Embed Size (px)
Citation preview

Ch10 Structural Equation
Models with Latent Variable

本章目標: 本章進一步考量測量模式中,因素 (潛伏變 數 )間彼此相依之關係

前言 結構方程式模型 (Structural Equation Model, SEM) 是
探討變數間的關係,並對顯性變數與潛在變數之因果模式做假設之檢定。
潛在變數( Latent Variable ) -意指在量測模式中無法直接觀察之因子 SEM 又稱為共變異數結構模型( Covariance Structure M
odels )、 LISREL Models SEM 的軟體程式:
LISREL (Joreskog and Sorbom, 1993), AMOS (Arbuckle, 1994), EQS (Bentler, 1993), PROC CALIS in SAS, RAMONA (Browne and Mels, 1998), and others.

10.1 Potential Applications SEM 適用之情況: -通常用來檢定無法直接觀察之潛在變 數間的相依關係 如果所有變數都是可觀察而且可無誤差的衡量可觀察而且可無誤差的衡量,則使用回歸分析回歸分析就足以分析變數間的相依關係
使用多重衡量 (multiple measures) 方式以獲取潛在變數與顯性變數間之關係,而非對個別潛在變數以單一指標做衡量
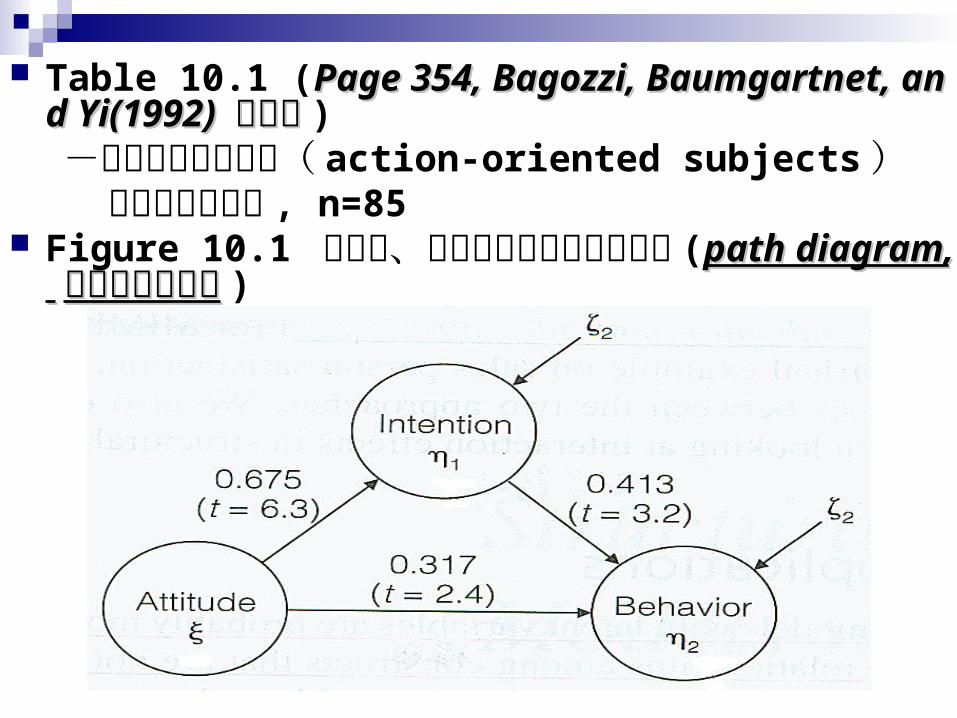
Table 10.1 (Page 354, Bagozzi, Baumgartnet, and Page 354, Bagozzi, Baumgartnet, and Yi(1992) Yi(1992) 的研究的研究 )
-行動導向的消費者( action-oriented subjects ) 之共變異數矩陣 , n=85 Figure 10.1 為態度、意向及行為關係之路徑圖 (path path
diagram, diagram, 表示結構方程式表示結構方程式 )

衡量 態度 ( 使用折價券在超市購物的態度 )
使用三個 7 點語意差異尺度 Pleasant or unpleasant Good or bad Favorable or unfavorable
意向 ( 使用折價券的意向 ) 1 題為關於下週使用折價券的可能性的 7 點尺度
Likely-or-unlikely 1 題為 11 點 no chance-or-certain 的機率尺度
行為 下一周真正使用折價券數量的平方根 (1 題 )

Figure 10.1 考慮因素間的 直接關係( attitude→behavior )與 間接關係( attitude→intention→behavior ) 由 Figure 10.1 可得知此三變數間的關係皆顯著(∵ t值> 2)
Bagozzi(1994) 證明當不將衡量誤差納入模型時,估計路徑係數將會較不一致且低估,若使用 SEM則可解決此問題

10.2 SEM-Latent Variable : How It Works 結構方程式包含兩種分析:
Analysis of interdependence 連接可觀察測量 X和 Y 與潛伏變數的測量方程式組( measurement equations )
Analysis of dependence 描述不可觀察之潛伏因子間的相依關係的結構方程式組( structural equations )

例子:銷售人員之工作滿意 工作滿意工作滿意(η)為內生變數自尊自尊( ξ)為外生變數 (不受模型內其他變數影 響 )
工作滿意(η)、自尊( ξ)皆為潛在變數 利用顯性變數( X1, X2)量測潛在變數( ξ) 顯性變數( Y1, Y2)量測潛在變數(η)
分下列三種情況分別討論: 1.Latent Variables 2.Structure Equations 3.Structure Equations with Latent Variable

