Embed Size (px)
Citation preview

1
第 1章
統計量・スカラー・距離・測度・
順序
1.1 統計量とは
統計量とは、データセット (標本)の属性に関数を適用して、単一の値にしたもののこ
と。または、その関数のこと。
例を挙げてみます。
• 標本の算術平均• 標本の最大値• 標本の分散• 標本から求める不偏分散• 標本が作る分割表から計算されるカイ二乗値• 標本が作る分割表から計算される正確確率検定の p値
• 標本が作る行列のセルの値の算術平均• 標本が作る行列のデターミナント
いずれも統計ソフトでは、データセットを引数として、関数を適用することで、統計量が
返されます。
> # データセットを作ります
> x <- rnorm(1000)
> hist(x)
> # 算術平均
> mean(x)
[1] -0.02355418
> # 最大値
> max(m)
[1] 300

2 第 1章 統計量・スカラー・距離・測度・順序
> # 標本分散
> hyouhon.bunsan <- function(x){
+ sum((x-mean(x))^2)/length(x)
+ }
> hyouhon.bunsan(x)
[1] 1.018915
> # 不偏分散
> var(x)
[1] 1.019935
2× 2 表を作ります。
10 20 30
15 25 40
25 45 70
> tab <- matrix(c(10,20,15,25),byrow=TRUE,2,2)
> tab
[,1] [,2]
[1,] 10 20
[2,] 15 25
> chisq.out <- chisq.test(tab)
> chisq.out$statistic
X-squared
0.01166667
> chisq.out$p.value
[1] 0.9139859
> �sher.out <- �sher.test(tab)
> �sher.out$p.value
[1] 0.8036278
この表を行列と見立てれば
> mean(tab)
[1] 17.5
> det(tab)
[1] -50

1.2 統計量を図示してみる 3
1.2 統計量を図示してみる
2つの数からなる標本の統計量を 2つの数をいろいろ変えて図示してみる。まずは、標
本の算術平均。
> x <- y <- seq(from=1,to=3,length=100)
> xy <- expand.grid(x,y)
> mean.xy <- apply(xy,1,mean)
> image(x,y,matrix(mean.xy,ncol=length(x)))
1.0 1.5 2.0 2.5 3.0
1.0
1.5
2.0
2.5
3.0
x
y
次に標本の最大
値
> max.xy <- apply(xy,1,max)
> image(x,y,matrix(max.xy,ncol=length(x)))

4 第 1章 統計量・スカラー・距離・測度・順序
1.0 1.5 2.0 2.5 3.0
1.0
1.5
2.0
2.5
3.0
x
y
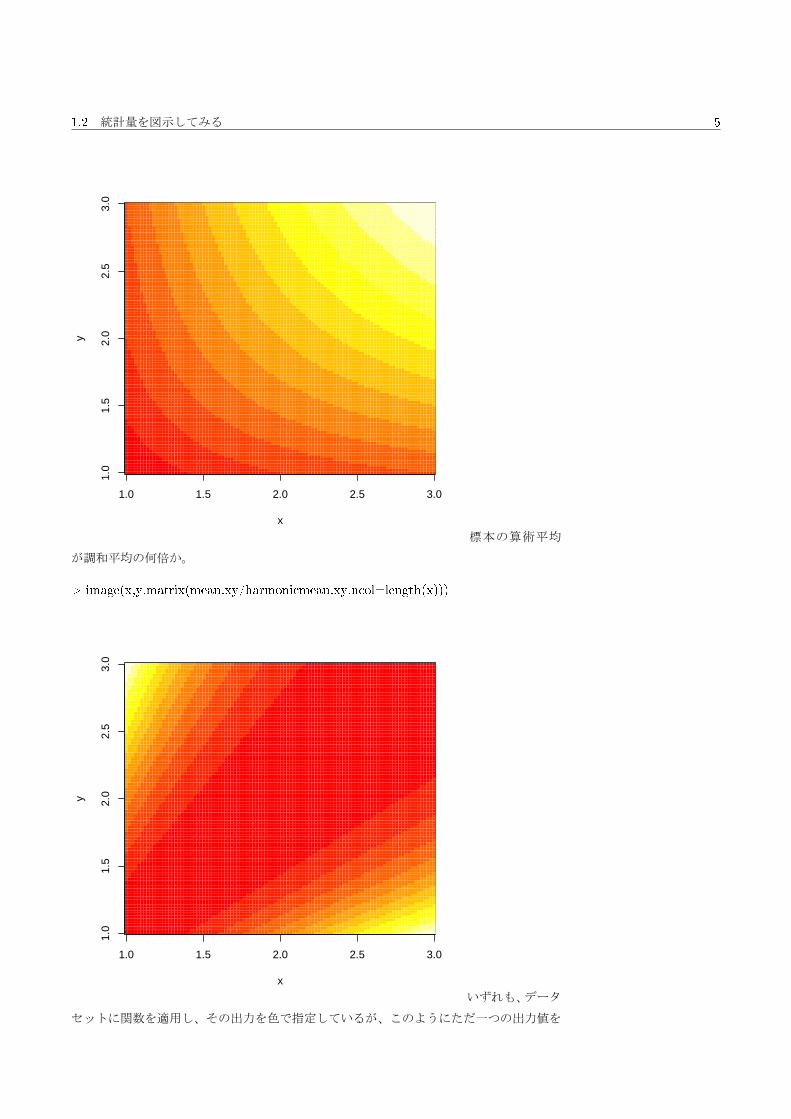
標本の算術平均
の代わりに、調和平均。
> harmonic.mean <- function(x){
+ length(n)/(sum(1/x))
+ }
> harmonicmean.xy <- apply(xy,1,harmonic.mean)
> image(x,y,matrix(harmonicmean.xy,ncol=length(x)))
1.2 統計量を図示してみる 5
1.0 1.5 2.0 2.5 3.0
1.0
1.5
2.0
2.5
3.0
x
y
標本の算術平均
が調和平均の何倍か。
> image(x,y,matrix(mean.xy/harmonicmean.xy,ncol=length(x)))
1.0 1.5 2.0 2.5 3.0
1.0
1.5
2.0
2.5
3.0
x
y
いずれも、データ
セットに関数を適用し、その出力を色で指定しているが、このようにただ一つの出力値を

