Embed Size (px)
DESCRIPTION
Compiler Improvement of Register Usage. Part 1 - Chapter 8, through Section 8.4 Anastasia Braginsky. Roadmap. Introduction Scalar Replacement Unroll-and-Jam. Introduction. Processor cycle time is decreasing; while memory time remains almost the same. - PowerPoint PPT Presentation
Citation preview

Compiler Compiler Improvement of Improvement of Register UsageRegister Usage
Part 1 - Chapter 8, through Section 8.4
Anastasia Braginsky

Roadmap
Introduction
Scalar Replacement
Unroll-and-Jam

Introduction
Processor cycle time is decreasing; while memory time remains almost the same.
Better usage of registers set (especially for RISC architectures)
No cache discussion here

Register Allocation Algorithms
1. Defining live range per variable.
2. Building interference graph to model which pairs of live ranges can not be assigned to the same register.
3. Using a fast heuristic coloring algorithm.
4. If coloring fails take at least one live range from registers and repeat from step 3.

Register Allocation Algorithms – so what’s the problem? Only non-array variables are assigned to
registers.
Almost no optimization for floating-point registers, typically used to hold temporarily individual elements of array variables.
7 9 4 05 6 1 8 32Array A:Register RFor Array A:

Register Allocation Algorithms – so what’s the problem? Only non-array variables are assigned to
registers.
Almost no optimization for floating-point registers, typically used to hold temporarily individual elements of array variables.
7 9 4 05 6 1 8 32Array A:

Register Allocation Algorithms – so what’s the problem? Only non-array variables are assigned to
registers.
Almost no optimization for floating-point registers, typically used to hold temporarily individual elements of array variables.
7 9 4 05 6 1 8 32Array A:
We want to eliminate the unneeded loads and stores.

Introduction – example:
DO I=1,N
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
ENDDO
1. Load from some memory location A(I) to register RA.
2. Load from some memory location B(J) to register RB.
3. RA = RA + RB
4. Store RA to memory – A(I)
1. Load from some memory location A(I) to register RA.
2. Load from some memory location B(J+1) to register RB.
3. RA = RA + RB
4. Store RA to memory – A(I)

Introduction – example (cont.)
DO I = 1, N
T = A(I)
DO J = 1, M
T = T + B(J)
ENDDO
A(I) = T
ENDDO
All loads and stores to A in the inner loop have been saved
High chance of T being allocated a register by the coloring algorithm
Source-to-source transformation

Data Dependence for Register Reuse Two application of dependence:
To determine the correctness of different transformations
To determine the transformations to improve the performance of particular memory accesses

Types of dependences
A true or flow dependence Assignment to variable and then usage of it
S1: V = … Store the register representing V to V’s
memory location
S2: … = V Load V to register representing V
Load can be saved (store after the usage). Cache miss can be saved
R1 R2
R1
R2

Types of dependences
An antidepencence dependence
Usage of variable and then assignment to it
S1: … = V Load V to register representing V
S2: V = … Store the register representing V to V’s
memory location
Nothing can be done to improve the registers usage (if used once), but cache miss can be saved.
R1 R2
1

Types of dependences
An output dependence
Assignment to variable repeats
S1: V = … Store the register representing V to V’s
memory location
S2: V = … Store the register representing V to V’s
memory location
First store is not needed.
R1 R2
o

Types of dependences - example
S1: A(I) = …
S2: … = A(I)
S3: A(I) = …
Store
Load
Store
True dependence between S1 and S2
Output dependence between S1 and S3
Types of dependences
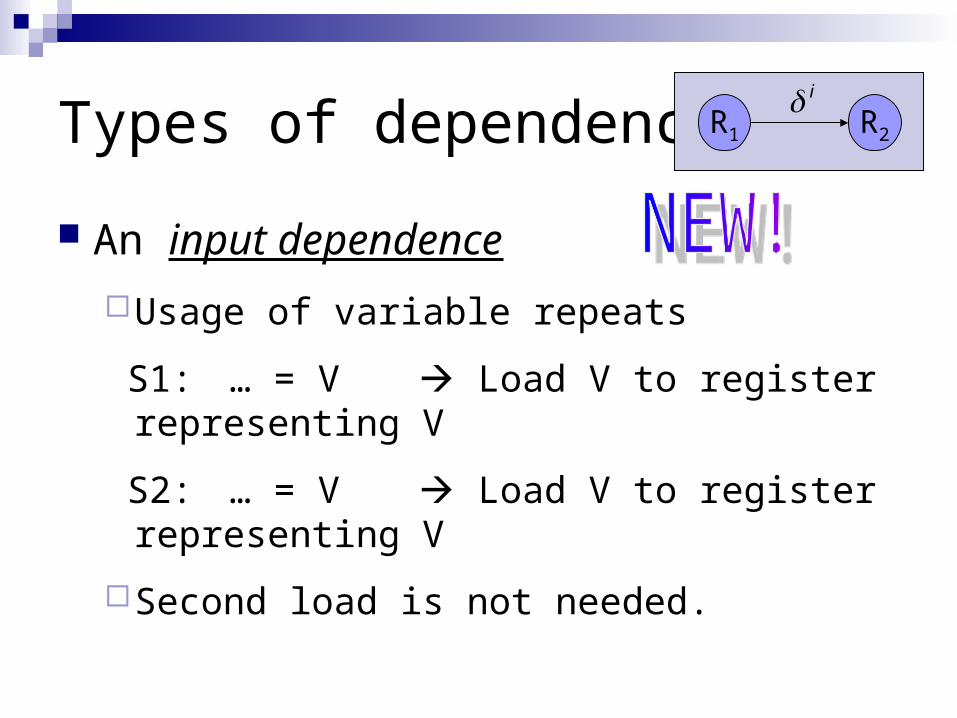
An input dependence
Usage of variable repeats
S1: … = V Load V to register representing V
S2: … = V Load V to register representing V
Second load is not needed.
R1 R2
i

Types of dependences
Loop-independent dependence
Loop-carried dependence:
Consistent dependence – a loop-carried dependence with a constant dependence distance throughout the loop.
Non consistent dependence – the opposite.

