Embed Size (px)
Citation preview

Chap. 9: Sorting [email protected] -‹#›-
정렬(sorting) 이란 ?
정의 – 물건을 크기순으로 오름차순이나 내림차순으로 나열하는 것
– 컴퓨터 공학분야에서 가장 기본적이고 중요한 알고리즘중의
하나
– 정렬은 자료 탐색에 있어서 필수적.
• (예) 만약 사전에서 단어들이 정렬이 안되어 있다면 ?

Chap. 9: Sorting [email protected] -‹#›-
정렬 알고리즘의 개요
정렬 알고리즘 분류
– 단순하지만 비효율적인 방법
• 삽입정렬, 선택정렬, 버블정렬, …
– 복잡하지만 효율적인 방법
• 퀵정렬, 히프정렬, 합병정렬, 기수정렬, …
정렬 알고리즘 선택 – 모든 경우에 최적인 알고리즘은 없음
– 응용에 맞추어 선택
– 정렬 알고리즘의 평가
• 비교횟수
• 이동횟수

Chap. 9: Sorting [email protected] -‹#›-
알고리즘
– 왼쪽부터 0,1,2,3,…,N-1로 가정
– 0에 있는 막대와 1에 있는 막대를 비교
• 오른쪽이 왼쪽보다 작으면 자리바꿈
• 그렇지 않으면 자리를 바꾸지 않음
– 위치를 오른쪽으로 한자리 이동
– 위치를 이동한 다음 1과 2를 비교
– 위 과정 반복
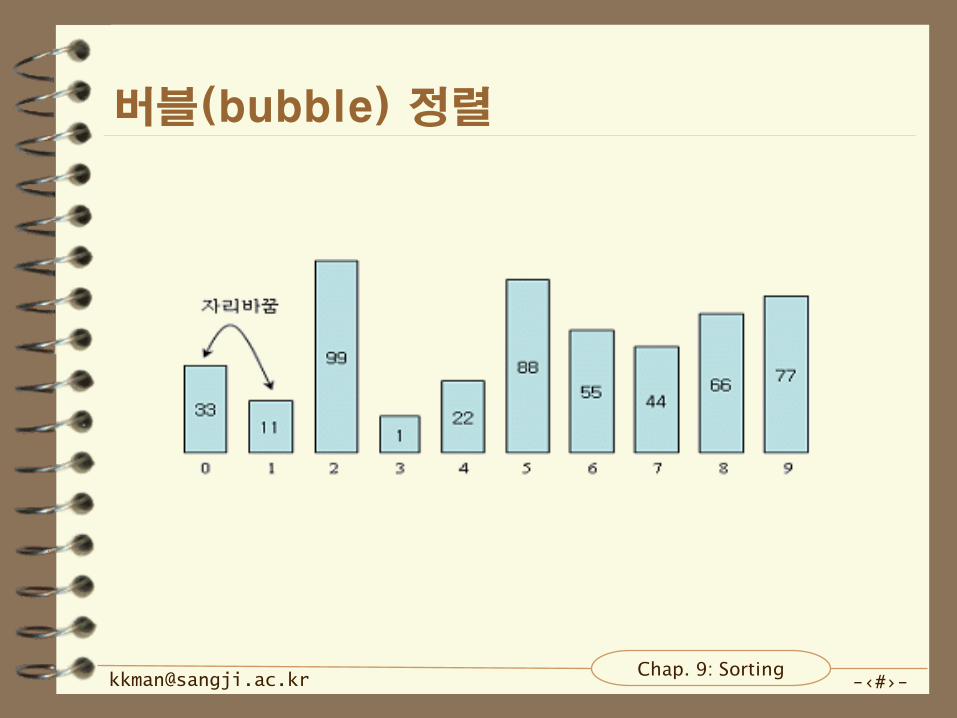
버블(bubble) 정렬

Chap. 9: Sorting [email protected] -‹#›-
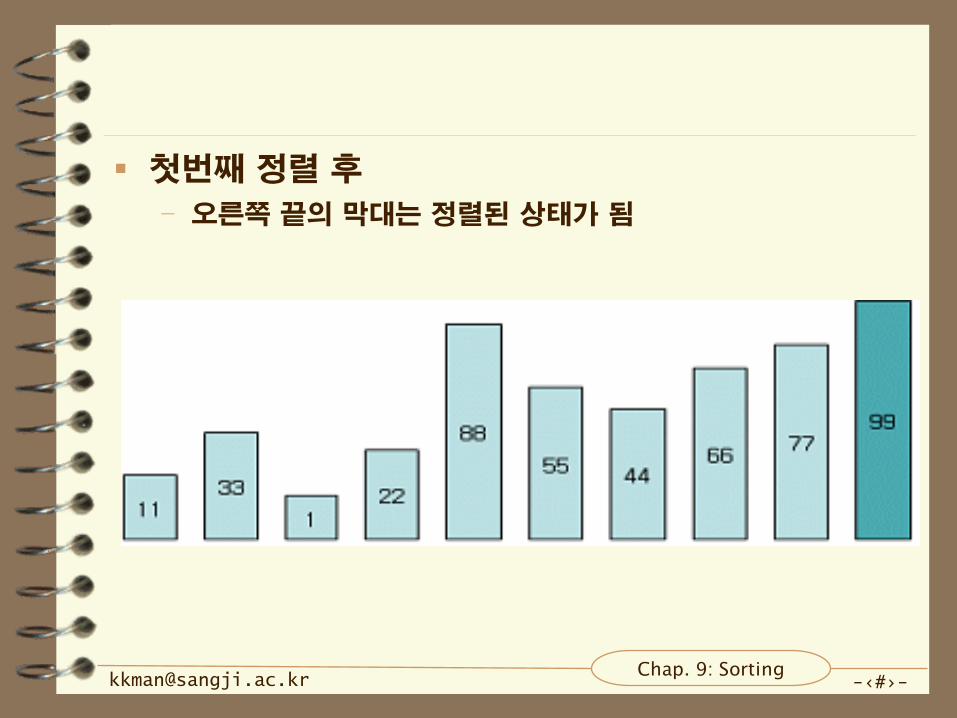
4가지 단계로 정리됨
– 첫 번째, 두 개의 항목을 비교.
– 두 번째, 오른쪽 항목이 작으면 자리 바꿈.
– 세 번째, 오른쪽으로 한 자리 이동.
– 네 번째, 가장 오른쪽에 한 항목을 비교할 때까지 앞의 3단계를
반복.
Chap. 9: Sorting [email protected] -‹#›-
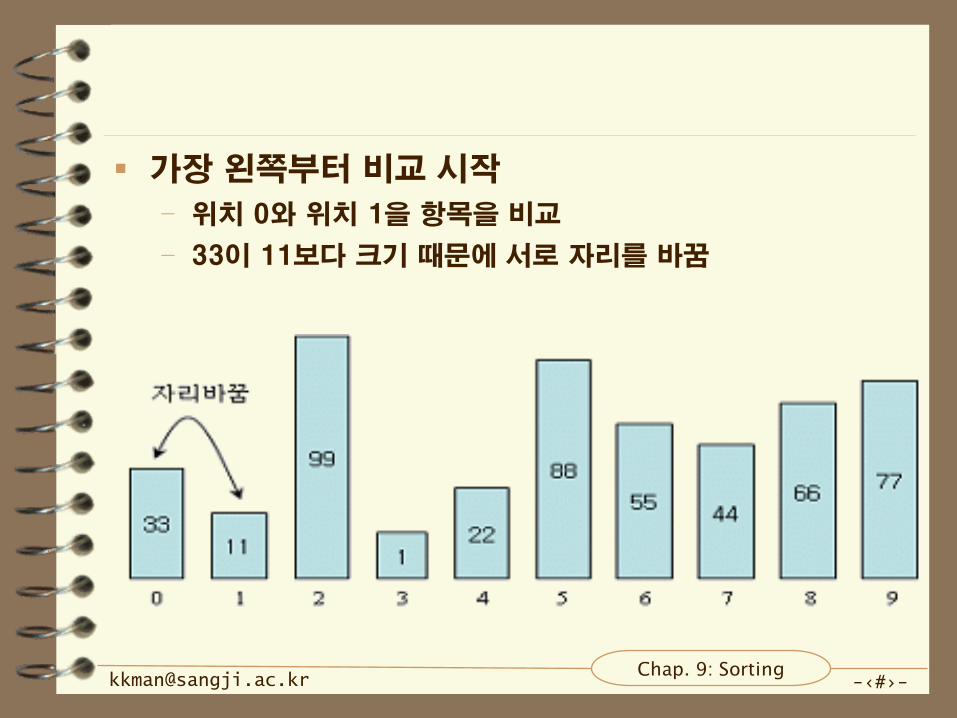
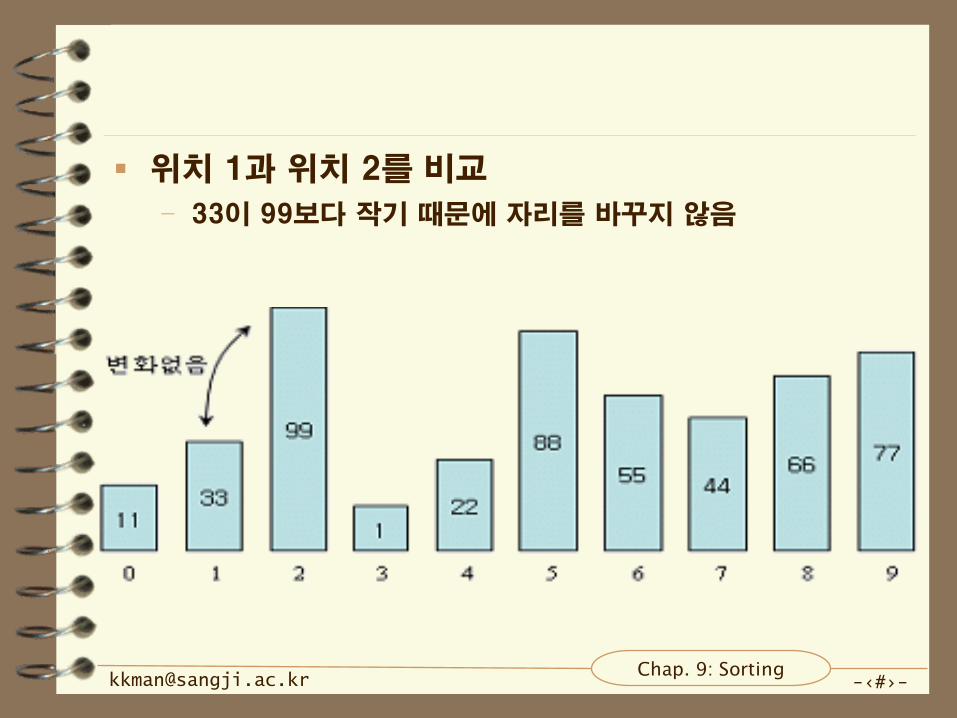
가장 왼쪽부터 비교 시작
– 위치 0와 위치 1을 항목을 비교
– 33이 11보다 크기 때문에 서로 자리를 바꿈
Chap. 9: Sorting [email protected] -‹#›-
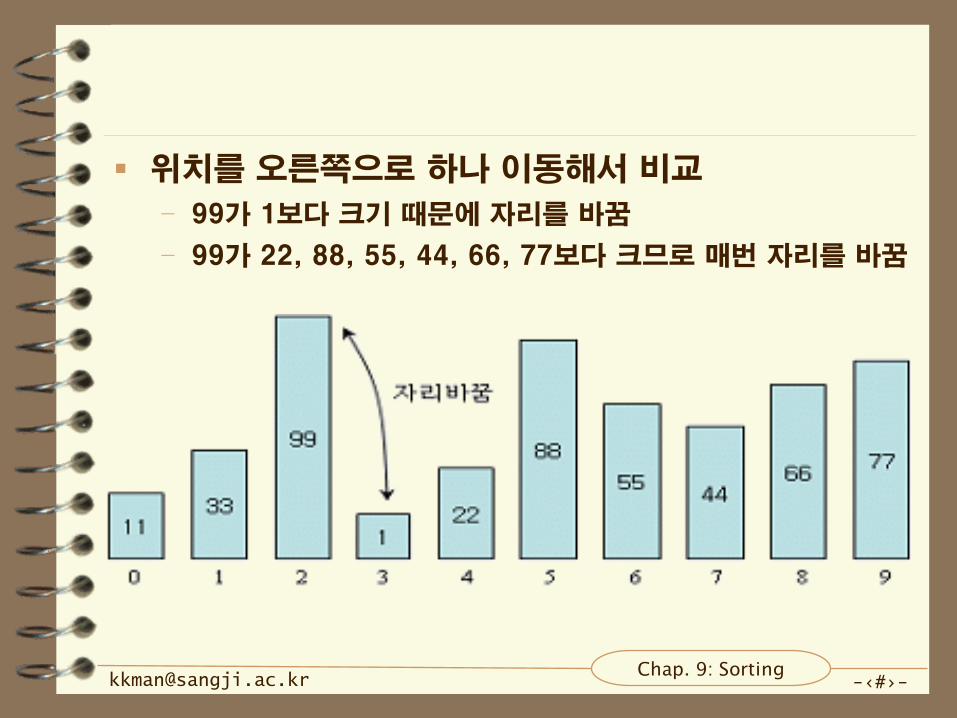
위치를 오른쪽으로 하나 이동해서 비교
– 99가 1보다 크기 때문에 자리를 바꿈
– 99가 22, 88, 55, 44, 66, 77보다 크므로 매번 자리를 바꿈

