aplatissement et les ratios de symétrie par catégorie.
31 Notre traduction de« For the word count, on/y words conveying new information were included, and therefore second parts of repeats, fa/se starts and repeated and reformulated words in re pair sequences were discounted, as were meta-comments in French».
93
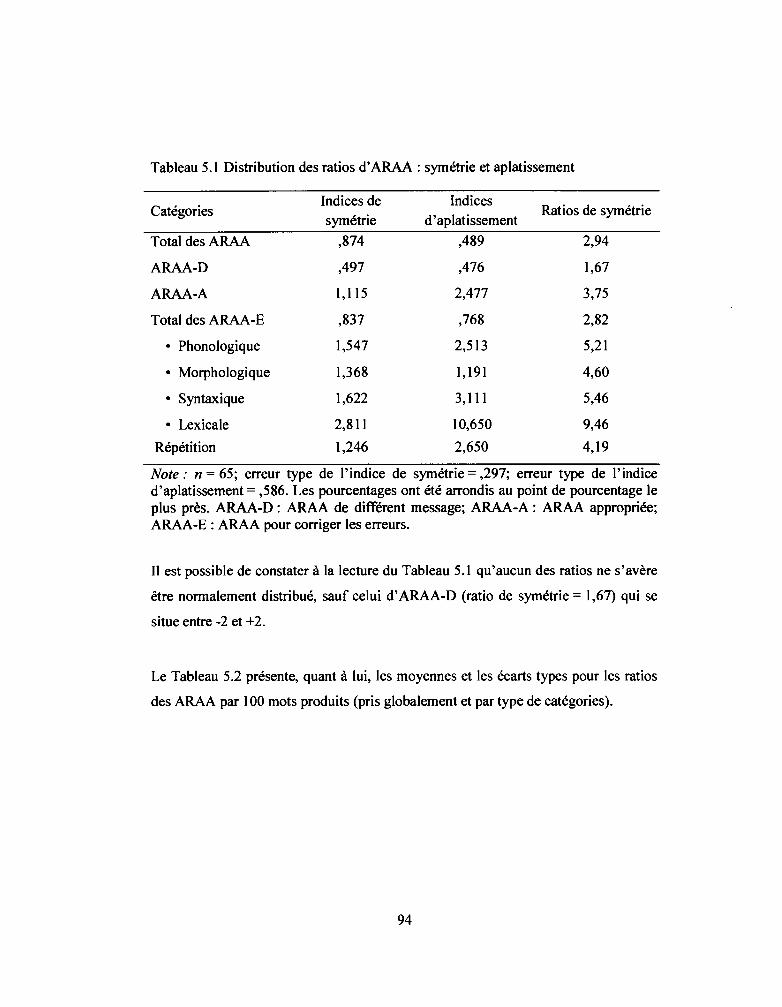
Tableau 5.1 Distribution des ratios d' ARAA : symétrie et aplatissement
Catégories Indices de Indices
Ratios de symétrie symétrie d'aplatissement
Total des ARAA ,874 ,489 2,94
ARAA-0 ,497 ,476 1,67
ARAA-A 1 '115 2,477 3,75
Total des ARAA-E ,837 ,768 2,82
• Phonologique 1,547 2,513 5,21
• Morphologique 1,368 1,191 4,60
• Syntaxique 1,622 3,111 5,46
• Lexicale 2,811 10,650 9,46
Répétition 1,246 2,650 4,19
Note: n = 65; erreur type de l'indice de symétrie= ,297; erreur type de l'indice d'aplatissement= ,586. Les pourcentages ont été arrondis au point de pourcentage le plus près. ARAA-0: ARAA de différent message; ARAA-A: ARAA appropriée; ARAA-E: ARAA pour corriger les erreurs.
Il est possible de constater à la lecture du Tableau 5.1 qu'aucun des ratios ne s'avère
être normalement distribué, sauf celui d' ARAA-0 (ratio de symétrie= 1 ,67) qui se
situe entre -2 et +2.
Le Tableau 5.2 présente, quant à lui, les moyennes et les écarts types pour les ratios
des ARAA par 1 00 mots produits (pris globalement et par type de catégories).
94
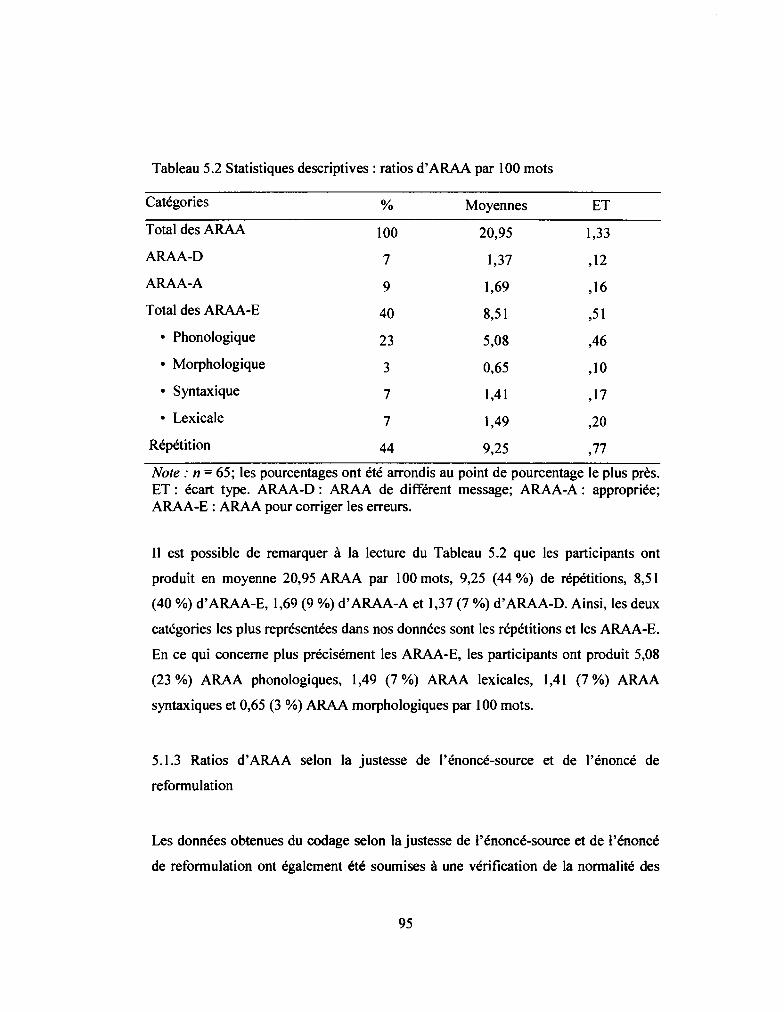
Tableau 5.2 Statistiques descriptives: ratios d'ARAA par lOO mots
Catégories % Moyennes ET
Total des ARAA 100 20,95 1,33
ARAA-D 7 1,37 ,12
ARAA-A 9 1,69 '16
Total des ARAA-E 40 8,51 ,51
• Phonologique 23 5,08 ,46
• Morphologique 3 0,65 ,10
• Syntaxique 7 1,41 ,17
• Lexicale 7 1,49 ,20
Répétition 44 9,25 ,77
Note: n = 65; les pourcentages ont été arrondis au point de pourcentage le plus près. ET: écart type. ARAA-D: ARAA de différent message; ARAA-A: appropriée; ARAA-E : ARAA pour corriger les erreurs.
Il est possible de remarquer à la lecture du Tableau 5.2 que les participants ont
produit en moyenne 20,95 ARAA par 100 mots, 9,25 (44 %) de répétitions, 8,51
(40 %) d' ARAA-E, 1,69 (9 %) d' ARAA-A et 1,37 (7 %) d' ARAA-D. Ainsi, les deux
catégories les plus représentées dans nos données sont les répétitions et les ARAA-E.
En ce qui concerne plus précisément les ARAA-E, les participants ont produit 5,08
(23 %) ARAA phonologiques, 1,49 (7 %) ARAA lexicales, 1,41 (7 %) ARAA
syntaxiques et 0,65 (3 %) ARAA morphologiques par 100 mots.
5.1.3 Ratios d'ARAA selon la justesse de l'énoncé-source et de l'énoncé de
reformulation
Les données obtenues du codage selon la justesse de l'énoncé-source et de l'énoncé
de reformulation ont également été soumises à une vérification de la normalité des
95
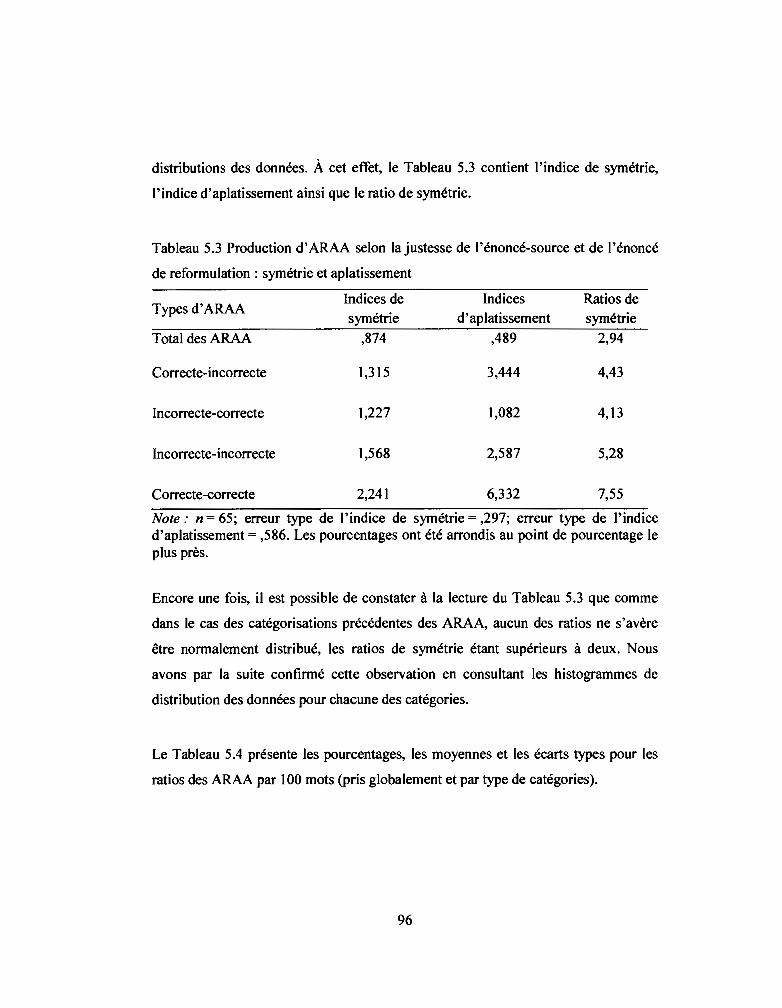
distributions des données. À cet effet, le Tableau 5.3 contient l'indice de symétrie,
l'indice d'aplatissement ainsi que le ratio de symétrie.
Tableau 5.3 Production d'ARAA selon lajustesse de l'énoncé-source et de l'énoncé
de reformulation : symétrie et aplatissement
Types d' ARAA Indices de Indices Ratios de symétrie d'aplatissement symétrie
Total des ARAA ,874 ,489 2,94
Correcte-incorrecte 1,315 3,444 4,43
Incorrecte-correcte 1,227 1,082 4,13
Incorrecte-incorrecte 1,568 2,587 5,28
Correcte-correcte 2,241 6,332 7,55
Note: n = 65; erreur type de l'indice de symétrie= ,297; erreur type de l'indice d'aplatissement= ,586. Les pourcentages ont été arrondis au point de pourcentage le plus près.
Encore une fois, il est possible de constater à la lecture du Tableau 5.3 que comme
dans le cas des catégorisations précédentes des ARAA, aucun des ratios ne s'avère
être normalement distribué, les ratios de symétrie étant supérieurs à deux. Nous
avons par la suite confirmé cette observation en consultant les histogrammes de
distribution des données pour chacune des catégories.
Le Tableau 5.4 présente les pourcentages, les moyennes et les écarts types pour les
ratios des ARAA par 100 mots (pris globalement et par type de catégories).
96
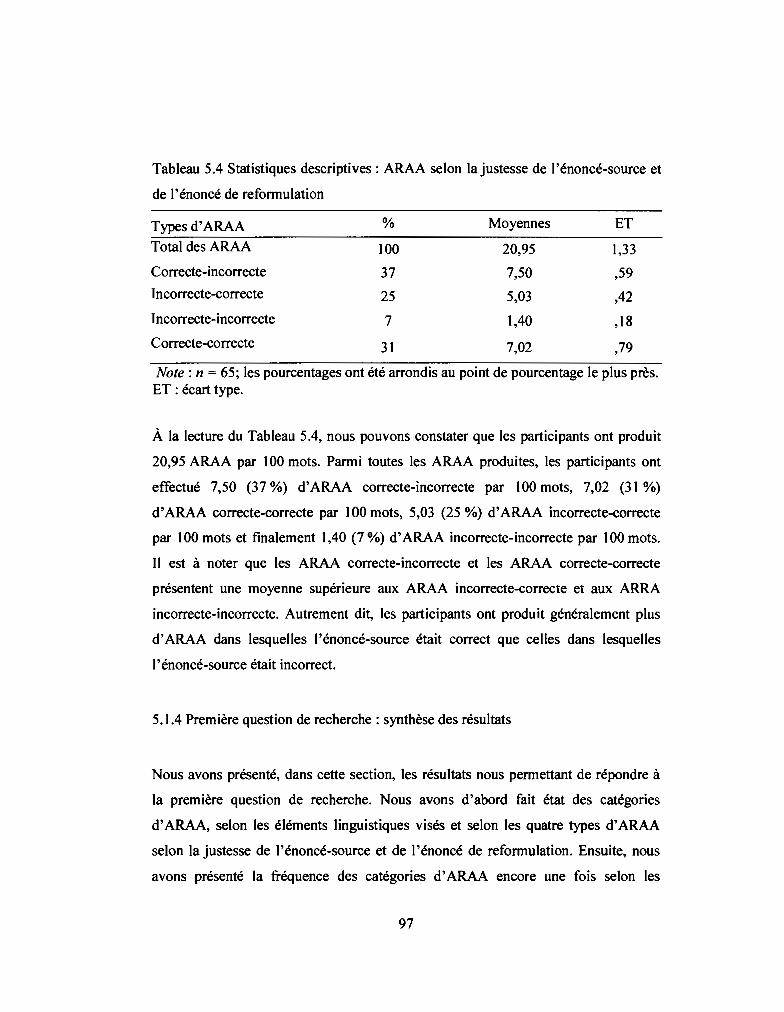
Tableau 5.4 Statistiques descriptives: ARAA selon la justesse de l'énoncé-source et
de l'énoncé de reformulation
Types d' ARAA % Moyennes ET
Total des ARAA 100 20,95 1,33
Correcte-incorrecte 37 7,50 ,59
Incorrecte-correcte 25 5,03 ,42
Incorrecte-incorrecte 7 1,40 , 18
Correcte-correcte 31 7,02 ,79
Note: n = 65; les pourcentages ont été arrondis au point de pourcentage le plus près. ET : écart type.
À la lecture du Tableau 5.4, nous pouvons constater que les participants ont produit
20,95 ARAA par 100 mots. Parmi toutes les ARAA produites, les participants ont
effectué 7,50 (37 %) d' ARAA correcte-incorrecte par 100 mots, 7,02 (31 %)
d' ARAA correcte-correcte par 100 mots, 5,03 (25 %) d' ARAA incorrecte-correcte
par 100 mots et finalement 1,40 (7 %) d' ARAA incorrecte-incorrecte par 100 mots.
Il est à noter que les ARAA correcte-incorrecte et les ARAA correcte-correcte
présentent une moyenne supérieure aux ARAA incorrecte-correcte et aux ARRA
incorrecte-incorrecte. Autrement dit, les participants ont produit généralement plus
d' ARAA dans lesquelles l'énoncé-source était correct que celles dans lesquelles
l'énoncé-source était incorrect.
5.1.4 Première question de recherche : synthèse des résultats
Nous avons présenté, dans cette section, les résultats nous permettant de répondre à
la première question de recherche. Nous avons d'abord fait état des catégories
d' ARAA, selon les éléments linguistiques visés et selon les quatre types d' ARAA
selon la justesse de l'énoncé-source et de l'énoncé de reformulation. Ensuite, nous
avons présenté la fréquence des catégories d' ARAA encore une fois selon les
97

éléments linguistiques visés et selon la justesse de 1' énoncé-source et de 1' énoncé de
reformulation.
Les ARAA-E représentent la majorité des ARAA identifiées dans notre étude, ce qui
laisse à penser que la production orale des participants a été caractérisée plutôt par
des erreurs grammaticales de bas niveau, et se sont produites notamment dans les
phases de l'encodage grammatical et phonétique, et de l'articulation. Par la suite,
nous avons constaté que les participants ont produit plus d' ARAA correcte
incorrecte que celles de type correcte-correcte, incorrecte-correcte et incorrecte
incorrecte.
Dans la prochaine partie, nous exposons les résultats nous permettant de répondre à
la deuxième question de recherche.
5.2 Réponse à la deuxième question de recherche
Rappelons que notre deuxième question était formulée comme suit : Est-ce que les
catégories d' ARAA et leur fréquence en français L2 varient en fonction du niveau de
compétence langagière chez les sinophones?
Pour répondre à la deuxième question de recherche, nous avons d'abord constitué les
groupes selon les niveaux de compétence langagière des participants (5.2.1). Nous
avons ensuite analysé les données afin de vérifier si la production d' ARAA de nos
participants sinophones variait selon le niveau de compétence langagière. Nous
présentons les résultats des analyses statistiques descriptives et des analyses
statistiques inférentielles dans la sous-partie 5.2.2.
98