6 第 1章 統計量・スカラー・距離・測度・順序
用いて絵が描けていることからも、この関数が統計量であること、関数の出力が統計量で
あることがわかる。
1.2.1 平均
算術平均と調和平均とを紹介した。平均はすべての要素を平等に扱う統計量であって、
一般化すると次のように書きます。
m(p) = (
∑ni=1 x
pi
n)
1p
算術平均はm(1)です。調和平均はm(−1)、相乗平均はm(p → 0)、最大値はm(∞)、最
小値はm(−∞)です。
1.3 等値線、等値面
統計量で色を指定して図示することで平面上に線が描くパターンが現れた。同じ値が同
色で表されているから、知覚される線は、地図で言うところの等高線である。統計量の場
合は「高さ」ではなく、「値」なので、「等値線」と呼ぶ。また、二次元平面上に描かれたも
のは「線」であるが、3次元空間に同じ値の点を結んで現れるのは「面」であり、4次元
空間では、「面」より高次元の「超面」であるから、これを一般に、「等値面 (isosurface)」
と言う。2× 4 の分割表は自由度が3であり、3次元空間に対応付けられるから、それを
例に3次元空間における等値面を描図してみる。第1行第1,2,3列の値を x,y,zとパ
x y z 100-(x+y+z) 100
25-x 45-y 60-z (x+y+z)-30 100
25 45 60 70 200
ラメタとしてとる。第1列を基準列として、1:2列、1:3列、1:4列についてのオッ
ズ比を OR2,OR3,OR4 とする (x×(45−y)y×(25−x) ,
x×(60−z)z×(25−x) ,
x×((x+y+z)−30)(100−(x+y+z))×(25−x) )。OR2,3,4 の
最大値が2となるような等値面を図示してみる。
> x <- seq(from=0,to=25,by=0.5)
> y <-seq(from=0,to=45,by=0.5)
> z <- seq(from=0,to=60,by=0.5)
> xyz <- expand.grid(x,y,z)
> maxOR <- rep(0,length(xyz[,1]))
> w <- 100-apply(xyz,1,sum)
> X <- 25-xyz[,1]
> Y <- 45-xyz[,2]
> Z <- 60-xyz[,3]
> W <- 70-w
> OR2 <- xyz[,1]*Y/(xyz[,2]*X)
> OR3 <- xyz[,1]*Z/(xyz[,3]*X)
> OR4 <- xyz[,1]*W/(w*X)

