Embed Size (px)
Citation preview

淺度機器學習:類神經網路
September 2, 2019
類神經網路(Aritficial Neural Network, ANN)風行於 90年代,帶動一波人工智慧學習
(AI)的熱潮。不過幾年的功夫,便被看破手腳,於是逐漸退潮並匿跡於學術圈。並不是
類神經網路不好,而是遇到實務面的瓶頸。當資料大,變數多時,電腦軟硬體的執行能力
讓人卻步。另一方面,類神經網路雖然具備學習的「智慧」,但在開發測試的過程中,處
處需要人工的介入,加上軟硬體的支援不力,常常搞得人仰馬翻,逐漸失去信心。
消失的人工智慧在電腦軟硬體逐步提升後,終於達到實務面能接受的效率,尤其配合影
像處理的技術,在圖形辨識(Pattern Recognition)的領域上異軍突起,獲得廣大的注視,
再度引領風騷,甚至成為深度機器學習(Deep Learning)的主力。本章介紹類神經網路
的概念,並以 MATLABMachine Learning套件為工具,以幾個典型的範例揭開類神經
網路的面紗。
本章將學到關於程式設計
Machine Learning App 的使用,包括監督式學習的 Neural Network Fitting、Neural
Network Pattern Recognition與非監督式學習的 Neural Network Clustering。
⟨本章關於MATLAB的指令與語法⟩指令:fitnet, gsubstract, net, nnstart, perform, plottrgression, train, view。
1

1 背景介紹
1.1 前饋式(Feedforward)類神經網路的原理
圖 1展示具備一個隱藏層的典型前饋式類神經網路,其中幾個須留意的數字為左邊輸入
端(Input)標示為 p個變數個數(圖中 p = 14),中間隱藏層(Hidden Layer)有 q 個
神經元(圖中 q = 10)及最右邊的輸出層(Output Layer),共有 r 個輸出變數(圖中
r = 3)。輸入與輸出變數的個數 p, r 依問題的結構而定,譬如下一節的機器手臂的範例
中 p = 2代表平面座標位置,而 r = 2代表機器手臂的兩個角度。值得一提的是中間的
隱藏層與輸出層,特別是隱藏層的結構與所含的神經元數量 q。q 越大,代表輸出與輸入
之間的關係越複雜,從數學關係的角度來說,便是彼此間的非線性程度越高。
圖 1: 具備一個隱藏層的典型前饋式類神經網路(本圖從 MATLAB輸出)
假設輸入端的 p個變數表示為 x1, x2, · · · , xp,輸出端的 r 個變數表示為 y1, y2, · · · , yr,則前饋式類神經網路的輸出與輸入間的數學關係寫成
yk =
q∑i=1
w2kig
(p∑
j=1
w1ijxj + b1i
)+ b2k, 1 ≤ k ≤ r (1)
其中函數 g(·)可以選擇為(−1 ≤ g(z) ≤ 1)
g(z) = c11− e−c2z
1 + e−c2z(2)
函數 g(z)的長相便如圖 1的隱藏層所繪製的函數圖。函數 g(z)也可以用在輸出層,以
增加複雜度,不過通常使用如圖 1的線性函數 y = x,也就是圖 1的輸出層所繪製直線
方程式。式 (1)中的 w1ij 與 b1i 代表第一個隱藏層的第 i個神經元與第 j 個輸入的權重係
數(Weightings)與位階係數(Biases)。同樣地,w2ki 與 b2k 則是第二層(在此為輸出層)
的第 k 個神經元與前一隱藏層的第 i個輸出的權重係數與位階係數。
類神經網路根據已知的輸入與輸出資料 xj(n)與 yk(n),調整係數 w1ij, w
2ki, b
1i 與 b2k,使
得真實資料 yk(n) 與類神經網路輸出資料 yk(n) 的誤差為最小。假設共有 N 筆真實資
料,則所謂類神經網路的訓練階段,寫成多變量函數的最小值問題,即
2

minΩ
e(Ω) (3)