Dependence graph modification
S1: A(I)=…
S2: …=A(I)
S3: …=A(I) load from A(I)
Two True dependences between S1 and S2
)Load can be saved(
and between S1 and S3
)Load can be saved(
Input dependence from S2 to S3
)Load can be saved(
It is not possible to save three memory references the dependence graph should be pruned.
load from A(I)
store to A(I)
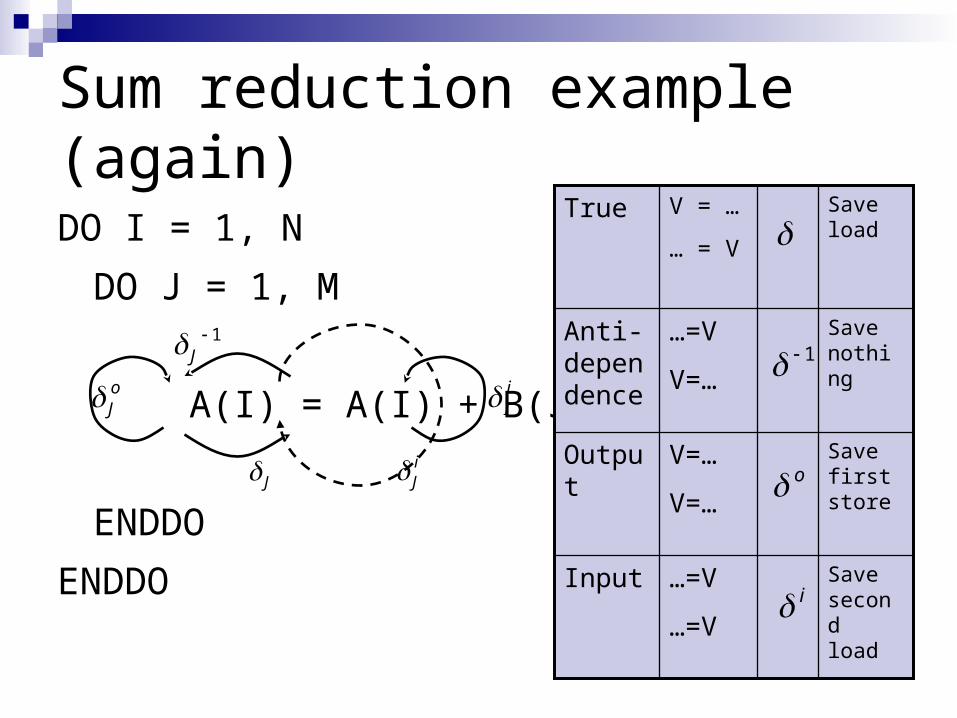
Sum reduction example (again)
DO I = 1, N
DO J = 1, M
A(I) = A(I) + B(J)
ENDDO
ENDDO Save second load
…=V
…=V
Input
Save first store
V=…
V=…
Output
Save nothing
…=V
V=…
Anti- dependence
Save load
V = …
… = V
True
1
o
i
1J
J
oJ i
I
iJ
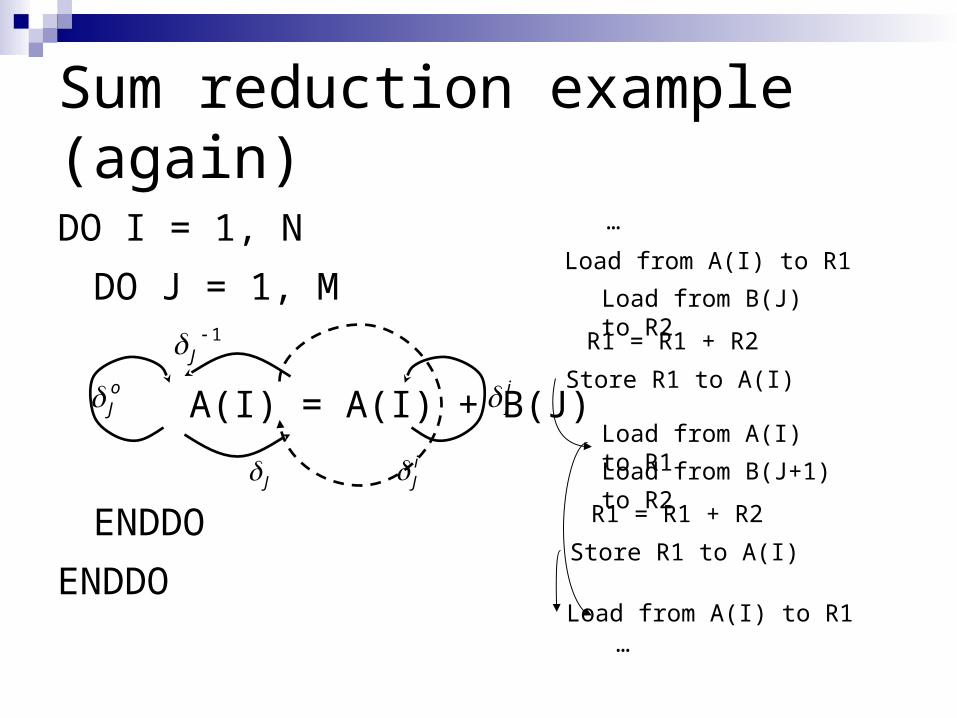
Sum reduction example (again)
DO I = 1, N
DO J = 1, M
A(I) = A(I) + B(J)
ENDDO
ENDDO
1J
J
oJ i
I
Load from A(I) to R1
…
Load from B(J) to R2
R1 = R1 + R2
Store R1 to A(I)
Load from A(I) to R1
Load from B(J+1) to R2
R1 = R1 + R2
Store R1 to A(I)
…Load from A(I) to R1
iJ

Scalar Register Allocation
DO I = 1, N
T = A(I)
DO J = 1, M
T = T + B(J)
ENDDO
A(I) = T
ENDDO