1.4 スカラー 7
> ORs <- cbind(OR2,OR3,OR4)
> max.ORs <- apply(ORs,1,max)
> selected <- which(abs(max.ORs-2)<0.1 & w>=0)
> library(rgl)
> plot3d(xyz[selected,])
> rgl.postscript("isosurface.eps")
4030
Var220
10
5 10 15
10203040
50
Var3
Var1
60
1.4 スカラー
複数の値に関数を適用して一つの値にするが、その一つの値を「スカラー」と呼ぶこと
もある。物理学では、取り扱う対象が質量のように1つの値で表される量 (スカラー)な
のか、方向を持った量 (速度ベクトルなど)なのかということを区別する。
多数の気体分子の熱運動の状態を温度という1つの値で表される量で表すこともある
が、これもスカラー量である。用語として紹介した。
スカラーは次空間・データ空間の量を表し、ベクトルは向きのある量を表し、テンソル
はそんな次空間の線形計算を一般化して扱う仕組みである。
統計量はスカラーであるが、次空間・データ空間を捉えようというときには、スカラー
としてとらえたりベクトルとしてとらえたりすることもあるので、データをとらえるより
大きな仕組みとして「スカラー・ベクトル・テンソル」の概念が重要であることは記憶し
ておくとよい。

8 第 1章 統計量・スカラー・距離・測度・順序
1.5 距離とは
距離は、2点間の近さ・遠さの指標であり、道のりの長さである。日常生活での距離は、
3次元空間上の2点の座標X = (x1, x2, x3),X = (y1, y2, y3)を用いて√(x1 − y1)2 + (x1 − y2)2 + (x3 − y3)2
と表される。または、V = X−Y = (v1, v2, v3)を用いて、√v21 + v22 + v23
のようにベクトルVの長さとして表現することもある。
データを扱う場合の距離は、この概念を数学的に一般化したものである。一般化したも
のではあるが、それをどういう視点・方向で一般化するかによって、様式が異なってくる。
この節では、距離の一般化の1つである測度を中心に取り扱う。
その後、測度ではない距離の例を挙げることで、2つのものの違い・遠近を表す「距離」
の取り方が多彩であることを知り、また、「距離」を一般化するときにどんな視点・方向
が用いられるのかを知ることとする。
1.6 距離の一般化としての距離関数
1.6.1 相対値
距離関数 (metric)は n個の要素からなるデータセットについて、n × n個の要素ペア
のそれぞれに、実数値を対応付ける関数である。統計量が、データセットに1つの値を対
応付ける関数であり、対応付けられた値そのものであることを思い出せば、「関数」「1つ
の値」という共通点があることに気づく。両者の違いは距離関数が要素ペアを問題にする
のに対し、統計量が1つのデータセットを対象にする点であろう。データセット1つから
何かしらの値を得ればその値は絶対値である。ペアに何かしらの値を対応付ければ、その
値は相対値である。
1.6.2 距離関数の定義
x, y 間の距離関数 d(x, y)は
• d(x, y) ≥ 0
• d(x, y) = 0 であるならば x = y であり x = y のときに限り d(x, y) = 0である
• d(x, y) = d(y, x)である
• d(x, z) ≤ d(x, y) + d(y, z):三角不等式

