Embed Size (px)
Citation preview

研究生模糊数学

第四章 隶属函数的确定方法

在模糊理论的应用中,我们面临的首要问
题就是建立模糊集的隶属函数。对于一个特定的模糊集来说,隶属函数不仅基本体现了它所反映的模糊概念的特性,而且通过量化还可以实现相应的数学运算和处理。因此,“正确地”确定隶属函数是应用模糊数学理论恰如其分地定量刻划模糊概念的基础,也是利用模糊数学方法解决各种实际问题的关键。

然而,建立一个能够恰如其分地描述模糊
概念的隶属函数,并不是一件容易的事情。其原因就在于,一个模糊概念所表现出来的模糊性通常是人对客观模糊现象的主观反映。隶属函数的形成过程基本上是人的心理过程,人的主观因素和心理因素的影响使得隶属函数的确定呈现出复杂性、多样性,也导致到目前为止如何确定隶属函数尚无定法,没有通用的定理或公式可以遵循。

但即便如此,鉴于隶属函数在模糊理论中
的重要地位,确定隶属函数的方法还是受到了特别的重视。
至今已经提出了十几种确定隶属函数的方
法,而且其中一些方法基本上摆脱了人的主观因素的影响。本章将选择 4 种经常使用的、具
有代表性的方法予以介绍,它们是:直觉方法,二元对比排序法,模糊统计试验法,最小模糊度法。

主要内容
4.1 直觉方法
4.2 二元对比排序法
4.3 模糊统计试验法
4.4 最小模糊度法
4.5 模糊分布
补充:待定系数法

4.1 直觉方法
直觉的方法就是人们用自己对模糊概念的
认识和理解或者人们对模糊概念的普遍认同来建立隶属函数。直觉的方法非常简单,也很直观,但它包含着对象的背景、环境以及语义上的有关知识,也包含了对这些知识的语言学描述,通常用于描述人们熟知、有共识的客观模糊现象,或者用于难于采集数据的情形。

例 1 考虑描述空气温度的模糊变量或语言
变量,我们取之为“很冷”、“冷”、“凉爽”、“适宜”和“热”,则凭借我们对这几个模糊概念的认知和理解,可以规定这些模糊集的隶属函数曲线如图 1 所示。
图 1 空气温度的隶属函数
0 5 10 15 20 25 30
0.5
1很冷 热适宜凉爽冷

例 2 根据人们对汽车行驶速度中“慢速”、
“中速”和“快速”这三个概念的普遍认同,可以给出描述这三个概念的模糊集的隶属函数如图 2 所示。
图 2 汽车行驶速度的隶属函数0 35 55 75 95
0.5
1慢速 中速 快速

虽然直觉的方法非常简单,也很直观,但
它却包含着对象的背景、环境以及语义上的有关知识,也包含了对这些知识的语言学描述。因此,对于同一个模糊概念,不同的背景、不同的人可能会建立出不完全相同的隶属函数。例如,模糊集 A = “高个子”的隶属函数。如
果论域是“成年男性”,其隶属函数的曲线如图 3(a) 所示;而如果论域是“初中一年级男生”,其隶属函数的曲线则为图 3(b) 所示的情形。

(a) (b)
图 3 不同论域下“高个子”的隶属函数
140 170 185 2000
0.5
1
x
T x( )
140 155 170 2000
0.5
1
x
T x( )

4.2 二元对比排序法
有些模糊概念不仅外延是模糊的,其内涵
也不十分清晰,如“舒适性”、“满意度”等。对于这样的模糊集建立隶属函数,实际上可以看成是对论域中每个元素隶属于这个模糊概念的程度进行比较、排序。但一般来讲,人们对多个对象的同时比较存在着度量上的困难,为此 Saaty 教授在设计层次分析法时提出了两两比
较的策略。借鉴两两比较排序的思想,人们提出了确定隶属函数的二元对比排序法。

二元对比排序方法就是通过对多个对象进
行两两对比来确定某种特征下的顺序,由此来决定这些对象对该特征的隶属程度。这种方法更适用于根据事物的抽象性质由专家来确定隶属函数的情形,可以通过多名专家或者一个委员会,甚至一次民意测验来实施,是一种比较实用的确定隶属函数的方法。