Chap. 9: Sorting [email protected] -‹#›-
버블 정렬 in C
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) )
void bubble_sort(int list[], int n)
{
int i, j, temp;
for(i=n-1; i>0; i--){
for(j=0; j<i; j++)
if( list[j] > list[j+1] )
SWAP(list[j], list[j+1], temp);
}
}

Chap. 9: Sorting [email protected] -‹#›-
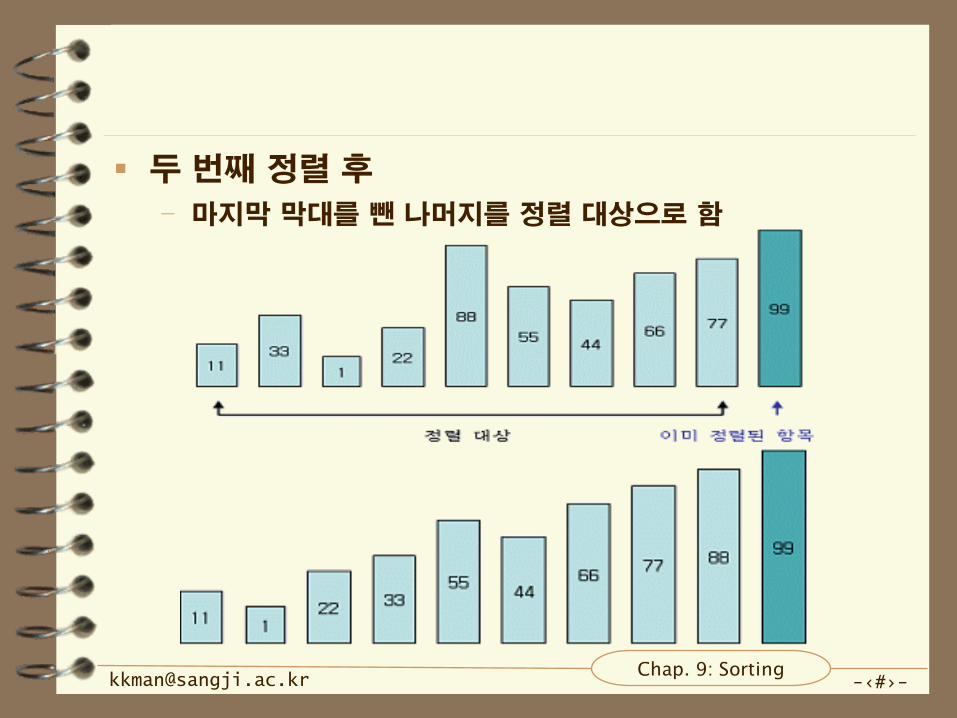
비교 횟수
– 항목의 개수가 N이면 비교횟수
• 첫 번째 과정은 N-1번
• 두 번째 과정은 N-2번
– 정리
• (N-1) + (N-2) + (N-3) + ... + 1 = N * (N-1) / 2
• 비교횟수는 최상, 평균, 최악의 어떠한 경우에도 항상
일정
버블 정렬 분석

Chap. 9: Sorting [email protected] -‹#›-
선택(selection) 정렬
선택 정렬
– 버블 정렬의 자리바꿈 횟수 감소 목적
– 정렬이 안된 숫자들중에서 최소값을 선택하여 배열의
첫번째 요소와 교환