1.Latent Variable
1 1 1
2 2 2
x
x
x
X
X
(10.1)
X= (10.2)
1 1 1
2 2 2
y
y
y
Y
Y
(10.3)
Y=H E (10.4)

若η與 ξ之間無關,則無法估計此模型之參數 (underidentified)
一個衡量模型參數要能估計,需要至少 3 個潛在變數的衡量尺度
故第二情況 ( SEM )介紹將η與 ξ做連結,以使模型中之參數可被估計
1.Latent Variable

2.Structure Equations
1 11 1
2 11 21 1 2
(10.5)
(10.6)

結構方程式描述內生潛在變數( η)與外生潛在變數( ξ)之間的相依關係
ξ 無法完全解釋 η中的所有變異性
ζ 為每一組外生變數與內生變數間關係的路徑之誤差項
2.Structure Equations
3.Structure Equations with Latent Variable
1 1 1
2 2 2
x
x
X
X
(10.1)
1 1 1
2 2 2
y
y
Y
Y
(10.3)
(10.5)

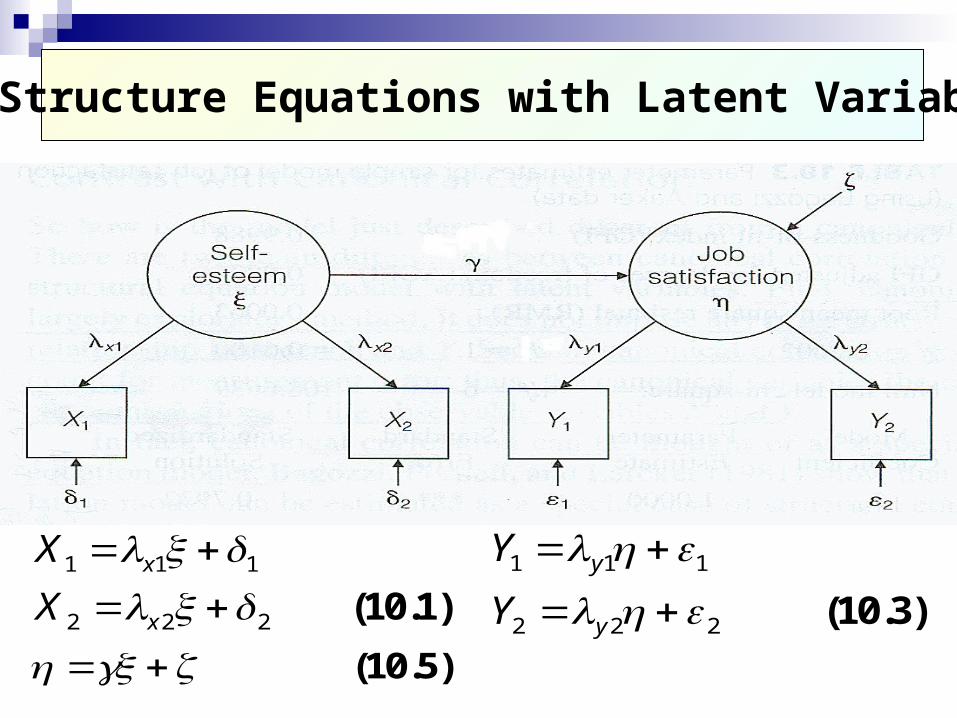
結合衡量模式(情況 1)與結構模式(情況 2) 形成單一結構方程式模型-潛在變數 共有 9個參數要估計,有 10個方程式 Measurement equations :
Structural equations :
1
2
xx
x
x
2δ11
δ 2δ22
y
2y1 ε11
y ε 2y2 ε22
X=ξΛ +Δ
θ 0 , Θ = , = 1
0 θ
Y=ηΛ +E
λ θ 0Λ = , Θ =
λ 0 θ
3.Structure Equations with Latent Variable
η=ξγ+ζ Ψ= ψ

共有 9個參數要估計,有 10個方程式,自由度為 1 ξ 的測量模型有尺度不定的問題,解決之道:
將潛在變數之變異數定為 1,或設定其中一個 λ係數為 1通常採用第一種做法
η的測量模型也有尺度不定的問題,但因為 cov(η)是模型中其他參數的函數,故採第二種做法,設定λy1=1
3.Structure Equations with Latent Variable

故 t 值 =3.3 ,在顯著水準 =0.01下,顯示η和 ξ間具有顯著關係
λ的標準解皆> 0.7,顯示η和 ξ被可靠的衡量
∴適合度高

10.2.2 Mechanics (10.18)
( ) ( )= (10.19)
( ) ( )
( ) ( ) ( )
YY YX
XY XX
y y
S SS
S S
E Y Y E Y X
E X Y E X X
E Y Y E H E H E
y = var( ) (10.21)
var( ) cov( , )= (10.22)
cov( , ) var( )
var( ) cov( , )
cov( , ) var( )
y
y y y x
x y x x
H
H H
H
H H
H
-1 1
-1 -1
1 1 1
1
(10.23)
var(H)=E B ( ) ( )
=B ( + )B (10.24)
( )
Z Z B
B B B
B
1 1 1
y1
(10.25)
( )= (10.26)
y y x
x y x x
B B B
B