设U = {x, y, z, …}为给定的论域,A是某一
模糊概念。二元对比排序法的实施步骤为:
1° 对任取的一对元素 x, y∈U 进行比较,得到以 y 为标准 x 隶属于 A 的程度值 fy(x),以及以 x 为标准 y 隶属于 A 的程度值 fx(y)。
2°计算相对优先度函数:
(4.1)
或
Uyxxfyf
xfyxf
yx
y ∈∀= , ,)}(),(max{
)()/(

(4.2)
显然,0 ≤ f (x/y) ≤ 1,∀ x, y∈U。
3° 以 f(x/y)为元素构造一个矩阵 G,称为相
对优先矩阵:
Uyxxfyf
xfyxf
yx
y ∈∀+
= , ,)()(
)()/(
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
MMMM
L
L
L
)/()/()/()/()/()/()/()/()/(
zzfyzfxzfzyfyyfxyfzxfyxfxxf
G

4° 对相对优先矩阵 G 的每一行取最小值或平均值,即得 A 的隶属函数为
或
UxyxfxAUy
∈∀=∈
)},/({min)(
UxyxfU
xAUy
∈∀= ∑∈
,)/(||
1)(

例 3 设U={x, y, z}表示三种服装款式构成的论域,A 表示按照某人的标准对服装款式“满意”。对于∀x, y∈U,按照表 1中给出的方法进行两两比较来计算 fy(x)、fx(y)的值。
表 1 两两比较评分表
元素 x,y 相比较 fx (y) 的取值 fy (x) 的取值
x 比 y 隶属于 A 的程度相同 1 1x 比 y 隶属于 A 的程度稍微大 1 3x 比 y 隶属于 A 的程度明显大 1 5x 比 y 隶属于 A 的程度突出大 1 7x 比 y 隶属于 A 的程度绝对大 1 9介于上述某两个判断之间 1 2、4、6、8

假设经过二元对比得到:
fy(x) = 7,fx(y) = 1fz(y) = 2,fy(z) = 1fz(x) = 8,fx(z) = 1
则根据相对优先度函数公式 (4.1) 有:
f (x/x) = 1,f (x/y) = 1,f (x/z) = 1f (y/x) = 1/7,f (y/y) = 1,f (y/z) = 1f (z/x) = 1/8,f (z/y) = 1/2,f (z/z) = 1

于是可以求得相对优先矩阵:
如果对 G 的每一行取最小值,则得 A(x) 为A(x) = 1,A(y) ≈ 0.1429,A(z) = 0.125
如果对 G 的每一行取平均值,则得 A(x) 为A(x) = 1,A(y) ≈ 0.7143,A(z) ≈ 0.5417
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡=
12/18/1117/1111
G
例 4 某汽车研究所拟对 4 种车型 a、b、c、d 的乘坐舒适性进行评估。为此,令 U = {a, b, c, d},A = {乘坐舒适性},并挑选 10 名长期从
事汽车道路试验的技术人员和司机,通过实际乘坐进行评估,评估方法为:任取两辆车编成一组进行对比,以先乘坐的一辆车为基准,以后乘坐的一辆车为对象作相对比较评分,评分标准如表 2 所示。
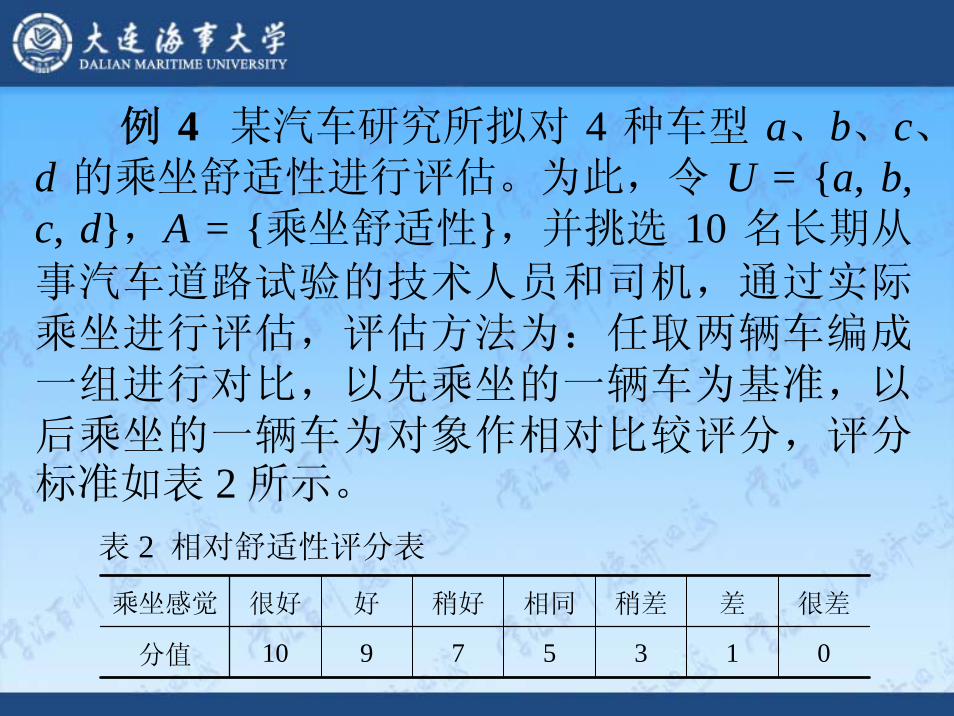
表 2 相对舒适性评分表
乘坐感觉 很好 好 稍好 相同 稍差 差 很差
分值 10 9 7 5 3 1 0