其中誤差函數
e(Ω) =N∑
n=1
r∑k=1
(yk(n)− yk(n))2
=N∑
n=1
r∑k=1
(yk(n)−
q∑i=1
w2kig
(p∑
j=1
w1ijxj + b1i
)+ b2k
)2
(4)
其中參數 Ω = w1ij, w
2ki, b
1i , b
2ki=1,2,··· ,q;j=1,2,··· ,p;k=1,2,··· ,r,共 pq + qr + q + r 個參數。
若以圖 1的類神經網路架構(p = 14, q = 10, r = 3)為例,式 (3)的誤差函數 e(Ω)的
變數共 183個。因此類神經網路可視為一個非常複雜、非線性程度很高到函數,能將輸
入(X)與輸出(Y)的關係配適的很完美。
前文說到類神經網路曾在 90年代刮起一陣旋風,雖然引起各界競相追逐並應用在許多領
域,但如式 (3)的高維度(變數多)最小值的計算問題卻是瓶頸。當輸入變數(p)越多,
所選擇的隱藏層神經元數量(q)也越多時,若要求訓練的很完美(e(Ω)越小),不可避
免地需要更大的計算量,而造成計算時間過長,讓研發人員望之卻步。諸如此類的困擾
隨著電腦軟硬體的提升,與演算法的成熟,已逐漸將類神經網路的學習優勢拉到「量產」
的程度了,帶起新一波的人工智慧風潮,譬如機器學習中的「深度學習」便是充分利用了
類神經網路的配適(fitting)能力。
另一個阻礙機器學習進程的因素是實用性。固然類神經網路能將輸入與輸出透過其高度
的非線性函數配適到完美的境地,但對訓練外的輸入測試資料,其輸出表現並不如預期,
中間還牽涉到隱藏層數、隱藏層的神經元數量及訓練程度都非常有關係。於是過多的測
試與過長的測試時間,終於讓類神經網路的實用價值受到質疑。下一節的機器人手臂的
範例也會展示不同的訓練過程將導致不同的測試結果。
2 機器人手臂的範例
2.1 解「逆運動方程式」(Inverse Kinematic Equations)
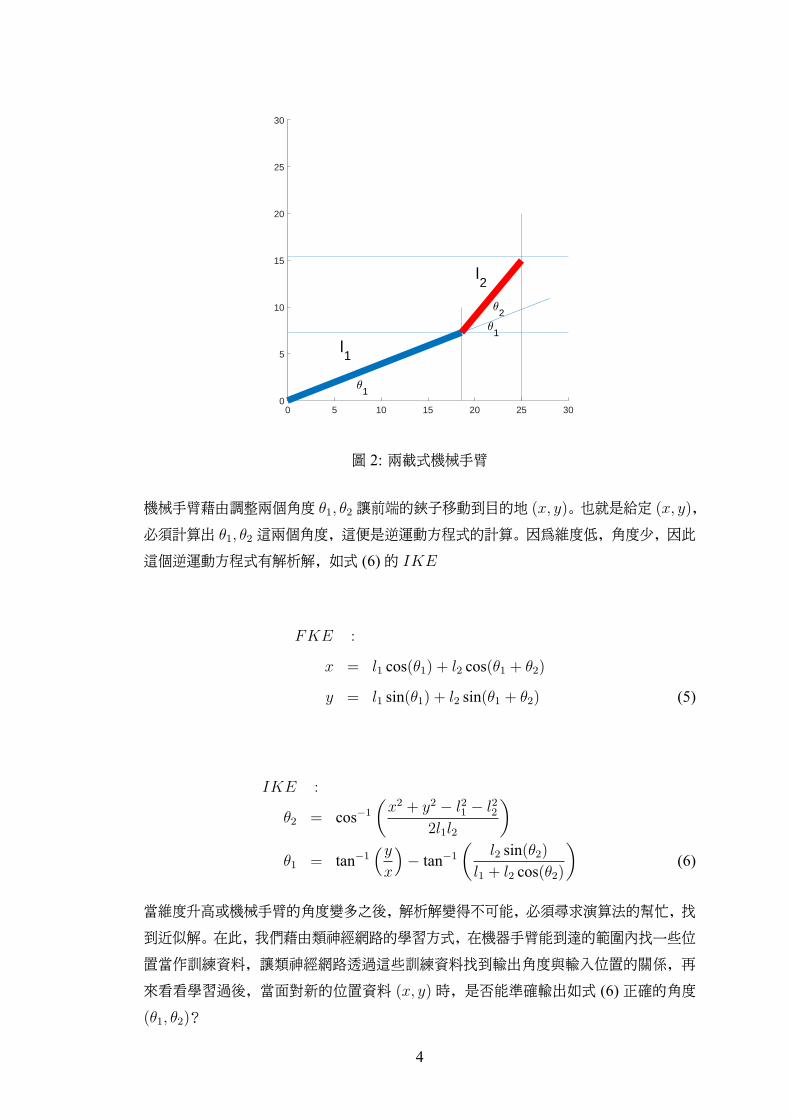
圖 2是一個低階自由度(DOF, Degree of Freedom)的機械手臂,有兩截手臂,長度分
別為 l1 = 20, l2 = 10。兩截手臂依據兩個角度 θ1, θ2 的改變,可以使手臂最前端的位置
(x, y)覆蓋如圖 3第一象限的陰影區域,也就是手臂前端的指頭或夾子可以碰觸到的地
方。
3
0 5 10 15 20 25 300
5
10
15
20
25
30
l1
l2
1
1
2
圖 2: 兩截式機械手臂
機械手臂藉由調整兩個角度 θ1, θ2 讓前端的鋏子移動到目的地 (x, y)。也就是給定 (x, y),
必須計算出 θ1, θ2 這兩個角度,這便是逆運動方程式的計算。因為維度低,角度少,因此
這個逆運動方程式有解析解,如式 (6)的 IKE
FKE :
x = l1 cos(θ1) + l2 cos(θ1 + θ2)
y = l1 sin(θ1) + l2 sin(θ1 + θ2) (5)
IKE :
θ2 = cos−1
(x2 + y2 − l21 − l22
2l1l2
)θ1 = tan−1
(yx
)− tan−1
(l2 sin(θ2)
l1 + l2 cos(θ2)
)(6)
當維度升高或機械手臂的角度變多之後,解析解變得不可能,必須尋求演算法的幫忙,找
到近似解。在此,我們藉由類神經網路的學習方式,在機器手臂能到達的範圍內找一些位
置當作訓練資料,讓類神經網路透過這些訓練資料找到輸出角度與輸入位置的關係,再
來看看學習過後,當面對新的位置資料 (x, y)時,是否能準確輸出如式 (6)正確的角度
(θ1, θ2)?
4
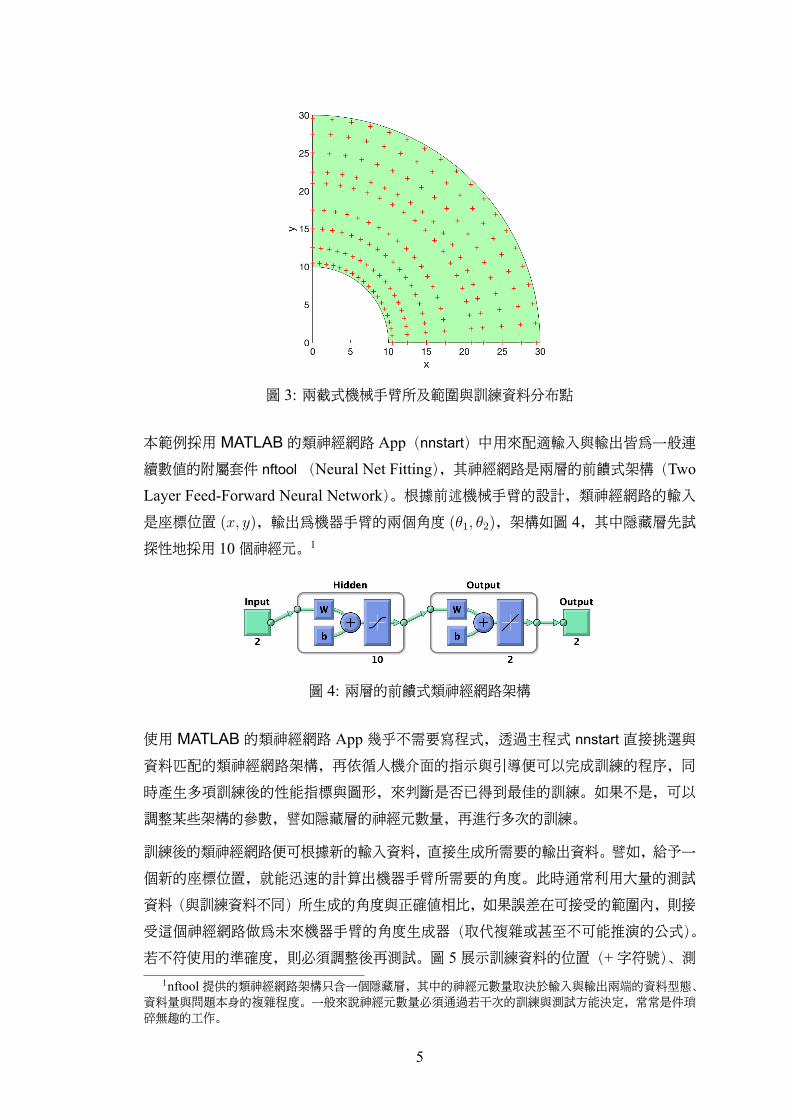
圖 3: 兩截式機械手臂所及範圍與訓練資料分布點
本範例採用 MATLAB的類神經網路 App(nnstart)中用來配適輸入與輸出皆為一般連