Roadmap
Introduction
Scalar Replacement
Unroll-and-Jam

Loop Independent Dependence
Simple replacement
DO I=1,N
A(I) = B(I) + C
X(I) = A(I) + Q
ENDDO
DO I=1,N
t = B(I) + C
X(I) = t + Q
A(I) = t
ENDDO

Loop Carried Dependences
Spanning single iteration
DO I=1,N
A(I) = B(I-1)
B(I) = A(I) + C(I)
ENDDO
I=1
A(1) = B(0)
B(1) = A(1)+C(1)
I=2
A(2) = B(1)
B(2) = A(2)+C(2)
I=3
A(3) = B(2)
B(3) = A(3)+C(3)
…
Loop Carried True dependence

Loop Carried Dependences
Spanning single iteration
DO I=1,N
A(I) = B(I-1)
B(I) = A(I) + C(I)
ENDDO
I=1
A(1) = B(0) or T
B(1) or T = A(1)+C(1)
I=2
A(2) = B(1) or T
B(2) or T = A(2)+C(2)
I=3
A(3) = B(2) or T
B(3) or T = A(3)+C(3)
…
T = B(0)
DO I=1,N
A(I) = T
T = A(I) + C(I)
B(I) = T
ENDDO

Dependences Spanning Multiple Iterations Distance for the dependence is 2 iterations
DO I=1, N
A(I) = B(I-1) + B(I+1)
ENDDO
Use 3 different scalar temporaries defined as follows: t1 = B(I-1) t2 = B(I) t3 = B(I+1)
Input dependenceiI

Dependences Spanning Multiple IterationsDO I=1, N
A(I) = B(I-1) + B(I+1)
ENDDO
t1 = B(I-1)
t2 = B(I)
t3 = B(I+1)
DO I=1, N t1 = B(I-1)
t2 = B(I)
t3 = B(I+1)
A(I) = t1 + t3
t1 = t2
t2 = t3
ENDDO
B[0]
B[1]
B[2]
B[3]
B[4]
t1
t2
t3
t1
t2
t3

Dependences Spanning Multiple IterationsDO I=1, N
A(I) = B(I-1) + B(I+1)
ENDDO
t1 = B(I-1)
t2 = B(I)
t3 = B(I+1)
t1 = B(0)
t2 = B(1)
DO I=1, N t3 = B(I+1)
A(I) = t1 + t3
t1 = t2
t2 = t3
ENDDO
2 pipeline cycles/slots wasted for each loop!

Dependences Spanning Multiple IterationsDO I=1, N
A(I) = B(I-1) + B(I+1)
ENDDO
t1 = B(I-1)
t2 = B(I)
t3 = B(I+1)
t1 = B(0)
t2 = B(1)
DO I=1, N t3 = B(I+1)
A(I) = t1 + t3
t1 = t2
t2 = t3
ENDDO
2 pipeline cycles/slots wasted for each loop!
B[0]
B[1]
B[2]
B[3]
B[4]
t1
t2
t3
t1
t2
t3
B[6]
B[5]
…

Dependences Spanning Multiple Iterations t1 = B(0) t2 = B(1) DO I=1, N
t3 = B(I+1) A(I) = t1 + t3 t1 = B(I+2) A(I+1) = + t2 = B(I+3) A(I+2) = t3 + t2
ENDDO
I = 1 A(1)=B(0)+B(2) I = 2 A(2)=B(1)+B(3) I = 3 A(3)=B(2)+B(4) I = 4 A(4)=B(3)+B(5) …
B[0]
B[1]
B[2]
B[3]
B[4]
t1
t2
t3
B[6]
B[5]
…
t2 t1t1
,3

Eliminating Scalar Copies
t1 = B(0)
t2 = B(1)
mN3 = MOD(N,3)
DO I = 1, mN3
t3 = B(I+1)
A(I) = t1 + t3
t1 = t2
t2 = t3
ENDDO
DO I = mN3 + 1, N, 3
t3 = B(I+1)
A(I) = t1 + t3
t1 = B(I+2)
A(I+1) = t2 + t1
t2 = B(I+3)
A(I+2) = t3 + t2
ENDDO
Pre-loop the same as the previous solution
Main loop - three sums in one iteration
t1 = B(0)
t2 = B(1)
DO I=1, N
t3 = B(I+1)
A(I) = t1 + t3
t1 = t2
t2 = t3
ENDDO

Scalar Replacement
1. Loop-independent dependence – simple replacement
2. Handling loop-carried dependence – spanning one iteration
3. Dependences spanning multiple iterations
4. Eliminating scalar copies
5. Pruning the dependence graph
6. Moderating register pressure

Break?
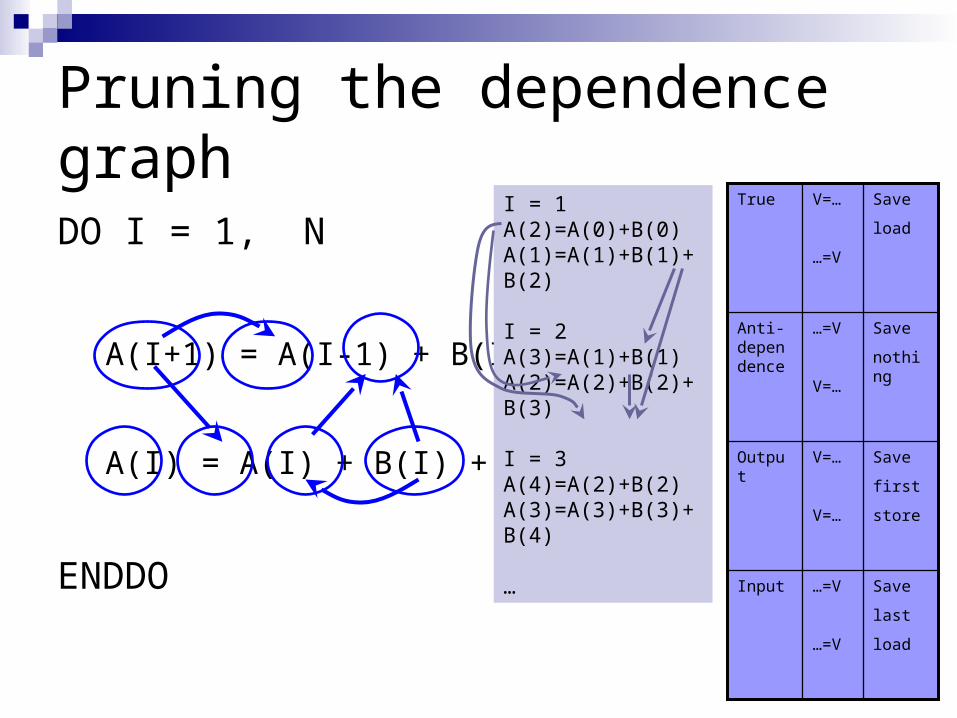
Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
I = 1A(2)=A(0)+B(0)A(1)=A(1)+B(1)+B(2)
I = 2A(3)=A(1)+B(1)A(2)=A(2)+B(2)+B(3)
I = 3A(4)=A(2)+B(2)A(3)=A(3)+B(3)+B(4)
…
Save
last
load
…=V
…=V
Input
Save
first
store
V=…
V=…
Output
Save
nothing
…=V
V=…
Anti-dependence
Save
load
V=…
…=V
True