例如,先乘 b 车再乘 a 车,相对于 b 车,10 人对 a 车评分的总和为 83 分,则取 fb(a) = 0.83,fa(b) = 0.17。如此得到的所有评分结果,如表 3 所示。
表 3 相对舒适性得分表
基准 yfy(x)
a b c d
a 0.50 0.63 0.70 0.79
b 0.37 0.50 0.68 0.69
c 0.30 0.32 0.50 0.74
d 0.21 0.31 0.26 0.50
对象x

(1) 如果采用相对优先度函数公式 (4.1),则
有:
f (a/a) = 1,f (a/b) = 1,f (a/c) = 1,f (a/d) = 1
f (b/a) = 37/63,f (b/b) = 1,f (b/c) = 1,f (b/d) = 1
f (c/a) = 30/70,f (c/b) = 32/68,f (c/c) = 1,f (c/d) = 1
f (d/a) = 21/79,f (d/b) = 31/69,f (d/c) = 26/74,f (d/d) = 1

可求得相应的相对优先矩阵为
于是
若对相对优先矩阵 G 的每一行取最小值,则得 A 的隶属函数为
A(a) = 1,A(b) ≈ 0.5873A(c) ≈ 0.4286,A(d) ≈ 0.2658
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
174/2669/3179/211168/3270/3011163/371111
G

若对相对优先矩阵 G 的每一行取平均值,则得 A 的隶属函数为
A(a) = 1,A(b) ≈ 0.8968A(c) ≈ 0.7248,A(d) ≈ 0.5166

(1) 如果采用相对优先度函数公式 (4.2),则
有:
f (a/a) = 0.5,f (a/b) = 0.63,f (a/c) = 0.70,f (a/d) = 0.79
f (b/a) = 0.37,f (b/b) = 0.50,f (b/c) = 0.68,f (b/d) = 0.69
f (c/a) = 0.30,f (c/b) = 0.32,f (c/c) = 0.50,f (c/d) = 0.74
f (d/a) = 0.21,f (d/b) = 0.31,f (d/c) = 0.26,f (d/d) = 0.50

可求得相应的相对优先矩阵为
于是
若对相对优先矩阵 G 的每一行取最小值,则得 A 的隶属函数为
A(a) = 0.50,A(b) = 0.37A(c) = 0.30,A(d) = 0.21
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
50.026.031.021.074.050.032.030.069.068.050.037.079.070.063.050.0
G

若对相对优先矩阵 G 的每一行取平均值,则得 A 的隶属函数为
A(a) = 0.655,A(b) = 0.56A(c) = 0.465,A(d) = 0.32

4.3 模糊统计试验法
由Bernoulli大数定律我们知道:在n次重复独立试验中,如果事件 A 发生的频数为 nA,则
对于任意的 ε > 0 有 ,其中p是
是事件 A 在每次试验中发生的概率。这一结论
说明,在次数足够多的重复独立随机试验中,随机事件的频率总是稳定在它发生的概率值附近,即事件发生的概率可以通过大量的统计试验来近似确定。
1 ||lim =⎭⎬⎫
⎩⎨⎧ <−
→∞εp
nnP A
n