續數值的附屬套件 nftool(Neural Net Fitting),其神經網路是兩層的前饋式架構(Two
Layer Feed-Forward Neural Network)。根據前述機械手臂的設計,類神經網路的輸入
是座標位置 (x, y),輸出為機器手臂的兩個角度 (θ1, θ2),架構如圖 4,其中隱藏層先試
探性地採用 10個神經元。1
圖 4: 兩層的前饋式類神經網路架構
使用 MATLAB的類神經網路 App幾乎不需要寫程式,透過主程式 nnstart直接挑選與
資料匹配的類神經網路架構,再依循人機介面的指示與引導便可以完成訓練的程序,同
時產生多項訓練後的性能指標與圖形,來判斷是否已得到最佳的訓練。如果不是,可以
調整某些架構的參數,譬如隱藏層的神經元數量,再進行多次的訓練。
訓練後的類神經網路便可根據新的輸入資料,直接生成所需要的輸出資料。譬如,給予一
個新的座標位置,就能迅速的計算出機器手臂所需要的角度。此時通常利用大量的測試
資料(與訓練資料不同)所生成的角度與正確值相比,如果誤差在可接受的範圍內,則接
受這個神經網路做為未來機器手臂的角度生成器(取代複雜或甚至不可能推演的公式)。
若不符使用的準確度,則必須調整後再測試。圖 5展示訓練資料的位置(+字符號)、測1nftool提供的類神經網路架構只含一個隱藏層,其中的神經元數量取決於輸入與輸出兩端的資料型態、
資料量與問題本身的複雜程度。一般來說神經元數量必須通過若干次的訓練與測試方能決定,常常是件瑣碎無趣的工作。
5

試資料(o符號)與預測資料(星符號)的關係位置。2其中測試資料(o符號)與預測資
料在某些位置有明顯的落差。這個情況可以考慮重新訓練並測試幾次比較看看,或直接
調高隱藏層的神經元個數,如圖 6呈現在相同的訓練與測試資料不變,僅調高隱藏層神
經元個數為 20之後的預測結果。與圖 5相比,圖 6預測值的落點與測試資料的位置明顯
貼近許多,近乎重疊。當然,這樣的準確度是否能被接受,必須從機器人手臂的實際運作
來論定。另外,不同的訓練資料與測試資料的選擇,都會影響評估的結果,若不能快速、
大量的執行各種測試評估直到滿意,再好的類神經網路也只是理想而已,這便是 90年代
的實際狀況。
圖 5: 隱藏層 q = 10下的訓練資料(+字符號)、測試資料(o符號)與預測資料(星符號)的關係位置
2有些資料來自觀察或測量所得,如圖 5的訓練資料則必須由研究者自行產生。
6
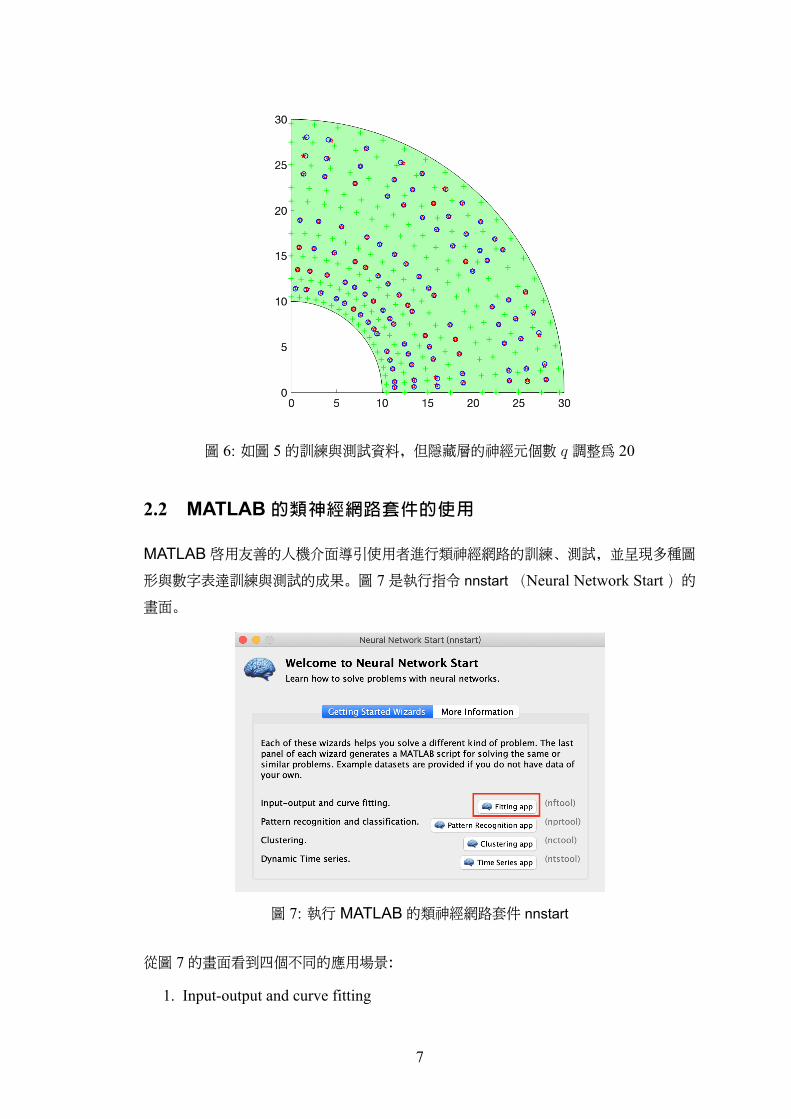
圖 6: 如圖 5的訓練與測試資料,但隱藏層的神經元個數 q 調整為 20
2.2 MATLAB的類神經網路套件的使用
MATLAB啟用友善的人機介面導引使用者進行類神經網路的訓練、測試,並呈現多種圖
形與數字表達訓練與測試的成果。圖 7是執行指令 nnstart(Neural Network Start)的
畫面。
圖 7: 執行 MATLAB的類神經網路套件 nnstart
從圖 7的畫面看到四個不同的應用場景:
1. Input-output and curve fitting
7

2. Pattern recognition and classification
3. Clustering
4. Dynamic time series
進入這四個場景的類神經網路也可以從 MATLAB主畫面的 APPS選擇,如圖 8
圖 8: MATLAB類神經網路 APPS的四個應用場景
選擇第一個 Fitting app來處理機器手臂的角度訓練。進入圖 9,畫面上方明白標示「Solving
an input-output fitting problem with a two-layor feed-forward neural network」,限制在
兩層(隱藏層與輸出層)的前饋式類神經網路。
圖 9: MATLAB類神經網路的 Fitting app模式
第一個畫面說明神經網路的架構與應用方向,之後進入圖 10 的神經網路訓練資料的選