1.6 距離の一般化としての距離関数 9
1.6.3 距離関数の例
ユークリッド距離
いわゆる df = 3次元空間の距離 √√√√df=3∑i=1
∆2i
の次元を一般化したもののことである。
> x <- y <- seq(from=-2,to=2,length=100)
> xy <- expand.grid(x,y)
> d <- sqrt(apply(xy^2,1,sum))
> image(x,y,matrix(d,ncol=length(x)))
−2 −1 0 1 2
−2
−1
01
2
x
y
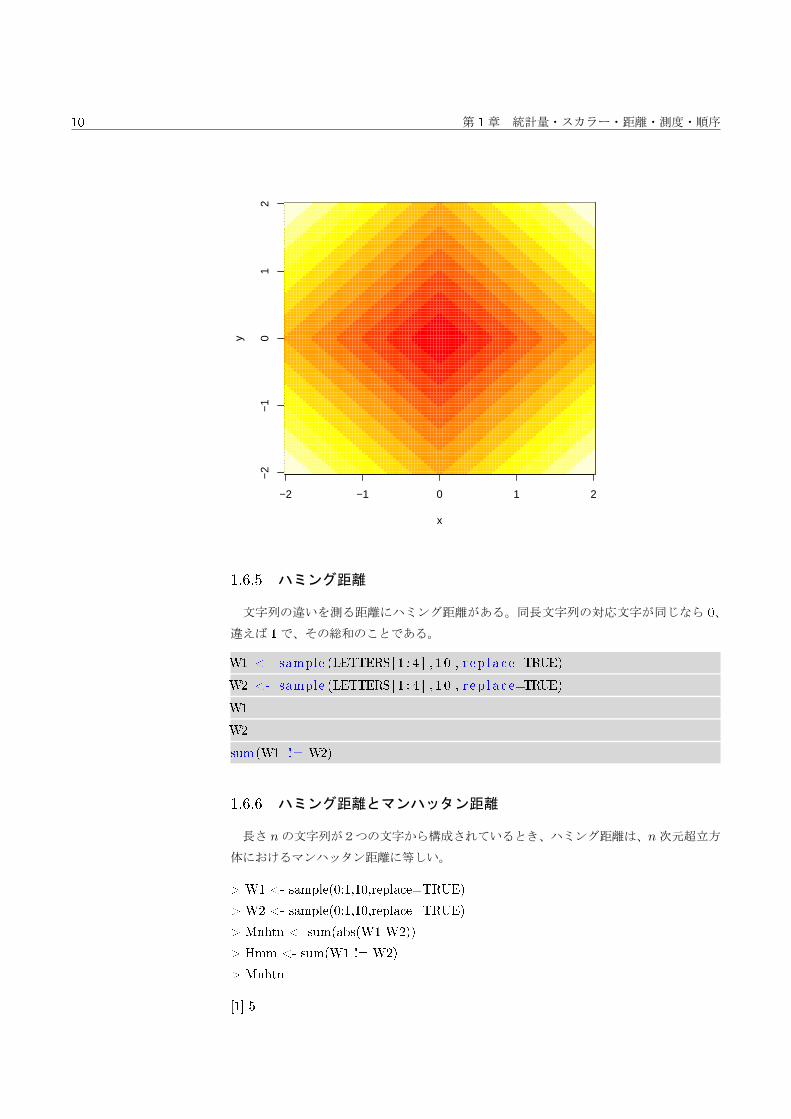
1.6.4 マンハッタン距離
格子状の街路をたどる場合の道のりのことである。
df∑i=1
|∆i|
> x <- y <- seq(from=-2,to=2,length=100)
> xy <- expand.grid(x,y)
> d <- apply(abs(xy),1,sum)
> image(x,y,matrix(d,ncol=length(x)))
10 第 1章 統計量・スカラー・距離・測度・順序
−2 −1 0 1 2
−2
−1
01
2
x
y
1.6.5 ハミング距離
文字列の違いを測る距離にハミング距離がある。同長文字列の対応文字が同じなら 0、
違えば 1で、その総和のことである。
W1 <- sample (LETTERS[ 1 : 4 ] , 1 0 , r ep l a c e=TRUE)
W2 <- sample (LETTERS[ 1 : 4 ] , 1 0 , r ep l a c e=TRUE)
W1
W2
sum(W1 != W2)
1.6.6 ハミング距離とマンハッタン距離
長さ nの文字列が2つの文字から構成されているとき、ハミング距離は、n次元超立方
体におけるマンハッタン距離に等しい。
> W1 <- sample(0:1,10,replace=TRUE)
> W2 <- sample(0:1,10,replace=TRUE)
> Mnhtn <- sum(abs(W1-W2))
> Hmm <- sum(W1 != W2)
> Mnhtn
[1] 5

1.6 距離の一般化としての距離関数 11
> Hmm
[1] 5
1.6.7 マハラノビス距離と正規化距離とカイ二乗統計量
分割表の第 i行 第 j 列の観測値が xij であり、その期待値が eij であるとき、カイ二乗
統計量は ∑i,j
(xij − eij)2
eij
で計算される。この式は、すべてのセルについて観測・期待間の値の差を期待値で補正し
たユークリッド距離の二乗という形をしている。補正してあるので「正規化」距離の二乗
と言う。何について正規化しているかというと、各セルの値 (各セルの値の期待値からの
ずれ)を正規分布と考え、ずれの平均は 0、ずれの分散は eij とみなして、多次元標準正規
分布に正規化している。
さて、v = x− e = (vij = xij − eij)とすると、上式は
vTS−1v
ただし
S =
e11 0 0 ... 00 e22 0 ... 0... ... ... ... ...0 0 0 ... en
行列 S が対角行列になっているが、せっかく vTS−1v という形をしているので、S が対
角行列とは限らないように制約を緩めるてもよいだろう。それがマハラノビス距離の二乗
である。
dMahalanobis =√vTS−1v
1.6.8 ミンコフスキー距離
ユークリッド距離とマンハッタン距離はそれぞれ
(
df∑i=1
|∆i|2)12 (
df∑i=1
|∆i|1)11
とも書き表せる。これを一般化すると
dmk(p) = (
df∑i=1
|∆i|p)1p
となる。この式は一般化平均の式の 1n を取り除いたものになっている。これをミンコフ
スキー距離、p−ノルム距離と言う。dmk(p = 1はマンハッタン距離、dmk(p = 2)はユー
クリッド距離、mk(p → ∞) = max(∆i)となっている。図示してみる。
> d.mk <- function(x,p){
+ sum(x^p)^(1/p)