5.2.1 Constitution des groupes de participants selon le niveau de compétence
langagière
Dans cette partie, nous présentons les résultats obtenus par les participants à la tâche
de texte à trous. Rappelons que cette tâche a été utilisée afin de mesurer le niveau de
compétence langagière de nos participants.
Le Tableau 5.5 présente la moyenne, l'écart type, l'indice de symétrie, l'indice
d'aplatissement ainsi que le ratio de symétrie.
Tableau 5.5 Résultats au texte à trous: symétrie et aplatissement
Moyenne ET
19,66 7,8
Indice de symétrie
,067
Indice d'aplatissement
'-716
Ratio de symétrie
,23
Note: n = 65; Max.= 45; ET= écart type; erreur type de l'indice de symétrie= ,297; erreur type de l'indice d'aplatissement= ,586. Les pourcentages ont été arrondis au point de pourcentage le plus près.
Les résultats présentés au Tableau 5.5 permettent de remarquer que la distribution
des résultats de la tâche de texte à trous est normale, comme l'indique le ratio de
symétrie qui est inférieur à deux. La normalité de la distribution des données est
aussi confirmée par l'observation de l'histogramme.
Afin de regrouper les 65 participants, nous avons appliqué la procédure de
classification par la méthode des nuées dynamiques (en anglais, K-means) aux
résultats obtenus à la tâche du texte à trous effectuée par l'ensemble des participants.
À la suite de cette classification, les 65 participants ont été répartis en trois groupes :
99
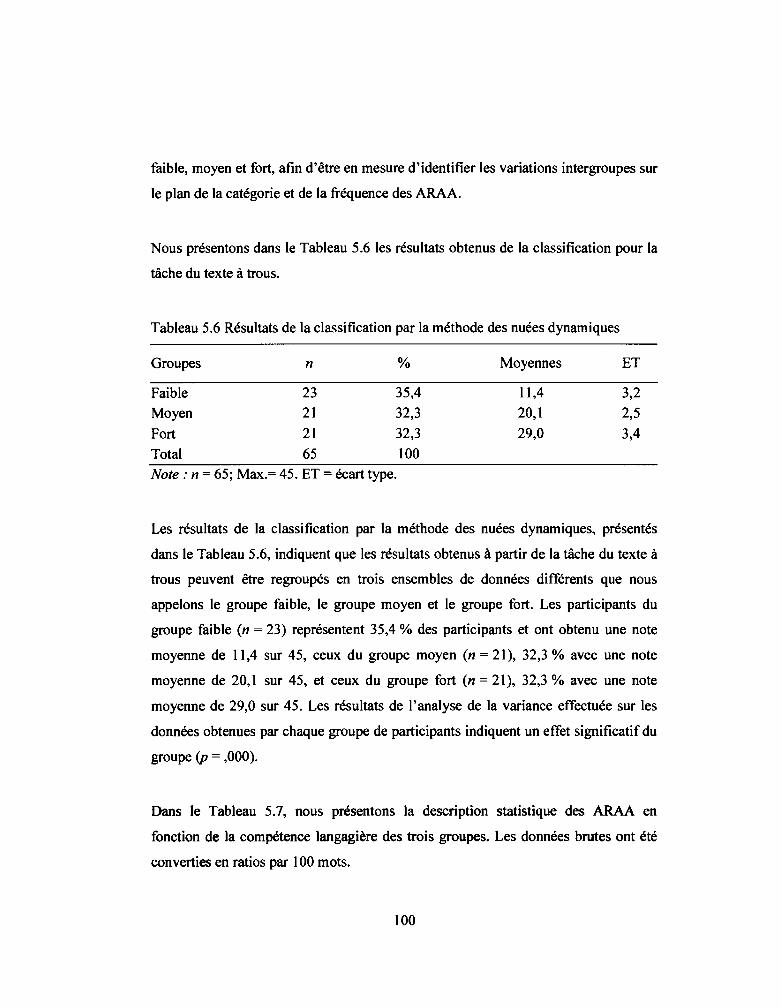
--------- -- ----------- --- --~-----
faible, moyen et fort, afin d'être en mesure d'identifier les variations intergroupes sur
le plan de la catégorie et de la fréquence des ARAA.
Nous présentons dans le Tableau 5.6 les résultats obtenus de la classification pour la
tâche du texte à trous.
Tableau 5.6 Résultats de la classification par la méthode des nuées dynamiques
Groupes n % Moyennes ET
Faible 23 35,4 11,4 3,2
Moyen 21 32,3 20,1 2,5
Fort 21 32,3 29,0 3,4
Total 65 100 Note : n = 65; Max.= 45. ET= écart type.
Les résultats de la classification par la méthode des nuées dynamiques, présentés
dans le Tableau 5.6, indiquent que les résultats obtenus à partir de la tâche du texte à
trous peuvent être regroupés en trois ensembles de données différents que nous
appelons le groupe faible, le groupe moyen et le groupe fort. Les participants du
groupe faible (n = 23) représentent 35,4% des participants et ont obtenu une note
moyenne de 11,4 sur 45, ceux du groupe moyen (n = 21 ), 32,3 % avec une note
moyenne de 20,1 sur 45, et ceux du groupe fort (n = 21 ), 32,3 % avec une note
moyenne de 29,0 sur 45. Les résultats de l'analyse de la variance effectuée sur les
données obtenues par chaque groupe de participants indiquent un effet significatif du
groupe (p = ,000).
Dans le Tableau 5.7, nous présentons la description statistique des ARAA en
fonction de la compétence langagière des trois groupes. Les données brutes ont été
converties en ratios par 100 mots.
100
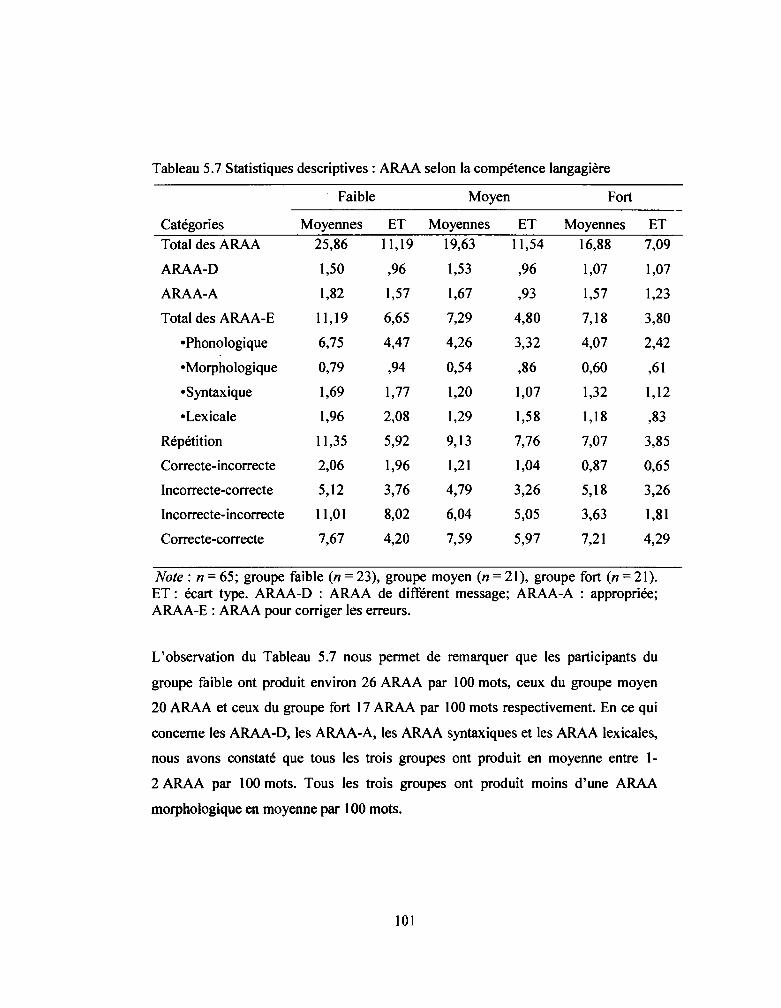
Tableau 5.7 Statistiques descriptives: ARAA selon la compétence langagière
Faible Moyen Fort
Catégories Moyennes ET Moyennes ET Moyennes ET Total des ARAA 25,86 11,19 19,63 11,54 16,88 7,09
ARAA-D 1,50 ,96 1,53 ,96 1,07 1,07
ARAA-A 1,82 1,57 1,67 ,93 1,57 1,23
Total des ARAA-E Il, 19 6,65 7,29 4,80 7,18 3,80
•Phonologique 6,75 4,47 4,26 3,32 4,07 2,42
•Morphologique 0,79 ,94 0,54 ,86 0,60 ,61
•Syntaxique 1,69 1,77 1,20 1,07 1,32 1,12
•Lexicale 1,96 2,08 1,29 1,58 1,18 ,83
Répétition 11,35 5,92 9,13 7,76 7,07 3,85
Correcte-incorrecte 2,06 1,96 1,21 1,04 0,87 0,65
Incorrecte-correcte 5,12 3,76 4,79 3,26 5,18 3,26
Incorrecte-incorrecte 11,01 8,02 6,04 5,05 3,63 1,81
Correcte-correcte 7,67 4,20 7,59 5,97 7,21 4,29
Note: n = 65; groupe faible (n = 23), groupe moyen (n = 21), groupe fort (n = 21). ET : écart type. ARAA-D : ARAA de différent message; ARAA-A : appropriée; ARAA-E: ARAA pour corriger les erreurs.
L'observation du Tableau 5.7 nous permet de remarquer que les participants du
groupe faible ont produit environ 26 ARAA par 100 mots, ceux du groupe moyen
20 ARAA et ceux du groupe fort 17 ARAA par 1 00 mots respectivement. En ce qui
concerne les ARAA-D, les ARAA-A, les ARAA syntaxiques et les ARAA lexicales,
nous avons constaté que tous les trois groupes ont produit en moyenne entre 1-
2 ARAA par 100 mots. Tous les trois groupes ont produit moins d'une ARAA
morphologique en moyenne par 1 00 mots.
101

Sur le plan des différences intergroupes, il est possible de constater que les
participants du groupe faible ont produit 6,75 ARAA phonologiques, 1,96 ARAA
lexicales, 11,35 répétitions, 2,06 ARAA correcte-incorrecte, et 11,01 ARAA
incorrecte-incorrecte tandis que ceux du groupe fort ont produit 4,07 ARAA
phonologiques, 1,18 ARAA lexicales, 7,07 répétitions, 0,87 ARAA correcte
incorrecte, et 3,63 ARAA incorrecte-incorrecte. De plus, les participants du groupe
moyen ne semblent pas présenter de différences importantes comparées à ceux du
groupe faible.
Nous présentons dans ce qui suit les résultats des analyses statistiques inférentielles
qui nous ont permis de vérifier si ces différences observées sont statistiquement
significatives.
5.2.2 Analyses statistiques inférentielles
Étant donné que les données ne sont pas normalement distribuées, nous présentons
dans cette partie les résultats des analyses de Kruskai-Wallis utilisées pour tester
1' effet global de groupe de compétence langagière en fonction des ARAA produites.
Il est à noter que cette absence de normalité dans la distribution des données est
typique des données d' ARAA (p. ex., Simard et coll., 2011). Dans les cas où les
résultats du test se sont avérés significatifs, nous présentons les résultats des
comparaisons multiples (test post hoc) effectuées au moyen de la méthode de Dunn
Bonferroni.
D'abord, le test omnibus révèle qu'il existe une différence statistiquement
significative intergroupe à l'intérieur de l'ensemble des données d' ARAA prises au
total (H = 8,209,p = ,016). De façon plus précise les résultats des analyses indiquent
que les différences intergroupes se situent dans les ARAA-E (H = 6,691, p = ,035),
102
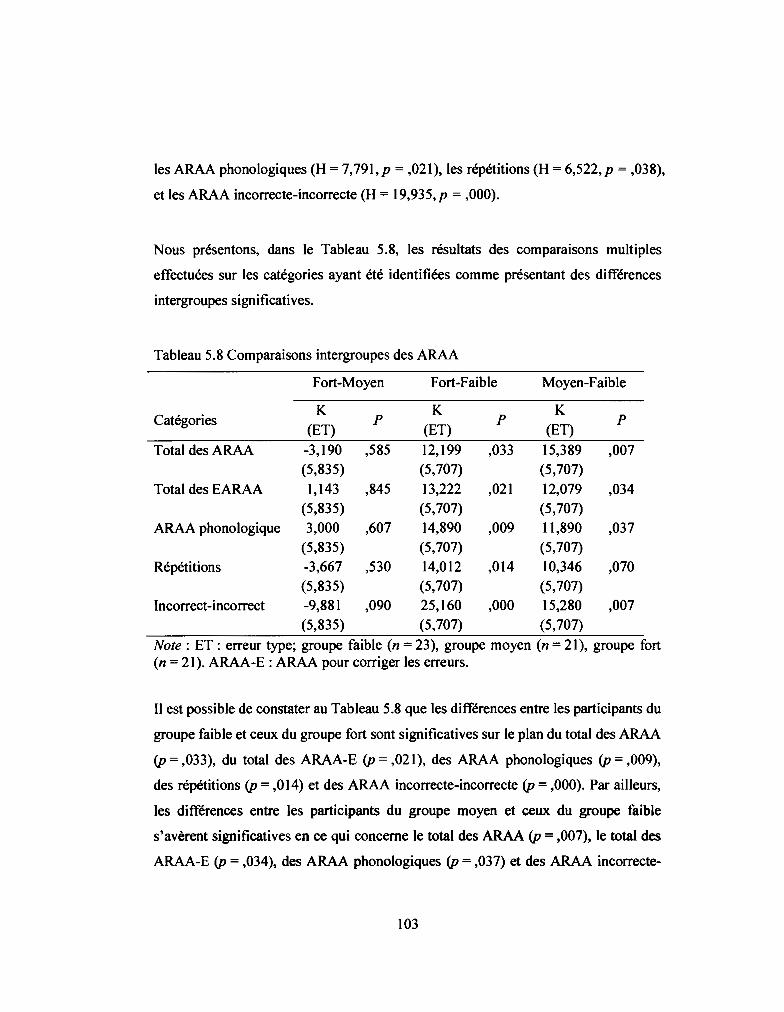
-------------------------------------
les ARAA phonologiques (H = 7,79l,p = ,021), les répétitions (H = 6,522,p = ,038),
et les ARAA incorrecte-incorrecte (H = 19,935,p = ,000).
Nous présentons, dans le Tableau 5.8, les résultats des comparaisons multiples
effectuées sur les catégories ayant été identifiées comme présentant des différences
intergroupes significatives.
Tableau 5.8 Comparaisons intergroupes des ARAA
Fort-Moyen Fort-Faible Moyen-Faible
Catégories K p K p K p
(ET) (ET) (ET)
Total des ARAA -3,190 ,585 12,199 ,033 15,389 ,007 (5,835) (5,707) (5,707)
Total des EARAA 1,143 ,845 13,222 ,021 12,079 ,034 (5,835) (5, 707) (5,707)
ARAA phonologique 3,000 ,607 14,890 ,009 11,890 ,037 (5,835) (5,707) (5,707)
Répétitions -3,667 ,530 14,012 ,014 10,346 ,070 (5,835) (5,707) (5,707)
Incorrect-incorrect -9,881 ,090 25,160 ,000 15,280 ,007 (5,835) (5,707) (5,707)
Note : ET : erreur type; groupe faible (n = 23), groupe moyen (n = 21 ), groupe fort (n = 21). ARAA-E: ARAA pour corriger les erreurs.
Il est possible de constater au Tableau 5.8 que les différences entre les participants du
groupe faible et ceux du groupe fort sont significatives sur le plan du total des ARAA
(p = ,033), du total des ARAA-E (p = ,021), des ARAA phonologiques (p = ,009),
des répétitions (p = ,014) et des ARAA incorrecte-incorrecte (p = ,000). Par ailleurs,
les différences entre les participants du groupe moyen et ceux du groupe faible
s'avèrent significatives en ce qui concerne le total des ARAA (p = ,007), le total des
ARAA-E (p = ,034), des ARAA phonologiques (p = ,037) et des ARAA incorrecte-
103

incorrecte (p = ,007). L'analyse des résultats n'a toutefois révélé aucune différence
significative entre les participants du groupe fort et ceux du groupe moyen dans
toutes les catégories évoquées ci-dessus.
5.3 Deuxième question de recherche : synthèse des résultats
Dans cette partie, nous avons présenté les analyses nous permettant de répondre à
notre deuxième question de recherche. Nos 65 participants ont été répartis en trois
groupes (faible, moyen et fort) à partir des résultats obtenus de la tâche de texte à
trous selon la méthode de classification en nuées dynamiques. Les analyses ont été
effectuées selon les ARAA produites par chacun des groupes de participants.
D'abord, nos résultats montrent que les trois groupes de participants ont tous produit
l'ensemble de catégories d'erreurs. Toutefois, ces analyses nous ont permis de
constater que le niveau de compétence langagière joue un rôle dans la variation de la
fréquence d' ARAA dans les différents groupes de participants de notre étude. En
effet, les participants du groupe faible ont produit en moyenne plus d' ARAA par
100 mots dans toutes les catégories d' ARAA que ceux du groupe moyen sauf dans
les ARAA-D alors qu'ils ont produit plus d' ARAA que ceux du groupe fort dans
toutes les catégories d' ARAA sauf dans les ARAA incorrecte-correcte; pour leur part,
les participants du groupe moyen ont produit plus d' ARAA que ceux du groupe fort
sauf dans les catégories d' ARAA morphologiques et syntaxiques et les ARAA
incorrecte-correcte. Plus précisément, les analyses effectuées nous ont permis de
constater qu'il existe des différences significatives intergroupes dans les ratios du
total des ARAA par 100 mots, du total des ARAA-E par lOO mots, des ARAA
phonologiques par 100 mots, des répétitions par 100 mots et des ARAA incorrecte
incorrecte par 100 mots. Nos résultats ont révélé qu'en production orale, la nature et
la fréquence de certains types d' ARAA produites par les participants avaient varié
104

avec l'augmentation de la compétence langagière. En effet, les participants du groupe
faible ont produit plus d' ARAA-E, d' ARAA phonologiques et d' ARAA incorrecte
incorrecte de façon statistiquement significative que ceux du groupe moyen.
D'ailleurs, les participants du groupe fort ont produit moins d' ARAA-E, d' ARAA
phonologiques, d' ARAA incorrecte-incorrecte et de répétitions que ceux du groupe
faible de façon statistiquement significative. Cela suggère qu'effectivement, la
compétence langagière influence dans une certaine mesure la fréquence des ARAA
produites par les participants en production orale.
Dans le chapitre suivant, nous apportons des réponses à nos questions de recherche et
discutons des résultats obtenus.
105