Pruning the dependence graph
Two kinds of edges to be pruned:
True and input dependence edges which are killed by an intervening assignment to the same location.
Input dependence edges that are redundant.

Three-phase algorithm for pruning edges Phase 1: Eliminate killed dependences
Can be true or input dependences
Looking for the store to the location involved in the dependence between the endpoints of the dependence.

Three-phase algorithm for pruning edges Phase 1: Eliminate killed dependences
True dependence
Looking for output dependence from the source to the assignment before the sink (there should be true dependence from the assignment to the sink).
S1: A(I+1) = …
S2: A(I) = …
S3: … = A(I)True
True
Output

Three-phase algorithm for pruning edges Phase 1: Eliminate killed dependences
Input dependence
Looking for anti-dependence from the source to the assignment before the sink (there should be true dependence from the assignment to the sink).
S1: …=A(I+1)
S2: A(I) = …
S3: … = A(I)Input
True
Anti

Three-phase algorithm for pruning edges Phase 2: Identify generators
Generator is a reference with at least one true or input dependence starting
from it
AND
with no input or true dependence into it
Actually if we are looking on the graph represented only by input and true dependences, generators are the sources.
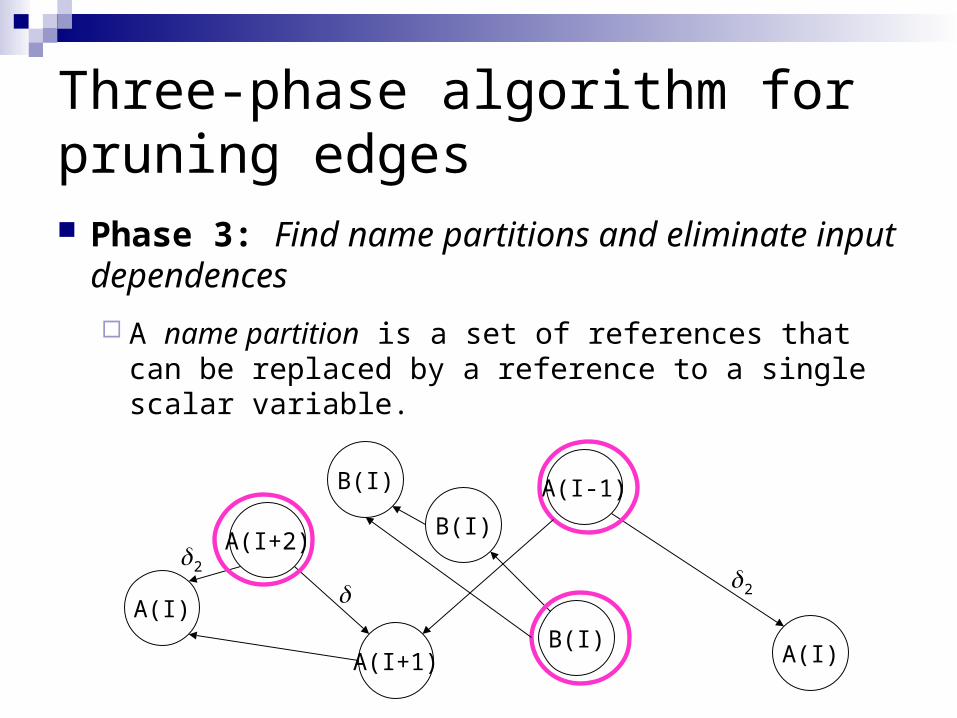
Three-phase algorithm for pruning edges Phase 3: Find name partitions and eliminate
input dependences
A name partition is a set of references that can be replaced by a reference to a single scalar variable.
A(I+2)
A(I)
B(I)
A(I+1)B(I)
A(I)
B(I)
A(I-1)
2 2

Three-phase algorithm for pruning edges Phase 3: Find name partitions and eliminate
input dependences A name partition is a set of references that can be
replaced by a reference to a single scalar variable.
Starting at each generator mark each reference reachable from the generator by a flow or input dependence as part of the name partition for that variable. (similar to the typed fusion problem)
Eliminate input dependences within same name partition, unless source is generator.

Three-phase algorithm for pruning edges Phase 3 and a half: Anti-dependence
Note that anti-dependence can’t directly give a rise to register reuse and are always pruned as the last step in the graph pruning.

Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
Phase 1 Try to eliminate true
dependences
Try to eliminate input dependences
Phase 2 Identify generators
Candidates are sources of true and input dependences
ii
io
i
1

Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
Phase 3 Starting each
generator mark each reference reachable from the generator by input or true dependence as part of the name partition for that variable.
Phase 3.5
i
i
io
1

Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
ii
io
i
1
How to start scalar replacement from here?
1. Generators: A(I+1) A(I) B(I+1)
2. The number of scalars for each generator = how many iterations are spanned by the dependence.
A(I-1) B(I-1) B(I)

Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
i
i
o
References: A(I-1) = tA1
A(I) = tA2
A(I+1) = tA3
B(I-1) = tB1
B(I) = tB2
B(I+1) = tB3

Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
tA1 = A(I-1), tA2=A(I), tA3=A(I+1)
tB1 = B(I-1), tB2=B(I), tB3=B(I+1)
tA1 = A(0)
tA2 = A(1)
tB1 = B(0)
tB2 = B(1)
DO I = 1, N
tA3 = tA1 + tB1
tB3 = B(I+1)
tA1 = tA2 + tB2 + tB3
// Above: tA1=tA2
A(I) = tA1
tA2 = tA3
tB1 = tB2
tB2 = tB3
ENDDO
A(N+1) = tA3
One Load
One Store

Pruning the dependence graph
DO I = 1, N
A(I+1) = A(I-1) + B(I-1)
A(I) = A(I) + B(I) + B(I+1)
ENDDO
1. Load A(I-1) to R1
2. Load B(I-1) to R2 R1 = R1 + R2
3. Store R1 to A(I+1)
4. Load A(I) to R1
5. Load B(I) to R2 R1 = R1 + R2
6. Load B(I+1) to R2 R1 = R1 + R2
7. Store R1 to A(I)

Pruning the dependence graph
Special cases: References in the Loop
DO I=1, N
= B(I) + C(I,J)
C(I,J) = + D(I)
ENDDO
A(J)
A(J)
1
i
otA
tA
A(J) = tA Assumption: N>1

Pruning the dependence graph
Special cases: Forcing stores and loads
DO I = 1, N
A(I) = A(I-1) + B(I)
A(J) = A(J) + A(I)
ENDDO
I=1
A(1) = A(0) + B(1)
A(J) = A(J) + A(1)
I=2 A(2) = A(1) + B(2) A(J) = A(J) + A(2)
I=3…

Pruning the dependence graph
Special cases: Forcing stores and loads
DO I = 1, N
tAI = A(I-1) + B(I)
A(I) = tAI
A(J) = A(J) + tAI
ENDDO
I=1
A(1) = A(0) + B(1)
A(J) = A(J) + A(1)
I=2 A(2) = A(1) + B(2) A(J) = A(J) + A(2)
I=3…

Pruning the dependence graph
Special cases: Forcing stores and loads
tAI = A(0)
DO I = 1, N
tAI = tAI(was A(I-1))+B(I)
A(J) = A(J) + tAI
A(I) = tAI
ENDDO
J ?= I
I=1
A(1) = A(0) + B(1)
A(J) = A(J) + A(1)
I=2 A(2) = A(1) + B(2) A(J) = A(J) + A(2)
I=3…

Special cases: Forcing stores and loads
tAI = A(0)
DO I = 1, N
tAI = tAI + B(I)
A(J) = A(J) + tAI
A(I) = tAI
ENDDO
A(J) ?= A(I)
DO I = 1, N
tAI = A(I-1) + B(I)
A(J) = A(J) + tAI
A(I) = tAI
ENDDO
tAI = A(0)
tAJ = A(J)
JU = MAX(J-1,0)
DO I = 1, JU
tAI = tAI + B(I)
tAJ = tAJ + tAI
A(I) = tAI
ENDDO
// Here I = J
IF(J.GT.0.AND.J.LE.N) THEN
tAI = tAI + B(J)
tAJ = tAJ + tAI
A(J) = tAI
tAI = tAJ
ENDIF
DO I = JU+2, N //I starting from J+1
tAI = tAI + B(I)
tAJ = tAJ + tAI
A(I) = tAI
ENDDO
A(J) = tAJ

Pruning the dependence graph
Special cases: Inconsistent dependence
DO I = 1, N
A(2*I) = A(I) + B(I)
ENDDO
Bag edge in the typed fusion framework above.

Moderating of Register Pressure
Scalar replacement may produce to many scalar quantities.
Have to choose name partitions for scalar replacement to maximize register usage

Moderating of Register Pressure
M name partitions R: {R1, R2, R3,…,Rm}
The value of the name partition: v(R) – the number of memory loads and stores saved by replacing
The cost of the name partition: c(R) – the number of registers needed to hold all the scalar values.

Moderating of Register Pressure
The desired solution, given the limit of register-resident scalars to use - n:
The sub-collection of name partitions:
or {R1, R2,…,Rm} where Ri=0/1
Such that:
And
1
( )m
i ii
c R R n
1
max[ ( ) ]m
i ii
v R R
1 2{ , ,..., }
ki i iR R R

0/1 knapsack problem solutions
Dynamic programming solution – O(nm)
Heuristic solution:
Order the name partition set in decreasing order of the ratio v(R)/c(R)
Select elements from the beginning of the list until the registers are full.

Scalar replacement algorithm
For the loops that do not include conditional flow of control:
1. Prune dependence graph. (Apply typed fusion.) Get set of name partitions as the part of the result.
2. Select a set of name partitions using register pressure moderation

Scalar replacement algorithm
For the loops that do not include conditional flow of control:
3. For each selected partition, replace it with a reference to scalars:
A) If non-cyclic, replace using set of temporaries
True dependence is replaced by set of temporaries. The number of temporaries is defined by how many iterations are spanned by the dependence.
Output dependence – move stores after the end of loop.
Input dependence – move loads before the beginning of loop.