12 第 1章 統計量・スカラー・距離・測度・順序
+ }
> x <- y <- seq(from=-2,to=2,length=100)
> xy <- expand.grid(x,y)
> ps <- 2^c(-10,-2,-1,-0.5,0,0.5,1,2,10)
> par(mfcol=c(3,3))
> for(i in 1:length(ps)){
+ d <- apply(abs(xy),1,d.mk,ps[i])
+ my.title <- paste("p=",ps[i])
+ image(x,y,matrix(d,ncol=length(x)),main=my.title)
+ }
> par(mfcol=c(1,1))
−2 −1 0 1 2
−2
01
2
p= 0.0009765625
x
y
−2 −1 0 1 2
−2
01
2
p= 0.25
x
y
−2 −1 0 1 2
−2
01
2
p= 0.5
x
y
−2 −1 0 1 2
−2
01
2
p= 0.707106781186548
x
y
−2 −1 0 1 2
−2
01
2
p= 1
x
y
−2 −1 0 1 2
−2
01
2
p= 1.4142135623731
x
y
−2 −1 0 1 2
−2
01
2
p= 2
xy
−2 −1 0 1 2
−2
01
2
p= 4
x
y
−2 −1 0 1 2
−2
01
2
p= 1024
x
y
なお、ミンコフス
キー距離では p < 1の場合には三角不等式が成り立たないから、p ≥ 1の場合に限り、距
離関数である。p < 1の場合に三角不等式が成り立たないことを確認しておく。
> # 次元は df
> df <- 4
> # 3点の組を n.iter通り発生させる
> n.iter <- 10000
> X <- matrix(runif(n.iter*df),ncol=df)
> Y <- matrix(runif(n.iter*df),ncol=df)
> Z <- matrix(runif(n.iter*df),ncol=df)
> # ミンコフスキー距離のための係数を乱数で指定する
> ps <- 2^(sample(seq(from=-2,to=2,length=1000),n.iter,replace=TRUE))

1.7 距離関数とその類似関数 13
> # 三角形の3辺のミンコフスキー距離を計算・格納
> Ds <- matrix(0,n.iter,3)
> for(i in 1:n.iter){
+ Ds[i,1] <- d.mk(abs(X[i,]-Y[i,]),ps[i])
+ Ds[i,2] <- d.mk(abs(Y[i,]-Z[i,]),ps[i])
+ Ds[i,3] <- d.mk(abs(Z[i,]-X[i,]),ps[i])
+ }
> # 三角不等式のチェックは、d(i,j)+d(j,k)-d(k,i) = (d(i,j)+d(j,k)+d(k,i))-2 d(i,j) の最小値が 0以上であることなので、その最小値を求める
> sumDs <- apply(Ds,1,sum)
> D.x <- sumDs-2*Ds[,1]
> D.y <- sumDs-2*Ds[,2]
> D.z <- sumDs-2*Ds[,3]
> D.xyz <- cbind(D.x,D.y,D.z)
> min.D.xyz <- apply(D.xyz,1,min)
> # 最小値が正か負かで色分け
> col <- sign(min.D.xyz)+3
> plot(ps,min.D.xyz,col=col,pch=20,cex=0.1)
> abline(h=0,col=2)
> abline(v=1,col=2)
1.7 距離関数とその類似関数
ミンコフスキー距離では、p ≥ 1の場合に距離関数であって、p < 1の場合は三角不等
式を満たすとは限らないことがわかった。では、ミンコフスキーの関数は距離関数とは言
えないわけであるが、さて、何と言えばよいだろうか。距離関数の定義から逸脱すると、
距離関数ではなくなり、何かしら別のものになる。三角不等式を満足しないが、それ以外
の定義条件を満足している、p < 1 のミンコフスキー距離は半距離関数 (semimetric)と
呼ばれる。
• 三角不等式を満足しないものは半距離関数 (semimetric)
• x ̸= y であっても d(x, y) = 0になりうるものは擬距離関数 (psuedometric)
• 対称性が保たれていない (d(x, y) ̸= d(y, x)は準距離 (quasimetric)
1.7.1 カルバック・ライブラー情報量
対称性が保たれない準距離にカルバック・ライブラー情報量がある。これは、2つの分
布 p(x), q(x)の間の違いを実数にする統計量であり、
dKL(p(x)|q(x)) =∫x∈X
p(x)
q(x)ln (p(x))dx
で表される。式の形から、p(x), q(x) に関して非対称であることが見て取れるが、
dKL(p(x)|q(x)) ̸= dKL(q(x)|p(x)) である。分布間に対称性のある距離関数をとりた