CHAPITRE VI
DISCUSSION DES RÉSULTATS
Les résultats présentés dans le chapitre précédent nous permettent de répondre à la
première question de recherche (6.1) et à la deuxième question de recherche (6.2).
Nous discutons ensuite des résultats obtenus en regard des recherches antérieures.
Par la suite, nous exposons les profils de participants (6.3). Enfin, nous terminons
avec les pistes de recherches futures (6.4).
Rappelons que les sinophones apprenants du français L2 présentent caractéristiques
particulières dans l'apprentissage du français L2, notamment à l'oral (p. ex., Liu,
1989; Wang, 1993; Yu, 1993). Dans le but d'étudier des caractéristiques de la
production orale de cette population, nous avons conçu la présente étude en ayant
recours aux ARAA produites par des participants sinophones. Puisqu'elles
constituent un point d'observation intéressant des caractéristiques de la production
orale (p. ex., Kormos, 1999a, 2006; Lennon, 1990), nous avons pu déterminer les
aspects langagiers dans lesquels les caractéristiques se situent. Ainsi la présente
étude avait pour objectif d'étudier des caractéristiques de la production orale des
locuteurs natifs du mandarin de différents niveaux de compétence langagière en
français L2 au moyen des ARAA, d'examiner les catégories d' ARAA produites en
français L2 chez les sinophones et leur fréquence, et de déterminer si ces dernières
106

------------- -
varient en fonction du niveau de compétence langagière chez les sinophones. Afin
d'atteindre notre objectif, nous avons recruté pour la partie expérimentale de notre
recherche 65 participants sinophones apprenant le français L2. Les données
provenant de la tâche de narration ont été enregistrées, transcrites et codées selon les
protocoles établis dans notre étude. Ensuite, des analyses ont été effectuées et les
résultats des analyses ont été présentés. Nous répondons maintenant de façon plus
précise à nos questions de recherche.
6.1 Première question de recherche
Notre première question de recherche était formulée comme suit : « Quelles sont les
catégories et la fréquence des ARAA produites en français L2 chez les sinophones? »
Nous avons abordé cette question en deux temps. Dans un premier temps, nous avons
codé et regroupé les ARAA identifiées dans les données selon le protocole établi
dans notre étude. Ainsi les catégories déterminées à partir des éléments linguistiques
visés par les ARAA sont: 1) ARAA-D, 2) ARAA-A, 3) ARAA-E comprenant les
ARAA phonologiques, morphologiques, syntaxiques et lexicales et 4) ARAA-M
(répétitions).
D'après les analyses des données d' ARAA, les participants de notre étude ont
produit en moyenne 20,95 ARAA par 100 mots, 9,25 ARAA-M (répétitions) par
100 mots, 8,51 ARAA-E par 100 mots, 5,08 ARAA phonologiques par 100 mots,
1,69 ARAA-A par 100 mots, 1,49 ARAA lexicales par 100 mots, 1,41 ARAA
syntaxiques par 100 mots, 1,37 ARAA-D par 100 mots et 0,65 ARAA
morphologiques par 100 mots. Les ARAA-M (répétitions) représentaient 44% du
total des ARAA et les ARAA-E (40 %) représentaient la majorité des ARAA. Parmi
les ARAA-E, les ARAA phonologiques représentaient 23% du total des ARAA, les
107
l i

ARRA lexicales 7 %, syntaxiques 7% et morphologiques 3 %, les ARAA-A 9 % et
les ARAA-D 7 %.
Dans un second temps, nous avons regroupé toutes les ARAA en quatre catégories
selon la justesse de l'énoncé-source et de l'énoncé de reforrnulation des ARAA:
1) correcte-incorrecte, 2) incorrecte-correcte, 3) correcte-correcte et 4) incorrecte
incorrecte. Parmi ces quatre types d' ARAA, les ARAA correcte-incorrecte et les
ARAA correcte-correcte représentent la majorité des ARAA de l'étude, à savoir 37%
et 31 % du total des ARAA tandis que les ARAA incorrecte-correcte et les ARAA
incorrecte-incorrecte représentent 25% et 7% du total des ARAA. Ces pourcentages
reflètent les ratios des ARAA par 1 00 mots pour chaque type. À propos de la
fréquence de ces quatre types d' ARAA, les participants ont produit 7,50 ARAA
correcte-incorrecte par 100 mots, 7,02 ARAA correcte-correcte par 100 mots,
5,03 ARAA incorrecte-correcte par 1 00 mots et 1 ,40 ARAA incorrecte-incorrecte
par 1 00 mots.
6.1.1 Réponse à la première question de recherche
Les catégories d' ARAA produites en français L2 chez les sinophones sont : ARAA
M (répétitions) (44 %), ARAA-E (40 %), ARAA-A (9 %) et ARAA-D (7 %). De
plus, les ARAA-E comprennent les ARAA phonologiques (23 %), les ARAA
lexicales (7 %), les ARAA syntaxiques (7 %) et les ARAA morphologiques (3 %).
Quant aux catégories d'ARAA selon lajustesse de l'énoncé-source et de l'énoncé de
reforrnulation, les ARAA correcte-incorrecte représentent 37% du total des ARAA,
les ARAA correcte-correcte 31 %, les ARAA incorrecte-correcte 25 % et les ARAA
incorrecte-incorrecte 7 %.
108

Selon les résultats des analyses, nous avons constaté que les sinophones apprenant le
français L2 produisent plus d' ARAA de bas niveau, par exemple, les ARAA
phonologiques, que de niveau de discours, p. ex. les ARAA-D. Nous croyons que
cela s'explique notamment par les différences qui existent sur les plans phonétique et
syntaxique entre le français et le chinois. Rappelons que, d'une part, à cause des
différences entre les deux langues, les apprenants sinophones éprouvent des
difficultés à distinguer certains phonèmes en français, ainsi ils n'entendent pas ce qui
leur est dit et ne sont pas capables de prononcer certains phonèmes de façon correcte
(Wang, 1993). Par ailleurs, l'absence d'opposition entre certaines consonnes
sourdes/sonores comme [b]/[p], [d]/[t], [g]/[k] en mandarin cause de la confusion
chez les apprenants sinophones (Ivanova-Foumier, 2009). D'autre part, certaines
caractéristiques syntaxiques du chinois diffèrent de celles du français. L'emploi
d'articles en fonction du genre et du nombre des noms qu'ils déterminent, le choix
des mots et la conjugaison verbale du français posent des problèmes aux sinophones
lors de la production orale en français L2 (Wang, 1993).
Nous discutons à présent des résultats de notre étude à la lumière des études
antérieures (6.1.2).
6.1.2 Discussion à la lumière des études antérieures
Plusieurs études antérieures ont examiné les catégories et la fréquence des ARAA en
L2 (p. ex., Bange et Kem, 1996; Kormos, 1999b; Kormos, 2000a; Simard et coll.,
2011; Simard et coll., 20 16; Simard et coll., 20 17; van Hest, 1996), et les ARAA en
L2 chez les apprenants sinophones d'anglais L2 (p. ex., Chen et Pu, 2007; Liu, 2009;
Yang, 2002). Cependant, à notre connaissance, aucune étude n'a été menée auprès
des apprenants sinophones de français L2. Malgré l'absence de recherche ayant le
109

même objectif que nous, il est toutefois possible d'effectuer certaines comparaisons
que nous étayons dans ce qui suit.
D'abord, rappelons que Bange et Kem (1996) ont mené une étude auprès de
24 locuteurs natifs adultes du français et visé, entre autres objectifs, à comparer les
ARAA en français Ll et en allemand L2. Les résultats de l'étude indiquaient que le
nombre d' ARAA en allemand L2 (262) était presque six fois plus important que
celui en français LI (46), et que les ARAA phonétiques représentaient 10% de
toutes les ARAA en L2, soit 22 tandis qu'aucune ARAA phonétique n'était observée
en LI.
Nos résultats rejoignent dans une certaine mesure ceux de Bange et Kem (1996) en
ce qui concerne la catégorie d'ARAA-A (9% versus 8,77 %), mais diffèrent en
matière d' ARAA phonologiques. En effet, les résultats des analyses que nous avons
effectuées indiquent que les ARAA phonologiques représentent 23 % du total des
ARAA tandis qu'elles représentaient seulement environ 10% dans Bange et Kem
(1996). La différence dans la production d' ARAA phonologiques entre notre étude et
celle de Bange et Kem (1996) serait en grande partie imputable à la langue étudiée.
Dans notre étude nous avons examiné les ARAA en français L2 chez des locuteurs
du mandarin tandis que Bange et Kem (1996) ont étudié les ARAA en allemand L2
chez des locuteurs francophones. Le français et l'allemand appartiennent tous deux à
la famille indo-européenne tandis que le chinois se rattache à la famille sino-tibétaine.
Comme le chinois est une langue éloignée de la famille indo-européenne, notamment
sur le plan phonétique, il est possible que cet éloignement linguistique puisse causer
plus de disfluence dans la production orale des participants sinophones de notre
étude que dans l'étude de Bange et Kem (1996). Conséquemment, plus d'ARAA ont
été produites dans la catégorie d' ARAA phonologiques que dans les autres catégories,
110

ce qui expliquerait la raison pour laquelle nos participants ont produit un pourcentage
plus élevé d' ARAA phonologiques que ceux de Bange et Kem.
L'étude de Kormos (2000a) visait aussi à examiner les catégories et la fréquence des
ARAA. Toutefois, son étude a été menée auprès de 40 participants hongrois, âgés de
16 à 35 ans, parmi lesquels 30 apprenants de l'anglais L2 ont accompli une tâche de
jeu de rôle de cinq minutes en L2. Les participants ont produit 2,32 ARAA par
100 mots en moyenne, une ARAA-E par 100 mots, 0,53 ARAA-A et 0,51 ARAA-D.
Les résultats obtenus de notre étude s'apparentent à ceux de Kormos (2000a) sur le
plan des ARAA-E. En effet, le pourcentage du total des ARAA-E (40 %) dans notre
étude s'avère similaire à celui de l'étude de Kormos (2000a) (38,7 %). Toutefois, sur
le plan de la production des sous-catégories des ARAA-E, le pourcentage des ARAA
phonologiques (23 %) dans notre étude est nettement supérieur à celui de Kormos
(2000a) (7,6 %). D'ailleurs, nos participants ont produit plus d' ARAA que ceux de
Kormos (2000a) dans toutes les catégories d' ARAA. Nous pensons encore une fois
que la langue étudiée pourrait jouer un rôle dans cet écart observé, notamment
concernant les ARAA phonologiques. Étant donné que le hongrois est une langue qui
s'écrit de manière quasiment phonétique en caractères latins (Csépe, 2006), nous
serions portés à croire que les différences sur le plan phonétique entre le hongrois et
l'anglais sont moins grandes comparativement à celles qui existent entre le français
et le chinois; par conséquent, il est possible que nos participants sinophones aient
produit plus d' ARAA phonologiques en français L2 que ceux dans Kormos (2000a)
à cause de ces différences.
Par ailleurs, le type de tâche à accomplir pourrait également expliquer en partie les
différences observées entre nos résultats et ceux de Kormos (2000a). Rappelons que
dans l'étude de Kormos, le jeu de rôle a été utilisé afin d'encourager le plus possible
111

----------
les participants à produire des données orales. L'étude de Gilabert (2007) a permis de
constater que le type de tâche à accomplir pourrait influencer les ARAA et que la
tâche de narration de type monologue a provoqué plus d'erreurs que d'autres types
de tâches comme le jeu de rôle, qui implique un interlocuteur. Par conséquent, lors
de la réalisation de la tâche de narration, plus d' ARAA ont été observées qu'au cours
d'autres types de tâches. Nous avons utilisé une tâche de narration de type
monologue tandis que Kormos a eu recours au jeu de rôle impliquant deux locuteurs.
Cette différence en matière de tâche utilisée pourrait expliquer le fait que les
participants aient produit moins d' ARAA dans l'étude de Kormos que dans notre
étude.
Pour sa part, Liu (2009) a étudié les ARAA des apprenants adultes sinophones de
l'anglais L2. Les 36 participants de l'étude ont accompli un test oral en anglais L2 de
trois minutes. Les participants ont produit en moyenne 11 ,4 ARAA par 100 mots,
8,93 répétitions par 100 mots, 1,05 ARAA-D par 100 mots, 0,9 ARAA-E par
100 mots et 0,53 ARAA-A par 100 mots.
Nos résultats rejoignent ceux de Liu (2009) dans plusieurs aspects d' ARAA. En ce
qui nous concerne, le pourcentage de production d' ARAA-D (7 %) va dans le sens
de l'étude de Liu (2009) {9,2 %), et le pourcentage des ARAA morphologiques (3 %)
est similaire à celui de Liu (2009) {4,6 %). Toutefois, le pourcentage des ARAA
phonologiques (23 %) est nettement supérieur à celui de Liu (2009) (0,65 %).
D'ailleurs, la fréquence des ARAA de notre étude (20,95 ARAA par 100 mots) était
aussi supérieure à celui de Liu (2009) (11 ,4 ARAA par 100 mots).
Nous pensons qu'entre autres facteurs, les instruments de mesure pourraient
contribuer aux différences entre les deux études. Pour obtenir des données orales, Liu
(2009) a utilisé un test oral. Les participants ont été invités à choisir un sujet parmi
112

les 10 sujets fournis, ce qui les avantageait puisqu'ils pouvaient sélectionner le sujet
qu'ils connaissaient le mieux et facilitait leur production orale. Selon les résultats de
1 'étude de Foster et Skehan (1996), le type de tâche a un effet sur la justesse de la
production orale. Leurs participants ont gagné à bien connaitre le sujet relatif à la
tâche, ce qui a favorisé une plus grande aisance lors de la réalisation d'une tâche de
narration. Il est possible que cette familiarité avec le sujet de la tâche de narration
dans 1 'étude de Liu contribue aux écarts observés de production d' ARAA entre
l'étude de Liu et notre étude. En effet, plusieurs participants de notre étude ont
mentionné à la fin de l'expérience avoir eu de la difficulté à trouver des expressions
justes ou les mots corrects pour décrire une ou plusieurs actions et scènes de l'extrait
du film visionné. Cette contrainte pourrait aussi rendre nos participants susceptibles
de produire plus fréquemment des ARAA que ceux des autres études. Toutefois, les
convergences entre notre étude et Liu (2009) nous ont permis de constater que les
apprenants sinophones d'une L2 montrent des caractéristiques uniques à cette
population en production orale en L2 et que les résultats similaires des deux études
pourraient en partie être imputables à la L 1 des participants sinophones, le chinois.
Nos résultats s'apparentent aussi à ceux de van Hest (1996). Rappelons que van Hest
( 1996) a étudié les ARAA en L 1 et L2, et le lien entre les ARAA et le niveau de
compétence langagière de la L2. Les 30 participants néerlandais dont la L2 était
l'anglais, âgés de 14 à 23 ans, ont accompli une tâche de narration à partir d'images
et passé une entrevue en anglais L2 et en néerlandais L 1. Les résultats ont montré
que les participants avaient produit en moyenne 2,28 ARAA par 1 00 mots.
En ce qui concerne la production d' ARAA dans notre étude, le pourcentage des
ARAA-D (7 %) va dans le sens de celui obtenu par van Hest (1996) (10,1 %). Sur le
plan des sous-catégories des ARAA-E, le pourcentage des ARAA phonologiques
(23 %) dans notre étude est toutefois nettement supérieur à celui de van Hest (1996)
113