10.3 Sample Problem 資料: Lattin & Roerts ( 1999)調查潛在顧客採用新套裝軟體 (Stateflow®) 的意願 (創新擴散的研究創新擴散的研究)
目的:利用潛在顧客個人層次之資訊來預測何種類型的使用者會採用新軟體,及何時採用
VALUE : Value of innovation( ξ1)---外生變數LEU:Leading edge usage ( ξ2) ---外生變數ADOPT : Early Adoption( η) ---內生變數
VALUE 、 LEU 分別影響 ADOPT ,且為正向影響
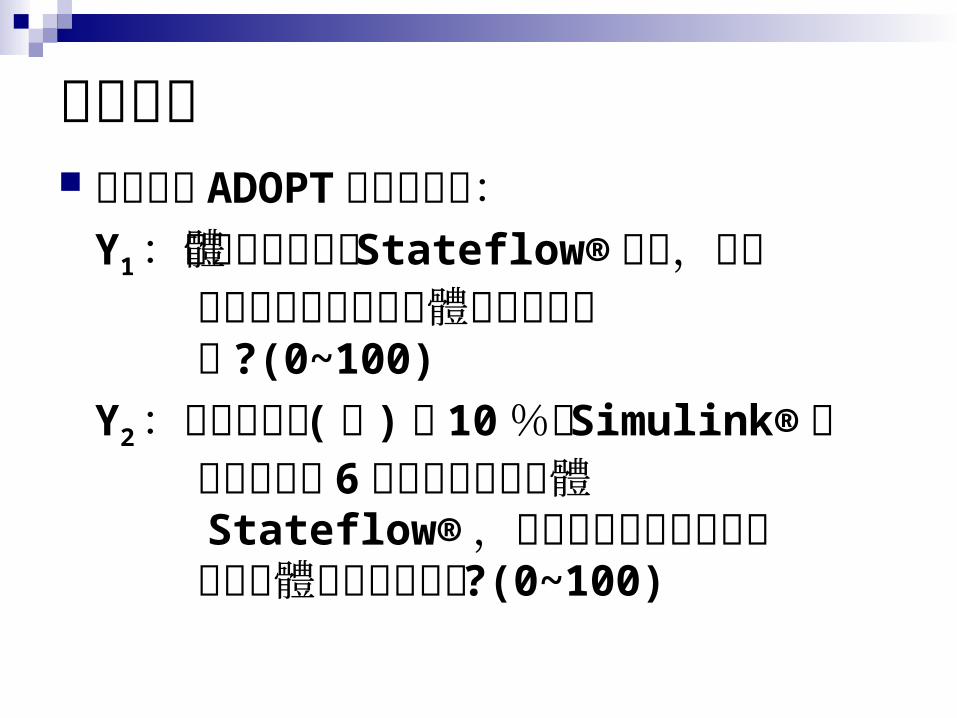
變數解釋 用來量測 ADOPT 的顯性變數:Y1:假設今天新軟體 Stateflow®上市,在下 個月你願意採用此軟體的可能性為 何 ?(0~100)Y2:假使你知道 (只 )有 10%的 Simulink®使 用者在未來 6個月會採用新軟體 Stateflow®,則你在同樣期間內會採 用此軟體的可能性為何?(0~100)

用來量測 VALUE 的顯性變數:X1:新軟體會增強我處理複雜模擬問題的能力X2:新軟體在處理我的應用領域的問題是適當的
X3:新軟體增加我處理離散型邏輯系統的能力
用來量測 LEU的顯性變數:X4:我們能很快利用新技術的機會X5:我們願意承擔採用新軟體的風險X6:在發現及規劃問題解時,我們領先於其他人
變數解釋(續)
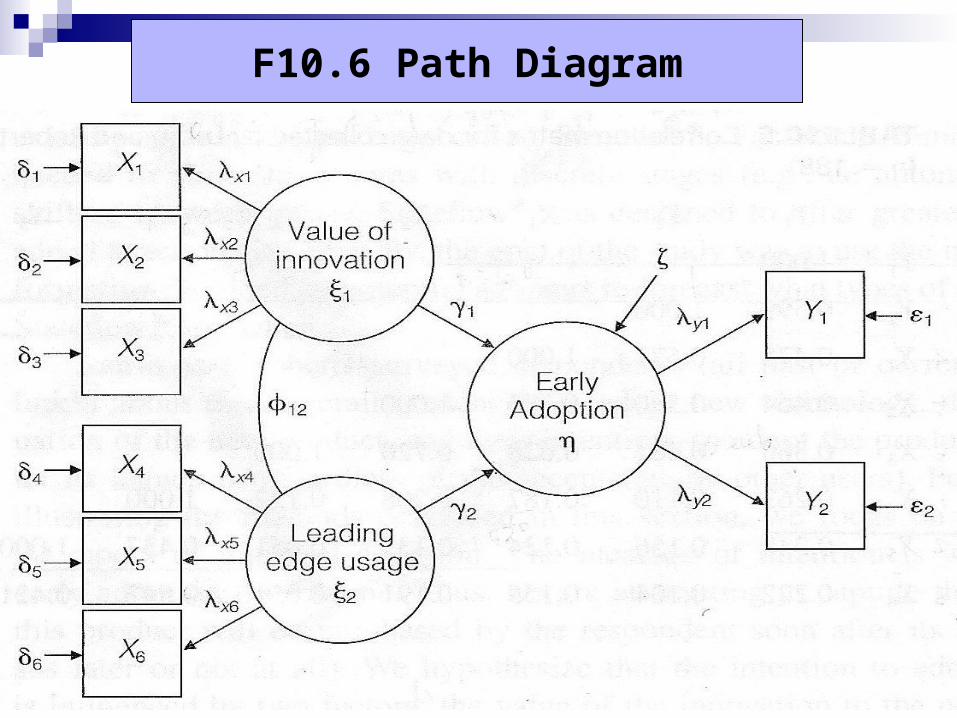
F10.6 Path Diagram