14 第 1章 統計量・スカラー・距離・測度・順序
いときにはdKL(p(x)|q(x)) + dKL(q(x)|p(x))
2
を使うこともある。
1.8 距離行列とその活用
複数の対象があって、その対象ペアに距離関数を適用すると距離行列ができる。距離関
数は対称的であるから、距離行列も対称行列である。距離行列の情報を木構造・階層的ク
ラスタ構造にまとめることもある。
> n.cl <- 4
> df <- 2
> X <- matrix(0,0,df)
> for(i in 1:n.cl){
+ n <- sample(10:30,1)
+ mx <- runif(1)
+ my <- runif(1)
+ sx <- runif(1)*0.2
+ sy <- runif(1)*0.2
+ tmp <- cbind(rnorm(n,mx,sx),rnorm(n,my,sy))
+ X <- rbind(X,tmp)
+ }
> xlim <- ylim <- range(X)
> par(mfcol=c(1,2))
> plot(X,xlim=xlim,ylim=ylim)
> D <- dist(X)
> plot(hclust(D))
> par(mfcol=c(1,1))

1.9 距離行列から座標を計算 15
0.0 0.4 0.8
0.0
0.2
0.4
0.6
0.8
1.0
X[,1]
X[,2
]
38 40 4 36 13 10 1512 8 6 14
3741
3943 44
42 45 46
49 7156 54 63
5062 23 66 11 60 52
53 575 2 681 16 55 69 70 3
61 659 28 31 7 64 26 33 18 27
1721 30 19 59 32 34 29
20 22 25 67 51
48 5824
35 47
0.0
0.2
0.4
0.6
0.8
1.0
1.2
Cluster Dendrogram
hclust (*, "complete")D
Hei
ght
1.9 距離行列から座標を計算
これまでは要素座標が持ち、そこに距離関数を定めて距離を計算してきた。また、距離
行列もそのようにして作成した。場合によっては要素ごとの違いを観察するために、距離
行列が先に求まることがある。
> loc <- cmdscale(eurodist)
> x <- loc[, 1]
> y <- -loc[, 2] # re�ect so North is at the top
> ## note asp = 1, to ensure Euclidean distances are represented correctly
> plot(x, y, type = "n", xlab = "", ylab = "", asp = 1, axes = FALSE,
+ main = "cmdscale(eurodist)")
> text(x, y, rownames(loc), cex = 0.6)

16 第 1章 統計量・スカラー・距離・測度・順序
cmdscale(eurodist)
Athens
Barcelona
BrusselsCalais
CherbourgCologne
Copenhagen
Geneva
Gibraltar
Hamburg
Hook of Holland
LisbonLyons
MadridMarseilles Milan
Munich
Paris
Rome
Stockholm
Vienna
> library(igraph)
> n <- 20
> d <- matrix(sample(0:1,n^2,replace=TRUE,prob=c(0.8,0.2)),n,n)
> d <- d+t(d)
> d <- sign(d)
> diag(d) <- 0
> g <- graph.adjacency(d)
> sh.p <- shortest.paths(g)
> loc <- cmdscale(sh.p)
> ed <- get.edgelist(g)
> plot(loc[,1],loc[,2])
> segments(loc[ed[,1],1],loc[ed[,1],2],loc[ed[,2],1],loc[ed[,2],2])