(6,8 %), tout comme celui des ARAA morphologiques de 3% et de 0,2% dans celle
de van Hest. Il en va de même des ARAA syntaxiques dans notre étude (7%) et dans
celle de van Hest (0,5%). Enfin, nos résultats montrent que nos participants ont
produit en moyenne 20,95 ARAA par 100 mots tandis que ceux de van Hest (1996)
ont produit 2,28 ARAA par 1 00 mots, presque dix fois moins que nos participants.
Nous pensons que la différence se trouve notamment dans les instruments de mesure.
En effet, van Hest (1996) a eu recours à une tâche de narration. Rappelons que lors
de la réalisation de la tâche de narration, ses participants bénéficiaient d'un support
visuel, dont l'objectif était de diminuer la charge mémorielle requise par le maintien
en mémoire de l'intrigue de l'histoire et qui permet aux participants de poursuivre
leur narration de manière ponctuelle en racontant l'histoire image par image
(Robinson, 1995). Dans notre étude, l'absence du support visuel a obligé nos
participants à s'efforcer de maintenir la cohérence globale de la narration tout en
surveillant la façon d'organiser les événements de l'histoire et de décrire le
déroulement des événements en L2. Cette charge supplémentaire causée par
l'absence du support visuel augmenterait les activités d'autorégulation qui servent à
tester et à réviser des énoncés dans la narration (Gilabert, 2007). Nous pensons que
cette augmentation de l'activité d'autorégulation contribuerait au fait que nos
participants ont produit de l' ARAA plus fréquemment que ceux de l'étude de van
Hest.
Passons maintenant à l'étude de Simard et ses collaborateurs (2017) visant à étudier
l'évolution des ARAA pendant cinq semaines chez des adultes anglophones
apprenant le français L2. Les 50 participants, âgés de 18 à 24 ans, ont accompli une
tâche de narration à partir de huit images. Les résultats indiquaient que les
participants ont produit en moyenne 3,55 ARAA par 100 mots, 1,30 A-choix et
2,26 A-forme parmi lesquelles les ARAA de genre représentaient 0,80 par 100 mots,
114

les ARAA de nombre 0,25, les ARAA de conjugaison 0, 78, les ARAA
phonologiques 0,32 et les ARAA syntaxiques 0,1 O.
Nos résultats di fièrent de ceux de Simard et ses collaborateurs (20 17), et ce, dans
presque toutes les catégories d' ARAA. En effet, nos participants ont produit
nettement plus d' ARAA que ceux de Simard et ses collaborateurs (2017) dans toutes
les catégories d' ARAA recensées. Pourtant ces études portent toutes deux sur les
ARAA chez les apprenants du français L2. De plus, les participants de l'étude de
Simard et ses collaborateurs (2017) ont suivi un processus expérimental similaire à
celui de notre étude.
Il est possible d'expliquer les écarts entre nos résultats et ceux de Simard et ses
collaborateurs (20 17) en comparant les L 1 des participants. Les participants de
l'étude de Simard et ses collaborateurs (2017) étaient des apprenants anglophones
tandis que nos participants étaient des sinophones. Rappelons que contrairement au
conceptualisateur, le formulateur serait spécifique à une langue et que des variations
se produiraient en tandem avec les variations des traits morphologiques spécifiques
d'une langue (de Bot, 1992, p. 8). Les locuteurs parlant deux langues fortement
apparentées auraient, pour la plupart du temps, recours aux mêmes connaissances
lexicales lorsqu'ils parlent l'une des deux langues tandis que dans le cas où deux
langues ne sont pas apparentées, les locuteurs auraient recours aux connaissances
spécifiques à une langue (de Bot, 1992, p. 9). Ainsi, il est probable que la distance
typologique entre le français, une langue apparentée aux langues indo-européennes et
dotée d'une morphologie riche et complexe (Arditty et Blanchet, 2008), et le
mandarin, une langue apparentée aux langues sino-tibétaines et dotée d'une
morphologie relativement pauvre (Xu, 2004), contribue partiellement aux écarts
observés entre notre étude et celle de Simard et ses collaborateurs (20 17) en ce qui
115

concerne la fréquence des catégories d' ARAA, par exemple, les ratios du total des
ARAA, des ARAA-E et des répétitions.
Par ailleurs, parmi les quatre catégories de justesse des ARAA, à savoir les ARAA
correcte-correcte, incorrecte-correcte, correcte-incorrecte et incorrecte-incorrecte, il
existe une différence importante concernant les ARAA correcte-correcte entre notre
étude et celle de Simard et ses collaborateurs (2017). Les résultats de notre étude ont
indiqué que les participants du groupe fort ont produit moins d' ARAA correcte
correcte par 100 mots (7,21) que ceux du groupe moyen (7,59) et que ceux du groupe
faible (7,67), tandis que les ratios du Tl et du T2 des ARAA correcte-correcte dans
Simard et ses collaborateurs (20 17) représentaient 0, 10 et 0,30 par 100 mots
respectivement, soit une augmentation significative de 200 %. À propos de cette
différence, outre le type de tâche à accomplir, nous croyons que la méthode de
codage pourrait être en cause. Rappelons que nous avons inclus les répétitions
(44,02% du total des ARAA) dans les ARAA alors que Simard et ses collaborateurs
(2017) n'ont pas pris les répétitions en considération, ce qui contribuerait à l'écart
observé entre les deux études.
6.2 Deuxième question de recherche
Notre deuxième question de recherche était formulée comme suit : « Est-ce que les
catégories d' ARAA et leur fréquence en français L2 varient en fonction du niveau de
compétence langagière chez les sinophones? »
Afin de répondre à la deuxième question, nous avons réparti nos 65 participants en
trois groupes selon leur niveau de compétence langagière au moyen de la méthode de
classification des nuées dynamiques : faible (n = 23), moyen (n = 21) et fort (n = 21 ).
Nous avons d'abord mesuré la production des ARAA des trois groupes en calculant
116

les pourcentages des ARAA pour chaque catégorie. Les résultats des analyses ont
indiqué que les répétitions (groupe faible, 43,72 %; groupe moyen, 46,51 %; groupe
fort, 41,88 %) et les totaux des ARAA-E (groupe faible, 43,27 %; groupe moyen,
37,14 %; groupe fort, 42,54 %) représentent la majorité des ARAA. Parmi le total
des ARAA-E, les pourcentages des ARAA phonologiques des trois groupes sont
de 26,10% (groupe faible), 21,70% (groupe moyen) et 24,11% (groupe fort); pour
les ARAA lexicales 7,58% (groupe faible), 6,57% (groupe moyen) et 6,99%
(groupe fort); pour les ARAA syntaxiques 6,54% (groupe faible), 6, Il % (groupe
moyen) et 7,82% (groupe fort); et pour les ARAA morphologiques: 3,06% (groupe
faible), 2,75% (groupe moyen) et 3,56% (groupe fort).
Ensuite, nous avons analysé la production des ARAA de chacun des groupes de
participants selon les quatre catégories de justesse des énoncés-sources et énoncés de
reformulation, à savoir correcte-correcte, incorrecte-correcte, correcte-incorrecte et
incorrecte-incorrecte. Pour les ARAA correcte-correcte, les pourcentages sont
de 29,66% pour le groupe faible, 38,67% pour le groupe moyen et 42,71 % pour le
groupe fort. Pour les ARAA incorrecte-correcte, les pourcentages sont de: 19,80%
pour le groupe faible, 24,40 % pour le groupe moyen et 30,69 % pour le groupe fort.
Pour les ARAA correcte-incorrecte, les pourcentages sont de 7,97% pour le groupe
faible, 6,16 % pour le groupe moyen et 5,15 % pour le groupe fort. Enfin, pour les
ARAA incorrecte-incorrecte, les pourcentages sont de 42,58 % pour le groupe faible,
30,77 % pour le groupe moyen et 20,51 % pour le groupe fort.
Par ailleurs, nous avons effectué des analyses statistiques inférentielles afin de
déterminer si les différences intergroupes en matière de catégories et de fréquence
des ARAA étaient significatives. Les résultats des analyses nous ont permis de
constater que des différences intergroupes (groupes faible, moyen et fort)
significatives sur l'ensemble des données d' ARAA existent, et que sur le plan de la
117

fréquence des ARAA, les différences entre le groupe faible et le groupe fort étaient
significatives en regard du total des ARAA (p = ,033), du total des ARAA-E
(p = ,021), des ARAA phonologiques (p = ,009), des répétitions (p = ,014). De plus,
les différences entre le groupe moyen et le groupe faible s'avéraient significatives en
regard du total des ARAA (p = ,007), du total des ARAA-E (p = ,034), des ARAA
phonologiques (p = ,037). En ce qui concerne les quatre catégories selon la justesse
de l'énoncé-source et de l'énoncé de reformulation des ARAA, à savoir les ARAA
correcte-incorrecte, incorrecte-correcte, incorrecte-incorrecte et correcte-correcte,
seules les ARAA incorrecte-incorrecte présentaient une différence intergroupe
significative entre le groupe fort et le groupe faible (p = ,000) et entre le groupe
moyen et le groupe faible (p = ,007).
6.2.1 Réponse à la deuxième question de recherche
Les résultats de notre étude nous ont permis de confirmer que la fréquence des
ARAA en français L2 variait de façon significative en fonction du niveau de
compétence langagière chez les sinophones pour ce qui est du total des ARAA
(p = ,016), des ARAA-E (p = ,035), des ARAA phonologiques (p = ,021), des
répétitions (p = ,038) et des ARAA incorrecte-incorrecte (p = ,000).
De plus, nous avons pu constater que les participants du groupe fort n'ont pas produit
significativement des ARAA du même type (p. ex., lexical versus discours) ni à la
même fréquence que ceux du groupe moyen, indiquant ainsi qu'ils présentent des
caractéristiques différentes lors de la production orale (p. ex., Camussi-ni, 2005;
Chen, 2003; Sun, 2003; Yu, 1993). En effet, les participants du groupe faible ont
produit plus d'ARAA-E (11,19 versus 7,29 par 100 mots), d'ARAA phonologiques
(6,75 versus 4,26 par 100 mots), d'ARAA incorrecte-incorrecte (11,01 versus 6,04
par 100 mots) que ceux du groupe moyen de façon statistiquement significative. De
118

plus, les participants du groupe fort ont produit moins d'ARAA-E (7,18 versus 11,19
par 100 mots), d'ARAA phonologiques (4,07 versus 6,75 par 100 mots), d'ARAA
incorrecte-incorrecte (3,63 versus 11,01 par 100 mots) et de répétitions (7,07 versus
11,35 par 100 mots) que ceux du groupe faible de façon statistiquement significative.
Par ailleurs, il est possible de remarquer que les participants du groupe faible ont
présenté des caractéristiques différentes sur le plan de la justesse langagière que ceux
du groupe avancé. En effet, les différences intergroupes en ce qui concerne le type et
la fréquence d' ARAA dans notre étude sont cohérentes avec les observations des
études antérieures (p. ex., Kormos, 2000a; van Hest, 1996), dans lesquelles les
participants plus avancés ont effectué moins d' ARAA grammaticales et lexicales que
les participants moins avancés.
Bien que les résultats que nous avons obtenus soient cohérents avec ceux des études
antérieures en ce qui a trait à plusieurs aspects d' ARAA, nous avons aussi observé
des écarts dans les catégories et la fréquence des ARAA parmi les participants des 1
différents niveaux de compétence langagière. Nous en discutons à la lumière des
études antérieures dans ce qui suit.
6.2.2 Discussion relative à la deuxième question de recherche
Comme pour notre étude, les résultats de l'étude de Kormos (2000a) indiquent que
les différences intergroupes (débutants n = 10; intermédiaires n = 10; avancés n = 10)
entre les pourcentages des ARAA, des ARAA lexicales, grammaticales et du total
des ARAA-E ne sont pas significatives. Cependant, Kormos n'a pas indiqué le
pourcentage de chaque catégorie d' ARAA, ce qui rend difficile l'interprétation pour
chaque groupe. Pour ce qui est de la fréquence des ARAA, les résultats de Kormos
(2000a) révèlent que par rapport aux participants débutants, les participants avancés
119

ont effectué moins d' ARAA lexicales, moins d' ARAA grammaticales et moins
d' ARAA-E, mais plus d' ARAA-A. Contrairement à notre étude, les participants
avancés de cette étude-là ont produit en général plus d' ARAA-D que les participants
débutants (0,55 versus 0,51) et plus d' ARAA-A que les participants débutants (0,55
versus 0,32}, mais les différences n'étaient néanmoins pas significatives. Kormos
(2000a) a attribué cette augmentation d' ARAA-D et d' ARAA-A à une division égale
de l'attention à la qualité et à la quantité de l'information transmise par les
participants.
En ce qui concerne les différences entre notre étude et celle de Kormos, outre la
langue étudiée mentionnée dans la section 6.1.2, il est possible que la méthode de
collecte de donnée joue un rôle. Souvenons-nous que dans le cadre de notre étude,
nous avons utilisé une tâche de narration tandis que Kormos a eu recours à un jeu de
rôle de type de recherche de l'information manquante (notre traduction de
information-gap-type ro/e play activity). Selon les études de Foster et Skehan (1996),
Skehan et Foster (1997) et Gilabert (2007), le type de tâche influence la fréquence
d' ARAA dans la production orale des participants. Ainsi, les participants dans
Kormos (2000a) auraient été censés se concentrer sur le sens au lieu de la forme
langagière puisque l'étude visait à produire des interactions authentiques, mais c'est
le type de tâche qui expliquerait l'augmentation des ARAA-A et des ARAA-D chez
les participants avancés par rapport aux débutants. Dans notre étude, le choix de la
tâche de narration pourrait expliquer le fait que les participants du groupe fort ont
produit moins d' ARAA-A et d' ARAA-D que ceux du groupe faible. Cette
observation pour notre étude rejoint celle de l'étude de van Hest (1996).
Dans son étude, van Hest (1996) a effectué une analyse détaillée des différences
intergroupes (débutants n = 10; intermédiaires n = 10; avancés n = 10) pour les
catégories d' ARAA et leur fréquence. Dans son étude, les participants avancés ont
120

produit moins d' ARAA-A que les participants débutants (351 versus 602), et moins
d' ARAA-D que les participants débutants (88 versus 63). En effet, les diminutions
que nous avons observées des ARAA-D (groupe faible, 1,50 versus groupe fort, 1,07)
et des ARAA-A (groupe faible, 1,82 versus groupe fort, 1,57) allant de pair avec une
plus grande compétence langagière sont en accord avec les résultats de l'étude de van
Hest ( 1996).
En général, la production des ARAA-D dans l'étude de van Hest (1996) s'avère
similaire à notre étude. Pourtant il existe de grands écarts quant à la production des
ARAA-E et des ARAA-A entre les deux études. Les trois groupes de participants de
notre étude ont effectué environ deux fois plus d' ARAA-E et quatre fois moins
d' ARAA-A que ceux de van Hest (1996). Sur le plan de la fréquence des ARAA, les
participants débutants et les participants intermédiaires dans l'étude de van Hest
(1996) ont produit environ le même nombre d'ARAA par 100 mots (2,63 versus 2,55)
tandis que les participants avancés en ont produit seulement 1, 75, et les participants
débutants et les participants intermédiaires ont produit beaucoup plus d' ARAA
lexicales et beaucoup moins d' ARAA-A que les participants avancés.
Il est possible que les différences entre van Hest ( 1996) et notre étude pour ce qui est
des catégories d' ARAA et de leur fréquence soient dues à plusieurs facteurs. Outre la
méthode de collecte de donnée évoquée dans la section précédente, nous croyons que
la taille d'échantillon contribuerait aussi aux écarts observés. Dans van Hest (1996),
le nombre de participants dans chaque groupe (débutants, intermédiaires et avancés)
était de 10. Bien que 45 heures d'enregistrement audio aient fourni à l'auteure
beaucoup de données à analyser, nous pensons que le nombre de participants pour
chaque groupe n'était vraisemblablement pas suffisant pour effectuer des analyses
inférentielles (Fraenkel et Wallen, 2003, p. 107). Cela pourrait limiter la portée des
conclusions que l'on pourrait tirer des résultats de van Hest (1996).
121