Scalar replacement algorithm
For the loops that do not include conditional flow of control:
B) If cyclic replace reference with single temporary
C) For each inconsistent dependence
Use index set splitting or insert loads and stores
4. Unroll loop to eliminate scalar copies
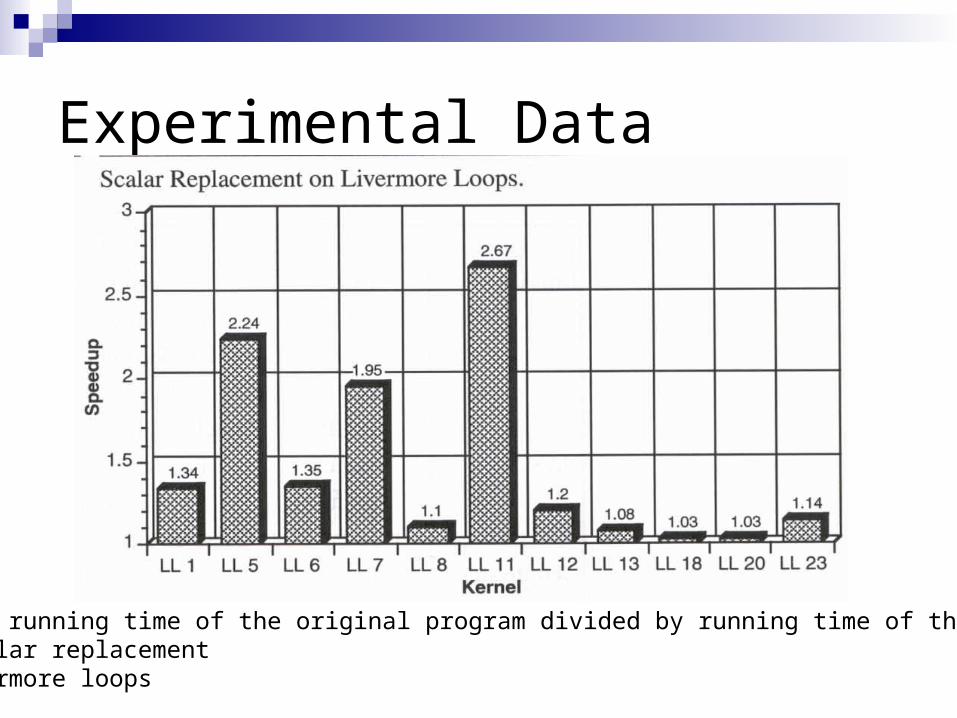
Experimental Data
Speedup = running time of the original program divided by running time of the versionafter scalar replacementLL = Livermore loops

Roadmap
Introduction
Scalar Replacement
Unroll-and-Jam

Unroll-and-Jam
Recall introduction example:
DO I=1,N
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
ENDDO

Unroll-and-Jam
After transformation called unroll-and-jam
Assume Nmod2=0
DO I=1,N,2
DO J=1,M
A(I)=A(I)+B(J)
A(I+1)=A(I+1)+B(J)
ENDDO
ENDDO
This is unroll-and-jam to factor 2

Improving the efficiency of pipelined functional unit
DO J=1, 2M
DO I=1, N
A(I,J) = A(I+1,J) + A(I-1,J)
ENDDO
ENDDO
A(1,J) = A(2,J) + A(0,J)
A(2,J) = A(3,J) + A(1,J)
A(3,J) = A(4,J) + A(2,J)
…
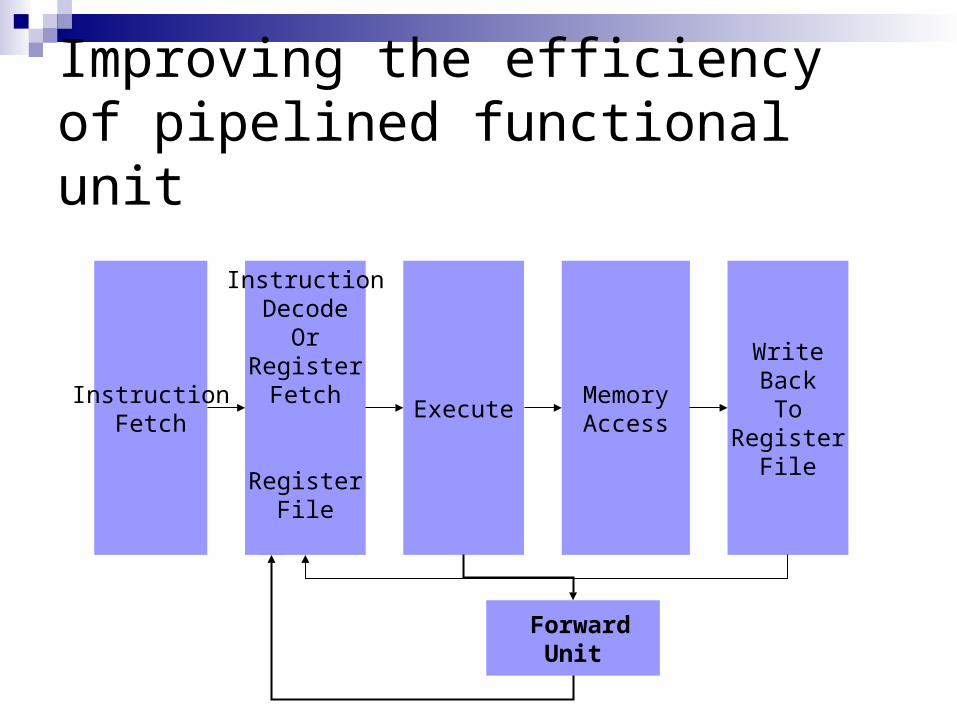
Improving the efficiency of pipelined functional unit
InstructionFetch
InstructionDecode
OrRegister
Fetch
RegisterFile
ExecuteMemoryAccess
WriteBackTo
RegisterFile
Improving the efficiency of pipelined functional unit
InstructionFetch
InstructionDecode
OrRegister
Fetch
RegisterFile
ExecuteMemoryAccess
WriteBackTo
RegisterFile
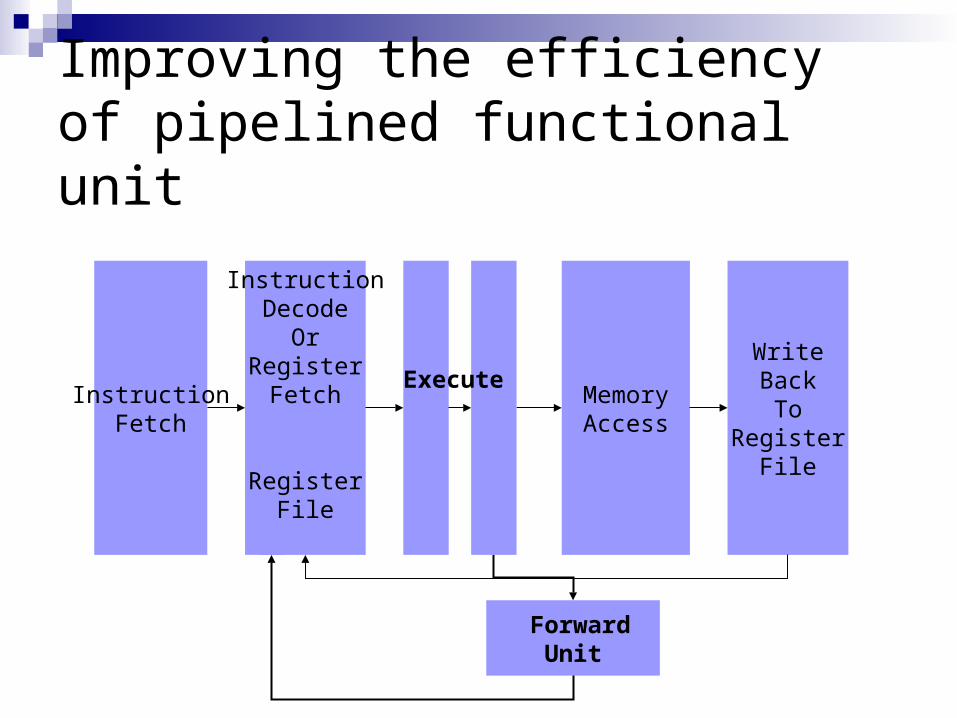
Improving the efficiency of pipelined functional unit
InstructionFetch
InstructionDecode
OrRegister
Fetch
RegisterFile
ExecuteMemoryAccess
WriteBackTo
RegisterFile
Forward Unit
Improving the efficiency of pipelined functional unit
InstructionFetch
InstructionDecode
OrRegister
Fetch
RegisterFile
MemoryAccess
WriteBackTo
RegisterFile
Forward Unit
Execute