1 1 2 2
1 1
2 2 2
1 11 1 1
2 21 1 2
3 31 1 3
4 42 2 4
5 52 2 5
6 62 2 6
12
21
1.0
1
1
y
x
x
x
x
x
x
Y
Y
X
X
X
X
X
X
Measurement equations Structural equations

模型解釋 19 個參數估計值 1. λx1 ~ λx6 2. var(δ1) ~ var(δ6)3. ψ12
4. γ1 、 γ25. λy26. var(ε1) 、 var(ε2)7. (即 var(ζ))
共變異數的觀察值共有 36個【 1/2(p+q)(p+q+1)】 自由度 17 【 36-19】
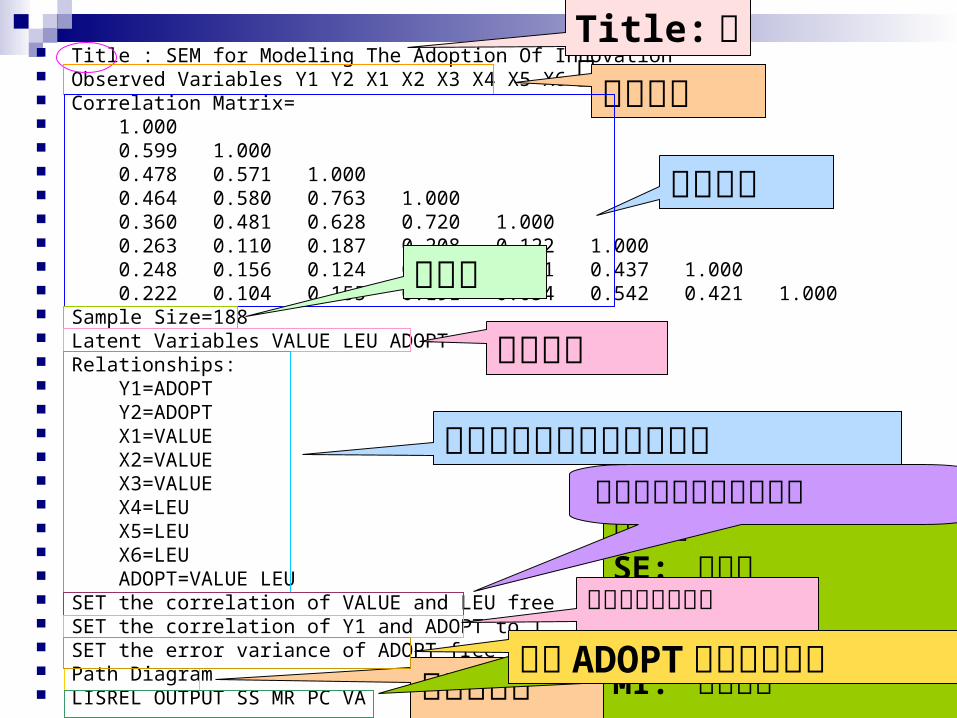
Title : SEM for Modeling The Adoption Of Innovation Observed Variables Y1 Y2 X1 X2 X3 X4 X5 X6 Correlation Matrix= 1.000 0.599 1.000 0.478 0.571 1.000 0.464 0.580 0.763 1.000 0.360 0.481 0.628 0.720 1.000 0.263 0.110 0.187 0.208 0.122 1.000 0.248 0.156 0.124 0.139 0.051 0.437 1.000 0.222 0.104 0.155 0.191 0.054 0.542 0.421 1.000 Sample Size=188 Latent Variables VALUE LEU ADOPT Relationships: Y1=ADOPT Y2=ADOPT X1=VALUE X2=VALUE X3=VALUE X4=LEU X5=LEU X6=LEU ADOPT=VALUE LEU SET the correlation of VALUE and LEU free SET the correlation of Y1 and ADOPT to 1 SET the error variance of ADOPT free Path Diagram LISREL OUTPUT SS MR PC VA
Title: 標題指標變數
相關矩陣
樣本量
潛伏變數
指標變數與潛伏變數的關係
繪製路徑圖
輸出指令 SE: 標準誤TV: t 檢定RS: 常態化殘差與 Q圖MI: 修飾指標
定義潛伏變數之間的關係
解決尺度不確定性
估計 ADOPT 的殘差變異數