En général, les résultats de notre étude vont dans le sens de Simard et ses
collaborateurs (20 17) concernant la diminution du total des ARAA et des simples
ARAA (p. ex., les ARAA phonologiques), et la diminution des ARAA incorrecte
correcte, correcte-incorrecte et incorrecte-incorrecte accompagnant une compétence
langagière plus grande chez les participants. Rappelons que Simard et ses
collaborateurs (2017) n'ont pas étudié les ARAA des groupes d'apprenants de
différents niveaux de compétence langagière, mais plutôt comparé les variations de
la fréquence des ARAA entre le Tl, début du programme d'immersion de français, et
le TI, fin du programme, dans le même groupe de participants anglophones. Les
résultats de leur étude ont indiqué qu'entre Tl et T2, les diminutions de 39%
relativement au ratio du total des ARAA, de 37% relativement au ratio des A-forme,
de 70 % relativement au ratio des ARAA de genre, et de 60 % relativement au ratio
des ARAA de déterminants étaient significatives. Quant aux ARAA selon la justesse
du réparandum et du réparatum, l'étude de Simard et ses collaborateurs (2017) a
révélé qu'entre Tl et T2, les diminutions de 37% du ratio des ARAA incorrecte
correcte, de 59% du ratio des ARAA incorrecte-incorrecte, et l'augmentation de
200 % du ratio des ARAA correcte-correcte étaient significatives tandis que la
diminution de 54% du ratio des ARAA correcte-incorrecte ne l'était pas.
Quant à la fréquence des ARAA, les résultats de l'étude de Simard et ses
collaborateurs (2017) ont montré qu'entre Tl et T2, la fréquence du total des ARAA
ainsi que celle des sous-catégories des ARAA avait diminué. Les auteurs attribuent
cette diminution au déclenchement de 1 'automatisation des processus de la
production langagière. Cette ligne d'argumentation nous semble plus convaincante
que l'explication proposée par Kormos (2000a) pour justifier dans notre étude les
variations de la fréquence des ARAA produites par les participants du groupe faible
et ceux du groupe fort. En effet, les processus complexes du formulateur
s'automatisaient à mesure que se développait la compétence langagière de la L2,
122

produisant ainsi moins de disfluence et moins d' ARAA (Segalowitz, 201 0).
D'ailleurs, les apprenants plus avancés connaissaient plus de vocabulaire et de règles
de grammaire, donc ils faisaient moins d'erreurs imputables à un manque de
compétence langagière que les apprenants moins avancés; par conséquent, un plus
petit nombre d' ARAA-E de bas niveau linguistique était observé dans la production
orale chez les apprenants plus avancés (Kormos, 2006).
II reste toutefois à expliquer une différence concernant les ARAA correcte-correcte
entre notre étude et celle de Simard et ses collaborateurs (20 17). Les résultats de
notre étude ont permis d'observer que les participants du groupe fort ont produit 7,21
ARAA correcte-correcte par 100 mots alors que ceux du groupe moyen et faible ont
produit 7,59 et 7,67 ARAA correcte-correcte par 100 mots respectivement. Précisons
qu'aucune différence statistiquement significative n'a été observée entre les trois
groupes en ce qui concerne les ARAA correcte-correcte tandis que les ratios du Tl et
du T2 des ARAA correcte-correcte dans Simard et ses collaborateurs (20 17)
représentaient 0,10 et 0,30 par 100 mots respectivement, une augmentation de 200 %
imputable, selon les auteurs, au développement de la compétence langagière de la L2
des participants. En effet, avec l'automatisation de l'encodage grammatical vient une
diminution de la disfluence et des ARAA; par conséquent, plus de ressources
attentionnelles sont libérées permettant de surveiller les traits langagiers relatifs au
discours (Kormos, 2000a). À propos de cette différence, outre le type de tâche à
accomplir, nous croyons que la méthode de codage pourrait être en cause. Rappelons
que nous avons codé les ARAA correcte-correcte selon la justesse de 1 'énoncé
source et de 1 'énoncé de reformulation tandis que Simard et ses collaborateurs (20 17)
les ont codées selon la justesse du réparandum et du réparatum. Selon Levelt (1983),
une ARAA est composée d'un énoncé-source, d'un terme de reformulation optionnel
et d'un énoncé de reformulation alors qu'un énoncé-source ou un énoncé de
reformulation lui-même peut contenir une ou plusieurs ARAA. Mais un réparandum
123

et un réparatum font partie d'une ARAA et ne peuvent contenir aucune ARAA. Donc,
le nombre d' ARAA par 100 mots codés selon notre méthode a été plus important que
dans 1 'étude de Simard et ses collaborateurs (20 17).
Les résultats des analyses montrent que les catégories d' ARAA ainsi que leur
fréquence rejoignent les résultats des études antérieures (p. ex., Kormos, 2000a; Liu,
2009; van Hest, 1996), mais que la fréquence des ARAA s'avère généralement
supérieure aux études comparables (Simard et coll., 2011; Simard et coll., 20 17; van
Hest, 1996). Des analyses de Kruskal-Wallis ont été effectuées afin d'explorer le lien
entre la compétence langagière et les catégories d' ARAA. Les résultats des analyses
révèlent des différences intergroupes significatives par rapport au total des ARAA,
au total des ARAA-E, aux ARAA phonologiques et aux répétitions. En général, les
participants ont produit plus d'ARAA par 100 mots que dans d'autres études menées
dans ce domaine (Kormos, 2000a; Liu, 2009; Simard et coll., 2011; Simard et coll.,
2016; Simard et coll., 2017; van Hest, 1996) alors que les participants du groupe fort
ont produit moins d' ARAA que ceux du groupe faible et que ceux du groupe moyen,
notamment dans les catégories d' ARAA évoquées.
Par ailleurs, les résultats des analyses selon la justesse de l'énoncé-source et de
l'énoncé de reformulation indiquent que les participants du groupe fort ont effectué
moins d' ARAA incorrecte-incorrecte que ceux du groupe faible de façon
significative tandis que les participants ont généralement produit moins d' ARAA
correcte-correcte, incorrecte-correcte et correcte-incorrecte avec l'augmentation de la
compétence langagière, mais pas de façon significative, ce qui rejoint les résultats de
l'étude de Simard et ses collaborateurs (2017). Les résultats que nous avons obtenus
révèlent aussi que les ARAA produites par nos participants en production orale
étaient majoritairement de bas niveau (p. ex., phonologique) plutôt que du niveau du
discours. La diminution globale des ARAA corrélant avec l'augmentation de la
124

compétence langagière laisse à penser que les participants plus avancés ont présenté
des caractéristiques en production orale différentes que les participants moins
avancés.
6.3 Profils des participants par niveau de compétence selon les ARAA produites
Comme notre étude porte sur les caractéristiques de la production orale des
apprenants sinophones du français L2, nous souhaitions en particulier présenter les
caractéristiques de chaque groupe d'apprenants constitué dans le cadre de notre étude
en utilisant des exemples tirés de notre corpus. De cette manière, nous espérons
pouvoir fournir une description des profils d'apprenants sinophones du français L2.
Nous commençons avec le profil des participants du groupe faible.
Rappelons toutefois que les participants ont tous produit l'ensemble des catégories
d'ARAA codées indépendamment de leur niveau de compétence langagière, et que
des différences statistiquement significatives n'ont pu être observées qu'entre
certaines de ces catégories.
6.3.1 Profil des participants du groupe faible
Le groupe faible (n = 23) est composé de quatre hommes et de 19 femmes, dont
l'âge moyen est 35,2 ans. Les participants du groupe faible ont étudié le français en
moyenne pendant 4,5 ans et ont atteint le niveau de scolarité universitaire. En
moyenne, ils vivaient au Québec depuis 4,1 ans au moment de l'étude. Ils ont obtenu
une note moyenne de Il ,4 sur un maximum de 45 au texte à trous, un taux de
réussite de 25,3 %. Par ailleurs, ils ont effectué plus d' ARAA par 100 mots dans
presque toutes les catégories d' ARAA recensées sauf les ARAA-D que ceux des
groupes moyen et fort.
125

Nous examinons les caractéristiques de la production orale de nos participants en
regardant 15 exemples d' ARAA' tirés des narrations des participants du groupe faible.
Nous les présentons dans le Tableau 6.1.
126
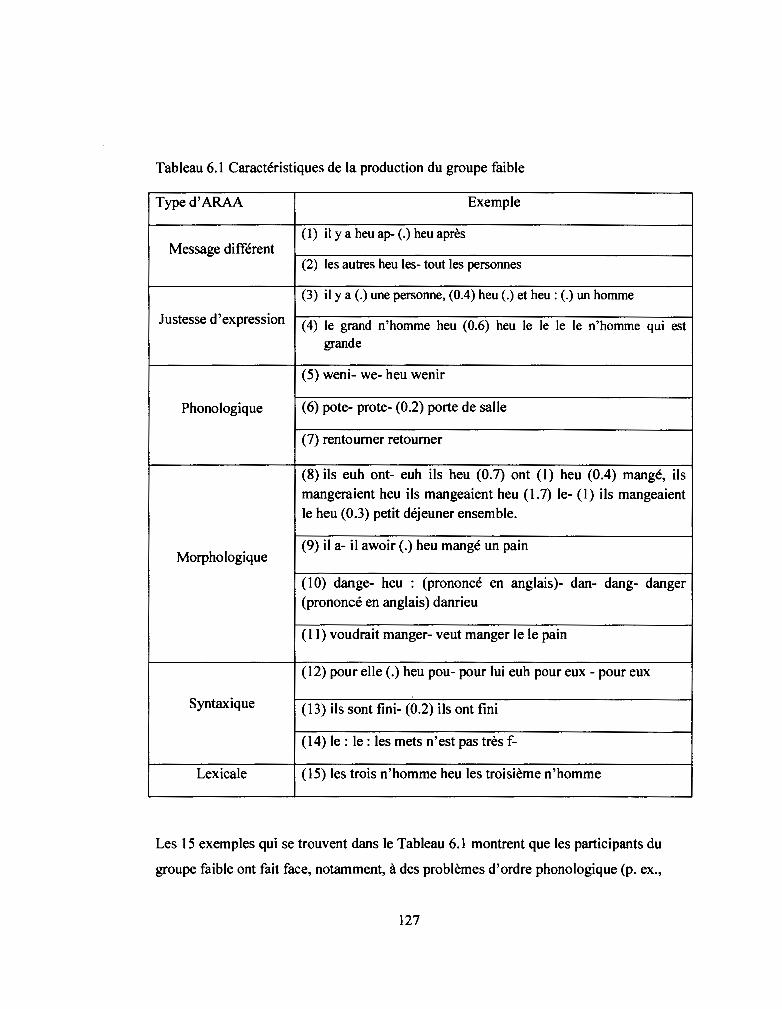
-------------
Tableau 6.1 Caractéristiques de la production du groupe faible
Typed'ARAA Exemple
(1) il y a heu ap- (.)heu après Message différent
(2) les autres heu les- tout les personnes
(3) il y a(.) une personne, (0.4) heu(.) et heu:(.) un homme
Justesse d'expression (4) le grand n'homme heu (0.6) heu le le le le n'homme qui est grande
(5) weni- we- heu wenir
Phonologique (6) pote- prote- (0.2) porte de salle
(7) rentoumer retourner
(8) ils euh ont- euh ils heu (0.7) ont (1) heu (0.4) mangé, ils mangeraient heu ils mangeaient heu ( 1. 7) le- (1) ils mangeaient le heu (0.3) petit déjeuner ensemble.
Morphologique (9) il a- il awoir (.)heu mangé un pain
(10) dange- heu : (prononcé en anglais)- dan- dang- danger (prononcé en anglais) danrieu
(11) voudrait manger- veut manger le le pain
(12) pour elle(.) heu pou- pour lui euh pour eux- pour eux
Syntaxique (13) ils sont fini- (0.2) ils ont fini
(14) le: le: les mets n'est pas très f-
Lexicale (15) les trois n'homme heu les troisième n'homme
Les 15 exemples qui se trouvent dans le Tableau 6.1 montrent que les participants du
groupe faible ont fait face, notamment, à des problèmes d'ordre phonologique (p. ex.,
127

« rentoumer retourner»), morphologique (p. ex., «voudrait manger- veut manger le
le pain»), syntaxique (p. ex., «ils sont fini- (0.2) ils ont fini le : (0.5) leur petit
déjeuner») et lexicale (p. ex., «les trois n'homme heu les troisième n'homme»). Il
est à remarquer que les participants du groupe faible ne semblent pas encore bien
maîtriser la prononciation de certains mots du français, ce qui est illustré par les
exemples 5, 6 et 7. De plus, les exemples 8, 9 et 11 indiquent que le choix du temps
de verbe représente un défi pour les participants du groupe faible.
Comme on peut s'y attendre, les participants de ce groupe manquent de vocabulaire
et ne maîtrisent pas encore certaines expressions verbales figées lorsqu'ils expriment
leurs idées. À titre d'exemple, mentionnons le verbe «manger» qui a été utilisé à
trois reprises dans les exemples 8, 9 et 11. Bien que ce groupe de participants ait
produit des ARAA-D et des ARAA-A, nous constatons que les énoncés de
reformulation des deux types d' ARAA contiennent souvent des erreurs
grammaticales (p. ex., «les autres heu les- tout les personnes»).
Par ailleurs, le choix du bon article pose également un autre problème aux
participants du groupe faible. Bien que les 15 exemples ne représentent pas toutes les
ARAA recensées, ils nous permettent de remarquer que les ARAA produites ne se
trouvent plutôt pas sur le plan du discours, mais plutôt sur le plan grammatical tel
qu'il l'a été observé dans des études antérieures (p. ex., O'Connor, 1988; van Hest,
1996; Yang, 2002). Dans ce qui suit, nous traiterons le profil des participants du
groupe moyen.
6.3.2 Profil des participants du groupe moyen
Le groupe moyen (n = 21) est pour sa part composé de cinq hommes et de 16
femmes, dont l'âge moyen de 35,1 ans. Les participants du groupe moyen ont étudié
128

le français en moyenne pendant 4,6 ans, ont atteint le niveau de scolarité universitaire
et vivaient au Québec depuis 4,05 ans au moment de l'étude. Les participants du
groupe moyen ont obtenu une note moyenne de 20,1 sur un maximum de 45 au texte
à trous, un taux de réussite de 44,7 %. Ils ont effectué en général plus d'ARAA par
100 mots dans presque toutes les catégories d' ARAA recensées que ceux du groupe
fort, mais moins d' ARAA que ceux du groupe faible.
Comme pour le groupe faible, nous avons sélectionné 15 exemples d' ARAA dans
notre corpus afin d'examiner les caractéristiques de la production orale de ce groupe
de participants (voir le Tableau 6.2).
129
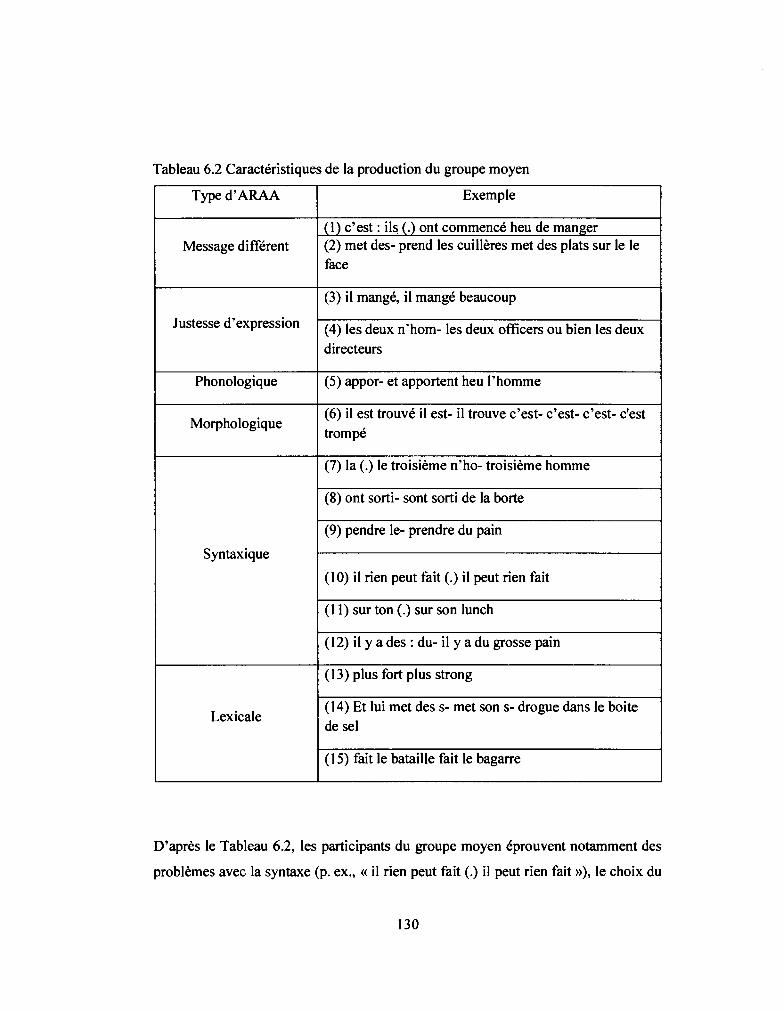
Tableau 6.2 Caractéristiques de la production du groupe moyen
Typed'ARAA Exemple
(1) c'est: il~(.) ont commencé heu de manger Message différent (2) met des- prend les cuillères met des plats sur le le
face
(3) il mangé, il mangé beaucoup
Justesse d'expression (4) les deux n'hom- les deux officers ou bien les deux directeurs
Phonologique (5) appor- et apportent heu l'homme
Morphologique (6) il est trouvé il est- il trouve c'est- c'est- c'est- c'est trompé
(7) la(.) le troisième n'ho- troisième homme
(8) ont sorti- sont sorti de la borte
(9) pendre le- prendre du pain
Syntaxique
(10) il rien peut fait(.) il peut rien fait
(Il) sur ton(.) sur son lunch
(12) il y a des : du- il y a du grosse pain
(13) plus fort plus strong
Lexicale ( 14) Et lui met des s- met son s- drogue dans le boite de sel
(15) fait le bataille fait le bagarre
D'après le Tableau 6.2, les participants du groupe moyen éprouvent notamment des
problèmes avec la syntaxe (p. ex., «il rien peut fait(.) il peut rien fait»), le choix du
130