借用概率论的思想,人们设计了一种称之
为模糊统计试验的方法来获得隶属函数:为了确定论域 X中的某个元素 u0 对描述某个模糊概念的模糊集A的隶属关系(即隶属度),进行n次重复独立统计试验。由于每次试验的条件不同(带有模糊性),那么每次试验中论域中哪些元素被判定为隶属于A是不大明确的。

如果将每次试验中被判定隶属于 A 的元素构成的集合均记为A*,显然A*是论域X上的分
明子集,并且是边界可变的、可移动的,我们通常将 A*作为模糊集 A的弹性疆域。由于每次试验中或者u0∈A*或者u0∉A*,因而令u0∈A*的次数为m,并称m/n为u0对A的隶属频率。随着n的增大,隶属频率会呈现稳定性,而隶属频率稳定所在的数值,就定为 u0 对 A的隶属度A(u0)。

模糊统计试验方法的基本步骤是:① 在每一次试验下,要对论域中固定的元
素 u0 是否属于一个可变动的分明集合 A* (A*作为模糊集A的弹性疆域)作一个确切的判断;注意,在每一次试验下,A*必须是一个确定的清
晰集合;
② 在各次试验中,u0是固定的,而A*在随机变动;如果在所作的 n 次试验中,元素 u0 属于A*的次数为m,则元素 u0 对A的隶属频率定义为:

当试验次数 n 足够大时,元素 u0 的隶属频率总是稳定于某一数,这个稳定的数即为元素u0对A的隶属度。
nmAuAu
*0
0试验的总次数
的次数”“的隶属频率对
∈=

例 5 为建立“青年人”的隶属函数,以人的年龄作为论域 X。
① 调查若干人选,各自认真考虑“青年人”
的含义之后,提出他认为“青年人”最合适的年龄区间(随机地将模糊概念明确化)。表 4 记录了 129 人关于“青年人”年龄区间的调查结果。如果设A =“青年人”,那么表中每个区间就是每次试验中的 A*。

18−25 18−30 17−30 20−35 15−28 18−25 18−35 19−28 17−30 16−30
15−28 15−25 16−28 18−30 18−25 18−28 17−30 15−30 18−30 18−35
15−25 17−25 17−30 18−35 18−25 18−30 16−28 18−30 18−35 15−30
18−35 15−28 15−25 16−32 18−30 18−35 17−30 18−35 16−28 20−30
16−30 18−35 18−35 18−29 17−28 18−35 18−35 18−25 18−30 16−28
17−27 15−26 16−35 18−35 15−25 15−27 18−35 16−30 14−25 18−25
18−30 20−30 18−28 18−30 15−30 18−28 18−25 16−25 20−30 18−35
18−30 18−30 16−28 17−25 16−30 18−30 15−25 18−35 18−30 18−28
18−26 16−35 16−28 16−25 15−35 17−30 15−25 16−35 15−30 18−30
15−25 16−30 16−30 15−28 15−36 15−25 17−28 18−30 16−25 18−30
17−25 18−29 17−29 15−30 17−30 16−30 16−35 15−30 14−25 18−35
16−30 18−30 18−35 16−28 18−25 18−30 18−28 18−35 16−24 18−30
17−30 15−30 18−35 18−25 18−30 15−30 15−30 17−30 18−30
② 对∀u0∈X,求出 u0对A的隶属频率稳定值,作为u0对A的隶属度值。
比如,对于 u0 = 27(岁),根据对表 4 的随机抽样得知:当样本总数n=10, 20, …, 120, 129时,样本区间覆盖 27 的频数 m = 6, 14, …, 95, 101,相应的隶属频率 f = m/n = 0.60, 0.70, …, 0.79, 0.78,具体数据参见表5。以n为横坐标、f为纵坐标绘制图形(图 4)可以发现,u0 = 27对 A的隶属频率稳定在 0.78 附近,因此“27(岁)”对模糊集“青年人”A的隶属度确定为0.78。

表 5 不同样本下 u0 = 27 的隶属频率
图 4 u0 = 27的隶属频率稳定值
n 10 20 30 40 50 60 70 80 90 100 110 120 129
m 6 14 23 31 39 47 53 62 68 76 85 95 101
f 0.60 0.70 0.77 0.78 0.78 0.78 0.76 0.78 0.76 0.76 0.77 0.79 0.78
0 10 30 50 70 90 110 129
0.6
0.7
0.78
x
f