Parameter estimates

Standardized solutions

T-values of estimated parameters
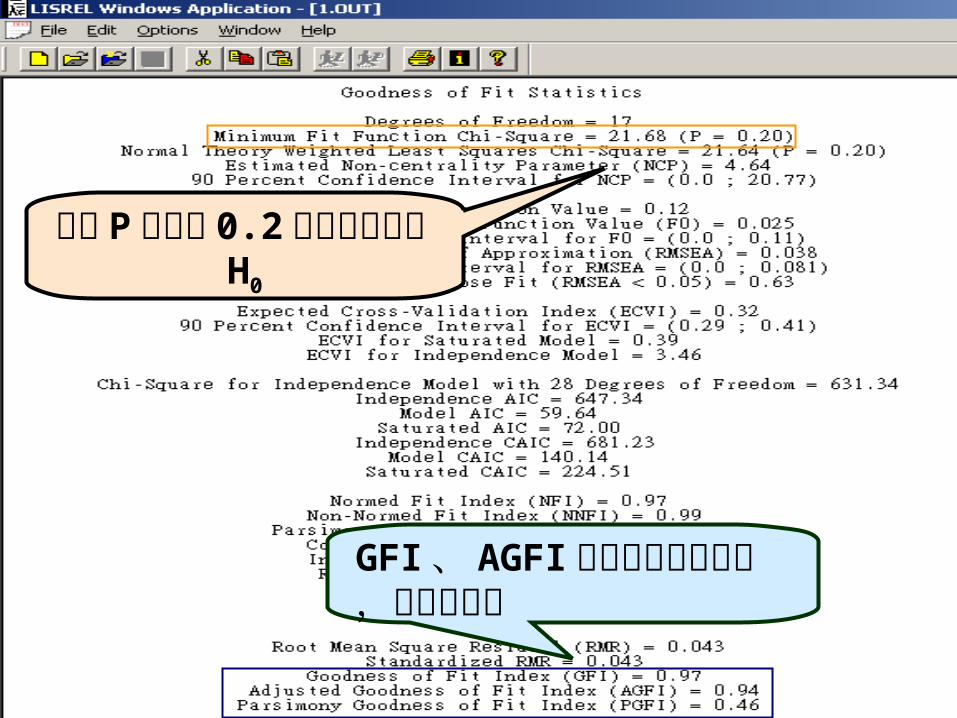
因為 P 值大於 0.2 所以無法拒絕 H0
GFI 、 AGFI 皆大於建議門檻值,故配適度佳
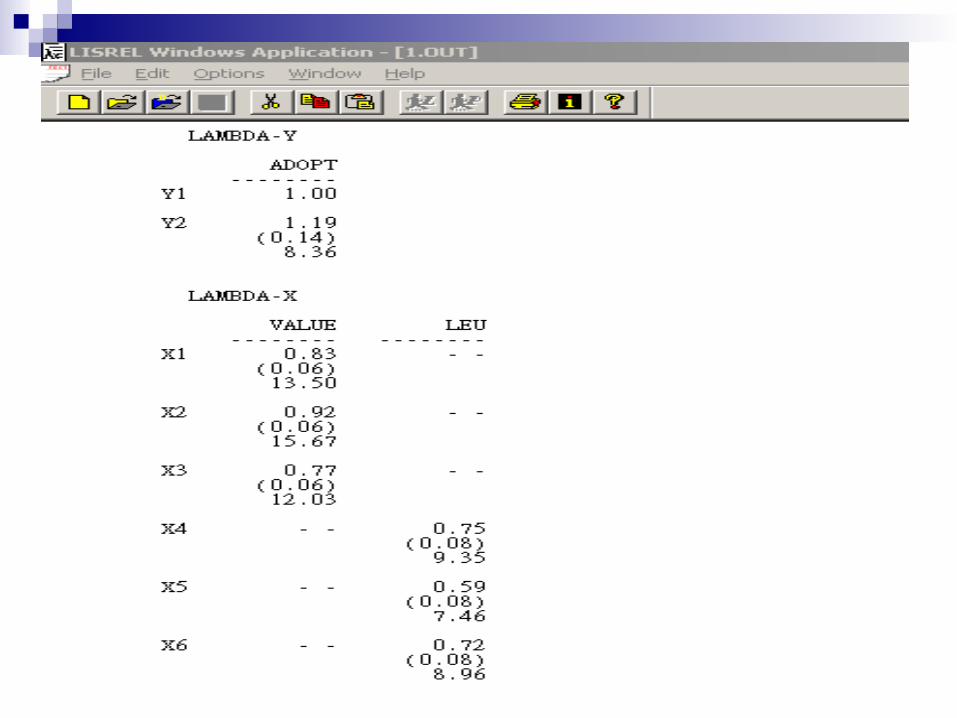

未出現在路徑圖上
係數估計值雖不高,但仍具顯著性。有領先使用特質的使用者未必都覺得可此套裝軟體對其有幫助

另一種寫法 TI SEM for Modeling The Adoption Of Innovation DA NI=10 NO=188 NG=1 MA=KM LA y1 y2 x1 x2 x3 x4 x5 x6 SE 1 2 3 4 5 6 7 8 / KM = 1.000 0.599 1.000 0.478 0.571 1.000 0.464 0.580 0.763 1.000 0.360 0.481 0.628 0.720 1.000 0.263 0.110 0.187 0.208 0.122 1.000 0.248 0.156 0.124 0.139 0.051 0.437 1.000 0.222 0.104 0.155 0.191 0.054 0.542 0.421 1.000/
MO NX=6 NY=2 NK=2 NE=1 LY=FU,FR LX=FU,FR GA=FU,FR PH=SY,FR PS=DI,FR TE=DI,FR TD=DI,FR LE adopt LK value leu PA GA 1 1 PA LY 0 1 PA LX 1 0 1 0 1 0 0 1 0 1 0 1 PA PH 0 1 0 PA PS 1 PA TE 1 1 PA TD 1 1 1 1 1 1 VALUE 1.0 LY(1,1) PH(1,1) PH(2,2) PD OU ALL

10.4 Questions Regarding The Application of Structural Equations - Latent Variable 模型診斷( Model Diagnostics ): - Failure to Converge - Infeasible Estimates - Pattern of Residuals - Modification Indices

1.Failure to Converge 在 SEM- Latent Variable 中,每個可觀察的共變異數被模型化為模型參數的高度非線性組合
在使目標函數最大化前 (get stuck) ,便停止尋找係數估計值,可能會使得此模型之係數估計值及標準差將會不正確
有時可使用另一組起始參數解,以解決此問題 Failure to Converge也有可能是因為模型設定不當但所產生