Improving the efficiency of pipelined functional unit
DO J=1, 2M
DO I=1, N
A(I,J) = A(I+1,J) + A(I-1,J)
ENDDO
ENDDO
A(1,J) = A(2,J) + A(0,J)
A(2,J) = A(3,J) + A(1,J)
A(3,J) = A(4,J) + A(2,J)
…
A(1,J+1) = A(2,J+1) + A(0,J+1)
A(2,J+1) = A(3,J+1) + A(1,J+1)
A(3,J+1) = A(4,J+1) + A(2,J+1)
…

Improving the efficiency of pipelined functional unitDO J=1, 2M, 2
DO I=1, N
A(I,J) = A(I+1,J) + A(I-1,J)
A(I,J+1)=A(I+1,J+1)+A(I-1,J+1)
ENDDO
ENDDO

Legality of Unroll-and-Jam
DO I=1, 2N
DO J=1, M
A(I+1, J-1) = A(I,J) + B(I,J)
A(I+2, J-1) = A(I+1,J) + B(I+1,J)
ENDDO
ENDDO
I=1, J=1A(2, 0) = A(1, 1) + B(1, 1)I=1, J=2A(2, 1) = A(1, 2) + B(1, 2)I=1, J=3A(2, 2) = A(1, 3) + B(1, 3)…I=2, J=1A(3, 0) = A(2, 1) + B(2, 1)I=2, J=2A(3, 1) = A(2, 2) + B(2, 2)I=2, J=3A(3, 2) = A(2, 3) + B(2, 3)…
,2

Legality of Unroll-and-Jam
I=1, J=1A(2, 0) = A(1, 1) + B(1, 1)I=1, J=2A(2, 1) = A(1, 2) + B(1, 2)I=1, J=3A(2, 2) = A(1, 3) + B(1, 3)…I=2, J=1A(3, 0) = A(2, 1) + B(2, 1)I=2, J=2A(3, 1) = A(2, 2) + B(2, 2)I=2, J=3A(3, 2) = A(2, 3) + B(2, 3)…

Legality of Unroll-and-Jam
I=1, J=1A(2, 0) = A(1, 1) + B(1, 1)I=1, J=2A(2, 1) = A(1, 2) + B(1, 2)I=1, J=3A(2, 2) = A(1, 3) + B(1, 3)…I=2, J=1A(3, 0) = A(2, 1) + B(2, 1)I=2, J=2A(3, 1) = A(2, 2) + B(2, 2)I=2, J=3A(3, 2) = A(2, 3) + B(2, 3)…

Legality of Unroll-and-Jam
DO I=1, 2N
DO J=1, M
A(I+1, J-1) = A(I,J) + B(I,J)
ENDDO
ENDDO
The direction vector of the loop: [<, >]
Swap [>, <] illegal
Should we assume that loop unroll-and-jam is illegal whenever loop interchange is illegal?

Legality of Unroll-and-Jam
DO I=1, 2N
DO J=1, M
A(I+2, J-1) = A(I,J) + B(I,J)
ENDDO
ENDDO
Direction vector is (<,>); still unroll-and-jam possible

Legality of Unroll-and-Jam
Definition:
An unroll-and-jam to factor n consist of:
Unrolling the outer loop n-1 times to create n copies of the inner loop
And fusing those copies together

Unroll-and-Jam to factor n=2
Recall introduction example:
DO I=1,2N
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
ENDDO
Unrolling the outer loop n-1=1 times to create n=2 copies of the inner loop
DO I=1,2N
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
ENDDO

Unroll-and-Jam to factor n=2
Unrolling the outer loop n-1=1 times to create n=2 copies of the inner loop
DO I=1,2N, 2
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
DO J=1,M
A(I+1)=A(I+1)+B(J)
ENDDO
ENDDO
Recall introduction example:
DO I=1,2N
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
ENDDO

Unroll-and-Jam to factor n=2
Unrolling the outer loop n-1=1 times to create n=2 copies of the inner loop
DO I=1,2N, 2
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
DO J=1,M
A(I+1)=A(I+1)+B(J)
ENDDO
ENDDO

Unroll-and-Jam to factor n=2
Unrolling the outer loop n-1=1 times to create n=2 copies of the inner loop
DO I=1,2N, 2
DO J=1,M
A(I)=A(I)+B(J)
ENDDO
DO J=1,M
A(I+1)=A(I+1)+B(J)
ENDDO
ENDDO
And fusing those copies together
DO I=1,2N,2
DO J=1,M
A(I)=A(I)+B(J)
A(I+1)=A(I+1)+B(J)
ENDDO
ENDDO

Legality of Unroll-and-Jam
Theorem:
An unroll-and-jam to factor n is legal if and only if there exist no dependence with direction vector (<, >) such that the distance for the outer loop is < n.
To check this note to use the full dependence graph and not the pruned one.