Chap. 9: Sorting [email protected] -‹#›-
알고리즘
– 첫 번째 항목을 기준으로 다른 항목과 비교
– 가장 작은 것과 기준 항목과 치환(교환)
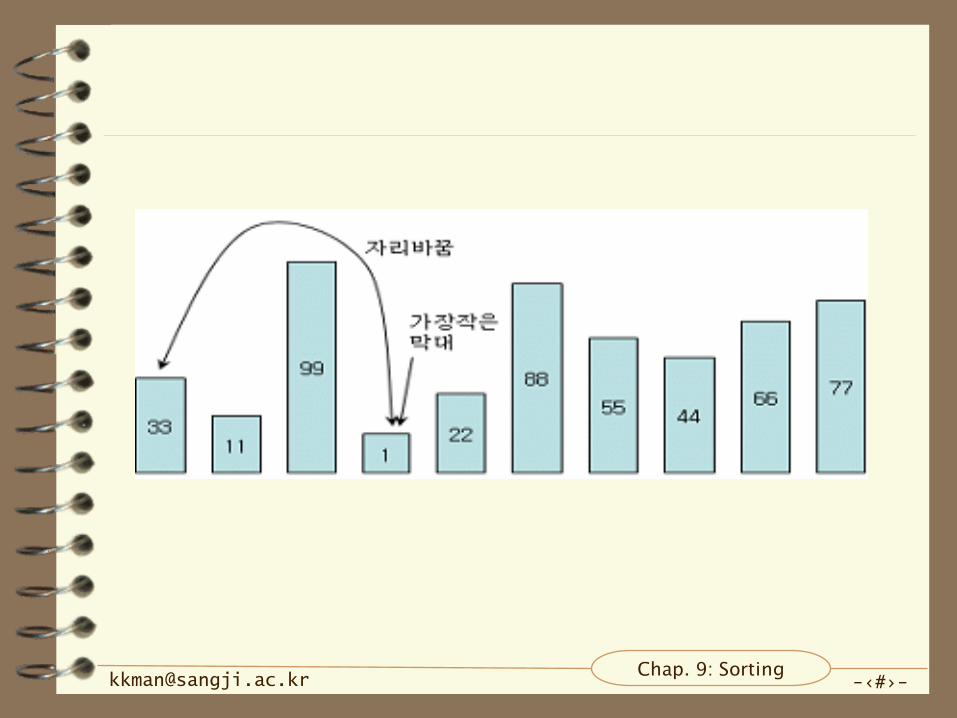
단계
– 0에 있는 막대와 1~9까지의 막대를 비교
– 가장 작은 막대를 0에 있는 막대와 치환
Chap. 9: Sorting [email protected] -‹#›-
Chap. 9: Sorting [email protected] -‹#›-
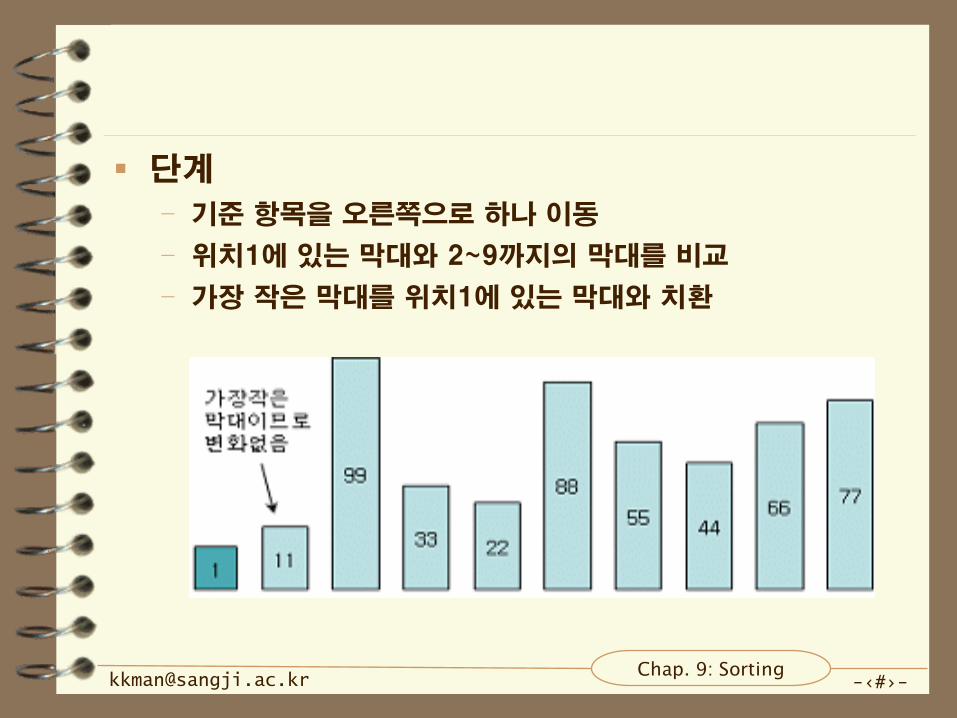
단계
– 기준 항목을 오른쪽으로 하나 이동
– 위치1에 있는 막대와 2~9까지의 막대를 비교
– 가장 작은 막대를 위치1에 있는 막대와 치환
Chap. 9: Sorting [email protected] -‹#›-
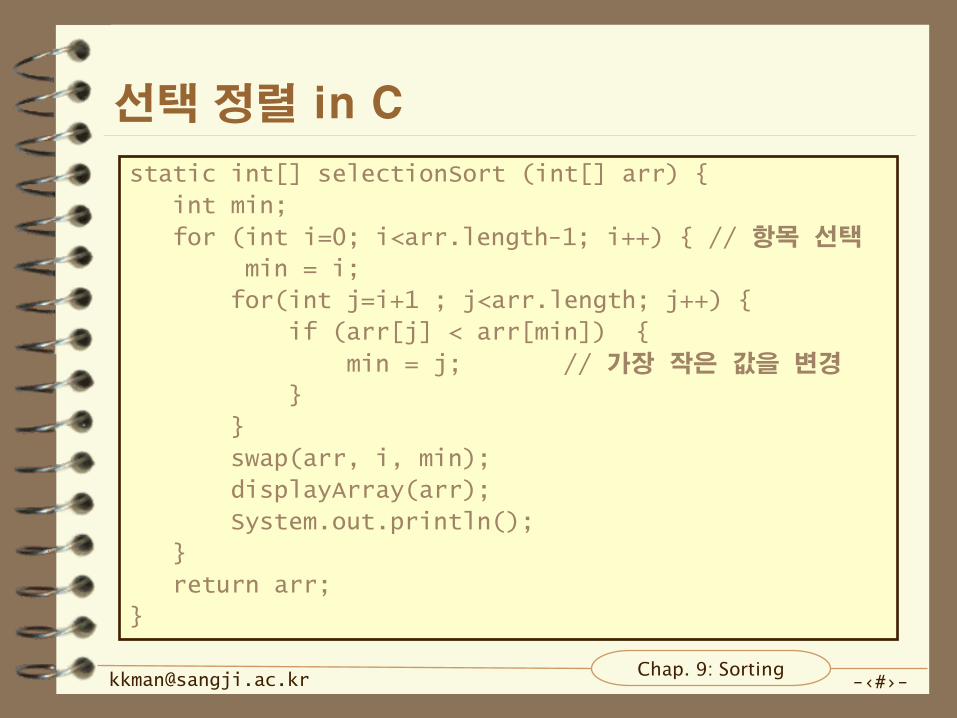
선택 정렬 in C
static int[] selectionSort (int[] arr) {
int min;
for (int i=0; i<arr.length-1; i++) { // 항목 선택
min = i;
for(int j=i+1 ; j<arr.length; j++) {
if (arr[j] < arr[min]) {
min = j; // 가장 작은 값을 변경
}
}
swap(arr, i, min);
displayArray(arr);
System.out.println();
}
return arr;
}

Chap. 9: Sorting [email protected] -‹#›-
10개의 자료에 대한 선택 정렬 결과
– 33, 11, 99, 1, 22, 88, 55, 44, 66, 77
*INPUT : 33 11 99 1 22 88 55 44 66 77
STEP 1 : 1 11 99 33 22 88 55 44 66 77
STEP 2 : 1 11 99 33 22 88 55 44 66 77
STEP 3 : 1 11 22 33 99 88 55 44 66 77
STEP 4 : 1 11 22 33 99 88 55 44 66 77
STEP 5 : 1 11 22 33 44 88 55 99 66 77
STEP 6 : 1 11 22 33 44 55 88 99 66 77
STEP 7 : 1 11 22 33 44 55 66 99 88 77
STEP 8 : 1 11 22 33 44 55 66 77 88 99
STEP 9 : 1 11 22 33 44 55 66 77 88 99

Chap. 9: Sorting [email protected] -‹#›-
선택 정렬 분석
비교 횟수
– 버블 정렬과 항목의 비교횟수는 동일
– 10개의 항목의 경우 비교회수는 N*(N-1)/2=45로 동일
자리바꿈 횟수
– 버블 정렬보다 작음
– 자리바꿈 횟수는 10회 이하
Chap. 9: Sorting [email protected] -‹#›-
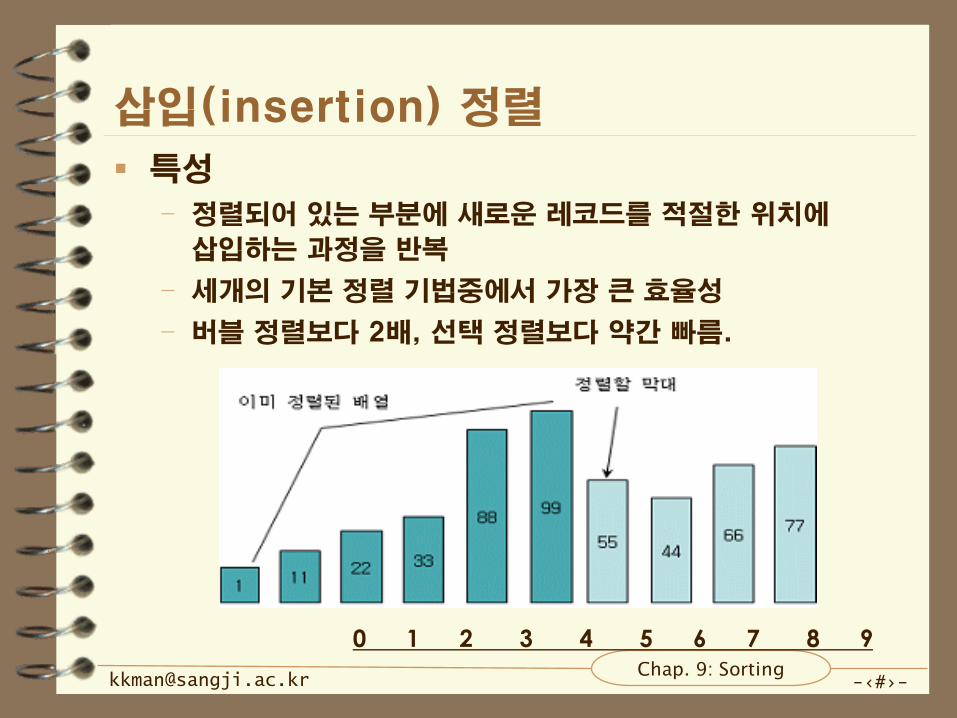
삽입(insertion) 정렬
특성
– 정렬되어 있는 부분에 새로운 레코드를 적절한 위치에
삽입하는 과정을 반복
– 세개의 기본 정렬 기법중에서 가장 큰 효율성
– 버블 정렬보다 2배, 선택 정렬보다 약간 빠름.
0 1 2 3 4 5 6 7 8 9
Chap. 9: Sorting [email protected] -‹#›-
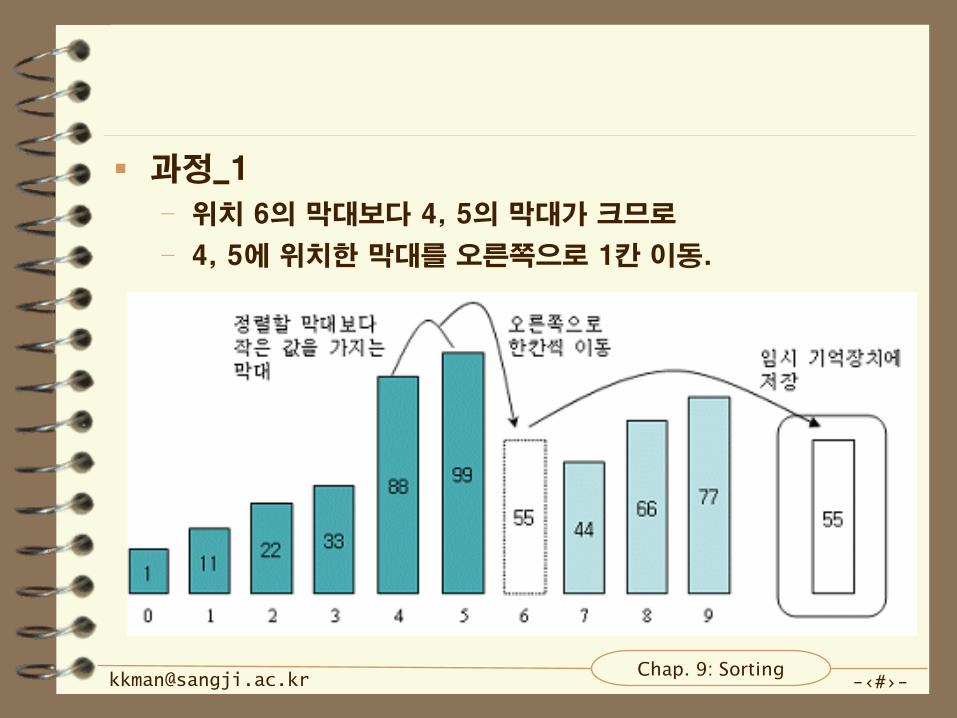
과정_1
– 위치 6의 막대보다 4, 5의 막대가 크므로
– 4, 5에 위치한 막대를 오른쪽으로 1칸 이동.
Chap. 9: Sorting [email protected] -‹#›-
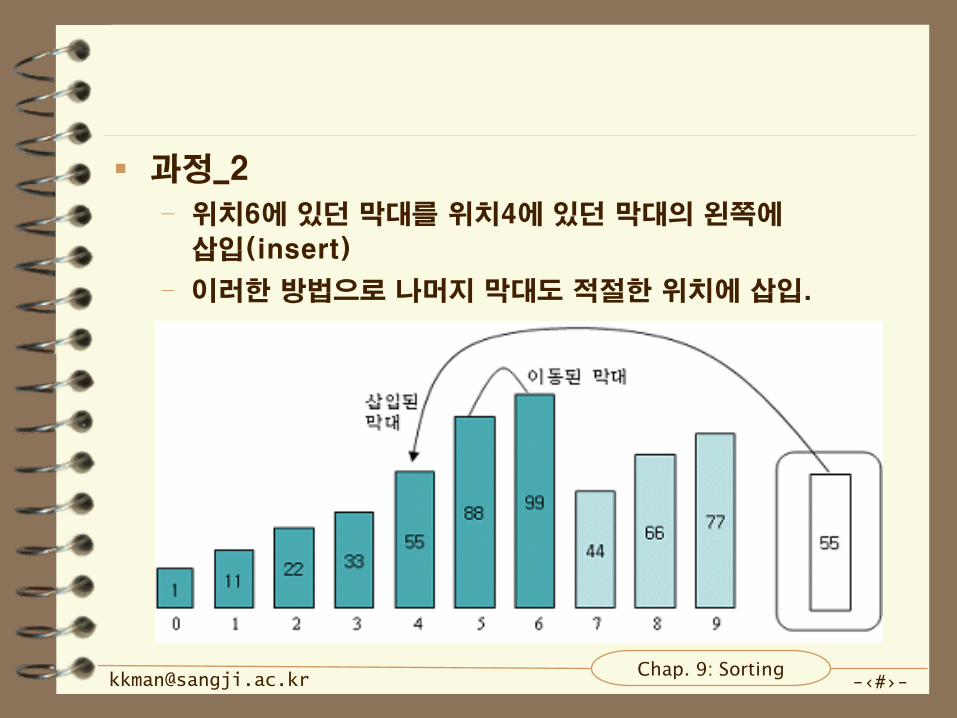
과정_2
– 위치6에 있던 막대를 위치4에 있던 막대의 왼쪽에
삽입(insert)
– 이러한 방법으로 나머지 막대도 적절한 위치에 삽입.