2.Infeasible Estimates
Infeasible Estimates -例如: Negative Variances 若在搜尋過程中產生負的變異數估計值,可能因為模型設定不當
有時亦可使用另一組起始參數解,以解決此問題 在此種情況下,不適合藉由固定參數值為〝正〞來解決此問題

3.Pattern of Residuals
Pattern of Residuals 可指出模型的潛在問題
可藉由繪製正規化殘差的機率圖加以觀察

4.Modification Indices Modification Indices 為模型適合度差且被拒絕時改善之依據
Modification Indices :某一未被估計之模型參數對目標函數的一階導數( first derivative ),即若估計此參數,目標函數的改善值
Free one parameter at a time, rerun the model, and then recalculate the modification indices.
一階導數為目標函數之斜率(反映〝目標函數所改善之值〞對〝每單位參數值變動〞之關係)

當對某一參數值作檢驗時,應固定其他參應固定其他參數值數值
檢驗方式:對個別參數值依序檢驗,並重新計算 Modification Indices
上述方法近似〝逐步迴歸法〞( Stepwise Regression Methods )
4.Modification Indices (續)

交互效果之檢定( Testing for Interactions )
某些情況下自變數對因變數的直接效果不顯著,但與其他自變數的交互作用對因變數的影響可能顯著;如前例中, Value 對 early adoption 影響顯著, leading-edge usage 對 adoption 影響不顯著,若進一步考慮 Value 與 leading-edge usage 的交互作用,則其有可能對 early adoption 影響顯著
當交互作用中,其變數之一為質性,則可使用多重組群分析( multiple group analysis )來檢定交互效果的顯著性

假設 LEU 為質性變數

Low LEU
High LEU
Value of innovation
Ado
ptio
n in
tent
ion
Interaction effect between leading-edge usage and leading-edge usage and value of innovationvalue of innovation on adoption intention

Testing for Interactions Across Groups系統性的檢測模型所有參數跨組的無差異性:
因素負荷衡量誤差變異數結構方程式係數結構關係的誤差變異數

例子:用Leading edge usage將 users分成兩群組
Testing for Interactions Across Groups

1. 設定兩群組之參數值完全不同
模型 I:配適度為 highly acceptable

2. 設定獨立潛在變數 (value) 的因素負荷 和誤差變異數跨組的無差異性
模型 II:配適度為 highly acceptable
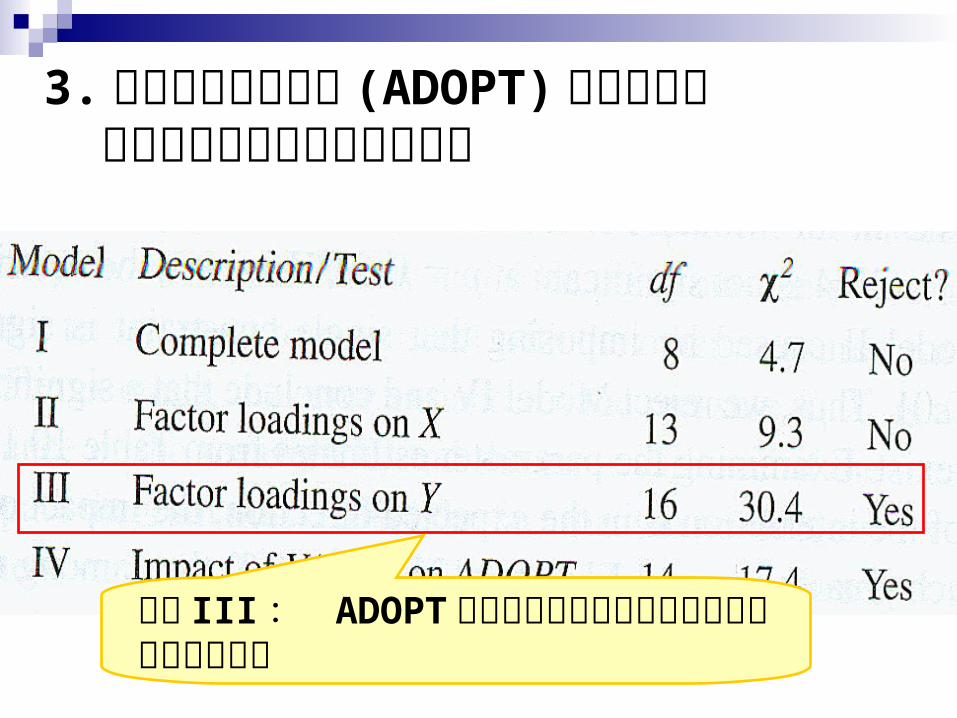
3. 設定相依潛在變數 (ADOPT) 的因素負荷 和誤差變異數跨組的無差異性
模型 III : ADOPT 的因素負荷和誤差變異數在兩群組有顯著差異

4. 設定 VALUE 對 ADOPT 的結構方程式係數 跨組的無差異性
模型 IV:此模型配適度雖可接受,但卻比模型 II的配適度差 (與模型 II有顯著差異 ,χ2(1)=8.1, p < 0.01 ) ,故拒絕此模型