1.10 順序 17
−1.5 −1.0 −0.5 0.0 0.5 1.0 1.5
−1.
5−
1.0
−0.
50.
00.
51.
0
loc[, 1]
loc[
, 2]
1.10 順序
1.10.1 順序と統計量
統計量はデータセットから一つの値 (実数)をもたらす関数であるから、統計量を取る
ことにより実数直線上の点に対応付けられている。実数直線上は1次元空間であって、そ
の上の点は「一列に並んで」いるから、v1 < v2 < v3 < ...という大小の『順序』がある。
先に持ち出した「等値面」の概念で言えば、2以上の次元の空間では等値面と取り方を
考えるときに等値面の形をどうするかを気にする必要があるが、1次元空間では、等値
面はただの点であり、点の勾配にはバリエーションはあるが、(一様増・一様減の範囲で
は)『順序』は不変である。統計量が1次元空間上の点への対応付けであるということは、
データセットを評価して、順序に迷いのない状態に変換してやる、という意図の現れであ
るとも言い換えられる。このように1次元空間における順序は統計量の評価・距離の評価
の基礎的な考え方である。では、この順序にとは何かについて考えておく。
1.10.2 全順序と半順序
順序とは、集合の要素のペアに定める大小に関する二項関係の秩序のことである。大小
の記号 ≤,≥, <,=, >で表現される。実数直線上には無限の数があるが、ここでは有限個
の要素で考えておく。
n個の要素があって、v1 ≤ v2 ≤ ... ≤ vn
という大小関係があるとする。これを全順序と言う。順序は集合の要素のペアに定める

18 第 1章 統計量・スカラー・距離・測度・順序
大小関係全体であるので、任意の vi, vj についても大小関係が定まっていなくてはならな
い。v1 ≤ v2 ≤ ... ≤ vn という全順序関係は
• vi ≤ vi がすべての vi に成り立つ
• vi ≤ vj であり、vi ≥ vj であるならば、vi = vj である
• vi < vj であり、vj < vk であるならば、vi < vk である
• すべての要素ペアについて vi ≤ vj または vi ≥ vj が成り立つ
距離関数を拡張するときに、距離関数の定義条件を一つずつ外してやった。全順序の定義
条件を一つ外してやることにする。外す用件は第4の条件『すべての要素ペアに大小関係
がある』を外すことにする。このような順序を「半順序」と言う。
全順序と半順序との違いが『すべての要素ペアに大小関係があるか、あるとは限らない
か』であることを強調するために、グラフを用いることとする。
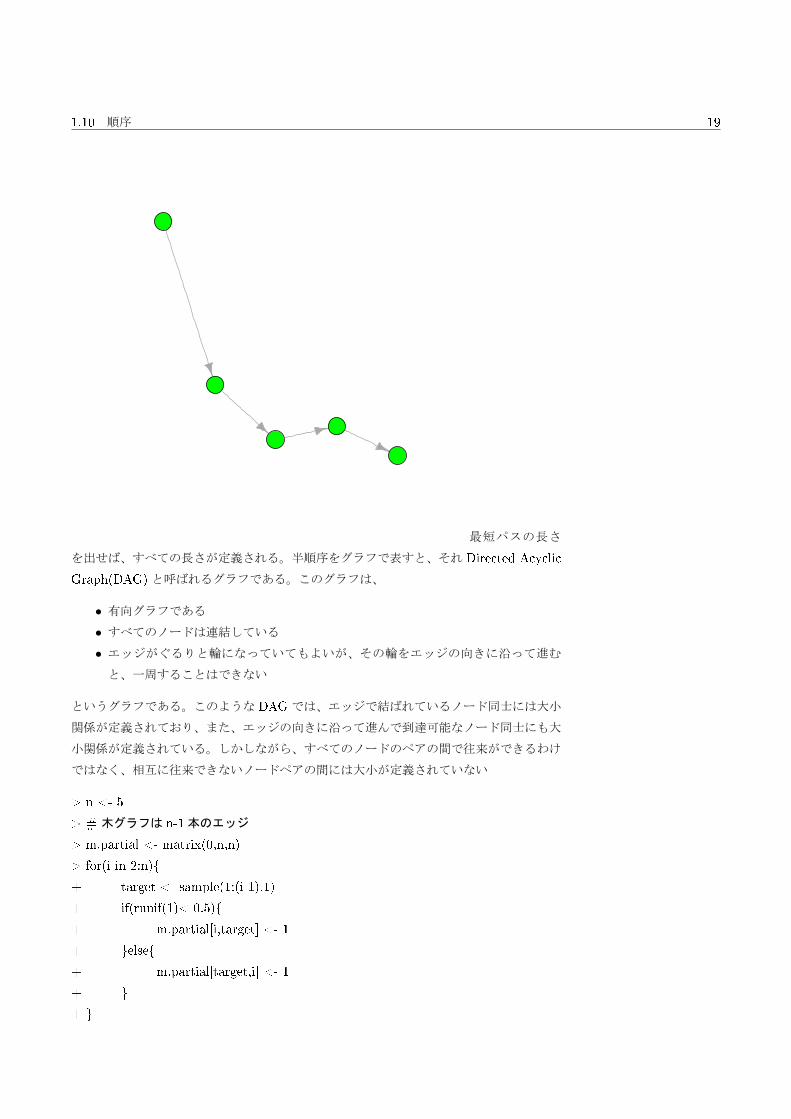
全順序のグラフは n個のノードが1本の鎖となったグラフである。
> n <- 5
> m.total <- matrix(0,n,n)
> for(i in 1:(n-1)){
+ m.total[i,i+1] <- 1
+ }
> g.total <- graph.adjacency(m.total)
> sh.total <- shortest.paths(g.total,mode="out")
> sh.total
[,1] [,2] [,3] [,4] [,5]
[1,] 0 1 2 3 4
[2,] Inf 0 1 2 3
[3,] Inf Inf 0 1 2
[4,] Inf Inf Inf 0 1
[5,] Inf Inf Inf Inf 0
> plot(g.total,layout=layout.kamada.kawai, vertex.color="green",vertex.label=NA)
1.10 順序 19
最短パスの長さ
を出せば、すべての長さが定義される。半順序をグラフで表すと、それ Directed Acyclic
Graph(DAG)と呼ばれるグラフである。このグラフは、
• 有向グラフである• すべてのノードは連結している• エッジがぐるりと輪になっていてもよいが、その輪をエッジの向きに沿って進むと、一周することはできない
というグラフである。このような DAGでは、エッジで結ばれているノード同士には大小
関係が定義されており、また、エッジの向きに沿って進んで到達可能なノード同士にも大
小関係が定義されている。しかしながら、すべてのノードのペアの間で往来ができるわけ
ではなく、相互に往来できないノードペアの間には大小が定義されていない
> n <- 5
> # 木グラフは n-1本のエッジ
> m.partial <- matrix(0,n,n)
> for(i in 2:n){
+ target <- sample(1:(i-1),1)
+ if(runif(1)< 0.5){
+ m.partial[i,target] <- 1
+ }else{
+ m.partial[target,i] <- 1
+ }
+ }