类似地,对 ∀x∈[0, 40],求出 x 对 A 的隶属频率值,作为 x 对 A 的隶属度值,见表 6。表 6 论域中每个元素对 A 的隶属频率
x 11 12 13 14 15 16 17 18 19 20
A(x) 0 0 0 0.016 0.209 0.395 0.519 0.961 0.969 1
x 21 22 23 24 25 26 27 28 29 30
A(x) 1 1 1 1 0.992 0.798 0.783 0.767 0.620 0.597
x 31 32 33 34 35 36 37 38 39 40
A(x) 0.209 0.209 0.202 0.202 0.202 0.008 0 0 0 0
A(x) = 0,当 x∈[0, 10]∪[40, 100] 时
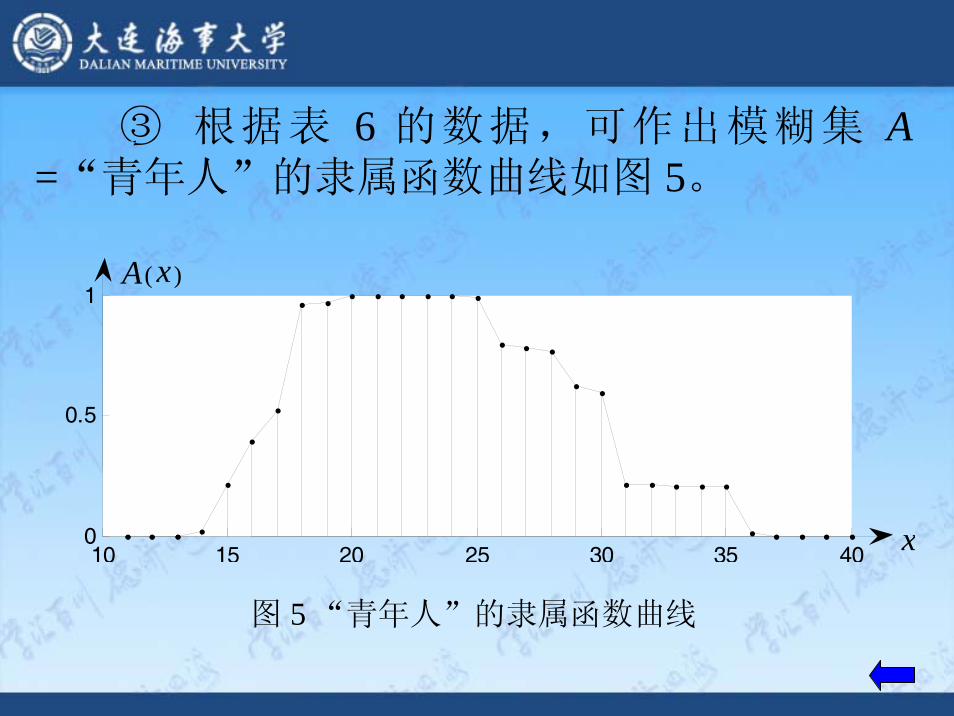
③ 根据表 6 的数据,可作出模糊集 A =“青年人”的隶属函数曲线如图 5。
图 5 “青年人”的隶属函数曲线
10 15 20 25 30 35 400
0.5
1
x
A x( )

模糊统计试验方法可以比较客观地反映论
域中元素相对于模糊概念的隶属程度,也具有一定的理论基础,因而是一种常用的确定隶属函数的方法。但需要指出的是,模糊统计与概率统计是有区别的:概率统计可以理解为“变动的点”是否落在“不动的圈内”,而模糊统计则可理解为“变动的圈”是否覆盖住“不动的点”,如图 6 所示。

概率统计试验:A 固定,ω随机变化
ΩA
ωS
A*
x0 X
模糊统计试验:x0 固定,A* 随机变化
图 6 模糊统计与概率统计的区别示意图

此外还应注意,在进行模糊统计试验时,
被调查人员应该对所统计的模糊概念比较熟悉,并且了解影响这一概念的重要因素。比如对于例5,被调查人员应该对影响“青年人”这
一概念的一些重要因素,诸如入学年龄、入团年龄、参军年龄、结婚年龄、生育年龄、身份证发放年龄等等比较熟悉,被调查人员还应该具备用数量近似表达某一概念的能力。同时,调查完毕后,要对原始数据进行初步分析,删去明显不合逻辑的数据。