Chap. 9: Sorting [email protected] -‹#›-
삽입 정렬 in C
// 삽입정렬
void insertion_sort(int list[], int n) {
int i, j, key;
for(i=1; i<n; i++){
key = list[i];
for(j=i-1; j>=0 && list[j]>key; j--)
list[j+1] = list[j];
list[j+1] = key;
}
}

Chap. 9: Sorting [email protected] -‹#›-
Chap. 9: Sorting [email protected] -‹#›-
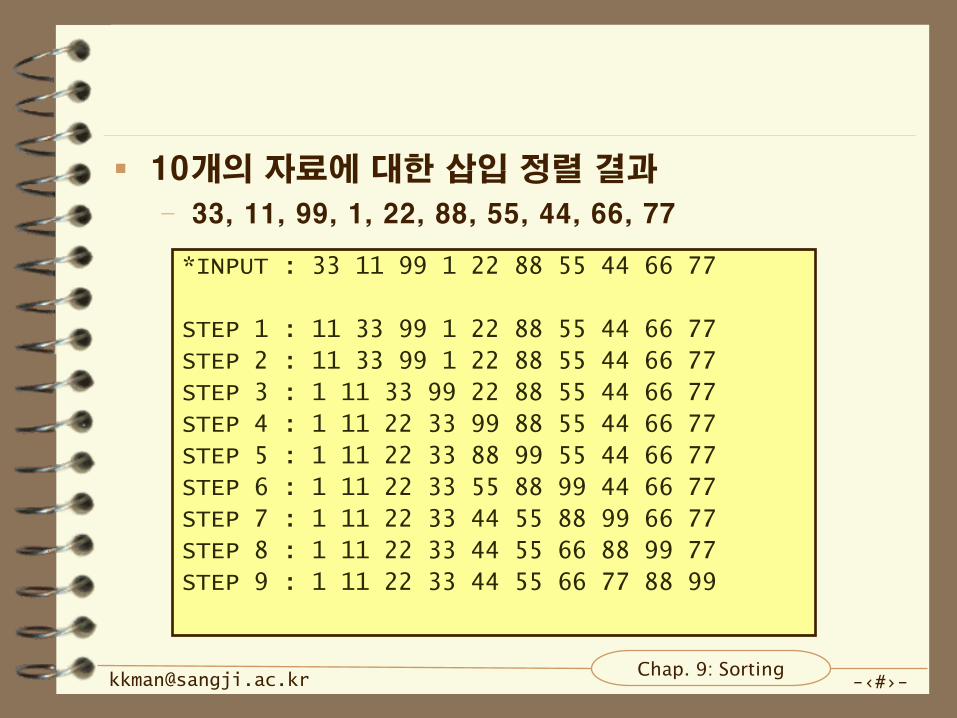
10개의 자료에 대한 삽입 정렬 결과
– 33, 11, 99, 1, 22, 88, 55, 44, 66, 77
*INPUT : 33 11 99 1 22 88 55 44 66 77
STEP 1 : 11 33 99 1 22 88 55 44 66 77
STEP 2 : 11 33 99 1 22 88 55 44 66 77
STEP 3 : 1 11 33 99 22 88 55 44 66 77
STEP 4 : 1 11 22 33 99 88 55 44 66 77
STEP 5 : 1 11 22 33 88 99 55 44 66 77
STEP 6 : 1 11 22 33 55 88 99 44 66 77
STEP 7 : 1 11 22 33 44 55 88 99 66 77
STEP 8 : 1 11 22 33 44 55 66 88 99 77
STEP 9 : 1 11 22 33 44 55 66 77 88 99

Chap. 9: Sorting [email protected] -‹#›-
삽입 정렬 분석
최상의 경우: 이미 정렬되어 있는 경우
– 비교: n-1번
– 이동: 2(n-1)번
최악의 경우: 역순으로 정렬
– 모든 단계에서 앞에 놓인 자료 전부 이동

Chap. 9: Sorting [email protected] -‹#›-
기본 정렬 비교
버블 정렬
– 가장 간단함
– 비효율적
– 정렬대상이 적을 경우 사용하는 것이 바람직함
선택 정렬
– 자리바꿈 횟수를 최소화
– 비교횟수는 여전히 많음
– 정렬할 대상이 적거나, 자리바꿈시간이 비교시간 보다
상대적으로 클 때 사용하는 것이 유용

Chap. 9: Sorting [email protected] -‹#›-
삽입 정렬
– 정렬 대상이 적은경우
– 부분적으로 정렬이 된 경우에 효율적
정렬의 위해 필요한 메모리의 양 ?
정렬 알고리즘에 대한 수행속도를 비교
– http://cg.scs.carleton.ca/~morin/misc/sortalg/

Chap. 9: Sorting [email protected] -‹#›-
쉘(shell) 정렬
특징
– 삽입 정렬의 단점을 극복하고 장점을 이용하여 만든 정렬
– 전체 N개라는 하나의 배열을 일정한 간격(interval)으로
나눔
– 작은 자료의 개수로 이루어진 하위 배열을 각각 삽입 정렬
– 더 좁은 간격으로 하위 배열로 나누고 최종적으로 전체
배열을 삽입 정렬

Chap. 9: Sorting [email protected] -‹#›-
3가지 단계로 정리됨
– N개의 항목으로 이루어진 하나의 배열을 일정한 간격으로
나눔
• 여러 개의 하위 배열로 구성.
– 여러 개의 하위 배열에 대해 각각 삽입 정렬
– 보다 작은 간격을 두어 여러 개의 하위 배열을 구성
• 위 단계 반복.
Chap. 9: Sorting [email protected] -‹#›-
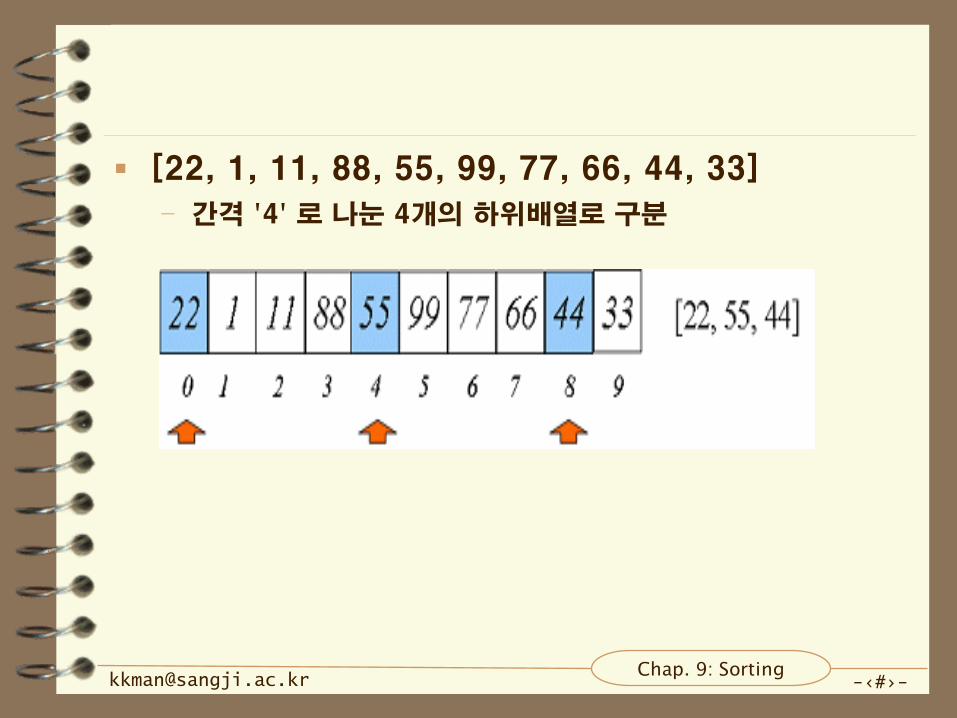
[22, 1, 11, 88, 55, 99, 77, 66, 44, 33]
– 간격 '4' 로 나눈 4개의 하위배열로 구분