假設 LEU 為量性變數
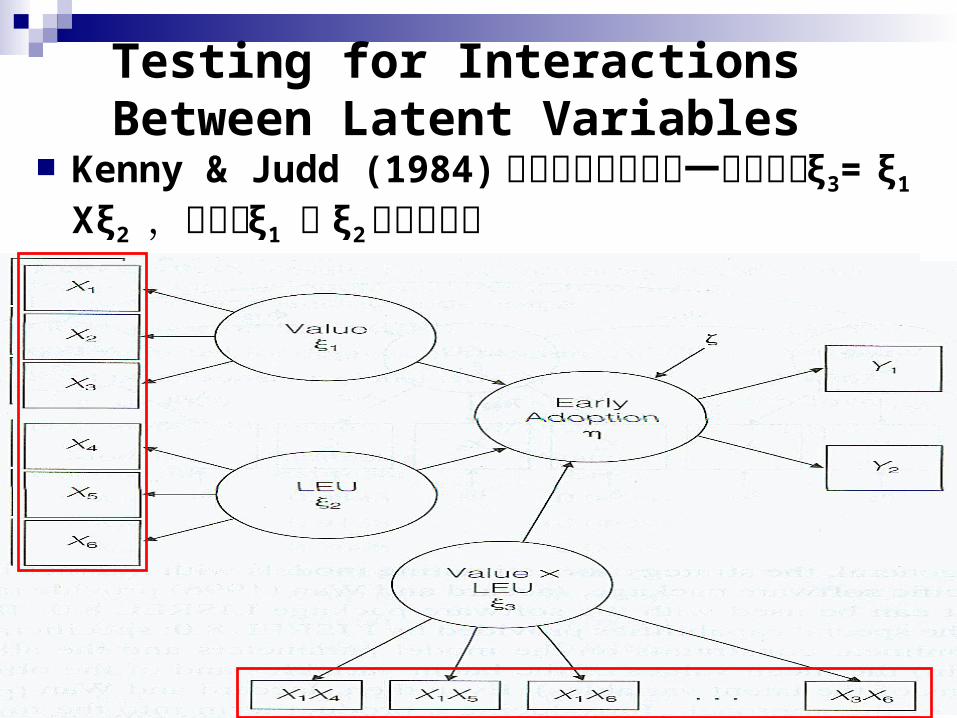
Kenny & Judd (1984)提出在模型中增加一潛在變數ξ3= ξ1 Xξ2 ,以表示 ξ1 與 ξ2的交互作用
Testing for Interactions Between Latent Variables

Testing for Interactions Between Latent Variables Lattin, Carroll and Green(2003) 的策略: 步驟如下: 1.建立並估計一個驗證性因素模型,此模型允許所有潛在
變數有相關 (不考慮相依關係 ) ;這個模型的 model fit要好
2. 利用驗證性因素模型計算因素分數 (即每一潛伏變數的值 )
3.建立兩潛伏自變數的乘積,作為交互項;使用迴歸分析,
分析潛伏自變數及其交互項對潛伏因變數的回歸關係
1^
RX s

LEU ξ2
X4 X5 X6
δ4 δ5 δ6
λ42 λ52 λ62
Value ξ1
X1 X2 X3
δ1 δ2 δ3
λ11 λ21 λ31
Adoptξ3
Y1 Y2
δ7 δ8
λ73 λ83
φ12 φ23
φ13

交互效果顯著

Model Validation
SEM- Latent Variable 的目的就是驗證模式
然而當建模者偏離純驗證的目的時,某種形式的驗證是必要的 (用 holdout sample)