4.4 最小模糊度法
实际应用中经常会出现这样的问题:通过
先验知识或者采集到的部分数据,已经对某个或某些模糊概念所呈现的状态特征有了粗略的了解。但由于同一个模糊概念可以用多种形式不完全相同的隶属函数(模糊集)来描述,因而需要找到一个隶属函数使之能够“恰当地”描述这个模糊概念。

那么,在描述同一个模糊概念的诸多隶属
函数中哪一个是所谓“好的”或“恰当的”?原则上来讲,一个好的描述应该在反映模糊概念的模糊特性同时,又尽可能清晰地描述出评价指标所表达的客观实际内容。

从模糊集的模糊性度量角度我们知道,只要是不恒为 1 或 0 的隶属函数均可反映出模糊
概念的模糊性,而反映事物客观性的清晰程度则可用模糊集的模糊度来度量,模糊度越小的模糊集其表达问题本质的把握性就越大。确定隶属函数的最小模糊度法就是基于这种思想提出的,其基本思路为:根据先验知识和采集的数据,确定出描述模糊概念的候选隶属函数,利用最小化模糊度的原则计算相关的参数,进而获得合适的隶属函数。
下面通过一个具体例子说明详细过程。

例 6 家用轿车通常可分为“经济型”、
“普通型”和“豪华型”三种类型,判别轿车属于哪种类型的一个重要评价指标就是价格。但实际生活中,三种类型轿车的价格是有交叠的,有时很难从车的价格明确判断出车的类型,也就是说所谓的“经济型”、“普通型”和“豪华型”三个概念本质上都是模糊的。
表 7 是从三种类型中各抽取 10 个典型车型
调查、统计的销售价格,我们希望以轿车的价格作为变量建立描述这三个模糊概念的隶属函数。

表 7 30 个车型的价格统计表
类 型 汽车价格(以 1000 美元为单位)
经济型 5.5,5.8,7.5,7.9,8.2,8.5,9.2,10.4,11.2,13.5
普通型 11.9,12.5,13.2,14.9,15.6,17.8,18.2,19.5,20.5,24.0
豪华型 22.0,23.5,25.0,26.0,27.5,29.0,32.0,37.0,43.0,47.5

按照统计学的观点,评价指标统计数据的
均值最能反映这个指标的平均特征,偏离均值越大的值,其所反映的特征偏离平均特征越大。于是以轿车的价格作为变量来描述“经济型”、“普通型”和“豪华型”这三个模糊概念时,图 7所示的三类隶属函数(三角形隶属函数、梯
形隶属函数、高斯型隶属函数)可以作为备选的隶属函数,需要我们进一步确定的就是待定参数 t1 和 t2。

(a) 三角形隶属函数
(b) 梯形隶属函数
0
0.5
1
8.8 16.8 31.3t t1 2
0
0.5
1
8.8 16.8 31.3t t1 2

(c) 高斯型隶属函数
图 7 描述“经济型”、“普通型”和“豪华型”三个模糊概念
备选的隶属函数
0
0.5
1
8.8 16.8 31.3t t1 2

然而, t1 和 t2 都是可变的(其中 t1∈(8.8, 16.8),t2∈(16.8, 31.3),8.8、16.8、31.3 分别是三种类型轿车价格的均值),因此,参数 t1 和 t2的最佳取值就是使得三个模糊集的模糊度达到最小的值。
设论域 X = {x1, x2, …, x30} = {5.5, 5.8, …, 43.0, 47.5},表示“经济型”、“普通型”和“豪华型”这三个模糊概念的模糊集分别为 A、B、C,如果我们选择三角形隶属函数,选择模
糊熵作为模糊度的度量,则可建立如下的优化模型:

⎪⎪⎩
⎪⎪⎨
⎧
>
≤<−−
<
=
⎪⎪⎪
⎩
⎪⎪⎪
⎨
⎧
≤<−−
≤<−
−
=
⎪⎪⎩
⎪⎪⎨
⎧
≤<−−
≤
=
++= ∑=
8.16,0
8.16,8.168.16
,1
)(
others,0
8.16,8.16
8.16,8.16
)(
others,0
8.16,8.168.16
,1
)(
.s.t
)]}([)]([)]([{2ln30
1),,(min
22
2
22
2
11
1
11
1
30
1
x
txtx
xt
xC
txt
xt
xtt
tx
xB
xttx
tx
xA
xCsxBsxAsCBAHi
iii