Chap. 9: Sorting [email protected] -‹#›-
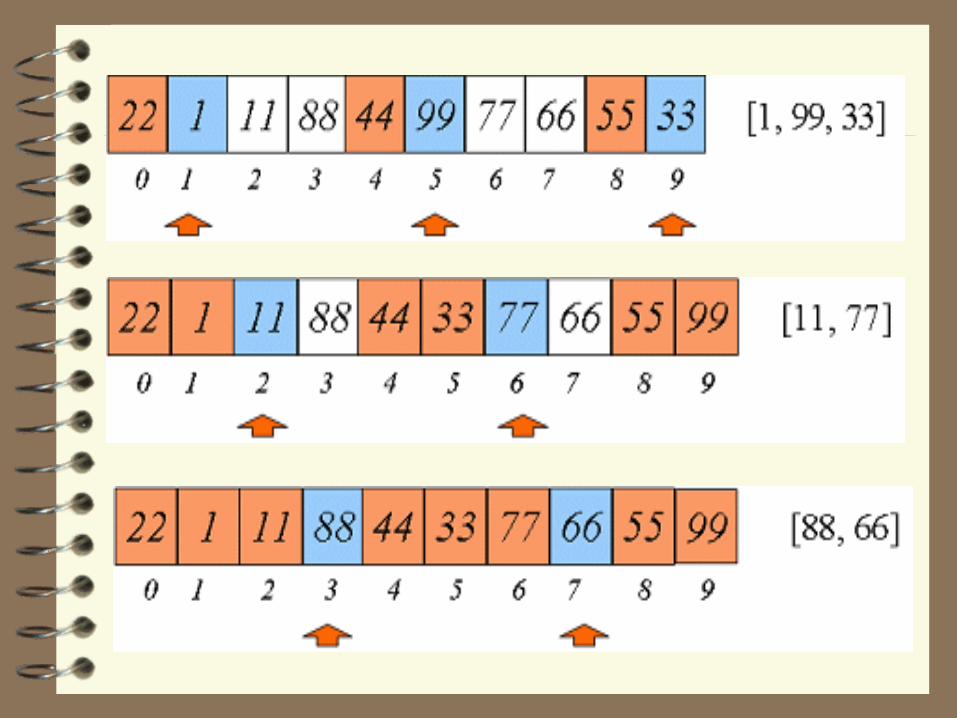
4-sort 과정 종료
– '4'가 아닌 간격 '1'로 줄여 삽입 정렬 알고리즘 적용
– 간격 '1‘, 삽입 정렬과 동일한 의미

Chap. 9: Sorting [email protected] -‹#›-

쉘 정렬 in C
inc_insertion_sort(int list[], int first, int last, int gap){
int i, j, key;
for(i=first+gap; i<=last; i=i+gap){
key = list[i];
for(j=i-gap; j>=first && key<list[j];j=j-gap)
list[j+gap]=list[j];
list[j+gap]=key;
}
}
void shell_sort( int list[], int n ) { // n = size
int i, gap;
for( gap=n/2; gap>0; gap = gap/2 ) {
if( (gap%2) == 0 ) gap++;
for(i=0;i<gap;i++) // 부분 리스트의 개수는 gap
inc_insertion_sort(list, i, n-1, gap);
}
}

Chap. 9: Sorting [email protected] -‹#›-
항목이 더 많아진다면 간격 조정 ?
– 10개의 항목을 정렬하기 위해 처음에는 간격을 '4'로 사용
– 최적의 성능을 보일 수 있는 간격
• 크누스 방식(Knuth’s interval sequence)
– 개발자 스스로 좋은 아이디어가 있으면 적용

Chap. 9: Sorting [email protected] -‹#›-

Chap. 9: Sorting [email protected] -‹#›-
퀵(quick) 정렬
특징
– C.A.R Hoare, 1962
– 정렬 알고리즘 중 가장 우수한 평균 수행 속도
– 분할 알고리즘(partition algorithm) 사용
• 2개의 그룹으로 분할
• 배열의 양끝 방향 즉, 왼쪽 끝에서 오른쪽으로 그리고
오른쪽 끝에서 왼쪽으로 탐색
• 각각 피봇 값보다 큰 값과 작은 값을 발견하면 그 값들을
서로 치환하는 방식

Chap. 9: Sorting [email protected] -‹#›-
분할 알고리즘
– 정렬하고자 하는 배열을 2개의 하위 배열로 분할
– 각각의 하위 배열에서 다시 재귀적으로 자신의 배열을 분할
– 멀리 떨어진 자료를 직접적으로 치환함으로써 정렬의
수행속도를 개선

Chap. 9: Sorting [email protected] -‹#›-
퀵 정렬 알고리즘
– 배열을 2개의 하위 배열로 분할
• 왼쪽 하위 배열은 피봇 값 보다 작은 값으로 이루어진
배열
• 오른쪽 하위 배열은 피봇 값 보다 큰 값으로 이루어진
배열.
– 왼쪽 하위 배열에 퀵 정렬을 다시 실행
– 오른쪽 하위 배열에 퀵 정렬을 다시 실행
피봇(pivot)
– 하위 배열로 분할하는 특정 값.