lexique (p. ex., « fait le bataille fait le bagarre » ), les articles (p. ex., « la (.) le
troisième n'ho- troisième homme») et la justesse des expressions (p. ex., « les deux
n'hom- les deux officers ou bien les deux directeurs»). Cependant, les exemples
montrent que les participants de ce groupe semblent éprouver moins de problèmes
sur le plan phonologique que ceux du groupe faible. Nous avons également remarqué
que la maîtrise des déterminants demeure fragile chez ces participants (p. ex., « sur
ton (.) sur son lunch»). Le genre et l'accord du genre leur posent également
problème (p. ex.,« dans le boite de sel, fait le bataille fait le bagarre»).
Par ailleurs, il est intéressant de noter que les participants du groupe moyen ont
également produit des ARAA de type différent message et de justesse d'expression
comme ceux du groupe faible. Cependant, d'après les exemples, ces participants ont
utilisé un vocabulaire plus riche et plus précis (p. ex., « prend les cuillères met des
plats sur le le face») et ont commis moins d'erreurs grammaticales dans les énoncés
de reformulation des ARAA-0 et ARAA-A que ceux du groupe faible. De plus, sont
apparus, comme on s'y attendrait, des énoncés plus complexes que ceux produits par
les participants du groupe faible (p. ex.,« ils(.) ont commencé heu de manger»).
6.3.3 Profil des participants du groupe fort
Le groupe fort (n = 21) est composé de neuf hommes et 12 de femmes, dont l'âge
moyen est de 33,7 ans. Les participants du groupe fort ont étudié le français en
moyenne pendant 4,4 ans et ont atteint le niveau de scolarité universitaire. En
moyenne, ils sont au Québec depuis 3,43 ans. Les participants du groupe fort ont
obtenu une note moyenne de 29 sur un maximum de 45 au texte à trous, un taux de
réussite de 64,4 %. En moyenne, les participants du groupe fort ont effectué moins
d' ARAA par 100 mots dans presque toutes les catégories d' ARAA recensées que
ceux du groupe faible et moyen. Comme pour les groupes faible et moyen, nous
131
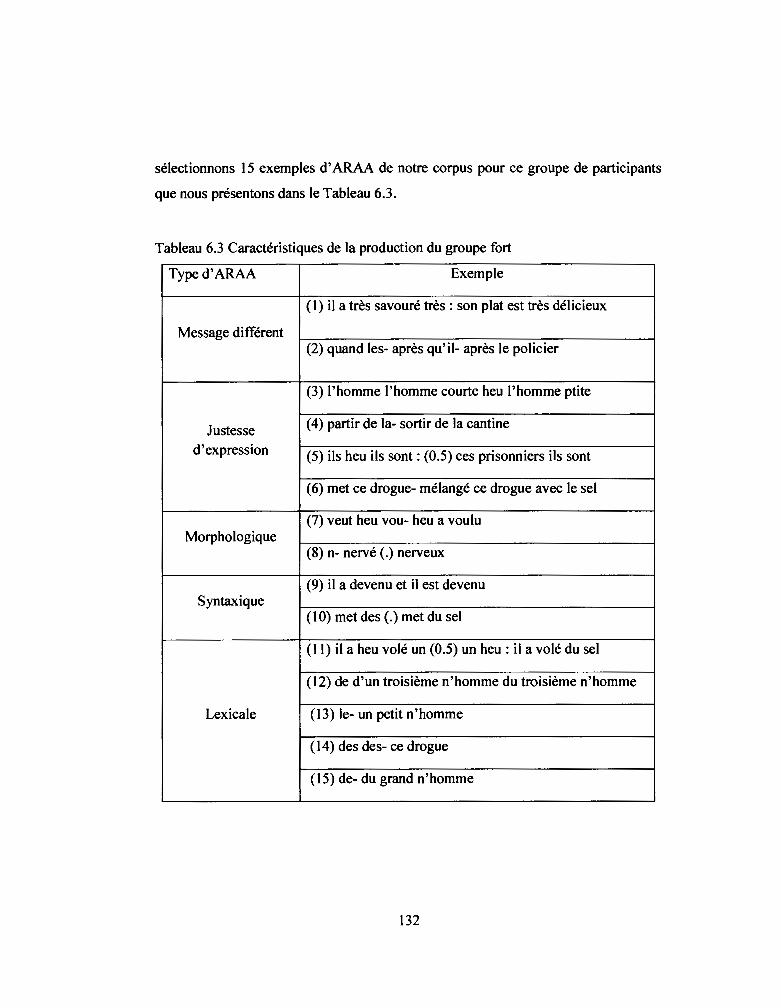
sélectionnons 15 exemples d' ARAA de notre corpus pour ce groupe de participants
que nous présentons dans le Tableau 6.3.
Tableau 6.3 Caractéristiques de la production du groupe fort
Typed'ARAA Exemple
( 1) il a très savouré très : son plat est très délicieux
Message différent (2) quand les- après qu'il- après le policier
(3) l'homme l'homme courte heu l'homme ptite
Justesse (4) partir de la- sortir de la cantine
d'expression (5) ils heu ils sont : (0.5) ces prisonniers ils sont
( 6) met ce drogue- mélangé ce drogue avec le sel
(7) veut heu vou- heu a voulu Morphologique
(8) n- nervé (.) nerveux
(9) il a devenu et il est devenu Syntaxique
(10) met des(.) met du sel
(11) il a heu volé un (0.5) un heu : il a volé du sel
(12) de d'un troisième n'homme du troisième n'homme
Lexicale (13) le- un petit n'homme
( 14) des des- ce drogue
(15) de- du grand n'homme
132

Les 15 exemples au Tableau 6.3 nous permettent de remarquer que les participants
du groupe fort éprouvent également des problèmes sur le plan du choix de lexique
(p. ex., «le- un petit n'homme))), du choix d'articles (p. ex., «met des met du sel))),
syntaxique (p. ex., « il a devenu et il est devenu )) ) et morphologique (p. ex., « nervé
nerveux))). Pourtant, le fait que les participants du groupe fort n'ont pas produit
beaucoup d' ARAA phonologiques nous permet de constater que la prononciation de
certains mots leur pose moins de défi à cette étape de leur acquisition. D'après les 15
exemples, nous avons également remarqué qu'ils ont produit quelques ARAA-D
(p. ex., «il a très savouré très son plat est très délicieux))) et ARAA-A (p. ex., «ils
heu ils sont ces prisonniers ils sont))).
Il est à noter que les participants du groupe fort ont employé un vocabulaire encore
plus riche et avec plus exactitude (p. ex., « met ce drogue- mélangé ce drogue avec le
sel )) ) dans leurs narrations que ceux du groupe moyen. Malgré quelques erreurs
grammaticales, il est clair que la complexité de leurs énoncés évolue vers celle des
productions de locuteurs natifs du français, et que les ARAA produites évoluent
plutôt vers celles de niveau de discours. Cette évolution différencie le groupe fort des
groupes faible et moyen dans une certaine mesure, ce que confirment les résultats des
analyses au chapitre V.
6.3.4 Synthèse
Rappelons que les études antérieures indiquent que les apprenants sinophones
présentent cinq catégories de difficultés dans l'apprentissage du français L2 : la
phonétique, les articles, les formes verbales, les choix des mots et la syntaxe (Wang,
1993). Par ailleurs, les apprenants sinophones du français L2 ont plus de difficultés
avec le verbe qu'avec le nom ou l'adjectif (Yu, 1993). Les exemples que nous avons
fournis dans la section des profils d'apprenants montrent en effet que nos participants
133

présentent également des caractéristiques présentées dans des études antérieures
(Wang 1993; Yu, 1993).
Il est intéressant de constater que les participants des trois groupes ont produit d'une
part des ARAA phonologiques, morphologiques, syntaxiques et lexicales, et d'autre
part des ARAA de type différent message et de justesse d'expression. Toutefois,
nous avons observé que plus leur niveau de compétence était élevé, plus le
vocabulaire des participants était sophistiqué, comme il se doit. Les participants du
groupe faible ont eu recours à un vocabulaire très restreint dans leurs narrations et
leur construction de phrase s'est avérée moins complexe que ceux des groupes
moyen et fort. Les participants du groupe fort ont quant à eux employé le vocabulaire
le plus riche et le plus varié dans leurs narrations et semblent avoir produit moins
d'erreurs grammaticales que les deux autres groupes.
Ces observations sont en général en accord avec les résultats obtenus dans les études
antérieures (Kormos, 2000a; Simard et coll., 20 17; van Hest, 1996). D'une part,
notre étude a permis de faire ressortir les caractéristiques particulières de la
production orale des apprenants de différents niveaux de compétences. D'autre part,
les résultats de notre étude permettent aux apprenants de mieux comprendre et cibler
les problèmes spécifiques à chaque niveau et de progresser dans leur apprentissage.
6.4 Pistes de recherches futures
Plusieurs études ont démontré que le type de tâche pouvait influencer les données
collectées de production orale, mais aussi la complexité langagière (p. ex., Skehan et
Poster, 1997), et l'aisance et la justesse (p. ex., Derwing, Munro, Thomas et Rossiter,
2009). Nous avons choisi une tâche de narration à effectuer à partir d'un extrait de
134

film muet, car selon certaines études antérieures (Mackey et Gass, 2005; Sun, 2003),
il s'agit d'un moyen efficace de collecter des données de production orale.
Conséquemment, il serait intéressant au cours de futures études de réutiliser ce type
de tâche avec des participants dont la L 1 est différente de celle de notre étude tout en
ajoutant d'autres mesures, par exemple, une mesure pour évaluer le niveau de
compétence langagière d'une troisième langue, ce qui pourrait contribuer à
l'explication des résultats que nous avons obtenus.
Des études menées auprès d'autres groupes de participants, par exemple, hongrois (p.
ex., Kormos, 2000a), français (p. ex., Bange et Kern, 1996) et néerlandais (p. ex., van
Hest, 1996), révèlent qu'il existe des différences entre les ARAA en LI et L2. Étant
donné que nous avons seulement examiné les ARAA en français L2, il serait donc
intéressant d'examiner les ARAA produites dans la LI des participants, le chinois,
afin de comparer les catégories d' ARAA et leur fréquence de la L 1 et à la L2, et de
faire ressortir les différences et les convergences du comportement des participants
sur le plan des ARAA. De cette manière, nous pourrions mieux évaluer l'étendue des
différences d' ARAA entre la L 1 et la L2.
Finalement, au sujet des écarts entre la fréquence des ARAA relativement au total
des ARAA et aux autres catégories des ARAA dans notre étude et celle des études
antérieures, il est probable que des différences typologiques de langue soient en
cause. Ainsi il serait souhaitable de vérifier si d'autres groupes de participants de
même langue d'origine, mais autre que le chinois et éloignée de la famille indo
européenne, comme le japonais ou le thaï, produiraient des ARAA à la même
fréquence lors de la réalisation de la même tâche de narration dans les mêmes
conditions d'expérience. Cette vérification permettrait de comparer la fréquence des
ARAA des participants d'origine non sinophones en ce qui a trait à la fréquence avec
celui observé dans notre étude, et de faire la lumière sur cet aspect.
135

CONCLUSION
Notre étude avait pour objectif d'étudier au moyen des ARAA les caractéristiques de
la production orale en français L2 chez les sinophones. Nous avons choisi de mener
notre étude auprès d'un groupe d'apprenants sinophones du français L2, une
population grandissante au Québec qui présentent souvent des caractéristiques
particulières dans l'apprentissage du français, notamment dans les cours de
francisation. Les ARAA que nous avons recueillies auprès de nos participants nous
ont permis de dévoiler les caractéristiques de la production orale des sinophones.
Afin de présenter les caractéristiques de la production orale de ce groupe
d'apprenants au moyen des ARAA, nous avons d'une part exploré les catégories
d' ARAA et leur fréquence en français L2 chez les sinophones. D'autre part, nous
avons visé à déterminer si les catégories d' ARAA et leur fréquence en français L2
variaient en fonction du niveau de compétence langagière chez les apprenants
sinophones.
Nous avons utilisé une tâche de narration à effectuer à partir d'un extrait de film
muet ainsi qu'un test de texte à trous afin de recueillir des données auprès de 65
participants sinophones âgés de 21 à 57 ans, divisés en trois groupes : faible, moyen
et fort. Dans les analyses, des ratios des ARAA par 100 mots ont été établis afin de
mesurer d'une part les catégories d'ARAA et d'autre part leur fréquence dans les
productions orales des participants.
136

Les résultats de notre étude sont cohérents avec ceux des études antérieures quant
aux catégories produites, mais les résultats sur la fréquence des ARAA dans notre
étude présentent des différences importantes par rapport aux études antérieures. Les
résultats de notre étude montrent que les participants ont produit généralement plus
d' ARAA dans presque toutes les catégories d' ARAA.
En ce qui concerne les variations intergroupes, les résultats des analyses ont indiqué
que la fréquence des ARAA variait de façon significative seulement pour le total des
ARAA et pour certaines catégories d' ARAA, à savoir les ARAA-E, les ARAA
phonologiques, les répétitions et les ARAA incorrecte-incorrecte entre les
participants du groupe faible, ceux du groupe moyen et ceux du groupe fort. Donc la
compétence langagière semble influencer la fréquence des ARAA dans une certaine
mesure chez nos participants, et être plutôt en lien avec les ratios du total des ARAA,
des ARAA-E, des ARAA phonologiques, des répétitions et des ARAA incorrecte
incorrecte.
Par ailleurs, mentionnons que le fait que les résultats obtenus à la tâche de texte à
trous n'étaient en lien qu'avec le total des ARAA, le total des ARAA-E, les ARAA
phonologiques, les répétitions et les ARAA correcte-incorrecte pourrait indiquer que
les écarts observés entre notre étude et les autres études sont liés, dans une certaine
mesure, à la tâche de texte de trous. Nous aurions pu en effet nous attendre à ce que
la fréquence des ARAA dans notre étude soit cohérente avec celle des études
antérieures. Les résultats obtenus ont indiqué aussi que le niveau de difficulté élevé
de la tâche pour nos participants a rendu délicate l'interprétation de nos résultats. En
effet, nos participants devaient-mémoriser l'histoire de l'extrait du film visionné et
reproduire l'histoire en français L2 afin d'accomplir la tâche de narration. Étant
donnée de la grande difficulté de la tâche de narration à partir d'un film, nous
n'avons pas pu obtenir des résultats cohérents sur la fréquence avec d'autres études
137

(Liu, 2009; Simard et coll., 2017; van Hest, 1996). Il aurait peut-être fallu bénéficier
d'un autre type de tâche (p. ex., narration à partir des images) afin de déterminer la
complexité de la tâche de narration à partir d'un extrait d'un film.
Notre étude nous a permis, d'une part, de mettre en lumière les particularités des
ARAA en français L2 chez les participants sinophones dans les catégories et la
fréquence des ARAA, et, d'autre part, de faire ressortir l'importance de tenir compte
des tâches de mesure des ARAA et des L 1 des participants lors du choix
méthodologique afin d'être en mesure d'interpréter les résultats obtenus avec plus de
certitude.
À cet effet, nous considérons que le type de tâche de narration, la taille de
l'échantillon, la distance typologique des langues étudiées et la langue d'origine des
participants pourraient contribuer aux écarts observés entre les résultats de notre
étude et ceux d'autres études évoquées ci-dessus. Cependant, nous n'avons pas pu
examiner les ARAA dans la L 1 des participants dans notre étude, ce qui constituerait
une piste de recherche intéressante pour de futures études. De plus, une étude ayant
pour but de comparer les ARAA en français L2 et en chinois L 1 pourrait aider à faire
la lumière sur les particularités des apprenants sinophones du français L2 par rapport
à la haute fréquence des ARAA observée dans notre étude.
Finalement, notre étude a permis de dresser des profils d'apprenants sinophones du
français L2 ainsi que des caractéristiques de la production orale des apprenants
sinophones du français L2 au moyen des ARAA, offrant ainsi une compréhension
plus approfondie des aspects langagiers dans lesquels ces apprenants éprouvent des
problèmes dans leur apprentissage. De futures études devraient chercher à mieux
comprendre l'influence du type de tâche et de l'interaction entre la langue à étudier
et la L 1 des participants.
138

ANNEXE 1
QUESTIONNAIRE SUR LES RENSEIGNEMENTS PERSONNELS

QUESTIONNAIRE SUR LES RENSEIGNEMENTS PERSONNELS
Ce questionnaire sert à obtenir des informations générales sur vous. Les réponses
données resteront confidentielles et ne serviront qu'à des fins de recherche. Votre
nom ne sera pas utilisé, car nous utiliserons à la place un numéro pour permettre
d'identifier les résultats à l'individu correspondant. Vous pouvez répondre en français
ou en mandarin.
Merci de votre collaboration, car vos réponses serviront à comprendre davantage
l'acquisition du français chez les adultes sinophones. Votre honnêteté est aussi
fortement appréciée.
1. Votre nom et prénom : _____ _
2. Êtes-vous : une femme ou un homme ·---
3. Quel âge avez-vous? ___ _
4. Depuis combien de temps êtes-vous au Canada ? ___ _ Au Québec? __ _
6. Quelle(s) langue(s) parlez-vous le plus couramment à la maison?
7. Depuis combien de temps avez-vous étudié les langues suivantes?
Langue Nombre d'années d'études
Mandarin
Anglais
Français
Autre langue :
Autre langue :
139

8. Quel est votre niveau d'étude?
a) secondaire
b) collégial
c) universitaire
d) maitrise
e) doctorat
d) autre, précisez : __ _
140

ANNEXE2
TEXTE À TROUS

"ù taux dt' CO! dans )'atmosphrl"t' aogmt'Dft' piUS lift' qat' prévu"
La croissance économique mondiale _(1)_ provoqué un accroissement de _(2)_ teneur eu dioxyde de _(3)_ (COl) dans l'atmosphère beaucoup _(4)_ rapidement que prévu. selon une étude _(5)_ hmdi dans les comptes rendus de l'Académie _(6)_ des sciences des ÉtatsUnis.
Cette émde _(7)_ que la concentration des émissions _(8)_ gaz carbonique dans l'atmosphère a _(9)_ de 35 <~,·;,en 2006. entre le début _(10)_ années 1990 et les _(11)_ 2000-2006. passant de 7 à 10 milliards de tonnes _(12)_ an, alors que le protocole de Kyoto prévoyait _(13)_ en 2012. ces émissions responsables _(14)_ réchauffement clitnatique devaient _(15)_ baissé de 5% par _(16)_ à 1990. ((Les améliorations dans l'itttensité carbonique de l'économie _(17)_ stagnent depuis 2000. après trente _(18)_ de progrès. ce qui a provoqué cette _(19)_ inattendue de la concentration de C02 _(20)_ l'atmosphère». indique dans _(21)_ communiqué le Blitish Antarctic Survey. _(22)_ a participé à cene étude.
_(23)_ les chercheurs. les carbmants polluants _(24)_ responsables de 17 % de cette augmentation. _(25)_ que les 18% restant sont _(26)_ à tm déclin de la capacité des« puits)) uamrels comme _(27)_ forèts ou les océans _(28)_ absorber le gaz carbonique. « _(29)_ y a cinquante ans. pour chaque tonne de C02 émise. 600 kg _(30)_ absorbés par les puits naturels. _(31)_ 2006. setùement 550 kg par tonne ont été _(32) __ . et cette quantité continue à baisser», explique _(33)_ auteur principal de l'émde. Pep Canadell. du Global Carbon Project. «La baisse de l'efficacité _(34)_ puits mondiamc laisse _(35)_ que la stabilisation de cette _(36)_ sera encore plus _l37)_ à obtenir que ce que l'on pensait jusqu'à _(38)_ ». indique pour sa _(39)_le British Antarctic Smvey.
Ces _(40)_ obligent à tme révision à la hausse _(41)_ prévisions du Groupe intergouvernemental d'ex-perts _(42)_l'évolution du climat qui. dans son_(43)_ de février. tablait sur l'augmentation de la température _(44)_ de la terre de 1.8 oc à 4 oc _(45)_ l'h01izon 2100.
141