擇。畫面中看到 Inputs為 X,Targets(就是 Outputs)選擇為 Y,其中 X, Y是事先輸入
到工作區(Workspace)的資料矩陣。選擇資料後,會在右側顯示資料的大小並解讀出輸
入 (p)、輸出(r)的數量與樣本數。這樣的解讀有助於使用者判斷資料矩陣的行列是否
需要轉置。
8
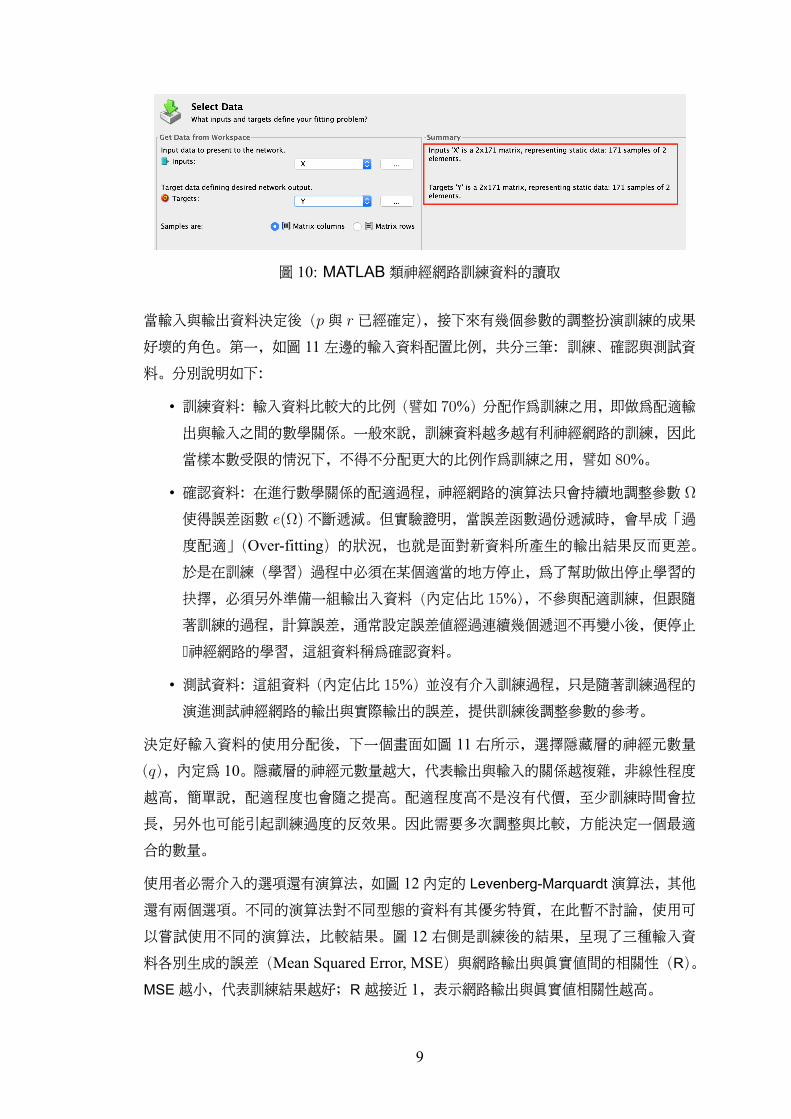
圖 10: MATLAB類神經網路訓練資料的讀取
當輸入與輸出資料決定後(p與 r 已經確定),接下來有幾個參數的調整扮演訓練的成果
好壞的角色。第一,如圖 11左邊的輸入資料配置比例,共分三筆:訓練、確認與測試資
料。分別說明如下:
• 訓練資料:輸入資料比較大的比例(譬如 70%)分配作為訓練之用,即做為配適輸
出與輸入之間的數學關係。一般來說,訓練資料越多越有利神經網路的訓練,因此
當樣本數受限的情況下,不得不分配更大的比例作為訓練之用,譬如 80%。
• 確認資料:在進行數學關係的配適過程,神經網路的演算法只會持續地調整參數 Ω
使得誤差函數 e(Ω)不斷遞減。但實驗證明,當誤差函數過份遞減時,會早成「過
度配適」(Over-fitting)的狀況,也就是面對新資料所產生的輸出結果反而更差。
於是在訓練(學習)過程中必須在某個適當的地方停止,為了幫助做出停止學習的
抉擇,必須另外準備一組輸出入資料(內定佔比 15%),不參與配適訓練,但跟隨
著訓練的過程,計算誤差,通常設定誤差值經過連續幾個遞迴不再變小後,便停止
神經網路的學習,這組資料稱為確認資料。
• 測試資料:這組資料(內定佔比 15%)並沒有介入訓練過程,只是隨著訓練過程的
演進測試神經網路的輸出與實際輸出的誤差,提供訓練後調整參數的參考。
決定好輸入資料的使用分配後,下一個畫面如圖 11 右所示,選擇隱藏層的神經元數量
(q),內定為 10。隱藏層的神經元數量越大,代表輸出與輸入的關係越複雜,非線性程度
越高,簡單說,配適程度也會隨之提高。配適程度高不是沒有代價,至少訓練時間會拉
長,另外也可能引起訓練過度的反效果。因此需要多次調整與比較,方能決定一個最適
合的數量。
使用者必需介入的選項還有演算法,如圖 12內定的 Levenberg-Marquardt演算法,其他
還有兩個選項。不同的演算法對不同型態的資料有其優劣特質,在此暫不討論,使用可
以嘗試使用不同的演算法,比較結果。圖 12 右側是訓練後的結果,呈現了三種輸入資
料各別生成的誤差(Mean Squared Error, MSE)與網路輸出與真實值間的相關性(R)。
MSE越小,代表訓練結果越好;R越接近 1,表示網路輸出與真實值相關性越高。
9
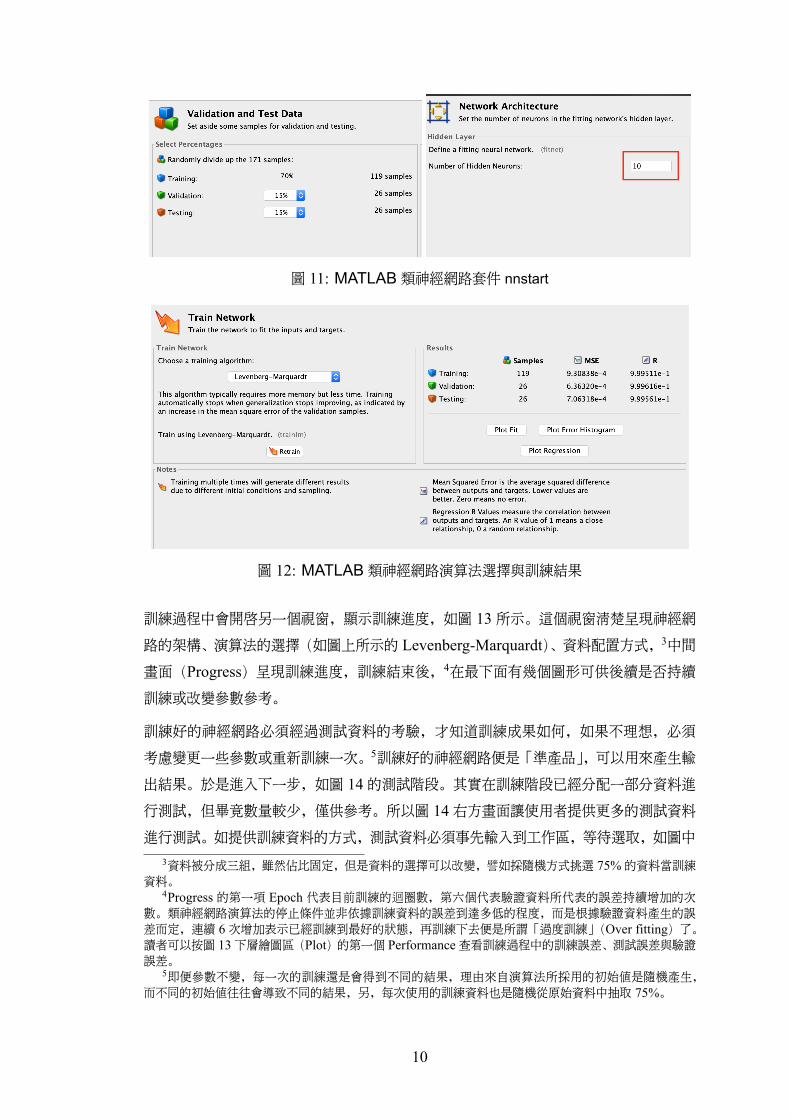
圖 11: MATLAB類神經網路套件 nnstart
圖 12: MATLAB類神經網路演算法選擇與訓練結果
訓練過程中會開啟另一個視窗,顯示訓練進度,如圖 13所示。這個視窗清楚呈現神經網
路的架構、演算法的選擇(如圖上所示的 Levenberg-Marquardt)、資料配置方式,3中間
畫面(Progress)呈現訓練進度,訓練結束後,4在最下面有幾個圖形可供後續是否持續
訓練或改變參數參考。
訓練好的神經網路必須經過測試資料的考驗,才知道訓練成果如何,如果不理想,必須
考慮變更一些參數或重新訓練一次。5訓練好的神經網路便是「準產品」,可以用來產生輸
出結果。於是進入下一步,如圖 14的測試階段。其實在訓練階段已經分配一部分資料進
行測試,但畢竟數量較少,僅供參考。所以圖 14右方畫面讓使用者提供更多的測試資料
進行測試。如提供訓練資料的方式,測試資料必須事先輸入到工作區,等待選取,如圖中3資料被分成三組,雖然佔比固定,但是資料的選擇可以改變,譬如採隨機方式挑選 75%的資料當訓練
資料。4Progress 的第一項 Epoch 代表目前訓練的迴圈數,第六個代表驗證資料所代表的誤差持續增加的次