Chap. 9: Sorting [email protected] -‹#›-
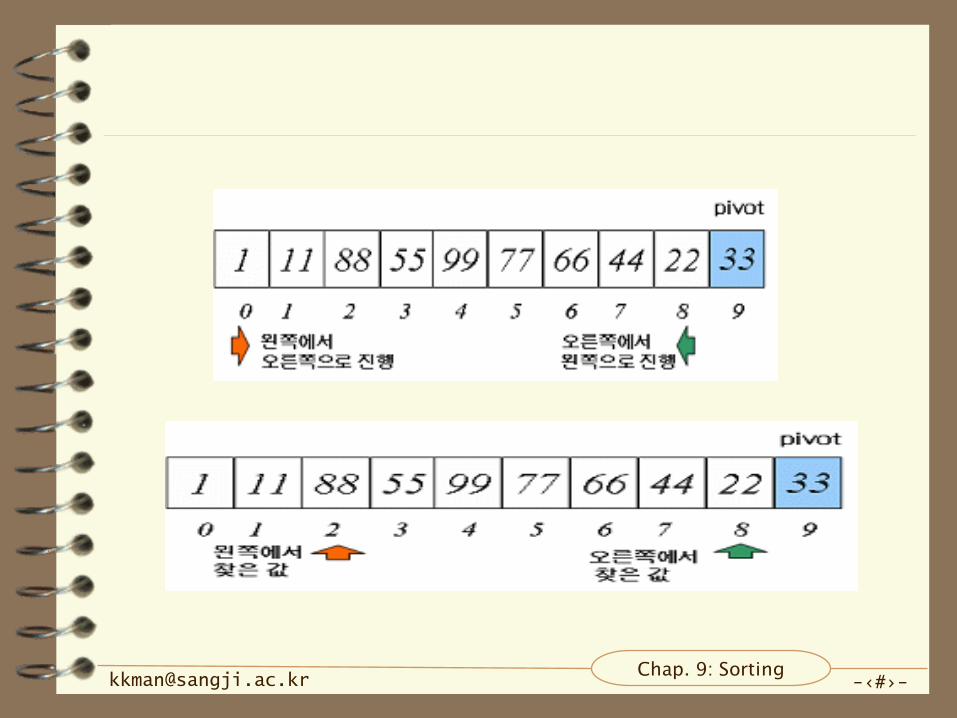
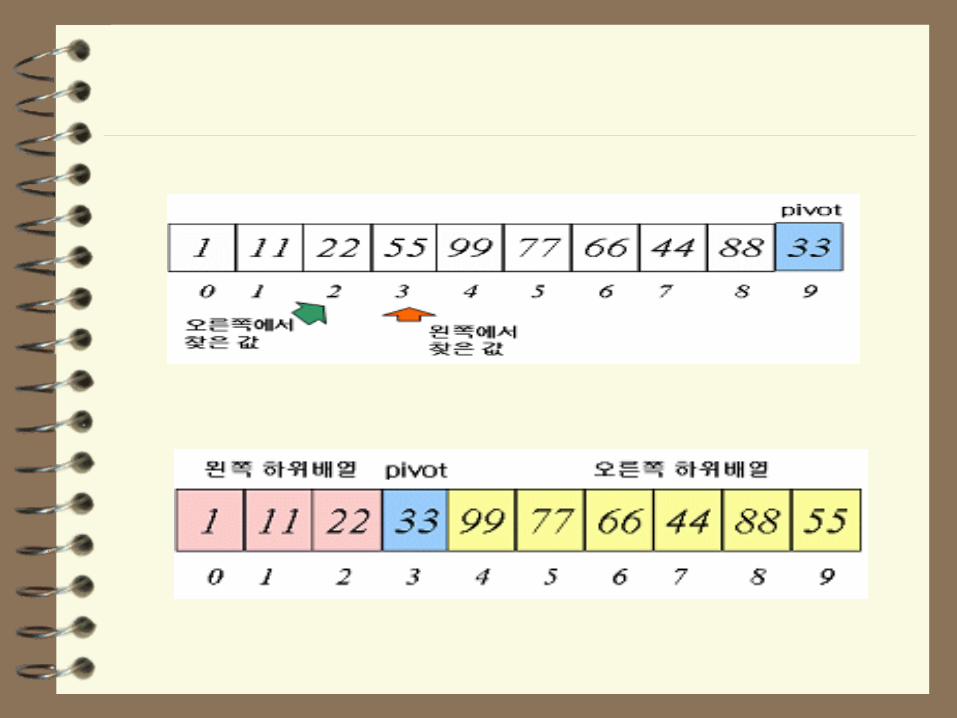
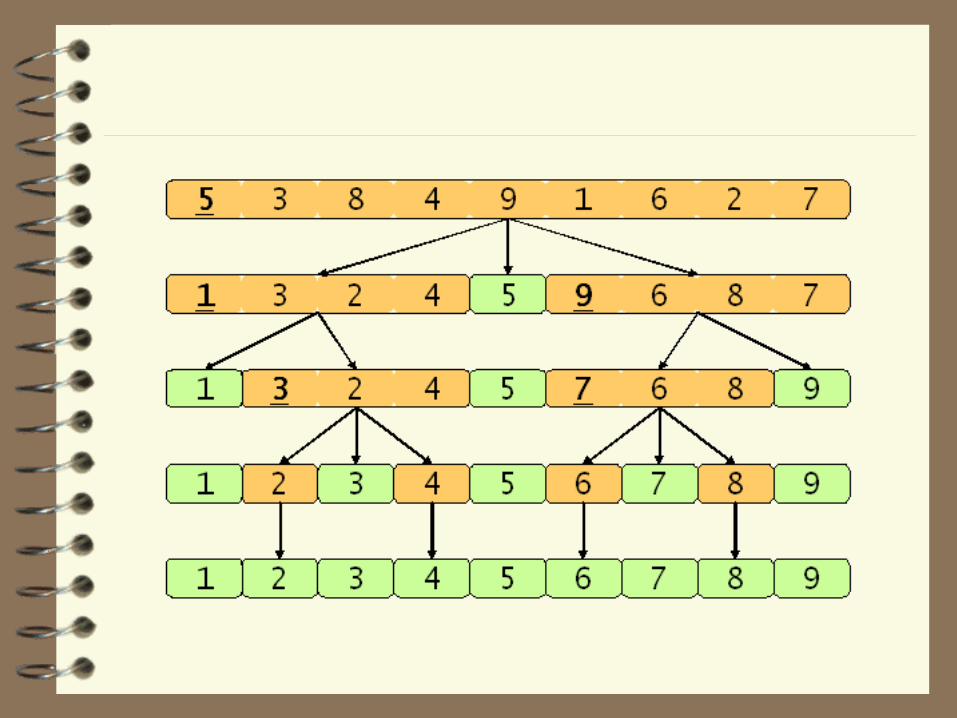
퀵 정렬 과정
배열 [1, 11, 88, 55, 99, 77, 66, 44, 22, 33]
– 피봇 값을 가장 우측의 값인 33
• 왼쪽에서 오른쪽으로 피봇 값보다 큰 값을 탐색
• 오른쪽에서 왼쪽으로 피봇 값보다 작은 값을 탐색
– 찾은 값끼리 서로 치환
– 이 과정을 계속해서 진행하되 서로의 자리 값이 엇갈리면
피봇 값과 왼쪽에서 찾은 값을 서로 바꿈
Chap. 9: Sorting [email protected] -‹#›-
Chap. 9: Sorting [email protected] -‹#›-
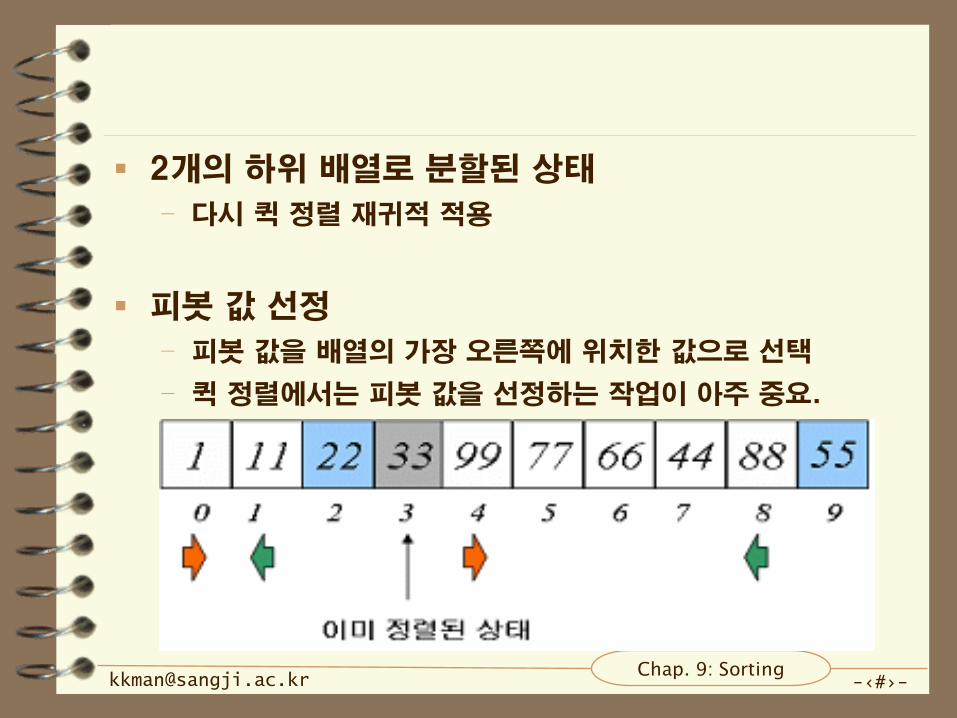
2개의 하위 배열로 분할된 상태
– 다시 퀵 정렬 재귀적 적용
피봇 값 선정
– 피봇 값을 배열의 가장 오른쪽에 위치한 값으로 선택
– 퀵 정렬에서는 피봇 값을 선정하는 작업이 아주 중요.
Chap. 9: Sorting [email protected] -‹#›-
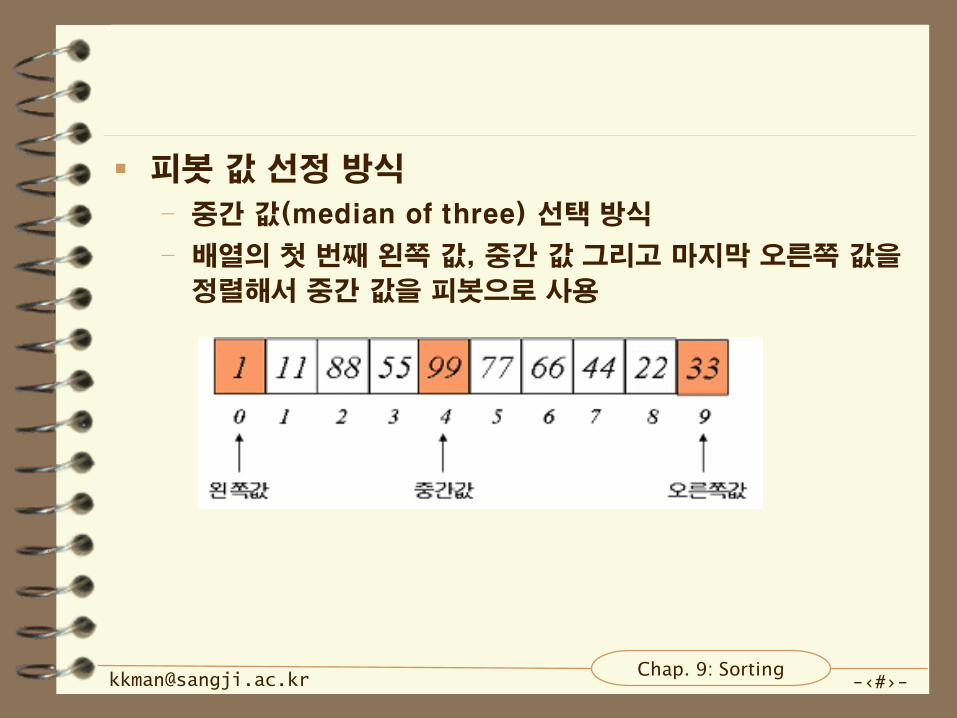
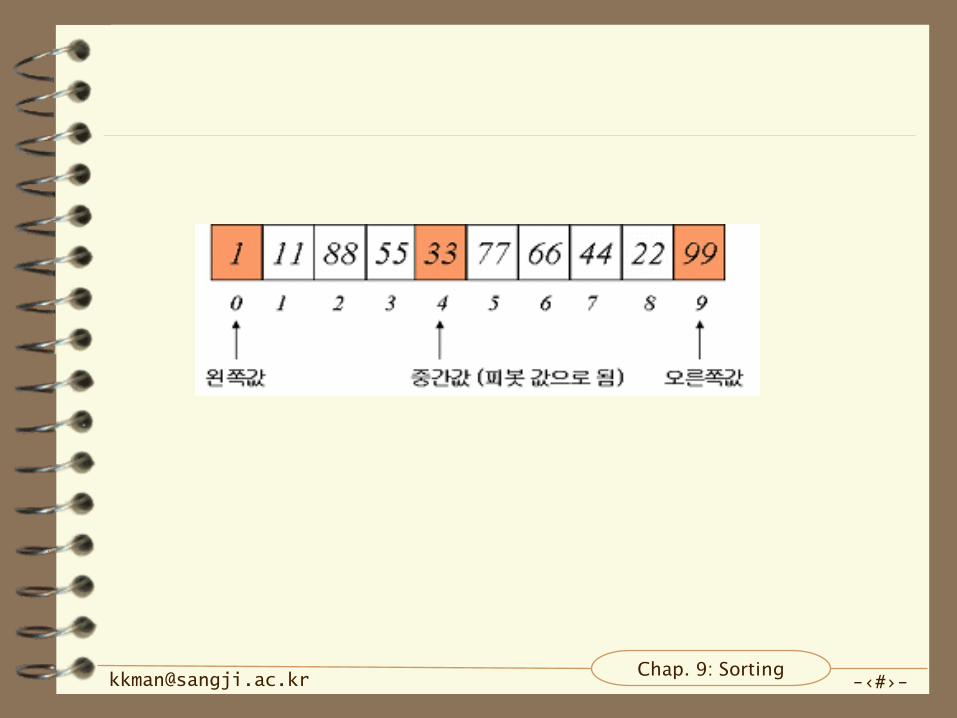
피봇 값 선정 방식
– 중간 값(median of three) 선택 방식
– 배열의 첫 번째 왼쪽 값, 중간 값 그리고 마지막 오른쪽 값을
정렬해서 중간 값을 피봇으로 사용
Chap. 9: Sorting [email protected] -‹#›-