ANNEXE3
FORMULAIRE D'INFORMATION ET DE CONSENTEMENT

FORMULAIRE D'INFORMATION ET DE CONSENTEMENT
UQÀM FORMULAIRE D'INFORMATION ET DE CONSENTEMENT
« Étude sur des caractéristiques de la production orale chez les sinophones »
IDENTIFICATION
Responsable du projet : Y ong Gang Liu Département, centre ou institut: Département de linguistique de l'UQAM Adresse postale: Département de linguistique Université du Québec à Montréal C.P. 8888, Succursale Centre-Ville Montréal (Québec) H3C 3P8 Canada Adresse courriel : [email protected]
BUT GÉNÉRAL DU PROJET
Vous êtes invité-e à prendre part à ce projet qui vise à comprendre les caractéristiques de la production orale des apprenants adultes sinophones au moyen des autoreformulations autoamorcées produites en français L2. Il vise également à comprendre l'incidence que celles-ci ont sur leur apprentissage.
PROCÉDURE(S)
Votre participation consiste à réaliser une tâche anonyme au cours de laquelle il vous sera demandé de réaliser une tâche de narration en français et un court test de français. La tâche langagière est une narration à réaliser après le visionnement d'un extrait de film muet sur ordinateur portable, et le tout prendra environ 45 minutes de votre temps. Le lieu et l'heure du test sont à convenir avec le responsable du projet. Les résultats de cette tâche anonyme ne permettront pas de vous identifier.
A V ANTAGES et RISQUES
Votre participation contribuera à l'avancement des connaissances. Il n'existe pas de risque d'inconfort important associé à votre participation à cette rencontre. Vous devez cependant prendre conscience que certaines parties du test pourraient raviver
142

des émotions désagréables liées à une expérience de recherche que vous avez peutêtre mal vécue. Il est de la responsabilité du responsable du projet de suspendre ou de mettre fin au test s'il estime que votre bien-être est menacé.
CONFIDENTIALITÉ
Il est entendu que les renseignements recueillis lors de l'entrevue sont confidentiels et que seuls moi-même et la professeure qui dirige mon travail aurons accès aux résultats du test. Le matériel de recherche (test en papier) ainsi que votre formulaire de consentement seront conservés dans un endroit sécuritaire. Les résultats ainsi que les formulaires de consentement seront détruits deux ans après les dernières publications.
PARTICIPATION VOLONTAIRE
Votre participation à ce projet est volontaire. Cela signifie que vous acceptez de participer au projet sans aucune contrainte ou pression extérieure, et que par ailleurs vous être libre de mettre fin à votre participation en tout temps au cours de cette recherche. Dans ce cas, les renseignements vous concernant seront détruits. Votre accord à participer implique également que vous acceptez que l'équipe de recherche puisse utiliser aux fins de la présente recherche (articles, conférences et communications scientifiques) les renseignements recueillis à la condition qu'aucune information permettant de vous identifier ne soit divulguée publiquement à moins d'un consentement explicite de votre part.
COMPENSATION FINANCIÈRE
Il est entendu que vous recevrez une compensation de 25 $ pour le projet.
DES QUESTIONS SUR LE PROJET OU SUR VOS DROITS?
Vous pouvez me contacter au numéro (438) 929-3456 pour toutes questions additionnelles sur le projet ou sur vos droits en tant que participant de recherche.
REMERCIEMENTS
Votre collaboration est essentielle à la réalisation de mon projet et je tiens à vous en remercier. Si vous souhaitez obtenir un résumé écrit des principaux résultats de cette recherche, veuillez ajouter vos coordonnées ci-dessous.
143

SIGNATURES
Je, reconnais avoir lu le présent formulaire de consentement et consens volontairement à participer à ce projet de recherche. Je reconnais aussi que l'intervieweur a répondu à mes questions de manière satisfaisante et que j'ai disposé de suffisamment de temps pour réfléchir à ma décision de participer. Je comprends que ma participation à cette recherche est totalement volontaire et que je peux y mettre fin en tout temps, sans pénalité d'aucune forme ni justification à donner. Il me suffit d'en informer la responsable du projet.
Signature du participant: Date:
Nom (lettres moulées) et coordonnées:
Signature du responsable du projet, ou de son ou sa délégué-e :
Date:
Veuillez conserver le premier exemplaire de ce formulaire de consentement pour communication éventuelle avec 1 'équipe de recherche et remettre le second à 1 'intervieweur.
144

ANNEXE4
CONSIGNES POUR LA TÂCHE DE NARRATION

CONSIGNES POUR LAT ÂCHE DE NARRATION
Voici les consignes présentées aux participants avant la réalisation de la tâche de
narration:
1) Dans cette étape, vous visionnerez un extrait d'un film muet qui s'intitule Les temps modernes et cet extrait dure environ quatre minutes. Vous êtes encouragé-e à prendre des notes pendant le visionnement du film afin de vous aider à organiser la narration pour la prochaine étape. 2) Après le visionnement, vous aurez trois minutes pour vous préparer à la tâche de narration. Vous pourrez vous servir de vos notes. Il est à noter que vous n'aurez pas accès à vos notes lorsque vous effectuerez la narration en français. 3) Après la préparation, vous raconterez l'extrait du film que vous avez visionné tout en décrivant chaque détail dont vous vous souvenez. La narration devra durer cinq à dix minutes et sera enregistrée sur un appareil d'enregistrement.
Merci de votre collaboration!
~~iJillA
*~~~§~~-~-a~~~~M~m~m~&m*mmff•~- A~•~ ~J'f~r:rf:
1) ~~. M2~~~AmA*~&~~--~~~~~~~~~*· 2) MJ§, 1~~-~-a*r-J 4 *flll~~~~~. Jt~~-*~ll'ffÇ. ~-~ll't. ga$~~~. ~œ~~~*~~~-M~~-3) ~%Z.J§, 1~ff 3 *i'P*ll-lr. Jltll'tïlJ~~!mf~B<J~iè.. ~-. ~m~m~~ll't, /f'~~~~~-
4) tit-lr%1$!~, ~~7fMJ.m~7, tJJ~~gey~~W~tl!!#i'i~~-~
~~--~~ll1~*~~5~10*Î'fl· #ff·····*~'
145

ANNEXES
CONVENTIONS DE TRANSCRIPTION

(0.5) Une pause et sa durée en dixième de seconde
(.) Une micro pause (moins de 0.2 seconde)
Discours sans pause entre la fin d'une ligne et le début de la ligne suivante
ei L'élément souligné est accentué
El Mot prononcé plus fort que les autres mots autour de ce dernier
le- Mot interrompu
Marque l'interruption d'un mot
Marque la prolongation d'un son
(table) Les segments entre parenthèses indiquent le doute de la personne qui transcrit
( ) Marque un mot ou un segment qui ne peut pas être identifié
Marque un arrêt par un ton descendant, pas nécessairement la fin d'une phrase
Marque une intonation de continuation, pas nécessairement entre deux
propositions
? Marque une inflexion ascendante, pas nécessairement une question
Marque un ton animé, pas nécessairement une exclamation
146

ANNEXE6
GRAPHIQUE P-P DES RÉSIDUS STANDARDISÉS, VARIABLE DÉPENDANTE
ANNEXE6
Graphique P-P des résidus standardisés, variable dépendante:
ARAA 1.~-------~~---------------~
O.
o.
0.4
o.
0.~---..,-----~-----.....------r----f 1.0 0.0 02 OA 0~ 0~
Probablitié cumulée observée
147

ANNEXE 7
DIAGRAMME DE DISPERSION DES VALEURS, VARIABLE DÉPENDANTE : RATIO DES ARAA
ANNEXE 7 DIAGRAMME DE DISPERSION DES VALEURS, VARIABLE DÉPENDANTE :
RATIO DES ARAA
0
0 0 0 0 0
0
0 0
0 0 0 0 0
0 0
0 0
~ 0 1 0 0 o- 0 0 0 0
0 0 0 0 8
0 0 0
0 0 0 8 0 0 0 0
-1 0 0 0 0 0 0
0 0
0 0
-2- 0
-:t"
1 1 1 1 1 -3 -2 -1 0 1 2
Valeurs prédites des résidus standardisés
148

ANNEXES
PROTOCOLE DE CODAGE DES ÉLÉMENTS LINGUISTIQUES

Protocole de codage
Catégories des ARAA à l'étude
ARAA-D se produit lorsqu'un locuteur décide qu'une autre idée doit être exprimée
avant celle en cours et qu'il interrompt son discours pour commencer à nouveau. Par
la suite, le message en cours est remplacé par un message différent. Il s'agit d'une
modification qui a lieu dans la phase de préparation conceptuelle.
Exemple:
quelqu'un qui- il y a des policiers
ARAA-A: l' ARAA-A se produit afin que toute ambiguïté de référence soit clarifiée.
Notons que l'énoncé de reformulation peut comprendre l'ajout ou la suppression d'un
adjectif, d'une proposition, d'un article, le remplacement d'un pronom par un
syntagme nominal, ou le changement de sujet et de verbe afin de faire l'accord avec
son antécédent. Cependant le message n'est pas remplacé par un autre message et il
reste toujours le même. De plus, il se peut que l'énoncé de reformulation contienne
des erreurs de nature morphologique, syntaxique ou phonologique. Par contre, on ne
tient pas compte des cas où des formulations sont courantes en français (Ex. : deux
monsieurs ils restent là-bas; mais lui il sais pas).
Exemples:
1. le l'homme (0.5) l'homme courte heu l'homme petite
2. de n'homme- de n'homme grande
3. il regard à: le grand monsieur regard à droite.
4. ils ont- il a pris le : le pistolet.
149

Les ARAA-E comprennent les ARAA d'ordre phonologique, morphologique,
syntaxique ou lexical.
ARAA phonologique : elle concerne la modification phonologique d'un son ou d'un
mot prononcé. Elle peut prendre la forme d'une élision, d'une liaison, de l'ajout et/ou
de la suppression d'une ou plusieurs syllabes. Lorsqu'il y a des consonnes ou des
voyelles isolées qui ne sont pas en lien avec les mots qui les précèdent ou qui les
suivent, on n'en tient pas compte puisqu'il n'est pas possible de déterminer de façon
définitive ce que le participant voulait dire par ces consonnes isolées. De plus, cette
catégorie n'inclut ni la modification des terminaisons de verbes ni la modification de
la catégorie grammaticale des mots en question (traitée ailleurs dans ce protocole).
Exemple:
rentourner (.)retourner.
ARAA de l'élision: l'élision est l'effacement de la voyelle finale d'un mot lorsque
celui-ci est suivi d'un mot commençant par une voyelle ou un h muet. L'élision est
marquée à l'écrit par l'apostrophe, qui remplace la voyelle élidée. L'élision ne touche
que des mots grammaticaux, habituellement courts, et seulement les voyelles a, e et i.
Exemple:
le heu l'homme
ARAA de la liaison : la liaison est un phénomène phonétique qui consiste à
prononcer la consonne finale d'un mot, consonne habituellement muette, avec la
voyelle initiale du mot suivant pour en faire une syllabe.
Exemple:
est entré heu (0.5) t'entré.
150

ARAA pour compléter un mot se produit lorsqu'un mot est complété par l'ajout
d'une ou plusieurs syllabes à une consonne, voyelle ou syllabe du mot, et/ou par la
modification d'une ou plusieurs syllabes du mot.
1. il v-- il vole le pain
2. sou- heu sauver?
ARAA morphologique se produit lorsqu'un locuteur effectue une modification
morphologique d'un mot prononcé. Ce type d' ARAA est subdivisé en deux
catégories : ARAA de type flexionnel et ARAA de type dérivationnel.
a. ARAA de type flexionnel : cette catégorie d' ARAA porte sur une modification de
verbe sans que le sujet change et elle peut prendre les formes suivantes :
Formes finies> formes non-finies: elle se produit lorsqu'un verbe change d'une
forme finie à une forme non-finie.
Exemple:
prende prende lui prendre he- prende il heu prende il (3) prende he- il.
Formes non-finies> formes finies: elle se produit lorsqu'un verbe change d'une
forme non-finie à une forme finie.
Exemple:
ils prendre- ils prennent leurs repas
Formes finies> autres formes finies: elle se produit lorsqu'un verbe change d'une
forme finie à autre forme finie.
Exemple:
qui : heu : qui portent ( 1) () qui : porté- qui portent le costume
151

Formes inexistantes> formes finies : elle se produit lorsqu'un verbe (y compris
l'auxiliaire de ce verbe) change d'une forme qui n'existe pas à une forme finie.
Exemple:
il- il était mangé heu (2) il mangé oui.
Formes inexistantes> formes inexistantes: elle se produit lorsqu'un verbe (y
compris l'auxiliaire de ce verbe) change d'une forme qui n'existe pas en français à
une autre forme inexistante.
Exemple:
diwen- diwe- diwené diwené the he
Formes finies> formes inexistantes: elle se produit lorsqu'un verbe change d'une
forme finie à une forme (y compris l'auxiliaire de ce verbe) qui n'existe pas.
Exemple:
il veut-? il veulé transporter et les dragues
b. ARAA de type dérivationnel se produit lorsque la catégorie grammaticale d'un
mot est changée par la modification, l'ajout ou la suppression d'un affixe attaché au
radical du mot changé.
Exemple:
1. nervé (.)nerveux.
2. danger (prononcé en anglais)- dan- dang- danger (prononcé en anglais) dangrieu.
ARAA syntaxique: ARAA de l'accord sujet-auxiliaire verbe (accord sur le même
verbe) se produit lorsque l'auxiliaire, ou l'auxiliaire et le verbe, est changé sans que
le sujet change afin que l'accord se fasse entre le sujet et l'auxiliaire, ou entre le sujet
et l'auxiliaire et verbe. Notons que dans le cas où l'auxiliaire et le verbe changent de
152

forme en même temps, les formes verbales dans une telle ARAA existent en français,
ce qui distingue ces dernières des formes inexistantes dans les ARAA
morphologiques. Si le sujet et l'auxiliaire, ou le sujet et le verbe (sans auxiliaire), sont
remplacés par un sujet et un verbe différents, ou un sujet et un auxiliaire différents
dans une ARAA, alors on la catégorise comme ARAA pour réduire l'ambiguïté ou
ARAA-D, dépendamment du cas.
Exemple:
1. qui- heu qui a man- heu qui ont mangent- qui ont mangé.
2. entrer- a(.) ont entré
ARAA du choix de l'auxiliaire: se produit lorsque l'auxiliaire est changé sans que
le sujet et le verbe changent.
Exemple:
1. il- il a devenu heu il est devenu très heu(0.5) affolé.
2. ils ont fini enfin les onpri- les prisonnières ils sont fini son : son diner ses dîners.
ARAA de genre (il y a deux types d' ARAA dans cette catégorie: l'accord du genre
sur l'article et l'accord de l'adjectif)
L'accord du genre sur l'article se produit lorsqu'un article est remplacé, ajouté ou
supprimé afin que l'accord sa fasse entre l'article et le nom qu'il qualifie.
Exemple:
1. le (.) la (.) le gros personne.
2. entre le salle entre la salle.
153

L'accord de l'adjectif se produit lorsqu'un adjectif est changé afin que l'accord sa
fasse entre l'adjectif et le nom qu'il qualifie.
Exemple:
grande heu grand.
ARAA d'ordre de mots se produit lorsque l'ordre de mots est changé sans d'autres
modifications dans un énoncé.
Exemple:
il rien peut fait(.) il peut rien fait.
ARAA de nombre se produit lorsque l'article est changé de la forme singulière à la
forme plurielle ou vice versa afin que l'accord se fasse entre l'article et le nom qu'il
qualifie.
Exemple:
le- (0.5) les boudres blancs.
ARAA de pronoms sujets se produit lorsque le pronom sujet d'un énoncé est changé
en nombre ou en genre sans que l'auxiliaire ou le verbe change.
Exemple:
elle a touché(.) elle- heu il a touché heu le pain
ARAA de négation se produit lorsque la position d'un adverbe de négation est
changée ou il y a une insertion ou suppression de ce dernier dans un énoncé.
Exemple:
pas man- mangé pas
154

ARAA de pronoms objets se produit lorsque la position d'un pronom objet, ou le
pronom même, est changée ou lorsqu'il y a une insertion ou suppression de ce dernier
dans un énoncé.
Exemple:
1. s- deman- lui demandé aller on sorti ensemble.
2. Il- il prend- il le prend oui il le prend.
3. pour elle heu pour lui pour-(.) pour eux.
4. prende prende lui prendre he- prende il heu prende il (3) prende he- il.
ARAA lexicale se produit lorsqu'un mot ou un syntagme est remplacé par un autre
mot ou un autre syntagme dans un énoncé, et ne tombe pas dans les catégories
d' ARAA mentionnées ci-dessus. Le mot remplacé ou le réparatum peut être
grammatical ou lexical, ou venir d'une autre langue. En général, le mot remplacé ou
le réparatum appartiennent à la même catégorie grammaticale.
Exemple:
1. rn- man heu (0.5) homme
2. another heu autre homme à heu à autre côté.
155