數。類神經網路演算法的停止條件並非依據訓練資料的誤差到達多低的程度,而是根據驗證資料產生的誤差而定,連續 6次增加表示已經訓練到最好的狀態,再訓練下去便是所謂「過度訓練」(Over fitting)了。讀者可以按圖 13下層繪圖區(Plot)的第一個 Performance查看訓練過程中的訓練誤差、測試誤差與驗證誤差。
5即便參數不變,每一次的訓練還是會得到不同的結果,理由來自演算法所採用的初始值是隨機產生,而不同的初始值往往會導致不同的結果,另,每次使用的訓練資料也是隨機從原始資料中抽取 75%。
10
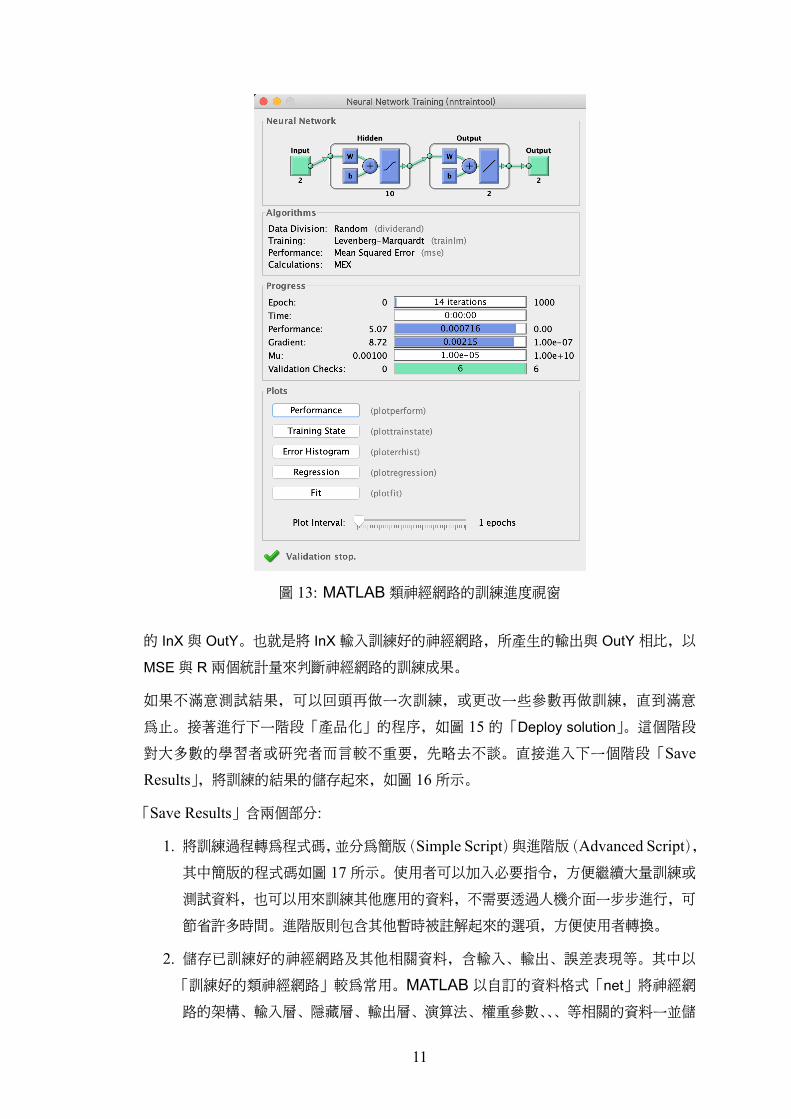
圖 13: MATLAB類神經網路的訓練進度視窗
的 InX與 OutY。也就是將 InX輸入訓練好的神經網路,所產生的輸出與 OutY相比,以
MSE與 R兩個統計量來判斷神經網路的訓練成果。
如果不滿意測試結果,可以回頭再做一次訓練,或更改一些參數再做訓練,直到滿意
為止。接著進行下一階段「產品化」的程序,如圖 15 的「Deploy solution」。這個階段
對大多數的學習者或研究者而言較不重要,先略去不談。直接進入下一個階段「Save
Results」,將訓練的結果的儲存起來,如圖 16所示。
「Save Results」含兩個部分:
1. 將訓練過程轉為程式碼,並分為簡版(Simple Script)與進階版(Advanced Script),
其中簡版的程式碼如圖 17所示。使用者可以加入必要指令,方便繼續大量訓練或
測試資料,也可以用來訓練其他應用的資料,不需要透過人機介面一步步進行,可
節省許多時間。進階版則包含其他暫時被註解起來的選項,方便使用者轉換。
2. 儲存已訓練好的神經網路及其他相關資料,含輸入、輸出、誤差表現等。其中以
「訓練好的類神經網路」較為常用。MATLAB以自訂的資料格式「net」將神經網
路的架構、輸入層、隱藏層、輸出層、演算法、權重參數、、、等相關的資料一並儲
11
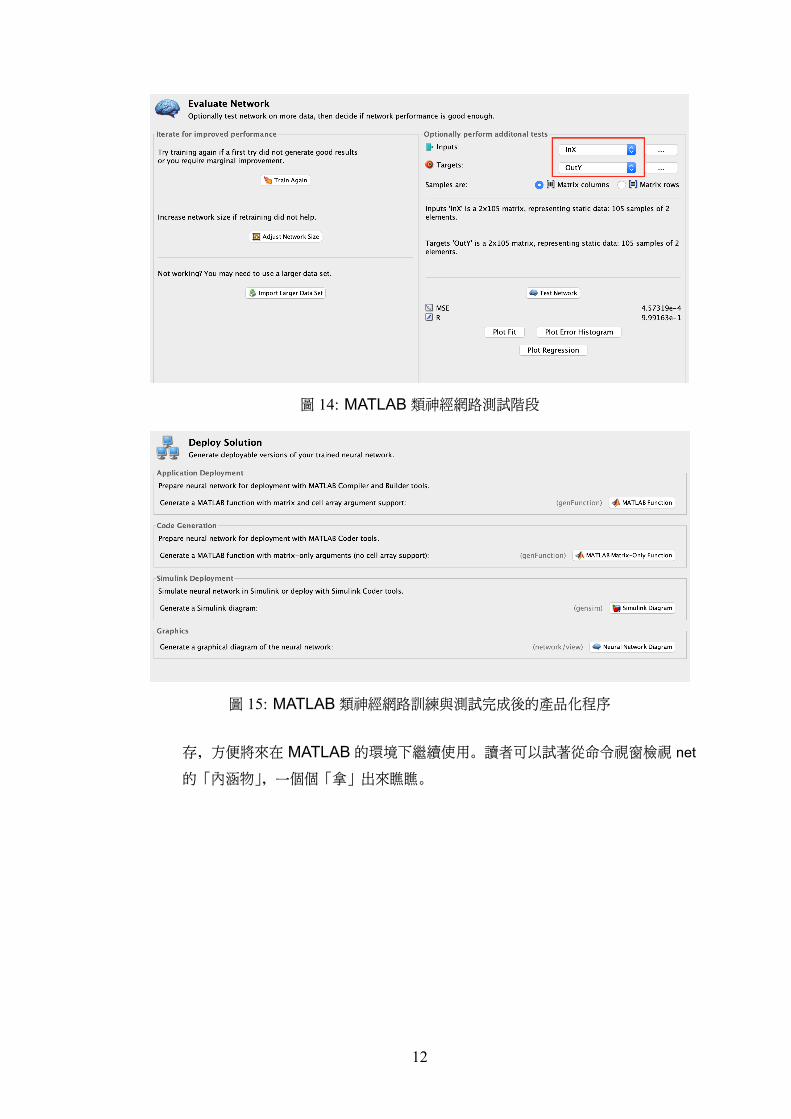
圖 14: MATLAB類神經網路測試階段
圖 15: MATLAB類神經網路訓練與測試完成後的產品化程序
存,方便將來在 MATLAB的環境下繼續使用。讀者可以試著從命令視窗檢視 net
的「內涵物」,一個個「拿」出來瞧瞧。
12
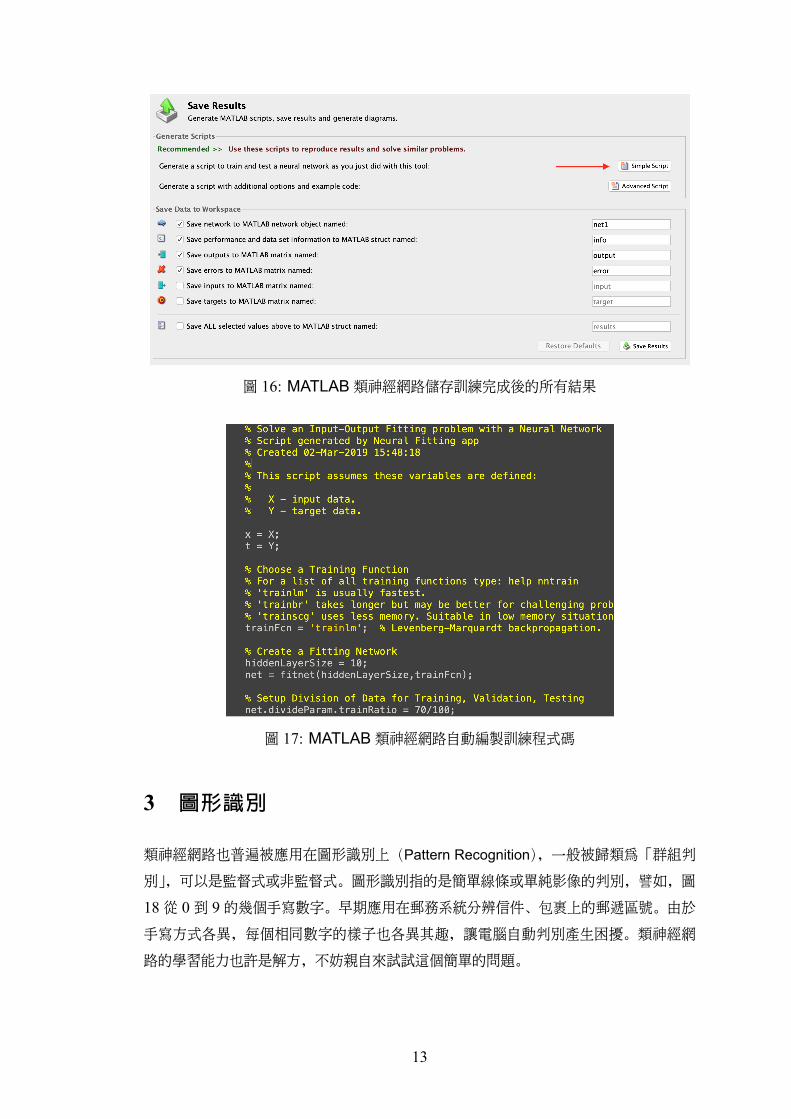
圖 16: MATLAB類神經網路儲存訓練完成後的所有結果
圖 17: MATLAB類神經網路自動編製訓練程式碼
3 圖形識別
類神經網路也普遍被應用在圖形識別上(Pattern Recognition),一般被歸類為「群組判
別」,可以是監督式或非監督式。圖形識別指的是簡單線條或單純影像的判別,譬如,圖
18從 0到 9的幾個手寫數字。早期應用在郵務系統分辨信件、包裹上的郵遞區號。由於
手寫方式各異,每個相同數字的樣子也各異其趣,讓電腦自動判別產生困擾。類神經網
路的學習能力也許是解方,不妨親自來試試這個簡單的問題。
13

在此我們準備了如圖 18 的手寫數字,6每個數字 100 張,每張大小為 16x16 的黑白影
像,作為類神經網路訓練用的資料。與前段機器手臂的應用不同的是,手寫辨識屬於群
組判別(共 10個群組),最好採用 MATLAB類神經網路 App中的「Neural Net Pattern
Recognition」,如圖 8所示的第 3個。與前述「Neural Network Fitting」最大不同在其
輸出層選擇了 Softmax 的機制,7共 10 個輸出,輸出值代表輸入值屬於該類別的機率
(總和為 1),網路架構如圖 19所示。
為配合 MATLAB類神經網路的圖形識別架構,輸入的影像資料必須從 16 x 16的矩陣展
開為 256x1的向量,也就是 1000張的影像必需轉為 256 x 1000的矩陣做為訓練用的輸