Chap. 9: Sorting [email protected] -‹#›-
퀵 정렬 in C
void quick_sort(int list[], int left, int right)
{
if(left<right){
int q=partition(list, left, right);
quick_sort(list, left, q-1);
quick_sort(list, q+1, right);
}
}

Chap. 9: Sorting [email protected] -‹#›-
특징
– 정렬할 범위가 2개 이상의 데이터이면
– partition 함수를 호출하여 피벗을 기준으로 2개의
리스트로 분할
• partition 함수의 반환 값은 피봇의 위치
– left에서 피봇 위치 바로 앞까지를 대상으로 순환
호출(피봇은 제외).
– 피봇 위치 바로 다음부터 right까지를 대상으로 순환
호출(피봇은 제외).

Chap. 9: Sorting [email protected] -‹#›-
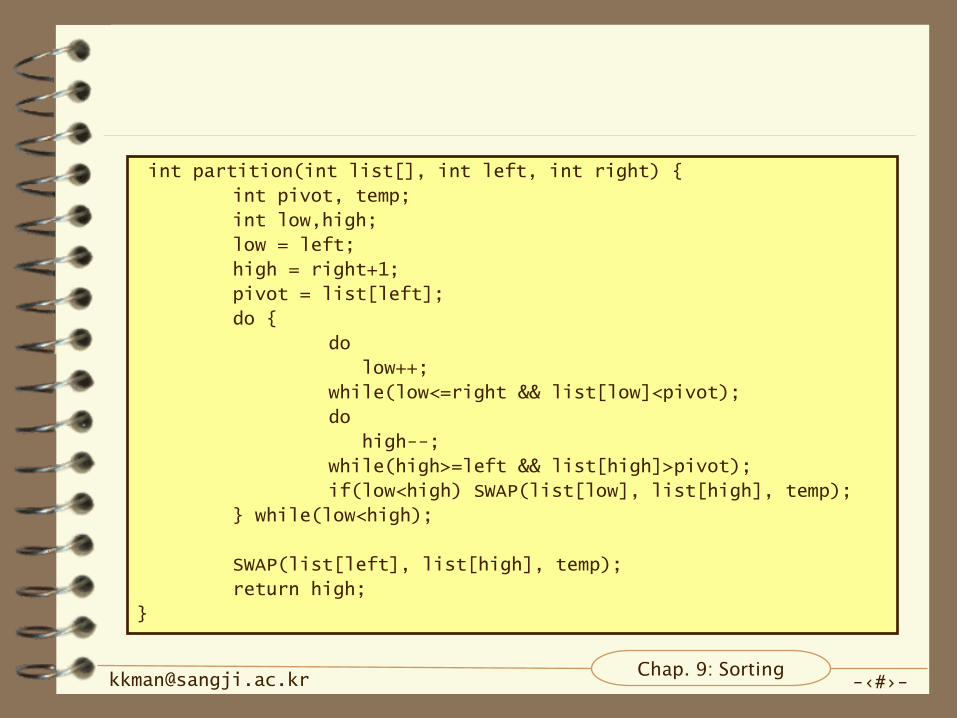
분할 함수
피봇(pivot)
– 가장 왼쪽 숫자라고 가정
두개의 변수
– low와 high를 사용
– low는 피봇보다 작으면 통과, 크면 정지
– high는 피봇보다 크면 통과, 작으면 정지
– 정지된 위치의 숫자를 교환
– low와 high가 교차하면 종료
Chap. 9: Sorting [email protected] -‹#›-
int partition(int list[], int left, int right) {
int pivot, temp;
int low,high;
low = left;
high = right+1;
pivot = list[left];
do {
do
low++;
while(low<=right && list[low]<pivot);
do
high--;
while(high>=left && list[high]>pivot);
if(low<high) SWAP(list[low], list[high], temp);
} while(low<high);
SWAP(list[left], list[high], temp);
return high;
}

Chap. 9: Sorting [email protected] -‹#›-
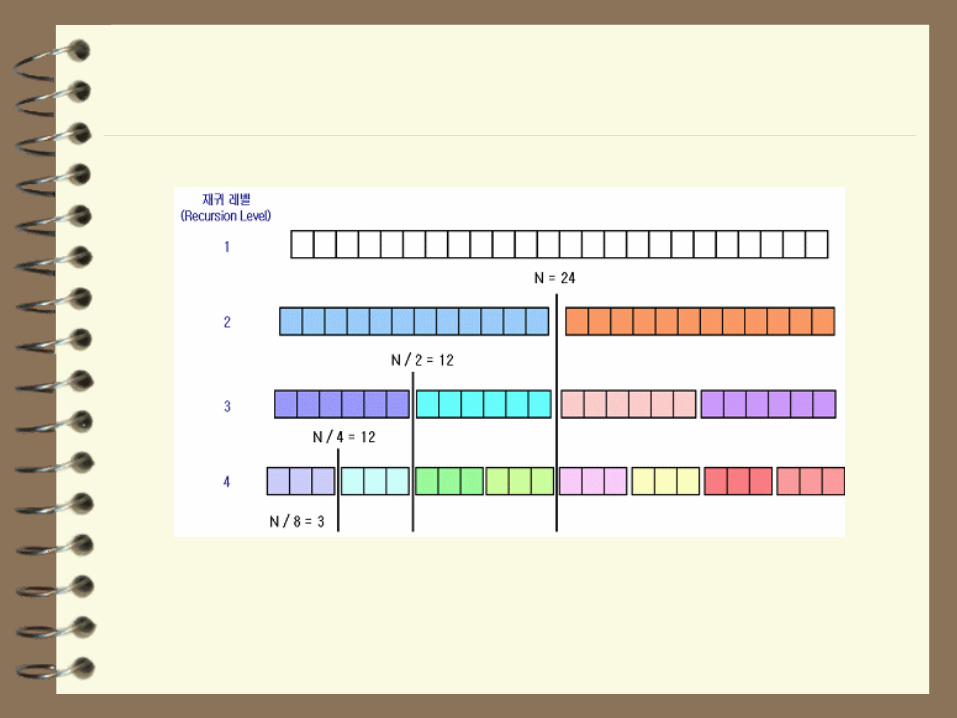
퀵 정렬 분석
퀵 정렬 알고리즘
– 분할 알고리즘을 기본으로 하는 방식
– 분할 알고리즘의 시간 복잡도는 O(N)
– 각각의 하위 배열은 처음에 2개, 그 다음 4, 8, 16, …
• 퀵 정렬을 재귀적 실행을 위한 시간 복잡도 O(N *
logN)

Chap. 9: Sorting [email protected] -‹#›-
최악의 경우
– 불균등한 리스트로 분할되는 경우
– 패스 수: n
– 각 패스안에서의 비교횟수: n
– 총비교횟수: n2
– 총이동횟수: 비교횟수에 비하여 무시가능

Chap. 9: Sorting [email protected] -‹#›-

Chap. 9: Sorting [email protected] -‹#›-
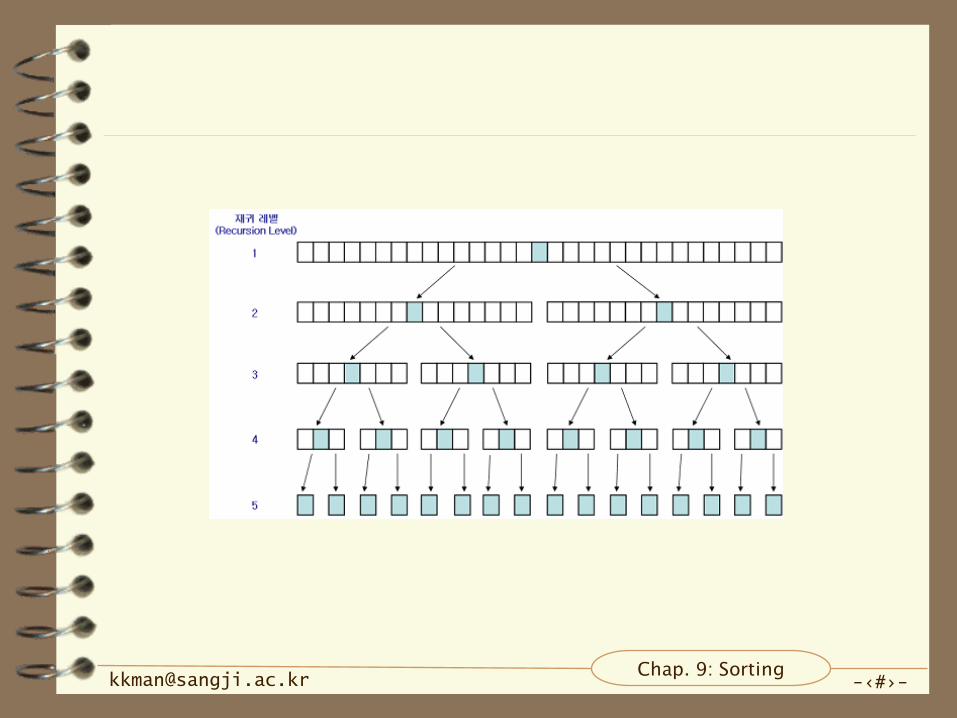
최선의 경우
– 거의 균등한 리스트로 분할되는 경우
– 패스 수: log2n
– 각 패스안에서의 비교횟수: n
– 총비교횟수: n log2n
– 총이동횟수: 비교횟수에 비하여 무시가능
Chap. 9: Sorting [email protected] -‹#›-