另一個例子
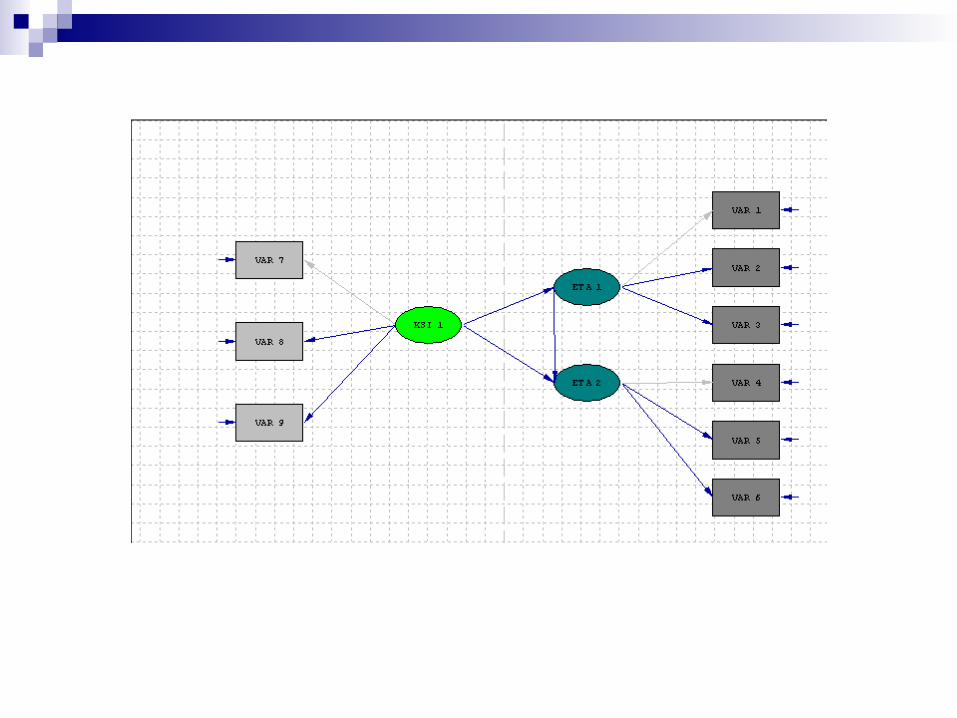
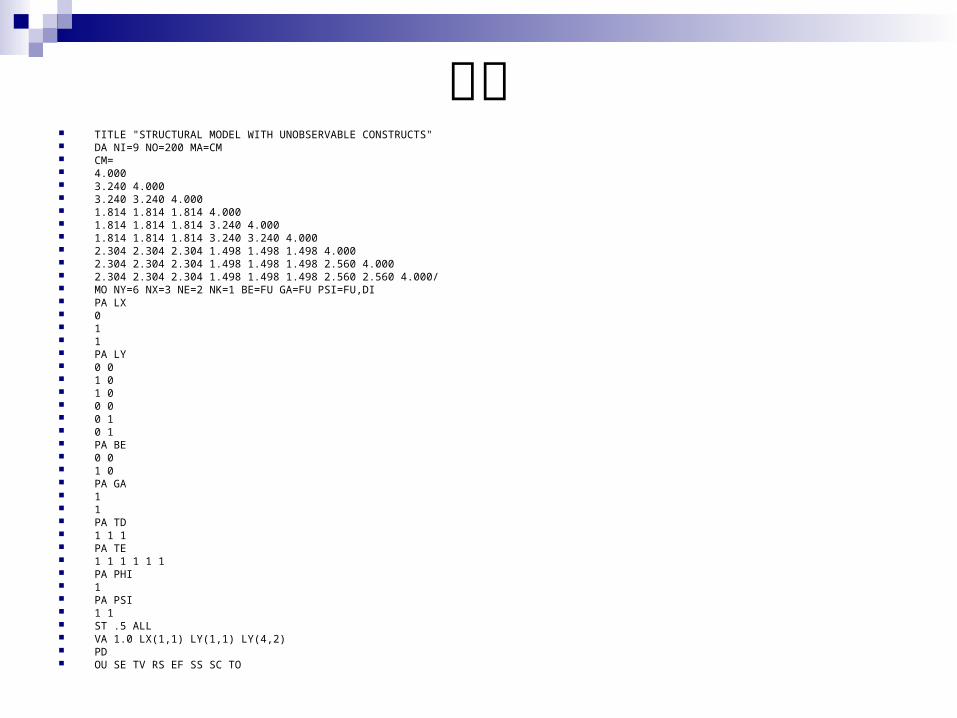
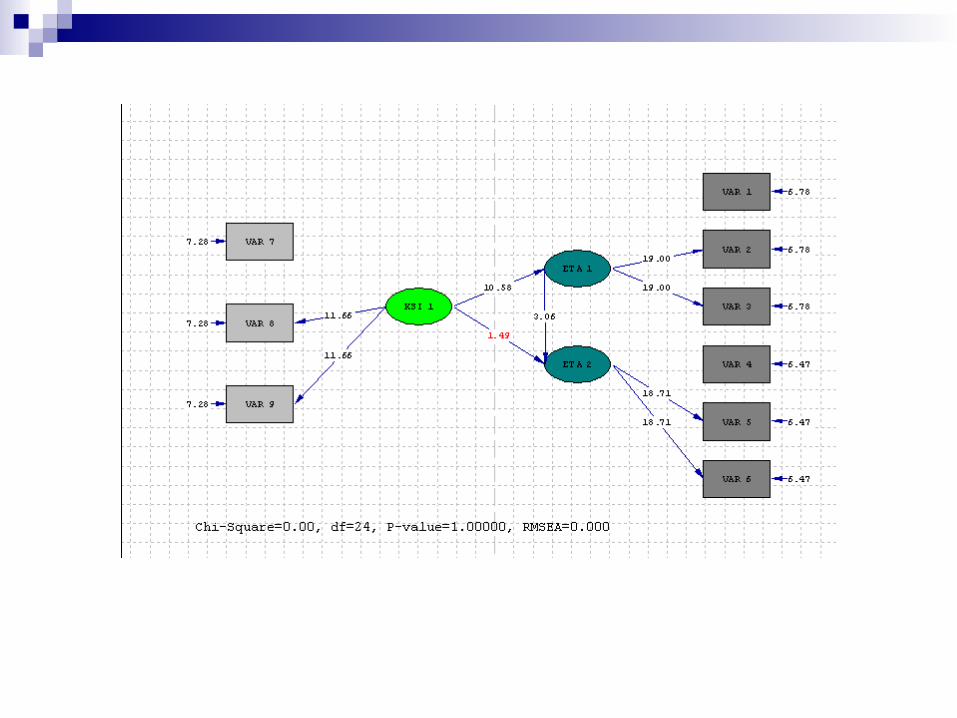
程式 TITLE "STRUCTURAL MODEL WITH UNOBSERVABLE CONSTRUCTS" DA NI=9 NO=200 MA=CM CM= 4.000 3.240 4.000 3.240 3.240 4.000 1.814 1.814 1.814 4.000 1.814 1.814 1.814 3.240 4.000 1.814 1.814 1.814 3.240 3.240 4.000 2.304 2.304 2.304 1.498 1.498 1.498 4.000 2.304 2.304 2.304 1.498 1.498 1.498 2.560 4.000 2.304 2.304 2.304 1.498 1.498 1.498 2.560 2.560 4.000/ MO NY=6 NX=3 NE=2 NK=1 BE=FU GA=FU PSI=FU,DI PA LX 0 1 1 PA LY 0 0 1 0 1 0 0 0 0 1 0 1 PA BE 0 0 1 0 PA GA 1 1 PA TD 1 1 1 PA TE 1 1 1 1 1 1 PA PHI 1 PA PSI 1 1 ST .5 ALL VA 1.0 LX(1,1) LY(1,1) LY(4,2) PD OU SE TV RS EF SS SC TO


End of Lecture





