其中
求解上述优化问题得:t1 = 13.5,t2 = 22,于是得到描述模糊概念“经济型”、“普通型”和“豪华型”的三个模糊集(三角形隶属函数)如图 8 所示。
⎩⎨⎧
==∈−−−−
=0 1,0
)1,0(),1ln()1(ln)(
xxxxxxx
xs或

图 8 描述“经济型”、“普通型”和“豪华型”三个模糊概念的隶属函数
10 13.5 16.8 22 30 400
0.5
1经济型 普通型 豪华型

4.5 模糊分布
模糊概念是客观事物本质属性在人们头脑
中的反映,是人类社会在长期发展过程中约定俗成的东西;隶属函数的形成过程既包含着人脑的加工,也包含着某种心理过程。所以,隶属函数的确定应该反映出客观模糊现象的具体特点,要符合客观规律。

但由于模糊现象本身存在着差异,并且每
个人在知识储备、实践经验、理解能力和判断能力等方面各有所长,因此即使对于同一模糊概念的认定和理解,也会具有差异性,不同的人可能会给出不同的隶属函数。值得庆幸的是,在实际应用中,描述模糊概念的曲线(隶属函数)其精确形状并不那么重要,我们所关注的是模糊集的数目及模糊集之间的交迭特征。

如果考虑以实数集 R 作论域,通常把实数集 R 上模糊集的隶属函数称为模糊分布。当所
讨论的客观模糊现象的隶属函数与某种给定的模糊分布相类似时,即可选择这个模糊分布作为所求的隶属函数,然后再通过先验知识或数据实验确定符合实际的参数,从而得到具体的隶属函数。

例如,在例 5 中我们利用模糊统计试验法
建立了“青年人”的隶属函数,其大致曲线如图 5 所示。通过分析比较,发现 图 5 的曲线与
岭形分布的中间型十分相似,于是选择岭形分布的中间型作为“青年人”的隶属函数。
⎪⎪⎪⎪
⎩
⎪⎪⎪⎪
⎨
⎧
<
≤<⎟⎠
⎞⎜⎝
⎛ +−
−−
≤<
≤<⎟⎠
⎞⎜⎝
⎛ +−
−+
≤
=
xa
axaaa
xaa
axa
axaaa
xaa
ax
xA
4
4343
34
32
2121
12
1
,0
,2
sin21
21,1
,2
sin21
21,0
)(π
π

根据例 5 中 表 6 的统计数据,取 a1 = 13,a2 = 20,a3 = 24,a4 = 37,则“青年人”这个概念的具体的隶属函数为
其隶属函数曲线如图 9 所示。
⎪⎪⎪
⎩
⎪⎪⎪
⎨
⎧
<
≤<⎟⎠⎞
⎜⎝⎛ −−
≤<
≤<⎟⎠⎞
⎜⎝⎛ −+
≤
=
x
xx
x
xx
x
xA
37,0
3724,261
13sin
21
21
2420,1
2013,233
7sin
21
21
13,0
)(π
π
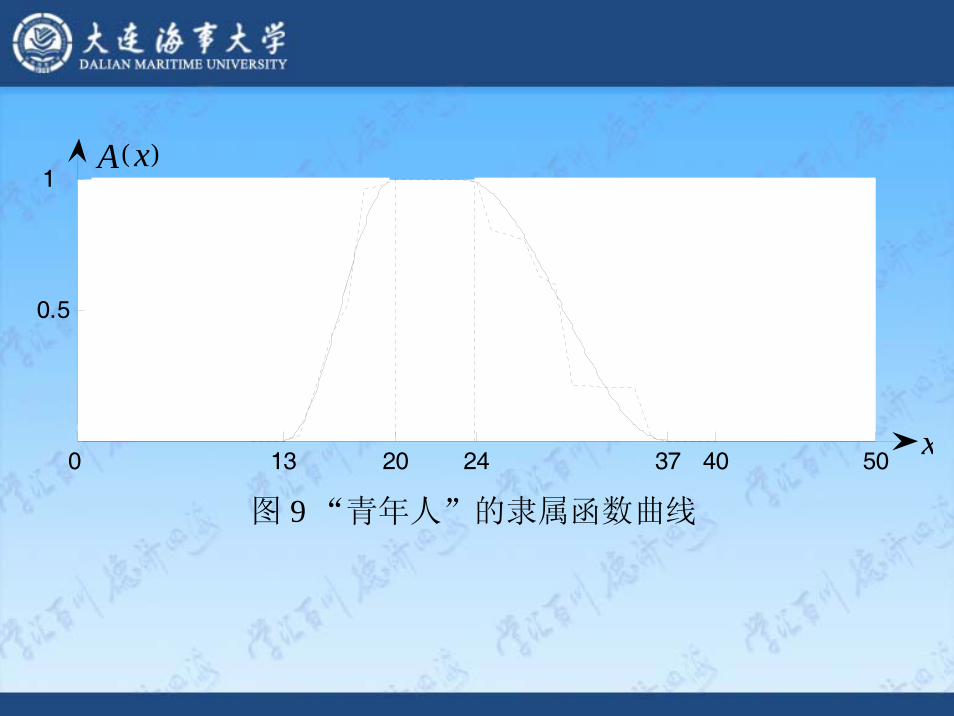
图 9 “青年人”的隶属函数曲线
0 13 20 24 37 40 50
0.5
1
x
xA( )