Chap. 9: Sorting [email protected] -‹#›-
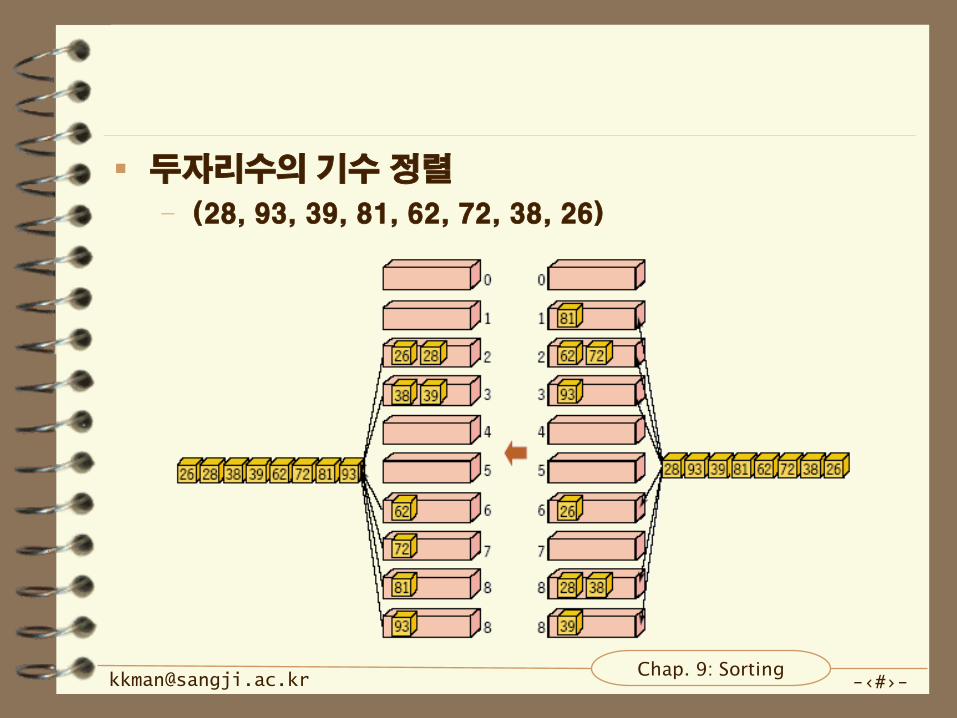
기수(radix) 정렬
특성
– 정렬할 대상에 대한 기본적인 가정을 가지고 출발
– 음수가 아닌 숫자(digit)로 이루어져 있을 때만 기수 정렬
알고리즘이 사용 가능
– 각각의 항목을 여러 자리로 나누어 각각의 자리에서의
숫자를 정렬
– 자료 항목 간 비교하는 단계는 존재하지 않음

Chap. 9: Sorting [email protected] -‹#›-
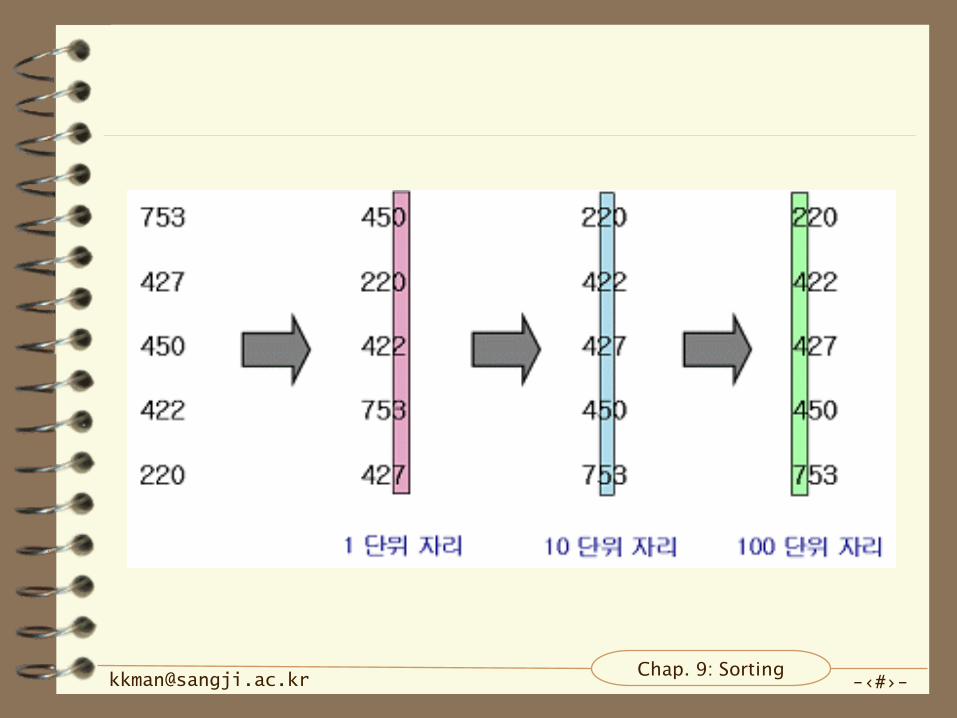
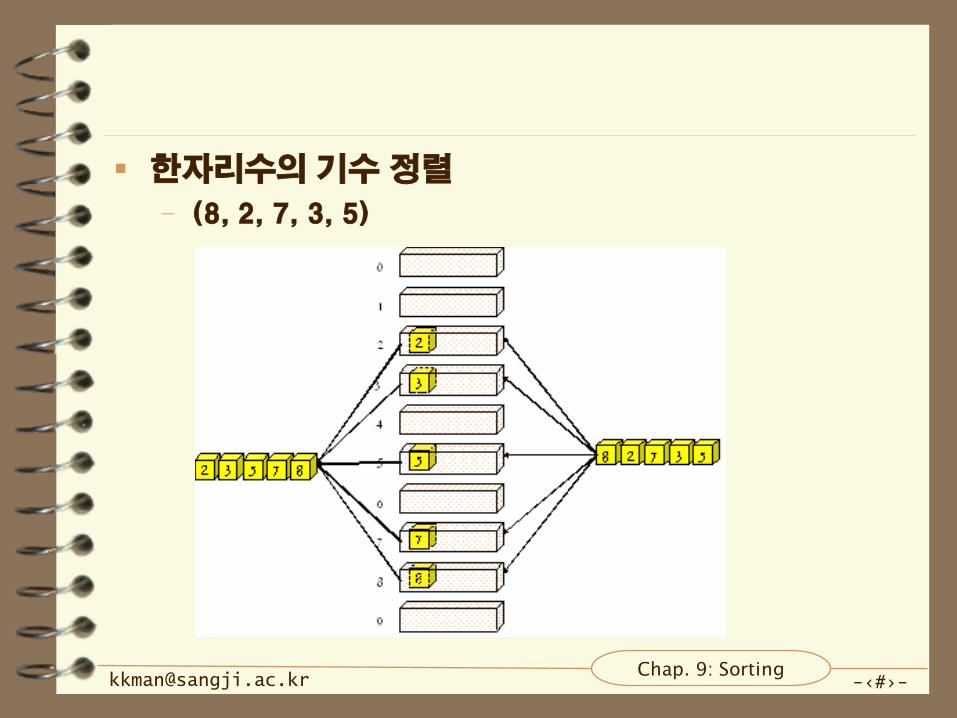
알고리즘
– 3개의 숫자로 이루어진 자료가 5개 있다고 할 때 이를
정렬하기 위해서 기수 정렬 규칙.
• 각각의 자료를 3개의 자리수로 나눈다.
• 1 단위 자리에서 각각의 자료의 숫자를 확인해 재배열.
• 10 단위 자리에서 각각의 자료의 숫자를 확인해 재배열,
1 단위 자리에서 재배열한 상태를 유지한 채 10 단위
재배열을 한다.
• 100 단위 자리에서 각각의 자료의 숫자를 확인해 재배열
하면 기수 정렬이 완성.
Chap. 9: Sorting [email protected] -‹#›-

Chap. 9: Sorting [email protected] -‹#›-
문제점
– 배열의 전체 크기와 동일한 크기의 기수 테이블을 위한
메모리가 필요
– 음수, 부동소수점처럼 특수한 비교 연산이 필요한 자료에는
적용 불가능
복잡도
– 복사 횟수는 자료 항목의 개수와 비례
– O(N)




![Lecture01: 유닉스/리눅스소개 - compiler.sangji.ac.krcompiler.sangji.ac.kr/lecture/linux/2018/lecture01.pdf · 유닉스버전트리[위키백과] Lecture 01: Unix & Linux,](https://img.pdfslide.tips/doc/110x75/5e185fe1ed687542ef6715d8/lecture01-oeeeeoeeoe-oeeeeoeee-lecture.jpg)













![[심화] 효율적인 입찰 전략](https://img.pdfslide.tips/doc/110x75/589da31b1a28abfb3d8b6e8d/-589da31b1a28abfb3d8b6e8d.jpg)





![[IGC 2016] 핀콘 전유범 - Mobile User Acquisition 효율적인 비용 집행을 위하여](https://img.pdfslide.tips/doc/110x75/5876914c1a28abab2f8b59b7/igc-2016-mobile-user-acquisition-.jpg)





![[6B-4] MBSFN서비스에서 주파수 효율적인 적응형 수직빔 틸팅](https://img.pdfslide.tips/doc/110x75/5861ae0f1a28ab0e308c0456/6b-4-mbsfn-.jpg)