Protocole du codage (deuxième étape)
Dans ce qui suit, toutes les ARAA recensées sont divisées en quatre catégories, à
savoir énoncé-source correct> énoncé de refonnulation incorrect, énoncé-source
incorrect > énoncé de refonnulation correct, énoncé-source incorrect > énoncé de
refonnulation incorrect et énoncé-source correct > énoncé de refonnulation correct.
D'ailleurs, on décide que les simples répétitions seront catégorisées en fonction de la
justesse de l'énoncé-source puisque dans une répétition, l'énoncé-source est identique
à l'énoncé de refonnulation; donc, elles seront placées dans 3 ou 4 dépendamment de
la justesse de l'énoncé-source.
1. Énoncé-source correct> énoncé de reformulation incorrect
Exemple:
ils ont fini enfin les onpri- les prisonnières ils sont fini
Dans l'énoncé ci-dessus, il y a deux ARAA. Dans la première, l'énoncé-source
correct correspond à ils ont fini et l'énoncé de refonnulation incorrect correspond à ils
sont fini. Dans la deuxième, l'énoncé-source incorrect correspond à les onpri et
l'énoncé de refonnulation incorrect correspond à les prisonnières (voir catégorie 3
Énoncé-source incorrect > énoncé de refonnulation incorrect).
2. Énoncé-source incorrect> énoncé de reformulation correct
Exemple:
another heu autre homme à heu à autre côté.
Dans l'énoncé ci-dessus, il y a deux ARAA. Dans la première, l'énoncé-source
incorrect correspond à another et l'énoncé de refonnulation correct correspond à
autre homme. Dans la deuxième, 1' énoncé-source correct correspond à à et 1' énoncé
de refonnulation correct correspond à à autre côté.
156

3. Énoncé-source incorrect > énoncé de reformulation incorrect
Exemple:
1. danger (prononcé en anglais)- dan- dang- danger (prononcé en anglais) dangrieu
Dans l'énoncé ci-dessus, l'énoncé-source incorrect correspond à danger- dan- dong
danger et l'énoncé de reformulation incorrect correspond à dangrieu.
2. mauvaise n'homme(.) mauvaise n'homm
Dans cette répétition, 1 'énoncé-source qui correspond à mauvaise n'homme est
incorrect.
4. Énoncé-source correct > énoncé de reformulation correct
Exemple:
quelqu'un qui- il y a des policiers
Dans l'énoncé ci-dessus, l'énoncé-source correct correspond à quelqu'un qui et
l'énoncé de reformulation correct correspond à il y a des policiers.
157

RÉFÉRENCES
Arroyo, E. (2003). La reformu1ation en communication exolingue chez des locuteurs hispanophones parlant français. Marges linguistiques, septembre-octobre. http://www.marges-linguistiques.com. Consulté le 4 juin 2015.
Arditty, J., & Blanchet, P., (2008). La 'mauvaise langue' des 'ghettos linguistiques': la glottophobie française, une xénophobie qui s'ignore. Asylon(s), n°4. http://www.reseau-terra.eu/article748. html. Consulté le 10 novembre 2016.
Bada, E. (20 1 0). Repetitions as vocalized fillers and self-repairs in English and French interlanguages. Journal of Pragmatics, 42, 1680-1688.
Baker, P., & Ellece, S. (2011). Key terms in discourse analysis. London: Continuum.
Bange, P., & Kem, S. (1996). La régulation du discours en LI et en L2. Études Romanes, 35, 69-103.
Berg, T. (1986). The problem of language control: Editing, monitoring and feedback. Psycho/ogica/ Research, 48, 133-144.
Blackmer, E. R., & Mitton, J. L. (1991). Theories of monitoring and the timing of repairs in spontaneous speech. Cognition, 39, 173-194.
Brédart, S. (1991 ). Word interruption in self-repairing. Journal of Psycho/inguistic Research, 20, 123-137.
Brown, J. D. (1980). Relative merits of four methods for scoring cloze tests. Modem · Language Journal, 64, 311-317.
Camussi-Ni, M. A. (2005). Difficultés linguistiques des apprenants chinois : les variations morphologiques. Actes du Colloque Diversités culturelles et apprentissage du FLE (pp. 167-178). Paris, Éditions de l'École Polytechnique.
Carroll, D. W. (2007). Psycho/ogy of language. Australia: Thomson/W adsworth.
Chen, L., Li, J ., & Zhao, W. (2005). Gender differences in self-repairs by Chinese non-English majors in their spoken English. Modem Foreign Languages (Xiandai Waiyu), 28, 279-287.
Chen, L., & Pu, J. (2007). A corpus-based analysis of self-repairs by college nonEnglish majors. Foreign Language Education (Waiyu Jiaoxue), 28, 57-61.
158

------------------------
Chen, Y. C. (2003). L'enseignement du français langue étrangère à Taiwan: analyse linguistique et praxéologique. Thèse de doctorat inédite, Université catholique de Louvain, Belgique.
Csépe, V. (2006). Lieracy Acquisition and Dyslexia in Hungarian. Dans R. M. Joshi et P. G. Aaron (Dir.), Handbook of Orthography and Literacy (Vol. 15, pp. 231-247). London: LEA.
de Bot, K. (1992). A bilingual production model: Levelt's "speaking" model adapted. Applied Linguistics, 13, 1-24.
Dell, G. S. (1986). A spreading-activation theory of retrieval in sentence production. Psychological Review, 93, 283-321.
Dell, G. S., & O'Seaghda, G. P. (1991). Mediated and convergent lexical priming in language production: A comment on Levelt et al. Psychological Review, 98, 604-614.
Derwing, T. M., Munro, M. J., Thomson, R. 1., & Rossiter, M. J. (2009). The relationship between L 1 fluency and L2 fluency development. Studies in Second Language Acquisition, 31, 533-557.
Derwing, T. M., & Munro, M. J. (2013). The development ofL2 oral language skills in two LI groups: A 7-year study. Language Learning, 63, 163-185.
Fathman, A. K. ( 1980). Repetition and correction as an indication of speech planning and execution processes among second language leamers. Dans H. W. Dechert & M. Raupach (dir.), Towards a crosslinguistic assessment of speech production (pp. 77-85). Frankfurt, Germany: Peter D. Lang.
Fincher, A. (2006). Functions of self-initiated self-repairs in an advanced Japanese language classroom. Thèse inédite. Griffith University, Australie.
Poster, P., & Skehan, P. (1996). The influence of planning and task type on second language performance. Studies in Second Language Acquisition, 18, 293-323.
Fox, B., Hayashi, M., & Jasperson, R. (1996). Resources and repair: A crosslinguistic study of the syntactic organization of repair. Dans E. Ochs, E. A. Schegloff & S. A. Thompson (dir.), Interaction and Grammar (pp. 185-237). Cambridge: Cambridge University Press.
Fox, B., & Jasperson, R. (1995). A syntactic exploration of repair in English conversation. Dans P. Davis (dir.), Alternative linguistics: Descriptive and theoretical modes (pp. 77-134). Amsterdam: John Benjamins.
159
l

Fox, B., Wouk, F., Hayashi, M., Fincke, S., Tao, L., Sorjonen, M. L., & Hemandez, W. F. (2009). A cross-linguistic investigation of the site of initiation in sametum self-repair. Dans J. Sidnell (dir.), Conversation analysis: Comparative perspectives (pp. 61-1 03). Cambridge: Cambridge University Press.
Fox, B., Maschler, Y., & Uhmann, S. (2010). A cross-linguistic study of self-repair: Evidence from English, German, and Hebrew. Journal of Pragmatics, 42, 2487-2505.
Fraenkel, J. R. & Wallen, N. E. (2003). How to design and evaluate research in education (5th ed.). Boston: McGraw-Hill.
Fromkin, V. A. ( 1971 ). The non-anomalous nature of anomalous utterances. Language, 47, 27-52.
Fromkin, V. A. (1973). Speech errors as linguistic evidence. The Hague: Mouton.
Garrett, M. F. (1975). The analysis of sentence production. Dans G. H. Bower (dir.), The psycho/ogy of learning and motivation (pp. 133-177). New York: Academie Press.
Gass, S., Mackey, A., Alvarez-Torres, M. J., & Femandez-Garcia, M. (1999). The effects oftask repetition on linguistic output. Language Learning, 49, 549-581.
Gilabert, R. (2007). Effects of manipulating task complexity on self-repairs during L2 oral production. International Journal of Applied Linguistics, 45, 215-240.
Griggs, P. (1997). Metalinguistic work and the development of language use in communicative pairwork activities involving second language leamers. Dans C. Perez et L. Diaz (Dir.), Views on the acquisition and use of a second language (pp. 403-415). Universitat Pompeu Fabra.
Griggs, P. (2002). À propos de l'effet de l'activité métalinguistique sur les processus de production en L2. Dans D. Véronique et F. Cicurel (dir.), Discours, action et appropriation des langues (pp. 53-66). Paris: Presses de la Sorbonne Nouvelle.
Hayashi, M. (1994). A comparative study of self-repair in English and Japanese conversation. Dans N. Akatsuka (dir.), Japanese/Korean Linguistics (pp. 77-93). Stanford: Center for the Study of Language and Information.
160

Hennoste, T. (2005). Repair-initiating particles and um-s in Estonian spontaneous speech. Dans Proceedings of Disjluency in Spontaneous Speech Workshop (pp. 83-88). Aix-en-Provence, France.
Ivanova-Foumier, P. (2009). Certaines difficultés de l'apprentissage du français par des sinophones, Études françaises, 7 4, 86-91.
Jefferson, G. (1984). Transcript notation. Dans J. M. Atkinson & J. Heritage (dir.), Structures of social action: Studies in conversation analysis (pp. ix-xvi). Cambridge: Cambridge University Press.
Kaur, J. (20 Il). Raising explicitness through self-repair in English as a lingua franca. Journal ofPragmatics, 43, 2704-2715.
Kempen, G., & Hoenkamp, E. (1987). An incrementai procedural grammar for sentence formulation. Cognitive Science, 11, 201-258.
Klein, W. (1994). Time in Language. London: Routledge.
Kormos, J. (1998). A new psycholinguistic taxonomy of self-repair in L2: A qualitative analysis with retrospection. Even Yearbook, ELTE SEAS Working Papers in Linguistics, 3, 43-68.
Kormos, J. (1999a). Monitoring and self-repair in L2. Language Learning, 49, 303-342.
Kormos, J. (1999b). The effect of speaker variables on the self-correction behaviour of L2 leamers. System, 27, 207-221.
Kormos, J. (2000a). The role of attention in monitoring second language speech production. Language Learning, 50, 343-384.
Kormos, J. (2006). The structure of self-repairs in the speech of Hungarian leamers of English. Acta Linguistica Hungarica, 53, 53-76.
Lennon, P. ( 1990). Investigating fluency in EFL: A quantitative approach. Language Learning, 40,387-417.
Larson-Hall, J. (2010). A guide to doing statistics in second language research using SPSS. New York: Routledge.
Levelt, W. J. M. (1983). Monitoring and self-repair in speech. Cognition, 33,41-103.
161

Levelt, W. J. M. (1989). Speaking: From intention to articulation. Cambridge: MIT Press.
Levelt, W. J. M. ( 1999). Language production: A blueprint of the speaker. Dans C. Brown & P. Hagoort (dir.), Neurocognition of language (pp. 83-122). Oxford, England: Oxford University Press.
Liu, L. (1989). Les Erreurs des étudiants chinois dans l'apprentissage du français. Québec : Centre international de recherche sur le bilinguisme.
Liu, J. T. (2009). Self-repair in oral production by intermediate Chinese learners of English. TESL-EJ, 13, 1-15.
Mackey, A., & Gass, S. M. (2005). Second language research: Methodology and design. Mahwah, NJ: Lawrence Erlbaum Associates.
Ministère de l'Immigration et des Communautés culturelles (MICC). (2006). Portraits statistiques des groupes ethnoculturels. Montréal: Direction de la recherche et de l'analyse prospective. Document accessible par Internet: http://www.quebecinterculturel.gouv.qc.ca/fr/diversite-ethnoculturelle/statsgroupes-ethno/recensement-2006.html
Ministère de l'Immigration et des Communautés culturelles (2012). Tableaux sur l'immigration permanente au Québec (2007-2011). Document accessible par Internet : http://www .micc.gouv .qc.ca/fr/recherches-statistiques/statsimmigrationrecente.html
Mojavezi, A., & Ahmadian, M. J. (2014). Working memory capacity and self-repair behavior in first and second language oral production. Journal of Psycho/inguistic Research, 43(3), 289-97.
Nagano, R. L. (1997). Self-repair of Japanese speakers of English: A preliminary comparison with a study by W. J. M. Levelt. Bulletin of Science and Humanities, 65-90.
O'Connor, N. ( 1988). Repairs as an indicative of interlanguage variation and change. Dans T. J. Walsh (dir.), Georgetown University Round Table in Languages and Linguistics 1988: Synchronie and Diachronie Approaches to Linguistic Variation and Change (pp. 251-259). Washington, DC: Georgetown University Press.
Olier, J. W., Jr. (1972a). Scoring methods and difficulty levels for cloze tests of proficiency in English as a second language. Modern Language Journal, 56, 151-158.
162

Postma, A., & Kolk, H. (1992). The effects of noise masking and required accuracy on speech errors, disfluencies, and self-repairs. Journal of Speech and Hearing Research, 35, 537-544.
Rieger, C. L. (2003). Repetitions as self-repair strategies in English and German conversations. Journal of Pragmatics, 35, 47-69.
Robinson, P. (1995). Attention, memory and the "noticing" hypothesis. Language Learning, 45, 283-331.
Salonen, T., & Laakso, M. (2009). Self-repair of speech by four-year-old Finnish children. Journal of Child Language, 36, 855-882.
Schegloff, E. A., Jefferson, G., & Sacks, H. (1977). The preference for self-correction in the organization ofrepair in conversation. Language, 53, 361-382.
Schegloff, E. A. (l997b ). Practices and actions: Boundary cases of other-initiated repair. Discourse Processes, 23, 499-545.
Sega1owitz, N. (20 1 0). The cognitive bases of second language flue ney. New York: Routledge.
Simard, D., Fortier, V., & Zuniga, M. (2011). Attention et production d'autoreformulations autoamorcées en français langue seconde, quelle relation? Journal of French Language Studies, 21, 417-4 36.
Simard, D., Bergeron, A., Liu, Y. G., Nader, M., & Redmond, L. (2016). Production d'autoreformulations autoamorcées en langue seconde: rôle de l'attention et de la mémoire phonologique. Canadian Modern Language Review.
Simard, D., French, L., & Zuniga, M. (2017). Evolution of L2 self-repair behavior over time among adult learners of French. Revue canadienne de linguistique appliquée.
Skehan, P., & Foster, P. (1997). Task type and task processing conditions as influences on foreign language performance. Language Teaching Research, 1,185-212.
Skehan, P., & Foster, P. (1999). The influence of task structure and processing conditions on narrative retellings. Language Learning, 49, 93-120.
Stemberger, J. P. (1985). An interactive activation model of language production. Dans A. W. Ellis (dir.), Progress in the psycho/ogy of language (pp. 143-186). Hillsdale NJ: Lawrence Erlbaum Associates.
163

Sun, J. L. (2003). Comment se développe la morphologie verbale en français L2 chez les sinophones. Marges Linguistiques, 5, 93-105.
Sun, J. L. (2008) Conceptualisation étendue du temps topique dans les narrations des apprenants sinophones en français langue étrangère. Acquisition et interaction en langue étrangère, 26, 71-88.
Stubbs, J. B., & Tucker, G. R. (1974). The cloze test as a measure ofESL proficiency for Arab students. Modern Language Journal, 58, 239-241.
Tan, J. (2011). L'acquisition de la spatialité en français chez les étudiants chinois: étude longitudinale. Thèse de doctorat inédite, Université Paris Ouest Nanterre La Défense, France.
Tarone, E. ( 1980). Communication strategies, foreigner talk and repair in interlanguage. Language Learning, 30, 417-431.
Tremblay, A & Garrison, M. O. (2010). Cloze Tests: A Tool for Proficiency Assessment in Research on L2 French. Dans M. T. Prior et al (dir.) Selected Proceedings of the 2008 Second Language Research Forum, (pp.73-88). Somerville, MA: Cascadilla Proceedings Project.
Tseng, S. C. (2006). Repairs in Mandarin conversation. Journal of Chinese Linguistics, 34, 80-120.
Xu, D. (2004). Introduction to Chinese Syntax. Beijing: Beijing Language and Culture University Press
Yang, L. (2002). The effect of English proficiency on self-repair behavior of EFL learners. Shandong Foreign Languages Journal (Shandong Waiyu Jiaoxue), 4, 74-76.
Yu, H. J. (1993). Difficultés d'apprentissage de la morphologie française par les étudiants chinois. Thèse de doctorat inédite, Université de Montréal, Canada.
Yuan, F., & Ellis, R. (2003). The effects ofpre-task planning and on-line planning on fluency, complexity and accuracy in L2 monologic oral production. Applied Linguistics, 24, 1-27.
van Hest, E. (1996). Selfrepair in L1 and L2 production. Tilburg: Tilburg University Press.
164

van Hest, E., Poulisse, N. & Bongaerts, T. (1997). Self-repair in LI and L2 production: an overview. International Journal of Applied linguistics, 117-118, 85-115.
Verhoeven, L. T. (1989). Monitoring in children's second language speech. Second Language Research, 5, 141-155.
Wang, P. (1993). L'apprentissage du français chez les immigrants d'origine chinoise: les difficultés d'apprentissage d'ordre linguistique. Québec français, 89, 52-55.
165