再如,建立模糊概念“年轻”的隶属函数。
根据统计资料,作出“年轻”的隶属函数的大致曲线(可参考例 5 的过程)。通过分析比较,
发现其与柯西分布的偏大型十分相似,于是选择柯西分布的偏大型作为“年轻”的隶属函数。
,α, β > 0⎪⎩
⎪⎨⎧
>−+
≤≤= ax
ax
axxA ,
)(11
0,1)(
βα

根据人们对“年轻”这个概念的普遍认同情况知道:不足 25 岁是真正的年轻人;从 25岁开始,“年轻”的隶属度随年龄的增大而减少,并且这个衰减明显不是线性的;30岁相对
于“年轻”是最模糊的。综合上述的先验知识,同时考虑到操作的方便性,我们选择参数:a = 25,α = 1/25,β = 2,于是得到描述“年轻”这个概念的具体的隶属函数为

其隶属函数曲线如图 10 所示。
图 10 “年轻人”的隶属函数曲线
⎪⎩
⎪⎨
⎧
>⎥⎥⎦
⎤
⎢⎢⎣
⎡⎟⎠⎞
⎜⎝⎛ −
+
≤≤
=−
25,5251
250,1)(
12
xx
xxY
0 25 30 50 80 100
0.5
1
x
Y

下面给出几种常见的模糊分布及其图形,
以供参考选择。











补充:待定系数法
在实际应用中,当论域 U 限制在实数域上
时,还有一种常用的建立隶属函数的方法:待定系数法。这种方法的基本思想是,结合实际背景和经验,将相对简单的实函数进行改造,进而得到相应的隶属函数。
设论域 U 为实数集,如果 A∈F (U) 是正规模糊集,则 KerA = [b, c] ≠ ∅,即 ∀x0∈[b, c] 有A(x0) = 1;如果根据经验还可以判定
Supp A = (a, d)

则可令
(4.1)
式中
Ux
daxdcxxfcbxbaxxf
xA ∈∀
⎪⎪⎩
⎪⎪⎨
⎧
∉∈∈∈
= ,
),(,0),(,)]([],[,1),(,)]([
)(2
1
β
α
)(1)( ),(1)( 21 xdcd
xfaxab
xf −−
=−−
=

为确定待定系数,需要根据实际背景定出模糊边界点 x1*∈(a, b) 和 x2*∈(c, d),使得
A(x1*) = A(x2*) = 0.5于是由 (4.1) 式可得:
α = −ln2/ln[f1(x1*)]β = −ln2/ln[f2(x2*)]
如此,即可构造出一个正规模糊集的隶属
函数。如图所示。

0
0.5
1
a b c d U
A
x x1 2* *

许多情况下,可取 α = β = 1。此时隶属函数A(x)的图形为梯形,特别地,若b = c 即 KerA是单点集,则隶属函数 A(x) 的图形为三角形。
0
1
a b c d

谢谢





