20 第 1章 統計量・スカラー・距離・測度・順序
> # サイクルができないように何本かエッジを足す
> n.add <- 5
> for(i in 1:n.add){
+ tmp <- m.partial
+ choice <- which(tmp==0,arr.ind=TRUE)
+ choice. <- choice[sample(1:length(choice[,1]),1),]
+ tmp[choice.] <- 1
+ tmp.g <- graph.adjacency(tmp)
+ if(is.dag(tmp.g)){
+ m.partial <- tmp
+ }
+ }
> g.partial <- graph.adjacency(m.partial)
> sh.total <- shortest.paths(g.partial,mode="out")
> # 最短パスが Infということはたどり着かない
> sh.total
[,1] [,2] [,3] [,4] [,5]
[1,] 0 Inf 1 Inf Inf
[2,] 1 0 2 Inf Inf
[3,] Inf Inf 0 Inf Inf
[4,] 1 Inf 2 0 Inf
[5,] 1 Inf 2 1 0
> plot(g.partial,layout=layout.kamada.kawai, vertex.color="green",vertex.label=NA)

1.11 関連する話題 21
1.11 関連する話題
1.11.1 曲がった空間
ユークリッド空間での距離について中心に書いてきた。データ空間は非ユークリッド幾
何空間になるかもしれない。非ユークリッド幾何学では距離・角などに関するルールが異
なる。また、データの作る空間を多様体としてとらえ、そこに微分幾何と言う考え方を持
ち込むこともある。
1.11.2 曲線
距離が曲がった経路の長さであることもある。円弧のように容易に長さを計算でき
る曲線もあるが、そうでない曲線もある。そのようなときに曲線をパラメタ表記して
(x = cos θ, y = sin θ というのは、x, y をパラメタ θ で表記したものである)、取り扱うと
便利なこともある。
1.11.3 測度
関連する用語に「測度 (measure)」がある。ユークリッド空間における、1次元での距
離、2次元での面積、3次元での体積を一般次元に拡張したものや、微分・積分と関連し
ている。また、測度は、統計学の分野の基礎をなす概念であって、事象の全体集合とその
部分集合との包含関係とその生起確率の定義になっている。

























![2012/06/11 · [敷地面積が3,000 以上の場合] 道路境界線からの距離 …5m以上 道路境界線以外の敷地境界線からの距離](https://img.pdfslide.tips/doc/110x75/60b254511d761d1d7437aa52/20120611-oeecoe3000-eefcoecee.jpg)