入資料。而輸出資料則配合 10個群組,製作出 10 x 1000的訓練用輸出資料,其中每欄
對應輸入群組的位置給 1其餘給 0,譬如,如果輸入影像代表 0,則輸出向量為 [1 0 0 0
0 0 0 0 0 0]’,其餘以此類推。
讀者可以試著調整隱藏層的數量來觀察訓練的成效,圖 19顯示隱藏層為 15。訓練後觀
察的重點在訓練資料(70%)、測試資料(15%)與驗證資料(15%)的分類正確率。圖
20展示了其中訓練資料的 Confusion Matrix,最右下角的 100%顯示訓練的過程是完美
無誤的。讀者可以自行選取一定數量的數字影像作為測試,並計算正確率。
圖 18: 手寫數字
4 非監督式學習:叢集運算(Clustering)
MATLAB 類神經網路的 App 也包含叢集運算(Neural Network Clusterig)。雖然與一6下載點 https://ntpuccw.blog/supplements/matlab-in-statistical-computing/7簡單地說,Softmax函數根據機率
P (y = j|x) = exTwj∑K
k=1 exTwk
將樣本向量 x對應到第 j 個類別。每個類別都會分配到機率值,以其中最大者最為類別判斷的依據。
14

圖 19: MATLAB類神經網路的圖形識別架構
圖 20: MATLAB類神經網路訓練完成後的 Confusion matrix
般的神經元表現不同,MATLAB將每個神經元當作一個叢集的中心點看待,並使用最常
被使用的 SOM網路(Self-Organizing Map Network)作為叢集演算法,如圖 21所示。
其中樣本資料來自著名的費雪鳶尾花資料(Fisher’s Iris data),共有樣本 150筆,每筆
資料含四種測量值,分別是 Sepal與 Petal的長與寬。屬於高度空間(四度)的資料判別
問題。
SOM網路與著名的 K-means叢集演算法的概念一樣,但是它以網路(Network)、拓墣
(Topology)的概念發展,讓後續對於叢集結果的呈現有更好的視覺效果。簡單說,SOM
網路有兩項特點:
1. 將多維度的樣本資料對應(叢集到)到 R個叢集中心,而這 R個叢集中心點以二
維格子狀的型態呈現出來,而且每個格子以六角形連結旁邊的格子。如圖 22所展
示的叢集前與叢集後的蜂巢格子。演算結束後,每格格子除了記載叢集的中心位置
(或稱為權重向量 weight vector),也記錄了屬於該叢集的樣本數(每個叢集最多累
15

圖 21: MATLAB類神經網路的 Cluster App的 SOM網路
積至 31個樣本)。8這也是一種以二度空間呈現高維空間資料的方式。
2. SOM 與 K-means 最大的不同在,當每個叢集中心往樣本移動時,同時還會影響
其周圍的叢集中心也向該樣本靠近,猶如一個黑洞般。經過幾次循環遞迴之後,具
有相同性質(或說空間距離接近)的樣本會吸引一些叢集中心成為「鄰居」。圖 23
展示叢集中心的鄰居關係(紅色兩端為鄰居),其中紅色線周圍的顏色深淺代表距
離遠近,顏色越深代表距離愈遠。圖中左側明顯出現一條較深的「鴻溝」,這意味
著樣本資料的兩群聚關係。9
0 2 4 6 8 10-1
0
1
2
3
4
5
6
7
8
SOM Topology
0 2 4 6 8 10-1
0
1
2
3
4
5
6
7
8
Hits
1 2 1 1 0 1 2 2 2 3
1 1 3 0 3 1 2 1 1 2
4 2 1 0 1 1 1 2 1 1
5 2 0 1 1 1 2 1 1 2
4 1 1 0 1 1 1 2 1 1
1 5 0 3 3 1 3 1 2 1
1 3 0 1 2 2 3 3 1 3
5 0 0 1 1 1 1 1 1 0
4 0 1 0 2 1 0 1 1 1
1 2 1 1 3 1 2 1 3 1
圖 22: SOM網路的 100個叢集中心的拓墣形狀,左:叢集前,右:叢集後。