Legality of Unroll-and-Jam
What happens if there exist dependence with direction vector (<, >) but that the distance for the outer loop is n.
Note that an unroll-and-jam was to factor n

Unroll-and-Jam to factor m Algorithm
1. Create preloop
2. Unroll main loop m times
3. Apply typed fusion to loops within the body of the unrolled loop
4. Apply unroll-and-jam recursively to the inner nested loop

Unroll-and-Jam example
DO I = 1, N
DO K = 1, N
A(I) = A(I) + X(I,K)
ENDDO
DO J = 1, M
DO K = 1, N
B(J,K) = B(J,K) + A(I)
ENDDO
ENDDO
DO J = 1, M
C(J,I) = B(J,N)/A(I)
ENDDO
ENDDO
DO I = Nmod2+1, N, 2
DO K = 1, N
A(I) = A(I) + X(I,K)
A(I+1) = A(I+1) + X(I+1,K)
ENDDO
DO J = 1, M
DO K = 1, N
B(J,K) = B(J,K) + A(I)
B(J,K) = B(J,K) + A(I+1)
ENDDO
C(J,I) = B(J,N)/A(I)
C(J,I+1) = B(J,N)/A(I+1)
ENDDO
ENDDO

DO I = Nmod2+1, N, 2
DO K = 1, N
A(I) = A(I) + X(I,K)
A(I+1) = A(I+1) + X(I+1,K)
ENDDO
DO J = 1, M
DO K = 1, N
B(J,K) = B(J,K) + A(I)
B(J,K) = B(J,K) + A(I+1)
ENDDO
C(J,I) = B(J,N)/A(I)
C(J,I+1) = B(J,N)/A(I+1)
ENDDO
ENDDO
DO I = Nmod2+1, N, 2
DO K = 1, N
A(I) = A(I) + X(I,K)
A(I+1) = A(I+1) + X(I+1,K)
ENDDO
DO J = 1, Mmod2
DO K = 1, N
B(J,K) = B(J,K) + A(I)
B(J,K) = B(J,K) + A(I+1)
ENDDO
C(J,I) = B(J,N)/A(I)
C(J,I+1) = B(J,N)/A(I+1)
ENDDO
DO J = Mmod2+1, M, 2
DO K = 1, N
B(J,K) = B(J,K) + A(I)
B(J,K) = B(J,K) + A(I+1)
B(J+1,K) = B(J+1,K) + A(I)
B(J+1,K) = B(J+1,K) + A(I+1)
ENDDO
C(J,I) = B(J,N)/A(I)
C(J,I+1) = B(J,N)/A(I+1)
C(J+1,I) = B(J+1,N)/A(I)
C(J+1,I+1) = B(J+1,N)/A(I+1)
ENDDO
ENDDO
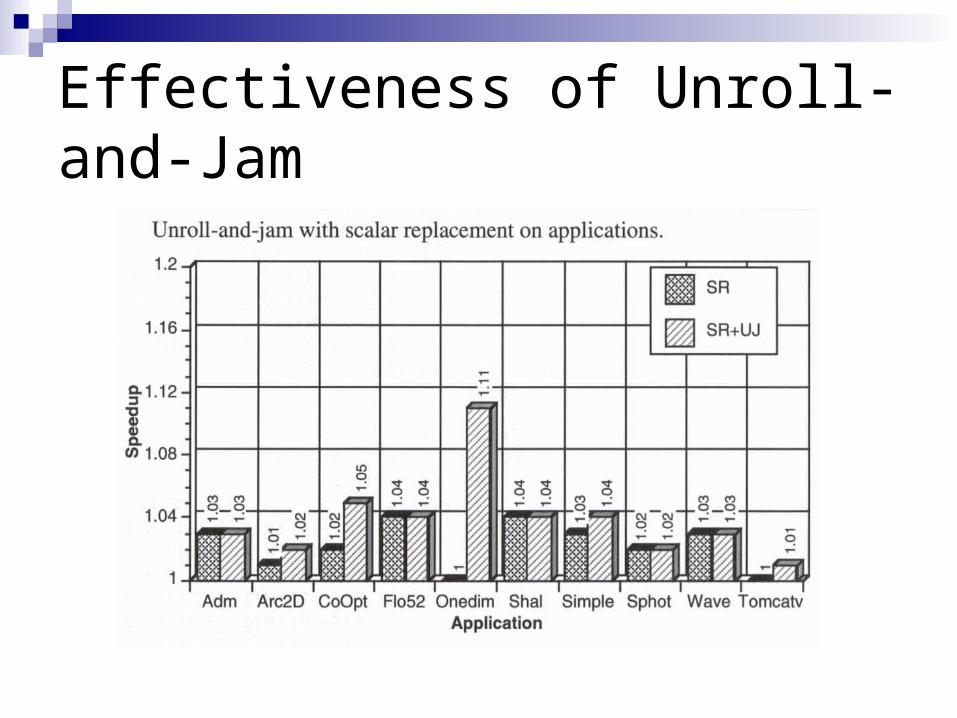
Effectiveness of Unroll-and-Jam

Improving the efficiency of pipelined functional unit
InstructionFetch
InstructionDecode
OrRegister
Fetch
RegisterFile
ExecuteMemoryAccess
WriteBackTo
RegisterFile





![[Lab5]IC Compiler](https://img.pdfslide.tips/doc/110x75/55321dbf5503462d668b4ba7/lab5ic-compiler.jpg)