從 SOM網路的格子狀結構,還能進一步觀察樣本資料的空間(或說資料來源)是否有相
關性。譬如圖 24展示 100個叢集中心的四個維度的叢集情形,其中較深顏色的地方代表
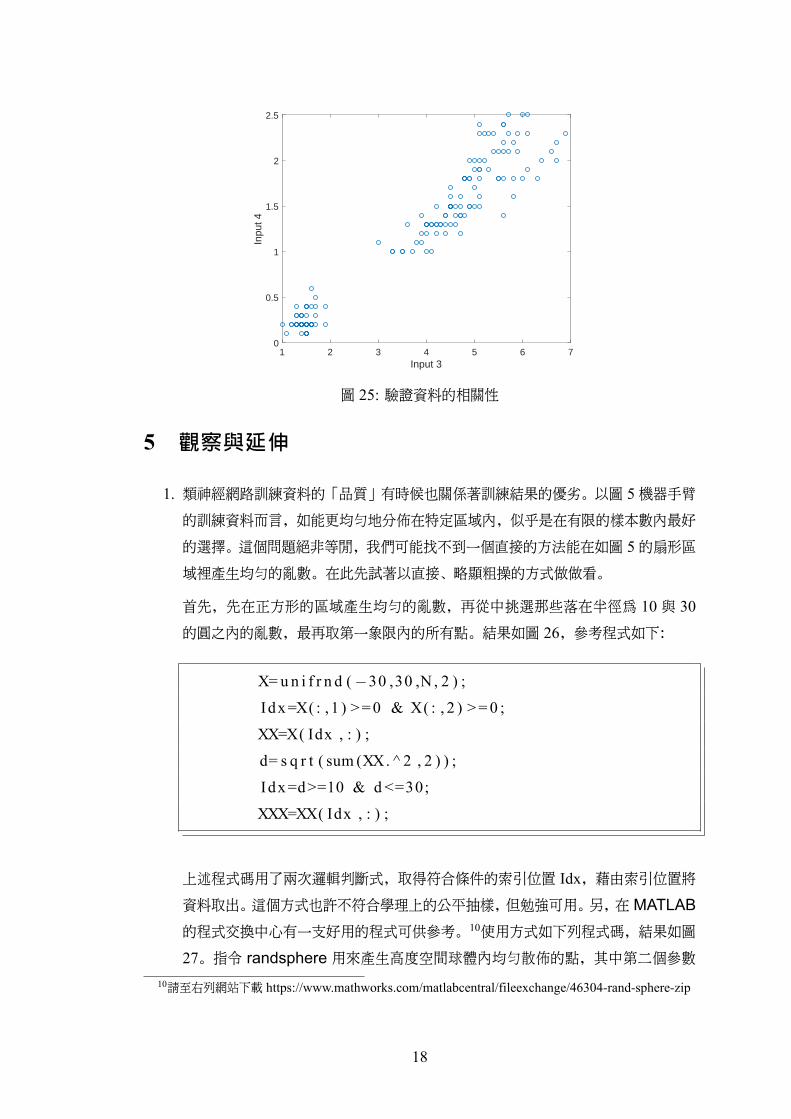
樣本資料聚集較多。從顏色的分佈可以看出資料空間是否相關,譬如圖中的第 3與第 4
張圖的顏色分佈極相似,可以推測樣本資料中第 3與第 4個資料高度相關。這個發現也
可以從實際的樣本資料發現,如圖 25的散佈圖,其中兩者間的相關係數為 0.9628。8MATLAB稱此圖為 SOM Sample Hits。而叢集前的圖稱為 SOM Topology。9「鄰居」可以設定為相鄰的兩個叢集中心,或是更遠的鄰居,即跨越兩條紅線。
16

0 2 4 6 8 10-1
0
1
2
3
4
5
6
7
8
SOM Neighbor Weight Distances
圖 23: SOM網路叢集的鄰居關係與鄰居間的距離(紅色線條代表鄰居關係,周圍的顏色代表距離,越深越遠)
0 2 4 6 8 10
0
2
4
6
8
Weights from Input 1
0 2 4 6 8 10
0
2
4
6
8
Weights from Input 2
0 2 4 6 8 10
0
2
4
6
8
Weights from Input 3
0 2 4 6 8 10
0
2
4
6
8
Weights from Input 4
圖 24: SOM網路的 100個叢集中心的四個維度的叢集情形
叢集運算是一種典型的非監督式學習,因為每筆資料並沒有群組資訊,純粹根據資料所
在位置劃分群組,資料的群組屬性是未知的,經過學習後才出現的。高維度資料的叢集
學習更加困難,也無從繪圖判斷學習的效果,因此經常以降維的方法將處理資料的維度
限縮在三度空間內。而 SOM運用顏色、符號、形狀等技巧希望突破維度的藩籬,值得欣
賞與讚嘆。
17
1 2 3 4 5 6 7Input 3
0
0.5
1
1.5
2
2.5
Inpu
t 4
圖 25: 驗證資料的相關性
5 觀察與延伸
1. 類神經網路訓練資料的「品質」有時候也關係著訓練結果的優劣。以圖 5機器手臂
的訓練資料而言,如能更均勻地分佈在特定區域內,似乎是在有限的樣本數內最好
的選擇。這個問題絕非等閒,我們可能找不到一個直接的方法能在如圖 5的扇形區
域裡產生均勻的亂數。在此先試著以直接、略顯粗操的方式做做看。
首先,先在正方形的區域產生均勻的亂數,再從中挑選那些落在半徑為 10 與 30
的圓之內的亂數,最再取第一象限內的所有點。結果如圖 26,參考程式如下:
X= un i f r n d (−30 ,30 ,N , 2 ) ;
Idx=X( : , 1 ) >=0 & X( : , 2 ) >=0 ;
XX=X( Idx , : ) ;
d= s q r t ( sum (XX. ^ 2 , 2 ) ) ;
Idx=d>=10 & d<=30;
XXX=XX( Idx , : ) ;
上述程式碼用了兩次邏輯判斷式,取得符合條件的索引位置 Idx,藉由索引位置將
資料取出。這個方式也許不符合學理上的公平抽樣,但勉強可用。另,在 MATLAB
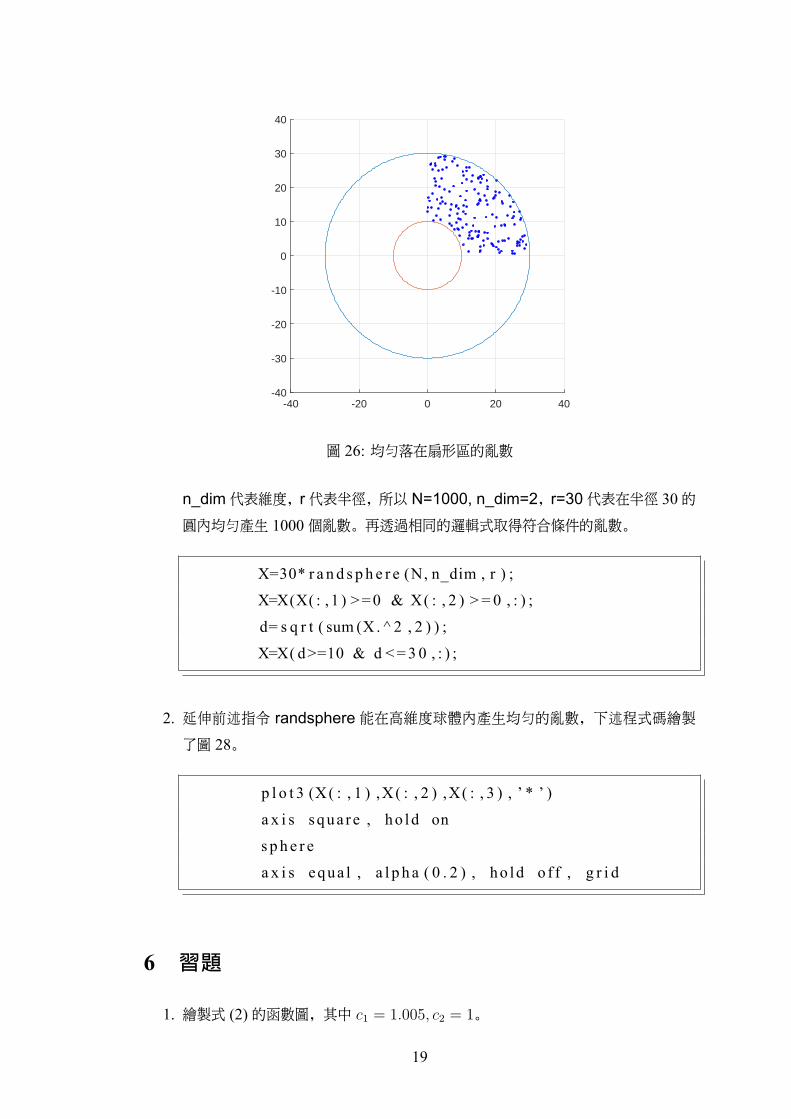
的程式交換中心有一支好用的程式可供參考。10使用方式如下列程式碼,結果如圖
27。指令 randsphere 用來產生高度空間球體內均勻散佈的點,其中第二個參數10請至右列網站下載 https://www.mathworks.com/matlabcentral/fileexchange/46304-rand-sphere-zip
18
-40 -20 0 20 40-40
-30
-20
-10
0
10
20
30
40
圖 26: 均勻落在扇形區的亂數
n_dim代表維度,r代表半徑,所以 N=1000, n_dim=2,r=30代表在半徑 30的
圓內均勻產生 1000個亂數。再透過相同的邏輯式取得符合條件的亂數。
X=30* r a n d s p h e r e (N, n_dim , r ) ;
X=X(X( : , 1 ) >=0 & X( : , 2 ) > = 0 , : ) ;
d= s q r t ( sum (X . ^ 2 , 2 ) ) ;
X=X( d>=10 & d <=30 , : ) ;
2. 延伸前述指令 randsphere 能在高維度球體內產生均勻的亂數,下述程式碼繪製
了圖 28。
p l o t 3 (X( : , 1 ) ,X( : , 2 ) ,X( : , 3 ) , ’ * ’ )
a x i s squa re , ho ld on
s ph e r e
a x i s equa l , a l p h a ( 0 . 2 ) , ho ld o f f , g r i d
6 習題
1. 繪製式 (2)的函數圖,其中 c1 = 1.005, c2 = 1。
19

-40 -30 -20 -10 0 10 20 30 40-40
-30
-20
-10
0
10
20
30
40
圖 27: 使用程式 randspere製作的亂數
2. 試著產生如圖 5的訓練資料 100筆,讓這些資料盡量均勻地散佈在機器手臂能及
的範圍內。
3. 自行找一個題目適用於 Neural Network Fitting的類神經網路訓練(如機器手臂的
學習)。輸入與輸出資料皆為連續型。來自現成資料或自行產生資料皆可。
4. 請從手寫數字資料繪製如圖 18的手寫數字圖。
5. 本章圖形識別的示範,得到完美的訓練結果,也就是圖 20展示的輸出類別(Output
Class)目標類別(Target Class)完全吻合(對角線的比例和為 100%,其他位置
皆為 0),表示訓練誤差降至 0。請降低隱藏層的數量(譬如 10),刻意讓訓練誤
差大於 0。此時,深入觀察誤判的影像有哪些?可能誤判的原因是什麼?其實,從
Confusion Matrix也可以看出些端倪,譬如圖 29的 All Confusion Matrix,其中
在 Traget Class為 6訓練準確率為 85%,這一欄上的數字代表錯認為其他數字的
次數。反觀其他數字並沒有這麼多誤判,懷疑數字 6的寫法容易誤判或是圖片品質
較差,於是有必要將這些數字圖片展示來看看。
6. 本章舉數字判讀作為圖形識別的範例與「Neural Network Pattern Recognition」
App的使用示範。請讀者模仿本章的做法,但使用不同的圖形,譬如手寫英文字母
的判別。所需的圖形可以上網搜尋取得。
7. 請自數字資料裡選取未接受訓練的數字資料,並寫一支程式來測試以訓練好的類神
經網路的判斷能力。
20
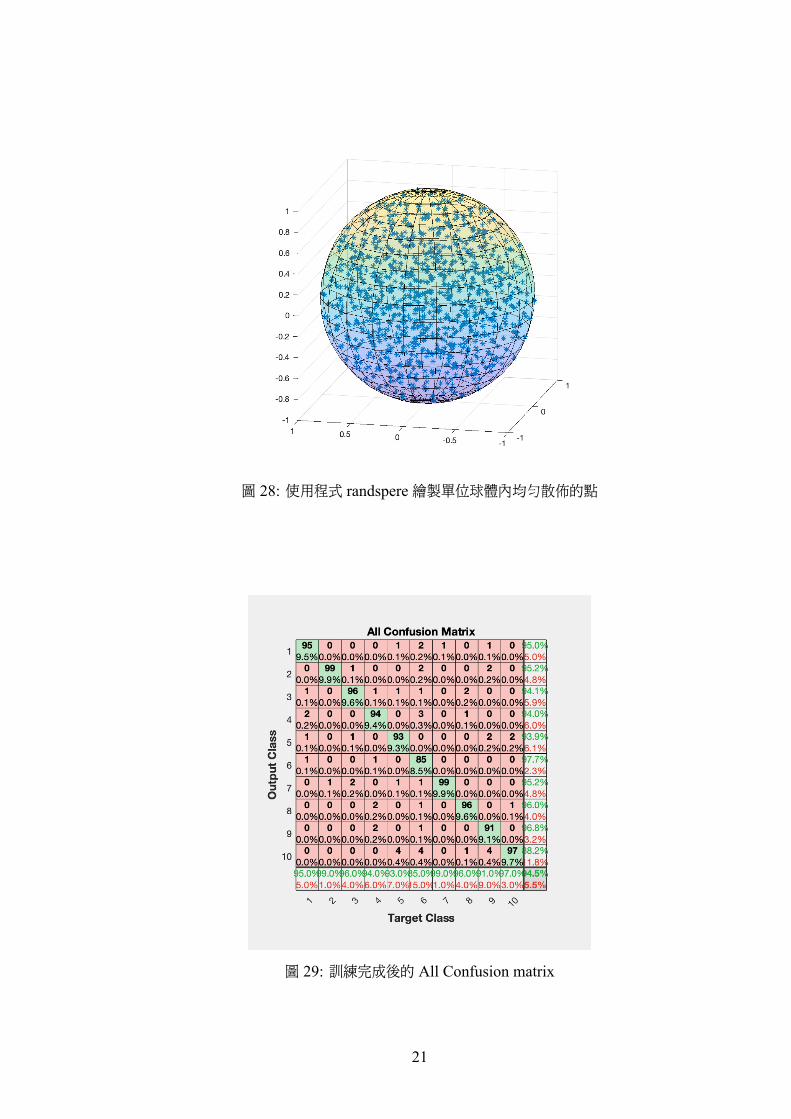
圖 28: 使用程式 randspere繪製單位球體內均勻散佈的點
圖 29: 訓練完成後的 All Confusion matrix
21





![工程實務 - ceci.com.tw · 分類法 [7] 等,這些分類法均相當的有效率。 WTA 類神經網路中,以反傳遞類神經網路 (Counter Propagation Artificial Neural](https://img.pdfslide.tips/doc/110x75/5f9f06e28f388d48b37e161f/c-cecicomtw-e-7-cioeeecccoec.jpg)








![身心障礙者鑑定作業辦法修正條文1].pdf神經科 ^含小兒 神經 科)、神經 外科、復 健科專科 醫師 臨床評估 1-相關病史 !.理學 3一神經學](https://img.pdfslide.tips/doc/110x75/5e4c20b125e0fc35994f79e3/efeoeceeoee-1pdf-ccc-cc.jpg)














